Résumé de la publication
Cet article vous propose de découvrir le framework Spark (ou Apache Spark2). Spark est un framework open source de calcul distribué. Il s’agit d’un ensemble d’outils et de composants logiciels structurés selon une architecture définie. Développé à l’université de Californie à Berkeley par AMPLab, Spark est aujourd’hui un projet de la fondation Apache. Ce produit est un cadre applicatif de traitements big data pour effectuer des analyses complexes à grande échelle. Depuis son installation à son exploitation l’article vise à expliquer son fonctionnement.
Objectifs de la publication
- Présentation de l’architecture Spark
- Installer, configurer et optimiser Apache Spark
- Création de DataFrame et Dataset
- Flux d’exécution des applications
- Gestion de SQL
- Streaming, Machine Learning et Graph Analysis
Chapitre 1. Introduction à Apache Spark
Apache Spark est un framework open source pour le traitement efficace et rapide de grands ensembles de données stockés dans des magasins de données hétérogènes.Des algorithmes analytiques sophistiqués peuvent être facilement exécutés sur ces grands ensembles de données. Spark peut exécuter un programme distribué 100 fois plus rapidement que MapReduce. Comme Spark est l’un des projets à croissance rapide dans la communauté open source, il fournit un grand nombre de bibliothèques à ses utilisateurs.
Nous aborderons les sujets suivants dans ce chapitre :
- Une brève introduction à Spark
- Architecture Spark et les différents langages pouvant être utilisés pour coder les applications Spark
- Composants Spark et comment ces composants peuvent être utilisés ensemble pour résoudre une variété de cas d’utilisation
- Une comparaison entre Spark et Hadoop
Qu’est-ce que Spark ?
Apache Spark est un cadre informatique distribué qui rend le traitement des mégadonnées assez facile, rapide et évolutif. Vous devez vous demander ce qui rend Spark si populaire dans l’industrie et en quoi est-il vraiment différent des outils existants disponibles pour le traitement des mégadonnées ? La raison en est qu’il fournit une pile unifiée pour le traitement de toutes sortes de mégadonnées, qu’il s’agisse de données par lots, en continu, d’apprentissage automatique ou de graphiques.
Spark a été développé à l’ AMPLab d’ UC Berkeley en 2009 et est ensuite tombé sous le parapluie Apache en 2010. Le cadre est principalement écrit en Scala et Java.
Spark fournit une interface avec de nombreux magasins de données distribués et non distribués différents, tels que Hadoop Distributed File System (HDFS), Cassandra, Openstack Swift, Amazon S3 et Kudu. Il fournit également une grande variété d’API linguistiques pour effectuer des analyses sur les données stockées dans ces magasins de données. Ces API incluent Scala, Java, Python et R.
L’entité de base de Spark est Resilient Distributed Dataset (RDD), qui est une collection de données partitionnée en lecture seule. Le RDD peut être créé en utilisant des données stockées dans différents magasins de données ou en utilisant un RDD existant. Nous en discuterons plus en détail au chapitre 3, Spark RDD.
Spark a besoin d’un gestionnaire de ressources pour distribuer et exécuter ses tâches. Par défaut, Spark propose son propre planificateur autonome, mais il s’intègre facilement avec Apache Mesos et Yet Another Resource Negotiator (YARN) pour la gestion des ressources du cluster et l’exécution des tâches.
L’une des principales caractéristiques de Spark est de conserver une grande quantité de données en mémoire pour une exécution plus rapide. Il possède également un composant qui génère un graphique acyclique dirigé (DAG) des opérations basées sur le programme utilisateur. Nous en discuterons plus en détail dans les prochains chapitres.
Le diagramme suivant montre certains des magasins de données populaires auxquels Spark peut se connecter :

Magasins de données
Remarque
Spark est un moteur informatique et ne doit pas être considéré comme un système de stockage également. Spark n’est pas non plus conçu pour la gestion des clusters. À cette fin, des cadres tels que Mesos et YARN sont utilisés.
Présentation de l’architecture Spark
Spark suit une architecture maître-esclave, car elle lui permet d’évoluer à la demande. L’ architecture de Spark comprend deux composants principaux :
Driver Program : un programme de pilote est l’endroit où un utilisateur écrit du code Spark à l’aide des API Scala, Java, Python ou R. Il est responsable du lancement de diverses opérations parallèles du cluster.
Executor : Executor est la machine virtuelle Java (JVM) qui s’exécute sur un nœud de travail du cluster. Executor fournit des ressources matérielles pour exécuter les tâches lancées par le programme du pilote.
Dès qu’un travail Spark est soumis, le programme pilote lance diverses opérations sur chaque exécuteur. Le pilote et les exécuteurs exécutent ensemble une application.
Le diagramme suivant illustre les relations entre le pilote, les travailleurs et les exécuteurs. Comme première étape, un processus de pilote analyse le code utilisateur (Spark programme) et crée plusieurs exécuteurs sur chaque nœud de travail. Le processus du pilote non seulement bifurque les exécuteurs sur les machines de travail, mais envoie également des tâches à ces exécuteurs pour exécuter l’ensemble de l’application en parallèle.
Une fois le calcul terminé, la sortie est envoyée au programme du pilote ou enregistrée dans le système de fichiers :
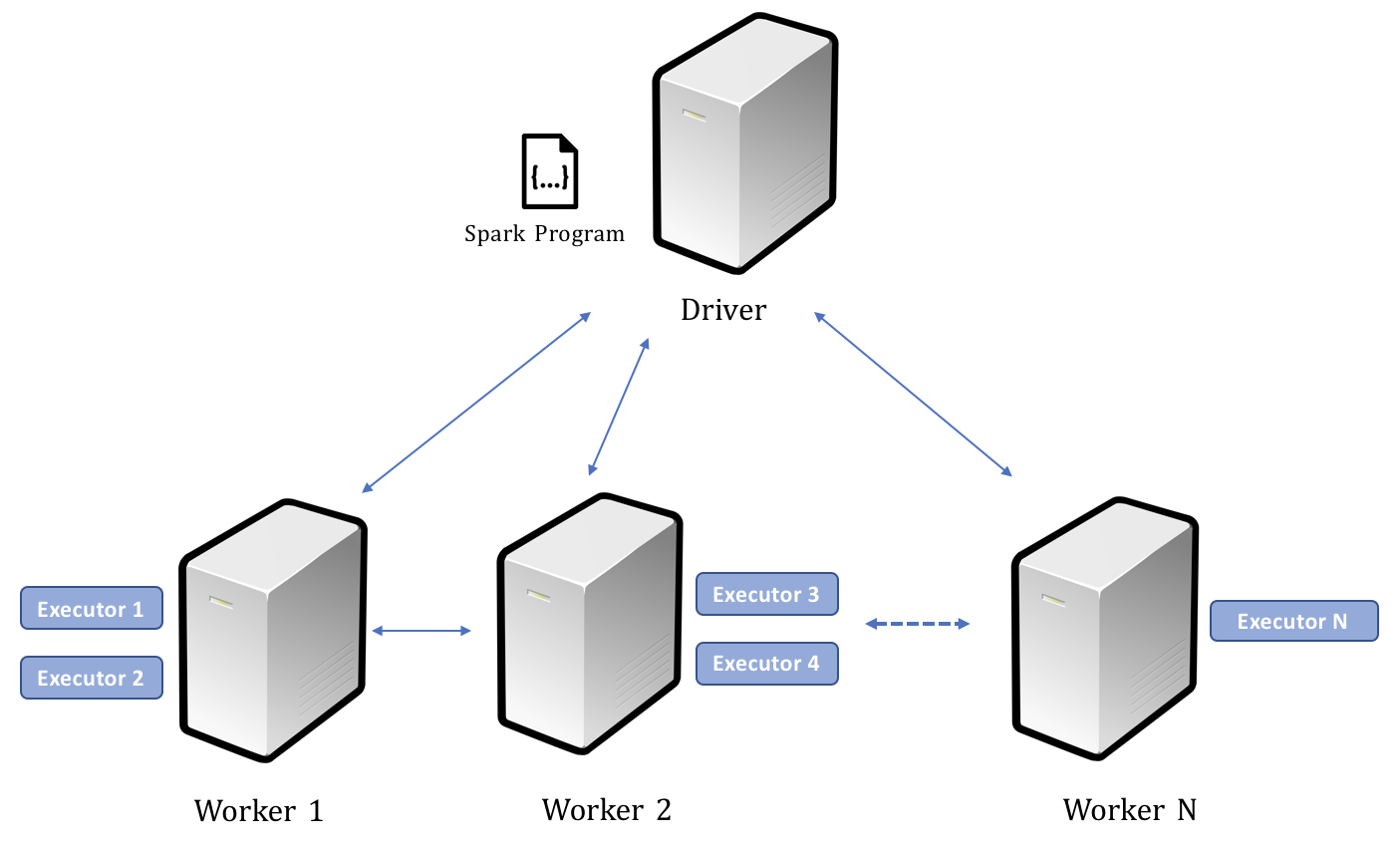
Driver, Workers, and Executors
API de langage Spark
Spark est intégré à une variété de langages de programmation tels que Scala, Java, Python et R. Les développeurs peuvent écrire leur programme Spark dans l’un de ces langages. Cette liberté de langage est également l’une des raisons pour lesquelles Spark est populaire parmi les développeurs. Si vous comparez cela à Hadoop MapReduce, dans MapReduce, les développeurs n’avaient qu’un seul choix: Java, ce qui rendait difficile pour les développeurs d’un autre langage de programmation de travailler sur MapReduce.
Scala
Scala est la langue principale de Spark. Plus de 70% du code de Spark est écrit en langage évolutif (Scala). Scala est une langue assez nouvelle. Il a été développé par Martin Odersky en 2001 et a été lancé publiquement pour la première fois en 2004. Comme Java, Scala génère également un bytecode qui fonctionne sur JVM. Scala apporte les avantages des mondes orientés objet et fonctionnels. Il fournit une programmation dynamique sans compromettre la sécurité des types. Comme Spark est principalement écrit en Scala, vous pouvez trouver presque toutes les nouvelles bibliothèques dans Scala API.
Java
La plupart d’entre nous connaissent Java. Java est un puissant langage de programmation orienté objet. La majorité des cadres de Big Data sont écrits en Java, qui fournit des bibliothèques riches pour connecter et traiter les données avec ces cadres.
Python
Python est un langage de programmation fonctionnel. Il a été développé par Guido van Rossum et a été publié pour la première fois en 1991. Pendant un certain temps, Python n’était pas populaire parmi les développeurs, mais plus tard, vers 2006-07, il a introduit certaines bibliothèques telles que Numerical Python ( NumPy ) et Pandas , qui sont devenues les pierres angulaires et a rendu Python populaire parmi tous les types de programmeurs. Dans Spark, lorsque le pilote lance des exécuteurs sur les nœuds de travail, il démarre également un interpréteur Python pour chaque exécuteur. Dans le cas de RDD, les données sont d’abord expédiées dans les machines virtuelles Java, puis transférées vers Python, ce qui ralentit le travail lorsque vous travaillez avec des RDD.
R
R est un langage de programmation statistique. Il fournit une bibliothèque riche pour analyser et manipuler les données, c’est pourquoi il est très populaire parmi les analystes de données, les statisticiens et les scientifiques des données. L’intégration de Spark R est un moyen de fournir aux scientifiques des données la flexibilité requise pour travailler sur les mégadonnées. Comme Python, SparkR crée également un processus R pour chaque exécuteur afin de travailler sur les données transférées depuis la JVM.
SQL
Structured Query Language (SQL) est l’une des langues les plus populaires et les plus puissants pour travailler avec des tables stockées dans la base de données. SQL permet également aux non-programmeurs de travailler avec des mégadonnées. Spark fournit Spark SQL, qui est un moteur de requête SQL distribué. Nous en apprendrons plus en détail au chapitre 6 , Spark SQL
Composants Spark
Comme expliqué précédemment dans ce chapitre, la philosophie principale de Spark est de fournir un moteur unifié pour créer différents types d’applications de Big Data. Spark fournit une variété de bibliothèques pour travailler avec l’analyse par lots, le streaming, l’apprentissage automatique et l’analyse graphique.
Ce n’est pas comme si ces types de traitement n’avaient jamais été effectués avant Spark, mais pour chaque nouveau problème de Big Data, il y avait un nouvel outil sur le marché; par exemple, pour l’analyse par lots, nous avions MapReduce, Hive et Pig. Pour le streaming , nous avions Apache Storm, pour l’apprentissage automatique, nous avions Mahout. Bien que ces outils résolvent les problèmes pour lesquels ils sont conçus, chacun d’eux nécessite une courbe d’apprentissage. C’est là que Spark apporte des avantages. Spark fournit une pile unifiée pour résoudre tous ces problèmes. Il comprend des composants conçus pour traiter toutes sortes de mégadonnées. Il fournit également de nombreuses bibliothèques pour lire ou écrire différents types de données telles que JSON, CSV et Parquet.
Voici un exemple de pile Spark :

Spark Stack
Avoir une pile unifiée apporte de nombreux avantages. Examinons certains des avantages :
- Le premier est le partage de code et la réutilisabilité. Les composants développés par l’équipe d’ingénierie des données peuvent facilement être intégrés par l’équipe de science des données pour éviter la redondance du code.
- En second lieu, il y a toujours un nouvel outil sur le marché pour résoudre un cas d’utilisation différent du big data. La plupart des développeurs ont du mal à apprendre de nouveaux outils et à acquérir une expertise afin de les utiliser efficacement. Avec Spark, les développeurs n’ont qu’à apprendre les concepts de base qui permettent aux développeurs de travailler sur différents cas d’utilisation du Big Data.
- Troisièmement, sa pile unifiée donne aux développeurs un grand pouvoir pour explorer de nouvelles idées sans installer de nouveaux outils.
Le diagramme suivant fournit un aperçu de haut niveau des différentes applications de Big Data alimentées par Spark :
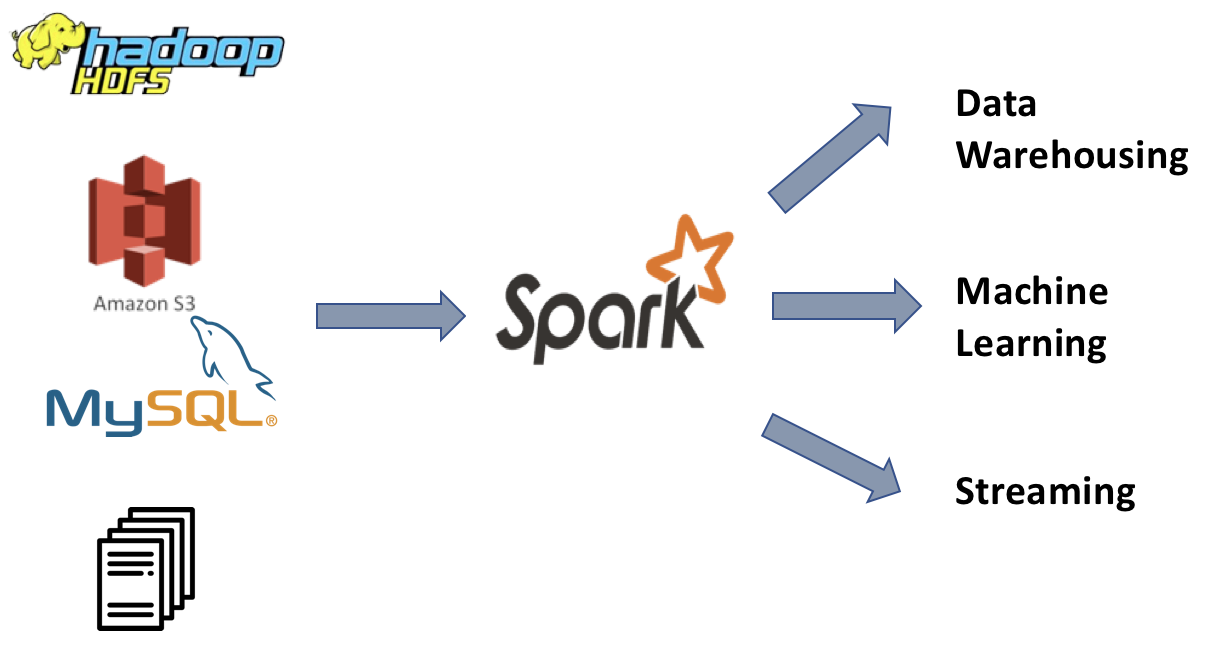
Cas d’utilisation de Spark
Spark Core
Spark Core est le composant principal de Spark. Spark Core définit les éléments suivants :
- Les composants de base, tels que RDD et DataFrames
- Les API disponibles pour effectuer des opérations sur ces abstractions de base
- Variables partagées ou distribuées, telles que les variables de diffusion et les accumulateurs
Nous les examinerons plus en détail dans les prochains chapitres.
Spark Core définit également toutes les fonctionnalités de base, telles que la gestion des tâches, la gestion de la mémoire, les fonctionnalités d’E / S de base, etc. C’est une bonne idée de jeter un œil au code Spark sur GitHub (https://github.com/apache/spark).
Spark SQL
Spark SQL est l’endroit où les développeurs peuvent travailler avec des données structurées et semi-structurées telles que les tables Hive, les tables MySQL, les fichiers Parquet, les fichiers AVRO, les fichiers JSON, les fichiers CSV, etc. Une autre alternative pour traiter les données structurées est d’utiliser Hive. Hive traite les données structurées stockées sur HDFS à l’aide de Hive Query Language (HQL). Il utilise en interne MapReduce pour son traitement, et nous verrons comment Spark peut fournir de meilleures performances que MapReduce. Dans la version initiale de Spark, les données structurées étaient définies comme RDD de schéma (un autre type de RDD). Lorsqu’il existe des données avec le schéma, SQL devient le premier choix de traitement de ces données. Spark SQL est le composant Spark qui permet aux développeurs de traiter les données avec langage Structured Query Language (SQL).
En utilisant Spark SQL, la logique métier peut être facilement écrite en SQL et HQL. Cela permet aux ingénieurs d’entrepôt de données ayant une bonne connaissance de SQL d’utiliser Spark pour leur traitement d’extraction, de transformation et de chargement (ETL). Les projets Hive peuvent facilement être migrés sur Spark à l’aide de Spark SQL, sans modifier les scripts Hive.
Spark SQL est également le premier choix pour l’analyse et l’entreposage de données. Spark SQL permet aux analystes de données d’écrire des requêtes ad hoc pour leur analyse exploratoire. Spark fournit un shell SQL Spark, où vous pouvez exécuter les requêtes de type SQL et elles sont exécutées sur Spark. Spark convertit en interne le code en une chaîne de calculs RDD, tandis que Hive convertit le travail HQL en une série de travaux MapReduce. En utilisant Spark SQL, les développeurs peuvent également utiliser la mise en cache (une fonctionnalité Spark qui permet de conserver les données en mémoire), ce qui peut augmenter considérablement les performances de leurs requêtes.
Spark Streaming
Spark Streaming est un package utilisé pour traiter un flux de données en temps réel. Il peut exister de nombreux types différents de flux de données en temps réel ; par exemple, un site Web de commerce électronique enregistrant des visites de page en temps réel, des transactions par carte de crédit, une application de fournisseur de taxi envoyant des informations sur les trajets et des informations de localisation des conducteurs et des passagers, etc. En bref, toutes ces applications sont hébergées sur plusieurs serveurs Web qui génèrent des journaux d’événements en temps réel.
Spark Streaming utilise RDD et définit d’autres API pour traiter le flux de données en temps réel. Comme Spark Streaming utilise RDD et ses API, il est facile pour les développeurs d’apprendre et d’exécuter les cas d’utilisation sans apprendre une toute nouvelle pile technologique.
Spark 2.x a introduit le streaming structuré, qui utilise des DataFrames plutôt que des RDD pour traiter le flux de données. L’utilisation de DataFrames comme abstraction de calcul apporte tous les avantages de l’API DataFrame au traitement en continu. Nous discuterons des avantages des DataFrames sur RDD dans les prochains chapitres.
Spark Streaming a une excellente intégration avec certaines des files d’attente de messagerie de données les plus populaires, comme Apache Flume et Kafka. Il peut être facilement connecté à ces files d’attente pour gérer une quantité massive de flux de données.
Apprentissage automatique Spark
Il est difficile d’exécuter un algorithme d’apprentissage automatique lorsque vos données sont réparties sur plusieurs machines. Il peut y avoir un cas où le calcul dépend d’un autre point qui est stocké ou traité sur un exécuteur différent. Les données peuvent être mélangées entre les exécuteurs ou les employés, mais le mélange entraîne un coût élevé. Spark fournit un moyen d’éviter de mélanger les données. Oui, c’est la mise en cache. La capacité de Spark à conserver une grande quantité de données en mémoire facilite l’écriture d’algorithmes d’apprentissage automatique.
Spark MLlib et ML sont les packages de Spark pour travailler avec des algorithmes d’apprentissage automatique. Ils fournissent les éléments suivants:
- Algorithmes d’apprentissage automatique intégrés tels que la classification, la régression, le clustering, etc.
- Des fonctionnalités telles que le pipelining, la création de vecteurs, etc.
Les algorithmes et fonctionnalités précédents sont optimisés pour la réorganisation des données et pour évoluer à travers le cluster.
Traitement de graphique Spark
Spark a également un composant pour traiter les données du graphique. Un graphique se compose de sommets et d’arêtes. Les arêtes définissent la relation entre les sommets. Quelques exemples de données graphiques sont les évaluations de produits des clients , les réseaux sociaux, les pages Wikipedia et leurs liens, les vols d’aéroport, etc.
Spark fournit GraphX pour traiter ces données. GraphX utilise RDD pour son calcul et permet aux utilisateurs de créer des sommets et des arêtes avec certaines propriétés. À l’aide de GraphX , vous pouvez définir et manipuler un graphique ou obtenir des informations à partir du graphique.
GraphFrames est un package externe qui utilise des DataFrames au lieu de RDD, et définit la relation sommet-bord à l’aide d’un DataFrame .
Gestionnaire de cluster
Spark fournit un mode local pour l’exécution du travail, où le pilote et les exécuteurs s’exécutent au sein d’une seule machine virtuelle Java sur la machine client. Cela permet aux développeurs de démarrer rapidement avec Spark sans créer de cluster. Nous utiliserons principalement ce mode d’exécution de travail tout au long de cet article pour nos exemples de code, et expliquerons les défis possibles avec un mode cluster autant que possible. Spark fonctionne également avec une variété d’horaires. Ayons un bref aperçu d’eux ici.
Planificateur autonome
Spark est livré avec son propre ordonnanceur, appelé ordonnanceur autonome . Si vous exécutez vos programmes Spark sur un cluster qui n’a pas d’installation Hadoop, il est possible que vous utilisiez le planificateur autonome par défaut de Spark.
YARN
YARN est le planificateur par défaut de Hadoop. Il est optimisé pour les travaux par lots tels que MapReduce, Hive et Pig. La plupart des organisations ont déjà installé Hadoop sur leurs clusters; par conséquent, Spark offre la possibilité de le configurer avec YARN pour la planification des travaux.
Mesos
Spark s’intègre également bien avec Apache Mesos qui est construit en utilisant les mêmes principes que le noyau Linux. Contrairement à YARN, Apache Mesos est un gestionnaire de cluster à usage général qui ne se lie pas à l’écosystème Hadoop. Une autre différence entre YARN et Mesos est que YARN est optimisé pour les charges de travail par lots de longue durée, tandis que Mesos, la capacité à fournir une allocation fine et dynamique des ressources, le rend plus optimisé pour les travaux de streaming.
Kubernetes
Kubernetes est un cadre d’orchestration à usage général pour exécuter des applications conteneurisées. Kubernetes fournit plusieurs fonctionnalités telles que l’hébergement multiclient (exécution de différentes versions de Spark sur un cluster physique) et le partage de l’espace de noms. Au moment de la rédaction de cet article, le planificateur Kubernetes est encore au stade expérimental. Pour plus de détails sur l’exécution d’une application Spark sur Kubernetes, veuillez consulter la documentation de Spark.
Tirer le meilleur parti de Hadoop et Spark
Les gens se confondent généralement entre Hadoop et Spark et comment ils sont liés. L’intention de cette section est de discuter des différences entre Hadoop et Spark, ainsi que de la façon dont elles peuvent être utilisées ensemble.
Hadoop est principalement une combinaison des composants suivants :
- Hive and Pig
- MapReduce
- FIL
- HDFS
HDFS est la couche de stockage où les données sous-jacentes peuvent être stockées. HDFS fournit des fonctionnalités telles que la réplication des données, la tolérance aux pannes, la haute disponibilité, etc. Hadoop est un schéma en lecture; par exemple, vous n’avez pas besoin de spécifier le schéma lors de l’écriture des données dans Hadoop, vous pouvez plutôt utiliser différents schémas lors de la lecture des données. HDFS fournit également différents types de formats de fichiers, tels que TextInputFormat , SequenceFile , NLInputFormat , etc. Si vous voulez en savoir plus sur ces formats de fichiers, je vous recommande de lire Hadoop: The Definitive Guide de Tom White.
MapReduce de Hadoop est un modèle de programmation utilisé pour traiter les données disponibles sur HDFS. Il se compose de quatre phases principales: mapper, trier, mélanger et réduire. L’une des principales différences entre Hadoop et Spark est que le modèle MapReduce de Hadoop est étroitement lié aux formats de fichier des données. D’autre part, Spark fournit une abstraction pour traiter les données à l’aide de RDD. RDD est comme un conteneur à usage général de données distribuées. C’est pourquoi Spark peut s’intégrer à une variété de magasins de données.
Une autre différence principale entre Hadoop et Spark est que Spark fait bon usage de la mémoire. Il peut mettre en cache les données en mémoire pour éviter les E / S disque. En revanche, les travaux MapReduce d’Hadoop impliquent généralement plusieurs E / S de disques. En règle générale, un travail Hadoop se compose de plusieurs travaux de mappage et de réduction. Ceci est connu sous le nom de chaînage MapReduce. Une chaîne MapReduce peut ressembler à ceci : Map -> Reduce -> Map -> Map -> Reduce.
Toutes les tâches réduites écrivent leur sortie sur HDFS pour plus de fiabilité ; par conséquent, chaque tâche de carte à côté devra la lire depuis HDFS. Cela implique plusieurs opérations d’E / S disque et rend le traitement global plus lent. Il y a eu plusieurs initiatives telles que Tez dans Hadoop pour optimiser le traitement MapReduce. Comme indiqué précédemment, Spark crée un DAG d’opérations et optimise automatiquement les lectures de disque.
Hormis les différences précédentes, Spark complète Hadoop en fournissant une autre façon de traiter les données. Comme indiqué précédemment dans ce chapitre, il s’intègre bien avec les composants Hadoop tels que Hive, YARN et HDFS. Le diagramme suivant montre un écosystème typique de Spark et Hadoop. Spark utilise YARN pour planifier et exécuter sa tâche dans le cluster :
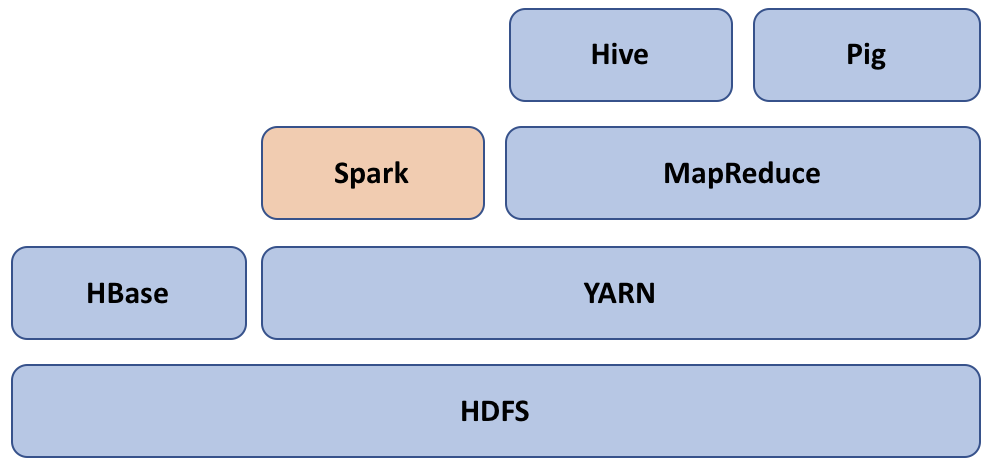
Spark et Hadoop
Résumé
Dans ce chapitre, nous avons présenté Apache Spark et son architecture. Nous avons discuté du concept de programme de pilote et d’exécuteurs, qui sont les principaux composants de Spark.
Nous avons ensuite brièvement discuté des différentes API de programmation pour Spark et de ses principaux composants, notamment Spark Core, Spark SQL, Spark Streaming et Spark GraphX.
Enfin, nous avons discuté de certaines différences majeures entre Spark et Hadoop et comment elles se complètent. Dans le chapitre suivant, nous allons installer Spark sur une instance AWS EC2 et passer par différents clients pour interagir avec Spark.
Chapitre 2. Installation d’Apache Spark
Dans le chapitre 1, Introduction à Apache Spark, nous avons découvert ce qu’est Spark, son architecture et les différents composants fournis par Spark. Dans ce chapitre, nous allons configurer Spark dans différents modes et examiner les différentes API que nous pouvons utiliser pour accéder aux clusters Spark ou soumettre une application Spark. Ce chapitre se couvrir les suivants sujets :
- Création d’un nœud unique (instance EC2 Linux) sur le cloud AWS
- Installation de Java sur une instance
- Installer Python sur une instance
- Installer Scala sur une instance
- Installation de Spark sur une instance
- Comment accéder à différents clients de composants Spark sur une instance
AWS elastic compute cloud (EC2)
Amazon Web Service (AWS) est une plate-forme cloud populaire qui fournit diverses offres pour l’infrastructure en tant que service (IAAS), la plate-forme en tant que service (PAAS) et les logiciels en tant que service (SAAS). AWS fournit des instances EC2 évolutives en tant que nœuds (machines) avec des ressources configurables (RAM et cœurs). Il fournit également un service de stockage simple (S3) en tant que stockage évolutif et à faible coût.
Créer un compte gratuit sur AWS
AWS vous fournit un compte gratuit afin que vous puissiez explorer différents services. Pour plus de détails sur ces services gratuits, veuillez visiter https://aws.amazon.com/free. Vous verrez l’écran suivant :

Suivez ces étapes pour obtenir votre nœud EC2 gratuit pour l’installation de Spark :
- Ouvrez un compte AWS avec votre Email address et votre Password, comme indiqué dans la capture d’écran suivante :
- Vous vous retrouverez dans la AWS Management Console, comme suit :
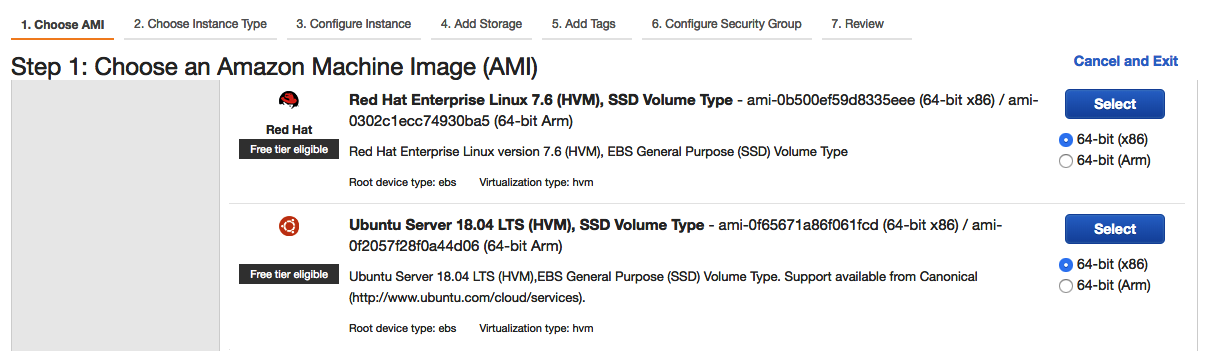
- Sélectionnez l’image de la machine Amazon (AMI) souhaitée. Nous avons choisi Ubuntu Server 18.04 ici :
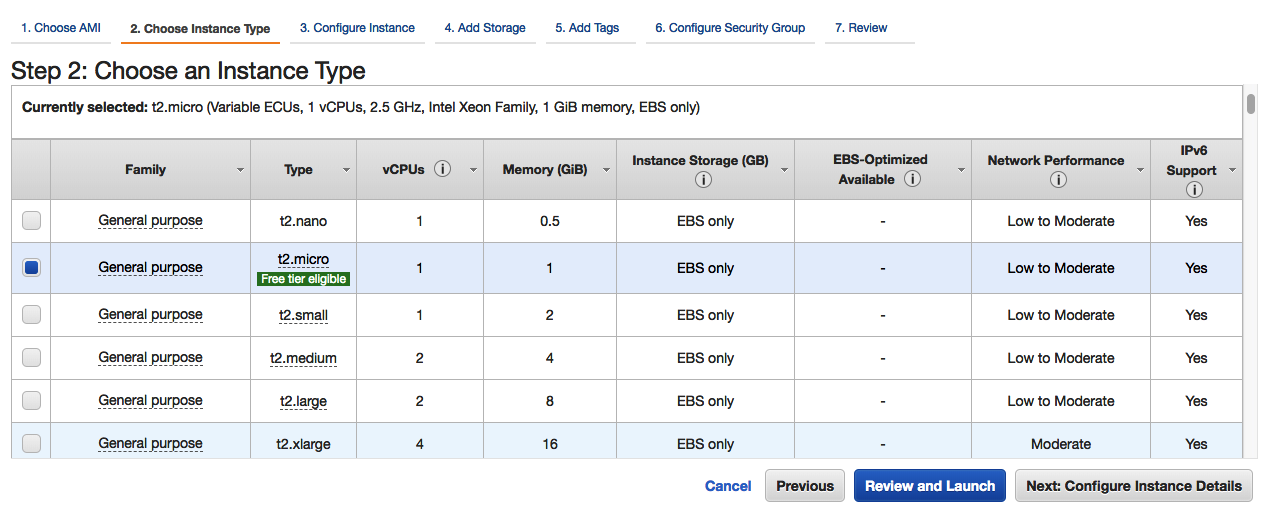
- Sélectionnez le Free tier eligible, t2.micro, comme suit:
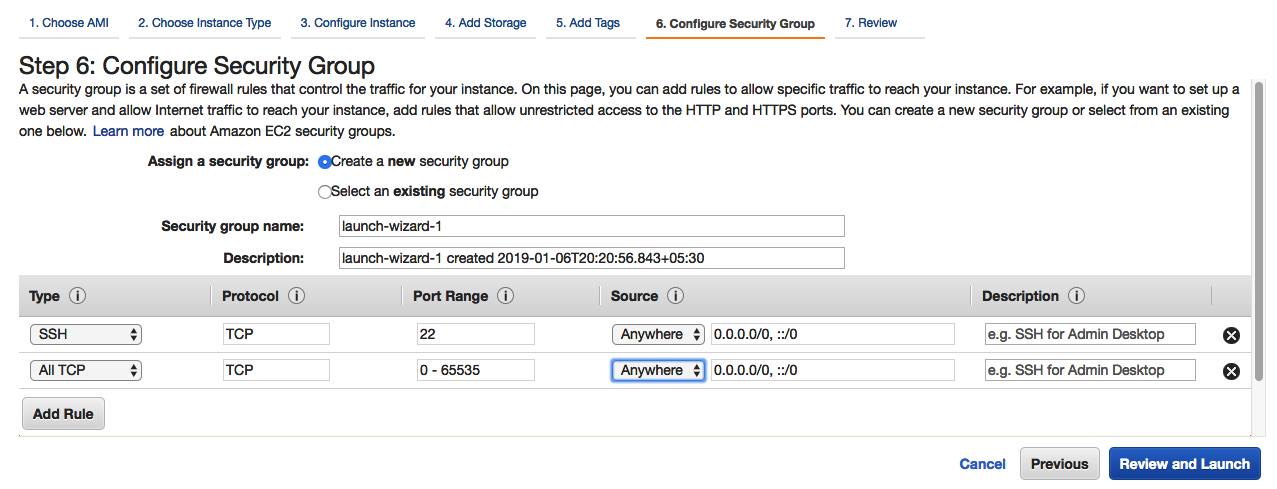
- Sélectionnez Configure Security Group pour permettre à toutes les machines de se connecter à l’instance que vous avez créée, comme suit :
- Vérifiez votre instance de lancement, comme suit :
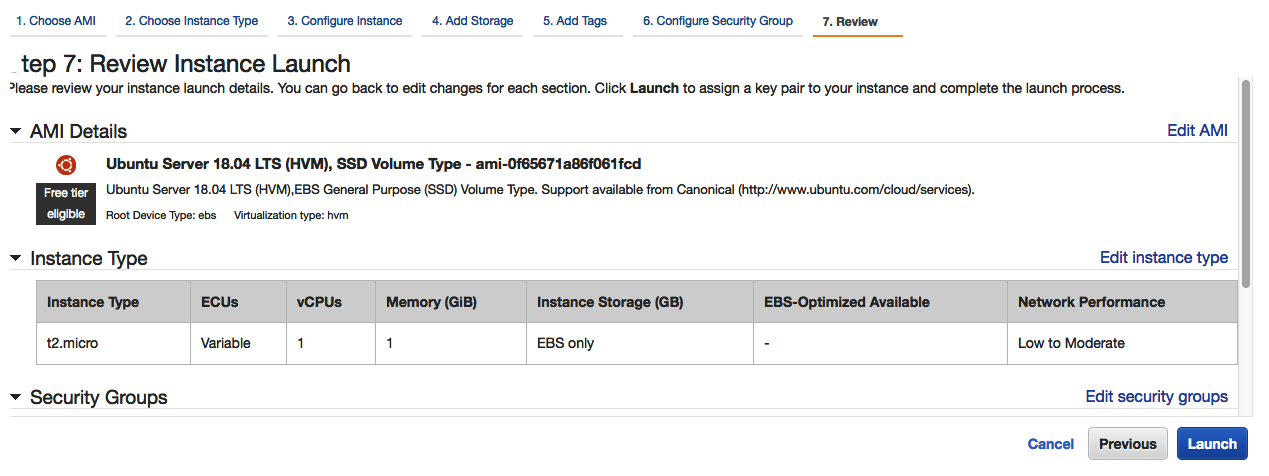
- En cliquant sur Lancer, vous verrez une fenêtre contextuelle, qui vous permettra de générer une nouvelle paire clé-valeur pour votre instance:
- Cela générera une clé publique et des clés privées pour votre instance. La clé publique est stockée dans une instance Amazon, tandis que vous devez télécharger la clé privée.
- Cliquez sur Download Key Pair. Cela téléchargera un fichier .pem sur votre machine. Conservez-le dans un endroit sûr sur votre machine.
- Après avoir téléchargé le fichier .pem, cliquez sur Launch. Cela prendra un certain temps et affichera la page suivante :
- Vous pouvez parcourir quelques ressources utiles au bas de cette page. Une fois votre instance démarrée, vous pouvez consulter le tableau de bord EC2 :
Connexion à votre instance Linux
Reportez-vous aux liens suivants pour vous connecter à votre instance à partir de différentes plateformes:
Une fois que vous avez téléchargé le fichier .pem, appliquez les paramètres d’autorisation suivants pour obtenir des informations sur votre machine:
- Définissez l’autorisation du fichier .pem sur 400 et fournissez un chemin d’accès complet dans la commande ssh
- Le nom d’utilisateur par défaut pour Ubuntu AMI est ubuntu
- ec2-18-219-82-165.us-east-2.compute.amazonaws.com est le nom d’hôte de l’instance. Vous pouvez obtenir le nom d’hôte (DNS public (IPv4)) et d’autres détails sur la machine depuis le tableau de bord de l’instance EC2:
Pour l’instance que nous avons créée, nous pouvons nous connecter à la machine avec les commandes suivantes :
chmod 400 shrey.pem
ssh -i “shrey.pem” ubuntu@ec2-18-219-82-165.us-east-2.compute.amazonaws.com
Vous verrez l’écran suivant lors de l’exécution des commandes précédentes:
Une fois que vous vous connectez à votre instance Amazon, votre machine sera prête à installer les frameworks requis.
Configuration de Spark
Apache Spark peut être configuré dans les modes suivants :
- Mode autonome
- Mode distribué ou cluster
Conditions préalables
Les conditions suivantes sont requises pour configurer Spark dans l’un des modes:
- Linux OS : Spark est le plus compatible avec toutes les versions du système d’exploitation Linux. Vous pouvez utiliser n’importe quel ordinateur de bureau, machine virtuelle, serveur ou machine à l’échelle du cloud pour installer Spark. Bien que vous puissiez l’installer sur votre machine Windows, nous utilisons la machine Ubuntu AWS pour configurer Spark.
- Scala / Python / Java : Spark prend en charge les API dans plusieurs langues, y compris Scala, Python et Java. Toutes les API d’actions et de transformations Spark sont disponibles dans ces différents langages.
Installer Java
Vous pouvez utiliser les commandes suivantes pour installer Java sur votre système :
sudo add-apt-repository ppa:webupd8team/java -y
sudo apt install java-common oracle-java8-installer oracle-java8-set-default
Installation de Scala
Si vous avez le fichier Scala .tar (par exemple, scala-2.12.6.tgz), copiez-le dans une instance Linux AWS EC2 à n’importe quel emplacement (par exemple, / opt ):
- Vous pouvez également télécharger le dernier fichier binaire .tar.gz depuis http://www.scala-lang.org/download/all.html
- Vous pouvez télécharger 2.12.6 à partir de l’emplacement suivant : https://downloads.lightbend.com/scala/2.12.6/scala-2.12.6.tgz
Remarque
Le fichier / opt est un dossier vide à la racine dans la plupart des dossiers d’exploitation basés sur Linux. Ici, nous pouvons utiliser ce dossier pour copier et installer des logiciels. Par défaut, ce dossier appartient à root. Exécutez la commande suivante si vous rencontrez des problèmes d’autorisation lors de l’accès à ce dossier :
sudo chmod -R 777 / opt
Suivez ces étapes pour installer Scala 2.12.6 sur votre machine virtuelle Linux :
- Accédez à l’emplacement où vous avez copié le package logiciel Scala et décompressez- le :
cd / opt
tar – xzvf scala-2.12.6.tgz
- Définissez la variable d’environnement dans. bash_profile, comme suit:
nano ~ /. bash_profile
- Ajoutez les lignes suivantes à la fin du du fichier:
export SCALA_HOME = / opt / scala-2.12.6
export PATH = $ PATH: $ SCALA_HOME / bin
- Exécutez la commande suivante pour mettre à jour les variables d’environnement dans la courant session :
source ~ /. bash_profile
- Recherchez une installation Scala en exécutant la commande suivante:
scala -version
Installer Python
Python sous Linux peut être facilement installé avec les commandes suivantes :
sudo apt-get update
sudo apt-get install python3.6
Installation de Spark
Suivez ces étapes pour installer Spark 2.3.1, compilé avec Hadoop 2.7:
- Si vous avez une distribution tar Spark 2.0 (par exemple, spark-2.3.1-bin-hadoop2.7.tgz), copiez-la dans votre machine virtuelle Linux à n’importe quel emplacement (par exemple, / opt ) à l’ aide de n’importe quel fichier Windows sur Linux logiciel de transfert (FileZilla ou WinSCP). Vous pouvez également télécharger le dernier fichier binaire .tar.gz à partir du lien Apache Spark suivant: http://spark.apache.org/downloads.html.
Remarque
Le fichier / opt est un dossier vide à la racine dans la plupart des dossiers d’exploitation basés sur Linux. Ici, nous utiliserions ce dossier pour copier et installer des logiciels. Par défaut, ce dossier appartient à Root. Par conséquent, exécutez la commande suivante si vous rencontrez des problèmes d’autorisation lors de l’accès à ce dossier. sudo chmod -R 777 / opt .
- Accédez à l’emplacement où vous avez copié le package logiciel Spark et décompressez- le :
cd /opt
tar -xzvf spark-2.3.1-bin-hadoop2.7.tgz
- Définissez la variable d’environnement dans bash_profile, comme suit :
nano ~ /. bash_profile
- Ajoutez les lignes suivantes à la fin du fichier :
export SPARK_HOME=/opt/spark-2.3.1-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/sbin
export PATH=$PATH:$SPARK_HOME/bin
- Exécutez la commande suivante pour mettre à jour les variables d’environnement dans la courant session :
source ~/.bash_profile
Utilisation de composants Spark
Spark fournit une interface de ligne de commande différente, c’est -à-dire une boucle de lecture-évaluation-impression (REPL) pour différents langages de programmation. Vous pouvez choisir le type de REPL parmi les options suivantes, en fonction de la langue de votre choix :
- Shell Spark pour Scala : Si vous souhaitez utiliser Scala pour accéder aux API Spark, vous pouvez démarrer le shell Spark Scala avec la commande suivante :
spark-shell
L’écran suivant s’affiche après l’exécution de la commande précédente :
Une fois le pilote (l’un des composants de Spark) démarré, vous pouvez accéder à toutes les API Scala et Java dans le shell :
- Shell Spark pour Python : Si votre choix de codage préféré est Python, vous pouvez démarrer le shell Python de Spark avec une commande :
- Ajoutez Python à Spark Path.
- Ouvrez le .bash_profile et ajoutez les lignes suivantes:
nano ~/.bash_profile
export PYSPARK_PYTHON=python3
export PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH
- Enregistrez-le ~/.bash_profile :
pyspark
Une fois le shell chargé, vous pouvez commencer à utiliser les commandes Python pour accéder aux API Spark, comme indiqué dans la sortie suivante :

- Spark SQL : si vous avez travaillé sur un système de gestion de base de données relationnelle (SGBDR) comme Oracle, MySQL ou Teradata et que vous souhaitez appliquer vos compétences en programmation SQL à Spark, vous pouvez utiliser le module Spark SQL pour écrire des requêtes pour différents jeux de données structurés. Pour démarrer le shell Spark SQL, il vous suffit de taper la commande suivante dans le terminal de votre machine :
spark- sql
La capture d’écran suivante montre l’ensemble des exécutions qui se produiraient lorsque vous ouvririez spark-sql. Comme vous pouvez le voir, spark-sql utilise la base de données sous-jacente, qui est DERBY par défaut. Dans le chapitre 6, Spark SQL, vous découvrirez comment nous pouvons connecter spark-sql au métastore Hive :

Vous auriez un shell spark-sql connecté par défaut magasin de données Derby:

- Soumission Spark : La fonctionnalité multilingue de Spark vous permet également d’utiliser Java pour accéder aux API Spark. Étant donné que Java (jusqu’à la version 8) ne fournit pas la fonctionnalité REPL, les API Spark sont accessibles et exécutées à l’aide de la commande suivante :
spark-submit
La syntaxe suivante explique comment nous pouvons spécifier jar avec logique, le nombre d’exécuteurs, la spécification des ressources de l’exécuteur et le mode d’exécution pour l’application (autonome ou YARN) :
./bin/spark-submit \
–class <main-class> \
–master <master-url> \
–deploy-mode <deploy-mode> \
–executor-memory 20G \
–total-executor-cores 100
–conf <key>=<value> \
<application-jar> \
[application-arguments]
Ici, nous pouvons décrire les différentes logiques comme suit :
- –class : il s’agit de la classe contenant la méthode main et c’est le point d’entrée de l’application (par exemple, org.apache.spark.examples.SparkPi).
- –master : Il s’agit de la propriété clé pour définir le master de votre application. En fonction du mode autonome ou en mode cluster, le master peut être local, YARN, ou spark://host:port (par exemple, spark://192.168.56.101:7077). Plus d’options sont disponibles sur https://spark.apache.org/docs/latest/submitting-applications.html#master-urls.
- –deploy-mode : il est utilisé pour démarrer le pilote sur l’un des nœuds de travail du cluster ou localement où la commande est exécutée (client) (par défaut : client).
- –conf : Spark configurations que vous souhaitez remplacer pour votre application au format key=value.
- application-jar : il s’agit du chemin de votre application jar. Si elle est présente dans HDFS, alors vous devez spécifier le chemin de HDFS comme hdfs:// path ou si elle est un chemin de fichier, alors il devrait être un chemin valide sur un nœud de pilote, file://path.
- application-arguments : Ce sont les arguments que vous devez spécifier pour la classe principale de votre application.
Différents modes d’exécution
L’application Spark peut s’exécuter dans différents modes, qui sont classés par où et comment nous voulons configurer le maître et quelles sont les besoins en ressources de l’exécuteur.
Le maître peut s’exécuter sur la même machine locale, avec des exécuteurs ; il peut également s’exécuter sur une machine spécifique avec l’hôte et le port fournis. Si nous configurons YARN en tant que gestionnaire de ressources Spark, le maître peut être géré par YARN:
# Exécuter l’application localement sur 8 cœurs
./bin/spark-submit \
–class org.apache.spark.examples.SparkPi \
–master local[8] \
/path/to/examples.jar \
100
# Exécuter sur un cluster autonome Spark en mode de déploiement client
./bin/spark-submit \
–class org.apache.spark.examples.SparkPi \
–master spark://host-ip:7077 \
–executor-memory 20G \
–total-executor-cores 100 \
/path/to/examples.jar \
1000
# Exécuter sur un cluster YARN
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
–class org.apache.spark.examples.SparkPi \
–master yarn \
–deploy-mode cluster \ # can be client for client mode
–executor-memory 20G \
–num-executors 50 \
/path/to/examples.jar \
1000
Source : https://spark.apache.org/docs/latest/submitting-applications.html.
Interface utilisateur Spark : Spark fournit une interface Web pour l’exécution des applications, accessible par défaut sur le port 4040: http://localhost:4040/jobs/ :

Spark sandbox
Pour démarrer rapidement le développement, vous pouvez également télécharger et configurer le bac à sable fourni par Hortonworks ou Cloudera. Voici les liens :
- Hortonworks : https://hortonworks.com/tutorial/hands-on-tour-of-apache-spark-in-5-minutes/
- Cloudera : https://www.cloudera.com/documentation/enterprise/5-6-x/topics/quickstart.html
Résumé
Ce chapitre vous a aidé à installer Java, Scala et Spark sur une machine Linux obtenue à partir d’une instance AWS EC2. Vous pouvez maintenant utiliser la même configuration pour exécuter les requêtes / exemples fournis dans d’autres chapitres de cet article.
Dans le chapitre suivant, vous découvrirez l’unité de base de Spark, qui est RDD. RDD fait référence à un ensemble de données distribué résilient immuable, sur lequel nous pouvons appliquer d’autres actions et transformations.
Chapitre 3. Spark RDD
Les jeux de données distribués résilients (RDD) sont le bloc de construction de base d’une application Spark. Un RDD représente une collection en lecture seule d’objets distribués sur plusieurs machines. Spark peut distribuer une collection d’enregistrements à l’aide d’un RDD et les traiter en parallèle sur différentes machines.
Dans ce chapitre, nous apprendrons ce qui suit :
-
- Qu’est – ce qu’un RDD ?
- Comment créez-vous des RDD ?
- Différentes opérations disponibles pour travailler sur les RDD
- Types importants de RDD
- Mise en cache d’un RDD
- Partitions d’un RDD
- Inconvénients de l’utilisation de RDD
Les exemples de code de ce chapitre sont écrits en Python et Scala uniquement. Si vous souhaitez passer par les API Java et R, vous pouvez visiter la page de documentation Spark sur https://spark.apache.org/.
Qu’est-ce qu’un RDD?
RDD est au cœur de chaque application Spark. Comprenons plus en détail la signification de chaque mot:
- Résilient : si nous regardons la signification de résilient dans le dictionnaire, nous pouvons voir que cela signifie être : capable de récupérer rapidement de conditions difficiles. Spark RDD a la capacité de se recréer en cas de problème. Vous devez vous demander, pourquoi a-t-il besoin de se recréer ? Vous vous souvenez comment HDFS et d’autres magasins de données parviennent à la tolérance aux pannes ? Oui, ces systèmes conservent une réplique des données sur plusieurs machines à récupérer en cas de panne. Mais, comme expliqué au chapitre 1, Introduction à Apache Spark, Spark n’est pas un magasin de données ; Spark est un moteur d’exécution. Il lit les données des systèmes source, les transforme et les charge dans le système cible. Si quelque chose ne va pas lors de l’exécution de l’une des étapes précédentes, nous perdrons les données. Pour fournir la tolérance aux pannes lors du traitement, un RDD est rendu résilient : il peut se recalculer. Chaque RDD conserve des informations sur son RDD parent et comment il a été créé à partir de son parent. Cela nous introduit au concept de Lineage. Les informations sur la maintenance du parent et de l’opération sont appelées lignées. La lignée ne peut être atteinte que si vos données sont immutables. Qu’est-ce que je veux dire par là ? Si vous perdez l’état actuel d’un objet et que vous êtes sûr que l’état précédent ne changera jamais, vous pouvez toujours revenir en arrière et utiliser son état passé avec les mêmes opérations, et vous récupérerez toujours l’état actuel de l’objet. C’est exactement ce qui se passe dans le cas des RDD. Si vous trouvez cela difficile, ne vous inquiétez pas ! Cela deviendra clair lorsque nous verrons comment les RDD sont créés. L’immuabilité apporte également un autre avantage : optimization. Si vous savez que quelque chose ne changera pas, vous avez toujours la possibilité de l’optimiser. Si vous y prêtez attention, tous ces concepts sont connectés, comme l’illustre le schéma suivant :
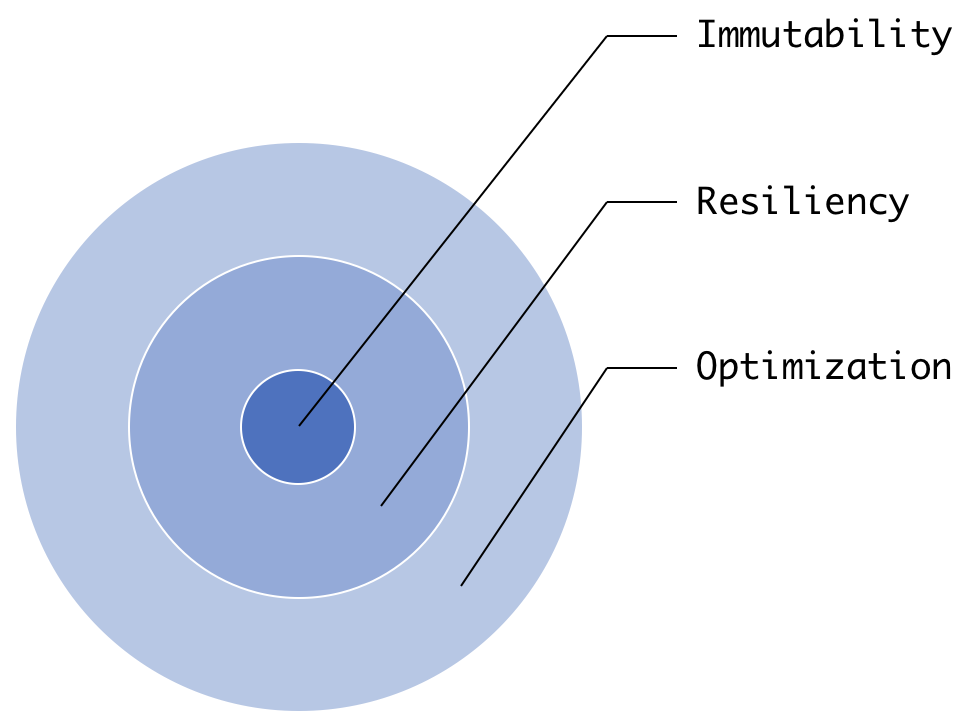
RDD
- Distribué : comme mentionné au point suivant, un ensemble de données n’est rien d’autre qu’une collection d’objets. Un RDD peut distribuer son ensemble de données sur un ensemble de machines, et chacune de ces machines sera responsable du traitement de sa partition de données. Si vous venez d’un arrière-plan Hadoop MapReduce, vous pouvez imaginer des partitions comme les divisions d’entrée pour la phase de carte.
- Jeu de données : un jeu de données n’est qu’une collection d’objets. Ces objets peuvent être un objet complexe Scala, Java ou Python ; Nombres ; cordes ; lignes d’une base de données; et plus.
Chaque programme Spark se résume à un RDD. Un programme Spark écrit en Spark SQL, DataFrame ou ensemble de données est converti en RDD au moment de l’exécution.
Le diagramme suivant illustre un RDD de nombres (1 à 18) ayant neuf partitions sur un cluster de trois nœuds :
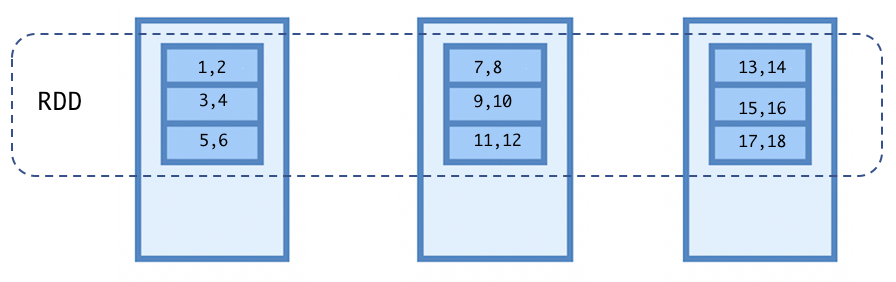
RDD
Métadonnées résilientes
Comme nous l’avons vu, outre les partitions, un RDD stocke également certaines métadonnées à l’intérieur. Ces métadonnées aident Spark à recalculer une partition RDD en cas d’échec et fournissent également des optimisations lors de l’exécution des opérations.
Les métadonnées comprennent les éléments suivants :
- Une liste des dépendances RDD parent
- Une fonction pour calculer une partition à partir de la liste des RDD parents
- L’emplacement préféré pour les partitions
- Les informations de partitionnement, en cas de pair de RDD
Bon, assez de théorie ! Créons un programme simple et comprenons les concepts plus en détail dans la section suivante.
Programmation à l’aide de RDD
Un RDD peut être créé de quatre manières :
- Paralléliser une collection : c’est l’un des moyens les plus simples de créer un RDD. Vous pouvez utiliser la collection existante de vos programmes, tels que List, Array ou Set, ainsi que d’autres, et demander à Spark de distribuer cette collection sur le cluster pour la traiter en parallèle. Une collection peut être distribuée à l’aide de parallelize (), comme illustré ici :
#Python
numberRDD = spark.sparkContext.parallelize(range(1,10))
numberRDD.collect()
Out[4]: [1, 2, 3, 4, 5, 6, 7, 8, 9]
Le code suivant effectue la même opération dans Scala :
//scala
val numberRDD = spark.sparkContext.parallelize(1 to 10)
numberRDD.collect()
res4: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
- À partir d’un jeu de données externe : bien que la parallélisation d’une collection soit le moyen le plus simple de créer un RDD, ce n’est pas le moyen recommandé pour les grands jeux de données. Les grands ensembles de données sont généralement stockés sur des systèmes de fichiers tels que HDFS, et nous savons que Spark est conçu pour traiter les mégadonnées. Par conséquent, Spark fournit un certain nombre d’API pour lire les données des jeux de données externes. L’une des méthodes de lecture des données externes est le textFile ( ) . Cette méthode accepte un nom de fichier et crée un RDD, où chaque élément du RDD est la ligne du fichier d’entrée.
Dans l’exemple suivant, nous initialisons d’abord une variable avec le chemin d’accès au fichier, puis utilisons la variable filePath comme argument de la méthode textFile ( ) :
//Scala
val filePath = “/FileStore/tables/sampleFile.log”
val logRDD = spark.sparkContext.textFile(filePath)
logRDD.collect()
res6: Array[String] = Array(2018-03-19 17:10:26 – myApp – DEBUG – debug message 1, 2018-03-19 17:10:27 – myApp – INFO – info message 1, 2018-03-19 17:10:28 – myApp – WARNING – warn message 1, 2018-03-19 17:10:29 – myApp – ERROR – error message 1, 2018-03-19 17:10:32 – myApp – CRITICAL – critical message with some error 1, 2018-03-19 17:10:33 – myApp – INFO – info message 2, 2018-03-19 17:10:37 – myApp – WARNING – warn message, 2018-03-19 17:10:41 – myApp – ERROR – error message 2, 2018-03-19 17:10:41 – myApp – ERROR – error message 3)
Si vos données sont présentes dans plusieurs fichiers, vous pouvez utiliser wholeTextFiles () au lieu d’utiliser la méthode textFile (). L’argument de wholeTextFiles () est le nom du répertoire qui contient tous les fichiers. Chaque élément sera représenté comme une paire de valeurs clés, où la clé sera le nom du fichier et la valeur sera le contenu entier de ce fichier. Ceci est utile dans les scénarios où vous avez beaucoup de petits fichiers et souhaitez traiter chaque fichier séparément.
Remarque
Les fichiers JSON et XML sont des entrées courantes de wholeTextFiles() car vous pouvez analyser chaque fichier séparément à l’aide d’une bibliothèque d’analyseur.
- À partir d’un autre RDD : Comme indiqué dans la première section, les RDD sont immuables par nature. Ils ne peuvent pas être modifiés, mais nous pouvons transformer un RDD en un autre RDD à l’aide des méthodes fournies par Spark. Nous allons discuter de ces méthodes plus en détail dans ce chapitre. L’exemple suivant utilise filter() pour transformer notre numberRDD en evenNumberRDD en Python. De même, il utilise également filter() pour créer oddNumberRDD dans Scala:
#Python
evenNumberRDD = numberRDD.filter(lambda num : num%2 == 0 )
evenNumberRDD.collect()
Out[10]: [2, 4, 6, 8]
Le code suivant effectue la même opération dans Scala :
//Scala
val oddNumberRDD = numberRDD.filter( num => num%2 != 0 )
oddNumberRDD.collect()
res8: Array[Int] = Array(1, 3, 5, 7, 9)
- À partir d’un DataFrame ou d’un ensemble de données : Vous devez penser, pourquoi créerions- nous jamais un RDD à partir d’un DataFrame ? Après tout, un DataFrame est une abstraction au-dessus d’un RDD. Tu as raison! Pour cette raison, il est conseillé d’utiliser des DataFrames ou un ensemble de données sur un RDD, car un DataFrame apporte des avantages en termes de performances.
Vous devrez peut-être convertir un RDD à partir d’un DataFrame dans certains scénarios où les éléments suivants s’appliquent :
- Les données sont très non structurées
- Les données sont réduites à une taille gérable après des calculs lourds, tels que des jointures ou des agrégations, et vous souhaitez plus de contrôle sur la distribution physique des données à l’aide d’un partitionnement personnalisé
- Vous avez du code écrit dans un langage de programmation différent ou un code RDD hérité
Créons un DataFrame et convertissons-le en RDD :
#Python
rangeDf = spark.range(1,5)
rangeRDD = rangeDf.rdd
rangeRDD.collect()
Out[15]: [Row(id=1), Row(id=2), Row(id=3), Row(id=4)]
Dans le code précédent, nous avons d’abord créé un rangeDf DataFrame avec une colonne id (le nom de colonne par défaut) à l’aide de la méthode range() de Spark , qui a créé 4 lignes, de 1 à 4 . Nous utilisons ensuite la rdd méthode pour convertir en rangeRDD.
Remarque
La méthode range (N) crée des valeurs de 0 à N-1 .
Comme nous avons maintenant une compréhension de base de la façon de créer des RDD, écrivons un programme simple qui lit un fichier journal et renvoie uniquement le nombre de messages avec des niveaux de journal d’ERRoR et d’INFO :
$ cat sampleFile.log
2018-03-19 17:10:26 – myApp – DEBUG – debug message 1
2018-03-19 17:10:27 – myApp – INFO – info message 1
2018-03-19 17:10:28 – myApp – WARNING – warn message 1
2018-03-19 17:10:29 – myApp – ERROR – error message 1
2018-03-19 17:10:32 – myApp – CRITICAL – critical message with some error 1
2018-03-19 17:10:33 – myApp – INFO – info message 2
2018-03-19 17:10:37 – myApp – WARNING – warn message
2018-03-19 17:10:41 – myApp – ERROR – error message 2
2018-03-19 17:10:41 – myApp – ERROR – error message 3
Le code précédent montre le contenu des fichiers sampleFile.log. Chaque ligne dans sampleFile.log représente un journal avec son niveau de journal.
Les extraits de code suivants calculent le nombre de messages ERROR et INFO dans le fichier journal à l’aide de l’API Python :
#Python
filePath = “/FileStore/tables/sampleFile.log”
logRDD = spark.sparkContext.textFile(filePath)
resultRDD = logRDD.filter(lambda line : line.split(” – “)[2] in [‘INFO’,’ERROR’])\
.map(lambda line : (line.split(” – “)[2], 1))\
.reduceByKey(lambda x, y : x + y)
resultRDD.collect()
Out[27]: [(‘INFO’, 2), (‘ERROR’, 3)]
Le code suivant effectue la même opération dans Scala:
//Scala
val filePath = “/FileStore/table/sampleFile.log”
val logRDD = spark.sparkContext.textFile(filePath)
val resultRDD = logRDD.filter(line => Array(“INFO”,”ERROR”).contains(line.split(” -“)(2)))
.map(line => (line.split(” – “)(2), 1))
.reduceByKey( _ + _ )
resultRDD.collect()
res12: Array[(String, Int)] = Array((ERROR,3), (INFO,2))
Dans les deux exemples précédents, nous avons d’abord créé une variable filePath qui contenait le chemin d’accès à notre fichier journal. Nous avons ensuite utilisé la méthode textFile () pour créer notre RDD de base, c’est-à-dire logRDD . Sous le capot, Spark ajoute cette opération à son DAG. Au moment de l’exécution, Spark lira notre sampleFile.log et le distribuera à plusieurs exécuteurs. Dans la ligne suivante, nous utilisons filter () pour obtenir uniquement les lignes qui ont “INFO” et “ERROR” comme niveau de journal. La méthode filter () accepte une fonction en entrée et renvoie un booléen. Nous avons également conduit la sortie du filter à un objet map (), et maintenant le problème est réduit au problème du mot-comte. À ce stade, map () ne recevra que les lignes filtrées et affectera 1 à chaque enregistrement. Nous agrégons les enregistrements en fonction du niveau de journal à l’aide de ReduceByKey (), qui ajoute toutes les valeurs pour chaque niveau de journal. Nous collectons enfin notre résultat en utilisant la méthode collect (). C’est le point où Spark commence réellement à exécuter le DAG.
Transformations et actions
Nous avons discuté de quelques opérations de base pour créer et manipuler des RDD. Il est maintenant temps de les classer en deux catégories principales:
- Transformations
- Actions
Transformation
Comme son nom l’indique, les transformations nous aident à transformer les RDD existants. En sortie, ils créent toujours un nouveau RDD qui est calculé paresseusement. Dans les exemples précédents, nous avons discuté de nombreuses transformations, telles que map() , filter() et ReduceByKey() .
Les transformations sont de deux types :
- Transformations étroites
- Transformations larges
Transformations étroites
Des transformations étroites transforment les données sans mélange. Ces transformations transforment les données par partition ; c’est-à-dire que chaque élément du RDD de sortie peut être calculé sans impliquer d’éléments de différentes partitions. Cela conduit à un point important : le nouveau RDD aura toujours le même nombre de partitions que ses RDD parents, et c’est pourquoi ils sont faciles à recalculer en cas d’échec. Comprenons cela avec l’exemple suivant :
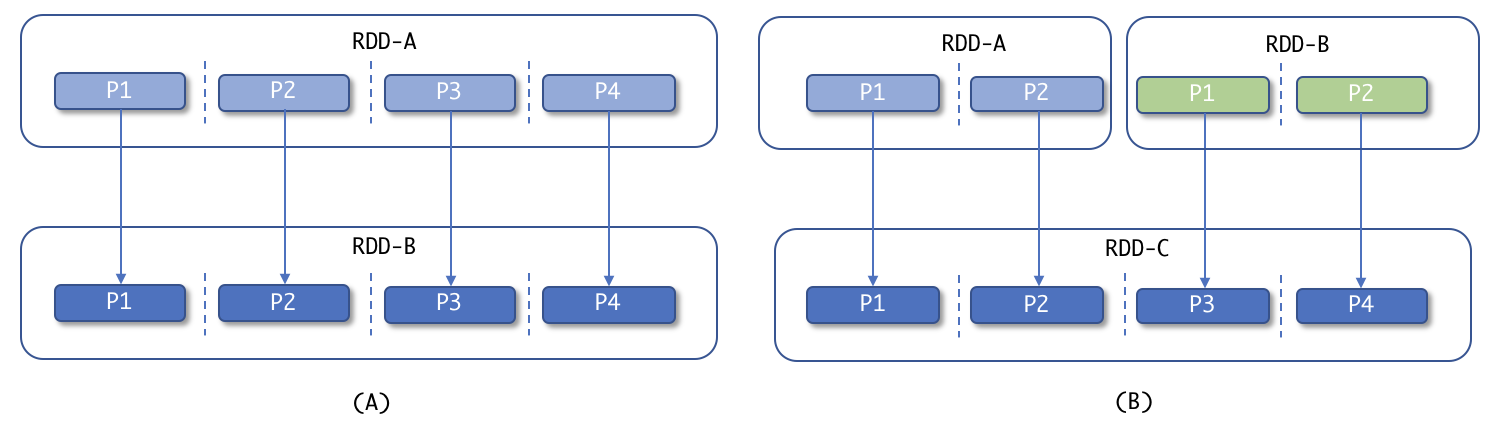
Transformations étroites
Donc, nous avons un RDD-A et nous effectuons une transformation étroite, comme map() ou filter() , et nous obtenons un nouveau RDD-B avec le même nombre de partitions que RDD-A . Dans la partie (B), nous en avons deux, RDD-A et RDD-B, et nous effectuons un autre type de transformation étroite comme union(), et nous obtenons un nouveau RDD-C avec le nombre de partitions égal à la somme de partitions de ses RDD parents ( A et B ). Regardons quelques exemples de transformations étroites.
map ( )
Cela applique une fonction donnée à chaque élément d’un RDD et renvoie un nouveau RDD avec le même nombre d’éléments. Par exemple, dans le code suivant, les nombres de 1 à 10 sont multipliés par le nombre 2 :
#Python
spark.sparkContext.parallelize(range(1,11)).map(lambda x : x * 2).collect()
Le code suivant effectue la même opération dans Scala :
//Scala
spark.sparkContext.parallelize(1 to 10).map(_ * 2).collect()
flatMap ( )
Cela applique une fonction donnée qui renvoie un itérateur à chaque élément d’un RDD et renvoie un nouveau RDD avec plus d’éléments. Dans certains cas, vous pourriez avoir besoin de plusieurs éléments à partir d’un seul élément. Par exemple, dans le code suivant, un RDD contenant des lignes est converti en un autre RDD contenant des mots :
#Python
spark.sparkContext.parallelize([“It’s fun to learn Spark”,”This is a flatMap example using Python”]).flatMap(lambda x : x.split(” “)).collect()
Le code suivant effectue la même opération dans Scala :
//Scala
spark.sparkContext.parallelize(Array(“It’s fun to learn Spark”,”This is a flatMap example using Python”)).flatMap(x => x.split(” “)).collect()
filtre ( )
La transformation filter( ) applique une fonction qui filtre les éléments qui ne répondent pas aux critères de condition, comme indiqué dans le code suivant. Par exemple, si nous avons besoin de nombres supérieurs à 5, nous pouvons passer cette condition à la transformation filter( ) . Créons un RDD de nombres 1 à 10 et filtrons les nombres supérieurs à 5 :
#Python
spark.sparkContext.parallelize(range(1,11)).filter(lambda x : x > 5).collect()
Le code suivant effectue la même opération dans Scala :
//Scala
spark.sparkContext.parallelize(1 to 10).filter(_ > 5).collect()
Toute fonction qui renvoie une valeur booléenne peut être utilisée pour filtrer les éléments.
union ( )
La transformation union() prend un autre RDD en entrée et produit un nouveau RDD contenant des éléments à partir des deux RDD, comme indiqué dans le code suivant. Créons deux RDD : l’un avec les numéros 1 à 5 et l’autre avec les numéros 5 à 10 , puis les concaténons ensemble pour obtenir un nouveau RDD avec les numéros 1 à 10 :
#Python
firstRDD = spark.sparkContext.parallelize(range(1,6))
secordRDD = spark.sparkContext.parallelize(range(5,11))
firstRDD.union(secordRDD).collect()
Le code suivant effectue la même opération dans Scala :
//scala
val firstRDD = spark.sparkContext.parallelize(1 to 5)
val secordRDD = spark.sparkContext.parallelize(5 to 10)
firstRDD.union(secordRDD).collect()
Remarque
La transformation union() ne supprime pas les doublons. Si vous venez d’un arrière-plan SQL, union() effectue la même opération que Union All dans SQL.
mapPartitions ( )
La transformation mapPartitions() est similaire à map() . Il permet également aux utilisateurs de manipuler les éléments d’un RDD, mais il offre plus de contrôle par partition. Il applique une fonction qui accepte un itérateur comme argument et renvoie un itérateur comme sortie. Si vous avez effectué des scripts shell et que vous connaissez la programmation AWK , vous pouvez corréler cela avec la transformation mapPartitions pour mieux la comprendre. Un exemple AWK typique ressemble à BEGIN { # Begin block } {#middle block} END {#end Block }. Le bloc Begin ne s’exécute qu’une seule fois avant de lire le contenu du fichier, le bloc du middle s’exécute pour chaque ligne du fichier d’entrée et le bloc end ne s’exécute également qu’une seule fois à la fin du fichier. De même, si vous souhaitez que certaines opérations soient effectuées au début ou à la fin du traitement de tous les éléments un par un, vous pouvez utiliser la transformation mapPartitions() . Dans le code suivant, nous multiplions chaque élément par 2, mais cette fois avec mapPartitions() :
#Python
spark.sparkContext.parallelize(range(1,11), 2).mapPartitions(lambda iterOfElements : [e*2 for e in iterOfElements]).collect()
Le code suivant effectue la même opération dans Scala :
//scala
spark.sparkContext.parallelize(1 to 10, 2).mapPartitions(iterOfElements => for (e <- iterOfElements) yield e*2 ).collect()
Un exemple où vous pourriez utiliser mapPartitions() est lorsque vous devez ouvrir une connexion de base de données au début de chaque partition.
Remarque
Si vous souhaitez créer un objet une seule fois et que cet objet doit être utilisé lors du calcul dans chaque partition, vous pouvez utiliser des variables de broadscast.
Transformations larges
Les transformations larges impliquent un brassage des données entre les partitions. Les groupByKey() , ReduceByKey() , join() , distinct() et intersect() sont quelques exemples de transformations larges. Dans le cas de ces transformations, le résultat sera calculé à l’aide des données de plusieurs partitions et nécessite donc un shuffle. Les transformations larges sont similaires à la phase de shuffle-and-sort de MapReduce. Comprenons le concept à l’aide de l’exemple suivant :
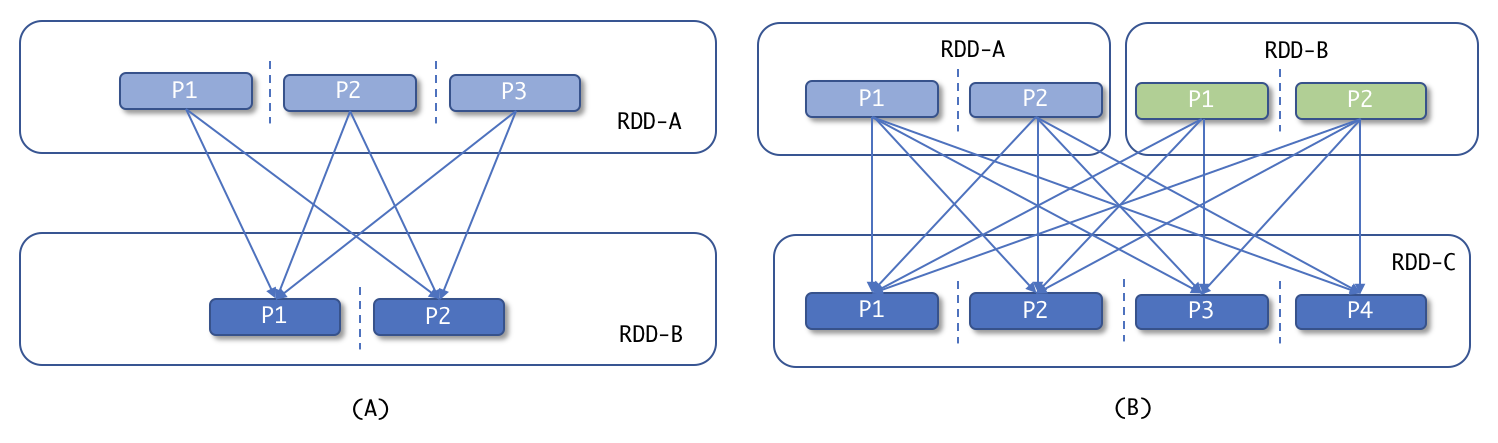
Transformations larges
Nous avons un RDD-A et nous effectuons une large transformation telle que groupByKey() et nous obtenons un nouveau RDD-B avec moins de partitions. RDD-B aura des données regroupées par chaque clé de l’ensemble de données. Dans la partie (B) , nous avons deux RDD : RDD-A et RDD-B et nous effectuons un autre type de transformation large comme join() ou intersection() et obtenons un nouveau RDD-C . Voici quelques exemples de transformations étendues.
distinct ( )
La transformation distinct() supprime les éléments en double et renvoie un nouveau RDD avec des éléments uniques comme indiqué. Créons un RDD avec des éléments dupliquées (1,2,3,4) et utilisons distinct() pour obtenir un RDD avec des nombres uniques:
#Python
spark.sparkContext.parallelize([1,1,2,2,3,3,4,4]).distinct().collect()
Le code suivant effectue la même opération dans Scala:
//scala
spark.sparkContext.parallelize(Array(1,1,2,2,3,3,4,4)).distinct().collect()
sortBy ( )
Nous pouvons trier un RDD à l’aide de la transformation sortBy() . Il accepte une fonction qui peut être utilisée pour trier les éléments RDD. Dans l’exemple suivant, nous trions notre RDD dans l’ordre décroissant à l’aide du deuxième élément du tuple :
#Python
spark.sparkContext.parallelize([(‘Rahul’, 4),(‘Aman’, 2),(‘Shrey’, 6),(‘Akash’, 1)]).sortBy(lambda x : -x[1]).collect()
Le code suivant effectue la même opération dans Scala :
//scala
spark.sparkContext.parallelize(Array((“Rahul”, 4),(“Aman”, 2),(“Shrey”, 6),(“Akash”, 1))).sortBy( _._2 * -1 ).collect()
Le code précédent entraînera ceci :
[(‘Shrey’, 6), (‘Rahul’, 4), (‘Aman’, 2), (‘Akash’, 1)]
intersection ( )
La transformation intersection() nous permet de trouver des éléments communs entre deux RDD. Comme la transformation union(), intersection() est également une opération d’ensemble entre deux RDD, mais implique un shuffle. Les exemples suivants montrent comment trouver des éléments communs entre deux RDD à l’aide d’intersection() :
#Python
firstRDD = spark.sparkContext.parallelize(range(1,6))
secordRDD = spark.sparkContext.parallelize(range(5,11))
firstRDD.intersection(secordRDD).collect()
Le code suivant effectue la même opération dans Scala :
//Scala
val firstRDD = spark.sparkContext.parallelize(1 to 5)
val secordRDD = spark.sparkContext.parallelize(5 to 10)
firstRDD.intersection(secordRDD).collect()
Le code précédent donne un résultat de 5.
substract ( )
Vous pouvez utiliser la transformation subtract() pour supprimer le contenu d’un RDD à l’aide d’un autre RDD. Créons deux RDD : le premier a des nombres de 1 à 10 et le second a des éléments de 6 à 10. Si nous utilisons subtract() , nous obtenons un nouveau RDD avec les nombres 1 à 5 :
#Python
firstRDD = spark.sparkContext.parallelize(range(1,11))
secordRDD = spark.sparkContext.parallelize(range(6,11))
firstRDD.subtract(secordRDD).collect()
Le code suivant effectue la même opération dans Scala:
//scala
val firstRDD = spark.sparkContext.parallelize(1 to 10)
val secordRDD = spark.sparkContext.parallelize(6 to 10)
firstRDD.subtract(secordRDD).collect()
Dans l’exemple précédent, nous avons deux RDD: firstRDD contient des éléments de 1 à 10 et secondRDD contient des éléments 6 à 10 . Après avoir appliqué la transformation subtract() , nous obtenons un nouveau RDD contenant des éléments de 1 à 5 .
cartesian()
La transformation cartesian() peut joindre des éléments d’un RDD à tous les éléments d’un autre RDD et donne le produit cartésien de deux. Dans les exemples suivants, firstRDD a des éléments [0,1,2] et secondRDD a des éléments [‘A’,’B’,’C’] . Nous utilisons cartesian() pour obtenir le produit cartésien de deux RDD :
#Python
firstRDD = spark.sparkContext.parallelize(range(3))
secordRDD = spark.sparkContext.parallelize([‘A’,’B’,’C’])
firstRDD.cartesian(secordRDD).collect()
Le code suivant effectue la même opération dans Scala :
//scala
val firstRDD = spark.sparkContext.parallelize(0 to 2)
val secordRDD = spark.sparkContext.parallelize(Array(“A”,”B”,”C”))
firstRDD.cartesian(secordRDD).collect()
Voici la sortie de l’exemple précédent :
//Scala
Array[(Int, String)] = Array((0,A), (0,B), (0,C), (1,A), (1,B), (1,C), (2,A), (2,B), (2,C))
N’oubliez pas que ces opérations impliquent un shuffle et nécessitent donc de nombreuses ressources informatiques telles que la mémoire, le disque et la bande passante du réseau.
Remarque
textFile() et wholeTextFiles() sont également considérés comme des transformations, car ils créent un nouveau RDD à partir de données externes.
Action
Vous auriez remarqué que dans chaque exemple que nous avons utilisé, la méthode collect() pour obtenir la sortie. Pour obtenir le résultat final pour le pilote, Spark fournit un autre type d’opération appelé actions. Au moment des transformations, Spark enchaîne ces opérations et construit un DAG, mais rien n’est exécuté. Une fois qu’une action est effectuée sur un RDD, elle force l’évaluation de toutes les transformations nécessaires pour calculer ce RDD.
Les actions ne créent pas de nouveau RDD. Ils sont utilisés pour :
- Retour des résultats finaux au pilote
- Écriture du résultat final sur un stockage externe
- Exécution d’une opération sur chaque élément de ce RDD (par exemple, foreach())
Discutons de certaines des actions de base.
collect ( )
L’action collect() renvoie tous les éléments d’un RDD au programme pilote. Vous ne devez utiliser collect() que si vous êtes sûr de la taille de votre sortie finale. Si la taille de la sortie finale est énorme, votre programme de pilote peut se bloquer lors de la réception des données des exécuteurs. L’utilisation de collect() n’est pas conseillée en production. L’exemple suivant collecte tous les éléments d’un RDD contenant des nombres de 0 à 9 :
#Python
spark.sparkContext.parallelize(range(10)).collect()
Out[26]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
count ( )
Utilisez count() pour compter le nombre d’éléments dans le RDD. Le code Scala suivant compte le nombre d’un RDD et renvoie 10 en sortie :
//scala
spark.sparkContext.parallelize(1 to 10).count()
res17: Long = 10
take ( )
L’action take() renvoie N nombre d’éléments d’un RDD. Le code suivant renvoie les deux premiers éléments d’un RDD contenant les nombres 0 à 9 :
#Python
spark.sparkContext.parallelize(range(10)).take(2)
Out[27]: [0, 1]
top ( )
L’action top() renvoie les N éléments supérieurs du RDD. Le code suivant renvoie les 2 premiers éléments d’un RDD :
#Python
spark.sparkContext.parallelize(range(10)).top(2)
Out[28]: [9, 8]
takeOrdered ( )
Si vous souhaitez obtenir l’élément N sur la base d’un ordre, vous pouvez utiliser une action takeOrdered(). Vous pouvez également utiliser la transformation sortBy(), suivie d’une action take(). Les deux approches déclenchent un remaniement des données. Dans l’exemple suivant, nous retirons 3 éléments du RDD, contenant des nombres de 0 à 9, en fournissant nos propres critères de tri :
#Python
spark.sparkContext.parallelize(range(10)).takeOrdered(3, key = lambda x: -x)
Out[3]: [9, 8, 7]
Ici, nous avons pris les 3 premiers éléments par ordre décroissant.
first ( )
L’action first() renvoie le premier élément du RDD. L’exemple suivant retourne le premier élément du RDD :
#Python
spark.sparkContext.parallelize(range(10)).first()
Out[4]: 0
countByValue ( )
L’action countByValue() peut être utilisée pour trouver l’occurrence de chaque élément dans le RDD. Voici le code Scala qui renvoie une Map de paire clé-valeur. Dans la sortie, Map , la clé est l’élément RDD et la valeur est le nombre d’occurrences de cet élément dans le RDD:
//Scala
spark.sparkContext.parallelize(Array(“A”,”A”,”B”,”C”)).countByValue()
res0: scala.collection.Map[String,Long] = Map(A -> 2, B -> 1, C -> 1)
reduce ( )
L’action reduce() combine les éléments RDD en parallèle et donne des résultats agrégés en sortie. Dans l’exemple suivant, nous calculons la somme des 10 premiers nombres naturels :
//Scala
spark.sparkContext.parallelize(1 to 10).reduce( _ + _ )
res1: Int = 55
saveAsTextFile ( )
Pour enregistrer les résultats dans un magasin de données externe, nous pouvons utiliser saveAsTextFile() pour enregistrer votre résultat dans un répertoire. Vous pouvez également spécifier un codec de compression pour stocker vos données sous forme compressée. Écrivons notre numéro RDD dans un fichier :
#Python
spark.sparkContext.parallelize(range(10)).saveAsTextFile(‘/FileStore/tables/result’)
Dans l’exemple précédent, nous fournissons un répertoire comme argument et Spark écrit des données dans ce répertoire dans plusieurs fichiers, avec le fichier de réussite ( _success ).
Remarque
Si un répertoire existant est fourni comme argument à l’action saveAsTextFile(), le travail échouera avec l’ exception FileAlreadyExistsException. Ce comportement est important car nous pourrions réécrire accidentellement un répertoire contenant les données d’un travail lourd.
foreach()
La fonction foreach() applique une fonction à chaque élément du RDD. L’exemple suivant concatène la chaîne Mr. à chaque élément à l’aide de foreach() :
//Scala
spark.sparkContext.parallelize(Array(“Smith”,”John”,”Brown”,”Dave”)).foreach{ x => println(“Mr. “+x) }
Si vous exécutez l’exemple précédent en mode local, vous verrez la sortie. Mais, dans le cas du mode cluster, vous ne pourrez pas voir les résultats, car foreach() exécute la fonction donnée à l’intérieur des exécuteurs et ne renvoie aucune donnée au pilote.
Ceci est principalement utilisé pour travailler avec des accumulateurs. Nous verrons cela plus en détail dans le chapitre 5, Flux d’exécution d’architecture et d’application Spark.
Vous pouvez trouver plus de transformations et d’actions sur https://spark.apache.org/docs/2.3.0/rdd-programming-guide.html#transformations.
Types de RDD
Les RDD peuvent être classés en plusieurs catégories. Voici quelques exemples :
| Hadoop RDD | Shuffled RDD | PairRDD |
| Mapped RDD | Union RDD | JSON RDD |
| Filtered RDD | Double RDD | Vertex RDD |
Nous ne les aborderons pas tous dans ce chapitre, car ils sortent du cadre de ce chapitre. Mais nous allons discuter de l’un des types importants de RDD: pair RDDs.
Pairs RDD
Un Pair RDD est un type spécial de RDD qui traite les données sous forme de paires clé-valeur. Pair RDD est très utile car il permet des fonctionnalités de base telles que join et les aggregations. Spark fournit certaines opérations spéciales sur ces RDD de manière optimisée. Si nous rappelons les exemples où nous avons calculé le nombre de messages INFO et ERROR dans sampleFile.log à l’aide de ReduceByKey(), nous pouvons clairement voir l’importance de la paire RDD.
L’une des façons de créer une paire RDD consiste à paralléliser une collection qui contient des éléments sous la forme de Tuple. Regardons quelques-unes des transformations fournies par une paire RDD.
groupByKey ( )
Les éléments ayant la même clé peuvent être regroupés à l’aide d’une transformation groupByKey(). L’exemple suivant regroupe les données de chaque clé :
#Python
pairRDD = spark.sparkContext.parallelize([(1, 5),(1, 10),(2, 4),(3, 1),(2, 6)])
result = pairRDD.groupByKey().collect()
for pair in result:
print ‘key -‘,pair[0],’, value -‘, list(pair[1])
Output:
key – 1 , value – [5, 10]
key – 2 , value – [4, 6]
key – 3 , value – [1]
Le code suivant effectue la même opération dans Scala :
//Scala
val pairRDD = spark.sparkContext.parallelize(Array((1, 5),(1, 10),(2, 4),(3, 1),(2, 6)))
val result = pairRDD.groupByKey().collect()
result.foreach {
pair => println(“key – “+pair._1+”, value -“+pair._2.toList)
}
Output:
key – 1, value -List(5, 10)
key – 2, value -List(4, 6)
key – 3, value -List(1)
La transformation groupByKey() est une transformation large qui mélange les données entre les exécuteurs en fonction de la clé. Un point important ici est de noter que groupByKey ( ) n’agrège pas les données, il regroupe seulement les groupes en fonction de la clé. La transformation groupByKey() doit être utilisée avec prudence. Si vous comprenez très bien vos données, alors groupByKey() peut apporter certains avantages dans certains scénarios. Par exemple, supposons que vous ayez des données de valeur-clé, où la clé est le code du pays et la valeur est le montant de la transaction, et vos données sont fortement asymétriques en raison du fait que plus de 90% de vos clients sont basés aux États-Unis. Dans ce cas, si vous utilisez groupByKey() pour regrouper vos données, vous risquez de rencontrer des problèmes car Spark mélangera toutes les données et tentera d’envoyer des enregistrements avec les États-Unis à une seule machine. Cela pourrait entraîner un échec. Il existe certaines techniques telles que les salted keys pour éviter de tels scénarios.
Malgré cet inconvénient, groupByKey peut être très utile dans certains scénarios. Si vous savez que vos données ne sont pas asymétriques et que vous souhaitez calculer plusieurs agrégations telles que max, min et average utilisant les mêmes données sous-jacentes, vous pouvez d’abord grouper les éléments à l’aide de groupByKey() et les conserver.
reduceByKey()
Une transformation ReduceByKey() est disponible sur Pair RDD. Il permet l’agrégation de données en minimisant le brassage de données et effectue des opérations sur chaque clé en parallèle. Une transformation ReduceByKey() effectue d’abord l’agrégation locale au sein de l’exécuteur, puis mélange les données agrégées entre chaque nœud. Dans l’exemple suivant, nous calculons la somme de chaque clé à l’aide de ReduceByKey :
#Python
pairRDD = spark.sparkContext.parallelize([(1, 5),(1, 10),(2, 4),(3, 1),(2, 6)])
pairRDD.reduceByKey(lambda x,y : x+y).collect()
Output:
[(1, 15), (2, 10), (3, 1)]
Le code suivant effectue la même opération dans Scala :
//Scala
val pairRDD = spark.sparkContext.parallelize(Array((1, 5),(1, 10),(2, 4),(3, 1),(2, 6)))
pairRDD.reduceByKey(_+_).collect()
Output:
Array[(Int, Int)] = Array((1,15), (2,10), (3,1))
Remarque
Une transformation ReduceByKey() ne peut être utilisée que pour les agrégations associatives, par exemple: (A + B) + C = A + (B + C).
sortByKey()
Le sortByKey() peut être utilisé pour trier la paire RDD en fonction des clés. Dans l’exemple suivant, nous créons d’abord un RDD en parallélisant une liste de tuples, puis nous le trions par le premier élément du tuple :
#Python
pairRDD = spark.sparkContext.parallelize([(1, 5),(1, 10),(2, 4),(3, 1),(2, 6)])
pairRDD.sortByKey().collect()
Output:
[(1, 5), (1, 10), (2, 4), (2, 6), (3, 1)]
Par défaut, sortByKey() trie les éléments dans l’ordre croissant, mais vous pouvez modifier l’ordre de tri en passant votre commande personnalisée. Par exemple, sortByKey ( keyfunc = lambda k: -k) triera le RDD dans l’ordre décroissant.
join()
La transformation join() joindra deux paires de RDD en fonction de leurs clés. L’exemple suivant joint les données en fonction du pays et renvoie uniquement les enregistrements correspondants :
//Scala
val salesRDD = spark.sparkContext.parallelize(Array((“US”,20),(“IND”, 30),(“UK”,10)))
val revenueRDD = spark.sparkContext.parallelize(Array((“US”,200),(“IND”, 300)))
salesRDD.join(revenueRDD).collect()
Output:
Array[(String, (Int, Int))] = Array((US,(20,200)), (IND,(30,300)))
Il y a quelques autres transformations disponibles sur la paire RDD tels que aggregateByKey ( ) , cogroup () , leftOuterJoin () , rightOuterJoin () , subtractByKey () , et plus encore. Certaines des actions spéciales incluent countByKey ( ) , collectAsMap () et lookup () .
Mise en cache et point de contrôle
La mise en cache et les points de contrôle sont quelques-unes des fonctionnalités importantes de Spark. Ces opérations peuvent améliorer considérablement les performances de vos travaux Spark.
Mise en cache
La mise en cache des données dans la mémoire est l’une des principales fonctionnalités de Spark. Vous pouvez mettre en cache de grands ensembles de données en mémoire ou sur disque en fonction du matériel de votre cluster. Vous pouvez choisir de mettre vos données en cache dans deux scénarios :
- Utilisez plusieurs fois le même RDD
- Évitez la réoccupation d’un RDD qui implique des calculs lourds, tels que join() et groupByKey()
Si vous souhaitez exécuter plusieurs actions d’un RDD, ce sera une bonne idée de le mettre en cache dans la mémoire afin d’éviter la recompilation de ce RDD. Par exemple, le code suivant extrait d’abord quelques éléments du RDD, puis renvoie le nombre d’éléments :
//Scala
val baseRDD = spark.sparkContext.parallelize(1 to 10)
baseRDD.take(2)
baseRDD.count()
Le code suivant utilise cache ( ) pour rendre l’application efficace:
//Scala
val baseRDD = spark.sparkContext.parallelize(1 to 10)
baseRDD.cache() //Caching baseRDD
baseRDD.take(2)
baseRDD.count()
Spark calculera deux fois baseRDD pour effectuer les actions take() et count() . Nous mettons en cache notre baseRDD puis exécutons les actions. Cela ne calcule le RDD qu’une seule fois et exécute l’action au-dessus des données mises en cache. Dans cet exemple, il pourrait ne pas y avoir beaucoup de différence dans les performances, car ici nous avons affaire à de très petits ensembles de données. Mais vous pouvez imaginer le goulot d’étranglement dans le cas des mégadonnées.
Spark ne met pas les données en cache immédiatement dès que nous écrivons l’opération cache(). Mais il prend note de cette opération, et une fois qu’il rencontre la première action, il calculera le RDD et le mettra en cache en fonction du niveau de mise en cache.
Le tableau suivant répertorie plusieurs niveaux de persistance des données fournis par Spark :
| Niveau | Définition |
| MEMORY_ONLY | Stocke les données en mémoire en tant qu’objets Java non sérialisés |
| MEMORY_ONLY_SER | Stocke les données en mémoire mais en tant qu’objets Java sérialisés |
| MEMORY_AND_DISK | Objets Java non sérialisés en mémoire et données sérialisées restantes sur le disque |
| MEMORY_AND_DISK_SER | Objets Java sérialisés en mémoire plus les données sérialisées restantes sur le disque |
| DISK_ONLY | Stocke les données sur le disque |
| OFF_HEAP | Stocke les RDD hors série en série dans Techyon (stockage en mémoire de Spark) |
Remarque
Vous pouvez répliquer les données mises en cache sur deux nœuds en écrivant _2 à la fin du niveau persistant.
Un point important à noter ici est que dans le cas du niveau de mise en cache MEMORY_ONLY , si certaines données ne rentrent pas dans la mémoire, les données restantes ne sont pas stockées par défaut dans le disque. Les partitions restantes sont recalculées au moment de l’exécution. Le cache n’est pas une transformation ni une action.
Remarque
Il est recommandé d’annuler la résistance de vos RDD mis en cache une fois que vous avez terminé avec ce RDD. Vous pouvez appeler unpersist() , qui supprime les données de la mémoire.
Checkpointing
Le cycle de vie du RDD mis en cache prendra fin à la fin de la session Spark. Si vous avez calculé un RDD et que vous souhaitez l’utiliser dans un autre programme Spark sans le recalculer, vous pouvez utiliser l’opération checkpoint(). Cela permet de stocker le contenu RDD sur le disque, qui peut être utilisé pour les opérations ultérieures. Discutons-en à l’aide d’un exemple :
#Python
baseRDD = spark.sparkContext.parallelize([‘A’,’B’,’C’])
spark.sparkContext.setCheckpointDir(“/FileStore/tables/checkpointing”)
baseRDD.checkpoint()
Nous créons d’abord un baseRDD et définissons un répertoire de point de contrôle à l’aide de la méthode setCheckpointDir(). Enfin, nous stockons le contenu de baseRDD en utilisant checkpoint().
Comprendre les partitions
Le partitionnement des données joue un rôle très important dans l’informatique distribuée, car il définit le degré de parallélisme des applications. Comprendre et définir les partitions de la bonne manière peut améliorer considérablement les performances des travaux Spark. Il existe deux façons de contrôler le degré de parallélisme des opérations RDD :
- repartition() et fusion()
- partitionBy()
repartition ( ) VS coalesce ()
Les partitions d’un RDD existant peuvent être modifiées à l’aide de repartition() ou coalesce() . Ces opérations peuvent redistribuer le RDD en fonction du nombre de partitions fournies. La repartition() peut être utilisée pour augmenter ou diminuer le nombre de partitions, mais elle implique un brassage important des données sur le cluster. D’un autre côté, coalesce() ne peut être utilisé que pour diminuer le nombre de partitions. Dans la plupart des cas, coalesce() ne déclenche pas de lecture aléatoire. Le coalesce() peut être utilisé peu de temps après un filtrage intensif pour optimiser le temps d’exécution. Il est important de noter que coalesce () n’évite pas toujours le brassage. Si le nombre de partitions fournies est beaucoup plus petit que le nombre de nœuds disponibles dans le cluster, les données seront mélangées sur certains nœuds, mais coalesce() donnera toujours de meilleures performances que repartition() . Le diagramme suivant montre la différence entre repartition() et coalesce() :

Répartition et fusion
La repartition() n’est pas si mauvaise après tout. Dans certains cas, lorsque votre travail n’utilise pas tous les emplacements disponibles, vous pouvez repartitionner vos données pour les exécuter plus rapidement.
partitionBy ( )
Toute opération qui mélange les données accepte un paramètre supplémentaire, à savoir des degrés de parallélisme. Cela permet aux utilisateurs de fournir le nombre de partitions pour le RDD produit. L’exemple suivant montre comment vous pouvez modifier le nombre de partitions du nouveau RDD en passant un paramètre supplémentaire :
//Scala
val baseRDD = spark.sparkContext.parallelize(Array((“US”,20),(“IND”, 30),(“UK”,10)), 3)
println(baseRDD.getNumPartitions)
Output:
3
Le code suivant modifie le nombre de partitions du nouveau RDD :
//Scala
val groupedRDD = baseRDD.groupByKey(2)
println(groupedRDD.getNumPartitions)
Output:
2
Le baseRDD a 3 partitions. Nous avons passé un paramètre supplémentaire à groupByKey qui dira à Spark de produire groupedRDD avec 2 partitions.
Spark fournit également une opération partitionBy() , qui peut être utilisée pour contrôler le nombre de partitions. Une fonction de partitionnement peut être passée comme argument à partitionBy() pour redistribuer les données d’un RDD. Ceci est très utile dans certaines opérations, comme join() . Comprenons cela à l’aide d’un exemple :
//Scala
import org.apache.spark.HashPartitioner
val baseRDD = spark.sparkContext.parallelize(Array((“US”,20),(“IND”, 30),(“UK”,10)), 3)
baseRDD.partitionBy(new HashPartitioner(2)).persist()
Cela montre l’utilisation de partitionBy() . Nous avons passé un HashPartitioner() qui redistribuera les données en fonction des valeurs clés et créera deux partitions de baseRDD . Spark peut tirer parti de ces informations et minimiser le brassage des données lors de la transformation join().
Remarque
Il est conseillé de conserver le RDD après le repartitionnement si le RDD va être utilisé fréquemment.
Inconvénients de l’utilisation de RDD
Un RDD est un type sûr à la compilation. Cela signifie, dans le cas de Scala et Java, si une opération est effectuée sur le RDD qui n’est pas applicable au type de données sous-jacent, alors Spark donnera une erreur de temps de compilation. Cela peut éviter des échecs de production.
Il existe cependant certains inconvénients à l’utilisation de RDD :
- Le code RDD peut parfois être très opaque. Les développeurs peuvent avoir du mal à découvrir exactement ce que le code essaie de calculer.
- Les RDD ne peuvent pas être optimisés par Spark, car Spark ne peut pas regarder à l’intérieur des fonctions lambda et optimiser les opérations. Dans certains cas, lorsqu’un filter ( ) est canalisé après une transformation large, Spark n’effectuera jamais le filtre avant la transformation large, tel que ReduceByKey () ou groupByKey () .
- Les RDD sont plus lents sur les langages non JVM tels que Python et R. Dans le cas de ces langages, une machine virtuelle Python / R est créée avec JVM. Il y a toujours un transfert de données impliqué entre ces machines virtuelles, ce qui peut augmenter considérablement le temps d’exécution.
Résumé
Dans ce chapitre, nous avons d’abord appris l’idée de base d’un RDD. Nous avons ensuite examiné comment créer des RDD à l’aide de différentes approches, telles que la création d’un RDD à partir d’un RDD existant, d’un magasin de données externe, de la mise en parallèle d’une collection et d’un DataFrame et d’ensembles de données. Nous avons également examiné les différents types de transformations et d’actions disponibles sur les RDD. Ensuite, les différents types de RDD ont été discutés, en particulier la paire RDD. Nous avons également discuté des avantages de la mise en cache et des points de contrôle dans les applications Spark, puis nous avons appris plus en détail les partitions et comment utiliser des fonctionnalités telles que le partitionnement, pour optimiser nos travaux Spark.
En fin de compte, nous avons également discuté de certains des inconvénients de l’utilisation de RDD. Dans le chapitre suivant, nous discuterons des DataFrame et des API de jeux de données et verrons comment ils peuvent surmonter ces défis.
Chapitre 4. Spark DataFrame et Dataset
Dans le chapitre précédent, nous avons découvert les concepts RDD et les API. Dans ce chapitre, nous explorerons les API DataFrame, qui sont des abstractions sur les RDD, et discuterons également des API d’ensemble de données fournies avec Spark 2.0 pour fournir diverses optimisations sur les DataFrames.
Les sujets suivants seront traités dans ce chapitre :
- DataFrames
- Jeux de données
DataFrames
Comme nous l’avons déjà mentionné, les API DataFrame sont des abstractions des API RDD. Les DataFrames sont des collections de données distribuées organisées sous forme de lignes et de colonnes. En d’autres termes, DataFrames fournit des API pour traiter efficacement les données structurées disponibles dans différentes sources. Les sources peuvent être un RDD, différents types de fichiers dans un système de fichiers, n’importe quel SGBDR ou des tables Hive.
Les fonctionnalités des DataFrames sont les suivantes :
- Les DataFrames peuvent traiter des données disponibles dans différents formats, tels que CSV, AVRO et JSON, ou stockées sur n’importe quel support de stockage, tel que Hive, HDFS et RDBMS
- Les DataFrames peuvent traiter des volumes de données de kilo-octets à pétaoctets
- Utilisez l’optimiseur de requêtes Spark-SQL pour traiter les données de manière distribuée et optimisée
- Prise en charge des API dans plusieurs langues, dont Java, Scala, Python et R
Création de DataFrames
Pour commencer, nous avons besoin d’un objet de session Spark , qui sera utilisé pour convertir les RDD en DataFrames , ou pour charger les données directement d’un fichier dans un DataFrame.
Nous utilisons l’ensemble de données sur les ventes dans ce chapitre. Vous pouvez obtenir le fichier de l’ensemble de données, ainsi que les fichiers de code de ce chapitre, à partir du lien suivant : https://github.com/PacktPublishing/Apache-Spark-Quick-Start-Guide:
//Scala
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().appName(“Spark DataFrame example”).config(“spark.some.config.option”, “value”).getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
//Java
import org.apache.spark.sql.SparkSession;
SparkSession spark = SparkSession.builder().appName(“Java Spark DataFrame example”).config(“spark.some.config.option”, “value”).getOrCreate();
#Python
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName(“Python Spark DataFrame example”).config(“spark.some.config.option”, “value”).getOrCreate()
Source : https://spark.apache.org/docs/latest/sql-programming-guide.html#starting-point-sparksession.
Une fois la session spark créée dans la langue de votre choix, vous pouvez soit convertir un RDD en DataFrame, soit charger des données depuis n’importe quel stockage de fichiers vers un DataFrame :
//Scala
val sales_df = spark.read.option(“sep”, “\t”).option(“header”, “true”).csv(“file:///opt/data/sales/sample_10000.txt”)
// Displays the content of the DataFrame to stdout
sales_df.show()
//Java
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
Dataset<Row> df_sales = spark.read.option(“sep”, “\t”).option(“header”, “true”).csv(“file:///opt/data/sales/sample_10000.txt”);
// Displays the content of the DataFrame to stdout
sales_df.show()
#Python
sales_df = spark.read.option(“sep”, “\t”).option(“header”, “true”).csv(“file:///opt/data/sales/sample_10000.txt”)
# Displays the content of the DataFrame to stdout
sales_df.show()
Remarque
Pour les fichiers en HDFS et S3, le format de chemin de fichier aura hdfs:// ou S3:// au lieu de file:// . Si les fichiers ne contiennent pas d’informations d’en-tête, vous pouvez ignorer l’option (header, true).
Source d’information
Spark SQL permet aux utilisateurs d’interroger une grande variété de sources de données. Ces sources peuvent être des fichiers, tels que Java Database Connectivity (JDBC).
Il existe plusieurs façons de charger des données. Jetons un coup d’œil aux deux méthodes :
- Charger les données du parquet :
//Scala
val sales_df = spark.read.option(“sep”, “\t”).option(“header”, “true”).csv(“file:///opt/data/sales/sample_10000.txt”)
sales_df.write.parquet(“sales.parquet”)
valparquet_sales_DF=spark.read.parquet(“sales.parquet”)
parquet_sales_DF.createOrReplaceTempView(“parquetSales”)
val ipDF=spark.sql(“SELECT ip FROM parquetSales WHERE id BETWEEN 10 AND 19”)
ipDF.map(attributes=>”IPS: “+attributes(0)).show()
//Java
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
Dataset<Row> df_sales = spark.read.option(“sep”, “\t”).option(“header”, “true”).csv(“file:///opt/data/sales/sample_10000.txt”);
// Write data to parquet filedf_sales.write().parquet(“sales.parquet”);// Parquet preserve the schema of fileDataset<Row>parquetSalesDF=spark.read().parquet(“sales.parquet”);parquetSalesDF.createOrReplaceTempView(“parquetSales”);Dataset<Row> ipDF=spark.sql(“SELECT ip FROM parquetSales WHERE id BETWEEN 10 AND 19”);Dataset<String> ipDS= ipDF.map((MapFunction<Row,String>)row->”IP: “+row.getString(0),Encoders.STRING());ipDS.show();
#Python
sales_df = spark.read.option(“sep”, “\t”).option(“header”, “true”).csv(“file:///opt/data/sales/sample_10000.txt”)
sales_df.write.parquet(“sales.parquet”)parquetSales=spark.read.parquet(“sales.parquet”)parquetSales.createOrReplaceTempView(“parquetSales”)ip=spark.sql(“SELECT ip FROM parquetsales WHERE id >= 10 AND id <= 19”)ip.show()
- Charger des données depuis JSON:
//Scala
val sales_df = spark.read.option(“sep”, “\t”).option(“header”, “true”).csv(“file:///opt/data/sales/sample_10000.txt”)
sales_df.write.json(“sales.json”)
val json_sales_DF = spark.read.json(“sales.json”)
json_sales_DF.createOrReplaceTempView(“jsonSales”)
var ipDF = spark.sql(“SELECT ip FROM jsonSales WHERE id BETWEEN 10 AND 19”)
ipDF.map(attributes => “IPS: ” + attributes(0)).show()
Opérations DataFrame et fonctions associées
Les DataFrames prennent en charge les transformations non typées avec les opérations suivantes :
- printSchema : Ceci imprime le mappage d’un Spark DataFrame dans une structure arborescente. Le code suivant vous donnera une idée claire du fonctionnement de cette opération :
//Scala
import spark.implicits._
// Print the schema in a tree format
sales_df.printSchema()
//Java
import static org.apache.spark.sql.functions.col;
// Print the schema in a tree format
sales_df.printSchema();
#Python
# Print the schema in a tree format
sales_df.printSchema()
La sortie que vous obtenez devrait ressembler à ceci:
- select : Cela vous permet de sélectionner un ensemble de colonnes à partir d’un DataFrame . Le code suivant vous donnera une idée claire du fonctionnement de cette opération :
//Scala
import spark.implicits._
sales_df.select(“firstname”).show()
//Java
import static org.apache.spark.sql.functions.col;
sales_df.select(“firstname”).show()
#Python
sales_df.select(“firstname”).show()
La sortie que vous obtenez devrait ressembler à ceci:
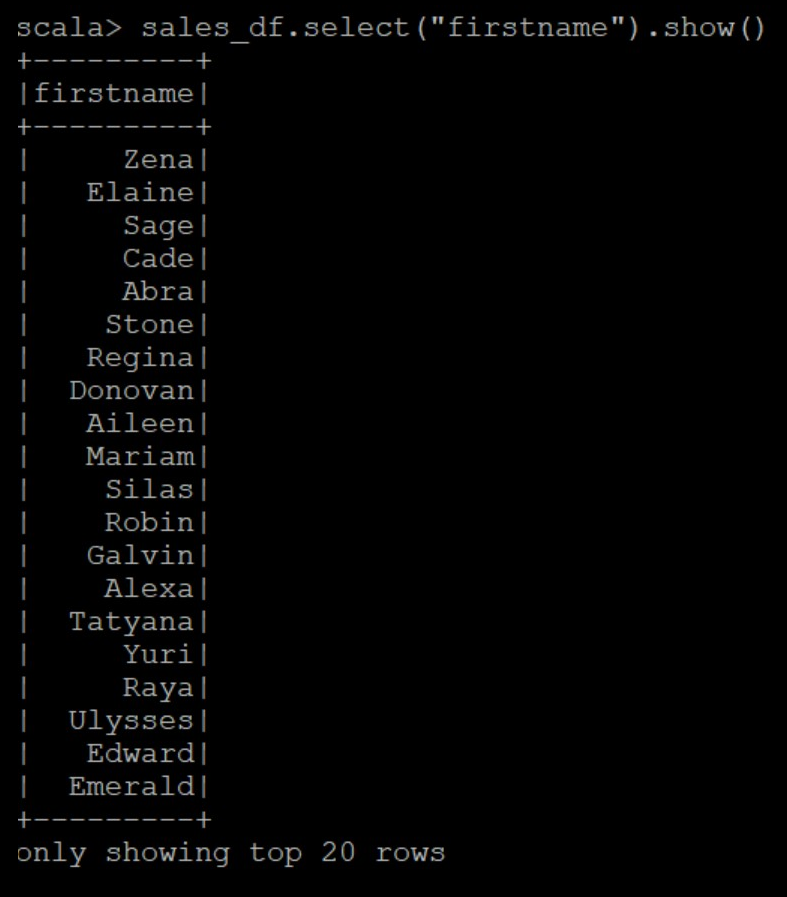
- filtre : cela vous permet de filtrer les lignes d’un DataFrame en fonction de certaines conditions. Le code suivant vous donnera une idée claire du fonctionnement de cette opération :
La sortie que vous obtenez devrait ressembler à ceci :
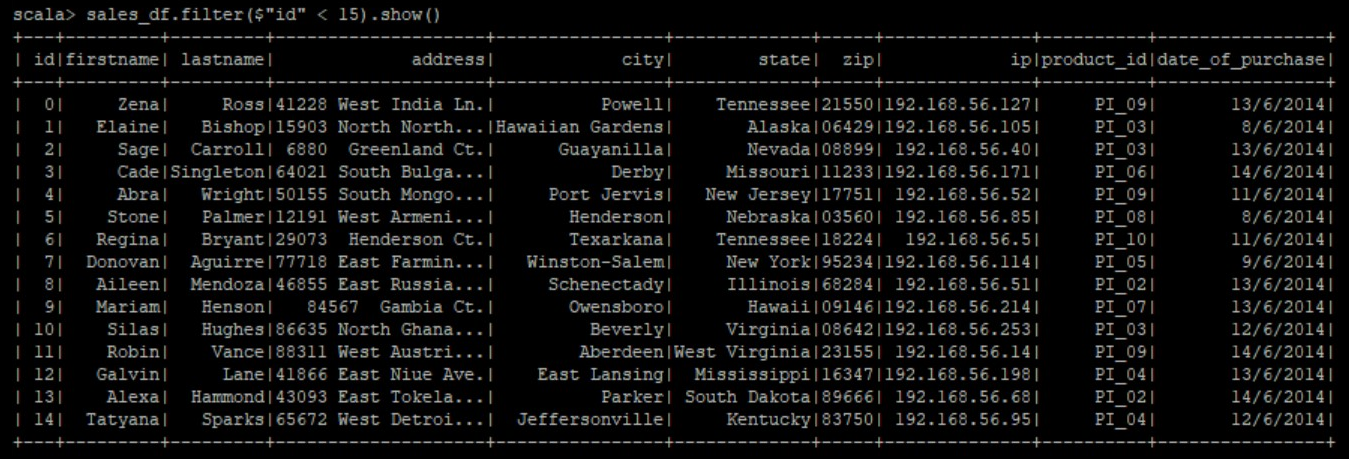
- groupBy : cela vous permet de grouper des lignes dans un DataFrame en fonction d’un ensemble de colonnes et d’appliquer des fonctions agrégées telles que count ( ) , avg () , etc. sur l’ensemble de données groupé. Le code suivant vous donnera une idée claire du fonctionnement de cette opération :
//Scala
import spark.implicits._
sales_df.groupBy(“ip”).count().show()
//Java
import static org.apache.spark.sql.functions.col;
sales_df.groupBy(“ip”).count().show();
#Python
sales_df.groupBy(“ip”).count().show()
La sortie que vous obtenez devrait ressembler à ceci :
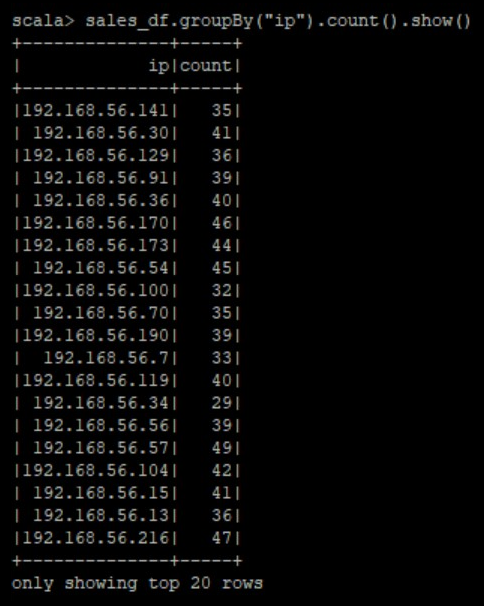
Une liste complète des fonctions DataFrame pouvant être utilisées avec ces opérations est disponible ici:
https://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.functions$.
Exécution de SQL sur des DataFrames
Autres que dataframe opérations et fonctions, DataFrames vous permettent également d’exécuter SQL directement sur les données. Pour cela, il nous suffit de créer des vues temporaires sur les DataFrames . Ces vues sont classées en vues locales ou globales.
Vues temporaires sur les DataFrames
Cette fonctionnalité permet aux développeurs d’exécuter des requêtes SQL dans un programme et d’obtenir le résultat sous forme de DataFrame :
//Scala
sales_df.createOrReplaceTempView(“sales”)
val sqlDF = spark.sql(“SELECT * FROM sales”)
sqlDF.show()
//Java
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
sales_df.createOrReplaceTempView(“sales”);
Dataset<Row> sqlDF = spark.sql(“SELECT * FROM sales”);
sqlDF.show();
#Python
sales_df.createOrReplaceTempView(“sales”)
sqlDF = spark.sql(“SELECT * FROM sales”)
sqlDF.show()
Vues temporaires globales sur les DataFrames
Les vues temporaires ne durent que pour la session dans laquelle elles sont créées. Si nous voulons avoir des vues disponibles sur différentes sessions, nous devons créer des vues temporaires globales. La définition de la vue est stockée dans la base de données par défaut, global_temp. Une fois qu’une vue est créée, nous devons utiliser le nom complet pour y accéder dans une requête :
// Scala
sales_ df.createGlobalTempView (“ventes”)
// vue temporaire globale est liée à une base de données du système ` global_temp `
spark.sql ( “SELECT * FROM global_temp.sales “) .show ()
spark.newSession (). sql (“SELECT * FROM global_temp.sales “) .show ()
//Java
sales_ df.createGlobalTempView (“ventes”);
spark.sql ( “SELECT * FROM global_temp.sales “) .show ();
spark.newSession (). sql (“SELECT * FROM global_temp.sales “) .show ();
#Python
sales_ df.createGlobalTempView (“ventes”)
# Global vue temporaire est liée à une base de données du système ` global_temp `
spark.sql ( “SELECT * FROM global_temp.sales “) .show ()
spark.newSession (). sql (“SELECT * FROM global_temp.sales “) .show ()
Jeux de données
Les jeux de données sont des collections d’objets fortement typées. Ces objets sont généralement spécifiques au domaine et peuvent être transformés en parallèle à l’aide d’opérations relationnelles ou fonctionnelles.
Ces opérations sont en outre classées en actions et transformations. Les transformations sont des fonctions qui génèrent de nouveaux ensembles de données, tandis que les actions calculent les ensembles de données et renvoient les résultats transformés. Les fonctions de transformation incluent Map, FlatMap , Filter, Select et Aggregate, tandis que les fonctions Action incluent count , show et save à n’importe quel système de fichiers.
Les instructions suivantes vous aideront à créer un ensemble de données à partir d’un fichier CSV :
- Initialiser SparkSession :
//Scala
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().appName(“Spark DataSet example”).config(“spark.config.option”, “value”).getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
//Java
import org.apache.spark.sql.SparkSession;
SparkSession spark = SparkSession.builder().appName(“Java Spark DataFrame example”).config(“spark.config.option”, “value”).getOrCreate();
#Python
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName(“Python Spark DataFrame example”).config(“spark.config.option”, “value”).getOrCreate()
- Définissez un encodeur pour ce CSV:
case class Sales (id: Int, firstname: String,lastname: String,address: String,city: String,state: String,zip: String,ip: String,product_id: String,date_of_purchase: String)
- Chargez l’ensemble de données à partir du CSV avec le type sales :
//Scala
importorg.apache.spark.sql.types._
import org.apache.spark.sql.Encoders
val sales_ds = spark.read.option(“sep”, “\t”).option(“header”, “true”).csv(“file:///opt/data/sales/sample_10000.txt”).withColumn(“id”, ‘id.cast(IntegerType)).as[Sales]
// Displays the content of the Dataset to stdout
sales_ds.show()
//Java
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
Dataset<Row> sales_ds = spark.read.option(“sep”, “\t”).option(“header”, “true”).csv(“file:///opt/data/sales/sample_10000.txt”);
// Displays the content of the Dataset to stdout
sales_ds.show()
#Python
sales_ds = spark.read.option(“sep”, “\t”).option(“header”, “true”).csv(“file:///opt/data/sales/sample_10000.txt”)
# Displays the content of the Dataset to stdout
sales_ds.show()
L’image suivante montre comment nous pouvons créer un Dataset des Sales données CSV, avec un Sale encodeur défini pour un ensemble de données :

Les différences importantes dans un ensemble de données par rapport aux DataFrames sont les suivantes :
- Définition d’une classe de cas pour définir les types de colonnes dans CSV
- Si l’interpréteur prend un type différent par inférence, nous devons convertir le type exact en utilisant la propriété withColumn
- La sortie est un ensemble de données de Type Sales, pas un DataFrame
Nous devons vérifier l’exactitude des données, car il est possible que les données réelles ne correspondent pas au type défini. Il existe trois options pour faire face à cette situation :
- Permissive : il s’agit du mode par défaut dans lequel, si le type de données ne correspond pas au type de schéma, les champs de données sont remplacés par null:
val sales_ds = spark.read.option(“sep”, “\t”).option(“header”, “true”).option(“mode”, “PERMISSIVE”).csv(“file:///opt/data/sales/sample_10000.txt”).withColumn(“id”, ‘id.cast(IntegerType)).as[Sales]
- DROPMALFORMED : Comme son nom l’indique, ce mode supprimera les enregistrements où l’analyseur trouvera une incompatibilité entre le type de données et le type de schéma :
val sales_ds = spark.read.option(“sep”, “\t”).option(“header”, “true”).option(“mode”, “DROPMALFORMED”).csv(“file:///opt/data/sales/sample_10000.txt”).withColumn(“id”, ‘id.cast(IntegerType)).as[Sales]
- FAILFAST : ce mode interrompra le traitement ultérieur lors de la première incompatibilité entre le type de données et le type de schéma :
val sales_ds = spark.read.option(“sep”, “\t”).option(“header”, “true”).option(“mode”, “FAILFAST”).csv(“file:///opt/data/sales/sample_10000.txt”).withColumn(“id”, ‘id.cast(IntegerType)).as[Sales]
Les jeux de données fonctionnent sur le concept d’ évaluation paresseuse, ce qui signifie que pour chaque transformation, une nouvelle définition de jeu de données est créée, mais aucune exécution ne se produit au niveau du backend. Dans ce cas, il crée uniquement un plan logique qui décrit le flux de calcul requis pour exécuter la transformation. L’évaluation proprement dite se produit une fois qu’une action est appelée sur l’ensemble de données. Avec une action, l’optimiseur de requêtes Spark optimise le plan logique et crée un plan d’exécution physique. Ce plan physique calcule ensuite les ensembles de données de manière parallèle et distribuée. La fonction d’explain est utilisée pour vérifier le plan physique logique et optimisé.
L’image suivante montre le plan d’explication de l’ensemble de données de sales :
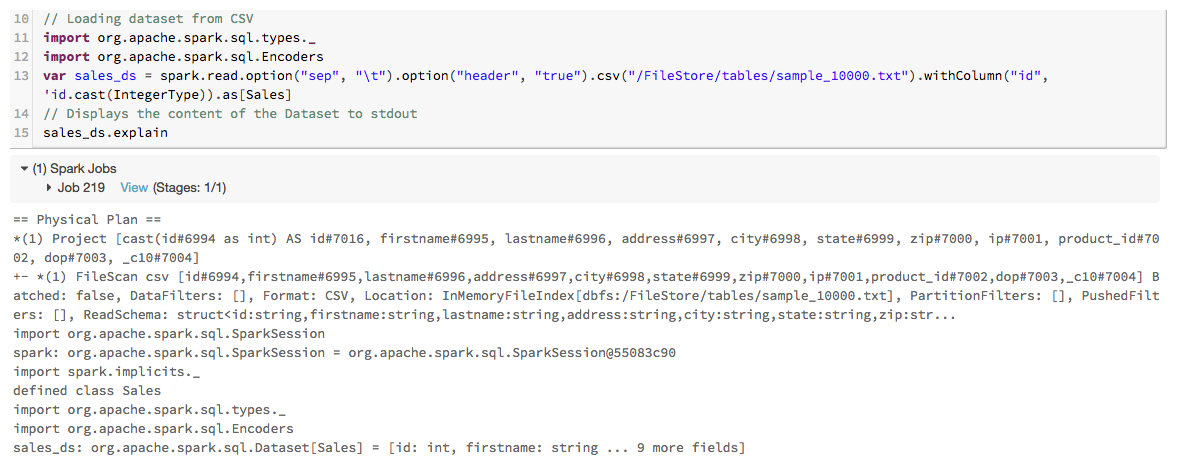
Encodeurs
Les encodeurs sont nécessaires pour mapper des objets spécifiques au domaine de type T au système de type Spark ou à la représentation SQL Spark interne. Un encoder de type T est un trait représenté par l’encoder [T] .
Les encodeurs sont disponibles avec chaque session Spark, et vous pouvez les importer explicitement avec des implicits comme import spark.implicits._.
Par exemple, étant donné une classe Employee avec les champs name (String) et salary (int), un encodeur est utilisé comme indicateur pour sérialiser l’objet Employee au format binaire. Cette structure binaire offre les avantages suivants :
- Occupe moins de mémoire
- Les données sont stockées sous forme de colonnes pour un traitement efficace
Jetons un coup d’œil aux principales fonctionnalités de l’encoder :
- Sérialisation rapide : les encodeurs sont utilisés pour le code d’exécution avec une génération de bytecode personnalisée pour la sérialisation et la désérialisation. Ils sont nettement plus rapides que les sérialiseurs Java et Kryo. Parallèlement à une sérialisation plus rapide, les encodeurs fournissent également une compression de données importante, ce qui permet de meilleurs transferts réseau. Les encodeurs produisent des données au format binaire Tungsten, ce qui permet également différentes opérations en place, plutôt que de matérialiser les données en un objet.
- Prise en charge des données semi-structurées : les encodeurs permettent à Spark de traiter un JSON complexe avec Scala et Java de type sécurisé.
Regardons un exemple. Considérez l’ensemble de données de sales suivant dans la structure JSON ou utilisez les commandes précédentes pour écrire le fichier JSON à partir d’un fichier CSV :
{“id”: “1”, “firstname”: “Elaine”, “lastname”: “Bishop”,”address”: “15903 North North Adams Blvd.”, “city”: “Hawaiian Gardens”, “state”: “Alaska”,”zip”: “06429”, “ip”: “192.168.56.105”, “product_id”: “PI_03”, “dop”:”8/6/2018″}
{“id”: “2”, “firstname”: “Sage”, “lastname”: “Carroll”,”address”: “6880 Greenland Ct.”, “city”: “Guayanilla”, “state”: “Nevada”,”zip”: “08899”, “ip”: “192.168.56.40”, “product_id”: “PI_04”, “dop”:”13/6/2018″}
Pour convertir des champs de données JSON en un type, nous pouvons définir une case class avec une structure et map les données d’entrée dans la structure définie. Les colonnes de la case class sont mappées aux clés dans JSON et les types sont mappés comme défini dans la case class :
case class Sales(id: String,firstname: String,lastname: String,address: String,city: String,state: String,zip: String,ip: String,product_id: String,dop: String )
val sales = sqlContext.read.json(“sales.json”).as[Sales]
sales.map(s => s”${s.firstname} purchased product ${s.product_id} on ${s.dop}”)
Les encodeurs vérifient également le type du schéma attendu avec les données et donnent une erreur en cas de non-concordance de type. Par exemple, si nous définissons un type d’octet dans une classe où l’encodeur trouve plus d’entiers, il se plaindra au lieu de traiter des To de données avec des transtypages automatiques en octets et de perdre en précision :
caseclassSales(id:byte)
val sales= sqlContext.read.json(“sales.json”).as[Sales]
org.apache.spark.sql.AnalysisException:Cannot upcast id
from int to smallint as it may truncate
Les encodeurs peuvent également gérer des types complexes, notamment des tableaux et des cartes.
Rangée interne
Les encodeurs sont codés en tant que traits dans Spark 2.0. Ils peuvent être considérés comme un moyen efficace de sérialisation / désérialisation pour Spark SQL 2.0, similaire à SerDes dans Hive :
trait Encoder[T] extends Serializable {
def schema: StructType
def clsTag: ClassTag[T]
}
Les encodeurs convertissent en interne le type T en type InternalRow de Spark SQL, qui est la représentation de ligne binaire.
Création d’encodeurs personnalisés
Les encodeurs peuvent être créés sur la base des sérialiseurs Java et Kryo . Les objets de fabrique d’encodeur sont disponibles dans le package org.apache.spark.sql :
import org.apache.spark.sql.Encoders
// Normal Encoder
scala> Encoders.LONG
res1: org.apache.spark.sql.Encoder[Long] = class[value[0]: bigint]
// Kryo and Java Serialization Encoders
case class Sales(id: String, firstname: String, product_id: Boolean)
scala> Encoders.kryo[Sales]
res3: org.apache.spark.sql.Encoder[Sales] = class[value[0]: binary]
scala> Encoders.javaSerialization[Sales]
res5: org.apache.spark.sql.Encoder[Sales] = class[value[0]: binary]
// Scala tuple encoders
scala> Encoders.tuple(Encoders.scalaLong, Encoders.STRING, Encoders.scalaBoolean)
res9: org.apache.spark.sql.Encoder[(Long, String, Boolean)] = class[_1[0]: bigint, _2[0]: string, _3[0]: boolean]
Résumé
Dans ce chapitre, nous avons commencé par charger un ensemble de données dans un DataFrame, puis appliquer différentes transformations au DataFrame. Plus tard, nous sommes passés par les derniers ajouts d’API et d’encodeurs de jeux de données dans Spark 2.0.
Dans le prochain chapitre, nous allons parcourir l’architecture de Spark et ses composants en détail. Nous verrons également en détail le flux d’une demande Spark une fois qu’elle aura été soumise.
Chapitre 5. Architecture Spark et flux d’exécution des applications
Jusqu’à présent dans cet article, nous avons discuté de la façon dont vous pouvez créer votre propre application Spark à l’aide de RDD et des API DataFrame et dataset. Nous avons également discuté de certains concepts de base de Spark, tels que les transformations, les actions, la mise en cache et les répartitions, qui vous permettent d’écrire efficacement vos applications Spark. Dans ce chapitre, nous allons discuter de ce qui se passe sous le capot lorsque vous exécutez votre application Spark. Nous vous guiderons également à travers les différents outils et techniques disponibles pour suivre vos travaux. Ce chapitre se discuter les suivants :
- Composants Spark et leurs rôles respectifs dans l’exécution de l’application
- Le cycle de vie d’une application Spark
- Surveillance des applications Spark
Un exemple d’application
Pour mieux comprendre le cycle de vie de l’application Spark, créons un exemple d’application et comprenons son exécution étape par étape. L’exemple suivant montre le contenu du fichier de données que nous utiliserons dans notre application. Le sale.csv fichier stocke des informations, telles que PRODUCT_CODE, COUNTRY_CODE, et l’ordre AMOUNT pour chaque ORDER_ID :
$ cat sale.csv
ORDER_ID,PRODUCT_CODE,COUNTRY_CODE,AMOUNT
1,PC_01,USA,200.00
2,PC_01,USA,46.34
3,PC_04,USA,123.54
4,PC_02,IND,99.76
5,PC_44,IND,245.00
6,PC_02,AUS,654.21
7,PC_03,USA,75.00
8,PC_01,SPN,355.00
9,PC_03,USA,34.02
10,PC_03,USA,567.07
Nous allons maintenant créer un exemple d’application à l’aide de l’API Python pour connaître le montant total des ventes par pays et les trier par ordre décroissant par montant total. L’exemple suivant montre le code de notre exemple d’application :
from pyspark.sql import SparkSession
from pyspark.sql.functions import desc
spark = SparkSession.Builder().appName(‘Sales Application’).getOrCreate()
sales_df = spark.read \
.option(“inferSchema”, “true”) \
.option(“header”, “true”) \
.csv(“/user/data/sales.csv”)
result = sales_df.groupBy(“COUNTRY_CODE”)\
.sum(“AMOUNT”)\
.orderBy(desc(“sum(AMOUNT)”))
result.show()
Dans l’exemple précédent, nous avons d’abord importé SparkSession du pyspark.sql, avec la fonction desc() du module de Functions . Dans Scala, SparkSession se trouve dans le package org.apache.spark.sql. SparkSession est principalement responsable de deux choses principales :
- Initialisation d’un cluster Spark, c’est-à-dire pilotes et exécuteurs
- Communiquer avec le gestionnaire de cluster pour la soumission des travaux et les mises à jour de statut
Remarque
Dans la version antérieure de Spark (1.x), il existe deux contextes distincts : SparkContext et SQLContext. Dans Spark 2.x, ils ont été combinés dans un seul contexte, SparkSession.
La première étape consiste à créer notre SparkSession en lui attribuant un nom d’application et en le stockant dans une variable spark. Nous chargeons ensuite les données de vente de sale.csv, disponibles sur le système de fichiers distribués Hadoop (HDFS), dans le DataFrame sales_df. Si vous souhaitez que Spark lit un fichier à partir du système de fichiers local, vous pouvez spécifier le chemin d’accès au fichier avec file:///. Nous utilisons. option() pour déduire le schéma de DataFrame sales_df. Ensuite, nous écrivons notre logique pour agréger les données de ventes par COUNTRY_CODE et calculer les ventes totales pour chaque pays. Enfin, nous exécutons une action show() pour déclencher le calcul. Maintenant, nous devons emballer notre application dans example.py afin de la soumettre à Spark. Nous utiliserons l’utilitaire spark-submit fourni par Spark pour soumettre notre travail. L’exemple suivant montre comment nous soumettons notre candidature dans un cluster YARN :
$ spark-submit \
–master yarn
–deploy-mode client
–num-executors 3
–executor-memory 2g \
–total-executor-cores 1\
example.py
Comme indiqué précédemment dans cet article, Spark s’intègre bien avec une variété de gestionnaires de cluster tels que YARN, Mesos et Kubernetes. Dans notre exemple, nous exécutons notre application sur YARN. Nous définissons le gestionnaire de cluster à l’aide de l’option –master de spark-submit. Des indicateurs tels que –num-executors, –executor-memory et –total-executor-cores sont utilisés pour fournir les besoins en ressources au gestionnaire de cluster. Nous expliquerons brièvement l’utilisation de l’indicateur –deploy-mode.
Voici la sortie de notre application de vente :
+ ———— + ———– +
| COUNTRY_CODE | sum(AMUONT) |
+ ———— + ———– +
| USA | 1045,97 |
| AUS | 654,21 |
| SPN | 355,0 |
| IND | 344,76 |
+ ———— + ———– +
Lorsque nous soumettons notre application, SparkSession dans le pilote de Spark communique avec le gestionnaire de ressources YARN pour allouer des ressources et initialiser les exécuteurs sur les machines de travail. Le diagramme suivant montre les états du cluster YARN, du pilote Spark et des exécuteurs. Le cluster se compose d’un nœud de gestionnaire de cluster et de deux nœuds de travail. Nous avons soumis notre travail à partir du nœud client. Ces machines sont également appelées nœuds de passerelle ou de périphérie. Notre processus de pilote s’exécute sur le nœud client et les exécuteurs (E1, E2 et E3) s’exécutent sur le nœud de travail de cluster. Tous les exécuteurs s’enregistrent auprès du programme Driver pour fournir une vue complète du cluster Spark :
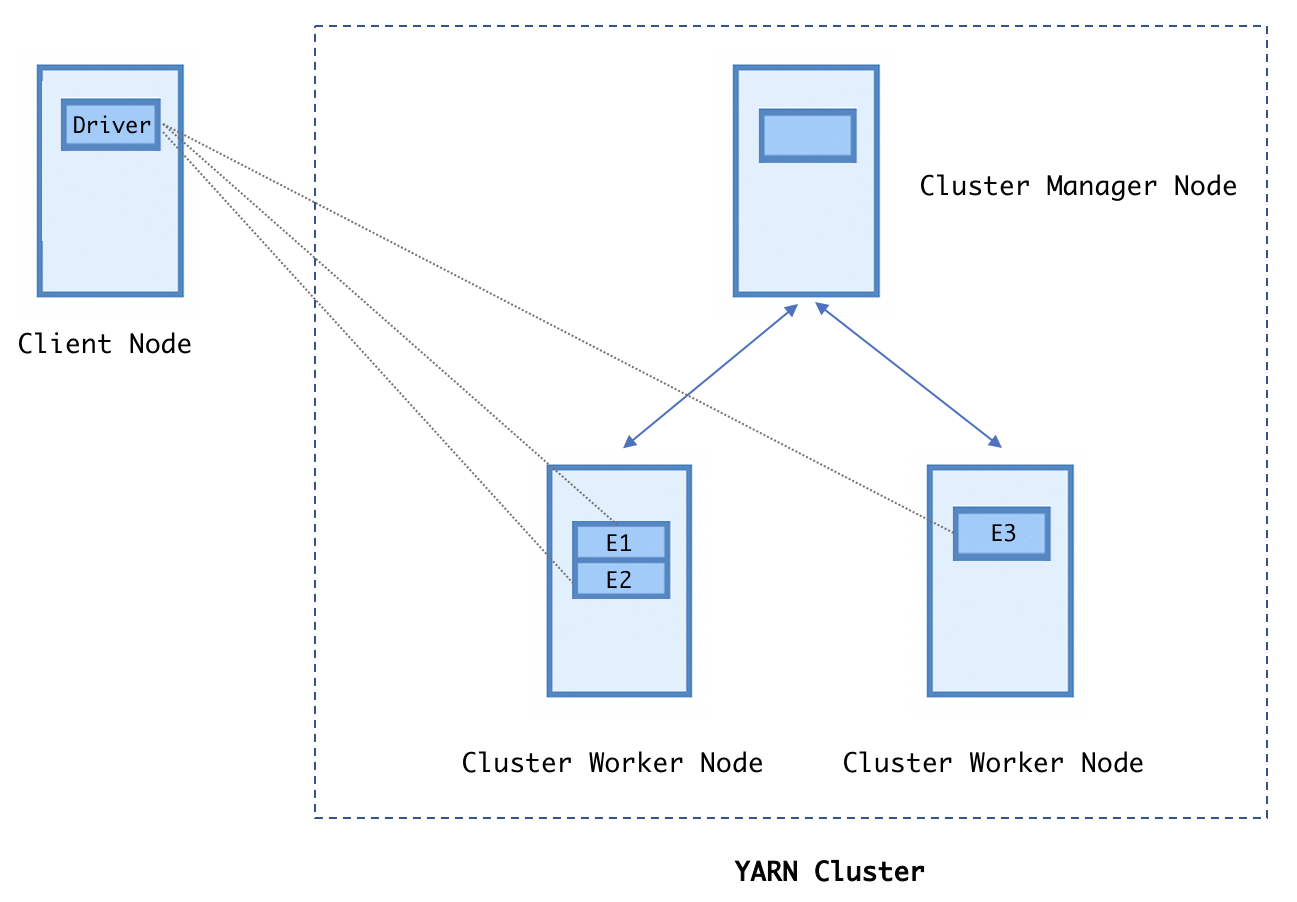
spark-submit en mode client
Un travail Spark est soumis automatiquement lorsque Spark rencontre une action (dans notre cas, show()). Cela signifie qu’une application Spark peut avoir plusieurs tâches en fonction du nombre d’actions. Le pilote Spark va maintenant appeler le planificateur, qui se compose de deux parties principales :
- DAG constructor
- Task scheduler
Constructeur DAG
Le constructeur DAG est chargé de décomposer un job en un ensemble stages.
Stage
Une étape n’est rien d’autre qu’un groupe de tâches que Spark peut exécuter ensemble sans impliquer de mélange. Une limite d’étape est décidée en fonction de la nature des transformations que nous utilisons dans nos applications. Dans le chapitre 3, Spark RDD, nous avons discuté des transformations larges et des transformations étroites. Les transformations étendues sont celles qui mélangent les données sur un réseau, telles que groupByKey, Join et Distinct. Ces transformations déterminent le nombre d’étapes d’un travail Spark. Dans notre fichier example.py, nous utilisons la transformation groupBy() pour connaître le montant total par chaque pays et orderBy () pour classer les données par montant total, et nous devrions donc avoir trois étapes pour notre travail. Nous pouvons afficher les informations de l’étape à l’aide d’une opération d’explain( ) sur un RDD ou un DataFrame . Ce qui suit montre la sortie d’explain() sur notre DataFrame result. On voit qu’il y a trois étapes au total :
result.explain()
== Physical Plan ==
*(3) Sort [sum(AMOUNT)#345 DESC NULLS LAST], true, 0
+- Exchange rangepartitioning(sum(AMOUNT)#345 DESC NULLS LAST, 200)
+- *(2) HashAggregate(keys=[COUNTRY_CODE#313], functions=[sum(AMOUNT#314)])
+- Exchange hashpartitioning(COUNTRY_CODE#313, 200)
+- *(1) HashAggregate(keys=[COUNTRY_CODE#313], functions=[partial_sum(AMOUNT#314)])
+- *(1) FileScan csv [COUNTRY_CODE#313,AMOUNT#314] Batched: false, Format: CSV, Location: InMemoryFileIndex[file:/Users/agrade/Akash/Work/Python/sales.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<COUNTRY_CODE:string,AMOUNT:double>
Plus tôt, nous avons vu le DAG des étapes pour notre exemple d’application dans graphique form. Dans les éléments suivants DAG, la première étape (Stage 1) correspond à la lecture des données à partir sale.csv et puis déclencher quelques lecture aléatoire (exchange) tâches. La deuxième étape (Stage 2) effectue l’agrégation, et enfin, la troisième étape (Stage 3) aboutit à une liste ordonnée des codes de pays et de leurs montants totaux respectifs :

Étapes
Tâches
Nous allons maintenant discuter d’un concept important : les tâches. Chaque étape consiste en un ensemble de tâches. Une tâche est une composition d’une partition de données et un ensemble de transformations. Comme indiqué précédemment, ces tâches peuvent être regroupées dans une étape. Les tâches sont de deux types :
- Tâches de carte aléatoire : les tâches de carte aléatoire sont comme les tâches côté carte d’un programme MapReduce. Ils effectuent la transformation et créent une nouvelle partition de données.
- Tâches de résultat : il s’agit de tâches effectuées par des opérations, telles que show(), pour renvoyer les résultats aux utilisateurs.
Il est important de comprendre ces concepts pour écrire des applications efficaces, car cela peut avoir un effet significatif sur vos travaux. Par exemple, si vous traitez une grande partition unique, vous n’aurez qu’une seule tâche en cours d’exécution et vous perdrez sur le parallélisme. En revanche, si vous traitez un grand nombre de petites partitions, vous aurez alors autant de tâches que le nombre de partitions. C’est pourquoi choisir le bon nombre de partitions est la clé pour de meilleures performances.
Planificateur de tâches
Il est de la responsabilité du planificateur de tâches de planifier ces tâches avec un exécuteur basé sur les cœurs disponibles et la localité des données. Par défaut, une tâche se voit attribuer un seul cœur pour effectuer son opération. Vous pouvez modifier ce comportement en configurant la propriété spark.task.cpus. Spark propose deux choix pour les politiques de planification :
- Premier entré, premier sorti (FIFO)
- FAIR
FIFO
FIFO est la politique de planification par défaut fournie par Spark. Il est acceptable d’utiliser FIFO lorsque vous êtes en phase d’apprentissage, mais ce n’est pas idéal pour les applications de production. Dans le cas de FIFO, lorsque les travaux sont soumis, leurs tâches s’exécutent dans l’ordre d’arrivée. Cela signifie que si une étape s’exécute sur un cluster Spark qui occupe la moitié des ressources, une autre étape peut exécuter sa tâche sur les ressources disponibles. Mais, parfois, cela devient un problème. Si la première étape est lourde et consomme toutes les ressources disponibles, la deuxième étape ne pourra pas exécuter ses tâches.
FAIR
La programmation FAIR est une alternative à FIFO. Cette stratégie offre des ressources égales à toutes les tâches à la manière d’un round robin. Par exemple, lorsque la première tâche est affectée aux ressources, elle n’est affectée qu’à une partie des ressources. La deuxième tâche se verra attribuer la partie suivante des ressources, etc. L’un des avantages est de limiter les applications à longue durée de vie à consommer toutes les ressources disponibles.
Vous pouvez modifier la stratégie par défaut en définissant la propriété spark.scheduler.mode:
spark.conf.set(“spark.scheduler.mode”,”FAIR”)
Modes d’exécution d’application
En ce qui concerne l’exécution de votre application, vous devrez décider de la façon dont votre travail va s’exécuter. Dans la section précédente, lorsque nous avons soumis notre travail à partir du nœud client, notre processus de pilote s’exécutait sur la même machine et les exécuteurs exécutaient sur les nœuds de travail du cluster. Spark n’est pas limité à ce seul mode d’exécution. Il propose trois modes d’exécution :
- Mode local
- Mode client
- Mode cluster
Dans cette section, nous allons discuter chacun d’eux en détail et comment vous pouvez utiliser spark-submit pour les configurer.
Mode local
Le mode local exécute le pilote et les exécuteurs sur une seule machine. Dans ce mode, les partitions sont traitées par plusieurs threads en parallèle. Le nombre de threads peut être contrôlé par l’utilisateur lors de la soumission du travail. Ce mode est utile dans la phase d’apprentissage mais n’est pas recommandé pour les applications de production, car vous n’utilisez qu’une seule machine pour traiter les données.
Ce qui suit montre comment vous pouvez soumettre un travail en mode local avec spark-submit :
$ spark-submit –master local example.py
Mode client
En mode client, le processus du pilote s’exécute sur le nœud client (c’est-à-dire le nœud périphérique ou passerelle) sur lequel le travail a été soumis. Le nœud client fournit des ressources, telles que la mémoire, le processeur et l’espace disque au programme du pilote, mais les exécuteurs s’exécutent sur les nœuds du cluster et ils sont gérés par le gestionnaire de cluster, tel que YARN. Plus tôt, nous avons vu comment nous avons utilisé le mode client pour soumettre notre demande de vente dans la section précédente. L’un des avantages de l’exécution de votre travail en mode client est que vous pouvez facilement accéder à vos journaux sur la même machine. Mais lorsque votre nombre d’applications Spark augmente en production, vous ne devez pas envisager le mode client pour l’exécution des travaux. En effet, le nœud client dispose de ressources limitées. Si certaines applications collectent des données auprès des exécuteurs, il existe un risque élevé de défaillance du nœud client.
Comme indiqué ici, nous utilisons le paramètre –deploy-mode de spark-submit pour spécifier le mode client :
$ spark-submit \
–master yarn
–deploy-mode client
–num-executors 3
–executor-memory 2g \
–total-executor-cores 1\
example.py
Mode cluster
Le mode cluster est similaire au mode client, sauf que le processus du pilote s’exécute sur l’une des machines de travail du cluster et que le gestionnaire de cluster est responsable des processus pilote et exécuteur. Cela donne l’avantage d’exécuter plusieurs applications en même temps car le gestionnaire de cluster répartira la charge du pilote sur le cluster. Ce mode est le mode le plus courant et recommandé pour exécuter les applications Spark. Dans ce mode, les journaux peuvent être collectés à partir du gestionnaire de cluster ou vous pouvez implémenter une solution de journalisation centrale pour collecter les journaux d’application.
Le diagramme suivant montre notre application de vente fonctionnant en mode cluster. Le processus du pilote s’exécute sur le premier nœud de travail et tous les exécuteurs s’exécutent sur différents nœuds de travail :

Mode cluster
L’exemple de code suivant montre comment vous pouvez soumettre un travail en mode cluster avec spark-submit :
$ spark-submit \
–master yarn
–deploy-mode cluster
–num-executors 3
–executor-memory 2g \
–total-executor-cores 1\
example.py
Le tableau suivant montre toutes les options possibles disponibles pour –master dans spark-submit :
| URL maître | Sens |
| local | Exécutez Spark localement avec un thread de travail (c’est-à-dire, aucun parallélisme du tout). |
| local[K] | Exécutez Spark localement avec K threads de travail (idéalement, définissez-le sur le nombre de cœurs sur votre machine). |
| local[K,F] | Exécutez Spark localement avec K threads de travail et F maxFailures (voir spark.task.maxFailures pour une explication de cette variable). |
| local[ *] | Exécutez Spark localement avec autant de threads de travail que de cœurs logiques sur votre machine. |
| local[*,F] | Exécutez Spark localement avec autant de threads de travail que de cœurs logiques sur votre machine et F maxFailures. |
| spark://HOST:PORT | Connectez-vous au maître de cluster autonome Spark donné. Le port doit être celui que votre maître est configuré pour utiliser, qui est 7077 par défaut. |
| spark://HOST1:PORT1, HOST2:PORT2 | Connectez-vous au cluster autonome Spark donné avec des maîtres de secours avec Zookeeper. La liste doit avoir tous les hôtes maîtres du cluster haute disponibilité configurés avec Zookeeper. Le port doit être celui que chaque maître est configuré pour utiliser, qui est 7077 par défaut. |
| mesos://HOST:PORT | Connectez-vous au cluster Mesos donné. Le port doit être celui que votre application est configurée pour utiliser, qui est 5050 par défaut. Ou, pour un cluster à l’aide Mesos ZooKeeper , utilisez mesos ://ZK://…. Pour soumettre avec le cluster –deploy-mode, HOST:PORT doit être configuré pour se connecter au MesosClusterDispatcher . |
| YARN | Connectez-vous à un cluster YARN en mode client ou cluster selon la valeur de –deploy-mode. L’emplacement du cluster sera trouvé en fonction de la variable HADOOP_CONF_DIR ou YARN_CONF_DIR. |
| k8s://HOST:PORT | Connectez-vous à un cluster Kubernetes en mode cluster. Le mode client n’est actuellement pas pris en charge et sera pris en charge dans les futures versions. HOST et PORT font référence au [Kubernetes API Server] (https://kubernetes.io/docs/reference/generated/kube-apiserver/). Il se connecte en utilisant TLS par défaut. Pour le forcer à utiliser une connexion non sécurisée, vous pouvez utiliser k8s://http://HOST:PORT. |
Plus d’informations peuvent être trouvées sur https://spark.apache.org/docs/latest/submitting-applications.html.
Surveillance des applications
Cette section couvre une autre façon de surveiller votre application Spark. Il est important de surveiller vos travaux pour mieux comprendre le comportement de votre application. Ces observations peuvent vous aider à optimiser votre code d’application. Il existe différentes façons de surveiller vos travaux.
Spark UI
Spark fournit une interface utilisateur de surveillance intégrée qui fournit des informations utiles sur vos applications Spark. Lorsque vous soumettez votre travail, Spark lance cette interface utilisateur sur l’hôte du pilote sur le port par défaut, 4040. Si le port 4040 n’est pas disponible, Spark essaie de le lier sur le port disponible suivant. Vous pouvez également modifier ce paramètre par défaut en modifiant la propriété spark.ui.port. L’interface utilisateur Spark a plusieurs onglets :
- Jobs : Fournit des informations telles que DAG, les étapes, les tâches et la durée sur vos travaux Spark
- Stages : Fournit des informations sur toutes les étapes en détail
- Storage : fournit des informations sur les partitions mises en cache
- Environnement : Des informations sur l’environnement d’exécution, telles que spark.scheduler.mode, peuvent être consultées ici
- Executors : cet onglet affiche des informations sur chaque exécuteur
- SQL : fournit des informations sur les API structurées (SQL, DataFrame et ensemble de données)
L’image suivante montre un exemple d’interface utilisateur Spark montrant des détails sur un travail Spark :
Spark UI
Journaux d’application
Une autre façon de surveiller votre application Spark consiste à consulter les journaux d’application. Vous pouvez utiliser des bibliothèques de journalisation (journalisation en Python; log 4j en Java / Scala) disponibles dans les différentes langues pour journaliser les événements afin de mieux comprendre votre application.
Solution de surveillance externe
Vous pouvez également intégrer la journalisation de votre application à un système de journalisation central tel que Graphite, Ganglia, Splunk, Elasticsearch, Logstash et Kibana ( ELK ) ou Prometheus. Ces systèmes vous offrent la possibilité d’interroger vos données de journal ou même de créer des tableaux de bord personnalisés.
Résumé
Dans ce chapitre, nous avons discuté du cycle de vie de l’application Spark, des composants Spark et de leurs rôles dans l’exécution des travaux. Nous avons d’abord créé un exemple d’application en Python et utilisé spark-submit pour exécuter notre application. Nous avons expliqué comment le processus du pilote construit le DAG et ses étapes, et comment les tâches sont planifiées sur un cluster. De plus, nous avons également discuté en détail des différents modes d’exécution proposés par Spark. Enfin, nous avons discuté des moyens possibles de surveiller votre application.
Dans le chapitre suivant, nous discuterons en détail de Spark SQL.
Chapitre 6. Spark SQL
Dans notre chapitre précédent, nous avons découvert les DataFrames et les ensembles de données et comment utiliser ou écrire des encodeurs personnalisés pour effectuer des opérations de type sécurisé sur les ensembles de données. Ce chapitre explique le composant SQL de Spark, qui aide les développeurs travaillant sur Hive ou familiers avec RDBMS SQL à utiliser un style similaire dans Spark.
Nous couvrirons les sujets suivants dans ce chapitre :
- Métastore Spark
- SQL langue manuelle
- Base de données SQL utilisant Java Database Connectivity (JDBC)
Spark SQL
Spark SQL est une abstraction de données à l’aide de SchemaRDD, qui vous permet de définir des ensembles de données avec un schéma, puis d’interroger des ensembles de données à l’aide de SQL. Pour commencer, il vous suffit de taper spark- sql dans le Terminal avec Spark installé. Cela va ouvrir une étincelle shell pour vous.
Métastore Spark
Pour stocker des bases de données, des noms de table et un schéma, Spark installe une base de données par défaut, metastore.db, au même emplacement que celui où vous avez démarré le shell SQL.
Utilisation du métastore Hive dans Spark SQL
Spark offre la flexibilité de tirer parti du métastore Hive existant. Cela permettra aux utilisateurs d’accéder aux définitions de table disponibles pour Hive dans Spark et d’exécuter le même HiveQL dans Spark.La différence sera que les requêtes s’exécutant sur Spark seront exécutées conformément au plan d’exécution Spark, et les données sous-jacentes seront traitées selon Spark exécution et optimisations. Ces requêtes ne suivront pas le chemin MapReduce, qui est la valeur par défaut dans Hive.
Pour de nombreuses requêtes, les utilisateurs peuvent constater un gain de performances considérable avec le moteur d’exécution Spark par rapport au moteur MapReduce, en raison du plan d’exécution optimisé dans Spark.
Configuration de la ruche avec Spark
Hive on Spark donne à Hive la capacité d’utiliser Apache comme moteur d’exécution. Nous utiliserons les étapes suivantes pour configurer Hive:
- Copiez hive-site.xml dans le dossier de configuration Spark comme suit :
cp $ HIVE_HOME / conf / hive-site.xml $ SPARK_HOME / conf /
- Ajoutez la ligne suivante à ~ /. bash_profile :
export SPARK_CLASSPATH=$HIVE_HOME/lib/mysql-connector-java-3.1.14-bin.jar
source ~/.bash_profile
- Exécutez la commande suivante pour accéder à Spark SQL:
spark-sql
Recherchez les bases de données et les tables existantes à l’aide des commandes Show Databases et Show Tables. Vous trouverez toutes les bases de données et les tables correspondantes que vous avez dans Hive.
Manuel du langage SQL
Spark SQL fournit un ensemble de langages de définition de données (DDL) et de langages de manipulation de données (DML). Celles-ci sont identiques ou très similaires à Hive et à d’autres spécifications de base du langage SQL.
Base de données
Dans cette section, nous allons examiner quelques opérations que nous pouvons effectuer sur une base de données :
Create Database if not exists mydb
location ‘/opt/sparkdb’;
La sortie après l’exécution sera similaire à ceci:
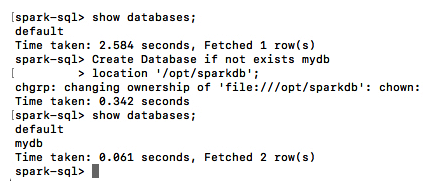
- Description de BDD : nous utiliserons la commande suivante pour décrire une base de données :
Describe Database [extended] mydb;
La sortie après l’exécution sera similaire à ceci :
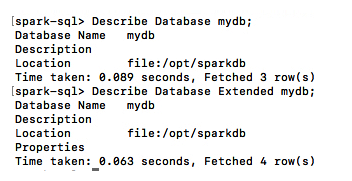
- Afficher les bases de données : Nous utiliserons la commande suivante pour afficher une base de données :
Showdatabases[like’pattern’]
‘pattern’ peut être n’importe quelle chaîne de recherche partielle ou *.
- use mydb : La commande suivante peut être donnée pour utiliser une base de données:
use mydb;
- DROP DATABASE : Nous utiliserons la commande suivante pour décrire une base de données :
DROPDATABASE [IFEXISTS] mydb [(RESTRICT | CASCADE)]
- CASCADE : cela supprimera toutes les tables sous-jacentes de la base de données
- RESTRICT : Cela lèvera une exception si nous l’exécutons sur une base de données non vide
Table et vue
Dans cette section, nous allons examiner certaines opérations que nous pouvons effectuer sur une table et afficher :
- Créer une table : nous utiliserons la commande suivante pour créer une table :
CREATE[EXTERNAL]TABLE[IFNOTEXISTS][mydb.]mytable[(col_name1:col_type1)]
–[PARTITIONEDBY(col_name2:col_type2)][ROWFORMATrow_format][STOREDASfile_format][LOCATIONpath][TBLPROPERTIES(key1=val1,key2=val2,…)][ASselect_statement]
Voici un exemple de création d’un tableau avec des valeurs réelles:
CREATETABLEmytable(idString,firstname String,address String, city String, State String, zip String, ip String, product_id String)ROWFORMATDELIMITEDFIELDSTERMINATEDBY’\t’
LOCATION ‘/opt/data’
Stored as TEXTFILE;
Vous verrez l’écran suivant lors de l’exécution de la commande précédente :

Voici les paramètres qui doivent être définis lors de la création de la table :
- Datasources : il s’agit du format de fichier auquel cette table est associée. Il peut s’agir de CSV, JSON, TEXT, ORC ou Parquet.
- n : spécifie le nombre de compartiments si vous souhaitez créer une table compartimentée.
- Créer une vue : nous utiliserons la commande suivante pour créer une VUE :
CREATE[ORREPLACE]VIEW mydb.myview
[(col1_name, col2_name)][TBLPROPERTIES(key1=val1,…)]ASselect …
Cela créera une vue logique sur une ou plusieurs tables. La définition de la vue stockera uniquement la définition de requête correspondante et, lorsque la vue est utilisée, la requête sous – jacente sera appelée lors de l’exécution.
- Décrire la table : nous utiliserons la commande suivante pour décrire une table :
DESCRIBE mydb.mytable
Remarque
Extended : Describe Extended donnera des informations plus détaillées sur la définition de la table.
- Modifier la table ou la vue : il existe différentes opérations sous ALTER que nous pouvons effectuer. Nous examinerons les opérations suivantes :
- Renommer : nous utiliserons la commande suivante pour renommer une table ou une vue :
MODIFIER | VOIR mydb.mytable RENAMETO mydb.mytable1
- Définir les propriétés : La commande suivante peut être utilisée pour définir les propriétés d’une table ou d’une vue :
ALTERTABLE | VIEWmytableSETTBLPROPERTIES (clé1 = val 1, clé 2 = val2, …)
- Supprimer les propriétés : la commande suivante peut être utilisée pour supprimer les propriétés d’une table ou d’une vue:
ALTERTABLE | VIEW mytable UNSETTBLPROPERTIES IFEXISTS ( clé1, clé2, …)
- Supprimer une Table : Nous utiliserons la commande suivante pour supprimer une table :
DROP TABLE mydb.mytable
- Afficher les propriétés de la table : nous allons utiliser la commande suivante pour afficher les propriétés d’une table particulière :
SHOWTBLPROPERTIES mydb.mytable [( prop_key )]
- Afficher les tables : La commande qui suit est utilisée pour afficher les tableaux :
SHOWTABLES[LIKE’pattern’]
Affiche toutes les tables de la base de données actuelle. Utilisez un modèle si vous souhaitez répertorier uniquement des tables spécifiques basées sur un modèle.
- Trunacte table : Nous utiliserons la commande suivante pour tronquer une table particulière :
TRUNCATETABLE mytable
Cela supprimera toutes les lignes de la table spécifiée. Il ne fonctionne pas sur les tables de vue ou temporaires.
- Afficher ou créer une table : La commande suivante fournit l’instruction de création d’une table mytable :
SHOWCREATETABLE mydb.mytable
- Afficher les colonnes : Nous utiliserons la commande suivante pour afficher la liste des colonnes dans le tableau spécifié :
SHOWCOLUMNS (FROM | IN) mydb.mytable
- INSÉRER : Nous utiliserons la commande suivante pour insérer des valeurs dans une table :
InsertInto mydb.mytable sélectionner … de mydb.mytable1
Dans le cas où la table est divisée, nous devons déterminer une partition particulière de la table. Nous pouvons utiliser la commande suivante pour INSERT dans la PARTITION d’une table :
INSERTINTO mydb.mytable PARTITION (part_col_name1=val1) select … from mydb.mytable1
Charger des données
Nous sommes autorisés à charger des données dans des tables Hive de trois manières différentes. Deux des méthodes sont des tâches DML de Hive. Le troisième utilise l’ordre HDFS. Ces trois méthodes sont expliquées comme suit :
- Charger des données à partir d’un système de fichiers local : nous utiliserons la commande suivante pour charger des données à partir d’un système de fichiers local :
LOADDATA LOCALINPATH ‘ local_path ‘ INTOTABLE mydb.mytable
La capture d’écran suivante montre comment nous pouvons charger sample_10000.txt à partir du système de fichiers local dans une table Spark :

- Charger des données depuis HDFS : Nous utiliserons la commande suivante pour charger des données depuis HDFS :
LOADDATA INPATH ‘ hdfs_path ‘ INTOTABLE mydb.mytable
- Charger des données dans une partition d’une table : nous pouvons utiliser la commande suivante pour charger des données dans une partition d’une table :
LOADDATA [LOCAL] INPATH ‘path’ INTOTABLE mydb.mytable PARTITION (part_col1_name = val1)
Création d’UDF
Les utilisateurs peuvent définir des fonctions définies par l’utilisateur (UDF) pour la logique personnalisée dans Scala ou Python. Les formats de définition et d’enregistrement UDF sont expliqués comme suit :
- La syntaxe d’enregistrement d’une fonction Spark SQL en tant qu’UDF dans Scala est donnée comme suit :
valsquared=(s:Int)=>{s*s }spark.udf.register(“square”,squared)
- La syntaxe pour appeler une fonction Spark SQL en tant qu’UDF dans Scala est donnée comme suit :
spark.range(1, 20).createOrReplaceTempView((“udf_test”))
%sql select id, square(id) as id_squared from udf_test
- La syntaxe d’enregistrement d’une fonction Spark SQL en tant qu’UDF en Python est donnée comme suit :
defsquared(s):returns*sspark.udf.register(“squaredWithPython”,squared)
- La syntaxe pour appeler une fonction Spark SQL en tant qu’UDF en Python est donnée comme suit :
spark.range(1, 20).registerTempTable(“test”)
%sql select id, squaredWithPython(id) as id_squared from test
Base de données SQL utilisant JDBC
Spark SQL permet également aux utilisateurs d’interroger directement à partir de différentes sources de données SGBDR. Les résultats de la requête sont renvoyés sous la forme d’un DataFrame qui peut être interrogé davantage avec Spark SQL ou joint à d’autres ensembles de données.
Pour utiliser une connexion JDBC, vous devez ajouter les fichiers JAR du pilote JDBC pour la base de données requise dans le chemin de classe Spark.
Par exemple, mysql peut être connecté à Spark SQL avec les commandes suivantes :
import org.apache.spark.sql.SparkSession
object JDBCMySQL {
def main(args: Array[String]) {
//At first create a Spark Session as the entry point of your app
val spark:SparkSession = SparkSession
.builder()
.appName(“JDBC-MYSQL”)
.master(“local[*]”)
.config(“spark.sql.warehouse.dir”, “C:/Spark”)
.getOrCreate();
val dataframe_mysql = spark.read.format(“jdbc”)
.option(“url”, “jdbc:mysql://localhost:3306/mydb”) // mydb is database name
.option(“driver”, “com.mysql.jdbc.Driver”)
.option(“dbtable”, “mytable”) //replace table name
.option(“user”, “root”) //replace user name
.option(“password”, “spark”) // replace password
.load()
dataframe_mysql.show()
}
}
Résumé
Dans ce chapitre, nous avons appris comment connecter Spark au métastore Hive et utiliser le langage Spark SQL pour effectuer des opérations DDL dans Spark. Nous avons également exploré comment nous pouvons connecter Spark SQL à différentes banques de données et tables de requêtes RDBMS, qui fournissent des DataFrames en tant que résultats. Dans le prochain chapitre, nous étudierons le Spark Streaming, l’apprentissage automatique et l’analyse graphique.
Chapitre 7. Spark Streaming, Machine Learning et Graph Analysis
Dans le chapitre précédent, nous avons découvert Spark SQL, qui est l’un des principaux composants qui fournit une interface SQL pour interroger de grands ensembles de données structurés et semi-structurés. Spark SQL fournit principalement des API pour l’analyse par lots des données structurées, mais il existe des domaines qui ont besoin d’analyser les données en streaming en temps réel ou d’exécuter un algorithme d’apprentissage automatique sur un grand volume de données de train. Spark fournit un ensemble différent d’API en fonction de ces exigences d’application.
Ce chapitre couvrira les sujets suivants :
- Spark Streaming
- Apprentissage automatique
- API graphique
Spark Streaming
Spark Streaming est une extension des API principales qui fournissent un traitement à haut débit et tolérant aux pannes des données en temps réel. Il fournit des API qui permettent le traitement évolutif des flux de données générés sur une source particulière. La source des données peut être l’une des suivantes :
- Droit- flux de données de sites Web
- Journaux d’application
- Données provenant d’un port TCP
Cas d’utilisation
Il existe de nombreux scénarios dans lesquels Spark Streaming apporte de la valeur à une organisation, soit en améliorant l’expérience client, soit en surveillant de manière proactive les données pour obtenir des recommandations. Différents domaines où les applications Spark Streaming sont populaires sont répertoriés ici :
- Détection des fraudes : les organisations financières utilisent Spark Streaming pour détecter les transactions frauduleuses en temps réel. Cela aide les organisations à prendre une décision proactive sur une transaction et à éviter les dommages en temps opportun.
- Recommandations : les domaines, y compris le commerce électronique, les médias et autres, utilisent Spark Streaming pour recommander le prochain ensemble de produits à acheter ou le prochain ensemble d’histoires à lire en fonction des activités en cours sur leur plate-forme.
- Évitement des risques : les fournisseurs de services utilisent Spark Streaming pour étendre leur champ de diligence raisonnable avant d’offrir un service ou un produit. Cela permet de réduire le risque de fournir des services ou des produits aux consommateurs non éligibles.
Source d’information
Spark Streaming permet aux développeurs / analystes d’analyser les données d’une variété de sources de données. Il fournit des API pour se connecter directement à partir de diverses files d’attente de messagerie et ports TCP, notamment les suivantes :
- Kafka
- Buse
- Kinesis
- ZeroMQ
Traitement de flux
Le flux de données provenant de différentes sources de données est traité en micro-lots. Ces micro-lots sont générés soit à partir de données provenant directement d’une source ou d’autres DStreams.
Microbatch
Au lieu de traiter chaque enregistrement ou événement à la fois, le récepteur Spark reçoit les données en parallèle et les conserve dans un tampon de nœuds de travail Spark. Ensuite, le moteur de Spark exécute des tâches sur ces flux discrétisés, également appelés microbatches.
Un microbatch est créé sur la base d’une fenêtre de temps, au lieu d’un certain nombre de messages.
DStreams
Les flux DS sont le flux de données provenant d’une source. Un DStream est une série continue de RDD où chaque RDD dans DStream contient des données d’un intervalle particulier. Les opérations sur DStream sont converties en opérations sur les RDD sous-jacents :

Chaque DStream est associé à un objet récepteur qui reçoit les données de flux d’une source et les stocke en mémoire pour traitement.
Architecture de streaming
L’architecture de streaming caractérise l’étendue de l’avancée d’une association. Les informations obtenues sont envoyées à de nombreuses administrations back-end qui totalisent les informations, les trient et les rendent accessibles aux experts commerciaux, aux ingénieurs d’application et aux calculs d’apprentissage automatique. Le diagramme suivant vous aidera à comprendre l’architecture :
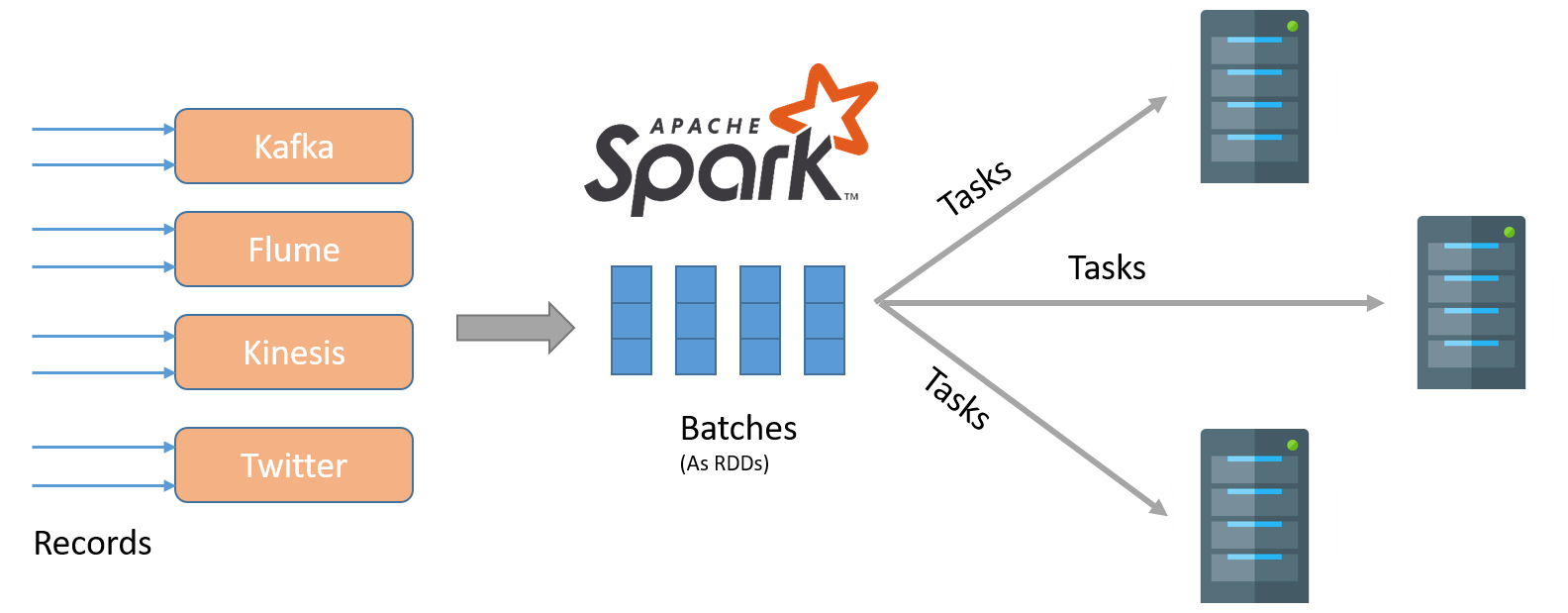
Exemple de streaming
Commençons par un simple exemple de comptage de mots utilisant des API de streaming. En tant que source de données, installons le package NC sous Linux :
Installation sur CentOS / Red Hat
# Supprime l’ancien paquet
yum erase nc
yum install nc
Installation sur Ubuntu
sudo apt-get install netcat
Le nc ou le ncat est similaire à la commande cat mais est utilisé pour les données de streaming réseau. Il est utilisé pour lire et écrire des données sur un réseau.
Démarrez nc sur le port 8888, comme suit :
nc – lk 8888
Ce qui suit est le code Python de l’API Streaming de Spark, pour compter le flux de mots venant sur le port TCP :
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# Create a StreamingContext with two thread on local machine and batch interval of 1 second
sc = SparkContext(“local[2]”, “StreamingWC”)
ssc = StreamingContext(sc, 1)
lines_stream = ssc.socketTextStream(“localhost”, 8888)
words = lines_stream.flatMap(lambda line: line.split(” “))
word_pairs = words.map(lambda word: (word, 1))
wordCount = word_pairs.reduceByKey(lambda x, y: x + y)
# Print ten elements of each RDD generated in this DStream to the console
wordCount.pprint()
ssc.start()
ssc.awaitTermination()
Créez un fichier streaming.py avec le code précédent et exécutez-le avec la commande suivante :
spark-submit –num-executors 1 –executor-memory 1g –total-executor-cores 1 streaming.py
Vous verrez l’écran suivant sur l’exécution de la commande donnée :
Ce code écoute toutes les données provenant de localhost sur le port 8888 :
nc – lk 8888
// sur terminal nc envoyer des données sur 8888
Vous verrez la sortie suivante sur l’exécution de la commande donnée:

Commencez à envoyer des données via le terminal nc et vérifiez les résultats dans l’application Spark Streaming. Vous devriez voir le résultat qui suit :
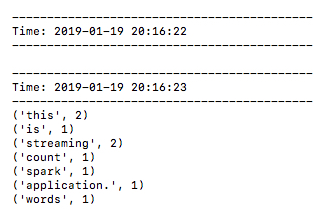
Apprentissage automatique
L’apprentissage automatique est l’une des analyses avancées qui exploitent les données. L’apprentissage automatique est un ensemble d’algorithmes qui aide les gens à comprendre les données de différentes manières. Ces algorithmes peuvent être classés en deux catégories :
- Apprentissage supervisé : les algorithmes d’apprentissage supervisé sont parmi les algorithmes d’apprentissage automatique les plus couramment utilisés. Ils utilisent des données historiques pour former un modèle d’apprentissage automatique. Ces algorithmes peuvent être davantage classés en algorithmes de classification et de régression. Dans les algorithmes de classification, le modèle est formé pour prédire une variable dépendante catégorielle / discrète. L’un des exemples de base consiste à prédire si un e-mail est du spam. D’un autre côté, les algorithmes de régression prédisent des variables continues. Un exemple d’algorithme de régression serait de prédire les cours des actions.
- Apprentissage non supervisé : dans l’apprentissage non supervisé, aucune donnée historique n’est utilisée pour former un modèle, mais essaie plutôt de découvrir les modèles cachés dans un ensemble de données donné. Le clustering est l’un des exemples célèbres d’apprentissage non supervisé. Dans les algorithmes de clustering, tels que k-means, un modèle est entraîné de manière itérative pour trouver les différents clusters dans les données.
En règle générale, un cas d’utilisation de l’apprentissage automatique suit différentes phases telles que la collecte de données, le nettoyage des données, l’ingénierie des fonctionnalités, la formation des modèles et les tests. Le produit final du processus d’apprentissage automatique est un modèle qui peut être utilisé pour prédire une variable dépendante ou pour découvrir des modèles de données.
Comme indiqué dans le chapitre 1, Introduction à Apache Spark, Spark fournit MLlib et ML pour fonctionner avec l’apprentissage automatique. Ces bibliothèques fournissent les éléments suivants :
- Un ensemble d’algorithmes courants d’apprentissage automatique, y compris la régression, la classification, le clustering et le filtrage collaboratif.
- Des fonctionnalités telles que l’extraction, la réduction de dimensionnalité, la transformation et les pipelines.
MLlib
MLlib est l’une des bibliothèques d’apprentissage automatique de Spark. MLlib fournit un ensemble de types de données qui utilise RDD pour représenter des points de données. Certains des types de données courants sont des vecteurs et des points étiquetés. Dans MLlib , l’algorithme supervisé utilise des RDD de points étiquetés et l’algorithme non supervisé utilise des vecteurs pour former un modèle. L’API MLlib fournit une large gamme d’algorithmes d’apprentissage automatique. Malheureusement, discuter de chacun d’entre eux est en dehors du cadre de cet article. Mais, nous allons implémenter l’un des algorithmes d’apprentissage supervisé et vous guider à travers certains des concepts de base.
L’un des algorithmes d’apprentissage supervisé les plus connus est la régression linéaire. Avant de créer notre modèle, regardons les données d’entrée. Pour comprendre l’algorithme, j’ai créé un petit ensemble de données :
$ cat train.data
1,10
2,20
3,30
4,40
5,50
L’exemple précédent montre le contenu du fichier train.data. Il a cinq lignes et deux colonnes. La première colonne représente un vecteur d’entité (variable indépendante), et la deuxième colonne est le point étiqueté (variable dépendante). Si vous regardez attentivement, la variable dépendante a une relation linéaire avec la variable indépendante. Nous devons nous attendre à ce que notre modèle prédit une valeur avec la même tendance. Pour tester la précision de notre modèle, nous avons également un fichier test.data :
$ cat test.data
6,60
7,70
8,80
9,90
L’exemple suivant montre comment créer un modèle de régression linéaire :
#Python
à partir de pyspark.mllib .regression import LabeledPoint , LinearRegressionWithSGD
#Charger et analyser les données
def getPoints (ligne):
values = [float (x) for x in line.split (‘,’)]
return LabeledPoint ( valeurs [ 1], [valeurs [0]])
#Lire les données brutes
trainDataRDD = spark.sparkContext.textFile (“/ FileStore / tables / train.data “)
parsedDataRDD = trainDataRDD.map ( getPoints )
#Modèle de train
modèle = LinearRegressionWithSGD.train ( parsedDataRDD , itérations = 100)
#Test Model
testDataRDD = spark.sparkContext.textFile (“/ FileStore / tables / test.data “)
testParsedDataRDD = testDataRDD.map ( getPoints )
actualAndPredRDD = testParsedDataRDD.map ( lambda p: ( p.label , model.predict ( p.features )))
actualAndPredRDD.collect ()
Passons en revue le code précédent en détail. Dans un premier temps, nous importons les classes LabeledPoint et LinearRegressionWithSGD à partir du package pyspark.mllib .regression . Ensuite, nous avons défini une fonction pour analyser le contenu de nos fichiers d’entrée. Cette fonction renvoie un objet LabeledPoint avec le point et le vecteur d’entité étiquetés. Dans notre test.data, la première valeur est notre ensemble de fonctionnalités et la deuxième valeur est le point étiqueté. Ensuite, nous utilisons ces points étiquetés pour créer notre parsedDataRDD. À ce stade, notre ensemble de données est prêt et nous pouvons construire notre premier modèle d’apprentissage automatique. Ensuite, nous utilisons la méthode train() de la bibliothèque LinearRegressionWithSGD (Stochastic Gradient Descent) avec parsedDataRDD et itérations pour créer notre modèle.
Notre modèle est maintenant prêt et nous pouvons le tester avec notre fichier test.data. Nous créons d’abord un testParsedDataRDD avec des étapes similaires et le mappage avec la méthode Predict() de notre modèle. Enfin, nous collectons les résultats du test à l’aide de collect(). L’exemple suivant montre la sortie du code précédent :
Out[49]: [(60.0, 59.996542573136239),
(70.0, 69.995966335325619),
(80.0, 79.995390097514985),
(90.0, 89.994813859704351)]
La sortie semble comme prévu. La première valeur de chaque tuple est la fonction d’entrée et la deuxième valeur est prédite par notre modèle. Notre exemple utilise un très petit ensemble de données. Dans les cas d’utilisation réelle, les données sont assez complexes et la vérification de chaque point n’est pas du tout possible. L’une des méthodes pour tester la précision d’un modèle d’apprentissage automatique est la méthode de l’erreur quadratique moyenne (MSE). L’exemple suivant montre comment calculer le MSE d’un modèle donné :
#Python
#Calculer l’erreur quadratique
MSE = actualAndPredRDD \
.map(lambda vp: (vp[0] – vp[1])**2) \
.reduce(lambda x, y: x + y) / actualAndPredRDD.count()
print(“Mean Squared Error => ” + str(MSE))
Out:Mean Squared Error => 1.90928758278e-05
Une fois qu’un modèle est finement réglé à l’aide de différents paramètres, il peut être enregistré sur le disque. L’exemple suivant montre comment enregistrer et charger un modèle dans Spark :
#Python
from pyspark.mllib.regression import LinearRegressionModel
#Save
model.save(spark.sparkContext, “/FileStore/tables/myLRModel”)
#load
myModel = LinearRegressionModel.load(spark.sparkContext,”/FileStore/tables/myLRModel”)
Dans l’exemple précédent, nous avons d’abord importé le LinearRegressionModel à partir du package pyspark.mllib.regression. Nous avons fourni le sparkContext et l’emplacement du modèle à la méthode save() , qui enregistre notre modèle sur le disque. Vous pouvez utiliser la méthode LinearRegressionModel.load() pour charger un modèle existant dans Spark.
ML
Comme indiqué dans la section précédente, MLlib utilise RDD pour travailler avec des algorithmes d’apprentissage automatique et, par conséquent, il présente tous les inconvénients du RDD. ML de Spark est une autre bibliothèque qui utilise l’API DataFrame. Toutes les nouvelles fonctionnalités ont maintenant été ajoutées à la bibliothèque ML et MLlib est désormais conservé en mode maintenance. Outre l’utilisation d’API structurées, le ML de Spark vous permet de définir le pipeline d’apprentissage automatique, qui est similaire au concept de pipeline dans scikit-learn.
La bibliothèque Spark ML fournit des API conviviales qui permettent aux utilisateurs de combiner un ensemble d’algorithmes en un seul pipeline d’étapes. Chacune de ces étapes peut effectuer une distincte des tâches (nettoyage des données, la formation de modèle, ou la prédiction) et fournit une entrée à l’autre étage. Procédé API de pipeline, il est facile d’utiliser une variété d’algorithmes de données en plus des algorithmes d’ apprentissage machine standard. Il prend également en charge la possibilité d’enregistrer l’intégralité du pipeline pour une utilisation ultérieure.
L’API du pipeline fournit deux fonctionnalités principales :
- Transformateur : un transformateur prend un DataFrame en entrée et produit un nouveau DataFrame en sortie
- Estimateur : un estimateur est un algorithme qui utilise un DataFrame pour produire un nouveau transformateur
Un pipeline n’est qu’une séquence de ces transformateurs et estimateurs. La bibliothèque ML fournit également une API de paramètres utilisée par les transformateurs et les estimateurs pour spécifier les paramètres.
Créons un modèle d’arbre de décision à l’aide de la bibliothèque ML :
// Scala
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.feature .VectorIndexer
import org.apache.spark.ml.regression .DecisionTreeRegressor
// Charger les données au format LIBSVM.
val dataDf = spark.read .format (” libsvm “) .load (“/ FileStore / tables / ML / dt.data “)
// Divisez les données en ensembles de formation et de test (données de formation – 70% | données de test – 30%).
val Array ( trainingDataDf , testDataDf ) = dataDf.randomSplit (Array (0.7, 0.3))
// Créer un indexeur de fonctionnalités [Estimateur]
val featureIndexer = new VectorIndexer ( ) .setInputCol (“features”). setOutputCol (“indexedFeatures”).fit(dataDf)
// Former un modèle DecisionTree [Estimateur]
val dtModel = new DecisionTreeRegressor ( ) .setLabelCol (“label”). setFeaturesCol (“indexedFeatures”)
// Créez un nouveau pipeline et indexeur de chaîne et un modèle DecisionTree .
val pipeline = nouveau Pipeline ( ). setStages (Array ( featureIndexer , dtModel ))
// Modèle de train.
modèle val = pipeline.fit ( trainingDataDf )
// Faire des prédictions.
val predictionsDf = model.transform ( testDataDf )
predictionsDf.select (“prediction”, “label”, “features” ) .show (10)
Dans l’exemple précédent, nous avons d’abord importé un pipeline et d’autres bibliothèques à partir du package org.apache.spark.ml. Nous avons ensuite créé un DataFrame qui contient nos données d’entrée. Ensuite, nous avons divisé notre ensemble de données en ensembles de données de formation et de test, où 70% des données sont conservées pour la formation de notre modèle. Nous avons ensuite utilisé un estimateur VectorIndexer() , qui identifie automatiquement les caractéristiques catégorielles et les indexe. À l’étape suivante, nous avons défini notre modèle d’arbre de décision et utilisé à la fois featureIndexer et dtModel pour définir un nouveau pipeline. Enfin, une méthode fit() sur le pipeline a été appelée pour former notre modèle d’arbre de décision. Cette étape exécute à la fois l’indexeur et l’estimateur d’arbre de décision.
Une fois que notre modèle est prêt, nous pouvons utiliser nos données de test pour faire des prédictions sur les étiquettes. Dans ce but, nous passons testDataDf comme paramètre à la méthode transform(). En fin de compte, nous pouvons voir les valeurs réelles et prévues en sélectionnant les prediction et label des colonnes de predictionsDf.
Databricks a récemment lancé MLFlow, qui peut être utilisé pour expérimenter rapidement avec des modèles d’apprentissage automatique. Vous pouvez trouver plus de détails sur MLFlow sur https://databricks.com/mlflow.
Traitement graphique
Dans le chapitre 1, Introduction à Apache Spark, nous avons fourni une brève introduction aux bibliothèques de graphes fournies par Spark. Dans cette section, nous aborderons ces bibliothèques plus en détail. Un graphique est l’une des structures de données utilisées en informatique pour résoudre certains problèmes du monde réel. Un graphique est représenté par un ensemble de vertices et edges. Un sommet est un objet et une arête définit une relation entre deux sommets. Un des exemples de graphiques est un réseau social, où chaque personne est représentée par un sommet, et une relation entre deux personnes est représentée par un bord. La figure suivante montre un graphique avec cinq sommets et cinq arêtes :
Un graphique avec cinq sommets et cinq arêtes
Le graphique représenté ici peut également être représenté comme un ensemble, V = {V1, V2, V3, V4, V5} et E = {E1, E2, E3, E4, E5}. Un graphique peut également être classé comme un graphique orienté ou non orienté. Dans le cas d’un graphe orienté, les arêtes représentent également une direction d’un sommet à l’autre.
La bibliothèque de graphes de Spark modélise les graphes à l’aide d’une idée appelée graphe de propriétés. Dans un graphique de propriétés, chaque sommet se voit attribuer des propriétés qui fournissent plus d’informations sur l’objet représenté par le sommet et une arête se voit également attribuer des propriétés telles que des poids et des relations. Dans un graphique de propriétés, deux sommets peuvent partager plus d’une arête. Par exemple, considérons le cas de l’industrie du transport aérien : chaque aéroport peut être considéré comme un sommet et les vols reliant ces aéroports peuvent être représentés comme des arêtes entre eux. Deux aéroports peuvent avoir plusieurs vols volant dans chaque direction.
Semblable à l’apprentissage automatique, le traitement graphique a toujours été un défi dans le domaine des mégadonnées, car les algorithmes graphiques impliquent beaucoup de brassage de données en mode distribué. Spark relève ces défis de manière unique et fournit deux API pour travailler avec des graphiques :
- GraphX
- GraphFrames
GraphX
Spark fournit l’API de bas niveau, GraphX, pour travailler avec des graphiques et utilise des RDD en dessous. Bien que vous souhaitiez peut-être écrire votre propre package pour le traitement graphique, GraphX est livré avec certaines des optimisations à portée de main. L’un des principaux défis de l’analyse graphique est le mouvement des données. GraphX relève ces défis en fournissant des fonctionnalités telles que les suivantes :
- Table de routage : cette table contient des informations sur les partitions qui ont une référence à un sommet particulier
- Mise en cache des informations de sommet : mise en cache des propriétés de sommet pour toutes les données de partition de bord
Dans GraphX, vous stockez les informations sur les sommets et les arêtes dans des RDD. Il est très facile de définir un graphique dans GraphX. Tout ce dont vous avez besoin est de deux RDD représentant à la fois les sommets et les bords. L’exemple suivant montre comment créer un graphique à l’aide de l’API Scala :
// Scala
// Importer GraphX
import org.apache.spark.graphx._
// Définir un nouveau type VertexId
type VertexId = Long
// Créer un RDD de sommets
val vertices: RDD[(VertexId, String)] = spark.sparkContext.parallelize(List((1L, “Sam”),(2L, “John”),(3L, “Sameer”),(4L, “Alice”),(5L, “Chris”)))
// Créer un RDD d’arêtes
val edges: RDD[Edge[String]] = spark.sparkContext.parallelize(List(Edge(1L, 2L, “friend”), Edge(1L, 3L, “brother”), Edge(3L, 5L, “brother”), Edge(1L, 4L, “friend”), Edge(4L, 5L, “wife”)))
// Définit enfin un graphe
val graph = Graph(vertices, edges)
Dans l’exemple précédent, nous importons d’abord tous les modules du package org.apache .spark.graphx . De plus, nous avons défini un nouveau type, VertexId, qui n’est qu’un alias pour un type Long. Ensuite, nous définissons les RDD, qui stockent toutes les informations sur les sommets et les arêtes. Enfin, nous créons un graphique en passant à la fois des vertices et des edges comme arguments à la classe Graph.
GraphX expose également une vue triplet, en dehors des sommets et des bords d’un graphique donné. La vue triplet combine les informations des sommets et des RDD de bord et représente une vue logique.
Spark propose une gamme d’opérations sur un graphique. Certaines opérations de base du graphique sont expliquées dans les sections suivantes.
mapVertices
La méthode mapVertices() peut être utilisée pour cartographier les propriétés de chaque sommet d’un graphe donné. L’exemple suivant montre l’utilisation de mapVertices():
//Scala
//Prefixing ‘Hi’ with each name
val newGraph = graph.mapVertices((VertexId, name) => “Hi “+name )
L’opération mapVertices() est similaire à la transformation mapValues(). Dans l’exemple précédent, nous venons d’ajouter «Hi» à chaque nom du sommet.
mapEdges
Semblable à mapVertices(), vous pouvez également transformer les propriétés de chaque arête en utilisant la méthode mapEdges() sur un graphique. Dans l’exemple suivant, nous modifions l’attribut relation de chaque arête mais en ajoutant la chaîne “relation”:
//Scala
val newGraph2 = newGraph.mapEdges( e => “relation : “+e.attr )
Sous-graphique
Une des opérations importantes d’un graphe est subgraph(). subgraph() permet aux utilisateurs de filtrer certaines parties d’un graphique en fonction d’un prédicat de filtre. Ce prédicat peut être appliqué à un sommet ou à une arête. L’exemple de code suivant montre comment créer un nouveau subgraph en filtrant les sommets et les arêtes:
// Scala
// Filtrage des arêtes qui ont une relation autre que friend’
val edgeFilterGraph = graph.subgraph(epred = (edge) => edge.attr.equals(“friend”))
edgeFilterGraph.edges.collect()
Comme le montre l’exemple précédent, nous passons un edge prédicat de (epred) pour filtrer toutes les relations attendons la relation ‘friend’. Un point important à noter ici est que tous les sommets feront toujours partie du nouveau edgeFilterGraph. Le prédicat de edge supprime uniquement les bords du RDD de bord en fonction du prédicat.
Nous pouvons également utiliser un prédicat de sommet pour filtrer les sommets. Dans l’exemple suivant, nous filtrons les sommets qui portent le nom de ‘Chris’. Dans ce cas, la méthode du subgraph supprimera toutes les arêtes qui lient les sommets filtrés :
// Scala
// Filtrage des sommets dont le nom est ‘Chris’
val vertexFilterGraph = graph.subgraph(vpred = (id, name) => ! name.equals(“Chris”))
vertexFilterGraph.vertices.collect()
Pour plus d’informations sur les opérations proposées par GraphX, vous pouvez vous référer à la documentation officielle de Spark.
GraphFrames
Une autre alternative à GraphX est GraphFrames. GraphFrames bénéficie de tous les avantages des API structurées, car il utilise DataFrames en dessous. GraphFrames est un package externe qui peut être utilisé avec Scala et Python. Vous devrez charger ce package au démarrage de votre application Spark. Vous pouvez télécharger ce package sur https://spark-packages.org/package/graphframes/graphframes. L’exemple suivant montre comment inclure ce package lors du démarrage d’un shell pyspark :
> $SPARK_HOME/bin/pyspark –packages graphframes:graphframes:0.6.0-spark2.3-s_2.11
Nous utiliserons les mêmes données que celles utilisées dans la section GraphX ; la seule différence sera que nous utiliserons cette fois l’API Python. La procédure pour créer un graphique dans GraphFrames est similaire à celle que nous avons suivie dans GraphX. L’exemple suivant montre comment créer un graphique dans GraphFrames :
#Python
#Importing GraphFrame
from graphframes import GraphFrame
#Création d’un DataFrame de sommets
vertices = spark.createDataFrame([(1, ‘Sam’),(2, ‘John’),(3, ‘Sameer’),(4, ‘Alice’),(5, ‘Chris’)],schema=[‘id’,’name’])
#Création d’une trame de données d’arêtes
edges = spark.createDataFrame([(1, 2, ‘friend’),(1, 3, ‘brother’),(3, 5, ‘brother’),(1, 4, ‘friend’),(4, 5, ‘wife’)],schema=[‘src’,’dst’, ‘attr’])
#Création d’un graphique
graph = GraphFrame(vertices, edges)
Dans l’exemple précédent, nous avons d’abord importé la GraphFrame classe de graphframes module. Nous avons ensuite créé deux DataFrames, vertices et edges. Enfin, nous avons utilisé ces DataFrames pour initialiser un objet graphique à l’aide de la classe GraphFrame. La plupart des opérations prévues par GraphFrames sont semblables à ce que GraphX fournit. Certaines des méthodes de base sont expliquées dans les sections suivantes.
degrees
Le nombre total d’arêtes connectées à un sommet est connu comme le degré de ce sommet. Nous pouvons utiliser la méthode degrés ( ) pour connaître le degré de chaque sommet du graphique:
#Python
graph.degrees.show()
Out:
+ — + —— +
| id | degré |
+ — + —— +
| 5 | 2 |
| 1 | 3 |
| 3 | 2 |
| 2 | 1 |
| 4 | 2 |
+ — + —— +
Comme indiqué dans l’exemple précédent, la sortie de la méthode degrees() est un nouveau DataFrame . Dans notre exemple, il y a cinq arêtes, qui sont connectées au sommet avec id1.
Subgraphs
Contrairement à GraphX, GraphFrames ne fournit aucune méthode directe pour créer des sous-graphiques, mais vous pouvez créer des sous-graphiques en écrivant simplement certaines conditions de filtre sur les sommets ou les bords. L’exemple suivant montre comment filtrer toutes les arêtes qui ont une propriété de relation autre que “friend” :
#Python
#filter out edges with relation other than “friend”
friendsGraph = GraphFrame(graph.vertices, graph.edges.filter(“attr == ‘friend'”))
Dans l’exemple précédent, nous n’obtiendrons que les arêtes qui ont une relation “friend“. Le friendsGraph conservera tous les sommets du graphique d’origine.
Algorithmes de graphe
Cette section fournira une brève introduction à certains des algorithmes fournis par GraphFrames. GraphFrames prend en charge plusieurs algorithmes de graphique, y compris le classement des pages, le nombre de triplets, les composants connectés, la recherche en priorité, etc. Malheureusement, une discussion sur tous ces algorithmes est hors de la portée de cet article, mais nous discuterons de l’un des célèbres algorithmes de graphes, PageRank.
Classement (PageRank)
L’algorithme PageRank a été conçu par les fondateurs de Google en 1996. Le moteur de recherche Google a utilisé cet algorithme pour attribuer des rangs à chaque page Web. PageRank a été utilisé pour classer les pages Web en fonction du nombre de pages pointant vers une page donnée. Cela signifie que plus le nombre de liens est élevé, plus l’importance de la page Web est élevée. De toute évidence, le PageRank n’est pas si simple après tout, car il existe d’autres facteurs qui sont utilisés dans cet algorithme. Dans notre exemple, nous pouvons appliquer PageRank pour découvrir l’importance de chaque personne dans notre graphique :
#Python
from pyspark.sql.functions import desc
ranks = graph.pageRank(resetProbability=0.15, maxIter=10)
ranks.vertices.orderBy(desc(“pagerank”)).select(“id”, “pagerank”).show(3)
Out:
+—+————————-+
| id | pagerank |
+—+————————-+
| 5 | 1.980701390329944 |
| 2 |0.7989209379539325|
| 4 |0.7989209379539325|
+—+————————-+
L’exemple précédent montre comment trouver les trois personnes les plus importantes de notre graphique. Nous avons utilisé l’algorithme PageRank pour d’abord attribuer le rang à chaque sommet, puis trié les sommets en fonction de ce rang dans l’ordre décroissant.
Résumé
Dans ce chapitre, nous sommes passés par l’architecture Spark Streaming et avons créé une application Spark Streaming simple. Ce chapitre a également couvert divers packages MLlib qui fournissent des API pour exécuter des applications d’apprentissage automatique sur Spark.
Enfin, nous avons couvert les API GraphX , couvrant les GraphFrames et les algorithmes graphiques implémentés sur Spark. Dans le chapitre suivant, nous examinerons quelques techniques d’optimisation pour exécuter efficacement notre code Spark.
Chapitre 8. Optimisations Spark
Dans les chapitres précédents, nous avons appris à utiliser Spark pour implémenter divers cas d’utilisation à l’aide de fonctionnalités telles que les RDD, les DataFrames, Spark SQL, MLlib, GraphX / Graphframes et Spark Streaming. Nous avons également discuté de la façon de surveiller vos applications pour mieux comprendre leur comportement en production. Cependant, parfois, vous souhaitez que vos travaux s’exécutent efficacement. Nous mesurons l’efficacité de tout travail sur deux paramètres : le temps d’exécution et l’espace de stockage. Dans l’application Spark, vous pourriez également être intéressé par la statistique des brassages de données entre les nœuds. Nous avons discuté de certaines des optimisations dans les chapitres précédents, mais, dans ce chapitre, nous discuterons d’autres optimisations qui peuvent vous aider à obtenir des avantages en termes de performances.
La plupart des développeurs se concentrent uniquement sur l’écriture de leurs applications sur Spark et ne se concentrent pas sur l’optimisation de leur travail pour diverses raisons. Ce chapitre aidera les développeurs à choisir des techniques d’optimisation en fonction de la nature du goulot d’étranglement.
Nous pouvons classer les optimisations en deux catégories :
- Optimisations au niveau du cluster, telles que le matériel physique et les clusters Spark
- Optimisations d’application
Cluster- niveau optimisations
Comme indiqué dans le chapitre 1, Introduction à Apache Spark, Spark peut évoluer horizontalement. Cela signifie que les performances augmenteront si vous ajoutez plus de nœuds à votre cluster, car Spark peut effectuer plus d’opérations en parallèle. Spark permet également aux utilisateurs de tirer pleinement parti de la mémoire, et un réseau rapide peut également aider à optimiser les données de lecture aléatoire. Pour toutes ces raisons, plus de matériel est toujours mieux.
Mémoire
Une utilisation efficace de la mémoire est essentielle pour de bonnes performances. Dans les versions antérieures de Spark, la mémoire était utilisée à trois fins principales:
- Stockage RDD
- Stockage aléatoire et d’agrégation
- Code d’utilisateur
La mémoire était partagée entre eux avec des proportions fixes. Par exemple, le stockage RDD comptait 60%, la lecture aléatoire 20% et le code utilisateur 20% par défaut. Ces propriétés peuvent être modifiées par les utilisateurs, selon la nature des applications Spark. Dans la version actuelle de Spark (1.6+), la gestion de la mémoire se fait automatiquement.
Dans le cas de la mise en cache, nous devons être prudents lors du choix du niveau de stockage. Le niveau de mise en cache par défaut est MEMORY_ONLY, qui conserve les données en mémoire. Si le RDD est assez grand et ne peut pas tenir en mémoire, alors Spark tient autant de partitions que possible et les partitions restantes seront recalculées. Cela peut être évité si votre RDD est coûteux à recalculer. Dans de tels cas, vous pouvez utiliser MEMORY_AND_DISK comme niveau de stockage. Cela déplacera les partitions restantes sur le disque et les remettra en mémoire quand elles seront nécessaires sans les recalculer.
Disque
Un disque est l’une des ressources matérielles utilisées par presque toutes les applications. Bien que les applications Spark bénéficient largement de la mémoire, le disque joue également un rôle important. Spark utilise l’espace disque pour stocker temporairement les données de lecture aléatoire. En mode autonome Spark et Mesos, cet emplacement peut être configuré dans la variable SPARK_LOCAL_DIRS. En mode YARN, Spark hérite des répertoires locaux de YARN.
Comme indiqué au chapitre 3, Spark RDD, Spark utilise également le disque dans des opérations telles que le point de contrôle et la mise en cache.
CPU Cores
L’unité centrale de traitement (CPU) est la ressource où se déroule le calcul. Les machines modernes sont livrées avec plusieurs cœurs de processeur, ce qui permet aux utilisateurs d’exécuter plusieurs applications en parallèle. Comme indiqué au chapitre 5 , Architecture Spark et flux d’exécution des applications , les tâches de vos travaux Spark sont exécutées sur ces cœurs. Ainsi, le degré de parallélisme dépend également du nombre de cœurs disponibles. Cela signifie que si vous disposez de 1 000 cœurs disponibles et que le nombre total de partitions est de 2 000, Spark planifiera d’abord les 1 000 tâches pour chaque partition, puis exécutera les autres après la fin des 1 000 premières tâches.
Nous avons déjà discuté de la façon dont nous pouvons contrôler ces ressources lors de la soumission de notre travail. Mais c’est une bonne idée d’en discuter à nouveau plus en détail. Nous expliquerons cela en utilisant un exemple d’un exemple de cluster. Le diagramme suivant montre un cluster de cinq nœuds, chacun ayant 16 cœurs de processeur et 64 Go de RAM :

Cluster avec cinq nœuds
Comme indiqué au chapitre 5, Architecture Spark et flux d’exécution des applications, nous pouvons fournir des configurations de ressources lorsque les paramètres suivants lors de la soumission de nos travaux Spark :
- –num-executors : nombre d’exécuteurs
- –executor-cores : cœurs attribués à chaque exécuteur
- –executor-memory : Mémoire pour chaque exécuteur
Lors de la prise de décision sur la configuration précédente, nous devons prendre en compte quelques éléments, tels que le débit d’E / S HDFS et les ressources du gestionnaire de cluster. L’une des façons de choisir la bonne configuration consiste à essayer différentes combinaisons et à choisir une combinaison qui vous convient le mieux, mais nous discuterons d’une manière qui peut vous aider à trouver un point de départ. Lors de la lecture des données de HDFS, nous devons prendre en compte les E / S. Il semble qu’avoir un grand nombre de cœurs par exemple, 15, peut entraîner un mauvais débit d’E / S. En effet, ces cœurs essaieront de lire la même petite partie des données sur cette seule machine. Au lieu de cela, nous pouvons avoir moins de cœurs (4-6) pour chaque exécuteur afin d’obtenir un meilleur débit. En gardant cela à l’esprit, nous pouvons calculer le nombre d’exécuteurs et de mémoire en procédant comme suit :
- Calculez le nombre total de cœurs disponibles pour votre application Spark :
- Nombre total de cœurs dans le cluster = 5 * 16 = 80 cœurs
- Cœurs réservés pour YARN et autres = 1 * 5 = 5 cœurs
- Noyaux restants disponibles pour l’application Spark = 80 – 5 = 75 cœurs
- Calculez le nombre total d’exécuteurs pour votre application Spark :
- Le nombre possible d’exécuteurs = 75 / 5 = 15 exécuteurs
- Réserver 1 cœur pour le maître d’application Spark (mode cluster) = 15 – 1 = 14
- Exécuteurs
- Calculez la mémoire de chaque exécuteur :
- Nombre d’exécuteurs exécutés sur chaque nœud ~ 3 exécuteurs
- Mémoire pour chaque exécuteur = 64 / 3 ~ 21 Go
- Exclure une partie de la mémoire pour YARN et la surcharge du tas = 21 – 2 = 19 Go
Cela nous donne un total de 14 exécuteurs pour notre application, chacun ayant 5 cœurs de processeur avec 19 Go de mémoire.
Il est maintenant temps de discuter de certaines propriétés du pilote Spark. Comme le pilote Spark est responsable de la construction du DAG et de la planification des tâches, le pilote devient parfois le goulot d’étranglement. Vous pouvez configurer le pilote Spark pour activer l’allocation dynamique d’exécuteur. Cela signifie que Spark peut ajouter ou supprimer dynamiquement des exécuteurs à la volée. Si l’allocation dynamique des exécuteurs est activée et que votre travail a effectué une opération telle que coalesce ( ) et ne nécessite pas d’exécuteurs, le pilote libérera les ressources. Par rapport à l’allocation traditionnelle des ressources, où nous devons réserver les ressources. Cette fonctionnalité permet une meilleure utilisation des ressources et peut être utile dans des environnements multi-locataires. Vous pouvez l’activer en ajoutant les propriétés suivantes à votre code d’application :
spark.dynamicAllocation.enabled = true
spark.dynamicAllocation.executorIdleTimeout = 2m
spark.dynamicAllocation.minExecutors = 1
spark.dynamicAllocation.maxExecutors = 2000
Vous pouvez également configurer la mémoire allouée au programme du pilote en définissant un indicateur pour –driver-memory.
Project Tungsten
Cette section abordera le projet Tungsten et les optimisations fournies par ce projet. En tant que développeur, vous n’avez pas à configurer de propriété liée à Tungsten car Spark fournit cette optimisation par défaut, mais cela vaut la peine de donner un aperçu de Tungsten à ce stade. Le projet Tungsten est axé sur les optimisations. Dans les premiers temps de l’informatique distribuée, les principaux goulots d’étranglement dans les performances étaient les E / S disque et la bande passante réseau. Ces dernières années, le matériel a considérablement progressé. Par exemple, les disques viennent maintenant avec de nouvelles options telles que l’état solide disques (SSD) et les lecteurs flash, ce qui a augmenté les performances du disque. Dans une étude récente, il a été observé que la plupart des applications distribuées ne fonctionnent pas mal pour ces raisons ; ce sont plutôt le CPU et la mémoire qui sont devenus les nouveaux goulots d’étranglement.
L’objectif du projet Tungsten est d’améliorer l’efficacité du CPU et de la mémoire pour les applications Spark. Trois des principales optimisations sont les suivantes :
- Gestion de la mémoire : cela permet à Spark de gérer la mémoire en éliminant la surcharge des objets de machine virtuelle Java (JVM), ce qui réduit la consommation de mémoire et la surcharge de la récupération de place (GC).
- Traitement binaire : l’un des objectifs du projet Tungsten est de traiter les données au format binaire lui-même, au lieu des objets JVM, qui sont de taille plus lourde. Ce format binaire est appelé format UnsafeRow.
- Génération de code : à l’aide de cette fonctionnalité, Spark utilise l’optimisation des API structurées pour générer directement le bytecode de votre code. Cela peut apporter de nombreux avantages lorsque vous écrivez de grandes requêtes.
Project Tungsten abrite également d’autres optimisations, telles que le tri, la jointure et la lecture aléatoire. Vous pouvez activer ou désactiver Tungsten à l’aide de la configuration spark.sql.tungsten.enabled. Pour plus de détails sur Project Tungsten, veuillez consulter la documentation Spark.
Optimisations d’application
Comme indiqué, il existe plusieurs façons d’améliorer les performances de vos applications Spark. Dans la section précédente, nous avons couvert certaines optimisations liées au matériel. Dans cette section, nous verrons comment appliquer certaines optimisations lors de l’écriture de vos applications Spark.
Choix de la langue
L’un des premiers choix que les développeurs doivent faire est de décider de l’API de langue dans laquelle ils vont écrire leurs applications. Dans le chapitre 1, Introduction à Apache Spark, nous avons donné un aperçu de toutes les langues prises en charge par Spark. Le choix de la langue dépend du cas d’utilisation et de la dynamique de l’équipe. Si vous faites partie d’une équipe de science des données et que vous êtes à l’aise pour écrire vos applications d’apprentissage automatique en Python ou R, alors vous pourriez envisager Python / R pour écrire vos applications Spark. Si vous écrivez votre code à l’aide des API structurées (DataFrame et Dataset), cela n’affectera pas les performances car à la fin le code Spark se résume au code RDD, qui ne nécessite pas d’interpréteur Python ou R. L’une des recommandations est d’écrire vos fonctions définies par l’utilisateur (UDF) dans Scala. Si vous prévoyez d’utiliser RDD en fonction de la nature des données, vous pouvez envisager d’écrire vos applications en Scala ou Java pour éviter les problèmes de sérialisation.
API structurée et non structurées
Nous avons déjà discuté des avantages et des inconvénients des RDD et des API structurées. Le chapitre 3, Spark RDD, a expliqué les différentes raisons pour lesquelles vous pourriez choisir d’écrire vos applications à l’aide de RDD. Écrire vos applications dans des API de haut niveau est toujours mieux car elles apportent de nombreux avantages, mais, si vous voulez plus de contrôle physique de votre travail, vous pouvez toujours passer aux RDD. Une bonne pratique consiste à commencer par les API DataFrames/Dataset pour les calculs lourds, puis à utiliser RDD pour obtenir un meilleur contrôle de votre application.
Choix du format de fichier
Votre choix de format de fichier peut également avoir un impact sur les performances de vos applications Spark. Vous devez considérer trois paramètres lors du choix du format de fichier pour votre application :
- Binaire contre texte
- Splittable versus non splittable
- Colonne versus ligne
Les formats de fichiers binaires améliorent à la fois les stockages et le transfert réseau. Le format binaire a un taux de compression plus élevé par rapport à un format de fichier texte tel que CSV et JSON. Vous devez toujours choisir un format de fichier séparable. Cela permet à différentes tâches de lire une partie différente des données en parallèle.
Le choix entre le format de fichier en colonnes et le format de fichier basé sur les lignes dépend du modèle d’accès aux données. Si votre modèle d’accès suggère une lecture fréquente et ne calcule que sur des champs spécifiques, les formats de fichier basés sur des colonnes sont de bons choix. Par exemple, si vous avez un jeu de données d’employé qui contient des champs tels que emp_id, emp_name, salaire et date_of_joining, et que vous calculez uniquement le salaire agrégé la plupart du temps, les formats de fichiers en colonnes tels que Parquet et ORC peuvent être le meilleur choix pour votre application.
Les formats de fichiers en colonnes ont également un taux de compression élevé. Spark recommande de stocker vos données au format Parquet ou ORC.
Optimisations RDD
Dans cette section, nous discuterons de certaines optimisations sur les RDD.
Choisir les bonnes transformations
L’une des façons d’optimiser vos applications est d’éviter le brassage de vos données. Moins de shuffle, moins de temps d’exécution. Si vous choisissez soigneusement vos transformations, vous pouvez éviter les brassages de données lourds. Par exemple, supposons que vous ayez un RDD de tuples (paire RDD) ayant le premier élément comme alphabet et le deuxième élément une valeur numérique. Vous souhaitez calculer la somme de tous les éléments du RDD sur la base des clés. Il existe de nombreuses façons de le faire, mais examinons deux des choix :
- groupByKey()
//groupByKey()
val rawData = Array((“A”,1),(“B”,1),(“C”,1),(“A”,2),(“B”,1))
val baseRDD = spark.sparkContext.parallelize(rawData)
baseRDD.groupByKey().mapValues(_.sum).collect()
//Output
res20: Array[(String, Int)] = Array((A,3), (B,2), (C,1))
Dans le code précédent, nous avons d’abord créé un tableau rawData. Ce tableau contenait des tuples. Nous avons ensuite parallélisé cette collection pour créer notre premier RDD (baseRDD). Nous avons ensuite utilisé groupByKey() pour regrouper des données avec des clés similaires, puis avons exécuté la transformation mapValues() pour résumer tous les éléments de chaque clé. Enfin, nous avons collecté le résultat à l’aide de collect().
- ReduceByKey()
L’exemple de code suivant utilise ReduceByKey() au lieu de groupByKey():
//reduceByKey()
baseRDD.reduceByKey( _+_ ).collect()
//Output
res14: Array[(String, Int)] = Array((A,3), (B,2), (C,1))
Bien que les deux approches aboutissent au même résultat, il existe une différence entre la façon dont chacune de ces transformations traite les données. Dans le cas de groupByKey(), les données seront mélangées entre les nœuds en fonction de la clé. Une fois les données disponibles sur chaque nœud, nous pouvons agréger les données à l’aide d’une transformation mapValues() . D’un autre côté, si les données de ReduceByKey() sont d’abord agrégées localement sur chaque nœud, elles sont ensuite transférées vers d’autres nœuds en fonction de la clé. De cette façon, ReduceByKey() mélange moins de données que groupByKey() . Dans certains cas, lorsque vos données sont très asymétriques, vous pouvez rencontrer des problèmes avec groupByKey() car tous les enregistrements avec la même clé seront envoyés à une seule machine.
Dans notre exemple, les données utilisées étaient très petites, c’est pourquoi vous ne voyez peut-être pas la différence entre le temps d’exécution, mais, dans le cas d’ensembles de données plus importants, cela fait une différence. Vous pouvez également utiliser Spark UI pour vérifier la quantité de données qui sont mélangées lors de l’exécution.
Vous devez toujours envisager d’utiliser la transformation filter() avant d’appliquer une transformation large.
Sérialisation et compression
Chaque fois que nous utilisons des types de données personnalisés dans notre application Spark, nous devons les sérialiser. La sérialisation Java est la sérialisation par défaut, mais la modification du format de sérialisation en Kryo peut augmenter les performances. Les objets sérialisés par le sérialiseur Java sont souvent lents et de plus grande taille par rapport au sérialiseur Kryo . Vous pouvez changer la propriété spark.serializer en org.apache.spark.serializer.KryoSerializer pour définir le sérialiseur Kryo . Vous auriez besoin que votre classe s’inscrive auprès du Kryo et vous pouvez être strict sur l’inscription à la classe. Dans l’exemple suivant, nous mandatons d’abord l’enregistrement de classe en définissant l’indicateur spark.kryo .registrationRequired sur true . Nous inscrivons ensuite deux de nos classes à Scala :
//Scala
conf.set(“spark.kryo.registrationRequired”, “true”) conf.registerKryoClasses(Array(ClassOf[FirstCustomClass],ClassOf[SecondCustomClass]))
Ces informations de sérialisation seront utilisées pendant la phase de lecture aléatoire ainsi que lors de l’écriture des données sur le disque. Vous pouvez également choisir une compression telle que Snappy ou LZF qui peut compresser les données dans une large mesure et peut améliorer les performances de lecture aléatoire.
Variables de diffusion
Avant d’expliquer la variable de diffusion, discutons du concept de fermeture. Prenons un exemple simple :
#Python
spark.sparkContext.parallelize (plage (1,11)) \
.map (lambda x: x * 2) \
.collect ()
#Production
Sortie [ 4]: [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
Dans l’exemple précédent, nous avons d’abord créé un RDD en utilisant la méthode parallelize() puis nous avons multiplié chaque élément par 2 pour générer les nombres pairs. Sous le capot, lorsque le pilote Spark planifie les tâches, chaque tâche a une copie de la fonction (lambda x: x * 2 ) ainsi que les données que la fonction utilise (dans notre exemple: 2 ) . Cela signifie que chaque tâche aura une copie du numéro 2. Dans notre exemple, vous pourriez ne pas remarquez un goulot d’étranglement que notre taille des données est très faible et aussi nous sommes juste un entier multiplierez mais, imaginez l’exécution des opérations similaires sur un très grand RDD, qui a utilisé une grande variable dans la fonction. Cela augmentera le temps d’expédition des tâches et l’espace mémoire sur les exécuteurs, car chaque tâche aura sa propre copie de la variable.
Pour éviter ce scénario, Spark fournit des variables de broadcast. Les variables de broadcast ne sont copiées qu’une seule fois dans chaque exécuteur, puis les tâches peuvent utiliser cette copie pour le calcul. Cela améliore à la fois le temps d’exécution et l’espace de stockage. L’exemple suivant utilise le broadcast. Nous avons d’abord broadcast numéro 2 à tous l’exécuteur testamentaire en utilisant la broadcast() et lui donner une référence numberTwo . Nous utilisons ensuite numberTwo.value pour accéder à la valeur réelle lors de la transformation map() :
#Python
numberTwo = spark.sparkContext.broadcast(2)
spark.sparkContext.parallelize(range(1,11))\
.map(lambda x : x*numberTwo.value)\
.collect()
#Output
Out[5]: [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
Les variables de broadcast sont des variables en lecture seule. Spark fournit également des accumulateurs équivalents aux compteurs de réduction de carte. Les accumulateurs sont les variables en écriture seule et peuvent être utilisés pour obtenir des statistiques telles que le nombre d’enregistrements incorrects dans le fichier d’entrée lors de l’exécution de votre application. Veuillez consulter la documentation Spark pour plus de détails sur les accumulateurs.
Optimisations de DataFrame et de dataset
Cette section présente certaines techniques d’optimisation que vous pouvez utiliser lorsque vous travaillez avec les API structurées.
Optimisation de catalyseur
Catalyst Optimizer est l’un des composants qui fonctionne avec l’API structurée Spark. L’objectif de l’optimiseur de catalyseur est de fournir des avantages de performances pour les API structurées telles que SQL, DataFrame et l’ensemble de données. L’idée est que lorsque vous disposez d’informations de schéma, vous pouvez optimiser le plan de requête. Pour chaque requête soumise par l’utilisateur, elle est d’abord convertie en un plan de requête logique. Ce plan de requête logique contient des informations de haut niveau sur la requête sous la forme d’un arbre d’expressions et d’opérations. L’optimiseur Catalyst effectue ensuite une série de transformations sur ce plan logique pour proposer le plan de requête le plus efficace et optimisé. Ce plan de requête logique optimisé est ensuite converti en plan de requête aphysique. Le plan de requête physique contient également des informations similaires à un plan logique, mais contient des informations supplémentaires telles que le fichier à lire ou la jointure à effectuer. Enfin, le projet Tungsten générera le code RDD pour la requête d’entrée. Le diagramme suivant montre la série d’étapes précédente :

Catalyst Optimizer
Dans le diagramme précédent, une fois qu’une requête Spark SQL, un DataFrame ou un code d’ensemble de données est soumis, Catalyst Optimizer reçoit un plan de requête logique. Catalyst Optimizer puis effectue des transformations sur celui-ci pour piloter ses versions optimisées. Ces optimisations peuvent inclure la suppression d’un prédicat de la source de données, l’évaluation d’une opération constante (par exemple 5 + 6 = 11) une seule fois ou le choix du bon type de jointure. Le plan de requête optimisé est ensuite soumis à Tungsten pour générer le code RDD équivalent.
Vous pouvez consulter les blogs de databricks pour plus de détails sur l’optimiseur de catalyseur.
Stockage
La façon dont vous stockez vos données détermine la vitesse à laquelle vous allez les récupérer. Il est toujours préférable de choisir des stratégies de partition ou de regroupement qui peuvent vous aider à traiter vos données plus rapidement. Spark fournit à la fois la partition et le regroupement tout en stockant les DataFrames. Dans le cas du partitionnement, les fichiers sont créés dans des répertoires basés sur un champ clé. Par exemple, vous pouvez choisir un champ de données pour partitionner vos données. Une chose à garder à l’esprit lorsque vous travaillez avec le partitionnement est que le champ clé doit avoir une faible cardinalité ; c’est-à-dire que le champ doit avoir moins de valeurs possibles. Si la cardinalité était trop élevée, vous finiriez par créer un grand nombre de partitions qui peuvent devenir un goulot d’étranglement, car de nombreuses tâches sont lancées pour traiter ces partitions. Idéalement, une partition devrait avoir au moins 128 Mo de données. Au moment de la lecture de ces données, Spark ne traitera que la partition donnée et ignorera le reste.
Dans le cas d’une cardinalité plus élevée, vous pouvez utiliser le regroupement pour regrouper et stocker les clés associées ensemble. Si deux tables sont regroupées dans les mêmes champs et ont un nombre (multiple) égal de compartiments, joindre ces deux tables sur les mêmes champs prendra moins de temps que de les joindre sans les compartiments.
Parallélisme
Le nombre par défaut de partitions de lecture aléatoire dans Spark SQL est 200. Cela signifie que si vous utilisez une transformation qui mélange les données, vous aurez 200 blocs de lecture aléatoire en sortie. Si vos données sont volumineuses et que vous utilisez toujours le paramètre par défaut de spark.sql.shuffle.partitions, les blocs shuffle auront une taille de bloc élevée. Dans Spark, la taille du bloc aléatoire ne peut pas être supérieure à 2 Go. Cela peut entraîner une exception d’exécution. Pour éviter de telles exceptions, vous devez toujours envisager d’augmenter le nombre de partitions de lecture aléatoire. Cela diminuera éventuellement la taille des partitions de lecture aléatoire. La taille idéale d’une partition est proche de 128 Mo. Dans Spark SQL, vous pouvez modifier la taille des blocs shuffle en modifiant la valeur de spark.sql.shuffle.partitions. Dans RDD, vous devriez considérer repartition() ou coalesce() pour changer le nombre de partitions.
Join Performance la performance
Spark SQL fournit une variété de jointures, telles que les suivantes :
- Shuffle hash Join
- Broadcast Hash Join
- Cartesian Join
Si la taille des deux tables est grande et qu’elles sont toutes les deux regroupées en compartiments / sur le même champ de jonction, la jonction de hachage aléatoire peut mieux répondre à vos besoins. Cela fonctionne mieux lorsque les données sont réparties uniformément en fonction du champ clé et qu’il y a suffisamment de valeurs uniques pour que ce champ clé atteigne le parallélisme nécessaire. Si l’une des tables est de petite taille, vous pouvez utiliser la diffusion join, qui met en cache les petites données sur chaque machine et évite la lecture aléatoire.
Génération de code
Comme indiqué précédemment dans ce chapitre, Spark peut générer du bytecode pour vos requêtes à la volée. Spark compile chaque requête en son code équivalent de bytecode Java lorsque spark.sql.codegen est défini sur true. Par défaut, cette propriété est définie sur false. Si vos requêtes sont importantes, vous pouvez définir cette propriété sur true pour améliorer les performances.
Exécution spéculative
Si vos travaux s’exécutent lentement et que, depuis Spark UI, vous découvrez que certaines tâches s’exécutent plus lentement que d’autres, vous pouvez envisager d’activer l’exécution de spéculations pour ces tâches. Si la propriété spark.speculation est définie sur true, Spark identifiera les tâches à exécution lente et exécutera les tâches spéculatives sur d’autres nœuds pour terminer le travail plus rapidement. Les tâches qui se terminent en premier sont acceptées et la deuxième tâche est tuée par Spark.
Le code suivant définit cette propriété sur true :
#Python
conf.set(“spark.speculation”,”true”)
Résumé
Dans ce chapitre, nous avons discuté de certaines des optimisations fournies par Spark. Tout d’abord, nous avons discuté de certaines optimisations au niveau du matériel, telles que la définition du nombre de cœurs, d’exécuteurs et de la quantité de mémoire pour vos applications Spark. Nous avons ensuite donné un aperçu du projet Tungsten et de ses optimisations. Ensuite, nous avons couvert les optimisations au niveau de l’application, telles que le choix de la bonne langue, de l’API et du format de fichier pour vos applications. Enfin, nous avons couvert les optimisations fournies par les API RDD et DataFrame.



Laisser un commentaire
Vous devez être dentifié pour poster un commentaire.