DevOps vs Site Reliability Engineering : concepts, pratiques et rôles
Depuis plus d’une décennie, deux concepts similaires – DevOps et Site Reliability Engineering (SRE) – coexistent dans le monde du développement logiciel. À première vue, ils peuvent ressembler à des concurrents. Mais une vue plus rapprochée révèle que les prétendus rivaux sont en fait des pièces complémentaires d’un puzzle qui s’emboîtent bien.
Cet article explique comment DevOps et SRE facilitent la création de logiciels fiables, où ils se chevauchent, en quoi ils diffèrent les uns des autres et quand ils peuvent travailler efficacement côte à côte. Nous espérons que ces informations seront utiles aux spécialistes DevOps, aux chefs de produit, aux directeurs techniques et aux autres cadres qui cherchent des moyens d’améliorer la fiabilité de leurs systèmes sans nuire à la vitesse des innovations.
Les bases de Google SRE vs DevOps : les deux faces d’une même pièce
Essentiellement, deux méthodologies font la même chose : elles essaient de combler le fossé entre les équipes de développement et d’exploitation. Les deux visent à améliorer le cycle de lancement et à obtenir une meilleure fiabilité du produit. Mais avant de plonger plus profondément dans les différences et les similitudes entre eux, revenons à quand et pour quelle raison SRE et DevOps sont apparus.

Comparaison entre l’ingénierie de la fiabilité du site et DevOps
Comparaison SRE vs DevOps.
Qu’est-ce que le SRE ?
L’ingénierie de fiabilité du site ou SRE est une approche unique, d’abord logicielle, des opérations informatiques soutenue par l’ensemble des pratiques correspondantes. Il est né au début des années 2000 chez Google pour assurer la santé d’un grand système complexe servant plus de 100 milliards de requêtes par jour. Pour reprendre les mots de Ben Treynor Sloss, vice-président de l’ingénierie de Google, qui a inventé le terme même SRE, « C’est ce qui se passe lorsque vous demandez à un ingénieur logiciel de concevoir une fonction d’exploitation ».
L’objectif principal de SRE est la fiabilité du système, qui est considérée comme la caractéristique la plus fondamentale de tout produit. La pyramide ci-dessous illustre les éléments contribuant à la fiabilité, des plus basiques (surveillance) aux plus avancés (lancements de produits fiables).
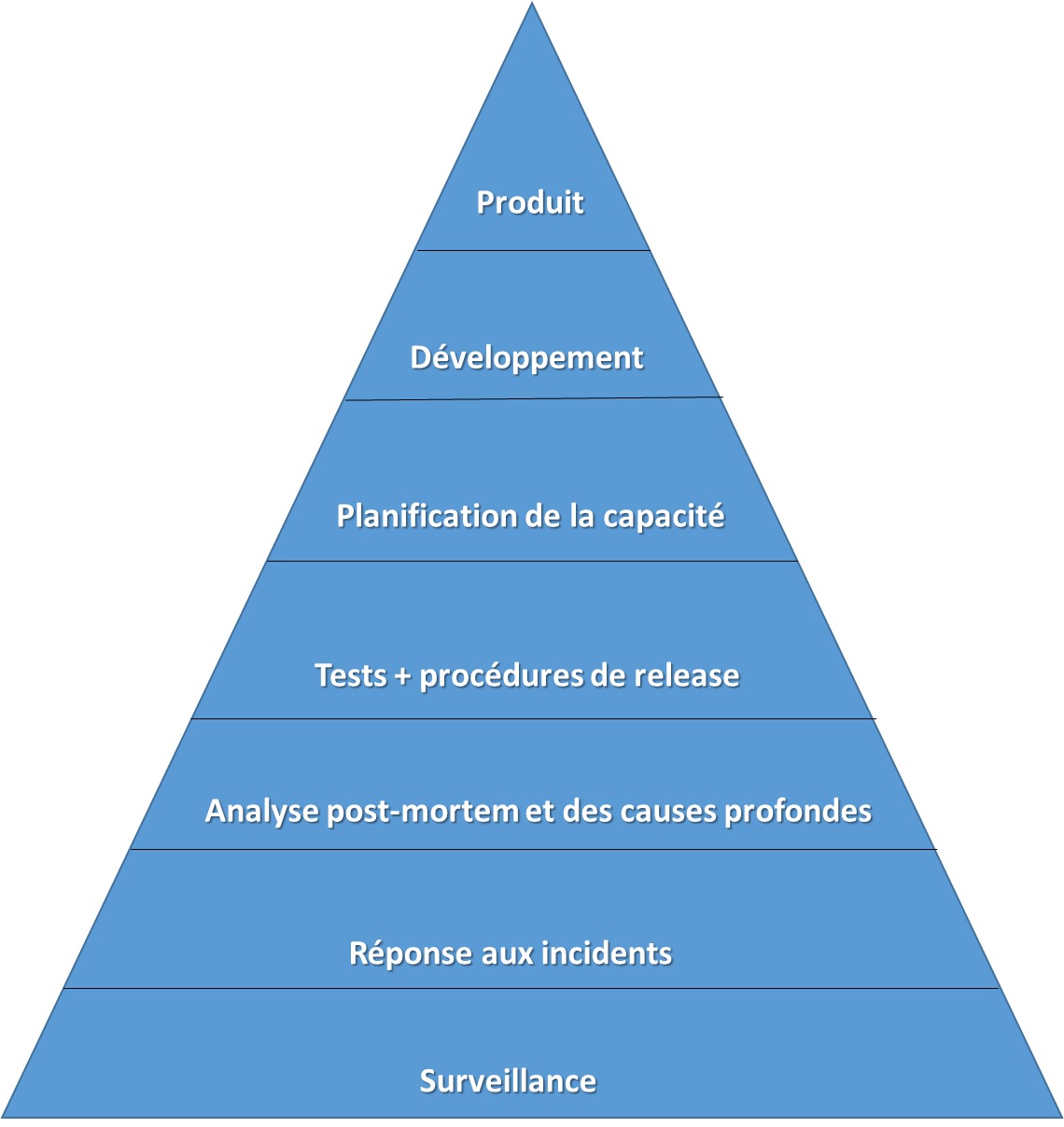
Pyramide de fiabilité
La hiérarchie des besoins de fiabilité des services, selon le livre SRE de Google. Source : Ingénierie de la fiabilité du site.
Une fois que le système est « assez fiable ». SRE déplace ses efforts vers l’ajout de nouvelles fonctionnalités ou la création de nouveaux produits. Il accorde également beaucoup d’attention au suivi des résultats, à l’amélioration mesurable des performances et à l’automatisation des tâches opérationnelles.
Qu’est-ce que DevOps ?
Le terme DevOps (abréviation de développement et opérations) a été inventé en 2009 par Patrick Debois, consultant informatique belge et praticien Agile. Ses principes de base sont similaires à ceux de la SRE : application de pratiques d’ingénierie aux tâches d’exploitation, mesure des résultats et recours à l’automatisation au lieu du travail manuel. Mais son objectif est beaucoup plus large.
Alors que SRE se concentre sur le maintien des services en cours d’exécution et disponibles pour les utilisateurs, DevOps vise à couvrir l’ensemble du cycle de vie du produit, de la conception aux opérations, rendant tous les processus continus après les méthodologies Agile. Une telle continuité de bout en bout est primordiale pour réduire les délais de mise sur le marché et apporter des changements rapides.
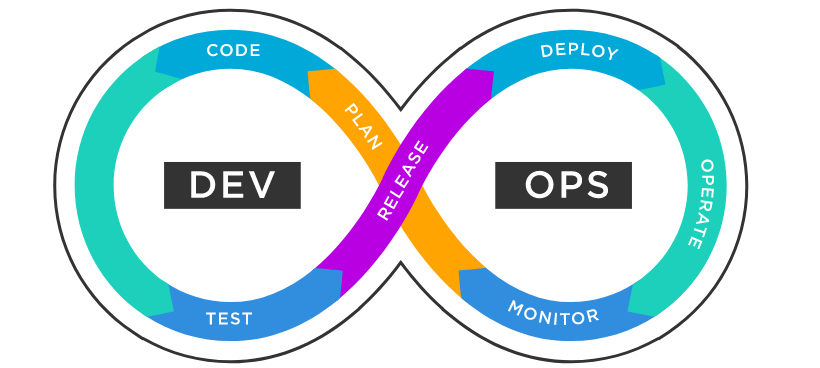
Un cycle de vie DevOps
Une autre différence par rapport à SRE est que DevOps a émergé en premier lieu comme une culture et un état d’esprit qui ne spécifiaient pas exactement comment mettre en œuvre ses idées. Il est souvent considéré comme une généralisation des méthodes SRE clés afin qu’elles puissent être utilisées par un plus large éventail d’organisations. De même, SRE peut être vu comme une incarnation des visions DevOps. La section suivante décrit plus en détail les interactions entre deux méthodologies.
Pratique vs état d’esprit : comment les Site Reliability Engineering mettent en œuvre la philosophie DevOps
De manière générale, DevOps décrit ce qui doit être fait pour unifier le développement et les opérations de logiciels. Alors que SRE prescrit comment cela peut être fait. La culture DevOps repose sur plusieurs piliers couverts par les pratiques SRE correspondantes.

Ce que SRE propose pour résoudre les tâches DevOps.
Cinq piliers clés de DevOps sont
- Fin des silos. L’idée vient du fait qu’un manque de collaboration et de flux d’informations entre les équipes réduit la productivité.
- Les échecs sont normaux. DevOps recommande d’apprendre des erreurs plutôt que de consacrer des ressources à un objectif impossible à atteindre : éviter tous les échecs.
- Le changement doit être progressif. Les changements sont plus efficaces et à faible risque lorsqu’ils sont petits et fréquents. Ce pilier, combiné aux tests automatisés de petits lots de code et à la restauration des mauvais, sous-tend les concepts d’intégration continue et de livraison continue (CI/CD).
- Plus il y a d’automatisation, mieux c’est. DevOps se concentre sur l’automatisation pour fournir des mises à jour plus rapidement et libérer des heures d’effort manuel.
- Les métriques sont cruciales. Chaque changement doit être mesuré pour comprendre s’il apporte les résultats que vous attendez.
Voyons maintenant ce que propose SRE pour mettre ces piliers en pratique.
Traiter les opérations comme un problème logiciel
Correspond à « plus de silos », « plus il y a d’automatisation, mieux c’est »
SRE utilise l’ingénierie logicielle pour résoudre les problèmes d’exploitation. En d’autres termes, des solutions logicielles sont créées pour indiquer à un ordinateur comment effectuer des opérations informatiques automatiquement, sans intervention humaine. Les spécialistes SRE appliquent les mêmes outils que ceux que les développeurs utilisent généralement et partagent la responsabilité du succès du produit avec une équipe de développement logiciel.
Minimiser le labeur
Correspond à “plus il y a d’automatisation, mieux c’est”, “les métriques sont cruciales”
En matière de SRE, le labeur est un travail manuel, répétitif, dépourvu de valeur à long terme et lié à la gestion d’un service de production. Des exemples de labeur sont
- Réinitialisations régulières des mots de passe,
- Releases manuelles,
- Examiner les alertes non critiques, et
- Mise à l’échelle manuelle de l’infrastructure.
La règle d’or de SRE est de maintenir le travail en dessous de 50 pour cent du temps de travail des ingénieurs. Une fois le seuil dépassé, l’équipe doit identifier la principale source de labeur. Ensuite, les ingénieurs développent une solution logicielle pour automatiser certaines tâches et atteindre un équilibre de travail sain. Une bonne pratique consiste à éliminer un peu de labeur chaque semaine.
Mesurer la disponibilité et la disponibilité du système
Correspond à « les métriques sont cruciales »
Selon SRE, la disponibilité est une condition préalable essentielle au succès d’un système. Si votre service n’est pas disponible à un moment donné, il ne peut pas exécuter ses fonctions. Pour mesurer la disponibilité et ainsi s’assurer que tout se passe bien, SRE propose trois métriques.
1. L’indicateur de niveau de service (SLI) est une mesure quantitative du comportement d’un système. Le SLI principal pour la plupart des services est la latence des demandes, c’est-à-dire le temps nécessaire pour répondre à une demande. D’autres SLI couramment utilisés sont le débit de requêtes par seconde et les erreurs par requête. Ces mesures sont généralement collectées au cours d’une certaine période de temps, puis converties en taux, moyennes ou centiles.
2. L’objectif de niveau de service par objectif (SLO) est une plage cible de valeurs définie par les parties prenantes (par exemple, la latence moyenne des requêtes doit être inférieure à 100 millisecondes). Le système est censé être fiable si ses SLI respectent en permanence les SLO.
3. L’accord de niveau de service (SLA) est une promesse faite aux clients que votre service respectera certains SLO sur une certaine période. Sinon, un fournisseur paiera une sorte de pénalité. SRE n’est pas directement impliqué dans la définition des SLA. Cependant, cela permet d’éviter les SLO manqués et les pertes financières qu’ils entraînent.
Définir la marge d’erreur
Correspond à « les échecs sont normaux », « les changements doivent être progressifs », « les mesures sont cruciales »
SRE ne vise pas à atteindre une fiabilité à 100 % car cet objectif est irréaliste. « … 100 % n’est pas le bon objectif de fiabilité, car aucun utilisateur ne peut faire la différence entre un système disponible à 100 % et, disons, disponible à 99,999 %. » De plus, une fois un certain niveau atteint, une nouvelle augmentation de la fiabilité ne profite pas au système, limitant la vitesse et la fréquence des mises à jour.
Ainsi, l’objectif de SRE est de fournir des services suffisamment bons sans sacrifier la capacité de fournir de nouvelles fonctionnalités souvent et rapidement. Cette approche tolère le risque d’échec acceptable appelé budget d’erreur.
Dans Google, le budget d’erreur est défini trimestriellement, en fonction des SLO. Il donne une vision claire du niveau de risque autorisé sur un trimestre. Une fois la métrique convenue dépassée, l’équipe passe du développement de mises à jour à l’amélioration de la fiabilité.
Réduire le coût de l’échec
Correspond à « les échecs sont normaux », « les changements doivent être progressifs »
Plus l’erreur est détectée tard dans le cycle de vie du produit, plus le coût de sa correction est élevé. SRE reconnaît ce fait et essaie de résoudre les problèmes le plus tôt possible en utilisant les pratiques suivantes.
Rollback tôt, rollback souvent. Lorsqu’une erreur est révélée ou même suspectée dans une version, l’équipe revient en arrière en premier et explore le problème en second. Cette approche réduit le temps moyen de récupération (MTTR) – ou le temps moyen nécessaire pour récupérer votre service après une panne.
Canary tous les déploiements. La version Canary est une méthode pour rendre le processus de déploiement plus sûr. Une mise à jour est d’abord présentée à une petite partie des utilisateurs. Ils le testent et donnent leur avis. Une fois toutes les modifications requises apportées, la version est mise à la disposition de tous. Les versions Canary réduisent le temps moyen de détection (MTTD) qui reflète le temps qu’il faut généralement à votre équipe pour détecter un problème. En outre, la méthode réduit le nombre de clients touchés par des défaillances du système.
Créer et maintenir des playbooks
Correspond à « Diminuer les silos », « tout automatiser »
Les playbooks ou runbooks sont des documents décrivant les procédures de diagnostic et les moyens de répondre aux alertes automatisées. Ils réduisent le temps moyen de réparation (MTTR), le stress et le risque d’erreur humaine.
Les entrées dans les playbooks sont obsolètes dès que l’environnement change. Ainsi, en ce qui concerne les versions quotidiennes, ces guides nécessitent également des mises à jour quotidiennes. Considérant qu’il est difficile de créer une bonne documentation, certains SRE préconisent de ne créer que des instructions générales qui changent lentement. D’autres insistent sur des manuels détaillés, étape par étape, pour éliminer la variabilité.
Le workbook SRE de Google recommande de mettre en œuvre l’automatisation si un playbook contient une liste de commandes que les ingénieurs exécutent à chaque fois dans le cas d’une alerte particulière.
Métiers SRE vs DevOps : une équipe de multitâches ou une équipe transverse
Ces dernières années, les rôles SRE et DevOps sont devenus très importants dans de nombreuses entreprises. Mais cela ne signifie pas que tout le monde est d’accord sur ce que font exactement les équipes SRE et DevOps. De même, il n’y a pas de description universelle pour les emplois DevOps et Site Reliability Engineer. Ci-dessous, nous essaierons de mettre en évidence les aspects les plus essentiels des fonctions DevOps et SRE.
Rôle d’ingénieur en fiabilité de site et équipe SRE
Une équipe SRE typique est composée soit de développeurs de logiciels ayant une expertise dans les opérations, soit de spécialistes des opérations informatiques ayant des compétences en développement de logiciels. Chez Google, ces équipes sont généralement composées d’un mélange de 50-50 de ceux qui ont plus d’expérience en logiciels et de ceux qui ont plus d’expérience en systèmes. D’autres entreprises forment des équipes SRE en ajoutant des ensembles de compétences et des approches en génie logiciel aux pratiques d’exploitation et au personnel existants.
Outre les opérations et l’ingénierie logicielle, les domaines d’expérience pertinents pour le rôle SRE englobent les systèmes de surveillance, l’automatisation de la production et l’architecture du système.
Tous les membres d’une équipe SRE partagent la responsabilité du déploiement du code, de la maintenance du système, de l’automatisation et de la gestion des changements. Et les fonctions de chaque ingénieur de fiabilité du site peuvent changer au fil du temps, en fonction de l’objectif actuel de l’équipe – le développement de nouvelles fonctionnalités ou l’amélioration de la fiabilité du système.
Rôle d’ingénieur DevOps et équipe DevOps
Contrairement à une équipe SRE où chaque membre est une sorte de touche-à-tout, une équipe DevOps contient différents professionnels avec des tâches spécifiques.
La structure de l’équipe varie d’une entreprise à l’autre et comprend généralement (mais sans s’y limiter) les spécialistes suivants :
- un Product Owner qui comprend comment le service doit fonctionner pour apporter de la valeur aux clients,
- un chef d’équipe déléguant des tâches à d’autres membres,
- un Cloud Architect bâtissant une infrastructure cloud pour le bon fonctionnement des services en production,
- un développeur logiciel écrivant du code et des tests unitaires,
- un ingénieur QA mettant en œuvre des méthodes de qualité pour le développement et la livraison des produits,
- a Release Manager programmant et coordonnant les releases, et
- un administrateur système en charge de la surveillance du cloud.
Bien entendu, il ne s’agit pas d’une liste exhaustive des rôles dans DevOps. Très souvent, une telle équipe interfonctionnelle invite un ingénieur en fiabilité du site pour assurer la disponibilité des services. En règle générale, lorsque les SRE travaillent au sein d’une équipe DevOps, ils ont un éventail de responsabilités plus restreint que dans les équipes SRE pleinement engagées.
Peu importe le nombre et l’expérience des membres de l’équipe, il est évident que DevOps n’est pas un rôle ou une personne contrairement à SRE. Cependant, au moment de la rédaction de cet article, près de 25 000 emplois d’ingénieur DevOps étaient publiés sur Glassdoor, ce qui est comparable à près de 33 000 ingénieurs en fiabilité de site recherchés sur le même site Web.
Un bref examen des postes vacants sur Glassdoor révèle que les antécédents, les responsabilités et les compétences requises pour les deux emplois se chevauchent beaucoup. Il semble que les employeurs utilisent souvent ces titres d’emploi de manière interchangeable.

Comparaison des emplois de DevOps vs SRE Engineer sur la base des offres d’emploi publiées par Glassdoor.
Cependant, les salaires annuels moyens sont un peu plus élevés parmi les SRE – grâce aux données financières soumises par les employés travaillant pour des géants de la technologie comme Google, LinkedIn, Twitter, Microsoft, Apple et Adobe, pour n’en nommer que quelques-uns.
Outils SRE vs DevOps : les mêmes solutions pour les deux
Matthew Flaming, vice-président de l’ingénierie logicielle chez New Relic Application Software Monitoring, décrit SRE comme « la distillation la plus pure des principes DevOps dans un rôle unique ». Cela étant dit, un ensemble d’outils SRE et DevOps peut être très similaire et inclure généralement les positions suivantes.
Les conteneurs et les microservices facilitent la création d’un système évolutif. Ainsi, Docker pour la création et le déploiement d’applications conteneurisées et Kubernetes pour l’orchestration de conteneurs font partie intégrante des chaînes d’outils SRE/DevOps.
Les outils CI/CD tels que Jenkins ou CircleCI prennent en charge l’idée d’un changement progressif, permettant aux équipes de créer, tester et déployer du code plus rapidement.
Les outils d’infrastructure en tant que code (IaS) correspondent exactement au concept « tout automatiser ». Terraform, AWS CloudFormation, Puppet, Chef et Ansible sont parmi les solutions les plus utilisées pour automatiser les déploiements et les configurations d’infrastructure.
Des tests fonctionnels et non fonctionnels automatisés en production peuvent être effectués à l’aide de Selenium, Zephyr, Nexus Lifecycle, Veracode et d’autres outils.
Les tests de résilience sont essentiels pour garantir la capacité du système à résister aux conditions réelles. Les options populaires pour cette tâche sont Chaos Monkey de Netflix, ChaosIQ et Gremlin.
Les systèmes de surveillance jouent un rôle crucial dans les frameworks SRE et DevOps. Les services fournis par Prometheus, DataDog, Broadcom, PRGT Network Monitor et de nombreuses autres plates-formes permettent une surveillance continue basée sur des métriques des performances du réseau et des applications dans les environnements cloud.
Quand les entreprises ont-elles besoin de DevOps et de SRE ?
Malgré toute la confusion et les chevauchements, une chose est à peu près sûre : SRE et DevOps ne sont pas des factions en conflit, mais plutôt deux parents travaillant vers le même objectif et avec les mêmes outils, mais avec des objectifs légèrement différents.
Alors que la culture SRE privilégie la fiabilité à la vitesse du changement, DevOps accentue plutôt l’agilité à toutes les étapes du cycle de développement du produit. Cependant, les deux approches tentent de trouver un équilibre entre deux pôles et peuvent se compléter en termes de méthodes, de pratiques et de solutions.
Selon leur taille et leurs objectifs, les entreprises peuvent mettre en œuvre différents scénarios de DevOps, SRE ou même leur combinaison.
Les équipes SRE calquées sur Google s’adaptent à de grandes entreprises axées sur la technologie telles qu’Adobe, Twitter ou Amazon qui traitent des milliards de demandes quotidiennes et font passer la disponibilité de leurs services avant toute autre chose.
La culture DevOps et les équipes interfonctionnelles profitent à toute entreprise travaillant dans un environnement hautement concurrentiel, où même un délai de mise sur le marché légèrement plus court donne un énorme avantage concurrentiel. De plus, une équipe DevOps peut être renforcée avec un ingénieur en fiabilité du site pour surveiller les performances du système et assurer sa stabilité.
Certaines organisations ont deux équipes : SRE et DevOps. Le premier est responsable du support et de la maintenance du service existant tandis que le second crée et fournit de nouvelles applications.
Les petites entreprises recherchent généralement une personne pour gérer l’infrastructure cloud et automatiser les tâches opérationnelles, en utilisant différents titres de poste pour les mêmes responsabilités : ingénieur DevOps, responsable DevOps, ingénieur en fiabilité de site ou même ingénieur cloud ou ingénieur CI/CD.
Quelle que soit la taille de votre entreprise, quelqu’un dans votre organisation fait probablement déjà le travail SRE, promeut la collaboration entre les développeurs et les informaticiens, ou écrit des scripts pour automatiser les tâches chronophages. Si vous trouvez ces personnes et reconnaissez officiellement leur travail, elles peuvent constituer l’épine dorsale d’une équipe SRE ou DevOps efficace, quel que soit le nom que vous préférez.



Laisser un commentaire
Vous devez être dentifié pour poster un commentaire.