La vision par ordinateur via l’apprentissage profond
Résumé de la publication
La vision par ordinateur (aussi appelée vision artificielle ou vision numérique) est une branche de l’intelligence artificielle dont le principal but est de permettre à une machine d’analyser, traiter et comprendre une ou plusieurs images prises par un système d’acquisition (par exemple : caméras, etc.). Dans cette publication nous allons analyser les méthodes utilisées pour permettre à un ordinateur d’acquérir ses capacités de vision.
Objectifs de la publication
- Compréhension des concepts de perceptron et réseaux neuronaux
- Découvrir la notion de Réseau neuronal artificiel (RNA)
- Décrypter les différents concepts liés aux réseaux neuronaux
- Comprendre les techniques de régularisation
- Comprendre l’importance de la taille des lots
Apprentissage profond dans la vision par ordinateur
Bienvenue sur le deuxième article de la série de vision sinipari. L’article a l’intention de transmettre un point de vue sur les bases de l’apprentissage profond pour la vision par ordinateur. Pour assurer une compréhension approfondie du sujet, l’article aborde les concepts avec une approche logique, visuelle et théorique. Le domaine le plus discuté de l’apprentissage automatique, l’apprentissage profond, est celui qui motive la vision par ordinateur, qui a de nombreuses applications dans monde réel et qui est sur le point de perturber le monde industriel.
L’apprentissage profond est un sous-ensemble de l’apprentissage automatique qui traite des grandes architectures de réseau neuronal. Nous discuterons des concepts de base de l’apprentissage profond, des types de réseaux neuronaux et des architectures, ainsi qu’une étude de cas dans ce domaine. Notre aventure dans l’Apprentissage profond commence avec l’unité de calcul la plus simple, appelée perceptron.
Qu’est-ce qu’un Perceptron ?
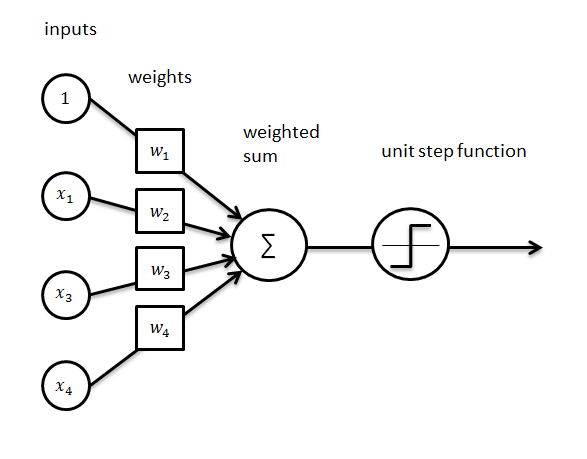
Un perceptron, également connu sous le nom de neurone artificiel, est un nœud computationnel qui prend de nombreuses entrées et effectue une synthèse pondérée pour produire une sortie. Un simple perceptron est une cartographie linéaire entre l’entrée et la sortie. Plusieurs neurones empilés ensemble donnent lieu à un réseau neuronal. Une opération de formation, discutée plus loin dans cet article, est utilisée pour trouver le « bon » ensemble de poids pour les réseaux neuronaux. La limite dans la gamme de fonctions modélisées est en raison de sa propriété de linéarité. Tous les modèles dans le monde ne sont pas linéaires, et donc la conclusion tient. La prochaine étape logique est d’ajouter la non-linéarité au perceptron. Nous réalisons la même chose grâce à l’utilisation de fonctions d’activation.
Fonctions d’activation
Les fonctions d’activation sont des fonctions mathématiques qui limitent la plage de valeurs de sortie d’un perceptron.
Pourquoi avons-nous besoin de fonctions d’activation non linéaires?
La non-linéarité est obtenue grâce à l’utilisation de fonctions d’activation, qui limitent ou écrasent la gamme de valeurs qu’un neurone peut exprimer. La fonction d’activation déclenche le perceptron. Le processus de formation comprend deux passes de données, l’une est en amont et l’autre est en aval. Les fonctions d’activation aident à modéliser les non-linéarités et la propagation efficace des erreurs, un concept appelé algorithme de rétro-propagation.
Exemples de fonctions d’activation
Par exemple, la tangente hyperbolique limite la gamme de valeurs qu’un perceptron peut prendre de [-1,1], alors qu’une fonction sigmoïde la limite à [0,1]. Habituellement, les fonctions d’activation sont des fonctions continues et différenciables, qui sont différenciables dans l’ensemble du domaine. En dehors de ces fonctions, il existe également des fonctions d’activation continue par morceaux.
Certaines fonctions d’activation :
- Sigmoid
- tanh (tangente hyperbolique)
- ReLU
Différents types de fonctions d’activation:
- Sigmoïd: Sigmoid est une fonction d’étape lissée et donc différenciable. Sigmoid est bénéfique dans le domaine de la classification binaire et des situations où la nécessité de convertir toute valeur en probabilités se pose. Il limite la valeur d’un perceptron à [0,1], ce qui n’est pas symétrique.
- tanh: La fonction tangente hyperbolique, également appelée fonction tanh, limite la sortie entre [-1,1] et donc la symétrie est préservée. Un point important à noter ici est que la symétrie est une propriété souhaitable lors de la propagation des poids. Vous pouvez trouver le graphique pour le même ci-dessous.
- L’unité linéaire rectifiée (ReLU) : Relu est définie comme une fonction y-x, qui permet à la sortie d’un perceptron, peu importe ce qui le traverse, étant donné qu’il s’agit d’une valeur positive, d’être la même. Si la sortie de la valeur est négative, alors elle cartographie la sortie à 0. Par conséquent, nous le définissons comme max(0, x), où x est la sortie du perceptron.
Réseau neuronal artificiel (ANN)
Les réseaux de neurones (NN), ou plus précisément les réseaux de neurones artificiels (ANN), est une classe d’algorithmes d’apprentissage automatique qui a récemment reçu beaucoup d’attention (encore une fois !) En raison de la disponibilité des Big Data et des installations informatiques rapides (la plupart du Deep Learning Les algorithmes sont essentiellement des variations différentes de ANN).
La classe d’ANN couvre plusieurs architectures, y compris les réseaux de neurones convolutionnels (CNN), les réseaux de neurones récurrents (RNN), par exemple LSTM et GRU, les encodeurs automatiques et les réseaux de croyances profondes. Par conséquent, CNN n’est qu’un type d’ANN.
D’une manière générale, un ANN est une collection d’unités connectées et réglables (alias nœuds, neurones et neurones artificiels) qui peuvent transmettre un signal (généralement un nombre réel) d’une unité à une autre. Le nombre (de couches) d’unités, leurs types et la façon dont ils sont connectés les uns aux autres est appelé architecture de réseau.
Un CNN, en particulier, possède une ou plusieurs couches d’unités de convolution. Une unité de convolution reçoit son entrée de plusieurs unités de la couche précédente qui créent ensemble une proximité. Par conséquent, les unités d’entrée (qui forment un petit quartier) partagent leurs poids.
Les unités de convolution (ainsi que les unités de mise en commun) sont particulièrement avantageuses car :
- Ils réduisent le nombre d’unités dans le réseau (car ce sont des mappages plusieurs à un). Cela signifie qu’il y a moins de paramètres à apprendre, ce qui réduit les risques de surajustement, car le modèle serait moins complexe qu’un réseau entièrement connecté.
- Ils tiennent compte du contexte / des informations partagées dans les petits quartiers. Cet avenir est très important dans de nombreuses applications comme l’image, la vidéo, le texte et le traitement / minage de la parole, car les entrées voisines (par exemple pixels, cadres, mots, etc.) véhiculent généralement des informations connexes.
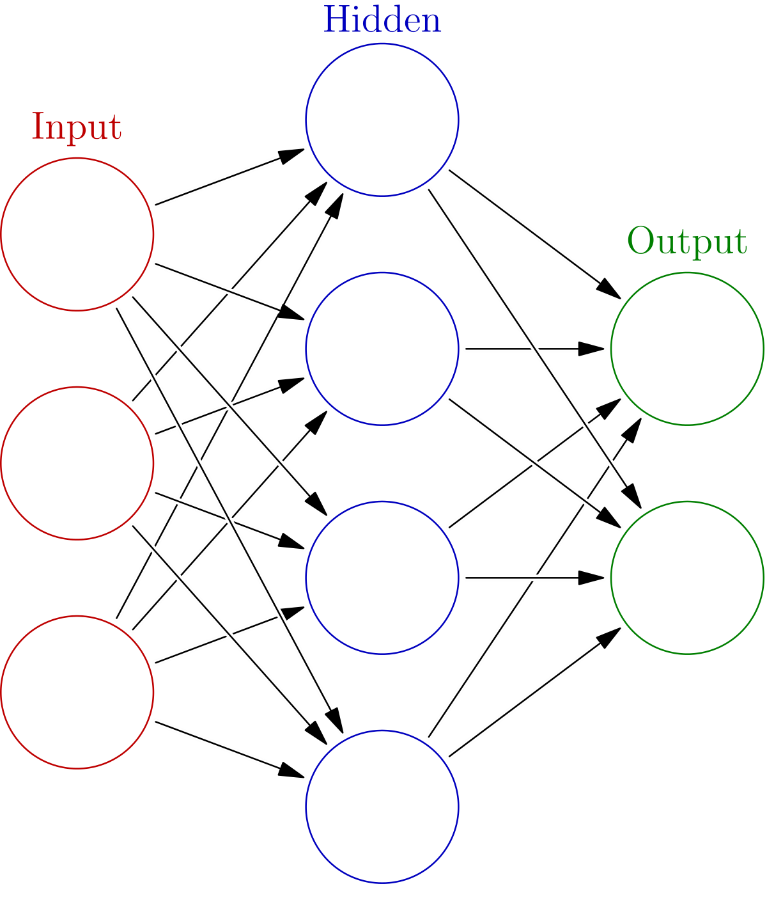
Comme mentionné précédemment, les ANN sont des perceptrons et des fonctions d’activation empilées ensemble. Les perceptrons sont connectés en interne pour former des couches cachées, qui forment la base non linéaire de la cartographie entre l’entrée et la sortie. Le nombre de couches cachées dans le réseau neuronal détermine la dimensionnalité de la cartographie. Plus le nombre de couches est élevé, plus la dimension dans laquelle la sortie est cartographiée est élevée. L’ANN apprend la fonction par l’apprentissage. Cet empilement de neurones est connu comme une architecture. Nous couvrirons quelques architectures dans le prochain article. Le modèle apprend les données à travers le processus de la passe avant et en arrière, comme mentionné précédemment.
Que se passe-t-il pendant la passe en avant (forward pass)?
- Pendant la passe avant, le réseau neuronal tente de modéliser l’erreur entre la sortie réelle et la sortie prévue pour une entrée. Il est fait avec l’aide d’une fonction de perte et l’initialisation aléatoire des poids.
- La fonction de perte signifie à quel point la sortie prévue est éloignée de la sortie réelle. Après le calcul de la passe avant, le réseau est prêt pour la passe arrière.
Que se passe-t-il pendant la passe arrière (backward pass) ?
- Le passage arrière vise à atterrir à un minimum global dans la fonction afin de minimiser l’erreur. L’objectif ici est de minimiser la différence entre la réalité et la réalité modélisée.
- Sur le calcul de la moindre erreur, l’erreur est rétro-propagée à travers le réseau.
- Ainsi, nous mettons à jour tous les poids dans le réseau de sorte que cette différence soit minimisée lors de la prochaine passe avant. L’apprentissage aléatoire permet un apprentissage précis spécifique à un ensemble de données.
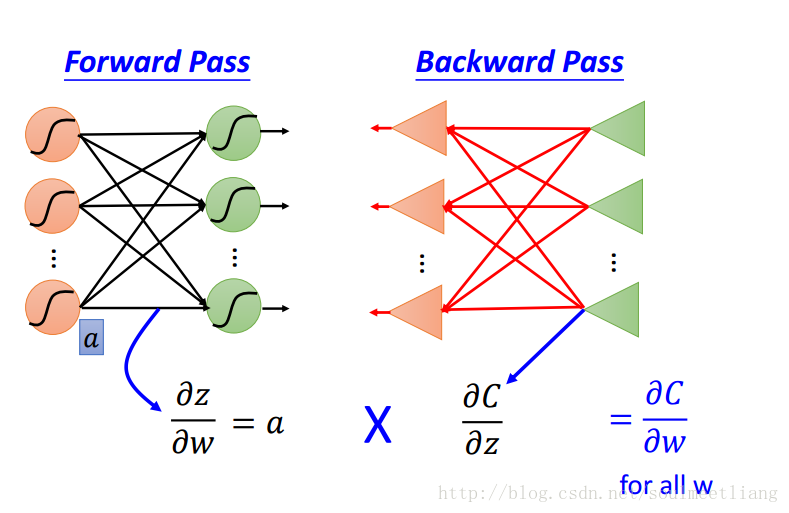
Ce sont les différents concepts liés aux réseaux neuronaux
- Softmax : La fonction Softmax aide à définir les sorties d’un point de vue probabiliste. Disons que nous avons un classifieur ternaire qui classe une image dans les classes : rat, chat et chien. La couche finale du réseau neuronal aura trois nœuds, un pour chaque classe. Si la prédiction s’avère être comme 0,001, 0,01 et 0,02. Nous ne pourrons pas déduire que l’image est celle d’un chien avec beaucoup de précision et de confiance. Au lieu de cela, si nous normalisions les sorties de telle sorte que la somme de toutes les sorties était de 1, nous réaliserions l’interprétation probabiliste des résultats. Softmax convertit les sorties en probabilités en divisant la sortie par la somme de toutes les valeurs de sortie.
- Entropie croisée : L’entropie croisée compare la mesure de distance entre les sorties de softmax et un codage à chaud. L’entropie croisée est définie comme la fonction de perte, qui modélise l’erreur entre les sorties prévues et réelles. Avec l’aide de la fonction softmax, les réseaux extradent la probabilité d’entrée appartenant à chaque classe. La bonne probabilité doit être maximisée. Nous définissons l’entropie croisée comme la synthèse de la logarithmique négative des probabilités. L’utilisation de logarithmes assure la stabilité numérique.
- Régularisation : Quand un étudiant apprend, mais seulement ce qui est dans les notes, c’est de l’apprentissage par cœur. L’apprentissage par cœur est inutile, car ce n’est pas l’intelligence, mais la mémoire qui joue un rôle clé dans la détermination de la sortie. Disons que si l’entrée donnée appartient à une source autre que l’ensemble d’apprentissage, c’est-à-dire les notes, dans ce cas, l’étudiant échouera. Par conséquent, nous devons nous assurer que le modèle n’est pas sur-ajusté aux données d’apprentissage et qu’il est capable de reconnaître des images invisibles de l’ensemble de test. Ceci est réalisé à l’aide de diverses techniques de régularisation. Ces techniques ont évolué au fil du temps au fur et à mesure de l’introduction de nouveaux concepts. Par exemple, Dropout est une technique relativement nouvelle utilisée dans le domaine de l’apprentissage en profondeur.
Quelles sont les diverses techniques de régularisation couramment utilisées ?
- Dropout (Abandon)
- Normalisation des lots
- Régularisation L1 et L2
- Dropout (Abandon)
Le premier type de technique de régularisation est l‘abandon. Il s’agit d’un type passionnant de technique de régularisation. Selon cette technique, nous supprimons un nombre aléatoire d’activations. Vous pouvez facilement deviner que la suppression des activations aléatoires conduira à des réseaux plus petits et que les petits réseaux sont toujours mieux à former. Maintenant, les activations sont la sortie obtenue en multipliant les poids et les entrées. Les activations renseignent sur l’entrée car elles proviennent uniquement des entrées. Donc, si nous supprimons une partie particulière des activations à chaque couche, aucune activation spécifique n’apprendrait donc le modèle d’entrée. Ainsi, il n’y aurait pas d’activation spécifique sur laquelle nous mettrions un poids supplémentaire puisque nous ne savons pas si cette activation se maintiendrait ou non. Par conséquent, il n’y aura pas de surajustement concernant le modèle d’entrée. Maintenant, la probabilité de supprimer toute activation est décidée par le praticien de l’apprentissage automatique.
Maintenant, parfois plutôt que de supprimer uniquement les activations, nous supprimons parfois les entrées. Ce n’est certainement pas un comportement normal pour supprimer l’entrée, mais selon votre modèle, l’élimination des entrées aide également.
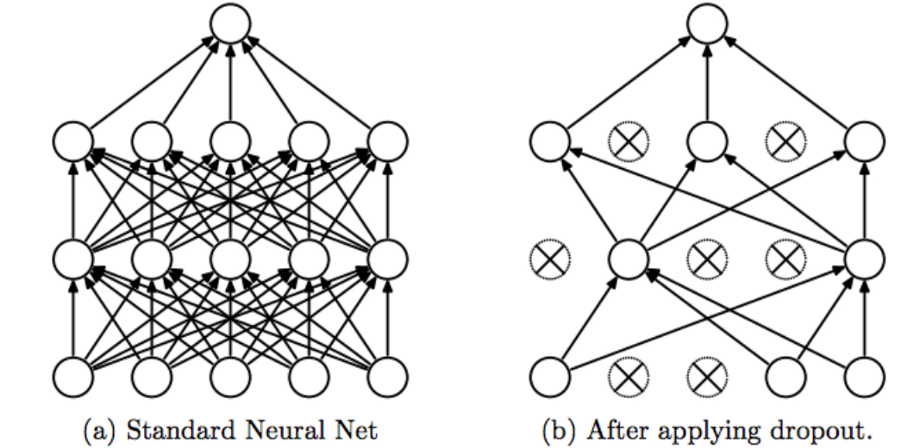
- La première couche de l’image représente les entrées. Ensuite, les calques représentent les activations de ce calque.
- Vous pouvez voir que nous avons supprimé certaines entrées dans la première couche, comme indiqué dans le deuxième diagramme. Nous avons également supprimé certaines des activations dans les couches suivantes. C’est ainsi que nous définissons le décrochage.
- Maintenant, nous pouvons initialiser une quantité différente de valeur d’abandon pour différentes couches. Par exemple, pour les couches ayant 10 unités cachées, nous pourrions définir la probabilité de chute à 0,5 par rapport à une couche n’ayant que 4 unités cachées pour lesquelles w = notre probabilité de chute ne serait que de 0,2. Pour, même les petites couches, nous pourrions définir la probabilité de chute à 0.
Le décrochage est un moyen efficace de régulariser les réseaux pour éviter le surajustement dans les ANN. Les couches de décrochage choisissent au hasard x pour cent des poids, les gèle, et procède à la formation. Ainsi, stochastiquement, la couche de décrochage paralyse le réseau neuronal en supprimant les unités cachées. Le décrochage est également utilisé pour empiler plusieurs réseaux neuronaux. Pour chaque cas de formation, nous sélectionnons au hasard quelques unités cachées afin que nous nous retrouvions avec différentes architectures pour chaque cas. Il ne doit pas être utilisé pendant le processus de test. La mise en œuvre des keras s’occupe de la même chose.
- Normalisation des lots
La normalisation par lots est une autre technique de régularisation importante qui aide beaucoup, empêchant le surajustement et l’entraînement dans le bon ordre.
L’intuition derrière la normalisation par lots
Nous normalisons toujours les entrées dans le cas de la régression logistique afin de mieux entraîner et apprendre les paramètres. Maintenant, si nous pensons aux réseaux de neurones profonds, nous voulons normaliser beaucoup de poids et de biais. Les pondérations et les biais dans la première couche seront plus faciles à optimiser car leur entrée serait normalisée X. Mais qu’en est-il des pondérations et des biais dans les dernières couches. Ainsi, pour leur optimisation, nous normalisons les activations afin de mieux connaître ces derniers paramètres.
Maintenant, la question vient après ceci: Et si nous ne voulons pas normaliser les activations pour une certaine couche? Pour gérer ce cas, nous multiplions l’entrée d’activation normalisée avec le paramètre gamma et ajoutons le paramètre bêta et entraînons ces paramètres de la manière traditionnelle. L’utilisation du gamma et de la bêta empêche la normalisation forcée des activations.
Pourquoi avons-nous besoin de la normalisation par lots?
Considérons une situation où nous avons 2 couches linéaires (LL1 et LL2) et 1 couche non linéaire (NL1).
- LL2 = NL1 (LL1)
Désormais, les activations au niveau LL2 dépendent fortement de la sortie des couches précédentes qui continuent de changer en raison d’une rétropropagation qui déstabilise le réseau neuronal dans une large mesure. Ainsi, nous devons normaliser les données afin de réduire ces variations.
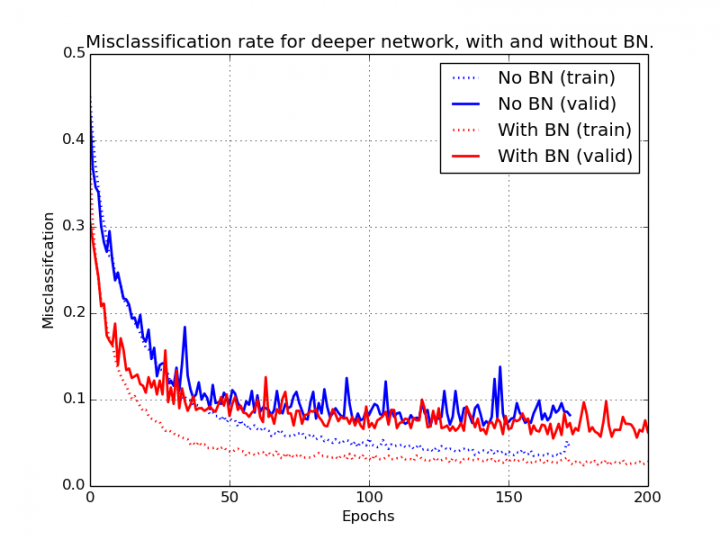
Avant de comprendre comment effectuer la normalisation par lots, laissez-nous comprendre comment cela aide à la perte. Sans normalisation par lots, la perte a beaucoup de surfaces bosselées (en bleu) car les activations ont un peu changé par rapport au résultat requis, et par conséquent, nous devons nous entraîner plus fort pour obtenir les résultats souhaités. Mais, lorsque nous appliquons la normalisation par lots, la surface de perte devient lisse car elle ajuste les activations vers la sortie souhaitée. La normalisation des lots est clairement appliquée au mini-lot d’activations. Par conséquent, nous pouvons appliquer un taux d’apprentissage plus élevé et donner également un élan à notre formation. Par conséquent, c’était une recherche fantastique.
Voyons maintenant comment obtenir la normalisation par lots?

Ceci est l’algorithme, et c’est simple.
- La première chose est de trouver la moyenne de ces activations – somme divisée par le nombre qui est juste la moyenne.
- La deuxième chose que nous faisons est que nous trouvons la variance de ces activations – une différence au carré divisée par la moyenne est la variance.
- Ensuite, nous normalisons – les valeurs moins la moyenne divisée par l’écart-type est la version normalisée.
- Enfin, nous multiplions les activations de sortie avec le gamma défini pour cette couche et en ajoutant les biais définis pour cette couche.
Comprenons-le plus simplement. Considérons une situation où nous voulons trouver la cote du film entre (0,5). Pour un mini-lot d’activations particulier, la sortie se situe entre (-1, 1), ce qui est sans aucun doute très loin de celui souhaité. Définissons la sortie en fonction de l’entrée et des poids.
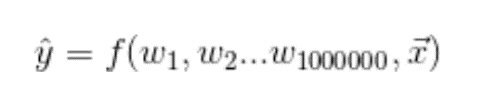
Cette fonction f est notre fonction de réseau neuronal. Ensuite, notre perte, disons que c’est une erreur quadratique moyenne, est juste notre valeur réelle moins notre carré prédit.
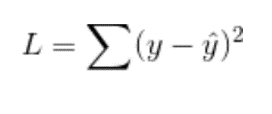
L est une perte. Maintenant, si nos activations de sortie ne sont pas souhaitées, la solution consiste à recycler l’ensemble du réseau, à ajuster les poids et à améliorer le taux d’apprentissage et bien d’autres choses, ce qui est compliqué et fastidieux. Donc, au lieu de cela, nous aimons ci-dessous :
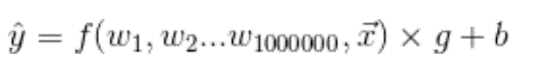
Nous avons ajouté deux autres vecteurs de paramètres. Maintenant c’est élémentaire. Pour augmenter l’échelle, ce nombre g (gamma) a un gradient direct pour augmenter l’échelle. Pour changer la moyenne, ce nombre b (bêta) a un gradient direct pour changer la moyenne. Il n’y a aucune interaction ou complexité. Ainsi, dans l’essentiel, nous pourrions dire comme :
- La normalisation de lot normalise la sortie d’une couche d’activation précédente en soustrayant la moyenne du lot et en la divisant par l’écart type du lot.
- La normalisation par lots ajoute deux paramètres entraînables à chaque couche, de sorte que la sortie normalisée est multipliée par gamma et bêta. Ensuite, les valeurs de gamma et bêta sont trouvées en utilisant la stratégie de réseau neuronal.
- Ainsi, il s’assure que la formation de l’échantillon est rapide et dans les limites.
Nous appliquons généralement la norme de lot après la non-linéarité et avant le décrochage.
Avantages de la normalisation par lots:
- Augmentez le taux d’apprentissage
- Réduisez le besoin d’abandon et d’autres techniques de régularisation.
- Atteint une précision plus élevée.
- Résout le problème du décalage de covariance car il affaiblit le couplage entre les paramètres des couches initiales et les paramètres des couches ultérieures, ainsi les modifications apportées aux couches sont indépendantes les unes des autres, accélérant ainsi le processus d’apprentissage du réseau.
Inconvénients de la normalisation par lots:
- Plus de calcul
- L’ensemble de données doit être suffisamment grand pour créer des tailles de lot considérables.
Avec la normalisation par lots, nous n’avons en fait pas besoin de termes de biais dans le fonctionnement linéaire, car nous normaliserons la sortie de la fonction affine, ce qui entravera l’effet du biais. Vous pouvez donc supprimer le terme de biais lors de l’utilisation de la normalisation par lots.
La normalisation par lots n’est en réalité pas une technique de régularisation car elle est utilisée pour normaliser les entrées. Mais avec de petits mini-lots de données, cela ajoute du bruit qui devient, encore plus, moins sur les mini-lots de grande taille. On pourrait donc dire que la norme batch ajoute un léger effet de régularisation.
En conclusion : la normalisation des lots, ou norme par lots, augmente l’efficacité de l’apprentissage en réseau neuronal. Il normalise la sortie à partir d’une couche avec une moyenne zéro et un écart standard de 1, ce qui se traduit par une réduction du surajustement et rend le réseau plus rapide. Il a des résultats remarquables dans le domaine des réseaux profonds.
La régularisation L1 et L2 sont deux façons différentes de représenter la même chose.
Selon la régularisation L2, la chose qui importe est une perte, et si la perte de sortie sera plus importante, nous propagerons davantage pour diminuer le paramètre, aussi appelé paramètres pour diminuer la perte. Dans cette procédure, les poids qui seraient non nuls ou légèrement proches de zéro auraient tendance à devenir nuls, donc inefficaces. C’est ainsi que se produit la régularisation L2.
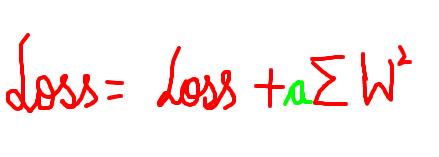
a = perte de poids
Ainsi, nous ajoutons la somme du carré des poids finaux multipliée par le nombre a à la perte. Ce nombre est également connu comme la perte de poids.
Donc ici, W au carré est juste égal à la somme de j est égal à 1 à n (nombre total d’éléments de poids) de W au carré, ou cela peut aussi être écrit comme w transpose w, c’est juste une normalisation euclidienne carrée du paramètre W.
Nous pourrions ajouter le terme de biais (b) aussi bien que W mais la plupart des calculs dépendent du W car c’est la matrice de haute dimension. Le terme de biais n’est qu’un nombre réel unique. Cela ne ferait aucune différence. Mais vous pouvez également ajouter des biais.
- Régularisation L1
La régularisation L1 est également connue sous le nom de perte de poids. Selon cette technique de régularisation, au lieu d’ajouter quelque chose aux poids, nous soustrayons directement des gradients. Maintenant, ce qui est soustrait des gradients est le dérivé de perte, tel que défini dans l’image ci-dessus. Donc, nous faisons la même chose, si la perte était plus élevée ; malgré tout, une rétropropagation se produirait et nos poids seraient améliorés. Et si nous soustrayons directement des gradients quelque chose, cela améliorerait également les poids.
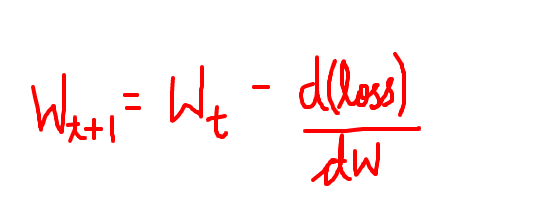
La L1 pénalise la distance absolue des poids, tandis que la L2 pénalise la distance carrée des poids. En visualisant le concept, on comprend que la L1 pénalise les distances absolues et la L2 pénalise les distances relatives.
Comment former les réseaux neuronaux ?
Passons à la formation. Nous devons garder à l’esprit le nombre de paramètres à optimiser lors du choix du modèle. Plus le nombre de paramètres est élevé, plus l’ensemble de données devra être grand et plus le temps de formation sera important. Ainsi, l’architecture du modèle doit être soigneusement choisie. La mise à jour des poids s’effectue via un processus appelé rétropropagation.
La rétropropagation (La connaissance du calcul est nécessaire pour comprendre ceci) : Il s’agit d’un algorithme qui traite de l’aspect de la mise à jour des poids dans un réseau neuronal pour minimiser les fonctions d’erreur / perte. Les poids dans le réseau sont mis à jour en propageant les erreurs sur le réseau.
Quelle est la quantité de poids à modifier ? La réponse réside dans l’erreur. Après avoir connu l’erreur, nous pouvons utiliser la descente de gradient pour la mise à jour du poids.
Descente en pente, que fait-elle? : L’algorithme de descente de gradient est responsable de l’optimisation multidimensionnelle, dans l’intention d’atteindre le maximum global. Il s’agit d’une technique d’optimisation de tri utilisée après la plupart des modèles d’apprentissage automatique. Une autre implémentation de descente de gradient, appelée descente de gradient stochastique (SGD) est souvent utilisée.
Taux d’apprentissage : Le taux d’apprentissage détermine la taille de chaque étape. Notez que l’ANN avec des activations non linéaires aura des minima locaux. Le choix du taux d’apprentissage joue un rôle important car il détermine le sort du processus d’apprentissage. Si le taux d’apprentissage est trop élevé, le réseau peut ne pas converger du tout et peut finir par diverger. Il existe différentes techniques pour obtenir le taux d’apprentissage idéal. Nous approfondirons le domaine du calendrier des taux d’apprentissage dans un prochain article.
Quelles fonctions SGD optimise-t-il ?
- SGD fonctionne mieux pour optimiser les fonctions non convexes. SGD diffère de la descente de gradient dans la façon dont nous l’utilisons avec les données de streaming en temps réel.
- La taille de la quantité de données partielle est la taille de celle du mini-lot. Elle décide donc de la fréquence à laquelle la mise à jour a lieu, car en réalité, les données peuvent provenir en temps réel et pas de la mémoire. L’utilisation d’un point de données pour la formation est également théoriquement possible. Il vaut mieux expérimenter.
Quelle est l’importance de la taille des lots ?
- Comprenons le rôle de la taille des lots. La taille de la quantité de lot détermine le nombre de points de données que le réseau voit à la fois.
- Si la valeur est très élevée, le réseau voit toutes les données ensemble, et ainsi le calcul devient mouvementé.
- S’il semble moins d’images à la fois, alors le réseau ne capture pas la corrélation présente entre les images.
Après avoir discuté des concepts de base, nous sommes maintenant prêts à comprendre comment fonctionne l’apprentissage profond de la vision par ordinateur.
Qu’est-ce que l’opération convolutionnelle exactement ?
Il s’agit d’une opération mathématique dérivée du domaine du traitement du signal. La convolution est utilisée pour obtenir une sortie compte tenu du modèle et de l’entrée. Le modèle est représenté comme une fonction de transfert. L’entrée alambiquée avec la fonction de transfert donne la sortie. La simple multiplication ne fera pas l’affaire ici.
Compte tenu de tous les concepts mentionnés ci-dessus, comment allons-nous les utiliser dans un CNN ? Quels sont les éléments clés d’un CNN ?
- Les CNN sont des réseaux neuronaux profonds qui ont des opérations spécifiques pour obtenir l’information spatiale présente dans les images.
- Avec deux ensembles de couches, l’une étant la couche convolutionnelle, et les autres des couches entièrement connectées, les CNN sont plus doués pour capturer l’information spatiale.
- En vision par ordinateur traditionnelle, nous considérons l’extraction de fonctionnalités comme un sujet de préoccupation majeur. Dans l’apprentissage profond, les couches convolutionnelles s’occupent de la même chose pour nous. Nous devons donc nous assurer qu’il existe suffisamment de couches convolutives pour capturer une gamme de caractéristiques, du niveau le plus bas au niveau le plus élevé.
Pourquoi ne pouvons-nous pas utiliser les réseaux neuronaux artificiels dans la vision par ordinateur ?
- Les ANN traitent des couches entièrement connectées, qui sont utilisées avec des images, car les neurones d’une même couche ne partagent pas de connexions. Ainsi, il en résulte une plus grande taille en raison d’un grand nombre de neurones.
- La solution est d’augmenter la taille du modèle car il nécessite un grand nombre de neurones. Nous pouvons regarder une image comme un volume avec de multiples dimensions de hauteur, de largeur et de profondeur. La profondeur est le nombre de canaux dans une image (RGB).
Le réseau de neurones à convolution apprend les filtres de la même manière que l’ANN apprend les poids. Diverses transformations codent ces filtres. Nous comprendrons ces transformations prochainement. Les filtres apprennent à détecter les motifs dans les images. Plus la couche est profonde, plus le motif est abstrait et moins la couche est profonde, plus les caractéristiques détectées sont du type de base. Ainsi, ces couches initiales détectent les bords, les coins et autres motifs de bas niveau.
Une question intéressante à considérer serait la suivante: que se passerait-il si nous changions les filtres appris par des quantités aléatoires, alors un sur-ajustement se produirait-il? De plus, quel est le comportement des filtres étant donné que le modèle a bien appris la classification, et comment ces filtres se comporteraient-ils lorsque le modèle l’aurait mal compris ?
Diverses composantes de CNN qui nous permettent d’apprendre l’information spatiale
1. Noyau (kernel) :
- Les couches convolutives utilisent le noyau pour effectuer une convolution sur l’image. Le noyau fonctionne avec deux paramètres appelés taille et foulée.
- Stride est le nombre de pixels déplacés sur l’image à chaque fois que nous effectuons l’opération de convolution.
- La taille est la dimension du noyau qui est une mesure du champ récepteur du CNN. Stride contrôle la taille de l’image de sortie.
- Par exemple, lorsque la foulée est égale à un, la convolution produit une image de la même taille et, avec une foulée de longueur 2, la moitié de la taille. Ainsi, une diminution de la taille de l’image se produit, et ainsi le remplissage de l’image obtient une sortie avec la même taille de l’entrée.
2. Mise en commun (pooling) :
- La mise en commun des couches réduit la taille de l’image à travers les couches par un processus appelé échantillonnage, effectué par diverses opérations mathématiques, comme le minimum, le maximum, la moyenne, etc., c’est-à-dire qu’il peut soit sélectionner la valeur maximale dans une fenêtre, soit prendre la moyenne de toutes les valeurs dans la fenêtre.
- Nous les plaçons entre les couches de convolution.
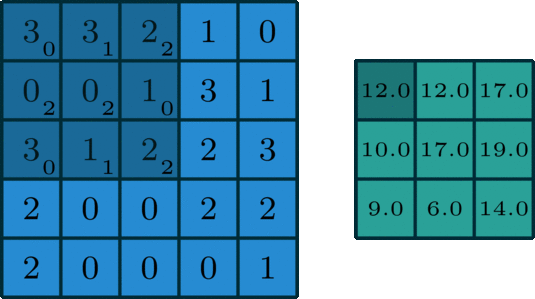
Considérez le noyau et l’opération de mise en commun. Dans l’exemple suivant, l’image est le carré bleu de dimensions 5 * 5. Le noyau est la matrice 3 * 3 représentée par la couleur bleu foncé. Grâce à une méthode de pas, l’opération de convolution est effectuée. L’image vert foncé est la sortie. Pour obtenir les valeurs, multipliez simplement les valeurs dans l’image et dans l’élément noyau.
Par exemple : 3×0+3×1+2×2+0x2+0x2+1×0+3×0+1×1+2×2=12
Quels sont les avantages de la mise en commun ?
- La mise en commun agit comme une technique de régularisation pour éviter un surajustement. Le regroupement est effectué sur tous les canaux de fonctionnalités et peut être effectué à différentes étapes.
CNN est l’aspect le plus important des modèles d’apprentissage profond pour la vision par ordinateur. Maintenant que nous avons appris les opérations de base effectuées dans un CNN, nous sommes prêts pour l’étude de cas.



Laisser un commentaire
Vous devez être dentifié pour poster un commentaire.