Architecture à base d’IoT et de Edge Computing
Résumé de la publication
Les industries adoptent les technologies IoT pour améliorer les dépenses opérationnelles, la durée de vie des produits et le bien-être des personnes. Un guide architectural est nécessaire si vous souhaitez parcourir le spectre des technologies nécessaires pour construire un système IoT réussi, qu’il s’agisse d’un seul appareil ou de millions d’appareils IoT.
IoT et Edge Computing for Architects, Second Edition englobe tout le spectre des solutions IoT, des capteurs IoT au cloud. Il examine les systèmes de capteurs modernes, en se concentrant sur leur puissance et leur fonctionnalité. Il examine également la théorie de la communication, en accordant une attention particulière au PAN à courte portée, y compris la nouvelle spécification Bluetooth® 5.0 et les réseaux maillés. Ensuite, cet article explore la communication basée sur IP en LAN et WAN, y compris 802.11ah, cellulaire 5G LTE, Sigfox et LoRaWAN. Il explique également l’informatique de périphérie, le routage et les passerelles, et leur rôle dans l’informatique de brouillard, ainsi que les protocoles de messagerie de MQTT 5.0 et CoAP.
Avec les données maintenant sous forme Internet, vous aurez une compréhension des architectures cloud et Edge, y compris les normes OpenFog. Cet article conclut la partie analytique avec l’application de l’analyse statistique, du traitement des événements complexes et des modèles d’apprentissage en profondeur. Cet article conclut ensuite en fournissant une vue holistique de la sécurité IoT, de la cryptographie et de la sécurité du shell en plus des périmètres et des chaînes de blocs définis par logiciel.
Objectifs de la publication
- Comprendre le rôle et la portée de l’architecture d’un déploiement IoT réussi
- Analysez le paysage des technologies IoT, des capteurs au cloud et plus encore
- Voir les compromis dans les choix de protocoles et de communications dans les déploiements IoT
- Se familiariser avec la terminologie nécessaire pour travailler dans l’espace IoT
- Élargissez vos compétences dans les multiples domaines d’ingénierie nécessaires à l’architecte IoT
- Mettez en œuvre les meilleures pratiques pour garantir la fiabilité, l’évolutivité et la sécurité de votre infrastructure IoT
Caractéristiques clés
- Créez un système IoT complet qui convient le mieux à votre organisation
- Découvrez les différents concepts, technologies et compromis dans la pile architecturale IoT
- Comprendre la théorie et la mise en œuvre de chaque élément qui comprend la conception IoT
Ce que vous apprendrez
- Comprendre le rôle et la portée de l’architecture d’un déploiement IoT réussi
- Analysez le paysage des technologies IoT, des capteurs au cloud et plus encore
- Voir les compromis dans les choix de protocoles et de communications dans les déploiements IoT
- Se familiariser avec la terminologie nécessaire pour travailler dans l’espace IoT
- Élargissez vos compétences dans les multiples domaines d’ingénierie nécessaires à l’architecte IoT
- Mettez en œuvre les meilleures pratiques pour garantir la fiabilité, l’évolutivité et la sécurité de votre infrastructure IoT
À propos
Les industries adoptent les technologies IoT pour améliorer les dépenses opérationnelles, la durée de vie des produits et le bien-être des personnes. Un guide architectural est nécessaire si vous souhaitez parcourir le spectre des technologies nécessaires pour construire un système IoT réussi, qu’il s’agisse d’un seul appareil ou de millions d’appareils IoT.
IoT et Edge Computing for Architects, Second Edition englobe tout le spectre des solutions IoT, des capteurs IoT au cloud. Il examine les systèmes de capteurs modernes, en se concentrant sur leur puissance et leur fonctionnalité. Il examine également la théorie de la communication, en accordant une attention particulière au PAN à courte portée, y compris la nouvelle spécification Bluetooth® 5.0 et les réseaux maillés. Ensuite, cet article explore la communication basée sur IP en LAN et WAN, y compris 802.11ah, cellulaire 5G LTE, Sigfox et LoRaWAN. Il explique également l’informatique de périphérie, le routage et les passerelles, et leur rôle dans l’informatique de brouillard, ainsi que les protocoles de messagerie de MQTT 5.0 et CoAP.
Avec les données maintenant sous forme Internet, vous aurez une compréhension des architectures cloud et brouillard, y compris les normes OpenFog. Cet article conclut la partie analytique avec l’application de l’analyse statistique, du traitement des événements complexes et des modèles d’apprentissage en profondeur. Cet article conclut ensuite en fournissant une vue holistique de la sécurité IoT, de la cryptographie et de la sécurité du shell en plus des périmètres et des chaînes de blocs définis par logiciel.
1 IoT et Edge Computing Définition et cas d’utilisation
Vous vous réveillez le mardi 17 mai 2022, vers 6 h 30 PST, comme vous le faites toujours. Vous n’avez jamais vraiment eu besoin d’un réveil. Vous êtes l’un de ces types avec une certaine forme d’horloge physiologique. Vos yeux s’ouvrent sur une fantastique matinée ensoleillée alors qu’il s’approche de 70 ° F à l’extérieur. Vous participerez à une journée qui sera complètement différente de la matinée du mercredi 17 mai 2017. Tout sur votre journée, votre style de vie, votre santé, vos finances, votre travail, vos déplacements, même votre place de parking sera différente. Tout dans le monde dans lequel vous vivez sera différent : énergie, soins de santé, agriculture, fabrication, logistique, transports en commun, environnement, sécurité, shopping et même vêtements. Il s’agit de l’impact de la connexion d’objets ordinaires à Internet ou à l’Internet des objets (IoT). Je pense qu’une meilleure analogie est l’Internet de tout.
Avant même que vous ne vous réveilliez, il s’est passé beaucoup de choses dans l’IoT qui vous entoure. Votre comportement de sommeil a été surveillé par un capteur de sommeil ou un oreiller intelligent. Les données ont été envoyées à une passerelle IoT, puis transmises à un service cloud que vous utilisez gratuitement et qui sont transmises à un tableau de bord sur votre téléphone. Vous n’avez pas besoin d’un réveil, mais si vous aviez un vol à 5 heures du matin, vous le régleriez – à nouveau, contrôlé par un agent cloud utilisant le protocole if this, then that (IFTTT). Votre fournaise à deux zones est connectée à un autre fournisseur de cloud et est connectée au Wi-Fi 802.11 de votre maison, tout comme vos détecteurs de fumée, sonnette, systèmes d’irrigation, porte de garage, caméras de surveillance et système de sécurité. Votre chien est équipé d’un capteur de proximité utilisant une source de récupération d’énergie qui lui permet d’ouvrir la porte du chien et de vous dire où il se trouve.
Vous n’avez plus vraiment de PC. Vous avez certainement un ordinateur de style tablette et un smartphone comme périphérique de création central, mais votre monde est basé sur l’utilisation d’un casque VR / AR puisque l’écran est tellement meilleur et plus grand. Vous avez une passerelle informatique de pointe dans votre placard. Il est connecté à un fournisseur de services 5G pour vous connecter à Internet et au WAN car les connexions filaires ne fonctionnent pas pour votre style de vie – vous êtes mobile, connecté et en ligne, peu importe où vous êtes, et 5G et votre opérateur préféré s’assurent que votre expérience est parfait dans une chambre d’hôtel à Miami ou chez vous à Boise, en Idaho. La passerelle effectue également de nombreuses actions dans votre maison, telles que le traitement des flux vidéo de ces webcams pour détecter s’il y a eu une chute ou un accident dans la maison. Le système de sécurité est analysé pour détecter des anomalies (bruits étranges, fuites d’eau possibles, lumières laissées allumées, votre chien mâchant à nouveau les meubles). Le nœud périphérique agit également comme hub domestique, sauvegardant votre téléphone quotidiennement parce que vous avez tendance à les casser, et sert de cloud privé même si vous ne savez rien des services cloud.
Vous roulez à vélo au bureau. Votre maillot de vélo utilise des capteurs imprimables et surveille votre fréquence cardiaque et votre température. Ces données sont diffusées simultanément via Bluetooth Low Energy sur votre smartphone pendant que vous écoutez le son Bluetooth diffusé depuis votre téléphone vers vos écouteurs Bluetooth. Sur le chemin, vous passez plusieurs panneaux d’affichage affichant tous des annonces vidéo et en temps réel. Vous vous arrêtez à votre café local et il y a un affichage numérique à l’avant vous appelant par son nom et vous demandant si vous voulez la dernière chose que vous avez commandée hier : un Americano de 12 oz avec place pour la crème. Il l’a fait par une balise et une passerelle reconnaissant votre présence à moins de cinq pieds et s’approchant de l’écran. Vous choisissez oui, bien sûr. La plupart des gens arrivent au travail via leur voiture et sont dirigés vers l’espace de stationnement optimal via des capteurs intelligents dans chaque emplacement de stationnement. Bien sûr, vous obtenez la place de stationnement optimale juste devant les autres cyclistes.
Votre bureau fait partie d’un programme d’énergie verte. Les politiques d’entreprise exigent un espace de bureau zéro émission. Chaque pièce a des capteurs de proximité pour détecter non seulement si une pièce est occupée, mais aussi qui est dans la pièce. Votre badge nominatif pour entrer au bureau est un dispositif de balisage sur une batterie de 10 ans. Votre présence est connue une fois que vous entrez dans la porte. Lumières, CVC, stores automatisés, ventilateurs de plafond, même affichage numérique sont connectés. Un nœud de brouillard central surveille toutes les informations du bâtiment et les synchronise avec un hôte cloud. Un moteur de règles a été mis en œuvre pour prendre des décisions en temps réel en fonction de l’occupation, de l’heure de la journée et de la saison de l’année, ainsi que des températures intérieures et extérieures. Les conditions environnementales augmentent ou diminuent pour maximiser l’utilisation de l’énergie. Il y a des capteurs sur les principaux disjoncteurs qui écoutent les modèles d’énergie et prennent une décision sur les nœuds de brouillard s’il y a des modèles étranges d’utilisation d’énergie qui doivent être examinés.
Il fait tout cela avec plusieurs algorithmes d’analyse et de machine learning en continu en temps réel qui ont été formés sur le cloud et poussés à la limite.
Le bureau héberge une petite cellule 5G pour communiquer à l’extérieur avec la porteuse en amont, mais il héberge également un certain nombre de passerelles à petites cellules en interne pour focaliser les signaux dans les limites du bâtiment. Le 5G interne fait également office de LAN.
Votre téléphone et votre tablette sont passés au signal 5G interne, et vous activez votre superposition réseau définie par logiciel et vous êtes instantanément sur le LAN de l’entreprise. Votre smartphone fait beaucoup de travail pour vous ; c’est essentiellement votre passerelle personnelle vers votre propre réseau personnel entourant votre corps. Vous passez à votre première réunion aujourd’hui, mais votre collègue n’est pas là et arrive quelques minutes en retard. Il s’excuse mais explique que sa volonté de travailler a été mouvementée.
Sa voiture plus récente a informé le constructeur d’un modèle d’anomalies dans le compresseur et le turbocompresseur. Le constructeur en a été immédiatement informé, et un représentant a appelé votre collègue pour l’informer que le véhicule a 70% de chances d’avoir un turbo défectueux dans les deux jours suivant son trajet habituel. Ils ont pris rendez-vous avec le concessionnaire et ont les nouvelles pièces qui arrivent pour réparer le compresseur. Cela lui a permis d’économiser des frais considérables pour remplacer le turbo et beaucoup d’aggravation.
Pour le déjeuner, l’équipe décide de sortir dans un nouveau lieu de tacos au centre-ville. Un groupe de quatre d’entre vous parvient à un coupé plus confortable pour deux et se fraye un chemin. Malheureusement, vous devrez vous garer dans l’une des structures de stationnement les plus chères.
Les tarifs de stationnement sont dynamiques et suivent une offre et une demande. En raison de certains événements et de la saturation des lots, les tarifs ont même doublé mardi midi. Du côté positif, les mêmes systèmes augmentant les frais de stationnement informent également votre voiture et votre smartphone exactement quels lots et quel espace pour conduire. Vous entrez l’adresse du taco au poisson, le lot et la capacité s’affichent et vous réservez une place avant votre arrivée. La voiture s’approche du portail, qui identifie la signature de votre téléphone, la plaque d’immatriculation ou une combinaison de plusieurs facteurs et s’ouvre. Vous conduisez sur place et l’application s’enregistre auprès du nuage de stationnement que vous êtes au bon endroit sur le bon capteur.
Cet après-midi, vous devez vous rendre sur le site de fabrication de l’autre côté de la ville. C’est un environnement d’usine typique : plusieurs machines de moulage par injection, des dispositifs de pick-and-place, des machines d’emballage et toute l’infrastructure de support. Récemment, la qualité du produit a chuté. Le produit final a des problèmes de connexion commune et est cosmétiquement inférieur au lot du mois dernier. Une fois arrivé sur le site, vous parlez au responsable et inspectez le site. Tout semble normal, mais la qualité a certainement été marginalisée. Vous vous rencontrez et montez les tableaux de bord de l’usine.
Le système utilise un certain nombre de capteurs (vibration, température, vitesse, vision et balises de suivi) pour surveiller le sol. Les données sont accumulées et visualisées en temps réel. Il existe un certain nombre d’algorithmes de maintenance prédictive surveillant les différents appareils pour détecter les signes d’usure et d’erreur. Ces informations sont également transmises au fabricant de l’équipement et à votre équipe. Les journaux d’automatisation de fabrication et de diagnostic n’ont détecté aucun modèle anormal, car ils avaient été formés par vos meilleurs experts. Cela ressemble au type de problème qui transformerait les heures en semaines et forcerait les meilleurs et les plus brillants de votre organisation à assister à des réunions d’équipe SWOT (forces, faiblesses, opportunités et menaces) quotidiennes coûteuses. Cependant, vous avez beaucoup de données. Toutes les données de l’usine sont conservées dans une base de données de stockage à long terme. Il y avait un coût pour ce service. Au début, le coût était difficile à justifier, mais maintenant vous pensez qu’il a peut-être été amorti mille fois. En prenant toutes ces données historiques à travers un processeur d’événements complexe et un package d’analyse, vous développez rapidement un ensemble de règles qui modélisent la qualité de vos pièces défaillantes. En travaillant en arrière sur les événements qui ont conduit aux échecs, vous vous rendez compte qu’il ne s’agit pas d’une défaillance ponctuelle, mais présente plusieurs aspects :
- La température interne de l’espace de travail a augmenté de 2 ° C pour conserver l’énergie pendant les mois d’été.
- L’assemblage a ralenti la production de 1,5% en raison de problèmes d’approvisionnement.
- L’une des machines de moulage approchait d’une période de maintenance prédictive, et la température et la vitesse d’assemblage ont poussé son boîtier défaillant au-dessus de la valeur prédite.
Vous avez trouvé le problème et recyclé les modèles de maintenance prédictive avec les nouveaux paramètres pour détecter ce cas à l’avenir. Dans l’ensemble, ce n’est pas une mauvaise journée de travail.
Bien que ce cas fictif puisse être vrai ou non, il est assez proche de la réalité aujourd’hui. Wikipédia définit l’IoT de cette façon : l’Internet des objets (IoT) est l’interconnexion des appareils physiques, des véhicules (également appelés “appareils connectés” et “appareils intelligents”), des bâtiments et d’autres éléments intégrés à l’électronique, aux logiciels, capteurs, actionneurs et connectivité réseau qui permettent à ces objets de collecter et d’échanger des données. ( https://en.wikipedia.org/wiki/internet_of_things )
1.1 Histoire de l’IoT
Le terme « IoT » peut très probablement être attribué à Kevin Ashton en 1997 et à son travail chez Procter and Gamble utilisant des étiquettes RFID pour gérer les chaînes d’approvisionnement. Le travail l’a amené au MIT en 1999, où lui et un groupe de personnes partageant les mêmes idées ont lancé le consortium de recherche Auto-ID Center (pour plus d’informations, visitez http://www.smithsonianmag.com/innovation/kevin-ashton-describes- l’internet des objets-180953749/ ).
Depuis lors, l’IoT est passé de simples balises RFID à un écosystème et à une industrie qui compteront 1 billion d’appareils connectés à Internet d’ici 2030. Le concept des choses connectées à Internet jusqu’en 2012 était principalement des smartphones, tablettes, PC et ordinateurs portables. Essentiellement, les choses qui ont d’abord fonctionné à tous égards comme un ordinateur. Depuis les humbles débuts d’Internet, à commencer par ARPANET en 1969, la plupart des technologies entourant l’IoT n’existaient pas. Jusqu’en 2000, la plupart des appareils associés à Internet étaient, comme indiqué, des ordinateurs de différentes tailles. La chronologie suivante montre la lente progression de la connexion des choses à Internet :
| Année | Périphérique | Référence |
| 1973 | Mario W. Cardullo reçoit le brevet pour la première étiquette RFID. | Brevet américain US 3713148 A |
| 1982 | Machine à soda connectée à Internet Carnegie Mellon. | https://www.cs.cmu.edu/~coke/history_long.txt |
| 1989 | Grille-pain connecté à Internet à Interop ’89. | IEEE Consumer Electronics Magazine (Volume : 6, numéro : 1, janvier 2017) |
| 1991 | HP présente HP LaserJet IIISi: la première imprimante réseau connectée à Ethernet. | http://hpmuseum.net/display_item.php?hw=350 |
| 1993 | Cafetière connectée à Internet à l’Université de Cambridge (la première caméra connectée à Internet). | https://www.cl.cam.ac.uk/coffee/qsf/coffee.html |
| 1996 | General Motors OnStar (2001 télédiagnostic). | https://en.wikipedia.org/wiki/OnStar |
| 1998 | Création du Bluetooth Special Interest Group (SIG). | https://www.bluetooth.com/about-us/our-history |
| 1999 | Réfrigérateur LG Internet Digital GOD. | https://www.telecompaper.com/news/lg-unveils-internetready-refrigerator–221266 |
| 2000 | Premiers exemples du concept Cooltown de l’informatique omniprésente partout: HP Labs, un système de technologies informatiques et de communication qui, combinées, créent une expérience connectée au Web pour les personnes, les lieux et les objets. | https://www.youtube.com/watch?v=U2AkkuIVV-I |
| 2001 | Premier produit Bluetooth lancé: le téléphone mobile compatible KDDI Bluetooth. | http://edition.cnn.com/2001/BUSINESS/asia/04/17/tokyo.kddibluetooth/index.html |
| 2005 | Le rapport de l’Union internationale des télécommunications des Nations Unies prédit pour la première fois la montée de l’IoT. | http://www.itu.int/osg/spu/publications/internetofthings/internetofThings_summary.pdf |
| 2008 | IPSO Alliance s’est formée pour promouvoir la propriété intellectuelle sur les objets, première alliance axée sur l’IoT. | https://www.ipso-alliance.org |
| 2010 | Le concept de Smart Lighting s’est formé après avoir réussi à développer des ampoules LED à semi-conducteurs. | https://www.bu.edu/smartlighting/files/2010/01/BobK.pdf |
| 2014 | Apple crée le protocole iBeacon pour les balises. | https://support.apple.com/en-us/HT202880 |
Certes, le terme IoT a suscité beaucoup d’intérêt et de battage médiatique. On peut facilement voir cela du point de vue d’un mot à la mode. Le nombre de brevets délivrés ( https://www.uspto.gov ) a augmenté de façon exponentielle depuis 2010. Le nombre de recherches Google ( https://trends.google.com/trends/ ) et de publications papier évaluées par des pairs IEEE a atteint le genou de la courbe en 2013:
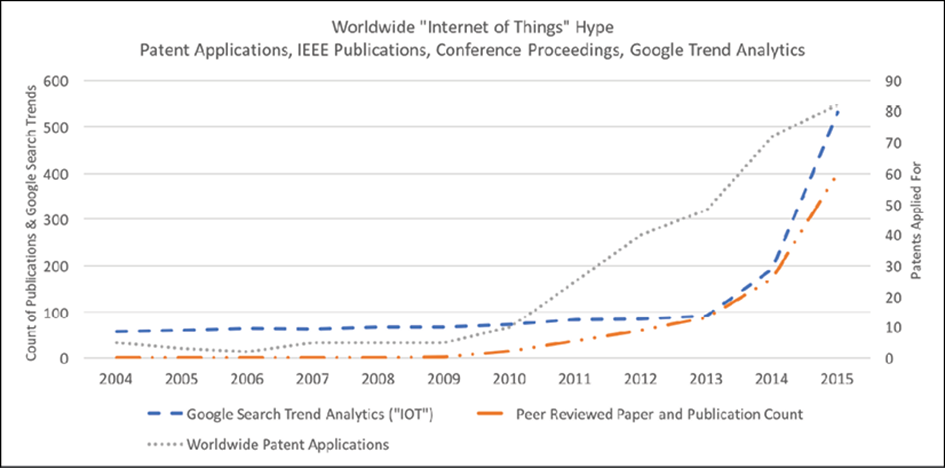
Figure 1: Analyse des recherches par mots clés pour l’IoT, les brevets et les publications techniques
1.2 Potentiel IoT
L’IoT affecte déjà tous les segments des produits industriels, d’entreprise, de santé et de consommation. Il est important de comprendre l’impact, ainsi que les raisons pour lesquelles ces industries insensées seront obligées de changer dans la façon dont elles fabriquent des produits et fournissent des services. Peut-être que votre rôle d’architecte vous oblige à vous concentrer sur un segment particulier ; Cependant, il est utile de comprendre le chevauchement avec d’autres cas d’utilisation.
Comme mentionné précédemment, il existe une opinion selon laquelle l’impact des industries, des services et du commerce liés à l’IoT affectera 3% (La route vers un billion d’appareils, ARM Ltd 2017) à 4% (L’Internet des objets : cartographier la valeur au-delà de la Hype, McKinsey and Company 2015) du PIB mondial d’ici 2020 (extrapolé). Le PIB mondial pour 2016 était de 75,64 billions de dollars, avec une estimation qu’en 2020, il s’élèvera à 81,5 billions de dollars. Cela fournit une gamme de valeur allant des solutions IoT de 2,4 billions de dollars à environ 4,9 billions de dollars.
L’échelle des objets connectés est sans précédent. La spéculation sur la croissance de l’industrie est menacée par des risques. Pour aider à normaliser l’impact, nous examinons plusieurs sociétés de recherche et des rapports sur le nombre d’objets connectés. La plage est large, mais toujours dans le même ordre de grandeur. La moyenne de ces 10 prévisions d’analystes est d’environ 33,4 milliards d’objets connectés d’ici 2020-2021. ARM a récemment mené une étude et prévu que d’ici 2035, un billion d’appareils connectés seront opérationnels. Par tous les comptes, le taux de croissance du déploiement de l’IoT à court terme est d’environ 20% sur un an.

Figure 2 : Analystes et déclarations de l’industrie sur le nombre d’objets connectés
Ces chiffres devraient à première vue impressionner le lecteur. Par exemple, si nous adoptions une position très conservatrice et prévoyions que seuls 20 milliards de nouveaux appareils connectés seraient déployés (à l’exclusion des produits informatiques et mobiles traditionnels), nous dirions que 211 nouveaux objets connectés à Internet seront mis en ligne chaque seconde.
Pourquoi cela est important pour l’industrie technologique et le secteur informatique est le fait que la population mondiale a actuellement un taux de croissance d’environ 0,9% à 1,09% par an ( https://esa.un.org/unpd/wpp/ ). Le taux de croissance de la population mondiale a culminé en 1962 à 2,6 pour cent d’une année à l’autre et n’a cessé de diminuer en raison d’un certain nombre de facteurs. D’abord et avant tout, l’amélioration du PIB mondial et des économies a tendance à réduire les taux de natalité. D’autres facteurs incluent les guerres et la famine. Cette croissance implique que les objets connectés par l’homme atteindront un plateau et que la machine à machine ( M2M ) et les objets connectés représenteront la majorité des appareils connectés à Internet. Ceci est important car l’industrie informatique applique de la valeur à un réseau non pas nécessairement par la quantité de données consommées, mais par le nombre de connexions. C’est, d’une manière générale, la loi de Metcalfe, et nous en parlerons plus loin dans cet article. Il convient également de noter qu’après la mise en ligne du premier site Web public au CERN en 1990, il a fallu 15 années supplémentaires pour qu’un milliard de personnes soient des utilisateurs réguliers d’Internet. L’IoT cherche à ajouter 6 milliards d’appareils connectés par an. Bien sûr, cela influence l’industrie.
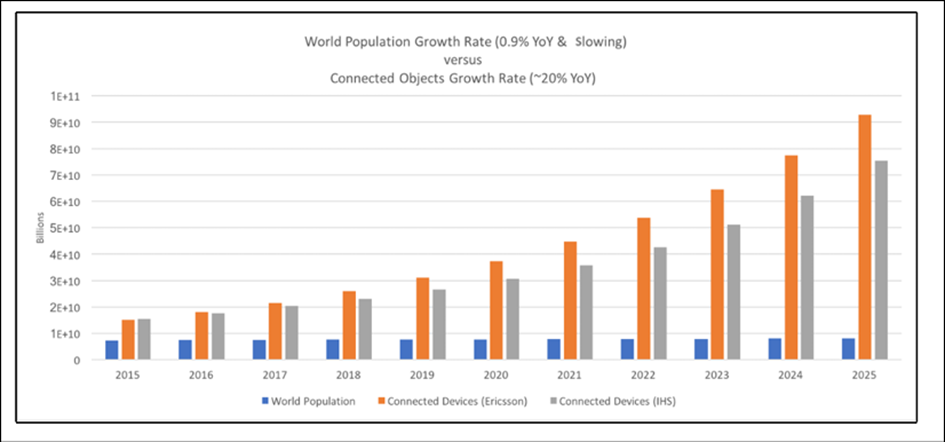
Figure 3 : La disparité entre la croissance de la population humaine et la croissance des objets connectés. La tendance a été une croissance de 20% des objets connectés contre une croissance humaine presque plate de 0,9%. Les humains ne dirigeront plus le réseau et la capacité informatique.
Il convient de noter que l’impact économique n’est pas uniquement la génération de revenus. L’impact de l’IoT ou de toute technologie se présente sous la forme de:
- De nouvelles sources de revenus (par exemple, des solutions d’énergie verte)
- Réduction des coûts (par exemple, soins de santé à domicile)
- Réduction du délai de mise sur le marché (par exemple, automatisation d’usine)
- Amélioration de la logistique de la chaîne d’approvisionnement (par exemple, suivi des actifs)
- Réduction des pertes de production (par exemple, vol ou détérioration de denrées périssables)
- Augmentation de la productivité (par exemple, apprentissage automatique et analyse des données)
- Cannibalisation (par exemple, Nest remplace les thermostats traditionnels)
Dans notre discussion tout au long de cet article, nous devrions nous préoccuper de la valeur d’une solution IoT. S’il s’agit simplement d’un nouveau gadget, le marché sera limité. Ce n’est que lorsque l’avantage prévisible l’emportera sur le coût qu’une industrie prospérera.
De manière générale, l’objectif utilisé devrait être une amélioration de 5 fois par rapport à une technologie traditionnelle. C’est mon objectif dans l’industrie informatique. Lorsque l’on considère le coût du changement, de la formation, de l’acquisition, du support, etc., un différentiel de 5x est une règle empirique équitable.
1.3 Définition de l’internet des objets
Il faut examiner certaines de ces affirmations avec un certain scepticisme. Il est presque impossible de quantifier le nombre exact d’appareils connectés à Internet. De plus, nous devons séparer les appareils qui sont naturellement connectés à Internet comme les smartphones, les PC, les serveurs, les routeurs de réseau et l’infrastructure informatique. Nous ne devrions pas non plus inclure dans le domaine de l’IoT les machines qui ont été présentes dans les bureaux, les maisons et les lieux de travail pendant des décennies et qui sont essentiellement connectées via une forme de mise en réseau. Nous n’incluons pas les imprimantes, copieurs ou scanners de bureau dans le spectre IoT.
Cet article examinera l’IoT du point de vue de la connexion d’appareils qui ne sont pas nécessairement connectés entre eux ou à Internet. Historiquement, ces appareils peuvent n’avoir que peu ou pas de capacités de calcul ou de communication. Par cela, nous supposons que les appareils ont historiquement eu des limites de coût, de puissance, d’espace, de poids, de taille ou thermiques.
Comme nous le voyons dans l’histoire des appareils IoT, la connexion d’objets traditionnellement non connectables comme les réfrigérateurs à Carnegie Mellon est possible depuis le début des années 1980, mais le coût était important. Il nécessitait la puissance de traitement d’un ordinateur central DEC PDP11. La loi de Moore démontre l’augmentation du nombre et de la densité des transistors dans les chipsets en silicium, tandis que la mise à l’échelle de Dennard améliore le profil de puissance des ordinateurs. Avec ces deux tendances, nous produisons maintenant des appareils qui utilisent des processeurs plus puissants et une capacité de mémoire accrue et exécutons des systèmes d’exploitation capables d’exécuter une pile réseau complète. Ce n’est qu’avec le respect de ces exigences que l’IoT est devenu une industrie à part entière.
Les exigences de base d’un appareil pour être considéré comme faisant partie de l’IoT :
- Capable par ordinateur d’héberger une pile logicielle de protocole Internet
- Matériel et alimentation capables d’utiliser un transport réseau tel que 802.3
- Pas un périphérique connecté à Internet traditionnel, tel qu’un PC, un ordinateur portable, un smartphone, un serveur, un appareil de centre de données, une machine de productivité de bureau ou une tablette
Nous incluons également des appareils « de pointe » dans cet article. Les appareils Edge eux-mêmes peuvent être des appareils IoT ou peuvent “héberger” des appareils IoT. Les périphériques Edge, comme détaillé plus loin dans cet article, seront généralement des nœuds informatiques gérés qui s’étendent plus près des sources de génération ou d’action des données. Ce ne sont peut-être pas des serveurs et des clusters typiques des centres de données, mais de l’espace, de l’alimentation et des appareils durcis pour l’environnement qui sont sur le terrain. Par exemple, une lame de centre de données serait constituée d’une électronique optimisée pour l’atmosphère à température contrôlée d’une batterie de serveurs avec des allées chaudes et froides, des échangeurs de chaleur et des alimentations sans coupure. Les dispositifs Edge peuvent être trouvés à l’extérieur et exposés à des éléments météorologiques et dans des zones où une alimentation constante et cohérente n’est pas une option. D’autres fois, ils peuvent inclure des nœuds de serveur traditionnels, mais en dehors des contraintes d’un centre de données.
Compte tenu de ces critères, la taille réelle du marché de l’IoT est inférieure aux prévisions des analystes. Lorsque nous séparons les appareils informatiques et connectés à Internet traditionnels des appareils IoT, nous constatons un taux de croissance différent, comme le montre la figure suivante.
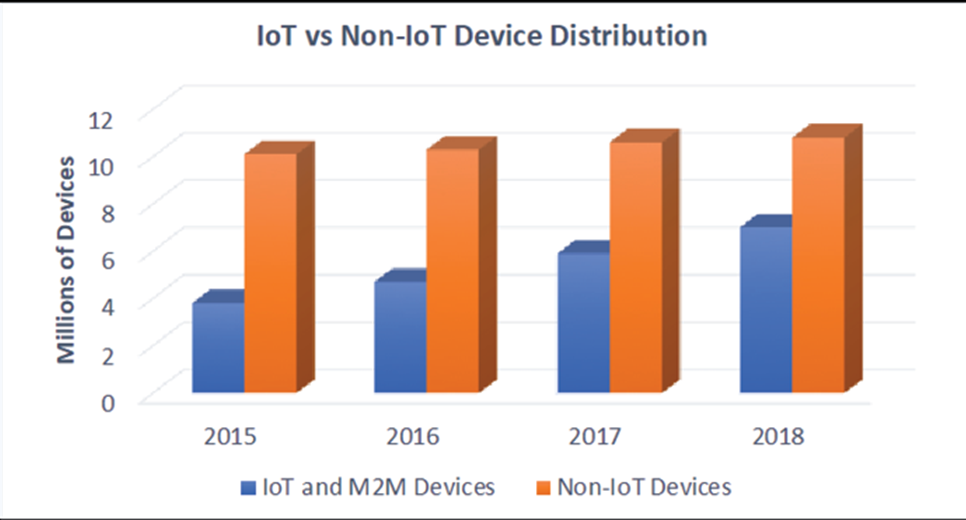
Figure 4 : Séparation du volume des ventes d’appareils IoT par définition des appareils non IoT (par exemple, équipement informatique et informatique mobile)
Une analyse plus approfondie des composants réels utilisés dans les appareils IoT révèle un autre modèle intéressant. Comme déjà mentionné, la plupart des appareils connectés à Internet nécessitent un certain niveau de performances et de matériel pour communiquer via des protocoles standard. Pourtant, le graphique suivant montre une différence entre le nombre de puces de communication et de processeurs par rapport au nombre de capteurs livrés. Cela renforce le concept selon lequel il existe un large éventail de capteurs vers les ordinateurs de bord et les appareils de communication.
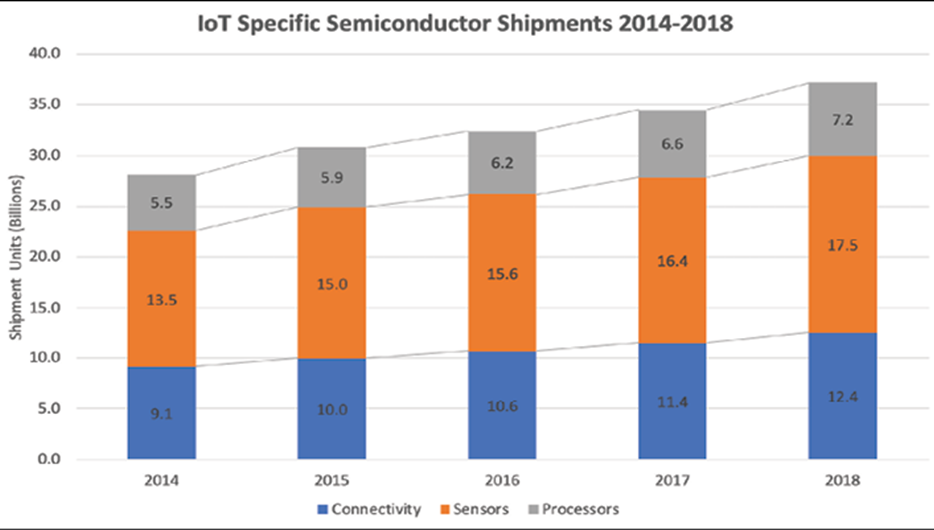
Figure 5 : Tendance des ventes de capteurs, processeurs et circuits intégrés de communication dans les ventes IoT
Ce qui est remarquable, c’est que la plupart des installations IoT ne sont pas un seul appareil qui a la capacité d’exécuter une pile matérielle et logicielle Internet. La plupart des capteurs et appareils n’ont pas la capacité d’accéder directement à Internet. Ils n’ont pas les capacités de traitement, les ressources de mémoire et la distribution d’énergie requises pour une connectivité Internet complète. Au contraire, une grande partie de ce qui est vraiment l’IoT repose sur des passerelles et des ordinateurs de périphérie dans un modèle de hub et de rayons. Il existe un large éventail d’appareils qui se connectent aux ordinateurs périphériques via des réseaux locaux personnels, des réseaux non IP (Bluetooth), des protocoles industriels (ModBus), des protocoles de friches industrielles héritées (RS232) et des signaux matériels.
1.3.1 Industrie et fabrication
L’IoT industriel (IIoT) est l’un des segments les plus dynamiques et les plus importants de l’espace IoT global par le nombre de choses connectées et la valeur que ces services apportent à la fabrication et à l’automatisation des usines. Ce segment a traditionnellement été le monde de la technologie des opérations (OT). Cela implique des outils matériels et logiciels pour surveiller les appareils physiques en temps réel. Historiquement, ces systèmes étaient des ordinateurs et des serveurs sur site pour gérer les performances et les sorties de l’usine. Nous appelons ces systèmes le contrôle de supervision et l’acquisition de données (SCADA). Les rôles informatiques traditionnels ont été administrés différemment des rôles OT. OT sera concerné par les mesures de rendement, la disponibilité, la collecte et la réponse des données en temps réel et la sécurité des systèmes. Le rôle informatique se concentrera sur la sécurité, les regroupements, la livraison de données et les services. Alors que l’IoT devient répandu dans l’industrie et la fabrication, ces mondes se combineront en particulier avec la maintenance prédictive de milliers de machines d’usine et de production pour fournir une quantité sans précédent de données aux infrastructures de cloud privé et public.
Certaines des caractéristiques de ce segment incluent la nécessité de fournir des décisions en temps quasi réel ou en temps réel pour OT. Cela signifie que la latence est un problème majeur pour l’IoT en usine.
De plus, les temps d’arrêt et la sécurité sont les principales préoccupations. Cela implique la nécessité d’une redondance et éventuellement de réseaux cloud privés et d’un stockage des données. Le segment industriel est l’un des marchés à la croissance la plus rapide. Une nuance de cette industrie est la dépendance à l’égard de la technologie des friches industrielles, c’est-à-dire des interfaces matérielles et logicielles qui ne sont pas courantes. Il arrive souvent que des machines de production vieilles de 30 ans s’appuient sur des interfaces série RS485 plutôt que sur des mailles sans fil modernes.
1.3.2 Cas d’utilisation de l’IoT industriel et manufacturier
Voici les cas d’utilisation de l’IoT industriel et manufacturier et leur impact :
- Maintenance préventive sur les machines d’usine neuves et préexistantes
- Augmentation du débit grâce à la demande en temps réel
- Économies d’énergie
- Systèmes de sécurité tels que la détection thermique, la détection de pression et les fuites de gaz
- Systèmes experts de plancher d’usine
1.3.3 Consommateur
Les appareils grand public ont été l’un des premiers segments à adopter des objets connectés à Internet. L’IdO grand public a d’abord pris la forme d’une cafetière connectée dans une université dans les années 1990. Il a prospéré avec l’adoption de Bluetooth pour une utilisation grand public au début des années 2000.
Des millions de foyers disposent désormais de thermostats Nest, d’ampoules Hue, d’assistants Alexa et de décodeurs Roku. Les gens sont également connectés avec Fitbits et d’autres technologies portables. Le marché de la consommation est généralement le premier à adopter ces nouvelles technologies. Nous pouvons également les considérer comme des gadgets. Tous sont des appareils soigneusement emballés et emballés qui sont essentiellement plug and play.
L’une des contraintes du marché de la consommation est la bifurcation des normes. Nous voyons, par exemple, plusieurs protocoles WPAN ont un jogging comme Bluetooth, Zigbee et Z-wave (tous étant non interopérables).
Ce segment a également des traits communs avec le marché des soins de santé, qui a des appareils portables et des moniteurs de santé à domicile. Nous les séparons pour cette discussion, et les soins de santé vont se développer au-delà des simples appareils de santé connectés à domicile (par exemple, au-delà des fonctionnalités d’un Fitbit).
1.3.4 Cas d’utilisation IoT grand public
Voici quelques-uns des cas d’utilisation IoT grand public :
- Gadgets pour la maison intelligente : irrigation intelligente, portes de garage intelligentes, serrures intelligentes, lumières intelligentes, thermostats intelligents et sécurité intelligente
- Wearables : trackers de santé et de mouvement, vêtements intelligents / wearables
- Animaux de compagnie : systèmes de localisation pour animaux de compagnie, portes intelligentes pour chiens
1.3.5 Commerce de détail, finance et marketing
Cette catégorie fait référence à tout espace où le commerce axé sur le consommateur effectue des transactions. Cela peut être un magasin de brique et de mortier ou un kiosque pop-up. Il s’agit notamment des services bancaires traditionnels et des assureurs, mais également des services de loisirs et d’accueil. L’impact de l’IdO sur le commerce de détail est déjà en cours, dans le but de réduire les coûts de vente et d’améliorer l’expérience client. Cela se fait avec une myriade d’outils IoT. Pour plus de simplicité dans cet article, nous ajoutons également de la publicité et du marketing à cette catégorie.
Ce segment mesure la valeur des transactions financières immédiates. Si la solution IoT ne fournit pas cette réponse, son investissement doit être examiné de près. Cela crée des contraintes sur la recherche de nouvelles façons soit de réduire les coûts, soit de générer des revenus. Permettre aux clients d’être plus efficaces permet aux détaillants et aux industries de services d’offrir une meilleure expérience client tout en minimisant les frais généraux et les pertes de coûts de vente.
1.3.6 Cas d’utilisation de l’IoT pour la vente au détail, la finance et le marketing
Certains des cas d’utilisation de l’IoT sont les suivants :
- Publicité ciblée, comme la localisation de clients connus ou potentiels par proximité et la fourniture d’informations sur les ventes.
- Le balisage, comme la détection des clients à proximité, les modèles de trafic et les heures entre les arrivées comme analyses marketing.
- Suivi des actifs, comme le contrôle des stocks, le contrôle des pertes et les optimisations de la chaîne d’approvisionnement.
- Surveillance du stockage à froid, telle que l’analyse du stockage à froid des stocks périssables. Appliquer des analyses prédictives à l’approvisionnement alimentaire.
- Assurer le suivi des actifs.
- Mesure du risque d’assurance des conducteurs.
- Affichage numérique dans le commerce de détail, l’hôtellerie ou la ville.
- Systèmes de balisage dans les lieux de divertissement, les conférences, les concerts, les parcs d’attractions et les musées.
1.3.7 Santé
L’industrie des soins de santé affrontera la fabrication et la logistique pour la première place des revenus et de l’impact sur l’IoT. Tous les systèmes qui améliorent la qualité de vie et réduisent les coûts de santé sont une préoccupation majeure dans presque tous les pays développés. L’IoT est prêt à permettre une surveillance à distance et flexible des patients où qu’ils se trouvent.
Des outils d’analyse et d’apprentissage automatique avancés observeront les patients afin de diagnostiquer la maladie et de prescrire des traitements. Ces systèmes seront également les chiens de garde en cas de soins vitaux nécessaires. Actuellement, il existe environ 500 millions de moniteurs de santé portables, avec une croissance à deux chiffres dans les années à venir.
Les contraintes pesant sur les systèmes de santé sont importantes. De la conformité HIPAA à la sécurité des données, les systèmes IoT doivent agir comme des outils et équipements de qualité hospitalière. Les systèmes de terrain doivent communiquer avec les centres de santé 24h / 24 et 7j / 7, de manière fiable et sans interruption si le patient est surveillé à domicile. Les systèmes peuvent devoir être sur un réseau hospitalier tout en surveillant un patient dans un véhicule d’urgence.
1.3.8 Cas d’utilisation de l’IoT pour les soins de santé
Certains des cas d’utilisation de l’IoT dans le domaine de la santé sont les suivants :
- Soins aux patients à domicile
- Modèles d’apprentissage des soins de santé prédictifs et préventifs
- Démence et soins et suivi des personnes âgées
- Équipement hospitalier et suivi des actifs d’approvisionnement
- Suivi pharmaceutique et sécurité
- Médecine à distance
- Recherche sur les médicaments
- Indicateurs de chute du patient
1.3.9 Transport et logistique
Le transport et la logistique seront un moteur important, sinon le principal moteur de l’IoT. Les cas d’utilisation impliquent l’utilisation d’appareils pour suivre les actifs livrés, transportés ou expédiés, que ce soit sur un camion, un train, un avion ou un bateau. C’est aussi le domaine des véhicules connectés qui communiquent pour proposer une assistance au conducteur, ou une maintenance préventive pour le compte du conducteur. À l’heure actuelle, un véhicule moyen acheté neuf a environ 100 capteurs. Ce nombre doublera alors que la communication de véhicule à véhicule, la communication de véhicule à route et la conduite automatisée deviendront des caractéristiques incontournables pour la sécurité ou le confort. Cela a des rôles importants au-delà des véhicules de consommation et s’étend aux lignes ferroviaires et aux flottes de navigation qui ne peuvent se permettre aucun temps d’arrêt. Nous verrons également des camions de service qui peuvent suivre des actifs tels que les outils des travailleurs, l’équipement de construction et d’autres actifs précieux. Certains des cas d’utilisation peuvent être très simples, mais aussi très coûteux, comme la surveillance de l’emplacement des véhicules de service dans la livraison du stock.
Des systèmes sont nécessaires pour acheminer automatiquement les camions et le personnel de service vers des emplacements basés sur la demande par rapport à la routine.
Cette catégorie de type mobile nécessite une connaissance de la géolocalisation. Une grande partie de cela vient de la navigation GPS. Du point de vue IoT, les données analysées incluraient les actifs et le temps, mais également les coordonnées spatiales.
1.3.10 Cas d’utilisation de l’IoT pour le transport et la logistique
Voici quelques-uns des cas d’utilisation de l’IoT pour le transport et la logistique :
- Suivi de la flotte et connaissance de l’emplacement
- Planification, acheminement et surveillance des véhicules municipaux (déneigement, élimination des déchets)
- Transport en chambre froide et sécurité de livraison des aliments
- Identification et suivi des wagons
- Suivi des actifs et des colis au sein des flottes
- Entretien préventif des véhicules sur la route
1.3.11 Agriculture et environnement
L’élevage et l’IdO environnemental comprennent des éléments de la santé du bétail, de l’analyse des terres et des sols, des prévisions micro-climatiques, une utilisation efficace de l’eau et même des prévisions de catastrophes dans le cas de catastrophes géologiques et météorologiques. Même si la croissance démographique mondiale ralentit, les économies mondiales deviennent plus riches. Même si les famines sont moins fréquentes qu’il y a 100 ans, la demande de production alimentaire devrait doubler d’ici 2035. Il est possible de réaliser d’importantes économies en agriculture grâce à l’IoT. L’utilisation d’un éclairage intelligent pour ajuster la fréquence du spectre en fonction de l’âge de la volaille peut augmenter les taux de croissance et diminuer les taux de mortalité en fonction du stress dans les élevages de poulets. De plus, les systèmes d’éclairage intelligents pourraient économiser 1 milliard de dollars par an en énergie par rapport à l’éclairage incandescent muet couramment utilisé. D’autres utilisations incluent la détection de la santé du bétail basée sur le mouvement et le positionnement des capteurs. Une ferme d’élevage pouvait trouver des animaux ayant la propension à la maladie avant qu’une infection bactérienne ou virale ne se propage. Les systèmes d’analyse de bord à distance pourraient trouver, localiser et isoler des têtes de bétail en temps réel, en utilisant des analyses de données ou des approches d’apprentissage automatique.
Ce segment a également la particularité d’être situé dans des zones reculées (volcans) ou dans des centres de population clairsemés (champs de maïs). Cela a des répercussions sur les systèmes de communication de données que nous devrons examiner plus loin dans le chapitre 5, WPAN non IP et le chapitre 7, Systèmes et protocoles de communication à longue portée (WAN).
1.3.12 Cas d’utilisation de l’IoT agricole et environnemental
Certains des cas d’utilisation de l’IoT agricole et environnemental sont les suivants :
- Techniques d’irrigation et de fertilisation intelligentes pour améliorer le rendement
- Éclairage intelligent en nidification ou en aviculture pour améliorer le rendement
- Santé du bétail et suivi des actifs
- Maintenance préventive des équipements agricoles à distance via le constructeur
- Relevés de terrain par drone
- Efficacité de la chaîne d’approvisionnement de la ferme au marché avec suivi des actifs
- Agriculture robotique
- Surveillance des volcans et des lignes de faille pour les catastrophes prédictives
1.3.13 Énergie
Le segment énergie comprend le suivi de la production d’énergie à la source de production pour le consommateur. Une quantité importante de recherche et développement s’est concentrée sur les moniteurs d’énergie grand public et commerciaux tels que les compteurs électriques intelligents qui communiquent via des protocoles à faible puissance et à longue portée pour révéler la consommation d’énergie en temps réel.
De nombreuses installations de production d’énergie se trouvent dans des environnements éloignés ou hostiles tels que les régions désertiques pour les panneaux solaires, les pentes abruptes pour les parcs éoliens et les installations dangereuses pour les réacteurs nucléaires. De plus, les données peuvent nécessiter une réponse en temps réel ou presque en temps réel pour les réponses critiques aux systèmes de contrôle de la production d’énergie (un peu comme les systèmes de fabrication). Cela peut avoir un impact sur le déploiement d’un système IoT dans cette catégorie. Nous parlerons des problèmes de réactivité en temps réel plus loin dans cet article.
1.3.14 Cas d’utilisation Energy IoT
Voici quelques cas d’utilisation de l’IoT énergétique :
- Analyse de plate-forme pétrolière de milliers de capteurs et de points de données pour des gains d’efficacité
- Surveillance et maintenance des panneaux solaires à distance
- Analyse dangereuse des installations nucléaires
- Compteurs électriques, de gaz et d’eau intelligents dans un déploiement à l’échelle de la ville pour surveiller l’utilisation et la demande
- Tarifs selon l’heure
- Réglages des pales en temps réel en fonction des conditions météorologiques sur les éoliennes à distance
1.3.15 Ville intelligente
«Ville intelligente» est une expression utilisée pour désigner une infrastructure connectée et intelligente, des citoyens et des véhicules. Les villes intelligentes sont l’un des segments à la croissance la plus rapide et affichent des ratios coûts / avantages substantiels, surtout si l’on considère les recettes fiscales. Les villes intelligentes touchent également la vie des citoyens par la sûreté, la sécurité et la facilité d’utilisation. Par exemple, plusieurs villes comme Barcelone ont adopté la connectivité IoT pour surveiller les conteneurs et les poubelles de collecte en fonction de la capacité actuelle, mais également du temps écoulé depuis la dernière collecte. Cela améliore l’efficacité de la collecte des ordures, permettant à la ville d’utiliser moins de ressources et de recettes fiscales pour le transport des déchets, mais élimine également les odeurs et les odeurs potentielles de matières organiques en décomposition.
L’une des caractéristiques du déploiement d’une ville intelligente peut être le nombre de capteurs utilisés. Par exemple, une installation de caméra intelligente à chaque coin de rue à New York nécessiterait plus de 3 000 caméras. Dans d’autres cas, une ville comme Barcelone déploiera près d’un million de capteurs environnementaux pour surveiller la consommation électrique, la température, les conditions ambiantes, la qualité de l’air, les niveaux de bruit et les espaces de stationnement. Ces Tous ont des besoins à faible bande passante par rapport à une caméra vidéo en continu, mais le montant total des données transmises seront les mêmes que les caméras de surveillance, près de New York. Ces caractéristiques de quantité et de bande passante doivent être prises en compte lors de la construction de l’architecture IoT correcte.
Les villes intelligentes sont également affectées par les mandats et les réglementations du gouvernement (comme nous l’explorerons plus loin) ; par conséquent, il existe des liens avec le segment gouvernemental.
1.3.16 Cas d’utilisation de l’IoT Smart City
Certains des cas d’utilisation de l’IoT Smart City sont les suivants :
- Contrôle de la pollution et analyse réglementaire par détection environnementale
- Prévisions météorologiques microclimatiques à l’aide de réseaux de capteurs à l’échelle de la ville
- Gains d’efficacité et amélioration des coûts grâce à un service de gestion des déchets sur demande
- Amélioration de la circulation et de l’économie de carburant grâce au contrôle et à la configuration intelligents des feux de circulation
- Efficacité énergétique de l’éclairage urbain sur demande
- Déneigement intelligent basé sur la demande routière en temps réel, les conditions météorologiques et les charrues à proximité
- Irrigation intelligente des parcs et des espaces publics, en fonction des conditions météorologiques et de l’utilisation actuelle
- Des caméras intelligentes pour détecter les délits et les alertes AMBER automatisées en temps réel
- Des parkings intelligents pour trouver automatiquement les meilleures places de parking sur demande
- Moniteurs d’usure et d’utilisation des ponts, des rues et des infrastructures pour améliorer la longévité et le service
1.3.17 Militaire et gouvernement
Les gouvernements municipaux, étatiques et fédéraux, ainsi que les militaires, s’intéressent vivement aux déploiements IoT. Prenez le décret exécutif de la Californie B-30-15 ( https://www.gov.ca.gov/news.php?id=18938 ), qui stipule que d’ici 2030, les émissions de gaz à effet de serre affectant le réchauffement climatique seront à des niveaux de 40% inférieurs à 1990 niveaux. Pour atteindre des objectifs agressifs comme celui-ci, les moniteurs environnementaux, les systèmes de détection d’énergie et l’intelligence artificielle devront intervenir pour modifier les schémas énergétiques à la demande, tout en maintenant la respiration de l’économie californienne. D’autres cas incluent des projets comme Internet Battlefield of Things, dans le but de fournir des efficacités pour les contre-attaques contre les ennemis. Ce segment s’inscrit également dans la catégorie des villes intelligentes lorsque l’on considère la surveillance des infrastructures gouvernementales comme les autoroutes et les ponts.
Le rôle du gouvernement dans l’IdO entre également en jeu sous la forme de normalisation, d’attribution du spectre de fréquences et de réglementations. Prenez, par exemple, la façon dont l’espace de fréquences est divisé, sécurisé et réparti entre différents fournisseurs. Nous verrons tout au long de ce texte comment certaines technologies ont vu le jour sous le contrôle fédéral.
1.3.18 Cas d’utilisation de l’IoT gouvernemental et militaire
Voici certains des cas d’utilisation de l’IoT gouvernemental et militaire :
- Analyse des menaces de terreur grâce à l’analyse des modèles d’appareils IoT et aux balises
- Des capteurs d’essaim à travers des drones
- Des bombes à capteurs déployées sur le champ de bataille pour former des réseaux de capteurs pour surveiller les menaces
- Systèmes de suivi des actifs du gouvernement
- Services de repérage et de localisation en temps réel du personnel militaire
- Capteurs synthétiques pour surveiller les environnements hostiles
- Surveillance du niveau d’eau pour mesurer le barrage et le confinement des inondations
1.4 Exemple de cas d’utilisation et de déploiement
La façon la plus efficace de comprendre un IoT et un système informatique de périphérie est de commencer par le cas d’utilisation d’un produit du monde réel. Ici, nous étudierons ce que la solution est censée offrir, puis nous nous concentrerons sur la technologie sous-jacente. Les utilisateurs et les clients ne détailleront pas les exigences système complètes, et les lacunes devront être dérivées des contraintes. Cet exemple illustrera également que les déploiements IoT sont une collaboration inter-domaines entre différentes disciplines et sciences de l’ingénierie. Souvent, il y aura des concepteurs numériques, des ingénieurs réseau, des ingénieurs de microprogrammes de bas niveau, des concepteurs industriels, des ingénieurs facteur humain, des ingénieurs électriciens en configuration de carte, ainsi que des développeurs cloud et SaaS. Cependant, la conception ne peut pas être architecturée dans divers silos. Souvent, un choix de conception dans un domaine peut entraîner des performances médiocres, une mauvaise durée de vie de la batterie, des charges de réseau exorbitantes ou une communication peu fiable avec les appareils distants.
1.4.1 Étude de cas – Télémédecine soins palliatifs
Un fournisseur de soins à domicile et de consultation pour les personnes âgées et les personnes âgées a l’intention de moderniser leur pratique actuelle des soins infirmiers à domicile et des soins d’assistance infirmière avec des solutions meilleures, plus exploitables et économiques pour faire face à la crise croissante des coûts et du nombre de patients. Actuellement, le service maintient des soins à domicile avec des visites de routine de 7 jours à plus de 500 patients dans un rayon de 100 miles d’une zone métropolitaine à Madison, Wisconsin. Les visites comprennent tout, de la livraison des médicaments et des services de soins spéciaux aux mesures de la vitale des patients. Les patients sont généralement âgés de plus de 70 ans et n’ont aucune capacité à administrer une infrastructure informatique apportée à domicile. De plus, les foyers pour patients peuvent ne pas avoir de connectivité Internet ou de connexion à large bande.
1.4.2 Exigences
Le fournisseur souhaite qu’un système fournisse ces fonctionnalités et services minimaux :
- Chaque patient se verra attribuer un appareil portable pour surveiller la fréquence cardiaque, l’oxygène sanguin, les mouvements, la température et les mesures prises.
- Un ou des dispositifs supplémentaires seront installés dans les maisons de patients pour surveiller les conditions spécifiques du patient et les signes vitaux tels que la pression artérielle, la glycémie, le poids, la température buccale, etc.
- Le système doit signaler les données sur les paramètres vitaux des patients à un tableau de bord central des opérations.
- Le système rappellera également aux patients des événements tels que quand prendre une certaine pilule ou quand administrer un test vital.
- Le système doit être en mesure de suivre l’état d’un patient en cas de panne de courant.
- Un système portable est fourni avec un bouton-poussoir facilement identifiable qui signalera une situation d’urgence (telle qu’une chute) au service opérateur en attente. L’appareil clignote pour indiquer qu’une urgence a été activée. L’appareil aura une communication audio bidirectionnelle avec l’opérateur. En cas de situation de patient malentendant, une autre méthode sera utilisée pour communiquer avec le patient.
- L’ensemble du réseau doit être capable de gérer 500 patients actuels et de croître à une échelle de 10% par an.
- Le système doit permettre une économie globale et un retour sur investissement de 33% dans les trois ans suivant sa mise en œuvre. Cet indicateur de performance clé ( ICP ) est mesuré en réduisant les soins infirmiers à domicile et les soins d’assistance infirmière de trois heures par jour à deux heures par jour tout en augmentant la qualité des soins de santé pour les patients du programme.
1.4.3 Mise en œuvre
L’IoT médical et la télémédecine sont l’un des domaines à plus forte croissance de l’IoT, de l’IA / ML et des systèmes de capteurs. Avec un taux de croissance d’une année sur l’autre (glissement annuel) de 19% et un marché de 534 milliards de dollars d’ici 2025, il a suscité beaucoup d’intérêt. Cependant, nous examinons cette étude de cas spécifique en raison des contraintes importantes qu’elle impose au concepteur de système. Plus précisément, dans les domaines des soins de santé, les exigences strictes et les réglementations HIPAA et FDA imposent des contraintes qui doivent être surmontées pour construire un système qui affecte le bien-être des patients. Par exemple, HIPAA exigera la sécurisation des données des patients, de sorte que le chiffrement et la sécurité des données devront être conçus et qualifiés pour l’ensemble du système. De plus, nous examinons ici les contraintes des personnes âgées, à savoir le manque de connectivité Internet robuste, tout en essayant de construire un système connecté à Internet.
Le système sera divisé en trois composantes principales :
- La couche du bord éloigné : elle sera constituée de deux appareils. Le premier sera un appareil portable pour le patient. Le second sera une myriade d’outils de mesure de qualité médicale différents. Le portable sera un appareil sans fil tandis que les autres appareils de mesure peuvent ou non être sans fil. Les deux établiront une communication sécurisée avec le composant de couche PAN-LAN décrit ci-après.
- La couche PAN-WAN proche du bord : Ce sera un dispositif sécurisé installé dans la localité du domicile du patient ou où il pourra être soigné. Il doit être portable mais une fois installé, il ne doit pas être utilisé et altéré par le patient. Il abritera l’équipement d’infrastructure de réseau PAN-LAN. Il contient également les systèmes informatiques de pointe pour gérer les appareils, contrôler la connaissance de la situation et stocker en toute sécurité les données des patients en cas de panne.
- Couche cloud : ce sera le point d’agrégation pour stocker, enregistrer et gérer les données des patients. Il présente également des tableaux de bord et des moteurs de règles de connaissance de la situation. Le clinicien gérera un parc de systèmes de soins à domicile installés par le biais d’un tableau de bord unique et d’un panneau de verre. Gérer 500 patients avec une croissance de 10% en glissement annuel présentera des défis pour gérer rapidement cette quantité de données, en particulier dans les situations d’urgence. Par conséquent, des moteurs de règles seront construits pour déterminer quand un événement ou une situation dépasse une limite.
Les trois couches de l’architecture composent le système du capteur au cloud. Les sections suivantes détaillent les aspects de chaque couche.
Le cas d’utilisation unique que nous avons choisi est simplement un événement IoT du portable qui doit se propager au cloud pour la visibilité du tableau de bord. Le flux de données s’étend sur les trois couches de ce cas d’utilisation IoT, comme illustré dans la figure suivante:
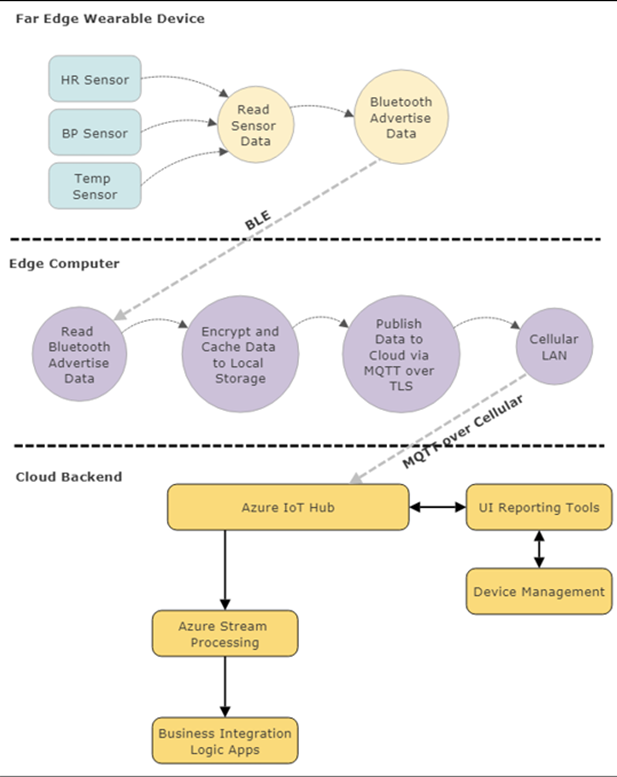
Figure 6 : flux de données de base et composants logiciels dans cet exemple de cas d’utilisation. Notez le rôle du périphérique informatique de périphérie assurant la traduction entre un périphérique Bluetooth et le cloud via un protocole de transport. Il remplit également les rôles de serveur de mise en cache et d’agent de chiffrement.
Ce cas d’utilisation lira à partir de capteurs intégrés et diffusera les données sous forme de paquets annoncés BLE en tant que périphérique BLE couplé à l’ordinateur de bord. Le système de périphérie gère la relation avec le PAN Bluetooth et récupère, crypte et stocke les données entrantes en cas de panne de courant ou de communication avec le cloud. Le système de périphérie a la responsabilité supplémentaire de convertir les données Bluetooth en paquets TCP / IP enveloppés dans un transport MQTT.
Il doit également configurer, gérer et contrôler une communication cellulaire avec un fournisseur d’abonnement. MQTT permet le transport fiable et robuste vers le système cloud en attente (Azure dans cet exemple). Ces données sont chiffrées via le câble via TLS, puis ingérées par le hub Azure IoT. À ce stade, les données seront authentifiées et rassemblées via le moteur Stream Analytics et vers les applications logiques où les services Web basés sur le cloud hébergeront un tableau de bord d’informations et d’événements sur les patients.
1.4.4 Architecture d’extrémité éloignée
Commençons par le bord éloigné et la conception portable. Pour ce projet, nous commençons par décomposer l’exigence utilisateur en exigences système exploitables :
| Cas d’utilisation | Choix | Description détaillée |
| Moniteur patient portable |
|
Dispositif portable pour le patient.
L’appareil doit maintenir l’intégrité sous plusieurs paramètres environnementaux tels que la submersion dans l’eau, le froid, la chaleur, l’humidité, etc. |
| Moniteurs vitaux portables | TI AFE4400 fréquence cardiaque et oxymètre de pouls | Moniteur de fréquence cardiaque et capteur d’oxygène sanguin de qualité médicale |
| Accéléromètre MEMS ST Micro MIS2DH de qualité médicale | Capteur de mouvement et podomètre | |
| Capteur de température corporelle Maxim MAX30205 | Capteur de température de qualité médicale | |
| Bouton d’appel d’urgence | Un seul bouton-poussoir visible avec une LED sur l’unité | Le bouton doit appuyer mais ne pas créer de faux événements positifs. De plus, une lumière doit clignoter lorsqu’une situation d’urgence est activée. De plus, une communication bidirectionnelle peut être initiée. |
| Système de contrôle des bords | Microcontrôleur ST Micro STM32WB | Système pour interfacer les capteurs et fournir une communication PAN à la couche PAN-WAN. Le système Edge contient le matériel radio et les codecs audio nécessaires. |
| Microphone | Knowles SPU0410LR5 audio, microphone et amplificateur | Communication bidirectionnelle en cas d’urgence. |
| Système d’alimentation | Batterie Li-ion sous boîtier portable. | Le système doit avoir une durée de vie de la batterie rechargeable de plusieurs jours avec des avertissements pour le patient et le clinicien en cas de faible puissance. Le système d’alimentation doit être rechargeable ou remplaçable. |
| Jumelage | Bluetooth
Zigbee Wi-Fi |
Besoin d’une méthode pour associer et associer des attributs portables dans le concentrateur PAN-LAN domestique. |
L’intention du dispositif portable dans une situation de soins palliatifs est d’être fiable, robuste et durable. Nous avons choisi des composants de qualité médicale et des composants électroniques testés pour résister aux cas d’utilisation pouvant survenir dans les soins à domicile. L’appareil n’aura également aucune pièce réparable. Par exemple, pour ce cas d’utilisation, nous avons choisi de ne pas charger le patient de recharger le portable car cette procédure peut ne pas être suivie de manière fiable. Le projet nécessitant toujours des soins infirmiers à domicile et des soins d’assistance infirmière, une partie de la tâche de l’assistance infirmière sera de recharger et de surveiller la santé du portable.
Un système commence généralement par les contraintes de réalisation des composants. Dans ce cas, un système portable pour les soins de santé à domicile des personnes âgées pourrait se présenter sous la forme d’un bracelet, d’une sangle de cou, d’une sangle de bras, etc. Ce projet a choisi une dragonne semblable à une bande de nom de style hospitalier avec laquelle un patient aurait déjà une certaine familiarité. La dragonne permet un ajustement près de la peau et des artères pour permettre la collecte des caractéristiques de santé. D’autres formes d’objets portables n’ont pas réussi à fournir un contact plus robuste. La dragonne présente des contraintes de taille, de puissance et de forme importantes qui doivent contenir tous les composants électroniques, l’alimentation et les radios décrits ci-dessous.
Du point de vue du diagramme, le portable sera composé du moins de composants possible pour minimiser l’espace et le poids tout en économisant le plus d’énergie possible. Ici, nous choisissons d’utiliser un microcontrôleur très économe en énergie avec une radio Bluetooth 5 (Bluetooth Low Energy – BLE). La radio BLE servira de communication PAN au hub PAN-WAN. Le BLE 5 a une portée allant jusqu’à 100 mètres (ou plus lorsque le mode longue portée LE est activé).
Cela sera suffisant pour les situations de soins à domicile où le patient ne partira pas nécessairement.

Figure 7 : Dispositif informatique portable pour les soins palliatifs à domicile
1.4.5 Architecture de la couche Edge
La couche périphérique PAN-WAN est l’ordinateur périphérique central, la passerelle et le routeur. Dans de nombreux cas, cette fonctionnalité est effectuée par un smartphone ; Cependant, dans cette mise en œuvre, nous devons construire un système utilisant un plan de service cellulaire différent et plus économique que ce qui est généralement proposé aux consommateurs de smartphones. Parce que notre échelle est de 500 utilisateurs et grandit, nous décidons de construire un hub en utilisant des composants matériels standard pour fournir la meilleure solution pour le client.
L’ordinateur de bord que nous avons choisi est un ordinateur monocarte de qualité industrielle capable d’exécuter une distribution d’entreprise de Linux. L’Inforce 6560 agit comme une passerelle entre le Bluetooth 5.0 PAN et un WAN cellulaire. Le système sur puce (SOC) intègre commodément le matériel suivant :
- Processeur Snapdragon 660 avec processeur Qualcomm Kryo 260
- 3 Go de DRAM LPDDR4 intégrée
- 32 Go de stockage eMMC
- Une interface pour carte microSD
- Radio Bluetooth 5.0
- Radio Wi-Fi 802.11n / ac 2,4 GHz et 5 GHz
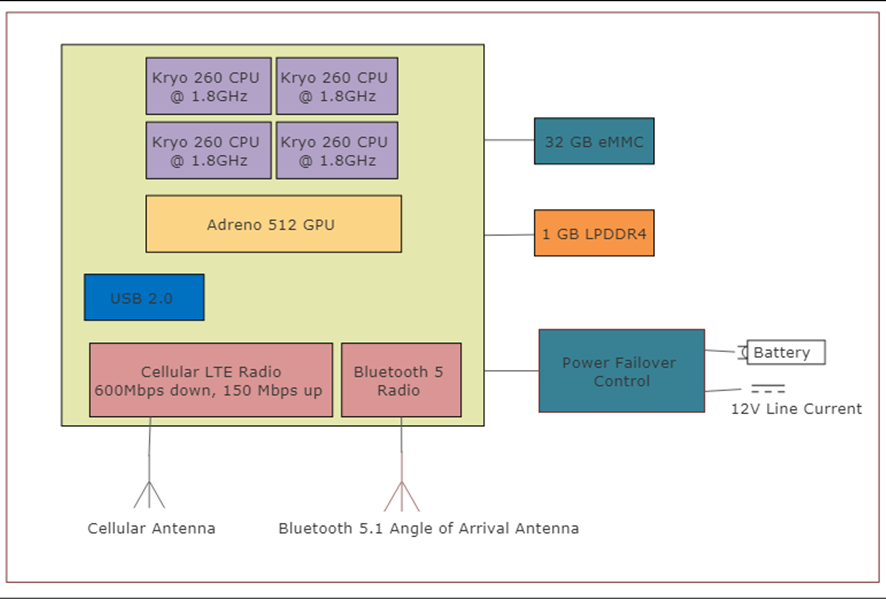
Figure 8 : Schéma fonctionnel du matériel du système Edge
L’ordinateur de bord utilisera également un réseau d’antennes d’angle d’arrivée à suivi de localisation Bluetooth 5.1. Cette nouvelle norme permettra au système de bord d’obtenir une précision centimétrique sur l’emplacement du portable et du patient dans le champ Bluetooth. Cela permettra de suivre les mouvements du patient, l’exercice, les fonctions de la salle de bain et les situations d’urgence.
La périphérie repose sur un système d’alimentation de basculement ou une alimentation sans coupure (UPS). L’onduleur passera du courant de ligne à la batterie en cas de coupure de courant ou de panne de courant. Il signalera au système de périphérie qu’un événement d’alimentation s’est produit via un signal USB ou série UART. À ce stade, le système Edge communiquera à la gestion du cloud qu’un événement d’alimentation s’est produit et une action peut être nécessaire.
1.4.6 Architecture logicielle
Avec trois couches de protocoles de communication et de matériel, il existe trois modèles différents de logiciels dans ce système relativement simple. Plutôt que d’analyser cet exemple de cas d’utilisation avec toutes les nuances de la conception, y compris chaque récupération de panne, provisionnement des appareils, sécurité et état du système, nous examinerons l’utilisation la plus courante de la fourniture de données de santé des patients en temps réel.
La structure logicielle de l’appareil portable doit être compatible avec le matériel que nous avons choisi. Cela implique que nous avons choisi des outils, des systèmes d’exploitation, des pilotes de périphériques et des bibliothèques compatibles avec l’architecture et les périphériques que nous utilisons. Nous commencerons par le portable, qui a les exigences les plus strictes en termes de taille de code, d’autonomie et de performances. Étant donné que le microcontrôleur STM32WB est conçu comme un double cœur, nous avons essentiellement deux systèmes à gérer : le cœur ARM M4 plus performant qui exécutera notre micrologiciel portable spécifique et un cœur M0 de faible puissance qui gère les E / S via Bluetooth. Nous avons choisi un système d’exploitation commercial en temps réel tel que ThreadX par Express Logic pour permettre une expérience de développement moderne plutôt qu’une simple boucle de contrôle qui n’est pas appropriée pour ce produit. Nous voulons également pouvoir certifier le produit pour une utilisation de qualité médicale, ce qui est plus facile lors de l’utilisation de systèmes d’exploitation commerciaux standard.
La structure logicielle sur le portable est divisée en deux processus qui hébergent de nombreux threads pour gérer l’affichage portable, le matériel du haut-parleur et du microphone, les E / S vers les capteurs de rythme cardiaque et de mouvement et la pile Bluetooth. La pile Bluetooth communique avec le cœur M0 qui gère les couches matérielles de la radio Bluetooth.

Figure 9 : pile logicielle du système portable divisée entre deux cœurs de traitement pour les services d’application et la communication IO
L’ordinateur périphérique dispose de plus de ressources de traitement car il doit fournir une pile TCP / IP complète, la communication et le routage PAN et WAN, des services de chiffrement, des services de stockage, le provisionnement des appareils et des mises à niveau de micrologiciel à sécurité intégrée. Pour le système Edge, nous avons choisi un système Linux Debian-variant car il fournit plus de fonctionnalités et de services qu’un RTOS étroitement intégré. La coordination avec le système cloud et tous les services sur l’ordinateur de bord ou sur le portable sont coordonnés via le « moteur de règles ». Le moteur de règles peut être un simple “système expert” utilisant une logique personnalisée pour ce client ou ce cas d’utilisation. Une conception plus robuste peut utiliser un cadre normalisé comme Drools. Étant donné que chaque patient peut avoir besoin d’un ensemble de règles différent, il est logique d’utiliser un moteur de règles dynamique et fongible qui peut être téléchargé avec différentes directives patient. Il s’agit d’un superviseur autonome de haut niveau qui capture périodiquement les données de santé, résout les problèmes de sécurité, publie de nouvelles mises à jour de micrologiciel de manière fiable, gère l’authentification et la sécurité et gère un nombre important de conditions d’erreur et d’échec. Le moteur de règles doit être autonome pour satisfaire l’exigence de produit du système fonctionnant sans contrôle direct via le cloud.
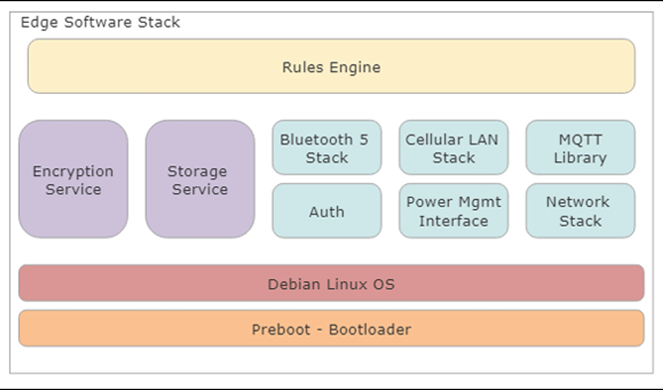
Figure 10 : pile logicielle informatique Edge composée d’un certain nombre de services gérés par un seul “moteur de règles” superviseur et autonome
La couche cloud fournit les services d’ingestion, de stockage de données à long terme, d’analyse de flux et de tableaux de bord de surveillance des patients. Il fournit l’interface aux fournisseurs de soins de santé pour gérer en toute sécurité des centaines de systèmes de périphérie via une interface commune. C’est également la méthode pour fournir rapidement des alertes sur les situations d’intégrité, les conditions d’erreur et les défaillances du système, et fournir des mises à niveau de périphérique en toute sécurité. Le partitionnement des services cloud par rapport aux services de périphérie est le suivant :
- Services cloud
- Ingestion et gestion des données pour les patients et les systèmes multi-périphériques
- Capacité de stockage presque illimitée
- Un déploiement logiciel contrôlé et des mises à jour vers Edge
- Services Edge
- Faible latence et réactions en temps réel aux événements
- Communication PAN aux capteurs
- Exigences minimales de connectivité
Les services cloud commerciaux s’accompagneront d’un contrat de service et d’un coût récurrent, tandis que les systèmes de périphérie n’entraîneront pour la plupart qu’un seul coût initial de matériel et de développement.
Lorsque nous considérons les composants du cloud, nous avons besoin d’un service pour ingérer les données de plusieurs périphériques périphériques en toute sécurité. Les données doivent être stockées pour analyse et surveillance. Les services cloud doivent également inclure une méthode de gestion et d’approvisionnement des installations de périphérie. Enfin, nous recherchons une méthode pour obtenir des données en temps réel des patients et les afficher au personnel qualifié.
Pour ce projet, nous avons choisi d’utiliser Microsoft Azure IoT comme fournisseur de cloud pour gérer cette grande installation et permettre la croissance et l’évolutivité. Azure IoT fournit une architecture illustrée dans l’illustration suivante :
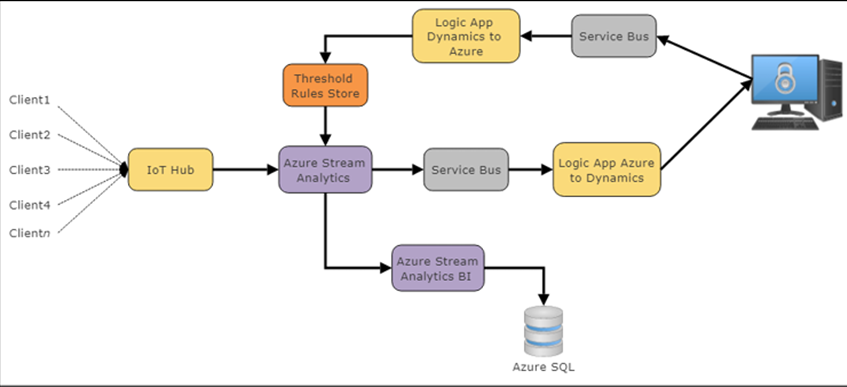
Figure 11 : pile logicielle Microsoft Azure IoT typique et architecture cloud
L’architecture logicielle Microsoft Azure IoT est généralement cohérente entre les conceptions au moins sur l’extrémité avant du hub IoT. Les données seront diffusées à partir de diverses sources authentifiées vers le hub Azure IoT. Il s’agit de la passerelle cloud et capable d’évoluer vers de très grandes installations IoT. Dans les coulisses, IoT Hub est une collection de processus et de services de centre de données qui écoutent et répondent aux événements entrants.
Le hub IoT achemine les flux qualifiés vers le moteur Stream Analytics. Ici, les données seront rapidement analysées en temps réel aussi vite que les données peuvent être ingérées. Les données peuvent être rassemblées vers des services de Business Intelligence et stockées pour une longue persistance dans une base de données Azure SQL et / ou déplacées vers un bus de service. Le bus de service répond aux événements et aux pannes sous forme de files d’attente pour permettre au système d’y répondre. Le dernier composant de notre architecture est les couches de « colle » du cloud qui acheminent les données vers l’appareil IoT (Logic App Dynamics vers Azure) ou répondent aux données entrantes (Logic App Azure vers Dynamics). Microsoft Dynamics 365 s’interface en tant qu’application logique et permet la visibilité des événements IoT, la création de tableaux de bord, de cadres Web et même des alertes mobiles et smartphone.
Ce cas d’utilisation n’est qu’une fraction des fonctionnalités réelles pour fabriquer un produit commercial d’expédition. Nous avons laissé de côté des domaines importants tels que l’approvisionnement, l’authentification, les conditions d’erreur, les mises à niveau résilientes du micrologiciel, la sécurité du système et la racine de confiance, les conditions de basculement, la communication audio, la gestion des clés, le travail d’affichage LCD et les systèmes de contrôle du tableau de bord eux-mêmes.
1.4.7 Rétrospective de cas d’utilisation
Ce que nous avons montré dans ce cas d’utilisation introductif très bref, c’est que les besoins en objets connectés et en informatique de bord pour les conceptions d’entreprise et commerciales impliquent de nombreuses disciplines, technologies et considérations. Tenter de banaliser la complexité de la transition de la connectivité Internet aux systèmes de périphérie avec les attentes modernes de performances, de fiabilité, de convivialité et de sécurité peut se solder par un échec.
Comme nous l’avons vu dans le cas d’utilisation portable abrégé médical, notre conception implique de nombreux composants interopérables qui composent un système. Il est essentiel qu’un architecte responsable d’un système IoT connaisse un certain niveau de ces composants du système :
- Conception matérielle
- Gestion de l’alimentation et conception de la batterie
- Conception et programmation de systèmes embarqués
- Systèmes de communication, signalisation radio, utilisation du protocole et économie de la communication
- Piles et protocoles réseau
- Sécurité, provisionnement, authentification et plateformes de confiance
- Analyse des performances et partitionnement du système
- Gestion du cloud, systèmes de streaming, systèmes de stockage dans le cloud et économie du cloud
- Analyse des données, gestion des données et science des données
- Gestion des middlewares et des appareils
Cet article est conçu pour aider l’architecte à naviguer à travers la myriade de détails et d’options pour chacun de ces niveaux.
1.5 Résumé
Bienvenue dans le monde de l’IoT. En tant qu’architectes dans ce nouveau domaine, nous devons comprendre ce que le client construit et ce que les cas d’utilisation exigent. Les systèmes IoT ne sont pas un type de conception qui consiste à tirer et à oublier. Un client attend plusieurs choses de sauter dans le train IoT.
Premièrement, il doit y avoir une récompense positive. Cela dépend de votre entreprise et de l’intention de votre client. D’après mon expérience, un gain 5x est la cible et a bien fonctionné pour l’introduction de nouvelles technologies dans les industries préexistantes. Deuxièmement, la conception de l’IoT est, par nature, une pluralité de dispositifs. La valeur de l’IoT n’est pas un seul appareil ou un seul emplacement diffusant des données vers un serveur. C’est un ensemble de choses diffusant des informations et comprenant la valeur que les informations globales essaient de vous dire. Tout ce qui est conçu doit évoluer ou être évolutif ; par conséquent, cela nécessite une attention lors de la conception initiale.
Nous avons découvert les segments de l’IoT et les taux de croissance prévus et réels de l’IoT. Nous avons également exploré un cas d’utilisation commerciale unique et constaté que l’IoT et l’informatique de périphérie couvrent plusieurs disciplines, technologies et fonctionnalités. Ces mécanismes de développement d’un IoT et d’un système informatique de bord commercialement viables nécessiteront que l’architecte comprenne ces différents segments et comment ils sont liés.
Nous commençons maintenant à explorer la topologie d’un IoT et d’un système informatique de périphérie dans son ensemble, puis nous décomposons les composants individuels dans le reste de l’article.
2 Architecture IoT et modules Core IoT
L’informatique de périphérie et l’écosphère de l’IoT commencent avec le plus simple des capteurs situés dans les coins les plus reculés de la terre et traduisent les effets physiques analogiques en signaux numériques (le langage d’Internet). Les données prennent ensuite un voyage complexe à travers des signaux filaires et sans fil, divers protocoles, des interférences naturelles et des collisions électromagnétiques, avant d’arriver dans l’éther d’Internet. À partir de là, les données en paquets traverseront divers canaux arrivant dans un cloud ou un grand centre de données. La force de l’IoT n’est pas seulement un signal provenant d’un capteur, mais l’ensemble de centaines, de milliers, potentiellement de millions de capteurs, d’événements et d’appareils.
Ce chapitre commence par une définition de l’IoT par rapport aux architectures machine à machine. Il aborde également le rôle de l’architecte dans la création d’une architecture IoT évolutive, sécurisée et d’entreprise. Pour ce faire, un architecte doit être capable de parler de la valeur que la conception apporte à un client. L’architecte doit également jouer plusieurs rôles d’ingénierie et de produit dans l’équilibre des différents choix de conception.
Ce chapitre donne un aperçu de l’organisation de l’article et de la manière dont un architecte devrait aborder la lecture de l’article et jouer son rôle d’architecte. Cet article traite l’architecture comme un exercice holistique impliquant de nombreux systèmes et domaines d’ingénierie. Ce chapitre mettra en évidence :
- Détection et puissance : Nous couvrons la transformation de la détection physique en numérique, des systèmes d’alimentation et du stockage d’énergie.
- Communication de données : nous nous penchons sur la communication d’appareils utilisant des systèmes et des protocoles de communication au mètre près, au kilomètre près et à portée extrême ainsi que sur la mise en réseau et la théorie de l’information.
- Informatique Edge : les appareils Edge ont plusieurs rôles, du routage aux passerelles, en passant par le traitement Edge et l’interconnexion Cloud-Edge (Fog). Nous examinons le rôle de la périphérie et comment construire et partitionner avec succès des machines de périphérie. Nous examinons également les protocoles de communication du bord au cloud.
- Calcul, analyse et apprentissage automatique : nous examinons ensuite le flux de données à travers le cloud et le brouillard informatique, ainsi que l’apprentissage automatique avancé et le traitement d’événements complexes.
- Menace et sécurité : le contenu final examine la sécurité et la vulnérabilité de la plus grande surface d’attaque au monde.
2.1 Un écosystème connecté
Presque toutes les grandes entreprises technologiques investissent ou ont investi massivement dans l’IoT et l’espace informatique de pointe. De nouveaux marchés et technologies se sont déjà formés (et certains se sont effondrés ou ont été acquis). Tout au long de cet article, nous aborderons presque tous les segments des technologies de l’information, car ils ont tous un rôle dans l’IoT.
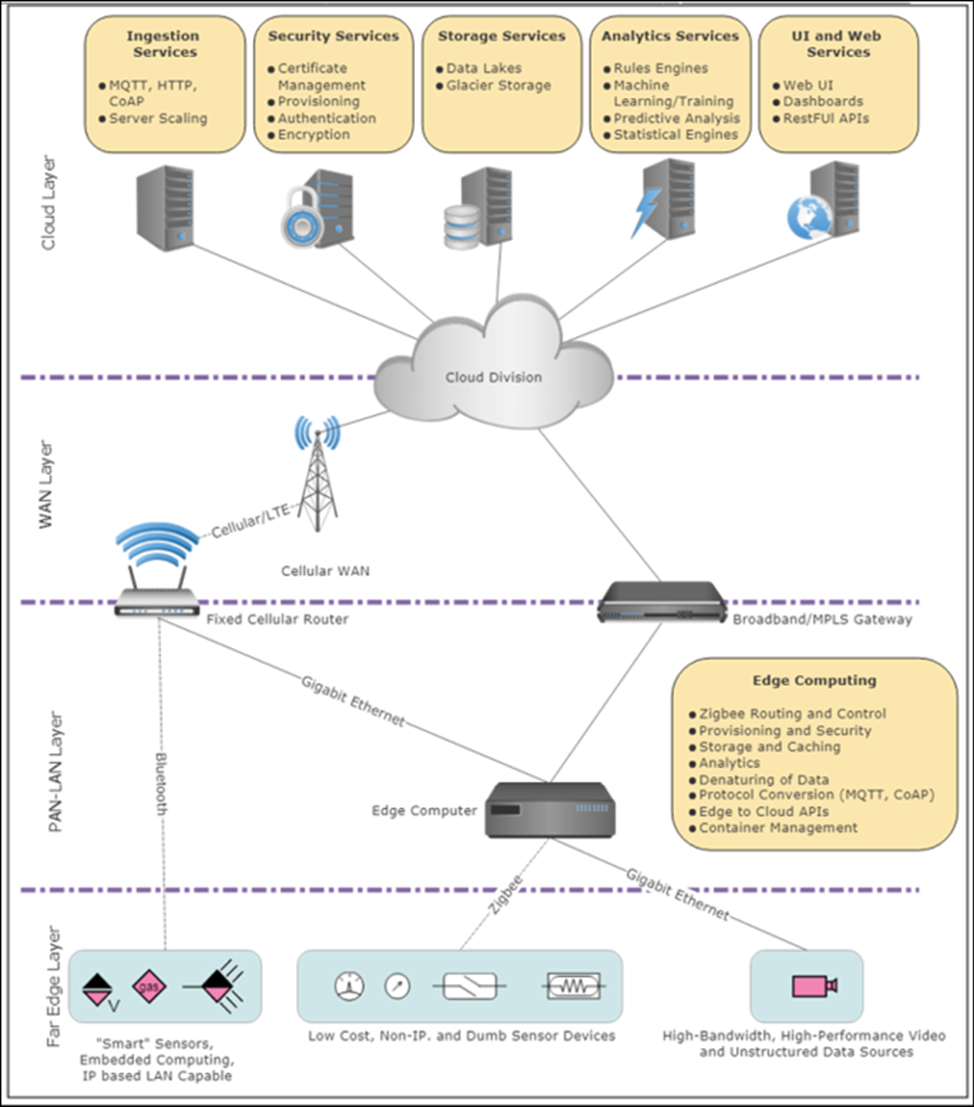
Figure 1 : Exemple des couches architecturales d’un système informatique IoT / edge. C’est l’une des nombreuses configurations potentielles qui doivent être prises en compte par l’architecte. Ici, nous montrons les routes du capteur au cloud via une communication directe et via des passerelles périphériques. Nous mettons également en évidence les fonctionnalités fournies par les nœuds de calcul de périphérie et les composants cloud.
Comme illustré dans la figure précédente, voici quelques composants d’une solution IoT / edge que nous étudierons :
- Capteurs, actionneurs et systèmes physiques : systèmes embarqués, systèmes d’exploitation en temps réel, sources de récupération d’énergie, systèmes micro-électromécaniques (MEM).
- Systèmes de communication par capteurs : les réseaux personnels sans fil ( WPAN ) atteignent de 0 cm à 100 m. Les canaux de communication à faible vitesse et à faible puissance, souvent non basés sur IP, ont une place dans la communication par capteur.
- Réseaux locaux (LAN) : En règle générale, les systèmes de communication IP tels que le Wi-Fi 802.11 sont utilisés pour des communications radio rapides, souvent dans des topologies poste à poste ou en étoile.
- Agrégateurs, routeurs, passerelles : fournisseurs de systèmes intégrés, fournisseurs les moins chers
- Réseaux étendus (WAN) : fournisseurs de réseaux cellulaires utilisant LTE ou Cat M1, fournisseurs de réseaux par satellite, fournisseurs de réseaux étendus à faible puissance (LPWAN) comme Sigfox ou LoRa. Ils utilisent généralement des protocoles de transport Internet ciblés pour l’IoT et des appareils contraints comme MQTT, CoAP et même HTTP.
- Edge computing : Distribution de l’informatique à partir des centres de données sur site et du cloud au plus près des sources de données (capteurs et systèmes). Il s’agit de supprimer les problèmes de latence, d’améliorer le temps de réponse et les systèmes en temps réel, de gérer le manque de connectivité et de créer la redondance d’un système. Nous couvrons les processeurs, la DRAM et le stockage. Nous étudions également les fournisseurs de modules, les fabricants de composants passifs, les fabricants de clients légers, les fabricants de radio cellulaire et sans fil, les fournisseurs de middleware, les fournisseurs de framework de brouillard, les packages d’analyse de périphérie, les fournisseurs de sécurité de périphérie, les systèmes de gestion de certificats, la conversion WPAN en WAN, les protocoles de routage et les logiciels. réseaux définis / périmètres définis par logiciel.
- Cloud : infrastructure en tant que fournisseur de services, plate-forme en tant que fournisseur de services, fabricants de bases de données, fabricants de streaming et de traitement par lots, packages d’analyse de données, logiciels en tant que fournisseur de services, fournisseurs de lacs de données et services d’apprentissage automatique.
- Analyse des données : au fur et à mesure que les informations se propagent en masse vers le cloud, le traitement des données de volumes et l’extraction de valeur incombent au traitement d’événements complexes, à l’analyse de données et aux techniques d’apprentissage automatique. Nous étudions différentes techniques analytiques de périphérie et de cloud, de l’analyse statistique et des moteurs de règles aux techniques d’apprentissage automatique plus avancées.
- Sécurité : lier l’ensemble de l’architecture est la sécurité. Sécurité de bout en bout, du durcissement des bords, de la sécurité des protocoles au cryptage. La sécurité touchera tous les composants, des capteurs physiques au processeur et au matériel numérique, aux systèmes de radiocommunication et aux protocoles de communication eux-mêmes. Chaque niveau doit garantir la sécurité, l’authenticité et l’ intégrité. Il ne peut pas y avoir de maillon faible dans la chaîne, car l’IdO formera la plus grande surface d’attaque au monde.
Cet écosystème aura besoin de talents issus du corps des disciplines de l’ingénierie, tels que:
- Des scientifiques en physique des dispositifs développent de nouvelles technologies de capteurs et des batteries de plusieurs années
- Ingénieurs de systèmes embarqués travaillant sur la conduite de capteurs en périphérie
- Ingénieurs réseau capables de travailler dans un réseau personnel ou un réseau étendu, ainsi que sur un réseau défini par logiciel
- Scientifiques des données travaillant sur de nouveaux schémas d’apprentissage automatique en périphérie et dans le cloud
- Les ingénieurs DevOps déploient avec succès des solutions cloud évolutives ainsi que des solutions de brouillard
L’IoT aura également besoin de fournisseurs de services tels que des sociétés de fourniture de solutions, des intégrateurs de systèmes, des revendeurs à valeur ajoutée et des OEM.
2.1.1 IoT contre machine à machine contre SCADA
Un domaine commun de confusion dans le monde de l’IoT est ce qui le sépare des technologies qui définissent la machine à machine (M2M). Avant que l’IoT ne fasse partie de la langue vernaculaire, M2M était le battage médiatique. Bien avant M2M, les systèmes SCADA (contrôle de supervision et acquisition de données) étaient le courant dominant des machines interconnectées pour l’automatisation industrielle. Bien que ces acronymes se réfèrent à des appareils interconnectés et puissent utiliser des technologies similaires, il existe des différences. Examinons- les de plus près :
- M2M : Il s’agit d’un concept général impliquant un appareil autonome communiquant directement avec un autre appareil autonome. Autonome fait référence à la capacité du nœud à instancier et à communiquer des informations avec un autre nœud sans intervention humaine. Le formulaire de communication est laissé ouvert à l’application. Il se peut très bien qu’un appareil M2M n’utilise aucun service ou topologie inhérent pour la communication. Cela exclut les appliances Internet typiques utilisées régulièrement pour les services cloud et le stockage. Un système M2M peut également communiquer sur des canaux non IP, tels qu’un port série ou un protocole personnalisé.
- IoT : les systèmes IoT peuvent incorporer certains nœuds M2M (comme un maillage Bluetooth utilisant une communication non IP), mais ils regroupent les données sur un routeur de périphérie ou une passerelle. Une appliance de périphérie comme une passerelle ou un routeur sert de point d’entrée sur Internet. Alternativement, certains capteurs dotés d’une puissance de calcul plus importante peuvent pousser les couches de mise en réseau Internet sur le capteur lui-même. Indépendamment de l’endroit où la rampe d’accès Internet existe, le fait qu’il dispose d’une méthode de connexion au tissu Internet est ce qui définit l’IoT.
- SCADA : Ce terme fait référence au contrôle de supervision et à l’acquisition de données. Ce sont des systèmes de contrôle industriels qui ont été utilisés dans les usines, les installations, les infrastructures et l’automatisation de la fabrication depuis les années 1960. Ils impliquent généralement des contrôleurs logiques programmables ( API ) qui surveillent ou contrôlent divers capteurs et actionneurs sur les machines. Les systèmes SCADA sont distribués et ne sont connectés que récemment aux services Internet. C’est là que se déroule l’Industrie 2.0 et la nouvelle croissance du secteur manufacturier. Ces systèmes utilisent des protocoles de communication tels que ModBus, BACNET et Profibus.
En déplaçant les données sur Internet pour les capteurs, les processeurs de périphérie et les appareils intelligents, le monde hérité des services cloud peut être appliqué au plus simple des appareils. Avant que la technologie cloud et la communication mobile ne soient devenues courantes et rentables, les capteurs simples et les dispositifs informatiques intégrés sur le terrain n’avaient aucun bon moyen de communiquer des données à l’échelle mondiale en quelques secondes, de stocker des informations à perpétuité et d’analyser les données pour trouver des tendances et des modèles. Au fur et à mesure que les technologies cloud évoluaient, les systèmes de communication sans fil sont devenus omniprésents, de nouveaux appareils à énergie comme le lithium-ion sont devenus rentables et les modèles d’apprentissage automatique ont évolué pour produire une valeur exploitable. Cela a considérablement amélioré la proposition de valeur IoT. Sans ces technologies, alors nous serions toujours dans un monde M2M.
2.1.2 La valeur d’un réseau et les lois de Metcalfe et Beckstrom
Il a été avancé que la valeur d’un réseau est basée sur la loi de Metcalfe. En 1980, Robert Metcalfe a formulé le concept selon lequel la valeur d’un réseau est proportionnelle au carré des utilisateurs connectés d’un système. Dans le cas de l’IoT, les « utilisateurs » peuvent signifier des capteurs ou des dispositifs périphériques avec une certaine forme de communication.
De manière générale, la loi de Metcalfe est représentée comme :
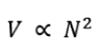
Où :
- V = Valeur du réseau
- N = nombre de nœuds dans le réseau
Un modèle graphique permet de comprendre l’interprétation ainsi que le point de croisement, où un retour sur investissement ( ROI ) positif peut être attendu:
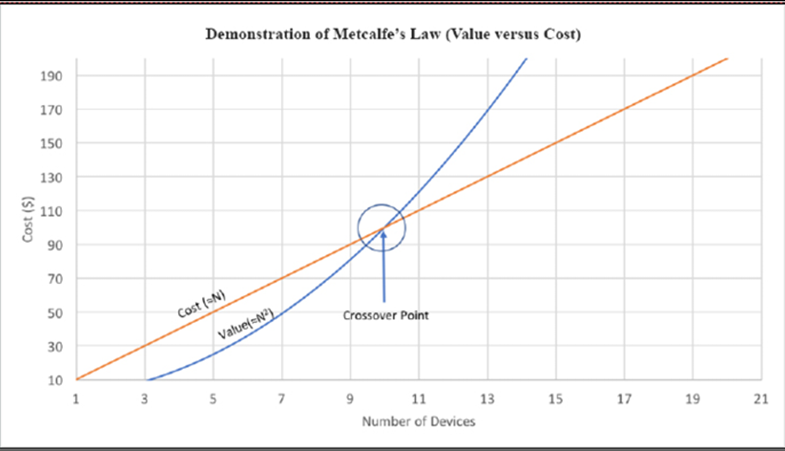
Figure 2: Loi de Metcalfe: La valeur d’un réseau est représentée proportionnelle à N 2 . Le coût de chaque nœud est représenté par kN où k est une constante arbitraire. Dans ce cas, k représente une constante de 10 $ par capteur de bord IoT. Le point clé à retenir est que le point de croisement se produit rapidement en raison de l’expansion de la valeur et indique quand ce déploiement IoT atteint un retour sur investissement positif.
Un exemple validant la loi de Metcalfe à la valeur des chaînes de blocs et des tendances des crypto-monnaies a été récemment réalisé. Nous allons approfondir les chaînes de blocs dans le chapitre sur la sécurité.
Un récent livre blanc de Ken Alabi constate que les réseaux de chaînes de blocs semblent également suivre la loi de Metcalfe, Electronic Commerce Research and Applications, Volume 24, C (juillet 2017), page numéro 23-29.
La loi de Metcalfe ne tient pas compte de la dégradation du service dans les cas où le service se dégrade à mesure que le nombre d’utilisateurs et / ou la consommation de données augmente, mais pas la bande passante du réseau. La loi de Metcalfe ne prend pas non plus en compte les différents niveaux de service réseau, les infrastructures peu fiables (telles que la 4G LTE dans un véhicule en mouvement) ou les mauvais acteurs affectant le réseau (par exemple, les attaques par déni de service).
Pour tenir compte de ces circonstances, nous utilisons la loi de Beckstrom:
Où :
- V i, j : représente la valeur actuelle du réseau pour le périphérique i sur le réseau j
- i : un utilisateur ou un appareil individuel sur le réseau
- j : Le réseau lui-même
- k : une seule transaction
- B i, j, k : l’avantage que la valeur k apportera à l’appareil i sur le réseau j
- C i, j, k : le coût d’une transaction k vers un appareil i sur le réseau j
- r k : le taux d’intérêt d’actualisation au moment de la transaction k
- t k : le temps écoulé (en années) pour la transaction k
- n : le nombre d’individus
- m : le nombre de transactions
La loi de Beckstrom nous enseigne que pour tenir compte de la valeur d’un réseau (par exemple, une solution IoT), nous devons tenir compte de toutes les transactions de tous les appareils et additionner leur valeur. Si le réseau j tombe en panne pour une raison quelconque, quel est le coût pour les utilisateurs ? C’est l’impact d’un réseau IoT et c’est une attribution de valeur plus représentative dans le monde réel. La plus variable difficile – le modèle dans l’équation est l’avantage d’une transaction B. En regardant chaque capteur IoT, la valeur peut être très petite et insignifiante (par exemple, un capteur de température sur une machine est perdu pendant une heure). À d’autres moments, cela peut être extrêmement important (par exemple, une batterie de capteur d’eau est morte et un sous-sol de détaillant est inondé, causant des dommages importants aux stocks et des ajustements d’assurance).
La première étape d’un architecte dans la construction d’une solution IoT devrait être de comprendre la valeur qu’il apporte à ce qu’il conçoit. Dans le pire des cas, un déploiement IoT devient un passif et produit en fait une valeur négative pour un client.
2.1.3 IoT et architecture de périphérie
La couverture de cet article couvrira de nombreuses technologies, disciplines et niveaux d’expertise. En tant qu’architecte, il faut comprendre l’impact que le choix d’un certain aspect de la conception aura sur l’évolutivité et d’autres parties du système. La complexité et les relations des technologies et des services IoT sont beaucoup plus interconnectées que les technologies traditionnelles non seulement en raison de leur échelle, mais également en raison des types d’architecture disparates. Il existe un nombre ahurissant de choix de conception. Par exemple, au moment d’écrire ces lignes, nous comptions plus de 700 fournisseurs de services IoT proposant à eux seuls un stockage basé sur le cloud, des composants SaaS, des systèmes de gestion IoT, des middlewares, des systèmes de sécurité IoT et toutes les formes d’analyse de données imaginables. Ajoutez à cela le nombre de protocoles PAN, LAN et WAN différents qui changent constamment et varient selon la région. Le choix du mauvais protocole PAN peut entraîner de mauvaises communications et une qualité de signal significativement faible qui ne peuvent être résolues qu’en ajoutant plus de nœuds pour compléter un maillage. Le rôle d’un architecte doit demander et apporter des solutions aux problèmes qui couvrent l’ensemble du système :
- L’architecte doit prendre en compte les effets d’interférence dans le LAN et le WAN – comment les données vont-elles sortir du bord et sur Internet ?
- L’architecte doit tenir compte de la résilience et du coût de la perte de données. La résilience doit-elle être gérée dans les couches inférieures de la pile ou dans le protocole lui-même ?
- L’architecte doit également choisir des protocoles Internet tels que MQTT par rapport à CoAP et AMQP, et comment cela fonctionnera s’il décide de migrer vers un autre fournisseur de cloud.
Les choix doivent également être pris en considération en ce qui concerne le lieu de traitement. Cela ouvre la notion de calcul de périphérie / brouillard pour traiter les données près de leur source pour résoudre les problèmes de latence, mais surtout pour réduire la bande passante et les coûts de déplacement des données sur les WAN et les nuages. Ensuite, nous considérons tous les choix dans l’analyse des données collectées. L’utilisation du mauvais moteur d’analyse peut entraîner du bruit inutile ou des algorithmes trop gourmands en ressources pour s’exécuter sur des nœuds périphériques. Comment les requêtes du cloud vers le capteur affecteront-elles l’autonomie de la batterie du capteur lui-même? Ajoutez à cette litanie de choix, et nous devons nous concentrer sur la sécurité car le déploiement IoT que nous avons construit est maintenant la plus grande surface d’attaque de notre ville. Comme vous pouvez le voir, les choix sont nombreux et ont des relations les uns avec les autres.
Il y a plusieurs choix à considérer. Lorsque vous tenez compte du nombre de systèmes et de routeurs informatiques de périphérie, de protocoles PAN, de protocoles WAN et de communications, vous avez le choix entre plus de 1,5 million de combinaisons d’architectures différentes :
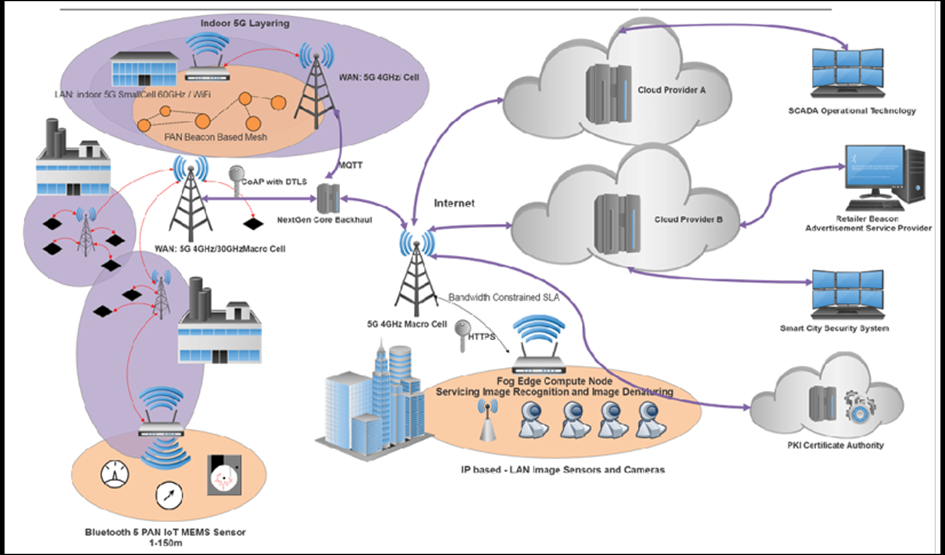
Figure 3 : choix de conception IoT : le spectre complet des différents niveaux d’architecture IoT, du capteur au cloud et inversement.
2.1.4 Rôle d’un architecte
Le terme architecte est souvent utilisé dans les disciplines techniques. Il existe des architectes logiciels, des architectes système et des architectes de solutions. Même dans des domaines spécifiques, tels que l’informatique et le génie logiciel, vous pouvez voir des personnes avec le titre d’architecte SaaS, d’architecte cloud, d’architecte de science des données, etc. Ce sont des individus qui sont des experts reconnus avec des compétences tangibles et une expérience dans un domaine. Ces types de domaines verticaux spécialisés recoupent plusieurs technologies horizontales. Dans cet article, nous ciblons l’architecte IoT.
Il s’agit d’un rôle horizontal, ce qui signifie qu’il touchera un certain nombre de ces domaines et les réunira pour un système utilisable, sécurisé et évolutif.
Nous irons aussi loin que nécessaire pour comprendre un système IoT complet et rassembler un système. Parfois, nous entrerons dans la théorie pure, comme la théorie de l’information et de la communication. D’autres fois, nous aborderons des sujets qui se trouvent à la périphérie des systèmes IoT ou qui sont enracinés dans d’autres technologies. En lisant et en référençant cet article, l’architecte aura un guide pratique sur les différents aspects de l’IoT qui sont tous nécessaires pour construire un système réussi.
Que vous soyez discipliné en génie électrique ou en informatique, ou que vous ayez une expertise dans le domaine des architectures cloud, ce matériel vous aidera à comprendre un système holistique – qui devrait, par définition, faire partie du rôle d’un architecte.
Cet article est également destiné à une mise à l’échelle géographique et massive. Construire une preuve de concept avec un ou deux terminaux est une chose. Construire une solution IoT qui s’étend sur plusieurs continents, différents prestataires de services et des milliers de terminaux est un défi de loin différent. Bien que chaque sujet puisse être utilisé pour les mouvements d’amateurs et de fabricants, il est destiné à s’adapter aux systèmes d’entreprise mondiaux de l’ordre de milliers à des millions de périphériques.
L’architecte posera des questions sur la pile complète de systèmes connectés. Il ou elle sera conscient de la façon dont l’optimisation d’une solution peut en fait produire un effet moins que souhaitable dans une autre partie du système.
Par exemple :
- Le système évoluera-t-il et à quelle capacité ? Cela affectera les décisions concernant la mise en réseau étendu, les protocoles de périphérie vers le cloud et les systèmes d’approvisionnement de middleware vers le cloud.
- Comment le système fonctionnera-t-il en cas de perte de connectivité ? Cela aura un impact sur les choix des systèmes de périphérie, des composants de stockage, des profils de service 5G et des protocoles réseau.
- Comment le cloud va-t-il gérer et approvisionner les périphériques de pointe ? Cela affectera les décisions concernant les composants middleware et de brouillard de périphérie et les services de sécurité.
- Comment la solution de mon client fonctionnera-t-elle dans un environnement RF bruyant ? Cela affectera les décisions sur les communications PAN et les composants de périphérie.
- Comment le logiciel sera-t-il mis à jour sur un capteur ? Cela affectera les décisions concernant les protocoles de sécurité, le matériel et le stockage de périphérie, les protocoles réseau PAN, les systèmes middleware, les coûts et ressources des capteurs et les couches de provisionnement cloud.
- Quelles données seront utiles pour améliorer les performances de mon client ? Cela affectera les décisions sur les outils d’analyse à utiliser, où analyser les données, comment les données seront sécurisées et dénaturées et le partitionnement Edge / Cloud.
- Comment les appareils, les transactions et la communication seront-ils sécurisés de bout en bout ?
2.2 Partie 1 – Détection et puissance
Une transaction IoT commence ou se termine par un événement: un simple mouvement, un changement de température, peut-être un actionneur se déplaçant sur une serrure. Contrairement à de nombreux appareils informatiques existants, l’IoT concerne en grande partie une action ou un événement physique. Il réagit pour affecter un attribut du monde réel. Parfois, cela implique la génération de données considérables à partir d’un seul capteur, comme la détection auditive pour l’entretien préventif des machines. D’autres fois, il s’agit d’un seul bit de données indiquant des données vitales sur la santé d’un patient. Quoi qu’il en soit, les systèmes de détection ont évolué et ont utilisé la loi de Moore pour passer à des tailles inférieures au nanomètre et réduire considérablement les coûts. La partie 1 explore les profondeurs des MEM, de la détection et d’autres formes d’appareils de périphérie à faible coût d’un point de vue physique et électrique. La partie détaille également les systèmes d’alimentation et d’énergie nécessaires pour entraîner ces machines de pointe. Nous ne pouvons pas tenir le pouvoir pour acquis à la limite. La collecte de milliards de petits capteurs nécessitera toujours une énorme quantité d’énergie au total pour alimenter. Nous reviendrons sur la puissance tout au long de cet article, et sur la façon dont les changements anodins dans le cloud peuvent gravement affecter l’architecture d’alimentation globale d’ un système.
2.3 Partie 2 – Communication de données
Une partie importante de cet article traite de la connectivité et du réseautage. Il existe d’innombrables autres sources qui plongent profondément dans le développement d’applications, l’analyse prédictive et l’apprentissage automatique. Cet article couvrira également ces sujets, mais une importance égale est accordée aux communications de données. L’IoT n’existerait pas sans des technologies importantes pour déplacer les données de l’environnement le plus éloigné et le plus hostile vers les plus grands centres de données de Google, Amazon, Microsoft et IBM. L’acronyme IoT contient le mot Internet, et à cause de cela, nous devons plonger profondément dans les réseaux, les communications et même la théorie du signal. Le point de départ pour l’IoT n’est pas les capteurs ou l’application ; il s’agit de connectivité, comme nous le verrons tout au long de cet article. Un architecte performant comprendra les contraintes de l’interconnexion d’un capteur à un WAN et vice-versa.
Cette section de communication et de réseautage commence par les fondements théoriques et mathématiques de la communication et de l’information. Un architecte performant a besoin d’outils et de modèles préliminaires non seulement pour comprendre pourquoi certains protocoles sont contraints, mais aussi pour concevoir de futurs systèmes qui évoluent avec succès au niveau de l’IoT.
Ces outils incluent la dynamique radio sans fil comme l’analyse de la portée et de la puissance, le rapport signal / bruit, la perte de trajet et les interférences. La partie 2 détaille également les fondements de la théorie de l’information et les contraintes qui affectent la capacité globale et la qualité des données. Les fondements de la loi de Shannon seront explorés. Le spectre sans fil étant également limité et partagé, un architecte déployant un système IoT massif devra comprendre comment le spectre est alloué et régi.
La théorie et les modèles explorés dans cette partie seront réutilisés dans d’autres parties de l’article.
La communication de données et la mise en réseau se développeront ensuite à partir des systèmes de communication à courte portée et à proximité du mètre appelés réseaux personnels (PAN), utilisant généralement des messages de protocole non Internet. Le chapitre sur PAN comprendra le nouveau protocole et maillage Bluetooth 5, ainsi que Zigbee et Z-Wave en profondeur. Ceux-ci représentent la pluralité de tous les systèmes de communication sans fil IoT. Ensuite, nous explorons les réseaux locaux sans fil et les systèmes de communication IP, y compris la vaste gamme de systèmes Wi-Fi IEEE 802.11, d’unités d’exécution et de 6LoWPAN. Le chapitre étudie également les nouvelles normes Wi-Fi telles que 802.11p pour la communication embarquée.
La partie se termine par une communication à longue portée utilisant les normes cellulaires (4G LTE) et plonge profondément dans la compréhension et l’infrastructure pour prendre en charge la 4G LTE et les nouvelles normes dédiées à l’IoT et à la communication machine à machine, telles que Cat-1 et Cat- NB. Le dernier chapitre couvre également la norme 5G et le cellulaire sous licence publique (MulteFire) pour préparer l’architecte aux futures transmissions à longue portée où chaque appareil est connecté d’une certaine capacité. Un protocole propriétaire comme LoRaWAN et Sigfox est également exploré pour comprendre les différences entre les architectures.
2.4 Partie 3 – Edge computing
Edge computing rapproche la puissance de calcul non traditionnelle des sources de données. Alors que les systèmes embarqués existent dans les appareils depuis 40 ans, l’informatique de bord est plus qu’un simple microcontrôleur 8 bits ou un circuit de conversion analogique-numérique utilisé pour afficher la température. Edge computing tente de résoudre des problèmes critiques à mesure que le nombre d’objets connectés et la complexité des cas d’utilisation augmentent dans l’industrie. Par exemple, dans les domaines de l’IoT, nous avons besoin des éléments suivants :
- Accumulez les données de plusieurs capteurs et fournissez un point d’entrée sur Internet.
- Résolvez les réponses critiques en temps réel aux situations critiques pour la sécurité comme la chirurgie à distance ou la conduite automatisée.
- Des solutions capables de gérer une quantité écrasante de traitement de données non structurées telles que des données vidéo ou même la diffusion de vidéo pour économiser sur les coûts de transport des données sur les opérateurs sans fil et les fournisseurs de cloud.
L’informatique de périphérie est également disponible en couches, comme nous l’examinerons avec l’infrastructure 5G, l’informatique de périphérie à accès multiple et l’informatique de brouillard.
Nous examinerons de près le matériel, les systèmes d’exploitation, la mécanique et la puissance qu’un architecte doit prendre en compte pour différents systèmes de périphérie. Par exemple, un architecte peut avoir besoin d’un système qui répond à une contrainte de coût et de puissance, mais peut renoncer à certaines capacités de traitement. D’autres conceptions peuvent devoir être extrêmement résistantes car l’ordinateur de bord peut se trouver dans une région très éloignée et doit essentiellement se gérer lui-même.
Pour relier les données des capteurs à Internet, deux technologies sont nécessaires : les routeurs de passerelle et les protocoles IP prenant en charge, conçus pour être efficaces. Cette partie explore le rôle des technologies de routeur en périphérie pour relier les capteurs d’un réseau PAN à Internet. Le rôle du routeur est particulièrement important dans la sécurisation, la gestion et le pilotage des données. Les routeurs Edge orchestrent et surveillent les réseaux maillés sous-jacents et équilibrent et nivellent la qualité des données. La privatisation et la sécurité des données sont également essentielles. La partie 3 explorera le rôle du routeur dans la création de réseaux privés virtuels, de réseaux locaux virtuels et de réseaux étendus définis par logiciel. Il peut y avoir littéralement des milliers de nœuds desservis par un seul routeur de périphérie, et dans un sens, il sert d’extension au cloud, comme nous le verrons au chapitre 11, Topologies de cloud et de brouillard.
Cette partie se poursuit avec les protocoles utilisés dans la communication IoT entre les nœuds, les routeurs et les nuages. L’IoT a cédé la place à de nouveaux protocoles plutôt qu’aux types de messagerie HTTP et SNMP hérités utilisés depuis des décennies. Les données IoT nécessitent des protocoles efficaces, écoénergétiques et à faible latence qui peuvent être facilement dirigés et sécurisés dans et hors du cloud. Cette partie explore les protocoles tels que le MQTT omniprésent, ainsi que l’AMPQ et CoAP. Des exemples sont donnés pour illustrer leur utilisation et leur efficacité.
2.5 Partie 4 – Calcul, analyse et apprentissage automatique
À ce stade, nous devons réfléchir à ce qu’il faut faire avec le streaming de données depuis les nœuds périphériques vers un service cloud. Tout d’abord, nous commençons par parler des aspects des architectures cloud telles que les systèmes SaaS, IaaS et PaaS. Un architecte doit comprendre le flux de données et la conception typique des services cloud (ce qu’ils sont et comment ils sont utilisés). Nous utilisons OpenStack comme modèle de conception de cloud et explorons les différents composants, des moteurs d’ingestion aux lacs de données en passant par les moteurs d’analyse.
Il est également important de comprendre les contraintes des architectures cloud pour juger de la manière dont un système se déploiera et évoluera. Un architecte doit également comprendre comment la latence peut affecter un système IoT. Alternativement, tout n’appartient pas au cloud. Il y a un coût mesurable à déplacer toutes les données IoT vers un cloud par rapport à leur traitement en périphérie (traitement de périphérie) ou à étendre les services cloud vers le bas dans un dispositif informatique de périphérie (calcul de brouillard). Cette partie plonge profondément dans les nouvelles normes de calcul du brouillard telles que l’architecture OpenFog.
Les données qui ont été transformées d’un événement analogique physique en un signal numérique peuvent avoir des conséquences exploitables. C’est là que les moteurs d’analyse et de règles de l’IoT entrent en jeu. Le niveau de sophistication d’un déploiement IoT dépend de la solution en cours d’architecture. Dans certaines situations, un moteur de règles simple recherchant des températures extrêmes anormales peut facilement être déployé sur un routeur périphérique surveillant plusieurs capteurs. Dans d’autres situations, une quantité massive de données structurées et non structurées peuvent être transmises en temps réel à un lac de données basé sur le cloud, et nécessitent à la fois un traitement rapide pour l’analyse prédictive et des prévisions à long terme à l’aide de modèles d’apprentissage automatique avancés, tels que les réseaux de neurones récurrents dans un package d’analyse de signal en corrélation temporelle. Cette partie détaille les utilisations et les contraintes de l’analyse des processeurs d’événements complexes aux réseaux bayésiens à l’inférence et à la formation des réseaux de neurones.
2.6 Partie 5 – Menace et sécurité dans l’IoT
Nous concluons cet article par une étude des compromis et des attaques IoT. Dans de nombreux cas, les systèmes IoT ne seront pas sécurisés dans une maison ou dans une entreprise. Ils seront en public, dans des zones très reculées, dans des véhicules en mouvement, ou même à l’intérieur d’une personne. L’IoT représente la plus grande surface d’attaque pour tout type de cyberattaque. Nous avons vu d’innombrables hacks universitaires, des cyberattaques bien organisées et même des violations de la sécurité des États-nations avec des appareils IoT comme cible. La partie 5 détaillera plusieurs aspects de ces violations et les types de remédiation que tout architecte doit prendre en compte pour faire d’un déploiement IoT grand public ou d’entreprise un bon citoyen d’Internet. Nous explorons le projet de loi du Congrès pour sécuriser l’IdO et comprenons la motivation et l’impact d’un tel mandat gouvernemental.
Cette partie répertorie les dispositions de sécurité typiques nécessaires pour l’IoT ou tout composant de réseau. Les détails des nouvelles technologies telles que les chaînes de blocs et les périmètres définis par logiciel seront également explorés pour donner un aperçu des technologies futures qui seront nécessaires pour sécuriser l’IoT.
2.7 Résumé
Cet article jettera un pont sur le spectre des technologies qui comprennent l’informatique de pointe et l’IoT. Dans ce chapitre, nous avons résumé les domaines et les sujets traités dans cet article. Un architecte doit être conscient des interactions entre ces disciplines d’ingénierie disparates pour construire un système évolutif, robuste et optimisé. Un architecte sera également appelé à fournir des preuves à l’appui que le système IoT fournit une valeur à l’utilisateur final ou au client. Ici, nous avons appris l’application des lois de Metcalfe et Beckstrom comme outils pour soutenir un déploiement IoT.
Dans les prochains chapitres, nous découvrirons la communication entre les capteurs et les nœuds périphériques vers Internet et le cloud. Tout d’abord, nous examinerons la théorie fondamentale derrière les signaux et les systèmes radio et leurs contraintes et limites, puis nous plongerons dans la communication sans fil à courte et longue portée.
3 capteurs, points d’extrémité et systèmes d’alimentation
L’Internet des objets (IoT) commence par des sources de données ou des appareils qui effectuent une action. Nous appelons ces points de terminaison ou nœuds, et ce sont les choses associées à Internet. Lorsque l’on discute de l’IoT, en général, les sources réelles de données sont souvent négligées. Ces sources sont des capteurs émettant un flux de données en corrélation temporelle qui doivent être transmises de manière sécurisée, éventuellement analysées et éventuellement stockées. La valeur de l’IoT se trouve dans les données agrégées. Par conséquent, les données fournies par un capteur sont cruciales. Cependant, pour un architecte, il est essentiel de comprendre les données ainsi que la façon dont les données sont interprétées. En plus de comprendre quelles données sont collectées et comment elles sont acquises, dans un déploiement IoT massif, il est utile de savoir ce qui peut être détecté et quelles sont les contraintes pour différents capteurs. Par exemple, un système doit tenir compte des appareils perdus et des données erronées. Un architecte doit comprendre les raisons pour lesquelles les données peuvent ne pas être fiables à partir de capteurs, et comment un capteur peut échouer sur le terrain. Essentiellement, nous connectons le monde analogique au numérique. La majorité des objets connectés seront des capteurs, il est donc important de comprendre leur rôle.
C’est ce que l’IoT est en bref. Comme nous l’avons appris au chapitre 1, IoT et cas de définition et d’utilisation de l’informatique de périphérie, les capteurs et les périphériques de périphérie représentent l’essentiel de la croissance de l’IoT, il est donc important de comprendre leur relation dans l’architecture. Ce chapitre mettra en évidence les dispositifs capteurs d’un point de vue électronique et système. Il est important de comprendre les principes de ce qui est mesuré et pourquoi.
On devrait se demander : “Quel type de capteur ou périphérique périphérique dois-je considérer pour le problème que j’essaie de résoudre ?” Un architecte doit prendre en compte des aspects de coût, de fonctionnalités, de taille, de durée de vie utile et de précision lors du déploiement d’une solution IoT. De plus, la puissance et l’énergie des dispositifs de périphérie sont rarement abordées dans la littérature IoT mais sont essentielles à la construction d’une technologie fiable et durable. Le lecteur doit quitter ce chapitre avec une compréhension de haut niveau de la technologie des capteurs et de ses contraintes.
Dans ce chapitre, nous couvrirons les sujets suivants :
- Appareils de détection, des thermocouples aux capteurs MEMS en passant par les systèmes de vision
- Systèmes de génération d’énergie
- Systèmes de stockage d’énergie
3.1 Dispositifs de détection
Nous commençons par nous concentrer sur les dispositifs de détection ou d’entrée. Ceux-ci se présentent sous une variété de formes et de complexités, des simples thermocouples aux systèmes vidéo avancés. L’une des raisons pour lesquelles l’IoT est un domaine de croissance important est le fait que ces systèmes de détection ont été considérablement réduits en taille et en coût, grâce aux progrès de la fabrication de semi-conducteurs et du micro-usinage.
3.1.1 Thermocouples et détection de température
Les capteurs de température sont la forme la plus répandue de produits de capteurs. Ils existent un peu partout. Des thermostats intelligents à la logistique de stockage à froid IoT, des réfrigérateurs aux machines industrielles, ils sont répandus et probablement le premier dispositif de détection auquel vous serez exposé dans une solution IoT.
3.1.1.1 Thermocouples
Un thermocouple (ou TC) est une forme d’appareil de détection de température qui ne dépend pas d’un signal d’excitation pour fonctionner. Par conséquent, ils produisent de très petits signaux (souvent des microvolts en amplitude). Deux fils de deux matériaux différents se rencontrent là où une mesure de température doit être échantillonnée. Chaque métal développe un différentiel de tension indépendamment les uns des autres. Cet effet est connu sous le nom d’effet électromoteur Seebeck, dans lequel la différence entre la tension des deux métaux a une relation non linéaire avec la température.
L’amplitude de la tension dépend du matériau métallique choisi. Il est essentiel que les extrémités des fils soient isolées thermiquement du système (et que les fils doivent être à la même température contrôlée). Dans le schéma suivant, vous verrez un bloc thermique dont la température est contrôlée par un capteur. Ceci est généralement contrôlé via une technique appelée compensation de soudure froide, où la température peut varier, mais est mesurée avec précision par le capteur de bloc.
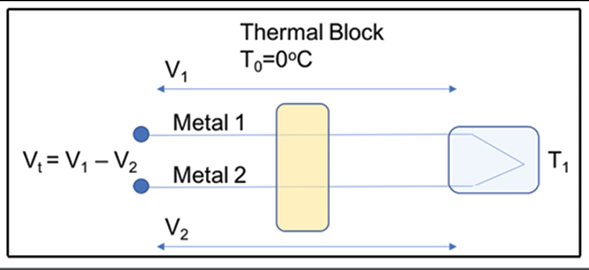
Figure 1 : Schéma du thermocouple
Lors de l’échantillonnage de la différence de tension, le logiciel aura généralement une table de recherche pour dériver la température en fonction de la relation non linéaire des métaux choisis.
Les thermocouples doivent être utilisés pour des mesures simples. La précision du système peut également varier, car des impuretés subtiles peuvent affecter la composition du fil et provoquer un décalage dans les tables de recherche. Des thermocouples de précision peuvent être nécessaires mais ont un coût plus élevé.
Un autre effet est le vieillissement. Étant donné que les thermocouples sont souvent utilisés dans des environnements industriels, les environnements à chaleur élevée peuvent dégrader les capteurs de précision au fil du temps. Par conséquent, les solutions IoT doivent tenir compte des changements sur la durée de vie d’un capteur.
Les thermocouples sont bons pour de larges plages de températures, codés par couleur pour différentes combinaisons de métaux et étiquetés par type (par exemple, E, M et PT-PD, pour n’en nommer que quelques-uns). En général, ces capteurs sont bons pour les mesures à longue distance avec de longs câbles et sont souvent utilisés dans des environnements industriels et à haute température.
La figure suivante montre différents types de métaux de thermocouple et leurs linéarités énergétiques respectives sur une plage de températures.
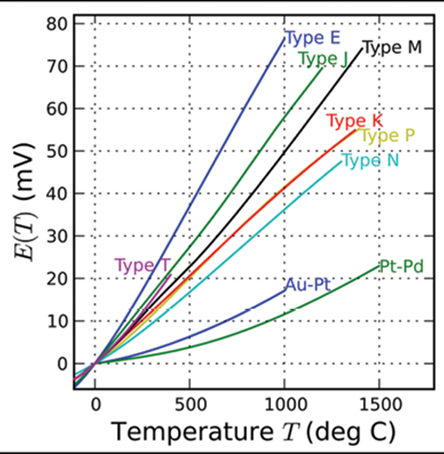
Figure 2 : Caractérisation du type de thermocouple E (T): T
3.1.1.2 Détecteurs de température à résistance
Les détecteurs de température à résistance (RTD) fonctionnent dans une plage de températures étroite mais ont une bien meilleure précision que les thermocouples (inférieurs à 600 degrés Celsius). Ceux-ci sont généralement construits avec un fil de platine très fin enroulé étroitement autour de la céramique ou du verre. Cela produit une relation résistance-température. Comme il s’agit d’une mesure basée sur la résistance, un courant d’excitation est nécessaire pour faire fonctionner un RTD (1 mA).
La résistance d’un RTD suit une pente prédéfinie. Les RTD sont spécifiés avec une résistance de base. À 200 PT100 RTD a une pente de 0,00200 Ohms / degrés Celsius de 0 à 100 degrés Celsius. Dans cette plage (0 à 100 degrés Celsius), la pente sera linéaire. Les RTD sont disponibles en boîtiers à deux, trois et quatre fils, avec des modèles à quatre fils utilisés pour les systèmes d’étalonnage de haute précision. Les RTD sont souvent utilisés avec des circuits en pont pour augmenter la résolution, avec un logiciel linéarisant les résultats. L’illustration suivante montre la conception du RTD filaire et le facteur de forme.
Figure 3 : RTD bobiné
Les RTD sont rarement utilisés au-dessus de 600 degrés Celsius, ce qui limite leur application dans l’industrie. À des températures élevées, le platine peut devenir contaminé, ce qui entraîne des résultats incorrects ; Cependant, lors de la mesure dans leur plage spécifiée, les RTD sont assez stables et précis.
3.1.1.3 Thermistances
Le dernier dispositif de détection de température est la thermistance. Ce sont également des capteurs de relation basés sur la résistance comme les RTD, mais qui produisent un degré de changement plus élevé pour une température donnée qu’un RTD. Ce sont essentiellement des résistances qui varient en fonction de la température. Ils sont également utilisés dans les circuits pour atténuer les courants d’appel. Alors qu’un RTD a une relation linéaire avec un changement de température, les thermistances ont une relation très non linéaire et conviennent lorsqu’une haute résolution est nécessaire pour une plage de température étroite. Il existe deux types de thermistances : le NTC, où la résistance diminue à mesure que la température augmente ; et PTC, où la résistance augmente avec l’augmentation des températures. La principale différence par rapport à un RTD est matériellement l’utilisation de céramiques ou de polymères, tandis que les métaux sont à la base des RTD.
Les thermistances se trouvent dans les dispositifs médicaux, les équipements scientifiques, les équipements de manipulation des aliments, les incubateurs et les appareils électroménagers tels que les thermostats.
3.1.1.4 Résumé du capteur de température
En résumé, le tableau suivant met en évidence les cas d’utilisation et les avantages de capteurs de température particuliers :
| Catégorie | Thermocouples | RTD | Thermistances |
| Plage de température (degrés Celsius) | -180 à 2320 | -200 à 500 | -90 à 130 |
| Temps de réponse | Rapide (microsecondes) | Lent (secondes) | Lent (secondes) |
| La taille | Grand (~ 1 mm) | Petit (5 mm) | Petit (5 mm) |
| Précision | Faible | Moyen | Très élevé |
En règle générale, un thermocouple sera utilisé pour mesurer les températures dans les applications industrielles et le chauffage grand public, comme un four ou un four. Ceux-ci nécessitent des temps de réponse rapides de l’électronique pour effectuer des ajustements en temps réel dans des environnements de températures extrêmes. Les thermistances sont utilisées pour la détection de température à usage général, comme les capteurs Bluetooth ou Zigbee de jardin, les thermomètres numériques, les moteurs électriques, les alarmes incendie, les chambres froides et les réfrigérateurs.
3.1.2 Capteurs à effet Hall et capteurs de courant
Un capteur à effet Hall se compose d’une bande de métal traversée par un courant. Un flux de particules chargées traversant un champ magnétique fera dévier le faisceau d’une ligne droite. Si un conducteur est placé dans le champ magnétique perpendiculairement au flux d’électrons, il rassemblera des porteurs de charge et produira une différence de tension entre le côté positif de la bande métallique et le côté négatif. Cela produira un différentiel de tension qui peut être mesuré. Le différentiel est appelé la tension de Hall, qui est responsable du phénomène connu sous le nom d’effet Hall. Ceci est illustré dans l’image suivante. Si un courant est appliqué à une bande métallique (comme le montre le diagramme) dans un champ magnétique, les électrons seront attirés d’un côté de la bande et des trous de l’autre (voir la ligne courbe). Cela induira un champ électrique qui peut être mesuré. Si le champ est suffisamment fort, il annulera la force magnétique et les électrons suivront la ligne droite.

Figure 4 : Exemple de l’effet Hall
Les capteurs de courant utilisent l’effet Hall pour mesurer les courants alternatifs et continus d’un système. Il existe deux formes de capteurs de courant : boucle ouverte et boucle fermée. Les boucles fermées sont plus chères que les capteurs à boucle ouverte et sont souvent utilisées dans les circuits alimentés par batterie.
Les utilisations typiques des capteurs à effet Hall comprennent la détection de position, les magnétomètres, les commutateurs très fiables et la détection du niveau d’eau. Ils sont utilisés dans les capteurs industriels pour mesurer la vitesse de rotation de différentes machines et moteurs. De plus, ces appareils peuvent être créés à peu de frais et tolèrent des conditions environnementales difficiles.
3.1.3 Capteurs photoélectriques
La détection de la lumière et de l’intensité lumineuse est utilisée dans de nombreux dispositifs capteurs IoT, tels que les systèmes de sécurité, les interrupteurs intelligents et l’éclairage public intelligent. Comme son nom l’indique, une photorésistance varie en résistance en fonction de l’intensité lumineuse, tandis que les photodiodes convertissent la lumière en un courant électrique.
Les photorésistances sont fabriquées à l’aide d’un semi-conducteur à haute résistance. La résistance diminue à mesure que plus de lumière est absorbée. Dans l’obscurité, une photorésistance peut avoir une résistance assez élevée (dans la gamme des mégohms). Les photons absorbés par le semi-conducteur permettent aux électrons de sauter vers la bande de conduction et de conduire l’électricité. Les photorésistances sont sensibles à la longueur d’onde, selon leur type et leur fabricant ; Cependant, les photodiodes sont de vrais semi-conducteurs avec une jonction pn. L’appareil réagit à la lumière en créant une paire électron-trou.
Les trous se déplacent vers une anode, les électrons migrent vers une cathode et un courant est produit. Les cellules solaires traditionnelles fonctionnent dans ce mode photovoltaïque, produisant de l’électricité. Alternativement, une polarisation inverse peut être utilisée sur la cathode pour améliorer la latence et le temps de réponse si nécessaire. Le tableau suivant contraste les photorésistances avec les photodiodes.
| Catégorie | Photorésistance | Photodiode |
| Sensibilité à la lumière | Faible | Élevé |
| Actif / passif (semi-conducteur) | Passif | Activer |
| Sensibilité à la température | Très sensible | Faible |
| Latence aux changements légers | Longue (10 millisecondes allumée, 1 seconde éteinte) | Court |
3.1.4 Capteurs PIR
Les capteurs infrarouges pyroélectriques (PIR) contiennent deux fentes remplies de matériau qui réagit au rayonnement infrarouge et à la chaleur. Les cas d’utilisation typiques sont la sécurité ou le mouvement du corps chaud. Dans sa forme la plus simple, une lentille de Fresnel se trouve au-dessus du capteur PIR, permettant aux deux fentes de former un arc s’élargissant vers l’extérieur. Ces deux arcs créent des zones de détection. Lorsqu’un corps chaud entre dans l’un des arcs ou en quitte un, il génère un signal échantillonné. Les capteurs PIR utilisent un matériau cristallin qui génère du courant lorsqu’ils sont soumis à un rayonnement IR. Un transistor à effet de champ (FET) détecte le changement de courant et envoie le signal à une unité d’amplification. Les capteurs PIR répondent bien dans la gamme de 8 à 14 um, ce qui est typique d’un corps humain.
Le diagramme suivant illustre deux régions IR détectant deux zones. Bien que cela soit bien à certaines fins, nous devons généralement inspecter une pièce ou une zone entière pour détecter les mouvements ou les activités :
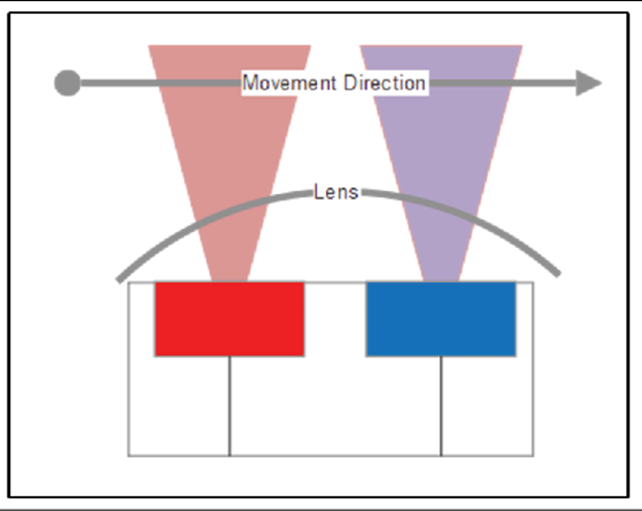
Figure 5 : PIR : Deux éléments qui répondent à une source d’IR se déplaçant à travers ITS field de vue
Pour balayer une zone plus grande avec un seul capteur, il faut plusieurs lentilles de Fresnel qui condensent la lumière des régions de la pièce pour créer des régions distinctes sur le réseau PIR. Cela a également pour effet de condenser l’énergie infrarouge en zones FET discrètes. En règle générale, ces dispositifs permettent à l’architecte de contrôler la sensibilité (plage) ainsi que le temps de maintien.
Le temps de maintien spécifie la durée de sortie d’un événement de mouvement après qu’un objet a été détecté se déplaçant sur la trajectoire du PIR. Plus le temps de maintien est court, plus les événements peuvent être émis.
Le diagramme suivant montre un capteur PIR typique avec une lentille de Fresnel focalisée sur le substrat par une distance focale fixe:
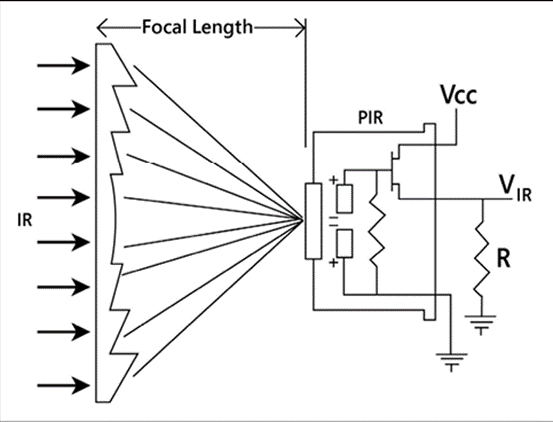
Figure 6: Gauche: région infrarouge de condensation de la lentille de Fresnel sur le capteur PIR
3.1.5 LiDAR et systèmes de détection active
Cette section couvrira les systèmes de détection actifs. Nous avons discuté de nombreux capteurs passifs qui répondent simplement aux changements environnementaux. La détection active consiste à diffuser un signal qui est référencé pour mesurer l’environnement spatialement ou temporellement. Bien que ce domaine soit vaste, nous nous concentrerons sur le LiDAR comme base pour les systèmes de détection actifs.
LiDAR signifie Light Detection and Ranging. Ce type de capteur mesure la distance d’une cible en mesurant une réflexion d’impulsion laser sur la cible. Lorsqu’un capteur PIR détecte un mouvement dans une plage, le LiDAR est capable de mesurer une plage. Le processus a été démontré pour la première fois dans les années 1960 et est maintenant utilisé de manière omniprésente dans l’agriculture, les véhicules automatisés et autonomes, la robotique, la surveillance et les études environnementales. Ce type de machine de détection active est également capable d’analyser tout ce qui croise son chemin. Ils sont utilisés pour analyser les gaz, les atmosphères, les formations et compositions de nuages, les particules, la vitesse des objets en mouvement, etc.
LiDAR est une technologie de capteur actif et diffuse l’énergie laser. Lorsqu’un laser frappe un objet, une partie de l’énergie sera réfléchie vers l’émetteur LiDAR. Les lasers utilisés sont typiquement dans la longueur d’onde de 600 à 1000 nm et relativement peu coûteux. Pour des raisons de sécurité, l’alimentation est limitée pour éviter les lésions oculaires. Certaines unités LiDAR fonctionnent dans la plage de 1550 nm, car cette longueur d’onde ne peut pas être focalisée par l’œil, ce qui les rend inoffensives même à haute énergie.
Les systèmes LiDAR sont capables de très longue portée et de balayage, même à partir de satellites. Le laser pulsera jusqu’à 150 000 impulsions par seconde, ce qui peut renvoyer un objet vers un réseau de photodiodes. L’appareil laser peut également balayer la scène via un miroir rotatif pour créer une image 3D complète de l’environnement. Chaque faisceau diffusé représente un angle, une mesure du temps de vol ( ToF ) et une position GPS. Cela permet aux faisceaux de former une scène représentative.
Pour calculer la distance à un objet, l’équation est relativement simple :
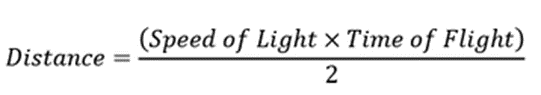
Le LiDAR et les autres capteurs actifs se comportent de manière similaire. Chacun a un signal de diffusion représentatif qui retourne à un capteur pour construire une image ou indiquer qu’un événement s’est produit. Ces capteurs sont beaucoup plus complexes que les simples capteurs passifs et prennent également plus de puissance, de coût et de surface.

Figure 7 : LiDAR: un exemple d’image LiDAR utilisée pour analyser les rafales de vent atmosphérique afin de protéger les éoliennes. Les zones bleues signifient des vitesses de vent de 0 à 2 m / s. Les zones vertes montrent des vitesses de vent de 3 à 6 m / s. La ligne rouge indique des rafales de vent de 7+ m / s. Image reproduite avec l’aimable autorisation de la NASA.
3.1.6 Capteurs MEMS
Les systèmes microélectromécaniques ( MEMS ) sont présents dans l’industrie depuis leur première production dans les années 80; Cependant, l’origine du premier capteur de pression MEMS remonte aux années 1960 chez Kulite Semiconductor, qui a développé un capteur de pression piézorésistif.
Essentiellement, ils intègrent des structures mécaniques miniaturisées qui interagissent avec les commandes électroniques. En règle générale, ces capteurs sont dans la plage de géométrie de 1 à 100 um. Contrairement aux autres capteurs mentionnés dans ce chapitre, les structures mécaniques MEMS peuvent tourner, s’étirer, se plier, se déplacer ou changer de forme, ce qui affecte à son tour un signal électrique. Il s’agit du signal capté et mesuré par un capteur particulier.
Les dispositifs MEMS sont fabriqués dans un processus de fabrication de silicone typique utilisant plusieurs masques, des procédés de lithographie, de dépôt et de gravure. Les matrices de silicium MEMS sont ensuite emballées avec d’autres composants tels que des amplificateurs opérationnels, des convertisseurs analogiques- numériques et des circuits de support. En règle générale, les dispositifs MEMS seront fabriqués dans une plage relativement large de 1 à 100 microns, tandis que les structures de silicium typiques sont fabriquées à 28 nm ou moins. Le processus implique un dépôt en couche mince et une gravure pour créer les structures 3D d’un appareil MEMS.
Outre les systèmes de capteurs, des appareils MEMS se trouvent dans les têtes des imprimantes à jet d’encre et des rétroprojecteurs modernes tels que les projecteurs DLP ( Digital Light Processor ). La capacité de synthétiser des dispositifs de détection MEMS dans des boîtiers aussi petits qu’une tête d’épingle a et permettra la croissance de l’IoT en milliards d’objets connectés.
3.1.6.1 Accéléromètres et gyroscopes MEMS
Les accéléromètres et les gyroscopes sont courants dans de nombreux appareils mobiles aujourd’hui et utilisés dans le positionnement et le suivi des mouvements, comme avec les podomètres et les trackers de fitness. Ces appareils utiliseront un MEMS piézoélectrique pour produire une tension en réponse au mouvement.
Les gyroscopes détectent le mouvement de rotation et les accéléromètres répondent aux changements du mouvement linéaire. Le schéma suivant illustre le principe de base d’un accéléromètre. Typiquement, une masse centrale qui est fixée à un emplacement calibré via un ressort répondra aux changements d’accélération qui sont mesurés en faisant varier la capacité dans un circuit MEMS. La masse centrale semblera stationnaire en réponse à l’accélération dans une direction.
Un accéléromètre sera synthétisé pour répondre à plusieurs dimensions ( X , Y , Z ) plutôt qu’à une dimension, comme le montre cette illustration:

Figure 8 : Accéléromètre : Le principe de la mesure de l’accélération à l’aide d’une masse centrale suspendue par un ressort. En règle générale, ceux-ci seront utilisés dans plusieurs dimensions.
Les gyroscopes fonctionnent légèrement différemment. Plutôt que de s’appuyer sur la réponse du mouvement à une masse centrale, les gyroscopes s’appuient sur l’effet Coriolis d’un cadre de référence rotatif. La figure suivante illustre le concept. Sans augmentation de la vitesse, l’objet se déplacerait en arc et n’atteindrait pas la cible en direction nord. Se déplacer vers le bord extérieur du disque nécessite une accélération supplémentaire pour maintenir un cap vers le nord. Il s’agit de l’accélération de Coriolis. Dans un appareil MEMS, il n’y a pas de disque en rotation ; Il existe plutôt une fréquence de résonance appliquée à une série d’anneaux fabriqués par MEMS sur un substrat en silicone :

Figure 9 : Accéléromètre : effet d’un disque rotatif sur une trajectoire se déplaçant vers le nord
Les anneaux sont concentriques et coupés en petits arcs. Les anneaux concentriques permettent une plus grande surface pour évaluer la précision du mouvement de rotation. Les anneaux simples nécessiteraient des poutres de support rigides et ne sont pas aussi fiables. En bifurquant les anneaux en arcs, la structure perd de sa rigidité et est plus sensible aux forces de rotation. La source CC crée une force électrostatique qui résonne à l’intérieur de l’anneau, tandis que les électrodes attachées aux anneaux détectent les changements dans le condensateur. Si les anneaux résonants sont perturbés, l’accélération de Coriolis est détectée. L’accélération de Coriolis est définie par l’équation suivante :

Cette équation indique que l’accélération est un produit de la rotation du système et de la vitesse du disque rotatif, comme indiqué dans le diagramme précédent, ou de la fréquence de résonance du dispositif MEMS, comme indiqué dans le diagramme suivant. Étant donné une source d’alimentation CC, une force modifie la taille de l’entrefer et la capacité globale du circuit.
Les électrodes externes détectent la déflexion dans l’anneau, tandis que les électrodes internes fournissent des mesures de capacité:
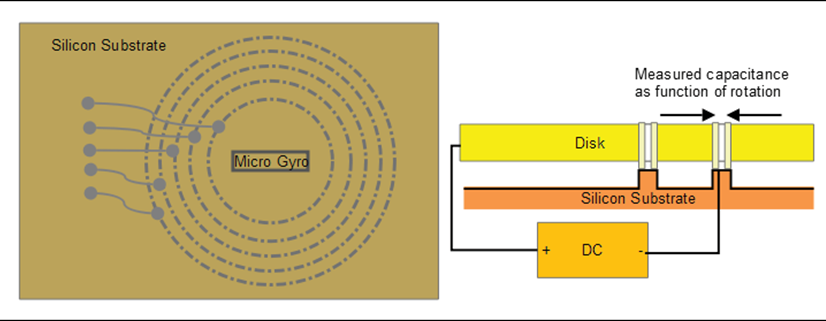
Figure 10 : Gauche : Anneaux coupés concentriques représentant le capteur gyroscopique assis sur un substrat de silicium. À droite : l’espace disque connecté à un substrat de silicone correspondant.
Les gyroscopes et les accéléromètres nécessiteront des alimentations et un amplificateur opérationnel pour le conditionnement du signal. Après conditionnement, la sortie est prête à être échantillonnée par un processeur de signal numérique.
Ces appareils peuvent être synthétisés dans de très petits boîtiers, comme l’InvenSense MPU-6050, qui comprend un gyroscope à six axes et un accéléromètre dans un petit boîtier de 4 mm x 4 mm x 1 mm.
L’appareil utilise 3,9 mA de courant et est bon pour la détection de faible puissance.
Un appareil tel que l’InvenSense MPU-6050 est généralement utilisé dans les consoles de jeux, les téléviseurs intelligents et les smartphones. Cela permet à un utilisateur d’avoir une expérience interactive et engageante avec l’appareil. Un appareil comme celui-ci peut suivre avec précision les mouvements de l’utilisateur dans un espace tridimensionnel.
3.1.6.2 Microphones MEMS
Les appareils MEMS peuvent également être utilisés pour la détection du son et des vibrations. Ces types de dispositifs MEMS sont liés aux accéléromètres précédemment couverts. Pour les déploiements IoT, les mesures du son et des vibrations sont courantes dans les applications industrielles IoT et de maintenance prédictive. Par exemple, une machine industrielle qui tourne ou mélange une charge de matière dans la fabrication de produits chimiques, ou dans des centrifugeuses pour séparer les mélanges, a besoin d’un nivellement précis. Une unité de son ou de vibration MEMS sera généralement utilisée pour surveiller la santé et la sécurité de ces équipements.
Ce type de capteur nécessitera un convertisseur analogique-numérique d’une fréquence d’échantillonnage suffisante. De plus, un amplificateur est utilisé pour renforcer le signal.
L’impédance d’un microphone MEMS est de l’ordre de plusieurs centaines d’ohms (ce qui nécessite une attention particulière à l’amplificateur utilisé). Un microphone MEMS peut être analogique ou numérique. Une variété analogique sera polarisée à une tension continue et connectée à un codec pour la conversion analogique-numérique. Un microphone numérique a l’ADC près de la source du microphone. Ceci est utile en cas d’interférence de signal provenant de signaux cellulaires ou Wi-Fi à proximité du codec.
La sortie d’un microphone numérique MEMS peut être modulée en densité d’impulsions (PDM) ou envoyée au format I 2 S. PDM est un protocole à taux d’échantillonnage élevé qui a la capacité d’échantillonner à partir de deux canaux de microphone. Il le fait en partageant une horloge et une ligne de données, et en échantillonnant à partir de l’un des deux microphones sur des périodes d’horloge différentes. I 2 S n’a pas un taux d’échantillonnage élevé et la décimation aux taux audio (plage Hz à kHz) donne une qualité passable. Cela permet toujours d’utiliser plusieurs microphones pour l’échantillonnage, mais peut ne pas nécessiter du tout d’ADC, car la décimation se produit dans le microphone. Un PDM, avec son taux d’échantillonnage élevé, devra être décimé par un processeur de signal numérique , ou DSP.
3.1.6.3 Capteurs de pression MEMS
Les jauges de pression et de contrainte sont utilisées dans une variété de déploiements IoT, des infrastructures de surveillance des villes intelligentes à la fabrication industrielle. Ceux-ci sont généralement utilisés pour mesurer les pressions de fluide et de gaz. Le cœur du capteur est un circuit piézoélectrique. Un diaphragme sera placé au-dessus ou au-dessous d’une cavité sur le substrat piézoélectrique. Le substrat est flexible et permet aux cristaux piézoélectriques de changer de forme. Ce changement de forme entraîne un changement de résistance directement corrélé dans le matériau.
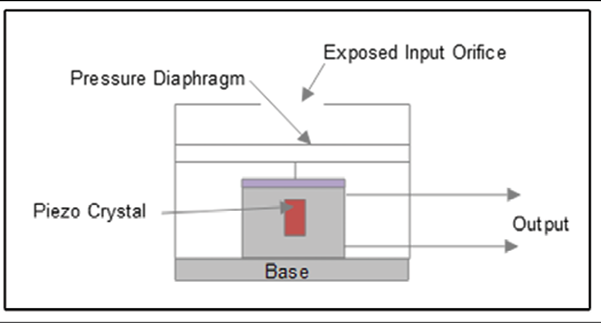
Figure 11 : Anatomie du capteur de pression
Ce type de capteur, ainsi que d’autres répertoriés dans ce chapitre sur la base d’un courant d’excitation, s’appuie sur un pont de Wheatstone pour mesurer les changements. Les ponts de Wheatstone peuvent être disponibles en combinaisons à deux, quatre ou six fils.
Le changement de tension est mesuré à travers le pont lorsque le substrat piézoélectrique fléchit et change de résistance :
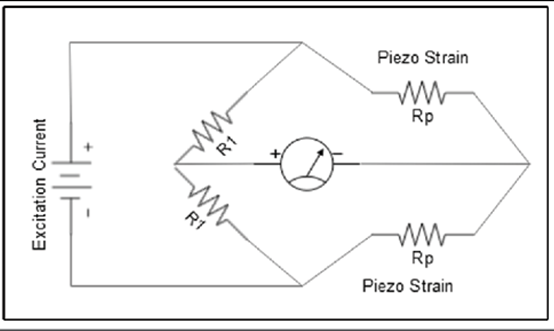
Figure 12 : Pont de Wheatstone utilisé pour l’ampli fi cation du capteur de pression MEMS
3.2 haute performance IdO endpoints
Jusqu’à présent, nous avons examiné des capteurs simples qui renvoient simplement des informations sous une forme binaire ou analogique qui doivent être échantillonnées. Il existe cependant des dispositifs et capteurs IoT qui ont une puissance de traitement et des performances substantielles pour les tâches qu’ils entreprennent. Les capteurs intelligents comprennent des appareils tels que des caméras vidéo et des systèmes de vision. Les capteurs intelligents peuvent inclure des quantités substantielles de capacité de traitement sous la forme de processeurs haut de gamme, de processeurs de signaux numériques, de FPGA et d’ASIC personnalisés. Dans cette section, nous explorerons les détails d’une forme de capteur intelligent : un système de vision.
3.2.1 Systèmes de vision
Contrairement aux capteurs simples explorés précédemment, les systèmes de vision sont beaucoup plus complexes, ce qui se traduit par du matériel, des optiques et du silicium d’imagerie substantiels. Les systèmes de vision commencent par une lentille qui observe une scène. Un objectif fournit la mise au point, mais fournit également plus de saturation de lumière à l’élément de détection. Dans les systèmes de vision modernes, l’un des deux types d’éléments de détection est utilisé : les dispositifs à couplage de charge (CCD) ou les dispositifs complémentaires à semi-conducteur à oxyde métallique (CMOS). La différence entre les CMOS et les CCD peut être généralisée comme suit :
- CCD : La charge est transportée du capteur vers le bord de la puce pour être échantillonnée séquentiellement via un convertisseur analogique-numérique. Les CCD créent des images haute résolution et à faible bruit. Ils consomment une puissance considérable (100 fois celle du CMOS). Ils nécessitent également un processus de fabrication unique.
- CMOS : les pixels individuels contiennent des transistors pour échantillonner la charge et permettent à chaque pixel d’être lu individuellement. Le CMOS est plus sensible au bruit mais utilise peu d’énergie.
La plupart des capteurs sont construits en utilisant CMOS sur le marché actuel. Un capteur CMOS est intégré dans une puce en silicium qui apparaît comme un réseau bidimensionnel de transistors disposés en lignes et en colonnes sur un substrat en silicium. Une série de microlentilles reposera sur chaque capteur rouge, vert ou bleu focalisant les rayons accidentels sur les éléments du transistor. Chacune de ces microlentilles atténue une couleur spécifique à un ensemble spécifique de photodiodes ( R , G ou B ) qui répondent au niveau de lumière; cependant, les lentilles ne sont pas parfaites. Ils peuvent ajouter des aberrations chromatiques où différentes longueurs d’onde se réfractent à des taux différents, ce qui conduit à des longueurs focales et à un flou différent. Un objectif peut également déformer une image, provoquant des effets d’amortissement.
Vient ensuite une série d’étapes pour filtrer, normaliser et convertir plusieurs fois l’image en une image numérique utilisable. C’est le cœur du processeur de signal d’image (ISP), et les étapes peuvent être suivies dans cet ordre :
Figure 13 : Capteur d’image : pipeline de processeur de signal d’image typique pour la vidéo couleur
Notez les nombreuses conversions et traitements de chaque étape du pipeline pour chaque pixel de l’image. La quantité de données et de traitement nécessite des processeurs de signaux personnalisés ou en silicium substantiels. La liste suivante répertorie les responsabilités des blocs fonctionnels dans le pipeline :
- Conversion analogique-numérique : amplification du signal du capteur, puis conversion sous forme numérique (10 bits). Les données sont lues à partir du réseau de capteurs à photodiode sous la forme d’une série aplatie de lignes / colonnes représentant l’image qui vient d’être capturée.
- Pince optique : supprime les effets de polarisation du capteur dus au niveau de noir du capteur.
- Balance des blancs : imite l’affichage chromatique dans l’œil pour différentes températures de couleur. Les tons neutres semblent neutres. Ceci est effectué à l’aide de conversions matricielles.
- Correction des pixels morts : identifie les pixels morts et les compensations de leur perte à l’aide de l’interpolation. Les pixels morts sont remplacés par la moyenne des pixels voisins.
- Filtrage Debayer et dématriçage : le filtrage Debayer sépare les données RVB pour saturer le contenu vert sur rouge et bleu pour le réglage de la sensibilité à la luminance. Il crée également un format plan d’images à partir de contenu entrelacé par capteur. Des algorithmes plus avancés préservent les bords des images.
- Réduction du bruit : les capteurs introduisent du bruit en raison des effets de repliement, des conversions analogique-numérique, etc. Le bruit peut être associé à la non-uniformité de la sensibilité des pixels au niveau du transistor ou à une fuite de la photodiode, révélant des régions sombres. Il existe également d’autres formes de bruit. Cette phase supprime le bruit blanc et cohérent introduit dans la capture d’image à travers un filtre médian (réseau 3 x 3) sur tous les pixels. Alternativement, un filtre de suppression des taches peut être utilisé, nécessitant le tri des pixels. D’autres méthodes existent également. Cependant, ils parcourent tous la matrice de pixels.
- Netteté : applique un flou à une image à l’aide d’une multiplication matricielle, puis combine le flou avec les détails dans les zones de contenu pour créer un effet de netteté.
- Conversion de l’espace colorimétrique 3 x 3 : conversion de l’espace colorimétrique en données RVB pour les traitements RVB particuliers.
- Correction gamma : corrige la réponse non linéaire du capteur d’image CMOS sur les données RVB à un rayonnement différent. La correction gamma utilise une table de correspondance (LUT) pour interpoler et corriger une image.
- Conversion d’espace colorimétrique 3 x 3 : conversion d’espace colorimétrique supplémentaire du format RVB au format Y’CbCr. YCC a été choisi car Y peut être stocké à une résolution plus élevée que CbCr sans perte de qualité visuelle. Cela utilise également une représentation 4 : 2 : 2 bits (4 bits Y, 2 bits de Cb et 2 bits Cr).
- Sous-échantillonnage de la chrominance : en raison des non-linéarités dans les tons RVB, corrige les images pour imiter d’autres médias tels que le film pour l’adéquation tonale et la qualité.
- Encodeur JPEG : algorithme de compression JPEG standard.
Il convient de souligner ici qu’il s’agit d’un bon exemple de la complexité d’un capteur et de la quantité de données, de matériel et de complexité pouvant être attribuée à un système de vision simple. La quantité de données passant par un système de vision ou une caméra à une vitesse conservatrice de 60 images par seconde à une résolution de 1080p est énorme.
Toutes les phases (à l’exception de la compression JPEG) passent par un FAI en silicium à fonction fixe (comme dans un ASIC) un cycle à la fois. La quantité totale de données traitées est de 1 368 Go par seconde. La prise en compte de la compression JPEG comme dernière étape porte la quantité de données à plus de 2 Go / s lors du traitement via des cœurs personnalisés en silicone et CPU / DSP. On ne diffuserait jamais de vidéo Raw Bayer sur le cloud pour traitement – ce travail doit être effectué aussi près que possible du capteur vidéo.
3.2.2 Fusion de capteurs
Un aspect qui doit être pris en compte avec tous les dispositifs capteurs décrits dans ce chapitre est le concept de fusion des capteurs. La fusion de capteurs est le processus de combinaison de plusieurs types de données de capteurs pour révéler plus sur le contexte qu’un seul capteur peut fournir. Ceci est important dans l’espace IoT, car un seul capteur thermique n’a aucune idée de ce qui provoque un changement rapide de température. Cependant, lorsqu’il est combiné avec des données provenant d’autres capteurs à proximité qui examinent la détection de mouvement PIR et l’intensité lumineuse, un système IoT pourrait discerner qu’un grand nombre de personnes se rassemblent dans une certaine zone pendant que le soleil brille et pourrait alors prendre la décision d’augmenter circulation de l’air dans un immeuble intelligent. Un simple capteur thermique enregistre uniquement la valeur de température actuelle et n’a aucune conscience contextuelle que la chaleur augmente en raison des rassemblements et de la lumière du soleil.
Avec des données corrélées dans le temps provenant de plusieurs capteurs (périphérie et cloud), le traitement peut prendre de meilleures décisions en fonction de davantage de données. C’est l’une des raisons pour lesquelles il y aura un afflux important de données des capteurs vers le cloud, et cela entraîne une croissance des mégadonnées. À mesure que les capteurs deviennent moins chers et plus faciles à intégrer, comme avec le TI SensorTag, nous verrons une détection plus combinée pour fournir une conscience contextuelle.
Il existe deux modes de fusion des capteurs :
- Centralisé : où les données brutes sont diffusées et agrégées vers un service central et où la fusion y a lieu (basée sur le cloud, par exemple)
- Décentralisé : où les données sont corrélées au niveau du capteur
La base de corrélation des données de capteur est généralement exprimée à travers le théorème de la limite centrale, où deux mesures de capteur, x 1 et x 2 , sont combinées pour révéler une mesure corrélée, x 3 , basée sur les variances combinées. Il s’agit simplement d’ajouter deux mesures et de pondérer la somme par les variances :
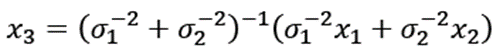
Les autres méthodes de fusion de capteurs utilisées sont les filtres de Kalman et les réseaux bayésiens.
Le chapitre 8 , Edge Computing , abordera en profondeur l’informatique de bord et illustrera un exemple de «fusion de capteurs», qui renforcera le fait que des technologies comme celle-ci ont des ressources et des exigences de traitement importantes qui s’étendent au-delà de la simple électronique de capteurs .
3.2.3 Périphériques de sortie
Les périphériques de sortie dans l’écosystème IoT peuvent être à peu près n’importe quoi, d’une simple LED à un système vidéo complet. Les autres types de sortie incluent les actionneurs, les moteurs pas à pas, les haut-parleurs et les systèmes audio, les vannes industrielles, etc. Il va de soi que ces appareils nécessitent divers systèmes de contrôle de complexité différente. Selon le type de sortie et le cas d’utilisation qu’ils servent, il faut également s’attendre à ce qu’une grande partie du contrôle et du traitement doivent être situés en périphérie ou à proximité de l’appareil (par rapport au contrôle complet dans le cloud). Un système vidéo, par exemple, peut diffuser des données à partir de fournisseurs de cloud, mais a besoin de matériel de sortie et de capacités de mise en mémoire tampon à la périphérie.
En général, les systèmes de sortie peuvent nécessiter une énergie considérable pour se convertir en mouvement mécanique, en énergie thermique ou même en lumière. Un petit solénoïde amateur pour contrôler le débit de fluide ou de gaz peut nécessiter de 9 à 24 VCC et tirer 100 mA pour fonctionner de manière fiable et produire cinq Newtons de force. Les solénoïdes industriels fonctionnent en centaines de volts.
3.3 Exemples fonctionnels (rassembler t tous ensemble)
Une collection de capteurs à elle seule n’a pas beaucoup de valeur tant que les données collectées ne sont pas transmises, traitées ou traitées. Ce traitement peut être effectué par un contrôleur intégré ou envoyé en amont vers un cloud. Plus de matériel est nécessaire pour construire le système. En règle générale, les capteurs utiliseront une interface IO établie et des systèmes de communication, tels que I 2 C, SPI, UART, SPI ou d’autres IO à faible vitesse (traités au chapitre 11, Topologies cloud et brouillard). D’autres périphériques, tels que les systèmes vidéo, auront besoin d’E / S beaucoup plus rapides pour maintenir une haute résolution et des fréquences d’images vidéo rapides. Ces E / S incluraient MIPI, USB ou même PCI-Express. Pour communiquer sans fil, les capteurs devront être utilisés avec du matériel de transport sans fil comme Bluetooth, Zigbee ou 802.11. Tout cela nécessite des composants supplémentaires, que nous couvrirons dans cette section.
3.3.1 Exemple fonctionnel – TI SensorTag CC2650
Le Texas Instruments CC2650 SensorTag est un bon exemple de module de capteur IoT pour le développement, le prototypage et la conception. SensorTag a les fonctionnalités et capteurs suivants dans le package :
- Entrée capteur
- Capteur de lumière ambiante (TI Light Sensor OPT3001)
- Capteur de température infrarouge (TI Thermopile infrarouge TMP007)
- Capteur de température ambiante (capteur de lumière TI OPT3001)
- Accéléromètre (InvenSense MPU-9250)
- Gyroscope (InvenSense MPU-9250)
- Magnétomètre (Bosch SensorTec BMP280)
- Altimètre / capteur de pression (Bosch SensorTec BMP280)
- Capteur d’humidité (TI HDC1000)
- Microphone MEMS (Knowles SPH0641LU4H)
- Capteur magnétique (Bosch SensorTec BMP280)
- Deux GPIO à bouton-poussoir
- Relais Reed (Meder MK24)
- Périphériques de sortie
- Buzzer / haut-parleur
- 2 LED
- Les communications
- Bluetooth Low Energy
- Zigbee
- 6LoWPAN
Ce package est alimenté par une seule pile bouton CR2032. Enfin, l’appareil peut être placé en mode balise (iBeacon) et utilisé comme diffuseur de messages.
Voici un schéma fonctionnel du module SensorTag CC2650:

Figure 14 : TI CC2650 SensorTag
L’image suivante est du schéma de principe du MCU. Le MCU fournit les E / S et la capacité de traitement à l’aide d’un ARM Cortex M3 et ARM Cortex M0, qui se connectent via diverses interfaces de bus aux composants du capteur sur le module :
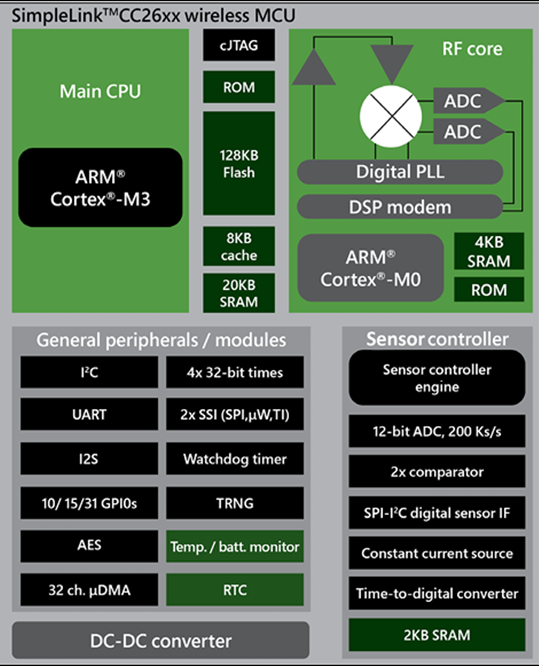
Figure 15: Schéma fonctionnel du microcontrôleur TI CC2650
Cet appareil est doté d’un certain nombre de capteurs, de systèmes de communication et d’interfaces, mais la quantité de puissance de traitement est limitée. L’appareil utilise un module de traitement de TI (MCU CC265), qui comprend un petit processeur ARM Cortex M3 avec seulement 128 Ko de mémoire flash et 20 Ko de SRAM. Celui-ci a été choisi pour sa très faible consommation d’énergie. Le cœur M0 (notamment moins performant que le M3) gère les transmissions radio.
Bien qu’économe en énergie, cela limite la quantité de traitement et de ressources sur ce système. En règle générale, des composants comme ceux-ci devront être accompagnés d’une passerelle, d’un routeur, d’un téléphone portable ou d’un autre appareil intelligent. De tels capteurs conçus pour une faible consommation et un faible coût ne disposeraient pas des ressources nécessaires pour des applications plus exigeantes telles que les piles de protocoles MQTT, l’agrégation de données, la communication cellulaire ou l’analyse. D’ailleurs, la plupart des dispositifs de détection de point final que l’on verra sur le terrain sont plus simples que ce composant pour réduire davantage le coût et la puissance.
3.3.2 Capteur au contrôleur
Dans bon nombre des exemples précédents de composants de détection, le signal nécessitera une amplification, un filtrage et un étalonnage avant de se rendre n’importe où. En règle générale, le matériel aura besoin d’un convertisseur analogique-numérique d’une certaine résolution. Ce qui suit est un simple CAN 24 bits qui émet un signal 5V:

Figure 16: Pont de Wheatstone: connecté à un convertisseur analogique-numérique AD7730 en entrée d’un microcontrôleur ou d’un système sur une puce
La sortie peut alors être des données brutes modulées par impulsions, ou une interface série telle que I 2 C, SPI ou UART vers un microcontrôleur ou un processeur de signal numérique. Un bon exemple de cela dans un système réel est le capteur à thermopile infrarouge Texas Instruments (TMP007). Il s’agit d’un capteur de température MEMS sans contact qui absorbe les longueurs d’onde infrarouges et les convertit en une tension de référence tout en utilisant une température de référence de jonction froide.
Il est conçu pour détecter avec précision les températures dans des environnements entre -40 degrés Celsius et +125 degrés Celsius. Nous pouvons voir les composants couverts dans ce chapitre pour cette partie dans la figure suivante :
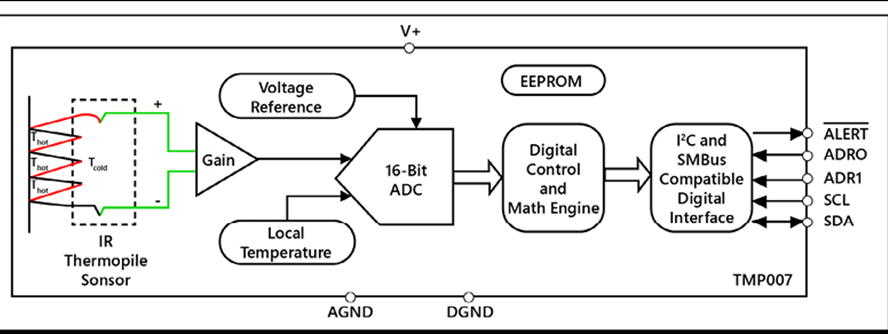
Figure 17: Système de capteur à thermopile infrarouge Texas Instruments TMP007
3.4 Sources d’énergie et gestion de l’énergie
Étant donné que les capteurs et les dispositifs périphériques se comptent par milliards et seront utilisés dans des zones très reculées, fournir une alimentation fiable devient un défi. En outre, il y aura des déploiements IoT où les capteurs seront enfouis sous la mer, ou intégrés dans des infrastructures en béton, compliquant davantage les sources d’énergie. Dans cette section, nous explorerons les concepts de récupération d’énergie et de gestion de l’énergie. Les deux sont des concepts très importants dans l’histoire globale de l’IoT.
3.4.1 Gestion de l’alimentation
La gestion de l’alimentation est un sujet très vaste qui couvre les logiciels et le matériel. Il est important de comprendre le rôle de la gestion de l’alimentation dans un déploiement IoT réussi et comment gérer efficacement l’énergie pour les appareils distants et les appareils à longue durée de vie. L’architecte doit établir un budget de puissance pour le périphérique, qui comprend :
- Puissance active du capteur
- Fréquence de collecte des données
- Puissance et puissance de la communication radio sans fil
- Fréquence de communication
- Puissance du microprocesseur ou du microcontrôleur en fonction de la fréquence centrale
- Puissance composante passive
- Perte d’énergie due à une fuite ou à une inefficacité de l’alimentation
- Réserve de marche pour actionneurs et moteurs
Le budget reflète simplement la somme de ces contributeurs d’énergie soustraite de la source d’énergie (batterie). Les batteries n’ont pas non plus un comportement de puissance linéaire dans le temps. À mesure que la batterie perd sa capacité énergétique pendant la décharge, la quantité de tension diminue de façon curviligne. Cela pose des problèmes pour les systèmes de communication sans fil. Si la batterie tombe en dessous d’une tension minimale, une radio ou un microprocesseur n’atteindra pas la tension de seuil et ne brunira pas.
Par exemple, le TI SensorTag C2650 a les caractéristiques de puissance suivantes :
- Mode veille : 0,24 mA
- Fonctionnement avec tous les capteurs désactivés (alimentant uniquement les LED): 0,33 mA
- Fonctionne avec tous les capteurs à 100 ms / débit d’échantillonnage et diffusion : 12,08 mA
- BLE : 5,5 mA
- Capteur de température : 0,84 mA
- Capteur de lumière : 0,56 mA
- Accéléromètre et gyroscopes : 4,68 mA
- Capteur barométrique : 0,5 mA
Le TI SensorTag utilise une pile bouton standard CR2032 évaluée à 240 mAh. Par conséquent, la durée de vie maximale devrait être d’environ 44 heures. Cependant, le taux de déclin change et n’est pas linéaire pour les appareils à batterie, comme nous le verrons lorsque nous couvrirons la capacité de Peukert.
De nombreuses pratiques de gestion de l’énergie sont utilisées, telles que les composants de synchronisation d’horloge non utilisés dans le silicium, la réduction des fréquences d’horloge des processeurs ou des microcontrôleurs, l’ajustement de la fréquence de détection et de la fréquence de diffusion, les stratégies de recul pour réduire la force de communication et divers niveaux de modes de sommeil. Ces techniques sont largement utilisées dans le secteur informatique en tant que pratique générale.
Les techniques décrites ici reflètent les techniques de gestion de l’énergie réactionnelle. Ils essaient de minimiser la consommation d’énergie en fonction de la tension dynamique, de la mise à l’échelle des fréquences et d’autres schémas. De nouvelles techniques à envisager à l’horizon comprennent le calcul approximatif et la conception probabiliste. Ces deux schémas reposent sur le fait qu’une précision absolue n’est pas nécessaire à tout moment dans un environnement de capteur fonctionnant en périphérie, en particulier dans les cas d’utilisation impliquant le traitement du signal et la communication sans fil. Le calcul approximatif peut être effectué au niveau matériel ou logiciel et réduit simplement le niveau de précision des entiers lorsqu’il est utilisé avec des unités fonctionnelles telles que des adresses et des multiplicateurs (par exemple, la valeur 17 962 est assez proche de 17 970). La conception probabiliste réalise que de nombreux déploiements IoT peuvent tolérer certains degrés de défaillance pour assouplir les contraintes de conception. Les deux techniques peuvent réduire le nombre de portes et la puissance à une baisse presque exponentielle par rapport aux conceptions matérielles régulières.
3.4.2 Récupération d’énergie
La récupération d’énergie n’est pas un nouveau concept mais est un concept important pour l’IoT. Essentiellement, tout système qui représente un changement d’état (par exemple, chaud à froid, signaux radio, lumière) peut convertir sa forme d’énergie en énergie électrique. Certains appareils utilisent cela comme leur seule forme d’énergie, tandis que d’autres sont des systèmes hybrides qui utilisent la récolte pour augmenter ou prolonger la durée de vie d’une batterie. À son tour, l’énergie récoltée peut être stockée et utilisée (avec parcimonie) pour alimenter des appareils à faible consommation d’énergie tels que des capteurs dans l’IoT. Les systèmes doivent être efficaces pour capter l’énergie et stocker l’énergie. Par conséquent, une gestion avancée de l’alimentation est nécessaire. Par exemple, si un système de récupération d’énergie utilise une technique de récolte mécanique piézoélectrique intégrée dans un trottoir, il devra compenser lorsqu’il n’y a pas suffisamment de circulation piétonne pour maintenir l’unité chargée. Une communication constante avec les systèmes de récupération d’énergie peut encore drainer l’énergie. En règle générale, ces déploiements IoT utiliseront des techniques avancées de gestion de l’alimentation pour éviter la perte complète de fonctionnalités.
Des techniques telles que les faibles courants de veille, les circuits à faible fuite et la limitation de l’horloge sont fréquemment utilisées. La figure suivante illustre le domaine dans lequel la récupération d’énergie est idéale et la technologie qu’elle peut alimenter. L’architecte doit veiller à ce que le système ne soit ni sous-alimenté ni sur-alimenté. Les systèmes de récolte, en général, ont un faible potentiel énergétique et une faible efficacité de conversion. Un architecte devrait envisager la récupération d’énergie dans les situations où il y a une grande quantité d’énergie résiduelle inexploitée, comme dans les milieux industriels.
Figure 18 : points chauds de récupération d’énergie. La figure Illustre la consommation typique d’énergie pour divers appareils.
Les techniques de récupération d’énergie sont courantes dans les produits IoT pour les villes intelligentes et la communication à distance. Par exemple, de nombreuses villes utilisent régulièrement le comptage du trafic et des moniteurs de sécurité utilisant des panneaux solaires comme source d’alimentation principale. Un autre exemple est les boîtes de dépôt de courrier et d’emballage qui utilisent une énergie mécanique momentanée qui est capturée lorsque la boîte est ouverte pour récolter l’énergie pour une électronique de puissance ultérieure, surveillant le niveau de remplissage de la boîte de dépôt.
3.4.2.1 Récolte solaire
L’énergie de la lumière, qu’elle soit naturelle ou artificielle, peut être captée et utilisée comme source d’énergie. Plus tôt dans ce chapitre, nous avons discuté des photodiodes et de leur relation avec la détection de la lumière. La même diode peut être utilisée en plus grande quantité pour construire un panneau solaire traditionnel. La capacité de production d’énergie est fonction de la surface du panneau solaire. En pratique, la génération solaire intérieure n’est pas aussi efficace que la lumière directe du soleil. Les panneaux sont évalués par leur puissance de sortie maximale sous forme de watts.
La récolte solaire est seulement aussi efficace que la luminosité du soleil, qui varie selon les saisons et la géographie. Une région comme le sud-ouest des États-Unis peut récupérer une énergie considérable à partir de sources photovoltaïques directes. La carte des ressources solaires photovoltaïques des États-Unis a été créée par le National Renewable Energy Laboratory pour le US Department of Energy, www.nrel.gov :

Schéma 19 : Carte d’énergie solaire des Etats-Unis dans la densité d’énergie de kWh / m2 1998-2009
Aux États-Unis, les régions du Sud-Ouest s’en sortent particulièrement bien avec l’intensité du soleil, manquent généralement de barrières lumineuses aux nuages et ont de bonnes conditions atmosphériques, tandis que l’Alaska a la densité d’énergie la plus faible. Le photovoltaïque solaire n’est généralement pas efficace. On peut s’attendre à une efficacité de 8% à 20%, 12% étant typique. Quoi qu’il en soit, un panneau solaire de 25 cm 2 pourrait produire 300 mW à la puissance de crête. Un autre facteur est l’incidence de la lumière. Pour qu’un capteur solaire atteigne une telle efficacité, la source lumineuse doit être perpendiculaire au réseau. Si l’angle d’incidence change au fur et à mesure que le soleil se déplace, l’efficacité diminue encore. Un collecteur à 12% d’efficacité lorsque le soleil est perpendiculaire aura une efficacité d’environ 9,6% lorsque le soleil est à 30 degrés de la perpendiculaire.
Le capteur solaire le plus élémentaire est la cellule solaire qui est un simple semi-conducteur pn et similaire aux capteurs photoélectriques discutés précédemment. Comme expliqué précédemment, un potentiel électrique est généré entre le matériau p et n lorsqu’un photon est capturé.
3.4.2.2 Récolte piézo-mécanique
Comme mentionné précédemment dans ce chapitre, les effets piézoélectriques peuvent être utilisés comme capteurs, mais ils peuvent également être utilisés pour générer de l’énergie. Les contraintes mécaniques peuvent être converties en énergie par le mouvement, les vibrations et même le son. Ces moissonneuses pourraient être utilisées dans des routes et des infrastructures intelligentes pour récolter et changer les systèmes en fonction du mouvement du trafic, même lorsqu’ils sont intégrés dans du béton. Ces dispositifs produisent des courants de l’ordre de milliwatts et conviennent donc aux très petits systèmes avec une certaine forme de collecte et de stockage d’énergie. Ce processus peut être effectué en utilisant des dispositifs piézo-mécaniques MEMS, des systèmes électrostatiques et électromagnétiques.
La récolte électrostatique incorpore la loi de Faraday, qui stipule essentiellement que l’on peut induire un courant électrique en modifiant le flux magnétique à travers une bobine de fil. Ici, la vibration est couplée soit à la bobine soit à un aimant. Malheureusement, ce schéma dans la zone des capteurs IoT fournit trop peu de tension pour la rectification.
Les systèmes électrostatiques utilisent le changement de distance entre deux plaques capacitives maintenues à une tension ou une charge constante. Comme la vibration fait varier la distance entre les plaques, l’énergie (E) peut être récoltée selon le modèle suivant :

Ici, Q est la charge constante sur les plaques, V est la tension constante et C représente la capacité dans l’équation précédente. La capacité peut également être représentée par la longueur de la plaque L w , la permittivité statique relative as et la distance entre les plaques d comme indiqué:
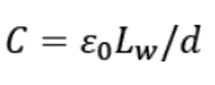
Une conversion électrostatique a l’avantage d’être évolutive et rentable à produire par micro-usinage et fabrication de semi-conducteurs.
La dernière méthode de conversion mécanique-électrique est piézo-mécanique. Les dispositifs piézoélectriques ont été abordés plus tôt dans ce chapitre lors de l’examen de l’entrée du capteur. Le même concept de base s’applique à la production d’énergie. Comme le dispositif piézo-mécanique MEMS tente d’amortir la masse qui lui est attachée, les oscillations seront converties en courant électrique.
Une autre considération pour la capture et la conversion d’énergie vibratoire ou mécanique est le besoin de conditionnement avant que l’énergie soit utilisée ou stockée. Normalement, un redresseur passif est utilisé pour le conditionnement en incorporant un grand condensateur de filtrage. D’autres formes de récupération d’énergie n’ont pas besoin d’un tel conditionnement.
3.4.2.3 Récupération d’énergie RF
La récupération d’énergie par radiofréquence (RF) est en production depuis des années sous la forme d’étiquettes RFID. La RFID a l’avantage d’être une communication en champ proche qui utilise un émetteur-récepteur qui alimente essentiellement l’étiquette RFID en raison de sa proximité.
Pour les applications en champ lointain, nous devons récupérer l’énergie des transmissions de diffusion. Les transmissions de diffusion sont presque partout, avec des services de télévision, de signaux cellulaires et de radio. La capture d’énergie à partir des fréquences radio par rapport à d’autres formes est particulièrement difficile, car les signaux RF ont la plus faible densité d’énergie de toutes les techniques de récolte. La capture de signaux RF est basée sur le fait d’avoir l’antenne appropriée pour capturer une bande de fréquence. Les bandes de fréquences typiques utilisées sont comprises entre 531 et 1611 kHz (toutes dans la gamme radio AM).
3.4.2.4 Récolte thermique
L’énergie thermique peut être convertie en courant électrique pour tout appareil présentant un flux de chaleur. L’énergie thermique peut être convertie en énergie électrique par deux processus de base :
- Thermoélectrique : Conversion directe de l’énergie thermique en énergie électrique grâce à l’effet Seebeck.
- Thermionique : également connu sous le nom de thermotunneling . Les électrons sont éjectés d’une électrode chauffée et insérés dans une électrode froide.
L’effet thermoélectrique (effet Seebeck) se produit lorsqu’un gradient de température existe dans les matériaux conducteurs. Le flux de porteurs d’une région chaude à une région froide entre deux conducteurs électriques différents crée une différence de tension. Un thermocouple, ou générateur thermoélectrique (TEG), pourrait efficacement produire une tension simplement en fonction de la différence de température d’un être humain, en fonction de sa température corporelle centrale et de la température extérieure. Une différence de température de 5 ° C pourrait générer 40 uW à 3V. Lorsque la chaleur circule à travers le matériau de conduction, une électrode côté chaud induit un flux d’électrons vers un courant produisant une électrode côté froid. Les dispositifs thermoélectriques modernes utilisent du tellurure de bismuth de type n ou p en série. Un côté est exposé à la source de chaleur (thermocouple) et l’autre est isolé.
L’énergie récoltée par la thermopile est proportionnelle au carré de la tension et équivalente à la différence de température entre les électrodes. On peut modéliser l’énergie récoltée par un thermocouple par l’équation suivante :

Ici, S 1 et S 2 représentent les différents coefficients de Seebeck pour chacun des deux matériaux (n et p – Type) dans la thermopile Lorsqu’il y a une différence de température, T H – T L . Comme les coefficients Seebeck sont fonction de la température et qu’il existe une différence de température, le résultat est une différence de tension. Cette tension étant généralement très faible, de nombreux thermocouples sont utilisés en série pour former une thermopile.
Les principales différences entre une thermopile et un thermocouple sont les suivantes :
- Les thermocouples produisent une sortie de tension dépendante de la température basée sur les deux conducteurs formant une connexion électrique et mesurant la différence de deux températures différentes. Ils ne sont pas aussi précis pour une mesure de température très précise.
- Les thermopiles sont également des appareils électroniques utilisant de nombreux thermocouples, généralement dans un circuit en série. Ils mesurent la différence de température à travers les couches de résistance thermique. Ils délivrent une tension proportionnelle à la différence de température locale.
Un problème important avec les thermocouples actuels est le faible rendement de la conversion d’énergie (moins de 10%) ; Cependant, leurs avantages sont remarquables, notamment leur petite taille et leur facilité de fabrication, d’où des coûts assez faibles. Ils ont également une très longue durée de vie de plus de 100 000 heures. Le problème principal, bien sûr, est de trouver une source de variance thermique relativement constante. L’utilisation d’un tel appareil dans un environnement pendant plusieurs saisons et températures est difficile. Pour les dispositifs IoT, la génération thermoélectrique réside généralement dans la plage de 50 mW.
La génération thermionique est basée sur l’éjection d’électrons d’une électrode chaude vers une électrode froide sur une barrière de potentiel. La barrière est la fonction de travail du matériau et est mieux utilisée lorsqu’il existe une source importante d’énergie thermique. Bien que son efficacité soit meilleure que celle des systèmes thermoélectriques, l’énergie nécessaire pour franchir la barrière de potentiel la rend généralement inadaptée aux dispositifs capteurs IoT. Des schémas alternatifs tels que la tunnelisation quantique pourraient être envisagés, mais cela reste actuellement une activité de recherche.
3.4.3 Stockage d’énergie
Le stockage typique d’un capteur IoT sera une batterie ou un supercondensateur. Lorsque l’on considère l’architecture de la puissance du capteur, il faut considérer plusieurs aspects :
- Allocation de volume pour un sous-système d’alimentation. Une batterie sera-t-elle même adaptée ?
- La capacité énergétique de la batterie.
- Accessibilité. Si l’unité est encastrée dans du béton, des formes limitées de régénération d’énergie peuvent être utilisées et la difficulté de remplacer les batteries peut être coûteuse.
- Poids. L’unité est-elle destinée à voler comme un drone ou à flotter sur l’eau ?
- À quelle fréquence la batterie sera-t-elle rechargée ?
- La forme renouvelable d’énergie est-elle constamment disponible ou intermittente, comme dans le solaire ?
- Les caractéristiques de puissance de la batterie. Comment l’énergie de la batterie variera au fil du temps lorsqu’elle sera déchargée.
- Le capteur est-il dans un environnement soumis à des contraintes thermiques qui peut affecter la durée de vie et la fiabilité de la batterie ?
- La batterie a-t-elle un profil qui garantit une disponibilité minimale actuelle ?
3.4.3.1 Modèles d’énergie et de puissance
La capacité de la batterie est mesurée en ampères-heures. Une équation simplifiée pour estimer la durée de vie d’une source d’alimentation par batterie est donnée comme suit :

Dans l’équation, C p est la capacité de Peukert, I représente le courant de décharge et n est l’exposant de Peukert. L’effet Peukert, comme on le sait, permet de prédire la durée de vie d’une batterie où la capacité d’une batterie diminue à un rythme différent à mesure que la décharge augmente. L’équation montre comment la décharge à des taux plus élevés supprime plus de puissance de la batterie. Alternativement, la décharge à des taux inférieurs augmentera l’autonomie effective de la batterie. Une façon de penser à ce phénomène est une batterie évaluée à 100 Ah, et la décharger complètement en 20 heures (5A, pour cet exemple). Si l’on devait le décharger plus rapidement (disons, en 10 heures), la capacité serait plus faible. Si l’on devait le décharger plus lentement (disons, plus de 40 heures), ce serait plus grand. Cependant, lorsqu’elle est représentée sur un graphique, la relation est non linéaire. L’exposant de Peukert se situe généralement entre 1,1 et 1,3. À mesure que n augmente, nous passons d’une batterie parfaite à une batterie qui se décharge plus rapidement à mesure que le courant augmente. La courbe de Peukert s’applique aux performances des batteries plomb-acide, et un exemple est illustré dans ce graphique suivant :
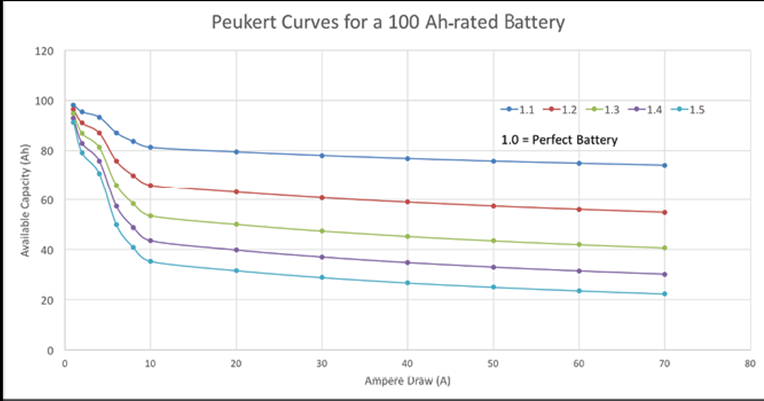
Figure 20 : Courbes de Peukert de 1,1 à 1,5 pour une batterie évaluée à 100 Ah sur 20 heures. Les courbes montrent la capacité décroissante à mesure que le coefficient Peukert augmente.
On peut voir la différence de taux de décharge pour différents types de batteries. Un avantage des piles alcalines est que le taux de décharge est presque linéaire dans une grande partie du graphique. Le lithium-ion a une fonction d’escalier dans les performances, ce qui rend les prévisions de charge de la batterie plus difficiles. Cela dit, le Li-ion fournit un niveau de tension presque constant et continu pendant la durée de vie de la charge et alimente constamment l’électronique sur la durée de sa charge :
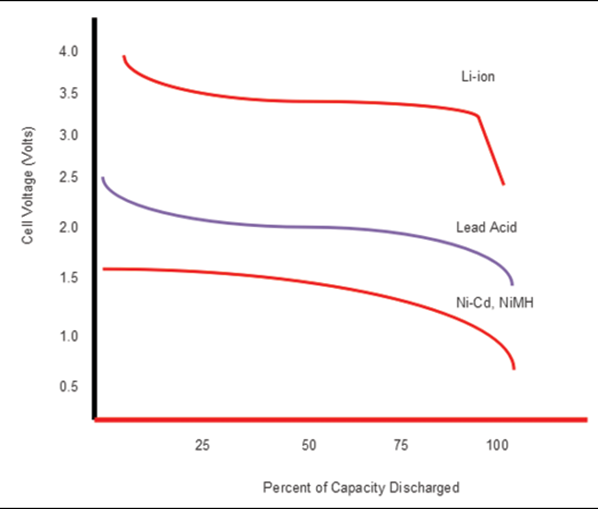
Figure 21 : Exemple de taux de décharge relatifs pour différentes batteries. Le Li-ion fournit une tension presque constante au cours de sa durée de vie mais a une chute abrupte vers la fin de sa capacité de stockage.
Le graphique montre également que le plomb et le Ni-Cd ont un potentiel de tension moindre et une dégradation curviligne de la puissance qui peut être calculée de manière plus fiable. Les pentes de fuite indiquent également la capacité de Peukert.
La température affecte considérablement la durée de vie de la batterie, et en particulier les supports électro-actifs dans une cellule. À mesure que la température augmente, la résistance interne d’une batterie diminue lorsqu’elle est déchargée. Même lorsque les batteries sont stockées, elles peuvent se décharger automatiquement, ce qui affecte la durée de vie totale d’une batterie.
Un graphique Ragone est un moyen utile de montrer la relation entre les systèmes de stockage d’énergie lors de l’échange de la capacité énergétique et de la gestion de l’énergie. Il s’agit d’une échelle logarithmique où la densité d’énergie (Wh / kg) d’une source d’alimentation est tracée en fonction de la densité de puissance (W / kg). Cette relation montre les appareils qui ont tendance à avoir une durée de vie plus longue (batteries) par rapport aux appareils qui ont tendance à stocker plus d’énergie (supercondensateurs):
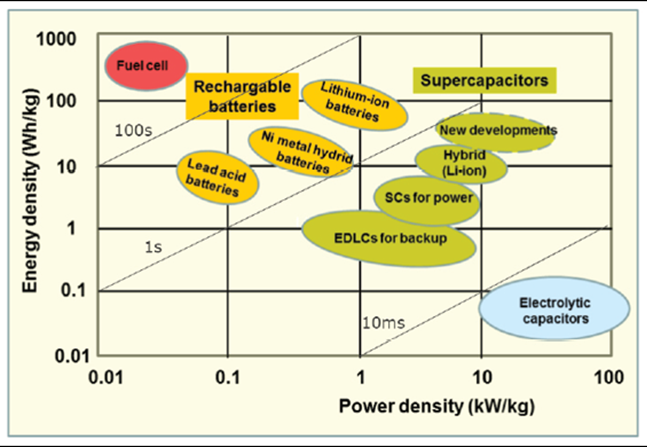
Figure 22 : Diagramme Ragone illustrant les différences de capacité énergétique des condensateurs, supercondensateurs, batteries et piles à combustible en fonction de la durée de vie de l’énergie fournie
Les batteries comme Li-ion ont une densité d’énergie et des taux de décharge plus élevés que les batteries nickel-cadmium et nickel-hydrure. Les condensateurs produisent des densités de puissance très élevées mais ont une densité d’énergie relativement faible. Notez que le tracé est basé sur un journal et montre également le temps de décharge pour divers systèmes de stockage.
3.4.3.2 Batteries
En règle générale, une batterie au lithium-ion (Li-ion) est la forme standard d’énergie dans les appareils mobiles en raison de sa densité d’énergie. Dans une telle batterie, les ions lithium se déplacent physiquement de l’électrode négative vers le positif. Pendant la recharge, les ions retournent dans la région négative. Ceci est connu comme un mouvement ionique.
Les batteries développent également des mémoires avec de nombreux cycles de charge-décharge. Cette perte de capacité est exprimée comme une mesure de la capacité initiale (par exemple, 30% de perte après 1 000 cycles). Cette dégradation est presque directement corrélée à la température ambiante, et la perte augmentera dans un environnement à haute température. Par conséquent, il est impératif que les architectes gèrent les thermiques dans un environnement contraint si le lithium-ion doit être utilisé.
L’autodécharge est un autre facteur de durée de vie de la batterie. Lorsque des réactions chimiques indésirables se produisent dans une cellule de batterie, de l’énergie est perdue. Le taux de perte dépend de la chimie et de la température. En règle générale, un Li-ion peut durer 10 ans (avec une perte de ~ 2% par mois), tandis qu’une batterie alcaline ne durera que 5 ans (15% à 20% de perte par mois).
3.4.3.3 supercondensateurs
Les supercondensateurs (ou supercondensateurs) stockent l’énergie à des volumes nettement plus élevés que les condensateurs typiques. Un condensateur typique aura une densité d’énergie comprise entre 0,01 watt-heure / kg. Un supercap a une densité d’énergie de 1 à 10 wattheures / kg, ce qui les place ainsi plus près de la densité d’énergie d’une batterie qui peut être de l’ordre de 200 wattheures / kg. Comme un condensateur, l’énergie est stockée électrostatiquement sur une plaque et n’implique pas le transfert chimique d’énergie comme une batterie. Habituellement, les supercaps sont faits de matériaux assez exotiques comme le graphène, ce qui peut avoir un impact sur le coût global. Les supercaps ont l’avantage de se recharger à leur plein potentiel en quelques secondes, tandis que les batteries Li-ion se rechargent en quelques minutes à environ 80%, mais nécessitent un courant de maintien pour monter en sécurité en toute sécurité.
De plus, les supercaps ne peuvent pas être surchargés, tandis que le Li-ion peut être surchargé et peut entraîner de graves problèmes de sécurité. Les supercaps se présentent sous deux formes :
- Condensateurs électriques à double couche (EDLC) : utilisez une électrode à charbon actif et stockez l’énergie électrostatiquement
- Pseudocondensateurs : utilisez un oxyde de métal de transition et un transfert de charge électrochimique
Les supercaps ont un avantage sur les batteries pour prédire le temps restant de puissance disponible. L’énergie restante peut être prédite à partir de la tension aux bornes, qui change avec le temps. Les batteries Li-ion ont un profil d’énergie plat de complètement chargé à déchargé, ce qui rend l’estimation du temps difficile. Étant donné que le profil de tension d’un supercap change au fil du temps, un convertisseur DC-DC est nécessaire pour compenser les grandes variations de tension.
En général, les principaux problèmes avec les supercondensateurs ou les condensateurs sont le courant de fuite et le coût. Comme on peut le voir dans le tableau plus loin dans cette section, les supercaps ont leur place. On les verra souvent dans une solution hybride avec des batteries régulières pour fournir une puissance instantanée (par exemple, une accélération de véhicule électrique), tandis que l’alimentation par batterie maintient la puissance de fonctionnement.
3.4.3.4 Sources d’énergie radioactives
Une source radioactive à haute densité d’énergie (10 5 kJ / cm 3 ) peut générer de l’énergie thermique grâce à l’énergie cinétique des particules émises. Des sources telles que le césium-137 ont une demi-vie de 30 ans et une capacité de puissance de 0,015 W / g. Cette méthode peut générer de l’énergie dans la plage de watts à kW, mais n’est pas pratique dans les niveaux de capteur à faible puissance pour les déploiements IoT. Les véhicules spatiaux utilisent cette technologie depuis des décennies. Des développements prometteurs utilisant la piézoélectronique MEMS qui capturent les électrons et forcent une micro-armature à se déplacer peuvent créer de l’énergie mécanique qui peut être récoltée. Un effet secondaire de la désintégration radioactive est le profil de densité de puissance relativement faible. Une source de rayonnement à longue demi-vie aura une densité de puissance plus faible. Ainsi, ils conviennent aux supercaps de charge en vrac pour fournir une énergie momentanée en cas de besoin. Le dernier problème avec les sources radioactives est le poids important du blindage au plomb requis. Le césium-137 nécessite un blindage de 80 mm / W, ce qui peut ajouter un coût et un poids importants à un capteur IoT.
Des exemples de sources d’énergie radioactives comprennent des véhicules spatiaux tels que le Curiosity Mars Rover et le vaisseau spatial New Horizon.
3.4.3.5 Résumé du stockage d’énergie et autres formes d’énergie
Le choix de la bonne source d’alimentation est essentiel, comme mentionné précédemment. Le tableau suivant fournit une comparaison récapitulative des différents composants d’un système à prendre en compte lors du choix de la bonne source d’alimentation :
| Catégorie | Batterie Li-ion | Supercap |
| Densité énergétique | 200 Wh / kg | 8-10 Wh / kg |
| Cycles de charge-décharge | La capacité chute après 100 à 1 000 cycles | Presque infini |
| Temps de charge-décharge | 1 à 10 heures | Millisecondes en secondes |
| Température de fonctionnement | -20 ° C à + 65 ° C | -40 ° C à + 85 ° C |
| Tension de fonctionnement | 2V à 4.2V | 1V à 3V |
| Livraison de puissance | Tension constante dans le temps | Décroissance linéaire ou exponentielle |
| Taux de charge | (Très lent) 40 C / x | (Très rapide) 1500 C / x |
| La vie opérationnelle | 5 à 5 ans | 5 à 20 ans |
| Facteur de forme | Très petite | Grand |
| Coût ($ / kWh) | Faible (250 $ à 1000 $) | Élevé (10 000 $) |
3.5 Résumé
Ce chapitre résume plusieurs capteurs et points de terminaison différents utilisés dans les déploiements IoT. L’IoT ne consiste pas simplement à connecter un appareil à Internet. Bien qu’il s’agisse d’un élément clé, l’essence de l’IoT est de connecter le monde analogique au numérique. Essentiellement, les choses et les appareils auparavant non connectés ont désormais la possibilité de collecter des informations et de les communiquer à d’autres appareils. C’est puissant car les données qui n’avaient jamais été capturées ont maintenant de la valeur. La capacité de détecter l’environnement conduira à plus d’efficacité, de flux de revenus et de valeur pour les clients. La détection permet les villes intelligentes, la maintenance prédictive, le suivi des actifs et l’analyse de la signification cachée dans des agrégats massifs de données. L’alimentation de tels systèmes est également essentielle et doit être comprise par les architectes. Un système mal conçu peut entraîner une durée de vie de la batterie trop courte, ce qui entraînera des coûts substantiels de réparation.
Le chapitre suivant établira un pont entre les points de terminaison et Internet via une communication non IP. Nous explorerons divers réseaux personnels sans fil et leurs divers traits et fonctions qui prévalent dans l’espace IoT.
4 Théorie des communications et de l’information
Il existe un nombre important de technologies et de chemins de données pour déplacer des données, et une grande partie du contenu de cet article étudiera les aspects, les contraintes et les comparaisons des choix de communication pour l’architecte. Le chapitre précédent a détaillé l’architecture et la conception des capteurs, et maintenant nous devons rassembler les données sur Internet. Cela nécessite une compréhension des communications et des limites du déplacement des données.
Nous commençons la discussion sur les communications à courte et longue portée par un examen des signaux RF sans fil et des facteurs contribuant à la qualité du signal, aux limitations, aux interférences, aux modèles, à la bande passante et à la portée. Il existe de nombreux protocoles de communication PAN / WAN dans différentes bandes, et l’architecte doit comprendre les avantages et les inconvénients du choix d’un spectre radio par rapport à l’autre.
À la fin de ce chapitre, vous devez comprendre les limites de la vitesse de communication radio et de la bande passante. Que vous architecturiez un appareil IoT compatible Bluetooth ou un routeur périphérique avec une radio 5G, les règles et la physique des radios s’appliquent toutes également.
Le graphique suivant permet de délimiter les divers débits et gammes de données pour les protocoles sans fil que nous couvrirons dans les chapitres suivants.
WPAN est souvent utilisé avec d’autres acronymes de communication à courte portée tels que réseau sans fil (FAN), réseau local sans fil (WLAN), réseau domestique sans fil (HAN), réseau local sans fil (NAN) et réseau sans fil corporel (WBAN):
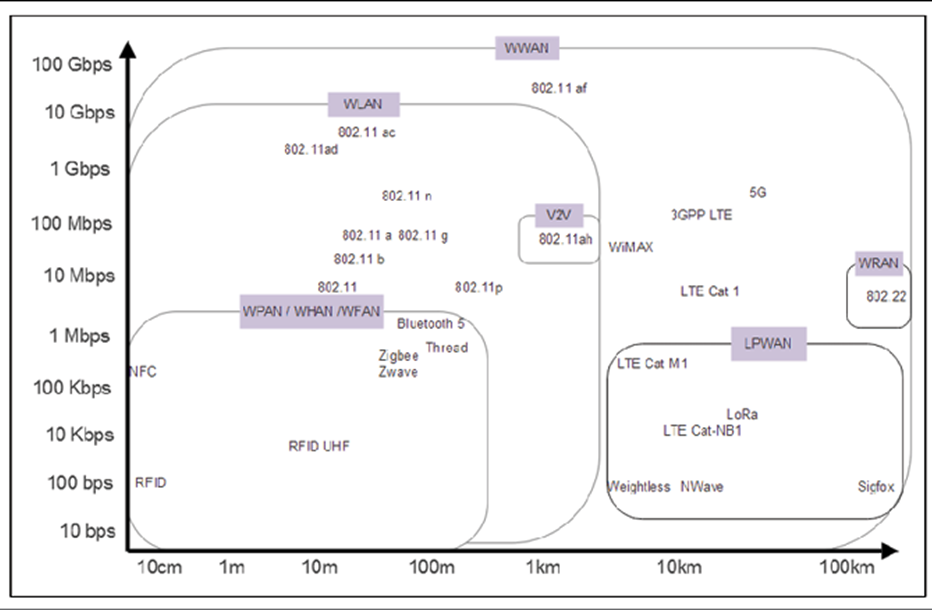
Figure 1 : Différents protocoles et catégories de communication sans fil conçus pour différentes gammes, débits de données et cas d’utilisation (alimentation, véhicule, etc.)
Ce chapitre fournira des modèles fondamentaux et une théorie sur les systèmes de communication, les espaces fréquentiels et la théorie de l’information. Des contraintes de communication et des modèles de comparaison seront fournis pour permettre à l’architecte de comprendre comment et pourquoi certains types de communication de données fonctionnent et où ils ne fonctionneront pas.
Nous commençons par la théorie de la communication car elle joue un rôle fondamental dans le choix de la bonne combinaison de technologies sans fil pour déployer une solution IoT.
4.1 Théorie de la communication
L’IoT est un conglomérat de nombreux appareils disparates produisant et / ou consommant de manière autonome des données à l’extrémité des couches de réseaux et de protocoles. Il est important de comprendre les contraintes de la construction de systèmes de communication pour l’IoT ou toute forme de mise en réseau. L’IoT combinera les réseaux corporels, les réseaux personnels, les réseaux locaux et les réseaux étendus à longue portée en un réseau de canaux de communication.
La plupart de ce qui rend l’IoT possible est construit autour d’un tissu de communication ; par conséquent, ce chapitre est consacré à l’examen des principes fondamentaux des réseaux et des systèmes de communication. Nous allons maintenant nous concentrer sur les systèmes de communication et de signalisation. Nous explorerons la gamme, l’énergie et les limites des systèmes de communication et comment l’architecte utilisera ces outils pour développer une solution IoT réussie.
4.1.1 Énergie RF et plage théorique
Il est important, lorsque l’on parle de réseaux personnels sans fil ou de tout protocole sans fil RF, de considérer la portée de transmission. Les protocoles concurrents utilisent la portée, la vitesse et la puissance comme différenciateurs. En tant qu’architectes, nous devons considérer différents protocoles et choix de conception lors de la mise en œuvre d’une solution complète. La portée de transmission est basée sur la distance entre les antennes émettrice et réceptrice , la fréquence de transmission et la puissance de transmission.
La meilleure forme de transmission RF est une ligne de vue dégagée dans une zone sans signal radio. Dans la plupart des situations, ce modèle idéal n’existera pas. Dans le monde réel, il y a des obstructions, des réflexions de signaux, plusieurs signaux RF sans fil et du bruit.
Lorsque vous envisagez un WAN particulier et un signal de vitesse plus lente comme 900 MHz par rapport à un signal porteur de 2,4 GHz, vous pouvez dériver l’atténuation d’une fonction de la longueur d’onde pour chaque fréquence. Cela fournira des indications sur la puissance du signal à n’importe quelle plage. La forme générale de l’équation de transmission de Friis nous aide ici :
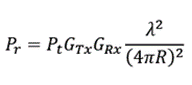
La variante en décibels (dB) de l’équation de Friis est donnée comme suit:
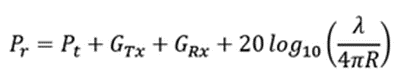
où G Tx et G Rx sont les gains d’antenne de l’émetteur et du récepteur, R est la distance entre l’émetteur et le récepteur, et P R et P T sont respectivement la puissance du récepteur et de l’émetteur.
La figure suivante illustre l’équation:

Figure 2 : représentation graphique de l’équation de Friis
Un signal de 900 MHz à 10 mètres aura une perte de 51,5 dB et un signal de 2,4 GHz à 10 mètres aura une perte de 60,0 dB.
Nous pouvons prouver comment la puissance et la portée affectent la qualité d’un signal en utilisant un rapport appelé bilan de liaison. Il s’agit d’une comparaison de la puissance de transmission au niveau de sensibilité et mesurée sur l’échelle logarithmique (dB). On peut simplement vouloir augmenter le niveau de puissance pour répondre aux exigences de la gamme, mais dans de nombreux cas, cela viole la conformité réglementaire ou affecte la durée de vie de la batterie. L’autre option consiste à améliorer le niveau de sensibilité du récepteur, ce qui est exactement ce que Bluetooth 5 a fait dans les dernières spécifications. Le bilan de liaison est donné par le rapport de la puissance de l’émetteur sur la sensibilité du récepteur, comme indiqué :

Le bilan de liaison est mesuré sur l’échelle logarithmique dB; par conséquent, l’ajout de décibels équivaut à multiplier les ratios numériques, ce qui nous donne l’équation:

En supposant qu’aucun facteur ne contribue aux gains de signal (par exemple, les gains d’antenne), les deux seules façons d’améliorer la réception sont d’augmenter la puissance d’émission ou de diminuer la perte.
Lorsque les architectes doivent modéliser la plage maximale d’un protocole particulier, ils utilisent la formule de perte de chemin en espace libre (FSPL). Il s’agit de la quantité de perte de signal d’une onde électromagnétique sur une ligne de visée dans l’espace libre (pas d’obstacles). Les facteurs contributifs de la formule FSPL sont la fréquence ( f ) du signal, la distance ( R ) entre l’émetteur et le récepteur, et la vitesse de la lumière ( c ). En termes de calcul de la formule FSPL en décibels, l’équation est :

La formule FSPL est un simple calcul de premier ordre. Une meilleure approximation prend en compte les réflexions et les interférences d’ondes du plan terre-terre, comme la formule de perte de terre du plan. Ici, h t est la hauteur de l’antenne d’émission et h r est la hauteur de l’antenne de réception. k représente le nombre d’onde en espace libre et est simplifié comme indiqué. Nous convertissons l’équation pour utiliser la notation dB:
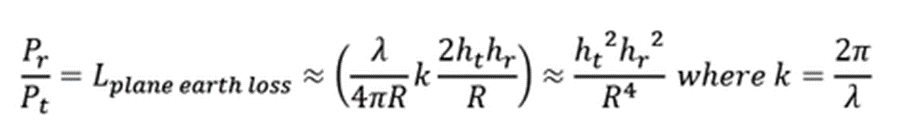
Ce qui est remarquable de la perte de terre plane est le fait que la distance affecte la perte de 40 dB par décennie. L’augmentation de la hauteur de l’antenne aide. Les types d’interférences pouvant survenir naturellement sont les suivants :
- Réflexions : lorsqu’une onde électromagnétique se propageant frappe un objet et se traduit par plusieurs ondes
- Diffraction : lorsqu’un chemin d’ondes radioélectriques entre un émetteur et un récepteur est obstrué par des objets aux arêtes vives
- Diffusion : lorsque le milieu traversé par l’onde est composé d’objets plus petits que la longueur d’onde et que le nombre d’obstacles est important
Il s’agit d’un concept important car l’architecte doit choisir une solution WAN dont la fréquence équilibre la bande passante des données, la plage ultime du signal et la capacité du signal à pénétrer dans les objets. L’augmentation de la fréquence augmente naturellement la perte d’espace libre (par exemple, un signal de 2,4 GHz a une couverture de 8,5 dB de moins qu’un signal de 900 MHz).
De manière générale, les signaux à 900 MHz seront fiables à une distance deux fois supérieure à celle des signaux à 2,4 GHz. 900 MHz a une longueur d’onde de 333 mm contre 125 mm pour un signal 2,4 GHz. Cela permet à un signal de 900 MHz d’avoir une meilleure capacité de pénétration et moins d’effets de diffusion.
La diffusion est un problème important pour les systèmes WAN car de nombreux déploiements n’ont pas de ligne de vue libre entre les antennes – au lieu de cela, le signal doit pénétrer les murs et les sols. Certains matériaux contribuent différemment à l’atténuation d’un signal.
À 6 dB, une perte équivaut à une réduction de 50% de la force du signal, tandis qu’une perte de 12 dB équivaut à une réduction de 75%.
On voit que 900 MHz a un avantage sur 2,4 GHz en matière de pénétration des matériaux:
| Matière | Perte (dB) 900 MHz | Perte (dB) 2,4 GHz |
| Verre 25 “ | -0,8 dB | -3 dB |
| Mur de blocs de brique ou de maçonnerie (8 “) | -13 dB | -15 dB |
| Sheet rock | -2 dB | -3 dB |
| Porte en bois massif | -2 dB | -3 dB |
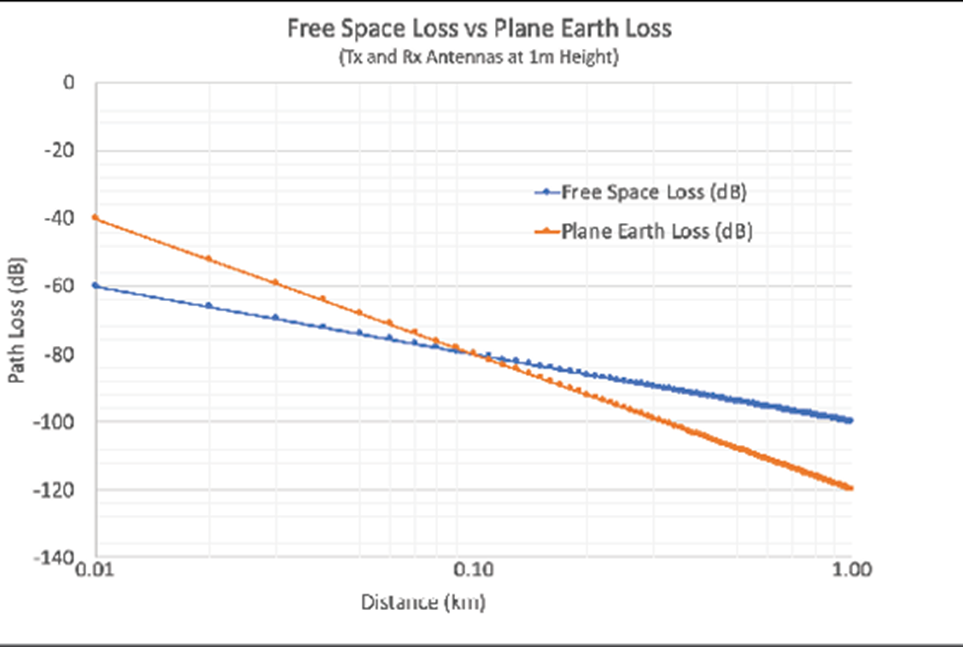
Figure 3: Perte d’espace libre par rapport à la perte de terre plane (en dB) en utilisant un signal de 2,4 GHz avec des antennes à 1 mètre de haut
Comme nous le verrons, de nombreux protocoles sont disponibles dans le commerce et utilisés à l’échelle mondiale dans le spectre 2,4 GHz. 2,4 GHz fournit jusqu’à cinq fois la bande passante de données comme un signal de 900 MHz et peut avoir une antenne beaucoup plus petite. De plus, le spectre 2,4 GHz est sans licence et disponible pour une utilisation dans plusieurs pays.
| 900 MHz | 2,4 GHz | |
| Force du signal | Généralement fiable | Bande bondée sujette aux interférences |
| La distance | 67x plus de 2,4 GHz | Plus court mais peut compenser avec un encodage amélioré (Bluetooth 5) |
| Pénétration | La longue longueur d’onde peut pénétrer la plupart des matériaux et de la végétation | Potentiel d’interférence avec certains matériaux de construction. Interférence potentielle avec la vapeur d’eau. |
| Débit de données | Limité | Environ 2x à 3x plus rapide que 900 MHz |
| Interférence de signal | Le signal peut être affecté par des objets hauts et des obstructions; mieux à travers le feuillage | Moins de risque d’interférence de canal avec certains objets |
| Interférence de canal | Interférence avec les téléphones sans fil 900 MHz, les scanners RFID, les signaux cellulaires, les moniteurs pour bébé | Interférence avec le Wi-Fi 802.11 |
| Coût | Moyen | Faible |
Ces équations fournissent un modèle théorique ; aucune équation analytique ne donne une prédiction précise pour certains scénarios du monde réel tels que les pertes par trajets multiples.
4.1.2 Interférence RF
Nous verrons tout au long de ce chapitre plusieurs nouveaux schémas pour réduire les interférences de signaux. C’est un problème pour de nombreuses formes de technologie sans fil car le spectre n’est pas autorisé et partagé. (Nous en discuterons plus dans la section suivante). Parce qu’il peut y avoir plusieurs appareils émettant de l’énergie RF dans un espace partagé, des interférences se produiront.
Prenez Bluetooth et Wi-Fi 802.11; les deux fonctionnent dans le spectre partagé de 2,4 GHz mais restent fonctionnels même dans des environnements encombrés. Le Bluetooth Low Energy ( BLE ), comme nous le verrons, sélectionnera au hasard l’un des canaux 40-2 MHz comme une forme de saut de fréquence.
Nous voyons dans la figure suivante 11 canaux gratuits (trois étant de la publicité) sur BLE qui ont 15% de chances de collision (d’autant plus que le 802.11 ne saute pas entre les canaux). La nouvelle spécification Bluetooth 5 fournit des techniques telles que des masques de disponibilité des emplacements pour verrouiller les zones Wi-Fi de la liste des sauts de fréquence. D’autres techniques existent également, que nous explorerons plus loin. Ici, nous montrons la bande ILM pour Zigbee et BLE. Un conflit potentiel avec trois canaux Wi-Fi dans le spectre 2,4 GHz est également illustré.
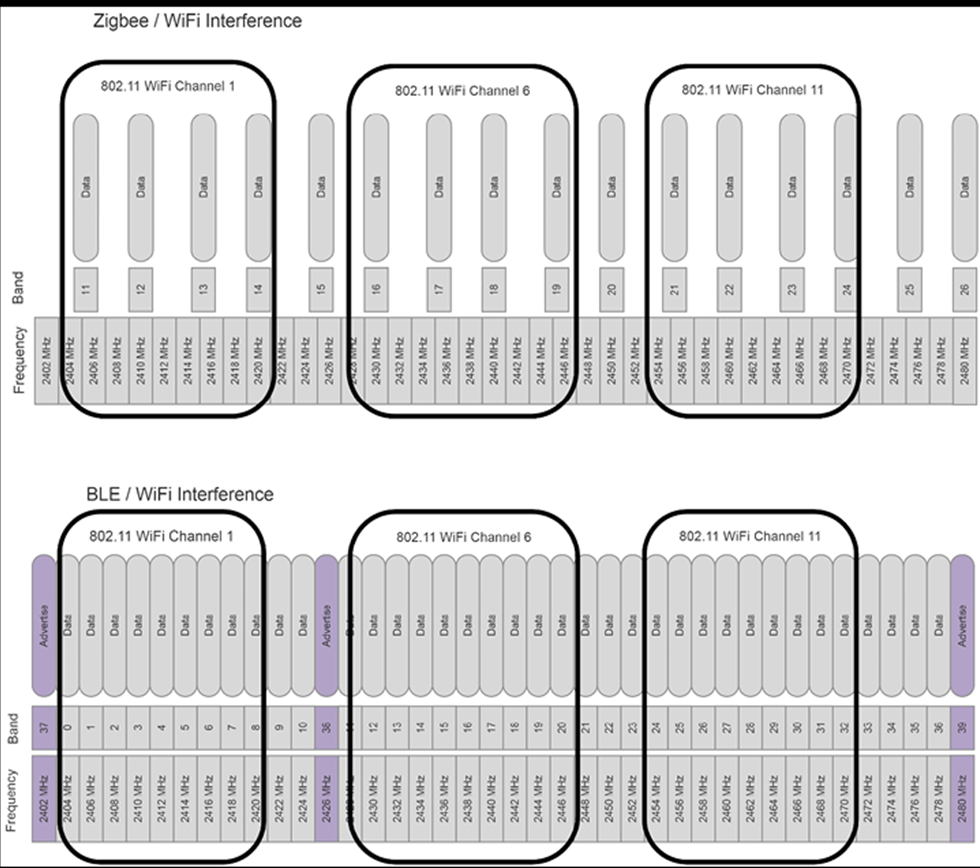
Figure 4 : Comparaison des interférences BLE et Zigbee avec les signaux Wi-Fi 802.11 dans la bande 2,4 GHz. BLE fournit plus de créneaux horaires et de sauts de fréquence pour communiquer en cas de collision Wi-Fi.
4.2 Théorie de l’information
Il existe des théories préliminaires qui doivent être comprises avant de détailler les spécificités du WAN. Une chose qui est pertinente pour la communication est de savoir comment le débit binaire affecte la puissance de transmission, qui à son tour affecte la portée. Il y a des limites à l’intégrité des données et des débits, comme nous l’apprendrons. De plus, nous devons classer les communications à bande étroite par rapport aux communications à large bande.
4.2.1 Limites de débit binaire et théorème de Shannon-Hartley
Dans la communication longue portée et la communication courte portée, l’objectif est de maximiser le débit et la distance dans les limites du spectre et du bruit. Le théorème de Shannon-Hartley est composé des travaux de Claude Shannon du MIT dans les années 1940 (CE Shannon (1949/1998). The Mathematical Theory. Communication. Urbana, IL: University of Illinois Press) et Ralph Hartley de Bell Labs dans les années 1920 ( RVL Hartley (juillet 1928). « Transmission de l’information » (PDF). Journal technique du système Bell). Le travail de base a été développé par Harry Nyquist, également de Bell Labs, qui a déterminé le nombre maximum d’impulsions (ou bits) qui pourraient voyager dans un télégraphe dans une unité de temps (H. Nyquist, Certains sujets dans la théorie de la transmission télégraphique, dans Transactions de l’American Institute of Electrical Engineers, vol. 47, n ° 2, pp. 617-644, avril 1928).
Essentiellement, Nyquist a développé une limite d’échantillonnage qui détermine la quantité de bande passante théorique dont on dispose à un taux d’échantillonnage donné. C’est ce qu’on appelle le taux de Nyquist et est illustré dans l’équation suivante :

Ici, f p est la fréquence d’impulsion et B est la largeur de bande en hertz. Cela indique que le débit binaire maximal est limité à deux fois la fréquence d’échantillonnage. En regardant les choses d’une autre manière, l’équation identifie le débit binaire minimum auquel un signal à largeur de bande finie doit être échantillonné pour conserver toutes les informations. Le sous-échantillonnage entraîne un effet de repliement et une distorsion.
Hartley a ensuite imaginé un moyen de quantifier les informations dans ce qu’on appelle le débit de ligne. Le débit de ligne peut être considéré comme des bits par seconde (par exemple, Mbps). Ceci est connu comme la loi de Hartley et est le précurseur du théorème de Shannon. La loi de Hartley indique simplement que le nombre maximal d’amplitudes d’impulsions distinctes pouvant être transmises de manière fiable est limité par la plage dynamique du signal et la précision avec laquelle un récepteur peut interpréter avec précision chaque signal individuel. Voici la loi de Hartley en termes de M (nombre de formes d’amplitude d’impulsion uniques), qui est équivalente au rapport du nombre de tension :
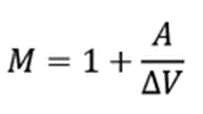
La conversion de l’équation en un journal de base 2 nous donne le débit de ligne R :
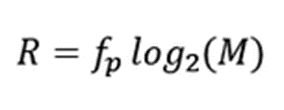
Si nous combinons esta Avec le taux PRÉCÉDANT de Nyquist, on obtient le nombre maximum d’impulsions peut être transmis sur un seul canal Ce largeur de bande B. Hartley, cependant, n’a pas travaillé avec précision ; la valeur de M (nombre d’impulsions distinctes) pourrait être affectée par le bruit.
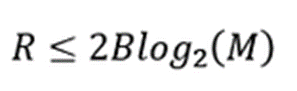
Shannon a renforcé l’équation de Hartley en considérant les effets du bruit gaussien et a complété l’équation de Hartley avec un rapport signal / bruit. Shannon a également introduit le concept de codage à correction d’erreur au lieu d’utiliser des amplitudes d’impulsion distinctes individuellement. Cette équation est affectueusement connue sous le nom de théorème de Shannon-Hartley :
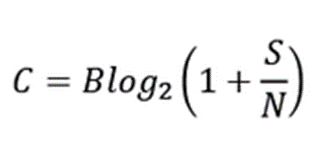
Ici, C’est la capacité du canal en bits par seconde, B est la largeur de bande du canal en hertz, S est le signal reçu moyen mesuré en watts, et N est le bruit moyen sur le canal mesuré en watts. L’effet de cette équation est subtil mais important. Pour chaque augmentation de niveau de décibels du bruit sur un signal, la capacité chute précipitamment. De même, l’amélioration du rapport signal / bruit augmentera la capacité. Sans aucun bruit, la capacité serait infinie.
Il est également possible d’améliorer le théorème de Shannon-Hartley en ajoutant un multiplicateur n à l’équation. Ici, n représente des antennes ou des tuyaux supplémentaires. Nous avons précédemment examiné cela comme une technologie à entrées multiples et sorties multiples (MIMO).

Pour comprendre comment la règle de Shannon s’applique aux limites des systèmes sans fil mentionnées dans cet article, nous devons exprimer l’équation en termes d’énergie par bit plutôt qu’en rapport signal / bruit (SNR). Un exemple utile dans la pratique est de déterminer le SNR minimum nécessaire pour atteindre un certain débit binaire. Par exemple, si nous voulons transmettre C = 200 kbps sur un canal avec une capacité de bande passante de B = 5000 kbps, alors le SNR minimum requis est donné comme :
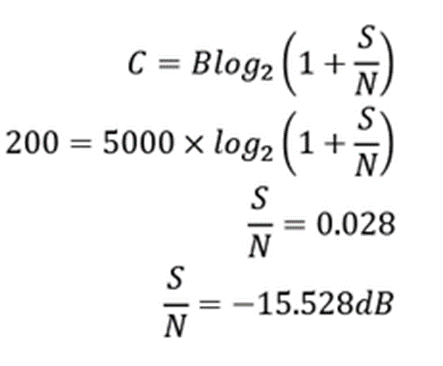
Cela montre qu’il est possible de transmettre des données en utilisant un signal plus faible que le bruit de fond.
Il y a cependant une limite au débit de données. Pour montrer l’effet, soit E b représente l’énergie d’un seul bit de données en joules. Soit N 0 la densité spectrale du bruit en watts / hertz. E b / N 0 est une unité sans dimension (cependant, généralement exprimée en dB) qui représente le SNR par bit, ou communément appelé efficacité énergétique. Les expressions d’efficacité énergétique suppriment les biais des techniques de modulation, du codage d’erreur et de la bande passante du signal de l’équation. Nous supposons que le système est parfait et idéal tel que R B = C où R est le débit. Le théorème de Shannon-Hartley peut être réécrit comme :
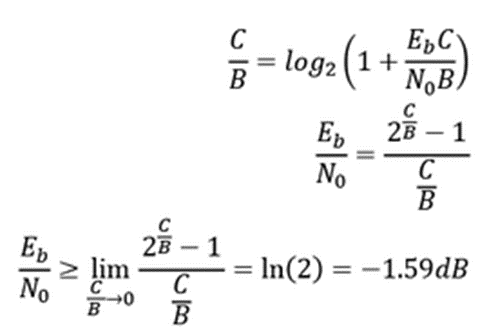
C’est ce qu’on appelle la limite de Shannon pour un bruit gaussien blanc additif (AWGN). Un AWGN est un canal et est simplement une forme de bruit de base couramment utilisée en théorie de l’information pour exprimer les effets de processus aléatoires dans la nature. Ces sources de bruit sont toujours présentes dans la nature et incluent des éléments tels que les vibrations thermiques, le rayonnement du corps noir et les effets résiduels du Big Bang. L’aspect “blanc” du bruit implique que des quantités égales de bruit sont ajoutées à chaque fréquence.
La limite peut être tracée sur un graphique montrant l’efficacité spectrale par rapport au SNR par bit :
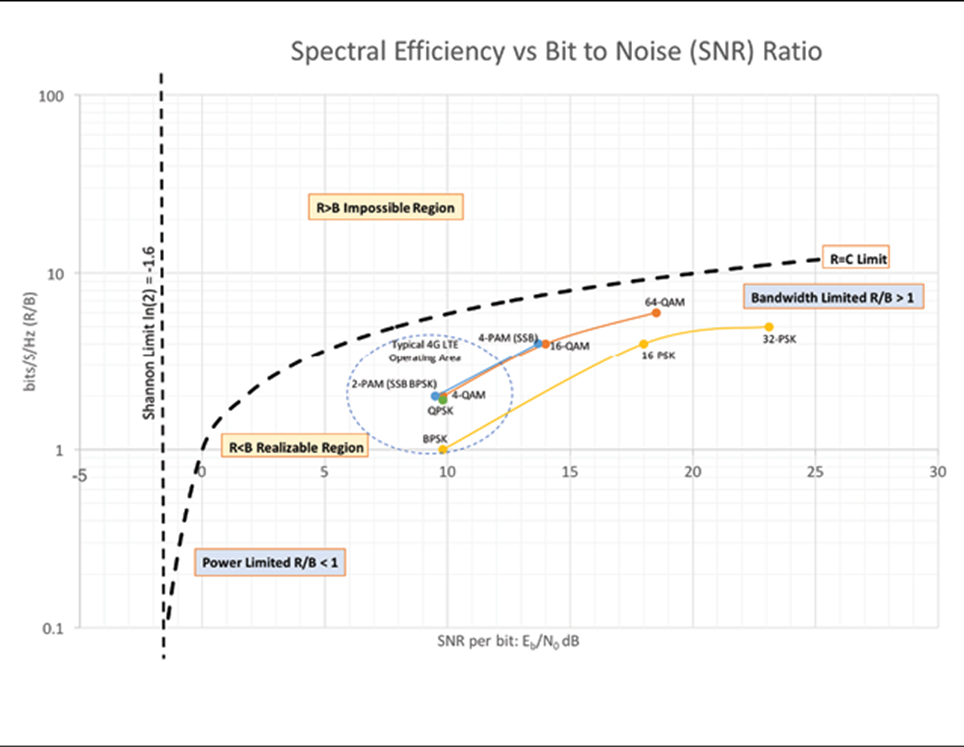
Figure 5 : Courbe efficacité spectrale / SNR (efficacité énergétique). La ligne pointillée représente la limite de Shannon, qui converge à ln (2) = – 1,6. Divers schémas de modulation sont présentés sous la limite de Shannon avec la gamme typique de signaux 4G-LTE.
Les régions d’intérêt sur la figure incluent la région impossible R> B. Cette région est au-dessus de la limite de Shannon de la courbe. Il indique qu’aucune forme fiable d’échange d’informations ne peut dépasser la limite. La région au-dessous de la limite de Shannon est appelée la région réalisable et est où R <B. Chaque protocole et technique de modulation dans toute forme de communication tente de se rapprocher le plus possible de la limite de Shannon. Nous pouvons voir où existent les 4G-LTE typiques utilisant diverses formes de modulation.
Il existe deux autres régions d’intérêt. Une région à largeur de bande limitée vers le haut à droite permet une efficacité spectrale élevée et de bonnes valeurs E b / N 0 SNR. La seule contrainte dans cet espace consiste à échanger une efficacité spectrale fixe ou obligatoire contre la puissance non contrainte de transmission P, ce qui signifie que la capacité a considérablement augmenté sur la bande passante disponible. L’effet inverse est appelé la région Power Limited vers le bas à gauche du graphique. La région de Power Limited est l’endroit où le rapport E b / N 0 SNR est très faible ; par conséquent, la limite de Shannon nous oblige à de faibles valeurs d’efficacité spectrale. Ici, nous sacrifions l’efficacité pour obtenir une qualité de transmission spectrale donnée P.
Un exemple de cas d’utilisation à puissance limitée est un véhicule de vol spatial, comme la sonde Cassini à Saturne. Dans ce cas, la perte de signal sur le trajet en espace libre est extrêmement importante et le seul moyen d’obtenir des données fiables est de réduire le débit de données à des valeurs très faibles. Nous voyons également cela dans Bluetooth 5 en utilisant le nouveau PHY codé BLE. Dans ce cas, Bluetooth passe de 1 ou 2 Mbps à 125 kbps pour améliorer la portée et l’intégrité des données.
Le graphique montre également certains schémas de modulation typiques utilisés aujourd’hui, tels que le déphasage, la QAM et autres. La limite de Shannon montre également que l’amélioration arbitraire d’une technique de modulation telle que la modulation d’amplitude en quadrature pour 4-QAM à 64-QAM n’est pas mise à l’échelle de façon linéaire. L’avantage des ordres de modulation plus élevés (par exemple, 4-QAM contre 64-QAM) est le fait que vous pouvez transmettre plus de bits par symbole (deux contre six). Les principaux inconvénients des ordres de modulation plus élevés sont :
- L’utilisation de modulations d’ordre supérieur nécessite des SNR toujours plus importants pour fonctionner.
- Des ordres de modulation plus élevés nécessitent des circuits beaucoup plus sophistiqués et des algorithmes DSP contribuant à la complexité.
- Augmenter le transfert de bits par symbole augmentera le taux d’erreur.
Le théorème de Shannon indique qu’il existe un taux maximal d’informations pouvant être transmises sur un canal de communication en présence de bruit blanc gaussien additif. À mesure que le bruit diminue, le taux d’information augmente mais a une limite ultime qui ne peut pas être violée. Dans toute situation, si le débit de transmission R est inférieur à la capacité du canal C, alors il devrait y avoir une méthode ou une technologie pour transmettre les données sans erreur.
4.2.2 Taux d’erreur sur les bits
Une autre caractéristique importante de la transmission de données est le taux d’erreur binaire ( BER ), qui fait référence au nombre d’erreurs binaires reçues sur un canal de communication. Le BER est une mesure sans unité exprimée en rapport ou en pourcentage. Par exemple :
Si une séquence de transmission d’origine est 1 0 1 0 1 1 0 1 0 0 et la séquence reçue est 0 0 1 0 1 0 1 0 1 0 (différences en gras), alors le BER est de 5 erreurs / 10 bits transférés = 50%
Le BER est affecté par le bruit de canal, les interférences, l’évanouissement par trajets multiples et l’atténuation. Les techniques pour améliorer le BER comprennent l’augmentation de la puissance de transmission, l’amélioration de la sensibilité du récepteur, l’utilisation de techniques de modulation d’ordre moins dense / inférieur ou l’ajout de données plus redondantes. La dernière technique est généralement appelée correction d’erreur directe (FEC). FEC ajoute simplement des informations supplémentaires à une transmission. Dans le sens le plus élémentaire, on ajouterait une triple redondance et un algorithme de vote majoritaire ; Cependant, cela réduirait la bande passante de 3 fois. Les techniques FEC modernes incluent les codes Hamming et les codes corrects d’erreur Reed-Solomon. Le BER peut être exprimé en fonction de E b / N 0 SNR.
Le diagramme suivant montre une variété de techniques de modulation et leurs BER respectifs pour divers SNR :
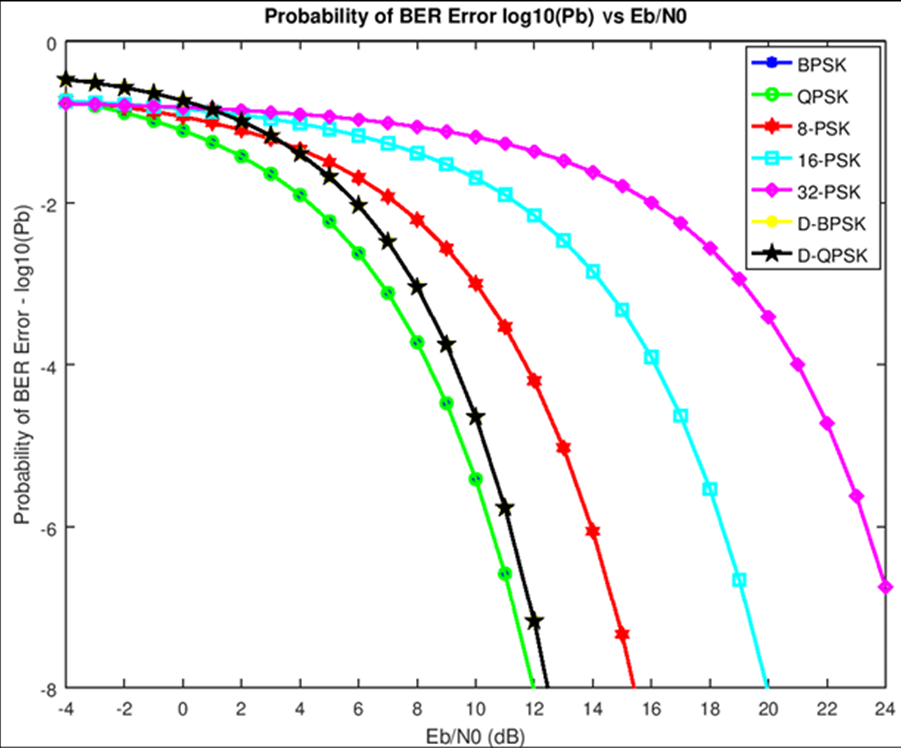
Figure 6: Taux d’erreur binaire (Pb) en fonction du rendement énergétique ( E b / N 0 ) SNR pour divers schémas de modulation. Lorsque le SNR augmente vers la droite, le BER diminue naturellement.
Ce qui doit être compris à ce stade est le suivant :
- Nous pouvons maintenant calculer le SNR minimum nécessaire pour atteindre un certain débit de données pour un système.
- La seule façon d’ajouter plus de capacité ou de bande passante à un service sans fil est de :
- Ajoutez plus de spectre et de capacité de canal, ce qui améliore la bande passante de manière linéaire.
- Ajoutez plus d’antennes (MIMO), ce qui améliore la bande passante de façon linéaire.
- Améliorez le SNR avec des antennes et des récepteurs avancés, ce qui améliore uniquement l’équation logarithmiquement.
- La limite de Shannon est la limite ultime de la transmission numérique ; dépasser la limite est possible, mais l’intégrité des données sera perdue.
- Les facteurs qui contribuent au bruit et la représentation du SNR.
- On ne peut pas simplement augmenter les niveaux de modulation sans entraîner de coûts liés aux taux d’erreur et à la complexité.
Pour les signaux cellulaires 4G-LTE, qui sont traités plus loin dans cet article, il fonctionne dans le spectre 700 MHz à 5 GHz avec des dizaines de bandes séparées dans cette plage. Un téléphone portable (ou un appareil IoT basé sur batterie) a beaucoup moins de puissance qu’une tour de téléphonie cellulaire, mais il arrive souvent qu’un appareil IoT transmette des données de capteur au cloud. La liaison montante de l’appareil IoT est ce que nous examinons ici. La limite de la puissance de liaison montante est de 200 mW, soit 23 dBm. Cela limite la portée globale de la transmission ; cette limite, cependant, est dynamique et variera en fonction de la bande passante du canal et du débit de données. Les systèmes 4G, comme plusieurs appareils WPAN et WLAN, utilisent le multiplexage orthogonal à répartition en fréquence. Chaque canal possède de nombreuses sous-porteuses pour résoudre les problèmes d’évanouissement par trajets multiples. Si vous additionnez toutes les données transmises sur des sous-porteuses, vous obtenez des débits de données élevés.
La 4G-LTE utilise généralement des canaux à 20 MHz et le LTE-A peut utiliser des canaux à 100 MHz. Ces canaux larges sont limités par le spectre global de disponibilité et sont en conflit avec plusieurs opérateurs (ATT, Verizon, etc.) et d’autres technologies partageant le spectre.
Une complexité supplémentaire de la communication cellulaire est qu’une porteuse peut avoir des parties du spectre divisées et disjointes les unes des autres.
Cat-3 LTE peut utiliser des canaux 5, 10 ou 20 MHz. La plus petite granularité de canal est de 1,4 MHz. Le LTE-A est autorisé à agréger jusqu’à cinq canaux de 20 MHz pour une bande passante agrégée de 100 MHz.
Une méthode pour mesurer la distance à laquelle un appareil sans fil est fonctionnel est la perte de couplage maximale (MCL). Le MCL est la distance maximale à laquelle une perte totale de canal se produit entre un émetteur et une antenne de réception, mais le service de données peut toujours être fourni. MCL est un moyen très courant de mesurer la couverture d’un système. Le MCL comprendra les gains d’antenne, la perte de trajet, l’ombrage et d’autres effets radio. Généralement, un système 4G-LTE aura un MCL d’environ 142 dB. Nous revisiterons MCL lors de l’examen des technologies IoT cellulaires telles que Cat-M1.
Ce que nous devons comprendre à ce stade, c’est que si nous augmentons le temps d’écoute par bit, le niveau de bruit diminuera. Si nous réduisons le débit binaire de 2x, alors ce qui suit est vrai: (Bit_Rate / 2) = (Bit_Duration * 2) . De plus, l’énergie par bit augmente de 2x et l’énergie sonore augmente de sqrt (2). Par exemple, si nous réduisons le Bit_Rate de 1 Mbps à 100 kbps, alors Bit_Duration = augmente de 10x. La plage s’améliore de sqrt (10) = 3,162x.
4.2.3 Communication à bande étroite versus communication à large bande
Bon nombre des protocoles sans fil que nous couvrirons sont appelés large bande. Nous verrons que l’inverse (bande étroite) a également sa place, notamment pour LPWAN. Les différences entre bande étroite et large bande sont les suivantes :
- Bande étroite : canal radio dont la bande passante opérationnelle ne dépasse pas la bande passante de cohérence du canal. Généralement, lorsque nous parlons de bande étroite, nous entendons des signaux dont la largeur de bande est de 100 kHz ou moins. En bande étroite, les trajets multiples entraînent des changements d’amplitude et de phase. Un signal à bande étroite s’estompe uniformément, donc l’ajout de fréquences ne profite pas au signal. Les canaux à bande étroite sont également appelés canaux à évanouissement plat car ils passent généralement toutes les composantes spectrales avec un gain et une phase égale.
- Large bande : canal radio dont la largeur de bande de fonctionnement peut dépasser considérablement sa largeur de bande de cohérence. Celles-ci ont généralement une largeur de bande supérieure à 1 MHz. Ici, les trajets multiples provoquent le problème “d’auto-interférence”. Les canaux à large bande sont également appelés sélectifs en fréquence, car différentes parties du signal global seront affectées par les différentes fréquences en large bande. C’est pourquoi les signaux à large bande utilisent une gamme de fréquences diversifiée pour répartir la puissance sur de nombreuses bandes de cohérence afin de réduire les effets de décoloration.
Le temps de cohérence est une mesure du temps minimum requis pour qu’un changement d’amplitude ou de phase ne soit pas corrélé de la valeur précédente.
Nous avons couvert certaines formes d’effets de décoloration ; cependant, il y en a beaucoup plus. La perte de chemin est un cas typique où la perte est proportionnelle à la distance. L’ombrage est l’endroit où le terrain, les bâtiments et les collines créent des obstructions de signal par rapport à l’espace libre, et la décoloration par trajets multiples se produit avec la diffusion recombinée et l’interférence des ondes d’un signal radio sur les objets (en raison de la diffraction et des réflexions). Les autres pertes comprennent les décalages Doppler si le signal RF est dans un véhicule en mouvement. Il existe deux catégories de phénomène de décoloration :
- Évanouissement rapide : c’est une caractéristique de l’évanouissement à trajets multiples lorsque le temps de cohérence est petit. Le canal changera tous les quelques symboles ; par conséquent, le temps de cohérence sera faible. Ce type de décoloration est également connu sous le nom de décoloration de Rayleigh, qui est la probabilité de variances aléatoires qui provoquent un signal RF en raison de particules atmosphériques ou de zones métropolitaines fortement bâties.
- Décoloration lente : cela se produit lorsque le temps de cohérence est long et qu’il y a un mouvement sur de longues distances généralement dû à la propagation ou à l’ombrage Doppler. Ici, le temps de cohérence est suffisamment long pour transmettre avec succès beaucoup plus de symboles qu’un chemin de fondu rapide.
La figure suivante illustre la différence entre les trajets d’évanouissement rapides et lents:
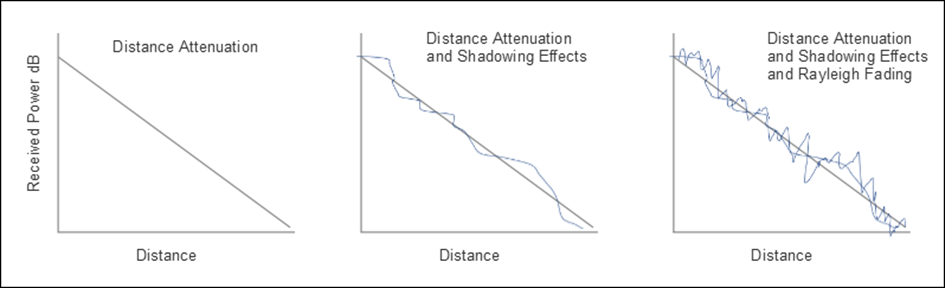
Figure 7 : Différents effets d’atténuation du signal RF. De gauche à droite : Perte de trajectoire générale sur une ligne de visée. Milieu : effets de la décoloration lente due aux grandes structures ou aux terrains. Droite : effets combinés de la distance, de la décoloration lente et de la décoloration rapide.
Nous verrons que les technologies utilisant des signaux à bande étroite utilisent ce que l’on appelle la diversité temporelle pour surmonter les problèmes de décoloration rapide. La diversité temporelle signifie simplement que le signal et la charge utile sont transmis plusieurs fois dans l’espoir que l’un des messages passe.
Dans un scénario à trajets multiples, l’étalement du retard est le temps entre les impulsions de divers signaux à trajets multiples. Plus précisément, il s’agit du délai entre la première arrivée d’un signal et la première arrivée d’une composante à trajets multiples du signal.
La largeur de bande de cohérence est définie comme la plage statistique de fréquences dans laquelle un canal est considéré comme plat. Il s’agit d’une période de temps où deux fréquences sont susceptibles d’avoir un évanouissement comparable. La largeur de bande de cohérence B c est inversement proportionnelle à l’étalement de retard D :
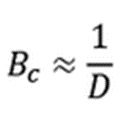
L’heure à laquelle un symbole peut être transmis sans interférence entre symboles est 1 / D . La figure suivante illustre la largeur de bande de cohérence pour les communications à bande étroite et à large bande. Étant donné que la large bande est plus grande que la largeur de bande de cohérence B c , elle est plus susceptible d’avoir des attributs d’évanouissement indépendants. Cela implique que différentes composantes de fréquence subiront une atténuation non corrélée, tandis que les composantes de fréquence à bande étroite s’inscrivent toutes dans B c et subiront une atténuation uniforme.

Figure 8: Largeur de bande de cohérence et effets sur la bande étroite et la large bande: les fréquences f 1 et f 2 s’estomperont indépendamment si | f 1 – f 2 | B c . Ici, il est clairement démontré que la bande étroite réside dans B c , et la bande large dépasse clairement la plage de B c d’une certaine marge.
Il faut s’assurer que le temps entre l’envoi de plusieurs signaux à partir d’un scénario à trajets multiples est suffisamment étendu pour ne pas interférer avec les symboles. C’est ce qu’on appelle l’interférence intersymbole (ISI). La figure suivante illustre un écart de retard trop court et provoquant un ISI. Étant donné que la largeur de bande globale B >> 1 / T (où T est le temps de largeur d’impulsion) et B1 / D est implicite, nous pouvons alors généralement déclarer que la largeur de bande doit être beaucoup plus grande que la largeur de bande de cohérence : B >> B .
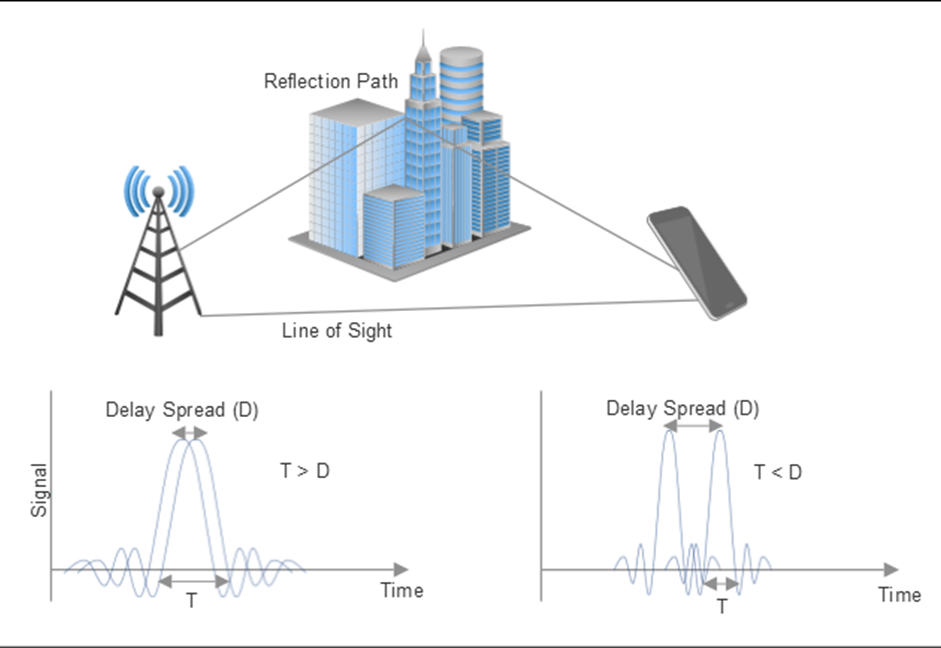
Figure 9: Exemple d’étalement de retard: deux signaux provenant d’un événement à trajets multiples. Si la propagation de retard D est inférieure à l’impulsion de largeur T, les signaux peuvent être épandus pas assez loin pour remplacer un autre composant multivoie, alors que si la propagation de retard est assez grande, il peut y avoir aucune multivoie avec fl ict.
Généralement, les basses fréquences ont une plus grande capacité de pénétration et moins d’interférences, mais elles nécessitent des antennes plus grandes et ont moins de bande passante disponible pour la transmission. Les fréquences plus élevées ont une plus grande perte de chemin mais des antennes plus petites et une plus grande bande passante.
Le débit global sera affecté par la propagation du retard. Par exemple, disons que nous utilisons la modulation QPSK et que le BER est de 10 -4 ; puis pour différents écarts de retard (D), nous avons :
- D = 256 μS: 8 Ko / s
- D = 2,5 μS: 80 Ko / s
- D = 100 ns: 2 Mbps
4.3 Le spectre radioélectrique
La communication sans fil est basée sur les ondes radio et les bandes de fréquences dans le spectre radio global. Nous couvrirons la communication à longue portée dans le prochain chapitre pour les cellulaires et autres médiums à longue portée. Ici, nous nous concentrons sur la plage de 1000 mètres ou moins. Nous examinerons le processus d’attribution du spectre ainsi que les utilisations de fréquence typiques pour les périphériques WAN.
4.3.1 Structure de gouvernance
Le spectre varie de 3 Hz à 3 THz, et l’attribution dans le spectre est régie par l’Union internationale des télécommunications (UIT). Une bande est considérée comme une partie du spectre qui peut être attribuée, concédée sous licence, vendue ou utilisée librement en fonction de la fréquence. Du point de vue de l’UIT, les bandes sont classées comme suit :
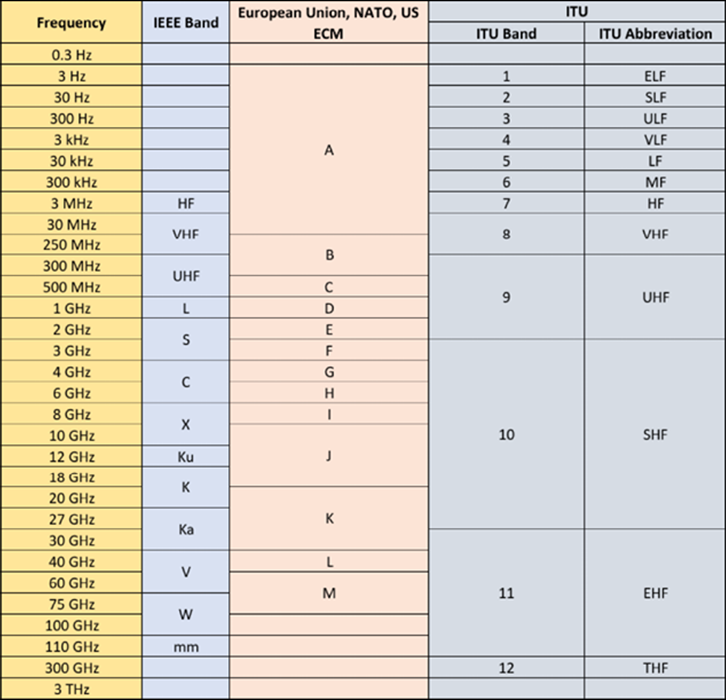
Figure 10 : Matrice d’identification des fréquences et des bandes pour IEEE, EU et ITU
Aux États-Unis, la Federal Communications Commission (FCC) et la National Telecommunications and Information Administration (NTIA) contrôlent les droits d’utilisation du spectre des fréquences. La FCC gère l’utilisation du spectre non fédéral, tandis que la NTIA gère l’utilisation fédérale (US Army, FAA, FBI, etc.).
Le spectre global géré par la FCC va du spectre KHz aux fréquences GHz comprises. La répartition et l’attribution globales des fréquences sont illustrées dans le graphique suivant. Les fréquences intéressantes qui seront discutées dans cet article sont mises en évidence.
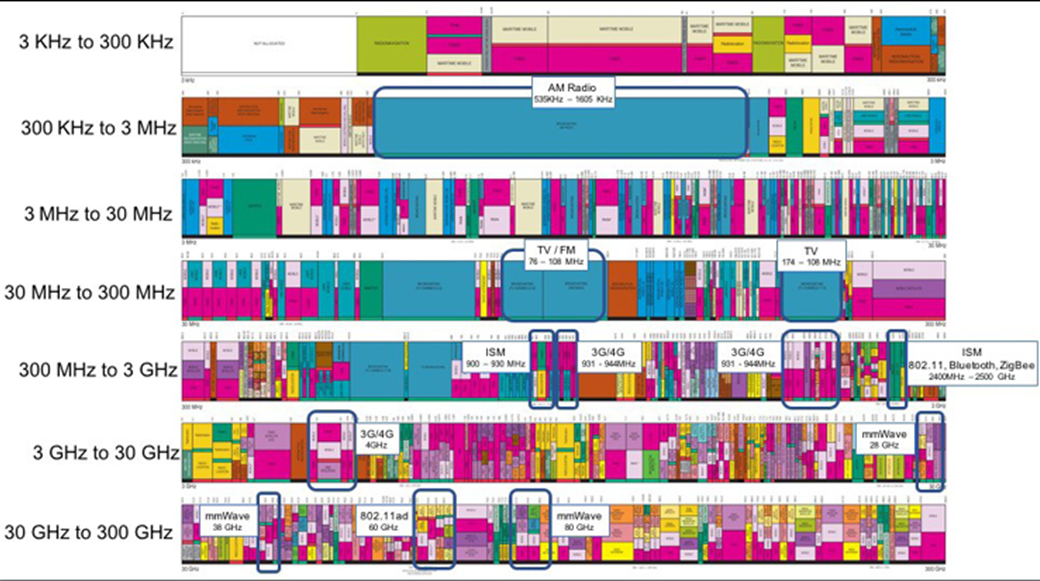
Figure 11 : Spectre d’attribution de fréquences complet de la FCC avec les faits saillants des gammes couvertes dans cet article
La figure suivante montre une petite partie de l’allocation des fréquences dans la gamme 900 MHz à 2,7 GHz (commune aux signaux WPAN) et comment les fréquences sont actuellement allouées et distribuées. Si vous souhaitez voir cette image plus en détail, veuillez vous référer à: https://www.fcc.gov/engineering-technology/policy-and-rules-division/general/radio-spectrum-allocation . Dans de nombreux domaines, l’utilisation est polyvalente et partagée:
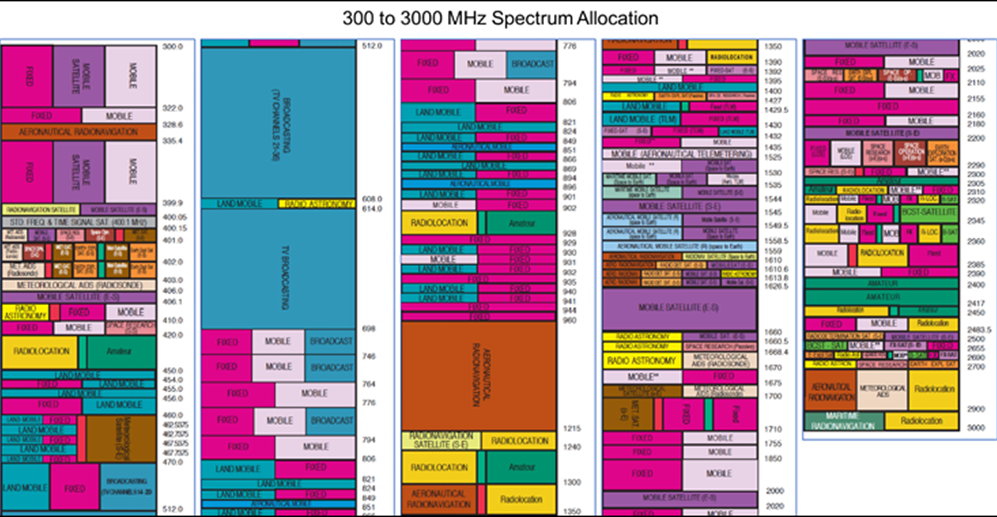
Figure 12 : Diagramme d’attribution des fréquences FCC et NTIA entre 300 MHz et 3 GHz. Le diagramme représente une petite partie de l’attribution globale des fréquences. Source: FCC, «United States Frequency Allocations: The Radio Spectrum», octobre 2003
La FCC attribue également des fréquences dans des spectres sous licence et sans licence. Dans les zones “sans licence” ou “exemptées de licence”, les utilisateurs peuvent fonctionner sans licence FCC mais doivent utiliser un équipement radio certifié et se conformer aux exigences techniques telles que les limites de puissance et les cycles de service. Celles-ci sont détaillées dans le document FCC Part 15 Rules. Les utilisateurs peuvent fonctionner dans ces spectres mais sont sujets aux interférences radio.
Les zones sous licence du spectre permettent une utilisation exclusive pour des zones / emplacements particuliers. L’allocation peut être accordée sur une base nationale ou en segments distincts site par site. Depuis 1994, l’exclusivité et les droits sur ces zones du spectre ont été accordés par enchères pour des zones / segments / marchés particuliers (par exemple, zones de marché cellulaire, zones économiques, etc.). Certaines bandes peuvent être un hybride des deux modèles, où les bandes peuvent avoir été autorisées sur une base site par site et les bandes ultérieures entourant ces licences ont été vendues aux enchères pour des zones géographiques ou nationales plus vastes. La FCC permet également un marché secondaire et a établi des politiques et des procédures par le biais de la location de spectre et du transfert de contrôle.
En Europe, la gouvernance de l’attribution des fréquences est contrôlée par la Commission européenne (CE). Les autres membres de l’Union européenne tentent de créer une attribution de spectre juste et équilibrée dans la région. Les pays européens étant petits et partageant plusieurs frontières, une autorité centrale est nécessaire pour parvenir à l’harmonie. La CE contrôle également le commerce et la vente de fréquences dans la région.
Les déploiements IoT utiliseront généralement les régions sous licence pour les communications à longue portée, ce qui est couvert dans le chapitre suivant. Le spectre sans licence est généralement utilisé pour les appareils industriels, scientifiques et médicaux (ISM). Pour les protocoles IoT, IEEE 802.11 Wi-Fi, Bluetooth et IEEE 802.15.4, tous résident dans le spectre sans licence 2,4 GHz.
4.4 Résumé
Ce chapitre a fourni des éléments de base pour comprendre la théorie et les limites de la communication sans fil. Davantage d’informations et une étude plus approfondie sont encouragées pour comprendre les contraintes du deuxième et du troisième ordre du transport de données. L’architecte doit comprendre les différents modèles et contraintes des signaux sans fil, la dispersion d’énergie RF, la portée et les limites fondamentales de la théorie de l’information fournies par le théorème de Shannon-Hartley. L’architecte doit également comprendre la gouvernance de l’espace des fréquences et la stratégie d’allocation. Ce chapitre fournit également un dialogue et une langue vernaculaire qui seront réutilisés dans les prochains chapitres sur WPAN, WLAN et WAN.
Le chapitre suivant commencera le voyage des données IoT du capteur vers le cloud sur son premier saut à travers un réseau personnel à courte portée. Nous construisons à partir de là vers les systèmes WLAN et WAN.
5 WPAN non IP
Les capteurs et autres objets connectés à Internet ont besoin d’une méthode de transmission et de réception d’informations. C’est le sujet des réseaux personnels ( PAN ) et de la communication à courte portée. Dans une écosphère IoT, la communication avec un capteur ou un actionneur peut être un fil de cuivre ou un réseau personnel sans fil ( WPAN ). Dans ce chapitre, nous nous concentrons sur le WPAN car c’est la méthode la plus répandue pour les connexions industrielles, commerciales et grand public aux choses d’Internet. La connectivité filaire est toujours utilisée, mais principalement dans les anciennes industries et les zones qui ne sont pas compatibles avec les radiofréquences. Il existe une grande variété de canaux de communication différents entre le terminal et Internet ; certains peuvent être construits sur une pile IP traditionnelle (6LoWPAN) et d’autres utilisent une communication non IP (protocole Internet) pour maximiser les économies d’énergie (BLE).
Nous séparons IP et non IP car les systèmes de communication basés sur IP ont besoin de plus de détails sur les ressources et les exigences pour une pile TCP / IP complète dont la communication non IP n’a pas nécessairement besoin. Les systèmes de communication non IP sont optimisés pour les coûts et la consommation d’énergie, tandis que les solutions basées sur IP ont généralement moins de contraintes (par exemple, le Wi-Fi 802.111). Le chapitre suivant détaillera le chevauchement des IP sur le WPAN et le WLAN.
Ce chapitre couvrira les normes de communication non IP, diverses topologies de WPAN (maillage, étoile) et les contraintes et objectifs des systèmes de communication WPAN. Ces types de systèmes de communication fonctionnent dans des gammes de sous-mètres à environ 200 mètres (bien que certains puissent aller beaucoup plus loin). Nous approfondirons le protocole sans fil Bluetooth® et la nouvelle spécification Bluetooth 5.0, car il jette les bases pour comprendre d’autres protocoles et constitue une partie répandue et puissante des solutions IoT.
Ce chapitre comprendra des détails techniques sur les normes propriétaires et ouvertes. Chaque protocole de communication a été adopté pour certaines raisons et cas d’utilisation ; eux aussi seront traités dans ce chapitre. Les sujets principaux de ce chapitre incluent :
- Qualité et portée du signal RF
- Attribution de spectre sans fil
- Protocole sans fil Bluetooth avec un accent particulier sur la nouvelle spécification Bluetooth 5
- 802.15.4
- Zigbee®
- Z-Wave®
Ce chapitre explorera quatre réseaux personnels sans fil pertinents dans l’espace IoT. Une bonne partie de cette section sera consacrée au Bluetooth car il fournit un nombre important de fonctionnalités et a une présence très profonde dans l’écosphère IoT. De plus, Bluetooth 5.0 ajoute de nombreuses fonctionnalités et capacités inédites dans la spécification Bluetooth et offre une portée, une puissance, une vitesse et une connectivité qui en font la solution WPAN la plus puissante pour de nombreux cas d’utilisation. Les réseaux basés sur Zigbee, Z-Wave et IEEE 802.15.4 seront également étudiés.
Il est également utile de savoir que le terme WPAN est surchargé. À l’origine, il devait être un corps littéral et un réseau personnel sur un individu spécifique connecté à des appareils portables, mais il a maintenant élargi son sens.
5.1 Normes 802.15
De nombreux protocoles et modèles de réseau décrits dans ce chapitre sont basés sur ou ont une base dans les groupes de travail IEEE 802.15. Le groupe 802.15 d’origine a été formé pour se concentrer sur les appareils portables et a inventé l’expression réseau personnel . Les travaux du groupe se sont considérablement étendus et se concentrent désormais sur des protocoles de débit de données plus élevés, des gammes de mètres en kilomètres et des communications spécialisées. Plus d’ un million d’appareils sont expédiés chaque jour à l’aide d’une certaine forme de protocole 802.15.x. Voici une liste des divers protocoles, normes et spécifications que l’IEEE maintient et régit :
- 802.15: définitions WPAN
- 802.15.1: fondation originale du Bluetooth PAN
- 802.15.2: Spécifications de coexistence pour WPAN et WLAN pour Bluetooth
- 802.15.3: débit de données élevé (55 Mbps +) sur WPAN pour le multimédia
- 802.15.3a: améliorations PHY (couche physique) à haute vitesse
- 802.15.3b: améliorations MAC haut débit
- 802.15.3c: haute vitesse (> 1 Gbit / s) utilisant la technologie à ondes millimétriques (ondes millimétriques)
- 802.15.4: faible débit de données, conception simple et simple, spécifications de durée de vie de la batterie sur plusieurs années (Zigbee)
- 802.15.4-2011 : le cumul (spécifications ac) inclut les PHY UWB, Chine et Japon
- 802.15.4-2015 : le cumul (spécifications dp) comprend la prise en charge RFID, la bande PHY médicale, la basse énergie, les espaces blancs TV, les communications ferroviaires
- 802.15.4r (en attente) : protocole de télémétrie
- 802.15.4s: utilisation des ressources du spectre (SRU)
- 802.15.t: PHY haut débit de 2 Mbps
- 802.15.5: réseau maillé
- 802.15.6: Mise en réseau de la zone corporelle pour le médical et le divertissement
- 802.15.7: Communications de lumière visible utilisant un éclairage structuré
- 802.15.7a: étend la portée aux UV et aux infrarouges proches, a changé le nom en sans-fil optique
- 802.15.8: Peer Aware Communications (PAC) sans infrastructure peer to peer à 10 Kbps à 55 Mbps
- 802.15.9: Key Management Protocol (KMP), norme de gestion pour la sécurité des clés
- 802.15.10: routage de maillage de couche 2, recommande le routage de maillage pour 802.15.4, multi PAN
- 802.15.12: interface de la couche supérieure, tente de rendre le 802.15.4 plus facile à utiliser que le 802.11 ou le 802.3
Le consortium a également des groupes d’intérêt (IG) qui étudient la fiabilité (IG DEP) pour aborder la fiabilité et la résilience sans fil, les communications à haut débit (HRRC IG) et les communications térahertz (THz IG).
5.2 Bluetooth
Le Bluetooth est une technologie de connectivité sans fil de faible puissance utilisée de manière omniprésente dans la technologie des téléphones cellulaires, des capteurs, des claviers et des systèmes de jeux vidéo. Le nom Bluetooth fait référence au roi Harald Blatand dans la région de ce qui est maintenant la Norvège et la Suède vers 958 après JC. Le roi Blatand tire son nom de son goût des myrtilles et / ou de la consommation de ses ennemis gelés. Quoi qu’il en soit, Bluetooth est dérivé de son nom parce que King Blatand a réuni des tribus en guerre, et la même chose pourrait être dite pour la formation du Bluetooth SIG initial. Même le logo Bluetooth est une combinaison de runes d’un ancien alphabet germanique utilisé par les Danois. Aujourd’hui, le Bluetooth est répandu, et cette section se concentrera sur le nouveau protocole Bluetooth 5 ratifié par le Bluetooth SIG en 2016. D’autres variantes seront également évoquées. Pour en savoir plus sur les anciennes technologies Bluetooth, reportez-vous au Bluetooth SIG sur www.bluetooth.org.
5.2.1 Historique Bluetooth
La technologie Bluetooth a été conçue pour la première fois à Ericsson en 1994 dans le but de remplacer la litanie de câbles et cordons reliant les périphériques informatiques à un support RF. Intel et Nokia se sont également associés avec l’intention de relier sans fil les téléphones portables aux ordinateurs de la même manière. Les trois ont formé un SIG en 1996 lors d’une conférence tenue à l’usine d’Ericsson à Lund, en Suède. En 1998, le Bluetooth SIG comptait cinq membres : Intel, Nokia, Toshiba, IBM et Ericsson. Cette année-là, la version 1.0 de la spécification Bluetooth est sortie. La version 2.0 a ensuite été ratifiée en 2005 lorsque le SIG comptait plus de 4000 membres. En 2007, le Bluetooth SIG a travaillé avec Nordic Semiconductor et Nokia pour développer le Bluetooth Ultra Low Power, qui s’appelle désormais Bluetooth Low Energy (BLE). BLE a introduit sur le marché un tout nouveau segment d’appareils capables de communiquer à l’aide d’une pile bouton. En 2010, le SIG a publié la spécification Bluetooth 4.0, qui comprenait officiellement BLE. Actuellement, plus de 2,5 milliards de produits Bluetooth sont expédiés et 30 000 membres dans le Bluetooth SIG.
Le Bluetooth est largement utilisé dans les déploiements IoT depuis un certain temps, étant le principal appareil lorsqu’il est utilisé en mode Low Energy (LE) pour les balises, les capteurs sans fil, les systèmes de suivi des actifs, les télécommandes, les moniteurs d’intégrité et les systèmes d’alarme. Le succès et l’omniprésence de Bluetooth par rapport à d’autres protocoles peuvent être attribués au timing, à la facilité de licence et à l’omniprésence des appareils mobiles. Par exemple, les dispositifs BLE sont désormais utilisés dans l’IoT sur le terrain à distance et les cas d’utilisation de l’industrie 4.0 tels que la surveillance des réservoirs d’huile.
Tout au long de son histoire, Bluetooth et tous les composants optionnels ont été sous licence GPL et sont essentiellement open source.
L’historique des révisions de Bluetooth au fur et à mesure de ses fonctionnalités et capacités s’est développé dans le tableau suivant :
| Révision | CARACTÉRISTIQUES | Date de sortie |
| Bluetooth 1.0 et 1.0B | Version initiale du débit de base Bluetooth (1 Mbps) | 1998 |
| Bluetooth 1.1 | Norme IEEE 802.15.1-2002
Défauts de spécification 0B résolus Prise en charge des canaux non cryptés Indicateur d’intensité du signal reçu (RSSI) |
2002 |
| Bluetooth 1.2 | IEEE 802.15.1-2005
Connexion et découverte rapides Spectre étalé à saut de fréquence adaptatif (AFH): Interface du contrôleur hôte (UART à trois fils) Modes de contrôle de flux et de retransmission |
2003 |
| Bluetooth 2.0 (+ EDR en option) | Mode de débit de données amélioré (EDR): 3 Mbps | 2004 |
| Bluetooth 2.1 (+ EDR en option) | Secure Simple Pairing (SSP) utilisant la cryptographie à clé publique avec quatre méthodes d’authentification uniques
La réponse d’interrogation étendue (EIR) permet un meilleur filtrage et une puissance réduite |
2007 |
| Bluetooth 3.0
(+ EDR en option) (+ HS en option) |
L2CAP mode amélioré de retransmission (de ERTMS) pour les états de connexion fiables et peu fiables
MAC / PHY (AMP) alternatif 24 Mbps utilisant des données sans connexion 802.11 PHY Unicast pour une faible latence Contrôle de puissance amélioré |
2009 |
| Bluetooth 4.0
(+ EDR en option) (+ HS en option) (+ LE en option) |
AKA BluetoothSmart
Introduction du mode Low Energy (LE) Introduction des protocoles et profils ATT et GATT Mode double : mode BR / EDR et LE Gestionnaire de sécurité avec cryptage AES |
2010 |
| Bluetooth 4.1 | Coexistence du service mobile sans fil (MWS)
Train nudging (fonction de coexistence) Balayage entrelacé (fonction de coexistence) Les appareils prennent en charge plusieurs rôles simultanés |
2013 |
| Bluetooth 4.2 | Connexions sécurisées LE
Confidentialité de la couche liaison Profil de support IPv6 |
2014 |
| Bluetooth 5.0 | Masques de disponibilité des emplacements (SAM) 2 Mbps PHY et LE
Mode longue portée LE Modes de publicité étendus LE Réseau maillé |
2016 |
| Bluetooth 5.1 | Recherche de direction
Mise en cache GATT Indexation aléatoire des canaux publicitaires Transfert de synchronisation publicitaire périodique |
2019 |
5.2.2 Processus de communication et topologies Bluetooth 5
La technologie sans fil Bluetooth comprend deux systèmes de technologie sans fil: le débit de base ( BR ) et la basse énergie ( LE ou BLE ). Les nœuds peuvent être des annonceurs, des scanners ou des initiateurs :
- Annonceur : appareils transmettant des paquets d’annonceurs
- Scanner : appareils recevant des paquets d’annonceurs sans intention de se connecter
- Initiateur : périphériques tentant d’établir une connexion
Plusieurs événements Bluetooth se produisent dans un WPAN Bluetooth :
- Publicité : elle est lancée par un appareil pour diffuser vers des appareils à balayage afin de les alerter de la présence d’un appareil souhaitant coupler ou simplement relayer un message dans le paquet publicitaire.
- Connexion : cet événement est le processus d’association d’un appareil et d’un hôte.
- Publicité périodique (pour Bluetooth 5) : cela permet à un appareil publicitaire d’annoncer périodiquement sur les 37 canaux non principaux par saut de canal à un intervalle de 7,5 ms à 81,91875 s.
- Publicité étendue (pour Bluetooth 5) : cela permet aux unités de données de protocole étendues (PDU) de prendre en charge le chaînage des publicités et les grandes charges utiles de PDU, ainsi que de nouveaux cas d’utilisation impliquant l’audio ou d’autres multimédias (traités dans la section Beaconing de ce chapitre).
En mode LE, un appareil peut terminer une communication entière en utilisant simplement le canal publicitaire. Alternativement, la communication peut nécessiter une communication bidirectionnelle par paire et forcer les appareils à se connecter formellement. Les appareils qui doivent former ce type de connexion démarreront le processus en écoutant les paquets publicitaires. L’auditeur est appelé un initiateur dans ce cas. Si l’annonceur émet un événement publicitaire connectable, l’initiateur peut faire une demande de connexion en utilisant le même canal PHY sur lequel il a reçu le paquet publicitaire connectable.
L’annonceur peut alors déterminer s’il souhaite établir une connexion. Si une connexion est établie, l’événement publicitaire se termine et l’initiateur est maintenant appelé le maître et l’annonceur est appelé l’esclave. Cette connexion est appelée un piconet dans le jargon Bluetooth et les événements de connexion se produisent. Les événements de connexion ont tous lieu sur le même canal de démarrage entre le maître et l’esclave. Une fois les données échangées et l’événement de connexion terminé, un nouveau canal peut être choisi pour la paire à l’aide d’un saut de fréquence.
Les piconets se forment de deux manières différentes selon le mode débit de base / débit de données amélioré (BR / EDR) ou le mode BLE. Dans BR / EDR, le piconet utilise l’adressage 3 bits et ne peut référencer que sept esclaves sur un piconet. Plusieurs piconets peuvent former une union et ensuite être appelés un scatternet, mais il doit y avoir un deuxième maître pour se connecter et gérer le réseau secondaire. Le nœud esclave / maître assume la responsabilité de relier deux piconets ensemble. En mode BR / EDR, le réseau utilise le même programme de sauts de fréquence et tous les nœuds seront garantis sur le même canal à un moment donné. En mode BLE, ce système utilise l’adressage 24 bits, de sorte que le nombre d’esclaves associés à un maître est de plusieurs millions. Chaque relation maître-esclave est elle-même un piconet et peut être sur un canal unique. Dans un piconet, les nœuds peuvent être un maître (M), des esclaves (S), un standby (SB) ou un parking (P). Le mode veille est l’état par défaut d’un appareil. Dans cet état, il a la possibilité d’être en mode basse consommation. Jusqu’à 255 autres appareils peuvent être en mode SB ou P sur un seul piconet.
Notez que Bluetooth 5.0 a déprécié et supprimé les états parqués dans les piconets; seuls les appareils Bluetooth jusqu’à la version 4.2 prendront en charge un état parqué. L’état de veille est toujours pris en charge par Bluetooth 5.0.
Une topologie de piconet est illustrée dans le diagramme suivant :
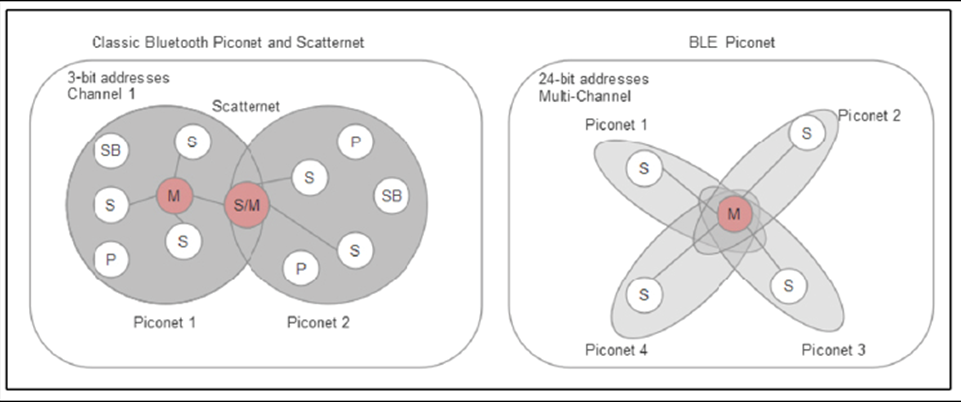
Figure 1 : La différence entre les piconets Bluetooth (BR / EDR) et BLE classiques. En mode BR / EDR, jusqu’à sept esclaves peuvent être associés sur un seul piconet en raison de l’adressage 3 bits. Ils partagent tous un canal commun entre les sept esclaves. D’autres piconets ne peuvent rejoindre le réseau et former un scatternet que si un maître associé sur le réseau secondaire est présent. En mode BLE, des millions d’esclaves peuvent rejoindre plusieurs piconets avec un seul maître grâce à l’adressage 24 bits. Chaque piconet peut être sur un canal différent mais un seul esclave peut s’associer au maître dans chaque piconet. En pratique, les piconets BLE ont tendance à être beaucoup plus petits.
5.2.3 Pile Bluetooth 5
Bluetooth a trois composants de base : un contrôleur matériel, un logiciel hôte et des profils d’application. Les appareils Bluetooth sont disponibles en versions monomode et double mode, ce qui signifie qu’ils prennent uniquement en charge la pile BLE ou qu’ils prennent en charge le mode classique et BLE simultanément. Dans la figure suivante, on peut voir la séparation entre le contrôleur et l’hôte au niveau de l’interface du contrôleur hôte (HCI). Bluetooth permet d’associer un ou plusieurs contrôleurs à un seul hôte.
5.2.3.1 Éléments de pile Bluetooth
La pile se compose de couches, ou protocoles et profils :
- Protocoles : niveaux et couches horizontaux représentant des blocs fonctionnels. Le diagramme suivant représente une pile de protocoles.
- Profils : ils représentent des fonctions verticales qui utilisent des protocoles. Les profils seront détaillés plus loin dans ce chapitre.
La figure suivante représente un schéma architectural complet de la pile Bluetooth, y compris les modes BR / EDR et BLE ainsi que le mode AMP.
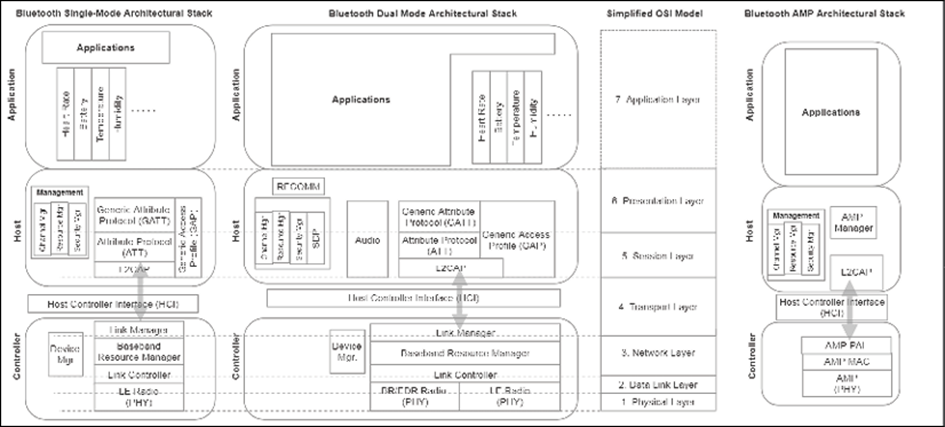
Figure 2 : Mode simple Bluetooth (BLE uniquement) et bimode (Classic et BLE) par rapport à une simpli fi ée OSI pile. Le diagramme de droite illustre le mode AMP. Notez la séparation des responsabilités entre la plate-forme logicielle hôte avec la pile supérieure et le matériel du contrôleur pour la pile inférieure. HCI est le canal de transport entre le matériel et l’hôte.
Il existe essentiellement trois modes de fonctionnement Bluetooth illustrés dans la figure précédente (chacun nécessitant un PHY différent):
- Mode LE : il utilise la bande ISM 2,4 GHz et utilise le spectre étalé à sauts de fréquence (FHSS) pour la protection contre les interférences. Le PHY diffère des radios BR / EDR et AMP par la modulation, le codage et les débits de données. LE fonctionne à 1 M de symboles / s à un débit binaire de 1 Mbps. Bluetooth 5 permet plusieurs débits de données configurables de 125 Kbps, 500 Kbps, 1 Mbps et 2 Mbps (plus à ce sujet plus tard).
- Mode BR / EDR : il utilise une radio différente de LE et AMP mais fonctionne dans la bande ISM 2,4 GHz. Le fonctionnement de base de la radio est évalué à 1 M de symboles / s et prend en charge un débit binaire de 1 Mbps. L’EDR maintient un débit de données de 2 ou 3 Mbps. Cette radio utilise le FHSS pour la protection contre les interférences.
- MAC / PHY (AMP) alternatif : il s’agit d’une fonctionnalité optionnelle qui utilise le 802.11 pour le transport à grande vitesse jusqu’à 24 Mbps. Ce mode nécessite que le périphérique maître et l’esclave prennent en charge AMP. Il s’agit d’un contrôleur physique secondaire, mais il nécessite que le système dispose d’un contrôleur BR / EDR pour établir la connexion et la négociation initiales.
Nous allons maintenant détailler la fonction de chaque élément de la pile. Nous commençons par les blocs communs de BR / EDR et LE, puis listons les détails pour AMP. Dans les trois cas, nous allons commencer par la couche physique et remonter la pile vers la couche application.
Blocs architecturaux de base – niveau contrôleur :
- BR / EDR PHY (bloc contrôleur) : responsable de la transmission et de la réception des paquets via un canal physique sur 79 canaux.
- LE PHY : Interface physique basse énergie responsable de la gestion de 40 canaux et des sauts de fréquence.
- Contrôleur de liaison : code et décode les paquets Bluetooth à partir de la charge utile des données.
- Gestionnaire de ressources en bande de base : responsable de tous les accès à la radio depuis n’importe quelle source. Il gère l’ordonnancement des canaux physiques et négocie les contrats d’accès avec toutes les entités pour garantir le respect des paramètres de qualité de service (QoS).
- Gestionnaire de liens : crée, modifie et publie des liens logiques et met à jour les paramètres liés aux liens physiques entre les périphériques. Il est réutilisé pour les modes BR / EDR et LE en utilisant différents protocoles.
- Gestionnaire de périphériques : bloquez le niveau de bande de base du contrôleur qui contrôle le comportement général de Bluetooth. Il est responsable de toutes les opérations non liées à la transmission de données, y compris la découverte ou la connexion d’appareils, la connexion à des appareils et la recherche d’appareils.
- HCI : une séparation entre l’hôte et le contrôleur de silicium dans la couche quatre de la pile réseau. Il expose des interfaces pour permettre à un hôte d’ajouter, de supprimer, de gérer et de découvrir des périphériques sur le piconet.
Blocs architecturaux de base – niveau hôte :
- L2CAP : le protocole de contrôle et d’adaptation de liaison logique. Il est utilisé pour multiplexer les connexions logiques entre deux périphériques différents en utilisant des protocoles de niveau supérieur à la couche physique. Il peut segmenter et réassembler les paquets.
- Gestionnaire de canaux : responsable de la création, de la gestion et de la fermeture des canaux L2CAP. Un maître utilisera le protocole L2CAP pour communiquer avec un gestionnaire de canaux esclaves.
- Gestionnaire de ressources : responsable de la gestion de l’ordre de soumission des fragments au niveau de la bande de base. Il permet de garantir la conformité de la qualité de service.
- Protocole Security Manager (SMP) : ce bloc est responsable de la génération des clés, des clés de qualification et du stockage des clés.
- Service Discovery Protocol (SDP) : découvre les services offerts sur d’autres appareils par UUID.
- Audio : Un profil de lecture audio en streaming efficace en option.
- RFCOMM : bloc responsable de l’émulation et de l’interfaçage RS-232. Il est utilisé pour prendre en charge la fonctionnalité de téléphonie.
- Protocole d’attribut (ATT) : Un protocole d’application de fil utilisé principalement dans BLE (mais peut s’appliquer à BR / EDR). ATT est optimisé pour fonctionner sur du matériel à batterie basse consommation BLE. Il est étroitement lié au GATT.
- Profil d’attribut générique (GATT) : bloc qui représente la fonctionnalité du serveur d’attributs et, éventuellement, du client d’attributs. Le profil décrit les services utilisés dans le serveur d’attributs. Chaque appareil BLE doit avoir un profil GATT. Il est principalement, sinon exclusivement, utilisé pour le BLE mais pourrait être utilisé sur un appareil BR / EDR vanille.
- Profil d’accès générique ( GAP ): contrôle les connexions et les états publicitaires. GAP permet à un appareil d’être visible par le monde extérieur et constitue la base de tous les autres profils.
La pile spécifique à AMP :
- AMP (PHY) : Couche physique responsable de la transmission et de la réception des paquets de données jusqu’à 24 Mbps.
- AMP MAC : couche de contrôle d’accès aux médias telle que définie dans le modèle de couche de référence IEEE 802. Il fournit des méthodes d’adresse pour le périphérique.
- AMP PAL : couche d’interfaçage du MAC AMP avec le système hôte (L2CAP et gestionnaire AMP). Ce bloc traduit les commandes de l’hôte en primitives MAC spécifiques et vice versa.
- Gestionnaire AMP : utilise L2CAP pour communiquer avec un gestionnaire AMP homologue sur un périphérique distant. Il découvre les périphériques AMP distants et détermine leur disponibilité.
5.2.3.2 Bluetooth 5 PHY et interférences
Les appareils Bluetooth fonctionnent dans la bande de fréquences sans licence industrielle, scientifique et médicale (ISM) de 2,4 000 à 2,4835 GHz. Comme mentionné précédemment dans ce chapitre, cette zone sans licence particulière est encombrée par un certain nombre d’autres médias sans fil, tels que le Wi-Fi 802.11. Pour atténuer les interférences, Bluetooth prend en charge le spectre étalé à sauts de fréquence (FHSS).
Lorsque vous avez le choix entre les modes classiques Bluetooth de BR / EDR, EDR aura moins de risques d’interférence et une meilleure coexistence avec le Wi-Fi et d’autres appareils Bluetooth car le temps d’antenne est plus court en raison de sa vitesse.
Le saut de fréquence adaptatif (AFH) a été introduit dans Bluetooth 1.2. AFH utilise deux types de canaux : utilisés et inutilisés. Les canaux utilisés sont en jeu dans le cadre de la séquence de saut. Les canaux inutilisés sont remplacés dans la séquence de saut par des canaux utilisés lorsque cela est nécessaire dans une méthode de remplacement aléatoire. Le mode BR / EDR a 79 canaux et BLE a 40 canaux.
Avec 79 canaux, le mode BR / EDR a moins de 1,5% de chances d’interférer avec un autre canal. C’est ce qui permet à un environnement de bureau d’avoir des centaines d’écouteurs, de périphériques et d’appareils tous dans la même plage qui se disputent l’espace des fréquences (par exemple, des sources d’interférences à usage fixe et continu).
AFH permet à un périphérique esclave de signaler les informations de classification de canal à un maître pour l’aider à configurer le saut de canal. Dans les situations où il y a des interférences avec le Wi-Fi 802.11, AFH est utilisé avec une combinaison de techniques propriétaires pour hiérarchiser le trafic entre les deux réseaux. Par exemple, si la séquence de saut se heurte régulièrement sur le canal 11, le maître et les esclaves du piconet négocieront et sauteront simplement sur le canal 11 à l’avenir.
En mode BR / EDR, le canal physique est divisé en slots. Les données sont positionnées pour la transmission dans des créneaux précis et des créneaux consécutifs peuvent être utilisés si nécessaire. En utilisant cette technique, Bluetooth obtient l’effet de la communication en duplex intégral via le duplexage par répartition dans le temps (TDD). BR utilise une modulation gaussienne à décalage de fréquence (GFSK) pour atteindre son débit de 1 Mbps, tandis que EDR utilise une modulation à décalage de phase quaternaire différentielle (DQPSK) à 2 Mbps et une modulation à décalage de phase différentielle à 8 phases (8DPSK) à 3 Mbps.
Le mode LE, d’autre part, utilise des schémas d’accès à accès multiple par répartition en fréquence (FDMA) et à accès multiple par répartition dans le temps (TDMA). Avec 40 canaux au lieu de 79 pour BR / EDR et chaque canal séparé par 2 MHz, le système divisera les 40 canaux en trois pour la publicité et les 37 restants pour la publicité secondaire et les données. Les canaux Bluetooth sont choisis de manière pseudo-aléatoire et sont commutés à une vitesse de 1600 sauts / seconde. La figure suivante illustre la distribution des fréquences BLE et le partitionnement dans l’espace ISM 2,4 GHz.

Figure 3 : fréquences BLE divisées en 40 bandes uniques avec une séparation de 2 MHz. Trois canaux sont dédiés à la publicité et les 37 autres à la transmission de données.
Le TDMA est utilisé pour orchestrer la communication en exigeant qu’un appareil transmette un paquet à un instant prédéterminé et que l’appareil récepteur réponde à un autre instant prédéterminé.
Les canaux physiques sont subdivisés en unités de temps pour des événements LE particuliers tels que la publicité, la publicité périodique, la publicité étendue et la connexion. Dans LE, un maître peut former un lien entre plusieurs esclaves. De même, un esclave peut avoir plusieurs liaisons physiques avec plusieurs maîtres et un appareil peut être à la fois maître et esclave.
Les changements de rôle de maître à esclave ou vice versa ne sont pas autorisés.
Comme indiqué précédemment, 37 des 40 canaux sont destinés à la transmission de données, mais trois sont dédiés à la publicité. Les canaux 37, 38 et 39 sont dédiés à la publicité des profils GATT. Pendant la publicité, un appareil transmet simultanément le paquet publicitaire sur les trois canaux. Cela permet d’augmenter la probabilité qu’un périphérique hôte de numérisation voit la publicité et réponde.
D’autres formes d’interférences se produisent avec les normes sans fil mobiles dans l’espace 2,4 GHz. Ici, une technique appelée train nudging a été introduite dans Bluetooth 4.1.
Bluetooth 5.0 a introduit les SAM. Un SAM permet à deux appareils Bluetooth de s’indiquer les intervalles de temps disponibles pour la transmission et la réception. Une carte est construite, indiquant la disponibilité des plages horaires. Grâce au mappage, les contrôleurs Bluetooth peuvent affiner leurs créneaux horaires BR / EDR et améliorer les performances globales.
Pour les modes BLE, les SAM ne sont pas disponibles. Cependant, un mécanisme négligé dans Bluetooth appelé algorithme de sélection de canal 2 (CSA2) peut aider au saut de fréquence dans des environnements bruyants susceptibles de s’estomper par trajets multiples. CSA2 a été introduit dans Bluetooth 4.1 et est un algorithme de mappage et de saut de canal très complexe. Il améliore la tolérance aux interférences de la radio et permet à la radio de limiter le nombre de canaux RF qu’elle peut utiliser dans les endroits à fortes interférences. Un effet secondaire de la limitation des canaux avec CSA2 est qu’il permet à la puissance de transmission d’augmenter à + 20 dBm. Comme mentionné, il y a des limites à la puissance de transmission imposées par les organismes de réglementation en vigueur, car les canaux publicitaires BLE et les canaux connectés sont si peu nombreux. CSA2 permet à plus de canaux d’être disponibles dans Bluetooth 5 que dans les versions précédentes, ce qui peut ouvrir des restrictions réglementaires.
Structure des paquets Bluetooth
Chaque appareil Bluetooth possède une adresse 48 bits unique appelée BD_ADDR. Les 24 bits supérieurs du BD_ADDR font référence à l’adresse spécifique du fabricant et sont achetés auprès de l’autorité d’enregistrement IEEE. Cette adresse comprend l’identifiant unique organisationnel (OUI), également connu sous le nom d’ID d’entreprise, et est attribué par l’IEEE. Les 24 bits les moins significatifs sont libres de modification pour l’entreprise.
Trois autres formats d’adresse sécurisés et randomisés sont disponibles mais seront discutés dans la partie sécurité BLE de ce chapitre. Le diagramme suivant montre la structure du paquet publicitaire BLE et les différents types de PDU. Cela représente certaines des PDU les plus couramment utilisées.
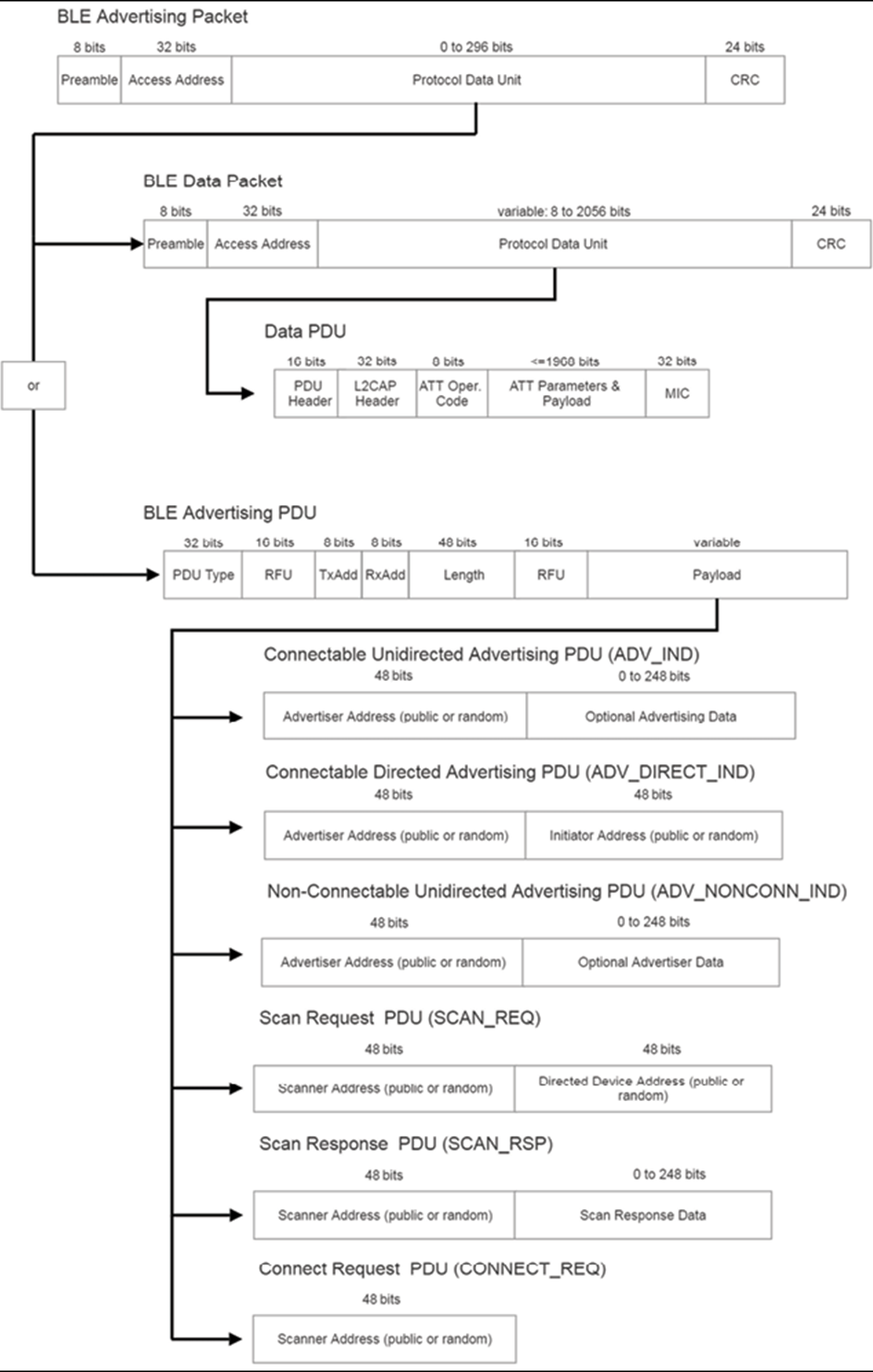
Figure 4: formats communs de publicité BLE et de paquets de données. Plusieurs autres types de paquets existent et devraient être mentionnés dans la spécification Bluetooth 5.0 fi cation.
5.2.4 Fonctionnement BR / EDR
Le mode Bluetooth classique (BR / EDR) est orienté connexion. Si un appareil est connecté, le lien est maintenu même si aucune donnée n’est communiquée. Avant toute connexion Bluetooth, un appareil doit être détectable pour qu’il puisse répondre aux analyses d’un canal physique et répondre ensuite avec son adresse d’appareil et d’autres paramètres. Un appareil doit être en mode connectable pour surveiller son balayage de page.
Le processus de connexion se déroule en trois étapes :
- Enquête : dans cette phase, deux appareils Bluetooth ne se sont jamais associés ou liés ; ils ne se connaissent pas. Les appareils doivent se découvrir mutuellement via une demande de renseignement. Si l’autre appareil écoute, il peut répondre avec son adresse BD_ADDR.
- Paging : La pagination ou la connexion forme une connexion entre les deux appareils. À ce stade, chaque périphérique connaît le BD_ADDR de l’autre.
- Connecté : Il existe quatre sous-modes de l’état de connexion. Il s’agit de l’état normal lorsque deux appareils communiquent activement :
- Mode actif : il s’agit du mode de fonctionnement normal pour la transmission et la réception de données Bluetooth ou l’attente du prochain créneau de transmission.
- Mode sniff : il s’agit d’un mode d’économie d’énergie. L’appareil est essentiellement endormi mais écoutera les transmissions pendant des créneaux spécifiques qui peuvent être modifiés par programme (par exemple, 50 ms).
- Mode Hold : il s’agit d’un mode temporaire de faible puissance initié par le maître ou l’esclave. Il n’écoutera pas les transmissions comme le mode sniff et l’esclave ignore temporairement les paquets de la liste de contrôle d’accès (ACL). Dans ce mode, le passage à l’état connecté se produit très rapidement.
- Mode parking : comme indiqué précédemment, ce mode est déconseillé dans Bluetooth 5.
Un diagramme d’état de ces phases est le suivant :
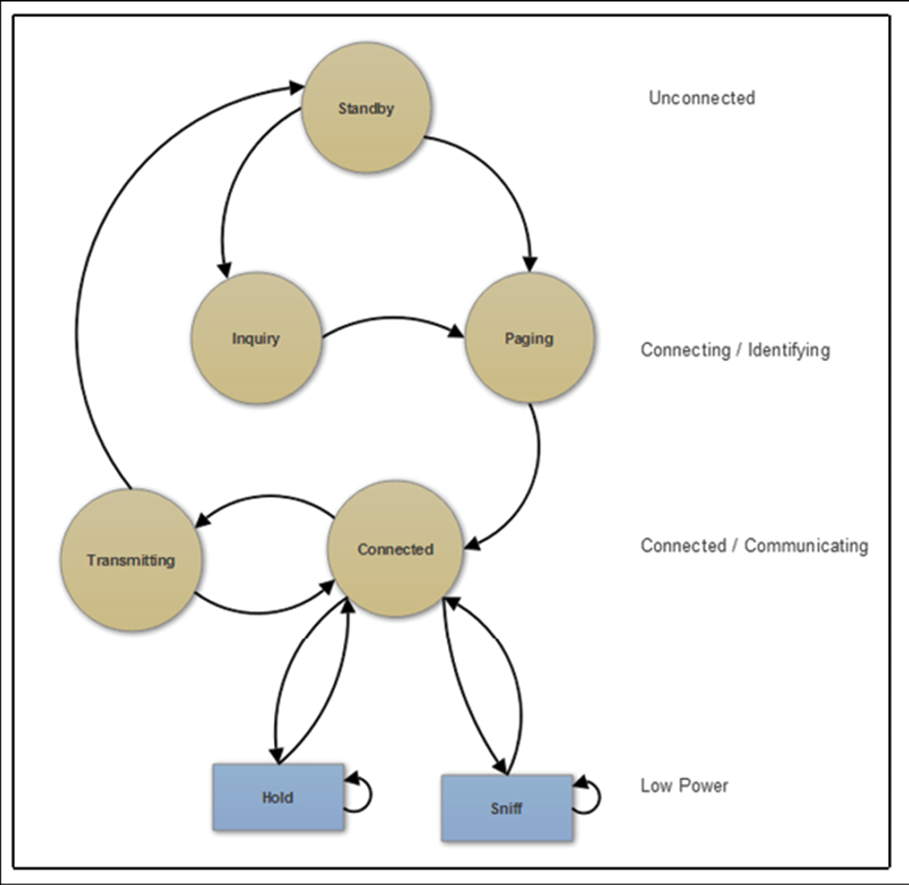
Figure 5 : Processus de connexion pour Bluetooth à partir du périphérique non connecté en mode veille, requête et découverte de périphérique, mode connecté / de transmission et modes basse consommation
Si ce processus se termine avec succès, les deux appareils peuvent être forcés de se connecter automatiquement lorsqu’ils sont à portée. Les appareils sont maintenant appairés. Le processus d’appariement unique est le plus courant pour connecter des smartphones à une chaîne stéréo de véhicule, mais il peut également s’appliquer partout dans l’IoT. Les appareils jumelés partageront une clé utilisée dans le processus d’authentification. Plus d’informations seront traitées sur les clés et l’authentification dans la section sur la sécurité avec Bluetooth.
Apple recommande d’utiliser un mode sniff réglé à un intervalle de 15 ms. Cela permet d’économiser beaucoup d’énergie sur le maintien de l’appareil en mode actif, mais permet également un meilleur partage du spectre avec le Wi-Fi et d’autres signaux Bluetooth dans la région. En outre, Apple recommande qu’un appareil définisse d’abord un intervalle de publicité pour la découverte initiale par un hôte à 20 ms et le diffuse pendant 30 secondes. Si l’appareil ne parvient toujours pas à se connecter à l’hôte, l’intervalle de publicité doit être augmenté par programme pour augmenter les chances de terminer le processus de connexion. Voir les directives de conception des accessoires Bluetooth pour les produits Apple version 8, ordinateur Apple, 16 juin 2017.
5.2.5 Rôles BLE
Étant donné que Bluetooth a une nomenclature différente pour les rôles des périphériques et des serveurs, cette liste permet de clarifier les différences. Certaines des couches seront étudiées plus loin dans ce chapitre.
- Rôles de couche de liaison (pré-connexion) :
- Maître : Habituellement, l’hôte, qui est responsable de la recherche sur le terrain de nouveaux appareils et de publicités de balises.
- Esclave : généralement l’appareil tente de se connecter au maître et lance des messages publicitaires.
- Rôles de couche GAP (pré-connexion) :
- Central : Le seul appareil qui peut envoyer une demande de connexion et établir une connexion fixe avec un périphérique.
- Périphérique : un appareil qui peut publier des messages Bluetooth sur n’importe quel autre appareil Bluetooth.
- Rôles de couche GATT (post-connexion) :
- Client : accède aux informations distantes sur un serveur. Initie des demandes de lecture ou d’écriture au serveur. Un client est généralement un maître (mais ce n’est pas une exigence difficile).
- Serveur : gère une base de données locale des ressources et des caractéristiques (GATT) du ou des clients distants. Il répond aux demandes de lecture ou d’écriture des clients. Un serveur est généralement un esclave.
Tout en prêtant à confusion pour de nombreux projets IoT, il faut comprendre que le capteur Bluetooth distant ou la balise de suivi des actifs est en fait le serveur tandis que le concentrateur hôte qui peut gérer de nombreuses connexions Bluetooth est le client.
5.2.6 Fonctionnement BLE
En mode BLE, cinq états de liaison sont négociés par l’hôte et le périphérique :
- Publicité : appareils qui transmettent les paquets publicitaires sur les canaux publicitaires.
- Numérisation : appareils qui reçoivent de la publicité sur les canaux publicitaires sans intention de se connecter. La numérisation peut être active ou passive :
- Analyse active : la couche de liaison écoute les PDU publicitaires. En fonction de la PDU reçue, il peut demander à un annonceur d’envoyer des informations supplémentaires.
- Analyse passive : la couche liaison ne recevra que des paquets ; transmission désactivée.
- Initiation : les appareils qui doivent établir une connexion avec un autre appareil écoutent les paquets publicitaires connectables et initient en envoyant un paquet de connexion.
- Connecté : il existe une relation entre maître et esclave dans l’état connecté. Le maître est l’initiateur et l’esclave est l’annonceur :
- Central : un initiateur transforme le rôle et le titre en périphérique central.
- Périphérique : le périphérique publicitaire devient le périphérique.
- Veille : appareil à l’état non connecté.
Une fois la liaison établie, le dispositif central peut être appelé maître, tandis que le périphérique est appelé esclave.
L’état publicitaire a plusieurs fonctions et propriétés. Les publicités peuvent être des publicités générales où un appareil diffuse une invitation générale à un autre appareil sur le réseau. Une publicité dirigée est unique et conçue pour inviter un pair spécifique à se connecter le plus rapidement possible. Ce mode de publicité contient l’adresse de l’appareil publicitaire et l’appareil invité.
Lorsque l’appareil récepteur reconnaît le paquet, il envoie immédiatement une demande de connexion. La publicité dirigée doit obtenir une attention rapide et immédiate, et les publicités sont envoyées à un rythme de 3,75 ms, mais seulement pendant 1,28 seconde. Une publicité non connectable est essentiellement une balise (et peut même ne pas avoir besoin d’un récepteur). Nous décrirons les balises plus loin dans ce chapitre. Enfin, l’annonce détectable peut répondre aux demandes de scan, mais elle n’accepte pas les connexions. Le diagramme d’état suivant présente les cinq états de liaison du fonctionnement BLE.
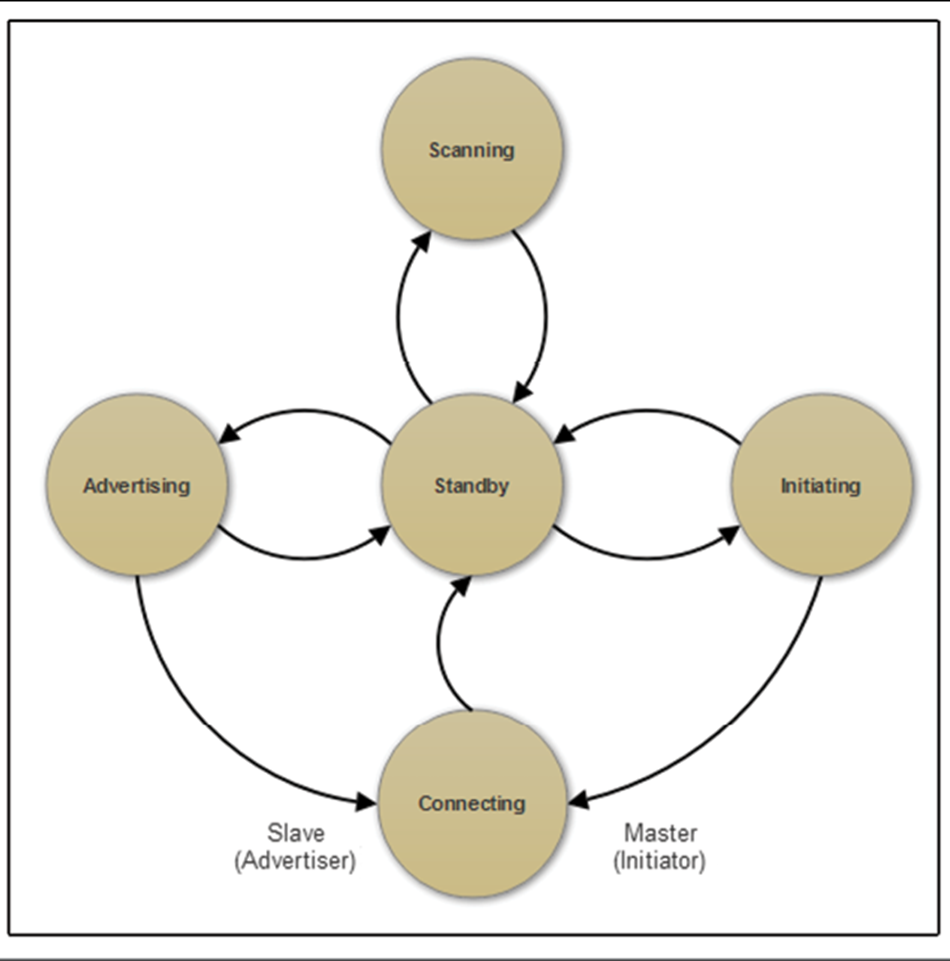
Figure 6 : Les états du lien BLE
Un appareil BLE qui ne s’est pas auparavant lié à un hôte lance la communication en diffusant des publicités sur les trois canaux publicitaires. L’hôte peut répondre avec un SCAN_REQ pour demander plus d’informations à l’appareil publicitaire. Le périphérique répond avec un SCAN_RSP et inclut le nom du périphérique ou éventuellement des services.
Le SCAN_RSP peut affecter la consommation d’énergie sur un périphérique. Si l’appareil prend en charge les réponses de balayage, il doit garder sa radio active en mode réception, consommant de l’énergie. Cela se produit même si aucun périphérique hôte n’émet de SCAN_REQ. Il est conseillé de désactiver les réponses de scan sur les périphériques IoT soumis à des contraintes de puissance.
Après l’analyse, l’hôte (scanner) lance une CONNECT_REQ, auquel cas l’analyseur et l’annonceur enverront des paquets PDU vides pour indiquer l’accusé de réception. Le scanner est maintenant appelé le maître et l’annonceur est appelé l’esclave. Le maître peut découvrir des profils et des services d’esclaves à travers le GATT. Une fois la découverte terminée, les données peuvent être échangées de l’esclave au maître et vice versa. À la résiliation, le maître reviendra à un mode de numérisation et l’esclave reviendra à un mode annonceur. La figure suivante illustre le processus d’appariement BLE de la publicité à la transmission de données.
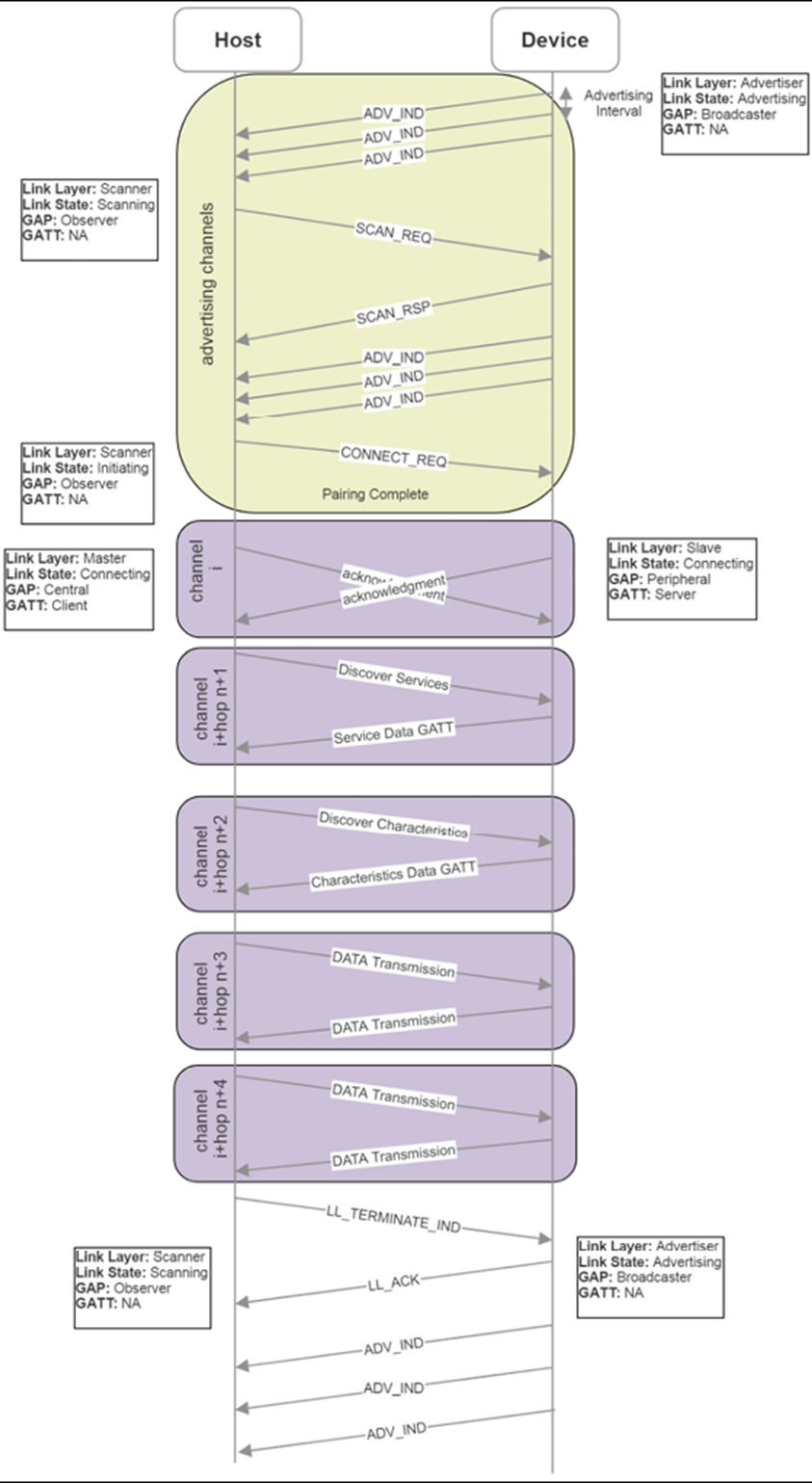
Figure 7 : Phases de la publicité BLE, de la connexion, de la requête de service GATT et de la transmission de données
5.2.7 Profils Bluetooth
Les applications s’interfacent avec divers appareils Bluetooth à l’aide de profils. Profils définit la fonctionnalité et les fonctionnalités de chaque couche de la pile Bluetooth. Essentiellement, les profils lient la pile ensemble et définissent comment les couches s’interfacent les unes avec les autres. Un profil décrit les caractéristiques de découverte annoncées par l’appareil. Ils sont également utilisés pour décrire les formats de données des services et les caractéristiques que les applications utilisent pour lire et écrire sur les appareils. Un profil n’existe pas sur un appareil ; ce sont plutôt des constructions prédéfinies maintenues et régies par le Bluetooth SIG.
Le profil Bluetooth de base doit contenir un GAP comme indiqué par la spécification. Le GAP définit la radio, la couche de bande de base, le gestionnaire de liens, le L2CAP et la découverte de service pour les appareils BR / EDR. De même, pour un périphérique BLE, le GAP définira la radio, la couche liaison, L2CAP, le gestionnaire de sécurité, le protocole d’attribut et le profil d’attribut générique.
Le protocole d’attribut ATT est un protocole filaire client-serveur optimisé pour les appareils de faible puissance (par exemple, la longueur n’est jamais transmise via BLE mais est impliquée par la taille de la PDU). Le TCA est également très générique, et il reste beaucoup au GATT à fournir une assistance. Le profil ATT comprend :
- Une poignée 16 bits
- Un UUID pour définir la valeur du type d’attribut contenant la longueur
Le GATT réside logiquement au-dessus de l’ATT et est utilisé principalement, sinon exclusivement, pour les appareils BLE. Le GATT spécifie les rôles du serveur et du client. Un client GATT est généralement un périphérique et le serveur GATT est l’hôte (par exemple, un PC ou un smartphone). Un profil GATT contient deux éléments :
- Services : un service divise les données en entités logiques. Il peut y avoir plusieurs services dans un profil et chaque service a un UUID unique pour le distinguer des autres.
- Caractéristiques : Une caractéristique est le niveau le plus bas d’un profil GATT et contient des données brutes associées à l’appareil. Les formats de données se distinguent par des UUID 16 bits ou 128 bits. Le concepteur est libre de créer ses propres caractéristiques que seule son application peut interpréter.
L’image suivante représente un exemple de profil Bluetooth GATT avec les UUID correspondants pour divers services et caractéristiques.
La spécification Bluetooth stipule qu’il ne peut y avoir qu’un seul serveur GATT.
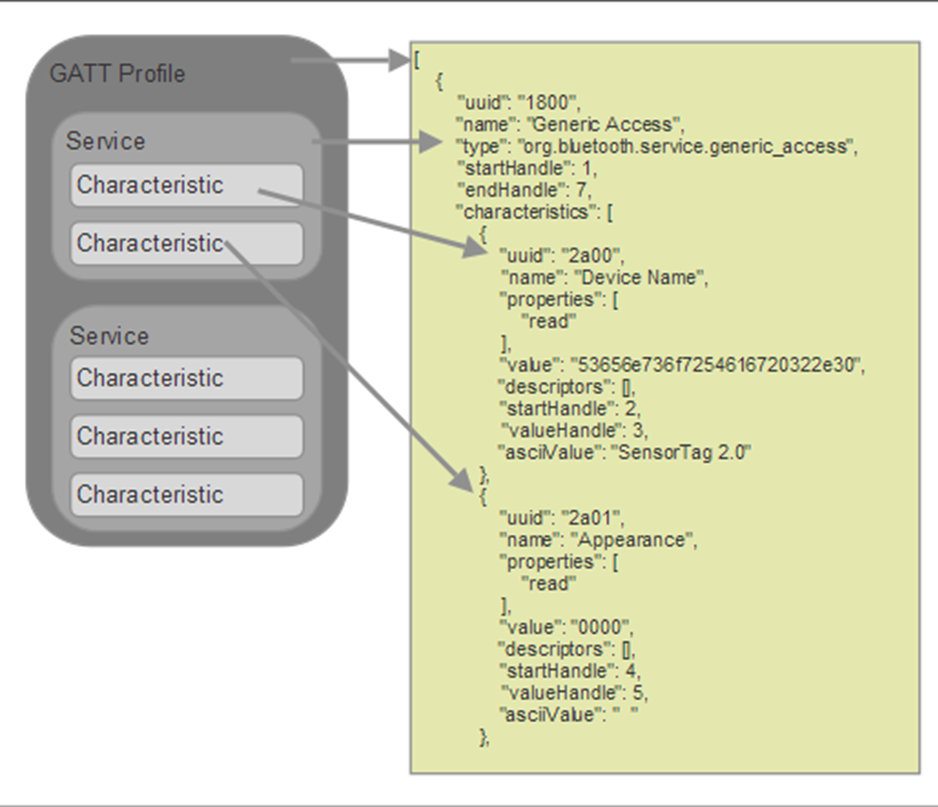
Figure 8 : GATT pro fi le hiérarchie et l’exemple du GATT utilisé sur Texas Instruments CC2650 SensorTag
Le Bluetooth SIG gère une collection de nombreux profils GATT. Au moment de la rédaction du présent document, 57 profils GATT étaient pris en charge par le Bluetooth SIG: https://www.bluetooth.com/specifications/gatt . Les profils pris en charge par le SIG comprennent les moniteurs de santé, les appareils de cyclisme et de fitness, les moniteurs environnementaux, les appareils d’interface humaine, le positionnement en intérieur, le transfert d’objets et les services de localisation et de navigation, ainsi que de nombreux autres.
5.2.8 Sécurité BR / EDR
Dans une certaine forme, la sécurité Bluetooth fait partie du protocole depuis 1.0. Nous discutons de la sécurité pour le mode BR / EDR et BLE séparément car les mécanismes sont différents. À partir du mode BR / EDR, il existe plusieurs modes d’authentification et de couplage. Pour la sécurité BR / EDR et BLE, il est recommandé de lire et de suivre le dernier guide de sécurité fourni par le US National Institute of Standards and Technology: Guide to Bluetooth Security, NIST Special Publication (SP) 800-121 Rev.2 , NIST , 5/8/2017 .
Le pairage nécessite la génération d’une clé symétrique secrète. En mode BR / EDR, cela s’appelle la clé de liaison, tandis qu’en mode BLE, elle est appelée la clé à long terme. Les appareils Bluetooth plus anciens utilisaient un mode d’appariement de numéro d’identification personnel (PIN) pour lancer les clés de liaison. Les appareils plus récents (4.1+) utilisent SSP.
SSP fournit un processus d’appariement avec un certain nombre de modèles d’association différents pour différents cas d’utilisation. SSP utilise également la cryptographie à clé publique pour se protéger des écoutes et des attaques de l’homme du milieu (MITM). Les modèles pris en charge par SSP incluent :
- Comparaison numérique : pour les cas d’utilisation où les deux appareils Bluetooth peuvent afficher une valeur numérique à six chiffres permettant à un utilisateur d’entrer une réponse oui / non sur chaque appareil si les chiffres correspondent.
- Saisie par clé : Utilisé dans les situations où un appareil a un affichage numérique et l’autre n’a qu’un clavier numérique. Dans ce cas, l’utilisateur entre la valeur affichée sur l’affichage du premier appareil sur le clavier du second appareil.
- Just Works TM : pour les situations où un appareil est sans tête et n’a ni clavier ni écran. Il ne fournit qu’une authentification minimale et ne contrecarrera pas une attaque MITM.
- Hors bande (OOB) : utilisé lorsque l’appareil a une forme de communication secondaire telle que NFC ou Wi-Fi. Le canal secondaire est utilisé pour la découverte et l’échange de valeurs cryptographiques. Il ne protègera de l’écoute et du MITM que si le canal OOB est sécurisé.
L’authentification en mode BR / EDR est une action de réponse au défi, par exemple, la saisie d’un code PIN sur un clavier. Si l’authentification échoue, l’appareil attendra un certain intervalle avant d’autoriser une nouvelle tentative. L’intervalle augmente exponentiellement à chaque tentative échouée. Il s’agit simplement de frustrer la personne qui tente de casser manuellement un code clé.
Le cryptage en mode BR / EDR peut être défini pour les éléments suivants :
- Désactivé pour tout le trafic
- Chiffré pour le trafic de données mais la communication de diffusion sera brute
- Toutes les communications sont cryptées
Le cryptage utilise la cryptographie AES-CCM.
5.2.8.1 Sécurité BLE
Le couplage BLE (expliqué plus haut dans ce chapitre) commence par un périphérique initiant un Pairing_Request et échangeant des capacités, des exigences, etc. Rien ne concerne les profils de sécurité lors de la phase initiale d’un processus de couplage. D’ailleurs, la sécurité d’appairage est similaire aux quatre méthodes BR / EDR (également connues sous le nom de modèles d’association), mais diffère légèrement dans Bluetooth BLE 4.2:
- Comparaison numérique : c’est la même chose que Just Works, mais à la fin, les deux appareils généreront une valeur de confirmation qui s’affiche sur les écrans de l’ hôte et de l’ appareil pour que l’utilisateur valide la correspondance.
- Entrée de clé d’accès : similaire au mode BR / EDR, sauf que le périphérique non initiateur crée une graine de 128 bits aléatoire appelée nonce pour authentifier la connexion. Chaque bit de la clé est authentifié séparément sur chaque périphérique en générant une valeur de confirmation pour ce bit. Les valeurs de confirmation sont échangées et doivent correspondre. Le processus se poursuit jusqu’à ce que tous les bits soient traités. Cela fournit une solution assez robuste pour les attaques MITM.
- Just Works TM : Après que les appareils ont échangé des clés publiques, l’appareil non initiateur crée un nonce pour générer une valeur de confirmation Cb. Il transmet le nonce et Cb au dispositif initiateur, qui à son tour génère son propre nonce et le transmet au premier. Le dispositif initiateur confirmera alors l’authenticité du nonce non initiateur en générant sa propre valeur de Ca, qui devrait correspondre à Cb. S’il ne correspond pas, la connexion est corrompue. Ceci est à nouveau différent du mode BR / EDR.
- Hors bande (OOB) : c’est la même chose qu’en mode BR / EDR. Il ne protègera de l’écoute et du MITM que si le canal OOB est sécurisé.
Dans BLE (à partir de Bluetooth 4.2), la génération de clés utilise des connexions sécurisées LE. La connexion sécurisée LE a été développée pour résoudre le trou de sécurité dans l’appariement BLE qui permettait à un espion de voir l’échange d’appariement. Ce processus utilise une clé à long terme (LTK) pour crypter la connexion. La clé est basée sur une cryptographie à clé publique Diffie-Hellman (ECDH) à courbe elliptique.
Le maître et l’esclave généreront des paires de clés publiques-privées ECDH. Les deux appareils échangeront leur partie publique de leurs paires respectives et traiteront la clé Diffie-Hellman. À ce stade, la connexion peut être chiffrée à l’aide de la cryptographie AES-CCM.
BLE a également la possibilité de randomiser son BD_ADDR. N’oubliez pas que le BD_ADDR est une adresse de type MAC 48 bits. Plutôt qu’une adresse statique pour la valeur, comme mentionné précédemment dans ce chapitre, il existe trois autres options :
- Statique aléatoire : ces adresses sont soit gravées dans le silicium de l’appareil lors de sa fabrication, soit générées lors des cycles d’alimentation de l’appareil. Si un appareil s’éteint régulièrement, une adresse unique est générée et celle-ci reste sécurisée tant que la fréquence des cycles d’alimentation est élevée. Dans un environnement de capteur IoT, cela peut ne pas être le cas.
- Résolu privé aléatoire : cette méthode d’adressage ne peut être utilisée que si la clé de résolution d’identité ( IRK ) est échangée entre les deux appareils pendant le processus de liaison. L’appareil utilisera l’IRK pour coder son adresse en une adresse aléatoire dans le paquet de publicité. Un deuxième appareil qui possède également l’IRK reconvertira l’adresse aléatoire en adresse authentique. Dans cette méthode, l’appareil génère périodiquement une nouvelle adresse aléatoire basée sur l’IRK.
- Aléatoire privé non résoluble : l’adresse de l’appareil est simplement un nombre aléatoire et une nouvelle adresse d’appareil peut être générée à tout moment. Cela offre le plus haut niveau de sécurité.
5.2.9 balisages
Le balisage Bluetooth est un effet secondaire du BLE; Cependant, il s’agit d’une technologie importante et significative pour l’IoT. Étant donné que les balises ne sont pas nécessairement des capteurs, nous ne les avons pas couvertes explicitement dans le chapitre 3 , Capteurs, points de terminaison et systèmes d’alimentation (bien que certains fournissent des informations de détection dans un paquet publicitaire). Le balisage utilise simplement des appareils Bluetooth en mode LE pour faire de la publicité sur une base périodique. Les balises ne se connectent ou ne s’associent jamais avec un hôte. Si une balise devait se connecter, toutes les publicités s’arrêteraient et aucun autre appareil ne pourrait entendre cette balise. Les trois cas d’utilisation importants pour la vente au détail, les soins de santé, le suivi des actifs, la logistique et de nombreux autres marchés sont:
- Point d’intérêt statique ( POI )
- Diffusion de données de télémétrie
- Services de positionnement et de géolocalisation en intérieur
La publicité Bluetooth utilise un message pour contenir des informations supplémentaires dans l’UUID de diffusion. Une application sur un appareil mobile peut répondre à cette publicité et effectuer une action si la publicité correcte est reçue. Un cas d’utilisation typique de la vente au détail utiliserait une application mobile qui répondrait à la présence d’une publicité de balise à proximité et afficherait une annonce ou des informations de vente sur l’appareil mobile de l’utilisateur. L’appareil mobile communiquerait via Wi-Fi ou cellulaire pour récupérer du contenu supplémentaire et fournir des données critiques sur le marché et les acheteurs à l’entreprise.
Les balises peuvent transmettre leur puissance de signal RSSI calibré comme une publicité. La force du signal des balises est calibrée par les fabricants généralement à une longueur d’un mètre. La navigation intérieure peut être effectuée de trois manières différentes :
- Balises multiples par pièce : Il s’agit d’une méthode de triangulation simple pour déterminer l’emplacement d’un utilisateur en fonction de la force du signal RSSI annoncé collectée à partir de nombreuses balises dans une pièce. Compte tenu du niveau calibré annoncé de chaque balise et de la force reçue de chaque balise, un algorithme pourrait déterminer l’emplacement approximatif d’un récepteur dans une pièce. Cela suppose que toutes les balises sont dans un endroit fixe.
- Une balise par pièce : dans ce schéma, une balise est placée dans chaque pièce, permettant à un utilisateur de naviguer entre les pièces et les salles, la fidélité de l’emplacement étant une pièce. Ceci est utile dans les musées, les aéroports, les salles de concert, etc.
- Quelques balises par bâtiment : en combinaison avec des accéléromètres et des gyroscopes dans un appareil mobile, plusieurs balises dans un bâtiment peuvent permettre une capacité de calcul à l’estime dans un grand espace ouvert. Cela permet à une seule balise de définir un emplacement de départ et à l’appareil mobile de calculer son emplacement en fonction des mouvements de l’utilisateur.
Deux protocoles de balisage fondamentaux sont utilisés : Eddystone par Google et iBeacon par Apple. Les appareils Bluetooth hérités ne peuvent prendre en charge qu’un message de balise de 31 octets. Cela limite la quantité de données qu’un appareil peut transmettre.
Un message iBeacon entier est simplement un UUID (16 octets), un nombre majeur (deux octets) et un nombre mineur (deux octets). L’UUID est spécifique à l’application et au cas d’utilisation. Le nombre majeur affine davantage le cas d’utilisation et mineur étend le cas d’utilisation à un cas encore plus étroit.
Les iBeacons offrent deux façons de détecter les périphériques :
- Surveillance : la surveillance fonctionne même si l’application pour smartphone associée n’est pas en cours d’exécution.
- Télémétrie : la télémétrie ne fonctionne que si l’application est active.
Eddystone (également connu sous le nom d’UriBeacons) peut transmettre quatre types de trames différents avec une longueur et un codage de trame variables :
- Eddystone-URL : l’emplacement uniforme des ressources. Ce cadre permet à un appareil récepteur d’afficher du contenu Web en fonction de l’emplacement de la balise. Il n’est pas nécessaire d’installer une application pour activer le contenu. Le contenu est de longueur variable et applique des schémas de compression uniques pour réduire la taille de l’URL à une limite de 17 octets.
- Eddystone-UID : ID de balise unique de 16 octets avec un espace de noms de 10 octets et une instance de 6 octets. Il utilise Google Beacon Registry pour renvoyer les pièces jointes.
- Eddystone-EID : identifiant de courte durée pour les balises nécessitant des niveaux de sécurité plus élevés. Sans espace de nom ni ID fixes, les identifiants tournent constamment et nécessitent une application autorisée pour décoder. Il utilise Google Beacon Registry pour renvoyer les pièces jointes.
- Eddystone-TLM : diffuse des données de télémétrie sur la balise elle-même (niveau de la batterie, temps écoulé depuis la mise sous tension, nombre de publicités). Il diffuse aux côtés des paquets URI ou URL.
Le diagramme suivant illustre la structure du paquet de publicité Bluetooth BLE pour Eddystones et iBeacons. L’iBeacon est le plus simple avec un seul type de cadre de longueur constante. Eddystone se compose de quatre types de trames différents et a des longueurs et des formats d’encodage variables. Notez que certains champs sont codés en dur, tels que la longueur, le type et l’ID de la société pour iBeacon, ainsi que l’identifiant pour Eddystone.

Figure 9 : Exemple de différence entre les paquets publicitaires iBeacon et Eddystone (PDU)
Les intervalles de balayage et les intervalles de publicité tentent de minimiser le nombre de publicités nécessaires pour transmettre des données utiles dans un laps de temps. La fenêtre de numérisation a généralement une durée plus longue que la publicité, car les scanners ont essentiellement plus de puissance qu’une pile bouton dans une balise. La figure suivante montre un processus de publicité par balise toutes les 180 ms tandis que l’hôte analyse toutes les 400 ms.
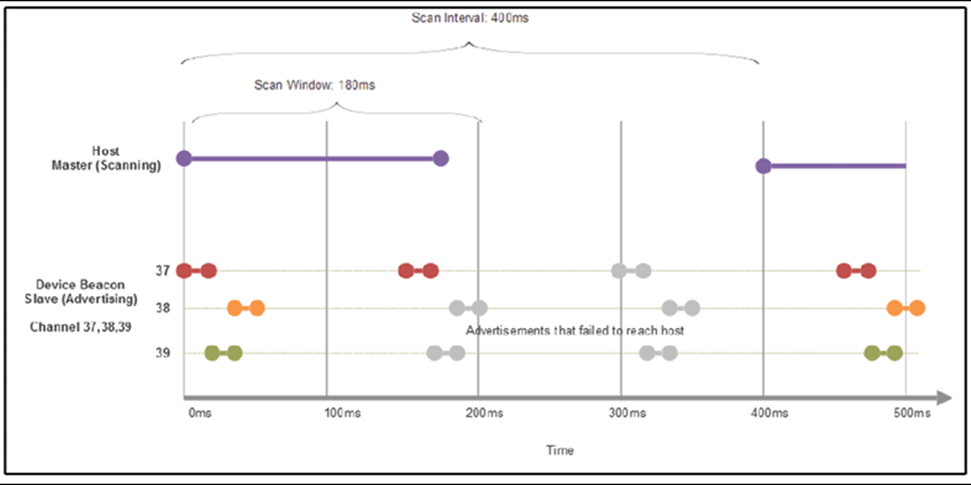
Figure 10 : Exemple de scan d’un hôte avec un intervalle de scan de 400 ms et une fenêtre de scan de 180 ms.
La balise fait de la publicité toutes les 150 ms sur les canaux dédiés 37, 38 et 39. Notez que l’ordre des canaux publicitaires n’est pas consécutif car le saut de fréquence peut avoir ajusté l’ordre. Certaines publicités n’ont pas pu atteindre l’hôte car l’intervalle d’analyse et l’intervalle de publicité sont déphasés. Une seule publicité dans la seconde rafale atteint l’hôte sur le canal 37, mais par conception, Bluetooth fait de la publicité sur les trois canaux afin de maximiser les chances de succès.
L’architecture d’un système de balises présente deux défis fondamentaux. Le premier est l’effet des intervalles publicitaires par rapport à la fidélité du suivi de localisation. Le second est l’effet des intervalles publicitaires par rapport à la longévité de la batterie alimentant la balise. Les deux effets s’équilibrent et une architecture soignée est nécessaire pour se déployer correctement et prolonger la durée de vie de la batterie.
Plus l’intervalle entre les annonces de balises est long, moins le système aura de précision sur une cible en mouvement. Par exemple, si un détaillant surveille l’emplacement des clients dans un magasin, les clients se déplacent à une vitesse de marche de 4,5 pieds / seconde, et un ensemble de balises annonce toutes les quatre secondes par rapport à un autre déploiement qui annonce toutes les 100 ms, il révélera différentes voies de mouvement vers le détaillant rassemblant les données du marché. La figure suivante illustre les effets de la publicité lente et rapide dans un cas d’utilisation au détail.
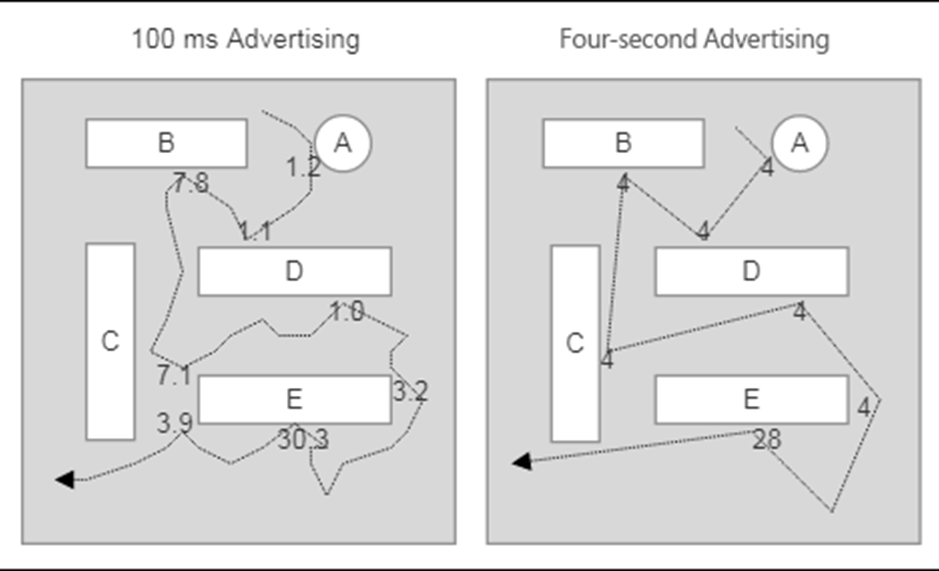
Figure 11 : Les effets de la haute fréquence à basse fréquence par rapport à la publicité de la publicité sur place fi délité. Les nombres entiers représentent le temps passé par le client à un point particulier du magasin.
Un intervalle de publicité de quatre secondes perd la précision des emplacements des clients lorsqu’ils se déplacent dans un magasin. De plus, le temps passé à un point particulier ne peut être suivi qu’à des intervalles discrets de quatre secondes. Le temps passé aux positions B et C (lorsque le client quitte le magasin) peut être perdu. Dans ce cas, le détaillant peut vouloir comprendre pourquoi le client a passé 7,8 secondes à l’emplacement B et pourquoi il est retourné au point C en sortant.
Le contre-effet de la publicité fréquente est l’impact sur la durée de vie de la batterie de la balise. En règle générale, les piles des balises sont des piles bouton Li-ion CR2032. The Hitchhikers Guide to iBeacon Hardware: A Comprehensive Report by Aislelabs. Web 14 mars 2016 ( https://www.aislelabs.com/reports/beacon-guide/ ) a effectué une analyse de la durée de vie de la batterie de certaines balises courantes et modifié leur intervalle publicitaire (100 ms, 645 ms et 900 ms) . Ils ont également utilisé différentes batteries avec une augmentation de l’énergie stockée. Les résultats montrent que la durée de vie moyenne varie de 0,6 mois à plus d’un an selon le chipset, mais surtout sur l’intervalle publicitaire. Parallèlement à l’intervalle publicitaire, la puissance Tx affecte certainement la durée de vie globale de la batterie, tout comme le nombre de trames transmises.
La définition d’intervalles publicitaires trop longs, bien que bénéfique pour la durée de vie de la batterie et mauvaise pour la localisation, a un effet secondaire. Si la balise fonctionne dans un environnement bruyant et que l’intervalle est réglé haut (> 700 ms), le scanner (smartphone) devra attendre une autre période complète pour recevoir le paquet publicitaire. Cela peut entraîner un dépassement du délai des applications.
Un intervalle rapide de 100 ms est utile pour suivre les objets en mouvement rapide (tels que le suivi des actifs dans la logistique de la flotte ou la récolte de balises par drone). Si l’architecte conçoit pour suivre les mouvements humains à une vitesse typique de 4,5 pieds / seconde, alors 250 ms à 400 ms sont adéquats.
Un exercice précieux pour l’architecte IoT est de comprendre le coût de la transmission en termes de puissance. Essentiellement, l’appareil IoT dispose d’un nombre limité de PDU qu’il peut envoyer avant que la batterie n’atteigne un point où il ne peut plus alimenter l’appareil à moins qu’il ne soit rafraîchi ou que l’énergie ne soit récupérée (voir le chapitre 4, Théorie des communications et de l’information). Supposons qu’un iBeacon soit annoncé toutes les 500 ms et que la longueur du paquet soit de 31 octets (elle peut être plus longue).
De plus, l’appareil utilise une pile bouton CR2032 évaluée à 220 mAh à 3,7 V. L’électronique de la balise consomme 49uA à 3V. On peut désormais prédire la durée de vie de la balise et l’efficacité de la transmission :
- Consommation électrique = 49 uA x 3 V = 0,147 mW
- Octets par seconde = 31 x (1 seconde / 500 ms) x 3 canaux = 186 octets / seconde
- Bits par seconde = 186 octets / seconde x 8 = 1488 bits / seconde
- Énergie par bit = 0,147 mW / (1488 bits / seconde) = 0,098 uJ / bit
- Énergie utilisée pour chaque annonce = 0,098 uJ / bit x 31 octets x 8 bits / octet = 24,30 uJ / annonce
- Énergie stockée dans la batterie : 220mAh x 3,7V x 3,6 secondes = 2930 J
- Durée de vie de la batterie = (2930 J x (1 000 000 uJ / J)) / ((24,30 uJ / publicité) x (1 publicité / 0,5 seconde)) x 0,7 = 42 201 646 secondes = 488 jours = 1,3 ans
La constante 0,7 est utilisée pour les tolérances liées à la baisse de la durée de vie de la batterie, comme décrit au chapitre 4, Communications et théorie de l’information. 1,3 an est une limite théorique et ne sera probablement pas obtenue sur le terrain en raison de facteurs tels que le courant de fuite, ainsi que d’autres fonctionnalités de l’appareil qui peuvent avoir besoin de fonctionner périodiquement.
En tant que note finale sur les balises par rapport à Bluetooth 5, la nouvelle spécification étend la longueur des publicités de balises en permettant aux paquets de publicité d’être transmis dans les canaux de données ainsi que les canaux de publicité. Cela casse fondamentalement la limite de 31 octets d’une annonce.
Avec Bluetooth 5, la taille du message peut être de 255 octets. Les nouveaux canaux publicitaires Bluetooth 5 sont appelés canaux publicitaires secondaires. Ils garantissent une compatibilité descendante avec les appareils Bluetooth 4 hérités en définissant un type étendu Bluetooth 5 spécifique dans l’en-tête. Les hôtes hérités jetteront l’en-tête non reconnu et n’écouteront tout simplement pas l’appareil.
Si un hôte Bluetooth reçoit une annonce de balise qui indique qu’il existe un canal d’annonce secondaire, il reconnaît que davantage de données devront être trouvées dans les canaux de données. La charge utile du paquet de publicité principal ne contient plus de données de balise, mais une charge utile de publicité étendue commune qui identifie un numéro de canal de données et un décalage temporel. L’hôte lira ensuite à partir de ce canal de données particulier au décalage temporel indiqué pour récupérer les données de balise réelles. Les données peuvent également pointer vers un autre paquet (appelé plusieurs chaînes de publicité secondaires).
Cette nouvelle méthode de transmission de messages balise très longs garantit que de grandes quantités de données peuvent être envoyées aux smartphones des clients. D’autres cas d’utilisation et fonctionnalités sont désormais également activés, comme la publicité utilisée pour transmettre des données synchrones comme des flux audio. Une balise pourrait envoyer des conférences audios sur un smartphone pendant qu’un visiteur se promène dans un musée et regarde diverses œuvres d’art.
Les publicités peuvent également être anonymisées, ce qui signifie que le paquet de publicité n’a pas besoin d’être lié à l’adresse de l’émetteur. Ainsi, lorsqu’un appareil produit une publicité anonyme, il ne transmet pas sa propre adresse d’appareil. Cela peut améliorer la confidentialité et réduire la consommation d’énergie.
Bluetooth 5 peut également transmettre plusieurs publicités individuelles (avec des données uniques et des intervalles différents) presque simultanément. Cela permettra aux balises Bluetooth 5 de transmettre des signaux Eddystone et iBeacon presque en même temps sans aucune reconfiguration.
De plus, la balise Bluetooth 5 peut détecter si elle est analysée par un hôte. Ceci est puissant car la balise peut détecter si un utilisateur a reçu une publicité, puis arrêter de transmettre pour économiser l’énergie.
5.2.10 Amélioration de la portée et de la vitesse Bluetooth 5
La force de la balise Bluetooth est limitée et peut être affectée par des limites placées sur la puissance de l’émetteur pour préserver la durée de vie de la batterie. Habituellement, une ligne de visée est nécessaire pour une portée et une force de signal optimales. La figure suivante montre la courbe d’intensité du signal par rapport à la distance pour une communication Bluetooth 4.0 en visibilité directe typique.
Bluetooth 5 étend la portée uniquement lorsque le mode codé LE est utilisé, comme nous l’examinerons plus tard.
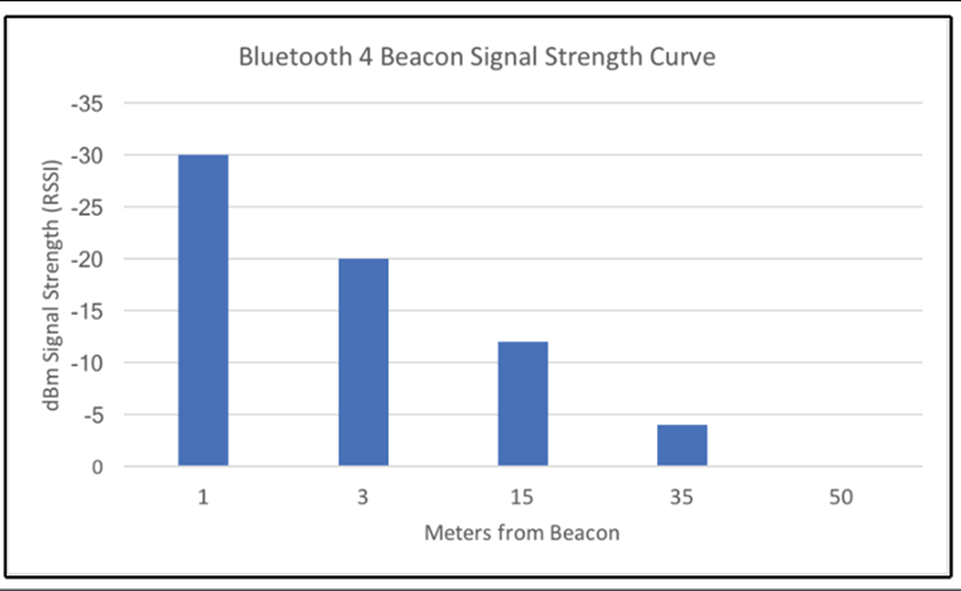
Figure 12 : La force de la balise est limitée. Souvent, un fabricant limite la puissance d’émission d’une balise pour préserver la durée de vie de la batterie. Lorsque l’on se déplace de la balise, la force du signal diminue comme prévu. Une portée de 30 pieds est généralement une distance de balise utilisable (Bluetooth 4.0).
Bluetooth a également différents niveaux de puissance, plages et puissance de transmission en fonction d’une classification pour chaque appareil :
| Numéro de classe | Niveau de sortie max (dBm) | Puissance de sortie maximale (mW) | Portée max | Cas d’utilisation |
| 1 | 20 dBm | 100 mW | 100 m | Adaptateurs USB, points d’accès |
| 2 | 10 dBm | 10 mW | 30m (typique 5m) | Balises, wearables |
| 2 | 4 dBm | 5 mW | 10 m | Appareils mobiles, adaptateurs Bluetooth, lecteurs de cartes à puce |
| 3 | 0 dBm | 1 mW | 10 cm | Adaptateurs Bluetooth |
Bluetooth 5 a amélioré la portée ainsi que le débit de données au-delà des anciennes limites Bluetooth. Une nouvelle radio PHY est disponible avec Bluetooth 5 appelée LE2M. Cela double le débit de données brutes de Bluetooth de 1 M symbole / seconde à 2 M symboles / seconde. Pour transférer une quantité égale de données sur Bluetooth 5 par opposition à Bluetooth 4, moins de temps sera nécessaire pour la transmission.
Cela est particulièrement pertinent pour les appareils IoT qui fonctionnent sur des piles bouton. Le nouveau PHY augmente également la puissance de +10 dBm à +20 dBm, permettant une plus grande portée.
En ce qui concerne la portée, Bluetooth 5 dispose d’un autre PHY en option pour la transmission à portée étendue en BLE. Cette PHY auxiliaire est étiquetée LE Coded . Cette PHY utilise toujours le débit de 1 M symbole / seconde comme dans Bluetooth 4.0, mais réduit le codage de paquet inférieur de 125 Kb / s ou 500 Kb / s et augmente la puissance de transmission de +20 dBm. Cela a pour effet d’augmenter la portée de 4x par Bluetooth 4.0 et d’avoir une meilleure pénétration dans les bâtiments. Le LE Coded PHY augmente la consommation d’énergie au profit d’une portée accrue.
5.2.11 Maillage Bluetooth
Bluetooth fournit également la spécification complémentaire pour la mise en réseau maillée à l’aide des piles BLE . Cette section couvre l’architecture de maille Bluetooth en détail.
Avant la spécification officielle du maillage Bluetooth SIG avec Bluetooth 5, il existait des schémas propriétaires et ad hoc utilisant des versions Bluetooth plus anciennes pour construire des tissus maillés. Cependant, après la publication de la spécification Bluetooth 5, le SIG s’est concentré sur la formalisation du réseau maillé en Bluetooth. Le Bluetooth SIG a publié le profil maillé, le périphérique et la spécification de modèle 1.0 le 13 juillet 2017. Cela est arrivé six mois après la publication de la spécification Bluetooth 5.0. Les trois spécifications publiées par le Bluetooth SIG sont les suivantes :
- Spécification de profil de maillage 1.0 : définit les exigences fondamentales pour permettre une solution de réseau maillé interopérable
- Spécification de modèle de maillage 1.0 : fonctionnalité de base des nœuds sur le réseau maillé
- Mesh device properties 1.0 : définit les propriétés de périphérique requises pour la spécification du modèle de maillage
On ne sait pas encore s’il existe une limite à la taille du réseau maillé. Il y a des limites intégrées dans la spécification. Selon la spécification 1.0, il peut y avoir jusqu’à 32 767 nœuds dans un maillage Bluetooth et 16 384 groupes physiques. La durée de vie maximale (TTL), qui indique la profondeur du maillage, est de 127.
Le maillage Bluetooth 5 permet théoriquement 2 128 groupes virtuels. En pratique, le regroupement sera beaucoup plus contraint.
Le maillage Bluetooth est basé sur BLE et se trouve sur la couche physique et de liaison BLE décrite précédemment. Au-dessus de cette couche se trouve une pile de couches spécifiques au maillage :
- Modèles : implémente des comportements, des états et des liaisons sur une ou plusieurs spécifications de modèle.
- Modèles de fondation : configuration et gestion du réseau maillé.
- Couche d’accès : définit le format des données d’application, le processus de chiffrement et la vérification des données.
- Couche de transport supérieure : gère l’authentification, le chiffrement et le déchiffrement des données transmises vers et depuis la couche d’accès. Transporte les messages de contrôle tels que les amitiés et les battements de cœur.
- Couche de transport inférieure : effectue la segmentation et le réassemblage (SAR) des PDU fragmentées si nécessaire.
- Couche réseau : déterminez l’interface réseau sur laquelle envoyer les messages. Il gère les différents types d’adresses et prend en charge de nombreux supports.
- Couche support : définit la façon dont les PDU maillés sont traités. Deux types de PDU sont pris en charge : le support publicitaire et le support GATT. Le support publicitaire gère la transmission et la réception des PDU maillés, tandis que le support GATT fournit un proxy pour les appareils qui ne prennent pas en charge le support publicitaire.
- BLE : la spécification BLE complète.
Le maillage Bluetooth peut incorporer un réseau maillé ou des fonctions BLE. Un appareil capable de prendre en charge le maillage et le BLE peut communiquer avec d’autres appareils comme les smartphones ou avoir des fonctions de balise. La figure suivante illustre la pile de mailles Bluetooth. Ce qui est important à réaliser, c’est le remplacement de la pile au-dessus de la couche de liaison.
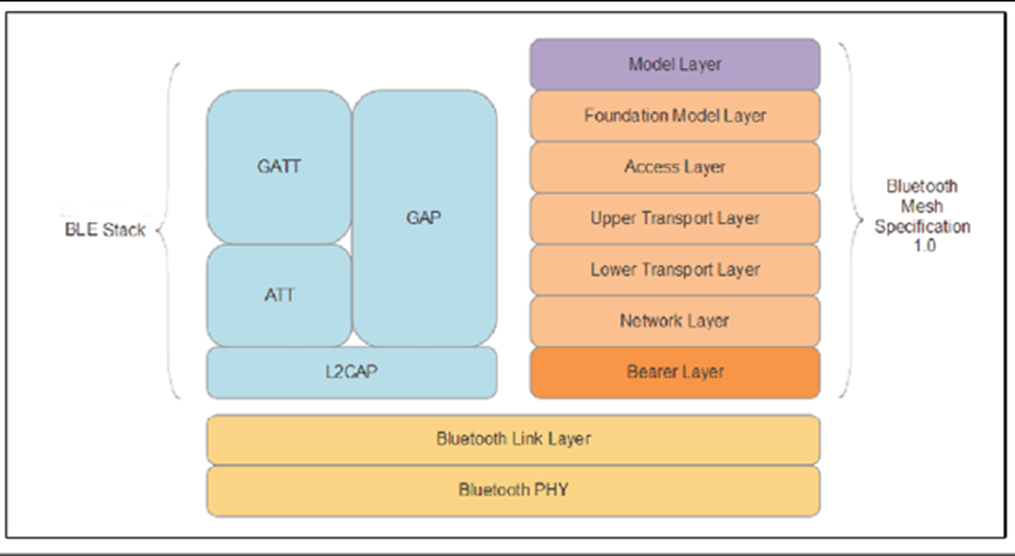
Figure 13 : pile de spécification de maillage Bluetooth 1.0
5.2.11.1 Topologie de maillage Bluetooth
Le maillage Bluetooth utilise le concept d’un réseau inondé. Dans un réseau flood, chaque paquet entrant reçu par un nœud du maillage est envoyé via chaque lien sortant, à l’exception du lien vers le parent du message. L’inondation a l’avantage que si un paquet peut être livré, il le sera (quoique probablement plusieurs fois via de nombreuses routes). Il trouvera automatiquement l’itinéraire le plus court (qui peut varier selon la qualité du signal et la distance dans un maillage dynamique). L’algorithme est le plus simple à implémenter en ce qui concerne les protocoles de routage.
De plus, il ne nécessite aucun gestionnaire central tel qu’un réseau Wi-Fi basé autour d’un routeur central. À titre de comparaison, les autres types de routage de maillage incluent des algorithmes basés sur des arbres. Avec les algorithmes d’arbre (ou algorithmes d’arborescence de cluster), un coordinateur est nécessaire pour instancier le réseau et devient le nœud parent. Cependant, les arbres ne sont pas nécessairement de véritables réseaux maillés. Les autres protocoles de routage maillé incluent le routage proactif, qui maintient les tables de routage à jour sur chaque nœud, et le routage réactif, qui ne met à jour que les tables de routage sur chaque nœud à la demande ; par exemple, lorsque des données doivent être envoyées via un nœud. Zigbee (abordé plus loin) est une forme de routage proactif appelée vecteur de distance à la demande ad hoc (AODV). La figure suivante illustre une diffusion par inondation. L’heure d’arrivée à chaque niveau peut varier dynamiquement d’un nœud à l’autre. En outre, le réseau maillé doit résister aux messages arrivant à un noeud en double comme dans le cas du noeud 7 et le noeud D.
Figure 14 : Architecture maillage Flood (S = Source, D = D ESTINATION) : Source de données produit qui se propage et fl ux à travers chaque nœud du maillage
Le principal inconvénient d’un réseau inondé est le gaspillage de bande passante. En fonction du fan out de chaque nœud, l’encombrement sur un maillage Bluetooth peut être important. Un autre problème est une attaque par déni de service. Si le maillage diffuse simplement des messages, une fonction est nécessaire pour savoir quand arrêter les transmissions. Bluetooth accomplit cela grâce à des identificateurs de durée de vie, que nous couvrirons plus loin dans ce chapitre.
Les entités qui composent le maillage Bluetooth sont les suivantes :
- Nœuds : périphériques Bluetooth qui ont été précédemment configurés et qui sont membres d’un maillage.
- Périphériques non provisionnés : périphériques susceptibles de rejoindre un maillage qui ne fait pas encore partie d’un maillage et qui n’a pas été provisionné.
- Éléments : si un nœud contient plusieurs périphériques constitutifs, ces sous-périphériques sont appelés éléments. Chaque partie peut être contrôlée et adressée indépendamment. Un exemple pourrait être un nœud Bluetooth avec des capteurs de température, d’humidité et de lumens. Ce serait un seul nœud (capteur) avec trois éléments.
- Passerelle maillée : Un nœud qui peut traduire des messages entre la maille et une technologie non Bluetooth.
Une fois provisionné, un nœud peut prendre en charge un ensemble facultatif de fonctionnalités, notamment :
- Relais : un nœud qui prend en charge le relais est appelé nœud de relais et peut retransmettre les messages reçus.
- Proxy : cela permet aux appareils BLE qui ne prennent pas en charge nativement le maillage Bluetooth d’interagir avec les nœuds du maillage. Elle est effectuée à l’aide d’un nœud proxy. Le proxy expose une interface GATT avec le périphérique Bluetooth hérité, et un protocole proxy basé sur un support orienté connexion est défini. Le périphérique hérité lit et écrit dans le protocole proxy GATT, et le nœud proxy transforme les messages en véritables PDU maillés.
- Faible puissance : certains nœuds du maillage doivent obtenir des niveaux de consommation d’énergie extrêmement faibles. Ils peuvent fournir des informations sur les capteurs environnementaux (comme la température) une fois par heure et être configurés par un outil géré par l’hôte ou le cloud une fois par an. Ce type d’appareil ne peut pas être placé en mode d’écoute lorsqu’un message n’arrivera qu’une fois par an. Le nœud entre dans un rôle appelé nœud de faible puissance (LPN), qui le couple avec un nœud ami. Le LPN entre dans un état de sommeil profond et interroge l’ami associé pour tous les messages qui pourraient être arrivés pendant qu’il dormait.
- Ami : un nœud ami est associé au LPN mais n’est pas nécessairement soumis à une contrainte de puissance comme un LPN. Un ami peut utiliser un circuit dédié ou une alimentation murale. Le devoir de l’ami est de stocker et de mettre en mémoire tampon les messages destinés au LPN jusqu’à ce que le LPN se réveille et l’interroge pour les messages. De nombreux messages peuvent être stockés et l’ami les transmettra dans l’ordre en utilisant un indicateur de données supplémentaires (MD).
Le diagramme suivant illustre une topologie de maillage Bluetooth avec les différents composants tels qu’ils seraient associés les uns aux autres dans un vrai maillage.

Figure 15 : Topologie du maillage Bluetooth. Notez les classes, notamment les nœuds, les LPN, les amis, les passerelles, les nœuds de relais et les nœuds non provisionnés.
Un maillage Bluetooth mettra en cache les messages sur chaque nœud ; ceci est crucial dans un réseau d’inondation. Comme le même message peut arriver à différents moments de différentes sources, le cache fournit une recherche des messages récents reçus et traités. Si le nouveau message est identique à celui du cache, il est rejeté. Cela garantit l’idempotence du système.
Chaque message comporte un champ TTL. Si un message est reçu par un nœud puis retransmis, le TTL est décrémenté d’un. Il s’agit d’un mécanisme de sécurité pour empêcher les boucles sans fin de traverser les messages dans un maillage. Il empêche également les réseaux de créer des attaques de déni de service amplificatrices.
Un message de pulsation est diffusé périodiquement de chaque nœud au maillage. Le rythme cardiaque informe le tissu que le nœud est toujours présent et sain. Il permet également au maillage de savoir à quelle distance le nœud est éloigné et s’il a changé de distance depuis le dernier battement de cœur. Essentiellement, il compte le nombre de sauts pour atteindre le nœud. Ce processus permet au maillage de se réorganiser et de s’auto-guérir.
5.2.11.2 Modes d’adressage maillé Bluetooth
Le maillage Bluetooth utilise trois formes d’adressage :
- Adressage monodiffusion : identifie de façon unique un seul élément du maillage. L’adresse est attribuée pendant le processus d’approvisionnement.
- Adressage de groupe : il s’agit d’une forme d’adressage multicast qui peut représenter un ou plusieurs éléments. Celles-ci sont prédéfinies par le Bluetooth SID en tant qu’adresses de groupe fixes SIG ou attribuées à la volée.
- Adressage virtuel : une adresse peut être attribuée à plusieurs nœuds et plusieurs éléments. L’adressage virtuel utilise un UUID 128 bits. L’objectif est que l’UUID puisse être prédéfini par un fabricant pour lui permettre d’adresser son produit à l’échelle mondiale.
Le protocole de maillage Bluetooth commence par des messages longs de 384 octets qui sont segmentés en parcelles de 11 octets. Toute communication dans un maillage Bluetooth est orientée message. Deux types de messages peuvent être transmis :
- Messages acquittés : ils nécessitent une réponse du ou des nœuds qui reçoivent le message. L’accusé de réception comprend également les données demandées par l’expéditeur dans le message d’origine. Par conséquent, ce message acquitté sert deux objectifs.
- Messages non acquittés : ils ne nécessitent pas de réponse du destinataire.
L’envoi d’un message à partir d’un nœud est également appelé publication. Lorsque les nœuds sont configurés pour traiter les messages sélectionnés envoyés à des adresses particulières, cela s’appelle abonnement. Chaque message est chiffré et authentifié à l’aide d’une clé réseau et d’une clé d’application.
La clé d’application est particulière à une application ou à un cas d’utilisation (par exemple, allumer une lumière ou configurer la couleur d’une lumière LED). Les nœuds publieront des événements (interrupteurs d’éclairage) et d’autres nœuds s’abonneront à ces événements (lampes et ampoules). La figure suivante illustre une topologie de maillage Bluetooth. Ici, les nœuds peuvent s’abonner à plusieurs événements (lumières du hall et lumières du couloir). Les cercles représentent les adresses de groupe. Un commutateur publierait dans un groupe.
Figure 16 : modèle de publication-abonnement au maillage Bluetooth
Le maillage Bluetooth introduit le concept de messagerie de groupe. Dans un maillage, vous pouvez avoir un regroupement d’objets similaires tels que des lampes de bain ou des lampes de hall. Cela facilite la convivialité ; par exemple, si une nouvelle lumière est ajoutée, seule cette lumière doit être provisionnée, et le reste du maillage n’a pas besoin d’être modifié.
Les interrupteurs d’éclairage de l’exemple précédent ont deux états : marche et arrêt. Le maillage Bluetooth définit les états, et dans ce cas, ils sont étiquetés génériques On-Off. Les états et messages génériques prennent en charge de nombreux types d’appareils, des lampes aux ventilateurs en passant par les actionneurs. Ils constituent un moyen rapide de réutiliser un modèle à des fins générales (ou génériques). Lorsque le système passe d’un état à un autre, cela s’appelle une transition d’état sur le maillage. Les États peuvent également être liés les uns aux autres. Si un état change, il peut affecter la transition vers un autre état. Par exemple, un maillage contrôlant un ventilateur de plafond peut avoir un état de contrôle de vitesse qui, lorsqu’il atteint une valeur de zéro, change l’état On-Off générique sur off.
Les propriétés sont similaires aux états mais ont plus que des valeurs binaires. Par exemple, un capteur de température peut avoir un état Température 8 pour signifier et publier une valeur de température de huit bits. Une propriété peut être définie en tant que fabricant (lecture seule) par le fournisseur de l’élément ou en tant qu’administrateur, ce qui permet un accès en lecture-écriture. Les états et les propriétés sont communiqués via des messages sur le maillage. Les messages sont de trois types :
- Get : demande une valeur d’un état donné à un ou plusieurs nœuds
- Définir : modifie la valeur d’un état
- Statut : est une réponse à un get contenant les données
Tous ces concepts d’états et de propriétés forment finalement un modèle (le plus haut niveau de la pile de mailles Bluetooth). Un modèle peut être un serveur, auquel cas il définit des états et des transitions d’états. Alternativement, un modèle peut être un client qui ne définit aucun état ; Il définit plutôt les messages d’interaction d’état à utiliser avec get, set et status. Un modèle de contrôle peut prendre en charge un hybride de modèles serveur et client.
La mise en réseau maillée peut également utiliser les fonctionnalités standard de Bluetooth 5 telles que les publicités anonymes et plusieurs ensembles de publicités. Prenons le cas d’un maillage qui se connecte à un téléphone pour la communication vocale, tout en relayant simultanément des paquets pour d’autres utilisations. En utilisant plusieurs ensembles de publicités, les deux cas d’utilisation peuvent être gérés simultanément.
5.2.11.3 Provisionnement du maillage Bluetooth
Un nœud peut rejoindre un maillage par l’acte d’approvisionnement. Le provisionnement est un processus sécurisé qui prend un périphérique non provisionné et non sécurisé et le transforme en nœud dans le maillage. Le nœud sécurisera d’abord une NetKey du maillage.
Au moins une NetKey doit se trouver sur chaque périphérique du maillage pour se joindre. Les périphériques sont ajoutés au maillage via un provisionneur. L’approvisionneur distribue la clé réseau et une adresse unique à un appareil non provisionné. Le processus d’approvisionnement utilise l’échange de clés ECDH pour créer une clé temporaire pour crypter la clé réseau. Cela offre une sécurité contre une attaque MITM pendant l’approvisionnement. La clé de périphérique dérivée de la courbe elliptique est utilisée pour crypter les messages envoyés du provisionneur au périphérique.
Le processus d’approvisionnement est le suivant :
- Un appareil non provisionné diffuse un paquet publicitaire de balise maillée.
- Le provisionneur envoie une invitation à l’appareil. Le périphérique non provisionné répond avec une PDU de capacités d’approvisionnement.
- Le provisionneur et le périphérique échangent des clés publiques.
- L’appareil non provisionné envoie un nombre aléatoire à l’utilisateur. L’utilisateur entre les chiffres (ou l’identité) dans le provisionneur, et un échange cryptographique commence pour terminer la phase d’authentification.
- Une clé de session est dérivée par chacun des deux appareils de la clé privée et des clés publiques échangées. La clé de session est utilisée pour sécuriser les données nécessaires pour terminer le processus d’approvisionnement, y compris la sécurisation de NetKey.
- Le périphérique change d’état d’un périphérique non provisionné en un nœud et est désormais en possession de NetKey, d’une adresse de monodiffusion et d’un paramètre de sécurité de maillage appelé l’index IV.
5.2.12 Technologie Bluetooth 5.1
En janvier 2019, le Bluetooth SIG a présenté la première mise à jour de la spécification 5.0: Bluetooth 5.1. Les principales améliorations comprenaient des fonctionnalités spécifiques pour le suivi de l’emplacement, la publicité et un approvisionnement plus rapide. Les nouvelles fonctionnalités spécifiques de la spécification incluent :
- Radiogoniométrie tridimensionnelle
- Améliorations de la mise en cache GATT
- Randomisation des indices des canaux publicitaires
- Transferts périodiques de synchronisation publicitaire
- Une myriade d’améliorations de fonctionnalités
5.2.12.1 Radiogoniométrie Bluetooth 5.1
Une nouvelle capacité importante de Bluetooth 5.1 est la possibilité de localiser des objets avec un haut degré de précision. Cette technologie serait utilisée lorsque le GPS n’est pas disponible ou n’est pas pratique. Par exemple, un musée pourrait utiliser des balises directionnelles dans de grandes salles d’exposition pour guider les clients et les orienter vers des expositions intéressantes. Ces cas d’utilisation relèvent des systèmes de localisation en temps réel ( RTLSes ) et des systèmes de positionnement intérieur ( IPSes ). Dans les conceptions Bluetooth précédentes (ainsi que dans d’autres protocoles sans fil), les solutions de proximité et de positionnement étaient dérivées simplement en fonction de la force du signal RSSI d’un objet. Plus un récepteur était éloigné d’un émetteur, plus le niveau RSSI était bas. À partir de cela, une forme dérivée de distance pourrait être générée. Cependant, cela présentait un degré élevé d’inexactitude et était soumis à des conditions environnementales telles que des changements de signal pénétrant diverses barrières.
Alors que les versions précédentes de Bluetooth fournissaient un suivi de proximité à peu près au mètre, Bluetooth 5.1 permet une précision et un suivi au centimètre près. Dans Bluetooth 5.1, deux méthodes différentes peuvent être utilisées pour dériver la distance et l’angle avec un très haut degré de précision. Les deux méthodes sont :
- Angle d’arrivée (AoA) : un appareil (par exemple, une balise active) transmet un paquet radiogoniométrique spécifique via une seule antenne tandis qu’un appareil récepteur capte le signal via un réseau d’antennes. Ceci est principalement utile pour les RTLS.
- Angle de départ (AoD) : un appareil (par exemple, balise ou IPS) utilise son réseau d’antennes pour transmettre un paquet spécifique à un appareil récepteur (smartphone) où le signal est traité pour déterminer les coordonnées de transmission. Ceci est principalement utile pour l’orientation en intérieur.
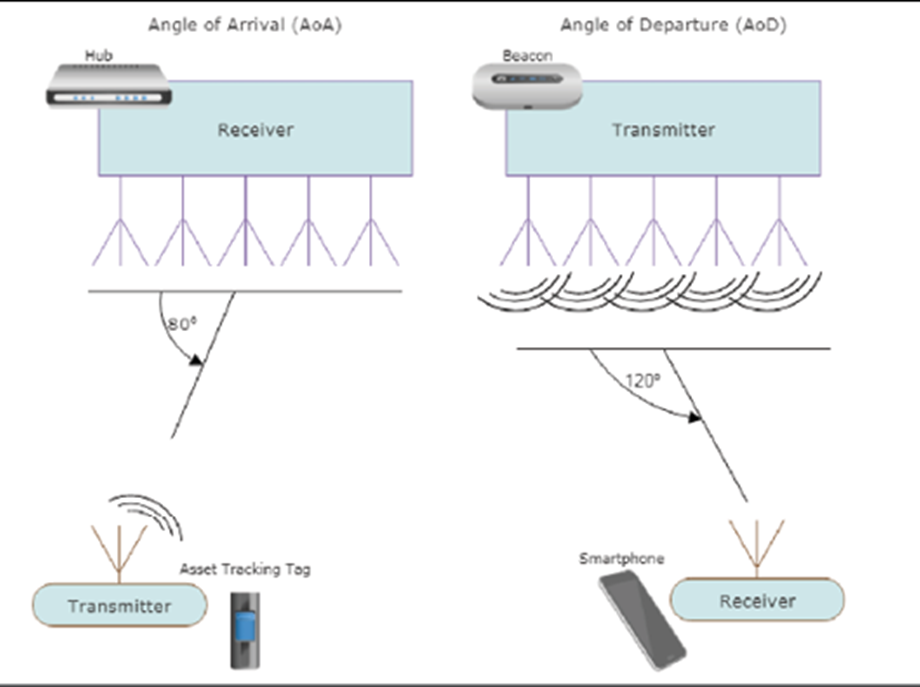
Figure 17 : Modes de fonctionnement du positionnement Bluetooth 5.1: AoA et AoD
Dans les cas AoA, un récepteur utilisera un réseau linéaire d’antennes. Si l’émetteur diffuse un signal dans le même plan normal que le réseau linéaire, chaque antenne du système récepteur verra le même signal dans la même phase. Cependant, si l’angle de transmission est décalé d’un certain degré, l’antenne de réception verra chacune le signal dans une phase différente. C’est ainsi que l’angle d’incidence peut être dérivé.
L’antenne de cette application Bluetooth serait un réseau linéaire uniforme (ULA) ou un réseau rectangulaire uniforme (URA). La différence est que le réseau linéaire est une seule ligne d’antennes rectiligne le long d’un plan, tandis que le réseau rectangulaire est une grille à deux dimensions. L’ULA ne peut mesurer qu’un seul angle incident (azimut), tandis que l’URA peut mesurer à la fois les angles d’élévation et d’azimut d’un signal. Les systèmes URA peuvent également être construits pour suivre et l’espace tridimensionnel entier en utilisant un tableau supplémentaire pour compléter les axes x , y et z . En général, la distance maximale entre deux antennes est d’une demi-longueur d’onde. En Bluetooth, la fréquence porteuse est de 2,4 GHz, tandis que la vitesse de la lumière est de 300 000 km / s. Cela implique que la longueur d’onde est de 0,125 m et que la séparation d’antenne maximale est de 0,0625 m.
Remarque : La construction d’un réseau d’antennes multidimensionnelles présente des défis considérables. Les antennes proches les unes des autres tenteront de s’influencer mutuellement par un processus appelé couplage mutuel. Il s’agit d’un effet électromagnétique en ce sens qu’une antenne proche absorbera l’énergie des voisins. Cela diminue à son tour la quantité d’énergie transmise au récepteur prévu et provoque des inefficacités ainsi que la cécité de balayage. La cécité par balayage crée des angles morts presque complets à certains angles de la matrice de transmission. Des précautions doivent être prises pour qualifier la source d’antenne.
Dans le suivi de direction Bluetooth, chaque antenne du réseau est échantillonnée en série. L’ordre dans lequel ils sont échantillonnés est finement réglé sur la conception du réseau d’antennes. Les données IQ capturées sont ensuite transmises à la pile BLE traditionnelle via le HCI. Bluetooth 5.1 a changé la couche de liaison et HCI pour prendre en charge un nouveau champ appelé l’extension de tonalité constante (CTE). CTE est un flux de “1” logique présenté sur le signal porteur. Cela se présente comme une onde logique de 250 kHz sur le signal porteur Bluetooth. Étant donné que le CTE existe à la fin des paquets normaux, il peut être utilisé simultanément avec des messages publicitaires et BLE normaux. Le graphique suivant illustre comment et où les informations CTE sont intégrées dans le paquet publicitaire Bluetooth existant.
Le message CTE ne peut être utilisé que pour les systèmes Bluetooth n’utilisant pas de PHY codé. Ainsi, les modes longue portée de Bluetooth 5 ne sont pas pris en charge pour le suivi de position.
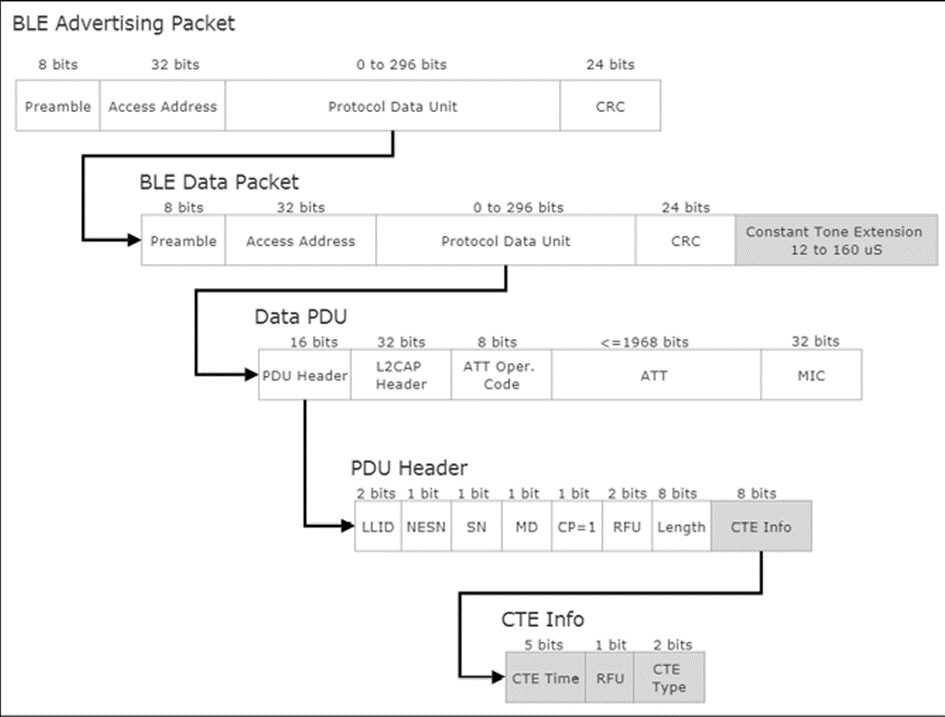
Figure 18 : Structure des paquets CTE. Notez que le bit CP dans le champ d’en-tête doit être activé pour utiliser les structures CTE. Les détails du CTE résident dans les informations CTE.
La théorie du fonctionnement est la suivante. La différence de phase entre les deux antennes est proportionnelle à la différence entre leurs distances respectives d’un émetteur. Les longueurs de trajet dépendent du sens de déplacement du signal entrant. La mesure commence par l’envoi du signal à tonalité constante CTE (sans modulation ni déphasage). Cela laisse suffisamment de temps au récepteur pour se synchroniser avec l’émetteur. Les échantillons de récepteur récupérés de la matrice sont appelés échantillons IQ pour “en phase” et “phase en quadrature”. Cette paire est considérée comme une valeur complexe de phase et d’amplitude. Il stocke ensuite les échantillons IQ et les traite dans le HCI.
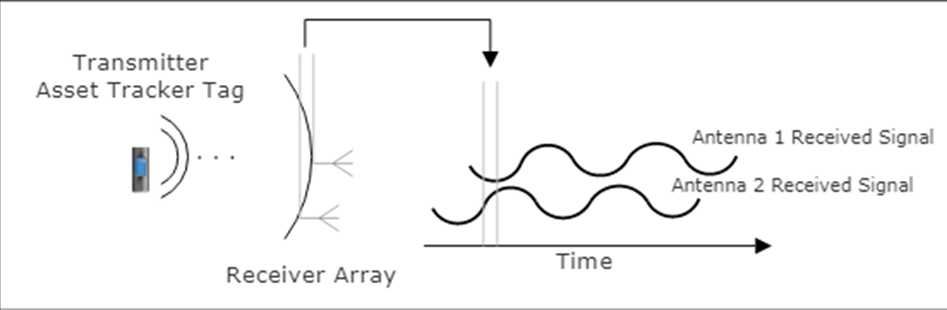
Figure 19 : Le signal reçu pour deux antennes diffère par une différence de phase (). Cette différence est proportionnelle aux distances respectives de chaque antenne de réception à la source d’émission.
Une autre façon de penser à la différence de phase consiste à utiliser les coordonnées polaires comme indiqué dans la figure suivante. Parce que nous mesurons les signaux de phase 2 ou plusieurs signaux (très probablement de nombreux signaux dans les réseaux d’antennes modernes), nous devons désactiver toutes les formes de modulation à décalage de phase pour Bluetooth.
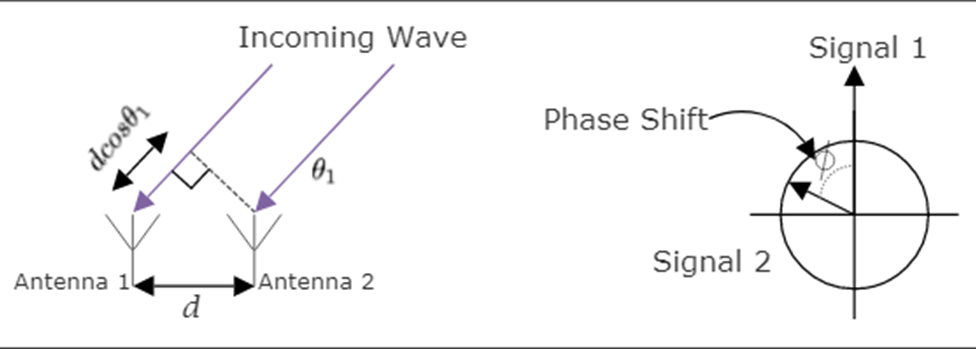
Figure 20 : Le signal reçu pour deux antennes diffère par une différence de phase (). Ici d est la distance entre les antennes. L’angle entrant qui doit être dérivé est. Cette différence est proportionnelle aux distances respectives des antennes de réception à la source d’émission.
L’algorithme de positionnement est exécuté dans le HCI pour déterminer l’angle de phase. Bluetooth 5.1 ne définit pas d’algorithme d’estimation d’angle spécifique à utiliser. L’algorithme le plus basique pour déterminer l’angle d’arrivée, basé sur la différence de phase, est par simple trigonométrie. Puisque nous connaissons les distances des antennes dans notre réseau, nous pouvons dériver l’AoA en calculant d’abord la différence de phase :

Et puis résoudre l’angle :
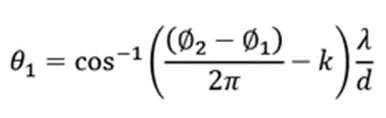
Bien que cette méthode fonctionne, elle présente des limites fondamentales. Tout d’abord, cela ne fonctionne que pour un seul signal entrant. Bluetooth peut utiliser des scénarios à trajets multiples, et cette formule d’angle simple ne compenserait pas bien. De plus, cet algorithme peut facilement être sujet au bruit.
D’autres algorithmes d’estimation de proximité et d’angle plus avancés à considérer dans la couche HCI sont :
| Technique | Théorie du fonctionnement | La qualité |
| Formation de faisceaux classique | Les algorithmes de formation de faisceaux utilisent plusieurs antennes et ajustent leur poids de signal respectif via un vecteur de direction a .
Ici, x est la collection d’échantillons IQ, s est le signal et n est le bruit. |
Mauvaise précision. |
| Formation de faisceaux Bartlett | Agrandit les signaux de certaines directions en ajustant le déphasage. | Basse résolution lors de la résolution de plusieurs sources. |
| Réponse sans distorsion à variance minimale | Tente de maintenir la direction du signal cible tout en minimisant les signaux provenant d’autres directions. | Résout mieux que la méthode Bartlett. |
| Lissage spatial | Résout les problèmes de trajets multiples et peut être utilisé conjointement avec des algorithmes de sous-espace comme MUSIC. | A tendance à réduire la matrice de covariance et donc à réduire la précision. |
| Classification des signaux multiples (MUSIQUE) | Estimateur de sous-espace qui utilise la décomposition propre sur une matrice de covariance.
L’algorithme parcourra tout pour trouver la valeur maximale ou le pic – c’est la direction souhaitée. |
Calcul le plus complexe mais produit une précision significative dans le suivi de direction. Il nécessite également un certain nombre de paramètres à connaître à l’avance.
Cela peut être problématique à l’intérieur ou lorsque les effets de trajets multiples sont répandus. |
| Estimation des paramètres du signal via des techniques invariantes rotationnelles (ESPRIT) | Règle le vecteur de direction en fonction du fait qu’un élément est en déphasage constant par rapport à un élément précédent. | Même une grande charge de calcul que MUSIC. |
ESPRIT et MUSIC sont appelés algorithmes de sous-espace car ils tentent de décomposer les signaux reçus en un “espace de signal” et un “espace de bruit”. Les algorithmes de sous-espace sont généralement plus précis que les algorithmes de formation de faisceau, mais ils sont également lourds en termes de calcul.
Ces algorithmes avancés de résolution d’angle sont extrêmement coûteux en termes de calcul en termes de ressources CPU et de mémoire. Du point de vue IoT, vous ne devez pas vous attendre à ce que ces algorithmes s’exécutent sur des appareils et des capteurs éloignés, en particulier des appareils à batterie à contrainte de puissance. Au contraire, des dispositifs informatiques de bord substantiels avec un traitement en virgule flottante suffisant seraient nécessaires pour exécuter ces algorithmes.
5.2.12.2 Mise en cache Bluetooth 5.1 GATT
Une nouvelle fonctionnalité de Bluetooth 5.1 est la mise en cache GATT, qui tente de mieux optimiser les performances des pièces jointes du service BLE. Nous avons appris que le GATT est interrogé pendant la phase de découverte de service de l’approvisionnement BLE. De nombreux appareils ne changeront jamais leur profil GATT, qui se compose généralement de services, de caractéristiques et de descripteurs. Par exemple, un capteur thermique Bluetooth client ne changera probablement jamais ses caractéristiques, décrivant le type de valeurs qui peuvent être interrogées sur l’appareil.
Bluetooth 4.0 a introduit la fonction d’indication de changement de service. Cette fonctionnalité permet aux clients qui avaient mis en cache les informations GATT d’un appareil de définir un indicateur de caractéristique (Service modifié) pour forcer un serveur à signaler tout changement dans sa structure GATT. Cela pose plusieurs problèmes :
- Chaque serveur devrait conserver les informations de stockage de chaque serveur auquel il se connectait et s’il avait informé ce serveur via l’indication de changement de service que ses caractéristiques GATT avaient changé. Cela a placé les charges de stockage sur de petits appareils IoT intégrés.
- La fonction de changement de service ne fonctionnait qu’avec des appareils déjà liés. Cette règle dans la spécification précédente a causé des problèmes inutiles de consommation d’énergie et d’expérience utilisateur pour divers appareils.
- Il pourrait y avoir une condition de concurrence. Par exemple, après une connexion à un serveur, un client peut expirer en attendant une notification de changement de service. Le client procédera ensuite à l’envoi normal de PDU ATT, mais recevra ultérieurement une indication de changement de service du serveur.
La mise en cache GATT dans Bluetooth 5.1 permet aux clients d’ignorer la phase de découverte de service lorsque rien n’a changé dans le GATT. Cela améliore la vitesse et la consommation d’énergie et élimine les conditions de course potentielles. Les périphériques non approuvés qui n’ont pas été précédemment liés peuvent désormais mettre en cache les tables d’attributs sur les connexions.
Pour utiliser cette fonctionnalité, deux membres du service d’attributs génériques sont utilisés: les fonctions de hachage de base de données et de support client . Le hachage de base de données est un hachage AES-CMAC 128 bits standard construit à partir de la table attributaire du serveur. Lors de l’établissement d’une connexion, un client doit immédiatement lire et mettre en cache la valeur de hachage. Si le serveur change ses caractéristiques (générant ainsi un nouveau hachage), le client reconnaîtra la différence. Dans ce cas, le client a probablement plus de ressources et de stockage que les petits points de terminaison IoT pour stocker de nombreuses valeurs de hachage pour une variété de périphériques approuvés et non approuvés. Le client a la capacité de reconnaître qu’il s’est déjà connecté à l’appareil et les attributs sont inchangés ; par conséquent, il peut ignorer la découverte de service. Cela offre une amélioration significative de la consommation d’énergie et du temps pour établir des connexions que les architectures précédentes.
Les fonctionnalités de support client permettent une technique appelée mise en cache robuste. Le système peut désormais être dans l’un des deux états suivants : sensible au changement et non sensible au changement. Si la mise en cache robuste est activée, le serveur qui a la visibilité de ces états peut envoyer une “erreur de synchronisation de la base de données” en réponse à toute opération GATT. Cela informe le client que la base de données est obsolète. Le client ignorera toutes les commandes ATT reçues tandis que le client pense que le serveur est dans un état sans changement. Si le client effectue une découverte de service et met à jour ses tables et son hachage de base de données, il peut alors envoyer une indication de changement de service et le client passera à un état sensible au changement. Ceci est similaire à l’ancienne indication de changement de service mais élimine la possibilité d’une condition de concurrence.
5.2.12.3 Indexation aléatoire des canaux publicitaires Bluetooth 5.1
BLE utilise les canaux 37 (2402 MHz), 38 (2426 MHz) et 39 (2480 MHz) pour les messages publicitaires. Dans Bluetooth 5.0 et les protocoles précédents, les messages publicitaires passent par ces canaux dans un ordre strict lorsque tous les canaux sont utilisés. Cela conduit souvent à des collisions de paquets lorsque deux ou plusieurs appareils sont à la même proximité. À mesure que davantage d’appareils entrent dans le champ Bluetooth, plus de collisions se produisent. Cela gaspillera de l’énergie et dégradera les performances. Pour y remédier, Bluetooth 5.1 permet de sélectionner des indices publicitaires au hasard, mais suit un schéma de six commandes potentielles:
- Canal 37 -> Canal 38 -> Canal 39
- Canal 37 -> Canal 39 -> Canal 38
- Canal 38 -> Canal 37 -> Canal 39
- Canal 38 -> Canal 39 -> Canal 37
- Canal 39 -> Canal 37 -> Canal 38
- Canal 39 -> Canal 38 -> Canal 37
Les figures suivantes montrent la différence entre la publicité par ordre strict Bluetooth précédente et les processus de publicité aléatoire Bluetooth 5.1:
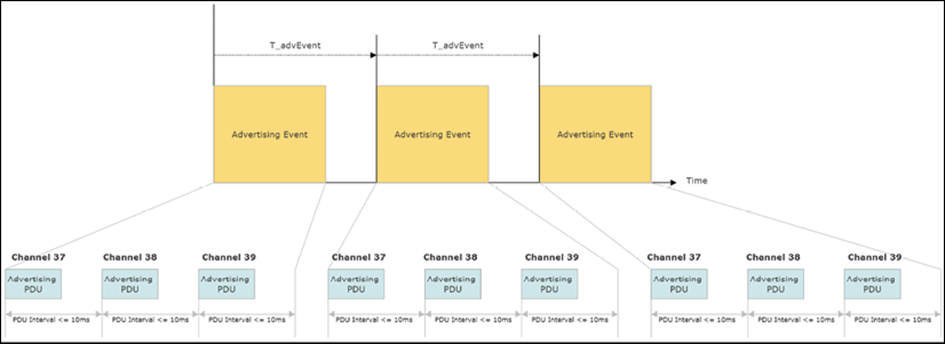
Figure 21 : Processus publicitaire hérité. Notez le canal strict ordonnant 37 à 38 à 39. Dans un PAN Bluetooth encombré, cela peut provoquer des collisions.
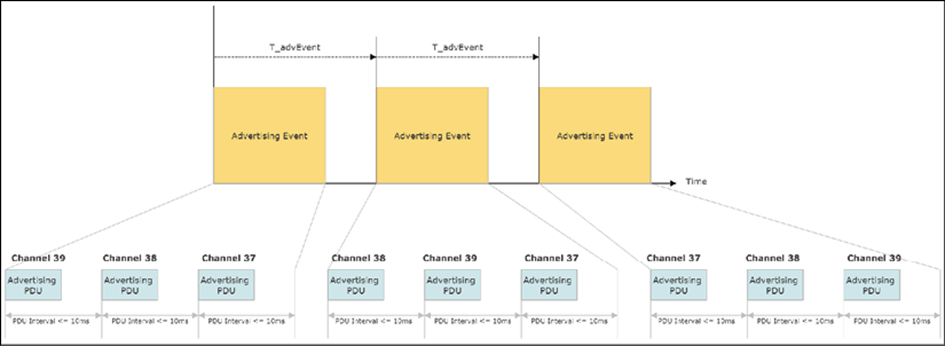
Figure 22 : Indexation aléatoire des canaux publicitaires Bluetooth 5.1
5.2.12.4 Transfert de synchronisation publicitaire périodique Bluetooth 5.1
Comme mentionné dans la dernière section, tous les messages publicitaires transpirent sur les canaux 37, 38 et 39. Les fenêtres d’événements publicitaires sont séparées les unes des autres par une valeur pseudo-aléatoire (advDelay) de 0 ms à 10 ms. Cela aide à éviter les collisions, mais il est restrictif pour une variété d’applications. Cependant, cela complique les rôles du système de numérisation qui doivent être synchronisés avec les publicités diffusées.
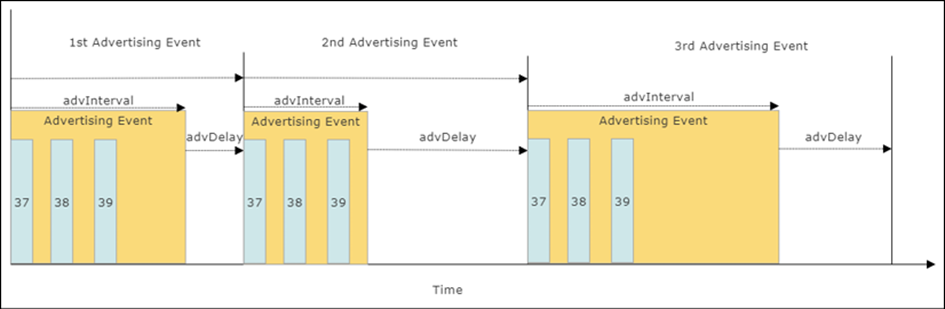
Figure 23 : Publicité Bluetooth héritée : l’intervalle de publicité (advInterval) est toujours un multiple entier de 0,625 ms et variera de 20 ms à 10,485.759375 s. Le délai entre les événements publicitaires (advDelay) est une valeur pseudo-aléatoire allant de 0 ms à 10 ms. L’écart aléatoire entre les événements publicitaires successifs aide à éviter les collisions, mais complique le rôle du scanner, qui doit tenter de se synchroniser avec la synchronisation aléatoire des paquets livrés.
Avec la publicité périodique, un appareil peut spécifier un intervalle prédéfini auquel l’hôte d’analyse peut se synchroniser. Ceci est accompli en utilisant des paquets publicitaires étendus. Cette méthode de publicité synchronisée peut présenter des avantages substantiels en termes d’économies d’énergie pour les appareils à faible consommation d’énergie en permettant à l’annonceur (ainsi qu’au scanner) de se mettre en veille et de se réveiller à intervalles fixes pour envoyer et recevoir des messages publicitaires.
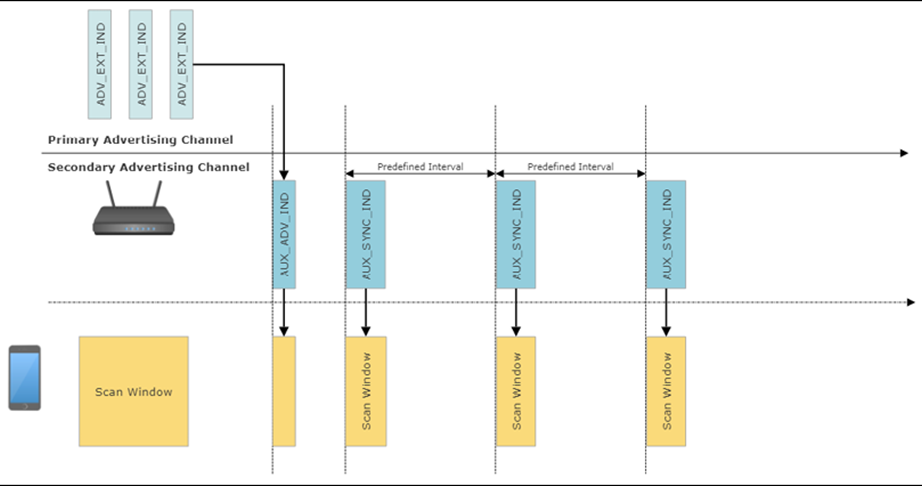
Figure 24 : l’activation de la publicité périodique commence par l’utilisation des canaux publicitaires principaux et la transmission des messages ADV_EXT_IND. Cela informe le scanner du PHY et du canal secondaire qui seront utilisés pour la communication. Le dispositif publicitaire enverra alors des informations telles que la carte des chaînes et l’intervalle de messages souhaité. Cet intervalle prédéfini sera ensuite fixé et utilisé par le scanner pour se synchroniser avec l’annonceur.
La publicité périodique a un rôle bénéfique dans de nombreux cas d’utilisation, mais certains appareils soumis à des contraintes de puissance peuvent ne pas avoir les ressources capables de prendre en charge des publicités fréquentes. Une fonctionnalité appelée transfert de synchronisation publicitaire périodique (PAST) permet à un autre périphérique proxy qui n’est pas limité en termes de puissance ou de ressources d’effectuer tout le travail de synchronisation, puis de transmettre les détails de la synchronisation aux périphériques contraints. Un cas d’utilisation typique peut être un smartphone qui agit comme un proxy pour une smartwatch couplée. Si le téléphone (scanner) reçoit des publicités d’une balise, il peut transmettre les données reçues des paquets AUX_SYNC_IND périodiques à la smartwatch. Étant donné que la montre est probablement plus contrainte par l’énergie que le smartphone, la montre ne recevra que des informations publicitaires sélectionnées.
Un nouveau message de contrôle de couche liaison appelé LL_PERIODIC_SYNC_IND a été créé dans Bluetooth 5.1 pour permettre au smartphone de transférer des messages publicitaires vers la smartwatch sans que la montre ne recherche constamment des messages publicitaires. Sans PAST, la smartwatch consommerait de l’énergie supplémentaire pour recevoir des publicités périodiques.
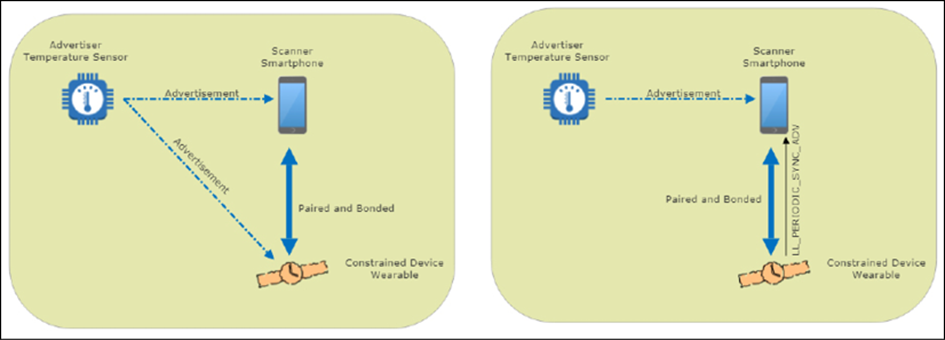
Figure 25 : Un exemple d’utilisation de PAST. Dans ce cas, un appareil à contrainte d’énergie (smartwatch ou wearable) s’est couplé à un smartphone. Les deux reçoivent des publicités périodiques d’un capteur de température IoT, ce qui n’est pas optimal en termes d’efficacité énergétique du système. Le système de droite utilise le LL_PERIODIC_SYNC_ADV permettant au portable de demander la synchronisation publicitaire du smartphone. Dans ce cas, le smartphone est un proxy pour les messages publicitaires que le portable peut vouloir utiliser.
5.2.12.5 Améliorations mineures de Bluetooth 5.1
Un certain nombre de problèmes supplémentaires et de petites fonctionnalités ont été ajoutés à la conception Bluetooth 5.1:
- Prise en charge HCI des clés de débogage dans les connexions sécurisées LE. Lorsque Bluetooth utilise un protocole de clé Diffie-Hellman sécurisé pour établir une communication sécurisée, il est impossible d’obtenir la clé partagée et de l’utiliser à des fins de débogage, de qualification ou de développement.
Cette modification permet aux connexions sécurisées LE de fonctionner avec les protocoles Diffie-Hellman en ajoutant une commande HCI pour informer l’hôte d’utiliser les valeurs de clé de débogage.
- Mécanisme de mise à jour de la précision de l’horloge de veille. Normalement, lorsque les connexions sont établies, un appareil maître informe un esclave de la précision de son horloge interne à l’aide du champ de précision de l’horloge de veille (SCA). Si le maître est connecté à plusieurs appareils, il peut être nécessaire de modifier sa précision d’horloge. Auparavant, un hôte n’avait aucun moyen d’informer les périphériques connectés que la précision de l’horloge avait changé. Un nouveau message de couche liaison appelé LL_CLOCK_ACCURACY_REQ peut être transmis aux appareils connectés pour leur permettre d’ajuster l’horloge en synchronisation avec le maître. Cela peut réduire la puissance du système.
- Utilisation du champ AdvDataInfo (ADI) dans les données de réponse d’analyse. Il s’agit d’un défaut hérité exposé dans la publicité étendue de Bluetooth 5.0. Ce champ n’a pas été utilisé dans les réponses de scan dans Bluetooth 5.0 mais est corrigé dans 5.1.
- Interaction entre QoS et spécification de flux. Il s’agit d’une amélioration BR / EDR héritée et d’une clarification des règles.
- Classification du canal hôte pour la publicité secondaire. Les canaux publicitaires secondaires peuvent désormais être classés comme “mauvais” via la commande HCI LE_Set_Host_Channel_Classification .
- Autoriser l’affichage des ID de jeu (SID) dans les rapports de réponse aux analyses. Ceux-ci sont utilisés dans les champs publicitaires étendus de Bluetooth 5.0 mais ne sont jamais apparus dans les réponses de numérisation.
5.3 IEEE 802.15.4
L’IEEE 802.15.4 est un WPAN standard défini par le groupe de travail IEEE 802.15. Le modèle a été ratifié en 2003 et constitue la base de nombreux autres protocoles, dont Thread (abordé plus loin), Zigbee (abordé plus loin dans ce chapitre), WirelessHART et autres.
15.4 définit uniquement la partie inférieure (PHY et couche de liaison de données) de la pile et non les couches supérieures. Il appartient à d’autres consortiums et groupes de travail de construire une solution réseau complète. L’objectif du 802.15.4 et des protocoles qui y sont associés est un WPAN à faible coût avec une faible consommation d’énergie. La dernière spécification est la spécification IEEE 802.15.4e ratifiée le 6 février 2012, qui est la version dont nous parlerons dans ce chapitre.
5.3.1 Architecture IEEE 802.15.4
Le protocole IEEE 802.15.4 fonctionne dans le spectre sans licence dans trois bandes de fréquences radio différentes : 868 MHz, 915 MHz et 2400 MHz. L’objectif est d’avoir une empreinte géographique aussi large que possible, ce qui implique trois bandes différentes et plusieurs techniques de modulation. Alors que les fréquences plus basses permettent au 802.15 d’avoir moins de problèmes d’interférences RF ou de portée, la bande 2,4 GHz est de loin la bande 802.15.4 la plus utilisée dans le monde. La bande de fréquence plus élevée a gagné en popularité parce que la vitesse plus élevée permet des cycles de service plus courts lors de la transmission et de la réception, économisant ainsi la puissance.
L’autre facteur qui a rendu la bande 2,4 GHz populaire est son acceptation sur le marché en raison de la popularité de Bluetooth. Le tableau suivant répertorie diverses techniques de modulation, zones géographiques et débits de données pour diverses bandes 802.15.4.
| Gamme de fréquences (MHz) | Numéros de chaîne | Modulation | Débit de données (Kbps) | Région |
| 3 | 1 canal: 0 | BPSK
O-QPSK ASK |
20
100 250 |
L’Europe |
| 902-928 | 10 canaux: 1-10 | BPSK
O-QPSK ASK |
40
250 250 |
Amérique du Nord, Australie |
| 2405-2480 | 16 canaux: 11-26 | O-QPSK | 250 | Dans le monde |
La portée typique d’un protocole basé sur 802.15.4 est d’environ 200 mètres dans un test de visibilité directe en plein air. À l’intérieur, la portée typique est d’environ 30 m. Des émetteurs-récepteurs de puissance supérieure (15 dBm) ou un réseau maillé peuvent être utilisés pour étendre la portée. Le graphique suivant montre les trois bandes utilisées par 802.15.4 et la distribution de fréquence.
Figure 26 : Bandes IEEE 802.15.4 et attributions de fréquences : la bande 915 MHz utilise une séparation de fréquence de 2 MHz et la bande 2,4 GHz utilise une séparation de fréquence de 5 MHz
Pour gérer un espace de fréquence partagé, 802.15.4 et la plupart des autres protocoles sans fil utilisent une forme d’accès multiple à détection de porteuse avec évitement de collision (CSMA/CA). Puisqu’il est impossible d’écouter un canal tout en transmettant sur le même canal, les schémas de détection de collision ne fonctionnent pas ; par conséquent, nous utilisons l’évitement de collision. CSMA / CA écoute simplement un canal spécifique pendant une durée prédéterminée. Si le canal est détecté comme “inactif”, il transmet en envoyant d’abord un signal indiquant à tous les autres émetteurs que le canal est occupé. Si le canal est occupé, la transmission est différée pendant une période de temps aléatoire. Dans un environnement fermé, CSMA / CA fournira 36% d’utilisation des canaux ; Cependant, dans des scénarios réels, seuls 18% des canaux seront utilisables.
Le groupe IEEE 802.15.4 définit la puissance de transmission opérationnelle à au moins 3 dBm et la sensibilité du récepteur à -85 dBm à 2,4 GHz et -91 dBm à 868/915 MHz. Cela implique généralement de 15 mA à 30 Courant mA pour la transmission et un courant de 18 mA à 37 mA pour la réception.
Le débit de données sous forme de pics d’état à 250 kbps à l’aide de la touche de décalage de phase en quadrature décalée.
La pile de protocoles se compose uniquement des deux couches inférieures du modèle OSI (PHY et MAC). Le PHY est responsable du codage des symboles, de la modulation des bits, de la démodulation des bits et de la synchronisation des paquets. Il effectue également une commutation en mode émission-réception et une commande de temporisation / acquittement intra-paquet. La figure suivante illustre la pile de protocoles 802.15.4 à titre de comparaison avec le modèle OSI.
Figure 27 : IEEE 802.15.4 pile de protocoles : des couches PHY et MAC sont uniquement des fi nis; d’autres normes et organisations sont libres d’incorporer les couches 3 à 7 au-dessus de PHY et MAC
Au-dessus de la couche physique se trouve la couche de liaison de données chargée de détecter et de corriger les erreurs sur la liaison physique. Cette couche contrôle également la couche MAC (Media Access Control) pour gérer l’évitement des collisions à l’aide de protocoles tels que CSMA / CA. La couche MAC est généralement implémentée dans un logiciel et s’exécute sur un microcontrôleur (MCU) tel que le populaire ARM Cortex M3 ou même un cœur ATmega 8 bits. Il y a quelques fournisseurs de silicium qui ont incorporé le MAC dans du silicium pur, comme Microchip Technology Inc.
L’interface entre le MAC et les couches supérieures de la pile est fournie par le biais de deux interfaces appelées points d’accès au service (SAP) :
- MAC-SAP : pour la gestion des données
- MLME-SAP : pour le contrôle et la surveillance (entité de gestion de couche MAC)
Il existe deux types de communication dans IEEE 802.15.4: la communication par balise et la communication sans balise.
Pour un réseau basé sur des balises, la couche MAC peut générer des balises qui permettent à un périphérique d’entrer dans un PAN ainsi que de fournir des événements de synchronisation pour qu’un périphérique entre dans un canal pour communiquer. La balise est également utilisée pour les appareils à batterie qui dorment normalement. L’appareil se réveille sur une minuterie périodique et écoute une balise de ses voisins. Si une balise est entendue, elle commence une phase appelée intervalle SuperFrame où les intervalles de temps sont pré-alloués pour garantir la bande passante aux appareils, et les appareils peuvent appeler l’attention d’un nœud voisin. L’intervalle SuperFrame ( SO ) et l’ intervalle de balise ( BO ) sont entièrement contrôlables par le coordinateur PAN. Le SuperFrame est divisé en 16 intervalles de temps de taille égale avec un dédié comme balise de ce SuperFrame. L’accès aux canaux CSMA / CA à fente est utilisé dans les réseaux basés sur des balises.
Les créneaux horaires garantis ( GTS ) peuvent être attribués à des appareils spécifiques, empêchant toute forme de conflit. Jusqu’à sept domaines GTS sont autorisés. Les créneaux horaires GTS sont attribués par le coordinateur PAN et annoncés dans la balise qu’il diffuse. Le coordinateur PAN peut modifier les allocations GTS à la volée en fonction de la charge du système, des exigences et de la capacité. Le sens GTS (émission ou réception) est prédéterminé avant le démarrage du GTS. Un appareil peut demander un GTS d’émission et / ou un GTS de réception.
Le SuperFrame a des périodes d’accès conflictuel (CAP) où il y a une diaphonie sur le canal et des périodes sans conflit (CFP) où la trame peut être utilisée pour la transmission et les GTS. La figure suivante illustre un SuperFrame composé de 16 intervalles de temps égaux délimités par des signaux de balise (dont l’un doit être une balise). Une période sans conflit sera ensuite divisée en GTS et une ou plusieurs fenêtres (GTSW) peuvent être attribuées à un appareil particulier. Aucun autre appareil ne peut utiliser ce canal pendant un GTS.
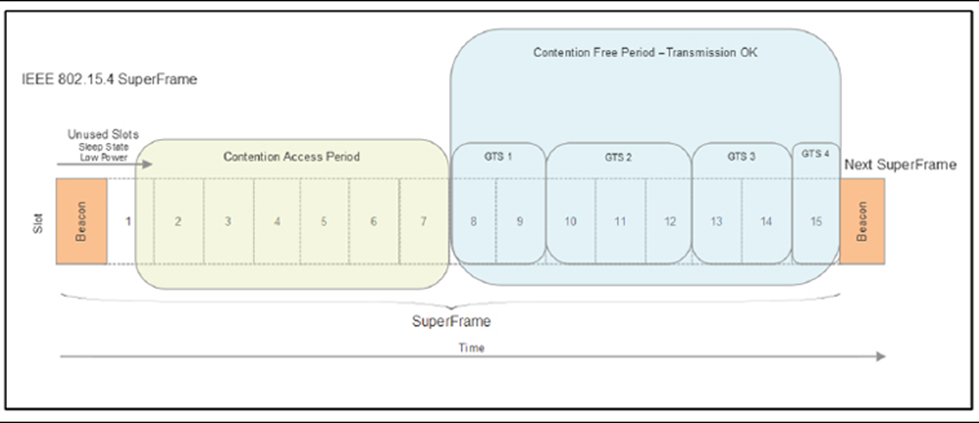
Figure 28 : séquence SuperFrame IEEE 802.15.4
En plus de la mise en réseau basée sur les balises, IEEE 802.15.4 permet une mise en réseau sans balise. Il s’agit d’un schéma beaucoup plus simple où aucune trame de balise n’est transmise par le coordinateur PAN. Cela implique cependant que tous les nœuds sont en permanence en mode réception. Cela fournit un accès à temps plein aux conflits grâce à l’utilisation de CSMA / CA sans emplacement. Un nœud émetteur effectuera une évaluation de canal clair (CCA) dans lequel il écoute le canal pour détecter s’il est utilisé, puis transmet s’il est clair. L’ACC fait partie d’un algorithme CSMA / CA et est utilisé pour « détecter » si un canal est utilisé. Un périphérique peut recevoir l’accès à un canal s’il est libre de tout autre trafic provenant d’autres périphériques (y compris des périphériques non 802.15.4). Dans le cas où un canal est occupé, l’algorithme entre dans un algorithme de “back-off” et attend une quantité aléatoire de temps pour réessayer le CCA. La spécification de groupe IEEE 802.15.4 est la suivante pour l’utilisation CCA :
- Mode CCA 1 : énergie supérieure au seuil (la plus basse). L’ACC signalera un milieu occupé pour détecter toute énergie supérieure à une valeur seuil (ED).
- Mode CCA 2 : détection de porteuse uniquement (moyenne – par défaut). Ce mode oblige CCA à signaler un support occupé uniquement si un signal à spectre étalé à séquence directe (DSSS) est détecté. Le signal peut être supérieur ou inférieur au seuil ED.
- Mode CCA 3 : détection de porteuse avec une énergie supérieure au seuil (la plus forte). Dans ce mode, le CCA signale occupé s’il détecte un signal DSSS avec une énergie supérieure au seuil ED.
- Mode CCA 4 : Un mode de détection de détection de porteuse avec une minuterie. Le CCA démarre un temporisateur d’un certain nombre de millisecondes et ne signalera occupé que s’il détecte un signal PHY à haut débit. L’ACC signalera que le support est inactif si le temporisateur expire et qu’aucun signal à haut débit n’est observé.
- CCA Mode 5 : une combinaison de détection de porteuse et d’énergie au-dessus d’un mode seuil.
Remarque concernant les modes CCA :
- La détection d’énergie sera au plus 10 dB au-dessus de la sensibilité spécifiée du récepteur. Le temps de détection CCA sera égal à huit périodes de symboles.
- Il convient de noter que les modes CCA basés sur la détection d’énergie consomment le moins d’énergie pour l’appareil.
Ce mode consommera beaucoup plus d’énergie que la communication basée sur une balise.
5.3.2 Topologie IEEE 802.15.4
Il existe deux types de périphériques fondamentaux dans IEEE 802.15.4:
- Périphérique à fonctions complètes (FFD) : prend en charge toute topologie de réseau, peut être un coordinateur de réseau (PAN) et peut communiquer avec n’importe quel coordinateur PAN de périphérique
- Dispositif à fonction réduite (RFD) : limité à une topologie en étoile uniquement, ne peut pas fonctionner en tant que coordinateur de réseau et ne peut communiquer qu’avec un coordinateur de réseau
La topologie en étoile est la plus simple mais nécessite que tous les messages entre les nœuds homologues transitent par le coordinateur PAN pour le routage. Une topologie d’égal à égal est un maillage typique et peut communiquer directement avec les nœuds voisins. La construction de réseaux et de topologies plus complexes est le devoir des protocoles de niveau supérieur, dont nous discuterons dans la section Zigbee.
Le coordinateur du PAN a un rôle unique qui est de mettre en place et de gérer le PAN. Il a également le devoir de transmettre des balises de réseau et de stocker des informations sur les nœuds. Contrairement aux capteurs qui peuvent utiliser une batterie ou des sources d’énergie récupératrices d’énergie, le coordinateur PAN reçoit constamment des transmissions et se trouve généralement sur une ligne électrique dédiée (alimentation murale). Le coordinateur PAN est toujours un FFD.
Les RFD ou même les FFD basse consommation peuvent être basés sur une batterie. Leur rôle est de rechercher les réseaux disponibles et de transférer les données si nécessaire. Ces appareils peuvent être mis en veille pendant de très longues périodes. La figure suivante est un diagramme d’une topologie en étoile par rapport à la topologie peer-to-peer.

Figure 29 : Guide IEEE 802.15.4 sur les topologies de réseau. L’implémenteur de 802.15.4 est libre de créer d’autres topologies de réseau.
Au sein du PAN, les messages diffusés sont autorisés. Pour diffuser à l’ensemble de la structure, il suffit de spécifier l’ID PAN de 0xFFFF.
5.3.3 Modes d’adresse IEEE 802.15.4 et structure de paquets
La norme impose que toutes les adresses soient basées sur des valeurs 64 bits uniques (adresse IEEE ou adresse MAC). Cependant, pour conserver la bande passante et réduire l’énergie de transmission de telles adresses, le 802.15.4 permet à un appareil rejoignant un réseau de “troquer” son adresse 64 bits unique contre une adresse locale courte 16 bits, permettant une transmission plus efficace et moins d’énergie.
Ce processus d’échange est la responsabilité du coordinateur PAN. Nous appelons cette adresse locale 16 bits l’ID PAN. L’ensemble du réseau PAN lui-même a un identifiant PAN, car plusieurs PAN peuvent exister. La figure suivante est un diagramme de la structure des paquets 802.15.4.
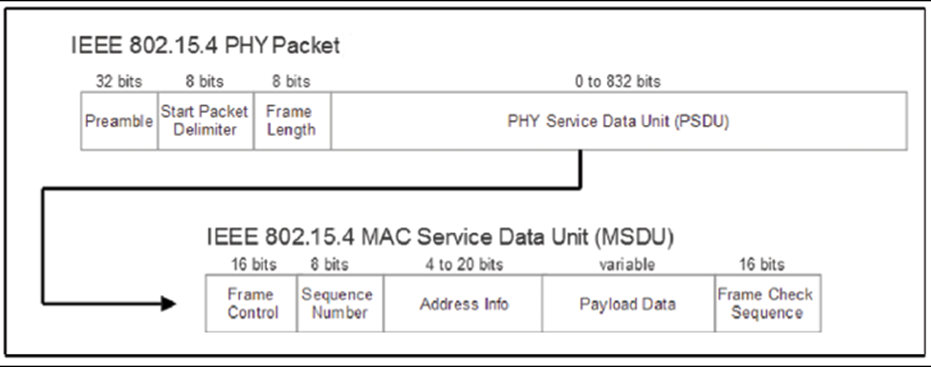
Figure 30 : codage des paquets IEEE 802.15.4 PHY et MAC
Les trames sont l’unité de base du transport de données, et il existe quatre types fondamentaux (certains des concepts sous-jacents ont été traités dans la dernière section):
- Trame de données : transport de données d’application
- Trame d’accusé de réception : Confirmation de réception
- Cadre Beacon : envoyé par le coordinateur PAN pour mettre en place une structure SuperFrame
- Cadre de commande MAC : gestion de la couche MAC (associer, dissocier, demande de balise, demande GTS)
5.3.4 Séquence de démarrage IEEE 802.15.4
IEEE 802.15.4 maintient un processus pour le démarrage, la configuration du réseau et la jonction des réseaux existants. Le processus est le suivant :
- Un appareil initialise sa pile (couches PHY et MAC).
- Un coordinateur PAN est créé. Chaque réseau n’a qu’un seul coordinateur PAN. Le coordinateur PAN doit être affecté à cette phase avant de poursuivre.
- Le coordinateur PAN écoutera les autres réseaux auxquels il a accès et obtient un identifiant PAN unique au PAN qu’il administrera. Il peut le faire sur plusieurs canaux de fréquence.
- Le coordinateur PAN choisira une fréquence radio spécifique à utiliser pour le réseau. Il le fera en utilisant un balayage de détection d’énergie où il balaye les fréquences que le PHY peut prendre en charge et écoute pour trouver un canal au repos.
- Le réseau sera démarré en configurant le coordinateur PAN puis en démarrant l’appareil en mode coordinateur. À ce stade, le coordinateur PAN peut accepter les demandes.
- Les nœuds peuvent rejoindre le réseau en trouvant le coordinateur PAN à l’aide d’un balayage de canal actif où il diffuse une demande de balise sur tous ses canaux de fréquence. Lorsque le coordinateur PAN détecte la balise, il répondra à l’appareil demandeur. Alternativement, dans un réseau basé sur une balise (détaillé plus haut), le coordinateur PAN enverra régulièrement une balise, et l’appareil peut effectuer un balayage de canal passif et écouter la balise. L’appareil enverra alors une demande d’association.
- Le coordinateur PAN déterminera si l’appareil doit ou peut rejoindre le réseau. Cela peut être basé sur des règles de contrôle d’accès, ou même si le coordinateur PAN dispose de suffisamment de ressources pour gérer un autre appareil. S’il est accepté, le coordinateur PAN attribuera une adresse courte de 16 bits à l’appareil.
5.3.5 Sécurité IEEE 802.15.4
La norme IEEE 802.15.4 comprend des dispositions de sécurité sous forme de cryptage et d’authentification. L’architecte dispose d’une flexibilité dans la sécurité du réseau basée sur le coût, les performances, la sécurité et la puissance. Les différentes suites de sécurité sont répertoriées dans le tableau suivant.
Le chiffrement basé sur AES utilise un chiffrement par bloc avec un mode compteur. L’AES-CBC-MAC fournit une protection d’authentification uniquement, et le mode AES-CCM fournit la suite complète de chiffrement et d’authentification. Les radios 802.15.4 fournissent une liste de contrôle d’accès ( ACL ) pour contrôler la suite de sécurité et les clés à utiliser. Les appareils peuvent stocker jusqu’à 255 entrées ACL.
La couche MAC calcule également des “vérifications de fraîcheur” entre les répétitions successives pour garantir que les anciennes trames ou les anciennes données ne sont plus considérées comme valides et empêcheront ces trames de remonter la pile.
Chaque émetteur-récepteur 802.15.4 doit gérer sa propre liste de contrôle d’accès et la remplir avec une liste de “voisins de confiance” ainsi que les politiques de sécurité. L’ACL comprend l’adresse du nœud autorisé à communiquer avec, la suite de sécurité particulière à utiliser (AES-CTR, AES-CCM-xx, AES-CBC-MAC-xx), la clé de l’algorithme AES et la dernière initiale vecteur (IV) et compteur de relecture.
Le tableau suivant répertorie les différents modes et fonctionnalités de sécurité 802.15.4.
| Tapez | La description | Contrôle d’accès | Confidentialité | Intégrité du cadre | Fraîcheur séquentielle |
| Aucun | Pas de sécurité | ||||
| AES-CTR | Cryptage uniquement, CTR | X | X | X | |
| AES-CBC-MAC-128 | MAC 128 bits | X | X | ||
| AES-CBC-MAC-64 | MAC 64 bits | X | X | ||
| AES-CBC-MAC-32 | MAC 32 bits | X | X | ||
| AES-CCM-128 | Cryptage et MAC 128 bits | X | X | X | X |
| AES-CCM-64 | Chiffrement et MAC 64 bits | X | X | X | X |
| AES-CCM-32 | Cryptage et MAC 32 bits | X | X | X | X |
La cryptographie symétrique repose sur les deux points de terminaison à l’aide de la même clé. Les clés peuvent être gérées au niveau du réseau à l’aide d’une clé de réseau partagée. Il s’agit d’une approche simple où tous les nœuds possèdent la même clé mais sont à risque d’attaques internes. Un schéma de clé par paire pourrait être utilisé lorsque des clés uniques sont partagées entre chaque paire de nœuds. Ce mode ajoute des frais généraux, en particulier pour les réseaux où il y a une forte diffusion des nœuds vers les voisins. La saisie de groupe est une autre option. Dans ce mode, une seule clé est partagée entre un ensemble de nœuds et est utilisée pour deux nœuds quelconques du groupe. Les groupes sont basés sur les similitudes des appareils, les zones géographiques, etc. Enfin, une approche hybride est possible, combinant l’un des trois schémas mentionnés.
5.4 Zigbee
Zigbee est un protocole WPAN basé sur la fondation IEEE 802.15.4 destiné aux réseaux IoT commerciaux et résidentiels limités par le coût, la puissance et l’espace. Cette section détaille le protocole Zigbee d’un point de vue matériel et logiciel. Zigbee tire son nom du concept d’une abeille volant. Lorsqu’une abeille vole entre des fleurs ramassant du pollen, elle ressemble à un paquet traversant un réseau maillé – appareil à appareil.
5.4.1 Histoire du zigbee
Le concept de réseau maillé sans fil à faible consommation d’énergie est devenu standard dans les années 1990 et la Zigbee Alliance a été formée pour respecter cette charte en 2002. Le protocole Zigbee a été conçu après la ratification de l’IEEE 802.15.4 en 2004. Il est devenu l’IEEE 802.15. 4.-Norme 2003 le 14 décembre 2004. La spécification 1.0, également connue sous le nom de spécification Zigbee 2004, a été rendue publique le 13 juin 2005. L’historique peut être décrit comme suit :
- 2005 : Sortie de Zigbee 2004
- 2006 : Sortie de Zigbee 2006
- 2007 : sortie de Zigbee 2007, également connue sous le nom de Zigbee Pro (introduction de bibliothèques de cluster, quelques contraintes de compatibilité descendante avec Zigbee 2004 et 2006)
La relation de l’alliance avec le groupe de travail IEEE 802.15.4 est similaire au groupe de travail IEEE 802.11 et à la Wi-Fi Alliance. La Zigbee Alliance maintient et publie des normes pour le protocole, organise des groupes de travail et gère la liste des profils d’application. L’IEEE 802.15.4 définit les couches PHY et MAC, mais rien de plus.
De plus, 802.15.4 ne spécifie rien sur les communications multi-sauts ou l’espace d’application. C’est là que Zigbee (et d’autres normes basées sur 802.15.4) entre en jeu.
Zigbee est propriétaire et un standard fermé. Cela nécessite des frais de licence et un accord fourni par la Zigbee Alliance. La licence accorde au porteur la conformité Zigbee et la certification du logo. Il garantit l’interopérabilité avec d’autres appareils Zigbee.
5.4.2 Présentation de Zigbee
Zigbee est basé sur le protocole 802.15.4 mais superpose des services réseau supplémentaires qui le rapprochent davantage de TCP / IP. Cela permet à Zigbee de former des réseaux, de découvrir des appareils, d’assurer la sécurité et de gérer le réseau. Il ne fournit pas de services de transport de données ni d’environnement d’exécution d’application. Parce qu’il s’agit essentiellement d’un réseau maillé, il est auto-réparateur et de forme ad hoc. De plus, Zigbee est fier de sa simplicité et revendique une réduction de 50% du support logiciel en utilisant une pile de protocoles légère.
Il existe trois principaux composants dans un réseau Zigbee:
- Contrôleur Zigbee (ZC) : Il s’agit d’un appareil hautement performant sur un réseau Zigbee qui est utilisé pour former et lancer des fonctions réseau. Chaque réseau Zigbee aura un seul ZC qui remplira le rôle de coordinateur PAN (FFD) 802.15.4 2003. Une fois le réseau formé, le ZC peut se comporter comme un ZR (routeur Zigbee). Il peut attribuer des adresses réseau logiques et permettre aux nœuds de rejoindre ou de quitter le maillage.
- Routeur Zigbee (ZR) : ce composant est facultatif mais gère une partie de la charge du réseau maillé et de la coordination du routage. Il peut également remplir le rôle d’un FFD et est associé à la ZC. Un ZR participe au routage multi-sauts des messages et peut attribuer des adresses de réseau logique et permettre aux nœuds de rejoindre ou de quitter le maillage.
- Dispositif final ZigBee (ZED) : Ceci est simplement à l’appareil endpoint En général, tel que un interrupteur ou thermostat. Il contient suffisamment de fonctionnalités pour communiquer avec le coordinateur. Il n’a pas de logique de routage; par conséquent, tous les messages arrivant sur un ZED qui ne sont pas ciblés sur cet appareil final sont simplement relayés. Il ne peut pas non plus effectuer d’associations (détaillées plus loin dans ce chapitre).
Zigbee cible trois types différents de trafic de données. Des données périodiques sont délivrées ou transmises à un rythme défini par les applications (par exemple, des capteurs transmettant périodiquement).
Des données intermittentes se produisent lorsqu’une application ou un stimulus externe se produit à un rythme aléatoire. Un bon exemple de données intermittentes adaptées à Zigbee est un interrupteur d’éclairage. Le type de trafic final desservi par Zigbee est constitué de données répétitives à faible latence. Zigbee alloue des créneaux horaires pour la transmission et peut avoir une latence très faible, ce qui convient à une souris ou un clavier d’ordinateur.
Zigbee prend en charge trois topologies de base (illustrées dans la figure suivante):
- Réseau en étoile : un seul ZC avec un ou plusieurs ZED. Il ne s’étend que sur deux sauts et est donc limité en distance de nœud. Il nécessite également une liaison fiable avec un point de défaillance unique au niveau du ZC.
- Arborescence de clusters : réseau à plusieurs sauts qui utilise la balise et étend la couverture et la portée du réseau sur un réseau en étoile. Les nœuds ZC et ZR peuvent avoir des enfants, mais les ZED restent de véritables points de terminaison. Les nœuds enfants ne communiquent qu’avec leur parent (comme un petit réseau en étoile). Un parent peut communiquer en aval avec ses enfants ou en amont avec son parent. Le problème existe toujours avec un seul point de défaillance au centre.
- Réseau maillé : formation et morphing de chemins dynamiques. Le routage peut se produire à partir de n’importe quel appareil source vers n’importe quel appareil de destination. Il utilise des algorithmes de routage pilotés par arbre et table. Les radios ZC et ZR doivent être alimentées à tout moment pour effectuer des tâches de routage, consommant ainsi la batterie. De plus, le calcul de la latence dans un réseau maillé peut être difficile sinon non déterministe. Dans ce mode, certaines règles de routage sont assouplies; Cependant, les routeurs dans une certaine plage les uns des autres peuvent communiquer directement entre eux. Le principal avantage est que le réseau peut s’étendre au-delà de la ligne de visée et possède plusieurs chemins redondants.
Zigbee, en théorie, peut déployer jusqu’à 65 536 ZED.
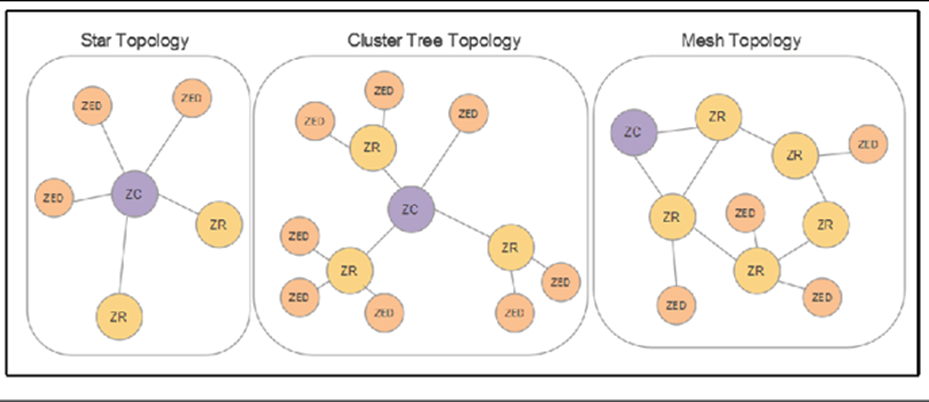
Figure 31 : Trois formes de topologies de réseau Zigbee, du réseau en étoile le plus simple à l’arborescence de cluster à un vrai maillage
5.4.3 Zigbee PHY et MAC (et différence par rapport à IEEE 802.15.4)
Zigbee, comme Bluetooth, fonctionne principalement dans la bande ISM 2,4 GHz. Contrairement à Bluetooth, il fonctionne également à 868 MHz en Europe et à 915 MHz aux États-Unis et en Australie. En raison de la fréquence plus basse, il a une meilleure propension à pénétrer les murs et les obstacles par rapport aux signaux traditionnels de 2,4 GHz. Zigbee n’utilise pas toutes les spécifications IEEE 802.15.4 PHY et MAC. Zigbee utilise le schéma d’évitement de collision CSMA / CA. Il utilise également le mécanisme de niveau MAC pour empêcher les nœuds de communiquer entre eux.
Zigbee n’utilise pas les modes de balisage IEEE 802.15.4. De plus, les GTS des SuperFrames ne sont pas non plus utilisés dans Zigbee.
La spécification de sécurité de 802.15.4 est légèrement modifiée. Les modes CCM qui fournissent l’authentification et le chiffrement nécessitent une sécurité différente pour chaque couche. Zigbee est destiné aux systèmes fortement limités en ressources et profondément intégrés et ne fournit pas le niveau de sécurité défini dans 802.15.4.
Zigbee est basé sur la spécification IEEE 802.15.4-2003 avant que des améliorations avec deux nouveaux PHY et radios soient standardisées dans la spécification IEEE 802.15.4-2006. Cela implique que les débits de données sont légèrement inférieurs à ce qu’ils pourraient être dans les bandes 868 MHz et 900 MHz.
5.4.4 Pile de protocoles Zigbee
La pile de protocoles Zigbee comprend une couche réseau (NWK) et une couche application (APS). Les composants supplémentaires incluent un fournisseur de services de sécurité, un plan de gestion ZDO et un objet périphérique Zigbee (ZDO). La structure de la pile illustre une véritable simplicité par rapport à la pile Bluetooth plus complexe mais riche en fonctionnalités.
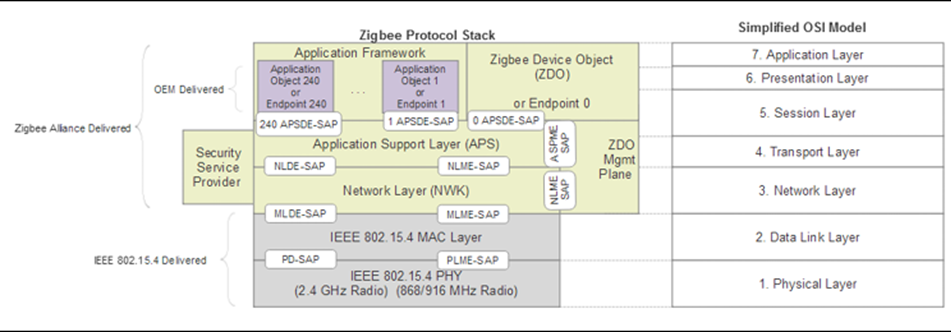
Figure 32 : pile de protocole Zigbee et la simpli correspondant fi ed modèle OSI en tant que cadre de référence
Le NWK est utilisé pour les trois principaux composants Zigbee (ZR, ZC, ZED). Cette couche effectue la gestion des périphériques et la découverte des itinéraires. De plus, puisqu’il administre un véritable maillage dynamique, il est également responsable de l’entretien et de la guérison des itinéraires. En tant que fonction la plus élémentaire, le NWK est responsable du transfert des paquets réseau et du routage des messages. Pendant le processus de jonction de nœuds à un maillage Zigbee, le NWK fournit l’adresse réseau logique pour le ZC et sécurise une connexion.
L’APS fournit une interface entre la couche réseau et la couche application. Il gère la base de données de la table de liaison, qui est utilisée pour trouver le bon périphérique en fonction du service requis par rapport à un service offert. Les applications sont modélisées par ce que l’on appelle des objets d’application. Les objets d’application communiquent entre eux via une carte d’attributs d’objets appelés clusters. La communication entre les objets est créée dans un fichier XML compressé pour permettre l’ubiquité. Tous les appareils doivent prendre en charge un ensemble de méthodes de base. Un total de 240 points de terminaison peut exister par appareil Zigbee.
L’APS relie le périphérique Zigbee à un utilisateur. La majorité des composants du protocole Zigbee réside ici, y compris l’objet périphérique Zigbee ( ZDO ). Le point de terminaison 0 est appelé ZDO et est un composant essentiel qui est responsable de la gestion globale des périphériques. Cela comprend la gestion des clés, des stratégies et des rôles des appareils. Il peut également découvrir de nouveaux appareils (à un saut) sur le réseau et les services offerts par ces appareils. Le ZDO initie et répond à toutes les demandes de liaison pour le périphérique. Il établit également une relation sécurisée entre les périphériques réseau en gérant la stratégie de sécurité et les clés du périphérique.
Les liaisons sont des connexions entre deux points de terminaison, chaque liaison prenant en charge un profil d’application particulier. Par conséquent, lorsque nous combinons le point de terminaison source et de destination, l’ID de cluster et l’ID de profil, nous pouvons créer un message unique entre deux points de terminaison et deux appareils. Les liaisons peuvent être un à un, un à plusieurs ou plusieurs à un. Un exemple de liaison serait plusieurs interrupteurs d’éclairage connectés à un ensemble d’ampoules. Les points de terminaison d’application du commutateur s’associeront aux points de terminaison légers. Le ZDO assure la gestion des liaisons en associant les points de terminaison du commutateur aux points de terminaison légers à l’aide d’objets d’application. Des grappes peuvent être créées, permettant à un interrupteur d’allumer toutes les lumières tandis qu’un autre interrupteur ne peut contrôler qu’une seule lumière.
Un profil d’application fourni par le fabricant d’équipement d’origine (OEM) décrira une collection d’appareils pour des fonctions spécifiques (par exemple, interrupteurs d’éclairage et avertisseurs de fumée). Les périphériques d’un profil d’application peuvent communiquer entre eux via des clusters. Chaque cluster aura un ID de cluster unique pour s’identifier au sein du réseau.
5.4.5 Adressage Zigbee et structure de paquets
Le protocole Zigbee, comme illustré dans la figure suivante, réside au-dessus des couches 802.15.4 PHY et MAC et réutilise ses structures de paquets. Le réseau diverge au niveau des couches réseau et application.
La figure suivante illustre la décomposition de l’un des paquets 802.15.4 PHY et MAC en le paquet de trame de couche réseau (NWK) correspondant ainsi que la trame de couche application (APS) :
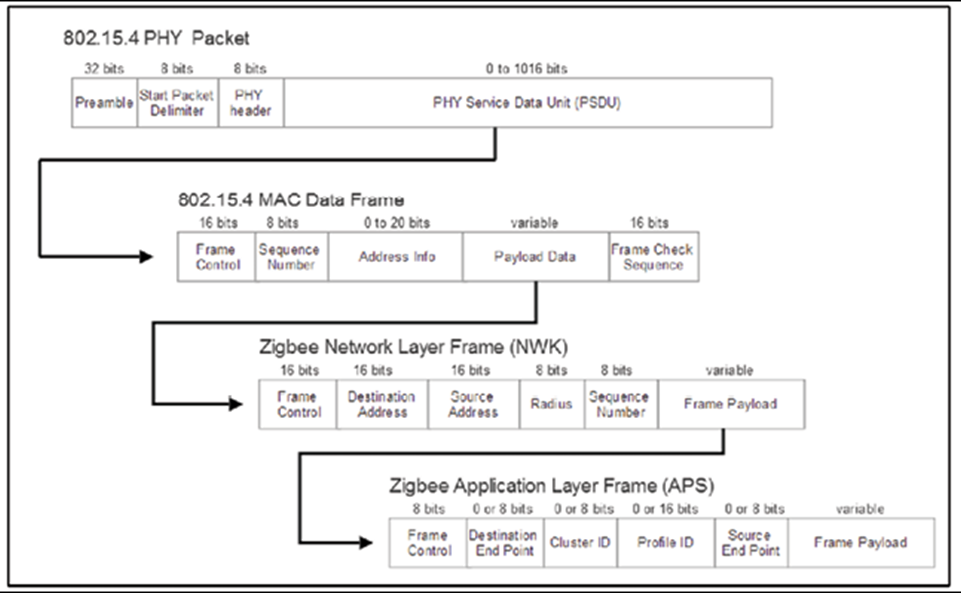
Figure 33 : réseau Zigbee (NWK) et trames de couche application (APS) résidant sur des paquets 802.15.4 PHY et MAC
Zigbee utilise deux adresses uniques par nœud :
- Adresse longue (64 bits) : attribuée par le fabricant de l’appareil et immuable. Cela identifie de manière unique le périphérique Zigbee de tous les autres périphériques Zigbee. C’est la même chose que l’adresse 802.15.4 64 bits. Les 24 bits supérieurs se réfèrent à l’OUI et les 40 bits inférieurs sont gérés par l’OEM. Les adresses sont gérées par blocs et peuvent être achetées via IEEE.
- Adresse courte (16 bits) : identique à l’ID PAN de la spécification 802.15.4 et également facultative.
5.4.6 Acheminement du maillage Zigbee
Le routage de table utilise le routage AODV et l’algorithme d’arborescence de cluster. AODV est un pur système de routage à la demande. Dans ce modèle, les nœuds n’ont pas à se découvrir jusqu’à ce qu’il y ait une association entre les deux (par exemple, deux nœuds doivent communiquer). AODV n’exige pas non plus de nœuds qui ne se trouvent pas dans le chemin de routage pour conserver les informations de routage. Si un nœud source doit communiquer avec une destination et qu’aucun chemin n’existe, un processus de découverte de chemin démarre. AODV fournit une prise en charge unicast et multicast. C’est un protocole réactif ; c’est-à-dire qu’il fournit uniquement un itinéraire vers une destination à la demande et non de manière proactive. L’ensemble du réseau est silencieux jusqu’à ce qu’une connexion soit nécessaire.
L’algorithme d’arborescence de cluster forme un réseau auto-organisé capable d’auto-réparation et de redondance. Les nœuds du maillage sélectionnent une tête de cluster et créent des clusters autour d’un nœud principal. Ces grappes autoformantes se connectent ensuite les unes aux autres via un dispositif désigné.
Zigbee a la capacité d’acheminer des paquets de plusieurs manières :
- Diffusion : transmettez le paquet à tous les autres nœuds de la structure.
- Routage maillé (routage de table) : s’il existe une table de routage pour la destination, l’itinéraire suivra les règles de la table en conséquence. Très efficace. Zigbee permettra à une maille et à une table d’acheminer jusqu’à 30 sauts.
- Routage de l’arborescence : messagerie unicast d’un nœud à un autre. Le routage de l’arborescence est purement facultatif et peut être interdit de l’ensemble du réseau. Il offre une meilleure efficacité de la mémoire que le routage maillé car il n’existe pas de grande table de routage. Le routage d’arbre n’a cependant pas la même redondance de connexion qu’un maillage. Zigbee prend en charge les tronçons de routage d’arbres jusqu’à 10 nœuds.
- Routage source : utilisé principalement lorsqu’un concentrateur de données est présent. C’est ainsi que Z-Wave fournit un routage de maillage.

Figure 34 : paquet de routage Zigbee pour émettre une trame de commande de demande de route et réponse ultérieure avec une trame de commande de réponse de route
La découverte d’itinéraire ou la découverte de chemin est le processus de découverte d’un nouvel itinéraire ou de réparation d’un itinéraire interrompu. Un périphérique émettra un cadre de commande de demande d’itinéraire vers l’ensemble du réseau. Si et quand la destination reçoit la trame de commande, elle répondra avec au moins une trame de commande de réponse d’itinéraire. Tous les itinéraires potentiels retournés sont inspectés et évalués pour trouver l’itinéraire optimal.
Les coûts de liaison signalés lors de la découverte du chemin peuvent être constants ou basés sur la probabilité de réception.
5.4.7 Association Zigbee
Comme mentionné précédemment, les ZED ne participent pas au routage. Les appareils terminaux communiquent avec le parent, qui est également un routeur. Lorsqu’un ZC autorise un nouveau périphérique à rejoindre un réseau, il entre dans un processus appelé association. Si un appareil perd le contact avec son parent, il peut à tout moment se réinscrire via le processus appelé orphelin.
Pour rejoindre officiellement un réseau Zigbee, une demande de balise est diffusée par un périphérique pour demander des balises ultérieures aux périphériques du maillage autorisés à permettre à de nouveaux nœuds de se joindre. Dans un premier temps, seul le coordinateur PAN est autorisé à fournir une telle demande ; une fois le réseau développé, d’autres appareils peuvent participer.
5.4.7.1 Sécurité Zigbee
Zigbee s’appuie sur les dispositions de sécurité d’IEEE 802.15.4. Zigbee propose trois mécanismes de sécurité : les listes de contrôle d’accès, le chiffrement AES 128 bits et les minuteries de fraîcheur des messages.
Le modèle de sécurité Zigbee est réparti sur plusieurs couches :
- La couche d’application fournit des services de création et de transport de clés à ZDO.
- La couche réseau gère le routage et les trames sortantes utiliseront la clé de liaison définie par le routage si elle est disponible ; sinon, une clé réseau est utilisée.
- La sécurité de la couche MAC est gérée via une API et contrôlée par les couches supérieures.
Il existe plusieurs clés gérées par un réseau Zigbee:
- Clé principale : La clé principale peut être préinstallée par un fabricant ou entrée par un processus manuel avec l’utilisateur. Il constitue la base de la sécurité de l’appareil Zigbee. Les clés principales sont toujours installées en premier et transmises depuis le centre de confiance.
- Clé réseau : cette clé assurera une protection au niveau du réseau contre les attaquants extérieurs.
- Clé de liaison : cela forme une liaison sécurisée entre deux appareils. Si deux appareils ont le choix entre utiliser des clés de liaison installées ou des clés de réseau, ils utiliseront toujours par défaut des clés de liaison pour fournir plus de protection.
Les clés de liaison sont gourmandes en ressources dans le sens d’un stockage de clés sur des appareils contraints. Les clés réseau peuvent être utilisées pour alléger une partie des coûts de stockage au risque d’une diminution de la sécurité.
La gestion des clés est essentielle pour la sécurité. La distribution des clés est contrôlée en établissant un centre de confiance (un nœud pour servir de distributeur de clés à tous les autres nœuds de la structure). Le ZC est supposé être le centre de confiance. On peut implémenter un réseau Zigbee avec un centre de confiance dédié en dehors du ZC. Le centre de confiance fournit les services suivants :
- Gestion de la confiance : authentifie les appareils rejoignant le réseau
- Gestion du réseau : maintient et distribue les clés
- Gestion de la configuration : active la sécurité de périphérique à périphérique
De plus, le centre de confiance peut être placé en mode résidentiel (il n’établira pas de clés avec les périphériques réseau), ou il peut être en mode commercial (établit les clés avec chaque périphérique du réseau).
Zigbee utilise des clés 128 bits dans le cadre de ses spécifications dans les couches MAC et NWK. La couche MAC propose trois modes de chiffrement : AES-CTR, AES-CBC-128 et AES-CCM-128 (tous définis dans la section IEEE 802.15.4). La couche NWK, cependant, ne prend en charge que AES-CCM-128 mais est légèrement modifiée pour fournir une protection uniquement par cryptage et intégrité.
L’intégrité des messages garantit que les messages n’ont pas été modifiés en transit. Ce type d’outil de sécurité est utilisé pour les attaques MITM. En se référant à la structure du paquet Zigbee, le code d’intégrité du message et l’en-tête auxiliaire fournissent des champs pour ajouter des vérifications supplémentaires pour chaque message d’application envoyé.
L’authentification est fournie via une clé réseau commune et des clés individuelles entre des paires d’appareils.
Les minuteries de fraîcheur des messages sont utilisées pour rechercher les messages qui ont expiré. Ces messages sont rejetés et supprimés du réseau en tant qu’outil de contrôle des attaques de relecture. Cela s’applique aux messages entrants et sortants. Chaque fois qu’une nouvelle clé est créée, les minuteries de fraîcheur sont réinitialisées.
5.5 Z-Wave
Z-Wave est une autre technologie de maillage dans la bande 900 MHz. Il s’agit d’un protocole WPAN utilisé principalement pour la consommation et la domotique, et environ 2 100 produits utilisent la technologie. Il a trouvé sa place dans les segments commerciaux et du bâtiment dans les domaines de l’éclairage et du contrôle CVC. En termes de part de marché, cependant, Z-Wave n’est pas à la capitalisation boursière comme Bluetooth ou Zigbee.
Sa première manifestation a eu lieu en 2001 chez Zensys, une société danoise développant des systèmes de contrôle d’éclairage. Zensys a formé une alliance avec Leviton Manufacturing, Danfoss et Ingersoll-Rand en 2005, officiellement connue sous le nom de Z-Wave Alliance . L’alliance a acquis Sigma Designs en 2008 et Sigma est désormais le seul fournisseur de modules matériels Z-Wave. Les sociétés membres de la Z-Wave Alliance incluent désormais SmartThings, Honeywell, Belkin, Bosch, Carrier, ADT et LG.
Z-Wave est un protocole fermé pour la plupart avec des fabricants de modules matériels limités. La spécification commence à s’ouvrir davantage dans le domaine public, mais une quantité substantielle de matériel n’est pas divulguée.
5.5.1 Présentation de Z-Wave
La conception de Z-Wave est axée sur l’éclairage / l’automatisation domestique et grand public. Il est prévu d’utiliser une bande passante très faible pour la communication avec les capteurs et les commutateurs. La conception est basée sur la norme UIT-T G.9959 au niveau PHY et MAC. L’UIT-T G.9959 est la spécification de l’Union internationale des télécommunications pour les émetteurs-récepteurs de radiocommunication à bande étroite à courte portée dans la bande inférieure à 1 GHz.
Il existe plusieurs bandes dans la gamme inférieure à 1 GHz qui sont utilisées pour la Z-Wave selon le pays d’origine. Aux États-Unis, la fréquence centrale de 908,40 MHz est la norme. Il existe trois débits de données que Z-Wave est capable de varier en fréquence pour chacun:
- 100 Kbps : 916,0 MHz avec une propagation de 400 KHz
- 40 Kbit / s : 916,0 MHz avec un étalement de 300 KHz
- 9,6 Kbps : 908,4 MHz avec une propagation de 300 KHz
Chaque bande fonctionne sur un seul canal.
La modulation effectuée au niveau PHY utilise une incrustation à décalage de fréquence pour des débits de données à 9,6 Kbps et 40 Kbps. Au taux rapide de 100 Kbps, une incrustation à décalage de fréquence gaussienne est utilisée. La puissance de sortie sera d’environ 1 mW à 0 dB.
Les conflits de canaux sont gérés à l’aide de CSMA / CA, comme décrit dans d’autres protocoles précédemment couverts. Ceci est géré dans la couche MAC de la pile. Les nœuds démarrent en mode de réception et attendent un certain temps avant de transmettre des données en cas de diffusion de données.
Du point de vue du rôle et de la responsabilité, le réseau Z-Wave est composé de différents nœuds avec des fonctions spécifiques :
- Périphérique contrôleur : ce périphérique de niveau supérieur fournit la table de routage du réseau maillé et est l’hôte / maître du maillage en dessous. Il existe deux types fondamentaux de contrôleurs :
- Contrôleur principal : le contrôleur principal est le maître et un seul maître peut exister dans un réseau. Il a la capacité de maintenir la topologie et la hiérarchie du réseau. Il peut également inclure ou exclure des nœuds de la topologie et a le devoir d’allouer des ID de nœud.
- Contrôleur secondaire : ces nœuds assistent un contrôleur principal lors du routage.
- Périphérique / nœud esclave : ces périphériques effectuent des actions en fonction des commandes qu’ils reçoivent. Ces périphériques ne peuvent pas communiquer avec les nœuds esclaves voisins à moins d’y être invités via une commande. Les esclaves peuvent stocker des informations de routage mais ne calculent ni ne mettent à jour les tables de routage. En règle générale, ils agissent comme un répéteur dans un maillage.
Les contrôleurs peuvent également être définis comme portables et statiques. Un contrôleur portable est conçu pour se déplacer comme une télécommande. Une fois qu’il a changé de position, il recalcule les itinéraires les plus rapides du réseau. Un contrôleur statique est destiné à être fixé, comme une passerelle branchée sur une prise murale. Le contrôleur statique peut toujours être “activé” et recevoir des messages d’état d’esclave.
Les contrôleurs peuvent également avoir différents attributs au sein du réseau :
- Contrôleur de mise à jour d’état (SUC) : Le contrôleur statique a également l’avantage de jouer le rôle de contrôleur de mise à jour d’état. Dans ce cas, il recevra des notifications d’un contrôleur principal concernant les changements de topologie. Il peut également aider au routage des esclaves.
- Serveur d’ID SUC (SIS) : un SUC peut également aider à inclure et à exclure des esclaves pour le primaire.
- Contrôleur de pont : il s’agit essentiellement d’un contrôleur statique qui a la capacité d’agir comme une passerelle entre le maillage Z-Wave et d’autres systèmes de réseau (par exemple, WAN ou Wi-Fi). Le pont est autorisé à contrôler jusqu’à 128 nœuds esclaves virtuels.
- Contrôleur d’installation : il s’agit d’un contrôleur portable qui peut aider à la gestion du réseau et à l’analyse de la qualité de service.
Les esclaves prennent également en charge différents attributs :
- Routage esclave : Fondamentalement, il s’agit d’un nœud esclave mais avec la possibilité d’envoyer des messages non sollicités à d’autres nœuds du maillage. En règle générale, les esclaves ne sont pas autorisés à envoyer un message à un autre nœud sans la commande d’un contrôleur principal. Le nœud stocke un ensemble de routes statiques qu’il utilise lors de l’envoi d’un message.
- Esclave amélioré : ceux-ci ont les mêmes capacités qu’un esclave de routage avec l’ajout d’une horloge en temps réel et d’un stockage persistant pour les données d’application. Un exemple pourrait être un compteur de gaz.
Les nœuds / appareils esclaves peuvent être basés sur une batterie, comme un capteur de mouvement dans une maison. Pour qu’un esclave soit un répéteur, il doit toujours être fonctionnel et à l’écoute des messages sur le maillage. Pour cette raison, les appareils à batterie ne sont jamais utilisés comme répéteurs.
5.5.2 Pile de protocoles Z-Wave
Étant donné que Z-Wave est un protocole à très faible bande passante conçu pour avoir une topologie de réseau clairsemée, la pile de protocoles tente de communiquer avec le moins d’octets par message possible. La pile se compose de cinq couches, comme illustré dans la figure suivante :
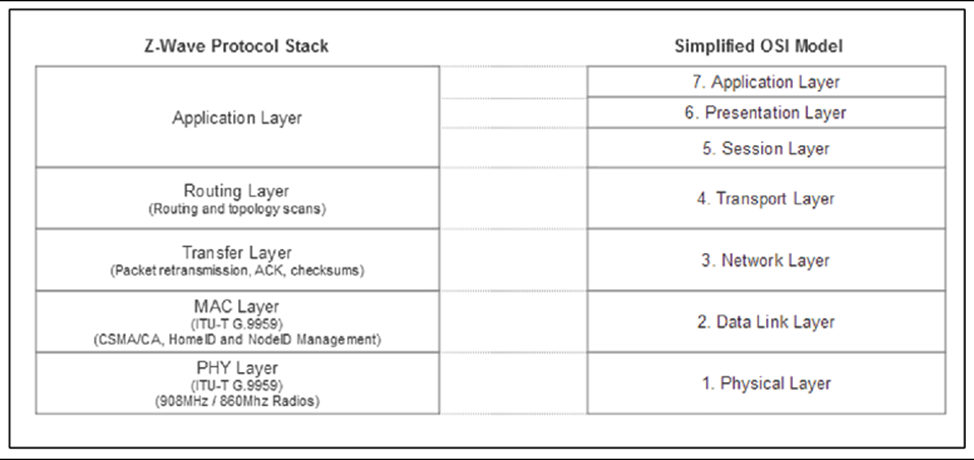
Figure 35 : Z-Wave pile de protocole et la comparaison du modèle OSI: utiliser Z-Wave a fi pile déjà couches avec les deux couches inférieures (PHY et MAC) fi nis par l’UIT-T G.9959 fi le cation
Les couches peuvent être décrites comme suit :
- Couche PHY : définie par la spécification UIT-T G.9959. Cette couche gère la modulation du signal, l’attribution des canaux et la liaison du préambule à l’émetteur et la synchronisation du préambule au récepteur.
- Couche MAC : gère les champs HomeID et NodeID, comme défini dans la section précédente. La couche MAC utilise également un algorithme d’évitement des collisions et une stratégie d’interruption pour réduire la congestion et les conflits sur le canal.
- Couche de transfert : gère la communication des trames Z-Wave. Cette couche est également responsable de la retransmission des trames selon les besoins. Les tâches supplémentaires incluent l’accusé de réception des transmissions et la liaison de la somme de contrôle.
- Couche de routage : fournit des services de routage. De plus, la couche réseau effectuera une analyse de la topologie et mettra à jour les tables de routage.
- Couche d’application : fournit l’interface utilisateur aux applications et aux données.
5.5.3 Adressage Z-Wave
Z-Wave a un mécanisme d’adressage assez simple par rapport aux protocoles Bluetooth et Zigbee. Le schéma d’adressage est simple car toutes les tentatives sont faites pour minimiser le trafic et économiser l’énergie. Il y a deux identificateurs d’adressage fondamentaux qui doivent être définis avant de continuer :
- Home ID : il s’agit d’un identifiant unique de 32 bits qui est préprogrammé dans les périphériques du contrôleur pour aider à identifier les réseaux Z-Wave les uns des autres. Lors du démarrage du réseau, tous les esclaves Z-Wave ont un ID de domicile nul et le contrôleur remplit systématiquement les nœuds esclaves avec l’ID de maison correct.
- ID de nœud : il s’agit d’une valeur de 8 bits qui est affectée à chaque esclave par le contrôleur et fournit l’adressage des esclaves dans le réseau Z-Wave.

Figure 36 : Structure du paquet Z-Wave de PHY à MAC à la couche application. Trois types sont paquets de fi nies ainsi : Unidestinataire, en déroute et multidiffusion.
La couche transport fournit plusieurs types de trames pour faciliter la retransmission, l’accusé de réception, le contrôle de puissance et l’authentification. Les quatre types de trames réseau comprennent :
- Trame à diffusion unique : il s’agit d’un paquet envoyé à un seul nœud Z-Wave. Ce type de paquet doit être suivi d’un accusé de réception. Si l’ACK ne se produit pas, une séquence de retransmission apparaît.
- Trame ACK : il s’agit de la réponse d’accusé de réception d’une trame à diffusion unique.
- Cadre Multicast : Ce message est transmis à plus d’un noeud (jusqu’à à 232). Aucun accusé de réception n’est utilisé pour ce type de message.
- Trame de diffusion : semblable à un message de multidiffusion, cette trame est transmise à tous les nœuds du réseau. Encore une fois, aucun ACK n’est utilisé.
Pour qu’un nouveau dispositif Z-Wave soit utilisé sur le maillage, il doit subir un processus d’appariement et d’ajout. Le processus est généralement démarré par une pression mécanique ou instanciée par l’utilisateur sur l’appareil. Comme mentionné, le processus d’appariement implique que le contrôleur principal attribue un ID de domicile au nouveau nœud. À ce stade, le nœud est censé être inclus.
5.5.4 Topologie et routage Z-Wave
La topologie du maillage Z-Wave est illustrée dans la figure suivante à l’aide de certains types de périphériques et attributs associés aux esclaves et aux contrôleurs. Un seul contrôleur principal gère le réseau et établit les comportements de routage :
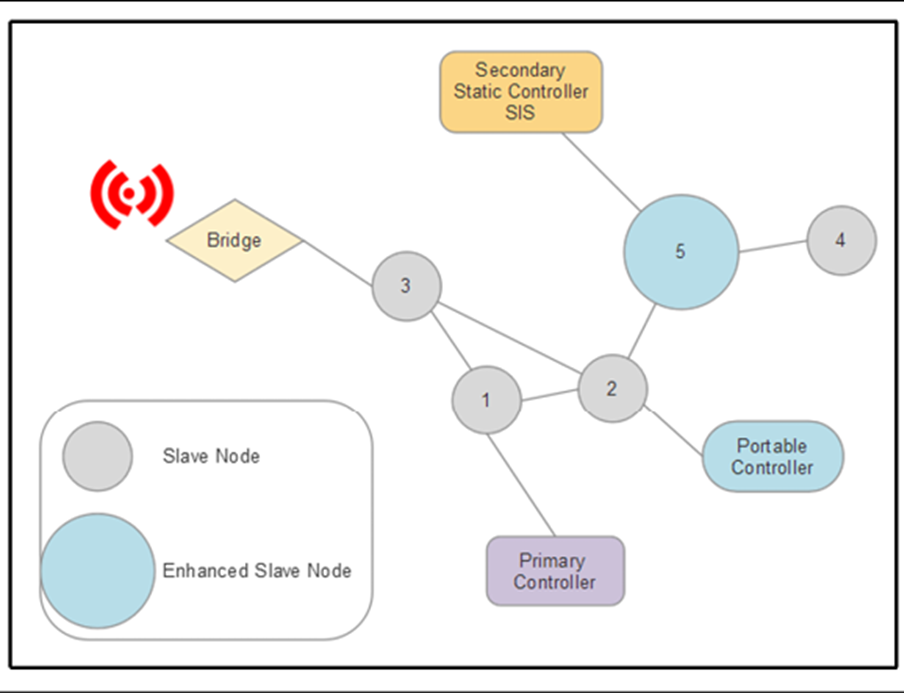
Figure 37 : Topologie Z-Wave comprenant le contrôleur principal unique, quatre esclaves et un esclave amélioré. Le contrôleur de pont agit comme une passerelle vers un réseau Wi-Fi. Un contrôleur portable et un contrôleur secondaire sont également assis sur le maillage pour aider le contrôleur principal.
La couche de routage de la pile Z-Wave gère le transport de trame d’un nœud à un autre. La couche de routage configurera la liste de répéteurs appropriée si nécessaire, analysera le réseau pour les changements de topologie et maintiendra la table de routage. Le tableau est assez simple et spécifie simplement quel voisin est connecté à un nœud donné. Il n’attend qu’un bond immédiat. La table est construite par le contrôleur principal en demandant à chaque nœud du maillage quels périphériques sont accessibles depuis son emplacement.
L’utilisation du routage source pour naviguer dans le maillage implique qu’au fur et à mesure que le message traverse le tissu. Pour chaque bond qui reçoit la trame, il transmet le paquet au nœud suivant de la chaîne. Par exemple, dans le tableau de routage suivant, le chemin le plus court de “Bridge” à “Slave 5” suit ce chemin logique : Bridge | Esclave 3 | Esclave 2 | Esclave 5.
Z-Wave limite les sauts de routage à un maximum de quatre.
Un tableau de routage de l’exemple de topologie précédent est donné ici :
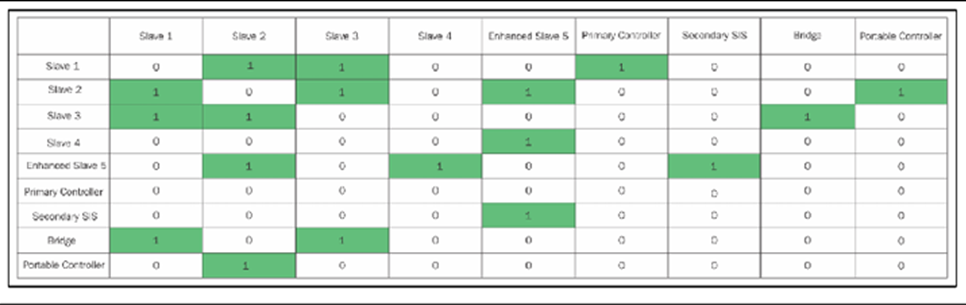
Figure 38 : Exemple algorithmique de routage de source Z-Wave
Les contrôleurs portables ont du mal à maintenir un chemin de routage optimal ; par conséquent, les contrôleurs portables utiliseront des techniques alternatives pour trouver la meilleure route vers un nœud de destination.
5.6 Résumé
Ce chapitre a couvert la première étape de la fourniture de données IoT à partir d’appareils sur Internet. La première étape pour connecter des milliards d’appareils consiste à utiliser le bon support de communication pour atteindre les capteurs, les objets et les actionneurs afin de provoquer une action. C’est le rôle du WPAN. Nous avons exploré la base du spectre sans licence et comment, en tant qu’architecte, nous mesurerons les performances et le comportement d’un WPAN.
Le chapitre a approfondi le nouveau protocole Bluetooth 5 et Bluetooth 5.1 et l’a comparé à d’autres normes telles que le protocole de base IEEE 802.15.4, Zigbee et Z-Wave. Nous avons exploré le balisage, diverses structures de paquets et de protocoles et des architectures de maillage. Un architecte doit comprendre comment ces architectures se comparent et contrastent à ce stade.
Le chapitre suivant explorera les réseaux PAN et LAN basés sur IP tels que le réseau Wi-Fi 802.11 omniprésent, Thread et 6LoWPAN, ainsi que les futures normes de communication Wi-Fi. Ces chapitres sur le réseautage explorant les architectures WPAN, WLAN et WAN reviendront régulièrement aux principes fondamentaux, tels que les mesures de la force du signal et les équations de portée enseignées au début de ce chapitre et devraient être utilisés comme référence à l’avenir.
6 WPAN et WLAN basés sur IP
Les réseaux WPAN ont adopté des protocoles qui ne sont généralement pas TCP / IP (Transmission Control Protocol / Internet Protocol), au moins depuis le début. Les piles de protocoles pour Bluetooth, Zigbee et Z-Wave ont des similitudes avec un vrai protocole TCP / IP mais ne communiquent pas intrinsèquement via TCP / IP. Il existe des adaptations d’IP sur Zigbee (en utilisant Zigbee-IP) et d’IP sur Bluetooth (en utilisant IPSP pour prendre en charge 6LoWPAN) qui existent. Plus loin dans ce chapitre, nous couvrirons un exemple de WPAN utilisant le protocole 802.15.4 avec une véritable couche compatible IPv6 (Thread) capable de rejoindre n’importe quel réseau IPv6.
Ce chapitre couvre les normes aussi autour Wi- Fi TM en utilisant les protocoles IEEE 802.11. Bien que généralement considérés comme un LAN sans fil ( WLAN ), les protocoles 802.11 sont omniprésents et utiles dans les déploiements IoT, en particulier dans les capteurs intelligents et les concentrateurs de passerelle. Ce chapitre fournira un traitement formel du catalogue de normes Wi-Fi 802.11, y compris le nouveau protocole haute vitesse IEEE802.11ac. 802.11 également s’étend dans le monde de l’IoT pour le marché de véhicule à véhicule et de transport en utilisant le protocole 802.11p, qui sera également couvert. Enfin, ce chapitre explorera la spécification IEEE 802.11ah, qui est une solution de réseau local sans fil basée sur le protocole 802.11 mais ciblée explicitement pour les dispositifs de détection IoT limités en termes de puissance et de coût.
Les sujets suivants seront traités dans le chapitre :
- TCP / IP
- WPAN avec IP – 6LoWPAN
- WPAN avec IP – Thread
- Protocoles IEEE 802.11 et WLAN
6.1 TCP / IP
La prise en charge d’une couche IP dans une pile de protocoles consomme des ressources qui pourraient être appliquées ailleurs. Cependant, la création d’un système IoT qui permet aux appareils de communiquer via TCP / IP présente des avantages clés. Nous commencerons par énumérer ces avantages ; Cependant, c’est le rôle de l’architecte d’équilibrer le coût de ces services et fonctionnalités contre l’impact sur un système.
Du point de vue de l’écosystème, quel que soit le protocole utilisé au niveau du capteur, les données du capteur seront finalement introduites dans un cloud public, privé ou hybride pour analyse, contrôle ou surveillance. En dehors du WPAN, le monde est basé sur TCP / IP, comme on le voit dans les configurations WLAN et WAN.
L’IP est la forme standard de communication globale pour diverses raisons:
- Ubiquité : les piles IP sont fournies par presque tous les systèmes d’exploitation et tous les supports. Les protocoles de communication IP sont capables de fonctionner sur divers systèmes WPAN, cellulaires, fil de cuivre, fibre optique, PCI Express et systèmes satellites. IP spécifie le format exact de toutes les communications de données et les règles utilisées pour communiquer, reconnaître et gérer la connectivité.
- Longévité : TCP a été créé en 1974 et la norme IPv4 encore en usage aujourd’hui a été conçue en 1978. Il a résisté à l’épreuve du temps pendant 40 ans. La longévité est primordiale pour de nombreuses solutions IoT industrielles et de terrain qui doivent prendre en charge les appareils et les systèmes pendant des décennies. Divers autres protocoles propriétaires ont été conçus par divers fabricants au cours de ces 40 années, tels que AppleTalk, SNA, DECnet et Novell IPX, mais aucun n’a gagné la traction du marché qu’IP a.
- Basé sur des normes : TCP / IP est régi par l’ Internet Engineering Task Force ( IETF ). L’IETF maintient un ensemble de normes ouvertes axées sur le protocole Internet.
- Évolutivité : IP a fait la preuve de son ampleur et de son adoption. Les réseaux IP ont démontré une évolutivité massive vers des milliards d’utilisateurs et de nombreux autres appareils. IPv6 pourrait fournir une adresse IP unique à chaque atome comprenant la Terre tout en prenant en charge 100 mondes supplémentaires.
- Fiabilité : l’IP en son cœur est un protocole fiable pour la transmission de données. Il y parvient grâce à un système de livraison de paquets basé sur un réseau sans connexion. L’IP est sans connexion car chaque paquet est traité indépendamment les uns des autres. La livraison des données est également appelée livraison au mieux car toutes les tentatives seront faites pour transmettre un paquet par différentes routes. La force de ce modèle permet à un architecte de remplacer le mécanisme de livraison par un autre – remplaçant essentiellement les couches un et deux de la pile par autre chose (par exemple, Wi-Fi avec cellulaire).
- Facilité de gestion : divers outils existent pour gérer les réseaux IP et les périphériques sur un réseau IP. Des outils de modélisation, des renifleurs de réseau, des outils de diagnostic et divers appareils existent pour aider à la création, à la mise à l’échelle et à la maintenance des réseaux.
La couche transport mérite également d’être prise en considération. Alors que IP répond au besoin d’une couche réseau robuste et bien prise en charge, TCP et le protocole UDP (Universal Datagram Protocol) sont nécessaires pour la couche transport. La couche transport est responsable de la communication de bout en bout. La communication logique entre différents hôtes et divers composants réseau est régie à ce niveau. TCP est utilisé pour les transmissions orientées sans connexion, tandis que UDP est utilisé pour les transmissions sans connexion. UDP est naturellement beaucoup plus simple à implémenter que TCP, mais pas aussi résilient. Les deux services assurent la réorganisation des segments, car les paquets ne sont pas garantis pour être livrés dans l’ordre à l’aide d’un protocole IP. TCP fournit également la couche de fiabilité à une couche de réseau IP non fiable grâce à l’utilisation de messages d’accusé de réception et de retransmissions de messages perdus. De plus, TCP fournit un contrôle de flux à l’aide de fenêtres coulissantes et d’algorithmes d’évitement de congestion. UDP fournit une méthode légère et à grande vitesse pour diffuser des données vers divers appareils qui peuvent ou non être présents ou fiables.
La pile de modèles OSI (Open Source Interconnection) standard à sept couches est la suivante :
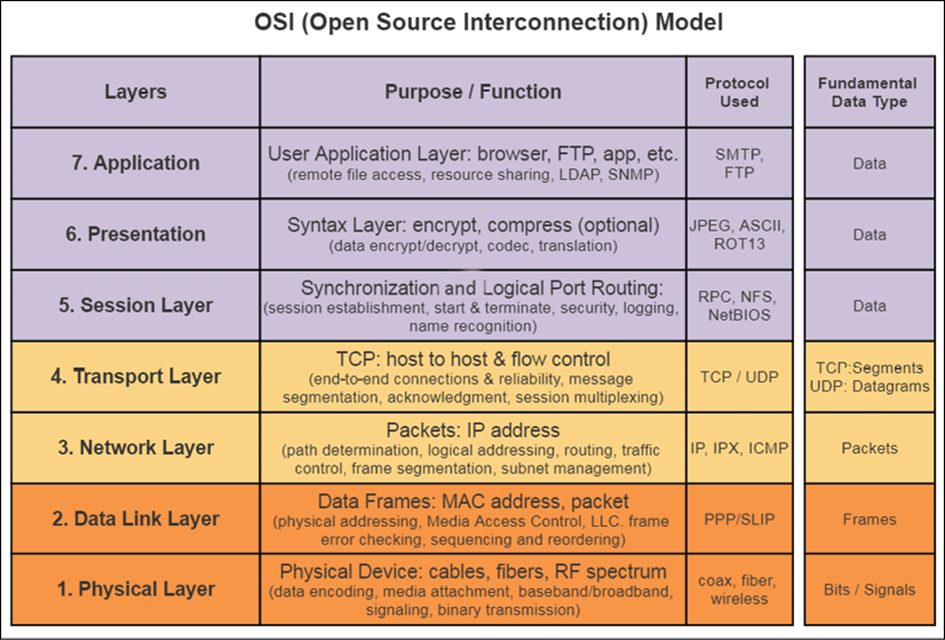
Figure 1 : Modèle OSI complet à sept couches. TCP / IP représente les couches 3 et 4.
La pile OSI fournit une référence au nombre de protocoles construits couche par couche. Le modèle commence à la couche 1, qui est généralement une entité physique comme un port réseau ou une interface physique (PHY). Chaque couche ajoute divers en-têtes et pieds de page qui entourent un paquet. Ce processus se poursuit dans la pile à mesure qu’une structure de paquet de plus en plus grande croît à mesure que des en-têtes et des pieds de page sont ajoutés.
Du point de vue IoT, rapprocher l’IP de la source de données relie deux mondes de la gestion des données. Le rôle des technologies de l’information (TI) gère l’infrastructure, la sécurité et l’approvisionnement des réseaux et des objets sur le réseau. Le rôle de la technologie opérationnelle (OT) gère la santé et le débit du système qui fonctionne pour produire quelque chose. Ces deux rôles sont traditionnellement séparés, car des éléments tels que les capteurs, les compteurs et les contrôleurs programmables ne sont pas connectés, du moins directement.
Des normes propriétaires ont régi les systèmes OT, du moins du point de vue de l’ IoT industriel .
6.2 WPAN avec IP – 6LoWPAN
Afin d’apporter l’adressabilité IP aux appareils les plus petits et les plus limités en ressources, le concept de 6LoWPAN a été formé en 2005. Un groupe de travail a officialisé la conception dans l’IETF sous la spécification RFC 4944 (demande de commentaire) et mis à jour plus tard avec RFC 6282 pour adresser la compression d’en-tête et RFC 6775 pour la découverte des voisins. Le consortium est fermé ; Cependant, la norme est ouverte à toute personne à utiliser et à mettre en œuvre.
6WPPAN est un acronyme qui signifie IPV6 sur les réseaux personnels sans fil à faible puissance. L’objectif est de mettre en réseau IP sur des systèmes de communication RF à faible puissance pour les appareils qui sont soumis à des contraintes d’alimentation et d’espace et qui n’ont pas besoin de services de réseau à large bande passante. Le protocole peut être utilisé avec d’autres communications WPAN telles que 802.15.4, ainsi qu’avec Bluetooth, des protocoles RF inférieurs à 1 GHz et un contrôleur de ligne électrique (PLC). Le principal avantage de 6LoWPAN est que le plus simple des capteurs peut avoir une adressabilité IP et agir en tant que citoyen du réseau sur des routeurs 3G / 4G / LTE / Wi-Fi / Ethernet. Un effet secondaire est que IPV6 fournit une adressabilité théorique significative de 2 128 ou 3,4 x 10 38 adresses uniques. Cela couvrirait suffisamment environ 50 milliards d’appareils connectés à Internet et continuerait de couvrir ces appareils bien au-delà. Par conséquent, 6LoWPAN est bien adapté à la croissance de l’IoT.
6.3 Protocoles IEE 802.11 et WLAN
L’un des premiers adoptants des bandes ISM que la FCC a libérées pour une utilisation sans licence était la technologie IEEE 802.11. L’IEEE 802.11 est une suite de protocoles avec une histoire riche et différents cas d’utilisation. 802.11 est la spécification définissant le Media Access Control (MAC) et la couche physique (PHY) d’une pile réseau. La définition et les spécifications sont régies par le comité des normes LAN / MAN de l’IEEE. Le Wi-Fi est la définition du WLAN basée sur les normes IEEE802.11 mais maintenue et régie par la Wi-Fi Alliance à but non lucratif.
11 doit sa création à NCR en 1991, qui a développé le protocole sans fil pour la mise en réseau des caisses enregistreuses. Ce n’est qu’en 1999, lorsque la Wi-Fi Alliance a été formée, que la technologie est devenue omniprésente et omniprésente sur le marché naissant des PC et des ordinateurs portables. Le protocole d’origine est très différent des protocoles 802.11 b / g / n / ac modernes. Il n’est pris en charge qu’à un débit de 2 Mbps avec correction d’erreur directe.
Le succès de IEEE802.11 peut être attribué à l’approche de pile en couches du modèle OSI. Le simple remplacement des couches MAC et PHY par des couches IEEE802.11 a permis d’utiliser l’infrastructure TCP / IP existante sans effort.
Aujourd’hui, presque tous les appareils mobiles, ordinateurs portables, tablettes, systèmes embarqués, jouets et jeux vidéo intègrent une radio IEEE802.11. Cela dit, le 802.11 a un passé riche en histoire, en particulier dans le modèle de sécurité. Le modèle de sécurité 802.11 d’origine était basé sur le mécanisme de sécurité UC Berkeley Wired Equivalent Privacy, qui s’est avéré par la suite peu fiable et facilement compromis. Plusieurs exploits notables, dont la violation de données TJ Maxx via le 802.11 WEP en 2007, ont provoqué le vol de 45 millions de cartes de crédit. Aujourd’hui, l’accès protégé Wi-Fi (WPA) et WPA2 utilisant des clés pré-partagées AES 256 bits ont certainement renforcé la sécurité, et le WEP est rarement utilisé.
Cette section détaille certaines des différences dans les protocoles 802.11 et des informations particulières concernant l’architecte IoT. Nous détaillerons la conception actuelle de l’IEEE802.11ac, puis examinerons le 802.11ah HaLow et le 802.11p V2V, car les trois sont pertinents pour l’IoT.
Une comparaison remarquable des normes 802.11 peut être trouvée dans R. Shaw, S Sharma, Comparative Study of IEEE 802.11 a, b, g & n Standards, International Journal of Engineering Research and Technology (IJERT), V3 Issue 4, April 2014.
6.3.1 Suite de protocoles IEEE 802.11 et comparaison
Le comité des normes IEEE LAN / MAN maintient et régit les spécifications IEEE 802. L’objectif initial de 802.11 était de fournir un protocole de couche liaison pour les réseaux sans fil. Cela est passé de la spécification de base 802.11 à 802.11ac en 2013. Depuis lors, le groupe de travail s’est concentré sur d’autres domaines, comme l’illustre le tableau suivant. Des variantes 802.11 spécifiques ont été examinées pour des cas d’utilisation et des segments tels que l’interconnexion IoT basse consommation / faible bande passante (802.11ah), la communication de véhicule à véhicule (802.11p), la réutilisation de l’espace RF analogique de télévision (802.11af), l’extrême communication de bande passante proche du mètre pour l’audio / vidéo (802.11ad), et bien sûr la suite de la norme 802.11ac (802.11ax).
Les nouvelles variantes sont conçues pour différentes zones du spectre RF ou pour réduire la latence et améliorer la sécurité en cas d’urgence véhiculaire. Le tableau suivant doit refléter les compromis entre la plage, la fréquence et la puissance. Nous couvrirons les aspects du graphique tels que la modulation, les flux MIMO et l’utilisation des fréquences plus loin dans cette section.
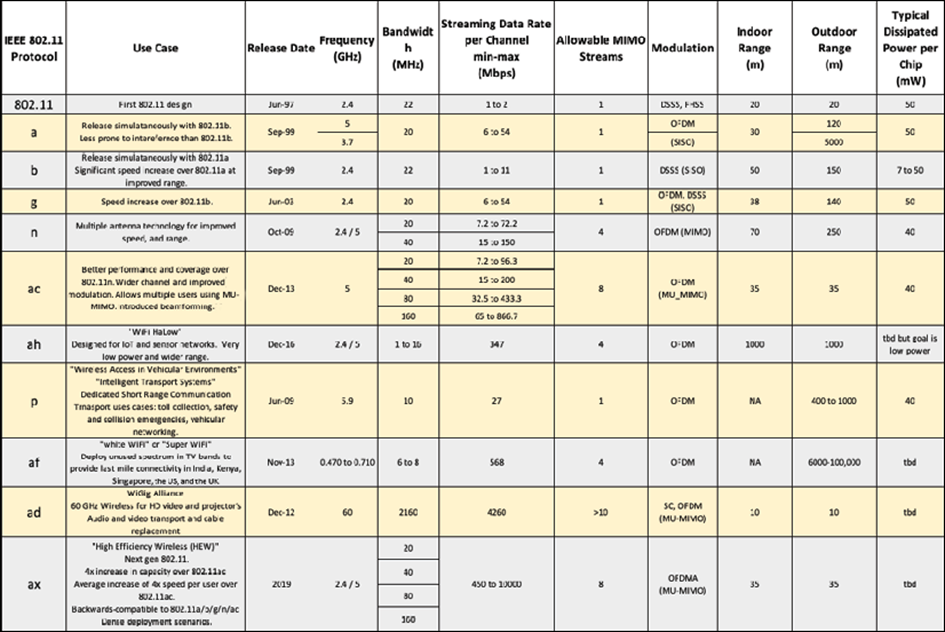
Figure 2 : Divers IEEE802.11 normes et spéci fi cations de l’héritage 802.11 spécifique fi cations à l’encore être rati fi ée 802.11ax
6.3.2 Architecture IEEE 802.11
Le protocole 802.11 représente une famille de communications radio sans fil basée sur différentes techniques de modulation dans les bandes ISM 2,4 GHz et 5 GHz du spectre sans licence. 802.11b et 802.11g résident dans la bande 2,4 GHz, tandis que 802.11n et 802.11ac ouvrent la bande 5 GHz. Le dernier chapitre a détaillé la bande 2,4 GHz et les différents protocoles qui résident dans cet espace. Le Wi-Fi est sensible au même bruit et aux mêmes interférences que Bluetooth et Zigbee et déploie une variété de techniques pour garantir la robustesse et la résilience.
Du point de vue de la pile, les protocoles 802.11 résident dans la couche liaison (un et deux) du modèle OSI, comme illustré dans la figure suivante :
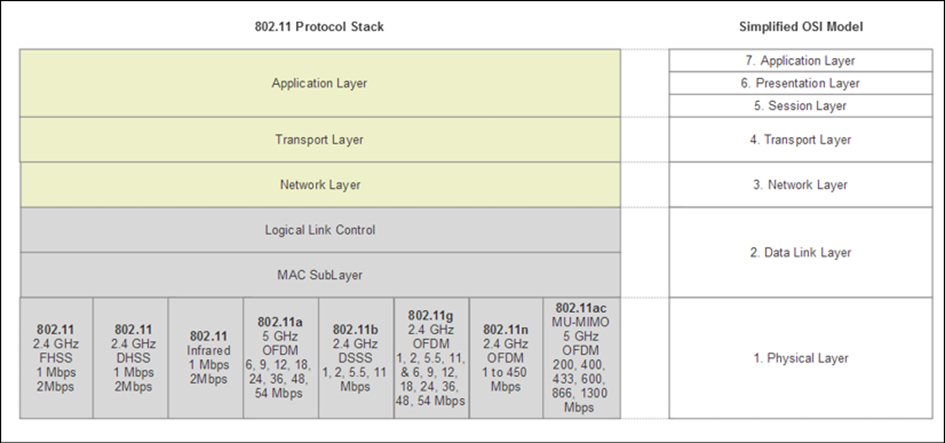
Figure 3 : pile IEEE 802.11ac
La pile comprend divers PHY d’anciennes spécifications 802.11 telles que les PHY d’origine 802.11 (y compris l’infrarouge), a, b, g et n. Il s’agit d’assurer la compatibilité descendante entre les réseaux. La plupart des chipsets incluent toute la collection PHY, et il est difficile de trouver une pièce avec un PHY plus ancien seul.
11 systèmes prennent en charge trois topologies de base :
- Infrastructure : sous cette forme, une station (STA) fait référence à un périphérique d’extrémité 802.11 (comme un smartphone) qui communique avec un point d’accès central (AP). Un AP peut être une passerelle vers d’autres réseaux (WAN), un routeur ou un véritable point d’accès dans un réseau plus grand. Ceci est également connu sous le nom de service de base d’infrastructure (BSS). Cette topologie est une topologie en étoile.
- Ad hoc : les nœuds 802.11 peuvent former ce qu’on appelle un service d’ensemble de base indépendant (IBSS) où chaque station communique et gère l’interface avec les autres stations. Aucun point d’accès ou topologie en étoile n’est utilisé dans cette configuration. Il s’agit d’un type de topologie d’égal à égal.
- Système de distribution (DS) : le DS combine deux ou plusieurs réseaux BSS indépendants via des interconnexions de points d’accès.
Remarque : IEEE802.11ah et IEEE802.11s prennent en charge les formes d’une topologie maillée.
Voici des exemples des trois topologies de base d’une architecture IEEE 802.11:
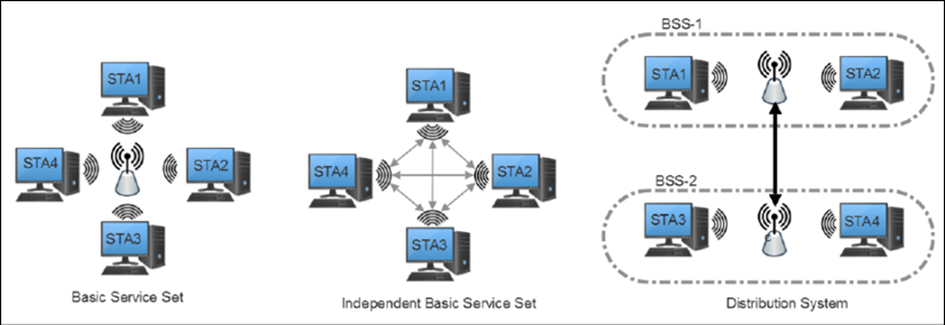
Figure 4 : architectures de réseau 802.11. BSS, IBSS et un système de distribution combinent deux BSS indépendants.
Au total, le protocole 802.11 permet d’associer jusqu’à 2 007 STA à un seul point d’accès. Ceci est pertinent lorsque nous explorons d’autres protocoles, tels que IEEE 802.11ah pour IoT, plus loin dans ce chapitre.
6.3.3 Attribution du spectre IEEE 802.11
Le premier protocole 802.11 utilisait un spectre dans la région ISM de 2 GHz et 5 GHz et des canaux régulièrement espacés d’environ 20 MHz les uns des autres. La largeur de bande du canal était de 20 MHz, mais des modifications ultérieures de l’IEEE ont permis à 5 MHz et 10 MHz de fonctionner également. Aux États-Unis, 802.11b et g autorisent 11 canaux (d’autres pays peuvent prendre en charge jusqu’à 14).
La figure suivante illustre la séparation des canaux. Trois des canaux ne se chevauchent pas (1,6,11) :
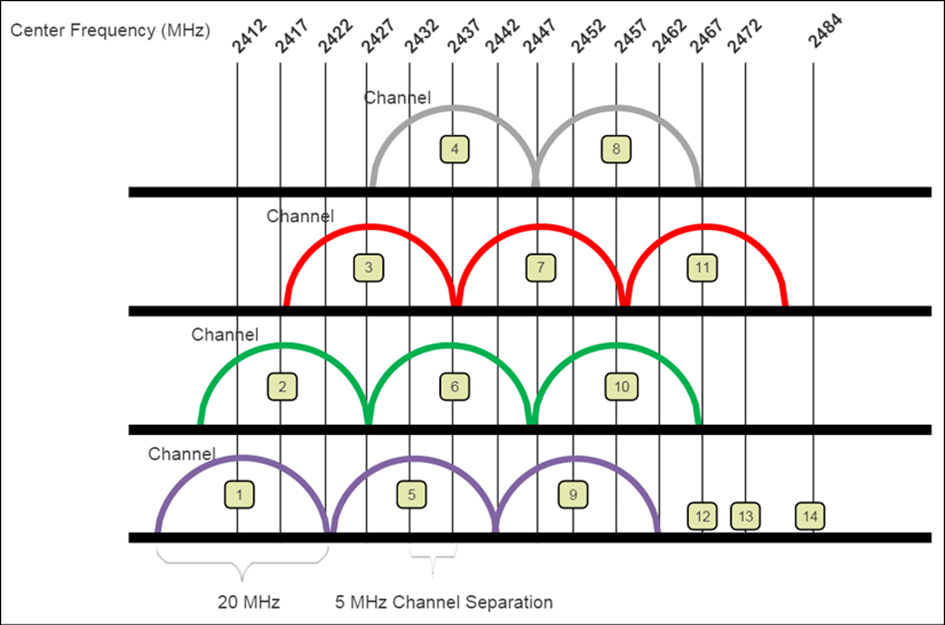
Figure 5 : espace de fréquence 802.11 2,4 GHz et combinaisons de canaux sans interférence. Notez la séparation des canaux de 5 MHz sur 14 canaux, chacun de 20 MHz de large.
11 spécifie un masque spectral, qui définit la distribution de puissance autorisée sur chaque canal. Le masque spectral nécessite que le signal soit atténué à certains niveaux (à partir de son amplitude de crête) à des décalages de fréquence spécifiés. Cela dit, les signaux auront tendance à rayonner dans les canaux adjacents. Le 802.11b utilisant le spectre étalé à séquence directe (DSSS) a un masque spectral complètement différent du 802.11n utilisant le multiplexage par répartition en fréquence orthogonale (OFDM). L’OFDM a une efficacité spectrale beaucoup plus dense et maintient donc également une bande passante beaucoup plus élevée. La figure suivante illustre les différences de canaux et de modulation entre 802.11 b, g et n. La largeur de canal limite le nombre de canaux simultanés de 4 à 3 à 1. La forme du signal varie également entre DSSS et OFDM, ce dernier étant beaucoup plus dense et donc capable d’une bande passante plus élevée.
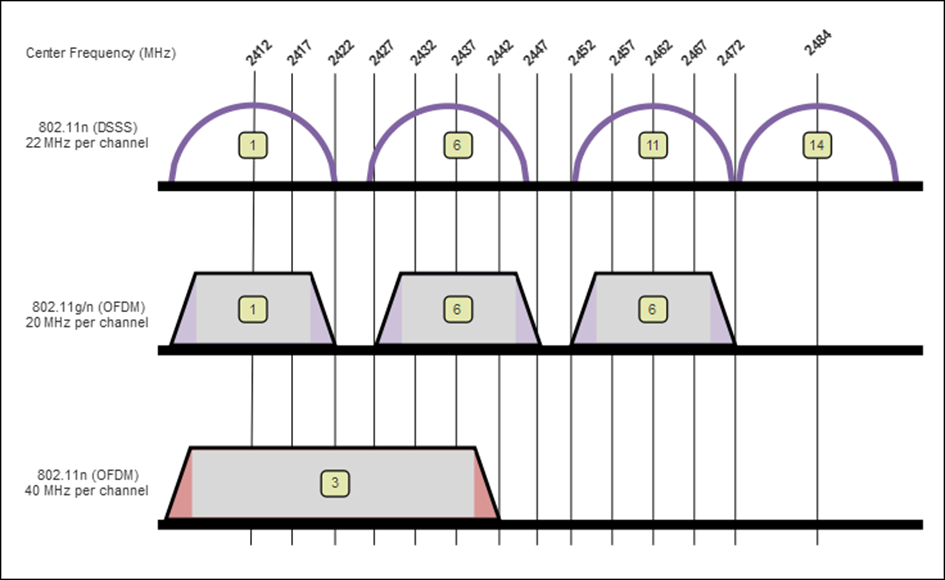
Figure 6 : Différences entre 802.11b, g et n en utilisant DSSS par rapport à OFDM et en transportant des largeurs de canal
Bien qu’il existe 14 canaux dans la gamme 2,4 GHz, l’utilisation des canaux est régie par la région et le pays. Par exemple, l’Amérique du Nord autorise l’utilisation des canaux 1 à 11, le Japon autorise les 14 canaux pour 802.11b et 1 à 13 pour 802.11g / n, l’Espagne n’autorise que les canaux 10 et 11 et la France autorise 10 à 13. Les allocations varient et les concepteurs doivent être conscients des restrictions nationales. L’IEEE utilise le nom de domaine de la nomenclature pour décrire le canal du pays, la puissance et les restrictions de temps qui ont un impact sur la PHY.
6.3.4 Techniques de modulation et d’encodage IEEE 802.11
Cette section détaille les techniques de modulation et d’encodage dans le protocole IEEE 802.11. Ces techniques ne sont pas propres au 802.11; ils s’appliquent également aux protocoles 802.15 et, comme nous le verrons, aux protocoles cellulaires également. Les méthodes de saut de fréquence, de modulation et de décalage de phase sont des méthodes fondamentales que vous devez comprendre, car différentes techniques équilibrent la plage, les interférences et le débit.
Les données numériques transmises par un signal RF doivent être transformées en analogique. Cela se produit au PHY, quel que soit le signal RF décrit (Bluetooth, Zigbee, 802.11, etc.). Un signal porteur analogique sera modulé par un signal numérique discret. Cela forme ce qu’on appelle un symbole ou un alphabet de modulation. Un moyen simple de penser à la modulation des symboles est un piano à quatre touches. Chaque clé représente deux bits (00, 01, 10, 11). Si vous pouvez jouer 100 touches par seconde, cela signifie que vous pouvez transmettre 100 symboles par seconde. Si chaque symbole (tonalité du piano) représente deux bits, il équivaut à un modulateur à 200 bps. Bien qu’il existe de nombreuses formes d’encodage de symboles à étudier, les trois formes de base incluent :
- Clé à décalage d’amplitude (ASK) : Il s’agit d’une forme de modulation d’amplitude. Le binaire 0 est représenté par une forme d’amplitude de modulation et 1 une amplitude différente. Un formulaire simple est illustré dans la figure suivante, mais des formulaires plus avancés peuvent représenter des données dans des groupes en utilisant des niveaux d’amplitude supplémentaires.
- Clé à décalage de fréquence (FSK) : cette technique de modulation module une fréquence porteuse pour représenter 0 ou 1. La forme la plus simple illustrée dans la figure suivante est la clé à décalage de fréquence binaire (BPSK), qui est la forme utilisée dans 802.11 et d’autres protocoles. Dans le dernier chapitre, nous avons parlé de Bluetooth et de Z-Wave. Ces protocoles utilisent une forme de FSK appelée détrompage par décalage de fréquence gaussien (GFSK), qui filtre les données à travers un filtre gaussien, qui lisse l’impulsion numérique (-1 ou +1) et la façonne pour limiter la largeur spectrale.
- Keying à déphasage (PSK) : il module la phase d’un signal de référence (signal porteur). Utilisé principalement dans les étiquettes 802.11b, Bluetooth et RFID, PSK utilise un nombre fini de symboles représentés comme différents changements de phase. Chaque phase code un nombre égal de bits. Un motif de bits formera un symbole. Le récepteur aura besoin d’un signal de référence contrasté et calculera la différence pour extraire les symboles puis démoduler les données. Une autre méthode ne nécessite aucun signal de référence pour le récepteur. Le récepteur inspectera le signal et déterminera s’il y a un changement de phase sans référencer un signal secondaire. C’est ce qu’on appelle la clé différentielle à décalage de phase (DPSK) et est utilisé dans 802.11b.
La figure suivante illustre graphiquement les différentes méthodes de codage:
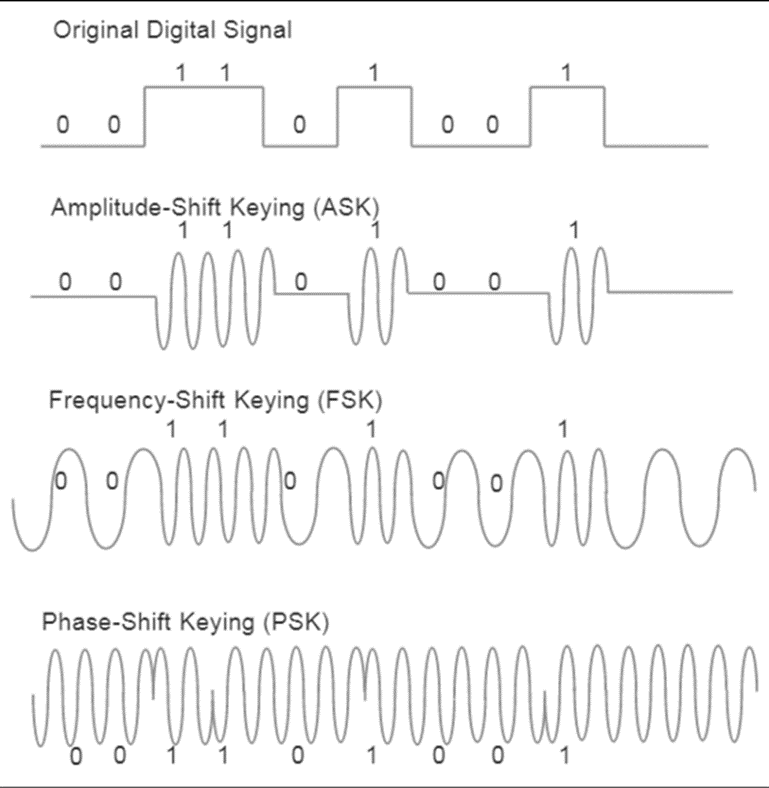
Figure 7 : Différentes formes de codage de symboles à l’aide de techniques de détrompage : codage d’amplitude, codage de fréquence et codage de phase. Notez comment la saisie de phase change de phase pour chaque “1” rencontré.
La prochaine forme de technique de modulation est la modulation hiérarchique, en particulier la modulation d’amplitude en quadrature (QAM). Le diagramme de constellation suivant représente l’encodage dans un système cartésien 2D. La longueur d’un vecteur quelconque représente l’amplitude et l’angle par rapport à un point de constellation représente la phase. De manière générale, il y a plus de phases qui peuvent être codées que d’amplitudes, comme le montre le diagramme de constellation 16-QAM suivant. Le 16-QAM a trois niveaux d’amplitude et 12 angles de phase totaux. Cela permet de coder 16 bits. 802.11a et 802.11g peuvent utiliser 16-QAM et 64-QAM encore plus haute densité. Évidemment, plus la constellation est dense, plus l’encodage peut être représenté et plus le débit est élevé.
La figure ci-dessous illustre un processus de codage QAM de manière illustrée. À gauche, une représentation d’un diagramme de constellation à 16 points (16-QAM). Il y a trois niveaux d’amplitude indiqués par la longueur des vecteurs et trois phases par quadrant indiqués par l’angle du vecteur. Cela permet de générer 16 symboles. Ces symboles se reflètent dans la variation de la phase et de l’amplitude du signal généré. À droite, un exemple de diagramme de forme d’onde 8-QAM montrant les différentes phases et amplitudes qui représentent un alphabet de modulation à 3 bits (8 valeurs):
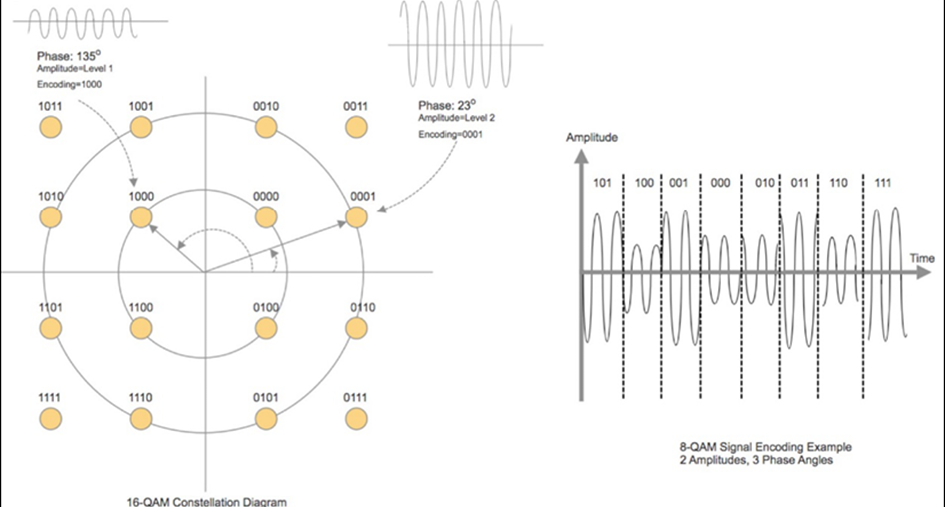
Figure 8 : Modulation d’amplitude en quadrature (QAM). Gauche : constellation 16-QAM. Droite : codage de forme d’onde 8-QAM.
QAM a des limites pratiques. Plus tard, nous verrons des constellations très denses qui augmentent radicalement le débit. Vous ne pouvez ajouter qu’un certain nombre d’angles de phase et d’amplitudes avant que le bruit généré par les convertisseurs analogique-numérique (ADC) et les convertisseurs numérique-analogique (DAC) n’introduise des erreurs de quantification. Le bruit finira par devenir répandu et le système devra échantillonner des signaux à des vitesses très élevées pour compenser. De plus, le rapport signal / bruit (SNR) doit dépasser une certaine valeur pour obtenir un bon taux d’erreur sur les bits (BER).
Les normes 802.11 utilisent différentes techniques d’atténuation des interférences qui répartissent essentiellement un signal sur une bande :
- Spectre étalé à sauts de fréquence (FHSS) : étale un signal sur 79 canaux sans chevauchement de 1 MHz de large dans la bande ISM 2,4 GHz. Il utilise un générateur de nombres pseudo-aléatoires pour démarrer le processus de saut. Le temps de pause fait référence au temps minimum pendant lequel un canal est utilisé avant le saut (400 ms). Le saut de fréquence a également été décrit dans le dernier chapitre et est un schéma typique d’étalement des signaux.
- Spectre étalé à séquence directe (DSSS): utilisé pour la première fois dans les protocoles 802.11b et doté de canaux de 22 MHz. Chaque bit est représenté par plusieurs bits dans le signal transmis. Les données transmises sont multipliées par un générateur de bruit. Cela répartira efficacement le signal sur l’ensemble du spectre de manière uniforme à l’aide d’une séquence de nombres pseudo-aléatoires, appelée code de pseudo-bruit (PN). Chaque bit est transmis avec une séquence de découpage de 11 bits (incrustation à déphasage). Le signal résultant est un OU exclusif du bit et la séquence aléatoire de 11 bits. Le DSSS fournit environ 11 millions de symboles par seconde si l’on considère le taux de chipping.
- OFDM : utilisé dans les protocoles IEEE 802.11a et plus récents. Cette technique divise un seul canal de 20 MHz en 52 sous-canaux (48 pour les données et quatre pour la synchronisation et la surveillance) pour coder les données en utilisant QAM et PSM. Une transformée de Fourier rapide (FFT) est utilisée pour générer chaque symbole OFDM. Un ensemble de données redondantes entoure chaque sous-canal. Cette bande de données redondante est appelée intervalle de garde (GI) et est utilisée pour empêcher les interférences intersymboles (ISI) entre les sous-porteuses voisines. Notez que les sous-porteuses sont très étroites et n’ont pas de bandes de garde pour la protection du signal. C’était intentionnel parce que chaque sous-porteuse est espacée également à l’inverse du temps symbole. C’est-à-dire que toutes les sous-porteuses transportent un nombre complet de cycles sinusoïdaux qui, une fois démodulés, totaliseront zéro. Pour cette raison, la conception est simple et n’a pas besoin du coût supplémentaire des filtres passe-bande. IEEE 802.11a utilise 250 000 symboles par seconde. OFDM est généralement plus efficace et plus dense (donc plus de bande passante) que DSSS et est utilisé dans les nouveaux protocoles.
L’utilisation de moins de symboles par seconde présente un avantage dans les situations où il y a des reflets de signaux sur les murs et les fenêtres. Étant donné que les réflexions provoquent ce que l’on appelle une distorsion par trajets multiples (des copies du symbole frappent le récepteur à différents moments), un débit de symboles plus lent laisse plus de temps pour transmettre un symbole et il y a plus de résilience pour retarder la propagation. Cependant, si un appareil se déplace, il peut y avoir des effets Doppler qui affectent OFDM plus que DSSS. D’autres protocoles, tels que Bluetooth, utilisent un million de symboles par seconde.
La figure suivante illustre un système OFDM avec 52 sous-porteuses dans deux canaux à 20 MHz :
Figure 9 : Un exemple d’OFDM. Ici, un canal est subdivisé en 52 tranches ou sous-porteuses plus petites (chacune portant un symbole).
L’ensemble des différentes modulations disponibles pour chaque norme est appelé Modulation and Coding Scheme (MCS). Le MCS est un tableau des types de modulation, des intervalles de garde et des taux de codage disponibles. Vous référencez cette table avec un index.
Les appareils 11b sont entrés sur le marché avant l’arrivée du 802.11a. 802.11b utilise un schéma de codage différent de 802.11a. Les schémas de codage ne sont pas compatibles. Ainsi, il existe une certaine confusion sur le marché concernant la différence, car les protocoles ont été publiés presque simultanément.
6.3.5 MIMO IEEE 802.11
MIMO est l’acronyme qui désigne les entrées multiples et les sorties multiples. MIMO exploite un phénomène RF mentionné précédemment appelé multipath. La transmission par trajets multiples implique que les signaux se reflètent sur les murs, les portes, les fenêtres et autres obstructions. Un récepteur verra de nombreux signaux, tous arrivant à des moments différents via des chemins différents.
Les trajets multiples ont tendance à déformer les signaux et à provoquer des interférences, ce qui finit par dégrader la qualité du signal. (Cet effet est appelé évanouissement par trajets multiples.) Avec l’ajout de plusieurs antennes, un système MIMO peut augmenter linéairement la capacité d’un canal donné en ajoutant simplement plus d’antennes. Il existe deux formes de MIMO :
- Diversité spatiale : il s’agit de la diversité d’émission et de réception. Un seul flux de données est transmis simultanément sur plusieurs antennes à l’aide d’un codage spatio-temporel. Celles-ci améliorent le rapport signal / bruit et se caractérisent par leur amélioration de la fiabilité des liaisons et de la couverture du système.
Dans le chapitre précédent, nous avons présenté les techniques de saut de fréquence dans les réseaux PAN tels que Bluetooth. Le saut de fréquence est une méthode pour surmonter le problème d’évanouissement par trajets multiples en changeant constamment les angles du trajet multiple. Cela a pour effet de fausser la taille du signal RF. Les systèmes Bluetooth ont généralement une seule antenne, ce qui rend difficile MIMO. En ce qui concerne le Wi-Fi , seule la norme 802.11 d’origine prend en charge une forme de FHSS. Les systèmes OFDM maintiennent un verrouillage de canal et peuvent donc être soumis au problème d’évanouissement par trajets multiples.
L’utilisation de plusieurs flux a un impact sur la consommation d’énergie globale. IEEE 802.11n inclut un mode pour activer MIMO uniquement lorsque l’effet aura un avantage en termes de performances, économisant ainsi de l’énergie à tout autre moment. La Wi-Fi Alliance exige que tous les produits prennent en charge au moins deux flux spatiaux pour recevoir la conformité 802.11n.
- Multiplexage spatial : il est utilisé pour fournir une capacité de données supplémentaire en utilisant les multiples chemins pour acheminer du trafic supplémentaire, c’est-à-dire en augmentant la capacité de débit de données. Essentiellement, un seul flux de données à haut débit sera divisé en plusieurs transmissions distinctes sur différentes antennes.
Un WLAN divisera les données en plusieurs flux appelés flux spatiaux. Chaque flux spatial transmis utilisera une antenne différente sur l’émetteur. IEEE 802.11n permet quatre antennes et quatre flux spatiaux. En utilisant plusieurs flux envoyés séparément pour des antennes espacées les unes des autres, la diversité spatiale dans 802.11n donne une certaine assurance qu’au moins un signal sera suffisamment fort pour atteindre le récepteur. Au moins deux antennes sont nécessaires pour prendre en charge la fonctionnalité MIMO. Le streaming est également indépendant de la modulation. BPSK, QAM et d’autres formes de modulation fonctionnent avec le streaming spatial.
Un processeur de signal numérique sur l’émetteur et le récepteur ajustera les effets de trajets multiples et retardera la transmission en visibilité directe juste assez de temps pour qu’elle s’aligne parfaitement avec les trajets sans visibilité directe. Cela entraînera le renforcement des signaux.
Le protocole IEEE 802.11n prend en charge une implémentation MIMO (SU-MIMO) à utilisateur unique à quatre flux, ce qui signifie que les émetteurs fonctionneraient à l’unisson pour communiquer avec un seul récepteur. Ici, quatre antennes d’émission et quatre antennes de réception fournissent plusieurs flux de données à un seul client. Voici une illustration de SU-MIMO et de l’utilisation de trajets multiples dans 802.11n:
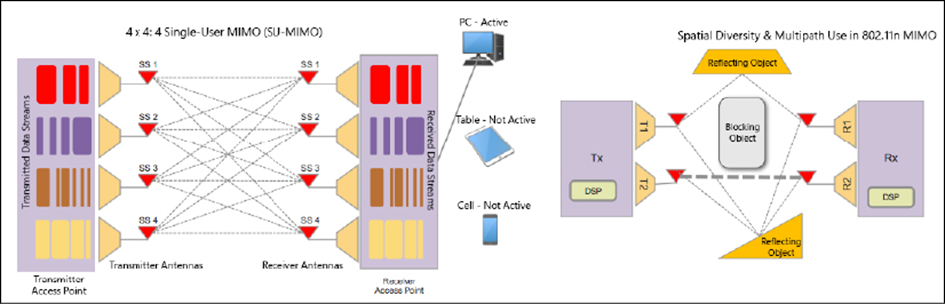
Figure 10 : Gauche : Illustration de SU-MIMO dans IEEE 802.11n. Droite : L’effet de la diversité spatiale MIMO dans 802.11n.
Sur la figure, quatre antennes d’émission et quatre antennes de réception fournissent plusieurs flux de données à un seul client (SU-MIMO). A droite, deux émetteurs espacés d’une distance fixe communiquent avec deux récepteurs. Plusieurs chemins existent sous forme de réflexions des deux émetteurs. Une voie en visibilité directe est plus forte et sera privilégiée. Les DSP côté émetteur et récepteur atténuent également l’évanouissement par trajets multiples en combinant les signaux de sorte que le signal résultant présente peu d’évanouissement.
Le protocole IEEE 802.11 identifie les flux MIMO par la notation M × N: Z , où M est le nombre maximal d’antennes d’émission et N est le nombre maximal d’antennes de réception. Z est le nombre maximal de flux de données pouvant être utilisés simultanément. Ainsi, un MIMO de 3 × 2 : 2 implique qu’il y a trois antennes de flux d’émission et deux antennes de flux de réception, mais ne peut envoyer ou recevoir que deux flux simultanés.
11n a également introduit la fonction optionnelle de formation de faisceau. 80211.n définit deux types de méthodes de formation de faisceau : rétroaction implicite et rétroaction explicite :
- Formation de faisceau à rétroaction implicite : ce mode suppose que le canal entre le formateur de faisceau (AP) et la forme de faisceau (client) est réciproque (la même qualité dans les deux directions). Si cela est vrai, le beamformer transmet une trame de demande d’apprentissage et reçoit un paquet de sondage. Avec le paquet de sondage, le formateur de faisceau peut estimer le canal du récepteur et construire une matrice de direction.
- Formation de faisceau à rétroaction explicite : dans ce mode, le beamformee répond à une demande de formation en calculant sa propre matrice de direction et renvoie la matrice au formateur de faisceau. Il s’agit d’ une méthode plus fiable .
Le diagramme suivant illustre les effets de la formation de faisceau dans une situation sans communication en visibilité directe. Dans le pire des cas, les signaux arrivent à 180 degrés hors phase et s’annulent mutuellement. Avec la formation de faisceaux, les signaux peuvent être ajustés par phases pour se renforcer mutuellement au niveau du récepteur.
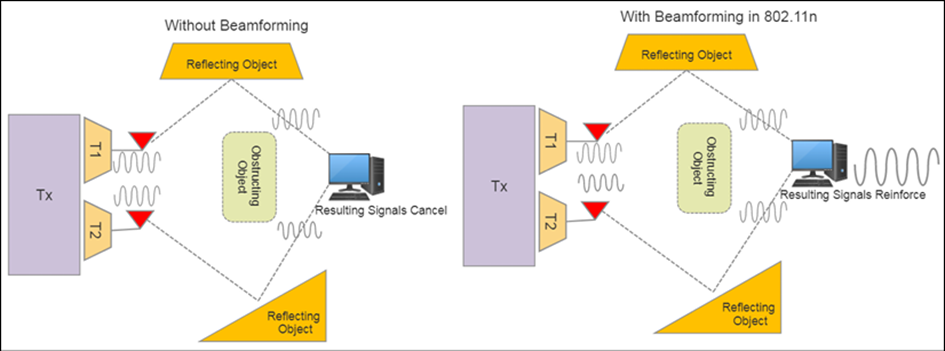
Figure 11 : Exemples de système avec et sans formation de faisceau. Dans ce cas, le système n’a pas de ligne directe de la vue et fait confiance à réflexions pour propager un signal.
La formation de faisceaux repose sur plusieurs antennes espacées pour focaliser un signal à un emplacement particulier. Les signaux peuvent être ajustés en phases et en amplitudes pour arriver au même endroit et se renforcer mutuellement, offrant une meilleure force et portée du signal. Malheureusement, 802.11n ne s’est pas normalisé sur une seule méthode de formation de faisceau et a laissé cela à l’implémenteur. Différents fabricants utilisaient des processus différents et ne pouvaient garantir que cela fonctionnerait avec du matériel identique. Ainsi, la formation de faisceaux n’a pas été adoptée massivement dans le délai 802.11n.
Nous couvrirons les technologies MIMO dans de nombreux autres domaines, tels que 802.11ac, et dans le chapitre suivant, sur les communications à longue portée utilisant les radios cellulaires 4G LTE.
6.3.6 Structure des paquets IEEE 802.11
11 utilise la structure de paquet typique que nous avons vue auparavant avec des en-têtes, des données de charge utile, des identificateurs de trame, etc. En commençant par l’organisation de la trame PHY, nous avons trois champs: un préambule, qui aide à la phase de synchronisation; un en-tête PLCP, qui décrit la configuration et les caractéristiques des paquets tels que les débits de données; et les données MAC MPDC.
Chaque spécification IEEE 802.11 a un préambule unique et est structurée par le nombre de symboles (décrits plus loin) et non par le nombre de bits pour chaque champ. Des exemples des préambule structures sont les Suit :
- 802.11 a / g : le préambule comprend un champ d’apprentissage court (deux symboles) et un champ d’apprentissage long (deux symboles). Ceux-ci sont utilisés par les sous-porteuses pour la synchronisation de synchronisation et l’estimation de fréquence. De plus, le préambule comprend un champ de signal qui décrit le débit de données, la longueur et la parité. Le signal détermine la quantité de données transmises dans cette trame particulière.
- 802.11 b : le préambule utilisera soit une longue séquence de 144 bits, soit une courte séquence de 72 bits. L’en-tête comprendra le débit du signal, les modes de service, la longueur des données en microsecondes et un CRC.
- 802.11n : a deux modes de fonctionnement : Greenfield (HT) et mixte (non-HT). Greenfield ne peut être utilisé que lorsqu’il n’existe aucun système existant. Le mode non HT est un mode de compatibilité avec les systèmes 802.11a / g et ne fournit pas de meilleures performances qu’un a / g. Le mode Greenfield permet un transport plus rapide.
L’illustration suivante est la structure de trame de paquets de couche liaison PHY 802.11:
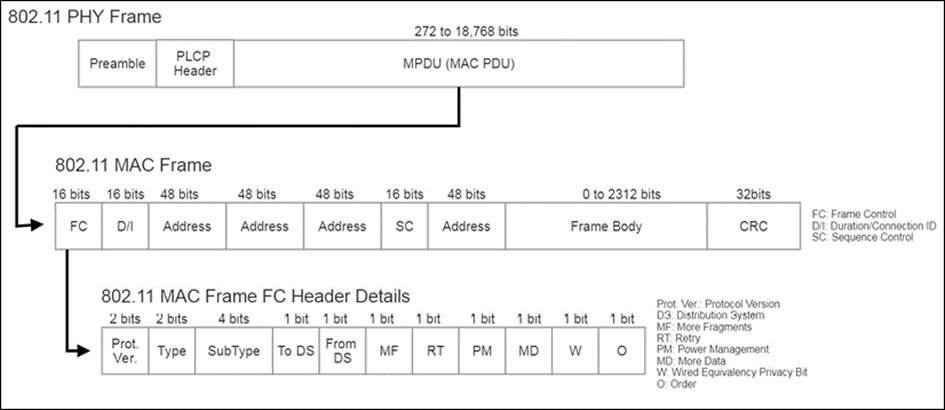
Figure 12 : Structure de trame PHY et MAC 802.11 généralisée
La structure de trame MAC est illustrée dans la figure précédente. La trame MAC contient la pluralité de champs représentatifs. Les sous-champs de contrôle de trame (champ FC) sont détaillés comme suit :
- Version du protocole : Ceci indique la version du protocole utilisé.
- Type : Ceci identifie la trame WLAN comme type de trame de contrôle, de données ou de gestion.
- Sous – type : cela fournit une délimitation supplémentaire du type de trame.
- ToDS et FromDS : les trames de données mettront un de ces bits à 1 pour indiquer si la trame est dirigée vers un système de distribution. Il s’agit d’un réseau ad hoc IBSS.
- Plus de fragments : si un paquet est divisé en plusieurs trames, alors chaque trame sauf la dernière aura ce bit-set.
- Réessayer : cela indique qu’une trame a été renvoyée et aide à résoudre les trames en double en cours de transmission.
- Gestion de l’alimentation : cela indique l’état d’alimentation de l’expéditeur. Les points d’accès ne peuvent pas définir ce bit.
- Plus de données : un AP utilisera ce bit pour aider lorsque les STA sont en mode d’économie d’énergie. Ce bit est utilisé pour mettre en mémoire tampon des trames dans un système de distribution.
- Confidentialité équivalente filaire : elle est définie sur 1 lorsqu’une trame est déchiffrée.
- Ordre : si un mode d’ordre strict est utilisé dans le réseau, ce bit sera défini. Les trames peuvent ne pas être envoyées dans l’ordre, et un mode de commande strict force la transmission dans l’ordre.
En remontant la trame MAC du champ de contrôle de trame, nous examinons d’abord le bit ID durée / connexion :
- Durée / ID de connexion : cela indique la durée, la période sans contention et l’ID d’association. L’identifiant d’association est enregistré lors de l’établissement de liaison initial Wi-Fi.
- Champs d’adresse : 802.11 peut gérer quatre adresses, qui peuvent inclure les informations suivantes :
- Adresse de destination (DA)
- Adresse source (SA)
- Adresse de la station émettrice (TA)
- Adresse de la station de réception (RA)
- SC : Le contrôle de séquence est un champ de 16 bits pour l’ordre des messages.
Le protocole 802.11 possède plusieurs types de trames représentés par les champs type et sous-type. Il existe trois types fondamentaux : les cadres de gestion, les cadres de contrôle et les cadres de données.
Les cadres de gestion assurent l’administration, la sécurité et la maintenance du réseau. Le tableau suivant définit les types de trames de gestion :
| Nom du cadre | La description |
| Cadre d’authentification | Une STA enverra une trame d’authentification à un AP, qui répond avec sa propre trame d’authentification. Ici, la clé partagée est envoyée et vérifiée à l’aide d’une réponse de défi. |
| Cadre de demande d’association | Transmis depuis un STA pour demander à un AP de se synchroniser. Il contient le SSID que la STA souhaite rejoindre et d’autres informations pour la synchronisation. |
| Cadre de réponse d’association | Transmis d’un AP à un STA et contient un message d’acceptation ou de rejet à une demande d’association. S’il est accepté, un identifiant d’association sera envoyé dans la charge utile. |
| Cadre de balise | Il s’agit de la balise périodique diffusée à partir d’un point d’accès. Il comprend le SSID. |
| Cadre de désauthentification | Transmis depuis une STA souhaitant quitter une connexion depuis une autre STA. |
| Cadre de dissociation | Transmis depuis une STA souhaitant mettre fin à une connexion. |
| Sonde demande cadre | Diffusion d’une STA vers une autre STA. |
| Sonde réponse châssis | Transmis depuis un AP en réponse à une demande de sonde. Il contient des informations telles que les débits de données pris en charge. |
| Cadre de réassociation | Utilisé quand un STA perd la force du signal avec un AP mais trouve un autre AP associé au réseau utilisant un signal plus fort. Le nouvel AP tentera de s’associer à la STA et de transmettre les informations stockées dans le tampon AP d’origine. |
| Réassociation réponse trame | Transmis par l’AP avec l’acceptation ou le rejet d’une demande de réassociation. |
Le prochain type de trame principale est la trame de contrôle. Les trames de contrôle aident à échanger des données entre les STA :
| Nom du cadre | La description |
| Trame d’accusé de réception (ACK) | Une STA réceptrice accusera toujours réception des données reçues si aucune erreur ne s’est produite. Si l’expéditeur ne reçoit pas d’accusé de réception après un temps déterminé, l’expéditeur renverra la trame. |
| Demande d’envoi de trame (RTS) | Cela fait partie du mécanisme d’évitement des collisions. Une STA commencera par envoyer un message RTS si elle souhaite transmettre des données. |
| Effacer pour envoyer la trame (CTS) | Il s’agit d’une réponse STA à une trame RTS. La requête STA peut désormais envoyer la trame de données. Il s’agit d’une forme de gestion des collisions. Une valeur de temps est utilisée pour bloquer les transmissions d’autres STA avec les transmissions STA demandeuses. |
Le dernier type de trame est la trame de données. C’est l’essentiel de la fonction de transport de données du protocole.
6.3.7 IEEE 802.11 opération
Comme mentionné précédemment, un STA est considéré comme un appareil équipé d’un contrôleur d’interface réseau sans fil. Un STA sera toujours à l’écoute de la communication active dans un canal spécifique. La première phase de connexion au Wi-Fi est la phase de numérisation. Il existe deux types de mécanismes de scan utilisés :
- Analyse passive : cette forme d’analyse utilise des balises et des requêtes de sonde. Une fois qu’un canal est sélectionné, l’appareil effectuant le balayage recevra des balises et des demandes de sonde des STA à proximité. Un point d’accès peut transmettre une balise et si la STA reçoit la transmission, elle peut progresser pour rejoindre le réseau.
- Balayage actif : dans ce mode, le STA tentera de localiser un point d’accès en instanciant les demandes de sonde. Ce mode de numérisation utilise plus d’énergie mais permet des connexions réseau plus rapides. L’AP peut répondre à une demande de sonde avec une réponse de demande de sonde, qui est similaire à un message de balise.
Un point d’accès diffusera généralement une balise à un intervalle de temps fixe appelé le temps de transmission de la balise cible (TBTT), qui est généralement une fois toutes les 100 ms.
Les balises sont toujours diffusées aux tarifs de base les plus bas pour garantir que chaque STA de la gamme a la capacité de recevoir la balise même si elle ne peut pas se connecter à ce réseau particulier. Après le traitement d’une balise, la phase suivante de la connectivité Wi-Fi est la phase de synchronisation. Cette phase est nécessaire pour garder les clients en phase avec le point d’accès. Le paquet balise contient les informations nécessaires à la STA :
- Service Set ID (SSID) : nom de réseau de 1 à 32 caractères. Ce champ peut éventuellement être masqué en définissant la longueur SSID sur zéro. Même si elle est masquée, les autres parties de la trame de balise sont transmises comme d’habitude. De manière générale, l’utilisation d’un SSID caché n’offre aucune sécurité réseau supplémentaire.
- ID de service de base (BSSID): Un 48 bits unique suivant les conventions d’adresse MAC de couche 2. Il est formé par la combinaison de l’identifiant unique d’organisation 24 bits et de l’identifiant 24 bits attribué par le fabricant pour le chipset radio.
- Largeur de canal : 20 MHz, 40 MHz, etc.
- Pays : liste des chaînes prises en charge (spécifiques au pays).
- Intervalle de balise : temps TBTT mentionné précédemment.
- TIM / DTIM : heures et intervalles de réveil pour récupérer les messages diffusés – permet une gestion avancée de l’alimentation.
- Services de sécurité : capacités WEP, WPA et WPA2.
Les balises sont un concept intéressant qui ressemble aux balises Bluetooth. Le sans fil Bluetooth offre des capacités de message et une flexibilité beaucoup plus grande dans les émissions de balises, mais il existe une gamme de produits et services qui utilisent également la balise Wi-Fi.
Si le STA trouve un AP ou un autre STA avec lequel établir une connexion, il entre alors dans une phase d’authentification. Plus d’informations seront discutées sur la variété des normes de sécurité utilisées dans 802.11 plus loin dans ce chapitre.
Si le processus de sécurité et d’authentification réussit, la phase suivante est l’association. Le périphérique enverra une trame de demande d’association à l’AP. L’AP répondra ensuite avec une trame de réponse d’association qui permettra à la STA de rejoindre le réseau ou d’être exclue. Si le STA est inclus, l’AP libérera un ID d’association au client et l’ajoutera à la liste des clients connectés.
À ce stade, les données peuvent être échangées avec l’AP et vice versa. Toutes les trames de données seront être suivis par un accusé de réception.
6.3.8 Sécurité IEEE 802.11
Dans la section précédente, nous avons décrit le processus d’association d’un périphérique Wi-Fi pour rejoindre un réseau. Une des phases impliquées était l’authentification. Cette section couvrira les différents types d’authentification utilisés sur les WLAN Wi-Fi et divers points forts et points faibles :
- Confidentialité équivalente filaire (WEP): le mode WEP envoie une clé en texte brut du client. La clé est ensuite chiffrée et renvoyée au client. WEP utilise des clés de tailles différentes, mais elles sont généralement de 128 bits ou 256 bits. WEP utilise une clé partagée, ce qui signifie que la même clé est disponible pour tous les clients. Il peut être facilement compromis en écoutant et en reniflant simplement toutes les trames d’authentification revenant aux clients rejoignant un réseau pour déterminer la clé utilisée pour tout le monde. En raison d’une faiblesse dans la génération de clé, les premiers octets de la chaîne pseudo-aléatoire peuvent révéler (5% de probabilité) une partie de la clé. En interceptant 5 à 10 millions de paquets, un attaquant pourrait, avec une confiance raisonnable, obtenir suffisamment d’informations pour révéler la clé.
- Accès protégé Wi-Fi (WPA): l’accès protégé Wi-Fi (ou WPA-Enterprise) a été développé en tant que norme de sécurité IEEE 802.11i pour remplacer WEP et est une solution logicielle / micrologicielle ne nécessitant aucun nouveau matériel. Une différence significative est que WPA utilise un protocole d’intégrité de clé temporelle (TKIP), qui effectue le mélange et la recomposition de clés par paquet. Cela signifie que chaque paquet utilisera une clé différente pour se chiffrer, contrairement au cas de WEP. WPA commence par générer une clé de session basée sur l’adresse MAC, la clé de session temporelle et le vecteur d’initialisation. Ceci est assez gourmand en ressources processeur mais n’est effectué qu’une seule fois par session. L’étape suivante consiste à extraire les 16 bits les plus bas d’un paquet reçu avec le résultat des bits générés dans la première phase. Il s’agit de la clé de 104 bits par paquet. Les données peuvent désormais être cryptées.
- Clé pré-partagée WPA (WPA-PSK): Le mode WPA-PSK ou WPA-Personal existe lorsqu’il n’y a pas d’infrastructure d’authentification 802.11. Ici, on utilise une phrase secrète comme clé pré-partagée. Chaque STA peut avoir sa propre clé pré-partagée associée à son adresse MAC. Ceci est similaire au WEP, et des faiblesses ont déjà été trouvées si la clé pré-partagée utilise une phrase de passe faible.
- WPA2 : remplace la conception WPA d’origine. WPA2 utilise AES pour le chiffrement, qui est beaucoup plus puissant que TKIP dans WPA. Ce chiffrement est également appelé mode CTR avec protocole CBC-MAC, ou CCMP pour faire court.
Pour atteindre des taux de bande passante élevés en 802.11n, le mode CCMP doit être utilisé, sinon le débit de données ne dépassera pas 54 Mbps. De plus, la certification WPA2 est nécessaire pour utiliser le logo de la marque Wi-Fi Alliance.
6.3.9 IEEE 802.11ac
IEEE802.11ac est le WLAN de nouvelle génération et le prolongement de la famille des normes 802.11. IEEE802.11ac a été approuvé en tant que norme en décembre 2013 après cinq ans de travaux. L’objectif est de fournir un débit multistation d’au moins 1 Go / s et un débit de liaison unique de 500 Mb / s. La technologie y parvient grâce à une bande passante plus large (160 MHz), davantage de flux spatiaux MIMO et une modulation de densité extrême (256-QAM). Le 802.11ac n’existe que dans la bande des 5 GHz, mais coexistera avec les normes précédentes (IEEE802.11a / n).
Les spécificités et les différences entre IEEE802.11ac et IEEE802.11n sont :
- Largeur de canal 80 MHz minimum avec largeur de canal 160 MHz maximum
- Huit flux spatiaux MIMO :
- Introduction de la liaison descendante MU-MIMO avec jusqu’à quatre clients de liaison descendante
- Plusieurs STA avec plusieurs antennes peuvent désormais transmettre et recevoir indépendamment sur plusieurs flux
- Modulation optionnelle 256-QAM avec la possibilité d’utiliser la formation de faisceaux standardisée 1024-WAM
Multiuser MIMO mérite plus de détails. Le 802.11ac étend le 802.11n de quatre flux spatiaux à huit. L’un des principaux facteurs contribuant à la vitesse 802.11ac est le multiplexage par répartition spatiale (SDM), mentionné précédemment. Lorsqu’elle est combinée à des aspects multi-utilisateurs ou à plusieurs clients du 802.11ac, cette technique s’appelle l’accès multiple par répartition en espace de nom (SDMA). Essentiellement, MU-MIMO dans 802.11ac est un analogue sans fil d’un commutateur réseau. L’illustration suivante représente un système MU-MIMO 802.11ac 4 × 4: 4 avec trois clients:
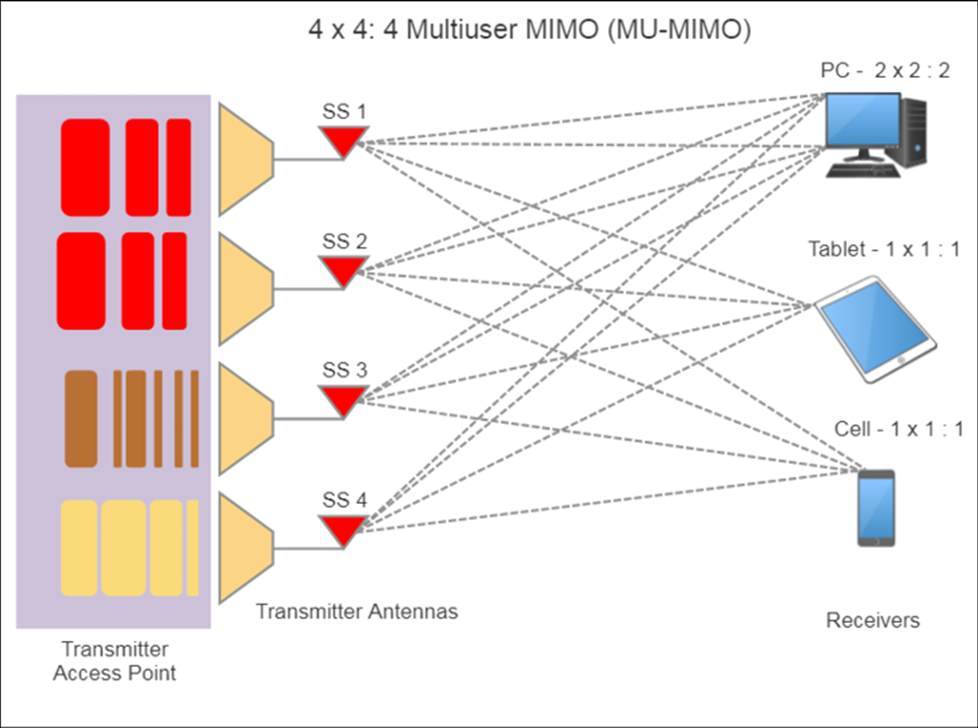
Figure 13 : Utilisation de MU-MIMO 802.11ac
11.ac étend également la constellation de modulation de 64-QAM à 256-WAM. Cela implique qu’il existe 16 niveaux d’amplitude et 16 angles de phase, nécessitant un matériel très précis à mettre en œuvre. 802.11n représentait six bits par symbole, tandis que 802.11ac représente huit bits par symbole.
Les méthodes de formation de faisceaux ont été officiellement normalisées par le comité IEEE. Par exemple, le comité a convenu que la rétroaction explicite est l’approche standard de l’association de formation de faisceau. Cela permettra à la formation de faisceaux et aux avantages de performances d’être disponibles auprès de plusieurs fournisseurs.
L’augmentation de la bande passante par canal (jusqu’à 80 MHz avec l’option de 160 MHz ou deux blocs de 80 MHz) fournit une augmentation substantielle du débit dans l’espace de 5 GHz.
Théoriquement, en utilisant un périphérique 8 × 8: 8, des canaux larges de 160 MHz et une modulation 256-QAM, on pourrait supporter un débit de 6 933 Go / s au total.
6.3.10 IEEE 802.11p véhicule de véhicule
Les réseaux de véhicules (parfois appelés réseaux ad hoc de véhicules ou VANET) sont spontanés et non structurés, fonctionnant comme une voiture se déplace dans une ville tout en interagissant avec d’autres véhicules et infrastructures. Ce modèle de réseau utilise des modèles de véhicule à véhicule (V2V) et de véhicule à infrastructure (V2I).
En 2004, le groupe de travail 802.11p a formé et développé le premier projet d’ici avril 2010. Le 802.11p est considéré comme un canal de communication à courte portée (DSRC) dédié au sein du département américain des Transports. L’objectif de ce réseau est de fournir un système V2V et V2I standard et sécurisé utilisé pour la sécurité des véhicules, la perception des péages, l’état du trafic / avertissements, l’assistance routière et le commerce électronique dans un véhicule.
La topologie et le cas d’utilisation générale d’un réseau IEEE 802.11p sont illustrés dans la figure suivante. Il existe deux types de nœuds dans le réseau. Le premier est l’unité routière (RSU), qui est un dispositif de localisation fixe un peu comme un point d’accès. Il sert à relier les véhicules et les appareils mobiles à Internet pour l’utilisation des services d’application et l’accès aux autorités de confiance. L’autre type de nœud est l’unité embarquée (OBU), qui réside dans le véhicule. Il est capable de communiquer avec d’autres OBU et les RSU fixes en cas de besoin.
Les OBU peuvent communiquer avec les RSU et entre eux pour relayer les données du véhicule et de la sécurité. Les RSU sont utilisées pour faire le pont avec les services d’application et les autorités de confiance pour l’authentification. Voici un exemple d’utilisation et de topologie 802.11p:

Figure 14 : Cas d’utilisation IEEE 802.11p: OBU dans les véhicules et RSU d’infrastructure fixe
Pour les systèmes de transport, plusieurs défis existent dans les communications sans fil. Il y a un niveau accru de sécurité nécessaire dans la communication et le contrôle des véhicules. Les effets physiques tels que les décalages Doppler, les effets de latence et la mise en réseau ad hoc robuste sont quelques problèmes à considérer.
De nombreuses différences par rapport aux normes 802.11 visent à garantir la qualité et la portée sur la vitesse de transmission. D’autres facteurs sont des changements pour réduire la latence lors du démarrage d’une connexion. Ce qui suit est un résumé des fonctionnalités de IEEE 802.11p et des différences par rapport aux normes IEEE 802.11a:
- La largeur du canal est de 10 MHz au lieu des 20 MHz utilisés en 802.11a.
- IEEE 802.11p fonctionne dans la bande passante 75 MHz de l’espace 5,9 GHz. Cela implique qu’il y a un total de sept canaux disponibles (un contrôle, deux canaux critiques et quatre canaux de service).
- Il prend en charge deux fois moins de débits que le 802.11a, c’est-à-dire 3 / 4,5 / 6/9/12/18/24/27 Mbps.
- Il a les mêmes schémas de modulation, tels que BPSK / QPSK / 16QAM / 64QAM et 52 sous-porteuses.
- La durée du symbole est devenue le double de celle de 802.11a: IEEE 802.11p prend en charge 8 µs, tandis que 11a prend en charge 4 µs.
- L’intervalle de temps de garde est de 1,6 µs en 802.11p, tandis que 11a a 0,8 µs.
- Des techniques telles que MIMO et la formation de faisceaux ne sont pas nécessaires ou ne font pas partie de la spécification.
Les canaux 75 MHz sont classés comme suit :
| Chaîne | 172 | 174 | 176 | 178 | 180 | 182 | 184 |
| Fréquence centrale (GHz) | 860 | 870 | 880 | 890 | 900 | 910 | 920 |
| But | Sécurité de la vie critique | Le service | Le service | Contrôle | Le service | Le service | Sécurité publique haute puissance |
Le modèle d’utilisation fondamental du 802.11p est de créer et d’associer rapidement des réseaux ad hoc. Ce lien va et vient à mesure que les véhicules s’éloignent les uns des autres et que d’autres véhicules finissent par reconstituer le tissu. Dans le modèle 802.11 standard, un BSS serait la topologie de réseau à utiliser, ce qui nécessite la synchronisation, l’association et l’authentification pour qu’un réseau sans fil se forme. 802.11p fournit un BSSID générique dans l’en-tête de toutes les trames échangées et permet aux liens de commencer à échanger des trames de données immédiatement après leur arrivée sur un canal de communication.
La pile de protocoles IEEE 802.11p est dérivée de 802.11a mais apporte des modifications importantes pour répondre à la sécurité et à la sûreté des véhicules. La figure suivante illustre la pile de protocoles. Un écart important par rapport aux autres piles IEEE 802.11 est l’utilisation des normes IEEE 1609.x pour traiter les modèles d’application et de sécurité. La pile complète est appelée accès sans fil dans les environnements véhiculaires ( WAVE ) et combine les couches 802.11p PHY et MAC avec les couches IEEE 1609.x:
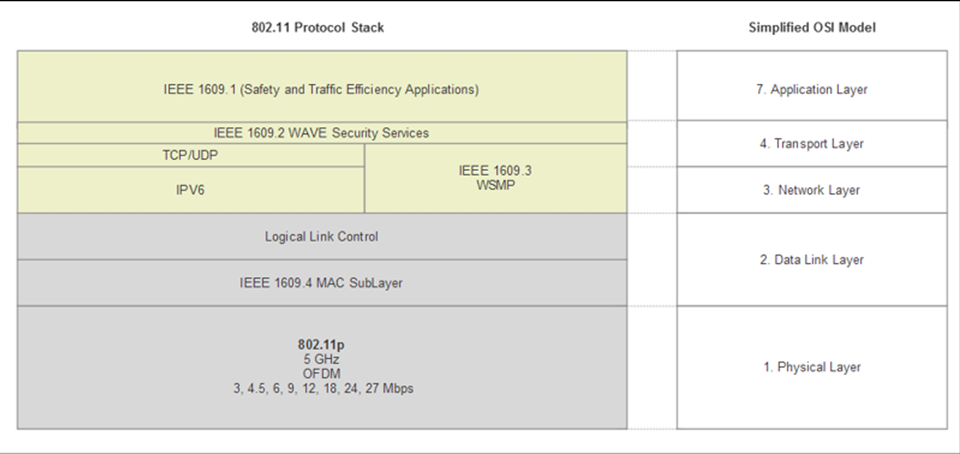
Figure 15 : pile de protocoles automobiles 802.11p
Les différences spécifiques à mettre en évidence dans la pile incluent :
- 1609.1 : gestionnaire de ressources WAVE. Il alloue et provisionne les ressources selon les besoins.
- 1609.2 : définit les services de sécurité pour les messages d’application et de gestion. Cette couche propose également deux modes de cryptage. Un algorithme à clé publique utilisant l’algorithme de signature ECDSA peut être utilisé. Alternativement, un algorithme symétrique basé sur AES-128 en mode CCM est disponible.
- 1609.3 : Aide à la configuration de la connexion et à la gestion des appareils compatibles WAVE.
- 1609.4 : fournit un fonctionnement multicanal au-dessus de la couche MAC 802.11p.
La sécurité est essentielle dans un VANET. Il existe des menaces potentielles qui peuvent affecter directement la sécurité publique. Des attaques peuvent se produire lorsque de fausses informations sont diffusées, affectant la réaction ou les performances des autres véhicules. Une attaque de cette nature pourrait être un dispositif voyou diffusant un danger sur une route et provoquant un arrêt brutal des véhicules. La sécurité doit également prendre en compte les données des véhicules privés, se faisant passer pour d’autres véhicules et provoquant une attaque par déni de services. Tout cela peut conduire à des événements catastrophiques et nécessiter des normes telles que l’IEEE 1609.2.
6.3.11 IEEE 802.11ah
Basé sur l’architecture 802.11ac et PHY, le 802.11ah est une variante des protocoles sans fil ciblés pour l’IoT. La conception tente d’optimiser les dispositifs de capteur contraints qui nécessitent une longue durée de vie de la batterie et peuvent optimiser la portée et la bande passante. 802.11ah est également appelé HaLow , qui est essentiellement un jeu de mots avec “ha” se référant à “ah” en arrière et “faible” impliquant une faible puissance et une fréquence inférieure. Mettez ensemble, il forme un dérivé de « bonjour ».
Le groupe de travail IEEE 802.11ah avait pour objectif de créer un protocole à portée étendue pour les communications rurales et le déchargement du trafic cellulaire. L’objectif secondaire était d’utiliser le protocole pour les communications sans fil à faible débit dans la gamme sub-gigahertz. La spécification a été publiée le 31 décembre 2016. L’architecture est la plus différente des autres formes de normes 802.11, notamment de la manière suivante :
- Fonctionne dans le spectre 900 MHz. Cela permet une bonne propagation et pénétration des matériaux et des conditions atmosphériques.
- La largeur des canaux varie et peut être réglée sur des canaux de 2, 4, 8 ou 16 MHz. Les méthodes de modulation disponibles sont diverses et incluent les techniques de modulation BPSK, QPSK, 16-QAM, 64-WAM et 256-QAM.
- Modulation basée sur la norme 802.11ac avec des modifications spécifiques. Un total de 56 sous-porteuses OFDM avec 52 dédiées aux données et 4 dédiées aux tonalités pilotes. La durée totale du symbole est de 36 ou 40 microsecondes.
- Prend en charge la formation de faisceaux SU-MIMO.
- Association rapide pour des réseaux de milliers de STA utilisant deux méthodes d’authentification différentes pour limiter les conflits.
- Fournit une connectivité à des milliers d’appareils sous un seul point d’accès. Il comprend la possibilité de relayer pour réduire la puissance sur les STA et permettre une forme brute de mise en réseau maillée en utilisant une méthode de portée à un saut.
- Permet une gestion avancée de l’alimentation sur chaque nœud 802.11ah.
- Permet la communication de topologie non-star via l’utilisation de fenêtres d’accès restreint (RAW).
- Permet la sectorisation, qui permet de regrouper des antennes pour couvrir différentes régions d’un SRS (appelées secteurs). Ceci est accompli en utilisant la formation de faisceaux adoptée à partir d’autres protocoles 802.11.
Le débit minimum sera de 150 Kbps, basé sur la modulation BPSK sur un seul flux MIMO à une bande passante de 1 MHz. Le débit théorique maximum sera de 347 Mbps basé sur une modulation 256 WAM utilisant 4 flux MIMO et des canaux 16 MHz.
La spécification IEEE 802.11ah requiert que les STA prennent en charge les bandes passantes des canaux 1 MHz et 2 GHz. Les points d’accès doivent prendre en charge les canaux 1, 2 et 4 MHz. Les canaux 8 MHz et 16 MHz sont facultatifs. Plus la bande passante du canal est étroite, plus la portée est longue mais plus le débit est lent.
Plus la bande passante du canal est large, plus la plage est courte mais plus le débit est rapide.
La largeur du canal variera selon la région dans laquelle le 802.11ah est déployé. Certaines combinaisons ne fonctionneront pas en raison de réglementations dans des régions spécifiques, comme indiqué :
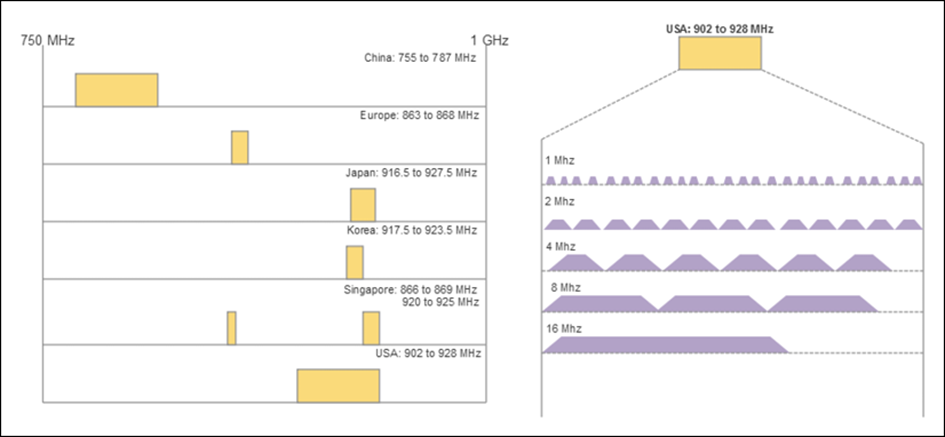
Figure 16 : à gauche : différentes options de canalisation en fonction des réglementations régionales. Droite : options de bande passante variables et liaison de canaux dans la région des États-Unis de 1 MHz à 16 MHz.
Chaque tentative dans l’architecture de la norme IEEE 802.11ah vise à optimiser la portée et l’efficacité globales. Cela descend jusqu’à la longueur des-en- têtes MAC.
L’objectif de connecter plusieurs milliers de périphériques à un seul point d’accès est également atteint à l’aide d’une affectation d’identificateur d’association unique (AID) de 13 bits. Cela permet de regrouper les STA en fonction de critères (éclairage de couloir, interrupteur d’éclairage, etc.). Cela permet à un AP de se connecter à plus de 8191 STA. (Le 802.11 ne pourrait prendre en charge que les STA 2007.) Ce nombre de nœuds, cependant, a le potentiel d’induire un nombre massif de collisions de canaux. Même si le nombre de STA connectés a augmenté, l’objectif était de réduire la quantité de données en transit pour adresser ces stations.
Le groupe de travail IEEE a accompli cela en supprimant un certain nombre de champs qui n’étaient pas particulièrement pertinents pour les cas d’utilisation IoT, tels que les champs QoS et DS. La figure suivante illustre les trames de liaison descendante et montante MAC 802.11ah par rapport à la norme 802.11.

Figure 17 : comparaison de la trame MAC 802.11 standard et des trames condensées 802.11ah
Une autre amélioration de la gestion de l’énergie et de l’efficacité des canaux est attribuée à la suppression des trames d’accusé de réception. Les ACK sont implicites pour les données bidirectionnelles. Autrement dit, les deux appareils s’envoient et reçoivent des données l’un de l’autre. Normalement, un ACK serait utilisé après la réception réussie d’un paquet. Dans ce mode de transport bidirectionnel (BDT), la réception de la trame suivante implique que les données précédentes ont été reçues avec succès et qu’aucun paquet ACK n’a besoin d’être échangé.
Pour éviter une mer de collisions, ce qui empêcherait un réseau fonctionnel, 802.11ah utilise un RAW. Comme les STA sont divisés en différents groupes à l’aide de l’AID, les canaux seront divisés en tranches de temps. Chaque groupe se verra attribuer un créneau horaire spécifique et aucun autre. Il existe des exceptions, mais dans le cas général, le regroupement forme un isolement arbitraire. L’avantage supplémentaire de RAW est que les appareils peuvent entrer dans un état d’hibernation pour économiser l’énergie chaque fois que ce n’est pas leur créneau horaire pour la transmission.
Sur le plan de la topologie, il existe trois types de stations dans un réseau 802.11ah :
- Point d’accès racine : la racine principale. En règle générale, il sert de passerelle vers d’autres réseaux (WAN).
- STA : station 802.11 ou client d’extrémité typique.
- Nœud relais : un nœud spécial qui combine une interface AP aux STA résidant sur un BSS inférieur et une interface STA aux autres nœuds relais ou un AP racine sur le BSS supérieur.
La figure suivante est la topologie IEEE802.11ah. Cette architecture diffère considérablement des autres protocoles 802.11 par l’utilisation de nœuds relais à un seul bond qui agissent pour créer un BSS identifiable. La hiérarchie des relais forme un réseau plus vaste. Chaque relais agit comme un AP et un STA :

Figure 18 : Topologie du réseau IEEE802.11ah
En plus des types de nœuds de base, il existe trois états d’économie d’énergie dans lesquels une STA peut résider :
- Carte d’indication de trafic (TIM): écoute AP pour le transfert de données. Les nœuds recevront périodiquement des informations sur les données mises en mémoire tampon pour eux depuis son point d’accès. L’ENVOYÉ un message est appelé l’informations TIM élément.
- Stations non-TIM : négocie avec AP directement pendant l’association pour obtenir le temps de transmission sur les fenêtres d’accès restreint périodique (PRAW).
- Stations non programmées : n’écoute aucune balise et utilise l’interrogation pour accéder aux canaux.
La puissance est essentielle dans les capteurs IoT et les dispositifs de bord basés sur les piles bouton ou la récupération d’énergie. Les protocoles 802.11 sont connus pour leurs demandes de puissance élevées. Pour remédier à la puissance de ce protocole sans fil, 802.11ah utilise une valeur de période d’inactivité maximale, qui fait partie des spécifications 802.11 normales. Dans un réseau 802.11 général, la période d’inactivité maximale est d’environ 16 heures sur la base d’une durée de résolution de 16 bits. En 802.11ah, les deux premiers bits du temporisateur 16 bits sont un facteur d’échelle qui permet à la durée de veille de dépasser cinq ans.
La puissance supplémentaire est atténuée par des modifications de la balise. Comme indiqué précédemment, les balises transmettent des informations sur la disponibilité des trames tamponnées. Les balises porteront un bitmap TIM, ce qui gonfle leur taille car 8191 STA entraîneront une croissance substantielle du bitmap. 802.11ah utilise un concept appelé segmentation TIM où certaines balises portent des parties de la bitmap globale. Chaque STA calcule quand leur balise respective avec des informations bitmap arrivera et permet à l’appareil d’entrer en mode d’économie d’énergie jusqu’au moment où il a besoin de se réveiller et de recevoir des informations de balise.
Une autre fonctionnalité d’économie d’énergie est appelée Target Wake Time (TWT), qui est destiné aux STA qui transmettent ou reçoivent rarement des données. Ceci est très fréquent dans les déploiements IoT tels que les données de capteur de température. Une STA et son AP associé négocieront pour parvenir à un TWT convenu, et la STA entrera dans un état de veille jusqu’à ce que ce temporisateur soit signalé.
Le processus des ACK implicites est appelé un échange de trames rapides , et il est illustré dans la figure suivante:
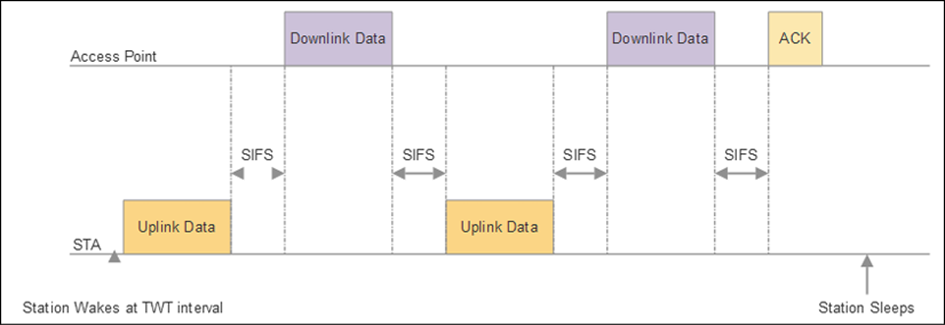
Figure 19 : Échange de trames de vitesse IEEE 802.11ah : un exemple de temps de réveil cible (TWT) utilisé pour démarrer une communication STA. SIFS représente l’écart entre les communications AP et STA. Aucun ACK n’est utilisé entre les paires de données. Un seul ACK à la fin de la transmission est envoyé avant que le STA ne revienne en mode veille.
6.3.12 Topologies 6LoWPAN
Les réseaux 6WPPAN sont des réseaux maillés résidant à la périphérie de réseaux plus importants. Les topologies sont flexibles, permettant des réseaux ad hoc et disjoints sans aucune liaison à Internet ou à d’autres systèmes, ou ils peuvent être connectés à la dorsale ou à Internet à l’aide de routeurs de périphérie. Les réseaux 6WPPAN peuvent être associés à plusieurs routeurs périphériques ; c’est ce qu’on appelle le multi hébergement. De plus, des réseaux ad hoc peuvent se former sans nécessiter la connectivité Internet d’un routeur périphérique.
Ces topologies sont illustrées dans la figure suivante :
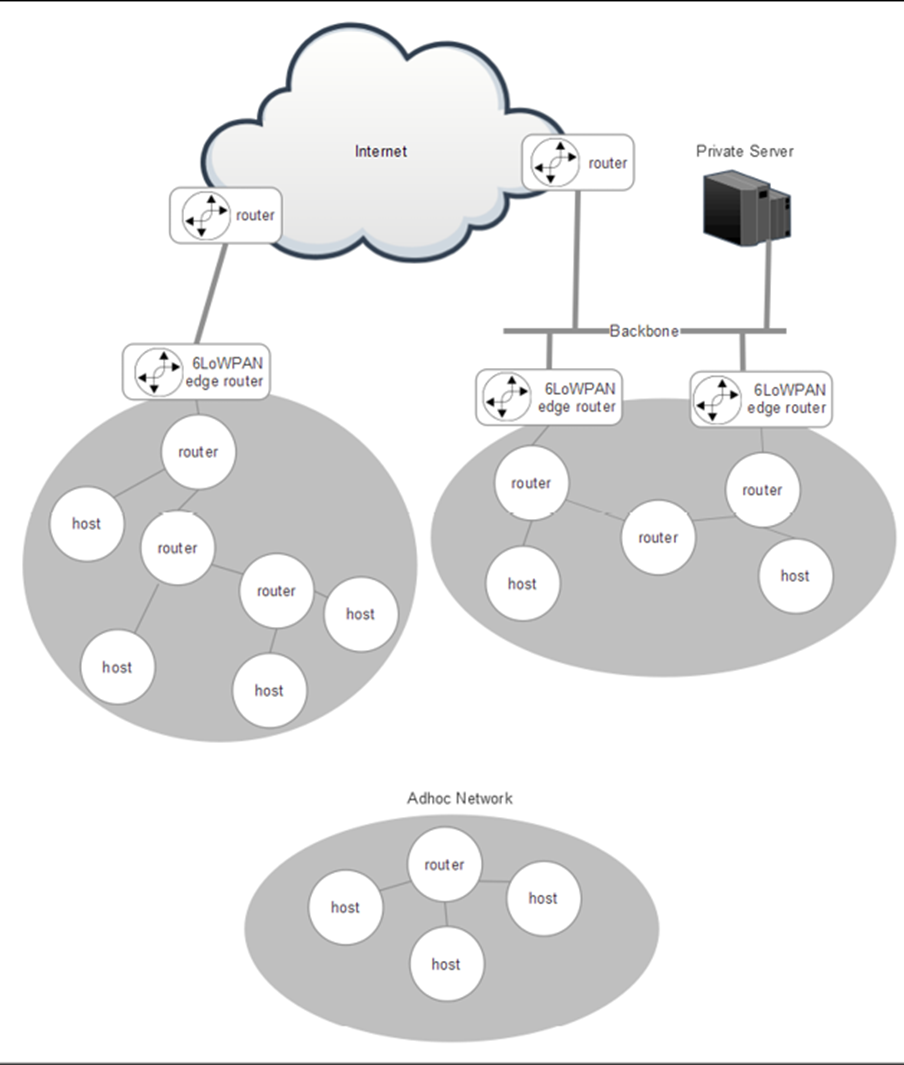
Figure 20 : Topologies 6LoWPAN
Un routeur périphérique (également appelé routeur frontière) est nécessaire pour une architecture 6LoWPAN car il a quatre fonctions :
- Gère la communication avec les appareils 6LoWPAN et relaie les données vers Internet.
- Effectue la compression des en-têtes IPv6 en réduisant un en-tête IPv6 de 40 octets et des en-têtes UDP de 8 octets pour plus d’efficacité dans un réseau de capteurs. Un en-tête IPv6 typique de 40 octets peut être compressé de 2 à 20 octets selon l’utilisation.
- Lance le réseau 6LoWPAN.
- Échange des données entre les appareils du réseau 6LoWPAN.
Les routeurs de périphérie forment des réseaux maillés 6LoWPAN sur de plus grands périmètres de réseau traditionnels. Ils peuvent également négocier des échanges entre IPV6 et IPV4 si nécessaire. Les datagrammes sont traités de la même manière que dans un réseau IP, ce qui présente certains avantages par rapport aux protocoles propriétaires. Tous les nœuds d’un réseau 6LoWPAN partagent le même préfixe IPv6 que celui établi par le routeur de périphérie. Les nœuds s’inscriront auprès des routeurs périphériques dans le cadre de la phase de découverte du réseau (ND).
ND contrôle la façon dont les hôtes et les routeurs du maillage 6LoWPAN local interagiront. Le multihébergement permet à plusieurs routeurs de périphérie 6LoWPAN de gérer un réseau – par exemple, lorsque plusieurs supports (4G et Wi-Fi) sont nécessaires pour le basculement ou la tolérance aux pannes.
Il existe trois types de nœuds dans le maillage 6LoWPAN :
- Nœuds de routeur : ces nœuds rassemblent les données d’un nœud de maillage 6LoWPAN à un autre. Les routeurs peuvent également communiquer vers l’extérieur avec le WAN et Internet.
- Noeuds hôtes : les hôtes du réseau maillé ne peuvent pas acheminer les données dans le maillage et sont simplement des points finaux consommant ou produisant des données. Les hôtes sont autorisés à être en veille, se réveillant parfois pour produire des données ou recevoir des données mises en cache par leurs routeurs parents.
- Routeurs de périphérie : comme indiqué, ce sont les passerelles et les contrôleurs de maillage généralement sur une périphérie WAN. Un maillage 6LoWPAN serait administré sous le routeur de bordure.
Les nœuds sont libres de se déplacer et de se réorganiser / réassembler dans un maillage. D’ailleurs, un nœud peut se déplacer et s’associer à un routeur de périphérie différent dans un scénario multihome ou même se déplacer entre différents maillages 6LoWPAN. Ces modifications de la topologie peuvent être causées pour diverses raisons, telles que des changements dans la force du signal ou le mouvement physique des nœuds. Lorsqu’un changement de topologie se produit, l’adresse IPv6 des nœuds associés change également naturellement.
Dans un maillage ad hoc sans routeur périphérique, un nœud de routeur 6LoWPAN pourrait gérer un maillage 6LoWPAN. Ce serait le cas lorsque la connectivité WAN à Internet n’est pas nécessaire. En règle générale, cela est rarement considéré comme l’adressabilité IPv6 pour un petit réseau ad hoc n’est pas nécessaire.
Le nœud de routeur serait configuré pour prendre en charge deux fonctions obligatoires :
- Génération d’adresses de monodiffusion locale unique
- Exécution de l’enregistrement ND de découverte de voisin
Le préfixe IPv6 maillé ad hoc serait un préfixe local plutôt que le préfixe IPv6 WAN global plus large.
6.3.13 6LoWPAN protocole pile
Pour activer 6LoWPAN sur une forme de support de communication tel que 802.15.4, il existe un ensemble de fonctionnalités recommandées nécessaires pour prendre en charge un protocole IP. Ces fonctionnalités incluent le tramage, la transmission monodiffusion et l’adressage. Comme le montre la figure suivante, la couche physique est responsable de la réception et de la conversion des bits de données en direct. Pour cet exemple, la couche de liaison à laquelle nous parlons est IEEE 802.15.4. Au-dessus de la couche physique se trouve la couche de liaison de données, chargée de détecter et de corriger les erreurs sur la liaison physique. Des informations détaillées sur la couche de liaison physique et de données de 802.15.4 sont traitées plus haut dans ce chapitre. Voici la comparaison entre la pile 6LoWPAN et le modèle OSI :
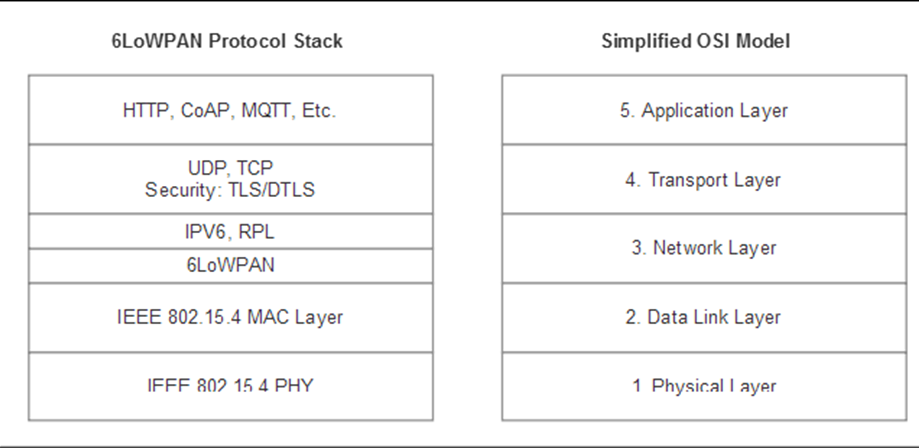
Figure 21: pile de protocoles 6WPAN par rapport au modèle OSI simpli fi é. 6WPPAN réside au-dessus d’autres protocoles comme 802.15.4 ou Bluetooth pour fournir l’adresse physique et MAC.
En activant le trafic IP au niveau d’un capteur, la relation entre l’appareil et la passerelle utiliserait une certaine forme de couche d’application pour convertir les données du protocole non IP en protocole IP. Bluetooth, Zigbee et Z-Wave ont tous une forme de conversion de leur protocole de base en quelque chose qui peut communiquer sur IP (si l’intention est de router les données). Les routeurs périphériques transmettent des datagrammes à une couche réseau. Pour cette raison, le routeur n’a pas besoin de maintenir un état d’application. Si un protocole d’application change, une passerelle 6LoWPAN s’en fiche.
Si un protocole d’application change pour l’un des protocoles non IP, la passerelle devra également modifier sa logique d’application. 6WPPAN fournit une couche d’adaptation dans la couche trois (la couche réseau) et au-dessus de la couche deux (la couche liaison de données). Cette couche d’adaptation est définie par l’IETF.
6.3.14 Adressage et routage de maillage
Le routage de maillage opère dans les couches physiques et de liaison de données pour permettre aux paquets de circuler dans un maillage dynamique en utilisant plusieurs sauts. Nous avons déjà parlé du routage maillé sous et routé, mais nous allons approfondir dans cette section cette forme de routage.
Les réseaux maillés 6LoWPAN utilisent deux schémas de routage :
- Réseau maillé: dans une topologie maillée, le routage est transparent et suppose un seul sous-réseau IP représentant l’intégralité du maillage. Un message est diffusé dans un seul domaine et envoyé à tous les appareils du maillage. Comme mentionné précédemment, cela génère un trafic considérable. Le routage sous maillage se déplacera d’un bond à l’autre dans le maillage, mais uniquement vers l’avant des paquets jusqu’à la couche deux (la couche de liaison de données) de la pile. 802.15.4 gère tout le routage pour chaque saut de la couche deux.
- Réseau de routage : dans une topologie de routage, les réseaux encourent la charge du transfert des paquets jusqu’à la couche trois (la couche réseau) de la pile. Les schémas de routage gèrent les itinéraires au niveau IP. Chaque saut représente un routeur IP.
Le graphique suivant illustre la différence entre le maillage sous et le routage de routage:
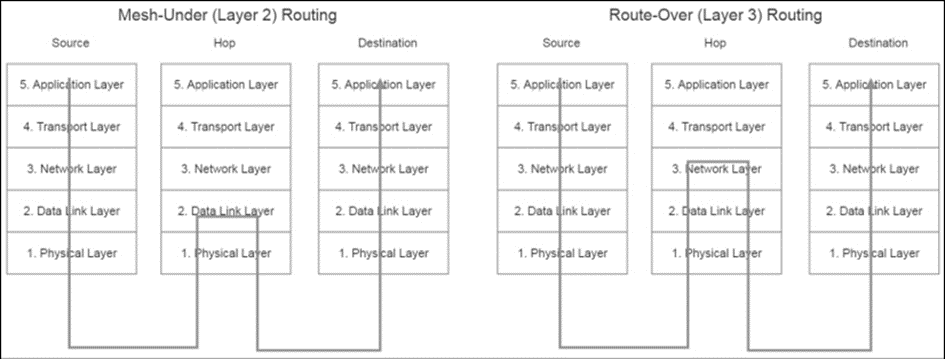
Figure 22 : Différence entre le maillage sous et le routage sur réseau. Les sauts intermédiaires révèlent la distance jusqu’à laquelle chaque paquet est livré avant de passer au nœud suivant du maillage.
Un réseau de routage implique que chaque nœud de routeur est également capable et peut exécuter le plus grand ensemble de fonctions comme un routeur IP normal, comme la détection d’adresses en double. Le RFC6550 définit formellement le protocole de routage RPL (ondulation). L’avantage de l’architecture de routage est la similitude avec la communication TCP / IP traditionnelle. RPL fournit une communication multipoint-à-point (où le trafic des périphériques dans un maillage communique avec un serveur central sur Internet) et une communication point à multipoint (service central aux périphériques dans le maillage).
Le protocole RPL a deux modes de gestion des tables de routage :
- Mode de stockage : tous les périphériques configurés en tant que routeurs dans un maillage 6LoWPAN conservent les tables de routage et de voisinage.
- Mode sans stockage : un seul périphérique, tel que le routeur périphérique, gère les tables de routage et de voisinage. Pour transmettre des données d’un hôte à un autre dans un maillage 6LoWPAN, les données sont envoyées au routeur où son itinéraire est calculé puis transmis au récepteur.
La table de routage, comme son nom l’indique, contient les chemins de routage du maillage, tandis que la table de voisinage maintient les voisins directement connectés de chaque nœud. Cela implique que le routeur périphérique sera toujours référencé pour fournir des paquets dans le maillage. Cela permet aux nœuds de routeur de ne pas gérer de grandes tables de routage, mais cela ajoutera de la latence aux paquets en mouvement, car le routeur de périphérie doit être référencé. Les systèmes en mode de stockage auront des exigences de traitement et de mémoire plus élevées pour gérer les tables de routage stockées sur chaque nœud, mais auront un chemin plus efficace pour établir une route.
Notez dans la figure suivante le nombre de sauts, l’adresse source et l’adresse de destination. Ces champs sont utilisés pendant la phase de résolution d’adresse et de routage. Le nombre de sauts est fixé à une valeur élevée initiale puis décrémenté à chaque fois que le paquet se propage de nœud en nœud dans le maillage. L’intention est lorsque la limite de saut atteint zéro, le paquet est abandonné et perdu du maillage. Cela permet d’éviter les réseaux incontrôlables si un nœud hôte se supprime du maillage et n’est plus accessible. L’adresse source et l’adresse de destination sont des adresses 802.15.4 et peuvent être au format court ou étendu, comme le permet 802.15.4. L’en-tête est construit comme suit :

Figure 23 : en-tête d’adressage du maillage 6LoWPAN
6.3.15 Compression et fragmentation des-en- têtes
Bien que l’avantage d’avoir des adresses IP pratiquement illimitées pour les choses soit une étape importante, placer IPv6 sur une liaison 802.15.4 pose certains défis qui doivent être surmontés pour rendre 6LoWPAN utilisable. Le premier est le fait qu’IPv6 a une taille maximale d’unité de transmission (MTU) de 1 280 octets, tandis que 802.15.4 a une limite de 127 octets. Le deuxième problème est que l’IPv6 en général ajoute une circonférence importante à un protocole déjà gonflé. Par exemple, dans les en-têtes IPv6, la longueur est de 40 octets.
Notez que IEEE 802.15.4g n’a pas de limitation de 127 octets pour une longueur de trame.
Semblable à IPv4, la découverte de chemin MTU dans IPv6 permet à un hôte de découvrir et de s’adapter dynamiquement aux différences de taille MTU de chaque lien le long d’un chemin de données donné. Dans IPv6, cependant, la fragmentation est gérée par la source d’un paquet lorsque le chemin MTU d’une liaison le long d’un chemin de données donné n’est pas assez grand pour s’adapter à la taille des paquets. Le fait que les hôtes IPv6 gèrent la fragmentation des paquets économise les ressources de traitement des périphériques IPv6 et aide les réseaux IPv6 à fonctionner plus efficacement. Cependant, IPv6 requiert que chaque lien sur Internet ait une MTU de 1 280 octets ou plus. (C’est ce que l’on appelle en effet la MTU de liaison minimale IPv6.) Sur toute liaison qui ne peut pas transporter un paquet de 1280 octets en une seule pièce, la fragmentation et le réassemblage spécifiques à la liaison doivent être fournis au niveau inférieur à IPv6.
La compression d’en-tête est un moyen de compresser et de supprimer la redondance dans l’en-tête standard IPv6 pour des raisons d’efficacité. Normalement, la compression d’en-tête est basée sur l’état, ce qui signifie que dans un réseau avec des liens statiques et des connexions stables, elle fonctionne assez bien. Dans un réseau maillé tel que 6LoWPAN, cela ne fonctionnera pas. Les paquets sautent entre les nœuds et nécessitent une compression / décompression à chaque traversée. De plus, les itinéraires sont dynamiques et autorisés à changer, et les transmissions peuvent ne pas être présentes pendant de longues durées. Par conséquent, 6LoWPAN a adopté la compression sans état et en contexte partagé.
Le type de compression peut être affecté par le respect de certaines spécifications, telles que l’utilisation de RFC4944 sur RFC6922, ainsi que par l’emplacement de la source et de la destination d’un paquet, comme suit :
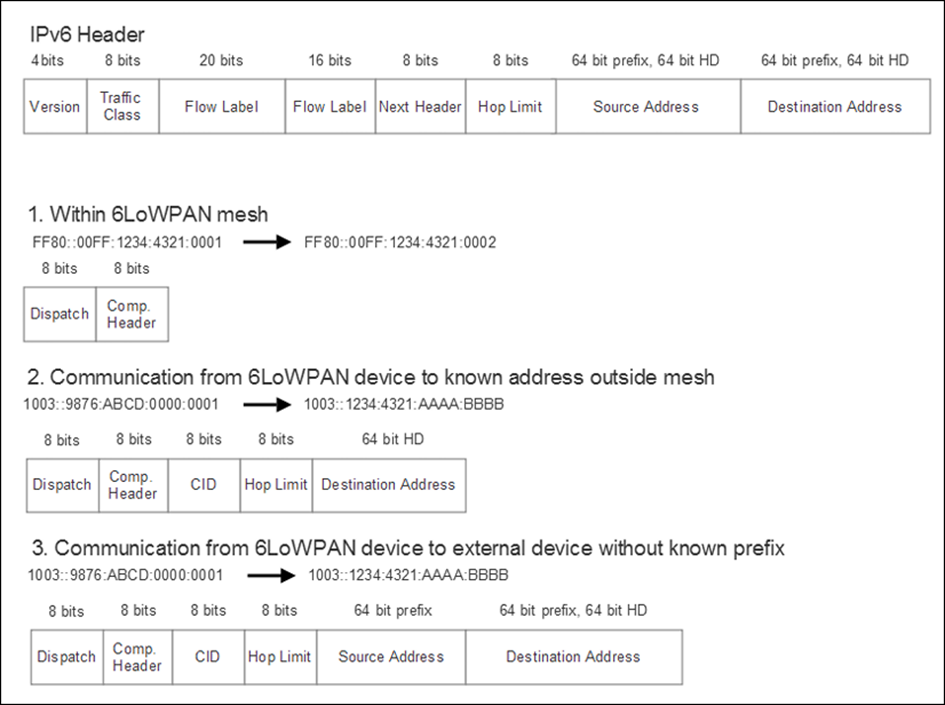
Figure 24 : compression d’en-tête dans 6LoWPAN
Les trois cas de compression d’en-tête pour 6LoWPAN sont basés sur le fait que l’itinéraire se trouve à l’intérieur du maillage local, à l’extérieur du maillage mais vers une adresse connue, ou à l’extérieur du maillage vers une adresse inconnue. Comparé à IPv6 standard avec un en-tête de 40 octets, 6 LoWPAN peut compresser entre 2 et 20 octets.
Le premier cas (dans la figure précédente) est la meilleure communication entre les nœuds d’un maillage local. Aucune donnée n’est envoyée vers le WAN avec ce format d’en-tête compressé. Le deuxième cas implique que des données sont envoyées vers le WAN vers une adresse connue, et le dernier cas est similaire mais à une adresse inconnue. Même dans le troisième cas, qui est le pire des cas, la compression représente toujours une réduction de 50% du trafic. 6WPPAN permet également la compression UDP, qui dépasse le cadre de cet article.
La fragmentation est un problème secondaire car les tailles MTU sont incompatibles entre 802.15.4 (127 octets) et IPv6 à 1280 octets. Le système de fragmentation divisera chaque trame IPv6 en segments plus petits. Côté réception, les fragments seront remontés. La fragmentation variera en fonction du type de routage choisi lors de la configuration du maillage (nous discuterons plus tard du maillage et du routage – au-dessus du routage). Les types de fragmentation et de contraintes sont donnés comme suit :
- Fragmentation du routage sous maillage : les fragments ne seront réassemblés qu’à la destination finale. Tous les fragments doivent être pris en compte lors du remontage. S’il en manque, le paquet entier doit être retransmis. En remarque, les systèmes à maillage inférieur nécessitent que tous les fragments soient transmis immédiatement. Cela va générer une rafale de trafic .
- Fragmentation du routage de routage : les fragments seront réassemblés à chaque saut du maillage. Chaque nœud le long de l’itinéraire contient suffisamment de ressources et d’informations pour reconstruire tous les fragments.
L’en-tête de fragmentation comprend un champ Taille de datagramme, qui spécifie la taille totale des données non fragmentées. Le champ Balise de datagramme identifie l’ensemble de fragments appartenant à une charge utile, et le décalage de datagramme indique où le fragment appartient dans une séquence de charge utile. Notez que le décalage de datagramme n’est pas utilisé pour le premier fragment envoyé, car le décalage d’une nouvelle séquence de fragments doit commencer à zéro.

Figure 25 : en-tête de fragmentation 6LoWPAN
La fragmentation est une tâche gourmande en ressources qui nécessite un traitement et une capacité énergétique qui peuvent taxer un nœud de capteur basé sur une batterie. Il est conseillé de limiter la taille des données (au niveau de l’application) et d’utiliser la compression d’en-tête pour réduire les contraintes de puissance et de ressources dans un grand maillage.
6.3.16 Neighbour Discovery
La découverte de voisin (ND) est définie par RFC4861 comme un protocole de routage à un saut. Il s’agit d’un contrat formel entre les nœuds voisins du maillage et permet aux nœuds de communiquer entre eux. ND est le processus de découverte de nouveaux voisins, car un maillage peut se développer, se rétrécir et se transformer, ce qui entraîne des relations de voisinage nouvelles et changeantes. Il existe deux processus de base et quatre types de messages de base dans ND :
- Recherche de voisins : cela comprend les phases d’enregistrement de voisin (NR) et de confirmation de voisin (NC).
- Recherche de routeurs : cela comprend les phases de sollicitation de routeur (RS) et de publicité de routeur (RA).
Pendant la ND, des conflits peuvent survenir. Par exemple, si un nœud hôte se dissocie d’un routeur et établit une liaison avec un routeur différent dans le même maillage. ND est requis pour trouver des adresses en double et des voisins inaccessibles dans le cadre de la spécification. DHCPv6 peut être utilisé conjointement avec ND.
Une fois qu’un périphérique compatible 802.15.4 a démarré via les couches physiques et de liaison de données, 6LoWPAN peut effectuer la découverte de voisins et développer le maillage. Ce processus se déroulera comme suit et comme indiqué dans la figure suivante :
- Recherche d’un lien et d’un sous-réseau appropriés pour une connexion sans fil à faible puissance.
- Minimiser le trafic de contrôle initié par le nœud.
- L’hôte envoie un message RS pour demander le préfixe du réseau maillé.
- Le routeur répond avec un préfixe.
- L’hôte s’assigne à une adresse unicast de liaison locale (FE 80 :: IID).
- L’hôte transmet cette adresse de monodiffusion de liaison locale dans un message NR au maillage.
- Exécution de la détection d’adresses en double (DAD) en attendant une CN pendant une durée définie. Si le délai expire, il suppose que l’adresse n’est pas utilisée.

Figure 26: Une séquence simplifiée de découverte de voisin à partir d’ un nœud de maille 6LoWPAN à travers un routeur maillé au routeur de bord, puis un arrêt au réseau étendu
Une fois l’hôte configuré, il peut commencer à communiquer sur Internet avec une adresse IPv6 unique.
Si un routage maillé sous est utilisé, l’adresse de liaison locale récupérée à l’étape cinq peut être utilisée pour communiquer avec tout autre nœud du maillage 6LoWPAN. Dans un schéma de routage, l’adresse de liaison locale peut être utilisée pour communiquer uniquement avec des nœuds à un seul bond. Tout ce qui dépasse un saut nécessitera une adresse routable complète.
6.3.17 6LoWPAN sécurité
Étant donné que, dans un système WPAN, il est facile de renifler et d’entendre la communication, 6LoWPAN offre une sécurité à plusieurs niveaux. Au niveau 802.15.4 deux du protocole, 6LoWPAN repose sur le cryptage AES-128 des données. De plus, 802.15.4 fournit un compteur avec le mode CBC-MAC (CCM) pour fournir le cryptage et un contrôle d’intégrité. La plupart des chipsets qui fournissent un bloc réseau 802.15.4 incluent également un moteur de chiffrement matériel pour améliorer les performances.
À la couche trois (la couche réseau) du protocole, 6LoWPAN a la possibilité d’utiliser la sécurité standard IPsec (RFC4301). Cela comprend :
- Gestionnaire d’authentification (AH): tel que défini dans RFC4302 pour la protection de l’intégrité et l’authentification
- Encapsulating Security Payload (ESP): dans la RFC4303, ajoute le chiffrement pour sécuriser la confidentialité des paquets
ESP est de loin le format de paquet sécurisé de couche trois le plus courant. De plus, un mode ESP définit la réutilisation AES / CCM utilisée également dans le matériel de couche deux pour le chiffrement de couche trois (RFC4309). Cela rend la sécurité de couche trois adaptée aux nœuds 6LoWPAN contraints.
En plus de la sécurité de couche liaison, 6LoWPAN utilise également TLS ( Transport Layer Security ) pour le trafic TCP et DTLS ( Datagram Transport Layer Security ) pour le trafic UDP .
6.4 WPAN avec IP – Thread
Thread est un protocole de mise en réseau relativement nouveau pour l’IoT et est basé sur IPV6 (6LoWPAN). Son objectif principal est la connectivité domestique et la domotique. Thread a été lancé en juillet 2014 avec la formation de la Thread Group Alliance, qui comprend des sociétés telles qu’Alphabet (la société holding de Google), Qualcomm, Samsung, ARM, Silicon Labs, Yale (serrures) et Tyco.
Basé sur le protocole IEEE 802.15.4 et 6LoWPAN, il a des points communs avec Zigbee et d’autres variantes 802.15.4, mais avec une différence significative étant que Thread est adressable IP. Ce protocole IP s’appuie sur les données et les couches physiques fournies par 802.15.4 et des fonctionnalités telles que la sécurité et le routage à partir de 6LoWPAN. Le fil est également basé sur le maillage, ce qui le rend attrayant pour les systèmes d’éclairage domestique avec jusqu’à 250 appareils dans un seul maillage. La philosophie de Thread est qu’en activant l’adressabilité IP dans le plus petit des capteurs et des systèmes domotiques, on peut réduire la consommation d’énergie et les coûts car le capteur compatible Thread n’a pas besoin de conserver l’état de l’application dans le stockage. Le thread est basé sur des datagrammes au niveau de la couche réseau, ce qui, par sa nature même, élimine le besoin de traiter les informations de la couche application, ce qui permet d’économiser l’énergie du système.
Enfin, le fait d’être conforme à IPV6 offre des options de sécurité grâce au chiffrement à l’aide de la norme de chiffrement avancé (AES). Jusqu’à 250 nœuds peuvent exister sur un maillage Thread, tous avec un transport et une authentification entièrement cryptée. Une mise à niveau logicielle permet à un périphérique 802.15.4 préexistant d’être compatible avec Thread.
6.4.1 Architecture et topologie des threads
Basé sur la norme IEEE 802.15.4-2006, Thread utilise la spécification pour définir les couches Medium Access Control (MAC) et physiques (PHY). Il fonctionne à 250 Kbps dans la bande GHz.
D’un point de vue topologique, Thread établit des communications avec d’autres appareils via un routeur frontière (généralement un signal Wi-Fi dans un foyer). Le reste de la communication est basé sur 802.15.4 et forme un maillage auto-réparateur. Un exemple d’une telle topologie est illustré comme suit :
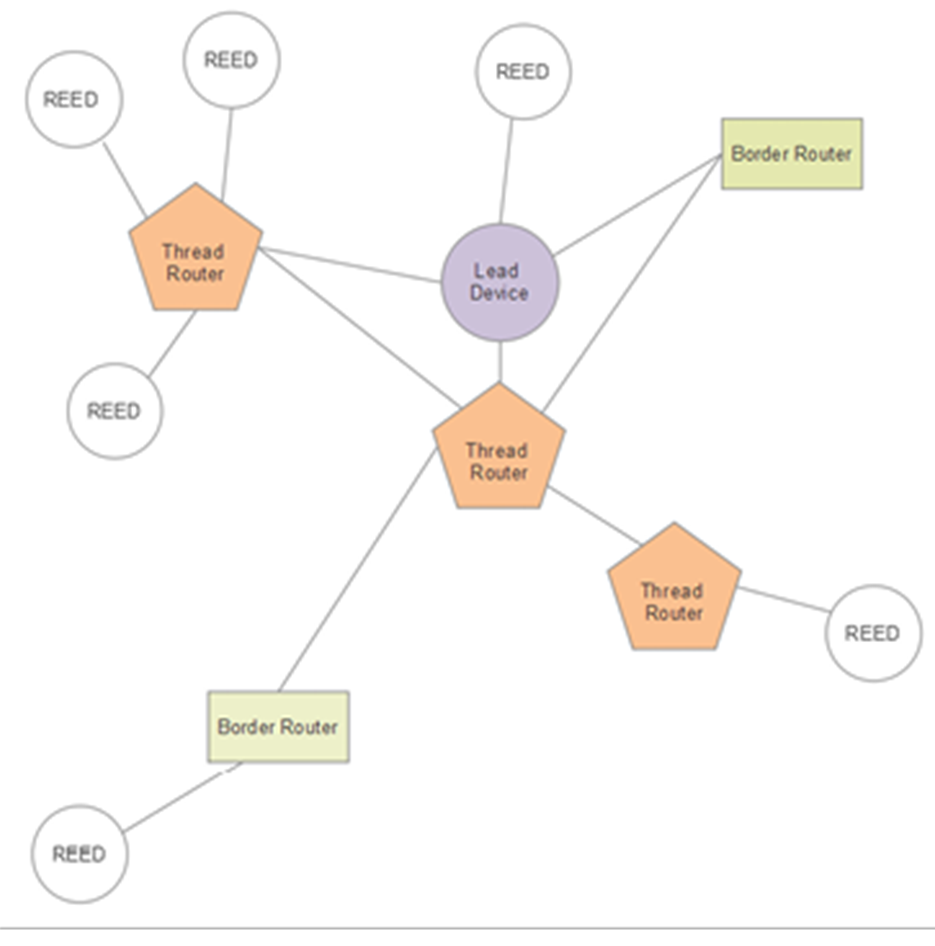
Figure 27 : Exemple de topologie de réseau Thread contenant des routeurs de bordure, des routeurs Thread, des périphériques principaux et des périphériques IoT éligibles pouvant être combinés dans le maillage. Les interconnexions sont variables et auto-réparatrices.
Voici les rôles de divers périphériques dans une architecture Thread :
- Routeur frontière : Un routeur frontière est essentiellement une passerelle. Dans le réseau domestique, il s’agirait d’un croisement des communications du Wi-Fi au Thread et constituerait le point d’entrée vers Internet à partir d’un maillage de Thread exécuté sous un routeur frontalier. Plusieurs routeurs de bordure sont autorisés dans la spécification Thread.
- Appareil principal : l’appareil principal gère un registre des ID de routeur attribués. Le responsable contrôle également les demandes de promotion des périphériques finaux admissibles au routeur (REED) en tant que routeurs. Un leader peut également agir en tant que routeur et avoir des enfants à l’extrémité de l’appareil. Le protocole d’attribution des adresses de routeur est le protocole d’application contrainte (CoAP). Les informations d’état gérées par un périphérique principal peuvent également être stockées dans les autres routeurs de threads. Cela permet l’auto-réparation et le basculement si le leader perd la connectivité.
- Routeurs de threads : les routeurs de threads gèrent les services de routage du maillage. Les routeurs de threads n’entrent jamais dans un état de veille mais sont autorisés par la spécification à se déclasser pour devenir un REED.
- REED : un périphérique hôte qui est un REED peut devenir un routeur ou un leader. Les REED ne sont pas responsables du routage dans le maillage à moins qu’ils ne soient promus routeur ou leader. Les REED ne peuvent pas non plus relayer de messages ou joindre des appareils au maillage. Les REED sont essentiellement des points d’extrémité ou des nœuds terminaux dans le réseau.
- Périphériques d’extrémité : certains points d’extrémité ne peuvent pas devenir des routeurs. Ces types de REED ont deux autres catégories auxquelles ils peuvent souscrire : les dispositifs complets (FED) et les dispositifs finaux minimaux (MED).
- Périphériques endormis : les périphériques hôtes qui sont entrés en veille ne communiquent qu’avec leur routeur Thread associé et ne peuvent pas relayer de messages.
6.4.2 La pile de protocoles Thread
Thread utilise tous les avantages de 6LoWPAN et bénéficie des avantages de la compression d’en-tête, de l’adressage IPv6 et de la sécurité. Thread utilise également le schéma de fragmentation de 6LoWPAN comme décrit dans la section précédente, mais ajoute deux composants de pile supplémentaires :
- Distance vecteur routage
- Mesh lien établissement
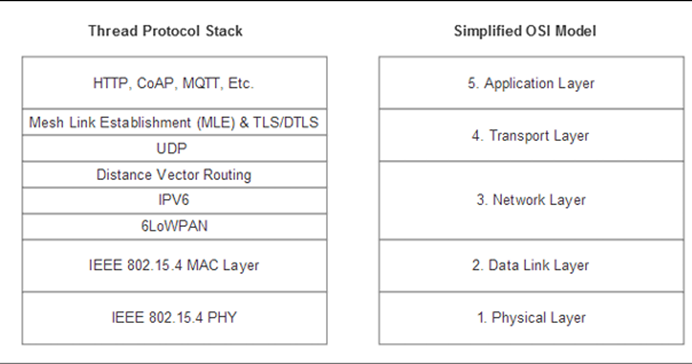
Figure 28 : pile de protocoles de thread
6.4.3 Discussion routage
Le thread utilise le routage de routage, comme décrit dans la section précédente, sur le routage 6LoWPAN. Jusqu’à 32 routeurs actifs sont autorisés dans un réseau Thread. La traversée de route est basée sur le routage du saut suivant. La table de routage maître est gérée par la pile. Tous les routeurs ont une copie à jour du routage pour le réseau.
L’établissement de liens maillés (MLE) est une méthode pour mettre à jour les coûts de traversée de chemin d’un routeur à un autre dans un réseau. De plus, MLE fournit un moyen d’identifier et de configurer les nœuds voisins dans le maillage et de les sécuriser. Comme un réseau maillé peut s’étendre, se rétrécir et changer de forme dynamiquement, MLE fournit le mécanisme pour reconstituer la topologie. MLE échange les coûts de trajet avec tous les autres routeurs dans un format compressé. Les messages MLE vont inonder le réseau d’une manière diffusée par le protocole de multidiffusion pour les réseaux à faible puissance et à pertes (MPL).
Les réseaux 802.15.4 typiques utilisent la découverte de routes à la demande. Cela peut être coûteux (la bande passante en raison de la découverte de routes inondant le réseau), et Thread tente d’éviter ce schéma. Périodiquement, un routeur de réseau Thread échangera des paquets de publicité MLE avec des informations de coût de liaison à ses voisins, forçant essentiellement tous les routeurs à avoir une liste de chemins d’accès actuelle. Si une route se termine (l’hôte quitte le réseau Thread), les routeurs tenteront de trouver le meilleur chemin suivant vers une destination.
Le fil mesure également la qualité des liens. N’oubliez pas que 802.15.4 est un WPAN et que la puissance du signal peut changer dynamiquement. La qualité de la liaison est mesurée par le coût de la liaison des messages entrants pour un voisin avec une valeur de zéro (coût inconnu) à trois (bonne qualité). Le tableau suivant résume la relation qualité / coût. La qualité et le coût sont continuellement contrôlés et, comme mentionné, périodiquement diffusés sur le réseau pour l’auto-guérison:
| Qualité des liens | Coût du lien |
| 0 | Inconnu |
| 1 | 6 |
| 2 | 2 |
| 3 | 1 |
6.4.4 Adressage des threads
Pour déterminer l’itinéraire vers un nœud enfant, une adresse courte de 16 bits est utilisée. Les bits de poids faible déterminent l’adresse enfant et les bits de poids fort déterminent le parent. Dans le cas où le nœud est un routeur, les bits de poids faible sont mis à zéro. À ce stade, la source de transmission connaît le coût pour atteindre l’enfant ainsi que les informations du prochain saut pour commencer la route.
Le routage à vecteur de distance est utilisé pour trouver des chemins vers des routeurs dans le réseau Thread. Les 6 bits supérieurs de l’adresse 16 bits indiquent le routeur de destination – c’est le préfixe. Si les 10 bits inférieurs de la destination sont définis sur 0, la destination finale est ce routeur. Alternativement, le routeur de destination transmettra le paquet sur la base des 10 bits inférieurs :
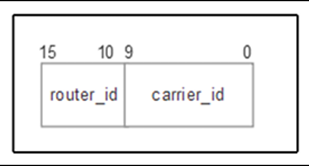
Figure 29 : 2 octets par adresse courte fil 802.15.4-2006 spéci fi cation
Si une route s’étend en dehors du réseau Thread, un routeur frontière signalera aux dirigeants les informations d’adresse de préfixe particulières, telles que les données de préfixe d’origine, le contexte 6LoWPAN, les routeurs de frontière et le serveur DHCPv6. Ces informations sont communiquées via des paquets MLE via le réseau Thread.
Au sein du réseau Thread, tout l’adressage est basé sur UDP. Si une nouvelle tentative est nécessaire, le réseau de threads s’appuiera sur :
- Nouvelles tentatives au niveau MAC : où chaque périphérique utilisant des accusés de réception MAC est un ACK qui n’est pas reçu du saut suivant
- Nouvelles tentatives d’application : où la couche d’application fournira son propre mécanisme de nouvelle tentative
6.4.5 Découverte du voisin
ND dans Thread, vous décidez du réseau 802.15.4 à rejoindre. Le processus est le suivant :
- Le dispositif de jonction contacte le routeur pour la mise en service.
- Le périphérique de jonction analyse tous les canaux et émet une demande de balise sur chaque canal. Il attend une réponse de balise.
- Si une balise contenant la charge utile avec l’identifiant de l’ensemble de services réseau (SSID) et le message de connexion d’autorisation est visible, le périphérique rejoindra le réseau Thread.
- Une fois qu’un périphérique est découvert, des messages MLE seront diffusés pour identifier un routeur voisin vers le périphérique. Ce routeur effectuera la mise en service. Il existe deux modes de mise en service :
- Configuration : utilise une méthode hors bande pour mettre en service un périphérique. Permet à un appareil de se connecter au réseau Thread dès qu’il est introduit sur le réseau.
- Établissement : crée une session de mise en service entre l’appareil et une application mise en service qui s’exécute sur un smartphone ou une tablette ou est basée sur le Web.
- L’appareil qui rejoint contacte le routeur parent et rejoint le réseau via l’échange MLE.
Le périphérique existera en tant que REED ou périphérique final et se verra attribuer une adresse courte 16 bits par le parent.
6.5 Résumé
Ce chapitre a couvert une partie nécessaire de la communication IoT. L’utilisation d’une communication standard basée sur IP simplifie considérablement la conception et permet une mise à l’échelle rapide et facile. La mise à l’échelle est essentielle pour les déploiements IoT qui atteignent des milliers ou des millions de nœuds. L’utilisation du transport IP permet aux outils courants de simplement fonctionner. 6WPAN et Thread présentent des normes qui peuvent être appliquées à des protocoles traditionnellement non IP tels que 802.15.4. Les deux protocoles permettent l’adressage IPv6 et la mise en réseau maillée vers des réseaux IoT massifs. Le 802.11 est un protocole important et extrêmement efficace qui constitue la base du WLAN, mais peut également atteindre les appareils et capteurs IoT utilisant le 802.11ah ou les systèmes de transport utilisant le 802.11p. Le tableau suivant contraste un protocole traditionnel non IP avec un protocole IP. Généralement, la différence sera en puissance, vitesse et portée.
L’architecte doit équilibrer ces paramètres pour déployer la bonne solution :
| 802.15.4 | 802.11ah | |
| IP de base | Non basé sur IP (nécessite 6LoWPAN ou Thread) | Basé sur IP |
| Gamme | 100 m | Ciblé à 1000 m |
| Structure du réseau | Full mesh | Hiérarchique avec un saut de nœud unique |
| Canalisation | ISM 2,4 GHz avec seulement DSSS | ISM inférieur à 1 GHz avec divers schémas de codage de modulation. Bande passante du canal : 1,2, 4, 8, 16 MHz |
| Gestion des interférences de canal | CSMA / CA | Mécanisme RAW permettant aux STA d’associer des créneaux horaires basés sur des groupes |
| Débit | 250 Kbps | 150 kbps à 347 Mbps |
| Latence | Bon | Meilleur (2x meilleur que 802.15.4) |
| Énergie efficacité | Meilleur (17 mJ / paquet) | Bon (63 mJ / paquet) |
| Économies d’énergie | Mécanismes veille-sommeil dans les cadres | Plusieurs structures de données pour contrôler et affiner la puissance à différents niveaux |
| Taille du réseau | Possible jusqu’à 65 000 | 8192 STA |
Le chapitre suivant abordera les protocoles à très longue portée ou les réseaux étendus. Cela comprendra les modèles cellulaires traditionnels (4G LTE) et IoT tels que Cat1. Le chapitre abordera également les protocoles LPWAN tels que Sigfox et LoRa. Le WAN est le prochain composant nécessaire pour obtenir des données sur Internet.
7 Systèmes et protocoles de communication à longue portée (WAN)
Jusqu’à présent, nous avons discuté des réseaux personnels sans fil (WPAN) et des réseaux locaux sans fil (WLAN). Ces types de communication relient les capteurs à un réseau local mais pas nécessairement à Internet ou à d’autres systèmes. Nous devons nous rappeler que l’écosphère de l’IoT comprendra des capteurs, des actionneurs, des caméras, des appareils embarqués intelligents, des véhicules et des robots dans les endroits les plus reculés. Pour le long terme, nous devons nous adresser au réseau étendu (WAN).
Ce chapitre couvre les différents appareils et topologies WAN, y compris les téléphones cellulaires (norme 4G LTE et 5G) ainsi que d’autres systèmes propriétaires, y compris la radio à longue portée (LoRa) et Sigfox. Bien que ce chapitre couvre les systèmes de communication cellulaires et à longue portée du point de vue des données, il ne se concentrera pas sur les parties analogiques et vocales des appareils mobiles. La communication à longue portée est généralement un service, ce qui signifie qu’elle a un abonnement à un opérateur fournissant des améliorations à la tour cellulaire et à l’infrastructure. Ceci est différent des architectures WPAN et WLAN précédentes car elles sont généralement contenues dans un appareil que le client ou le développeur produit ou revend. Un contrat d’abonnement ou de niveau de service (SLA) a un autre effet sur l’architecture et les contraintes des systèmes qui doivent être compris par l’architecte.
7.1 Connectivité cellulaire
La forme de communication la plus répandue est la radio cellulaire et en particulier les données cellulaires. Alors que les appareils de communication mobiles existaient depuis de nombreuses années avant la technologie cellulaire, ils avaient une couverture limitée, un espace de fréquences partagé et étaient essentiellement des radios bidirectionnelles. Les Bell Labs ont construit des technologies d’essai de téléphonie mobile dans les années 40 (service de téléphonie mobile) et dans les années 50 (service de téléphonie mobile amélioré) mais ont eu un succès très limité. Il n’existait pas non plus de normes uniformes pour la téléphonie mobile à l’époque. Ce n’est que lorsque le concept cellulaire a été conçu par Douglas H. Ring et Rae Young en 1947, puis construit par Richard H. Frenkiel , Joel S. Engel et Philip T. Porter chez Bell Labs dans les années 1960 qu’un mobile plus grand et robuste des déploiements pourraient être réalisés. Le transfert entre les cellules a été conçu et construit par Amos E. Joel Jr., également de Bell Labs, qui a permis le transfert lors du déplacement des appareils cellulaires. Toutes ces technologies se sont combinées pour former le premier système de téléphone cellulaire, le premier téléphone cellulaire et le premier appel cellulaire effectué par Martin Cooper de Motorola le 3 avril 1979. Voici un modèle cellulaire idéal où les cellules sont représentées comme des zones hexagonales de placement optimal .
Figure 1 : Théorie cellulaire : le motif hexagonal garantit la séparation des fréquences des voisins les plus proches. Il n’y a pas deux fréquences similaires à moins d’un espace hexadécimal l’une de l’autre, comme le montre la fréquence A dans deux régions différentes. Cela permet la réutilisation des fréquences.
Les technologies et les conceptions de preuve de concept ont finalement conduit aux premiers déploiements commerciaux et à l’acceptation publique des systèmes de téléphonie mobile en 1979 par NTT au Japon, puis au Danemark, en Finlande, en Norvège et en Suède en 1981. Les Amériques n’avaient pas un système cellulaire jusqu’en 1983. Ces premières technologies sont appelées 1G, ou la première génération de la technologie cellulaire. Une introduction aux générations et à leurs caractéristiques sera détaillée ensuite ; Cependant, la section suivante décrira spécifiquement la 4G LTE car il s’agit de la norme moderne pour la communication et les données cellulaires.
Les sections suivantes décrivent d’autres normes IoT et cellulaires telles que NB-IoT et 5G.
7.1.1 Modèles et normes de gouvernance
L’Union internationale des télécommunications (UIT) est une institution spécialisée fondée en 1865 ; elle prend son nom actuel en 1932, avant de devenir une agence spécialisée des Nations Unies. Il joue un rôle important dans le monde entier dans les normes de communication sans fil, la navigation, le mobile, Internet, les données, la voix et les réseaux de nouvelle génération. Il comprend 193 pays membres et 700 organisations publiques et privées. Il compte également un certain nombre de groupes de travail appelés secteurs. Le secteur pertinent pour les normes cellulaires est le Secteur des radiocommunications (UIT-R). L’UIT-R est l’organisme qui définit les normes et objectifs internationaux pour diverses générations de communications radio et cellulaires. Il s’agit notamment des objectifs de fiabilité et des débits de données minimum.
L’UIT-R a produit deux spécifications fondamentales qui ont régi les communications cellulaires au cours de la dernière décennie. Le premier était l’International Mobile Telecommunications-2000 (IMT-2000), qui spécifie les exigences pour qu’un appareil soit commercialisé en 3G. Plus récemment, l’UIT-R a produit une spécification d’exigence appelée International Mobile Telecommunications-Advanced (IMT-Advanced). Le système IMT-Advanced est basé sur un système sans fil mobile à large bande tout IP. L’IMT-Advanced définit ce qui peut être commercialisé comme 4G dans le monde entier. L’UIT est le groupe qui a approuvé la technologie d’évolution à long terme (LTE) dans la feuille de route 3GPP pour soutenir les objectifs de la communication cellulaire 4G en octobre 2010. L’UIT-R continue de répondre aux nouvelles exigences de la 5G.
Des exemples de l’ensemble des exigences avancées de l’UIT pour qu’un système cellulaire soit étiqueté 4G incluent :
- Doit être un réseau tout IP à commutation de paquets interopérable avec les réseaux sans fil existants
- Un débit de données nominal de 100 Mbps lorsque le client se déplace et de 1 Go / s lorsque le client est fixe
- Partagez et utilisez dynamiquement les ressources réseau pour prendre en charge plus d’un utilisateur par cellule
- Bande passante de canal évolutive de 5 à 20 MHz
- Connectivité transparente et itinérance mondiale sur plusieurs réseaux
Le problème est que souvent l’ensemble des objectifs de l’UIT ne sont pas atteints, et il y a une confusion de nom et de marque :
| Fonctionnalité | 1G | 2 / 2,5G | 3G | 4G | 5G |
| Première disponibilité | 1979 | 1999 | 2002 | 2010 | 2020 |
| Spécification UIT-R | NA | NA | IMT-2000 | IMT-Advanced | IMT-2020 |
| Spécification de fréquence UIT-R | NA | NA | 400 MHz à
3 GHz |
450 MHz à 3,6 GHz | 600 MHz à 6 GHz
24-86 GHz ( mmWave ) |
| Spécification de la bande passante de l’ UIT-R | NA | NA | Stationnaire : 2 Mbps
Déplacement : 384 Kbps |
Stationnaire : 1 Gbit / s
Déplacement : 100 Mbps |
Min down : 20 Gbps
Min jusqu’à : 10 Gbps |
| Bande passante typique | 2 Kbps | 4-64 Kbps | 500 à 700 Kbps | 100 à 300 Mbps (crête) | 1 Gbit / s |
| Utilisation / fonctionnalités | Mobile téléphonie seulement | Voix numérique, SMS, identification de l’appelant, données unidirectionnelles | Audio, vidéo et données de qualité supérieure
Itinérance améliorée |
IP unifiée et LAN / WAN / WLAN sans couture | IoT, ultra densité, faible latence |
| Normes et multiplexage | AMPS | 2G: TDMA, CDMA, GSM 2.5G: GPRS, EDGE, 1xRTT | FDMA, TDMA WCDMA, CDMA-2000,
TD-SCDMA |
CDMA | CDMA |
| Transfert | Horizontal | Horizontal | Horizontal | Horizontale et verticale | Horizontale et verticale |
| Réseau central | PSTN | PSTN | Commutateur de paquets | Internet | Internet |
| Commutation | Circuit | Circuit pour réseau d’accès et réseau aérien | Basé sur les paquets sauf pour l’interface radio | Basé sur des paquets | Basé sur des paquets |
| La technologie | analogique cellulaire | Cellulaire numérique | CDMA à large bande passante, WiMAX, basé sur IP | Basé sur LTE Advanced Pro | LTE
Advanced Pro-based, mmWave |
Le projet de partenariat de troisième génération ( 3GPP ) est l’autre organisme standard dans le monde cellulaire. Il s’agit d’un groupe de sept organisations de télécommunications (également connues sous le nom de Partenaires organisationnels) du monde entier qui gèrent et régissent la technologie cellulaire. Le groupe s’est formé en 1998 avec le partenariat de Nortel Networks et d’AT & T Wireless et a publié la première norme en 2000. Les partenaires organisationnels et les représentants du marché contribuent au 3GPP en provenance du Japon, des États-Unis, de la Chine, de l’Europe, de l’Inde et de la Corée. L’objectif global du groupe est de reconnaître les normes et spécifications du Système mondial de communications mobiles (GSM) dans la création des spécifications 3G pour les communications cellulaires. Le travail 3GPP est effectué par trois groupes de spécifications techniques (TSG) et six groupes de travail (WG). Les groupes se réunissent plusieurs fois par an dans différentes régions. L’objectif principal des versions 3GPP est de rendre le système compatible en amont et en aval (autant que possible).
Il existe une certaine confusion dans l’industrie quant aux différences entre les définitions UIT, 3GPP et LTE. La manière la plus simple de conceptualiser la relation est que l’UIT définira les objectifs et les normes dans le monde entier pour qu’un appareil soit étiqueté 4G ou 5G. Le 3GPP répond aux objectifs avec des technologies telles que la famille d’améliorations LTE. L’UIT ratifie toujours que ces avancées LTE répondent à leurs exigences pour être étiquetées 4G ou 5G.
La figure suivante montre les versions de la technologie 3GPP depuis 2008. Les technologies d’évolution LTE sont encadrées.

Figure 2 : versions 3GPP de 2008 à 2020
Le LTE et son rôle dans le vernaculaire cellulaire sont également souvent confondus. LTE signifie Long-Term Evolution et est la voie suivie pour atteindre les vitesses et les exigences de l’UIT-R (qui sont initialement assez agressives). Les fournisseurs de téléphones mobiles publieront de nouveaux smartphones dans un quartier cellulaire existant en utilisant une technologie d’arrière-plan héritée telle que la 3G. Les opérateurs annoncent la connectivité 4G LTE s’ils démontrent une amélioration substantielle de la vitesse et des fonctionnalités sur leurs réseaux 3G hérités. Au milieu de la fin des années 2000, de nombreux opérateurs ne respectaient pas la spécification UIT-R 4G mais se sont essentiellement rapprochés. Les opérateurs ont utilisé des technologies héritées et se sont rebaptisés 4G dans de nombreux cas. LTE-Advanced est encore une autre amélioration qui se rapproche encore plus des objectifs de l’UIT-R.
En résumé, la terminologie peut être déroutante et trompeuse, et un architecte doit lire au-delà des étiquettes de marque pour comprendre la technologie.
7.1.2 Technologies d’accès cellulaire
Il est important de comprendre comment les systèmes cellulaires fonctionnent avec plusieurs utilisateurs de voix et de données. Il existe plusieurs normes à examiner, similaires aux concepts couverts pour les systèmes WPAN et WLAN. Avant que le LTE ne soit pris en charge par le 3GPP, il existait plusieurs normes pour la technologie cellulaire, en particulier les appareils GSM et les appareils CDMA. Il est à noter que ces technologies sont incompatibles entre elles, de l’infrastructure à l’appareil :
- Accès multiple par répartition en fréquence (FDMA) : commun dans les systèmes analogiques mais rarement utilisé aujourd’hui dans les domaines numériques. Il s’agit d’une technique par laquelle le spectre est divisé en fréquences puis attribué aux utilisateurs. Un émetteur-récepteur à un moment donné est affecté à un canal. Par conséquent, le canal est fermé aux autres conversations jusqu’à ce que l’appel initial soit terminé ou jusqu’à ce qu’il soit transféré vers un autre canal. Une transmission FDMA en duplex intégral nécessite deux canaux, un pour la transmission et un pour la réception.
- Accès multiple par répartition en code (CDMA) : basé sur la technologie à spectre étalé. CDMA augmente la capacité du spectre en permettant à tous les utilisateurs d’occuper tous les canaux en même temps. Les transmissions sont réparties sur toute la bande radio et chaque appel vocal ou de données se voit attribuer un code unique pour se différencier des autres appels acheminés sur le même spectre. CDMA permet un transfert progressif, ce qui signifie que les terminaux peuvent communiquer avec plusieurs stations de base en même temps. L’interface radio dominante pour les mobiles de troisième génération a été initialement conçue par Qualcomm comme CDMA2000 et ciblait la 3G. En raison de sa nature exclusive, il n’a pas atteint une adoption mondiale et est utilisé dans moins de 18% du marché mondial. Cela s’est manifesté aux États-Unis, Verizon et Sprint étant de solides transporteurs CDMA.
- Accès multiple par répartition dans le temps (TDMA) : augmente la capacité du spectre en divisant chaque fréquence en tranches de temps. TDMA permet à chaque utilisateur d’accéder à l’ensemble du canal de radiofréquence pendant la courte période d’un appel. D’autres utilisateurs partagent ce même canal de fréquence à différents intervalles de temps. La station de base bascule continuellement d’utilisateur à utilisateur sur le canal. TDMA est la technologie dominante pour les réseaux cellulaires mobiles de deuxième génération. L’organisation GSM a adopté TDMA comme modèle multi-accès. Il réside dans quatre bandes distinctes : 900 MHz / 1800 MHz en Europe et en Asie et 850 MHz / 1900 MHz en Amérique du Nord et du Sud.
Certains appareils et modems peuvent toujours prendre en charge GSM / LTE ou CDMA / LTE. GSM et CDMA sont incompatibles. GSM / LTE et CDMA / LTE peuvent cependant être compatibles s’ils prennent en charge les bandes LTE. Dans les appareils plus anciens, les informations vocales sont délivrées sur un spectre 2G ou 3G, qui sont très différents pour CDMA et GSM (TDMA). Les données sont également incompatibles, car les données LTE fonctionnent sur des bandes 4G .
7.1.3 Catégories d’équipement utilisateur 3GPP
Dans la version 8, il y avait cinq types de catégories d’équipement utilisateur, chacune avec des débits de données et des architectures MIMO différents. Les catégories ont permis au 3GPP de différencier les évolutions du LTE. Depuis la version 8, plus de catégories ont été ajoutées. Les catégories combinent les capacités de liaison montante et de liaison descendante telles que spécifiées par l’organisation 3GPP. En règle générale, vous acquérez une radio cellulaire ou un chipset qui identifie la catégorie qu’il est capable de prendre en charge. Alors que l’équipement utilisateur peut prendre en charge une catégorie particulière, le système cellulaire ( eNodeB , discuté plus loin) doit également prendre en charge la catégorie.
L’échange d’informations sur les capacités, telles que la catégorie, fait partie du processus d’association entre un périphérique cellulaire et une infrastructure :
| Version 3GPP | Catégorie | Débit de liaison descendante max L1 (Mbps) | Débit de liaison montante max L1 (Mbps) | Nombre maximum de liaisons descendantes MIMO |
| 8 | 5 | 6 | 4 | 4 |
| 8 | 4 | 8 | 51 | 2 |
| 8 | 3 | 102 | 51 | 2 |
| 8 | 2 | 51 | 5 | 2 |
| 8 | 1 | 3 | 2 | 1 |
| 10 | 8 | 2 998,60 | 1,497,80 | 8 |
| 10 | 7 | 5 | 102 | 2 ou 4 |
| 10 | 6 | 5 | 51 | 2 ou 4 |
| 11 | 9 | 2 | 51 | 2 ou 4 |
| 11 | 12 | 603 | 102 | 2 ou 4 |
| 11 | 11 | 603 | 51 | 2 ou 4 |
| 11 | 10 | 2 | 102 | 2 ou 4 |
| 12 | 16 | 979 | NA | 2 ou 4 |
| 12 | 15 | 750 | 226 | 2 ou 4 |
| 12 | 14 | 3 917 | 9 585 | 8 |
| 12 | 13 | 7 | 8 | 2 ou 4 |
| 12 | 0 | 1 | 1 | 1 |
| 13 | NB1 | 68 | 1 | 1 |
| 13 | M1 | 1 | 1 | 1 |
| 13 | 19 | 1,566 | NA | 2, 4 ou 8 |
| 13 | 18 | 1 174 | NA | 2, 4 ou 8 |
| 13 | 17 | 25,065 | NA | 8 |
Remarquez Cat M1 et Cat NB1 dans la version 13. Ici, l’organisation 3GPP a considérablement réduit les débits de données à 1 Mbps ou moins. Ce sont les catégories dédiées aux appareils IoT qui ont besoin de faibles débits de données et ne communiquent que par courtes rafales.
7.1.4 Attribution du spectre 4G LTE et bandes
Il existe 55 bandes LTE, en partie à cause de la fragmentation du spectre et des stratégies de marché. La prolifération des bandes LTE est également une manifestation de l’allocation gouvernementale et de la mise aux enchères de l’espace de fréquences. Le LTE est également divisé en deux catégories qui ne sont pas compatibles :
- Duplex à répartition dans le temps (TDD) : TDD utilise un seul espace de fréquence pour les données de liaison montante et de liaison descendante. La direction de transmission est contrôlée via des tranches de temps.
- Duplex à répartition en fréquence (FDD) : dans une configuration FDD, la station de base ( eNodeB ) et l’ équipement utilisateur ( UE ) ouvriront une paire d’espaces de fréquence pour les données de liaison montante et de liaison descendante. Un exemple peut être la bande LTE 13, qui a une plage de liaison montante de 777 à 787 MHz et une plage de liaison descendante de 746 à 756 MHz. Les données peuvent être envoyées simultanément à la fois à la liaison montante et à la liaison descendante.
Il existe des modules de combinaison TDD / FDD qui combinent les deux technologies en un seul modem permettant plusieurs utilisations de porteuses.
FDD utilisera une paire de fréquences dédiée pour le trafic de liaison montante et de liaison descendante. TDD utilise la même fréquence porteuse pour la liaison montante et la liaison descendante. Chacun est basé sur une structure de trame et la durée totale de trame est de 10 ms en 4G LTE. Il y a 10 sous-trames qui composent chaque grande trame de 10 ms. Chacune des 10 sous-trames est en outre composée de deux tranches de temps.
Pour FDD, un total de 20 intervalles de temps, chaque 0,5 ms, compose la trame globale. En TDD, les sous-trames sont en fait deux demi-trames, chacune d’une durée de 0,5 ms. Par conséquent, une trame de 10 ms aura 10 sous-trames et 20 intervalles de temps. TDD utilise également une sous-trame spéciale (SS). Cette trame divise une sous-trame en une partie de liaison montante et une partie de liaison descendante.
Le SS transporte ce que l’on appelle des créneaux horaires pilotes (PTS) pour le trafic descendant et montant ( DwPTS et UpPTS , respectivement).
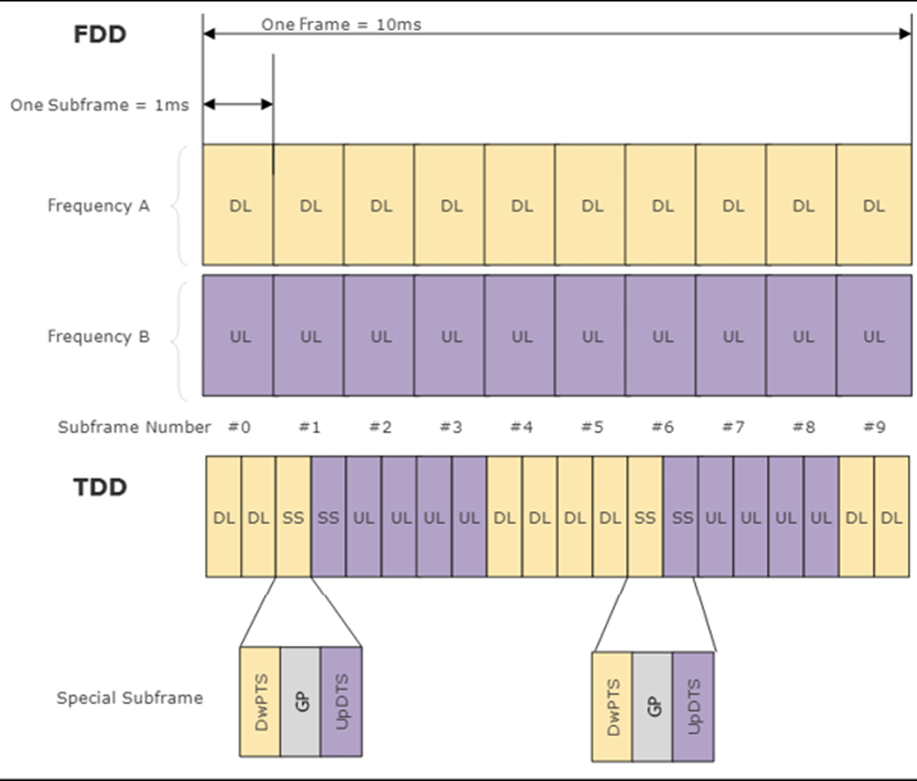
Figure 3 : FDD contre TDD dans 4G LTE : FDD utilise deux paires de fréquences simultanées de trafic de liaison montante et de liaison descendante. TDD utilisera une fréquence unique divisée en « intervalles de temps » organisés pour le trafic de liaison montante et de liaison descendante.
TDD peut avoir sept modèles de liaison montante et de liaison descendante différents qui régulent son trafic :
| Config | Périodicité | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 0 | 5 ms | DL | SS | UL | UL | UL | DL | SS | UL | UL | UL |
| 1 | 5 ms | DL | SS | UL | UL | DL | DL | SS | UL | UL | DL |
| 2 | 5 ms | DL | SS | UL | DL | DL | DL | SS | UL | DL | DL |
| 3 | 10 ms | DL | SS | UL | UL | UL | DL | DL | DL | DL | DL |
| 4 | 10 ms | DL | SS | UL | UL | DL | DL | DL | DL | DL | DL |
| 5 | 10 ms | DL | SS | UL | DL | DL | DL | DL | DL | DL | DL |
| 6 | 5 ms | DL | SS | UL | UL | UL | DL | SS | UL | UL | DL |
Notez que la liaison descendante fera toujours référence à la communication entre l’ eNodeB et l’équipement utilisateur, et la liaison montante fera référence à la direction opposée.
Quelques autres termes spécifiques au LTE sont nécessaires pour comprendre l’utilisation du spectre :
- Élément de ressource (RE) : il s’agit de la plus petite unité de transmission du LTE. Le RE se compose d’une sous-porteuse pour exactement une unité de temps de symbole (OFDM ou SC-FDM).
- Espacement des sous-porteuses : il s’agit de l’espace entre les sous-porteuses. LTE utilise un espacement de 15 kHz sans bandes de garde.
- Préfixe cyclique : Puisqu’il n’y a pas de bandes de garde, un temps de préfixe cyclique est utilisé pour empêcher les interférences inter symboles à trajets multiples entre les sous-porteuses.
- Intervalle de temps : LTE utilise une période de 0,5 ms pour les trames LTE. Cela équivaut à six ou sept symboles OFDM selon le timing du préfixe cyclique.
- Bloc de ressources : il s’agit d’une unité de transmission. Il contient 12 sous-porteuses et 7 symboles, ce qui équivaut à 84 éléments de ressource.
Une trame LTE d’une longueur de 10 ms comprendrait 10 sous-trames. Si 10% de la bande passante totale d’un canal à 20 MHz est utilisé pour un préfixe cyclique, la bande passante effective est réduite à 18 MHz. Le nombre de sous-porteuses à 18 MHz est de 18 MHz / 15 kHz = 1 200. Le nombre de blocs de ressources est de 18 MHz / 180 kHz = 100 :

Figure 4: Un emplacement d’une trame LTE. Une trame LTE de 10 ms se compose de 20 intervalles. Les créneaux sont basés sur 12 sous-porteuses espacées de 15 kHz et 7 symboles OFDM. Cela se combine en 12×7 = 84 éléments de ressource.
Les bandes attribuées pour la 4G LTE sont spécifiques aux réglementations régionales (Amérique du Nord, Asie-Pacifique, etc.). Chaque bande a un ensemble de normes développées et ratifiées par le 3GPP et l’UIT. Les bandes sont réparties entre les zones FDD et TDD et ont des acronymes de noms communs couramment utilisés dans l’industrie, tels que Advanced Wireless Service (AWS). Les tableaux suivants séparent les bandes FDD et TDD pour la région nord-américaine uniquement :

Figure 5 : Allocation de bande duplex à répartition en fréquence 4G LTE et propriété des opérateurs nord-américains
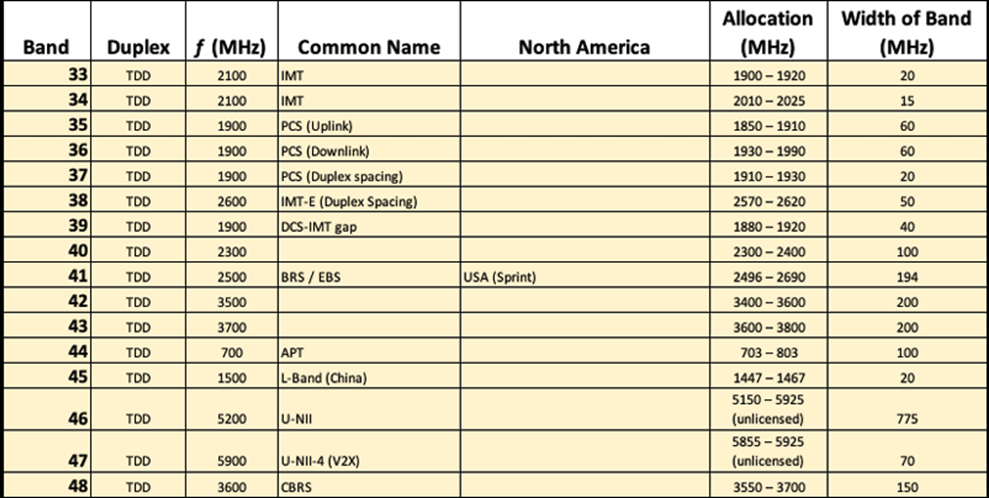
Figure 6 : allocation de bande duplex à répartition dans le temps 4G LTE pour la propriété des opérateurs en Amérique du Nord et en Amérique du Nord
En Europe, l’utilisation des bandes suit un modèle différent. Les États membres de l’Union européenne ont accepté l’inventaire du spectre. Bandes typiques utilisées dans divers pays : 800 MHz 1 452 MHz à 1 492 MHz 1 800, 2 300, 2 600 MHz
LTE a également été développé pour fonctionner dans le spectre sans licence. Initialement une proposition Qualcomm, il fonctionnerait dans la bande 5 GHz avec IEEE 802.11a. L’intention était qu’il serve d’alternative aux points d’accès Wi-Fi. Cette bande de fréquences comprise entre 5 150 MHz et 5 350 MHz nécessite généralement que les radios fonctionnent à 200 mW maximum et à l’intérieur uniquement. À ce jour, seul T-Mobile prend en charge l’utilisation sans licence de LTE dans certaines régions des États-Unis. AT&T et Verizon effectuent des tests publics avec le mode LAA. Il existe deux catégories d’utilisation du spectre sans licence pour le cellulaire :
- LTE sans licence (LTE-U) : Comme mentionné, cela coexisterait dans la bande des 5 GHz avec les appareils Wi-Fi. Le canal de contrôle du LTE resterait le même tandis que la voix et les données migreraient vers la bande des 5 GHz. Au sein de LTE-U, le concept veut que l’équipement utilisateur ne peut prendre en charge que les liaisons descendantes unidirectionnelles dans la bande sans licence ou en duplex intégral.
- Accès sous licence (LAA) : similaire à LTE-U mais régi et conçu par l’organisation 3GPP. Il utilise un protocole de contention appelé écouter avant de parler ( LBT ) pour aider à coexister avec le Wi-Fi.
LTE permet un processus appelé agrégation de porteuses pour augmenter le débit binaire utilisable. Depuis les versions 8 et 9 du 3GPP, l’agrégation de porteuses est utilisée pour les déploiements FDD et TDD. Autrement dit, l’agrégation de porteuses tente d’utiliser plusieurs bandes simultanément si elles sont disponibles pour le trafic de liaison montante et de liaison descendante. Par exemple, l’appareil d’un utilisateur peut utiliser des canaux avec des bandes passantes de 1,4, 3, 5, 10, 15 ou 20 MHz. Jusqu’à cinq canaux peuvent être utilisés au total pour une capacité maximale combinée de 100 MHz. En outre, en mode FDD, les canaux de liaison montante et de liaison descendante peuvent ne pas être symétriques et utiliser des capacités différentes, mais les porteuses de liaison montante doivent être égales ou inférieures aux porteuses de liaison descendante.
Les porteuses de canal peuvent être arrangées en utilisant un ensemble contigu de porteuses ou peuvent être disjointes comme indiqué dans le graphique suivant. Il peut y avoir des lacunes dans une bande ou même des porteuses réparties sur plusieurs bandes.
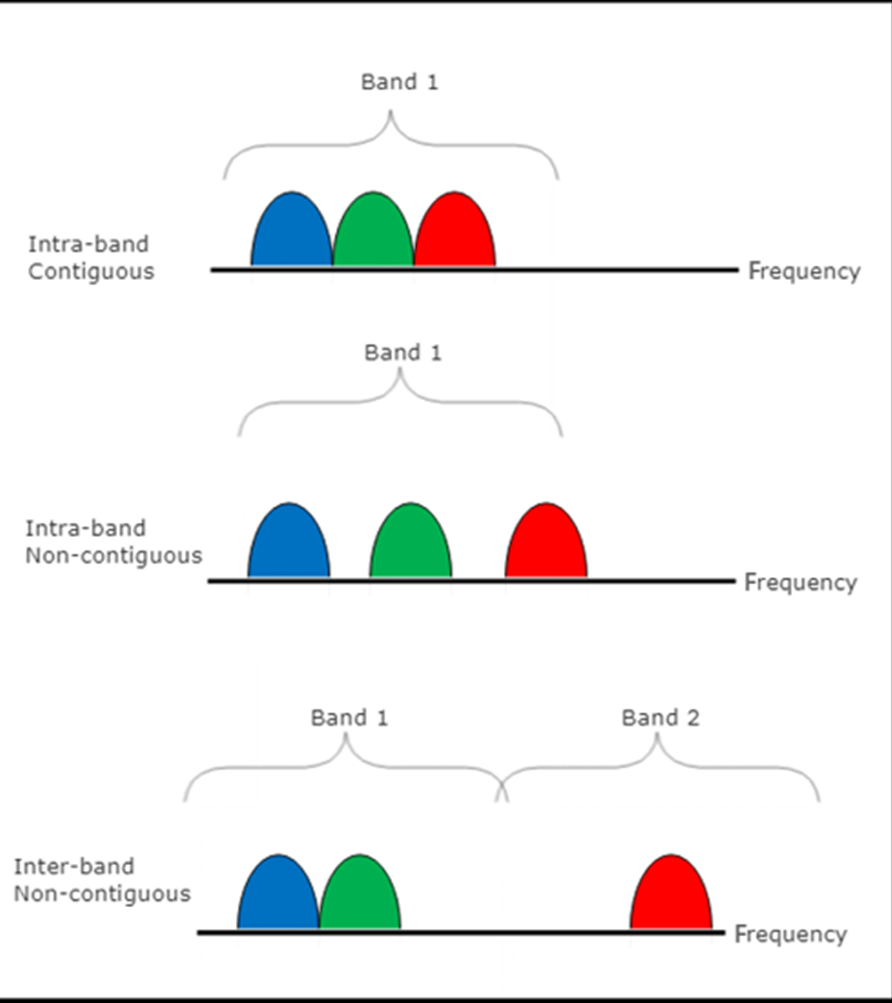
Figure 7 : agrégation de porteuses 4G LTE. L’agrégation de porteuses tente d’utiliser plusieurs bandes pour obtenir des débits de données plus élevés et permettre une meilleure utilisation de la capacité du réseau. Trois méthodes différentes sont utilisées pour l’agrégation de porteuses : intra-bande contiguë, intra-bande non contiguë et inter-bande non contiguë.
Il existe trois méthodes d’agrégation de porteuses :
- Intra-bande contiguë : c’est la méthode la plus simple. Les fréquences sont regroupées dans la même fréquence sans lacunes. L’émetteur-récepteur voit le canal agrégé comme un grand canal.
- Intra-interdiction non contiguë : cette méthode prendra deux porteuses ou plus et les placera à la même fréquence, mais il peut y avoir des écarts entre les blocs.
- Inter-bande non contiguë : il s’agit de la forme la plus courante d’agrégation de porteuses. Les blocs de fréquences sont répartis sur différentes fréquences et peuvent être regroupés en différentes combinaisons.
7.1.5 Topologie et architecture 4G LTE
L’architecture 3GPP LTE est appelée System Architecture Evolution (SEA), et son objectif global est de fournir une architecture simplifiée basée sur le trafic tout IP. Il prend également en charge la communication à haut débit et la faible latence sur les réseaux d’accès radio (RAN). Dans la version 8 de la feuille de route 3GPP, LTE a été introduit. Étant donné que le réseau est entièrement composé de composants à commutation de paquets IP, cela signifie que les données vocales sont également transmises sous forme de paquets IP numériques. C’est une autre différence fondamentale par rapport au réseau 3G hérité.
La topologie 3G utilise la commutation de circuits pour le trafic voix et SMS et la commutation de paquets pour les données. La commutation de circuits diffère fondamentalement de la commutation de paquets. La commutation de circuits se manifeste à partir du réseau de commutation téléphonique d’origine. Il utilisera un canal et un chemin dédiés entre une source et un nœud de destination pendant la durée de la communication. Dans un réseau à commutation de paquets, les messages seront divisés en fragments plus petits (appelés paquets dans le cas des données IP) et rechercheront l’itinéraire le plus efficace d’une source de données vers la destination. Un en-tête enveloppant le paquet fournit entre autres des informations de destination.
Le réseau 4G LTE typique comprend trois composants : un client, un réseau radio et un réseau central. Le client est simplement l’appareil radio de l’utilisateur. Le réseau radio représente la communication frontale entre le client et le réseau central et comprend des équipements radio tels que la tour. Le réseau central représente l’interface de gestion et de contrôle de la porteuse et peut gérer un ou plusieurs réseaux radio.
L’architecture peut être décomposée comme suit :
- Équipement utilisateur (UE) : il s’agit du matériel client et se compose de terminaisons mobiles (MT), qui exécutent toutes les fonctions de communication, de l’équipement terminal (TE), qui gère les flux de données de terminaison, et de la carte de circuit intégré universel (UICC), qui est la carte SIM pour la gestion de l’identité.
- Réseau évolué universel d’accès radio terrestre (E-UTRAN) : il s’agit de l’interface aérienne 4G LTE avec les appareils UE LTE. E-UTRAN utilise OFDMA pour la partie de liaison descendante et SC-FDMA pour la liaison montante. Par la suite, cela le rend incompatible avec la technologie 3G W-CDMA héritée. L’E-UTRAN se compose d’eNodeBs mais peut en contenir plusieurs qui sont liés par un canal appelé l’interface X2.
- eNodeB : C’est le cœur du réseau radio. Il gère les communications entre l’UE et le cœur (EPC). Chaque eNodeB est une station de base qui contrôle les eUE dans une ou plusieurs zones cellulaires et alloue des ressources à un client spécifique en segments de 1 ms appelés TTI. Il allouera des ressources de canal en fonction des conditions d’utilisation à divers UE dans sa proximité cellulaire. Les systèmes eNodeB sont également responsables du déclenchement des transitions d’état de IDLE à CONNECTED. Il gère également la mobilité de l’UE, comme le transfert à d’autres eNodeB , et est responsable de la transmission et du contrôle de l’encombrement. L’interface hors de l’ eNodeB et dans l’EPC est l’interface S1.
- Evolved Packet Core (EPC) : lors de la conception du LTE, le 3GPP a décidé de construire une architecture plate et de séparer les données utilisateur (appelé le plan utilisateur) et les données de contrôle (appelé le plan de contrôle). Ceci est autorisé pour une mise à l’échelle plus efficace. L’EPC comprend cinq composants de base répertoriés ici :
- Entité de gestion de la mobilité (MME) : responsable du contrôle du trafic des avions, de l’authentification et de la sécurité, de la localisation et du suivi et des gestionnaires de problèmes de mobilité. Le MME doit également reconnaître la mobilité en mode IDLE. Ceci est géré à l’aide d’un code de zone de suivi (TA). Le MME régit également la signalisation de la couche non-d’accès (NAS) et le contrôle du support (décrits plus loin).
- Home Subscriber Server (HSS) : base de données centrale associée au MME qui contient des informations sur les abonnés de l’opérateur de réseau. Cela peut inclure des clés, des données utilisateur, des débits de données maximum sur le plan, des abonnements, etc. Le HSS est un résidu des réseaux 3G UMTS et GSM.
- Servicing Gateway (SGW) : Responsable du plan utilisateur et du flux de données utilisateur. Essentiellement, il agit comme un routeur et transfère directement les paquets entre l’eNodeB et le PGW. L’interface hors du SGW s’appelle l’interface S5 / S8. S5 est utilisé si deux appareils sont sur le même réseau et S8 est utilisé s’ils se trouvent sur des réseaux différents.
- Passerelle de réseau de données publiques (PGW) : connecte les réseaux mobiles à des sources externes, notamment Internet ou d’autres réseaux PDN. Il attribue également l’adresse IP aux appareils mobiles connectés. Le PGW gère la qualité de service (QoS) pour divers services Internet tels que le streaming vidéo et la navigation Web. Il utilise une interface appelée SGi pour accéder à divers services externes.
- Fonction de contrôle des règles et de tarification (PCRF) : une autre base de données qui stocke les règles et les règles de prise de décision. Il également contrôle les accréditive en fonction de charge des fonctions.
- Réseau public de données (PDN) : il s’agit de l’interface externe et, pour l’essentiel, d’Internet. Il peut inclure d’autres services, centres de données, services privés, etc.
Dans un service 4G LTE, un client aura un opérateur ou un opérateur connu sous le nom de son réseau mobile terrestre public (PLMN). Si l’utilisateur est dans le PLMN de ce transporteur, il est dit qu’il est dans le Home-PLMN. Si l’utilisateur se déplace vers un PLMN différent en dehors de son réseau domestique (par exemple, pendant un voyage international), alors le nouveau réseau est appelé le PLMN visité. L’utilisateur connectera son UE à un PLMN visité qui nécessite des ressources de E-UTRAN, MME, SGW et PGW sur le nouveau réseau. Le PGW peut accorder l’accès à une interruption locale (une passerelle) à Internet. C’est effectivement là que les frais d’itinérance commencent à affecter les plans de service. Les frais d’itinérance sont appliqués par le PLMN visité et comptabilisés sur la facture du client. Le graphique suivant illustre cette architecture. Sur le côté gauche est une vue de haut niveau de l’évolution de l’architecture du système 3GPP pour 4G LTE. Dans ce cas, il représente le client UE, le nœud radio E-UTRAN et le réseau central EPC, tous résidant dans un Home-PLMN. Sur la droite, un modèle du client mobile se déplaçant vers un PLMN visité et distribuant la fonctionnalité entre le E-UTRAN PLMN visité et EPC, ainsi que le retour au réseau domestique.
L’interconnexion S5 est utilisée si le client et l’opérateur résident sur le même réseau et l’interface S8 si le client traverse plusieurs réseaux.

Figure 8 : En haut : architecture du système 3GPP. En bas : vue de haut niveau de l’architecture 4G LTE.
La signalisation des strates de non-accès (NAS) a été mentionnée dans le MME. Il s’agit d’un mécanisme de transmission de messages entre l’UE et les nœuds centraux tels que les centres de commutation. Les exemples peuvent inclure des messages tels que des messages d’authentification, des mises à jour ou des messages joints. Le NAS se trouve en haut de la pile de protocoles SAE.
Le GPRS Tunneling Protocol (GTP) est un protocole basé sur IP / UDP utilisé dans LTE. Le GTP est utilisé dans toute l’infrastructure de communication LTE pour les données de contrôle, les données utilisateur et les données de charge. Dans la figure précédente, la plupart des composants de connexion du canal S * utilisent des paquets GTP.
L’architecture LTE et la pile de protocoles utilisent ce que l’on appelle des supports. Les supports sont un concept virtuel utilisé pour fournir un canal pour transporter des données d’un nœud à un autre nœud. Le tuyau entre le PGW et l’UE est appelé EPS Bearer . Au fur et à mesure que les données pénètrent dans le PGW à partir d’Internet, elles regroupent les données dans un paquet GTP-U et les envoient au SGW. GTP signifie GPRS Tunneling Protocol (ou General Packet Radio Service Tunneling Protocol). Il s’agit de la norme mobile pour la communication cellulaire par paquets depuis la 2G et permet à des services tels que SMS et push-to-talk d’exister. GTP prend en charge la communication par paquets basée sur IP ainsi que le protocole point à point (PPP) et X.25. GTP-U représente les données du plan utilisateur, tandis que GTP-C gère les données du plan de contrôle. Le SGW recevra le paquet, supprimera l’en-tête GTP-U et reconditionnera les données utilisateur dans un nouveau paquet GTP-U sur son chemin vers l’eN ( eNodeB ).
L’eNodeB est un composant essentiel de la communication cellulaire et souvent référencé dans ce texte. Le «e» dans eNodeB signifie «évolué». Il s’agit du matériel qui gère la communication radio et la liaison entre les combinés mobiles et le reste du réseau cellulaire. Il utilise des plans de contrôle et de données séparés où l’interface S1-MME gère le trafic de contrôle et le S1-U gère les données utilisateur.
Encore une fois, l’eNodeB répète le processus et reconditionnera les données utilisateur après la compression, le cryptage et le routage vers les canaux logiques. Le message sera ensuite transmis à l’UE via un support radio. Un avantage que les porteurs apportent au LTE est le contrôle de la QoS. À l’aide de supports, l’infrastructure peut garantir certains débits binaires en fonction du client, de l’application ou de l’utilisation.
Lorsqu’une UE se connecte à un réseau cellulaire pour la première fois, un support par défaut lui est attribué. Chaque support par défaut a une adresse IP, et une UE peut avoir plusieurs supports par défaut, chacun avec une adresse IP unique. Il s’agit d’un service au meilleur effort, ce qui signifie qu’il ne serait pas utilisé pour des voix de type QoS garanties. Un support dédié, dans ce cas, est utilisé pour la qualité de service et une bonne expérience utilisateur. Il sera lancé lorsque le support par défaut est incapable de fournir un service. Le support dédié réside toujours au-dessus du support par défaut. Un smartphone typique peut avoir les porteurs suivants en cours d’exécution à tout moment :
- Porteuse par défaut 1 : messagerie et signalisation SIP
- Support dédié : données vocales (VOIP) liées au support par défaut 1
- Porteur par défaut 2 : tous les services de données de smartphone tels que la messagerie électronique et le navigateur
L’aspect de commutation du LTE mérite également d’être mentionné. Nous avons examiné les différentes générations d’évolutions du 3GPP de 1G à 5G. L’un des objectifs du 3GPP et des opérateurs était de passer à une solution de voix sur IP (VOIP) standard et acceptée. Non seulement les données seraient envoyées sur des interfaces IP standard, mais la voix aussi. Après quelques différends entre des méthodes concurrentes, l’organisme de normalisation a choisi VoLTE (Voice over Long-Term Evolution) comme architecture. VoLTE utilise une variante étendue du protocole SIP (Session Initiation Protocol) pour gérer les messages vocaux et texte. Un codec connu sous le nom de codec AMR (Adaptive Multi-Rate) fournit des communications vocales et vidéo à large bande de haute qualité. Plus tard, nous examinerons les nouvelles catégories 3GPP LTE qui abandonnent VoLTE pour prendre en charge les déploiements IoT.
Il convient de noter que le LTE est l’une des deux normes pour le haut débit mobile. L’accès Internet à mobilité sans fil ( WiMAX ) est l’alternative. LTE WiMAX est un protocole de communication OFDMA à large bande basé sur IP.
WiMAX est basé sur les normes IEEE 802.16 et géré par le WiMAX Forum. WiMAX réside dans la plage 2,3 et 3,5 GHz du spectre, mais peut atteindre la plage 2,1 GHz et 2,5 GHz, comme le LTE. Lancé commercialement avant le décollage du LTE, WiMAX était le choix Sprint et Clearwire pour les données à haut débit.
WiMAX, cependant, n’a trouvé que des utilisations de niche. Le LTE est généralement beaucoup plus flexible et largement adopté. Le LTE a également progressé lentement dans le but de maintenir la compatibilité descendante avec les anciennes infrastructures et technologies, tandis que WiMAX était destiné aux nouveaux déploiements. WiMAX avait un avantage en termes de facilité de configuration et d’installation sur LTE ; mais LTE a remporté la course à la bande passante, et à la fin, la bande passante a défini la révolution mobile.
7.1.6 Pile de protocoles 4G LTE E-UTRAN
La pile 4G LTE a des caractéristiques similaires à d’autres dérivés du modèle OSI ; Cependant, il existe d’autres caractéristiques du plan de contrôle 4G, comme le montre la figure suivante. Une différence est que le Radio Resource Control (RRC) a une portée étendue à travers les couches de la pile. C’est ce qu’on appelle le plan de contrôle. Ce plan de contrôle a deux états : inactif et connecté. Lorsqu’il est inactif, l’UE attend dans une cellule après son association avec lui et peut surveiller un canal de radiomessagerie pour détecter si un appel entrant ou des informations système lui sont destinés. En mode connecté, l’UE établira un canal de liaison descendante et des informations sur la cellule voisine. L’E-UTRAN utilisera les informations pour trouver la cellule la plus appropriée à ce moment :

Figure 9 : pile de protocole E-UTRAN pour 4G LTE, et la comparaison du modèle OSI simplifié
Le plan de contrôle et le plan utilisateur se comportent également légèrement différemment et ont des latences indépendantes. Le plan utilisateur a généralement une latence de 4,9 ms, tandis que le plan de contrôle utilise une latence de 50 ms.
La pile est composée des couches et fonctionnalités suivantes :
- couche physique 1 : Ceci est la couche d’interface radio, également connu l’ interface air . Les responsabilités comprennent l’adaptation de liaison (AMC), la gestion de l’alimentation, la modulation du signal (OFDM), le traitement numérique du signal, la recherche de signaux cellulaires, la synchronisation avec les cellules, le contrôle de transfert et les mesures de cellule pour la couche RRC.
- Contrôle d’accès moyen (MAC) : semblable à d’autres piles dérivées OSI, il effectue un mappage entre les canaux logiques et les couches de transport. La couche MAC multiplexe différents paquets sur des blocs de transport (TB) pour la couche physique. Les autres responsabilités incluent la planification des rapports, la correction des erreurs, la hiérarchisation des canaux et la gestion de plusieurs UE.
- Radio Link Control (RLC) : RLC transfère les PDU de couche supérieure, effectue la correction des erreurs via ARQ et gère la concaténation / segmentation des paquets. De plus, il fournit une interface de canal logique et la détection des paquets en double et effectue le réassemblage des données reçues.
- PDCP (Packet Data Convergence Control Protocol) : cette couche est responsable de la compression et de la décompression des paquets. Le PDCP gère également le routage des données du plan utilisateur ainsi que les données du plan de contrôle avec rétroaction dans le RRC. La gestion des SDU en double (comme dans une procédure de transfert) est gérée dans cette couche. Les autres fonctionnalités comprennent le chiffrement et le déchiffrement, la protection de l’intégrité, la suppression des données par temporisation et le rétablissement des canaux.
- Radio Resource Control (RRC) : la couche RRC diffuse les informations système à toutes les couches, y compris les strates sans accès et les strates d’accès. Il gère les clés de sécurité, les configurations et le contrôle des supports radio.
- Strate sans accès (NAS) : elle représente le niveau le plus élevé du plan de contrôle et constitue l’interface principale entre un UE et le MME. Le rôle principal est la gestion de session; par conséquent, la mobilité de l’UE est établie à ce niveau.
- Access Stratum (AS) : il s’agit d’une couche sous le NAS dont le but est de transporter des signaux non radio entre l’UE et le réseau radio.
7.1.7 Zones géographiques 4G LTE, flux de données et procédures de transfert
Avant d’envisager le processus de transfert cellulaire, nous devons d’abord définir les zones environnantes vernaculaires et l’identification du réseau. Il existe trois types de zones géographiques dans un réseau LTE :
- Zones de pool MME : elles sont définies comme une région dans laquelle une UE peut se déplacer sans changer le MME serveur.
- Zones de service SGW : elles sont définies comme une zone dans laquelle une ou plusieurs SGW continueront de fournir un service à un UE.
- Zones de suivi (TA) : elles définissent des sous-zones composées de petites zones MME et SGW qui ne se chevauchent pas. Ils sont utilisés pour suivre l’emplacement d’une UE en mode veille. Ceci est essentiel pour le transfert.
Chaque réseau d’un réseau 4G LTE doit être identifiable de manière unique pour que ces services fonctionnent. Pour aider à identifier les réseaux, le 3GPP utilise un ID de réseau composé de:
- Code de pays mobile (MCC) : identification à trois chiffres du pays dans lequel le réseau réside (par exemple, le Canada est 302)
- Code de réseau mobile (MNC) : valeur à deux ou trois chiffres indiquant l’opérateur (par exemple, Rogers Wireless est 720)
Chaque transporteur doit également identifier de manière unique chaque MME qu’il utilise et entretient. Le MME est nécessaire localement au sein du même réseau et globalement lorsqu’un appareil se déplace et se déplace pour trouver le réseau domestique. Chaque MME a trois identités :
- Identifiant MME : il s’agit de l’ID unique qui localisera un MME particulier au sein d’un réseau. Il est composé des suivants deux champs :
- Code MME (MMEC) : il identifie tous les MME qui appartiennent à la même zone de pool mentionnée précédemment.
- Identité de groupe MME (MMEI) : définit un groupe ou un cluster de MME.
- Identifiant MME globalement unique (GUMMEI) : il s’agit de la combinaison d’un ID PLNM et du MMEI décrit précédemment. La combinaison forme un identifiant qui peut être localisé n’importe où dans le monde à partir de n’importe quel réseau.
L’identité de zone de suivi (TAI) permet à un appareil UE d’être suivi globalement à partir de n’importe quelle position. Il s’agit de la combinaison du PLMN-ID et du code de zone de suivi (TAC). Le TAC est une sous-région physique particulière d’une zone de couverture cellulaire.
L’ID de cellule est construit à partir d’une combinaison de l’identité de cellule E-UTRAM (ECI ), qui identifie la cellule dans un réseau, de l’ identifiant global de cellule E-UTRAN ( ECGI ), qui identifie la cellule n’importe où dans le monde, et d’un élément physique. Identité de cellule (valeur entière 0 à 503) utilisée pour la distinguer d’une autre UE voisine.
Le processus de transfert consiste à transférer un appel ou une session de données d’un canal à un autre dans un réseau cellulaire. Le transfert se produit le plus évidemment si le client déménage. Un transfert peut également être déclenché si la station de base a atteint sa capacité et force certains appareils à se déplacer vers une autre station de base du même réseau. C’est ce qu’on appelle un transfert intra-LTE. Le transfert intercellulaire peut également se produire entre des porteuses en itinérance, appelé transfert inter-LTE. Il est également possible de passer à d’autres réseaux (transfert inter-RAT), comme par exemple passer d’un signal cellulaire à un signal Wi-Fi.
Si le transfert existe dans le même réseau (transfert intra-LTE), deux eNodeB communiqueront via l’interface X2 et le réseau central EPC n’est pas impliqué dans le processus. Si le X2 n’est pas disponible, le transfert doit être géré par l’EPC via l’interface S1. Dans chaque cas, l’ eNodeB source lance la demande de transaction. Si le client effectue un inter-LTE, le transfert est plus compliqué car deux MME sont impliqués : une source (S-MME) et une cible (T-MME).
Le processus permet un transfert transparent, comme illustré dans la série d’étapes de la figure suivante. Tout d’abord, l’eNodeB source décidera d’instancier une demande de transfert en fonction de la capacité ou du mouvement du client. L’eNodeB le fait en diffusant un message REQ CONTROL MEASUREMENT CONTROL à l’UE.
Ce sont des rapports de mesure du réseau envoyés lorsque certains seuils sont atteints. Une configuration de tunnel directe (DTS) est créée où le support de transport X2 communique entre l’eNodeB source et l’ eNodeB de destination . Si l’eNodeB détermine qu’il est approprié de lancer un transfert, il trouve l’eNodeB de destination et envoie une DEMANDE D’ÉTAT DES RESSOURCES sur l’interface X2 pour déterminer si la cible peut accepter un transfert. Le transfert est lancé avec le message HANDOVER REQUEST.
L’eNodeB de destination prépare les ressources pour la nouvelle connexion. L’eNodeB source détaillera l’UE client. Le transfert direct de paquets de l’eNodeB source vers l’eNodeB de destination garantit qu’aucun paquet en vol n’est perdu. Ensuite, le transfert se termine en utilisant un message PATH SWITCH REQUEST entre l’eNodeB de destination et le MME pour l’informer que l’UE a changé de cellule. Le support S1 sera libéré, de même que le support de transport X2, car aucun paquet de résidus ne devrait être acheminé vers le client UE à ce moment :
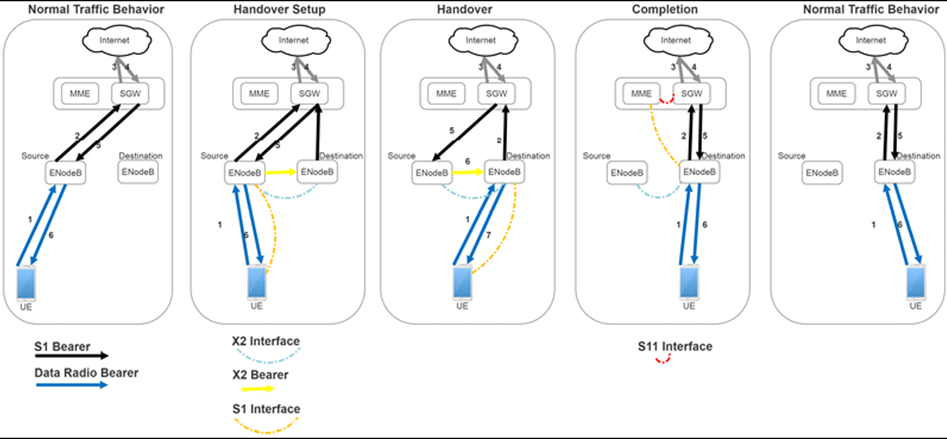
Figure 10 : un exemple de transfert intra-LTE entre deux eNodeB
Un certain nombre de dispositifs de passerelle IoT utilisant la 4G LTE permettent à plusieurs opérateurs (tels que Verizon et ATT) d’être disponibles sur une seule passerelle de périphérique ou routeur. Ces passerelles peuvent basculer et passer d’un opérateur à l’autre de manière transparente sans perte de données. Il s’agit d’une caractéristique importante pour les systèmes IoT mobiles et basés sur le transport tels que la logistique, les véhicules d’urgence et le suivi des actifs. Le transfert permet à ces systèmes mobiles de migrer entre les transporteurs pour une meilleure couverture et des tarifs efficaces.
7.1.8 Structure des paquets 4G LTE
La structure de trame de paquet LTE est similaire à d’autres modèles OSI. La figure ci-dessous illustre la décomposition du paquet de PHY jusqu’à la couche IP. Le paquet IP est enveloppé dans les couches 4G LTE :
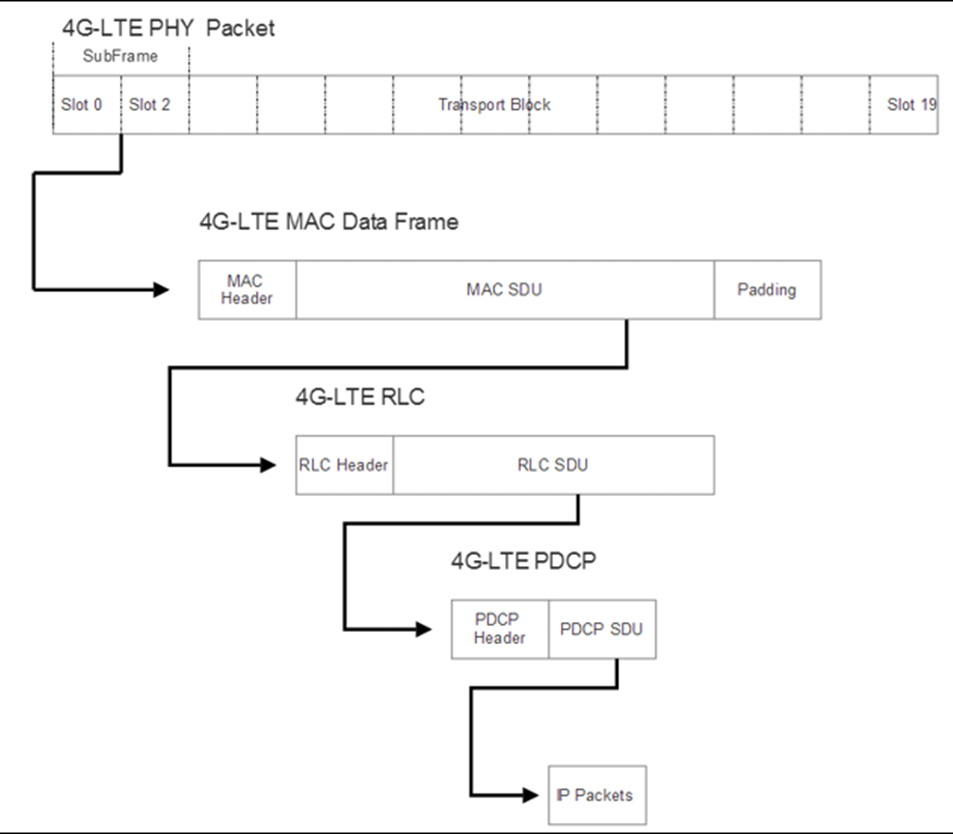
Figure 11 : Structure de paquets 4G LTE : les paquets IP sont réformées dans le SDU PDCP et fl ux à travers le RLC, MAC et PHY. Le PHY crée des emplacements et des sous-trames de blocs de transport à partir de la couche MAC.
7.1.9 Cat-0, Cat-1, Cat-M1 et NB-IoT
La connectivité d’un appareil IoT à Internet est différente de celle des appareils cellulaires grand public tels qu’un smartphone. Un smartphone extrait principalement des informations d’Internet dans une liaison descendante. Souvent, ces données sont volumineuses et diffusées en temps réel, comme les données vidéo et les données musicales. Dans un déploiement IoT, les données peuvent être très clairsemées et arriver en courtes rafales. La majorité des données seront générées par l’appareil et voyageront sur la liaison montante. L’évolution du LTE a progressé dans la construction d’une infrastructure cellulaire et d’un modèle commercial axé et optimisé pour les consommateurs mobiles. Le nouveau changement consiste à satisfaire les producteurs de données IoT à la limite, car cela éclipsera le nombre de consommateurs. Les sections suivantes couvrent les réseaux étendus basse consommation (LPWAN) et plus particulièrement la variété LTE de LPWAN. Ceux-ci conviennent aux déploiements IoT et les fonctionnalités varient.
L’abréviation “Cat” signifie “Catégorie”. Jusqu’à la version 13, le débit de données le plus bas adapté aux appareils IoT typiques était Cat-1. La révolution mobile exigeant des vitesses et des services plus élevés, Cat-1 a été ignoré dans la chronologie 3G et 4G. Les versions 12 et 13 répondaient aux exigences des dispositifs IoT pour des extensions à faible coût, à faible consommation d’énergie, à faible transmission et à portée.
Une chose que tous ces protocoles partagent par conception est qu’ils sont tous compatibles avec l’infrastructure matérielle cellulaire existante. Cependant, pour activer de nouvelles fonctionnalités, des modifications logicielles de la pile de protocoles sont nécessaires pour l’infrastructure. Sans ces changements, les UE Cat-0, Cat-M1 et Cat-NB ne verront même pas le réseau. L’architecte IoT doit s’assurer que l’infrastructure cellulaire dans laquelle ils ont l’intention de se déployer a été mise à jour pour prendre en charge ces normes.
Cat-1 n’a pas gagné une traction significative sur le marché, et nous n’entrerons pas dans les spécifications ici car il est similaire au matériau 4G LTE discuté précédemment.
7.1.9.1 LTE Cat-0
Cat-0 a été introduit dans la version 12 et a été la première architecture en dehors de Cat-1 ciblée sur les besoins de l’IoT. La conception, comme de nombreuses autres spécifications LTE, est basée sur IP et fonctionne dans le spectre sous licence. Une différence significative est dans les débits de données de pointe de liaison montante et de liaison descendante (1 Mbps chacun), par opposition à Cat-1 à 10 Mbps pour la liaison descendante et 5 Mbps pour la liaison montante.
Alors que la largeur de bande du canal reste à 20 MHz, la réduction des débits de données simplifie considérablement la conception et réduit les coûts. De plus, le passage d’une architecture full-duplex à une architecture semi-duplex améliore encore les coûts et la puissance.
Habituellement, la couche NAS de la pile LTE n’a pas beaucoup de rôle dans la maintenance des UE. Dans Cat-0, les architectes 3GPP ont modifié les capacités du NAS pour aider à économiser l’énergie au niveau de l’UE. Cat-0 introduit le mode d’économie d’énergie ( PSM ) dans la spécification LTE pour répondre aux fortes contraintes d’alimentation. Dans un appareil LTE traditionnel, le modem reste connecté à un réseau cellulaire, consommant de l’énergie que l’appareil soit actif, inactif ou en veille. Pour éviter une surcharge d’alimentation de connexion, un appareil peut se déconnecter et se dissocier d’un réseau, mais cela entraînerait une phase de reconnexion et de recherche de 15 à 30 secondes. PSM permet au modem d’entrer dans un état de sommeil très profond – à tout moment il ne communique pas activement – tout en se réveillant rapidement. Pour ce faire, il effectue périodiquement une mise à jour de la zone de suivi ( TAU ) et reste accessible via la pagination pendant une période de temps programmable. Essentiellement, un appareil IoT pourrait entrer dans une période d’inactivité de 24 heures et se réveiller une fois par jour pour diffuser les données des capteurs tout en restant connecté. Toutes les négociations pour définir ces temporisateurs individuels sont gérées via les modifications au niveau du NAS et sont relativement simples à activer en définissant deux temporisateurs :
- T3324 : Temps pendant lequel l’UE reste en mode inactif. Si l’application de périphérique IoT est certaine qu’aucun message n’est en attente, elle peut réduire la valeur du minuteur.
- T3412 : Une fois le temporisateur T3324 expiré, l’appareil entrera dans PSM pour une période de T3412. L’appareil sera à l’état d’énergie le plus bas possible. Il ne peut pas participer à la pagination ou à la signalisation réseau. Le périphérique conserve cependant tous les états UE (supports, identités). Le délai maximum autorisé est de 12,1 jours.
Lorsque vous utilisez PSM ou d’autres modes avancés de gestion de l’alimentation, il est judicieux de tester la conformité avec l’infrastructure de l’opérateur. Certains systèmes de cellules nécessitent un ping toutes les deux à quatre heures vers l’UE. Si l’opérateur perd la connectivité pendant des périodes supérieures à deux à quatre heures, il peut juger l’UE inaccessible et se détacher.
Il y a peu de couverture et d’adoption de Cat-0, et sa croissance a été limitée. La plupart des nouvelles fonctionnalités de Cat-0 ont été incluses dans Cat-1 et d’autres protocoles.
7.1.9.2 LTE Cat-1
LTE Cat-1 réutilise les mêmes chipsets et infrastructure de support que Cat-4, il peut donc être utilisé à travers les États-Unis sur les infrastructures Verizon et AT&T. Cat-1 a une forte traction sur le marché dans l’industrie M2M. La spécification faisait partie de la version 8 et a ensuite été mise à jour pour prendre en charge le mode d’économie d’énergie et l’antenne LTE unique de Cat-0.
Cat-1 est considéré comme une norme LTE à vitesse moyenne, ce qui signifie que la liaison descendante est de 10 Mbps et la liaison montante est de 5 Mbps. À ces débits, il est toujours capable de transporter des flux vocaux et vidéo ainsi que des charges utiles de données M2M et IoT. En adoptant le PSM Cat-0 et la conception d’antenne, le Cat-1 fonctionne avec moins d’énergie que le 4G LTE traditionnel. La conception de radios et d’appareils électroniques est également beaucoup moins coûteuse.
Cat-1 est actuellement le meilleur choix en matière de connectivité cellulaire pour les appareils IoT et M2M avec la couverture la plus large et la plus faible puissance. Bien que beaucoup plus lente que la 4G LTE ordinaire (10 Mbps contre 300 Mbps en liaison descendante), la radio peut être conçue pour se replier sur les réseaux 2G et 3G selon les besoins. Cat-1 réduit la complexité de la conception en incorporant le découpage temporel, ce qui réduit également considérablement la vitesse.
Cat-1 peut être considéré comme un complément aux nouveaux protocoles à bande étroite, qui sont traités ci-après.
7.1.9.3 LTE Cat-M1 ( eMTC )
Cat-M1, également connu sous le nom de communication de type machine améliorée (et parfois simplement appelé Cat-M), a été conçu pour cibler les cas d’utilisation IoT et M2M avec des améliorations à faible coût, à faible puissance et à portée. Cat-M1 est sorti dans le calendrier 3GPP release 13. La conception est une version optimisée de l’architecture Cat-0. La plus grande différence est que la bande passante du canal est réduite de 20 MHz à 1,4 MHz. La réduction de la bande passante du canal d’un point de vue matériel assouplit les contraintes de synchronisation, la puissance et les circuits. Les coûts sont également réduits jusqu’à 33% par rapport à Cat-0 car les circuits n’ont pas besoin de gérer un large spectre de 20 MHz. L’autre changement significatif concerne la puissance d’émission, qui est réduite de 23 dB à 20 dB. La réduction de la puissance d’émission de 50% réduit encore les coûts en éliminant un amplificateur de puissance externe et permet une conception monopuce. Même avec la réduction de la puissance d’émission, la couverture s’améliore de +20 dB.
Cat-M1 suit d’autres protocoles 3GPP tardifs basés sur IP. Bien qu’il ne s’agisse pas d’une architecture MIMO, le débit est capable de 375 Kbps ou 1 Mbps sur la liaison montante et la liaison descendante. L’architecture permet des solutions mobiles pour la communication embarquée ou V2V. La bande passante est suffisamment large pour permettre également la communication vocale à l’aide de VoLTE. Plusieurs appareils sont autorisés sur un réseau Cat-M1 en utilisant l’algorithme traditionnel SC-FDMA. Cat-M1 utilise également des fonctionnalités plus complexes telles que le saut de fréquence et le turbo-codage.
La puissance est essentielle dans les appareils de périphérie IoT. La caractéristique de réduction de puissance la plus importante de Cat-M1 est le changement de puissance de transmission. Comme mentionné, l’organisation 3GPP a réduit la puissance de transmission de 23 dB à 20 dB. Cette réduction de puissance ne signifie pas nécessairement une réduction de portée. Les tours cellulaires rediffuseront les paquets six à huit fois. Il s’agit d’assurer la réception dans les zones particulièrement problématiques. Les radios Cat-M1 peuvent désactiver la réception dès qu’elles reçoivent un paquet sans erreur.
Une autre fonction d’économie d’énergie est le mode de réception discontinue étendue (eDRX), qui permet une période de sommeil de 10,24 secondes entre les cycles de radiomessagerie. Cela réduit considérablement la puissance et permet à l’UE de dormir pendant un nombre programmable d’hypertrames (HF) de 10,24 secondes chacune. L’appareil peut entrer dans ce mode de veille prolongée jusqu’à 40 minutes. Cela permet à la radio d’avoir un courant de repos aussi bas que 15 µA.
Les capacités et fonctionnalités supplémentaires d’atténuation de la puissance incluent PSM, comme introduit dans Cat-0 et la version 13 :
- Détendre les mesures des cellules voisines et les périodes de rapport. Si l’appareil IoT est stationnaire ou se déplace lentement (capteur sur un bâtiment, bétail dans un parc d’engraissement), l’infrastructure d’appel peut être réglée pour limiter les messages de contrôle.
- Optimisation CIoT EPS utilisateur et plan de contrôle. Cette optimisation est une fonctionnalité qui fait partie du RRC dans la pile E-UTRAN. Dans les systèmes LTE normaux, un nouveau contexte RRC doit être créé chaque fois que l’UE sort du mode IDLE. Cela consomme la majorité de l’énergie lorsque l’appareil a simplement besoin d’envoyer une quantité limitée de données. En utilisant l’optimisation EPS, le contexte du RRC est préservé.
- Compression d’en-tête des paquets TCP ou UDP.
- Réduction du temps de synchronisation après de longues périodes de sommeil.
La section suivante couvre Cat-NB. Le marché a développé une perception selon laquelle Cat-NB est considérablement plus faible en puissance et en coût que tous les autres protocoles tels que Cat-M1. Cela est partiellement vrai, et un architecte IoT doit comprendre les cas d’utilisation et choisir soigneusement le protocole qui convient. Par exemple, si nous maintenons la puissance de transmission constante entre Cat-NB et Cat-M1, nous voyons que Cat-M1 a un gain de couverture de 8 dB. Un autre exemple est le pouvoir ; Alors que Cat-M1 et Cat-NB ont des fonctionnalités de gestion de l’alimentation similaires et agressives, Cat-M1 utilisera moins d’énergie pour les grandes tailles de données.
Cat-M1 peut transmettre les données plus rapidement que Cat-NB et entrer dans un état de sommeil profond beaucoup plus tôt. Il s’agit du même concept que Bluetooth 5 utilisé pour réduire la puissance, simplement en envoyant les données plus rapidement, puis en entrant en veille. De plus, au moment de la rédaction du présent document, Cat-M1 est disponible aujourd’hui, tandis que Cat-NB n’a pas atteint les marchés américains.
7.1.9.4 LTE Cat-NB
Cat-NB, également connu sous le nom de NB-IoT, NB1 ou Narrowband IoT, est un autre protocole LPWAN régi par le 3GPP dans la version 13. Comme Cat-M1, Cat-NB opère dans le spectre sous licence. Comme Cat-M1, l’objectif est de réduire la puissance (autonomie de 10 ans), d’étendre la couverture (+20 dB) et de réduire les coûts (5 $ par module). Cat-NB est basé sur le système évolué de paquets (EPS) et les optimisations de l’ nternet cellulaire des objets ( CIoT ). Étant donné que les canaux sont beaucoup plus étroits que même le Cat-M1 1,4 MHz, le coût et la puissance peuvent être encore réduits avec les conceptions plus simples des convertisseurs analogique-numérique et numérique-analogique.
Les différences importantes entre Cat-NB et Cat-M1 comprennent :
- Bande passante de canal très étroite : comme avec Cat-M1, qui a réduit la largeur de canal à 1,4 MHz, Cat-NB la réduit encore à 180 kHz pour les mêmes raisons (réduction des coûts et de la puissance).
- Pas de VoLTE : la largeur du canal étant si faible, il n’a pas la capacité de trafic vocal ou vidéo.
- Pas de mobilité : Cat-NB ne prend pas en charge le transfert et doit rester associé à une seule cellule ou rester immobile. C’est très bien pour la majorité des instruments de capteur IoT sécurisés et fixés. Cela comprend le transfert vers d’autres cellules et d’autres réseaux.
Indépendamment de ces différences importantes, Cat-NB est basé sur le multiplexage OFDMA (liaison descendante) et SC-FDMA (liaison montante) et utilise le même espacement de sous-porteuse et la même durée de symbole.
La pile de protocoles E-UTRAN est également la même avec les couches RLC, RRC et MAC typiques ; il reste basé sur IP, mais est considéré comme une nouvelle interface radio pour LTE.
Étant donné que la largeur du canal est si petite (180 kHz), elle offre la possibilité d’enterrer le signal Cat-NB à l’intérieur d’un canal LTE plus grand, de remplacer un canal GSM ou même d’exister dans le canal de garde des signaux LTE réguliers. Cela permet une flexibilité dans les déploiements LTE, WCDMA et GSM. L’option GSM est la plus simple et la plus rapide du marché. Certaines parties du trafic GSM existant peuvent être placées sur le réseau WCDMA ou LTE. Cela libère un opérateur GSM pour le trafic IoT. Dans la bande fournit une quantité énorme de spectre à utiliser car les bandes LTE sont beaucoup plus grandes que la bande de 180 kHz. Cela permet des déploiements allant jusqu’à 200 000 appareils en théorie par cellule. Dans cette configuration, la station cellulaire de base multiplexera les données LTE avec le trafic Cat-NB. Ceci est tout à fait possible car l’architecture Cat-NB est un réseau autonome et s’interface proprement avec l’infrastructure LTE existante. Enfin, l’utilisation de Cat-NB comme bande de garde LTE est un concept unique et nouveau. Étant donné que l’architecture réutilise les mêmes sous-porteuses et conception de 15 kHz, elle peut être réalisée avec l’infrastructure existante.
La figure suivante illustre où le signal peut résider :
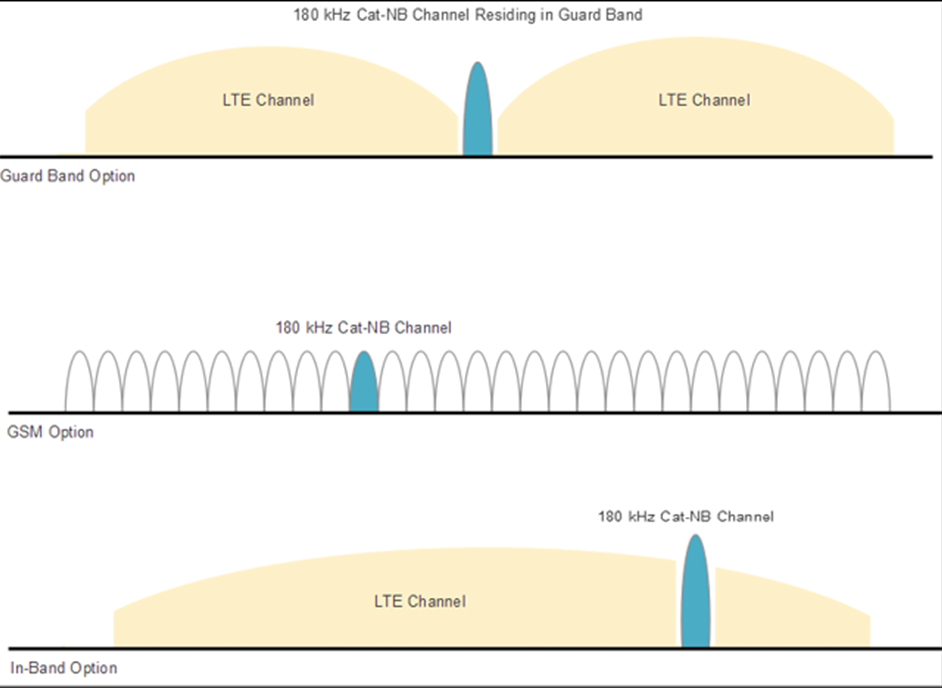
Figure 12 : Options de déploiement de Cat-NB en tant que bande de garde, dans un signal GSM ou en bande avec LTE
Étant donné que la perte de couplage maximale (MCL) est de 164 dB, elle permet une couverture profonde dans les sous-sols, les tunnels, les zones rurales et les environnements ouverts. L’amélioration de 20 dB par rapport au LTE standard représente une augmentation de 7 fois la zone de couverture. Le débit de données pouvant être obtenu est fonction du SNR et de la largeur de bande du canal, comme nous l’avons vu dans le théorème de Shannon-Hartley. Pour la communication en liaison montante, Cat-NB attribuera à chaque UE une ou plusieurs sous-porteuses de 15 kHz dans un bloc de ressources de 180 kHz. Cat-NB a la possibilité de réduire la largeur de la sous-porteuse à 3,75 kHz, ce qui permet à davantage d’appareils de partager l’espace. Cependant, il faut inspecter soigneusement le potentiel d’interférence entre les sous-porteuses de 3,75 kHz de bord et la sous-porteuse de 15 kHz suivante.
Le débit de données, comme nous l’avons appris, est fonction de la couverture. Ericsson a effectué des tests illustrant l’effet de la variation de la couverture et de la force du signal. Les débits de données affectent à la fois la consommation d’énergie (presque linéairement) et la latence. Des débits de données plus élevés équivalent à une puissance plus élevée mais à une latence plus faible.
À la frontière des cellules : couverture = +0 dB, temps de liaison montante = 39 ms , temps de transmission total = 1,604 ms.
À couverture moyenne : couverture = +10 dB, temps de liaison montante = 553 ms , temps de transmission total = 3085 ms.
Pire cas : couverture = +20 dB, temps de liaison montante = 1923 ms , temps de transmission total = 7,623 ms.
Tiré de : NB-IoT : une technologie durable pour connecter des milliards d’appareils, Ericsson Technology Review, Volume 93, Stockholm, Suède, # 3 2016.
La gestion de l’alimentation est très similaire à Cat-M1. Toutes les techniques de gestion de l’alimentation des versions 12 et 13 s’appliquent également à Cat-NB. (PSM, eDRX et toutes les autres fonctionnalités sont incluses.)
7.1.10 Multefire , CBRS et cellulaire à spectre partagé
Nous nous sommes concentrés sur les réseaux radio utilisant l’allocation de spectre sous licence. Il existe une autre solution de réseau à longue portée basée sur une architecture cellulaire et une topologie qui utilise le spectre sans licence.
Le service radio à large bande citoyen (CBRS) est une bande large de 150 MHz dans l’espace 3,5 GHz. L’Alliance CBRS est un consortium d’industries et d’opérateurs nord-américains. Cet espace a été alloué par la FCC pour les systèmes radar gouvernementaux ainsi que pour les opérateurs sans fil sans licence.
Un autre système est appelé Multefire , qui a été rédigé en janvier 2017. Cette technologie s’appuie sur la norme 3GPP mais fonctionne dans la bande de spectre sans licence de 5 GHz. La spécification actuelle est Multefire version 1.1, ratifiée en 2019.
CBRS et Multefire 1.1 spécifient les bandes de disponibilité suivantes :
- 800 et 900 MHz : Multefire avec bande passante NB-IoT-U 200 kHz
- 1,9 GHz (sans licence) : Multefire Japan (global), canal 20 MHz avec bande passante 5 MHz
- 2,4 GHz (sans licence) : Multefire eMTC -U, canal 80 MHz avec bande passante 1,4 MHz
- 3,5 GHz (3550 à 3700 MHz) : CBRS pour l’Amérique du Nord, canal 150 MHz avec bande passante 10/20 MHz
- 5 GHz (sans licence) : Multefire 1.0 dans la plupart des pays, canal 500 MHz avec bande passante 10/20 MHz
La gamme 800/900 MHz est destinée aux applications à très faible consommation d’énergie, tandis que la gamme 2,4 GHz fournit le plus grand espace disponible pour les applications IoT à faible bande passante.
Multefire est basé sur les normes LAA qui définissent la communication LTE et est basé sur les versions 3GPP 13 et 14. De plus, l’utilisation de ces bandes sans licence est considérée comme un catalyseur pour une adoption plus rapide de la technologie 5G. Nous couvrirons la 5G plus loin dans ce chapitre.
Les différences techniques spécifiques entre Multefire et 4G LTE incluent la suppression de la nécessité d’un point d’ancrage. LTE et LAA nécessitent un canal d’ancrage dans le spectre sous licence. Multefire fonctionne uniquement dans un espace sans licence et ne nécessite aucune ancre LTE. Cela permet à tout appareil Multefire d’être essentiellement indépendant du transporteur. Tout appareil Multefire peut essentiellement se connecter à n’importe quel fournisseur de services dans la bande 5 GHz. Cela permet aux opérateurs privés ou aux utilisateurs finaux de déployer une infrastructure privée sans avoir besoin d’un accord de service avec un opérateur sans fil.
Pour répondre aux réglementations internationales opérant dans ce spectre sans licence, il utilise un protocole LBT ( Listen Before Talk ). Étant donné que le canal doit être clair avant l’envoi, cela représente une différence significative entre la communication LTE traditionnelle avec Multefire . Cette forme de négociation de fréquence est courante dans des protocoles tels que 802.11, qui, par coïncidence, partagent le même spectre de fonctionnement.
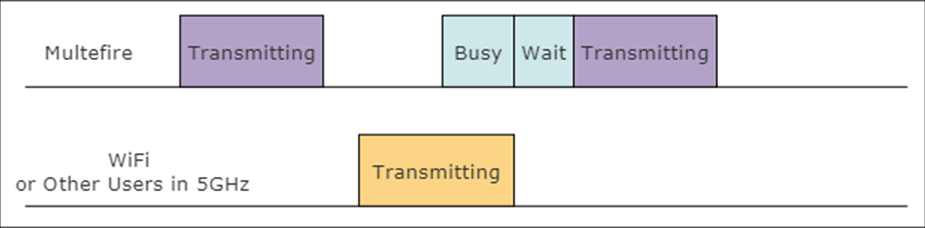
Figure 13 : Utilisation Multefire du LBT pour faciliter la coexistence dans l’espace partagé 2,4 GHz et 5 GHz
Pour maintenir l’équité supplémentaire dans cette bande contestée, Multefire utilise également une méthode d’agrégation de canaux lorsqu’elle est disponible (reportez-vous à l’agrégation de canaux plus haut dans ce chapitre).
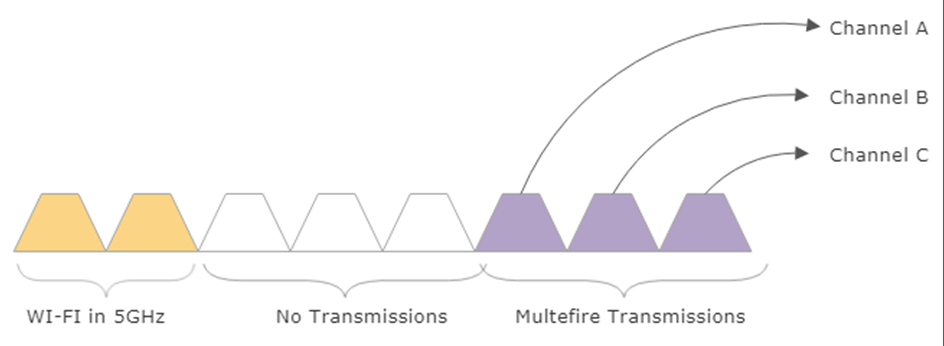
Figure 14 : Agrégation des canaux Multefire
La bande 5G est découpée en canaux de 20 MHz. Les futures versions de Multefire pourraient atteindre 100 MHz.
Du point de vue d’un architecte IoT, Multefire peut servir de nombreux cas d’utilisation plus efficacement que le cellulaire ou le Wi-Fi. Par exemple, un port peut avoir besoin de suivre des actifs comme les conteneurs d’expédition et le fret, ainsi que de communiquer avec les navires arrivant et partant. Si le port couvre une superficie de 10 kilomètres carrés, la couverture globale nécessiterait 120 petites cellules Multefire . Un système Wi-Fi nécessiterait plus de 500 points d’accès. Dans ce cas, le coût de Multefire pour le déploiement seul représente un quart du coût du Wi-Fi. La couverture cellulaire serait basée sur un contrat de service et un abonnement. En fonction du coût de l’abonnement par rapport au coût initial du déploiement de Multefire et des années d’amortissement, il peut être considérablement moins coûteux d’incorporer un système CBRS comme Multefire.
7.1.11 5G
La 5G (ou 5G-NR pour la nouvelle radio) est la norme de communication IP de nouvelle génération en cours d’élaboration et conçue pour remplacer la 4G LTE. Cela dit, il s’appuie sur certaines technologies de 4G LTE mais s’accompagne de différences substantielles et de nouvelles capacités. Tant de matériel a été écrit sur la 5G qu’il éclipse même le matériel Cat-1 et Cat-M1 actuel. En partie, la 5G promet de fournir des capacités substantielles pour les cas d’utilisation IoT, commercial, mobile et véhiculaire. La 5G améliore également la bande passante, la latence, la densité et les coûts d’utilisation.
Plutôt que de créer différents services et catégories cellulaires pour chaque cas d’utilisation, la 5G tente d’être une seule norme parapluie pour tous les servir. Pendant ce temps, la 4G LTE continuera d’être la technologie prédominante pour la couverture cellulaire et continuera d’évoluer. La 5G n’est pas une évolution continue de la 4G ; il dérive de la 4G mais est un nouvel ensemble de technologies. Dans cette section, nous ne discuterons que des éléments spécifiques aux cas d’utilisation de l’IoT et de l’informatique de périphérie.
La 5G vise un premier lancement client en 2020 ; Cependant, le déploiement et l’adoption de masse pourraient suivre des années plus tard au milieu des années 2020. Les objectifs et l’architecture de la 5G sont toujours en évolution et le sont depuis 2012. Il y avait trois objectifs distincts et différents pour la 5G ( http://www.gsmhistory.com/5g/ ). Les objectifs comprennent :
- Infrastructure convergente de fibre et cellulaire
- Mobiles ultra-rapides utilisant de petites cellules
- Réduction des barrières de coût du mobile
Encore une fois, l’UIT-R a approuvé les spécifications et normes internationales, tandis que le 3GPP suit avec un ensemble de normes correspondant à la chronologie de l’UIT-R. Le RAN 3GPP a déjà commencé à analyser les éléments de l’étude à partir de la version 14. L’objectif est de produire une version en deux phases des technologies 5G.
Nous étendons la feuille de route de l’UIT et du 3GPP pour la 5G dans le graphique ci-dessous. Nous montrons ici un déploiement progressif de la 5G sur plusieurs années. La version 14 et la version 15 peuvent être considérées comme eLTE eNodeB , ce qui signifie qu’une cellule eLTE peut être déployée en tant que noyau Next Gen autonome ou eLTE eNodeB non autonome.

Figure 15 : Vue étendue des feuilles de route 3GPP, LTE et ITU pour la 5G
Le 3GPP a accéléré la 5G en utilisant un concept appelé non autonome (NSA). La NSA réutilise l’infrastructure de base LTE. Inversement, la solution autonome (SA) reposera uniquement sur l’infrastructure de base 5G Next Generation.
Les réunions de la Conférence mondiale des radiocommunications (CMR) à l’UIT ont attribué la distribution de fréquences pour les premiers essais 5G lors de la réunion de la CMR-15. Les cas de distribution et d’utilisation pour divers marchés et marchés sont représentés dans le graphique suivant.
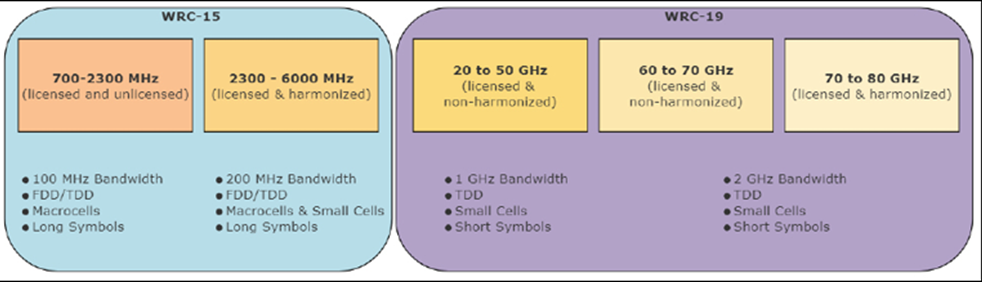
Figure 16 : Objectifs de l’UIT WRC. Notez les décisions concernant l’utilisation des fréquences et la bande passante. Notez également la combinaison de spectre sous licence et sans licence pour la 5G
Il existe trois catégories de cas d’utilisation pour la 5G. Ces cas d’utilisation présentent des caractéristiques similaires mais différenciantes. La même infrastructure réseau sera conçue pour prendre en charge ces clients et utiliser des cas simultanément. Cela se fera grâce à la virtualisation et au découpage du réseau, qui sont traités plus loin dans ce chapitre.
- Haut débit mobile amélioré (eMBB) :
- Connexions de 1 à 10 Go / s aux UE / points d’extrémité sur le terrain (non théorique)
- Couverture à 100% à travers le monde (ou perception de)
- 10 à 100 fois le nombre d’appareils connectés via 4G LTE
- Connectivité à une vitesse de 500 km / h
- Communications ultra-fiables et à faible latence (URLLC) :
- Latence aller-retour de bout en bout <1 ms
- Disponibilité de 99,999% (ou perception de)
- Communications massives de type machine (mMTC) :
- 1 000 fois la bande passante par unité de surface ; implique environ 1 million de nœuds sur 1 km 2
- Jusqu’à 10 ans d’autonomie de batterie sur les nœuds IoT d’extrémité
- 90% de réduction de la consommation d’énergie du réseau
Deux types principaux de déploiements 5G sont pris en compte. Le premier est le sans-fil mobile traditionnel. Il utilise le spectre inférieur à 2 GHz et est destiné à la plage, à la mobilité et à l’alimentation. Il s’appuie fortement sur les macrocellules et la compatibilité LTE actuelle. Il doit également être capable de pénétrer les signaux contre la pluie, le brouillard et d’autres obstacles. La bande passante de pointe est à peine 100 MHz.
Le deuxième déploiement est sans fil fixe. Cela utilisera des fréquences supérieures à la plage de 6 GHz. Il s’appuie fortement sur de nouvelles infrastructures de petites cellules et est destiné aux cas géographiques à faible mobilité ou fixes. La portée sera limitée, tout comme la capacité de pénétration. La bande passante sera cependant substantielle à 400 MHz.
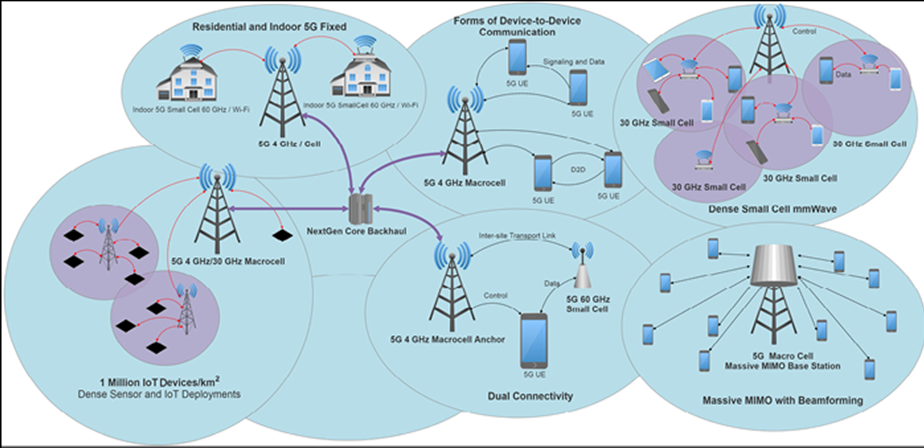
Figure 17 : Topologies 5G : De gauche à droite : densité de 1 million de nœuds grâce au déploiement de petites cellules et de macrocellules. Utilisation en intérieur et à domicile de 60 GHz avec macrocellule à backhaul 4 GHz. Exemple de double connectivité avec contrôle partagé et plans de données utilisant deux radios pour les données utilisateur et des macrocellules 4 GHz pour le plan de contrôle. Connectivité de périphérique à périphérique. MIMI massif avec formation de faisceau à partir d’une seule antenne mmWave. Augmentation de la densité avec un mélange de petites cellules en mmWave pour une couverture globale des données utilisateur.
7.1.11.1 Distribution de fréquence 5G
Les systèmes 4G LTE actuels utilisent principalement des fréquences inférieures à la plage de 3 GHz. La 5G changera radicalement l’utilisation du spectre. Alors que l’espace au-dessous de 3 GHz est considérablement congestionné et découpé en tranches de bande passante, la 5G peut utiliser une multitude de fréquences. L’utilisation d’ondes millimétriques (mmWave ) dans la plage de 24 à 100 GHz sans licence est à l’ étude . Ces fréquences s’adressent directement à la loi de Shannon en augmentant la bande passante B de la loi avec des canaux extrêmement larges. Étant donné que l’espace mmWave n’est pas saturé ou découpé par divers organismes de réglementation, des canaux aussi larges que 100 MHz dans les fréquences de 30 GHz à 60 GHz sont possibles. Cela fournira la technologie pour prendre en charge des vitesses multi Gbps.
Les principaux problèmes rencontrés avec la technologie mmWave sont la perte, l’atténuation et la pénétration de l’espace libre. Si nous nous souvenons que la perte de chemin d’espace libre peut être calculée comme L fs = 32,4 + 20log 10 f + 20log 10 R (où f est la fréquence et R est la plage), alors nous pouvons voir comment la perte est affectée par un 2,4, Signal 30 et 60 GHz comme :
- 2,4 GHz, plage de 100 m : 80,1 dB
- 30 GHz, plage de 100 m : 102,0 dB
- 60 GHz, plage de 100 m : 108,0 dB
- 2,4 GHz, plage de 1 km : 100,1 dB
- 30 GHz, plage de 1 km : 122,0 dB
- 60 GHz, plage de 1 km : 128,0 dB
5G-NR permet une meilleure efficacité du spectre. Le 5G-NR utilise la numérologie OFDM, mais l’espacement des sous-porteuses peut différer selon la bande utilisée. Les bandes inférieures à 1 GHz peuvent utiliser un espacement de sous-porteuse de 15 kHz et avoir moins de bande passante, mais offrent une meilleure couverture macro extérieure, tandis que les fréquences mmWave à 28 GHz peuvent utiliser un espacement de 120 kHz plus grand et transporter plus de bande passante.
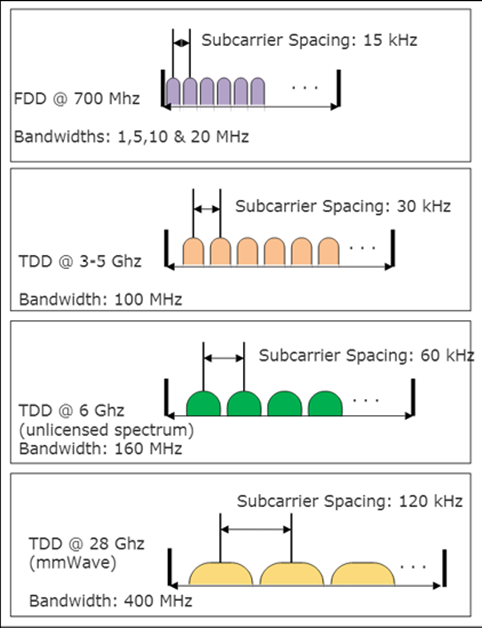
Figure 18 : différences 5G dans l’espacement des sous-porteuses et la largeur de bande pour différentes bandes (700 à 28 GHz)
20 dB est important, mais avec mmWave, les antennes peuvent accueillir beaucoup plus d’éléments d’antenne qu’une antenne 2,4 GHz. La perte de libre parcours n’est significative que si le gain d’antenne est indépendant de la fréquence. Si nous gardons la zone d’antenne constante, il est possible d’atténuer les effets de la perte de chemin. Cela nécessite la technologie Massive-MIMO (M-MIMO). M-MIMO incorporera des tours de macrocellules avec 256 à 1 024 antennes. La formation de faisceaux au niveau de la macrocellule sera également utilisée. Lorsqu’il est combiné avec mmWaves, M-MIMO a des défis en termes de contamination des tours à proximité, et les protocoles de multiplexage comme TDD devront être ré-architecturés.
MIMO permet une densité plus élevée d’équipements UE dans une zone, mais permet également à un appareil d’augmenter la bande passante en recevant et en transmettant sur plus de fréquences simultanément.
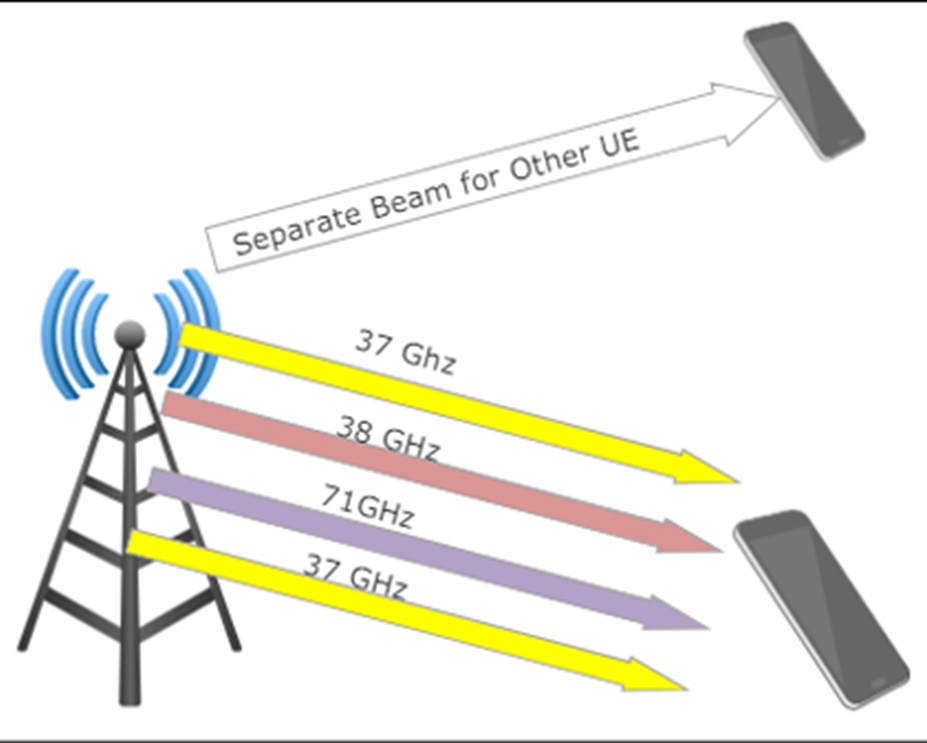
Figure 19 : La formation de faisceaux multifréquences 5G et MIMO permettent d’utiliser plusieurs fréquences et bandes simultanément et dirigées vers un seul UE.
Un autre défi avec la 5G est la nécessité de très grands réseaux d’antennes pour prendre en charge M-MIMO avec des centaines d’antennes dans une configuration de tour dense. Des structures 3D d’antennes compactes sont à l’étude pour soutenir la formation de faisceaux à la tour. Des facteurs tels que les effets du vent et des tempêtes sur ces tours doivent encore être résolus.
L’atténuation est un problème très important. À 60 GHz, un signal sera absorbé par l’oxygène dans l’atmosphère. Même la végétation et le corps humain lui-même auront un effet sérieux sur les signaux. Un corps humain absorbera tellement d’énergie RF à 60 GHz qu’il formera une ombre. Un signal se déplaçant à 60 GHz aura une perte de 15 dB / km. Ainsi, la communication à longue portée sera inférieure à la 5G à 60 GHz et nécessitera soit une couverture de petites cellules, soit une chute vers un espace de fréquence plus lent. C’est l’une des raisons pour lesquelles l’architecture 5G nécessitera plusieurs bandes, de petites cellules, des macrocellules et un réseau hétérogène.
La pénétration des matériaux dans le spectre mmWave est difficile. Les signaux mmWave s’atténuent à travers les cloisons sèches à 15 dB et les fenêtres en verre des bâtiments contribuent à une perte de 40 dB. Par conséquent, une couverture intérieure avec une macrocellule est presque impossible. Ce problème et d’autres types de problèmes de signalisation seront atténués grâce à l’utilisation généralisée de petites cellules intérieures :
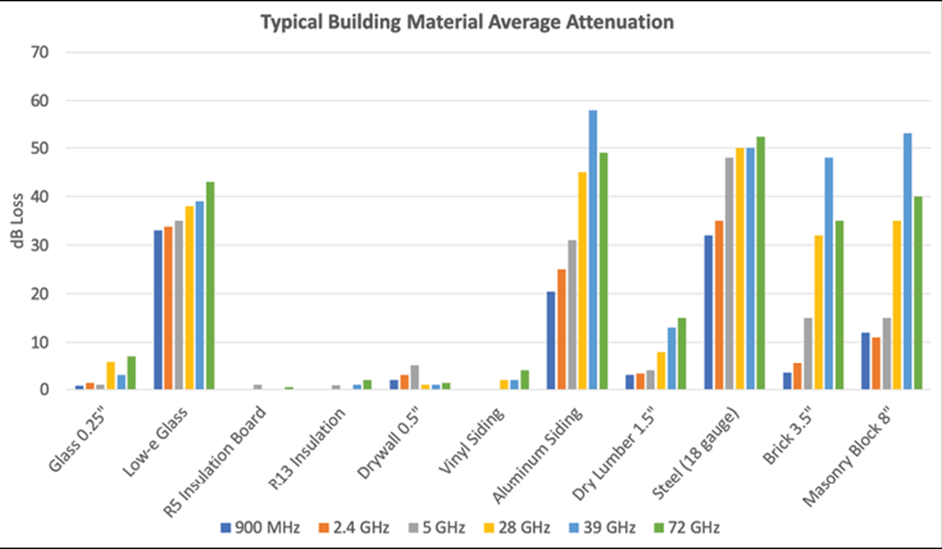
Figure 20 : Différentes fréquences par rapport à la perte de pénétration (dB): des matériaux composites de construction typiques ont été testés (verre, brique, bois) des zones externes aux zones internes. La perte de verre de réduction infrarouge est particulièrement difficile pour les fréquences mmWave .
Les UE peuvent utiliser plusieurs bandes simultanément. Par exemple, un périphérique d’extrémité peut utiliser des fréquences plus basses pour une communication à longue portée et basculer sur mmWave pour une communication intérieure et personnelle. Un autre schéma envisagé est la double connectivité, qui dirige le trafic de données sur plusieurs bandes en fonction du type de données. Par exemple, le plan de contrôle et le plan utilisateur de la pile sont déjà divisés. Les données du plan utilisateur peuvent se diriger vers une petite cellule proche en utilisant une fréquence de 30 GHz, tandis que les données de contrôle peuvent être dirigées vers une tour de macrocellule eNodeB à longue portée au taux typique de 4 GHz.
Une autre amélioration pour une vitesse accrue est l’efficacité spectrale. Le 3GPP se concentre sur certaines règles de conception :
- Espacement des sous-porteuses de 15 kHz pour améliorer l’efficacité du multiplexage
- Numérologie flexible et évolutive des symboles de 2 M symboles à 1 symbole pour réduire la latence
Comme discuté précédemment, l’efficacité spectrale est donnée en unités de bps / Hz. L’utilisation de D2D et M-MIMO ainsi que des modifications de l’interface radio et de la nouvelle radio peuvent améliorer l’efficacité spectrale. La 4G LTE utilise OFDM, qui fonctionne bien pour les grandes transmissions de données. Cependant, pour l’IoT et mMTC , les paquets sont beaucoup plus petits. La surcharge pour OFDM a également un impact sur la latence dans les déploiements IoT très denses. Par conséquent, de nouvelles formes d’onde sont en cours d’architecture pour examen :
- Accès multiple non orthogonal (NOMA) : permet à plusieurs utilisateurs de partager un support sans fil
- Filter Bank Multicarrier (FBMC) : contrôle la forme des signaux de sous-porteuse pour éliminer les lobes latéraux via les DSP
- Accès multiple par code fragmenté (SCMA) : permet de mapper les données sur un code différent provenant de différents livres de codes.
La réduction de la latence est également un objectif de l’UIT et du 3GPP. La réduction de la latence est cruciale pour les cas d’utilisation 5G tels que les casques de divertissement interactif et de réalité virtuelle, mais aussi pour l’automatisation industrielle. Cependant, il joue un rôle important dans la réduction de puissance (un autre objectif de l’UIT). La 4G LTE peut avoir une latence allant jusqu’à 15 ms sur des sous-trames de 1 ms. La 5G se prépare à une latence inférieure à 1 ms. Cela aussi sera accompli en utilisant de petites cellules pour rassembler les données plutôt que des macrocellules congestionnées. L’architecture prévoit également une communication de périphérique à périphérique (D2D), retirant essentiellement l’infrastructure cellulaire du chemin de données pour la communication entre les UE.
Les systèmes 4G continueront d’exister, car le déploiement de la 5G prendra plusieurs années. Il y aura une période de coexistence qui devra être établie. La version 15 ajoutera d’autres définitions à l’architecture globale telles que les choix de canaux et de fréquences. Du point de vue de l’architecte IoT, la 5G est une technologie à surveiller et à planifier. Les appareils IoT peuvent prédire un WAN qui devra fonctionner pendant une douzaine d’années ou plus sur le terrain. Pour une bonne perspective sur les points clés, les contraintes et la conception détaillée de la 5G, les lecteurs doivent se référer à 5G: A Tutorial Overview of Standards, Trials, Challenges, Deployment, and Practice, par M. Shafi et al., In IEEE Journal sur certains domaines des communications, vol. 35, non. 6, pp. 1201-1221, juin 2017.
7.1.11.2 Architecture RAN 5G
L’architecture et la pile 5G évoluent à partir des normes 4G. Cette section examine les composants architecturaux de haut niveau, la décomposition et les compromis des différentes conceptions 5G.
L’interface entre l’unité radio (RU) et l’unité de distribution (DU) a été l’interface fibre CPRI héritée. De nouveaux types d’interfaces basées sur différentes architectures sont à l’étude comme nous le verrons plus loin dans ce chapitre. CPRI est une interface série propriétaire du fournisseur avec une bande passante de 2,5 Gbps.
CPRI amélioré ou e-CPRI est une interface alternative pour la 5G basée sur des normes ouvertes sans verrouillage du fournisseur. e-CPRI permet également l’architecture de division fonctionnelle décrite plus loin et de décomposer le réseau en utilisant les normes IP ou Ethernet par rapport à IQ sur CPRI.
L’architecture 5G est conçue pour la flexibilité et l’infrastructure régionale. Par exemple, les régions d’Asie ont une grande fibre préexistante, mais pas l’Amérique du Nord et l’Europe. L’architecture RAN a été conçue pour être flexible afin de pouvoir être déployée sans infrastructure de fibre. Cela nécessite différentes options de connectivité. Comme mentionné, la 5G s’appuiera sur une infrastructure 4G LTE traditionnelle, qui n’a pas été conçue pour la capacité ou la vitesse de la 5G. Les versions non autonomes différeront davantage en architecture que les systèmes autonomes. Pour plus de flexibilité, l’architecture est fongible. Par exemple, l’interface traditionnelle entre le DU et le RU est l’interface CPRI. L’interface CPRI nécessite une liaison dédiée à chaque antenne. Étant donné que la 5G est basée sur la technologie MIMO, elle aggrave le problème de bande passante. Prenez une antenne MIMO 2×2 qui utilise trois vecteurs. Cela nécessite 2 * 2 * 3 = 12 canaux CPRI ou longueurs d’onde pour une seule antenne. Le nombre réel d’antennes MIMO sera beaucoup plus élevé dans les tours 5G. Le CPRI ne peut tout simplement pas s’adapter à la capacité et à la demande. Par conséquent, nous introduisons la notion de “divisions fonctionnelles” entre les couches 1, 2 et / ou 3 du réseau cellulaire. Nous avons la flexibilité de savoir quelles fonctions résident où dans l’architecture et les systèmes respectifs. Le graphique suivant illustre certaines options quant à l’endroit où la division se produirait entre le RU et le BBU.
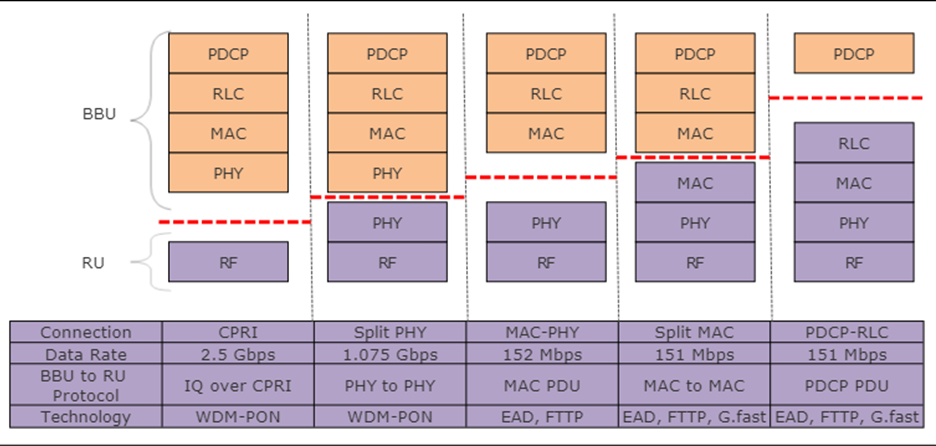
Figure 21: Configuration flexible de l’utilisation de “séparations fonctionnelles” du RAN 5G entre l’unité de bande de base et l’unité radio. Notez la différence de débit de données. Déplacer plus de fonctionnalités vers la RU impose un niveau de charge de traitement plus élevé à chaque radio et diminue la vitesse globale, tandis que déplacer plus de fonctionnalités vers la BBU exercera une pression importante sur l’interface CPRI mais fournira les vitesses les plus rapides.
L’autre facteur contribuant à cette décomposition fonctionnelle est la latence supplémentaire du CPRI. La distance entre une tour cellulaire et un DU peut atteindre 10 km. Cette latence supplémentaire en plus du calcul supplémentaire à la RU peut être défavorable à certaines applications 5G comme AR / VR et la vidéo en streaming. Cela provoque une juxtaposition dans l’architecture. Soit réduit la latence avec un calcul supplémentaire sur le BBU / DU et utilisez CPRI gourmand en bande passante, soit déplacez plus de traitement vers le RU, ce qui réduira la latence mais diminuera la bande passante.
L’unité de bande de base (BBU), parfois appelée unité centrale ou CU, est un nœud logique responsable du transfert de données, du contrôle de la mobilité, du partage de réseau d’accès radio, du positionnement et de la gestion de session. La BBU contrôle toutes les opérations DU sous sa gestion de services via l’interface de liaison.
Le DU , parfois appelé tête radio distante ( RRH ), est également un nœud logique et fournit un sous-ensemble de la fonctionnalité gNB . La fonctionnalité peut être divisée afin que ce qui se trouve soit dynamique. Ses opérations sont contrôlées par la BBU.
Comme le montre le diagramme, les niveaux intermédiaires de l’architecture 5G autorisent ce que l’on appelle l’informatique périphérique à accès multiple, ou MEC. Cette rubrique sera traitée plus loin dans le chapitre informatique de périphérie, mais elle permet essentiellement aux applications qui ne sont pas axées sur la communication et les opérateurs de coexister sur du matériel de périphérie commun via des interfaces de virtualisation. Il rapproche le cloud computing des utilisateurs périphériques et finaux ou des sources de données qui nécessitent une bande passante plus élevée ou une latence inférieure à ce qui peut être fourni via plusieurs tronçons de réseau à un service cloud traditionnel.
7.1.11.3 Architecture Core 5G
Le 5G Core (ou 5GC) est une architecture basée sur les services basée sur différentes fonctions de réseau. Ces fonctions existent exclusivement dans le 5GC ou ont des interfaces et des connexions au RAN via le plan de contrôle. Cela diffère de l’héritage 4G LTE où toutes les fonctionnalités de base avaient un point de référence commun. Des points de référence existent toujours dans le plan utilisateur, mais des fonctions comme l’authentification et la gestion de session seront des services.
L’architecture est organisée comme suit :
- Référentiel d’authentification (ARPF / UDM) : responsable du stockage des informations d’identification de sécurité à long terme et réside dans le réseau domestique de l’opérateur.
- Fonction de serveur d’authentification (AUSF) : interagit avec ARPF et met fin aux demandes de SEAF. Il réside dans le réseau domestique de l’opérateur.
- Fonction d’ancrage de sécurité (SEAF) : reçoit la clé intermédiaire de l’AUSF. Il s’agit du système de sécurité du réseau central. SEAF et AMF doivent être colocalisés et il doit y avoir un seul point d’ancrage pour chaque PLMN.
- Fonction de contrôle de politique (PCF) : analogue à la politique 4G LTE et à la fonction de règles de charge (PCRF) existantes.
- Fonction de gestion de session (SMF) : identifie les sessions inactives et actives. Il attribue des adresses IP aux appareils UE, gère les adresses IP et adapte la politique et la terminaison de l’interface de charge hors ligne / en ligne.
- Fonction de plan utilisateur (UPF): configure le réseau pour une réduction de la latence globale. Il définit le point d’ancrage de la mobilité intra et inter RAT. L’UPF porte également l’adresse IP externe pour l’interconnexion. De plus, il gère le routage des paquets, la transmission des paquets et la QoS du plan utilisateur.
- Fonctions d’application (AF) : services supplémentaires approuvés par le transporteur. Ces services peuvent être fournis pour accéder directement aux fonctions réseau.
- Réseau de données (DN) : accès Internet généralement sortant, mais également services d’opérateurs directs et services tiers.
Ces services de base sont conçus pour être alignés sur le cloud et indépendants du cloud, ce qui signifie que les services peuvent exister via plusieurs fournisseurs. Cependant, une différence fondamentale entre la 5G et la 4G LTE est l’ajout de fonctions de plan utilisateur (UPF) dans la 5G. Celles-ci sont destinées à découpler le contrôle de la passerelle de paquets du plan utilisateur des données. Cela reprend des architectures SDN.
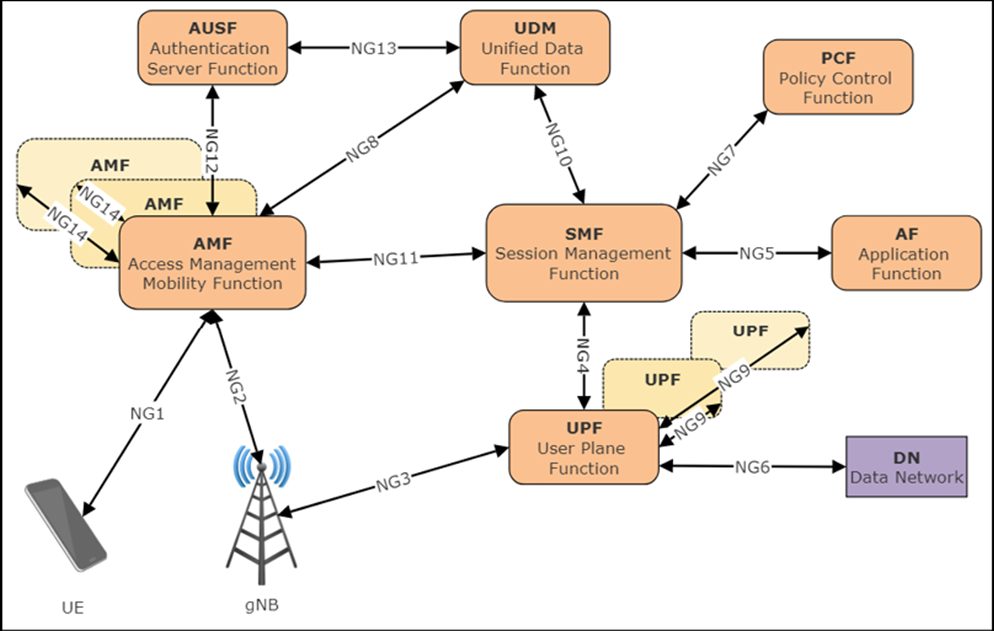
Figure 22 : Image conceptuelle 3GPP de l’architecture 5GC
7.1.11.4 Sécurité 5G et enregistrement
Outre les nouvelles capacités de sécurité utilisant NFV et la virtualisation, la 5G améliore la sécurité grâce à l’authentification unifiée. C’est ce qu’on appelle un cadre d’authentification unifié. Cette technologie dissocie l’authentification des points d’accès. De plus, il permet des algorithmes d’authentification extensibles, des politiques de sécurité adaptables et l’utilisation d’identificateurs permanents d’abonné (SUPI).
SUPI démarre le processus en créant un identifiant caché d’abonné (SUCI). La dissimulation peut être effectuée dans la carte SIM UE si elle est présente ou dans l’équipement UE si elle n’est pas présente.
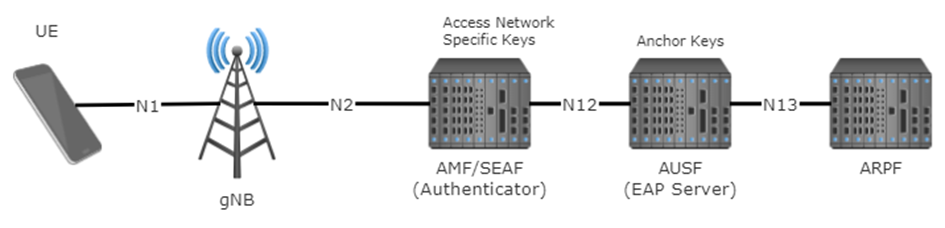
Figure 23 : Diagramme de haut niveau des acteurs de la sécurité 5G
Lorsqu’une UE souhaite s’inscrire auprès d’un réseau, il envoie d’abord une demande d’enregistrement. Ce message comprend tous les éléments d’information (IE) et d’autres détails nécessaires pour identifier le périphérique. L’AMF / SEAF (fonction de serveur d’authentification et fonction d’ancrage de sécurité) préparera une demande d’initiation d’authentification (5G-AIR) et l’enverra à l’AUSF. L’AUSF réside dans le réseau domestique tandis que le SEAF réside dans le réseau de service.
Une fois que l’AUSF a reçu et validé le message 5G-AIR, il génère un message Auth-Info-Req et rassemble les données vers l’UDM / ARPF (Authentication Credential Repository). Ici, le vecteur d’authentification est généré et la réponse SUPI est renvoyée à la couche AMF.
Une vue générale de cette transaction est illustrée dans la figure suivante :

Figure 24 : Flux de processus typique pour l’authentification 5G et l’échange de sécurité. Une fois la trame SUCI envoyée à l’UDM, sa réponse est soit acceptée, soit refusée via la réponse d’authentification SUPI . Tous les nouveaux enregistrements peuvent réutiliser le même SUPI si le mappage existe déjà
7.1.11.5 Communications ultra-fiables à faible latence (URLCC)
L’un des trois cas d’utilisation de la 5G est la communication à faible latence et la haute fiabilité. Ces services seraient adaptés aux situations de grande valeur et vitales comme la chirurgie à distance, les drones ou les systèmes de sécurité publique. Ces systèmes ont de fortes dépendances en temps réel et doivent répondre à un signal dans un délai spécifié. Pensez à une voiture autonome qui doit répondre à une commande de freinage en temps réel. Pour répondre à cette exigence, les concepteurs ont modifié l’ordonnanceur physique et l’encodeur de canal. Essentiellement, tout le trafic URLCC peut préempter toutes les autres formes de trafic. La communication en liaison montante peut réduire sa latence grâce à de meilleurs schémas de codage de canal. Ces schémas impliquent la possibilité de décoder simultanément plusieurs transmissions en liaison montante. Les retransmissions sont un autre facteur notoire dans l’impact sur la latence. HARQ à faible latence est une méthode intégrée à la 5G pour résoudre l’impact des performances de retransmission. Nous couvrirons HARQ plus tard dans le chapitre. Enfin, la fiabilité du signal est améliorée en utilisant des blocs raccourcis dans le codage des canaux ainsi qu’en augmentant la diversité et le mélange des blocs.
L’illustration suivante est du trafic 5G-NR flexible basé sur un slot. Le trafic eMBB , mMTC et URLCC coexisteront dans le même espace de fréquence et de temps. Cependant, seul le trafic URLCC a la capacité de préempter toutes les autres classes de trafic en injectant des symboles URLCC dans les mêmes canaux que les autres sources de trafic. Voir J. Hyoungju et. al., Ultra Reliable and Low Latency Communications in 5G Downlink: Physical Layer Aspects, IEEE Wireless Communications Vol 25, No 3. 2018.
Cette technique permet des durées de tranche évolutives où le multiplexage de trafic de différents types, durées et exigences de QoS coexistent. La structure de fente elle-même est autonome. Cela signifie que la capacité de décoder les emplacements et d’éviter les relations de synchronisation statiques s’étend sur tous les emplacements.
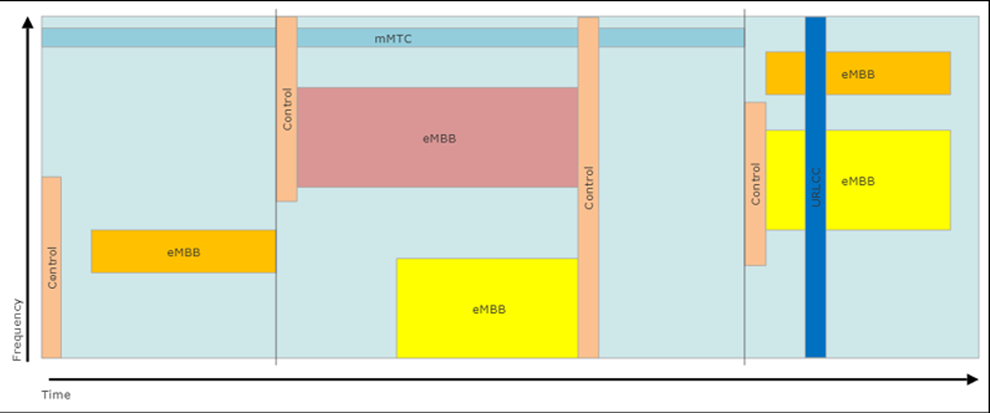
Figure 25 : Plusieurs types de trafic peuvent coexister de manière transparente dans les transmissions 5G sur plusieurs fréquences et des espaces temporels variables. Notez que la structure URLCC se propage sur toutes les fréquences simultanément. URLCC peut également être injecté à tout moment dans la séquence pour atteindre son objectif de latence de 1 ms. Notez également que les temps de transmission ne sont pas de longueur égale ou fixe. Les intervalles de temps de transmission (TTI) sont évolutifs, dynamiques et variables.
7.1.11.6 Duplexage temporel à grain fin (TDD) et HARQ à faible latence
HARQ signifie demande de répétition automatique hybride. Il s’agit d’un autre changement spécifique à la 5G par rapport aux systèmes LTE pour prendre en charge les exigences de faible latence d’URLCC. LTE-Advanced a le concept de HARQ et permet un temps d’ aller-retour ( RTT ) de ~ 10 ms. URLCC, comme indiqué par 3GPP, est ciblé sur 1 ms. Pour accomplir cette amélioration de 10x de la latence, la 5G permet la réorganisation des créneaux du signal porteur. Ceci est appelé TDD à grain fin .
La 5G permet un multiplexage efficace des données critiques avec d’autres services. Cela a été discuté dans la dernière section. La conception HARQ permet l’injection de trafic URLCC à tout moment dans la séquence et le flux de données globaux.
Le temps de transmission est également évolutif et flexible. L’ intervalle de temps de transmission ( TTI ) n’est plus fixe. Le TTI peut être réglé plus court pour une communication à faible latence et très fiable, ou il peut être allongé pour une efficacité spectrale plus élevée. Plusieurs types de trafic et différentes longueurs TTI peuvent coexister dans le même flux de données. Les TTI longs et les TTI courts peuvent être multiplexés pour permettre aux transmissions de commencer aux frontières des symboles.
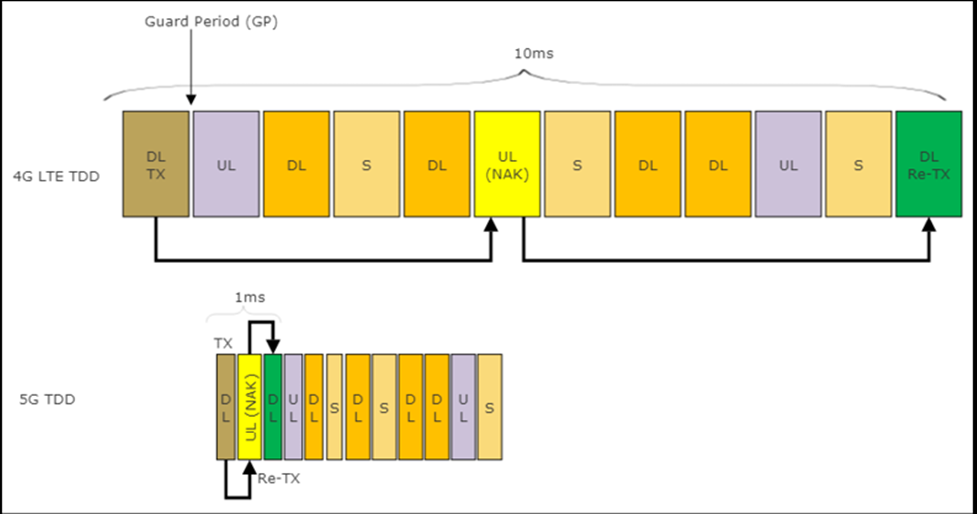
Figure 26 : Illustrer les différents dans la retransmission TDD. En 4G LTE, une retransmission pourrait entraîner une pénalité de latence importante pouvant atteindre 10 ms. 5G URLLC TDD peut réduire le temps d’aller-retour (RTT) et la latence globale en accusant réception des données reçues dans la même sous-trame. Étant donné que le TTI est variable, cela peut être accompli. Ici, nous illustrons que le NAK du premier paquet peut être transmis presque immédiatement après la réception.
Le paquet URLCC peut également être programmé brusquement. 3GPP recommande deux solutions pour planifier ce paquet :
- Planification instantanée : cela permet à une transmission existante d’interrompre puis d’initier un paquet URLCC.
- Planification basée sur la réservation : ici, les ressources URLCC sont réservées avant la planification des données. Une station de base peut diffuser une nouvelle politique d’ordonnancement et une nouvelle numérologie des fréquences. Par exemple, la station de base peut sélectionner 14 symboles OFDM pour le trafic eMBB mais garantir que 4 des symboles seront pour le trafic URLCC. Si aucun trafic existe , la bande passante serait être gaspillé .
7.1.11.7 Réseau tranchage
Une partie de l’architecture de la 5G implique le découplage des piles technologiques de contrôle et de plan de données courantes dans l’architecture cellulaire actuelle. Le découpage de réseau implique l’utilisation de réseaux définis par logiciel (SDN) et de virtualisation des fonctions réseau (NFV). Il s’agit de types de conceptions de virtualisation de réseau courants dans les implémentations d’entreprise, de centres de données et d’hyperscale. Les techniques de virtualisation de réseau permettent une flexibilité plus facile du matériel pour les fournisseurs de services, des méthodes pour vendre ou partitionner les services différemment pour les clients, et la possibilité de déplacer et d’acheminer des données sur une infrastructure physique partagée, mais de présenter le service comme un réseau privé de confiance. Une plongée profonde dans l’architecture SDN sera présentée dans le chapitre sur le routage de périphérie.
En bref, SDN sépare le plan de contrôle, qui gère le routage d’un réseau, du plan de données, qui gère la transmission des informations. NFV virtualise les applications réseau telles que l’inspection approfondie des paquets et les services de sécurité. Plutôt que de lier ces fonctionnalités en un seul périphérique matériel spécifique au fournisseur, nous pouvons décomposer ces fonctions et même exécuter des services dans le cloud. Ces technologies permettent des changements de réseau très rapides et adaptatifs basés sur les abonnements, la sécurité et la demande.
Pour la 5G, le découpage réseau permet :
- La possibilité de créer des sous-réseaux virtuels sur une infrastructure privée et partagée existante
- Réseaux sur mesure de bout en bout
- Qualité de service et méthodes d’approvisionnement contrôlées et adaptatives
- Ajustement dynamique de la charge pour des types de trafic spécifiques
- Modèles d’abonnement et SLA payants pour des services à latence plus rapide ou plus faible
Du point de vue de l’architecture IoT, le découpage devient une option ou une nécessité dépendant de la façon dont la 5G est utilisée et consommée par le produit et le déploiement. Dans un cas d’utilisation virtuel, une tranche de réseau peut être provisionnée via un SLA pour un service premium, une garantie de faible latence, une bande passante plus élevée ou un réseau dédié sécurisé. Les appareils IoT immobiles ou nécessitant une bande passante élevée peuvent être provisionnés pour des services spécifiques à leur cas d’utilisation sur la même infrastructure réseau 5G.
Dans les systèmes 4G LTE, de nombreux composants du RAN (DU) et du Core utilisaient du matériel spécifique aux OEM. Cela empêche la possibilité de personnaliser et d’adapter le trafic de communication aux clients et d’utiliser efficacement les cas.
La 5G migre vers une infrastructure virtualisée et SDN, permettant flexibilité et adaptabilité dans la conception du réseau.
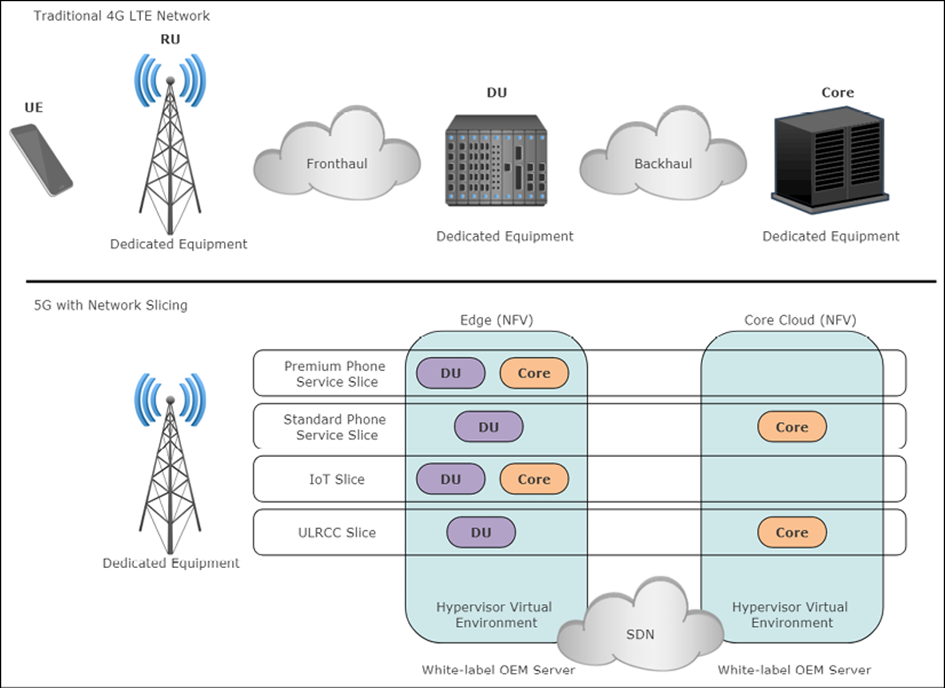
Figure 27 : découpage du réseau 5G. Les systèmes 4G LTE en haut de l’illustration montrent un flux linéaire de l’UE vers le cœur à l’aide d’équipements et de logiciels spécifiques OEM. Le provisioning dépendant du cas d’utilisation UE n’est pas une option dans 4G LTE, tandis que 5G permet le découpage du réseau au niveau du service. Ici, les systèmes de périphérie peuvent diviser et fournir des services en fonction des besoins des clients et des SLA. Les services peuvent migrer dynamiquement du cloud vers la périphérie via une infrastructure définie par logiciel.
7.1.11.8 5G énergie considérations
Une considération lors de l’utilisation de la 5G (ou de tout autre protocole sans fil) est l’énergie qu’elle consomme non seulement sur l’appareil client, mais également sur l’infrastructure du serveur telle qu’un eNodeB. Comme la 5G peut théoriquement fournir 1 000 fois plus de données que les architectures cellulaires et la densité précédentes, elle le fait avec un coût en énergie.
Tout d’abord, l’architecte doit considérer que la 5G est construite à grande échelle sur des systèmes à petites cellules plutôt que sur de grandes tours. Les petites cellules fonctionneront à une puissance inférieure à celle des systèmes cellulaires traditionnels, mais leur simple volume contribuera à une plus grande densité d’énergie.
Un problème secondaire est l’utilisation de MIMO en 5G. Comme indiqué précédemment, la 5G-NR est basée sur un déploiement progressif et utilise l’infrastructure 4G LTE existante. Une partie de cela comprend l’utilisation du multiplexage par répartition en fréquence orthogonale (OFDM). L’OFDM divisera simultanément une partie d’émission de données sur différentes fréquences. C’est ce qui donne à la technologie la base d’être « orthogonale ». Cependant, cette capacité à se propager sur plusieurs fréquences a un effet secondaire appelé rapport de puissance crête à moyenne (PAPR). L’OFDM est connu pour avoir un PAPR très élevé (A. Zaidi, et. Al. Waveforms and Numerology to 5G Services and Requirements, Ericsson Research, 2016). Pour permettre à l’OFDM de fonctionner, un récepteur d’un signal OFDM doit être capable d’absorber l’énergie combinée de plusieurs fréquences et un émetteur doit être capable de générer et de diffuser cette énergie. PAPR est la relation entre la puissance maximale d’un échantillon pour un symbole OFDM donné et la puissance moyenne de ce symbole mesurée en dB.
La version 15 de 3GPP standardisée sur OFDM comme méthode de codage telle qu’elle était utilisée sur 4G LTE.
Un exemple de la puissance peut être montré par un exemple. Si un émetteur produit un signal à 31 dBm, cela équivaut à 1 259 W de puissance. Si le PAPR est de 12 dB, le point de saturation est de 31 dBm + 12 dBm = 43 dBm. Cela équivaut à 19,95 W.
Ce que cela signifie pour les appareils IoT, c’est le potentiel de dégradation significative de la durée de vie de la batterie et d’augmentation de la consommation d’énergie. Une radio émetteur-récepteur ne fonctionne jamais à 100% d’efficacité en convertissant l’énergie CC en énergie RF. Près de 30% de la puissance d’un émetteur-récepteur est perdue à cause de l’inefficacité de la chaleur et de l’amplificateur de puissance. L’effet du PAPR signifie que l’amplificateur de puissance devra réduire sa puissance opérationnelle pour compenser les pics de puissance de pointe du MIMO.
Il existe des techniques pour atténuer les effets du PAPR :
- Écrêtage : il s’agit essentiellement de la suppression d’une partie du signal qui dépasse la zone autorisée. Cette technique provoque une distorsion. De même, il augmente les taux d’erreur sur les bits et réduit l’efficacité spectrale, mais est plus facile à mettre en œuvre.
- SLM : cette technique utilise différentes séquences de symboles générées en multipliant les données transmises par la séquence de phases. Celui avec le PAPR minimal est transmis. Il peut être trop complexe à mettre en œuvre. Il n’y a pas de distorsion, mais cela entraîne une réduction des débits de données.
- PTS : cette méthode génère des informations codées supplémentaires envoyées au récepteur pour aider à déterminer les meilleurs facteurs de phase possibles. Il peut être trop complexe à mettre en œuvre. Il n’y a pas de distorsion, mais cela entraîne une réduction des débits de données.
- Accès multiple non orthogonal : il dessert plusieurs UE sur les mêmes ressources temps / fréquence via le multiplexage de domaine de puissance ou le multiplexage de domaine de code. Ceci est contraire à l’OFDM, qui est entièrement un schéma de multiplexage dans le domaine fréquentiel. Le principal problème de cette méthode est qu’elle rompt la compatibilité avec la 4G LTE et entraînera un coût considérable pour transformer chaque station de base et chaque petite cellule. Il présente également des défis en termes de complexité et de réduction du nombre d’utilisateurs desservis simultanément.
Cet effet sur la puissance par rapport aux performances et à la densité doit être pris en compte par l’architecte lors de l’examen et / ou du déploiement de la 5G pour un cas d’utilisation IoT par rapport à d’autres normes.
7.2 LoRa et LoRaWAN
LPWAN comprend également des technologies propriétaires et non sponsorisées par 3GPP. On peut faire valoir que certains protocoles IEEE 802.11 devraient également être classés dans LPWAN, mais les deux sections suivantes mettront en évidence LoRa et Sigfox. LoRa est une couche physique pour un protocole IoT longue portée et basse consommation tandis que LoRaWAN représente la couche MAC.
Ces technologies et transporteurs propriétaires LPWAN ont l’avantage d’utiliser le spectre sans licence et c’est tout simplement le coût du plan de données.
LoRa / LoRaWAN peut être construit, personnalisé et géré par n’importe qui. Il n’y a pas de contrat de transporteur ou de niveau de service si vous choisissez de ne pas utiliser de transporteur. LoRa et LoRaWAN offrent un degré de flexibilité uniquement visible dans CBRS et Multefire . Il est important de comprendre l’impact de la monétisation sur la mise à l’échelle lors de la création d’une architecture utilisant n’importe quelle communication.
En règle générale, les technologies comme Sigfox et LoRaWAN seront 5 à 10 fois plus faibles dans leurs débits de données par rapport aux connexions 3G ou LTE traditionnelles pour les déploiements à grand volume (> 100 000 unités). Cela pourrait changer avec une concurrence accrue de Cat-M1, Cat-NB et Cat-5, mais il est trop tôt pour le dire.
L’architecture a été initialement développée par Cycleo en France, mais a ensuite été acquise par Semtech Corporation (un fabricant français d’électronique à signaux mixtes) en 2012 pour 5 millions de dollars en espèces. L’Alliance LoRa a été formée en mars 2015. L’alliance est l’organisme standard pour la spécification et la technologie LoRaWAN . Ils ont également un processus de conformité et de certification pour assurer l’interopérabilité et la conformité à la norme. L’alliance est soutenue par IBM, Cisco et plus de 160 autres membres.
LoRaWAN a gagné du terrain en Europe avec des déploiements de réseaux par KPN, Proximus, Orange, Bouygues, Senet, Tata et Swisscom. À ce jour, d’autres régions ont une couverture éparse.
Une raison de la différence de prix, en plus d’être dans le spectre sans licence, est qu’une seule passerelle LoRaWAN a le potentiel de couvrir une quantité importante de zone. La Belgique, avec une superficie de 30 500 km 2 , est entièrement couverte par sept passerelles LoRaWAN . La portée typique est de 2 à 5 km dans les zones urbaines et 15 km dans les zones suburbaines. Cette réduction des coûts d’infrastructure est très différente de la 4G LTE avec des cellules beaucoup plus petites.
Puisque LoRa est le bas de la pile, il a été adopté dans des architectures concurrentes de LoRaWAN. Symphony Link, par exemple, est la solution LPWAN de Link Labs basée sur LoRa PHY, utilisant une station de base sub-GHz à huit canaux pour les déploiements IoT industriels et municipaux. Un autre concurrent utilisant LoRa est Haystack, qui produit le système DASH7. DASH7 est une pile réseau complète sur LoRa PHY (pas seulement la couche MAC).
La prochaine section se concentrera exclusivement sur LoRaWAN.
7.2.1 Couche physique LoRa
LoRa représente la couche physique d’un réseau LoRaWAN. Il gère la modulation, la puissance, les radios de réception et de transmission et le conditionnement du signal.
L’architecture est basée sur les bandes suivantes dans l’espace sans licence ISM :
- 915 MHz : aux États-Unis avec des limites de puissance mais pas de limite de rapport cyclique
- 868 MHz : en Europe avec un rapport cyclique de 1% et 10%
- 433 MHz : en Asie
Un dérivé du spectre étalé chirp (CSS) est la technique de modulation utilisée dans LoRa. CSS équilibre le débit de données avec la sensibilité dans une bande passante de canal fixe. CSS a été utilisée dans les années 1940 pour la communication militaire à longue distance en utilisant modulés chirp impulsions à des données de codage et a été trouvée être particulièrement élastique contre les interférences, les effets Doppler et multitrajet. Les gazouillis sont des ondes sinusoïdales qui augmentent ou diminuent avec le temps. Puisqu’ils utilisent la totalité du canal pour la communication, ils sont relativement robustes en termes d’interférences. Nous pouvons penser à des signaux de gazouillis avec des fréquences croissantes ou décroissantes (ressemblant à un appel de baleine). Le débit binaire utilisé par LoRa est fonction du taux de chirp et du taux de symbole. Le débit binaire est représenté par R b , le facteur d’ étalement par S , la bande passante par B .
Par conséquent, le débit binaire (bps) peut varier de 0,3 kbps à 5 kbps et est dérivé comme :
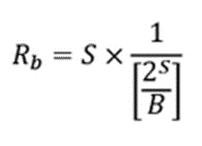
Cette forme de modulation permet une faible puissance sur de longues distances, comme les militaires l’ont constaté. Les données sont codées en utilisant le taux de fréquence croissant ou décroissant et plusieurs transmissions peuvent être envoyées avec différents taux de données sur la même fréquence. CSS permet aux signaux d’être reçus à 19,4 dB sous le plancher de bruit en utilisant la FEC. La bande est également subdivisée en plusieurs sous-bandes. LoRa utilise des canaux à 125 kHz et consacre six canaux à 125 kHz et un saut de canal pseudo-aléatoire. Une trame sera transmise avec un facteur d’étalement spécifique. Plus le facteur d’étalement est élevé, plus la transmission est lente mais plus la plage de transmission est longue. Les trames dans LoRa sont orthogonales, ce qui signifie que plusieurs trames peuvent être envoyées simultanément tant que chacune est envoyée avec un facteur d’étalement différent. Au total, il existe six facteurs d’étalement différents (SF = 7 à SF = 12).
Le paquet LoRa typique contient un préambule, un en-tête et une charge utile de 51 à 222 octets.
Les réseaux LoRa ont une fonctionnalité puissante appelée Adaptive Data Rate (ADR). Cela permet essentiellement une capacité évolutive dynamique basée sur la densité des nœuds et de l’infrastructure.
L’ADR est contrôlé par la gestion du réseau dans le cloud. Les nœuds proches d’une station de base peuvent être réglés sur un débit de données plus élevé en raison de la confiance du signal. Ces nœuds à proximité peuvent transmettre des données, libérer leur bande passante et entrer rapidement en veille par rapport aux nœuds distants qui transmettent à des vitesses plus lentes.
Le tableau suivant décrit les fonctionnalités de liaison montante et de liaison descendante :
| Fonctionnalité | Uplink | Liaison descendante |
| Modulation | CSS | CSS |
| Budget de liaison | 156 dB | 164 dB |
| Débit binaire (adaptatif) | 3 à 5 kbps | 3 à 5 kbps |
| Taille du message par charge utile | 0 à 250 octets | 0 à 250 octets |
| Durée du message | 40 ms à 1,2 s | 20 à 160 ms |
| Énergie dépensée par message | E tx = 1,2 s * 32 mA = 11 µAh à pleine sensibilité
E tx = 40 ms * 32 mA = 0,36 µAh à une sensibilité minimale |
E tx = 160 ms * 11 mA = 0,5 µAh |
7.2.2 Couche LoRaWAN MAC
LoRaWAN représente le MAC qui réside au-dessus d’un LoRa PHY. Le LoRaWAN MAC est un protocole ouvert, tandis que le PHY est fermé. Il existe trois protocoles MAC qui font partie de la couche liaison de données. Ces trois protocoles équilibrent la latence avec la consommation d’énergie. La classe A est la meilleure pour l’atténuation de l’énergie tout en ayant la latence la plus élevée. La classe B se situe entre la classe A et la classe C. La classe C a la latence minimale mais la consommation d’énergie la plus élevée.
Les appareils de classe A sont des capteurs et des points d’extrémité basés sur batterie. Tous les points d’extrémité qui rejoignent un réseau LoRaWAN sont d’abord associés en tant que classe A avec la possibilité de changer de classe pendant le fonctionnement. La classe A optimise la puissance en définissant divers délais de réception pendant la transmission. Un point de terminaison commence par l’envoi d’un paquet de données à la passerelle. Après la transmission, l’appareil entre en état de veille jusqu’à l’expiration du délai de réception. Lorsque le temporisateur expire, le point d’extrémité se réveille et ouvre un créneau de réception et attend une transmission pendant un certain temps, puis revient à l’état de veille. L’appareil se réveillera à nouveau à l’expiration d’une autre minuterie. Cela implique que toutes les communications de liaison descendante se produisent pendant une courte période de temps après qu’un périphérique envoie une liaison montante de paquets. Cependant, cette période peut être extrêmement longue.
Les appareils de classe B équilibrent puissance et latence. Ce type d’appareil repose sur une balise envoyée par la passerelle à intervalles réguliers. La balise synchronise tous les points de terminaison du réseau et est diffusée sur le réseau. Lorsqu’un appareil reçoit une balise, il crée un emplacement ping, qui est une courte fenêtre de réception. Pendant ces périodes de créneau ping, les messages peuvent être envoyés et reçus. Dans tous les autres cas, l’appareil est en veille. Il s’agit essentiellement d’une session initiée par une passerelle et basée sur une méthode de communication à créneaux.
Les points de terminaison de classe C consomment le plus d’énergie mais ont la latence la plus courte. Ces appareils ouvrent deux fenêtres de réception de classe A ainsi qu’une fenêtre de réception alimentée en continu. Les appareils de classe C sont généralement sous tension et peuvent être des actionneurs ou des appareils enfichables. Il n’y a pas de latence pour la transmission en liaison descendante. Les appareils de classe C ne peuvent pas implémenter la classe B.
La pile de protocoles LoRa / LoRaWAN peut être visualisée comme suit:
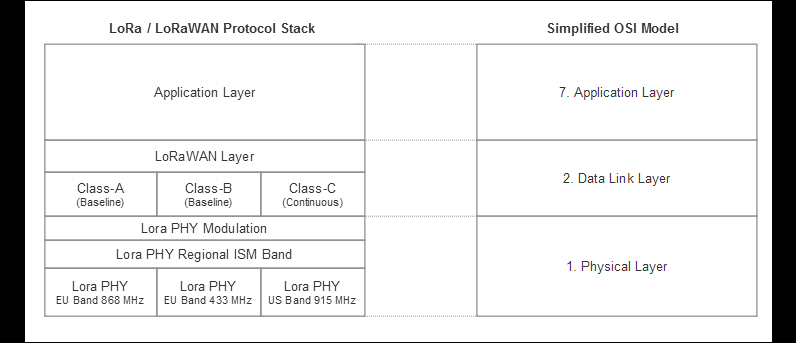
Figure 28 : pile de protocoles LoRa et LoRaWAN par rapport à un modèle OSI standard. Remarque : LoRa / LoRaWAN ne représente que les couches 1 et 2 du modèle de pile
La sécurité LoRaWAN chiffre les données à l’aide du modèle AES128. Une différence dans sa sécurité par rapport aux autres réseaux est que LoRaWAn sépare l’authentification et le cryptage. L’authentification utilise une clé (NwkSKey) et les données utilisateur une clé distincte ( AppSKey ). Pour rejoindre un réseau LoRa, les appareils enverront une demande JOIN. Une passerelle répondra avec une adresse d’appareil et un jeton d’authentification. Les clés d’application et de session réseau seront dérivées pendant la procédure JOIN. Ce processus est appelé l’activation en direct (OTAA). Alternativement, un appareil basé sur LoRa peut utiliser l’activation par personnalisation (ABP). Dans ce cas, un opérateur / opérateur LoRaWAN préalloue 32 bits de clés de réseau et de session. Un client achètera un plan de connectivité et obtiendra un jeu de clés auprès d’un fabricant de terminaux avec les clés gravées dans l’appareil.
LoRaWAN est un protocole asynchrone basé sur ALOHA. Le protocole ALOHA pur a été initialement conçu à l’Université d’Hawaï en 1968 comme une forme de communication à accès multiple avant que des technologies telles que CSMA n’existent. Dans ALOHA, les clients peuvent transmettre des messages sans savoir si d’autres clients sont en train de transmettre simultanément. Il n’y a aucune réservation ou technique de multiplexage. Le principe de base est que le concentrateur (ou passerelle dans le cas de LoRaWAN) retransmet immédiatement les paquets qu’il a reçus. Si un point d’extrémité remarque qu’un de ses paquets n’a pas été reconnu, il attendra puis retransmettra le paquet. Dans LoRaWAN, les collisions ne se produisent que si les transmissions utilisent les mêmes canaux et le même facteur d’étalement.
7.2.3 Topologie LoRaWAN
LoRaWAN est basé sur une topologie de réseau en étoile. La communication LoRa est également basée sur la diffusion plutôt que sur l’établissement d’une relation d’égal à égal. D’ailleurs, on peut dire qu’il prend en charge une topologie d’étoile d’étoiles. Plutôt qu’un modèle à rayons concentrateur unique, un LoRaWAN peut assumer plusieurs passerelles. Cela permet d’améliorer la capacité et la portée du réseau. Cela implique également qu’un fournisseur de cloud peut recevoir des messages en double de plusieurs passerelles. Il incombe au fournisseur de cloud de gérer et de traiter les diffusions en double.
Un composant essentiel de LoRaWAN qui le distingue de la plupart des transports répertoriés dans cet article est le fait que les données utilisateur seront transportées d’un nœud d’extrémité à la passerelle via le protocole LoRaWAN . À ce stade, la passerelle LoRaWAN transfère le paquet sur n’importe quel backhaul (tel que 4G LTE, Ethernet ou Wi-Fi) à un service réseau LoRaWAN dédié dans le cloud. Ceci est unique car la plupart des autres architectures WAN libèrent tout contrôle des données client au moment où il quitte leur réseau vers une destination sur Internet.
Le service réseau possède les règles et la logique pour effectuer les couches supérieures nécessaires de la pile réseau. Un effet secondaire de cette architecture est qu’un transfert d’une passerelle à une autre n’est pas nécessaire comme dans la communication LTE. Si un nœud est mobile et se déplace d’antenne en antenne, les services de réseau captureront plusieurs paquets identiques provenant de chemins différents. Ces services réseau basés sur le cloud permettent aux systèmes LoRaWAN de choisir le meilleur itinéraire et la meilleure source d’informations lorsqu’un nœud d’extrémité est associé à plusieurs passerelles. Les responsabilités des services réseau comprennent :
- Services d’identification de paquets en double et de sécurité de terminaison
- Routage de liaison descendante
- Messages d’accusé de réception
De plus, les systèmes LPWAN comme LoRaWAN auront 5 à 10 fois moins de stations de base pour une couverture similaire à un réseau 4G. Toutes les stations de base écoutent le même ensemble de fréquences ; par conséquent, il s’agit logiquement d’une très grande station de base.
Ceci, bien sûr, renforce l’affirmation selon laquelle les systèmes LPWAN peuvent être un point de coût inférieur à un réseau cellulaire traditionnel :
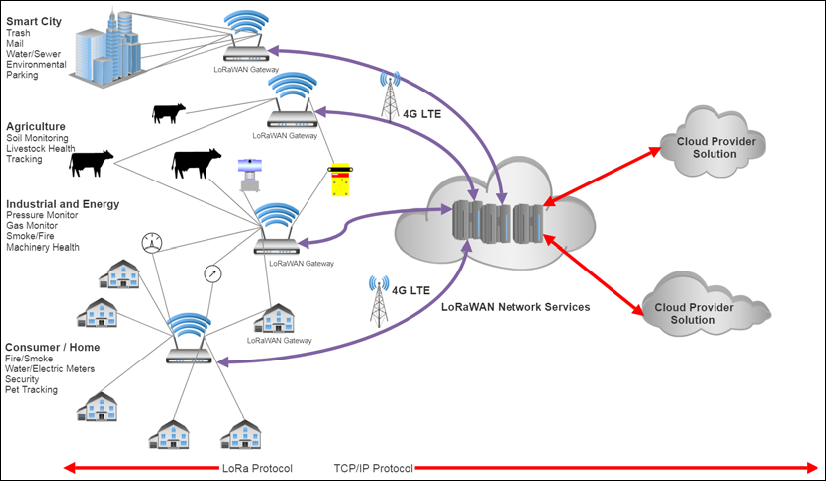
Figure 29 : Topologie du réseau LoRaWAN : LoRaWAN est construit sur une topologie de type étoile par étoile avec des passerelles servant de concentrateurs ainsi que des agents de communication sur les réseaux IP traditionnels à l’administration LoRaWAN dans le cloud. Plusieurs nœuds peuvent s’associer à plusieurs passerelles LoRaWAN .
7.2.4 Résumé LoRaWAN
LoRaWAN est un économiseur d’énergie de réseau étendu longue portée. C’est l’une des technologies les plus adaptées aux objets utilisant des piles. Sa distance de transmission et sa pénétration le rendent très adapté à une utilisation intelligente de la ville (lampadaires, détecteurs de parking, etc.), qui est une application IoT clé. Cependant, il a en effet un faible débit de données et une charge utile limitée, et la régulation du cycle de service peut ne pas répondre aux applications nécessitant une communication en temps réel.
LoRaWAN présente des lacunes dans l’architecture et les protocoles qui nécessitent une attention particulière de la part de l’architecte IoT :
- Certaines fonctionnalités communes aux réseaux LTE ne sont tout simplement pas conçues dans l’architecture LoRaWAN. LoRaWAN n’est pas une pile réseau complète dans le modèle OSI. Il lui manque les caractéristiques communes d’une couche réseau, d’une couche session et d’une couche transport : itinérance, mise en paquets, mécanismes de nouvelle tentative, QoS et déconnexions. Il appartient au développeur et à l’intégrateur d’ajouter ces services si nécessaire.
- LoRaWAN s’appuie sur une interface réseau basée sur le cloud. À un moment donné de la chaîne de valeur, un abonnement cloud est nécessaire.
- Le fournisseur de puces est Semtech, qui est la seule source de la technologie, bien que des partenariats aient été annoncés avec ST Microelectronics. Ceci est similaire à la chaîne de valeur Z- Wave.
- LoRaWAN est basé sur le protocole ALOHA. Validation et reconnaissance des complications ALOHA et contribue à des taux d’erreur supérieurs à 50%.
- La capacité de liaison descendante est toujours limitée. Dans certains cas d’utilisation, cela suffit, mais cela tempère la flexibilité.
- LoRaWAN a une latence élevée et aucune capacité en temps réel.
- Mises à jour du firmware OTA très lentes.
- La mobilité et les nœuds mobiles sont difficiles à gérer dans LoRaWAN . Un message de 40 à 60 octets peut prendre de 1 à 1,5 s pour être transmis. Cela peut être problématique pour déplacer des véhicules à vitesse d’autoroute.
- Une station de base LoRa doit également être invariante dans le temps linéaire (LTI), ce qui signifie que la forme d’onde radio ne devrait pas changer le temps de vol.
- La précision de géolocalisation est d’environ 100 m. En utilisant des mesures de force du signal RSSI ou des mesures de temps de vol, un certain degré de précision peut être obtenu. La meilleure solution est que trois stations de base triangulent un nœud. Plus de stations de base peuvent améliorer la précision.
7.3 Sigfox
Sigfox est un protocole LPWAN à bande étroite (comme NB-IoT) développé en 2009 à Toulouse, en France. La société fondatrice porte le même nom. Il s’agit d’une autre technologie LPWAN utilisant les bandes ISM sans licence pour un protocole propriétaire. Sigfox a quelques traits qui réduisent considérablement son utilité :
- Jusqu’à 140 messages par appareil par jour sur la liaison montante (rapport cyclique de 1%, 6 messages / heure).
- Une taille de charge utile de 12 octets pour chaque message (liaison montante) et 8 octets (liaison descendante). Un débit allant jusqu’à 100 bps en liaison montante et 600 bps en liaison descendante.
À l’origine, Sigfox était unidirectionnel et conçu comme un pur réseau de capteurs. Cela implique que seule la communication de la liaison montante du capteur était prise en charge. Depuis lors, un canal de liaison descendante est devenu disponible.
Sigfox est une technologie brevetée et fermée. Cependant, alors que leur matériel est ouvert, le réseau ne l’est pas et nécessite un abonnement. Les partenaires matériels Sigfox incluent Atmel, TI, Silicon Labs et autres.
Sigfox construit et exploite son infrastructure de réseau de la même manière que les opérateurs LTE. Il s’agit d’un modèle très différent de LoRaWAN . LoRaWAN nécessite l’utilisation d’un PHY matériel propriétaire sur leur réseau, tandis que Sigfox utilise plusieurs fournisseurs de matériel mais une seule infrastructure réseau gérée. Sigfox calcule les tarifs en fonction du nombre d’appareils connectés à l’abonnement réseau d’un client, du profil de trafic par appareil et de la durée du contrat.
Bien qu’il existe des limitations strictes de Sigfox en termes de débit et d’utilisation, il est destiné aux systèmes qui envoient de petites rafales de données peu fréquentes. Les dispositifs IoT comme les systèmes d’alarme, les simples wattmètres et les capteurs environnementaux seraient des candidats. Les données de divers capteurs peuvent généralement s’adapter aux contraintes, telles que les données de température / humidité représentées sur 2 octets avec une précision de 0,004 degré. Vous devez être prudent avec le degré de précision fourni par le capteur et la quantité de données pouvant être transmises. Une astuce à utiliser est les données d’état ; un état ou un événement peut simplement être le message sans aucune charge utile. Dans ce cas, il consomme 0 octet. Bien que cela n’élimine pas les restrictions de diffusion, il peut être utilisé pour optimiser la puissance.
7.3.1 Couche physique Sigfox
Comme mentionné précédemment, Sigfox est à bande ultra-étroite ( UNB ). Comme son nom l’indique, la transmission utilise un canal de communication très étroit. Plutôt que de répartir l’énergie sur un large canal, une tranche étroite de cette énergie est confinée à ces bandes :
- 868 MHz : Europe (réglementation ETSI 300-200)
- 902 MHz : Amérique du Nord (réglementation FCC partie 15)
Certaines régions comme le Japon ont des limitations strictes de densité spectrale qui rendent actuellement le déploiement de la bande ultra-étroite difficile.
La bande a une largeur de 100 Hz et utilise le spectre d’étalement de séquence orthogonale (OSSS) pour le signal de liaison montante et 600 Hz en utilisant la modulation de fréquence gaussienne (GFSK) pour la liaison descendante. Sigfox enverra un court paquet sur un canal aléatoire à un délai aléatoire (500 à 525 ms). Ce type de codage est appelé accès multiple à fréquence aléatoire et à répartition dans le temps (RFTDMA). Sigfox, comme indiqué, a des paramètres d’utilisation stricts, notamment des limitations de taille des données. Le tableau suivant met en évidence ces paramètres pour les canaux de liaison montante et de liaison descendante :
| Uplink | Liaison descendante | |
| Limite de charge utile (octets) | 12 | 8 |
| Débit (bps) | 100 | 600 |
| Nombre maximum de messages par jour | 140 | 4 |
| Schéma de modulation | DBPSK | GFSK |
| Sensibilité (dBm) | <14 | <27 |
La communication bidirectionnelle est une caractéristique importante de Sigfox par rapport aux autres protocoles. Cependant, la communication bidirectionnelle dans Sigfox nécessite quelques explications. Il n’y a pas de mode de réception passif, ce qui signifie qu’une station de base ne peut tout simplement pas envoyer un message à un périphérique d’extrémité à tout moment. Une fenêtre de réception s’ouvre pour la communication uniquement une fois les fenêtres de transmission terminées. La fenêtre de réception ne s’ouvrira qu’après une période de 20 secondes après l’envoi du premier message par un nœud d’extrémité. La fenêtre restera ouverte pendant 25 secondes, permettant la réception d’un message court (4 octets) d’une station de base.
333 canaux, chacun de 100 Hz de largeur, sont utilisés dans Sigfox. La sensibilité du récepteur est de -120 dBm / -142 dBm. Le saut de fréquence est pris en charge en utilisant une méthode pseudo-aléatoire de 3 des 333 canaux. Enfin, la puissance d’émission est spécifiée à +14 dBm et +22 dBm en Amérique du Nord :
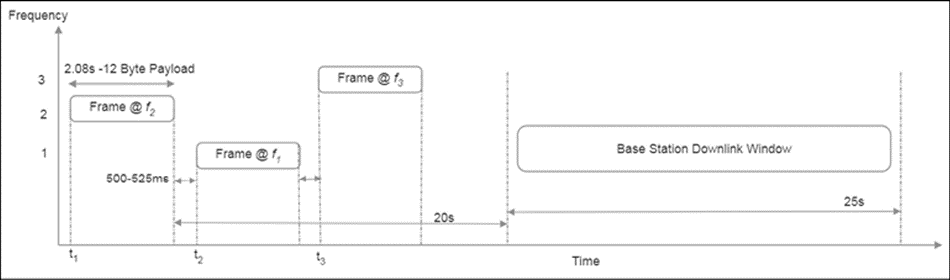
Figure 30: Chronologie de transmission de Sigfox: trois copies de la charge utile sont transmises sur trois fréquences aléatoires uniques avec différents retards. Une fenêtre de transmission de liaison descendante ne s’ouvre qu’après la dernière liaison montante.
7.3.2 Couche Sigfox MAC
Chaque appareil d’un réseau Sigfox possède un identifiant Sigfox unique. L’ID est utilisé pour le routage et la signature des messages. L’ID est utilisé pour authentifier l’appareil Sigfox. Une autre caractéristique de la communication Sigfox est qu’elle utilise le feu et oublie. Les messages ne sont pas acquittés par le récepteur. Un message est plutôt envoyé trois fois sur trois fréquences différentes à trois moments différents par le nœud.
Cela aide à garantir l’intégrité de la transmission d’un message. Le modèle de tir et d’oubli n’a aucun moyen de garantir que le message a bien été reçu, il appartient donc à l’émetteur d’en faire autant que possible pour assurer une transmission précise :
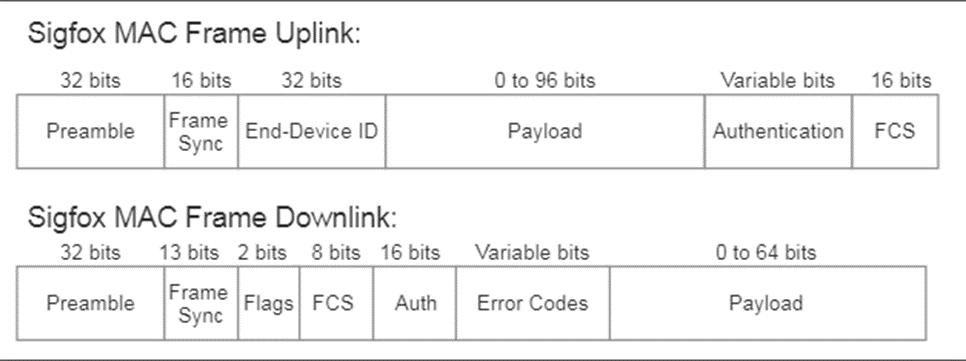
Figure 31 : Structure du paquet de trames MAC Sigfox pour la liaison montante et la liaison descendante
Les trames contiennent un préambule de symboles prédéfinis utilisés pour la synchronisation en transmission. Les champs de synchronisation de trame spécifient les types de trames à transmettre. La séquence de vérification de trame (FCS) est utilisée pour la détection d’erreur.
Aucun paquet ne contient une adresse de destination ou un autre nœud. Toutes les données seront envoyées par les différentes passerelles au service cloud Sigfox.
La limite de données peut être comprise et modélisée à partir du format de paquet de couche MAC :
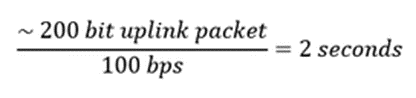
Étant donné que chaque paquet est transmis trois fois, et nous savons que la réglementation européenne (ETSI) limite la transmission à un cycle de service de 1%, nous pouvons calculer le nombre de messages par heure en utilisant la taille de charge utile maximale de 12 octets:

Même si 12 octets est la limite d’une charge utile, ce message peut prendre plus d’une seconde pour être transmis. Les premières versions de Sigfox étaient unidirectionnelles, mais le protocole prend désormais en charge la communication bidirectionnelle.
7.3.3 Pile de protocoles Sigfox
La pile de protocoles est similaire à d’autres piles suivant le modèle OSI. Il existe trois niveaux, détaillés ici :
- Couche PHY : synthétise et module les signaux radio en utilisant DBPSK dans le sens montant et GFSK dans le sens descendant, comme détaillé précédemment.
- Couche MAC : ajoute des champs pour l’identification / l’authentification de l’appareil (HMAC) et le code de correction d’erreur (CRC). Le Sigfox MAC ne fournit aucune signalisation. Cela implique que les appareils ne sont pas synchronisés avec le réseau.
- Couche de trame : génère la trame radio à partir des données d’application. De plus, il attache systématiquement un numéro de séquence à la trame :
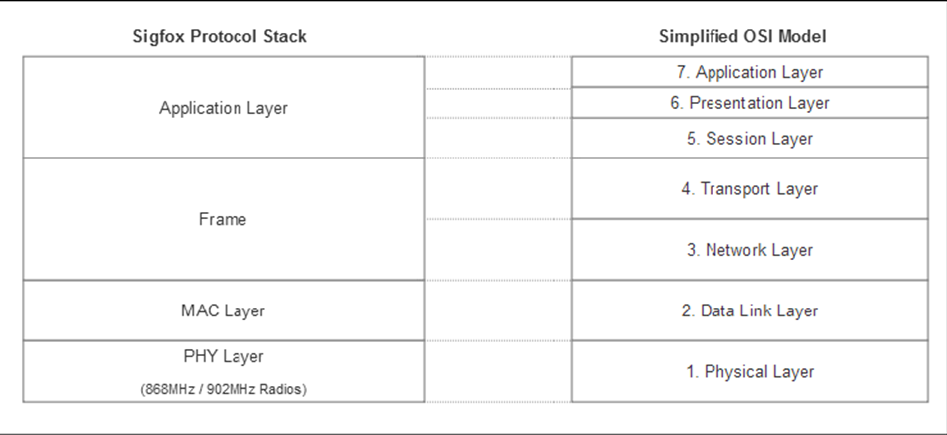
Figure 32 : La pile de protocoles Sigfox par rapport au modèle OSI simpli fi é
En ce qui concerne la sécurité, les messages ne sont chiffrés nulle part dans la pile de protocoles Sigfox. Il appartient au client de fournir un schéma de chiffrement des données utiles. Aucune clé n’est échangée sur un réseau Sigfox ; Cependant, chaque message est signé avec une clé unique à l’appareil pour identification.
7.3.4 Topologie Sigfox
Un réseau Sigfox peut être aussi dense qu’un million de nœuds par station de base. La densité est fonction du nombre de messages envoyés par la structure du réseau. Tous les nœuds qui se connectent à une station de base formeront un réseau en étoile.
Toutes les données sont gérées via le réseau backend Sigfox. Tous les messages d’une station de base Sigfox doivent parvenir au serveur principal via la connectivité IP. Le service cloud backend Sigfox est la seule destination pour un paquet.
Le backend stockera et enverra un message au client après l’avoir authentifié et vérifié qu’il n’y a pas de doublons. Si des données doivent être transmises à un nœud de point d’extrémité, le serveur principal sélectionnera une passerelle avec la meilleure connectivité au point d’extrémité et transmettra le message sur la liaison descendante. Le backend a déjà identifié l’appareil par ID de paquet, et l’approvisionnement préalable forcera les données à être envoyées à une destination finale. Dans une architecture Sigfox, un appareil n’est pas directement accessible.
Ni le backend ni la station de base ne se connecteront directement à un périphérique d’extrémité.
Le backend est également l’administration, l’octroi de licences et le service aux clients. Le cloud Sigfox achemine les données vers la destination choisie par le client. Le service cloud propose des API via un modèle pull pour intégrer les fonctions cloud Sigfox dans une plateforme tierce. Les appareils peuvent être enregistrés via un autre service cloud. Sigfox propose également des rappels vers d’autres services cloud. Il s’agit de la méthode préférée pour récupérer des données:
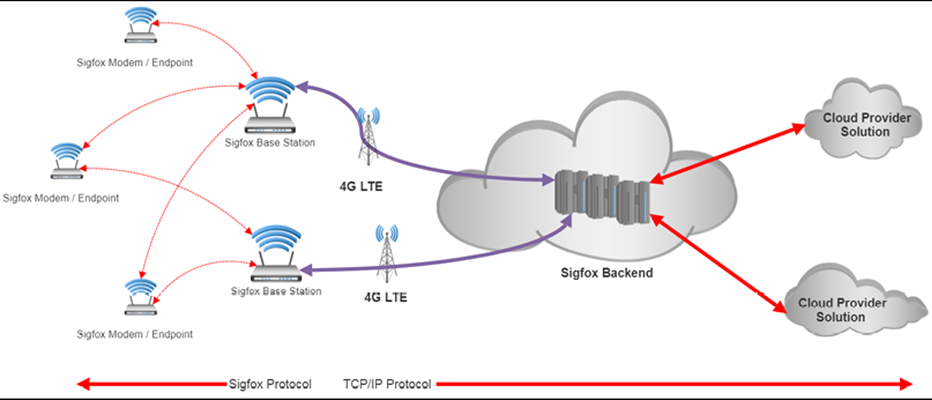
Figure 33 : Topologie Sigfox : Sigfox utilise son protocole propriétaire non IP et fait converger les données vers un backend réseau Sigfox en tant que données IP.
Pour aider à garantir l’intégrité des données du modèle de communication de type “ignorer”, plusieurs passerelles peuvent recevoir une transmission d’un nœud ; tous les messages suivants seront transmis au backend Sigfox et les doublons seront supprimés. Cela ajoute un niveau de redondance à la réception des données.
La connexion d’un nœud de nœud final Sigfox est destinée à faciliter l’installation. Il n’y a pas d’appairage ou de signalisation.
7.4 Résumé
Bien qu’il existe une certaine similitude entre les types de technologies de communication à longue portée, ils ciblent également différents cas d’utilisation et segments. L’architecte IoT doit choisir judicieusement le système à longue portée qu’il compte adopter. Comme les autres composants du système IoT, le LPWAN est difficile à modifier une fois déployé.
Les considérations lors du choix du LPWAN correct incluent :
- Quel débit de données le déploiement IoT doit-il utiliser ?
- La solution peut-elle évoluer avec le même LPWAN dans toutes les régions ? La couverture est-elle adéquate ou doit-elle être construite ?
- Quelle plage de transmission est appropriée ?
- Existe-t-il une exigence de latence pour cette solution IoT ? La solution peut-elle fonctionner avec des latences très élevées (plusieurs secondes) ?
- Les terminaux IoT sont-ils alimentés par batterie et quel est le coût de leur maintenance ? Quelles sont les contraintes de coût des endpoints ?
Pour référence, le tableau suivant détaille les similitudes et les différences entre les protocoles LPWAN mis en évidence dans ce chapitre :
| Spécification | Cat-0 (LTE-M) version 12 | Cat-1 version 8 | Cat-M1 version 13 | Cat-NB version 13 | LoRa / LoRaWAN | Sigfox |
| Bandes ISM | Non | Non | Non | Non | Oui | Oui |
| Bande passante totale | 20 MHz | 20 MHz | 4 MHz | 180 kHz | 125 kHz | 100 kHz |
| Taux de pointe sur la liaison descendante | 1 Mbps | 10 Mbps | 1 Mbps ou
375 Kbps |
200 Kbps | 3 à 5 Kbps adaptatif | 100 bps |
| Taux de pointe en liaison montante | 1 Mbps | 5 Mbps | 1 Mbps ou
375 Kbps |
200 Kbps | 5 Kbps à 5 Kbps adaptatifs | 600 bps |
| Gamme | LTE
Gamme |
LTE
Gamme |
~ 4x Cat-1 | ~ 7x Cat-1 | 5 km urbain , 15 km rural | Jusqu’à 50 km |
| Perte de couplage maximale (MCL) | 7 dB | 7 dB | 7 dB | 164 dB | 165 dB | 168 dB |
| Puissance de sommeil | Faible
– |
Élevé
~ 2 mA au repos |
Très faible
~ 15 µA inactif |
Très faible
~ 15 µA inactif |
Extrêmement faible
5 µA |
Extrêmement faible 1,5 µA |
| Configuration duplex | Demi / Complet | Complet | Demi / Complet | Demi | Demi | Demi |
| Antennes (MIMO) | 1 | 2 MIMO | 1 | 1 | 1 | 1 |
| Latence | 50-100
ms |
50-100
ms |
10-15 ms | 6-10 s | 500 ms à 2 s | Jusqu’à 60 secondes |
| Puissance d’émission (UE) | 23 dB | 23 dB | 20 dB | 23 dB | 14 dB | 14 dB |
| Complexité de conception | 50%
Cat-1 |
Complexe | 25% Cat-1 | 10% Cat-1 | Faible | Faible |
| Coût ( prix relatif ) | ~ 15 $ | ~ 30 $ | ~ 10 $ | ~ 5 $ | ~ 15 $ | ~ 3 $ |
| La mobilité | Mobile | Mobile | Mobile | Limité | Mobile | Limité |
Après avoir couvert la capture des données d’un capteur à la communication de ces données via l’architecture PAN et WAN, il est maintenant temps de discuter du marshaling et du traitement des données IoT. Les prochains chapitres étudieront l’informatique de pointe et son rôle dans l’informatique à partir de données et le marshaling de données vers et depuis un cloud ou d’autres services. Nous examinerons les protocoles pour empaqueter les données, les sécuriser et les acheminer vers le bon emplacement. Cet emplacement peut être un nœud périphérique / brouillard ou le nuage. Nous détaillerons également le type de protocoles de communication basés sur IP, comme MQTT et CoAP , nécessaires pour diffuser des données du bord vers le cloud. Les chapitres suivants couvriront l’ingestion, le stockage et l’analyse des données générées par l’IoT.
8 Edge Computing
L’IoT bénéficie d’une grande attention industrielle et économique en raison du nombre d’appareils qui seront finalement déployés et de la quantité de données que ces appareils produiront. Il existe deux méthodes concernant le fonctionnement et la communication des périphériques et des capteurs avec Internet :
- Les capteurs et appareils au niveau de la périphérie fourniront un chemin direct vers le cloud. Cela implique que ces nœuds et capteurs de niveau périphérique disposeront de suffisamment de ressources, de matériel, de logiciels et d’accords de niveau de service pour transmettre directement les données via le WAN.
- Les capteurs au niveau de la périphérie formeront des agrégations et des grappes autour des passerelles et des routeurs pour fournir des zones de transit, des conversions de protocole et des capacités de traitement de la périphérie / brouillard, et ils géreront la sécurité et l’authentification entre les capteurs et le WAN.
Ce chapitre détaille l’informatique de bord. Le rôle de l’informatique de périphérie implique une grande partie de ce que nous avons déjà appris sur les communications, mais nous devons également prendre soin de la gestion informatique et de l’interfaçage cloud. Nous explorerons différentes fonctions de l’informatique de périphérie, telles que les considérations relatives aux processeurs et au matériel, la conception du système d’exploitation, les techniques de gestion, la conteneurisation, le stockage et la mise en cache, et des exemples d’utilisation. La conception des ordinateurs de bord est si variée, étant dépendante de chaque solution et de chaque client, il est injuste de se concentrer sur un cas d’utilisation unique. Un cas d’utilisation est dans les systèmes 5G, que nous explorerons lorsque nous couvrirons l’informatique de bord “multi-accès”. Un autre cas d’utilisation pour l’informatique de périphérie concerne les passerelles, les concentrateurs et les routeurs, qui seront traités dans un chapitre séparé.
Un cas d’utilisation supplémentaire concerne le traitement de capteurs avancés comme la capture vidéo et les dispositifs d’apprentissage automatique à proximité de sources de données. Nous généraliserons donc autant que possible et aiderons l’architecte à prendre des décisions éclairées sur la technologie sous-jacente.
De plus, nous approfondirons divers aspects de l’électronique de pointe, des architectures informatiques, des systèmes de mémoire et des middlewares. Bien que ces sujets soient vastes, un architecte doit être familiarisé avec la façon dont divers aspects et choix dans la conception matérielle peuvent affecter le coût, la fiabilité et la valeur.
8.1 But du bord dans la définition
Bien que les plates-formes informatiques fonctionnant en dehors des environnements d’entreprise et des centres de données gérés par l’informatique ne soient pas nouvelles, les systèmes de périphérie sont aujourd’hui des extensions des composants généraux gérés par l’informatique comme s’ils étaient sous le contrôle et la sécurité d’un centre de données d’entreprise. Les systèmes Edge sont essentiellement des systèmes informatiques distants et empruntent des éléments des domaines d’ingénierie établis des systèmes embarqués, du cloud computing, de la sécurité informatique et des télécommunications.
L’une des premières formes d’informatique gérée à distance existait bien avant les systèmes cloud et l’informatique générale. Dans les années 1930 et 1940, la production d’énergie se développait rapidement aux États-Unis à mesure que les projets hydroélectriques et le réseau électrique se formaient. Pour gérer la vaste étendue des postes de commutation électrique, un système de télécommande a été mis en place à l’aide de fils pilotes. Nous pouvons considérer les fils pilotes comme des signaux de commande de bande latérale à l’extérieur des lignes à haute puissance et attachés à un circuit d’urgence pour contrôler le flux d’énergie et résoudre à distance les problèmes de capacité et détecter les défauts CA. Les opérateurs à distance pourraient contrôler le réseau national à partir des centres d’exploitation centraux plutôt que de gérer chaque centrale et sous-station. Plus tard, ces dispositifs ont évolué et sont devenus ce que l’on appelle des contrôleurs logiques programmables (API).
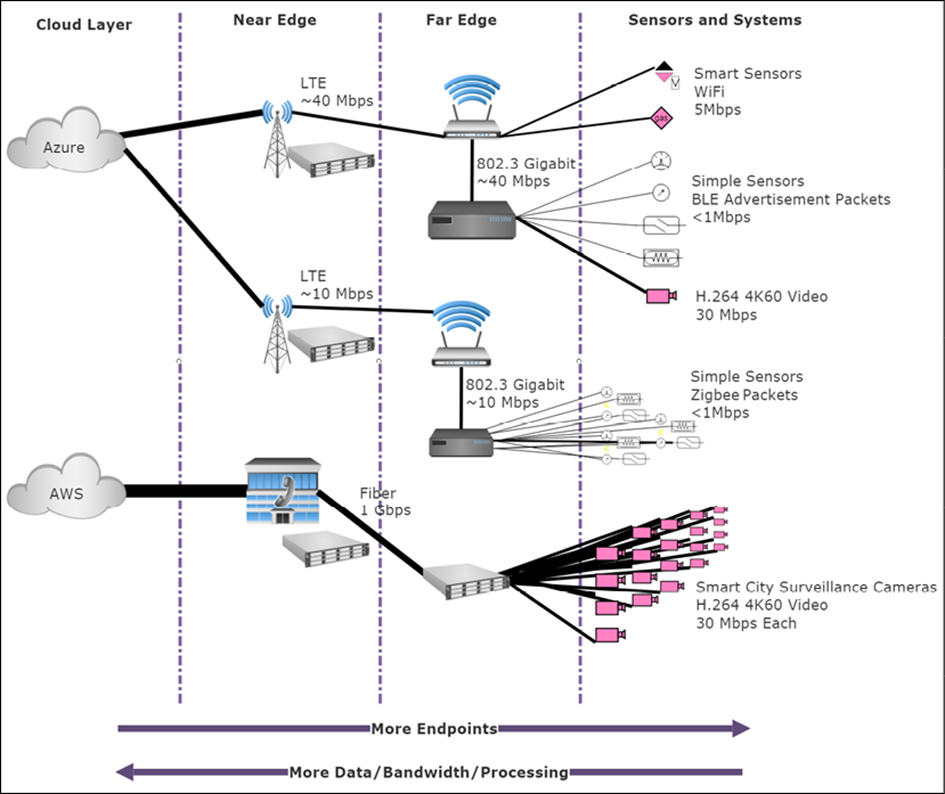
Figure 1 : Différence de proximité et de ressources entre l’informatique proche et éloignée
Aux fins de définition, nous ferons référence aux composants de bord proche et de bord éloigné comme suit :
- Composants proches : partie de l’infrastructure située entre la limite éloignée et les couches de nuages. Les systèmes à proximité peuvent coexister avec une infrastructure de porteuse WAN telle que la colocation de matériel dans les tours de cellules et les stations de commutation cellulaires. Cette couche peut héberger des services complexes sur le plan des calculs, comme un réseau étendu défini par logiciel (SDWAN) (que nous examinerons plus loin dans ce chapitre).
- Composants éloignés : consistent en des dispositifs de traitement capables de communiquer, de gérer et d’échanger des données avec des appliances cloud et / ou proches. Cette couche est la plus éloignée de la couche nuageuse globale, mais elle maintient toujours une relation avec le nuage, ainsi qu’avec ses composants proches du bord. Cette couche est la plus proche des utilisateurs finaux ou des systèmes de capteurs. Cette couche a des exigences telles qu’une conception en temps réel difficile ou critique pour la sécurité et une faible latence, et peut héberger de grands réseaux PAN en tant que passerelle.
Il faut comprendre que le simple fait de connecter un capteur à un ordinateur à distance ne constitue pas une informatique de bord, tout comme une personne utilisant un PC non connecté pour jouer à un jeu vidéo n’est pas un joueur en ligne. Cependant, dès que ce capteur fournit des données à un service cloud ou que l’humain joue à un jeu de réalité virtuelle interactif, ils travaillent avec des dispositifs informatiques de pointe qui doivent agir de concert avec des services cloud centralisés.
Généralement, plus ils sont éloignés des couches nuageuses, plus les systèmes informatiques seront limités en ressources. Cependant, il y aura plus de points finaux à mesure que nous nous éloignerons des couches de nuage sous la forme de systèmes non IP tels que des capteurs Bluetooth et des systèmes SCADA. Nous appelons cette expansion fan-out.
Outre la définition large de l’informatique de périphérie, il existe également un jargon lié à l’approche de la conception de l’informatique de périphérie :
- Informatique de brouillard : L’informatique de brouillard fait référence à une architecture de services cloud qui s’étend des systèmes de cloud du centre de données central aux périphériques proches et éloignés. Le brouillard représente une abstraction unique d’un ensemble géographiquement disparate d’ordinateurs cloud et périphériques pour se comporter et agir comme une seule entité. Plus d’informations seront discutées sur le calcul du brouillard dans les chapitres suivants.
- Informatique de périphérie à accès multiple (MEC) : anciennement appelée informatique de périphérie mobile, MEC permet aux applications à faible latence, à large bande passante et en temps réel d’exister et d’être distribuées à la périphérie de réseaux plus importants. MEC est défini par l’Institut européen des normes de télécommunications (ETSI) et consiste à permettre aux développeurs d’exécuter des applications au sein du réseau d’accès radio (RAN) d’un opérateur de télécommunications. Le RAN a été défini précédemment dans le chapitre 7, Systèmes et protocoles de communication à longue portée (WAN). En règle générale, le RAN existe physiquement avec le contrôleur de réseau radio dans une station de base cellulaire. MEC pourrait autoriser le streaming vidéo à faible latence ou les jeux en nuage.
- Cloudlets : un cloudlet est un centre de données cloud à petite échelle. Vous pouvez le considérer comme un “cloud-in-a-box”. En d’autres termes, c’est un appareil pour prendre en charge des cas d’utilisation gourmands en ressources dans les types d’applications client-serveur. Ceci est similaire au concept MEC pour faciliter de meilleurs temps de réponse et une latence plus faible, mais ne s’associe pas nécessairement à une infrastructure de télécommunication ou de transporteur.
8.2 Cas d’utilisation Edge
Les systèmes de périphérie sont colocalisés comme indiqué dans la figure précédente, à proximité de l’endroit où les données sont générées ou des personnes se trouvent. Actuellement, environ 20% des données des entreprises sont collectées en dehors des murs des entreprises. Gartner prévoit que d’ici 2023, jusqu’à 75% des données d’entreprise et d’entreprise seront collectées et gérées par des systèmes en dehors des frontières physiques de l’informatique d’entreprise et des centres de données.
Edge computing sert quatre modèles d’utilisation principaux :
- Latence réduite : les systèmes Edge peuvent être placés plus près des utilisateurs finaux et des services. Cela peut naturellement éviter divers sauts de réseau et propagation. Certaines applications sensibles à la latence, comme les jeux en ligne et le streaming vidéo, ont des exigences strictes de latence et de performances en temps réel. Cela inclut également les appareils qui nécessitent une prise de décision en temps réel ou l’exécution de moteurs de règles pour les machines critiques pour la sécurité.
- Préservation de la bande passante : certains environnements ont une bande passante limitée vers et / ou depuis le système de périphérie. Dans d’autres cas, les coûts de données pour le cloud ou les centres de données peuvent devenir prohibitifs à l’échelle ou à un volume important. De nombreux opérateurs ont des plafonds de données ou des barèmes de frais en fonction de l’utilisation. L’informatique de périphérie peut mieux répondre à ce problème grâce aux techniques de filtrage, de mise en cache et de compression des données pour maximiser efficacement la bande passante disponible.
- Informatique résiliente : certaines situations n’ont pas de communication fiable. Un exemple peut être une application de transport ou de logistique qui suit une flotte de véhicules et de marchandises en temps réel ainsi que des données critiques sur la température des marchandises. Un véhicule en mouvement peut parfois perdre sa connexion de transporteur lors de ses déplacements dans les tunnels, les zones rurales et les passages souterrains. Il est inacceptable dans ces cas d’utilisation de simplement “perdre” des données. Par conséquent, ces types de systèmes doivent examiner la mise en cache locale de périphérie pour stocker les données jusqu’à ce que la communication soit rétablie. Ces systèmes peuvent également disposer de techniques de routage de basculement ou de transfert pour basculer vers différentes porteuses en cas de perte de porteuse principale.
- Sécurité et confidentialité : certaines situations doivent sécuriser ou même supprimer certaines données avant qu’elles ne se déplacent plus loin dans le cloud ou d’autres bords. Cela est particulièrement vrai pour les situations impliquant des données et des images de santé ou la confidentialité personnelle pour la surveillance. Dans de nombreux cas, la sécurité des données est définie par des réglementations gouvernementales. Par exemple, un système de bord utilisé pour la vidéosurveillance peut avoir besoin de dénaturer des images contenant des images d’enfants si les images sont utilisées dans une émission publique. Cela peut impliquer d’énormes quantités de ressources informatiques à la périphérie.
Avec ces modèles, certains cas d’utilisation courants dans l’industrie sont les suivants :
| Catégorie | La description | Utilisation Edge |
| Automatisation des appareils | Interaction, contrôle et surveillance des « objets », capteurs, systèmes et environnements basés sur les bords. Ceux-ci nécessitent une interaction basée sur le cloud, mais ont des besoins en temps réel. | Systèmes de contrôle industriels, véhicules autonomes. |
| Environnements d’immersion | Types d’interactions AR et VR, chirurgie à distance, systèmes de commande vocale (Alexa). | Systèmes Edge utilisés pour réduire la latence et augmenter la bande passante pour les applications sensibles au bon timing et à la synchronisation. |
| Surveillance des patients | Solutions de soins de santé, de soins à domicile et de surveillance des patients qui doivent être robustes, infaillibles et sécurisées. | Les systèmes Edge peuvent coexister avec les patients pour fournir une communication sécurisée et résiliente avec les systèmes de prestataires de soins de santé en amont. |
| Agrégation PAN | Environnements avec des systèmes non IP et des environnements maillés nécessitant un pont et une traduction entre les piles de protocoles. | Les systèmes Edge agissant comme des concentrateurs, des ponts et des passerelles peuvent être gérés et participent en tant que composants sécurisés dans un réseau d’entreprise. |
| Gestion de la communication résiliente | Transport et logistique, flottes et entreprises de camionnage qui nécessitent une communication cohérente avec les systèmes de cloud ou de centre de données. | Les systèmes Edge peuvent surveiller et maintenir la résilience dans un environnement de communication défectueuse grâce à la mise en cache, aux techniques de basculement et aux méthodes de commutation des opérateurs. |
| Réseaux immersifs de divertissement et de livraison aux clients | Jeux, streaming vidéo et divertissement mobile basés sur le cloud. | Les systèmes de périphérie peuvent être placés dans des emplacements stratégiques pour aider à équilibrer la latence et la capacité des applications de streaming vidéo et de jeu à grande échelle généralement hébergées dans de grands centres de données non-sens. |
| Traitement IoT | Gestion de plusieurs capteurs et entrées. Les données doivent être filtrées, nettoyées pour détecter les anomalies, empaquetées et compressées. Les données peuvent également être transmises via des moteurs de règles, des moteurs d’inférence ou du matériel de traitement du signal et être traitées localement. | Les systèmes Edge offrent la possibilité de traiter efficacement des données en vrac localement en temps réel et sans coût de déplacement de ces données vers le cloud. |
| Gestion des appareils | Appareils IoT et périphériques nécessitant une gestion du système, des mises à niveau du micrologiciel et des correctifs. | Les systèmes Edge peuvent maintenir un «manifeste» de correctifs et de mises à niveau qualifiés et authentifiés des périphériques qu’il gère. Ils peuvent organiser et qualifier les mises à niveau du firmware sans intervention humaine. |
8.3 Architectures matérielles Edge
Les systèmes Edge peuvent être des serveurs lame de classe identique aux systèmes utilisés dans les centres de données d’entreprise ou peuvent être des périphériques informatiques éloignés plus proches d’un ordinateur embarqué renforcé. Dans cette section, nous explorons certains des aspects du matériel pour les appliances éloignées qui doivent exister en dehors des limites de l’infrastructure du centre de données.
En fonction des circonstances et de l’environnement, de nombreux choix de conception matérielle existent. Vous pouvez utiliser un module informatique standard fourni par divers OEM ou choisir de construire du matériel à partir d’un ensemble de composants discrets ou de modules de sous-système. Quelle que soit la méthode, le matériel final doit répondre à la charge de travail et aux cas d’utilisation destinés à être placés sur le système de périphérie.
Quelle que soit l’architecture, tous les appareils informatiques modernes se composent d’une unité de calcul, d’un bus et d’une mémoire. C’est ce qu’on appelle l’architecture von Neumann. Que nous travaillions avec un ordinateur Edge multi-accès sous la forme d’une lame Intel Xeon à double socket avec 512 Go de DRAM et consommant 1000 watts de puissance ou un ordinateur distant chargé d’agréger le trafic à partir d’un certain nombre de capteurs Bluetooth et de filtrage les données vers un service de réseau étendu à faible puissance (LPWAN) ont toutes des architectures similaires.
Il y a des différences que nous allons examiner et comprendre, à commencer par le matériel. Nous allons examiner chaque pièce dans un ordinateur de modèle de pensée illustré dans la figure suivante. Ici, nous représentons un système sur puce (SOC) typique avec deux cœurs, un processeur de signal numérique intégré (DSP) et plusieurs blocs d’E / S.
Cela peut être étendu à des topologies plus grandes comme le matériel de classe serveur tout aussi facilement :
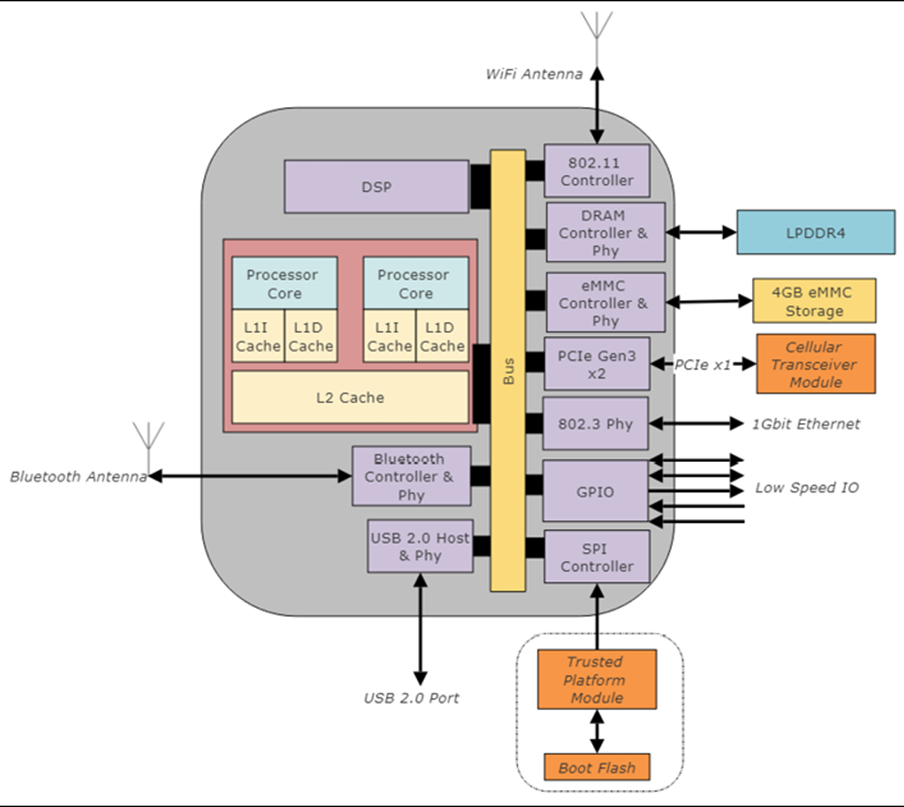
Figure 2 : Exemple d’architecture de schéma de principe d’un SOC typique et des interconnexions. Notez la construction générale des processeurs, du bus et de la mémoire selon le principe architectural de von Neumann.
8.3.1 Processeurs
L’élément central du périphérique de calcul est le processeur. Les architectures de processeur modernes couramment utilisées incluent des variantes x86 comme Intel et AMD, ARM et, dans une bien moindre mesure, MIPS, RISCV, SuperH , Sparc et PowerPC. Cette sous-section examinera certains des traits communs de divers processeurs et leur utilisation à la périphérie. Pour certaines applications de périphérie, il peut être judicieux d’avoir un processeur multicœur multithread robuste avec une exécution dans le désordre. Pour les autres cas d’utilisation et les clients périphériques, un système monocœur plus étroitement intégré peut suffire.
8.3.1.1 Vitesse et puissance
L’unité de mesure la plus fondamentale pour les performances du processeur est la vitesse d’horloge. Chaque processeur a un temps de cycle auquel tous ses composants sont synchronisés. Les processeurs typiques d’aujourd’hui auront des vitesses de 1, 2 ou 3 GHz La vitesse de la conception est fonction de la géométrie du processus et de la méthodologie utilisée pour créer les structures en silicone. Nous ne doublons plus la vitesse du processeur tous les 2 ans comme nous l’avons fait au milieu des années 90. Il est devenu de plus en plus difficile d’améliorer la vitesse du processeur en raison des défis associés au rétrécissement des structures en silicone. Les procédés de lithographie d’aujourd’hui utilisés pour créer des SOC et des ASIC construisent des nœuds à 14 nm et 7 nm en utilisant les systèmes de lithographie UV et d’immersion humide les plus avancés et les types de transistors avancés comme les FINFET. L’horloge plus rapide d’un appareil ne fonctionne tout simplement pas. Le facteur limitant pour forcer un appareil à fonctionner plus rapidement est la chaleur. Toute l’électronique dissipe l’énergie résiduelle sous forme de chaleur. La puissance générée par les circuits de commutation, comme un transistor, est fonction de la fréquence de fonctionnement de l’appareil, de la capacité interne et du carré de la tension :

À mesure que la fréquence augmente, il faut souvent augmenter également la tension pour augmenter la tension de seuil V T des circuits. L’augmentation de la tension réduira alors la propension aux erreurs lors des transitions numériques (de la logique 0 à 1 ou 1 à 0). Cependant, l’utilisation de la partie V 2 de l’équation de puissance a un effet néfaste sur la puissance de fonctionnement de l’électronique.
T J est la température de fonctionnement la plus élevée à laquelle un semi-conducteur est spécifié pour fonctionner correctement. Si la température dépasse la température de jonction maximale autorisée, un phénomène appelé migration ionique se produira. Les structures en silicium sont dopées avec des ions spéciaux tels que le bore et infusées dans le réseau cristallin des atomes de silicium. C’est ce qui donne aux semi-conducteurs leur structure et leurs traits conducteurs ou non conducteurs. Ces ions dopants ne sont pas naturels dans les cristaux de silicone et auront tendance à migrer vers un état plus naturel basé sur les lois de la thermodynamique. Si la température augmente, ce phénomène s’accélère rapidement au point que la puce perd toutes ses propriétés de semi-conducteur.
La plupart des processeurs modernes se protégeront contre l’overclocking hors de portée pour éviter une situation d’emballement thermique et de graves dommages aux circuits. Ils ralentiront leur vitesse de base ou s’arrêteront en toute sécurité. Le moniteur thermique d’Intel, par exemple, est un système interne qui surveille T J pour éviter tout dommage.
Pour les appareils IoT et périphériques, les décisions de vitesse du processeur sont essentielles :
- Pour économiser l’énergie et la durée de vie de la batterie dans les appareils électroniques éloignés et les appareils récupérant l’électricité. Dans ces situations, le sous-cadencement et la réduction de la tension sont essentiels.
- Augmenter les performances (statiquement ou dynamiquement) pour gérer les charges de travail importantes des performances les plus exigeantes telles que l’imagerie, la vision par ordinateur et l’apprentissage automatique.
8.3.1.2 Registres
Tous les processeurs modernes ont une sorte de jeu de registres. Les registres sont la forme de stockage la plus rapide et sont essentiellement des SRAM situés à proximité des pipelines de processeur et accessibles en un seul cycle d’horloge. Les architectures ARM ont 16 registres, dont 3 à usage spécial : R13 contient le point de pile, R14 est le registre de liaison pour les retours d’appels et R15 est le compteur de programme. Les architectures X86 sont différentes. X86 possède 16 registres à usage général avec le noyau 9 couramment utilisé appelé :
- AX / EAX / RAX : Registre d’accumulateur
- BX / EBX / RBX : Registre de base
- CX / ECX / RCX : compteur
- DX / EDX / RDX : accumulateur à précision étendue
- SI / ESI / RSI : Index source
- DI / EDI / RDI : Indice de destination
- SP / ESP / RSP : pointeur de pile
- BP / EBP / RBP : Pointeur de base de pile
- IP / EIP / RIP : pointeur d’instruction
Les registres sont polyvalents et servent à des opérations 16 bits / 32 bits / 64 bits, d’où la nomenclature dans la dénomination des registres. Les architectures ARM sont un type appelé magasin de chargement où toutes les données doivent être chargées de la mémoire principale dans les registres avant de pouvoir être utilisées. X86 peut également fonctionner sur les registres et l’espace mémoire.
8.3.1.3 Architectures de jeux d’instructions (ISA)
Un ISA est le langage mnémonique d’assemblage interne utilisé au niveau d’une instruction machine pour exécuter des opérations de base. Le codage des instructions ISA X86 n’est pas compatible avec ARM. L’ISA dicte quelles instructions existent sur la machine, ce qu’elles font et comment la mémoire est accessible. Par exemple, une architecture ARM fonctionne exclusivement en adressant des données dans un registre local défini à l’unité d’exécution.
Une architecture x86 peut fonctionner sur un ensemble de registres internes ou adresser directement la mémoire DRAM. Voici une instruction CISC x86 pour comparer simplement la valeur d’une adresse mémoire à celle stockée dans un registre local :
cmp 0x400A101C,% ECX: comparer la valeur de l’adresse mémoire 0x400A101C au registre ECX
Ce qui suit est la même instruction sur un ordinateur de jeu d’instructions RISC-V RISC. Ici, nous avons besoin de trois opcodes pour effectuer le travail d’une seule instruction CISC. Cependant, l’instruction CMP peut nécessiter plusieurs cycles d’horloge pour s’exécuter sur une architecture CISC par rapport à un cycle sur un RISC :
lui x6, 0x010C4 : charger un entier non signé dans le registre 6 à partir de la mémoire située à 0x010C4
lw x1, 0x6900 (x6 ): charger le mot dans le registre x1 à partir du décalage de 0x6900 à partir de la valeur dans x6
slt x5, x2, x1 : définir x5 si x2 est inférieur à x1
En termes généraux, cela définit également les différences entre un ordinateur à jeu d’instructions complexe (CISC) et un ordinateur à jeu d’instructions réduit (RISC). Une architecture CISC aura plus d’instructions et de fonctionnalités au prix de plus de matériel et de silicium pour prendre en charge divers modes et capacités d’adressage, tandis qu’une conception RISC aura une architecture matérielle plus simple et plus efficace au prix ou en s’appuyant davantage sur le compilateur et le logiciel pour effectuer opérations complexes.
| RISC | CISC |
| Accent sur la conception de logiciels pour la fonctionnalité | Accent sur la conception matérielle pour la fonctionnalité |
| Enregistrement – pour enregistrer les opérations | Opérations de mémoire à mémoire, d’enregistrement à mémoire et de mémoire à mémoire |
| Charge et stocke les opcodes vers et depuis la mémoire / les registres uniquement | De la mémoire pour enregistrer des charges et des magasins comme RISC mais aussi des références de mémoire également intégrées aux opcodes généraux. Par exemple, l’instruction x86 ADD peut référencer directement la mémoire :
ajouter BYTE PTR [ var], 10 ajoutera 10 à l’octet unique situé à l’adresse mémoire var. |
| Grandes tailles de code | Petites tailles de code |
| Instructions de montage à longueur fixe | Instructions de montage à longueur variable |
| Cycle d’horloge CPU unique par instruction exécutée | Plusieurs cycles d’horloge par instruction exécutée |
8.3.1.4 Endianité
L’autre facteur critique dans la sélection du processeur est l’endianité , qui fait référence à l’ ordre des octets lors de la représentation d’un nombre sous forme binaire. Il indique à quelle extrémité d’une adresse de mot multi-octets dans la mémoire de l’ordinateur se trouve le bit le plus significatif (MSB) et le bit le moins significatif (LSB). Habituellement, un système prend en charge une forme d’endianité au moment de l’exécution, mais de nombreux cœurs de processeur modernes peuvent définir l’endianité au démarrage. Cela dit, les logiciels et binaires précompilés doivent être compatibles avec le bon formulaire.
Il est important de comprendre les formats de données lors de la construction d’un système IoT qui implique plusieurs composants, processeurs et systèmes hétérogènes. Les données collectées par un capteur peuvent être peu endiennes tandis que l’ordinateur de bord qui traite ces données peut être gros endian, et enfin les couches de cloud computing peuvent être peu endiennes.
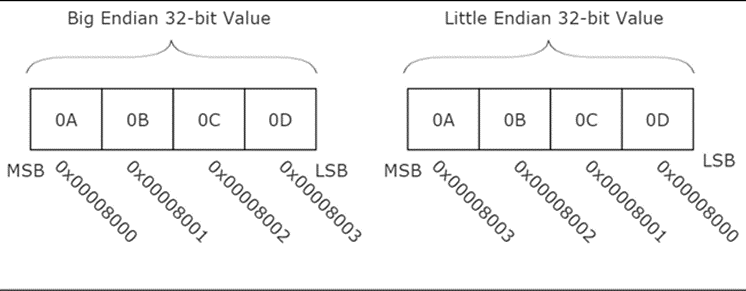
Figure 3 : Différence entre l’ordre des gros et des petits octets d’un mot de 32 bits dans la mémoire de l’ordinateur
Un problème dans les logiciels hérités qui ont été portés sur des générations de CPU, de systèmes d’exploitation et de frameworks est les conversions d’endianisme. Une méthode simple pour migrer des logiciels d’un processeur à un autre où l’endianité est permutée (par exemple, grande à petite) consiste à écrire des permutateurs d’octets logiciels. Il y a eu des produits commerciaux qui comportaient une dizaine de méthodes d’échange d’octets enroulées autour de fonctions, car le code a été porté sur différents processeurs. Il en résulte une perte de performances et une consommation d’énergie importantes.
Lorsque nous examinons les conceptions de processeurs, nous considérons également le nombre de cœurs et le multithreading. De nombreux SOC modernes sont livrés aujourd’hui avec plusieurs cœurs de processeur. Les noyaux peuvent être conçus pour être cohérents ou placés sur le SOC indépendamment. Dans le schéma de principe SOC de la figure 2 plus haut dans ce chapitre, le processeur illustré a deux cœurs CPU identiques.
Ces cœurs ont des caches de premier niveau indépendants mais un cache de deuxième niveau partagé. De plus, les deux cœurs agissent comme un seul complexe CPU lors de l’accès à d’autres blocs matériels sur la mémoire SOC ou DRAM hors SOC. L’accès aux caches de premier niveau est isolé et indépendant de chaque cœur, mais l’accès au cache de deuxième niveau sera cohérent car il s’agit d’une entité partagée. Les deux cœurs agissent comme un processeur logique unique du point de vue logiciel et système d’exploitation. Les threads peuvent être attribués à un noyau particulier via des méthodes appelées affinité de thread, mais généralement le système d’exploitation planifie les processus et les threads selon le noyau disponible.
Le DSP montré dans le schéma fonctionnel n’a aucune cohérence avec le processeur. Même si un processeur de signal numérique est un périphérique programmable, il n’a pas la capacité dans cet exemple de fouiner ou de scruter les caches du processeur ou l’espace mémoire. Par conséquent, d’un point de vue logiciel, si des données doivent être partagées entre deux processeurs ou entités programmables qui ne sont pas cohérents dans le cache, des sémaphores basés sur logiciel, des techniques de mémoire partagée ou des interfaces de passage de messages (MPI) devraient être construits.
8.3.1.5 Processeur parallélisme
Les processeurs modernes tentent diverses techniques microarchitecturales et méthodes grossières pour obtenir le parallélisme dans la mesure du possible. Le but de l’architecture informatique est de conserver autant de silicone et de processeur que nécessaire pour effectuer les tâches efficacement plutôt que d’attendre au repos.
Une technique pour atteindre le parallélisme au niveau de l’instruction ( ILP ) est par pipelining. Presque tous les processeurs modernes ont un pipeline de phases que suit chaque instruction d’un programme. En règle générale, les phases du pipeline comprennent :
- Récupération de l’instruction : le processeur lira une instruction entrante comme indiqué par le pointeur du compteur d’instructions actuel.
- Décodage de l’instruction : l’instruction sera décodée et les parties de l’instruction qui utilisent des valeurs dans le fichier de registre seront immédiatement accessibles.
- Exécution : elle est connue sous le nom d’unité logique arithmétique (ALU) et est l’endroit où les opérations logiques et mathématiques auront lieu.
- Accès à la mémoire : cette étape servira les opérandes de mémoire qui doivent être lus ou écrits à partir / vers des adresses de mémoire.
- Écriture différée : l’étape finale réécrira les données dans le fichier de registre.
L’augmentation du nombre d’étages dans un pipeline a pour effet de simplifier le circuit de chaque étage et de permettre au circuit de fonctionner plus rapidement, bien qu’il y ait une limite à ce type de conception. Chaque étape du tuyau a besoin d’un verrou matériel pour stocker les données à transmettre à l’étape suivante.
En augmentant le nombre d’étapes, il existe un risque accru qu’une dépendance à un certain point du pipeline provoque une «bulle» et que le pipeline doive être vidangé. Les gros pipelines ont des rendements décroissants. Les cœurs modernes comme les systèmes ARM A15 utilisés dans de nombreux projets IoT ont 15 étapes et les conceptions Intel comme Skylake auront 14 à 19 étapes:
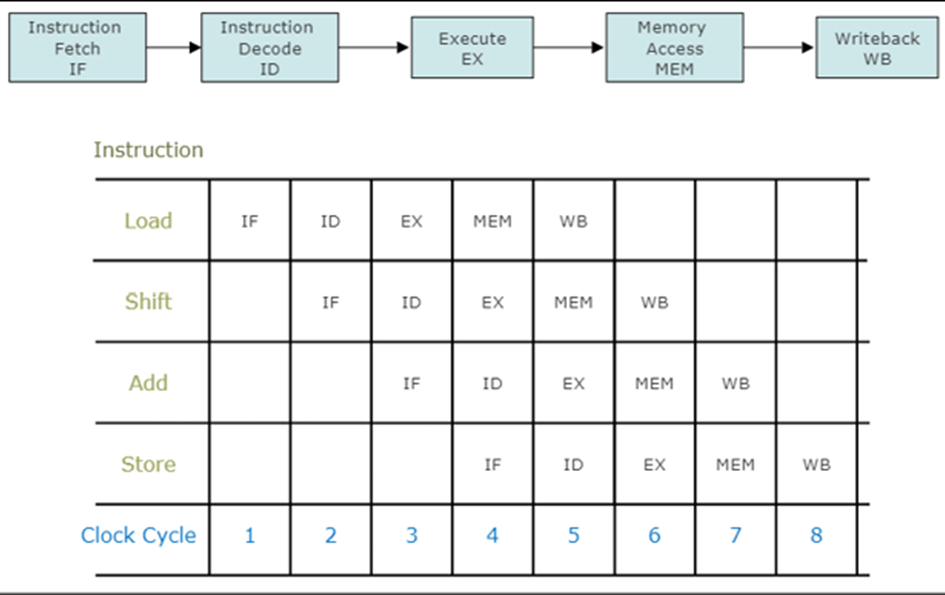
Figure 4 : Le pipeline RISC classique en 5 étapes. Montré est un pipeline avec un flux d’instructions entrantes. Le pipeline décompose les tâches d’exécution en cinq étapes respectives et traite la prochaine instruction entrante lorsque l’étape en cours est libre. Lorsque l’instruction termine le tuyau, elle est dite « retirée ».
Lors de la sélection des processeurs pour le bord, l’autre considération est la conception multithreading et superscalaire. Ce sont des techniques matérielles pour améliorer les performances et l’efficacité énergétique grâce au parallélisme au niveau des threads (TLP). Cependant, l’utilisation de plusieurs cœurs se fait au détriment de la surface en silicone et contribue au coût, et certaines applications peuvent ne pas utiliser TLP. Le multithreading ajoute de la complexité au cœur mais permet une plus grande efficacité dans l’utilisation des processeurs lorsqu’ils sont inactifs. Pour ce faire, il profite des cycles de décrochage dans les pipelines de microprocesseur pendant qu’ils attendent que les données soient extraites de la DRAM ou quelque part dans la hiérarchie de la mémoire. Aux fins de définition :
- Superscalaire : une architecture superscalaire est une forme de base du parallélisme au niveau des instructions du processeur. Un noyau superscalaire peut exécuter plusieurs instructions par cycle en utilisant plusieurs pipelines indépendants.
- Multithreading à grain grossier : Il s’agit d’une forme de multithreading où les threads commutent sur de grands blocages de mémoire (par exemple, L2 manque). Ce n’est que sur un décrochage important qu’un thread différent prêt à fonctionner sera lancé. Ce formulaire souffre de lourdes pénalités de démarrage de pipeline.
- Multithreading à grain fin : cette forme de multithreading bascule entre les threads disponibles au niveau de l’instruction à chaque cycle d’horloge successif. Les fils peuvent être entrelacés sur différents pipelines.
- Multiprocessing : La technique de multiprocessing du parallélisme au niveau du thread sépare simplement un pipeline superscalaire traditionnel en deux ou plusieurs unités d’exécution isolées et différenciables. Les threads conservent leur affinité avec un pipeline particulier et ne migreront pas.
- Multithreading symétrique : SMT est la forme la plus avancée de parallélisme multithread. Cette forme de TLP étend essentiellement le multithreading à grain fin en permettant aux threads exécutables de s’exécuter sur n’importe quel pipeline disponible. Remarquez comment le grain fin ne lance qu’un seul fil sur un ou deux des pipelines. SMT permet aux pipelines de se diviser.
En règle générale, vous pouvez vous attendre à une amélioration de 30% en utilisant le parallélisme SMT. Un effet secondaire est une meilleure utilisation de l’énergie. Cependant, vous devez avoir une architecture logicielle multithread en premier lieu. De plus, il y aura des cas où les unités d’exécution seront inactives. Cela peut être le résultat de threads qui ne sont pas prêts à être exécutés ou de threads qui attendent tous des recharges de cache de la mémoire. Selon les modèles d’accès à la mémoire, les résultats peuvent varier :

Figure 5 : Techniques de parallélisme au niveau du thread. Illustré à partir de pipelines superscalaires simples via SMT.
8.3.1.6 Caches et hiérarchie mémoire
Tous les processeurs modernes ont une mémoire haute vitesse associée qui sert de cache. La hiérarchie de mémoire décompose les caches en niveaux ou niveaux : L1, L2, etc. L1 est généralement associé à la mémoire la plus rapide et la plus proche des pipelines d’exécution des instructions. L2 étant la couche suivante, qui peut avoir un accès légèrement plus lent et peut avoir une conception uniforme et cohérente en cache pour partager des données entre plusieurs cœurs. L’intention avec des espaces de cache et une hiérarchie de mémoire à plusieurs niveaux est de placer les données précieuses et récemment utilisées au plus près des pipelines d’exécution des instructions. L’espace de cache est l’un des principaux facteurs de coût des puces, car il prend une quantité considérable de zone de matrice par rapport aux pipelines d’exécution des instructions. De grands espaces de cache peuvent être nécessaires si les données sont réutilisées, mais pour les données temporelles ou en streaming (par exemple, l’analyse de streaming vidéo), un espace de cache plus petit peut être aussi utile mais moins cher.
Il existe trois façons pour un processeur de ne pas avoir les données ou les instructions à une adresse référencée dans son cache :
- Manquements de conflit : ce type de manquement se produit lorsque des adresses d’alias de mémoire référencées sur la même ligne de cache. Les caches associatifs multi-voies aident ici jusqu’à une limite. Dans le cas où la ligne est aliasée, les anciennes données seront réécrites en mémoire pendant le chargement des nouvelles données.
- Manquements obligatoires : le premier accès à une ligne de cache ne contiendra pas les données de la mémoire principale. Cela va nécessiter une force ligne de cache recharge.
- Manques de capacité : un échec de cache se produit lorsque des blocs de ligne de cache sont rejetés ou expulsés pour faire place à de nouvelles recharges de ligne de cache. Le cache a une capacité limitée (par exemple, 32 Ko) et l’ensemble de travail d’un programme en cours d’exécution peut avoir une taille de mégaoctets.
Les échecs de cache peuvent être extrêmement coûteux, surtout si le résultat implique que le système doit accéder à la mémoire DRAM principale pour recharger une ligne de cache. L’utilisation de processeurs avec des caches de plus en plus grands améliore les performances, mais le coût associatif peut être complètement hors de portée pour certains cas d’utilisation de périphérie. Le tableau suivant présente un graphique typique des performances et de la latence de la hiérarchie de la mémoire pour un processeur Intel Skylake i7 :
| Hiérarchie du cache | Latence |
| Cache de données L1
(32 Ko, 64 octets / ligne, 8 voies associatives) |
1 ns (4 cycles) |
| Cache d’instructions L1
(32 Ko, 64 octets / ligne, 8 voies associatives) |
1 ns (4 cycles) |
| Cache L2 unifié
(1024 Ko, 64 octets / ligne, ensemble associatif 16 voies) |
8 ns (14 cycles) |
| Cache L3
(11 Mo, 64 octets / ligne, ensemble 11 voies associatif) |
20 ns (68 cycles) |
| Mémoire DDR4-3400 | 70 ns (79 cycles + 60ns) |
L’augmentation de l’espace de cache a un coût, comme mentionné. La mémoire cache intégrée dans un processeur utilise un processus différent de celui utilisé pour fabriquer la DRAM. C’est pourquoi la densité de la zone de cache est de quelques kilo-octets à mégaoctets, alors que la DRAM est désormais disponible en paquets de gigaoctets. L’autre effet est qu’une mémoire cache SOC est fondamentalement beaucoup plus rapide que la DRAM. Vous pouvez évaluer la quantité respective de surface utilisée par la hiérarchie de la mémoire cache dans un processeur moderne, comme le microprocesseur Intel Skylake, comme illustré dans la figure suivante. Ici, le dé montre une grande zone pour un GPU ; Cependant, les quatre cœurs de processeur Skylake ont une zone importante pour L2 et un espace de cache de dernier niveau.
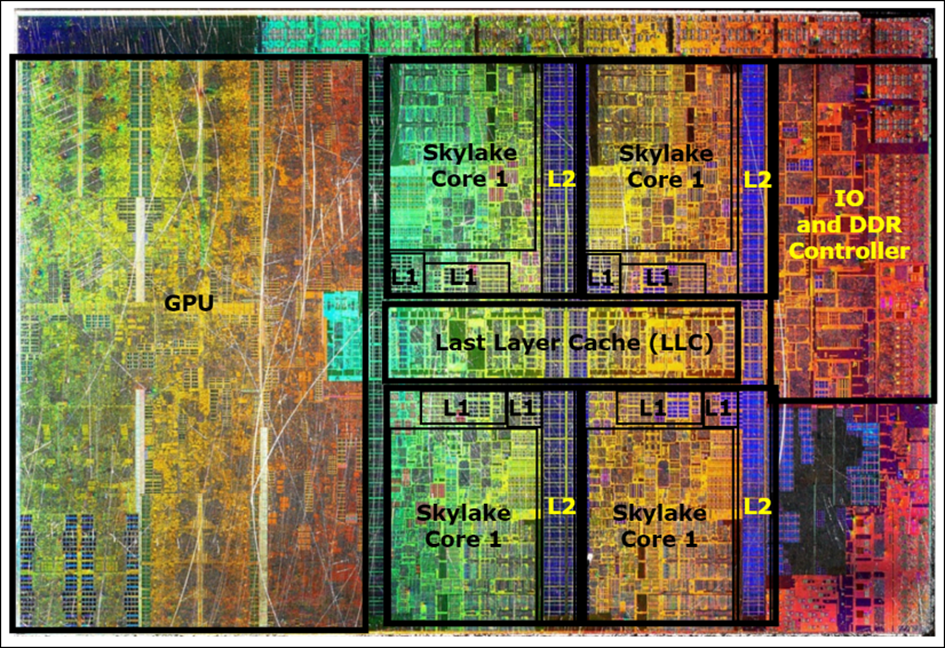
Figure 6 : Die micrographie d’un processeur Intel Skylake. Grandes zones représentant des complexes GPU et quad-CPU. Notez les zones pour différents niveaux de caches au sein de chaque CPU et le LLC partagé entre les quatre.
8.3.1.7 Autres caractéristiques du processeur
Une analyse complète des cœurs de processeur nécessite une compréhension approfondie de l’architecture informatique. Cependant, il est important de comprendre ce pour quoi vous concevez et d’éviter le matériel inutile. Les fonctions CPU suivantes traitent différentes formes de performances grâce au parallélisme et aux modifications du flux de code. N’importe lequel de ces types d’améliorations peut être effectué à l’aide d’un logiciel. Par exemple, les unités à virgule flottante sont courantes, mais de nombreux cœurs de la série ARM M ne disposent pas d’une unité matérielle à virgule flottante incluse en standard (uniquement en tant que module complémentaire en option). Cela n’empêche pas l’exécution de code à virgule flottante. Vous pouvez toujours utiliser des types flottants et doubles, mais toutes les opérations sont émulées au prix de performances inférieures et d’une puissance excessive.
Exécution dans le désordre : les processeurs modernes avancés ont une certaine forme d’exécution spéculative ou des mécanismes d’exécution dans le désordre intégrés dans les pipelines. L’exécution dans le désordre, comme son nom l’indique, ne suivra pas le flux d’exécution logique d’un programme. Au contraire, le matériel émet des hypothèses heuristiques et implicites sur l’instruction à exécuter en fonction des traces de code, des prédictions de branchement et des intervalles de délai de chargement / stockage.
L’exécution dans le désordre dépend d’une énorme quantité de support matériel à gérer. Les registres peuvent être renommés, les pipelines peuvent être redémarrés et les branches sont suivies à la volée. Ce matériel a un coût important en termes de superficie et de dollars ; par conséquent, l’architecte doit connaître les charges de travail sous-jacentes et savoir comment elles peuvent tirer parti de l’exécution spéculative.
Unités à virgule flottante (FPU): les FPU sont courantes dans la plupart des grandes conceptions de CPU, mais pas toutes. La plupart des opérations en virgule flottante sont normalisées par le format IEEE754, qui stipule comment l’arrondi se produit, la génération de mantisse, etc. Comme mentionné, de nombreux cœurs ARM ont des unités à virgule flottante en option. Le FPU ajoute au moins un pipeline supplémentaire et un ensemble de registres à un ensemble de registres entiers de CPU. Les registres FPU peuvent avoir une largeur de 64 bits ou plus.
Les FPU sont essentielles pour certaines charges de travail telles que l’apprentissage automatique utilisant des valeurs de précision simple ou double, les charges de travail d’imagerie et de vision, le traitement numérique du signal et les mathématiques statistiques. Sans unité à virgule flottante, les résultats passent par un émulateur à virgule flottante. Cela peut être un goulot d’étranglement des performances extrêmes. L’émulation à virgule flottante est généralement 10x à 100x plus lente que les virgules flottantes matérielles.
Unités SIMD / AVX : Les moteurs d’exécution à données multiples (SIMD) à instruction unique sont liés aux unités à virgule flottante. AVX signifie Advanced Vector Extensions, qui sont Intel / AMD ISA pour ces types de décharges. Il s’agit de coprocesseurs auxiliaires spécialisés dans le traitement des supports et les charges de travail de traitement des données en masse. Ils s’exécutent sur des vecteurs unitaires à l’aide d’une instruction unique vers un très large vecteur d’unités de données. La largeur de l’unité de registre SIMD peut être de 256 bits de large ou plus, et plusieurs fois ils partagent le même espace de registre que le FPU. Les unités de données sont segmentées en quantités de même taille dans chaque registre. Par exemple, un registre de 256 bits peut être divisé en seize vecteurs de 16 bits.
Il existe un certain support du compilateur pour ces extensions vectorielles ; Cependant, vous devez souvent compter sur des fonctions intrinsèques dans le code C ou C ++, un assemblage en ligne dans le code C ou C ++ ou un assemblage brut pour les activer. Les intrinsèques sont plus faciles à utiliser ; ils peuvent être codés directement dans des fichiers C existants et utiliser leur pile d’appels, mais exécutent généralement en dessous de l’assemblage brut.
Les unités SIMD s’appuient sur un ensemble d’instructions et un pipeline spécial pour exécuter ces opérations. Ceux-ci fonctionnent généralement sur des types de données vectorielles dans un registre plus grand. La figure suivante montre un ensemble de registres ARM Neon 128 bits qui peut être divisé en de nombreuses unités vectorielles plus petites adressées par extension :
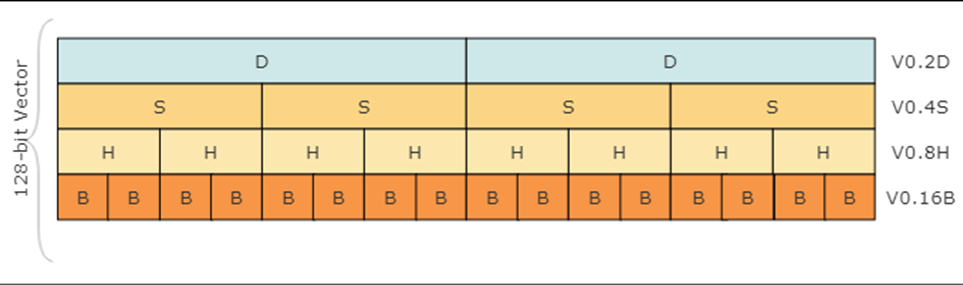
Figure 7 : Un exemple d’un espace de registre SIMD ARM NEON divisé en vecteurs respectifs.
Pour illustrer le fonctionnement des instructions SIMD, nous examinerons deux instructions SIMD ARM AArch64 Neon :
UADDLP V0.8H, V1.16B
FADD V0.4S, V0.4S, V0.4S
UADDLP se traduit par :
- U : entier non signé
- ADD : opération ADD
- L : type de données long
- Q : Par paire, fonctionne sur des paires de vecteurs à deux sources
- V0.8H: Registre de destination v0 organisé en huit demi-mots
- V1.16B: Registre source v1 organisé en 16 octets
FADD se traduit par :
- FADD : vecteurs d’ajout à virgule flottante
- V0.4S: registre de destination v0 organisé en quatre valeurs de précision unique
- V0.4S: Premier registre source v0 organisé en quatre valeurs de précision unique
- V0.4S: Deuxième registre source v0 organisé en quatre valeurs de précision unique
Pour illustrer comment cela fonctionne, prenez UADDLP. Ici, nous ajoutons des paires de vecteurs 8 bits dans le registre V1 et stockons le résultat dans le registre V0. Cela effectue huit ajouts parallèles en un cycle et une instruction :
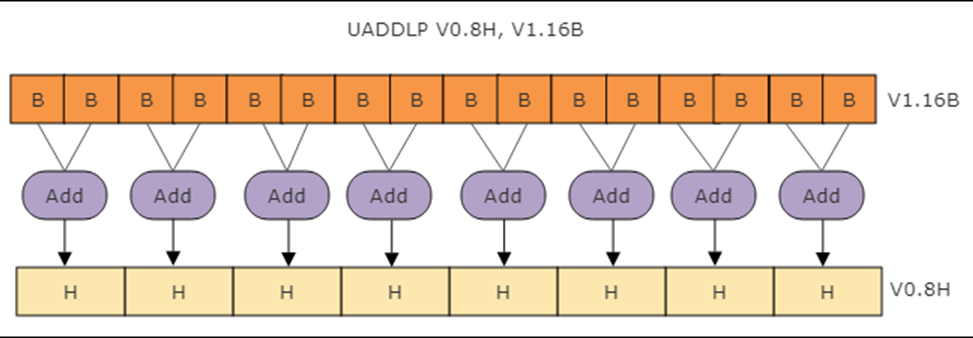
Figure 8 : Exemple simple d’exécution SIMD utilisant l’addition par paire
8.3.2 DRAM et mémoire volatile
La mémoire volatile dans les systèmes de périphérie est comme la variété de jardin vue dans le matériel mobile, embarqué et de classe serveur. Cependant, plus le système doit être proche du bord et plus sensible à la puissance, plus le couplage de la mémoire au SOC est serré. Certains SOC lieront même la SRAM interne à la puce ou ajouteront la DRAM et un module filaire sur une puce multi-module.
En règle générale, vous trouverez des systèmes avec DRAM à double débit (DDR), DDR à faible consommation (LPDDR) et DDR graphique (GDDR). Tous sont essentiellement les mêmes du point de vue des cellules DRAM. Le facteur de forme, le prix et la puissance diffèrent considérablement.
Prenons par exemple ce tableau qui contraste les types de mémoire et leurs différences :
| La mémoire | DDR4 | LPDDR4 | GDDR5 |
| Débit de données maximum par broche | 2 Gbit / s | 267 Gbps | 8 Gbit / s |
| Largeur d’interface | 64 + 8 bits | Deux canaux 16 bits | Plusieurs canaux 32 bits |
| Densité max | 128 Go | 2 Go | 1 Go |
| La tension | 2V | 1V | 6V |
| Montage | Surface ou DIMM | Surface ou module | Surface |
| Coût | $ | $$ | $$$ |
Pour la plupart des charges de travail sur les systèmes de périphérie, le DDR standard dans les boîtiers montés en surface ou les boîtiers DIMM sera utilisé pour l’informatique à usage général. GDDR sera utilisé lorsque nous ajouterons la fonctionnalité d’assistance matérielle GPU. Les GPU nécessitent une mémoire à large bande passante et cela à l’aide de plusieurs modules GDDR connectés à plusieurs canaux sur la puce. Les GPU seront utilisés pour les applications d’imagerie, de vision et d’apprentissage automatique en périphérie.
Une autre préoccupation est la robustesse du centre de données. La plupart des infrastructures de classe serveur reposent sur la mémoire du code correcteur d’erreurs ou ECC. La mémoire ECC détectera et corrigera les défauts les plus courants dans la DRAM. La mémoire DRAM est sensible aux effets aléatoires des rayons cosmiques, des éruptions solaires ou des neutrons qui ont tendance à affecter les condensateurs porteurs de charge dans une cellule DRAM et à « basculer un peu ». L’effet devient plus prononcé à mesure que le système gagne en altitude et a moins de l’atmosphère terrestre comme barrière. Dans un système avec mémoire ECC, l’ordinateur peut fonctionner normalement, se bloquer, planter ou signaler des résultats erronés.
8.3.3 Stockage et mémoire non volatile
Le stockage est un composant central pour de nombreux systèmes de périphérie. Nous avons parlé de la façon dont le stockage peut être utilisé comme service de mise en cache pour stocker des données en cas d’échec de communication ou comment le stockage peut être utilisé pour stocker des données qui seront diffusées aux points de terminaison à partir d’un ordinateur périphérique pour réduire la latence.
La gestion du stockage en périphérie est essentielle à la robustesse de la solution. Comme le système de périphérie peut ne pas être intrinsèquement accessible, un stockage autogéré est nécessaire.
8.3.3.1 Classes de stockage et interfaces
Le stockage peut prendre différentes formes :
- Lecteurs SATA directement connectés : il s’agit de composants de stockage de masse hérités qui s’interfacent à l’aide de l’interconnexion standard SATA. Les disques peuvent être des disques durs rotatifs ou des disques SSD plus récents. SATA est omniprésent et les pilotes sont courants sous Linux et Windows pour prendre en charge cette forme de stockage. Ils sont également les moins chers du marché aujourd’hui. Cependant, les disques basés sur SATA n’ont ni le débit ni la faible latence du stockage de masse NVMe plus récent. SATA a progressé à travers plusieurs générations d’interfaces avec des performances progressivement plus élevées. Le SATA I de première génération était capable de 1,5 Gb / s, le SATA II a augmenté à 3 Gb / s, et le SATAIII moderne est capable de 6 Gb / s.
- Stockage NVMe directement connecté : NVMe signifie mémoire non volatile. Il s’agit d’une forme de stockage qui utilise une interface PCI Express et un protocole optimisé pour communiquer avec les puces flash NAND du module. Les modules peuvent se présenter sous la forme de petits appareils M.2 à embase ou de facteurs de forme standard 2,5 U.2. D’autres formes existent également. NVMe offre une empreinte compacte d’un point de vue matériel et la solution de latence la plus rapide / la plus faible pour tous les composants de mémoire.
- Modules eMMC : eMMC signifie carte multimédia intégrée. La génération actuelle de la spécification est eMMC version 5.0. Ces modules de stockage sont typiques de l’électronique grand public, et les variantes se présentent sous la forme de cartes flash SDIO. Ils sont connus pour leur petite taille et leur facilité de retrait, mais n’ont pas les performances ou la densité des autres supports. Par exemple, un périphérique eMMC typique aura des densités de 16 Go à 64 Go et des performances d’environ 250 Mo / s pour les lectures séquentielles. C’est bien en dessous de la vitesse et des densités de NVMe , mais le coût, la puissance et la taille des pièces sont bien inférieurs.
- Flash USB : Le stockage peut également se présenter sous la forme d’un périphérique de stockage USB connecté. Les mêmes pièces NAND sont utilisées ; Cependant, l’interface avec l’hôte est un bus USB. Ils peuvent être trouvés dans des densités de plus de 1 To et prennent en charge des vitesses d’environ 30 Mo / s en utilisant des interfaces USB 2.0 et 20 Gb / s (2,6 Go / s) en utilisant le mode USB 3.2 Superspeed et des câbles USBC dédiés.
- Flash SPI : tous les périphériques de mémoire répertoriés sont basés sur de la mémoire brute (mémoire NAND dans la plupart des cas) et un contrôleur qui gère les cellules NAND, la conservation, la correction d’erreurs et l’interface API vers un hôte. Un CPU hôte n’a pas besoin du contrôleur pour accéder à la mémoire NAND. Dans le cas du flash SPI, les pièces brutes NAND peuvent être placées sur une carte de circuit imprimé et accessibles par un processeur hôte via une interface SPI à faible vitesse.
C’est généralement ainsi que les appareils démarrent. Dans notre exemple d’ordinateur de bord, un flash SPI est connecté au module de plateforme sécurisée (TPM) qui contient le code de démarrage initial en tant que racine de confiance. La bande passante sera sévèrement limitée par la vitesse de SPI. À 10 Mb / s, l’interface ne fonctionnera pas aussi bien que les autres périphériques de stockage répertoriés. C’est principalement bon pour le démarrage et le stockage embarqué critique.
Le tableau suivant identifie les avantages et les inconvénients de ces types de périphériques de stockage.
| Classe de stockage | Performances | Densité disponible | Coût par bit | Cas d’utilisation |
| SATA | Élevé : 300 à 500 Mo / s | 128 Go à 32 To | $$ (notez que les disques SATA rotatifs sont généralement plus denses et moins chers que les disques SSD) | Stockage standard stockage à faible coût. Edge peut l’utiliser pour des logiciels, des journaux et des systèmes d’exploitation à usage général. |
| NVMe | Très haut. 1 à 32 Go / s | 512 Go à 32 To | $$$$ | Applications à performances extrêmes (capture vidéo). Celles-ci nécessitent également moins d’espace que les disques 2,5 “classiques. |
| USB | Élevé: 30 Mo / s à 2,6 Go / s | 512 Mo à 4 To | $$ | Dispositifs à espace limité. Stockage connecté en externe. Clés de sécurité. |
| eMMC | Faible: <250 Mo / s | 1 Mo à 128 Go | $ | Code de démarrage. Petits systèmes de bord intégrés. |
| SPI | Très faible, 1 Ko / s à 10 Mo / s | 1 Ko à 128 Mo | $ | Clés de sécurité. Informations sur l’identité du système. Numéros de série. Données immuables. |
Les caractéristiques de performance de stockage sont généralement mesurées et annoncées par les fournisseurs utilisant IOPS (entrée / sortie par seconde). Il s’agit d’une mesure des demandes de lecture et d’écriture non contiguës au stockage.
Nous pouvons également traduire les IOPS en octets par seconde en utilisant la formule suivante :
Octets par seconde = IOPS × TransferSizeInBytes
Pour comprendre cette unité de mesure, nous devons revenir à la technologie des disques durs rotatifs. À l’époque où une tête magnétique était placée sur un plateau rotatif, le déplacement de la tête vers différentes positions du plateau a perdu beaucoup de temps dans les performances de stockage. C’est ce qu’on appelle le temps de recherche.
Pour illustrer le problème, nous allons examiner un disque rotatif qui doit lire la même quantité de données de deux manières :
- Exemple de charge de travail 1 : lecture de 10 fichiers de 1 000 Mo. Nous mesurons cela pour prendre un total de 120 secondes. Le taux de transfert est du : 83,33 Mo / s. Comme il y a 10 demandes, le nombre d’IOPS est 10. Même un ancien tournant disque dur peut prendre en charge ESTA.
- Exemple de charge de travail 2 : lecture de 10 000 fichiers de 1 Mo. Même si la quantité totale de données lues est la même que dans l’exemple 1, le disque rotatif aura du mal à atteindre 10 000 IOPS en raison du temps de mouvement de recherche de tête. Cela serait presque impossible à prendre en charge en utilisant un disque dur rotatif.
Étant donné que les dispositifs flash n’ont pas de pièces mobiles, il n’y a pas de temps de recherche. Cependant, de nouveaux effets affecteront les performances du flash :
- Porter le nivellement et la collecte des ordures. Il s’agit du problème d’effacement lent et de fragmentation abordé dans la section suivante.
- Canaux de contrôleur NAND (combien de parties NAND sont accessibles en parallèle).
- Lire et écrire le mélange en pourcentage.
- Utilisation ou mauvaise utilisation des commandes Trim générées par le système d’exploitation.
Lors de l’analyse des performances IOPS dans les systèmes flash NAND, les résultats peuvent varier d’un fournisseur à l’autre. Assurez-vous que les IOPS sont comparés avec la même taille de transfert (4 Ko). Il est également important de traiter le mélange des temps de lecture et d’écriture de la même manière. En règle générale, 70% des données sont lues et 30% sont écrites. Cela affecte les performances globales comme nous le verrons dans la section suivante. En fin de compte, il est préférable d’évaluer les performances à l’aide d’une suite spécifique de tests de référence pour votre cas d’utilisation particulier et de simuler une utilisation sur plusieurs années avec des remplacements complets du stockage.
Enfin, la durabilité du stockage est généralement répertoriée comme des écritures de lecteur par jour (DWPD). Comme nous l’étudierons dans la section suivante, cela est particulièrement important pour les périphériques de type flash NAND qui ont un nombre limité de cycles d’écriture. Cette mesure indique le nombre de fois où la capacité totale de l’appareil peut être entièrement remplacée par jour.
8.3.3.2 Conception et considérations relatives à la mémoire flash NAND
Lors de la détermination du stockage pour un système de périphérie, certains facteurs doivent être pris en compte à l’aide d’un support flash à semi-conducteurs. Le fonctionnement du support flash est très différent de celui des disques magnétiques rotatifs plus anciens. La mémoire flash est basée sur le stockage cellulaire utilisant une « porte flottante » principale. La grille flottante accumule l’électronique pendant le processus d’écriture. La grille flottante se trouve au-dessus d’un canal 1um connecté par une électrode de source et de drain typique trouvée dans un transistor. Au-dessus du portail flottant se trouve un portail de contrôle.
Essentiellement, les données sont stockées sous forme d’électronique piégée dans chaque cellule. Un “1” lu à la sortie d’une cellule représente un état de faible résistance, et la valeur correspondante est un “1” logique. L’écriture de données est un processus plus difficile, connu sous le nom d’injection d’électrons chauds :
- La grille de commande augmente la tension de la grille flottante à travers le diélectrique.
- Cela élève la grille flottante au niveau de tension de programmation et inverse le canal en dessous.
- Les électrons dans le canal sous la grille flottante augmentent leur vitesse de dérive et leur énergie.
- Ces électrons entrent en collision les uns avec les autres dans le réseau, ce qui provoque de la chaleur et élève la température du silicium.
- Les électrons ont suffisamment d’énergie pour surmonter « l’effet de barrière » et s’accumulent dans la grille flottante sous forme d’informations stockées.
La seule méthode pour éliminer ces électrons piégés consiste à utiliser un cycle d’effacement (également connu sous le nom d’effet tunnel Fowler- Nordheim). Le processus d’effacement est le suivant :
- L’électrode source est réglée sur la “tension de programmation” et la grille de commande est mise à la terre. Le drain est laissé flottant.
- Cela force tous les électrons capturés dans la grille flottante à se propager vers la source, laissant la grille flottante sans frais – l’effaçant efficacement.
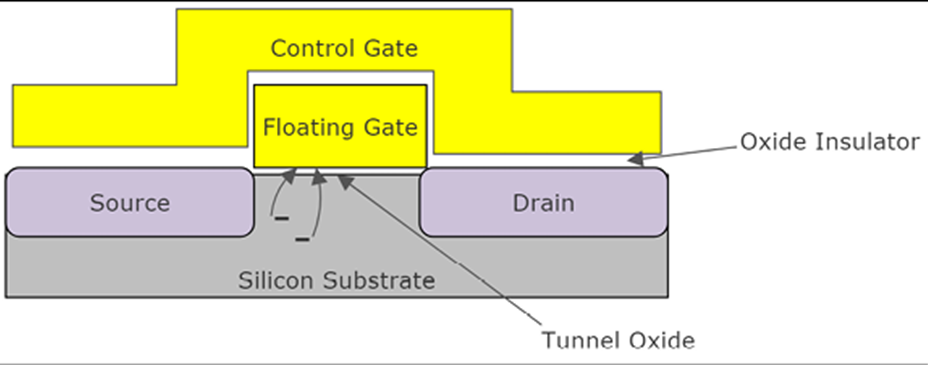
Figure 9 : Cellule NAND à grille flottante : la grille flottante réside “en sandwich” entre les couches d’isolant d’oxyde. Le tunnel d’oxyde présente la barrière pour le flux d’électrons du substrat vers la grille flottante.
Les dispositifs NAND sont vendus sous différentes formes : cellules à un niveau (SLC), cellules à plusieurs niveaux (MLC), cellules à trois niveaux (TLC), et bientôt des cellules à quatre niveaux (QLC). La différence étant la quantité de stockage de bits qui peut être conservée dans une seule cellule. Un NAND MLC, par exemple, peut stocker quatre états par cellule : 00, 01, 10, 11. Ces états correspondent aux niveaux de tension. En revanche, un appareil SLC a deux états (0 et 1) et donc deux niveaux de tension.
Toute cellule à plusieurs niveaux devra lire plusieurs fois les mêmes données à partir de la NAND pour s’enregistrer avec différentes tensions de seuil : TLC lit trois fois et un QLC lit quatre fois. Avec plus de capacité dans la même structure NAND, les performances globales et la longévité diminuent. C’est quelque chose à prendre en compte dans les conceptions de systèmes de bord.
Les cellules Flash ne peuvent être effacées qu’un nombre de fois défini. Bien que les processus se soient améliorés, il existe encore un certain nombre de fois où une cellule peut être utilisée efficacement. Une cellule peut être effacée environ 3 000 à 5 000 fois avant que les caractéristiques électriques de la cellule ne se dégradent pour la rendre peu fiable à retenir une charge. Cela se produit au fil du temps lorsque les électrons sont piégés dans la couche d’oxyde du tunnel. Cela réduit le champ électrique dans le tunnel et la possibilité d’avoir un cycle d’effacement réussi.
Pour y remédier, les contrôleurs de flash NAND utilisent des stratégies de mise à niveau d’usure. Tous les algorithmes de nivellement d’usure gardent une trace des blocs de données sur le périphérique flash qui ont été utilisés et à quelle fréquence. Deux méthodes sont utilisées : le nivellement d’usure dynamique et statique.
Le nivellement d’usure dynamique utilise une structure appelée adresse de bloc logique, ou LBA. Chaque fois que de nouvelles données sont écrites sur le périphérique de stockage, les blocs d’origine utilisés par les données sont marqués comme non valides et les nouveaux blocs sont mappés aux données écrites. Le problème ici est que le nivellement de l’usure se produit uniquement pour les données en mouvement et en cours de réécriture.
Dans de nombreux systèmes, il peut y avoir des comportements pathologiques du système où certains fichiers sont constamment réécrits (tels que les journaux). Cette forme de nivellement de l’usure est meilleure que l’absence de nivellement, mais certaines zones de la NAND peuvent s’user prématurément :
| La mémoire | SLC | MLC | TLC | QLC |
| Capacité en bits par cellule | 1 bit | 2 bits | 3 bits | 4 bits |
| Temps de lecture | 25us | 50us | ~ 75us | > 100us |
| Durée du programme | 200-300us | 600-900us | 900-1350us | > 1500us |
| Effacer le temps | 2-2ms | 3ms | 5ms | > 6 ms |
| Cycles P / E | 100 000 | 3 000 | 1 000 | ~ 100 |
| Coût | $$$$ | $$$ | $$ | $ |
| Densité typique | 1 Gbit à 32 Gbit | 32 Gbit à 128 Gbit | 128 Gbit à 256 Gbit | > 256 Gbit |
Le nivellement statique est plus avancé. Comme son nom l’indique, toutes les données sur le périphérique NAND seront déplacées pour équilibrer les effets de certains fichiers en cours de réécriture. Même pour les données qui restent inchangées, elles finiront par migrer vers différentes pages physiques. Ce type de mise à niveau d’usure est ce qui est nécessaire pour assurer la durabilité du cycle d’effacement de programme (PE) de plus de 300 000+ que les fournisseurs revendiquent maintenant.
Les pages qui étaient destinées à être effacées par des algorithmes dynamiques ou statiques ne doivent pas nécessairement être effacées immédiatement. De nombreux appareils utilisent le “garbage collection” pour effacer les pages invalides. Au cours de ce processus, le contrôleur lira toutes les « bonnes pages » d’un bloc et les migrera vers un bloc nouvellement effacé. Comme vous pouvez le voir dans le tableau ci-dessus, les cycles d’effacement peuvent être excessivement longs, de sorte que la récupération de place peut introduire une “gigue” dans les demandes en temps réel placées sur le lecteur.
Surapprovisionnement et performances d’écriture : une considération lors de l’utilisation de flash de tout type est de réserver une capacité inutilisée supplémentaire sur le lecteur. Un fabricant de mémoire peut réserver un minimum d’espace sur le flash pour les pièces de rechange. Le minimum est généralement la différence entre la taille binaire du lecteur et la taille décimale du lecteur. En d’autres termes, si vous achetez un lecteur de 32 gigaoctets, la zone utilisable réelle est de 32 000 000 000 octets, tandis que la zone réelle est au format binaire : 32 073 741 824 octets. Cela équivaut à 7,37% de capacité supplémentaire utilisée pour les blocs en panne et d’autres fonctionnalités. Bien que 7% soit bon, les performances d’écriture du lecteur diminuent à mesure que le lecteur est presque rempli à 50%. Sans surprovisionner plus d’espace, lors de l’écriture aléatoire de données, il y a une forte probabilité que vous n’ayez pas de bloc de rechange et que vous deviez libérer un bloc via un cycle de récupération de place.
Avec la surprovision, les écritures aléatoires ont une plus grande probabilité qu’un bloc de rechange soit disponible pour une réaffectation. Les écritures séquentielles ne sont cependant pas affectées par ce comportement. Si vos flux de données sont de nature séquentielle, ils auront tendance à être écrits et réécrits en blocs entiers du début à la fin du fichier.

Figure 10 : Disposition du tableau NAND en pages et blocs. La figure illustre la configuration des pages du réseau de cellules et des cellules de rechange. Les données sont lues en quantités de pages et écrites en quantités séquentielles.
Les périphériques de stockage de masse accèdent à la mémoire de stockage en tant que blocs de données plutôt que de manière aléatoire comme la DRAM. Les cellules sont organisées en pages constituées d’une zone de données (appelée la matrice de cellules) et d’une “zone de réserve”. La zone de réserve est constituée de blocs réservés au remappage des cellules défectueuses. Un tableau de cellules sera séparé en plusieurs blocs constitués de pages plus petites. Les nouvelles données sont écrites dans la NAND en quantité de pages. Les cellules sont effacées sur les quantités de bloc. MAND NAND utilise 128 pages par bloc, tandis que SLC NAND utilise 64 pages par bloc. Ainsi, pour une partie NAND de 2 gigabits, il y aura 2 048 blocs composés de 64 pages (2 112 octets) par bloc. La page fait 2 112 octets car elle comprend 2 048 octets de matrice de cellules et 64 octets de cellules de rechange.
La tendance de la collecte des ordures et du nivellement de l’usure à réécrire des blocs de données qui n’ont pas changé est appelée amplification d’écriture. L’unité de mesure de l’amplification est le nombre de réécritures qui se produisent. Par exemple, si vous écrivez un fichier de 256 Mo une fois sur un périphérique NAND et qu’il réécrit 96 Mo du fichier par le biais de techniques de mise à niveau d’usure, la valeur d’amplification d’écriture est de 1 375. Plus la valeur est élevée, plus l’usure synthétique du disque est mauvaise.
Le dernier conseil pour la conception des bords est l’utilisation de la commande Trim. Les fabricants de périphériques NAND ont introduit la commande trim pour informer la pièce que l’espace sur le SSD est devenu disponible et pourrait être utilisé pour un surprovisionnement. Le périphérique ne sait pas quelles données sont valides et ce qui n’est pas valide dans la baie, seul le système d’exploitation le sait. Le système d’exploitation peut émettre une garniture pour alerter le dispositif de commande des pages qui contiennent des données non nécessaires. Ces fichiers pourraient être supprimés. Le périphérique NAND peut ignorer toutes les pages qui ont été capturées avec la garniture lors du nivellement de l’usure et de la collecte des déchets, ce qui permet de gagner du temps lors du prochain cycle d’écriture. Cela réduit également l’amplification d’écriture et l’usure de la pièce et augmente les performances.
8.3.4 IO basse vitesse
La plupart des SOC nécessiteront des E / S à faible vitesse. Ceux-ci sont utilisés pour s’interfacer avec différents composants tels que le flash série, les microcontrôleurs et les périphériques embarqués. Dans l’espace IoT, de nombreux capteurs et actionneurs utilisent des signaux à faible vitesse, ou même des E / S à usage général pour les commandes numériques ou les signaux analogiques qui sont échantillonnés et traités via des convertisseurs analogiques-numériques.
| Cas d’utilisation | Solution |
| Interface avec des capteurs sans interface de traitement ou sans fil | Les capteurs comme les séries Texas Instruments TMP-122 et TMP-125 n’ont pas d’interface sauf SPI. |
| Automobile entoilage | Les systèmes automobiles contrôlent et surveillent divers appareils d’un véhicule, des fenêtres aux caractéristiques du moteur. Cette interface utilise le bus CAN depuis des décennies. |
| Contrôles industriels et automatisation d’usine | Les machines et les systèmes de contrôle d’usine utilisent un protocole série appelé ModBus depuis plusieurs décennies pour surveiller la santé et le contrôle des processus industriels. |
Les interfaces à bas débit à considérer et que vous trouverez dans la plupart des SOC peuvent inclure les éléments suivants :
- Interface périphérique série (SPI) : il s’agit d’une interface de communication à faible vitesse synchrone utilisée pour la communication avec les modules TPM, les écrans LCD et les cartes de stockage numériques sécurisées. Il peut prendre en charge jusqu’à 10 Mbps de bande passante. Il communique en duplex intégral dans une relation maître-esclave. Il n’y a qu’un seul maître, mais il peut y avoir différents esclaves utilisant une ligne de sélection de puce indépendante pour adresser différents esclaves.
SPI a un débit plus élevé que I 2 C ou SMbus mais ne peut tolérer que de courtes distances de communication. L’architecture est flexible, permettant une interface Dual SPI et Quad SPI pour plus de bande passante là où le duplex intégral peut ne pas être nécessaire.
- I 2 C : Il s’agit d’un système de communication série synchrone multi-maître et multi-esclave. Les cas d’utilisation typiques incluent la communication avec les barrettes DIMM de mémoire DRAM dans les PC et les serveurs et la gestion des informations d’affichage pour les moniteurs HDMI et VGA. Alors que SPI peut utiliser quatre lignes de communication, I2C n’en utilise que deux. I 2 C prend en charge 100 Kbps en mode standard, 400 Kbps en mode rapide, 3,4 Mbps en mode haute vitesse et 5 Mbps en mode ultra rapide. Comme indiqué, il s’agit d’un format basé sur des paquets utilisant des symboles de début et de fin.
- Récepteur / émetteur asynchrone universel (UART) : Il s’agit de l’une des formes les plus simples et les plus anciennes de communication informatique et est largement utilisé. Il s’agit d’un système de communication et de signalisation série asynchrone à deux fils, et non d’un protocole comme I 2 C. Un UART ne prend en charge qu’un seul maître et un seul esclave. Un UART utilise un registre à décalage pour pousser les bits à travers le fil. Puisqu’il ne s’agit que d’une interface filaire, elle peut être utilisée de nombreuses manières telles que les modes duplex intégral, semi-duplex ou même simplex. Les données sont encadrées par un bit de démarrage et d’arrêt autour de chaque 8 bits de données transmis. Un UART sera la base de la communication pour les systèmes SCADA IoT comme RS485 ou RS232. RS232 spécifie les niveaux de tension spécifiques à cette mise en œuvre et nécessiterait des pilotes de ligne supplémentaires pour aider au contrôle de la tension. En revanche, le protocole ModBus très populaire et hérité est généralement utilisé sur les interfaces RS485 et spécifie sa propre signalisation électrique, qui n’est pas compatible avec RS232.
- Entrée / sortie à usage général (GPIO) : elles sont largement utilisées en informatique et sont essentiellement des broches de signal numérique sur le SOC ou le circuit intégré qui n’ont aucune fonction spécifique mais sont contrôlées par programme. Les broches GPIO peuvent être utilisées comme pilotes de sortie ou entrée de capture. Ils peuvent être bidirectionnels ou unidirectionnels. Les GPIO peuvent également être affectés à une interruption sur la puce pour signaler des événements. Ils peuvent même être utilisés en groupe comme une forme de bus défini par logiciel ou d’interface de frappe. Les GPIO seront utilisés pour contrôler les appareils, attachés aux capteurs ou attachés aux valeurs des résistances et lus au démarrage comme une forme d’identification ou de sécurité.
- Réseau d’accès au contrôleur (CAN) : il s’agit d’une architecture de bus synchrone standard véhiculaire conçue pour que les microcontrôleurs communiquent entre eux sans ordinateur hôte. Il s’agit d’une norme propriétaire avec des brevets détenus par Bosch qui concède également une licence sur la technologie.
Il utilise un protocole en couches basé sur des paquets pour la communication entre plusieurs maîtres et plusieurs esclaves. La communication CAN peut être utilisée avec aussi peu que quatre signaux ou un connecteur DB9 standard. La vitesse du CAN varie de 40 Kbps à 125 Kbps lorsqu’il est utilisé en mode tolérant aux pannes à faible vitesse à 40 Kbps à 1 Mbps en mode haute vitesse.
8.3.5 IO haute vitesse
Nous classons les E / S haute vitesse comme tout ce qui permet d’atteindre une vitesse d’environ 100 Mbps ou d’utiliser des E / S avancées telles que des paires différentielles. Celles-ci nécessitent des règles de conception, des PHY et un câblage spécial. Vous verrez des interconnexions à grande vitesse sous la forme d’émetteurs-récepteurs Ethernet simples, d’interfaces USB et de bus PCI Express. Bien que courantes, ces interfaces méritent une attention particulière.
PCI Express (PCIe) est la forme d’interconnexion puce à puce et périphérique la plus courante. PCIe utilise une paire d’émetteurs-récepteurs différentiels et a une portée limitée en fonction de la génération de PCIe que vous utilisez.
Du point de vue de l’architecture des systèmes, PCIe est un choix d’interconnexion privilégié pour les E / S haut débit vers et depuis les périphériques tels que les périphériques de stockage NVMe, les GPU externes et les modems haute vitesse. PCI utilise ce que l’on appelle la signalisation sérialiseur / désérialiseur (SerDes). Les SerDes sont essentiellement des signaux complémentaires qui sont déphasés de 180 degrés les uns par rapport aux autres. Cela permet une communication à très haute vitesse avec moins d’impact sur le bruit et les aberrations du signal. Il nécessite une fonctionnalité de système d’exploitation spécifique pour effectuer une énumération de bus PCI et découvrir la topologie et les interconnexions de bus. L’USB est une interconnexion privilégiée pour les appareils plug-and-play plus robustes. L’USB aura moins de débit que PCI Express et nécessitera plus de surcharge logicielle dans le noyau du système d’exploitation, mais il offrira la possibilité d’utiliser une large gamme de périphériques génériques et de composants montés en externe comme des clés USB, des émetteurs sans fil et des modems externes. Ethernet est la plus ancienne spécification et est principalement utilisé pour la communication basée sur le réseau.
| Bus | Ethernet | USB 3.0 | PCIe Gen3 | PCIe Gen4 |
| Largeur du bus | 1 paire torsadée jusqu’à 10+ | 9 broches | 1 à 32 voies | 1 à 32 voies |
| Plage de vitesse | 1 Mbps à 400 Gbps | 5 Gbit / s | 6 Mbps par voie | 1969 Mbps |
| Signalisation | Air torsadé ou fibre optique | Signalisation différentielle à paire torsadée | SerDes différentiel | SerDes différentiel |
| Topologie | Connexion commutée | Maître unique – esclave multiple | Maître unique – esclave multiple | |
| Gestion de l’alimentation | Aucun | Intégré au protocole | Intégré au protocole | Intégré au protocole |
| Distance de routage | Pieds en milles | Les pieds | Pouces | Pouces |
8.3.6 Assistance matérielle et coprocessing
L’assistance matérielle dans les systèmes de périphérie est courante sous la forme de GPU, de DSP, de convertisseurs analogique-numérique et d’une myriade d’autres fonctionnalités. Les systèmes lame de classe serveur utiliseront des composants discrets, tandis que les systèmes plus étroitement intégrés incorporeront du matériel super intégré dans un SOC unique ou une puce multi-modules.
Pourquoi inclure du matériel pour la fonctionnalité algorithmique ? L’assistance au silicium ou au matériel à fonction fixe présente deux avantages principaux par rapport à la programmation d’un algorithme dans un logiciel :
- 1. Les algorithmes matériels seront des ordres de grandeur plus rapides que le logiciel ne peut les traiter. Les données peuvent être acheminées entre des blocs d’assistance matérielle et diffusées directement vers et depuis IO.
- 2. La consommation électrique sera généralement inférieure. Le silicium à fonction fixe et les coprocesseurs nécessitent un travail supplémentaire sur les équipes matérielles et logicielles et de nouveaux pilotes de périphérique, mais les avantages peuvent être importants.
L’exemple SOC que nous avons présenté plus tôt dans ce chapitre comprenait un processeur de signal numérique. Il existe de nombreuses formes de silicium à fonction fixe pour faciliter le traitement et le flux de données :
- Blocs et pipelines de traitement du signal d’image (comme nous l’avons examiné dans le chapitre sur la technologie des capteurs)
- Unités de traitement graphique pour l’imagerie, calcul général sur la programmation d’unités de traitement graphique (GPGPU), accélération d’apprentissage automatique et accélération SIMD
- Processeurs de signaux numériques pour l’entrée audio, la sortie audio et l’analyse de signal en temps réel
- Compresseurs et décompresseurs
- Accélérateurs de chiffrement (Advanced Encryption Standard ou AES)
- Moteurs d’inférence assistés par matériel pour la multiplication matricielle et l’accélération des réseaux de neurones convolutionnels
L’utilisation de ces types de modules assistés par matériel a un coût. Le premier est la zone de silicone supplémentaire et le coût de licence du matériel. Deuxièmement, l’impact logiciel et architectural sur le flux de données. Les architectes doivent évaluer soigneusement ces options lors de la construction d’un système informatique de pointe.
8.3.7 Modules de démarrage et de sécurité
Nous avons discuté des aspects de sécurité de l’IoT tout au long de l’articleet à différents niveaux de la pile. Plus d’informations seront discutées en profondeur dans le chapitre 13, IoT et Edge Security. Lors du déploiement en périphérie, il est essentiel d’avoir l’assurance de l’intégrité du logiciel dès le démarrage. Aujourd’hui, nous utilisons des modules de plateforme sécurisée (TPM) pour accomplir cette tâche. Un TPM est un module matériel dédié à l’authentification des logiciels, au stockage des clés cryptées et à la protection des mots de passe.
Un module matériel TPM fournit :
- Rapports racine de confiance
- Interface de stockage Root-of-Trust
- Rangement pour les clés
- Génération de nombres aléatoires pour la génération de clés
- Fonctions cryptographiques : cryptage / décryptage, signature, certification de clé, génération de hachage SHA-1
Un module de plateforme sécurisée peut être un module matériel autonome comme dans notre exemple de schéma de principe précédent. Il communique avec le SOC principal via une interface SPI à faible vitesse. Le rôle d’un TPM dans le processus de démarrage est de vérifier l’intégrité de la toute première phase de démarrage stockée en flash à laquelle le TPM accède. Lorsque le système sort de la réinitialisation, le TPM vérifie la signature du code de démarrage. Si la signature est vérifiée, le démarrage progresse normalement. De plus, le module de plateforme sécurisée peut également vérifier chaque phase du processus de démarrage dans un démarrage de confiance complet du système d’exploitation et d’autres composants chargés.
8.3.8 Exemples de matériel périphérique
Maintenant que nous avons examiné les caractéristiques des processeurs, du stockage, de la mémoire et des composants matériels associés pour l’informatique de périphérie, nous allons examiner différents appareils déployés dans des déploiements de traitement de périphérie dans le monde réel pour contraster leurs capacités et fonctionnalités.
Les trois modules différents servent différents cas d’utilisation. Le dispositif NXP est destiné à l’informatique de pointe, comme un assistant vocal comme Alexa ou un ordinateur télématique mobile ou mobile. Il a un riche ensemble d’E / S basse vitesse et les meilleures caractéristiques thermiques et la plus faible puissance des trois. Le serveur Advantech Edge est un ordinateur de petit format dans un boîtier renforcé. Il est destiné aux environnements difficiles mais conserve la compatibilité avec le logiciel x86 et est capable d’exécuter une pile Microsoft Windows complète en périphérie. Enfin, le dispositif Supermicro est un boîtier de lame de centre de données complet 1U destiné à l’informatique de périphérie. Il utilise un chipset Intel Xeon bas de gamme, mais c’est toujours l’appareil le plus puissant des trois. Il n’a cependant aucune capacité à être utilisé dans un environnement hostile :
| Composant | Module IoT NXP LPC54018 | Serveur Edge Advantech EIS-D210 | Supermicro 1019C-HTN2 |
| CPU | ARM M4 | Intel Celeron | Intel Xeon E-2200
(9 e génération) |
| Architecture, largeur de bit | ARM-7, 32 bits | X86, 64 bits | X86, 64 bits |
| Noyaux | 1 | 2 | 4 |
| Multithreading | Non | Non | Oui 2x |
| La vitesse | 180 MHz | 1 GHz | 4 GHz |
| Floating Point | Oui | Oui | Oui |
| Virtualisation matérielle | Non | Non | Oui |
| HWA, GPU | Sous-système DAC et ADC | Intel HD Graphics à 200 MHz | Graphiques UHD @ 350 MHz |
| TDP, TJ | 2W, 150 ° C | 8 W, 105 ° C | 95 W, 73 ° C |
| Caches | Aucun –
voir sur puce SRAM |
16 KB L1
2 Mo L2 |
64 Ko L1 par cœur
256 Ko L2 par cœur 8 Mo L3 partagés |
| La mémoire | SRAM sur puce de 360 Ko | 4 Go de DDR3 | 64 Go DDR4 – ECC |
| Stockage | 4 Mo de mémoire flash SPI sur puce,
carte microSD |
SSD SATA III de 64 Go | 4 To M.2 NVMe
SATA en option |
| Communication sans fil | 11 b / g / n | 11 2,4 et 5 GHz
Bluetooth 4.1 |
Aucun |
| IO basse vitesse | 10 ports série Flexcomm , SPI, I 2 C, I 2 S, GPIO, CAN, SDIO, | 2 RS232 UART | UART, I2C |
| E / S haute vitesse | USB | Ethernet 3 Gbit, 4 USB 3.0, VGA, PCI Express Gen2 | 2 SATA2, 2 802.3 Gbit Ethernet, 3 USB 3.1, 2 DisplayPort, 1 VGA. PCI Express Gen3 |
| La sécurité | Démarrage d’image chiffrée | Module TPM | Module TPM |
| Temp de fonctionnement | -40 ° C à 105 ° C | -20 ° C à 60 ° C | 10 ° C à 40 ° C |
Les cellules en surbrillance dans le tableau illustrent la force de chaque ordinateur de bord.
8.3.9 Protection contre la pénétration
Lors du déploiement de matériel qui doit exister à l’extérieur ou dans une zone où les conditions environnementales ne peuvent pas être contrôlées, l’architecte doit choisir la façon de protéger l’électronique contre la contamination et l’humidité ainsi que d’atténuer les problèmes thermiques. En règle générale, l’électronique sera logée dans certains boîtiers. L’industrie électronique utilise une convention internationale pour qualifier la dureté des boîtiers électroniques.
Cette norme est appelée la marque de protection d’entrée, ou IP pour faire court. Les tests IP testent la capacité d’un produit à se protéger contre l’infiltration d’eau, de poussière et de corps étrangers. En général, les produits nécessitant un test IP comprennent les ordinateurs, l’équipement de laboratoire, de nombreux appareils médicaux, les luminaires et les produits qui doivent rester sans poussière ou résistants à l’humidité. Les articles scellés et qui seront probablement placés dans des endroits dangereux doivent également être classés IP. Il existe des normes relatives aux tests IP, en particulier MIL-STD-810 (militaire), RTCA / DO-160 (Commission technique radio pour l’aéronautique) et CEI 60529 (Commission électrotechnique internationale). Ils sont définis selon la norme internationale EN 60529.
Le tableau suivant détaille le codage à deux chiffres pour les classifications IP :
| Protection contre la pénétration de corps étrangers | L’humidité Ingress Protection | ||
| Marqueur du premier chiffre | La description | Marqueur de deuxième chiffre | La description |
| 0 ou X | Non noté | 0 ou X | Non noté |
| 1 | Protection contre les intrusions d’objets volumineux, comme une main ou tout objet de plus de 50 mm de diamètre. Aucune protection pour un accès délibéré. | 1 | Protège contre la chute des gouttelettes et la condensation (1 mm de pluie par minute). |
| 2 | Protège contre les objets ne dépassant pas 80 mm de long et 12 mm de diamètre, comme un doigt. | 2 | Protège contre les gouttes d’eau verticalement lorsque l’enceinte est inclinée jusqu’à 15 ° par rapport à la verticale (3 mm de pluie par minute). |
| 3 | Protection contre l’intrusion d’outils ou d’objets d’un diamètre de 2,5 mm ou plus. | 3 | Protège contre les projections d’humidité jusqu’à 60 ° par rapport à la verticale. |
| 4 | Protège contre les objets solides de plus de 1 mm (fils, clous, insectes). | 4 | Protège contre les projections d’eau dans toutes les directions testées pendant au moins 10 minutes. |
| 5 | Protection partielle contre la poussière – “protégé contre la poussière”. | 5 | Protège contre les jets à basse pression (6,3 mm) à 30 kPa contre les projections d’eau dirigées à n’importe quel angle à partir de 3 m de distance. |
| 6 | Protection complète contre la poussière et autres particules, y compris un joint sous vide testé contre le flux d’air continu – « étanche à la poussière ». | 6 | Protège contre les jets d’eau dirigés à haute pression à 100 kPa. |
| 7 | Protection complète contre une immersion complète jusqu’à 30 minutes à des profondeurs de 15 cm à 1 m. | ||
| 8 | Protège contre l’immersion prolongée sous haute pression et jusqu’à 3 m de profondeur. | ||
| 9K | Protège contre les hautes pressions (80-100bar), les jets à haute température (80 ° C), les lavages et le nettoyage à la vapeur. Souvent vu dans les systèmes automobiles et de transport ISO 20653: 2013. | ||
Par exemple, un boîtier pour un système de bord qui est évalué par un fabricant comme IP65 implique qu’il est “étanche à la poussière” et protégé contre l’eau projetée contre un jet à basse pression tel qu’un tuyau d’arrosage. Dispositif avec une cote de IP68 impliquerait qu’il est « étanche à la poussière » et protégé à nouveau une immersion totale pendant de longues périodes de temps.
8.4 Systèmes d’exploitation
Les choix de système d’exploitation pour un système de périphérie sont nombreux et méritent une attention particulière. Du point de vue d’un architecte, le choix doit faire l’objet d’une diligence raisonnable car il sera le fondement de générations de solutions logicielles éventuellement déployées dans cet environnement. Un système d’exploitation existe en tant que couche d’abstraction et de protection logicielle entre le matériel et les applications. Cependant, un système d’exploitation fournit également une interface binaire d’application ( ABI ) pour que le logiciel existe. Il peut fournir une réponse en temps réel et une maintenance garantie, il forme des protections de processus logiciel et de niveau thread, et il fournit des interfaces pour partager la mémoire et les E / S entre les applications logicielles et gère la mémoire et les ressources du système.
8.4.1 Points de choix du système d’exploitation
Dans de nombreuses situations, un OEM matériel fournira ou recommandera un système de prise en charge de système d’exploitation et de carte (BSP) pour le matériel qu’il a conçu. D’autres fois, le choix du système d’exploitation ne sera pas aussi net, ce qui est vrai pour le matériel spécialement conçu et personnalisé.
Voici les questions que l’architecte doit prendre en compte et peser pour faire un choix de système d’exploitation :
- Coût de la distribution OS. S’agit-il d’une licence publique comme Linux ou d’une licence commerciale comme Windows ?
- Existe-t-il un contrat de support ?
- Existe-t-il un besoin en temps réel, le système d’exploitation prend-il en charge RT ou existe-t-il des extensions ?
- Sur quelle architecture de processeur le système d’exploitation prend-il en charge (ARM, x86) ?
- Le système d’exploitation prend-il en charge toutes les caractéristiques du processeur nécessaires : mémoire virtuelle, caches à plusieurs niveaux, extensions SIMD, émulation à virgule flottante ?
- Comment les packages ou extensions sont-ils obtenus ? Linux: APT, miam, RPM, PACMAN.
- Combien de packages ou d’extensions ont été créés pour cette distribution de système d’exploitation ?
- Comment allez-vous démarrer l’appareil – Flash, réseau ( PXEboot )?
- Quelle forme de services de sécurité sont intégrés au système d’exploitation et au noyau ?
- Pour les systèmes profondément intégrés et éloignés, dans quelle mesure le système d’exploitation peut-il être réduit en RAM et en taille de stockage ?
- Le temps de démarrage est-il une préoccupation ?
- Quels systèmes de fichiers sont nécessaires ?
- Si le support logiciel et pilote est fourni avec du matériel périphérique, quel système d’exploitation cible-t-il ?
- Le système d’exploitation prend-il en charge les formes de communication, de mise en réseau et de piles de protocoles souhaitées ?
- Faut-il une interface graphique ?
Cette liste n’est pas exhaustive mais devrait indiquer qu’il existe de nombreux facteurs dans le choix d’un système d’exploitation. L’OS existe en tant que couche fondamentale sur laquelle le reste du système s’appuie. Changer un système d’exploitation nécessite souvent une refactorisation importante des logiciels et des pilotes. Plus tard, nous examinerons une approche basée sur des conteneurs pour le déploiement de logiciels qui aide quelque peu à abstraire un système d’exploitation, mais à un certain niveau fondamental, un système d’exploitation (ou noyau) doit exister.
8.4.2 Processus de démarrage typique
Un processus de démarrage Unix typique est illustré dans la figure suivante. Il s’agit d’une variante de démarrage Linux à partir d’un vecteur de réinitialisation après la mise sous tension vers une interface utilisateur graphique. Le diagramme illustre les éléments les plus significatifs du flux de démarrage. Le démarrage précoce peut commencer encore plus tôt grâce à l’utilisation d’un module de plateforme sécurisée, qui sera abordé plus loin, chapitre 13, IoT et Edge Security. Le TPM garantit une racine de confiance lors de la mise sous tension de l’électronique et garantit que la prochaine image de code chargée à partir de divers supports est qualifiée et authentique.
Mis à part le cas particulier d’un module de plateforme sécurisée, le système émet généralement un auto-test de mise sous tension (POST) dans le matériel pour garantir que les composants sont montés de manière fiable. Les systèmes utilisaient traditionnellement un BIOS hérité pour démarrer, mais les systèmes modernes utilisent désormais le système EFI (Extensible Firmware Interface) comme alternative à l’ancien code du BIOS. EFI est une véritable interface 32 bits construite à l’aide d’outils modernes et d’encapsulation, tandis que l’architecture du BIOS est une interface 16 bits et monolithique.
Une variante du système d’exploitation Linux démarre généralement après le chargement de son image par EFI ou GRUB et entre dans l’initialisation du noyau. Un disque RAM temporaire est utilisé pour aider à organiser le processus d’amorçage. Une étape importante est l’exécution de différents niveaux d’exécution. Les niveaux d’exécution sont des niveaux d’exploitation sémantique logicielle pour signifier des modes spécifiques dans lesquels le système d’exploitation s’exécutera. Par convention, il existe sept niveaux d’exécution numérotés de 0 à 7 :

Figure 11 : Processus de démarrage typique d’une réinitialisation à froid à une invite de niveau utilisateur sous Linux. Notez les deux chemins différents de démarrage précoce à partir d’un BIOS traditionnel et GRUB par rapport à un démarrage EFI.
8.4.3 Réglage du système d’exploitation
Un système d’exploitation comme Linux permet la flexibilité d’ajouter des volumes de différents cadres, outils, utilitaires et packages à l’image du micrologiciel du système. Cependant, des précautions doivent être prises lors de la construction de systèmes basés sur les bords fiables et robustes. La philosophie que vous devez utiliser pour créer l’image de base d’une machine Edge est de fournir l’ensemble minimal de packages et de bibliothèques nécessaires pour effectuer la tâche donnée. Cette méthodologie diffère des installations de machines virtuelles traditionnelles basées sur le cloud qui sont fournies avec des images Linux préemballées composées de gigaoctets de packages et de logiciels.
À la limite, nous nous préoccupons de la sécurité de l’appareil, de sa robustesse à son environnement et de la difficulté de maintenance de l’appareil. Il arrive le plus souvent que l’ordinateur périphérique soit limité en ressources et que les packages non critiques consomment du stockage et de la RAM qui pourraient être utilisés pour des cas d’utilisation réels.
8.5 Plates-formes Edge
Le logiciel et les applications fonctionnant en périphérie définissent sa fonction. Lorsque vous faites évoluer des périphériques de pointe, leur gestion à distance devient le défi. Certes, des modèles de contrôle et de déploiement personnalisés existent et sont utilisés en production. Cependant, aujourd’hui, nous avons des cadres commerciaux de gestion de périphérie prêts à l’emploi ainsi que des méthodologies basées sur des conteneurs qui allégent le fardeau du déploiement de logiciels de manière sécurisée et contrôlée sur des ordinateurs de périphérie distants.
Dans les deux cas, nous voulons que le logiciel et le système soient :
- Robuste : capable de recevoir, de réimaginer et de réexécuter un logiciel lors de son déploiement
- Contrôlé : disposer d’un cloud ou d’un service central qui gère et surveille le déploiement
- Responsive : Reporting des informations sur le succès ou l’échec de la réimagerie logicielle
8.5.1 Virtualisation
Nous pouvons comparer les types de virtualisation comme suit :
Virtualisation matérielle : abstraction de niveau matériel qui est généralement capable d’exécuter n’importe quel logiciel pouvant fonctionner sur du métal nu. Il utilise un hyperviseur pour gérer une ou plusieurs machines virtuelles sur le processeur et peut prendre en charge la réplication virtuelle du matériel vers plusieurs systèmes d’exploitation virtuels via la virtualisation des E / S matérielles. Ces techniques nécessitent une prise en charge du processeur et du matériel pour la virtualisation que l’on trouve généralement sur les processeurs haut de gamme comme les pièces de la série ARM Cortex A.
En tant que sous-catégorie, il existe deux types d’hyperviseurs : les hyperviseurs de type 1 s’exécutent directement sur du métal nu et le type 2 a un système d’exploitation sous-jacent hébergé. Un exemple d’hyperviseur de type 1 est Microsoft HyperV. Un exemple d’hyperviseur de type 2 est Microsoft Virtual PC.
Paravirtualisation : fournit une couche d’abstraction appelée couche d’abstraction matérielle (HAL) et nécessite des pilotes spéciaux. Ces pilotes sont liés via l’hyperviseur soulignant et accèdent au matériel par le biais d’ hyperappels . Il nécessite des modifications de l’OS invité pour permettre cette forme de virtualisation et offre à l’OS invité des performances supérieures et la possibilité de communiquer directement avec l’hyperviseur.
Conteneurs : gérez l’abstraction au niveau de l’application. Il n’y a pas d’hyperviseur ou de système d’exploitation invité. Au contraire, les conteneurs ne nécessitent que le système d’exploitation hôte pour fournir des services de base.
Les conteneurs maintiennent la séparation les uns des autres, offrant un niveau de protection similaire à une machine virtuelle. Les gestionnaires de conteneurs peuvent également s’adapter à l’évolution des ressources de la machine. Par exemple, ils peuvent affecter dynamiquement plus de mémoire à un conteneur lors de l’exécution.
Pour certaines applications informatiques de pointe, les abstractions basées sur des conteneurs sont particulièrement attrayantes. Les conteneurs nécessitent des ressources au niveau du système qui doivent être prises en compte, telles que les performances de calcul, la capacité de stockage et même les fonctionnalités du processeur. Ils offrent une méthode très légère et portable de création et de déploiement d’applications sur des ordinateurs périphériques. Étant donné que l’approche par conteneur n’utilise aucun système d’exploitation invité, elle est naturellement plus légère et plus économe en ressources que la virtualisation traditionnelle. Ceci est essentiel pour les périphériques périphériques limités en ressources. De plus, une image qualifiée et fonctionnelle peut être conteneurisée , et des modifications et des tests peuvent être exécutés par rapport à cette image. Un conteneur est également très portable et peut être déployé dans n’importe quel environnement et sur presque n’importe quel système d’exploitation hôte. Pour cette raison, nous nous concentrerons sur les conteneurs comme méthode de déploiement de périphérie :
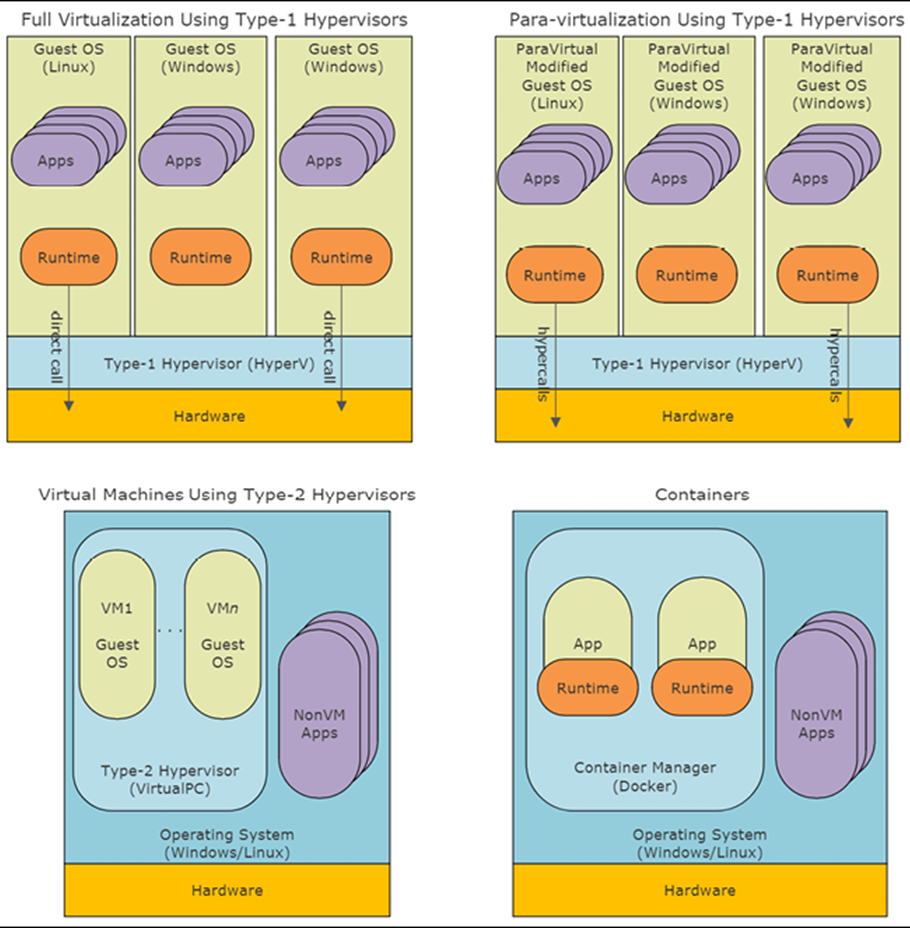
Figure 12 : Quatre types d’abstractions virtuelles : virtualisation complète, paravirtualisation, hyperviseurs de type 2 et conteneurs
Bien qu’un hyperviseur de type 2 puisse sembler similaire à une conception de conteneur dans le diagramme précédent, il n’est pas analogue aux conteneurs. Un hyperviseur de type 2 a toujours un impact important sur les frais généraux et les performances. Essentiellement, vous exécutez au moins un système d’exploitation invité sur un système d’exploitation hôte complet. Compte tenu de l’hyperviseur et des services d’exécution, la quantité de mémoire et de traitement requise est beaucoup plus importante que les conteneurs légers.
8.5.2 Conteneurs
Les conteneurs sont une méthode pour virtualiser le matériel et les services sous-jacents comme une machine virtuelle (VM). Alors qu’une machine virtuelle traditionnelle nécessitera un hyperviseur qui se trouve au-dessus du matériel et fournit un niveau d’abstraction, un conteneur ne nécessite aucun hyperviseur. Au contraire, SES services se trouvent au- dessus du système d’exploitation couche.
8.5.3 Architecture des conteneurs
L’acte de créer un conteneur et d’exécuter une application en tant que processus est appelé conteneurisation. Deux définitions fondamentales sont nécessaires pour comprendre les éléments de base d’un conteneur :
- Conteneur : il s’agit d’une instanciation unique d’une image de conteneur. Plusieurs instances peuvent exister sur un seul hôte.
- Image : L’image du conteneur est un ensemble de fichiers ne contenant aucun état mais définit le package (ou l’instantané) d’un conteneur.
Pour comprendre l’architecture du conteneur, nous allons explorer Docker. C’est un outil pour construire et gérer des conteneurs et propose une version gratuite appelée DockerEE pour les services de base. Un déploiement de conteneur se composera d’un moteur de gestion de conteneur d’application et d’un référentiel.
Pour lier une application dans une image de conteneur, nous commençons par rassembler le code de l’application et les dépendances requises. Ces dépendances sont des bibliothèques, binaires, middleware et composants logiciels associés dont l’application peut avoir besoin. Toutes les dépendances doivent être incluses dans l’image du conteneur pour garantir qu’elles résident même pour des fonctionnalités qui peuvent rarement s’exécuter. Cette agrégation d’applications et de dépendances s’appelle le conteneur.
La création d’un nouveau conteneur est simple dans Docker. Tout d’abord, nous choisissons une image de base à référencer. Docker possède de nombreuses images de base de divers systèmes d’exploitation et environnements tels que Fedora ou Ubuntu.
Une liste d’images de base minimales peut être trouvée à https://hub.docker.com/search?q=&type=image . Ensuite, nous créons un fichier image Docker. Ce fichier détaille comment l’image sera construite. Un exemple est le suivant :
DE ubuntu
RUN apt-get update
RUN apt-get install iostat -y
CMD [“/ usr / bin / iostat “]
Dans cet exemple, le dockerfile extrait de l’image de base Ubuntu, puis utilise l’outil d’installation apt-get pour installer l’utilitaire iostat , puis l’exécute.
Une fois le fichier docker construit, nous devons ensuite créer cette image Docker. Le champ dockerID n’est nécessaire que si vous avez l’intention de télécharger l’image sur le système global Docker Hub, où vous devez vous inscrire pour un compte :
docker build -t < dockerID > / <image-name >.
L’image résultante peut ensuite être déployée et instanciée n’importe où à l’aide de la commande suivante sur l’hôte :
docker run [options] [ dockerID / nom-image] [ commande]
Un périphérique informatique périphérique, ainsi que tout autre système connecté utilisant Docker, peut extraire cette nouvelle image et l’exécuter de la même manière. Cela facilite considérablement la tâche de déploiement et de développement. En outre, il permet aux modèles de développement pour les périphériques de périphérie d’être comme des processus sur de grandes solutions SaaS ( logiciel en tant que service ) en utilisant des techniques telles que l’intégration continue et la livraison continue ( CI / CD ).
8.5.4 Une plateforme Edge – Microsoft Azure IoT Edge
Alors qu’une plate-forme de gestion complète pouvant être utilisée de concert avec d’autres outils informatiques, des services de sécurité et des exigences de gestion peut être conçue à partir de zéro, il existe plusieurs plates-formes de gestion qui fournissent de nombreux services nécessaires pour déployer l’informatique de pointe en tant que parc.
Microsoft Azure IoT Edge est un moteur de déploiement de conteneurs et un service de gestion qui s’exécute sur un ordinateur ou un périphérique Windows ou Linux. Il fournit un runtime gratuit et open source, une plate-forme de conteneur (Docker), un processus de gestion et de déploiement de conteneur compatible pour les périphériques de périphérie, une API d’interface cloud avec le Azure IoT Hub et des services de provisioning. De nombreuses tâches de périphérie de routine sont également fournies, telles que la possibilité de fonctionner hors ligne ou avec des connexions intermittentes ; mettre en cache et stocker localement les données ; synchronisation vers le cloud à la demande, services de sécurité pour la protection de bout en bout contre les menaces et gestion de la posture ; et filtrer / dénaturer les données avant d’envoyer les résultats au cloud pour l’archivage ou l’analyse.
Les exigences générales pour Azure IoT Edge sont les suivantes :
- Un ordinateur Edge exécutant x64, AMD64, ARM32v7 ou ARM64
- Un système d’exploitation de pointe : Linux ou Windows
- Variantes Linux testées : Ubuntu Server 16.04, Ubuntu Server 18.04. D’autres non pleinement qualifiés : CentOS, Debian 8, Debian 9, Debian 10, Raspian Buster, RHEL 7.5, Wind River 8, Yocto Linux
- Variantes Windows testées: Windows 10 IoT Core, Windows 10 IoT Enterprise, Windows Server 2019, Windows Server IoT 2019
- Runtime de conteneur : un runtime de conteneur compatible OCI tel que le moteur Moby. Les images des conteneurs Docker CE / EE sont compatibles avec Moby.
- Ressources pour la charge de travail et le cas d’utilisation : stockage pour la mise en cache hors ligne des données, la RAM et le traitement des charges de travail du module.
- Une interface WAN TCP / IP en amont vers le hub Azure IoT via les protocoles MQTT ou AMPQ.
Si ces exigences de base sont remplies, le gestionnaire d’exécution et de conteneur doit fonctionner :
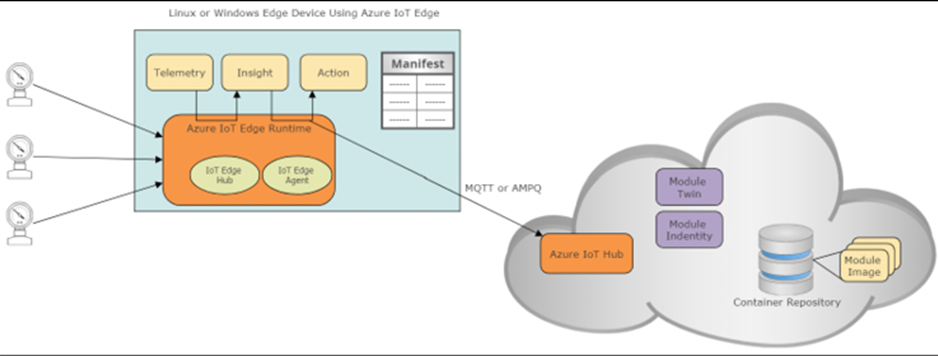
Figure 13: Microsoft Azure IoT Edge. Montré est le périphérique Edge hébergeant le runtime Edge IoT Edge. Plusieurs modules sont gérés comme des déploiements de conteneurs via le runtime de concert avec le hub Azure IoT. Un manifeste contrôle les modules qualifiés pour l’utilisation et le routage général entre les modules.
L’architecture globale d’Azure IoT Edge de concert avec le hub IoT d’Azure exécuté dans le cloud peut être vue dans le diagramme précédent. Le diagramme montre trois capteurs connectés à un ordinateur de bord. L’ordinateur Edge héberge le service d’exécution Azure IoT Edge. Le runtime de service Edge est léger et constitue le cœur du système. Le runtime Edge gère les installations de modules / charges de travail, la sécurité, la surveillance de l’intégrité et toutes les communications. Le concentrateur a deux rôles : IoT Edge Agent et IoT Edge Hub. Le service d’agent gère les modules tandis que le concentrateur gère la communication et agit en tant que proxy pour le plus grand concentrateur Microsoft Azure IoT. Cela nécessite quelques explications supplémentaires.
IoT Hub exécuté dans le cloud Azure exécute un surensemble de fonctions, et c’est l’interface principale utilisée dans Azure pour se connecter aux appareils IoT. IoT Edge Hub n’est pas une version complète d’IoT Hub, mais il permet à un programmeur de s’interfacer avec la périphérie comme il concevrait un logiciel pour s’interfacer avec IoT Hub dans le cloud via le SDK Azure IoT Device. Le IoT Edge Hub gère également un manifeste. Ce manifeste identifie les modules qualifiés et authentifiés autorisés à s’exécuter sur le périphérique périphérique. Il déclare également les règles de routage entre différents modules fonctionnant en périphérie.
L’agent IoT Edge gère l’image du conteneur pour chaque module exécuté sur l’appareil, les informations d’identification pour accéder aux registres de conteneurs privés et les règles de création et de gestion des modules.
Le manifeste qui contrôle le runtime Edge peut ressembler à l’exemple suivant. Notez que chaque itinéraire avait besoin d’une source et d’un puits. La condition est un champ facultatif vous permettant de filtrer les messages. Le IoT Edge Hub garantit la livraison “au moins une fois” des messages. Toute destination dans le champ récepteur recevra son message au moins une fois. En cas de problème ou d’échec de communication, il stockera et mettra en cache tous les messages localement. Cela peut être affiné pour stocker les messages pendant une durée définie.
La première partie détaille le contenu du module et les informations de connexion :
{
“modulesContent”: {
“$edgeAgent”: {
“properties.desired”: {
// This section lists Edge agent properties, locations, and credentials
“runtime”: {
“type”: “docker”,
“settings”: {
“minDockerVersion”: “v1.25”,
“loggingOptions”: “”,
“registryCredentials”: {
“ContosoRegistry”: {
“username”: “testaccount”,
“password”: “<password>”,
“address”: “test.microsoft.io”
}
}
}
},
Le manifeste doit également inclure les sections $ edgeHub et $ edgeAgent . La section edgeHub définit les itinéraires et les propriétés IoT Edge Hub. La section edgeAgent répertorie les URI des modules et des informations d’identification :
“systemModules”: {
“edgeAgent”: {
“type”: “docker”,
“settings”: {
“image”: “mcr.microsoft.com/azureiotedge-agent:1.0”,
“createOptions”: “”
}
},
“$edgeHub”: { //required
“properties.desired”: {
// IoT Edge Hub properties and routing rules
“type”: “docker”,
“status”: “running”,
“restartPolicy”: “always”,
“settings”: {
“image”: “mcr.microsoft.com/azureiotedge-hub:1.0”,
“createOptions”: “”
}
“routes”: {
“route1”: “FROM <source> WHERE <condition> INTO <sink>”,
“route2”: “FROM <source> WHERE <condition> INTO <sink>”
},
}
},
La section modules définit toutes les propriétés de chaque module fonctionnant dans le périphérique :
“modules”: {
“Sensor”: {
“version”: “1.0”,
“type”: “docker”,
“status”: “running”,
“restartPolicy”: “always”,
“settings”: {
“image”: “mcr.microsoft.com/sensor:1.0”,
“createOptions”: “{}”
}
},
L’un des concepts les plus puissants d’Azure IoT Edge est que certains services et fonctionnalités spécifiquement conçus pour s’exécuter sur le cloud Azure peuvent désormais être exécutés localement sur l’appareil Edge s’il répond aux exigences minimales du runtime. Cette fonctionnalité comprend :
- Déploiement et utilisation des fonctions Azure dans un module Azure IoT Edge
- Utilisation des systèmes Stream Analytics d’Azure comme module IoT Edge
- Utilisation des sous-systèmes d’apprentissage automatique d’Azure dans un module IoT Edge
- Exécution d’une classification d’images avec le service de vision personnalisée d’Azure en tant que module IoT Edge
- Exécution de bases de données SQL en tant que conteneur IoT Edge
Cette capacité à migrer des services de classe de centre de données cloud permet un développement rapide et une facilité d’exécution.
8.6 Cas d’utilisation pour Edge Computing
Edge computing offre la possibilité de rapprocher le traitement des sources de données. Jusqu’à présent, nous avons exploré plusieurs cas d’utilisation traditionnels dans cet article, mais de nouvelles utilisations de l’informatique de pointe ont émergé récemment. L’informatique ambiante propose le concept de l’informatique naturelle qui se fond dans un environnement, tandis que la détection synthétique offre la possibilité d’agréger les capteurs au niveau des bords dans un vaste système respectueux de l’environnement.
Dans cet article, nous avons étudié différents types de capteurs utilisés sur le bord éloigné. Des appareils tels que les capteurs MEM, les capteurs thermiques et les capteurs de mouvement PIR sont conçus pour mesurer des caractéristiques spécifiques de l’environnement comme la pression, la température ou le mouvement. Ces capteurs à eux seuls n’ont pas la capacité de comprendre des actions plus complexes dans un environnement, par exemple, un brûleur de poêle laissé allumer ou si le café est terminé. Bien que ces tâches puissent être accomplies simplement en ajoutant des capteurs directement à chaque appareil, la détection synthétique tente de condenser tous les capteurs en un seul appareil matériel confiné qui analyse l’ensemble de l’environnement d’une pièce ou d’un bureau.
8.6.1 Informatique ambiante
L’informatique ambiante (parfois appelée informatique omniprésente) est un paradigme de la façon dont nous interagissons avec les machines. En règle générale, les interactions humaines avec un ordinateur impliquent une interface homme-machine via un moniteur, un clavier et une souris. C’est peut-être grâce à un écran tactile sur un smartphone. Quoi qu’il en soit, il existe une association avec le dispositif informatique en tant qu’unité de distinction séparable avec laquelle il faut interagir.
En informatique ambiante, il n’y a pas d’ordinateur avec lequel interagir – l’ordinateur est l’environnement. L’interaction se fait avec l’environnement dans lequel vous vous trouvez. Les choses elles-mêmes sont utilisées, manipulées, consommées ou portées. Les choses elles-mêmes font partie du tissu informatique. Les appareils fonctionnent avec l’IA pour aider et servir en cas de besoin, puis disparaissent en arrière-plan dans le cas contraire. À toutes fins utiles, aucun ordinateur typique n’est vu au premier plan jouer un rôle actif.
Cela fonctionne en incorporant ce que nous avons appris jusqu’à présent sur les capteurs, l’IoT et l’informatique de bord. Essentiellement, rassembler et analyser la collecte de données dans un environnement et agir en conséquence. Du point de vue informatique de pointe, l’objectif est de le faire sans être envahissant. Au contraire, l’ordinateur de bord a un rôle important, mais il ne devrait pas être évident qu’il est au centre de ce rôle. Les principes de l’informatique ambiante sont :
- Invisible : les systèmes ne doivent pas attirer l’attention sur eux-mêmes. L’informatique doit être omniprésente et tout autour, mais pas associée à un appareil. La technologie est en vue lorsqu’elle est nécessaire et hors de vue lorsqu’elle n’est pas nécessaire.
- Embarqué : les objets peuvent intégrer l’intelligence en eux-mêmes sous forme de capteurs et de calcul.
- Sans friction : l’informatique ambiante consiste à simplifier les interactions complexes avec les ordinateurs. Il place les humains au centre de l’informatique plutôt que d’un PC, d’une souris et d’un clavier. L’informatique est là où vous êtes et cognitif de votre environnement.
- Interconnecté : un environnement composé de différentes choses et objets doit fonctionner ensemble et communiquer entre eux. Cela devient difficile avec les normes et protocoles concurrents.
L’informatique de périphérie est au cœur de l’informatique ambiante. Les premiers vestiges de cela sont des choses comme Amazon Alexa, qui tente de placer un assistant vocal et un appareil connecté au cloud dans un environnement. Pour la plupart, vous ne savez peut-être même pas que cet ordinateur de bord est dans l’environnement jusqu’à ce que vous le signaliez via un message de halo “Alexa”. Il peut s’interfacer avec certains capteurs environnementaux et dispositifs IoT et interagir de manière invisible et sans frottement.
Le défi pour le concepteur informatique de pointe est de prendre les technologies décrites plus haut dans ce chapitre et de créer un appareil qui interagit avec les humains mais n’est pas vu par les humains. Les systèmes de périphérie peuvent avoir de grandes quantités de puissance de calcul – autant que les lames de centre de données ; mais, cependant, ils rendent leur fonctionnalité apparente, ce qui rend leur structure physique transparente est le défi d’ingénierie. Cela implique que nous devons prendre le matériel, les systèmes de communication et l’infrastructure, et la conception pour la forme, l’espace, le son et la vue : pas de lumières clignotantes, pas de ventilateurs à haute vitesse, pas de câblage envahissant.
Un bon exemple de calcul ambiant utilisant un périphérique informatique de bord est la détection synthétique, que nous verrons dans la section suivante.
8.6.2 Détection synthétique
La détection synthétique a été introduite par Gierad Laput , Yang Zhang et Chris Harrison dans Synthetic Sensors: Towards General Purpose Sensing (Actes de la Conférence CHI 2017 sur les facteurs humains dans les systèmes informatiques. Pp 3986-3999. ACM, 2017). Ici, un appareil est placé dans un environnement où il a été formé pour apprendre ce qui se passe sur la base de différents capteurs intégrés à l’ordinateur de bord. Ces capteurs peuvent comprendre des accéléromètres, des capteurs de température, des capteurs de pression acoustique, etc. L’appareil est formé pour comprendre comment ces capteurs sont affectés par l’environnement. Par exemple, l’un de ces ordinateurs à capteur synthétique peut être placé dans une pièce et savoir quel brûleur sur une cuisinière est allumé, si le lave-vaisselle fonctionne, si le robinet a été laissé ouvert.
Dans le diagramme suivant, nous montrons cinq capteurs accumulant des données sur un ordinateur à bord unique. Ces signaux en temps réel sont traités et rassemblés via un moteur d’inférence formé pour détecter les événements. Ce qui manque à cet ensemble de capteurs, c’est un véritable appareil photo. La détection synthétique peut ne jamais utiliser de données vidéo ou photographiques. Au contraire, tous les autres ensembles de caractéristiques environnementales sont rassemblés sous la forme d’un ensemble de signaux corrélés au temps. La vidéo représente un “blob” de données non structurées qui nécessite une forme différente d’apprentissage automatique (dont nous parlerons plus loin dans cet article):
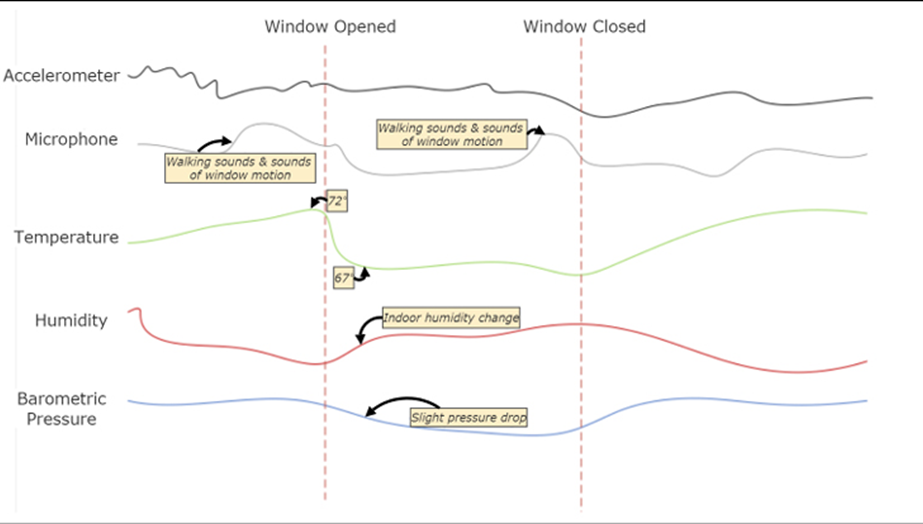
Figure 14 : Détection synthétique utilisant cinq capteurs environnementaux accumulant des signaux corrélés au temps traités en temps réel via un moteur d’inférence de bord. Les événements sont entraînés en fonction de la signature de ces signaux, comme la façon dont les événements de température et d’humidité peuvent indiquer qu’une fenêtre est ouverte ou fermée dans une pièce.
Lorsque le périphérique périphérique acquiert des données de capteur, il tente d’abord de supprimer le bruit et les aberrations dans les signaux. Ensuite, il tentera de normaliser les bases de temps et les horodatages des données collectées. En d’autres termes, certains capteurs peuvent être échantillonnés à une fréquence plus élevée et certains à des fréquences plus basses ; logiciel ajustera correctement les nombreux échantillons à une base de temps dérivée commune. Après avoir corrigé les signaux, le dispositif périphérique exécutera un modèle d’inférence entraîné sur les données en temps quasi réel possible. Le produit final sera une classification de l’état dans lequel l’environnement se trouve.
D’un point de vue matériel, un ordinateur de bord pourrait utiliser quelque chose comme un IC à photons de particules qui incorpore un microcontrôleur ST Micro STM32F205. L’objectif est de mélanger autant d’entrées de capteurs en corrélation temporelle que possible dans un seul module. Dans ce cas, les capteurs d’intérêt comprennent :
- Grideye AMG833 pour la détection de niveau infrarouge
- Capteur de couleur et de luminosité AMS TCS34725
- Xtrinsic MAG3110 trois -axis magnétomètre
- Bosch BM280 Capteur de température, baromètre et humidité
- Capteur gyroscopique et accéléromètre TDK Invensense MPU6500 à six axes
- Détection Wi-Fi 2,4 GHz des changements d’intensité de champ RSSI
- Panasonic AMN2111 mouvement PIR capteur
- Analog ADMP401 microphone MEMS capteur
- 100mH inductance EMI capteur
Tous les appareils, le processeur et la mémoire, ainsi que l’USB et une interface réseau Wi-Fi, tiennent sur un module de 45,4 mm par 48,6 mm. Cela suit le paradigme de l’informatique ambiante en créant un dispositif de détection d’espace qui connaît les comportements centrés sur l’utilisateur, mais ne nécessite pas une pléthore de capteurs et d’appareils pour être connecté à chaque objet. L’appareil peut être masqué mais fournir des informations utiles sur l’état d’un environnement à un propriétaire ou un propriétaire d’entreprise.
8.7 Résumé
L’Edge computing est un vaste espace qui nécessite la discipline de l’ingénieur en informatique et de l’informaticien (ainsi que de l’administrateur réseau, du directeur commercial et du professionnel de la sécurité) pour créer une solution robuste. Dans ce chapitre, nous avons découvert les cas d’utilisation et les définitions de périphérie et comment ils sont mappés à partir de systèmes embarqués vers des conceptions analogues aux centres de données situés à la périphérie. Il est également impératif de comprendre l’architecture matérielle de la machine Edge comme un début.
Nous avons plongé profondément dans les architectures de silicium et de processeur et quels types d’architectures sont pertinents pour divers problèmes de calcul de périphérie. Il faut également tenir compte du périphérique physique et de la façon dont il sera protégé dans une zone éloignée et non surveillée. Vient ensuite la conception du logiciel et du système d’exploitation. Construire un système robuste et fiable en périphérie signifie que le logiciel doit être autogéré, allégé et fiable. Nous avons exploré des façons de régler la surface des bords pour réduire l’entretien, la taille de l’image et les vulnérabilités potentielles. Pour gérer les systèmes de périphérie, l’architecte doit également tenir compte des paradigmes de virtualisation basés sur des conteneurs. Nous avons exploré ces méthodes et comment elles fonctionneraient à grande échelle sur des machines de pointe.
Dans le prochain chapitre, nous continuerons notre apprentissage de l’informatique de pointe et explorerons son rôle spécifique dans les réseaux et les communications.
9 Bord de routage et de réseau
Les routeurs, ponts et passerelles Edge jouent un rôle essentiel dans le développement de l’IoT. L’une des fonctions principales de l’informatique périphérique est sa capacité à créer des ponts entre les réseaux, à les acheminer entre les réseaux et à fournir une gestion de réseau avancée pour permettre une gestion transparente au niveau de l’entreprise, d’un centre de données géré par l’entreprise à un périphérique périphérique distant. Cela nécessite une mise en réseau robuste, autonome et à sécurité intégrée.
Nous avons déjà discuté des différents protocoles PAN et WAN plus haut dans cet article. Une fonction importante du routeur ou de la passerelle éloignée est d’effectuer le pontage entre les réseaux non IP et d’autres réseaux IP, y compris les réseaux cellulaires et 5G.
Nous commençons ce chapitre en passant en revue certains des principes fondamentaux du routage en général. Le bord est l’endroit où nous agrégons les données des capteurs et des communications PAN ainsi que les connexions sortantes aux sources cloud via Internet. Les appareils IoT nécessitent un certain type de communication avec Internet. Souvent, ces appareils ne disposent pas des ressources nécessaires pour accéder directement à Internet (par exemple, un manque de matériel et de logiciels de mise en réseau TCP / IP) ; par conséquent, le calcul et le routage de périphérie sont nécessaires pour faciliter le déplacement des données.
Il est important de comprendre et de concevoir correctement le routage des données dans et hors des nœuds périphériques. Nous abordons ensuite les sujets des VLAN et des réseaux définis par logiciel, qui prennent racine dans les déploiements IoT. Ces technologies permettent aux routeurs gérés en périphérie de séparer intelligemment le trafic.
9.1 Fonctions réseau TCP / IP en périphérie
Le routage fait référence au pilotage des données entre plusieurs clients et réseaux. Pour cette discussion, nous examinerons le routage basé sur TCP / IP et son applicabilité en périphérie.
9.1.1 Fonctions de routage
La fonction de base d’un routeur est de relier les connexions entre les segments du réseau. Le routage est considéré comme une fonction de couche trois du modèle standard OSI car il utilise la couche d’adresse IP pour guider le mouvement des paquets. Essentiellement, tous les routeurs s’appuient sur une table de routage pour guider le flux de données. La table de routage est utilisée pour trouver la meilleure correspondance avec l’adresse IP de destination d’un paquet.
Il existe plusieurs algorithmes éprouvés utilisés pour un routage efficace. Un type de routage est le routage dynamique, où les algorithmes réagissent aux changements du réseau et de la topologie. Les informations sur l’état du réseau sont partagées via un protocole de routage sur une base temporisée ou lors d’une mise à jour déclenchée. Des exemples de routage dynamique sont le routage à vecteur de distance et le routage à état de liaison. Alternativement, le routage statique est important et utile pour les petits réseaux qui ont besoin de chemins spécifiques configurés entre les routeurs. Les routes statiques ne sont pas adaptatives et n’ont donc pas besoin d’analyser les topologies ou de mettre à jour les métriques. Ceux – ci sont prédéfinis sur le routeur :
- Routage du chemin le plus court : un graphique est construit représentant les routeurs sur le réseau. Un arc entre les nœuds représente un lien ou une connexion connue. L’algorithme trouve simplement le chemin le plus court depuis n’importe quelle source vers n’importe quelle destination.
- Inondation : chaque paquet est répété et diffusé depuis chaque routeur vers chaque point de terminaison sur sa liaison. Cela génère un nombre considérable de paquets en double et nécessite un compteur de sauts dans l’en-tête de paquet pour garantir aux paquets un temps de vie limité. Une alternative est l’inondation sélective, qui inonde uniquement un réseau dans la direction générale de la destination. Les réseaux d’inondation sont à la base de la mise en réseau maillée Bluetooth.
- Routage basé sur le flux : cet algorithme inspecte le flux actuel dans le réseau avant de déterminer un chemin. Pour une connexion donnée, si la capacité et le débit moyen sont connus, il calcule le retard moyen des paquets sur cette liaison. Cet algorithme trouve la moyenne minimale.
- Routage à vecteur de distance : la table des routeurs contient la distance la plus connue jusqu’à chaque destination. Les tables sont mises à jour par les routeurs voisins. Le tableau contient une entrée pour chaque routeur du sous-réseau. Chaque entrée contient un itinéraire / chemin préféré et la distance estimée jusqu’à la destination. La distance peut être une métrique d’un certain nombre de sauts, de latence ou de longueurs de file d’attente.
- Routage à l’état de liaison : un routeur découvre initialement tous ses voisins via un paquet HELLO spécial. Le routeur mesure le retard à chacun de ses voisins en envoyant un paquet ECHO. Ces informations de topologie et de synchronisation sont ensuite partagées avec tous les routeurs du sous-réseau. Une topologie complète est construite et partagée entre tous les routeurs.
- Routage hiérarchique : les routeurs sont divisés en régions et ont une topologie hiérarchique. Chaque routeur conserve une compréhension de sa propre région, mais pas de l’ensemble du sous-réseau. Le routage hiérarchique est également un moyen efficace de contrôler la taille et les ressources de la table du routeur dans les appareils contraints.
- Routage de diffusion : chaque paquet contient une liste d’adresses de destination. Un routeur de diffusion examine les adresses et détermine l’ensemble des lignes de sortie à transmettre au paquet. Le routeur va générer un nouveau paquet pour chaque ligne de sortie et inclure uniquement les destinations nécessaires dans ce paquet nouvellement formé.
- Routage multidiffusion : le réseau est partitionné en groupes bien définis. Une application peut envoyer un paquet à un groupe entier plutôt qu’à une seule destination ou à une diffusion.
Une métrique importante dans le routage est le temps de convergence. La convergence se produit lorsque tous les routeurs d’un réseau partagent les mêmes informations et états topologiques.
Les routeurs périphériques typiques prennent en charge les protocoles de routage tels que le protocole BGP (Border Gateway Protocol), le protocole OSPF (Open Shortest Path First), le protocole RIP (Routing Information Protocol) et le protocole RIPng. Un architecte utilisant des routeurs de périphérie sur le terrain doit être conscient de l’encombrement et des coûts d’utilisation d’un certain protocole de routage par rapport à d’autres, en particulier si l’interconnexion entre les routeurs est une connexion WAN limitée par des données :
- BGP : BGP-4 est la norme pour les protocoles de routage de domaine Internet et est décrit dans la RFC 1771 ; il est utilisé par la plupart des FAI. BGP est un algorithme de routage dynamique à vecteur de distance et annonce des chemins entiers dans les messages de mise à jour de routage. Si les tables de routage sont volumineuses, cela nécessite une bande passante importante. BGP enverra un message de maintien en vie de 19 octets toutes les 60 secondes pour maintenir une connexion. BGP peut être un mauvais protocole de routage pour les topologies maillées car BGP maintient une connexion avec les voisins. BGP lutte également avec la croissance des tables de routage dans les grandes topologies. BGP est également unique car c’est l’un des seuls protocoles de routage basés sur des paquets TCP.
- OSPF : ce protocole est décrit dans la RFC 2328 et offre des avantages de mise à l’échelle et de convergence du réseau. Le réseau fédérateur Internet et les réseaux d’entreprise utilisent beaucoup OSPF. OSPF est un algorithme d’état de liaison qui prend en charge IPv4 et IPV6 (RFC 5340) et fonctionne sur les paquets IP. Il a l’avantage de détecter les changements de liens dynamiques en quelques secondes et de répondre.
- RIP : La version 2 de RIP est un algorithme de routage à vecteur de distance basé sur le nombre de sauts utilisant un protocole de passerelle intérieure. Initialement basé sur l’algorithme Bellman-Ford, il prend désormais en charge les sous-réseaux de taille variable, surmontant les limitations de la version d’origine. Les boucles dans une table de routage sont restreintes en limitant le nombre maximal de sauts dans un chemin (15). RIP est basé sur UDP et prend uniquement en charge le trafic IPv4. RIP a un temps de convergence plus long que les protocoles tels que OSPF mais est facile à administrer pour les topologies de routeur de petite taille. Pourtant, la convergence pour RIP avec seulement quelques routeurs peut prendre plusieurs minutes.
- RIPng : RIPng signifie RIP nouvelle génération (RFC 2080). Cela permet la prise en charge du trafic IPv6 et IPsec pour l’authentification.
Une table de routage typique est la suivante :
[administrator@Edge-Computer: /]$ route
Table: wan
Destination Gateway Device UID Flags Metric Type
default 96.19.152.1 wan onlink 0 unicast
Table: main
Destination Gateway Device UID Flags Metric Type
96.19.152.0/21 * wan 0 unicast
172.86.160.0/20 * iface:cloud-edge1 0 unicast
172.86.160.0/20 None None 256 blackhole
192.168.1.0/24 * primarylan 0 unicast
2001:470:813b::/48 * *iface:cloud-edge1 256 unicast
fe80::/64 * lan 256 unicast
Table: local
Destination Gateway Device UID Flags Metric Type
96.19.152.0 * wan 0 broadcast
96.19.153.13 * wan 0 local
96.19.159.255 * wan 0 broadcast
127.0.0.0 * *iface:lo 0 broadcast
.
.
Dans cet exemple, il y a trois tables: wan , main et local . Un routeur peut avoir une seule table de routage ou plusieurs tables de routage. L’exemple ci-dessus provenait d’un véritable système de routage de périphérie sur le terrain qui avait une liaison montante WAN de cave utilisée et avait un sous-réseau local avec plusieurs réseaux et un LAN virtuel. Chaque table contient des chemins de routage particuliers spécifiques à cette interface :
- Destination : l’adresse IP complète ou partielle de la destination du paquet. Si le tableau contient l’IP, il fera référence au reste de l’entrée pour résoudre l’interface et l’itinéraire. Pour ce faire, il utilise une adresse partielle, qui peut être préfixée par une barre oblique (/). Ceci spécifie les positions de bits fixes de l’adresse à résoudre. Par exemple, / 24 dans 192.168.1.0/24 spécifie que les 24 premiers bits de 192.168.1 sont fixes et les 8 bits inférieurs peuvent résoudre n’importe quelle adresse sur le sous-réseau 192.168.1. *.
- Passerelle : il s’agit de l’interface utilisée pour les paquets directs qui correspondent à la recherche de destination. Dans le cas précédent, la passerelle est spécifiée comme 96.19.152.1 et la destination est par défaut. Cela implique que le WAN sortant au 96.19.152.1 sera utilisé pour toutes les adresses de destination. Il s’agit essentiellement d’ un relais IP .
- UID de l’appareil : il s’agit d’un identifiant alphanumérique pour l’interface vers laquelle diriger les données. Par exemple, toute destination du sous-réseau 172.19.152.0/21 achemine les paquets vers une interface intitulée iface : cloud-edge1 . Souvent, ce champ sera exprimé avec une adresse IP numérique plutôt qu’une référence symbolique.
- Indicateurs : ils sont utilisés pour les diagnostics et indiquent l’état de l’itinéraire. Les indicateurs d’état spécifiques utilisés peuvent être: route montante , route descendante ou passerelle d’utilisation .
- Métrique : il s’agit de la distance jusqu’à la destination et est généralement comptée par le nombre de sauts.
- Type : Plusieurs types d’itinéraire peuvent être utilisés:
- Unicast : l’itinéraire est un véritable chemin vers une destination.
- Unreachable : la destination est inaccessible. Les paquets sont rejetés et un message ICMP est généré indiquant que l’hôte est inaccessible. L’ expéditeur local reçoit une erreur EHOSTUNREACH .
- Blackhole : les destinations sont inaccessibles. Contrairement aux types interdits , les paquets chutent doucement. Les expéditeurs locaux obtiennent une erreur EINVAL .
- Prohibit : les destinations sont inaccessibles. Les paquets seront supprimés et les messages ICMP générés. Les expéditeurs locaux reçoivent une erreur EACCES .
- Local : les destinations sont affectées à cet hôte. Les paquets sont rebouclés et livrés localement.
- Broadcast: les paquets seront envoyés en tant que diffusions via l’interface vers toutes les destinations.
- Throw : Ceci est une route de contrôle spéciale pour forcer les paquets à tomber et à générer des messages ICMP inaccessibles.
Il convient également de noter dans l’exemple précédent que les adresses IPv6 sont mélangées avec les adresses IPv4. Par exemple, 2001: 470: 813 b :: / 48 dans le tableau principal est une adresse IPv6 avec un sous-réseau / 48 bits.
9.1.2 Pont PAN-WAN
Un domaine critique de l’IoT et du pontage est la conversion de la communication non IP en réseau WAN basé sur IP. Un exemple est la conversion de paquets publicitaires Bluetooth capturés en flux MQTT sur 5G. Il s’agit d’un processus complexe impliquant plusieurs composants matériels, radios, pilotes de périphériques et piles de communication. Cependant, il est essentiel au processus.
À ce stade, nous supposons que le matériel PAN et WAN nécessaire est installé sur l’ordinateur de bord. Normalement, le processus sera soit piloté par des événements, soit interrogé. Pour la génération de trafic événementiel, l’arrivée des données PAN signalera un événement (l’arrivée d’un message publicitaire Bluetooth). Si l’événement est qualifié, il peut avoir les actions suivantes:
- Ignoré : le paquet a été filtré, conformément à un ensemble de règles, pour des raisons de gestion de l’alimentation ou parce que le paquet ou le message publicitaire n’a pas été authentifié.
- En cache : le paquet peut être stocké localement dans la RAM ou dans un stockage non volatile. Les données de paquets pertinentes, un horodatage et peut-être d’autres métadonnées peuvent être stockées dans un fichier journal de plus en plus important pour une transmission ou une récupération ultérieure. La mise en cache est également efficace en cas de communication non fiable lorsque des tentatives sont nécessaires pour la résilience.
- Transmis : le paquet est enveloppé dans un protocole sortant tel que MQTT ou HTTP et envoyé sur un réseau sécurisé et sécurisé à un service authentifié tel qu’un moteur d’ingestion cloud ou un lac de données.
Bien qu’il s’agisse d’une simple représentation d’un pont, la logique au sein du système de contrôle est ce qui fait de la périphérie une technologie puissante avec des moteurs de règles, l’apprentissage automatique, des techniques avancées de gestion de l’énergie et des analyses de périphérie. Ces concepts seront discutés en détail plus loin dans cet article.
Un exemple d’un tel pontage est illustré dans la figure suivante. Ici, un module NBIOT cellulaire typique est utilisé (dans ce cas, un module cellulaire Telit ). Ces modules se connectent généralement à un ordinateur hôte via des interfaces UART ou USB (pour des communications jusqu’à 480 Mbit / s). Les modules tels que le module cellulaire Telit peuvent fonctionner à l’aide d’un jeu de commandes AT compatible Hayes intégré et utiliser une pile TCP intégrée au module ou se connecter au format brut via USB à l’aide de la spécification RNDIS ( Remote Network Driver Interface Specification ) ou Ethernet sur USB. Les deux sont des protocoles qui transportent des trames Ethernet sur USB.
Étant donné que l’Ethernet 802.3 typique transporte des données dans des trames et que l’USB ne le fait pas, un protocole doit être utilisé si vous essayez d’utiliser une connexion USB en tant que composant de réseau TCP. Le modèle de contrôle Ethernet ( ECM ) et le modèle d’émulation Ethernet ( EEM ) sont deux de ces protocoles. Des deux, ECM est le plus simple à implémenter et à utiliser.
Le côté non IP du pont est contrôlé par le routeur de périphérie lorsque des paquets ou des publicités capturés à partir d’un périphérique Bluetooth se propagent dans la pile BLE typique vers l’application. Dans ce cas, l’application de liaison est l’application de contrôle de périphérie qui effectue toutes les initialisations et liaisons de réseau nécessaires pour combler les deux segments de réseau non-sens.
L’application est également l’entité appropriée pour filtrer, dénaturer (filtrer les données en fonction de règles telles que les règles de confidentialité), mettre en cache et analyser le flux de données entrant et prendre la décision de transmettre les données vers le WAN:

Figure 1 : conversion PAN-WAN sur le routage de périphérie. Ici, un module Telit Cellular NB-IoT est utilisé qui communique avec l’ordinateur périphérique d’hébergement via une interface USB haute vitesse. RNDIS est utilisé pour forcer les trames Ethernet sur la liaison USB. L’application de contrôle de périphérie effectue la plupart de la configuration, de la liaison et de l’interface réseau. De plus, il contrôle le moteur de règles et la logique quant aux paquets à propager du PAN vers le WAN.
Bien que toutes les radios cellulaires nécessitent une carte SIM pour identifier l’appareil sur le support cellulaire, il existe deux méthodes à considérer pour les conceptions de périphérie. Une carte SIM traditionnelle peut être utilisée et intégrée dans un support de carte sur la carte PCB. Alternativement, des appareils comme le Telit HE910 prennent en charge « SIM sur puce », qui est une conception SIM fixe et non amovible destinée à être montée en surface en permanence sur le PCB. Ceci est destiné à la résilience dans les déploiements IoT durs ou hostiles comme les véhicules tout-terrain ou lorsque l’humidité est un problème.
L’exemple suivant montre comment une session de communication fonctionnera avec une radio cellulaire, comme le Telit HE910, à l’aide des commandes AT. L’ordinateur de bord ou le processeur dans ce cas peut avoir plusieurs applications destinées à ouvrir des sockets réseau et à transmettre ou recevoir des données via Internet. Chaque application se verra attribuer un port virtuel AT (attention) (AT0, AT1, etc.). Le jeu de commandes Hayes AT fonctionne en mode COMMANDE ou en mode EN LIGNE. En mode COMMAND, des instructions préfixées AT configurent et contrôlent le modem, tandis qu’en mode ONLINE, les données saisies par l’application ou l’utilisateur sont librement envoyées en amont vers le réseau. Une adresse IP est attribuée à chaque port AT du modem pour correspondre à l’application.
Voici un exemple d’ouverture d’un socket cellulaire sur le module Telit .
En mode COMMAND, ouvrez le socket à l’aide de:
AT#SD=3,0,80,”host name”
CONNECT
[data is delivered]
+++
OK
La commande AT SD signifie “socket dial” et ouvrira une connexion TCP / UDP à un hôte connu comme azure.microsoft.com. La commande est analysée comme :
AT#SD=<connId>,<txProt>, <rPort>, <IPaddr> [, <closureType> [, <IPort>[,<connMode>]]]
- connId fait référence à l’interface AT virtuelle dans le graphique, également connue sous le nom d’ID de connexion.
- txProt est le protocole de transmission (soit 0 pour TCP ou 1 pour UDP).
- rPort est le port du récepteur hôte auquel se connecter. Dans cet exemple, nous nous connectons à Microsoft Azure sur le port 80.
- IPaddr peut être une adresse IP valide sous la forme xxx.xxx.xxx.xxx ou un nom qui doit être résolu via une requête DNS.
- closeType est l’action à entreprendre lorsque l’hôte ferme une connexion. La valeur par défaut (0) est que l’hôte se ferme immédiatement, ou 255, ce qui nécessite que l’hôte émette une commande AT # SH pour se déconnecter.
- IPort est pour la connexion locale UDP utilisant un port de choix.
- connMode est le mode de connexion, qui peut être 0 pour les connexions en mode EN LIGNE ou 1 pour les connexions en mode COMMANDE.
Il existe des centaines de commandes AT uniques et définies par le fournisseur. Ceci a été un bref aperçu de la façon dont la radio forme une connexion IP. Différents modèles de modules peuvent utiliser différentes commandes ou interfaces. Il appartient à l’architecte de comprendre les caractéristiques radio de la solution qu’il développe.
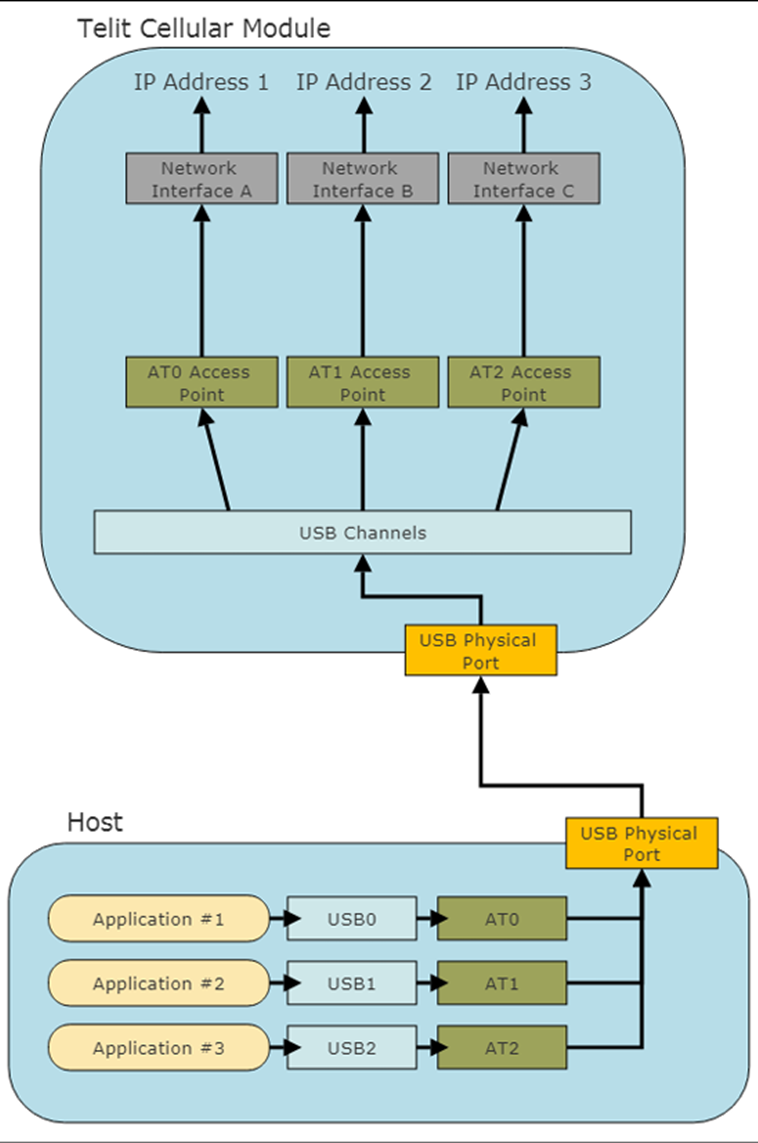
Figure 2 : exemple de radio cellulaire Telit HE910. Ici, trois applications créent des ports AT virtuels qui s’étendent via une connexion USB du processeur de périphérie au module radio Telit.
9.1.3 Basculement et gestion hors bande
Le basculement est une fonctionnalité essentielle pour certains routeurs de périphérie IoT, en particulier pour les véhicules en mouvement et les applications de soins aux patients. Le basculement, comme son nom l’indique, passe d’une interface WAN à une autre en cas de perte d’une source principale. La perte de WAN pourrait être attribuée à la perte de connectivité cellulaire dans un tunnel. Une entreprise de logistique avec une flotte de camions frigorifiques peut avoir besoin de garantir la connectivité là où le service cellulaire varie à l’échelle nationale. Un basculement d’un fournisseur cellulaire à un autre en utilisant plusieurs identités SIM peut aider à atténuer et à fluidifier la connectivité. Un autre cas d’utilisation pourrait être d’utiliser le Wi-Fi client comme interface WAN principale pour la surveillance de la santé à domicile, mais en permettant un basculement vers le WAN cellulaire si le signal Wi-Fi est perdu. Le basculement doit être transparent et automatique sans perte de paquets ni impact notable sur la latence des données.
La gestion hors bande ( OOBM ) doit également être envisagée pour les appareils IoT. OOBM est utile dans les conditions où un canal dédié et isolé est nécessaire pour la gestion des équipements. Parfois, cela s’appelle la gestion de l’éclairage ( LOM ) si les systèmes principaux sont hors ligne, endommagés ou ont une perte d’alimentation; on est toujours capable de gérer et d’inspecter l’équipement à distance via un canal à bande latérale. Dans l’IoT, cela peut être utile pour les situations qui nécessitent une disponibilité garantie et une gestion à distance, comme la surveillance du pétrole et du gaz ou l’automatisation industrielle. Un système OOBM bien conçu ne devrait pas dépendre du système surveillé pour être fonctionnel. Les plans de gestion typiques, tels que les tunnels VNC ou SSH, nécessitent que le périphérique soit démarré et fonctionnel.
Lors de la création d’une architecture IoT, vous devez vous demander quels actifs ont besoin d’OOBM. En règle générale, vous souhaitez cette forme de gestion pour les points cruciaux de votre réseau de périphérie vers le cloud. Si un routeur périphérique peut être compromis ou est crucial à gérer (par exemple, les transactions fiduciaires ou les services d’urgence), il est utile d’avoir OOBM pour déterminer la santé de la machine sans compter sur le réseau normal. Cela permet à un responsable informatique de réinitialiser l’appareil, d’arrêter les attaques de logiciels malveillants et de reprogrammer l’appareil même si le chemin d’accès réseau traditionnel est perdu.
Un OOBM doit être complémentaire et isolé du système, comme illustré dans la figure suivante :
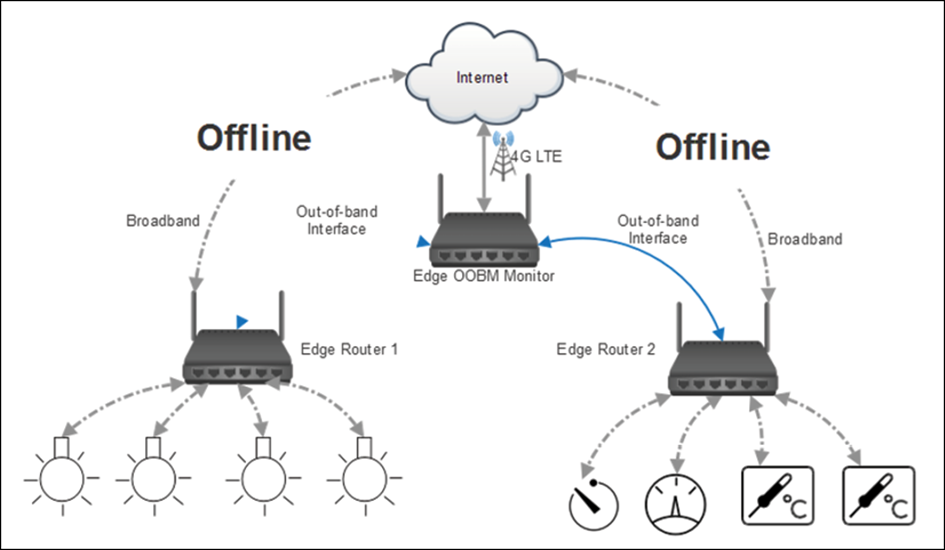
Figure 3: Exemple avec figuration pour la gestion hors bande
Un exemple de cas d’utilisation où le basculement est utilisé dans les déploiements IoT se trouve dans les zones de vente au détail des supermarchés. Les épiciers modernes, ainsi que les nouveaux Amazon (épiciers sans caissier), disposeront de machines de point de vente comme des caisses enregistreuses ainsi que des capteurs IoT, des balises Bluetooth et des systèmes de sécurité. Ils comprennent également des services de musique sur Internet et une connexion Wi-Fi client. En cas de défaillance d’un service Internet traditionnel, le système bascule vers un service cellulaire de basculement. Ce service a moins de bande passante et des accords de service coûteux, de sorte que les systèmes de pointe limitent la qualité de service pour des choses comme le Wi-Fi client et la musique basée sur Internet, au lieu de garder les caissiers et les transactions financières en état de marche.
9.2 Edge- niveau réseau de sécurité
La sécurité doit être prise en compte du capteur au cloud lors de l’architecture des solutions IoT. La périphérie joue un rôle important dans la communication sécurisée des données ainsi que dans l’isolement des différents chemins de données les uns des autres. Cette section explorera certaines normes de réseau qui devraient être déployées en périphérie.
9.2.1 VLAN
Un LAN virtuel (VLAN) fonctionne comme n’importe quel autre LAN physique, mais il permet de regrouper des ordinateurs et d’autres périphériques même s’ils ne sont pas physiquement connectés au même commutateur réseau. Le partitionnement se produit dans la couche de liaison de données (deux) du modèle OSI. Les VLANs sont une forme de segmentation du réseau des appareils, des applications ou des utilisateurs, bien qu’ils partagent le même réseau physique. Un VLAN peut également regrouper des hôtes, bien qu’ils ne soient pas sur le même commutateur réseau, ce qui allège essentiellement la charge de partitionnement du réseau sans utiliser de câbles supplémentaires. IEEE 802.1Q est la norme par laquelle les VLAN sont construits. Essentiellement, un VLAN utilise un identifiant ou une étiquette composée de 12 bits dans la trame Ethernet. Par conséquent, il existe une limite stricte de 4 096 VLANs potentiels sur un seul réseau physique.
Un commutateur peut affecter un port à mapper directement sur un VLAN particulier. Étant donné que le VLAN est conçu dans la couche deux de la pile, le trafic peut être acheminé via la couche trois, permettant aux VLAN géographiquement séparés de partager une topologie commune.
La figure suivante montre un point de vente d’entreprise (POS) et un système VOIP qui est pratiquement isolé d’un ensemble d’appareils IoT ainsi que du Wi-Fi invité. Cela se fait via l’adressage VLAN, bien que le système partage le même réseau physique. Ici, nous supposons qu’il s’agit d’un déploiement IoT intelligent où tous les périphériques et capteurs IoT de périphérie transportent une pile IP et sont adressables via le LAN :

Figure 4 : Un exemple d’architecture VLAN dans un scénario de franchise ou de vente au détail
La conception de VLAN est particulièrement utile dans l’espace IoT. Isoler les appareils IoT des autres fonctions de l’entreprise est un scénario typique. Les VLANs ne sont utiles que lorsqu’il s’agit de périphériques adressables IP.
9.2.2 VPN
Les tunnels VPN sont utilisés pour établir une connexion sécurisée à un réseau distant sur un réseau public. Par exemple, les tunnels VPN peuvent être utilisés sur Internet par un individu pour se connecter à un réseau d’entreprise sécurisé lors d’un voyage, ou par deux réseaux de bureau pour fonctionner comme un seul réseau. Les deux réseaux établissent une connexion sécurisée à Internet (normalement) non sécurisé en attribuant des protocoles de cryptage VPN.
Pour le déploiement de l’IoT, un VPN est nécessaire pour déplacer les données des capteurs distants et des périphériques périphériques vers un LAN d’entreprise ou privé. En règle générale, une entreprise sera derrière un pare-feu et un VPN est le seul moyen de déplacer des données directement vers un serveur privé sur site. Dans ces cas, un VPN peut être un composant nécessaire du routeur pour relier les réseaux. Plus loin dans ce chapitre, une discussion sur les réseaux définis par logiciel présentera une méthode alternative à la sécurisation des réseaux.
Il existe plusieurs VPN :
- VPN de sécurité de protocole Internet (IPsec) : forme traditionnelle de la technologie VPN qui réside sur la couche réseau de la pile OSI et sécurise les données via un tunnel entre deux points de terminaison.
- OpenVPN : VPN open source pour des connexions point à point et site à site sécurisées dans des configurations routées ou pontées. Il intègre un protocole de sécurité personnalisé utilisant SSL / TLS (OpenSSL) pour l’échange de clés et le chiffrement des plans de contrôle et de données. Il peut s’exécuter sur des transports UDP et TCP. SSL est courant dans la plupart des applications de navigateur ; Par conséquent, les systèmes SSL VPN peuvent fournir des tunnels sécurisés sur une base d’application plutôt que sur un réseau entier.
- WireGuard : Un autre VPN open source. WireGuard est souvent beaucoup plus facile à configurer et à installer qu’OpenVPN ou IPSec . La base de code VPN entière comprend 4 000 lignes. Il a moins de fonctionnalités et de configurabilité qu’OpenVPN (500 000 lignes de code source) mais peut remplir de manière adéquate la plupart des fonctions importantes.
- Encapsulation de routage générique (GRE) : crée des connexions point à point entre les points d’extrémité via un tunnel similaire à un tunnel VPN mais encapsule sa charge utile. Il enveloppe ce paquet intérieur dans un paquet extérieur. Cela permet à la charge utile de données de passer sans problème sur d’autres routeurs IP et tunnels. De plus, les tunnels GRE peuvent transporter des transmissions IPV6 et multicast.
- Protocole de tunneling de couche 2 (L2TP) : crée une connexion entre deux réseaux privés via des datagrammes UDP généralement utilisés pour les VPN ou dans le cadre des services de livraison par les FAI. Il n’y a pas de sécurité ou de cryptage intégré dans le protocole, et il s’appuie souvent sur IPsec pour cette capacité.
Lors de la comparaison des fonctionnalités VPN, il est important de considérer des fonctions telles que la journalisation (journaux de la bande passante utilisateur, nombre de connexions d’utilisateurs) si le service a son propre DNS, la prise en charge IPV6, la prise en charge SSL et SSH, le cryptage des données et les méthodes de cryptage de la poignée de main (par exemple, AES256) et les évaluations de service SSL. Les évaluations des services SSL sont signalées par les outils de test Qualsys SSL Lab ( www.qualsys.com ).
Un VPN doit soit faire confiance aux protocoles réseau sous-jacents, soit fournir sa propre sécurité. Les tunnels VPN utilisent généralement IPsec pour authentifier et crypter les paquets échangés entre les tunnels. Pour configurer un routeur tunnel VPN à une extrémité, il doit y avoir un autre appareil (généralement un routeur) qui prend également en charge IPsec à l’autre extrémité. Internet Key Exchange (IKE) est le protocole de sécurité dans IPsec. IKE a deux phases. La première phase est responsable de l’établissement d’un canal de communication sécurisé, et dans la deuxième phase, le canal établi est utilisé par les pairs IKE. Le routeur dispose de plusieurs options de protocole de sécurité différentes pour chaque phase, mais les sélections par défaut seront suffisantes pour la plupart des utilisateurs. Chaque échange IKE utilise un algorithme de chiffrement, une fonction de hachage et un groupe DH pour effectuer un échange sécurisé :
- Cryptage : utilisé pour crypter les messages envoyés et reçus par IPsec. Les normes et algorithmes de chiffrement typiques incluent AES 128, AES 256, DES et 3DES.
- Hachage : utilisé pour comparer, authentifier et valider les données sur le VPN, en s’assurant qu’elles arrivent sous sa forme prévue, et pour dériver les clés utilisées par IPsec. Les fonctions de hachage typiques auxquelles on devrait s’attendre dans un routeur de niveau entreprise incluent MD5, SHA1, SHA2 256, SHA2 384 et SHA2 512. Notez que certaines combinaisons de chiffrement / hachage (telles que 3DES avec SHA2 384/512) sont coûteuses en termes de calcul, affectant le WAN performance. AES fournit un bon cryptage et fonctionne bien mieux que 3DES.
- Groupes Diffie-Hellman (DH) : propriété de IKE utilisée pour déterminer la longueur des nombres premiers associés à la génération de clés. La force de la clé générée est partiellement déterminée par la force du groupe DH. Le groupe 5, par exemple, a plus de force que le groupe 2 :
- Groupe 1 : clé 768 bits
- Groupe 2 : clé 1024 bits
- Groupe 5 : clé 1536 bits
Dans la première phase d’IKE, vous ne pouvez sélectionner qu’un seul groupe DH si vous utilisez un mode d’échange agressif.
Les algorithmes sont répertoriés par ordre de priorité. Vous pouvez réorganiser cette liste de priorités en cliquant et en faisant glisser les algorithmes vers le haut ou vers le bas. Tout algorithme sélectionné peut être utilisé pour IKE, mais les algorithmes en haut de la liste sont susceptibles d’être utilisés plus souvent.
Un mot d’avertissement sur les déploiements IoT mobiles et à puissance limitée : un VPN traditionnel ne peut pas résister à l’entrée et à la sortie d’une connexion réseau persistante (comme l’itinérance cellulaire, la commutation de l’opérateur ou les appareils alimentés occasionnellement). Si le tunnel réseau est perturbé, il provoque des délais d’attente, des déconnexions et des échecs. Certains logiciels VPN mobiles, tels que Host Identity Protocol (HIP) de l’IETF, tentent de résoudre le problème en dissociant les différentes adresses IP utilisées lors de l’itinérance vers la connexion logique VPN. Une autre alternative est la mise en réseau définie par logiciel (SDN), qui sera traitée plus loin dans ce chapitre.
9.2.3 Mise en forme du trafic et QoS
Les fonctionnalités de mise en forme du trafic et de qualité de services (QoS) sont utiles dans les déploiements qui nécessitent un niveau de service garanti en cas de congestion ou de charges réseau variables. Par exemple, dans un cas d’utilisation de l’IoT, lors du mixage de flux vidéo en direct ainsi que du Wi-Fi public, les flux vidéo peuvent avoir besoin d’une priorité et d’un niveau de qualité garanti, en particulier dans une situation de sécurité publique ou de surveillance. Laissés à eux-mêmes, les données entrantes du WAN vers un routeur périphérique seront traitées selon le principe du premier arrivé, premier servi :
- Fonctions QoS : ces fonctions permettent à l’administrateur d’attribuer des niveaux de priorité pour une adresse IP donnée hébergée par le routeur ou un port spécifique. Les fonctions QoS contrôlent uniquement le canal de liaison montante. Ils sont particulièrement utiles dans les cas où le canal de liaison montante a une capacité bien inférieure à celle de la liaison descendante.
En règle générale, le large bande grand public aura quelque chose comme une liaison montante de 5 Mbps et une liaison descendante de 100 Mbps, et la QoS fournit une méthode d’équilibrage de charge de la liaison amont contrainte. La QoS n’attribue pas de limites strictes ni ne segmente le lien comme le fait la mise en forme du trafic.
- Fonctions de mise en forme du trafic : la mise en forme du trafic est une forme statique de pré – allocation de bande passante. Par exemple, une liaison de 15 Mbps peut être partitionnée en segments plus petits de 5 Mbps. Ces segments seraient préaffectés. En général, cela est un gaspillage car cette bande passante ne serait pas nécessairement retournée à l’agrégat si nécessaire.
- Mise en forme dynamique et priorité des paquets : les routeurs modernes activent les attributs de mise en forme dynamique. Celles-ci permettent à l’administrateur d’attribuer dynamiquement des règles de segmentation de la bande passante au trafic entrant et sortant. Il peut également gérer les paquets sensibles à la latence (tels que la vidéo ou l’interface utilisateur) pour les applications en temps réel.
La mise en forme dynamique et la priorité des paquets permettent de créer des règles en fonction du type de données ou d’application plutôt que simplement de l’adresse IP ou du port.
Une méthode pour classer et gérer le trafic réseau est la différenciation des services (DiffServ). DiffServ utilise un point de code de service différencié 6 bits (DSCP) dans l’en-tête IP pour la classification des paquets. Le concept de DiffServ est que des fonctions complexes (telles que la classification et la régulation des paquets) peuvent être exécutées à la périphérie du réseau par des routeurs de périphérie, qui marquent ensuite le paquet pour recevoir un type particulier de comportement par bond. Le trafic entrant dans un routeur DiffServ est soumis à la classification et au conditionnement. De plus, un routeur DiffServ est libre de modifier la classification d’un paquet précédemment marqué par un autre routeur. DiffServ est un outil à grain grossier pour la gestion du trafic car la chaîne de routeurs dans un lien n’a pas tous besoin de le prendre en charge. Le routeur gèrera ensuite les différentes classes de paquets via les fonctionnalités QoS. Alternativement, IntServ, qui signifie services intégrés, assiste la QoS et exige que tous les routeurs de la chaîne le prennent en charge. Il s’agit d’une forme de QoS à grain fin.
Un autre aspect de la qualité du réseau est le score d’opinion moyen (MOS). MOS est la moyenne arithmétique des valeurs individuelles sur une échelle de la qualité d’un système du point de vue de l’utilisateur. Ceci est couramment utilisé dans les applications Voice over Internet Protocol (VOIP) mais peut certainement être utilisé pour les systèmes de vision, l’imagerie, les données en streaming et la convivialité de l’interface utilisateur. Il est basé sur une note subjective de un à cinq (un étant la pire qualité, cinq étant la meilleure qualité) et doit être utilisé dans une boucle de rétroaction pour augmenter la capacité ou réduire la taille des données pour correspondre à la capacité.
Un routeur périphérique reliant un PAN à un WAN basé sur IP a plusieurs options à sa disposition pour répondre aux changements de qualité de liaison et à la dégradation des services réseau, par exemple, dans un déploiement IoT pour le camionnage de flotte où le signal de l’opérateur peut se dégrader. Dans ces situations, le routeur peut utiliser des proxys améliorant les performances TCP (PEP) pour surmonter et compenser les changements de qualité (RFC 3135). Les PEP peuvent être utilisés dans la couche de transport ou la couche d’application de la pile et diffèrent en fonction du support physique. Les formes de PEP comprennent :
- Proxy PEP : Ici, le proxy agit en tant qu’intermédiaire pour imiter un point de terminaison.
- Distribution PEP : un PEP peut s’exécuter à une extrémité de la liaison ou aux deux (modèle de distribution).
Un PEP comprend les fonctions suivantes :
- TCP divisé : le PEP rompt la connexion de bout en bout en plusieurs segments pour surmonter les temps de retard importants qui affectent les fenêtres TCP. Ils sont généralement utilisés dans les communications par satellite.
- Filtrage ACK : dans les liens où les débits de données ne sont pas symétriques (comme Cat-1 : 10 Mbps vers le bas, 5 Mbps vers le haut), un filtre ACK aide en accumulant ou en décimant les ACK TCP pour améliorer les performances.
- Snooping : Il s’agit d’une forme de proxy intégré et est utilisé pour masquer les interférences et les collisions sur les liaisons sans fil. Il intercepte les ACK en double dans le réseau et les supprime et les remplace par un paquet perdu. Cela empêche l’expéditeur de réduire arbitrairement la taille de la fenêtre TCP.
- D-Proxy : PEP pour aider dans les réseaux sans fil en distribuant un proxy TCP de chaque côté de la liaison. Les mandataires surveillent les numéros de séquence des paquets de données TCP en recherchant la perte de paquets. Lors de la détection, les mandataires ouvrent un tampon temporaire et absorbent les paquets jusqu’à ce que celui manquant soit récupéré et re-séquencé.
9.2.4 Fonctions de sécurité
Un routeur ou une passerelle périphérique remplit un autre rôle important en fournissant une couche de sécurité entre le WAN, Internet et les appareils PAN / IoT sous-jacents. De nombreux appareils ne disposeront pas des ressources, de la mémoire et de la puissance de calcul nécessaires pour assurer une sécurité et un approvisionnement robustes. Que l’architecte crée son propre service de passerelle ou en achète un, les fonctionnalités suivantes doivent être prises en compte pour sécuriser les composants IoT.
La protection par pare-feu est la forme de sécurité la plus élémentaire. Il existe deux formes de base de pare-feu pour les télécommunications. Le premier est un pare – feu réseau qui filtre et contrôle le flux d’informations d’un réseau à l’autre. Le second est un pare-feu basé sur l’hôte qui protège les applications et les services locaux sur cette machine. Dans le cas des routeurs de périphérie IoT, nous nous concentrons sur les pares-feux réseau. Par défaut, un pare-feu empêche certains types de trafic réseau de circuler dans une zone protégée par pare-feu, mais tout trafic provenant de cette zone est autorisé à circuler vers l’extérieur. Un pare-feu trouvera et isolera les informations en fonction des paquets, des états ou des applications en fonction de la sophistication du pare-feu. En règle générale, les zones seront créées autour des interfaces réseau avec des règles conçues pour contrôler le flux de trafic entre les zones. Un exemple serait un routeur périphérique avec une zone Wi-Fi invité et une zone privée d’entreprise.
Un pare-feu de paquets peut isoler et contenir un certain trafic en fonction de l’IP source ou de destination, des ports, des adresses MAC, des protocoles IP et d’autres informations contenues dans l’en-tête du paquet. Un pare-feu dynamique fonctionne dans la couche quatre de la pile OSI. Il rassemble et agrège les paquets à la recherche de modèles et d’informations d’état telles que les nouvelles connexions par rapport aux connexions existantes. Le filtrage des applications est encore plus sophistiqué en ce qu’il peut rechercher certains types de flux de réseau d’applications, y compris le trafic FTP ou les données HTTP.
Un pare-feu peut également utiliser une zone démilitarisée (DMZ). Une DMZ est simplement une zone logique. Un hôte DMZ n’est en fait pas protégé par un pare-feu, dans le sens où n’importe quel ordinateur sur Internet peut tenter d’accéder à distance aux services réseau à l’adresse IP DMZ. Les utilisations typiques impliquent l’exécution d’un serveur Web public et le partage de fichiers. L’hôte DMZ est généralement spécifié par une adresse IP directe.
La redirection de port est un concept qui permet à certains ports derrière un pare-feu d’être exposés. Plusieurs appareils IoT ont besoin d’un port ouvert pour fournir des services contrôlés par des composants cloud. Encore une fois, une règle est construite qui permet à une adresse IP spécifiée dans la zone pare-feu d’avoir un port exposé.
Les DMZ et les ports ouverts de redirection de port et les interfaces au sein d’un réseau autrement protégé. Il faut être prudent pour s’assurer que telle est l’intention de l’architecte. Dans un déploiement IoT de masse avec de nombreux routeurs périphériques, une règle générique pour ouvrir un port peut être utile pour un emplacement mais un risque de sécurité important pour un autre. De plus, la vérification de la DMZ et des ports ouverts doit être un processus de sécurité car la topologie et les configurations du réseau changent avec le temps. Une zone démilitarisée, à tout moment, pourrait conduire à un trou dans la sécurité du réseau plus tard.
9.2.5 Mesures et analyses
Dans de nombreux cas, les appareils de périphérie IoT seront soumis à des accords de niveau de service ou à des plafonds de données lors de l’utilisation de données mesurées telles que la 4G LTE. Dans d’autres situations, le routeur ou la passerelle périphérique est un hôte d’autres réseaux PAN et appareils IoT. Il devrait servir d’autorité centrale (mais locale) sur la santé du réseau / maillage PAN. Les métriques et les analyses sont utiles pour collecter et résoudre les problèmes de connectivité et de coûts, en particulier à mesure que l’échelle de l’IoT augmente. Les mesures et les collections types doivent inclure les éléments suivants :
- Analyses de disponibilité WAN : tendances historiques, niveaux de service
- Utilisation des données : entrée, sortie, agrégat, par client, par application
- Bande passante : analyse aléatoire ou planifiée de la bande passante à l’entrée et à la sortie
- Latence : temps de réponse Ping, latence moyenne, latence de pointe
- Santé PAN : Bande passante, trafic anormal, réorganisation du maillage
- Intégrité du signal : intensité du signal, étude de site
- Emplacement : coordonnées GPS , mouvement , changements d’emplacement
- Contrôle d’ accès : clients connectés , connexions administrateur , modifications de configuration du routeur, succès / échec de l’ authentification PAN
- Basculement : nombre d’événements de basculement, heure et durée
Un exemple d’utilisation des métriques est l’IoT mobile pour les véhicules municipaux. Dans ce cas, une grande municipalité du Midwest a exigé que sa flotte de véhicules de déneigement soit connectée à Internet et fournisse des informations telles que l’emplacement GPS, l’état du sel et l’état de la charrue. Cela était nécessaire pour créer des cartes en temps réel des rues de la ville et positionner efficacement les charrues là où elles étaient nécessaires. Des mesures ont été recueillies pour comprendre l’intégrité du signal et la disponibilité du WAN. Certaines zones étaient dans des “ombres” cellulaires dans des zones plus vallonnées. Ces informations ont été utilisées pour créer une solution de périphérie qui a mis en cache les données jusqu’à ce que le signal cellulaire soit rétabli .
Ces types de mesures doivent être collectées et surveillées de manière planifiée et automatique. De plus, les routeurs avancés devraient être en mesure de créer des règles et des alertes lorsque certains événements ou comportements anormaux sont observés en périphérie.
9.3 Définition du réseau par le logiciel
La mise en réseau définie par logiciel (SDN) est une méthode de découplage du logiciel et des algorithmes qui définissent le plan de contrôle de mise en réseau du matériel sous-jacent qui gère le plan de transfert.
De plus, la virtualisation des fonctions réseau (NFV) est définie comme fournissant des fonctions réseau qui s’exécutent sur du matériel indépendant du fournisseur. NFV décrit la virtualisation des fonctionnalités réseau généralement présentes dans les couches quatre à sept de la pile. Ces deux paradigmes fournissent les méthodes de l’industrie pour construire, faire évoluer et déployer une architecture de réseau complexe de manière très flexible. Avant tout, cela réduit considérablement les coûts d’entreprise dans l’infrastructure réseau, car la plupart des services peuvent s’exécuter dans le cloud.
Pourquoi est-ce important pour les appareils en périphérie et où cela s’intègre-t-il avec l’IoT ? Nous avons passé une bonne partie de cet article à détailler le mouvement des données d’un capteur vers un cloud et pourtant nous avons pris pour acquis la manière dont l’infrastructure d’interconnexion globale évoluerait jusqu’à un milliard de nœuds supplémentaires sur un réseau. Il suffit de demander à un administrateur informatique de placer un million de points de terminaison supplémentaires sur un réseau d’entreprise où les nœuds sont hétérogènes, dans des emplacements distants, et certains se déplacent dans des véhicules pour comprendre l’impact sur l’infrastructure réseau globale. La mise en réseau traditionnelle n’est pas évolutive et nous sommes obligés d’envisager des moyens alternatifs pour construire de grands réseaux avec un impact et un coût minimal.
Le SDN est important pour les déploiements IoT et doit être pris en compte lorsqu’il s’agit de périphériques qui doivent être séparés pour des raisons de sécurité ou de performances. Par exemple, un système mobile et de pointe mobile compatible SDN peut établir un hôte SDN cloud sécurisé. Le système de périphérie peut se déplacer entre différents opérateurs et systèmes de communication, mais conserve toujours une adresse IP statique sur Internet.
9.3.1 Architecture SDN
L’article de revue Software-Defined Networking: A Comprehensive Survey (D. Kreutz, FMV Ramos, PE Veríssimo , CE Rothenberg, S. Azodolmolky et S. Uhlig, in Proceedings of the IEEE, vol. 103, no. 1, p. 14). -76, janvier 2015) définit le SDN comme ayant quatre caractéristiques :
- Le plan de contrôle est découplé du plan de données. Le matériel du plan de données devient de simples dispositifs de transfert de paquets.
- Toutes les décisions de transfert sont basées sur le flux plutôt que sur la destination. Un flux est un ensemble de paquets qui correspondent à un critère ou un filtre. Tous les paquets d’un flux sont traités avec les mêmes politiques de transfert et de service. La programmation de flux permet une évolutivité et une flexibilité faciles avec des commutateurs virtuels, des pares-feux et des middlewares.
- La logique de contrôle est également connue sous le nom de contrôleur SDN. Cette version logicielle du matériel hérité peut fonctionner sur du matériel standard et des instances basées sur le cloud. Son but est de commander et de gouverner les nœuds de commutation simplifiés. La portée de l’abstraction du contrôleur SDN aux nœuds de commutation est l’interface vers le sud.
- Le logiciel d’application réseau peut résider sur le contrôleur SDN via une interface vers le nord. Ce logiciel peut interagir avec le plan de données et le manipuler avec des services tels que l’inspection approfondie des paquets, les pares-feux et les équilibreurs de charge.
L’infrastructure d’une SDN est similaire à un réseau traditionnel car elle utilise un matériel similaire : commutateurs, routeurs et boîtiers de médiation. La principale différence, cependant, est un NRS qui utilise AU serveur classe rapide impromptu puissance de calcul sans contrôle de matériel embarqué complexe et unique. Ces plates-formes de serveur sont généralement dans le cloud et exécutent des services réseau dans des logiciels plutôt que des ASIC personnalisés. Les routeurs périphériques sont essentiellement muets sans contrôle autonome. L’architecture SDN sépare le plan de contrôle (la logique et le contrôle de fonction) et le plan de données (qui exécute les décisions de chemin de données et transfère le trafic). Le plan de données se compose de routeurs et de commutateurs associés à un contrôleur SDN.
Tout ce qui se trouve au-dessus du matériel de transfert du plan de données peut généralement résider dans le cloud ou sur le matériel d’un centre de données privé, comme le montre la figure suivante :
Figure 5 : abstraction typique de l’architecture SDN
L’illustration montre des nœuds de commutation et de transmission simplifiés qui résident sur le plan de données et rassemblent les informations le long des chemins prescrits déterminés par un contrôleur SDN abstrait qui peut vivre dans une instance de cloud. Le contrôleur SDN gère le plan de contrôle via une interface vers le sud vers les nœuds de transfert. Les applications réseau peuvent résider au-dessus du contrôleur SDN et manipuler le plan de données avec des services tels que la surveillance des menaces et la détection des intrusions. Ces services nécessitent généralement le déploiement et la gestion de solutions matérielles personnalisées et uniques par le client.
9.3.2 traditionnelle Internetworking
Une architecture d’interconnexion de réseaux typique utilisera une collection de composants matériels / logiciels gérés qui sont à usage unique et contiennent des logiciels / solutions intégrés. Souvent, ceux-ci utilisent du matériel sans marchandise et des conceptions ASIC dédiées. Les fonctions typiques incluent le routage, les commutateurs gérés, les pare-feu, l’inspection approfondie des paquets et la détection des intrusions, les équilibreurs de charge et les analyseurs de données. Ces appareils dédiés doivent être gérés par le client et dotés d’un personnel informatique réseau qualifié pour les entretenir et les administrer. Ces composants peuvent provenir de plusieurs fournisseurs et nécessitent des méthodes de gestion considérablement différentes.
Dans cette configuration, le plan de données et le plan de contrôle sont unifiés. Lorsque le système a besoin d’ajouter ou supprimer un autre nœud ou ensemble – un nouveau chemin de données, de nombreux les systèmes dédiés doivent être mis à jour avec les nouveaux paramètres VLAN, les paramètres de qualité de service, des listes de contrôle d’accès, les routes statiques et pare – feu les passe-. Cela peut être gérable lorsqu’il s’agit de plusieurs milliers de points de terminaison. Cependant, lorsque nous évoluons vers des millions de nœuds distants, mobiles et connectés / déconnectés, une telle technologie traditionnelle devient régulièrement intenable :
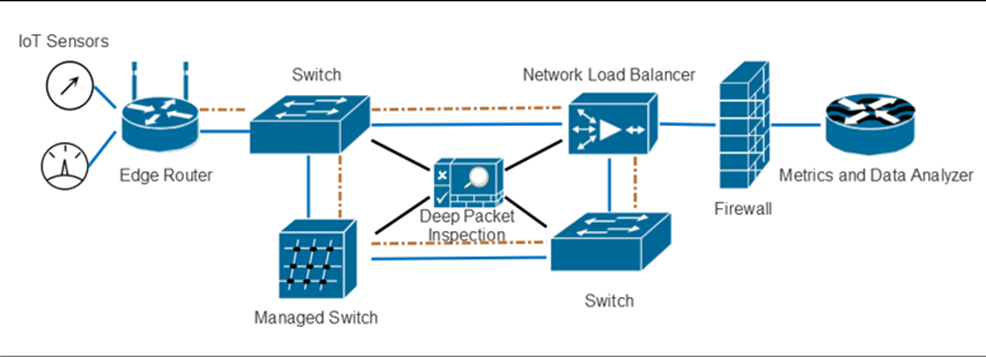
Figure 6 : Composants réseau traditionnels. Dans un scénario d’interconnexion de réseaux typique, les systèmes fournissant des services tels que la sécurité, l’inspection approfondie des paquets, l’équilibrage de charge et la collecte de métriques nécessitent du matériel et des systèmes de gestion personnalisés. Cette difficulté dans la gestion et entrez échelle pour les grandes installations, des appareils à distance et des systèmes en mouvement depuis les plans de contrôle et les données sont uni fi é.
9.3.3 Avantages SDN
Un modèle SDN de mise en réseau doit être envisagé pour les déploiements IoT de masse, en particulier lorsqu’un client doit établir la provenance et la sécurité d’un large déploiement de nœuds. Un architecte doit prendre en compte les situations suivantes lors de l’utilisation d’une SDN :
- Les serveurs et les centres de données avec lesquels les périphériques de périphérie IoT doivent communiquer peuvent être à des milliers de milliers.
- L’ampleur de la croissance de l’IoT de millions de points de terminaison à des milliards de points de terminaison nécessite des technologies de mise à l’échelle appropriées en dehors du modèle hub-and-speak de l’infrastructure Internet actuelle.
Trois aspects du SDN le rendent attrayant pour les déploiements IoT :
- Chaînage de services : cela permet à un client ou à un fournisseur de vendre des services à la carte. Les services de réseau cloud tels que les pare-feu, l’inspection approfondie des paquets, les VPN, les services d’authentification et les courtiers en politiques peuvent être liés et utilisés par abonnement. Certains clients peuvent souhaiter un ensemble complet de fonctionnalités, d’autres peuvent ne pas en choisir ou peuvent modifier leur configuration régulièrement. Service Enchaînement Permet d’importantes flexibilité dans les déploiements.
- Gestion dynamique de la charge : une SDN bénéficie de la flexibilité de l’architecture cloud et, par sa conception, il peut évoluer de manière dynamique en fonction de la charge. Ce type de flexibilité est crucial pour l’IoT, car les architectes doivent planifier la capacité et l’échelle à mesure que le nombre de choses augmente de façon exponentielle. Seul le réseautage virtuel dans le cloud permet de faire évoluer la capacité en cas de besoin. Un exemple de ceci serait le suivi des personnes dans les parcs d’attractions et autres lieux. Le nombre de personnes varie en fonction de la saison, de l’heure et de la météo. Un réseau dynamique peut s’adapter au nombre de visiteurs sans aucune modification du matériel du fournisseur.
- Calendrier de la bande passante : cela permet à un opérateur de partitionner la bande passante et l’utilisation des données à des heures et des jours spécifiés. Cela est pertinent pour l’IoT, car de nombreux capteurs de bord ne fournissent des données que périodiquement ou à une certaine heure de la journée. Des algorithmes de partage de bande passante sophistiqués peuvent être construits pour une capacité de tranche de temps.
Plus loin dans cet article, le chapitre 13, IoT et Edge Security , explorera les périmètres définis par logiciel ( SDP ) comme un autre exemple de virtualisation des fonctions réseau et comment il peut être utilisé pour créer des micro-segments et l’isolement des périphériques, ce qui est essentiel pour la sécurité IoT .
9.4 Résumé
Les routeurs, ponts et passerelles Edge jouent un rôle essentiel dans le développement de l’IoT. La fonctionnalité fournie par un routeur périphérique permet la sécurité, le routage, la résilience et la qualité de service au niveau de l’entreprise. Le pont / passerelle joue un rôle important dans la traduction des réseaux non IP en protocoles IP nécessaires à la connectivité Internet et cloud. Il est également important de réaliser que la croissance de l’IoT à des milliards de nœuds prendra forme avec une électronique à faible coût et contrainte. Des fonctionnalités telles que le routage d’entreprise, le tunneling et les VPN nécessitent des capacités matérielles et de traitement important, et il est logique d’utiliser des routeurs et des passerelles pour cette fonction de service. Plus loin dans cet article, nous verrons également comment les routeurs de périphérie jouent un rôle vital dans le traitement des périphéries et le calcul du brouillard.
Le chapitre suivant abordera en profondeur les protocoles basés sur l’IoT tels que MQTT et CoAP , avec des exemples pratiques. Ces protocoles sont le langage léger de l’IoT et utilisent le plus souvent des passerelles et des routeurs périphériques comme traducteurs.
10 protocoles Edge vers Cloud
Jusqu’à présent dans cet article, nous avons généré des données ou un événement à partir d’un périphérique fonctionnant à la périphérie du réseau. Nous avons discuté de divers moyens et technologies de télécommunication pour déplacer ces données du WPAN, du WLAN et du WAN. Il existe de nombreuses complexités et subtilités dans la création et le pontage de ces connexions réseau à partir de réseaux PAN non IP vers des réseaux WAN IP. Il existe également des conversions de protocole qui doivent être comprises.
Les protocoles standard sont les outils qui lient et encapsulent les données brutes d’un capteur et les transforment en quelque chose de significatif et formaté pour que le cloud l’accepte. L’une des principales différences entre un système IoT et un système Machine-to-Machine (M2M) est que M2M peut communiquer via un WAN vers un serveur ou un système dédié sans aucun protocole encapsulé. Par exemple, un système d’automatisation industrielle SCADA peut utiliser BACNET ou ModBus exclusivement pour la communication des machines aux différents ordinateurs de contrôle. L’IoT, par définition, est basé sur la communication entre les points de terminaison et les services, Internet étant la structure réseau commune.
Ce chapitre détaillera également les protocoles nécessaires répandus dans l’espace IoT, tels que le transport de télémétrie Message Queue (MQTT) et le protocole d’application contrainte (CoAP).
10.1 Protocoles
Une question naturelle est, pourquoi existe-t-il des protocoles en dehors de HTTP pour transporter des données à travers le WAN ? HTTP fournit des services et des capacités importants pour Internet depuis plus de 20 ans, mais a été conçu et architecturé pour l’informatique à usage général dans les modèles client / serveur.
Les appareils IoT peuvent être très contraints, distants et à bande passante limitée. Par conséquent, des protocoles plus efficaces, sécurisés et évolutifs sont nécessaires pour gérer une pléthore de périphériques dans diverses topologies de réseau telles que les réseaux maillés.
Cela dit, HTTP est utilisé et a un objectif dans l’IoT et les systèmes de périphérie. Bien que HTTP ne soit pas efficace sur un réseau, les protocoles HTTP2 et HTTP3 sont relativement efficaces. De plus, la sécurité via TLS est naturelle et courante dans les sessions HTTP. Enfin, HTTP est partout et couramment utilisé dans un assortiment de communications et d’API RESTful.
Lors du transport de données vers Internet, les conceptions sont reléguées aux couches de base TCP / IP. Les protocoles TCP et UDP sont les seuls choix évidents en communication de données, TCP étant beaucoup plus complexe dans sa mise en œuvre que UDP (étant un protocole de multidiffusion). UDP, cependant, n’a pas la stabilité et la fiabilité de TCP, forçant certaines conceptions à compenser en ajoutant de la résilience dans les couches d’application au-dessus d’UDP. Il convient également de noter que l’UDP est utilisé pour certains protocoles de communication IoT tels que NB-IoT, qui a été traité dans le chapitre sur la communication à longue portée.
La plupart des protocoles répertoriés dans ce chapitre sont des implémentations de middleware orienté message (MOM). L’idée de base d’un MOM est que la communication entre deux appareils se fait à l’aide de files d’attente de messages distribuées. Un MOM délivre des messages d’une application de l’espace utilisateur à une autre. Certains appareils produisent des données à ajouter à une file d’attente tandis que d’autres consomment des données stockées dans une file d’attente. Certaines implémentations nécessitent un courtier ou un intermédiaire pour être le service central. Dans ce cas, les producteurs et les consommateurs ont une relation de type publication et abonnement avec le courtier. AMQP, MQTT et STOMP sont des implémentations MOM ; d’autres incluent les services de messagerie CORBA et Java. Une implémentation MOM utilisant des files d’attente peut les utiliser pour la résilience dans la conception. Les données peuvent persister dans les files d’attente, même en cas de défaillance du serveur.
L’alternative à l’implémentation MOM est RESTful. Dans un modèle RESTful, un serveur possède l’état d’une ressource, mais l’état n’est pas transféré dans un message au serveur à partir du client. Les conceptions RESTful utilisent des méthodes HTTP telles que GET, PUT, POST et DELETE pour placer des demandes sur l’identificateur de ressource universel (URI) d’une ressource. Aucun courtier ou agent intermédiaire n’est nécessaire dans cette architecture. Comme ils sont basés sur la pile HTTP, ils bénéficient de la majorité des services offerts, tels que la sécurité HTTPS. Les conceptions RESTful sont typiques des architectures client-serveur. Les clients lancent l’accès aux ressources via des modèles de demande-réponse synchrones.
L’URI est utilisé comme identifiant pour le trafic de données basé sur le Web. L’URI le plus notable est le localisateur de ressources universel (URL), tel que http://www.iotforarchitects.net:8080/iot/?id=”temperature “. L’URI peut être divisé en composants qui sont utilisés par différents niveaux de la pile réseau :
Schéma : http://
Autorité : www.iotforarchitects.net
Port : 8080
Chemin : / iot
Requête : ? Id = “température”
De plus, les clients sont responsables des erreurs, même en cas de panne du serveur. La figure suivante illustre un service MOM par rapport à un service RESTful. À gauche, un service de messagerie (basé sur MQTT) utilisant un serveur intermédiaire et des éditeurs et abonnés à un événement. Ici, de nombreux clients peuvent être à la fois des éditeurs et des abonnés, et les informations peuvent ou non être stockées dans des files d’attente pour la résilience. Sur la droite se trouve une conception RESTful où l’architecture est construite sur HTTP et utilise des paradigmes HTTP pour communiquer du client au serveur:

Figure 1 : un exemple comparant un MOM à une implémentation RESTful
10.2 MQTT
La technologie IBM WebSphere Message Queue a été conçue pour la première fois en 1993 pour résoudre les problèmes des systèmes distribués indépendants et non simultanés et les aider à communiquer en toute sécurité. Un dérivé de WebSphere Message Queue a été rédigé par Andy Stanford-Clark et Arlen Nipper chez IBM en 1999 pour répondre aux contraintes particulières de la connexion à distance de pipelines de pétrole et de gaz via une connexion satellite. Ce protocole est devenu connu sous le nom de MQTT. Les objectifs de ce protocole de transport basé sur IP sont les suivants :
- Soyez simple à mettre en œuvre
- Offrir une forme de qualité de service
- Soyez très léger et efficace en bande passante
- Soyez indépendant des données
- Avoir une conscience de session continue
- Résoudre les problèmes de sécurité
MQTT répond à ces exigences. Une façon de penser le protocole est mieux définie par l’organisme standard MQTT.org ( mqtt.org ), qui présente un résumé très bien défini du protocole:
MQTT signifie MQ Telemetry Transport. Il s’agit d’un protocole de messagerie de publication / abonnement, extrêmement simple et léger, conçu pour les appareils contraints et les réseaux à faible bande passante, à latence élevée ou peu fiables. Les principes de conception sont de minimiser la bande passante du réseau et les besoins en ressources de l’appareil tout en essayant également d’assurer la fiabilité et une certaine assurance de livraison. Ces principes s’avèrent également faire du protocole l’idéal du monde émergent “machine-to-machine” (M2M) ou “Internet des objets” des appareils connectés, et pour les applications mobiles où la bande passante et la puissance de la batterie sont très importantes.
MQTT était un protocole interne et propriétaire d’IBM pendant de nombreuses années jusqu’à sa sortie dans la version 3.1 en 2010 en tant que produit libre de droits. En 2013, MQTT a été normalisé et accepté dans le consortium OASIS. En 2014, OASIS l’a rendu public sous la version MQTT 3.1.1. MQTT est également une norme ISO (ISO / IEC PRF 20922). Plus récemment, OASIS a publié la spécification MQTT 5.
Le tableau suivant illustre la version et la chronologie des fonctionnalités de la norme OASIS MQTT, ainsi que les versions HiveMQ. HiveMQ est un fournisseur leader de courtiers MQTT et de logiciels et solutions clients.
| Spécifications MQTT | Date de sortie | CARACTÉRISTIQUES |
| Version initiale | 1999 | Création et invention initiales |
| MQTT 3.1 | 2010 | Libération sans redevance |
| HiveMQ | 2013 | Première diffusion publique |
| MQTT3.1.1 | 2014 | Norme OASIS |
| MQTT 3.1.1 | 2016 | Norme ISO |
| HiveMQ 4 | 2018 | Version de compatibilité MQTT |
| Client HiveMQ MQTT | 2019 | Publication publique du client |
| MQTT5 | 2019 | Norme OASIS |
| HiveMQ | 2019 | Édition open source |
MQTT 5 est sorti en 2019 et résout deux problèmes avec le protocole MQTT 3.1.1 très utilisé :
- MQTT 3.1.1 a des problèmes de personnalisation ou d’ajout de métadonnées au protocole, ce qui est courant dans les données HTTP.
- MQTT 3.1.1 a des difficultés d’interopérabilité lors de la communication entre différentes plates-formes de fournisseurs, bibliothèques et chemins de données.
Pour résoudre ces problèmes, MQTT 5 a introduit les propriétés utilisateur. Nous allons discuter de ces nouvelles propriétés et capacités tout au long de cette section et souligner les différences avec MQTT 5.
10.2.1 MQTT publier-abonner
Alors que les architectures client-serveur sont le pilier des services de centre de données depuis des années, les modèles de publication-abonnement représentent une alternative utile pour les utilisations de l’IoT. Publish-subscribe , également connu sous le nom de pub / sub , est un moyen de découpler un client transmettant un message d’un autre client recevant un message. Contrairement au modèle client-serveur traditionnel, les clients ne connaissent aucun identifiant physique tel que l’adresse IP ou le port. MQTT est une architecture pub / sub mais n’est pas une file d’attente de messages.
Les files d’attente de messages par nature stockent les messages, contrairement à MQTT. Dans MQTT, si personne ne s’abonne (ou n’écoute) à un sujet, il est simplement ignoré et perdu. Les files d’attente de messages conservent également une topologie client-serveur dans laquelle un consommateur est associé à un producteur.
Les messages conservés sont disponibles dans MQTT et seront traités plus tard. Un message conservé est une instance unique d’un message qui est préservée pour une analyse future.
Un client transmettant un message est appelé un éditeur ; un client recevant un message est appelé un abonné. Au centre se trouve un courtier MQTT qui a la responsabilité de connecter les clients et de filtrer les données. Ces filtres fournissent :
- Filtrage des sujets : de par leur conception, les clients s’abonnent aux rubriques et à certaines branches de rubriques et ne reçoivent pas plus de données qu’ils ne le souhaitent. Chaque message publié doit contenir un sujet, et le courtier est responsable de la rediffusion de ce message aux clients abonnés ou de l’ignorer.
- Filtrage de contenu : les courtiers ont la possibilité d’inspecter et de filtrer les données publiées. Ainsi, toutes les données non cryptées peuvent être gérées par le courtier avant d’être stockées ou publiées sur d’autres clients.
- Filtrage de type : un client qui écoute un flux de données abonné peut également appliquer ses propres filtres. Les données entrantes peuvent être analysées et le flux de données soit traité davantage, soit ignoré.
MQTT peut avoir de nombreux producteurs et de nombreux consommateurs, comme le montre la figure suivante :
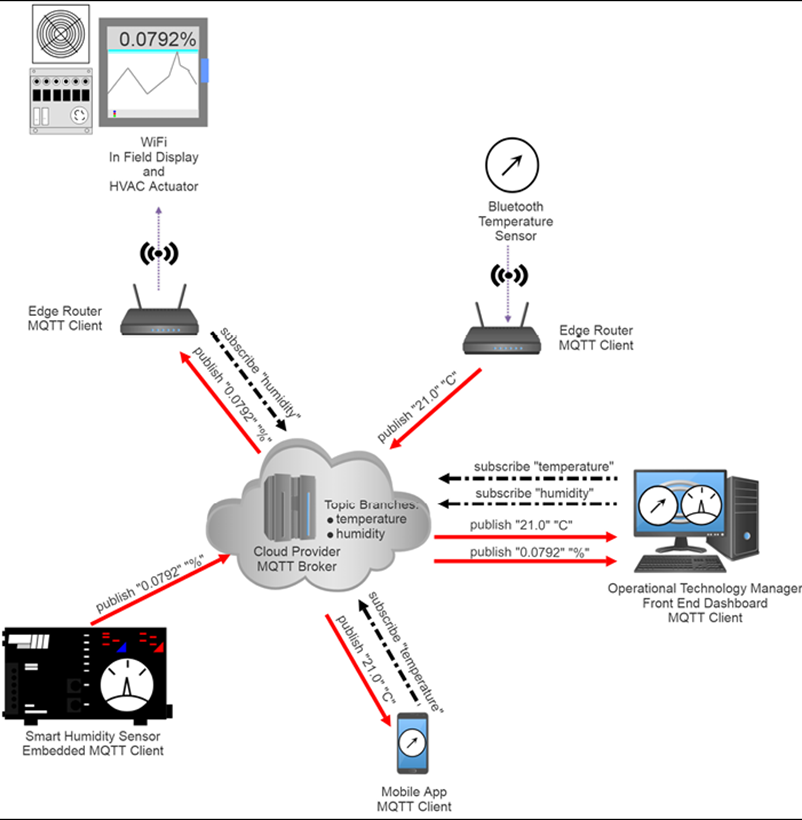
Figure 2 : Modèle et topologie de publication-abonnement MQTT : les clients s’exécutent en périphérie et publient et / ou s’abonnent à des rubriques gérées par le courtier MQTT. Ici, deux sujets sont considérés – l’humidité et la température. Un client peut s’abonner à plusieurs sujets. La fi gurer Représente que les capteurs intelligents comprennent suffisamment de ressources pour gérer leurs propres clients MQTT et routeurs de périphérie MQTT qui fournissent les clients des services pour le compte de capteurs ou appareils ne sont pas que MQTT-activé.
Une mise en garde du modèle informatique éditeur / abonné est que l’éditeur et l’abonné doivent connaître la branche thématique et le format de données avant de lancer la transmission.
MQTT dissocie avec succès les éditeurs des consommateurs. Étant donné que le courtier est l’organe directeur entre les éditeurs et les consommateurs, il n’est pas nécessaire d’identifier directement un éditeur et un consommateur sur la base d’aspects physiques (comme une adresse IP). Ceci est très utile dans les déploiements IoT car l’identité physique peut être inconnue ou omniprésente. MQTT et d’autres modèles pub / sub sont également invariants dans le temps. Cela implique qu’un message publié par un client peut être lu et répondu à tout moment par un abonné. Un abonné peut être dans un état très faible consommation / bande passante limitée (par exemple, communication Sigfox) et répondre quelques minutes ou heures plus tard à un message. En raison du manque de relations physiques et temporelles, les modèles de pub / sous-échelle évoluent très bien à une capacité extrême.
Les courtiers MQTT gérés dans le cloud peuvent généralement ingérer des millions de messages par heure et prendre en charge des dizaines de milliers d’éditeurs.
MQTT est indépendant du format de données. Tout type de données peut résider dans la charge utile, c’est pourquoi les éditeurs et les abonnés doivent tous deux comprendre et accepter le format des données. Il est possible de transmettre des messages texte, des données d’image, des données audio, des données chiffrées, des données binaires, des objets JSON ou pratiquement toute autre structure dans la charge utile. Le texte JSON et les données binaires sont cependant les types de données utiles les plus courants.
La taille de paquet maximale autorisée dans MQTT est de 256 Mo, ce qui permet une charge utile extrêmement importante.
Notez cependant que la taille maximale de la charge utile des données dépend du cloud et du courtier. Par exemple, IBM Watson autorise des tailles de charge utile allant jusqu’à 128 Ko, tandis que Google prend en charge 256 Ko. Alternativement, un message publié peut inclure une charge utile de longueur nulle. Le champ de charge utile est facultatif. Il est conseillé de vérifier auprès de votre fournisseur de cloud pour vous assurer que les tailles de charge utile correspondent. Le non-respect de cette consigne entraînera des erreurs et des déconnexions du courtier cloud.
Un aspect du modèle de publication-abonnement qui est nouveau dans MQTT 5 est la possibilité d’avoir des abonnements partagés. Dans les versions précédentes de MQTT, différents clients abonnés à un abonnement commun recevaient chacun une copie d’un message. Cela fonctionne dans de nombreux cas, mais dans certains cas, vous souhaiterez peut-être concevoir une solution qui équilibre la charge des abonnements pour les clients. Dans MQTT 5, cela s’appelle les abonnements partagés. Dans ce schéma, si un abonnement est partagé avec plusieurs clients, ils peuvent être placés dans leur propre groupe d’abonnement. Chaque client reçoit des messages du groupe de façon circulaire. Il n’y a pas non plus de limite au nombre de groupes d’abonnements autorisés ou au nombre de clients au sein d’un groupe d’abonnements.
Un abonnement partagé a une structure différente pour le modèle de publication / abonnement : $ share / GROUPID / TOPIC :
- $ share: l’identifiant d’abonnement partagé statique.
- GROUPID : l’identifiant indiquant le groupe à référencer. Plusieurs groupes peuvent être utilisés sur le même abonnement.
- SUJET : La référence de branche de sujet standard MQTT 3.1.1, y compris les caractères génériques.
Voici un exemple illustratif d’abonnements partagés :
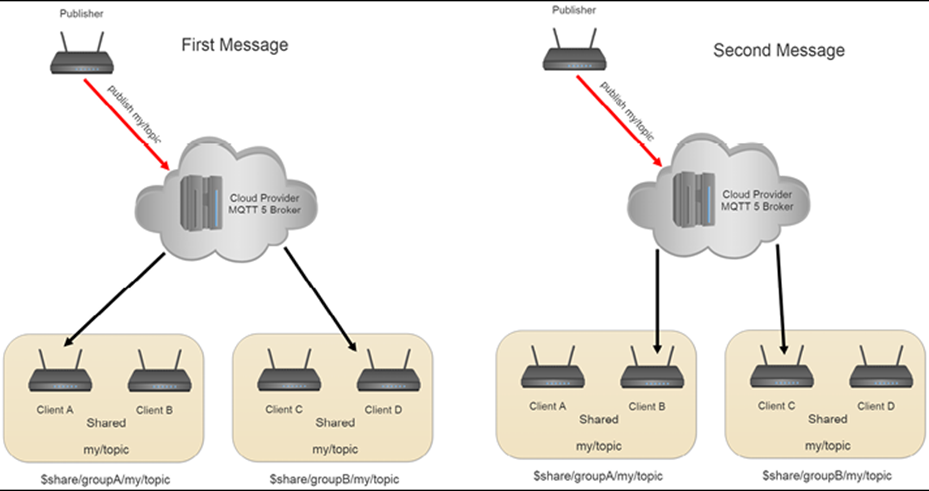
Figure 3 : fonction d’abonnements partagés MQTT 5. Ici, un éditeur envoie des données à la branche my / topic, et deux groupes d’abonnements partagés indépendants les reçoivent. Les données sont envoyées à l’un des deux clients du groupe d’abonnement de manière circulaire. Cela permet un équilibrage de charge. Plusieurs groupes d’abonnement sont autorisés.
L’utilisation de groupes d’abonnements dans MQTT 5 est utile pour les scénarios où l’équilibrage de charge est nécessaire, comme lorsque les clients MQTT sont submergés de données ou que les fonctions de travail sur les systèmes cloud back-end doivent évoluer.
Un autre changement dans MQTT 5 est Alias de sujet. Celles-ci permettent à un architecte de résoudre le problème de l’évolutivité massive avec de nombreux appareils publiant constamment de petits messages mais à une fréquence élevée. Certes, les abonnements partagés peuvent aider sur le centre de données principal, mais les appareils qui publient des données peuvent avoir une puissance limitée disponible. Par conséquent, la gestion de la quantité de données transmises est cruciale. Une partie importante de ces données peut être de très longs noms de sujets tels que données /US/Idaho/Ada/Boise/36/Hill/3607/home/temperature/.
Les alias de rubrique permettent de remplacer les noms de rubrique longs par une valeur entière. L’expéditeur peut attribuer un alias de rubrique à l’aide d’une méthode PUBLISH. Le nombre d’alias disponibles est contrôlé pendant la phase d’établissement de la connexion. Le client définira une limite maximale à l’aide d’un maximum d’alias de rubrique pendant CONNECT et le courtier la définira dans la réponse CONNACK. Ensuite, la branche de sujet peut être adressée directement avec le nouvel alias. Si aucun maximum d’alias de rubrique n’est affecté, la valeur par défaut est qu’aucun alias n’est autorisé.
10.2.2 Détails de l’architecture MQTT
MQTT est un terme impropre. Il n’y a pas de files d’attente de messages inhérentes au protocole. Bien qu’il soit possible de mettre les messages en file d’attente, ce n’est pas nécessaire et souvent cela n’est pas fait. MQTT est basé sur TCP et inclut donc une certaine garantie qu’un paquet est transféré de manière fiable.
MQTT est également un protocole asymétrique, tandis que HTTP est un protocole non symétrique. Dites noeud A doit communiquer avec le noeud B. Un protocole asymétrique entre A et B ne nécessiterait qu’un seul côté (A) pour utiliser le protocole ; Cependant, toutes les informations nécessaires pour le réassemblage des paquets doit être contenu dans l’ en- tête de fragmentation envoyé par A . Les systèmes asymétriques ont un maître et un esclave (FTP étant un exemple classique). Dans un protocole symétrique, A et B auraient le protocole installé. A ou B peuvent assumer le rôle de maître ou d’esclave (Telnet étant un exemple principal). MQTT a des rôles distincts qui ont du sens dans la topologie des capteurs / nuages.
MQTT peut conserver indéfiniment un message sur un courtier. Ce mode de fonctionnement est contrôlé par un drapeau sur une transmission de message normale. Un message conservé sur un courtier est envoyé à tout client abonné à cette branche de rubrique MQTT. Le message est transmis immédiatement à ce nouveau client. Cela permet à un nouveau client de recevoir un statut ou un signal d’un sujet nouvellement abonné sans attendre. En règle générale, un client abonné à un sujet peut devoir attendre des heures, voire des jours, avant qu’un client publie de nouvelles données.
MQTT définit une fonction facultative appelée Last Will and Testament (LWT). Un LWT (ou simplement Will) est un message qu’un client spécifie pendant la phase de connexion. Le LWT contient la rubrique Last Will, Quality of Service (QoS) et le message réel. Si un client se déconnecte d’une connexion de courtier de manière non gracieuse (par exemple, délai d’expiration de maintien en vie, erreur d’E / S ou le client fermant la session sans se déconnecter), le courtier est alors obligé de diffuser le message LWT à tous les autres clients abonnés pour ce sujet.
Même si MQTT est basé sur TCP, les connexions peuvent toujours être perdues, en particulier dans un environnement de capteur sans fil. Un appareil peut perdre de la puissance, perdre la puissance du signal ou simplement planter sur le terrain, et une session entrera dans un état semi-ouvert. Ici, le serveur pensera que la connexion est toujours fiable et attendra des données. Pour remédier à cet état semi-ouvert, MQTT utilise un système de maintien en vie.
En utilisant ce système, le courtier MQTT et le client ont l’assurance que la connexion est toujours valide même s’il n’y a pas eu de transmission depuis un certain temps. Le client envoie un paquet PINGREQ au courtier, qui à son tour accuse réception du message avec un PINGRESP. Une minuterie est prédéfinie à la fois côté client et côté courtier. Si un message n’a pas été transmis depuis l’un ou l’autre dans un délai prédéterminé, un paquet de maintien en vie doit être envoyé. Soit un PINGREQ soit un message réinitialise le temporisateur de maintien en vie.
Dans le cas où une connexion persistante n’est pas reçue et que le temporisateur expire, le courtier ferme la connexion et envoie le paquet LWT à tous les clients. Le client peut ultérieurement tenter de se reconnecter. Dans ce cas, une connexion semi-ouverte sera fermée par le courtier, qui ouvrira alors une nouvelle connexion au client.
La durée de conservation maximale est de 18 heures, 12 minutes et 15 secondes. La définition de la valeur de maintien interne à 0 désactivera la fonctionnalité de conservation. La minuterie est contrôlée par le client et peut être modifiée dynamiquement pour refléter les modes de sommeil ou les changements d’intensité du signal.
Bien que Keep-Alive aide à rompre les connexions, le rétablissement de tous les abonnements et paramètres QoS d’un client peut entraîner des frais inutiles sur une connexion limitée par les données. Pour alléger ces données supplémentaires, MQTT permet des connexions persistantes. Une connexion persistante enregistre les éléments suivants du côté du courtier:
- Tous les abonnements des clients
- Tous les messages QoS non confirmés par le client
- Tous les nouveaux messages QoS manqués par le client
Ces informations sont référencées par le paramètre client_id pour identifier les clients uniques. Un client peut demander une connexion persistante ; Cependant, le courtier peut refuser la demande et forcer une nouvelle session à redémarrer. Lors de la connexion, l’indicateur cleanSession est utilisé par le courtier pour autoriser ou refuser les connexions persistantes. Le client peut déterminer si une connexion persistante a été stockée à l’aide du message CONNACK.
Pour MQTT 3.1.1, les sessions persistantes doivent être utilisées pour les clients qui doivent recevoir tous les messages même lorsqu’ils sont hors ligne. Ils ne doivent pas être utilisés dans des situations où un client ne publie (écrit) que des données sur des rubriques.
MQTT 5 introduit le code de champ cleanStart, qui simplifie la gestion des sessions. L’ancienne alternative utilisant MQTT 3.1.1 nécessitait cleanSession et le concept de session persistante. Désormais, toutes les sessions MQTT5 sont persistantes par défaut. Cela simplifie considérablement l’établissement des connexions.
Il existe trois niveaux de qualité de service dans MQTT :
- QoS-0 (transmission non assurée) : il s’agit du niveau de QoS minimal. Ceci est analogue à un modèle de tir et d’oubli détaillé dans certains des protocoles sans fil. Il s’agit d’un processus de livraison au mieux sans que le destinataire accuse réception d’un message ou que l’expéditeur réessaye la transmission.
- QoS-1 (transmission assurée) : ce mode garantira la livraison du message au moins une fois au récepteur. Il peut être remis plus d’une fois et le destinataire enverra un accusé de réception avec une réponse PUBACK.
- QoS-2 (service assuré sur les applications) : il s’agit du plus haut niveau de QoS, qui garantit et informe à la fois l’expéditeur et le destinataire qu’un message a été transmis correctement. Ce mode génère plus de trafic avec une négociation en plusieurs étapes entre l’expéditeur et le récepteur. Si un récepteur reçoit un message défini sur QoS-2, il répondra par un message PUBREC à l’expéditeur. Cela accuse réception du message et l’expéditeur répondra par un message PUBREL. PUBREL permet au récepteur de rejeter en toute sécurité toute retransmission du message. Le PUBREL est alors reconnu par le récepteur avec un PUBCOMP. Jusqu’à ce que le message PUBCOMP soit envoyé, le récepteur mettra en cache le message d’origine pour des raisons de sécurité. Il convient de noter que toutes les implémentations et bibliothèques MQTT ne prennent pas en charge toutes les valeurs de QoS. La QoS-2, par exemple, a été exclue de nombreuses implémentations.
La qualité de service dans MQTT est définie et contrôlée par l’expéditeur, et chaque expéditeur peut avoir une stratégie différente.
Cas d’utilisation typiques :
QoS-0 : cela doit être utilisé lorsque la mise en file d’attente des messages n’est pas nécessaire. Il est préférable pour les connexions câblées ou lorsque le système est fortement limité sur la bande passante.
QoS-1 : Cela devrait être l’utilisation par défaut. QoS-1 est beaucoup plus rapide que QoS-2 et réduit considérablement les coûts de transmission.
QoS-2 : Ceci est pour les applications critiques et dans les cas où la retransmission d’un message en double pourrait provoquer des défauts.
MQTT 5 a modifié le comportement des messages QoS-1 et QoS-2. MQTT 3.1.1 permet des tentatives et une nouvelle remise des messages si une connexion TCP est opérationnelle, mais il y a des situations où ce n’est pas optimal. Par exemple, si un client est saturé de messages MQTT, l’ajout de nouvelles tentatives exerce une pression supplémentaire sur ce client.
Dans MQTT 5, les courtiers et les clients ne peuvent pas retransmettre les messages MQTT si une connexion TCP fonctionne. Les clients et les courtiers doivent plutôt renvoyer des paquets non acquittés à la fermeture de la session TCP. Par conséquent, si vous concevez une solution qui repose sur des retransmissions, vous souhaiterez peut-être reconsidérer l’utilisation de MQTT 5 pour cette solution.
10.2.3 Transitions d’état MQTT
MQTT gère l’état en fonction de la connexion entre le client et le courtier. Les sessions commencent par un message CONNECT et se terminent normalement par un message DISCONNECT. Le testament est envoyé si la connexion se termine. Il s’agit d’une différence entre MQTT 3.1.1 et MQTT 5. Dans MQTT 3.1.1, si le réseau perd une connexion ou est interrompu (malheureusement), un message Will sera envoyé et le courtier supprimera l’état de la session. Cela n’est pas pratique lorsque la connexion et l’intégrité du réseau peuvent ne pas être robustes. Il est préférable de conserver intact l’état de la session jusqu’à ce que le client termine son travail et se termine sans problème via un message DISCONNECT.
De plus, MQTT 3.1.1 n’avait pas la notion de temporisateur d’expiration. Si un client ne se connecte pas dans un certain laps de temps dans MQTT 5, la session sera ignorée. Cela réduit la charge de travail des clients. Un client ne peut pas envoyer officiellement un message DISCONNECT ou simplement se déconnecter avec la garantie que la session sera nettoyée par le serveur à une heure définie. Dans MQTT3.1.1, les clients devraient se reconnecter uniquement pour nettoyer l’état avant de se déconnecter correctement. Le temporisateur d’expiration s’applique non seulement à l’état des clients en ligne mais également à tous les messages en file d’attente. Le délai d’expiration de la session peut être contrôlé en unités de secondes via le message PUBLIER.
Ce nouveau processus de transition d’état est appelé Gestion simplifiée des états dans MQTT 5.
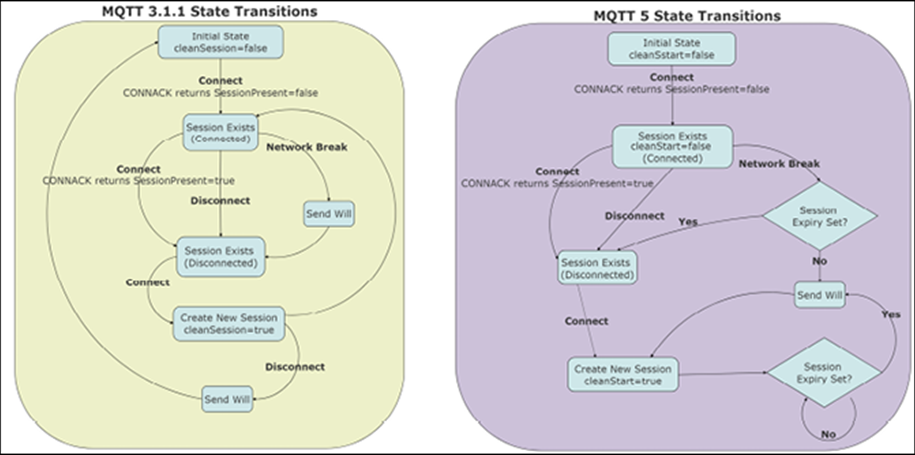
Figure 4 : transitions d’état MQTT 3.1.1 et MQTT 5. Notez l’utilisation des temporisateurs d’expiration de session et l’ état cleanStart dans MQTT 5.
10.2.4 Structure des paquets MQTT
Un paquet MQTT se trouve au-dessus de la couche TCP de la pile réseau du modèle OSI. Le paquet se compose d’un en-tête fixe de 2 octets, qui doit toujours être présent, et d’un en-tête de taille variable (facultatif), et il se termine par la charge utile (encore une fois, facultatif):
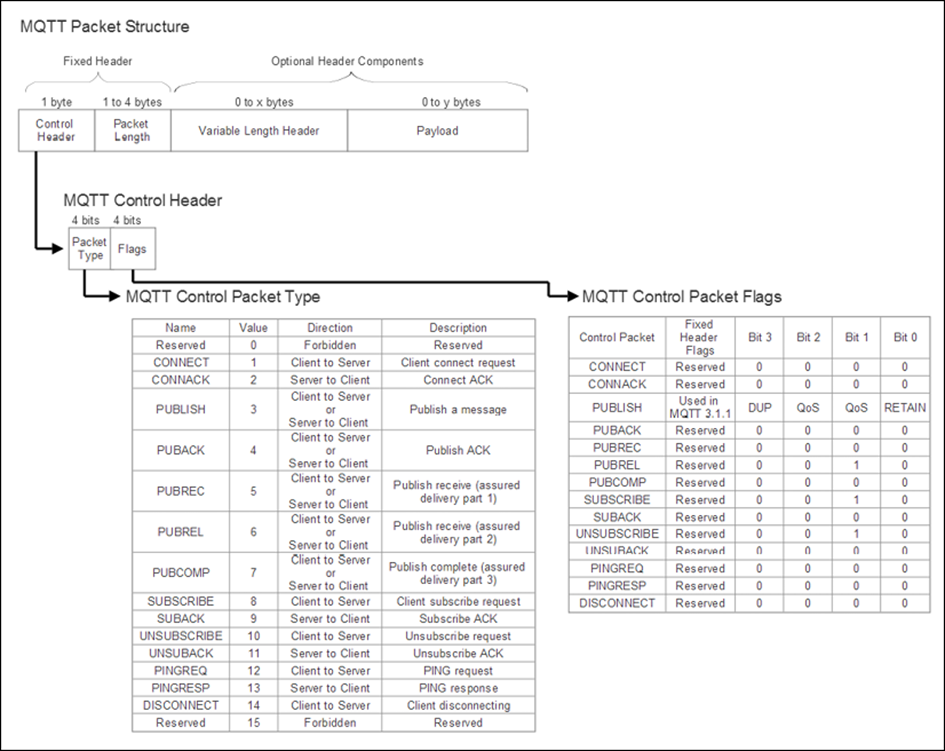
Figure 5 : Structure de paquet commune de MQTT de MQTT 3.1.1 et MQTT 5 (notez le type de paquet AUTH)
MQTT 5 introduit le concept de propriétés utilisateur pour surmonter certaines des faiblesses dans l’extensibilité, la personnalisation et l’interopérabilité de MQTT 3.1.1. Ces propriétés permettent d’utiliser des paires clé-valeur personnalisées ou des propriétés à incorporer dans l’en-tête. Cette fonctionnalité imite HTTP et AMQP, ce qui a permis l’utilisation d’en-têtes pour transporter des métadonnées. Un exemple de métadonnées personnalisées dans HTTP :
HTTP/1.1 200 OK
Date: Sat, 23 Jul 2011 07:28:50 GMT
Server: Apache/2
Content-Location: qa-http-and-lang.en.php
Vary: negotiate,accept-language,Accept-Encoding
TCN: choice
P3P: policyref=”http://www.w3.org/2001/05/P3P/p3p.xml”
Connection: close
Transfer-Encoding: chunked
Content-Type: text/html; charset=utf-8
Content-Language: en
Ici, les métadonnées intégrées dans l’en- tête HTML contient la clé Content- Langue: , qui contient la valeur en pour la langue Inglés.
Dans MQTT 5, les métadonnées sont incorporées dans l’en-tête en tant que chaîne UTF-8 de paires clé-valeur ajoutées à chaque paquet (même les paquets de contrôle comme PUBREL et PUBCOMP). La signification de ces paires clé-valeur n’est pas définie par la spécification et est personnalisable par le fournisseur. Les propriétés utilisateur sur PUBLISH sont transmises avec le message et définies par les applications clientes. Ils sont transmis par le serveur au destinataire du message. Les propriétés utilisateur sur CONNECT et ACKS sont définies par l’expéditeur et uniques à l’implémentation de l’expéditeur. La propriété utilisateur peut apparaître plusieurs fois pour représenter plusieurs paires nom-valeur. Le même nom peut apparaître plusieurs fois. Un exemple utilisant MQTT et les propriétés utilisateur suit (en supposant une représentation générique d’une bibliothèque cliente MQTT) :
SOUSCRIRE “température” ” Unité: Celsius ”
Dans ce cas, le client utilise une bibliothèque compatible MQTT 5 et s’abonne à une branche de sujet appelée température mais transmet une propriété utilisateur appelée Unit avec une valeur de Celsius. Le courtier peut ensuite utiliser la valeur-clé pour effectuer une conversion en temps réel de Fahrenheit à Celsius lors du stockage des données.
Les propriétés utilisateur sont une extension puissante du protocole MQTT. Tout d’abord, la fonctionnalité permet une meilleure interopérabilité, car différentes plates-formes, fournisseurs et même des équipes de développement peuvent utiliser presque tous les formats de données à partir d’objets JSON, de données compressées, de données chiffrées, de texte brut, binaire ou XML et sont garantis que leurs messages arriveront. En utilisant les propriétés des utilisateurs, chaque format de message unique au fournisseur inclurait des métadonnées dans l’en-tête MQTT 5 pour signifier ce que sont les données et à quoi elles servent. Un courtier peut prendre des décisions pour transmettre les données ou effectuer certaines actions. Les métadonnées peuvent également être utilisées pour horodater des données, des ID système ou toute caractéristique spécifique au fournisseur.
Un autre élément supplémentaire de MQTT 5 est le type de paquet AUTH. Ce nouveau type de paquet peut être utilisé par les courtiers et les clients MQTT après avoir établi une connexion pour permettre des séquences d’authentification de défi / réponse complexes.
Kerberos et OAuth sont des exemples d’un tel schéma d’authentification qui pourrait être activé sur MQTT 5 où il n’était pas possible (ou extrêmement complexe) d’utiliser des versions plus anciennes du protocole.
MQTT 5 a également modifié les codes de retour (également appelés codes de motif) en incluant des accusés de réception négatifs de tous les messages de réponse. Les paquets CONNACK, PUBACK, PUBREC, PUBREL, PUBCOMP, UNSUBACK, DISCONNECT, SUBACK et AUTH prennent tous en charge les codes retour facultatifs. Ces codes de retour d’accusé de réception négatif permettent désormais à un client de mieux comprendre pourquoi un paquet, un message ou un événement particulier a échoué et améliore le rapport d’erreurs. Ce sont les codes de retour d’accusé de réception négatifs potentiels pour divers paquets. Certains cas d’utilisation qui devraient être intégrés dans un système bien conçu comprennent :
- Un serveur émet un message DISCONNECT avec un code retour informant que le serveur est en panne (code retour 0x139). Les clients peuvent prendre les mesures appropriées.
- Un serveur peut répondre à un client via CONACK que le client a utilisé des informations d’identification, un nom d’utilisateur ou un mot de passe incorrects (code de retour 0x86) lors de la tentative de connexion.
- Un serveur peut informer un client qu’il a violé la longueur maximale de message pour les données envoyées via le code retour 0x95.
L’envoi des codes retour est sans danger car ils sont facultatifs et peuvent être ignorés par un client. Cependant, l’utilisation de ces nouveaux codes de retour devrait être mise en œuvre par les clients et les serveurs dans un système bien formé et évolutif.
10.2.5 Types de données MQTT
MQTT prend en charge plusieurs types de données pour différents éléments du paquet. Il existe sept types de données pris en charge dans MQTT 5:
- Bits
- Deux -Byte entiers
- Quatre octets entiers
- UTF-8 codé cordes
- Octet variable entiers
- Données binaires
- Paires de chaînes UTB-8 (uniquement dans MQTT 5)
Le tableau suivant peut être utilisé pour comprendre les différents formats de types de données et les paquets correspondants :
| Name | Type | Packet / Will Properties |
| Payload Format Indicator | Byte | PUBLISH, Will Properties |
| Message Expiry Interval | Four-Byte Integer | PUBLISH, Will Properties |
| Content Type | UTF-8 Encoded String | PUBLISH, Will Properties |
| Response Topic | UTF-8 Encoded String | PUBLISH, Will Properties |
| Correlation Data | Binary Data | PUBLISH, Will Properties |
| Subscription Identifier | Variable Byte Integer | PUBLISH, SUBSCRIBE |
| Session Expiry Interval | Four-Byte Integer | CONNECT, CONNACK, DISCONNECT |
| Assigned Client Identifier | UTF-8 Encoded String | CONNACK |
| Server Keep Alive | Two-Byte Integer | CONNACK |
| Authentication Method | UTF-8 Encoded String | CONNECT, CONNACK, AUTH |
| Authentication Data | Binary Data | CONNECT, CONNACK, AUTH |
| Request Problem Information | Byte | CONNECT |
| Will Delay Interval | Four-Byte Integer | Will Properties |
| Request Response Information | Byte | CONNECT |
| Response Information | UTF-8 Encoded String | CONNACK |
| Server Reference | UTF-8 Encoded String | CONNACK, DISCONNECT |
| Reason String | UTF-8 Encoded String | CONNACK, PUBACK, PUBREC, PUBREL, PUBCOMP, SUBACK, UNSUBACK, DISCONNECT, AUTH |
| Receive Maximum | Two-Byte Integer | CONNECT, CONNACK |
| Topic Alias Maximum | Two-Byte Integer | CONNECT, CONNACK |
| Topic Alias | Two-Byte Integer | PUBLISH |
| Maximum QoS | Byte | CONNACK |
| Retain Available | Byte | CONNACK |
| User Property | UTF-8 String Pair | CONNECT, CONNACK, PUBLISH, Will Properties, PUBACK, PUBREC, PUBREL, PUBCOMP, SUBSCRIBE, SUBACK, UNSUBSCRIBE, UNSUBACK, DISCONNECT, AUTH |
| Maximum Packet Size | Four-Byte Integer | CONNECT, CONNACK |
| Wildcard Subscription Available | Byte | CONNACK |
| Subscription Identifier Available | Byte | CONNACK |
| Shared Subscription Available | Byte | CONNACK |
Copyright © OASIS Open 2019. Tous droits réservés.
10.2.6 Formats de communication MQTT
Une liaison de communication utilisant MQTT commence avec l’envoi par le client d’un message CONNECT à un courtier. Seul un client peut lancer une session et aucun client ne peut communiquer directement avec un autre client. Le courtier répondra toujours à un message CONNECT avec une réponse CONNACK et un code d’état. Une fois établie, la connexion reste ouverte. Les messages et formats MQTT sont les suivants :
- Format CONNECT (client à serveur) : un message CONNECT typique contiendra les éléments suivants. (Seul l’ID client est requis pour lancer une session.)
| Field | Requirement | Description |
| clientID | Required | Identifies client to the server. Each client has a unique client ID. It can be between 1 and 23 UTF-8 bytes long. |
| cleanSession | Optional
MQTT 3.1.1 |
0: Server must resume communications with the client. Client and server must save session state after disconnecting.
1: Client and server must discard the previous session and start a new one. |
| cleanStart | Required MQTT5 | A client can use cleanStart as a flag to allow the broker to discard any previous session data. The client then starts a fresh session. The cleanStart flag does not purge the last session when the TCP connection closes. Rather, a timer called Session Expiry Interval will set a timeout when the session will actually clean up. |
| Username | Optional
(Required in MQTT 3.1.1 if a password is used.) |
Name used by the server for authentication. |
| password | Optional | 0 to 65536 byte binary password prefixed by two bytes of length. |
| lastWillTopic | Optional | Topic branch to publish Will message. |
| lastWillQos | Optional | Two bits specifying QoS level when publishing Will message. |
| lastWillMessage | Optional | Defines the Will message payload. |
| lastWillRetain | Optional | Specifies if the Will is to be retained when published. |
| keepAlive | Optional | Time interval in seconds. The client is responsible for sending a message or a PINGREQ packet before the keepAlive timer expires. The server will disconnect from the network at 1.5x the Keep Alive period. A value of zero(0) will disable the keepAlive mechanism. |
Il convient de noter que MQTT 3.1.1 nécessite l’utilisation de noms d’utilisateur si un mot de passe a été choisi. Cela entraîne des inconvénients pour certaines solutions. Par exemple, si votre solution nécessite l’utilisation d’un objet JSON pour un nom d’utilisateur, il n’y avait aucune méthode prescrite pour le faire dans MQTT 3.1.1. Cela a provoqué des problèmes lors de l’utilisation des services d’authentification OAuth. La solution de contournement consistait à utiliser un nom d’utilisateur statique. Maintenant, avec MQTT 5, les champs de nom d’utilisateur et de mot de passe sont vraiment facultatifs. Vous pouvez utiliser un mot de passe ou un champ de nom d’utilisateur indépendamment avec MQTT 5.
- Codes retour CONNECT (serveur à client) : le courtier répondra à un message CONNECT avec un code de réponse. Un concepteur doit savoir que toutes les connexions ne peuvent pas être approuvées par un courtier. Veuillez noter que MQTT 5 a ajouté des codes de retour supplémentaires comme mentionné précédemment dans ce chapitre. Les codes retour sont les suivants :
| Return code | Description |
| 0 | Successful connection |
| 1 | Connection refused—unacceptable MQTT protocol version |
| 2 | Connection refused—client identified is the correct UTF-8, but not allowed by the server |
| 3 | Connection refused—server is unavailable |
| 4 | Connection refused—bad username or password |
| 5 | Connection refused—the client is not authorized to connect |
Format PUBLISH (client vers serveur) : à ce stade, un client peut publier des données dans une branche de rubrique. Chaque message contient un sujet :
| Field | Requirement | Description |
| packetID | Required | Uniquely identifies the packet in the variable header. Client library responsibility. Always set to zero(0) for QoS-0. |
| topicName | Required | Topics branch to publish to (such as US/Wisconsin/Milwaukee/temperature). |
| qos | Required | QoS level 0,1, or 2. |
| retainFlag | Required | Name used by the server for authentication. |
| payload | Optional | Data format-agnostic payload. |
| dupFlag | Required | Message is a duplicate and is resent. |
Format SUBSCRIBE (client vers serveur) : la charge utile d’un paquet d’abonnement comprend au moins une paire d’ID de rubrique codés UTF-8 et de niveaux de QoS. Il peut y avoir plusieurs ID de sujet souscrits dans cette charge utile pour épargner au client de multiples diffusions :
| Field | Requirement | Description |
| packetID | Required | Uniquely identifies the packet in the variable header. Client library responsibility. |
| topic_1 | Required | Subscribed topic branch. |
| qos_1 | Required | QoS level of messages published to topic_1. |
| topic_2 | Optional | Name used by the server for authentication. |
| qos2 | Optional | QoS level of messages published to topic_2. |
Les caractères génériques peuvent être utilisés pour s’abonner à plusieurs sujets dans un seul message. Pour ces exemples, le sujet sera le chemin complet de ” {pays} / {états} / {villes} / {température, humidité} “.
- + Caractère générique à niveau unique : remplace un niveau unique dans le nom d’une chaîne de rubrique. Par exemple, US / + / Milwaukee remplacera le niveau d’État et le remplacera par les 50 États, de l’Alaska au Wyoming.
- # Caractère générique à plusieurs niveaux : remplace plusieurs niveaux plutôt qu’un seul niveau. Il s’agit toujours du dernier caractère du nom du sujet. Par exemple, US / Wisconsin / # s’abonnera à toutes les villes du Wisconsin : Milwaukee, Madison, Glendale, Whitefish Bay, Brookfield, etc.
- $ Sujets spéciaux : il s’agit d’un mode statistique spécial pour les courtiers MQTT. Les clients ne peuvent pas publier sur $ topics. Il n’y a pas de norme officielle pour le moment. Un modèle utilise $ SYS de la manière suivante : $ SYS / broker / clients / connected.
Un serveur MQTT doit prendre en charge les caractères génériques dans le nom de rubrique (mais cela n’est pas explicitement requis par la spécification). S’il ne prend pas en charge les caractères génériques, le serveur doit les rejeter. La définition du packetID est la responsabilité de la bibliothèque client MQTT.
Plusieurs autres messages sont dans la spécification MQTT. Plus de détails sur l’API de programmation MQTT peuvent être trouvés dans les normes OASIS MQTT :
- MQTT 3.1.1: http://docs.oasis-open.org/mqtt/mqtt/v3.1.1/os/mqtt-v3.1.1-os.pdf
- MQTT 5: https://docs.oasis-open.org/mqtt/mqtt/v5.0/os/mqtt-v5.0-os.pdf
10.2.7 Exemple de travail MQTT 3.1.1
Pour un exemple de travail, Google Cloud Platform ( GCP ) sera utilisé comme récepteur et ingesteur MQTT 3.1.1 dans leur cloud. La plupart des services cloud MQTT suivent un modèle similaire, ce cadre peut donc être utilisé comme référence. Nous utiliserons des outils open source pour démarrer un client MQTT et un simple exemple Python pour publier une chaîne hello world dans une branche de sujets.
Des étapes préliminaires sont nécessaires pour commencer à utiliser GCP. Les comptes et les systèmes de paiement Google doivent être sécurisés avant de continuer. Veuillez vous référer à ces instructions concernant la mise en route de Google IoT Core: https://cloud.google.com/iot/docs/how-tos/getting-started .
Procédez dans GCP pour créer un appareil, activer l’API Google, créer une branche de sujets et ajouter un membre au pub / sous-éditeur.
Google est unique en ce qu’il nécessite un cryptage fort (TLS) en plus de MQTT pour crypter tous les paquets de données à l’aide de JSON Web Token ( JWT ) et d’un agent de certificat. Chaque appareil créera une paire de clés publique / privée. Google s’assure que chaque appareil possède un identifiant et une clé uniques; dans le cas où l’un est compromis, il n’affectera qu’un seul nœud et contiendra la surface d’une attaque.
Le courtier MQTT 3.1.1 commence par importer plusieurs bibliothèques. La bibliothèque paho.mqtt .client Python est un projet parrainé par Eclipse et la maison référencée du projet IBM MQTT d’origine. Paho est également le principal produit livrable du groupe de travail industriel Eclipse M2M. Il existe d’autres variantes des courtiers de messages MQTT, comme le projet Eclipse Mosquitto et Rabbit MQ:
#Simple MQTT Client publishing example for Google Cloud Platform
import datetime
import os
import time
import paho.mqtt.client as mqtt
import jwt
project_id = ‘name_of_your_project’
cloud_region = ‘us-central1’
registry_id = ‘name_of_your_registry’
device_id = ‘name_of_your_device’
algorithm = ‘RS256’
mqtt_hostname = ‘mqtt.googleapis.com’
mqtt_port = 8883
ca_certs_name = ‘roots.pem’
private_key_file = ‘/Users/joeuser/mqtt/rsa_private.pem’
L’étape suivante est l’authentification auprès de Google grâce à l’utilisation d’une clé. Ici, nous utilisons un objet JWT pour contenir le certificat:
#Google requires certificate-based authentication using JSON Web Tokens
(JWT) per device.
#This limits surface area of attacks
def create_jwt(project_id, private_key_file, algorithm):
token = {
# The time that the token was issued
‘iat’: datetime.datetime.utcnow(),
# The time the token expires.
‘exp’: datetime.datetime.utcnow() +
datetime.timedelta(minutes=60),
# Audience field = project_id
‘aud’: project_id
}
# Read the private key file.
with open(private_key_file, ‘r’) as
f: private_key = f.read()
return jwt.encode(token, private_key, algorithm=algorithm)
Nous définissons plusieurs rappels à l’aide de la bibliothèque MQTT tels que les erreurs, les connexions, les déconnexions et la publication:
#Typical MQTT callbacks
def error_str(rc):
return ‘{}: {}’.format(rc, mqtt.error_string(rc))
def on_connect(unused_client, unused_userdata, unused_flags,
rc): print(‘on_connect’, error_str(rc))
def on_disconnect(unused_client, unused_userdata,
rc): print(‘on_disconnect’, error_str(rc))
def on_publish(unused_client, unused_userdata,
unused_mid): print(‘on_publish’)
La structure principale d’un client MQTT suit. Tout d’abord, nous enregistrons le client conformément aux prescriptions de Google . Google IoT nécessite qu’un projet soit identifié, une région, un ID de registre et un ID d’appareil. Nous ignorons également le nom d’utilisateur et utilisons le champ de mot de passe via la méthode create_jwt . C’est également là que nous activons le cryptage SSL dans MQTT – de nombreux fournisseurs de cloud MQTT nécessitent cette disposition. Après la connexion au serveur cloud MQTT de Google, la boucle principale du programme publie une simple chaîne hello world dans une branche de sujets, à laquelle vous êtes abonné. Le niveau de QoS défini dans le message PUBLISH est également à noter .
Si un paramètre est requis mais n’est pas explicitement défini dans le programme, la bibliothèque cliente est obligée d’utiliser des valeurs par défaut (par exemple, les drapeaux RETAIN et DUP utilisés comme valeurs par défaut pendant le message PUBLISH ):
def main():
client = mqtt.Client(
client_id=(‘projects/{}/locations/{}/registries/{}/devices/{}’
.format(
project_id,
cloud_region,
registry_id,
device_id))) #Google requires this format
client.username_pw_set(
username=’unused’, #Google ignores the user name.
password=create_jwt( #Google needs the JWT for authorization
project_id, private_key_file, algorithm))
# Enable SSL/TLS support.
client.tls_set(ca_certs=ca_certs_name)
#callback unused in this example:
client.on_connect = on_connect
client.on_publish = on_publish
client.on_disconnect = on_disconnect
# Connect to the Google pub/sub
client.connect(mqtt_hostname, mqtt_port)
# Loop
client.loop_start()
# Publish to the events or state topic based on the flag.
sub_topic = ‘events’
mqtt_topic = ‘/devices/{}/{}’.format(device_id, sub_topic)
# Publish num_messages messages to the MQTT bridge once per second.
for i in range(1,10):
payload = ‘Hello World!: {}’.format(i)
print(‘Publishing message\'{}\”.format(payload))
client.publish(mqtt_topic, payload, qos=1)
time.sleep(1)
if __name == ‘__main__’:
main()
10.3 MQTT-SN
Un dérivé de MQTT est appelé MQTT-SN (parfois appelé MQTT-S) pour les réseaux de capteurs. Il conserve la même philosophie de MQTT qu’un protocole léger pour les périphériques périphériques, mais il est spécialement conçu pour les nuances d’un réseau personnel sans fil typique des environnements de capteurs. Ces caractéristiques incluent la prise en charge des liaisons à faible bande passante, l’échec de la liaison, la longueur des messages courts et le matériel à ressources limitées. MQTT-SN est, en fait, si léger qu’il peut être exécuté avec succès sur BLE et Zigbee.
MQTT-SN ne nécessite pas de pile TCP / IP. Il peut être utilisé sur une liaison série (méthode préférée), où un simple protocole de liaison (pour distinguer différents périphériques sur la ligne) est vraiment faible. Alternativement, il peut être utilisé sur UDP, qui a moins faim que TCP.
10.3.1 Architecture et topologie MQTT-SN
Il existe quatre composants fondamentaux dans une topologie MQTT-SN:
- Passerelles : Dans MQTT-SN, une passerelle a la responsabilité de la conversion de protocole de MQTT-SN en MQTT et vice versa (bien que d’autres traductions soient possibles). Les passerelles peuvent également être agrégées ou transparentes (traitées plus loin dans ce chapitre).
- Transitaires : un itinéraire entre un capteur et une passerelle MQTT-SN peut emprunter de nombreux chemins et parcourir plusieurs routeurs en cours de route. Les nœuds entre le client source et la passerelle MQTT-SN sont appelés redirecteurs et réencapsulent simplement les trames MQTT-SN dans des trames MQTT-SN nouvelles et inchangées qui sont envoyées à la destination jusqu’à ce qu’elles arrivent à la passerelle MQTT-SN correcte pour la conversion de protocole.
- Clients : les clients se comportent de la même manière que dans MQTT et sont capables de s’abonner et de publier des données.
- Courtiers : Les courtiers se comportent de la même manière que dans MQTT.
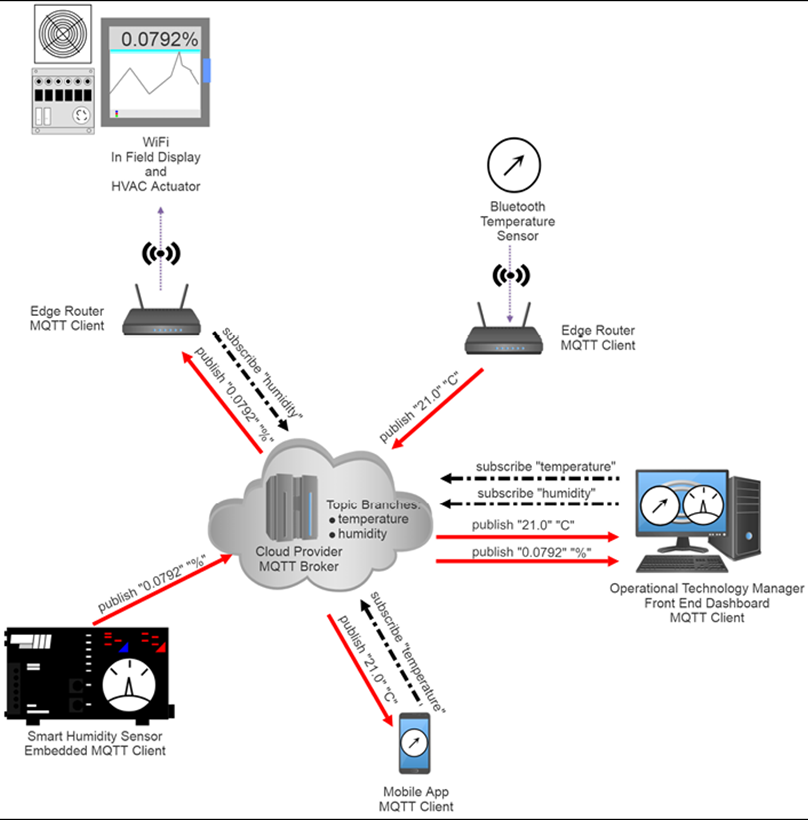
Figure 6 : Topologie MQTT-SN: les capteurs sans fil communiquent soit avec les passerelles MQTT-SN (qui traduisent MQTT-SN en MQTT), soit avec d’autres formes de protocole, soit avec des redirecteurs qui encapsulent simplement les trames MQTT-SN reçues dans des messages MQTT-SN transmis à à la passerelle.
10.3.2 transparentes et de concentration passerelles
Dans MQTT-SN, les passerelles peuvent jouer deux rôles distincts. Premièrement, une passerelle transparente gérera de nombreux flux MQTT-SN indépendants à partir de périphériques capteurs et convertira chaque flux en un message MQTT. Une passerelle d’agrégation fusionnera un certain nombre de flux MQTT-SN en un nombre réduit de flux MQTT envoyés au courtier MQTT cloud. Une passerelle d’agrégation est plus complexe dans sa conception, mais réduira le volume de communication et le nombre de connexions simultanées laissées ouvertes sur le serveur. Pour qu’une topologie de passerelle d’agrégation fonctionne, les clients doivent publier ou s’abonner au même sujet :
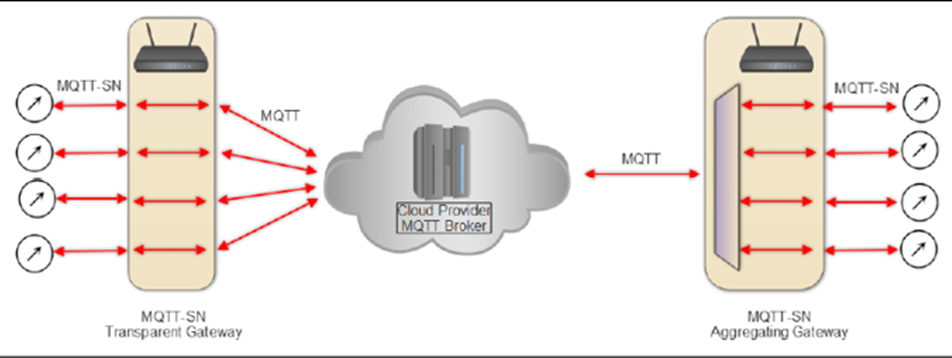
Figure 7 : passerelle MQTT-SN avec fi gurations : A effectue des passerelles transparentes une conversion de protocole simplement sur chaque flux entrant MQTT-SN et a une relation un-à-un avec les connexions MQTT-SN et les connexions MQTT au courtier. Une passerelle d’agrégation, cependant, fusionnera plusieurs flux MQTT-SN en une seule connexion MQTT au serveur.
10.3.3 Annonce et découverte de la passerelle
Étant donné que la topologie de MQTT-SN est légèrement plus compliquée que MQTT, un processus de découverte est utilisé pour établir des routes via plusieurs passerelles et nœuds de redirection.
Les passerelles rejoignant une topologie MQTT-SN commencent par se lier d’abord à un courtier MQTT. Par la suite, ils peuvent émettre un paquet ADVERTISE aux clients connectés ou à d’autres passerelles. Plusieurs passerelles peuvent exister sur le réseau, mais un client ne peut se connecter qu’à une seule passerelle. Le client a la responsabilité de stocker une liste de passerelles actives et leurs adresses réseau. Cette liste est construite à partir des différents messages ADVERTISEMENT et GWINFO diffusés.
En raison des nouveaux types de passerelles et de topologies dans MQTT-SN, plusieurs nouveaux messages sont disponibles pour faciliter la découverte et la publicité :
- ANNONCE : Diffusez périodiquement depuis une passerelle pour annoncer sa présence.
- SEARCHGW : diffusé par un client lors de la recherche d’une passerelle particulière. Une partie du message est un paramètre de rayon, qui indique le nombre de sauts que le message SEARCHGW doit suivre dans une topologie de réseau. Par exemple, une valeur de 1 indique un seul bond dans un réseau très dense où chaque client est accessible avec un seul bond.
- GWINFO : Il s’agit de la réponse des passerelles lors de la réception d’un message SEARCHGW. Il contient l’ID de passerelle et l’adresse de passerelle, qui ne sont diffusés que lorsque SEARCHGW est envoyé à partir d’un client.
10.3.4 Différences entre MQTT et MQTT-SN
Les principales différences entre MQTT-SN et MQTT sont les suivantes :
- MQTT-SN n’est pas aussi populaire que MQTT.
- Il y a trois messages CONNECT dans MQTT-SN contre un dans MQTT. Les deux autres sont utilisés pour transporter le sujet Will et le message Will de manière explicite. MQTT-SN peut fonctionner sur des supports simplifiés et UDP.
- Les noms de rubrique MQTT sont remplacés par des messages d’ID de rubrique courts et longs de deux octets dans MQTT-SN. Ceci est pour aider avec les contraintes de bande passante dans les réseaux sans fil.
- Les ID de rubrique prédéfinis et les noms de rubrique courts peuvent être utilisés sans inscription dans MQTT-SN. Pour utiliser cette fonctionnalité, le client et le serveur doivent utiliser le même ID de rubrique. Les noms de rubrique courts sont suffisamment courts pour être incorporés dans le message PUBLISH.
- Une procédure de découverte est introduite dans MQTT-SN pour aider les clients et leur permettre de trouver les adresses réseau des serveurs et des passerelles. Plusieurs passerelles peuvent exister dans la topologie et peuvent être utilisées pour charger la communication partagée avec les clients.
- La session propre est étendue dans MQTT-SN à la fonctionnalité Will. Un abonnement client peut être conservé et préservé, mais maintenant les données du testament sont également préservées.
- Une procédure keepAlive révisée est utilisée dans MQTT-SN. Il s’agit de prendre en charge les clients en veille dans lesquels tous les messages qui leur sont destinés sont mis en mémoire tampon par un serveur ou un routeur périphérique et remis au réveil.
10.3.5 Choisir un courtier MQTT
Il existe de nombreux courtiers commerciaux et open source qu’un architecte peut choisir lors de la création d’une solution MQTT. Le tableau suivant aide à identifier certains des points de choix et des fonctionnalités actuelles au moment de la rédaction :
| Courtier | Organisation des développeurs | Client et / ou courtier | Prise en charge de la version MQTT | Open source / commercial | Caractéristiques notables |
| Adafruit IO | Adafruit | Client | 1.1 | Ouvert (MIT) | Écrit en Ruby on Rails, Node.js, Python
Prise en charge de divers systèmes d’exploitation Prise en charge Web Socket QoS 1 et 2 uniquement |
| Moustique | Eclipse | Les deux | 1, 3.1.1, 5 | Ouvert (EPL) | Écrit en C
QoS 1,2,3 Prise en charge Web Socket BSD, Linux, macOS, QNX, Windows |
| HiveMQ | dc -Square | Les deux | 1 (Courtier), 3.1.1, 5 | Les deux :
Ouvert (APL v2) Version commerciale disponible |
Écrit en Java
Prise en charge Web Socket CentOS, Debian, Docker, Ubuntu, Red Hat, macOS, Windows |
| MQTT-C | Liam Bindle | Client | 1, 3.1.1 | Ouvert (MIT) | Écrit en C
Thread-Safe Linux, macOS, Windows Capable en métal nu |
| Paho MQTT | Eclipse | Client | MQTT-SN, 3.1, 3.1.1, 5 | Ouvert (EPL) | Disponible en C, C ++, Java, JavaScript, Python, Go
Prise en charge de plusieurs systèmes d’exploitation |
| PubSub + | Consolation | Courtier | 1.1 | Commercial | Écrit en C et C ++
CentOS, Debian, KVM, Ubuntu, Red Hat, macOS X, Windows |
| Thingstream | Thingstream | Les deux | MQTT-SN, 3.1.1, 5 | Commercial | LoRaWAN Integrated |
| WolfMQTT | woldSSL | Les deux | MQTT-SN, 3.1.1, 5 | Ouvert (GPLv2) | Windows, Linux, macOS, FreeRTOS , Harmony, Nucleus
Capable en métal nu |
10.4 Protocole d’application contraint
Le protocole d’application contrainte (CoAP) est le produit de l’IETF (RFC7228). Le groupe de travail IETF Constrained RESTful Environments (CoRE) a créé le premier projet de protocole en juin 2014, mais a travaillé pendant plusieurs années à sa création. Il est spécifiquement conçu comme un protocole de communication pour les appareils contraints. Le protocole principal est désormais basé sur RFC7252. Le protocole est unique car il a été conçu pour la communication M2M entre les nœuds périphériques. Il prend également en charge le mappage vers HTTP via l’utilisation de proxys. Ce mappage HTTP est la fonction intégrée pour obtenir des données sur Internet.
CoAP est excellent pour fournir une structure similaire et facile d’adressage de ressources familière à toute personne ayant une expérience de l’utilisation du Web mais avec des ressources et des demandes de bande passante réduites.
Une étude réalisée par Colitti et al., A démontré l’efficacité de CoAP sur HTTP standard (Colitti , Walter & Steenhaut , Kris & De, Niccolò. 2017. Integrating Wireless Sensor Networks with the Web). CoAP fournit une fonctionnalité similaire avec des frais généraux et des besoins en énergie nettement inférieurs.
De plus, certaines implémentations de CoAP fonctionnent jusqu’à 64 fois mieux que les équivalents HTTP sur du matériel similaire.
| Octets par transaction | Puissance | Durée de vie de la batterie | |
| CoAP | 154 | 744 mW | 151 jours |
| HTTP | 1451 | 333 mW | 84 jours |
10.4.1 Détails de l’architecture CoAP
CoAP est basé sur le concept d’imiter et de remplacer les capacités et l’utilisation HTTP lourdes par un équivalent léger pour l’IoT. Ce n’est pas un remplacement HTTP car il manque de fonctionnalités ; HTTP nécessite des systèmes plus puissants et orientés services. Les fonctionnalités CoAP peuvent être résumées comme suit :
- Comme HTTP
- Connection- moins protocoles
- Sécurité via DTLS plutôt que TLS dans une transmission HTTP normale
- Échanges de messages asynchrones
- Conception légère et besoins en ressources et faible en-tête
- Prise en charge de l’URI et des types de contenu
- Construit sur UDP contre TCP / UDP pour une session HTTP normale
- Un mappage HTTP sans état permettant aux proxys de se connecter aux sessions HTTP
CoAP a deux couches de base :
- Couche demande / réponse : responsable de l’envoi et de la réception des requêtes basées sur RESTful. Les requêtes REST sont superposées sur des messages CON ou NON. Une réponse REST est superposée sur le message ACK correspondant.
- Couche transactionnelle : gère les échanges de messages uniques entre les points d’extrémité à l’aide de l’un des quatre types de messages de base. La couche de transaction prend également en charge la multidiffusion et le contrôle de la congestion :
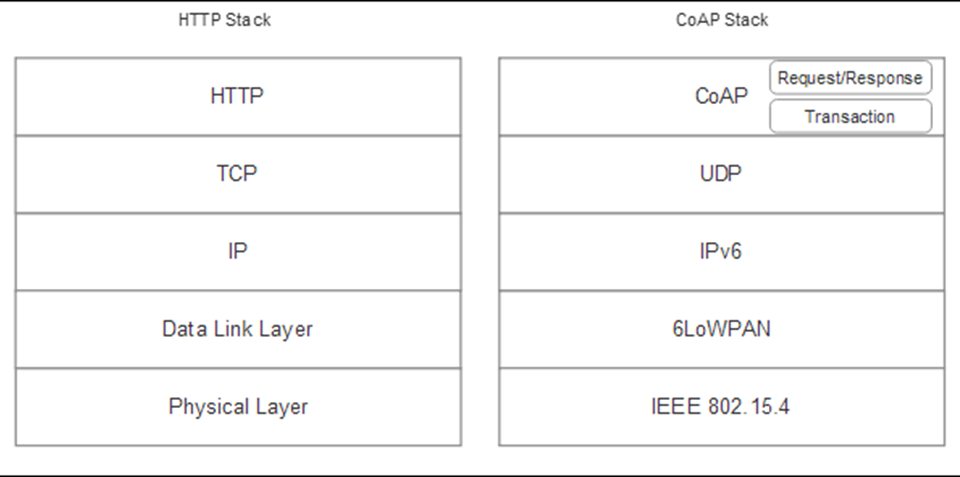
Figure 8 : pile HTTP par rapport à CoAP
CoAP partage son contexte, sa syntaxe et son utilisation avec HTTP. L’adressage dans CoAP est également conçu comme HTTP. Une adresse s’étend à la structure URI. Comme dans les URI HTTP, l’utilisateur doit connaître l’adresse au préalable pour accéder à une ressource. Au niveau le plus élevé, CoAP utilise des demandes telles que GET, PUT, POST et DELETE, comme dans HTTP. De même, les codes de réponse imitent HTTP, tels que :
- 2.01 : créé
- 2.02 : supprimé
- 2.04 : modifié
- 2.05 : Contenu
- 4.04 : introuvable (ressource)
- 4.05 : Méthode non autorisée
La forme d’un URI typique dans CoAP serait :
coap: // hôte [: port ] / [chemin] [? requête]
Un système CoAP comprend sept acteurs principaux :
- Points de terminaison : sources et destinations d’un message CoAP . La définition spécifique d’un point d’extrémité dépend du transport utilisé.
- Proxy : points de terminaison CoAP chargés par les clients CoAP d’exécuter des demandes en leur nom. Réduire la charge du réseau, accéder aux nœuds dormants et fournir une couche de sécurité sont quelques-uns des rôles d’un proxy. Les proxys peuvent être explicitement sélectionnés par un client (proxy direct) ou peuvent être utilisés comme serveurs in situ (proxy inverse).
Alternativement, un proxy peut mapper d’une requête CoAP vers une autre requête CoAP ou même traduire vers un protocole différent (proxy croisé). Une situation courante est un routeur de périphérie procurant un proxy à partir d’un réseau CoAP à des services HTTP pour les connexions Internet basées sur le cloud.
- Client : l’auteur d’une demande. Le point de terminaison de destination d’une réponse.
- Serveur : point de terminaison de destination d’une demande. L’auteur d’une réponse.
- Intermédiaire : client agissant à la fois comme serveur et client envers un serveur d’origine. Un mandataire est un intermédiaire.
- Serveur d’origine : serveur sur lequel réside une ressource donnée.
- Observateur : un client qui peut s’enregistrer à l’aide d’un message GET modifié. L’observateur est alors connecté à une ressource, et si l’état de cette ressource change, le serveur renverra une notification à l’observateur.
Les observateurs sont uniques dans CoAP et permettent à un appareil de surveiller les modifications d’une ressource particulière. En substance, cela est similaire au modèle d’abonnement MQTT où un nœud s’abonnera à un événement.
La figure suivante est un exemple d’architecture CoAP. Être un système HTTP léger permet aux clients CoAP de communiquer entre eux ou avec des services dans le cloud prenant en charge CoAP . Alternativement, un proxy peut être utilisé pour créer un pont vers un service HTTP dans le cloud. Les points de terminaison CoAP peuvent établir des relations entre eux, même au niveau du capteur. Les observateurs autorisent des attributs de type abonnement pour faciliter ce changement d’une manière similaire à MQTT. Le graphique illustre également les serveurs d’origine contenant la ressource partagée. Les deux proxys permettent à CoAP d’effectuer une traduction HTTP ou autorisent le transfert de demandes au nom d’un client.
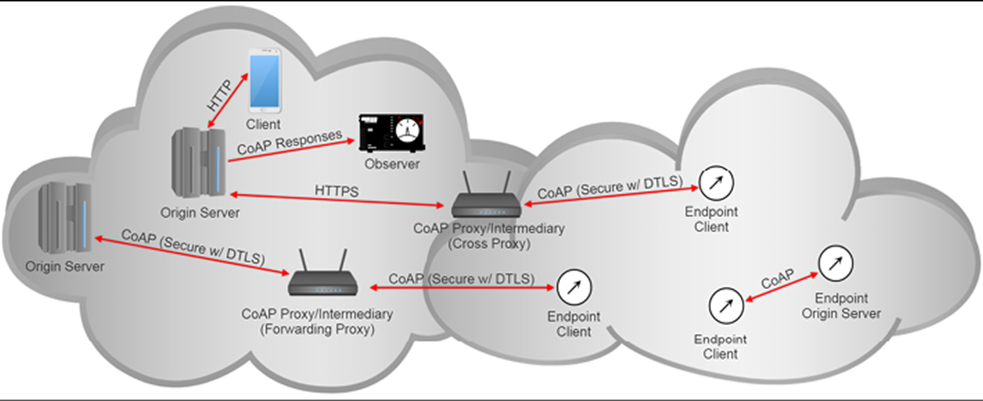
Figure 9 : Architecture CoAP
CoAP utilise le port 5683. Ce port doit être pris en charge par un serveur qui offre des ressources car le port est utilisé pour la découverte des ressources. Le port 5684 est utilisé lorsque DTLS est activé.
10.4.2 Formats de messagerie CoAP
Les protocoles basés sur le transport UDP impliquent que la connexion peut ne pas être intrinsèquement fiable. Pour compenser les problèmes de fiabilité, CoAP introduit deux types de messages qui diffèrent en exigeant ou non un accusé de réception. Une caractéristique supplémentaire de cette approche est que les messages peuvent être asynchrones.
Au total, il n’y a que quatre messages dans CoAP :
- Confirmable (CON) : nécessite un ACK. Si un message CON est envoyé, un ACK doit être reçu dans un intervalle de temps aléatoire entre ACK_TIMEOUT et (ACK_TIMEOUT * ACK_RANDOM_FACTOR). Si l’ACK n’est pas reçu, l’expéditeur transmet le message CON à plusieurs reprises à des intervalles croissants jusqu’à ce qu’il reçoive l’ACK ou un RST. Il s’agit essentiellement de la forme CoAP de contrôle de la congestion. Il y a un nombre maximum de tentatives défini par MAX_RETRANSMIT. Il s’agit du mécanisme de résilience pour compenser le manque de résilience dans l’UDP.
- Non confirmable (NON) : ne nécessite aucun ACK. Il s’agit essentiellement d’un message ou d’une diffusion de type “tirer et oublier”.
- Accusé de réception (ACK) : acquitte un message CON. Le message ACK peut être superposé avec d’autres données.
- Reset (RST) : indique qu’un message CON a été reçu mais que le contexte est manquant. Le RST message peut ferroutage le long avec d’autres données.
CoAP est une conception RESTful utilisant des messages de demande / réponse superposés aux messages CoAP. Cela permet une plus grande efficacité et une meilleure conservation de la bande passante, comme le montre la figure suivante :
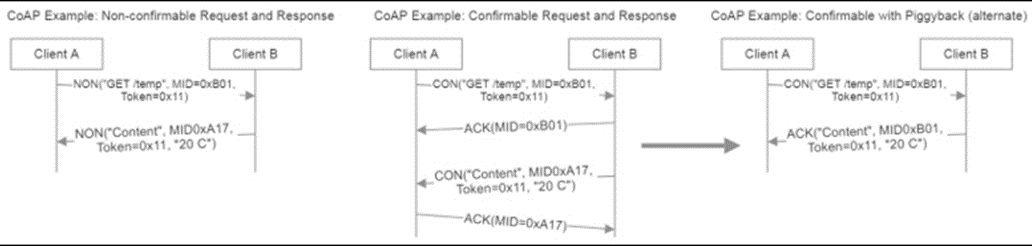
Figure 10 : Messagerie CoAP NON et CON
Le graphique montre trois exemples de transactions de demande / réponse non confirmables et confirmables CoAP. Celles – ci sont énumérées et décrites comme suit :
- Demande / réponse non confirmable (à gauche) : message diffusé entre les clients A et B à l’aide de la construction HTTP GET typique. B échange avec les données de contenu un peu plus tard et renvoie la température de 20 degrés Celsius.
- Demande / réponse confirmable (milieu) : L’ID du message est inclus, un identifiant unique pour chaque message. Le jeton représente une valeur qui doit correspondre pendant la durée de l’échange.
- Demande / réponse confirmable (à droite) : Ici, le message est confirmable. Les clients A et B attendent tous deux un ACK après chaque échange de message. Pour optimiser la communication, le client B peut choisir de superposer l’ACK avec les données renvoyées comme illustré à l’extrême droite.
Le journal réel des transactions CoAP peut être vu dans l’extension Copper Firefox sur Firefox version 55 :

Figure 11 : journal Copper CoAP : ici, nous voyons plusieurs messages initiés par le client CON-GET à californium.eclipse org: 5683. Le chemin URI pointe vers coap: //californium.eclipse.org: 5683 / .well-known / core. Le MID s’incrémente à chaque message tandis que le jeton est inutilisé et facultatif.
Le processus de retransmission est illustré dans la figure suivante :
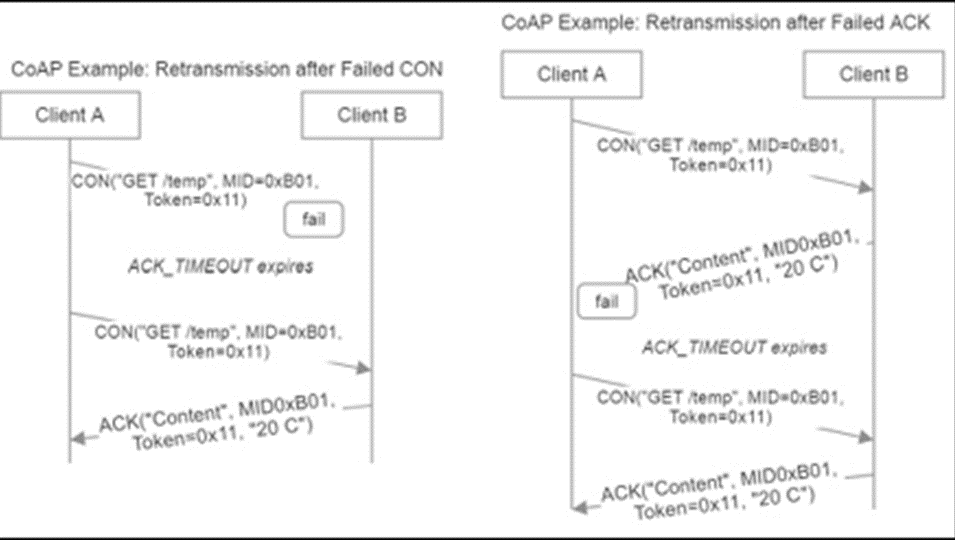
Figure 12 : Mécanisme de retransmission CoAP : Pour tenir compte du manque de résilience dans UDP, CoAP utilise un mécanisme de temporisation lors de la communication avec des messages con fi rmables . Si le délai expire, soit en envoyant un message CON, soit en recevant l’ACK, l’expéditeur retransmet le message. L’expéditeur est responsable de la gestion du délai d’expiration et de la retransmission jusqu’à un nombre maximum de retransmissions. Notez que la retransmission de l’ACK échoué réutilise le même ID de message.
Alors que d’autres architectures de messagerie nécessitent un serveur central pour propager les messages entre les clients, CoAP permet d’envoyer des messages entre n’importe quel client CoAP, y compris les capteurs et les serveurs. CoAP comprend un modèle de mise en cache simple. La mise en cache est contrôlée par des codes de réponse dans l’en-tête du message. Un masque de numéro d’option déterminera s’il s’agit d’une clé de cache. L’option Max_Age est utilisée pour contrôler les durées de vie des éléments de cache et garantir la fraîcheur des données. En d’autres termes, Max_Age définit la durée maximale pendant laquelle une réponse peut être mise en cache avant de devoir être actualisée. La valeur par défaut de Max_Age est de 60 secondes et peut s’étendre jusqu’à 136,1 ans. Les proxys jouent un rôle dans la mise en cache ; par exemple, un capteur de bord dormant peut utiliser un proxy pour mettre en cache les données et conserver l’énergie.
L’en- tête de message CoAP est spécialement conçu pour une efficacité maximale et une préservation de la bande passante. L’en-tête a une longueur de quatre octets et un message de demande typique ne prend que des en-têtes de 10 à 20 octets. Ceci est généralement 10 fois plus petit qu’un en-tête HTTP. La structure se compose d’identificateurs de type de message (T), qui doivent être inclus dans chaque en-tête avec un ID de message unique associé. Le champ Code est utilisé pour signaler des erreurs ou des états de réussite sur tous les canaux. Après l’en-tête, tous les autres champs sont facultatifs et incluent des jetons de longueur variable, des options et une charge utile :
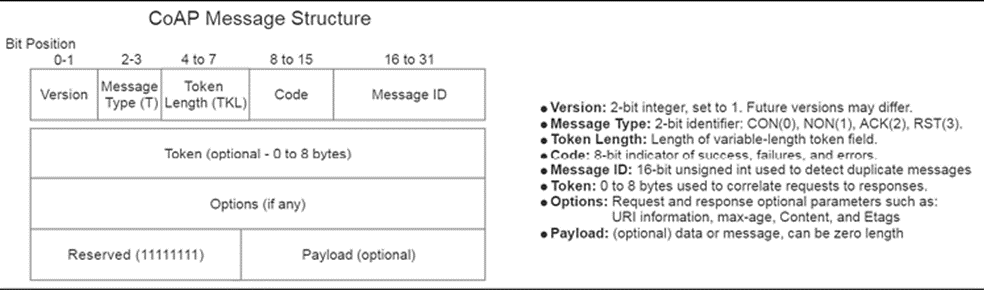
Figure 13 : Structure des messages CoAP
UDP peut également provoquer l’arrivée de messages en double pour les transmissions CON et NON. Si des ID_message identiques sont livrés à un destinataire dans le délai EXCHANGE_LIFETIME prescrit, un doublon est supposé exister. Cela peut clairement se produire, comme illustré dans les figures précédentes, lorsqu’un ACK est manquant ou supprimé et que le client retransmet le message avec le même Message_ID . La spécification CoAP indique que le destinataire doit ACK chaque message en double qu’il reçoit mais ne doit traiter qu’une seule demande ou réponse. Cette règle peut être assouplie si un message CON transporte une demande idempotente.
Comme mentionné, CoAP permet le rôle d’un observateur dans un système. Ceci est unique car il permet à CoAP de se comporter d’une manière similaire à MQTT. Le processus d’observation permet à un client de s’inscrire pour l’observation et le serveur avertit le client chaque fois que la ressource surveillée change d’état.
La durée d’observation peut être définie lors de l’inscription. De plus, la relation d’observation se termine lorsque le client initiateur envoie un RST ou un autre message GET :
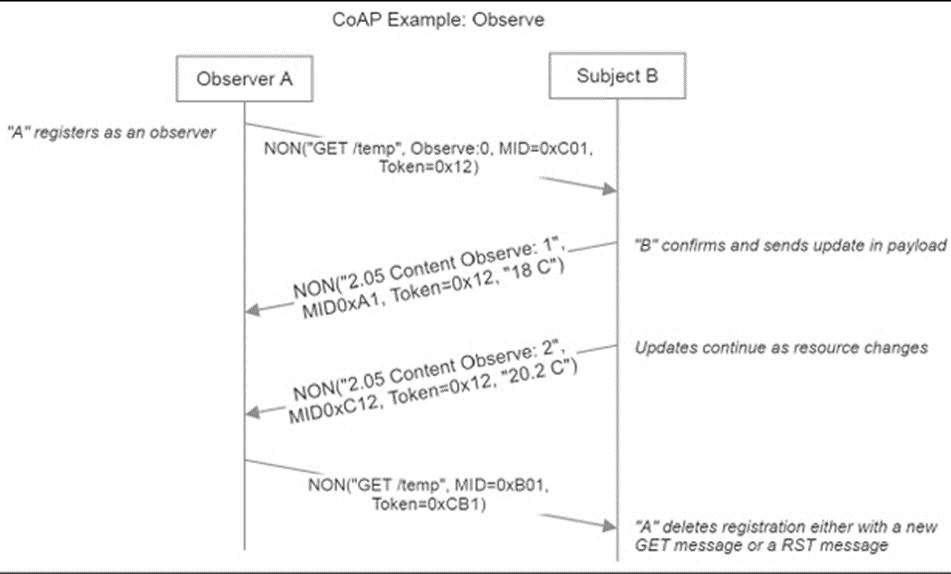
Figure 14 : Processus d’enregistrement et de mise à jour des observateurs CoAP
Comme mentionné précédemment, il n’y a pas d’authentification ou de cryptage inhérent dans la norme CoAP ; l’utilisateur doit plutôt compter sur DTLS pour fournir ce niveau de sécurité. Si DTLS est utilisé, alors un exemple d’URI serait :
// insérer coap: //example.net: 1234 / ~ temperature / value.xml
// coaps sécurisés: //example.net: 1234 / ~ temperature / value.xml
CoAP propose également des mécanismes de découverte des ressources. Le simple fait d’envoyer une demande GET à /.well -known / core affichera une liste des ressources connues sur l’appareil. De plus, des chaînes de requête peuvent être utilisées dans la demande d’application de filtres spécifiques.
10.4.3 Exemple d’utilisation de CoAP
CoAP est léger et sa mise en œuvre à la fois sur le client et sur le serveur devrait prendre peu de ressources. Ici, nous utilisons la bibliothèque aiocoap basée sur Python. Plus peut être lu A propos de ce qui est aiocoap dans Amsüss , Christian et Wasilak , Maciej. aiocoap : bibliothèque Python CoAP . Energy Harvesting Solutions, 2013 – https://github.com/chrysn/aiocoap/ . De nombreux autres clients et serveurs CoAP gratuits existent avec plusieurs écrits en code C de bas niveau pour les environnements de capteurs extrêmement contraints. Ici, nous utilisons un environnement Python pour plus de brièveté.
L’implémentation client est:
#!/usr/bin/env python3
#necessary for asynchronous processing in Python from aiocoap
import asyncio
#using the aiocoap library
import *
Ce qui suit est la boucle principale pour le client. Le client utilise PUT pour diffuser la température aux URI connus:
async def main():
context = await Context.create_client_context()
#wait 2 seconds after initialization
await asyncio.sleep(2)
payload = b”20.2 C”
request = Message(code=PUT, payload=payload)
#URI for localhost address
request.opt.uri_host = ‘127.0.0.1’
#URI for path to /temp/celcius
request.opt.uri_path = (“temp”, “celcius”)
response = await context.request(request).response
print(‘Result: %s\n%r’%(response.code,response.payload))
if __name__ == “__main__”:
asyncio.get_event_loop().run_until_complete(main())
L’implémentation du serveur est:
#!/usr/bin/env python3
#necessary for asynchronous processing in Python
import asyncio
#using aiocoap library import aiocoap
import aiocoap.resource as resource
Le code suivant illustre les services pour les méthodes PUT et GET :
class GetPutResource(resource.Resource):
def __init__(self):
super().__init__()
self.set_content(b”Default Data
(padded) “)
def set_content(self, content):
#Apply padding
self.content = content
while len(self.content) <= 1024:
self.content = self.content + b”0123456789\n”
#GET handler
async def render_get(self, request):
return aiocoap.Message(payload=self.content)
#PUT handler
async def render_put(self, request):
print(‘PUT payload: %s’ % request.payload)
#replaces set_content with received payload
self.set_content(request.payload)
#set response code to 2.04
return aiocoap.Message(code=aiocoap.CHANGED, payload=self.content)
La boucle principale est:
def main():
#root element that contains all resources found on server
root = resource.Site()
#this is the typical .well-known/core and
#resource list for well-known/core
root.add_resource((‘.well-known’, ‘core’),
resource.WKCResource(root.get_resources_as_linkheader))
#adds the resource /tmp/celcius
root.add_resource((‘temp’, ‘celcius’), GetPutResource()))
asyncio.Task(aiocoap.Context.create_server_context(root)
) asyncio.get_event_loop().run_forever()
if __name__ == “__main__”:
main()
10.5 Autres protocoles
Il existe de nombreux protocoles de messagerie utilisés ou proposés pour les déploiements IoT et M2M. Les plus répandus sont de loin le MQTT et le CoAP ; les sections suivantes explorent quelques alternatives pour des cas d’utilisation spécifiques.
10.5.1 STOMP
STOMP signifie Simple (ou Streaming) Text-Oriented Middleware Protocol. Il s’agit d’un protocole textuel conçu par Codehaus pour fonctionner avec un middleware orienté message. Un courtier développé dans un langage de programmation peut recevoir des messages d’un client écrits dans un autre. Le protocole a des similitudes avec HTTP et fonctionne sur TCP. STOMP se compose d’un en-tête de trame et d’un corps de trame. La spécification actuelle est STOMP 1.2, datée du 22 octobre 2012, et est disponible sous licence gratuite.
STOMP est optimisé pour la lisibilité humaine, l’analyse tolérante aux pannes et les données auto-décrites. Il n’est pas efficace sur les réseaux et les protocoles de communication lors de la prise en compte des bits / messages (ce n’est pas son objectif de conception prévu). Tout ce qui a une connectivité limitée, des frais de service élevés pour la communication ou une enveloppe d’alimentation limitée comme un appareil à batterie ne doit pas utiliser STOMP.
De plus, les protocoles MOM comme STOMP ont leurs structures de messages définies par l’application. Cela oblige l’éditeur et l’abonné à avoir une structure de message au pas. Autrement dit, si vous apportez des modifications à l’éditeur, vous devez également modifier l’abonné. Cela peut provoquer des turbulences importantes dans les appareils IoT qui sont massivement déployés.
Il est différent de nombreux protocoles présentés dans ce chapitre car il ne traite pas des sujets d’abonnement ou des files d’attente. Il utilise simplement une sémantique de type HTTP telle que SEND avec une chaîne de destination. Un courtier doit disséquer le message et mapper vers un sujet ou une file d’attente pour le client. Un consommateur des données S’ABONNERA aux destinations fournies par le courtier.
STOMP a des clients écrits en Python ( Stomp.py), TCL (tStomp) et Erlang (stomp.erl). Plusieurs serveurs ont une prise en charge native de STOMP, comme RabbitMQ (via un plugin), et certains serveurs ont été conçus dans des langages spécifiques (Ruby, Perl ou OCaml).
10.5.2 AMQP
AMQP signifie Advanced Message Queuing Protocol . Il s’agit d’un protocole MOM durci et éprouvé utilisé par des sources de données massives telles que JP Morgan Chase pour traiter plus d’un milliard de messages par jour, et l’Observatoire de l’océan pour collecter plus de 8 téraoctets de données océanographiques chaque jour. Il a été initialement conçu chez JP Morgan Chase en 2003, ce qui a conduit à la création d’un groupe de travail de 23 entreprises en 2006 chargé de l’architecture et de la gouvernance du protocole. En 2011, le groupe de travail a été fusionné avec le groupe OASIS où il est actuellement hébergé. De plus, les versions 0.9 et 1.0 d’AMQP coexistent dans divers déploiements.
Aujourd’hui, il est bien implanté dans les secteurs bancaires et des transactions de crédit, mais a également sa place dans l’IoT. De plus, l’AMQP est normalisé par l’ISO et l’IEM comme ISO / IEC 19464: 2014. Un groupe de travail officiel de l’AMQP est disponible sur www.amqp.org.
Le protocole AMQP réside au sommet de la pile TCP et utilise le port 5672 pour la communication. Les données sont sérialisées sur AMQP, ce qui signifie que les messages sont diffusés dans des trames unitaires. Les trames sont transmises dans des canaux virtuels identifiés par un channel_id unique . Les trames se composent d’en-têtes, de channel_ids , d’informations de charge utile et de pieds de page. Un canal, cependant, ne peut être associé qu’à un seul hôte. Les messages sont attribués à un identifiant global unique.
AMQP est un système de communication à flux contrôlé et orienté message. Il s’agit d’un protocole filaire et d’une interface de bas niveau. Un protocole câblé fait référence aux API immédiatement au-dessus de la couche physique d’un réseau. Une API filaire permet à différents services de messagerie tels que .NET (NMS) et Java (JMS) de communiquer entre eux. De même, AMQP tente de dissocier les éditeurs des abonnés. Contrairement à MQTT, il dispose de mécanismes d’équilibrage de charge et de mise en file d’attente formelle. Un protocole bien utilisé basé sur AMQP est RabbitMQ, qui est un courtier de messages AMQP écrit en Erlang. De plus, plusieurs clients AMQP sont disponibles, tels que le client RabbitMQ écrit en Java, C #, JavaScript et Erlang, ainsi qu’Apache Qpid écrit en Python, C ++, C #, Java et Ruby.
Un ou plusieurs hôtes virtuels avec leurs propres espaces de noms, échanges et files d’attente de messages résideront sur un ou plusieurs serveurs centraux. Les producteurs et les consommateurs sont abonnés au service d’échange.
Le service d’échange reçoit des messages d’un éditeur et achemine les données vers une file d’attente associée. Cette relation est appelée liaison, qui peut être directe sur une file d’attente ou déployée sur plusieurs files d’attente (comme dans une diffusion). Alternativement, la liaison peut associer un échange à une file d’attente à l’aide d’une clé de routage ; c’est ce qu’on appelle officiellement un échange direct. Un autre type d’échange est l’échange de sujets.
Ici, un modèle est utilisé pour wildcard une clé de routage gestionnaire (comme * .temp. # Matches idaho.temp.celsius et wisconsin.temp.fahrenheit ):
Figure 15 : Topologie architecturale AMQP : il existe des producteurs et des consommateurs dans une implémentation AMQP typique. Les producteurs peuvent utiliser différentes langues et espaces de noms, car AMQP est indépendant de la langue compte tenu de ses API et de son protocole de connexion. Le courtier réside dans le cloud et fournit des échanges pour chaque producteur. Échange les messages de routage vers les files d’attente appropriées en fonction des règles de liaison. Les files d’attente sont des tampons de messages qui produisent des messages destinés aux consommateurs en attente.
La topologie de réseau d’un déploiement AMQP est concentrateur et permet aux concentrateurs de communiquer entre eux. AMQP se compose de nœuds et de liens. Un nœud est une source nommée ou un puits de messages. Une trame de message se déplace entre les nœuds sur des liaisons unidirectionnelles.
Si un message est transmis via un nœud, l’identifiant global est inchangé. Si le nœud effectue une transformation, un nouvel ID est attribué. Un lien a la capacité de filtrer les messages. Il existe trois modèles de messagerie distincts qui peuvent être utilisés dans AMQP :
- Messages dirigés asynchrones : le message est transmis sans nécessiter d’accusé de réception du récepteur.
- Demande / réponse ou pub / sub : Ceci est similaire à MQTT, avec un serveur central agissant comme un service pub / sub.
- Stockage et retransmission : utilisé pour le relais du concentrateur, où un message est envoyé à un concentrateur intermédiaire puis envoyé vers sa destination.
Un échange dirigé de base écrit en Python est montré ici, en utilisant les bibliothèques RabbitMQ et Pika Python. Ici, nous créons un échange direct simple appelé Idaho et le lions à une file d’attente appelée météo :
#!/usr/bin/env python
#AMQP basic Python example the pika Python library
from pika import BlockingConnection, BasicProperties, ConnectionParameters
#initialize connections
connection = BlockingConnection(ConnectionParameters(‘localhost’))
channel = connection.channel()
#declare a direct exchange
channel.exchange_declare(exchange=’Idaho’, type=’direct’)
#declare the queue
channel.queue_declare(queue=’weather’)
#bindings
channel.queue_bind(exchange=’Idaho’, queue=’weather’, routing_key=’Idaho’)
#produce the message
channel.basic_publish(exchange=’Idaho’, routing_key=’Idaho’,
body=’new important task’)
#consume the message
method_frame, header_frame, body = ch.basic_get(‘weather’)
#acknowledge
channel.basic_ack(method_frame.delivery_tag)
10.6 Protocole Edge à protocole Cloud
Un résumé et une comparaison des différents protocoles sont maintenant présentés. Il convient de noter qu’il existe des exceptions à certaines de ces catégories. Par exemple, bien que MQTT n’offre aucun provisionnement de sécurité intégré, il peut être publié au niveau de l’application. Dans tous les cas, il existe des exceptions et le tableau est construit à partir des spécifications formelles :
| MQTT | MQTT-SN | CoAP | AMQP | STOMP | HTTP / RESTful | |
| Modèle | Maman
pub / sous |
Maman
pub / sous |
RESTful | Maman | Maman | RESTful |
| Protocole de découverte | Non | Oui (via des passerelles) | Oui | Non | Non | Oui |
| Ressources demandes | Faible | Très faible | Très faible | Élevé | Moyen | Très élevé |
| Taille d’en-tête (octets) | 2 | 2 | 4 | 8 | 8 | 8 |
| Consommation d’énergie moyenne | Le plus bas | Faible | Moyen | Élevé | Moyen | Élevé |
| Authentification | Non (SSL / TLS) | Non (/ TLS) | Non (DTLS) | Oui | Non | Oui (TLS) |
| Cryptage | Non (SSL / TLS) | Non (SSL / TLS) | Non (DTLS) | Oui | Non | Oui
(TLS) |
| Contrôles d’accès | Non | Non | Non (proxy) | Oui | Non | Oui |
| Frais généraux de communication | Faible | Très faible | Très faible | Élevé | Haut, verbeux | Élevé |
| Complexité du protocole | Faible | Faible | Faible | Élevé | Faible | Très élevé |
| TCP / UDP | TCP | TCP / UDP | UDP | TCP / UDP | TCP | TCP |
| Diffusion | Indirecte | Indirecte | Oui | Non | Non | Non |
| Qualité de service | Oui | Oui | Avec des messages CON | Oui | Non | Non |
10.7 Résumé
MQTT, CoAP et HTTP sont de loin les protocoles Internet IoT prédominants de l’industrie avec le soutien de presque tous les fournisseurs de cloud. MQTT et MQTT-SN fournissent un modèle pub / sub évolutif et efficace de communication de données tandis que CoAP fournit toutes les fonctionnalités pertinentes d’un modèle HTTP RESTful sans la surcharge. Un architecte doit tenir compte de la surcharge, de la puissance, de la bande passante et des ressources nécessaires pour prendre en charge un protocole donné et avoir une vision prospective suffisante pour assurer la mise à l’échelle de la solution.
Maintenant qu’une méthode de transport a été définie pour rassembler les données sur Internet, nous pouvons examiner ce qu’il faut faire avec ces données. Le chapitre suivant se concentrera sur l’architecture cloud et brouillard, des principes fondateurs aux configurations plus avancées.
11 Topologies cloud et brouillard
Sans le cloud, la croissance de l’IoT et son marché seraient inexistants. Essentiellement, des milliards d’appareils d’extrémité qui étaient historiquement stupides et non connectés devraient se gérer eux-mêmes sans pouvoir partager ou agréger des données. Des milliards de ces petits systèmes embarqués n’apportent aucune valeur marginale aux clients. La valeur de l’IoT réside dans les données qu’il produit – non pas sur un seul point de terminaison, mais sur des milliers ou des millions de nœuds. Le cloud offre la possibilité de faire participer des capteurs, caméras, commutateurs, balises et actionneurs simples dans un langage commun. Le cloud est le dénominateur commun de la devise des données.
La métaphore omniprésente du cloud fait référence à une infrastructure de services informatiques généralement à la demande. Le pool de ressources (informatique, réseau, stockage et les services logiciels associés) peut évoluer de manière dynamique vers le haut ou vers le bas en fonction de la moyenne de charge ou de la qualité du service. Les nuages sont généralement de grands centres de données qui fournissent des services tournés vers l’extérieur aux clients sur un modèle de paiement à l’utilisation. Ces centres fournissent l’illusion d’une ressource cloud unique alors qu’en fait, il peut y avoir de nombreuses ressources dispersées géographiquement. Cela donne à l’utilisateur un sentiment d’indépendance de l’emplacement. Les ressources sont élastiques (c’est-à-dire évolutives) et les services sont à la demande, générant une source de revenus récurrents pour le fournisseur. Les services qui s’exécutent dans le cloud diffèrent dans leur construction et leur déploiement des logiciels traditionnels. Les applications basées sur le cloud peuvent être développées et déployées plus rapidement et avec moins de degrés de variabilité environnementale. Ainsi, le déploiement du cloud bénéficie d’une vitesse de fonctionnalité rapide.
Il existe des témoignages selon lesquels la première description du cloud est née à Compaq au milieu des années 1990, où les futurologues de la technologie ont prédit un modèle informatique qui a déplacé l’informatique sur le Web plutôt que sur les plates-formes hôtes. Essentiellement, c’était la base du cloud computing, mais ce n’est qu’avec l’avènement de certaines autres technologies que le cloud computing est devenu pratique pour l’industrie.
L’industrie des télécommunications reposait traditionnellement sur un système de circuits point à point. La création de VPN permet un accès sécurisé et contrôlé aux clusters et a permis aux hybrides de cloud privé-public d’exister.
Ce chapitre étudie l’architecture cloud et les domaines suivants :
- Une définition formelle des topologies de nuages et une langue vernaculaire
- Un aperçu architectural du cloud OpenStack
- Une étude du problème fondamental de l’architecture cloud uniquement
- Un aperçu du calcul du brouillard
- Architecture de référence OpenFog
- Topologies de calcul de brouillard et cas d’utilisation
Tout au long du chapitre, plusieurs cas d’utilisation seront abordés afin que vous puissiez comprendre l’impact de la sémantique du Big Data sur les environnements de capteurs IoT.
11.1 Modèle de services cloud
Les fournisseurs de cloud prennent généralement en charge une gamme de produits Everything as a Service ( XaaS ); c’est-à-dire en tant que service logiciel payant. Les services incluent Networking as a Service ( NaaS ), Software as a Service ( SaaS ), Platform as a Service ( PaaS ) et Infrastructure as a Service ( IaaS ). Chaque modèle introduit de plus en plus de services de fournisseurs de cloud . Ces offres de services représentent la valeur ajoutée du cloud computing. Au minimum, ces services devraient compenser les dépenses en capital auxquelles un client doit faire face pour l’achat et l’entretien de ces équipements de datacenter et les remplacer en tant que dépenses opérationnelles. La définition standard du cloud computing peut être trouvée via le National Institute of Standards and Technology: Peter M. Mell et Timothy Grance. 2011. SP 800-145. La définition NIST du Cloud Computing . Rapport technique. NIST, Gaithersburg, MD, États-Unis ( https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-145.pdf ).
La figure suivante illustre les différences de gestion des modèles de cloud qui seront décrites dans les sections suivantes :
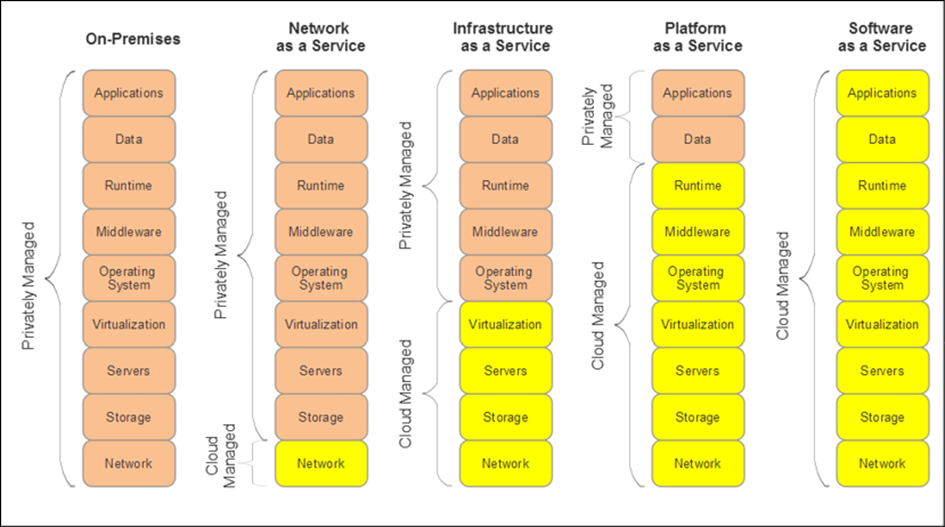
Figure 1 : Modèles d’architecture cloud. Sur site, tous les services, l’infrastructure et le stockage sont gérés par le propriétaire.
NaaS comprend des services comme SDP et SDN. L’IaaS pousse les systèmes matériels et le stockage vers le cloud. PaaS comprend l’infrastructure mais gère également le système d’exploitation et le système d’exécution ou les conteneurs dans le cloud. Enfin, le SaaS transmet tous les services, infrastructures et services au fournisseur de cloud.
11.1.1 NaaS
Les services tels que la mise en réseau définie par logiciel (SDN) et les périmètres définis par logiciel (SDP) sont typiques de NaaS. Ces produits sont des mécanismes gérés et organisés dans le cloud pour fournir des réseaux de superposition et la sécurité de l’entreprise. Plutôt que de construire une infrastructure et des capitaux mondiaux pour soutenir les communications d’une entreprise, une approche cloud peut être utilisée pour former un réseau virtuel. Cela permet au réseau d’augmenter ou de diminuer les ressources de manière optimale en fonction de la demande, et de nouvelles fonctionnalités réseau peuvent être achetées et déployées rapidement. Ce sujet sera traité en profondeur dans le chapitre SDN correspondant.
11.1.2 SaaS
Le SaaS est le fondement du cloud computing. Un fournisseur propose généralement des applications ou des services qui s’exposent à l’utilisateur final via des clients tels que des appareils mobiles, des clients légers ou des frameworks sur d’autres clouds. D’un point de vue utilisateur, la couche SaaS s’exécute virtuellement sur leur client. Cette abstraction logicielle a permis à l’industrie de réaliser une croissance substantielle dans le cloud. Les services SaaS incluent des appliances de marque telles que Google Apps, Salesforce et Microsoft Office 365.
11.1.3 PaaS
PaaS fait référence au matériel sous-jacent et aux installations logicielles de couche inférieure fournies par le cloud. Dans ce cas, l’utilisateur final utilise simplement le matériel, le système d’exploitation, le middleware et les cadres de base de données d’un fournisseur pour héberger son application ou ses services privés.
Le middleware peut être composé de systèmes de base de données. De nombreuses industries ont été construites à l’aide de matériel de base de fournisseurs de cloud tels que Swedbank, Trek Bicycles et Toshiba.
IBM Bluemix, Google App Engine et Microsoft Azure sont des exemples de fournisseurs PaaS publics. La valeur d’un déploiement PaaS par rapport à IaaS est le fait que vous bénéficiez des avantages de l’évolutivité et des dépenses d’exploitation (OPEX) avec une infrastructure cloud, mais vous disposez également de middleware et de systèmes d’exploitation éprouvés du fournisseur. C’est le domaine de systèmes tels que Docker, où le logiciel est déployé en tant que conteneurs. Si votre application globale reste dans les contraintes du cadre et de l’infrastructure fournis par le fournisseur, vous pouvez obtenir un délai de commercialisation plus rapide, car la plupart des composants, du système d’exploitation et du middleware sont garantis d’être disponibles.
11.1.4 IaaS
L’IaaS était le concept original des services cloud. Dans ce modèle, le fournisseur crée des services matériels évolutifs dans le cloud et fournit un minimum de frameworks logiciels pour construire des machines virtuelles clientes. Cela offre la plus grande flexibilité de déploiement mais nécessite plus de travail de la part du client.
11.2 Cloud public, privé et hybride
Dans l’environnement cloud, trois modèles différents de topologies de cloud sont généralement utilisés : cloud privé, cloud public et cloud hybride. Quel que soit le modèle, les frameworks cloud devraient tous fournir la capacité d’évoluer dynamiquement, de se développer et de se déployer rapidement, et d’avoir l’apparence d’une localité indépendamment de la proximité :
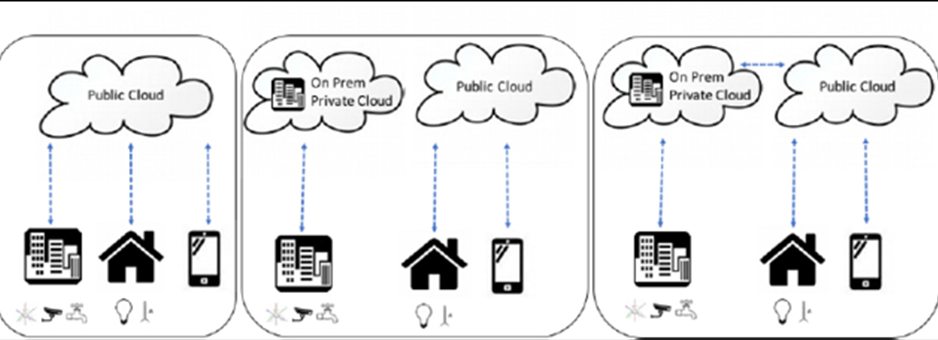
Figure 2 : à gauche : cloud public. Milieu : Cloud privé contre cloud public. À droite : Cloud hybride.
Les clouds privés impliquent également des composants gérés sur site. Les systèmes d’entreprise modernes ont tendance à utiliser une architecture hybride pour garantir la sécurité des applications et des données critiques sur site, et utilisent le cloud public pour la connectivité, la facilité de déploiement et le développement rapide.
11.2.1 Cloud privé
Dans un cloud privé, l’infrastructure est provisionnée pour une seule organisation ou entreprise. Il n’existe aucun concept de partage ou de mise en commun des ressources en dehors de la propre infrastructure du propriétaire. Dans les locaux, le partage et la mutualisation sont communs. Un cloud privé existe pour un certain nombre de raisons, notamment la sécurité et l’assurance – c’est-à-dire pour garantir que les informations sont limitées uniquement aux systèmes gérés par le client. Cependant, pour être considéré comme un cloud, certains aspects des services de type cloud doivent exister, tels que la virtualisation et l’équilibrage de charge. Un cloud privé peut être sur site ou il peut s’agir de machines dédiées fournies par un tiers exclusivement pour leur usage.
11.2.2 Cloud public
Un cloud public est la situation inverse. Ici, l’infrastructure est provisionnée à la demande pour une multitude de clients et d’applications. L’infrastructure est un pool de ressources que n’importe qui peut utiliser à tout moment dans le cadre de ses accords de niveau de service. L’avantage ici est que l’échelle des centres de données cloud permet une évolutivité sans précédent pour de nombreux clients, qui ne sont limités qu’à la quantité du service qu’ils souhaitent acheter. Un exemple de cloud public est Microsoft Azure ou Amazon AWS.
11.2.3 Cloud hybride
Le modèle architectural hybride est une combinaison de nuages privés et publics. Ces combinaisons peuvent être de multiples clouds publics utilisés simultanément ou une combinaison d’infrastructures de cloud public et privé. Les organisations ont tendance à privilégier un modèle hybride si les données sensibles nécessitent une gestion unique, tandis que l’interface frontale peut tirer parti de la portée et de l’échelle du cloud. Un autre cas d’utilisation est le maintien d’un accord de cloud public pour compenser les conditions dans lesquelles l’évolutivité dépasse l’infrastructure de cloud privé de l’entreprise. Dans ce cas, le cloud public sera utilisé comme équilibreur de charge jusqu’à ce que le gonflement des données et de l’utilisation retombe dans les contraintes du cloud privé. Ce cas d’utilisation est appelé éclatement de nuages et fait référence à l’utilisation de nuages en tant que dispositions de ressources contingentes.
De nombreuses entreprises disposent d’une infrastructure cloud publique et privée. Cela est particulièrement répandu dans les situations où les services frontaux et les portails Web peuvent être des services dans le cloud public pour l’évolutivité, tandis que les données client sont situées dans des systèmes privés pour la sécurité.
11.3 L’architecture cloud OpenStack
OpenStack est un framework sous licence open source Apache 2.0 utilisé pour construire des plateformes cloud. Il s’agit principalement d’un IaaS et fait partie de la communauté des développeurs depuis 2010. La Fondation OpenStack gère le logiciel et bénéficie du soutien de plus de 500 entreprises, notamment Intel, IBM, Red Hat et Ericsson.
OpenStack a commencé comme un projet conjoint entre la NASA et Rackspace vers 2010. L’architecture comprend tous les principaux composants d’autres systèmes cloud, y compris le calcul et l’équilibrage de charge ; les composants de stockage, y compris la sauvegarde et la restauration ; composants de réseau, tableaux de bord, sécurité et identité, packages de données et d’analyse, outils de déploiement, moniteurs et compteurs et services d’application. Ce sont les composants qu’un architecte rechercherait lors du choix d’un service cloud.
Plutôt que de nous concentrer sur une architecture cloud commerciale unique, nous examinerons OpenStack en profondeur car de nombreux artefacts d’OpenStack sont utilisés ou analogues à des composants dans des services cloud commerciaux comme Microsoft Azure.
Sur le plan architectural, OpenStack est une couche de composants entrelacés. La forme de base d’un cloud OpenStack est illustrée dans la figure suivante. Chaque service a une fonction particulière et un nom unique (comme Nova). Le système agit dans son ensemble, offrant une fonctionnalité cloud évolutive de classe entreprise :
Toutes les communications au sein des composants OpenStack se font via des files d’attente de messages AMQP (Advanced Message Queuing Protocol), en particulier, RabbitMQ ou Qpid. Les messages peuvent être non bloquants ou bloquants selon la façon dont le message a été envoyé. Un message serait envoyé en tant qu’objet JSON dans RabbitMQ, et les récepteurs trouveraient et chercheraient leurs messages dans le même service. Il s’agit d’une méthode de communication d’appel de procédure distante (RPC) à couplage lâche entre les principaux sous-systèmes. L’avantage dans un environnement cloud est que le client et le serveur sont complètement découplés, ce qui permet aux serveurs d’augmenter ou de diminuer dynamiquement. Les messages ne sont pas diffusés mais dirigés, ce qui réduit le trafic au minimum. Vous vous souvenez peut-être également que AMQP est un protocole de messagerie courant utilisé dans l’espace IoT.
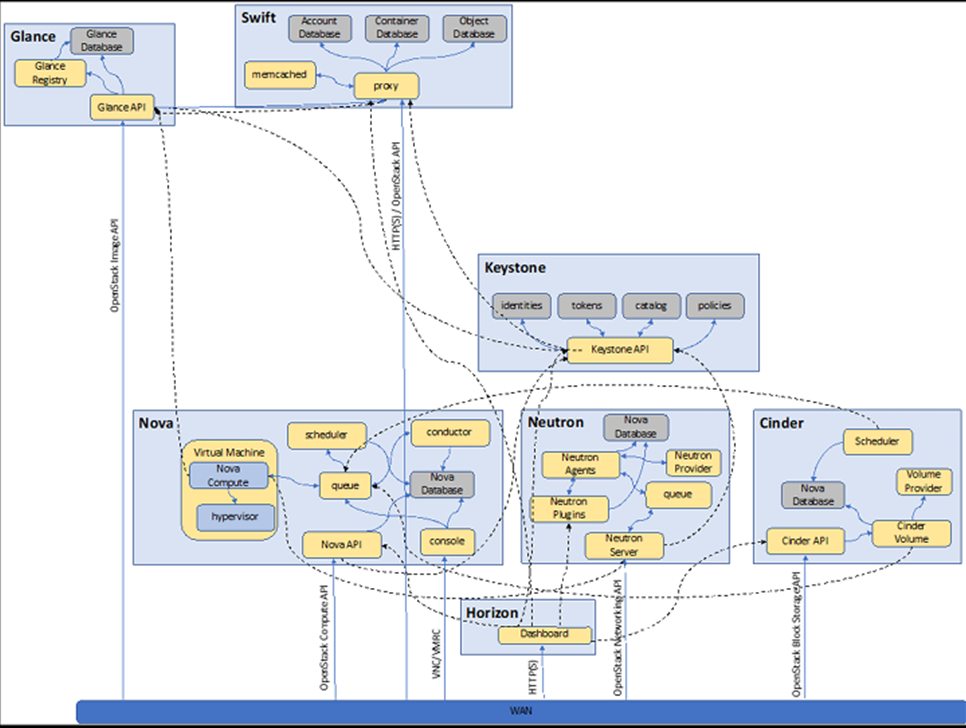
Figure 3 : Diagramme architectural de niveau supérieur OpenStack
11.3.1 Keystone – gestion des identités et des services
Keystone est le service de gestion des identités du cloud OpenStack. Un gestionnaire d’identité établit les informations d’identification de l’utilisateur et l’autorisation de connexion. Il s’agit essentiellement du point de départ ou du point d’entrée dans le cloud. Cette ressource conservera un répertoire central des utilisateurs et de leurs droits d’accès. Il s’agit du niveau de sécurité le plus élevé pour garantir que les environnements utilisateur sont mutuellement exclusifs et sécurisés. Keystone peut s’interfacer avec des services comme LDAP dans un annuaire d’entreprise. Keystone gère également une base de données de jetons et fournit des jetons temporaires aux utilisateurs de manière similaire à la façon dont Amazon Web Services (AWS) établit les informations d’identification. Un registre de services est utilisé pour interroger par programme les produits ou services disponibles pour l’utilisateur.
11.3.2 Coup d’œil – service d’imagerie
Glance constitue le cœur de la gestion des machines virtuelles pour OpenStack. La plupart des services cloud fourniront un certain degré de virtualisation et disposeront d’une ressource analogique similaire à Glance. L’API de service d’image est un service RESTful et permet à un client de développer des modèles de VM, de découvrir des VM disponibles, de cloner des images vers d’autres serveurs, d’enregistrer des VM et même de déplacer des machines virtuelles en cours d’exécution vers différents serveurs physiques sans interruption. Glance appelle Swift (le magasin d’objets) pour récupérer ou stocker différentes images. Glance prend en charge différents styles d’images virtuelles :
- raw : les images non structurées
- vhd : VMWare, Xen, Oracle VirtualBox
- vmdk : format de disque commun
- vdi : image de l’émulateur QEMU
- iso : Image du lecteur optique (CD-ROM)
- aki / ari / ami : image d’Amazon
Une machine virtuelle se compose de tout le contenu de l’image du volume du disque dur, y compris les systèmes d’exploitation invités, les exécutions, les applications et les services.
11.3.3 Calcul Nova
Nova est le cœur du service de gestion des ressources de calcul OpenStack. Son objectif est d’identifier et de s’approprier les ressources de calcul en fonction de la demande. Il a également la responsabilité de contrôler l’hyperviseur du système et les machines virtuelles. Nova fonctionnera avec plusieurs machines virtuelles, comme mentionné, comme VMware ou Xen, ou il peut gérer des conteneurs. La mise à l’échelle à la demande fait partie intégrante de toute offre de cloud.
Nova est basé sur un service Web API RESTful pour un contrôle simplifié.
Pour obtenir une liste des serveurs, vous GET ce qui suit dans Nova via l’API :
{your_compute_service_url}/serveurs
Pour créer une banque de serveurs (allant d’un minimum de 10 à un maximum de 20), vous POSTERIEZ les éléments suivants :
{
“server”: {
“name”: “IoT-Server-Array”,
“imageRef”: “8a9a114e-71e1-aa7e-4181-92cc41c72721”, “flavorRef”: “1”,
“metadata”: {
“My Server Name”: “IoT”
},
“return_reservation_id”: “True”, “min_count”: “10”,
“max_count”: “20”
}
}
Nova répondrait avec un reservation_id :
{
“reservation_id”: “84.urcyplh”
}
Ainsi, le modèle de programmation est assez simple pour gérer l’infrastructure.
La base de données Nova est nécessaire pour maintenir l’état actuel de tous les objets du cluster. Par exemple, quelques-uns des états que les différents serveurs du cluster peuvent inclure sont les suivants :
- ACTIVE : le serveur est en cours d’exécution.
- BUILD : Le serveur est en cours de construction et n’est pas terminé.
- DELETED : le serveur a été supprimé.
- MIGRATING : le serveur migre vers un nouvel hôte.
Nova s’appuie sur un planificateur pour déterminer quelle tâche exécuter et où l’exécuter. Le planificateur peut associer une affinité au hasard ou utiliser des filtres pour choisir un ensemble d’hôtes qui correspondent le mieux à certains ensembles de paramètres. Le produit final du filtre sera une liste ordonnée de serveurs hôtes à utiliser du meilleur au pire (avec des hôtes incompatibles supprimés de la liste).
Voici le filtre par défaut utilisé pour attribuer l’affinité du serveur :
scheduler_available_filters = nova.scheduler.filters.all_filters
Un filtre personnalisé peut être créé (par exemple, un filtre Python ou JSON appelé IoTFilter.IoTFilter) et attaché au planificateur comme suit :
scheduler_available_filters=IoTFilter.IoTFilter
Pour définir un filtre pour rechercher des serveurs qui ont 16 VCPU par programme via l’API, nous construisons un fichier JSON comme suit :
{
“server”: {
“name”: “IoT_16”,
“imageRef”: “8a9a114e-71e1-aa7e-4181-92cc41c72721”, “flavorRef”: “1”
},
“os:scheduler_hints”: {
“query”: “[>=,$vcpus_used,16]”
}
}
Alternativement, OpenStack vous permet également de contrôler le cloud via une interface de ligne de commande:
$ openstack server create –image 8a9a114e-71e1-aa7e-4181-92cc41c72721 \
–flavor 1 –hint query='[“>=”,”$vcpus_used”,16]’ IoT_16
OpenStack dispose d’un riche ensemble de filtres pour permettre l’allocation personnalisée des serveurs et des services. Cela permet un contrôle très explicite du provisionnement et de la mise à l’échelle du serveur. Il s’agit d’un aspect classique et très important de la conception du cloud. Ces filtres incluent, mais ne sont pas limités à:
- Taille de la RAM
- Capacité et type de disque
- Niveaux IOPS
- Allocation CPU
- Affinités de groupe
- Affinité CIDR
11.3.4 Swift – stockage d’objets
Swift fournit un système de stockage redondant pour le centre de données OpenStack. Swift permet aux clusters d’évoluer en ajoutant de nouveaux serveurs. Le stockage d’objets contiendra des éléments tels que les comptes et les conteneurs. La machine virtuelle d’un utilisateur peut être stockée ou mise en cache dans Swift. Un nœud de calcul Nova peut appeler directement dans Swift et télécharger l’image lors de la première exécution.
11.3.5 Neutron – services de réseautage
Neutron est la gestion de réseau OpenStack et le service VLAN. L’ensemble du réseau est configurable et fournit des services tels que :
- Services de nom de domaine
- DHCP
- Fonctions de passerelle
- Gestion des VLAN
- Connectivité L2
- SDN
- Protocoles de superposition et de tunneling
- VPN
- NAT (SNAT et DNAT)
- Systèmes de détection d’intrusion
- Équilibrage de charge
- Pare-feu
11.3.6 Cinder – stockage de blocs
Cinder fournit à OpenStack les services de stockage de blocs persistants nécessaires à un cloud. Il agit comme un stockage en tant que service pour les cas d’utilisation tels que les bases de données et les systèmes de fichiers à croissance dynamique, y compris les lacs de données, qui sont particulièrement importants dans les scénarios IoT en streaming. Comme les autres composants d’OpenStack, le système de stockage est lui – même dynamique et évolue selon les besoins. L’architecture repose sur une haute disponibilité et des normes ouvertes.
La fonctionnalité fournie par Cinder comprend les éléments suivants :
- Création, suppression et liaison de périphériques de stockage aux instances de calcul Nova
- Interopérabilité avec plusieurs fournisseurs de stockage (HP 3PAR, EMC, IBM, Ceph, CloudByte, Scality)
- Prise en charge de plusieurs interfaces (Fibre Channel, NFS, SAS partagé, IBM GPFS, iSCSI)
- Sauvegarde et récupération d’images disque
- Images instantanées d’un point dans le temps
- Stockage alternatif pour les images VM
11.3.7 Horizon
Le dernier élément abordé ici est Horizon. Horizon est le tableau de bord OpenStack. Il s’agit de la vue à vitre unique dans OpenStack pour le client. Il fournit une vue Web des différents composants qui composent OpenStack (Nova, Cinder, Neutron et autres).
Horizon fournit une vue d’interface utilisateur du système cloud comme moyen alternatif sur l’API. Horizon est extensible afin qu’un tiers puisse ajouter ses widgets ou outils au tableau de bord. Un nouveau composant de facturation peut être ajouté et un élément de tableau de bord Horizon peut ensuite être instancié pour les clients.
La plupart des objets connectés qui utilisent des déploiements cloud incluent une forme de tableau de bord avec des fonctionnalités similaires.
11.3.8 Heat – orchestration (facultatif)
Heat peut lancer plusieurs applications cloud composites et gérer l’infrastructure cloud basée sur des modèles sur une instance OpenStack. Heat s’intègre à la télémétrie pour mettre à l’échelle automatiquement un système en fonction des besoins de charge. Les modèles dans Heat essaient de se conformer aux formats AWS CloudFormation, et les relations entre les ressources peuvent être spécifiées de manière similaire (par exemple, ce volume est connecté à ce serveur).
Un modèle Heat peut ressembler à ce qui suit:
heat_template_version: 2015-04-30 description:
example template
resources:
my_instance:
type: OS::Nova::Server
properties:
key_name: { get_param: key_name } image: {
get_param: image } flavor: { get_param: flavor }
admin_pass: { get_param: admin_pass } user_data:
str_replace:
template: |
#!/bin/bash
echo hello_world
11.3.9 Ceilomètre – télémétrie (facultatif)
OpenStack fournit un service optionnel appelé Ceilometer qui peut être utilisé pour la collecte de données de télémétrie et la mesure des ressources utilisées par chaque service. La mesure est utilisée pour collecter des informations sur l’utilisation et les convertir en factures clients. Ceilometer fournit également des outils de tarification et de facturation. La notation convertit une valeur facturée en devise équivalente et la facturation est utilisée pour démarrer un processus de paiement.
Ceilometer surveille et mesure différents événements, tels que le démarrage d’un service, l’attachement d’un volume et l’arrêt d’une instance. Les mesures sont collectées sur l’utilisation du processeur, le nombre de cœurs, l’utilisation de la mémoire et le mouvement des données. Tout cela est collecté et stocké dans une base de données MongoDB.
11.4 Contraintes des architectures cloud pour Io T
Un fournisseur de services cloud se trouve en dehors de l’appareil périphérique IoT et préside le réseau étendu. Une caractéristique particulière de l’architecture IoT est que les appareils PAN et WPAN peuvent ne pas être compatibles IP. Les protocoles tels que Bluetooth Low Energy ( BLE ) et Zigbee ne sont pas basés sur IP, tandis que tout sur le WAN, y compris le cloud, est basé sur IP.
Ainsi, le rôle de la passerelle de périphérie est d’effectuer ce niveau de traduction:
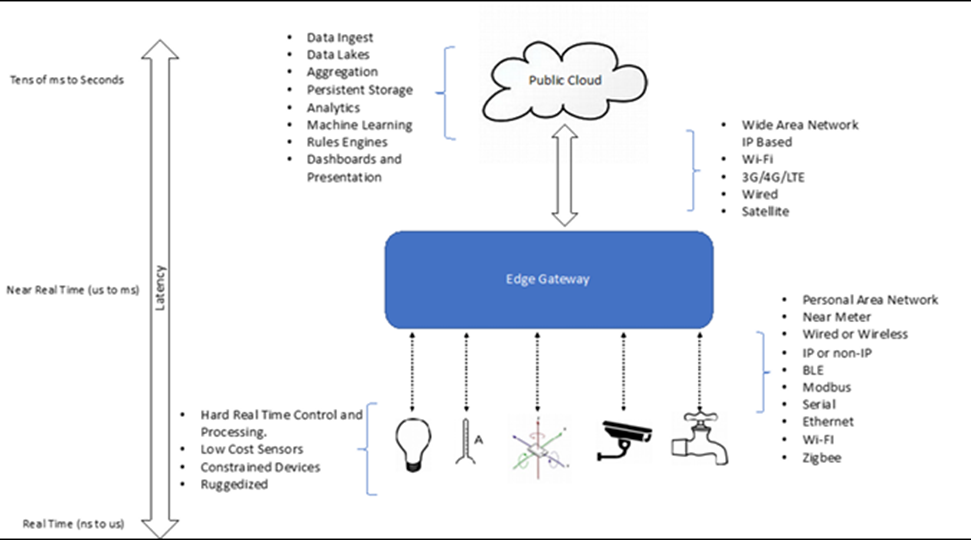
Figure 4 : Effets de latence dans le cloud. Une réponse en temps réel difficile est essentielle dans de nombreuses applications IoT et force le traitement à se rapprocher du périphérique d’extrémité
11.4.1 Effet de latence
Un autre effet est la latence et le temps de réponse aux événements. À mesure que vous vous rapprochez du capteur, vous entrez dans le domaine des exigences difficiles en temps réel. Ces systèmes sont généralement des systèmes profondément intégrés ou des microcontrôleurs dont la latence est définie par des événements réels. Par exemple, une caméra vidéo est sensible à la fréquence d’images (généralement 30 ou 60 ips) et doit effectuer un certain nombre de tâches séquentielles dans un pipeline de flux de données (dématriçage, dénotation, balance des blancs et ajustement gamma, mappage de gamme, mise à l’échelle et compression). La quantité de données circulant dans un pipeline d’imagerie vidéo (vidéo 1080p utilisant 8 bits par canal à 60 ips) est d’environ 1,5 Go / s. Chaque trame doit traverser ce pipeline en temps réel ; par conséquent, la plupart des processeurs de signaux d’image vidéo effectuent ces transformations dans le silicium.
Si nous remontons la pile, la passerelle a le meilleur temps de réponse suivant et se situe généralement dans la plage des millisecondes à un chiffre. Le facteur de déclenchement dans le temps de réponse est la latence WPAN et la charge sur la passerelle. Comme mentionné précédemment dans le chapitre WPAN, la plupart des WPAN, tels que BLE, sont variables et dépendent du nombre de périphériques BLE sous la passerelle, des intervalles d’analyse, des intervalles de publication, etc. Les intervalles de connexion BLE peuvent être aussi bas que quelques millisecondes mais peuvent varier en fonction de la façon dont le client ajuste les intervalles de publicité pour minimiser la consommation d’énergie. Les signaux Wi-Fi ont généralement une latence de 1,5 ms. La latence à ce niveau nécessite une interface physique avec le PAN. Vous ne vous attendriez pas à transmettre des paquets BLE bruts au cloud avec l’espoir d’un contrôle en temps quasi réel.
Le composant cloud introduit un autre degré de latence sur le WAN. La route entre la passerelle et le fournisseur de cloud peut prendre plusieurs chemins en fonction de l’emplacement des centres de données et de la passerelle. Les fournisseurs de cloud fournissent généralement un ensemble de centres de données régionaux pour normaliser le trafic. Pour comprendre l’impact réel de la latence d’un fournisseur de cloud, vous devez échantillonner le ping de latence au cours des semaines ou des mois et dans toutes les régions :
| Région | Latence |
| États-Unis (Virginie) | 91 ms |
| États-Unis (Ohio) | 80 ms |
| US-West (Californie) | 50 ms |
| US-Ouest (Oregon) | 37 ms |
| Canada (Centre) | 90 ms |
| Europe (Irlande) | 177 ms |
| Europe (Londres) | 168 ms |
| Europe (Francfort) | 180 ms |
| Europe (Paris) | 172 ms |
| Europe (Stockholm) | 192 ms |
| Moyen-Orient (Bahreïn) | 309 ms |
| Asie-Pacifique (Hong Kong) | 216 ms |
| Asie Pacifique (Mumbai) | 281 ms |
| Asie-Pacifique (Osaka-Local) | 170 ms |
| Asie-Pacifique (Séoul) | 192 ms |
| Asie Pacifique (Singapour) | 232 ms |
| Asie-Pacifique (Sydney) | 219 ms |
| Asie Pacifique (Tokyo) | 161 ms |
| Amérique du Sud (São Paulo) | 208 ms |
| Chine (Pékin) | 205 ms |
| Chine (Ningxia) | 227 ms |
| AWS GovCloud (États-Unis-Est) | 80 ms |
| AWS GovCloud (États-Unis) | 37 ms |
Les données ont été analysées à l’aide d’un service appelé CloudPing sur les centres de données Amazon AWS et à l’aide du client US-West sur CloudPing.info (pour plus d’informations, visitez http://www.cloudping.info)
Une analyse exhaustive de la latence du cloud et des temps de réponse est conservée par CLAudit (pour plus d’informations, visitez http://claudit.feld.cvut.cz/index.php#). D’autres outils existent pour analyser la latence, tels que Azurespeed.com, Fathom et SmokePing (pour plus d’ informations, visitez https://oss.oetiker.ch/smokeping/). Ces sites recherchent, surveillent et archivent quotidiennement la latence des bases de données TCP, HTTP et SQL sur AWS et Microsoft Azure dans de nombreuses régions du monde. Cela produit la meilleure visibilité sur l’impact de latence global que vous pouvez attendre d’une solution cloud. Par exemple, la figure suivante illustre les temps d’aller-retour (RTT) pour un client de test aux États-Unis communiquant avec un fournisseur de solutions cloud de premier plan et ses différents centres de données mondiaux. Il est également utile de noter la variabilité du RTT. Alors qu’un pic de 5 ms peut être tolérable dans de nombreuses applications, il peut entraîner une défaillance dans un système de contrôle en temps réel ou une automatisation d’usine:
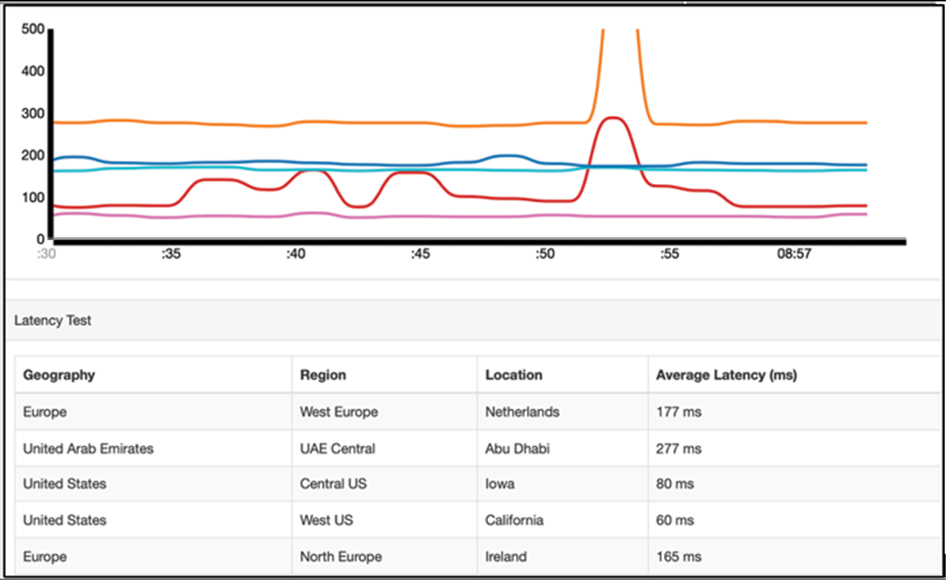
Figure 5 : RTT et latence pour un fournisseur de cloud leader d’un client dans le fuseau horaire US Mountain vers divers centres de données dans le monde
En règle générale, la latence du cloud sera de l’ordre de dizaines, voire de centaines, de millisecondes sans tenir compte des frais généraux de traitement des données entrantes. Cela devrait désormais définir une attente pour les différents niveaux de réponse lors de la création d’une architecture cloud pour l’IoT. Les architectures proches des périphériques permettent des réponses inférieures à 10 ms et bénéficient également de l’avantage d’être répétables et déterministes. Les solutions cloud peuvent introduire une variabilité dans les temps de réponse ainsi qu’un ordre de grandeur / temps de réponse supérieur à un périphérique proche. Un architecte doit déterminer où déployer des parties de la solution en fonction de ces deux effets.
Les fournisseurs de cloud doivent également être choisis en fonction de leurs modèles de déploiement de centre de données. Si une solution IoT est déployée dans le monde entier ou va peut-être se développer pour couvrir plusieurs régions, le service cloud devrait avoir des centres de données situés dans des zones géographiquement similaires pour aider à normaliser le temps de réponse. Le graphique révèle la grande variance de la latence basée sur un client unique atteignant les centres de données dans le monde entier. Ce n’est pas une architecture optimale.
11.5 Calcul du brouillard
Le brouillard informatique est l’extension évolutive du cloud computing à la périphérie. Le brouillard représente une architecture horizontale au niveau du système qui distribue les ressources et les services sur une structure réseau. Ces services et ressources incluent des composants de stockage, des appareils informatiques, des fonctions de mise en réseau, etc. Les nœuds peuvent être situés n’importe où entre le nuage et les « choses » (capteurs). Cette section détaille la différence entre le brouillard et l’informatique périphérique et fournit les différentes topologies et références architecturales pour le calcul du brouillard.
11.5.1 La philosophie Hadoop pour le calcul du brouillard
L’informatique de brouillard tire son analogie du succès de Hadoop et de MapReduce, et pour mieux comprendre l’importance de l’informatique de brouillard, il convient de prendre un peu de temps pour réfléchir au fonctionnement de Hadoop. MapReduce est une méthode de mappage, et Hadoop est un framework open source basée sur l’algorithme MapReduce.
MapReduce comporte trois étapes : mapper, mélanger et réduire. Dans la phase de cartographie, les fonctions de calcul sont appliquées aux données locales. L’étape de lecture aléatoire redistribue les données selon les besoins. Il s’agit d’une étape critique car le système tente de colocaliser toutes les données dépendantes sur un nœud. La dernière étape est la phase de réduction, où le traitement sur tous les nœuds se déroule en parallèle.
La conclusion générale ici est que MapReduce tente d’amener le traitement là où se trouvent les données et non de déplacer les données là où se trouvent les processeurs. Ce schéma supprime efficacement les frais généraux de communication et un goulot d’étranglement naturel dans les systèmes qui ont des ensembles de données structurés ou non structurés extrêmement volumineux. Ce paradigme s’applique également à l’IoT. Dans l’espace IoT, les données (éventuellement une très grande quantité de données) sont produites en temps réel sous forme de flux de données. Ce sont les mégadonnées dans le cas de l’IoT. Ce ne sont pas des données statiques comme une base de données ou un cluster de stockage Google, mais un flux en direct sans fin de données de tous les coins du monde. Une conception basée sur le brouillard est le moyen naturel de résoudre ce nouveau problème de Big Data.
11.5.2 Comparaison du brouillard, des bords, du cloud et du brouillard
Nous avons déjà défini l’ informatique de bord comme un déplacement du traitement près de l’endroit où les données sont générées. Dans le cas de l’IoT, un périphérique périphérique pourrait être le capteur lui-même avec un petit microcontrôleur ou un système embarqué capable de communication WAN. D’autres fois, le bord sera une passerelle dans les architectures avec des points d’extrémité particulièrement contraints suspendus à la passerelle. Le traitement de périphérie est également généralement mentionné dans un contexte de machine à machine où il existe une corrélation étroite entre la périphérie (client) et un serveur situé ailleurs. Comme indiqué, Edge computing existe pour résoudre les problèmes de latence et de consommation de bande passante inutile, et pour ajouter des services tels que la dénaturation et la sécurité à proximité de la source de données. Un périphérique périphérique peut avoir une relation avec un service cloud au détriment de la latence et d’un opérateur; il ne participe pas activement à l’infrastructure cloud.
Le calcul du brouillard est légèrement différent d’un paradigme informatique de bord. Le brouillard informatique partage avant tout une API de framework et une norme de communication avec d’autres nœuds de brouillard et / ou un service cloud de superposition. Les nœuds de brouillard sont des extensions du cloud, alors que les périphériques périphériques peuvent impliquer ou non un cloud. Un autre principe clé du calcul du brouillard est que le brouillard peut exister dans des couches de hiérarchie. Le calcul du brouillard peut également équilibrer la charge et orienter les données est-ouest et nord-sud pour faciliter l’équilibrage des ressources. D’après la définition du cloud et des services qu’il propose dans la section précédente, vous pouvez considérer ces nœuds de brouillard comme des infrastructures simplement plus (quoique moins puissantes) dans un cloud hybride.
Le brouillard informatique est parfois appelé « cloudlets ». Le brouillard dessert l’extrême bord d’un réseau, généralement sur des microcontrôleurs à faible coût et à faible consommation ou sur des ordinateurs intégrés. Ils sont aussi physiquement proches des capteurs que possible pour collecter des données et effectuer un calcul proche de la source. Ils s’interfacent avec les nœuds de brouillard via des protocoles standard, et les composants de brouillard font généralement partie de la topologie globale du réseau. Un exemple de brumisateur est un thermostat intelligent :
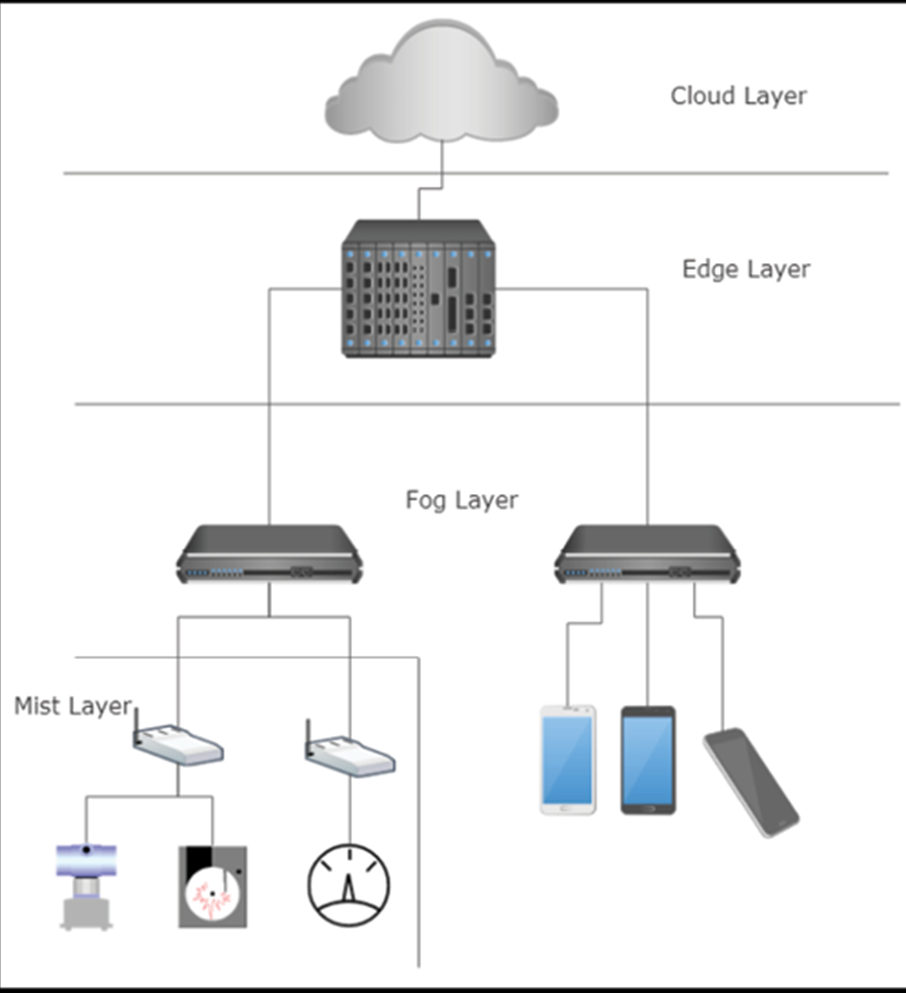
Figure 6 : Relation entre les composants du nuage, des bords, du brouillard et du brouillard
11.5.3 Architecture de référence OpenFog
Un cadre architectural de brouillard tel qu’un cadre cloud est nécessaire pour comprendre l’interfonctionnement et les contrats de données entre les différentes couches. Ici, nous explorons l’architecture de référence d’OpenFog Consortium: https://www.openfogconsortium.org/wp-content/uploads/OpenFog_Reference_Architecture_2_09_17-FINAL.pdf . L’OpenFog Consortium est un groupe industriel à but non lucratif chargé de définir les normes d’interopérabilité pour le calcul du brouillard. Bien qu’ils ne soient pas un organisme de normalisation, ils influencent la direction d’autres organisations par la liaison et l’influence de l’industrie. L’architecture de référence OpenFog est un modèle pour aider les architectes et les chefs d’entreprise à créer du matériel, à créer des logiciels et à acquérir une infrastructure pour le calcul du brouillard. OpenFog réalise l’avantage des solutions basées sur le cloud et le désir de déplacer ce niveau d’informatique, de stockage, de mise en réseau et de mise à l’échelle vers la périphérie sans sacrifier la latence et la bande passante.
L’architecture de référence OpenFog consiste en une approche en couches, des capteurs de bord et des actionneurs en bas aux services d’application en haut. L’architecture présente quelques similitudes avec l’architecture cloud typique telle qu’OpenStack, mais elle l’étend davantage car elle est plus analogue à une PaaS qu’à un IaaS. D’ailleurs, OpenFog fournit une pile complète et est généralement indépendant du matériel, ou du moins résume la plate-forme du reste du système :
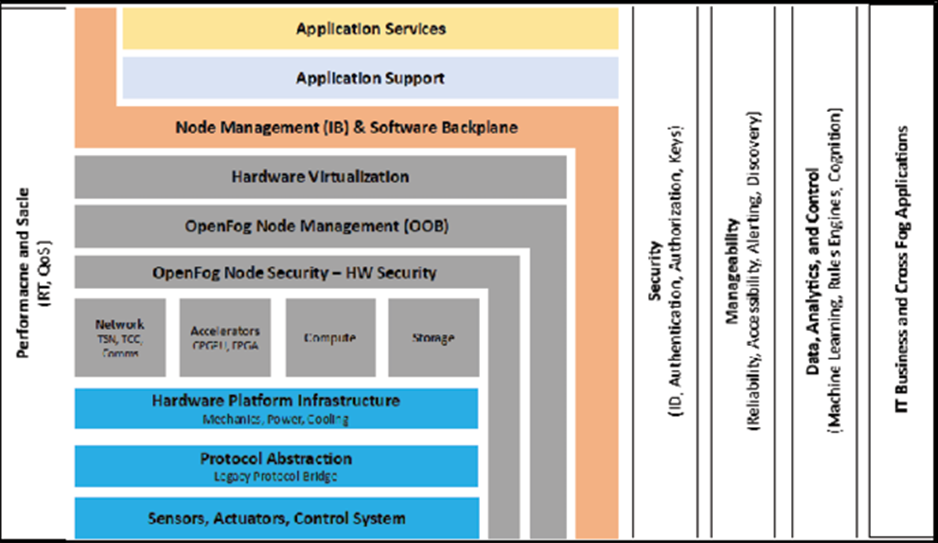
Figure 7 : Architecture de référence OpenFog
11.5.3.1 Services d’application
Le rôle de la couche service est de fournir la vitre et les services personnalisés nécessaires à la mission. Cela comprend la fourniture de connecteurs à d’autres services, l’hébergement de packages d’analyse de données, la fourniture d’une interface utilisateur si nécessaire et la fourniture de services de base.
Les connecteurs de la couche application connectent les services à la couche de support. La couche d’abstraction de protocole fournit la voie permettant à un connecteur de parler directement à un capteur. Chaque service doit être considéré comme un microservice dans un conteneur. L’OpenFog Consortium préconise le déploiement de conteneurs comme méthode appropriée pour le déploiement du logiciel en périphérie. Cela a du sens lorsque nous considérons les périphériques périphériques comme des extensions du cloud. Un exemple de déploiement de conteneur pourrait ressembler au diagramme suivant.
Chaque cylindre représente un conteneur individuel qui peut être déployé et géré séparément. Chaque service expose ensuite les API à atteindre entre les conteneurs et les couches :
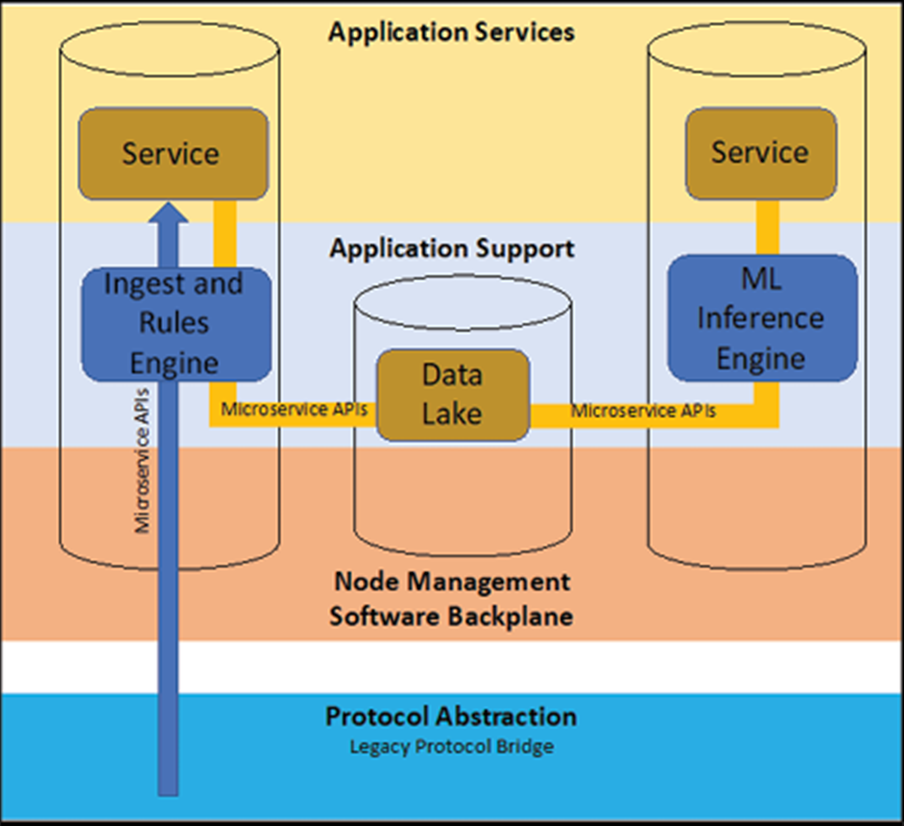
Figure 8 : Exemple d’application OpenFog. Ici, plusieurs conteneurs peuvent être déployés, chacun fournissant différents services et fonctions de support.
11.5.3.2 Support d’application
Il s’agit d’un composant d’infrastructure pour aider à créer la solution client final. Cette couche peut avoir des dépendances en termes de déploiement (par exemple, en tant que conteneur). L’assistance se présente sous plusieurs formes, notamment :
- Gestion des applications (identification d’image, vérification d’image, déploiement d’image et authentification)
- Outils de journalisation
- Enregistrement des composants et des services
- Moteurs d’exécution (conteneurs, VM)
- Langages d’exécution (Node.js, Java, Python)
- Serveurs d’applications (Tomcat)
- Bus de messages (RabbitMQ)
- Bases de données et archives (SQL, NoSQL, Cassandra)
- Cadres analytiques (Spark)
- Services de sécurité
- Serveurs Web (Apache)
- Outils d’analyse (Spark, Drool)
OpenFog suggère que ces services devraient être regroupés sous forme de conteneurs, comme indiqué dans le diagramme précédent. L’architecture de référence n’est pas une directive stricte, et l’architecte doit choisir la quantité de support correcte qui peut être activée sur un périphérique de bord contraint. Par exemple, le traitement et les ressources peuvent uniquement permettre un moteur de règles simple et interdire tout ce qui ressemble à un processeur de flux, sans parler d’un réseau de neurones récurrent.
11.5.3.3 Gestion des nœuds et fond de panier logiciel
Cela fait référence à la gestion intrabande (IB) et régit la façon dont un nœud de brouillard communique avec les autres nœuds de son domaine. Les nœuds sont également gérés via cette interface pour les mises à niveau, l’état et le déploiement. Le fond de panier peut inclure le système d’exploitation du nœud, des pilotes et micrologiciels personnalisés, des protocoles de communication et de gestion, le contrôle du système de fichiers, un logiciel de virtualisation et la conteneurisation des microservices.
Ce niveau de la pile logicielle touche presque toutes les autres couches de l’architecture de référence OpenFog. Les caractéristiques typiques du fond de panier comprennent :
- Découverte de service : permet des modèles de confiance ad hoc, brouillard à brouillard.
- Découverte de nœuds : permet l’ajout de nœuds de brouillard et les jointures dans un cluster similaires aux techniques de clustering cloud.
- Gestion des états : permet différents modèles de calcul pour les calculs avec état et sans état avec plusieurs nœuds.
- Gestion des pubs / sous : permet aux données d’être poussées plutôt que tirées. De plus, il permet des niveaux d’abstraction dans la construction de logiciels.
L’architecture de référence OpenFog, ou d’ailleurs toute architecture basée sur le brouillard, devrait permettre des niveaux de déploiement. Autrement dit, une architecture de brouillard n’est pas simplement limitée à un nuage connecté à une passerelle de brouillard connectée à une poignée de capteurs. En fait, il existe plusieurs topologies qui dépendent de l’échelle, de la bande passante, de la charge de traitement et des économies qui peuvent être conçues. L’architecture de référence doit se provisionner pour plusieurs topologies, tout comme le cloud réel peut évoluer et s’équilibrer dynamiquement en fonction de la demande.
11.5.3.4 Virtualisation matérielle
Comme les systèmes cloud typiques, OpenFog définit le matériel comme une couche de virtualisation. Les applications ne doivent pas avoir de liaisons avec un ensemble particulier de matériel. Ici, le système doit équilibrer la charge dans le brouillard et migrer ou ajouter des ressources selon les besoins. Tous les composants matériels sont virtualisés à ce niveau, y compris le calcul, le réseau et le stockage.
11.5.3.5 Sécurité des nœuds OpenFog
Le consortium définit ce niveau comme la partie de sécurité matérielle de la pile. Les nœuds de brouillard de niveau supérieur devraient pouvoir surveiller les nœuds de brouillard de niveau inférieur dans le cadre de la hiérarchie de la topologie (traité plus loin dans ce chapitre). Les nœuds homologues devraient être en mesure de surveiller leurs voisins est-ouest.
Cette couche a également les responsabilités suivantes :
- Cryptage
- Tamper et moniteurs de sécurité physique
- Inspection et surveillance des paquets (est-ouest et nord-sud)
11.5.3.6 Réseau
Il s’agit du premier composant de la couche système matérielle. Le module réseau est le module de communication est-ouest et nord-sud. La couche réseau est consciente de la topologie du brouillard et du routage. Il a pour rôle de router physiquement vers d’autres nœuds. Il s’agit d’une différence majeure par rapport à un réseau cloud traditionnel qui virtualise toutes les interfaces internes. Ici, le réseau a un sens et une présence géographique dans un déploiement IoT. Par exemple, un nœud parent hébergeant quatre nœuds enfants tous connectés à des caméras peut avoir la responsabilité d’agréger les données vidéo des quatre sources et de coller (fusionner) le contenu de l’image pour créer un champ de vision à 360 degrés. Pour ce faire, il doit savoir quel nœud enfant appartient à quelle direction, et il ne peut pas le faire de manière arbitraire ou aléatoire.
Les exigences des composants réseau incluent :
- Résilience en cas de rupture d’un lien de communication. En effet, il peut être nécessaire de comprendre comment reconstruire un maillage pour maintenir le flux de données.
- Traduire et reconditionner les données des capteurs non IP en protocoles IP. Les capteurs Bluetooth, Z-Wave et câblés en sont des exemples.
- Gestion des cas de basculement.
- Liaison à une variété de tissus de communication (Wi-Fi, filaire, 5G).
- Fournir l’infrastructure réseau typique requise pour un déploiement d’entreprise (sécurité, routage, etc.).
11.5.3.7 Accélérateurs
Un autre aspect d’OpenFog qui diffère des autres schémas de cloud est la notion de services accélérateurs. Les accélérateurs sont désormais monnaie courante sous la forme de GPGPU et même de FPGA pour fournir des services d’imagerie, d’apprentissage automatique, de vision et de perception par ordinateur, de traitement du signal et de chiffrement / déchiffrement.
OpenFog envisage des nœuds de brouillard qui peuvent être dotés de ressources et alloués en fonction des besoins. Vous pouvez forcer une batterie de nœuds de deuxième ou troisième niveau dans la hiérarchie qui pourrait fournir dynamiquement des installations informatiques supplémentaires selon les besoins.
On peut même forcer d’autres formes d’accélération dans le brouillard, par exemple:
- Noeuds dédiés au stockage de masse en vrac en cas de génération d’ un grand lac de données
- Noeuds qui incluent des liens de communication alternatifs tels que la radio par satellite en cas de catastrophe où toutes les communications terrestres sont perdues
11.5.3.8 Calcul
La partie de calcul de la pile est similaire à la fonctionnalité de calcul de la couche Nova dans OpenStack. Les fonctions principales comprennent :
- Exécution de tâche
- Surveillance et approvisionnement des ressources
- Équilibrage de charge
- Requêtes de capacité
11.5.3.9 Stockage
La tranche de stockage de l’architecture maintient l’interface de bas niveau avec le stockage de brouillard. Les types de stockage dont nous avons parlé plus tôt, tels que les lacs de données ou la mémoire de l’espace de travail, peuvent être nécessaires en périphérie pour une analyse en temps réel difficile. La couche de stockage gérera également tous les types traditionnels de périphériques de stockage, tels que :
- Tableaux RAM
- Disques rotatifs
- Flash
- RAID
- Cryptage des données
11.5.3.10 Infrastructure de la plate-forme matérielle
La couche d’infrastructure n’est pas vraiment une couche réelle entre le logiciel et le matériel, mais plutôt la structure physique et mécanique du nœud de brouillard. Étant donné que les dispositifs antibrouillard se trouvent souvent dans des endroits difficiles et éloignés, ils doivent être robustes et résistants ainsi que autonomes.
OpenFog définit les cas qui doivent être pris en compte dans un déploiement de brouillard, notamment:
- Caractéristiques de taille, puissance et poids
- Systèmes de refroidissement
- Support mécanique et rétention
- Mécanique d’entretien
- Résistance aux attaques physiques et rapports
11.5.3.11 Abstraction du protocole
La couche d’abstraction de protocole lie les éléments les plus bas du système IoT (capteurs) avec d’autres couches du nœud de brouillard, d’autres nœuds de brouillard et le nuage. OpenFog préconise un modèle d’abstraction pour identifier et communiquer avec un dispositif capteur via la couche d’abstraction de protocole. En faisant abstraction de l’interface des capteurs et des dispositifs périphériques, un mélange hétérogène de capteurs peut être déployé sur un seul nœud de brouillard, par exemple, des dispositifs analogiques qui transitent par des convertisseurs numérique -analogique ou des capteurs numériques. Même les interfaces avec les capteurs peuvent être personnalisées, telles que les appareils Bluetooth pour mesurer la température dans les véhicules, le bus CAN pour l’interfaçage avec les capteurs de diagnostic du moteur, les capteurs interfacés SPI sur diverses électroniques du véhicule et les capteurs GPIO d’entrée / sortie à usage général pour les différentes portes et capteurs de vol. En faisant abstraction de l’interface, les couches supérieures de la pile logicielle peuvent accéder à ces appareils disparates grâce à une approche standardisée.
11.5.3.12 Capteurs, actionneurs et systèmes de commande
Il s’agit de l’extrémité inférieure de la pile IoT: les capteurs et appareils réels à la périphérie. Ces appareils peuvent être intelligents, muets, filaires, sans fil, à courte portée, à longue distance, etc. L’association, cependant, est qu’ils communiquent d’une certaine manière au nœud de brouillard, et le nœud de brouillard a la responsabilité de fournir, sécuriser et gérer ce capteur.
11.5.4 EdgeX
OpenFog représente une architecture au niveau du brouillard, et EdgeX offre un autre exemple de frameworks basés sur le brouillard à considérer. EdgeX représente un projet open source hébergé par la Fondation Linux (comme LF Edge) avec des objectifs similaires à OpenFog. Les membres d’EdgeX incluent des fournisseurs de silicium et de logiciels tels que ARM, ATT, IBM, HP, Dell, Qualcomm, Red Hat et Samsung, et des consortiums tels que l’Industrial Internet Consortium.
Les objectifs d’EdgeX incluent :
- Construire une plateforme ouverte pour l’informatique de bord IoT
- Assurer l’interopérabilité et le plug-and-play des composants
- Accroître la valeur commerciale positive en accélérant les délais de mise sur le marché, en permettant aux utilisateurs d’ajouter de la valeur et en fournissant des outils facilement adaptables
- Réduire le risque d’adoption de l’IoT en certifiant les composants EdgeX, en créant un écosystème mondial d’utilisateurs et de contributeurs et en réduisant les coûts grâce à des économies d’échelle
- Collaboration avec d’autres projets open source et groupes de normalisation
11.5.4.1 Architecture EdgeX
EdgeX est conçu pour être compatible avec n’importe quelle architecture de silicium et de processeur (par exemple, x86 ou ARM), tout système d’exploitation et tout environnement d’application. En outre, EdgeX utilise des concepts natifs du cloud tels que l’utilisation de microservices. Les microservices sont des services qui sont structurés comme une architecture logicielle faiblement couplée. Ils sont déployables indépendamment et donc hautement maintenables et testables. Cela permet aux petites équipes de posséder un service qui peut être déployé pour créer des applications plus importantes. Les services étant faiblement couplés, EdgeX offre la possibilité de distribuer divers composants de microservices sur différents nœuds périphériques ou peut-être sur un seul nœud. L’architecture est flexible à la façon dont l’architecte souhaite l’adapter à sa solution.

Figure 9: Architecture de référence EdgeX. Notez l’utilisation du déploiement basé sur les conteneurs et de la séparation architecturale basée sur les microservices.
11.5.4.2 Projets EdgeX et composants supplémentaires
En raison de l’architecture de microservice, davantage de projets sont en cours de construction pour s’ajouter à la fondation EdgeX. Cela comprend :
- Akraino Edge Stack : pile logicielle open source pour les services cloud à haute disponibilité pour l’informatique de périphérie.
- Baetyl : permet aux solutions cloud de fonctionner de manière transparente (et de migrer) vers des nœuds périphériques à l’aide de conteneurs et de concepts informatiques sans serveur. Il était initialement destiné aux appareils ménagers intelligents, aux appareils portables et à d’autres appareils IoT.
- Moteur virtuel EdgeX (EVE) : crée un hyperviseur de type 1 sur du matériel nu. Ce projet dispose également de services de déploiement d’exécution et d’un moteur d’exécution de conteneur. Grâce à cette solution, les périphériques de périphérie peuvent être rapidement gérés à l’aide de « gouttes » de conteneur de code. Reportez-vous au chapitre sur l’informatique de périphérie pour mieux comprendre les moteurs de déploiement basés sur des conteneurs.
- Fledge : destiné à l’IoT industriel. Fledge est un framework open source pour effectuer une maintenance prédictive et traiter les données des capteurs dans les paramètres d’usine et de fabrication. Il utilise une API RESTful pour développer, gérer et sécuriser les applications IoT.
- Home Edge : conçu par Samsung Electronics, un cadre et une plate – forme open source pour les solutions IoT à domicile.
11.5.5 Amazon Greengrass et Lambda
Dans cette section, nous couvrons un service de brouillard alternatif appelé Amazon Greengrass . Amazon a fourni des années de services et d’infrastructures cloud de classe mondiale tels que AWS, S3, EC2, Glacier et autres. Depuis 2016, Amazon a investi dans un nouveau style d’informatique de pointe appelé Greengrass . Il s’agit d’une extension d’AWS qui permet à un programmeur de télécharger un client sur le dispositif de brouillard, de passerelle ou de capteur intelligent.
Semblable à d’autres cadres de brouillard, le but de Greengrass est de fournir une solution pour réduire la latence et le temps de réponse, récuser les coûts de bande passante et assurer la sécurité de la périphérie. Les caractéristiques de Greengrass comprennent :
- Mettre en cache les données en cas de perte de connexion
- Synchronisation des données et de l’état de l’appareil sur le cloud AWS lors de la reconnexion
- Sécurité locale (services d’authentification et d’autorisation)
- Courtier de messages sur l’appareil et à l’extérieur de l’appareil
- Filtrage des données
- Commande et contrôle de l’appareil et des données
- Agrégation de données
- Fonctionnement hors ligne
- Apprentissage itératif
- Appeler n’importe quel service AWS directement depuis Greengrass en périphérie
Pour utiliser Greengrass, un programme va concevoir une plateforme cloud dans AWS IoT et définir certaines fonctions Lambda dans le cloud. Ces fonctions Lambda sont ensuite attribuées aux périphériques périphériques et déployées sur les périphériques exécutant le client et autorisées à exécuter les fonctions Greengrass Lambda.
Actuellement, les fonctions Lambda sont écrites en Python 2.7. Les ombres sont des abstractions JSON dans Greengrass qui représentent l’état du périphérique et des fonctions Lambda. Ceux-ci sont synchronisés avec AWS lorsque vous le souhaitez.
Dans les coulisses, la communication entre Greengrass on the edge et AWS dans le cloud se fait via MQTT.
Notez que les fonctions Lambda ne doivent pas être confondues avec les architectures Lambda mentionnées précédemment. Une fonction Lambda dans le contexte Greengrass fait référence à une fonction de calcul pilotée par les événements.
Un exemple de définition Lambda utilisée dans Greengrass ressemblerait à ce qui suit. À partir de la console dans AWS, nous exécutons une ligne de commande ; nous exécutons l’outil suivant et spécifions la définition de la fonction Lambda par son nom :
aws greengrass create-function-definition –name “sensorDefinition”
Cela produira les éléments suivants :
{
“LastUpdatedTimestamp”: “2017-07-08T20:16:31.101Z”,
“CreationTimestamp”: “2017-07-08T20:16:31.101Z”, “Id”: “26309147-58a1-490e-a1a6-
0d4894d6ca1e”,
“Arn”:”arn:aws:greengrass:us-west-2:123451234510:
/greengrass/definition/functions/26309147-58a1-490e-a1a6-0d4894d6ca1e”,
“Name”: “sensorDefinition”
}
Nous créons maintenant un objet JSON avec les définitions de fonction Lambda et utilisons l’ID fourni dans le précédent et appelons create-functiondefinition-version à partir de la ligne de commande :
- Exécutable est la fonction Lambda par son nom.
- MemorySize est la quantité de mémoire à allouer au gestionnaire.
- Timeout est le temps en secondes avant l’expiration du compteur de délai d’attente.
Voici un exemple de l’objet JSON à utiliser avec une fonction Lambda :
aws greengrass create-function-definition-version –function-definition-id “26309147-58a1-490e-a1a6-0d4894d6ca1e”. –functions
‘[
{
“Id”: “26309147-58a1-490e-a1a6-0d4894d6ca1e”,
“FunctionArn”: “arn:aws:greengrass:us-west-2:123451234510:
/greengrass/definition/functions/26309147-58a1-490e- a1a6-0d4894d6ca1e”,
“FunctionConfiguration”: {
“Executable”: “sensorLambda.sensor_handler”, “MemorySize”: 32000,
“Timeout”: 3
}
}]’
Plusieurs autres étapes sont nécessaires pour provisionner et créer un abonnement entre le nœud périphérique et le cloud, mais le gestionnaire Lambda sera déployé. Cela fournit une vue alternative de l’informatique de brouillard, telle que fournie par Amazon. Vous pouvez considérer ce modèle comme une méthode d’extension des services cloud à un nœud de périphérie et la périphérie étant autorisée à faire appel à n’importe quelle ressource fournie par le cloud. Il s’agit, par définition, d’une véritable plateforme informatique de brouillard.
11.5.6 Topologies de brouillard
Les topologies de brouillard peuvent exister sous de nombreuses formes, et l’architecte doit prendre en compte plusieurs aspects lors de la conception d’un système de brouillard de bout en bout. En particulier, des contraintes telles que le coût, la charge de traitement, l’interface du fabricant et le trafic est-ouest entrent en jeu lors de la conception de la topologie. Un réseau de brouillard peut être aussi simple qu’un routeur de périphérie activé par le brouillard connectant des capteurs à un service cloud. Il peut également devenir plus complexe en une hiérarchie de brouillard à plusieurs niveaux avec différents degrés de capacité de traitement et des rôles à chaque niveau distribuant simultanément les charges de traitement quand et où cela est nécessaire (est-ouest et nord-sud). Les facteurs déterminants des modèles sont basés sur :
- Réduction du volume de données : par exemple, le système collecte-t-il des données vidéo non structurées de milliers de capteurs ou de caméras, agrège-t-il les données et recherche-t-il des événements particuliers en temps réel ? Si tel est le cas, la réduction de l’ensemble de données sera importante, car des milliers de caméras produiront des centaines de Go de données par jour, et les nœuds de brouillard devront distiller de grandes quantités de données en simples jetons oui, non, danger et événement sûr.
- Le nombre d’appareils périphériques : si le système IoT est simplement un capteur, alors l’ensemble de données est petit et peut ne pas justifier du tout un nœud de bord de brouillard. Cependant, si le nombre de capteurs augmente, ou dans le pire des cas, le nombre de capteurs est imprévisible et dynamique, alors la topologie de brouillard peut devoir augmenter ou diminuer dynamiquement. Un cas d’utilisation serait un site de stade utilisant le balisage Bluetooth. À mesure que le public augmente pour certains sites, le système doit pouvoir évoluer de manière non linéaire. À d’autres moments, le stade ne peut accueillir qu’une fraction de son espace et nécessiter des ressources de traitement et de connectivité marginales.
- Capacités des nœuds de brouillard : selon la structure et le coût de la topologie, certains nœuds peuvent être mieux adaptés à la connectivité aux systèmes WPAN, tandis que d’autres nœuds de la hiérarchie peuvent avoir des capacités de traitement supplémentaires pour l’apprentissage automatique, la reconnaissance de formes ou le traitement d’images. Un exemple serait les nœuds de brouillard de périphérie qui gèrent un réseau maillé Zigbee sécurisé et disposent d’un matériel spécial pour les situations de basculement ou la sécurité WPAN. Au-dessus de ce niveau de brouillard, il existerait un nœud de traitement de brouillard qui aurait du RAM supplémentaire et du matériel GPGPU pour prendre en charge le traitement du streaming de données brutes à partir des passerelles WPAN.
- Fiabilité du système : un architecte peut avoir besoin de prendre en compte les formes de défaillance dans un modèle IoT. Si un nœud de brouillard périphérique devait tomber en panne, un autre pourrait prendre sa place pour effectuer une action ou un service. Ce cas est important dans des environnements critiques ou en temps réel. Par exemple, dans une appliance de premier intervenant, vous pouvez avoir besoin de périphériques informatiques de périphérie qui doivent être fiables, comme lors d’une intervention en cas de catastrophe. Si un nœud de brouillard devait échouer ou perdre sa connectivité, un nœud frère pourrait reprendre ses fonctions jusqu’à ce que la connectivité soit restaurée. De la même manière, des nœuds de brouillard supplémentaires peuvent être provisionnés à la demande ; des nœuds redondants peuvent être nécessaires dans des situations tolérantes aux pannes. Dans le cas où il n’y a pas de nœuds redondants supplémentaires, certains traitements peuvent être partagés avec les nœuds voisins au détriment des ressources système et de la latence, mais le système continuera de fonctionner. Le dernier cas d’utilisation est celui où les nœuds voisins agissent comme des chiens de garde les uns pour les autres. En cas de défaillance d’un nœud de brouillard ou de communication avec le nœud, le chien de garde signalera un événement d’échec au cloud et pourra effectuer localement certaines actions vitales. Un bon exemple est lorsqu’un nœud de brouillard ne parvient pas à surveiller le trafic sur une autoroute; un nœud voisin peut voir l’échec du point, alerter le nuage de l’événement et signaler sur un panneau d’affichage sur l’autoroute pour réduire la vitesse.
Lorsque nous référençons des topologies de réseau et des architectures de brouillard, nous utilisons parfois des termes tels que trafic nord-sud ou trafic est-ouest. Cela correspond à la direction dans laquelle les données se déplacent. Nord-sud implique le déplacement des données d’un niveau du réseau vers un parent ou un enfant (par exemple, d’un routeur de périphérie vers le cloud). Est-ouest implique de passer à des homologues au même niveau de la hiérarchie du réseau, tels que des nœuds frères dans un réseau maillé ou des points d’accès dans un réseau Wi-Fi.
La solution de brouillard la plus simple est une unité de traitement de périphérie (passerelle, clients légers, routeur) placée à proximité d’un réseau de capteurs.
Ici, un nœud de brouillard peut être utilisé comme passerelle vers un réseau WPAN ou un maillage et communiquer avec un hôte :
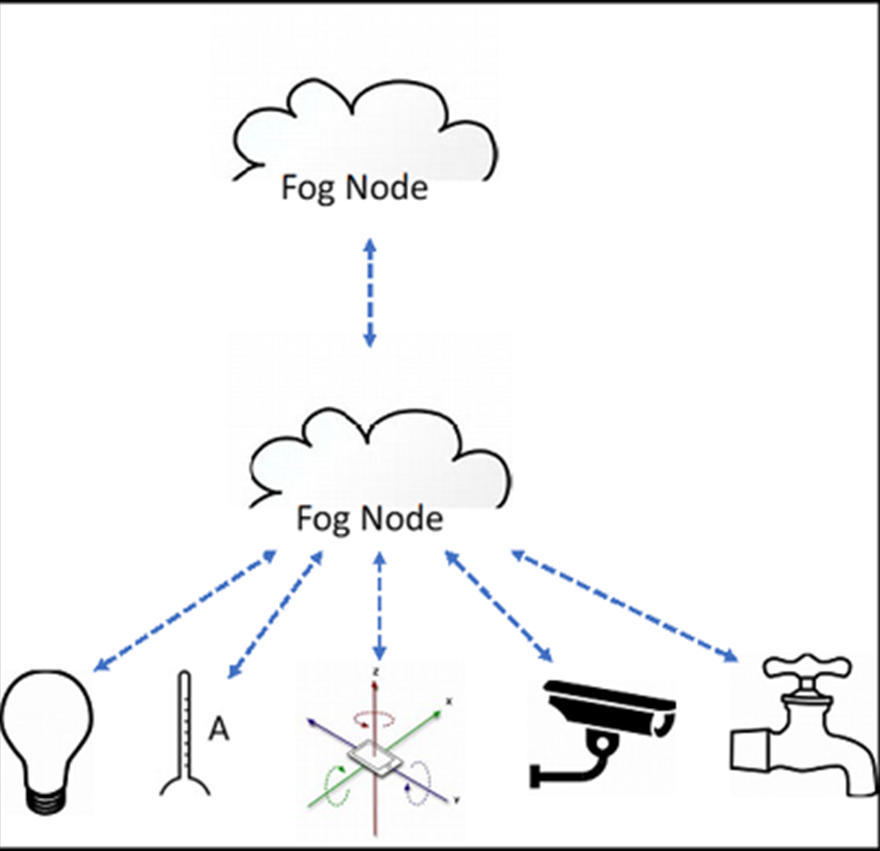
Figure 10 : Topologie de brouillard simple. Le dispositif de brouillard périphérique gère un réseau de capteurs et peut communiquer de manière M2M avec un autre nœud de brouillard.
La topologie de brouillard de base suivante inclut le cloud en tant que parent sur un réseau de brouillard. Le nœud de brouillard, dans ce cas, agrégera les données, sécurisera la périphérie et effectuera le traitement nécessaire pour communiquer avec le cloud. Ce qui sépare ce modèle de l’informatique de pointe, c’est que les couches de service et de logiciel du nœud de brouillard partagent une relation avec le cadre cloud :
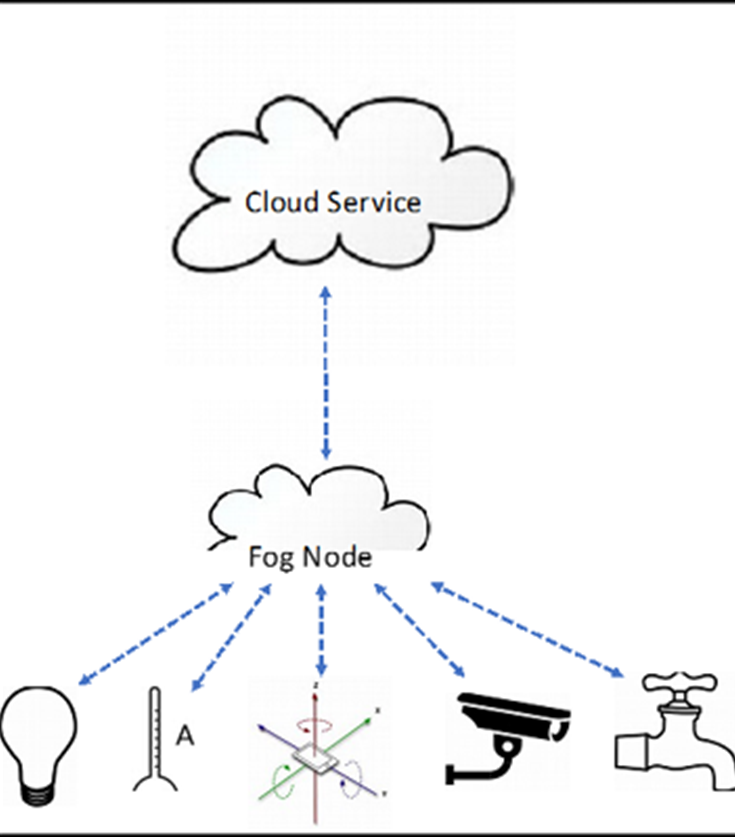
Figure 11 : Topologie du brouillard au nuage. Ici, un nœud de brouillard établit un lien vers un fournisseur de cloud
Le modèle suivant utilise plusieurs nœuds de brouillard responsables des services et du traitement des bords, et chacun se connecte à un ensemble de capteurs. Un nuage parent provisionne chaque nœud de brouillard comme il le ferait pour un nœud unique. Chaque nœud a une identité unique afin de pouvoir fournir un ensemble unique de services basé sur la géographie. Par exemple, chaque nœud de brouillard peut se trouver à un emplacement différent pour une franchise de vente au détail. Les nœuds de brouillard peuvent également communiquer et acheminer les données d’est en ouest entre les nœuds périphériques. Un exemple d’utilisation serait un environnement de stockage au froid où un certain nombre de refroidisseurs et de congélateurs doivent être entretenus et régis pour éviter la détérioration des aliments. Un détaillant peut avoir plusieurs refroidisseurs à plusieurs endroits, tous gérés par un seul service cloud, mais travaillant avec des nœuds de brouillard en périphérie :

Figure 12 : plusieurs nœuds de brouillard avec un seul nuage maître
Un autre modèle étend la topologie avec la possibilité de communiquer en toute sécurité et en privé à plusieurs fournisseurs de cloud à partir de plusieurs nœuds de brouillard. Dans ce modèle, plusieurs nuages parents peuvent être déployés. Par exemple, dans les villes intelligentes, plusieurs zones géographiques peuvent exister et être couvertes par différentes municipalités. Chaque municipalité peut préférer un fournisseur de cloud à l’autre, mais toutes les municipalités sont tenues d’utiliser un fabricant de caméras et de capteurs approuvé et budgétisé. Dans ce cas, le fabricant de caméras et de capteurs verrait leur instance de cloud unique coexister avec plusieurs municipalités.
Les nœuds de brouillard doivent pouvoir diriger les données vers plusieurs fournisseurs de cloud :
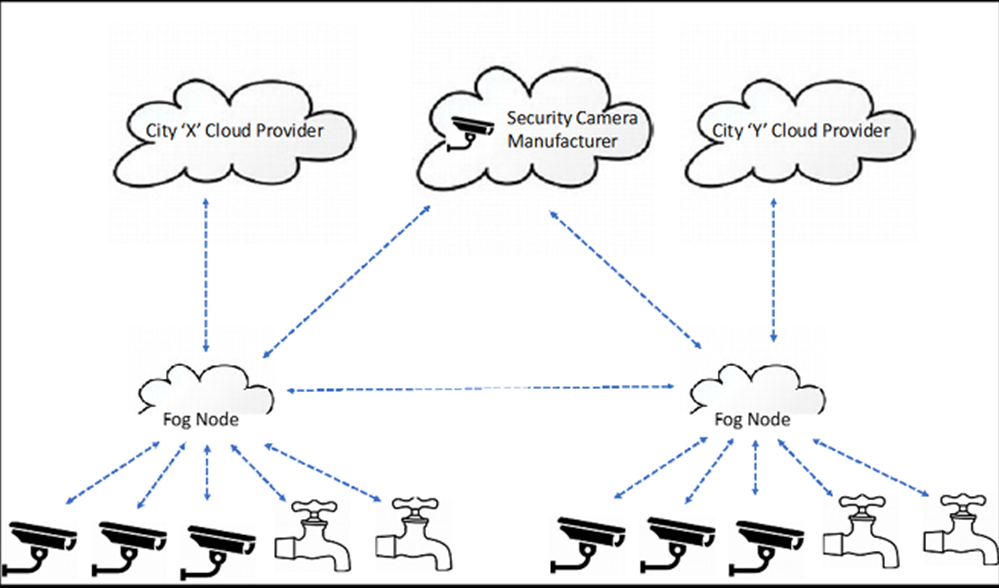
Figure 13 : plusieurs nœuds de brouillard avec plusieurs fournisseurs de cloud. Les nuages peuvent être un mélange de nuages publics et privés.
Les nœuds de brouillard n’ont pas non plus besoin d’une relation univoque stricte en ce qui concerne le pontage des capteurs vers les nuages. Les nœuds de brouillard peuvent être empilés, hiérarchisés ou même maintenus en stase jusqu’à ce qu’ils soient nécessaires. La hiérarchisation des couches de nœuds de brouillard les unes au-dessus des autres peut sembler contre-intuitive si nous essayons de réduire la latence, mais, comme mentionné précédemment, les nœuds peuvent être spécialisés. Par exemple, des nœuds plus proches des capteurs peuvent fournir des services durs en temps réel ou avoir des contraintes de coût les obligeant à avoir la quantité minimale de stockage et de calcul. Un niveau au-dessus d’eux peut fournir les ressources de calcul nécessaires pour le stockage agrégé, l’apprentissage automatique ou la reconnaissance d’image grâce à l’utilisation de périphériques de stockage de masse supplémentaires ou de processeurs GPGPU. L’exemple suivant illustre un cas d’utilisation dans un scénario d’éclairage urbain.
Ici, un certain nombre de caméras détectent les piétons en mouvement et la circulation; les nœuds de brouillard les plus proches des caméras effectuent l’agrégation et l’extraction des fonctionnalités et transmettent ces fonctionnalités en amont au niveau suivant. Le nœud de brouillard parent récupère les fonctionnalités et effectue la reconnaissance d’image nécessaire via un algorithme d’apprentissage en profondeur. Si un événement d’intérêt est vu (comme un piéton marchant la nuit le long d’un chemin), l’événement sera signalé au nuage. La composante nuage enregistrera l’événement et signalera à un ensemble de lampadaires à proximité du piéton pour augmenter l’éclairage. Ce schéma se poursuivra tant que les nœuds de brouillard verront le piéton se déplacer. L’objectif final est l’énergie globale économisée en n’allumant pas chaque lampadaire à pleine intensité en tout temps:
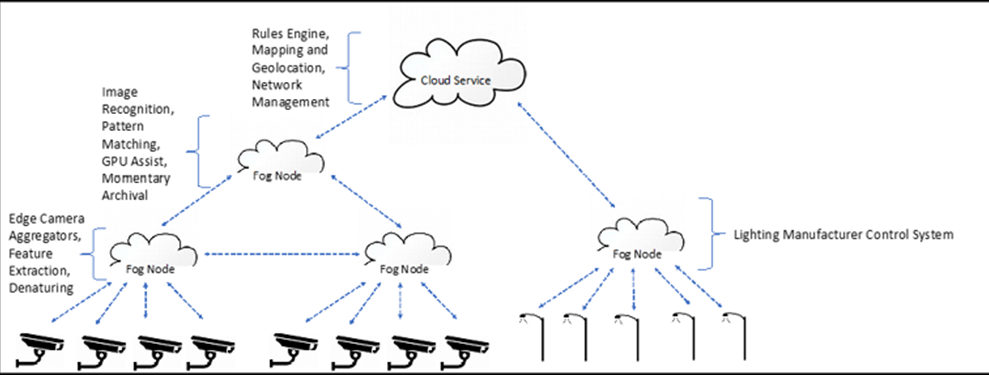
Figure 14 : Topologie de brouillard à plusieurs niveaux: les nœuds de brouillard s’empilent dans une hiérarchie de niveaux pour fournir des services ou des abstractions supplémentaires
11.6 Résumé
La collecte, l’analyse et l’action sur les données et l’obtention de conclusions significatives à partir d’un capteur est l’objectif de l’IoT. Lorsque nous évoluons vers des milliers ou des millions et potentiellement des milliards d’objets communiquant et diffusant des données en continu, nous devons introduire des outils avancés pour ingérer, stocker, rassembler, analyser et prédire la signification de cette mer de données. Le cloud computing est l’un des éléments permettant de fournir ce service sous la forme de grappes de matériel et de logiciels évolutifs. Le brouillard informatique rapproche le traitement du cloud pour résoudre les problèmes de latence, de sécurité et de coûts de communication. Les deux technologies fonctionnent ensemble pour exécuter des packages d’analyse sous la forme de moteurs de règles avec des agents de traitement d’événements complexes. Le choix du modèle de fournisseurs de cloud, de frameworks, de nœuds de brouillard et de modules d’analyse est une tâche importante et de nombreuses publications approfondissent la sémantique de la programmation et de la construction de ces services. Un architecte doit comprendre la topologie et l’objectif final du système pour construire une structure qui répond aux besoins d’aujourd’hui et évolue vers l’avenir.
Dans le chapitre suivant, nous discuterons de la partie analytique des données de l’IoT. Le cloud peut certainement héberger un certain nombre de fonctions analytiques. Cependant, nous devons être prêts à comprendre que certaines analyses doivent être effectuées sur le bord proche de la source de données (capteur) ou, si cela a plus de sens, dans le cloud (en utilisant des données historiques à long terme).
12 Analyse des données et apprentissage automatique dans le cloud et Edge
La valeur d’un système IoT n’est pas un événement de capteur unique, ni un million d’événements de capteur archivés. Une part importante de la valeur de l’IoT réside dans l’interprétation des données et des décisions basées sur ces données.
Alors qu’un monde de milliards de choses connectées et communiquant entre elles et que le cloud est bel et bien, la valeur réside dans ce qui se trouve dans les données, ce qui ne se trouve pas dans les données et ce que les modèles de données nous disent. Ce sont les parties de la science des données et de l’analyse des données de l’IoT, et probablement les domaines les plus précieux pour le client.
Les analyses pour le segment IoT portent sur :
- Données structurées (par exemple, stockage SQL) : un format prévisible de données
- Données non structurées (par exemple, données ou signaux vidéo bruts) : degré élevé de caractère aléatoire et de variance
- Semi-structuré (par exemple, flux Twitter) : un certain degré de variance et de caractère aléatoire dans la forme
Les données peuvent également avoir besoin d’être interprétées et analysées en temps réel comme un flux de données en continu, ou elles peuvent être archivées et récupérées pour une analyse approfondie dans le cloud. Il s’agit de la phase d’acquisition des données. Selon le cas d’utilisation, les données peuvent devoir être corrélées avec d’autres sources en vol. Dans d’autres cas, les données sont simplement enregistrées et sauvegardées dans un lac de données comme une base de données Hadoop.
Vient ensuite un certain type de transfert, ce qui signifie qu’un système de messagerie comme Kafka acheminera les données vers un processeur de flux, ou un processeur par lots, ou peut-être les deux. Le traitement de flux tolère un flux continu de données. Le traitement est généralement contraint et très rapide, car les données sont traitées en mémoire. Par conséquent, le traitement doit être aussi rapide, ou plus rapide, que le taux de données entrant dans le système. Alors que le traitement de flux fournit un traitement en temps quasi réel dans le cloud, lorsque nous considérons les machines industrielles et les voitures autonomes, le traitement de flux ne fournit pas de caractéristiques de fonctionnement difficiles en temps réel.
Le traitement par lots, en revanche, est efficace pour traiter des données à volume élevé. Il est particulièrement utile lorsque les données IoT doivent être corrélées avec des données historiques.
Après cette phase, il peut y avoir une phase de prédiction et de réponse où les informations peuvent être présentées sur une certaine forme de tableau de bord et enregistrées, ou peut-être que le système répondra au périphérique périphérique, où des actions correctives peuvent être appliquées pour résoudre un problème.
Ce chapitre abordera différents modèles d’analyse de données, du traitement d’événements complexes à l’apprentissage automatique. Plusieurs cas d’utilisation seront enseignés pour aider à généraliser où un modèle peut fonctionner et d’autres peuvent échouer.
12.1 Analyse de données de base dans l’IoT
L’analyse de données vise à trouver des événements, généralement dans une série de données en continu. Il existe plusieurs types d’événements et de rôles qu’une machine d’analyse de streaming en temps réel doit fournir. Ce qui suit est un surensemble de fonctions analytiques basées sur les travaux de Srinath Perera et Sriskandarajah Suhothayan ( Modèles de solution pour l’analyse en streaming en temps réel . Actes de la 9e conférence internationale ACM sur les systèmes basés sur les événements distribués (DEBS ’15). ACM, New York, NY, USA, 247 à 255. Ce qui suit est une liste énumérée de ces fonctions analytiques :
- Prétraitement : cela inclut le filtrage des événements de peu d’intérêt, la dénaturation, l’extraction d’entités, la segmentation, la transformation des données sous une forme plus appropriée (bien que les lacs de données préfèrent aucune transformation immédiate) et l’ajout d’attributs à des données telles qu’une balise (les lacs de données ont besoin de balises).
- Alerte : inspectez les données et, si elles dépassent certaines conditions aux limites, lancez une alerte. L’exemple le plus simple est lorsque la température dépasse une limite définie sur un capteur.
- Fenêtre de fenêtrage : une fenêtre coulissante d’événements est créée et ne dessine que des règles sur cette fenêtre. Les fenêtres peuvent être basées sur le temps (par exemple, une heure) ou la longueur (2000 échantillons de capteur).
Il peut s’agir de fenêtres coulissantes (par exemple, inspecter uniquement les 10 derniers événements de capteur et produire un résultat chaque fois qu’un nouvel événement se produit), ou des fenêtres batch (par exemple, produire un événement uniquement à la fin de la fenêtre). Le fenêtrage est bon pour les règles et pour compter les événements. Par exemple, vous pouvez rechercher le nombre de pointes de température au cours de la dernière heure et déterminer qu’un défaut se produira sur une machine.
- Jointures : elles combinent plusieurs flux de données en un nouveau flux unique. Un scénario où cela s’applique est un exemple de logistique, par exemple, une compagnie maritime suit ses expéditions avec des balises de suivi des actifs et sa flotte de camions, d’avions et d’installations dispose également d’un flux d’informations de géolocalisation. Il existe initialement deux flux de données: un pour le colis et un pour un camion donné. Lorsqu’un camion ramasse un colis, ces deux flux sont joints.
- Erreurs : des millions de capteurs généreront des données manquantes, des données tronquées et des données hors séquence. Ceci est important dans les cas IoT avec plusieurs flux de données asynchrones et indépendantes. Par exemple, des données peuvent être perdues dans un WAN cellulaire si un véhicule entre dans un parking souterrain. Ce modèle analytique corrèle les données au sein de son propre flux pour tenter de trouver ces conditions d’erreur.
- Bases de données : le package d’analyse devra interagir avec certains entrepôts de données. Par exemple, si les données transitent par un certain nombre de capteurs. Un exemple de cela pourrait être les étiquettes de ressources Bluetooth qui surveillent si un article est volé ou perdu. Une base de données des identifiants de balises manquants serait référencée à partir de toutes les passerelles diffusant des identifiants de balises Bluetooth vers le système.
- Événements et modèles temporels : ils sont le plus souvent utilisés avec le modèle de fenêtre mentionné précédemment. Ici, une série ou une séquence d’événements constitue un modèle d’intérêt. Vous pouvez considérer cela comme une machine d’état. Supposons que nous surveillons la santé d’une machine en fonction de la température, des vibrations et du bruit. Une séquence d’événements temporaire peut être la suivante :
- Détectez si la température dépasse 100 ° C.
- Détectez ensuite si les vibrations dépassent 1 m / s.
- Ensuite, détectez si la machine émet du bruit à 110 dB.
- Si ces événements ont lieu dans cette séquence, alors seulement, lancez une alerte.
- Suivi : Le suivi implique quand ou où quelque chose existe ou un événement s’est produit, ou quand quelque chose n’existe pas là où il devrait. Un exemple très basique est la géolocalisation des camions de service où une entreprise peut avoir besoin de savoir exactement où se trouvait un camion et quand il y était pour la dernière fois. Cela a une application dans l’agriculture, le mouvement humain, le suivi des patients, le suivi des actifs de grande valeur, les systèmes de bagages, les déchets urbains intelligents, le déneigement, etc.
- Tendances : ce modèle est particulièrement utile pour la maintenance prédictive. Ici, une règle est conçue pour détecter un événement sur la base de données de série en corrélation temporelle. Ceci est similaire aux événements temporels mais diffère dans le sens où les événements temporels n’ont aucune notion du temps, seulement un ordre de séquence. Ce modèle utilise le temps comme dimension dans le processus. Un historique de données en corrélation temporelle pourrait être utilisé pour trouver des modèles comme le fait un capteur de bétail en agriculture. Ici, une tête de bétail peut porter un capteur qui détecte le mouvement et la température de l’animal. Une séquence d’événements peut être construite pour voir si le bétail s’est déplacé le dernier jour. S’il n’y a pas eu de mouvement, le bétail peut être malade ou mort.
- Requêtes par lots : le traitement par lots est généralement plus complet et plus approfondi que le traitement de flux en temps réel. Une plateforme de streaming bien conçue peut générer des analyses et faire appel à un système de traitement par lots. Nous en parlerons plus tard sous forme de traitement lambda.
- Voie d’analyse approfondie : dans le traitement en temps réel, nous décidons à la volée qu’un événement s’est produit. Que cet événement doive vraiment signaler une alarme peut nécessiter un traitement supplémentaire qui ne fonctionnera pas en temps réel. Un exemple est un système de vidéosurveillance. Supposons qu’une ville intelligente émette une alerte orange pour un enfant perdu. La ville intelligente peut publier un modèle d’extraction et de classification des fonctionnalités simple pour les moteurs de streaming en temps réel. Le modèle détecterait les plaques d’immatriculation d’un véhicule dans lequel l’enfant pourrait se trouver, ou potentiellement un logo sur la chemise de l’enfant. La première étape consisterait à capturer les numéros de plaque d’immatriculation ou les logos des véhicules sur les piétons et à les envoyer dans le cloud. Le package d’analyse peut identifier une plaque d’intérêt ou un logo parmi des millions d’échantillons d’image comme passe de premier niveau. Cette image identifiée de manière positive (et les images vidéo environnantes) serait transmise à un package d’analyse plus profond qui résout l’image avec des algorithmes de reconnaissance d’objet plus profonds (fusion d’images, super-résolution, apprentissage automatique) pour éliminer les faux positifs.
- Modèles et formation : Le modèle de premier niveau décrit précédemment peut, en fait, être un moteur d’inférence pour un système d’apprentissage automatique. Ces outils d’apprentissage automatique sont construits sur des modèles formés qui peuvent être utilisés pour une analyse en temps réel en vol.
- Signalisation : il arrive souvent qu’une action doive se propager vers le bord et le capteur. Un cas typique est l’automatisation d’usine et la sécurité. Par exemple, si la température dépasse une certaine limite sur une machine, enregistrez l’événement mais renvoyez également un signal au périphérique pour ralentir la machine. Le système doit être bidirectionnel en communication.
- Contrôle : Enfin, nous avons besoin d’un moyen de contrôler ces outils d’analyse. Que ce soit le démarrage, l’arrêt, la génération de rapports, la journalisation ou le débogage, des installations doivent être en place pour gérer ce système.
Maintenant, nous allons nous concentrer sur la façon de construire une architecture d’analyse basée sur le cloud qui doit ingérer des flux de données imprévisibles et imparables et fournir des interprétations de ces données aussi proches que possible du temps réel.
12.1.1 Pipeline cloud de niveau supérieur
Le diagramme suivant est un flux de données typique d’un capteur vers un tableau de bord. Les données transitent par plusieurs supports (liaisons WPAN, haut débit, stockage cloud sous la forme d’un lac de données, etc.). Lorsque nous considérons les architectures suivantes pour créer une solution d’analyse cloud, nous devons considérer les effets de la mise à l’échelle. Les choix faits au début de la conception qui conviennent à 10 nœuds IoT et à un cluster de cloud unique peuvent ne pas évoluer efficacement lorsque le nombre d’appareils IoT de point de terminaison atteint des milliers et sont basés dans plusieurs zones géographiques :
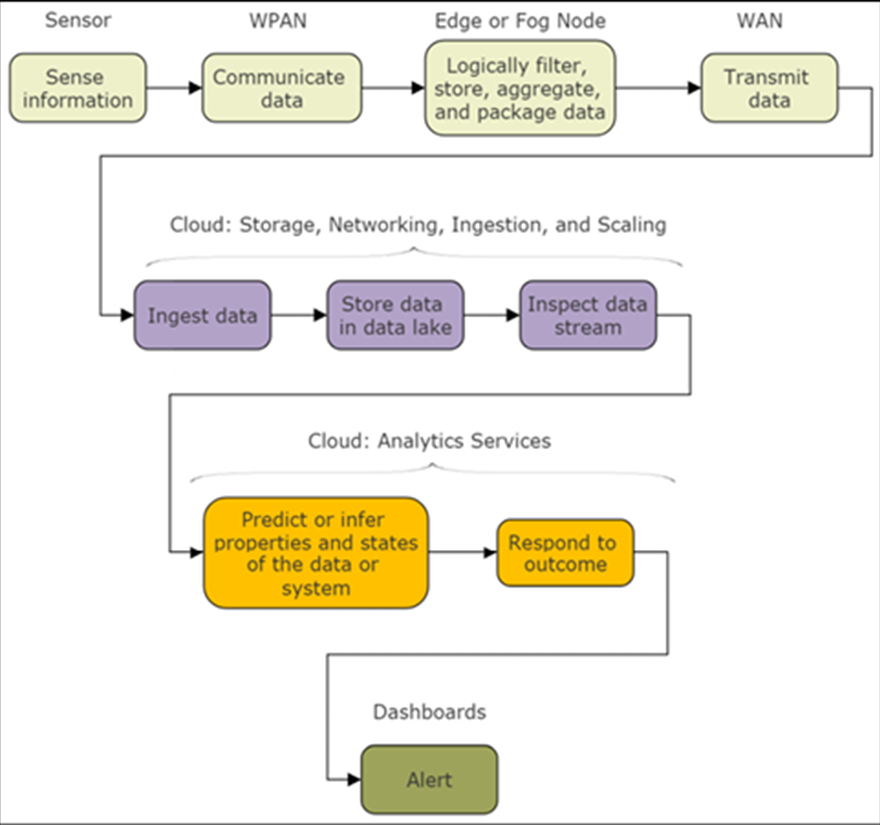
Figure 1 : Un pipeline IoT typique du capteur au cloud
La partie analytique (prédire-répondre) du cloud peut prendre plusieurs formes :
- Moteurs de règles : ils définissent simplement une action et produisent un résultat.
- Traitement de flux : c’est là que des événements tels que des lectures de capteur sont injectés dans le processeur de flux. Le chemin de traitement est un graphique dans lequel les nœuds du graphique représentent des opérateurs et envoient des événements à d’autres opérateurs. Les nœuds contiennent le code de cette partie du traitement et un chemin pour se connecter au nœud suivant dans le graphique. Ce graphique peut être répliqué et exécuté en parallèle sur un cluster, il peut donc être étendu à des centaines de machines.
- Traitement d’événements complexes : il est basé sur des requêtes comme SQL et écrit dans ce langage de niveau supérieur. Il est basé sur le traitement des événements et optimisé pour une faible latence.
- Architecture Lambda : ce modèle tente d’équilibrer le débit et la latence en effectuant un traitement par lots et un traitement de flux en parallèle sur des ensembles de données massifs.
La raison pour laquelle nous parlons de l’analyse en temps réel est que les données sont diffusées sans interruption à partir de millions de nœuds simultanément et de manière asynchrone avec diverses erreurs, problèmes de format et temporisations. La ville de New York compte 250 000 lampadaires ( http://www.nyc.gov/html/dot/html/infrastructure/streetlights.shtml ). Supposons que chaque lumière soit intelligente, ce qui signifie qu’elle surveille s’il y a un mouvement à proximité et, dans l’affirmative, elle éclaire la lumière ; sinon, il reste grisé pour économiser de l’énergie (2 octets). Chaque lumière peut également vérifier s’il y a un problème avec la lumière qui a besoin d’entretien (1 octet). De plus, chaque lumière surveille la température (1 octet) et l’humidité (1 octet) pour aider à générer des prévisions météorologiques microclimatiques. Enfin, les données contiennent également l’ID de la lumière et un horodatage (8 octets). L’ensemble de toutes les lumières produit nominalement 250 000 messages par seconde et peut culminer à 325 000 en raison de périodes de pointe, de foules, de sites touristiques, de vacances, etc. Dans l’ensemble, disons que notre service cloud peut traiter 250 000 messages par seconde ; cela implique un carnet de commandes pouvant atteindre 75 000 événements / seconde. Si l’heure de pointe est vraiment une heure, alors nous accumulons 270 000 000 événements / heure. Ce n’est que si nous fournissons plus de traitement dans le cluster ou réduisons le flux entrant que le système ne rattrapera jamais. Si le flux entrant tombe à 200 000 messages / seconde pendant un temps calme, le cluster cloud prendra 1,1 heure pour résoudre et consommer 585 Mo de mémoire (270 millions de messages en attente à 13 octets par message). En règle générale, vous aurez un backend cloud à mise à l’échelle automatique pour croître avec la demande et la longueur de la file d’attente de messages.
Pour formaliser le processus et anticiper les demandes que vous placerez sur un backend cloud, les équations suivantes peuvent aider à modéliser la capacité :

Où :
R Event = Taux d’événement
T Burst = heure des événements de rafale
T c = Temps pour achever l’arriéré
M Backlog = Message Backlog (taille)
TailleM = Taille du message
12.1.2 Moteurs de règles
Un moteur de règles est simplement une construction logicielle qui exécute des actions sur les événements. Par exemple, si l’humidité dans une pièce dépasse 50%, envoyez un SMS au propriétaire. Ils sont également appelés systèmes de gestion des règles métier (BRMS).
Les moteurs de règles peuvent ou non avoir un état et être appelés avec état. Autrement dit, ils peuvent avoir un historique de l’événement et prendre des mesures différentes selon l’ordre, le montant ou les modèles d’événements tels qu’ils se sont produits historiquement. Alternativement, ils ne peuvent pas maintenir l’état et inspecter uniquement l’événement en cours (sans état) :

Figure 2 : exemple de moteur de règles simples
Dans notre exemple de moteur de règles, nous allons voir Drools. Il s’agit d’un BRMS développé par Red Hat et sous licence Apache 2.0. JBoss Enterprise est une version de production du logiciel. Tous les objets d’intérêt résident dans la mémoire de travail des Drools . Considérez la mémoire de travail comme l’ensemble des événements de capteur IoT intéressants à comparer pour satisfaire une règle donnée. Drools peut prendre en charge deux formes de chaînage : avant et arrière. Le chaînage est une méthode d’inférence tirée de la théorie des jeux.
Le chaînage direct prend les données disponibles jusqu’à ce qu’une chaîne de règles soit satisfaite. Par exemple, une chaîne de règles peut être une série de clauses if / then, comme illustré dans le diagramme précédent. Le chaînage direct recherchera en permanence l’un des chemins if / then pour déduire d’une action. L’enchaînement vers l’arrière est l’inverse. Plutôt que de commencer par les données à déduire, nous commençons par l’action et travaillons en arrière. Le pseudocode suivant illustre un moteur de règles simple :
Smoke Sensor = Smoke Detected Heat Sensor = Heat Detected
if (Smoke_Sensor == Smoke_Detected) && (Heat_Sensor == Heat_Detected) then Fire
if (Smoke_Sensor == !Smoke_Detected) && (Heat_Sensor == Heat_Detected) then Furnace_On
if (Smoke_Sensor == Smoke_Detected) && (Heat_Sensor == !Heat_Detected) then Smoking
if (Fire) then Alarm
if (Furnace_On) then Log_Temperature
if (Smoking) then SMS_No_Smoking_Allowed
Supposons que:
Smoke_Sensor: Off
Heat_Sensor: On
Le chaînage direct résoudrait l’antécédent de la deuxième clause et en déduit que les températures sont enregistrées.
Le chaînage vers l’arrière tente de prouver que le four est allumé et fonctionne en arrière dans une série d’étapes :
- Pouvons-nous prouver que les températures sont enregistrées ? Jetez un oeil à ce code :
if (Furnace_On) then Log_Temperature
- Puisque les températures sont enregistrées, l’antécédent ( Furnace_On ) devient le nouvel objectif:
if (Smoke_Sensor ==! Smoke_Detected) && (Heat_Sensor == Heat_Detected) alors Furnace_On
- Comme le four est allumé, le nouvel antécédent se compose de deux parties: Smoke_Sensor et Heat_Sensor . Le moteur de règles le divise désormais en deux objectifs :
Smoke_Sensor off
Heat_Sensor activé
- Le moteur de règles tente désormais de satisfaire les deux sous-objectifs. Ce faisant, l’inférence est terminée.
Le chaînage avant a l’avantage de répondre aux nouvelles données à mesure qu’elles arrivent, ce qui peut déclencher de nouvelles inférences.
Le langage sémantique de Drools est intentionnellement simple. Drools est composé des éléments de base suivants :
- Sessions, qui définissent les règles par défaut
- Points d’entrée, qui définissent les règles à utiliser
- When instructions, la clause conditionnelle
- Then déclarations, les mesures à prendre
Une règle de base de Drools est présentée dans le pseudocode suivant. L’opération d’insertion place une modification dans la mémoire de travail. Vous modifiez normalement la mémoire de travail lorsqu’une règle a la valeur true.
rule “Furnace_On” when
Smoke_Sensor(value > 0) && Heat_Sensor(value > 0) then
insert(Furnace_On()) end
Une fois toutes les règles de Drools exécutées, le programme peut interroger la mémoire de travail pour voir quelles règles ont été évaluées comme vraies à l’aide d’une syntaxe comme celle-ci :
query “Check_Furnace_On”
$result: Furnace_On() end
Une règle a deux modèles :
- Syntactic : il a le format des données, la parité, le hachage et la plage de valeurs.
- Sémantique : les valeurs doivent appartenir à un ensemble dans une liste; le nombre de valeurs à haute température ne doit pas dépasser 20 en 1 heure. Ce sont essentiellement des événements significatifs.
Drools prend en charge la création de règles très complexes et élaborées au point qu’une base de données de règles peut être nécessaire pour les stocker. La sémantique du langage permet les modèles, l’évaluation des plages, la saillance, les moments où une règle est en vigueur, la correspondance des types et le travail sur les collections d’objets.
12.1.3 Ingestion – streaming, traitement et lacs de données
Un appareil IoT est généralement associé à un capteur ou à un appareil dont le but est de mesurer ou de surveiller le monde physique. Il le fait de manière asynchrone par rapport au reste de la pile technologique IoT. Autrement dit, un capteur tente toujours de diffuser des données, qu’un nuage ou un nœud de brouillard soit à l’écoute ou non. C’est important, car la valeur d’une entreprise est dans les données.
Même si la plupart des données produites sont redondantes, il existe toujours la possibilité qu’un événement significatif puisse se produire. Ceci est le flux de données.
Le flux IoT d’un capteur vers un nuage est supposé être :
- Constante et sans fin
- Asynchrone
- Non structuré ou structuré
- Le plus près possible du temps réel
Nous avons discuté du problème de latence du cloud plus tôt dans le chapitre 11, Topologies de cloud et de brouillard. Nous avons également appris la nécessité du calcul de brouillard pour aider à résoudre le problème de latence, mais même sans nœuds de calcul de brouillard, des efforts sont déployés pour optimiser l’architecture du cloud afin de prendre en charge les besoins en temps réel de l’IoT. Pour ce faire, les nuages doivent maintenir un flux de données et le faire bouger. Essentiellement, les données passant d’un service à un autre dans le cloud doivent le faire comme un pipeline, sans avoir besoin d’interroger les données. La forme alternative de traitement des données est appelée traitement par lots. La plupart des architectures matérielles traitent le flux de données de la même manière, en déplaçant les données d’un bloc à un autre, et le processus d’arrivée des données déclenche la fonction suivante.
De plus, une utilisation prudente du stockage et de l’accès au système de fichiers est essentielle pour réduire la latence globale.
Pour cette raison, la plupart des frameworks de streaming prendront en charge les opérations en mémoire et éviteront le coût du stockage temporaire sur un système de fichiers de masse. Michael Stonebraker a souligné l’importance du streaming de données de cette manière. (Voir Michael Stonebraker, Ugur Çetintemel et Stan Zdonik. 2005. The 8 Requirements of Real-time Stream Processing. “SIGMOD Rec. 34, 4, décembre 2005, 42-47.) Une file d’attente de messages bien conçue facilite ce modèle. Pour construire une architecture réussie dans un cloud qui évolue de centaines de nœuds à des millions, il faut prendre en compte.
Le flux de données ne sera pas non plus parfait. Avec des centaines à des milliers de capteurs diffusant des données asynchrones, le plus souvent, les données seront manquantes (perte de communication du capteur), les données seront mal formées (erreur de transmission) ou les données seront désordonnées (les données peuvent circuler vers le cloud de plusieurs chemins). Au minimum, un système de streaming doit :
- Évoluez avec la croissance des événements et les pics
- Fournir une API de publication / abonnement à l’interface
- Approche de la latence en temps quasi réel
- Fournir une mise à l’échelle du traitement des règles
- Prise en charge des lacs de données et de l’entreposage de données
Apache fournit plusieurs projets logiciels open source (sous la licence Apache 2) qui aident à créer une architecture de traitement de flux. Apache Spark est un framework de traitement de flux qui traite les données en petits lots. Il est particulièrement utile lorsque la taille de la mémoire est limitée sur un cluster dans le cloud (par exemple, & lt; 1 To ). Spark est construit sur un traitement en mémoire, qui présente les avantages de réduire la dépendance et la latence du système de fichiers, comme mentionné précédemment. L’autre avantage de travailler sur des données par lots est qu’il est particulièrement utile lorsqu’il s’agit de modèles d’apprentissage automatique, qui seront traités plus loin dans ce chapitre. Plusieurs modèles, tels que les réseaux de neurones convolutifs (CNN), peuvent travailler sur des données par lots. Une alternative à Apache est Storm. Storm tente de traiter les données le plus près possible du temps réel dans une architecture cloud. Il dispose d’une API de bas niveau par rapport à Spark et traite les données comme des événements importants plutôt que de les diviser en lots. Cela a pour effet d’être à faible latence (performance inférieure à la seconde).
Pour alimenter les frameworks de traitement de flux, nous pouvons utiliser Apache Kafka ou Flume. Apache Kafka est un MQTT sur l’ingestion de divers capteurs et clients IoT, et il se connecte à Spark ou Storm du côté sortant. MQTT ne met pas en mémoire tampon les données. Si des milliers de clients communiquent avec le cloud via MQTT, un système sera nécessaire pour réagir à un flux entrant et fournir la mise en mémoire tampon nécessaire. Cela permet à Kafka d’évoluer à la demande (un autre attribut important du cloud) et peut bien réagir aux pics d’événements. Un flux de 100 000 événements par seconde peut être pris en charge avec Kafka. Flume, d’autre part, est un système distribué pour collecter, agréger et déplacer des données d’une source à une autre, et il est légèrement plus facile à utiliser hors de la boîte. Il est également étroitement intégré à Hadoop. Flume est légèrement moins évolutif que Kafka, car ajouter plus de consommateurs signifie changer l’architecture de Flume. Les deux investisseurs pourraient diffuser en mémoire sans jamais le stocker. En général, cependant, nous ne voulons pas faire cela ; nous voulons prendre les données brutes des capteurs et les stocker sous une forme aussi brute que possible avec tous les autres capteurs en streaming simultanément.
Lorsque nous pensons aux déploiements IoT dans des milliers ou des millions de capteurs et de nœuds terminaux, un environnement cloud peut utiliser un lac de données. Un lac de données est essentiellement une installation de stockage massive contenant des données brutes non filtrées provenant de nombreuses sources. Les lacs de données sont des systèmes de fichiers plats. Un système de fichiers typique sera organisé de manière hiérarchique, avec le volume, les répertoires, les fichiers et les dossiers dans un sens de base. Un lac de données organise les éléments dans son stockage en attachant un élément de métadonnées (balises) à chaque entrée. Le modèle de lac de données classique est Apache Hadoop, et presque tous les fournisseurs de cloud utilisent une certaine forme de lac de données sous leurs services.
Le stockage en lac de données est particulièrement utile dans l’IoT, car il stockera toute forme de données, qu’elles soient structurées ou non structurées. Un lac de données suppose également que toutes les données sont précieuses et seront conservées en permanence. Cette masse de données persistante en vrac est optimale pour les moteurs d’analyse de données. Beaucoup de ces algorithmes fonctionnent mieux en fonction de la quantité de données qu’ils alimentent ou de la quantité de données utilisée pour former leurs modèles.
Une architecture conceptuelle utilisant le traitement par lots traditionnel et le traitement de flux est illustrée dans le diagramme suivant. Dans l’architecture, le lac de données est alimenté par une instance de Kafka. Kafka pourrait fournir l’interface à Spark par lots et envoyer des données à un entrepôt de données.
Il existe plusieurs façons de reconfigurer la topologie dans le diagramme suivant, car les connecteurs entre les composants sont normalisés :
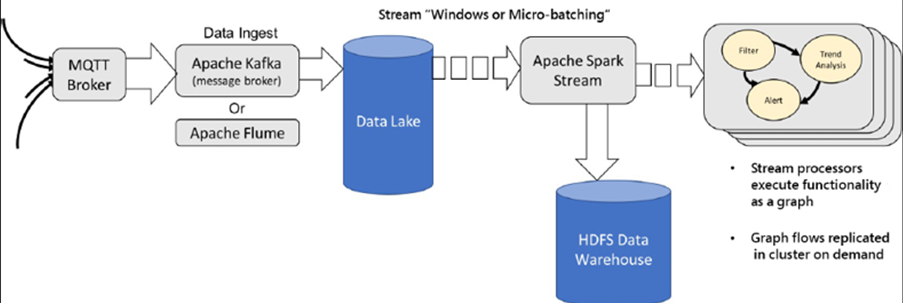
Figure 3 : Diagramme de base du moteur d’ingestion du cloud vers un entrepôt de données. Spark agit comme le service de canal de diffusion.
12.1.4 Traitement d’événements complexes
Le traitement des événements complexes ( CEP ) est un autre moteur d’analyse souvent utilisé pour la détection des modèles. De par ses racines dans la simulation d’événements discrets et le trading de volatilité boursière dans les années 1990, c’est par nature une méthode capable d’analyser un flux en direct de données en streaming en temps quasi réel. À mesure que des centaines et des milliers d’événements entrent dans le système, ils sont réduits et distillés en événements de niveau supérieur. Ces données sont plus abstraites que les données brutes des capteurs. Les moteurs CEP ont l’avantage d’un délai d’exécution rapide dans l’analyse en temps réel sur un processeur de flux. Un processeur de flux peut résoudre un événement dans le délai de millisecondes. L’inconvénient est qu’un moteur CEP n’a pas le même niveau de redondance ou de mise à l’échelle dynamique qu’Apache Spark.
Les systèmes CEP utilisent des requêtes de type SQL, mais plutôt que d’utiliser un backend de base de données, ils recherchent dans un flux entrant le modèle ou la règle que vous suggérez. Un système CEP se compose de l’élément de données tuple : discret avec un horodatage. Un système CEP utilise les différents modèles d’analyse décrits au début de ce chapitre et fonctionne bien avec une fenêtre coulissante d’événements. Puisqu’il ressemble à SQL en sémantique et qu’il est conçu pour être sensiblement plus rapide qu’une requête de base de données classique, toutes les règles et données résident dans la mémoire (généralement une base de données de plusieurs Go). De plus, ils doivent être alimentés à partir d’un système de messagerie de flux moderne tel que Kafka.
CEP a des opérations comme les fenêtres coulissantes, les jointures et la détection de séquence. De plus, les moteurs CEP peuvent être basés sur le transfert ou le chaînage arrière comme le sont les moteurs de règles. Un système CEP standard est le CEP Apache WSO2. WSO2 couplé à Apache Storm peut traiter plus d’un million d’événements par seconde, sans aucun événement de stockage nécessaire. WSO2 est un système CEP utilisant un langage SQL mais peut être scripté en JavaScript et Scala. L’avantage supplémentaire est qu’il peut être étendu avec un package appelé Siddhi pour permettre des services tels que :
- Géolocalisation
- Traitement du langage naturel
- Apprentissage automatique
- Corrélation et régression des séries chronologiques
- Opérations mathématiques
- String et RegEx
Les flux de données peuvent être interrogés comme dans le code Siddhi QL suivant :
define stream SensorStream (time int, temperature single); @name(‘Filter Query’)
from SensorStream[temperature > 98.6′ select *
insert into FeverStream;
Tout cela fonctionne comme des événements discrets permettant d’appliquer des règles sophistiquées à des millions d’événements se déroulant simultanément.
Maintenant que nous avons décrit CEP, il est temps que vous compreniez où un moteur CEP et un moteur de règles doivent être utilisés. Si l’évaluation est un état simple, comme deux gammes de températures, alors le système est sans état, et un moteur de règles simple doit être utilisé. Si le système maintient une notion temporaire ou une série d’états, alors un moteur CEP doit être utilisé.
12.1.5 Architecture Lambda
Une architecture lambda tente d’équilibrer la latence avec le débit. Essentiellement, il mélange le traitement par lots avec le traitement par flux. Semblable à la topologie cloud générale d’OpenStack ou d’autres frameworks cloud, lambda ingère et stocke dans un référentiel de données immuable. Il existe trois couches de la topologie :
- Couche batch : la couche batch est généralement basée sur des clusters Hadoop. La couche batch est beaucoup plus lente à traiter que la couche stream. En sacrifiant la latence, il maximise le débit et la précision.
- Couche de vitesse : il s’agit du flux de données en mémoire en temps réel. Les données peuvent être erronées, manquantes et hors service. Apache Spark, comme nous l’avons vu, est très bon pour fournir un moteur de traitement de flux.
- Couche de service : La couche de service est l’endroit où la recombinaison des résultats de lots et de flux est stockée, analysée et visualisée. Les composants typiques de la couche de service sont Druid, qui fournit des installations pour combiner les couches batch et speed ; Apache Cassandra pour une gestion de base de données évolutive ; et Apache Hive pour l’entreposage de données.

Figure 4 : Complexité d’une architecture Lambda. Ici, une couche batch migre les données vers le stockage HDFS, et la couche vitesse est livrée directement à un package d’analyse en temps réel via Spark.
Les architectures lambda sont, par nature, plus complexes que les autres moteurs d’analyse. Ils sont hybrides et ajoutent une complexité et des ressources supplémentaires pour fonctionner correctement.
12.2 Cas d’utilisation sectoriels
Nous allons maintenant essayer de considérer les cas d’utilisation typiques dans une variété d’industries adoptant l’IoT et l’analyse cloud. Lors de l’architecture de la solution, nous devons prendre en compte l’échelle, la bande passante, les besoins en temps réel et les types de données pour dériver la bonne architecture cloud, ainsi que la bonne architecture d’analyse.
Ce sont des exemples généralisés – il est impératif de comprendre l’ensemble du flux et de l’échelle / capacité future lors du dessin d’un tableau similaire :
| L’industrie | Cas d’utilisation | Services cloud | Bande passante typique | Temps réel | Analytique |
| Fabrication | Technologie opérationnelle
Brown fi eld Suivi des actifs Automatisation d’usine |
Tableaux de bord
Stockage en vrac Lacs de données SDN Faible latence |
500 Go / jour / pièce d’usine produite
Opérations minières de 2 To / minute |
Moins de 1s | RNN
Réseaux bayésiens |
| Logistique et transport | Suivi de géolocalisation
Suivi des actifs Détection d’équipement |
Tableaux de bord
Journalisation Stockage |
Véhicules: 4 To / jour / véhicule (50 capteurs)
Avion: 2,5 à 10 To / jour (6000 capteurs) Suivi des actifs: 1 Mo / jour / balise |
Moins de 1 s (temps réel)
Quotidien (lot) |
Moteurs de règles |
| Santé | Suivi des actifs
Suivi des patients Surveillance de la santé à domicile Équipement de santé sans fil |
Fiabilité et HIPPA
Option de cloud privé Stockage et archivage Équilibrage de charge |
1 Mo / jour / capteur | Moins de 1 s: critique pour la vie
Non critique pour la vie: à chaque changement |
RNN
Arbres de décision Moteurs de règles |
| L’agriculture | Santé du bétail et suivi de l’emplacement
Analyse de chimie du sol |
Stockage en vrac – archivage
Provisionnement cloud à cloud |
512 Ko / jour / tête de bétail
1 000 à 10 000 têtes de bétail par parc d’engraissement |
1 seconde ( temps réel )
10 minutes (lot) |
Moteurs de règles |
| Énergie | Compteurs intelligents
Surveillance à distance de l’énergie (solaire, gaz naturel, pétrole) Prédiction d’échec |
Tableaux de bord
Lacs de données Stockage en vrac pour la prévision de taux historique SDN Faible latence |
100-200 Go / jour / éolienne
1 à 2 To / jour / plate-forme pétrolière 100 Mo / jour / compteur intelligent |
Moins de 1 s: production d’énergie
1 minute: compteurs intelligents |
RNN
Réseaux bayésiens Moteurs de règles |
| Consommateur | Journalisation de la santé en temps réel
Détection de présence Éclairage et chauffage / AC La sécurité Maison connectée |
Tableaux de bord
PaaS Équilibrage de charge Stockage en vrac |
Caméra de sécurité: 500 Go / jour / caméra
Appareil intelligent: 1-1000 Ko / jour / appareil à capteur Maison intelligente: 100 Mo / jour / maison |
Vidéo: moins de 1s
Maison intelligente: 1s |
CNN (détection d’image)
Moteurs de règles |
| Vente au détail | Détection de la chaîne du froid
Machines POS Systèmes de sécurité Balisage |
SDN
Micro-segmentation Tableaux de bord |
Sécurité: 500 Go / jour / appareil photo
Général: 1-1000 Mo / jour / appareil |
POS et transaction de crédit: 100ms
Balise: 1s |
Moteurs de règles
CNN pour la sécurité |
| Ville intelligente | Stationnement intelligent
Ramassage intelligent des déchets Capteurs environnementaux |
Tableaux de bord
Lacs de données Services cloud à cloud |
Moniteurs d’énergie: 2,5 Go / jour / ville (capteurs 70K)
Places de parking: 300 Mo / jour (80 000 capteurs) Moniteurs de déchets: 350 Mo / jour (200 000 capteurs) Moniteurs de bruit: 650 Mo / jour (30 000 capteurs) |
Compteurs électriques: 1 minute
Température: 15 minutes Bruit: 1 minute Déchets: 10 minutes Places de parking: chaque changement |
Moteur de règles
Arbres de décision |
12.3 Apprentissage automatique dans l’IoT
L’apprentissage automatique n’est pas un nouveau développement informatique. Au contraire, les modèles mathématiques d’ajustement et de probabilité des données remontent au début des années 1800, et le théorème de Bayes et la méthode des moindres carrés d’ajustement des données. Les deux sont encore largement utilisés dans les modèles d’apprentissage automatique aujourd’hui, et nous les explorerons brièvement plus loin dans le chapitre.
12.3.1 Un bref historique des étapes de l’IA et de l’apprentissage automatique
Ce n’est que lorsque Marvin Minsky (MIT) a produit les premiers dispositifs de réseau neuronal appelés perceptrons au début des années 1950 que les ordinateurs et l’apprentissage ont été unifiés. Il a ensuite écrit un article en 1969 qui a été interprété comme une critique des limites des réseaux de neurones. Certes, au cours de cette période, la puissance de calcul était élevée. Les mathématiques dépassaient les ressources raisonnables des ordinateurs IBM S / 360 et CDC. Comme nous le verrons, les années 1960 ont introduit une grande partie des mathématiques et des fondements de l’intelligence artificielle dans des domaines tels que les réseaux de neurones, les machines à vecteurs de support, la logique floue, etc.
Le calcul évolutif tel que les algorithmes génétiques et l’intelligence en essaim est devenu un axe de recherche à la fin des années 1960 et 1970, avec les travaux d’Ingo Rechenberg, Evolutionsstrategie (1973). Il a gagné du terrain dans la résolution de problèmes d’ingénierie complexes. Les algorithmes génétiques sont encore utilisés aujourd’hui en génie mécanique, et même en conception de logiciels automatiques.
Le milieu des années 1960 a également introduit le concept de modèles de Markov cachés comme une forme d’IA probabiliste, comme les modèles bayésiens. Il avait été appliqué à la recherche en reconnaissance des gestes et en bioinformatique.
La recherche sur l’intelligence artificielle s’est endormie avec le tarissement du financement public jusqu’aux années 1980 et l’avènement des systèmes logiques. Cela a commencé le domaine de l’IA connu sous le nom d’IA basée sur la logique et prenant en charge les langages de programmation appelés Prolog et LISP, qui ont permis aux programmeurs de décrire facilement les expressions symboliques. Les chercheurs ont trouvé des limites à cette approche de l’IA: la sémantique principalement basée sur la logique ne pensait pas comme un humain. Les tentatives d’utilisation de modèles anti-logiques ou délabrés pour essayer de décrire des objets n’ont pas bien fonctionné non plus. Essentiellement, on ne peut pas décrire un objet avec précision en utilisant des concepts faiblement couplés. Plus tard dans les années 80, des systèmes experts ont pris racine. Les systèmes experts sont une autre forme de systèmes logiques pour un problème bien défini, formés par des experts dans ce domaine particulier. On pourrait les considérer comme un moteur basé sur des règles pour un système de contrôle. Les systèmes experts ont fait leurs preuves dans les entreprises et les entreprises et sont devenus les premiers systèmes d’IA disponibles dans le commerce. De nouvelles industries ont commencé à se former autour de systèmes experts. Ces types d’IA se sont développés et IBM a utilisé le concept pour construire Deep Thought pour vaincre le grand maître d’échecs Garry Kasparov en 1997.
La logique floue s’est manifestée pour la première fois dans les recherches de Lotfi A. Zadeh à UC Berkeley en 1965, mais ce n’est qu’en 1985 que les chercheurs d’Hitachi ont montré comment la logique floue pouvait être appliquée avec succès aux systèmes de contrôle. Cela a suscité un intérêt considérable chez les entreprises japonaises de l’automobile et de l’électronique pour adopter des systèmes flous dans les produits réels. La logique floue a été utilisée avec succès dans les systèmes de contrôle, et nous en discuterons formellement plus loin dans ce chapitre.
Alors que les systèmes experts et la logique floue semblaient être le pilier de l’IA, il y avait un écart croissant et notable entre ce qu’elle pouvait faire et ce qu’elle ne pourrait jamais faire. Les chercheurs du début des années 90 ont vu que les systèmes experts, ou les systèmes basés sur la logique, en général, ne pouvaient jamais imiter l’esprit. Les années 1990 ont amené l’avènement de l’IA statistique sous la forme de modèles de Markov cachés et de réseaux bayésiens. Essentiellement, l’informatique a adopté des modèles couramment utilisés en économie, en commerce et en recherche opérationnelle pour prendre des décisions.
Les machines à vecteurs de support ont été proposées pour la première fois par Vladimir N.Vapnik et Alexey Chervonenkis en 1963, mais sont devenues populaires après l’hiver IA des années 1970 et au début des années 1980. Les machines à vecteurs de support (SVM) sont devenues le fondement de la classification linéaire et non linéaire en utilisant une nouvelle technique pour trouver les meilleurs hyperplans pour catégoriser les ensembles de données. Cette technique est devenue populaire avec l’analyse de l’écriture manuscrite. Bientôt, cela a évolué vers des utilisations pour les réseaux de neurones.
Les réseaux de neurones récurrents (RNN) sont également devenus un sujet d’intérêt dans les années 1990. Ce type de réseau était unique et différent des réseaux neuronaux d’apprentissage en profondeur tels que les réseaux de neurones convolutionnels, car il maintenait l’état et pouvait être appliqué à un problème impliquant la notion de temps, comme la reconnaissance audio et vocale. Les RNN ont un impact direct sur les modèles prédictifs de l’IoT aujourd’hui, dont nous parlerons plus loin dans ce chapitre.
Un événement majeur s’est produit en 2012 dans le domaine de la reconnaissance d’image. Lors d’un concours, des équipes du monde entier ont participé à une tâche informatique consistant à reconnaître l’objet dans une vignette de 50 pixels par 30 pixels. Une fois l’objet étiqueté, la tâche suivante consistait à dessiner une boîte autour de lui. La tâche consistait à le faire pour 1 million d’images. Une équipe de l’Université de Toronto a construit le premier réseau de neurones à convolution profonde pour traiter des images afin de remporter ce concours. D’autres réseaux de neurones avaient tenté cet exercice de vision industrielle dans le passé, mais l’équipe a développé une approche qui identifiait les images avec plus de précision que toute autre approche auparavant, avec un taux d’erreur de 16,4%. Google a développé un autre réseau neuronal qui a ramené le taux d’erreur à 6,4%. C’est également à cette époque qu’Alex Krizhevsky a développé AlexNet, qui a introduit les GPU à l’équation pour accélérer considérablement la formation. Tous ces modèles ont été construits autour de réseaux de neurones convolutifs et avaient des exigences de traitement qui étaient prohibitives jusqu’à l’avènement des GPU.
Aujourd’hui, nous trouvons l’IA partout, des voitures autonomes à la reconnaissance vocale dans Siri, aux outils imitant les humains dans le service client en ligne, à l’imagerie médicale, aux détaillants utilisant des modèles d’apprentissage automatique pour identifier l’intérêt des consommateurs pour le shopping et la mode au fur et à mesure qu’ils se déplacent :
Figure 5 : Le spectre des arti fi des algorithmes d’intelligence cielles
Qu’est-ce que cela a à voir avec l’IoT ? Eh bien, l’IoT ouvre le robinet à une énorme quantité de données en continu. La valeur d’un système de capteurs n’est pas ce qu’un capteur mesure, mais ce qu’une collection de capteurs mesure et nous parle d’un système beaucoup plus grand. L’IoT, comme mentionné précédemment, sera le catalyseur pour générer une fonction d’étape dans la quantité de données collectées. Certaines de ces données seront structurées : séries temporelles. D’autres données ne seront pas structurées : caméras, capteurs synthétiques, signaux audios et analogiques. Le client souhaite prendre des décisions utiles pour son entreprise sur la base de ces données – par exemple, dans une usine de fabrication qui prévoit d’optimiser les dépenses opérationnelles et potentiellement les dépenses en capital en adoptant l’IoT et l’apprentissage automatique (du moins, c’est ce sur quoi ils ont été vendus). Lorsque nous pensons à un cas d’utilisation de l’IoT en usine, le fabricant aura de nombreux systèmes interdépendants. Ils peuvent avoir un outil d’assemblage pour produire un widget, un robot pour couper des pièces en métal ou en plastique, une autre machine pour effectuer un certain type de moulage par injection, des bandes transporteuses, des systèmes d’éclairage et de chauffage, des machines d’emballage, des systèmes de contrôle des stocks et des stocks, des robots pour déplacer le matériel et divers niveaux de systèmes de contrôle. En fait, cette entreprise peut avoir plusieurs de ces espaces répartis sur un campus ou une géographie. Une usine comme celle-ci a adopté tous les modèles traditionnels d’efficacité, et ses dirigeants ont lu la littérature de W. Edwards Deming ; Cependant, la prochaine révolution industrielle prendra la forme de l’IoT et de l’intelligence artificielle.
Les personnes spécialisées savent quoi faire lorsqu’un événement erratique se produit. Par exemple, un technicien qui exploite l’une des machines d’assemblage depuis des années sait quand la machine a besoin de services en fonction de son comportement. Il peut commencer à grincer d’une certaine manière. Peut-être qu’il est épuisé sa capacité de choisir et de placer des pièces et en a laissé tomber quelques-uns au cours des deux derniers jours. Ces effets comportementaux simples sont des choses que l’apprentissage automatique peut voir et prédire avant même qu’un humain ne le puisse. Les capteurs peuvent entourer ces appareils et surveiller les actions perçues et présumées. Une usine entière pourrait être perçue dans un tel cas pour comprendre comment cette usine fonctionne à l’instant même sur la base d’une collection de millions ou de milliards d’événements de chaque machine et de chaque travailleur de ce système.
Avec cette quantité de données, seul un appareil d’apprentissage automatique peut filtrer le bruit et trouver ce qui est pertinent. Ce ne sont pas des problèmes gérables par l’homme, mais le problème gérable des mégadonnées et de l’apprentissage automatique.
12.3.2 Modèles d’apprentissage automatique
Nous allons maintenant nous concentrer sur des modèles d’apprentissage automatique spécifiques qui sont applicables à l’IoT. Il n’y a pas un seul gagnant pour vous de choisir de passer au crible une collection de données. Chaque modèle a une force particulière et des cas d’utilisation qu’il sert le mieux. Le but de tout outil d’apprentissage automatique est d’arriver à une prédiction ou à une inférence de ce qu’un ensemble de données vous dit. Vous voulez être meilleur que le résultat de 50% de lancer une pièce.
Il y a deux types de systèmes d’apprentissage à considérer, qui sont les suivants :
- Apprentissage supervisé : Cela implique simplement que les données de formation fournies au modèle ont une étiquette associée à chaque entrée. Par exemple, un ensemble peut être une collection d’images étiquetées chacune avec le contenu de cette image : par exemple, chat, chien, banane, voiture. De nombreux modèles d’apprentissage automatique sont aujourd’hui supervisés. L’apprentissage supervisé implique un humain (ou des groupes d’humains). La formation d’un modèle à un degré élevé de précision peut être longue.
L’apprentissage supervisé permet de résoudre les problèmes de classification et de régression. Nous discuterons de la classification et de la régression plus loin dans ce chapitre.
- Apprentissage non supervisé : il n’a pas d’étiquette pour les données d’entraînement. De toute évidence, ce type d’apprentissage ne peut pas résoudre une image d’un chien au chien étiquette. Ce type de modèle d’apprentissage utilise des règles mathématiques pour réduire la redondance. Un cas d’utilisation typique consiste à trouver des groupes de choses similaires.
Il existe également un hybride des deux modèles, appelé apprentissage semi-supervisé, qui mélange des données étiquetées et des données non étiquetées. L’objectif est de forcer le modèle d’apprentissage automatique à organiser les données ainsi qu’à faire des inférences.
Les trois utilisations fondamentales de l’apprentissage automatique sont les suivantes:
- Classification
- Régression
- Détection d’anomalies
Il y a des dizaines de constructions d’apprentissage automatique et d’intelligence artificielle dont on pourrait parler avec une application à l’IoT, mais cela dépasserait largement le cadre de cet article. Nous nous concentrerons sur un petit ensemble de modèles pour comprendre où ils se situent les uns par rapport aux autres, ce qu’ils ciblent et quelles sont leurs forces. Nous voulons explorer les utilisations et les limites de l’apprentissage statistique, probabiliste et approfondi, car ce sont les domaines prédominants applicables à l’intelligence artificielle IoT.
Au sein de chacun de ces grands segments, nous généraliserons et plongerons dans les éléments suivants :
- Forêts aléatoires : modèles statistiques (modèles rapides, bons pour les systèmes avec de nombreux attributs nécessaires pour la détection des anomalies)
- Réseaux bayésiens : modèles probabilistes
- Réseaux de neurones convolutifs (CNN) : modèle d’apprentissage profond pour les données d’images non structurées
- Réseaux de neurones récurrents (RNN) : modèle d’apprentissage profond pour l’analyse de séries chronologiques
Certains modèles ne sont plus applicables dans l’espace d’intelligence artificielle, du moins pour les cas d’utilisation IoT que nous considérons. Nous ne nous concentrerons donc pas sur les modèles logiques, les algorithmes génétiques ou la logique floue.
Nous parlerons d’abord d’une nomenclature initiale autour des classificateurs et de la régression.
12.3.3 Classification
La classification est une forme d’apprentissage supervisé où les données sont utilisées pour choisir un nom, une valeur ou une catégorie – par exemple, en utilisant un réseau neuronal pour numériser des images pour trouver des images d’une chaussure. Dans ce domaine, il existe deux variantes de classification :
- Classification binaire ou binomiale : lorsque vous choisissez entre l’un des deux groupes ou catégories. Par exemple : café contre thé, noir contre blanc.
- Classification multiclasse : lorsqu’il y a plus de deux groupes ou catégories. Par exemple, la classification des fruits peut inclure l’ensemble des oranges, des bananes, des raisins et des pommes. Un fruit peut être une pomme ou une banane mais pas les deux.
Nous utilisons l’outil de classificateur linéaire de Stanford pour aider à comprendre le concept d’hyperplans ( http://vision.stanford.edu/teaching/cs231n-demos/linear-classify/ ). Le diagramme suivant montre les tentatives d’un système d’apprentissage formé pour trouver le meilleur hyperplan pour diviser les boules colorées. Nous pouvons voir qu’après plusieurs milliers d’itérations, la division est quelque peu optimale, mais il y a toujours des problèmes avec la région en haut à droite, où l’hyperplan correspondant comprend une balle qui appartient à l’hyperplan supérieur. Ci-dessous est un exemple d’une classification moins qu’optimale.
Ici, les hyperplans sont utilisés pour créer des segments artificiels. En haut à droite montre une seule balle qui devrait être classée avec les deux autres balles en haut mais qui a été classée pour appartenir à l’ensemble en bas à droite. Le coin supérieur gauche montre également une boule rouge qui devrait être classée avec les boules rouges en haut à droite, mais l’hyperplan la force incorrectement au cluster vert.
Figure 6 : Moins optimale classification
Remarquez dans l’exemple précédent de Stanford que l’hyperplan est une ligne droite. Ceci est appelé un classificateur linéaire, et il comprend des constructions telles que les machines à vecteurs de support (qui tentent de maximiser la linéarité) et la régression logistique (qui peuvent être utilisées pour la classe binomiale et l’ajustement multiclasse). Le graphique suivant montre une classification linéaire binomiale de deux ensembles de données : les cercles et les diamants.
Ici, une ligne tente de former un hyperplan pour diviser deux régions distinctes de variables. Notez que la meilleure relation linéaire inclut des erreurs :
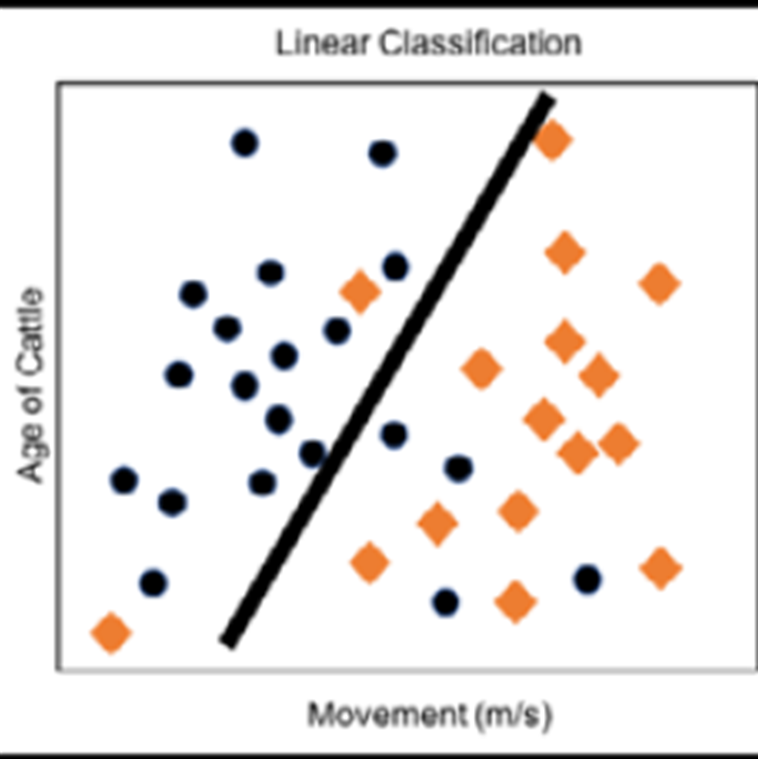
Figure 7 : linéaire classifieur
Les relations non linéaires sont également courantes dans l’apprentissage automatique lorsque l’utilisation d’un modèle linéaire entraînerait de graves taux d’erreur. Un problème avec le modèle non linéaire est la tendance à surcharger la série de tests. Comme nous le verrons plus loin, cela a la propension à rendre l’outil d’apprentissage automatique précis lorsqu’il est exécuté sur les données de test de formation, mais inutile sur le terrain. La figure suivante est une comparaison d’un classificateur linéaire et non linéaire :
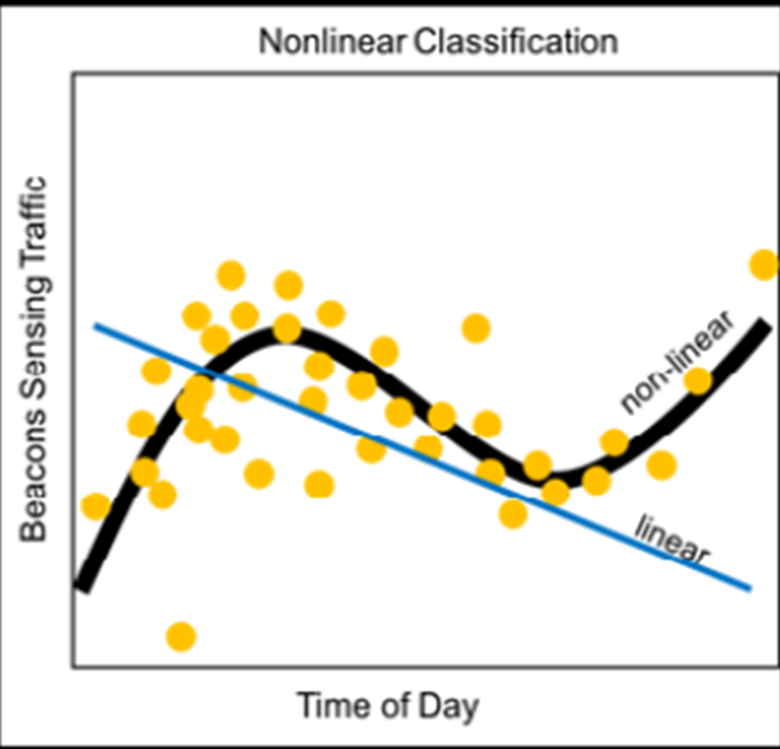
Figure 8 : Ici, une courbe polynomiale du nième ordre tente de construire un modèle beaucoup plus précis de l’ensemble des points de données. Les modèles très précis tendent à bien s’adapter à un ensemble d’entraînement connu mais ont échoué lorsqu’ils ont été présentés avec des données réelles.
12.3.4 Régression
La classification vise à prédire une valeur discrète (cercle ou diamants), tandis que les modèles de régression sont utilisés pour prédire une valeur continue. Par exemple, une analyse de régression serait utilisée pour prédire le prix de vente moyen de votre maison en fonction des prix de vente de toutes les maisons de votre quartier et des quartiers environnants.
Plusieurs techniques existent pour former l’analyse de régression : la méthode des moindres carrés, la régression linéaire et la régression logistique.
La méthode des moindres carrés est la méthode de régression standard et d’ajustement des données la plus fréquemment utilisée. Autrement dit, la méthode minimise la somme des carrés de toutes les erreurs dans un ensemble de données. Par exemple, dans un tracé x, y bidimensionnel, l’ajustement de la courbe d’une série de points tente de minimiser l’erreur de tous les points du graphique :

Figure 9 : Méthode de régression linéaire. Ici, nous essayons de réduire l’erreur dans une équation d’ajustement de courbe en mettant au carré et en additionnant chaque valeur d’erreur.
Les méthodes des moindres carrés sont sujettes à des données aberrantes qui peuvent fausser les résultats de manière incorrecte. Il est recommandé de nettoyer les données des valeurs aberrantes. Dans les cas d’utilisation Edge et IoT, cela peut et devrait très probablement être effectué à proximité des capteurs pour éviter de déplacer des données erronées en premier lieu.
La régression linéaire est une méthode très courante utilisée en science des données et en analyse statistique où la relation entre deux variables est modélisée en leur ajustant une équation linéaire. Une variable assume le rôle d’une variable explicative (également appelée variable indépendante), et l’autre est une variable dépendante. La régression linéaire tente de trouver la ligne droite la mieux adaptée à travers un ensemble de points. La ligne droite la mieux adaptée est appelée ligne de régression. Pour calculer la droite de régression, une équation de pente simple peut être utilisée : y = mx + b.
Cependant, nous pouvons utiliser une approche statistique où M x est la valeur moyenne de la variable x, M y est la moyenne de la variable y , S x est l’écart-type de x , S y est l’écart-type de y et r est la corrélation entre x et y . La pente devient alors :
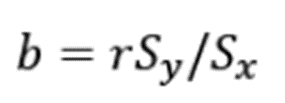
L’ordonnée à l’origine (A) devient :
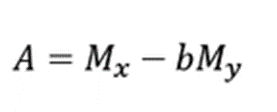
La régression logistique, également connue sous le nom de fonction sigmoïde, est une forme d’algèbre linéaire utilisée pour modéliser la probabilité d’une classe ou d’un événement. Par exemple, vous pouvez modéliser la probabilité de défaillance d’une turbine en fonction de la chaleur entourant le moteur. Nous modélisons essentiellement la probabilité qu’une entrée X appartient à la classe Y = 1. Écrit d’une autre manière :

La probabilité représentée ici est binaire (0 ou 1). Il s’agit d’une différence essentielle par rapport à la régression linéaire. La valeur b 0 représente l’ordonnée à l’origine et b 1 représente le coefficient à apprendre. Ces coefficients doivent être trouvés par des méthodes d’estimation et de minimisation. Les meilleurs coefficients de régression logistique auraient une valeur proche de 1 pour la classe par défaut et de 0 pour toutes les autres classes.

Appliquer cela comme une fonction probabiliste :
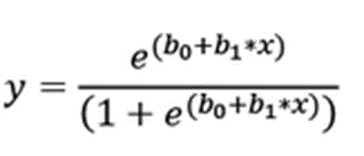
Un exemple de régression logistique consiste à prédire si un réfrigérateur à chambre froide peut conserver les aliments congelés en fonction de la température de l’air extérieur. Supposons que nous avons utilisé une procédure d’estimation de minimisation pour calculer les b coefficients et trouvé b 0 à -10 et b 1 à 0,5. Si la température extérieure est de 24 degrés Celsius, le résultat sera de 99,5%. Brancher les valeurs dans l’équation :
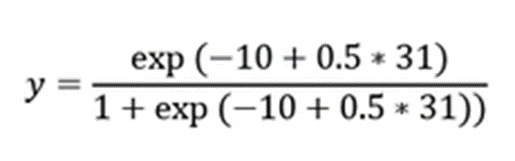
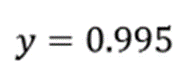
12.3.5 Forêt aléatoire
Une forêt aléatoire est un sous-ensemble d’un autre modèle d’apprentissage automatique appelé arbre de décision . Un arbre de décision, comme le montre le diagramme au début de cette section, est un groupe d’algorithmes d’apprentissage qui font partie de l’ensemble statistique. Un arbre de décision prend simplement en compte plusieurs variables et produit une sortie unique qui classe les éléments. Chaque élément évalué est appelé l’ensemble. L’arbre de décision produit un ensemble de probabilités qu’un chemin a été pris en fonction de l’entrée. Une forme d’arbre de décision est l’arbre de classification et de régression (CART), développé par Leo Breiman en 1983.
Nous introduisons maintenant la notion d’agrégation bootstrap ou d’ensachage. Lorsque vous avez un seul arbre de décision en cours de formation, il est sensible au bruit qui y est injecté et peut former un biais. Si, en revanche, vous avez de nombreux arbres de décision en cours de formation, nous pouvons réduire le risque de biaiser le résultat. Chaque arbre choisira un ensemble aléatoire de données d’entraînement ou d’échantillons.
La sortie de la formation forestière aléatoire traite un arbre de décision basé sur une sélection aléatoire des données de formation et une sélection aléatoire de variables :

Figure 10: Modèle de forêt aléatoire. Ici, deux forêts sont construites pour choisir un ensemble aléatoire, mais pas l’ensemble, de variables.
Les forêts aléatoires étendent l’ensachage en sélectionnant non seulement un ensemble d’échantillons aléatoires, mais également un sous-ensemble du nombre de caractéristiques à qualifier. Cela peut être vu dans l’image précédente. C’est contre-intuitif, car vous voulez vous entraîner sur autant de données que possible. La justification est que :
- La plupart des arbres sont précis et fournissent des prévisions correctes pour la plupart des données
- Des erreurs dans l’arbre de décision peuvent se produire à différents endroits, dans différents arbres
C’est la règle de la pensée de groupe, également appelée décision majoritaire. Si les résultats de plusieurs arbres sont en accord, même s’ils sont arrivés à cette décision par différents chemins et qu’un seul arbre est une valeur aberrante, on se rangera naturellement du côté de la majorité. Cela crée un modèle avec une faible variance, par rapport à un modèle d’arbre de décision unique, qui peut être extrêmement biaisé. Nous pouvons voir l’exemple suivant avec quatre arbres dans une forêt aléatoire. Chacun a été formé sur un sous-ensemble différent de données et chacun a choisi des variables aléatoires. Le résultat du flux est que trois des arbres produisent un résultat de 9, tandis que le quatrième arbre produit un résultat différent.
Indépendamment de ce que le quatrième arbre a produit, la majorité a convenu par un ensemble de données différent, une variable différente et des structures d’arbre différentes que le résultat de la logique devrait être un 9 :

Figure 11 : Décision majoritaire d’une forêt aléatoire. Ici, plusieurs arbres basés sur une collection aléatoire de variables arrivent à 9 comme décision. Arriver à une réponse similaire basée sur des données différentes renforce généralement le modèle.
12.3.6 Modèles bayésiens
Les modèles bayésiens sont basés sur le théorème de Bayes de 1812. Le théorème de Bayes décrit la probabilité qu’un événement se produise sur la base d’une connaissance préalable du système. Par exemple, quelle est la probabilité qu’une machine tombe en panne en fonction de la température de l’appareil ?
Le théorème de Bayes s’exprime comme suit :
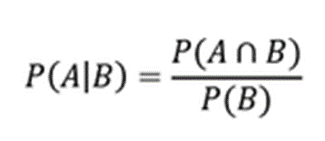
A et B sont les événements intéressants. P (A | B) demande, quelle est la probabilité que l’événement A se produise, étant donné que l’événement B s’est produit? Ils n’ont aucun rapport les uns avec les autres et s’excluent mutuellement.
L’équation peut être réécrite en utilisant le théorème de la probabilité totale, qui remplace P (B) . Nous pouvons étendre esta également à i nombre d’événements. P (B | A) est la probabilité que l’événement B se produise, étant donné que l’événement A s’est produit. Voici la définition formelle du théorème de Bayes :
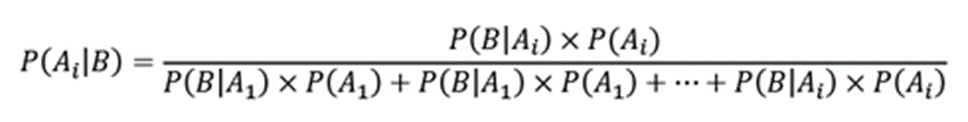
Dans ce cas, nous avons affaire à une seule probabilité et à son complément (réussite / échec). L’équation peut être réécrite comme suit :
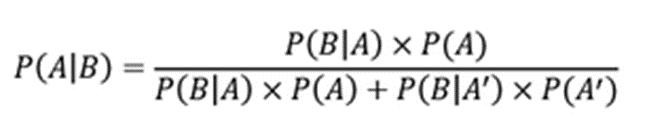
Un exemple suit. Supposons que nous ayons deux machines produisant des pièces identiques pour un widget. Supposons qu’une machine puisse tomber en panne si sa température dépasse une certaine valeur. La machine A tombera en panne 2% du temps si la température dépasse une certaine température. La machine B tombera en panne 4% du temps si elle dépasse une certaine température. La machine A produit 70% des pièces et la machine B les 30% restants. Si je prends une pièce au hasard et qu’elle échoue, quelle est la probabilité qu’elle ait été produite par la machine A et quelle est la probabilité qu’elle ait été produite par la machine B ?
Dans ce cas, A est un article produit par la machine A, et B est un article produit par la machine B . F représente la partie choisie ayant échoué. Nous savons :
- P (A) = 0,7
- P (B) = 0,3
- P (F | A) = 0,02
- P (F | B) = 0,04
Par conséquent, la probabilité que vous choisissiez une pièce défectueuse de la machine A ou B est :
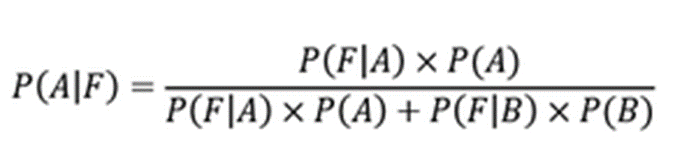
Remplacement des valeurs :
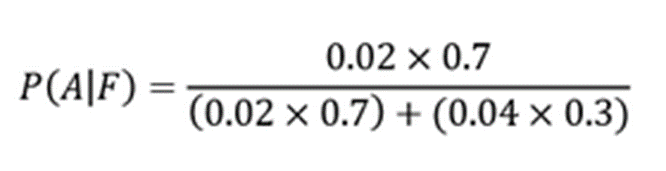
Par conséquent, P (A | F) = 53% et P (B | F) est le complément (1 – 0,53) = 47%.
Un réseau bayésien est une extension du théorème de Bayes sous la forme d’un modèle de probabilité graphique, spécifiquement un graphe acyclique dirigé. Remarquez que le graphique s’écoule dans un sens et qu’il n’y a pas de bouclage vers les états précédents; c’est une exigence du réseau bayésien:

Figure 12 : Modèle de réseau bayésien
Ici, les différentes probabilités de chaque état proviennent de connaissances d’experts, de données historiques, de journaux, de tendances ou de combinaisons de ceux-ci. Il s’agit du processus de formation d’un réseau bayésien. Ces règles peuvent être appliquées à un modèle d’apprentissage dans un environnement IoT. À mesure que les données des capteurs affluent, le modèle pourrait prédire les défaillances de la machine. De plus, le modèle pourrait être utilisé pour faire des inférences. Par exemple, si les capteurs lisent une condition de surchauffe, on pourrait en déduire qu’il existe une probabilité qu’elle soit liée à la vitesse de la machine ou à une obstruction.
Il existe des variantes de réseaux bayésiens qui dépassent le cadre de cet article, mais présentent des avantages pour certains types de données et ensembles de problèmes :
- Naive Bayes
- Bayes naïfs gaussiens
- Réseaux de croyances bayésiennes
Un réseau bayésien est bon pour les environnements IoT qui ne peuvent pas être complètement observés. De plus, dans une situation où les données ne sont pas fiables, les réseaux bayésiens ont un avantage. Des données d’échantillon médiocres, des données bruyantes et des données manquantes ont moins d’effet sur les réseaux bayésiens que d’autres formes d’analyse prédictive. La mise en garde est que le nombre d’échantillons devra être très important. Les méthodes bayésiennes évitent également le problème de surajustement, dont nous discuterons plus tard lorsque nous examinerons les réseaux de neurones. De plus, les modèles bayésiens s’intègrent bien avec les données en streaming, ce qui est un cas d’utilisation typique dans l’IoT. Des réseaux bayésiens ont été déployés pour trouver des aberrations dans les signaux et les séries en corrélation temporelle provenant de capteurs et également pour trouver et filtrer les paquets malveillants dans les réseaux.
12.3.7 Réseaux de neurones convolutifs
Un CNN est une forme de réseau neuronal artificiel dans l’apprentissage automatique. Nous allons d’abord inspecter le CNN, puis passer au RNN. Un CNN s’est avéré très fiable et précis pour la classification d’images et est utilisé dans les déploiements IoT pour la reconnaissance visuelle, en particulier dans les systèmes de sécurité. C’est un bon point de départ pour comprendre le processus et les mathématiques derrière tout réseau neuronal artificiel. Toutes les données pouvant être représentées sous forme de bitmap fixe (par exemple, une image de 1024 x 768 pixels sur trois plans). Un CNN tente de classer une image sur une étiquette (par exemple, chat, chien, poisson, oiseau) sur la base d’un ensemble additif de caractéristiques décomposables. Les fonctions primitives qui composent le contenu de l’image sont constituées de petits ensembles de lignes horizontales, de lignes verticales, de courbes, de nuances, de directions de dégradé, etc.
12.3.7.1 Première couche et filtres
Cet ensemble de fonctionnalités de base dans la première couche d’un CNN serait des identificateurs de fonctionnalités tels que de petites courbes, de minuscules lignes, des taches de couleur ou de petites fonctionnalités distinctives (dans le cas des classificateurs d’images). Les filtres tournent autour de l’image à la recherche de similitudes. L’algorithme de convolution prendra le filtre et multipliera la somme des valeurs de matrice résultantes. Les filtres s’activent lorsqu’une fonctionnalité spécifique entraîne une valeur d’activation élevée:

Figure 13 : La première couche d’un CNN. Ici, de grandes primitives sont utilisées pour mettre en correspondance les entrées.
12.3.7.2 Regroupement maximal et sous-échantillonnage
La couche suivante sera généralement une couche de regroupement ou de regroupement maximal. Cette couche prendra en entrée toutes les valeurs dérivées de la dernière couche. Il renvoie ensuite la valeur maximale pour un ensemble de neurones voisins, qui est utilisée comme entrée pour un seul neurone dans la couche de convolution suivante. Il s’agit essentiellement d’une forme de sous-échantillonnage. En règle générale, la couche de mise en commun sera une matrice de sous-région 2×2 comme résultat:
Figure 14 : Mise en commun maximale. Les tentatives de fi nd la valeur maximale dans une fenêtre glissante sur une image.
Le regroupement a plusieurs options : maximisation (comme illustré dans le diagramme précédent), moyenne et autres méthodes sophistiquées. Le regroupement maximal a pour but d’indiquer qu’une caractéristique particulière a été trouvée dans une région de l’image. Nous n’avons pas besoin de connaître la position exacte, juste une localité générale. Cette couche reproduit également les dimensions auxquelles nous devons faire face, qui affectent finalement les performances du réseau neuronal, la mémoire et l’utilisation du processeur. La mise en commun maximale contrôle également le sur-ajustement. Les chercheurs ont appris que si le réseau neuronal est finement réglé sur les images sans ce type de sous-échantillonnage, il fonctionnera bien sur l’ensemble de données d’apprentissage avec lequel il a été programmé, mais échouera lamentablement avec des images du monde réel.
12.3.7.3 Le modèle fondamental d’apprentissage en profondeur
Les deuxièmes couches convolutives utilisent les résultats de la première couche comme entrée. N’oubliez pas que l’entrée de la première couche était le bitmap d’origine. La sortie de la première couche représente en fait l’emplacement dans le bitmap 2D où une primitive spécifique a été vue. Les fonctionnalités de la deuxième couche sont plus complètes que la première. La deuxième couche aurait des structures composites telles que des splines et des courbes. Ici, nous décrirons le rôle du neurone et les calculs nécessaires pour forcer une sortie d’un neurone.
Le rôle du neurone est de saisir la somme de tous les poids y entrant par rapport aux valeurs des pixels. Dans le graphique suivant, nous voyons le neurone accepter les entrées de la couche précédente sous la forme de poids et de valeurs bitmap.
Le rôle du neurone est de additionner les poids et les valeurs et de les forcer à travers une fonction d’activation comme entrée dans la couche suivante:

Figure 15: élément de base CNN. Ici, le neurone est une unité de base de calcul avec des poids et d’autres valeurs bitmap prises en entrée. Les Neuron fi res (ou non) en fonction de la fonction d’activation.
L’équation de la fonction neuronale est:
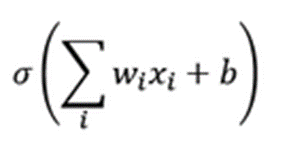
Cela peut être un problème de multiplication de matrice très important. L’image d’entrée est aplatie en un tableau unidimensionnel. Le biais fournit une méthode pour influencer la sortie sans interagir avec les données réelles. Dans le diagramme suivant, nous voyons un exemple d’une matrice de poids multipliée par une image unidimensionnelle aplatie et avec le biais ajouté. Notez que dans les appareils CNN réels, vous pouvez ajouter le biais à la matrice de poids et ajouter une seule valeur 1.0 au bas du vecteur bitmap comme forme d’optimisation. Ici, la deuxième valeur dans la matrice de résultat de 29,6 est la valeur choisie:

Figure 16 : Relation matricielle de CNN. Ici, les poids et le bitmap sont multipliés par matrice et ajoutés à un biais.
Les valeurs d’entrée sont multipliées par la pondération à chaque entrée dans le neurone. Il s’agit d’une simple transformation linéaire en mathématiques matricielles. Cette valeur doit passer par une fonction d’activation pour déterminer si le neurone doit se déclencher. Un système numérique construit sur des transistors prend des tensions en entrée, et si la tension atteint une valeur seuil, le transistor se met sous tension.
L’analogue biologique est le neurone qui se comporte de façon non linéaire avec l’entrée. Puisque nous modélisons un réseau de neurones, nous essayons d’utiliser des fonctions d’activation non linéaires. Les fonctions d’activation typiques qui peuvent être choisies comprennent :
- Logistique (sigmoïde)
- soH
- Unité linéaire rectifiée (ReLU)
- Unité linéaire exponentielle sinusoïdale (ELU)
La fonction d’activation sigmoïde est :
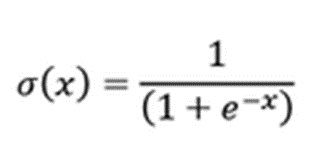
Sans couche sigmoïde (ou tout autre type de fonction d’activation), le système serait une fonction de transformation linéaire et aurait une précision sensiblement moindre pour la reconnaissance d’images ou de motifs.
12.3.7.4 Exemples CNN

Figure 17 : CNN à quatre couches. Ici, une image est convolutionnée pour extraire de grandes fonctionnalités basées sur Primitives Et puis utiliser une piscine max à l’échelle de l’image vers le bas et l’alimenter en entrée à la fonction fi ltres. La couche entièrement connectée termine le chemin CNN et génère la meilleure estimation.
Un exemple de fonctionnalités primitives qui composent les couches est fourni par TensorFlow ( http://playground.tensorflow.org ). L’exemple TensorFlow d’un système avec six entités sur la couche d’entrée 1, suivi de 33 couches cachées de quatre neurones, suivi de deux neurones et se terminant par deux autres est illustré dans le diagramme suivant. Dans ce modèle, les fonctions tentent de classer les groupes de couleurs de points.
Ici, nous essayons de trouver l’ensemble optimal de fonctionnalités qui décrivent une spirale de deux boules colorées. Les primitives de la fonction initiale sont essentiellement des lignes et des rayures. Celles-ci se combineront et seront renforcées grâce aux pondérations formées pour décrire la prochaine couche de taches et de taches. Lorsque vous vous déplacez vers la droite, des représentations plus détaillées et composites se forment.
Ce test a parcouru plusieurs milliers d’époques dans le but de montrer les régions qui décrivent une spirale à droite. Vous pouvez voir la courbe de sortie en haut à droite, qui indique la quantité d’erreur dans le processus de formation. Les erreurs ont en fait augmenté au milieu de la séance d’entraînement, car des effets chaotiques et aléatoires ont été observés pendant la rétropropagation. Le système a ensuite guéri et optimisé pour le résultat final. Les lignes entre les neurones indiquent la force du poids dans la description du motif en spirale:
Figure 18 : Exemple CNN dans TensorFlow Playground. Avec l’aimable autorisation de Daniel Smilkov et TensorFlow Playground sous Apache License 2.0.
Dans l’image précédente, un CNN est modélisé à l’aide d’un outil d’apprentissage appelé TensorFlow Playground . Ici, nous voyons la formation d’un réseau neuronal à quatre couches dont le but est de classer une spirale de boules de différentes couleurs. Les fonctionnalités de gauche sont les primitives initiales, telles que les changements de couleur horizontaux ou les changements de couleur verticaux. Les couches cachées sont entraînées par rétropropagation. Le facteur de pondération est illustré par l’épaisseur d’une ligne jusqu’à la couche cachée suivante. Le résultat est affiché à droite, après plusieurs minutes d’entraînement.
La dernière couche est une couche entièrement connectée, ainsi appelée car il est nécessaire que chaque nœud de la couche finale soit connecté à chaque nœud du niveau précédent. Le rôle de la couche entièrement connectée est de résoudre finalement l’image en une étiquette.
Pour ce faire, il inspecte la sortie et les fonctionnalités de la dernière couche et détermine que l’ensemble des fonctionnalités correspond à une étiquette particulière, telle qu’une voiture. Une voiture aura des roues, des vitres, etc. pendant ce temps, un chat aura des yeux, des pattes, de la fourrure, etc.
12.3.7.5 Vernaculaire des CNN
L’utilisation des CNN comprend une litanie de termes et de concepts. TensorFlow Playground est un bon outil pour comprendre le comportement et l’effet de différents modèles, des identificateurs de fonction et le rôle des tailles de lots et des époques dans la formation d’un modèle. L’image suivante est un balisage sur TensorFlow Playground décrivant les différents termes et paramètres qui composent un modèle CNN.
Figure 19 : Les différents paramètres des modèles d’apprentissage profond CNN. Notez en particulier les effets de la taille des lots, des époques et du taux d’apprentissage.
12.3.7.6 Propagation vers l’avant, formation CNN et rétropropagation
Nous avons vu le processus de propagation en aval comme un CNN s’exécute. La formation d’un CNN repose sur le processus de rétropropagation des erreurs et des gradients, la dérivation d’un nouveau résultat et la correction des erreurs encore et encore.
Le même réseau, comprenant toutes les couches de mise en commun, les fonctions d’activation et les matrices, est utilisé comme flux de propagation vers l’arrière à travers le réseau dans le but d’optimiser ou de corriger la pondération :
Figure 20: Propagation vers l’avant du CNN pendant l’entraînement et l’inférence
La rétropropagation est l’abréviation de « propagation arrière des erreurs ». Ici, une fonction d’erreur calculera le gradient d’une fonction d’erreur sur la base des poids du réseau neuronal. Le calcul du dégradé est forcé vers l’arrière à travers toutes les couches cachées. Le processus de rétropropagation est illustré ci-dessous :
Figure 21: propagation vers l’arrière du CNN pendant l’entraînement
Nous allons maintenant explorer le processus de formation. Tout d’abord, nous devons fournir un ensemble de formation pour que le réseau se normalise. L’ensemble de formation et les paramètres de fonction sont cruciaux pour développer un système qui se comporte bien sur le terrain. Les données d’entraînement auront une image (ou simplement des données bitmap) et une étiquette connue. Cet ensemble de formation est itéré contre l’utilisation de la technique de rétropropagation pour finalement construire un modèle de réseau neuronal qui produit les classifications ou les prévisions les plus précises. Un ensemble d’entraînement trop petit produira de mauvais résultats. Par exemple, si vous construisiez un appareil pour classer toutes les marques de chaussures, vous auriez besoin de plus qu’une seule image d’une marque de chaussures particulière. Vous voulez que l’ensemble inclue différentes chaussures, différentes couleurs, différentes marques et différentes images en utilisant différents éclairages et angles.
Deuxièmement, le réseau neuronal est composé de valeurs initiales identiques ou de valeurs aléatoires pour chaque poids sur chaque neurone qui doit être entraîné. La première passe en avant entraîne des erreurs substantielles qui entrent dans une fonction de perte :

Ici, les nouveaux poids sont basés sur le poids précédent W (t – 1) moins la dérivée partielle de l’erreur E sur le poids W (fonction de perte). Cela s’appelle également le gradient . Dans l’équation, lambda fait référence au taux d’apprentissage. C’est au concepteur de régler. Si le taux est élevé (supérieur à 1), l’algorithme utilisera des étapes plus importantes dans le processus d’essai. Cela peut permettre au réseau de converger vers une réponse optimale plus rapidement, ou cela pourrait produire un réseau mal formé qui ne convergera jamais vers une solution. Alternativement, si lambda est réglé bas (moins de 0,01), la formation prendra de très petites étapes et beaucoup plus de temps pour converger, mais la précision du modèle peut être meilleure. Dans l’exemple suivant, la convergence optimale est tout en bas de la courbe représentant l’erreur et les pondérations. C’est ce qu’on appelle la descente en pente, Si le taux d’apprentissage est trop élevé, nous ne pourrions jamais atteindre le fond et devoir nous contenter d’ un fond proche vers l’un des côtés:
Figure 22 : Minimum global. Cette illustration montre la base d’une fonction d’apprentissage. L’objectif est de fi e la valeur minimale par une descente de gradient. La précision du modèle d’apprentissage est proportionnelle au nombre de pas (temps) pris pour converger au minimum.
Trouver un minimum global d’une fonction d’erreur n’est pas garanti. C’est-à-dire qu’un minimum local peut être trouvé et résolu comme un faux minimum global. L’algorithme aura souvent du mal à échapper au minimum local une fois trouvé. Dans le graphique suivant, vous voyez le minimum global correct et comment un minimum local peut être fixé:
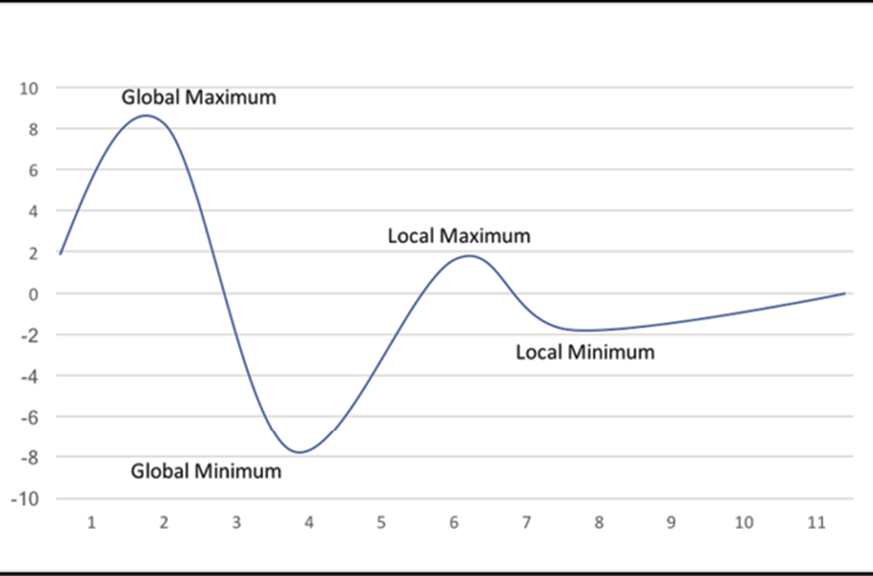
Figure 23 : Erreurs lors de la formation. Nous voyons le vrai minimum et maximum global. En fonction de facteurs tels que la taille de l’étape d’entraînement ou même le point de départ initial de la descente, un CNN pourrait être entraîné à un faux minimum.
Alors qu’un réseau de neurones s’entraîne et tente de trouver le minimum global, un problème se pose, appelé le problème du gradient de fuite. Lorsque les poids dans le réseau neuronal sont mis à jour, le gradient peut devenir artificiellement très petit. Cela a pour effet que le poids ne peut pas changer sa valeur. Cela peut même empêcher un réseau de neurones de poursuivre sa formation. L’exemple TensorFlow Playground utilise une fonction d’activation dont les valeurs vont de -1 à 1. Lorsque le réseau neuronal termine une époque et propage en arrière les erreurs pour recalculer les poids, vous pouvez atteindre un point où le signal d’erreur (gradient) diminue de façon exponentielle et le système peut s’entraîner extrêmement lentement. L’exemple suivant de TensorFlow Playground illustre comment le réseau neuronal a cessé de s’entraîner en raison du problème de gradient disparaissant après 1300 époques. La poursuite de la formation du modèle n’a permis d’obtenir aucune précision supplémentaire.
Pour atténuer le problème, des techniques telles que la mémoire à court terme à long terme (couverte dans la section Réseaux de neurones récurrents) peuvent aider ; un matériel rapide et un réglage fin des fonctions et paramètres d’entraînement appropriés peuvent être utiles.
Nous pouvons voir qu’il y a encore un certain degré d’erreur que la formation n’a pas pu résoudre :

Figure 24 : exemple de formation TensorFlow. La première image est le résultat de 100 époques en utilisant une taille de lot de 10. La seconde image est le résultat après 400 époques. Le résultat final est après 1316 époques et 10 minutes d’entraînement sur un processeur i7 à 3 GHz. Notez que le résultat final montre des “boules” incorrectement classées dans la zone inférieure gauche et supérieure droite de la spirale. Avec l’aimable autorisation de Daniel Smilkov et TensorFlow Playground sous Apache License 2.0.
Ici, nous voyons la progression de la formation (de gauche à droite) avec plus de précision. L’illustration de gauche montre clairement la forte influence des caractéristiques primitives horizontales et verticales. Après plusieurs époques, la formation commence à converger vers la vraie solution. Même après 1316 époques, il y a encore des cas d’erreur où la formation n’a pas convergé vers la bonne réponse.
La perte sera particulièrement lourde lors des premières exécutions du réseau. Nous pouvons visualiser cela avec TensorFlow Playground. Là encore, nous formons un réseau de neurones pour identifier les spirales. Au début de l’entraînement, la perte est lourde à 0,516 . Après 1531 époques, nous arrivons aux poids de ce réseau et à une perte de 0,061 .
Il est bon de comprendre la différence entre les lots et les époques pendant le processus de formation :
- Batch : cela fait référence au nombre d’échantillons d’apprentissage qui sont traités avant qu’une prédiction ne soit faite et les poids sont ajustés dans le modèle.
- Epoch : Cela fait référence au nombre d’itérations de la formation sur l’ensemble des données de formation. C’est généralement très élevé pour les modèles bien entraînés.
- Learning rate : il s’agit d’un paramètre qui contrôle le gradient. Il peut être ajusté, mais le risque est le problème de descente de gradient.
Par exemple, supposons que vous disposez de 200 images de chaussures différentes que vous utilisez pour former un modèle d’apprentissage en profondeur afin de détecter les marques de chaussures. Vous commencez par une formation utilisant 1000 itérations d’époque pour gérer les calendriers des produits et maintenir les dates d’expédition.
Si vous définissez une taille de lot de 5, vous parcourrez cinq images avant de corriger le modèle.
Les 5 images donnent 40 ensembles d’entraînement sur les 200 images. Cela implique qu’il existe 40 lots d’images pour traiter l’ensemble de la formation. Chaque fois que vous passez par l’ensemble de formation, vous terminez une époque.
Il y a donc 40 lots * 1 000 époques, soit 40 000 séances d’entraînement au total.
La formation peut produire des résultats imprévisibles. Il faut une formation pour comprendre comment les différents paramètres affectent les résultats. C’est aussi un équilibre entre le taux d’apprentissage et le nombre d’époques pour obtenir le meilleur modèle (par exemple la moindre perte sur un ensemble d’entraînement). Réduire le taux d’apprentissage ou augmenter le nombre d’époques ne signifie pas nécessairement que vous obtiendrez le meilleur modèle. La figure suivante illustre ce point.
Un taux d’apprentissage très élevé produira souvent le pire modèle.
Un bon taux d’apprentissage (équilibré) peut ne pas produire les meilleurs résultats par rapport à un taux d’apprentissage élevé sur un petit nombre d’époques. Cependant, au fil du temps, il s’entraînera généralement avec les meilleurs résultats.
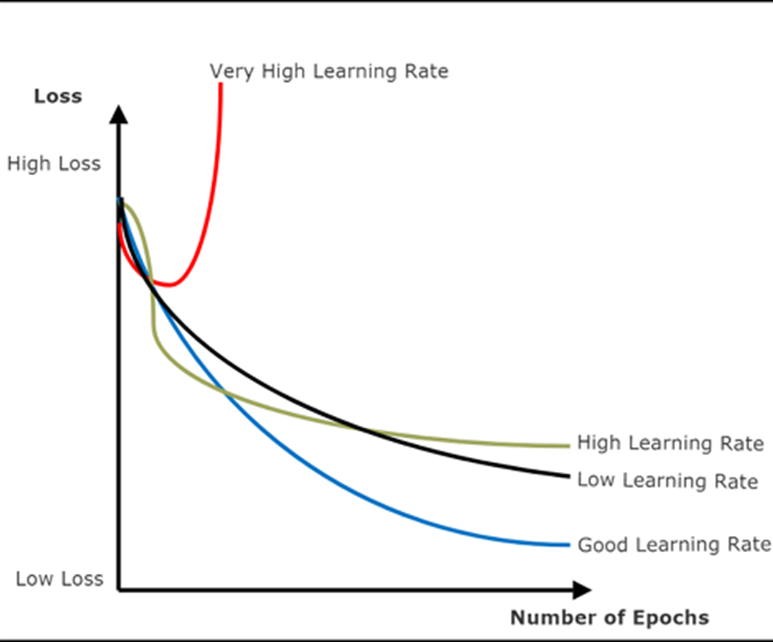
Figure 25: Exemple de taux d’apprentissage et d’époques en fonction de la précision (perte) dans la formation en apprentissage profond. Une approche équilibrée de la formation et du taux d’apprentissage est généralement la meilleure pour les modèles CNN.
12.3.8 Réseaux de neurones récurrents
Les RNN , ou réseaux de neurones récurrents , constituent un domaine distinct de l’apprentissage automatique et sont extrêmement importants et pertinents pour les données IoT. La grande différence entre un RNN et un CNN est qu’un CNN traite l’entrée sur des vecteurs de données de taille fixe. Considérez-les comme des images en deux dimensions, c’est-à-dire une entrée de taille connue. Les CNN passent également d’une couche à l’autre sous forme d’unités de données de taille fixe. Un RNN a des similitudes mais est fondamentalement différent: au lieu de prendre un bloc de données d’image de taille fixe, il a en entrée un vecteur et en sortie un autre vecteur. En son cœur, le vecteur de sortie n’est pas influencé par la seule entrée que nous venons de lui fournir, mais par toute l’histoire des entrées qu’il a alimentées. Cela implique qu’un RNN comprend la nature temporelle des choses ou peut être dit maintenir son état . Il y a des informations à déduire des données, mais aussi de l’ordre dans lequel les données ont été envoyées.
Les RNN sont particulièrement utiles dans l’espace IoT, en particulier dans les séries de données corrélées au temps , telles que la description d’une scène dans une image, la description du sentiment d’une série de texte ou de valeurs et la classification des flux vidéo. Les données peuvent être transmises à un RNN à partir d’un réseau de capteurs qui contiennent un tuple (temps: valeur). Ce serait les données d’entrée à envoyer au RNN. En particulier, ces modèles RNN peuvent être utilisés dans l’analyse prédictive pour trouver des défauts dans les systèmes d’automatisation d’usine, évaluer les données des capteurs pour les anomalies, évaluer les données horodatées des compteurs électriques et même pour détecter des modèles dans les données audio. Les données de signaux provenant d’appareils industriels en sont un autre excellent exemple. Un RNN pourrait être utilisé pour trouver des motifs dans un signal électrique ou une onde. Un CNN aurait du mal avec ce cas d’utilisation. Un RNN ira de l’avant et prédira quelle sera la prochaine valeur dans une séquence si la valeur tombe hors de la plage prédite, ce qui pourrait indiquer une défaillance ou un événement significatif :
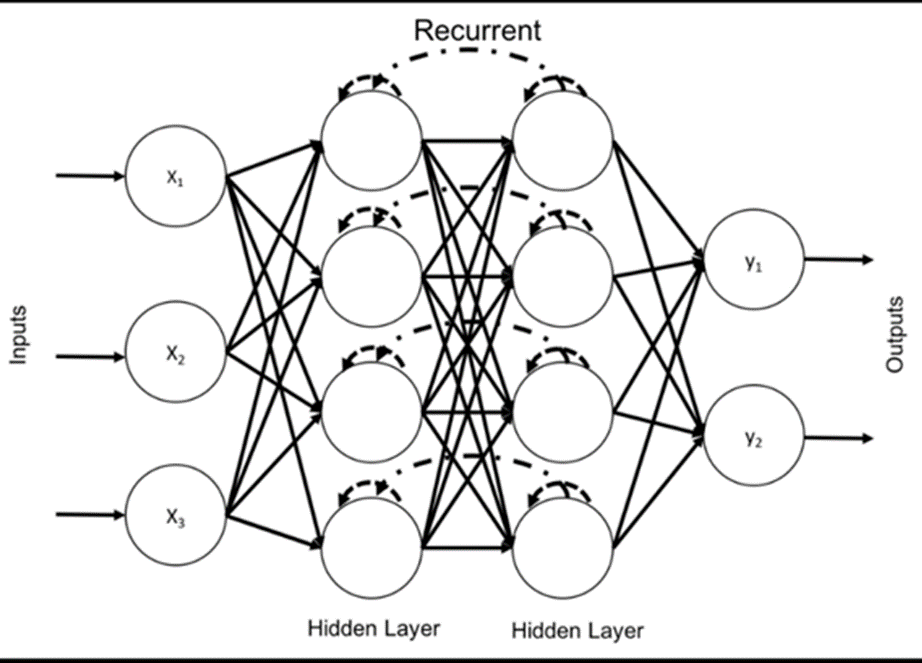
Figure 26 : La principale différence entre un RNN et un CNN est la référence à l’ordre temporel ou séquentiel
Si vous deviez examiner un neurone dans un RNN, il semblerait qu’il se reboucle sur lui-même. Essentiellement, le RNN est un ensemble d’États remontant dans le temps. C’est clair si vous pensez de la RNN à dérouler chaque neurone :

Figure 27: neurone RNN. Ceci illustre l’entrée de l’étape précédente xn-1 alimentant l’étape suivante xn comme base de l’algorithme RNN.
Le défi avec les systèmes RNN est qu’ils sont plus difficiles à former sur un CNN ou d’autres modèles. N’oubliez pas que les systèmes CNN utilisent la rétropropagation pour former et renforcer le modèle. Les systèmes RNN n’ont pas la notion de rétropropagation. Chaque fois que nous envoyons une entrée dans le RNN, il porte un horodatage unique. Cela conduit au problème de gradient de fuite évoqué plus haut, qui réduit le taux d’apprentissage du réseau à être inutile. Un CNN est également exposé à un gradient de fuite, mais la différence avec un RNN est que la profondeur du RNN peut remonter de nombreuses itérations, alors qu’un CNN n’a traditionnellement que quelques couches cachées. Par exemple, un RNN résolvant une structure de phrase comme Un renard brun rapide sauté par-dessus le chien paresseux s’étendra sur neuf niveaux. Le problème du gradient de fuite peut être pensé intuitivement : si les poids dans le réseau sont petits, alors le gradient diminuera de façon exponentielle menant le gradient de fuite. Si les composantes des poids sont grandes, alors le gradient augmentera de façon exponentielle et pourrait exploser, provoquant une NaN (pas une erreur de nombre). L’explosion entraîne un crash évident, mais le gradient est généralement tronqué ou plafonné avant que cela ne se produise. Un gradient de fuite est plus difficile à gérer pour un ordinateur.
Une méthode pour surmonter cet effet consiste à utiliser la fonction d’activation ReLU mentionnée dans la section CNN. Cette fonction d’activation fournit un résultat de 0 ou 1, elle n’est donc pas sujette à la disparition des gradients. Une autre option est le concept de mémoire à court terme à long terme (LSTM), qui a été proposé par les chercheurs Sepp Hochreiter et Juergen Schmidhuber. (Mémoire à court terme, calcul neuronal, 9 (8) : 1735-1780, 1997.) Le LSTM a résolu le problème du gradient de fuite et a permis à un RNN d’être formé.
Ici, le neurone RNN était composé de trois ou quatre portes. Ces portes permettent aux neurones de contenir des informations d’état et sont contrôlées par des fonctions logistiques d’une valeur comprise entre 0 et 1 :
- Garder la porte K : contrôle la durée pendant laquelle une valeur restera en mémoire
- Porte d’écriture W : contrôle dans quelle mesure une nouvelle valeur affectera la mémoire
- Porte de lecture R : contrôle la quantité de valeur en mémoire utilisée pour créer la fonction d’activation de sortie
Vous pouvez voir que ces portes sont de nature quelque peu analogique. Les portes varient la quantité d’informations qui seront conservées. La cellule LSTM interceptera les erreurs dans la mémoire de la cellule. Cela s’appelle le carrousel d’erreurs et permet à la cellule LSTM de propager les erreurs sur de longues périodes. La cellule LSTM ressemble à la structure logique suivante où le neurone est essentiellement le même, en termes d’apparences extérieures, qu’un CNN, mais en interne, il maintient l’état et la mémoire. La cellule LSTM du RNN est illustrée comme suit :
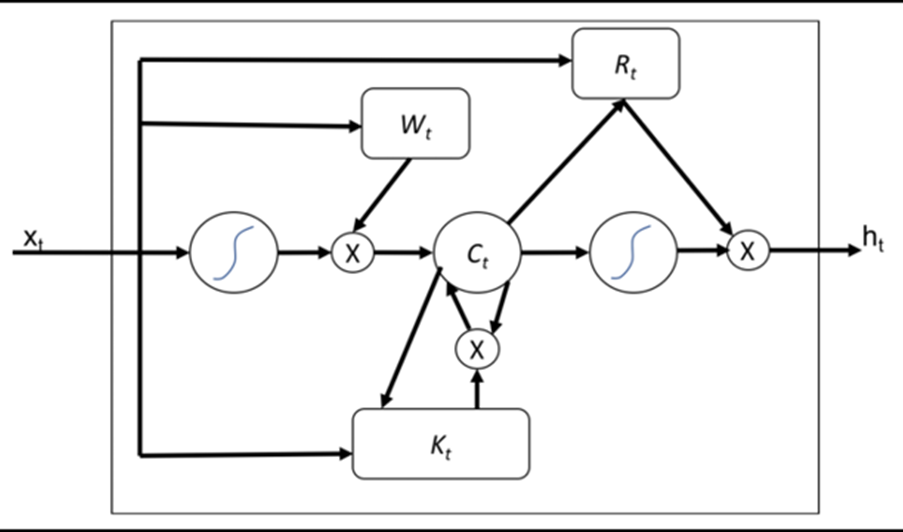
Figure 28 : cellule LSTM. Voici l’algorithme de base RNN utilisant la mémoire interne pour traiter des séquences arbitraires d’entrées.
Un RNN accumule de la mémoire dans le processus de formation. Ceci est vu dans le diagramme comme la couche d’état sous une couche cachée. Un RNN ne recherche pas les mêmes motifs sur une image ou un bitmap comme un CNN ; Au contraire, il recherche un modèle sur plusieurs étapes séquentielles (ce qui pourrait être du temps).
La couche masquée et le complément de couche d’état sont illustrés dans le diagramme suivant :
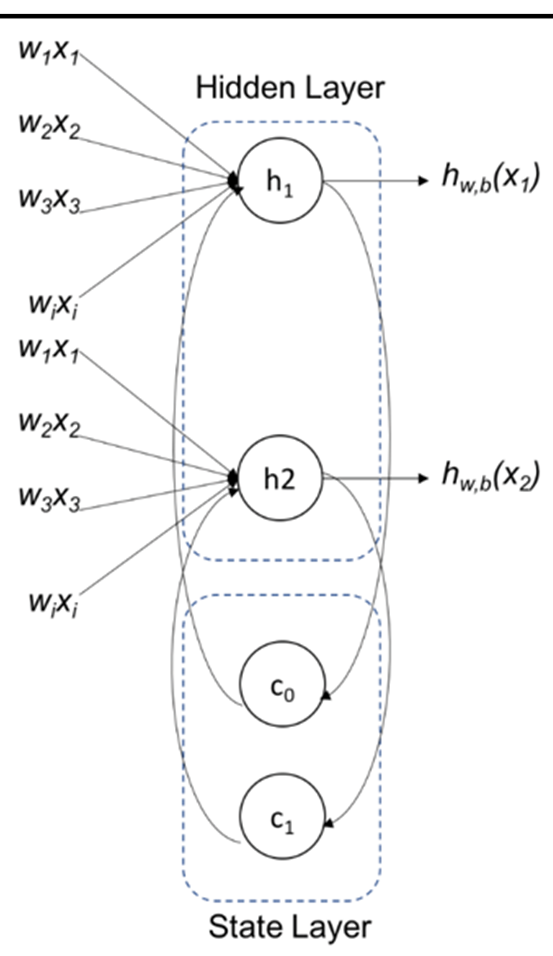
Figure 29 : Les couches cachées sont alimentées à partir des étapes précédentes en tant qu’entrées supplémentaires à l’étape suivante
On peut voir la quantité de calcul dans la formation avec les mathématiques logistiques LSTM, ainsi que la façon dont la rétropropagation régulière est plus lourde qu’un CNN. Le processus de formation implique une rétropropagation des gradients à travers le réseau jusqu’au temps zéro. Cependant, la contribution d’un gradient de loin dans le passé (disons, le temps zéro) approche zéro et ne contribuera pas à l’apprentissage.
Un bon cas d’utilisation pour illustrer un RNN est un problème d’analyse de signal. Dans un environnement industriel, vous pouvez collecter des données de signaux historiques et tenter d’en déduire si une machine était défectueuse ou s’il y avait des thermiques d’emballement dans certains composants. Un dispositif capteur serait attaché à un outil d’échantillonnage et une analyse de Fourier effectuée sur les données. Les composantes de fréquence pouvaient ensuite être inspectées pour voir si une aberration particulière était présente. Dans le graphique suivant, nous avons une onde sinusoïdale simple qui indique un comportement normal, peut-être d’une machine utilisant des rouleaux et des roulements en fonte. Nous voyons également deux aberrations introduites (l’anomalie). Une transformée de Fourier rapide (FFT) est généralement utilisée pour trouver des aberrations dans un signal basé sur les harmoniques. Ici, le défaut est un pic à haute fréquence similaire à un delta de Dirac ou à une fonction d’impulsion.

Figure 30 : Cas d’utilisation RNN. Ici, une forme d’onde avec une aberration de l’analyse audio pourrait être utilisée comme entrée d’un RNN.
Nous voyons que la FFT suivante enregistre uniquement la fréquence porteuse et ne voit pas l’aberration :
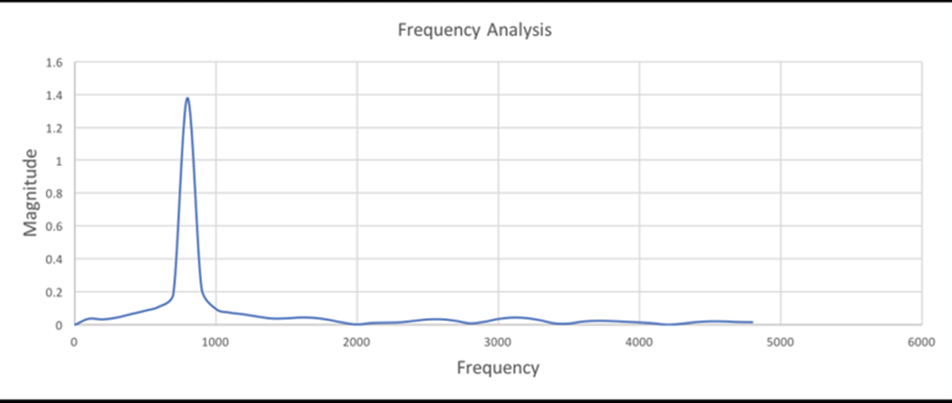
Figure 31 : Pic de haute fréquence via une FFT
Un RNN spécifiquement formé pour identifier la corrélation de séries temporelles d’une tonalité ou d’une séquence audio particulière est une application simple. Dans ce cas, un RNN pourrait remplacer une FFT, en particulier lorsque plusieurs séquences de fréquences ou d’états sont utilisées pour classer un système, ce qui le rend idéal pour la reconnaissance du son ou de la parole.
Les outils de maintenance prédictive industriels s’appuient sur ce type d’analyse de signal pour trouver les défaillances thermiques et vibratoires de différentes machines. Cette approche traditionnelle a des limites, on le voit. Un modèle d’apprentissage automatique (en particulier un RNN) peut être utilisé pour inspecter le flux de données entrant pour des composants de caractéristique (fréquence) particuliers et pourrait trouver des défaillances ponctuelles comme indiqué dans le graphique précédent. Les données brutes, présentées dans le graphique précédent, ne sont sans doute jamais aussi propres qu’une onde sinusoïdale. Habituellement, les données sont assez bruyantes avec des périodes de perte.
Un autre cas d’utilisation concerne la fusion de capteurs dans les soins de santé. Les produits de santé, comme les glucomètres, les cardiofréquencemètres, les indicateurs de chute, les appareils de mesure respiratoire et les pompes à perfusion, transmettront des échantillons de données périodiques ou pourront envoyer un flux de données. Tous ces capteurs sont indépendants les uns des autres, mais constituent ensemble une image de la santé du patient. Ils sont également corrélés dans le temps. Un RNN peut relier ces données non structurées de manière agrégée et prédire la santé du patient, tout dépendant de l’activité du patient tout au long de la journée. Cela peut être utile pour la surveillance de la santé à domicile, l’entraînement sportif, la réadaptation et les soins gériatriques.
Vous devez être prudent avec les RNN. Bien qu’ils puissent faire de bonnes inférences sur les données de séries chronologiques et prédire les oscillations et les comportements des vagues, ils peuvent se comporter de manière chaotique et sont très difficiles à former.
12.3.9 Formation et inférence pour l’IoT
Alors que les réseaux de neurones offrent des avantages significatifs à ce qu’une machine se comporte plus près d’un humain dans les domaines de la perception, de la reconnaissance des formes et de la classification, il appartient principalement à la formation de développer un modèle qui fonctionne bien avec une perte faible, sans sur-ajustement et adéquat performance. Dans le monde de l’IoT, la latence est un problème majeur, en particulier pour les infrastructures critiques pour la sécurité. Les contraintes de ressources sont un autre facteur. La plupart des dispositifs informatiques de pointe qui existent aujourd’hui ne disposent pas d’accélérateurs matériels tels que le calcul général sur matériel graphique (GPGPU) et les matrices de portes programmables (FPGA) à leur disposition pour aider avec les mathématiques de la matrice lourde et les virgules flottantes entourant les neurones les réseaux. Les données peuvent être envoyées au cloud, mais cela peut avoir des effets de latence importants ainsi que des coûts de bande passante. Le groupe OpenFog provisionne un cadre dans lequel les nœuds de brouillard de périphérie peuvent être provisionnés avec des ressources de calcul supplémentaires et tirés à la demande pour fournir une assistance pour le levage de ces algorithmes.
La formation, pour l’instant, devrait être le domaine du cloud, où les ressources informatiques sont disponibles et des ensembles de tests peuvent être créés. Les périphériques périphériques doivent signaler au parent du cloud lorsqu’un modèle de formation échoue ou si de nouvelles données apparaissent nécessitant un effort de recyclage. Le cloud permet à un train de déployer de nombreux concepts, ce qui est une force. Alternativement, il est sage d’envisager la formation sur une base régionale avec biais.
Le concept ici est que les nœuds de brouillard dans certaines régions peuvent être plus sensibles à certains modèles qui sont différents sur le plan environnemental. Par exemple, la surveillance de la température et de l’humidité sur l’équipement sur le terrain dans l’Arctique différera considérablement d’une région tropicale.
Le tableau suivant illustre le traitement CPU requis pour la formation. Généralement, des milliers à des millions d’images sont nécessaires pour former avec succès un modèle. Les processeurs et les GPU présentés ont un coût et une demande d’énergie substantiels qui n’ont pas nécessairement de sens pour fonctionner à la limite.
| Processeur | Vitesse d’entraînement TensorFlow (images / seconde) |
| AMD Opteron 6168 (CPU) | 440 |
| Intel i7 7500U (CPU) | 415 |
| Nvidia GeForce 940MX (GPU) | 1190 |
| Nvidia GeForce 1070 | 6500 |
| Nvidia RTX2080 | 17000 |
Le bord est plus apte à exécuter des modèles entraînés dans un mode d’inférence. Cependant, le déploiement de moteurs d’inférence doit être bien architecturé. Certains réseaux CNN comme AlexNet ont 61 millions de paramètres, consomment 249 Mo de mémoire et effectuent 1,5 milliard d’opérations en virgule flottante pour classer une seule image.
La précision réduite, l’élagage et d’autres techniques pour effectuer des heuristiques de première exécution sur les données d’image conviennent mieux aux périphériques périphériques. De plus, la préparation des données pour l’analyse en amont peut également aider. Les exemples incluent :
- Envoi en amont : seules les données répondant à une condition spécifique (heure, événement d’intérêt)
- Nettoyage des données : réduisez, recadrez et coupez un ensemble de données uniquement pour le contenu pertinent
- Segment : Forcer les données en niveaux de gris pour réduire le trafic et les préparer pour un CNN
12.4 Sécurité IoT et Edge
Les algorithmes d’apprentissage automatique ont leur place dans l’IoT. Le cas typique est quand il y a une pléthore de données en streaming qui doivent produire une conclusion significative. Une petite collection de capteurs peut ne nécessiter qu’un moteur de règles simple en périphérie dans une application sensible à la latence. D’autres peuvent diffuser des données vers un service cloud et y appliquer des règles pour les systèmes avec des exigences de latence moins agressives.
Lorsque de grandes quantités de données, des données non structurées et des analyses en temps réel entrent en jeu, nous devons envisager l’utilisation de l’apprentissage automatique pour résoudre certains des problèmes les plus difficiles.
Dans cette section, nous détaillons quelques conseils et rappels lors du déploiement d’analyses d’apprentissage automatique et les cas d’utilisation pouvant justifier de tels outils.
Phase de formation :
- Pour une forêt aléatoire, utilisez des techniques d’ensachage pour créer des ensembles.
- Lorsque vous utilisez une forêt aléatoire, assurez-vous de maximiser le nombre d’arbres de décision.
- Regardez le surajustement. Un sur-ajustement entraînera des modèles de terrain inexacts. Des techniques telles que la régularisation et même l’injection de bruit dans un système renforceront le mode.
- Ne vous entraînez pas sur le bord.
- Une descente en pente entraînera des erreurs. Les RNN sont naturellement sensibles.
Modèle dans le domaine :
- Mettez à jour le modèle avec de nouveaux ensembles de données dès qu’ils sont disponibles. Gardez l’ensemble de formation à jour.
- L’exécution de modèles en périphérie peut être renforcée par des modèles plus grands et plus complets dans le cloud.
- L’exécution du réseau neuronal peut être optimisée dans le cloud et en périphérie avec un minimum de perte en considérant des techniques telles que l’élagage des nœuds et la réduction de la précision.
| Modèle | Meilleure application | Pire ajustement et effets secondaires | Demandes de ressources | La formation |
| Forêts aléatoires (modèles statistiques) | Détection d’anomalies
Systèmes avec des milliers de points de choix et des centaines d’entrées Régression et classi fi cation Gère les types de données mixtes Ignore les valeurs manquantes Mise à l’échelle linéaire avec entrée |
Extraction de fonctionnalités
Analyse de temps et de séquence |
Faible | Formation basée sur des techniques d’ensachage pour une efficacité maximale
Formation assez légère Principalement supervisé |
| RNN
(Réseaux de neurones temporels et basés sur des séquences) |
Prédiction d’un événement basé sur une séquence
Modèles de données en streaming Données de série en corrélation temporelle Maintient la connaissance des états passés pour prédire de nouveaux états (signaux électriques, audio, reconnaissance vocale) Données non structurées Les variables d’entrée peuvent dépendre ou non |
Analyse d’images et de vidéos
Des modèles qui utilisent des milliers de fonctionnalités. |
Très haut pour l’entraînement
Élevé pour l’exécution d’inférence |
Formation plus lourde que la rétropropagation CNN
Très difficile à former Supervisé |
| CNN
(apprentissage en profondeur) |
Prédiction d’un objet sur la base des valeurs environnantes
Identi fi cation des motifs et des caractéristiques Reconnaissance d’images 2D Données non structurées Les variables d’entrée peuvent dépendre ou non |
Prédictions temporelles et séquentielles
Des modèles qui utilisent des milliers de fonctionnalités. |
Très élevé pour la formation ( fl précision ottante, de grands ensembles de formation, de grandes exigences de mémoire)
Élevé pour l’exécution d’inférence |
Supervisé et non supervisé |
| Réseaux bayésiens (modèles probabilistes) | Ensembles de données bruyants et incomplets
Modèles de données en streaming Séries à corrélation temporelle Données structurées Analyse du signal Des modèles développés rapidement |
Suppose que toutes les variables d’entrée sont indépendantes
Fonctionne mal avec des ordres de dimensions de données élevés |
Faible | Peu ont besoin de formation de données En ce qui concerne les autres arti fi réseaux de neurones cielles |
12.5 Résumé
Ce chapitre était une brève introduction à l’analyse de données pour l’IoT dans le cloud et dans le brouillard. L’analyse de données est l’endroit où la valeur est extraite de la mer de données produites par des millions ou des milliards de capteurs. Analytics est le domaine du data scientist et consiste à tenter de trouver des modèles cachés et de développer des prédictions à partir d’une quantité écrasante de données. Pour être utile, toute cette analyse doit être effectuée en temps réel ou presque pour prendre des décisions cruciales pour la vie. Vous devez comprendre le problème résolu et les données nécessaires pour révéler la solution. Ce n’est qu’alors qu’un pipeline d’analyse de données peut être bien conçu. Ce chapitre a présenté plusieurs modèles d’analyse de données ainsi qu’une introduction aux quatre domaines d’apprentissage machine pertinents.
Ces outils d’analyse sont au cœur de la valeur de l’IoT pour tirer du sens des nuances de quantités massives de données en temps réel. Les modèles d’apprentissage automatique peuvent prédire les événements futurs en fonction des modèles actuels et historiques. Nous voyons comment les cas RNN et CNN satisfont ce contexte grâce à une formation appropriée. En tant qu’architecte, le pipeline, le stockage, les modèles et la formation doivent tous être pris en compte.
Dans le chapitre suivant, nous parlerons de la sécurité de l’IoT d’un point de vue holistique, du capteur au cloud. Nous examinerons les attaques spécifiques du monde réel contre l’IoT ces dernières années, ainsi que les méthodes pour contrer de telles attaques à l’avenir.
13 IoT et sécurité Edge
Le premier chapitre de cet article a révélé la taille, la croissance et le potentiel de l’ Internet des objets ( IoT ). Il existe actuellement des milliards d’appareils et la croissance à deux chiffres de la connexion du monde analogique à Internet constitue également la plus grande surface d’attaque sur Terre. Les exploits, les dégâts et les agents voyous ont déjà été développés, déployés et diffusés dans le monde entier, perturbant d’innombrables entreprises, réseaux et vies. En tant qu’architectes, nous avons la responsabilité de comprendre la pile de technologies IoT et de les sécuriser. Comme nous plaçons des appareils qui n’ont jamais été connectés à Internet, en tant que bons citoyens, nous sommes responsables de leur conception.
Cela a été particulièrement difficile pour de nombreux déploiements IoT, la sécurité étant souvent envisagée en dernier. Souvent, les systèmes sont si limités qu’il est difficile, voire impossible, de créer une sécurité de niveau entreprise dont bénéficient les systèmes Web et PC modernes sur de simples capteurs IoT. Cet article parle également de sécurité après avoir compris toutes les autres technologies. Cependant, chaque chapitre a abordé les dispositions de sécurité à chaque niveau.
Ce chapitre explorera certaines attaques particulièrement odieuses axées sur l’IoT et réfléchira à la faiblesse de la sécurité dans l’IoT et aux dommages pouvant être causés. Plus tard, nous discutons des dispositions de sécurité à chaque niveau de la pile : périphériques physiques, systèmes de communication et réseaux. Nous abordons ensuite les périmètres définis par logiciel et les chaînes de blocs utilisées pour sécuriser la valeur des données IoT. Le chapitre se termine en examinant la loi américaine sur l’amélioration de la cybersécurité de 2017 et ce que cela pourrait signifier pour les appareils IoT.
La chose la plus importante en matière de sécurité est de l’utiliser à tous les niveaux, du capteur au système de communication, au routeur et au cloud.
13.1 Vernaculaire de la cybersécurité
La cybersécurité est associée à un ensemble de définitions décrivant différents types d’attaques et de dispositions. Cette section couvre brièvement le jargon de l’industrie tel qu’il est présenté dans le reste de ce chapitre.
13.1.1 Termes d’attaque et de menace
Les termes et définitions des différentes attaques ou cybermenaces malveillantes sont les suivants :
- Attaque d’amplification : agrandit la bande passante envoyée à une victime. Souvent, un attaquant utilisera un service légitime tel que NTP, Steam ou DNS pour refléter l’attaque contre une victime. NTP peut amplifier 556x et l’amplification DNS peut augmenter la bande passante de 179x.
- Usurpation ARP : type d’attaque qui envoie un message ARP falsifié entraînant la liaison de l’adresse MAC de l’attaquant avec l’IP d’un système légitime.
- Analyses de bannière : technique généralement utilisée pour faire l’inventaire des systèmes sur un réseau qui peut également être utilisée par un attaquant pour obtenir des informations sur une cible d’attaque potentielle en effectuant des requêtes HTTP et en inspectant les informations renvoyées du système d’exploitation (OS) et de l’ordinateur ( par exemple, nc www.target.com 80 ).
- Botnets : appareils connectés à Internet infectés et compromis par des logiciels malveillants fonctionnant collectivement par un contrôle commun, principalement utilisés à l’unisson pour générer des attaques DDoS massives à partir de plusieurs clients. D’autres attaques incluent le spam et les logiciels espions.
- Force brute : méthode d’essai et d’erreur pour accéder à un système ou contourner le chiffrement.
- Débordement de tampon : Exploite un bogue ou un défaut dans l’exécution d’un logiciel qui dépasse simplement un tampon ou un bloc de mémoire avec plus de données que prévu. Ce dépassement peut écraser d’autres données dans des adresses de mémoire adjacentes. Un attaquant peut placer du code malveillant dans cette zone et forcer le pointeur d’instruction à s’exécuter à partir de là. Les langages compilés tels que C et C ++ sont particulièrement sensibles aux attaques de dépassement de tampon car ils manquent de protection interne. La plupart des bogues de débordement sont le résultat d’un logiciel mal construit qui ne vérifie pas les limites des valeurs d’entrée.
- C2 : serveur de commande et de contrôle qui rassemble les commandes vers les botnets.
- Attaque d’analyse de puissance de corrélation : permet de découvrir des clés de chiffrement secrètes stockées dans un appareil en quatre étapes :
- Examinez la consommation électrique dynamique d’une cible et enregistrez-la pour chaque phase du processus de cryptage normal.
- Ensuite, forcez la cible à chiffrer plusieurs objets en texte brut et à enregistrer leur consommation d’énergie.
- Ensuite, attaquez de petites parties de la clé (sous-clés) en considérant toutes les combinaisons possibles et en calculant le coefficient de corrélation de Pearson entre la puissance modélisée et la puissance réelle.
- Enfin, assemblez la meilleure sous-clé pour obtenir la clé complète.
- Attaque par dictionnaire : méthode permettant d’accéder à un système réseau en saisissant systématiquement des mots à partir d’un fichier de dictionnaire contenant les paires nom d’utilisateur et mot de passe.
- Déni de service distribué (DDoS) : attaque tentant de perturber ou de rendre un service en ligne indisponible en l’écrasant à partir de plusieurs sources (distribuées).
- Fuzzing : une attaque qui consiste à envoyer des données malformées ou non standard à un appareil et à observer comment l’appareil réagit. Par exemple, si un appareil fonctionne mal ou présente des effets indésirables, l’attaque de fuzz peut avoir révélé une faiblesse.
- Attaque de l’homme du milieu (MITM) : forme d’attaque courante qui place un appareil au milieu d’un flux de communication entre deux parties sans méfiance. L’appareil écoute, filtre et s’approprie les informations de l’émetteur et retransmet les informations sélectionnées au récepteur. Un MITM peut être dans la boucle agissant comme un répéteur ou peut être une bande latérale écoutant la transmission sans intercepter les données.
- Traîneaux NOP : séquence d’instructions d’assemblage NOP injectées utilisées pour faire glisser le pointeur d’instructions d’un processeur vers la zone souhaitée de code malveillant. Il fait généralement partie d’une attaque par dépassement de tampon.
- Attaque de relecture : une attaque de réseau, également connue sous le nom d’attaque de lecture, où les données sont répétées ou rejouées de manière malveillante par l’expéditeur ou un adversaire qui intercepte les données, les stocke et les transmet à volonté.
- Exploit RCE : exécution de code à distance qui permet à un attaquant d’exécuter du code arbitraire. Cela se présente généralement sous la forme d’une attaque par dépassement de tampon sur HTTP ou d’autres protocoles réseau qui injecte du code malveillant.
- Attaque de programmation orientée retour (ROP) : Un exploit de sécurité difficile qu’un attaquant peut utiliser pour potentiellement renverser les protections avec de la mémoire non exécutée ou exécuter du code à partir de la mémoire morte. Si un attaquant prend le contrôle d’une pile de processus via un débordement de tampon ou tout autre moyen, il peut passer à des séquences d’instructions légitimes et inchangées déjà présentes. L’attaquant recherche des séquences d’instructions pour appeler des gadgets qui peuvent être reconstitués pour former une attaque malveillante.
- Return-to-libc : Type d’attaque qui commence par un débordement de tampon où l’attaquant injecte du code pour passer à libc ou à d’autres bibliothèques couramment utilisées dans l’espace mémoire des processus dans le but d’appeler directement des routines système. Contourne la protection offerte par la mémoire non exécutable et les bandes de garde. Il s’agit d’une forme spécifique d’attaque ROP.
- Rootkit : En règle générale, les logiciels malveillants (bien que souvent utilisés pour déverrouiller les smartphones) permettaient aux autres charges utiles logicielles d’être indétectables. Les rootkits utilisent plusieurs techniques ciblées telles que les dépassements de tampon pour attaquer les services du noyau, les hyperviseurs et les programmes en mode utilisateur.
- Attaque par canal latéral : attaque utilisée pour obtenir des informations du système d’une victime en observant les effets secondaires du système physique plutôt qu’en trouvant des exploits d’exécution ou des exploits zero-day. Des exemples d’attaques par canal latéral comprennent l’analyse de la puissance de corrélation, l’analyse acoustique et la lecture des résidus de données après leur suppression de la mémoire.
- Ingénierie sociale : en ce qui concerne la sécurité de l’information, une forme d’attaque basée sur la manipulation psychologique et la tromperie personnelle pour obtenir des informations privées.
- Usurpation d’identité : une partie ou un appareil malveillant usurpe l’identité d’un autre appareil ou utilisateur sur un réseau.
- Injection SQL : forme d’attaque visant à détruire le contenu de la base de données. Il est utilisé sur des bases de données utilisant des instructions SQL ( Structured Query Language ).
- SYN flood : se produit lorsqu’un hôte envoie un paquet TCP : SYN qu’un agent escroc usurpera et forgera. Cela entraînera l’hôte à créer des connexions semi-ouvertes vers de nombreuses adresses inexistantes, ce qui entraînera l’épuisement de toutes les ressources par l’hôte.
- XSS : vulnérabilité, également appelée script intersite, dans les applications Web où les attaquants injectent des scripts côté client. Il s’agissait de la forme d’attaque d’information la plus répandue jusqu’en 2007.
- Exploits zero-day : Défauts de sécurité ou bogues dans des logiciels commerciaux ou de production inconnue du concepteur ou du fabricant.
13.1.2 Termes de défense
Les termes et définitions des différents mécanismes et technologies de cyberdéfense sont les suivants :
- Randomisation de la disposition de l’espace d’adressage (ASLR) : mécanisme de défense qui protège la mémoire et empêche les attaques par dépassement de tampon en randomisant où un exécutable est chargé en mémoire. Un dépassement de tampon injectant un malware ne peut pas prédire où il sera chargé en mémoire, donc manipuler le pointeur d’instruction devient extrêmement difficile. Protège contre les attaques de retour à la bibliothèque.
- Trou noir (gouffre) : défend contre les attaques DDoS. Après avoir détecté une attaque DDoS, des routes sont établies à partir du serveur DNS ou de l’adresse IP affectés pour forcer les données non fiables vers un trou noir ou un point de terminaison inexistant. Les sinkholes effectuent une analyse plus approfondie pour filtrer les bonnes données.
- Prévention de l’exécution des données (DEP) : marque une zone comme exécutable ou non exécutable. Cela empêche un attaquant d’exécuter du code injecté de manière malveillante dans une telle région via une attaque par dépassement de tampon. Le résultat est une erreur ou une exception système.
- Inspection approfondie des paquets (DPI) : méthode d’inspection de chaque paquet (données et éventuellement informations d’en-tête) dans un flux de données pour isoler les intrusions, les virus, le spam et d’autres critères filtrés.
- Pare – feu : construction de sécurité réseau qui accorde ou rejette l’accès réseau aux flux de paquets entre une zone non approuvée et une zone approuvée. Le trafic peut être contrôlé et géré via des listes de contrôle d’accès (ACL) sur les routeurs. Les pares-feux peuvent effectuer un filtrage avec état et fournir des règles basées sur les ports de destination et l’état du trafic.
- Bandes de garde et mémoire non exécutable : protège les régions de mémoire qui sont inscriptibles et non exécutables. Protège contre les traîneaux NOP. Intel : bit NX, bit ARM XN.
- Honeypots : outil de sécurité pour détecter, dévier ou inverser les attaques malveillantes. Les pots de miel apparaissent comme des sites Web légitimes ou des nœuds accessibles dans un réseau mais sont en réalité isolés et surveillés. Les données et les interactions avec l’appareil sont enregistrées.
- Contrôle d’accès à la mémoire basé sur des instructions : technique permettant de séparer la partie donnée d’une pile de la partie adresse de retour. Cette technique aide à protéger contre les attaques ROP et est particulièrement utile dans les systèmes IoT contraints.
- Système de détection d’intrusion (IDS) : une structure de réseau pour détecter les menaces dans un réseau grâce à l’analyse hors bande du flux de paquets ; par conséquent, ne correspond pas à la source et à la destination de manière à affecter la réponse en temps réel.
- Système de prévention des intrusions (IPS) : bloque les menaces sur un réseau via une véritable analyse en ligne et une détection statistique ou de signature des menaces.
- Milkers : Un outil défensif qui émule un périphérique de botnet infecté et se connecte à son hôte malveillant permettant de comprendre et de “traire” les commandes de logiciels malveillants envoyées au botnet contrôlé.
- Analyse de port : une méthode pour trouver un port ouvert et accessible sur un réseau local.
- Clé publique : une clé publique est générée avec une clé privée et est accessible aux entités externes. Une clé publique peut être utilisée pour déchiffrer les hachages.
- Infrastructure à clé publique (PKI) : fournit une définition des hiérarchies de vérificateurs pour garantir l’origine d’une clé publique. Un certificat est signé par les autorités de certification.
- Clé privée : générée avec une clé publique, jamais publiée en externe et stockée en toute sécurité. Il est utilisé pour crypter les hachages.
- Root of Trust (RoT) : démarre l’exécution sur un périphérique de démarrage à froid à partir d’une source de mémoire fiable immuable (telle que la ROM). Si le logiciel / BIOS de démarrage précoce peut être modifié sans contrôle, alors aucune RoT n’existe. Le RoT est généralement la première phase d’un démarrage sécurisé multiphase.
- Démarrage sécurisé : série d’étapes de démarrage pour un périphérique qui démarre à un RoT et se poursuit via le chargement du système d’exploitation et des applications, où chaque signature de composant est vérifiée comme authentique. La vérification est effectuée via des clés publiques chargées lors des précédentes étapes de démarrage de confiance.
- Canaries de pile : les gardes traitent l’espace de pile à partir des dépassements de pile et empêchent l’exécution de code à partir d’une pile.
- Environnement d’exécution fiable (TEE) : zone sécurisée d’un processeur qui garantit que le code et les données résidant dans cette zone sont protégés. Il s’agit généralement d’un environnement d’exécution sur le cœur du processeur principal où le code de démarrage sécurisé, les transferts monétaires ou la gestion des clés privées seront exécutés avec un niveau de sécurité supérieur à la majorité du code.
13.2 Sécurité IoT et Edge
Le domaine de la cybersécurité est un sujet vaste et massif au-delà de la portée de ce chapitre. Cependant, il est utile de comprendre trois types d’attaques et d’exploits basés sur l’IoT. Étant donné que la topologie de l’IoT comprend le matériel, la mise en réseau, les protocoles, les signaux, les composants cloud, les cadres, les systèmes d’exploitation et tout le reste, nous allons maintenant détailler trois formes d’attaques répandues :
- Mirai : L’attaque DoS la plus dommageable de l’histoire, qui s’est produite à partir d’appareils IoT non sécurisés dans des zones reculées.
- Stuxnet : Une cyber-arme d’État-nation ciblant les dispositifs industriels IoT SCADA contrôlant les centrifugeuses d’enrichissement d’uranium et causant des dommages substantiels et irréversibles au programme nucléaire iranien.
- Réaction en chaîne : une méthode de recherche pour exploiter le PAN en utilisant uniquement une ampoule – pas besoin d’Internet.
En comprenant les comportements de ces menaces, l’architecte peut dériver des technologies et des processus préventifs pour garantir que des événements similaires sont atténués.
13.2.1 Mirai
Mirai est le nom d’un malware qui a infecté des appareils Linux IoT en août 2016. L’attaque a pris la forme d’un botnet qui a généré une énorme tempête DDoS. Les cibles les plus en vue étaient Krebs on Security, un blog de sécurité Internet populaire ; Dyn, un fournisseur DNS très populaire et largement utilisé pour Internet ; et Lonestar cell, un grand opérateur de télécommunications au Libéria. Les cibles plus petites comprenaient des sites politiques italiens, des serveurs Minecraft au Brésil et des sites d’enchères russes. Le DDoS sur Dyn a eu des effets secondaires sur d’autres fournisseurs extrêmement importants qui utilisaient leurs services, tels que les serveurs Sony Playstation, Amazon, GitHub, Netflix, PayPal, Reddit et Twitter. Au total, 600 000 appareils IoT ont été infectés dans le cadre du collectif de botnet.
Le code source de Mirai a été publié sur hackforums.net (un site de blog hacker). À partir de la source et à travers des traces et des journaux, les chercheurs ont découvert le fonctionnement et le déroulement de l’attaque de Mirai :
- Recherche de victimes : il a d’abord effectué une analyse asynchrone rapide à l’aide de paquets TCP SYN pour sonder des adresses IPV4 aléatoires. Il a spécifiquement recherché le port TCP et le port 2323 de SSH / Telnet. Si l’analyse et le port ont réussi, ils sont entrés dans la phase deux.
Mirai a inclus une liste noire d’adresses à éviter. La liste noire comprenait 3,4 millions d’adresses IP et contenait des adresses IP appartenant au US Postal Service, à Hewlett-Packard, GE et au département américain de la Défense. Mirai était capable de numériser à environ 250 octets par seconde. C’est relativement faible en ce qui concerne un botnet. Des attaques comme le SQL Slammer ont généré des analyses à 1,5 Mbps, la raison principale étant que les appareils IoT sont généralement beaucoup plus limités en puissance de traitement que les appareils de bureau et mobiles.
- Telnet à force brute : à ce stade, Mirai a tenté d’établir une session Telnet fonctionnelle avec une victime en envoyant 10 paires de noms d’utilisateur et de mots de passe au hasard à l’aide d’une attaque par dictionnaire de 62 paires. Si une connexion a réussi, Mirai a connecté l’hôte à un serveur C2 central. Des variantes ultérieures de Mirai ont fait évoluer le bot pour effectuer des exploits RCE.
- Infect : Un programme de chargement a ensuite été envoyé à la victime potentielle depuis le serveur. Il était chargé d’identifier le système d’exploitation et d’installer les logiciels malveillants spécifiques aux appareils. Il a ensuite recherché d’autres processus concurrents en utilisant le port 22 ou 23 et les a tués (ainsi que d’autres logiciels malveillants qui pourraient déjà être présents sur l’appareil). Le fichier binaire du chargeur a ensuite été supprimé et le nom du processus a été masqué pour masquer sa présence. Le malware ne résidait pas dans un stockage persistant et n’a pas survécu à un redémarrage. Le bot est maintenant resté en sommeil jusqu’à ce qu’il reçoive un ordre d’attaque.
Les appareils visés étaient des appareils IoT composés de caméras IP, de DVR, de routeurs grand public, de téléphones VOIP, d’imprimantes et de décodeurs. Il s’agissait de fichiers binaires ARM 32 bits, MIPS 32 bits et X86 32 bits spécifiques au périphérique IoT piraté.
La première analyse a eu lieu le 1er août 2016 à partir d’un site d’hébergement Web américain. L’analyse a pris 120 minutes avant de trouver un hôte avec un port ouvert et un mot de passe dans le dictionnaire. Après une minute supplémentaire, 834 autres appareils ont été infectés. En 20 heures, 64 500 appareils ont été infectés. Mirai a doublé de taille en 75 minutes. La plupart des appareils infectés qui se sont transformés en réseaux de zombies se trouvent au Brésil (15,0%), en Colombie (14,0%) et au Vietnam (12,5%), bien que les cibles des attaques DDoS se trouvent dans d’autres régions.
Les dégâts se sont limités aux attaques DDoS. Les attaques ont pris la forme d’inondations SYN, d’inondations du réseau IP GRE, d’inondations STOMP et d’inondations DNS. En cinq mois, 15 194 commandes d’attaques individuelles ont été émises par les serveurs C2 et ont touché 5 042 sites Internet. Le 21 septembre 2016, le botnet Mirai a déclenché une attaque DDoS massive sur le site du blog Krebs on Security et a généré 623 Gbps de trafic. Cela représentait la pire attaque DDoS de tous les temps. Ce qui suit est une capture d’écran en temps réel capturée lors de l’attaque de Mirai en utilisant www.digitalattackmap.com : une collaboration entre NETSCOUT Arbour et Google Jigsaw.
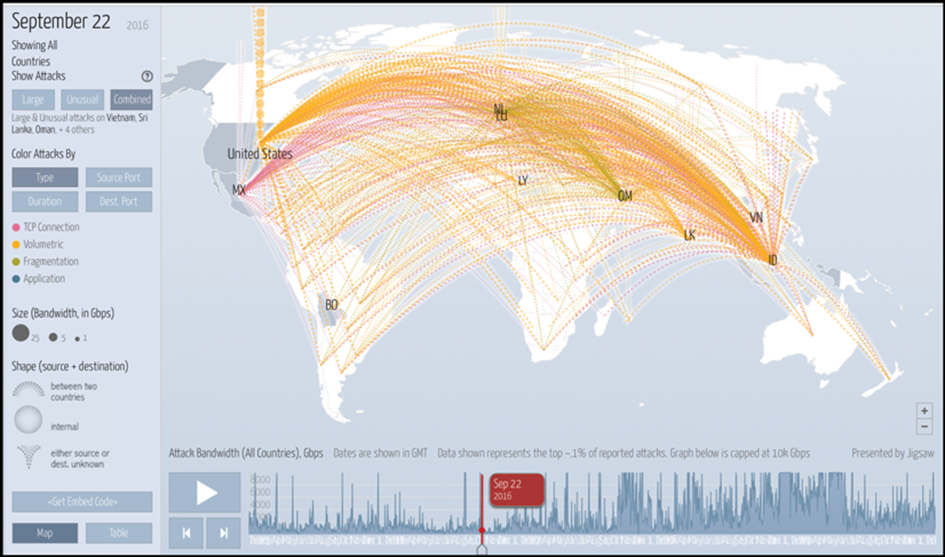
Figure 1 : une vue de l’attaque DaiS Mirai sur le site Web Krebs on Security, gracieuseté de DigitalAttackMap.com, une collaboration entre NETSCOUT Arbour et Google Jigsaw
13.2.2 Stuxnet
Stuxnet a été la première cyber-arme documentée connue à être libérée pour endommager de façon permanente les actifs de l’Iran. Dans ce cas, c’est un ver qui a été libéré pour endommager les contrôleurs logiques programmables (PLC) Siemens basés sur SCADA et a utilisé un rootkit pour modifier la vitesse de rotation des moteurs sous le contrôle direct de l’automate. Les concepteurs se sont efforcés de s’assurer que le virus ciblait uniquement les appareils avec des taux de rotation en rotation des variateurs esclaves à fréquence variable connectés aux API Siemens S7-300 tournant à 807 Hz et 1210 Hz, car ils sont généralement utilisés pour les pompes et les centrifugeuses à gaz pour l’uranium enrichissement.
L’attaque a vraisemblablement commencé en avril ou mars 2010. Le processus d’infection a suivi les étapes suivantes :
- Infection initiale : le ver a commencé par infecter une machine Windows hôte exploitant les vulnérabilités trouvées dans les attaques de virus précédentes. On pense qu’il s’est propagé par l’insertion d’une clé USB dans la machine initiale. Il a utilisé simultanément quatre exploits zero-day (un niveau de sophistication sans précédent). Les exploits ont utilisé une attaque rootkit en utilisant du code en mode utilisateur et en mode noyau et ont installé un pilote de périphérique volé mais correctement signé et certifié de Realtek. Ce pilote signé en mode noyau était nécessaire pour cacher Stuxnet des packages antivirus prudents.
- Attaque et propagation de Windows : Une fois installé via le rootkit, le ver a commencé à rechercher dans le système Windows les fichiers typiques d’un contrôleur Siemens SCADA, WinCC / PCS 7 SCADA, également connu sous le nom de Step-7. Si le ver est arrivé à trouver un logiciel de surveillance SCADA Siemens, il a tenté d’accéder à Internet via un C2 en utilisant des URL malformées ( www.mypremierfutbol.com et www.todaysfutbol.com ) pour télécharger des versions plus récentes de sa charge utile. Il a ensuite creusé plus loin dans le système de fichiers pour rechercher un fichier appelé s7otbdx.dll, qui servait de bibliothèque de communication critique entre la machine Windows et l’automate. L’étape 7 comprenait une base de données de mots de passe codée en dur qui a été exploitée par une autre attaque zero-day. Stuxnet s’est inséré entre le système WinCC et s7otbdx.dll pour agir comme un attaquant man-in-the-middle. Le virus a commencé son opération en enregistrant le fonctionnement normal des centrifugeuses.
- Destruction : lorsqu’elle a décidé de coordonner l’attaque, elle a rejoué les données préenregistrées sur les systèmes SCADA, qui n’avaient aucune raison de croire que quelque chose était compromis ou se comportait de manière erratique. Stuxnet a infligé ses dégâts en manipulant les PLC avec deux attaques coordonnées différentes pour endommager l’ensemble des installations iraniennes. Les dommages aux rotors de la centrifugeuse se sont produits lentement au fil du temps, fonctionnant par incréments de 15 ou 50 minutes séparés par 27 jours de fonctionnement normal. Il en est résulté de l’uranium mal enrichi ainsi que des tubes de rotor fissurés et détruits dans les centrifugeuses.
On pense que plus de 1 000 centrifugeuses d’enrichissement d’uranium ont été paralysées et endommagées par cette attaque contre la principale installation d’enrichissement de l’Iran à Natanz, en Iran. Aujourd’hui, le code Stuxnet est disponible en ligne et est essentiellement un terrain de jeu open source pour créer des exploits dérivés ( https://github.com/micrictor/stuxnet ).
13.2.3 Réaction en chaîne
Chain Reaction est une étude universitaire qui montre une nouvelle race de cyberattaques ciblant les réseaux maillés PAN qui peuvent être exécutés sans aucun lien avec Internet. De plus, il montre à quel point les systèmes de capteurs et de contrôle IoT distants peuvent être vulnérables. Le vecteur d’attaque était les ampoules Philips Hue que l’on trouve généralement dans les maisons de consommation et qui peuvent être contrôlées par Internet et les applications pour smartphone. L’exploit peut être étendu aux attaques de ville intelligente et lancé en insérant simplement une seule lumière intelligente infectée.
Les lampes Philips Hue utilisent le protocole Zigbee pour établir un maillage. Les systèmes d’éclairage Zigbee relèvent d’un programme appelé Zigbee Light Link (ZLL) pour forcer une méthode standard d’interopérabilité d’éclairage. Les messages ZLL ne sont ni chiffrés ni signés, mais le chiffrement est utilisé pour sécuriser les clés échangées si une lumière est ajoutée au maillage. Cette clé principale est connue de tous les membres de l’alliance ZLL et a ensuite été divulguée. ZLL oblige également les ampoules à rejoindre le maillage à être très proches de l’initiateur. Cela empêche de prendre le contrôle des lumières de leur voisin. Aussi ZigBee offre une over-the-air (OTA) reprogrammation procédée ; Cependant, les ensembles de micrologiciels sont cryptés et signés.
Les chercheurs ont utilisé un plan d’attaque en quatre phases :
- L’attaque briserait le chiffrement et la signature du paquet de micrologiciels OTA.
- Il rédigerait et déploierait une mise à niveau malveillante du micrologiciel vers une seule ampoule à l’aide des clés de cryptage et de signature cassées.
- L’ampoule compromise rejoindrait le réseau sur la base de la clé principale volée et exploiterait la sécurité de proximité grâce à un défaut zero-day trouvé dans la partie Atmel AtMega couramment utilisée.
- Après avoir réussi à rejoindre un maillage Zigbee, il enverrait ensuite sa charge utile aux lumières voisines et les infecterait rapidement. Cela se développerait sur la base de la théorie de la percolation et infecterait des populations entières de la ville de systèmes d’éclairage.
Zigbee utilise le cryptage AES-CCM (faisant partie de la norme IEEE 802.15.4 et traité plus loin dans ce chapitre) pour crypter les mises à jour du firmware OTA. Pour briser le cryptage du firmware, les attaquants ont utilisé l’analyse de corrélation de puissance (CPA) et l’analyse de puissance différentielle (DPA).
Il s’agit d’une forme d’attaque sophistiquée où un appareil tel que le matériel du contrôleur d’ampoule est placé sur un banc et la puissance qu’il consomme est mesurée. Avec un contrôle sophistiqué, on peut mesurer la puissance dynamique utilisée par une CPU exécutant une instruction ou en déplaçant des données (par exemple, lorsqu’un algorithme de chiffrement est exécuté). C’est ce qu’on appelle la simple analyse de puissance (SPA), dans laquelle il est toujours très difficile de casser la clé. CPA et DPA étendent les capacités au-delà de SPA en utilisant une corrélation statistique.
Plutôt que de tenter de déterminer un bit à la fois lors du craquage d’une clé, le CPA peut résoudre des quantités à l’échelle de l’octet. Les traces de puissance sont capturées par un oscilloscope et divisées en deux ensembles. Le premier ensemble suppose qu’une valeur intermédiaire étant fissurée est définie sur 1 et l’autre ensemble suppose qu’elle est définie sur 0. En soustrayant la moyenne de ces ensembles, la vraie valeur d’une valeur intermédiaire est exposée.
En utilisant à la fois le DPA et le CPA, les chercheurs ont cassé le système d’éclairage Philips Hue comme suit:
- Les chercheurs ont utilisé le CPA pour casser l’AES-CBC. Les attaquants n’avaient ni clé, ni nonce, ni vecteur d’initialisation. Cela a résolu la clé, qui a été utilisée de la même manière pour attaquer le nonce.
- Ils ont utilisé DPA pour casser le mode de compteur AES-CTR pour briser le cryptage de regroupement de micrologiciels. Les chercheurs ont trouvé 10 emplacements que l’AES-CTR semblait exécuter, ce qui créait 10 fois plus de possibilités.
- Ils se sont ensuite concentrés sur la suppression de la protection de proximité Zigbee pour rejoindre un réseau. L’exploitation du jour zéro a été le résultat trouvé en inspectant le code source d’Atmel pour le chargeur de démarrage sur le SOC. Après avoir examiné le code, ils ont constaté que le contrôle de proximité était valide lors du démarrage d’une demande d’analyse dans Zigbee. S’ils ont commencé avec un autre message, le contrôle de proximité a été ignoré. Cela leur a permis de rejoindre n’importe quel réseau.
Une véritable attaque pourrait forcer une ampoule infectée à infecter d’autres personnes à quelques centaines de mètres avec une charge utile pour supprimer la capacité de mise à jour du firmware de chaque ampoule afin qu’elles ne puissent jamais être récupérées. Les ampoules seraient effectivement sous contrôle malveillant et devraient être détruites. Les chercheurs ont réussi à construire un système d’attaque entièrement automatisé et l’ont attaché à un drone qui a systématiquement volé à portée des lumières Philips Hue dans un environnement de campus et détourné chacun.
Plus d’informations sur l’attaque CPA contre Zigbee peuvent être trouvées ici: E. Ronen, A. Shamir, AO Weingarten et C. O’Flynn, IoT Goes Nuclear: Création d’une réaction en chaîne ZigBee , 2017 IEEE Symposium on Security and Privacy (SP) , San Jose, Californie, 2017, pp. 195-212. Un excellent tutoriel et le code source pour générer une attaque CPA peuvent être trouvés sur le wiki ChipWhisperer: https://wiki.newae.com/AES-CCM_Attack .
13.3 Sécurité physique et matérielle
De nombreux déploiements IoT se feront dans des zones éloignées et isolées, laissant les capteurs et les routeurs périphériques vulnérables aux attaques physiques. De plus, le matériel lui-même a besoin de mécanismes de protection modernes communs aux processeurs et aux circuits des appareils mobiles et de l’électronique personnelle.
13.3.1 RoT
La première couche de sécurité matérielle est la mise en place d’un RoT. Le RoT est un processus de démarrage validé par le matériel qui garantit que le premier opcode exécutable démarre à partir d’une source immuable. Il s’agit de l’ancrage du processus de démarrage qui joue par la suite un rôle dans l’amorçage du reste du système du BIOS vers le système d’exploitation vers l’application. Un RoT est une défense de base contre un rootkit.
Chaque phase valide la phase suivante du processus de démarrage et crée une chaîne de confiance. Un RoT peut avoir différentes méthodes de démarrage telles que :
- Démarrez à partir de la ROM ou de la mémoire non inscriptible pour stocker l’image et la clé racine
- Mémoire programmable unique utilisant des bits de fusible pour le stockage de la clé racine
- Démarrage à partir d’une région de mémoire protégée qui charge du code dans un magasin de mémoire protégé
Un RoT doit également valider chaque nouvelle phase de démarrage. Chaque phase de démarrage conserve un ensemble de clés signées cryptographiquement qui sont utilisées pour vérifier la prochaine phase de démarrage :
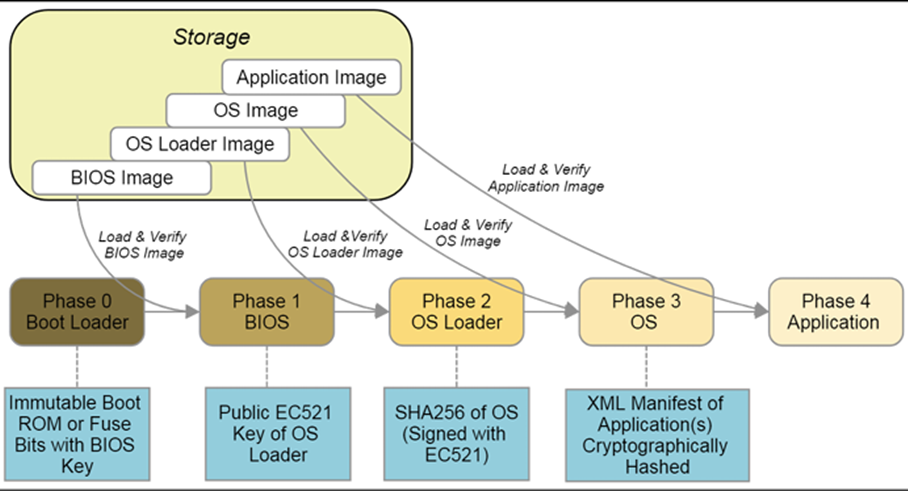
Figure 2 : établissement d’une RoT. Voici un fi démarrage cinq phases construction d’une chaîne de confiance et à partir d’un chargeur de démarrage dans immuable mémoire en lecture seule. Chaque phase conserve une clé publique qui est utilisée pour vérifier l’authenticité du composant suivant chargé.
Les processeurs qui prennent en charge une RoT sont uniques sur le plan architectural. Intel et ARM prennent en charge les éléments suivants :
- ARM TrustZone : ARM vend un bloc IP de silicium de sécurité pour les fabricants de SOC qui fournit un RoT matériel ainsi que d’autres services de sécurité. TrustZone divise le matériel en « mondes » sécurisés et non sécurisés. TrustZone est un microprocesseur séparé du cœur non sécurisé. Il exécute un système d’exploitation sécurisé spécialement conçu pour la sécurité qui possède une interface bien définie avec le monde non sécurisé. Les actifs et les fonctions protégés résident dans le noyau de confiance et doivent être légers de par leur conception. La commutation entre les mondes se fait par la commutation du contexte matériel, éliminant ainsi le besoin d’un logiciel de surveillance sécurisé. TrustZone sert également à gérer les clés système, les transactions par carte de crédit et la gestion des droits numériques. TrustZone est disponible pour les processeurs A “application” et M “microcontrôleur”. Cette forme de CPU sécurisé, de système d’exploitation sécurisé et de RoT est appelée environnement d’exécution de confiance (TEE).
- Intel Boot Guard : il s’agit d’un mécanisme matériel qui fournit un démarrage vérifié qui vérifie cryptographiquement le bloc de démarrage initial ou utilise un processus de mesure pour la validation. Boot Guard nécessite qu’un fabricant génère une clé de 2048 bits pour vérifier le bloc initial. La clé est divisée en une partie privée et publique. La clé publique est imprimée en “soufflant” par programmation des bits de fusible pendant la fabrication. Ce sont des fusibles à usage unique immuables. La partie privée génère la signature de la partie vérifiée ultérieurement de la phase de démarrage.
13.3.2 Gestion des clés et modules de plateforme de confiance
Les clés publiques et privées sont essentielles pour garantir un système sécurisé. Les clés elles-mêmes nécessitent une gestion appropriée pour assurer leur sécurité. Il existe des normes matérielles pour la sécurité des clés et un mécanisme particulièrement populaire est le module de plateforme sécurisée (TPM). La spécification pour TPM a été écrite par le Trusted Computing Group et est une norme ISO et CEI. La spécification actuelle est TPM 2.0 publiée en septembre 2016. Les actifs informatiques vendus au DoD nécessitent TPM 1.2.
Un TPM est un composant matériel discret avec une clé RSA secrète gravée dans l’appareil lors de la fabrication.
Généralement, un module de plateforme sécurisée est utilisé pour conserver, sécuriser et gérer d’autres clés pour des services tels que le chiffrement de disque, le démarrage RoT, la vérification de l’authenticité du matériel (ainsi que des logiciels) et la gestion des mots de passe.
Un module de plateforme sécurisée peut créer un hachage d’une litanie de logiciels et de matériel dans une configuration “bonne connue” qui peut être utilisée pour vérifier la falsification au moment de l’exécution. Les services supplémentaires incluent l’assistance au hachage SHA-1 et SHA-256, les blocs de chiffrement AES, le chiffrement asymétrique et la génération de nombres aléatoires. Plusieurs fournisseurs produisent des dispositifs TPM tels que Broadcom, Nation Semiconductor et Texas Instruments.
13.3.3 Processeur et espace mémoire
Nous avons déjà discuté de divers exploits et technologies de processeur qui agissent comme des contre-mesures. Deux technologies prédominantes à rechercher dans les installations de processeur et de système d’exploitation incluent la mémoire de non-exécution et la randomisation de la configuration de l’espace d’adressage. Les deux types de technologies sont censés alourdir ou empêcher les types d’injection de logiciels malveillants à débordement de tampon et à dépassement de pile :
- Protection contre les non-exécutions (ou protection de l’espace exécutable) : il s’agit d’une fonctionnalité activée par le matériel utilisé par le système d’exploitation pour marquer les zones de mémoire comme non exécutables. L’intention est de mapper uniquement les zones où le code vérifié et légitime réside pour être les seules régions de mémoire adressable qui peuvent exécuter une opération. Si une tentative est faite pour implanter un malware par le biais d’une attaque de type débordement de pile, la pile sera marquée comme non exécutable et une tentative de forcer le pointeur d’instruction à s’exécuter entraînerait une exception de machine.
La mémoire non exécutable utilise un bit NX comme moyen de mapper la région en tant que non exécutable (via la mémoire tampon de traduction). Intel utilise le bit Execute Disable (XD) et ARM utilise un bit Execute Never (XN). La plupart des systèmes d’exploitation, tels que Linux, Windows et plusieurs RTOS, prennent en charge ces fonctionnalités.
- Randomisation de la disposition de l’espace d’adressage (ASLR) : bien qu’il s’agisse davantage d’un traitement du système d’exploitation de l’espace de mémoire virtuelle que d’une fonctionnalité matérielle, il est important de considérer l’ASLR. Ce type de contre-mesure cible les dépassements de tampon ainsi que les attaques de retour à la libc. Ces attaques sont basées sur un attaquant comprenant la disposition de la mémoire et forçant les appels à certains codes et bibliothèques bénins. L’appel de ces bibliothèques devient particulièrement laborieux si l’espace mémoire est aléatoire à chaque démarrage. Linux fournit la capacité ASLR en utilisant les correctifs PAX et Exec Shield. Microsoft fournit également une protection pour les blocs de tas, de pile et de processus.
13.3.4 Sécurité du stockage
Souvent, les appareils IoT auront un stockage persistant au niveau du nœud périphérique ou sur un routeur / passerelle. Les nœuds de brouillard intelligents nécessiteront également un stockage persistant.
La sécurité des données sur l’appareil est impérative pour empêcher le déploiement de logiciels malveillants malveillants et pour protéger les données en cas de vol de l’appareil IoT. La plupart des périphériques de stockage de masse, tels que les modules flash et les disques rotatifs, ont des modèles dotés d’une technologie de cryptage et de sécurité.
La norme FIPS 140-2 (Federal Information Processing Standard) est une réglementation gouvernementale détaillant les exigences de chiffrement et de sécurité pour les appareils informatiques qui gèrent ou stockent des données sensibles. Il spécifie non seulement les exigences techniques, mais définit également les politiques et procédures. FIPS 140-2 a plusieurs niveaux de conformité :
- Niveau 1 : cryptage logiciel uniquement. Sécurité limitée.
- Niveau 2 : l’authentification basée sur les rôles est nécessaire. Nécessite la capacité de détecter une altération physique à l’aide de scellés inviolables.
- Niveau 3 : Comprend la résistance physique à la falsification. Si l’appareil est altéré, il s’agira de paramètres de sécurité critiques. Comprend une protection cryptographique et une gestion des clés. Comprend l’authentification basée sur l’identité.
- Niveau 4 : protection avancée contre les manipulations pour les produits conçus pour fonctionner dans des environnements physiquement non protégés.
En plus du chiffrement, il est également nécessaire de prendre en compte la sécurité des médias lorsqu’ils sont mis hors service ou éliminés. Il est assez facile de récupérer le contenu d’anciens systèmes de stockage. Il existe des normes supplémentaires sur la façon d’effacer et d’effacer le contenu du support en toute sécurité (qu’il s’agisse d’un disque à base magnétique ou d’un composant flash à changement de phase). Le NIST publie également des documents sur l’effacement et l’effacement sécurisés du contenu, comme la publication spéciale NIST 800-88 pour Secure Erase.
13.3.5 Sécurité physique
La résistance au sabotage et la sécurité physique sont particulièrement importantes pour les appareils IoT. Dans de nombreux scénarios, un appareil IoT sera distant et sans les protections des appareils sur site. Ceci est analogue à la machine Enigma de la Seconde Guerre mondiale. La récupération d’une machine en état de marche du sous-marin allemand U-110 a permis de briser le chiffre. Un attaquant ayant accès au dispositif IoT peut utiliser tous les outils à sa guise pour casser le système, comme nous l’avons vu avec l’exploit Chain Reaction.
Les attaques latérales, comme indiqué, traitent de l’analyse de puissance ; les autres formes sont les attaques temporelles, les attaques de cache, les émissions de champs électromagnétiques et les attaques par chaîne de balayage. Le thème commun d’une attaque par canal latéral est que l’unité compromise est essentiellement un appareil sous test (DUT). Cela signifie que l’appareil sera observé et mesuré dans un environnement contrôlé.
De plus, des techniques telles que l’analyse de puissance différentielle (DPA) utilisent des approches d’analyse statistique pour rechercher les corrélations d’entrée aléatoire à la sortie. L’analyse statistique ne fonctionne que si le système se comporte de manière identique d’une exécution à l’autre avec la même entrée :
| Méthodologie | |
| Attaques temporelles | Tente d’exploiter de petites différences dans le timing des algorithmes. Par exemple, mesurer la synchronisation d’un algorithme de décodage de mot de passe et observer les premières sorties de la routine. Les attaquants peuvent également observer l’utilisation du cache pour observer les caractéristiques de l’algorithme. |
| Analyse de puissance simple (SPA) | Similaire à une attaque temporelle, mais mesure les grands changements de puissance dynamique ou de courant dus au comportement d’un algorithme et d’opcodes. Les clés publiques sont particulièrement sensibles. L’analyse nécessite peu de traces pour fonctionner, mais les traces nécessitent un degré élevé de précision. Comme la plupart des algorithmes cryptographiques sont mathématiquement intensifs, différents opcodes apparaîtront comme différentes signatures de puissance dans une trace. |
| Analyse de puissance différentielle (DPA) | Mesure la puissance dynamique mais peut observer des changements trop faibles pour être observés directement comme dans le SPA. En injectant des entrées aléatoires (telles que différentes clés aléatoires) dans un système, l’attaquant peut effectuer des milliers de traces pour créer un ensemble dépendant des données. Attaquer un algorithme AES, par exemple, signifie simplement construire deux ensembles de traces en fonction de la valeur du bit (0 ou 1) craqué. Les ensembles sont moyennés et la différence entre les ensembles 0 et 1 est tracée pour montrer l’effet de l’entrée aléatoire sur la sortie. |
Les méthodes de prévention sont bien connues et plusieurs peuvent être autorisées et utilisées dans une variété de matériel. Les contre-mesures pour ces types d’attaques incluent:
- Modifiez la fonction de cryptage pour minimiser l’utilisation de la clé. Utilisez une clé de session de courte durée basée sur un hachage de la clé réelle.
- Pour les attaques temporelles, insérez au hasard des fonctions qui ne perturberont pas l’algorithme d’origine. Utilisez différents opcodes aléatoires pour créer une grande fonction de travail pour les attaques.
- Supprimez les branches conditionnelles qui dépendent de la clé.
- Pour les attaques de puissance, réduisez les fuites à chaque occasion et limitez le nombre d’opérations par clé. Cela réduit le jeu de travail de l’attaquant.
- Faire du bruit dans les lignes électriques. Utilisez des opérations de synchronisation variable ou des horloges de biais. Modifiez l’ordre des opérations indépendantes. Cela réduit les facteurs de corrélation autour du calcul de la S-Box.
D’autres considérations matérielles incluent:
- Empêchez l’accès aux ports et canaux de débogage. Ils sont souvent exposés sur le PCA en tant que ports série et ports JTAG. Les en-têtes doivent être supprimés et les fusibles sautés pour empêcher l’accès au débogage dans les cas les plus durcis.
- Les ASIC utilisent généralement des plots à grille de billes ( BGA ) pour se connecter à un PCA. Des adhésifs haute performance et de la colle thermiquement résistante doivent être utilisés pour entourer l’ emballage et peuvent causer des dommages irréparables s’ils sont altérés.
13.4 Sécurité du shell
Nous avons examiné la sécurité matérielle jusqu’à présent, mais l’architecte doit également tenir compte de la sécurité du réseau et du shell du système. La sécurité du réseau est traitée dans le chapitre 9 , Routage de périphérie et mise en réseau . Nous allons explorer un domaine de connectivité shell dans cette section : SSH, ou shell sécurisé.
SSH est un protocole de réseau cryptographique utilisé pour fournir des services tels que la connexion, le contrôle en ligne de commande, l’accès à distance et l’accès root aux systèmes d’exploitation modernes. SSH utilise un canal sécurisé sur un réseau non sécurisé, en utilisant des méthodes telles que SHA-2 et SHA25. De plus, l’authentification est effectuée à l’aide de diverses méthodes, telles que l’échange de clés publiques ou de simples mots de passe. En règle générale, les sessions SSH utilisent le port 22.
Bien que le protocole utilise des méthodes d’authentification et de cryptage, il existe toujours des vulnérabilités :
- Une méthode préférée consiste à utiliser l’échange de clés publiques lors de l’authentification. Celles-ci sont bien meilleures que la sécurité par mot de passe.
- Un vecteur d’attaque typique est la tentative de nom d’utilisateur / mot de passe par force brute. Les ports SSH offrent une opportunité facile pour les attaques car les appareils peuvent garder le port ouvert et exposé sur Internet. Il ne devrait jamais y avoir de mots de passe vides sur aucun système. De plus, utilisez des noms d’utilisateur et des mots de passe très forts, en utilisant des générateurs de mots de passe psuedorandom.
- Les sessions SSH ne doivent jamais rester inactives. Il est possible qu’une session SSH se termine s’il n’y a pas d’activité en modifiant ClientAliveInterval .
- Utilisez un autre port à côté du port 22. Beaucoup de gens ont simplement choisi le port 222 ou 2222 pour plus de commodité. Il est recommandé d’utiliser un port inutilisé loin de ces entiers faciles à deviner.
- Utilisez des méthodes d’authentification à deux facteurs.
13.5 Cryptographie
Le chiffrement et la confidentialité sont des exigences absolues des déploiements IoT. Ils sont utilisés pour sécuriser la communication, protéger le micrologiciel et l’authentification. Concernant le cryptage, il y a généralement trois formes à considérer :
- Cryptage à clé symétrique : les clés de cryptage et de décryptage sont identiques. RC5, DES, 3DES et AES sont toutes des formes de chiffrement de clé symétrique.
- Cryptage à clé publique : la clé de cryptage est publiée publiquement pour que quiconque puisse utiliser et crypter des données. Seul le destinataire a une clé privée utilisée pour déchiffrer le message. Ceci est également connu sous le nom de cryptage asymétrique. La cryptographie asymétrique gère la confidentialité des données, authentifie les participants et force la non-répudiation. Les protocoles de chiffrement et de messages Internet bien connus tels que la courbe elliptique, PGP, RSA, TLS et S / MIME sont considérés comme des clés publiques.
- Hachage cryptographique : Mappe données d’une taille arbitraire à une chaîne de bits (appelé le digest). Cette fonction de hachage est conçue pour être “à sens unique”. Essentiellement, la seule façon de recréer le hachage de sortie est de forcer toutes les combinaisons d’entrée possibles (il ne peut pas être exécuté en sens inverse). MD5, SHA1, SHA2 et SHA3 sont toutes des formes de hachage unidirectionnel. Ils sont généralement utilisés pour coder des signatures numériques telles que des images de micrologiciel signées, des codes d’authentification de message (MAC) ou l’authentification. Lors du chiffrement d’un court message comme un mot de passe, l’entrée peut être trop petite pour créer efficacement un hachage équitable; dans ce cas, un sel ou une chaîne non privée est ajouté au mot de passe pour augmenter l’entropie. Un sel est une forme de fonction de dérivation clé (KDF):
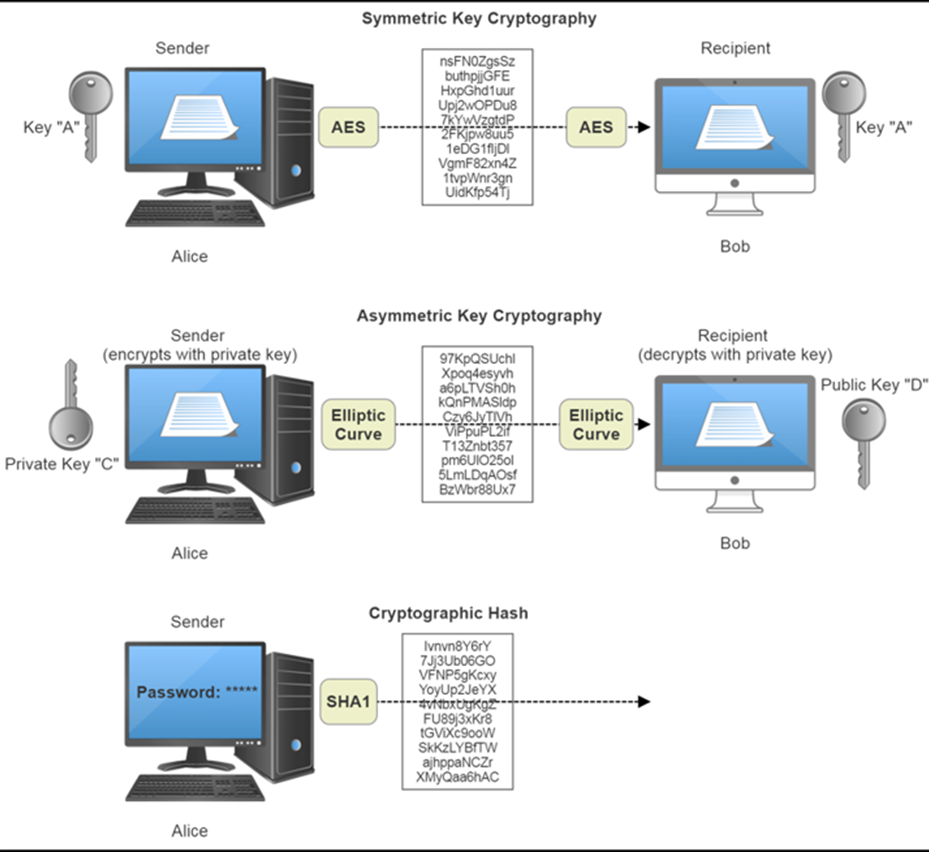
Figure 3 : Éléments de cryptographie. Voici les fonctions symétriques, asymétriques et de hachage. Notez l’utilisation des clés en cryptographie symétrique et asymétrique. Le hachage symétrique a l’obligation d’utiliser des clés identiques pour chiffrer et déchiffrer les données. Bien que plus rapide que le cryptage asymétrique, les clés doivent être sécurisées.
13.5.1 Cryptographie symétrique
En cryptage, le texte en clair fait référence à l’entrée non cryptée et la sortie est appelée texte chiffré, car elle est cryptée. La norme de cryptage est la norme de cryptage avancée ( AES ), qui a remplacé les anciens algorithmes DES datant des années 1970. L’AES fait partie de la spécification FIPS et de la norme ISO / IEC 18033-3 utilisée dans le monde entier. Les algorithmes AES utilisent des blocs fixes de 128, 192 ou 256 bits. Les messages supérieurs à la largeur en bits seront divisés en plusieurs blocs. AES a quatre phases de base de fonctionnement pendant le chiffrement. Le pseudocode pour un cryptage AES générique est affiché ici:
// Pseudo code for an AES-128 Cipher
// in: 128 bits (plaintext)
// out: 128 bits (ciphertext)
// w: 44 words, 32 bits each (expanded key) state = in
w=KeyExpansion(key) //Key Expansion phase (effectively encrypts key itself)
AddRoundKey(state, w[0, Nb-1]) //Initial Round
for round = 1 step 1 to Nr–1 //128 bit= 10 rounds, 192 bit = 12 rounds, 256 bit = 14 rounds
SubBytes(state) //Provide non-linearity in the cipher
ShiftRows(state) //Avoids columns being encrypted independently
MixColumns(state) //Transforms each column and adds diffusion to the cipher
AddRoundKey(state, w[round*Nb, (round+1)*Nb-1]) //Generates a subkey
end for
SubBytes(state) //Final round and cleanup.
ShiftRows(state)
AddRoundKey(state, w[Nr*Nb, (Nr+1)*Nb-1]) out = state
Les longueurs de clé AES peuvent être de 128, 192 ou 256 bits. Généralement, plus la longueur de clé est grande, meilleure est la protection. La taille de la clé est proportionnelle au nombre de cycles CPU nécessaires pour chiffrer ou déchiffrer un bloc: 128 bits nécessitent 10 cycles, 192 bits nécessitent 12 cycles et 256 bits nécessitent 14 cycles.
Comme AES est un chiffrement par blocs, les données doivent être remplies au multiple de la longueur de clé. L’architecte d’une solution IoT ou périphérique doit tenir compte de cela si les données en transit sont sensibles à la longueur.
Les chiffrements par blocs représentent des algorithmes de chiffrement basés sur une clé symétrique et opérant sur un seul bloc de données. Les chiffrements modernes sont basés sur les travaux de Claude Shannon sur les chiffrements de produits en 1949. Un mode de fonctionnement de chiffrement est un algorithme qui utilise un chiffrement par blocs et décrit comment appliquer à plusieurs reprises un chiffrement pour transformer de grandes quantités de données composées de nombreux blocs. La plupart des chiffrements modernes nécessitent également un vecteur d’initialisation (IV) pour garantir des textes chiffrés distincts, même si le même texte en clair est entré à plusieurs reprises. Il existe plusieurs modes de fonctionnement, tels que :
- Electronic Codebook (ECB) : La forme la plus basique de cryptage AES, mais utilisée avec d’autres modes pour créer une sécurité plus avancée. Les données sont divisées en blocs et chacun est chiffré individuellement. Des blocs identiques produiront des chiffres identiques, ce qui rend ce mode relativement faible.
- Chaînage de blocs de chiffrement (CBC) : messages en texte clair XOR avec le texte chiffré précédent avant d’être chiffrés.
- Chaînage de rétroaction de chiffrement (CFB) : semblable à CBC, mais forme un flux de chiffrements (la sortie du chiffrement précédent alimente le suivant). Le chaînage CFB dépend du chiffrement de bloc précédent pour fournir une entrée au chiffrement en cours de génération. En raison de la dépendance des chiffrements précédents, le chaînage CFB ne peut pas être traité en parallèle. Le chiffrement en continu permet de perdre un bloc en transit, mais les blocs suivants peuvent récupérer des dommages.
- Chaîne de retour de sortie (OFB) : similaire à CFB, un chiffrement en continu, mais permet d’appliquer des codes de correction d’erreur avant le chiffrement.
- Compteur (CTR) : transforme un chiffrement de bloc en chiffrement de flux mais utilise un compteur. Le compteur d’incrémentation alimente chaque bloc de chiffrement en parallèle, permettant une exécution rapide. Le nonce et le compteur sont concaténés ensemble pour alimenter le chiffrement par bloc.
- CBC avec code d’authentification de message (CBC-MAC) : un MAC (également appelé balise ou MIC) est utilisé pour authentifier un message et confirmer que le message provient de l’expéditeur indiqué. Le MAC ou le MIC est ensuite ajouté au message pour vérification par le récepteur.
Ces modes ont été construits pour la première fois à la fin des années 1970 et au début des années 1980 et ont été préconisés par le National Institute of Standards and Technology (NIST) dans FIPS 81 en tant que modes DES. Ces modes fournissent un cryptage pour la confidentialité des informations mais ne protègent pas contre la modification ou l’altération. Pour ce faire, une signature numérique est nécessaire et la communauté de la sécurité a développé CBC-MAC pour l’authentification. La combinaison de CBC-MAC avec l’un des modes hérités était difficile jusqu’à ce que des algorithmes comme AES-CCM soient établis, qui fournissent à la fois l’authentification et le secret. CCM signifie compteur avec mode CBC-MAC.
CCM est un mode de cryptage important utilisé pour signer et crypter les données et est utilisé dans une pléthore de protocoles traités dans cet article, y compris Zigbee, Bluetooth Low Energy, TLS 1.2 (après échange de clés), IPSEC et 802.11 Wi-Fi WPA2.
AES-CCM utilise des chiffrements doubles : CBC et CTR. AES-CTR, ou AES Counter Mode, est utilisé pour le décryptage général du flux de texte chiffré entrant. Le flux entrant contient une balise d’authentification chiffrée. AES-CTR décryptera l’étiquette ainsi que les données de charge utile. Un “tag attendu” est formé à partir de cette phase de l’algorithme. La phase AES-CBC de l’algorithme marque en entrée les blocs déchiffrés à partir de la sortie AES-CTR et de l’en-tête d’origine de la trame. Les données sont cryptées ; Cependant, les seules données pertinentes nécessaires à l’authentification sont la balise calculée. Si l’étiquette calculée AES-CBC diffère de l’étiquette attendue AES-CTR, il est possible que les données aient été falsifiées en transit.
La figure suivante illustre un flux de données chiffré entrant qui est à la fois authentifié à l’aide d’AES-CBC et déchiffré à l’aide d’AES-CTR. Cela garantit à la fois le secret et l’authenticité de l’origine d’un message :

Figure 4 : Le mode AES-CCM
Une considération pour les déploiements IoT dans un maillage entièrement connecté est le nombre de clés nécessaires. Pour n nœuds dans un maillage qui souhaitent une communication bidirectionnelle, il y a n (n-1) / 2 clés ou O (n 2 ).
13.5.2 Cryptographie asymétrique
Comme indiqué précédemment, la cryptographie asymétrique est également appelée cryptographie à clé publique. Les clés asymétriques sont générées par paires (chiffrement et déchiffrement). Les clés peuvent être interchangeables, ce qui signifie qu’une clé peut à la fois crypter et décrypter, mais ce n’est pas une exigence. L’usage typique, cependant, est de générer une paire de clés et de garder l’une privée et l’autre publique. Cette section décrit les trois cryptogrammes de clé publique fondamentaux : RSA, Diffie-Hellman et Elliptical Curves.
Notez que contrairement au nombre de clés symétriques dans un maillage où n’importe quel nœud peut communiquer avec n’importe quel autre nœud, la cryptographie asymétrique ne nécessite que 2n clés ou O (n).
La première méthode de chiffrement asymétrique à clé publique décrite est l’algorithme Rivest-Shamir-Adleman, ou RSA, développé en 1978. Il est basé sur un utilisateur trouvant et publiant le produit de deux grands nombres premiers et d’une valeur auxiliaire (clé publique). La clé publique peut être utilisée par n’importe qui pour crypter un message, mais les facteurs premiers sont privés. L’algorithme fonctionne comme suit :
- Trouvez deux grands nombres premiers, p et q.
n = pq
![]()
- Exposant de clé publique : choisissez un entier et ainsi, et est coprime à; une valeur typique est 2 16 + 1 = 65537.
- Exposant de clé privée : calculez d pour résoudre la relation de congruence.
Par conséquent, pour chiffrer un message à l’aide de la clé publique (n, e) et pour déchiffrer un message à l’aide de la clé privée (n, d) :
- Crypter : Ciphertext = (texte en clair) et mod n
- Déchiffrer : Plaintext = (texte chiffré) d mod n
Il arrive souvent qu’un remplissage artificiel soit injecté dans un message avant le chiffrement pour éviter que des messages courts ne produisent un bon texte chiffré.
La forme d’échange de clés asymétrique la plus connue est peut-être le processus d’échange de clés Diffie-Hellman (du nom de Whitfield Diffie et Martin Hellman). Typique de la cryptographie asymétrique est la notion de fonction de trappe, qui prend valeur donnée A et produit un signal de sortie B. Cependant, la fonction trapdoor B n’a pas produit A.
La méthode d’échange de clés Diffie-Hellman permet à deux parties (Alice A et Bob B) à échanger des clés sans aucune connaissance préalable d’une clé secrète partagée s. L’algorithme est basé sur l’échange de texte en clair d’un nombre premier de départ, p, et d’un générateur premier. Le générateur g est une racine primitive modulo p. Laissez la clé privée d’Alice soit sur et la clé privée de Bob soit b. Ensuite, A = g a mod p et B = g b mod p. Alice calcule la clé secrète comme s = B a mod p, et Bob calcule la clé secrète comme s = B a mod p.
En général, (g a mod p) b mod p = (g b mod p) a mod p :

Figure 5 : échange de clés Diffie-Hellman. Le processus commence par l’échange de texte en clair d’un prime convenu et d’un générateur de prime. Avec une clé privée indépendante générée par Alice et Bob, les clés publiques sont générées et envoyées en texte brut sur le réseau. Ceci est utilisé pour générer une clé secrète utilisée pour le chiffrement et le déchiffrement.
La force de cette forme d’échange de clés sécurisé est de générer un vrai nombre aléatoire pour chaque clé privée. Même la légère prévisibilité d’un générateur de nombres pseudo-aléatoires (PRNG) peut conduire à briser le cryptage. Cependant, le principal problème est le manque d’authentification, qui peut conduire à une attaque MITM.
L’autre forme d’échange de clés est Ellie-Curve Diffie-Hellman (ECDH) et a été proposée par Koblitz et Miller en 1985. Elle est basée sur l’algèbre des courbes elliptiques sur un champ fini. Le NIST a approuvé l’ECDH, et la NSA autorise l’ECDH pour le matériel top secret en utilisant des clés de 384 bits. La cryptographie à courbe elliptique (ECC) partage ces principes de base concernant les propriétés d’une courbe elliptique :
- La courbe est symétrique par rapport à l’axe des x. Si (x, y) représente un point sur la courbe, alors (x, – y) sera également sur la courbe. Voir la figure suivante, qui illustre ce fait.
- Une ligne droite coupera la courbe elliptique en trois points au maximum.
Le processus d’ECC commence par tracer une ligne droite d’un point donné sur le bord vers MAX. Une ligne est tracée à partir du point A à B. Une fonction point est utilisée pour tracer une ligne entre deux points, puis tracer une ligne directement vers le haut (ou vers le bas) de la nouvelle intersection sans étiquette jusqu’à son homologue sur l’axe y positif ou négatif. Ce processus est répété n fois, où n est la taille de la clé.
Ce processus est analogue à la visualisation des résultats finaux d’une table de billard après qu’une balle a été frappée et frappe plusieurs fois les coussins. Un observateur voyant l’emplacement final de la balle aurait du mal à déterminer où se trouvait la position d’origine de la balle.
MAX correspond à la valeur maximale sur l’axe des x, ce qui limite l’étendue d’un sommet. Si par hasard le sommet est supérieur à MAX, les forces de l’algorithme, la valeur qui aurait prolongé au – delà de la MAX limite et définit un nouveau point x-MAX distance de l’origine A. MAX est équivalent à la taille de clé utilisée. Une grande taille de clé entraîne la construction de plus de sommets et augmente la force du secret. Il s’agit essentiellement d’une fonction enveloppante :
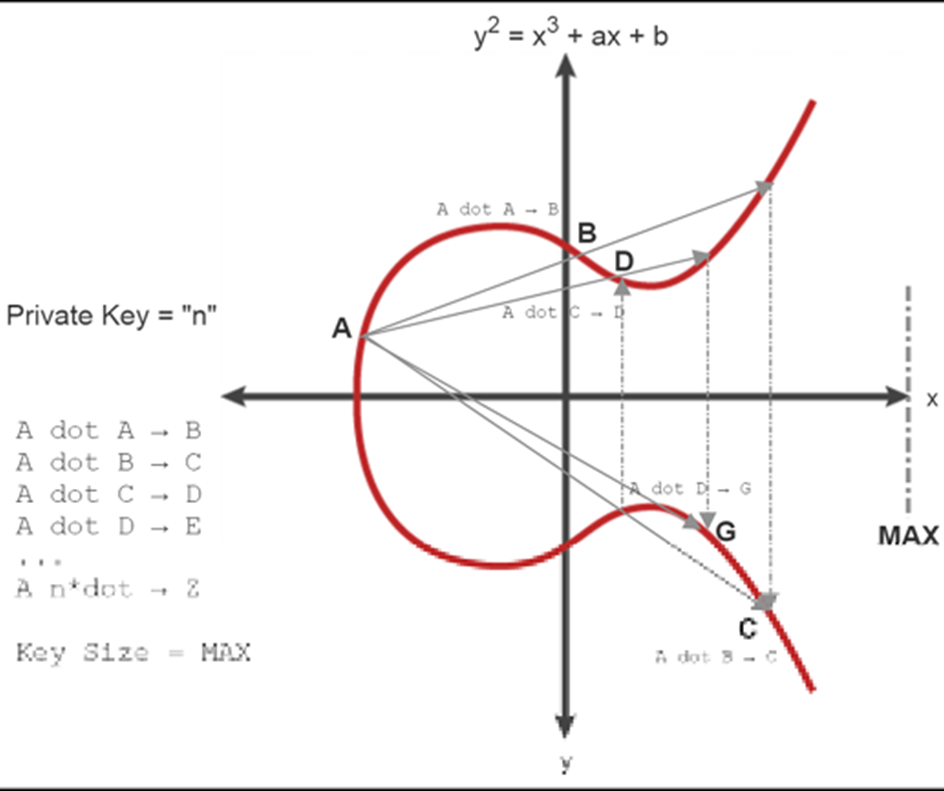
Figure 6 : Cryptographie à courbe elliptique (ECC). Voici une courbe elliptique standard sur un axe x, y. Le processus commence par suivre des trajets en ligne droite d’un point donné A à un deuxième point et localiser la troisième nouvelle intersection sans étiquette. Une ligne est tracée vers la coordonnée opposée mais identique et plane, qui devient maintenant une entité étiquetée. Le processus se poursuit pour n points, qui correspondent à la longueur de clé.
Les courbes elliptiques sont de plus en plus répandues par rapport au RSA. Les navigateurs modernes sont capables de prendre en charge ECDH, qui est la méthode préférée d’authentification sur SLL / TLS. ECDH se trouve également dans Bitcoin, comme nous le verrons plus tard, et dans plusieurs autres protocoles. RSA n’est utilisé maintenant que si un certificat SSL a une clé RSA correspondante.
L’autre avantage est que les longueurs de clé peuvent être maintenues courtes et avoir toujours la même force cryptographique qu’une méthode héritée. Par exemple, une clé de 256 bits dans ECC est équivalente à une clé de 3072 bits dans RSA. L’importance de ceci devrait être considérée pour les dispositifs IoT contraints.
13.5.3 Hachage cryptographique (authentification et signature)
Les fonctions de hachage représentent le troisième type de technologie de chiffrement à considérer. Ceux-ci sont généralement utilisés pour générer une signature numérique. Ils sont également considérés comme “à sens unique” ou impossibles à inverser. Recréer les données d’origine après avoir traversé une fonction de hachage serait une attaque par force brute de toutes les combinaisons possibles d’entrées. Les attributs clés d’une fonction de hachage incluent :
- La fonction génère toujours le même hachage à partir de la même entrée.
- Il est rapide à calculer mais pas gratuit (voir preuve de travail).
- Il est irréversible et ne peut pas régénérer le message d’origine à partir de la valeur de hachage.
- Une petite modification de l’entrée entraînera une entropie importante ou une modification de la sortie.
Deux messages différents n’auront jamais la même valeur de hachage.
Les effets des fonctions de hachage cryptographiques comme SHA1 (Secure Hash Algorithm) peuvent être démontrés en modifiant un seul caractère dans une chaîne plus longue :
Input: Boise Idaho
SHA1 Hash Output: 375941d3fb91836fb7c76e811d527d6c0a251ed4
Input: Milwaukee Wisconsin
SHA1 Hash Output: 9e318d4243262e59e2515b47a5c99771071acd8d
Les algorithmes SHA sont largement utilisés dans des applications telles que:
- Référentiels Git
- Signature de certificat TLS pour la navigation Web (HTTPS)
- Validation de l’authenticité du contenu d’un fichier ou d’une image disque
La plupart des fonctions de hachage sont basées sur la construction Merkle-Damgård . Ici, l’entrée est divisée en blocs de taille égale qui sont traités en série avec une fonction de compression combinée avec la sortie de la compression précédente. Un vecteur d’initialisation (IV) est utilisé pour ensemencer le processus. En utilisant une fonction de compression, le hachage résiste aux collisions. SHA-1 est construit sur cette construction Merkle-Damgård:
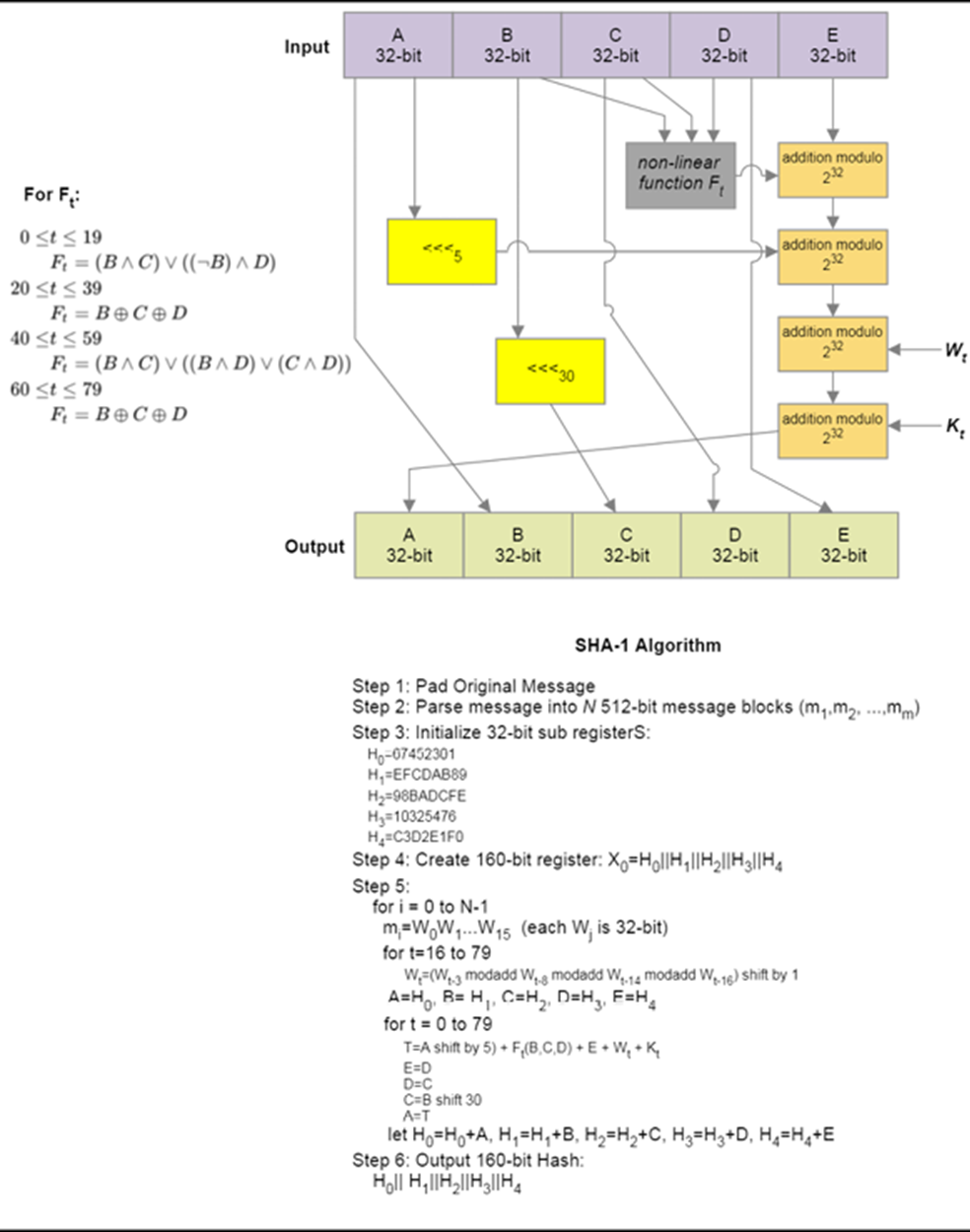
Figure 7 : algorithme SHA-1. Split entrée en fi voir des morceaux de 32 bits
En général, le message d’entrée de l’algorithme SHA doit être inférieur à 264 bits. Le message est traité séquentiellement en blocs de 512 bits. SHA-1 est désormais remplacé par des noyaux puissants tels que SHA-256 et SHA-3. SHA-1 s’est avéré avoir une “collision” dans le hachage. Alors qu’il faudrait environ 251 à 257 opérations pour trouver une collision, il ne faudrait que quelques milliers de dollars de temps GPU loué pour résoudre le hachage. Ainsi, la recommandation est de passer aux modèles SHA solides.
MD5 n’est plus considéré comme sûr et n’est plus approuvé pour une utilisation en cryptographie. Des méthodes plutôt plus fortes telles que SHA-3 sont recommandées.
13.5.4 Infrastructure à clé publique
La cryptographie asymétrique (clé publique) est un pilier du commerce et de la communication Internet. Il a été régulièrement utilisé pour la connexion SSL et TLS sur le Web. Une utilisation typique est le cryptage à clé publique, où les données en transit sont cryptées par toute personne détenant la clé publique mais ne peuvent être décryptées que par le détenteur de la clé privée. Une autre utilisation est la signature numérique, où un blob de données est signé avec la clé privée de l’expéditeur et la partie réceptrice peut vérifier l’authenticité si elle détient la clé publique.
Pour aider à fournir des clés publiques en toute confiance, un processus appelé infrastructure à clé publique (PKI) est utilisé. Pour garantir l’authenticité, des tiers de confiance connus sous le nom d’autorités de certification (CA) gèrent les rôles et les politiques pour créer et distribuer des certificats numériques. Symantec, Comodo, Let’s Encrypt et GoDaddy sont les plus grands émetteurs publics de certificats TLS. X.509 est une norme qui définit les formats de certificat de clé publique. C’est la base de la communication sécurisée TLS / SSL et HTTPS. X.509 définit des éléments tels que l’algorithme de chiffrement utilisé, les dates d’expiration et l’émetteur du certificat.
L’ICP se compose d’une autorité d’enregistrement (RA) qui vérifie l’expéditeur et gère des rôles et des politiques spécifiques et peut révoquer des certificats. L’AR communique également avec une autorité de validation (VA) pour transférer les listes de révocation. L’AC délivre le certificat à l’expéditeur. Lorsqu’un message est reçu, la clé peut être validée par le VA pour vérifier qu’elle n’a pas été révoquée.
La figure suivante montre un exemple d’infrastructure PKI. Il comprend les systèmes CA, RA et VA utilisés et les phases d’octroi et de vérification d’une clé accordée pour chiffrer un message :

Figure 8 : Exemple d’infrastructure PKI
13.5.5 Pile réseau – Sécurité de la couche de transport
La sécurité de la couche de transport (TLS) a été abordée dans de nombreux domaines de cet article, depuis TLS et DTLS pour MQTT et CoAP jusqu’à la sécurité réseau via la sécurité WAN et PAN. Chacun a eu une certaine forme de dépendance à TLS. Il rassemble également tous les protocoles et technologies cryptographiques que nous avons mentionnés. Cette section couvre brièvement la technologie et le processus TLS1.2.
À l’origine, SSL (Secure Sockets Layer) a été introduit dans les années 1990 mais a été remplacé par TLS en 1999. TLS 1.2 est la spécification actuelle de la RFC5246 en 2008. TLS 1.2 comprend un générateur de hachage SHA-256 pour remplacer SHA-1 et renforcer son profil de sécurité.
Dans le chiffrement TLS, le processus est le suivant :
- Le client ouvre une connexion à un serveur compatible TLS (port 443 pour HTTPS).
- Le client présente une liste de chiffrements pris en charge qui peuvent être utilisés.
- Le serveur choisit une fonction de chiffrement et de hachage et avertit le client.
- Le serveur envoie un certificat numérique au client qui comprend une autorité de certification et la clé publique du serveur.
- Le client confirme la validité du secret.
- Une clé de session est générée soit par:
- Chiffrement d’un nombre aléatoire avec la clé publique du serveur et envoi du résultat au serveur. Le serveur et le client utilisent ensuite le nombre aléatoire pour créer une clé de session qui est utilisée pour la durée de la communication.
- Utilisation d’un échange de clés Dixie-Hellman pour générer une clé de session utilisée pour le chiffrement et le déchiffrement. La clé de session est utilisée jusqu’à la fermeture de la connexion.
- La communication commence à utiliser le canal crypté.
Le processus d’établissement de liaison pour la communication TLS1.2 entre deux appareils est illustré ci-dessous :
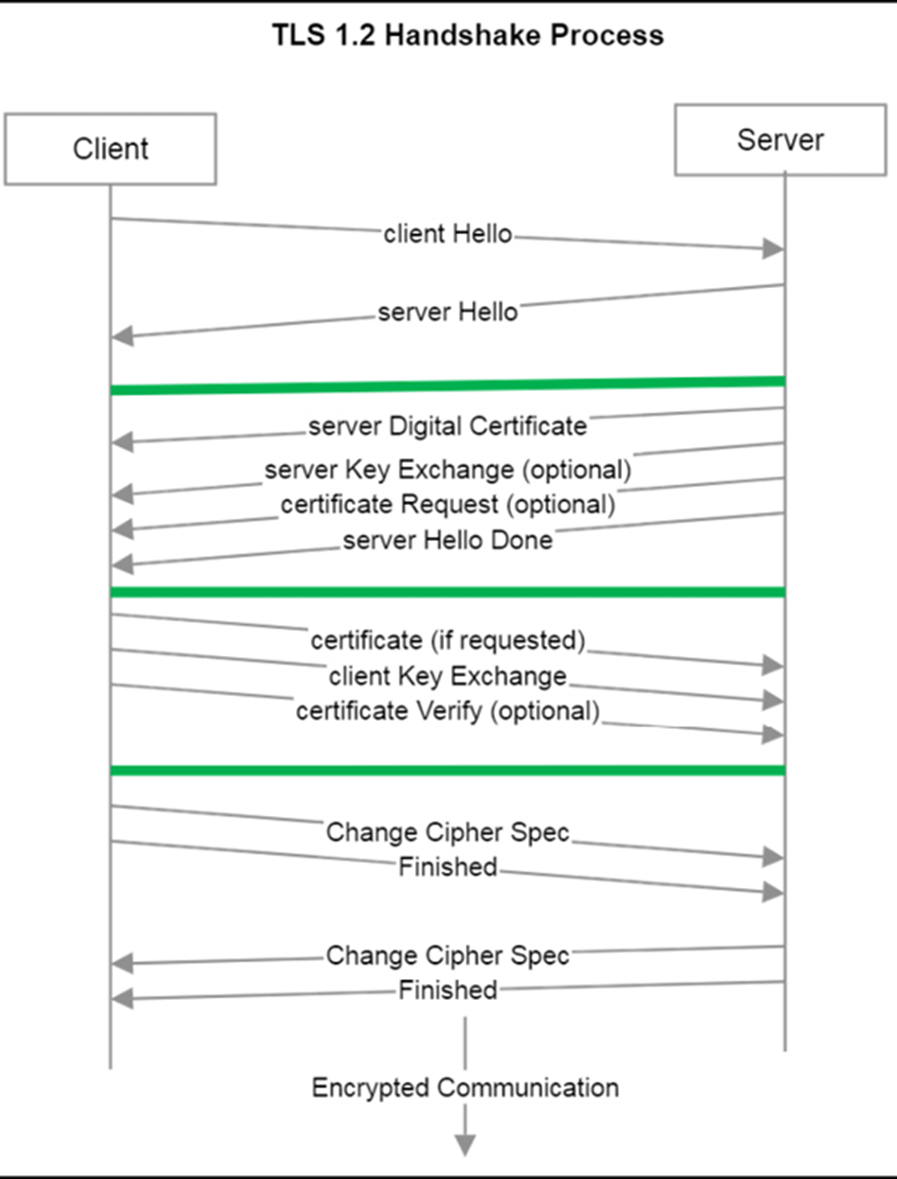
Figure 9 : séquence de négociation TLS 1.2
La sécurité de la couche de transport de datagrammes (DTLS) est un protocole de communication au niveau de la couche de datagrammes basé sur TLS. (DTLS 1.2 est basé sur TLS 1.2.) Il est destiné à produire des garanties de sécurité similaires. Le protocole léger CoAP utilise DTLS pour la sécurité.
13.6 Logiciel à périmètre défini
Plus tôt dans cet article, le chapitre 9, Routage de périphérie et mise en réseau, les concepts de réseaux définis par logiciel et de réseaux de superposition ont été discutés. Les réseaux de superposition et leur capacité à créer des microsegments sont extrêmement puissants, en particulier dans la mise à l’échelle de l’IoT de masse et les situations où une attaque DDoS peut être atténuée. Un composant supplémentaire du réseau défini par logiciel est appelé Périmètre défini par logiciel (SDP) et mérite une discussion en termes de sécurité globale.
13.6.1 Architecture SDP
Un SDP est une approche de la sécurité des réseaux et des communications où aucun modèle de confiance n’existe. Il est basé sur le nuage noir de la Defense Information Systems Agency (DISA). Le nuage noir signifie que les informations sont partagées selon les besoins. Un SDP peut atténuer les attaques telles que DDoS, MITM, les exploits zero-day et l’analyse de serveur, entre autres. En plus de fournir une superposition et une micro-segmentation pour chaque appareil connecté, le périmètre crée un périmètre de sécurité sur invitation uniquement (basé sur l’identité) autour des utilisateurs, des clients et des appareils IoT.
Un SDP peut être utilisé pour créer un réseau de superposition, qui est un réseau construit au-dessus d’un autre réseau. Une référence historique est les services Internet existants construits sur le réseau téléphonique préexistant. Dans cette approche de mise en réseau hybride, le plan de contrôle distribué reste le même. Les routeurs de périphérie et les commutateurs virtuels dirigent les données en fonction des règles du plan de contrôle. Plusieurs réseaux de superposition peuvent être construits sur la même infrastructure. Puisqu’un réseau défini par logiciel (SDN) reste persistant à peu près de la même manière qu’un réseau câblé, il est idéal pour les applications en temps réel, la surveillance à distance et le traitement d’événements complexes. La possibilité de créer plusieurs réseaux de superposition en utilisant les mêmes composants de périphérie permet la micro-segmentation, où différentes ressources ont une relation directe avec différents consommateurs de données. Chaque paire ressource-consommateur est un réseau immuable distinct qui ne peut voir l’extérieur de sa superposition virtuelle que si l’administrateur le souhaite.
La possibilité de créer plusieurs réseaux de superposition en utilisant les mêmes composants de périphérie permet une micro-segmentation où chaque point de terminaison d’un réseau IoT distribué mondialement peut créer des segments de réseau individuels et isolés sur l’infrastructure réseau existante. En théorie, chaque capteur pourrait être isolé d’un autre. Il s’agit d’un outil puissant pour activer la connectivité d’entreprise pour les déploiements IoT, car les services et les appareils peuvent être isolés et protégés les uns des autres.
Le graphique suivant illustre un exemple de superposition SDN. Ici, une entreprise possède trois franchises distantes avec un certain nombre d’appareils IoT et périphériques différents dans chaque magasin. Le réseau réside sur un réseau de superposition SDN avec des micro-segments isolant les systèmes POS et VOIP qui sont gérés collectivement à partir de divers capteurs pour la surveillance de la sécurité, des assurances et du stockage à froid. Les fournisseurs de services tiers peuvent gérer divers capteurs distants à l’aide d’un réseau de superposition virtuel isolé et sécurisé uniquement pour l’appareil qu’ils gèrent :
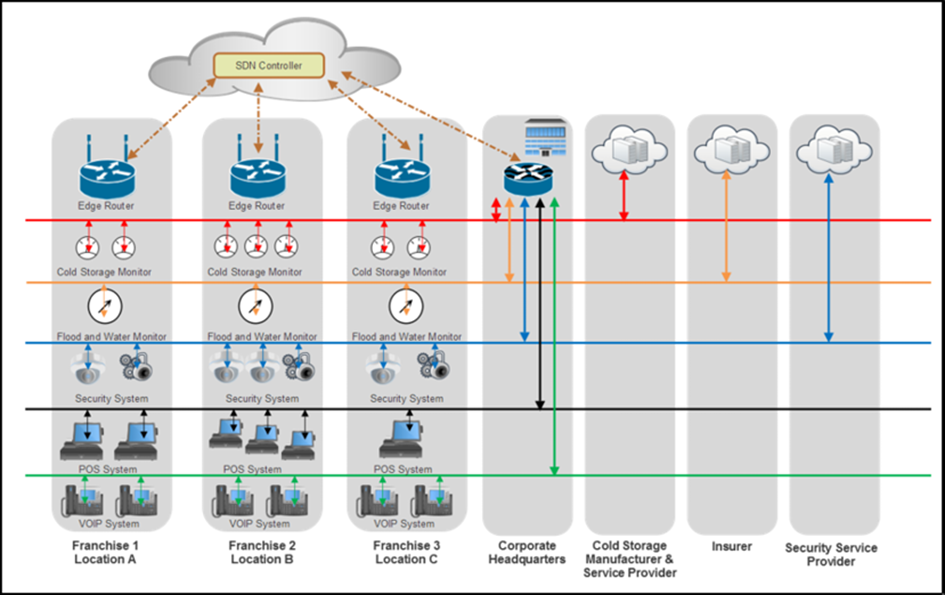
Figure 10 : Un exemple de réseau de superposition SDN
Un SDP peut étendre davantage la sécurité en développant un système d’invitation, forçant une paire d’appareils à s’authentifier en premier et à se connecter ensuite. Seul un utilisateur ou un client préautorisé peut être ajouté à un réseau. Cette autorisation est prorogée par une invitation du plan de contrôle par e-mail ou par quelque moyen d’enregistrement. Si l’utilisateur accepte l’invitation, les certificats clients et les informations d’identification sont étendus à ce système uniquement. La ressource qui étend l’invitation conserve un enregistrement des certificats étendus et fournira une connexion de superposition uniquement lorsque les deux parties acceptent le rôle.
L’analogie du monde réel est de savoir comment envoyer des invitations à une fête. Les invitations sont envoyées à des personnes sélectionnées avec une date, une heure, une adresse et d’autres détails. Ces personnes peuvent ou non vouloir assister à la fête (c’est à eux de décider). L’alternative consiste à annoncer sur le Web, à la télévision et à la radio que vous organisez une fête, puis d’authentifier chaque personne lorsqu’elle arrive à la porte.
13.7 Blockchains et crypto-monnaies dans l’IoT
Les chaînes de blocs existent pour résoudre un modèle de confiance (pas nécessairement un problème de sécurité). Les blockchains sont des registres publics, numériques et décentralisés ou des transactions de crypto-monnaie. La blockchain de crypto-monnaie d’origine était Bitcoin, mais il y a plus de 2000 nouvelles devises sur le marché, telles que Ethereum, Ripple et Dash. Le pouvoir d’une blockchain est qu’il n’y a pas d’entité unique contrôlant l’état des transactions. Cela force également la redondance dans le système en garantissant que tout le monde utilisant une blockchain conserve également une copie du grand livre.
En supposant qu’il n’y ait pas de confiance inhérente aux participants à la blockchain, le système doit vivre dans un consensus.
Une bonne question à poser est de savoir si nous avons résolu la gestion et la sécurité des identités avec une cryptographie asymétrique et des échanges de clés, pourquoi des chaînes de blocs sont-elles nécessaires pour échanger des données ou des devises ? Cela ne suffit pas pour l’échange d’argent ou de données de valeur. Une chose à noter est que depuis le début de la théorie de l’information, lorsque deux appareils communiquent, Bob et Alice, ils envoient un message ou un peu de données. Cette information est toujours conservée par Bob même si Alice en reçoit une copie. Lors de l’échange d’argent ou de contrats, ces données doivent quitter une source et arriver à une autre.
Il n’y a qu’une seule instance. L’authenticité et le chiffrement sont des outils nécessaires à la communication, mais une nouvelle méthode de transfert de propriété a dû être inventée:

Figure 11 : Topologies de grand livre. Un grand livre centralisé est le processus typique d’un seul agent de contrôle qui tient “les livres”. Les crypto-monnaies utilisent des registres décentralisés ou distribués.
Les crypto-monnaies sécurisées Blockchain sont particulièrement pertinentes pour l’IoT. Voici quelques exemples de cas d’utilisation :
- Paiements de machine à machine : l’IoT doit se préparer pour les services d’échange de machines contre des devises.
- Gestion de la chaîne d’approvisionnement : dans ce cas, le mouvement et la logistique dans la gestion des stocks, le déplacement des marchandises et la logistique peuvent remplacer le suivi sur papier par l’immuabilité et la sécurité de la blockchain. Chaque conteneur, mouvement, emplacement et état peut être suivi, vérifié et certifié. Les tentatives de falsification, de suppression ou de modification des informations de suivi deviennent impossibles.
- Énergie solaire : imaginez le solaire résidentiel comme un service. Dans ce cas, les panneaux solaires installés sur la maison d’un client génèrent de l’énergie pour la maison. Alternativement, ils peuvent également renvoyer de l’énergie au réseau pour alimenter quelqu’un d’autre (peut-être en échange de crédits carbone).
13.7.1 Bitcoin (basé sur la blockchain)
La partie crypto-monnaie de Bitcoin est différente de la blockchain elle-même. Le Bitcoin est une monnaie artificielle. Il n’a aucun produit ou valeur comme l’or ou un gouvernement (dans le cas d’une monnaie fiduciaire). Ce n’est pas non plus physique ; il n’existe que dans une construction de réseau. Enfin, l’offre ou le nombre de Bitcoins n’est pas déterminé par une banque centrale ou une autorité. Il est complètement décentralisé. Comme les autres blockchains, il est construit à partir de la cryptographie à clé publique, d’un grand réseau peer-to-peer distribué et d’un protocole qui définit la structure Bitcoin. Bien qu’il ne soit pas le premier à concevoir de l’argent numérique, Satoshi Nakamoto (alias) a publié en 2008 un document intitulé Bitcoin : A Peer-to-Peer Electronic Cash System dans une liste de cryptographie. En 2009, le premier réseau Bitcoin était en ligne et Satoshi a extrait le premier bloc (le bloc Genesis).
Le concept de blockchain signifie qu’il existe un bloc représentant la partie actuelle d’une blockchain. Un ordinateur connecté au réseau blockchain est appelé un nœud . Chaque nœud participe à la validation et au relais des transactions en obtenant une copie de la blockchain et est essentiellement un administrateur.
Un réseau distribué basé sur des topologies d’égal à égal existe pour Bitcoin. La loi de Metcalfe s’applique ici, car la valeur d’une crypto-monnaie comme Bitcoin est basée sur la taille du réseau. Le réseau gère le système des enregistrements (le grand livre). Le problème est, où trouvez-vous une source informatique prête à partager son temps de calcul pour surveiller les registres ? La réponse est de créer un système de récompense appelé Bitcoin mining.
Le processus de transaction est illustré dans la figure suivante. Cela commence par une demande de transaction. La demande est diffusée sur un réseau d’ordinateurs peer-to-peer (P2P) appelé nœuds. Le réseau homologue est chargé de valider l’authenticité de l’utilisateur. Lors de la validation, la transaction est vérifiée et combinée avec d’autres transactions pour créer un nouveau bloc de données pour le grand livre distribué. Lorsqu’un bloc est plein, il est ajouté à la blockchain existante, ce qui le rend immuable.
Le processus d’authentification, d’exploration de données et de validation Bitcoin est illustré dans l’illustration suivante :
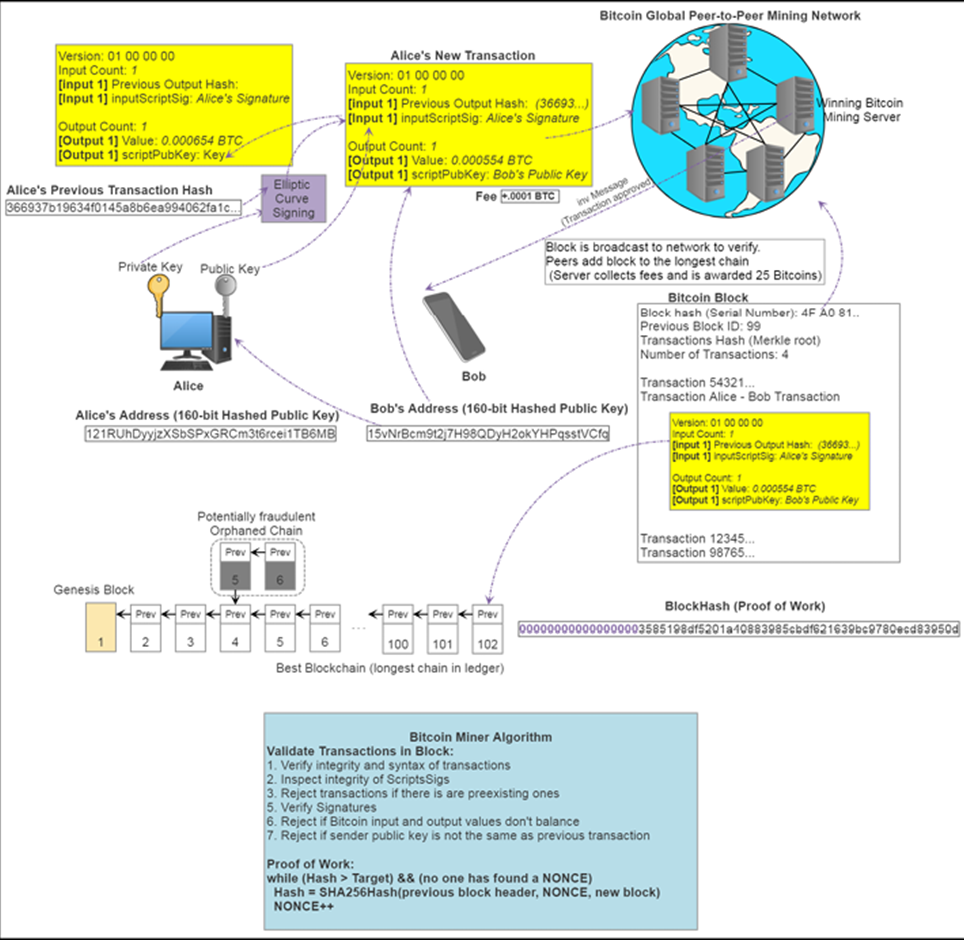
Figure 12 : Processus de transaction Bitcoin blockchain
Le graphique illustre l’échange de 0,000554 Bitcoins entre Alice et Bob avec des frais de service de 0,0001 BTC. Alice lance la transaction en signant le contenu de la transaction avec le hachage de transaction précédent contre la clé privée d’Alice. Alice inclut également sa clé publique dans le script inputScriptSig. La transaction est ensuite diffusée sur le réseau Bitcoin P2P pour inclusion dans un bloc et validation. Le réseau est en concurrence pour valider et découvrir un nonce fonctionnel basé sur la force actuelle de la complexité. Si un bloc est découvert, le serveur diffuse le bloc aux pairs pour validation puis inclusion dans la chaîne.
Ce qui suit est une analyse qualitative de la blockchain et en particulier du traitement Bitcoin. Il est important de comprendre ces principes fondamentaux, qui s’appuient sur tous les fondements de la sécurité mentionnés plus haut dans ce chapitre :
- Transaction signée numériquement : Alice a l’intention de donner à Bob un Bitcoin. La première étape consiste à annoncer au monde qu’Alice a l’intention de donner à Bob un Bitcoin. Alice le fait en écrivant ce message : “Alice donnera à Bob un Bitcoin” et en le signant numériquement pour l’authentification avec sa clé privée. N’importe qui peut vérifier que le message est authentique compte tenu de la clé publique. Cependant, Alice pourrait rejouer le message et forger artificiellement de l’argent.
- Identification unique : pour résoudre le problème de la contrefaçon, Bitcoin crée un ID unique avec un numéro de série. L’argent émis par les États-Unis a des numéros de série, et les Bitcoins font aussi bien dans un sens général. Bitcoin utilise un hachage plutôt qu’un numéro de série administré centralement. Le hachage qui identifie les transactions est généré automatiquement dans le cadre d’une transaction.
Un problème sérieux se pose avec la double dépense. Même si la transaction est signée et hachée de manière unique, Alice pourrait potentiellement réutiliser le même Bitcoin avec d’autres parties. Bob vérifiera la transaction d’Alice et tout vérifiera. Si Alice utilise également la même transaction mais achète quelque chose à Charlie, elle triche efficacement le système. Le réseau Bitcoin est très grand, mais il y a encore une petite chance qu’un vol puisse se produire. Les utilisateurs de Bitcoin se protègent contre les doubles dépenses en attendant une confirmation lors de la réception des paiements sur la blockchain. Au fur et à mesure qu’une transaction devient datée, plus de confirmations surviennent et sa validation devient plus irréversible.
- Sécurité via la validation par les pairs : pour résoudre la triche à double dépense, ce qui se fait dans les chaînes de blocs, c’est que les destinataires de la transaction (Bob et Charlie) diffusent leur paiement potentiel sur le réseau et demandent au réseau de pairs de l’aider à le légitimer. Ce service de demande d’assistance pour vérifier une transaction n’est pas gratuit.
- Fardeau de la preuve du travail : cela n’a toujours pas complètement résolu le problème des doubles dépenses. Alice pourrait simplement détourner le réseau avec ses propres serveurs et prétendre que toutes ses transactions sont valides. Pour enfin résoudre ce problème, Bitcoin a introduit le concept de preuve de travail. Les concepts de preuve de travail comportent deux aspects. Le premier aspect consiste à valider l’authenticité d’une transaction qui devrait être coûteux en calcul pour un appareil informatique. Cela doit être plus fastidieux sur le plan du calcul que la simple vérification des clés, des noms de connexion, des ID de transaction et d’autres étapes triviales du processus d’authentification. Deuxièmement, les utilisateurs doivent être récompensés pour aider à résoudre les échanges d’argent d’autres personnes – cela est couvert à l’étape 5.
La méthode utilisée par Bitcoin pour forcer une fonction de travail sur les personnes validant les transactions consiste à attacher un nonce à l’en-tête des transactions en cours. Bitcoin utilise ensuite l’algorithme SHA-256 cryptographiquement sécurisé pour hacher le nonce et le message d’en-tête. L’objectif est de continuer à modifier le nonce et de fournir des valeurs de début de hachage inférieures à 256 bits, appelées la cible.
Un objectif bas le rend beaucoup plus intensif en termes de calcul. Étant donné que chaque hachage génère essentiellement un nombre complètement aléatoire, de nombreux hachages SHA-256 doivent être effectués. En moyenne, cela prend environ 10 minutes à résoudre.
La preuve de travail de 10 minutes implique également qu’une transaction prendra en moyenne 10 minutes pour être validée. Les mineurs travaillent sur des blocs, qui sont des collections de nombreuses transactions. Un bloc est limité (actuellement) à 1 Mo de transactions, ce qui implique que votre transaction ne sera pas traitée avant la fin du bloc actuel. Cela peut avoir des implications pour un appareil IoT avec des demandes en temps réel.
- Incitations à l’exploitation minière de Bitcoin : pour encourager les individus à construire un réseau peer-to-peer pour valider les dépenses des autres, des incitations sont utilisées pour récompenser ces individus pour leur service. Il existe deux formes de récompense. Le premier est le Bitcoin mining, qui récompense les personnes qui valident un bloc de transactions. L’autre forme de récompense est une commission de transaction. Les frais de transaction sont donnés à un mineur qui aide à valider un bloc et sont pris dans le cadre de la transaction. Au départ, il n’y avait pas de frais, mais comme les Bitcoins ont gagné en popularité, les frais ont augmenté. En moyenne, les frais sont d’environ 35 $ (en devise Bitcoin) pour une transaction réussie. Comme autre incitation, les frais sont dynamiques et on peut augmenter les frais, ce qui oblige artificiellement la transaction à être traitée plus rapidement pour un utilisateur. Même lorsque la nouvelle génération de Bitcoin est épuisée, il y a toujours une incitation à gérer les transactions.
Initialement, la récompense minière était très élevée (50 Bitcoins), mais elle diminue de moitié environ tous les quatre ans après la découverte de 210 000 blocs. Cela se poursuivra jusqu’en 2140, lorsque le taux de réduction de moitié atteindra un point d’épuisement et que les récompenses seront inférieures à la valeur unitaire la plus basse d’un Bitcoin (appelé Satoshi ou 10 -8 Bitcoins).
Étant donné qu’un bloc est miné toutes les 10 minutes et que la récompense est divisée par deux tous les quatre ans, nous pouvons atteindre le nombre maximal de Bitcoins existant. Nous savons également que la récompense initiale pour une pièce extraite est de 50 Bitcoins. Cela produit une série qui converge vers la limite Satoshi : 50 BTC + 25 BTC + 12,5 BTC … = 100 BTC. 210 000 * 100 = 21 millions de Bitcoins au total possibles.
- Sécurité par ordre de chaînage : L’ordre dans lequel les transactions ont lieu est également vital pour l’intégrité d’une devise. Si un Bitcoin est transféré d’Alice à Bob puis à Charlie, vous ne voulez pas que les registres enregistrent les événements comme Bob vers Charlie puis Alice vers Bob. Les blockchains gèrent la commande en enchaînant les transactions. Tous les nouveaux blocs ajoutés au réseau contiennent un pointeur sur le dernier bloc validé dans la chaîne. Bitcoin déclare qu’aucune transaction n’est valide jusqu’à ce qu’elle soit enchaînée à la fourche la plus longue et qu’au moins cinq blocs la suivent dans la fourche la plus longue.
Cette disposition résout le problème asynchrone de ce qui se passe si Alice essaie de dépenser deux fois un Bitcoin avec Bob et Charlie. Elle pourrait essayer de diffuser la transaction avec Bob pour un ensemble de mineurs et avec Charlie sur un deuxième ensemble. Cependant, le processus trouvera cette fraude lorsque le réseau converge. Bob peut avoir une transaction valide, mais le réseau invalidera la transaction de Charlie.
Même si Alice essaie de se payer et essaie de payer Bob, les règles de commande l’arrêtent. Elle le fait en envoyant à Bob un Bitcoin et en attendant le moment où la transaction est vérifiée (cinq blocs la suivent). Elle se paie alors immédiatement le même Bitcoin, ce qui provoque une fourchette dans la chaîne. Elle doit maintenant valider cinq blocs de Bitcoins supplémentaires. Cela prend environ 50 minutes (5 blocs à 10 minutes chacun) comme indiqué à l’étape 4. Cela nécessite une énorme quantité de puissance de calcul car elle doit traiter plus rapidement que tous les autres mineurs réunis.
Un autre concept intéressant sur les blockchains est leur utilisation dans la gestion des attaques DoS. Un système de preuve du travail (ou protocole / fonction) est une mesure économique pour dissuader les attaques DoS. Une attaque vise à saturer un réseau avec autant de données que possible pour submerger un système. Une blockchain impliquant une fonction de travail réduit l’efficacité d’une telle attaque. Une caractéristique clé de ces régimes est leur asymétrie: le travail doit être modérément difficile (mais réalisable) du côté du demandeur, mais facile à vérifier auprès du prestataire de services.
13.7.2 IOTA et modèles de confiance basés sur des graphiques acycliques dirigés (DAG)
Une nouvelle crypto-monnaie intéressante a été développée uniquement pour l’IoT appelée IOTA. Dans ce cas, les appareils IoT eux-mêmes sont l’épine dorsale du réseau de confiance, et l’architecture est basée sur un graphe acyclique dirigé (DAG). Bitcoin a des frais associés par transaction. IOTA n’a aucun frais.
Ceci est très important dans le monde de l’IoT, qui peut servir des microtransactions. Par exemple, un capteur peut fournir un service de rapport à de nombreux abonnés de MQTT. Le service a une valeur globale, mais il est mesurablement très faible par transaction, si petit que les frais de Bitcoin pour fournir ces informations peuvent être supérieurs à la valeur des données.
L’architecture IOTA présente les aspects suivants :
- Pas de centralisation du contrôle monétaire. Avec la blockchain, les mineurs peuvent former de grands groupes afin d’augmenter le nombre de blocs qu’ils peuvent extraire ainsi que d’augmenter leurs récompenses. Cela peut potentiellement entraîner une concentration d’énergie et éventuellement endommager le réseau.
- Aucun équipement matériel coûteux. Afin d’exploiter la crypto-monnaie Bitcoin, des processeurs puissants sont nécessaires en raison de la complexité de la logique de traitement requise.
- Microtransactions et nanotransactions au niveau des données IoT.
- Sécurité éprouvée même contre les attaques par force brute de l’informatique quantique.
- Des données qui peuvent être transférées via IOTA tout comme la monnaie. Les données sont entièrement authentifiées et inviolables.
- Il est indépendant de la charge utile d’une transaction. En conséquence, un système national de vote inviolable peut être conçu.
- Tout ce qui a un petit SOC peut devenir un service. Si vous possédez un appareil tel qu’une perceuse, une connexion Wi-Fi personnelle, un four à micro-ondes ou un vélo, les appareils avec un petit SOC ou un microcontrôleur peuvent rejoindre IOTA et devenir des sources de revenus de location.
Le DAG IOTA est appelé un enchevêtrement et est utilisé pour les transactions de magasin comme un livre distribué. Les transactions sont émises par des nœuds (appareils IoT) et constituent un ensemble sur le DAG enchevêtrement. S’il n’y a pas de bord dirigé entre la transaction A et la transaction B, mais qu’il existe un chemin d’au moins deux de A à B, on peut dire que A approuve indirectement B.
Il y a aussi la notion de transaction de genèse. Puisqu’il n’y a pas d’exploration pour les bords du graphique (et aucune incitation ou frais) pour démarrer l’enchevêtrement, un nœud contient tous les jetons. L’événement de genèse envoie les jetons à d’autres adresses “fondatrices”. Il s’agit de l’ensemble statique de tous les jetons, et aucun nouveau jeton ne sera jamais créé.
Lorsqu’une nouvelle transaction arrive, elle doit approuver (ou refuser) deux transactions précédentes ; c’est ce qu’on appelle l’approbation directe. Cela forme un bord direct sur le graphique. Tout ce qui exécute une transaction est nécessaire pour produire un produit “de travail” au nom de l’enchevêtrement.
Ce travail consiste à trouver un nonce qui fonctionne avec le hachage d’une partie de la transaction approuvée. Ainsi, en utilisant IOTA, le réseau devient plus distribué et plus sécurisé. La transaction peut avoir de nombreux approbateurs. Plus il y a de transactions, plus la confiance que la transaction est légitime augmente. Si un nœud tente d’approuver une transaction qui, à toutes fins pratiques, n’est pas légitime, il risque de voir sa propre transaction constamment réfutée et de tomber dans l’oubli.
Bien qu’il soit encore tôt dans le déploiement, c’est une technologie à surveiller. Plus d’informations peuvent être trouvées sur http://iota.org .
13.8 Réglementation gouvernementale et interventionIoT et Edge Security
Les organismes gouvernementaux et les organismes de réglementation sont intervenus pour recommander et imposer des niveaux de sécurité qui doivent être respectés par les fournisseurs pour être considérés comme sûrs. Ces derniers temps, le gouvernement américain s’est davantage intéressé à garantir le respect de certaines normes de sécurité pour les appareils connectés, en particulier avec les attaques croissantes contre les systèmes IoT. Il est important de connaître ces règles et lois car d’autres pays peuvent adopter des réglementations similaires ou, dans d’autres cas, complètement différentes, ce qui rend le travail d’un architecte IoT difficile lors d’une mise à l’échelle mondiale. Ces lois affectent la vie privée et la sécurité de l’individu ainsi que de la nation.
13.8.1 US Congressional Bill – Internet of Things (IoT) Cybersecurity Improvement Act of 2017
La sécurité de l’IoT a retenu l’attention de divers gouvernements. Un projet de loi bipartite (S.1691 – Internet of Things IoT Cybersecurity Improvement Act of 2017, https://www.congress.gov/bill/115th-congress/senate-bill/1691/text ) a été présenté au Sénat américain en août. 1, 2017. L’intention du projet de loi est d’officialiser et de réglementer les normes de sécurité minimales qui doivent être respectées pour que les appareils connectés à Internet soient vendus à des agences fédérales américaines. Bien que le projet de loi n’ait pas encore été adopté, les dispositions indiquent clairement le degré de réglementation de la sécurité de l’IoT qui est envisagé.
Le projet de loi énonce spécifiquement les exigences suivantes pour un entrepreneur fournissant des solutions IoT fédérales :
- Le matériel, les logiciels et les micrologiciels des solutions doivent être exempts de vulnérabilités, comme indiqué dans la base de données nationale de vulnérabilité du NIST.
- Le logiciel et le micrologiciel doivent pouvoir accepter les mises à jour et les correctifs authentifiés. De plus, les entrepreneurs doivent corriger les vulnérabilités en temps opportun. L’entrepreneur est également responsable de la prise en charge des déploiements et de la date de fin du support et de la manière dont le support sera géré pour les appareils IoT.
- Seuls les protocoles et technologies non obsolètes pour les communications, le chiffrement et l’interconnexion doivent être utilisés.
- Aucune information d’identification codée en dur installée pour l’administration à distance.
- Une méthode doit être fournie pour que tout logiciel ou micrologiciel de périphérique connecté à Internet soit mis à jour ou corrigé en tout point pour corriger une vulnérabilité.
- Certification écrite lorsque l’appareil IoT fournit des technologies tierces conformes à ces normes.
- Le directeur du Bureau de la gestion et du budget (OMB) peut fixer des délais pour le retrait et le remplacement des dispositifs IoT existants qui sont considérés comme non sécurisés.
- Soixante jours après son entrée en vigueur, la Cybersecurity and Infrastructure Security Agency (CISA), avec l’aide de technologues privés et universitaires, publiera des directives officielles sur la cybersécurité pour tous les appareils IoT utilisés par le gouvernement fédéral.
Le projet de loi contient des dispositions permettant aux agences d’adopter ou de continuer à utiliser de meilleures technologies de sécurité que ce qui est inscrit dans le projet de loi (après approbation du directeur de la CAMO). En outre, le projet de loi reconnaît que certains appareils IoT sont sévèrement limités en termes de puissance de traitement et de mémoire et peuvent ne pas avoir de parité avec les dispositions du projet de loi. Encore une fois, dans ce cas, les demandes de dérogation seraient gérées par le directeur avec un plan de mise à niveau et de remplacement. Pour ces appareils non conformes, le projet de loi stipule que les technologies suivantes peuvent être approuvées avec une coordination entre le NIST et le directeur pour atténuer le risque :
- Segmentation et micro-segmentation de réseau définies par logiciel
- Conteneurs et microservices contrôlés au niveau du système d’exploitation pour isoler les temps d’exécution
- Authentification multifactorielle
- Solutions de périphérie de réseau intelligentes telles que des passerelles qui peuvent isoler et corriger les menaces
Bien que le projet de loi soit toujours en comité au moment de la rédaction, il montre certainement la préoccupation de la sécurité et des vulnérabilités de l’IoT au niveau fédéral. Le projet de loi peut se transformer ou être tué, mais l’importance de la sécurité de l’IoT a attiré l’attention du gouvernement et des législateurs américains.
13.8.2 Autres organismes gouvernementaux
D’autres agences du gouvernement fédéral américain ont déjà publié des lignes directrices et des recommandations pour une litanie de technologies entourant l’IoT. Le plus notable est le National Institute of Standards and Technology (NIST), qui a produit plusieurs documents et guides pour la sécurité des appareils connectés. Ils maintiennent également des normes nationales et internationales reconnues en matière de sécurité. Le matériel d’appui peut être trouvé à http://csrc.nist.gov . Plusieurs documents importants relatifs à la cryptographie et aux normes FIPS sont répertoriés ici :
- Publication spéciale NIST 800-121 révision 2, Guide de la sécurité Bluetooth. Cela spécifie un ensemble de dispositions de sécurité recommandées pour Bluetooth Classic et Bluetooth BLE: http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-121r2.pdf .
- Publication spéciale du NIST 800-175A, Guidelines for Using Cryptographic Standards in the Federal Government : http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-175A.pdf .
- Normes NIST FIPS: https://www.nist.gov/itl/current-fips .
Le Department of Homeland Security (DHS) fournit des directives opérationnelles contraignantes pour toutes les agences fédérales en termes de sécurité nationale, y compris dans le domaine des technologies de l’information. Les directives récentes incluent 18-01, qui impose la “cyber-hygiène” via des politiques de messagerie, la gestion des clés, l’authentification de message basée sur le domaine, le reporting et la conformité (DMARC), la sécurité Web en utilisant HTTPS uniquement et d’autres actions similaires. Le DHS est également impliqué dans des directives normatives pour le Congrès, d’autres agences et le secteur privé concernant les normes de cybersécurité: https://www.dhs.gov/topic/cybersecurity .
L’ US-CERT , ou Computer Emergency Response Team , est également essentiel pour quiconque se soucie de la sécurité. L’US-CERT a été affrété pour trouver, isoler, informer et arrêter les menaces de cybersécurité sur une base nationale depuis 2000. Ils fournissent des services de criminalistique numérique, de formation, de surveillance en temps réel, de rapports et de défenses exploitables pour les exploits connus du jour zéro et actifs. Menaces pour la sécurité. Les alertes et atténuations actives actuelles peuvent être trouvées ici: https://www.us-cert.gov/ncas/alerts .
En Europe, l’Agence de l’Union européenne pour la cybersécurité publie des normes et des publications sur diverses pratiques de sécurité de l’information. De bonnes informations peuvent être obtenues à:
- ENISA Sécurité de l’Internet des objets : https://www.enisa.europa.eu/news/enisa-news/defining-and-securing-the-internet-of-things
- Rapport de l’atelier sur la confidentialité et la sécurité de l’Internet des objets : https://ec.europa.eu/digital-single-market/en/news/internet-things-privacy-and-security-workshops-report
- La loi sur la cybersécurité: pour une cyber-résilience renforcée : https://ec.europa.eu/digital-single-market/en/cyber-security
En Australie, l’IoT Alliance Australia maintient un ensemble de directives et de pratiques pour la sécurité des informations, disponible ici: http://www.iot.org.au/wp/wp-content/uploads/2016/12/IoTAA-Security-Guideline- V1.2.pdf .
13.9 Meilleures pratiques de sécurité IoT
La sécurité de l’IoT doit être prise en compte dès le début de la conception et non mise à niveau à la fin d’un programme ou sur le terrain. À ce stade, il est trop tard. La sécurité doit également être vue de manière globale, du matériel au cloud. Cette section illustre un projet IoT simple du capteur au cloud et illustre la « couverture » de sécurité à considérer. L’intention est de déployer un système avec différents niveaux de garanties, tous là pour augmenter la fonction de travail de l’attaquant.
13.9.1 Sécurité holistique
Se concentrer étroitement sur un segment de l’IoT n’assure pas la sécurité et établit un maillon faible dans la chaîne de sécurité. Il faut établir la sécurité du capteur au cloud et inversement – une approche holistique. Chaque composant de la chaîne de contrôle et de données doit avoir une liste de contrôle des paramètres de sécurité et des facilitateurs. Le diagramme suivant illustre un exemple des couches de sécurité du capteur au cloud à prendre en compte dans un déploiement :
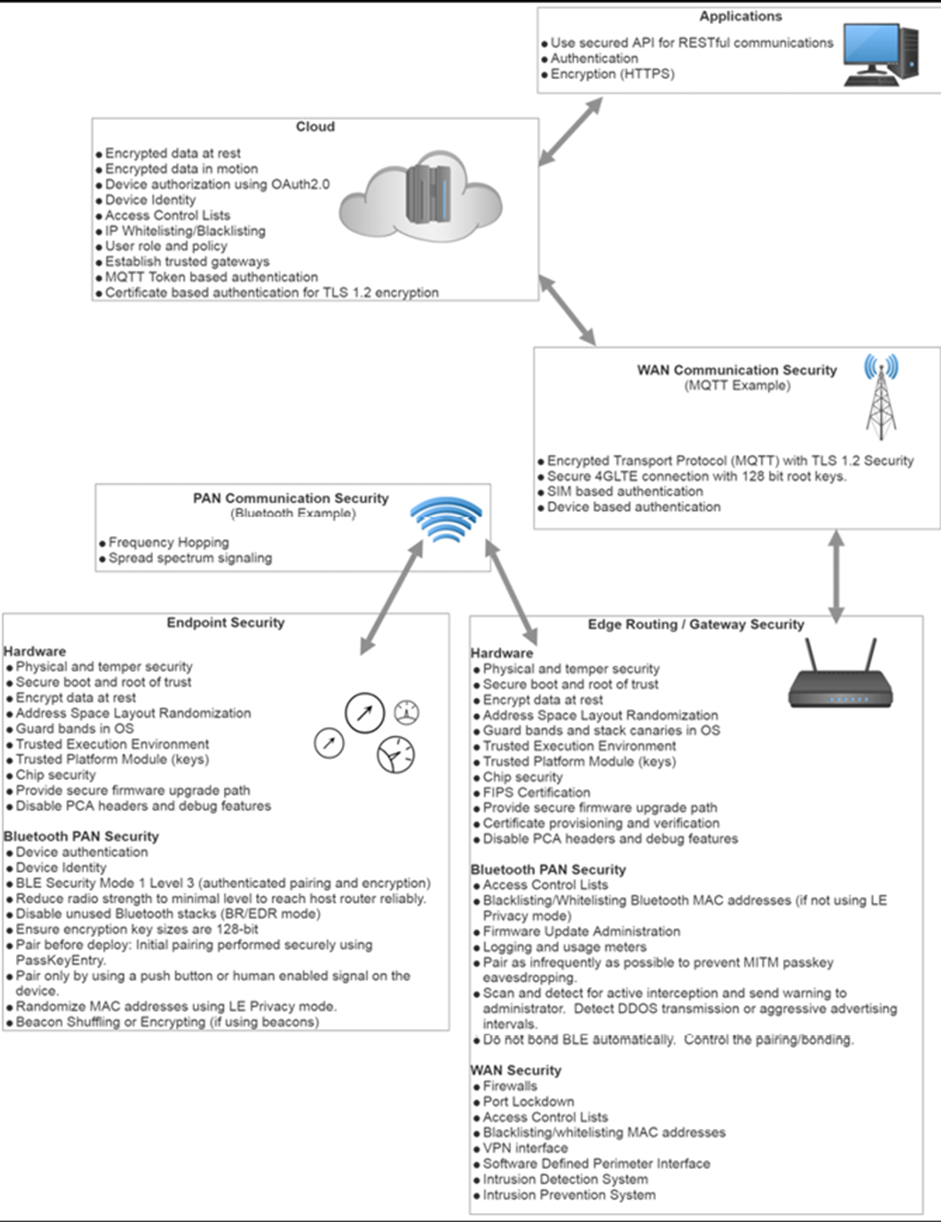
Figure 13 : Sécurité holistique du capteur au cloud. Voici un exemple de capteurs compatibles Bluetooth communiquant via une passerelle de périphérie vers un service cloud. Chaque couche doit fournir intégrité et protection. La sécurité implique à la fois des composants matériels et logiciels. Cela inclut la sécurité physique des dispositifs empêcher toute manipulation, des signaux radio pour prévenir le brouillage et DoS, le matériel ROT et ASLR au code Empêcher l’injection malveillante, données en utilisant le cryptage, l’appariement et d’association par l’utilisation de l’authentification, le réseau par des réseaux VPN et fi pare – feux, et ainsi de suite.
13.9.2 Liste de contrôle de sécurité
Voici une liste de recommandations et d’idées de sécurité qui ont toujours fonctionné. Encore une fois, il est important d’avoir une couverture de sécurité :
- Utilisez le système d’exploitation et les bibliothèques les plus récents avec tous les correctifs pertinents.
- Utilisez les conventions standard de l’industrie.
- Ne réinventez ni ne personnalisez les protocoles et processus de sécurité éprouvés.
- Utilisez du matériel qui intègre des fonctionnalités de sécurité comme Trusted Execution.
- Environnements, modules de plateforme sécurisée et espaces non exécutables.
- Signez, cryptez et protégez vos images de micrologiciel et de logiciel, en particulier celles disponibles gratuitement sur le site Web d’une entreprise. Obscurcir le code dans l’espoir qu’un pirate ne procédera pas à une rétro-ingénierie, il est relativement inutile.
- Randomisez les mots de passe par défaut.
- Utilisez un RoT et un démarrage sécurisé pour vous assurer d’avoir une image «dorée» des logiciels exécutés sur un appareil client.
- Éliminez les mots de passe codés en dur dans les images ROM.
- Assurez-vous que tous les ports IP restent fermés par défaut.
- Utilisez la randomisation de la configuration de l’espace d’adressage, empilez les canaris et les bandes de garde en mémoire via les systèmes d’exploitation modernes.
- Utilisez les mises à jour automatiques. Fournir aux fabricants un mécanisme pour corriger et corriger les bogues et les vulnérabilités sur le terrain. Cela nécessite une architecture logicielle modulaire.
- Prévoyez la fin de vie. Un appareil IoT peut avoir une longue durée de vie utile, mais il devra être éliminé à terme. Cela devrait inclure des méthodes pour effacer et détruire en toute sécurité toute la mémoire persistante (flash) de l’appareil.
- Utilisez des programmes de primes de bogues. Récompensez vos clients et utilisateurs pour avoir trouvé et signalé des bogues, en particulier des défauts susceptibles d’exposer à un exploit zero-day.
- Abonnez-vous et participez à la gestion active des menaces US-CERT pour être immédiatement informé des exploits actifs et des cybermenaces.
- Aussi tentant que cela soit de simplement construire un projet avec MQTT, HTTP ou d’autres protocoles non sécurisés, livrés uniquement avec la sécurité et l’authentification activées via TLS ou DTLS. Chiffrez les données du capteur vers le cloud.
- Utilisez des fusibles anti-débogage sur le package. Faites sauter les fusibles dans la fabrication pour déboguer les canaux en toute sécurité avant de libérer un produit.
13.10 Résumé
Ce chapitre a détaillé les risques de sécurité dans l’IoT. Avec des attaques bien connues telles que Mirai et Stuxnet, qui ciblent les appareils IoT comme hôtes cibles, les architectes devraient concevoir la sécurité dans un déploiement IoT dès le départ. L’IoT constitue le meilleur espace de jeu pour lancer une attaque. Les systèmes sont généralement moins sécurisés que les systèmes serveur et PC. Les appareils IoT offrent la plus grande surface d’attaque de la planète. Enfin, l’éloignement de certains systèmes IoT permet aux attaquants d’être physiquement présents et de manipuler le matériel, ce qui ne se produirait pas dans un environnement de bureau sécurisé. Ces menaces doivent être prises au sérieux, car les ramifications pourraient avoir un impact prononcé sur un appareil, une ville ou une nation.
D’autres liens de sécurité intéressants sont :
- Chapeau noir : https://www.blackhat.com
- Defcon : https://www.defcon.org
- Carte d’attaque numérique : http://www.digitalattackmap.com
- Gattack : http://gattack.io
- Désassembleur interactif IDA Pro : https://www.hex-rays.com
- Conférence RSA : https://www.rsaconference.com
- Shodan : https://www.shodan.io
Nous concluons cet article avec une liste de consortiums et d’organisations pour aider au développement, aux technologies, aux réglementations et aux normes de l’ IoT .
14 Consortiums et communautés
Les consortiums industriels existent pour plusieurs raisons et sont essentiels pour la promotion, la gouvernance et l’élaboration de normes. L’industrie de l’IoT est similaire à d’autres technologies et a sa juste part de normes propriétaires et ouvertes. Ce chapitre couvre les différents consortiums à travers les PAN, les protocoles, les WAN et l’informatique de brouillard et de périphérie, ainsi que divers consortiums parapluie. Une description détaillée et catégorique de chaque alliance sera détaillée pour vous aider à décider quelle organisation, le cas échéant, vaut le temps et l’investissement à associer. Il convient de noter qu’une organisation n’a pas besoin d’être impliquée dans une alliance industrielle ; de nombreux grands produits et entreprises ont été construits sans dépendre d’un consortium. Cependant, certaines organisations exigeront une adhésion d’entreprise pour l’utilisation du logo ou même la possibilité de produire certaines normes.
Un segment de marché en croissance comme l’IoT engendrera des alliances au début de son cycle de battage médiatique, car un certain nombre d’acteurs se disputent la mise en place de normes. Il s’agit d’un phénomène naturel au cours de la phase de croissance rapide de toute entreprise. Souvent, des alliances se forment lorsqu’une norme similaire entre en concurrence avec une autre, et les organisations s’alignent sur des lignes concurrentielles. D’autres fois, des normes sont définies pour l’industrie par le biais d’organismes sans but lucratif et universitaires. Si pour aucune autre raison, la liste des consortiums dans ce chapitre devrait aider à orienter les architectes vers les ressources et les garanties techniques nécessaires à leurs conceptions.
Ce chapitre fournira le contexte, l’historique et les informations sur les membres de diverses organisations et consortiums dans l’espace IoT, y compris les organes de communication, de cloud et de brouillard standard.
14.1 Consortiums PAN
Les PAN (IP et non IP) ont plusieurs consortiums et comités de gouvernance. Beaucoup sont formés par des partenaires fondateurs et nécessitent une adhésion ou une affiliation pour les droits d’utilisation.
14.1.1 Bluetooth
Les détails de l’organisation sont les suivants :
- Fondé : 1998
- Adhésion d’entreprise : 20 000
- Lien vers le site Web : www.bluetooth.org
Le Bluetooth SIG a été créé en 1998 par cinq sociétés membres : Ericsson, IBM, Intel, Nokia et Toshiba. À la fin de 1998, ils comptaient 400 membres dans l’organisation. La charte de l’organisation est de faire progresser les normes, les forums, les marchés et la compréhension des technologies Bluetooth. L’organisation supervise le développement, ainsi que les licences et les marques déposées, de Bluetooth. Sur le plan organisationnel, le SIG est divisé en petits groupes ciblés : des groupes d’étude pour la recherche, des groupes d’experts couvrant plusieurs domaines Bluetooth, des groupes de travail dédiés à l’élaboration de nouvelles normes et des comités qui se concentrent sur les licences et le marketing. L’adhésion est divisée en membres associés, qui peuvent rejoindre des groupes de travail, obtenir des spécifications précoces et avancées, obtenir du matériel de marketing, assister à PlugFest et recevoir des listes de qualification ; et l’adhésion Adopter, qui est le seul niveau d’abonnement gratuit. Les adoptants ne peuvent pas rejoindre un groupe de travail.
14.1.2 Groupe de threads
Les détails de l’organisation sont les suivants:
- Fondé : 2014
- Adhésion corporative : 182
- Lien vers le site Web : www.threadgroup.org
Le Thread Group a été initialement formé par Alphabet (société holding Google), Samsung, ARM, Qualcomm, NXP et six autres. Thread est un protocole PAN basé sur 6LoWPAN, qui est basé sur 802.15.4. Le groupe de travail octroie des licences Thread en utilisant le modèle de licence BSD du domaine public. L’intention du groupe était de contrer directement le protocole Zigbee, en particulier autour de l’utilisation des réseaux maillés PAN. Il existe trois niveaux d’adhésion d’entreprise.
Le niveau inférieur est l’ Academictier , et le niveau Affilié autorise une organisation à utiliser le logo, des interviews de presse et l’accès aux livrables. Le niveau de mise en œuvre accède à des produits IP et de test libres de droits, mais ne permet pas la certification de logo. Le niveau Contributeur de niveau intermédiaire permet d’accéder aux groupes de travail et aux comités et permet la certification du logo. Le niveau de parrainage de niveau supérieur fournit un siège au conseil d’administration et supervise le budget de l’organisation.
14.1.3 Alliance Zigbee
Les détails de l’organisation sont les suivants :
- Fondé : 2002
- Adhésion corporative : 446
- Lien vers le site Internet : www.zigbee.org
L’Alliance Zigbee a été formée autour du protocole Zigbee conçu pour la première fois en 1998 pour combler l’écart dans les réseaux maillés auto-organisés et sécurisés. Zigbee se trouve sur les couches de base 802.15.4 comme Thread mais n’est pas basé sur IP. La pile logicielle est restée basée sur la GPL après plusieurs demandes pour offrir plus de flexibilité dans les licences. Il existe trois niveaux d’adhésion. Les adoptants ont un accès précoce aux spécifications, assistent à des conférences et peuvent utiliser le logo Zigbee. Les membres participants peuvent proposer et travailler dans divers comités techniques, ainsi que voter sur les spécifications. Enfin, les membres promoteurs reçoivent des sièges au conseil d’administration et sont le seul organisme à ratifier les spécifications.
14.1.4 Divers
Diverses organisations de connectivité d’intérêt comprennent :
- DASH7 Alliance : l’organe directeur du protocole DASH 7 ( www.dash7-alliance.org )
- ModBus : un consortium industriel régissant le protocole Modbus pour les cas d’utilisation industrielle ( www.modbus.org )
- BACnet : Organisation parrainée par la Société américaine de chauffage, de réfrigération et de climatisation pour la communication et les normes industrielles BACnet ( www.bacnet.org )
- Alliance Z-Wave : une industrie et un organe directeur pour la technologie spécifique à Z-Wave ( z-wavealliance.org )
14.2 Consortiums de protocoles
Ces organisations maintiennent des protocoles et des abstractions de couche supérieure tels que MQTT. Alors que de nombreux protocoles sont open source, comme le MQTT, l’adhésion permet le droit de vote et la participation à de nouvelles normes.
14.2.1 Open Connectivity Foundation et Allseen Alliance
Les détails de l’organisation sont les suivants :
- Fondation : 2015
- Adhésion corporative : 300
- Lien vers le site Internet : www.openconnectivity.org
L’Open Connectivity Foundation était à l’origine appelée Open Interconnect Foundation, mais a changé de nom en 2016 pour devenir Open Connectivity Foundation après la séparation de Samsung du groupe de travail et l’ajout de nouveaux membres. Pendant plusieurs années, il s’agissait d’une entité distincte de l’Allseen Alliance, mais en 2016, les organisations ont fusionné. Leur charte combinée consiste à créer des plates-formes d’interopérabilité pour les consommateurs, les entreprises et les industries grâce à des normes, des cadres et un programme de certification sous le nom d’Open Connectivity Foundation. Il couvre plusieurs segments : automobile, électronique grand public, entreprise, santé, domotique, industriel et wearables. Leurs cadres sont plus connus pour la spécification Universal Plug and Play (UPnP) et maintenant pour le cadre de connectivité IoTivity et AllJoyn. Ils utilisent le modèle de licence Internet Systems Consortium (ISC), qui est censé être fonctionnellement équivalent à BSD. Il existe cinq niveaux d’adhésion avec des degrés divers sur les cotisations annuelles. L’abonnement Basic est gratuit pour tous et donne accès aux outils de test et aux droits en lecture seule sur les spécifications. Il existe un niveau Or éducatif à but non lucratif qui permet à ces organisations d’accéder à des groupes de travail et à une certification. Au-dessus se trouvent les niveaux Or, Platine et Diamant, chacun avec différents degrés d’accès de la participation au groupe de travail à l’adhésion au conseil d’administration.
14.2.2 OASIS
Les détails de l’organisation sont les suivants :
- Fondation : 1993
- Adhésion corporative : 300
- Lien vers le site Internet : www.oasis-open.org
OASIS est l’Organisation pour l’avancement des normes d’information structurées. OASIS est une grande organisation à but non lucratif créée en 1993. Elle a largement contribué à des dizaines de langages et protocoles standard de l’industrie et définit les protocoles MQTT et AMQP largement utilisés dans la communauté IoT. Leurs technologies touchent l’IoT, le cloud computing, les secteurs de l’énergie et la gestion des urgences pour n’en nommer que quelques-uns. OASIS prend en charge trois types d’adhésion. Le niveau Contributeur offre une participation illimitée au comité. Le niveau Sponsor ajoute de la visibilité et des avantages marketing tels que la démonstration Interop et l’utilisation du logo. Enfin, le niveau de sponsor fondateur a la plus grande visibilité, avec des avantages tels que des présentations OASIS au sein d’une entreprise et des bourses. Les leaders de l’industrie représentant des normes ouvertes se joignent généralement à un niveau de sponsor fondateur. Les cotisations annuelles de l’entreprise sont fonction du type d’adhésion et du nombre d’employés.
14.2.3 Groupe de gestion des objets
Les détails de l’organisation sont les suivants:
- Fondation : 1989
- Adhésion corporative : 250
- Lien vers le site Internet : www.omg.org
L’Object Management Group (OMG) est une organisation à but non lucratif formée à l’origine en partenariat avec Hewlett-Packard, IBM, Sun, Apple, American Airlines et Data General pour se concentrer sur des normes d’objets hétérogènes en informatique. Ils sont surtout connus pour avoir établi la norme UML et CORBA, et récemment dans l’arène IoT, le consortium OMG a repris la gestion du consortium Internet industriel. Ils sont impliqués dans un certain nombre d’aspects de l’IoT industriel, ainsi que des réseaux définis par logiciel (SDN). Les domaines IoT ciblés incluent les services de données distribués pour assurer l’interopérabilité du réseau ainsi que la gestion des menaces dans l’IoT. Le groupe maintient un modèle de gouvernance à trois segments : un conseil d’architecture, un comité de technologie de plate-forme et un comité de technologie de domaine. Il existe six niveaux d’adhésion différents. Une adhésion d’influence permet aux entreprises de participer et de ne pas voter dans les groupes de travail (TF) et est appropriée si votre entreprise n’est pas entièrement basée sur ou n’adopte pas les spécifications OMG. Les membres influents ne peuvent pas participer aux comités de plate-forme ou de domaine. Les trois niveaux suivants sont appelés Soumission d’adhésions et sont destinés à permettre aux entreprises de participer avec des groupes de pairs pour aider à guider l’industrie. Les niveaux de plate – forme et de domaine sont destinés aux entreprises qui contribueront aux normes des plates-formes ou des domaines et rejoindront les TF respectifs. Ils peuvent également proposer des candidats pour siéger au conseil d’administration d’architecture (AB).
L’adhésion contributrice permet d’accéder à tous les comités, aux sièges du conseil d’administration, etc. Le niveau supérieur est un niveau d’adhésion au Conseil d’administration, qui est le conseil d’administration global de l’organisation entière. Il existe de nombreuses autres classes d’adhésion pour les organismes gouvernementaux, les analystes, les universitaires et les détaillants, et il y a même une adhésion d’essai.
La figure suivante illustre la structure organisationnelle d’OMG :
Figure 1: niveaux d’adhésion à l’OMG. Les membres influents peuvent participer et voter en dessous de la ligne pointillée dans les TF. Les membres soumissionnaires peuvent participer et voter au-dessus de la ligne pointillée dans divers comités.
14.2.4 OMA Specworks
Les détails de l’organisation sont les suivants:
- Fondé : 2008
- Adhésion corporative : 60
- Lien vers le site Internet : www.omaspecworks.org
L’Open Mobile Alliance (OMA) et l’IPSO Alliance (IPSO) ont joint leurs organisations en 2018 pour former une coentreprise appelée OMA Specworks. OMA existe depuis 2002 en tant qu’organisation pour aider les développeurs à transformer les idées en spécifications industrielles. IPSO Alliance n’est pas une organisation de normalisation mais une alliance qui promeut l’activation IP pour les objets intelligents et mène l’industrie sur l’utilisation de l’IP pour résoudre les problèmes d’interopérabilité.
Le groupe existe pour compléter l’IETF à travers divers groupes de travail affrétés avec la sémantique (normes de méta-information à travers les objets), les protocoles IoT et l’analyse de différentes normes, et la sécurité et la confidentialité. Le nouvel OMA Specworks gère LightWEightM2M (LwM2M) en tant que protocole de gestion des appareils pour les réseaux de capteurs et les solutions M2M.
Il existe quatre niveaux d’adhésion: Supporter , qui est désigné pour une organisation souhaitant contribuer aux spécifications mais sans droit de vote; le niveau associé , qui accorde à la société la moitié des voix pour les projets de spécifications et la possibilité de pourvoir un siège de vice-président dans un groupe de travail; la qualité de membre à part entière, qui ajoute la possibilité d’exprimer un vote complet et d’être éligible aux sièges de président et de conseil d’administration des groupes de travail ; et enfin le niveau Sponsor , qui place automatiquement le membre sur le plateau.
14.2.5 Divers
Diverses autres organisations se concentrant sur les protocoles IoT et la sécurité comprennent :
- Online Trust Alliance (OTA) : une organisation mondiale à but non lucratif développant les meilleures pratiques pour la sécurité de l’IoT ( https://otalliance.org )
- oneM2M : couche de service, protocoles et architecture communs pour les objets connectés ( http://www.onem2m.org )
14.3 Consortiums WAN
Ces organisations couvrent les diverses communications et protocoles à longue portée (LPWAN). Certains nécessitent l’adhésion pour les droits d’utilisation, tandis que d’autres sont des protocoles ouverts.
14.3.1 SIG en apesanteur
Les détails de l’organisation sont les suivants :
- Fondé : 2012
- Adhésion d’entreprise : inconnue
- Lien vers le site Web : www.weightless.org
Le Weightless SIG à but non lucratif a été créé pour parrainer et soutenir les différents protocoles LPWAN Weightless. Le SIG prend en charge trois normes : Weightless-N pour une batterie à faible coût et longue durée de vie, Weightless-P pour une communication bidirectionnelle avec un ensemble complet de fonctionnalités et Weightless-W, qui comprend un ensemble complet de fonctionnalités et de capacités.
L’intention est d’établir une norme pour les cas d’utilisation tels que les compteurs intelligents, le suivi des véhicules et même le haut débit rural. L’apesanteur se concentre principalement sur l’utilisation dans des environnements médicaux et industriels. Bien que la norme soit ouverte, un processus de qualification est requis. Les membres ont le droit d’utiliser Weightless IP sans redevance et ont accès au programme de certification. L’adhésion est assez simple à un niveau: développeur .
14.3.2 Alliance LoRa
Les détails de l’organisation sont les suivants :
- Fondé : 2014
- Membres corporatifs : 419 (44 membres institutionnels supplémentaires)
- Lien vers le site Internet : www.lora-alliance.org
La LoRa Alliance est un consortium à but non lucratif qui sponsorise la technologie LoRaWAN LPWAN. LoRaWAN est une architecture de couche de protocole pour la communication à longue portée dans le spectre sub-Gigahertz. LoRaWAN s’adresse généralement aux déploiements M2M et Smart City. Il existe quatre niveaux d’abonnement payant, y compris le niveau Adopter, qui accorde au titulaire des droits sur les produits certifiés, l’accès aux livrables finaux et des invitations à certaines réunions. Le niveau suivant est l’adhésion institutionnelle, qui accorde au titulaire le droit de participer à des groupes de travail et d’accéder aux premières versions. Vient ensuite le niveau Contributeur, qui ajoute le droit de vote au sein des groupes de travail. Enfin, il y a le niveau Sponsor, qui permet à l’entreprise de demander un siège au conseil d’administration, de superviser les données opérationnelles et de présider un groupe de travail.
14.3.3 Internet Engineering Task Force (IETF)
Les détails de l’organisation sont les suivants :
- Fondation : 1986
- Adhésion d’entreprise : 1200 (le nombre de participants dans les réunions de l’IETF)
- Lien vers le site Internet : www.ietf.org
Établie à l’origine avec 21 chercheurs américains, l’IETF s’est considérablement développée au fil des ans et est surtout connue comme l’organisme contrôlant les normes de l’industrie telles que TCP / IP et divers documents RFC. Ils couvrent désormais de larges domaines qui couvrent le segment IoT, tels que les protocoles LPWAN, 6lo et IPVS sur 802.15.4. Au sein de l’IETF, existe le Internet Engineering Steering Group, qui régit le processus de normalisation.
Il est structurellement divisé en sept zones, telles que la zone de routage ou la zone de transport. Chaque zone peut également accueillir des dizaines de groupes de travail différents. (Il y a plus de 140 groupes de travail.) Rejoindre l’IETF est simple et peut être fait en souscrivant simplement à et en participant à une liste de diffusion de groupe de travail, en comprenant la charte et les normes, et en s’engageant activement avec le groupe plus large. Le processus de normalisation est rigoureux car ce groupe définit les fondements de la communication Internet.
14.3.4 Alliance Wi-Fi
Les détails de l’organisation sont les suivants :
- Fondé : 1999
- Adhésion corporative : 700
- Lien vers le site Internet : www.wi-fi.org
La Wi-Fi Alliance est un organisme standard à but non lucratif qui a été construit pour combler les lacunes de l’interopérabilité sans fil au milieu des années 90. Avec l’avènement du 802.11b, un consortium à l’échelle de l’industrie a été formé pour créer un organe de gouvernance efficace. L’alliance contrôle le processus de certification Wi-Fi et le logo et la marque associés pour les appareils qui répondent à leurs normes. Il existe 19 zones de travail et groupes de discussion, tels que 802.11ax, sécurité et IoT.
Il existe deux niveaux d’adhésion : une adhésion de mise en œuvre permet au titulaire d’utiliser des produits Wi-Fi précédemment certifiés pour sa solution finale, et l’adhésion de contributeur permet à une organisation de participer à des programmes de certification et à de nouvelles définitions technologiques.
14.4 Consortiums Fog et Edge
L’informatique de brouillard et de périphérie devient un besoin croissant, et un ensemble bifurqué de normes industrielles est en cours d’adoption. L’organisation industrielle et les normes de l’industrie sont nécessaires pour aider à résoudre les problèmes croissants d’interopérabilité avec le calcul du brouillard. Cette section présente certaines des organisations qui élaborent des normes et des cadres pour l’interopérabilité industrielle.
14.4.1 OpenFog
Les détails de l’organisation sont les suivants :
- Fondation : 2015
- Adhésion corporative : 55
- Lien vers le site Internet : www.openfogconsortium.org
OpenFog a adhéré sous l’égide de l’Industrial Internet Consortium (IIC) en 2019. Les informations IIC sont répertoriées dans la section suivante.
14.4.2 Eclipse Foundation et EdgeX Foundry
Les détails de l’organisation sont les suivants:
- Fondation : Eclipse: 2001; EdgeX: 2017
- Adhésion d’entreprise : Eclipse: 275; EdgeX: 50
- Liens Internet : www.eclipse.org et www.edgexfoundry.org
La Fondation Eclipse a été créée en 2001 par IBM. Il est surtout connu pour le projet Eclipse utilisé quotidiennement par des millions de développeurs. L’organisation à but non lucratif contrôle plus de 350 projets open source depuis divers environnements de développement jusqu’aux frameworks logiciels.
La fonderie EdgeX est chargée de fournir une plate-forme de périphérie conçue pour résoudre l’interopérabilité du matériel et des systèmes d’exploitation pour l’écosystème IoT via un logiciel open source. Les microservices comprennent un middleware important pour les moteurs de règles, les alertes, la journalisation, l’enregistrement et les connexions de périphériques. Le projet est hébergé par la Linux Foundation et est autorisé sous le modèle Apache. Dell est une graine principale pour la conception initiale du code, qui est une série de microservices conçus pour être agnostiques au matériel. Il existe deux niveaux d’adhésion : un niveau de membre général et des membres Premier. Un membre général peut participer à des sièges élus au conseil d’administration, utiliser du matériel de logo et participer à des événements organisés. L’adhésion Premier ajoute la possibilité de travailler sur les budgets des comités, de changer les stratégies de marketing grâce aux sièges de vote, l’accès au personnel opérationnel et au leadership, de changer les politiques de l’organisation et un siège de vote sur les conseils consultatifs techniques (TAC).
14.5 Organisations faîtières
Les organisations suivantes gouvernent ou dirigent une myriade de différents aspects techniques et fonctionnels de l’IoT (ainsi que d’autres segments). Ils représentent des aspects des protocoles, des tests, de l’opérabilité, de la technologie, de la communication et de la théorie.
14.5.1 Consortium Internet industriel
Les détails de l’organisation sont les suivants :
- Fondé : 2014
- Adhésion corporative : 258
- Lien vers le site Internet : www.iiconsortium.org
Organisme à but non lucratif qui a été lancé en 2014 par AT&T, Cisco, GE, IBM et Intel, le consortium existe pour rassembler des partenaires de l’industrie afin d’aider à l’adoption et au développement de l’IoT industriel. Le groupe n’est pas un organisme de normalisation mais pilote des architectures de référence et des bancs d’essai pour la fabrication, la santé, les transports, les villes intelligentes et le secteur de l’énergie. Il existe actuellement 19 groupes de travail couvrant des domaines tels que la connectivité, la sécurité, l’énergie, les usines intelligentes et les soins de santé.
En 2019, l’organisation OpenFog d’origine a fusionné avec l’IIC. Il remplit la même fonction qu’avant la fusion. OpenFog gère les normes et l’architecture de l’architecture OpenFog. Ils relèvent les défis de l’informatique de pointe et du brouillard grâce à des technologies ouvertes avec pour mission de créer un cadre pour un traitement sécurisé et efficace et l’interopérabilité entre le cloud, les points de terminaison et les services.
Le groupe compte six niveaux d’adhésion, dont les niveaux gouvernementaux et à but non lucratif / universitaire. Les adhésions aux entreprises évoluent en influence et en coût en fonction des ventes annuelles de l’entreprise. Ces niveaux comprennent la fondation, la contribution, la grande industrie et la petite industrie. Les définitions des bancs d’essai sont larges et bien définies et incluent des cas d’utilisation industrielle spécifiques tels que les tests de traitement des bagages des compagnies aériennes. Comme mentionné précédemment, le groupe OMG gère les opérations du groupe, mais l’IIC est lui-même sa propre organisation.
14.5.2 IEEE IoT
Les détails de l’organisation sont les suivants :
- Fondé : 2014
- Adhésion d’entreprise : N / A
- Lien vers le site Web : iot.ieee.org
Bien qu’il ne soit pas un consortium, l’IEEE IoT est un groupe d’intérêt spécial sous l’égide de l’IEEE. Il s’agit d’une organisation multidisciplinaire composée d’établissements universitaires, d’organismes gouvernementaux et de professionnels de l’industrie et de l’ingénierie pour piloter le développement de l’IoT. L’IEE IoT influence ou héberge des normes spécifiques dans le monde de l’IoT, telles que les protocoles 802.15 et les normes Wi-Fi 802.11. Le groupe propose des webinaires, des cours et du matériel en ligne gratuits pour aider à développer la base de connaissances de l’industrie. Des conférences, des ateliers et des sommets influents de classe mondiale sont gérés par le groupe IEEE IoT, ainsi que par l’une des revues de recherche les plus actives : l’IEEE Internet of Things Journal.
14.5.3 Divers
Diverses organisations faîtières d’intérêt comprennent :
- Genivi : Groupe de logiciels ouverts pour l’infodivertissement embarqué et les voitures connectées ( www.genivi.org )
- HomeKit : normes d’automatisation pour les particuliers et les maisons mobiles Apple ( https://developer.apple.com/homekit/ )
- Open Automotive Alliance : groupe automobile et technologie visant à utiliser Android dans les véhicules ( https://www.openautoalliance.net/#about )
- Wireless Life Sciences Alliance : initiative et industrie des soins de santé connectés et sans fil ( http://wirelesslifesciences.org/ )
14.6 titres du gouvernement américain IdO et entit s
Voici les organisations gouvernementales et fédérales que vous devez connaître, en particulier dans le domaine de la sécurité de l’IoT :
- Institut national des normes et de la technologie : définit les normes nationales en matière de sécurité, de chiffrement et de mise en réseau ( https://www.nist.gov )
- Comité consultatif sur les télécommunications de la sécurité nationale (Department of Homeland Security) : chargé de renforcer la cybersécurité et l’infrastructure de communication mondiale ( https://www.dhs.gov/national-security-telecommunications-advisory-committee )
- Administration nationale des télécommunications et de l’information : partie du département américain du Commerce qui contrôle l’attribution du spectre radio américain, la dénomination des domaines et la sécurité ( https://www.ntia.doc.gov/home )
- US-CERT : Computer Emergency Response Team qui identifie et répond aux urgences nationales de sécurité informatique à fort impact ( https://www.us-cert.gov/ncas/current-activity )
14.7 IdO et périphérie industrielle et commerciaux
Il convient également de noter que certaines des meilleures entreprises développent des systèmes et des services pour l’IoT et l’informatique de pointe. Ceci est basé sur les titres récents, les employés, les revenus, les offres de produits, la capitalisation boursière, les offres de produits, la fiabilité des produits et la participation aux normes. Les sections suivantes incluent les appareils et services que j’ai utilisés et déployés avec succès dans des projets commerciaux.
Bien que les technologies amateurs telles que les appareils Arduino et Raspberry Pi aient certainement leur place dans l’IoT et l’informatique de pointe, elles sont traditionnellement utilisées dans les exercices de validation de principe ou académiques. Cet article s’adresse davantage aux solutions commerciales et industrielles à grande échelle IoT et informatique de pointe qui nécessitent des dispositifs de terrain renforcés et des technologies évolutives pour la production de masse et le déploiement dans le monde entier.
14.7.1 Fabricants et vendeurs de capteurs et de MEMS commerciaux et industriels
Ce tableau sert à mettre en évidence les principaux fabricants et entreprises de capteurs.
| Compagnie | Produits et services | URL |
| Périphériques analogiques | Accéléromètres, gyroscopes, capteurs de mesure inertielle, capteurs de champ magnétique, capteurs optiques, capteurs de température et d’environnement. | www.analog.com |
| Bosch | Sensortec TM , des accéléromètres, des gyroscopes, des magnétomètres, des unités de mouvement d’ inertie, de capteurs d’orientation, des capteurs environnementaux, des systèmes optiques | www.bosch-sensortec.com |
| Broadcom | Capteurs optiques, encodeurs de contrôle de mouvement | www.broadcom.com |
| Infineon Technologies | Capteurs magnétiques, capteurs de courant et électriques, microphones MEMS, capteurs de pression, capteurs environnementaux, détection radar, capteurs d’image | www.infineon.com |
| Inventer | CPU / capteurs tout-en-un, capteurs de mouvement, capteurs d’imagerie et optiques, détection du son, détection et suivi de localisation, capteurs de mouvement | www.invensense.com |
| Microchip | Capteurs de CO et de fumée, contrôleurs de ventilateur, capteurs de position inductifs, thermocouples, amplificateurs de détection de courant | www.microchip.com |
| NXP Semiconductors | Capteurs de mouvement, capteurs de pression, capteurs magnétiques, détection tactile, capteurs de température numériques, détection silicium, capteurs tactiles capacitifs, capteurs automobiles | www.nxp.com |
| Omron | Capteurs industriels et médicaux, capteurs à fibres optiques, capteurs photoélectriques, capteurs de déplacement et de géométrie, capteurs de vision, lecteurs OCR, détection optique, capteurs à ultrasons, capteurs de pression, détection de contact, capteurs de fuite et de fluide, capteurs environnementaux durcis | www.omron.com |
| onSemi | Capteurs et processeurs d’images, capteurs thermiques, capteurs tactiles, détection de la lumière ambiante, étiquettes de ressources sans batterie | www.onsemi.com |
| ST Microelectronics | Accéléromètres, capteurs automobiles, gyroscopes, détection de boussole, capteurs d’humidité, microphones MEMS, modules inertiels, capteurs industriels haute performance, capteurs de pression, capteurs de proximité, capteurs de température | www.st.com |
| Connectivité TE | Capteurs et solutions de câblage industriels, médicaux et commerciaux; capteurs automobiles, capteurs piézo, capteurs de couple, capteurs de vibrations, etc. | www.te.com |
| Texas Instruments | Capteurs de température, capteurs mmWave, détection de courant et électrique, capteurs à ultrasons, capteurs de temps de vol, capteurs magnétiques à effet Hall, capteurs environnementaux | www.ti.com |
14.7.2 Fabricants de silicium, de microprocesseurs et de composants
Ce tableau sert à mettre en évidence les principales entreprises de l’IoT et des fabricants de composants et de matériel informatique de pointe.
| Compagnie | Produits et services | URL |
| AMD | Cœurs, SOC, GPU x86 de performances moyennes à extrêmes | www.amd.com |
| BRAS | Silicon IP, microcontrôleurs, processeurs en temps réel, cœurs 32 et 64 bits, cœurs d’apprentissage automatique, processeurs d’images, systèmes de sécurité de l’environnement d’exécution de confiance, GPU, interconnexion de bus | www.arm.com |
| Intel | Cœurs, SOC, systèmes de mémoire de performance moyenne à extrême x86 | www.intel.com |
| Microchip Technologies | Microcontrôleurs ARM et MIPS 8 à 32 bits | www.microchip.com |
| Nvidia | Bord Jetson SOCs, Smart City Metropolis TM système de vision, les moteurs AI | www.nvidia.com |
| Qualcomm | Snapdragon TM CPU, GPU SOCs | www.qualcomm.com |
| ST Microelectronics | Microcontrôleurs 8 bits à 32 bits, SOC entièrement intégrés | www.st.com |
| Texas Instruments | Sitara TM processeurs ARM, circuits intégrés automobiles, processeurs de signaux numériques | www.ti.com |
14.7.3 Entreprises de communication PAN
Ce tableau sert à mettre en évidence les principales sociétés de fabricants et fournisseurs de connectivité PAN et sans fil.
| Compagnie | Produits et services | URL |
| Digi | Modules Zigbee, système sur modules, ordinateurs monocarte | www.digi.com |
| Microchip | 15.4, radios Bluetooth, systèmes infrarouges, modules LoRa, modules Wi-Fi, radios sous 1 GHz, Zigbee | www.microchip.com |
| Nordic Semiconductor | Fabricant Bluetooth leader, maille Bluetooth, contrôleurs de fil, radios Zigbee, protocoles ANT, radiogoniomètres | www.nordic.com |
| NXP | Modules Wi-Fi, radios Bluetooth, radios 802.15.4, NFC, modules RFID, modules Bluetooth, Zigbee, Thread, radios inférieures à 1 GHz | www.nxp.com |
| Sur semi-conducteur | CI micro-ondes monolithiques, émetteurs RF sans fil (802.15.4, Bluetooth, Zigbee, Sigfox, EnOcean, 6LoWPAN, Thread), Wi-Fi, CI IO basse vitesse | www.onsemi.com |
| Silicon Labs | Bluetooth, Thread, Wi-Fi, Zigbee, Zwave, RF propriétaire, émetteurs-récepteurs multiprotocoles | www.silabs.com |
| ST Microelectronics | Modules Bluetooth, Thread, Zigbee, systèmes LoRaWAN, systèmes Sigfox, radios sous 1 GHz | www.st.com |
| Texas Instruments | SimpleLink TM contrôleurs MCU, radios Bluetooth, fil, 6LoWPAN, Wi-Fi, les radios sous-1GHz, multiprotocole | www.ti.com |
14.7.4 Entreprises de technologie WAN
Ce tableau sert à mettre en évidence les entreprises leaders dans la connectivité IoT et WAN Edge, la mise en réseau, le routage et les communications.
| Compagnie | Produits et services | URL |
| Cisco Meraki | WAN, points d’accès, sécurité SD-WAN, caméras intelligentes, commutateurs de classe entreprise | meraki.cisco.com |
| Digi | Passerelles et routeurs certifiés FirstNet, routeurs cellulaires industriels et de transport (2G, 3G, 4G LTE), systèmes de gestion cloud, système sur modules | www.digi.com |
| Freewave | Routeurs IoT industriels, WAN 900 MHz, radios 436 MHz à 1,4 GHz, routeurs 2,4 GHz, systèmes SCADA | www.freewave.com |
| Peplink | Routeurs cellulaires 4G LTE, solutions SD-WAN, Wi-Fi d’entreprise et industriel, routeurs mobiles et de parc, routeurs cellulaires multiporteuses | www.peplink.com |
| Semtech | Technologies LoRa | www.semtech.com |
| Sierra Wireless | AIRVANTAGE TM plate – forme IdO, des services de gestion de la connectivité, 2G, 3G, 4G LTE, Cat-M1 et puces NB-IdO et des modules, des modules Wi-Fi, Bluetooth, routeurs de bord, bord, émetteurs – récepteurs GPS | www.sierrawireless.com |
| Telit | Radios et modules cellulaires 2G, 3G, 4G LTE, 5G, NB-IoT, Cat M1, modules LoRa, modules de positionnement GPS, logiciel de gestion à distance, plans de données IoT mondiaux | www.telit.com |
| Ublox | Systèmes et modules cellulaires 2G, 3G, 4G LTE, NB-IoT, Cat M1, modules GPS | www.u-blox.com |
14.7.5 Entreprises de calcul et de solutions Edge
Ce tableau sert à mettre en évidence le matériel informatique de pointe ainsi que les fournisseurs de solutions IoT dans le monde entier.
| Compagnie | Produits et services | URL |
| Advantech | Modules intégrés, ordinateurs de bord industriels, systèmes de bord d’environnement durci, calcul ARM et X86 de bord, automatisation industrielle, plates-formes AI de bord, passerelles industrielles, systèmes informatiques médicaux | www.advantech.com |
| Dell | Passerelles Edge et boîtiers X86 renforcés | www.dell.com |
| Digi | i.MX ordinateurs à carte unique, ConnectCore TM informatique industrielle | www.digi.com |
| Inforce Computing | Système X86 et Qualcomm sur modules, ordinateurs monocarte, plates-formes informatiques prêtes pour l’entreprise et le commerce | www.inforcecomputing.com |
| Lenovo | Haute performance ThinkSystem TM serveurs Edge | www.lenovo.com |
| IOT RUMBLE | Systèmes de bord, solutions intégrées, télématique pour véhicules et parcs de véhicules, systèmes de bord industriels | www.rumbleiot.com |
14.7.6 Entreprises de systèmes d’exploitation, de middleware et de logiciels
Ce tableau sert à mettre en évidence les systèmes d’exploitation, les middlewares, les solutions logicielles et les sociétés de services.
| Compagnie | Produits et services | URL |
| Amazon | Middleware Greengrass Lambda | www.amazon.com |
| BRAS | MBed OS TM , services et plates-formes de sécurité, logiciel de gestion Edge et IoT | www.arm.com |
| Bosch | Plateforme de périphérie de la passerelle IoT et services middleware | www.bosch.com |
| DataMonsters | Analyse de bord et apprentissage automatique | www.datamonsters.com |
| Fondation Eclipse | Fonderie EdgeX, produits de développement Eclipse | www.eclipse.org |
| Hitachi | Vantara TM intelligence de bord industriel et IdO, bord d’ apprentissage de la machine, la visualisation en temps réel et des tableaux de bord, gestion des données vidéo | www.hitachivantera.com |
| Microsoft | Conteneur et système de gestion Azure Edge IoT, logiciel d’analyse Edge, systèmes d’exploitation Microsoft Edge et IoT | www.microsoft.com |
14.7.7 Fournisseurs cloud
Ce tableau sert à mettre en évidence les principaux fournisseurs de solutions et de services cloud et IoT.
| Compagnie | Produits et services | URL |
| Amazon | Fournisseur de cloud, gestion des appareils IoT, analyses IoT, IoT Device Defender TM , connecteur AWS IoT Core TM , moteur de règles AWS IoT Events TM | www.amazon.com |
| services cloud Google, Nuage IdO de base Gestionnaire de périphériques et de protocole, pont – Cloud Pub / Sub analyse de flux, Firebase TM IdO développement de la plate – forme | www.google.com | |
| IBM | IBM Watson IdO Platform TM , IdO Service de connexion, Blockchain Services, Cloud Engine Analytics | www.ibm.com |
| Microsoft | Azure Cloud Services, connecteur Azure IoT Central TM , modeleur physique Azure Digital Twins, système de surveillance IoT Hub TM , visualiseur et analyse des séries chronologiques Insights, système de géolocalisation Azure Maps | www.microsoft.com |
14.8 Résumé
Les consortiums et les organisations industrielles offrent des avantages importants à la communauté sous forme de normalisation, de feuilles de route techniques et d’interopérabilité. Devenir membre permet à une organisation d’accéder sans restriction aux spécifications et à la documentation. Dans de nombreux cas, l’adhésion et l’affiliation sont nécessaires pour les droits d’utilisation. Stratégiquement, les comités membres fournissent également une force concurrentielle en nombre, car divers protocoles et normes se font concurrence dans l’espace IoT.




Laisser un commentaire
Vous devez être dentifié pour poster un commentaire.