0. Développer avec la plateforme Cloud Foundry
0.1 Résumé de la publication
Cloud Foundry est la plateforme open source pour déployer, exécuter et faire évoluer des applications. Cloud Foundry se développe rapidement et est un produit leader qui fournit des capacités PaaS (Platform as a Service) aux entreprises, aux gouvernements et aux organisations du monde entier. Des géants comme Dell Technologies, GE, IBM, HP et le gouvernement américain utilisent Cloud Foundry pour innover plus rapidement dans un monde en évolution rapide.
Cloud Foundry est le rêve d’un développeur. Leur permettre de créer des applications modernes qui peuvent tirer parti des dernières réflexions, techniques et capacités du cloud, notamment :
- DevOps
- Virtualisation des applications
- Agnosticisme des infrastructures
- Conteneurs orchestrés
- Automatisation
- Aucune mise à niveau de temps d’arrêt
- Déploiement A / B
- Faire évoluer ou déployer rapidement les applications
Cet article emmène les lecteurs dans un voyage où ils apprendront d’abord les bases de Cloud Foundry, y compris comment déployer et faire évoluer une application simple en quelques secondes. Les lecteurs approfondiront leurs connaissances sur la façon de créer des applications et des microservices natifs du cloud hautement évolutifs et résilients exécutés sur Cloud Foundry. Les lecteurs apprendront à intégrer leur application aux services fournis par Cloud Foundry et à ceux externes à Cloud Foundry. Les lecteurs apprendront à structurer leur environnement Cloud Foundry avec des organisations et des espaces. Après cela, nous discuterons des aspects de l’intégration continue / livraison continue (CI / CD), de la surveillance et de la journalisation. Les lecteurs apprendront également comment activer les contrôles d’intégrité, dépanner et déboguer les applications.
À la fin de cet article, les lecteurs auront une expérience pratique de l’exécution de diverses tâches de déploiement et de mise à l’échelle. De plus, ils auront une compréhension de ce qu’il faut pour migrer et développer des applications pour Cloud Foundry.
0.2 Objectifs de la publication
- Comprendre les outils et les concepts de Cloud Foundry (CF).
- Comprenez l’étendue des possibilités offertes grâce à une approche agile légère pour la création et le déploiement d’applications.
- Concevez et déployez des applications natives cloud qui fonctionnent bien sur Cloud Foundry.
- Apprenez les concepts de conception de microservices et les applications de travail.
- Personnalisez les courtiers de services pour publier vos services sur le marché Cloud Foundry.
- Utilisation, gestion et création de buildpacks pour la plateforme Cloud Foundry.
- Dépanner les applications sur Cloud Foundry
- Effectuez des déploiements sans temps d’arrêt à l’aide de routes bleues / vertes, de tests A / B et de restaurations indolores vers les versions antérieures de l’application.
1 Chapitre 1. Présentation de Cloud Foundry
Dans ce chapitre, nous présentons Cloud Foundry en fournissant des informations sur le produit lui-même et certains concepts connexes qui peuvent être utiles à ceux qui ne le connaissent pas. Nous approfondissons ensuite les détails de l’utilisation de Cloud Foundry du point de vue des développeurs d’applications dans les chapitres suivants.
Dans ce chapitre, nous couvrirons les sujets suivants :
- Pourquoi Cloud Foundry ?
- Qu’est-ce que le PaaS ?
- Qu’est-ce que Cloud Foundry ?
- Qu’est-ce que Pivotal Cloud Foundry ?
1.1 Pourquoi Cloud Foundry ?
cf push
C’est ça. C’est la réponse essentielle à la question Pourquoi Cloud Foundry?, Anti-climatique, non? Du moins, jusqu’à ce que vous compreniez le saut révolutionnaire qu’a entraîné le développement d’applications.
Sans cf push , le cycle de développement d’application typique est compliqué et complexe car, souvent, une grande partie de l’activité de développement est consommée en trouvant un endroit où votre application peut vivre et servir le monde en toute sécurité, fiabilité et robustesse. Trois problèmes ont entravé le développement:
- Il est difficile de fournir des applications qui sont précieuses pour vous, votre organisation et / ou le monde si vous n’êtes pas en mesure de vous concentrer sur la création de l’application elle-même. Dans certaines grandes organisations, les développeurs ont déclaré que 80% de nos efforts sont en train de préparer l’infrastructure. Imaginez un jour où vous n’avez qu’à créer votre application, pas à assembler un middleware; installer les temps d’exécution des applications; ou jouer avec un système d’exploitation (OS), une machine virtuelle (VM), des serveurs, un stockage ou un réseau.
- Les développeurs d’applications ne sont pas des administrateurs système ou des opérateurs système, et ils ne devraient pas non plus être obligés de l’être. Si vous demandez aux opérateurs de développer du code que l’on attend d’un développeur d’applications, la plupart déclineront probablement. Il y a des limites de leur point de vue. Les deux disciplines relèvent de l’informatique, oui. Les deux sont des rôles extrêmement techniques, nécessitant une expertise approfondie pour être sûr. Les deux font le gros du travail nécessaire pour finalement mettre une application d’une certaine valeur à la disposition d’un public qui en a besoin. Cependant, le fossé entre Dev et Ops est large et profond. Il existe des spécialisations, des préoccupations et des risques fondamentaux qui entraînent un comportement dans les deux rôles, ce qui crée une ligne de fracture évidente et tout à fait naturelle à suivre lors de la division de la charge de travail liée au démarrage et à l’exécution des applications en production. Bien sûr, les deux doivent travailler ensemble, partager et apprendre des techniques qui sont interfonctionnelles et pertinentes pour être plus efficaces et agiles dans leurs rôles respectifs, telles que l’intégration continue et le déploiement continu (CI / CD). En fin de compte, les développeurs d’applications prospèrent s’ils se concentrent sur le développement d’applications et la résolution de problèmes dans cet espace très difficile, sans se soucier d’être un ingénieur ou un opérateur de plate-forme fantôme.
- Il est difficile de créer un environnement de production cohérent, fiable, sécurisé et hautement disponible. Bien plus encore en regroupant les capacités de calcul, de stockage et de réseau dans un système cohérent qui répond aux exigences des entreprises modernes et aux attentes des consommateurs d’applications. Tout en offrant la rigueur et la flexibilité qui permettent aux développeurs de se concentrer sur le développement d’applications en toute simplicité. VMware a révolutionné le monde de l’informatique avec la virtualisation des serveurs en 1998. Ils ont fait abstraction des limites du matériel physique en pools de serveurs virtuels. Cela nous a permis de mieux utiliser le matériel sous-jacent en répartissant et en adaptant des charges de travail importantes et complexes sur les boîtiers physiques.
Ce sont les problèmes que Cloud Foundry a dû résoudre : mettre fin à la bataille éternelle de la concentration du développeur sur les applications par rapport à l’exploitation et à l’ingénierie de la plate-forme sur laquelle ces applications sont exécutées.
Cloud Foundry y parvient en proposant une virtualisation des applications de niveau entreprise. Pour ce faire, il exploite et orchestre une symphonie de conteneurs dans un système distribué élastiquement évolutif comprenant tous les composants dont une application donnée a besoin pour servir le monde. Cela change le jeu de la même manière que VMware l’a fait avec les machines virtuelles et la virtualisation des serveurs. Cloud Foundry est une plate-forme de virtualisation d’applications éprouvée qui redonne le contrôle au développeur, permettant aux développeurs de se concentrer sur le développement d’applications, plutôt que sur les opérations d’infrastructure.
Remarque
cf push était à l’origine vmc push, qui signifiait VMware Cloud. Cloud Foundry a été conçu chez VMware en 2009 et est né en tant que projet open source en 2011. Le code original pour VMC peut être trouvé sur https://github.com/cloudfoundry-attic/vmc .
1.2 Qu’est-ce que le PaaS ?
Platform as a Service (Paas) est l’un des nombreux termes de la taxonomie du cloud computing, notamment Infrastructure as a Service (Iaas) et Software as a Service (Saas).
Alors que, en général, IaaS est axé sur le serveur et SaaS est axé sur l’utilisateur, PaaS est axé sur les développeurs. PaaS améliore la productivité des développeurs en activant la virtualisation des applications, il y a donc une réduction significative de la nécessité pour les développeurs d’effectuer le levage de charges indifférencié associé à la plomberie, ce qui nuit au travail réel sur le code d’application et les préoccupations. Souvent, cela s’appelle le rasage de yak. Par exemple, cela peut inclure tout, de l’installation des durées d’exécution des applications, des dépendances, de l’empaquetage des applications, de la mise en attente et du déploiement, à la configuration plus en profondeur de la pile dans des problèmes d’infrastructure tels que la configuration des équilibreurs de charge, la mise en réseau, la sécurité, le provisionnement des machines virtuelles – presque tout ce qui vous intéresse hors construction d’une excellente application.
Remarque
Selon Jeremy H. Brown au MIT vers l’an 2000, le rasage de yak est ce que vous faites lorsque vous effectuez une petite tâche stupide et délicate qui n’a aucun lien évident avec ce sur quoi vous êtes censé travailler, mais pourtant une chaîne de douze relations causales relie ce que vous faites à la méta-tâche d’origine. Le terme a été inventé par Carlin Vieri . L’e-mail d’origine sur le sujet peut être trouvé à http://projects.csail.mit.edu/gsb/old-archive/gsb-archive/gsb2000-02-11.html.

Le logo de l’application à douze facteurs sur https://12factor.net © 2017 Salesforce.com. Tous les droits sont réservés.
Heroku (https://www.heroku.com) est le nom de l’un des pionniers originaux de PaaS. Disponible depuis 2007, Heroku est une plate-forme cloud qui permet aux développeurs de pousser des applications dans un service hébergé sur Internet. L’idée était de concentrer les développeurs sur la création d’applications et non sur l’infrastructure. En utilisant les connaissances acquises par l’équipe Heroku grâce à l’exploitation d’une grande plate-forme avec diverses applications en cours d’exécution, Adam Wiggins et son équipe ont constitué la base de ce que l’on appelle désormais des applications natives du cloud via leur application à douze facteurs d’origine (https://12factor.net ) motifs. Ils étaient motivés pour sensibiliser à certains problèmes systémiques rencontrés dans le développement d’applications modernes, pour fournir un vocabulaire partagé pour discuter de ces problèmes et pour proposer un ensemble de solutions conceptuelles générales à ces problèmes avec la terminologie qui l’accompagne. Nous discuterons des applications natives du cloud et des développements ultérieurs depuis l’écriture de la méthodologie originale de l’application à douze facteurs dans les prochains chapitres. De plus, le modèle de buildpack de Heroku est utilisé pour Cloud Foundry et sera également discuté un peu plus loin dans l’article.
1.2.1 La définition de Cloud Foundry de PaaS
À l’ère du cloud, la plateforme d’application est livrée en tant que service, souvent appelé PaaS. PaaS facilite le déploiement, l’exécution et la mise à l’échelle des applications. Certaines offres PaaS ont une prise en charge limitée du langage et du cadre, ne fournissent pas de services d’application clés ou ne limitent pas le déploiement à un seul cloud. Cloud Foundry est le PaaS ouvert de l’industrie et propose un choix de clouds, de frameworks et de services d’application.
1.3 Qui sont Pivotal et la Cloud Foundry Foundation?
En avril 2013, Dell EMC et VMware ont formé une nouvelle société appelée Pivotal. Chaque société mère a apporté à cette nouvelle entité des personnes, des logiciels, des produits et des garanties qui n’étaient pas au cœur de ses propres activités. Cela comprenait 11 sociétés qui avaient été acquises par les sociétés mères à un moment ou à un autre. Peu de temps après, avec de nouveaux investissements de sociétés supplémentaires, telles que General Electric, Ford et Microsoft, la mission de Pivotal s’est fortement concentrée sur la transformation de la façon dont le monde fabrique des logiciels.
Cloud Foundry, ainsi que plusieurs autres projets notables comme Spring Framework pour Java (https://spring.io) et RabbitMQ (http://www.rabbitmq.com) pour le courtage de messages, ont été inclus dans l’histoire d’origine Pivotal.

Le logo Pivotal. © 2017 Pivotal Software, Inc. Tous droits réservés.
Peu de temps après sa création, Pivotal, en collaboration avec d’autres chefs d’entreprise, a cherché à créer la Cloud Foundry Foundation pour assurer la gestion continue de la communauté Cloud Foundry et de ses logiciels open source. La fondation a été créée en tant qu’organisme à but non lucratif indépendant sous la Fondation Linux. Depuis sa création en janvier 2015, plus de 70 entreprises (https://www.cloudfoundry.org/members/) ont rejoint la Cloud Foundry Foundation et poursuivent leur mission de sensibilisation et d’adoption mondiale du projet open source Cloud Foundry, pour développer une communauté dynamique de contributeurs et créer une cohérence dans la stratégie et l’action dans toutes les entreprises membres pour le projet.
La Fondation Cloud Foundry existe pour :
- Établir et maintenir Cloud Foundry en tant que technologie open source PaaS standard de l’industrie avec un écosystème florissant
- Offrir une qualité, une valeur et une innovation continues aux utilisateurs, aux opérateurs et aux fournisseurs de technologie Cloud Foundry
- Fournissez une expérience dynamique et agile aux contributeurs de la communauté qui fournit des applications et des logiciels natifs du cloud de la plus haute qualité, à grande vitesse et à l’échelle mondiale.
Remarque
Vous pouvez trouver plus de détails sur la Cloud Foundry Foundation et sa mission sur https://www.cloudfoundry.org/foundation .
1.4 Qu’est-ce que Cloud Foundry?
Cloud Foundry est une plate-forme pour développer et exécuter des applications natives du cloud. Il s’agit d’une plate-forme polyglotte qui vous permet de déployer une myriade d’applications écrites dans de nombreux langages informatiques différents – Java, Python, Node.js, Ruby, Go, langages .NET, et bien d’autres. Utilisez simplement le meilleur langage pour la tâche à accomplir avec la liberté de savoir que Cloud Foundry le prend en charge.

Le logo Cloud Foundry. © 2017 Cloud Foundry, Inc. Tous droits réservés.
Cloud Foundry est agnostique IaaS et open source. Il résume l’IaaS sous-jacent, que vous exécutiez sur VMware vSphere, Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure, OpenStack ou autres. Cela signifie qu’une véritable portabilité des applications est possible quels que soient les choix d’infrastructure et permet une stratégie multicloud cohérente – publique, privée ou hybride.
Le développement d’applications Cloud Foundry nécessite que les ingénieurs logiciels comprennent comment créer et déployer des applications prêtes pour le cloud. Cependant, il y a un petit secret: vos applications n’ont pas besoin d’être entièrement natives dans le cloud, les applications à douze facteurs pour fonctionner sur Cloud Foundry. Souvent, les applications existantes fonctionneront très bien sur Cloud Foundry avec quelques modifications mineures – si vous connaissez des recettes simples!
Remarque
Le moyen le plus simple de voir si une application a besoin de quelques modifications pour s’exécuter sur Cloud Foundry est simplement de cf pousser l’application. Voir les éventuelles erreurs pouvant survenir. Ensuite , faire les corrections nécessaires, puis cf pousser à nouveau. Répétez ce processus jusqu’à ce que l’application s’exécute dans Cloud Foundry. Il est souvent surprenant de constater le peu d’efforts nécessaires pour faire fonctionner une application sur Cloud Foundry. Et, dans de nombreux cas, ce sont les personnalisations spécifiques au middleware du code de l’application qui sont destinées à intégrer ou à lancer l’application sur un serveur d’application donné comme WebLogic ou WebSphere où certains points de friction se trouvent couramment dans la pratique – plus encore que le code fonctionnel de l’application réelle.
Cloud Foundry fournit une plate-forme hautement disponible, évolutive et sécurisée pour déployer votre application. Et avec la mise à l’échelle automatique, votre application peut évoluer pour s’adapter aux pics de trafic, puis évoluer une fois le trafic diminué – automatiquement !
Voici un guide de Cloud Foundry en un coup d’œil :
- Sortie initiale en 2011
- Une plate-forme ouverte native du cloud (PaaS)
- Construire, tester, déployer et faire évoluer des applications rapidement et facilement
- Fonctionne avec n’importe quel langage ou cadre
- Disponible en open source, en distribution commerciale ou en offres hébergées
- Open source avec une licence Apache, hébergé sur GitHub
- Les développeurs utilisent l’ utilitaire de ligne de commande cf pour interagir avec un déploiement CF
- L’ interface de ligne de commande cf (interpréteur de ligne de commande) est préconfigurée pour Windows, Mac et Linux
- Le cf prend en charge n’importe quel langage ou framework via des buildpacks
En tant que développeur, Cloud Foundry effectue les opérations suivantes:
- Vous permet de vous concentrer sur la création d’applications
- Vous fait sortir du jeu de provisionnement de VM
- Vous permet de recréer en continu l’environnement d’exécution d’une application
- Déploie et fait évoluer une application en quelques secondes
- Externalise et injecte des dépendances spécifiques à l’environnement
- Possède une API qui améliore la productivité de la gestion des versions
- Utilise des conteneurs pour isoler les applications et créer la virtualisation d’applications
- Gère le cycle de vie complet de votre application
Le code du projet Cloud Foundry se trouve à l’adresse suivante:
- https://github.com/cloudfoundry/
- https://github.com/cloudfoundry-incubator/
1.4.1 Architecture de Cloud Foundry
L’architecture Cloud Foundry résume de nombreuses complexités du développement d’applications au quotidien pour fournir un environnement riche et robuste pour le déploiement. Cloud Foundry gère de nombreuses demandes opérationnelles et infrastructurelles dans les coulisses de manière unifiée et cohérente afin que les opérateurs et les ingénieurs de Cloud Foundry puissent gérer et entretenir la plate-forme sans temps d’arrêt dans la plupart des cas, permettant ainsi des mises à niveau sans interruption et des correctifs à la plate-forme sans que les développeurs ne remarquent quoi que ce soit en baisse. La mise à l’échelle de Cloud Foundry en ajoutant plus d’infrastructure est intégrée à la plate-forme pour permettre la croissance au fil du temps à mesure que la demande augmente.
La plateforme Cloud Foundry est composée d’un ensemble de services distribués évolutifs horizontalement. Il comprend des outils qui automatisent et orchestrent l’infrastructure sous-jacente, fournissant une couche d’abstraction sur les plates-formes IaaS.
Cloud Foundry est très robuste. Il utilise ce qui peut être nominalement appelé IA faible en raison de sa focalisation étroite sur le maintien d’une boucle de rétroaction d’auto-guérison sous le capot via son ingénierie de libération et ses outils de gestion, appelés BOSH. Par exemple, lorsqu’une machine virtuelle dans Cloud Foundry se comporte mal, elle est mise hors service et remplacée rapidement. Cela permet la détection et la récupération des pannes à tous les niveaux : application, conteneur, machine virtuelle ou l’ensemble de la Cloud Foundry Foundation lorsqu’ils sont configurés pour la haute disponibilité (HA).
Du point de vue d’un ingénieur de plate-forme, l’aspect le plus inhabituel de Cloud Foundry est qu’il est indépendant de l’infrastructure, ce qui signifie qu’un opérateur peut exécuter Cloud Foundry sur une variété d’IaaS telles que VMware vSphere, Amazon Web Services, Google Cloud Platform, Microsoft Azure, OpenStack, serveurs bare-metal et autres. C’est aussi révolutionnaire que le concept de l’écriture unique, exécutez n’importe où le rêve de portabilité des applications que les développeurs d’applications recherchaient avec le slogan créé par Sun Microsystems pour illustrer les avantages multiplateformes du langage Java. Cloud Foundry le fait en utilisant une abstraction, appelée Cloud Provider Interface (CPI), qui traduit un ensemble commun de commandes de construction d’infrastructure en une traduction spécifique à l’IaaS à l’aide d’un projet open source appelé Fog (http://fog.io). Le brouillard permet à Cloud Foundry d’éviter le blocage des fournisseurs, ce qui vous contraint à un seul IaaS. Fait intéressant, de nombreux fournisseurs IaaS ajoutent directement la prise en charge de Fog, comme la plate-forme Google Compute. Ce faisant, Cloud Foundry bénéficie de ce riche héritage qui lui permettra de s’exécuter sur une liste sans cesse croissante de fournisseurs de cloud à mesure qu’ils deviennent disponibles et pris en charge.
Remarque
AI faible versus IA forte : l’IA faible est une intelligence artificielle non sensible qui se concentre sur une tâche étroite, tandis que l’IA forte est une machine capable d’appliquer l’intelligence à n’importe quel problème, plutôt qu’à un seul problème spécifique. La plupart des systèmes actuellement existants considérés sous l’égide de l’intelligence artificielle sont tout au plus une IA faible.
Les capacités et les aspects opérationnels de Cloud Foundry sont vraiment remarquables, sinon révolutionnaires, du point de vue de l’ingénieur système et de l’ingénierie de la plate-forme.
Remarque
BOSH est l’un des composants les plus intéressants de l’écosystème Cloud Foundry. Bien qu’il appartienne fermement au domaine de l’ingénieur de plate-forme, car il automatise et dirige le déploiement des composants Cloud Foundry eux-mêmes, il est utilisé pour déployer et maintenir une fondation Cloud Foundry (installation). BOSH est une chaîne d’outils open source pour l’ingénierie des versions, le déploiement et la gestion du cycle de vie des systèmes distribués à grande échelle. Si vous êtes intéressé à regarder le côté opérationnel de Cloud Foundry, vous pouvez en savoir plus sur BOSH à https://bosh.io et trouver le code open source pour celui-ci à https://github.com/cloudfoundry/bosh.
La plateforme Cloud Foundry fournit des éléments clés tels que le routage, la gestion des conteneurs, la journalisation et les métriques, ainsi que la configuration des applications, le catalogue de services et la messagerie intégrés.
Cloud Foundry est une plateforme polyglotte, en ce que vous êtes libre d’utiliser n’importe quel langage de programmation de votre choix pour développer votre application pour le déploiement. Il prend en charge Java, .NET Core, Python, Ruby, Go, Node.js et PHP et peut en prendre davantage en ajoutant une variété de buildpacks qui contiennent tout le nécessaire pour l’exécution des applications dans des langages supplémentaires. La plupart des buildpacks sont open source et gérés par la communauté. Ils peuvent être trouvés sur https://github.com/cloudfoundry-community/cf-docs-contrib/wiki/Buildpacks#community-created.
Un aperçu simplifié de l’écosystème Cloud Foundry:
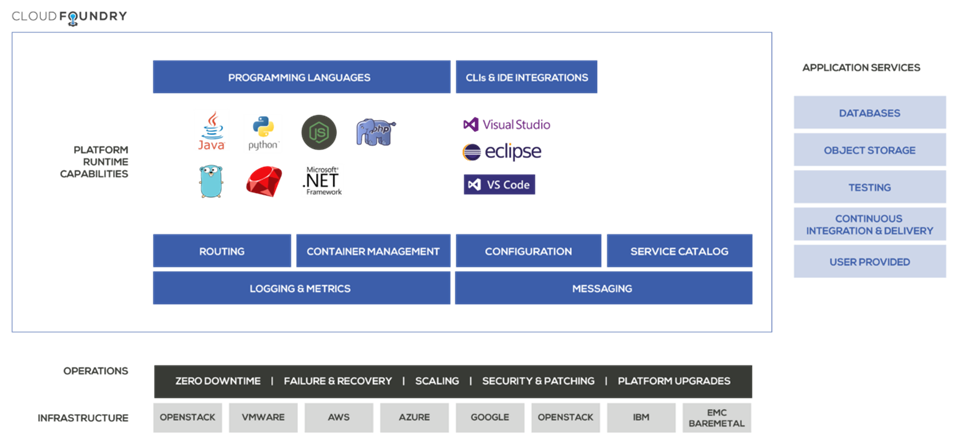
Une vue d’ensemble de l’écosystème Cloud Foundry. Plus de détails peuvent être trouvés sur https://cloudfoundry.org/ © 2017 Cloud Foundry, Inc. Tous droits réservés.
De plus, il existe des intégrations CLI (Command Line Interpreter) et IDE (Integrated Development Environment) pour les outils de développement populaires tels qu’Eclipse, Visual Studio, IntelliJ IDEA et VS Code, entre autres.
Qu’en est-il de la connexion de votre application à des services tels que des bases de données, des courtiers de messages, des magasins d’objets, etc. ? La plupart des applications dépendent de ces types d’externalités. Cloud Foundry répond à cette nécessité avec élégance, offrant bien sûr plusieurs façons de répondre à ces capacités. Nous en discuterons en détail dans les prochains chapitres.
Un aperçu simplifié de l’architecture de la plateforme Cloud Foundry:

Un aperçu conceptuel de l’architecture de la plateforme Cloud Foundry. Plus de détails peuvent être trouvés sur https://cloudfoundry.org/application-runtime/ © 2017 Cloud Foundry, Inc. Tous droits réservés.
La figure précédente montre la pile d’infrastructure et de BOSH que les ingénieurs de la plateforme Cloud Foundry utilisent pour installer, gérer et entretenir Cloud Foundry. Il y a le Cloud Foundry Application Runtime ™ (précédemment connu sous le nom d’Elastic Runtime) à l’intérieur du contour de la grande boîte qui comprend les différents composants. Du point de vue du développeur, il s’agit de Cloud Foundry. Mais du point de vue holistique des systèmes, ce n’est qu’une partie, quoique très, très importante. Le CF Application Runtime est exactement comme son nom l’indique :
L’environnement d’exécution d’application évolutif et élastique qui rassemble le recueil de composants nécessaires pour s’étendre sur les ressources d’infrastructure sous-jacentes afin de créer et gérer des pools de calcul, de mémoire, de banque de données, de blobstore et de réseaux pour prendre en charge la vue centrée sur l’application du monde que nous appelons application virtualisation. Cela comprend tous les systèmes d’orchestration, de mise en réseau, de conteneurisation, de gestion et de contrôle que vous pourriez imaginer nécessaires pour rassembler un ballet aussi complexe de technologie dynamique.
Principalement, ceux-ci entrent dans les catégories suivantes :
- Acheminement
- Authentification
- Gestion du cycle de vie des applications
- Exécution d’application
- Services de plateforme
- Messagerie, mesures et journalisation
- Tous ces éléments sont unifiés derrière l’API Cloud Controller, qui permet une intégration RESTful avec CF Application Runtime via la Cloud Foundry CLI (alias la cf CLI) et d’autres interfaces utilisateur commerciales (UI) telles que l’interface utilisateur Web Pivotal Cloud Foundry Application Manager basée sur le Web
Nous les détaillerons plus en détail dans les prochains chapitres. De plus amples informations sont disponibles sur https://www.cloudfoundry.org/platform/.
1.4.2 Sécurité de Cloud Foundry
Cloud Foundry permet une réévaluation à l’avenir, sur le cloud, des fondamentaux et hypothèses de sécurité de longue date en raison de la façon dont son composant BOSH fonctionne en arrière-plan. C’est une période passionnante pour repenser et recadrer la sécurité de manière proactive, ce qui n’était pas imaginable il y a encore quelques années sans les boucles d’automatisation et de rétroaction que nous offre BOSH. BOSH détruit constamment les machines virtuelles qui ne sont plus en bon état ou ne fonctionnent pas comme prévu, et les recrée à la volée. BOSH élimine toujours un fléau que toute infrastructure qui n’est pas entièrement automatisée rencontrera éventuellement : la dérive de la configuration.
BOSH fonctionne toujours sur une boucle de rétroaction, validant l’état de l’infrastructure du monde réel avec la configuration attendue. En cas de dérive, BOSH élimine cette mauvaise pomme et la remplace rapidement par une qui répond aux spécifications exactes de la configuration. Il s’agit d’un processus appelé repavage. Le repavage garantit en permanence que nous avons une infrastructure sous-jacente en douceur qui répond aux besoins de notre Cloud Foundry Foundation et de nos applications. BOSH le fait en toute transparence dans les coulisses sans aucun temps d’arrêt pour votre application (à condition que vous ayez au moins deux instances d’application en cours d’exécution).
Remarque
La dérive de la configuration se produit naturellement dans les environnements de datacenter lorsque les modifications apportées au logiciel et au matériel sont apportées de manière ponctuelle et ne sont pas enregistrées ou suivies de manière complète et systématique. Souvent, les gens, aussi variés que les opérateurs ou les développeurs, se connectent directement à un serveur ou à une machine virtuelle et apportent des modifications qui feront fonctionner quelque chose avec la configuration réglée d’un serveur, mais ne fonctionneront pas ailleurs si ce changement n’est pas présent. Souvent, cet endroit est un environnement de production et le problème n’est découvert que lorsque quelque chose a mal tourné. La dérive de configuration est analogue à l’excuse insidieusement formulée de Cela fonctionne sur ma machine. Cela afflige les développeurs qui ont des variations fondamentales et non prises en compte dans leurs configurations système qui permettent à une application de s’exécuter uniquement sur leur machine. Nous entendrions probablement moins cette phrase si nous amenions immédiatement cette machine particulière dans le centre de données et la faisions fonctionner en production chaque fois qu’elle était entendue.
Pour cette raison, une nouvelle façon de penser la posture de sécurité est devenue courante avec l’avènement des trois R de la sécurité : réparer, repaver et faire pivoter.
Ces principes ont été formulés pour la première fois par Justin Smith, un leader d’opinion chez Pivotal, dans une présentation intitulée Cloud Native Security : Repair, Repave, Rotate en 2016, qui peut être trouvée à https://www.infoq.com/presentations/cloud- sécurité native.
Justin définit la sécurité d’entreprise native du cloud comme :
- Réparation : réparez les logiciels vulnérables dès que les mises à jour sont disponibles.
- Repave : repave les serveurs et les applications d’un bon état connu. Faites-le souvent.
- Rotation : faites souvent pivoter les informations d’identification de l’utilisateur afin qu’elles ne soient utiles que pendant de courtes périodes. Minimiser le vecteur d’attaque du temps.
Cloud Foundry gère déjà certains d’entre eux pour vous. Et, il s’améliore rapidement car les trois R sont devenus un élément clé pour la communauté Cloud Foundry pour faire avancer l’histoire de la posture de sécurité basée sur le cloud.
1.4.3 Conteneurs Cloud Foundry
Tout comme Cloud Foundry change la façon de penser à une posture de sécurité proactive, moderne, agile et adaptable qui répare, repavage et tourne en permanence aux niveaux opérationnels des composants Cloud Foundry, il en va de même pour la réflexion sur l’approvisionnement, la mise à l’échelle et la gestion de la capacité a été modifiée pour refléter la manière dynamique et adaptable dont Cloud Foundry permet aux conteneurs de fonctionner.
Dans le passé, au moins dans la plupart des entreprises, si vous vouliez une infrastructure, vous auriez probablement besoin de vous frayer un chemin à travers les cercles de l’enfer de l’approvisionnement. Souvent, le processus ressemble à ceci :
- Demandez un serveur ou une machine virtuelle à approvisionner ou à acheter.
- Attendez que ce serveur ou cette machine virtuelle ait été provisionné.
- En attendant, vous devez vous mettre au travail pour créer l’application. Alors non plus,
- Trouvez une boîte que vous pouvez exécuter temporairement sous votre bureau en tant que bac à sable de votre application.
- Ou, sortez la carte de crédit et fournissez un calcul à partir d’un fournisseur de cloud public comme un trou d’arrêt.
- Ou, tirez parti d’une version de l’informatique fantôme vers laquelle votre organisation ferme les yeux tandis que le processus informatique normal exécute le gant officiel
- Obtenez le serveur en rack dans le centre de données ou la machine virtuelle lancée.
- Obtenez l’accès et les informations d’identification à ssh et connectez-vous à la boîte.
- Découvrez les problèmes de configuration.
- Demander la résolution des problèmes par l’équipe des opérations.
- Une fois que tout est en ordre, installez et configurez votre environnement d’exécution d’application et votre middleware.
- Enfin, après une semaine, des mois ou des années, déployez votre application pour livrer la valeur commerciale ou de mission promise.
- Découvrez que vous êtes sous-provisionné pour gérer la demande – puis recommencez rapidement le processus pour obtenir plus de capacité et calculez pour maintenir l’application en ligne et disponible à mesure qu’elle grandit.
- Apprenez votre leçon et commandez toujours bien plus de capacité que vous ne pensez en avoir besoin, juste au cas où, car cela prend trop de temps pour mettre plus en ligne une fois que vous êtes en production.
La dernière étape est très courante dans les grandes organisations avec beaucoup de processus et de paperasserie. Et, souvent en raison de la protection des ressources limitées des serveurs montés dans le centre de données et des watts gorgés par ces serveurs supplémentaires, les organisations se retrouvent largement surapprovisionnées, ce qui signifie qu’elles ont plus de capacité à prendre en pieds carrés dans le centre de données qu’elles ne le font avoir besoin. Dans certaines organisations où cela a été mesuré, le surapprovisionnement peut être bien supérieur à 40%. C’est-à-dire que plus de 40% des serveurs en rack peuvent être non rackés et mis hors ligne sans aucun effet sur la capacité de l’organisation à fournir une bonne maison à partir de laquelle les applications peuvent servir leurs utilisateurs.
Ce serait une situation entièrement évitable si ce n’était de la montée difficile et du temps requis par les développeurs et les opérateurs pour passer à travers le processus et les formalités administratives. La psychologie qui prend le relais est celle d’avoir des animaux de compagnie à longue durée de vie. En raison de l’effort considérable requis pour obtenir ces serveurs ou machines virtuelles, les développeurs dans cette situation demandent toujours plus qu’ils ne pensent pouvoir répondre à leurs besoins immédiats. Ils deviennent attachés et même si certains de ces serveurs n’ont encore rien sur eux, ils les défendent et les protègent contre la récupération, et à juste titre.
Dans les grandes organisations, la partie la plus difficile du développement d’applications est la mise en production. Il n’est pas surprenant dans les organisations de grande envergure d’attendre un mois entier, en passant pas à pas les barrages routiers, jusqu’à ce que l’infrastructure de production soit provisionnée et dispose d’une tonalité pour enfin déployer votre application dans le monde. Cloud Foundry raccourcit cela du côté de l’infrastructure, mais il y a souvent encore des améliorations bien nécessaires sur la bureaucratie du processus.
Une partie de la solution consiste à se débarrasser des serveurs en tant que vision du monde des animaux de compagnie qui alimente ce comportement. Les conteneurs sont une bonne réponse à ce défi. En effet, ils peuvent être traités comme des objets jetables qui peuvent être reproduits très rapidement pour permettre à nos applications de se développer automatiquement lorsque la demande est élevée, puis de les adapter une fois que la demande se dissipe, ce qui permet de toujours dimensionner correctement notre capacité de calcul et la consommation d’énergie à ce dont nous avons réellement besoin à l’époque, et, éliminant la peur et les maux de tête que l’on doit toujours parcourir à travers le fourré de jungles de billets pour obtenir plus de capacité lorsque nous en avons besoin.
1.4.3.1 Que sont les conteneurs ?
Les conteneurs sont omniprésents dans la discussion sur le cloud. Une bonne définition vient d’Amazon Web Services (AWS):
Les conteneurs sont une méthode de virtualisation du système d’exploitation qui vous permet d’exécuter une application et ses dépendances dans des processus isolés de ressources. Les conteneurs vous permettent de regrouper facilement le code, les configurations et les dépendances d’une application dans des blocs de construction faciles à utiliser qui assurent la cohérence environnementale, l’efficacité opérationnelle, la productivité des développeurs et le contrôle des versions. Les conteneurs peuvent aider à garantir un déploiement rapide, fiable et cohérent des applications, quel que soit l’environnement de déploiement.
Source : AWS, Que sont les conteneurs ? (Https://aws.amazon.com/containers/)
Les conteneurs sont excellents, mais orchestrer et gérer les correctifs de sécurité et les mises à niveau en continu sans temps d’arrêt est un problème très difficile dans la plupart des scénarios, laissant nos applications ouvertes aux vulnérabilités et nous exposant à des risques que nous ne voulons pas prendre.
Cloud Foundry améliore le fonctionnement des conteneurs en les orchestrant automatiquement. Il fait toutes les choses difficiles dont les conteneurs ont besoin pour les garder à jour, corrigés, heureux et sains – et tout cela sans aucun temps d’arrêt. Il existe peu d’autres PaaS basés sur des conteneurs qui peuvent bien faire cela dans une entreprise ou un environnement critique à l’heure actuelle.
Les conteneurs Cloud Foundry sont basés sur des normes. La spécification provient de l’Open Container Initiative (OCI) (https://www.opencontainers.org). L’OCI est un consortium d’organisations hautement visibles telles que Docker, Dell Technologies, Microsoft, IBM, Google, Red Hat, etc. qui servent de gardien de la flamme de la bibliothèque runC que Cloud Foundry utilise comme bibliothèque d’exécution principale du conteneur pour Noeuds basés sur Linux. L’engagement envers cette norme d’interopérabilité des conteneurs par une grande variété d’acteurs permet à Cloud Foundry de faire des choses intéressantes pour tirer parti de la norme et étendre les capacités de la plateforme. Par exemple, Cloud Foundry peut exécuter des images Docker à partir de référentiels Docker, tels que Docker Hub. Pour plus d’informations, voir https://github.com/opencontainers/runc.
Cela permet à Cloud Foundry d’exécuter tout sur les applications Linux et Windows (tout noyau .NET et la plupart des classiques .NET), de charger et d’exécuter des images Docker précuites avec des configurations et des exécutions d’applications spécifiques.
1.5 Qu’est-ce que Pivotal Cloud Foundry?
Pivotal Cloud Foundry ™ ou Pivotal CF ™, communément appelé PCF, est actuellement la principale entreprise PaaS alimentée par Cloud Foundry. De nombreuses entreprises qui composent le Fortune 1000 utilisent Pivotal Cloud Foundry en interne dans le cadre de leur offre de portefeuille cloud. À l’aide de cette distribution Cloud Foundry particulière, ils créent leurs propres applications natives du cloud et migrent les applications existantes afin qu’ils puissent tirer parti de nombreux avantages du passage à un PaaS. C’est en raison de cette pénétration profonde de l’entreprise et de la probabilité plus élevée de rencontrer Pivotal Cloud Foundry dans les limites des entreprises, du gouvernement et des organisations que nous discuterons de certaines des capacités supplémentaires fournies par Pivotal Cloud Foundry au-dessus de la version open source de Cloud Foundry.
Pivotal Cloud Foundry offre une expérience clé en main toujours disponible pour la mise à l’échelle et la mise à jour de PaaS sur des infrastructures multicloud publiques, privées ou hybrides telles que VMware vSphere, Amazon Web Services, Google Cloud Platform, Microsoft Azure et OpenStack.
En tant que distribution commerciale de Cloud Foundry, il fournit plusieurs fonctionnalités supplémentaires importantes et un engagement à prendre en charge le produit auquel les organisations sont habituées par les fournisseurs. Par exemple, Pivotal Cloud Foundry fournit des outils supplémentaires pour simplifier l’installation et l’administration non inclus dans le produit logiciel open source.

Par exemple, si vous souhaitez installer une distribution Cloud Foundry sur votre propre infrastructure, vous devez effectuer les opérations suivantes à un niveau élevé:
- Configurez toutes les dépendances externes, telles qu’un compte IaaS, des équilibreurs de charge externes, des enregistrements DNS et tout composant supplémentaire.
- Créez un manifeste pour déployer un directeur BOSH.
- Déployez le directeur BOSH.
- Créez un manifeste pour déployer Cloud Foundry.
- Déployez Cloud Foundry.
Source : Déploiement de Cloud Foundry sur http://docs.cloudfoundry.org/deploying/index.html
Il s’agit initialement d’un processus manuel qui nécessite une grande expertise BOSH et en ingénierie de plate-forme, bien que tout ingénieur de plate-forme digne de ce nom commence généralement à automatiser une bonne partie de ce processus. Cependant, il peut être très difficile d’obtenir la configuration distribuée d’un grand système composé d’une variété de machines virtuelles multiples, de composants réseau, de calcul, d’accès IaaS, de stockage, de DNS, de certificats SSL, et bien plus encore correctement décrits dans le fichier manifeste que vous doit définir, que BOSH utilise ensuite pour construire la fondation Cloud Foundry. Même pour atteindre la ligne de départ, il faut créer un manifeste pour déployer un directeur BOSH, ce qui peut être difficile si vous n’êtes pas familier avec le fonctionnement interne de BOSH ; un sujet intéressant certes, mais aussi profond et complexe avec une courbe d’apprentissage et un engagement abrupts.
En s’appuyant sur les bases fournies par la version open source de Cloud Foundry (https://github.com/cloudfoundry/cf-release), comme on pourrait s’y attendre, Pivotal Cloud Foundry ajoute de nombreuses fonctionnalités au sommet de la version open source qui ont été pilotées et façonné par les besoins des entreprises, du gouvernement et des organisations pour simplifier l’administration et les opérations quotidiennes de Cloud Foundry.
Sans fournir les détails les plus fins des différences entre les distributions open source et pivot de Cloud Foundry, il y a quelques différences qui méritent d’être soulignées.
Comme mentionné précédemment, une bonne expertise en BOSH est une condition préalable à l’installation de la version open source de Cloud Foundry. Pivotal Cloud Foundry fournit une interface utilisateur Web simplifiée pour l’installation et la gestion de l’installation de Cloud Foundry et de divers composants, tels que CF Application Runtime, et d’autres services tels que RabbitMQ, Redis, MySQL, etc., sous forme de tuiles de service simplifiées. Normalement, chacun aurait besoin de sa propre installation BOSH et de la création de manifeste pour se déployer de manière cohérente – un défi plutôt important s’il est fait manuellement. Cette interface utilisateur est appelée Ops Manager et permet des mises à niveau sans interruption de service pour la plate-forme et les services, ainsi qu’une maintenance simplifiée et des modifications des configurations de déploiement sur lesquelles repose la Fondation Pivotal Cloud Foundry.
Une deuxième différence significative entre les versions open source et Pivotal de Cloud Foundry est centrée sur les développeurs. Apps Manager est une interface utilisateur administrative qui permet aux développeurs d’accéder à de nombreuses fonctionnalités de la CLI Cloud Foundry de manière plus intuitive. Apps Manager fournit un moyen visuel de configurer et de gérer de nombreuses fonctionnalités essentielles nécessaires pour gérer les tenants et aboutissants quotidiens de la gestion de vos applications en termes d’évolutivité, de performances, de paramètres, de services, de journalisation et d’intégrations telles que la mise à l’échelle automatique qui ne sont disponibles qu’avec Pivotal Distribution Cloud Foundry.
La distribution Pivotal Cloud Foundry fournit un support supplémentaire pour les applications natives du cloud via une grande partie de la fonctionnalité NetFlixOSS sous le couvert de Spring Cloud et Spring Cloud Services (SCS). Cela fournit des implémentations de modèles communs qui améliorent la résilience, la facilité de configuration et la haute disponibilité dans les applications que vous concevez et déployez sur Cloud Foundry, y compris la coordination et la découverte des services, les modèles de disjoncteurs pour éviter les temps d’arrêt et d’autres modèles particulièrement utiles pour les microservices. .
Une autre caractéristique notable de la distribution Pivotal est le tableau de bord PCF Metrics, qui présente un accès et des visualisations faciles des événements d’application récents, des mesures et de la journalisation.
1.5.1 Glossaire des composants de Pivotal Cloud Foundry
Les composants Pivotal Cloud Foundry et ce qu’ils font inclus :
- Ops Manager : une interface Web pour installer, configurer, mettre à niveau et faire évoluer Pivotal CF et Pivotal Services
- Apps Manager : une interface Web pour travailler avec Cloud Foundry et gérer les organisations, les espaces, les utilisateurs, les applications, les services, les itinéraires, etc.
- Pivotal Cloud Foundry Metrics: composant de surveillance, d’événement et de journalisation du tableau de bord pour les applications exécutées dans PCF
- Services pivots : services gérés, y compris la mise à l’échelle automatique, MySQL, RabbitMQ, Redis, Spring Cloud Services, etc.
1.5.2 Autres distributions Cloud Foundry et fournisseurs publics
En plus de l’offre commerciale de Pivotal Cloud Foundry, la Cloud Foundry Foundation certifie des fournisseurs de plate-forme supplémentaires pour garantir la cohérence des principaux composants de Cloud Foundry afin d’assurer la portabilité. La certification Cloud Foundry Certified PaaS nécessite des offres certifiées pour utiliser réellement le logiciel publié par les équipes de projet de la Fondation. Pour plus de détails sur les fournisseurs de plateformes certifiées Cloud Foundry, veuillez consulter https://www.cloudfoundry.org/provider-faq/.
Une liste partielle des offres des fournisseurs comprend :
- AppFog de CenturyLink (https://www.ctl.io/appfog/): plateforme de CenturyLink basée sur Cloud Foundry.
- Atos Cloud Foundry (https://atos.net/en/solutions/application-cloudenablement-devops): une Pivotal Cloud Foundry sous licence et gérée commercialement.
- GE Predix (https://www.predix.io/registration/): une offre Internet industrielle de Cloud Foundry pour l’IoT (dispositifs Internet of Things) et d’analyse.
- IBM Cloud (https://www.ibm.com/cloud/): plateforme cloud d’IBM basée sur Cloud Foundry, qui permet d’accéder aux services IBM, y compris Watson. Anciennement appelé IBM Bluemix.
- Pivotal Web Services (https://run.pivotal.io/): Pivotal le Cloud Foundry Pivotal publique. Une version entièrement gérée de Cloud Foundry qui s’exécute sur un cloud public.
- Plateforme SAP HANACloud (https://cloudplatform.sap.com/capabilities/runtimes-containers/cloud-foundry.html): plateforme cloud HANA de SAP basée sur Cloud Foundry, qui donne accès aux services SAP.
- Swisscom Developer Portal (https://developer.swisscom.com/): Application Cloud de Swisscom. Une version entièrement gérée de Cloud Foundry offerte sur un cloud public qui stocke toutes vos données en Suisse.
Une liste complète des fournisseurs de plates-formes certifiées Cloud Foundry et leurs offres peut être consultée à l’ adresse https://www.cloudfoundry.org/how-can-i-try-out-cloud-foundry-2016/ .
1.6 Résumé
Nous avons exploré comment Cloud Foundry simplifie le développement et le déploiement d’applications évolutives hautement disponibles. En se concentrant moins sur les préoccupations opérationnelles et administratives de la plate-forme, les développeurs d’applications peuvent plutôt transférer cet effort en écrivant un meilleur code et en améliorant la valeur des fonctionnalités qui composent l’application.
Nous avons abordé une conception d’application native pour le cloud qui permet aux développeurs de tirer pleinement parti d’une plate-forme en tant que service (PaaS) comme Cloud Foundry. De plus, nous avons constaté que tirer parti de Cloud Foundry ouvre la possibilité de mettre à l’échelle rapidement les applications pour répondre à la demande en pleine augmentation tout en offrant d’autres avantages, tels que des déploiements sans interruption, qui seraient difficiles à réaliser dans un environnement de déploiement de middleware traditionnel.
Enfin, nous avons discuté de certaines différences de haut niveau entre notre distribution open source Cloud Foundry et une distribution commerciale populaire appelée Pivotal Cloud Foundry parmi d’autres offres qui sont généralement disponibles.
2 Chapitre 2. CLI de Cloud Foundry et Gestionnaire d’applications
Dans ce chapitre, nous allons explorer les façons les plus courantes un des développeurs interagit avec l’application Cloud Foundry: la cf Interface ligne de commande (CLI) et le Gestionnaire Apps sur Pivotal Web Services (PWS) Les. Nous allons nous familiariser avec les bases de pousser les applications à Cloud Foundry à la fois le cf CLI et le Gestionnaire Apps, et comment ils se rapportent les uns aux autres.
Plus précisément, nous couvrirons les éléments suivants :
- Création d’un compte PWS
- Installation du cf CLI
- Configuration initiale du cf CLI
- La commande d’aide cf CLI
- Déployer une application dans Cloud Foundry
- Accès au gestionnaire d’applications sur PWS
2.1 Le cf CLI
Presque tous les grands progrès de l’informatique ont commencé à un moment donné dans un terminal. Baigné dans la gloire d’une interface utilisateur à base de texte (UI), les cf CLI émet des commandes en texte tapé par l’utilisateur à un programme invisible en cours d’exécution dans les coulisses de la scène une séquence complexe d’étapes pour exécuter la volonté du développeur. L’interpréteur de ligne de commande, souvent confondu avec l’interface de ligne de commande, est également abrégé en acronyme CLI. Les programmes CLI basés sur terminal sont un outil quotidien commun dans le monde de l’opérateur système, mais souvent moins courant dans le monde des développeurs d’applications. L’essor des environnements de développement intégrés (IDE) tels qu’Eclipse, Visual Studio et IntelliJ en tant qu’endroits où tout le code est écrit et compilé, avec des améliorateurs de productivité tels que des suggestions de code et la saisie semi-automatique, a réduit la nécessité pour les développeurs de descendre au niveau du terminal aussi souvent que leurs racines historiques le leur ont demandé. L’IDE est un excellent outil dans la façon dont il résume les commandes du terminal en les exécutant pour le développeur dans les coulisses.
En fonction de leurs antécédents, une partie importante des développeurs d’applications peut trembler à l’idée d’utiliser une CLI pour déployer leur application. Soyez assuré qu’il existe en effet une belle interface utilisateur pour interagir avec Cloud Foundry sur Pivotal Web Services, appelé Apps Manager. Cependant, l’apprentissage de la cf CLI vous servira extraordinairement bien une fois que vous commencez à l’automatisation de loin le travail du temps de déploiement d’applications avec la cohérence et la facilité à différents environnements de déploiement (appelés espaces dans le langage Cloud Foundry), de bac à sable les tests utilisateurs (UAT), à la mise en scène (pré-production), à la production ou à tout autre nom que vous ou votre organisation les appelez.
Avec cf CLI, vous obtenez :
- CI / CD simplifié
- La possibilité de créer des scripts pour les tests automatisés, le code, la sécurité et les contrôles de conformité
- ZDD (Zero Downtime Deployments), connus sous le nom de déploiements bleu-vert, qui vous donnent un test A / B comme effet secondaire.
- Dépannage approfondi lorsque les choses tournent mal avec votre application ou votre déploiement
- Un ensemble complet de fonctionnalités qu’une interface utilisateur ne peut encapsuler qu’un sous-ensemble sans être trop complexe pour fonctionner de manière simplifiée
Lorsque vous utilisez la version open source de Cloud Foundry, la cf CLI va être l’outil principal de gestion pour le déploiement et la gestion des applications, la gestion des instances de services, des organisations, des espaces, des domaines, des routes, des utilisateurs et des quotas. Si vous utilisez la distribution Pivotal Cloud Foundry, vous bénéficierez de l’utilisation supplémentaire de l’interface utilisateur Apps Manager.
Tout d’abord, nous aurons besoin d’une Cloud Foundry pour travailler et un moyen facile d’accéder à un déploiement Cloud Foundry consiste à utiliser Pivotal Web Services (PWS).
Deuxièmement, nous allons installer la CLI cf et explorer certaines configurations et commandes de base.
Troisièmement, nous proposerons une application de test simple pour comprendre le flux de base du déploiement d’applications dans Cloud Foundry.
Quatrièmement, nous allons explorer le gestionnaire d’applications fourni par PWS.
À la fin, vous aurez les éléments suivants :
- Accès à une fondation Cloud Foundry pour pousser votre code et attacher des services
- Une CLI Cloud Foundry installée
- Accès au gestionnaire d’applications sur PWS
2.2 Qu’est – ce que Pivotal Web Services (PWS)?
Pivotal Web Services (PWS, prononcé P-Dubs), est l’une des plus grandes fondations Pivotal Cloud Foundry en activité. Il est hébergé sur AWS et est une rampe d’accès facile à Cloud Foundry pour les développeurs, car il est accessible au public sur Internet. PWS est une version entièrement gérée de Cloud Foundry qui s’exécute sur un cloud public. Vous pouvez être opérationnel immédiatement avec un abonnement d’essai gratuit, sans avoir besoin d’utiliser une carte de crédit, ce qui en fait une offre exceptionnelle pour les développeurs d’applications qui souhaitent apprendre et se familiariser avec Cloud Foundry et les fonctionnalités supplémentaires fournies par Pivotal Cloud Distribution de fonderie.
Les services Web Pivotal sont disponibles sur Internet à l’adresse https://run.pivotal.io.
Le site Web Pivotal Web Services. © 2017 Pivotal Software, Inc. Tous droits réservés.
Au moment de la rédaction du présent document, l’essai gratuit des services Web Pivotal comprend :
- Crédit de 87 $ US pour l’utilisation de l’application jusqu’à 1 an
- Jusqu’à 2 Go de mémoire à partager entre les instances d’application
- Choix de services de marché gratuits à essayer
- Collaborateurs illimités
2.3 Création d’ un compte PWS
La création d’un compte PWS est un processus simple. Et, une fois que vous aurez accès à PWS, vous pourrez explorer un vaste écosystème de services tiers, tels que les bases de données, la messagerie et les métriques, que les développeurs d’applications peuvent exploiter lors de la création de leurs applications. Avec PWS, vous pouvez déployer, mettre à jour et faire évoluer vos applications comme vous le feriez sur n’importe quel PaaS Cloud Foundry.
2.3.1 Ce que vous obtenez lorsque vous vous inscrivez à PWS
Lorsque vous vous inscrivez pour un compte PWS, un compte utilisateur Cloud Foundry est créé pour vous qui vous donne une fonderie Nuage Org et S rythme. Toutes les fondations Cloud Foundry vous offriront la même chose une fois votre compte utilisateur créé. Nous aborderons en détail les organisations et les espaces dans le chapitre 4 , Utilisateurs, organisations, espaces et rôles . Pour l’instant, considérez les organisations et les espaces comme de simples systèmes d’organisation avec l’organisation au niveau supérieur, sous lesquels vous disposerez de plusieurs espaces, qui sont à peu près équivalents à un environnement de déploiement comme un bac à sable, développement, assurance qualité, mise en scène, prod et ainsi de suite, que l’on trouve dans la plupart des entreprises pour permettre à une application de progresser dans la chaîne des environnements jusqu’à ce qu’ils soient finalement promus en production, où les consommateurs interagiront avec l’application.
2.3.2 Inscription
Commencez par ouvrir https://try.run.pivotal.io/gettingstarted dans votre navigateur Internet. Cela vous amènera directement à l’écran de création de compte PWS pour remplir les informations de base nécessaires pour créer un compte, comme indiqué dans la capture d’écran suivante :
Un e-mail de vérification sera envoyé à votre adresse e-mail qui vous fournira un lien pour créer votre compte PWS :
Lorsque vous êtes prêt à vous connecter, ouvrez https://login.run.pivotal.io/login et il ouvrira la page de connexion, comme suit :
Sélectionnez Pivotal Web Services dans l’ensemble d’applications par défaut que vous obtenez avec votre compte PWS :
Donnez un nom à votre organisation (dans l’exemple suivant, la nôtre s’appelle cf -developers), puis vous verrez l’interface utilisateur du gestionnaire d’applications avec un espace par défaut créé, appelé développement, pour commencer à déployer des applications dans :
2.4 Installation du cf CLI
Pour installer la cf CLI, accédez à https://console.run.pivotal.io/tools. Téléchargez et exécutez le programme d’installation de votre plate-forme.
Vérifiez l’installation en ouvrant une fenêtre Terminale et en tapant cf –version. Avec cela, vous avez maintenant un client Cloud Foundry qui peut communiquer avec n’importe quelle installation Cloud Foundry, y compris PWS.
Remarque
Assurez-vous que la dernière version de l’interface de ligne de commande cf est installée. Il peut y avoir des cas où une version précédemment installée de la CLI cf est déjà présente. Cela causera de la frustration s’il y a eu des changements importants dans l’outil depuis l’installation de la version précédente.
Si vous êtes intéressé par d’autres manières d’installer la cf CLI, il existe quelques possibilités supplémentaires, notamment :
- Téléchargement et installation depuis GitHub
- L’installer à l’aide d’un gestionnaire de packages
Remarque
L’ interface de ligne de commande cf est écrite dans le langage de programmation Go de sorte qu’il s’agit d’une application très performante. Il est distribué comme un binaire autonome sans dépendances externes. Si le code de la CLI cf vous intéresse , vous pouvez le trouver sur https://github.com/cloudfoundry/cli .
2.4.1 Téléchargement et installation depuis GitHub
Depuis Cloud Foundry est un logiciel open source (OSS), vous pouvez télécharger la dernière version de composants tels que le cf CLI de GitHub et les installer directement :
- Accédez à https://github.com/cloudfoundry/cli/releases .
- Téléchargez le programme d’installation de votre plate-forme, tel que macOS X, Windows, Debian ou Red Hat.
Installez la cf CLI en suivant les instructions de votre système d’exploitation :
- Installer cf CLI sur Windows
- Décompressez le fichier .zip.
- Double-cliquez sur le cf CLI exécutable.
- Lorsque vous y êtes invité, cliquez sur Installer, puis sur Fermer.
- Installer cf CLI sur macOS X et Linux
- Ouvrez le .pkg | .deb | Fichier .rpm.
- Suivez l’assistant d’installation du package.
- Lorsque vous y êtes invité, cliquez sur Installer, puis sur Fermer.
2.4.2 Installation à l’aide d’un gestionnaire de packages
Pour les utilisateurs de Mac OS X, vous pouvez utiliser le gestionnaire de packages Homebrew . Factures homebrew lui – même comme le gestionnaire de paquets manquants pour OS X .
Remarque
Vous pouvez trouver Homebrew sur https://brew.sh – il est utile pour bien plus que simplement installer la cf CLI. Il fournit également un moyen facile de simplifier la mise à jour des outils que vous avez installés à l’aide de la commande brew update .
$ brew tap cloudfoundry/tap
$ brew install cf-cli
Pour les distributions Linux basées sur Debian et Ubuntu:
# …first add the Cloud Foundry Foundation public key and package repository to your system$ wget -q -O – https://packages.cloudfoundry.org/debian/cli.cloudfoundry.org.key | sudo apt-key add –
echo”deb http://packages.cloudfoundry.org/debian stable main”| sudo tee /etc/apt/sources.list.d/cloudfoundry-cli.list# …then, update your local package index, then finally install the cf CLI$ sudo apt-get update$ sudo apt-get install cf-cli
Systèmes Enterprise Linux et Fedora (RHEL6 / CentOS6 et plus) :
# …first configure the Cloud Foundry Foundation package repository$ sudo wget -O /etc/yum.repos.d/cloudfoundry-cli.repo https://packages.cloudfoundry.org/fedora/cloudfoundry-cli.repo# …then, install the cf CLI (which will also download and add the public key to your system)$ sudo yum install cf-cli
2.5 Configuration initiale de cf CLI
Après avoir installé le cf CLI, vérifiez qu’il fonctionne correctement en tapant la commande suivante :
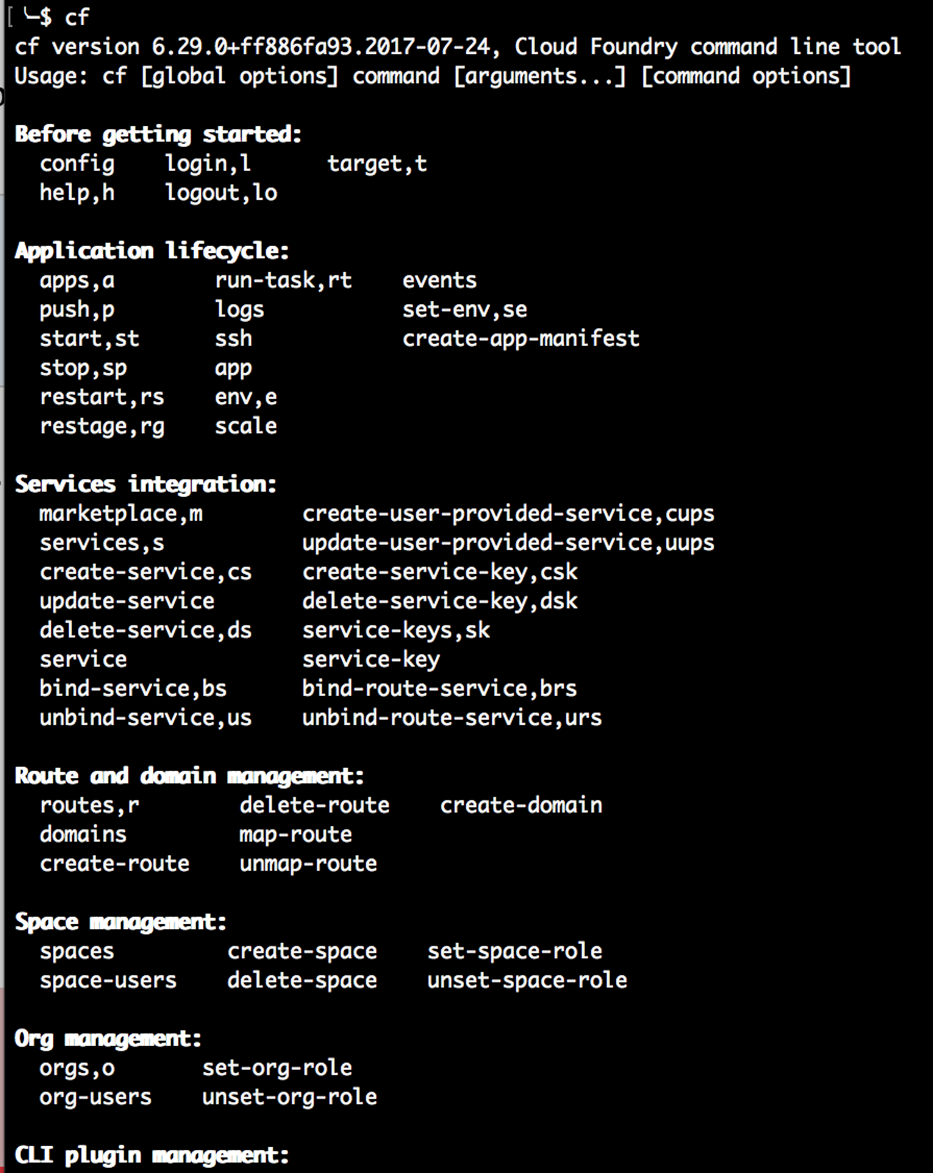
$ cf
Si tout se passe bien, vous devriez voir apparaître le texte d’aide cf CLI, ressemblant à ceci :
Pour voir la version de la CLI cf installée, tapez la commande suivante :
$ cf – version
2.6 La commande d’aide cf CLI
Peut-être la commande la plus utile lors du démarrage avec la CLI cf est la suivante:
$ cf help
Cela vous permet de voir les commandes CLI disponibles et de comprendre leur utilisation et leur syntaxe. La CLI cf vous permet de contrôler une large gamme de commandes qui vous aident à déployer et configurer vos applications sur Cloud Foundry.
2.6.1 Recherche des commandes CLI cf
Comme il y a beaucoup cf commandes CLI disponibles, il peut être un peu écrasante pour trouver la commande que vous êtes vraiment intéressé à un moment donné. Si vous l’avez disponible sur votre système, vous pouvez trouver des commandes contenant des mots clés cf CLI en utilisant grep :
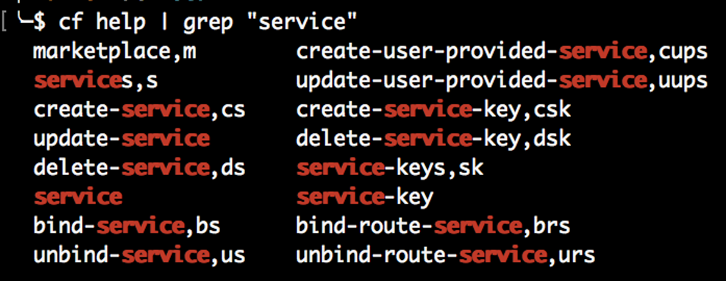
2.6.2 Aide spécifique à la commande
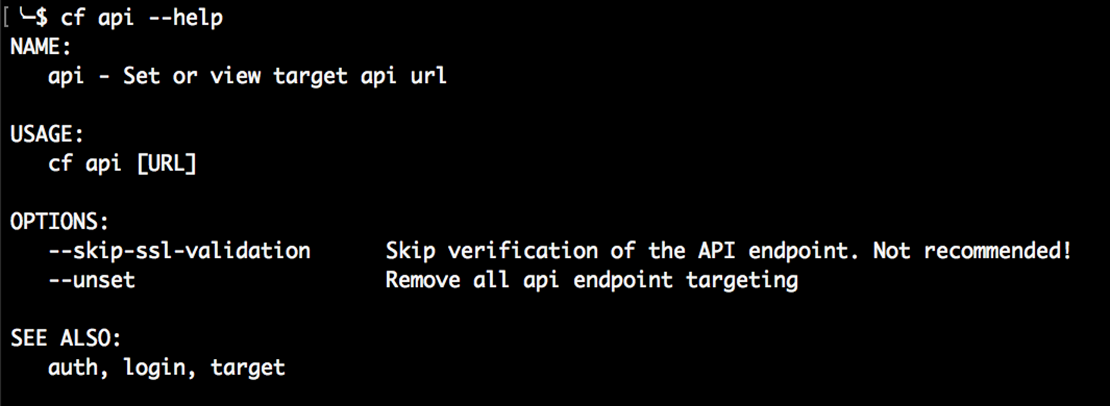
Avec cf CLI, les commandes peuvent avoir des sous-commandes spécifiques sur lesquelles vous pouvez demander de l’aide pour obtenir plus d’informations.
Pour voir la syntaxe cf CLI pour des commandes spécifiques, ajoutez –help ou -h après la commande, comme illustré ici:
Remarque
La documentation officielle de la CF CLI se trouve sur http://docs.cloudfoundry.org/cf-cli . Il comprend des détails importants sur les différentes commandes. De plus, il existe un guide de référence CLI Cloud Foundry officiel qui peut être trouvé à http://cli.cloudfoundry.org/en-US/cf/.
2.7 Déployer une application dans Cloud Foundry
Nous avons maintenant notre compte PWS configuré et fonctionnel, et nous avons également notre CF CLI installé et fonctionnel. Maintenant, nous voulons simplement pousser une application simple pour la voir s’exécuter sur Cloud Foundry. Pour ce faire que , nous devons faire quelques choses :
- Définissez l’instance Cloud Foundry cible afin que notre CLI cf sache où nous poussons nos bits d’application.
- Connectez-vous à l’instance Cloud Foundry ciblée à l’aide de la CLI cf.
- Poussez notre application simple.
2.7.1 Ciblage du point de terminaison Pivotal cf API
Quoi de plus logique que de cibler l’instance Cloud Foundry dans laquelle vous souhaitez déployer votre application ? Pour ce faire, vous devez définir le point de terminaison de l’API Cloud Foundry vers lequel votre cf CLI émettra des commandes. Dans les coulisses, votre cf CLI aura une conversation aller-retour avec l’instance Cloud Foundry à l’aide d’appels RESTful. Et, comme pour tous les appels RESTful, vous devez disposer d’un point de terminaison API avec lequel communiquer.
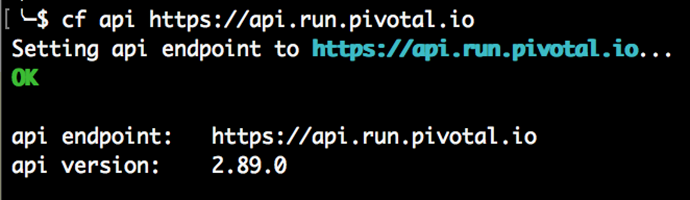
Pour définir le point de terminaison API sur PWS, tapez la commande suivante dans votre terminal :
$ cf api https://api.run.pivotal.io
Vous devriez voir la cible API définie avec les commentaires de la ligne de commande, comme ceci :
Si tel est le cas, vous avez correctement ciblé le point de terminaison de l’API PWS et êtes prêt à vous connecter.
Remarque
Si vous n’utilisez pas PWS ou une instance Cloud Foundry qui possède tous les certificats SSL publics nécessaires en place, il est possible que vous voyiez une erreur de validation SSL lorsque vous essayez de cibler le point de terminaison API. Cela se produit généralement si votre système utilise des certificats auto-signés. Si vous voyez cela, utilisez simplement le –skip ssl -validation drapeau avec l’habituel cf api commande.
2.8 Connexion au point de terminaison de l’API Cloud Foundry
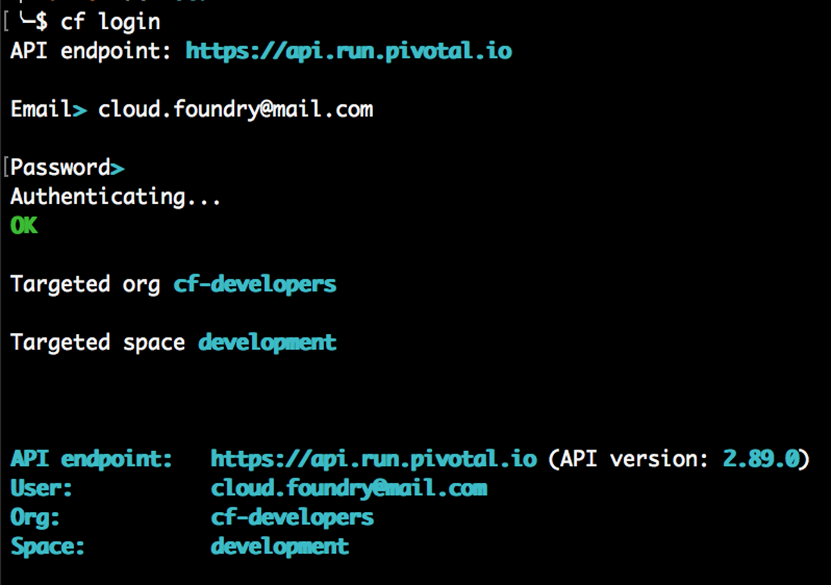
Nous avons indiqué à la CLI cf à quel point de terminaison Cloud Foundry parler avec la commande cf api ; nous allons maintenant utiliser la commande cf login pour s’authentifier auprès de ce point de terminaison API. Pour ce faire, tapez simplement ce qui suit dans votre terminal :
$ cf connexion
À ce stade, il vous indiquera le point de terminaison API de l’instance Cloud Foundry que vous ciblez et vous demandera votre nom d’utilisateur, qui est souvent sous la forme d’une adresse e-mail, et le mot de passe que vous avez défini lors de votre inscription pour votre utilisateur PWS Compte. Une fois que vous avez entré ces informations, vous verrez les cibles définies pour l’organisation et l’espace que vous avez configuré sur votre instance Cloud Foundry chez PWS, comme suit:
Remarque
Nous avons suivi un processus en deux étapes pour vous familiariser avec ce qui se passe dans les coulisses, en ciblant d’abord l’instance Cloud Foundry puis en vous y connectant. Mais il existe un processus simple en une seule étape que vous pouvez utiliser pour faire les deux en même temps à l’avenir: utilisez la commande $ cf login -a https://api.run.pivotal.io .
2.9 Pousser une application simple
Non seulement allons-nous pousser une application simple vers Cloud Foundry, mais nous allons pousser l’application Cloud Foundry la plus simple au monde. Vous ne pouvez pas obtenir plus de base qu’une simple page HTML statique qui affiche le bonjour Hello World !.
Téléchargez l’application avec Git :
$ git clone https://github.com/rickfarmer/worlds-simplest-cloud-foundry-app.git
Remarque
Si vous n’avez pas encore installé Git, vous pouvez télécharger un fichier ZIP de la simple application Cloud Foundry sur https://github.com/rickfarmer/worlds-simplest-cloud-foundry-app/archive/master.zip .
Accédez au répertoire de l’application :
$ cd worlds-simplest-cloud-foundry-app
Poussez l’application vers Cloud Foundry:
$ cf push
L’application sera poussée vers Cloud Foundry, et dans la sortie du terminal, vous verrez l’URL à ouvrir dans votre navigateur afin de visualiser l’application en cours d’exécution, comme suit :
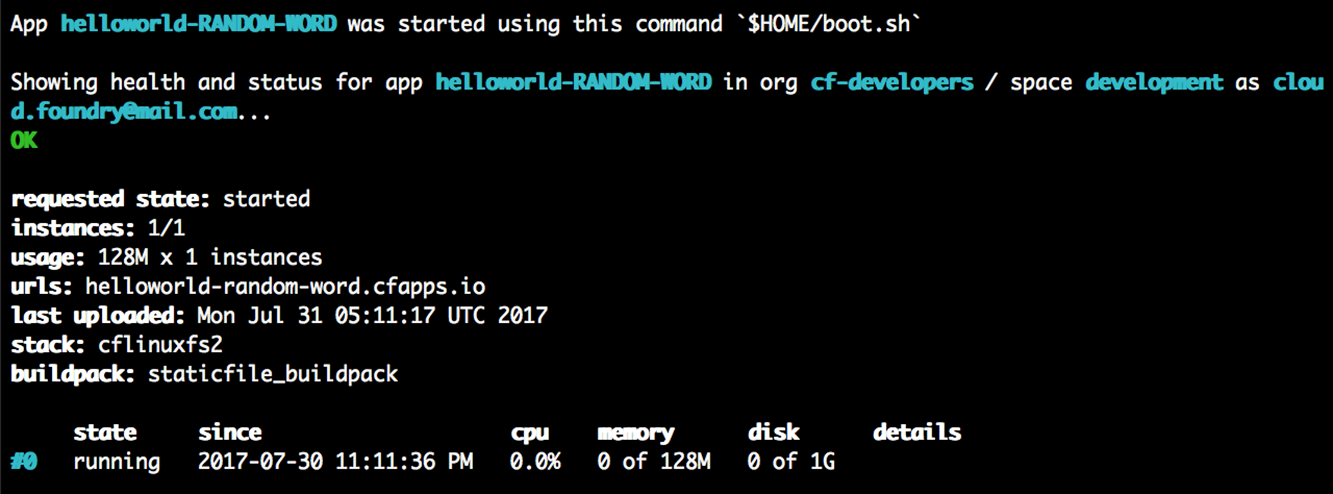
Dans l’exemple de sortie précédent, l’application en cours d’exécution se trouve sur http://helloworld-random-word.cfapps.io .
Votre déploiement sera à une URL aléatoire différente qui est automatiquement générée pour vous afin de vous assurer qu’elle est unique parmi toutes les URL d’application sur PWS.
Remarque
Lorsque vous déployez cette application simple, des mots générés de manière aléatoire seront ajoutés au nom de base de l’application pour créer une URL unique. Dans ce cas, cela se fait car chaque URL sur une instance Cloud Foundry donnée doit être unique pour une application déployée. Par exemple, avec PWS, il est probable que quelqu’un d’autre lisant cet article aura déjà utilisé le nom de l’application comme URL. Pour éviter ce problème, un indicateur a été ajouté à manifest.yml qui effectue la génération aléatoire de l’URL via random-route: true . Plus d’informations sur manifest.yml et les différentes configurations que vous pouvez utiliser avec lui viendront plus tard.
L’ouverture du navigateur révélera l’application Cloud Foundry la plus simple au monde dans toute sa splendeur :
Toutes nos félicitations ! Vous venez de déployer une application sur Cloud Foundry.
2.10 Accès au gestionnaire d’applications sur PWS
Qu’est-ce que Cloud Foundry Apps Manager ?
- Une interface Web pour gérer les organisations, les espaces, les applications et d’autres paramètres
- Il offre un sous-ensemble des fonctionnalités de gestion disponibles via l’interface de ligne de commande cf
- Il vous offre un marché de services que vous pouvez attacher et exploiter dans le développement de votre application
Rappelez-vous qu’après vous être inscrit au compte PWS et vous y être connecté, nous avons eu un aperçu de l’interface utilisateur d’Apps Manager en cours d’exécution sur https://console.run.pivotal.io. Maintenant, avec une application simple déployée, vous pouvez voir l’application nommée hello world-RANDOM-WORD s’exécuter correctement dans le gestionnaire d’applications.
Les informations incluent l’état, le nombre d’instances en cours d’exécution, la dernière fois que l’application a été poussée et l’itinéraire, le terme de Cloud Foundry pour l’URL de l’application:
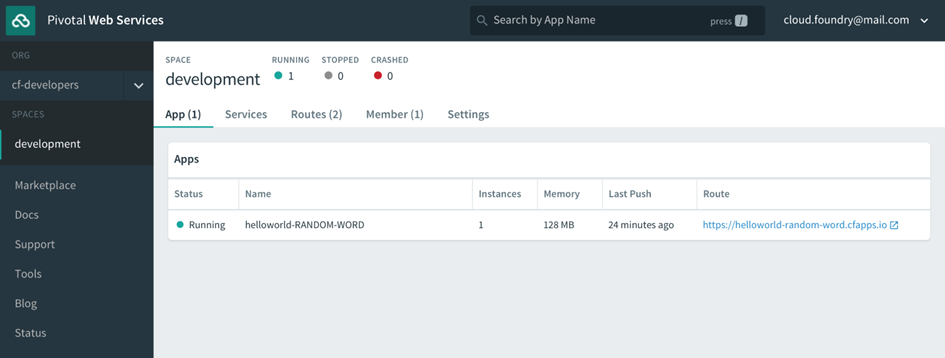
Le gestionnaire d’applications nous donne un sous-ensemble des fonctionnalités de la CLI cf. Dans les coulisses, il parle au même point de terminaison RESTful avec lequel le cf CLI parle et fait en grande partie le même travail pour nous. Nous ne passons beaucoup de temps sur le Gestionnaire Apps à ce stade, car il ne s’applique qu’à Pivotal Cloud Foundry, mais il est une interface standard pour l’affichage de certaines fonctionnalités disponibles dans la cf CLI, et pour la gestion et le déploiement d’applications dans un moyen visuel pour ceux qui peuvent être moins à l’aise avec la ligne de commande.
Remarque
La documentation officielle d’Apps Manager est disponible à l’ adresse http://docs.run.pivotal.io/console .
2.11 Résumé
Dans ce chapitre, nous avons abordé le gestionnaire d’applications qui fournit une interface utilisateur conviviale pour les paramètres et commandes communs liés au déploiement et à la gestion des applications et des services utilisés dans Cloud Foundry. Nous avons également pris notre premier coup d’œil à la cf CLI et trouvé qu’il prend en charge un large éventail de commandes pour la gestion des applications et des activités connexes dans Cloud Foundry.
La configuration initiale de la cf CLI est nécessaire avant d’effectuer la plupart des tâches de gestion liées au développement sur le Cloud Foundry. Nous avons constaté que la cf CLI est un outil qui peut être utilisé avec l’une des différentes distributions de Cloud Foundry, y compris Cloud Foundry déploiements open source, Pivotal Web Services, Pivotal Cloud Foundry et PCF Dev (utilisé pour le développement local et déploiement). Et cf CLI est utilisé avec d’autres public Cloud Foundry variantes, telles que IBM Cloud (anciennement Bluemix), GE Predix, et plus encore.
3 Chapitre 3. Premiers pas avec PCF Dev
Le développement TDD ou piloté par les tests est essentiel aux 3 piliers d’un grand développement logiciel :
- Développement piloté par les tests (TDD)
- Intégration et déploiement continus (CI / CD)
- Programmation en binôme
Cependant, pour exécuter la boucle TDD rapidement et pour que TDD en vaille la peine à partir du moment où les mains sont placées sur les clés, les développeurs préfèrent raccourcir le cycle de déploiement de code autant que possible. Tout en équilibrant la nécessité d’exécuter leur code par rapport à un environnement en cours d’exécution local qui imite de manière fiable l’environnement de production, le code finira par s’exécuter. Et, avec le moins de sauts possible sur des sites potentiellement latents ou, dans des installations hautement sécurisées, une connexion Internet inexistante. Et, tout aussi important, pour éviter une grande partie des ennuis et du labeur qui découlent des différences entre ces environnements locaux où le code est développé et l’environnement de production à partir duquel le code servira finalement le monde.
Entrez PCF Dev.
PCF Dev vous permet de pousser des applications vers PCF dès le premier jour de votre projet.
Dans ce chapitre, nous explorerons comment installer PCF Dev de Pivotal pour développer des applications localement. Nous couvrirons les bases de PCF Dev et où il s’intègre dans votre ceinture d’outils en tant que développeur d’applications Cloud Foundry. De plus, PCF Dev est un autre moyen facile de vous présenter au développement d’applications Cloud Foundry ou d’évaluer PCF sans avoir à installer une fondation Cloud Foundry complète. Peut-être, plus important encore, PCF Dev vous permet également d’itérer plus rapidement lors du développement d’applications CF. Vous permettant d’utiliser confortablement TDD dans le cadre de votre flux de travail. Et, si vous êtes déjà développeur CF, PCF Dev peut être une alternative plus simple et plus rapide à BOSH-lite, qui est une autre voie vers le développement de Cloud Foundry qui s’adresse davantage aux ingénieurs de plate-forme, aux administrateurs et aux opérateurs, en particulier si vous ne le faites pas. t besoin d’utiliser BOSH pour déployer des produits supplémentaires au-delà de Cloud Foundry. Et, PCF Dev est un moyen facile de démarrer avec Cloud Foundry avec un minimum d’agitation.
Dans ce chapitre, nous couvrirons les sujets suivants :
- Une brève introduction au TDD
- Pourquoi PCF Dev?
- Exigences techniques PCF
- 20 minutes pour cf push avec PCF Dev
- Alternatives à PCF Dev
3.1 Une brève introduction au TDD
Souvent, en tant que développeurs, nous préférons exécuter nos applications localement pendant que nous les développons. C’est un gain de temps énorme dans de nombreux cas, car nous rincons et répétons les mises à jour ou le débogage tout en exécutant notre code à travers le cycle TDD bien usé de rouge, vert, itéré. Cela signifie que nous commençons par créer un nouveau test qui prouve un aspect d’une fonctionnalité que nous voulons que notre code ait avant que le code de fonctionnalité soit créé, de sorte que le test, lorsqu’il est exécuté, échoue (devient rouge). Nous créons ensuite le code de fonctionnalité réel pour satisfaire le test précédemment écrit qui permet au test de réussir (passer au vert), suivi d’itérations répétées de débogage du code de fonctionnalité ou de création de tests supplémentaires à l’aide du même flux de travail. Le bon effet secondaire de TDD est que, non seulement nous nous retrouvons avec du code qui fonctionne comme prévu – respectant la promesse de valeur que la fonction incarne; mais, nous avons également des tests clairement écrits qui peuvent servir de documentation pour chaque fonctionnalité.
Avec TDD, nous obtenons du code prouvable qui a de nombreux tests qui peuvent être exécutés de manière automatisée chaque fois que nous déployons et exécutons notre dernier code de fonctionnalité. Le résultat le plus important de la création de code prouvable est qu’il nous permet d’apporter des ajouts et des modifications à une base de code existante sans craindre inquiétant de casser les fonctionnalités qui fonctionnent déjà bien, provoquant des échecs difficiles à éliminer et à corriger. La méthodologie TDD crée une couverture contre la régression de la base de code dans un état de bogue involontaire. Essentiellement, lors de l’automatisation de l’exécution du test, nous avons une base de référence vivante de code prouvable qui nous permet d’apporter des modifications en toute confiance, sans craindre que nous ayons accidentellement cassé quelque chose d’autre, quelque part ailleurs dans le code et sans avoir la moindre idée de ce qui s’est mal passé sans creuser profondément dans les recoins d’une base de code qui a peut-être été écrite par quelqu’un d’autre il y a longtemps.
Fait intéressant, il y a cette montée sismique révolutionnaire de DevOps en cours qui remodèle la façon dont les opérateurs de systèmes, les ingénieurs de plate-forme et les administrateurs abordent la construction des infrastructures. Avec DevOps, ils développent maintenant l’infrastructure sous forme de code en utilisant les mêmes processus et techniques reproductibles, idempotents, pilotés par les tests et axés sur l’automatisation CI / CD que les développeurs d’applications sont les praticiens depuis des décennies.
Cela change le monde informatique de manière fondamentale, affectant les processus et les pratiques en place depuis l’aube de l’époque Unix le 1er janvier 1970. Maintenant, avec l’adoption de ces techniques de développement, les rôles opérationnels traditionnels se transforment en ceux de la fiabilité de la plate-forme Des ingénieurs (PRE) hyperfocalisés et orientés vers l’augmentation de la fiabilité de ces plateformes et infrastructures extrêmement complexes qui sont l’axe autour duquel tourne le monde numérique moderne. Pour ce faire, ils créent les mêmes couvertures contre la régression et réduisent les risques tout en offrant une valeur commerciale, comme le fait toute équipe de développement logiciel agile. En utilisant les trois piliers pour favoriser l’excellence opérationnelle et la résilience face au changement.
Cette approche même est profondément encapsulée dans l’installation de Cloud Foundry et les processus du jour 1. Par exemple, il existe des pipelines CI / CD qui, non seulement installent Cloud Foundry sur un IaaS donné; mais qui génèrent l’infrastructure elle-même dans une architecture de référence normalisée, créant les réseaux, renforçant la sécurité, provisionnant la capacité de la mémoire au CPU aux banques de données, et bien plus encore. De plus, il existe des pipelines qui automatisent également les processus de gestion et de maintenance en cours de Cloud Foundry jour 2 – en cours d’exécution en continu pour effectuer des mises à niveau et des correctifs automatisés sans temps d’arrêt, sauvegardant des fondations Cloud Foundry entières, l’intégration des utilisateurs, des organisations et des espaces dans une fondation donnée, repavage de la fondation, rotation régulière des informations d’identification et bien d’autres encore. Et, tous ces pipelines sont définis dans des fichiers texte yaml qui sont écrits comme tout autre code, qui est versionné et archivé dans un référentiel de code – exactement comme le ferait n’importe quel développeur d’application.
Remarque
Tous les pipelines open source Pivotal Cloud Foundry sont disponibles sur: https://github.com/pivotal-cf/pcf-pipelines et https://github.com/pivotalservices/concourse-pipeline-samples .
3.2 Pourquoi PCF Dev?
Un déploiement Cloud Foundry typique, communément appelé fondation Cloud Foundry , peut exiger de l’infrastructure sur laquelle il doit fonctionner. Cloud Foundry nécessite un ensemble important de ressources de l’infrastructure sous-jacente en tant que service (IaaS) sur laquelle il est déployé, par exemple, vSphere, AWS, Azure, GCP, etc. De plus, Cloud Foundry nécessite une grande expertise en ingénierie de plate-forme spécialisée pour le déployer et le configurer correctement avant que la première commande cf push puisse même être émise par une équipe de développement d’applications.
Les ressources typiques à large spectre pour les déploiements Cloud Foundry courants peuvent être lourdes:
Pivotal Cloud Foundry requiert au minimum les éléments suivants:
- Plus de 50 Go de mémoire
- Plus de 100 Go d’espace disque
- 2 à 6 cœurs de processeur physiques au minimum
- Plus d’une heure à déployer (uniquement lorsque l’infrastructure et les autres exigences sont prêtes)
Open Source Cloud Foundry nécessite au minimum les éléments suivants:
- Plus de 48 Go de mémoire
- Plus de 50 Go d’espace disque
- 2 à 6 cœurs de processeur physiques au minimum
- Plus d’une heure à déployer (uniquement lorsque l’infrastructure et les autres exigences sont prêtes)
Et ces déploiements sont considérés comme des installations jouets car ils ne prennent pas en compte les stratégies de haute disponibilité ( HA ) et de reprise après sinistre ( DR ).
Notez que les déploiements Open Source Cloud Foundry peuvent être très variables selon les composants que l’on déploie et la capacité souhaitée. Par exemple, un déploiement Cloud Foundry donné peut ne pas inclure de services communs, tels que Redis, MySQL et RabbitMQ, que les développeurs d’applications trouvent utiles.
De toute évidence, une solution doit être disponible pour permettre aux développeurs d’exécuter Cloud Foundry sur une seule machine avec des spécifications matérielles beaucoup plus faibles, ce qui permet également une boucle TDD serrée tout en réduisant les barrières à l’entrée dans le jeu Cloud Foundry avec une complexité de déploiement réduite.
Même aux premiers jours du développement de Cloud Foundry, il était sincèrement reconnu qu’il était difficile d’exécuter et d’administrer une fondation à part entière sur l’ordinateur d’ un développeur d’application typique , et qu’une solution était nécessaire pour permettre la boucle TDD la plus rapide possible pour les développeurs. car ils ont créé du code. Et c’est ainsi qu’au départ, il y avait une petite version locale soignée de Cloud Foundry appelée MicroCF ou Micro Cloud Foundry.
Micro Cloud Foundry a fait un travail raisonnable en tant que remplaçant pour une fondation Cloud Foundry à part entière. Il y avait des incompatibilités qui empêcheraient une application développée de l’utiliser de fonctionner de manière transparente une fois déployée sur la fondation de production quelque part dans le cloud. Il était assez bon par rapport à l’exécution d’un middleware local, tel que Web Logic Server (WLS) ou WebSphere, où les développeurs supposaient souvent que des deltas importants existeraient entre les déploiements locaux et les déploiements de production.
Mais il y avait des opportunités pour la communauté Cloud Foundry d’améliorer les outils dont les développeurs d’applications avaient besoin. En vérité, MicroCF était relativement complexe à déployer, nécessitant l’installation et l’exécution de Ruby et d’autres dépendances. Il y avait d’autres limitations que l’on pourrait rencontrer qui rendaient un peu frustrant de développer contre MicroCF à certaines occasions. Ici, nous trouvons un modèle dont nous pouvons apprendre. Il existe d’excellentes pratiques de développement que nous pouvons adopter pour nos applications auprès des développeurs et des équipes qui créent et écrivent le code de Cloud Foundry et de ses outils.
Ils sont une étude de cas intéressante car ils mangent leur propre nourriture pour chien. En substance, ils réitèrent et réévaluent toujours l’état actuel de ce qu’ils créent dans le contexte de la réalité dans laquelle le produit fonctionne. Cette boucle de rétroaction informe des améliorations à apporter lors de la prochaine itération des fonctionnalités. Tout comme la boucle de rétroaction du TDD – rouge, vert, itérer. Nous constaterons que des boucles de rétroaction courtes et itératives font toute la différence dans la création de fonctionnalités et de produits logiciels de manière à faible risque, ce qui encourage l’approche spartiate de ne créer que ce qui est minimalement nécessaire pour fournir une valeur commerciale définie. Également connu sous le nom de MVP ou produit minimal viable. Cette approche garantit que nous suivons les principes lean du développement logiciel.
Remarque
Ce n’est pas une coïncidence si l’équipe qui construit le produit Cloud Foundry chez Pivotal suit la philosophie de manger votre propre nourriture pour chien en utilisant son propre outillage pour révéler des façons de l’améliorer. Ce concept est né avec l’exécutif visionnaire Paul Maritz chez Microsoft dans les années 1980. M. Maritz deviendrait plus tard le PDG de Pivotal Software lorsque l’entreprise a été initialement séparée et financée par EMC (qui fait désormais partie de Dell Technologies), VMware et General Electric (GE).
En fin de compte, MicroCF a été déconseillé car les composants Cloud Foundry ont commencé à être réécrits dans le langage Go à partir de leur Ruby d’origine. L’équipe de développement de Cloud Foundry a découvert que Ruby, qui n’est pas un langage compilé au niveau des systèmes, s’est fissuré à grande échelle sous les pressions d’un système complexe de l’ordre de Cloud Foundry, qui fait tourner de nombreuses machines virtuelles apportant de nombreuses complexités au niveau des systèmes. Éléments entrelacés cachés sous les couvertures. Le langage Go est un langage compilé de niveau système plus récent créé par Google qui a le potentiel d’être utilisé à la place d’autres langages de systèmes populaires tels que C et C ++ tout en corrigeant certaines faiblesses actuelles présentes dans ces langages.
L’équipe de développement de Cloud Foundry a tiré parti de l’avènement de Go et du concept de réévaluation continue de l’état actuel pour créer une boucle de rétroaction des opportunités d’apprentissage continu et d’expérimentation. En pratique, cela devient un microcosme d’un cycle vertueux qui se produit de manière itérative tout le temps lors du couplage et de l’écriture de tests dans le cadre des 3 piliers d’un grand développement logiciel.
Remarque
Pour en savoir plus sur la langue Go, voir: https://golang.org.
Une fois MicroCF disparu, l’écart a été plus ou moins comblé par une solution appelée BOSH-lite, dont nous parlerons brièvement plus loin dans ce chapitre.
Remarque
Saviez-vous que Cloud Foundry a un grenier ? C’est un endroit où tout l’ancien code disparaît lorsqu’il est retiré du service. Il y a de nombreux jalons historiques et des parties intéressantes de l’histoire de Cloud Foundry qui sont mises dans une sorte de boneyard ouvert au public pour lecture. Le Cloud Foundry Attic peut être trouvé à: https://github.com/cloudfoundry-attic/ et peut-être le code le plus intéressant est le projet VCAP, qui représentait la plate-forme d’application cloud de VMware, qui est la version originale de la datation de Cloud Foundry retour vers 2009. VCAP peut être trouvé à: https://github.com/cloudfoundry-attic/vcap .
La bonne nouvelle est que votre timing pour commencer le développement local de Cloud Foundry ne pourrait pas être meilleur ! Il existe maintenant une excellente solution appelée PCF Dev créée par Pivotal, qui peut être trouvée sur : https://pivotal.io/pcf-dev. Vous pouvez développer localement contre PCF Dev tout en offrant une expérience de développement similaire à celle utilisée par Pivotal Web Services (PWS) que nous avons utilisée précédemment. Et, il ne nécessite que 3 Go à 6 Go de mémoire pour être libre. Comparez cela avec les exigences minimales mentionnées précédemment des déploiements Pivotal Cloud Foundry et Open Source Cloud Foundry:
Pivotal Cloud Foundry requiert au minimum les éléments suivants :
- 3 Go de mémoire sont répertoriés comme une exigence ; mais, en pratique, vous aurez besoin d’au moins 8 Go (16 Go recommandés) sur votre machine
- 20 Go d’espace disque
- 1 cœur de processeur physique
- Environ 10-20 minutes à déployer (une fois que vous avez les pré-requis en place)
Environ 10 à 20 minutes pour déployer PCF Dev est impressionnant compte tenu de la complexité de Cloud Foundry. Nous mettrons cela à l’épreuve sous peu.
Et, en ce qui concerne la parité de l’environnement de production, Pivotal fait une déclaration claire : si une application s’exécute sur PCF Dev, elle s’exécute sur PCF sans aucune modification dans presque tous les cas – c’est un autre énorme avantage de PCF Dev en tant que solution de rêve pour les développeurs d’applications. Développement local. En effet, il utilise les mêmes composants sous le capot qu’une fondation Cloud Foundry complète.
3.2.1 Comparaison de PCF Dev avec Pivotal Cloud Foundry
Pour voir la profondeur de PCF Dev par rapport à PCF et CF, Pivotal maintient une liste de comparaison. Vous pouvez trouver la dernière déclaration de compatibilité pour PCF Dev par Pivotal, ainsi qu’une comparaison complète des fonctionnalités sur: https://docs.pivotal.io/pcf-dev/index.html#comparison-to-pcf .
| PCF Dev | PCF | CF | |
| Espace requis | 20 Go | 100 Go + | 50 Go + |
| Mémoire requise | 3 Go | 50 Go + | variable |
| Déploiement | cf dev start | Gestionnaire des opérations | bosh create-env |
| Estimation du temps-to deploy | 10 minutes | Heure + | Heure + |
| Services prêts à l’emploi | Redis
MySQL RabbitMQ |
Redis
MySQL RabbitMQ GemFire |
N / A |
| PAS | ✓ | ✓ | ✓ |
| Journalisation / métriques | ✓ | ✓ | ✓ |
| Acheminement | ✓ | ✓ | ✓ |
| Compatible avec CF CLI | ✓ | ✓ | ✓ |
| Déployer des applications avec n’importe quel buildpack pris en charge | ✓ | ✓ | ✓ |
| Prend en charge la mutualisation | ✓ | ✓ | ✓ |
| Assistance: Diego | ✓ | ✓ | ✓ |
| Prise en charge de Docker | ✓ | ✓ | ✓ |
| Utilisateur- fournis services | ✓ | ✓ | ✓ |
| Haute disponibilité | ✓ | ✓ | |
| Intégration avec une autorisation tierce | ✓ | ✓ | |
| Directeur BOSH
(Autrement dit, peut effectuer des déploiements BOSH supplémentaires) |
✓ | ✓ | |
| Opérations du cycle de vie du deuxième jour
(Par exemple, mises à niveau continues, correctifs de sécurité) |
✓ | ✓ | |
| Gestionnaire des opérations | ✓ | ||
| Gestionnaire d’applications | ✓ | ✓ | |
| Support de tuile | ✓ | ||
| Les développeurs ont un accès de niveau racine à travers le cluster | ✓ | ||
| pré – provisionné | ✓ | ||
| Ne dépend pas de BOSH | ✓ |
Tableau de comparaison des fonctionnalités © 2017 Pivotal Software, Inc. Tous droits réservés — Reproduit avec permission
Pour les développeurs d’applications Cloud Foundry, quelques éléments supplémentaires ressortent de cette liste à propos de PCF Dev :
- Apps Manager est inclus, ce qui vous offre une belle interface utilisateur basée sur le Web pour interagir avec Pivotal Cloud Foundry pour le déploiement et la gestion de vos applications.
- Redis, MySQL et RabbitMQ sont inclus en tant que services par défaut contre lesquels vous pouvez écrire des applications.
- Le support Docker est inclus.
- BOSH n’est pas inclus, ce qui signifie que vous n’avez pas toutes les capacités d’exploitation de la plate-forme qui font de Cloud Foundry l’environnement de production hautement gérable et hautement disponible qui ne tombe pas facilement. Soyez donc particulièrement prudent, PCF Dev n’est vraiment que pour le développement. Ne dépendez pas de lui pour les charges de travail importantes, telles que les applications de production. Avec PCF Dev, les garde-corps et les pare-chocs de sécurité sont retirés afin de réduire le déploiement pour fonctionner sur une seule machine virtuelle.
3.3 Exigences techniques P CF Dev
Pour installer et exécuter PCF Dev, il y a peu de prérequis :
- La CLI cf doit être installée; voir le chapitre 2 , Cloud Foundry CLI et Apps Manager .
- Une version actuelle de VirtualBox doit être installée. La dernière distribution d’installation et les instructions pour votre système d’exploitation sont disponibles sur : https://www.virtualbox.org/wiki/Downloads.
- Une connexion Internet pour résoudre automatiquement les URL génériques en PCF Dev.
Remarque
La capacité de résoudre le DNS générique est une nécessité fondamentale pour que la magie Cloud Foundry fonctionne. Si vous vous attendez à être dans un endroit où l’accès à Internet n’est pas disponible, vous pouvez configurer un serveur DNS local sur votre machine locale PCF Dev pour gérer la résolution DNS générique. En tant que telle, l’option hors ligne nécessite une configuration supplémentaire. Les détails d’une configuration de résolution DNS hors ligne utilisant DNSmasq ( http://www.thekelleys.org.uk/dnsmasq/doc.html ) pour OS X et Ubuntu ou Acrylic pour Windows peuvent être trouvés à l’ adresse : https: //docs.pivotal .io / pcf-dev / work-offline.html . Pour Ubuntu, des détails supplémentaires sur la configuration de DNSmasq peuvent être trouvés sur le blog de LeaseWeb Labs à: https://www.leaseweb.com/labs/2013/08/wildcard-dns-ubuntu-hosts-file-using-dnsmasq/ .
3.4 20 minutes pour cf push avec PCF Dev
Une priorité a été accordée à la réduction de la complexité d’une installation Cloud Foundry en ce qui concerne PCF Dev. PCF Dev démarre en tant que plug-in cf CLI téléchargé à partir de PivNet qui étend les capacités de la CF cf précédemment installée sur votre système. Les 10 à 20 minutes qui vous séparent de votre première poussée cf locale dépendent fortement de la vitesse de votre connexion Internet, car la première fois que PCF Dev est démarré, il télécharge une appliance virtuelle de 4 Go qui s’installe en tant qu’image virtuelle de 20 Go dans l’application VirtualBox s’exécutant sur la machine locale.
3.4.1 Installation de PCF Dev
Utilisez les étapes suivantes pour installer PCF Dev sur votre ordinateur local :
- Ouvrez l’URL de PCF Dev sur PivNet à l’aide de : https://network.pivotal.io/products/pcfdev.
- Téléchargez la dernière version du plug-in PCF Dev CLI pour votre système d’exploitation, qui sera au format suivant :
pcfdev-VERSION-PLATFORM.zip
- Décompressez le fichier ZIP :
$ unzip pcfdev-VERSION-osx.zip
- Accédez au dossier dans lequel il a été décompressé à l’aide de PowerShell (Windows) ou d’un terminal Unix (OS X ou Linux).
- Exécutez le binaire PCF Dev. Cela installera le plug-in PCF Dev pour l’interface de ligne de commande cf. Une fois réussie l’installation, vous verrez un message comme cela :
Plugin successfully installed. Current version: X.XX.X. For more info run: cf dev help
- Vérifiez que le plug-in PCF Dev fonctionne correctement en exécutant la commande cf dev help :
$ cf dev help
NAME:
dev – Control PCF Dev VMs running on your workstation
ALIAS:
pcfdev
USAGE:
cf dev SUBCOMMAND
SUBCOMMANDS:
start Start the PCF Dev VM. When creating a VM, http proxy env vars are respected.
…
- Démarrez PCF Dev en exécutant la commande cf dev start :
$ cf dev start
Remarque
Si vous rencontrez des problèmes lors de l’exécution de la commande cf dev start . Il peut s’agir d’un problème de proxy Internet qui vous empêche de télécharger le fichier OVA PCF Dev à distance à partir de PivNet , ou que la version de votre plug-in de développement PCF ne correspond pas à la dernière version disponible. Le fichier OVA est l’appliance virtuelle qui s’exécutera sur notre machine locale dans VirtualBox, nous en aurons donc besoin pour continuer avec PCF Dev.
Le plug-in PCF Dev CLI doit pouvoir se connecter à PivNet à l’ adresse : https://network.pivotal.io pour télécharger le fichier OVA. Vous pouvez tester si votre machine peut télécharger le fichier à l’aide d’une commande curl pour obtenir une réponse de PivNet en utilisant:
$ curl https: //network.pivotal.iodf
- Si vous ne récupérez pas une réponse réussie, il est probable que votre variable d’environnement local, https_proxy , n’est pas définie pour utiliser un serveur proxy qui vous permettra d’accéder à https://network.pivotal.io à partir de votre ordinateur local. À titre de comparaison, essayez d’obtenir avec succès la page d’exemple Internet universel en utilisant curl https://example.com pour voir si certains sites sont bloqués alors que d’autres ne le sont pas. Si le proxy Internet est le problème, vous souhaiterez obtenir un paramètre de proxy qui autorise le trafic vers PivNet ou vous connecter à un réseau sans proxy.
- S’il n’y a pas de problème avec le proxy Internet bloquant le trafic vers PivNet , assurez-vous que vous utilisez les dernières versions de cf CLI et du plug-in cf CLI PCF Dev de PivNet . Des différences dans les versions cf et plug-in installées peuvent parfois provoquer des problèmes d’incompatibilité.
- S’il s’agit des dernières versions des deux, et que vous avez exclu qu’il ne s’agissait pas d’un problème de proxy Internet – vous pouvez télécharger manuellement le fichier OVA de PCF Dev à partir de https://network.pivotal.io/products/pcfdev#/ releases / 1622 qui correspond à votre version du plug-in de développement PCF, puis exécutez-le manuellement. Pour ce faire, les étapes sont les suivantes:
- Trouvez la version OVA correspondante pour votre plug-in en exécutant la commande cf dev version . Cela vous donnera des informations similaires à PCF Dev version 0.28.0 (CLI: 5cda315, OVA: 0.547.0).
- Téléchargez manuellement la version du fichier OVA répertoriée à partir de PivNet à l’ adresse : https://network.pivotal.io/products/pcfdev#/releases/1622.
- Enfin, exécutez la commande cf dev import / path / to / ova pour installer votre environnement PCF Dev. Si tout se passe bien, vous pouvez maintenant continuer en utilisant cf dev start .
- La première fois que vous démarrez PCF Dev, il peut vous inviter à vous connecter à votre compte PivNet :
Please sign in with your Pivotal Network account.
Need an account? Join Pivotal Network: https://network.pivotal.io
Email>
Password>
- Une fois connecté, la première fois que vous serez invité à accepter le contrat de licence utilisateur final (CLUF) ; si vous acceptez les conditions, vous pouvez appuyer sur la touche Y pour continuer :
PRE-RELEASE END USER LICENSE AGREEMENT
This Pre-Release End User License Agreement (“Pre-Release EULA”) is an agreement to license Pre-Release Software between Licensee and Pivotal Software, Inc. (“Pivotal”). Unless otherwise set forth in a signed agreement between Pivotal and Licensee, by downloading, installing or using Pre-Release
Software, Licensee is agreeing to these terms.
…
[, ] Scroll up
[, ] Scroll down
[y] Accept
[n] Do Not Accept
- À ce stade, la première fois que vous exécutez la commande cf dev start , le dispositif virtuel est téléchargé, installé et exécuté à l’aide de l’application VirtualBox. Vous verrez une activité similaire à la suivante car elle exécute les étapes nécessaires pour démarrer PCF Dev et prêt à partir pour le déploiement de vos applications:
Downloading VM…
Progress: |====================>| 100%
VM downloaded.
Allocating 4096 MB out of 16384 MB total system memory (5565 MB free).
Importing VM…
Starting VM…
Provisioning VM…
Waiting for services to start…
7 out of 58 running
7 out of 58 running
7 out of 58 running
7 out of 58 running
40 out of 58 running
56 out of 58 running
58 out of 58 running
is now running.
To begin using PCF Dev, please run:
cf login -a https://api.local.pcfdev.io –skip-ssl-validation
Apps Manager URL: https://apps.local.pcfdev.io
Admin user => Email: admin / Password: admin
Regular user => Email: user / Password: pass
cf dev start 69.83s user 180.36s system 5% cpu 0:10:35.59 total
Une fois installé et exécuté, PCF Dev affichera la connexion et d’autres informations pertinentes telles que les URL à utiliser. Assurez-vous de prendre note des informations. Vous en aurez besoin plus tard pour continuer à travailler avec PCF Dev.
3.4.2 Explorer PCF Dev
Une fois l’installation de PCF Dev terminée, nous pouvons maintenant nous y connecter et la traiter comme n’importe quelle autre fondation Cloud Foundry sur laquelle nous déploierions une application.
Puisque PCF Dev n’est accessible que sur la machine locale ; il est livré avec un ensemble préconfiguré d’informations d’identification utilisateur, d’URL, de points de terminaison, d’organisations et d’espaces que vous pouvez utiliser pour votre développement.
Ces informations d’identification sont affichées lors du démarrage réussi de PCF Dev à l’aide de la commande cf dev start .
Par exemple, considérez la liste suivante qui prend par défaut les valeurs données:
- Point de terminaison API : https://api.local.pcfdev.io
- URL du gestionnaire d’applications : https://apps.local.pcfdev.io
- Un utilisateur Admin avec le courriel : admin et le mot de passe : admin
- Un utilisateur régulier avec l’e-mail : user et mot de passe : pass
- Une organisation pour que les applications soient nommées : pcfdev -org
- Avec un espace pour déployer les applications à être nommé pcfdev -espace
Avec ces informations en main, la première chose que nous voudrons faire est de nous connecter à notre fondation PCF Dev à l’aide de la commande suivante:
$ cf login -a https://api.local.pcfdev.io –skip- ssl -validation
Cela nous incitera à entrer nos informations de connexion. Pour commencer, nous utiliserons notre utilisateur régulier, avec l’ utilisateur email> , qui n’a pas de privilèges administratifs à la fondation pour garder les choses simples.
Remarque
Vous verrez une invite pour saisir un e-mail>. Cela peut être déroutant car il peut s’agir de n’importe quel identifiant unique pour ce qui est plus précisément décrit comme un nom d’utilisateur que vous utiliserez pour vous connecter à Cloud Foundry. Le courrier électronique est certainement un choix courant; mais ce n’est pas la seule forme de nom d’utilisateur acceptée, comme vous pouvez le voir.
Le terminal ressemblera à ceci une fois que nous serons connectés correctement:
API endpoint: https://api.local.pcfdev.io
Email> user
Password> pass
Authenticating…
OK
Targeted org pcfdev-org
Targeted space pcfdev-space
API endpoint: https://api.local.pcfdev.io (API version: 2.82.0)
User: user
Org: pcfdev-org
Space: pcfdev-space
Par défaut, l’utilisateur régulier est affecté à l’Org appelé pcfdev -org et l’ espace pcfdev -espace .
Pour rester simple, nous pouvons déployer notre exemple d’application ici. Dans les chapitres suivants, nous aborderons les organisations et les espaces plus en détail, ainsi que la façon de créer de nouvelles organisations et espaces pour vous aider à mettre en page vos cibles de développement et de déploiement et vos flux de travail.
3.5 Déployer une application de test sur PCF Dev
Scott Frederick, le célèbre gourou de Spring Java et Cloud Foundry – qui est bien connu pour ses contributions de grande envergure aux communautés Cloud Foundry et Spring Java au début de l’ère Cloud Foundry – a développé ce qui est peut-être le Java le plus connu et le plus commun. application utilisée pour tester une fondation Cloud Foundry. Nous exploiterons l’application de test Spring Music pour valider le fonctionnement de notre fondation PCF Dev. L’une des raisons de la popularité de Spring Music est que l’application a la propriété intéressante de permettre aux développeurs de modifier dynamiquement la banque de données de sauvegarde de la base de données en mémoire par défaut incluse dans l’application Spring Music elle-même à l’une des nombreuses banques de données de sauvegarde potentielles que Cloud Foundry exploite. en tant que services, un concept Cloud Foundry important que nous explorerons plus en détail dans les prochains chapitres.
En tant qu’application Java, vous devez vous assurer que la version appropriée du Java JDK est installée sur votre système pour exécuter Spring Music. Vous pouvez installer Java JDK à partir de http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html .
Remarque
Si vous n’êtes pas familier avec le développement Java, assurez-vous que votre installation Java Standard Edition ( Java SE ) est la version Java Development Kit ( JDK ) qu’un développeur Java utiliserait pour développer du code. Pas l’ environnement d’exécution Java ( JRE ) qui n’inclut pas le terme JDK. La version JDK comprend à la fois le JRE sur lequel s’exécutent les programmes Java, ainsi que les outils du kit de développement Java utilisés pour créer des programmes Java. Ce n’est pas du tout déroutant, non?
Remarque
Des informations détaillées sur l’application Spring Music sont disponibles à l’ adresse : https://github.com/cloudfoundry-samples/spring-music.
3.5.1 Cloner et créer l’application Spring Music
Afin d’obtenir une version déployable de l’application Spring Music, nous devrons la télécharger à partir d’un référentiel de code en ligne et la créer. Nous procédons comme suit:
- Clonez le référentiel Git qui contient l’application Spring Music à l’aide de la commande suivante :
$ git clone https://github.com/cloudfoundry-samples/spring-music
- Accédez au répertoire Spring-Music :
$ cd./spring-music
- Assemblez l’application Spring Music à l’aide d’un Windows PowerShell ou d’un terminal Unix à l’aide des éléments suivants,
Sur les plateformes de type Unix telles que Linux et macOS X sur lesquelles Gradle n’est pas encore installé, utilisez:
$. / assemblage propre gradlew
Les plates-formes de type Unix telles que Linux et macOS X sur lesquelles Gradle est installé, utilisent :
$ gradle nettoyer assembler
Sous Windows, utilisez le fichier de commandes gradlew.bat en utilisant :
$ gradlew nettoyer assembler
- Déployez l’application Spring-Music sur PCF Dev à l’aide du code suivant :
cf push –hostname spring-music
- Vous verrez la commande cf push faire un peu de travail, jusqu’à ce qu’elle se termine enfin par une sortie, comme suit:
…
état demandé: démarré
instances: 1/1
utilisation: 1G x 1 instances
urls : spring-music.local.pcfdev.io
Dernière mise en ligne: dim 12 nov 08:53:46 UTC 2017
pile: cflinuxfs2
buildpack : container-certificate-trust-store = 2.0.0_RELEASE java-buildpack = v3.13-offline-https: //github.com/cloudfoundry/java-buildpack.git#03b493f java-main open- jdk -like- jre = 1.8.0_121 open- jdk -like -memory-calculator = 2.0.2_RELEASE spring-auto-reconfiguration = 1.10 …
état depuis les détails du disque de la mémoire du processeur
# 0 en cours d’exécution 2017-11-12 02:57:23 AM 0.0% 328.9M of 1G 170M of 512M
- Maintenant que l’application est déployée, nous pouvons la visualiser à l’aide de la CLI cf , comme nous l’avons fait avec PWS dans le chapitre précédent à l’aide de la commande cf apps :
$ cf apps
Obtention d’applications dans org pcfdev -org / space pcfdev -space en tant qu’utilisateur …
D’accord
nom demandé instances d’instance mémoire disque urls
printemps-musique commencée 1/1 1G 512M spring-music.local.pcfdev.io
Et, comme nous l’avons fait précédemment avec PWS, nous pouvons ouvrir l’interface utilisateur Web Apps Manager pour afficher les applications déployées dans notre fondation PCF Dev en ouvrant son URL. Dans le cas de PCF Dev, c’est https://apps.local.pcfdev.io/.
Si vous n’avez pas encore fait confiance aux certificats créés automatiquement et auto-signés générés par le processus de démarrage de PCF Dev, vous verrez divers problèmes de certificat SSL qui vous avertissent de la validité de votre PCF Dev à partir du gestionnaire d’applications dans le navigateur, ainsi que sur l’interface de ligne de commande cf lorsque vous vous connectez au point de terminaison PCF Dev API. Vous avez peut – être remarqué que, d’abord, nous avons ouvert une session dans PCF Dev en utilisant la cf commande de connexion avec le –skip ssl -validation drapeau pour contourner l’avertissement SSL à la ligne de commande, comme suit :
$ cf login -a https://api.local.pcfdev.io –skip- ssl -validation
La connexion au gestionnaire d’applications à l’URL https://apps.local.pcfdev.io/ sans faire confiance à l’installation de PCF Dev produira un avertissement comme celui-ci :
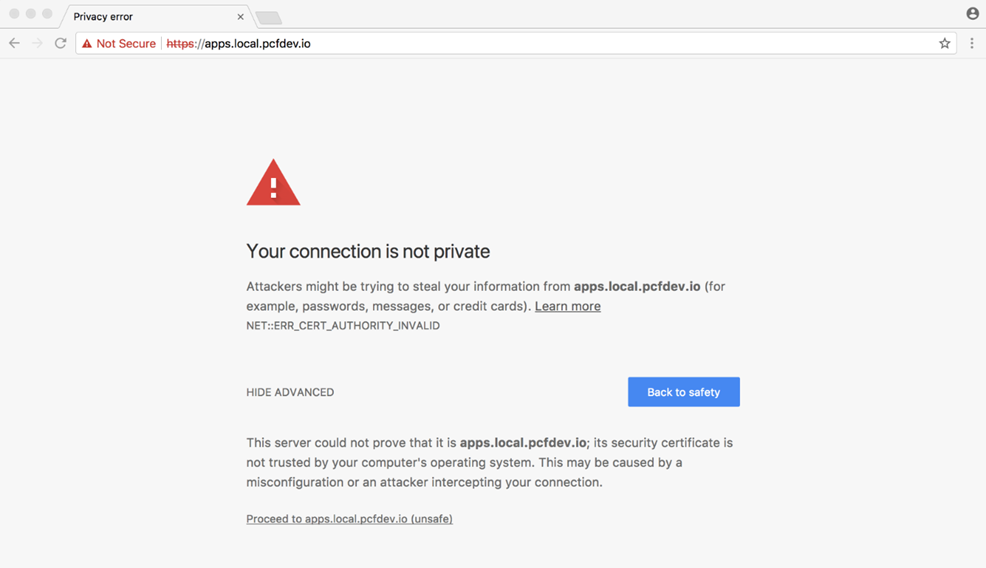
Vous pouvez choisir de contourner l’avertissement dans le navigateur. Par exemple, dans Google Chrome, vous pouvez cliquer sur Avancé et passer à apps.local.pcfdev.io (dangereux) . Si vous préférez ne pas gérer le contournement des avertissements SSL dans la CLI cf et le navigateur Web chaque fois que vous les utilisez, vous pouvez approuver l’installation de PCF Dev à l’aide de la commande cf dev trust. Cela ajoutera le certificat auto-signé PCF Dev dans votre magasin de certificats de système d’exploitation. Il vous faudra probablement autoriser l’ajout au magasin de certificats en utilisant votre utilisateur ou un compte d’administrateur sur votre ordinateur.
Pour faire confiance à PCF Dev, exécutez la commande suivante:
$ cf dev trust
*** Avertissement: un certificat auto-signé pour * .local.pcfdev.io a été inséré dans votre magasin de certificats de système d’exploitation. Pour supprimer ce certificat, exécutez: cf dev untrust ***
Comme indiqué dans le message d’avertissement, vous pouvez ultérieurement exécuter la commande cf dev untrust pour supprimer le certificat de votre magasin de certificats de système d’exploitation.
Vous pouvez ensuite vous déconnecter du point de terminaison PCF Dev à l’aide de la commande suivante :
$ cf déconnexion
Déconnecter…
D’accord
Et reconnectez-vous ensuite sans l’indicateur –skip- ssl -validation, au lieu d’utiliser uniquement la commande suivante :
$ cf login -a https://api.local.pcfdev.io
De même, vous pouvez vous connecter à l’interface utilisateur Apps Manager à l’aide des informations d’identification de l’utilisateur standard pour voir l’application déployée à cet endroit :
Une fois connecté à Apps Manager, vous pouvez voir qu’une application a été envoyée:
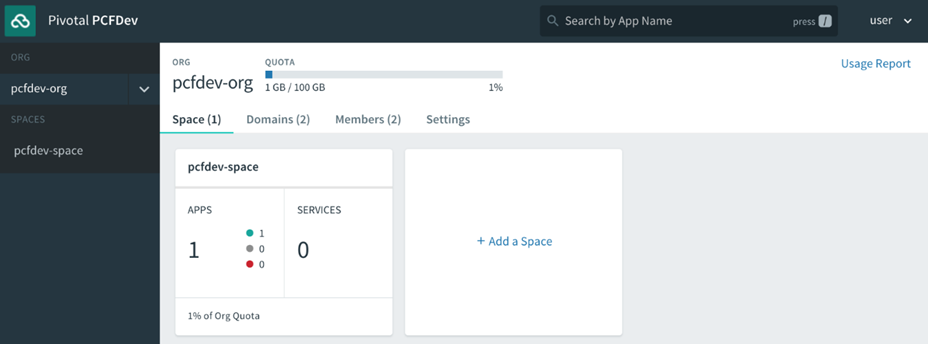
Remarque
Dans les coulisses, le gestionnaire d’applications fonctionne comme n’importe quelle autre application dans Cloud Foundry. Si vous souhaitez le voir fonctionner, passez simplement de pcfdev -org à l’organisation système. L’organisation du système est l’endroit où vous pouvez avoir un aperçu de certaines des applications qui composent Cloud Foundry lui-même, s’exécutant récursivement sur Cloud Foundry pour gérer la fonctionnalité Cloud Foundry. Inception, n’importe qui?
Cliquez sur la case intitulée APPS pour afficher les applications actuellement déployées. Ici, nous pouvons voir que Spring-Music a été déployé avec le nom d’hôte spring-music , qui le place à l’URL http://spring-music.local.pcfdev.io :
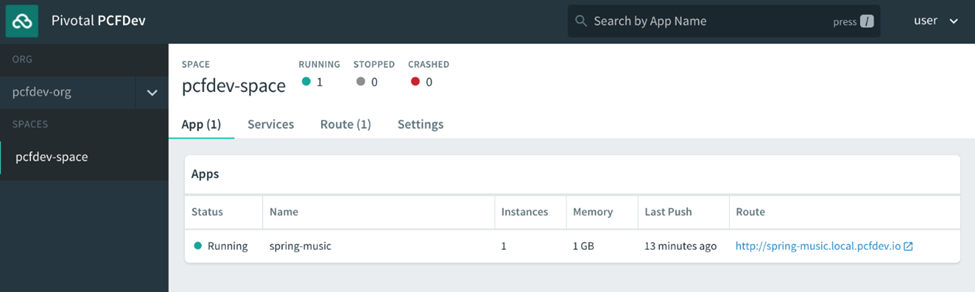
Cliquez sur l’URL de Spring Music pour ouvrir l’application Spring Music dans votre navigateur Web . Et puis, cliquer sur l’icône d’information dans le coin supérieur droit nous permet de voir quel magasin de données Spring Music utilise actuellement comme source de données. Comme nous n’avons pas encore configuré nos services, Spring Music a opté par défaut pour le profil du Cloud à l’aide d’une base de données en mémoire. Comme nous le verrons lorsque nous arriverons aux services, nous pouvons facilement attacher des applications à une variété de services disponibles dans Cloud Foundry Service Marketplace.
Toutes nos félicitations! Vous avez maintenant prouvé que votre fondation Cloud Foundry locale de PCF Dev est capable d’exécuter une application de test, de la même manière que vous avez pu pousser et exécuter une application de test dans PWS sur Internet public.
3.5.2 Entretien ménager PCF Dev
Dans les coulisses PCF Dev exécute de nombreux conteneurs sur une seule machine virtuelle hébergée sur l’application VirtualBox que vous avez installée sur votre ordinateur pour commencer. Si vous souhaitez jeter un œil derrière le rideau, vous pouvez ouvrir l’application VirtualBox et voir que vous exécutez réellement une fondation Cloud Foundry sur une seule machine virtuelle. De l’interface utilisateur de VirtualBox, cela ressemble à ceci:
Étant donné que VirtualBox fonctionne dans les coulisses, il peut être facile d’oublier que la machine virtuelle PCF Dev démarre en arrière-plan en consommant une partie de la mémoire qui serait autrement disponible pour votre machine pour d’autres choses.
En tant que tel, nous allons maintenant voir quelques commandes de gestion pratiques qui vous aideront à gérer votre installation PCF Dev.
Arrêtez
$ cf dev stop
Cela arrêtera la machine virtuelle de développement PCF tout en préservant toutes les données que vous y avez ajoutées. Voici la sortie typique de cette commande:
$ cf dev stop
Stopping VM…
PCF Dev is now stopped.
Le résultat dans VirtualBox est le suivant:
Utilisez cf dev start pour redémarrer une machine virtuelle PCF Dev arrêtée.
Suspendre
$ cf dev suspend
Cela enregistre l’état actuel de la machine virtuelle de développement PCF sur le disque, puis arrête la machine virtuelle. Voici la sortie typique de cette commande:
$ cf dev suspend
Suspending VM…
PCF Dev is now suspended.
CV
$ cf dev resume
Cela reprend la machine virtuelle de développement PCF à partir d’un état suspendu. Voici la sortie typique de cette commande:
$ cf dev resume
Resuming VM…
PCF Dev is now running.
Détruire
$ cf dev destroy
Cela supprime la machine virtuelle PCF Dev et détruit toutes les données qu’elle contient. Voici la sortie typique de cette commande :
$ cf dev destroy
PCF Dev VM has been destroyed.
Statut
$ cf dev status
Parfois, vous pouvez perdre de vue si la machine virtuelle de développement PCF est toujours en cours d’exécution ou non. Cela vous indiquera l’état de la machine virtuelle de développement PCF. Voici la sortie typique de cette commande :
$ cf dev status
Running
CLI Login: cf login -a https://api.local.pcfdev.io –skip-ssl-validation
Apps Manager URL: https://apps.local.pcfdev.io
Admin user => Email: admin / Password: admin
Regular user => Email: user / Password: pass
3.6 Alternatives à PCF Dev
Jusqu’à ce que PCF Dev soit disponible, le produit open source BOSH-lite était une bonne solution pour démarrer avec Cloud Foundry. Cependant, BOSH-lite est plus centré sur BOSH et, en tant que tel, nécessite un peu d’expertise BOSH pour déployer Cloud Foundry. BOSH est présenté comme un outil open source pour l’ingénierie des versions, le déploiement, la gestion du cycle de vie et la surveillance des systèmes distribués. Cloud Foundry ne nécessite pas réellement que BOSH soit utilisé pour le déployer. Et, inversement, BOSH n’est pas strictement destiné au déploiement de Cloud Foundry. Il s’agit d’un outil généralisé qui peut être utilisé pour déployer et maintenir en fonctionnement et en bon état n’importe quel système distribué. Cependant, les deux outils sont comme le beurre d’arachide et le chocolat, vraiment bons ensembles.
BOSH est un outil majeur de la boîte à outils Platform Engineers. Moins souvent maintenant, les outils BOSH et BOSH-lite qu’un développeur d’applications Cloud Foundry utiliseraient au début de leur processus d’apprentissage Cloud Foundry étant donné l’avènement de PCF Dev. PCF Dev est un point de départ plus approprié car il se concentre fortement sur le point idéal des préoccupations des développeurs telles que le déploiement d’applications, les services, la journalisation, les métriques et le développement local. PCF Dev gère une grande partie des tâches lourdes nécessaires lors de la mise en route du développement de Cloud Foundry, ce qui vous permet d’accéder au travail de développement d’applications plus rapidement tout en éliminant en grande partie le travail opérationnel requis pour maintenir votre environnement de déploiement local à l’aide d’un outil tel que BOSH-lite . Tout cela est un accélérateur pour un développeur, et il aide à raccourcir le temps de déploiement du code de l’application, au lieu de nécessiter de bricoler sous le capot de la plate-forme sur laquelle l’application s’exécutera.
Tout cela ne veut pas dire que BOSH et BOSH-lite ne sont pas intéressants. Plutôt l’inverse. Ce sont des technologies extrêmement intéressantes et un sujet qui va très, très profondément si l’on se sent obligé de décoller le couvercle et d’examiner les rouages et les roues qui font les subtilités des systèmes distribués hautement disponibles et robustes, tels que Cloud Foundry, cocher comme un puits fait montre suisse. Mais, c’est un sujet qui mérite un traitement distinct.
Au-delà de BOSH-lite, il n’y a pas grand-chose d’autre à l’heure actuelle qui donne au développeur un moyen rapide et facile de disposer d’une Cloud Foundry locale pour travailler lors du développement de code natif du cloud.
3.7 Résumé
Dans ce chapitre, nous avons installé une version machine locale de Cloud Foundry appelée PCF Dev. Ensuite, nous nous sommes connectés et avons poussé une application pour vérifier qu’elle fonctionnait. Nous l’avons fait pour raccourcir notre cycle de développement et de débogage, qui consiste généralement en la pratique éprouvée de TDD pour écrire du bon code qui résiste aux échecs de régression. En utilisant TDD, nous suivons le flux de travail du rouge, du vert, itérons jusqu’à ce que notre code soit complet.
Nous avons examiné les principales différences entre PCF Dev et d’autres distributions de Cloud Foundry. PCF Dev est un complément pratique à votre boîte à outils de développement Cloud Foundry. Cela garantit que vous créez des applications qui sont très susceptibles de fonctionner avec peu ou pas de modification de votre fondation de production de Cloud Foundry.
4 Chapitre 4. Utilisateurs, organisations, espaces et rôles
Cloud Foundry permet aux opérateurs de plate-forme d’organiser le déploiement de Cloud Foundry selon leur structure organisationnelle et d’ajouter des utilisateurs avec diverses capacités via des rôles. Un déploiement Cloud Foundry peut être structuré autour d’organisations (organisations) et d’espaces. Il est très important de comprendre les concepts d’organisations et d’espaces, afin de pouvoir concevoir votre déploiement Cloud Foundry selon les exigences de votre entreprise.
Dans ce chapitre, nous explorerons les façons les plus courantes de concevoir une organisation et un espace, de comprendre les rôles et d’accorder l’accès aux utilisateurs à une organisation ou à un espace sur Pivotal PCF Dev. Nous utiliserons la CF CLI et le gestionnaire d’applications pour créer une organisation, un espace, un utilisateur et leur attribuer des rôles.
Plus précisément, nous couvrirons les éléments suivants :
- Création d’une organisation
- Créer un espace
- Ajout d’utilisateurs
- Attribution de rôles aux utilisateurs
4.1 Organisations (Orgs)
Une organisation peut être considérée comme le nom d’un groupe d’applications, d’un groupe de produits ou d’une unité commerciale. Une organisation consiste à calculer des ressources et des espaces. Chaque organisation a un quota de ressources par défaut qui est partagé par plusieurs espaces. Les organisations peuvent être gérées par un ou plusieurs utilisateurs, qui peuvent ensuite gérer l’organisation et créer des quotas de ressources pour chaque espace.
4.1.1 Créer une organisation à l’aide d’Apps Manager
Pour créer une organisation à l’aide du gestionnaire d’applications fonctionnant sur PCF Dev, connectez-vous au gestionnaire d’applications en accédant à https://apps.local.pcfdev.io avec le compte d’utilisateur administrateur . Utilisez les informations de connexion PCF Dev pour vous connecter au gestionnaire d’applications:

Figure 1: Informations de connexion PCF Dev
Remarque
Les détails par défaut pour se connecter à Pivotal PCF Dev sont : Pour commencer à utiliser PCF Dev, veuillez exécuter: cf login -a https://api.local.pcfdev.io –skip- ssl -validation URL du gestionnaire d’applications: https: / /apps.local.pcfdev.io Admin user => Email: admin / Password: admin Utilisateur normal => Email: user / Password: pass
Lors de la signature, cliquez sur le menu déroulant sous l’ Org dans le volet gauche, puis sélectionnez + Créer un nouveau Org :
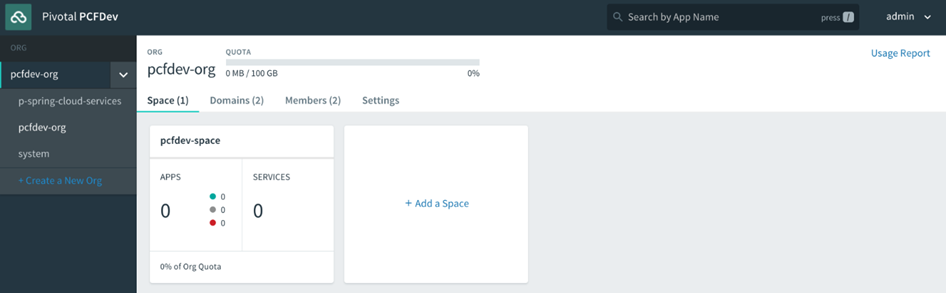
Figure 2 : sélectionnez l’option pour créer une nouvelle organisation
Désormais, indiquez un nom d’organisation, qui peut être le nom du groupe d’applications, de l’unité commerciale ou du groupe de produits, selon le cas. Une fois que vous avez défini le nom, sélectionnez le bouton CRÉER ORG. À des fins d’illustration, nous allons créer une organisation avec le nom cf -my-first-org :
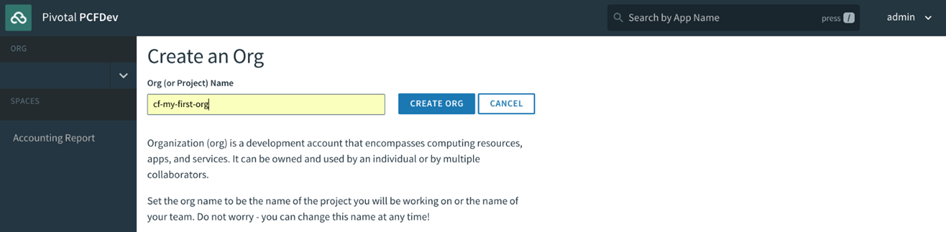
Figure 3 : créer une organisation
Une fois que l’organisation a été créée, vous verrez le message de réussite, et l’organisation sera initialisée avec le quota par défaut de 100 Go de RAM sur le Pivotal PCF Dev :
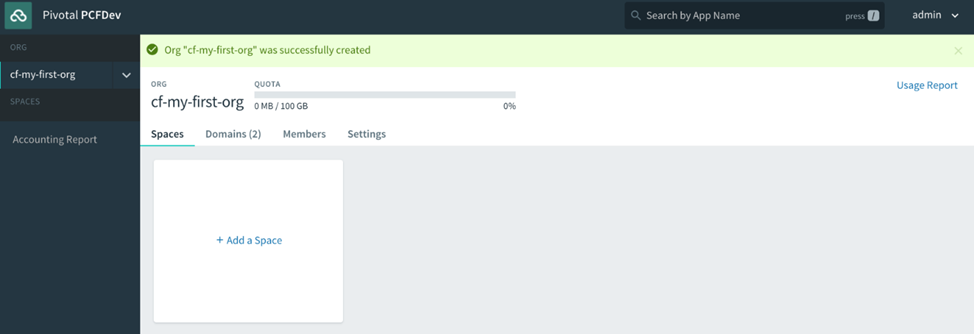
Figure 4 : création de l’organisation réussie
Les domaines par défaut seront répertoriés sous l’onglet Domaines :
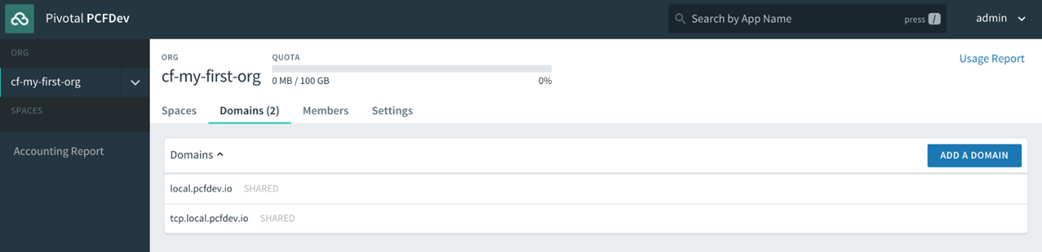
Figure 5 : répertorier les domaines par défaut sous une organisation
Toutes nos félicitations ! Vous avez réussi à créer votre très Org cf -my-first-org à l’aide du Gestionnaire d’applications sur PCF Dev.
4.1.2 Créer une organisation (Org) à l’aide de la CLI cf
Les organisations peuvent également être créées à l’aide de l’interface CLI cf. Pour ce faire, nous vous connecter à l’environnement Dev PCF en exécutant la cf connexion -a https://api.local.pcfdev.io –skip ssl -validation commande.
Avant d’aller plus loin, examinons le texte d’aide sur la façon de créer une organisation. Nous exécuterons la commande cf create-org –help :
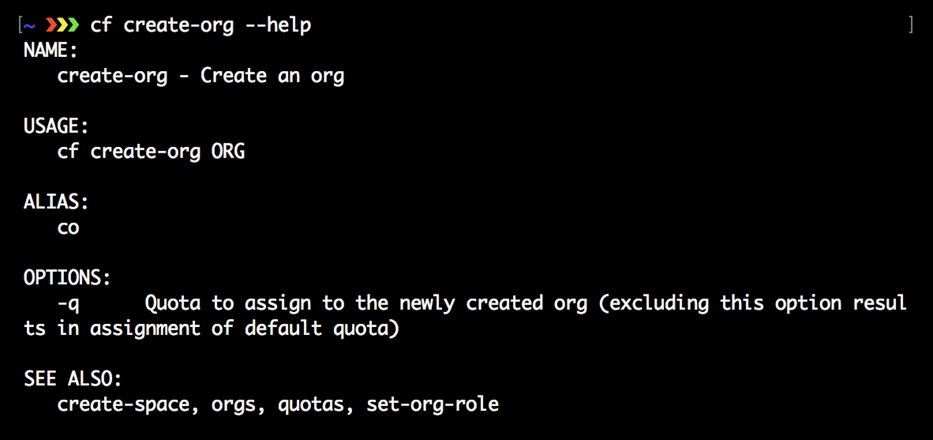
Figure 6 : commande d’aide sur la création d’une organisation à l’aide de cf CLI
Maintenant, afin de créer l’organisation, nous devons exécuter la commande cf create-org ORG-NAME , où ORG-NAME serait le nom du groupe d’applications, de l’unité commerciale ou du groupe de produits.
À des fins d’illustration, nous allons créer une organisation avec le nom cf -my-first-org :
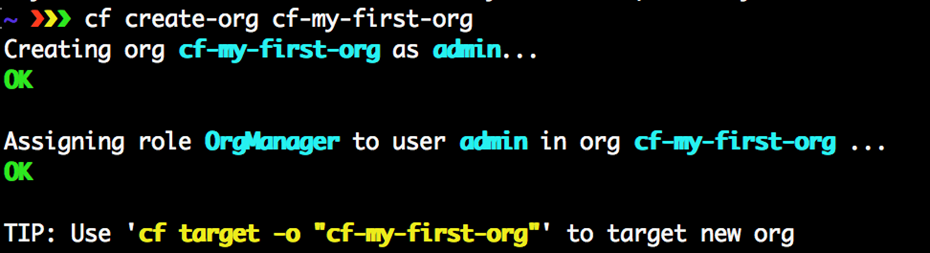
Figure 7 : créer une organisation à l’aide de l’ interface CLI cf
Si l’Org existe déjà, le cf CLI ne sera pas recréer l’organigramme et répondra avec un message amical que l’ Org cf -mon-première org existe déjà :
Figure 8 : sortie lorsqu’un Org existe déjà à l’aide de la CLI cf
Toutes nos félicitations ! Vous avez réussi à créer votre très Org cf -my-first-org à l’aide de cf CLI sur PCF Dev.
4.1.3 Liste des organisations à l’aide de la CLI cf
Une fois que vous avez créé votre organisation avec succès, vous pouvez maintenant répertorier toutes les organisations pour vérifier toutes les organisations auxquelles vous avez accès. Cela se fait en exécutant la commande cf orgs :
Figure 9 : Liste de toutes les organisations à l’aide de la CLI cf
Remarque
En fonction de la Business Unit ou du groupe d’applications, l’administrateur Cloud Foundry ou l’utilisateur avec le rôle Org Manager peut ajouter de nouveaux domaines génériques en cliquant sur le bouton ADD DOMAIN et en suivant les instructions. Une fois que l’administrateur de Cloud Foundry a créé une organisation, celle-ci est dans un état actif. L’administrateur Cloud Foundry peut désactiver l’organisation si l’application, le groupe de produits ou l’unité commerciale en a fait un mauvais usage, n’ont pas payé leur utilisation ou n’ont plus besoin de l’organisation.
4.2 Espaces
Un espace est l’endroit où les applications sont poussées. Toutes les liaisons de service sont créées et gérées dans un espace. Les espaces peuvent être mappés à un environnement spécifique, tel que le développement, les tests, l’intégration ou la production. Les espaces peuvent également être mappés à une sous-équipe sous l’unité commerciale, l’application ou le groupe de produits. Les services utilisés par les applications sont définis par Spaces. Les développeurs poussent leurs applications dans l’espace, puis continuent de développer et de maintenir leurs applications dans le même espace.
Si un espace donné nécessite un quota de ressources différent de celui défini dans l’organisation, l’administrateur Cloud Foundry ou le gestionnaire d’organisation de cette organisation peut créer un quota de ressources personnalisé et l’affecter à l’espace.
4.2.1 Création d’un espace à l’aide du gestionnaire d’applications
Voyons maintenant comment créer un espace à l’aide du gestionnaire d’applications sur Pivotal PCF Dev. Nous commençons par nous connecter à https://apps.local.pcfdev.io/ avec l’administrateur du compte utilisateur PCF Dev.
Sélectionnez le cf -my-first-org dans la liste déroulante ORG du menu en haut à gauche :
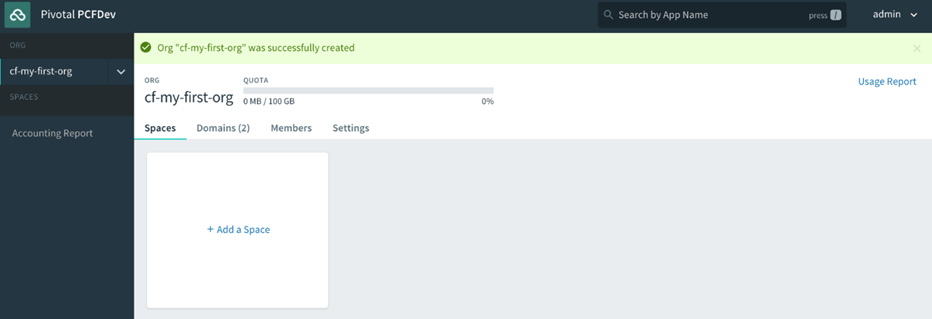
Figure 10 : ciblage d’un espace dans l’organisation cf -my-first-org à l’aide du gestionnaire d’applications
Maintenant, cliquez sur l’Ajouter un espace bouton, indiquez le nom Spaces comme le développement, et cliquez sur le SAUVER bouton :
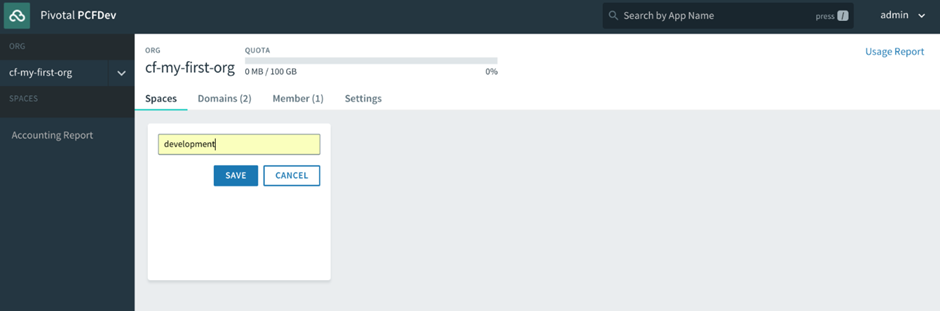
Figure 11 : Création d’un espace de développement dans l’organisation cf -my-first-org à l’aide du gestionnaire d’applications
Si la création de l’espace réussit, vous devriez voir l’espace répertorié sous l’organisation cf -my-first- org:
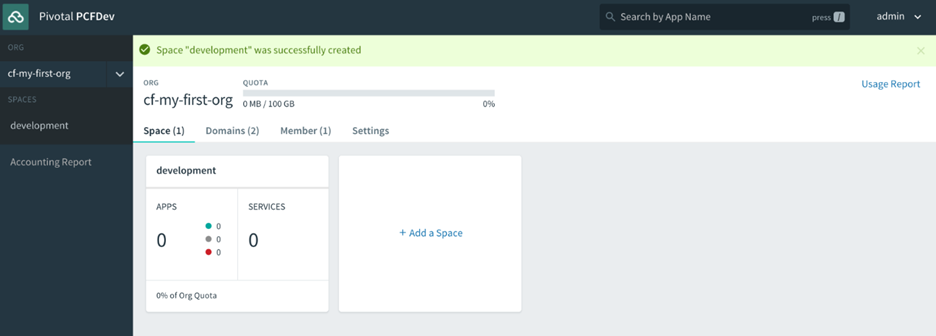
Figure 12 : la création d’un espace de développement à l’aide d’Apps Manager est un succès
Toutes nos félicitations ! Vous avez réussi à créer votre tout premier espace sous cf -my-first-org à l’aide du gestionnaire d’applications sur PCF Dev.
4.2.2 Création d’un espace à l’aide de cf CLI
Pour créer un espace à l’aide de la CLI cf sur Pivotal PCF Dev, nous devons d’ abord nous connecter. Pour ce faire, nous devons spécifier le point de terminaison de l’ API Cloud Foundry de PCF Dev, qui est https://api.local.pcfdev.io et ignorer également la validation SSL:
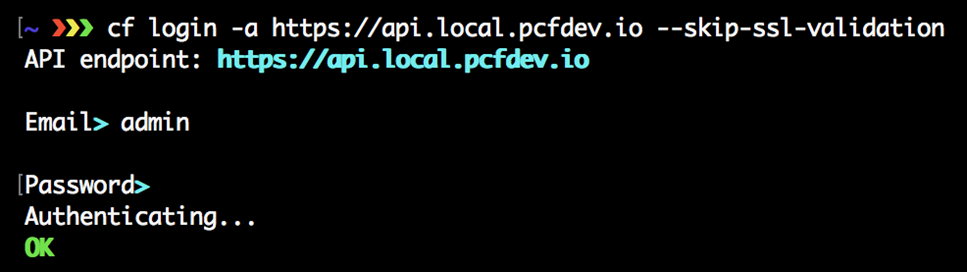
Figure 13: Connectez-vous à PCF Dev à l’aide de cf CLI
Ensuite, sélectionnez le cf -my-first-org dans la liste des organisations qui vous est présentée sur la ligne de commande et appuyez sur Entrée :
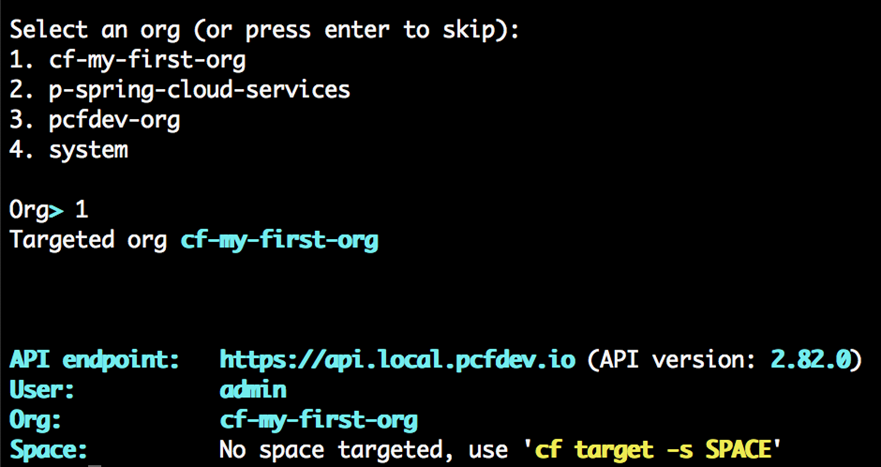
Figure 14 : Sélectionnez cf -my-first-org parmi les options présentées lors d’une connexion réussie
Notez dans la sortie précédente que l’Org n’a pas d’espace. Afin de créer un espace avec le nom développement, nous exécutons la commande cf create-space development :
Figure 15 : Créer un espace de développement sous cf -my-first-org Org à l’aide de cf CLI
Si l’espace portant le nom de développement existe déjà, vous obtiendrez un message, le développement d’espace existe déjà :

Figure 16 : sortie de l’interface de ligne de commande cf lorsque l’espace de développement existe déjà
Enfin, nous ciblons l’espace en exécutant cf target -o ORG -s SPACE. Dans ce cas, cf développement -o cf -my-first-org -s :
Figure 17 : Utilisation de cf CLI pour cibler l’organisation cf -my-first-org et le développement d’espace
Toutes nos félicitations ! Vous avez réussi à créer votre tout premier espace sous cf -my-first-org à l’aide de cf CLI sur PCF Dev.
4.2.3 Lister les espaces à l’aide de la CLI cf
Une fois que vous avez réussi à créer votre espace sous l’organisation, vous pouvez maintenant répertorier tous les espaces qui appartiennent à l’organisation.
Cela se fait en exécutant la commande cf espaces :
Figure 18 : répertorier tous les espaces sous cf -my-first-org à l’aide de cf CLI
Remarque
Vous devez vous assurer que vous avez défini le cf target -o ORG avant d’exécuter la commande répertoriée précédemment.
4.3 Comptes User
Un compte d’utilisateur permet à un utilisateur de se connecter à Cloud Foundry et d’effectuer certaines opérations qui sont limitées par les rôles qui leur sont attribués par l’administrateur Cloud Foundry.
Les comptes d’utilisateurs peuvent être créés au niveau de l’organisation ou de l’espace, en fonction du rôle qu’ils jouent dans l’organisation. Le même utilisateur peut administrer l’organisation et l’espace, ou peut se limiter à pousser des applications vers un ou des espaces donnés.
De plus, un utilisateur peut s’étendre sur plusieurs espaces dans une organisation et, sous chaque espace, il peut être contrôlé par le rôle Espace.
4.3.1 Créer un utilisateur à l’aide de la CLI cf
Voyons comment ajouter un utilisateur à notre organisation cf -my-first-org dans Pivotal PCF Dev. Pour ce faire, nous devons spécifier le point de terminaison de l’API Cloud Foundry de PCF Dev, qui est https://api.local.pcfdev.io, et ignorer également la validation SSL :

Figure 19 : Connectez-vous au PCF Dev à l’aide de cf CLI
Ensuite, sélectionnez le cf -my-first-org dans la liste des organisations qui vous est présentée sur la ligne de commande :
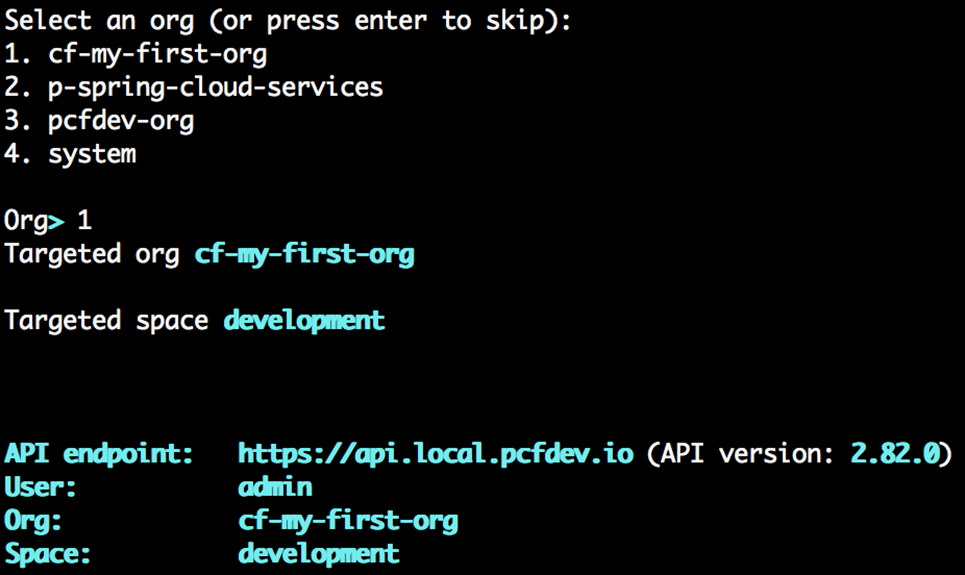
Figure 20 : Sélectionnez l’organisation et l’espace lors d’une connexion réussie à l’aide de cf CLI
Puisqu’il n’y a qu’un seul espace, la CLI cf ciblera le développement de l’espace. Si nous avions plus d’un espace, alors la CLI cf vous demanderait de choisir l’espace que vous souhaitez cibler.
Nous allons maintenant créer notre premier utilisateur en exécutant la commande cf create-user USERNAME PASSWORD. Par exemple, créons un utilisateur, John, avec le mot de passe welcome , en exécutant cf create-user John welcome :

Figure 21 : créer l’utilisateur John avec un mot de passe par défaut à l’aide de la CLI cf
En exécutant cette commande, nous avons enregistré un utilisateur dans Cloud Foundry, mais lorsque l’utilisateur John se connecte au gestionnaire d’applications , il n’aura accès à aucune organisation ou espace:

Figure 22 : l’utilisateur John n’a accès à aucune organisation ni aucun espace
Toutes nos félicitations ! Vous avez créé votre premier utilisateur à l’aide de la CLI cf. Dans la section suivante, nous allons discuter des différents rôles qui existent dans Cloud Foundry, puis attribuer l’un d’eux à l’utilisateur John.
4.4 Rôles
Les rôles restreignent ce qu’un utilisateur peut faire au sein d’une organisation ou d’un espace de fonderie cloud. Les rôles sont prédéfinis et gérés dans CloudFoundry.
Les utilisateurs se voient attribuer les rôles par l’administrateur de Cloud Foundry, Org Manager ou Space Manager. Seuls les utilisateurs disposant de privilèges d’administrateur peuvent créer de nouveaux comptes d’utilisateurs.
Les rôles pouvant être attribués aux utilisateurs au niveau de l’organisation sont les suivants :
- OrgManager
- BillingManager
- OrgAuditor
Les rôles pouvant être attribués aux utilisateurs à ces niveaux d’espace sont :
- SpaceManager
- SpaceDeveloper
- SpaceAuditor
Voyons ce que chacun des rôles peut jouer.
4.4.1 OrgManager rôle
Un utilisateur avec le rôle OrgManager peut exécuter les fonctions suivantes :
- Invitez et gérez les autorisations utilisateur au niveau de l’organisation et de l’espace
- Créer et gérer les quotas au niveau de l’organisation et de l’espace
- Ajouter des domaines privés
- Créez et gérez des espaces. Il peut également supprimer les espaces.
4.4.2 BillingManager rôle
Un utilisateur avec le rôle BillingManager peut effectuer toutes les opérations en lecture seule à des fins de facturation, comme :
- Affichage des utilisateurs et de leurs rôles attribués à une organisation
- Afficher les quotas d’organisation
- Afficher les instances d’application, l’état de l’application, les instances de service et les liaisons entre l’application et les services
4.4.3 OrgAuditor rôle
Un utilisateur avec le rôle OrgAuditor peut exécuter les fonctions suivantes :
- Afficher tous les utilisateurs et rôles attribués à l’organisation et à l’espace
- Voir tous les quotas d’Org
4.4.4 Rôle SpaceManager
Avec le rôle SpaceManager , un utilisateur peut exécuter les fonctions suivantes:
- Invitez et gérez les autorisations utilisateur au niveau de l’espace
- Voir les plans de quotas organisationnels
- Afficher et modifier l’espace
- Afficher les instances d’application, l’état de l’application, les ressources d’application, les instances de service et les liaisons entre l’application et les services
4.4.5 Rôle de SpaceDeveloper
Un utilisateur avec le rôle SpaceDeveloper peut exécuter les fonctions suivantes :
- Afficher tous les utilisateurs de Space et leurs rôles
- Voir les plans de quotas organisationnels
- Voir tous les espaces sous l’organisation
- Afficher l’état de l’application, le nombre d’instances, les liaisons de service et les ressources allouées à chaque application
- Déployer, exécuter et gérer des applications
- Créer et lier des services aux applications
- Attribuer des routes, mettre à l’échelle des instances d’application, l’allocation de mémoire et les limites de disque des applications
- Renommer des applications
4.4.6 SpaceAuditor rôle
Avec le rôle SpaceAuditor, un utilisateur peut effectuer les fonctions suivantes :
- Afficher les utilisateurs et les rôles
- Voir les plans de quotas organisationnels
- Voir tous les espaces sous l’organisation
- Afficher l’état, le nombre d’instances, les liaisons de service et l’utilisation des ressources des applications
4.4.7 Attribution de rôles à un utilisateur à l’aide de cf CLI
Attribuons maintenant le rôle OrgManager à l’utilisateur, John, que nous avons créé dans la section précédente, pour l’Org cf -my-first-org et affectons également le rôle SpaceDeveloper pour l’espace de développement sous l’Org, à l’aide de la CLI cf sur Pivotal PCF Dev.
Pour ce faire, nous devons spécifier le point de terminaison de l’API Cloud Foundry de PCF Dev, qui est https://api.local.pcfdev.io , et ignorer également la validation SSL:
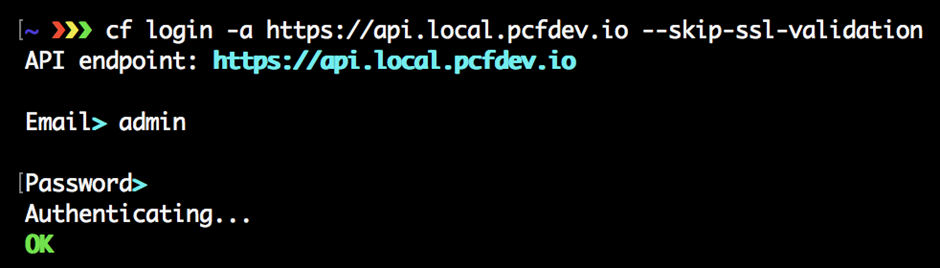
Figure 23 : Connectez-vous à PCF Dev à l’aide de cf CLI
Ensuite, sélectionnez le cf -my-first-org dans la liste ORG qui vous est présentée sur la ligne de commande, suivi de l’espace de développement :
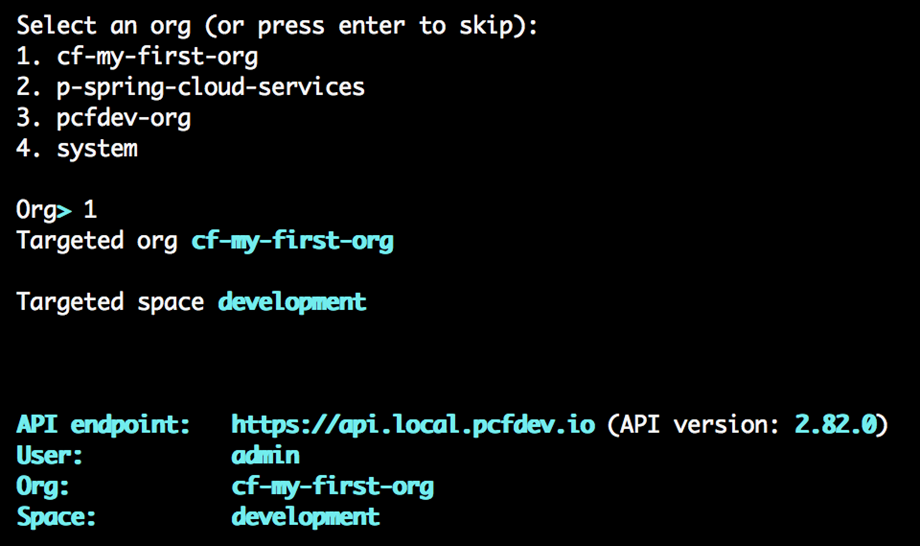
Figure 24 : Sélectionnez l’organisation et l’espace en cas de connexion réussie à l’aide de la CLI cf
Puisqu’il n’y a qu’un seul espace, la CLI cf ciblera le développement de l’espace. Si nous avions plus d’un espace, alors la CLI cf vous demanderait de choisir l’espace que vous souhaitez cibler.
Maintenant, nous allons attribuer le rôle OrgManager à l’utilisateur John en exécutant cf set-org-role USERNAME ORG ROLE, par exemple, cf set-org-role John cf -my-first-org OrgManager :

Figure 25 : Attribuer à l’utilisateur John le rôle OrgManager à l’aide de cf CLI
Nous allons maintenant nous connecter au gestionnaire d’applications sur PCF Dev en tant qu’utilisateur John, et vérifier que John est en mesure de visualiser l’organisation cf -my-first-org. Alors connectez-vous à https://apps.local.pcfdev.io et connectez-vous avec le nom d’utilisateur John et le mot de passe Bienvenue :
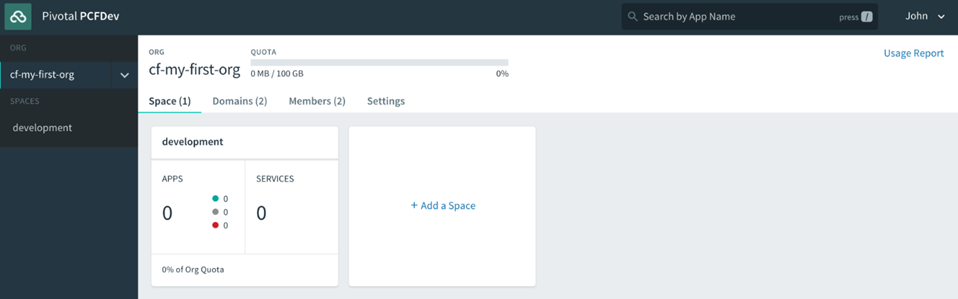
Figure 26 : Connectez-vous au gestionnaire d’applications avec les informations d’identification de John
Accédez à la section Membres pour vérifier le rôle attribué à l’utilisateur John. Nous devrions voir que le rôle est OrgManager :
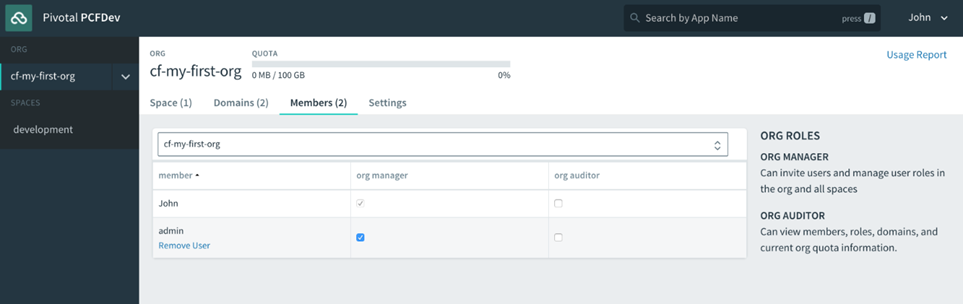
Figure 27 : Affichage de tous les membres et de leurs autorisations sous l’organisation cf -my-first-org
Étant donné que nous n’avons attribué aucun rôle à John dans l’espace de développement, aucun rôle ne devrait lui être sélectionné. Nous pouvons le vérifier en accédant à l’espace de développement et en sélectionnant les membres :
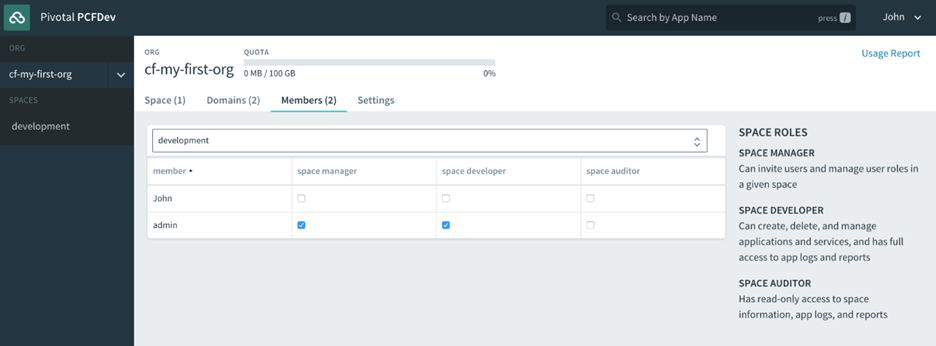
Figure 28: Affichage de tous les membres et de leurs autorisations dans l’espace de développement
Revenons à la CLI cf et assignons le rôle SpaceDeveloper à John. Cela se fait en exécutant cf set-space-role USERNAME ORG SPACE ROLE, par exemple, cf set-space-role John cf -my-first-org development SpaceDeveloper :

Figure 29: Attribuer le rôle SpaceDeveloper à l’utilisateur John à l’aide de cf CLI
Actualisez le gestionnaire d’applications et vérifiez le rôle de John dans le gestionnaire d’applications. À ce stade, John devrait se voir attribuer le rôle SpaceDeveloper :
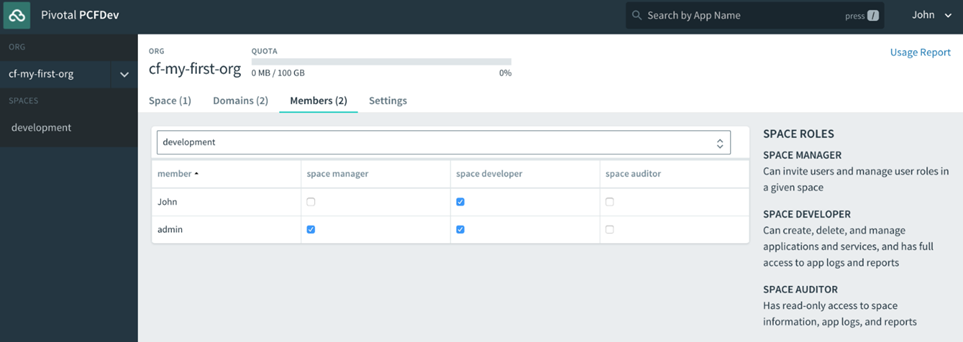
Figure 30 : Affichage des membres et de leurs autorisations sous l’espace de développement à l’aide d’Apps Manager
À ce stade, John peut effectuer les opérations d’un OrgManager pour l’organisation cf -my-first-org. Il peut également effectuer les activités d’un SpaceDeveloper dans l’espace de développement.
Vous pouvez voir à quel point il est simple d’intégrer de nouveaux utilisateurs pour utiliser Cloud Foundry. Si votre installation Cloud Foundry est configurée avec un magasin d’utilisateurs externe, comme Active Directory ou SAML, les utilisateurs devront d’abord se connecter, puis contacter l’opérateur de la plateforme Cloud Foundry pour attribuer un rôle approprié à l’utilisateur. Tous les rôles sont gérés dans Cloud Foundry.
4.5 Résumé
Dans cette section, nous avons discuté de la création d’Org, d’espaces et de comptes d’utilisateurs à l’aide de la CLI cf et du gestionnaire d’applications. Nous avons examiné les différents types de rôles pris en charge dans Cloud Foundry et avons appris comment attribuer des rôles aux utilisateurs à l’aide de cf CLI.
5 Chapitre 5. Architecture et création d’applications pour le cloud
Le chapitre 1 de cet article a présenté l’architecture de Pivotal Cloud Foundry. Cela a suivi les bases de l’interface de ligne de commande Cloud Foundry, puis les concepts des organisations, des utilisateurs, des espaces et des rôles. Dans les chapitres précédents, nous examinerons le déploiement d’applications et divers sujets avancés pour le développement d’applications Cloud. Cependant, avant de continuer, nous devons savoir comment développer une application pour le Cloud. Des questions se posent à quoi devrait ressembler l’application idéale sur la fonderie Cloud ? Comment peut-on même créer des applications pour le Cloud ? Quelles sont les considérations de conception d’application et les meilleures pratiques ? Comment et que faut-il pour déplacer une application existante vers Cloud Foundry? À la fin de ce chapitre, vous serez en mesure de répondre à ces questions.
Il s’agit d’un chapitre très important qui définira comment développer son application en tirant parti de Cloud Foundry. Nous allons couvrir les sujets suivants :
- Qu’est-ce qu’une application native du cloud ?
- Principes de la conception native du cloud
- Migration d’applications et parcours vers la conception native du cloud
- Techniques de modernisation des applications
- La modernisation des applications et votre organisation
Il s’agit en effet d’un chapitre avec beaucoup de contenu mais, une fois maîtrisé, il sera à la fois libérateur et gratifiant à mesure que vous évoluerez vers le développement de votre application Cloud.
5.1 Qu’est-ce qu’une application native du cloud ?
Une application native du cloud est une application qui embrasse entièrement les caractéristiques et le comportement d’une plateforme cloud, indépendamment de son infrastructure sous-jacente. De telles applications sont effectivement hautement évolutives et fonctionnent de manière résiliente et cohérente tout au long de leur cycle de vie.
Plongeons-nous dans cette définition. Une plateforme cloud est une plateforme qui fonctionne sur ou est intégrée à une infrastructure cloud. Cloud Foundry, comme décrit dans le chapitre 1, est une telle plate-forme qui offre les avantages de l’orchestration de conteneurs sur un certain nombre de cellules (machines virtuelles), qui offre la capacité de mise à l’échelle, de résilience et de cohérence des applications. La mise à l’échelle horizontale / d’application permet de tirer parti efficacement des ressources sur une infrastructure, de manière à ce que les instances d’application puissent être augmentées ou réduites pour répondre à différents niveaux de charges de trafic entrant. Cela maximiserait l’utilisation de l’infrastructure. Contrairement à cela est le concept de mise à l’échelle verticale, où la mise à l’échelle ici signifie augmenter / diminuer les ressources physiquement disponibles pour une application. Traditionnellement, cela implique d’augmenter le matériel du serveur physique tel que la RAM pour fournir plus de mémoire pour une application. Nous verrons plus tard que Cloud Foundry permet une mise à l’échelle verticale en réglant les applications sur une ressource allouée numériquement fixe, telle que la mémoire. Cela serait toujours limité par la quantité physique de ressources disponibles sur l’infrastructure.
La résilience fournit un moyen de récupérer des pannes d’applications ou des problèmes d’infrastructure imprévisibles. Ceci est réalisé par l’arrêt et le démarrage des cellules et des conteneurs. Enfin, la cohérence permet aux applications de fonctionner avec un environnement fixe connu qui est toujours cohérent dans toutes les cellules et tous les conteneurs. Tout cela conduit à un comportement prévisible des applications en cours d’exécution au cours de leur durée de vie, pendant et après le développement. En tant que tel, il est important de noter qu’une application native pour le cloud peut être en champ vert ou en champ brun. Il s’agit de savoir si une demande entre ou non dans la définition susmentionnée.
Outre l’héritage des avantages de la cohérence procurés par une plate-forme, le fait d’avoir une application déployée sur une plate-forme cloud ne la considère pas automatiquement comme native du cloud. Les applications doivent être architecturées et mises en œuvre pour tirer parti des avantages de l’évolutivité et de la résilience. La mise à l’échelle doit être effectuée de manière à permettre une utilisation efficace des ressources d’infrastructure. Par exemple, une application monolithique fonctionnant sur Cloud Foundry avec une mise à l’échelle horizontale peut ne pas être un moyen efficace de tirer parti des ressources de l’infrastructure.
Idéalement, l’application monolithique doit être décomposée ou architecturée en unités suffisamment dimensionnées de manière à permettre une mise à l’échelle fine d’une application, par exemple, si une seule fonction d’une application particulière, telle que “ recherche ”, subit une charge élevée, uniquement cette fonction devrait être étendue. Ceci est contraire à la mise à l’échelle d’une application monolithique complète, ce qui conduit à une utilisation inefficace des ressources d’infrastructure. Le problème supplémentaire de ne pas disposer d’unités décomposées de manière optimale est qu’une application monolithique peut ne pas être évolutive du tout et ne fonctionnerait pas une fois mise à l’échelle.
La résilience, d’autre part, garantit qu’une application, dans son intégralité, n’arrête pas de fonctionner ou ne cause pas de problèmes d’intégrité des données, tout en offrant une expérience utilisateur potentiellement améliorée. Un exemple simpliste, dans ce cas, serait la mise à jour d’une application monolithique. La mise à jour directe de l’application entraînerait des temps d’arrêt. Une alternative serait d’utiliser une stratégie de déploiement vert-bleu et d’augmenter le nombre d’instances. Pour une application monolithique, cela entraînerait potentiellement une utilisation très élevée des ressources dictée par le nombre d’instances d’application, ou entraînerait le blocage de l’application car elle n’était pas conçue pour être évolutive. Le scénario idéal et efficace serait, encore une fois, de suivre une stratégie de décomposition mentionnée pour la mise à l’échelle, en utilisant un modèle architectural connu sous le nom de Microservices. Nous en discuterons plus en détail au chapitre 7, Microservices et applications de travail. Néanmoins, avec les microservices, il serait possible de mettre à jour efficacement une petite partie de l’application sans la supprimer complètement, bien qu’avec des fonctionnalités limitées, lorsqu’elle est implémentée avec un modèle de disjoncteur. Nous pourrions aller plus loin et marier cette approche avec une stratégie de déploiement vert-bleu, qui conduirait à une efficacité des ressources de l’infrastructure et à une mise à jour sans interruption des applications.
5.2 Les principes de la conception native du cloud
Il existe 12 principes directeurs pour la conception d’applications cloud, appelés application à 12 facteurs. Ces 12 principes ont été formulés à l’origine par Heroku, qui a offert des conseils pour développer des applications natives du cloud. Plus récemment, trois principes supplémentaires ont été proposés par Hoffman, qui ont conduit à la conception d’applications natives du cloud pour des microservices sécurisés et activement profilés. Certaines parties des 12 principes originaux ont également été développées afin de clarifier et de traiter les récentes approches architecturales réussies. Nous introduisons également un principe supplémentaire dans cet article. Nous décrivons les 16 principes dans les sections précédentes.
5.2.1 Une base de code, une application
Le principe d’origine était Codebase, qui décrivait, dans un cadre plus large, un processus consistant à avoir une base de code unique déployable pour différents environnements, tels que l’assurance qualité et la production. Cela a été élargi pour englober la nécessité d’une base de code unique à couplage lâche et hautement cohésif. Pour un développeur, cela facilite la création de pipelines CI / CD. De plus, la base de code unique facilite l’intégration de nouveaux développeurs et garantit un code beaucoup plus facile à maintenir.
5.2.2 API First
Cela ne faisait pas partie des principes originaux à 12 facteurs. Le concept introduit le concept de la première approche de l’interface de programmation d’application (API) pour la conception d’une application. La conception de l’application commence aux coutures qui définissent un contrat sur quoi et comment d’autres applications interagiraient avec votre application. Cela définit le but, résultant en une application qui est indépendante, unique et facilement compréhensible dans son écosystème. Ce n’est qu’à ce moment que l’application est mise en œuvre pour ce contrat. Pour le développeur, cela signifie qu’il sait déjà quelles sont ses responsabilités en matière de service et qu’il peut facilement comprendre les fonctionnalités d’autres services qui lui sont exposées. Cela facilite le développement d’applications une fois que les responsabilités sont comprises, conduisant à un code beaucoup plus facile à maintenir.
5.2.3 Gestion des dépendances
Dans le cadre du principe original à 12 facteurs, il exige que les dépendances d’une application soient clairement définies et ne reposent pas sur un emballage / emplacement à l’échelle du système. Par exemple, ne comptez pas sur un emplacement sur le disque, comme / usr / local / lib ou le Global Assembly Cache (GAC) pour. Applications NET, où l’emplacement des dépendances est connu et devrait toujours exister. En effet, il est peu probable que ces emplacements soient configurés ou existent lors de la migration vers une plateforme cloud. Dans la gestion moderne des dépendances, nous avons des applications Maven / Gradle / NuGet pour Java et .NET, respectivement, où les dépendances sont définies et récupérées lors d’une génération. Plus loin dans le chapitre 9, Buildpacks , nous explorerons le concept des buildpacks , qui mettent en place des cadres de dépendance et la prise en charge de l’exécution, nécessaires pour créer et / ou exécuter une application, sur une plate-forme cloud telle que Cloud Foundry . Avec ce principe, les dépendances et les versions sont connues dès le départ par tous les développeurs travaillant sur la base de code. Cela facilite également l’intégration de nouveaux développeurs. Il n’y a pas d’erreur entre les différentes versions de dépendances pour chaque développeur et les environnements sur lesquels elles sont exécutées.
5.2.4 Concevoir, construire, publier et exécuter
Ce principe décrit le concept selon lequel chaque phase doit être exécutée en tant qu’étapes indépendantes isolées. Dans les 15 principes, cela a été élargi pour inclure une phase de conception initiale. Cela a clarifié la nécessité de définir les dépendances nécessaires pour l’application. En substance, la phase de conception déclare les dépendances. La phase de génération rassemble les dépendances pour produire un artefact de génération avec un numéro de génération. La phase de publication combine l’artefact de génération avec des configurations spécifiques à l’application ou à l’environnement et marque la sortie avec un certain contrôle de version à des fins de suivi / d’audit et enfin, la phase d’exécution définit le processus de lancement et d’exécution de l’application. La phase d’exécution est généralement la responsabilité d’une plate-forme cloud, mais il est nécessaire de prendre en compte les situations dans lesquelles les applications peuvent devoir être exécutées localement sur une machine de développement. Une approche populaire du contrôle de version a été l’approche de contrôle de version sémantique, qui suit le numéro de version major.minor .patch . Plus de détails peuvent être trouvés dans la spécification de version sémantique à: http://semver.org/.
L’objectif final de ce principe est le haut niveau de confiance de la reproduction d’une sortie de build. Il ne devrait pas y avoir de problème de build travaillé sur ma machine, il ne devrait pas nécessiter d’interventions supplémentaires ou avoir des builds résultants différents. En général, ce principe devrait être automatisé avec l’utilisation de pipelines CI / CD. Pour le développeur, cela conduit à des exécutables publiés qui sont traçables depuis la source de génération, ce qui facilite l’audit et le débogage.
Remarque
Dans des cas exceptionnels, il peut ne pas toujours être possible d’avoir des builds identiques à partir du même code source, par exemple, le firmware FPGA (Field-Programmable Gate Array) n’est pas garanti d’être identique après chaque build. Dans ces cas, un numéro de build associé supplémentaire serait très avantageux pour les comparatifs et les audits.
5.2.5 Configuration, informations d’identification et code
Dans les 12 principes d’origine, cela s’appelait Configuration. Le principe exige que la configuration d’une application soit externalisée en variables d’environnement. Cela permet à une application d’être configurable sans avoir besoin de modifier une version. Ceci est particulièrement utile pour automatiser le processus de génération de versions. Les informations d’identification et le code ont été inclus dans les 15 principes pour fournir une démarcation claire des informations d’identification et de la configuration du code. Il ne doit pas y avoir d’informations d’identification codées en dur et aucune configuration dans le code. Ceux-ci doivent être externalisés à des fins de configurabilité et pour garantir que les informations sensibles ne soient pas révélées si le code source est rendu public délibérément ou accidentellement.
Bien que nous ayons discuté de l’externalisation de la configuration en variables d’environnement, il reste toujours le problème de la version contrôlant le changement de configuration ou de l’ajustement net des ensembles de configuration à un objectif spécifique, par exemple pour l’assurance qualité, le développement ou la production. Une telle solution consiste à utiliser des serveurs de configuration. Spring Cloud Configuration Server est une de ces instances, qui permet de s’approvisionner en variables d’environnement à partir d’un serveur qui pointe vers un référentiel git contenant la configuration pour l’environnement d’exécution donné. Un référentiel git de la configuration signifie que les changements de configuration peuvent être suivis et ajustés en toute sécurité. Pour le développeur, cela leur permet de se concentrer uniquement sur le développement de code et de s’assurer que la configuration et les informations d’identification sont découplées et cohérentes dans tous les environnements et autres développeurs.
5.2.6 Journaux
Dans le cadre des 12 principes d’origine, les journaux dictent que la sortie de journalisation doit être traitée comme des flux d’événements et doit être simplement émise via la sortie standard et l’erreur standard. Les avantages de ce principe sont triples. La première est que les applications sont simplifiées et n’ont plus besoin de mettre en œuvre les subtilités du stockage des journaux. Au lieu de cela, toute la gestion et le traitement des journaux sont gérés en externe par la plate-forme Cloud et des outils externes. Cela simplifie le code de l’application et réduit potentiellement le risque de bogues, et permet simplement au développeur de se concentrer sur l’application pour fournir la valeur commerciale souhaitée. Le second est le support de la mise à l’échelle horizontale. Si une application était mise à l’échelle horizontalement et que la journalisation était gérée par l’application, les développeurs devraient introduire une logique pour gérer l’identification de l’instance d’application dont provient un journal. Troisièmement, une application exécutée sur le Cloud ne peut pas faire d’hypothèses sur la quantité d’espace disponible dans un conteneur et sur la durée du contenu stocké sur le disque du conteneur. Le conteneur est éphémère et, par conséquent, tout contenu stocké disparaîtra. En reportant le flux de journalisation à l’extérieur de la plateforme cloud, le stockage, le traitement et la visualisation des journaux peuvent être effectués indépendamment de l’application elle-même. Pour le développeur, cela les libère finalement d’un travail supplémentaire pour garantir la conservation des journaux. La seule responsabilité qui leur incombe est de s’assurer que les conditions d’erreur et tout autre aspect enregistrable de leur application sont émis. Cela présente également l’avantage secondaire d’avoir un code moins complexe.
5.2.7 Jetabilité
Comme c’est le cas dans les 12 principes d’origine, la possibilité de mise à disposition se réfère à la capacité d’une application à démarrer et à s’arrêter correctement, dans les deux scénarios de manière rapide. La jetabilité est une exigence en raison de la nature éphémère des applications Cloud. En termes simples, une application doit être arrêtée et démarrée rapidement afin d’être prête à gérer le trafic entrant. Dans le même temps, les applications doivent être fermées correctement, afin que les informations critiques d’une application ne soient pas perdues ou corrompues. Pour le développeur, cela leur impose une bonne contrainte pour s’assurer que le code est efficace pour le démarrage et l’arrêt. En outre, tout code qu’ils écrivent doit garantir la possibilité d’arrêts rapides et harmonieux.
5.2.8 Services de support
Les services de soutien font partie des 12 principes originaux. Tous les services de support doivent être traités comme des ressources liées / attachées. Un service de support est tout simplement un service consommé par une application. Une ressource liée / attachée est simplement la connexion entre une application et un service de support. Certains exemples de services de support incluent les magasins de données (MySQL, S3), la mise en cache (Redis) et la messagerie (RabbitMQ). En substance, une application liée à un service de support ne doit pas avoir de code spécifique à ce type de service de support. La nature générique de la mise en œuvre permettra aux services de support d’être attachés / détachés à volonté. De tels scénarios permettent aux administrateurs de remplacer rapidement et de manière fiable les services de support défaillants sans avoir à coder les mises à jour ni à redéployer les applications. Pour le développeur, cela nécessite qu’il écrive du code découplé des ressources de service. Cela conduit à un code beaucoup plus facile à tester.
5.2.9 Parité d’environnement
Initialement appelé la parité dev / prod dans les 12 principes, l’objectif était de s’assurer que les écarts entre le développement et la production étaient faibles ou inexistants. Cela a été élargi pour être la parité de l’environnement afin d’atteindre l’objectif selon lequel l’application, lorsqu’elle est créée et publiée conformément aux directives, devrait « fonctionner n’importe où » dans n’importe quel environnement connexe. Il existe trois facteurs connus pour affecter la parité, à savoir le temps, les personnes et les ressources. Le délai est lié à la situation où une application met des jours, des semaines, voire des mois pour entrer en production. D’ici là, plusieurs changements ou facteurs (professionnels, corrections de bogues, externes, etc.) peuvent avoir affecté le résultat de l’application à passer en production. En réduisant le temps, il est possible d’identifier rapidement les problèmes, de fournir la valeur commerciale souhaitée et d’itérer. Le deuxième facteur, les gens, décrit l’écart entre le développeur et l’équipe DevOps qui déploie l’application, dans une grande entreprise. Réduire l’écart entre ces personnes donnerait une meilleure parité environnementale.
Idéalement, le développeur doit être la même personne qui déploie l’application. Cependant, cela n’est pas toujours pratiquement possible, en particulier dans certaines situations de cloud privé. L’alternative serait d’impliquer étroitement le développeur dans le déploiement de l’application en production. Ou, mieux encore, utilisez des pipelines CI / CD et automatisez l’ensemble du processus. Moins l’intervention est humaine, meilleure est la cohérence et la prévisibilité du déploiement. Le troisième et dernier facteur, les ressources, concerne les différences entre les ressources utilisées pour le développement et celles utilisées pour la production. Par exemple, un développeur peut utiliser une base de données mémoire pour le développement, tandis qu’en production, une vraie base de données telle que SQL Server est utilisée à la place. Cela peut entraîner des différences de performances et de comportement des applications. Pour la parité de l’environnement, les ressources entre ces étapes doivent être identiques. En suivant le 8 e principe : Sauvegarde des services avec le 5 e principe : la configuration, les informations d’identification, et le code, il est possible de modéliser votre application à être lié avec les ressources à volonté et le même type de base de données (par exemple, un SQL Server), mais différentes instances devaient être configurées pour le développement ou pour la production. Plus loin dans cet article, nous discuterons des services, qui vous permettront de faire tourner rapidement des bases de données ou d’autres types de ressources disponibles pour une utilisation dans votre application. La principale leçon à retenir de ce principe est que tout ce que vous faites différemment d’un environnement à l’autre ne fera qu’augmenter l’écart de différence. Le but est d’éviter autant que possible d’introduire ces différences. Ce principe affecte les équipes de développement, les équipes de plate-forme et l’organisation dans son ensemble. Les équipes de la plateforme doivent garantir que les ressources et les environnements, tels que l’assurance qualité, le développement et la production, sont identiques dans toute l’organisation. Pour les équipes de développement, il permet une cadence de versions rapides qui leur permettent d’itérer leur code beaucoup plus rapidement sans se soucier des différences d’environnement. La cohérence donne confiance à toutes les équipes et permet une détermination plus rapide des problèmes. Pour l’organisation, cela conduit à la rupture des silos entre les équipes, conduisant à un développement plus rapide et innovant.
5.2.10 Processus administratifs
Ce principe décrit la nécessité d’exécuter des tâches d’administration et de maintenance, telles que les migrations de base de données en tant que processus distinct dans le même environnement de production que l’application. Le code de la tâche administrative doit être fourni avec et être exécuté sur la version pour la même base de code et la même configuration données. Cela est logique car l’outil d’administration doit faire ce que l’application fait / travaille avec la version donnée. Cependant, selon la plate-forme Cloud, il convient d’évaluer et de considérer le meilleur cours pour effectuer les tâches administratives. Par exemple, sur Cloud Foundry, il ne serait pas possible d’exécuter la tâche administrative en tant que processus généré séparément avec une instance d’une application dans le même conteneur. L’application elle-même peut être étendue à plusieurs instances, ou rien ne garantit le comportement / la vie d’une application pendant la durée du processus administratif. Le premier scénario peut introduire des complexités dans la gestion de la tâche administrative relative à chaque instance.
Ce dernier, en revanche, en cas d’échec d’une instance d’application, peut forcer l’arrêt complet du conteneur. Une solution possible, dans ce cas, serait d’introduire une application administrative avec une API reposante, qui est déployée dans le même environnement et exécutée si nécessaire. Pour le développeur, cela supprime le besoin de code administratif dans l’application elle-même et ainsi, la base de code est plus simple et plus facile à maintenir.
5.2.11 Liaison de port
Le principe original à 12 facteurs stipule que les services doivent être exportés via la liaison de port. Fondamentalement, le conteneur lui-même ne devrait pas nécessiter l’injection d’un serveur Web afin que l’application puisse être orientée Web. L’application elle-même doit contenir le service Web et se lier à un port disponible donné à partir du conteneur. Du point de vue d’un développeur, cela signifie pouvoir recevoir un numéro de port, instancier un serveur Web à partir d’une bibliothèque de serveur Web et les lier ensemble. Cependant, étant donné la nature des applications d’entreprise existantes, cela peut ne pas toujours être réalisable et peut encore nécessiter une certaine forme de serveur Web léger. Par conséquent, les contraintes imposées par ce principe devraient, dans certains cas, être assouplies. Pour les développeurs, cette contrainte assouplie les libère de la nécessité d’avoir du code de service Web dans la base de code. On Cloud Foundry, un exemple serait en cours d’exécution du framework .NET classique en utilisant l’hébergé WebCore (HWC) buildpack . Comme vous l’apprendrez plus tard, les buildpacks fournissent le runtime de support nécessaire pour construire et exécuter une application. Dans ce cas, HWC est essentiellement le cœur d’IIS sous le capot, qui reçoit un numéro de port attribué du conteneur et héberge l’application .NET Framework.
5.2.12 Processus sans état
Cela s’appelait Processus dans le principe original à 12 facteurs et déclarait que les processus d’une application devaient être sans état et ne rien partager. Les processus sans état signifient ici qu’un seul processus ne doit pas s’attendre à conserver des informations d’état, que ce soit sur le disque d’un conteneur ou dans sa mémoire, car il n’y a aucune garantie que les informations seront conservées. Si l’état doit être conservé, il doit l’être à l’extérieur de l’application via des services de support, tels que Redis. Les processus de partage de données ne se rapportent pas à l’exécution simultanée de plusieurs processus dans le conteneur. Une bonne pratique serait d’éviter de partager et de stocker l’état entre ces processus ; cela rend l’application moins complexe et plus facile à maintenir. Encore une fois, utilisez un service de support externe pour stocker les informations d’état, si cela est nécessaire.
Enfin, dans les 15 principes de Hoffman, il a été soutenu que, si les 12 principes originaux étaient plus détendus avec plusieurs processus dans un conteneur, il est préférable de n’avoir qu’un seul processus par conteneur. Pour le développeur, cela conduira à une application plus simple qui sera plus facile à maintenir et positionnera mieux leur application pour la mise à l’échelle et qui sera durable dans la gestion de l’intégrité des données en présence de conteneurs éphémères.
5.2.13 Concurrence
Ce principe, conformément à l’original 12, décrit l’exigence d’une application à l’échelle horizontale, en utilisant les principes 12 et 7. Ce faisant, il en résultera des processus qui ne partagent rien, apatrides et jetables, ce qui en fait des candidats privilégiés pour un horizontal efficace mise à l’échelle. L’alternative à la mise à l’échelle horizontale est la mise à l’échelle verticale, par laquelle le serveur / système sous-jacent d’une application est mis à l’échelle en augmentant son CPU ou sa RAM. En général, les processus sans état suivent un modèle de processus Unix qui permet aux développeurs d’architecturer leur application de manière à leur permettre de diviser les charges de travail en tant que programmes indépendants distincts et de les adapter en conséquence (https://en.wikibooks.org/wiki/A_Quick_Introduction_to_Unix/Files_and_Processes). Dans les modèles architecturaux plus récents, les microservices ont un travail de division bien défini et chaque microservice en soi est une application unique qui peut être mise à l’échelle individuellement et horizontalement. Pour le développeur suivant ce principe, cela conduira à avoir un code moins complexe et plus facile à maintenir sans avoir besoin d’avoir des informations en cache entre lui-même et ses services dépendants ou appelants.
5.2.14 Télémétrie
Ce principe est un ajout aux 12 principes et décrit le besoin de mesures et de surveillance des applications. Le déploiement d’applications sur le Cloud signifie généralement une accessibilité réduite à une instance en cours d’exécution pour effectuer une certaine forme de débogage ou de diagnostic. Il faut considérer les informations dont ils auront besoin pour saisir afin de surveiller et diagnostiquer les problèmes et les performances d’une application. Pour les équipes de développeurs et de plates-formes, cela leur donne un aperçu immédiat des besoins de leurs applications, des futurs plans de capacité et des problèmes potentiels d’application. En général, les types d’informations peuvent être classés en trois types :
- Surveillance des performances des applications (APM) : il s’agit d’un flux d’événements générés par votre application et capturés par des outils externes pour fournir des informations sur les performances de votre application. Les indicateurs / marqueurs du flux d’événements, afin de fournir les informations de performance, sont définis par vous.
- Télémétrie spécifique au domaine : il s’agit d’un flux d’événements généré par votre application et utilisé par les outils analytiques pour fournir des informations spécifiques à votre entreprise.
- Journaux d’intégrité et du système : il s’agit d’un flux de données d’événements de votre plate-forme cloud qui fournit des indicateurs tels que le démarrage, l’arrêt, la mise à l’échelle des applications et tous les contrôles d’intégrité périodiques.
5.2.15 Authentification et autorisation
Bien que ne faisant pas partie des 12 principes d’origine, l’authentification et l’autorisation décrivent la nécessité pour les applications d’être sécurisées afin d’être natives du cloud. Avant d’aller plus loin, définissons l’authentification et l’autorisation. L’authentification est l’acte de savoir qui vous êtes, c’est-à-dire vos identifiants de connexion. L’autorisation est le processus de règles qui déterminent ce sur quoi vous êtes autorisé ou non à agir pour une ressource cible, c’est-à-dire les autorisations. En sachant cela, tous les points de terminaison API doivent être sécurisés avec un contrôle d’accès basé sur les rôles (RBAC). Chaque demande entrante doit être authentifiée et, associée, une autorisation qui détermine si la demande entrante a ou non l’autorisation d’accéder au point de terminaison. Des technologies de développement d’applications modernes sont disponibles pour aider le développeur à cet égard. Le Single Sign-On (SSO) (https://www.techopedia.com/definition/4106/single-sign-on-sso) Concept avec OAuth2 (https://en.wikipedia.org/wiki/OAuth) norme d’autorisation, sont de telles idées qui peuvent être rassemblées pour atteindre cet objectif. Pour toutes les équipes, ce principe donne l’assurance que les applications et les ressources sont sécurisées.
5.2.16 Tolérance aux pannes gracieuse
Bien qu’il ne fasse pas partie des 12 principes originaux ou des 15 principes de Hoffman, cet article présente un nouveau principe qui dicte qu’une application native du cloud doit être à la fois gracieuse et tolérante aux pannes. Bien que les tests devraient toujours être en place pour détecter les problèmes avant la publication, il est toujours possible que les couvertures de test ne soient pas à 100% et que les cas d’angle soient manqués. Tout composant défaillant d’une application ne doit pas entraîner la fermeture complète de l’application ou entraîner des problèmes d’intégrité des données. En outre, un tel échec devrait être gracieux. Un échec gracieux ne doit pas planter le système / navigateur d’un utilisateur et doit plutôt fournir des informations conviviales sur l’échec. Parallèlement, cet échec doit être consigné et alerter les équipes de développement impliquées. Le disjoncteur est l’un de ces modèles de conception qui pourrait être mis en œuvre pour y parvenir. Pour le développeur, cela permet à leur application de gérer les échecs afin qu’ils ne se propagent pas et ne provoquent pas de problèmes d’intégrité des données, tout en ayant un retour rapide sur ces échecs.
5.3 Migration d’applications et parcours vers une conception native du cloud sur Cloud Foundry
Comme brièvement mentionné précédemment, une application native du cloud n’a pas besoin d’être une nouvelle application à partir de zéro, c’est-à-dire une application en vert ; nous pouvons réaliser un cloud natif à partir d’applications monolithiques existantes. Dans le contexte des affaires : ce qui est important pour la migration des applications, c’est de générer de la valeur commerciale et de recevoir un retour sur investissement de cela, rapidement, avec des commentaires critiques sur les applications, ce qui atténue un certain nombre de risques du projet. Nous pouvons appliquer ce concept en utilisant le modèle de maturité natif du cloud. Ce modèle sert de bon indicateur pour comparer l’évolution d’une application à l’épiphanie de la conception native du cloud.
Remarque
Votre application n’a pas besoin d’être native du cloud pour être déployée et exécutée sur Cloud Foundry.
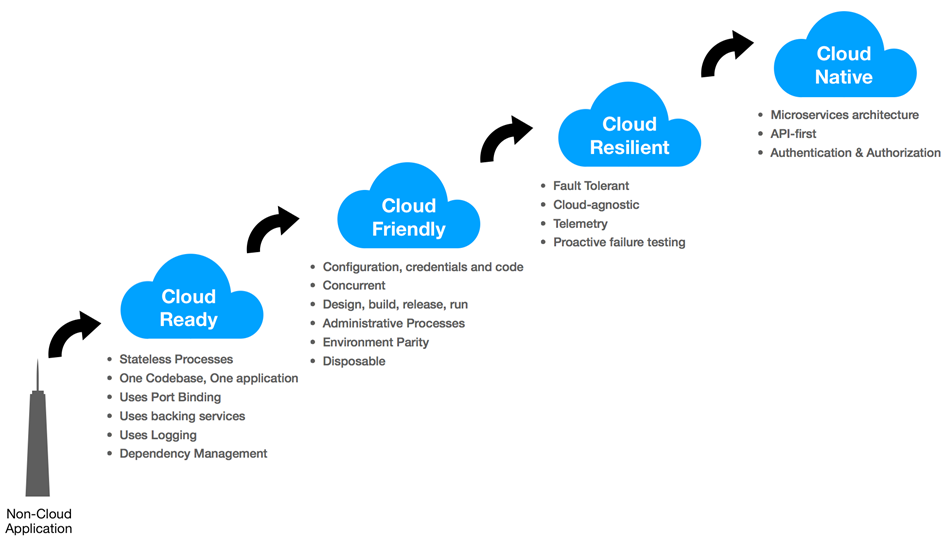
Figure 1 : Le modèle de maturité natif du cloud
Comme le montre la figure précédente, le modèle de maturité natif du cloud suit les 16 principes directeurs de la conception native du cloud. Pour réaliser la première phase, on examinerait comment ils peuvent déplacer une application monolithique existante vers le Cloud avec des changements minimes allant jusqu’à et incluant ceux mentionnés ci-dessus. Pour réaliser les phases suivantes, un certain nombre d’étapes de refactorisation devraient être effectuées. Nous appelons cela les étapes de modernisation de l’application. La modernisation est le processus d’application des 16 principes à une application monolithique et de sa décomposition en micro services. Les techniques pour des applications natives cloud résilientes sont abordées dans le chapitre 7, Micro services et applications de travail.
5.3.1 Devenir prêt pour le cloud
Génial ! Nous savons maintenant quels sont les 16 principes et le modèle de maturité natif du cloud. Mais comment commencer cette tâche monumentale ? Comme mentionné précédemment, il n’est pas toujours nécessaire de suivre l’un des principaux pour qu’une application s’exécute sur une plate-forme cloud. Le chemin le plus simple consiste à suivre une approche de développement piloté par les tests et à pousser votre application, voir ce qui se passe, corriger et itérer. Cependant, dans une approche d’investigation structurée, une façon consiste à ne rien faire au départ et à définir d’abord la structure de votre application, par exemple :
- Quelles sont les dépendances logicielles ?
- Quels sont / sont les cadres linguistiques ?
- Quelles sont les exigences du système ?
- Quels sont les magasins de données et les services de ressources que votre application utilise ?
- Comment démarrer l’application ?
D’une manière générale, l’objectif est de soulever et déplacer l’ensemble de l’application vers une nouvelle plate-forme, par exemple, Cloud Foundry. Ici, nous supposons que le système d’exploitation et le langage de développement sont identiques sur la nouvelle plate-forme. Considérez votre application monolithique comme un bâtiment. Il a une base de base pour le soutenir, il a une porte d’entrée pour vous permettre d’entrer et potentiellement, il y a d’autres sorties, une antenne parabolique géante pour la télévision, des lignes téléphoniques et des fenêtres pour la visibilité. Comprenez les fondements de base de votre application. Par la suite, comprenez ses entrées et sorties. Une fois celles-ci répertoriées, quelles sont les fonctionnalités compatibles entre la fondation d’application existante et la fondation de la nouvelle plateforme ? Quelles fonctionnalités incompatibles peuvent être remplacées ? Faites de même pour les entrées et les sorties. Si nécessaire, écrivez de petits morceaux de programmes de test pour chaque fonctionnalité et exécutez-la sur la nouvelle plateforme pour déterminer sa compatibilité.
Une fois la cartographie terminée, nous pouvons commencer à déplacer l’application monolithique vers la plate-forme. À ce stade, vous devrez choisir le buildpack adapté à votre application. Faites d’abord de petites étapes et celles qui ont un impact minimal sur le code et des effets secondaires minimes. Pour un résultat Cloud Ready, nous pourrions utiliser l’approche par étapes suivante :
- Gestion des dépendances : passez votre application à un outil de gestion des dépendances, si ce n’est déjà fait. Votre application doit toujours fonctionner sur votre serveur / plate-forme existant. S’il y a des dépendances qui ne sont pas disponibles comme outil, essayez de conditionner cette dépendance à votre demande, si practiceable et juridique de le faire.
- Une base de code, une application : assurez-vous qu’il n’y a qu’une seule application. Séparez-les dans un référentiel différent si possible. Les scripts de configuration supplémentaires ne doivent pas être exécutés initialement sur la plate-forme Cloud. Les scripts de configuration se réfèrent ici à la mise en place de serveurs d’hébergement d’applications et de ressources de disque, etc. Ceux-ci doivent être internalisés dans le code d’application ou obsolètes et permettre aux buildpacks Cloud Platform de gérer cela pour vous.
- Liaison de port : assurez-vous que votre application peut recevoir un numéro de port de la nouvelle plate-forme et s’y lier. Cela permettra à votre application de recevoir et de sortir des informations.
- Journalisation : basculez toutes les sorties de débogage sur stdout ou stderr. Selon la complexité de votre application, vous souhaiterez peut-être séparer cette étape en deux parties. Certaines applications peuvent générer des journaux de débogage et des journaux d’audit dans une base de données ou un fichier. La première consiste à basculer la sortie des informations générales de débogage sur stderr. Si possible, la seconde consiste à gérer les journaux d’audit. Nous aimerions vraiment séparer les journaux d’audit pour l’instant car ils pourraient compliquer la sortie de débogage pour faciliter votre processus de migration. Il existe plusieurs façons à ce stade de gérer cela. Soit :
- Balisez les journaux d’audit avec une balise, telle qu’Audit, puis sortez vers stdout. Par la suite, lorsque vous affichez les journaux, vous pouvez filtrer les journaux balisés d’audit.
- Laissez les journaux d’audit seuls et laissez-le continuer à écrire sur le disque / la base de données.
- Ou, désactivez la journalisation des journaux d’audit. Les options 2 et 3 reportent le refactoring de journalisation jusqu’à ce que nous commencions le refactoring des services de support et des processus sans état. Soyez conscient de l’option 2, que le disque éphémère d’un conteneur a un espace disque limité et peut provoquer des exceptions relatives à l’espace disque insuffisant.
- Services de support : Traitez tous les services de ressources d’entrée et de sortie comme un service dépendant de votre application. Votre application doit être en mesure de connaître les services dépendants à l’avance et de configurer les dépendances / pilotes logiciels nécessaires pour fonctionner dans votre application. Nous en apprendrons plus sur les services dans les chapitres suivants.
- Processus sans état : avec les services de support prêts, votre application peut facilement se connecter aux services dépendants pour garantir un processus sans état. Comme mentionné, un processus sans état ne doit pas conserver son état dans le processus d’instance d’application en cours d’exécution. Aucun fichier ne doit être écrit ou lu sur le disque local. Les journaux d’audit doivent être stockés dans une base de données. D’autres informations avec état, telles que les cookies de session, doivent être mises en cache sur certains services de mise en cache tels que Pivotal Cloud Cache, Redis, Couchbase, etc.
- Configuration, informations d’identification et code : cela tombe dans la phase suivante, étant compatible avec le cloud, il est cependant recommandé qu’au moins les informations d’identification ne soient pas dans le code et ne soient pas archivées dans un référentiel de code source ! Vous pouvez soit mettre en place un outil de gestion des secrets en tant que service de support et lire les informations d’identification, par exemple, en utilisant le coffre – fort de HashiCorp, soit stocker des informations d’identification cryptées et utiliser un service de décryptage externe au sein de votre organisation pour obtenir les informations d’identification.
À ce stade, votre application devrait pouvoir fonctionner au minimum sur la nouvelle plateforme cloud. Vous souhaiterez peut-être répéter les étapes ci-dessus pour voir s’il existe des refacteurs supplémentaires, afin de rendre votre application Cloud Ready étanche. L’étape suivante examine des étapes de modernisation d’application plus spécifiques.
5.4 Moderniser le monolithe
L’approche de modernisation d’une application vers une maturité native du cloud conduit à une application hautement évolutive et résiliente. Nous avons discuté de la manière dont une application native dans le cloud pouvait mettre à l’échelle un composant d’une application plutôt que de mettre à l’échelle l’ensemble de l’application. Considérez le scénario où un composant de recherche, qui représente 50 mégaoctets de mémoire utilisée, d’une application monolithique qui nécessite 1 gigaoctet de mémoire. L’application monolithique subit alors le double de la charge sur le composant de recherche. Naturellement, nous redimensionnerions l’instance de deux, ce qui se traduirait par 2 gigaoctets de mémoire utilisé au total. Si nous devions extraire le composant de recherche en tant que microservice, nous serions en mesure de mettre à l’échelle uniquement le composant de recherche.
Dans un monde idéal, en ignorant les frais généraux de configuration de la mémoire d’une application de microservice séparée, cela signifierait que nous aurions seulement augmenté l’utilisation totale de la mémoire de l’application à 1,1 gigaoctets. C’est une économie significative de 45% de l’utilisation de la mémoire. Il y a, bien sûr, des coûts associés à la refactorisation du code, comme l’introduction de nouveaux bogues. Cependant, ceux-ci peuvent être atténués avec des pipelines CI / CD automatisés et un développement piloté par les tests.
Pour moderniser une application monolithique existante afin qu’elle soit native du cloud, plusieurs techniques sont disponibles. Une discussion approfondie de ces techniques mérite un article entier à lui seul, cependant, nous discuterons ici d’une approche commune.
L’approche commune pour moderniser le monolithe est la suivante :
- Arrêtez d’ajouter de nouvelles fonctionnalités à l’application monolithique existante.
- Créez toutes les nouvelles fonctionnalités en tant que microservices.
- Ajoutez des couches anti-corruption entre l’application monolithique et les nouveaux microservices.
- Effectuer l’étranglement du monolithe.
En général, la première et principale étape de la modernisation de l’application consiste à cesser d’ajouter de nouvelles fonctionnalités à l’application monolithique elle-même. De nouvelles fonctionnalités devraient plutôt être développées en tant que microservices qui communiqueront avec le monolithe. La question se pose cependant de savoir comment permettre la communication entre un microservice et une application monolithique ? Le modèle de couche anti-corruption (ACL) est une réponse à cela. Le principe de base est qu’un monolithe devrait ressembler à un microservice existant pour le nouveau microservice. Ensuite, lorsqu’il n’y a pas de nouvelles fonctionnalités à ajouter, l’étranglement du monolithe est utilisé pour identifier et extraire le code existant qui peut être refactorisé hors du monolithe en tant que microservice. Naturellement, nous devrons ensuite revisiter le modèle d’ACL pour assurer la communication entre le monolithe et le nouveau microservice, et également supprimer tous les ACL existants qui ne sont plus nécessaires, c’est-à-dire que nous extrayons un nouveau microservice du monolithe qu’une fois avait une liste de contrôle d’accès et n’est plus nécessaire maintenant. Ce processus se poursuit jusqu’à ce que le monolithe soit complètement décomposé ou s’il n’y a plus de valeur pour continuer la décomposition. La figure 2 présente un chemin possible pour l’approche de la modernisation des applications :
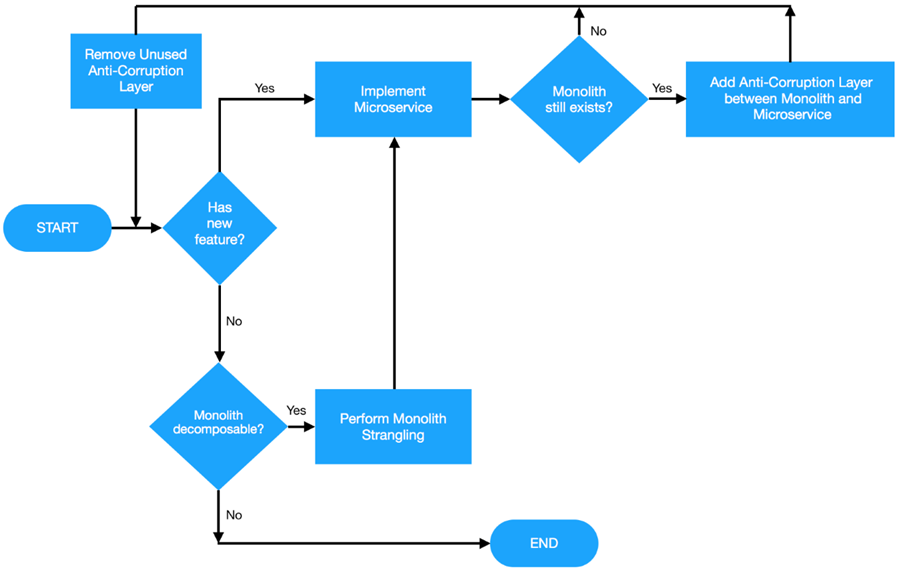
Figure 2 : Un chemin de flux pour la modernisation des applications
5.4.1 Couche anti-corruption
La couche anti-corruption (ACL) est un modèle du livre Domain-Driven Design d’Eric Evans. Le concept décrit la situation où l’on a deux systèmes qui doivent communiquer entre eux et que s’ils sont incompatibles, il doit y avoir une couche déléguée de communication pour garantir que les demandes et les réponses sont comprises par les deux systèmes. L’ACL se compose de 3 composants : une façade, un adaptateur et un traducteur. La façade, comme son nom l’indique, est un élément faisant face ou construit dans le monolithe. Le monolithe utilise cela comme un moyen de publier ses fonctionnalités. Le composant adaptateur publie des points de terminaison de service sur le monolithe afin qu’ils soient disponibles pour les micro services externes.
Le traducteur est un composant qui servirait de couche de traduction pour convertir les modèles de demande et de réponse entre le monolithe et le nouveau micro service. La figure 3 décrit cela visuellement :
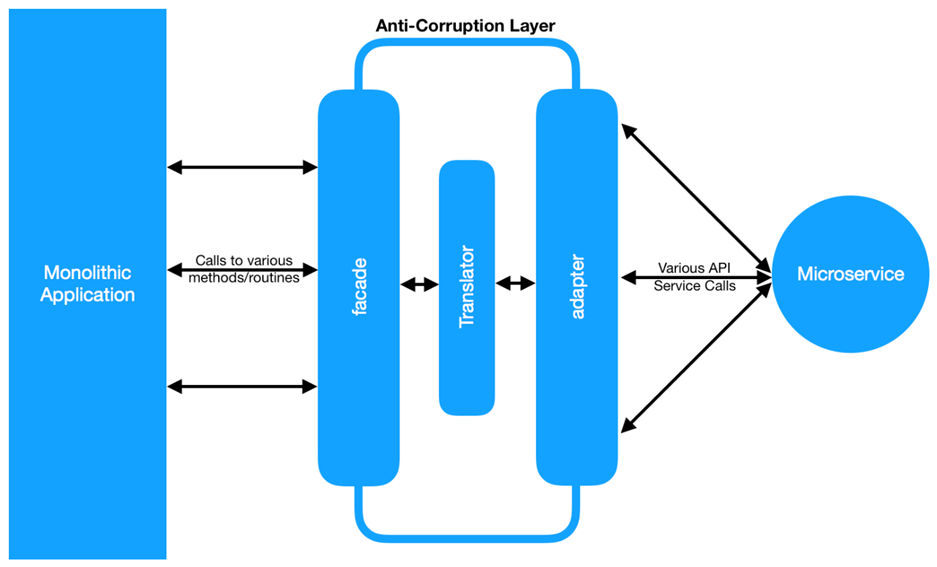
Figure 3: Le modèle de couche anti-corruption entre un monolithe et un micro service
5.4.2 Étrangler le monolithe
Le processus d’étranglement du monolithe consiste à identifier les parties du monolithe qui peuvent être extraites en tant que microservice. Le chapitre 7, Microservices et applications de travail, décrira cela plus en détail en termes de définition d’un microservice. Une fois un microservice candidat identifié, il est extrait en tant que nouveau microservice et une nouvelle couche anti-corruption est introduite pour assurer la communication avec le monolithe. La figure 4 montre cela en action :
Remarque
Dans certaines publications, l’application de monolithes est parfois appelée la grosse boule de boue .
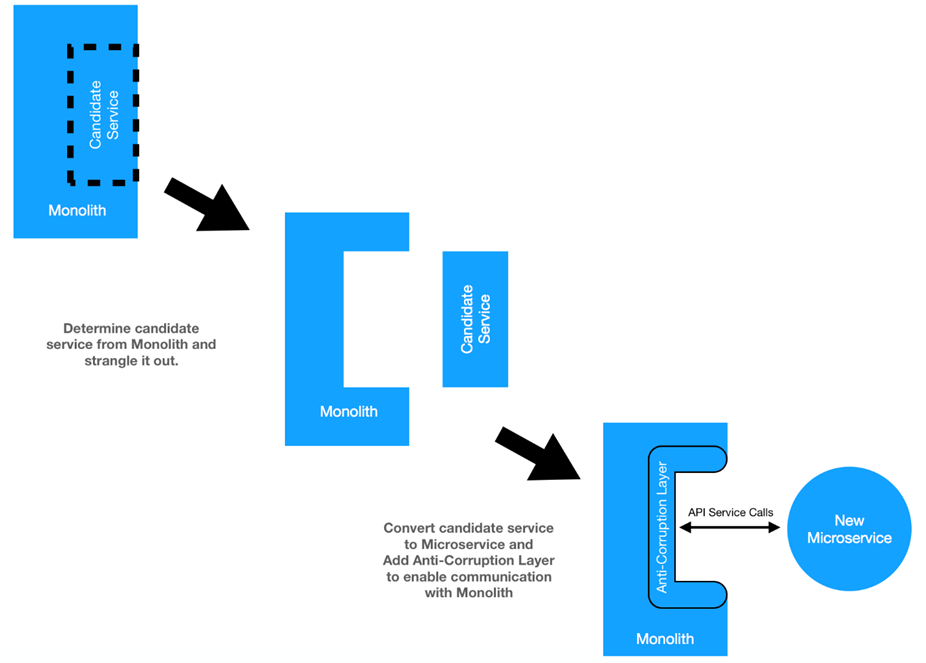
Figure 4 : étrangler le monolithe
Comment définit-on ce qu’est un service candidat ? Une approche courante consiste à comprendre les capacités métier d’une application pour former des contextes délimités, à partir desquels les microservices sont définis avec une frontière contractuelle stricte à laquelle elle communique avec le monolithe et potentiellement d’autres microservices. Ce service candidat doit être isolé et ne pas partager de services de ressources, tels que des bases de données, entre d’autres microservices et le monolithe. Ceci est communément connu sous le nom de conception pilotée par domaine et est bien présenté dans le livre, Domain-Driven Design, par Eric Evans, qui aide à déterminer les capacités commerciales d’une application à définir en tant que services.
5.5 La modernisation des applications et votre organisation
Afin de réaliser véritablement l’adoption d’une conception native du cloud et d’appliquer la modernisation à une application, un certain nombre de changements sont nécessaires dans une organisation. Le premier, évident, consiste à adopter des pipelines CI / CD tandis que les changements ultérieurs impliquent de changer l’organisation elle-même.
Dans l’article du Dr ME Conway, intitulé How Do Comités Invent ??, Publié en 1967, une observation, décrite de manière informelle par le Dr Conway, la relation entre la structure de l’organisation et la conception des systèmes dans cette organisation est discutée:
Toute organisation qui conçoit un système (défini ici plus largement que les seuls systèmes d’information) produira inévitablement une conception dont la structure est une copie de la structure de communication de l’organisation.
Essentiellement, dans le contexte du développement de logiciels, la structure d’une application suit généralement la structure d’une organisation. Par exemple, l’informatique d’entreprise est traditionnellement organisée en structures cloisonnées telles que le développement de logiciels, la gestion des versions, les opérations informatiques et l’administration des systèmes. Le résultat est tel que le personnel de chaque département est expert dans son domaine et dispose de son propre ensemble d’outils, de vocabulaires, de styles de communication et de performances cibles, c’est-à-dire qu’il est cloisonné. La collaboration entre ces services est généralement sous-optimale en raison de leurs différences. Dans le contexte d’une application, nous voyons cela comme un niveau de base de données, un niveau MVC, un niveau de moteur de service, etc. Cela conduit inévitablement à une conception d’application par laquelle il est difficile de déployer des changements innovants dans un niveau sans affecter les autres.
Dans un sens générique, la rupture des silos, ou désilofication, est une étape importante, contribuant au changement dans une organisation. Il s’agit d’un processus visant à éliminer les barrières et à encourager la communication entre les équipes d’une organisation afin de partager une richesse de connaissances et de compétences culminantes, conduisant à une accélération de l’innovation. Un exemple de ceci est l’utilisation de connaissances et de compétences partagées pour résoudre des problèmes. Considérez un scénario hypothétique plutôt simpliste où un développeur construit un module logiciel critique pour verrouiller une porte sur un produit. Comment déterminer que le module logiciel verrouille de manière fiable une porte de chambre pour permettre un fonctionnement sûr d’un produit ? Pour les logiciels, cela fonctionnerait, mais mesurer et prouver la fiabilité à long terme peut être difficile, c’est-à-dire qu’il suffit d’un bogue pour supprimer toute la fiabilité du module.
Pire encore, le module logiciel défectueux signale que la porte est verrouillée, lorsqu’elle est toujours ouverte et que le produit continue de fonctionner. Cela présenterait une situation dangereuse pour un utilisateur. Une solution consiste à collaborer avec un ingénieur en mécanique et en électricité pour construire un mécanisme de verrouillage physique qui pourrait physiquement déconnecter l’alimentation lorsque la porte est ouverte, avec lequel le développeur travaillerait en étroite collaboration pour intégrer la détection logicielle de la serrure, à des fins de rapport. Le travail du développeur est simplifié et il peut désormais se concentrer sur d’autres aspects du logiciel. Même si la détection du logiciel échoue, la porte est toujours physiquement verrouillée et le produit fonctionne ou non. Bien sûr, cela peut apporter de nouveaux facteurs à prendre en compte, mais l’idée est qu’il n’y a pas de cloisonnement entre les équipes et qu’un problème est rapidement résolu grâce à la collaboration, conduisant à un potentiel plus rapide de livraison du produit sur le marché.
C’est l’idée menant à DevOps, pour rassembler un état de communauté d’idées, d’outils, de vocabulaires, de styles de communication, etc., qui permettent l’objectif commun de produire un résultat rapidement et en toute sécurité.
Ce changement n’est pas simple à lui seul et proposer une structure organisationnelle initiale qui fonctionne est généralement difficile et peut être coûteux. Les solutions employées par les organisations souhaitant adopter des architectures natives du cloud consistent à utiliser la manœuvre inverse de Conway proposée par Leroy et Simon en 2010, dans leur article intitulé Dealing with creaky legacy Platforms, par lequel plutôt que de proposer une organisation qui change d’avance, déterminez une architecture d’application qui fonctionne et change l’organisation autour de cela. Cependant, ces changements peuvent même en fait se mettre en place naturellement pour les organisations qui adoptent une conception native du cloud, de sorte que leur culture est ouverte au changement et adopte une approche rapide de l’innovation. Essentiellement, une organisation qui subit des changements technologiques est le moteur des préférences et des comportements de ses clients. En fin de compte, cela entraînera des changements dans l’organisation elle-même ou cela aura pour conséquence que les organisations concurrentes innoveront plus rapidement et prendront les devants, comme le dit bien le rapport annuel de GE en 2000:
… lorsque le taux de changement à l’intérieur d’une institution devient plus lent que le taux de changement à l’extérieur, la fin est en vue. La seule question est quand.
5.6 Résumé
Dans ce chapitre, nous avons discuté de l’architecture et de la création d’applications pour le cloud. En particulier, nous avons appris ce qu’est une application native du cloud et quels sont les 16 principes directeurs qui nous mèneront à une application native du cloud. Plus important encore, nous avons examiné comment nous pouvons migrer les applications existantes vers le cloud, le modèle de maturité natif du cloud et le concept de modernisation des applications, ses techniques et comment il affecte votre organisation. Dans le chapitre suivant, nous verrons comment déployer des applications sur Cloud Foundry!
6 Chapitre 6. Déploiement d’applications sur Cloud Foundry
Dans le dernier chapitre, nous avions visité les concepts d’architecture et de construction d’applications pour le Cloud. Ce chapitre explore le déploiement d’applications sur Cloud Foundry. Il vous permettra de comprendre comment déployer des applications et les faire fonctionner sur Cloud Foundry.
À la fin de ce chapitre, vous saurez ce qui suit:
- Ce dont vous aurez besoin avant de pousser une application vers Cloud Foundry
- Que sont les buildpacks et comment ils sont utilisés pendant le déploiement
- Quels sont les services et comment les créer
- Comment déployer des applications sur Cloud Foundry
- Comment mettre à jour une application déployée
- Que se passe-t-il lorsqu’une application est déployée sur Cloud Foundry
- Comment faire évoluer les applications
- Comment accéder aux journaux des applications
- Utilisation d’Apps Manager
6.1 Pousser votre première application vers Cloud Foundry
Pour que les applications s’exécutent sur Cloud Foundry, nous devons d’abord pouvoir les déployer sur Cloud Foundry. Familièrement, le pousser vers le cloud est ce que vous entendrez et lirez pour indiquer le déploiement de l’application sur le cloud. La commande magique pour ce faire est :
cf push
C’est ça ! Il y a bien sûr un certain nombre de paramètres dont vous aurez besoin, tels que la spécification du nom de l’application et peut-être d’autres paramètres qui peuvent être nécessaires pour que l’application s’exécute. Cependant, avant de procéder au transfert d’une application vers Cloud Foundry, un certain nombre de conditions préalables doivent être remplies au préalable.
6.1.1 Ce dont vous avez besoin avant de pousser
Les conditions préalables minimales importantes avant de pousser une application vers Cloud Foundry sont :
- Assurez-vous que votre application est prise en charge par Cloud Foundry et / ou possède le buildpack nécessaire.
- Assurez-vous que votre application est prête pour le cloud. Bien que cela ne soit pas strictement nécessaire, cela facilitera le démarrage du développement sur le cloud en évitant les problèmes qui autrement vous gêneraient.
- Si vous avez des services de support qui seront consommés par votre application, assurez-vous qu’ils sont instanciés. Vous en apprendrez plus à ce sujet plus loin dans ce chapitre.
- Activez la sortie de débogage de votre application, si vous développez toujours votre application.
- Excluez tous les fichiers superflus du push qui ne sont pas nécessaires pour exécuter l’application. Vous pouvez éventuellement envisager de séparer les actifs statiques en tant qu’application distincte ou récupérables en tant qu’actifs de ressources, si cela est possible.
- Vous avez la cf CLI installée et vous l’avez initialisée pour pointer vers un contrôleur Cloud Foundry cible, via cf login dans pcfdev -org en utilisant l’espace de développement.
Nous avons décrit le concept et suggéré des étapes pour atteindre Cloud Ready dans le chapitre 5, Architecture et création d’applications pour le cloud. Pour être complet, nous résumerons ici les étapes minimales du Cloud Ready:
- Processus sans état : pas d’accès permanent au disque.
- Une base de code, une application : il n’y a qu’une seule application qui est poussée. Il ne doit pas y avoir de serveurs exécutables supplémentaires exécutés au préalable ou des scripts de démarrage.
- Liaison de port : l’application est indépendante du port et la reçoit de Cloud Foundry.
- Services de support : l’application traite et consomme toutes les ressources en tant que service de support.
- Journalisation : au minimum, tous les messages d’erreur et d’événement sont envoyés à stdout ou stderr.
- Gestion des dépendances : toutes les dépendances sont incluses ou répertoriées pour être récupérées via Maven / Gradle / Nuget (comme cela est pris en charge par un buildpack ).
6.2 Services
Dans le chapitre 5 , Architecture et création d’applications pour le cloud, l’ une des conditions nécessaires à la réalisation d’ applications Cloud Ready était la sauvegarde des services. Un service de support, ou service pour faire court, est tout simplement tout service en réseau qu’une application consommera. Par exemple, MySQL, SQL Server et les magasins d’objets blob S3 pour DataStores , RabbitMQ pour les services de messagerie et d’e-mailing. Notez que lorsque nous disons service, cela correspond à un plan de ce service. Pour que les applications utilisent le service, nous devons créer une instance du service, ou ce que nous appelons une instance de service. Une fois ces instances de service créées, une instance d’application peut les utiliser une fois qu’elles sont limitées.
Autrement dit, ces services sont en fait accessibles par le code d’application via une URL ou une autre forme de localisateur qui nécessite potentiellement des informations d’identification, c’est-à-dire que cela pourrait être une forme de chaîne de connexion. Lorsque cela se produit, nous disons qu’une application est désormais liée à une instance de service . Pour les exemples suivants, il est supposé que vous utilisez PCF Dev et qu’il utilise l’utilisateur admin. Dans un scénario réel, tous les utilisateurs et certaines organisations elles-mêmes ne sont pas autorisés à créer et à lier des services.
Remarque
Idéalement, votre application devrait pouvoir se connecter à l’un de ces types de services et simplement l’utiliser telle quelle. Un concept clé pour l’abstraction de service pour votre application est qu’elle connaisse le service comme ce qu’il fait réellement plutôt que de savoir ce qu’il est . Par exemple, votre application nécessite une base de données pour écrire. Ce serait formidable s’il savait qu’il n’avait qu’à gérer l’écriture et la lecture de données à partir d’une base de données, plutôt que les subtilités d’ implémentation de traiter avec un serveur MySQL ou SQL Server. De cette façon, vous pouvez simplement permuter entre les deux si vous en avez vraiment besoin (gardez à l’esprit le principe 9 : parité de l’environnement , ne faites pas cela entre l’environnement de développement et de production). Un outil pour cela est un cadre de mappage relationnel objet ( ORM ), tel que Hibernate et EntityFramework , qui pourrait lire les informations de connexion à la base de données à partir d’un service de support de base de données lié et consommer la base de données si elle est prise en charge.
Dans cette section, nous aborderons des questions telles que Comment savoir quels services de support sont disponibles pour moi ? Comment créer un de ces services et le lier à mon application ?
6.2.1 Liste des services disponibles à créer
Il existe deux façons de nous procurer un service. L’une provient de ce que nous appelons le marché et une autre se fait par le biais d’un service fourni par l’utilisateur. Le marché est simplement une liste des services disponibles sur votre fondation et votre organisation, et peut contenir des services avec des plans gratuits sur votre plate-forme ou il peut contenir des services publiés par un fournisseur de services, qui peuvent avoir un coût d’abonnement associé pour chaque plan donné. Les services répertoriés sur le marché sont mis en œuvre via l’API Service Broker, vous pouvez donc également créer vos propres services personnalisés si nécessaire. Le service fourni par l’utilisateur est simplement un service utilisateur qui fournit la configuration de connexion de liaison à votre service qui est externe à Cloud Foundry. Vous en apprendrez plus sur les services, les services fournis par les utilisateurs et les courtiers de services au chapitre 8, Services et courtiers de services.
La commande cf marketplace répertorie les services disponibles sur votre fondation.
Remarque
Le cf CLI a quelques commandes abrégées. Le marché est une de ces commandes avec un raccourci. Essayez de taper et d’ exécuter cf m .
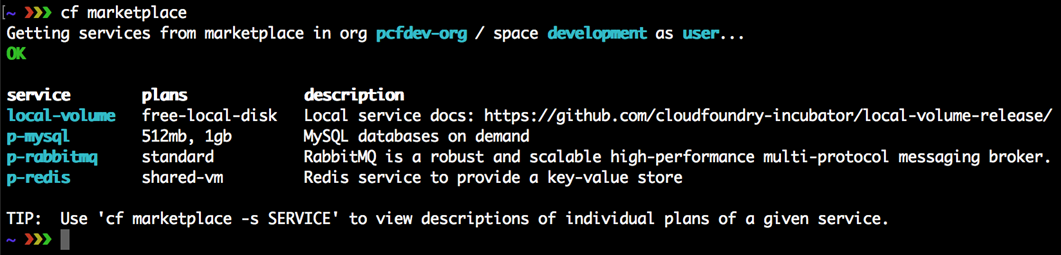
Figure 5 : liste des services disponibles sur notre fondation lors de l’exécution de la commande cf marketplace
La figure 5 montre la sortie des services disponibles après l’exécution de la commande marketplace. Par colonne, de gauche à droite, nous voyons le nom du service, les plans de service et la description du service. Dans ce cas, sur notre environnement PCF Dev, nous voyons le volume local pour l’accès au disque local (PCF Dev uniquement !), P- mysql pour la base de données MySQL, p- rabbitmq pour le service de messagerie RabbitMQ et p- redis pour la mise en cache des valeurs-clés . Les plans associés indiquent la capacité disponible ou les accords de niveau de service qu’un service peut fournir. Selon le fournisseur de services, certains de ces plans peuvent entraîner des frais.
6.2.2 Création d’un service
Avant de poursuivre avec le foll , assurez-vous que vous disposez des autorisations pour créer et lier des services. Pour les exemples suivants, vérifiez également que vous êtes connecté en tant qu’administrateur sur PCF Dev. Sinon, vous recevrez un message d’erreur Vous n’êtes pas autorisé à effectuer l’action demandée.
Pour créer un service, exécutez la commande cf create-service . Ici, SERVICE_NAME et PLAN font respectivement référence au nom du service et aux noms de plan trouvés dans la liste du marché. L’INSTANCE_NAME est le nom du service instancié. Vous aurez besoin de ce nom d’instance ultérieurement pour lier ce service à une application. Notez que vous pouvez également utiliser le raccourci, cf cs.
Donc, instancions une base de données MySQL avec un plan de capacité de 1 Go et appelons ce service my-database. La commande pour ce faire serait :
cf create-service p- mysql 1gb my-database-service

Figure 2 : résultat de l’exécution de la commande cf create-service pour instancier un plan de base de données MySQL 1 Go appelé my-database-service
Pour voir l’état du service et voir une liste de services instanciés, nous pouvons exécuter la commande suivante:
cf services

Figure 3 : résultat de l’exécution de la commande cf services pour répertorier les services instanciés
La figure 3 montre la sortie de la commande. Nous pouvons voir que notre service, my-database-service, a été instancié avec le statut de création réussi. Il est possible que d’autres services prennent plus de temps à instancier. Cela montrerait que la dernière opération était en attente. Pour le moment, rien n’est répertorié sous les applications liées, car nous n’avons pas effectué la liaison du service de base de données à notre application.
Pour voir plus de détails sur notre service instancié, nous pouvons exécuter la commande suivante:
cf service ma-base de données-service
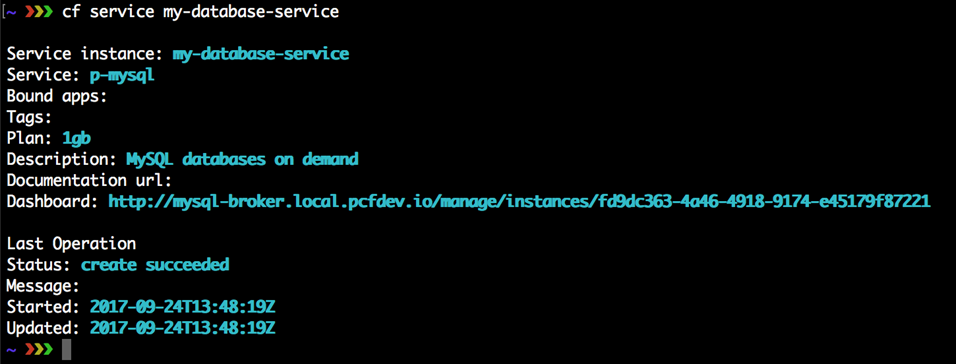
Figure 4 : Récupération d’informations supplémentaires sur le service my-database-instancié
Pour lier mon service de base de données à une application, il suffit d’exécuter : cf bind-service .
Cela liera une application nommée APP_NAME à un service nommé SERVICE_INSTANCE_NAME. Alternativement, cela peut être spécifié dans un fichier manifeste CF Push, que nous couvrirons plus loin dans ce chapitre.
Remarque
Bien que notre exemple de commande montre comment se lier à une seule application, il est possible de se lier à de nombreuses applications au sein de la même organisation ou du même espace. Vous apprendrez plus loin dans ce manuel qu’une étendue d’instance de service se trouve dans une organisation ou, dans certains cas, en fonction de l’inscription de Service Broker, limitée à l’espace. Encore une fois, nous discuterons davantage des courtiers de services plus loin dans cet article.
Bien sûr, pour le moment, nous n’avons pas encore déployé d’application sur Cloud Foundry. Ainsi, le saut à la let section suivante pour commencer à pousser une application Cloud Foundry.
Remarque
Vous apprendrez plus tard qu’après le processus de liaison d’un service à une application, une variable d’environnement JSON sera mise à jour avec une entrée appelée VCAP_SERVICES, contenant la configuration du service et des informations d’identification potentiellement aléatoires. Ces informations d’identification et cette configuration changent et ne sont pas garanties d’être toujours les mêmes pour chaque liaison. Cette variable d’environnement JSON est spécifique à chaque application et contient également une autre section appelée VCAP_APPLICATION, qui contient des informations sur l’application. C’est à partir de cette structure de données variables d’environnement que l’application lit dans sa configuration. Vous pouvez voir cette variable d’environnement avec la commande cf env .
6.3 Buildpacks
Afin de déployer et d’exécuter avec succès une application sur Cloud Foundry, un buildpack est requis pour garantir que la prise en charge d’exécution nécessaire pour votre application est configurée, ainsi que votre application pendant la transmission. Essentiellement, un buildpack se compose d’un ensemble d’outils, de composants d’exécution potentiels et de scripts qui sont programmés pour récupérer les dépendances requises par l’application pour un langage donné; déplacer la sortie compilée vers un emplacement d’exécution, compiler le code et / ou configurer l’application pour qu’elle s’exécute dans le conteneur.
Du point de vue d’un développeur, un buildpack fait ressortir les avantages polyglottes de Cloud Foundry. Il permet le développement d’applications utilisant différents types de langages de prise en charge avec des dépendances versionnées cohérentes. Du point de vue d’une équipe de plate-forme, toutes les dépendances sont cohérentes dans tous les environnements, tels que le développement et la production. Il n’est pas nécessaire de créer une dépendance de flocon de neige et une configuration de framework pour différentes équipes de développement.
Pour obtenir une liste des buildpacks actuellement installés sur votre Cloud Foundry Foundation cible, tapez cf buildpacks :
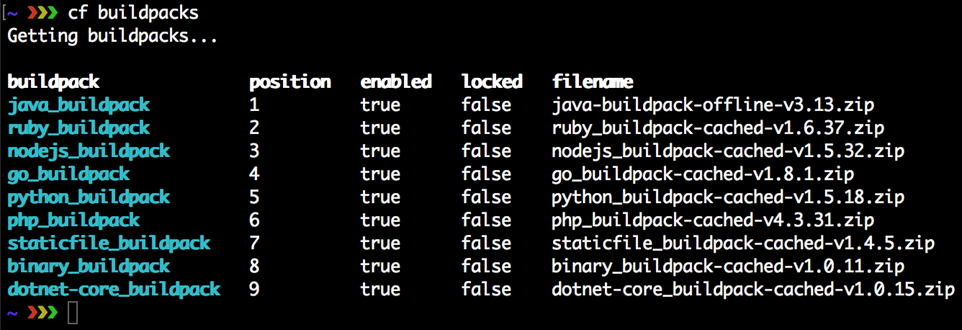
Figure 5: en tapant cf buildpacks , vous récupérerez une liste des buildpacks actuellement installés sur votre Cloud Foundry Foundation.
Remarque
Une plateforme Cloud Foundry installée est communément appelée fondation . Utilisation: Q: Combien de fondations avez-vous ? R : J’ai 500 fondations. [Naturellement, le demandeur répondra sous le choc ou le scepticisme].
Vous en apprendrez plus sur l’installation de buildpacks supplémentaires, la création de buildpacks et d’autres sujets avancés traitant des buildpacks plus loin dans cet article. Pour l’instant, la partie la plus importante de ce chapitre est de savoir comment utiliser le buildpack avec notre commande push. Eh bien, en général, nous ne le faisons pas, car cela devrait simplement fonctionner ! La commande cf push détectera automatiquement le type d’application et lui associera le buildpack correct. Chaque buildpack possède un script de détection qui déterminera si le buildpack est compatible à utiliser avec l’application grâce à la présence de certains fichiers d’application. Par exemple, le pack de build du framework HWC .NET sera utilisé en présence d’un fichier Web.config.
Alors que cf push effectue automatiquement la détection du buildpack, nous pouvons accélérer le processus de push en spécifiant le buildpack que nous voulons utiliser avec la commande cf push via le paramètre -b. Cela forcera à sauter le processus de détection. Pour utiliser le paramètre -b, tapez la commande suivante : cf push myapp -b binary_buildpack . Le nom du buildpack utilisé avec la commande -b est le même que ceux répertoriés à l’aide de la commande cf buildpacks. Alternativement, au lieu de spécifier le nom du buildpack , un URI (Uniform Resource Identifier) peut être utilisé à la place. Par exemple, cf push myapp -b https://github.com/cloudfoundry/binary-buildpack spécifie que myapp utilisera le buildpack binaire téléchargé à partir de l’URL Github spécifiée.
6.4 Déployer votre première application sur cf à l’aide de la CLI cf
Nous avons discuté des buildpacks et des services. Nous avons instancié un service à utiliser, mais nous devons d’abord le lier à une application qui est déployée sur Cloud Foundry afin de l’utiliser. Cette section va maintenant vous montrer comment déployer l’application. À des fins de démonstration, cette section utilisera l’exemple d’application Hello Spring Cloud. Le Bonjour Printemps – Cloud est un simple Java application API Web qui utilise le Cloud Connectors Spring bibliothèque afin d’inspecter les services bornés et afficher leur état de connexion.
Pour déployer notre premier exemple d’application, procédez comme suit :
- Ce projet nécessite Maven, un outil de construction et de gestion de projets Java. Si ce n’est déjà fait, téléchargez Maven à partir de: https://maven.apache.org et suivez les instructions d’installation sur le site.
- Téléchargez ou git clonez le référentiel Hello Spring Cloud sur https://github.com/Cloud-Foundry-For-Developers/hello-spring-cloud.git.
- Si l’exemple d’application a été téléchargé, extrayez le contenu du fichier ZIP dans un répertoire.
- Accédez au répertoire Hello Spring Cloud et exécutez mvn clean package pour créer l’application.
- Tapez et exécutez cf push.
Figure 6 : Exécution de cf push sur l’application Hello Spring Cloud
Toutes nos félicitations ! Vous venez de pousser votre première application vers Cloud Foundry! La figure 6 montre le résultat de l’exécution de cf push sur le projet Hello Spring Cloud. Nous reviendrons sur ce sujet plus en détail plus loin dans ce chapitre. Mais pour l’instant, exécutons l’application et voyons-la en action. Copiez simplement l’URL et collez-la dans une barre d’adresse du navigateur. L’URL de la figure 6 est hello-spring-cloud-calisthenical-padeye.local.pcfdev.io, mais vous pouvez avoir une URL différente :
Figure 7: Sortie de l’application Hello Spring Cloud sans aucun service lié
La figure 7 montre la sortie de l’application Hello Spring Cloud. Qu’est-ce qui se passe avec tous les mauvais URL et messages d’adresse invalides, vous demandez peut-être ? Cette erreur est due au fait que nous n’avons lié aucun service à notre application. Nous allons bientôt régler ce problème. Tout d’abord, discutons de ce qui se passe lors du déploiement d’une application.
6.4.1 Applications versus instances d’application
Soyez prudent quant à leur utilisation. En ce moment, nous avons parlé de déployer une application. Une application dans Cloud Foundry décrit ici l’application réelle qui a été déployée sur Cloud Foundry. Une instance d’application est une instanciation de l’application. Cela signifie qu’une application peut avoir plusieurs instances d’application en cours d’exécution. Ceci est similaire à la discussion précédente sur les services et les instances de service. Il s’agit d’un différenciateur important une fois que nous commençons à étudier les applications de mise à l’échelle.
6.4.2 Les phases du déploiement de l’application
De la figure 6, nous pouvons voir un certain nombre de choses qui se produisent pendant le déploiement d’une application. Nous pouvons séparer cela en plusieurs phases :
- Lecture manifeste : Cette phase lit dans un fichier de configuration YAML qui contient les paramètres cf push. Par défaut, le fichier est appelé manifest.yml et est inclus au même emplacement que la source de votre application. L’utilisation d’un fichier manifeste est facultative. Sans cela, vous devrez exécuter cf push avec le nom de l’application et tout autre paramètre sur la CLI. Si le fichier YAML n’existe pas, cette étape est ignorée pendant le processus de déploiement.
- Création d’entrée d’application : cette phase crée un enregistrement d’application pour l’organisation et l’espace donnés pour l’utilisateur actuel donné. À ce stade, les métadonnées sont également stockées. Les métadonnées contiennent ici des paramètres relatifs à la mémoire et à la taille du disque, au nombre d’instances d’application et à un buildpack spécifique, s’il a été entré.
- Création d’itinéraire : cette phase crée un itinéraire URL vers votre application. L’itinéraire est facultatif et peut être ignoré si votre application ne nécessite pas d’itinéraire.
- Mappage d’itinéraire : après avoir créé un itinéraire, il est mappé à votre application.
- Téléchargement du fichier d’application : les fichiers d’application sont maintenant téléchargés. Pour les nouveaux déploiements, tous les fichiers spécifiés pour le déploiement sont téléchargés. Les déploiements ultérieurs, par exemple, vous modifiez l’application et reconstruisez et repoussez exécutera un processus de hachage qui permet au processus de déploiement d’effectuer une comparaison de différenciation. Seuls les fichiers qui diffèrent seront téléchargés.
- Détection de buildpack : une fois les fichiers d’application téléchargés, le processus de détection de buildpack est effectué. Cela signifie que tous les buildpacks disponibles sur votre plate-forme sont téléchargés et comparés aux fichiers d’application pour déterminer le buildpack le mieux adapté à utiliser. Cela peut être ignoré en déclarant implicitement le buildpack que vous souhaitez utiliser avant d’effectuer un push.
- Staging : En utilisant le buildpack d’entrée, toutes les dépendances sont extraites / regroupées et les applications peuvent être construites avec une pile donnée pour produire une droplet.
- Téléchargement de gouttelettes : la gouttelette est maintenant stockée dans un blobstore interne.
- Lancement de l’application : L’application est lancée en la soumettant à un système de babillard interne qui démarre un processus d’enchères à Diego qui interroge et reçoit une réponse pour la prochaine cellule candidate Diego qui est prête à exécuter l’application.
Remarque
Diego est le cœur de Cloud Foundry qui réalise l’orchestration des conteneurs. Une cellule Diego est un type de machine virtuelle ayant un système d’exploitation, tel que Linux.
6.4.2.1 La gouttelette
Plus loin dans cet article, vous apprendrez en détail les buildpacks , mais pour l’instant, nous allons discuter brièvement du processus. Une fois qu’un buildpack approprié est associé à l’application, il procède au package du buildpack , avec la source d’application ou le binaire sur une pile cible. Une pile est un système de fichiers racine préconstruit pour un système d’exploitation pris en charge ciblé. Dans cet article, la pile est cflinuxfs2 . Pour Windows, ce sera Windows2012R2 ou le prochain Windows2016 . Ce package est stocké sous forme de gouttelettes tarball intermédiaires et une demande à une cellule Diego est lancée pour démarrer un conteneur afin de commencer un processus de transfert. Le processus de transfert prend en charge le droplet intermédiaire et exécute un certain nombre de scripts de buildpack qui extraire les dépendances, le cadre d’exécution et peut compiler l’application pour produire un exécutable. La pile reste, aux côtés des cadres de dépendances exécutables de l’application, et est reconditionnée dans une goutte finale. Cette droplet est stockée / mise en cache en interne sur Cloud Foundry et est copiée pour être utilisée par Diego Cells pour chaque lancement d’une instance d’une application.
6.4.3 Redéploiement de l’application
Pour redéployer une application, après quelques modifications, il suffit d’exécuter cf push et c’est tout ! Vous remarquerez que le processus de transmission peut être légèrement plus rapide car la plupart de l’application a déjà été créée et n’a pas besoin d’être recréée.
Remarque
Vous apprendrez que certains éléments sont conservés lorsque vous redéployez une application. En particulier, si une commande de démarrage spécifiée est utilisée avec cf push, par exemple, cf push -c “. \ Application” , cela ne changera pas après des appels successifs à cf push! Vous devrez appeler cf push -c “null” pour effacer cette commande de démarrage ou supprimer l’application et redéployer.
Pour rendre les choses intéressantes, il est également possible de redéployer une application sur Cloud Foundry avec un nom différent. Appelez simplement cf push . Ceci est très utile dans les cas où vous souhaiterez peut-être tester des modifications de code et les comparer avec une version précédente. Cela donne également la possibilité d’effectuer des déploiements vert-bleu dans un pipeline de déploiement automatisé. Nous en apprendrons plus sur les déploiements vert-bleu plus loin dans cet article au chapitre 11, Intégration continue et déploiement continu.
6.4.4 Liaison d’un service à l’application
Alors, lions maintenant notre service, my-database-service, de la section précédente et voyons ce qui se passe. Exécutez la commande comme suit :
cf bind-service hello-spring-cloud my-database-service

Figure 8 : résultat de la liaison de maintenance entre l’application Hello Spring Cloud et le service my-database
Cette commande liera le service, nommé my-database-service, que nous avons créé précédemment à notre application nommée hello-spring-cloud. Si nous actualisons notre navigateur pour la même page d’application, vous pourriez être surpris de constater qu’il apparaîtrait comme étant le même Figure 7. C’est parce que nous avons effectué la connexion ; cependant, l’application elle-même n’a pas lu les nouvelles informations de service borné et a instancié les objets nécessaires pour effectuer la lecture. Pour résoudre ce problème, il suffit d’appeler cf restart hello-spring-cloud pour relancer l’application sur Cloud Foundry.
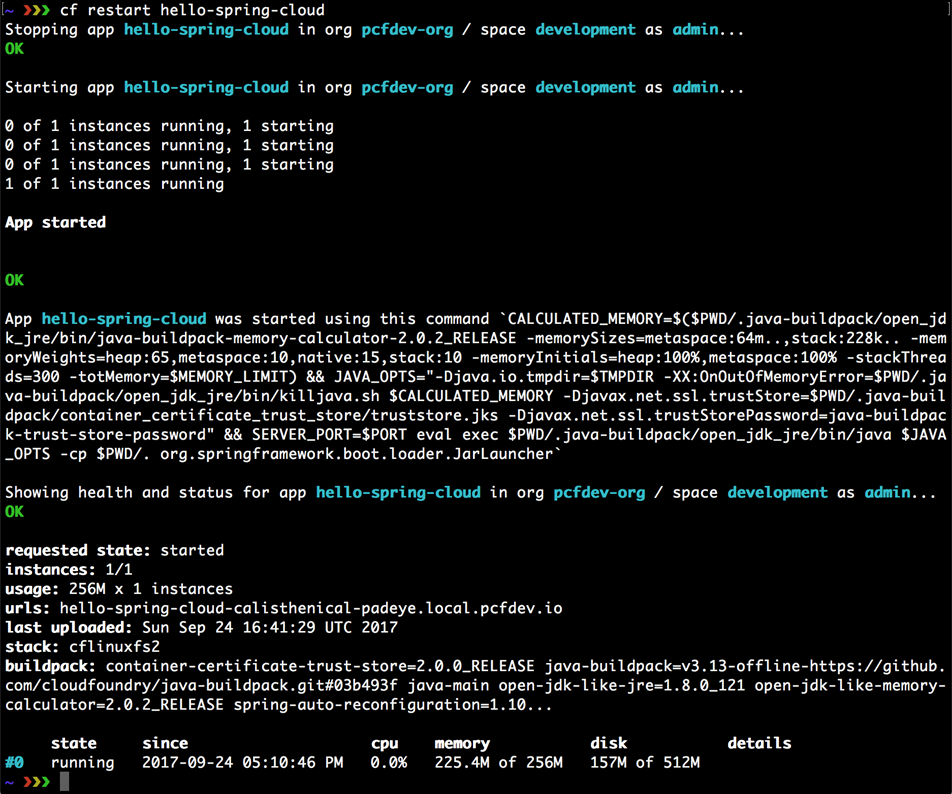
Figure 9: résultat de l’exécution du redémarrage de cf sur l’application Hello Spring Cloud après la liaison d’un service
La figure 9 montre que l’application a été redémarrée avec succès après la liaison de my-database-service. Revenez au navigateur et rechargez la page de l’application :
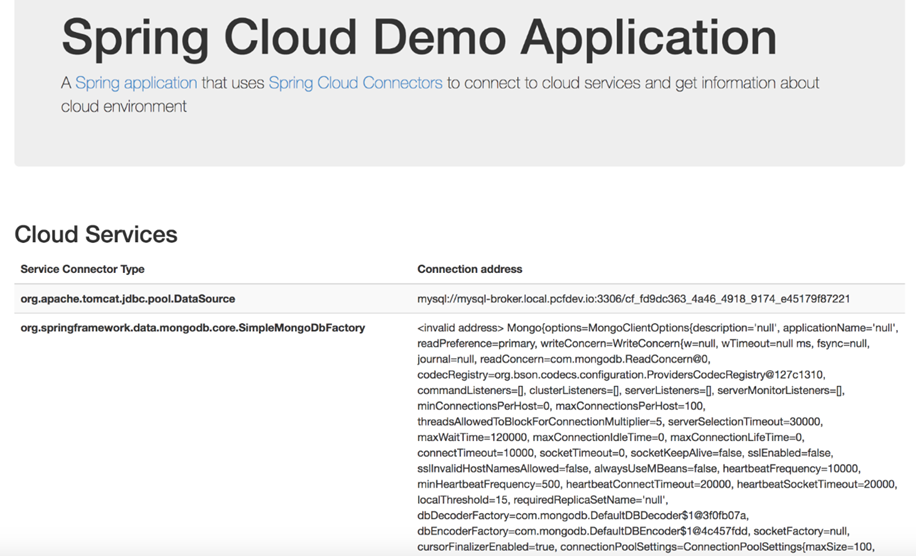
Figure 10: La sortie de l’application Hello Spring Cloud après sa liaison avec le service my-database
Avis à la figure 10 que le type de connecteur org.apache .tomcat.jdbc.pool.DataSource est maintenant rempli avec l’entrée résultante mysql: //mysql-broker.local.pcfdev.io: 3306 / cf_fd9dc363_4a46_4918_9174_e45179f87221 , au lieu de comme le montre la figure 7 . Cela montre visuellement que notre service a été correctement délimité et détecté par l’application, grâce au Spring Cloud Connector .
6.4.4.1 Recréation des applications par rapport au redémarrage des applications
Vous vous êtes déjà demandé pourquoi nous avons utilisé cf restart au lieu de cf restage comme indiqué dans la figure 8 .
cf restart demandera à une cellule Diego de prendre une gouttelette compilée, de la décompresser et de l’exécuter dans un conteneur. Un redémarrage n’est nécessaire que lorsqu’une application doit être réexécutée pour intégrer la nouvelle configuration et doit être utilisé dans les situations où un service est lié à une application pour la première fois, ou en cas de mise à jour de l’environnement variable cf env.
L’exécution de cf restage demandera à une cellule Diego de recompiler la gouttelette comme indiqué précédemment, de la décompresser et de l’exécuter dans un conteneur. Un rétablissement est utilisé lorsqu’il y a des changements de variables d’environnement dans le transfert de l’application sur Cloud Foundry. Par exemple, changer les variables d’environnement qui affectent un Buildpack. Le pack de construction Java possède une variable d’environnement, JBP_CONFIG_OPEN_JDK_JRE, qui peut être utilisée pour modifier la mémoire jvm. La modification du paramètre de mémoire et l’exécution d’un redémarrage cf ne prendront pas en compte la modification, car elle utilise une droplet qui possède déjà les paramètres de variable d’environnement précédents pour JBP_CONFIG_OPEN_JDK_JRE. Un restage est afin de recompiler la droplet avec un buildpack qui prend en compte les nouvelles modifications.
6.4.5 Fichiers manifestes
Les fichiers manifestes sont des fichiers de configuration push facultatifs. Il simplifie le processus de transmission d’une application vers Cloud Foundry en plaçant tous les paramètres de transmission dans un fichier, ce qui nécessiterait autrement qu’un utilisateur saisisse via des arguments de ligne de commande. Par défaut, cf push recherchera automatiquement un fichier appelé manifest.yml situé dans le même répertoire que les fichiers d’application. Si vous avez un fichier YAML différent, celui-ci peut être remplacé à l’aide de cf push -f . Alternativement, le fichier manifeste peut être ignoré en exécutant cf push [ … < PARAMn >] –no-manifest. En ignorant le fichier manifeste, cela signifierait que tous les paramètres push doivent être spécifiés ! Un concept important à noter est que les arguments de la ligne de commande ont toujours priorité sur le fichier manifeste. Par exemple, l’appel à cf push- i 2 forcera le processus push à ignorer le nombre d’instances spécifié dans le manifeste et à la place, à créer deux instances.
Regardons à l’intérieur du manifeste de l’application hello-spring-cloud :
Figure 11 : Le contenu du manifest.yml pour l’application Hello-Spring-Cloud
La première ligne — signifie le début d’un fichier YAML. Le mot-clé applications est un attribut qui représente l’ensemble des applications à pousser. Il est donc possible d’avoir plusieurs applications spécifiées dans un fichier manifeste à pousser. Le mot-clé suivant, – name, est le nom de l’application sur Cloud Foundry. Le mot clé, instances, signifie le nombre d’instances à mettre à l’échelle verticalement sur cette application. L’ hôte: hello-spring-cloud – $ {random-word} , représente le nom d’hôte de l’itinéraire à utiliser. Notez qu’il y a un $ {random-word} , qui fondamentalement ajoutera quelques mots aléatoires à l’URL de l’itinéraire. Enfin, un chemin est l’attribut pour indiquer à cf push où sur le disque local, les fichiers doivent être déployés sur Cloud Foundry. Un certain nombre d’autres attributs peuvent être trouvés sur: https://docs.cloudfoundry.org/devguide/deploy-apps/manifest.html . Un attribut d’intérêt particulier qui ne figure pas sur la figure 11 est l’attribut services. Cet attribut permet d’associer des applications à une ou plusieurs instances de service existantes selon les besoins. La seule exigence est que les services soient instanciés en premier.
Du point de vue d’une organisation, le processus push peut être standardisé par des fichiers manifestes, qui s’intégreraient parfaitement dans les pipelines CI / CD automatisés. À des fins de développement, ces manifestes peuvent être remplacés via la ligne de commande.
6.5 Surveillance et gestion des applications
Jusqu’à présent, nous avons déployé notre application sur Cloud Foundry. Cependant, les prochaines étapes impliqueront des étapes sur la façon dont nous pouvons gérer et surveiller nos applications. Cela peut être fait de deux manières, soit via Apps Manager, soit via l’ interface CLI cf. Vous avez déjà appris à vous connecter à Apps Manager pour créer des organisations, des espaces et ajouter des utilisateurs. Avec Apps Manager, vous pouvez également surveiller et gérer des applications. Nous allons voir comment procéder dans cette section. À des fins de script éventuelles, vous pouvez également emprunter la route CLI cf pour créer, gérer et surveiller votre application.
6.5.1 Surveillance et gestion de l’application à l’aide de cf CLI
L’utilisation de cf CLI est aussi simple que l’utilisation d’Apps Manager. Cette section vous montrera comment les principales commandes cf cf CLI sont utilisées pour gérer et surveiller votre application sur Cloud Foundry. Nous allons diviser cette section en deux parties. Le premier est la surveillance des applications et le second est la gestion des applications.
6.5.1.1 Surveillance de votre application
Dans la surveillance de nos applications, nous aimons voir un état de santé instantané et l’état de nos applications et également plonger plus profondément pour voir et déboguer la sortie de nos applications. Le suivi de votre application se compose de deux parties. Le premier voit l’état de l’application et le second utilise les journaux. Avec ces outils, il est possible pour un développeur de déterminer facilement les applications qui échouent ou ont le potentiel d’échouer. De plus, la fonction de journal aide les développeurs à évaluer et à déboguer les applications. Cela est précieux pour une organisation car les développeurs n’ont plus besoin de demander à accéder aux journaux et aux informations de surveillance. L’ensemble de la plateforme, une fois configurée, peut être en libre-service en toute sécurité, ce qui permet un développement rapide des applications.
6.5.1.2 Liste de toutes les applications dans un espace
Tout d’abord, trouvons notre application. Exécutez la commande cf apps :

Figure 12 : cf apps vous aidera à répertorier toutes les applications déployées sur votre fondation
Comme dans la figure 12 , nous voyons que l’application hello-spring-cloud a deux instances et 512 mégaoctets de mémoire, comme nous l’avions mis à l’échelle dans la dernière section.
6.5.1.3 Obtenir la santé et l’état de votre application
Pour voir l’état et l’état de notre application, exécutez la commande cf app hello-spring-cloud :
Figure 13 : cf app hello-spring-cloud montre l’état actuel et l’état de notre application
La sortie d’état et de santé donne plus de détails sur notre application. En particulier, les informations du buildpack, l’état et l’utilisation des ressources de chaque instance d’application.
6.5.1.4 Affichage des journaux d’application
La prochaine étape de la surveillance de notre application consiste à consulter les journaux de notre application. Exécutez cf logs hello-spring-cloud –recent :
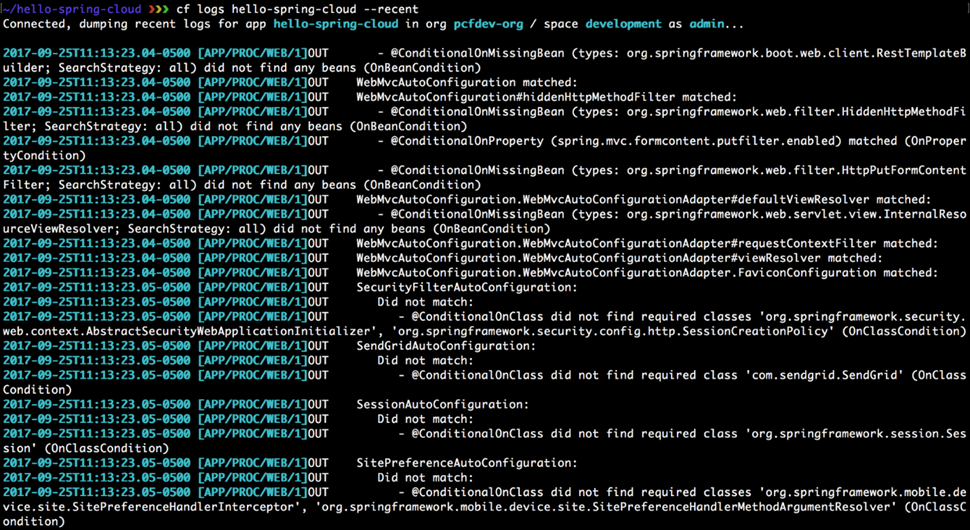
Figure 14 : cf logs hello-spring-cloud –recent montre la sortie de journal la plus récente de l’application hello-spring-cloud
Alternativement, il est possible de suivre la sortie des journaux. Exécutez cf logs hello-spring-cloud :

Figure 15 : cf logs hello-spring-cloud attend et fournit une sortie immédiate des journaux
Dans la figure 15, la commande cf logs a été exécutée sans l’option – recent. Cela signifie que les journaux sont désormais en queue et sortira une fois qu’une activité se produit avec l’application. Cette approche est très utile pour le débogage d’applications. Pour obtenir une sortie, entrons dans notre application depuis le navigateur et voyons ce qui se passe :
Figure 16 : La saisie de l’application hello-spring-cloud sur notre navigateur provoque une sortie d’activité de la journalisation
La figure 16 montre le résultat de la saisie de notre application via le navigateur Web. Il génère un certain nombre de journaux d’événements pour montrer que l’application est en cours d’exécution. Cette journalisation reste en attente et indéfiniment et renvoie les journaux à l’écran des utilisateurs. Pour quitter et revenir de retour à l’invite, entrez Ctrl + C.
6.5.2 Gérer votre application
Vous avez déjà appris à consulter nos applications et à consulter leur état de santé et leur état. Mais, nous aimerions effectuer plus de fonctions, telles que la possibilité d’exécuter certaines tâches de maintenance, de modifier les itinéraires, la mise à l’échelle de l’application ou de supprimer une application.
6.5.2.1 Mise à l’échelle de votre application
Comme vous l’avez déjà vu dans App Manager, il existe deux options de mise à l’échelle. La première consiste à redimensionner verticalement et la seconde à redimensionner horizontalement. La mise à l’échelle verticale nous permet de définir toutes les instances d’application avec une capacité de mémoire et d’espace disque définie. La mise à l’échelle horizontale, d’autre part, nous permet de définir le nombre d’applications simultanées qui s’exécuteront en même temps. Généralement, une mise à l’échelle horizontale est souhaitée pour maximiser l’utilisation des ressources de calcul et la gestion de la charge de trafic pour une application donnée. La mise à l’échelle verticale, en revanche, serait utilisée dans les situations où il existe une augmentation connue de l’utilisation des ressources de calcul par instance d’application. Par exemple, une plus grande mise en mémoire tampon des jeux de données entrants.
L’utilisation de la commande de mise à l’échelle CLI est cf scale [- i < instance_count >] [-k < disk_capacity >] [-m < memory_limit >]. Notez que seul le nom de l’application est une entrée obligatoire pour cette commande. Les autres options pour le nombre d’instances, la capacité du disque et la limite de mémoire sont facultatives et peuvent être entrées dans n’importe quelle combinaison :

Figure 17: Exécuter l’ échelle cf avec hello-spring-cloud comme seul argument affichera les paramètres mis à l’échelle actuels de l’application
L’exécution de la commande cf scale hello-spring-cloud produira une sortie qui affichera les paramètres de mise à l’échelle actuels pour l’application hello-spring-cloud. Modifions maintenant notre application pour avoir 1 instance, 256 mégaoctets de mémoire et 256 mégaoctets de capacité de disque. Nous exécutons la commande cf scale hello-spring-cloud – i 1 -k 256M -m 256M. Les M signifient mégaoctets. Nous pouvons également saisir G pour Gigabyte :
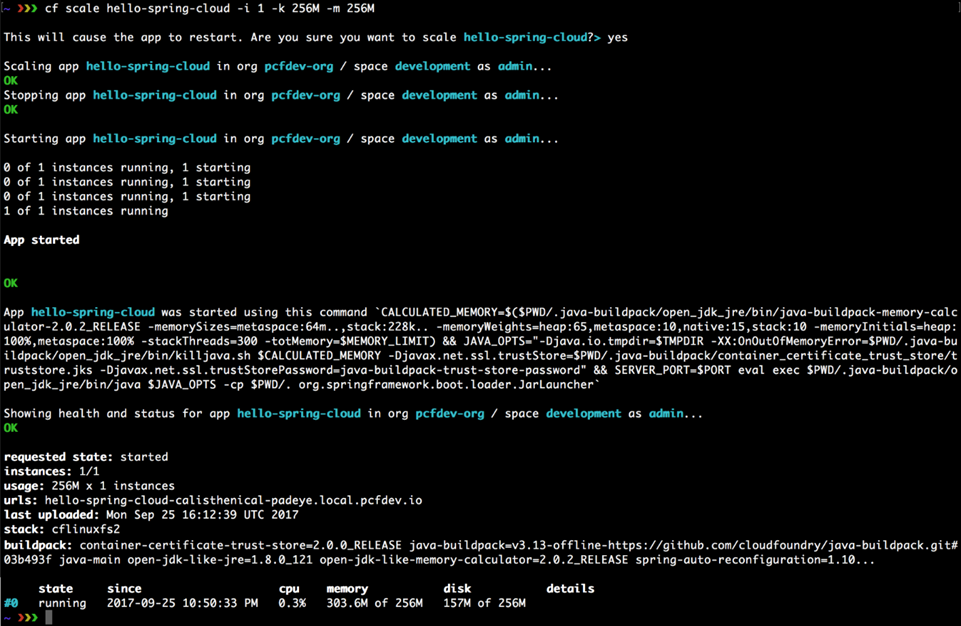
Figure 18 : Mise à l’échelle de l’application hello-spring-cloud avec 256 mégaoctets de mémoire et de capacité de disque et horizontalement sur 1 instance
Lors de l’exécution du paramètre cf scale comme illustré à la figure 18, vous serez invité à confirmer l’opération de mise à l’échelle. Nous sommes invités parce que nous avons décidé de mettre à l’échelle verticalement. N’oubliez pas que la mise à l’échelle verticale est un processus destructeur et nécessitera une nouvelle restauration et un redémarrage de l’application. Si vous ne faites évoluer qu’horizontalement, cela ne nécessitera pas l’arrêt des instances d’application existantes.
À ce stade, vous avez peut-être réalisé sur la figure 18 que l’utilisation de la mémoire avait dépassé la limite de mémoire réelle que nous avions définie (303,6 M sur 256 M) ! Ceci est probablement temporaire, en raison du démarrage initial de l’application. Cependant, cela reste un signe de danger de réduire trop les limites de mémoire sur une application en cours d’exécution et de la nécessité d’analyser davantage les besoins en mémoire de l’application. Lorsque la limite de disque ou de mémoire est atteinte, l’instance d’application sera forcée de s’arrêter. Cloud Foundry enverra à l’application un signal SIGTERM pour l’informer de cet événement imminent et qu’il dispose de 10 secondes pour effectuer son nettoyage s’il n’est pas encore tombé en panne. Après 10 secondes, l’application sera fermée de force. Lorsqu’il y a trop de redémarrages consécutifs, c’est-à-dire des battements, l’application commencera à échelonner les tentatives afin qu’une certaine latitude soit fournie pour répondre au scénario dans lequel un service ou un système a besoin de temps pour récupérer avant que l’application ne soit réactivée.
6.5.2.2 Tâches d’application
Les tâches d’application sont simplement des applications ou un script qui sont exécutés séparément de l’application principale et de ses instances. L’application principale est considérée comme un processus de longue durée, tandis que les tâches d’application sont des processus de courte durée. Ce faisant, cela permet d’exécuter des tâches administratives / de maintenance pour l’application, c’est-à-dire Principal 10 : Processus administratifs. Certaines tâches incluent les migrations de base de données et les travaux par lots. Notez que la tâche n’est exécutée qu’une seule fois dans un conteneur pour une application donnée. Il n’y a pas d’option pour choisir quel conteneur, car il crée un nouveau conteneur avec les fichiers d’application et exécute la commande souhaitée.
Dans la forme la plus simple, nous pouvons exécuter des commandes de script Linux sur une cellule basée sur Linux. Veuillez noter que l’exécution manuelle des tâches n’est généralement pas une approche recommandée, car elle introduit un changement qui peut ne pas faire partie d’un processus CI / CD. Néanmoins, le résultat de sortie de ces tâches est collecté dans les journaux, qui peuvent être consultés après. La commande run task est cf run-task

Figure 19: Résultat de l’exécution de la tâche d’exécution cf. La tâche est mise en file d’attente pour exécution
La liste des répertoires devrait être une opération rapide. Voyons le résultat. Exécutez la commande cf logs hello-spring-cloud –recent | grep “my-ls”. Cette commande affichera les journaux les plus récents et ne renverra que ceux qui contiennent le nom my-ls, comme nous le verrons dans la figure 20. Notez la création et la destruction du conteneur qui exécute la tâche.
Remarque
Les cf journaux bonjour-printemps-nuage – recents | grep “my-ls” utilisera grep . Pour d’autres systèmes d’exploitation qui n’ont pas grep, par exemple Windows, vous pouvez soit télécharger un outil grep , utiliser FINDSTR dans l’invite de commande ou Select-String dans PowerShell. Sinon, il suffit d’appeler cf logs hello-spring-cloud –recent seul pour afficher tous les résultats du journal et trouver la sortie de la tâche, qui se trouve généralement à la fin de la sortie.
Figure 20: Le résultat de sortie de la tâche d’exécution my-ls
6.5.2.3 Routes et domaines
Un itinéraire permet d’activer un accès adressable (URL) à une application. Un itinéraire se compose d’un nom d’hôte et d’un domaine. Un nom d’hôte est, par défaut, représenté par le nom de l’application et le domaine est une adresse affectée à une organisation. Avec les routes et les domaines, il est possible de séparer proprement les applications et de les organiser en organisations, afin que les applications d’un domaine donné coexistent. Nous explorerons également d’autres types de routes et de domaines, ainsi que la façon de les mapper et de les démapper plus loin dans ce chapitre.
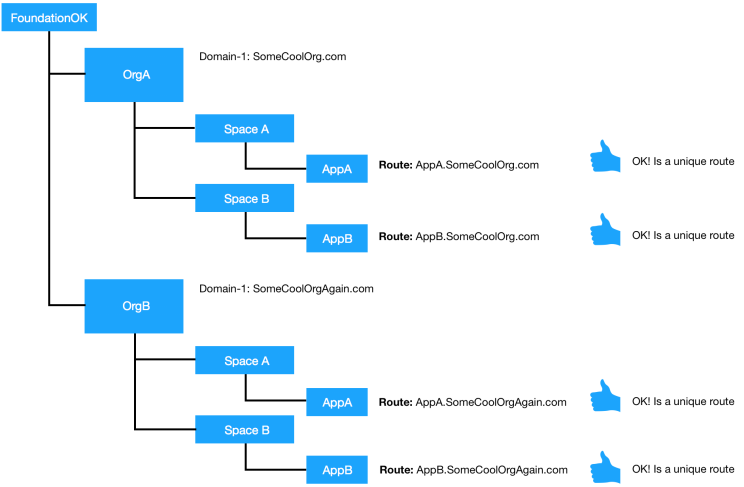
Figure 21 : Un exemple de route et de domaine valides. Les itinéraires doivent toujours être uniques
Il est également possible d’avoir le même domaine entre les organisations, mais il n’est pas possible d’avoir le même itinéraire entre les organisations. Une disposition visuelle de cette structure peut être vue sur la figure 22.
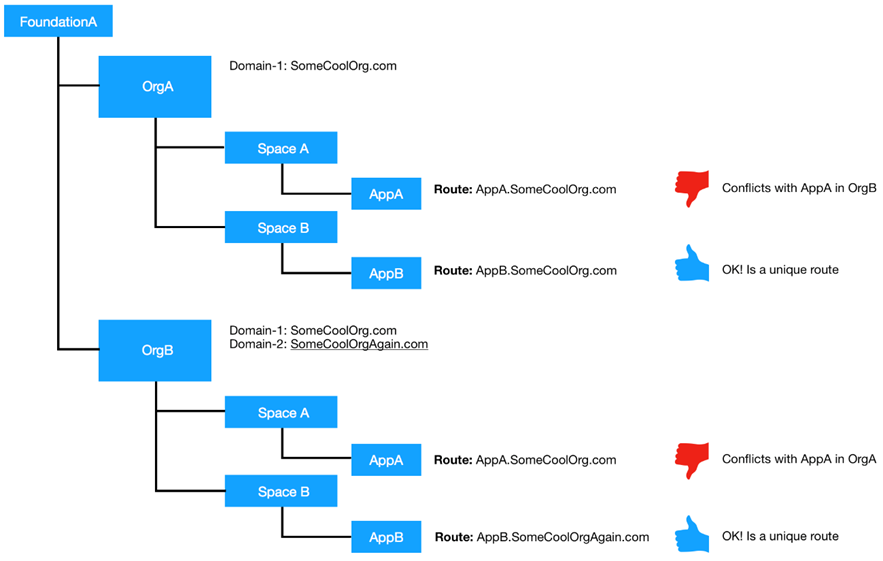
Figure 22 : Un exemple de cas d’échec de routes et de domaine. Les itinéraires doivent être uniques mais les domaines peuvent être partagés entre différentes organisations
6.5.2.4 Domaines, domaines HTTP et domaines TCP
Les domaines ont quelques différences de terminologie par rapport au domaine conventionnel. En dehors de cela, les domaines sont uniques et doivent être résolus par un serveur DNS ; dans Cloud Foundry, un domaine peut être un domaine partagé ou un domaine privé. Un domaine partagé est celui où un domaine est disponible pour tous les utilisateurs de toutes les organisations. Un domaine privé, en revanche, est personnalisé et enregistré en privé. Ils peuvent également être partagés entre les organisations, mais des autorisations doivent être accordées à des membres spécifiques d’une organisation pour mapper les routes de leurs applications afin d’utiliser ces domaines. Une autre différence entre un domaine partagé et un domaine privé est qu’un domaine partagé peut être configuré pour fonctionner avec HTTP et TCP, tandis qu’un domaine privé ne peut fonctionner qu’avec des protocoles HTTP / HTTPS uniquement.
Les domaines qui fonctionnent dans le protocole HTTP sont appelés domaines HTTP, tandis que les domaines qui fonctionnent dans TCP sont appelés domaines TCP. En raison de la nature de TCP étant la couche 4 sur la pile OSI et agnostique au protocole, il doit y avoir un groupe de routeurs TCP qui définit une plage de ports réservés pour les routes TCP. Nous verrons plus loin la définition des routes TCP. En général, un cas d’utilisation des routes TCP concerne les exigences réglementaires qui exigent que la terminaison de Transport Layer Security (TLS) soit proche de l’application afin que le déchiffrement des paquets ne soit pas effectué avant d’atteindre l’application, mais plutôt par l’application.
6.5.2.5 Affichage et gestion des domaines partagés HTTP
Pour afficher les domaines disponibles pour une organisation, exécutez la commande cf domaines :
Figure 23 : La sortie des domaines cf , montre les domaines actuellement dans l’organisation
Pour créer un nouveau domaine partagé, nous exécutons la commande cf create-shared-domain < nom_domaine >. Créons un nouveau domaine HTTP partagé appelé my-shared-domain.coolorg.com :
Figure 24 : Résultat de la création du domaine HTTP partagé my-shared-domain.coolorg.com et de l’exécution des domaines cf pour obtenir la liste des domaines actuellement disponibles pour notre organisation
Pour supprimer le domaine HTTP partagé, nous pouvons exécuter la commande cf delete-shared-domain my-shared-domain.coolorg.com. Vous serez invité à confirmer la suppression du domaine partagé. Ceci est important car une fois le domaine supprimé, il ne peut pas être récupéré et les applications perdront leurs itinéraires respectifs :
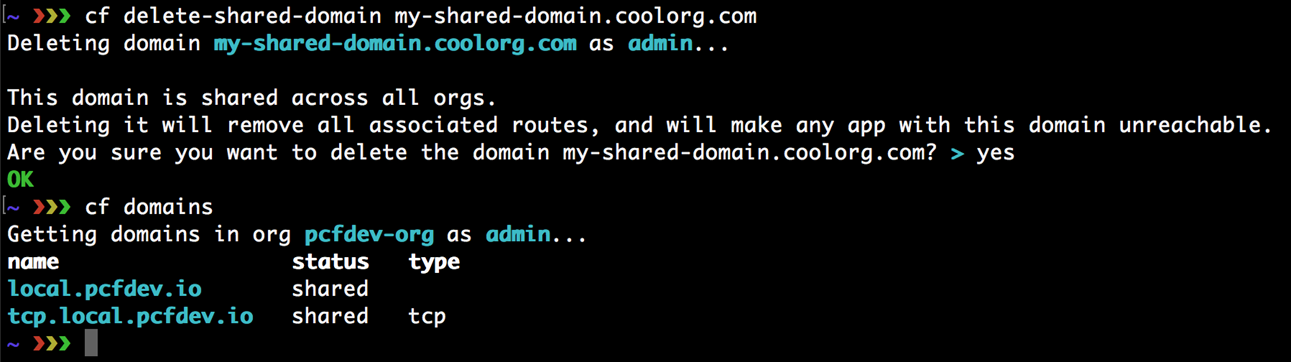
Figure 25 : résultat de la suppression du domaine partagé HTTP my-shared-domain.coolorg.com
6.5.2.6 Affichage et gestion des domaines partagés TCP
Comme nous l’avons mentionné précédemment, un domaine partagé peut fonctionner en HTTP ou en TCP. Les étapes précédentes ont montré comment créer un domaine partagé HTTP. Nous allons maintenant explorer la création de domaines partagés TCP.
La création de domaines partagés TCP suit le même chemin que les domaines partagés HTTP ; l’exception ici est l’exigence d’un groupe de routeurs dans la commande, c’est-à-dire cf create-shared-domain –router-group . Pour récupérer la liste des groupes de routeurs, nous pouvons le faire via la commande cf router-groups. La figure 26 effectue cette étape et montre le résultat de la création d’un domaine TCP :

Figure 26 : résultat de la création d’un domaine partagé TCP tcp.my-shared-domain.coolorg.com
6.5.2.7 Affichage et gestion des domaines privés HTTP
Jusqu’à présent, nous avons discuté des domaines partagés. Il reste un autre type de domaine que nous allons examiner et c’est le domaine privé. Il est important de se rappeler que Cloud Foundry ne prend actuellement en charge que les domaines privés HTTP et non TCP. La création de domaines privés suit également un modèle de commande similaire aux domaines partagés, sauf qu’elle nécessite un nom d’organisation à associer et le nom de domaine privé. La commande est cf create-domain . Créons un domaine privé avec un sous-domaine privé. Tout d’abord, nous exécutons la commande cf create-domain pcfdev -org my-private-domain.com suivie de cf create-domain mycorner.pcfdev -org my-private-domain.com :
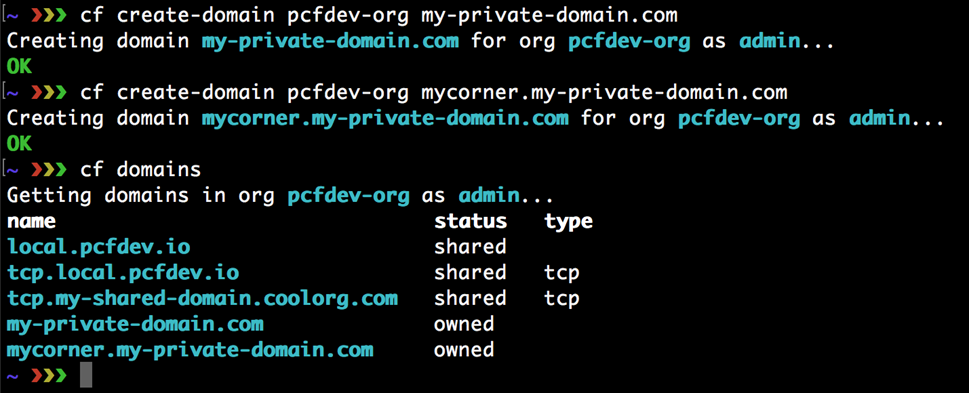
Figure 27 : Création du domaine privé my-private-domain.com et de son sous-domaine mycorner.my-private-domain.com. Ces domaines privés sont créés pour pcfdev -org
Remarquez comment nous pouvons créer un sous-domaine pour le domaine privé. Nous pouvons également créer un sous-domaine privé d’un domaine partagé ; cependant, nous ne pouvons pas créer un sous-domaine partagé pour un domaine privé. Pour faire la différence entre les domaines partagés et privés, la sortie d’état dans les domaines cf montre partagée ou possédée, respectivement.
Pour permettre à un domaine privé d’être utilisé avec un autre Org, disons OrgB , nous exécutons la commande cf share-private-domain OrgB my-private-domain.com :
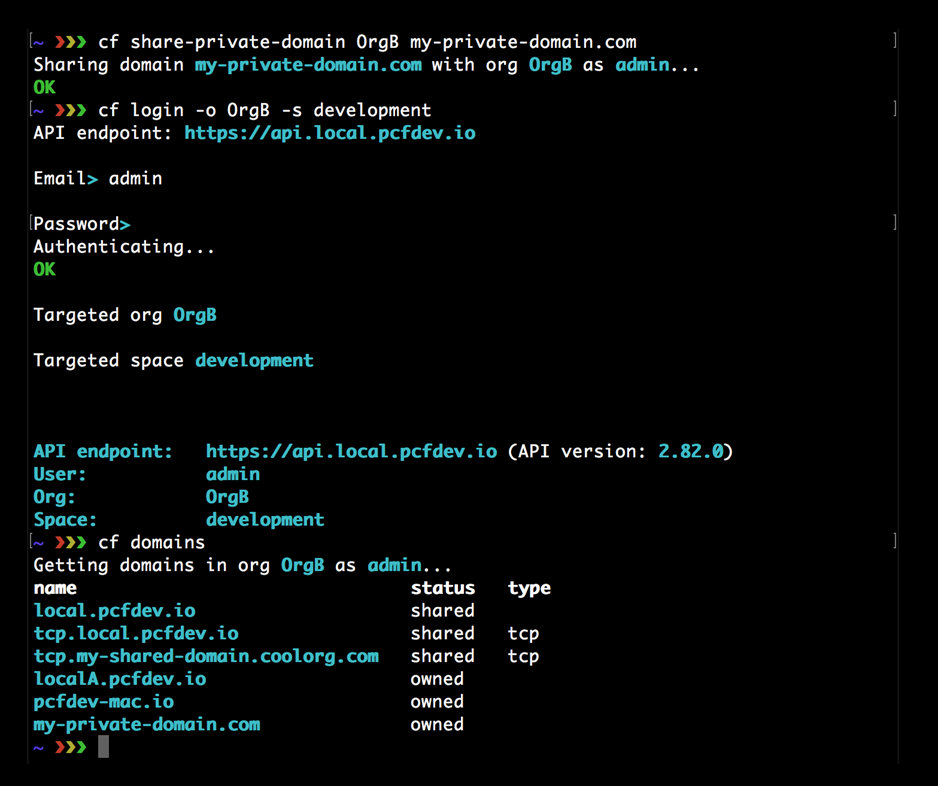
Figure 28 : résultat du partage d’un domaine privé avec OrgB . Nous nous sommes connectés à OrgB afin de voir les domaines disponibles pour OrgB
Notez dans la figure 28 que même si nous partagions le domaine privé parent, le sous-domaine privé n’était pas partagé. De même, pour annuler l’utilisation d’un domaine privé, exécutez cf unshare -private -domain OrgB my-private-domain.com. La figure 29 montre le résultat de la séparation du domaine privé :
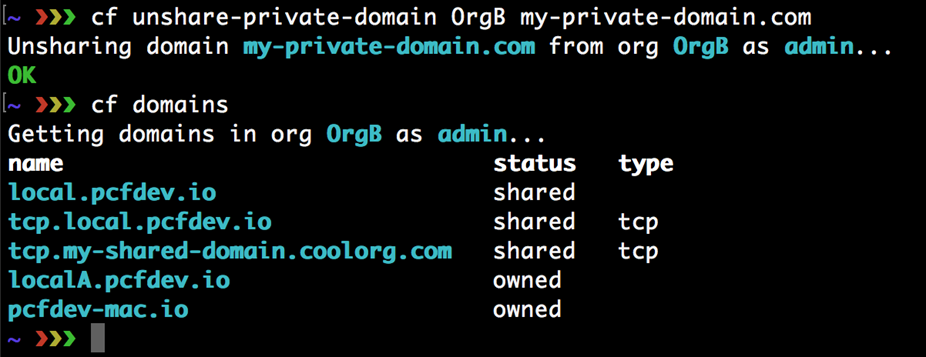
Figure 29 : Le résultat du partage d’un domaine privé avec OrgB
6.5.2.8 Routes, routes HTTP et routes TCP
Un itinéraire est une adresse à partir de laquelle les applications sont accessibles. Les deux principaux types de routes sont les routes HTTP, qui sont celles créées dans les domaines HTTP, et les routes TCP, qui sont celles créées dans les domaines TCP.
La différence ici, en dehors des types de domaine, est que les routes HTTP communiquent sur les ports 80 et 443 et ne peuvent réserver aucun autre port. Contrairement aux routes TCP, qui ne prennent pas en charge le nom d’hôte et les chemins d’accès et ont un port à usage unique, qui, une fois réservé, ne peut plus être utilisé pour une autre route différente. Un aspect clé des routes HTTP dans Cloud Foundry est que les demandes entrantes atteindront le GoRouter , après un équilibreur de charge, qui mappe des routes HTTP spécifiques aux applications. S’il existe plusieurs instances de l’application, le GoRouter alloue le trafic à chaque instance d’application de manière circulaire pour équilibrer la charge. Les routes TCP, en revanche, sont basées sur le concept de mappage de port où les demandes TCP entrantes sur un port donné sont mappées à une application via un routeur TCP, après un équilibreur de charge.
Avant d’aller plus loin, assurez-vous que vous vous êtes reconnecté à l’espace pcfdev -org et au développement. Pour répertorier toutes les routes de l’organisation et de l’espace actuels auxquels vous êtes connecté, exécutez la commande cf routes. La figure suivante montre ce résultat :
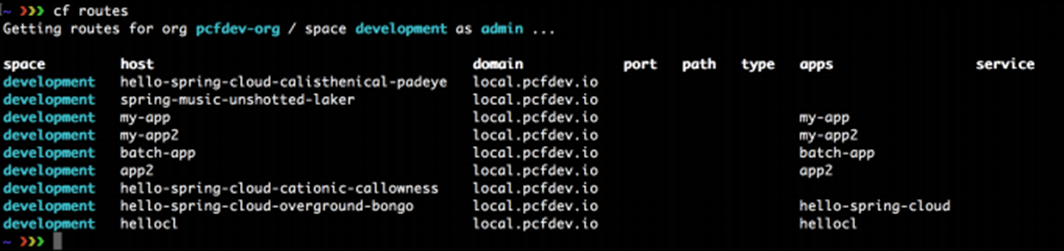
Figure 30 : Liste de toutes les routes pour pcfdev -org dans l’espace de développement
6.5.2.9 Création de routes HTTP
Pour créer une route HTTP, exécutez la commande cf create-route < nom_espace > < nom_domaine > [–hostname < nom_hôte >] [–path < nom_chemin >]. La création d’itinéraire nécessite la saisie de l’espace auquel nous souhaitons affecter l’itinéraire ainsi que le domaine des itinéraires. Facultatif se rapportant à cette commande sont le nom d’ hôte et le chemin, qui décrit une adresse URL construite du format < hostname_ name.domain _name > / < path_name > . Au fur et à mesure que nous approfondirons les itinéraires, vous apprendrez quoi et comment ils sont utilisés.
L’exécution de la commande cf create-route sans le nom d’hôte et le chemin facultatifs ne fonctionnera que pour les domaines privés. Notez qu’un domaine privé doit d’abord être défini avant de pouvoir créer un itinéraire vers le domaine privé. Nous pouvons créer le domaine privé à l’aide de la commande cf create-domain, que nous avions couverte dans la section précédente, Affichage et gestion des domaines privés HTTP :

Figure 31: Création d’une route privée HTTP, my-private-domain.com dans l’ espace pcfdev -org et de développement
6.5.2.10 Création de routes HTTP avec l’option de nom d’hôte
Créons d’abord une route avec le nom d’hôte, superRoute, pour notre espace de développement sur le domaine local.pcfdev.io :

Figure 32 : Création de la route HTTP superRoute.local.pcfdev.io
De la figure précédente, vous remarquerez que nous créons un itinéraire nommé superRoute sans nécessiter une application appelée superRoute. Ceci est contraire au cas général où le nom de l’application sert de nom d’hôte. Cela présente des cas d’utilisation très importants, dont l’un est les déploiements bleu-vert, dont nous parlerons plus loin dans cet article au chapitre 11, Intégration continue et déploiement continu, sous la section Déploiements à temps d’arrêt zéro .
6.5.2.11 Création de routes HTTP avec un nom d’hôte générique
En utilisant l’option hostname, il est possible de créer une route générique :

Figure 33: Création d’une route générique HTTP
Une route générique signifie que toutes les demandes avec une route qui a n’importe quel nom d’hôte entré par l’utilisateur seront transmises au domaine spécifié, par exemple, local.pcfdev.io , comme dans la figure précédente.
6.5.2.12 Création d’un routage de chemin de contexte HTTP
Dans les sections précédentes, nous avons visité les concepts de création de routes HTTP. Dans cette section, nous examinerons le routage de chemin de contexte HTTP. L’utilisation de cf create-route avec l’option –path nous permet de créer un chemin pour une route donnée pour n’importe quelle application :
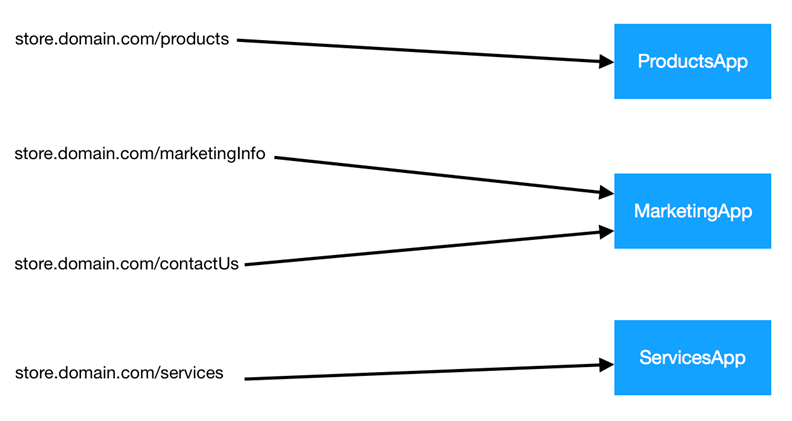
Figure 34: Un exemple de routage de chemin de contexte. Chaque route identique a un chemin qui achemine les demandes vers une application
Le routage de chemin de contexte nous permet de mapper des applications sur la base d’un chemin pour un itinéraire donné, comme nous pouvons le voir dans la figure précédente. Pour l’un des chemins précédents, nous pouvons créer une route de chemin de contexte par la commande cf create-route development domain.com –hostname store –path products. Ceci est extrêmement utile dans les architectures d’une application, où il y a une séparation claire des responsabilités. Cela permet une évolution vers un modèle de type microservice si cela est fait correctement.
Remarque
Au moment de l’écriture, le routage de chemin de contexte n’est pas encore pris en charge dans ASP.NET sur Cloud Foundry. Cela nécessite la configuration du Hosted Web Core, situé dans le buildpack HWC . Cependant, des travaux sont en cours pour cette fonctionnalité.
Faisons maintenant un exemple d’application pour montrer le routage du chemin de contexte en action. Nous allons modifier l’application hello-spring-cloud-services afin que sa page d’accueil affiche Hello Services. Nous allons ensuite créer des chemins de contexte, en mappant le chemin / home vers hello-spring-cloud et / services vers hello-spring-cloud-services. Par la suite, nous les déploierons dans Cloud Foundry. Avant de commencer, cependant, nous devrons modifier le code de mappage de route afin que le HomeController puisse router toutes les demandes entrantes vers le code de contrôleur approprié.
- Modifiez l’application HomeController hello-spring-cloud pour suivre n’importe quel itinéraire :
- Ouvrez le fichier source situé dans hello-spring-cloud / src / main / java / helloworld /HomeController.java avec votre éditeur préféré.
- Remplacez @ RequestMapping ( “/”) par @ RequestMapping (“/ *”) .
- Accédez au répertoire racine source, c’est-à-dire hello-spring-cloud, et exécutez mvn clean package.
- Mettre à jour l’itinéraire contextuel hello-spring-cloud : accédez au répertoire hello-spring-cloud et utilisez votre éditeur préféré pour modifier le fichier manifest.yml . Suivez ces étapes :
- Renommez le nom de l’application en hello-spring-cloud-home.
- Supprimez l’hôte de ligne : hello-spring-cloud – $ {random-word} line.
- Ajoutez la route hello-spring-cloud-context-path.local.pcfdev.io/home comme route vers l’application.
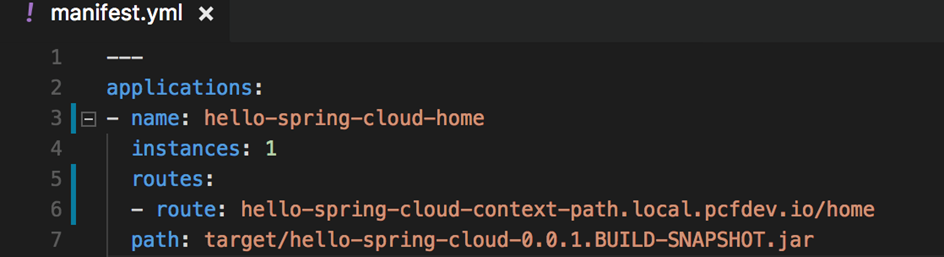
Figure 35: Ajout d’un routage de chemin de contexte dans le manifeste à l’aide de la route hello-spring-cloud-context-path.local.pcfdev.io/home
- Déployez l’application hello-spring-cloud sur CF : exécutez cf push.
- Créez une copie de l’application hello-spring-cloud et nommez-la hello-spring-cloud-services : accédez au répertoire racine de l’emplacement de votre répertoire d’application hello-spring-cloud et exécutez la commande cp -rf hello-spring- cloud hello-spring-cloud-services.
- Mettre à jour la route contextuelle hello-spring-cloud-services : accédez au répertoire hello-spring-cloud-services et utilisez votre éditeur préféré pour modifier le fichier manifest.yml .
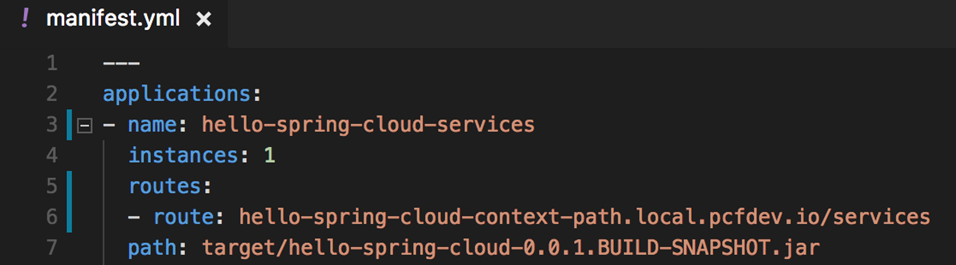
Figure 36: Ajout d’un routage de chemin de contexte dans le manifeste à l’aide de la route hello-spring-cloud-context-path.local.pcfdev.io/services
- Modifiez la page HTML avant de hello-spring-cloud-services pour afficher Hello Services :
- Ouvrez le fichier source situé dans hello-spring-cloud-services/src/main/java/resources/templates/home.html avec votre éditeur préféré.
- Remplacez l’application de démonstration Spring Cloud par Hello Services.
- Accédez au répertoire racine source, c’est-à-dire hello-spring-cloud-services, et exécutez mvn clean package.
Figure 37 : Mise à jour du document home.html dans hello-spring-cloud-services
- Déployez l’application hello-spring-cloud-services sur CF : exécutez cf push.
- Maintenant, ouvrez un navigateur et accédez à http://hello-spring-cloud-context-path.local.pcfdev.io/home et http://hello-spring-cloud-context-path.local.pcfdev.io / services. Vous verrez les écrans suivants :
Figure 38 : Sortie de l’application hello-spring-cloud-home sur http://hello-spring-cloud-context-path.local.pcfdev.io/home
Figure 39 : Sortie de l’application hello-spring-cloud-services sur http://hello-spring-cloud-context-path.local.pcfdev.io/services
Toutes nos félicitations ! Vous avez implémenté une application simple avec un routage de chemin de contexte.
6.5.2.13 Création de routes TCP
Nous avons créé des routes HTTP ; maintenant, nous pouvons tourner notre attention vers les routes TCP, qui dépendent des ports. La commande à exécuter est cf create-route < nom_espace > < nom_domaine > (–port < numéro_port > | –random-port). Ceci est presque identique à la création de la route HTTP, mais il doit accepter une option –port ou –random-port. Utilisez l’option –random-port, si votre application peut se lier à n’importe quel numéro de port attribué. Sinon, utilisez –port s’il est lié à un numéro de port fixe.
6.5.2.14 Gestion des itinéraires
Dans les sections précédentes, vous avez appris à créer des itinéraires. Mis à part le routage de chemin de contexte, à part le routage de chemin de contexte, nous les avons uniquement créés, mais nous ne les avons pas mappés à une application.
Pour mapper une route HTTP vers une application, exécutez la commande : cf map-route < nom_app > < nom_domaine > [–hostname < nom_hôte >] [–path < nom_chemin >] ou pour les routes TCP cf map-route < nom_app>> < nom_domaine > (–port < numéro_port > | – port_aléatoire).
Notez que les arguments de cf map-route sont presque identiques à cf create-route. La seule différence est que map-route prend un nom d’application, tandis que create-route prend un nom d’espace. Le cf map-route créera un itinéraire et mappera l’itinéraire vers une application en une seule commande. Le cf create-route créera un itinéraire et le stockera dans un espace pour une utilisation ultérieure.
Pour démapper un itinéraire, les commandes sont presque identiques à la commande map-route. HTTP Routes cf unmap -Route < app_name > < nom_domaine > [–hostname < nom_hôte >] [–path < path_name >] ou pour les routes TCP cf unmap -Route < app_name > < nom_domaine > –port <numéro_port>. La seule différence entre la route de mappage et de démappage est que la route TCP de démappage n’accepte qu’un numéro de port. Pour démapper l’itinéraire exact, il faudra bien sûr les mêmes paramètres connus pour inverser le processus. C’est, à unmap le foo.domain.com/product , nous devons foo d’entrée comme le nom d’ hôte et le produit comme le chemin.
Enfin, une commande très utile à utiliser est cf check-route . Cette commande recherchera la fondation pour voir si une route d’entrée existe déjà. La commande pour exécuter ceci est cf check-route [–path < path_name >] . Cela retournera un résultat pour indiquer si l’itinéraire est emprunté ou non.
6.5.2.15 Supprimer votre application
S’il est nécessaire de supprimer une application, vous pouvez le faire en exécutant la commande cf delete [- r] [ -f] . Le paramètre -f force la suppression de l’application sans vous y inviter, comme il le ferait quand aucun paramètre de force n’est spécifié. L’option -r supprime également les itinéraires mappés à cette application. Par défaut, la suppression d’applications sans l’option -r signifie que les itinéraires mappés seront conservés. Notez que la suppression est un processus destructeur et irréversible (à part le redéploiement), par conséquent, utilisez-le avec prudence !

Figure 40: résultat de la suppression de l’application hello-spring-cloud sans suppression forcée. Vous serez invité à confirmer la suppression avant qu’elle ne commence
6.5.3 Surveillance et gestion des applications à l’aide d’Apps Manager
La surveillance et la gestion des applications peuvent également être effectuées via une interface utilisateur graphique basée sur le Web, appelée App Manager. C’est une bonne alternative pour les utilisateurs qui ne sont pas à l’aise avec l’utilisation des interfaces de ligne de commande ou qui n’ont tout simplement pas la cf CLI à portée de main.
Avant de commencer, connectez-vous d’abord à Apps Manager sur PCF Dev avec les informations d’identification d’administrateur. Accédez à pcfdev -org et dans l’espace de développement :

Figure 41 : Les applications actuelles ont déployé pcf dev-org dans l’espace de développement
La figure précédente montre la première page après avoir accédé à la page de développement . L’application actuelle, hello-spring-cloud, est déployée dans l’espace de développement de pcfdev -org. Nous pouvons voir à l’écran ici l’état de l’application, son nom, le nombre d’instances d’application en cours d’exécution, la taille de mémoire maximale de l’instance, la dernière date de transmission et l’itinéraire de l’URL.
Cliquez sur le nom de l’application hello-spring-cloud et cela nous amènera à une page de présentation de l’application, comme dans la figure ici :
Figure 42 : La page de présentation de l’application hello-spring-cloud sur Apps Manager
La page de détails de l’application hello-spring-cloud a un certain nombre de fonctionnalités. Cette page affiche une liste historique des événements, tels que l’application déclarée, terminée, mise à jour ou arrêtée. Cette page affiche également des informations sur chaque instance d’application, dans la zone Instances, avec le libellé # 0, sa mémoire, l’espace disque et le temps de disponibilité. Ce sont des informations essentielles pour vous permettre de surveiller l’application et son état. Ci-dessus, les options de mise à l’échelle. Les options sont Instances, limite de mémoire et limite de disque – chacune avec son propre boîtier de commande pour ajuster la valeur. L’option de mise à l’échelle des instances permet à l’utilisateur de sélectionner manuellement le nombre d’instances qu’il souhaite générer. Les options de mise à l’échelle de la limite de mémoire et du disque mettent à l’échelle chaque instance d’application verticalement.
Essayons de changer le nombre d’instances à deux et la limite de mémoire à 512 mégaoctets à l’aide des cases de contrôle ci-dessus. Notez que le niveau de mise à l’échelle dépend de la quantité de mémoire et d’espace disque dont vous disposez sur votre machine ! Après avoir modifié les valeurs, cliquez sur le bouton SCALE APP :

Figure 43: Boîte de dialogue d’ invite de confirmation de mise à l’ échelle de l’ application
Vous serez invité à confirmer vos modifications comme indiqué dans la figure précédente. Cliquez sur le bouton SCALE APP pour poursuivre la mise à l’échelle. La mise à l’échelle procédera à la création de deux instances d’application avec 512 mégaoctets de mémoire par instance. Cela peut prendre quelques secondes :
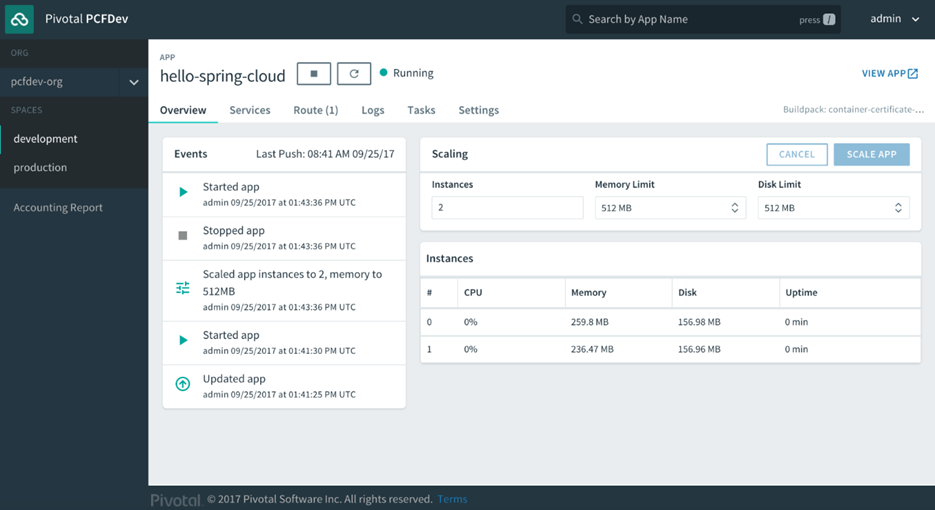
Figure 44 : résultat de la mise à l’échelle de l’application sur 2 instances avec 512 mégaoctets par instance
Remarque
La mise à l’échelle verticale de l’application arrêtera toutes les applications actuelles, qu’elle soit en train de traiter une transaction ou non. Alors, méfiez-vous lorsque vous faites cela dans un environnement en cours d’exécution.
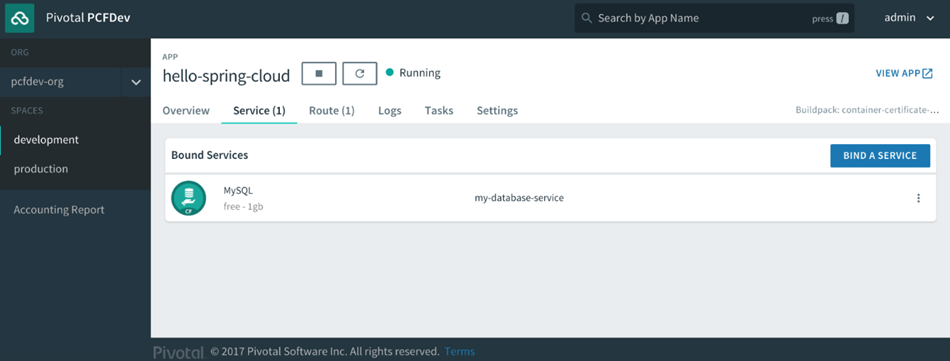
Figure 45 : L’onglet services du nuage de bonjour-printemps demande
L’onglet Services affichera les services liés à cette application. Pour lier un service instancié, cliquez sur le bouton Lier un service. Actuellement, il existe le service MySQL my-database- service lié à cette application, comme nous nous y attendions :

Figure 46 : L’onglet Route du -nuage bonjour-printemps demande
L’onglet Route affichera les routes actuellement définies pour cette application. Vous pouvez cartographier un nouvel itinéraire supplémentaire en cliquant sur le bouton MAP A ROUTE.
Figure 47 : L’onglet Journaux de la -nuage bonjour-printemps demande
L’onglet Journaux affichera la sortie des journaux d’application. Cette sortie est le résultat de la sortie du texte par l’application vers stdout et stderr. Appuyez sur le bouton de lecture pour activer la sortie continue des journaux. Vous pouvez appuyer plusieurs fois sur ce bouton pour obtenir une actualisation immédiate de la sortie. Notez que les journaux sont le résultat d’une sortie directe à partir d’un tampon en anneau temporaire interne et sont donc limités et disparaîtront. Votre plate-forme doit être configurée pour générer le journal vers un service de gestion des journaux, tel que Splunk ou ELK :
Figure 48 : L’onglet Tâches du nuage de bonjour-printemps demande
L’onglet Tâches permet de configurer des tâches administratives / de maintenance, telles que la migration de la base de données. Cliquez sur le bouton RUN TASK pour définir une tâche à exécuter pour l’application :
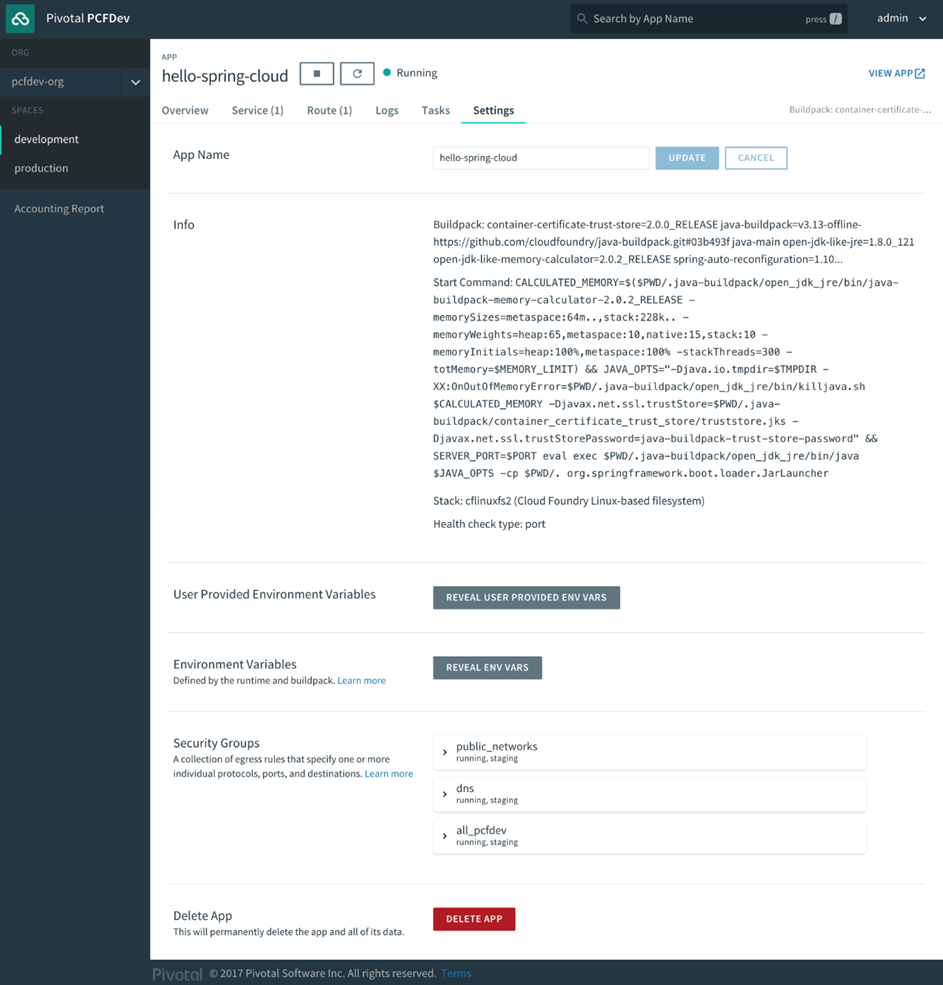
Figure 49 : L’onglet Paramètres du nuage de bonjour-printemps demande
L’onglet Paramètres permet un certain contrôle administratif de l’application. Cette page vous permet de modifier le nom de l’application sur Cloud Foundry, d’afficher les informations du pack de construction actuel, d’afficher les variables d’environnement et les variables d’environnement système fournies par l’utilisateur, d’afficher les groupes de sécurité d’application et de supprimer l’application.
6.5.4 Surveillance des performances des applications (APM)
Nous avons examiné les capacités de journalisation et de surveillance de base fournies par Cloud Foundry, mais que faire si nous souhaitons avoir une mesure profilée des performances d’une application ? L’APM fournit un moyen pour cela à travers la collecte et l’agrégation de certaines données émises par les applications. Nous ne passerons pas en détail sur APM ici en raison d’un grand nombre de services disponibles sur https://pivotal.io/platform/pcf-marketplace/monitoring-metrics-and-logging qui pourraient s’intégrer dans votre application. En substance, les APM aident les développeurs à surveiller leur application et à fournir potentiellement des indicateurs de performance précieux pour les applications qui peuvent nécessiter plus de ressources à différents moments de la journée, ou lorsque l’application elle-même a un bogue qui consomme trop de ressources.
Les méthodes d’intégration de ces services APM varient en fonction de votre organisation sur le service APM qu’elles adopteront. Par exemple, les mesures PCF nécessiteront l’installation de la tuile Mesures PCF par les opérateurs de plate-forme de votre organisation, ce qui donnerait des informations sur les performances de toutes les applications de la plate-forme. D’un autre côté, Application Dynamics (AppD) nécessitera une tuile de plate-forme installée, des packs de build pris en charge avec l’agent AppD, un contrôleur AppD et des applications pour instancier et se lier au service AppD. De cette façon, les applications sont enregistrées, leurs métriques collectées et agrégées et peuvent être consultées sur un tableau de bord AppD.
6.6 Résumé
Dans ce chapitre, nous avons déployé la première application sur Cloud Foundry. Par la suite, nous avons visité les concepts de gestion et de surveillance de vos applications via cf CLI et via Apps Manager. En particulier, pour gérer nos applications, nous pouvons le faire évoluer, gérer des itinéraires, effectuer des tâches administratives à l’aide de tâches cf et supprimer nos applications. Pour surveiller nos applications, nous pouvons afficher les journaux des applications en les personnalisant pour afficher la sortie de vos applications en temps réel ou simplement afficher le dernier instantané de ce qui s’est récemment produit. Dans le prochain chapitre, nous allons regarder dans la construction microservices .
7 Chapitre 7. Microservices et applications de travail
Une application monolithique traditionnelle est développée comme une grande application, puis déployée dans son ensemble. L’un des inconvénients des applications monolithiques est que, si l’un des modules de l’application cesse de fonctionner, il supprime l’intégralité de l’application, entraînant des temps d’arrêt importants, ce qui n’est pas souhaitable. De plus, les équipes d’application ne sont pas agiles pour publier de nouvelles fonctionnalités, rendant les nouvelles fonctionnalités disponibles avec une version dans quatre à six mois.
Pour pouvoir publier des fonctionnalités plus rapidement et plus efficacement, les entreprises ont commencé à investir dans la technologie et à encourager les développeurs à concevoir des applications à l’aide de l’architecture de microservices.
L’architecture des microservices n’est pas un nouveau concept et suscite plus d’attention en raison de l’évolution de nouveaux cadres et modèles de conception.
Dans ce chapitre, nous aborderons l’architecture des microservices dans le contexte de Cloud Foundry. Au chapitre 5, Architecture et création d’applications pour le cloud, vous avez découvert les principes directeurs des 15 facteurs et nous utiliserons quelques-uns de ces principes pour créer une application de travail simple.
Les bibliothèques Netflix OSS, telles qu’Eureka, Hystrix et Config Server peuvent être utilisées pour renforcer la résilience des microservices. Nous discuterons de ces modèles et les intégrerons dans notre application de travail.
7.1 Que sont les microservices ?
Certaines applications sont plus faciles à créer et à entretenir lorsqu’elles sont réparties en petits services qui fonctionnent ensemble. Chaque service est développé indépendamment et il a son propre cycle de vie. Une application est composée de plusieurs de ces services. Un microservice est un service modulaire qui peut être développé et déployé indépendamment.
Une architecture de microservices est une approche pour développer une application composée de services plus petits. Chaque service s’exécute dans son propre processus et communique avec d’autres processus sur le réseau en utilisant HTTP / HTTPS, la messagerie, les WebSockets ou tout autre protocole TCP. Chaque microservice implémente un domaine de bout en bout ou une capacité métier spécifique dans un contexte délimité, et chaque service est développé de manière autonome et déployé indépendamment. Un microservice doit posséder son modèle de données de domaine et sa logique de domaine connexes (souveraineté et gestion décentralisée des données), basés sur différentes technologies de stockage de données (mise en cache, SQL et NoSQL) et différents langages de programmation. Une architecture de microservices offre une agilité à long terme.
Un développeur ne doit pas s’inquiéter de la taille ou du nombre de lignes de code nécessaires au développement de ce service. L’objectif principal doit être de créer un service faiblement couplé qui peut être développé, déployé et mis à l’échelle indépendamment. Lors de l’identification et de la conception d’un microservice, évitez de créer des dépendances directes avec d’autres microservices.
Les microservices peuvent évoluer indépendamment. Avec une seule application monolithique, vous devez la mettre à l’échelle en tant qu’unité, mais avec une architecture de microservice, vous pouvez à la place mettre à l’échelle des microservices spécifiques. De cette façon, les services qui ont besoin de plus de puissance de traitement ou de bande passante réseau pour répondre à la demande peuvent ensuite être mis à l’échelle horizontalement. Cela signifie des économies car vous avez besoin de moins de matériel.
L’architecture des microservices permet une intégration et une livraison continues de l’application, ce qui accélère à son tour la livraison de nouvelles fonctionnalités dans l’application. Cette architecture nous permet d’exécuter et de tester le microservice individuel de manière isolée, et nous permet de les améliorer de manière autonome tout en maintenant des contrats clairs entre eux. Lorsque vous améliorez les fonctionnalités d’un microservice, vous ne devez pas modifier les contrats ou les interfaces et vous pouvez continuer à améliorer l’implémentation interne du microservice. La modification de l’interface entraînerait des changements de rupture pour d’autres microservices dépendants.
Pour réussir la mise en production d’un système basé sur des microservices à l’aide de Pivotal Cloud Foundry, les aspects suivants doivent être pris en compte :
- Livraison rapide des applications, généralement avec différentes équipes se concentrant sur différents microservices
- Surveillance et contrôles de santé des services par la plateforme
- Mise à l’échelle automatique des microservices
- Déploiement sans temps d’arrêt des microservices à l’aide de stratégies CI / CD
- Aucun ticket supplémentaire requis pour créer un nouvel ensemble de machines virtuelles pour permettre le déploiement de ces microservices
7.2 Applications pour les travailleurs
Au chapitre 6, Déploiement d’applications dans Cloud Foundry , vous avez appris à créer et à déployer une application Web simple dans Cloud Foundry sur PCF Dev. Une fois l’application poussée sur PCF Dev, la plateforme a créé un itinéraire vers l’application qui pourrait ensuite être utilisé par les utilisateurs pour communiquer avec les différents points de terminaison exposés par l’application. Dans cette section, nous parlerons des applications qui n’ont pas de route, mais qui s’exécutent en arrière-plan, effectuant une tâche. Une application de travail est essentiellement un processus, de niveau inférieur à une application Web, qui correspond naturellement à de nombreux emplois dits de back-office.
Ces applications n’ont généralement pas de points de terminaison API et peuvent être traitées comme les tâches exécutées chaque nuit, afin de maintenir la synchronisation de divers systèmes. Une application de travail peut être écrite dans n’importe quelle langue et déployée dans Cloud Foundry.
7.2.1 Application de travailleur Fortune Teller
Nous allons maintenant créer une application Spring Boot qui s’exécutera toutes les cinq secondes et produira une fortune aléatoire. Appelons cette application diseuse de bonne aventure.
Cette application est une application Spring Boot (https://spring.io/guides/gs/spring-boot/). Vous pouvez utiliser l’IDE de votre choix pour cet exercice.
Nous allons commencer par créer une classe appelée FortuneCookieGenerator.java . Cette classe sera responsable de générer des fortunes aléatoires en utilisant la liste de mots. La longueur de la fortune sera limitée par l’attribut fortuneLength . Le contenu de FortuneCookieGenerator.java est le suivant :
package cf.developers;
import java.util.Random;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
@Component
public class FortuneCookieGenerator {
@Value(“${words}”)
private String[] words;
@Value(“${length}”)
private int fortuneLength;
public void generate() {
Random random = new Random();
int wordsInSentence = 0;
StringBuilder randomSentenceStringBuilder = new StringBuilder();
while(fortuneLength != wordsInSentence) {
int pos = random.nextInt(words.length);
String word = words[pos];
randomSentenceStringBuilder.append(word).append(” “);
wordsInSentence++;
}
System.out.println(randomSentenceStringBuilder.toString());
}
}
Quelques points à noter ici:
- Les @component annotation définit cette classe à être considéré comme un candidat pour la détection automatique lorsque la configuration à l’ aide basée sur les annotations et classpath la numérisation.
- Nous injectons les valeurs des mots et fortuneLength . Les valeurs sont lues à partir du fichier application.properties sous le directeur src / main / resources du projet.
- Nous utilisons System.out.println () pour écrire la fortune sur la console. Ces informations seront disponibles lorsque nous examinerons les journaux des applications.
Maintenant que la logique métier est prête, nous pouvons construire la classe principale et l’appeler FortuneTellerApplication.java . Cette classe sera responsable du démarrage d’un conteneur tomcat intégré . L’annotation @ EnableScheduling active la capacité d’exécution de tâche planifiée au printemps , et l’ annotation @ Planifiée marque la méthode en tant que tâche planifiée.
Le contenu de FortuneTellerApplication.java est le suivant:
package cf.developers;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
@SpringBootApplication
@EnableScheduling
public class FortuneTellerApplication {
@Autowired
FortuneCookieGenerator fortuneCookieGenerator;
public static void main(String[] args) {
SpringApplication.run(FortuneTellerApplication.class, args);
}
@Scheduled(cron = “${cron.schedule}”)
private void generateFortune() {
fortuneCookieGenerator.generate();
}
}
Le maven pom.xml définit le parent de démarrage de démarrage de printemps , qui a une liste de toutes les dernières versions et leurs dépendances définies. Ceci est géré par l’équipe Spring Boot. La dépendance Spring-Boot-Starter est suffisamment intelligente pour gérer toutes les dépendances sur les bibliothèques open source dont cette application a besoin. Le contenu de pom.xml est le suivant:
xsi:schemaLocation=”http://maven.apache.org/POM/4.0.0http://maven.apache.org/xsd/maven-4.0.0.xsd”>
4.0.0
cf.developers
fortune-teller
0.0.1-SNAPSHOT
jar
fortune-tellerCF For Developers – Fortune Teller Worker Application
org.springframework.boot
spring-boot-starter-parent
1.5.7.RELEASE
UTF-8
UTF-8
1.8
org.springframework.boot
spring-boot-starter\
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-maven-plugin
Le fichier application.properties est lu par l’application Spring Boot. Au démarrage de l’ application , les annotations @Value sont résolues en examinant l’environnement du système suivi d’autres fichiers de propriétés. Le fichier application.properties peut également être personnalisé selon les profils Spring, par exemple, application-dev.properties ou application-prod.properties , où dev et pro d sont les profils Spring. Le contenu de application.properties est le suivant:
words=…
length=6
cron.schedule=*/5 * * * * *
7.2.2 Construire et déployer l’application Fortune Teller sur PCF Dev
Pour créer et déployer l’application Fortune Teller sur PCF Dev, commençons par cloner le référentiel GitHub et construire le code :
- Clonez le code source sur : https://github.com/Cloud-Foundry-For-Developers/chapter-7
- Basculez vers le répertoire chapter-7 / fortune-teller et exécutez mvn clean install
Nous aurons besoin d’une organisation et d’un espace pour déployer nos applications. Donc, nous devons d’abord créer une organisation, puis un espace. Pour créer une organisation, exécutez cf create-org cloudfoundry -for-developers :
Figure 1 : créer une organisation sur PCF Dev
Ensuite, créez un espace en exécutant cf create-space -o cloudfoundry -pour les développeurs :
Figure 2 : créer un espace dans l’organisation créée précédemment sur PCF Dev
Maintenant, ciblons l’organisation et l’espace que nous avons créés dans la section précédente, en exécutant cf target -o ” cloudfoundry -for-developers” -s “development” :

Figure 3 : cible de l’organisation et de l’espace sur PCF Dev à l’aide de la CLI cf
Maintenant que nous avons le code compilé et un Org / Space disponibles sur PCF Dev, nous allons pousser cette application. Exécutez le processus cf push fortune-teller -p target / fortune-teller-0.0.1-SNAPSHOT.jar –no-route –health-check-type = à partir du répertoire fortune-teller :
Figure 4 : Déployer l’application diseuse de bonne aventure sur PCF Dev
Une fois l’application démarrée avec succès, vous devriez voir les statistiques de l’application dans la sortie du terminal :
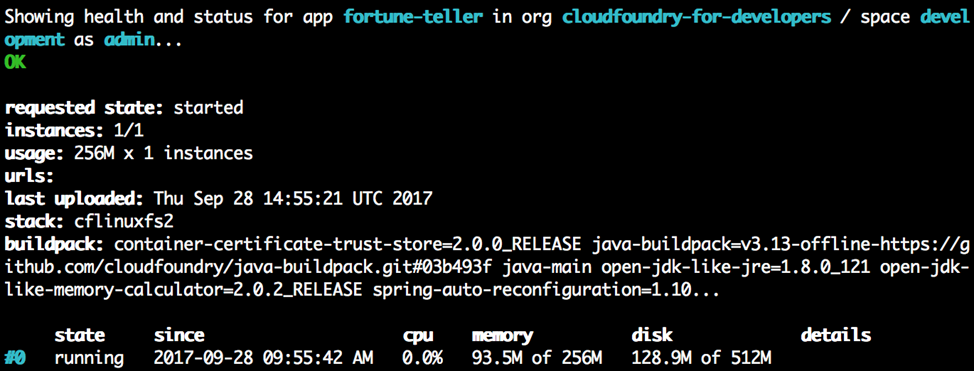
Figure 5 : sortie de l’interface CLI cf après le démarrage réussi de l’application diseuse de bonne aventure
Examinons maintenant les journaux de cette application et vérifions si la fortune est générée sur la sortie de la console. Cela se fait en exécutant cf logs fortune-teller :

Figure 6 : Utilisation de cf CLI pour afficher les journaux des applications de diseuse de bonne aventure
Les mêmes informations sont disponibles dans Apps Manager PCF Dev. Si vous vous connectez à votre gestionnaire d’applications PCF Dev et sélectionnez l’application diseuse de bonne aventure qui s’exécute dans l’organisation Cloudfoundry – for -developers et l’espace de développement, vous pouvez sélectionner Journaux et afficher la sortie générée par l’application :
Figure 7 : Utilisation d’Apps Manager sur PCF Dev pour afficher les journaux des applications de diseuse de bonne aventure
Il y a quelques points clés à retenir ici :
- Lorsque l’application est poussée, nous spécifions –no-route pour indiquer à Cloud Foundry de ne pas créer de route pour l’application car il s’agit d’une application de travail.
- Ensuite, nous spécifions –health-check-type = process et cela indique à Cloud Foundry de surveiller l’application de travail en tant que processus d’arrière-plan.
- Lorsque l’application est poussée, la diseuse de bonne aventure de sortie des journaux est un travailleur qui ignore la création de l’itinéraire. Cela confirme que Cloud Foundry ignorera la création d’itinéraire pour cette application.
- La mémoire par défaut attribué à l’application Boot Spring est 256 MB.
- L’application a été déployée avec java_buildpack détecté, car ce buildpack a le runtime requis pour prendre en charge cette application. Vous en apprendrez plus sur les buildpacks dans les chapitres suivants.
7.3 Résilience des applications
Chaque application doit avoir une certaine résilience intégrée. Des problèmes peuvent survenir dans une application composée de plusieurs microservices.
Dans cette section, nous parlerons de la résilience fournie par l’application. Nous discuterons également de certains modèles de conception connus qui peuvent nous aider à résoudre les problèmes répertoriés dans la section précédente.
7.3.1 Résilience fournie par Cloud Foundry
Avant de parler de la construction de la résilience dans l’application, parlons de ce que Cloud Foundry fournit dès le départ pour rendre les applications résilientes aux pannes de Platform as a Service (PaaS):
- Cloud Foundry dispose d’un mécanisme intégré pour surveiller les applications. Lorsqu’une application est poussée dans Cloud Foundry, le nombre d’instances demandées pendant le déploiement définit l’état souhaité pour une application. Si l’application est mise à l’échelle manuellement, le nouveau nombre d’instances remplace l’état souhaité. En interne à Cloud Foundry, il existe des composants qui surveillent les instances d’application en cours d’exécution pour toutes les applications et les comparent à l’état souhaité. Si des écarts sont détectés, Cloud Foundry ressuscite les instances d’application manquantes.
- Pour qu’une application soit hautement disponible dans Cloud Foundry, il doit y avoir au moins deux instances déployées à tout moment. Donc, si l’une des instances d’application tombe en panne pour une raison quelconque, alors l’autre instance d’application servira les demandes, tandis que l’autre est ressuscitée par Cloud Foundry. Cela offre une meilleure expérience à l’utilisateur final. À tout moment, les demandes sont réparties uniformément entre toutes les instances d’application en cours d’exécution.
7.3.2 Renforcer la résilience dans les microservices
Tout comme la plate-forme offre une certaine résilience, l’application doit également créer une logique pour gérer les échecs. Il pourrait y avoir des scénarios où l’application, composée de plusieurs microservices, pourrait échouer en raison de l’indisponibilité d’un ou plusieurs microservices. Il existe de nombreuses raisons possibles à l’échec de l’application dans son ensemble :
- Étant donné que les microservices communiquent les uns avec les autres sur le réseau, il y a de fortes chances de défaillance en raison de la latence du réseau ou des pannes de réseau.
- Une fois les connexions réseau rétablies, en général, les applications doivent être recyclées, afin de restaurer les connexions avec les applications en aval.
- Une interruption d’un service supprime généralement la totalité de l’application.
- La gestion du changement entraîne également des pannes. Tout nouveau déploiement de microservices peut échouer en raison de modifications de configuration ou d’une mauvaise version.
Pour répondre à certaines des préoccupations de conception répertoriées précédemment, Netflix a créé quelques services et bibliothèques communs d’exécution ( https://netflix.github.io/ ), tels que Eureka, Hystrix , Ribbon et Turbine. Depuis que ces logiciels ont été créés Open Source par Netflix, l’équipe de Spring a construit un projet Spring Cloud qui enveloppe toutes ces bibliothèques et fournit un moyen pratique de créer une logique métier en les utilisant. Le projet est disponible sur le site Web de Spring Cloud: http://projects.spring.io/spring-cloud/ .
Selon la documentation de Spring Cloud, Spring Cloud ( http://cloud.spring.io/spring-cloud-static/spring-cloud.html ) fournit des outils permettant aux développeurs de créer rapidement certains des modèles courants dans les systèmes distribués (par exemple, gestion de configuration, découverte de services, disjoncteurs, routage intelligent, micro-proxy, bus de contrôle, jetons uniques, verrous globaux, élection de dirigeants, sessions distribuées et état de cluster). La coordination des systèmes distribués conduit à des modèles passe-partout ; en utilisant Spring Cloud, les développeurs peuvent rapidement mettre en place des services et des applications qui implémentent ces modèles. Ils fonctionneront bien dans n’importe quel environnement distribué, y compris le propre ordinateur portable du développeur, les centres de données bare metal et les plateformes gérées telles que Cloud Foundry.
7.3.3 Utilisation de Config Server pour gérer la configuration des applications
Spring Cloud Config fournit une prise en charge côté serveur et côté client pour la configuration externalisée dans un système distribué. Avec Config Server, vous disposez d’un emplacement central pour gérer les propriétés externes des applications dans tous les environnements. L’implémentation par défaut du backend de stockage du serveur utilise Git.
Le serveur Spring Cloud Config aide à la gestion des changements et permet aux développeurs de maintenir la configuration de l’application dans un emplacement centralisé:
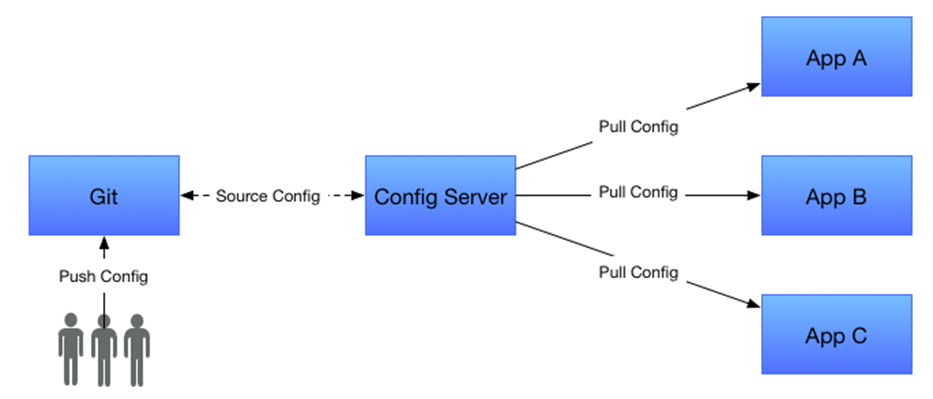
Figure 8 : Workflow du serveur de configuration
Le flux de travail impliqué dans le stockage et la récupération de la configuration d’application à partir du contrôle de source comme Git ou SVN est le suivant:
- Les développeurs valident les fichiers de configuration dans un contrôle de source, tel que Git ou SVN.
- L’application Config Server est configurée pour extraire la configuration de Git. La configuration implique la transmission des détails de connexion du contrôle de source, du nom du référentiel, de l’étiquette et des détails d’authentification.
- L’application extrait ensuite la configuration du serveur de configuration en spécifiant le nom spring.application.name dans le fichier bootstrap.yml .
Pour mieux comprendre le processus, modifions notre application de diseuse de bonne aventure pour utiliser le service PCF Spring Config Server pour récupérer la configuration de l’application depuis Git.
Commencez par ajouter la dépendance Spring-Cloud-Services-Starter-Config-Client dans notre pom.xml. Nous avons besoin de cette bibliothèque, car cette application sera un client pour l’instance Config Server que nous créerons dans les étapes suivantes:
io.pivotal.spring.cloud
spring-cloud-services-starter-config-client
Nous devons également ajouter la dépendance suivante dans la section dependencyManagement du pom.xml :
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud.version}
pom
import
io.pivotal.spring.cloud
spring-cloud-services-dependencies
${spring-cloud-services.version}
pom
import
Ensuite, nous devons créer un fichier avec le nom bootstrap.yml dans le répertoire src/main/resources. Au démarrage de l’application, le fichier bootstrap.yml est lu en premier et le runtime fournit le nom de l’application au serveur de configuration. Le serveur de configuration essaie ensuite de trouver les propriétés du nom et du profil d’application demandés dans GitHub. Collons donc le contenu suivant dans le fichier bootstrap.yml :
—
spring:
application:
name: fortune-teller
Nous allons maintenant supprimer les mots et les paramètres de longueur de application.properties . Nous voulons obtenir un nouvel ensemble de valeurs pour ces deux paramètres à partir de la configuration hébergée sur Git :
cron.schedule = * / 5 * * * * *
Enfin, mettons à jour FortuneCookieGenerator.java pour inclure l’annotation @ RefreshScope. Placez cette annotation juste au-dessus de l’annotation @Component. Les beans annotés de cette façon peuvent être actualisés au moment de l’exécution, et tous les composants qui les utilisent obtiendront une nouvelle instance lors du prochain appel de méthode, entièrement initialisée et injectée avec toutes les dépendances :
@RefreshScope
@Component
public class FortuneCookieGenerator {
…
…
…
}
Le code complet est disponible sur: https://github.com/Cloud-Foundry-For-Developers/chapter-7/tree/master/fortune-teller-with-config-server.
Déployons maintenant l’application sur PCF Dev. Pour ce faire, nous devons d’abord nous assurer que le code se construit. Exécutez mvn clean install depuis le répertoire chapter-7 / fortune-teller-with-config-server.
Maintenant, à l’aide de cf CLI, nous allons créer une instance de Config Server dans PCF Dev. Avant cela, énumérons tous les services disponibles sur le marché. Pour répertorier tous les services, exécutez cf marketplace :

Figure 9 : Liste des services disponibles dans PCF Dev
Nous sommes intéressés par le service avec la description Config Server for Spring Cloud Applications.
Pour créer une instance de Config Server, nous devons exécuter cf create-service -c ‘{“Git”: {” uri “: “https://github.com/Cloud-Foundry-For-Developers/chapter-7” , “label”: “master”, ” searchPaths “: “application-configuration”}} ‘p-config-server serveur de configuration standard . Dans cette commande, nous effectuons deux tâches : l’une, la création d’une instance du serveur de configuration, et deux, nous spécifions la configuration Git pour le serveur de configuration pour récupérer les propriétés de l’application:

Figure 10: Création d’une instance de service de serveur de configuration proposé sur la place de marché PCF Dev à l’aide de cf CLI
Pour vérifier si l’instance de service que nous avons créée à l’étape précédente s’est terminée avec succès, nous pouvons utiliser le texte d’aide de la sortie générée pour rechercher la création d’instance de service. Cela se fait en exécutant cf service config-server. Si l’état est create a réussi, il indique que la création de services est complète :

Figure 11: Requête pour la création réussie d’une instance de service
Connectez-vous au gestionnaire d’applications et dans l’espace de développement, sélectionnez Service | Config Server, puis cliquez sur le bouton Gérer :
Figure 12 : Affichage de l’instance de service du serveur de configuration à l’aide d’Apps Manager sur PCF Dev
Si la configuration de référentiel Git spécifiée est correcte, vous devriez voir le message Le serveur de configuration est en ligne :
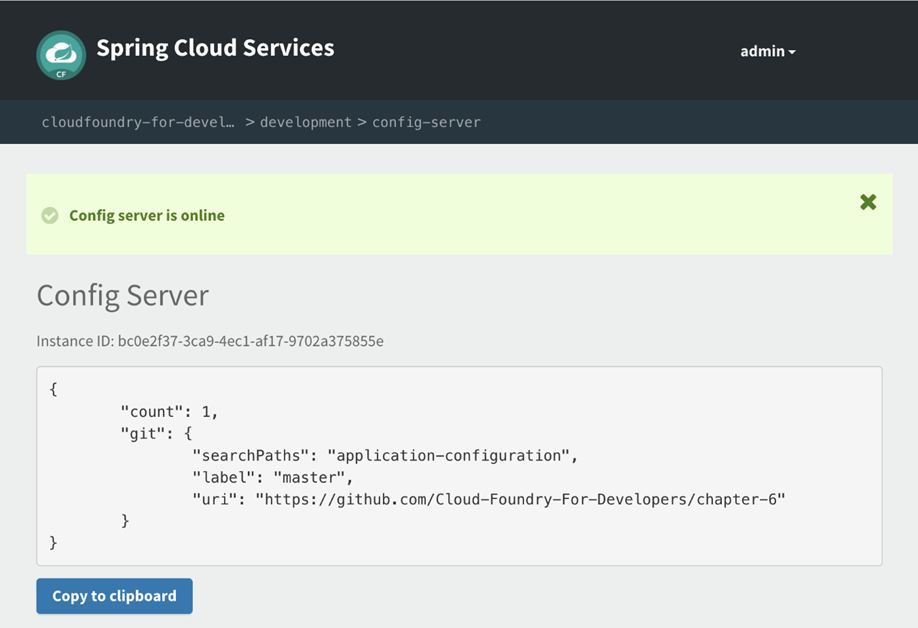
Figure 13 : Vérification du tableau de bord de l’instance du service de configuration du serveur à l’aide d’Apps Manager sur PCF Dev
À ce stade, nous pouvons pousser l’application mise à jour sur PCF Dev et demander à Cloud Foundry de ne pas démarrer l’application. Ceci est fait pour éviter l’échec du déploiement de l’application, car les paramètres, mots et longueur requis n’ont pas encore été fournis. Nous lierons l’application à l’instance de Config Server que nous avons créée après que l’application a été poussée dans Cloud Foundry. Donc, exécutez cf push fortune-teller -p target / fortune-teller-with-config-server-0.0.1-SNAPSHOT.jar –no-route –health-check-type = process –no-start:
Figure 14: pousser l’application de diseuse de bonne aventure dans PCF Dev à l’aide de cf CLI
Maintenant que nous avons poussé les bits d’application dans PCF Dev, nous lierons l’application fortune-teller à l’ instance Config Server fortune-teller-config-server-instance . Cela se fait en exécutant cf bind-service fortune-teller config-server . Ce faisant, nous créons une dépendance entre l’application et le service Config Server :

Figure 15 : Liez l’application diseuse de bonne aventure à l’instance de service Config Server à l’aide de cf CLI
À ce stade, nous pouvons démarrer l’application. Une fois que nous démarrons l’application, il communiquera avec le serveur de configuration pour dérouler les propriétés de l’application depuis Git. Pour faire cela, course cf commencer la bonne aventure diseur :
Figure 16 : Démarrez l’application diseuse de bonne aventure après que l’instance de service Config Server a été liée à l’application
Une fois l’application en cours d’exécution, la sortie sur le terminal montrera que l’application a démarré et fournira toutes les statistiques sur l’application :
Figure 17 : Statut de l’application de diseuse de bonne aventure après le démarrage de l’application
Nous pouvons maintenant consulter les journaux de cette nouvelle application et voir de nouvelles fortunes générées. La liste de mots est définie dans la configuration qui se trouve sur Git. Pour consulter les journaux, exécutez cf logs fortune-teller :
Figure 18 : Afficher les journaux de l’application diseuse de bonne aventure lorsqu’elle est configurée avec une instance de service de serveur de configuration
Toutes nos félicitations ! L’application dispose désormais d’un emplacement central pour héberger ses propriétés. La version de ce microservice devrait être simple et moins sujette aux erreurs. S’il y a une configuration incorrecte dans le contrôle de code source, l’utilisateur peut annuler les modifications dans le contrôle de code source et mettre à jour la configuration sur l’application sans redémarrer l’application. Pour plus de détails sur la façon d’utiliser les points de terminaison de l’actionneur pour extraire les dernières modifications de configuration sans redémarrer l’application, reportez-vous à la documentation de Spring Cloud Config Server à l’ adresse : https://spring.io/guides/gs/centralized-configuration/ .
- Registre de service pour l’enregistrement et la découverte des applications
Service Registry dans Cloud Foundry fournit aux applications une implémentation du modèle de découverte de service, l’un des principes clés d’une architecture basée sur les microservices. Le registre de service est basé sur Eureka ( https://github.com/Netflix/eureka ), le serveur et client de découverte de service de Netflix.
Configurer manuellement chaque client d’un service ou adopter une certaine forme de convention d’accès peut être difficile et s’avérer fragile en production. Au lieu de cela, les applications peuvent utiliser le registre des services pour découvrir et appeler dynamiquement les services enregistrés :

Figure 19 : Workflow du registre de service
Ici, au démarrage, le producteur s’enregistre en fournissant des métadonnées sur lui-même, telles que les informations d’hôte et de port. Le registre de services attend un message de pulsation régulier de chaque instance de service. Si une instance d’application commence à échouer de manière cohérente à envoyer la pulsation, le registre de service supprimera cette instance d’application de son registre. Le consommateur obtient les informations sur le producteur à partir du registre des services, puis utilise ces métadonnées pour appeler le producteur.
Avec ce modèle de découverte de service dynamique, il facilite la création et la gestion de microservices. De plus, les informations de service dépendantes ne sont pas directement codées en dur dans les propriétés de l’application, ce qui les rend moins sujettes aux erreurs. S’il existe plusieurs instances d’application de l’application de production, le consommateur n’a pas à s’inquiéter de l’implémentation de techniques spéciales d’équilibrage de charge, car la logique d’équilibrage de charge est gérée en interne par le client du ruban, qui est déjà fourni avec l’application.
Maintenant, modifions l’application à laquelle l’instance de service Config Server est liée, pour utiliser maintenant le service Service Registry pour extraire les phrases aléatoires de l’application fortune-teller- api.
Avant la modifions cartomancienne l’application, nous allons pousser la fortune teller- api application. Pour ce faire, basculez vers le répertoire chapter-7 / fortune-teller- api et exécutez mvn clean install.
Poussez l’application fortune-teller- api dans PCF Dev, en exécutant cf push fortune-teller- api -p target / fortune-teller-api-0.0.1-SNAPSHOT.jar –no-start. Nous allons démarrer cette application après avoir créé l’instance du registre de service :
Figure 20 : Poussez la diseuse de bonne aventure – application api
Pour créer l’instance de registre de service à partir de la place de marché PCF Dev, nous exécutons cf create-service p-service-registry standard service-registry , où p-service-registry est le nom du registre de service , standard est le nom du plan et service. -registry est le nom d’instance que nous utiliserons pour nous lier à l’application :

Figure 21: Créer une instance de service de registre de service
Validez si la création de l’instance du service registre de services a réussi en exécutant cf service registre de services et en validant si le statut est créé a réussi :
Figure 22 : valider si la création d’une instance de service de registre de services a réussi
Nous devons lier l’application fortune-teller- api à l’instance du service de registre de service. Pour ce faire, exécutez cf bind-service fortune-teller- api service-registry :

Figure 23 : Lier l’application fortune-teller- api à l’instance du service service-registry
Enfin, lancez l’application fortune-teller- api, en exécutant cf start fortune-teller- api :
Figure 24 : Démarrez l’application fortune-teller- api après la liaison à l’instance de service service-registry
Vérifiez si l’application est en cours d’exécution en regardant la sortie générée par la commande cf push précédente :
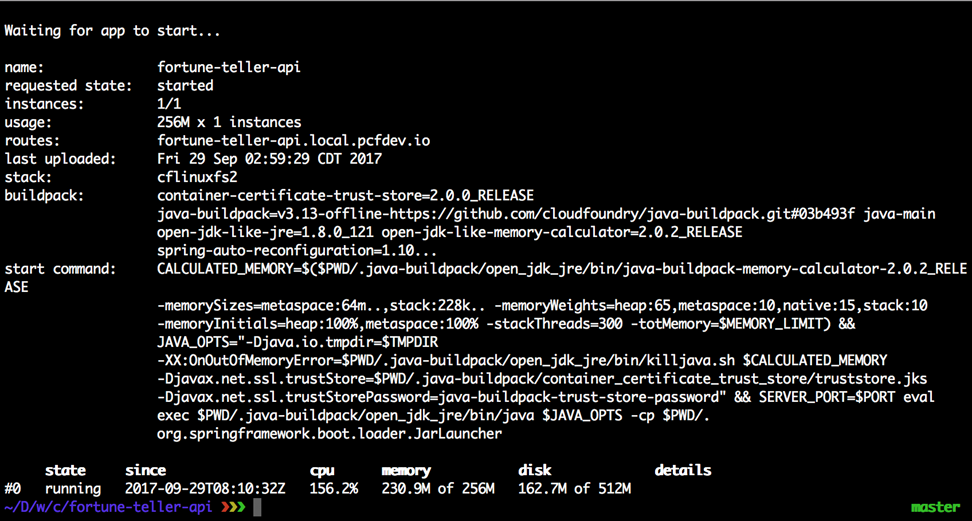
Figure 25 : état de l’application fortune-teller- api après la liaison à l’instance de service service-registry
Si l’application a démarré avec succès, le tableau de bord de l’instance Service Registry doit répertorier l’application fortune-teller- api, dans la section Applications enregistrées. Pour vérifier ces informations, connectez-vous à Apps Manager, sélectionnez Cloudfoundry -for-developers Org, sous cet espace de développement, puis cliquez sur l’onglet Services :

Figure 26 : Affichage des services liés à l’application fortune-teller- api à l’aide d’App Manager
Ensuite, cliquez sur le registre de services qui porte le nom registre de services :
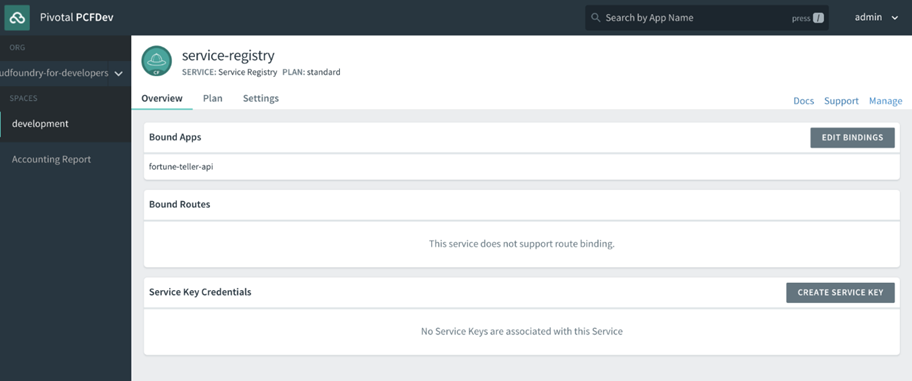
Figure 27 : Afficher l’instance de service de registre de service à l’aide d’App Manager
Le tableau de bord de l’instance Service Registry doit répertorier le diseur de bonne aventure – api :
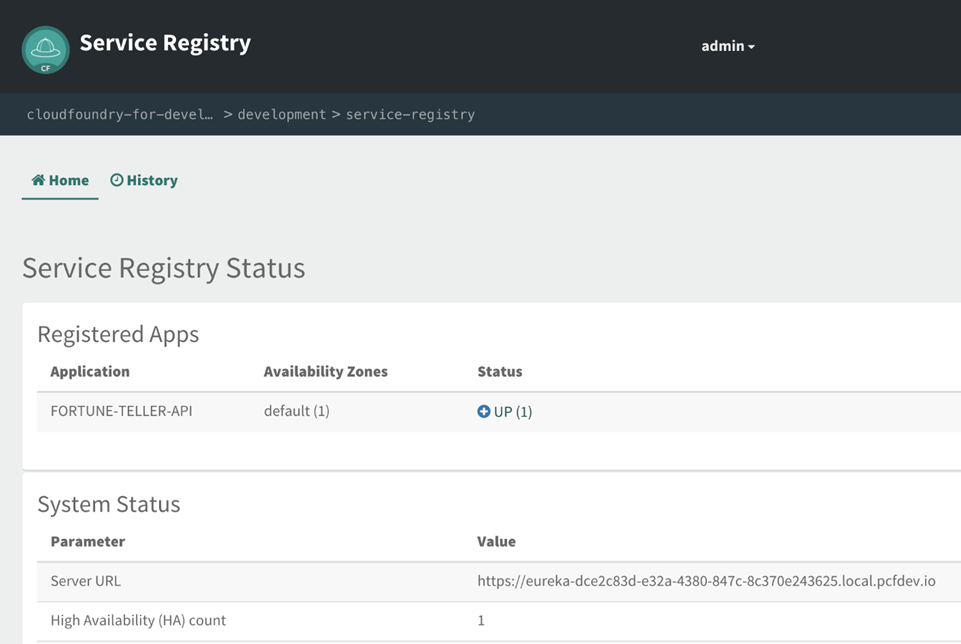
Figure 28 : Afficher le tableau de bord d’instance de service de registre de services à l’aide d’Apps Manager
Maintenant, concentrons notre attention sur l’application diseuse de bonne aventure. Basculez vers le répertoire chapter-7 / fortune-teller-with-config-server-and-service- Registry et modifiez le fichier pom.xml pour inclure le fichier jar Spring-Cloud-Services-Starter-Service- Registry. Ce projet de démarrage récupérera toutes les dépendances requises par l’application pour consommer le service Service Registry , lorsqu’elle y est liée:
io.pivotal.spring.cloud
spring-cloud-services-starter-service-registry
org.springframework.cloud
spring-cloud-dependencies
${spring-cloud.version}
pom
import
io.pivotal.spring.cloud
spring-cloud-services-dependencies
${spring-cloud-services.version}
pom
import
Une fois que nous avons défini les dépendances, nous devons mettre à jour le fichier bootstrap.yml . Comme il s’agit d’une application de travail, elle n’a pas de route. Nous devons donc dire au client Eureka d’utiliser l’adresse IP au lieu de la valeur par défaut, qui est le nom d’hôte. Si cette configuration est manquée, l’application ne s’enregistrera pas correctement avec l’ instance du service Service Registry . Alors, ajoutez ce qui suit au bootstrap.yml :
eureka:
instance:
prefer-ip-address: true
Nous devrons ajouter @ EnableDiscoveryClient dans FortuneTellerApplication.java . Cette annotation indique à l’application de s’enregistrer auprès du registre de service à l’aide de l’adresse IP de l’application:
@SpringBootApplication
@EnableScheduling
@EnableDiscoveryClient
public class FortuneTellerApplication {
@Autowired
FortuneCookieGenerator fortuneCookieGenerator;
….
….
}
Dans FortuneTellerApplication.java, nous devrons définir le bean RestTemplate et l’annoter avec @ LoadBalanced. L’annotation marque le bean RestTemplate à configurer pour utiliser un LoadBalancerClient, qui est fourni par le client du ruban :
@Haricot
@ LoadBalanced
public RestTemplate restTemplate ( ) {
return new RestTemplate ( );
}
Dans le FortuneCookieGenerator.java , nous mettrons à jour la méthode generate pour invoquer la méthode generate de l’application fortune-teller- api afin qu’elle génère un ensemble aléatoire de mots. Ici, nous allons spécifier l’URI comme // fortune-teller- api / generator et passer la longueur en paramètre. Le RestTemplate résoudra l’URI en obtenant les informations de diseuse de bonne aventure- api du registre de service :
public void generate ( ) {
URI uri = UriComponentsBuilder.fromUriString (“// fortune-teller-api / generator”)
. queryParam (“longueur”, fortuneLength ) .build (). toUri ();
Phrase de chaîne = restTemplate.getForObject ( uri , String.class );
System.out.println (phrase);
}
À ce stade , nous pouvons compiler le code en exécutant mvn clean install à partir du répertoire chapter-7 / fortune-teller-with-config-server-and-service-registry .
Une fois le code compilé, nous pouvons pousser les nouveaux bits en exécutant cf push fortune-teller -p target / fortune-teller-with-config-server-and-service-registry-0.0.1-SNAPSHOT.jar –no- route –health-check-type = process –no-start. Nous spécifions l’option –no-start, car nous devons encore lier l’application diseuse de bonne aventure à l’instance du service Service Registry que nous avions créé lorsque nous avons poussé l’application fortune-teller-api :
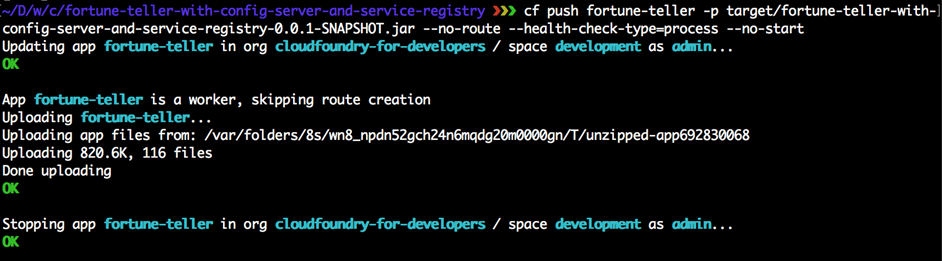
Figure 29 : Poussez l’application de diseuse de bonne aventure mise à jour sur PCF Dev
Nous lierons l’application de diseuse de bonne aventure au service Service Registry, en exécutant cf bind-service fortune-teller service-registry :

Figure 30 : Lier l’application diseuse de bonne aventure avec l’instance de service Service-Registry
Nous pouvons maintenant démarrer l’application diseuse de bonne aventure en exécutant cf start fortune-teller , et valider le statut de l’application:
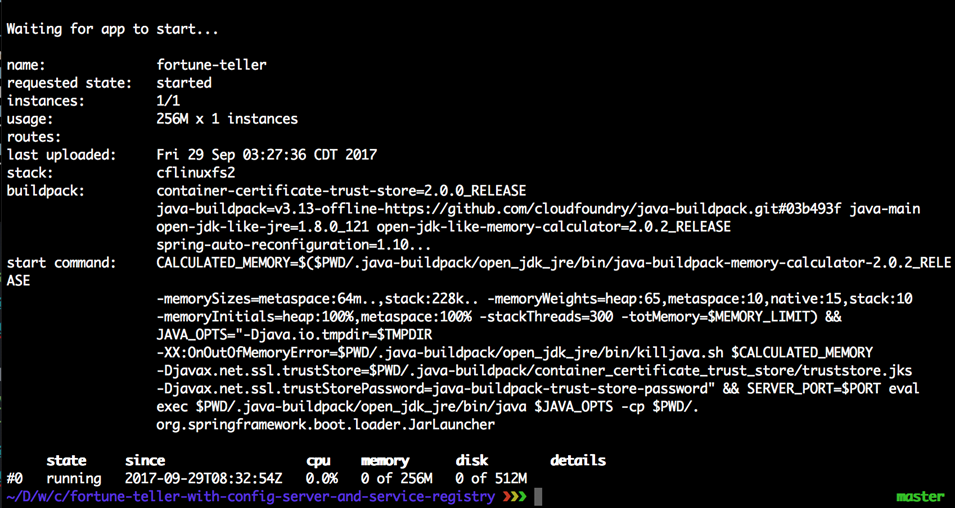
Figure 31 : Sortie de l’application de diseuse de bonne aventure après son démarrage réussi
Enfin, nous pouvons valider les journaux d’application de diseuse de bonne aventure. Cette fois -ci, la fortune est générée par la fortune teller-api demande, et non par la cartomancienne application. Jetons un coup d’œil aux journaux en exécutant cf logs fortune-teller :
Figure 32 : Journaux de sortie de l’application diseuse de bonne aventure
C’est aussi simple que d’utiliser le service Service Registry pour découvrir d’autres microservices. Ce modèle rend la configuration simple et facile à gérer.
Un problème qui existe toujours dans cette application est que lorsque l’application fortune-teller-api est arrêtée, l’application fortune-teller cesse de générer des phrases aléatoires et génère des exceptions dans les journaux.
Arrêtez l’application fortune-teller-api en exécutant cf stop fortune-teller-api :

Figure 33 : Arrêt de la fortune teller- api demande
Dans les journaux des applications de diseuse de bonne aventure, nous verrons un tas d’exceptions :

Figure 34 : Les erreurs figurant dans la demande diseuse de bonne aventure après l’arrêt de la fortune teller- api demande
Ce n’est pas souhaité, et nous voulons toujours le diseur de bonne aventure application à revenir à sa propre logique génératrice de phrase si la fortune teller-api demande va pour une raison quelconque. Nous allons résoudre ce problème en utilisant le modèle de disjoncteur, qui est discuté dans la section suivante.
7.3.4 Disjoncteurs et tableau de bord
Pour limiter la durée des opérations, nous pouvons utiliser des timeouts. Les délais d’attente peuvent empêcher les opérations de suspension et garder le système réactif. Cependant, l’utilisation de délais d’attente statiques et précis dans la communication des micro services est un anti-modèle ; nous sommes dans un environnement très dynamique où il est presque impossible de trouver les bonnes limitations de temps qui fonctionnent bien dans tous les cas.
Les disjoncteurs isolent un service de ses dépendances en empêchant les appels distants lorsqu’une dépendance est jugée malsaine, tout comme les disjoncteurs électriques protègent les maisons contre les incendies en raison d’une utilisation excessive de l’alimentation. Les disjoncteurs sont implémentés comme des machines à états :
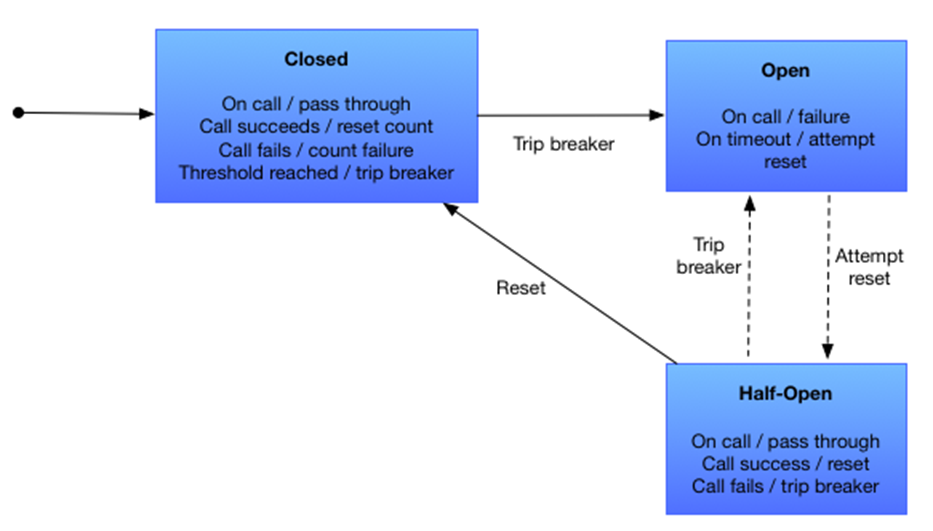
Figure 35: Flux de travail du disjoncteur
À l’état fermé, tous les appels sont simplement transmis à la dépendance. Si l’un de ces appels échoue, l’échec est compté. Lorsque le nombre de défaillances atteint un seuil spécifié dans une période de temps spécifiée, le circuit se déclenche à l’état ouvert. À l’état ouvert, les appels échouent toujours immédiatement. Après une période de temps prédéterminée, le circuit passe à un état semi-ouvert. Dans cet état, les appels sont à nouveau tentés vers la dépendance distante. Les appels réussis ramènent le disjoncteur à l’état fermé, tandis que les appels échoués ramènent le disjoncteur à l’état ouvert.
La cloison est utilisée dans l’industrie pour cloisonner un navire en sections, de sorte que les sections peuvent être scellées en cas de rupture de coque. Dans le développement logiciel, il est utilisé pour partitionner un service, pour éviter que l’application entière ne tombe en panne. La création de partitions dans le micro service est l’un des moyens d’éviter toute panne d’application.
Netflix a produit une bibliothèque très puissante de tolérance aux pannes dans Hystrix qui utilise ces modèles et plus encore. Hystrix permet au code d’être enveloppé dans des objets HystrixCommand afin d’envelopper ce code dans un disjoncteur.
Nous allons maintenant modifier la cartomancienne demande d’inclure le motif du disjoncteur, pour empêcher l’application de descendre lorsque la fortune teller-api application est disponible pour diverses raisons.
Nous devons ajouter la dépendance de la bibliothèque Spring-Cloud-Services-Starter-Circuit-Disjoncteur dans le pom.xml pour inclure la fonctionnalité CircuitBreaker dans l’application diseuse de bonne aventure :
io.pivotal.spring.cloud
spring-cloud-services-starter-circuit-breaker
Nous devons ajouter l’annotation @ EnableCircuitBreaker dans FortuneTellerApplication.java, pour activer une implémentation de CircuitBreaker :
@SpringBootApplication
@EnableScheduling
@EnableCircuitBreaker
@EnableDiscoveryClient
public class FortuneTellerApplication {
@Autowired
FortuneCookieGenerator fortuneCookieGenerator;
…
…
}
Nous devons modifier le FortuneCookieGenerator.java pour inclure l’annotation @ HystrixCommand sur les méthodes qui dépendent d’autres microservices. Cette annotation nous permet de définir un FallbackMethod, qui est invoqué chaque fois que le système en aval n’est pas disponible. Voyons comment nous implémentons cela dans notre classe. Nous allons d’abord ajouter l’annotation @ HystrixCommand sur la méthode generate, puis nous allons écrire une méthode supplémentaire et l’appeler defaultGenerate, qui sera appelée lorsque l’application fortune-teller- api n’est pas disponible :
@HystrixCommand(fallbackMethod = “defaultGenerate”)
public void generate() {
URI uri = UriComponentsBuilder.fromUriString(“//fortune-teller-api/generator”)
.queryParam(“length”, fortuneLength).build().toUri();
String sentence = restTemplate.getForObject(uri, String.class);
System.out.println(sentence);
}
public void defaultGenerate() {
Random random = new Random();
int wordsInSentence = 0;
StringBuilder randomSentenceStringBuilder = new StringBuilder();
while (fortuneLength != wordsInSentence) {
int pos = random.nextInt(words.length);
String word = words[pos];
randomSentenceStringBuilder.append(word).append(” “);
wordsInSentence++;
}
System.out.println(randomSentenceStringBuilder.toString());
}
Ainsi, en cas d’échec de la méthode generate, la méthode defaultGenerate est invoquée. Cela se produit jusqu’à ce que l’application fortune-teller- api revienne en ligne, puis la fonction de génération reprendra ses opérations normales.
Compilons maintenant le code. Donc, passez au chapitre 7 / fortune-teller-with-config-server-and-service-registry-and-hystrix, et exécutez mvn clean install .
Puisque nous avons besoin du service de disjoncteur, nous devons créer l’instance de service du tableau de bord du disjoncteur pour les applications Spring Cloud à partir du marché. Pour ce faire, exécutez cf create-service p-circuit-breaker-dashboard standard disjoncteur, où p-circuit-breaker-dashboard est le nom de service du service de disjoncteur, standard est le plan disponible pour ce service et circuit -breaker est le nom d’instance que nous utiliserons pour nous lier à l’application :

Figure 36 : création de l’instance de service du disjoncteur à l’aide de cf CLI
Nous allons maintenant pousser l’application mise à jour de diseuse de bonne aventure sur PCF Dev, en exécutant cf push fortune-teller -p target / fortune-teller-with-config-server-and-service-registry-and-hystrix-0.0.1-SNAPSHOT .jar –no-route –health-check-type = process –no-start :
Figure 37 : Poussez l’application de diseuse de bonne aventure mise à jour sur PCF Dev
Vérifions si la création du service du disjoncteur est terminée en exécutant cf service disjoncteur :
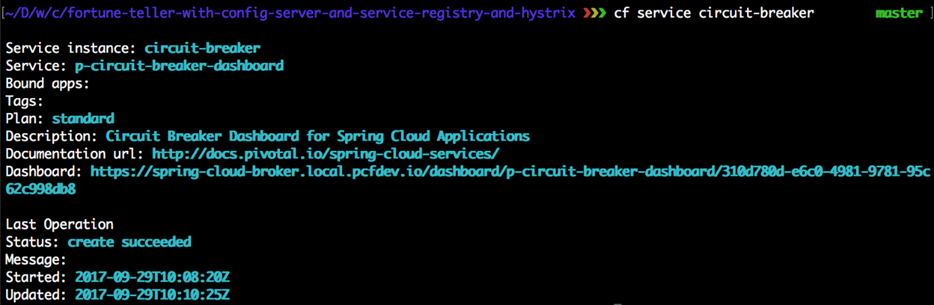
Figure 38 : valider si la création de l’instance de service du disjoncteur a réussi
Si la création d’instance de service est réussie, nous pouvons lier l’application diseuse de bonne aventure à ce service nouvellement créé. Cela se fait en exécutant cf coupe-circuit diseuse de bonne aventure bind service :

Figure 39 : Lier l’application diseuse de bonne aventure à l’instance de service de disjoncteur
Maintenant, nous pouvons commencer la cartomancienne demande, et aussi la fortune teller- api demande, si elle n’est pas déjà en cours d’exécution. Cela se fait en exécutant cf start fortune-teller et cf start fortune-teller- api, en conséquence.
Remarque
Si l’application ne démarre pas en raison d’erreurs de mémoire insuffisante , exécutez cf scalefortune -teller -m 1024M.
Une fois l’application de diseuse de bonne aventure lancée, jetons un œil aux journaux, en exécutant cf logs fortune-teller :
Figure 40: Afficher les journaux d’application de diseuse de bonne aventure à l’aide de cf CLI
Simulons un échec en arrêtant l’application fortune-teller- api . Pour ce faire, exécutez cf stop fortune-teller- api.
Maintenant, si nous continuons à regarder les journaux d’application de diseuse de bonne aventure, nous ne verrons pas les erreurs précédentes que nous avons vues dans la dernière section. Cette fois, les phrases sont générées à l’aide des mots que l’application a récupérés de Git, via l’instance de service Config Server :

Figure 41 : Afficher les journaux de l’application de diseuse de bonne aventure lorsque l’ api de la diseuse de bonne aventure n’est pas disponible
Nous pouvons également consulter le tableau de bord Hystrix, en vous connectant à Apps Manager, en sélectionnant notre organisation et espace de travail et en cliquant sur l’onglet Services :
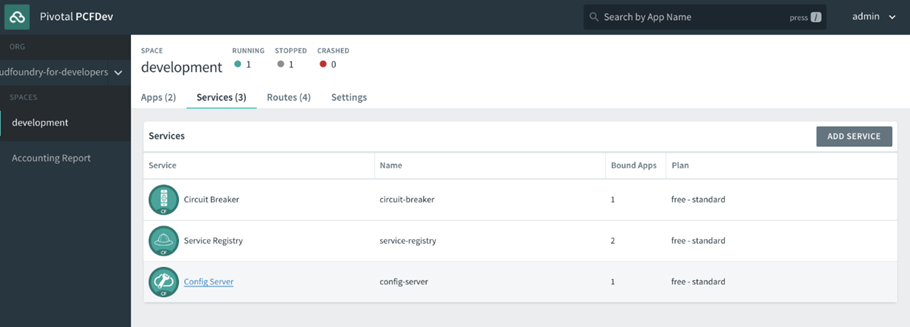
Figure 42 : Afficher les services liés à l’application de diseuse de bonne aventure à l’aide d’Apps Manager
Sélectionnez le service de disjoncteur et cliquez sur le bouton Gérer . Il ouvrira un nouvel onglet et vous amènera au tableau de bord Hystrix :

Figure 43 : Afficher le tableau de bord d’instance de service de disjoncteur à l’aide d’Apps Manager
Remarque
Pour provoquer l’ouverture du circuit, modifiez la méthode de génération dans l’ application diseuse de bonne aventure pour augmenter le nombre d’appels.
Si nous relançons maintenant l’application fortune-teller- api, les échecs seront réduits à zéro et les phrases seront générées par l’application fortune-teller- api. Alors, démarrez l’application et regardez les journaux de diseuse de bonne aventure pour voir si le circuit est à nouveau fermé. Démarrez fortune-teller- api en exécutant cf start fortune-teller- api, et continuez à suivre les journaux :
Figure 44 : Afficher les journaux de l’application de diseuse de bonne aventure après que l’ api de la diseuse de bonne aventure est accessible
Maintenant, lorsque nous actualisons le tableau de bord Hystrix , nous pouvons voir qu’il n’y a pas d’échecs et que les applications s’exécutent comme vous le souhaitez:

Figure 45 : Affichez le tableau de bord du disjoncteur une fois la connexion avec l’application fortune-teller- api rétablie
Ceci conclut notre discussion sur les tableaux de bord Disjoncteur et Hystrix. Nous savons maintenant comment utiliser les services Spring Cloud fournis par Pivotal Cloud Foundry pour rendre nos applications plus résistantes.
7.4 Résumé
Dans ce chapitre, nous avons discuté de ce que sont les micro services. Nous avons également parlé des applications des travailleurs et implémenté et déployé une application sur PCF Dev.
Nous avons expliqué comment demander à Cloud Foundry de ne pas créer de routes pour l’application de travail à l’aide de l’option –no-route lors de la transmission de l’application et des différents types de vérification de l’état de santé que Cloud Foundry utilise pour surveiller une application. Dans notre exemple de travailleur, nous avons utilisé –health-check-type = process.
Nous avons découvert la résilience fournie par la plate-forme Cloud Foundry et discuté de la manière dont l’application peut être rendue résiliente à l’aide des services de tableau de bord Config Server, Service Registry et Hystrix fournis par la plate-forme Pivotal Cloud Foundry.
8 Chapitre 8. Services et courtiers de services
Dans cet article, nous avons appris à visualiser les services disponibles, à créer une instance de service et à le lier à nos applications pour utilisation. Ce chapitre se concentre sur des concepts plus approfondis de services et sur la façon de créer des services et de les publier sur le marché afin qu’ils puissent être consommés par d’autres applications. Les concepts clés que vous apprendrez dans ce chapitre sont :
- Services de liaison aux applications
- Services fournis par l’utilisateur
- Qu’est-ce qu’un courtier de services ?
- Création et déploiement de courtiers de services personnalisés
- Services de route
- Stratégies d’intégration de services
8.1 Services sur Cloud Foundry
Les services apportent de la valeur aux équipes de développement et aux organisations en faisant abstraction de la nature dynamique de ces services des applications et en découplant le chemin de mise à niveau des applications dans un véritable modèle de microservices.
Revoyons brièvement les étapes les plus simples pour créer un service et le lier à notre application:
- Le développeur trouve les détails du service qu’il souhaite utiliser via la place de marché en appelant cf marketplace. Le marché est simplement une liste de tous les services qui peuvent être fournis sur votre fondation pour votre organisation et / ou espace. Ces services peuvent être gratuits ou avoir des frais d’abonnement associés. Nous avons couvert la plupart de cela au chapitre 6, Déploiement d’applications sur Cloud Foundry . Nous détaillerons plus loin dans ce chapitre comment nous pouvons publier nos propres services sur le marché.
- Ensuite, le développeur crée une instance du service via la commande cf create-service [-c ].
- Une fois l’instance de service disponible, le développeur la lie à leur application via la commande cf bind-service . Alternativement, ils peuvent le spécifier dans un manifeste push CF pour effectuer la liaison lors du déploiement de l’application.
C’est un excellent moyen de provisionner et de lier de nouveaux services sur Cloud Foundry, mais que se passe-t-il si la ressource de service est déjà provisionnée et réside en dehors de Cloud Foundry? Une approche pour résoudre ce problème consiste à exposer les chaînes de connexion et les informations d’identification en tant que configuration externe pour une application particulière. Si d’autres applications doivent utiliser ce service, elles devront également inclure la configuration externe supplémentaire par elles-mêmes. Comme vous pouvez probablement l’imaginer, cela conduit potentiellement à un grand niveau de maintenance. C’est-à-dire que si la configuration ou les informations d’identification changent, toute la configuration de l’application doit également changer. Deux approches peuvent être envisagées pour éviter cela. Le premier est par le biais d’un service fourni par l’utilisateur et le second par le biais de courtiers de services.
Les services fournis par l’utilisateur sont ceux qui n’apparaissent pas sur le marché et existent en tant qu’instances de service, une fois créés, avec des informations d’identification et des champs de configuration personnalisés. Ces services sont ensuite consommés comme tout autre service sur le marché, à l’exception qu’ils sont limités à l’étendue de l’espace où ils sont créés. Par conséquent, l’application doit également se trouver dans le même espace. Par la suite, une application doit également pouvoir lire la configuration de service fournie par l’utilisateur à partir de la variable d’environnement VCAP_SERVICES.
La seconde approche, via les courtiers de services, permet de publier des services sur le marché et de permettre à toute application ayant accès au courtier de services de consommer les services publiés disponibles sur le marché. Les courtiers de services sont essentiellement une API exposée par Cloud Foundry qui permet la gestion des services à travers le marché.
Un autre type de service qui sera discuté dans ce chapitre est les services de route. Les services de routage sont ceux qui travaillent sur / transforment toutes les demandes entrantes en une application. Tout d’abord, cependant, nous explorerons en profondeur comment les services sont consommés par les applications.
8.2 Liaison de service des applications
Chaque fois qu’un service est lié à une application (ou à plusieurs applications), l’étape clé qu’il effectue consiste à injecter la configuration et les informations d’identification du service dans une application. Ces informations se trouvent dans les variables d’environnement d’une application, dans VCAP_SERVICES. Le VCAP_SERVICES est un objet JSON qui contient un tableau d’informations relatives à des services liés à cette application. Ceci est au contraire de son objet JSON sœur, VCAP_APPLICATION, qui contient des informations relatives à la configuration de l’application elle-même, telles que son URL, les limites de mémoire et la capacité du disque. Nous pouvons afficher la variable d’environnement d’une application via la commande cf env .
Si nous clonons une nouvelle copie de l’application hello-spring-cloud de https://github.com/Cloud-Foundry-For-Developers/hello-spring-cloud.git et la déployons sur Cloud Foundry, nous pouvons effectuer une cf env bonjour-printemps-nuage :
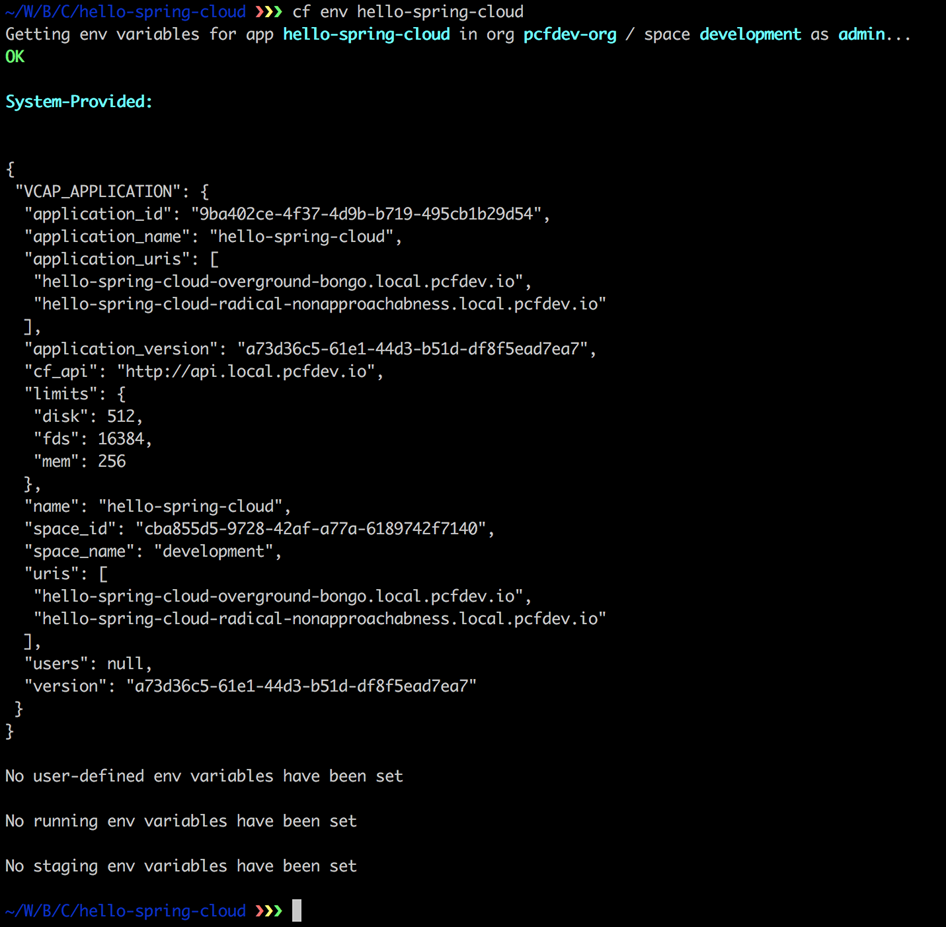
Figure 1: Obtention des variables d’environnement d’une nouvelle copie de l’application hello-spring-cloud sans services limités
La figure 1 montre les variables d’environnement de hello-spring-cloud. Notez qu’il n’y a que VCAP_APPLICATION et que VCAP_SERVICES n’est pas visible. En effet, nous n’avons lié aucun service à notre nouvelle copie de l’application hello-spring-cloud. Si ce n’est pas déjà fait, instanciez un service de base de données MySQL ( p- mysql ) nommé my-database-service et liez l’instance de service à hello-spring-cloud . Exécutez à nouveau cf env hello-spring-cloud. Notez que vous devrez effectuer un redémarrage cf hello-spring-cloud si vous souhaitez voir la sortie dans un navigateur :
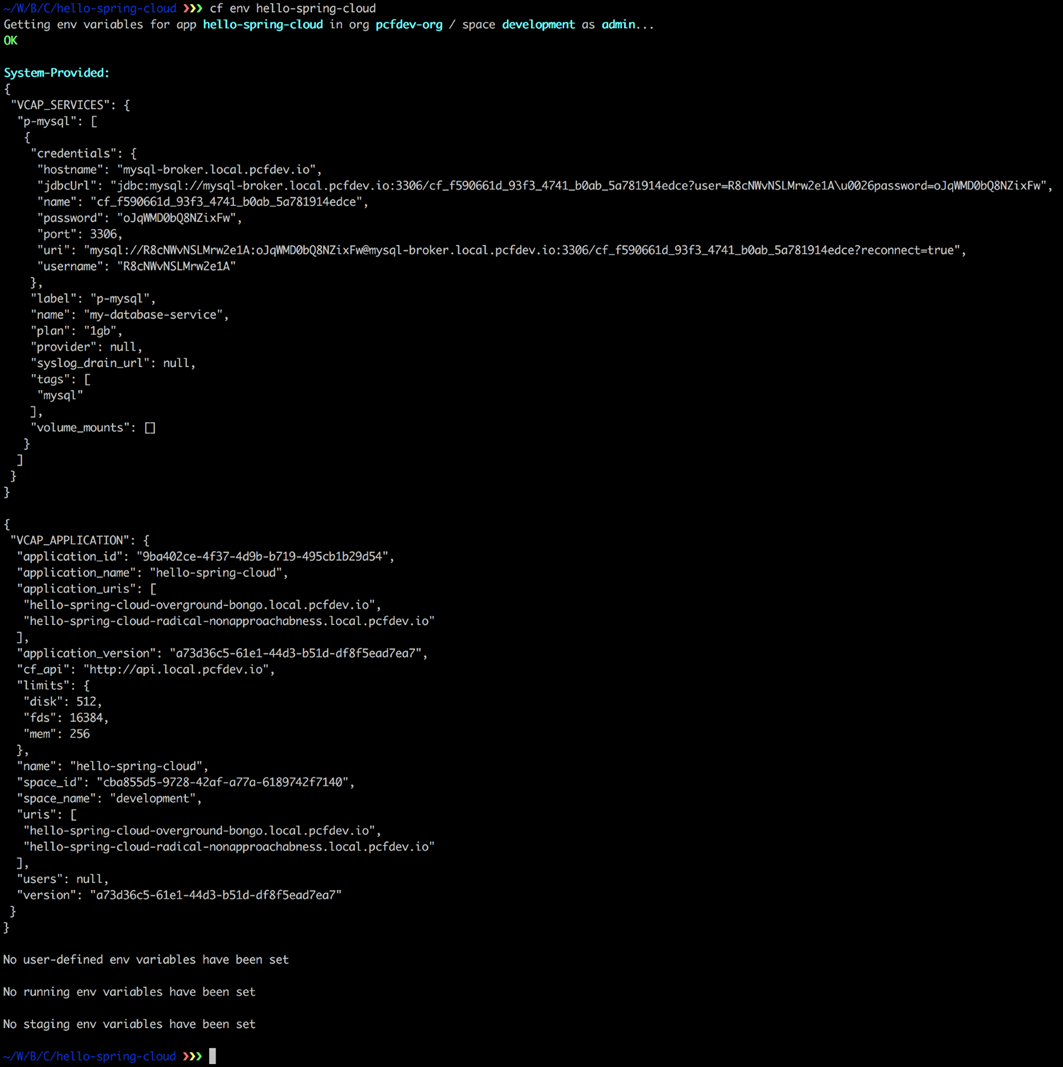
Figure 2 : Obtention des variables d’environnement d’une nouvelle copie de l’application hello-spring-cloud avec un service délimité MySQL
La figure 2 montre maintenant l’objet JSON VCAP_SERVICES. Il montre actuellement un seul service MySQL lié à l’application hello-spring-cloud. Les informations que nous voyons injectées sont le nom du courtier de services, le plan de service, les balises et, surtout, les informations de configuration du service telles que les chaînes de connexion et les informations d’identification générées de manière aléatoire.
Pour que notre application utilise ce service, il lui suffit de lire les détails et les informations d’identification de l’hôte et de former la chaîne de connexion ou d’utiliser l’entrée jdbcUrl, si elle est prise en charge, et d’instancier un pilote d’accès à la base de données pour interagir avec la ressource. Pour généraliser notre implémentation, notre code d’application n’aurait qu’à rechercher des informations clés telles que la balise ou le début du schéma d’URI, c’est-à-dire mysql://, pour savoir quel type de classe de pilote de base de données nous devons instancier. C’est essentiellement ainsi que fonctionne le connecteur Spring-Cloud pour Cloud Foundry. Il utilise le nom de balise et le schéma d’URI pour former une chaîne de connexion à utiliser avec les pilotes de base de données appropriés.
Remarque
OK, alors comment puis-je obtenir exactement le VCAP_SERVICES JSON dans mon application ? Il est fortement recommandé d’utiliser des bibliothèques existantes telles que Spring Cloud Connector et Steeltoe pour accéder aux variables d’environnement. Cependant, si l’on a besoin d’un accès personnalisé, la solution dépendra de la langue utilisée. Ce qui suit est un pseudo-code, plus un exemple d’extrait de code Java d’interaction avec les informations d’identification p- mysql. N’oubliez pas cependant que ce code ne fonctionnera que lorsqu’une application a été déployée sur Cloud Foundry et est liée à un service. Si vous essayez d’exécuter le code localement, il échouera car il n’y a pas de variable d’environnement VCAP_SERVICES. Par conséquent, si vous utilisez ce code, assurez-vous que votre code est correctement géré pour les tests locaux ou s’il n’y a aucun service lié à votre application. Alternativement, pour tester votre code localement, vous pouvez simuler les variables d’environnement VCAP_SERVICES sur votre machine locale avant d’exécuter votre application :
| /* pseudo-code for access VCAP_SERVICES and do something with the credentials – using p-mysql as an example */
VCAP_SERVICES_jsonString = get_environment_variable(“VCAP_SERVICES”) VCAP_SERVICES_json = JSONReader_ParseToJSON(VCAP_SERVICES_jsonString) mysqlCredentials = VCAP_SERVICES_json[“p-mysql”][0][“credentials”] |
| /* Java code snippet for access VCAP_SERVICES and do something with the credentials – using p-mysql as an example */
try { JSONObject vcap_services = new JSONObject(System.getenv(“VCAP_SERVICES”)); JSONObject p_mysql_credentials = vcap_services .getJSONArray(“p-mysql”) .getJSONObject(0) .getJSONObject(“credentials”)); } catch(JSONException exception) { System.out.println(exception.getMessage()); System.out.println ( exception.getStackTrace ()); } |
8.3 utilisateur- fourni des services
Jusqu’à présent, nous comprenons comment instancier un nouveau service à partir du marché et nous comprenons comment les applications fonctionnent avec les services liés via l’ objet VCAP_SERVICES JSON dans la variable d’environnement d’application. Nous allons maintenant visiter les services fournis par les utilisateurs. Avec les services fournis par l’utilisateur, un développeur a la liberté de définir une instance de service qui a des champs de données de configuration de service personnalisés que son application lira afin d’identifier et de se connecter à la ressource. Il s’agit du travail le plus simple et le moins exigé pour commencer à vous connecter à un service externe à votre plateforme Cloud Foundry; cependant, sachez que les services fournis par l’utilisateur, une fois qu’ils sont créés, sont des instances de service et sont étendus dans un espace dans Cloud Foundry. Une application dans un autre espace ne verra pas l’instance de service fournie par l’utilisateur.
La commande pour créer un service fourni par l’utilisateur est cf create-user-provided-service [-p ]. Le est le nom de l’instance de service qui sera créé et sont les champs qui sont injectés dans l’application d’une VCAP_SERVICES variable d’environnement. Les peut être une chaîne de noms de champs, qui est, « hostUrl , nom d’ utilisateur, mot de passe, extraInfo » , ou il peut être une chaîne JSON réelle avec les valeurs correspondantes, qui est, « { « hostUrl »: « www. service.com “,” nom d’utilisateur “:” dave “,” mot de passe “:” blah “,” extraInfo “:” Il s’agit d’un service fourni par l’utilisateur “} ‘ . Si nous utilisons la chaîne des noms de champs, le cf CLI nous demandera d’entrer de manière interactive les valeurs pour chaque champ et générer l’objet JSON pour nous. Créons maintenant un service fourni par l’utilisateur avec une chaîne d’objet JSON en entrée. Exécutez la commande suivante :
cf create-user-provided-service my-user-service -p ‘{“hostUrl”: “www.service.com”, “username”: “dave”, “password”:”blah”, “extraInfo”: “This is a user-provided service”}’
Remarque
Sous Windows, nous devons échapper les guillemets doubles dans la chaîne d’objet JSON, c’est-à-dire cf create-user-provided-service my-user-service -p ‘{\ ” hostUrl \”: \ “www.service.com \ “, \” nom d’utilisateur \ “: \” dave \ “, \” mot de passe \ “: \” blah \ “, \” extraInfo \ “: \” Il s’agit d’un service fourni par l’utilisateur \ “} ‘ .

Figure 3 : Création d’un service fourni par l’utilisateur avec nos propres champs définis
Nous pouvons maintenant lier le service fourni par l’utilisateur à l’aide de la commande cf bind-service hello-spring-cloud my-user-service. Lions le service à l’application hello-spring-cloud et observons ce qui se passe :

Figure 4 : Liaison de l’application hello-spring-cloud à un service fourni par l’utilisateur et les variables d’environnement de l’application par la suite
La figure 4 montre le résultat de la liaison d’une application au service fourni par l’utilisateur créé précédemment. Ce que nous voyons dans l’objet JSON VCAP_SERVICES est une nouvelle entrée appelée fournie par l’utilisateur, contenant les champs entrés lorsque nous avons exécuté la commande create-user-provided-service.
Pour mettre à jour les champs et la valeur de notre service fourni par l’utilisateur, nous pouvons exécuter la commande cf update-user-provided-service [-p ]. Soyez conscient lors de l’exécution de la commande de mise à jour, tous les champs de doivent être tapés à nouveau, même si le champ n’a pas de modifications, sinon, ils seront remplacés par les nouveaux champs de la chaîne.
Enfin, pour supprimer un service fourni par l’utilisateur, il suffit d’appeler cf delete-service et de confirmer la suppression. Cependant, sachez que l’instance de service doit d’abord être indépendante de toutes les applications avant de pouvoir être supprimée.
L’utilisation de services fournis par les utilisateurs est une approche de premier niveau des services. Il est simple et nécessite le moins de travail pour obtenir un service externe disponible pour vos applications. Toutefois, vous pouvez constater que le service fourni par l’utilisateur ne peut pas être utilisé avec des applications situées dans un espace différent. Une façon consiste à créer le service fourni par l’utilisateur dans chaque espace, mais cela entraînera des problèmes de maintenance à l’avenir. Pour surmonter la limitation d’espace, nous pouvons envisager de créer nos propres courtiers de services personnalisés. Avec des courtiers de services personnalisés, nous sommes en mesure de publier la disponibilité des services externes au niveau d’une organisation ou d’un espace. Idéalement, si vous souhaitez effectuer un test rapide, il existe un courtier de services fixes sur : https://github.com/cloudfoundry-community/worlds-simplest-service-broker. Cette implémentation est similaire à un service fourni par l’utilisateur, sauf qu’elle est orientée vers la publication d’un service externe unique via un courtier de services. Cela vous permettrait d’étendre le service, selon les besoins, à plusieurs organisations et espaces. Cependant, il est préférable de développer votre propre courtier de services qui convient le mieux à votre organisation pour publier tous les services externes de votre organisation selon vos besoins. Nous fournirons un modèle et les étapes de déploiement de ce modèle dans la section suivante.
8.4 Courtiers de services
À présent, vous vous demandez peut-être comment publier son service sur le marché et comment tout cela fonctionne-t-il ensemble ? Le composant clé à cela est par le biais d’un courtier de services. Un courtier de services est responsable de la plupart, sinon de tous, les aspects du cycle de vie des services sur le marché. Ils sont responsables de la publication des services et des plans offerts, de l’exécution de l’approvisionnement des services sur demande, de la liaison des applications aux instances de service et, potentiellement, vice-versa lors de la dissociation et de l’annulation de l’approvisionnement. Les courtiers de services sont déployés au sein d’une organisation et configurés pour être un espace restreint. Une implémentation d’un Service Broker est une application qui implémente l’API Service Broker.
8.4.1 Structure des services sur un courtier de services
Avant de poursuivre, discutons de la structure des services sur un courtier de services. Un courtier de services publie une liste de services qu’il propose. Pour chaque service publié, il doit y avoir au moins un plan associé pour ce service correspondant. Un plan de service est simplement une variante du service offert. Par exemple, il peut y avoir un plan qui est gratuit mais avec une capacité de disque limitée, et il peut y avoir un autre plan qui a une capacité de disque plus élevée mais a un coût qui lui est associé. C’est pourquoi, lors de l’instanciation d’un service via cf create-service, il est nécessaire de spécifier le nom du service, le plan de service souhaité et un nom d’instance auquel vos applications peuvent se référer.
Dans cet esprit, si votre organisation dispose d’un certain nombre de services hébergés en externe sur Cloud Foundry, vous pouvez créer un courtier de services unique qui consolide tous les services disponibles en externe et les publie pour être utilisés en toute sécurité par vos développeurs. Il est utilisable en toute sécurité car votre courtier de services serait en mesure de lier des applications avec les informations d’identification sans que les développeurs ne les connaissent et les stockent. Par la suite, vous pourrez limiter l’accès aux services et le plan de service à certaines organisations.
Remarque
Bien que vous puissiez créer un courtier de services avec des plans de services payants, n’oubliez pas comment cela fonctionne dans votre organisation. Tout d’abord, comprenez les modèles d’utilisation et leurs implications avant de procéder à une approche de facturation. La partie la plus importante des services est qu’ils devraient permettre et encourager l’adoption. Soyez agile et adaptez-vous si nécessaire par la suite.
8.4.2 L’API Open Service Broker
L’API Open Service Broker ( API OSB ) est une norme ouverte qui décrit la manière dont le marché d’une plate-forme interagit avec les courtiers de services via HTTP. Cette prise en charge de plate-forme inclut Cloud Foundry, Heroku, Kubernetes et OpenShift. La norme décrit un protocole RESTful utilisé pour communiquer entre une plate-forme et un courtier de services. Par conséquent, la mise en œuvre de points de terminaison spécifiques doit être effectuée pour qu’un courtier de services puisse fonctionner avec une plate-forme. Comme nous l’avons décrit précédemment, les opérations clés sont la gestion du catalogue de services, l’approvisionnement, la liaison, la mise à jour, la dissociation et la suppression de l’approvisionnement. Il existe également une opération supplémentaire, le dernier état de l’opération, utilisée pour les opérations de service asynchrones. Chaque opération correspond à un point de terminaison RESTful spécifique, que nous décrivons dans la figure suivante. Cependant, outre les points de terminaison, il existe également une description normalisée du protocole de réponse / demande HTTP, qui peut être trouvée à l’ adresse : https://github.com/openservicebrokerapi/servicebroker . La figure suivante décrit ces points de terminaison REST, à partir de la version 2.13 de l’API OSB.
| Opération | Endpoint |
| Catalogue | GET / v2 / catalogue |
| Disposition | PUT / v2 / service_instances / {instance_id}? accepte_incomplete =
Paramètres :
|
| Contraignant | PUT / v2 / service_instances / {instance_id} / service_bindings / {binding_id}
|
| Mise à jour | PATCH / v2 / service_instances / {instance_id}? Accepte_incomplete =
Paramètres :
|
| Délier | SUPPRIMER / v2 / service_instances / {instance_id} / service_bindings / {binding_id}? Service_id = & plan_id =
Paramètres :
|
| Déprovision | SUPPRIMER / v2 / service_instances / {instance_id}? Accepte_incomplete = & service_id = & plan_id =
Paramètres :
|
| Dernier état de fonctionnement | GET / v2 / service_instances / {instance_id} / last_operation? Operation = & service_id = & plan_id =
Paramètres :
|
Examinons un diagramme de séquence de la façon dont ils sont utilisés et interagissent avec CF et un serveur de ressources dans un scénario typique:
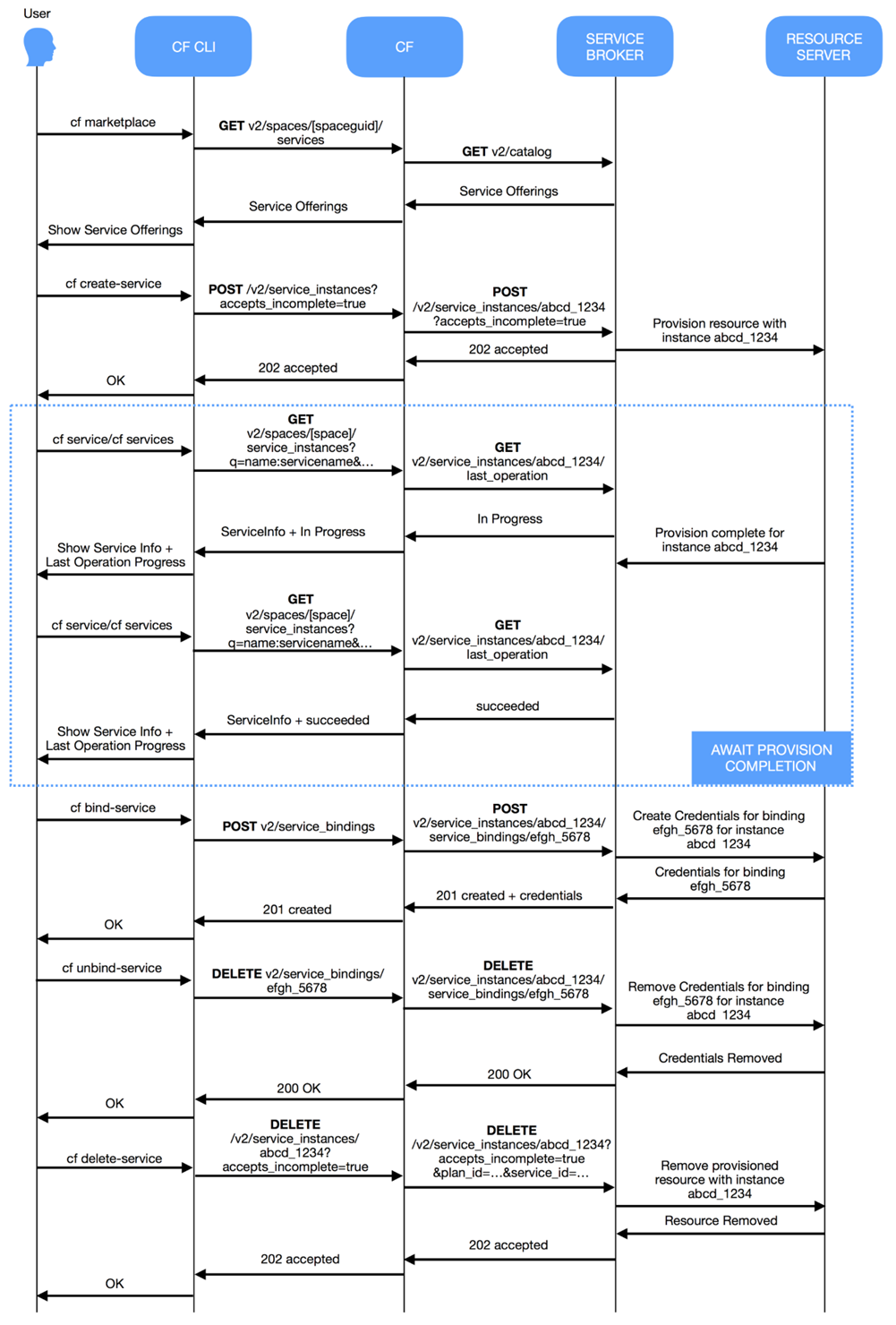
Figure 5 : Diagramme de séquence montrant un cas d’utilisation typique de l’interaction du courtier avec Cloud Foundry et un utilisateur initiant les opérations. Nous supposons dans cette figure que l’ID d’instance est abcd_1234 et l’ID de liaison est efgh_5678. Notez que par défaut, l’interaction de la création de services entre Cloud Foundry et le courtier de services est asynchrone. L’interaction entre le courtier de services et le serveur de ressources n’est qu’un exemple et peut être implémentée d’une manière autorisée par un serveur de ressources et un courtier.
La figure 5 montre un diagramme de séquence d’événements lorsqu’un utilisateur effectue un appel de commande CLI cf en relation avec les services et le courtier de services correspondant. Dans un scénario réel, des commandes telles que cf marketplace fourniraient une sortie des services disponibles auprès de tous les courtiers de services enregistrés sur une plate-forme. De plus, une implémentation peut varier entre les courtiers de services. Par exemple, tous les services ne doivent pas nécessairement être liés à une application, ils doivent simplement être provisionnés pour fournir certains services sur la plate-forme. Dans ce cas, il n’est pas nécessaire d’implémenter bind et unbind et nous avons seulement besoin que le champ bindable du catalogue soit défini sur false . Ce champ est spécifié dans le corps de réponse HTTP du point de terminaison de catalogue.
Remarque
Il est recommandé de garantir qu’un code d’application Service Broker ne conserve jamais son état. Cela garantit une implémentation propre et réduit le fardeau d’exiger du code supplémentaire pour maintenir l’état dans divers scénarios.
8.4.2.1 Structure de demande et de réponse HTTP
Bien que nous ne listions pas tout le contenu des requêtes et des réponses HTTP ici, nous allons décrire sa structure générale. La spécification complète des structures de demande et de réponse HTTP pour chaque point de terminaison se trouve dans la norme API OSB. Une requête HTTP est celle qui est envoyée d’une plateforme Cloud Foundry à un courtier de services et une réponse HTTP est, au contraire, envoyée du courtier de services à une plateforme Cloud Foundry:
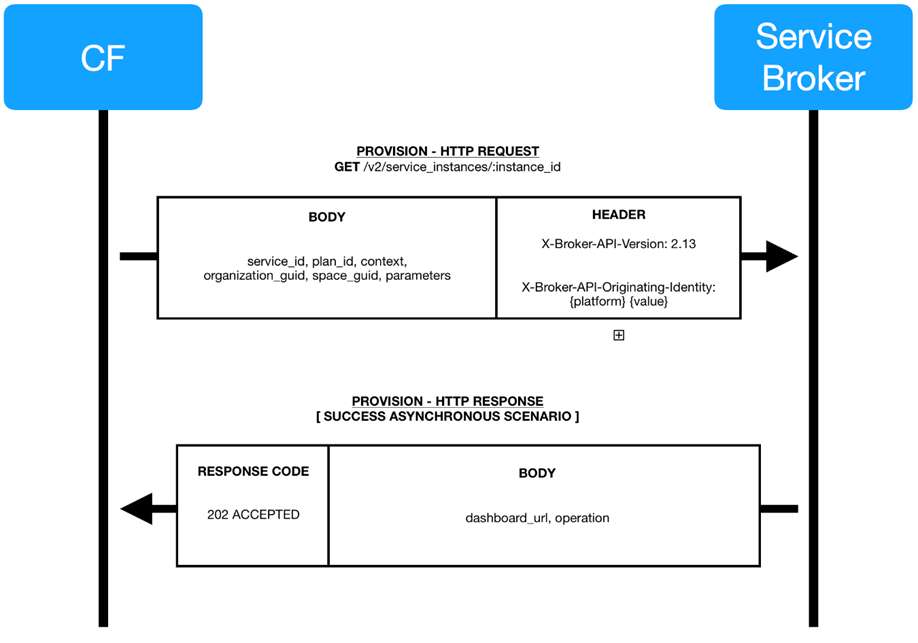
Figure 6 : Un scénario de réussite pour la disposition, montrant le contenu de la demande / réponse HTTP pour une demande asynchrone réussie.
La figure 6 montre une requête / réponse HTTP réussie avec une opération de provisionnement asynchrone. Un code de réponse différent serait émis si une autre opération s’était produite. Par exemple, 200 OK est émis s’il y a eu une demande de fourniture d’un service mais que le service a déjà été créé avec les mêmes paramètres. En outre, l’en-tête de requête HTTP contient X-Broker-API-Originating-Identity, qui est un paramètre d’en-tête facultatif. Toutes les autres opérations suivent le protocole HTTP susmentionné mais avec un contenu de demande / réponse différent.
8.4.2.2 Opérations asynchrones et synchrones
Les opérations asynchrones, pour l’API OSB, représentent une manière dont les opérations de longue durée telles que l’approvisionnement, la suppression de l’approvisionnement et la mise à jour ne sont pas bloquantes. Le résultat est qu’une réponse incomplète est retournée, généralement avec le code de réponse 202 Accepté. Cela permet à la plate-forme de terminer l’opération de demande et de fournir des informations en temps opportun qui permettraient à un utilisateur d’exécuter d’autres fonctions. Comparez cela à une opération synchrone ; la plate-forme serait bloquée dans l’attente d’une réponse et l’utilisateur devrait attendre la fin avant de pouvoir faire autre chose. Sur certaines demandes, la chaîne de requête allow_incomplete = true est fournie avec une demande à un point de terminaison pour indiquer que la plate-forme est disponible pour accepter des opérations asynchrones. Cela signifie que le courtier de services doit également prendre en charge les opérations asynchrones. Si le courtier de services ne prend pas en charge allow_incomplete = true , il ignore ce paramètre et effectue ses opérations de manière synchrone. Toutefois, si le courtier de services ne prend pas en charge les opérations synchrones et allow_incomplete = false, ou s’il n’est pas inclus en tant que paramètre, le courtier de services échouera et renverra un code de réponse 422 Entité non traitable. Cela signifie que la plate-forme doit prendre en charge les opérations asynchrones afin de travailler avec le courtier de services. Sur Cloud Foundry, les opérations asynchrones sont prises en charge et le paramètre allow_incomplete = true est toujours inclus avec chaque point de terminaison d’opération de prise en charge lors de l’utilisation de cf CLI.
8.4.2.3 Authentification
Il est possible de déployer et d’utiliser des courtiers de services qui communiquent de manière non sécurisée avec Cloud Foundry sans aucune authentification. Cependant, il est recommandé par l’API OSB que les communications entre le courtier et CF soient sécurisées avec TLS et l’authentification. Si l’authentification est implémentée, l’authentification de base HTTP doit être utilisée pour authentifier les communications entre CF et le courtier. Avec une application Java, la sécurité Spring Boot peut être utilisée pour y parvenir.
8.4.3 Courtiers de services personnalisés sur Cloud Foundry
En général, il existe quelques façons connues de déployer un courtier de services sur Cloud Foundry. Le message clé à retenir est que Cloud Foundry ne nécessite qu’une implémentation de l’application Service Broker qui suit l’API OSB. Cela signifie, par exemple, qu’il est possible d’implémenter un courtier de services dans une application de service existante et d’exposer simplement les points de terminaison de l’API OSB.
Voici quelques alternatives :
- Le courtier de services est intégré aux services et déployé par BOSH aux côtés des FC
- Le courtier de services est déployé par BOSH, mais les services sont facultativement fournis, si besoin est, et maintenus à l’extérieur de CF
- Le courtier de services est déployé sur CF avec des services fournis par un serveur de ressources externe ou ils existent déjà à l’extérieur de CF
- Le courtier de services et les services sont gérés et maintenus à l’extérieur des FC
Un facteur important à retenir est qu’un courtier de services ne peut être inscrit qu’une seule fois par fondation. Ceci est contrôlé par les ID de service fournis par le courtier, le nom du courtier de service et l’itinéraire vers le courtier. Par conséquent, il est important de cartographier la visibilité de ces services et où le courtier de services doit être déployé en premier. La portée du courtier de services disponible peut être limitée à un nombre quelconque d’organisations, à un espace particulier et à un plan particulier. Par défaut, lors de l’inscription d’un courtier à CF, les services sont désactivés pour toutes les organisations et tous les espaces.
8.4.3.1 Déploiement et enregistrement de courtiers de services personnalisés sur Cloud Foundry
Nous utiliserons un exemple d’application Service Broker pour cette section. L’exemple d’application Service Broker est un modèle d’application contenant tous les points de terminaison RESTful définis qui vous aideront à développer d’autres applications Service Broker. L’application de modèle se trouve sur https://github.com/Cloud-Foundry-For-Developers/chapter-10.git , que vous pouvez utiliser pour modèle votre propre courtier de services à l’avenir. Le modèle de code source Java est structuré de manière à ce que le package Controller contienne le contrôleur Service Broker avec les points de terminaison de l’API OSB et que le package Models contienne des structures de données en corrélation avec les objets corps de demande et de réponse. Du point de vue d’un développeur, il leur suffit d’ajouter leur propre code d’implémentation au contrôleur Service Broker, tout en renvoyant une réponse en utilisant les structures de données de modèle appropriées et les codes de réponse d’état HTTP spécifiés par l’API OSB:
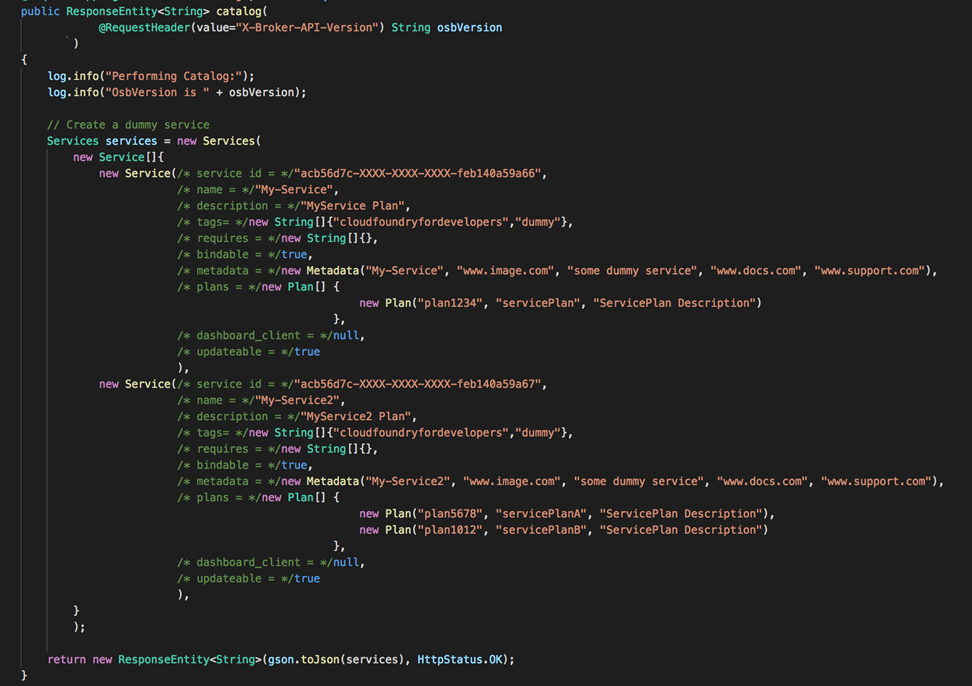
Figure 7 : un extrait du code de l’exemple d’application Service Broker. Le modèle affiche les données simulées qui renvoient deux services pour le point de terminaison du catalogue
Récupérons et déployons maintenant l’application Service Broker personnalisée. Veuillez-vous assurer que vous êtes l’utilisateur administrateur pour cet exemple:
- Téléchargez le clone ZIP ou Git sur https://github.com/Cloud-Foundry-For-Developers/chapter-10.git .
- Accédez au répertoire d’application Service Broker, ServiceBrokerTemplateApplication et exécutez le package propre mvn .
- Exécutez la commande cf push.
Après les finalise push, nous devons enregistrer l’application Service Broker avec Cloud Foundry par le cf CLI. Pour ce faire, exécutez la commande cf create-service-broker [–space-scoped] . Ici, est le nom du courtier de services. Cela ne sert que d’étiquette pour d’autres opérations des FC, comme la suppression du courtier de services. Les deux et sont les pouvoirs nécessaires pour communiquer avec les terminaux de courtage de services. Cela, comme mentionné précédemment, nécessite une authentification de base HTTP. S’il n’y a pas d’authentification, ces champs doivent toujours être entrés avec n’importe quelle chaîne, mais seront ignorés par le courtier de services. Le est l’URL HTTP / HTTPS à l’application. Dans ce cas, il doit s’agir de l’URL fournie après avoir poussé le courtier de services vers CF. –space-scoped est un paramètre qui spécifie que le courtier de services est uniquement visible dans l’espace actuel. Pour les développeurs d’espace, ce n’est pas facultatif et doit être spécifié. Pour cet exemple, nous allons exécuter la commande suivante :
cf create-service-broker my-broker none none http://service-broker-template.local.pcfdev.io

Figure 8 : Le résultat de l’exécution de cf create-service-broker suivi de cf service-brokers montre le courtier de service nouvellement enregistré
La figure 8 montre le résultat de l’exécution de la commande cf create-service-broker. Nous pouvons également exécuter le cf courtiers de- commande pour afficher les courtiers en services actuellement enregistrés.
Remarque
L’exécution de la commande cf create-service-broker oblige Cloud Foundry à interroger le catalogue du courtier de services pour récupérer toutes les informations sur l’offre de service. En cas de problème avec les données de catalogue renvoyées, la commande create-service-broker échoue et renvoie les données JSON de catalogue non valides à stdout pour examen.
Si nous exécutons cf marketplace, nous constaterons que notre service n’est pas répertorié, comme le montre la figure 9 :
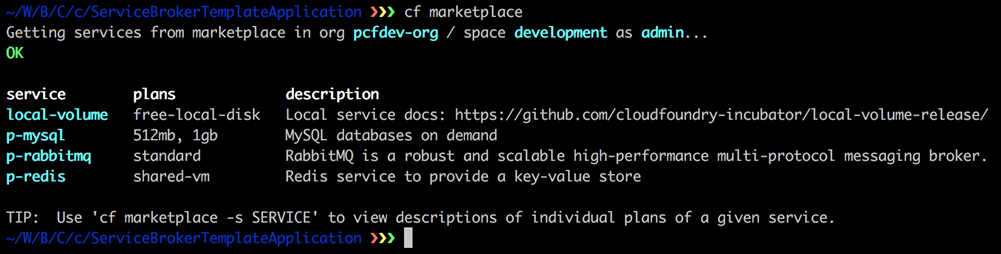
Figure 9: résultat de l’exécution de cf marketplace immédiatement après l’inscription de notre courtier de services
Cela est dû au fait que Cloud Foundry a défini l’accès au service sur aucun par défaut. Pour vérifier cela, exécutez cf service-access :

Figure 10 : résultat de l’exécution de cf service-access. Notez qu’il n’y a pas d’accès aux services fournis par le courtier de services que nous venons d’inscrire
La figure 10 montre que les services fournis par le courtier de services que nous venons d’enregistrer sont définis sur aucun. Pour activer l’accès à notre service, nous pouvons exécuter la commande cf enable-service-access [-p plan] [-o org]. Cette commande, essentiellement, permet l’accès au service pour un service particulier de notre courtier de services pour un plan donné à une organisation donnée. Le paramètre est le nom du service de notre courtier de services. -p nous permet de contrôler finement la disponibilité des plans pour une organisation donnée via le paramètre -o. Si -o n’est pas spécifié, il est supposé que l’accès soit activé pour toutes les organisations de la fondation. Si -p n’est pas spécifié, il est supposé que tous les plans du service doivent être activés. L’inverse de cette commande est le cf disable-accès de service de commande avec les mêmes paramètres, ce qui désactive l’accès d’un service à une organisation. Activons tous les services de notre courtier. Exécutez les commandes cf enable-service-access My- Service et cf enable-service-access My- Service2 -p servicePlanB. Exécutez cf marketplace pour afficher les services disponibles pour la création :
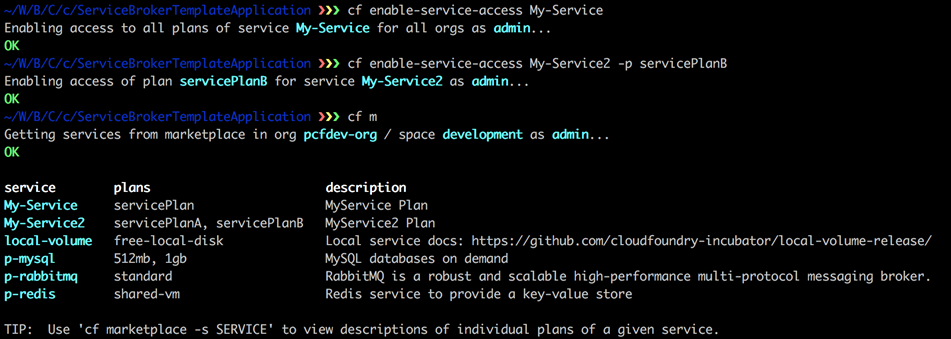
Figure 11 : Nous avons activé les deux offres de services de notre courtier de services. Nous n’avons cependant pas activé l’accès à My-Service2 avec servicePlanA
La figure 11 montre l’état actuel du marché. Notez que nous n’avions pas activé My-Service2 avec servicePlanA auparavant, cependant, il est toujours affiché sur le marché. Si nous essayons de créer un service pour servicePlanA, la cf CLI renvoie un résultat d’échec conseillait qu’il n’y a pas la permission.
Toutes nos félicitations ! Vous avez déployé et enregistré un courtier de services sur Cloud Foundry. Essayez cf create-service et cf bind-service, puis cf env , pour voir les informations d’identification répertoriées dans l’exemple d’application à lier à notre application.
Les figures 12 et 13 en montrent un exemple :
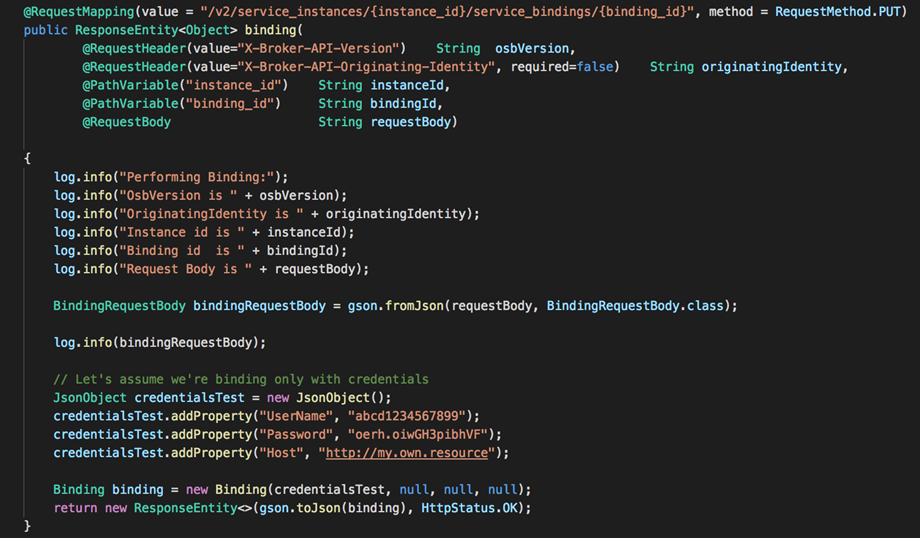
Figure 12: extrait de code du point de terminaison du service de liaison. Il renvoie un ensemble fixe d’informations d’identification pour toute demande de liaison entrante.
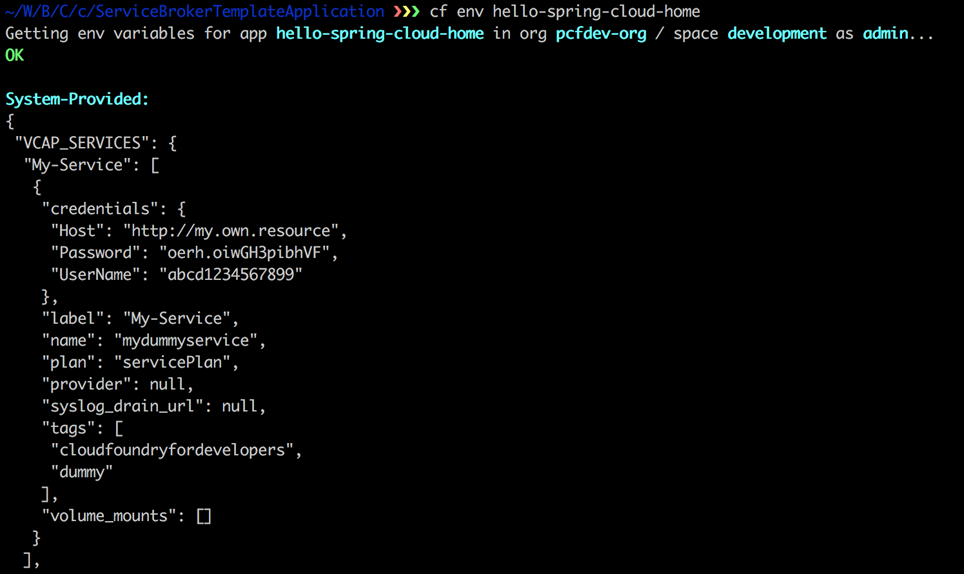
Figure 13 : Les variables d’environnement de notre application liée à My-Service. Notez que les informations d’identification sont identiques à celles du code de la figure 12
8.4.3.2 Mise à jour des courtiers de services personnalisés
Si le catalogue ou l’implémentation d’une partie quelconque change pour l’application Service Broker, un appel de mise à jour doit être exécuté plutôt que de repousser l’application Service Broker vers Cloud Foundry. Le fait de repousser l’application n’imposera pas les modifications à propager à Cloud Foundry. L’appel de mise à jour, en revanche, actualisera toutes les modifications. La commande pour ce faire est : cf update-service-broker .
8.5 Services d’itinéraire
Nous avons visité les concepts de services, de services fournis par les utilisateurs et de courtiers de services personnalisés. Que faire s’il était nécessaire de fournir des services aux applications sur la base du trafic entrant vers cette application ? C’est-à-dire, fournir un traitement / une analyse et une action sur le trafic des demandes entrantes pour une application donnée, avant qu’il n’atteigne l’application. C’est ce que proposent les services d’itinéraire. Les services d’itinéraire peuvent être instanciés par l’intermédiaire de courtiers de services sur le marché ou par le biais de services d’itinéraire fournis par l’utilisateur. Nous les explorerons en détail dans cette section. Alternativement, cela pourrait être fait à la manière d’un microservice en utilisant un registre de services pour effectuer la mise en réseau de conteneur à conteneur. Cependant, cela ne prendrait pas la forme d’un service utilisant les capacités de service de Cloud Foundry.
8.5.1 Activation des services de route
Pour utiliser les services de route, l’opérateur de la plateforme doit mettre à jour le manifeste cf -release avec une phrase de passe appropriée et des configurations supplémentaires relatives à l’activation des certificats HTTPS et SSL. La phrase secrète est utilisée par le Gorouter pour crypter les informations d’en-tête qui sont envoyées à un service de route , puis à une application. Les détails de l’activation du service de routage pour la plate-forme Cloud Foundry sont disponibles à l’ adresse : https://docs.cloudfoundry.org/services/route-services.html#architecture-comparison .
8.5.2 Exigences de mise en œuvre de Service Broker et d’instance de service
Pour que les services de routage fonctionnent avec une application, le courtier de services et l’implémentation de l’instance de service doivent répondre à certaines exigences. La signification de l’implémentation d’instance de service fait référence à l’implémentation réelle du service de routage.
Du point de vue du courtier de services, il doit renvoyer les informations de liaison d’itinéraire pour les opérations suivantes :
- Catalogue : Le catalogue de services doit inclure requiert : [” route_forwarding “]. Ne pas le faire empêchera les instances de service d’être liées à une route.
- Liaison : lorsqu’un utilisateur lie une instance de service à une route, Cloud Foundry appelle le point de terminaison de liaison du courtier de services avec une adresse de route dans le champ bind_ resource.route . Le champ bind_ resource.route est une URL qui spécifie l’itinéraire mappé à une application que les clients avaient utilisée pour atteindre l’application. En retour, le processus de liaison peut éventuellement renvoyer route_service_url dans le corps de réponse HTTP. Il s’agit d’une adresse proxy pour signaler à Cloud Foundry où il doit acheminer ses demandes. L’URL doit être un schéma HTTPS pour que cela fonctionne. Si un courtier de services ne spécifie pas route_service_url , le courtier de services reste libre de mettre à jour le service qui se trouve déjà dans le chemin de demande.
Du point de vue de l’implémentation du service de routage, les exigences ne sont nécessaires et applicables que lorsque l’application Service Broker envoie un route_service_url au cours du processus de liaison susmentionné. Au cours du processus de liaison, lorsqu’un courtier de services fournit une route_service_url, toutes les demandes sont transmises par proxy à cette URL. Cela se produit car Cloud Foundry détecte la présence de route_service_url et met à jour son Gorouter pour associer toutes les demandes entrantes à cette URL.
Il y a trois questions clés de mise en œuvre du service de route à considérer :
- Délai d’expiration : un service de routage doit terminer sa tâche dans un délai imparti spécifié dans le manifeste de configuration du Cloud Foundry Gorouter dans BOSH. Ces modifications doivent être effectuées au niveau de la plate-forme si nécessaire. Les deux éléments clés sont router.route _service_timeout et request_timeout_in_seconds . Le premier concerne le délai dans lequel un service de route doit transmettre une demande à une application. Cette valeur par défaut est de 60 secondes. Ce dernier représente le temps de réponse pour toutes les demandes, par défaut à 900 secondes.
- Certificats SSL : lorsqu’un service de routage est en cours de développement, Gorouter on Cloud Foundry transfère les certificats auto-signés au service au lieu de ceux signés par une autorité de confiance. Le service de routage devra gérer les certificats auto-signés, dans ce cas, une fois le traitement des demandes entrantes terminé et la décision de transmettre la demande à l’URL spécifiée dans l’en – tête X-CF-Forwarded- Url.
- Transfert de demande : lorsque le service de routage a terminé sa tâche, il peut choisir de transférer la demande vers l’URL demandée d’origine, une URL différente, ou même de la rejeter en cas d’échec. Lorsqu’un rejet se produit, les demandes sont renvoyées vers l’URL d’origine demandée. Notez que lors du transfert d’une demande vers une autre URL, il ne doit pas s’agir d’une application existante déjà liée à un service de routage. Le Cloud Foundry GoRouter fournira trois en-têtes dans les demandes entrantes. L’un est l’URL de demande d’origine et deux autres sont des en-têtes utilisés par le Cloud Foundry Gorouter pour valider les demandes d’un service de route. Ces en-têtes en détail sont :
- X-CF-Forwarded-URL : cet en-tête contient l’URL de destination du demandeur d’origine. Un service de routage est libre de transmettre des demandes à cette URL ou à une autre.
- X-CF-Proxy-Signature : la signature proxy contient des informations chiffrées qui ne sont déchiffrables que par le Cloud Foundry Gorouter . Les informations sont essentiellement l’URL du demandeur d’origine et un horodatage. Le Gorouter a trois utilisations pour cet en-tête :
- Vérifiez que la demande à transférer correspond à l’URL du demandeur d’origine.
- Vérifiez qu’aucun délai d’attente ne s’est produit. Si une URL de demande transférée ne correspond pas à l’URL du demandeur d’origine et que l’URL transférée se résout en une application qui est également liée à un service de routage, la demande est rejetée par le Gorouter .
- Empêcher la livraison récursive des demandes d’acheminement des services. Autrement dit, si le Gorouter voit cet en-tête, il ne le retransmettra pas à un service de route. Par conséquent, il est essentiel qu’un service de routage ne supprime pas les en – têtes X-CF-Proxy-Signature et X-CF-Proxy-Metadata.
- X-CF-Proxy-Metadata : contient des informations qui facilitent le cryptage et le décryptage de la signature X-CF-Proxy.
Remarque
Nous l’avons déjà mentionné, mais nous allons le remettre ici car il est courant de voir ce problème; assurez-vous que les signatures X-CF-Proxy-Signature et X-CF-Proxy-Metadata ne sont pas supprimées , sinon une livraison récursive des demandes se produira!
8.5.3 Stratégies de déploiement des services de routage
Il existe trois façons de déployer un service de routage, à savoir un service de routage entièrement négocié, un service de routage négocié en statique et un service de routage fourni par l’utilisateur. Ils fournissent tous un service de route, cependant, chaque stratégie a ses avantages et ses inconvénients, que nous énumérerons ici. L’inconvénient commun à toutes les stratégies de déploiement est qu’elles nécessitent toutes des sauts de réseau supplémentaires pour atteindre l’application.
1.5.3.1 Service de route entièrement négocié
Dans un service de routage entièrement négocié, toutes les demandes entrantes vers les applications sont, comme d’habitude, envoyées au Gorouter via un équilibreur de charge, qui détectera s’il existe un service de routage. Conformément à la figure 14 , lors de la détection du service de routage, le Gorouter transmet la demande à l’instance de service de routage attachée avec les en-têtes de transfert, de signature et de métadonnées URL. L’instance de service d’itinéraire achèvera sa tâche et retransmettra la demande à l’ URL de destination via l’équilibreur de charge, qui transmettra la demande au Gorouter . Le Gorouter détectera la présence des en-têtes de signature et de métadonnées, et donc ne transmettra plus au service de route, mais transmettra à la place à l’application :

Figure 14 : Un organigramme d’un service de routage entièrement négocié
Avantages :
- Le courtier peut mettre à jour dynamiquement le service de routage selon les besoins
- Le trafic vers les applications qui n’utilisent pas ce service d’itinéraire n’est pas affecté par un tronçon de réseau supplémentaire
- La configuration du service de routage est effectuée entièrement sur Cloud Foundry et ne nécessite pas d’infrastructure externe
Inconvénients :
- Le trafic vers les applications qui utilisent ce service d’itinéraire nécessitera des sauts de réseau supplémentaires
1.5.3.2 Service de routage à courtage statique
Dans un scénario de service de routage à courtage statique, une instance de service de routage est configurée en externe sur Cloud Foundry avant un équilibreur de charge. Les applications sur Cloud Foundry devront toujours se lier au service afin que le courtier de services puisse configurer le service de routage pour traiter les applications enregistrées, puis transmettre les demandes à l’équilibreur de charge :
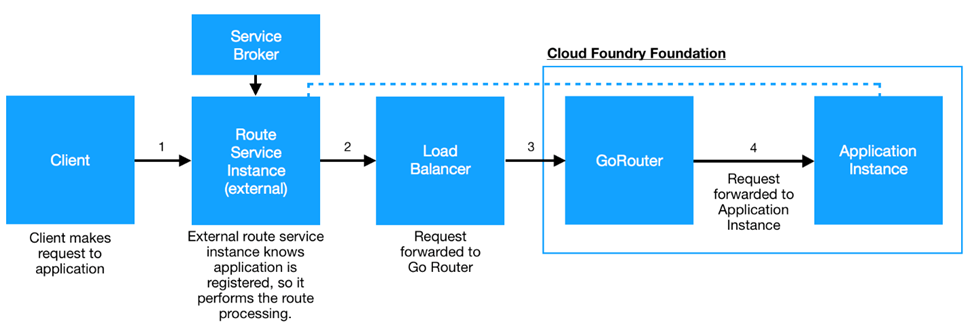
Figure 15 : Un organigramme d’un service de routage à courtage statique
Avantages :
- Le courtier peut mettre à jour dynamiquement le service de routage selon les besoins
- Le trafic vers les applications qui utilisent le service de routage nécessite moins de sauts de réseau, par rapport à la configuration du service de routage entièrement négocié
Désavantages :
- Tout le trafic vers les applications sur Cloud Foundry sera acheminé vers le service de routage et nécessitera des sauts de réseau supplémentaires
- Les opérateurs doivent configurer l’infrastructure en dehors de Cloud Foundry pour que cela fonctionne
1.5.3.3 Service d’itinéraire fourni par l’utilisateur
Un service de routage fourni par l’utilisateur permet d’associer des services de routage à une application dans un espace Cloud Foundry. Le service fourni par l’utilisateur pointe vers une instance de service de routage qui peut être sur Cloud Foundry ou située à l’extérieur. Ceci est similaire à la solution entièrement négociée, à l’exception de l’absence de courtier de services. Cela présente un avantage en termes de simplicité de mise en œuvre, en ce sens qu’un courtier de services n’a pas besoin d’être implémenté et que le service fourni par l’utilisateur doit uniquement être lié à une route. Bien sûr, comme pour tous les services fournis par les utilisateurs, ceux-ci doivent être gérés manuellement car le courtier de services n’est pas là pour effectuer l’administration et ils n’existent qu’au niveau de l’espace à partir duquel ils sont instanciés. En substance, le Gorouter transmettra les demandes entrantes au service de routage via l’instance de service fournie par l’utilisateur s’il détecte qu’une application est liée à cette instance de service de route fournie par l’utilisateur. Par conséquent, la prise en compte du pare-feu pour les services de routage externes doit être configurée au préalable:
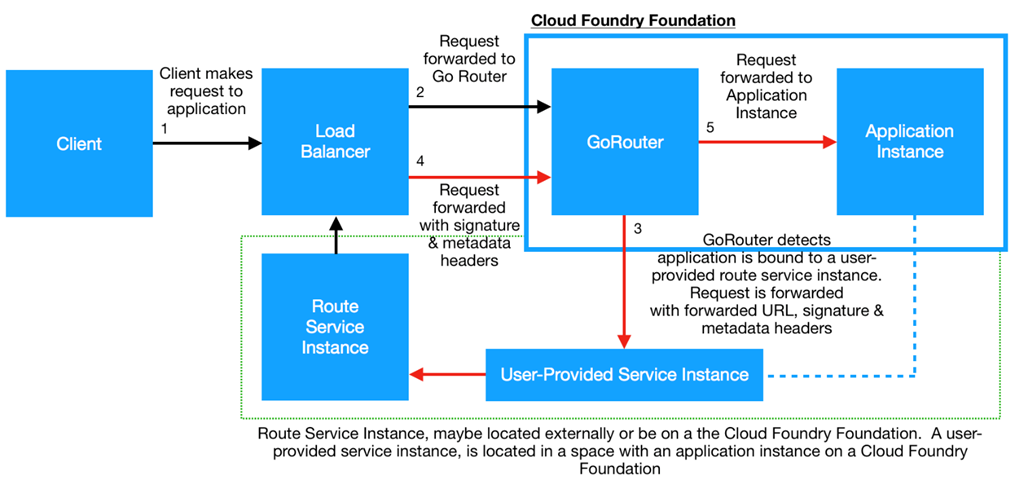
Figure 16 : Un organigramme d’un service de route fourni par l’utilisateur
Avantages :
- Simplicité en termes de moindre quantité de travail pour faire fonctionner un service d’itinéraire
- Le trafic vers les applications qui n’utilisent pas ce service d’itinéraire n’est pas affecté par un tronçon de réseau supplémentaire
- La configuration du service de routage est effectuée entièrement sur Cloud Foundry et ne nécessite pas d’infrastructure externe
Inconvénients :
- Le trafic vers les applications qui utilisent ce service d’itinéraire nécessitera des sauts de réseau supplémentaires
- Pour les services de route externes, les opérateurs doivent configurer l’accès pour permettre au trafic d’être accepté à partir du Cloud Foundry Gorouter
- La gestion du service de route est un processus manuel sans le courtier de services
8.5.4 Exemple de service d’itinéraire
Nous utiliserons ici un exemple de service de route de journalisation. Le but du service de journalisation de l’itinéraire est de simplement enregistrer toutes les demandes entrantes sur stdout . Pour déployer cet exemple, suivez les étapes de la procédure. Le service d’itinéraire de journalisation peut être lié à n’importe quelle application. Pour cet exemple, nous utiliserons l’ exemple d’application hello-spring-cloud du chapitre 6 , Deploying Apps To Cloud Foundry, qui se trouve à l’ adresse : https://github.com/Cloud-Foundry-For-Developers/logging-route -service . Envoyez cette application à Cloud Foundry si vous ne l’avez pas déjà fait:
- Téléchargez l’exemple d’application de service de route de journalisation à partir de: https://github.com/Cloud-Foundry-For-Developers/logging-route-service .
- Poussez cette application vers Cloud Foundry en exécutant cf push . L’application est développée dans Go. Par défaut, PCF Dev a le pack de construction Go .
- Une fois l’application poussée, créez un service d’itinéraire fourni par l’utilisateur à l’aide du paramètre -r : cf create-user-provided-service logRouteService -r https://log-route-service-application.local.pcfdev.io . Cela permettra la liaison des services à une application via l’URL de l’itinéraire.
- Liez l’application de service de journalisation de l’itinéraire à l’exemple d’application hello-spring-cloud via la commande cf bind-route-service local.pcfdev.io logRouteService –hostname hello-spring-cloud.
- Effectuez un suivi de l’application de service de journalisation de la route via la commande cf logs log-route-service-application.
- Exécutez l’application hello-spring-cloud dans un navigateur via l’URL fournie après avoir poussé l’application. Maintenant, jetez un œil aux journaux à queue de notre application log-route-service-application :
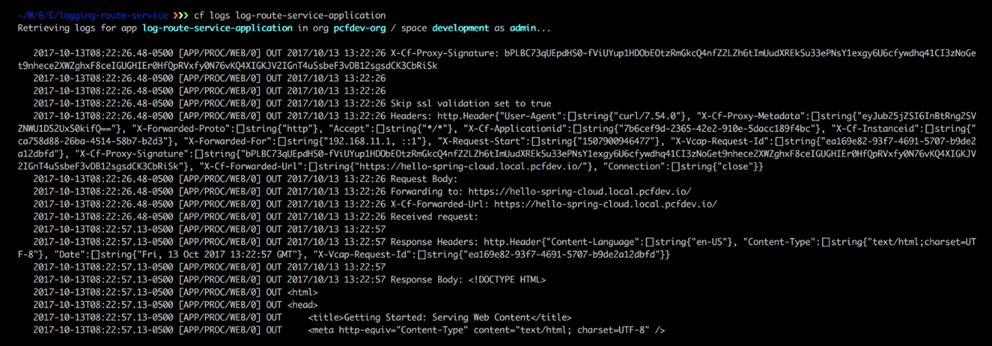
Figure 17 : Sortie du service de route de journalisation, après l’exécution de l’application hello-spring-cloud, à laquelle le service de route était lié
8.6 Stratégies d’intégration de services
Vous avez appris les services fournis par les utilisateurs et les courtiers de services pour gérer les services externes à PCF, mais quelle stratégie de service est la meilleure pour votre organisation ? Cela pourrait varier d’une organisation à l’autre. À moins que la réponse ne soit connue avec toutes les données d’utilisation des services disponibles, la meilleure approche est d’être agile et de s’adapter au besoin pour minimiser l’effort nécessaire pour atteindre votre objectif. Suivez une approche pilotée par les tests. Commencez avec la solution la plus simple, apprenez et adaptez-vous. S’il existe, à l’heure actuelle, un nombre gérable d’organismes ou d’espaces, par exemple cinq espaces, en utilisant un service externe, une approche de service fournie par l’utilisateur serait la meilleure. Par la suite, si le nombre de services externes augmente et s’étend à plusieurs organisations, un courtier de services serait une bonne solution.
Le concept clé à retenir est que jusqu’à présent nous avons parlé de services externes à PCF. Cela signifie que l’équipe de la plateforme de votre organisation serait responsable de la gestion du service. Il existe deux stratégies d’intégration de services supplémentaires, les services gérés et les services à la demande. Ces deux stratégies nécessitent des courtiers de services et le développement de tuiles de services. Nous n’abordons pas le sujet des tuiles de service dans cet article, car elles sont gérées par l’équipe de plate-forme de votre organisation. Plus de détails peuvent être trouvés sur: https://docs.pivotal.io/tiledev/index.html . Cependant, en dehors du niveau plus élevé de complexité de mise en œuvre et de planification de la haute disponibilité, la vraie différence réside dans le lieu où ces services résident et comment ils sont fournis. En termes plus simples, une approche de service géré nécessite qu’un service externe soit déplacé vers Cloud Foundry et exécuté avec un nombre fixe de machines virtuelles ( VM ) avec une quantité fixe de ressources allouées. Cela permet à Cloud Foundry de surveiller et de gérer ces machines virtuelles. Ainsi, s’il existe des machines virtuelles défaillantes, Cloud Foundry recréerait ces machines virtuelles défaillantes selon les besoins. Dans un scénario de service à la demande, les machines virtuelles fixes ne sont pas créées et allouées au préalable. Au lieu de cela, les machines virtuelles du service sont provisionnées à la demande lorsque les développeurs appellent cf create-service.
8.7 Résumé
Dans ce chapitre, nous avons brièvement revu les concepts de services et comment ils sont liés aux applications. Nous avons ensuite introduit les services fournis par les utilisateurs, les courtiers de services et les services d’itinéraire. À présent, vous serez en mesure de mettre en œuvre vos propres courtiers de services et services d’itinéraire. Nous avons également cherché à comprendre les différentes stratégies de déploiement des courtiers de services et des services de route. Les implications des différentes approches pour acheminer les services étaient particulièrement importantes, car elles peuvent affecter les demandes entrantes pour toutes les applications de votre fondation Cloud Foundry. Enfin, nous avons brièvement discuté des stratégies d’intégration de vos services. Dans le chapitre suivant, nous étudierons les Buildpacks et comment créer le vôtre sur Cloud Foundry!
9 Chapitre 9. Buildpacks
Dans le chapitre 6 , Déploiement d’applications sur Cloud Foundry , nous avons brièvement abordé les buildpacks . Nous approfondirons les buildpacks dans ce chapitre. À la fin du chapitre, vous serez en mesure de comprendre :
- Vue d’ensemble des buildpacks et de leur rôle par rapport aux applications sur Cloud Foundry
- Buildpacks communs
- Consommation et gestion des buildpacks
- Fonctionnement des buildpacks en arrière-plan
- Création de buildpacks
9.1 Buildpacks sur Cloud Foundry
Historiquement, grâce aux efforts pionniers de Heroku, la gestion des dépendances de Ruby (le langage de programmation) a été fusionnée avec l’image du système d’exploitation de base, appelée pile dans le monde Heroku. Sur Cloud Foundry, cela s’appelle une cellule souche. Il a été identifié plus tard qu’en séparant les dépendances Ruby en un composant appelé Buildpacks , ils ont pu itérer rapidement sur les dépendances Ruby par rapport à l’image du système d’exploitation. En substance, un buildpack est le support d’exécution et de framework pour une application.
Pour la plupart des applications construites sur un framework, les dépendances et les frameworks d’exécution doivent généralement être fournis avec l’application, ou ils sont installés sur la plateforme cible sur laquelle les applications doivent être exécutées. Quelques exemples incluent .NET Framework et Java Runtime. Bien sûr, une alternative est de compiler statiquement toutes les dépendances en un seul binaire exécutable, s’il y a une option, mais cela aboutirait généralement à un fichier très volumineux. Avec les buildpacks , la fonctionnalité polyglotte de Cloud Foundry brille.
Dans le cas de l’exécution d’une application sur Cloud Foundry, ces dépendances et cadres d’exécution doivent être inclus avec l’application pour qu’elle s’exécute. Ceux-ci sont regroupés dans un package appelé buildpack . Cependant, un buildpack contient beaucoup plus de capacités qu’un simple framework d’exécution. Comme mentionné précédemment, un buildpack se compose d’un ensemble d’outils, de composants d’exécution potentiels et de scripts qui sont programmés pour récupérer les dépendances requises par l’application, déplacer la sortie compilée vers un emplacement d’exécution, compiler le code et / ou configurer l’application pour en cours d’exécution dans le conteneur. Ce qui est vraiment bien dans tout cela, c’est que les dépendances et le packaging sont cohérents dans tous les environnements. Pour le développeur, en dehors d’une pléthore de langages de développement à utiliser, cela signifie qu’ils peuvent être sûrs qu’ils utilisent des dépendances et des cadres liés à une version connue, ce qui conduit à une plus grande confiance dans leur code. Pour l’équipe de la plateforme, c’est un moyen de fournir un framework packagé et une dépendance toujours cohérente sur toutes les bases, pour toutes les équipes de développement. Cela conduit à moins de problèmes de travail liés au maintien de différentes dépendances et durées d’exécution sur différentes fondations.
Remarque
Pour certains buildpacks , il est possible de pousser le code source sur Cloud Foundry et de permettre à un buildpack d’extraire les dépendances marquées et de compiler l’application dans un binaire exécutable. Cependant, ce n’est pas recommandé. Considérez la situation dans laquelle le cadre d’exécution du buildpack est la version 1 mais votre machine de développement locale est la version 2. Cela introduira un problème de parité d’environnement et introduira potentiellement un comportement d’application différent. Il est recommandé de créer des applications avec tous les artefacts inclus dans un package avant de les déployer sur Cloud Foundry. Cela se fait généralement dans le cadre d’un pipeline CI / CD. L’application que vous envoyez est construite avec une version de framework d’exécution connue et balisée avec une version de build, garantissant la parité de l’environnement. Bien sûr, dans ce cas, si la version du buildpack est plus ancienne que celle qui a été compilée avec l’application, elle est généralement perceptible à l’avance, les applications générant des erreurs avec les versions requises du cadre d’exécution. C’est beaucoup plus facile à diagnostiquer et à corriger.
9.1.1 Buildpacks communs sur Cloud Foundry
L’exécution de la commande cf buildpacks affichera une liste des buildpacks disponibles sur votre fondation. Ces buildpacks sont généralement disponibles sur la plupart des fondations. Cela peut être configuré différemment par votre équipe de plateforme en fonction des politiques de votre organisation:
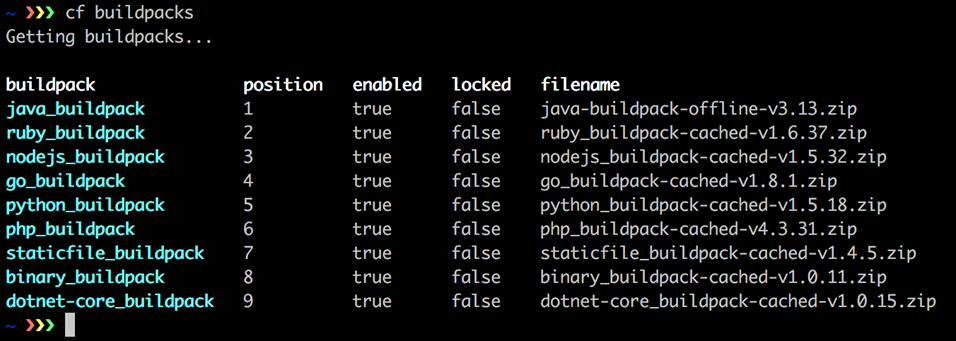
Figure 1: L’exécution de cf buildpacks affichera une liste des buildpacks disponibles sur votre fondation. Dans ce cas, cette figure montre les buildpacks disponibles sur PCFDev
Dans la figure 1 , la liste des buildpacks est installée sur PCFDev avec des informations supplémentaires, notamment la position, activé, verrouillé et le nom de fichier. Ces informations sont liées à l’ordre de vérifier et d’associer un buildpack à une application pendant le déploiement, quand aucun buildpack n’est spécifié pour l’application. Activé indique si un buildpack est utilisé sur la base, le verrouillage fournit un moyen de verrouiller un buildpack afin que ses restes de version et ne met en aucun buildpack événement de mise à niveau et le nom de fichier est le nom du fichier source du buildpack .
Généralement, la modification / définition de l’ordre est effectuée par l’équipe de la plate-forme et est la plus utile pour élaborer une stratégie de migration des applications vers l’utilisation de nouvelles versions d’un buildpack . Par exemple, mettre la version 1 d’un buildpack à la position 5 et mettre la version 2 du même buildpack à la position 6. Cela permettrait aux applications de niveau de production d’utiliser automatiquement la version 1 du buildpack pendant un certain temps, tandis que les équipes de développement testent la version 2 du buildpack . Plus tard, à une date limite donnée, une migration échangerait les positions des buildpacks version 1 et version 2 afin que toutes les applications utilisent désormais le buildpack version 2 . La version 1 peut rester sur la liste des tests de régression. Tout cela serait réalisé par les pipelines de mise à niveau automatisés de l’équipe de la plate-forme, qui obtiendraient les buildpacks à jour et favoriseraient et mettraient à jour les buildpacks définis par une stratégie, telle que celle mentionnée précédemment.
D’après la figure 1, la plupart des langues prises en charge par les buildpacks sont explicites, c’est-à-dire dotnet- core_buildpack pour les applications .NET Core. Il existe, bien sûr, une prise en charge de framework détaillée supplémentaire, à savoir Java avec Spring ; il peut être possible de configurer les buildpacks via des variables d’environnement, que vous définirez via la commande cf set-env ou dans le manifeste de votre application. Une liste des buildpacks communs, leurs informations de support et leur configuration sont tous documentés dans leurs pages GitHub respectives à https://docs.cloudfoundry.org/buildpacks .
Il y a deux buildpacks spéciaux qui seront discutés ici. Ce sont le buildpack binaire et le buildpack de fichiers statiques. Le buildpack binaire permet à toute forme de serveur Web, en tant que binaire, de s’exécuter dans un conteneur. Deux conditions doivent être respectées pour que votre application s’exécute. La première : votre application Web doit lire dans la variable d’environnement PORT que votre application de service Web va lier pour recevoir et envoyer des demandes ou des réponses. La seconde : une commande de démarrage, pour que le buildpack binaire sache comment démarrer votre application. Cela peut être fait en incluant un fichier nommé procfile dans le répertoire racine de l’application ou via une option -c sur la commande ou le manifeste cf push :
- Exemple de contenu du fichier Procfile :
Web :. / exécutable-app-binaire
- Exemple d’ option -c :
cf push -c “./ exécutable-app-binaire”
Remarque
Si vous ne souhaitez pas lire la variable d’environnement PORT dans votre application, vous pouvez créer une application de serveur Web qui est démarrée avec le PORT comme argument d’entrée dans votre application. Par exemple, cf push -c “./ executable-app-binary $ PORT” .
Le deuxième buildpack spécial est le buildpack statique, qui est utilisé pour servir du contenu statique, tel que des sites Web contenant des fichiers HTML, CSS et JavaScript. La configuration minimale requise pour ce buildpack est d’inclure un fichier nommé Staticfile avec votre contenu statique dans le répertoire racine. Le fichier statique peut être vide et servira un fichier index.html au même emplacement que le fichier. Alternativement, Staticfile peut contenir divers paramètres de configuration, par exemple, l’emplacement d’un fichier index.html à utiliser se trouve dans un sous-répertoire. Plus de détails sur les paramètres StaticFile peuvent être trouvés sur: https://docs.cloudfoundry.org/buildpacks/staticfile/#configure-and-push .
Bien que nous venions de discuter des buildpacks communs et des deux types spéciaux de buildpacks , cela ne signifie pas que vous seriez limité à ceux-ci uniquement. Une approche consiste à créer ou personnaliser des buildpacks, et l’autre consiste à explorer les buildpacks qui ont déjà été apportés à la communauté Cloud Foundry à https://github.com/cloudfoundry-community/cf-docs-contrib/wiki/Buildpacks .
9.1.2 Consommation et gestion des buildpacks sur Cloud Foundry
Remarque
En fonction des politiques de votre organisation, il se peut que vous ne soyez pas autorisé à gérer et / ou à utiliser des buildpacks externes . Les buildpacks peuvent être administrés par l’équipe de plate-forme de votre organisation.
9.1.2.1 Buildpacks hors ligne et en ligne
Vous remarquerez que lorsque vous téléchargez des buildpacks, il existe parfois une option pour les versions hors ligne (mises en cache) ou en ligne (non mises en cache) qui peuvent être téléchargées. Un buildpack est en ligne / non mis en cache lorsqu’il dispose d’un accès Internet à distance pendant le transfert d’application. Cela permet à un buildpack d’avoir une empreinte plus petite et de télécharger les dépendances nécessaires pour l’application en cas de besoin. Cependant, cela présente un problème de sécurité lors du déploiement dans des environnements de production. Idéalement, il ne devrait pas y avoir d’accès distant externe pour un pack de build dans ces types d’environnements. Par conséquent, il existe des buildpacks hors ligne / mis en cache qui contiennent des dépendances préchargées et du code interne qui empêche l’accès à distance. Les buildpacks hors ligne / mis en cache sont souvent de taille beaucoup plus grande que leurs homologues en ligne.
9.1.2.2 Consommation de buildpacks externes sur Cloud Foundry
Maintenant, nous savons déjà comment consommer les paquets installés sur Cloud Foundry par le cf CLI. Et si nous voulons utiliser un buildpack qui n’est pas installé sur notre fondation ? Ceci peut être réalisé en spécifiant un emplacement de buildpack externe via l’option -b avec cf push .
cf push java-app-name -b https://github.com/cloudfoundry/java-buildpack.git
Par exemple, la commande précédente poussera une application nommée java-app-name et la forcera à télécharger et à utiliser le dernier buildpack depuis https://github.com/cloudfoundry/java-buildpack.git .
Remarque
Pour les applications Windows, vous devrez spécifier directement le fichier ZIP, c’est-à-dire, cf push winapp -s windows2012R2 -b https://github.com/cloudfoundry/hwc-buildpack/releases/download/v2.3.11/hwc-buildpack -v2.3.11.zip .
9.1.2.3 Ajout d’un nouveau pack de build à Cloud Foundry
Cependant, s’il y a un besoin, l’installation d’un buildpack pré-téléchargera le buildpack sur votre fondation. Cela est beaucoup plus rapide que re-télécharger le buildpack pour chaque cf poussée. Nous installons un nouveau buildpack via la commande cf create- buildpack [–enable | –disable]. est le nom du nouveau buildpack . Cela sera utilisé dans votre commande et manifeste cf push. doit contenir un chemin vers un fichier ZIP de buildpack, le chemin peut provenir d’une URL ou d’un répertoire local. représente l’ordre dans la liste de buildpack à partir duquel le transfert effectuera le test de détection. –enable et –disable activeront ou désactiveront le buildpack de la mise en scène, respectivement. Par défaut, le nouveau buildpack est activé. Ajoutons une nouvelle version de notre buildpack Java à la fondation. Dans ce cas, nous ajouterons la version 4.6 du pack de construction Java, mais la placerons en position deux, car nous ne voulons pas que les applications Java utilisent la version 4.6 immédiatement, sans quelques tests. Exécutez la commande suivante :
cf create-buildpack java_buildpack_v4_6 https://github.com/cloudfoundry/java-buildpack/releases/download/v4.6/java-buildpack-offline-v4.6.zip 2
La commande précédente créera un nouveau buildpack Java nommé java_buildpack_v4_6 qui contient Java buildpack version 4.6 et le place à la position numéro deux sur notre liste de buildpack :
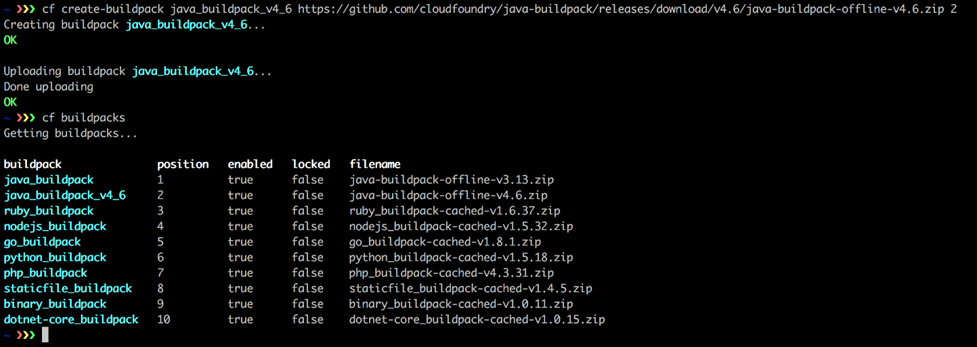
Figure 2: création d’un nouveau pack de build Java version 4.6 et placement en position numéro 2
9.1.2.4 Mise à jour d’un buildpack sur Cloud Foundry
Pour mettre à jour une existante buildpack sur notre fondation, nous pouvons exécuter le cf update- buildpack [CHEMIN -p] [- i POSITION] [–enable | disable] | [–unlock –lock] commande. fait référence au nom du buildpack actuel trouvé dans la liste des buildpacks. Les paramètres restants, -p PATH, – i POSITION, –enable / – disable et –lock / – unlock effectuent respectivement les opérations suivantes : spécifiez le chemin d’accès au nouveau fichier ZIP pour le buildpack , la nouvelle position– sous forme d’entier – pour le buildpack , activez / désactivez le buildpack et définissez l’état de verrouillage / déverrouillage du buildpack .
Cependant, notez que la commande précédente ne renomme pas le buildpack. Pour renommer un buildpack , nous pouvons le faire via la commande cf rename- buildpack , qui le renomme en .
Essayons de mettre à jour le buildpack Go vers la version 1.8.11 et de renommer notre buildpack en gogo_buildpack . Nous exécuterons les commandes suivantes :
cf update-buildpack go_buildpack -p https://github.com/cloudfoundry/go-buildpack/releases/download/v1.8.11/go-buildpack-v1.8.11.zip
et,
cf rename-buildpack go_buildpack gogo_buildpack
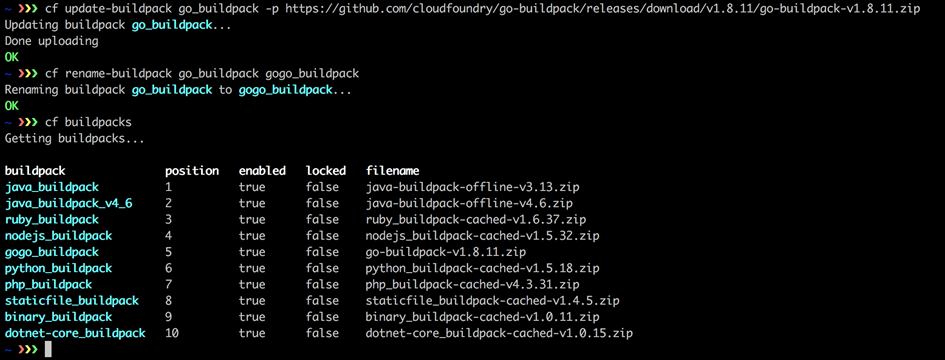
Figure 3 : résultat de la mise à jour du buildpack Go vers la version 1.8.11 et de son changement de nom
9.1.2.5 Suppression d’un buildpack
Pour supprimer un buildpack de notre fondation, il suffit d’exécuter la commande cf delete- buildpack [-f]. Ici, -f force la suppression du buildpack sans invite. Étant donné que la suppression est un processus irréversible, des précautions doivent être prises lors de l’utilisation de -f. Supprimons le buildpack java_buildpack_v4_6. Exécutez la commande cf delete- buildpack java_buildpack_v4_6 :
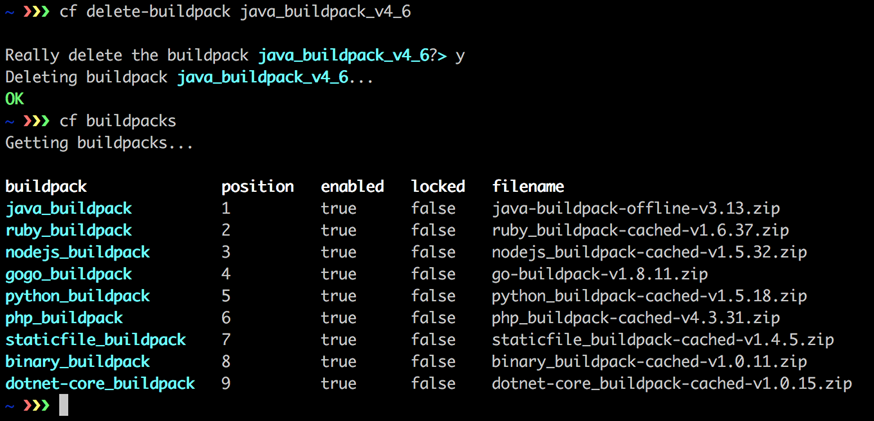
Figure 4 : résultat de la suppression du pack de build Java version 4.6
9.1.2.6 Gouttelettes en cache existantes et maintenance des buildpacks installés
Il y a un effet secondaire important qui doit être précisé ici. Nous avons appris que le redémarrage d’une application réutilise uniquement un droplet mis en cache qui a déjà un buildpack associé, extrait des dépendances, des cadres et diverses variables d’environnement. Sauf si nous effectuons un restage, ce qui reconstruit la gouttelette. Ce que cela nous dit, c’est que si nous modifions un buildpack de quelque manière que ce soit à l’aide de l’une des commandes précédentes, nous serions toujours en mesure d’exécuter une application qui est déjà déployée sur Cloud Foundry car elle utilise le droplet mis en cache. Ce n’est que lorsque nous effectuons un restage sur cette application, que de nouvelles modifications seront appliquées via la reconstruction de la droplet.
9.2 profonde -dive en buildpacks
À présent, vous vous demandez peut-être comment les buildpacks fonctionnent réellement et comment créer / personnaliser vos propres buildpacks. Pour créer / personnaliser des buildpacks, nous devons d’abord comprendre comment ils fonctionnent avec Cloud Foundry en arrière-plan.
9.2.1 Fonctionnement des buildpacks avec Cloud Foundry
Lorsqu’une poussée cf est effectuée, tous les fichiers d’application sont téléchargés dans un blobstore ; par la suite, une tâche intermédiaire est créée. Cette tâche de transfert est essentiellement un nouveau conteneur avec les fichiers d’application. Le processus de buildpack suivant commence par exécuter une série de scripts situés dans un répertoire bin contenant un certain nombre de fichiers de script, étiquetés comme détecter, compiler et publier. Ceux-ci sont appelés, dans cet ordre, pendant le processus de transfert pour récupérer les dépendances nécessaires, créer des artefacts et / ou configurer l’application :

Figure 5 : Le processus buildpack
Comme le montre la figure 5, une fois les fichiers d’application téléchargés, le processus continue pour vérifier si un buildpack a été spécifié avec cf push. Sinon, le processus trouve de manière itérative le bon pack de construction parmi tous ceux installés sur la fondation. Chacun de ces buildpacks est téléchargé dans le conteneur et le script de détection est exécuté pour déterminer la compatibilité. Sinon, il téléchargera directement le buildpack spécifié. Le processus de transfert se poursuit avec le script de compilation, qui extrait toutes les dépendances et effectue la construction / configuration nécessaire. Dans le script de publication, une commande d’exécution sous la forme d’un fichier YAML est générée. Il est utilisé pour exécuter l’application avec les arguments nécessaires, le cas échéant.
Remarque
Pour les piles basées sur Windows, les scripts doivent être des fichiers batch, par exemple, detect.bat . Pour appeler des scripts PowerShell, utilisez le script batch:
@echo offpowershell.exe – ExecutionPolicy Unrestricted% ~ dp0 \ detect.ps1% 1
À partir de la version 1.12 de Cloud Foundry, il existe un support pour les multi- buildpacks , qui est essentiellement une liste d’ entrées de buildpacks pendant le processus de push. Cela modifie la structure mentionnée précédemment pour inclure deux scripts supplémentaires : fournir et finaliser. L’approvisionnement est responsable de l’extraction de toutes les dépendances et cadres de l’application. Finalize effectue la construction / configuration réelle de l’application. Ces deux scripts constituent essentiellement le script de compilation. Cependant, dans la plupart des cas, vous constaterez que le script de compilation reste dans le répertoire bin pour une compatibilité descendante. Pour migrer un buildpack sans prise en charge multi- buildpack , copiez le contenu du script de compilation et insérez-le dans un script de finalisation . Le script d’approvisionnement existerait mais serait vide. Pour plus d’informations, voir https://docs.pivotal.io/pivotalcf/1-12/buildpacks/understand-buildpacks.html .
Remarque
La prise en charge de Cloud Foundry 1.12 pour le multi- buildpack signifie qu’il est possible d’avoir plusieurs support de buildpack par application. Cela signifie qu’il est possible de spécifier un certain nombre de buildpacks pour une application donnée, par exemple, le buildpack binaire et le buildpack Java. Comme nous écrivons ces lignes, il y a un certain nombre de changements à venir, tels que le cf CLI multi – buildpack poussée, appelés cf v3-push, et la mise à jour buildpacks à soutenir cette nouvelle interface. Nous en apprendrons plus à ce sujet dans la section création de buildpacks . Plus d’informations sont disponibles sur https://docs.pivotal.io/pivotalcf/1-12/buildpacks/use-multiple-buildpacks.html .
9.2.2 Le script de détection
Arguments d’entrée :
- < build_path >
Valeur de retour :
- 0, si buildpack est compatible avec l’application dans < build_path >
- 1, sinon
Le but du script de détection est de déterminer la compatibilité de l’application avec le buildpack . Il n’y a qu’un seul argument d’entrée et c’est < build_path > , qui est un chemin vers un répertoire contenant les fichiers d’application lorsqu’un utilisateur a effectué une cf poussée . Ce script devra retourner 0 (zéro) si le buildpack est compatible avec l’application, ou retourner 1 sinon. Pour afficher les commentaires des utilisateurs, le texte peut être sorti vers stdout.
9.2.3 Le script de compilation
Arguments d’entrée :
- < build_path >
- < cache_path >
Valeur de retour :
- Aucun
Le but du script de compilation est d’extraire tous les frameworks / dépendances et, si nécessaire, d’effectuer une compilation ou une configuration source réelle. Il existe deux arguments d’entrée. La première est < build_path > , qui est un chemin vers un répertoire contenant les fichiers d’application lorsqu’un utilisateur a effectué une cf poussée . Le deuxième paramètre, < cache_path > , contient le chemin d’accès à un magasin d’annuaire qui contient les actifs pendant le processus de génération. Pour afficher les commentaires des utilisateurs, le texte peut être sorti vers stdout .
Remarque
Pour obtenir le répertoire de fichiers du buildpack pendant le transfert de l’un de ces scripts, vous pouvez utiliser le script bash suivant: export buildpack_directory = ` dirname $ ( readlink -f $ {BASH_SOURCE% / * })` .
9.2.4 Le script de sortie
Arguments d’entrée :
- < build_path >
Valeur de retour :
- Chaîne YAML
Le but du script de version est de générer un YAML de la forme suivante. Notez que les nouvelles lignes sont importantes, y compris les deux premiers espaces devant le web: … sur la deuxième ligne:
default_process_types:
web:
Remarque
Pour les conteneurs Linux, pour définir des variables d’environnement pour votre application après le transfert, placez des scripts bash exécutables (par exemple, script.sh ) qui exportent les variables d’environnement dans un répertoire nommé . profil .d qui se trouve dans le répertoire racine de votre application.
Cela indique au processus de lancement de démarrer une application de type Web avec la commande < start_command >. Actuellement, les applications de type Web sont le seul type pris en charge. Ici, la < start_command > est généralement un exécutable de serveur Web utilisé pour servir votre application ou, si votre application est le serveur Web lui-même, il peut démarrer cette application avec des paramètres d’entrée. Le < build_path > Paramètre d’entrée est un chemin vers un répertoire contenant les fichiers d’application lorsqu’un utilisateur a effectué une cf push. Ceci est sorti sous forme de texte vers stdout.
Voici un exemple:
default_process_types:
web: ./path_to_app/webserver_app_executable $PORT
Remarque
Vous constaterez que la variable d’environnement $ PORT n’est pas disponible pendant le transfert car elle n’est pas encore affectée. En tant que tel, $ PORT dans la dans default_process_types n’est qu’une chaîne d’exécution et est évalué lorsqu’une droplet est créée et que l’application est sur le point d’être lancée.
9.2.4.1 La gouttelette
Une fois que le buildpack a terminé la mise en scène, c’est-à-dire le buildpack plus le résultat des scripts de compilation et de publication, il crée une goutte de tarball de sortie finale avec un système de fichiers de pile correspondant. Comme mentionné précédemment, le nom de la pile du système de fichiers utilisé dans cet article est cflinuxfs2. Pour Windows, le nom de la pile sera window2012R2 ou les prochaines fenêtres 2016. La droplet est stockée dans un référentiel de blobstore interne sur la fondation, qui peut être configuré pour être stocké en externe dans un magasin S3.
La structure de la gouttelette est la suivante :
apps/
deps/
logs/
tmp/
staging_info.yml
apps/ contient le contenu du < build_directory > qui a interagi avec le script de compilation; staging_info.yml contient des métadonnées relatives au processus de transfert , telles que le buildpack détecté et la commande start. Une fois qu’une instance d’application est sur le point d’être lancée, le droplet est extrait dans chaque nouveau conteneur et la commande de démarrage est exécutée. Chaque fois que votre application démarre, le répertoire de travail est toujours supposé se trouver dans le répertoire app / et il n’est donc pas nécessaire de spécifier le répertoire parent de l’application dans vos commandes de start.
9.2.5 Création de buildpacks
Maintenant que vous avez appris les buildpacks, nous allons étudier la création d’un buildpack . L’alternative à cela est de personnaliser un buildpack, ce qui signifie créer et modifier un buildpack existant. Créer un buildpack signifie partir de zéro avec un framework ou un langage qui n’est actuellement pas pris en charge sur Cloud Foundry. En général, il est très courant de personnaliser un buildpack existant, car les frameworks et les langages les plus courants sont déjà construits pour Cloud Foundry. Alors, pourquoi auriez-vous besoin de personnaliser un buildpack exactement ? Peut-être avez-vous besoin d’un buildpack qui a des composants / dépendances compatibles avec la configuration existante de votre organisation. Par exemple, ApplicationDynamics (AppD) pour la surveillance des performances des applications dans le buildpack Java nécessite un agent qui communiquera avec un contrôleur AppD. Cependant, votre organisation a décidé d’utiliser une ancienne version du contrôleur pour des raisons de stabilité et d’atténuation des risques ; en même temps, pour des raisons de sécurité, votre fondation de production n’a pas d’accès direct à Internet, vous utilisez donc un buildpack hors ligne qui ne pourra pas se connecter à Internet pour obtenir des dépendances. Pour que AppD fonctionne, vous devez utiliser une version d’agent correspondante avec le contrôleur. Vous pouvez simplement spécifier un numéro de version dans le paramètre de configuration AppD dans le buildpack Java, mais il n’y a pas de connexion Internet, donc le transfert ne peut pas obtenir les dépendances à distance. Il existe plusieurs façons de résoudre ce problème, mais l’une d’elles consiste simplement à spécifier la version de l’agent AppD et à exécuter un reconditionnement à l’aide de la commande Ruby repacking du buildpack Java dans le pipeline automatisé d’une équipe de plate-forme qui s’exécute régulièrement pour mettre à niveau vos buildpacks.
La clé prendre est loin ici : créer un buildpack s’il n’y a pas Cloud Foundry buildpack support pour votre langue. Sinon, envisagez la personnalisation. Cependant, gardez à l’esprit que ces deux approches nécessiteront potentiellement un niveau de maintenance à l’avenir, comme l’extraction des mises à jour de la branche principale ou la mise à jour du code pour prendre en charge de nouvelles fonctionnalités. Par conséquent, la prise en compte de l’effort de maintenance doit être prise en compte lors de la décision de poursuivre dans cette voie. Bien sûr, si les modifications personnalisées s’avèrent être une caractéristique très demandée par d’autres utilisateurs de Cloud Foundry, envisagez de parler avec les auteurs de buildpack existants et soumettez une demande d’extraction avec vos modifications pour contribuer au développement du buildpack principal.
Nous avons uniquement exploré la création de buildpacks dans cette section car la personnalisation est essentiellement similaire à la création, mais limitée aux caractéristiques d’un buildpack existant telles que la structure, le style et les protocoles. Chaque pack de build sur Cloud Foundry aura un ensemble différent de traits en fonction de la façon dont ils ont été développés. Par conséquent, commun à tous ces buildpacks est ce que vous apprendrez à créer un buildpack . Les traits sont les connaissances clés supplémentaires que vous n’aurez à acquérir que lorsque vous décidez de personnaliser un pack de construction. Voir https://docs.pivotal.io/pivotalcf/1-12/buildpacks/merging_upstream.html et https://docs.pivotal.io/pivotalcf/1-12/buildpacks/upgrading_dependency_versions.html pour des informations sur la synchronisation et la maintenance buildpacks lors de la descente d’un itinéraire de personnalisation.
9.2.5.1 Création du simple HTTP buildpack
Pour notre exemple de création de buildpack, nous viserons à créer un buildpack très simple qui sert un seul document HTML simple. Ce n’est pas un buildpack de niveau production, et ne sert que de ressource pédagogique utile. Vous utiliseriez plutôt un buildpack statique à cet effet, qui peut servir de simples documents HTML et bien plus encore ! Le pack de construction Simple-HTTP servira un document HTML à partir d’un fichier étiqueté index.http.index.http contient un document HTML simple. Dans ce cas, nous aurons besoin d’un serveur Web en cours d’exécution pour écouter les demandes HTTP entrantes, puis répondre avec une réponse HTTP.
Pour continuer avec cet exemple, vous devrez télécharger le compilateur Golang. Les instructions pour cela peuvent être trouvées sur https://golang.org/doc/install. Il sera utilisé pour le packager libbuildpack, qui est un ensemble d’outils pour aider à l’empaquetage buildpack.
Remarque
Le buildpack -packager (BPP outil) est utile pour l’emballage d’un de buildpack actifs. Vous constaterez que cela est largement utilisé dans un certain nombre de packs de builds système existants sur Cloud Foundry. L’outil BPP lit à partir d’un fichier local manifest.yml qui définit les dépendances et les fichiers qui seront inclus / exclus pendant le processus de conditionnement. Les dépendances sont téléchargées à l’aide de la commande buildpack -packager -cached. L’outil BPP et la définition du manifeste peuvent être trouvés sur https://github.com/cloudfoundry/buildpack-packager .
Remarque
Au moment de la rédaction, nous utilisons la bibliothèque libbuildpack , qui présente de légères différences dans l’outil de ligne de commande par rapport au buildpack -packager sur le Cloud Foundry GitHub. La bibliothèque libbuildpack est utilisée par un certain nombre de buildpacks sur Cloud Foundry.
Pour ignorer toutes les créations de fichiers suivantes, vous pouvez télécharger le code source final depuis https://github.com/Cloud-Foundry-For-Developers/chapter-8 .
9.2.5.2 Mise en place Buildpack -packager
Clonez ou téléchargez le packpack Buildpack depuis https://github.com/cloudfoundry/libbuildpack. Accédez au répertoire à libbuildpack / emballeur / buildpack -packager. Exécutez la commande go build. Cela va construire l’exécutable buildpack -packager. Pour plus de commodité, il est recommandé de déplacer cet exécutable vers un emplacement binaire commun, tel que /usr/local/bin, ou de définir l’environnement PATH pour pointer vers l’exécutable buildpack -packer.
9.2.5.3 Création du buildpack
Sur votre répertoire d’espace de travail local, créez un nouveau répertoire appelé simple- http- buildpack. Dans ce répertoire, nous devrons créer un fichier manifest.yml, un fichier VERSION et un répertoire nommé bin contenant trois fichiers de script : détecter, compiler et publier. Le fichier manifest.yml est utilisé par buildpack -packager pour extraire les dépendances et les fichiers inclus dans un seul fichier ZIP buildpack. Le fichier VERSION est utilisé par le buildpack -packager pour ajouter une version au nom de fichier ZIP de votre buildpack. Enfin, le répertoire bin contient les trois fichiers de script utilisés pendant le processus de transfert, comme décrit précédemment. Les éléments clés de ces trois fichiers sont les suivants :
- Le script de détection : vérifie s’il existe un fichier appelé index.http dans le répertoire de génération . Si oui, ce buildpack est compatible.
- Le script de compilation : extrait le serveur HTTP simple de Git dans le répertoire de cache et déplace le script exécutable (run.sh) vers le répertoire de construction pour qu’il se trouve à côté du fichier index.http .
- Le script de publication : configure la commande de démarrage à appeler. Cela appelle simplement run.sh.
Créons ces artefacts :
| Filename | Content | |
| VERSION | 0 | |
| manifest.yml | ||
| —
language: simple-http exclude_files: – .gitignore include_files: – VERSION – bin/compile – bin/detect – bin/release – manifest.yml |
||
| bin/detect | ||
| #!/usr/bin/env bash
# bin/detect build_dir_path=$(dirname $(dirname $0)) # Check if there is an index.http file, # if so, this is the right buildpack # The output echo’d here will be used # in the application launch summary, which you will # later see under ‘buildpack: ‘, after a cf push if [ -f $1/index.http ]; then echo “Simple Http Buildpack” && exit 0 else echo “No index.http file found. \ This is required for the SimpleHttp buildpack” && exit 1 fi |
|
| bin/compile |
| #!/usr/bin/env bash
# If anything goes wrong during compile process, # we should just bail and stop the whole buildpack process. set -euo pipefail build_directory=$1 cache_directory=$2 # Clone in the simple http server into a cache directory # But first, remove any existing cloned directory # in the cache, if it exists rm -rf $cache_directory/simplehttpbp git clone https://github.com/Cloud-Foundry-For-Developers/chapter-8.git $cache_directory/simplehttpbp # Copy the server over into the root directory # of our build directory. This will be the root directory # of the application. cp $cache_directory/simplehttpbp/simple-http-server/run.sh $build_directory/. |
|
| bin/release |
| #!/usr/bin/env bash
echo -e “—\ndefault_process_types:\n web: ./run.sh” |
Une fois que nous avons créé les fichiers précédents, exécutez la commande buildpack -packager -cache. Cela emballera le buildpack que nous venons de créer dans un fichier ZIP avec le nom de fichier simple-http_buildpack-v1.0.0.zip.
Remarque
Le buildpack -packager -cache va télécharger toutes les dépendances, alors qu’un appel à buildpack -packager lui – même produira une buildpack qui ne télécharge pas toutes les dépendances.
9.2.6 Installation du buildpack
Lançons le cf create- buildpack simple- http_buildpack simple-http_buildpack-v1.0.0.zip 5 commande. Cela devrait maintenant télécharger le buildpack et créer une nouvelle entrée dans notre liste de buildpacks, comme nous pouvons le voir dans la figure 6 :
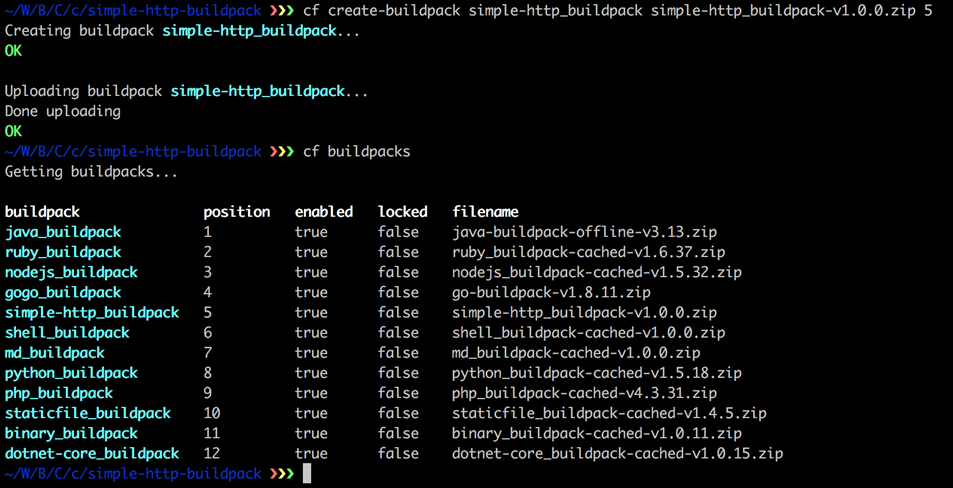
Figure 6 : Le résultat de la création et du téléchargement du simple- http_buildpack
Pour les mises à jour ultérieures à nos buildpacks , exécutez la cf update- buildpack [CHEMIN -p] [- i POSITION] [–enable | disable] | [–unlock –lock] commande. Enfin, pour supprimer le buildpack, exécutez la commande cf delete- buildpack .
9.2.7 Test de conduite du buildpack Simple-Http
Créons une application simple-http et déployons-la sur Cloud Foundry. Nous aurons besoin d’un seul fichier, appelé index.http . Facultativement, nous pouvons créer un fichier manifeste cf push pour plus de commodité. Créez un nouveau répertoire, nommé simple-http-app, et remplissez-le avec les fichiers suivants :
| Filename | Content | |
| index.http |
Cloud Foundry For DevelopersBuildpack Creation Sample |
|
| manifest.yml | —
applications: – name: simple-http instances: 1 env: SIMPLE_HTTP_BP_VERBOSE: false |
|
Le fichier index.http est un simple document HTML contenant uniquement du texte. Notre serveur Simple-HTTP ne peut servir que des documents texte HTML simples. Le fichier manifest.yml contient le nom de l’application à pousser et une variable d’environnement pour contrôler si nous voulons avoir la sortie du serveur Simple-HTTP qui a envoyé la réponse aux journaux. Nous avons omis de déclarer explicitement le buildpack parce que nous voulons tester le script de détection du buildpack.
Exécutez cf push une fois que vous êtes prêt :
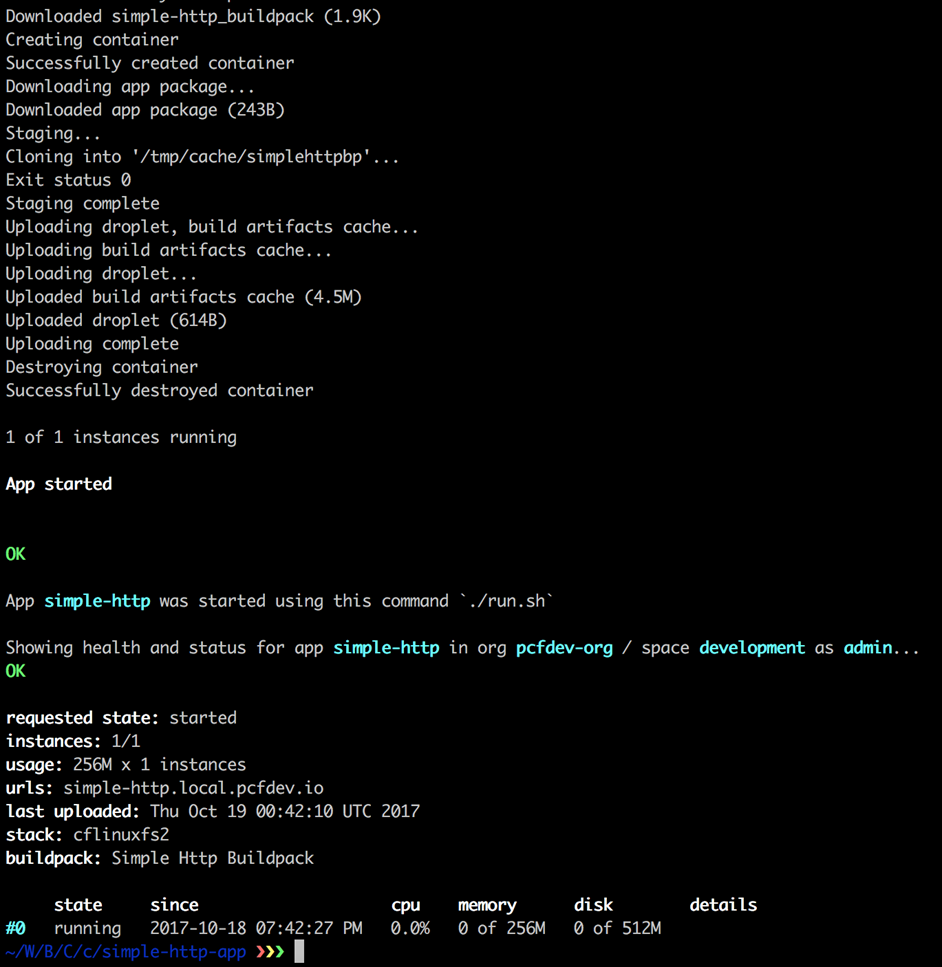
Figure 7 : Le résultat de la poussée de notre application simple-http
Comme le montre la figure 7, notre buildpack a été détecté avec succès pour être compatible avec notre application et a été utilisé pour le lancer. Prenez note de buildpack : Simple Http Buildpack. Ce texte est obtenu à partir de la sortie du script de détection.
C’est ça ! Voyons maintenant le résultat de sortie dans notre navigateur :

Figure 8 : La sortie du navigateur lorsque nous naviguons vers simple-http.local.pcfdev.io
Toutes nos félicitations ! Vous venez de créer un buildpack fonctionnel.
9.3 Résumé
Dans ce chapitre, nous avons étudié en profondeur le fonctionnement des buildpacks , en particulier le fonctionnement d’un buildpack avec Cloud Foundry et les buildpacks communs disponibles. Nous avons ensuite examiné en profondeur les mécanismes programmés pour le faire fonctionner avec Cloud Foundry avec les trois scripts, détecter, compiler et publier. Cette connaissance permet la personnalisation et la création de buildpacks, que nous avons utilisés pour créer un buildpack HTTP simple comme exemple. Dans le chapitre suivant, nous verrons comment nous pouvons dépanner les applications et les services sur Cloud Foundry.
10 Chapitre 10. Dépannage des applications dans Cloud Foundry
Les choses peuvent toujours mal tourner ; des problèmes peuvent survenir avec les applications, les services ou les infrastructures. Étant donné que cet article est destiné aux développeurs d’applications, nous limiterons nos discussions au dépannage des applications et des services dépendants.
Dans ce chapitre, nous parlerons des techniques que les développeurs peuvent adopter pour dépanner les applications qui s’exécutent sur Cloud Foundry.
Les développeurs doivent savoir comment dépanner leurs applications lorsqu’ils s’exécutent sur Cloud Foundry. Une application peut se bloquer pour de nombreuses raisons, telles qu’une mémoire insuffisante (MOO), une logique métier complexe, des échecs de vérification de l’intégrité de l’application ou une interruption anormale de l’application, etc.
10.1 Échec dû aux paramètres de quota Org / Space
Un opérateur Cloud Foundry peut limiter les ressources au niveau de l’organisation ou de l’espace. Ces limites sont définies par des quotas et l’opérateur peut allouer la mémoire maximale, la mémoire d’instance, les routes, les instances de service, les instances d’application et les ports de routage. Une fois que ces quotas sont définis et attribués au niveau de l’organisation ou de l’espace, toutes les applications poussées dans cette organisation ou cet espace seront limitées par ces quotas.
Supposons que l’opérateur définisse un quota pour notre Org cloudfoundry -for-developers, dans lequel il limite le nombre d’instances d’application à 5 :

Figure 1 : Liste des quotas d’espace pour l’espace ciblé
Supposons également que dans l’espace de développement, nous avons déjà les 5 applications en cours d’exécution :

Figure 2 : répertorier toutes les applications en cours d’exécution dans l’espace cible
Dans les circonstances précédentes, lorsqu’un développeur tente de pousser une application vers cet espace, il obtient l’erreur suivante : Error restarting application: Server error, status code: 400, error code: 310008, message: You have exceeded the instance limit for your space’s quota:
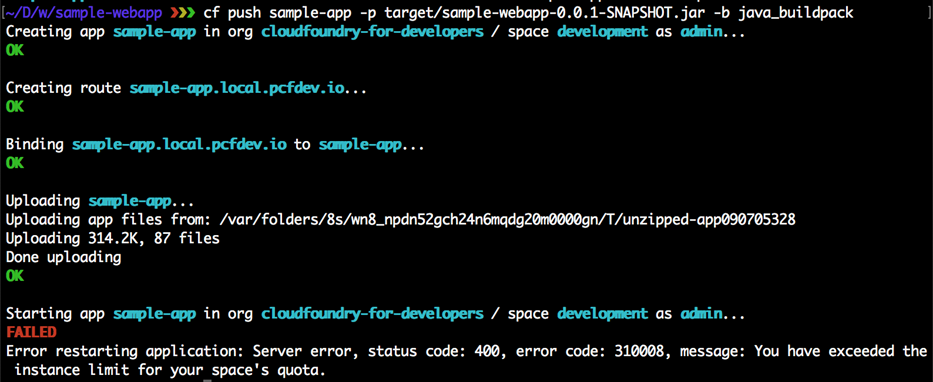
Figure 3 : erreur lorsque la limite de quota d’espace a été atteinte
Pour résoudre ce problème, le développeur doit demander à l’opérateur de la plateforme Cloud Foundry d’augmenter le quota d’espace pour prendre en compte les nouvelles applications et leurs instances.
10.1.1 Échecs dus à des plantages d’applications
Lorsqu’une application se bloque, Cloud Foundry enregistre l’événement de plantage. Ces événements de plantage peuvent être affichés en exécutant la commande cf events APP_NAME. L’événement fournira à l’équipe d’assistance aux applications ou au développeur l’heure à laquelle l’événement s’est produit, une brève raison et les mesures prises par Cloud Foundry. Ces informations seules ne suffisent pas à l’équipe pour déboguer le problème de plantage. La deuxième meilleure façon de savoir pourquoi l’application s’est bloquée consiste à analyser les journaux récents de l’application. Cela peut être fait en exécutant cf logs APP_NAME –recent.
Une meilleure approche serait de configurer la buse firehose-to-syslog (https://github.com/cloudfoundry-community/firehose-to-syslog) pour drainer tous les journaux d’application vers un outil de journalisation externe, afin que les développeurs et l’application l’équipe de support peut consulter les journaux d’application en un seul endroit.
Si l’application était tombée en panne, un message similaire au suivant apparaîtrait dans les journaux :
App instance exited with guid 5086fcc4-fcdb-4c5b-86dc-22d503ce8897 payload:
{
“instance” => “10cca234-4510-4589-7e2d-85da”,
“index” => 11,
“reason” => “CRASHED”,
“exit_description” => “2 error(s) occurred:\n\n* 1 error(s) occurred:\n\n* Exited with status 4\n* 2 error(s) occurred:\n\n* cancelled\n* cancelled”,
“crash_count” => 2,
“crash_timestamp” => 1508786598112606214,
“version” => “9d7d4b7c-8cca-476d-8f62-f2ce3fd364ee”
}
Dans les sections suivantes, nous discuterons des différents états de sortie et examinerons également certaines des solutions possibles pour surmonter ces erreurs.
10.1.2 Quitté avec le statut 0
Les applications qui sont poussées dans Cloud Foundry sont censées s’exécuter indéfiniment, ce qui signifie qu’elles exécutent et acceptent toujours des demandes via HTTP / TCP, ou s’exécutent en continu en tant qu’application de travail. Si le processus d’application se termine normalement et se termine avec un code 0, l’application est signalée comme une application bloquée. Si vous voyez cette erreur, consultez le code de l’application pour trouver la logique susceptible de provoquer la fermeture de l’application sans déclencher d’exceptions.
10.1.3 Quitté avec le statut 4 ou le statut 64
Lorsqu’une application est poussée sur Cloud Foundry et que l’application ne répond pas aux vérifications de l’état TCP, l’application se bloque et ces codes d’état sont enregistrés dans les journaux d’application. Le code de sortie 4 signifie que la vérification de l’état TCP a échoué car l’application n’écoute pas sur le port qui lui est attribué par Cloud Foundry. Le code de sortie 64 signifie que l’application est liée au port attribué par Cloud Foundry, mais qu’elle a échoué au contrôle d’intégrité après un certain laps de temps.
Vous pouvez rechercher le message Expiré après 1m0s: le contrôle de santé n’a jamais réussi dans les journaux d’application. Ce message peut se produire lors de l’envoi ou du redémarrage d’une application ; cela indique que votre application n’a pas démarré dans la durée spécifiée par le délai d’expiration, qui est par défaut de 1 minute.
Vous pouvez spécifier le délai d’expiration en passant l’argument -t à cf push. Si vous utilisez manifest.yml pour pousser l’application, vous pouvez spécifier l’attribut timeout dans un fichier manifest.yml :
Ex: cf push -t 180 sample -app
Bien que l’augmentation du délai d’attente retarderait les contrôles d’intégrité, cela ne garantit pas que l’application démarrera dans le nouveau délai d’attente défini par le développeur. Le code de l’application doit être examiné pour trouver la cause des retards lors du démarrage de l’application.
Il existe quelques modèles d’application qui pourraient s’ajouter au temps de démarrage de l’application. Jetons-y un œil :
- Mise en cache au démarrage de l’application : pour améliorer les performances de l’application, les développeurs choisissent de charger certaines informations de métadonnées dans le cache. Bien qu’il semble raisonnable d’initialiser le cache lors du démarrage, il constitue une menace pour l’application, car le temps de démarrage augmente considérablement. Il pourrait y avoir deux options pour contourner ce problème. La première approche est le chargement paresseux des données dans le cache, ce qui pourrait être fait à la première demande que l’application reçoit. La deuxième approche pourrait consister à décharger les données vers un service de mise en cache externe tel que Redis ou Gemfire . En utilisant la deuxième approche, toutes les instances d’application liront et écriront dans le même service de mise en cache, et si une instance d’application se bloque, les autres instances auront toujours accès aux données mises en cache. La deuxième approche permettra également de réduire l’empreinte mémoire requise par l’application.
- Mémoire allouée : Cloud Foundry utilise des groupes de contrôle Linux ( cgroups ) pour affecter le partage CPU à une application. Les partages CPU sont proportionnels à la mémoire affectée à l’application. Ainsi, vous pouvez augmenter la mémoire de l’application pour permettre à l’application d’obtenir plus de partages CPU. Ce n’est pas recommandé, car cela augmente les besoins en mémoire pour une application qui ne consomme pas beaucoup de CPU et serait donc exagérée.
- Dépendances de l’application sur les services externes : lors du démarrage de l’application, il est courant d’établir des connexions aux services dépendants. Dans de nombreux cas, les applications ne démarrent pas si les paramètres de connexion configurés pour l’application sont incorrects, puis l’application s’assoit et attend jusqu’à ce que la connexion au service dépendant expire. Le réglage fin des paramètres de connexion aux services dépendants permettra d’identifier plus rapidement les problèmes de démarrage des applications.
Le code de sortie 4 peut également se produire lorsqu’il n’y a plus de capacité sur la plate-forme pour exécuter l’application. Au cours de cette opération, l’opérateur de la plateforme Cloud Foundry doit revoir la configuration des composants d’exécution Cloud Foundry et les mettre à l’échelle en conséquence. Surtout, la mise à l’échelle des cellules Diego résout les problèmes.
L’un des scénarios les plus courants lorsqu’une application se bloque est lorsque l’application n’écoute pas sur le port qui lui est affecté par le runtime Cloud Foundry. La variable d’environnement $ PORT est attribuée dynamiquement par le runtime Cloud Foundry à chaque application. L’application écoute toutes les demandes sur ce port. De plus, ce port n’est pas visible pour les utilisateurs finaux de l’application. Toutes les requêtes sont transmises par les Cloud Foundry Gorouters à l’application identifiée par leur port. Maintenant, si l’application ne démarre pas et que les journaux affichent le code de sortie 4 avec échec de vérification de la santé : échec de l’établissement de la connexion TCP : composez tcp : 8080: getsockopt : connexion refusée , cela indique que le contrôle de santé pour l’application a échoué. La solution possible à cela serait de revoir le code pour voir si la panne est due à la liaison du port.
Si les contrôles d’intégrité échouent après qu’une application a été en cours d’exécution pendant un certain temps, vous verrez la même erreur : échec de contrôle de santé : échec de l’établissement de la connexion TCP: composez tcp : 8080: getsockopt : connexion refusée . Contrairement au scénario précédent, ici, l’application a cessé d’écouter les demandes ou n’a pas répondu assez rapidement à une demande de contrôle d’intégrité. C’est lorsque l’application est bloquée en raison des demandes entrantes. À ce stade, il serait préférable de faire évoluer l’application manuellement. Il existe un service de mise à l’échelle automatique fourni par Pivotal Cloud Foundry que l’application peut utiliser ; il peut définir les règles de mise à l’échelle avec les instances minimum et maximum auxquelles cette application peut évoluer.
- Quitté avec le statut 6 ou 65
Ceux-ci indiquent qu’un contrôle d’intégrité basé sur HTTP a échoué. Le code de sortie 6 indique que la connexion a été activement refusée, tandis qu’un 65 indique que la connexion a expiré. Ceci est très similaire à la sortie avec le statut 4 et 64.
- Quitté avec le statut 255
Ce message s’affiche lorsque l’application a été supprimée par le système en raison d’une utilisation excessive de la mémoire. Vous devriez consulter les journaux d’application pour plus de détails. Si vous souhaitez profiler votre application, vous pouvez utiliser un profileur. Assurez-vous que le buildpack utilisé par l’application prend en charge l’agent de profilage. Le buildpack Java prend en charge les profileurs tels que AppDynamics et New Relic.
Le profilage des applications n’est pas conseillé dans les environnements de production, car les agents de profilage absorbent beaucoup de mémoire, et donc augmentent les besoins en mémoire des applications. Si l’application est une application Spring Boot, le point de terminaison de vidage peut être utilisé pour obtenir un vidage de thread.
- Quitté avec le statut X
Si le code d’application entraîne la fermeture de l’application en cas d’exception, cet état apparaîtra dans les journaux d’application. Si les journaux sont vidés vers un service de journalisation externe, consultez les journaux pour trouver la cause première du problème. Les développeurs doivent consigner toutes les exceptions et tracer la pile afin de faciliter le débogage des problèmes en production.
Le X dans le message d’erreur peut être un entier compris entre 0 et 255 (caractère non signé). Si l’application renvoie un entier négatif, il sera converti en un caractère non signé. Cela signifie que si X est 255, l’application aurait pu renvoyer -1 ou 255, car ils sont tous les deux le résultat lorsqu’ils sont interprétés comme un caractère non signé.
Remarque
Dans tous les scénarios décrits précédemment, lorsque l’application n’est pas en cours d’exécution, si l’utilisateur essaie d’accéder à l’URL de l’application, il obtiendra une réponse HTTP de 404 , avec un 404 introuvable: l’itinéraire demandé (APPLICATION- URL ) n’existe pas. t message. Par exemple, 404 Introuvable: la route demandée (‘test-app.local.pcfdev.io’) n’existe pas ,
où test-app.local.pcfdev.io est le nom de l’application qui n’est pas en cours d’exécution. Gardez donc un œil sur ces erreurs, qui sont disponibles via les journaux générés par la plateforme Cloud Foundry.
10.2 Résumé
Dans ce chapitre, nous avons discuté des différents codes de sortie et avons également examiné différentes façons de détecter les problèmes courants liés à la mise en place et à l’exécution des applications dans Pivotal Cloud Foundry. En règle générale, analysez toujours le code avant d’augmenter la mémoire de l’application.
Félicitations, vous êtes maintenant prêt à développer vos applications à l’aide de l’architecture de microservices. Vous avez également appris à dépanner des applications lorsqu’elles s’exécutent sur Cloud Foundry.
Dans le chapitre suivant, nous aborderons les concepts d’intégration continue et de livraison continue, qui aideront les équipes d’application à vérifier et à fournir rapidement leurs fonctionnalités à leurs utilisateurs finaux.
11 Chapitre 11. Intégration et déploiement continus
Avec le processus Agile, les équipes d’application ont besoin de fournir rapidement de nouvelles fonctionnalités aux utilisateurs finaux. Pour ce faire, il doit y avoir un système en place qui peut permettre aux développeurs de valider, construire, vérifier et déployer le code en production. Dans ce chapitre, nous allons discuter des points suivants :
- Intégration continue
- Livraison continue
- Stratégies de déploiement continu
Nous verrons également comment Cloud Foundry simplifie la promotion du code d’un environnement à un autre sans que l’utilisateur final n’ait à subir de temps d’arrêt.
11.1 Qu’est-ce que l’intégration continue ?
L’intégration continue (CI) est une pratique que les développeurs adoptent pour maintenir leur base de code dans un référentiel partagé, et ils continuent de développer et d’intégrer leur code dans une même branche de développement. Les développeurs travaillent hors de la branche de développement, et valident continuellement leurs modifications dans la branche de développement, et empêchent ainsi le code de devenir obsolète au cours de la période. Cette pratique signifie également que les développeurs n’ont pas à se soucier des conflits de code.
Auparavant, les développeurs travaillaient sur une fonctionnalité de manière isolée et intégraient leurs fonctionnalités à la fin du cycle de développement. Cela posait un risque énorme de rencontrer des conflits de code ou des fonctionnalités qui ne fonctionnaient pas en raison de modifications d’interfaces, etc. CI du code minimise ces risques, et donc la qualité du code augmente.
De plus, avec CI en place, le processus manuel de test d’intégration est réduit, car tous les tests d’intégration sont automatisés à ce stade.
Les développeurs créent de nouvelles fonctionnalités et les engagent régulièrement dans la branche de développement. Généralement, il y aura un minimum de deux branches, développer et maîtriser. Le maître branche aura tous les commits pour les fonctions qui sont complètes, et toutes les versions seront versionné et étiquetés. La branche develop aura tous les commits pour les fonctionnalités qui sont encore en développement. Les développeurs travaillent à partir de la branche de développement et continuent de créer de nouvelles fonctionnalités. Une fois le sprint de développement terminé, l’équipe d’application fusionne toutes les modifications du développement dans la branche principale, puis la version marque la version. Certains logiciels de contrôle de source populaires sont GitHub, GitLab, Bitbucket et Visual Studio Team Services.
Sans prescrire aucun outil, examinons à quoi ressemble le flux de travail CI dans le monde réel :

Figure 1 : flux de travail CI
L’équipe de développement d’applications s’engage régulièrement dans la branche de développement. Le logiciel de contrôle de source informera l’environnement de génération qu’un nouveau commit est disponible pour l’application. L’environnement de génération allouera une machine de travail pour agir sur la notification reçue.
Sur la machine de travail, les travaux suivants seront exécutés :
- Clonez le code source de l’application.
- Compilez le code source. Étant donné que les machines de travail ne stockent aucune dépendance requise par l’application, pendant le processus de génération, toutes les dépendances sont tirées vers le bas sur cette machine de travail et le code est compilé.
- Exécutez les tests unitaires, fonctionnels, de sécurité, d’analyse de code statique et / ou d’intégration.
- Empaquetez le code pour générer un artefact déployable.
- Stockez l’artefact généré dans le référentiel d’artefacts.
Une fois la génération terminée, la machine de travail est nettoyée et attend la prochaine notification pour recommencer les étapes précédentes.
Dans cette section, nous avons vu à quel point le processus CI est simple et efficace. Le principal avantage de ce processus est qu’il s’agit d’un processus reproductible, dans lequel il réduit le temps passé à exécuter des tests manuels et la boucle de rétroaction si la fonctionnalité est rompue. Échouer rapidement est la clé pour trouver des bogues et les résoudre. L’autre avantage clé ici est que les artefacts sont générés à partir d’une machine non développeur, et sont donc plus fiables et cohérents, car les dépendances requises par l’application sont récupérées pendant la phase de génération de cette application.
11.2 Qu’est – ce qu’un déploiement continu ?
Le déploiement continu est une extension du CD qui déploie automatiquement chaque build en production après avoir passé toutes les différentes suites de tests. L’objectif du déploiement continu est de supprimer tous les points de contrôle ou processus manuels et d’accélérer la publication des builds en production.
La différence entre le CI et le déploiement continu est que le CI valide tous les artefacts d’application dans les environnements inférieurs uniquement, tandis que le déploiement continu déploie les artefacts qui sont validés dans les environnements inférieurs en production.
Le processus de déploiement continu permet également de déployer de petites modifications incrémentielles en production. Il s’agit d’un bon moyen de publier rapidement des correctifs et de nouvelles fonctionnalités pour les utilisateurs finaux, comme le montre la figure 3 . La stratégie de déploiement A / B peut être appliquée pour limiter le nombre de demandes des utilisateurs qui peuvent afficher les nouvelles fonctionnalités. Nous allons discuter de cette stratégie plus loin dans ce chapitre.

Figure 3 : flux de travail de déploiement continu
Discutons du flux de travail précédent. Une fois que l’artefact d’application est mis en scène dans le référentiel d’artefacts, il est déployé dans les environnements de développement / QA / UAT, et les différents tests sont exécutés dans chaque environnement. Si les tests réussissent dans tous les environnements, l’artefact d’application est déployé dans l’environnement de production ; avant que la nouvelle version de l’application ne soit exposée à l’utilisateur final, les tests de fumée sont exécutés par rapport à la nouvelle version. Une fois les tests de fumée réussis, la nouvelle version de l’application est exposée aux utilisateurs finaux et l’ancienne version de l’application est supprimée.
La transition du trafic de l’ancienne version vers la nouvelle version implique un certain temps d’arrêt. Le temps d’arrêt minimal n’est pas souhaité, et il existe des moyens dans Cloud Foundry pour contourner ce temps d’arrêt. Cloud Foundry a le concept de routes d’application qui peuvent être utilisées pour éviter tout temps d’arrêt.
Examinons maintenant les deux stratégies les plus utilisées pour déployer des applications dans Cloud Foundry sans interruption de service.
11.2.1 Déploiement sans interruption de service
Une stratégie de déploiement sans interruption de service permet aux équipes de déployer de nouvelles versions d’application sans interruption. Il existe une transition transparente sans intervention manuelle et de nouvelles fonctionnalités sont publiées rapidement sans aucune demande de service supplémentaire pour ouvrir des pares-feux, configurer des équilibreurs de charge, etc.
Cloud Foundry offre un mécanisme pour effectuer des déploiements d’applications sans interruption de service en manipulant les routes entre la version d’application déployée et la nouvelle version d’application.
Toute application déployée dans Cloud Foundry aura au moins deux routes : une route externe et une route interne. Seule la route externe est exposée aux utilisateurs finaux, et c’est la seule façon dont toutes les demandes des utilisateurs seront traitées par l’application. La route interne n’est pas exposée aux utilisateurs finaux et est destinée uniquement aux tests internes pendant les workflows CI / CD.
Alors, comprenons le concept précédent à l’aide d’un exemple. Supposons que nous ayons une application, my-app, qui doit être déployée sans aucun temps d’arrêt lorsqu’une nouvelle version est disponible. Dans un premier temps, lorsque la ma-application l’application est poussé dans Cloud Foundry, il est poussé avec un numéro de version en utilisant la commande suivante :
cf push APP_NAME_VERSION – i 1 -d INTERNAL_DOMAIN_NAME -p ARTIFACT_PATH
Par exemple, consultez la commande suivante :
cf push my-app-v1 – i 1 -d local.pcfdev.io -p target / sample-webapp-0.0.1-SNAPSHOT.jar
Une fois l’application en cours d’exécution, nous aurons une instance de my-app-v1 en cours d’exécution et l’itinéraire sera my-app-v1.local.pcfdev.io :
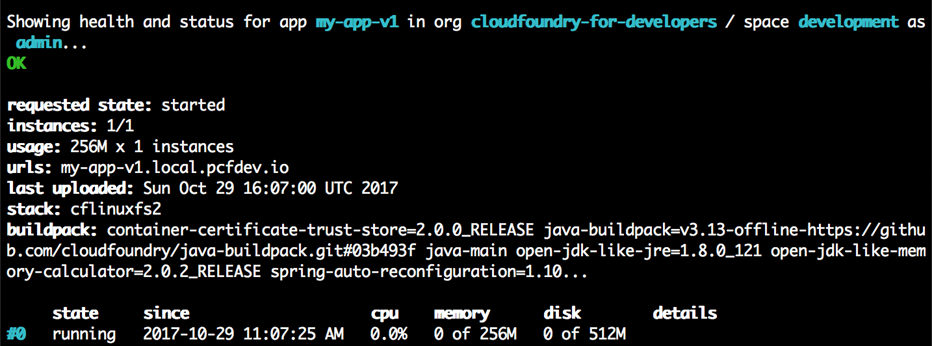
Figure 4 : Déployer my-app sur PCF Dev
À ce stade, vous pouvez exécuter les différents tests applicables à cet environnement donné en accédant à l’application sur my-app-v1.local.pcfdev.io. Une fois tous les tests réussis, vous pouvez créer la route externe pour cette application en exécutant cf map-route APP_NAME EXTERNAL_DOMAIN_NAME -n EXTERNAL_HOSTNAME, qui dans ce cas sera cf map-route my-app-v1 local.pcfdev.io -n my-app :

Figure 5 : mapper la route externe vers l’application versionnée
Nous pouvons lister les routes affectées à l’application en exécutant cf routes APP_NAME, qui dans notre cas est cf routes my-app-v1 :

Figure 6 : Liste des itinéraires d’application
Dans la sortie précédente, vous verrez qu’il existe deux itinéraires pour l’application my-app-v1. Tout le trafic d’application externe sera reçu sur my-app.local.pcfdev.io et les tests internes sont effectués sur my-app-v1.local.pcfdev.io.
Nous pouvons maintenant mettre à l’échelle l’application pour la rendre hautement disponible, en exécutant cf scale – i INSTANCES APP_NAME.
Lorsqu’une nouvelle version de l’application est disponible, nous la déployons avec le préfixe v2 et exécutons à nouveau les étapes précédentes. À ce stade, les deux versions d’application seront mappées sur la route externe. Ainsi, les demandes des utilisateurs seront équilibrées entre les deux versions de l’application :

Figure 7 : Route externe affectée aux deux versions d’application
Enfin, nous supprimerons l’ancienne application de la route externe en exécutant cf unmap -route my-app-v1 local.pcfdev.io -n my-app, et maintenant seule my-app-v2 sera mappée sur la route externe :

Figure 8 : Route externe affectée à la nouvelle version de l’application uniquement
Dans tout ce processus, il n’y a pas de temps d’arrêt du point de vue de l’utilisateur final, mais pendant une petite période de temps, certains utilisateurs verront les nouvelles fonctionnalités tandis que les autres continueront de voir les anciennes fonctionnalités. Facultativement, vous pouvez choisir de supprimer les anciennes versions après la promotion de la nouvelle version.
Nous pouvons voir comment Cloud Foundry simplifie la promotion de code avec plusieurs versions s’exécutant en même temps, puis en arrêtant les anciennes versions, sans perturber l’expérience de l’utilisateur final.
11.2.2 Déploiement A / B
La stratégie de déploiement A / B permet aux équipes d’avoir de nouvelles versions d’application fonctionnant avec les anciennes versions d’application. Étant donné que seule une fraction des demandes de trafic utilisateur sera traitée par la nouvelle version de l’application en cours d’exécution, cela permet aux équipes d’application d’en savoir plus sur la façon dont l’utilisateur utilise les nouvelles fonctionnalités avant qu’elles ne soient mises à la disposition de tous les utilisateurs.
Comme nous l’avons expliqué dans la section de déploiement sans interruption de service, nous avons appris qu’à tout moment donné, il peut y avoir deux versions d’application acceptant le trafic utilisateur. Avant de supprimer la route externe de l’ancienne version de l’application, nous pouvons faire fonctionner les deux versions de l’application côte à côte pendant quelques jours. Lorsque les équipes d’application sont ravies de fournir la nouvelle version d’application à tous leurs utilisateurs, elles peuvent adapter les nouvelles instances de version d’application à ce que les anciennes instances de version d’application ont été définies. Ensuite, ils peuvent progressivement réduire l’ancienne version de l’application à 1 et, enfin, supprimer la route externe de l’ancienne version de l’application.
En exécutant le flux de travail précédent, vous pouvez équilibrer les demandes des utilisateurs finaux entre les deux versions d’application, en fonction de leurs instances en cours d’exécution. Si l’ancienne version exécute trois instances et la nouvelle version exécute deux instances, vous autorisez 40% de vos utilisateurs à utiliser la nouvelle version de l’application et les 60% restants utiliseront l’ancienne version de l’application.
Ainsi, vous pouvez équilibrer le pourcentage des demandes de vos utilisateurs en fonction de la façon dont vous mettez à l’échelle vos instances de version d’application.
11.3 Résumé
Dans ce chapitre, nous avons découvert les concepts d’intégration, de livraison et de déploiement continus. Les équipes d’application doivent intégrer de nombreuses maturités lorsqu’il s’agit de valider leurs applications avec différents tests. Les tests doivent être fiables et doivent tester tous les scénarios positifs et négatifs. Le développement piloté par les tests est un excellent moyen d’écrire du bon code.
Nous avons également discuté de la manière dont nous pouvons effectuer des déploiements sans interruption et A / B à l’aide de Cloud Foundry. Ces stratégies offrent une meilleure expérience utilisateur lorsqu’une nouvelle application est mise en production, permettant aux équipes de fournir rapidement des produits et des fonctionnalités.

Laisser un commentaire
Vous devez être dentifié pour poster un commentaire.