Questions simples pour comprendre la notion d’Apprentissage Machine
Résumé de la publication
L’apprentissage automatique ou machine learning n’est pas seulement intéressant pour la science et pour les entreprises informatiques comme Google ou Microsoft. Mais l’intelligence artificielle a aussi un impact direct sur le marketing Web. Dans les paragraphes suivants, nous allons voir comment l’intelligence artificielle (IA) a évolué ces dernières années et ce que le machine learning signifie exactement, et enfin nous étudierons les méthodes du machine learning et pourquoi les spécialistes du marketing doivent aujourd’hui tenir compte des systèmes d’apprentissages automatiques.
Nous allons au travers de cet article répondre à l’ensemble des questions régulièrement posées au sujet de de l’apprentissage machine.
Objectifs de la publication
- S’entrainer à comprendre l’apprentissage et sa discipline maitresse la statistique
- Devenir un professionnel de l’apprentissage machine et devenir incollable sur l’apprentissage machine.
Questions fréquentes sur l’apprentissage automatique (IA faible)
L’apprentissage automatique (en anglais machine learning, littéralement « apprentissage machine ») ou apprentissage statistique est un champ d’étude de l’intelligence artificielle qui se fonde sur des approches mathématiques et statistiques pour donner aux ordinateurs la capacité d’ « apprendre » à partir de données, c’est-à-dire d’améliorer leurs performances à résoudre des tâches sans être explicitement programmés pour chacune. Plus largement, il concerne la conception, l’analyse, l’optimisation, le développement et l’implémentation de telles méthodes.
L’apprentissage automatique comporte généralement deux phases. La première consiste à estimer un modèle à partir de données, appelées observations, qui sont disponibles et en nombre fini, lors de la phase de conception du système. L’estimation du modèle consiste à résoudre une tâche pratique, telle que traduire un discours, estimer une densité de probabilité, reconnaître la présence d’un chat dans une photographie ou participer à la conduite d’un véhicule autonome. Cette phase dite « d’apprentissage » ou « d’entraînement » est généralement réalisée préalablement à l’utilisation pratique du modèle. La seconde phase correspond à la mise en production : le modèle étant déterminé, de nouvelles données peuvent alors être soumises afin d’obtenir le résultat correspondant à la tâche souhaitée. En pratique, certains systèmes peuvent poursuivre leur apprentissage une fois en production, pour peu qu’ils aient un moyen d’obtenir un retour sur la qualité des résultats produits.
Qu’est-ce qu’une probabilité ?
La probabilité d’un événement est un nombre réel compris entre 0 et 1. Plus ce nombre est grand, plus le risque, ou la chance, que l’événement se produise est grand. L’étude scientifique des probabilités est relativement récente dans l’histoire des mathématiques.
Quels sont les différents types de modèles d’apprentissage et de formation en apprentissage machine ?
Les algorithmes d’apprentissage machine (machine learning) peuvent être classés principalement en fonction de la présence ou de l’absence de variables cibles.
A. Apprentissage supervisé : Bien que les deux types d’apprentissages relèvent de l’intelligence artificielle, dans le premier cas un chercheur est là pour “guider” l’algorithme sur la voie de l’apprentissage en lui fournissant des exemples qu’il estime probants après les avoir préalablement étiquetés des résultats attendus. L’intelligence artificielle apprend alors de chaque exemple en ajustant ses paramètres (les poids des neurones) de façon à diminuer l’écart entre les résultats obtenus et les résultats attendus. La marge d’erreur se réduit ainsi au fil des entraînements, avec pour but, d’être capable de généraliser son apprentissage à de nouveaux cas.
La variable cible est continue : Régression linéaire, Régression polynomiale, Régression quadratique.
La variable cible est catégorique : Régression logistique, Bayes naïfs, Méthode des k plus proches voisins, séparateurs à vaste marge, Arbre de décision, Amplification du gradient, AdaBoost (adaptive boosting), Bagging (Bootstrap aggregating), forêts d’arbres décisionnels, etc.
B. Apprentissage non supervisé : Dans le cas de l’apprentissage non supervisé, l’apprentissage par la machine se fait de façon totalement autonome. Des données sont alors communiquées à la machine sans lui fournir les exemples de résultats attendus en sortie.
Si cette solution semble idéale sur le papier car elle ne nécessite pas de grands jeux de données étiquetés (dont les résultats attendus sont connus et communiqués à l’algorithme), il est important de comprendre que ces deux types d’apprentissages ne sont par nature pas adaptés aux mêmes types de situations.
C. Apprentissage de renforcement : Le modèle apprend par une méthode d’essai et d’erreur. Ce type d’apprentissage implique un agent qui interagira avec l’environnement pour créer des actions et ensuite découvrir des erreurs ou des récompenses de cette action.
Quelle est la différence entre l’apprentissage profond (deep learning) et l’apprentissage automatique (machine learning) ?
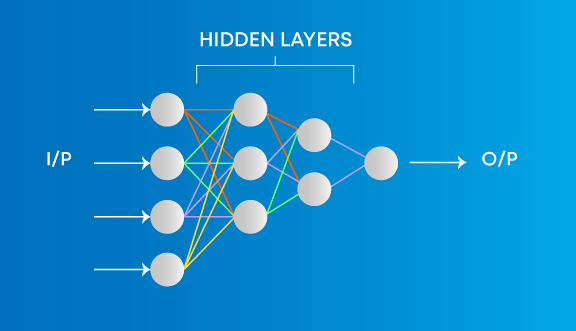
L’apprentissage automatique implique des algorithmes qui apprennent des modèles de données et les appliquent ensuite à la prise de décision. Deep Learning, d’autre part, est capable d’apprendre par le traitement des données par lui-même et est assez similaire au cerveau humain où il identifie quelque chose, l’analyse, et prend une décision.
Les principales différences sont les suivantes :
- La façon dont les données sont présentées au système.
- Les algorithmes d’apprentissage automatique nécessitent toujours des données structurées et les réseaux d’apprentissage profond s’appuyant sur des couches de réseaux neuronaux artificiels.
Comment sélectionner des variables importantes lorsque l’on travaille sur un ensemble de données ?
Il existe différents moyens de sélectionner des variables importantes à partir d’un ensemble de données qui comprennent les éléments suivants :
- Identifier et rejeter les variables corrélées avant de finaliser sur des variables importantes.
- Les variables pourraient être sélectionnées en fonction des valeurs ‘p’ de la régression linéaire.
- Sélection directe, élimination rétrograde et en élimination bidirectionnelle.
- La sélection directe, qui consiste à commencer sans variable dans le modèle, à tester l’ajout de chaque variable en utilisant un critère d’ajustement de modèle choisi, à ajouter la variable (le cas échéant) dont l’inclusion donne l’amélioration la plus statistiquement significative de l’ajustement et à répéter ce processus jusqu’à ce qu’aucune n’améliore le modèle dans une mesure statistiquement significative.
- Élimination rétrograde, qui implique de commencer par toutes les variables candidates, de tester la suppression de chaque variable en utilisant un critère d’ajustement du modèle choisi, de supprimer la variable (le cas échéant) dont la perte donne la détérioration la plus statistiquement non significative de l’ajustement du modèle et de répéter ce processus jusqu’à ce que non d’autres variables peuvent être supprimées sans perte d’ajustement statistiquement significative.
- Élimination bidirectionnelle, une combinaison de ce qui précède, test à chaque étape pour les variables à inclure ou à exclure.
- Régression régularisée : Lasso, Ridge, Elasticnet
- Graphique variable de forêt et de parcelle aléatoire.
- Les principales fonctionnalités peuvent être sélectionnées en fonction du gain d’information pour l’ensemble de fonctionnalités disponibles.
En quoi la covariance et la corrélation sont-elles différentes les unes des autres ?
La covariance mesure la façon dont deux variables sont liées l’une à l’autre et comment l’une varierait en ce qui concerne les changements dans l’autre variable. Si la valeur est positive, cela signifie qu’il y a une relation directe entre les variables et que l’on augmenterait ou diminuerait avec une augmentation ou une diminution de la variable de base respectivement, étant donné que toutes les autres conditions restent constantes.
La corrélation quantifie la relation entre deux variables aléatoires et n’a que trois valeurs spécifiques, c’est-à-dire 1, 0 et -1.
1 désigne une relation positive, -1 indique une relation négative, et 0 indique que les deux variables sont indépendantes l’une de l’autre.
La covariance est une extension de la notion de variance. La corrélation est une forme normalisée de la covariance (la dimension de la covariance entre deux variables est le produit de leurs dimensions, alors que la corrélation est une grandeur adimensionnelle).
Quand la régularisation entre-t-elle en jeu dans l’apprentissage automatique ?
Lorsque le modèle commence à être sous-ajusté ou sur-aajusté, la régularisation devient nécessaire. Il s’agit d’une régression qui détourne ou régularise les estimations de coefficient vers zéro. Il réduit la flexibilité et décourage l’apprentissage dans un modèle pour éviter le risque de surajustement. La complexité du modèle est réduite et il devient meilleur pour les prédictions.
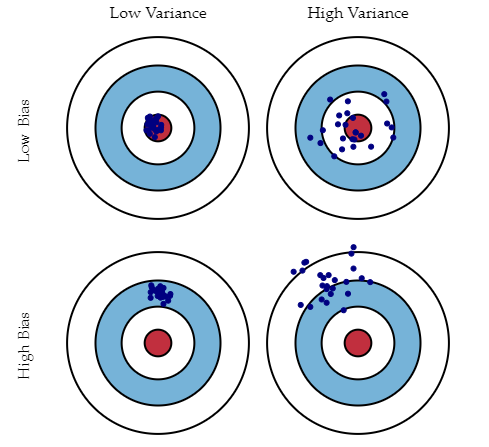
Qu’est-ce que le biais, la variance et que comprendre par compromis biais-variance?
Les deux sont des erreurs dans les algorithmes d’apprentissage automatique. Lorsque l’algorithme a une flexibilité limitée pour déduire l’observation correcte de l’ensemble de données, il en résulte un biais. D’autre part, la variance se produit lorsque le modèle est extrêmement sensible aux petites fluctuations.
Si l’on ajoute plus de variables lors de la construction d’un modèle, il ajoutera plus de complexité et nous perdrons parti pris, mais obtiendrons une certaine variance. Afin de maintenir la quantité optimale d’erreur, nous effectuons un compromis entre biais et variance en fonction des besoins d’une entreprise.
Comment pouvons-nous établir un lien entre l’écart-type et la variance ?
L’écart standard se réfère à la diffusion de vos données à partir de la moyenne. La variance est le degré moyen auquel chaque point diffère de la moyenne, c’est-à-dire la moyenne de tous les points de données. Nous pouvons établir un lien entre l’écart standard et la variance parce qu’elle est la racine carrée de la variance.
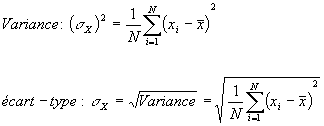
Est-ce qu’une variation élevée des données est bonne ou mauvaise ?
Une variance plus élevée signifie directement que la diffusion des données est importante et que le jeu de données possède une variété de données. Habituellement, la variance élevée dans une fonctionnalité est considérée comme de qualité faible.
Quelle est la différence entre la descente de gradient stochastique (SGD) et la descente de gradient (GD) ?
Dans la descente de gradient (GD) et la descente de gradient stochastique (SGD), vous mettez à jour un ensemble de paramètres de manière itérative pour minimiser une fonction d’erreur.
Dans GD, vous devez parcourir TOUS les échantillons de votre ensemble d’entraînement pour effectuer une mise à jour unique pour un paramètre dans une itération particulière, dans SGD, d’autre part, vous utilisez UNIQUEMENT UN ou SOUS-ENSEMBLE d’échantillon d’apprentissage de votre ensemble d’entraînement. pour faire la mise à jour d’un paramètre dans une itération particulière. Si vous utilisez SUBSET, il est appelé descente de gradient stochastique Minibatch.
Ainsi, si le nombre d’échantillons d’apprentissage est grand, en fait très grand, l’utilisation de la descente de gradient peut prendre trop de temps car à chaque itération lorsque vous mettez à jour les valeurs des paramètres, vous parcourez l’ensemble complet d’apprentissage. D’un autre côté, l’utilisation de SGD sera plus rapide car vous n’utilisez qu’un seul échantillon d’apprentissage et il commence à s’améliorer tout de suite à partir du premier échantillon.
SGD converge souvent beaucoup plus rapidement que GD mais la fonction d’erreur n’est pas aussi bien minimisée que dans le cas de GD. Souvent, dans la plupart des cas, l’approximation étroite que vous obtenez dans SGD pour les valeurs des paramètres est suffisante car elles atteignent les valeurs optimales et continuent à y osciller.
Quels sont avantages et inconvénients des arbres de décision ?
Les avantages des arbres de décision sont qu’ils sont plus faciles à interpréter, sont non paramétriques et donc robustes pour les valeurs aberrantes, et ont relativement peu de paramètres à régler. D’autre part, l’inconvénient est qu’ils sont enclins au surajustement.
Qu’est-ce que l’analyse des composantes principales ?
L’idée ici est de réduire la dimensionnalité de l’ensemble de données en réduisant le nombre de variables qui sont corrélées les unes avec les autres. Bien que la variation doive être maintenue dans la mesure maximale.
Les variables sont transformées en un nouvel ensemble de variables qui sont connues sous le nom de composants principaux. Ces composants principaux sont les vecteurs propres d’une matrice de covariance et sont donc orthogonaux.
Qu’est-ce que les valeurs aberrantes ? Mentionnez trois méthodes pour traiter les valeurs aberrantes.

Un point de données qui est considérablement éloigné des autres points de données similaires est connu comme un aberrant. Ils peuvent se produire en raison d’erreurs expérimentales ou de variabilité dans la mesure. Ils sont problématiques et peuvent induire en erreur un processus de formation, ce qui se traduit par un temps de formation plus long, des modèles inexacts et de mauvais résultats.
Les trois méthodes pour traiter les valeurs aberrantes sont les suivants :
- La Méthode Univariée – recherche des points de données ayant des valeurs extrêmes sur une seule méthode variable
- La Méthode Multivariée – cherche des combinaisons inhabituelles sur toutes les variables
- L’erreur de Minkowski – réduit la contribution des valeurs aberrantes potentielles dans le processus de formation
Quelle est la différence entre régularisation et normalisation ?
La normalisation ajuste les données ; la régularisation ajuste la fonction de prédiction. Si vos données sont à des échelles très différentes (particulièrement faible à élevée), vous souhaitez normaliser les données. Modifier chaque colonne pour avoir des statistiques de base compatibles. Cela peut être utile pour s’assurer qu’il n’y a pas de perte de précision. L’un des objectifs de la formation du modèle est d’identifier le signal et d’ignorer le bruit si le modèle est donné libre cours pour minimiser les erreurs, il y a une possibilité de souffrir de surajustement. La régularisation impose un certain contrôle à ce sujet en fournissant des fonctions d’ajustement plus simples que les fonctions complexes.
Énumérez les courbes de distribution les plus populaires ainsi que les scénarios où vous les utiliserez dans un algorithme.
Les courbes de distribution les plus populaires sont les suivantes – la loi de Bernoulli, la loi uniforme continue, la loi binomiale, la loi normale (courbe de Gauss), la loi de Poisson, et la loi Exponentielle. Chacune de ces courbes de distribution est utilisée dans diverses Scénarios.
- La loi de Bernoulli : peut être utilisé pour vérifier si une équipe va gagner un championnat ou non, un nouveau-né est soit un homme ou une femme, vous passez un examen ou non, etc.
- La loi uniforme continue : est une distribution de probabilité qui a une probabilité constante. Le roulement d’un seul dé est un exemple parce qu’il a un nombre fixe de résultats.
- La distribution binomiale : est une probabilité avec seulement deux résultats possibles, le préfixe ‘bi’ signifie deux ou deux fois. Un exemple de ceci serait un tirage au sort. Le résultat sera soit des têtes ou des queues.
- La loi normale (courbe de Gauss) : décrit la répartition des valeurs d’une variable. Il s’agit généralement d’une distribution symétrique où la plupart des observations se regroupent autour du pic central. Les valeurs plus loin de la moyenne s’effilent également dans les deux sens. Un exemple serait la hauteur des élèves dans une salle de classe.
- La loi de Poisson : prédire la probabilité que certains événements se produisent lorsque vous savez à quelle fréquence cet événement s’est produit. Il peut être utilisé par les hommes d’affaires pour faire des prévisions sur le nombre de clients certains jours et leur permet d’ajuster l’offre en fonction de la demande.
- La loi exponentielle : concerne le temps jusqu’à ce qu’un événement spécifique se produise. Par exemple, combien de temps une batterie de voiture durerait, en mois.
Comment vérifier la normalité d’un ensemble de données ou d’une fonctionnalité ?
Visuellement, nous pouvons le vérifier à l’aide de parcelles. Il y a une liste de contrôles de normalité, ils sont comme suit :
- Le test de Shapiro-Wilk : Cela teste l’hypothèse nulle selon laquelle un échantillon est issu d’une population normalement distribuée.
- Le test d’Anderson-Darling : c’est un test de normalité de l’échantillon statistique. Permet de détecter l’écart par rapport à la normalité des valeurs maximales et minimales d’une distribution.
- Le test de Martinez-Iglewicz : C’est un test basé sur la médiane et sur un estimateur de la dispersion.
- Le test de Kolmogorov-Smirnov : C’est un test d’hypothèse utilisé pour déterminer si un échantillon suit bien une loi donnée connue par sa fonction de répartition continue, ou bien si deux échantillons suivent la même loi.
- Test de biais de D’Agostino : Il s’agit d’un test de normalité c’est-à-dire un test qui évalue si la distribution des valeurs dans un échantillon provient d’une population avec une distribution normale. Le test est basé sur les transformations du kurtosis et de l’asymétrie de l’échantillon et est plus puissant uniquement face aux tests alternatifs qui vérifie si la distribution est asymétrique ou kurtique.
Qu’est-ce que la régression linéaire ?
Une fonction linéaire peut être définie comme une fonction mathématique sur un plan 2D comme, Y=Mx+C, où Y est une variable dépendante et X est variable indépendante, C est l’ordonnée à l’origine et M est le coefficient directeur et peut être exprimé comme Y est une fonction de X ou Y=F (x).
À n’importe quelle valeur donnée de X, on peut calculer la valeur de Y, en utilisant l’équation de la ligne. Cette relation entre Y et X, avec un degré du polynomial comme 1 est appelée régression linéaire.
Dans la modélisation prédictive, la régression linéaire est représentée sous la forme de Y=Bo+b1x1+B2x2. La valeur de B1 et B2 détermine la force de la corrélation entre les entités et la variable dépendante.
Exemple : Valeur de l’action en €= ordonnée à l’origine + (+/-B1)*((valeur d’ouverture de l’action) + (+/-B2)*(valeur la plus élevée de l’action du jour précédent)
Quelle Différence y a t il entre la régression et la classification.
La régression et la classification sont classées dans le même cadre de l’apprentissage automatique supervisé. La principale différence entre eux est que la variable de sortie dans la régression est numérique (ou continue) tandis que celle de la classification est catégorique (ou discrète).
Exemple : Prédire la température définie d’un lieu est un problème de régression alors que prédire si la journée sera ensoleillée ou s’il y aura de la pluie est un cas de classification.
Qu’est-ce que le déséquilibre cible ? Comment pouvons-nous le réparer ? Trouvez un scénario où il faut effectuer un déséquilibre cible sur les données. Quelles mesures et algorithmes trouvez-vous appropriés pour entrer ces données ?
Si vous avez des variables catégorielles comme cible lorsque vous les regroupez ou effectuez un comptage de fréquence sur eux s’il y a certaines catégories qui sont plus nombreuses que d’autres par un nombre très significatif. C’est ce qu’on appelle le déséquilibre cible.
Exemple : Colonne cible – 0,0,0,1,0,2,0,0,1,1 [0s: 60%, 1: 30%, 2:10%] Les 0 sont majoritaires. Pour résoudre ce problème, nous pouvons effectuer un échantillonnage à la hausse ou à la baisse. Avant de résoudre ce problème, supposons que les mesures de performance utilisées étaient des mesures de confusion.
Après avoir résolu ce problème, nous pouvons déplacer le système métrique à AUC*: ROC*. Depuis que nous avons ajouté/supprimé des données [échantillonnage ou sous-échantillonnage], nous pouvons alors utiliser un algorithme plus strict comme SVM, Gradient boosting ou ADA boosting.
*Une courbe ROC (receiver operating characteristic) est un graphique représentant les performances d’un modèle de classification pour tous les seuils de classification. Cette courbe trace le taux de vrais positifs en fonction du taux de faux positifs :
- Taux de vrais positifs (TVP)
- Taux de faux positifs (TFP)
*AUC signifie “aire sous la courbe ROC”. Cette valeur mesure l’intégralité de l’aire à deux dimensions situées sous l’ensemble de la courbe ROC (par calculs d’intégrales) de (0,0) à (1,1).
Énumérer toutes les hypothèses pour que les données soient satisfaites avant de commencer par une régression linéaire.
Avant de commencer la régression linéaire, les hypothèses à respecter sont les suivantes :
- Relation linéaire : Lorsque les deux variables augmentent ou diminuent simultanément et à un taux constant, il existe une relation linéaire positive entre ces deux variables. Lorsqu’une variable augmente alors que l’autre diminue, il existe entre elles une relation linéaire négative.
- Loi normale multivariée : On appelle loi normale multidimensionnelle, ou Normale multivariée ou loi multinormale ou loi de Gauss à plusieurs variables, une loi de probabilité qui est la généralisation multidimensionnelle de la loi normale.
- Pas ou peu de multicolinéarité : la multicolinéarité est un phénomène dans lequel une variable prédictive d’un modèle de régression multiple peut être prédite linéairement à partir des autres avec un degré de précision important.
- Homoscédasticité : Cette hypothèse signifie que la variance autour de la droite de régression est la même pour toutes les valeurs de la variable prédictive (X). L’intrigue montre une violation de cette hypothèse. Pour les valeurs inférieures sur l’axe X, les points sont tous très proches de la ligne de régression.
- Pas d’autocorrélation.
Quand la ligne de régression linéaire cesse-t-elle de tourner ou trouve-t-elle un endroit optimal où elle est installée sur les données ?
Un endroit où la valeur La plus élevée « Rsquared » est trouvé, soit l’endroit où la ligne vient au repos. « Rsquared » représente la quantité de variance capturée par la ligne de régression linéaire virtuelle par rapport à la variance totale capturée par le jeu de données.
Pourquoi la régression logistique est-elle un type de technique de classification et non une régression ? Nommez la fonction dont il est dérivé ?
Étant donné que la colonne cible est catégorique, elle utilise la régression linéaire pour créer une fonction étrange qui est enveloppée d’une fonction de journal pour utiliser la régression comme classificateur. Il s’agit donc d’un type de technique de classification et non d’une régression. Il est dérivé de la fonction de coût.
Quel algorithme d’apprentissage automatique est connu comme l’apprenant paresseux et pourquoi est-il appelé ainsi ?
KNN (k-nearest neighbors en français la Méthode des k plus proches voisins) est un algorithme d’apprentissage automatique connu sous le nom d’apprenant paresseux. KNN est un apprenant paresseux parce qu’il n’apprend pas de valeurs ou de variables apprises à la machine à partir des données de formation, mais calcule dynamiquement la distance à chaque fois qu’il veut classer, donc mémorise le jeu de données de formation à la place.
Est-il possible d’utiliser KNN pour le traitement d’images ?
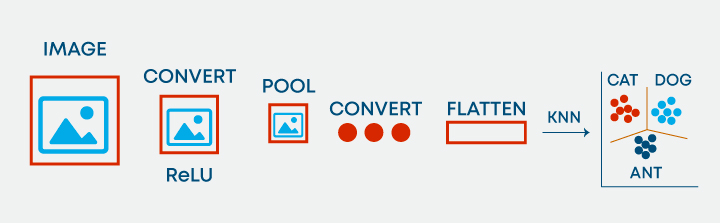
Oui, il est possible d’utiliser KNN pour le traitement d’image. Il peut être fait en convertissant l’image tridimensionnelle en un vecteur unidimensionnel et en utilisant la même chose que l’entrée à KNN.
Comment faire la différence entre les algorithmes K-Means et KNN?
KNN est de l’apprentissage supervisé et K-Means est de l’apprentissage non supervisé. Avec KNN, nous prédisons l’étiquette de l’élément non identifié en fonction de son voisin le plus proche et étendons davantage cette approche pour résoudre les problèmes de classification/régression.
K-Means est un apprentissage non supervisé, où nous n’avons pas d’étiquettes présentes, en d’autres termes, aucune variable cible et donc nous essayons de regrouper les données en fonction de leurs coordonnées et essayons d’établir la nature du cluster en fonction des éléments filtrés pour ce cluster.
Comment l’algorithme SVM traite-t-il l’auto-apprentissage ?
SVM a un taux d’apprentissage et un taux d’expansion qui s’en occupent. Le taux d’apprentissage compense ou pénalise les hyperplans pour avoir fait tous les mauvais mouvements et le taux d’expansion traite de la recherche de la zone de séparation maximale entre les classes.
Qu’est-ce que les kernels dans la SVM ? Énumérez les kernels populaires utilisés dans SVM ainsi qu’un scénario de leurs applications.
La fonction du noyau est de prendre les données comme entrée et de les transformer en la forme requise. Quelques kernels populaires utilisés dans SVM sont les suivants :
- Polynomial kernel,
![]() (d est le degré du polynôme)
(d est le degré du polynôme)
Fréquemment utilisé dans le traitement de l’image.
- Gaussian Kernel
![]()
C’est un kernel à usage général ; utilisé en l’absence de connaissances préalables sur les données.
- Gaussian radial basis function (RBF)
![]()
![]() ou
ou ![]()
C’est un kernel à usage général ; utilisé en l’absence de connaissances préalables sur les données.
- Laplace RBF kernel
![]()
C’est un kernel à usage général ; utilisé en l’absence de connaissances préalables sur les données.
- Hyperbolic tangent kernel
![]()
Nous pouvons l’utiliser dans des réseaux de neurones.
- Sigmoid kernel
![]()
Nous pouvons l’utiliser comme proxy pour les réseaux de neurones.
- Bessel function of the first kind Kernel
![]() où j est la fonction de Bessel de premier type.
où j est la fonction de Bessel de premier type.
Nous pouvons l’utiliser pour supprimer le terme croisé dans les fonctions mathématiques.
- ANOVA radial basis kernel
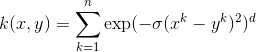
Nous pouvons l’utiliser dans des problèmes de régression.
- Linear splines kernel in one-dimension
![]()
Il est utile lorsqu’il s’agit de grands vecteurs de données clairsemés. Il est souvent utilisé dans la catégorisation de texte. Le kernel splines fonctionne également bien dans les problèmes de régression.
Qu’est-ce que le « kernel trick » dans un algorithme SVM ?
Kernel Trick est une méthode qui permet d’utiliser un classifieur linéaire pour résoudre un problème non linéaire. L’idée est de transformer l’espace de représentation des données d’entrées en un espace de plus grande dimension, où un classifieur linéaire peut être utilisé et obtenir de bonnes performances. La discrimination linéaire dans l’espace de grande dimension (appelé aussi espace de redescription) est équivalente à une discrimination non linéaire dans l’espace d’origine.
L’astuce du noyau consiste donc à remplacer un produit scalaire dans un espace de grande dimension par une fonction noyau, facile à calculer. De cette manière, un classifieur linéaire peut facilement être transformé en un classifieur non linéaire. Un autre avantage des fonctions noyau est qu’il n’est pas nécessaire d’expliciter la transformation φ. Celle-ci peut même transformer l’espace d’entrée en un espace de redescription infini, comme le noyau gaussien :
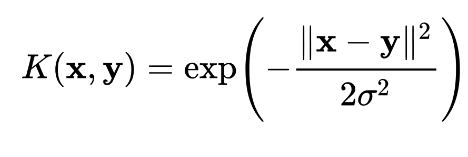
Expliquer comment les techniques d’ensemble donnent un meilleur apprentissage par rapport aux algorithmes traditionnels de classification de l’apprentissage automatique ?
Ensemble est un groupe de modèles qui sont utilisés ensemble pour la prédiction à la fois dans la classification et la classe de régression. L’apprentissage en ensemble permet d’améliorer les résultats de l’apprentissage automatique car il combine plusieurs modèles. Ce faisant, il permet une meilleure performance prédictive par rapport à un seul modèle. Ils sont supérieurs aux modèles individuels car ils réduisent la variance, les biais de sortie, et ont moins de chances de surajustement.
Qu’est-ce que le surajustement et le sous-ajustement ? Pourquoi l’algorithme de l’arbre de décision souffre-t-il souvent d’un problème de surajustement ?
Le surajustement est un modèle statistique ou un algorithme d’apprentissage automatique qui capture le bruit des données. Le sous-ajustement est un modèle ou un algorithme d’apprentissage automatique qui ne correspond pas assez bien aux données et se produit si le modèle ou l’algorithme montre une faible variance mais un biais élevé.
Dans les arbres de décision, le surajustement se produit lorsque l’arbre est conçu pour s’adapter parfaitement à tous les échantillons de l’ensemble de données de formation. Il en résulte des branches avec des règles strictes ou des données clairsemées et affecte l’exactitude lors de la prédiction des échantillons qui ne font pas partie de l’ensemble de formation.
Qu’est-ce que l’erreur OOB et comment se produit-elle ?
Pour chaque échantillon de bootstrap, il y a un tiers des données qui n’ont pas été utilisées dans la création de l’arbre, c’est-à-dire qu’elles étaient hors de l’échantillon, d’où le nom de OOB (Out of bag Hors du sac).
Afin d’obtenir une mesure impartiale de l’exactitude du modèle sur les données de test, hors erreur sac est utilisé. Les données hors sac sont passées pour chaque arbre est passé à travers cet arbre et les sorties sont agrégées pour donner hors de l’erreur sac. Cette erreur de pourcentage est très efficace pour estimer l’erreur dans l’ensemble de tests et ne nécessite pas d’autres validations croisées.
Pourquoi le renforcement est un algorithme plus stable par rapport à d’autres algorithmes d’ensemble ?
Le renforcement se concentre sur les erreurs trouvées dans les itérations précédentes jusqu’à ce qu’elles deviennent obsolètes. Alors que dans bagging, il n’y a pas de boucle corrective. C’est pourquoi le renforcement est un algorithme plus stable que les autres algorithmes d’ensemble.
Liste des techniques populaires de validation croisée.
Il existe principalement six types de techniques de validation croisée. Ils sont comme suit:
- K fold
- Stratified k fold
- Leave one out
- Bootstrapping
- Random search cv
- Grid search cv
Est-il possible de vérifier la probabilité d’améliorer la précision du modèle sans techniques de validation croisée ? Et l’expliquer.
Oui, il est possible de tester la probabilité d’améliorer la précision du modèle sans techniques de validation croisée. Nous pouvons le faire en exécutant le modèle ML pour dire n nombre d’itérations, l’enregistrement de la précision. Tracez toutes les précisions et supprimez les 5% de valeurs de faible probabilité. Mesurer la coupure gauche [faible] et droite [haute] coupée. Avec les 95% restants de confiance, on peut dire que le modèle peut aller aussi bas ou aussi haut [que mentionné dans les points de coupure].
Nommez un algorithme populaire de réduction de la dimensionnalité.
Les algorithmes de réduction de la dimensionnalité populaire sont
- L’analyse des composants principaux (Principal Component Analysis)
- L’analyse des factorielle (Factor Analysis)
L’analyse des composants principaux (Principal Component Analysis)
L’analyse en composantes principales, ou selon le domaine d’application la transformation de Karhunen–Loève (KLT), est une méthode de la famille de l’analyse des données et plus généralement de la statistique multivariée, qui consiste à transformer des variables liées entre elles (dites « corrélées » en statistique) en nouvelles variables décorrélées les unes des autres. Ces nouvelles variables sont nommées « composantes principales », ou axes principaux. Elle permet au praticien de réduire le nombre de variables et de rendre l’information moins redondante.
Il s’agit d’une approche à la fois géométrique (les variables étant représentées dans un nouvel espace, selon des directions d’inertie maximale) et statistique (la recherche portant sur des axes indépendants expliquant au mieux la variabilité — la variance — des données).
L’analyse des factorielle (Factor Analysis)
Le terme analyse factorielle désigne une sous-famille de méthodes de l’analyse des données, aux côtés des méthodes de classification automatique. L’analyse des facteurs est un modèle de mesure d’une variable latente. Cette variable latente ne peut pas être mesurée avec une seule variable et est vue à travers une relation qu’elle provoque dans un ensemble de variables y.
Comment pouvons-nous utiliser un jeu de données sans la variable cible dans les algorithmes d’apprentissage supervisé ?
Entrez l’ensemble de données dans un algorithme de clustering, génèrez des clusters optimaux, étiquetez les nombres de clusters comme la nouvelle variable cible. Maintenant, l’ensemble de données a des variables indépendantes et ciblées présentes. Cela garantit que le jeu de données est prêt à être utilisé dans les algorithmes d’apprentissage supervisé.
Liste de tous les types de systèmes de recommandation populaires ? Nommez et expliquez deux systèmes de recommandation personnalisés ainsi que leur facilité de mise en œuvre.
Les systèmes de recommandation sont une forme spécifique de filtrage de l’information visant à présenter les éléments d’information (films, musique, livres, news, images, pages Web, etc) qui sont susceptibles d’intéresser l’utilisateur. Généralement, un système de recommandation permet de comparer le profil d’un utilisateur à certaines caractéristiques de référence, et cherche à prédire l’« avis » que donnerait un utilisateur. On retrouve les systèmes suivants :
Des systèmes de recommandation basés :
- L’objet lui-même, on parle « d’approche basée sur le contenu » ou content-based approach ;
- L’utilisateur ;
- L’environnement social, on parle d’approche de filtrage collaboratif ou collaborative filtering.
Comment pouvons-nous traiter les problèmes de rareté dans les systèmes de recommandation ? Comment mesurer leur efficacité ? Expliquer.
La décomposition de la valeur unique peut être utilisée pour générer une matrice de prédiction. –L’erreur quadratique moyenne (RMSE :Root Mean Square Deviation) est la mesure qui nous aide à comprendre à quel point la matrice de prédiction est proche de la matrice d’origine.
Nommer et définir les techniques utilisées pour trouver des similitudes dans le système de recommandation.
Le test de corrélation est utilisé pour évaluer une association (dépendance) entre deux variables. Le calcul du coefficient de corrélation peut être effectué en utilisant différentes méthodes. Il existe la corrélation r de pearson, la corrélation tau de Kendall et le coefficient de corrélation rho de Spearman. Ces méthodes de calcul de corrélation sont décrites dans les sections suivantes.
Dans le cas ou la méthode utilisée est de type “kendall” ou “spearman”, les statistiques tau de kendall et rho de Spearman sont respectivement utilisées pour estimer le coefficient de corrélation basé sur le rang. Ce sont des tests statistiques dits robustes car ils ne dépendent pas de la distribution des données. Le test de corrélation de Kendall et celui de Spearman sont recommandés lorsque les variables ne suivent pas une loi normale.
D’autre part, il est possible d’utiliser la similarité cosinus (ou mesure cosinus) qui permet de calculer la similarité entre deux vecteurs à n dimensions en déterminant le cosinus de l’angle entre eux. Cette métrique est fréquemment utilisée en fouille de textes.
En gardant à l’esprit les critères de répartition des trains et des essais, est-il bon d’effectuer une mise à l’échelle avant ou après la scission ?
La mise à l’échelle devrait être faite après le train et le déflecage d’essai idéalement. Si les données sont étroitement emballées, alors la mise à l’échelle de poste ou pré-split ne devrait pas faire beaucoup de différence.
Définir la précision, le rappel (recall) et le score F1?
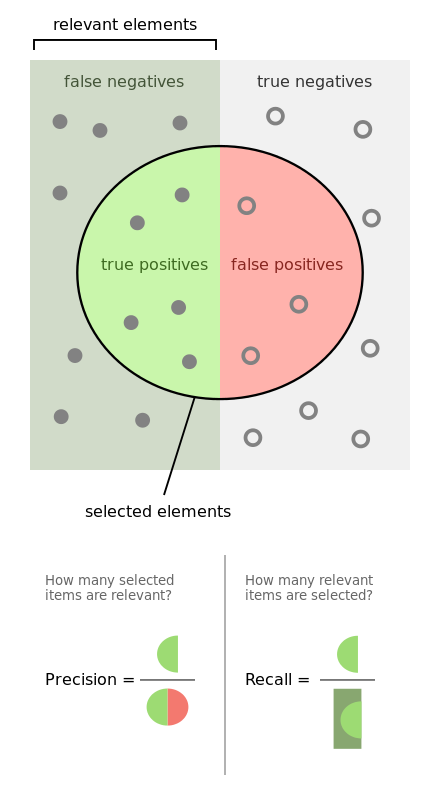
La mesure utilisée pour accéder aux performances du modèle de classification est la métrique de confusion. Confusion Metric peut être interprété avec les termes suivants :
- Vrai positifs (TP) – Ce sont les valeurs positives correctement prédites. Cela implique que la valeur de la classe réelle est oui et la valeur de la classe prédite est également oui.
- Vrais négatifs (TN) – Ce sont les valeurs négatives correctement prédites. Cela implique que la valeur de la classe réelle est non et la valeur de la classe prévue est également non.
- Faux positifs et faux négatifs, ces valeurs se produisent lorsque votre classe réelle se contredit avec la classe prédite.
Rappel (recall), également connu sous le nom de sensibilité est le rapport du taux positif réel (TP), à toutes les observations dans la classe réelle – yes
Recall = TP/(TP+FN)
La précision est le rapport de la valeur prédictive positive, qui mesure la quantité de modèle positif précis prédit viz un nombre de points positifs qu’il prétend.
Precision = TP/(TP+FP)
La précision est la mesure de performance la plus intuitive et il s’agit simplement d’un rapport entre l’observation correctement prédite et le total des observations.
Accuracy = (TP+TN)/(TP+FP+FN+TN)
F1 Score est la moyenne pondérée de précision et de rappel (recall). Par conséquent, ce score tient compte à la fois des faux positifs et des faux négatifs. Intuitivement, il n’est pas aussi facile à comprendre que la précision, mais la F1 est généralement plus utile que la précision, surtout si vous avez une distribution de classe inégale. La précision fonctionne mieux si les faux positifs et les faux négatifs ont un coût similaire. Si le coût des faux positifs et des faux négatifs est très différent, il est préférable de regarder à la fois la précision et le rappel (recall).
Qu’est-ce que le théorème de Bayes ? Établir au moins 1 cas d’utilisation en ce qui concerne le contexte d’apprentissage automatique ?
La formule de Bayes a longtemps été appelée formule de probabilité des causes. Elle permet en effet de remonter le temps, c’est-à-dire de calculer la probabilité d’une cause sachant celle de sa conséquence. Longtemps, elle a été regardée avec beaucoup de circonspection par les statisticiens de tous bords.
Le théorème de Bayes est un résultat de base en théorie des probabilités, dont l’énoncé est :
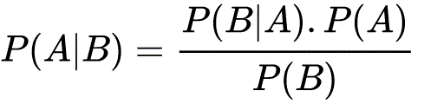
P(A|B) désigne la probabilité conditionnelle de A sachant B.
Le théorème de Bayes décrit la probabilité d’un événement, en se basant sur une connaissance préalable des conditions qui pourraient être liées à l’événement.
Par exemple, si le cancer est lié à l’âge, alors, en utilisant le théorème de Bayes, l’âge d’une personne peut être utilisé pour évaluer plus précisément la probabilité qu’elle ait un cancer qu’on ne peut le faire sans connaître l’âge de la personne.
La règle de chaîne pour la probabilité bayésienne peut être utilisée pour prédire la probabilité du mot suivant dans la phrase.
Expliquer la différence entre Lasso et Ridge ?
Lasso(L1) et Ridge(L2) sont les techniques de régularisation où nous pénalisons les coefficients pour trouver la solution optimale. En Ridge, la fonction de pénalité est définie par la somme des carrés des coefficients et pour le Lasso, nous pénalisons la somme des valeurs absolues des coefficients. Un autre type de méthode de régularisation est ElasticNet, c’est une fonction de pénalisation hybride du lasso et de Ridge.
Pourquoi élaguez-vous votre arbre ?
Les arbres décisionnels sont enclins au surajustement, l’élagage de l’arbre aide à réduire la taille et minimise les chances de surajustement. Il sert d’outil pour effectuer le compromis.
Précision du modèle ou performance du modèle ? Lequel préférerez-vous et pourquoi ?
C’est une question piège, il faut d’abord se faire une idée claire, quelle est la performance du modèle ? Si les performances signifient la vitesse, cela dépend de la nature de l’application, toute application liée au scénario en temps réel aura besoin d’une vitesse élevée comme caractéristique importante. Exemple : le meilleur des résultats de recherche perdra sa vertu si les résultats de la requête n’apparaissent pas rapidement.
Si les performances suggèrent pourquoi la précision n’est pas la vertu la plus importante – pour tout ensemble de données déséquilibrées, plus que la précision, ce sera un score F1 qui expliquera l’analyse de rentabilisation et si les données sont déséquilibrées, alors la précision et le rappel seront plus important que le repos.
Comment gérer un ensemble de données déséquilibré ?
Les techniques d’échantillonnage peuvent aider avec un ensemble de données déséquilibré. Il existe deux façons d’effectuer l’échantillonnage : sous-échantillonnage ou sur-échantillonnage.
Dans le sous-échantillonnage, nous réduisons la taille de la classe majoritaire pour qu’elle corresponde à la classe minoritaire, aidant ainsi en améliorant les performances avec le stockage et l’exécution au moment de l’exécution, mais cela élimine potentiellement les informations utiles.
Pour le suréchantillonnage, nous suréchantillonnons la classe minoritaire et résolvons ainsi le problème de la perte d’informations, cependant, nous avons le problème d’avoir un surajustement.
Il existe également d’autres techniques :
Suréchantillonnage basé sur un cluster – Dans ce cas, l’algorithme de clustering K-means est appliqué indépendamment aux instances de classe minoritaire et majoritaire. Il s’agit d’identifier les clusters dans l’ensemble de données. Par la suite, chaque cluster est suréchantillonné de sorte que tous les clusters de la même classe ont un nombre égal d’instances et toutes les classes ont la même taille.
Technique de suréchantillonnage des minorités synthétiques (SMOTE) – Un sous-ensemble de données est tiré de la classe minoritaire à titre d’exemple, puis de nouvelles instances synthétiques similaires sont créées qui sont ensuite ajoutées à l’ensemble de données d’origine. Cette technique est bonne pour les points de données numériques.
Mentionner certaines des techniques de l’AED ?
L’analyse exploratoire des données (EDA) aide les analystes à mieux comprendre les données et constitue le fondement de meilleurs modèles.
Visualisation
- Visualisation univariée
- Visualisation bivariée
- Visualisation multivariée
Traitement de valeur manquante – Remplacer les valeurs manquantes par une moyenne/médiane
Détection aberrante – Utilisez Boxplot pour identifier la distribution des valeurs aberrantes, puis appliquez IQR pour définir la limite de l’IQR
Transformation – Basé sur la distribution, appliquer une transformation sur les fonctionnalités
Mise à l’échelle du jeu de données – Appliquer MinMax, Scaler standard ou Z Score Scaling mécanisme pour l’échelle des données.
Ingénierie des fonctionnalités – Besoin du domaine, et les connaissances des PME aident l’analyste à trouver des champs dérivés qui peuvent obtenir plus d’informations sur la nature des données
Réduction de la dimensionnalité — aide à réduire le volume de données sans perdre beaucoup d’informations
Différencier la modélisation statistique et l’apprentissage automatique ?
Les modèles d’apprentissage automatique consistent à faire des prédictions précises sur les situations, comme la chute des pieds dans les restaurants, le cours des actions, etc. où, les modèles statistiques sont conçus pour déduire les relations entre les variables, car ce qui stimule les ventes dans un restaurant est-ce la nourriture ou l’ambiance ?
Différencier entre boosting et Bagging?
Bagging et Boosting sont des variantes des techniques d’ensemble, dans bagging, l’objectif est de réduire la variance d’un classifieur d’arbre de décision de créer plusieurs sous-ensembles de données à partir de l’échantillon d’apprentissage choisi au hasard avec remplacement. Chaque collection de données de sous-ensemble est utilisée pour former leurs arbres de décision.
- Exemple – classificateur de forêt aléatoire
Dans Boosting, les apprenants ont appris séquentiellement avec les premiers apprenants ajustant des modèles simples aux données, puis analysant les données pour détecter les erreurs. Les arbres consécutifs (échantillon aléatoire) sont en forme et à chaque étape, l’objectif est d’améliorer la précision de l’arbre précédent. Lorsqu’une entrée est mal classée par une hypothèse, son poids est augmenté de sorte que l’hypothèse suivante est plus susceptible de la classer correctement. Ce processus convertit les apprenants faibles en un modèle plus performant.
- Exemple – AdaBoosting, Gradient Boosting, XGboosting
Quelle est l’importance de gamma et de régularisation dans la SVM?
Le gamma définit l’influence. Valeurs basses signifiant « loin » et valeurs élevées signifiant « proche ». Si le gamma est trop grand, le rayon de la zone d’influence des vecteurs de soutien ne comprend que le vecteur de support lui-même et aucune quantité de régularisation avec C ne sera en mesure d’empêcher le surajustement. Si le gamma est très petit, le modèle est trop limité et ne peut pas capturer la complexité des données.
Le paramètre de régularisation (lambda) sert de degré d’importance qui est accordé aux classifications manquées. Cela peut être utilisé pour dessiner le compromis avec surajustement.
Expliquer comment fonctionne la courbe ROC
La représentation graphique du contraste entre les taux positifs réels et les taux faux positifs à différents seuils est connue sous le nom de courbe ROC. Il est utilisé comme proxy pour le compromis entre les vrais positifs et les faux positifs.
Quelle est la différence entre un modèle génératif et discriminant ?
Un modèle génératif apprend les différentes catégories de données. En revanche, un modèle discriminant n’apprendra que les distinctions entre les différentes catégories de données. Les modèles discriminants fonctionnent beaucoup mieux que les modèles génératifs en ce qui concerne les tâches de classification.
En quoi KNN est-il différent du clustering k-means?
La première différence et la plus importante est que K-Nearest Neighbors est un algorithme de classification supervisé, tandis que le clustering k-means est un algorithme de clustering non supervisé.
Les mécanismes de ces approches peuvent sembler similaires au début, pour que K-Nearest Neighbors fonctionne, vous avez besoin de données étiquetées dans lesquelles vous souhaitez classer un point sans étiquette (donc la partie voisine la plus proche).
D’un autre côté, le clustering K-means ne nécessite qu’un ensemble de points non étiquetés et un seuil. L’algorithme de regroupement prendra des points non étiquetés et apprendra progressivement à les regrouper en groupes en calculant la moyenne de la distance entre différents points.
La différence essentielle ici est que KNN a besoin de points étiquetés et relève donc de l’apprentissage supervisé, tandis que k-means relève de l’apprentissage non supervisé.




Laisser un commentaire
Vous devez être dentifié pour poster un commentaire.