0. Gestion des conteneurs avec Docker Enterprise – Partie 1
0.1 Résumé de la publication
Bien que connu principalement comme le moteur open source derrière des dizaines de millions de nœuds de serveur, Docker propose également des outils d’entreprise pris en charge commercialement appelés Docker Enterprise. Cette plate-forme exploite les racines profondes de Docker Engine – Community (anciennement Docker CE) et Kubernetes, mais ajoute un support et des outils pour exploiter efficacement une plate-forme de conteneurs sécurisée à grande échelle. Avec des centaines d’entreprises à bord, les meilleures pratiques et les modèles d’adoption émergent rapidement. Ces points d’apprentissage peuvent être utilisés pour informer les adoptants et aider à gérer la transformation d’entreprise associée à l’adoption du conteneur d’entreprise.
Cet article commence par expliquer le cas de Docker Enterprise, ainsi que sa structure et son architecture de référence. À partir de là, nous progressons à travers les étapes du PoC, du pilote et de la production en tant que modèle de travail pour l’adoption, en faisant évoluer la conception et la configuration de la plate-forme pour chaque étape et en utilisant des exemples d’application détaillés en cours de route pour clarifier et démontrer les concepts importants. L’article conclut avec l’impact de Docker sur d’autres technologies logicielles émergentes, telles que la Blockchain et l’informatique sans serveur.
À la fin de cet article, vous comprendrez mieux ce qu’il faut pour que votre entreprise soit opérationnelle avec Docker Enterprise et au-delà.
0.2 Objectifs de la publication
- Comprendre pourquoi les conteneurs sont importants pour une entreprise
- Comprendre les fonctionnalités et les composants de Docker Enterprise 2
- Découvrez les phases PoC, pilote et adoption de la production
- Découvrez les meilleures pratiques d’installation et d’exploitation de Docker Enterprise
- Comprendre ce qui est important pour une entreprise Docker en production
- Exécutez Kubernetes sur Docker Enterprise
0.3 Lien vers la partie 2
1 Docker Enterprise – L’apogée d’une architecture
1.1 De zéro à partout en cinq ans
Les équipes d’opérations techniques sont à juste titre sceptiques quant aux nouvelles plateformes technologiques telles que les conteneurs. Ils sont généralement plus préoccupés par le renforcement de la sécurité et de la fiabilité, car ils existent pour maintenir les applications d’entreprise opérationnelles et en toute sécurité. Dans le même temps, les propriétaires de produits au sein de leurs organisations doivent fournir des logiciels meilleurs, souvent plus complexes, plus rapidement. Oui, le paysage des affaires a profondément changé ; dans le monde des affaires d’aujourd’hui, les logiciels ne sont pas seulement utilisés pour obtenir un avantage concurrentiel, ils constituent l’entreprise et fournissent l’expérience client de première ligne.
Par la suite, une pression importante monte pour accélérer le pipeline de logiciels dans presque toutes les organisations. Cette section explique brièvement les racines des conteneurs et pourquoi leurs avantages (un pipeline logiciel sécurisé et rapide) ont conduit à une adoption aussi rapide des conteneurs.
1.1.1 L’histoire de Docker
Docker est né d’une présentation éclair, intitulée The future of Linux Containers, livrée à PyCon le vendredi 15 mars 2013. Le présentateur était Solomon Hykes, le fondateur de Docker. Ce jour-là, le monde du logiciel a changé même si les conteneurs Linux évoluaient dans la communauté Linux depuis près de 13 ans. Ce n’est pas la technologie que Salomon a dirigée qui a fait décoller le mouvement Docker, c’est la vision derrière elle et l’emballage de l’écosystème de conteneurs. La vision de Salomon était de créer des outils pour l’innovation de masse et son emballage de conteneurs Linux dans l’expérience Docker a livré cette technologie puissante et a mis les conteneurs à la portée de simples mortels. Aujourd’hui, Docker fonctionne sur des dizaines de millions de serveurs dans le monde.
Voici quelques notes sur les conteneurs Linux :
- Ils évoluent depuis 2000
- LinuxContainers (LXC) est sorti en 2008
- Le lmctfy de Google (laissez-moi le conteneur pour vous) prend en charge le libcontainer de Docker en 2015
- Des normes sont apparues, notamment OCI et CNCF, vers 2015
- Centre de support de référence de sécurité Internet
Au cours des 5 dernières années, des milliers de développeurs ont rejoint la communauté open source de Docker pour proposer ce que l’on appelle Docker Community Edition ( Docker Engine-Community ). Docker est resté attaché à une plateforme ouverte et à des règles du jeu équitables. Docker a fait don d’importants actifs à la communauté open source et aux normes, y compris le format de conteneur Docker et le runtime, pour fournir la pierre angulaire de l’Open Container Initiative (OCI) en 2015 et le runtime du conteneur à la Cloud Native Computing Foundation (CNCF) en 2017.
À Dockercon en 2017, Solomon Hykes a lancé Project Moby, qui donne à quiconque les outils dont ils ont besoin pour construire leur propre Docker. C’était très cool et finalement dans le meilleur intérêt de la communauté des conteneurs. Cependant, cet effort bien intentionné a conduit à un reconditionnement complet des actifs de la communauté Docker sans adhésion de la communauté. D’un point de vue global, Docker a démontré son engagement envers la communauté et la vision de Salomon des outils pour l’innovation de masse.
1.1.2 Les conteneurs modifient le développement et le déploiement d’applications
Les conteneurs permettent aux développeurs d’applications de regrouper leur application, ainsi que toutes leurs dépendances, dans une unité portable appelée image. Ces images sont ensuite stockées dans un référentiel distant où elles peuvent être extraites et exécutées sur n’importe quel moteur de conteneur compatible. De plus, les applications exécutées sur chaque moteur de conteneur sont isolées les unes des autres et du système d’exploitation hôte :
- Scénario illustratif : Disons que je veux tester NGINX sans rien installer (j’ai déjà Docker bien sûr installé). Je crée un exemple de page HTML appelée index.html dans mon répertoire local et exécute ce qui suit :
docker run -p 8000:80 -v ${PWD}:/usr/share/nginx/html:ro -d nginx
- Que se passe-t-il ici ?
- Je dis à Docker d’exécuter l’image nginx officielle en arrière-plan sur mon Docker Engine local, de transmettre le port 8000 de mon adaptateur hôte au port 80 du conteneur et de monter mon répertoire local pour partager mon fichier HTML avec nginx en tant que dossier en lecture seule.
- Ensuite, je pointe mon navigateur local sur http://localhost:8000 et je vois ma page HTML rendue. Quand j’ai fini, je demande à Docker de retirer le conteneur. Donc, en l’espace d’une minute environ, j’ai créé une page Web de test, utilisé NGINX pour le rendre localement sans rien installer localement, et l’ai exécuté en toute isolation. La seule collision possible avec une ressource hôte était autour du port 8000 de l’adaptateur hôte, ce qui était arbitraire.
- C’est cool, mais les VM ne le font-elles pas déjà pour nous ?
- Sur le plan conceptuel, il existe certaines similitudes, mais la mise en œuvre des conteneurs est beaucoup plus légère et efficace. Les principales différences de mise en œuvre sont :
- Tous les conteneurs partagent le noyau de l’hôte :
- Docker utilise les contrats à terme de sécurité des conteneurs Linux pour isoler les conteneurs de l’hôte et d’autres conteneurs.
- Étant donné que le noyau est déjà en cours d’exécution, le temps de démarrage des conteneurs est généralement d’une seconde ou deux, par rapport à l’attente d’une minute ou deux pour que le système d’exploitation invité démarre sur une machine virtuelle.
- Les conteneurs utilisent un système de fichiers en couches avec mise en cache :
- Les images Docker sont composées de couches en lecture seule qui peuvent être mises en cache et partagées sur plusieurs conteneurs.
- Les parties principales des images Docker peuvent être partagées entre les conteneurs, ce qui signifie que vous n’avez pas à extraire l’image entière à chaque fois. D’un autre côté, les machines virtuelles ont un système de fichiers monolithique et opaque qui est complètement rechargé à chaque démarrage. Cela entraîne des temps de chargement lents et un stockage d’image inefficace avec les machines virtuelles.
- Tous les conteneurs partagent le noyau de l’hôte :
- Sur le plan conceptuel, il existe certaines similitudes, mais la mise en œuvre des conteneurs est beaucoup plus légère et efficace. Les principales différences de mise en œuvre sont :
Dans la figure suivante, vous pouvez voir comment les applications des machines virtuelles (côté droit du diagramme) ont une copie complète du système d’exploitation et des binaires de prise en charge dans chaque machine virtuelle, tandis que les applications conteneurisées (côté gauche du diagramme) partagent toutes les mêmes binaires Alpine (aucun noyau nécessaire ~ 3 Mo) et binaires d’exécution. Il y a eu divers rapports sur l’impact financier des conteneurs par rapport aux machines virtuelles, mais le nombre que j’ai vu varie de 15% à 70% de réduction des coûts d’exploitation. Comme ils le disent, votre kilométrage peut varier en fonction de votre système d’exploitation, de vos binaires et de votre passage au bare metal pour éliminer les coûts de licence de l’hyperviseur :
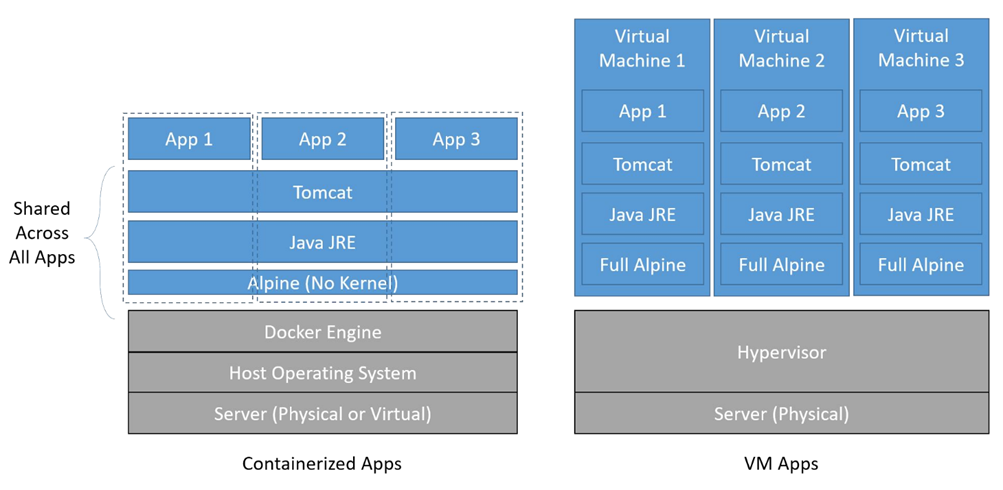
Applications conteneurisées vs applications VM
1.1.3 Les conteneurs gagnent en popularité
Ce qui suit est globalement un résumé de ce que j’entends des clients et des étudiants :
- Intégration plus rapide des développeurs : développement basé sur des conteneurs
- Facile à exécuter et à tester sur les machines de développement : idéal pour simuler la production
- Cycles de publication plus rapides et temps plus court pour corriger les bogues : plus de déploiements monolithiques
- Logiciel de meilleure qualité : images cohérentes dans tous les environnements
- Il est trop difficile de gérer les microservices sans eux : les piles sont idéales pour l’isolement et le déploiement
- Prise en charge plus facile des applications Web héritées : conteneurisez les anciennes applications et gérez-les sur une plate-forme moderne
- Réduction de la taxe VMware : meilleure utilisation des ressources de calcul grâce à une densité et une consolidation accrues de plusieurs environnements non prod (à l’aide de Docker Enterprise RBAC)
Même le matériel gratuit vous coûtera quelque chose: je termine cette section sur une note pratique en suggérant que vos économies opérationnelles initiales seront compensées par l’investissement nécessaire pour transformer votre entreprise en une plate-forme de conteneurs. Une fois bien fait, l’impact de l’adoption des conteneurs affecte un large groupe au sein de l’entreprise, couvrant l’ensemble du développement de logiciels et du pipeline de livraison. Comme toute transformation qui en vaut la peine, certains investissements sont nécessaires. Plus d’informations sur l’impact de l’adoption de conteneurs plus tard.
1.1.4 Docker Engine-Community – Docker gratuit
La version open source de Docker s’appelle Docker Engine-Community et est distribuée sous la licence Apache 2.0. Parfois appelée Docker gratuit, cette version est prise en charge par la communauté et elle-même. Docker a deux schémas d’emballage :
- Docker Engine-Community pour les architectures de bureau x86 64 bits pour Mac et Windows 10 Pro +
- CE Server pour le ciblage CentOS, Debian, Fedora et Ubuntu Linux distributions
Outre le packaging de la plateforme, Docker Engine-Community est livré avec deux canaux. Il est important de noter qu’à partir de la version 18.09 de Docker Engine-Community, le canal stable sortira sur une cadence de six mois et le canal périphérique sera remplacé par une version nocturne :
- Canal stable : le code de disponibilité générale est publié via ce canal après avoir été soigneusement testé.
- Canal Edge pour les plates – formes de bureau : version mensuelle du code préliminaire qui se trouve à différentes étapes des tests.
- Chaîne nocturne : Un nouveau code est publié ici ! Par la suite, de nouvelles fonctionnalités intéressantes apparaissent ici en premier, mais cette base de code n’est pas complètement testée et ne doit pas être utilisée pour la production. De plus, si vos développeurs utilisent le canal de périphérie (ou s’exécutent avec le drapeau —experimental) sur leurs postes de travail, vous devrez être très prudent pour éviter les travaux sur mon scénario de machine ! Veillez à ce que le nouveau code ne repose pas sur des fonctionnalités GA inédites ou expérimentales qui fonctionneront sur la station de travail du développeur, mais se rompra plus tard à mesure que les images et / ou les configurations se déplaceront dans le pipeline.
Vous pouvez envisager d’avoir un cluster de développement où les développeurs déploient leur code sur une infrastructure Docker qui correspond aux versions de production. Si un cluster de développement est disponible, les développeurs doivent toujours se déployer sur le développement avant que leur code ne soit archivé, pour garantir qu’aucune génération n’est rompue.
1.1.4.1 Docker Engine-Community comprend des fonctionnalités clés
Docker Engine-Community est une plate-forme de conteneur riche en fonctionnalités qui comprend une API complète, une CLI (client Docker) et une architecture de plug-in riche pour l’intégration et l’extension. Il vous permet d’exécuter des applications de production sur un seul nœud ou dans un cluster sécurisé qui inclut un réseau de superposition et un équilibrage de charge de couche 4. Tout est inclus lorsque vous installez le moteur Docker Engine-Community !
1.1.4.2 Exécution de Docker Engine-Community sur AWS ou Azure
Veuillez noter qu’il existe des packages de démarrage rapide AWS et Azure pour les utilisateurs du cloud. Ces bundles pratiques incluent une image AMI / VM prise en charge par Docker, ainsi que des utilitaires cloud pour câbler et prendre en charge un cluster de nœuds Docker Engine-Community. Les véritables atouts ici sont les modèles IaaS natifs du fournisseur cloud (AWS CloudFormation ou Azure resource manager), les images Docker VM et les conteneurs d’utilitaires Docker4x pour interagir avec les services du fournisseur cloud. Par exemple, le bundle AWS vous permet d’inclure le plug-in de volume cloudstore, où au lieu d’utiliser des volumes EBS locaux, vous pouvez utiliser des volumes sauvegardés EFS et S3 sur l’ensemble du cluster.
Bien que vous puissiez utiliser NFS pour obtenir une solution de stockage à l’échelle du cluster sur site, en raison d’une latence imprévisible sur les réseaux des fournisseurs de cloud, où les montages NFS peuvent devenir inopinément en lecture seule, je recommande fortement d’utiliser Cloudstor sur AWS et Azure. Plus d’informations peuvent être trouvées sur https://docs.docker.com/docker-for-aws/persistent-data-volumes/ .
Enfin, veuillez noter que Docker pour AWS et Docker pour Azure s’appliquent uniquement aux installations Docker Engine-Community. Docker Enterprise utilise désormais les outils d’infrastructure certifiés Docker, utilisant Terraform et Ansible pour cibler les implémentations VMware, Azure et AWS de Docker Enteprise.
1.1.5 Docker Enterprise – prise en charge et fonctionnalités d’entreprise
Docker gratuit est super ! Mais vous soutenir n’est pas toujours aussi génial. Par conséquent, Docker Engine-Community est généralement un bon choix pour apprendre et démarrer, mais dès que vous vous dirigez vers la production, vous devriez envisager de passer à Docker Enterprise pour le support et / ou les outils de classe entreprise qu’il fournit.
Docker Enterprise s’appuie sur l’ensemble de fonctionnalités déjà riche de Docker Engine-Community et ajoute une prise en charge commerciale du Docker Engine (Docker Enterprise Basic), ainsi que des outils importants pour la gestion de plusieurs équipes et applications de production, y compris les applications Kubernetes (Kubernetes est inclus dans Docker Enterprise Standard et avancé).
Docker offre les modèles de support suivants pour Docker Engine-Community et Docker Enterprise :
- Docker Engine-Community : à partir de CE 18.09, vous devrez mettre à niveau (gérer les éventuelles modifications) tous les 7 mois si vous souhaitez des correctifs et une prise en charge des correctifs. Il s’agit d’une amélioration récente car, avant CE 18.09, le cycle de support n’était que de quatre mois. Docker Engine-Community s’appuie sur des forums de support communautaire ; vous postez un problème dans un forum public et attendez que quelqu’un vous aide ou génère un correctif. Docker a une grande communauté, mais avec Docker Engine-Community, il n’y a pas d’accords de niveau de service (SLA).
- Docker Enterprise : vous devrez mettre à niveau (gérer les éventuels changements de rupture) tous les 24 mois pour maintenir l’accès aux correctifs et à la prise en charge des correctifs. La pierre angulaire de Docker Enteprise est son canal de support privé de niveau entreprise avec un accord de niveau de support critique pour l’entreprise ou le jour ouvrable.
- Astuce : l’entreprise critique a un SLA de temps de réponse plus rapide, mais coûte plus cher.
Docker Enterprise inclut également une prise en charge transparente des plug-ins et des conteneurs certifiés Docker fournis par ISV. Cela signifie que si vous avez un problème avec un plugin ou un conteneur certifié, vous appelez simplement Docker pour obtenir de l’aide.
Les problèmes de support de Docker Engine-Community sont publiés publiquement pour que tout le monde puisse les voir. Cela peut être un problème si vous êtes, par exemple, une institution financière annonçant publiquement une vulnérabilité de sécurité que vous avez découverte et donc en prévenant les pirates. Si vous avez des inquiétudes concernant la visibilité publique de vos problèmes ou si vous avez besoin de SLA, vous pouvez envisager d’acheter Docker Enterprise Basic avec une assistance le jour ouvrable.
Docker Enterprise est également disponible en trois niveaux :
- Niveau de base de Docker Enterprise : ensemble de fonctionnalités Docker Engine-Community avec prise en charge de Docker Enterprise, comme décrit précédemment.
- Niveau standard de Docker Enterprise : intégré à Docker Engine-Community avec prise en charge de Docker Enterprise comme décrit précédemment, mais ajoute le plan de contrôle universel (UCP; sécurité intégrée avec les connexions LDAP et RBAC via un bundle GUI ou CLI pour la gestion des politiques, couche 7) routage, Kubernetes prêt à l’emploi et une interface Web) et le Docker Trusted Registry (DTR; un registre d’images privé lié au modèle de sécurité UCP avec signature d’images, promotions, webhooks et API complète) accès).
- Niveau avancé de Docker Enterprise : inclut toutes les fonctionnalités du niveau standard de Docker Enterprise, mais donne à Universal Control Plane (UCP) un RBAC plus fin pour permettre l’isolement des nœuds. Le niveau avancé améliore le Docker Trusted Registry (DTR) avec l’analyse de la vulnérabilité des images et la mise en miroir d’images sur les DTR distants.
Le niveau avancé applique un degré élevé d’isolement des ressources jusqu’au niveau du nœud. Cela permet à une entreprise de consolider tous ses environnements de non-production en un seul cluster de dockers non prod. Cela peut considérablement réduire le nombre de services requis pour les activités hors production. Les développeurs, testeurs et opérateurs reçoivent des subventions RBAC appropriées pour travailler de manière isolée.
1.1.6 Kubernetes et Docker Enterprise
À moins que vous ne vous cachiez sous un rocher, vous avez probablement entendu parler de Kubernetes. Trop souvent, j’ai entendu des membres (non informés) de la communauté technologique dire que nous n’utilisons pas Docker, nous utilisons Kubernetes. C’est un peu naïf puisque la grande majorité des clusters exécutant Kubernetes orchestration le font avec le Docker Engine.
Les orchestrateurs permettent aux développeurs de câbler des nœuds de conteneur individuels dans un cluster pour améliorer l’évolutivité et la disponibilité, et récolter les avantages de l’auto-réparation et de la gestion des applications distribuées / microservices. Dès que les applications multiservices devaient coordonner plus d’un conteneur pour s’exécuter, l’orchestration est devenue une chose. Orchestrators permet aux développeurs d’applications conteneurisées de spécifier comment leur collection de conteneurs fonctionne ensemble pour former une application. Ils déploient ensuite l’application à l’aide de cette spécification pour planifier les conteneurs requis sur un cluster (généralement Docker) d’hôtes.
Au début, les startups nées dans le cloud qui fonctionnaient à grande échelle et déployaient généralement des microservices ont pris conscience d’un besoin d’orchestration. Par conséquent, les esprits brillants de Google ont créé ce qui est devenu le cadre d’orchestration Kubernetes et ont ensuite créé un organisme indépendant pour le gérer, la Cloud Native Computing Foundation (CNCF), avec Kubernetes comme projet de pierre angulaire de la CNCF. Pendant ce temps, la communauté Docker a commencé à travailler sur son propre projet d’orchestration appelé Swarmkit.
1.1.6.1 Orchestration de Kubernetes et Swarm
Bien qu’il existe de nombreuses variations et incantations dans l’espace d’orchestration, le marché se résume à des acteurs très différents : Kubernetes et Swarm. Et non, Swarm n’est pas mort.
Kubernetes a rapidement évolué en tant que plateforme d’orchestration tierce modulaire et hautement configurable prise en charge et utilisée par des développeurs natifs du cloud à 12 facteurs. D’un point de vue technique, c’est une plateforme très intéressante avec de nombreux degrés de liberté et des points d’extensibilité. Pour les gens hardcore à 12 facteurs (également connus sous le nom de cool kids) qui fournissent généralement des systèmes très complexes à grande échelle, l’utilisation de Kubernetes est une évidence. Cependant, si vous n’êtes pas Google ou eBay, Kubernetes pourrait être un peu pour vous, surtout au début.
Swarm, l’outil d’orchestration de Docker, a commencé comme un complément, mais dans la version 1.12 a été ajouté au moteur Docker. En tant que tel, il n’y a rien à installer ; vous l’activez plutôt à l’aide des commandes docker swarm init et docker swarm join pour créer un cluster crypté TLS avec un réseau de superposition prêt à l’emploi ! Donc, c’est en quelque sorte le bouton facile pour l’orchestration car il n’y a rien de plus à installer, et il est à la fois sécurisé et prêt à l’emploi. Swarm est inclus dans Docker Engine-Community et les ferroutages UCP de Docker Enterprise directement hors de Swarm.
1.1.6.2 Kubernetes et Swarm – différentes philosophies pour résoudre différents problèmes
Quel est le meilleur (pour vous) ? En fait ça dépend…
Débuter avec Kubernetes est assez difficile. Cela est dû au fait qu’en plus d’un environnement d’exécution de conteneur (tel que Docker Engine-Community), vous devez installer et configurer kubectl , kubeadm et kubelet , mais ce n’est que le début. Vous devez également prendre certaines décisions à l’avance, comme choisir un modèle de mise en réseau et configurer / installer l’implémentation CNI du conteneur du fournisseur. Kubernetes ne fournit généralement pas d’options par défaut (certains services cloud le font pour vous), ce qui vous donne une grande flexibilité, mais vous oblige naturellement à prendre une décision initiale et complique l’installation. Encore une fois, c’est parfait si vous avez besoin de cette flexibilité et que vous savez exactement ce que vous faites.
D’un autre côté, si vous avez Docker 1.12 ou plus récent (nous vous recommandons fortement d’avoir quelque chose de beaucoup plus récent), il vous suffit de l’activer avec la commande docker swarm init. Il crée une autorité de certification, un magasin Raft chiffré et un réseau de superposition automatiquement, ainsi qu’une commande de jointure à jetons pour ajouter en toute sécurité des nœuds supplémentaires à votre cluster. Cependant, dans un esprit de simplicité et de sécurité, Docker a fait certains choix par défaut pour vous. C’est formidable si vous pouvez vivre avec ces choix, au moins pendant que vous vous familiarisez avec les plates-formes de conteneurs d’entreprise.
Au-delà de l’installation, la description du déploiement d’applications (à l’aide de fichiers YAML) dans Kubernetes est intrinsèquement plus complexe. En ce qui concerne les styles de déploiement, Kubernetes déploie des composants discrets et les relie à une collection de fichiers YAML qui s’appuient sur des étiquettes et des sélecteurs pour les connecter. Toujours dans le style Kubernetes, lors de la création de composants, vous devez définir un large éventail de paramètres de comportement pour décrire exactement ce que vous voulez, plutôt que de supposer un comportement par défaut. Cela peut être verbeux, mais c’est très puissant, précis et flexible !
Kubernetes inclut également le pod en tant qu’unité de déploiement atomique, ce qui peut être pratique pour isoler un ensemble de conteneurs du modèle de mise en réseau plat. Cela conduit à l’utilisation de conteneurs side-car qui interfacent essentiellement les pods avec le reste du monde. C’est très cool et c’est un excellent moyen de gérer des réseaux de services partagés, de longue durée et faiblement couplés dans un espace d’adressage plat :
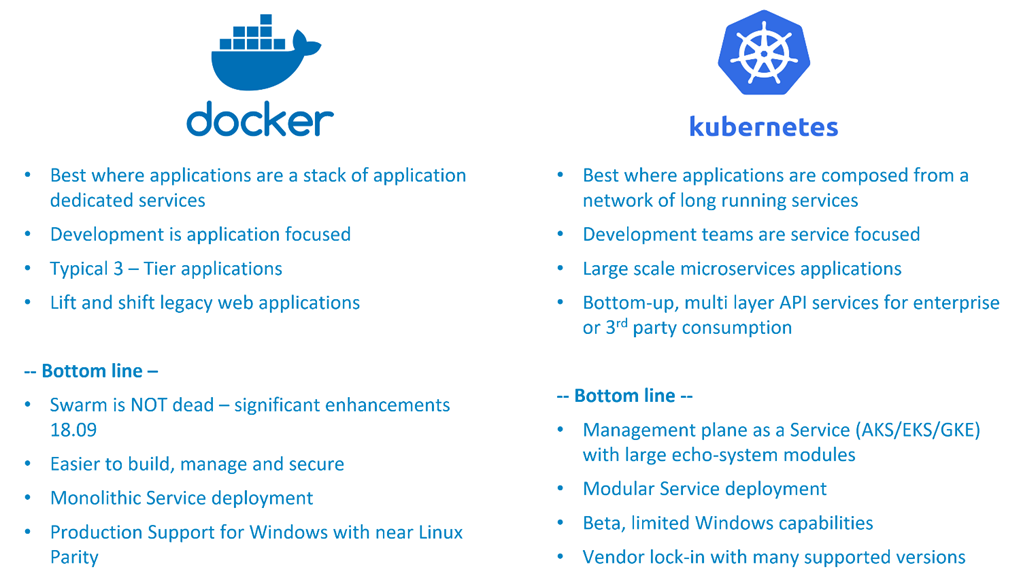
Docker Swarm et Kubernetes
Swarm adopte une approche monolithique centrée sur l’application en définissant une pile de services associés dans un fichier .yaml . Les piles d’essaim supposent que vous exécutez une collection de services connexes, isolés par des réseaux de superposition, pour prendre en charge des fonctionnalités spécifiques dans le contexte d’une application. Cela facilite le déploiement d’une pile d’applications typique telle qu’un frontend angulaire avec l’API RESTful d’une application et une base de données Postgres.
1.1.6.3 Déplacer Kubernetes vers le courant dominant
De nombreux fournisseurs PaaS et IaaS plongent dans Kubernetes et proposent des configurations clé en main. Ils parient sur l’API Kubernetes comme spécification pour déployer des charges de travail d’application dans leur service. Les exemples incluent le moteur Kubernetes de Google, le service Azure Kubernetes et enfin et surtout, le service Amazon Elastic Container Service pour Kubernetes (Amazon EKS). Celles-ci sont excellentes pour vous aider à démarrer, mais qu’en est-il si / quand vous transférez des charges de travail stables sur site en raison de problèmes de coût ou de sécurité ?
Enfin, méfiez-vous des limitations liées aux solutions PaaS. Si vous utilisez un plan de gestion PaaS Kubernetes, vous pouvez être limité à utiliser le plug-in CNI du fournisseur PaaS et leur implémentation peut limiter vos options. Par exemple, si vous exécutez Kubernetes sur AWS, la mise en œuvre réseau peut nécessiter une IP / pod virtuelle, mais vous n’obtenez qu’un nombre limité d’IP virtuelles par type d’instance. Par la suite, vous devrez peut-être passer à un type d’instance plus grand et plus cher pour prendre en charge plus de pods, même si vous n’avez pas vraiment besoin de CPU, de réseau ou de stockage plus / meilleurs.
1.2 Nouvelle ère pour les applications Dev, DevOps et les opérations informatiques
L’utilisation de conteneurs et d’orchestrateurs change la façon dont nous envisageons la création de logiciels et la définition d’un pipeline de livraison de logiciels. Le développement basé sur des conteneurs prend en charge fondamentalement ce que les gens de DevOps appellent un décalage vers la gauche, où les développeurs de systèmes distribués deviennent plus responsables de la qualité de la solution globale, c’est-à-dire les binaires et la façon dont ils sont connectés. Par conséquent, le câblage de mes services n’est plus le problème des équipes de mise en réseau, d’intégration ou d’exploitation ; il appartient aux développeurs. En fait, la spécification YAML pour la connexion et le déploiement de leur application est maintenant un artefact qui est vérifié dans le contrôle du code source !
Un déploiement plus rapide des correctifs et des améliorations est une motivation essentielle pour conteneuriser des applications Web monolithiques conçues avec Job et .NET. La conteneurisation permet à chaque équipe de fonctionner de manière indépendante et de déployer son application dès qu’elle est prête à fonctionner, sans avoir à attendre toutes les autres équipes d’application ou le prochain cycle de publication trimestriel.
La conteneurisation des applications peut être très utile pour éliminer les bourrages de journaux d’organisation associés aux déploiements monolithiques pré-conteneur, car chaque application obtient son propre conteneur d’exécution. Ce conteneur comprend toutes leurs dépendances d’exécution spécifiques, telles que Java et Tomcat, pour l’application à exécuter. Étant donné que nous utilisons des conteneurs, nous nous préoccupons moins des frais généraux associés au démarrage et à l’exploitation de conteneurs similaires en production en nous rappelant comment Docker isole l’exécution des applications, tout en partageant les couches communes du système de fichiers pour des heures de démarrage rapides et une utilisation efficace des ressources. Ainsi, plutôt que de devoir coordonner toutes les équipes impliquées dans un déploiement, chaque équipe a sa propre pile isolée de dépendances, ce qui lui permet de se déployer et de tester selon son propre calendrier. Sans surprise, une fois les applications conteneurisées, il est beaucoup plus facile de les refactoriser indépendamment.
Commencez par conteneuriser les applications sans changer de code si possible. Une fois l’application conteneurisée, procédez à une refactorisation. Essayer d’accomplir simultanément la conteneurisation et la refactorisation peut être intimidant et peut bloquer le projet.
1.2.1 DevOps
Tirer parti des conteneurs dans votre pipeline d’intégration continue et de déploiement continu est devenu une meilleure pratique pour la plupart des équipes DevOps. Même le pipeline lui-même est souvent exécuté comme une plateforme conteneurisée. La motivation ici est un produit de meilleure qualité, basé sur le modèle de serveur immuable où les conteneurs sont construits une fois et promus à travers le pipeline. En d’autres termes, l’application n’est pas réinstallée sur un nouveau serveur virtuel entre chaque étape du pipeline. Au lieu de cela, la même image de conteneur est extraite d’un référentiel central et exécutée à l’étape suivante. Les variables d’environnement et les fichiers de configuration sont utilisés pour tenir compte des variations entre les environnements.
1.2.2 Opérations
Étant donné que l’équipe d’application a assumé les tâches de câblage et de configuration de l’application pour le déploiement, l’équipe des opérations peut se concentrer sur la plate-forme de conteneurs. Cela inclut la configuration et la maintenance des environnements opérationnels de la plate-forme de conteneurs, la surveillance et la journalisation centralisée des applications s’exécutant dans le cluster, et la gestion de la sécurité / des politiques au sein du cluster pour garantir que les applications et les utilisateurs se comportent comme prévu.
1.3 Impact sur les conteneurs d’abord et stratégique des conteneurs
Les conteneurs ajoutent de nouvelles possibilités à l’approche de la stratégie d’application de votre entreprise, principalement en ce qui concerne la migration vers le cloud et la modernisation des applications. Les conteneurs permettent aux organisations d’élever cette conversation des tactiques de migration vers le cloud et des piles d’applications à une plate-forme d’application commune où pratiquement n’importe quelle pile d’applications s’exécute plus efficacement tout en rendant les applications portables dans le cloud.
1.3.1 Le conteneur d’abord comme stratégie d’adoption du cloud
Que se passe-t-il si, avant de commencer la migration de toutes vos applications vers un fournisseur spécifique au cloud, vous préférez d’abord conteneuriser vos applications, puis les migrer vers le cloud. Ceci est parfois appelé une stratégie de conteneur d’abord. Cette approche présente plusieurs avantages importants :
- Résumé des connaissances spécifiques à la plate-forme des équipes d’application
- Gagner en efficacité opérationnelle (généralement entre 15% et 70%) grâce aux applications conteneurisées
- Il vous donne la possibilité de déplacer vos applications entre sur site et tout fournisseur de cloud avec un minimum d’effort
La réflexion sur les conteneurs devrait réduire les besoins en personnel spécifiques au cloud; au lieu d’un administrateur / application cloud, vous disposez d’un cluster administrateur / conteneur cloud. Une fois conteneurisées, les migrations d’applications entre les fournisseurs de cloud et sur site doivent être mesurées en heures et non en semaines ou en mois.
1.3.2 Préparez-vous à ramener les charges de travail du cloud public
Passer au cloud est amusant et cool! Cependant, cela peut devenir très coûteux et difficile à contrôler pour une entreprise. La plupart de ce que je vois des clients est que le cloud est logique pour les charges de travail très variables où la capacité élastique est très importante. Cependant, lorsque des charges de travail stables et prévisibles sont impliquées, de nombreuses organisations trouvent le cloud public trop cher et les migrent finalement vers leur centre de données ou leur cloud privé. C’est ce qu’on appelle le rapatriement de la charge de travail et cela devient un événement très courant.
1.3.3 Modernisation des applications – le chemin de la conteneurisation
Les clients Docker ont documenté des réductions significatives des coûts opérationnels obtenus en conteneurisant simplement les applications Web traditionnelles (.NET 2.0+ et Java) et en mettant en place une infrastructure Docker Enterprise pour les exécuter. Cette infrastructure peut fonctionner dans le cloud, VMware ou même le bare metal. Il existe une méthodologie utilisée par les architectes de solutions Docker pour aider les entreprises à migrer les applications traditionnelles. Il commence par un PoC accéléré, passe à une application pilote et enfin à la production, où chaque étape s’appuie sur la dernière.
1.3.4 Prise en charge des microservices et DevOps
À ce stade du jeu, la plupart des équipes de développement n’essaieront même pas de créer et de déployer des microservices sans conteneurs ni orchestrateurs. Les équipes de développement de style à 12 facteurs ont beaucoup de pièces mobiles et se déploient souvent – un ajustement parfait pour Docker et Kubernetes! Ces équipes utilisent des systèmes CI / CD décentralisés et conteneurisés qui prennent en charge les conteneurs intégrés pour atteindre de faibles taux d’erreur à l’aide de déploiements automatisés à haute vitesse.
1.3.5 Conformité
Alors que la conformité pour les plates-formes de conteneurs est réalisable avec des produits tiers tels que Sysdig Secure, Twistlock et AquaSec, Docker Enterprise 2.1 ajoute la prise en charge de la conformité FIPS pour les plates-formes Windows et RHEL. Cela signifie que la plate-forme Docker est validée par rapport aux normes et aux meilleures pratiques largement acceptées lors du développement de produits Docker Enterprise.Ainsi, les entreprises et les agences obtiennent une confiance supplémentaire pour adopter les conteneurs Docker. La publication 140-2 de la norme FIPS (Federal Information Processing Standard) étant les normes les plus remarquables, vérifie et autorise l’utilisation de divers modules de chiffrement de sécurité au sein d’une pile logicielle d’organisation qui comprend désormais le Docker Enterprise Engine.
Pour plus d’informations sur les FIP, veuillez visiter le site Web de Docker : https://docs.docker.com/compliance/nist/fips140_2/ . Pour plus d’informations sur la conformité générale de Docker, veuillez visiter: https://docs.docker.com/compliance/ .
1.4 Comment Docker Enterprise 2.0 a changé le jeu
En avril 2018, Docker Enterprise 2.0 était une version. Dans cette version, Docker a ajouté la prise en charge de Kubernetes. Pas une version emballée ou reconditionnée, mais la vraie version open source. L’avantage de l’exécution de Kubernetes sur Docker Enterprise 2.0 est la simplicité. Avec Docker Enterprise 2.0, le plan de contrôle universel comprend Kubernetes préinstallé, qui fonctionne avec Swarm. Cela signifie que les entreprises n’ont pas besoin de choisir entre Kubernetes et Swarm; ils peuvent les avoir tous les deux. C’est un gros problème pour les organisations qui doivent gérer à la fois des poches d’applications avancées de microservices et des applications traditionnelles à n niveaux plus simples. Avec Docker Enterprise 2.0, les équipes de microservices sont libres de mettre leur Kube en marche, tandis que les autres équipes se familiarisent avec Swarm. En outre, il permet à une entreprise de gérer une courbe d’apprentissage plus facile à gérer en démarrant avec Swarm et en introduisant plus tard des configurations Kubernetes plus complexes si nécessaire.
De plus, lors de Dockercon 2018, Docker a annoncé des fonctionnalités très intéressantes sur sa feuille de route à court terme concernant l’intégration entre Docker Enterprise et les services Kubernetes basés sur le cloud. Essentiellement, Docker Enterprise 2 pourra utiliser une application Kubernetes sur site exécutée sur Docker Enterprise 2.0 et la déployer sur un fournisseur Kubernetes basé sur le Web tel qu’Amazon ou Google.
Bien que Docker Enterprise 2.0 ne soit pas le choix parfait pour une petite startup native du cloud, sa flexibilité, son modèle de sécurité intégré et sa plate-forme unique devraient en faire une considération primordiale pour les plates-formes de conteneurs sur site et hybrides.
1.5 Résumé
Au cours des 5 dernières années, les conteneurs sont sortis de l’obscurité et ont été mis à l’honneur dans l’industrie du logiciel et DevOps. L’impact organisationnel profond des conteneurs s’étend aux développeurs de logiciels, aux administrateurs informatiques, aux ingénieurs DevOps, aux architectes et aux cadres. Depuis le début, Docker, Inc. a été au centre du mouvement des conteneurs et reste attaché au succès à long terme en soutenant les normes de l’industrie, la communauté open source et, plus récemment, les clients d’entreprise avec un Docker Enterprise 2 compatible Kubernetes.
Au cours des 5 prochaines années, l’adoption par les entreprises de conteneurs va s’épanouir. Par la suite, la plupart des organisations commenceront à rechercher une solution de niveau entreprise qui équilibre les coûts et la sécurité avec la vitesse et les fonctionnalités de plate-forme de pointe. La vitre unique de Docker Enterprise pour le cloud hybride et les clusters sur site, ainsi que la prise en charge des dernières technologies de conteneurs, y compris la prise en charge de Kubernetes, sont très susceptibles d’attirer l’attention des leaders informatiques astucieux du monde entier.
À venir dans le chapitre 2 , Docker Enterprise – an Architectural Overview , notre voyage continue alors que nous explorons les fonctionnalités et l’architecture de Docker Enterprise.
2 Docker Enterprise – un aperçu architectural
Alors que nous approfondissons les détails de Docker Enterprise, il est important de savoir où il s’inscrit dans le paysage concurrentiel des fournisseurs de plates-formes de conteneurs d’entreprise. Informer les acheteurs des grandes catégories de fournisseurs peut les aider à décider si Docker Enterprise est le meilleur pour leur organisation. De plus, nous fournissons une vue d’ensemble de l’économie de Docker Enterprise ainsi que des fonctionnalités clés, de l’architecture et des composants pour prendre en charge des produits ouverts et pris en charge pour les clients d’entreprise.
Les sujets suivants seront traités dans ce chapitre :
- Position de Docker Enterprise sur le marché émergent des plates-formes de conteneurs d’entreprise
- Les coûts / avantages économiques de l’architecture de Docker Enterprise
- Le contexte architectural de Docker Enterprise
- Les composants clés de Docker Enterprise
- Architecture de référence de Docker Enterprise
2.1 Passer des projets scientifiques aux plateformes de production
Au début, et pour les conteneurs jusqu’à la mi-2017 environ, les applications basées sur Docker ressemblent davantage à des projets scientifiques qu’à des plates-formes de production bien conçues. Il semble qu’aucun montant de dette technique ne soit trop élevé tant que votre application est en cours d’exécution, stable et cool. De plus, l’outillage roulé à la main qu’il a fallu pour prendre en charge les premières applications Docker / Kubernetes n’était pleinement compris que par un ou deux membres d’une équipe d’entreprise, et ils étaient généralement plus alignés avec les développeurs et moins alignés avec l’équipe des opérations, créant un énorme écart dans l’ensemble de compétences de l’entreprise requis pour soutenir les conteneurs dans la production. Alors que la dette technique augmentait et que l’écart de compétences se creusait, une grande opportunité de marché s’est présentée.
Avec la croissance explosive de Docker depuis 2013, une opportunité de marché importante est apparue pour prendre en charge les conteneurs dans l’entreprise. Pour réussir, ces plateformes doivent considérer les objectifs suivants :
- Donner aux développeurs la possibilité de construire, de tester (localement sur des postes de travail de développement ainsi que sur un cluster de développement distant) et de déployer des applications multi-conteneurs sécurisées à volonté
- Fournir un pipeline CI efficace et sécurisé, géré par les développeurs
- Permettre aux opérateurs (DevOps, TechOps et SecOps) de sécuriser, gérer, surveiller et faire évoluer efficacement plusieurs environnements pour des applications de développement, de test, d’assurance qualité et de production
- Prise en charge des exigences de conformité au niveau de la plate-forme, pas seulement au niveau de l’application
2.1.1 Le paysage des plateformes de conteneurs émergentes
De nombreuses sociétés technologiques de pointe sont impliquées dans le jeu de plate-forme de conteneurs et je vais les regrouper en trois grandes catégories pour résumer la place de Docker Enterprise. Les noms de fournisseurs spécifiques sont intentionnellement cachés pour éviter tout argument émotionnel ou guerre juridique, donc juste quelques tamisage et tri de niveau pour l’instant:
- Des catégories de plateformes de conteneurs émergent :
- Plates-formes de conteneurs de fournisseurs de virtualisation :
- Résumé : Les grands fournisseurs de virtualisation d’entreprise sont à juste titre préoccupés par l’érosion des revenus de virtualisation par les conteneurs. En effet, l’exécution de Docker peut réduire, ou dans le cas de Docker sur du métal nu, éliminer le besoin de produits de virtualisation commerciaux. Actuellement, Docker sur du métal nu est assez rare dans la nature, mais il représente une menace énorme pour l’industrie de la virtualisation de plusieurs milliards de dollars au cours des 10 prochaines années.
- Plates-formes de conteneurs de fournisseurs de virtualisation :
De manière réaliste, les conteneurs et les technologies de virtualisation seront considérés comme des technologies complémentaires à court terme, mais à plus long terme, il existe un risque réel pour l’industrie de la virtualisation.
En réponse à la menace des conteneurs, les fournisseurs de virtualisation répondent avec leur propre plateforme de conteneurs, mais ils ont besoin d’une licence de leur dernière plateforme de produit pour l’utiliser.
-
-
- Avantages :
- S’appuyer sur les plates-formes technologiques et les compétences existantes
- Tirer parti des contrats juridiques existants (peut nécessiter certaines mises à niveau cependant)
- Facile à utiliser / mêmes canaux de support
- Inconvénients :
- Nécessite généralement des mises à niveau vers les options les plus récentes / avancées
- Bloqué dans leur pile et pas facile de passer à des plates-formes différentes, peut-être moins chères à l’avenir
- Taxe de virtualisation : nécessite une pile complète de fournisseurs et des licences partout où vous déployez, sur site ou dans le cloud
- Avantages :
- Piles de fournisseurs de plate-forme de système d’exploitation :
- Résumé : Les fournisseurs fournissant un support d’entreprise pour les systèmes d’exploitation Linux ont également jeté leur chapeau dans le ring. Dans l’espoir de conserver des parts de marché grâce à la commodité, ces fournisseurs offrent des options intéressantes, mais vous enferment dans leurs modèles de licence pour utiliser leur version de conteneurs. Ces plates-formes fournissent généralement des versions plus anciennes de Docker (presque 2 ans dans certains cas) ou des moteurs de conteneur alternatifs dont elles sont propriétaires.
- Avantages :
- S’appuyer sur les plateformes technologiques et les compétences existantes du système d’exploitation
- Tirer parti des contrats juridiques existants
- Facile à utiliser / mêmes canaux de support
- Inconvénients :
- Habituellement, plusieurs versions derrière leurs homologues open source
- Verrouillé dans leur version du système d’exploitation et doit utiliser leur pile de système d’exploitation sous licence pour être pris en charge
- Enveloppez les API sous-jacentes : nécessite des API supplémentaires et de longs délais entre la version de fonctionnalité ouverte et la version de version encapsulée du fournisseur
- Plates-formes de conteneurs basées sur les fournisseurs de cloud :
- Résumé : La plupart des déploiements initiaux d’applications de microservices utilisant Docker et Kubernetes étaient des applications nées dans le cloud. Initialement, ceux-ci étaient roulés à la main avec des réseaux virtuels et des machines virtuelles cloud, mais les fournisseurs de cloud ont vu une grande opportunité sur le marché des conteneurs et ont commencé à offrir des services de plate-forme liés aux conteneurs (* CS) en 2015. Initialement, ces services étaient axés sur d’héberger des déploiements de conteneurs, mais la maturité rapide de l’orchestration de conteneurs a conduit à la sortie d’une nouvelle génération de services de plateforme cloud liés à l’orchestration (* KS) en 2017 et 2018.
- Avantages :
- Facile à démarrer
- Facile à connecter aux autres services du fournisseur de cloud
- Coût initialement bas
- Inconvénients :
-
- Besoin de fournir, de câbler, de gérer et de payer vos propres clusters
- Versions antérieures de Docker et Kubernetes
- L’isolement par groupe de ressources ou VPC conduit à l’étalement des clusters – devient coûteux et compliqué pour une gestion d’accès intégrée centralisée
- Intégration permanente : services de fournisseurs de cloud faciles à utiliser, difficiles à migrer vers un autre fournisseur de cloud ou sur site
-
- Plateforme ouverte prise en charge, technologies extensibles :
- Résumé : Docker Enterprise appartient à la catégorie des technologies ouvertes et extensibles prises en charge. La complexité de rassembler de nombreux produits open source sous un même toit est un défi, mais en fin de compte, c’est beaucoup pour les clients. Les clients Docker ont le choix et la transparence de cette plate-forme, mais une intégration plus poussée est nécessaire. C’est ce que la plupart des entreprises feraient si elles le pouvaient, mais elles ne peuvent généralement pas se permettre une équipe dédiée d’ingénieurs rock star.
-
Docker Enterprise est soutenu par des ingénieurs dédiés et ils s’efforcent de fournir une plate-forme de conteneur portable dans le cloud, offrant au client le choix de s’exécuter sur n’importe quelle plate-forme cloud / OS populaire avec prise en charge Docker et un cycle de publication stable pour les technologies ouvertes sous-jacentes – et cela sans emballer ou bifurquer des technologies clés telles que Kubernetes. Docker Enterprise comprend l’API Docker / conteneur D et la véritable API Kubernetes prête à l’emploi.
-
-
- Avantages :
- Une plate-forme de conteneur d’entreprise portable ou compatible avec les hybrides que Docker prend en charge du moteur jusqu’au plan de contrôle, y compris des plug-ins certifiés Docker pour la mise en réseau et le stockage
- Tout ce dont vous avez besoin (Docker Enterprise Standard +) pour exécuter une plateforme de conteneur d’entreprise, y compris un cluster sécurisé, un plan de contrôle universel et un registre de conteneurs sécurisé et riche en fonctionnalités
- Très rentable pour les plateformes à l’échelle de l’entreprise
- En raison de RBAC, il suffit généralement de deux clusters pour tous les environnements
- Inconvénients :
- Peut être coûteux pour un petit cluster HA: les clusters HA nécessitent généralement trois gestionnaires / maîtres, trois nœuds DTR et nécessitent donc un 7e nœud pour démarrer l’exécution des charges de travail. Veuillez noter que cette surcharge est rapidement compensée par la consolidation de tous les environnements de non-production dans un seul cluster non-prod avec RBAC.
- Une version initiale de Docker Enterprise peut prendre un peu de temps et de réflexion. Étant donné que l’approche de plate-forme ouverte de Docker permet d’innombrables permutations de l’infrastructure appropriée, la préparation d’une plate-forme spécifique à l’entreprise pour l’installation nécessite une certaine planification et expertise (matériel / machines virtuelles, système d’exploitation, réseaux, stockage, surveillance / alerte). Les services professionnels de Docker et les partenaires de conseil autorisés peuvent vous aider (beaucoup) ici, mais je couvrirai beaucoup de ces éléments de configuration dans les chapitres suivants pour vous aider à démarrer par vous-même.
- Avantages :
-
Plus récemment, les analystes de l’industrie technologique ont créé une catégorie de suite logicielle de plate-forme de conteneurs. Au quatrième trimestre 2018, les recherches de Forrester ont affirmé que Docker Enerprise était en tête du peloton: https://goto.docker.com/the-forrester-wave-enterprise-container-platform-software-suites-2018.html .
2.1.2 Économie, fonctionnalités et composants clés de Docker Enterprise
Quand il s’agit de décider d’une plate-forme de conteneurs d’entreprise dans le monde des affaires numérique d’aujourd’hui, il s’agit d’équilibrer l’innovation (généralement dans le but d’augmenter les revenus du top) avec les coûts associés pour prendre en charge et opérationnaliser ces nouvelles applications. Ainsi, comme la plupart des décisions commerciales importantes, cela se résume à l’économie et dans ce cas à l’économie associée aux applications conteneurisées à l’appui de l’innovation, ou peut-être à la conteneurisation d’anciennes applications Web pour des coûts de support continus plus bas afin de libérer des ressources pour le budget de l’innovation. Dans tous les cas, vous devrez comprendre les coûts et les avantages de Docker Enterprise.
2.1.2.1 Le coût estimé de Docker Enterprise
Nous commençons notre brève discussion coûts / avantages par le côté coût de l’équation et en commençant par la plate-forme Docker Enterprise et les licences.
Pour exécuter Docker Enterprise, vous aurez besoin de serveurs virtuels pour chaque nœud, d’un réseau pour les connecter et d’un stockage basé sur cluster (NFS fonctionne généralement très bien pour le stockage en cluster sur site). N’oubliez pas que Docker Enterprise peut s’exécuter dans le cloud, sur site, sur une machine virtuelle ou sur des serveurs bare-metal, à vous de choisir. À des fins d’estimation des coûts, prévoyez six nœuds de gestionnaire avec quatre cœurs et 16 Go de RAM pour les gestionnaires et les nœuds Docker Trusted Registry ( DTR ). Les ressources requises pour les nœuds de travail dépendent des types de charges de travail que vous exécutez sur votre cluster. Par exemple, avec une application basée sur Java, vous avez généralement besoin d’une grande empreinte mémoire de peut-être quatre cœurs et 32 Go de RAM par nœud de travail. Alors qu’avec une application basée sur un nœud, vous pouvez avoir plus d’équilibre entre le processeur et la mémoire et pouvez exécuter plusieurs applications confortablement avec deux cœurs et 16 Go de RAM.
Quelle que soit la plate-forme d’infrastructure que vous choisissez, il est généralement judicieux de cibler une plate-forme sur laquelle votre équipe d’exploitation dispose d’un ensemble de compétences existant, afin qu’elle puisse concentrer son apprentissage énergétique Docker Enterprise sans avoir à gravir une nouvelle courbe d’apprentissage de plate-forme en même temps.
En outre, gardez à l’esprit qu’un cluster de démarrage typique aura environ 10 nœuds, car six des nœuds sont utilisés pour la gestion des clusters et des images, laissant quatre nœuds pour gérer les charges de travail. Cela peut sembler être un ratio élevé de nœuds de surcharge par rapport à la charge de travail, mais n’oubliez pas que vous pouvez probablement ajouter des centaines de nœuds de travail supplémentaires sans ajouter de surcharge.
Docker Enterprise est un produit commercial et peut être acheté auprès de Docker, Inc. ou d’un revendeur agréé Docker. Les coûts estimatifs suivants sont susceptibles de changer et sont basés sur des informations accessibles au public provenant de la boutique en ligne de Docker. Lorsque vous envisagez sérieusement Docker Enterprise, vous devez contacter directement Docker ou un revendeur agréé pour obtenir des prix actualisés et éventuellement réduits.
Par conséquent, à titre d’exemple, voici une tarification représentative (à partir de https://hub.docker.com/ ) pour les configurations de cluster haute disponibilité ( HA ) courantes . Veuillez noter que l’assistance le jour ouvrable est de 9 h à 18 h, heure locale, du lundi au vendredi, et l’assistance critique pour l’entreprise est de 24 heures / jour x 7 jours / semaine x 365 jours / an.
2.1.2.2 Illustration de la tarification de Docker Enterprise
Le tableau suivant montre un exemple de matrice de tarification pour Docker Enterprise:
| Édition standard de Docker Enterprise (support le jour ouvrable) | Docker Enterprise advanced (support le jour ouvrable) | Docker Enterprise advanced (support stratégique) | |
| Nœuds de gestionnaire | 3 x 150 $ / mois | 3 x 200 $ / mois | 3 x 350 $ / mois |
| DTRnodes | 3 x 150 $ / mois | 3 x 200 $ / mois | 3 x 350 $ / mois |
| Noeuds de travail | 4 x 150 $ / mois | 4 x 200 $ / mois | 4 x 350 $ / mois |
| Total | 10 nœuds = 1500 $ / mois | 10 nœuds = 2000 $ / mois | 10 nœuds = 3500 $ / mois |
Ce tableau des prix est fourni à des fins d’illustration uniquement. Pour obtenir un numéro de planification budgétaire réel, veuillez contacter Docker, Inc. ou un revendeur agréé Docker. Trois gestionnaires et trois nœuds DTR sont requis pour les clusters HA. Bien que cela puisse sembler une surcharge, vous pouvez ajouter des centaines de nœuds de travail supplémentaires sans ajouter d’autres nœuds de gestionnaire ou DTR.
2.1.2.3 Avantages liés à l’architecture de Docker Enterprise
Docker Enterprise offre un large éventail d’avantages spécifiquement destinés aux utilisateurs Enterprise qui souhaitent opérer à grande échelle avec des niveaux de support commerciaux. Cependant, ils souhaitent également que leur personnel de développement soit en mesure d’innover rapidement et de fournir des applications sécurisées et évolutives.
2.1.2.3.1 Avantages du support Docker
L’une des principales raisons pour lesquelles les entreprises commencent à envisager Docker Enterprise est le support. Alors que l’édition communautaire de Docker fournit un support communautaire ; cela oblige les organisations à publier leurs problèmes dans des forums publics. Non seulement il n’y a aucune garantie que le problème soit résolu en temps opportun, il peut être inapproprié de publier un rapport de bogue lié à une vulnérabilité dans l’infrastructure d’une entreprise. Ceci est particulièrement sensible pour les utilisateurs d’une industrie réglementée.
La prise en charge de la pile complète de Docker commence au Docker Engine. Bien que nous nous concentrions principalement sur Docker Enterprise Standard et Advanced, il existe une offre de base qui prend en charge uniquement le moteur Docker et ne fournit pas UCP et DTR. Il s’agit également du niveau de prise en charge inclus avec Windows Server 2016. Toutes les plates-formes prises en charge par Docker permettent aux clients de recevoir des correctifs sur le même niveau de version pendant jusqu’à 2 ans. Sans support, vous êtes obligé de mettre à niveau tous les 6 mois.
Avec les éditions Docker Enterprise Standard et Advanced, la prise en charge s’étend au-delà du moteur jusqu’au plan de contrôle universel, au registre de confiance Docker et à tous les plug-ins ou conteneurs certifiés Docker utilisés par le client.
Encore une fois, comme mentionné précédemment, il existe deux niveaux de support : stratégique, qui fournit un support 24/7, et jour ouvrable, qui est disponible pendant les heures normales de bureau.
2.1.2.3.2 Avantages de l’efficacité de calcul
L’exécution d’applications avec une architecture de conteneur a démontré une réduction significative des coûts d’exploitation pour de nombreuses applications Web traditionnelles. Ces réductions de coûts ont été documentées jusqu’à 70% et sont généralement réalisées en réduisant les frais généraux associés aux machines virtuelles, ainsi qu’en créant une densité d’applications plus élevée par serveur.
2.1.2.3.3 Avantages du choix
Docker Enterprise propose un large éventail de choix d’infrastructure pour exécuter votre plate-forme EE. Cela signifie que vous pouvez installer Docker Enterprise dans le cloud, sur site, sur une machine virtuelle ou sur du bare metal. Vous disposez également d’une grande variété de systèmes d’exploitation Linux ouverts et pris en charge commercialement pour exécuter UCP et DTR. Les nœuds de travail peuvent être installés sur Linux, Windows Server 2016 et même sur OS 390. Il est courant d’utiliser des clusters mixtes avec des nœuds Linux et Windows pour fournir une pile d’applications distribuée polyglotte de conteneurs Linux et Windows.
Ce genre de choix est vraiment important ! Il permet aux clients Docker de migrer une plate-forme de conteneurs entière d’un fournisseur d’infrastructure à un autre avec une relative facilitée. Par conséquent, si un fournisseur d’infrastructure devient trop cher, un client Docker Enterprise peut récupérer son cluster et le déplacer vers un fournisseur à moindre coût avec une relative facilité.
En plus des choix d’infrastructure, Docker propose également un choix d’orchestrateurs. Docker Enterprise inclut Swarm et Kubernetes prêts à l’emploi. Alors que certains experts natifs du cloud ne prétendent pas grand-chose à Swarm, c’est là que la plupart des entreprises, lorsqu’elles ont le choix, aiment démarrer en raison de sa sécurité et de sa simplicité. Plus tard, ils peuvent passer à des applications Kubernetes plus sophistiquées.
2.1.2.3.4 Innovation rapide – les compétences DevOps indépendantes de la plateforme bénéficient à la stratégie de décalage à gauche
Dans le monde DevOps, nous entendons beaucoup parler de décalage vers la gauche. Cela signifie prendre des responsabilités qui faisaient autrefois partie de l’organisation des opérations techniques et les déplacer dans les domaines DevOps et de développement d’applications. Dans ce monde, Docker devient un outil vraiment important pour ce type de migration car le langage utilisé pour décrire la manière dont les applications sont construites, câblées et déployées est basé sur les API Docker et Kubernetes indépendantes de la plateforme. Sans cette approche, votre personnel de développement d’applications et de DevOps aurait besoin d’apprendre des détails spécifiques à la plate-forme pour chaque environnement cible, comme AWS, Azure ou GCE. Cela crée non seulement une courbe d’apprentissage plus abrupte, mais crée également une autre couche de verrouillage dans la plate-forme d’un fournisseur.
2.1.2.3.5 Avantages UCP et DTR
Docker Enterprise standard et avancé est livré avec le plan de contrôle universel (UCP) et le Docker Trusted Registry (DTR).
L’UCP de Docker comprend des fonctionnalités d’entreprise essentielles telles que le contrôle d’accès basé sur les rôles intégré LDAP, une interface de ligne de commande gérée par certificat, une interface graphique Web et l’orchestrateur Kubernetes installé et prêt à l’emploi. UCP fournit également une interface API sécurisée pour les scripts et l’extensibilité.
Plutôt que d’utiliser un référentiel d’images public tel que Docker Hub pour les images d’entreprise, Docker Enterprise utilise un référentiel d’images privé appelé DTR pour des raisons de sécurité et de disponibilité. Si, pour une raison quelconque, un référentiel d’images devient indisponible pour un cluster, les applications ne peuvent pas être déployées. Ainsi, DTR est une partie intégrante répliquée de la plate-forme Docker Enterprise.
Le DTR de Docker s’exécute dans le même cluster où les images du conteneur de charge de travail sont déployées. Le DTR est l’endroit où les images d’entreprise sont stockées en toute sécurité après leur construction et d’où elles sont extraites au moment du déploiement. DTR est un élément essentiel d’un cluster de conteneurs de classe entreprise et est également le cœur et l’âme d’un pipeline d’images sécurisé. À cet effet, DTR inclut la numérisation d’images (fonctionnalité Advanced Edition uniquement), la signature d’images avec l’implémentation TUF du notaire et des webhooks pour l’intégration de CI / CD et les politiques de promotion d’image, et est entièrement intégré au système UCP RBAC.
2.1.2.3.6 Avantages du conteneur d’abord
La mise en place d’une plate-forme de conteneur vous aide à commencer à réaliser les avantages du développement sans serveur. Dans une entreprise Docker Enterprise, un monde de conteneurs d’abord, les développeurs créent et testent des piles de conteneurs à l’aide des outils indépendants de la plate-forme Docker, y compris Docker Desktop et Docker Enterprise. Par la suite, leur application peut être déployée sur une plateforme Docker Desktop ou Docker Enterprise sans savoir si elle s’exécute localement sur un ordinateur de bureau, sur site ou dans le cloud. En outre, les conteneurs d’une pile d’applications peuvent communiquer librement entre eux, mais sont isolés des autres conteneurs dans différentes piles d’applications à l’aide de réseaux de superposition Swarm ou d’espaces de noms Kubernetes.
2.2 Architecture opérationnelle de Docker Enterprise
Cette section fournit une introduction aux principaux composants de Docker Enterprise, les place dans un contexte architectural orienté opérationnellement, puis décrit chaque couche dans le contexte. L’objectif est de présenter les principales parties de Docker Enterprise dans un environnement opérationnel et de décrire leur fonctionnement dans un environnement réel. En d’autres termes, décrivez les composants et la plate-forme Docker Enterprise du point de vue quotidien d’un développeur / DevOps et d’un membre de l’équipe d’exploitation.
2.2.1 Principaux composants de Docker Enterprise
Puisque Docker Enterprise se superpose au mode Swarm de Docker Engine-Community, notre discussion commence par un aperçu des clusters Swarm. La figure 1 représente un cluster Docker Swarm à 10 nœuds. Il est composé de trois nœuds de gestionnaire et de sept nœuds de travail. Chacun des nœuds est une machine virtuelle ou un serveur nu exécutant le moteur Docker en mode Swarm.
Nos trois nœuds de gestion sont membres d’un groupe de consensus Raft soutenu par un cluster Etcd chiffré pour stocker des éléments tels que l’état du cluster, les certificats et les secrets. Pour fonctionner correctement, il doit y avoir un nombre impair de nœuds de gestionnaire dans l’état d’intégrité, car vous devez maintenir un quorum (la majorité des gestionnaires doivent se mettre d’accord sur les modifications apportées à l’état du cluster). Un cluster de nœuds de gestionnaire est efficace, mais si le gestionnaire tombe en panne, le cluster est mort. Pour une meilleure disponibilité, les clusters ont généralement trois et parfois cinq gestionnaires pour la redondance.
Comme son nom l’indique, les nœuds de travail sont l’endroit où s’exécutent les charges de travail conteneurisées. Il peut y avoir un nombre illimité de travailleurs et ces nœuds peuvent être augmentés et diminués selon les besoins :
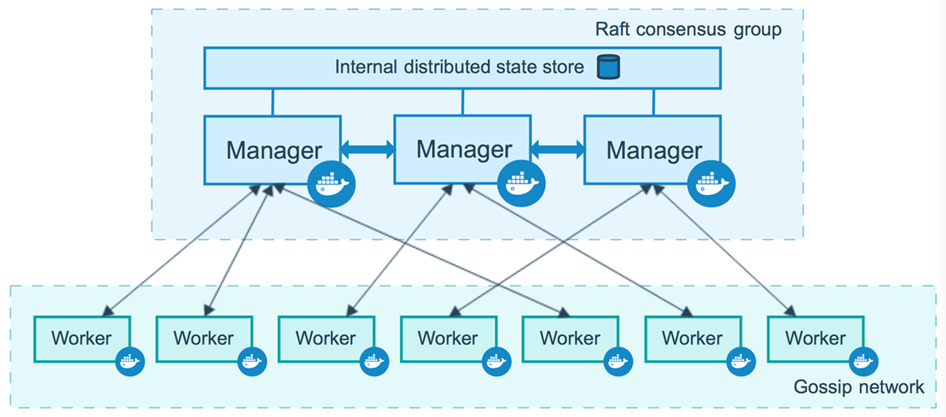
Figure 1: cluster Swarm hautement disponible © 2013-2018 Docker, Inc. Tous droits réservés
À ce jour, la plupart des gens ont entendu l’expression animaux de compagnie contre bétail. Il semble remonter à la présentation de Bill Baker ( http://www.pass.org/eventdownload.aspx?suid=1902 ), mais s’applique également aux clusters de conteneurs. Nous parlons du bétail comme de bêtes anonymes qui vont et viennent, en grande partie sans connexion personnelle. S’il y a quelque chose qui ne va pas avec une vache, vous ne la remettez pas à la santé, mais vous en obtenez une autre pour la remplacer. D’un autre côté, les animaux domestiques sont nommés, soignés avec amour et nous les gardons le plus longtemps possible. Dans un cluster Docker Enterprise, les gestionnaires sont vos animaux de compagnie et les nœuds de travail sont vos bovins.
Docker Enterprise ajoute 3 nouvelles parties à l’image :
- Docker Enterprise Engine : une version prise en charge de la plate-forme Docker Engine-Community qui inclut une prise en charge des correctifs de 2 ans pour chaque version principale. Vous avez besoin d’une clé de la boutique Docker pour installer Docker Enterprise Engine.
- Plan de contrôle universel (UCP) : fournit GUI, RBAC, un ensemble d’interfaces de ligne de commande basé sur certificat sécurisé, l’intégration LDAP et l’orchestration (Swarm et Kubernetes). UCP fournit un accès sécurisé à l’API via un jeton au porteur pour les scripts tels que les structures et les subventions UCP RBAC.
- Docker Trusted Registry (DTR) : un registre d’images privé intégré au cluster Docker Enterprise en tant que composant essentiel d’un pipeline logiciel sécurisé. DTR prend en charge les référentiels gérés par RBAC (liens avec l’infrastructure UCP RBAC), la signature d’images, la numérisation d’images et la promotion d’images. Toutes les fonctionnalités DTR sont disponibles via une API sécurisée utilisant un jeton d’autorisation pour gérer à la fois les images et les métadonnées du référentiel.
Maintenant, pour mieux comprendre comment les composants de Docker Enterprise s’intègrent dans un environnement réel, nous allons examiner comment les utiliser pour déployer des logiciels.
2.2.2 Architecture d’exploitation Docker Enterprise – infrastructure, plate-forme et couches d’application
L’élaboration d’une perspective architecturale orientée vers l’exploitation aide à décrire le point de vue de l’utilisateur constituant. La plate-forme Docker Enterprise atteint à la fois l’efficacité et la sécurité grâce à une séparation des préoccupations en isolant les développeurs d’applications de l’infrastructure à l’aide d’abstractions au niveau de la plate-forme telles que les services, les réseaux, les volumes, les configurations et les secrets. Pendant ce temps, la mise en œuvre réelle de ces abstractions de plate-forme et de leur infrastructure sous-jacente est gérée par un petit groupe de spécialistes des opérations hautement qualifiés. Cette approche permet aux travaux de développement d’applications, y compris les activités DevOps, de créer et de déployer des applications à l’aide d’API indépendantes de la plate-forme (Docker et Kubernetes CLI).
La séparation des plates-formes de Docker Enterprise stimule l’efficacité, la sécurité et l’innovation ! L’utilisation d’une petite équipe d’exploitation pour sauvegarder les abstractions de la plateforme Docker Enterprise avec des implémentations adaptées à l’infrastructure (meilleures pratiques sécurisées et efficaces pour les plates-formes de fournisseurs sur site ou cloud utilisant des plug-ins Docker) permet à toutes les équipes d’applications conteneurisées d’accéder à ces abstractions via un fichier de déploiement .yaml . L’équipe de développement ne se soucie pas de l’endroit où l’application est déployée tant que les abstractions sont correctement implémentées. Cela donne à l’application des outils puissants pour l’innovation de masse (le rêve de Solomon Hykes s’est réalisé), tandis qu’une petite équipe d’exploitation maintient les choses en sécurité et fonctionne sur l’infrastructure sous-jacente.
Les compétences en infrastructure pour AWS, Azure, GCE et VMware sont difficiles à trouver! La séparation des plates-formes de Docker Enterprise permet à une entreprise de tirer parti d’une équipe relativement petite d’experts en infrastructure au sein d’un grand nombre d’équipes d’applications. De plus, la séparation de plate-forme permet un décalage DevOps vers la gauche, permettant aux développeurs de décrire le déploiement de leur pile de services d’application à l’aide de constructions neutres de plate-forme.
La figure 2 décrit les couches de séparation des plates-formes en action. Tout d’abord, l’équipe des opérations installe et configure l’infrastructure à l’aide des directives d’infrastructure certifiées Docker. Cela comprend la préparation du système d’exploitation hôte, la configuration du stockage (NFS), l’installation de Docker Enterprise Engine (pilotes et plug-ins de stockage d’images), l’installation de Docker UCP et l’installation de DTR. Dans notre exemple, l’équipe Ops configure le Docker Enterprise Engine pour la journalisation centrale et installe le plug-in pour le stockage NFS.
Ensuite, l’équipe de la plate-forme (qui peut être une fonction d’exploitation ou un groupe spécialisé d’opérateurs Docker Enterprise formés à la configuration, aux opérations, au support et à la maintenance de la plate-forme) configure l’accès au cluster avec RBAC afin que les utilisateurs puissent déployer leur pile à l’aide des ressources de cluster appropriées. Enfin, un développeur / membre de l’équipe DevOps utilise un bundle CLI Docker Enterprise pour déployer une pile de conteneurs dans le cluster à l’aide d’une commande de déploiement de pile docker avec le fichier ApplicationStack.yml . Les conteneurs sont planifiés sur le cluster à l’aide des abstractions de plate-forme pour les services, la mise en réseau et les volumes.
Normalement, ce processus de déploiement sur le cluster est géré par un système CI / CD tel que Jenkins, GitLab ou Azure DevOps. L’utilisateur du système CI possède son propre compte utilisateur + certificat UCP RBAC pour accéder au cluster, gérer les images DTR et signer les images qu’il a créées avant de les pousser vers DTR.
Dans ce cas, l’application est déployée sur deux nœuds de travail comme indiqué ci-dessous, connectés par le réseau My-2-tier et a accès aux données externes stockées sur un point de montage NFS. En outre, le fichier ApplicationStack.yml peut décrire la façon dont l’application est exposée en externe à l’aide du routage de couche 7 et peut rendre l’application immédiatement opérationnelle. Au final, l’application peut être entièrement déployée sans aucune intervention de l’équipe infrastructure / opérations :
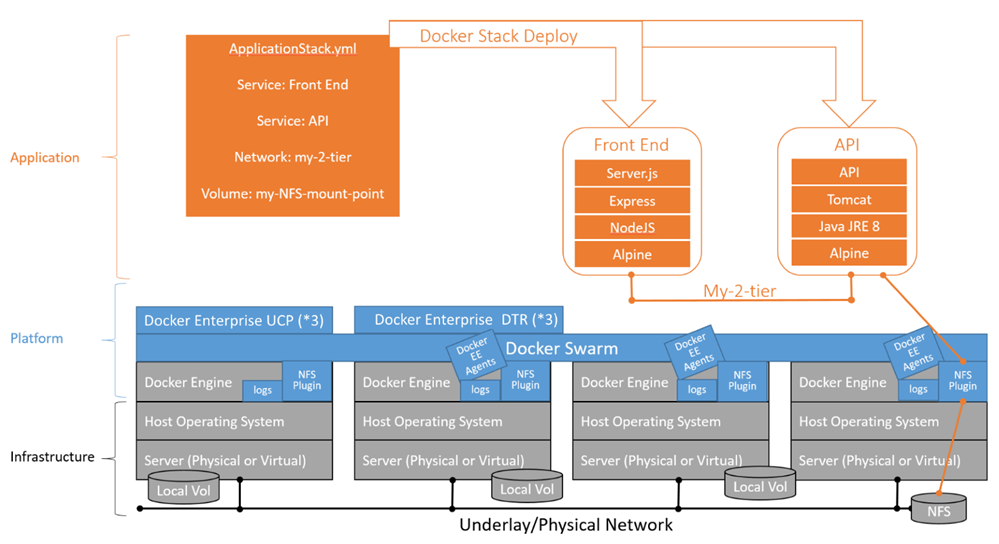
Figure 2: piles de service sur l’essaim
2.2.3 Décomposition des couches
Un examen des couches à un niveau élevé, de bas en haut, révèle leur contenu ainsi que les principales préoccupations architecturales de chaque couche. Nous commencerons par la couche d’infrastructure fondamentale en examinant les fondements de Docker Enterprise. En remontant la pile jusqu’à la couche de plate-forme, nous passerons en revue les composants sous-jacents de Docker Enterprise. Enfin, nous verrons à quoi ressemble la plateforme du point de vue d’un développeur d’applications.
2.2.3.1 Couche infrastructure – réseau, nœuds et stockage
Au niveau de la couche infrastructure, l’accent est mis sur le réseau opérationnel, les nœuds de calcul et le stockage backend.
Lors de la définition de votre couche d’infrastructure, c’est une très bonne idée de consulter la documentation d’infrastructure certifiée Docker sur le site Web de Docker, https://success.docker.com/ (architecture certifiée). Des guides d’architecture de référence spécifiques sont disponibles pour VMware, AWS et Azure. Ces guides fournissent des informations clés pour la planification et la conception de la couche d’infrastructure Docker Enterprise par l’équipe des opérations.
Le réseau opérationnel se préoccupe principalement de l’entrée, de la sortie et du flux de données inter-nœuds avec l’isolement et le chiffrement appropriés des nœuds de cluster Docker. La création d’espace d’adressage et la définition d’une stratégie de groupe de sécurité réseau sont généralement au centre de l’attention. Bien que cela soit généralement assez simple, l’architecture de référence Docker couvre des détails importants. Les éléments suivants sont globalement quelques considérations clés à souligner :
- Considération 1 : Bien qu’il existe une documentation contradictoire sur le sujet, c’est une bonne idée d’épingler vos nœuds de gestionnaire à des adresses IP fixes.
- Considération 2 : Assurez-vous que les espaces réseau de superposition de Docker ne chevauchent pas d’autres espaces d’adressage sur votre réseau. Il existe de nouveaux paramètres à partir de Docker 18.09 pour lancer le cluster Swarm sous-jacent de Docker Enterprise afin de créer des blocs CIDR réseau sûrs pour la mise en réseau de superposition de Docker à utiliser :
docker swarm init –default-addr-pool 10.85.0.0/16 –default-addr-pool 10.91.0.0/16 –default-addr-pool-mask-length 25
Pour une introduction complète à la mise en réseau Docker, veuillez lire l’ article https://success.docker.com/ sur la mise en réseau.
Les nœuds de calcul sont les machines virtuelles ou les nœuds bare-metal exécutant un moteur Docker Enterprise au-dessus d’un système d’exploitation pris en charge. Le moteur Docker Enterprise est actuellement pris en charge sur CentOS, Oracle Linux, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Ubuntu, Microsoft Windows Server 2016, Microsoft Windows Server 1709 et Microsoft Windows Server 1803. Les principales préoccupations pour la configuration d’un nœud de calcul sont les points de terminaison CPU, RAM, stockage local et stockage de cluster.
Bien qu’il n’y ait pas de formules magiques pour prédire des nœuds de taille parfaite, il existe des paris assez sûrs, tels qu’utilisés à des fins de planification dans la section des coûts précédente. En règle générale, il est prudent d’utiliser quatre cœurs et 16 Go de RAM pour les gestionnaires et les nœuds Docker Trusted Registry (DTR). Encore une fois, les nœuds de travail dépendent des types de charge de travail que vous exécutez sur eux. Les applications Java conteneurisées nécessitent souvent un encombrement mémoire important et peut-être un processeur quatre cœurs et 32 Go de RAM est logique. La plupart des organisations ont des statistiques sur les applications qu’elles exécutent actuellement et peuvent être utilisées à des fins d’estimation. Ne vous attardez pas trop sur le dimensionnement des travailleurs – ce sont vos bovins et en tant que tels peuvent être facilement remplacés.
Une autre considération de nœud de calcul est le stockage. Il y a trois considérations liées au stockage :
- Sauvegarde des systèmes de fichiers pour les pilotes de stockage d’images Docker : Lorsque le moteur Docker est installé (dans la couche de plate-forme), vous avez besoin d’un pilote de stockage d’images pour implémenter efficacement un système de fichiers en couches, copie sur écriture. Ces pilotes nécessitent un système de fichiers de support compatible. La plupart des systèmes Linux modernes utiliseront automatiquement le pilote de stockage Overlay2 soutenu par des systèmes de fichiers ext4. Les versions plus anciennes de CentOS et RHEL (7.3 et antérieures) utilisent généralement le pilote de stockage devicemapper soutenu par un système de fichiers direct-lvm (n’exécutez pas les charges de travail de production direct-lvm en mode boucle). Sur SUSE, utilisez le pilote btrfs et le système de fichiers.
- Stockage local pour les volumes spécifiques aux nœuds : les volumes Docker liés à des nœuds spécifiques peuvent être utiles lorsque vous avez des nœuds spécialisés dans votre cluster. Ces nœuds sont ensuite étiquetés afin que les conteneurs puissent être déployés spécifiquement sur ces nœuds. Cela garantit que tous les volumes sont toujours disponibles sur ces nœuds et est pratique pour les serveurs de construction centralisés basés sur des conteneurs pour stocker les plugins et les espaces de travail. N’oubliez pas que ces volumes doivent être ajoutés à votre liste de sauvegarde !
- Stockage basé sur un cluster : lorsque les nœuds montent des points de terminaison de stockage distant à l’aide de quelque chose comme NFS, vous pouvez ensuite autoriser les conteneurs à monter ces points de montage en tant que volumes pour accéder au stockage distant à partir d’un conteneur. Ceci est courant pour les déploiements sur site plus anciens, mais les installations sur site plus récentes peuvent envisager d’installer NFS sur l’hôte et d’utiliser le volume local opt: nfs , ou ils peuvent envisager d’utiliser un plug-in de volume tiers lié à l’infrastructure de votre fournisseur de stockage pour plus de flexibilité et de stabilité.
Veuillez noter que le stockage NFS fonctionne généralement bien pour les installations sur site où vous avez un contrôle total sur le réseau, mais dans le cloud, les montages NFS peuvent être moins fiables en raison de la latence des voisins bruyants.
N’utilisez NFS que pour les implémentations sur site avec une latence faible prévisible. Lorsque vous exécutez Docker Enterprise dans le cloud, envisagez d’utiliser quelque chose comme CloudStor ou RexRay pour éviter les problèmes NFS liés à des pics soudains de latence du réseau. De tels pics peuvent faire passer NFS en mode lecture seule, ce qui entraîne des échecs d’application en cascade.
Enfin, voici deux considérations pour les nœuds de calcul prêts à fonctionner en tant que nœuds de gestionnaire :
- Ces nœuds doivent avoir des adresses IP fixes. Il existe des conseils contradictoires quant à savoir si le traitement de réconciliation de Docker Enterprise compense ou non les changements d’adresse IP du gestionnaire. Bien que les IP dynamiques conviennent aux nœuds de travail, en ce qui concerne les nœuds de gestionnaire, jouez en toute sécurité et utilisez des adresses IP fixes.
- Ils doivent être sauvegardés régulièrement, y compris / var / lib / docker / swarm .
Plus d’informations sur les sauvegardes plus tard dans la préparation de la production, mais rappelez-vous que vos nœuds de gestionnaire sont des animaux de compagnie et vous devrez peut-être en restaurer un à partir des sauvegardes un jour !
2.2.3.2 La couche plateforme – moteur Docker Enterprise, UCP et DTR
Au niveau de la couche plateforme, le logiciel Docker est installé et configuré au-dessus de la couche infrastructure, dont nous avons discuté dans la section précédente. Nous préparons chacun des nœuds Docker du cluster en installant Docker Enterprise Engine. Avant de commencer ce processus, vous devez acheter votre licence Docker ou obtenir une licence d’essai gratuite de 30 jours. Dans les deux cas, le lien des clés de licence des magasins apparaîtra dans votre compte Docker Store sous Mes contenus.
Nous allons parcourir une installation réelle plus loin dans l’article en utilisant un exemple d’installation AWS avec Ubuntu. Mais de manière générale, nous installons le moteur Docker Enterprise à l’aide d’un lien chiffré pour configurer un référentiel de gestionnaire de packages Linux sur chaque nœud, puis utilisons le gestionnaire de packages pour installer la version appropriée du moteur.
Une fois le moteur Docker installé et démarré, vous devez effectuer certaines opérations :
- Mettez à jour le pilote de stockage et le pilote de journalisation dans le fichier /etc/docker/daemon.json . Un redémarrage du service est requis pour que ces modifications deviennent actives.
- Ajoutez votre utilisateur Linux au groupe Docker pour ne pas avoir à exécuter les commandes Docker avec le privilège root.
- Installez et configurez tous les plugins Docker.
Une fois les moteurs installés, il est temps pour nous de passer à la configuration du cluster. Nous installons UCP sur le premier nœud gestionnaire, puis joignons les autres nœuds au cluster. Une fois UCP activé et tous les nœuds de gestionnaire et de travail joints, le registre approuvé Docker est installé. Encore une fois, il y aura beaucoup plus de détails pendant que nous parcourons une véritable configuration dans le chapitre d’installation.
Maintenant, vous avez un nouveau cluster avec un DTR opérationnel. L’administrateur ajoute des utilisateurs au système RBAC du cluster, généralement en se connectant à un système LDAP et en utilisant une requête spéciale pour définir un point de synchronisation pour les utilisateurs UCP avec l’annuaire LDAP à l’échelle de l’entreprise. Docker Enterprise 2.1 dispose également d’une option de connexion unique basée sur SAML, dont nous discuterons plus tard. Vous pouvez également configurer de nouveaux utilisateurs UCP avec l’interface graphique ou en exécutant un script sur l’API UCP.
Une fois que vous avez créé des utilisateurs, vous pouvez leur donner l’accès approprié aux ressources UCP et DTR. Cela se fait par un système d’octroi où vous pouvez attribuer des droits affinés aux clusters (collections Swarm et ressources d’espace de noms Kubernetes) en fonction de l’appartenance organisationnelle, de l’appartenance à une équipe ou par compte individuel. Une fois les comptes configurés, les développeurs peuvent accéder aux ressources du cluster en fonction des privilèges accordés par l’administrateur. Maintenant que UCP et DTR sont installés et configurés initialement, nous pouvons concentrer notre attention sur la couche application.
2.2.3.3 Couche application – interaction avec le cluster
Enfin, nous avons la couche d’application où les applications conteneurisées s’exécutent à l’aide d’API de plate-forme (Swarm ou Kubernetes) pour les décrire et les déployer, comme décrit précédemment dans la figure 2.
Maintenant, nous allons construire sur ce que nous avons appris et fait au cours de notre visite de la couche plate-forme et discuter du déploiement de l’application plus en détail. De retour au niveau de la plate-forme, lors de la création d’utilisateurs, disons que nous avons créé un nom d’utilisateur John Doe et lui avons accordé le “contrôle total” de sa collection privée de ressources de développement. Maintenant, il est capable de déployer des ressources Swarm et Kubernetes sur son propre site (bac à sable). ) l’espace, mais comment cela fonctionne-t-il réellement?
- L’administrateur système fournit à John ses informations d’identification UCP.
- John peut se connecter au cluster, mais ne voit que ce qu’il a déployé sur le cluster, ce qui n’est rien jusqu’à présent.
- Dans la figure 3, John ouvre son profil dans l’UCP Web UI et télécharge un ensemble client. Le bundle contient certains certificats et scripts (pour Linux et Windows) pour connecter en toute sécurité le shell du bureau aux API Swarm et Kubernetes du cluster :
Figure 3 Téléchargement du bundle client UCP
- John décompresse les fichiers et exécute le script de connexion à l’aide des commandes Import-module ou source avec les fichiers de script shell PowerShell bash. Les commandes $ docker et $ kubectl locales de John s’exécutent désormais sur le cluster distant, mais sont bien sûr soumises à ses droits d’accès RBAC.
- John exécute désormais les commandes $ docker stack deploy ou $ kubectl create , en utilisant le fichier YAML qu’il a créé pour son application, et déploie son application sur le cluster.
- Consultez l’exemple de fichier YAML suivant pour une application Kubernetes, utilisez un $ kubectl create -f nginx-deployment.yml à partir d’un bundle de ligne de commande :
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
– name: nginx
image: nginx:1.7.9
ports:
– containerPort: 80
- Dans l’exemple de code précédent, trois pods Kubernetes sont déployés dans le cluster, chacun contenant un conteneur nginx . L’exécution de la commande $ kubectl get pods affiche les pods en cours d’exécution comme suit :
NAME READY STATUS RESTARTS AGE
nginx-deployment-75675f5897-45dvt 1/1 Running 0 26s
nginx-deployment-75675f5897-hrgmg 1/1 Running 0 26s
nginx-deployment-75675f5897-vskh8 1/1 Running 0 26s
- La commande $ kubectl get pods répertorie les trois pods de réplique nginx s’exécutant dans l’espace de noms par défaut, chacun avec 1 des 1 conteneurs prêts, et le statut de chaque pod est En cours d’exécution.
2.3 Architecture de référence de Docker Enterprise
Maintenant, nous allons commencer à creuser dans l’architecture Docker Enterprise. Au fur et à mesure que nous intervenons, nous devons comprendre que l’adoption complète peut prendre plusieurs mois, au cours desquels les entreprises acquièrent une expérience précieuse lors de la préparation de leur plateforme de production. Bien que le parcours d’adoption de Docker Enterprise soit discuté plus en détail dans un chapitre ultérieur, il est logique d’introduire le concept général d’une approche d’adoption agile par étapes (illustrée à la figure 4) afin que les nouveaux arrivants ne soient pas submergés. Voyons comment aborder au mieux l’adoption d’une technologie de conteneur d’entreprise :
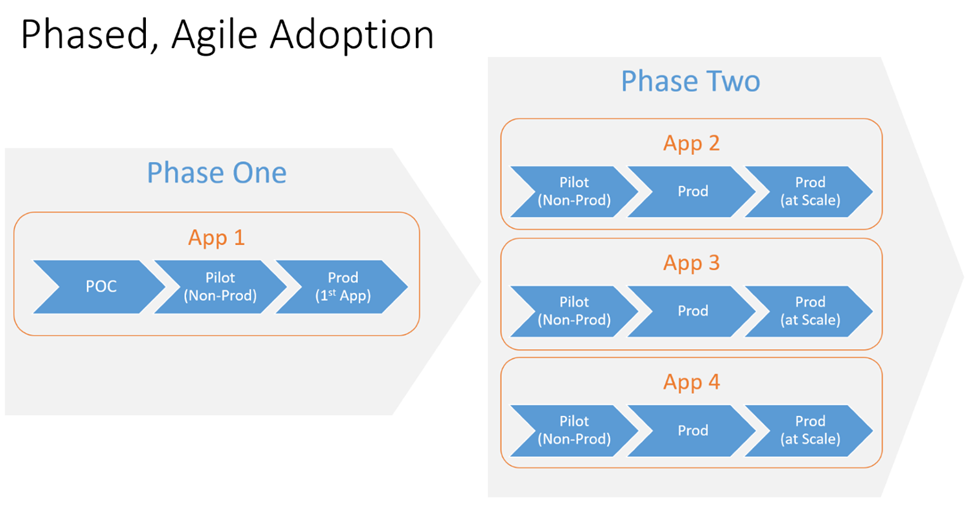
Figure 4 : Cycles d’adoption agiles
Il est généralement préférable de commencer avec une petite équipe multidisciplinaire dans le but de déplacer une seule application du PoC vers le pilote et enfin la première application en production. De plus, l’adoption de conteneurs par l’entreprise nécessite de grands changements avec de grands avantages potentiels, mais elle nécessite une nouvelle mentalité de conteneur d’abord. Le moyen le plus rapide d’atteindre cet état d’esprit de conteneur d’abord et tous les avantages associés est de tirer parti de l’expérience d’experts grâce à des services de formation et de conseil disponibles directement auprès de Docker ou via des partenaires agréés par Docker. En toute divulgation, en tant que partenaire agréé Docker, cela peut sembler biaisé et égoïste, mais le fait d’avoir une connexion directe à la source Docker fournit des informations précises sur les dernières meilleures pratiques. Je dis les meilleures pratiques les plus récentes, car cette plateforme en évolution rapide évolue rapidement, tout comme les meilleures pratiques associées. Soyez très prudent de ne pas parier votre plate-forme de prochaine génération sur les opinions des articles de blog éventuellement obsolètes.
2.3.1 Vue simple de l’architecture de cluster Docker Enterprise
Docker Enterprise fournit une base de gestion de cluster sécurisée soutenue par deux orchestrateurs : Docker Swarm, intégré à Docker Engine-Community, et CNCF de Kubernetes, la principale plate-forme d’orchestration née dans le cloud. Lorsque vous installez le plan de contrôle universel (UCP) de Docker Enterprise, les deux orchestrateurs sont installés et prêts à fonctionner. Cela inclut la mise en réseau par superposition par défaut pour permettre la communication du réseau de conteneurs entre les conteneurs situés sur différents nœuds du cluster et la découverte de services. La figure 5 illustre votre choix de planificateur dans une collection de nœuds de travail gérés par cluster. Notez que Docker Enterprise s’appuie sur la gestion sécurisée en cluster de Swarm comme base pour les deux orchestrateurs. La figure 6 montre un cluster chiffré Docker Swarm TLS simple :
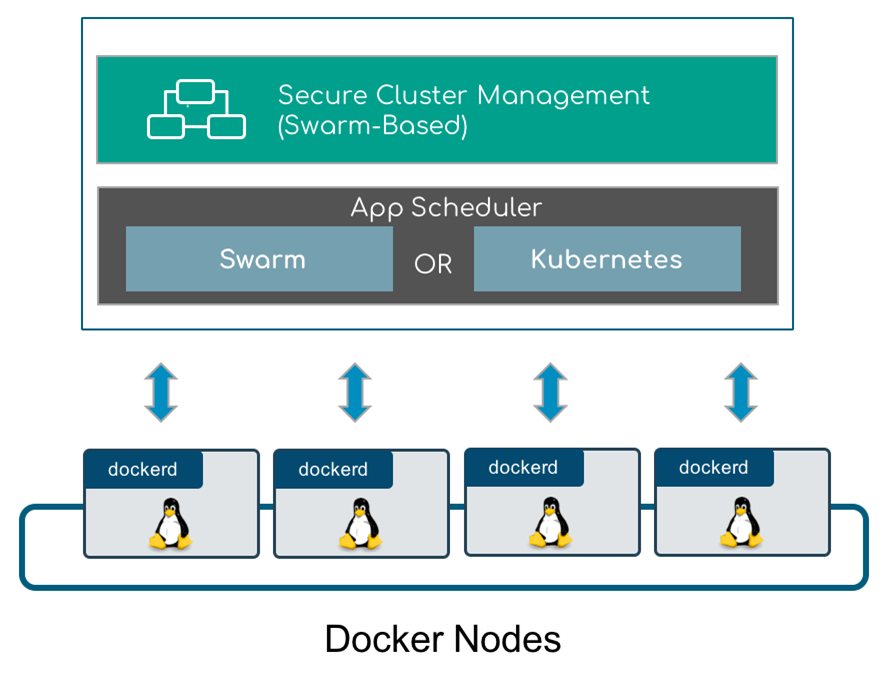
Figure 5: Présentation du cluster Swarm © 2013-2018 Docker, Inc. Tous droits réservés
Peler l’oignon une couche plus profondément révèle comment un cluster HA comprend plusieurs nœuds de gestionnaire en plus des nœuds de travail, et comment toutes les communications intra-nœuds sont cryptées TLS. Lorsqu’un cluster Swarm est créé, le premier gestionnaire établit une autorité de certification (CA) et utilise l’autorité de certification de l’AC pour signer et sécuriser les certificats échangés lors de l’ajout de nœuds au cluster, à l’aide d’un jeton de jointure sécurisé. De plus, les gestionnaires font pivoter les certificats à un intervalle configurable au cas où l’un des certificats devrait être compromis au fil du temps :
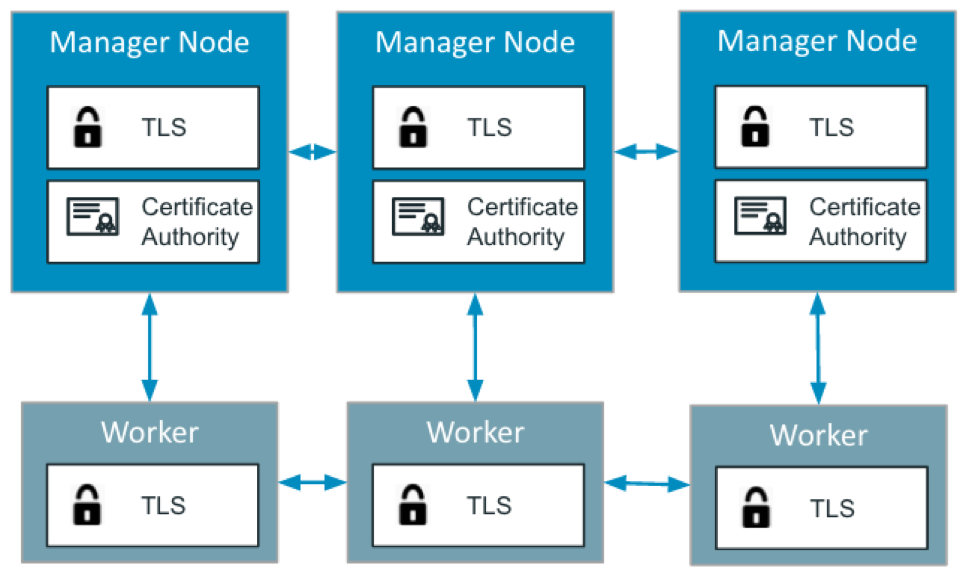
Figure 6 : chiffrement TLS mutuel Swarm © 2013-2018 Docker, Inc. Tous droits réservés
Souvent, aux premiers stades de l’adoption de Docker et généralement avant l’adoption de Docker Enterprise, il est courant d’avoir un cluster Docker Swarm simple avec un seul nœud de gestionnaire et quelques nœuds de travail. Cependant, à mesure que les entreprises migrent vers Docker Enterprise, la disponibilité, la sécurité et l’évolutivité deviennent le centre d’intérêt. L’architecture de référence illustrée à la figure 7 reflète un cluster Docker Enterprise hautement disponible avec trois gestionnaires UCP, trois répliques DTR, trois nœuds de travail et trois équilibreurs de charge répartis sur trois zones de disponibilité. Veuillez noter que vous pouvez ajouter une centaine de travailleurs supplémentaires sans ajouter de gestionnaire ou de nœuds DTR supplémentaires :

Figure 7: Docker Enterprise avec Kubernetes
Docker Enterprise UCP est installé sur les gestionnaires Docker Swarm. Dans cette configuration, si un nœud de gestionnaire est perdu, le cluster continue de fonctionner. Il en va de même pour le DTR. En fait, le découpage UCP et DTR à travers les zones de disponibilité permet au cluster de continuer à fonctionner même si l’une des zones de disponibilité échoue. Il est important de noter que, bien que le cluster, et plus important encore les applications du cluster, continuent de fonctionner, le cluster peut signaler un état malsain. Cela signifie que les opérateurs doivent restaurer tous les gestionnaires ou réplicas DTR défectueux dès que possible pour restaurer un quorum sur le cluster ASAP et s’assurer que le cluster reste disponible.
Veuillez noter que toutes les interfaces principales du cluster (UCP – interface d’administration, DTR – interface de gestion d’image et accès aux applications) sont toutes dotées d’un équilibreur de charge. UCP et DTR ont tous deux des points de terminaison de contrôle d’intégrité pour les équilibreurs de charge afin de vérifier la disponibilité du service. Les équilibreurs de charge d’application sont généralement un peu différents en ce que chaque application doit implémenter ses propres contrôles d’intégrité. En outre, la configuration de l’équilibrage de charge de l’application est probablement divisée en deux parties. La première partie est un équilibreur de charge classique répondant à la cible DNS de l’application (souvent quelque chose comme * .app.mydomain.com ) et il transfère le trafic vers des instances de serveurs proxy inverses s’exécutant dans le cluster. Il y aura une discussion plus détaillée sur le routage de couche 7 plus tard dans l’article.
2.3.2 Exploration – composants Docker Enterprise 2 de haut niveau
Alors que Docker Enterprise 2 s’appuie sur Docker Engine-Community Swarm, il présente les composants supplémentaires nécessaires pour prendre en charge des fonctionnalités telles que Kubernetes, le contrôle d’accès basé sur les rôles (RBAC) et une interface utilisateur Web. La figure 8 illustre les composants de Docker Enterprise 2 à un niveau élevé. La compréhension de ces composants est pratique pour les équipes d’exploitation pour surveiller et prendre en charge Docker Enterprise pour une utilisation en entreprise, mais la plupart des utilisateurs ignorent parfaitement ces détails d’implémentation :
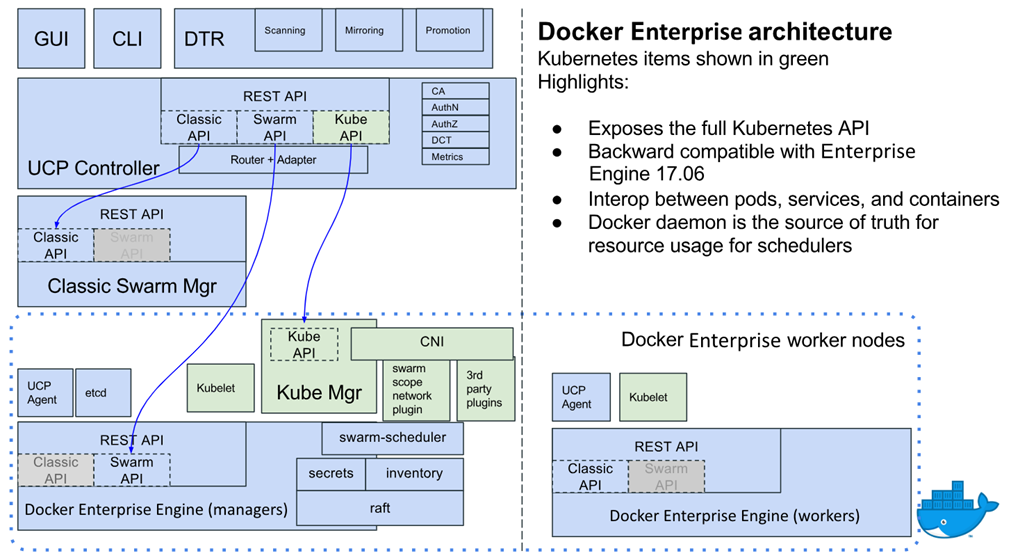
Figure 8 : Docker Enterprise avec Kubernetes © 2013-2018 Docker, Inc. Tous droits réservés
La couche supérieure représente les composants d’un gestionnaire avec lesquels les utilisateurs interagissent directement. À partir de là, le contrôleur UCP sert de contrôleur / routeur sécurisé aux services Swarm et Kubernetes sous-jacents. Voici quelques faits saillants des composants décrits dans la figure 8. Veuillez noter qu’il s’agit d’un aperçu de niveau supérieur pour plus de clarté et de concision, alors qu’il existe en fait plus de 30 composants conteneurisés inclus dans une installation UCP de gestionnaire UCP / nœud maître Kubernetes:
| GUI | L’interface Web Docker UCP, exécutée à l’intérieur du conteneur ucp-controller sur chaque nœud du gestionnaire Docker UCP, est l’endroit où les informations d’identification d’un utilisateur peuvent être utilisées pour se connecter au portail Web de Docker Enterprise et, en fonction de leurs droits d’accès, interagir avec des objets dans le cluster. |
| CLI | L’interface de ligne de commande Docker est accessible à l’aide d’un ensemble de lignes de commande Docker. Le bundle contient les certificats de l’utilisateur Docker Enterprise et une clé privée pour l’authentification du cluster, ainsi que des scripts pour se connecter au cluster à partir d’un bash local ou d’un terminal PowerShell. |
| DTR | Le registre de confiance Docker stocke et gère en toute sécurité les images en fonction des politiques. |
| Contrôleur UCP | Ce bloc représente une variété de composants UCP, à commencer par l’API UCP RESTful. À l’aide d’un jeton d’autorisation de support, les utilisateurs autorisés peuvent appeler l’API UCP pour gérer les ressources UCP telles que les services, les conteneurs, les réseaux, les utilisateurs, les subventions et les collections à partir de scripts. De plus, le contrôleur UCP gère la sécurité, la confiance et la surveillance liées à l’accès aux API d’orchestration sous-jacentes. |
| Agent UCP | L’agent UCP s’assure que tous les services UCP corrects s’exécutent sur chaque membre de nœud de cluster UCP. |
| Etcd | Etcd est l’implémentation derrière ucp-kv où Swarm et Kubernetes conservent leur magasin de cluster crypté dans Docker Enterprise. |
| Kubelet | Kubelet s’exécute à l’intérieur du conteneur ucp-kubelet sur chaque nœud Kubernetes. Le Kubelet est responsable de l’exécution des pods réels sur un nœud et de la notification de l’intégrité du nœud et de l’utilisation des ressources. En plus de Kubelet, vous devez vous attendre à voir un proxy ucp-kube sur chaque nœud comme un moyen de câbler l’espace d’adressage du cluster entre les nœuds, les services et les pods. |
| Kube MGR | Le bloc du gestionnaire Kube représente l’implémentation du contrôleur, du planificateur et de l’API Kubernetes. |
| CNI | Ce bloc représente l’interface réseau du conteneur dont Kubernetes a besoin pour implémenter les fonctionnalités de mise en réseau. Par défaut, Docker Enterprise utilise le plugin Calico CNI. En utilisant l’ indicateur –cni-installer-url pendant l’installation de Docker UCP, l’administrateur peut utiliser un autre plug-in CNI tel que weave ou flannel. |
Il est intéressant de voir comment l’architecture de Docker Enterprise offre une excellente expérience combinée avec Swarm et Kubernetes coexistant sur une seule plate-forme d’entreprise.
2.4 Résumé
Le mouvement des conteneurs, dirigé par la communauté Docker, change la façon dont les logiciels sont créés, conditionnés et livrés. L’espace naissant des plates-formes de conteneurs d’entreprise change la façon dont les entreprises conçoivent les plates-formes logicielles et la virtualisation. Docker, Inc. ouvre la voie, comme l’a reconnu Forrester Research avec la plateforme Docker Enterprise.
La prise en charge supplémentaire de Docker Enterprise 2 pour Kubernetes, en plus de Swarm, en fait un excellent choix d’entreprise. Les équipes de modernisation peuvent démarrer sur la courbe d’apprentissage des conteneurs d’entreprise avec Swarm et utiliser Kubernetes pour intégrer les microservices lorsqu’ils sont prêts. De plus, les entreprises ont le choix d’exécuter Docker Enterprise sur le cloud ou sur site dans une machine virtuelle ou sur du bare metal.
Ce chapitre présente une approche progressive et agile pour l’adoption de Docker en entreprise. Tout au long de l’article, nous nous appuierons sur ces phases d’adoption pour créer une application pilote et la préparer pour la production.
Dans le chapitre 3 , Mise en route – Proof of Concept de Docker Enterprise , nous entamons notre parcours d’adoption agile avec notre PoC. Nous allons configurer un cluster PoC avec Docker Enterprise, conteneuriser une application .NET et déployer l’application conteneurisée sur notre cluster PoC.
3 Prise en main – Docker Enterprise Proof of Concept
Ce chapitre représente une première étape critique dans votre cheminement vers l’adoption de Docker Enterprise. Nous avons parlé de l’importance d’une approche d’exploration, de marche et de course grâce à l’adoption agile. Tant de fois, dans un effort pour être le plus efficace, nous voulons sauter directement à la réponse. Par la suite, de nombreuses organisations courent juste après les étapes de ramper et de marcher pour commencer à courir (quelque part). Le problème est qu’en sautant notre étape d’exploration, où un projet de preuve de concept ( PoC ) est utilisé pour introduire et démontrer la plate-forme Docker Enterprise, ils manquent de découvrir leur propre opinion éclairée pendant le PoC. Essentiellement, la phase PoC est un élément essentiel de l’expérience d’apprentissage des entreprises. Commencez donc avec un PoC, permettez à l’équipe d’essayer des choses, de faire des erreurs et d’apprendre librement.
Ici, nous présentons la phase PoC de notre approche agile, où nous apprenons comment utiliser et configurer Docker Enterprise en travaillant à travers les premières étapes de la phase d’application où nous prenons une seule application d’un PoC, à un pilote et à la production.
Dans ce chapitre, nous nous concentrons sur l’étape PoC et plus tard, nous portons notre application au cluster pilote (non-production) mais hautement disponible, et enfin nous amenons l’application dans un environnement de production pour explorer les considérations clés pour obtenir une production d’application- prêt.
Les sujets suivants seront traités dans ce chapitre :
- Préparation des nœuds, du réseau et du stockage pour votre PoC
- Installation de Docker Enterprise pour votre PoC:
- Installation de Docker Enterprise Engine
- Installation de Docker UCP
- Installation de DTR
- Test de la plateforme PoC
- Préparation de l’application et de la plateforme PoC
- Création et déploiement de l’application PoC
3.1 Constitution d’une équipe interfonctionnelle Docker Enterprise PoC
Comme prescrit précédemment, il est préférable d’intégrer Docker Enterprise dans une organisation avec une approche d’exploration, de marche et d’exécution progressive mais agile. La partie agile de la description provient de l’exploitation d’un backlog, où une liste prioritaire de tâches appropriées à la phase est utilisée pour fournir les éléments de base pour planifier chaque phase. De plus, nous filtrons et trions les priorités des éléments du carnet de commandes en fonction des besoins et des exigences uniques de chaque organisation. L’équipe des services professionnels (PS) de Docker, Inc. a développé un carnet de commandes complet et exclusif pour prendre en charge leur méthodologie d’adoption d’entreprise afin de prendre en charge les PoC des clients, les pilotes et les trajets de production.
Tout au long de cet article, nous établissons un parallèle avec l’approche agile en plusieurs phases de Docker, Inc. en tant que validation et introduction de l’approche. Nous avons donc l’intention d’introduire et de soutenir l’approche de Docker en présentant quelques exemples de chemins et de concepts importants, mais cet article n’est pas destiné à se substituer à l’expérience ou à la propriété intellectuelle de l’équipe Docker PS. Veuillez contacter Docker, Inc. pour plus de détails et une assistance professionnelle.
L’objectif principal d’un Docker Enterprise PoC est de partager une première expérience avec une petite équipe interfonctionnelle dans une entreprise. L’équipe centrale PoC comprend normalement un ou deux représentants des domaines fonctionnels de développement d’applications, de DevOps, de plate-forme et de gouvernance. Idéalement, les représentants fonctionnels sont des membres d’équipe influents et expérimentés ayant suffisamment d’expérience pour comprendre les problèmes importants, et suffisamment expérimentés pour effectuer le travail PoC ou au moins superviser étroitement le travail PoC à un niveau détaillé.
Garder une équipe PoC petite et pratique conduit généralement à des délais plus courts pour le PoC. Le calendrier d’un PoC devrait être de plusieurs semaines et NON de plusieurs mois. Idéalement, un PoC a une équipe de base de quatre à six acteurs et, avec quelques conseils d’experts, devrait être en mesure de livrer le PoC en 3-6 semaines. L’apprentissage du PoC devrait se transformer en une étape pilote, pour maintenir l’élan.
Dans la figure 1 , vous pouvez voir les différents domaines organisationnels qui doivent être impliqués dans le processus d’adoption agile. Ce ne sont pas seulement des développeurs ou une poignée d’administrateurs système. L’adoption par l’entreprise de conteneurs aura un impact direct sur la gouvernance, les opérations, le développement d’applications et les domaines DevOps, à commencer par le PoC:
Figure 1: Préoccupations transversales PoC
Des représentants de l’équipe de gouvernance dirigeront les efforts pour réaliser les actions suivantes :
- Faciliter l’apprentissage partagé et la collaboration (c’est-à-dire les équipes Wiki ou MS)
- Solliciter et documenter les objectifs et les critères de réussite du PoC
- Commencer à solliciter et à documenter les exigences de conformité, de sécurité et d’accès pour la phase pilote
Des représentants de l’équipe de la plateforme dirigeront les efforts pour effectuer les actions suivantes :
- Préparer les nœuds, le réseau et le stockage Docker Enterprise PoC
- Installer le moteur Docker Enterprise PoC avec la journalisation facultative configurée
- Installer Docker Enterprise PoC Universal Control Plane (UCP)
- Installer PoC Docker Trusted Registry (DTR)
- Configurer des clusters pour les utilisateurs et les ressources PoC
Des représentants de l’équipe d’application dirigeront les efforts pour effectuer les tâches suivantes :
- Choisissez un exemple d’application à conteneuriser et à déployer pendant le PoC
- Conteneuriser l’application PoC à l’aide d’images Docker Hub officielles
- Créez un fichier YAML pour Swarm et / ou Kubernetes pour déployer l’application PoC
Des représentants de l’équipe DevOps dirigeront les efforts pour effectuer les actions suivantes :
- Préparer une CLI Docker Enterprise utilisateur DevOps pour un accès à distance aux API Docker Enterprise / Kubernetes
- Scriptez le déploiement de l’application PoC à l’aide des API Docker Enterprise / Kubernetes
- Mises à jour de l’application Script PoC à l’aide des API Docker Enterprise / Kubernetes
- Exécutez une démo PoC pendant la présentation de synthèse PoC
De nombreux livres ont été et seront écrits sur la gouvernance de la transformation d’entreprise et DevOps. Ainsi, pour les besoins de cet article, nous nous concentrerons principalement sur les préoccupations des équipes de plate-forme et d’application.
3.2 Préparation d’une plateforme Docker Enterprise pour l’étape PoC
Le but de cette section est de vous familiariser avec une configuration simple de bout en bout de Docker Enterprise aussi rapidement que possible. Considérez-le comme la création d’une plate-forme MVP Docker Enterprise qui inclut Docker UCP et DTR comme un endroit pour déployer notre application PoC. À cette fin, nous allons parcourir les détails de la constitution d’un cluster PoC et nous utiliserons Amazon Web Services (AWS) pour démontrer le processus pour effectuer les opérations suivantes :
- Nous allons préparer un cluster Linux à quatre nœuds :
- Installer une version d’essai de Docker Enterprise Engine sur tous les nœuds (configurer le stockage et la journalisation)
- Installez UCP et DTR sur deux des nœuds
- Créer un utilisateur PoC et des bundles CLI Docker pour l’utilisateur PoC
- Nous allons créer et envoyer des exemples d’images d’application Swarm et Kubernetes.
- Nous allons déployer un exemple d’application et tester l’accès en tant qu’utilisateur PoC avec CLI pour tester le cluster.
- Nous mettrons à jour l’image de l’application et redéployer.
3.2.1 Préparation d’un cluster à quatre nœuds
Pour commencer, nous avons besoin de trois ou quatre nœuds Linux connectés sur un réseau commun où nous pouvons installer Docker Enterprise et héberger notre PoC. Gardez à l’esprit que pour notre PoC, un nœud est pour UCP, un autre pour DTR, et les nœuds restants sont des travailleurs. Une configuration minimale à quatre nœuds est fortement recommandée pour les PoC afin de démontrer plusieurs travailleurs, et donc un cluster orchestré réel. Dans Kubernetes, nous aurions un maître et trois nœuds, où un nœud exécute DTR et les nœuds restants exécutent des charges de travail conteneurisées.
L’utilisation d’un seul travailleur (cluster à trois nœuds) peut sembler plus simple ou plus simple. Cependant, un seul travailleur commence à se sentir plus comme une configuration Docker à l’ancienne utilisant docker-compose. Ils étaient excellents à l’époque, mais nous comptons maintenant sur des orchestrateurs tels que Swarm et Kubernetes pour gérer des fonctionnalités de cluster importantes telles que la planification des applications, la mise à l’échelle, la disponibilité et la mise en réseau de superposition.
Veuillez garder à l’esprit qu’il s’agit d’un PoC et ne reflète pas votre plate-forme finale pour Docker Enterprise ; les décisions préliminaires sur votre plate-forme cible réelle ne sont pas nécessaires jusqu’à ce que vous passiez à l’étape pilote. Ces décisions sont intentionnellement différées car, lorsque vous commencez avec Docker Enterprise et à l’étape PoC, vous ne disposez pas des connaissances et de l’expérience de première main nécessaires pour prendre des décisions éclairées à plus long terme. De plus, essayer de forcer ces décisions pendant le PoC ajoute à la courbe d’apprentissage et introduit plus d’erreurs débutantes, entraînant des retards coûteux et potentiellement institutionnalisant des anti-modèles. Commencez donc dans votre zone de confort en choisissant une infrastructure prise en charge par Docker Enterprise qui s’aligne sur vos compétences actuelles. N’oubliez pas que l’objectif ici est d’acquérir une certaine expérience avec Docker Enterprise en tant que plate-forme cible pour votre PoC et de ne pas essayer un tas de nouvelles choses en même temps.
3.2.1.1 Configurer un cluster à quatre nœuds
Choisissez d’abord la plate-forme sur laquelle vous allez héberger votre cluster Docker Enterprise. Encore une fois, ce n’est pas le moment d’essayer quelque chose de nouveau et de peu familier. Plutôt et si possible, utilisez votre plate-forme go-to, qu’elle soit basée sur le cloud, sur site, virtualisée ou bare metal. Pour ce faire, nous avons besoin de quatre nœuds avec stockage local et connectés à un réseau commun auquel nous pouvons accéder.
3.2.1.1.1 Présentation d’un exemple d’environnement PoC
Préparez un réseau avec quatre nouveaux nœuds Linux connectés :
- Quatre nœuds sont connectés au même réseau, ce qui autorise tout le trafic / les ports entre les nœuds (veuillez noter que le trafic sera verrouillé lors des étapes pilote et de production).
- Il y a une nouvelle installation de Linux sur au moins deux nœuds (Linux requis pour les nœuds UCP et DTR):
- Deux vCPU / cœurs pour chaque nœud
- 8 Go de RAM
- 32 Go d’espace disque
- Une distribution Linux prise en charge par Docker Enterprise : CentOS, Oracle Linux, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Ubuntu, Microsoft Windows Server 2016, Microsoft Windows Server 1709 ou Microsoft Windows Server 1803
- Il y a une nouvelle installation de Linux ou Windows sur un ou plusieurs nœuds de travail :
- Deux vCPU / cœurs pour chaque nœud
- 8 Go de RAM
- 32 Go d’espace disque pour Linux et 80 Go pour Windows Server
- Une distribution Linux prise en charge par Docker Enterprise : CentOS, Oracle Linux, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Ubuntu, Microsoft Windows Server 2016, Microsoft Windows Server 1709 ou Microsoft Windows Server 1803
La figure 2 montre un exemple de travail dans lequel nous avons créé quatre instances t2.large exécutant AWS avec deux vCPU et 8 Go de RAM. Tous ont des adresses IP publiques et privées attribuées à leur carte réseau. Tous les boîtiers Linux ont 32 Go d’espace disque et le travailleur Windows a 80 Go d’espace disque :
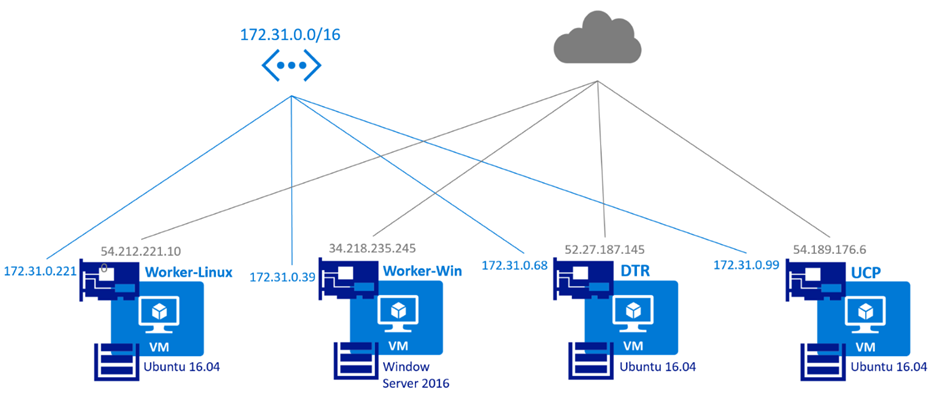
Figure 2 : cluster PoC à nœuds mixtes
Ici, les nœuds Docker communiquent entre eux sur le réseau privé local à l’aide de l’espace d’adressage 172.31.0.x. Cependant, pour accéder à nos nœuds en externe et installer Docker, nous voulons pouvoir SSH directement pour le PoC. Veuillez noter que pour notre configuration post-PoC, tout le trafic externe passera par un pare-feu ou un équilibreur de charge, où l’équilibreur de charge sert d’hôte bastion / jump pour éviter d’exposer les nœuds à l’extérieur.
3.2.1.2 Installation de Docker Enterprise Engine sur tous les nœuds
Maintenant que nous avons des nœuds en cours d’exécution, nous allons installer Docker Enterprise Engine sur chacun de vos nouveaux nœuds. Pour installer et utiliser Docker Enterprise, vous aurez besoin d’une clé de licence logicielle valide ainsi que de l’URL de votre abonnement aux Storebits. L’URL des bits de stockage est une URL unique émise par Docker aux abonnés et leur permet d’accéder à leurs fichiers liés à l’abonnement pendant l’installation. Vous pouvez les obtenir dans la boutique Docker en vous connectant avec ou en créant un ID Docker et en vous inscrivant à un abonnement d’essai gratuit.
Si vous avez déjà un ID Docker depuis Docker Hub, votre même ID Docker fonctionnera dans la boutique Docker. Si vous ne disposez pas déjà d’un identifiant Docker, cliquez simplement sur Se connecter dans le coin supérieur droit de la page d’accueil de store.docker.com ou visitez simplement https://store.docker.com/signup . Une liste de liens utilisés dans cette section se trouve dans un référentiel GitHub : https://github.com/PacktPublishing/Mastering-Docker-Enterprise .
3.2.1.3 Obtention d’une licence d’essai de Docker Enterprise de 30 jours et d’une URL de magasin
Connectez-vous à votre boutique Docker et utilisez l’onglet Docker Enterprise pour sélectionner votre plateforme certifiée préférée.
Veuillez choisir une distribution Linux pour le PoC, en notant que tous les produits cloud tels que AWS et Azure ont été déconseillés. Ces anciennes offres cloud exécutent un petit noyau appelé MobyLinuxVM, qui est un moyen très simple et efficace d’exécuter Docker, mais ce n’est pas quelque chose que vous pouvez facilement entretenir et est difficile à travailler (il n’a pas de capacités SSH). Pour ces raisons et peut-être aussi pour d’autres, la plate-forme Moby ne sera utilisée que dans des installations gérées par Docker spéciales telles que Docker Desktop, Docker pour Windows et Docker pour Mac.
Une fois que vous avez sélectionné votre distribution Linux préférée, cliquez sur Démarrer l’essai d’un mois. Maintenant, remplissez le formulaire d’essai et soumettez vos informations. Vous devriez immédiatement trouver vos informations de licence dans la section Mon contenu de la boutique Docker. Il y a une sélection de menu sous la liste déroulante de votre profil en haut à droite de l’écran.
Enfin, vous devez cliquer sur le bouton Configuration pour afficher les informations dont vous aurez besoin pour installer Docker Enterprise Engine, comme illustré à la figure 3 . C’est ici que vous trouverez un lien pour télécharger votre fichier de licence Docker et votre URL de boutique. C’est le bon moment pour télécharger la licence dans un répertoire sûr sur votre ordinateur local. Copiez et collez également l’URL des bits de stockage dans votre éditeur préféré. Vous en aurez besoin dans la section suivante lorsque nous configurerons le gestionnaire de packages pour utiliser les référentiels Docker:
Figure 3: Essai Docker Enterprise d’un mois
3.2.1.4 Installation de Docker Enterprise Engine sur tous les nœuds
Avec votre clé de licence et l’URL des magasins Docker enregistrés sur votre ordinateur local, il est temps d’installer Docker Enterprise Engine sur tous vos nœuds. Pour cette section, nous utiliserons une distribution Ubuntu de Linux et un serveur Windows 2016 comme deuxième nœud de travail. Donc, tous ensemble, nous avons un cluster à quatre nœuds.
Afin de garder ces informations à jour et rationalisées, il existe une page de référentiel GitHub pour les commandes de cette section. Il peut être trouvé ici: https://github.com/PacktPublishing/Mastering-Docker-Enterprise .
Commencez par créer des sessions SSH dans chacun de vos nœuds Linux et une session RDP dans votre travailleur Windows. Vous êtes maintenant prêt à commencer le processus d’installation du moteur. Veuillez noter que les commandes d’installation bash varieront légèrement selon les différentes versions de Linux et seront complètement différentes sous Windows 2016, où nous utilisons PowerShell.
Nous commencerons par les nœuds Linux, où nous utiliserons le gestionnaire de packages et le référentiel Docker officiel pour installer notre logiciel. Une fois les moteurs Docker installés, tous les autres logiciels Docker Enterprise s’exécutent dans des conteneurs et proviendront du registre des conteneurs de Docker.
Veuillez suivre attentivement ces instructions! N’utilisez pas le référentiel par défaut de votre distribution Linux pour installer le moteur Docker! Cela entraîne généralement une version ancienne ou fourchue (parfois appelée FrankenDocker) de l’édition communautaire. De plus, les instructions suivantes supposent que vous utilisez une nouvelle installation du logiciel OS sur vos nœuds. Si ce n’est pas le cas, assurez-vous de supprimer les anciennes versions de Docker avant de continuer.
Je vais vous montrer comment commencer, en utilisant le code VS. Tout d’abord, nous ouvrons quelques fichiers à l’aide de la barre de menus Fichier | Ouvrir pour ouvrir deux fichiers vides. Dans le premier fichier, enregistrez vos informations de connexion (adresses IP publiques / privées) sur vos serveurs cloud et dans le deuxième fichier, juste un bloc-notes pour stocker l’URL de vos magasins Docker et un emplacement pour coller les commandes à partir de la page de référentiel de ce chapitre: https: //github.com/NVISIA/MasteringDockerEE/blob/master/PoC/install/Install-EE-Engine-notes.md . Ensuite, ouvrez certaines sessions du terminal SSH, une pour chaque nœud. Vous êtes maintenant prêt à installer :
Figure 4 : Essai Docker Enterprise d’un mois
3.2.1.5 Exemple d’installation d’Ubuntu Docker Engine
Cette section est adaptée de docs.docker.com (documentation officielle de Docker pour les éditions communautaires et d’entreprise) et nous guide à travers le processus d’installation de Docker Enterprise— https://docs.docker.com/install/linux/docker-ee/ ubuntu / .
Pour notre exemple PoC, nous utiliserons la version Beta3 de Docker Enterprise de 2.1 pour garantir que les informations sont aussi à jour que possible. Comme il s’agit de la troisième version bêta de la version 2.1, elle devrait être très similaire à la version de production fin 2018. Cependant, notez que l’emplacement des informations sur la version Docker est susceptible de changer.
- Mettez à jour le gestionnaire de paquets Ubuntu :
- Sur chaque nœud Linux, mettez à jour le gestionnaire de packages comme suit :
sudo apt-get update
-
- Maintenant, activez APT pour s’exécuter sur HTTPS à l’aide de la commande suivante :
sudo apt-get install -y \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
- Configurez les référentiels du gestionnaire de paquets Ubuntu pour utiliser les binaires Docker officiels :
- Configurez les variables d’environnement DOCKER_EE_URL à l’aide de l’URL des bits de stockage de votre Docker Store que vous avez enregistrée précédemment. Ensuite, choisissez la version Docker souhaitée. Vous pouvez les trouver répertoriés en utilisant l’URL de vos magasins (en remplaçant les x) avec ce modèle: https://storebits.docker.com/ee/ubuntu/sub-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxx/dists/xenial/ . Vos commandes devraient ressembler à ce qui suit.
DOCKER_EE_URL = “https://storebits.docker.com/ee/ubuntu/sub-aff4b542-98da-438b-924e-8cc2c8f54b69”
DOCKER_EE_VERSION = test
-
- Ici, nous ajoutons le référentiel de Docker à votre gestionnaire de packages Linux, mettons à jour APT, puis installons la version de Docker Enterprise :
curl -fsSL “${DOCKER_EE_URL}/ubuntu/gpg” | sudo apt-key add –
sudo add-apt-repository \
“deb [arch=amd64] $DOCKER_EE_URL/ubuntu \
$(lsb_release -cs) \
stable-17.06″
sudo apt-get update
- Installez Docker officiel à partir de référentiels correctement configurés :
- Cela indique au package de gérer l’installation de Docker Enterprise:
sudo apt-get install -y docker-ee
- Ajouter un utilisateur au groupe Docker (facultatif) :
- Nous ajoutons votre utilisateur actuel au groupe Docker pour éviter d’exécuter des commandes Docker en utilisant root ou sudo:
sudo usermod -aG docker $ USER
- Testez l’installation :
- Se déconnecter. Ensuite, reconnectez-vous et essayez d’exécuter la commande Docker (sans sudo) pour tester les autorisations des groupes Docker et Docker. Exécutez les informations de docker et vous devriez voir la sortie comme dans la figure 5.
- Notez que le libellé de la version du serveur est 18.09X a été installé et des informations sur l’hôte, y compris la version du noyau, qui doit être> 3.10:
$ docker info
Voici la sortie de la commande info docker. Veuillez noter la version :
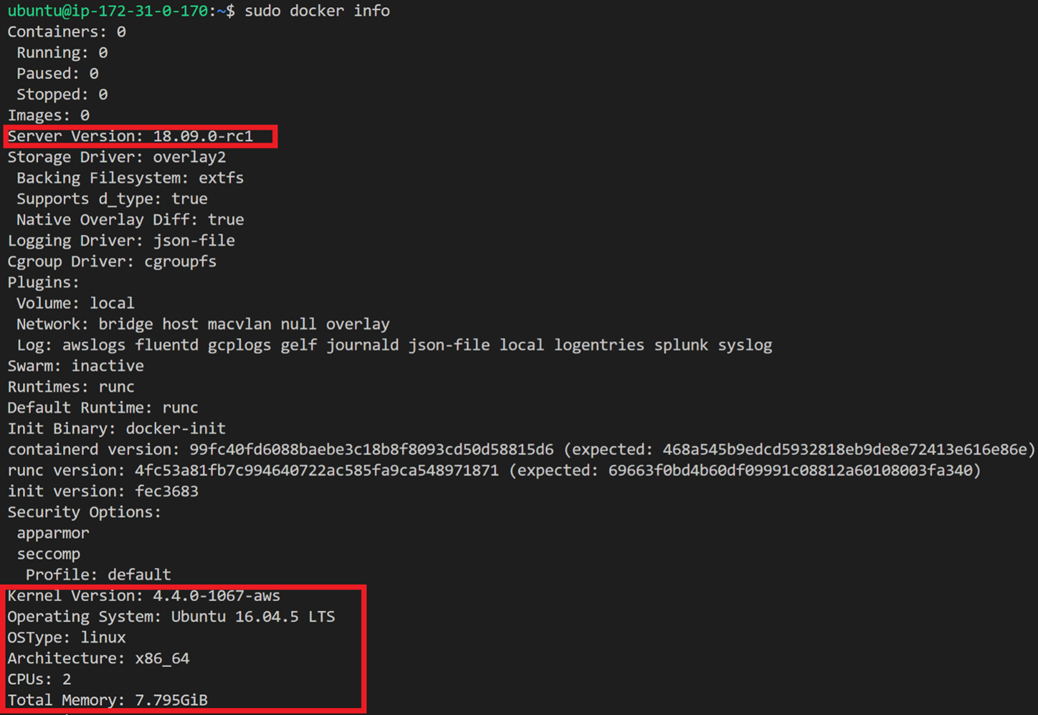
Figure 5 : Informations sur Docker après l’installation de Docker Linux
Si vous créez des modèles de machine virtuelle pour vos nœuds Docker Enterprise à partir de la première configuration de nœud que vous avez déjà installée, vous devez supprimer le fichier / etc / docker / key.json de l’image de la machine virtuelle. Ensuite, après avoir provisionné une machine virtuelle à partir de l’image, redémarrez simplement le démon Docker pour créer un nouveau fichier /etc/docker/key.json .
-
- Ensuite, nous passons à la configuration du nœud de travail Windows.
3.2.2 Installation du moteur Docker de Windows 2016
Sur notre sous-réseau Docker Enterprise, nous installons un nœud Windows Server 2016 et lancons une session de bureau à distance. Ouvrez un terminal PowerShell standard pour installer le module DockerMsftProvider , puis installez le package Docker. Pour les dernières informations sur l’installation de Docker Enterprise sur Windows Server, visitez https://beta.docs.docker.com/install/windows/docker-ee/#use-a-script-to-install-docker-ee :
Install-Module DockerMsftProvider -Force
Install-Package Docker -ProviderName DockerMsftProvider -Force
Dans le bloc PowerShell suivant, nous vérifions si un redémarrage est nécessaire. Si tel est le cas, nous émettons la commande Restart-Computer pour redémarrer Windows 2016 Server :
(Install-WindowsFeature Containers).RestartNeeded
Restart-Computer
Après un redémarrage possible, nous nous connectons à nouveau au serveur et examinons la commande docker info pour voir que la version Docker Enterprise est installée, comme illustré dans la figure 6 suivante.
Pour notre configuration, nous devrions voir un serveur 18.09 s’exécuter sur le noyau Windows 10. La commande info docker affiche de nombreux détails utiles sur le moteur Docker et peut être très utile pour le dépannage :
PS> docker info
Voici la sortie de la commande docker info. Veuillez noter les versions surlignées :

Figure 6: Informations Docker après l’installation de Docker Windows
Vous vous demandez peut-être pourquoi vous n’avez pas eu besoin de l’URL des bits de stockage du Docker Store pour installer Docker Enterprise Engine sur Windows Server. En effet, Docker Enterprise Basic est livré avec Windows Server 2016 Datacenter, Standard et Essentials Editions et sa prise en charge est fournie par Microsoft et soutenue par Docker. Donc, si vous possédez Microsoft Windows 2016, l’accès à Docker Enterprise Basic est déjà inclus.
3.2.3 Installation du plan de commande universel de Docker
SSH dans votre nœud UCP / gestionnaire et installez le Docker UCP. Comme vous pouvez vous y attendre, le programme d’installation UCP s’exécute à l’intérieur d’un conteneur appelé docker / ucp: 3.1.2 . Remarquez comment le conteneur monte le socket Docker en tant que volume afin qu’il puisse émettre des commandes docker vers un démon Docker exécuté sur l’hôte depuis l’intérieur du conteneur du programme d’installation UCP. Il s’agit de l’approche préférée par rapport à Docker dans Docker (DinD), qui nécessite l’indicateur –privileged et peut entraîner une corruption du système de fichiers.
Pour le moment, les applications UCP et DTR de Docker ne sont prises en charge que sur les plates-formes Linux. Windows pourrait être pris en charge dans une future version, car Docker sur Windows Server complète l’ensemble de fonctionnalités pour correspondre à Linux et complète la certification Kubernetes.
Le bloc de code suivant montre la commande d’installation UCP avec un exemple.
$ docker container run -it –rm –name ucp \
-v /var/run/docker.sock:/var/run/docker.sock \
docker/ucp:3.1.2 install \
–host-address {internal IP Address of UCP Node} \
–admin-username admin \
–admin-password {add your password here} \
–san {Internal IP of UCP node, i.e., 172.31.0.99} \
–san {External DNS name UCP node, i.e., ucp.mydomain.com} \
–san {External IP of UCP node, i.e., 54.189.176.6} \
–interactive
## — Actual example with my clusters values —
$ docker run -it –rm –name ucp \
-v /var/run/docker.sock:/var/run/docker.sock \
docker/ucp:3.1.2 install \
–swarm-port 3376 \
–host-address 172.31.0.170 \
–admin-username admin \
–admin-password notReallyThePassword \
–san ip-172-31-0-170.us-west-2.compute.internal \
–san ec2-54-245-193-10.us-west-2.compute.amazonaws.com \
–san 54.245.193.10 \
–interactive
En regardant la commande Docker dans le bloc de code précédent, nous voyons que le conteneur Docker exécute le binaire d’installation à l’intérieur du conteneur ucp: 3.1.2 avec un indicateur Terminal -it interactif (la sortie du conteneur s’affiche dans l’écran du terminal hôte et l’entrée, si est dirigé vers l’entrée standard du conteneur) et –name ucp nomme le conteneur ucp . Le –rm enlève le conteneur UCP du nœud local après l’installation terminée. Nous voyons le montage de volume du socket Docker avec -v /var/run/docker.sock:/var/run/docker.sock utilisé par le conteneur pour accéder au démon Docker de l’hôte. Assurez-vous de remplacer toutes vos valeurs spécifiques au nœud {…} avant d’exécuter la commande d’installation. La partie suivante de la commande est docker / ucp: 3.1.2 install avec les paramètres suivants:
- –host-address est l’adresse IP interne du nœud UCP activé, quelque chose comme 172.o.31.2.
- –admin-username est le nom d’utilisateur du compte administrateur principal, généralement quelque chose comme admin.
- –admin-password est le mot de passe du compte administrateur principal ; cela devrait être un mot de passe fort, où vous pouvez envisager d’utiliser un générateur de mot de passe.
- –san est un autre nom de sujet, un autre nom valide pour le certificat. UCP génère un certificat auto-signé lors de l’installation et ajoute sans pour chaque nom alternatif fourni. Voir la suite exemple de commande, où l’ on ajoute une possible UCP IP ou le nom DNS qui pourrait être accès utilisé le nœud UCP. Cela inclut les adresses IP internes / externes ainsi que les adresses IP internes / externes. Sans cela, vous pouvez obtenir des erreurs de certificat x509 lors de l’interaction avec le nœud UCP.
- –interactive est pour le mode interactif où l’installateur demande des informations supplémentaires si nécessaire.
Une fois l’installation terminée, il est temps de vous connecter. Puisque l’indicateur –interactive est utilisé, vous pouvez être invité à fournir des informations supplémentaires.
3.2.4 Connexion à l’interface Web UCP et téléchargement de votre licence d’essai
Assurez-vous que l’accès au port 443 est ouvert entre votre navigateur et le nœud UCP. Ensuite, pointez votre navigateur sur l’IP externe de votre nœud UCP ; assurez-vous de commencer par https://. Veuillez noter que, par défaut et aux fins de notre PoC, la session HTTPS utilise un certificat auto-signé. Pour accéder à UCP, vous devrez contourner l’avertissement de confidentialité du navigateur et accepter le certificat auto-signé.
Connectez-vous et obtenez une licence :
- Utilisez le nom d’utilisateur / mot de passe que vous avez fourni à la commande d’installation précédente pour vous connecter
- Utilisez le fichier de licence d’essai Docker Enterprise que vous avez téléchargé à partir de la boutique Docker lors de la connexion
3.2.5 Ajout de nœuds de travail au cluster UCP
Après vous être connecté au plan de contrôle universel de Docker Enterprise, vous verrez un tableau de bord montrant votre cluster sain à un nœud. Maintenant, nous devons ajouter nos nœuds supplémentaires au Docker UCP (cluster soutenu par Swarm). Nous allons commencer par les nœuds Linux puis le nœud Windows, notant que le nœud Windows prend un peu plus de préparation avant d’exécuter la commande docker swarm join.
Alors que nous utilisons SSH pour accéder à nos nœuds lors de l’installation des moteurs Docker, UCP et DTR, une fois les installations terminées, nous ne devons plus utiliser l’accès SSH. Plutôt que SSH, autorisez uniquement les utilisateurs à accéder au cluster à partir d’un ensemble client UCP. Chaque utilisateur UCP a son propre ensemble personnalisé associé à son compte d’accès basé sur les rôles UCP, tel que spécifié par un administrateur Docker Enterprise.
3.2.5.1 Joindre des nœuds de travail Linux au cluster
Tout d’abord, nous ajoutons le nœud DTR, qui est un nœud de travail. L’interface Web UCP fournit une interface graphique pour formater les opérations de ligne de commande importantes, y compris la jonction de nœuds au cluster et l’installation de DTR. Bien que nous ayons encore besoin d’exécuter ces commandes à partir de la ligne de commande, l’outil GUI nous aide à définir correctement les paramètres. Pour joindre des nœuds, nous sélectionnons d’abord l’élément de menu Nœuds sous Ressources partagées et cliquez sur Ajouter un nœud, comme illustré à la figure 7. Ensuite, sur l’écran suivant, nous nous assurons que LINUX et WORKER sont sélectionnés et copions la commande dans le presse-papiers, comme le montre la figure 8 :
Figure 7: Noeuds du plan de contrôle universel
Voici la boîte de dialogue Ajouter un nœud dans l’interface utilisateur Web Docker UCP. Sélectionnez LINUX et WORKER, puis cliquez sur le bouton copier :
Figure 8 : Plan de contrôle universel Ajouter un nœud Linux
Pour rejoindre le nœud DTR, nous nous connectons au nœud et exécutons la commande que nous avons copiée à partir de l’écran UCP Add Node de la figure 8. Assurez-vous d’utiliser le jeton de votre UCP, pas l’exemple suivant :
DTR-node$ docker swarm join –token SWMTKN-1-3ggoagvdn7jm27pflayqj3z7zmylz72fix6jqv0vrh4giv9785-xxxxxxxxxxxxxxxxxxxxx 172.31.0.170:2377
Ce nœud a rejoint un essaim en tant que travailleur.
3.2.5.2 Joindre les nœuds de travail restants au cluster
Maintenant, SSH dans le nœud de travail Linux et passez la même commande docker swarm join :
Worker-node$ docker swarm join –token SWMTKN-1-3ggoagvdn7jm27pflayqj3z7zmylz72fix6jqv0vrh4giv9785-xxxxxxxxxxxxxxxxxxxxx 172.31.0.170:2377
This node joined a swarm as a worker.
3.2.5.3 Rejoindre un nœud de travail Windows Server 2016 au cluster
Nous commençons par regarder le gestionnaire UCP pour les versions de l’agent UCP Windows et dsinfo . SSH sur le nœud UCP et exécutez ce qui suit :
UCP-node$ docker container run –rm docker/ucp:3.1.2 images –list –enable-windows
docker/ucp-agent-win:3.1.2
docker/ucp-dsinfo-win:3.1.2
Nous devons nous assurer que les mêmes images sont tirées vers les nœuds de travail Windows. Utilisez une session RDP pour accéder au nœud Windows 2016 et ouvrez un terminal PowerShell standard. Du terminal, nous tirons les images comme suit:
PS> docker image pull docker/ucp-agent-win:3.1.2
PS> docker image pull docker/ucp-dsinfo-win:3.1.2
Maintenant, nous devons exécuter un script qui:
- Vérifie le noyau de Windows Server
- Vérifie les certificats Docker
- Sécurise Dockerd sur le port 2376 avec un canal nommé chiffré tls
- Ouvre les ports de pare-feu Windows entrants 2376, 12376 et 2377
- Ouvre les ports entrants / sortants 7946, 4789 et 7946.
- Redémarre le service Docker.
Pour faciliter cela, Docker a créé un script dans le conteneur docker.ucp-agent-win qui peut être utilisé pour générer un script PowerShell comme suit :
PS> $script = [ScriptBlock]::Create((docker run –rm docker/ucp-agent-win:3.1.2 windows-script | Out-String))
PS> Invoke-Command $script
Une fois que le script a redémarré le service Docker, revenez à votre UCP et cliquez sur Ressources partagées | Nœuds et ajouter un nœud comme indiqué dans la figure 8a suivante. Cette fois, sélectionnez l’option Windows et reconnaissez que vous avez effectué les étapes précédentes en cochant la case 2: J’ai suivi les instructions et je suis prêt à rejoindre mon nœud Windows . La commande docker join apparaît. Copiez la commande docker swarm run dans PowerShell et exécutez-la.
Voici la boîte de dialogue Ajouter un nœud UCP dans laquelle vous ajoutez un nœud de travail Windows à notre cluster :

Figure 8a: Plan de contrôle universel Ajouter un nœud Windows
Maintenant, revenez au tableau de bord UCP dans notre navigateur et attendez que le nouveau nœud Windows s’initialise et redevienne sain:
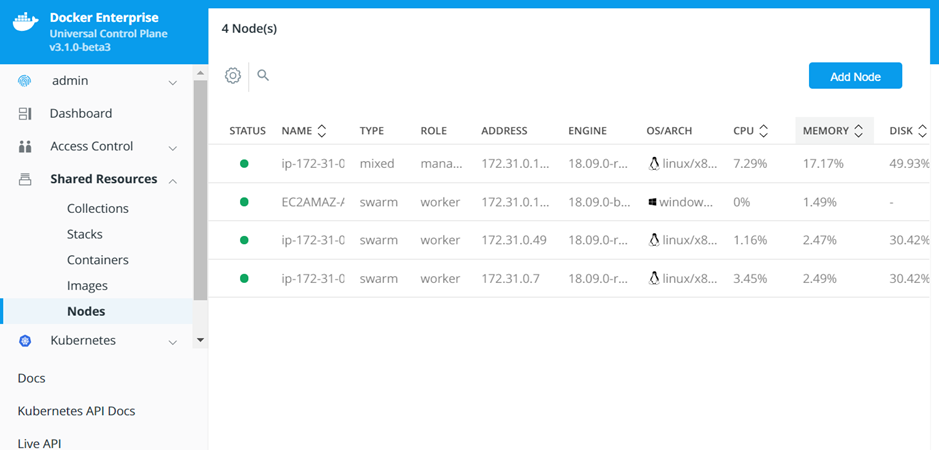
Figure 9: Plan de contrôle universel, tous les nœuds sont joints
Maintenant, nous avons le plan de contrôle universel Docker Enterprise installé sur un cluster sain à quatre nœuds. Il est maintenant temps d’installer le DTR.
3.2.6 Installation du DTR
Pour notre PoC, nous aurons besoin d’un registre d’images privé et fiable pour stocker, sécuriser et servir nos images. Pour cela, nous utiliserons Docker Trusted Registry (DTR). Nous utiliserons un terminal SSH pour le nœud de gestionnaire UCP.
Connectez-vous au nœud UCP et exécutez la commande docker node ls pour obtenir une liste des noms de nœud appropriés. Pour notre exemple, le nom de nœud approprié pour DTR est ip-172-31-0-168. Il peut s’agir d’un nœud de travail Linux. Ensuite, à partir de notre terminal UCP SSH, nous exécutons l’installation DTR comme indiqué dans le bloc de code suivant. Remarquez comment nous utilisons le nom de nœud UCP où le DTR doit être installé –ucp-node ip-172-31-0-68.
Jetons un coup d’œil à la structure de commande de notre installation PoC DTR:
$ docker run -it –rm docker/dtr:2.6.2 install \
–ucp-url :443 \
–ucp-username admin \
–ucp-password \
–ucp-insecure-tls \
–ucp-node
## — Actual example with my clusters values —
$ docker run -it –rm docker/dtr:2.6.2 install \
–ucp-url ec2-54-245-193-10.us-west-2.compute.amazonaws.com:443 \
–ucp-username admin \
–ucp-node ip-172-31-0-68 \
–ucp-password notReallyThePassword \
–ucp-insecure-tls
Il est important de comprendre que DTR et UCP fonctionnent en étroite collaboration et que DTR ne peut pas être déployé sans UCP associé. Toutes les informations sur l’utilisateur, l’équipe et l’organisation sont stockées dans UCP, mais sont utilisées par DTR. Lorsque vous vous connectez à DTR, vous utilisez les mêmes informations d’identification que UCP et vous serez momentanément redirigé vers UCP pendant le processus d’authentification.
Comme vous l’avez probablement deviné, l’URL UCP est la même que celle que vous avez utilisée lors de l’installation du DockerUniversal Control Plane. Par la suite, vous utiliserez le même nom d’utilisateur et mot de passe pour l’utilisateur administrateur que vous avez utilisé lors de l’installation d’UCP. Notez également que vous serez invité à entrer le nom du nœud où vous souhaitez installer le DTR. L’invite inclura une liste de nœuds candidats dans le cluster UCP.
Une fois l’installation terminée, vous pouvez utiliser l’adresse IP externe de votre DTR pour vous connecter. N’oubliez pas d’utiliser le préfixe HTTPS lorsque vous accédez au DTR. Et encore une fois, vous devrez cliquer sur les avertissements de confidentialité pour accepter un certificat auto-signé. Utilisez votre nom d’utilisateur et votre mot de passe d’administrateur UCP pour vous connecter.
Voici la page de connexion Docker Trusted Registry https://{external-ip-DTR-Node} :
Figure 10: Connexion au registre de confiance Docker
Maintenant que nous avons installé la plate-forme de base pour notre PoC, nous pouvons prendre en charge une partie de la configuration de base et des tests de notre nouvelle brillante installation Docker Enterprise.
3.2.7 Configuration de RBAC pour PoC
Pour le PoC, nous utiliserons une configuration minimale pour notre contrôle d’accès basé sur les rôles. Nous allons créer un compte développeur PoC avec un contrôle total de la collection partagée Docker Enterprise. Nous allons générer et distribuer un bundle Docker Enterprise CLI à l’équipe des applications à l’aide du compte d’utilisateur du développeur PoC afin que l’application conteneurisée puisse être testée et les images d’application puissent être transmises au DTR. Nous allons également créer un compte d’administrateur PoC utilisé pour déployer et prendre en charge l’application PoC, principalement à des fins de démonstration.
Dans le chapitre 4 , Préparer le cluster pilote Docker Enterprise , nous passons à l’étape pilote de notre parcours d’adoption Docker, où nous consacrerons plus de temps aux fonctionnalités d’authentification et d’accès de Docker Enterprise.
3.3 Application PoC
Maintenant que notre plateforme PoC est installée et prête pour les charges de travail PoC, il est temps de préparer une charge de travail Docker Enterprise.
Dans cette section, nous ferons ce qui suit :
- Choisissez une application PoC
- Installer Docker localement
- Conteneuriser et tester l’application sur notre poste de travail local
- Poussez l’application vers le DTR du PoC
- Déployer l’application sur le cluster Docker Enterprise
3.3.1 Choisir une application PoC
Choisir la bonne application pour un Docker PoC peut être difficile. Tout d’abord, gardez à l’esprit que le délai global de conteneurisation de l’application devrait être d’environ trois jours. Cette contrainte de timebox est vraiment importante pour garder le POC en mouvement. Deuxièmement, il existe quelques critères concurrents fondamentaux qui doivent être équilibrés tout en décidant quelle application utiliser pour votre PoC.
Le premier critère est de choisir une application qui peut être facilement conteneurisée avec un minimum de changements de code et sans refactoring. Étant donné que les efforts de refactoring peuvent se répercuter sur des projets majeurs et que vous n’avez que quelques jours pour terminer le processus de conteneurisation, l’idée de modifications minimales du code devrait avoir un sens. Le deuxième critère est de choisir une application qui sera intéressante pour les parties prenantes car elle est représentative d’autres applications qui seraient bénéfiques pour la conteneurisation. Par exemple, si vous avez un tas d’anciennes applications .NET qui sont difficiles à prendre en charge (cela devient généralement un problème car la prise en charge des couchers de soleil Microsoft pour une plate-forme de longue date telle que Windows Server 2008) et vous pouvez réussir à conteneuriser l’une de ces applications. Applications dans le cadre de votre POC, il sera facile pour les parties prenantes d’imaginer conteneuriser l’équilibre des anciennes applications .NET pour réduire considérablement les coûts de support. Le problème est que ces applications peuvent être un peu plus difficiles à conteneuriser sans modifications de code.
Alors que nous approfondissons un peu plus, je recommande un article de success.docker.com intitulé Docker Reference Architecture : Modernizing Traditional .NET Framework Applications . Je recommande également un autre article https://success.docker.com/ rédigé par Lee Namba et intitulé Docker Reference Architecture: Design Considerations and Best Practices to Modernize Traditional Apps (MTA) . Je vais utiliser les articles de Bart et de Lee comme matériel de support pour répondre à la question suivante : quelles applications sont les meilleurs candidats pour la conteneurisation (ou la modernisation, selon le cas) ?
Pour donner la meilleure réponse, nous examinons séparément les deux plates-formes d’application les plus courantes : les applications Windows et les applications Linux, en commençant par la plate-forme Windows. Le plus souvent, les applications .NET personnalisées et les applications de console Windows constituent les meilleures cibles pour la conteneurisation. Les services WCF et Windows peuvent généralement être conteneurisés avec quelques modifications, tandis que la plupart des applications commerciales ont tendance à être très difficiles à conteneuriser. Enfin, les applications Windows Desktop ne peuvent pas être conteneurisées, du moins pour l’instant.
Choisir une application Linux candidate pour votre PoC favorise également une application développée en interne personnalisée. Il s’agit généralement d’applications Java à trois niveaux avec un serveur Web Apache ou NGINX frontal ; un serveur intermédiaire de serveur d’applications Tomcat, JBoss, WebLogic ou Websphere, où l’application Java est déployée dans un seul fichier JAR ou WAR, et un backend DB relationnel. Vous ne pouvez pas avoir de liaisons JNI et vous devez éviter la terminaison TLS du serveur d’applications. TLS peut être interrompu sur un équilibreur de charge en amont ou sur le serveur frontal / proxy inverse du serveur Web. Recherchez également tout autre service dépendant qui pourrait rendre l’application difficile à isoler, comme la messagerie et les connexions de base de données distantes.
Une fois que vous avez identifié une liste restreinte de trois ou quatre candidats, recherchez rapidement des images de base appropriées à l’aide de google.com pour rechercher quelque chose de similaire à tomcat inurl: hub.docker.com ou asp.net 2.2 inurl: hub.docker .com . Cela pourrait éliminer certains de vos candidats. J’espère que vous trouverez une image de base raisonnable qui devrait fonctionner.
Faites attention ici! Essayez d’éviter la recherche du PoC parfait. Tout d’abord, car il y a de fortes chances que vous changiez d’avis après avoir commencé à conteneuriser l’application. Deuxièmement, parce que vous devez répartir le processus de sélection des candidatures sur un ou deux jours. Donc, gardez à l’esprit qu’il est très possible de démarrer / redémarrer le processus de conteneurisation plusieurs fois. C’est l’une de ces situations d’échec / d’apprentissage rapide. Il est donc pratique d’avoir une file d’attente de candidatures à parcourir si nécessaire.
Donc, pour conclure le processus de sélection des candidatures, vous devriez avoir une liste de trois ou quatre candidatures partagées avec l’équipe PoC comme point de départ. Avant de commencer la conteneurisation, nous devons configurer notre poste de travail.
3.3.2 Installation de Docker sur un poste de travail local
Nous allons conteneuriser notre application PoC sur un poste de travail local ; cela se produit généralement sur le bureau d’un développeur. De nos jours, la plupart des développeurs d’applications utilisent macOS ou Windows 10. Ainsi, Docker a créé un produit gratuit basé sur la communauté Docker Engine appelé Docker Desktop. Docker Desktop est conçu pour faciliter l’installation de Docker Engine-Community avec Kubernetes sur les versions récentes de macOS et de Windows 10 Professionnel. La raison de l’utilisation de Windows Professionnel est due à l’utilisation par Docker de Hyper-V sur Windows et d’Hyper-Vis uniquement disponible sur Windows Professionnel et versions supérieures. L’installation de Docker Desktop est disponible ici: https://www.docker.com/products/docker-desktop .
Si vous utilisez une ancienne version de Windows, vous allez vouloir utiliser la Docker Toolbox disponible ici: https://docs.docker.com/toolbox/overview/ . La boîte à outils est une façon classique d’installer votre propre virtualiseur, dans ce cas VirtualBox, sur votre bureau Windows, puis d’exécuter Docker dans les machines virtuelles Linux. Dans les coulisses, tous ces produits utilisent un noyau Linux très dépouillé pour exécuter la dernière version de Docker. Cette image est appelée MobyLinuxVM et cette même image s’exécute sur Hyperkit (macOS) et Hyper-V (Windows 10 Pro +) et dans VirtualBox à l’aide de Docker Toolbox (Windows 7 et 8).
Si vous exécutez une distribution Linux sur votre bureau de développeur, le processus d’installation est un peu plus manuel. Tout d’abord, vous devez installer le moteur Docker: https://docs.docker.com/install/linux/docker-ce/ubuntu/ . Ce lien est pour la distribution Ubuntu, mais il y en a d’autres disponibles, comme vous le verrez dans le menu de navigation de gauche. Après avoir installé le Docker Engine sur votre box Linux, vous devrez également installer Docker -compose séparément. Des instructions détaillées peuvent être trouvées en suivant ce lien: https://docs.docker.com/compose/install/#install-compose .
Si vous prévoyez de conteneuriser une application Windows, vous devrez exécuter des conteneurs Windows. L’option de conteneur Windows n’est disponible que sur les machines hébergées Windows, y compris Docker Desktop pour Windows ou Windows Server 2016+. Étant donné que Docker Desktop pour Windows prend en charge les conteneurs Linux et Windows, vous devrez choisir l’option de conteneur Windows illustrée à la figure 11 . Ce menu est accessible en cliquant avec le bouton droit sur la baleine Docker (Moby) dans la barre d’état système de Windows. Si la baleine n’est pas là, cela signifie que Docker ne court pas. Maintenant, ouvrez votre menu Démarrer de Windows et tapez Docker pour Windows , appuyez sur Entrée pour sélectionner et démarrer Docker. Veuillez noter que Docker peut prendre 1 à 2 minutes pour démarrer. Vous avez peut-être également remarqué l’élément de menu Kubernetes dans le menu contextuel. C’est là que vous iriez pour activer Kubernetes. Vous n’en aurez pas encore besoin, mais cela ne ferait pas de mal de l’activer.
La figure 11 montre le menu contextuel de Docker Desktop. Cliquez avec le bouton droit sur l’icône Docker whale dans la barre d’état système de Windows pour y accéder :
Figure 11: Menu contextuel de Docker Desktop
Lorsque vous passez d’un conteneur Linux à un conteneur Windows, vous vous connectez à un autre moteur Docker sur votre machine locale et chaque moteur a son propre emplacement / système de fichiers pour stocker le cache d’image Docker. Ainsi, lorsque vous passez de Linux à Windows, vos images Linux locales ne seront pas disponibles jusqu’à ce que vous reveniez. De plus, certaines mises à jour Docker peuvent entraîner une perte d’images locales. C’est donc une bonne idée de pousser des images locales vers un référentiel distant (comme Docker Hub – https://hub.docker.com/ ) avant de changer de type de conteneur ou de mettre à jour Docker.
3.3.3 Conteneurisation et test de l’application PoC sur un poste de travail Dev
Des livres entiers ont été écrits sur la conteneurisation des applications et, en fait, nous en discuterons un plus tard dans cette section. La conteneurisation est probablement l’un des domaines les plus difficiles pour les organisations qui travaillent via un PoC, et est donc un excellent endroit pour obtenir de l’aide si vous êtes nouveau dans les conteneurs. Docker Inc et MTA activés Les partenaires agréés Docker ont des offres de services complètes dédiées au processus PoC et la plupart de leur expertise est appliquée à la section de conteneurisation des applications. Cependant, en supposant que vous lisez cet article dans le but de travailler par vous-même, je ferai de mon mieux pour présenter un processus clair, ainsi que des documents à l’appui d’experts Docker.
Image2Docker est un outil conçu pour aider les équipes à conteneuriser les applications à partir de fichiers VHD ou WIM. Si votre application cible est packagée dans une machine virtuelle, cela peut vous aider à démarrer, mais ce n’est pas magique. Pour exécuter l’outil, installez Docker et le module Docker2Image PowerShell 5 sur une boîte Windows. Ensuite, exécutez l’application sur le fichier VHD ou WIM pour générer Dockerfile. Bien que l’outil puisse être utile au début, il existe certaines limitations. De plus, l’équipe des services professionnels Docker et les partenaires Docker compatibles MTA ont une version plus puissante de cet outil appelée Docker Application Converter (DAC). Ils l’utiliseront pour analyser les serveurs et créer des Dockerfiles initiaux pour les applications Windows et Linux. Ces fichiers initiaux sont affinés et refactorisés pour le PoC. Plus d’informations sur Image2Docker peuvent être trouvées sur https://github.com/docker/communitytools-image2docker-win .
Votre objectif dans cette section est de créer une application PoC conteneurisée qui peut être déployée sur le cluster Docker PoC que nous avons créé dans la section précédente. Bien que l’application PoC puisse être n’importe quelle application personnalisée qui cible Windows ou Linux, pour notre PoC, nous allons démontrer le processus à l’aide d’une application Web .NET avec une base de données SQL Server. Fans de Java et JavaScript, ne désespérez pas ! Dans le chapitre 4 , Préparer le cluster pilote Docker Enterprise , lorsque nous entrerons dans la phase pilote, nous utiliserons une application de Java avec un frontend React comme exemple.
Pour notre application PoC, nous suivrons ce processus de conteneurisation :
- Consultez la documentation de l’application
- Conteneuriser chaque composant / processus d’application dans une image
- Testez chaque image conteneurisée localement
- Créez une application de fichier de déploiement et testez-la localement
- Images push
- Test de déploiement sur la plate-forme Docker Enterprise PoC
- Revue avec l’équipe
Notre exemple d’application .NET présenté dans le PoC provient d’un blog Docker publié par Elton Stoneman. Nous avons choisi cette application d’Elton parce qu’il est un expert Docker et qu’il fournit des informations supplémentaires détaillées, y compris son blog ( https://blog.docker.com/2018/02/video-series-modernizing-net-apps-developers/ ).
Le référentiel GitHub pour l’exemple PoC est ici: https://github.com/dockersamples/mta-netfx-dev/tree/part-1 .
3.3.3.1 Examiner la documentation de la demande
Nous commençons le processus de conteneurisation en collectant des informations sur notre PoC, en commençant par le processus d’installation. En d’autres termes, nous voulons voir comment cette application serait installée sur un serveur propre. Ces informations sont souvent disponibles dans la documentation opérationnelle liée à l’application ou à une sorte de script automatisé. Dans d’autres cas, lorsque la documentation ou les scripts ne sont pas disponibles, un expert en la matière tel qu’un développeur de logiciels peut généralement vous aider tout au long du processus.
Notre documentation d’application comprend ce schéma :
Figure 12 : Architecture d’application PoC
Notre exemple d’architecture d’application PoC comprend deux composants clés: la machine virtuelle d’application et la machine virtuelle de base de données. Au sein de la machine virtuelle de base de données, nous voyons la base de données de l’application appelée SignUpDb , s’exécutant dans une base de données SQL Server Express 2016 SP1 sur un système d’exploitation Windows Server core 2016. Dans la machine virtuelle de l’application, nous voyons notre application de newsletter, une application de formulaires Web ASP.NET 3.5. Le serveur d’applications dispose des modules serveur Web, web-asp-net et ServiceMonitor installés sur un système d’exploitation invité Windows Server 2016. Notre application dispose de deux processus de haut niveau, l’application et la base de données. Nous allons diviser chacun de ces éléments en une image distincte et les connecter ensemble avec un réseau commun lorsque nous les déploierons. Lors de la conteneurisation, il est souvent utile de construire de bas en haut, en testant chacune des images en cours de route. Nous allons donc commencer par la base de données.
3.3.3.2 Conteneurisation et test local de chaque composant d’application
Une meilleure pratique consiste à créer des images Docker à l’aide de quelque chose appelé Dockerfiles. Dockerfile est un fichier texte contenant des commandes pour créer une image Docker couche par couche, en commençant par une image de base. Notre objectif pour la section sera de créer deux Dockerfiles distincts. Un Dockerfile est pour l’application et l’autre Dockerfile est pour la base de données. Veuillez noter que la dénomination par défaut de Dockerfile n’a pas d’extension de fichier par convention. Faites donc attention aux éditeurs de texte qui ajoutent à votre Dockerfile une extension .txt . Si vous n’êtes pas familier avec Dockerfiles, veuillez prendre une minute pour lire ceci: https://docs.docker.com/engine/reference/builder/ .
3.3.3.3 Conteneurisation de la base de données
Notre première tâche lors de la conteneurisation d’un processus est de trouver la base appropriée pour notre image de base de données. Lors d’un PoC, c’est une bonne idée d’utiliser une image officielle préfabriquée du Docker Hub. Dans notre cas, nous rechercherons des images créées par Microsoft. Veuillez noter que, plus tard sur le chemin de l’adoption, vous souhaiterez probablement créer vos propres images basées sur le durcissement pour le développement d’entreprise. Nous en parlerons plus lors du chapitre pilote. Il existe plusieurs façons de découvrir des images de base. La première consiste à simplement Google pour l’image et à rechercher des liens vers Docker Hub. Une autre approche consiste à rechercher simplement dans Docker Hub.
Nous commençons notre recherche d’une image de base de la manière la plus familière, en recherchant sur Google “le serveur Docker SQL express 2016”. Le premier résultat est un lien vers une image Microsoft sur Docker Hub – il semble prometteur, nous suivons donc le lien vers https://hub.docker.com/r/microsoft/mssql-server-windows-express/ et examinons les informations sur l’image page. Jusqu’à présent, cela ressemble à un bon ajustement. Cependant, je veux m’assurer de trouver une version compatible avec notre application. Donc, je clique sur l’ onglet Balises , où nous trouvons une balise 2016-sp1 pour cette image. Ainsi, l’adresse de notre image est microsoft / mssql-server-windows-express: 2016-sp1 . Il s’agit d’une image dans le registre public Docker Hub, située dans l’espace de noms Microsoft, dans un référentiel appelé mssql-server-windows-express , avec une balise 2016-sp1 .
Rappel! Bien qu’il puisse être tentant d’essayer la dernière version d’une image (la dernière pour MS SQL Server Express: 2017-dernière, 2017-CU1), ce n’est pas ce que notre application utilise. L’utilisation de la nouvelle image ajoute effectivement un projet de mise à niveau au chemin critique du PoC, ainsi que tous les maux de tête associés et les problèmes d’élimination de l’élan. Soyez très prudent pour éviter toute mise à niveau ou refactorisation de votre application dans le processus PoC, de peur de vous enliser et de perdre votre élan. Vous pouvez revoir tous les efforts de refactorisation lors de la définition de la portée de la prochaine phase pilote.
Félicitations, nous avons les débuts de notre base de données Dockerfile . La première ligne est une pratique importante pour la création d’images Windows. Le # fuite = ` dit la construction de docker commande pour traiter la backtick ( ` ) comme caractère d’échappement au lieu de la barre oblique inverse par défaut ( \ ). Sous Windows, la barre oblique inverse est bien sûr utilisée dans les chemins de fichiers et vous ne voulez pas que les caractères de chemin de fichier soient confondus avec les caractères d’échappement.
Dans la deuxième ligne, nous voyons l’image de base que nous avons découverte sur Docker Hub:
# escape=`
FROM microsoft/mssql-server-windows-express:2016-sp1
Nous revenons maintenant à la page d’informations du référentiel Docker Hub pour l’ image express du serveur sql pour plus d’instructions sur l’utilisation de cette image. Nous avons remarqué des instructions intéressantes sur la définition des variables d’environnement. Nous créons une section dans notre Dockerfile pour définir les variables d’environnement qui seront utilisées par MS SQL lors de son exécution dans le conteneur. Une variable permet d’accepter le contrat de licence utilisateur final (CLUF) et l’autre variable est le mot de passe administrateur système. Veuillez noter que le mot de passe utilisé ici pour l’image de base de données devra correspondre à la chaîne de connexion de notre application Web telle qu’elle est stockée dans le fichier Web.config de notre image d’application (nous le construirons ensuite). Veuillez également noter l’utilisation du caractère backtick ( ` ) comme continuation de ligne et donc toutes les lignes suivantes font partie d’une seule commande ENV dans le Dockerfile :
ENV ACCEPT_EULA=”Y” `
sa_password=”DockerCon!!!” `
DATA_PATH=”C:\mssql”
La variable d’environnement DATA_PATH est utilisée conjointement avec le volume Docker (illustré ci-dessous).
VOLUME ${DATA_PATH}
WORKDIR C:\init
COPY docker\db .
CMD ./init.ps1 -sa_password $env:sa_password -Verbose
L’utilisation d’un volume Docker de cette façon stocke les fichiers de base de données MS SQL en dehors du conteneur de base de données sur le système de fichiers hôte. Plus tard, nous pouvons utiliser ce volume pour monter les fichiers de notre base de données dans ce volume et partager les mêmes fichiers entre différentes exécutions du conteneur. Par conséquent, si le conteneur exécutant la base de données est arrêté et redémarré, l’état de la base de données sera conservé dans les nouveaux et anciens conteneurs.
WORKDIR définit le répertoire actif dans le conteneur que vous créez, un peu comme une commande change directory (cd), où votre emplacement sur le système de fichiers est conservé en tant que répertoire de travail jusqu’à ce que vous le changiez à nouveau. Veuillez noter que si j’émets une commande de changement de répertoire, elle n’est valide que sur la ligne actuelle du Dockerfile . Cela signifie que si vous cd dans un répertoire sur une ligne, et dans la ligne suivante du Dockerfile que vous exécutez PWD, vous verrez que vous êtes de retour dans le répertoire racine par défaut. Cela concerne la façon dont Docker utilise un conteneur intermédiaire pour générer des couches d’image ; il y a plus à venir sur ce sujet plus tard, lorsque nous parlerons de l’optimisation des Dockerfiles dans le chapitre pilote.
COPY déplace les fichiers de la source {my-build-context} \ docker \ db vers le répertoire courant, = WORKDIR = C:\init. Ainsi, mes fichiers dans le répertoire docker \ db se retrouvent dans le répertoire c:\init.
CMD est la commande par défaut qui est exécutée lorsque le conteneur est exécuté (sans commande dans la ligne de commande de docker run). Dans notre cas, CMD exécute le script init.ps1 PowerShell. Le script init.ps1 masque la logique qui détermine s’il existe déjà une base de données dans le répertoire C:\mssql. Si les fichiers de base de données existent, il les utilisera. Si les fichiers n’existent pas, un script de suite est exécuté pour remplir la base de données initiale. C’est un modèle qui peut être vraiment utile pour les applications de test, où vous autorisez Docker à créer un volume éphémère et donc à générer une nouvelle base de données à chaque exécution :
La HealthCheck section Elton Dockerfile (indiqué ci – après) sera utilisé plus tard lorsque nous déployons notre conteneur dans un cluster Docker. Un contrôle d’intégrité définit le code qui est exécuté par l’orchestrateur afin de déterminer l’intégrité d’un conteneur. Dans notre cas, il exécute une commande SQL depuis l’intérieur de notre conteneur de base de données SQL. Si un orchestrateur trouve un conteneur malsain, il le tuera et le remplacera par un nouveau conteneur :
HEALTHCHECK CMD powershell -command `
try { `
$result = Invoke-SqlCmd -Query ‘SELECT TOP 1 1 FROM Countries’ -Database SignUpDb; `
if ($result[0] -eq 1) { return 0} `
else {return 1}; `
} catch { return 1 }
Nous avons maintenant un docker \ db \ Dockerfile complet pour construire notre image de serveur de base de données conteneurisée montrée dans le bloc de code suivant:
# escape=`
FROM microsoft/mssql-server-windows-express:2016-sp1
SHELL [“powershell”, “-Command”, “$ErrorActionPreference = ‘Stop’; $ProgressPreference = ‘SilentlyContinue’;”]
ENV ACCEPT_EULA=”Y” `
sa_password=”DockerCon!!!” `
DATA_PATH=”C:\mssql”
VOLUME ${DATA_PATH}
WORKDIR C:\init
COPY .\docker\db .
CMD ./init.ps1 -sa_password $env:sa_password -Verbose
HEALTHCHECK CMD powershell -command `
try { `
$result = Invoke-SqlCmd -Query ‘SELECT TOP 1 1 FROM Countries’ -Database SignUpDb; `
if ($result[0] -eq 1) { return 0} `
else {return 1}; `
} catch { return 1 }
Nous avons discuté de chaque ligne du bloc de code précédent, à l’exception de la ligne shell du fichier. La partie clé de cette ligne est la section $ ErrorActionPreference = ‘Stop’ qui indique au shell de s’arrêter à la première erreur et non à l’erreur, reprendre ensuite, la préférence d’erreur par défaut. En d’autres termes, arrêtez d’exécuter le script en cas d’erreur.
Il est temps de créer une image à l’aide de Dockerfile. Nous avons copié le code d’Elton sur notre machine de génération Windows, qui est soit un bureau Windows 10 soit un serveur Windows 2016.
Si vous créez un nouveau Windows Server 2016 pour créer et tester vos applications Windows conteneurisées, assurez-vous de mettre à jour Docker sur l’hôte, sinon vous pouvez obtenir une version ancienne telle que Docker 1.12. Pour mettre à jour Docker sur Windows 2016, exécutez cette commande: Install-Package -Name docker -ProviderName DockerMsftProvider -Verbose -Update -Force. Vous devrez probablement redémarrer le service Docker manuellement après la mise à jour.
Supposons que vous ayez copié vos fichiers dans le répertoire mta-netfx-dev. Nous concentrons ensuite notre attention sur la sous-arborescence db sous le répertoire docker pour mieux comprendre la commande docker build que nous allons exécuter (illustrée ci-dessous). Veuillez noter l’emplacement des fichiers Dockerfile, init-db.sql et init.ps1 de la base de données :
mta-netfx-dev
├── docker
│ ├── db
│ │ ├── Dockerfile
│ │ ├── init-db.sql
│ │ └── init.ps1
À partir du répertoire mta-netfx-dev, nous exécutons la commande docker image build pour créer l’image db-image : v1 et utilisons Dockerfile dans le dossier docker \ db que nous venons de créer. Vous devriez voir quelques images construites et marquées avec succès au bas de la sortie. N’oubliez pas la période de fin dans cette commande. Il fournit le contexte de construction où la commande COPY obtient sa base, dans ce cas, le répertoire mta-netfx-dev :
mta-netfx-dev$ docker image build -t db-image:v1 –file .\docker\db\Dockerfile .
…
Successfully built 026c23401784
Successfully tagged db-image:v1
Maintenant, nous pouvons lancer et tester notre serveur de base de données (illustré ci- dessous). Tout d’abord, nous allons exécuter un conteneur en utilisant l’image de base de données que nous créons. Nous utilisons -d pour l’exécuter en arrière-plan, exposer le port 5432 sur l’hôte et le transmettre au port 5432 à l’intérieur du conteneur. Ce sont les ports MS SQL standard. Ensuite, nous testons notre conteneur de base de données en exécutant une commande SQL sur notre base de données depuis l’intérieur du conteneur. Pour ce faire, nous devons obtenir une invite PowerShell à l’intérieur du conteneur. Nous pouvons utiliser la commande docker container exec pour créer un nouveau processus PowerShell et une invite de commande. À l’intérieur du conteneur, nous voyons l’invite PowerShell PS C: \ init> dans le WORKDIR . Nous utilisons le module de commande SQL (le même que nous utilisons pour le contrôle de santé dans le Dockerfile) pour interroger SignUpDb . Nous voyons que 1 est retourné. Vous pouvez bien sûr exécuter n’importe quel SQL dont vous souhaitez vérifier les données :
$ docker container run -d -p 5432:5432 db-image:v1
1fe040d1acf242d4cfdb47761db2a59f1bb44b5eedf17376b9455120d86281a5
$ docker container exec -it 1fe0 powershell
PS C:\init> Invoke-SqlCmd -Query ‘SELECT TOP 1 1 FROM Countries’ -Database SignUpDb
Column1
——-
1
3.3.3.4 Conteneurisation de l’application Webforms
Pour l’application Webforms, Elton adopte une approche plus sophistiquée. Ici, nous allons en fait créer deux fichiers image pour créer l’application Webform.
La figure 13 montre la dépendance de l’image :
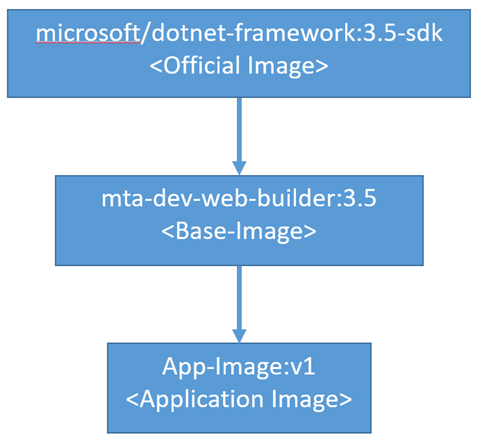
Figure 13: Graphique de dépendance d’image (pas de hiérarchie d’image)
Le premier fichier image est une image de générateur de base que nous pouvons utiliser pour cette application et réutiliser pour conteneuriser d’autres applications Webform .NET 3.5. Jetons donc un coup d’œil à l’image de base Dockerfile affichée dans le bloc de code suivant :
# escape=`
FROM microsoft/dotnet-framework:3.5-sdk
SHELL [“powershell”, “-Command”, “$ErrorActionPreference = ‘Stop’; $ProgressPreference = ‘SilentlyContinue’;”]
# Install web workload:
RUN Invoke-WebRequest -UseBasicParsing https://download.visualstudio.microsoft.com/download/pr/100196686/e64d79b40219aea618ce2fe10ebd5f0d/vs_BuildTools.exe -OutFile vs_BuildTools.exe; `
Start-Process vs_BuildTools.exe -ArgumentList ‘–add’, ‘Microsoft.VisualStudio.Workload.WebBuildTools’, ‘–quiet’, ‘–norestart’, ‘–nocache’ -NoNewWindow -Wait;
# Install WebDeploy
RUN Install-PackageProvider -Name chocolatey -RequiredVersion 2.8.5.130 -Force; `
Install-Package -Name webdeploy -RequiredVersion 3.6.0 -Force;
Ce fichier démarre de la manière habituelle, en remplaçant le caractère d’échappement par défaut pour une génération d’image Windows, en utilisant le backtick au lieu de la barre oblique inverse par défaut. Ensuite, nous voyons l’image de base de l’appel Microsoft, microsoft / dotnet-framework: 3.5-sdk . Veuillez noter que nous avons mis à jour la référence de l’image de base pour utiliser le nouveau schéma de référentiel de Microsoft à partir de l’exemple de docker / web-builder / 3.5 / Dockerfile d’Elton (illustré ci- dessous). Dans la deuxième section de ce Dockerfile , nous voyons les outils de génération de Visual Studio téléchargés et installés. Dans la dernière étape, nous voyons le fournisseur chocolatey utilisé pour installer le module webdeploy :
Pour référence, voici l’arborescence du système de fichiers docker / web :
mta-netfx-dev
├── docker
│ ├── web
│ │ └── Dockerfile
│ └── web-builder
│ └── 3.5
│ └── Dockerfile
Ceci est la complète docker / web-constructeur / 3,5 / Dockerfile fichier ; nous pouvons construire et étiqueter notre nouvelle image de base à l’aide de ce Dockerfile , et il agira comme image de base pour le Dockerfile de notre application :
mta-netfx-dev$ docker image build -t mta-sdk-web-builder:3.5 –file .\docker\web-builder\3.5\Dockerfile .
…
Successfully built df1102a58630
Successfully tagged mta-sdk-web-builder:3.5
Maintenant, nous pouvons utiliser cette nouvelle image comme image de base pour l’application Webforms, comme suit:
# escape=`
FROM mta-sdk-web-builder:3.5 AS builder
SHELL [“powershell”, “-Command”, “$ErrorActionPreference = ‘Stop’;”]
WORKDIR C:\src\SignUp.Web
COPY .\src\SignUp\SignUp.Web\packages.config .
RUN nuget restore packages.config -PackagesDirectory ..\packages
COPY src\SignUp C:\src
RUN msbuild SignUp.Web.csproj /p:OutputPath=c:\out /p:DeployOnBuild=true
# app image
FROM microsoft/aspnet:3.5-windowsservercore-10.0.14393.1884
SHELL [“powershell”, “-Command”, “$ErrorActionPreference = ‘Stop’;”]
ENV APP_ROOT=”C:\web-app” `
DB_CONNECTION_STRING_PATH=””
WORKDIR $APP_ROOT
RUN Import-Module WebAdministration; `
Set-ItemProperty ‘IIS:\AppPools\.NET v2.0’ -Name processModel.identityType -Value LocalSystem; `
Remove-Website -Name ‘Default Web Site’; `
New-Website -Name ‘web-app’ -Port 80 -PhysicalPath $env:APP_ROOT -ApplicationPool ‘.NET v2.0’
COPY .\docker\web\start.ps1 .
ENTRYPOINT [“powershell”, “.\\start.ps1”]
COPY –from=builder C:\out\_PublishedWebsites\SignUp.Web .
Le Dockerfile précédent est appelé une génération en plusieurs étapes car le fichier contient plusieurs instructions FROM. La première instruction FROM désigne la première étape de la génération, et elle est appelée générateur. C’est là que msbuild s’exécute pour réellement créer l’application. Cependant, il comprend de nombreux utilitaires dont nous n’avons pas besoin au moment de l’exécution. Ainsi, dans la toute dernière ligne du Dockerfile, nous copions les actifs de l’étape de génération dans la deuxième et dernière étape d’image. Par conséquent, tous les composants de construction sont laissés pour compte, ce qui réduit la taille de l’image finale et crée une surface d’attaque plus petite.
Un autre élément notable dans ce Dockerfile est l’avant-dernière ligne, où nous utilisons un ENTRYPOINT. Un ENTRYPOINT désigne le binaire qui sera exécuté au démarrage de ce conteneur. C’est différent de ce que nous avons fait dans la base de données Dockerfile , où nous avons défini un CMD. Bien que ceux-ci soient similaires, le CMD sera remplacé par tout ce qui est transmis depuis la ligne de commande et ENTRYPOINT ajoutera l’argument de ligne de commande en tant que paramètre à l’application définie par ENTRYPOINT :
# DB Image used CMD, easily overridden with any other command after the image name
$ docker container run -it run db-image:v1 dir
…directory listing from working directory C:\init
…container exits
# App Image used ENTRYPOINT, command after image name is passed as argument to start.ps1
$ docker container run -it db-image:v1 dir
… passes argument to “dir” as parameter to start.ps1 script and it’s ignored
… tries to start web application
Pour plus d’informations, consultez la documentation Docker suivante: https://docs.docker.com/engine/reference/builder/#cmd .
Maintenant, construisons notre image d’application :
docker image build -t app-image:v1 –file .\docker\web\Dockerfile .
…
Successfully built dec1102a58630
Successfully tagged app-image:v1
Nous avons donc construit trois images: une image de base pour la création d’applications Web ( mta-sdk-web-builder: 3.5 ) et deux images finales pour exécuter notre base de données et notre application ( db-image: v1 et app-image: v1 ). Il est temps de démarrer notre application et de la tester:
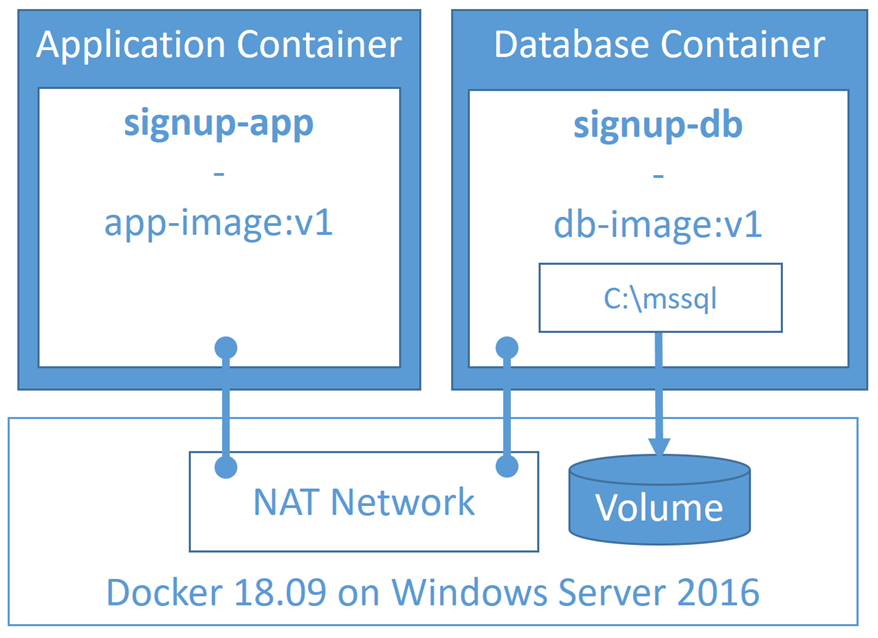
Figure 14: Test d’intégration locale
La figure 14 montre la configuration Docker à nœud unique de notre machine de génération locale utilisée pour tester les conteneurs d’applications locaux. Nous avons notre conteneur d’application, appelé signup-app , et notre conteneur de base de données, appelé signup-db . Le nom du conteneur de base de données ( signup-db ) est particulièrement important car le conteneur d’application s’appuie sur ce nom pour la recherche DNS pour la résolution de service (adresse IP routable localement) de la base de données. Les commandes suivantes montrent comment démarrer le conteneur de base de données, puis démarrer le conteneur d’application et partager un réseau nat commun. Les conteneurs doivent être sur le même réseau pour communiquer et partager des noms DNS :
# Start the database container
$ docker container run –network nat –name signup-db -d db-image:v1
# Start the application container
$ docker container run –network nat -p 8000:80 –name signup-app -d app-image:v1
La première commande d’exécution de conteneur démarre le conteneur de base de données en arrière-plan ( -d ) à partir de l’ image db-image: v1 , le nomme signup-db et l’attache au réseau nat . La deuxième commande d’exécution de conteneur démarre le conteneur d’application en arrière-plan ( -d ) à partir de l’ image app-image: v1 , la nomme signup-app et l’attache au réseau nat .
Avez-vous remarqué que le réseau nat est déjà là? Sur les hôtes Windows à nœud unique, Docker fournit un réseau Docker unique appelé nat . Contrairement aux réseaux de ponts Linux, vous ne pouvez pas créer de nouveaux réseaux. Cela est dû au fait que d’autres conteneurs Windows peuvent ou non s’exécuter sur le même démon / hôte Docker que Windows prend en charge l’isolement Hyper-V (c’est-à-dire, docker run -d –isolation hyperv microsoft / nanoserver powershell echo hyperv ). Par conséquent, les réseaux Docker doivent être liés avant le niveau de l’hôte, au niveau du réseau Hyper-V, avec un réseau natif Hyper-V . Pour faire simple, il existe un réseau pour Windows appelé nat ; il est disponible au démarrage et fournit le DNS à d’autres conteneurs nommés attachés au réseau nat .
Sur ma machine de test, je pointe mon navigateur vers mon adresse IP locale, 8000 (l’utilisation de localhost avec IIS peut être configurée avec une certaine autorisation bousculant dans IIS, mais nous pouvons utiliser l’IP de la machine de développement à la place) et je vois l’écran glorieux suivant sur la figure 15 :
Figure 15: Page d’application locale dans le navigateur
Nous pouvons maintenant arrêter notre conteneur à l’aide de la commande docker container rm -f .
3.3.3.5 Création de fichiers de déploiement et test localement
Nous avons maintenant testé les conteneurs individuels et il est temps de créer un fichier de composition de docker que nous pouvons utiliser pour rassembler la pile d’applications de services. L’outil de composition de Docker (docker-compose) fait partie de Docker gratuit. Historiquement, il a été un outil pour définir et exécuter des applications multi-conteneurs sur un seul nœud Docker. Cependant, dans Docker 1.13, Docker a introduit le mode Swarm avec des fonctionnalités étendues pour exécuter des applications multi-conteneurs sur plusieurs nœuds. Docker utilise le même format de fichier YAML (bien que les extensions Docker Swarm nécessitent la version 3+) pour configurer les multiples services de votre application. Lorsque le fichier docker-compose est configuré, nous pouvons démarrer notre base de données et nos services / conteneurs d’application avec une seule commande.
Ensuite, nous avons notre docker-compose pour les nœuds locaux. Suivant dans notre fichier docker-compose.yml, les noms d’image sont uniquement locaux (pas d’espace de nom devant le nom de l’image) et doivent être dans le cache d’image de l’hôte Docker pour être exécutés. Nous aborderons ce problème d’image locale plus tard. Notez également les noms de service (en gras dans le code suivant), qui seront utilisés pour la résolution DNS lorsque signup-app recherche signup-db dans la chaîne de connexion :
version: ‘3.3’
services:
signup-db:
image: db-image:v1
networks:
– app-net
signup-app:
image: app-image:v1
ports:
– “8000:80”
depends_on:
– signup-db
networks:
– app-net
networks:
app-net:
external:
name: nat
Pour exécuter notre application sur un seul nœud, nous utilisons la commande docker-compose up. Il est généralement préférable d’exécuter les commandes docker-compose dans le même répertoire que docker-compose.yml. Ensuite, nous voyons la commande en cours d’exécution et les entrées de journal suivantes :
PS mta-netfx-dev-part-2\app> docker-compose up
…
Creating app_signup-db_1_3084b8816d59 … done
Creating app_signup-app_1_cf2adb1663f8 … done
Attaching to app_signup-db_1_7dc594a2a1cf, app_signup-app_1_3c8d26d0a674
signup-db_1_7dc594a2a1cf | VERBOSE: Starting SQL Server
signup-db_1_7dc594a2a1cf | VERBOSE: Changing SA login credentials
signup-app_1_3c8d26d0a674 | Configuring DB connection
signup-app_1_3c8d26d0a674 | Starting IIS
signup-app_1_3c8d26d0a674 | Tailing log
signup-db_1_7dc594a2a1cf | VERBOSE: No existing data files – will create new database
signup-db_1_7dc594a2a1cf | VERBOSE: Changed database context to ‘master’.
signup-db_1_7dc594a2a1cf | VERBOSE: Changed database context to ‘SignUpDb’.
signup-db_1_7dc594a2a1cf |
signup-app_1_3c8d26d0a674 | 2018-11-11 01:47:55,705 [1 ] INFO – Completed pre-load data cache, took: 7020ms
signup-app_1_3c8d26d0a674 | 2018-11-11 01:48:14,908 [1 ] INFO – Starting pre-load data cache
signup-app_1_3c8d26d0a674 | 2018-11-11 01:48:15,033 [1 ] INFO – Completed pre-load data cache, took: 99ms
(press Ctrl+C twice to terminate)
$ docker-compose down
… clean up messages
Maintenant, nous avons un fichier docker-compose ou stack que nous pouvons utiliser pour exécuter notre application. Cependant, si nous voulons pouvoir exécuter ce fichier de pile à partir de n’importe où, nous devrons renommer et déplacer les images vers un registre central.
3.3.3.6 Pousser des images
Actuellement, nos images d’application et de base de données ne sont stockées que sur le nœud Docker où nous avons exécuté la commande de génération d’image docker. Pour notre PoC, nous utiliserons le DTR que nous avons installé dans notre cluster PoC.
3.3.3.6.1 Connexion au PoC DTR
Étant donné que vous utilisez un certificat auto-signé pour le DTR du PoC, vous devrez configurer le démon Docker de votre machine de génération locale pour faire confiance au certificat DTR utilisé lors de la connexion https. Si vous ne configurez pas votre machine de génération locale pour approuver le certificat DTR, vous obtiendrez une erreur de certificat x509 lorsque vous tenterez de vous connecter à DTR. Pour plus d’informations sur la configuration du système d’exploitation sur votre machine de génération, veuillez lire ceci: https://docs.docker.com/ee/dtr/user/access-dtr/ .
À ce stade, vous aurez besoin de vos informations de connexion pour l’UCP / DTR du PoC auprès de votre administrateur Docker Enterprise. En plus du nom d’utilisateur et du mot de passe, vous aurez également besoin du nom DNS ou de l’adresse IP routable de l’UCP et du DTR. Utilisez la commande suivante pour connecter un Docker Engine au DTR; suivez les invites pour les informations d’identification:
$ docker login url-of-docker-trusted-registry
username: dev-user
password: *******
…
WARNING! Your password will be stored unencrypted in C:\Users\Administrator\.docker\config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
Après l’avertissement, vous devez être connecté au DTR. Pour le PoC, ne vous inquiétez pas d’installer un assistant d’identification, mais ce n’est pas une mauvaise idée pour les postes de travail de développeur qui ont accès au cluster Docker Enterprise.
3.3.3.6.2 Préparer et pousser vos images
Maintenant que vous êtes connecté au DTR, vous pourrez pousser vos images une fois que vous les aurez correctement nommées / étiquetées. Les images sont identifiées par les propriétés de dénomination suivantes :
- L’URL du registre où ils sont stockés
- Le nom d’utilisateur ou l’espace de noms dans le registre
- Le nom du référentiel
- La balise image
Le format de dénomination de l’image Docker est le suivant : Repo_URL / Namespace / Repo_name: Tag
- Repo_URL : c’est là que se trouve votre Docker DTR. La valeur par défaut est docker.io (Docker Hub).
- Espace de noms : il s’agit du nom de l’organisation ou du nom d’utilisateur. La valeur par défaut est vide (images officielles Docker).
- Repo_name : il s’agit du nom du référentiel. C’est une valeur requise sans défaut.
- Tag : il s’agit du nom de la balise du référentiel. La valeur par défaut est la plus récente.
Les exemples de Docker Hub (docker.io) sont les suivants :
- Référentiel pour l’image officielle de CentOS avec la dernière balise : CentOS
- Référentiel pour l’image Ubuntu officielle avec la balise 16.04 : Ubuntu 16.04
- Organisation Microsoft, image de cadre .Net avec balise 3.5-sdk : microsoft / dotnet-framework: 3.5-sdk
Voici des exemples de mon organisation app-dev dans mon DTR PoC privé sur AWS:
- L’image de mon application : ec2-xxx-xxx-xxx-xxx.us-west-2.compute.amazonaws.com/app-dev/app-image:v1
- Mon image de base de données : ec2-xxx-xxx-xxx-xxx.us-west-2.compute.amazonaws.com/app-dev/db-image:v1
Comme vous pouvez le constater, mon référentiel a une organisation nommée app-dev et mon utilisateur fait partie de cette organisation. Votre administrateur Docker Enterprise peut les configurer ; vous êtes alors prêt à renommer vos images. Afin de préparer votre image, vous devrez renommer vos images au format approprié pour les stocker dans votre PoC DTR. Pour cela, nous utilisons la commande tag docker :
$ docker image tag db-image:v1 {insert-your-DTR-URL-here}/{user-name or org-name}/db-image:v1
$ docker image push {insert-your-DTR-URL-here}/{user-name or org-name}/db-image:v1
$ docker image tag app-image:v1 {insert-your-DTR-URL-here}/{user-name or org-name}/app-image:v1
$ docker image push {insert-your-DTR-URL-here}/{user-name or org-name}/app-image:v1
Une fois l’image poussée, entrez votre URL DTR dans le navigateur et n’oubliez pas le préfixe https://. Ensuite, regardez les référentiels. Vous devriez voir quelque chose comme l’écran montré dans la figure 16 :
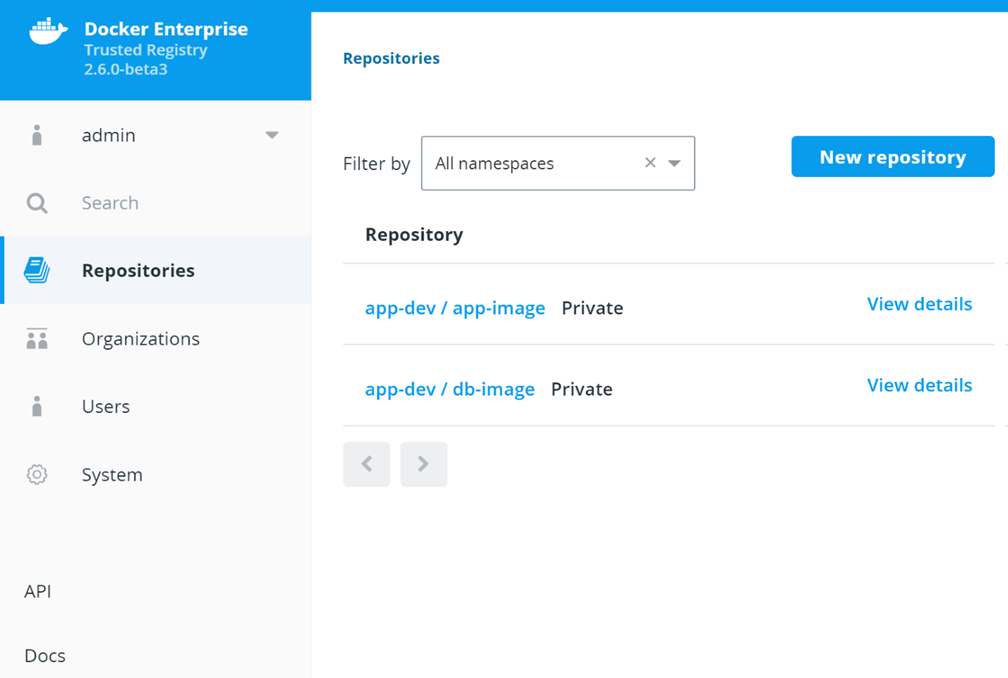
Figure 16: Images PoC dans le Docker Trusted Registry
Ensuite, nous examinerons le déploiement de notre application PoC sur le cluster Docker Enterprise.
3.4 Déploiement d’une application PoC sur un cluster Docker Enterprise
Afin de sécuriser l’accès à un cluster Docker Enterprise, nous utilisons le système de contrôle d’accès basé sur les rôles de Docker. Nous entrerons dans plus de détails sur le système de contrôle d’accès basé sur les rôles dans la phase pilote, mais pour notre PoC, nous avons besoin d’un utilisateur avec un accès suffisant pour déployer nos conteneurs d’applications PoC sur le cluster.
3.4.1 Le bundle CLI Docker Enterprise
Docker Enterprise facilite la gestion de l’accès à votre cluster. Il vous offre des contrôles d’accès précis aux ressources du cluster en générant un ensemble ( fichier .zip ) composé de vos certificats utilisateur signés par l’autorité de certification UCP qui a été créée lorsque vous avez installé UCP et des scripts pour connecter votre terminal à un cluster distant . Les scripts du bundle prennent en charge à la fois le PowerShell de Windows et le shell Bash Terminal de Linux. Non seulement ces scripts vous connectent en toute sécurité au démon de cluster Docker Enterprise, mais ils vous donnent également accès à l’API Kubernetes exécutée dans le cluster UCP. Assurez-vous simplement que le port 6443 est disponible pour accéder à l’API Kubernetes.
Le bundle peut être téléchargé de deux manières. La première consiste à se connecter à l’interface Web avec les informations d’identification que votre administrateur système vous a fournies. Ensuite, sous votre profil, vous pouvez générer un bundle et il téléchargera les certificats et les scripts dans un fichier ZIP sur votre lecteur local depuis le navigateur. La figure 17 montre la méthode de l’interface Web. Développez le menu d’ administration et cliquez sur Mon profil . Ensuite, choisissez Ensembles clients | Nouveau pack client | Générer un ensemble client . Par la suite, un fichier zip sera téléchargé via votre navigateur. Décompressez le contenu de ce fichier et déplacez-le dans un répertoire facile d’accès depuis votre shell:
Figure 17: Télécharger le pack client UCP
Une autre façon d’obtenir le bundle de ligne de commande sans utiliser l’interface Web consiste à utiliser l’API Docker Enterprise. L’API nécessite que vous génériez un jeton au porteur en transmettant votre nom d’utilisateur et votre mot de passe à l’API. Les résultats de l’appel seront un jeton que vous devrez transmettre avec l’en-tête aux appels API suivants. Donc, dans notre cas, nous générons d’abord notre jeton porteur. Ensuite, nous l’utilisons pour demander notre fichier de bundle UCP CLI. C’est un moyen très pratique d’accéder à l’API à partir de scripts PowerShell ou bash:
3.4.2 Utilisation de Bash avec Docker API pour obtenir le bundle CLI
Reportez-vous aux étapes suivantes :
- Avant de commencer le processus de téléchargement du bundle de ligne de commande via l’API, assurez-vous que les utilitaires curl , jq (un formateur léger pour les charges utiles JSON) et décompressez sont installés:
sudo apt-get update && sudo apt-get install curl jq unzip
- Maintenant, obtenez le jeton du porteur et appelez l’API pour récupérer les fichiers CLI. Assurez-vous de remplacer par l’IP ou le DNS de votre IP Docker PoC:
# Stash your Bearer token in an environment variable
AUTHTOKEN=$(curl -sk -d ‘{“username”:””,”password”:””}’ https:///auth/login | jq -r .auth_token)
# Download the client certificate bundle
curl -k -H “Authorization: Bearer $AUTHTOKEN” https:///api/clientbundle -o bundle.zip
# Unzip the bundle.
unzip bundle.zip
# Run the utility script.
eval “$(<env.sh)”
# You are connected to the cluster – test it.
docker node ls
… listing of your Docker Enterprise nodes
3.4.3 Utilisation de PowerShell avec l’API Docker pour obtenir le bundle CLI
Si vous préférez vous connecter à votre cluster EE avec un Windows PowerShell standard, utilisez les commandes suivantes. Encore une fois, assurez-vous de remplacer le , le et le par l’IP ou le DNS de votre IP Docker PoC:
PS> $AUTHTOKEN=((Invoke-WebRequest -Body ‘{“username”:”<username>”, “password”:”<password>”}’ -Uri https:///auth/login -Method POST).Content)|ConvertFrom-Json|select auth_token -ExpandProperty auth_token
PS> [io.file]::WriteAllBytes(“ucp-bundle.zip”, ((Invoke-WebRequest -Uri https:///api/clientbundle -Headers @{“Authorization”=”Bearer $AUTHTOKEN”}).Content))
PS> Expand-Archive -Path ucp-bundle.zip -DestinationPath .
PS> Import-Module .\env.ps1
Security warning
Run only scripts that you trust. While scripts from the internet can be useful, this script can potentially harm your
computer. If you trust this script, use the Unblock-File cmdlet to allow the script to run without this warning
message. Do you want to run C:\Users\Administrator\PoC CLI\env.ps1?
[D] Do not run [R] Run once [S] Suspend [?] Help (default is “D”): R
PS> docker node ls
… listing of your Docker Enterprise nodes
Visitez la documentation Docker ici pour plus d’informations sur le bundle de ligne de commande: https://docs.docker.com/ee/ucp/user-access/cli/ .
3.4.4 Déploiement de l’application PoC sur le cluster Docker Enterprise
Maintenant que vous êtes connecté au cluster Docker via le bundle d’interface de ligne de commande, il est temps de déployer votre application. Jusqu’à présent, nous avons déployé les conteneurs sur votre machine de développement ou de génération pour vous assurer que l’application fonctionne correctement. Ensuite, nous avons poussé les images vers le DTR afin qu’elles soient disponibles pour notre orchestrateur lorsque nous déployons notre pile sur le cluster.
Jusqu’à présent, nous avons créé notre fichier docker-compose.yml et l’avons exécuté avec la commande docker-compose up pour que notre pile de conteneurs (décrits comme services dans le fichier YAML) exécute notre hôte Docker unique / local. Maintenant, nous voulons exécuter cette même pile de conteneurs sur notre cluster Docker Enterprise. Docker facilite les choses en nous permettant d’utiliser le format de fichier familier docker-compose.yml pour déployer sur un cluster Docker Enterprise (ou Swarm) à l’aide de la commande docker stack deploy. Cependant, il y a certaines choses que nous devons faire pour préparer ce cluster. Par exemple, il est vraiment important de noter comment les noms d’images doivent utiliser un chemin d’accès complet à votre référentiel de registres de confiance. Sinon, l’orchestrateur ne pourra pas extraire les images des nœuds du cluster et le déploiement échouera.
Tout d’abord, renommons le fichier docker-compose en quelque chose comme stack.yml . Cela aidera à éviter toute confusion lorsque nous essayons de déterminer le fichier à utiliser pour un déploiement de cluster. Étant donné que la commande Docker Swarm pour le déploiement est le déploiement de la pile Docker, la pile devrait être un choix assez logique et que nous voyons souvent utilisé.
Les fichiers docker-compose peuvent être utilisés pour les déploiements Swarm avec la commande docker stack deploy , mais nécessitent la version 3.0 ou plus récente (déclarée en haut du fichier). Remarquez comment nous utilisons la version 3.3, qui nous permettra d’ajouter la section de déploiement à notre fichier de pile.
En examinant le fichier stack.yml , nous allons passer en revue les modifications du fichier qui sont nécessaires lors de la mise à niveau d’un fichier Docker -compose à un seul nœud vers un fichier de cluster Swarm. Tout d’abord, notez que l’image utilise un chemin DTR complet vers votre registre PoC. Deuxièmement, notez l’ajout de la section de déploiement dans le fichier. Ici, nous utilisons le mode de point de terminaison DNS Round Robin (DNSRR) car nous utilisons Windows Server 2016 où VIP (Virtual IP, l’approche d’équilibrage de charge intégrée Docker préférée) n’est pas disponible. Recherchez VIP sur Windows dans Windows Server 2019.
En conjonction avec un point de terminaison DNSRR, nous devons utiliser le mode hôte pour publier les ports IP pour le trafic externe. Cela signifie que le port est publié uniquement sur l’adaptateur à l’hôte sur lequel le conteneur d’inscription à l’application s’exécute. Pour nous, cela signifie que nous devrons pointer tout le trafic entrant vers notre nœud de travail Windows sur le port 8000. Bien que cela puisse sembler un peu limitatif, il s’agit d’une configuration assez courante pour certaines des implémentations Docker à l’ancienne.
Enfin, notez le léger changement de notre réseau. Auparavant, nous l’avions en tant que réseau externe lorsque nous fonctionnions sur un seul nœud Windows 2016. Cela était principalement dû à certaines limitations de Docker fonctionnant sur un seul nœud avec Windows Server 2016, où vous êtes limité à un réseau nat préconfiguré pour connecter les conteneurs. Donc, pour accéder au réseau préexistant, nous avons utilisé le réseau externe. Maintenant, cependant, nous fonctionnons en mode Swarm et Swarm fournit un réseau de superposition, permettant à nos conteneurs de communiquer entre plusieurs nœuds du cluster. L’implémentation par défaut du réseau de superposition Docker est VXLAN dans les coulisses :
# stack.yml file
version: ‘3.3’
services:
signup-db:
image: {insert-your-DTR-URL-here}/{user-name or org-name}/db-image:v1
networks:
– app-neto
deploy:
endpoint_mode: dnsrr
placement:
constraints:
– node.platform.os==windows
signup-app:
image: {insert-your-DTR-URL-here}/{user-name or org-name}/app-image:v1
ports:
– mode: host
target: 80
published: 8000
depends_on:
– signup-db
networks:
– app-neto
deploy:
endpoint_mode: dnsrr
placement:
constraints:
– node.platform.os==windows
networks:
app-neto:
driver: overlay
Pour plus d’informations sur la création de fichiers Docker -compose , consultez le manuel Docker docs: https://docs.docker.com/compose/compose-file/ .
Maintenant, pour exécuter l’application dans le cluster, vous devez procéder comme suit :
# Deploy the test stack
docker stack deploy -c .\stack.yml.txt test
# Look at the services
docker service ls
ID NAME MODE REPLICAS IMAGE
paoo6ej3ubcz test_signup-app replicated 1/1 ec2-xx-xx-x-xx.us-west-2.compute.amazonaws.com/app-dev/app-image:v1
w32lxzt14khc test_signup-db replicated 1/1 ec2-xx-xx-x-xx.us-west-2.compute.amazonaws.com/app-dev/db-image:v1
Pour tester l’application, pointez votre navigateur sur l’adresse IP externe du nœud de travail Windows sur le port 8000. Vous pourriez voir ceci :

Figure 18: Écran d’erreur d’application PoC
Cela signifie que l’application d’inscription est apparue avant que la base de données ne soit prête. Vous voyez, le depends_on paramètre dans le stack.yml fichier est fiable avec docker-Compose et non docker deploy pile. En outre, depend_on signifie uniquement que le PID 1 du processus dépendant est opérationnel et non que la base de données est complètement initialisée et prête. Bien que ce soit certainement quelque chose que nous voudrions voir dans la phase pilote, nous pouvons le modifier manuellement pour le PoC. Pour notre ajustement, nous redémarrerons le service d’application, et la façon la plus simple de le faire est de réduire le service d’inscription à 0 réplicas, puis de sauvegarder jusqu’à 1 réplique. Voici les commandes pour le faire :
docker service scale test_signup-app=0
…
docker service scale test_signup-app=1
Maintenant, nous pouvons revenir à notre navigateur et actualiser la page. Maintenant, nous devrions voir le site de newsletter Dockercon.
3.5 Mise à jour de l’application PoC
Toutes nos félicitations ! Vous avez conteneurisé votre application PoC et l’avez exécutée sur votre plateforme Docker POC. Vous devriez être à l’aise pour déployer le code que vous avez conteneurisé précédemment à l’aide de l’aperçu du processus. Cependant, c’est une bonne idée de démontrer à quel point il est facile de mettre à jour et de déployer votre application PoC sur le cluster.
Pour illustrer le processus de mise à jour, essayez ce qui suit :
- Faites un petit ajustement de code qui apparaîtra dans l’interface utilisateur.
- Dans le fichier src / SignUp.aspx, modifiez les éléments suivants :
Play with Docker is the best thing I’ve ever heard of!
Here are my details. Sign me up.
- Modifiez-le comme suit:
Play with Docker Enterprise Rocks!
Here are my details. Sign me up.
- Reconstruisez votre conteneur d’application et testez-le localement:
docker image build -t app-image:v1 –file .\docker\web\Dockerfile
docker-compose up
- Étiquetez votre conteneur mis à jour avec une balise v2 et poussez- le vers DTR:
docker image tag app-image:v1 {insert-your-DTR-URL-here}/{user-name or org-name}/app-image:v2
docker image push {insert-your-DTR-URL-here}/{user-name or org-name}/app-image:v2
- Mettez à jour votre fichier de pile pour utiliser la nouvelle image avec la balise v2 pour la section d’application app-image (illustrée ci-dessous) et n’oubliez pas d’enregistrer vos modifications:
signup-app:
image: {insert-your-DTR-URL-here}/{user-name or org-name}/app-image:v2
ports:
– mode: host
target: 80
published: 8000
depends_on:
– signup-db
networks:
– app-neto
deploy:
endpoint_mode: dnsrr
placement:
constraints:
– node.platform.os==windows
- Avec l’ancienne pile toujours en cours d’exécution (l’ancienne version de app-image), réexécutez la commande docker stack deploy :
docker stack deploy -c .\stack.yml.txt test
- L’image mise à jour doit être mise à jour.
- Vérifiez les modifications dans le navigateur en jouant avec Docker Enterprise Rocks !
3.6 Résumé
Dans ce dernier chapitre de notre section Mise en route , nous avons véritablement lancé notre parcours Docker Enterprise en créant notre propre environnement, où nous pouvons exécuter une application PoC conteneurisée. L’objectif est de pouvoir montrer comment Docker Enterprise fonctionnera dans votre environnement et à quoi il ressemble en exécutant l’une de vos propres applications.
Tout d’abord, nous avons préparé l’environnement pour le PoC. Nous avons commencé avec quelques nœuds PoC sur un réseau commun. Ensuite, nous avons préparé chaque nœud en installant le Docker Engine, ainsi que les composants Docker Enterprise, comprenant le plan de contrôle universel et le DTR. Ensuite, avec l’environnement PoC prêt à l’emploi, nous nous sommes concentrés sur la sélection et la conteneurisation d’une application PoC.
La sélection d’une application de validation de principe peut être un peu délicate. Nous voulons en trouver une qui peut être conteneurisée sans aucune refactorisation de code, et en même temps, nous voulons trouver une application représentative d’autres applications susceptibles de suivre le chemin de la conteneurisation. Une fois que nous avons sélectionné l’application et l’avons conteneurisée, nous pouvons démontrer les processus de déploiement et de mise à jour à l’aide d’un environnement Docker Enterprise réel.
Donc, à ce stade, nous avons une certaine expérience de travail avec notre nouvelle plate-forme de conteneurs, ainsi que notre première application conteneurisée sous notre ceinture. Après notre démonstration de PoC et nos discussions avec les parties prenantes, nous devrions être prêts à passer à l’étape pilote du chapitre 4 , Préparer le cluster pilote Docker Enterprise.
4 Préparez le cluster pilote Docker Enterprise
Alors que nous entrons dans la phase pilote de notre adoption de conteneurs d’entreprise, nous commençons par une table rase. Forts de notre expérience de la preuve de concept, nous commencerons à prendre des décisions de conception à long terme concernant notre plateforme Docker Enterprise. L’objectif ici est d’avoir une plateforme prête pour les déploiements de pilotes internes. Tout le montage n’est pas nécessaire pour une application de production complète, mais plutôt une plate-forme de développement interne qui est prête à prendre en charge plusieurs équipes de développement d’applications internes.
Dans ce chapitre, nous allons commencer la phase pilote et parcourir la conception, la configuration et la construction d’un cluster pilote Docker Enterprise. Avant que nous soyons prêts à prendre des décisions de conception concernant la plate-forme pilote, cependant, nous devrons revoir certains concepts Docker importants liés à la mise en réseau. De plus, nous devons configurer notre cluster en apprenant davantage sur les paramètres de configuration du plan de contrôle universel (UCP) de Docker. La configuration comprend également la manière dont les utilisateurs interagiront avec le cluster pour concevoir un schéma de contrôle d’accès basé sur les rôles (RBAC). Enfin, dans ce chapitre, nous sauvegardons nos concepts clés avec une présentation d’une installation sans système d’exploitation de Docker Enterprise 2.1 sur CentOS 7.5. Bien que nous revenions à l’infrastructure certifiée Docker pour le cloud et les machines virtuelles (VM), le bare metal est un excellent moyen d’apprendre des détails de configuration importants pour Docker Enterprise.
Nous aborderons les sujets suivants dans ce chapitre:
- Clusters hautement disponibles pour Swarm et Kubernetes
- Contrôle d’accès basé sur les rôles (RBAC) pour isoler plusieurs équipes sur un seul cluster
- Cluster sécurisé avec certificats clients externes
- Journalisation centralisée
- Surveillance
- Pipeline logiciel sécurisé avec des référentiels d’organisation distincts
- Numérisation d’image et alerte de vulnérabilité
Pendant la phase PoC, notre seule exigence liée au réseau était d’avoir tous les nœuds sur le même réseau et une configuration de réseau qui permettrait une libre circulation du trafic entre les nœuds. Alors que nous passons à la phase pilote, nous devons commencer à comprendre les réseaux Docker plus en détail. Nous commencerons par décrire la mise en réseau que Docker fournit sur un nœud de moteur unique. Ensuite, nous entrerons dans une discussion concernant la mise en réseau dans un environnement en cluster, comme un essaim dans Kubernetes.
4.1 Introduction à la mise en réseau à nœud unique Docker
Alors que la mise en réseau à nœud unique peut sembler un oxymore, dans les premiers jours de Docker, de nombreux conteneurs s’exécutaient sur un seul nœud. De plus, il n’y avait pas de grappes. Il était nécessaire que les conteneurs puissent communiquer entre eux de manière sûre et facile, même sur un seul nœud Docker. Ainsi, bien qu’il ne soit généralement pas utilisé dans le domaine Docker Enterprise, nous fournissons un aperçu rapide ici. Cela fournira une base pour les modèles de mise en réseau de conteneurs basés sur un cluster pertinents utilisés par Swarm et Kubernetes.
Au cœur de la mise en réseau Docker se trouve le modèle de réseau de conteneurs ( CNM ) de Libnetwork . Le CNM est un modèle Docker pour composer des réseaux de conteneurs de manière abstraite, distinct de l’implémentation du réseau sous-jacent, et donc portable. C’est un peu comme la version de Docker de l’infrastructure en tant que code, en utilisant l’API réseau comme abstraction de l’infrastructure. Pour nos besoins, nous allons résumer les points clés de la mise en réseau à nœud unique Docker.
Dépannage du réseau de conteneurs Veuillez vous référer au référentiel Libnetwork, ainsi qu’au célèbre conteneur utilitaire de dépannage réseau de Nicola Kabar; c’est le couteau suisse des utilitaires de mise en réseau de conteneurs. Pour plus d’informations, veuillez consulter la documentation ici: https://github.com/nicolaka/netshoot .
En ce qui concerne la mise en réseau de conteneurs, Docker a adopté une approche très pragmatique. C’était difficile car ils ont essayé d’équilibrer la sécurité et la convivialité. En conséquence, il est généralement facile à utiliser, mais il existe des bizarreries compréhensibles basées sur des décisions de conception fondamentales. Dans la figure 1, nous voyons un seul nœud hôte Docker avec un seul conteneur en cours d’exécution. De bas en haut, nous voyons l’adaptateur hôte connecté au réseau de pont Docker0 Linux, attaché à un seul conteneur (Docker prend en charge plusieurs conteneurs sur un hôte, mais nous nous concentrerons sur un seul conteneur pour notre premier exemple) via un Ethernet virtuel ( veth) point final. Notez que l’espace de noms d’hôte et l’espace de noms de conteneur sont séparés. Ceci est important pour que les utilisateurs et les applications à l’intérieur de l’espace de noms du conteneur ne puissent pas voir l’espace de noms du réseau hôte. Il s’agit d’une fonctionnalité de sécurité importante fournie par les réseaux de ponts Linux :
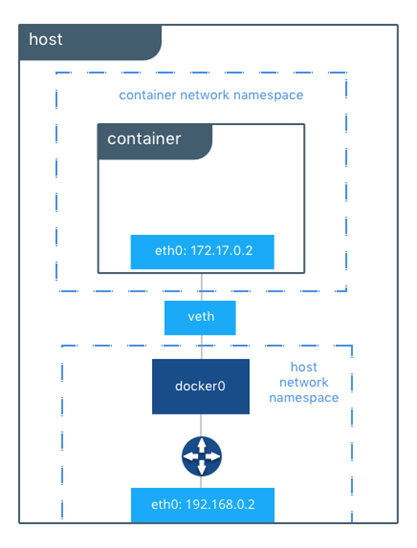
Figure 1: Docker0 Bridge Network – Copyright © 2018 Docker Inc. Tous droits réservés
Le réseau de pontage Docker0 Linux, qui est le réseau par défaut utilisé lors du lancement de conteneurs, possède certaines propriétés spéciales. Par défaut, les conteneurs lancés avec la commande runer docker sont attachés à ce réseau par défaut et sont accessibles par d’autres conteneurs sur le réseau Docker0 via leur adresse IP (c’est-à-dire 172.17.0.2 sur la figure 1). Si vous souhaitez que votre conteneur soit complètement isolé des autres conteneurs, exécutez votre conteneur avec le réseau none, comme indiqué dans le bloc de code suivant. Sinon, il sera automatiquement connecté au réseau Docker0 :
$ docker run –rm -dit \
–network none \
–name no-net-alpine \
alpine:latest \
ash
Il existe trois types de réseaux de base utilisés avec les réseaux de conteneurs à nœud unique, comme suit :
- Réseaux de ponts Linux
- réseaux hôtes
- aucun réseau
Ces types de réseaux sont créés à l’aide de pilotes réseau Docker lors de la création du réseau. Nous l’avons vu lorsque nous avons précédemment créé le réseau none pour isoler notre conteneur. Docker utilise le réseau de pont Linux lorsqu’il crée le réseau par défaut Docker0 sur chaque hôte Docker. Nous examinerons les réseaux de ponts plus en profondeur dans un instant, en particulier lorsqu’ils s’appliquent à la coutume qui fonctionne. Le pilote de réseau none, comme nous l’avons déjà décrit, peut être utilisé pour isoler complètement un conteneur.
L’utilisation du pilote de réseau hôte n’est pas recommandée car elle donne au conteneur l’accès à l’espace de noms du réseau hôte. En d’autres termes, toutes les ressources réseau de l’hôte sont accessibles en tant que root depuis l’intérieur du conteneur lors de l’utilisation d’un pilote de réseau hôte. Cela introduit évidemment des menaces de sécurité potentielles.
4.1.1 Pas de système de noms de domaine (DNS) pour le réseau par défaut Docker0
Par défaut, les conteneurs peuvent communiquer avec d’autres conteneurs locaux sur le réseau Docker0 en utilisant uniquement leurs adresses IP, car le réseau Docker0 ne fournit aucun service DNS. Veuillez noter qu’au départ, Docker fournissait un mécanisme primitif pour référencer les conteneurs à l’aide de quelque chose appelé liens, mais les liens ont été dépréciés en faveur des réseaux définis par l’utilisateur. Les réseaux définis par l’utilisateur, qui pontent les réseaux par défaut sur les hôtes Docker à nœud unique, peuvent être utilisés à la fois pour l’isolement et la découverte de services.
Dans la figure 2 suivante, nous voyons trois conteneurs s’exécuter sur un hôte Docker :
- Le premier conteneur, c1 , a été exécuté et automatiquement connecté au réseau Docker0 par défaut.
- Les conteneurs c2 et c3 sont connectés à un réseau de ponts personnalisé appelé my_bridge . Dans ce scénario, le conteneur c2 peut communiquer avec le conteneur c3 en utilisant l’adresse IP, 10.10.0.254, ou en utilisant le nom du conteneur c3 .
- Le conteneur c3 peut communiquer avec le conteneur c2 en utilisant soit l’adresse IP de 10.0.0.2, soit le nom du conteneur c2 .
- c2 et c3 peuvent communiquer librement sur leur réseau de pont personnalisé, mais ils ne peuvent pas interagir avec le conteneur c1 .
Docker isole le conteneur qui fonctionne en ajoutant des règles de blocage de table IP pour interdire tout routage du trafic entre les réseaux Docker. Cela signifie que vous ne pouvez pas utiliser les adresses DNS ou IP pour communiquer entre les conteneurs du Docker0 et le réseau de pont personnalisé.
La figure 2 montre un réseau Docker à nœud unique configuré avec un réseau par défaut ( docker0 ) et personnalisé ( my_bridge ):
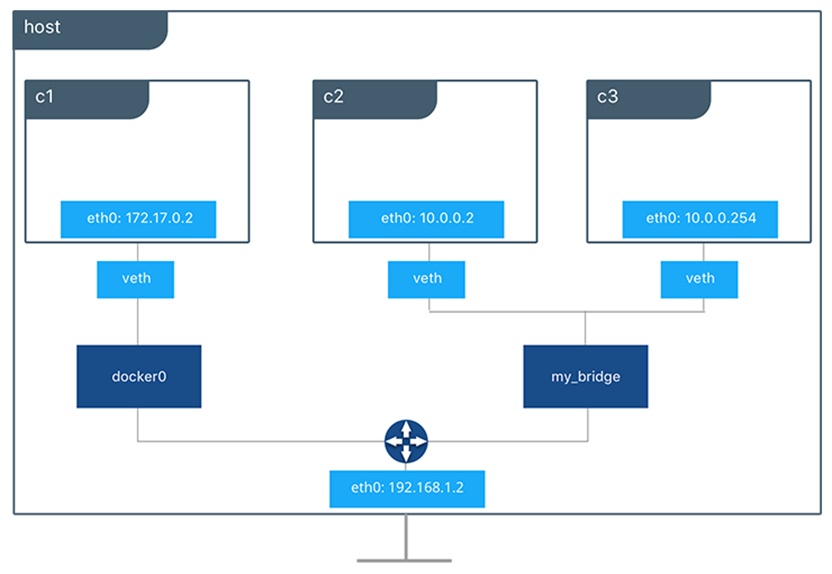
Figure 2: Réseau de pont personnalisé – Copyright © 2018 Docker Inc. Tous droits réservés
Ce type d’isolement doit être pris en compte lors de la transition de l’ancien concept de sous-réseau DMZ physique et de serveur Web vers une application basée sur un conteneur sur un réseau Docker. Ces mêmes principes d’isolement s’appliquent aux réseaux Docker dans les clusters ainsi que les nœuds uniques, et deviennent un concept vraiment important à saisir lors de l’utilisation des conteneurs dans Enterprise.
En raison des fonctionnalités d’isolation de réseau de Docker, nous pouvons créer notre propre réseau web frontal isolé et notre réseau de données backend pour chaque pile d’applications à 3 niveaux. Cela isolera non seulement les couches de votre application, mais isolera également les conteneurs de chaque application les uns des autres. Ainsi, sur le même cluster, nous pouvons avoir des versions de développement, de test et d’assurance qualité de la même application qui s’exécutent côte à côte sans interférer les unes avec les autres. Dans le chapitre 5 , Préparer et déployer une application pilote Docker Enterprise, nous discuterons du contrôle d’accès basé sur les rôles qui peut être utilisé en combinaison avec l’isolement du réseau comme une fonctionnalité puissante pour prendre en charge en toute sécurité plusieurs équipes dans les mêmes ressources de cluster hors production.
4.1.2 Introduction à la mise en réseau de conteneurs basée sur un cluster
Jusqu’à présent, notre discussion s’est concentrée sur un environnement de réseau Docker à nœud unique. Bien que la mise en réseau Docker à nœud unique soit riche en fonctionnalités avec l’isolement du réseau et DNS, elle est toujours contenue dans un seul hôte. Cela signifie que le trafic entre les conteneurs ne doit pas frapper un réseau externe. De plus, cela signifie que notre plate-forme est limitée à un seul nœud, ce qui limite notre capacité à évoluer et à basculer. Ainsi, nous étendons maintenant notre attention aux clusters exécutant des conteneurs avec les orchestrateurs Swarm et Kubernetes. Cela signifie que nos conteneurs doivent non seulement communiquer avec d’autres conteneurs sur le même nœud, mais ils doivent également s’étendre sur le réseau et communiquer avec des conteneurs s’exécutant sur différents nœuds du cluster.
Les conversations de mise en réseau basées sur un cluster sont souvent organisées autour de trois plans de mise en réseau clés : le plan de données, le plan de contrôle et le plan de gestion. Le concept de communication entre conteneurs sur l’ensemble du cluster est souvent appelé le plan de données. Bien que le plan de données soit la caractéristique clé qui intéresse la plupart des développeurs d’applications distribuées, il nécessite le soutien des plans de contrôle et de gestion pour fonctionner.
Afin de faciliter la maintenance nécessaire au fonctionnement du plan de données – c’est-à-dire quels conteneurs s’exécutent sur un nœud particulier et comment y accéder – il existe un composant réseau supplémentaire basé sur un cluster appelé plan de contrôle. Enfin, la catégorie de mise en réseau de cluster liée aux fonctions de gestion de cluster, avec des responsabilités telles que l’ajout et la suppression de nœuds membres de cluster et le maintien de l’intégrité du cluster et de la planification des conteneurs, est appelée le plan de gestion.
Docker Swarm et Kubernetes prennent tous deux en charge les plans de données pour les communications inter-cluster et inter-conteneurs. Cependant, ils adoptent une approche différente de la mise en œuvre. Docker Swarm utilise des réseaux de superposition VXLAN pour créer des réseaux isolés et éventuellement chiffrés pour un sous-ensemble sélectionné de services Swarm.
Cela signifie que nous pouvons définir un réseau personnalisé au sein d’une pile d’applications Swarm et isoler quels conteneurs peuvent communiquer directement au sein de ma pile d’applications. Voici comment nous pouvons créer un réseau frontal pour votre application Web et votre API à partager, et un réseau principal pour que l’API de la base de données se connecte, comme le montre la figure 3 :
Figure 3: Exemple d’isolement du réseau Swarm
Ce type d’isolement du réseau est facilement réalisé en utilisant les réseaux de superposition intégrés de Docker avec Swarm. Kubernetes adopte une approche différente.
Kubernetes réalise une communication inter-cluster et inter-conteneurs avec un modèle de mise en réseau à superposition plate. La figure 4 montre comment nos composants d’application sont connectés au réseau plat unique et l’isolement est appliqué à l’aide de stratégies réseau pour limiter le flux de trafic entre nos composants d’application :
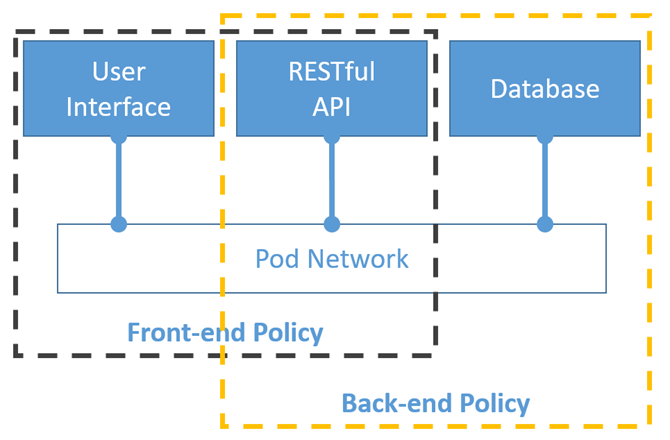
Figure 4: Isolement de la politique du réseau Calico
Le modèle de mise en réseau de cluster Kubernetes est implémenté à l’aide d’un plug-in CNI (Container Networking Interface) tiers . Cela signifie que Kubernetes ne fournit pas de mise en réseau prête à l’emploi, juste la spécification pour les tiers de construire des implémentations de mise en réseau appropriées. Par conséquent, vous devez installer un plugin CNI lors de l’installation de Kubernetes. C’est là que Docker Enterprise facilite les choses.
Docker Enterprise installe automatiquement l’orchestrateur Kubernetes lors de l’installation de l’UCP. De plus, Docker Enterprise fournit un plug-in Calico CNI intégré par défaut lors de l’installation de l’UCP. Calico utilise une combinaison de BGB et IP dans IP pour établir un plan de données.
Il existe plusieurs plug-ins Kubernetes CNI populaires pour la mise en réseau. Calico est devenu un choix très populaire, mais il y en a d’autres comme Weave, Flannel et Romana. Docker facilite l’échange de plug-ins CNI lors de l’installation d’UCP. Pour ce faire, vous devez trouver l’URL appropriée pour le fournisseur CNI et utiliser le paramètre –cni-installer-url pour la commande d’installation UCP. Docker a un article sur ce sujet, que vous pouvez lire ici: https://docs.docker.com/ee/ucp/kubernetes/install-cni-plugin/ .
Docker Enterprise propose diverses options de mise en réseau Kubernetes. Ceci est particulièrement important lors de l’installation de Docker Enterprise sur une plate-forme cloud où il existe des restrictions sur les protocoles réseau. Par exemple, sur Azure, l’IP dans le protocole IP n’est pas autorisé, donc l’implémentation Calico prête à l’emploi n’est pas une option. AWS et Azure proposent des plug-ins Kubernetes CNI personnalisés pour prendre en charge la mise en réseau Kubernetes avec la prise en charge de la mise en réseau native. Sachez que ces plug-ins CNI de plateforme cloud sont livrés avec des limitations (éventuellement importantes) et sont spécifiques à la plateforme – conduisant éventuellement au verrouillage de la plateforme cloud, ou du moins à l’adhérence.
4.1.2.1 DNS Swarm et Kubernetes et découverte de services
Swarm et Kubernetes fournissent des services DNS, qui sont principalement utilisés pour prendre en charge la découverte de services. Le DNS est vraiment important pour une plate-forme d’application distribuée comme moyen d’exécution, de découverte de service. Disons que vous avez deux composants d’application : une API et un service de base de données. L’API a besoin du service de base de données pour stocker et récupérer des données. Désormais, au moment de l’exécution lorsque l’application est déployée (les deux services sont déployés par un orchestrateur dans des conteneurs individuels), l’API doit trouver le service de base de données et se connecter sur un port particulier.
Dans notre ancien monde statique, nous connections simplement une adresse IP ou, espérons-le, une entrée DNS locale qui se résoudrait en adresse IP du service de base de données au moment de l’exécution. Comme les composants d’application sont devenus de plus en plus éphémères, des mécanismes de serveur ont émergé pour accomplir ce type de découverte de service pour les architectures d’applications distribuées, y compris Consul.io et Eureka.
Bien que ces outils de découverte de services externes fonctionnent très bien, ils introduisent une autre partie mobile dans votre environnement. Dans un effort pour simplifier la plate-forme, Docker Swarm et Kubernetes ont un DNS intégré. Alors que Swarm et Kubernetes fonctionnent différemment en termes de configuration et d’implémentation, du point de vue des applications, ils sont assez similaires.
Essentiellement, une application exécutée avec l’un ou l’autre orchestrateur peut faire référence à un point de terminaison durable d’un processus dépendant et distinct, appelé service. Le nom du service se résout en une adresse IP routable. De plus, ces services surveillent l’intégrité des conteneurs ou des pods sous-jacents et les remplacent s’ils deviennent malsains. Enfin, un service peut agir comme un équilibreur de charge devant un groupe de conteneurs et une demande d’équilibrage de charge entre eux.
Dans la figure 5, nous avons un service redis avec quatre modules (tous utilisant la même image de conteneur redis), mais accessible via un seul point de terminaison de service redis : 6379. Les appelants font référence au nom du service redis à partir de leur code et la demande a été résolue dans l’un des quatre conteneurs de sauvegarde, comme suit :
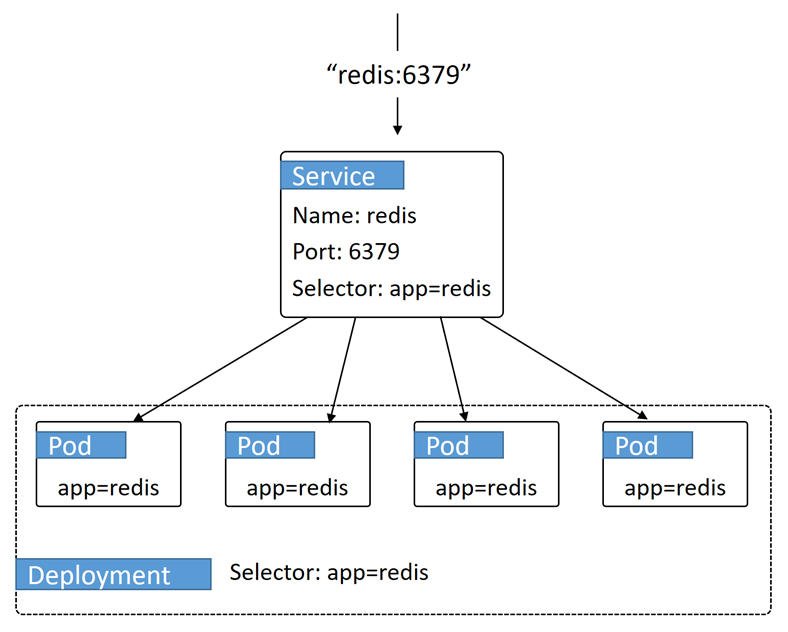
Figure 5: Service Kubernetes
Comme vous pouvez le voir, le plan de données est une partie essentielle d’un cluster de conteneurs. Il fournit non seulement un moyen de communication entre les conteneurs répartis sur le cluster, mais le DNS intégré fournit également le mécanisme pour les lier ensemble lors de l’exécution. Kubernetes et Swarm sont conçus pour que les applications conteneurisées soient aussi portables que possible, et les solutions de données et DNS standard le permettent.
4.1.2.2 Les plans de gestion et de contrôle
Les plans de gestion et de contrôle sont les éléments constitutifs d’une grande partie de la technologie de cluster moderne. Comme mentionné au chapitre 2 , Docker Enterprise – an Architectural Overview , les nœuds du gestionnaire sont membres d’un groupe de consensus Raft soutenu par un cluster Etcd chiffré pour stocker des éléments tels que l’état, les certificats et les secrets du cluster. De plus, les nœuds de gestionnaire sont responsables de la planification des charges de travail sur le cluster. La figure 6 montre le plan de gestion dans l’ombrage bleu et le plan de contrôle dans l’ombrage vert.
Pour fonctionner correctement, il doit y avoir un nombre impair de nœuds de gestionnaire dans l’état d’intégrité car vous devez maintenir un quorum (c’est-à-dire que la majorité des gestionnaires doivent se mettre d’accord sur les modifications apportées à l’état du cluster). Bien que les clusters avec un nœud de gestionnaire unique soient efficaces, en cas de problème avec le gestionnaire unique, notre cluster sera inutilisable jusqu’à ce que le gestionnaire soit restauré. Alors que nous passons à la phase pilote, il est fortement recommandé d’utiliser des clusters avec trois à cinq nœuds gestionnaire / maître pour la redondance :
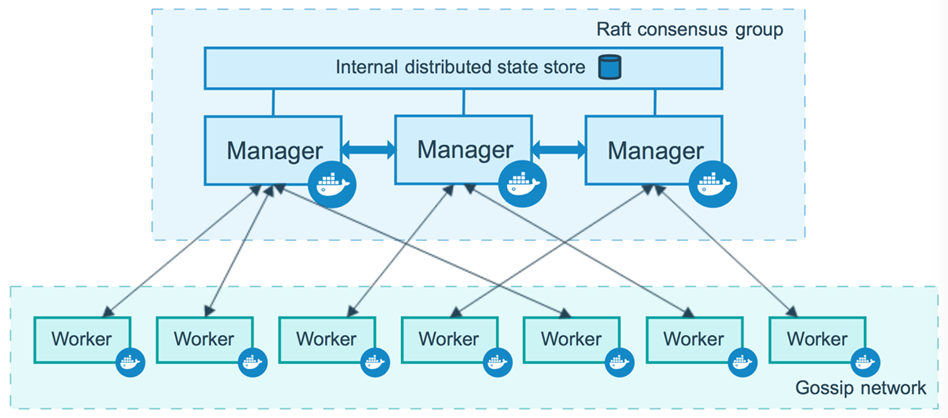
Figure 6: Plan de gestion et de contrôle de l’essaim – Copyright © 2018 Docker Inc. Tous droits réservés
En règle générale, pour la plupart des implémentations à haute disponibilité, trois nœuds gestionnaire / maître suffisent. Certains opérateurs de cluster optent pour cinq nœuds de gestionnaire pour plus de résilience lors de la maintenance de routine sur le cluster. N’oubliez pas, comme indiqué au chapitre 2 , Docker Enterprise – an Architectural Overview , nous avons besoin d’un nombre impair de gestionnaires. Bien qu’il soit agréable d’avoir cinq nœuds de gestionnaire / maître, cela ajoute du trafic réseau, des ressources de calcul et des coûts de licence à votre cluster. Aller au-delà de cinq nœuds de gestionnaire / maître entraîne généralement des rendements décroissants rapidement.
N’oubliez pas que les gestionnaires et les maîtres sont vos animaux de compagnie et que les nœuds de travail sont vos bovins. Les nœuds de gestionnaire sont sauvegardés et reposent sur des adresses IP fixes, tandis que les nœuds de travail peuvent être augmentés et réduits selon les besoins sur les adresses IP dynamiques.
Alors que nous nous préparons pour notre environnement pilote, il est important pour nous de comprendre quels ports sont utilisés par les différents plans de travail du cluster Docker EE. Nous devons nous assurer que nos politiques de réseau et nos pares-feux permettent à ces ports de passer librement. Le tableau suivant présente une liste de tous les ports utilisés dans les plans de contrôle de gestion et de données du cluster Docker Enterprise :
Voici les ports réseau pour divers plans de mise en réseau :
| Noeuds | Port | Avion | Objectif |
| gestionnaires, travailleurs | TCP 179 | Les données | Port pour les homologues BGP, utilisé pour la mise en réseau Kubernetes |
| gestionnaires | TCP 443 (configurable) | La gestion | Port pour l’interface utilisateur Web et l’API UCP |
| gestionnaires | TCP 2376 (configurable) | La gestion | Port pour le Docker Swarm Manager. Utilisé pour la compatibilité descendante |
| gestionnaires | TCP 2377 (configurable) | La gestion | Port pour contrôler la communication entre les nœuds Swarm |
| gestionnaires, travailleurs | UDP 4789 | Les données | Port pour réseau de superposition |
| gestionnaires | TCP 6443 (configurable) | La gestion | Port pour le point de terminaison du serveur API Kubernetes |
| gestionnaires, travailleurs | TCP 6444 | La gestion | Port pour le proxy inverse de l’API Kubernetes |
| gestionnaires, travailleurs | TCP, UDP 7946 | Contrôle | Port pour le clustering basé sur les ragots |
| gestionnaires, travailleurs | TCP 10250 | La gestion | Port pour Kubelet |
| gestionnaires, travailleurs | TCP 12376 | La gestion | Port pour un proxy d’authentification TLS qui donne accès au Docker Engine |
| gestionnaires, travailleurs | TCP 12378 | La gestion | Port pour proxy inverse Etcd |
| gestionnaires | TCP 12379 | La gestion | Port pour l’API de contrôle Etcd |
| gestionnaires | TCP 12380 | La gestion | Port pour l’API Etcd Peer |
| gestionnaires | TCP 12381 | La gestion | Port pour l’autorité de certification de cluster UCP |
| gestionnaires | TCP 12382 | La gestion | Port pour l’autorité de certification du client UCP |
| gestionnaires | TCP 12383 | La gestion | Port pour le backend de stockage d’authentification |
| gestionnaires | TCP 12384 | La gestion | Port pour le backend de stockage d’authentification pour la réplication entre les gestionnaires |
| gestionnaires | TCP 12385 | La gestion | Port pour l’API du service d’authentification |
| gestionnaires | TCP 12386 | La gestion | Port pour le travailleur d’authentification |
| gestionnaires | TCP 12388 | La gestion | Port interne pour le serveur API Kubernetes |
Veuillez noter que les ports Kubernetes peuvent changer si vous choisissez un autre fournisseur CNI. De plus, Kubernetes avec Calico nécessite le protocole d’encapsulation IPv4 4 et la superposition Swarm VXLAN nécessite le protocole ESP 50. Cela peut être des informations très utiles lorsque vous configurez tout type de filtrage réseau, de groupes de sécurité réseau ou de paramètres de règles de pare-feu.
Maintenant que nous comprenons un peu les plans de mise en réseau de clusters et comment ils sont utilisés, nous allons commencer à planifier les détails de la mise en œuvre de la plate-forme pilote.
4.1.3 Mise en œuvre du réseau pilote Docker Enterprise
Passons maintenant à l’implémentation de notre plan de gestion, plan de contrôle et plan de données. Dans cette section, nous verrons comment planifier et implémenter le travail pour prendre en charge les différents plans de travail utilisés par Docker Enterprise. Bien que tout cela puisse sembler interne au cluster, ce n’est pas très bien sans obtenir le trafic entrant et sortant du cluster, ainsi que pour prendre en charge deux cas d’utilisation clés. Par conséquent, nous clarifierons la portée et les exigences de notre implémentation de réseau en présentant ces deux cas d’utilisation clés pour le cluster, comme suit :
- Utilisateurs internes interagissant avec le cluster
- Utilisateurs finaux d’applications d’applications hébergées dans notre environnement de cluster
4.1.3.1 Utilisateurs du cluster interne
Dans un cluster Docker Enterprise, il existe deux manières principales pour les utilisateurs internes d’accéder aux API et ressources de cluster sécurisées. Le premier est via l’interface utilisateur Web UCP, en utilisant un nom d’utilisateur et un mot de passe émis par un administrateur UCP. La seconde se fait via un bundle client Docker Enterprise. Ce bundle est généré par UCP et comprend des certificats et des scripts pour connecter à distance une session de terminal local au cluster, à l’aide de certificats spécifiques à l’utilisateur pour un accès sécurisé, une authentification de cluster et une autorisation de cluster. Le bundle comprend des scripts pour les shells Linux et Windows PowerShell.
Ne donnez accès à SSH à aucun utilisateur, à l’exception d’un groupe spécial d’administrateurs et de responsables de cluster. Accorder l’accès SSH à un nœud de gestionnaire de cluster permet aux utilisateurs d’exécuter de puissantes fonctions administratives, telles que la récupération du mot de passe de l’administrateur UCP. Par conséquent, l’accès SSH aux nœuds de cluster doit être très restreint / réglementé et non disponible pour les opérateurs de cluster et les développeurs d’applications.
Les deux méthodes ont précédemment décrit notre sujet aux autorisations établies par l’administrateur du cluster, ce qui signifie que vos vues, à la fois du bundle client et du Web, seront filtrées en fonction de vos droits de contrôle d’accès. Normalement, les utilisateurs du cluster auront accès à leur propre sandbox personnel, où ils peuvent créer des conteneurs, des réseaux, des volumes, des secrets et des configurations, qui sont tous isolés dans leur sandbox utilisateur. Lors de l’utilisation de Docker Enterprise Advanced, l’administrateur peut choisir de restreindre les nœuds que vous pouvez déployer dans les charges de travail.
Dans la figure 7, nous voyons une illustration de la façon dont le trafic circule depuis les shells de commande (Linux et Windows PowerShell) et les navigateurs des utilisateurs internes vers le cluster. L’interface utilisateur Web UCP résout une adresse IP externe pour l’équilibreur de charge UCP via une entrée DNS de portée appropriée. Dans notre exemple suivant, nous l’avons appelé ucp.mydomain.com. L’équilibreur de charge transmet ensuite le trafic à l’un des trois nœuds UCP en cours d’exécution dans notre cluster. Notez que ce trafic circule sur le port 443 à l’aide de TLS et nécessite l’échange et la vérification de certificats. Avec UCP, ceci est réalisé en utilisant un passthrough SNI dans l’équilibreur de charge, où le certificat se termine au nœud UCP final et non dans l’équilibreur de charge. Nous reviendrons à une discussion sur les certificats après la section suivante. Tout d’abord, nous devons parler de la façon dont les utilisateurs externes accèdent à notre cluster, comme suit:
Figure 7: accès au cluster distant avec UCP
4.1.3.2 Utilisateurs finaux des applications hébergées par Docker Enterprise
Le prochain cas d’utilisation en termes d’information sur la conception et la mise en œuvre de notre réseau est le cas d’utilisation d’un utilisateur final d’applications hébergées en cluster. Comme son nom l’indique, nous parlons ici de la façon dont les utilisateurs finaux accèdent aux applications que nous avons déployées sur le cluster Docker Enterprise. La méthode que j’illustre dans la figure 8 est un modèle qui offre le maximum de flexibilité pour les déploiements de cluster. Cette approche permet aux équipes de développement, de DevOps ou d’Ops (avec le droit d’accès) de déployer complètement une application sur le cluster sans apporter de modifications d’équilibreur de charge externes ni de mises à jour DNS. Cela simplifie considérablement les déploiements et réduit le nombre de pièces mobiles majeures dans une plate-forme d’entreprise. Il existe bien sûr d’autres approches qui utilisent des clusters de services et des services sans tête pour créer un modèle de trafic plus déterministe pour le chemin réseau d’une application particulière, mais ces approches nécessitent une configuration plus coordonnée des équilibreurs de charge et du DNS lorsqu’une application est déployée.
La figure 8 illustre l’accès de l’utilisateur final à une application déployée en cluster avec un équilibreur de charge proxy inverse de couche 7 pour les applications. Ici, nous voyons l’utilisateur final de l’application entrer le nom de domaine complet (FQDN) de l’application dans son navigateur. Une fois la demande effectuée, une entrée DNS générique récupère le nom de l’application et le transmet à l’équilibreur de charge d’application externe. L’équilibreur de charge d’application externe traduit ensuite la demande en un port spécial où le cluster attend le trafic d’application. Par exemple, nous utiliserons le port 8443 pour les applications Swarm et un port éphémère (32768+) pour une application Kubernetes.
Normalement, cela ressemblera à un simple relais NAT entre le port / IP externe de l’équilibreur de charge et le port / IP interne du contrôleur d’entrée du cluster. Cependant, il est possible de diviser les applications entre différents contrôleurs d’entrée. Cela peut être fait pour accueillir Swarm et Kubernetes s’exécutant dans le même cluster, ou en utilisant quelque chose appelé des clusters de services, pour regrouper certains services au sein d’un contrôleur d’entrée particulier. Bien que vous puissiez en avoir besoin à un moment donné, la phase pilote n’est généralement pas le point de départ. Restez simple à ce stade de votre implémentation, avec un seul contrôleur d’entrée, si possible.
Lorsque le trafic atteint le contrôleur d’entrée L7 dans le cluster, l’en-tête est examiné pour déterminer s’il correspond à l’une des règles de proxy inverse à l’aide d’un nom d’hôte ou d’un chemin. Si une correspondance est trouvée, le contrôleur d’entrée L7 transfère le trafic vers le service IP de cluster ou Swarm approprié. Plus loin dans cet article, nous explorerons les mécanismes du cycle de vie du contrôleur d’entrée pour Kubernetes et Swarm; mais pour l’instant, il est important de se concentrer sur le flux de trafic réseau, comme suit:
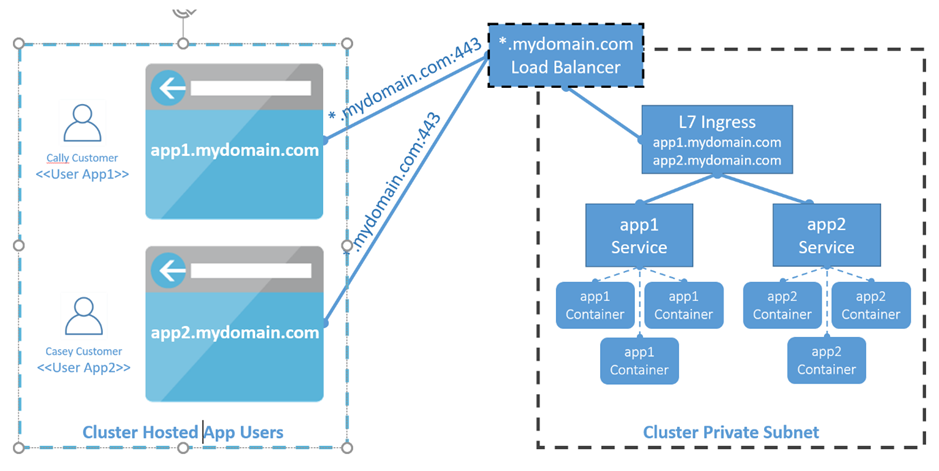
Figure 8: accès au cluster distant avec UCP
Nous voyons maintenant comment le réseau circule pour les utilisateurs internes et les utilisateurs d’applications hébergées en cluster. Maintenant, parlons de la façon dont nous sécurisons nos connexions entre les utilisateurs internes accédant au cluster et les utilisateurs finaux se connectant aux applications exécutées dans le cluster.
4.1.3.3 Cluster hautement disponible
L’un des principaux objectifs du projet pilote est de mieux comprendre le modèle opérationnel de Docker Enterprise requis pour prendre en charge les applications stratégiques. Par conséquent, le pilotage d’un cluster Docker HA est fortement recommandé pendant la phase pilote.
L’architecture de référence d’un cluster Docker Enterprise inclut des considérations de résilience et d’évolutivité. Comme indiqué dans le chapitre sur l’architecture Docker Enterprise, les clusters hautement disponibles incluent les nœuds de gestionnaire sur lesquels le logiciel Docker UCP est installé. En raison de la nature de l’algorithme de consensus de radeau, qui nécessite un nombre impair de gestionnaires, le plus petit cluster redondant comprend trois nœuds de gestionnaire. Pour la plupart des plateformes pilotes, trois nœuds de gestion devraient suffire pour prendre en charge la haute disponibilité et l’évolutivité jusqu’à 100 nœuds. Gardez à l’esprit que 100 nœuds constitueront un très grand cluster pour une plateforme pilote.
Plus d’informations sur Raft peuvent être trouvées sur: https://raft.github.io/ , et plus d’informations sur Docker Swarm Raft peuvent être trouvées sur: https://docs.docker.com/engine/swarm/raft/ .
Il est également judicieux de s’assurer que le Docker Trusted Registry (DTR) est hautement disponible. Après tout, sans registre d’images fonctionnel, les applications ne peuvent pas être déployées. Pour satisfaire une exigence HA DTR, nous utilisons trois répliques du DTR s’exécutant sur un sous-ensemble spécial de nœuds de travail, réservés aux charges de travail DTR uniquement.
4.1.3.4 DNS, certificats et terminaison de certificat
Pendant notre PoC, il était acceptable d’utiliser des certificats auto-signés générés par l’UCP au moment de l’installation. Cependant, alors que nous entrons dans la phase pilote, c’est le bon moment pour introduire des certificats tiers émis par une source de confiance.
Il existe deux types de certificats impliqués dans Docker Enterprise :
- Certificats de cluster internes
- Certificats clients externes
Chaque type possède sa propre autorité de signature racine CA. Les certificats internes sont ceux utilisés par le cluster Swarm pour le chiffrement TLS entre les nœuds Swarm. Les certificats clients externes sont utilisés pour accéder au cluster à partir de sources externes avec un accès géré via l’UCP. Les certificats qui nous intéressent principalement pour la configuration sont les certificats clients externes. Ceux-ci doivent être configurés pour utiliser des certificats de confiance tiers afin d’éviter à la fois les erreurs de certificat x509 des serveurs distants et les avertissements de sécurité du navigateur.
La norme de l’industrie pour la sécurisation des connexions Internet est Transport Layer Security ( TLS ). Une prise de contact TLS a plusieurs exigences, mais deux éléments clés pour notre discussion. Tout d’abord, le serveur doit avoir un certificat de serveur valide, signé par une autorité de certification approuvée. Deuxièmement, le certificat de serveur doit être valide pour l’URL demandée.
Le premier élément est assez simple. Lorsqu’un client demande un certificat au serveur, il valide le certificat signé par une autorité de certification de confiance. Si ce n’est pas le cas, nous obtenons les avertissements de sécurité habituels du navigateur. Par conséquent, nous avons besoin d’un certificat délivré par un tiers de confiance. Ces certificats sont disponibles auprès de divers émetteurs, ou votre organisation peut déjà avoir sa propre chaîne de CA établie.
Le deuxième élément nécessite une correspondance entre le nom commun du certificat (CN ou domaine vers lequel le certificat a été émis) et l’URL utilisée pour acheminer la demande vers le serveur sur lequel le certificat est installé. Cela signifie que si un certificat a été délivré avec un CN de app1.mydomain.com, et une demande arrive à un serveur sur lequel le certificat est installé, avec l’en- tête montrant un nom d’hôte cible de app1.mydomain.com, la connexion sécurisée sera autorisée car le CN et les noms d’hôte de l’en-tête correspondent. Bien que cela soit excellent pour la sécurité, il est très lourd d’avoir un certificat distinct pour chaque nom d’hôte URL utilisé dans mon cluster. Pour résoudre ce problème, il existe deux façons courantes de gérer le défi du certificat à l’aide de certificats multi-domaines ou génériques.
L’objectif pour les deux types de certificats est de permettre la prise en charge de plusieurs domaines dérivés d’un seul serveur avec un seul certificat. Cependant, le multi-domaine et le caractère générique accomplissent cela différemment. Les certificats multi-domaines ont un CN, plus une liste d’autres domaines valides, utilisant des noms alternatifs de sujet (SAN). L’idée principale ici est que la structure de domaine du SAN peut être complètement différente. Par conséquent, les certificats multi-domaines sont parfaits lorsque vos noms de domaine internes et externes sont différents (c’est-à-dire app1.mydomain.com et app2.test.mydomain.local ). Une autre considération pour les certificats multi-domaines est que tous les domaines doivent être connus lors de la génération du certificat. Sinon, le SAN supplémentaire peut être ajouté, mais le nouveau certificat avec ces mains doit être distribué aux serveurs. Enfin, les domaines multiples sont une meilleure option si vous utilisez votre propre chaîne d’autorité de certification de certificat interne approuvée. Sinon, ils peuvent être coûteux et maladroits à entretenir auprès d’un fournisseur tiers.
Les certificats génériques sont une autre option populaire. Ils vous donnent des domaines illimités, mais il y a un hic, car tous les domaines doivent partager la même base. Par exemple, un certificat générique pour * .mydomain.com fonctionne pour des domaines tels que app1.mydomain.com et app2.mydomain.com , mais pas app2.test.mydomain.com . Au lieu de cela, vous vous retrouvez avec des domaines ressemblant à quelque chose comme app1-test.mydomain.com pour le test et app1.mydomain.com pour la production. La bonne nouvelle ici est que vous n’avez pas besoin de connaître tous vos domaines lorsque vous émettez le certificat, et les certificats génériques ont tendance à être moins chers que les certificats multi-domaines d’émetteurs tiers. Cependant, cela force une structure de domaine cohérente en interne et en externe, ce qui signifie que les serveurs de cluster internes devront s’adapter au schéma avec quelque chose comme prod-ucp-1.mydomain.com, et vous devrez généralement utiliser une approche DNS partagée / interne pour vos noms DNS accessibles en externe, tels que app1.mydomain.com.
Les résultats de cette configuration DNS signifient que lorsque app1.mydomain.com est référencé en interne, il obtient une adresse IP interne privée (quelque chose comme 10.1.1.23). Inversement, lorsqu’il est accessible publiquement, le même nom de domaine se résout en une adresse IP publiquement routable sur votre pare-feu qui est NAT à l’IP interne (10.1.1.23). En raison des attaques de rebond DNS, le trafic n’est généralement pas autorisé à sortir du pare-feu et à y revenir. Sinon, vous pouvez simplement compter sur le NAT, mais la plupart des configurations sur site ne le permettront pas.
Une fois que vous avez décidé du type de certificat et de la structure DNS le mieux adapté à votre environnement, vous devez ensuite déterminer où mettre fin aux connexions TLS côté serveur.
Il existe trois approches courantes pour la terminaison TLS. La première approche se termine au niveau de l’équilibreur de charge externe. Par conséquent, les connexions sont chiffrées entre le client et l’équilibreur de charge externe et autorisées à circuler non chiffrées sur le réseau interne. Il s’agit d’une approche de sécurité basée sur le périmètre assez classique et qui présente l’avantage de plus petits paquets sur votre réseau interne et la possibilité d’afficher les paquets sur votre réseau interne pour le débogage. Ce schéma est simple à mettre en œuvre et efficace pour la mise en réseau interne, mais il est généralement inadéquat pour les exigences de sécurité actuelles.
La deuxième approche de terminaison met fin à la connexion à la destination finale. Dans un environnement basé sur un conteneur, cela signifie mettre fin à la connexion TLS à l’intérieur d’un point de terminaison de conteneur. Le résultat est une connexion sécurisée tout au long du chemin entre le client et le serveur final – nulle part dans le chemin d’accès au réseau les paquets ne peuvent être décryptés. Il s’agit d’un moyen très sécurisé de connecter des points de terminaison. Cependant, cela signifie que les certificats devront être distribués et maintenus à l’intérieur de chaque conteneur avec un point de terminaison sécurisé, à l’aide de TLS. Auparavant, il était vraiment difficile de mettre à jour vos certificats, mais avec l’introduction de secrets dans Swarm et Kubernetes, il peut être très gérable et sécurisé de stocker des certificats en tant que secrets dans les environnements de développement, de test, d’assurance qualité et de production. et injecter les secrets / certificats appropriés lors de l’exécution.
La troisième approche de terminaison commence comme la première, où nous terminons au niveau de l’équilibreur de charge externe, mais nous rechiffrons ensuite pour le réseau interne à l’aide d’un certificat différent. Avec ce schéma, le certificat externe critique est verrouillé, tandis que le certificat interne est utilisé uniquement en interne pour inspecter les paquets à des fins de dépannage et de débogage, mais uniquement sur le réseau interne. Donc, si la clé de certificat interne était compromise, vous auriez toujours besoin d’un accès physique au réseau interne pour l’utiliser. Avec cette approche, si votre application escroc se détache à l’intérieur de votre réseau, à moins qu’elle ne possède la clé de votre certificat / clé interne, elle ne pourra voir aucun trafic sur les réseaux communs car elle est chiffrée avec le certificat interne. L’inconvénient est que vous avez des paquets cryptés plus importants qui transitent par votre réseau interne, mais le compromis est généralement acceptable dans le but de fournir des niveaux de sécurité élevés.
Bien que vous puissiez choisir l’une de ces approches de terminaison pour vos propres applications lorsque vous les déployez sur votre cluster, UCP et DTR attendent la deuxième approche de terminaison, où vous mettez fin aux connexions dans l’UCP dans des conteneurs DTR. UCP et DTR stockent leurs certificats à l’aide des volumes Docker, ucp-client-root-ca et dtr-ca- (où chaque nœud DTR a un ID de réplique unique), respectivement.
La terminaison des certificats DTR et UCP se produit à l’intérieur des conteneurs de point de terminaison DTR et UCP réels. En d’autres termes, ils ne doivent pas être interrompus par un équilibreur de charge en amont. De plus, ces certificats sont stockés dans des volumes Docker spéciaux où ils sont accessibles par les conteneurs DTR et UCP. Nous pouvons utiliser ces volumes pour configurer les certificats avant d’installer le logiciel Docker EE, ou les certificats tiers DTR et UCP peuvent être injectés dans les commandes d’installation DTR et UCP en tant que paramètres.
Une autre exigence importante pour votre cluster est un nom d’hôte résolvable DNS pour votre nœud de cluster.
4.1.3.5 Noms d’ hôte pour les nœuds de cluster Docker
Docker s’appuie sur un nom d’hôte interne pour fonctionner correctement. Avant d’installer Docker Enterprise sur vos nœuds de cluster, vous devez choisir un nom d’hôte. Vous pouvez utiliser des noms d’hôte courts ou des noms de domaine complets. Soyez cohérent avec votre schéma de dénomination dans le cluster, car Docker Engine et UCP reposent tous deux sur des noms d’hôtes. Cela signifie que vos noms d’hôtes doivent être résolus avec DNS sur tous les nœuds du cluster.
Si vous exécutez sur une plate-forme cloud, assurez-vous que les noms DNS privés sont activés pour vos hôtes Docker afin que vos noms d’hôtes soient résolus en interne.
Dans un environnement sans système d’exploitation, vous devrez ajouter les noms d’hôte des adaptateurs réseau. Dans une configuration cloud, la plupart des plateformes offrent une option pour activer le DNS interne pour vos nœuds de cluster.
4.1.3.6 Cluster métal nu – exemple de configuration réseau
À ce stade, nous avons parlé de suffisamment de sujets théoriques et conceptuels pour préparer le terrain et souligner les décisions clés associées à la plomberie sous-jacente de notre grappe. Maintenant, il est temps de commencer à parcourir les étapes de la création d’un exemple de configuration de cluster pilote bare metal pour voir à quoi ressemblent ces décisions et comment elles sont mises en œuvre.
4.1.3.6.1 Étape 1 – définir un nom de domaine et une structure de nom d’hôte
Pour un exemple de limitation, nous avons choisi la structure de nom de domaine externe suivante :
- ucp.mydomain.com : cette adresse de domaine est utilisée pour accéder à l’interface utilisateur Web UCP et pour se connecter à distance à l’API UCP.
- dtr.mydomain.com : Cette adresse de domaine est utilisée pour accéder à l’interface utilisateur Web DTR et pour se connecter à distance à l’API DTR pour pousser et tirer des images.
- * .mydomain.com : ce domaine est utilisé pour accéder aux applications hébergées dans notre cluster DTR.
Les noms d’hôtes internes en métal nu que nous avons utilisés sont les suivants :
- ntc-ucp-1.mydomain.com
- ntc-ucp-2.mydomain.com
- ntc-ucp-3.mydomain.com
- ntc-dtr-1.mydomain.com
- ntc-dtr-2.mydomain.com
- ntc-dtr-3.mydomain.com
- ntc-wrk-1.mydomain.com
- ntc-wrk-2.mydomain.com
- ntc-wrk-3.mydomain.com
- ntc-nfs-server.mydomain.com
Quelques notes importantes doivent être mentionnées ici. Tout d’abord, tous ces noms DNS se résolvent correctement à l’intérieur du réseau. Deuxièmement, le certificat générique ( * .mydomain.com ) fonctionnera correctement car tous les noms d’hôtes partagent la même structure de domaine de base de mydomain.com .
4.1.3.6.2 Étape 2 – définir une structure de certificat et un plan de terminaison
Dans notre exemple, nous utilisons un certificat générique émis par un tiers pour sécuriser les trois points d’entrée de domaine (*.mydomain.com). Notre choix fonctionne pour un exemple relativement simple où tous nos domaines DTR partagent le même domaine de base ( mondomaine.com). Non seulement ces domaines doivent partager la même structure de domaine de base en externe, mais ils doivent également partager le même schéma en interne. Pour ce faire, nous utilisons une configuration DNS divisée, où nous avons un redirecteur DNS interne pour intercepter les demandes pour notre structure de domaine depuis l’intérieur de notre réseau et répondre avec des adresses IP privées internes. Nous reviendrons plus en détail à ce sujet plus tard, mais vous pouvez vous référer à la figure 9 pour plus d’informations.
Les certificats UCP et DTR sont couverts par le certificat générique et se terminent à l’intérieur des conteneurs de contrôleur UCP s’exécutant sur les nœuds UCP et DTR de notre cluster. Tous les autres certificats d’application couverts par le DNS générique et le certificat correspondant seront terminés, soit dans le conteneur d’application, soit dans le serveur proxy inverse du contrôleur d’entrée.
4.1.3.6.3 Étape 3 – concevoir et mettre en œuvre une infrastructure réseau
Le cluster est accessible lorsque les utilisateurs adressent le cluster à l’aide de l’un des noms de domaine externes. Nous avons trois entrées de domaine externe pour UCP, DTR et une entrée DNS générique pour nos applications hébergées en cluster. Toutes ces entrées DNS sont résolues en adresses IP publiques sur le pare-feu externe.
Veuillez noter que, dans notre exemple, nous utilisons des adresses IP représentatives mais fictives. Un aperçu de l’exemple de configuration de métal nu est illustré à la figure 9 , comme suit:
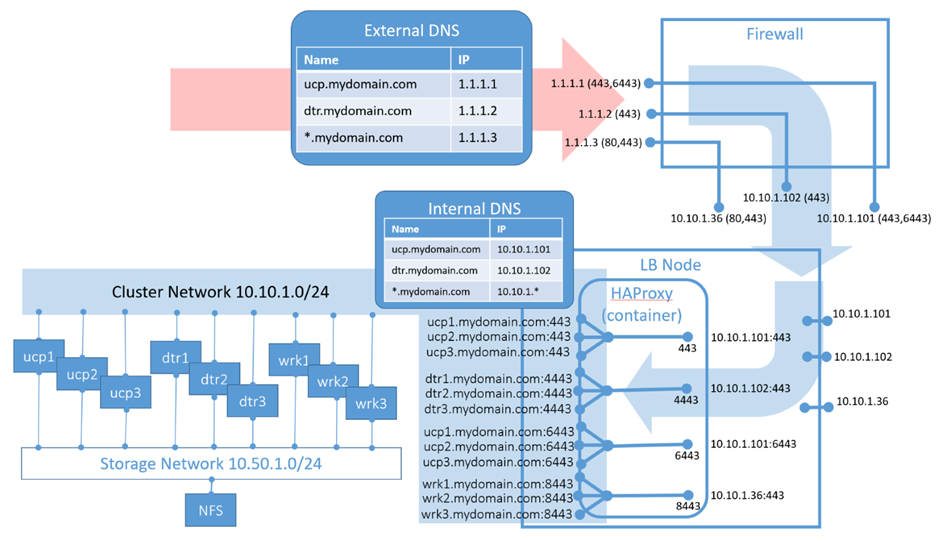
Figure 9: Diagramme du réseau du cluster
Le trafic provenant de l’entrée de domaine UCP se résout à l’adresse 1.1.1.1 sur le port 443 ou 6443. Le port 443 est destiné à l’interface utilisateur Web et à l’API UCP. Le trafic sur le port 6443 est destiné à l’API Kubernetes. Ces deux API sont généralement accessibles à l’aide d’un ensemble d’interface de ligne de commande locale généré à partir de l’UCP. Comme mentionné précédemment, ces bundles contiennent des certificats et des scripts pour acheminer en toute sécurité le trafic depuis un shell distant en dehors du cluster vers les ports UCP du cluster. Le trafic UCP atteint alors l’adresse IP externe du pare-feu au 1.1.1.1, et est traduit à l’aide de NAT en une adresse de réseau privé interne de 10.10.1.101. L’adresse interne 10.10.1.101 est routée vers la carte réseau de l’équilibreur de charge HAProxy . À partir de là, l’application d’équilibrage de charge HAProxy se lie à 10.10.1.101 sur les ports 443 et 6443, où elle équilibre les demandes sur les trois nœuds du gestionnaire UCP sur le réseau interne – ucp1.mydomain.com:443, ucp2.mydomain.com:443 et ucp3.mydomain.com:443.
Le trafic provenant de l’entrée de domaine DTR se résout à l’adresse 1.1.1.2 sur le port 443. Le port 443 est destiné à l’interface utilisateur Web et à l’API DTR utilisées pour pousser et tirer des images Docker. Le trafic DTR atteint alors l’adresse IP externe du pare-feu à 1.1.1.2, et est traduit à l’aide de NAT en une adresse de réseau privé interne de 10.10.1.102. L’adresse 10.10.1.102 interne est routée vers la carte réseau de l’équilibreur de charge HAProxy. À partir de là, l’application d’équilibrage de charge HAProxy se lie à 10.10.1.102 sur le port 443, où elle équilibre les demandes sur les trois nœuds du gestionnaire DTR sur le réseau interne à l’aide du port 4443 sur le backend – dtr1.mydomain.com:4443, dtr2.mydomain.com: 4443 , et dtr3.mydomain.com:4443 .
Le trafic provenant du domaine d’application hébergé en cluster avec caractères génériques (c’est-à-dire app1.mydomain.com) est résolu par l’entrée DNS externe * .mydomain.com , pointant vers l’ adresse IP publique 1.1.1.3 . Il s’agit d’une adresse externe sur le pare-feu, qui utilise les NAT vers 10.10.1.36 sur le réseau interne privé à l’aide des ports 80 et 443 connectés au nœud d’équilibrage de charge HAProxy. HAProxy lie le 10.10.1.36:443 à la configuration frontale pour équilibrer la charge entre les nœuds de travail du cluster sur le port 8443 – wrk1.mydomain.com:8443, wrk2.mydomain.com:8443 et wrk3.mydomain.com: 8443 . Le port 8443 est le port entrant attribué au cluster connecté au routage L7 d’UCP à l’aide du verrouillage 2 de Docker Enterprise pour Swarm.
Nous parlerons davantage de l’équilibrage de charge de couche 7 avec interlock 2 pour les applications Swarm lorsque nous déploierons notre application pilote dans le chapitre 5 , Préparer et déployer une application pilote Docker Enterprise . De plus, nous examinerons un schéma similaire utilisant un contrôleur d’entrée Kubernetes vers la fin de l’article.
4.1.3.6.4 Installation et conception de la configuration de l’équilibreur de charge
L’utilisation d’un équilibreur de charge logiciel conteneurisé est un excellent moyen de gérer et de mettre à niveau un pare-feu logiciel. Il existe plusieurs excellentes options d’équilibrage de charge, notamment NGINX et HAProxy. Pour notre exemple, nous utilisons HAProxy.
Afin de donner un sens à la configuration HAProxy, nous devons d’abord comprendre comment les ports de l’adaptateur hôte sont liés au conteneur sur lequel le logiciel HAProxy est exécuté. Voici un exemple de script utilisé pour démarrer l’équilibreur de charge HAProxy. Notez soigneusement les mappages de ports (-p host-adapter:host-port:container-port) lorsque le conteneur Docker pour HAProxy est lancé. Les ports 80 , 443 , 4443 , 6443 et 8443 sont mappés à l’intérieur du conteneur, comme suit:
- Le port 80 est destiné au trafic des applications entrantes basé sur un cluster – il n’existe que comme redirection vers le port 443.
- Le port 443 est destiné à l’interface Web UCP entrante et au trafic API
- Le port 4443 est destiné à l’interface Web entrante DTR et au trafic API
- Le port 6443 est destiné au trafic de l’API Kubernetes (généralement à partir d’un ensemble de clients UCP).
- Le port 8443 est destiné aux connexions TLS entrantes vers des applications hébergées en cluster (vos applications exécutées déployées sur le cluster)
- Remarque
Par défaut, l’image HAProxy officielle se connecte à syslogd. Cela signifie que vous devez soit configurer syslogd pour transférer les journaux vers un agent de journal (central), soit rediriger syslogd vers stdout depuis l’intérieur du conteneur. Dans mon cas, j’ai ajouté la ligne suivante à la fin de mon fichier docker-entrypoint.sh utilisé dans le conteneur haproxy Docker officiel : / sbin / syslogd -O / proc / 1 / fd / 1
Script de démarrage HAProxy :
Le script shell suivant démarrera un équilibreur de charge HAProxy à l’aide du fichier haproxy.cfg :
#!/bin/sh
docker run -d –name ntc-haproxy -p 10.10.1.36:80:80 -p 10.10.1.36:443:8443 -p 10.10.1.101:443:443 -p 10.10.1.101:6443:6443 -p 10.10.1.102:443:4443 -v ~/haproxy:/usr/local/etc/haproxy:ro nvisiantc/haproxy-log-forward:1.0
Maintenant, regardons le fichier de configuration haproxy.cfg suivant. Les deux premières sections sont assez standard avec deux éléments notables. Le premier élément est que mes configurations pilotes sont définies pour déboguer la journalisation. C’est quelque chose que je peux désactiver peu de temps après mon implémentation, mais il est vraiment utile de voir ce qui se passe avec votre équilibreur de charge. Deuxièmement, le tunnel de temporisation est défini sur 1 heure. Bien que cela ne doive pas nécessairement être une heure, la valeur par défaut peut entraîner des délais d’attente lors de l’installation de UCP et DTR.
En commençant en haut du fichier de configuration, nous avons les sections suivantes :
- Dans les sections frontales, nous avons d’abord la liaison du port 80, que nous avons configurée comme redirection vers SSL. Par conséquent, si une demande parvient à une application hébergée en cluster sur le port 80, nous redirigerons l’appelant pour réessayer sa demande à l’aide de ssl / tls sur le port 443, comme suit:
# Sample haproxy.cfg
global
maxconn 2048
log /dev/log local0 debug
log /dev/log local1 notice
defaults
mode tcp
option dontlognull
timeout connect 5s
timeout client 50s
timeout server 50s
timeout tunnel 1h
timeout client-fin 50s
frontend http_80
mode http
bind *:80
option httplog
log /dev/log local0 debug
redirect scheme https code 301 if !{ ssl_fc }
- Le frontend ucp_443 se lie au port 443 et transfère le trafic vers l’équilibreur de charge du backend ucp_upstream_server_443. L’équilibreur de charge principal est configuré à l’aide d’une stratégie de tournoi à la ronde avec un contrôle d’ intégrité fourni par l’UCP avec un point de terminaison / _ping pour vérifier l’ intégrité du conteneur de contrôleur UCP, comme suit:
frontend ucp_443
mode tcp
bind *:443
option tcplog
log /dev/log local0 debug
default_backend ucp_upstream_servers_443
- Le frontal dtr_4443 se lie au port 4443 et transfère le trafic vers l’équilibreur de charge principal dtr_upstream_server_4443. L’équilibreur de charge principal est configuré à l’aide d’une stratégie de tournoi à la ronde avec un contrôle d’intégrité fourni par l’UCP avec un point de terminaison / _ping pour vérifier l’intégrité du conteneur DTR nginx :
frontend dtr_4443
mode tcp
bind *:4443
option tcplog
log /dev/log local0 debug
default_backend dtr_upstream_servers_4443
- Le frontend kube_6443 se lie au port 6443 et transfère le trafic vers le backend kubectl_upstream_servers_6443. Ce backend équilibre simplement la demande entre les nœuds UCP sur le port 6443, comme suit :
frontend kube_6443
mode tcp
bind *:6443
option tcplog
log /dev/log local0 debug
default_backend kubectl_upstream_servers_6443
- Le trafic d’application entrant arrive dans le port 8443 et transfère le trafic vers le backend interlock_app_upstream_8443 , comme suit:
frontend app_8443
mode tcp
bind *:8443
option tcplog
log /dev/log local0 debug
default_backend interlock_app_upstream_8443
- La charge principale équilibre les demandes entre les nœuds de travail sur le port 8443, où elle est récupérée par le contrôleur d’entrée du verrouillage 2 pour Swarm. À partir de là, le verrouillage 2 examinera l’en-tête de la demande pour déterminer quelle application basée sur un cluster recevra le trafic, comme suit:
## Backend
backend ucp_upstream_servers_443
mode tcp
balance roundrobin
option log-health-checks
option httpchk GET /_ping HTTP/1.1\r\nHost:\ ucp.mydomain.com
server UCPNode01 ntc-ucp-1:443 check check-ssl verify none
server UCPNode02 ntc-ucp-2:443 check check-ssl verify none
server UCPNode03 ntc-ucp-3:443 check check-ssl verify none
backend dtr_upstream_servers_4443
mode tcp
balance roundrobin
option log-health-checks
option httpchk GET /_ping HTTP/1.1\r\nHost:\ dtr.mydomain.com
server DTRNode01 ntc-dtr-1:4443 check check-ssl verify none
server DTRNode02 ntc-dtr-2:4443 check check-ssl verify none
server DTRNode03 ntc-dtr-3:4443 check check-ssl verify none
backend kubectl_upstream_servers_6443
mode tcp
balance roundrobin
option log-health-checks
server KubeNode01 ntc-ucp-1:6443 check check-ssl verify none
server KubeNode02 ntc-ucp-2:6443 check check-ssl verify none
server KubeNode03 ntc-ucp-3:6443 check check-ssl verify none
#backend interlock_app_upstream_8443
mode tcp
option log-health-checks
server AppNode01 ntc-wrk-1:8443 weight 100 check check-ssl verify none
server AppNode02 ntc-wrk-2:8443 weight 100 check check-ssl verify none
server AppNode03 ntc-wrk-3:8443 weight 100 check check-ssl verify none
L’utilisation de HAProxy avec ce fichier de configuration haproxy.cfg démarrera un équilibreur de charge, qui redirigera le trafic vers notre cluster. Cela nous permettra de commencer à construire les nœuds de cluster dans la section suivante.
4.2 Plateforme pilote Docker Enterprise
Nous avons maintenant une configuration réseau avec un équilibreur de charge pour diriger le trafic vers notre cluster et nous sommes prêts à commencer la construction des nœuds. Nous allons parcourir un flux similaire à celui présenté dans la configuration de la plate-forme PoC dans le dernier chapitre. Cette fois, cependant, nous mettrons en évidence des détails importants liés à une plate-forme d’entreprise avec un cluster hautement disponible et sécurisé.
Dans cette section, nous couvrirons les sujets suivants :
- Configuration des nœuds de cluster
- Installation et configuration de Docker Enterprise Engine
- Création / configuration d’un Docker Swarm
- Installation de l’UCP
- Installation du DTR
4.2.1 Préparation des nœuds de cluster
Un cluster pilote typique comprendra 10 nœuds : 3 nœuds sont des gestionnaires UCP, 3 nœuds sont des répliques DTR et 4 nœuds sont des travailleurs.
4.2.1.1 Considération de dimensionnement des nœuds
À la fin de la journée, notre pilote nous aidera à composer le bon dimensionnement des nœuds pour nos clusters de non-production et de production finaux. Cependant, nous voulons faire un effort spécial pour que nos nœuds UCP et DTR soient dimensionnés dès le départ, en se souvenant que les nœuds UCP (et, dans une certaine mesure, DTR) ressemblent plus à des animaux de compagnie qu’à des bovins. Par conséquent, prévoyez 4 cœurs de processeur, 16 Go de RAM et 32 Go de SSD pour chaque nœud UCP et DTR. Cette recommandation est une valeur sûre tant que nous respectons les meilleures pratiques, où nous n’exécutons pas de charges de travail sur nos gestionnaires ou nœuds DTR.
Le dimensionnement des nœuds de travail est moins critique car nous les traitons davantage comme du bétail, et si un nœud de travail est sous-dimensionné, nous pouvons simplement le remplacer par un plus grand et avec une perturbation minimale des opérations du cluster.
Veuillez noter que si la plate-forme pilote comprend des nœuds Windows dans le cluster pour exécuter des conteneurs Windows, prévoyez d’avoir au moins 100 Go d’espace disque pour prendre en charge l’encombrement plus important associé aux images de conteneurs Docker Windows.
4.2.1.2 Considérations relatives aux adaptateurs réseau
D’une manière générale, pour une implémentation bare metal, nous aurons besoin d’au moins deux adaptateurs réseau pour chaque nœud. Un adaptateur sera connecté au réseau du cluster pour la communication avec les autres membres du cluster ainsi que le trafic entrant provenant de l’extérieur du cluster. Le deuxième adaptateur sera utilisé pour un réseau de stockage isolé, afin de fournir des services de stockage backend hautes performances à l’appui des volumes de conteneurs basés sur des clusters.
En conjonction avec les adaptateurs réseau, veuillez configurer un pare-feu logiciel tel que firewalld . Le pare-feu sera configuré pour autoriser le trafic Docker Enterprise comme décrit précédemment dans la figure 9 .
Installez et configurez complètement le pare-feu (les ports ouverts sont décrits dans la figure 9 ) avant d’installer le logiciel Docker. L’installation du pare-feu après l’installation de Docker Enterprise peut entraîner des problèmes de mise en réseau potentiels. Si vous rencontrez ces problèmes, exécutez une info docker à partir de la ligne de commande et recherchez les avertissements au bas de la liste. Les conflits entre firewalld et iptables peuvent parfois entraîner la suppression de certains protocoles par Docker. N’oubliez pas non plus de suivre toute reconfiguration de la carte réseau lors d’un redémarrage du système.
N’oubliez pas que votre choix de technologies réseau aura un impact sur les configurations de pare-feu. Ici, nous utilisons des implémentations de réseau de superposition, VXLAN pour Swarm et BGP / IPinIP de Calico pour vos Kubernetes, pour vous isoler du réseau sous-jacent. Ces technologies reposent sur la création de tunnels via des ports bien connus sur nos nœuds de cluster. Nous devons nous assurer que ces ports sont ouverts sur le pare-feu.
4.2.1.3 Considérations relatives au stockage basé sur un cluster
Le stockage basé sur un cluster permet de déplacer des charges de travail basées sur des conteneurs d’un nœud de travail à un autre sans perte de données. En d’autres termes, si le volume A apparaît sur tous les nœuds du cluster et est mappé sur le même point de montage backend à l’aide du stockage en cluster, tel que NFS, une application peut s’exécuter sur n’importe quel nœud et trouver ses données actuelles au même endroit.
Bien que le stockage basé sur cluster ne soit pas une exigence pour certaines applications dans un environnement de cluster, il est requis pour l’infrastructure Docker Enterprise HA, en ce qui concerne le support de stockage pour le DTR. DTR nécessite un backend de stockage commun sur les multiples répliques afin de fonctionner correctement en mode HA.
Si vous prévoyez d’utiliser une implémentation basée sur le cloud pour votre plateforme pilote, il existe d’excellentes options de stockage basées sur un cluster pour AWS et Azure à l’aide du plug-in de volume docker4x / cloudstor. Sur AWS, le plug-in de volume cloudstor peut être soutenu par EBS ou EFS, selon vos besoins. Sur Azure, le plug-in de volume cloudstor est soutenu par un compte de stockage.
4.2.1.4 Synchronisation du réseau et synchronisation des nœuds
Tous les nœuds du cluster doivent être placés sur un réseau local commun. Les sous-réseaux peuvent être répartis sur plusieurs zones de disponibilité, mais doivent être géographiquement colocalisés afin de réduire la latence. Si la latence dépasse 500 millisecondes, la réplication de données importantes peut expirer et provoquer une instabilité dans le cluster. Dans les versions plus récentes de Docker Enterprise, les valeurs de délai d’expiration Etcd peuvent être configurées pour une tolérance plus élevée, mais ce n’est généralement pas recommandé.
En outre, vous devez vous assurer que toutes vos horloges de nœuds sont synchronisées à l’aide du protocole NTP (Network Time Protocol). Le décalage d’horloge sur le cluster peut entraîner des problèmes désagréables liés à des problèmes de synchronisation du gestionnaire, ainsi que des rejets de certificats erronés (par exemple, un horodatage non synchronisé sur un certificat peut ressembler à une attaque de relecture et être rejeté).
4.2.1.5 Visite virtuelle sans pilote de Docker Enterprise
Nous commencerons par configurer nos nœuds avec un système d’exploitation Docker Enterprise pris en charge. Veuillez vérifier la compatibilité de votre plateforme à l’aide de la matrice de compatibilité Docker Enterprise 2.1 sur le site Web Docker Success: https://success.docker.com/article/compatibility-matrix .
Pendant la phase pilote, recherchez une plate-forme de système d’exploitation pour s’aligner sur votre stratégie de support et de licence à long terme. Bien que notre exemple utilise une plate-forme pilote bare metal, vous pouvez très bien choisir une configuration basée sur le cloud à la place, car elle s’aligne sur votre stratégie. N’oubliez pas que nous utilisons simplement l’environnement de métal nu pour éliminer toute magie des nuages de nos exemples. Si vous utilisez une plate-forme cloud telle qu’AWS ou Azure, ne vous inquiétez pas. Vers la fin de l’article, nous couvrons les modèles d’infrastructure certifiés Docker, y compris les détails d’implémentation spécifiques pour Azure, AWS et VMWare.
Un aperçu de l’environnement pilote de métal nu est le suivant :
- 2 commutateurs isolés connectés à 10 nouveaux nœuds CentOS 7.5 connectés :
- 10 nœuds connectés à 2 réseaux :
- Un réseau de clusters
- Un réseau de stockage, comme décrit précédemment
- Nouvelle installation de CentOS 7.5 Linux :
- 4 processeurs virtuels / cœurs pour chaque nœud
- 16+ Go de RAM
- 32+ Go d’espace disque
- Système de fichiers EXT4 / var
- Deux cartes réseau 10.10.1.x / 24 + 10.10.50.x / 24
- Nom d’hôte ntc-XXX-Y avec le suffixe de domaine commun mydomain.com
- DNS interne, comme le montre la figure 10
- NTP, firewalld, IPTables et Docker Enterprise Engine sur tous les nœuds :
- Docker Enterprise 18.09
- Pilote de stockage Overlay 2
- UCP 3.1.x installé sur 3 gestionnaires ntc-ucp-1, ntc-ucp-2 et ntc-ucp-3
- DTR 2.6.x installé sur 3 nœuds DTR / Worker ntc-dtr-1, ntc-dtr-2 et ntc-dtr-3
- 10 nœuds connectés à 2 réseaux :
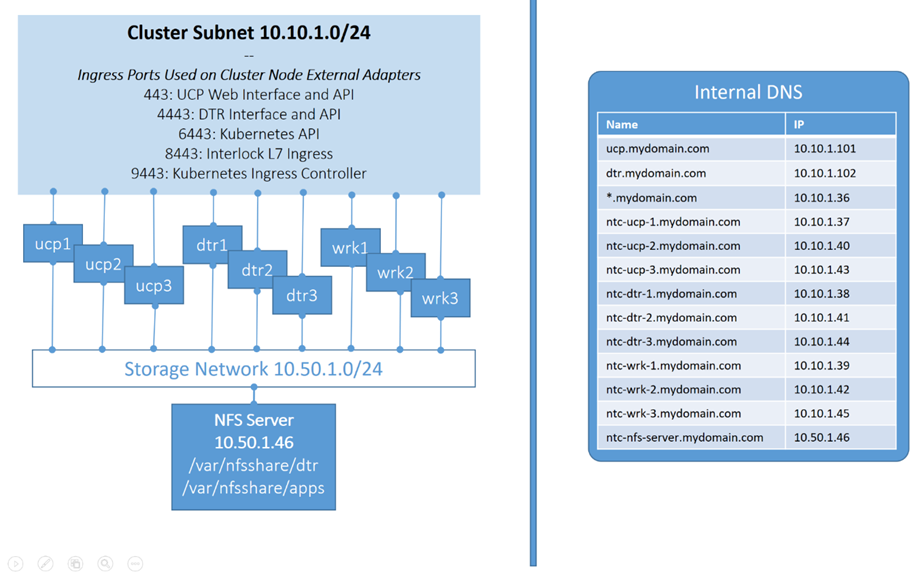
Figure 10: DNS interne du cluster
Une fois vos nœuds configurés, il est temps d’installer le logiciel.
4.2.1.5.1 Installation de Docker Enterprise Engine sur tous les nœuds
Pour notre pilote, nous avons choisi d’utiliser un système d’exploitation CentOS 7.5 fonctionnant sur des serveurs Intel à base de métal nu. Nous avons choisi le système d’exploitation CentOS car il nous permet de commencer avec une distribution open source et de migrer facilement vers une plate-forme commercialement prise en charge telle que RHEL.
Comme indiqué lors du PoC, une clé de licence logicielle valide, ainsi que l’URL de votre abonnement aux bits de stockage, sont nécessaires pour installer Docker Enterprise. Vous pouvez les obtenir à partir de la boutique Docker en vous connectant avec ou en créant un ID Docker.
À ce stade, la plupart des clients ont déjà réussi un PoC réussi. Par la suite, ils sont prêts à s’engager sur au moins une licence Docker Enterprise à 10 nœuds. Cependant, si vous n’êtes pas prêt à faire le saut, veuillez travailler avec votre équipe commerciale Docker locale pour étendre votre licence d’essai pour couvrir le pilote.
Après avoir acquis votre licence, vous trouverez un lien pour télécharger votre fichier de licence Docker et votre URL Storebits dans votre compte store.docker.com. Faites un clic droit sur votre profil et accédez au menu Mon contenu. Sur la page Mon contenu, cliquez sur le bouton Configuration à côté de votre abonnement actif. Ensuite, téléchargez le fichier de clé de licence dans un répertoire sécurisé sur votre ordinateur local. Copiez et collez également l’URL Storebits dans votre éditeur préféré. Vous en aurez besoin dans la section suivante lorsque nous configurerons le gestionnaire de packages pour utiliser les dépôts Docker.
Avec votre clé de licence et l’URL Docker Storebits enregistrés sur votre machine locale, il est temps d’installer Docker Enterprise Engine sur tous vos nœuds. Commencez par créer des sessions SSH dans chacun de vos nœuds Linux.
Nous commençons par configurer le gestionnaire de packages CentOS et le référentiel officiel Docker Enterprise pour l’installation de notre logiciel. Une fois les moteurs Docker installés, nous pouvons installer les composants logiciels conteneurisés de notre plateforme Docker Enterprise au-dessus des moteurs Docker en utilisant des images spéciales du registre de conteneurs Docker.
N’utilisez pas le référentiel par défaut de la distribution CentOS pour installer le moteur Docker! Cela entraîne généralement une version ancienne et non prise en charge de l’édition communautaire. N’oubliez pas que nous utilisons Docker Enterprise Engine. De plus, les instructions suivantes supposent que vous utilisez une nouvelle installation du logiciel OS sur vos nœuds. Si ce n’est pas le cas, assurez-vous de supprimer les anciennes versions de Docker avant de continuer.
4.2.1.5.2 Installation de Docker Enterprise Engine sur chaque nœud du cluster
Les instructions suivantes dans cette section sont un résumé de https://docs.docker.com/install/linux/docker-ee/centos/ :
- Étape 1: préparez le nœud CentOS 7.5, comme suit :
- Sur chaque nœud Linux, installez NTP pour garder les horloges du serveur synchronisées ; yum-utils pour le processus d’installation de Docker et nfs-utils pour notre accès au stockage en cluster:
$ sudo yum install ntp
$ sudo systemctl start ntpd
$ sudo systemctl enable ntpd
$ sudo yum install -y yum-utils
$ sudo yum install -y nfs-utils
-
- Configurez et activez firewalld avec les commandes suivantes:
$ sudo firewall-cmd –permanent –add-port=22/tcp
$ sudo firewall-cmd –permanent –add-port=80/tcp
$ sudo firewall-cmd –permanent –add-port=179/tcp
$ sudo firewall-cmd –permanent –add-port=443/tcp
$ sudo firewall-cmd –permanent –add-port=4443/tcp
$ sudo firewall-cmd –permanent –add-port=8443/tcp
$ sudo firewall-cmd –permanent –add-port=2376/tcp
$ sudo firewall-cmd –permanent –add-port=2377/tcp
$ sudo firewall-cmd –permanent –add-port=4789/udp
$ sudo firewall-cmd –permanent –add-port=6443/tcp
$ sudo firewall-cmd –permanent –add-port=6444/tcp
$ sudo firewall-cmd –permanent –add-port=7946/tcp
$ sudo firewall-cmd –permanent –add-port=7946/udp
$ sudo firewall-cmd –permanent –add-port=10250/tcp
$ sudo firewall-cmd –permanent –add-port=12376/tcp
$ sudo firewall-cmd –permanent –add-port=12378/tcp
$ sudo firewall-cmd –permanent –add-port=12379/tcp
$ sudo firewall-cmd –permanent –add-port=12380/tcp
$ sudo firewall-cmd –permanent –add-port=12381/tcp
$ sudo firewall-cmd –permanent –add-port=12382/tcp
$ sudo firewall-cmd –permanent –add-port=12383/tcp
$ sudo firewall-cmd –permanent –add-port=12384/tcp
$ sudo firewall-cmd –permanent –add-port=12385/tcp
$ sudo firewall-cmd –permanent –add-port=12386/tcp
$ sudo firewall-cmd –permanent –add-port=12387/tcp
$ sudo firewall-cmd –permanent –add-port=12388/tcp
$ sudo firewall-cmd –permanent –add-service=nfs
$ sudo firewall-cmd –permanent –add-service=ntp
$ sudo firewall-cmd –reload
-
- Débarrassez-vous de tous les dépôts Docker existants :
$ sudo rm /etc/yum.repos.d/docker*.repo
- Étape 2: configurez le référentiel du gestionnaire de packages yum pour utiliser les binaires Docker officiels, comme suit :
- Configurez les variables d’environnement DOCKER_EE_URL à l’aide de l’URL Storebits de votre Docker Store que vous avez enregistrée précédemment. Il devrait ressembler à ce qui suit :
$ export DOCKERURL = “https://storebits.docker.com/ee/m/sub-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx”
Avec votre URL Storebits définie dans la variable d’environnement $ DOCKERURL , il est temps d’installer Docker:
- Étape 3 configure le fonctionnaire Docker repo, installez le moteur Enterprise Docker, et démarrer le moteur Docker, comme suit :
$ sudo -E sh -c ‘echo “$DOCKERURL/centos” > /etc/yum/vars/dockerurl’
$ sudo -E yum-config-manager –add-repo “$DOCKERURL/centos/docker-ee.repo”
$ sudo yum-config-manager –enable docker-ee-stable-18.09
$ sudo yum -y install docker-ee
$ sudo systemctl start docker
Après l’installation, quelques étapes supplémentaires faciliteront l’utilisation de Docker:
- Étape 4 – appliquez la touche finale, comme suit :
- Enfin, nous ajoutons notre utilisateur au groupe Docker (nous n’avons donc pas à taper sudo avant toutes nos commandes Docker) et nous permettons à Docker de s’exécuter au démarrage. Veuillez noter que vous devez vous déconnecter et vous reconnecter pour que l’adhésion au groupe Docker prenne effet, comme suit :
$ sudo usermod -aG docker $USER
$ sudo systemctl enable docker
-
- Vérifiez l’installation avec la commande docker info comme suit et notez que la version du serveur est 18.09.1 et que la version 3.10 du noyau de l’hôte (doit être 3.10 ou supérieure) a été installée et que les informations sur l’hôte, y compris la version du noyau, qui doivent être supérieures à 3.10 , comme suit:
$ docker info
…
Server Version: 18.09.0
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Native Overlay Diff: true
…
Kernel Version: 3.10.0-862.14.4.el7.x86_64
Operating System: CentOS Linux 7 (Core)
OSType: linux
…
Maintenant, nous allons devoir tester la configuration.
- Étape 5 : essayez d’exécuter le conteneur hello-world , comme suit :
- Déconnectez-vous, puis reconnectez-vous et essayez d’exécuter la commande docker (sans sudo) pour tester les autorisations des groupes Docker et Docker. Exécutez les informations Docker et vous devriez voir quelque chose comme ceci :
$ docker run hello-world
Unable to find image ‘hello-world:latest’ locally
latest: Pulling from library/hello-world
d1725b59e92d: Pull complete
Digest: sha256:0add3ace90ecb4adbf7777e9aacf18357296e799f81cabc9fde470971e499788
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
Le message précédent montre que votre installation semble fonctionner correctement.
Pour générer ce message, Docker a suivi les étapes suivantes :
- Le client Docker a contacté le démon Docker.
- Le démon Docker a extrait l’image du monde bonjour du Docker Hub (amd64).
- Le démon Docker a créé un nouveau conteneur à partir de cette image, qui exécute l’exécutable qui produit la sortie que vous lisez actuellement.
- Le démon Docker a diffusé la sortie sur le client Docker, qui l’a envoyée à votre terminal.
Répétez ces étapes pour tous les nœuds de gestionnaire et de travail Docker.
4.2.1.5.3 Configuration du nœud de serveur NFS
Reportez-vous aux étapes suivantes :
- Connectez-vous au nœud du serveur NFS ; dans mon cas, j’utilise un adaptateur connecté au réseau du cluster. Installez NFS, créez les partages et activez les services au démarrage, comme suit :
sudo yum install -y nfs-utils
sudo mkdir -p /var/nfsshare/dtr
sudo mkdir -p /var/nfsshare/apps
sudo chmod -R 755 /var/nfsshare
sudo chmod -R 755 /var/nfsshare/dtr
sudo chmod -R 755 /var/nfsshare/apps
sudo chown nfsnobody:nfsnobody /var/nfsshare
sudo chown nfsnobody:nfsnobody /var/nfsshare/dtr
sudo chown nfsnobody:nfsnobody /var/nfsshare/apps
sudo systemctl enable rpcbind
sudo systemctl enable nfs-server
sudo systemctl enable nfs-lock
sudo systemctl enable nfs-idmap
sudo systemctl start rpcbind
sudo systemctl start nfs-server
sudo systemctl start nfs-lock
sudo systemctl start nfs-idmap
- Pour terminer la configuration, ajoutez une ligne au fichier / etc / exports, comme suit :
sudo vi /etc/exports
- Ajoutez la ligne suivante au fichier:
/var/nfsshare *.mydomain.com (rw,sync,no_root_squash,no_all_squash)
- Redémarrez le serveur nfs pour récupérer la nouvelle configuration / etc / exports, comme suit :
sudo systemctl restart nfs-server
- Ouvrez les ports de pare-feu requis comme suit:
sudo firewall-cmd –permanent –zone=public –add-service=nfs
sudo firewall-cmd –permanent –zone=public –add-service=mountd
sudo firewall-cmd –permanent –zone=public –add-service=rpc-bind
sudo firewall-cmd –reload
Vous avez maintenant le Docker Enterprise Engine installé sur chaque nœud. Ensuite, nous devons créer le cluster Swarm en initialisant le premier nœud de gestionnaire.
4.2.1.5.4 Installation du premier nœud gestionnaire
Nous avons maintenant tous nos nœuds de cluster Docker initialisés avec Docker Enterprise Engine et sommes prêts à commencer à configurer notre premier nœud de gestionnaire. Notre approche ici consiste à créer un Swarm avec un pool d’adresses spécifié – le pool d’adresses est l’endroit où les réseaux VXLAN de Docker attribuent / 26 réseaux.
Il y a quelques éléments importants à noter : tout d’abord, il est important que le CIDR de ce paramètre de pool d’adresses soit un bloc réseau non routable dans votre espace d’adressage privé. Sinon, il pourrait y avoir des conflits avec les réseaux de superposition internes de Docker. Deuxièmement, ce paramètre de pool d’adresses ne peut être attribué qu’avec une commande d’ initialisation Docker Swarm . Il n’est pas disponible en tant que paramètre d’installation UCP. Par conséquent, nous allons initialiser notre Swarm avec la configuration de pool d’adresses souhaitée et installer le logiciel UCP par-dessus. Cela fonctionnera très bien, car UCP utilisera un essaim existant s’il est détecté au moment de l’installation. Sinon, il créera un nouvel essaim lors de l’installation d’UCP. En outre, si le cluster Swarm avec plusieurs nœuds est déjà en cours d’exécution avec UCP installé, il répliquera automatiquement tous les logiciels UCP sur l’ensemble du cluster Swarm.
À partir de notre premier nœud UCP, nous initialisons le Docker Swarm avec l’allocation du pool d’adresses, comme suit:
[ntc-ucp-1 ~]$ docker swarm init –advertise-addr 10.10.1.37 –default-addr-pool 10.60.0.0/16 –default-addr-pool-mask-length 26
Notez également l’utilisation du paramètre –advertised-addr. En effet, le nœud Docker possède deux adaptateurs réseau avec des adresses IP différentes. Nous devons indiquer à Docker Swarm quel adaptateur nous allons utiliser pour communiquer à travers le cluster avec d’autres nœuds. Notre conception a désigné le réseau 10.10.1.x / 24 comme réseau de cluster et le réseau 10.10.50.x / 24 comme réseau de stockage :
- Copiez le fichier de licence Docker Enterprise sur le nœud UCP 1, comme suit :
Avant d’installer UCP, copiez les fichiers de clé de licence sur mon premier nœud de gestionnaire et stockez-les dans mon répertoire personnel ( ~ ). À partir d’ici, nous injecterons la clé de licence dans la commande d’installation UCP en tant que paramètre –license “$ (cat license.lic)” dans la commande d’installation UCP, comme indiqué dans le bloc de code suivant. Si vous souhaitez différer l’installation du fichier de licence, vous pouvez le faire en téléchargeant le fichier de licence la première fois que vous vous connectez à l’interface Web UCP ou, en le téléchargeant depuis l’intérieur de l’interface Web UCP à l’aide de Paramètres administrateur | Option de menu de licence. Veuillez noter que si vous choisissez de différer l’installation de la clé de licence, vous devrez supprimer le paramètre –license de la commande d’installation UCP que nous utilisons lorsque nous installons l’UCP au-dessus de notre nouveau cluster Swarm.
- Copiez les certificats tiers sur le nœud UCP 1, comme suit:
C’est également le moment idéal pour configurer vos certificats tiers en créant un volume Docker appelé ucp-controller-server-certs . Après cela, copiez votre fichier de certificat dans le volume. Copiez ou collez les valeurs de certificat de vos certificats tiers dans trois fichiers: le fichier d’autorité de certification ( ca.pem ), le fichier de certificat du serveur ( cert.pem ) et le fichier de clé de certificat ( key.pem ) dans votre maison. , puis copiez-les dans le conteneur indiqué.
Alternativement, vous pouvez exécuter un script bash à partir d’un conteneur qui monte à la fois le volume de certificat UCP nouvellement créé et votre répertoire personnel pour copier les fichiers de certificat pour vous. En fait, si vous ne disposez pas d’un accès root au nœud du gestionnaire UCP, vous n’auriez pas accès au répertoire / var. Ainsi, le script conteneurisé pourrait être votre seule option :
docker volume create ucp-controller-server-certs
sudo -s
cp ./ca.pem /var/lib/docker/volumes/ucp-controller-server-certs/_data/
cp ./cert.pem /var/lib/docker/volumes/ucp-controller-server-certs/_data/
cp ./key.pem /var/lib/docker/volumes/ucp-controller-server-certs/_data/
exit
Dans la première ligne, nous créons le volume docker où UCP conserve ses certificats. Lors de l’installation, nous fournirons le paramètre –external-server-cert au programme d’installation UCP afin que UCP ne génère pas de nouveaux certificats sur nos certificats existants dans le volume. Le reste des commandes implique la copie des fichiers de certificat dans le conteneur à l’aide du point de montage interne de Docker pour le volume ucp-controller-server-certs .
Maintenant, nous pouvons installer l’UCP au-dessus de notre nouveau cluster Swarm, comme suit:
[ntc-ucp-1 ~]$ docker image pull docker/ucp:3.1.1
[ntc-ucp-1 ~]$ docker container run –rm -it –name ucp \
-v /var/run/docker.sock:/var/run/docker.sock \
docker/ucp:3.1.1 install \
–host-address 10.10.1.37 \
–external-server-cert \
–external-service-lb ucp.mydomain.com \
–license “$(cat license.lic)” \
–interactive
Il est maintenant temps de tester l’installation UCP de votre premier nœud. Pour ce faire, pointez votre navigateur vers l’URL UCP externe. N’oubliez pas d’utiliser le préfixe d’ URL https: // lorsque vous accédez à l’interface utilisateur Web UCP. Vous devriez voir l’écran de connexion Docker à partir de là. Utilisez les informations d’identification que vous avez fournies lors de l’installation UCP pour vous connecter à l’interface utilisateur Web UCP.
Si vous n’avez pas inclus le paramètre de licence dans le processus d’installation d’UCP, vous serez invité à télécharger une clé de licence lors de votre première connexion à UCP. Encore une fois, vous pouvez le reporter et le télécharger plus tard en utilisant l’option de menu de licence des paramètres d’administration dans l’interface utilisateur UCP.
J’espère que votre navigateur atteint l’interface utilisateur Web UCP et que vous accédez au tableau de bord UCP affichant 1 gestionnaire et 0 nœud de travail. Si vous ne pouvez pas atteindre l’interface utilisateur Web UCP, essayez de curling le point de terminaison de l’interface utilisateur Web UCP depuis l’intérieur de votre cluster. Si la boucle fonctionne et que le navigateur externe ne fonctionne pas, il est temps de tracer à partir de votre connexion externe, via DNS, via le pare-feu et via l’équilibreur de charge, pour voir où la demande est bloquée. C’est là que vos journaux d’équilibreur de charge peuvent être très utiles.
À ce stade, nous avons un cluster de gestionnaire UCP à nœud unique en cours d’exécution. Bien que les autres nœuds Docker soient connectés au même réseau, ils n’ont pas été joints au cluster. Nous le ferons dans la section suivante.
4.2.1.5.5 Rejoindre les nœuds DTR 1 et travailleur 1 initiaux
Avant de pouvoir ajouter d’autres nœuds au cluster, nous aurons besoin d’un jeton de jointure sécurisé. Le jeton de jointure garantit que tout nœud essayant de rejoindre le cluster le fait avec un jeton de jointure sécurisé émis par un gestionnaire de cluster. Le jeton de jointure lui-même est utilisé comme paramètre de la commande docker swarm join . Pour obtenir un jeton de jointure de travailleur, vous devez utiliser une connexion SSH à un nœud de gestionnaire et exécuter le code suivant :
[ntc-ucp-1 ~]$ docker swarm join-token worker
To add a worker to this swarm, run the following command:
docker swarm join –token SWMTKN-1-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxx 10.10.1.37:2377
Copiez l’intégralité de la commande docker swarm join –token … dans le presse-papiers. Connectez-vous à chacun de vos nœuds DTR et de travail pour coller et exécuter la commande join. En quelques secondes, le moteur Docker devrait fournir un message de confirmation sur le nœud joint au Swarm.
Confirmez l’état du nœud de cluster, puis ouvrez le terminal UCP 1 pour vérifier que les nœuds sont prêts, comme suit :
[ntc-ucp-1 ~]$ docker node ls
ID HOSTNAME STATUS AVAILABILITY
1rqhb4rzj3gk4mdgk8kza53jp ntc-dtr-1.mydomain.com Ready Active
1rqhb4rzj3gk4mdgk8kza53jp ntc-dtr-1.mydomain.com Ready Active
x27m3yjlh6b0wczmo0mcahkjv ntc-dtr-2.mydomain.com Ready Active
rw2tuw53wl34pv6sfj213845a ntc-dtr-3.mydomain.com Ready Active
q5q9u0yr7p8r0mcz4ob24s2kz* ntc-ucp-1.mydomain.com Ready Active
3lw64q2o818xgnberjry410o7 ntc-wrk-1.mydomain.com Ready Active
zxcosutrxr3rhzkz2h6ld0khj ntc-wrk-2.mydomain.com Ready Active
sfuxfiwhf2tpd6q3i7fbmaziv ntc-wrk-3.mydomain.com Ready Active
À ce stade, tout ce que vous devriez voir est une liste de nœuds avec le nœud de gestionnaire UCP-1, trois nœuds DTR et trois nœuds de travail. Notre prochaine étape consiste à rejoindre les deux nœuds de gestionnaire UCP supplémentaires. Maintenant, nous avons besoin d’un jeton de gestionnaire de jointure à ajouter aux nœuds de gestionnaire UCP supplémentaires, comme suit :
[ntc-ucp-1 ~]$ docker swarm join-token manager
To add a manager to this swarm, run the following command:
docker swarm join –token SWMTKN-1-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxx 10.10.1.37:2377
Copiez à nouveau l’intégralité de la commande docker swarm join –token … dans le presse-papiers. Cette fois, connectez-vous aux nœuds UCP-2 et UCP-3 pour coller et exécuter la commande join . En quelques secondes, le moteur Docker devrait fournir un message de confirmation sur le nœud joint au Swarm.
Maintenant, connectez-vous à l’interface utilisateur Web UCP et notez que le tableau de bord affiche trois nœuds de gestionnaire et six nœuds de travail. Les nœuds de gestionnaire UCP peuvent prendre quelques minutes pour initialiser et signaler un état sain. Accordez environ 10 minutes à UCP pour réconcilier complètement les nouveaux nœuds avant d’essayer de réparer quoi que ce soit. Dans la plupart des cas, l’UCP se redressera et ajoutera les nœuds avec succès, comme suit:
Figure 11: Tableau de bord du plan de contrôle universel
Maintenant que notre cluster est opérationnel, nous sommes prêts à exécuter les charges de travail Swarm et Kubernetes. Cependant, afin de prendre en charge ces charges de travail conteneurisées, nous devons installer un DTR privé pour nos orchestrateurs de cluster afin de garantir un pipeline logiciel sécurisé.
4.2.1.5.6 Installation du DTR
Maintenant, nous sommes prêts à installer le DTR. Le logiciel DTR est déployé en tant que pile de conteneurs de base sur chaque nœud DTR cible. Il est important de noter que nous initialisons le programme d’installation DTR à partir d’un shell sur le nœud du gestionnaire UCP ou à l’aide d’un ensemble de lignes de commande généré à partir de l’UCP.
Les nouveaux administrateurs Docker font souvent l’erreur d’essayer de lancer une commande d’installation DTR à partir d’un nœud DTR. Nous n’initions pas de commandes d’installation DTR à partir de nœuds DTR. Nous exécutons les commandes d’installation DTR à partir d’un nœud de gestionnaire UCP.
En préparation de l’installation DTR, assurez-vous d’avoir vos certificats tiers à portée de main pour l’accès DTR. Dans notre exemple, nous utilisons un certificat générique qui couvre l’accès aux applications UCP, DTR et hébergées en cluster. Nos exemples de certificats fonctionneront pour dtr.mydomain.com, ucp.mydomain.com et anyapp.mydomain.com. Par conséquent, nous pouvons également réutiliser les certificats UCP que nous avons créés dans notre répertoire personnel lors de l’installation UCP pour installer DTR.
Ici, nous lançons l’installation DTR à partir du nœud UCP 1 et de votre répertoire personnel, comme suit:
[ntc-ucp-1 ~]$ docker run -it –rm docker/dtr:2.6.0 install \
–dtr-external-url dtr.mydomain.com \
–ucp-node ntc-dtr-1.mydomain.com \
–ucp-username admin \
–ucp-password yourUcpPassword \
–ucp-url https://ucp.mydomain.com \
–replica-http-port 81 \
–replica-https-port 4443 \
–nfs-storage-url nfs://ntc-nfs-server.mydomain.com/var/nfsshare/dtr \
–ucp-ca “$(cat ca.pem)” \
–dtr-ca “$(cat ca.pem)” \
–dtr-cert “$(cat cert.pem)” \
–dtr-key “$(cat key.pem)”
Notez que nfs-storage-url ( nfs: //ntc-nfs-server.mydomain.com ) est le chemin d’accès au stockage principal pour le DTR. C’est là que les gros fichiers d’images binaires sont stockés et seront partagés par toutes les répliques DTR. N’oubliez pas que le nom DNS se résout en carte d’interface réseau de stockage. En d’autres termes, il utilise l’adaptateur 10.10.50.X / 24 pour communiquer avec NFS sur le réseau de stockage isolé lors du déplacement de fichiers image. Il s’agit de l’emplacement de l’EGR de retour dans le stockage qui sera partagé entre toutes les répliques DTR pour stocker des fichiers binaires d’image volumineux. N’oubliez pas qu’un magasin de données backend commun est une condition requise pour la haute disponibilité DTR.
Notez les deux paramètres de port : replica-http-port et replica-https-port. C’est là que nous fournissons des ports alternatifs pour l’accès DTR. Nous avons spécifié ces ports alternatifs DTR lors de la conception de notre réseau pour correspondre à nos ports réseau internes backend de l’équilibreur de charge pour DTR. Il est bien sûr important que le backend de l’équilibreur de charge et les ports alternatifs DTR correspondent.
Le processus d’installation de DTR prendra plusieurs minutes. Une fois l’opération terminée, vous pouvez vous connecter à l’aide de l’URL externe DTR, en vous assurant d’utiliser un préfixe HTTPS. Lors de la connexion, utilisez les mêmes informations d’identification que celles utilisées avec UCP.
C’est le point où nous voulons exécuter des tests de fumée sur le tableau de bord du cluster avant de répliquer sur tous les nœuds. Exécutez les tests suivants :
- Connectez-vous à l’interface utilisateur Web UCP, comme suit :
- Générez un groupe de clients (admin> Mon profil> Groupes de clients> Nouveau groupe).
- Vous pouvez également utiliser l’approche suivante :
- Réglage | Général
- Définissez Create On Push sur Oui
- Ouvrez un shell distant et sourcez le bundle, comme suit :
- Connectez un terminal distant au cluster, comme suit :
$ source env.sh
-
- Ou, comme suit:
PS> Import-module env.ps1
-
- Testez la connectivité de l’API Docker, comme suit :
docker node ls
-
- Testez la connectivité kubectl , comme suit:
kubectl get nodes
-
- Tirez une image de test, comme suit :
docker image pull alpine:latest
-
- Redéfinissez une image de test, comme suit :
docker image tag alpine:latest dtr.mydomain.com/admin/test:v1
-
- Poussez l’image, comme suit :
docker image push dtr.mydomain.com/admin/test:v1
-
- Revenez à l’interface utilisateur Web du DTR et recherchez l’image.
4.2.1.5.7 Ajout de répliques DTR supplémentaires
Maintenant que nous avons testé notre première réplique DTR, il est temps d’ajouter deux répliques supplémentaires pour créer un cluster DTR haute disponibilité. La figure 12 montre l’exemple de configuration de réplique DTR en métal nu, comme suit :
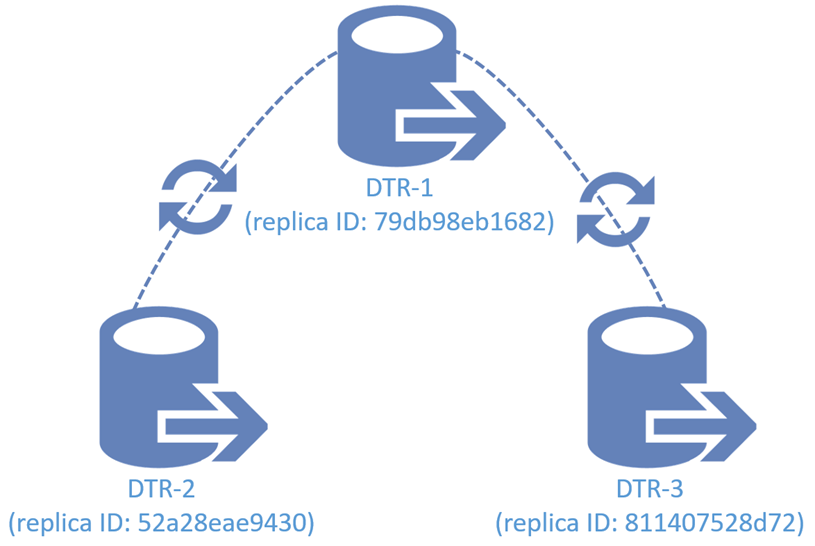
Figure 12: Répliques de registre approuvées Docker
Encore une fois, à partir du même endroit où nous avons installé DTR (nœud UCP-1), nous allons rejoindre des répliques DTR supplémentaires. Lorsque nous exécutons la commande de jointure DTR , nous devons spécifier un nœud cible. Nous utilisons le paramètre –ucp-node pour ce descripteur. Dans notre cas, nous installons la deuxième réplique sur le nœud ntc-dtr-2.mydomain.com. Un autre paramètre affiché ici est le mot de passe administrateur UCP. Vous devez remplacer la valeur {yourUcpPassword} par votre mot de passe administrateur. Vous pouvez omettre le paramètre ucp-password si vous souhaitez être invité à entrer le mot de passe administrateur pendant le processus de jointure. Encore une fois, nous fournissons les ports alternatifs (mêmes ports pour chacun de nos nœuds DTR) utilisés par notre deuxième nœud DTR, comme suit :
[ntc-ucp-1 ~]$ docker run -it –rm docker/dtr:2.6.0 join \
–ucp-node ntc-dtr-2.mydomain.com \
–ucp-username admin \
–ucp-password {yourUcpPassword} \
–ucp-url https://ucp.mydomain.com \
–replica-http-port 81 \
–replica-https-port 4443 \
–ucp-ca “$(cat ca.pem)”
Lorsque la commande join est émise, un nouvel ID de réplique est généré. Recherchez dans les journaux quelque chose comme ceci, l’ID de la réplique est défini sur : 52a28eae9430. Si la commande de jointure DTR échoue, vous souhaiterez vous référer à cet ID de réplique pour supprimer l’installation de la réplique ayant échoué. Si cela échoue, résolvez les problèmes et supprimez la réplique cassée avant de tenter de vous réinscrire.
Vous devez le faire uniquement si la jointure DTR échoue, comme suit :
docker run -it –rm docker/dtr:2.6.0 remove –force –ucp-insecure-tlsusername admin
Lors de l’exécution de la commande de suppression DTR, il vous sera demandé l’ID de réplique que vous souhaitez supprimer. Assurez-vous de choisir l’ID dans la sortie de la commande de jointure échouée (c’est-à-dire que l’ID de réplique est défini sur 52a28eae9430 ). En outre, vous serez invité à entrer l’ID de la réplique principale pour la notification (il doit afficher un ID de réplique par défaut à choisir). La fourniture de l’ID de réplique DTR principale empêche la réplique principale d’essayer de se synchroniser avec la réplique DTR cassée / supprimée.
4.2.1.5.8 Configuration finale des équilibreurs de charge
Maintenant, nous avons notre réplique UCP et DTR configurée. N’oubliez pas de terminer la configuration de nos équilibreurs de charge en ajoutant des entrées pour les répliques UCP et DTR. Le backend de l’équilibreur de charge pour UCP doit pointer vers trois serveurs : les nœuds UCP-1, UCP-2 et UCP-3 sur le port 443 . Le backend de l’équilibreur de charge pour DTR doit pointer vers trois serveurs : les nœuds DTR-1, DTR-2 et DTR-3 sur le port 4443. Enfin, le backend de l’équilibreur de charge pour Kubernetes devrait pointer vers 3 serveurs : les nœuds UCP-1, UCP-2 et UCP-3 sur le port 6443 .
4.3 Résumé
Toutes nos félicitations ! Nous avons parcouru la mise en œuvre initiale de notre plateforme pilote Docker Enterprise. Bien que nous ayons encore du travail de configuration en préparation du déploiement d’applications de notre équipe d’application pilote, nous avons travaillé sur de nombreuses décisions initiales importantes concernant la conception du réseau, les spécifications de la plateforme et la sécurité.
Dans les prochains chapitres, nous examinerons un certain nombre de sujets relatifs aux réseaux et aux plateformes de manière plus approfondie en termes de performances, de sécurité et de récupération.
5 Préparer et déployer une application pilote Docker Enterprise
Dans le chapitre 4 , Préparation du cluster pilote Docker Enterprise , nous avons effectué une installation pilote de base du plan de contrôle universel ( UCP ) de Docker Enterprise et du registre de confiance Docker ( DTR ). Nous allons maintenant configurer les structures de contrôle d’accès pour notre cluster pilote pour permettre à notre équipe pilote de créer et de déployer leurs applications.
L’objectif principal du pilote est de déployer deux applications pilotes. À titre d’illustration, dans ce chapitre, nous présenterons la première des deux applications pour le pilote. La première application est une application Web Java conteneurisée fonctionnant avec Tomcat et un backend de base de données Postgres. La deuxième application, présentée dans le chapitre 6 , Concevoir et piloter un pipeline CI Docker Enterprise , est un exemple d’application Java personnalisée dans laquelle nous simulons le processus de développement pour illustrer l’interaction d’une équipe de développement avec la plateforme Docker Enterprise, ainsi qu’un pipeline pour DevOps et opérations. Ainsi, bien que la technologie empile pour les deux applications est similaire, vous verrez les considérations supplémentaires requises pour le déploiement d’applications personnalisées dans le chapitre suivant.
Dans ce chapitre, nous couvrirons les sujets suivants :
- Planification du pilote
- Configurer UCP et DTR pour une application pilote
- Sélection d’applications pilotes, conteneurisation, mise en réseau, découverte de services et routage de couche 4
- Script de déploiement d’application pilote avec gestion des secrets et de la configuration
5.1 Planification d’une application pilote
La préparation du pilote Docker Enterprise proprement dit nécessite une coordination entre les développeurs d’applications, DevOps et les membres de l’équipe des opérations techniques. Pour illustrer l’éventail des tâches typiques et leurs domaines d’impact associés, nous avons fourni un tableau de style responsable, responsable, consulté et informé (RACI), présenté brièvement, comme outil de communication pour décrire ce qui doit être fait et qui sera impliqués dans chaque tâche. Bien que nous n’allions pas couvrir chacune de ces tâches en profondeur, nous concentrerons notre discussion sur les éléments présentés en gras.
Generally, an RACI chart/matrix/table lists the tasks on the left column and team members across the top, with the R, A , C, or I roles placed at the intersection of a team member and a task (deliverable or milestone).
La première section du tableau traite des principales activités de gestion / gouvernance de projet liées à l’organisation et au lancement du pilote. Il est, bien sûr, important d’identifier les objectifs, les activités, les livrables et les délais du projet pilote, et d’examiner les progrès réalisés quotidiennement.
Vous remarquerez un fort accent sur la formation vers le haut du tableau. Bien qu’une formation Docker initiale soit souvent très utile pendant la phase de PoC, la formation suivante devrait être considérée comme une exigence pendant la phase pilote, où tous les membres de l’équipe pilote de base devraient suivre une formation comme indiqué dans le tableau suivant dans les premières étapes de la pilote :
| Graphique RACI de rôle de tâche | Coordinateur pilote | Architecte d’ application | App Dev | DevOps | sys admin | Ops Mgr |
| Planifier la formation | R | je | je | je | je | je |
| Capture d’objectif pilote | R | je | je | je | je | je |
| Planification et exécution du pilote | R | C | je | C | je | C |
| Coup d’envoi du pilote | R | C | C | C | C | C |
| Assister aux principes fondamentaux de Docker | je | R | R | R | R | R |
| Assister à Docker Ent Ops | je | R | R | R | ||
| Assister à Docker Ent Dev | je | UNE | R | R | je | je |
| Prise en charge de Docker | je | je | je | R | R | UNE |
| Assister à la sécurité Docker | je | R | R | R | R | UNE |
| Configurer UCP et DTR pour le pilote | je | je | C | R | UNE | |
| Synchronisation LDAP / équipe pour le pilote | C | C | UNE | R | ||
| Configuration de stockage pour le pilote | C | C | C | UNE | R | |
| Configurer DTR pour le pilote | R | UNE | R | |||
| Distribuer les informations d’identification du pilote | R | |||||
| Image de base de l’application pilote | S | S | S | S | UNE | |
| Architecture d’application pilote | UNE | R | R | S | S | |
| Application pilote de conteneurisation | UNE | R | S | |||
| Configuration du repo de l’image pilote | C | je | C | C | R | |
| Balise d’image pilote et push | UNE | R | UNE | |||
| Numérisation d’image pilote | je | je | C | UNE | R | |
| Pilote docker-compose-dev | R | UNE | S | |||
| Secrets des pilotes | je | je | S | UNE | R | |
| Déploiement de la pile pilote | C | C | UNE | S | C |
* R: Responsable (éventuellement partagé) | A: Responsable (un seul) | C: Consulté | S: Prise en charge | J’ai informé
Avant le lancement du projet pilote, un coordinateur pilote (chef de projet, type de rôle pour accélérer le programme pilote) et l’équipe pilote de base développeront un plan dans lequel ils définiront les responsabilités clés et les délais. Il est important que les différents acteurs impliqués dans le programme pilote identifient leurs principaux objectifs d’apprentissage pour l’initiative pilote et s’assurent que le plan couvre une implication réelle et pratique pour soutenir leurs objectifs. Enfin, avant le début du projet pilote, une réunion de lancement devrait être organisée pour examiner les buts, les objectifs (d’apprentissage et fonctionnels), les rôles des participants et le calendrier du projet pilote.
5.2 Exemple de planification et d’exécution d’un pilote
Pour illustrer efficacement les tâches de planification du pilote, nous continuerons de travailler sur notre exemple d’application pilote. Nous commencerons par un tableau récapitulatif des décisions prises pour notre pilote, où nous les lierons aux tâches clés décrites dans le tableau RACI précédent. À partir de là, nous allons parcourir l’exécution des tâches ainsi qu’une description plus détaillée de chacune des décisions et comment elles sont mises en œuvre dans l’environnement Docker Enterprise.
Pour notre exemple de pilote, nous avons identifié les objectifs :
- Configurer une installation Docker Enterprise sans système d’exploitation avec CentOS 7.5 – architecture de référence guidée
- Concevoir et implémenter un schéma DNS divisé pour une résolution interne et externe appropriée
- Sécurisez l’installation avec NAT, pare-feu, isolation du réseau et équilibrage de charge frontal
- Utiliser NFS sur un réseau isolé pour sauvegarder le DTR et éventuellement les volumes de données d’application
- Implémenter la journalisation, la surveillance et les alertes de cluster et d’application (abordé plus loin dans le chapitre 7 , Surveillance et journalisation de la plate-forme Pilot Docker Enterprise )
- Déployez une application de site wiki HTTPS accessible sur Internet pour les utilisateurs internes, mais essayez de maintenir un temps d’arrêt presque nul
- Déployer un exemple d’application personnalisée avec un pipeline représentatif pour d’autres applications personnalisées (couvert dans le chapitre 6 , Concevoir et piloter un pipeline Docker Enterprise CI )
Notre échantillon d’équipe pilote comprend une équipe de base composée de cinq membres. Nous listons leurs rôles et noms fictifs pour nos exemples suivants :
- Un gestionnaire des opérations pour agir en tant qu’administrateur Docker Enterprise — Otto OpsManager
- Un administrateur système pour vous aider avec l’infrastructure sous-jacente de Docker Enterprise et les ressources de cluster — Sandy SysAdmin
- Un ingénieur DevOps pour prendre en charge le pipeline de logiciels et les déploiements de pile de cluster – Deepti DevOps
- Un architecte logiciel pour superviser la conception de logiciels conteneurisés – Andrew Architect
- Un ingénieur logiciel pour conteneuriser, tester et envoyer des artefacts au contrôle du code source — Sally Software
Notre calendrier était d’une durée de 6 semaines avec les activités clés suivantes qui se chevauchent :
- Activités clés couvertes dans ce chapitre :
- 2 semaines pour la construction de la plateforme
- 1 semaine pour conteneuriser et déployer une application wiki de confluence
- 1 semaine pour opérationnaliser l’application wiki de confluence – sauvegardes, mises à jour et processus de rupture / correction d’application
- Principales activités couvertes au chapitre 6 , Conception et pilotage d’un pipeline Docker Enterprise CI :
- 1 semaine pour conteneuriser l’application personnalisée avec des tests d’intégration locale
- 2 semaines pour piloter un pipeline de CI basé sur des conteneurs pour créer une application client
- 1 semaine vers une plateforme d’application personnalisée opérationnalisée – sauvegardes, mises à jour et processus de pause / correction d’application
- Principales activités couvertes au chapitre 7 , Pilot Docker Enterprise Platform Monitoring and Logging :
- 2 semaines de configuration de la journalisation, de la surveillance et des alertes
- 1 semaine pour documenter la plate-forme pour l’intégration post-pilote
Le tableau suivant présente les décisions clés pour notre exemple d’application pilote. Encore une fois, pour des raisons de cohérence, rattachez les tâches au tableau RACI montré précédemment:
| Tâche | Résumé de la décision clé prise pour le pilote |
| Configurer UCP et DTR pour le pilote |
|
| Synchronisation LDAP / équipe pour le pilote |
|
| Configuration de stockage pour le pilote |
|
| Concevoir et configurer RBAC |
|
| Image de base de l’application pilote |
|
| Architecture d’application pilote |
|
| Application pilote de conteneur UCP et DTR |
|
| Configuration du repo de l’image pilote |
|
| Balise d’image pilote et push |
|
| Numérisation d’image pilote |
|
| Pilote docker-compose-dev |
|
| Secrets des pilotes |
|
| Déploiement de la pile pilote |
|
Résumé des décisions pilotes
5.2.1 Configurer les paramètres du pilote UCP
L’installation d’UCP et de DTR a été la première étape vers le lancement de la phase pilote ; nous devons maintenant configurer les paramètres d’administration UCP et le système de contrôle d’accès basé sur les rôles ( RBAC ). Les paramètres administratifs incluent les informations de configuration et les options pour Swarm, les certificats clients UCP, le routage de couche 7, la configuration du cluster, l’authentification et l’autorisation, les journaux, la licence, le DTR, la confiance du contenu, l’utilisation, le planificateur et les mises à niveau.
Nous commençons par nous connecter à l’interface utilisateur Web UCP en utilisant les informations d’identification spécifiées lors du processus d’installation UCP. Après la connexion, nous regardons la colonne de gauche où nous voyons les six titres principaux de la structure de menu (les menus sont réduits par défaut). À partir de là, nous développons le menu administrateur et cliquez sur l’élément de menu Paramètres administrateur, comme indiqué dans la capture d’écran suivante :
Figure 1: Menu Paramètres administrateur UCP
La page des paramètres Swarm (Paramètres Admin | Swarm) affiche les jetons de jointure du travailleur et du gestionnaire, permet la rotation des certificats et des jetons de cluster et fournit des ajustements au calendrier lié aux opérations du cluster. Bien que vous puissiez trouver l’occasion de faire pivoter les certificats / jetons (généralement en raison d’un compromis), les paramètres Swarm ne nécessitent normalement aucun ajustement.
La page des paramètres des certificats client UCP (Paramètres administrateur | Certificats) permet aux utilisateurs de remplacer le certificat client UCP auto-signé par un certificat tiers de confiance. De retour au chapitre 3 , Prise en main – Docker Enterprise Proof of Concept , nous avons montré comment fournir un certificat tiers lors de l’installation d’UCP. Cependant, si vous avez différé au cours du processus d’installation, voici l’endroit où coller ou télécharger vos certificats tiers.
Si vous avez déjà installé DTR puis mis à jour les certificats clients d’UCP, vous devrez probablement reconfigurer votre installation DTR avec les nouveaux certificats UCP à l’aide d’une commande docker run -it –rm docker / dtr: 2.6.0 reconfigure avec la commande –ucp -ca paramètre. Sinon, vous obtiendrez une erreur lors de l’accès au DTR car il redirige vers UCP pour l’authentification à inscription unique.
Après avoir installé les certificats clients UCP tiers, vous devrez peut-être reconfigurer votre installation DTR. La mise à jour du certificat UCP peut interrompre la liaison entre DTR et UCP et entraîner un problème de connexion DTR. Si vous rencontrez ce problème, il est facilement résolu avec la commande de reconfiguration DTR. Vous pouvez également profiter de cette occasion pour ajouter votre certificat client DTR tiers en même temps en utilisant une commande ressemblant à ceci :
$ docker run -it –rm docker / dtr \
reconfigurer \
–ucp-url https://ucp.mydomain.com:443 \
–ucp-username admin \
–ucp-password {votre-mot-de-passe-va}} \
–replica-http-port 81 \
–replica-https-port 4443 \
–dtr-external-url dtr.mydomain.com \
–ucp-ca “$ (cat ucp.ca)” \
–dtr-ca “$ (cat dtr.ca)” \
–dtr-cert “$ (cat dtr.cert)” \
–dtr-key “$ (cat dtr.key)”
Les paramètres de routage UCP de couche 7 (Paramètres administrateur | Routage de couche 7 ) sont utilisés pour activer et configurer le système d’entrée Interlock 2 de Docker Enterprise. Le routage de couche 7 nécessite quelques paramètres clés. La première chose que vous voulez faire est de confirmer que les ports HTTP et HTTPS sont correctement définis. Dans le dernier chapitre, nous avons parlé de la conception du réseau et décrit comment notre équilibreur de charge transmettrait le trafic d’application entrant sur le port 8443 au cluster. Lorsque nous activons Interlock 2, un proxy reçoit du trafic sur le port 4443 de l’équilibreur de charge d’application, examine les en-têtes HTTP et achemine le trafic vers les conteneurs prévus. Nous reviendrons plus en détail sur le routage de la couche 7 lorsque nous déploierons notre application personnalisée plus loin dans le chapitre.
Les paramètres de configuration du cluster peuvent être utilisés pour remplacer les paramètres par défaut du cluster Swarm. Les deux premières options sont les paramètres de port pour le port du contrôleur Docker et le port Swarm. Le port du contrôleur est utilisé par l’interface utilisateur Web et l’API et généralement défini sur 443, mais peut être remplacé lorsque UCP est installé. Le port Swarm, également appelé port démon Docker, est défini sur 2376 par défaut et est utilisé pour la communication de gestion de cluster chiffrée entre les nœuds Swarm.
Si le port du démon est défini sur 2375 , cela signifie qu’il utilise un protocole non chiffré. C’est très dangereux! Toute personne accédant à ce port peut émettre des commandes Docker sur ce nœud, y compris des commandes Docker pour s’exécuter en mode privilège ou monter un répertoire sensible sur le système de fichiers hôte. L’utilisation de 2375 n’est ni normale ni attendue pour une configuration de cluster pilote.
Outre les paramètres de port, les paramètres de configuration du cluster permettent aux administrateurs de modifier la stratégie de planification pour le déploiement de conteneurs individuels dans le cluster. Ce n’est pas pour la planification du service Swarm, juste des conteneurs. Les services Swarm sont toujours planifiés à l’aide de la stratégie de planification répartie pour répartir uniformément les conteneurs sur le cluster. Pour plus d’informations sur le déploiement des services Swarm, veuillez consulter les documents Docker: https://docs.docker.com/engine/swarm/how-swarm-mode-works/services/
Le dernier paramètre pour le paramètre de cluster que vous devez connaître (nous ignorerons les paramètres du magasin KV car ils ne sont pas vraiment utilisés par de simples mortels) est l’URL de l’équilibreur de charge de service externe. Cela doit être défini sur la façon dont votre URL attendue pour l’accès externe qui correspond à votre CN de votre certificat.
La page Authentication & AuthorizationSettings comprend un certain nombre de paramètres importants. Le premier paramètre est le rôle par défaut pour toutes les collections privées. Ce paramètre a un impact sur l’accès par défaut accordé au sandbox privé de chaque utilisateur. Par défaut, il est défini sur un contrôle restreint. Dans certains cas, vous pouvez envisager de donner aux utilisateurs un contrôle total sur leur sandbox, en gardant à l’esprit les problèmes de sécurité supplémentaires qui peuvent survenir.
Le prochain regroupement de paramètres concerne la durée de vie, le renouvellement et les limites par utilisateur d’une session de connexion. Généralement, ceux-ci peuvent être laissés aux paramètres par défaut d’une durée de vie de session de 60 minutes, d’un seuil de renouvellement de 20 minutes et d’une limite de 10 utilisateurs (un utilisateur donné ne peut avoir que 10 sessions).
Deux dernières sections de la page des paramètres d’authentification et d’autorisation permettent l’intégration avec les mécanismes d’entreprise externes, y compris les services d’annuaire LDAP et l’authentification unique SAML 2.0 avec Okta ou ADFS. La fonctionnalité SAML 2.0 est nouvelle dans Docker EE2.1 / UCP 3.1 et présente actuellement certaines limitations. L’intégration LDAP, en revanche, fait partie de la plate-forme depuis longtemps et est généralement utilisée par les grandes entreprises.
L’intégration Docker UCP LDAP comprend deux parties. La première partie consiste à établir une connexion à votre serveur LDAP d’entreprise avec un compte de lecture, puis à définir comment rechercher des utilisateurs dans l’annuaire. Ces paramètres sont assez simples et vous permettent de tester la connexion à partir de la page Authentification et autorisation de l’UCP. Nous discuterons de la deuxième partie lorsque nous arriverons à ajouter des équipes au système Docker Enterprise RBAC.
C’est là que nous pouvons synchroniser activement les utilisateurs de (basé sur les paramètres de requête LDAP tels que les appartenances aux groupes) LDAP à l’équipe Docker RBAC. Par activement, je veux dire que si un utilisateur est supprimé d’un LDAP, il devient inactif dans UCP lors de la prochaine synchronisation LDAP, mais uniquement si le paramètre de provisionnement d’utilisateur juste à temps est faux.
La définition de True -In-Time User Provisioning sur true est intéressante car elle configure uniquement les utilisateurs LDAP autorisés dans UCP lors de leur première connexion. Donc, vous n’avez pas un tas de comptes d’utilisateurs inactifs dans UCP, mais il y a un inconvénient. Si l’ approvisionnement utilisateur juste à temps est vrai et qu’un utilisateur est supprimé d’un groupe dans LDAP, UCP refusera l’authentification du compte lors de la prochaine synchronisation, mais le bundle CLI de l’utilisateur autorisera toujours l’accès au cluster! Pour un environnement plus sécurisé, envisagez d’utiliser la requête de recherche d’utilisateurs LDAP la plus étroite possible pour limiter le nombre de comptes d’utilisateurs synchronisés avec UCP et définissez le paramètre de provisionnement utilisateur juste à temps sur false .
La page des paramètres des journaux est l’endroit où nous définissons le niveau de journalisation Docker UCP. Cela redémarre les conteneurs UCP avec un niveau de journalisation mis à jour et n’est qu’un petit aspect de la journalisation. Dans le chapitre 7 , Pilot Docker Enterprise Platform Monitoring and Logging , nous discutons des détails de la journalisation et de l’approche de Docker Enterprise à intégrer aux plates-formes de journalisation open source et commerciales.
Le paramètre de licence de page répertorie les informations sur le Docker actuellement installé licence Enterprise. Il vous donne également la possibilité de télécharger une nouvelle licence.
La page Docker Trusted RegistrySettings répertorie le nom de domaine complet ( FQDN ) du DTR associé au cluster.
La page des paramètres Content Trust permet aux administrateurs Docker Enterprise de restreindre les moteurs Docker Enterprise d’UCP pour exécuter uniquement le conteneur avec des images signées. Lorsque cette fonctionnalité est activée, en cochant la case Exécuter uniquement les images signées, vous spécifierez en outre les équipes Docker Enterprise qui doivent signer les images avant de pouvoir les déployer. Par exemple, l’équipe Ops de notre organisation pilote peut être tenue de signer numériquement toutes les images avant de les exécuter dans le cluster. Cela rend difficile la substitution d’images non autorisées et potentiellement malveillantes dans des conteneurs de production. Cette fonctionnalité est généralement réservée aux clusters de production.
La page Paramètres d’utilisation est l’endroit où les utilisateurs configurent les options concernant si et comment votre cluster partage les rapports d’utilisation avec l’équipe du produit Docker. Comme la plupart des éditeurs de logiciels, Docker est toujours à la recherche de commentaires pour améliorer son produit. En examinant vos informations d’utilisation ainsi que le suivi de l’API et de l’interface utilisateur, ils sont capables d’identifier des modèles d’utilisation importants pour guider les efforts de développement de produits. Si vous vous méfiez un peu du partage, vous pouvez toujours cocher la dernière case, ce qui rend les rapports anonymes en supprimant vos informations de licence des rapports.
La page des paramètres du planificateur permet aux administrateurs Docker Enterprise de limiter les déploiements de charge de travail aux nœuds de travail (nœuds non UCP et non DTR). Il existe deux niveaux de contraintes pour Kubernetes et Swarm. Le premier niveau permet aux utilisateurs de planifier des charges de travail sur tous les nœuds, y compris les gestionnaires UCP dans les nœuds DTR. Cette case est presque toujours décochée: n’autorisez pas les non-administrateurs à déployer des charges de travail sur les gestionnaires et les nœuds DTR. Autoriser la charge de travail des utilisateurs sur les nœuds de gestionnaires (et DTR) est contraire aux meilleures pratiques de Docker. Le deuxième paramètre permet aux administrateurs Docker Enterprise de déployer des conteneurs sur des gestionnaires UCP ou des nœuds DTR. Une fois que le cluster est complètement configuré, cela peut être décoché, mais cette case doit être cochée pendant que vous installez DTR et d’autres utilitaires système, y compris certains cadres de journalisation tels qu’une pile ELK, où les collecteurs de journaux doivent être sur tous les nœuds.
La page de mise à niveau est l’endroit où les administrateurs de Docker Enterprise peuvent vérifier la version actuelle du logiciel et s’il existe des mises à niveau UCP disponibles. Si des versions plus récentes sont disponibles, vous pouvez effectuer une mise à niveau à partir de cette page. Cependant, sauvegardez toujours UCP avant de choisir de mettre à niveau.
La procédure générale de maintenance d’un cluster comprend la mise à jour / l’application de correctifs au système d’exploitation et au moteur Docker sur chaque nœud de cluster. Cela doit être fait avant de mettre à jour UCP ou DTR car ils peuvent nécessiter des correctifs ou des capacités disponibles dans la dernière version du moteur Docker. De plus, avant de mettre à jour à partir de la page des paramètres de mise à niveau de Docker , sauvegardez UCP et DTR. Alors que les versions de correctifs fonctionnent presque toujours sans problème, les mises à jour / mises à niveau plus importantes peuvent rencontrer des problèmes et la sauvegarde est rarement regrettée!
Docker a également exposé l’API du fichier de configuration UCP. Cela permet aux administrateurs Docker Enterprise d’utiliser un format TOML pour exporter / importer des configurations UCP plutôt que d’utiliser l’interface utilisateur pour configurer les paramètres. Par exemple, en utilisant un bundle de ligne de commande d’un administrateur Docker Enterprise, nous pouvons vider la configuration de notre UCP. Tout d’abord, nous blottis notre critère d’évaluation de l’API UCP en fournissant à notre certificat d’utilisateur admin CA et la touche info et vidons la réponse dans la locale UCP-config.toml fichier. Ensuite, nous pouvons voir le contenu :
[local-CLI-DOcker-EE-Admin]$ curl –cacert ca.pem –cert cert.pem –key key.pem https://ucp.mydomain.com/api/ucp/config-toml > ucp-config.toml
[local-CLI-DOcker-EE-Admin]$ cat ucp-config.toml
[auth]
default_new_user_role = “restrictedcontrol”
backend = “managed”
samlEnabled = false
samlLoginText = “”
[auth.sessions]
lifetime_minutes = 60
renewal_threshold_minutes = 20
per_user_limit = 10
[auth.saml]
idpMetadataURL = “”
spHost = “”
rootCerts = “”
tlsSkipVerify = false
[[registries]]
host_address = “dtr.mydomain.com”
service_id = “8c599992-8996-43b5-b511-f26c94631fea”
ca_bundle = “—–BEGIN CERTIFICATE—–\n \n—–END CERTIFICATE—–\n”
batch_scanning_data_enabled = true
[scheduling_configuration]
enable_admin_ucp_scheduling = false
default_node_orchestrator = “swarm”
[tracking_configuration]
disable_usageinfo = true
disable_tracking = true
anonymize_tracking = false
cluster_label = “”
[trust_configuration]
require_content_trust = false
[log_configuration]
level = “INFO”
[audit_log_configuration]
level = “”
support_dump_include_audit_logs = false
[license_configuration]
auto_refresh = false
[cluster_config]
controller_port = 443
kube_apiserver_port = 6443
swarm_port = 2376
swarm_strategy = “spread”
kv_timeout = 5000
kv_snapshot_count = 20000
profiling_enabled = false
external_service_lb = “ucp.nvisia.io”
metrics_retention_time = “24h”
metrics_scrape_interval = “1m”
rethinkdb_cache_size = “1GB”
cloud_provider = “”
cni_installer_url = “”
pod_cidr = “192.168.0.0/16”
calico_mtu = “1480”
ipip_mtu = “1480”
unmanaged_cni = false
nodeport_range = “32768-35535”
azure_ip_count = “”
local_volume_collection_mapping = false
manager_kube_reserved_resources = “cpu=250m,memory=2Gi,ephemeral-storage=4Gi”
worker_kube_reserved_resources = “cpu=50m,memory=300Mi,ephemeral-storage=500Mi”
L’API de configuration UCP est également un excellent moyen d’initialiser un cluster. Pour plus d’informations sur les configurations UCP, consultez les documents sur https://docs.docker.com/ee/ucp/admin/configure/ucp-configuration-file/ .
Maintenant que nous avons expliqué les paramètres UCP, nous allons configurer le système RBAC pour notre groupe pilote.
5.2.2 RBAC dans Docker Enterprise
Le système RBAC (Dock -Based Access Control) de Docker Enterprise permet aux administrateurs de définir l’accès des utilisateurs à leur cluster à un niveau très fin. Tout d’abord, nous parlerons des concepts RBAC applicables dans Docker Enterprise. Ensuite, nous allons plonger dans un exemple spécifique de notre exemple d’application pilote pour clarifier et démontrer les concepts dans la pratique.
Pour travailler avec le système Docker Enterprise RBAC, vous devez comprendre les quatre constructions principales suivantes dans Docker Enterprise :
- Sujets : organisation, équipes, utilisateurs et comptes de service
- Groupes de ressources : collections et espaces de noms
- Rôles : regroupements d’autorisations pour effectuer des opérations de cluster
- Subventions : application du rôle à un sujet pour un groupe de ressources spécifique
Nous commençons notre discussion par la subvention car elle décrit le mieux les aspects fonctionnels de tous les composants. La subvention est la colle qui lie le sujet à un ensemble de ressources à travers un rôle spécifique. Dans la figure 2, nous pouvons voir comment une subvention associe un sujet à une liste d’opérations autorisées (regroupées en rôles) sur un ensemble défini de ressources.
Dans Docker Enterprise, les sujets peuvent faire référence à une organisation, un utilisateur, une équipe ou un compte de service. Les ensembles de ressources sont implémentés avec des collections et des espaces de noms (Kubernetes). Les collections peuvent contenir des conteneurs, des services, des images, des réseaux, des volumes, des secrets, des configurations (d’application) et des nœuds de cluster. Un rôle répertorie toutes les opérations autorisées sur les objets de la collection cible, telles qu’une commande de création de conteneur de conteneur ou de connexion réseau, comme illustré dans le diagramme suivant :

Figure 2: Contrôle d’accès basé sur les rôles de Docker Enterprise
Pour plus de commodité, Docker Enterprise a plusieurs rôles prédéfinis utiles. Bien que vous puissiez trouver nécessaire ou pratique de définir le vôtre, ces rôles prédéfinis sont à la fois typiques et illustratifs de scénarios réels. Les rôles prêts à l’emploi inclus sont aucun, affichage uniquement, contrôle restreint, contrôle total et planification (pour les opérations liées aux nœuds), comme indiqué dans le diagramme suivant :

Figure 3: Rôles intégrés de Docker
Les rôles sont immuables et ne peuvent donc pas être modifiés (uniquement supprimés et recréés). Cela a du sens, car toute modification pourrait créer de la confusion et entraîner des failles de sécurité possibles. Par exemple, que se passe-t-il si un administrateur modifie un rôle d’utilisateur en lecture seule pour autoriser les mises à jour et les suppressions? Toutes les subventions existantes utilisant le rôle en lecture seule modifié seraient compromises.
Le système RBAC peut être configuré via le menu Contrôle d’accès de l’interface utilisateur Web de Docker Enterprise ou à l’aide de l’API Docker, mais veuillez noter que les paramètres RBAC ne sont disponibles que pour les utilisateurs administratifs de Docker Enterprise. Le menu Contrôle d’accès comprend les quatre éléments de sous-menu : Organisations et équipes, Utilisateurs, Rôles et Subventions.
Dans la figure 4, nous montrons une configuration spécifique pour notre exemple pilote. Veuillez noter que la figure montre la relation entre les organisations et les utilisateurs avec UCP (en utilisant des subventions) et DTR (en utilisant les autorisations de référentiel d’équipe dans DTR) :
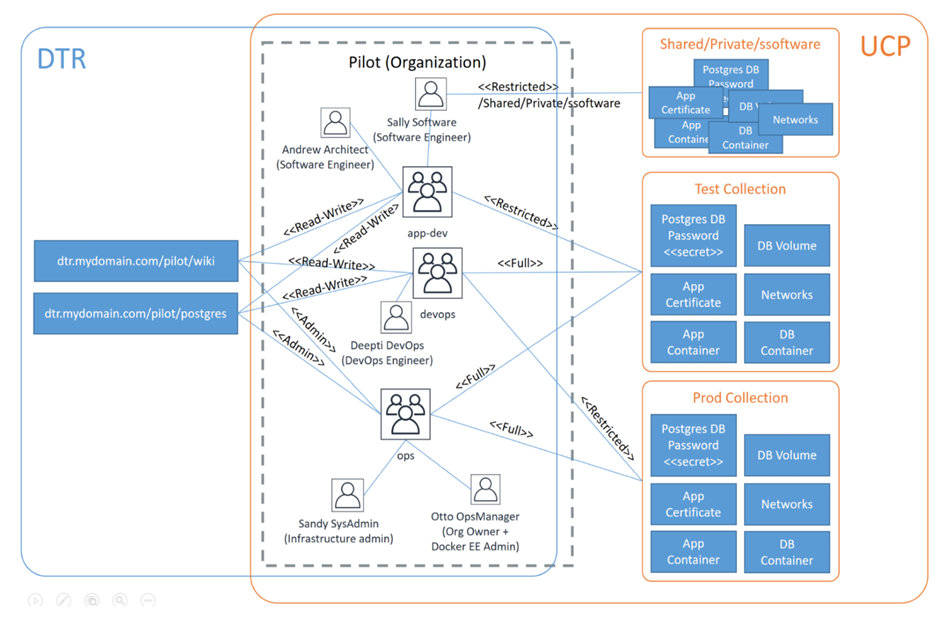
Figure 4: Exemple de configuration RBAC pilote
5.2.2.1 Configuration des équipes et des organisations Docker Enterprise
Docker Enterprise Orgs and Teams fournit des mécanismes de regroupement pour les utilisateurs et fait l’objet des systèmes RBAC. Lors du discernement des options pour les organisations et les équipes, gardez à l’esprit que l’organisation a un impact sur les structures des espaces de noms du référentiel DTR. Le nom de l’image DTR est composé de la balise DTR_FQDN + nom de l’utilisateur ou de l’organisation + nom du référentiel : Le nom des images d’entreprise est généralement associé au nom de l’organisation plutôt qu’au nom d’un utilisateur. Ces noms d’organisations peuvent être alignés sur une unité commerciale (c’est-à-dire la souscription ou les ventes) ou une phase de pipeline pour la promotion de l’image (développement, test, assurance qualité, mise en scène et production), selon votre approche et les contrôles d’accès entre les unités commerciales ou le pipeline. Étapes.
Les équipes Docker Enterprise sont des sous-groupes au sein des organisations. Les utilisateurs sont associés à des équipes et lorsqu’un utilisateur est ajouté à une équipe, cet utilisateur devient automatiquement membre de l’organisation parent.
Les étapes de configuration et de remplissage manuel d’une équipe dans Docker Enterprise sont les suivantes :
- Connectez-vous avec un compte administrateur Docker Enterprise.
- Ajouter des utilisateurs :
- Contrôle d’accès ouvert | Utilisateurs et cliquez sur le bouton Créer
- Entrez les informations du nouvel utilisateur et cliquez sur Créer pour créer les nouveaux utilisateurs
- Répétez les étapes 2 et 3 pour chaque nouvel utilisateur
- Ajouter des organisations et des équipes :
- Contrôle d’accès ouvert | Organisations et équipes et utilisez le bouton Créer pour créer une nouvelle organisation
- Entrez les informations sur l’organisation et cliquez sur le bouton Créer en bas du formulaire
- Cliquez sur le nouveau nom de l’organisation dans la liste pour afficher / créer des équipes pour l’organisation sélectionnée
- Cliquez sur + dans le menu supérieur droit pour ajouter une nouvelle équipe
- Saisissez le nom et la description de l’équipe, puis cliquez sur Créer en bas du formulaire
- Ajoutez des utilisateurs aux équipes :
- Accédez au contrôle d’accès | Organisations et équipes | Nom de l’organisation pour voir la liste des équipes
- Cliquez sur une équipe et utilisez-le + dans le coin supérieur droit pour ajouter des utilisateurs à l’équipe
Dans le menu Org, vous pouvez remarquer l’organisation Docker-datacenter. Il s’agit d’une organisation interne à laquelle les utilisateurs sont ajoutés la première fois qu’ils se connectent à Docker Enterprise et se voient accorder par défaut un accès de contrôle restreint (le niveau de contrôle d’accès par défaut est configurable via Paramètres administrateur | Authentification et autorisation ) à leur profil personnel / partagé / privé / { nom_utilisateur} collection: la collection par défaut des utilisateurs (elle peut être remplacée dans le profil d’un utilisateur).
Comme vous pouvez vous y attendre, l’ajout d’utilisateurs individuels à UCP peut devenir très fastidieux dans une grande organisation. C’est pourquoi Docker Enterprise permet aux administrateurs Docker Enterprise de synchroniser les membres du groupe LDAP en équipes UCP. Non seulement cela remplit les membres de l’équipe, mais comme mentionné précédemment, dans la section Paramètres d’authentification et d’autorisation UCP , il peut également être utilisé pour synchroniser les membres de l’équipe avec les mises à jour apportées aux groupes LDAP.
5.2.2.2 Synchronisation des membres de l’équipe à l’aide de LDAP
Pour votre projet pilote, vous pouvez décider d’utiliser l’accès utilisateur et l’authentification intégrés de Docker Enterprise plutôt que de vous synchroniser avec un annuaire AD / LDAP d’entreprise afin de limiter la portée du projet pilote. Bien que le déplacement de l’intégration AD / LDAP hors de la portée puisse être un excellent moyen de faire avancer le pilote, il s’agit d’un point de contact important pour la plate-forme Docker Enterprise et devra être résolu à un moment donné. Le système de contrôle d’accès intégré de Docker étant flexible, il est possible d’ajouter la synchronisation AD / LDAP ultérieurement. Cependant, le pilote est un très bon moment pour entamer des conversations avec les équipes d’administration et de sécurité des utilisateurs du système sur les plans d’intégration détaillés. Un bon compromis pourrait être de commencer par ajouter manuellement les utilisateurs de la première équipe, puis de commencer à expérimenter avec la fonction de synchronisation AD / LDAP pour implémenter une solution synchronisée à long terme.
Avant d’utiliser la synchronisation Docker EE LDAP, votre cluster UCP doit être connecté au serveur LDAP à l’aide de la page des paramètres d’authentification et d’autorisation UCP . Non seulement cela se connectera au serveur AD / LDAP de l’entreprise, mais cela vous permettra d’isoler un sous-ensemble de membres d’équipe UCP candidats grâce à l’utilisation d’un filtre de requête LDAP.
Une fois qu’une connexion LDAP est établie entre UCP et votre serveur LDAP, vous aurez de nouvelles options lors de la création d’une équipe UCP. Ensuite, lors de la création d’une équipe UCP, en définissant Activer les membres de l’équipe de synchronisation sur Oui , vous pouvez ajouter tous les membres d’un groupe LDAP ou vous pouvez fournir une requête LDAP personnalisée pour remplir votre équipe. N’oubliez pas que ceux-ci seront synchronisés à des intervalles comme spécifié dans la configuration UCP.
Si des membres sont supprimés du groupe LDAP, leur accès à UCP sera réduit ou éliminé en fonction du paramètre de provisionnement juste à temps pour la synchronisation LDAP :
Figure 5: Exemple de hiérarchie d’images de base – https://docs.docker.com/ee/ucp/authorization/ee-standard/
Dans la figure 5 , nous voyons un exemple d’un didacticiel Docker Enterprise sur https://docs.docker.com/ . Il s’agit d’un excellent exemple pour montrer le spectre de bout en bout de la façon dont un utilisateur LDAP accède aux ressources d’une collection Docker Enterprise via des groupes, des équipes et des subventions. Sur le côté gauche, nous avons des collections de ressources (ou espaces de noms pour Kubernetes) à l’intérieur de notre sous-système de contrôle d’accès UCP. À droite, nous avons un annuaire actif d’entreprise ou LDAP avec les utilisateurs de notre entreprise. Encore une fois, cela suppose que UCP est configuré pour se synchroniser avec votre serveur LDAP d’entreprise.
Pour connecter les ressources UCP aux utilisateurs AD / LDAP, nous nous déplaçons de droite à gauche, des utilisateurs du répertoire d’entreprise vers leurs groupes associés qui représentent des regroupements fonctionnels. Ici, dans notre exemple, les développeurs sont organisés en deux groupes d’applications ( AD_payments et AD_mobile ) et les autres utilisateurs administratifs sont organisés par souci fonctionnel tels que les administrateurs de base de données ( AD_db ) et les opérations de sécurité ( AD_sec ).
Le regroupement AD / LDAP, bien sûr, a lieu à l’intérieur du répertoire d’entreprise AD / LDAP (en dehors du domaine Docker Enterprise) et est idéalement déjà mis en place dans le cadre des pratiques normales de votre administrateur système / équipe de sécurité. Si ce n’est pas le cas, vous avez deux options. La première option consiste à rencontrer les administrateurs système et l’équipe de sécurité pour établir des regroupements logiques similaires à l’exemple illustré précédemment. La deuxième option consiste à créer une requête AD / LDAP pour cibler les utilisateurs associés à une équipe spécifique. La deuxième option peut être plus rapide, mais elle a tendance à être fragile et difficile à entretenir. Nous vous suggérons fortement de travailler avec vos équipes d’administration et de sécurité pour développer un schéma de regroupement logique pour votre annuaire.
Une fois vos regroupements AD / ADAP configurés, il est temps de vous diriger vers l’interface utilisateur de l’UCP. Dans le menu des organisations et des équipes de contrôle d’accès, vous pouvez cliquer sur votre organisation principale. Ensuite, cliquez sur le signe plus dans le coin supérieur droit pour ajouter une nouvelle équipe. Notez l’option d’activation de la synchronisation des membres de l’équipe. C’est là que vous pouvez le définir sur Oui, puis vous pouvez spécifier comment vous souhaitez que votre équipe UCP soit synchronisée avec votre équipe AD / LDAP. Généralement, vous utiliserez l’option Correspondance avec les membres du groupe (liaison directe) en fournissant dans le champ DN du groupe les descripteurs qui correspondent à votre équipe dans l’annuaire AD / LDAP. L’attribut membre du groupe indique à UCP où extraire les membres du groupe pour distinguer les noms du répertoire AD / LDAP. Une fois cela fait, vous avez maintenant connecté vos groupes AD avec vos équipes UCP. Cette connexion sera synchronisée à intervalles réguliers en fonction des paramètres de votre serveur UCP / LDAP.
Toutes nos félicitations ! Vous avez maintenant configuré vos organisations, équipes et utilisateurs dans UCP. La prochaine étape consiste à établir des collections UCP à utiliser par notre équipe pilote.
5.2.2.3 Collecte pour l’équipe pilote
Nos utilisateurs étant configurés manuellement ou importés dans nos équipes à l’aide de la synchronisation AD / LDAP, nous pouvons désormais leur accorder l’accès aux ressources UCP. Comme décrit précédemment, les ressources UCP sont organisées en collections. Pour la configuration de la collection du pilote, revenons à la figure 4 où nous voyons trois collections illustrées.
Les principales collections d’intérêt pour l’équipe pilote sont les collections de test et de production. Pour notre discussion pilote, la collection de tests contient des ressources utilisées pour tester l’application après des déploiements (automatisés). Nous en apprendrons davantage sur les pipelines automatisés avec Docker au chapitre 6 , Concevoir et piloter un pipeline Docker Enterprise CI , où nous déclencherons des builds automatisés et déploierons des artefacts mis à jour dans la collection de tests pour les tests d’intégration.
Les développeurs d’applications auront un accès restreint à l’environnement de test afin de résoudre les problèmes. L’équipe DevOps testera leurs scripts de déploiement au sein de la collection de tests et l’équipe app-dev aura un accès complet à toutes les ressources. La collection de tests ne devrait pas avoir de données sensibles ou de secrets partagés, car les membres de l’équipe de développement d’applications pourront potentiellement voire à la fois les données et les secrets dans cet environnement.
La collection prod est une collection plus verrouillée et imitera plus étroitement ce qui sera finalement un cluster de production distinct. En fait, la base de données prod peut commencer par une copie récente d’une base de données de production avec une fidélité totale des données, y compris des données personnelles ou financières potentiellement sensibles. Cet environnement peut également inclure des secrets de production tels que des jetons d’accès à des API tierces. Notez que les développeurs d’applications n’ont pas accès à la collection prod de la figure 4 pour cette raison.
Remarque de sécurité importante: si vous utilisez un système de journalisation centralisé pour votre cluster de conteneurs, veillez à ne pas enregistrer de données de type PMI ou HIPAA dans les journaux, à moins qu’elles ne soient chiffrées et verrouillées de manière appropriée. Souvent, les informations privées sont partagées via des variables d’environnement qui peuvent être révélées lors d’un vidage de pile dans l’enregistreur lorsqu’une application échoue.
Donc, pour des raisons de simplicité dans notre pilote, nous avons deux collections principales pour notre équipe sans structures de collecte imbriquées ou hiérarchiques. Les collections test et prod sont plates sans aucun chevauchement. Cependant, dans la figure 4, nous voyons comment l’équipe de Docker docs a exploité une structure de collection hiérarchique imbriquée.
L’exemple montre trois rôles utilisés :
- Controle total
- Afficher / utiliser des secrets et des réseaux
- Voir seulement
Dans l’exemple, nous voyons qu’une subvention est accordée à l’équipe des paiements pour un contrôle total sur la collecte / staging / paiements . De plus, deux subventions supplémentaires sont appliquées à l’équipe de paiement, ce qui lui permet de contrôler pleinement la collection / prod / paiements et de visualiser / utiliser l’accès secret et réseau à / prod . Notez soigneusement comment les collections UCP sont imbriquées (contrairement à la conception de collection plate de notre pilote). Par conséquent, la collection / prod est un sur-ensemble de / prod,/prod/paiements,/prod/mobile et/prod/DB. Ainsi, toutes les subventions à / prod se propageront également à toutes les collections sous / prod !
Pour notre projet pilote, veuillez noter que chaque utilisateur recevra un accès restreint à sa propre collection de bac à sable appelée / shared / private / {username} (pour l’utilisateur Sally Software, / shared / private / ssoftware ). Cette collection sera créée et une autorisation de contrôle restreinte sera ajoutée la première fois que l’utilisateur se connectera. C’est là qu’il peut vouloir tester une pile de conteneurs en utilisant les ressources du cluster plutôt que sa propre machine de développement. Cela doit être soigneusement géré dans le cadre de votre processus de développement logiciel. Encore une fois, nous en parlerons davantage dans le chapitre sur le pipeline.
5.2.3 Paramètres du pilote DTR
Dans le chapitre précédent, où nous avons pris en charge certaines infrastructures critiques associées à notre configuration pilote DTR pendant le processus d’installation, nous avons configuré le support NFS pour notre stockage d’images DTR. Cela fournit un magasin de données principal commun pour les images DTR volumineuses sur toutes les répliques du cluster. Ceci est particulièrement important pour le bon fonctionnement de la fonction de numérisation d’images de la version Docker Enterprise Advanced. Veuillez noter que le stockage backend DTR est destiné aux couches d’images binaires. Les autres métadonnées du référentiel sont stockées et répliquées sur les répliques DTR à l’aide de rethinkdb . Les autres paramètres de réplique DTR du cluster sont stockés dans le magasin de clés / valeurs etcd du cluster ( ucp-kv ).
Pour accéder aux paramètres DTR, connectez-vous à DTR en tant qu’administrateur Docker Enterprise. Ensuite, accédez au menu Système, comme illustré à la figure 6 . Le menu Système DTR comprend cinq sous-menus principaux : Général, Stockage, Sécurité, Collecte des ordures et Journaux des travaux :
Figure 6: Paramètres généraux du registre approuvé Docker
La page des paramètres généraux est divisée en plusieurs sections, y compris les mises à jour, la licence , les domaines et les proxys , l’ authentification unique , les référentiels , les événements de référentiel , les journaux des travaux , les analyses et les notifications .
La section Mise à jour de la page des paramètres généraux vous permet de voir si de nouvelles versions de DTR sont disponibles. En activant la vérification des mises à jour, DTR recherchera automatiquement les nouvelles versions du logiciel et avisera les utilisateurs avec une bannière d’en-tête dans l’interface utilisateur DTR si une version plus récente est disponible. Il est important de noter que, bien que les utilisateurs soient informés des mises à jour disponibles, les mises à jour ne seront pas automatiquement installées. Le processus de mise à jour lui-même est une opération manuelle effectuée par un administrateur Docker Enterprise.
Lors d’un pilote, il peut être tentant d’accorder à chacun des droits d’accès administrateur Docker Enterprise. Cela est problématique pour plusieurs raisons, allant des problèmes de sécurité à la déstabilisation du cluster! Les utilisateurs peuvent supprimer par inadvertance des ressources système et provoquer une instabilité dans le cluster, ou les utilisateurs disposant de droits d’administrateur Docker Enterprise peuvent également effectuer des mises à jour sur le logiciel Docker Enterprise. Habituellement, cela se produit assez innocemment, où une bannière avec un lien indique à l’utilisateur (avec les droits d’administrateur) qu’une nouvelle version de DTR ou UCP est disponible. L’utilisateur clique sur le lien et applique la mise à jour sans lire les notes de publication, qui peuvent inclure les mises à niveau requises du Docker Engine avant la mise à jour. Limitez les administrateurs Docker Enterprise à un petit groupe d’administrateurs système .
La section Licence, tout comme les paramètres UCP, fournit des informations sur la licence Docker actuelle, telles que la date d’expiration du niveau de licence et l’ID de licence. Dans la plupart des cas, vous ne devriez pas avoir à vous soucier de la section Licence car elle doit être automatiquement copiée à partir de vos informations de licence UCP lorsque DTR est installé.
La section Paramètres du domaine et des proxys est l’endroit où la configuration de l’accès client est définie pour l’interface utilisateur Web DTR. Lors de la configuration du mode pilote, à l’aide d’un équilibreur de charge externe, vous devrez remplir le champ Load Balancer the Public Address. Il s’agit généralement du nom de domaine complet (dtr.mydomain.com) de votre DTR en externe. Il est également en corrélation avec le FQDN utilisé pour générer le certificat DTR. Veuillez noter que l’accès au DTR avec toute autre adresse IP ou nom de domaine peut entraîner des échecs d’authentification de connexion unique.
Le Single Sign-On paramètre vous permet de rationaliser les connexions DTR par redirection vers UCP pour l’authentification. Cela devrait être activé avec le curseur vers la droite.
Le paramètre Référentiels permet aux utilisateurs (avec les autorisations appropriées) de créer des référentiels lorsqu’ils envoient leur première image. Le paramètre est désactivé par défaut, mais l’activer est généralement le comportement attendu des utilisateurs expérimentés. Encore une fois, s’ils n’ont pas accès à l’espace de noms du référentiel où ils essaient de pousser l’image, cela ne réussira pas de toute façon.
Par exemple, si la création sur push est activée et que Sally Software envoie une image à son espace de noms de référentiel, dtr.mydomain.com/ssoftware/somerepo:v1 , cela devrait simplement fonctionner. Cependant, si elle essaie de pousser une image avec un espace de noms de référentiel d’organisation pilote, dtr.mydomain.com/ssoftware/somerepo:v1 , car elle n’est qu’un membre et non propriétaire d’une organisation pilote de l’organisation pilote, l’opération échouera.
Les paramètres des événements du référentiel et des journaux des travaux permettent de gérer automatiquement les événements du référentiel et les journaux des travaux. D’une manière générale, c’est une bonne idée de mettre des limites finies sur les sorties de traitement continu qui s’accumulent au fil du temps, en particulier les journaux. Pour notre échantillon pilote DTR, nous avons défini la suppression automatique des événements du référentiel sur sept jours et les journaux des travaux sur six semaines.
Les paramètres d’ analyse DTR , similaires aux paramètres d’analyse UCP, envoient des rapports d’utilisation à Docker pour analyse afin d’améliorer le produit DTR. Il existe deux paramètres : l’un pour autoriser l’envoi de données à Docker et le second pour n’envoyer que des données anonymes à Docker.
Le paramètre final sur la page générale est Notifications. L’activation de l’avertissement Afficher “sauvegarde nécessaire” fait exactement cela. Lorsque DTR n’a pas été sauvegardé depuis au moins sept jours, une bannière apparaît en haut de l’interface Web DTR.
Ensuite, la section principale des paramètres DTR concerne les paramètres de stockage externe . Encore une fois, nous avons configuré notre stockage pilote DTR lorsque nous avons installé DTR, en utilisant un système de fichiers NFS. Cependant, si vous utilisez un système de fichiers différent et que vous n’avez pas spécifié les paramètres au moment de l’installation, c’est l’endroit où le faire. Le stockage externe DTR prend en charge le système de fichiers local (qui est le système par défaut et n’est pas recommandé pour les clusters HA DTR), NFS (standard standard pour les installations réseau gérées sur permis), Amazon S3 ou similaire (installations Docker Enterprise hébergées par AWS), Google Cloud Stockage (installations Docker Enterprise hébergées par Google), comptes de stockage Microsoft Azure Blob (installations Docker Enterprise hébergées par Azure) et OpenStack Swift (installations Openshift Docker Enterprise).
L’onglet de l’interface utilisateur des paramètres de sécurité du système DTR configure les préférences de numérisation d’image et n’est disponible que pour les abonnés de Docker Enterprise Advanced. La première section est destinée aux administrateurs Docker Enterprise pour spécifier comment le scanner d’images obtient sa base de données de vulnérabilités. Il y a deux options. La première et la plus simple option est l’option de mise à jour en ligne, qui se synchronise automatiquement tous les jours à 3 h UTC. La deuxième option, l’option de mise à jour hors ligne, nécessite qu’un administrateur télécharge manuellement une base de données de vulnérabilités à intervalles réguliers, auquel cas vous pouvez recevoir quotidiennement un lien par e-mail. Bien que fastidieux, le mode hors ligne est la seule option pour les DTR fonctionnant dans un environnement sans sortie Internet, comme un environnement de réseau à entrefer sécurisé que vous pourriez voir dans les finances ou une installation gouvernementale sécurisée.
Il existe deux paramètres de sécurité supplémentaires. Le premier définit un seuil d’expiration de l’analyse et est spécifié en heures. Étant donné que la numérisation d’images peut être un processus gourmand en ressources, il est judicieux de définir un seuil. Pour notre pilote DTR, j’ai fixé la limite de balayage à 1 heure. Le dernier paramètre de sécurité pour DTR implique l’analyse des webhooks.
Avec ce paramètre, DTR peut exécuter automatiquement une publication HTTP vers une URL externe chaque fois que le scanner de sécurité a été mis à jour. Bien que cela ne soit certainement pas nécessaire, c’est un bon coup de pouce pour l’équipe de sécurité / SecOps d’examiner la base de données CVE et de déterminer l’impact potentiel sur les conteneurs en cours de production.
L’onglet d’interface utilisateur de récupération de place du système DTR configure le comportement de la récupération de place lors du nettoyage du stockage principal (balises et images supprimées). Il existe trois options principales pour la récupération de place. La première option exécute la tâche de récupération de place jusqu’à ce qu’elle se termine, ce qui, en fonction du trafic DTR et des performances de l’IOP backend, peut prendre du temps. La deuxième option est exécutée pendant N minutes, où vous définissez N comme limite pour la durée pendant laquelle le garbage collector doit s’exécuter à chaque fois qu’il est déclenché. La troisième option consiste à ne jamais exécuter le garbage collection, que vous ne devriez probablement considérer que si vous rencontrez des problèmes de performances avec votre backend DTR et que vous pensez qu’ils sont liés au garbage collection. Une approche raisonnable consiste ici à le configurer pour qu’il s’exécute une fois par jour (en utilisant le paramètre de déclenchement cron) pendant les heures de non-traitement et à surveiller les actions DTR onlinegc dans les journaux des travaux. S’ils s’exécutent trop longtemps, mettez à jour les paramètres de récupération de place.
Selon vos temps de traitement de pointe, vous souhaiterez définir l’option de répétition en utilisant un format de planification cron (ish). Pour notre configuration pilote DTR, nous avons utilisé un calendrier cron personnalisé défini sur 8 * * * afin de déclencher la collecte des ordures à 2 h du matin, heure normale du Centre.
5.2.4 L’exemple d’application wiki pilote
Pour la sélection de notre application pilote, nous avons choisi une application wiki héritée lift-and-shift à partir d’un hôte de cloud privé. Cette application est attrayante pour notre pilote en raison de ses dépendances limitées. Il existe des ressources Web pour des choses telles que SMTP, mais elles ne nécessitent aucune modification pour fonctionner dans notre environnement conteneurisé. De plus, nos parties prenantes sont motivées à ré-héberger cela dans notre cluster de centre de données en métal nu Docker en raison des frais de serveur cloud privé de 1 500 $ par mois que nous payons actuellement. En fait, les frais de cloud privé actuels sont équivalents à la licence pour un cluster standard Docker Enterprise à 10 nœuds avec une prise en charge le jour ouvrable. Donc, de manière conservatrice, lorsque nous supposons que 6 de nos 10 nœuds sont consommés pour UCP et DTR, nous avons toujours 4 nœuds de travail disponibles dans notre nouvel environnement HA Docker Enterprise, par opposition à 1 hôte non HA dans notre environnement de cloud privé actuel.
Le but de notre exemple d’application wiki est de simplement conteneuriser et déployer l’application wiki et sa base de données dans notre cluster. Au fil du temps, nous expérimenterons des fonctionnalités plus avancées (routage de couche 7 et NFS pour la sauvegarde de volume), mais notre objectif principal est de fournir une alternative stable à la plate-forme hébergée dans le cloud privé.
Commencez par conteneuriser l’application et testez-la sur une machine locale. Une fois l’application testée et vérifiée, nous la préparerons pour un déploiement en cluster comprenant : le stockage des images dans notre registre de confiance, la préparation de volumes de données persistants pour l’application et la base de données, et enfin la création d’un fichier de pile Docker à déployer sur le cluster Docker Enterprise.
5.2.4.1 Conteneurisation de l’application
Plus tôt, dans le chapitre 3 , Mise en route – Preuve de concept de Docker Enterprise , nous avons décrit le processus de conteneurisation d’un exemple d’application .NET en utilisant l’exemple d’application d’abonnement à la newsletter d’Elton Stoneman comme toile de fond. Maintenant, pour notre première application pilote, nous allons conteneuriser une ancienne application Wiki Confluence construite avec Java 7, Tomcat. et Postgres.
Nous commençons le processus de conteneurisation de notre application wiki en identifiant et en collectant les actifs de l’application. Les actifs de l’application incluent le code source, la configuration et les fichiers de données. Une fois que nous avons collecté ces actifs, nous documentons les composants de l’application et les relations de dépendance.
5.2.4.1.1 Collecte et documentation des actifs d’application
Une technique éprouvée utilisée pour acquérir une compréhension approfondie et précise des composants et des dépendances d’une application consiste à étudier le processus d’installation de l’application sur un serveur propre. S’il existe une documentation solide et à jour pour installer l’application sur un nouveau serveur, cela fonctionne très bien. Sinon, vous devez prévoir du temps avec un expert en la matière de l’application qui est responsable de l’installation de l’application. Cependant, dans les deux cas, vous souhaiterez configurer une procédure d’installation sur un serveur propre / nouveau. Il s’agit parfois d’une installation sandbox pour l’application. Cela nécessite le provisionnement d’une machine sandbox accessible, généralement une machine virtuelle, avec les ressources réseau d’accès appropriées.
Pour notre exemple d’application, nous avons accès au sudoer à la boîte de production où l’application est déployée. C’est clairement un peu effrayant car nous ne voulons pas interférer avec le fonctionnement du système de production actuel ! Nous devons donc procéder avec une grande prudence. Heureusement pour notre échantillon de l’équipe pilote, nous avions un architecte Java pour nous guider à travers l’architecture d’application pour l’application Wiki de confluence et nous avons pu construire le diagramme illustré à la figure 7.
Après avoir examiné l’application Java fonctionnant avec un serveur Tomcat, nous avons découvert qu’il y avait quelques actifs majeurs dont nous avions besoin pour capturer et reproduire pour notre application conteneurisée. Le code source, le répertoire où l’application a stocké les fichiers locaux et les fichiers de base de données. De plus, puisque l’application utilise un backend de base de données Postgres, nous pouvons facilement vider le contenu de la base de données dans un fichier SQL et utiliser ce fichier pour initialiser une nouvelle base de données dans notre environnement conteneurisé. En raison de la fonctionnalité stupide de Postgres DB, nous sommes en mesure de saisir des instantanés (vidages DB) de l’environnement de production sans interrompre le traitement normal du wiki:
Figure 7: Exemple d’architecture d’application Wiki
À l’intérieur de notre conteneur Wiki, nous avons des fichiers d’archives Java. Un fichier d’archive est destiné au code de l’application wiki confluence et l’autre au serveur d’application Tomcat. L’application de confluence utilise également un volume de fichiers local pour stocker les documents et autres objets blob. Pour le stockage des données persistantes (relationnelles) des métadonnées, les informations de configuration, l’application wiki utilise le serveur principal de la base de données Postgres.
Nous commençons le processus de conteneurisation de bas en haut, en commençant par la base de données Postgres de Wiki.
5.2.4.1.2 Conteneurisation et test de la base de données Postgres
Pour le conteneur postgres , nous sommes armés de la configuration (informations utilisateur et connexion) de l’installation de production et du fichier wiki.sql que nous avons généré à l’aide de la commande pg_dump . Ce fichier sera utilisé pour remplir notre base de données de conteneurs de test au démarrage. Veuillez noter que ceci est une copie de la base de données de production du wiki et est donc soumis aux contrôles de données de notre organisation, à la prévention de la perte de données et à d’autres politiques et / ou réglementations applicables.
Nous allons commencer par une image Docker Postgres officielle qui correspond à notre version Postgres, dans notre cas Postgres 9.3. Nous recherchons Docker Hub pour trouver le référentiel officiel de Postgres. Ensuite, nous cliquons sur l’ onglet des balises pour trouver une balise correspondant à la version attendue par notre application wiki et nous trouvons 9.3 ( https://hub.docker.com/_/postgres?tab=tags ).
Lors de la conteneurisation d’applications avec des connexions de base de données, il est très important de faire correspondre les versions correctes entre le client Postgres dans l’application et le serveur de base de données lui-même. Si vous essayez de mettre à niveau le serveur, le client peut ne pas se connecter en raison des modifications de protocole qui se produisent entre les versions. Cette situation peut être très difficile à retrouver. Ainsi, lorsque vous conteneurisez une application avec une base de données Postgres, assurez-vous que la version client de l’application correspond à la version de votre serveur, pour éviter d’éventuels maux de tête.
Pour en savoir plus sur l’image officielle de Postgres, à partir de l’onglet de description de Docker Hub, nous cliquons sur un lien Dockerfile vers n’importe quelle version de Postgres, ce qui nous amène au dépôt GitHub associé. Nous remarquons que la structure du dépôt GitHub est organisée par tag. Nous suivons ensuite ce chemin de repo la version Postgres / 9.3 / Alpine. Voici l’URL du dépôt pour notre version Postgres: https://github.com/docker-library/postgres/tree/d564da5142b2e5fa235707b05d8aa0fc76250418/9.3/alpine . Nous voyons le Dockerfile utilisé pour construire notre image.
Si nous regardons vers le bas du Dockerfile, nous pouvons noter quelques éléments. Le premier est l’utilisation de la variable d’environnement PGDATA et son volume associé utilisé pour spécifier l’emplacement des fichiers de la base de données Postgres. Il est défini sur / var / lib / postgresql / data. Par conséquent, c’est le répertoire où nous pouvons monter en volume nos fichiers de base de données sur un système de fichiers externe pour préserver l’état de notre base de données sur plusieurs instances de base de données Postgres.
Cela signifie que nous pouvons arrêter un conteneur postgres et en créer un nouveau avec le même point de montage de volume et la base de données reprendra là où elle s’était arrêtée, comme suit:
# … end of postgres 9.3 alpine Dockerfile
ENV PGDATA /var/lib/postgresql/data
RUN mkdir -p “$PGDATA” && chown -R postgres:postgres “$PGDATA” && chmod 777 “$PGDATA” # this 777 will be replaced by 700 at runtime (allows semi-arbitrary “–user” values)
VOLUME /var/lib/postgresql/data
COPY docker-entrypoint.sh /usr/local/bin/
RUN ln -s usr/local/bin/docker-entrypoint.sh / # backwards compat
ENTRYPOINT [“docker-entrypoint.sh”]
EXPOSE 5432
CMD [“postgres”]
Le deuxième élément à noter dans le Dockerfile Postgres précédent est l’utilisation de la combinaison ENTRYPOINT + CMD. L’image Postgres utilise un script shell au démarrage appelé usr / local / bin / docker-entrypoint.sh pour initialiser la base de données et transmet Postgres comme paramètre.
Nous pouvons ensuite fouiller dans le fichier docker-entrypoint.sh pour voir comment il est responsable de l’utilisation du fichier wiki.sql pour initialiser la base de données si nécessaire. Nous voyons l’extrait docker-entrypoint.sh (illustré ci-dessous), où le script recherche le fichier PG_VERSION à l’emplacement où Postgres stocke les fichiers de données. S’il ne trouve pas le fichier, il suppose que la base de données doit être créée et continue d’exécuter / charger les fichiers * .sh ou * .sql trouvés dans le répertoire docker-entrypoint-initdb.d :
# look specifically for PG_VERSION, as it is expected in the DB dir
if [ ! -s “$PGDATA/PG_VERSION” ]; then
Par conséquent, en prenant le fichier wiki.sql que nous avons créé à l’aide de la commande pg_dump et en le copiant dans le répertoire docker-entrypoint-initdb.d , nous pouvons demander à Postgres de charger une copie de notre base de données de production.
Commençons maintenant à construire notre base de données Postgres conteneurisée. Voici la structure de répertoires que nous utilisons pour l’exemple d’application:
wiki-app
├── docker-compose-dev.yml
└── postgres
├── db-init
│ └── wiki.sql
└── Dockerfile
Ainsi, le Dockerfile initial pour notre conteneur postgres commence avec la version 9.3 de Postgress fonctionnant sur un système d’exploitation Alpine. Ensuite, nous définissons certaines variables environnementales utilisées par Postgres. Enfin, nous avons configuré un utilisateur et un groupe afin que la base de données mydomain-conf se charge correctement à partir du fichier SQL, comme suit:
# /wiki-app/postgres/Dockerfile
FROM postgres:9.3-alpine
ENV POSTGRES_DB mydomain-conf
ENV POSTGRES_USER mydomain-conf
#POSTGRESS_PASSWORD is supplied from the command line or docker-compose
#To load our wiki.sql file, our DB expects to find a password file
#…in specific user directory, mydomain-conf who is a member of a group called my-domain.conf
RUN addgroup -S mydomain-conf && adduser -S -G mydomain-conf mydomain-conf
Rappelez-vous, cette première application est un effort de levage et de décalage. Idéalement, nous ne voudrions pas que nos noms de base de données, nom d’utilisateur et nom de groupe d’utilisateurs soient tous identiques. Ceci est juste un sous-produit de la façon dont la base de données d’application initiale pour notre wiki a été configurée. Si vous souhaitez effectuer une refactorisation de base pendant le pilote, cela dépend de votre équipe. Cependant, au début, nous vous recommandons fortement de simplement exécuter la version conteneurisée telle quelle avant de commencer à la modifier.
OK, vous pourriez être un peu confus à ce stade, mais j’espère que cela deviendra plus clair lorsque nous construirons et testerons le conteneur.
À ce stade, nous pourrions simplement exécuter une commande docker image build pour créer une image à partir de notre Dockerfile. Cependant, les utilisateurs Docker dev / DevOps plus expérimentés aiment profiter des fonctionnalités fournies par docker-compose, où nous pouvons créer et tester une image en utilisant le même fichier de spécifications YML. L’ utilitaire docker-compose permet aux développeurs ou aux ingénieurs DevOps de créer puis d’exécuter / tester un ensemble de conteneurs associés à l’aide d’une seule commande à partir d’un seul fichier de spécification YML. Par convention, les fichiers de spécifications sont appelés docker-compose.yml. Vous pouvez modifier le nom de fichier en utilisant le paramètre -f pour spécifier un autre nom de fichier. Cependant, lorsque vous utilisez docker-compose pour créer et tester une image locale, nous ajoutons souvent un -dev au nom de fichier de base du fichier de spécifications docker-compose.yml. Pour nous, cela signifie que notre fichier s’appelle docker-compose-dev.yml et qu’il est utilisé par l’équipe pilote pour construire et tester notre application wiki.
Jetons un coup d’œil à notre exemple de fichier de spécification de construction / test wiki appelé /wiki-app/docker-compose-dev.yml. La première chose que nous voyons après notre commentaire est le numéro de version. Cela indique à docker-compose quelles fonctionnalités ce fichier de spécifications s’attend à trouver en fonction de la version, et garantit donc que la spécification est compatible avec la version de docker-compose installée sur la machine de génération.
Ensuite, nous voyons deux constructions YML de haut niveau : les services et les volumes . Les services spécifient l’état souhaité pour nos conteneurs Postgres, mais incluent également des informations de construction. Ici, les attributs de build indiquent où trouver le contexte de build pour notre image Postgres. Pour notre exemple, lorsque nous construisons l’image Postgres, docker-Compose regarde dans le postgres répertoire pour le Dockerfile et les étiquettes puis les my-postgres: v1 l’ image , comme suit:
# /wiki-app/docker-compose-dev.yml
version: ‘3.7’
services:
postgres:
build: postgres
image: my-postgres:v1
environment:
– POSTGRES_PASSWORD=xxxxxxx
volumes:
– pgdata:/var/lib/postgresql/data
– ./postgres:/docker-entrypoint-initdb.d
volumes:
pgdata:
Nous voyons également que le mot de passe postgres est défini comme une variable d’environnement où Postgres s’attend à le trouver par convention.
Enfin, nous déclarons les volumes que ce conteneur s’attend à trouver lors de l’exécution. Le premier volume, pgdata, est un volume local sur la machine de génération / test où les fichiers de base de données doivent être stockés. Cela vous permet de sauvegarder les données entre les exécutions de votre pile et de ne pas avoir à réinitialiser la base de données pour chaque test. Le deuxième volume utilise le point de montage sur le système de fichiers local qui est monté dans le répertoire /docker-entrypoint-initdb.d du conteneur, où Postgres recherche des scripts d’initialisation de base de données ou des fichiers SQL. C’est le répertoire où nous avons caché notre fichier de vidage de base de données. Ainsi, le comportement attendu est que, lorsque le conteneur démarre pour la première fois, il trouvera un volume pgdata vide puis utilisera le wiki. Fichier SQL pour initialiser la base de données.
À partir du répertoire wiki-app, nous exécutons docker-compose -f docker-compose-dev.yml up –build -d pour construire notre image my-postgres: v1 et démarrer notre conteneur. À partir de la sortie suivante, il semble avoir réussi, mais nous devons être sûrs:
[wiki-app]$ docker-compose -f docker-compose-dev.yml up –build -d
Building postgres
Step 1/4 : FROM postgres:9.3-alpine
—> e26433e300a4
Step 2/4 : ENV POSTGRES_DB nvisia-conf
—> Running in 0ce302897ed3
Removing intermediate container 0ce302897ed3
—> 579eaa40f99c
Step 3/4 : ENV POSTGRES_USER nvisia-conf
—> Running in eecfde4c3689
Removing intermediate container eecfde4c3689
—> 861d4fdf597b
Step 4/4 : RUN addgroup -S nvisia-conf && adduser -S -G nvisia-conf nvisia-conf
—> Running in 8728f40e1b04
Removing intermediate container 8728f40e1b04
—> 6779fb8a1eef
Successfully built 6779fb8a1eef
Successfully tagged my-postgres:v1
Creating network “wiki-app_default” with the default driver
Creating wiki-app_postgres_1 … done
Pour confirmer si le script de base de données s’est exécuté pour initialiser la base de données, nous devons consulter les journaux du conteneur. Pour cela, nous utilisons la commande docker container logs. Prenez note du nom du conteneur créé par la commande docker-compose up. Le préfixe est le nom du répertoire à partir duquel docker-compose a été exécuté. La partie postgres du nom du conteneur au milieu est le nom du service et le suffixe _1 indique le premier conteneur pour ce service. Oui, le suffixe implique correctement que nous pourrions avoir plusieurs répliques d’un conteneur exécutant l’image my-postgres: v1 en utilisant respectivement l’ échelle Docker-compose ou les directives de répliques pour Compose ou Swarm. L’exécution de la commande logs affiche tous les messages de démarrage Postgres docker-entrypoint.sh et postgress .
Exécutez le conteneur de base de données. Nous recherchons un message spécifique où le fichier wiki.sql est exécuté. Dans le bloc suivant, j’ai mis en évidence une section de sortie de journal abrégée montrant que nous avons réussi à créer la base de données affichant le message /usr/local/bin/docker-entrypoint.sh: running /docker-entrypoint-initdb.d/wiki.sql :
[wiki-app]$ docker container logs wiki-app_postgres_1
…
/usr/local/bin/docker-entrypoint.sh: running /docker-entrypoint-initdb.d/wiki.sql
SET
SET
SET
SET
SET
SET
SET
5.2.4.1.3 CRÉER UNE FONCTION
ALTER FUNCTION
SET
SET
CREATE TABLE
ALTER TABLE
CREATE SEQUENCE
ALTER TABLE
ALTER SEQUENCE
…
Nous avons maintenant la Postgres DB conteneurisée et initialisée avec des données réelles.
5.2.4.1.4 Conteneurisation et test de l’application wiki
Nous continuerons à bâtir sur notre succès en créant un conteneur Java 7 pour exécuter notre wiki à l’aide de Tomcat. Avant d’installer l’application Java et le serveur Tomcat, nous créons un conteneur Java vide et nous l’utilisons pour se connecter et tester le backend Postgres DB.
Tout d’abord, nous devons sélectionner une image de base appropriée pour notre conteneur Java 7. Notre voyage nous ramène à hub.docker.com où nous recherchons ( https://hub.docker.com/search?q=java&type=image&image_filter=official&category=base ) et trouvons l’image Java officielle de Docker. Nous cliquons sur le référentiel Java, sélectionnons l’onglet Balises et recherchons la balise associée au JDK Java version 7.
Nous y trouvons l’image java: 7-JDK comme point de départ. Maintenant, nous allons ajouter un dossier wiki sous le répertoire wiki-apps et créer un Dockerfile pour construire l’image du conteneur wiki, comme suit:
# /wiki-app/wiki/Dockerfile – Simple shell
FROM java:7-jdk
CMD ping localhost
Nous commençons avec un shell vraiment simple pour notre application wiki. Le but ici est de démarrer l’image de base, et pour notre exemple, nous allons simplement exécuter une commande ping continue pour maintenir le PID 1 ouvert. Nous allons bien sûr changer cela pour exécuter une application Java plus tard, mais c’est tout ce dont nous avons besoin pour l’instant.
Nous devons maintenant mettre à jour notre fichier docker-compose-dev.yml pour construire et exécuter l’application shell wiki. Dans l’exemple de code suivant, portez une attention particulière aux éléments en gras, car ils ont été ajoutés au fichier de composition pour prendre en charge la création et l’exécution de l’application shell wiki :
# /wiki-app/docker-compose-dev.yml
version: ‘3.7’
services:
postgres:
build: postgres
image: my-postgres:v1
environment:
– POSTGRES_PASSWORD=xxxxxxxx
networks:
– db_net
volumes:
– pgdata:/var/lib/postgresql/data
– ./postgres/db-init:/docker-entrypoint-initdb.d
wiki:
build: wiki
image: my-wiki:v1
networks:
– db_net
networks:
db_net:
volumes:
pgdata:
Le premier élément en gras est l’ attribut réseaux ajouté à la spécification de service Postgres. Pour que les conteneurs ou services Docker communiquent à l’aide de DNS (se réfèrent les uns aux autres à l’aide du nom de service – découverte de service), ils doivent partager un réseau commun. Dans notre cas, nous allons appeler ce réseau db_net . Remarquez comment l’attribut networks est également déclaré sous la spécification de service du wiki ainsi qu’à la fin du fichier dans la section des réseaux.
Remarquez la nouvelle section du service wiki où nous indiquons à docker-compose où trouver le contexte de construction (le Dockerfile, pour l’instant) dans le répertoire wiki et pour marquer l’image nouvellement construite comme my-wiki: v1 .
Donc, encore une fois, nous créons et exécutons les services avec la commande docker-compose , cette fois pour créer et déployer le service Postgres et le shell wiki sur le même réseau afin que nous puissions tester l’accès aux bases de données à partir du conteneur wiki , comme suit:
[wiki-app]$ docker-compose -f docker-compose-dev.yml up -d –build
Creating network “wiki-app_db_net” with the default driver
Building postgres
Step 1/4 : FROM postgres:9.3-alpine
—> e26433e300a4
Step 2/4 : ENV POSTGRES_DB nvisia-conf
—> Using cache
—> 579eaa40f99c
Step 3/4 : ENV POSTGRES_USER nvisia-conf
—> Using cache
—> 861d4fdf597b
Step 4/4 : RUN addgroup -S nvisia-conf && adduser -S -G nvisia-conf nvisia-conf
—> Using cache
—> 6779fb8a1eef
Successfully built 6779fb8a1eef
Successfully tagged my-postgres:v1
Building wiki
Step 1/2 : FROM java:7-jdk
—> 5dc48a6b75af
Step 2/2 : CMD ping localhost
—> Using cache
—> 9bce8d0254d9
Successfully built 9bce8d0254d9
Successfully tagged my-wiki:v1
Creating wiki-app_wiki_1 … done
Creating wiki-app_postgres_1 … done
Notre première étape consiste à vérifier la connectivité du wiki-app_wiki_1 conteneur au wiki-app_postgres_1 conteneur. Pour ce faire, nous exécuterons un processus shell à l’intérieur du conteneur wiki-app_wiki_1 à l’aide de la commande docker exec . Ensuite, nous installerons un client psql (version 9.3), puis nous nous connecterons à Postgres s’exécutant dans wiki-app_postgres_1 et rechercherons le schéma de la table Postgres, comme suit :
# Exec into the wiki container…
[wiki-app]$ docker exec -it wiki-app_wiki_1 bash
# Install the repo sources for postgres
root@424766f9fa1f:/# echo “deb http://apt.postgresql.org/pub/repos/apt/ jessie-pgdg main” > /etc/apt/sources.list.d/pgdg.list
# Get the to authenticate repos
root@424766f9fa1f:/# wget –quiet -O – https://www.postgresql.org/media/keys/ACCC4CF8.asc | apt-key add –
OK
# Update package managers repository info
root@424766f9fa1f:/# apt-get update
…
done.
# Install the postgresql version 9.3 client
root@424766f9fa1f:/# apt-get install -y postgresql-9.3
…
Processing triggers for libc-bin (2.19-18+deb8u7)…
# Connect the client to the postgres host using service name spec’ed in docker-compose-dev.yml
root@424766f9fa1f:/# psql -h postgres mydomain-conf mydomain-conf
Password for user nvisia-conf: xxxxxxxx
psql (9.3.25)
Type “help” for help.
mydomain-conf=# \dit
List of relations
Schema | Name | Type | Owner | Table
——–+——————————————–+——-+————-+—————————-
public | AO_187CCC_SIDEBAR_LINK | table | mydomain-conf |
public | AO_187CCC_SIDEBAR_LINK_pkey | index | mydomain-conf | AO_187CCC_SIDEBAR_LINK
public | AO_21D670_WHITELIST_RULES | table | mydomain-conf |
public | AO_21D670_WHITELIST_RULES_pkey | index | mydomain-conf | AO_21D670_WHITELIST_RULES
public | AO_38321B_CUSTOM_CONTENT_LINK | table | mydomain-conf |
public | AO_38321B_CUSTOM_CONTENT_LINK_pkey | index | mydomain-conf | AO_38321B_CUSTOM_CONTENT_LINK
public | AO_42E351_HEALTH_CHECK_ENTITY | table | mydomain-conf |
public | AO_42E351_HEALTH_CHECK_ENTITY_pkey | index | mydomain-conf | AO_42E351_HEALTH_CHECK_ENTITY
–MORE–
^c
mydomain-conf=# \q
root@424766f9fa1f:/#
Nous pouvons nous connecter du conteneur wiki au serveur Postgres en utilisant le nom DNS et lister les tables. Gardez à l’esprit qu’une fois connecté à la base de données Postgres, vous pouvez exécuter n’importe quelle requête de votre choix, telle que sélectionner * dans public.users , pour vérifier votre base de données. Nous devons maintenant installer et exécuter l’application wiki dans le conteneur local.
Une fois que le conteneur shell du wiki est capable de se connecter à la base de données, nous devons installer le reste des actifs pour l’application wiki, à savoir le JAR et les fichiers de configuration. Nous ajoutons les actifs supplémentaires dans une structure de fichiers de projet wiki sur notre machine de génération locale comme indiqué ci-dessous, où nous mettons en évidence les actifs de l’application :
wiki-app$ tree -L 3
.
├── docker-compose-dev.yml
├── postgres
│ ├── db-init
│ │ └── wiki.sql
│ └── Dockerfile
└── wiki
├── Dockerfile
├── wiki-conf
│ ├── confluence-init.properties
│ ├── ROOT.xml
│ └── server.xml
├── wiki-files
│ └── current …lots of files 19GB
└── wiki-jar
├── apache-tomcat-6.0.35.tar.gz
└── atlassian-confluence-5.4.3-deployment.tar.gz
Maintenant, revenons à notre Dockerfile situé dans le dossier wiki . Comme indiqué précédemment, nos ressources du wiki de production ont été copiées dans la structure du répertoire et affichées en gras. Nous utilisons maintenant le Dockerfile du wiki suivant pour ajouter ces fichiers JAR et fichiers de configuration à notre image wiki. Ensuite, également montré dans le suivant wiki Dockerfile, nous avons mis les variables d’environnement requises pour Tomcat (Catalina) et Java pour fonctionner correctement. Enfin, nous ajoutons le JAR Tomcat et les fichiers de configuration pour trouver les emplacements cibles (où Tomcat s’attend à trouver les fichiers de configuration et d’application). À la fin du fichier, nous définissons le démarrage par défaut du conteneur sur la commande d’ exécution catalina.sh , comme suit:
# /wiki-app/wiki/Dockerfile – install confluence and Tomcat
FROM java:7-jdk
ADD ./wiki-jar/atlassian-confluence-5.4.3-deployment.tar.gz /opt/j2ee/domains/mydomain.com/wiki/webapps/atlassian-confluence/deployment/
COPY ./wiki-conf/confluence-init.properties /opt/j2ee/domains/mydoamin.com/wiki/webapps/atlassian-confluence/deployment/exploded_war/WEB-INF/classes/confluence-init.properties
ENV CATALINA_HOME /usr/local/tomcat
ENV PATH $CATALINA_HOME/bin:$PATH
ENV JAVA_OPTS -Xms1536m -Xmx1536m -Dinstance.id=wiki.nvisia.com -Djava.awt.headless=true -XX:MaxPermSize=384m
ADD ./wiki-jar/apache-tomcat-6.0.35.tar.gz /usr/local/
RUN mv /usr/local/apache-tomcat-6.0.35 /usr/local/tomcat
COPY ./wiki-conf/ROOT.xml /usr/local/tomcat/conf/Catalina/localhost/
COPY ./wiki-conf/server.xml /usr/local/tomcat/conf/
CMD catalina.sh run
Ensuite, nous mettons à jour Docker-compose-dev.yml pour monter nos fichiers wiki (fichiers de données copiés à partir du wiki de production lorsque nous avons collecté les actifs de l’application) et nous exposons également le port d’interface utilisateur Web de notre wiki, comme suit :
# /wiki-app/docker-compose-dev.yml
version: ‘3.7’
services:
wiki:
build: wiki
image: dtr.mydoamin.com/pilot/wiki:v1
volumes:
– ./wiki/wiki-files/current:/opt/j2ee/domains/mydomain.com/wiki/webapps/atlassian-confluence/data/current
ports:
– 8080:8080
networks:
– db_net
postgres:
build: postgres
image: dtr.mydoamin.com/pilot/postgres:v1
environment:
– POSTGRES_PASSWORD=xxxxxxxxx
networks:
– db_net
volumes:
– pgdata:/var/lib/postgresql/data
– ./postgres/db-init:/docker-entrypoint-initdb.d
networks:
db_net:
volumes:
pgdata:
Remarquez comment nous avons également renommé les fichiers image pour les préparer à être stockés dans notre DTR situé sur dtr.mydomain.com .
Encore une fois, nous exécutons docker-compose -f docker-compose-dev.yml up -d pour construire et démarrer nos conteneurs. Ensuite, nous exécutons une commande -f docker-compose-dev.yml logs et remarquons quelque chose d’étrange. Le wiki démarre avant la base de données. Pour résoudre cette condition de concurrence de démarrage, nous introduisons une logique de programmation défensive dans notre démarrage wiki en utilisant entrypoint.sh .
La programmation défensive est une bonne pratique dans le monde des orchestrateurs et des conteneurs éphémères. Étant donné que les conteneurs peuvent aller et venir, nous ne pouvons pas garantir l’ordre de démarrage et les dépendances associées. Par conséquent, si notre conteneur dépend d’un autre conteneur, tel que notre conteneur wiki dépendant du conteneur Postgres, vous devriez envisager d’ajouter du code défensif. Ce code doit attendre que la dépendance soit respectée avant de démarrer. De cette façon, si les deux conteneurs sont déployés en même temps, le wiki attendra que la base de données soit prête et démarrera.
Le but du script d’entrée est de s’assurer que la base de données Postgres fonctionne avant de démarrer notre application wiki. Dans le fichier entrypoint.sh, il y a quelques points saillants, tous en gras. La première est la commande nc pour Netcat, qui vérifie si Postgres répond sur le port 5432. N’oubliez pas que le nom d’hôte Postgres est résolu par le Docker DNS en utilisant le nom de service fourni dans le fichier docker-compose . Si Postgres répond avec succès, le statut sera nul, nous faisons écho à postgres est accessible! à la sortie standard, puis nous rompons notre boucle, où nous faisons écho au message Tomcat catalina de départ en 10 secondes … , puis dormons pendant 10 secondes avant de démarrer Tomcat / Catalina, comme suit :
#!/bin/bash
while :
do
echo “Probing postgres:5432 …”
nc -z -w 1 postgres 5432 </dev/null
result=$?
if [[ $result -eq 0 ]]; then
echo “postgres is reachable!”
break
fi
sleep 5
done
echo “starting tomcat catalina in 10 seconds…”
sleep 10
catalina.sh run
Pour utiliser la commande nc , nous devons installer le package netcat . Nous avons donc dû revenir au Dockerfile de notre wiki et ajouter l’installation du package netcat en haut du fichier, comme suit:
# /wiki-app/wiki/Dockerfile – Added netcat to test postgres port from enterypoint.sh script
FROM java:7-jdk
RUN apt update && apt install -y netcat
…
Maintenant, nous reconstruisons en utilisant docker-compose avec up –build pour reconstruire et démarrer notre application. Ce qui suit est un extrait de journaux où nous voyons wiki_1 sonder le port de la base de données plusieurs fois avant de signaler que Postgres est accessible. Puis, après 10 secondes, le wiki démarre avec succès. Nous testons le wiki en pointant notre navigateur vers le port 8080 sur la machine de construction pour voir si le wiki est opérationnel :
…
Successfully built 6779fb8a1eef
Successfully tagged my-postgres:v1
Creating wiki-app_postgres_1 … done
Creating wiki-app_wiki_1 … done
Attaching to wiki-app_postgres_1, wiki-app_wiki_1
wiki_1 | Probing postgres:5432 …
…
postgres_1 | LOG: database system is ready to accept connections
postgres_1 | LOG: autovacuum launcher started
wiki_1 | Probing postgres:5432 …
postgres_1 | LOG: incomplete startup packet
wiki_1 | postgres is reachable!
wiki_1 | starting tomcat catalina in 10 seconds…
…
wiki_1 | Jan 06, 2019 7:15:45 PM org.apache.coyote.http11.Http11Protocol start
wiki_1 | INFO: Starting Coyote HTTP/1.1 on http-8080
wiki_1 | Jan 06, 2019 7:15:45 PM org.apache.jk.common.ChannelSocket init
wiki_1 | INFO: JK: ajp13 listening on /0.0.0.0:8009
wiki_1 | Jan 06, 2019 7:15:45 PM org.apache.jk.server.JkMain start
wiki_1 | INFO: Jk running ID=0 time=0/24 config=null
wiki_1 | Jan 06, 2019 7:15:45 PM org.apache.catalina.startup.Catalina start
wiki_1 | INFO: Server startup in 178492 ms
Nous avons maintenant créé, conteneurisé et testé les conteneurs wiki et Postgres sur une boîte de build locale. Il est maintenant temps de préparer l’application à s’exécuter dans notre cluster Docker Enterprise.
5.2.4.1.5 Pousser les images
Maintenant que nous avons les images prêtes à l’emploi et que nous sommes prêts pour le déploiement du cluster pilote, nous devons pousser les images vers notre DTR. Dans la dernière version du fichier docker-compose-dev.yml , nous avons redéfini les images en tant que dtr.mydomain.com/pilot/wiki:v1 et dtr.mydomain.com/pilot/postgres:v1 . Maintenant, nous devons nous connecter au DTR et pousser nos images wiki et Postgres. Étant donné que toute l’équipe pilote a accès à nos référentiels pilotes de registre de confiance, nous pouvons utiliser n’importe lequel des comptes de l’utilisateur. Par exemple, nous utiliserons notre compte de développeur Sally Software pour vous connecter et envoyer nos images au DTR, comme suit:
ssoftware::ssCLI$ docker login dtr.mydomain.com -u ssoftware
Password:xxxxxxxx
WARNING! Your password will be stored unencrypted in /home/ssoftware/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
ssoftware::ssCLI$ docker image push dtr.mydomain.com/pilot/wiki:v1
…
ssoftware::ssCLI$ docker image push dtr.mydomain.com/pilot/postgres:v1
5.2.4.2 Déploiement du wiki sur le cluster pilote
Lorsque vous passez de la machine de génération locale au cluster pilote Docker Enterprise, nous devons commencer à réfléchir aux problèmes de déploiement du pilote, tels que les suivants :
- Comment les utilisateurs pilotes utilisent-ils l’application – comme bac à sable ou système de production limité ?
- Comment les utilisateurs vont-ils accéder à l’application (DNS | Wiki Service Ingress)?
- Comment allons-nous sécuriser la connexion entre l’utilisateur et le wiki ?
- Comment allons-nous initialiser, actualiser et sauvegarder la base de données ?
- Qui va déployer l’application et comment le fera-t-il ?
5.2.4.2.1 Stratégie d’application pilote
Alors que nous commençons à concevoir l’architecture de déploiement de notre application pilote, nous devons comprendre comment les utilisateurs pilotes vont utiliser l’application. Par exemple, l’application pilote sera-t-elle simplement un bac à sable avec lequel les utilisateurs pourront jouer, séparé du système de production ? Ce serait une approche conservatrice en bac à sable où l’application pilote s’exécute en parallèle avec le système de production, permettant aux utilisateurs de fouiller dans un cadre de type bac à sable et où les données pilotes sont actualisées pour correspondre à la production chaque nuit. Bien que l’approche pilote du bac à sable soit plus sûre, elle est également moins attrayante pour les utilisateurs puisque les utilisateurs, le travail dans le système pilote est réinitialisé à la production chaque nuit. De plus, le pilote de bac à sable ne force pas le type de répétition générale pour le support des applications, comme le fait l’exécution d’une application pilote en direct avec des utilisateurs et des données réels (bien que internes).
En fonction des objectifs et de l’application choisis pour votre pilote, vous devrez décider quelle approche vous convient le mieux. Cependant, si votre application peut être étendue aux utilisateurs internes, vous souhaiterez peut-être envisager une approche qui couvre à la fois un sandbox et une stratégie pilote en direct, où vous commencez par l’approche sandbox pour vérifier la fonction de base de l’application lors de son exécution sur la plate-forme Docker Enterprise et puis migrez les utilisateurs internes vers la plateforme pilote en direct, mais en ayant toujours un chemin de retour vers l’environnement de production en tant que plan B en cas de défaillance du pilote. Dans les deux cas, vous souhaiterez consulter les utilisateurs pour expliquer les compromis entre le travail en double pour le pilote sandbox et le risque de perdre des données / du temps de travail si le retour d’un pilote en direct vers le système de production devient nécessaire.
Pour notre exemple de pilote wiki, nous allons commencer par un bac à sable, puis migrer vers un pilote en direct, en utilisant l’ancienne installation de cloud privé comme sauvegarde au cas où nous aurions besoin de revenir en arrière. Notre première étape consiste à déployer l’application en tant que sandbox et à fournir un accès limité à l’équipe de test pour vérification. Ensuite, après vérification, nous actualiserons les données de l’application pilote de la production et redirigerons les utilisateurs internes vers l’application pilote en direct.
5.2.4.2.2 Flux d’ application pour le pilote wiki
Quelle que soit votre stratégie pilote, vous devrez déterminer comment le trafic des utilisateurs ciblés atteindra l’application pilote dans votre cluster Docker Enterprise. Pour notre exemple de phase sandbox d’application, nous allons modifier le fichier hôte local du testeur pour pointer vers notre équilibreur de charge de test (test de l’utilisateur dans les bureaux) ou l’IP de l’application pare-feu (pour les tests en dehors du bureau), et donc le pilote se comporte juste comme le wiki de production. Cependant, pour éviter toute confusion, nous allons nous assurer que l’en-tête du wiki pilote est clairement différent de la production pour rappeler aux utilisateurs à quel environnement ils sont connectés.
Lorsque nous passons à la phase pilote en direct, nous mettrons à jour DNS pour l’application pilote afin de rediriger tous les utilisateurs (dans notre cas, internes) vers le pilote, où nous surveillerons attentivement l’application en cours d’exécution – cela est couvert dans le Chapitre 7 , Pilot Docker Surveillance et journalisation de la plateforme d’entreprise .
5.2.4.2.3 Architecture de déploiement pour le wiki pilote
Pour le wiki pilote, nous allons garder notre déploiement relativement simple pour garder le pilote en mouvement et pour montrer quelques options d’implémentation de Docker Enterprise courantes. Dans cette section, nous commençons à transformer notre fichier docker-compose-dev.yml en une spécification de pile Docker utilisée pour déployer l’application sur notre cluster, mais nous commençons par une vue d’ensemble du flux d’entrée du trafic du cluster.
Dans la figure 8 , nous voyons comment le trafic circule du monde extérieur vers notre application wiki s’exécutant sur le nœud de travail 3; du DNS externe au pare – feu , du NAT du pare – feu au nœud LB , et enfin au nœud de travail 3:
Figure 8: Flux de trafic du réseau Wiki
Tout d’abord, pourquoi le nœud de travail 3, et pourquoi ne pas simplement laisser Docker Swarm placer la charge de travail wiki sur l’un des travailleurs ? La réponse, ce sont les données ! Comme décrit dans la figure 7, l’application wiki et la base de données Postgres nécessitent des volumes externes. Nous avons besoin de ces volumes pour stocker l’état de l’application en dehors du conteneur. Par conséquent, nous pouvons facilement sauvegarder et restaurer les données ainsi que redémarrer nos conteneurs et les faire reprendre leur dernier état connu.
Afin d’utiliser des volumes dans un cluster, nous devons soit utiliser une sorte de support de système de fichiers de cluster tel que NFS sur tous les nœuds de travail, soit contraindre nos services wiki et Postgres à un nœud de travail spécifique (dans notre cas, nous avons choisi travailleur 3), de sorte que les conteneurs s’exécutent de manière cohérente sur le nœud sur lequel le volume hôte local est monté. Il s’agit du nœud où nous allons sauvegarder et actualiser les données de production pendant le pilote. Pour limiter le placement des nœuds de nos services dans le cluster, nous appliquons une étiquette au nœud de travail 3 à l’aide de la commande docker node update –label-add com.mydomain.wiki.stage = pilot wrk3.mydomain.com . Une fois le nœud étiqueté, nous pouvons spécifier la contrainte de déploiement dans notre version Swarm de docker-compose file.yml dans la section service wiki du fichier, comme suit :
deploy:
placement:
constraints:
– node.labels.com.mydomain.wiki.stage==pilot
Ensuite, dans la figure 8, en travaillant de l’intérieur vers l’extérieur, parlons du nœud d’équilibrage de charge exécutant HAProxy dans un conteneur. Ici, nous avons mappé l’interface réseau de l’équilibreur de charge pour 10. 10. 1. 36 port 443 rapport 7443 à l’intérieur de notre conteneur HAProxy. De plus, nous utilisons HAProxy pour mettre fin à notre connexion SSL entrante (TLS) sur 7443 à l’aide d’un certificat tiers pour wiki.mydomain.com. Il s’agit d’une configuration HAProxy simple : nous avons juste besoin d’avoir le fichier .pem dans le répertoire / usr / local / etc / haproxy / certs / . Dans notre cas, nous montons en volume notre répertoire certifié lorsque nous exécutons le conteneur HAProxy.
Il existe trois modèles de terminaison TLS différents que vous pouvez envisager lors de votre pilote. Nous avons choisi de mettre fin à notre certificat sur l’équilibreur de charge en amont avec HAProxy pour notre exemple d’application et d’utiliser le routage HTTP / couche 4 dans Swarm, mais vous pouvez également terminer à l’intérieur du conteneur sur le serveur d’applications ou en utilisant un contrôleur d’entrée de couche 7 pour les deux. proxy inverse et terminaison TLS. Dans le chapitre sur le pipeline, nous aborderons plus en détail l’option d’entrée de la couche 7.
La terminaison à l’intérieur du conteneur n’est généralement pas préférée car il peut être difficile de faire pivoter les certificats lorsqu’ils expirent à l’avenir. Si la terminaison dans le conteneur est choisie, pensez à utiliser des secrets pour stocker les certificats en externe dans Swarm pour la sécurité et la gérabilité. Pour plus d’informations, veuillez consulter https://docs.docker.com/engine/swarm/secrets/ .
Le bloc de code suivant montre comment nous mettons fin à nos certificats TLS au niveau de l’équilibreur de charge :
frontend wiki_80_7443
mode http
option tcplog
bind *:80
bind *:7443 ssl crt /usr/local/etc/haproxy/certs/wiki.mydomain.com.pem
redirect scheme https if !{ ssl_fc }
default_backend wiki_upstream_servers_7443
5.2.4.2.4 Déploiement de l’application wiki pilote
Pour le wiki pilote, notre équipe travaille avec notre responsable des opérations fictives, Otto OpsManager, pour déployer l’application wiki sur notre plateforme pilote Docker Enterprise. Étant donné que la boîte d’équilibrage de charge est en amont du cluster, Otto demande à un administrateur système de configurer et d’exécuter son conteneur HAProxy.
L’échantillon config HAProxy frontend section se présente comme suit:
global
maxconn 2048
log /dev/log local0 debug
log /dev/log local1 notice
defaults
mode tcp
option dontlognull
timeout connect 5s
timeout client 50s
timeout server 50s
timeout tunnel 1h
timeout client-fin 50s
frontend ucp_443
mode tcp
bind *:443
option tcplog
log /dev/log local0 debug
default_backend ucp_upstream_servers_443
frontend dtr_4443
mode tcp
bind *:4443
option tcplog
log /dev/log local0 debug
default_backend dtr_upstream_servers_4443
frontend kube_6443
mode tcp
bind *:6443
option tcplog
log /dev/log local0 debug
default_backend kubectl_upstream_servers_6443
frontend wiki_80_7443
mode http
option tcplog
log global
bind *:80
bind *:7443 ssl crt /usr/local/etc/haproxy/certs/wiki.mydomain.com.pem
redirect scheme https if !{ ssl_fc }
default_backend wiki_upstream_servers_7443
L’exemple de section backend de configuration HAProxy se présente comme suit:
## Backend
backend ucp_upstream_servers_443
mode tcp
balance roundrobin
option log-health-checks
option httpchk GET /_ping HTTP/1.1\r\nHost:\ ucp.mydimain.com
server UCPNode01 ucp-1:443 check check-ssl verify none
server UCPNode02 ucp-2:443 check check-ssl verify none
server UCPNode03 ucp-3:443 check check-ssl verify none
backend dtr_upstream_servers_4443
mode tcp
balance roundrobin
option log-health-checks
option httpchk GET /_ping HTTP/1.1\r\nHost:\ dtr.mydomain.com
server DTRNode01 dtr-1:4443 check check-ssl verify none
server DTRNode02 dtr-2:4443 check check-ssl verify none
server DTRNode03 dtr-3:4443 check check-ssl verify none
backend kubectl_upstream_servers_6443
mode tcp
balance roundrobin
option log-health-checks
server KubeNode01 ucp-1:6443 check check-ssl verify none
server KubeNode02 ucp-2:6443 check check-ssl verify none
server KubeNode03 ucp-3:6443 check check-ssl verify none
backend wiki_upstream_servers_7443
mode http
balance roundrobin
# server wikiServer1 wrk-1:8080
# server wikiServer2 wrk-2:8080
server wikiServer3 wrk-3:8080
http-request set-header X-Forwarded-Port %[dst_port]
http-request add-header X-Forwarded-Proto https if { ssl_fc }
Ensuite, à l’aide d’un shell de terminal SSH connecté à l’ équilibreur de charge, Otto lance le script de démarrage du conteneur HAProxy comme suit:
#!/bin/sh
docker run -d –name haproxy -p 10.10.1.36:80:80 -p 10.10.1.36:443:7443 -p 10.10.1.101:443:443 -p 10.10.1.101:6443:6443 -p 10.10.1.102:443:4443 -v ~/haproxy:/usr/local/etc/haproxy:ro haproxy:1.7
En plus de la configuration de l’équilibreur de charge, nous devons également obtenir les fichiers wiki et le script d’initialisation de la base de données dans les points de montage de volume Docker locaux sur le travailleur 3. Normalement, je recommande de concevoir votre schéma d’autorisation de fichier avec le plus grand soin. Pour notre exemple, l’implémentation d’origine de la base de données Postgres a utilisé un autre propriétaire. Je voulais m’assurer que les processus de conteneur wiki Postgres et Atlassian pouvaient accéder à tous leurs fichiers pour lire, écrire et exécuter:
sysadmin@worker-node-3$ sudo -s
root@worker-node-3$ mkdir -p /var/local/wiki-init-data
root@worker-node-3$ mkdir -p /var/local/wiki-db-data
root@worker-node-3$ mkdir -p /var/local/atlassian-data
root@worker-node-3$ chmod 777 /var/local/wiki-init-data
root@worker-node-3$ chmod 777 /var/local/wiki-db-data
root@worker-node-3$ chmod 777 /var/local/atlassian-data
root@worker-node-3$ tar -C ./atlassian-data -xzf ./someZipSourceDir/atlassian-data.tar.gz
root@worker-node-3$ cp ./someSQLsourceDir/wiki.sql /var/local/wiki-init-data/wiki.sql
root@worker-node-3$ tree L2 /var/local/
├── atlassian-data
│ └── current …
├── wiki-db-data
├── wiki-init-data
│ └── wiki.sql
root@worker-node-3$ exit
sysadmin@worker-node-3$
Maintenant, Otto se connecte à l’interface utilisateur Web UCP pilote et génère un ensemble de ligne de commande, comme illustré dans la figure 9 :

Figure 9: Créer un ensemble de clients à partir de l’interface utilisateur Web UCP
Otto décompresse le bundle dans son dossier opsCLI. Otto ouvre un shell Bash dans le dossier opsCLI et se connecte à l’aide de la source env.sh au cluster avec ses autorisations OpsManager. Il vérifie sa connexion à l’aide d’une commande docker node ls comme indiqué dans le code suivant :
otto::opsCLI$ source env.sh
Cluster “ucp_ucp.mydomain.com:6443_oopsmanager” set.
User “ucp_ucp.mydomain.com:6443_oopsmanager” set.
Context “ucp_ucp.mydomain.com:6443_oopsmanager” modified.
otto::opsCLI$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
1rqhb4rzj3gk4mdgk8kza53jp dtr-1.mydomain.com Ready Active 18.09.0
x27m3yjlh6b0wczmo0mcahkjv dtr-2.mydomain.com Ready Active 18.09.0
rw2tuw53wl34pv6sfj213845a dtr-3.mydomain.com Ready Active 18.09.0
q5q9u0yr7p8r0mcz4ob24s2kz* ucp-1.mydomain.com Ready Active Reachable 18.09.0
6ce10w7leu0a9my91w39j5eai ucp-2.mydomain.com Ready Active Reachable 18.09.0
bd1bwcbqkpbulhwvm0fllgm55 upc-3.mydomain.com Ready Active Leader 18.09.0
3lw64q2o818xgnberjry410o7 wrk-1.mydomain.com Ready Active 18.09.0
zxcosutrxr3rhzkz2h6ld0khj wrk-2.mydomain.com Ready Active 18.09.0
sfuxfiwhf2tpd6q3i7fbmaziv wrk-3.mydomain.com Ready Active 18.09.0
Otto fabrique le docker-compose.yml suivant :
version: ‘3.7’
services:
wiki:
image: dtr.mydomain.com/pilot/wiki:v1
volumes:
– /var/local/atlassian-data:/opt/j2ee/domains/mydomain.com/wiki/webapps/atlassian-confluence/data/
ports:
– 8080:8080
networks:
– wiki_net
deploy:
placement:
constraints:
– node.labels.com.mydomain.wiki.stage==pilot
postgres:
image: dtr.mydomain.com/pilot/postgress:v1
environment:
– POSTGRES_PASSWORD=xxxxxxxx
volumes:
– /var/local/wiki-db-data:/var/lib/postgresql/data
– /var/local/wiki-init-data:/docker-entrypoint-initdb.d
networks:
– wiki_net
deploy:
placement:
constraints:
– node.labels.com.mydomain.wiki.stage==pilot
networks:
wiki_net:
Otto runs and deploys the application from his command-line bundle using docker stack deploy -c docker-compose.yml mydomain-wiki from the directory where he stored docker-compose.yml file. Otto verifies the stack is deployed as follows:
opsCLI$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
2v9s2aikk80g mydomain-wiki_postgres replicated 1/1 dtr.mydomain.com/pilot/postgress:v1
3q1cxwa1mw0a mydomain-wiki_wiki replicated 1/1 dtr.mydomain.com/pilot/wiki:v1 *:8080->8080/tcp
Enfin, Otto définit son fichier hôte local pour résoudre wiki.mydomain.com sur l’ équilibreur de charge 10.10.1.36 , car il s’exécute depuis l’intérieur du réseau. Il pointe ensuite son navigateur sur https://10.10.1.36 et commence à tester le wiki.
5.3 Résumé
Dans ce chapitre, nous avons discuté de la planification et de la mise en œuvre de votre application pilote. Nous avons présenté quelques exemples de rôles et de responsabilités pour les membres de l’équipe pilote, ainsi que la configuration pour UCP et DTR lors d’un pilote. De plus, nous avons parcouru en détail le déploiement de notre exemple d’application wiki de levage et de décalage, après le parcours d’un exemple d’équipe pilote.
Dans le chapitre 6 , Concevoir et piloter un pipeline Docker Enterprise CI , nous abordons un parcours pilote parallèle pour une organisation travaillant via un pilote de développement d’applications personnalisé.



Laisser un commentaire
Vous devez être dentifié pour poster un commentaire.