0. Gestion des conteneurs avec Docker Enterprise – Partie 2
0.1 Résumé de la publication
Bien que connu principalement comme le moteur open source derrière des dizaines de millions de nœuds de serveur, Docker propose également des outils d’entreprise pris en charge commercialement appelés Docker Enterprise. Cette plate-forme exploite les racines profondes de Docker Engine – Community (anciennement Docker CE) et Kubernetes, mais ajoute un support et des outils pour exploiter efficacement une plate-forme de conteneurs sécurisée à grande échelle. Avec des centaines d’entreprises à bord, les meilleures pratiques et les modèles d’adoption émergent rapidement. Ces points d’apprentissage peuvent être utilisés pour informer les adoptants et aider à gérer la transformation d’entreprise associée à l’adoption du conteneur d’entreprise.
Cet article commence par expliquer le cas de Docker Enterprise, ainsi que sa structure et son architecture de référence. À partir de là, nous progressons à travers les étapes du PoC, du pilote et de la production en tant que modèle de travail pour l’adoption, en faisant évoluer la conception et la configuration de la plate-forme pour chaque étape et en utilisant des exemples d’application détaillés en cours de route pour clarifier et démontrer les concepts importants. L’article conclut avec l’impact de Docker sur d’autres technologies logicielles émergentes, telles que la Blockchain et l’informatique sans serveur.
À la fin de cet article, vous comprendrez mieux ce qu’il faut pour que votre entreprise soit opérationnelle avec Docker Enterprise et au-delà.
0.2 Objectifs de la publication
- Comprendre pourquoi les conteneurs sont importants pour une entreprise
- Comprendre les fonctionnalités et les composants de Docker Enterprise 2
- Découvrez les phases PoC, pilote et adoption de la production
- Découvrez les meilleures pratiques d’installation et d’exploitation de Docker Enterprise
- Comprendre ce qui est important pour une entreprise Docker en production
- Exécutez Kubernetes sur Docker Enterprise
0.3 Lien vers la partie 1
1 Concevoir et piloter un pipeline Docker Enterprise CI
Dans le chapitre 8 , Première application en production avec Docker Enterprise , nous avons examiné le pilotage avec une approche de levage et de décalage avec notre équipe de pilotes, où nous avons consacré beaucoup d’attention à la configuration de la plateforme pilote Docker Enterprise pour le déploiement conteneurisé pour héberger un Java application wiki basée sur une base de données PostgreSQL. Dans ce chapitre, nous allons plonger dans la création d’une application pilote Java personnalisée et dans sa prise en charge avec un pipeline d’intégration continue (CI).
Avant de configurer tout type de solution CI, nous devons commencer par une conception d’application optimisée pour les conteneurs, prête à utiliser un orchestrateur, tel que Kubernetes ou la découverte de services, la gestion des volumes, la mise en réseau et les secrets de Kubernetes ou Swarm. Ensuite, nous créerons un environnement de développement et de test local conteneurisé pour notre application Java pilote personnalisée comme point de départ et à partir de là, nous ferons notre voyage à travers un pipeline d’intégration continue conteneurisé à l’aide de notre cluster pilote Docker Enterprise.
Dans ce chapitre, nous aborderons les sujets suivants :
- Principes clés pour le développement d’applications distribuées avec des conteneurs
- Processus de développement, de construction et de test de logiciels basés sur des conteneurs locaux
- Exemple de développement, de construction et de test d’applications pilotes
- Conception d’un pipeline CI conteneurisé avec Docker Enterprise
- Implémentation d’un pipeline CI pour notre exemple d’application Java client
1.1 Développement d’application pilote avec Docker Enterprise
Pour les développeurs, les conteneurs sont souvent présentés comme un outil de test local, créant des composants d’application tiers localement, plutôt que de configurer une plate-forme de test partagée. Docker est idéal pour les tests locaux, mais il y a d’autres avantages pour les développeurs, notamment une intégration plus rapide des développeurs, l’exploitation du modèle de serveur immuable (éliminant la situation “fonctionne sur ma machine” ), des tests locaux complets et un cluster rapide / efficace – tests d’intégration basés sur.
1.1.1 Utilisation de Docker pour une intégration plus rapide des développeurs
Docker prend en charge l’intégration plus rapide des développeurs ; les développeurs n’ont qu’à installer Docker et tout le reste peut s’exécuter dans des conteneurs (isolés). Alors que certains développeurs peuvent toujours installer un IDE et un JDK local pour tester et déboguer leur code Java, tout développeur peut cloner un référentiel de code source, créer l’application et l’exécuter localement en quelques minutes avec seulement Docker installé. Il s’agit d’une énorme amélioration pour la correction des défauts dans un environnement de grande équipe où un membre de l’équipe aléatoire peut être affecté à la correction d’un bogue.
1.1.2 Utilisation de Docker pour améliorer les cycles de développement logiciel
Imaginez un scénario où un bogue a été signalé dans un système de production et est affecté au prochain développeur disponible. Le développeur examine le rapport de bogue, clone le référentiel de code source pour la version de production de l’application, crée l’application localement et commence les tests sur sa station de travail de développement. Notez qu’ils n’ont pas eu à installer d’outils de développement spéciaux localement, ni à ajuster la version des outils déjà installés ; ils avaient juste besoin que Docker s’exécute sur leur poste de travail. Désormais, ils identifient le bogue, modifient le code source, reconstruisent et retestent l’application localement. Ce cycle de correction, même pour un développeur débutant dans l’équipe, peut prendre moins de 10 minutes dans un environnement de développement Dockerized.
Désormais, le développeur peut vérifier en toute confiance leurs modifications et créer une demande d’extraction. En revanche, si un développeur doit configurer son environnement local avec la version correcte de tous les outils requis pour la version de production actuelle, cela peut prendre des jours, sans aucune garantie qu’il corresponde à la production. Pour les équipes de développement les plus informées, il devient clair que l’intégration de Docker dans un environnement de développement logiciel a beaucoup de sens.
1.1.3 Docker Containers as a Service (CaaS)
Maintenant, réfléchissons un instant à une équipe qui démarre un nouveau projet de développement. Normalement, vous effectuez des recherches et commencez à installer différents composants sur votre poste de travail de développement. À partir de là, vous commenceriez à modifier ces composants pour les faire fonctionner ensemble. Ensuite, une fois que vous les aurez mis en place, vous voudrez probablement faire réviser l’architecture par un développeur senior pour approbation. Une fois que vous avez le feu vert, vous devez maintenant essayer de recréer les instructions d’installation pour le reste de votre équipe et espérer qu’ils obtiennent la même version que celle que vous utilisez sur votre machine. Cela peut être une sorte de tracas, surtout si vous considérez que chaque équipe le fait seule. Maintenant, réfléchissons à la même équipe de développement dans un environnement Docker Enterprise.
Dans un monde Docker, l’équipe peut afficher le Docker Trusted Registry ( DTR ) pour l’image de base correcte. Heureusement, les administrateurs système ont créé un conteneur de base d’application pour l’équipe pour commencer. Sinon, l’équipe peut travailler avec les administrateurs système pour localiser une image de base candidate à partir du référentiel d’images public de Docker, Docker Hub. Docker Hub possède littéralement des dizaines de milliers de plates-formes d’application déjà configurées pour les développeurs. Lorsqu’une image candidate appropriée est identifiée, l’équipe peut travailler avec l’administrateur système pour ajouter la nouvelle image de base au catalogue d’entreprise à utiliser par les équipes. Cette approche est parfois appelée conteneurs en tant que service ( CaaS ) et améliore la sécurité, l’efficacité et les délais de commercialisation.
Étant donné que ces images sont analysées par les administrateurs système avant que les équipes ne les utilisent, les vulnérabilités critiques auront été corrigées avant que la plupart des équipes ne commencent le développement. Une fois que l’équipe a une image de base, il lui suffit de se concentrer sur la création et le test de ses composants à l’aide de l’image de base. Étant donné que ces images sont partagées entre plusieurs équipes, vous aurez probablement un nombre élevé d’accès au cache lors du déploiement d’applications Dockerized sur des clusters de test et de production. Enfin, les images de base ont été pré-approuvées par l’équipe administrative du système, il y aura donc moins de résistance à les mettre en production rapidement. Cela peut être un gros avantage dans un environnement de microservices où les équipes introduisent souvent de nouvelles plateformes à chaque version.
Dans le diagramme suivant, nous pouvons voir un exemple de hiérarchie d’images de base à partir d’un article sur https://success.docker.com/article/mta-best-practices#imagehierarchy . Cet exemple commence avec deux images racine, une pour les conteneurs Linux et une pour les conteneurs Windows. Suivant l’exemple de Linux, il utilise une distribution Linux CentOS 7.2. À partir de l’image racine CentOS, trois images d’application différentes sont dérivées pour une application Apache, une application Java et un serveur de base de données PostgreSQL. De plus, nous pouvons voir comment l’application Java a trois variétés de serveurs d’applications différentes, dont une version JBoss et deux versions Tomcat. Sur le côté droit de l’image, les images ombrées vertes sont gérées par les équipes d’application, mais sur la base de l’une des images de base d’entreprise bleues de gauche comme image de base.
Les équipes d’application ajoutent leur code pour créer une image d’application. Par conséquent, seules les couches externes de l’image varient pour chaque application, tandis que les autres sont communes à toutes les équipes utilisant une image de base commune :
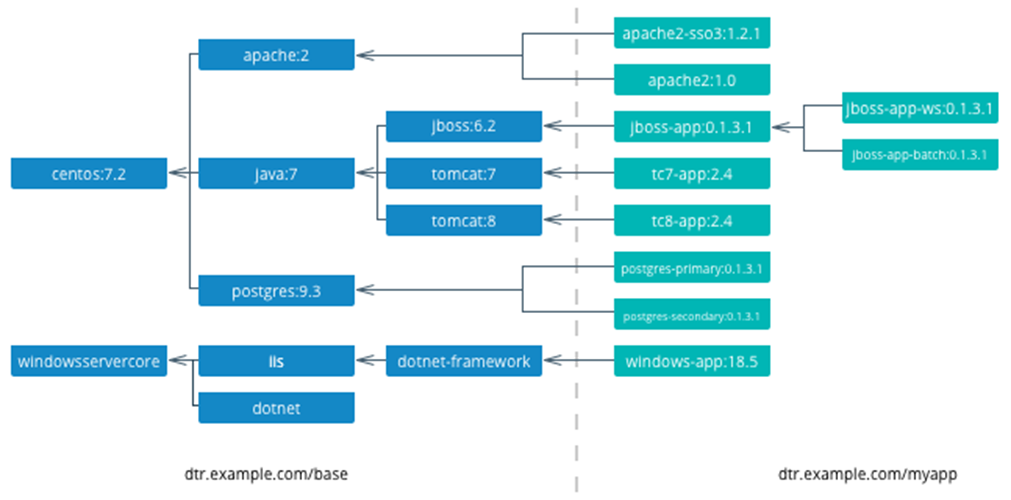
Figure 1: exemple de hiérarchie d’images – Copyright © 2013-2018 Docker, Inc. Tous droits réservés.
Encore une fois, étant donné que Docker utilise un système de fichiers en couches pour exécuter des conteneurs, il est avantageux de partager des images de base. Essentiellement, les images d’application tc7-app et tc8-app partagent deux couches de base communes : CentOS et Java, ce qui signifie que lorsque ces images d’application sont extraites d’un référentiel central, ces couches sont probablement déjà résidentes sur le nœud Docker, et par conséquent, peut être ignoré pour plus d’efficacité.
Le dernier point concernant l’utilisation de Docker pour le développement de logiciels est de s’attaquer aux syndromes séculaires « ça marche sur ma machine » . Le problème se produit lorsque la plate-forme d’un développeur est différente d’une plate-forme de test car, au cours du processus de développement, le développeur a mis à niveau l’un de ses composants locaux ou installé un nouveau composant local. Maintenant, leur machine locale est différente de l’environnement de test. Dans cette situation, le développeur du logiciel envoie le code au système de contrôle du code source où il est ensuite déployé sur une plate-forme de test. En raison du composant manquant ou modifié, le test échoue et lorsque le développeur est interrogé sur l’échec, le développeur montrera au testeur comment l’application s’exécute correctement sur sa machine locale. La capacité inhérente de Docker à empaqueter l’application et toutes les dépendances de composants requises éliminent essentiellement ce problème.
1.1.4 Ce que vous devez savoir sur les applications distribuées
Traditionnellement, la plupart des développeurs d’applications sont habitués à développer des applications monolithiques ou à utiliser un modèle de déploiement d’applications monolithiques, où plusieurs applications partagent les mêmes composants de plate-forme, tels que IIS et .NET, ou Java et Tomcat. Les conteneurs offrent aux développeurs la possibilité de diviser leurs applications en unités plus petites et déployables indépendamment. Pour cette raison, Docker est devenu un outil essentiel pour les équipes de développement de microservices. La division des applications en composants plus petits présente de nombreux avantages, mais en même temps, elle introduit une complexité supplémentaire.
Ces avantages incluent la possibilité de répartir efficacement le développement d’applications des composants d’application discrets au sein d’une grande équipe de développement, où les développeurs peuvent travailler de manière plus indépendante. En outre, ces composants plus petits offrent des possibilités d’évolutivité horizontale avec de meilleures performances et une meilleure disponibilité dans un environnement en cluster. À l’inverse, certaines complexités découlent du câblage de tous ces composants indépendants au moment de l’exécution. Par conséquent, nous aborderons certains sujets clés des principes de développement d’applications distribuées car ils se rapportent directement aux conteneurs.
1.1.4.1 Principes clés pour la conception d’applications de conteneurs
Avant de créer notre application, nous devons comprendre certaines choses afin de pouvoir créer une solution de conteneur orchestrée. Dans un souci de simplicité, nous fournirons des détails et des exemples utilisant Docker dans ce chapitre. Plus loin dans cet article, au chapitre 10 , Plus d’informations sur Kubernetes avec Docker Enterprise , nous reviendrons sur l’utilisation de Kubernetes pour accomplir les mêmes tâches avec les constructions et les API de Kubernetes.
1.1.4.1.1 Services Docker Swarm
Swarm et Kubernetes s’appuient tous deux sur le concept de services en tant qu’élément d’orchestration clé et point de terminaison durable pour la collecte de conteneurs similaires. Par des conteneurs similaires, nous voulons dire qu’ils partagent exactement la même image pour toutes les instances de conteneur. Par exemple, si un conteneur exécuté dans votre cluster doit appeler une API exécutée dans un autre conteneur, l’appelant peut utiliser le nom de service du conteneur d’API, plutôt que d’utiliser une adresse IP de conteneur. Ceci est très important car, dans un environnement orchestré, les conteneurs peuvent être remplacés par l’orchestrateur à tout moment et le conteneur résultant aura une nouvelle adresse IP. Par conséquent, l’utilisation du nom de service garantit à l’appelant une connexion à une version en cours d’exécution du conteneur, dont ils ont besoin.
Le diagramme suivant montre comment un conteneur appelant accède à un conteneur à l’aide d’un point de terminaison de service. Dans ce cas, l’appelant effectue un appel à distance en utilisant le nom de service de l’API. Le nom du service est résolu via le service DNS de l’orchestrateur en VIP pour le service API. Le VIP de l’appel est résolu par un équilibrage de charge à tour de rôle vers les conteneurs 1, 2 ou 3. Les points de terminaison du service Docker peuvent également être de type DNS à tour de rôle (DNSRR) au lieu de VIP :

Figure 2: point de terminaison de service pour myAPI
Le nom DNSRR est un peu déroutant car il s’agit en fait de son homologue, le point de terminaison du service Virtual IP (VIP), qui arrondit automatiquement les demandes d’équilibrage de charge robin, tandis que DNSRR laisse tout équilibrage de charge au client. Avec DNSRR, le client appelant reçoit une liste d’adresses IP pour les conteneurs du service sous-jacent, puis peut manuellement équilibrer la charge en utilisant quelque chose comme le dernier temps de réponse pour chaque conteneur afin de choisir l’IP du conteneur le plus rapide, ou de transmettre le trafic à l’IP avec le moins de connexions. Vraisemblablement, DNSRR est conçu pour s’intégrer aux équilibreurs de charge initiaux qui attendent plusieurs adresses IP de leur recherche DNS. Bien qu’il existe certainement des cas pour DNSRR, il est considéré comme une meilleure pratique de concevoir vos conteneurs pour qu’ils soient le plus sans état possible et d’utiliser VIP.
Il existe des avantages importants lors de l’utilisation de VIP pour des services sans état avec plusieurs répliques. Tout d’abord, les répliques peuvent être augmentées ou réduites (mise à l’échelle horizontale) pour répondre aux demandes de charge. En outre, si un conteneur échoue, l’orchestrateur peut supprimer le conteneur défectueux et le remplacer par un nouveau. Dans les deux cas, l’utilisation du nom de service au lieu d’une adresse IP de conteneur vous protège contre le référencement de conteneurs morts. Il convient de noter que, lorsque l’orchestrateur détecte un conteneur défaillant, il le supprime du pool d’arrière-plan de l’équilibreur de charge. En outre, lorsqu’un nouveau conteneur démarre, il est ajouté au pool d’arrière-plan de l’équilibreur de charge, uniquement après qu’il a été déterminé comme étant en cours d’exécution et sain. Nous parlerons des bilans de santé un peu plus tard.
Avec Docker Swarm, le service est un citoyen de première classe dans l’API Docker. Par conséquent, vous pouvez facilement créer un service à l’aide d’une commande, comme indiqué dans le diagramme suivant. Veuillez noter que la commande suivante doit être exécutée à partir d’un nœud de gestionnaire Docker, ou en utilisant une commande Docker Enterprise comme un ensemble correspondant à un utilisateur avec le privilège correct :
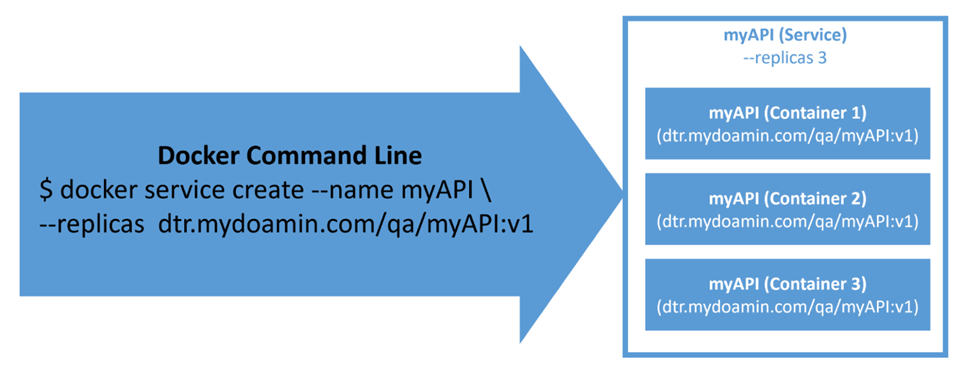
Figure 3: créer un service Docker à partir de la ligne de commande
De plus, dans un premier temps, nous répertorierons les services à l’aide du service Docker ls , comme illustré dans l’extrait de code suivant:
admin@docker-CLI$ docker service ls
ID NAME MODE REPLICAS IMAGE
m10ynu62iv02 myAPI replicated 3/3 dtr.mydoamin.com/qa/myAPI:v1
Ici, nous pouvons voir l’ID unique du service, le nom du service et les trois réplicas en cours d’exécution, ainsi que l’image que le service exécute pour chaque conteneur.
Si nous voulons des informations supplémentaires de l’orchestrateur Swarm concernant le placement de nos conteneurs et leur état actuel, nous pouvons utiliser la commande docker service ps , comme indiqué dans l’extrait de code suivant. Étant donné que mes tests proviennent d’un cluster Swarm à nœud unique (mon ordinateur portable de développement), tous les noms de nœuds sont les mêmes – linuxkit-00155d16dc03 :
admin@docker-CLI$ docker service ps myAPI
ID NAME IMAGE NODE DESIRED CURRENT
STATE STATE
5qs15ifju352 myStack_myAPI.1 dtr.mydoamin.com/qa/myAPI:v1 linuxkit-00155d16dc03 Running Running
p64jp0asuzes myStack_myAPI.2 dtr.mydoamin.com/qa/myAPI:v1 linuxkit-00155d16dc03 Running Running
xuber5oqgtkq myStack_myAPI.3 dtr.mydoamin.com/qa/myAPI:v1 linuxkit-00155d16dc03 Running Running
Plus tard, dans notre exemple d’application client, nous montrons les spécifications de l’API des services via un fichier docker-compose au format YAML pour lancer, composer et Swarm applications.
1.1.4.1.2 Réseaux de services Swarm et maillage de routage
Dans le chapitre 4 , Préparer le cluster pilote Docker Enterprise , nous avons présenté une introduction à la mise en réseau de conteneurs basée sur un cluster. Par conséquent, nous ne le répéterons pas ici et nous résumerons brièvement les domaines les plus importants de la mise en réseau d’applications dans un cluster Swarm. La chose la plus importante à comprendre est que les services partageant le même réseau peuvent communiquer sur tous les ports en utilisant le nom du service pour la résolution DNS. Si mon API doit communiquer avec un backend de base de données PostgreSQL, il me suffit de partager un réseau commun entre les services, comme nous l’avons vu au chapitre 8 , Première application en production avec Docker Enterprise . Ce faisant, il n’est pas nécessaire d’exposer les ports de la base de données PostgreSQL car le réseau commun donnera à l’appelant l’accès à tous les ports. Veuillez noter que, sauf si les ports sont explicitement exposés avec une certaine forme de -P / -p , le service ne sera disponible que pour d’autres services via un réseau partagé, et ne sera pas exposé en externe.
Lorsque nous traitons avec Docker Swarm et que nous publions un port pour l’accès externe, nous nous retrouvons avec IPVS mappant un port sur le réseau d’entrée Swarm (le réseau d’entrée est configuré par Docker lorsque le cluster est initialisé, puis connecté aux nœuds de cluster en tant qu’ils rejoignent le cluster) qui couvre tous les nœuds du cluster. Cela signifie que, si j’expose le port 8000 d’un service exécuté dans un cluster Swarm à l’aide de -p 8000: 80 , une demande à n’importe quel nœud du cluster sur le port 8000 sera transmise au port 80 à l’intérieur de l’un des conteneurs en cours d’exécution derrière ce Swarm. un service. Si le service possède plusieurs réplicas, par défaut, la demande sera équilibrée en charge entre chacune des réplicas de conteneur de sauvegarde :
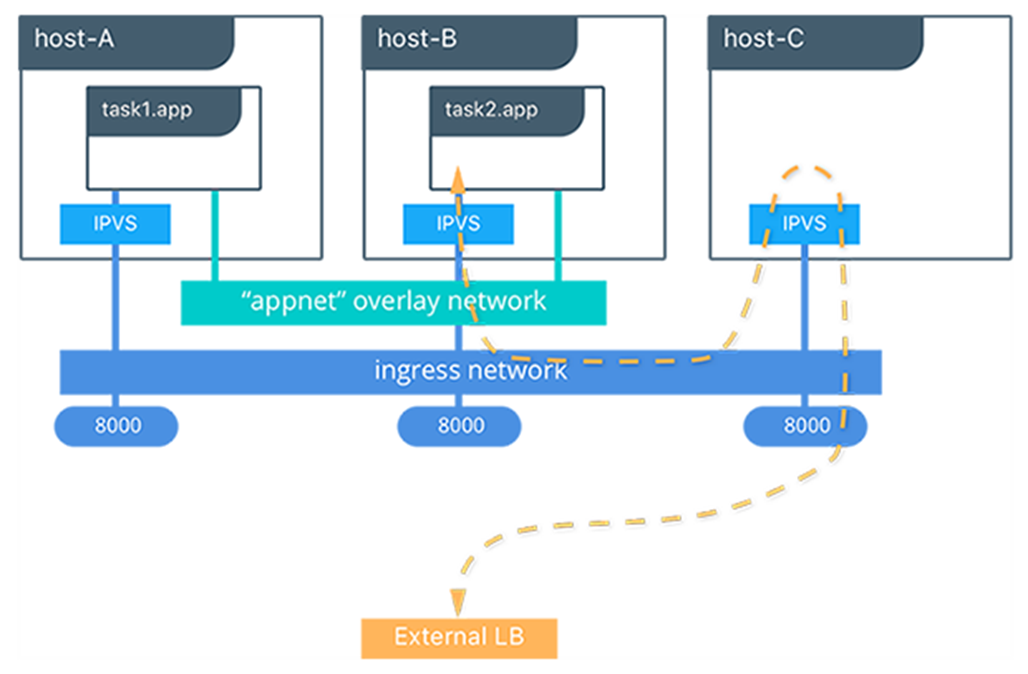
Figure 4: Copyright © 2013-2018 Docker, Inc. Tous droits – Ingress Networking
Il est important de noter que la mise en réseau du service Docker (par défaut, les réseaux Docker Overlay sont soutenus par VXLAN) et le maillage de routage Docker sont disponibles dans le cadre de la mise en œuvre Swarm de Community Edition. Ces fonctionnalités ne nécessitent pas Docker Enterprise, mais elles sont couramment utilisées dans les paramètres CE et EE.
Ainsi, pour la mise en réseau interne entre les composants de votre application, ajoutez-les à un réseau commun. Pour l’accès externe aux services, vous devez publier un port ( -p ) pour le service et il sera ajouté au réseau d’entrée, appelé maillage de routage Swarm, où un numéro de port unique au cluster est routé vers le service VIP pour le chargement équilibrage.
Lorsque vous utilisez le maillage de routage Docker Swarm, conservez les ports publiés du service uniques sur tous les services du cluster. Cela peut être un peu déroutant pour les développeurs qui passent des conteneurs aux services car nous pouvons réutiliser le même numéro de port sur autant de conteneurs que nous le voulons, car chaque conteneur a une adresse IP unique. Cependant, pour le maillage de service, le numéro de port est enregistré avec chaque adaptateur de nœud dans le cluster et, par conséquent, les numéros de port non uniques provoqueront un conflit de port sur l’adaptateur de nœuds.
1.1.4.1.3 Routage Docker Enterprise couche 7
Imaginez qu’un développeur assiste à sa réunion debout du matin et que le propriétaire du produit demande une nouvelle fonctionnalité. Le développeur retourne à son bureau et implémente la fonctionnalité telle qu’il la comprend. Ils peuvent ensuite utiliser le routage Docker Enterprise layer 7, déployer leur branche de fonctionnalités sur le cluster et envoyer une URL au propriétaire du produit pour vérification. Cette branche de fonctionnalité est complètement isolée de toutes les autres piles en cours d’exécution dans le cluster, et elle est immédiatement disponible avec soit un nom d’hôte unique dans l’en-tête de demande pour la future branche, soit un chemin spécial pour la branche de fonctionnalité.
Docker Enterprise fournit une infrastructure de routage de couche 7 utilisant une configuration de proxy inverse (soutenue par HAProxy ou NGINX) avec Interlock 2, ou simplement un routage de couche 7. Cette technologie est vraiment efficace pour gérer les déploiements de base de cluster, en particulier dans les clusters hors production, car une nouvelle pile d’applications peut être déployée et rendue accessible aux utilisateurs sans DNS en amont ni reconfiguration d’équilibrage de charge.
Lorsqu’il est activé, le plan de contrôle universel (UCP) de Docker Enterprise crée un réseau de superposition de verrouillage ucp et connecte les services ucp-interlock et ucp-intelock-extension au réseau. Le service ucp-interlock surveille les événements du système Docker et recherche des services avec des étiquettes de déploiement à l’aide du préfixe com.docker.lb. Lorsqu’un événement est publié avec une étiquette correspondante, ucp-interlock appelle ucp-interlock-extension pour configurer le proxy ucp-interlock comme proxy inverse pour acheminer le trafic en fonction de l’en-tête de la demande de l’utilisateur entrant et / ou du chemin vers le VIP du service Swarm correspondant.
Plus loin dans ce chapitre, vous verrez un exemple de travail dans lequel notre application AtSea utilise le routage Docker Enterprise layer 7. Plus tard, nous démontrerons l’utilisation d’étiquettes de service pour représenter un proxy inverse de couche 7 en utilisant l’extension NGINX. Il existe une configuration simple et de production pour le déploiement d’Interlock 2. Dans ce chapitre, pour le pilote, vous utiliserez une implémentation simple. Plus tard dans notre chapitre de préparation à la production, nous allons reconfigurer Interlock 2 pour le mode de production haute disponibilité.
Pour plus d’informations sur la configuration d’Interlock, voir https://docs.docker.com/ee/ucp/interlock/architecture/ .
Il existe un excellent article sur l’architecture de référence par Anoop Kumar sur ce sujet: https://success.docker.com/article/ucp-service-discovery . Dans l’article, Anoop décrit comment un routage Docker Enterprise layer 7 est activé et configuré par un administrateur.
Nous reviendrons sur ce sujet et discuterons davantage de la configuration de proxy hautement disponible plus loin dans cet article lorsque nous préparerons notre application pour la production.
1.1.4.1.4 Codage défensif
Les services sont parfaits pour fournir un employé durable et fiable. Cependant, lorsqu’une application est déployée par un orchestrateur, les services sont mis en ligne rapidement, mais pas simultanément. Par conséquent, nous pouvons rencontrer des problèmes de synchronisation lorsqu’un appelant est en ligne avant ses services dépendants.
Nous avons vu un exemple de cette situation dans le dernier chapitre lorsque notre application wiki a démarré avant que la base de données Postgres ne soit prête. En conséquence, nous avons créé un script de point d’entrée pour démarrer l’application wiki. Le script du point d’entrée interroge le port de la base de données Postgres jusqu’à ce qu’il soit prêt. Lorsque la base de données est prête, le script de point d’entrée démarre le serveur Tomcat du wiki au premier plan à l’aide de la commande run catalina.sh.
Voici le point d’ entrée.sh que nous avions l’habitude d’attendre pour que la base de données Postgres démarre:
#!/bin/bash
while :
do
echo “Probing postgres:5432 …”
nc -z -w 1 postgres 5432 </dev/null
result=$?
if [[ $result -eq 0 ]]; then
echo “postgres is reachable!”
break
fi
sleep 5
done
echo “starting tomcat catalina in 10 seconds…”
sleep 10
catalina.sh run
Par la suite, nous avons dû mettre à jour le Dockerfile du wiki pour lancer directement le script entrypoint.sh au lieu de la commande Java. Nous l’avons fait en ajoutant les commandes suivantes à la fin du Dockerfile:
COPY entrypoint.sh /usr/local/tomcat/
CMD ./usr/local/tomcat/entrypoint.sh
Au-delà du démarrage, il existe un autre aspect important du codage défensif, qui consiste à garantir que vos appels d’application résistent à l’échec.
Dans une application monolithique, si un appel de méthode échoue, cela signifie généralement que quelque chose ne va vraiment pas avec l’application puisque l’appelant et la méthode appelée s’exécutent dans le même espace de processus. Lorsque ce type d’échec se produit, il est typique de lever une exception, de vider une trace de pile et de quitter l’application. Dans un environnement d’application répartie, ces échecs sont assez courants et sont souvent liés à des problèmes de synchronisation transitoires lorsque les conteneurs en aval démarrent ou sont remplacés par l’orchestrateur. Donc, pour les applications robustes et distribuées, nous ne voulons pas que l’application appelante plante. Au lieu de cela, nous voulons que l’appelant se retire et réessaye, où nous augmentons le temps de pause entre les tentatives à mesure que le nombre de tentatives échouées augmente afin de ne pas submerger le service échoué. Cela peut entraîner votre propre attaque, bien que non intentionnelle, par déni de service.
Comme il ne s’agit pas d’un article de programmation en soi, nous n’entrerons pas dans les détails avec ces exemples, mais les adoptants de Docker Enterprise qui créent des applications distribuées doivent connaître ces concepts et rechercher leurs options de mise en œuvre. La plupart des environnements de programmation ont des fonctionnalités ou des extensions intégrées pour aider les développeurs à réessayer la logique de manière propre. Si vous utilisez JavaScript, vous voudrez peut-être examiner les exceptions de promesse, et si vous utilisez Java, vous voudrez peut-être regarder Spring Retry. Des liens pour ceux-ci sont inclus dans la section Lectures complémentaires à la fin de ce chapitre.
Il est important de savoir qu’il existe des cadres complets et une technologie évolutive dédiés à la gestion des appels de systèmes distants de manière très sophistiquée, et généralement en le faisant en implémentant un modèle de disjoncteur. Un cadre populaire pour cela est Hystrix de Netflix. Hystrix fournit un proxy pour encapsuler votre appel distant. Le proxy est instrumenté avec des données de temps de réponse associées à l’API distante cible. Si les temps de réponse de l’API distante dépassent les paramètres prédéfinis, le proxy interceptera l’appel et renverra immédiatement un échec. Cela s’appelle un circuit ouvert et peut fermer la récupération de l’API.
Enfin, Istio de Google est l’approche la plus sophistiquée et la plus complète conçue pour prendre en charge les microservices à grande échelle exécutés dans les clusters Kubernetes. Istio s’exécute en tant que service dans un cluster Kube, activé avec des conteneurs side-car adjacents à vos modules de service d’application, pour créer un maillage de service hautement conçu. Istio n’en est encore qu’à ses débuts et est excessif pour la plupart des utilisateurs de conteneurs, mais il est probable qu’il influe sur la façon dont les futures applications à l’échelle de Google sont conçues et déployées avec Kubernetes.
1.1.4.1.5 Journalisation centralisée
Dans le chapitre 10 , Plus d’informations sur Kubernetes avec Docker Enterprise , nous parlerons davantage de la surveillance, de la journalisation et des alertes dans un environnement Docker Enterprise. Cependant, dans ce chapitre, nous devons discuter du côté application de la journalisation dans un environnement Docker. Traditionnellement, la plupart des applications utilisent une sorte de framework pour se connecter à un système de fichiers local. C’est formidable lorsque vous savez exactement où votre application s’exécute et lorsque ses composants dépendants sont colocalisés sur le même serveur. En cas de problème, il vous suffit de consulter les journaux sur le serveur hôte pour comprendre ce qui s’est passé. Les applications distribuées basées sur un cluster sont différentes.
Dans un environnement distribué, en particulier lorsqu’un orchestrateur distribue des charges de travail à travers le cluster, nous envisageons une conception de journalisation centralisée. Cela signifie que les applications ne se connectent plus à un fichier local. Ces applications conteneurisées doivent plutôt écrire leurs informations de journalisation sur l’erreur standard et la sortie standard, et permettre au Docker Engine de capturer les messages journalisés. Cela dit, comme vous pouvez l’imaginer, une structure de messages de journalisation cohérente entre les applications facilite le filtrage des journaux et la construction de requêtes de journal raisonnables sans doctorat dans les expressions régulières.
1.1.4.1.6 Secrets
Le concept final pour le développement et le déploiement d’applications de base de cluster est secret. Les secrets fournissent un moyen de stocker des éléments de données privés spéciaux dans un cluster. Ils sont créés par un détenteur secret et stockés dans un format crypté dans le cluster. Plus tard, le secret peut être remis à un conteneur cible (chiffré en transit) à un emplacement spécifié (par défaut, / run / secrets ) où il peut être consulté dans un format non chiffré à l’intérieur du conteneur. Ceci est très utile pour stocker des mots de passe, des jetons d’autorisation, des clés privées et des certificats.
Voici un exemple simple où, à partir d’un nœud de gestionnaire Swarm, nous créons un secret appelé my_secret_data :
$ echo “secret-secret” | docker secret create my_secret_data –
Ensuite, nous créons un service qui utilise my_secret_data dans l’emplacement cible par défaut / run / secrets / my_secret_data :
docker service create –name redis –secret my_secret_data redis:alpine
Pour vérifier que le secret a été remis au conteneur Redis, nous voulons répertorier le contenu de / run / secrets / my_secret_data, mais nous avons besoin de l’ID du conteneur exécuté derrière le service. Nous pouvons y parvenir en utilisant le conteneur docker ls avec un indicateur –filter pour répertorier les informations de notre conteneur Redis et le paramètre -q pour renvoyer uniquement l’ID du conteneur. Enfin, nous imbriquons l’expression de filtre d’ID de conteneur à l’intérieur de la commande d’ exécution du conteneur docker :
$ docker container exec $(docker container ls –filter name=redis -q) cat /run/secrets/my_secret_data
secret-secret
Nous pouvons voir le résultat de notre commande cat, montrant le contenu de my_secret_data qui correspond à notre secret.
Les secrets peuvent être utilisés dans Docker Engine-Community Swarm et Kubernetes.
Pour plus d’informations sur l’utilisation des secrets Docker, consultez la documentation Docker sur https://docs.docker.com/engine/swarm/secrets/ .
Plus loin dans ce chapitre, nous utiliserons des certificats pour stocker notre certificat SSL et notre clé privée pour le site Web AtSea lors du déploiement sur notre cluster.
1.1.5 Outils Docker pour le développement local et les tests de l’application AtSea
Pour notre exemple d’application, nous allons adapter AtSea, un exemple d’application bien connu du référentiel public GitHub de dockersamples sur https://github.com/dockersamples/atsea-sample-shop-app . AtSea est une application vraiment intéressante car elle présente de nombreuses fonctionnalités populaires et intéressantes, comme suit:
- Interface de Reactapplication
- Une API RESTful écrite avec Java Spring Boot
- Base de données backend PostgreSQL
- Un service de support de passerelle de paiement
- Un service de proxy inverse pour la terminaison TLS
1.1.5.1 Structure d’application AtSea
Dans un premier temps, nous clonons atsea-sample-shop-app sur notre poste de développement. Avec le code source sur notre machine de développement local, nous serons en mesure de construire les images d’application localement. Veuillez noter la structure de l’application dans l’arborescence de fichiers abrégée suivante. Remarquez comment chaque dossier principal possède son propre Dockerfile pour créer une image Docker distincte pour chaque composant.
Les principaux composants de l’application se trouvent dans le répertoire de l’application et comprennent le dossier react-app pour le frontend JS et le dossier src pour l’API Java Spring Boot. Veuillez noter la colocalisation des applications JavaScript et Java dans le même dossier, reflétant une décision de conception de les exécuter toutes les deux dans une seule instance de serveur Web / d’application Tomcat, plutôt que de les séparer. Vous le verrez plus clairement lorsque nous examinerons l’ application / Dockerfile . Le dossier de l’ application contient le fichier Maven pom.xml pour l’application ainsi qu’un Dockerfile et Dockerfile-dev . Le Dockerfile-dev est utilisé pour créer une version spéciale de l’image, où l’application est pilotée à partir d’une session de débogage à distance pour tester l’API à partir d’un IDE comme IntelliJ ou Eclipse. La structure des dossiers et des fichiers sera similaire à la structure suivante:
atsea-app
├── app
│ ├── Dockerfile
│ ├── Dockerfile-dev
│ ├── pom.xml
│ ├── react-app
│ └── src
├── database
│ ├── docker-entrypoint-initdb.d
│ ├── Dockerfile
│ ├── mysql
│ ├── pg_hba.conf
│ └── postgresql.conf
├── payment_gateway
│ ├── Dockerfile
│ └── process.sh
├── reverse_proxy
│ ├── build-certs.sh
│ ├── certs
│ ├── Dockerfile
│ └── nginx.conf
├── docker-compose-dev.yml
├── docker-compose.yml
├── docker-stack-local.yml
├── docker-stack-cluster.yml
Le dossier de la base de données contient les fichiers de configuration et d’initialisation Postgres, ainsi que le Dockerfile utilisé pour créer l’image de la base de données Postgres, dont nous discuterons sous peu. Le dossier payment_gateway contient le script de démarrage de la passerelle de paiement, ainsi que le Dockerfile utilisé pour créer l’image payment_gateway. Le dossier reverse_proxy n’est utilisé que localement pour les tests. Lorsque nous déploierons l’application sur le cluster Docker Enterprise, nous utiliserons Interlock 2 de Docker Enterprise pour le routage de couche 7, ainsi que la capacité de terminaison SSL du proxy.
Enfin, nous avons quatre fichiers YAML différents utilisés pour créer et déployer l’application avec l’API Docker. Ces fichiers sont traités dans les sections suivantes.
1.1.5.2 Utiliser docker-compose comme Makefile
Nous avons examiné les composants de l’application, mais maintenant, nous allons voir comment ils sont assemblés. Pour ce faire, nous examinerons la première des deux docker-Compose fichiers, docker-Compose-dev.yml, en affichant le contenu du bloc de code suivant. Encore une fois, il s’agit d’un fichier de composition spécial utilisé pendant le processus de développement, d’où le suffixe de nom de fichier -dev. Au plus haut niveau, le fichier répertorie les services constituant la version de débogage locale de l’application, c’est-à-dire les services de base de données et de serveur d’applications. Notez que les services payment_gateway et reverse_proxy sont absents du fichier. Cela fournit un strict minimum pour le débogage de l’API locale. Il y a deux éléments à noter sur la définition du service appserver. Tout d’abord, le Dockerfile alternatif (Dockerfile-dev) est utilisé pour créer le conteneur comme spécifié dans le paramètre build: dockerfile:. Le second expose le port 5005, permettant au débogueur de se connecter de l’hôte au conteneur du serveur d’applications :
version: “3.7”
services:
database:
build:
context: ./database
image: atsea_db
environment:
POSTGRES_USER: gordonuser
POSTGRES_DB: atsea
ports:
– “5432:5432”
networks:
– back-tier
secrets:
– postgres_password
appserver:
build:
context: ./app
dockerfile: Dockerfile-dev
image: atsea_app
ports:
– “8080:8080”
– “5005:5005”
networks:
– front-tier
– back-tier
secrets:
– postgres_password
secrets:
postgres_password:
file: ./devsecrets/postgres_password
networks:
front-tier:
back-tier:
Dans le bloc de code suivant, nous allons jeter un rapide coup d’œil aux fichiers docker-compose-dev.yml, référence, Dockerfile-dev, qui est utilisé pour créer la version de débogage du serveur d’applications. Ce fichier est un Dockerfile de construction en plusieurs étapes avec trois étapes de construction. N’oubliez pas que seule la dernière étape reste après la génération, et seul un sous-ensemble ciblé d’actifs est copié à partir des deux premières étapes de la construction. Dans ce cas, le contenu du répertoire/usr/src/atsea/app/react-app/build/ est copié de l’image jsbuild vers le répertoire de travail /static de la dernière étape de construction. De plus, le fichier Java /usr/src/atsea/target/AtSea-0.0.1-SNAPSHOT.jar est copié de l’étape Maven vers le répertoire /app de l’ image de l’étape de construction finale . Tout cela est un problème assez standard pour une application React et une application Java Spring Boot construite avec Maven. Ce qui est différent ici est la commande EXPOSE pour le port de débogage 5005 et la commande Java ENTRYPOINT pour la dernière étape. Bien qu’elle ne soit pas obligatoire, la directive EXPOSE est une indication pour l’utilisateur de l’image de l’image qui s’attend à ce que le port 5005 soit mappé au port hôte ou cluster. La commande ENTRYPOINT alternative appelle le débogage à distance de l’API Java. Dans ce cas, le CMD est utilisé comme paramètre par défaut pour charger la section postgres du profil Spring :
FROM node:latest As jsbuild
WORKDIR /usr/src/atsea/app/react-app
COPY react-app .
RUN npm install
RUN npm run build
FROM maven:latest As maven
WORKDIR /usr/src/atsea
COPY pom.xml .
RUN mvn -B -f pom.xml -s /usr/share/maven/ref/settings-docker.xml dependency:resolve
COPY . .
RUN mvn -B -s /usr/share/maven/ref/settings-docker.xml package -DskipTests
FROM java:8-jdk-alpine
WORKDIR /static
COPY –from=jsbuild /usr/src/atsea/app/react-app/build/ .
WORKDIR /app
COPY –from=maven /usr/src/atsea/target/AtSea-0.0.1-SNAPSHOT.jar .
EXPOSE 5005
ENTRYPOINT [“java”, “-agentlib:jdwp=transport=dt_socket,server=y,suspend=y,address=5005″,”-jar”, “/app/AtSea-0.0.1-SNAPSHOT.jar”]
CMD [“–spring.profiles.active=postgres”]
docker-compose-dev.yml est un fichier que nous utilisons avec une commande docker-compose -f docker-compose-dev.yml –build pour construire des images atsea_app et atsea_db pour les tests locaux. Ensuite, nous pouvons utiliser une commande docker-compose -f docker-compose-dev.yml up -d pour démarrer l’application pour les tests locaux avec un IDE. Pour vérifier que l’application a démarré correctement, nous pouvons voir que les processus docker-compose s’exécutent à l’aide de la commande docker-compose ps , comme indiqué dans le code suivant:
Name Command State Ports
——————————————————————————————————-
atsea-app_appserver_1 java -agentlib:jdwp=transp … Up 0.0.0.0:5005->5005/tcp, 0.0.0.0:8080->8080/tcp
atsea-app_database_1 docker-entrypoint.sh postgres Up 0.0.0.0:5432->5432/tcp
Pour plus d’informations sur le débogage à distance et l’exemple d’application AtSea, consultez https://blog.docker.com/2017/05/spring-boot-development-docker/ .
1.1.5.3 Création et exécution d’une application avec Compose et Swarm
En plus de créer une version locale de développement / débogage de l’application, nous allons maintenant examiner l’utilisation du fichier YAML de composition de docker pour définir un Makefile d’ image de production , principalement pour les tests locaux de pile complète, mais peut-être pour nos scripts CI.
Dans la section suivante de ce chapitre, nous examinerons les options de CI qui gravitent généralement vers un script de build par référentiel, mais peuvent avoir trois étapes distinctes pour la construction de chaque image (étape un pour construire, étape deux pour tester et étape trois pour pousser la nouvelle image). Pour l’instant, nous devons créer une pile locale qui s’exécute avec les images de production.
Dans la dernière section, nous avons décrit le fichier docker-compose-dev.yml, où nous avons laissé nos services reverse_proxy et payment_gateway. Maintenant, nous voulons exécuter tous les services localement pour imiter étroitement la production. Depuis notre plateforme de bureau Docker locale, nous pouvons exécuter une pile d’applications Swarm pour obtenir la plupart des fonctionnalités de notre cluster Docker Enterprise. Nous pouvons initialiser Docker Swarm, nous laissant avec un cluster à nœud unique qui active les réseaux de superposition, les configurations et les secrets. La seule chose qui manque est le routage Docker de couche 7, où nous utilisons le routage basé sur les en-têtes et la terminaison TLS. Pour un test local raisonnable, nous pouvons utiliser le service reverse_proxy avec NGINX (après tout, Docker Enterprise utilise NGINX en arrière-plan par défaut) pour être un espace réservé fonctionnel pour le routage de la couche 7 de Docker Enterprise sur notre hôte local.
1.1.5.3.1 Routage moqueur de la couche 7 et terminaison TSL pour les tests Swarm locaux
La première étape de la création de notre service de routage de couche 7 simulée consiste à générer un certificat pour notre domaine de test (pour les tests locaux, ajoutez simplement at-sea.mydomain.com à votre fichier hôte de machine de développement). Dans le diagramme suivant, nous générons les certificats avec une demande de signature de certificat interactive (CSR) (la commande openssl req vous demandera les paramètres CSR, et c’est là que vous fournissez le nom commun de votre domaine) à l’aide de la commande openssl req pour générer les certificats (.crt) et les fichiers de clé privée (.key) requis par NGINX pour la résiliation.
Nous utiliserons les secrets Docker (nécessite l’initialisation de Docker Engine-Community Swarm) pour stocker en toute sécurité le certificat et la clé jusqu’à ce que notre service reverse_proxy les utilise plus tard :
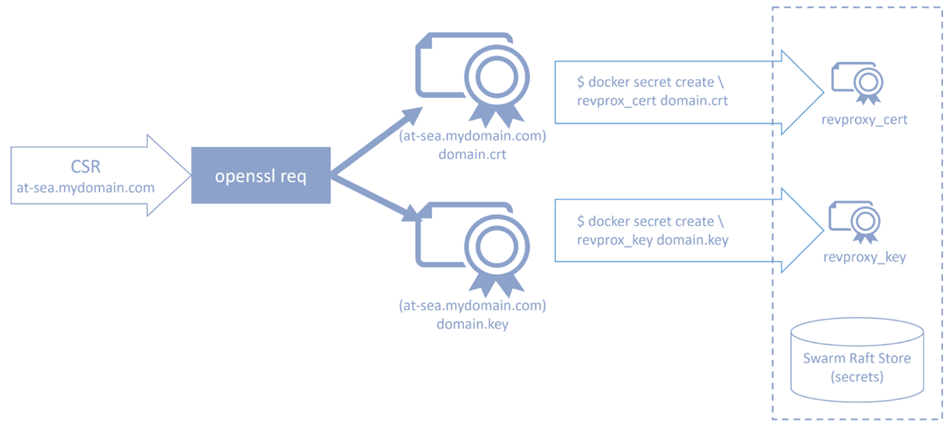
Figure 5
Voici le script Bash pour générer les certificats dans le répertoire certs. Ensuite, nous stockons le certificat et les clés privées en tant que secrets Swarm, comme suit :
#!/bin/bash
#Generate Certificates
mkdir certs
openssl req -newkey rsa:4096 -nodes -sha256 -keyout certs/domain.key -x509 -days 365 -out certs/domain.crt
#Store Certificates as Secrets in Local Swarm Cluster
docker secret create revprox_cert certs/domain.crt
docker secret create revprox_key certs/domain.key
Une fois les secrets créés, vous pouvez répertorier le secret (pas le contenu, bien sûr) à l’aide de la commande docker secret ls pour obtenir la sortie suivante :
ID NAME CREATED UPDATED
5hhayjj711wszm9xcmym0gk6k revprox_cert 2 days ago 2 days ago
vx5oiwizjlywuphkrz65vb7or revprox_key 2 days ago 2 days ago
Nous allons maintenant ajouter la section de service reverse_proxy à notre fichier docker-stack-local.yml, comme indiqué dans le bloc de code suivant. Remarquez comment le service reverse_proxy publie les ports 80 et 443 sur le réseau d’entrée du réseau Swarm de tests local. Nous pouvons voir comment les secrets que nous avons créés sont utilisés par le service reverse_proxy. Le service Docker extrait le nom secret fourni comme paramètre source du magasin de cluster et l’injecte dans le répertoire /run/secrets, en utilisant le paramètre cible comme nom. Dans quelques instants, nous verrons où cela est utilisé lorsque nous examinons le fichier local nginx.config.
Enfin, nous pouvons voir comment le service reverse_proxy est connecté au réseau de premier niveau, ce qui lui permet de communiquer avec le service d’application at_sea (port 8080) lorsqu’il transfère les demandes du reverse_proxy à l’interface utilisateur Web de l’application :
services:
reverse_proxy:
image: reverse_proxy
ports:
– “80:80”
– “443:443”
secrets:
– source: revprox_cert
target: revprox_cert
– source: revprox_key
target: revprox_key
networks:
– front-tier
Comme nous n’avons pas Interlock 2.0 de Docker Enterprise sur notre station de travail de développement, nous pouvons configurer un service NGINX reverse_proxy pour gérer le routage de couche 7 et la terminaison TLS. Nous fournissons notre propre fichier pour les tests locaux en fournissant un fichier nxinx.conf lorsque nous construisons l’image. Dans l’extrait suivant du fichier nginx.conf, nous pouvons voir les liaisons de serveur pour le port 80 et le port 443. Le port 80 redirige simplement tout trafic HTTP vers HTTPS sur le même hôte avec le même URI. La liaison serveur 443 est un peu plus intéressante.
La liaison de serveur 443 montre comment le conteneur NGINX peut trouver le certificat SSL et la clé dans le répertoire /run/secrets (en raison de ces directives secrètes précédentes) et les utilise pour la terminaison TLS. Ensuite, la demande est transmise via le protocole HTTP standard sur le réseau interne de premier niveau isolé au serveur d’applications sur le port 8080. Enfin, nous pouvons voir comment les journaux d’accès et d’erreur sont dirigés vers /dev/stdout et /dev/stderr où les journaux Docker peuvent les récupérer :
server {
listen 80;
server_name at-sea.nvisia.io;
return 301 https://$host$request_uri;
}
server {
listen 443;
ssl on;
ssl_certificate /run/secrets/revprox_cert;
ssl_certificate_key /run/secrets/revprox_key;
server_name at-sea.mydomain.com;
access_log /dev/stdout;
error_log /dev/stderr;
location / {
proxy_pass http://appserver:8080;
}
Enfin, nous avons le Dockerfile que nous utiliserons pour construire un serveur proxy inverse. C’était à l’origine un Dockerfile assez simple, mais il y avait quelques problèmes. Tout d’abord, spécifiez toujours une version pour une image de base ! Deuxièmement, nous avons dû ajouter un script entrypoint.sh pour éliminer un problème de synchronisation de la résolution DNS NGINX. Par conséquent, nous avons verrouillé Nginx : 1.14-alpine comme image de base, et pour que cela fonctionne, il nous suffit de copier le fichier nginx.conf dans un dossier à l’intérieur du conteneur où NGINX s’attend à le trouver. Enfin, au lieu d’exécuter le binaire nginx directement à partir de la ligne de commande, nous exécutons plutôt notre script entrypoint.sh comme CMD de démarrage :
FROM nginx:1.14-alpine
COPY nginx.conf /etc/nginx/nginx.conf
# Added entrypoint.sh.
# Need to add sleep command before starting NGINX services to avoid a DNS problem.
COPY entrypoint.sh .
CMD ./entrypoint.sh
Voici le petit script enterypoint.sh pour démarrer notre service reverse_proxy . S’il s’agissait de plus qu’un faux conteneur pour les tests locaux, quelque chose de plus qu’une commande sleep semblerait appropriée :
#!/bin/sh
sleep 30
nginx -g ‘daemon off;’
Maintenant, notre service de reverse_proxy de couche 7 simulé est prêt pour les tests locaux, et nous pouvons mettre la touche finale à la pile de tests locale.
1.1.5.3.2 Étapes finales pour les tests Swarm locaux
Pour nous assurer que toutes les images sont prêtes pour le test final, nous devons nous assurer que nous utilisons le nom complet de l’image, y compris le nom de domaine complet / le nom de domaine complet du registre privé, et nous assurer que la version réelle (pas la dev) du Dockerfile est utilisée pour la construction. Pour ce faire, nous créons un fichier docker-compose-build.yml, comme indiqué dans le code suivant, avec uniquement des informations de build (pas de déploiement).
Nous n’avons pas besoin d’un espace de noms, ni besoin de pousser l’image reverse_proxy, car elle est réservée aux développeurs locaux. Nous ajoutons le préfixe dtr.mydomain.com/dev aux images afin de pouvoir utiliser l’organisation de développement du DTR en tant que sandbox d’image de développeur. Nous ajoutons une balise : local à nos images afin que nous sachions qu’elles sont construites et poussées localement. Plus tard, les images de construction automatisées proviendront du pipeline CI et nous utiliserons différentes balises pour ces images.
Les développeurs peuvent utiliser leur espace de noms privé, par exemple dtr.mydomain.com/ssoftware, afin de pouvoir également pousser leurs propres images de test basées sur un cluster. Nous avons utilisé / dev car il peut être facilement partagé par un groupe de développeurs qui travaillent ensemble sur une branche / version de fonctionnalité :
version: “3.7”
services:
reverse_proxy:
build:
context: ./reverse_proxy
user: nginx
image: reverse_proxy
database:
build:
context: ./database
image: dtr.mydomain.com/dev/atsea_db:local
appserver:
build:
context: app
dockerfile: Dockerfile
image: dtr.mydomain.com/dev/atsea_app:local
payment_gateway:
build:
context: payment_gateway
image: dtr.mydomain.com/dev/payment_gateway:local
Maintenant, nous pouvons utiliser cette approche de création de fichiers pour créer nos images en utilisant une commande de construction docker-compose -f docker-compose-build.yml et l’image de docker ls pour les examiner.
Notre dernière étape pour le déploiement de la machine de génération et de développement local consiste à créer un fichier docker-stack-local.yml, comme indiqué dans le code suivant. Ce fichier est une étape intermédiaire pour un déploiement Swarm local et deviendra la base de notre fichier de pile de déploiement de cluster Docker Enterprise, qui sera utilisé par le système CI plus tard dans ce chapitre. Comme nous avons déjà discuté du service reverse_proxy dans la section précédente, nous allons directement accéder au service de base de données :
version: “3.7”
services:
reverse_proxy:
image: reverse_proxy
ports:
– “80:80”
– “443:443”
secrets:
– source: revprox_cert
target: revprox_cert
– source: revprox_key
target: revprox_key
networks:
– front-tier
database:
image: dtr.nvisia.io/dev/atsea_db:local
environment:
POSTGRES_USER: gordonuser
POSTGRES_DB_PASSWORD_FILE: /run/secrets/postgres_password
POSTGRES_DB: atsea
networks:
– back-tier
secrets:
– postgres_password
appserver:
image: dtr.nvisia.io/dev/atsea_app:local
networks:
– front-tier
– back-tier
– payment
deploy:
replicas: 2
update_config:
parallelism: 2
failure_action: rollback
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
secrets:
– postgres_password
visualizer:
image: dockersamples/visualizer:stable
ports:
– “8001:8080”
stop_grace_period: 1m30s
volumes:
– “/var/run/docker.sock:/var/run/docker.sock”
deploy:
update_config:
failure_action: rollback
payment_gateway:
image: dtr.nvisia.io/dev/payment_gateway:local
secrets:
– source: staging_token
target: payment_token
networks:
– payment
deploy:
update_config:
failure_action: rollback
networks:
front-tier:
back-tier:
payment:
driver: overlay
driver_opts:
encrypted: ‘yes’
secrets:
postgres_password:
external: true
staging_token:
external: true
revprox_key:
external: true
revprox_cert:
external: true
Le service de base de données est isolé sur le réseau de back-tier, avec le serveur d’applications, et par conséquent, seul le service de serveur d’applications peut accéder à la base de données. Le service de base de données utilise une variable d’environnement POSTGRES_DB_PASSWORD_FILE pour indiquer à Postgres où trouver le fichier de mots de passe. Pour notre exemple, il se trouve dans le répertoire / run / secrets. Veuillez noter que le secret de la base de données ne spécifie pas de source et de cible, comme spécifié pour le service reverse_proxy. Dans ce cas, le nom secret et le fichier créés dans le répertoire / run / secrets sont identiques et appelés postgres_password . Ce secret est également nécessaire au service appserver pour se connecter à la base de données.
Notez que tous les services utilisent le nom d’image complet avec le nom de domaine complet des registres privés, l’espace de noms (organisation ou nom d’utilisateur), le référentiel / nom d’image et la balise. Celles-ci, bien sûr, correspondent à la sortie générée à l’aide de notre fichier docker-compose-build.yml pour créer et étiqueter nos images.
La dernière fonctionnalité notable que nous avons introduite était la section de déploiement du fichier. Cela indique littéralement à Swarm comment se comporter lors du déploiement des services. Sous déploiement, nous avons d’abord défini la propriété des répliques sur «2» , en disant à l’orchestrateur de garder deux conteneurs exécutant l’ image atsea_app à tout moment.
Les paramètres deploy: > update config: > sont liés à la façon dont un service est mis à jour. Dans notre cas, lorsque le service est mis à jour (peut-être qu’une nouvelle version de l’image avec quelques corrections de bugs doit être déployée), Swarm mettra à jour deux conteneurs à la fois. C’est un peu idiot pour cet exemple car nous n’avons que deux réplicas en cours d’exécution, mais les deux seront mis à jour en même temps. failure_action indique à l’orchestrateur quoi faire en cas d’échec du service mis à jour. Les options sont la restauration ou la pause, la pause étant la valeur par défaut. L’option de pause peut être utile pour déboguer un problème de déploiement. La partie suivante de la spécification de déploiement traite de la fonction restart_policy du service.
La politique de redémarrage décrit comment et si le service redémarre les réplicas. Dans notre exemple, nous ne redémarrons les répliques qu’en cas d’échec, mais les options n’incluent également aucune (jamais redémarrer) et any (pour toujours tenter un redémarrage, ce qui est la valeur par défaut). Le délai correspond au temps d’attente entre les tentatives (la valeur par défaut est 0). Le nombre maximal de tentatives décrit le nombre de tentatives de redémarrage d’un conteneur avant d’abandonner (la valeur par défaut est “ne jamais abandonner”). Enfin, la fenêtre est le temps total autorisé pour qu’un redémarrage réussisse.
Vous pouvez trouver plus d’informations sur les options de déploiement Swarm ici: https://docs.docker.com/compose/compose-file/#deploy .
Notez que j’ai quitté le service de visualisation dans notre pile. C’est un peu grésillement que vous pourriez trouver plus utile dans un cluster multi-nœuds, mais essentiellement, ce service affiche les conteneurs en cours d’exécution dans chaque nœud de votre cluster Docker. Le service monte le socket Docker afin qu’il puisse surveiller l’état de l’essaim. Le visualiseur doit s’exécuter sur un nœud du gestionnaire Swarm pour accéder à l’API et obtenir les informations dont il a besoin. Puisque nous sommes un cluster d’un, il sera sur un nœud gestionnaire. Sinon, nous aurions besoin d’utiliser une contrainte de déploiement comme celle-ci :
deploy:
update_config:
failure_action: rollback
placement:
constraints:
– ‘node.role == manager’
Maintenant, nous avons juste besoin d’exécuter le fichier docker-stack-local.yml sur le cluster Swarm de notre machine de développement local à l’aide de la commande docker stack deploy -c docker-stack-local.yml at-sea-local pour lancer notre nouvelle pile, appelée en mer-local.
Après avoir lancé la pile, vous pouvez exécuter la commande docker stack ps at-sea-local et vérifier l’état actuel du processus de la pile en cours d’exécution. Ensuite, vous devez également mettre à jour votre fichier hôte local, afin que le nom de domaine at-sea.mydomain.com soit résolu en 127.0.0.1. Ensuite, pointez votre navigateur sur https://at-sea.mydomain.com pour voir l’application en cours d’exécution.
Nettoyez avec une commande docker stack rm at-sea-local pour supprimer votre pile locale.
1.1.6 Déploiement d’une application personnalisée sur le cluster Docker Enterprise
Ici, nous allons commencer à voir comment les rôles de développement et d’exploitation se divisent alors que nous isolons un ensemble parallèle d’actifs pour nos déploiements d’applications. Ce faisant, nous avons divisé les actifs de déploiement et commencé à écrire le déploiement de la plateforme en préparation de nos pipelines CI dans la section suivante. Plus précisément, nous allons maintenant introduire des scripts, ainsi que de nouveaux fichiers de pile Docker pour gérer le déploiement des services d’application.
Nous commencerons par séparer un référentiel de déploiement distinct du référentiel de déploiement d’applications. C’est l’endroit où nos scripts de déploiement et nos fichiers de pile de test, d’assurance qualité et de production basés sur les clusters vivront et seront régis par les administrateurs système et l’équipe d’exploitation.
L’équipe de développement contribuera à la production de ces actifs, tous les changements seront de retour fusionnés dans le maître branche par les administrateurs et les opérateurs qui sont responsables de leur utilisation. C’est là que nous commençons également à réfléchir à la gestion des ressources de déploiement pour chaque environnement (par exemple, dev, test et prod) également.
À cet effet, nous allons créer un dossier ATSEA-DEPLOY en tant que pair de notre application ATSEA , comme ici pour les actifs d’ application que nous avons clonés à partir du référentiel Dockersamples AtSea GitHub ( https://github.com/dockersamples/atsea-sample- boutique-app ). La structure du contenu ATSEA-DEPLOY est illustrée dans la liste d’arborescence suivante. Il existe bien sûr de nombreuses façons d’organiser les ressources de déploiement, mais il s’agit d’un exemple assez raisonnable. De plus, vous pouvez avoir un dossier configs en tant qu’homologue du dossier secrets pour échanger différents fichiers de configuration (c’est-à-dire les configurations NGINX et les propriétés Spring).
Veuillez noter que le contenu des répertoires secrets, peut-être à l’exception du dossier secrets/dev, est rempli une fois le code extrait du contrôle de code source. Ces répertoires d’échafaudage ou d’espace réservé et les artefacts par défaut ne sont pas nécessaires, mais illustrent certaines des façons d’extraire des actifs environnementaux de votre fichier de script de déploiement :
ATSEA-DEPLOY
├── deploy-cluster.sh
├── docker-stack-cluster.yml
├── .gitignore (DON’T STORE YOUR SECRETS IN SCC)
└── secrets
├── dev
│ ├── domain.crt
│ ├── domain.key
│ ├── payment_token
│ └── postgres_password
├── prod
│ ├── payment_token
│ ├── postgres_password
| ├── wildcard.mydomain.com.key
| └── wildcard.mydomain.com.server.crt
└── test
├── payment_token
├── postgres_password
├── wildcard.mydomain.com.key
└── wildcard.mydomain.com.server.crt
Notre référentiel de déploiement commencera comme un simple script de déploiement avec un paramètre de ligne de commande pour déployer des applications basées sur un cluster pour soit développer, tester ou produire à l’aide du déploiement de la pile de Docker. C’est ici que nous écrivons la création de tous les actifs externes dépendants dans le cadre du déploiement. Ces actifs incluent généralement des réseaux, des configurations et des secrets externes à la pile. En outre, j’ai laissé quelques commentaires, indiquant où vous pouvez extraire des secrets d’un emplacement distant sécurisé dans le répertoire de secrets approprié.
Par exemple, avant de commencer le processus de déploiement, nous souhaitons peut-être extraire certains secrets d’un coffre-fort HashiCorp et les injecter dans le magasin crypté TLS de notre Docker Swarm. Dans d’autres cas, il s’agira simplement d’un opérateur accédant à des fichiers sécurisés à partir de la ligne de commande et utilisant leurs droits d’accès pour créer des secrets Swarm requis par les services d’application. Voici un exemple de la commande vault pour créer un secret Docker Swarm:
# snippet from http://work.haufegroup.io/spring-cloud-config-and-vault/
$ vault write -f –format=json auth/approle/role/myapprole/secret-id | jq -r ‘.secret_id’ | \
docker secret create myapprole_secretid –
Ce qui suit est un script simple et une version mise à jour de notre fichier de pile YAML utilisant le format 3.x du fichier docker-compose :
#!/bin/bash
# deploy_cluster.sh
# Add your code to fetch and populate ./secrets/test ./secrets/prod using copy or vault etc.
# Set stack name
if [[ -z “$1” ]]; then
echo “Usage: please specify dev, test or prod”;
exit 1;
else
export STACK_ENV=$1
export STACK=${STACK_ENV}_at-sea
fi
# Clean up old external stuff
echo -e “Remove old stuff…\n”
echo $(docker network rm front-tier)
echo $(docker secret rm wildcard.mydomain.com.key)
echo $(docker secret rm wildcard.mydomain.com.server.crt)
echo $(docker secret rm postgres_password)
echo $(docker secret rm payment_token)
echo -e “Waiting for 5 seconds…\n” $(sleep 5) “\n\n”
echo -e “Creating new external networks and certificates…\n”
echo -e $(docker network create -d overlay front-tier) “\n”
echo -e $(docker secret create wildcard.mydoamin.com.key ./secrets/${STACK_ENV}/wildcard.mydomain.com.key) “\n”
echo -e $(docker secret create wildcard.mydomain.com.server.crt ./secrets/${STACK_ENV}/wildcard.mydomain.com.server.crt) “\n”
echo -e $(docker secret create postgres_password secrets/${STACK_ENV}/postgres_password) “\n”
echo -e $(docker secret create payment_token secrets/${STACK_ENV}/payment_token) “\n”
echo -e “Waiting for 5 seconds…\n” $(sleep 5) “\n”
echo -e “Launching stack…” $(docker stack deploy -c docker-stack-cluster.yml ${STACK}) “\n”
Nous commençons par le script deploy_cluster.sh en recherchant l’existence d’un paramètre de ligne de commande, en nous assurant d’avoir un nom d’environnement transmis. Nous gardons l’exemple de script bref et recherchons simplement l’existence d’un paramètre, mais en validant que la valeur du paramètre est en fait dev, test ou prod serait un bon ajout pour une vraie version de script. Ensuite, nous nettoyons les anciens réseaux externes et les secrets du Swarm. À partir de là, nous créons le réseau externe, créons les secrets Swarm en chargeant leur contenu à partir des fichiers / secrets et enfin déployons la pile.
Le script configure les dépendances et déploie la pile docker-stack-cluster.yml . Maintenant, nous allons plonger dans le docker-stack-cluster.yml associé que nous lançons dans la dernière ligne de deploy_cluster.sh .
1.1.6.1 Routage de couche 7 avec Docker Enterprise
Étant donné que nous passons d’un déploiement Docker Engine-Community Swarm local sur une machine de développeur local à un déploiement Docker Enterprise Cluster, nous pouvons tirer parti de la fonctionnalité de routage Interlock 2 layer 7 de Docker Enterprise. En plus du routage de couche 7, nous pouvons également utiliser Interlock 2 pour notre terminaison TLS, comme indiqué dans le diagramme suivant. Par conséquent, en utilisant cette fonctionnalité dans notre application, nous remplacerons le service reverse_proxy que nous avons utilisé pour notre pile de déploiement locale.
Pour décrire le fonctionnement de cette fonctionnalité pour notre exemple d’application, nous pouvons suivre le trafic entrant depuis un ordinateur distant, en commençant par l’entrée DNS générique, qui résout l’ URL atsea.mydoamin.com sur le port 443 de notre équilibreur de charge externe. L’équilibreur de charge a dirigé la demande entrante vers l’un des nœuds de cluster sur le port 8443. Plus tôt, nous avons utilisé les paramètres d’administration de Docker Enterprise pour activer le routage de couche 7 sur les ports d’entrée 80 et 8443. Ainsi, tout trafic entrant dans le cluster sur les ports 80 et 8443 est acheminé vers le service proxy Interlock. Plus tard, lorsque nous déployons notre application avec la commande docker stack deploy, Interlock 2 détecte que le service a utilisé les étiquettes d’Interlock 2, en commençant par com.docker.lb. * Et il utilise les valeurs d’étiquette pour configurer le proxy (pensez à un nginx. mise à jour conf ).
Cela configure le proxy Interlock 2 pour inspecter les en-têtes et inverser les demandes de trafic entrant du proxy avec le nom d’hôte atsea.mydoamin.com au VIP du service Swarm du serveur d’applications sur le port 8080 sur le réseau de premier niveau. Dans le service appserver , le serveur Tomcat intégré de Spring écoute sur le port 8080 et répond aux demandes Web. La réponse est redirigée via le même chemin que celui entré:
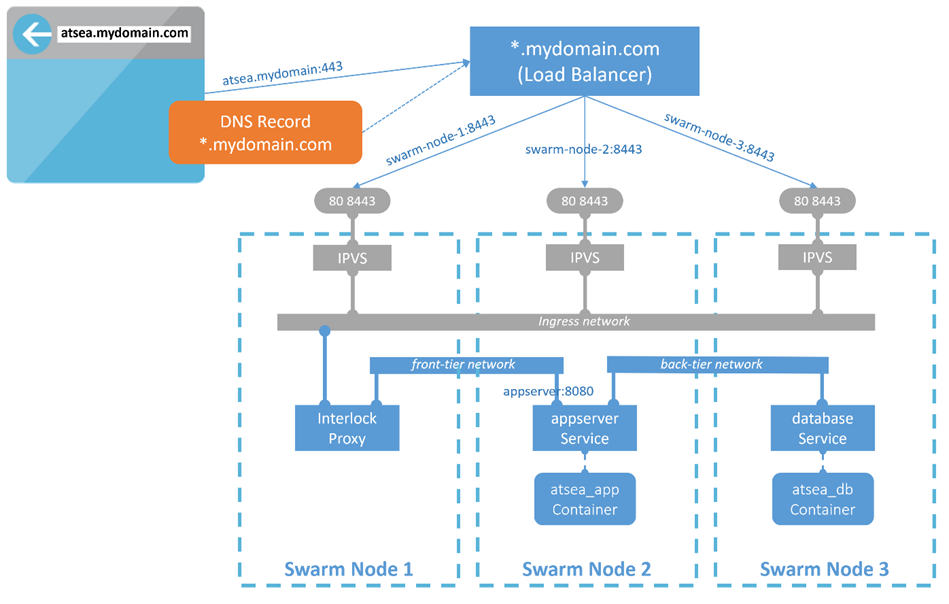
Figure 6: routage de couche 7 avec AtSea
Dans le code suivant, nous pouvons voir la version abrégée du fichier de pile mis à jour. Veuillez faire attention à la section services > serveur d’applications > déployer > étiquettes :
version: “3.7”
prestations de service:
<…>
serveur d’application:
image: dtr.mydomain.com/dev/atsea_app:local
réseaux:
– niveau supérieur
– back-tier
– Paiement
déployer:
répliques: 2
update_config:
parallélisme: 2
failure_action: restauration
restart_policy:
condition: en cas d’échec
retard: 5s
max_attempts: 3
fenêtre: 120s
Étiquettes:
com.docker.lb.hosts: at-sea.mydomain.com
com.docker.lb.network: front-tier
com.docker.lb.port: 8080
com.docker.lb.ssl_cert: wildcard.mydomain.com.server.crt
com.docker.lb.ssl_key: wildcard.mydomain.com.key
secrets:
– postgres_password
<…>
Ici, nous pouvons voir comment Docker utilise les étiquettes pour configurer à la fois le routage de couche 7 et la terminaison TLS. com.docker.lb.hosts indique à Interlock de rechercher des en-têtes avec ce nom d’hôte ( at-sea.mydomain.com ) et de les transmettre au service appserver sur com.docker.lb.port ( 8080 ) via com.docker. lb.network (front-tier) network. Interlock aime avoir com.docker.lb.network en tant que réseau externe, créé avant le lancement de la pile.
Notez à la fin du fichier YAML précédent que le réseau de premier niveau et les secrets sont déclarés externes: true . Cela signifie que le réseau de premier niveau et les secrets doivent être créés avant le déploiement de la pile, et s’ils ne sont pas l’orchestrateur, le déploiement des services échouera. Encore une fois, nous déployons ce fichier de pile à l’aide de docker stack deploy à partir de deploy_cluster.sh, où nous créons les ressources externes attendues.
Enfin, pour déployer, nous utilisons la commande de test ./deploy_cluster.sh . Ensuite, après avoir attendu environ 30 secondes pour qu’Interlock 2 configure et mette à jour le service ucp-interlock-proxy , nous devrions pouvoir tester le site à l’aide de notre navigateur, https://at-sea.mydomain.com . Bien sûr, vous devez vous assurer que votre enregistrement DNS (fichier hôte, DNS interne ou DNS public) pointe vers un équilibreur de charge externe. Il peut s’agir d’une entrée de site unique (at-sea.mydomain.com) ou d’une entrée DNS générique ( * .mydomain.com ).
Félicitations pour le déploiement manuel de votre application personnalisée avec routage de couche 7 et terminaison DNS! À ce stade, vous avez déployé une application sur un cluster Docker Enterprise Docker. Alors que nous sommes en mode pilote, notre déploiement cible un cluster Docker Enterprise hors production où les utilisateurs internes auront accès à l’application pour évaluer ses performances et sa fonction. Pour la plupart, outre l’échange de certains paramètres de configuration, nous devrions être très proches d’un déploiement en production. Par conséquent, les actifs développés doivent être réutilisables dans plusieurs environnements de déploiement en changeant simplement un script le paramètre tel que test ou prod (par exemple, ./deploy_cluster.sh prod). Dans notre exemple, nous utilisons le paramètre test, provoquant le script et composons les ressources du fichier à partir du répertoire secrets / test . Un schéma similaire pourrait également être utilisé pour le développement et la production.
1.1.7 Création et déploiement de l’application personnalisée avec un pipeline CI
Maintenant, nos activités liées aux pilotes se déplacent dans l’espace DevOps alors que nous construisons un pipeline d’intégration continue pour notre application personnalisée. Le but de cette section est de montrer comment créer un pipeline Docker pour construire et déployer notre application sur notre cluster Docker Enterprise. Armés de notre nouveau référentiel de déploiement et des actifs applicatifs que nous avons développés dans le référentiel d’applications, nous nous sommes lancés dans l’aventure du pipeline Docker CI!
1.1.7.1 Exemple de présentation du pipeline CI
Maintenant, nous allons faire en sorte que notre application ressemble davantage à une application de microservices (multiservices), où différentes personnes, voire des équipes, travaillent sur des services déployables indépendamment. Nous allons diviser notre application pilote AtSea personnalisée en référentiels de code source de services distincts.
Pour illustrer notre exemple de pipeline CI avec un niveau de détail élevé, nous allons le construire en utilisant gitlab.com . Nous n’approuvons pas nécessairement GitLab ici, mais nous l’avons choisi pour deux raisons. Premièrement, il devient un choix très populaire dans la communauté du développement. Deuxièmement, en raison de la convivialité de ses conteneurs, et enfin, parce qu’il est basé sur des pipelines en tant que code utilisant une définition YAML à la racine de chaque référentiel de services. Cette philosophie nous maintient hors de l’enfer des plugins en utilisant des coureurs basés sur des conteneurs pour exécuter nos builds et déploiements sur nos propres serveurs distants.
Nous aurions pu aller plus loin dans cet exemple en déployant notre propre serveur GitLab CE en tant que service Swarm sur notre cluster Docker Enterprise aux fins de ce chapitre. Lors de l’exécution d’un service Docker Pipeline, comme Jenkins ou GitLab, à partir d’un cluster Docker est un exercice assez simple (et bien documenté). Cela ajoute une couche de complexité inutile à ce chapitre qui peut prêter à confusion et détourner notre attention des détails importants des interactions d’un pipeline CI avec Docker Enterprise.
Nous avons choisi d’utiliser la version hébergée dans le cloud de gitlab.com (anciennement GitLab Cloud), mais nous déploierons nos propres exécuteurs GitLab sur un serveur de build basé sur Docker qui est adjacent à notre cluster EE. Le diagramme suivant présente une vue d’ensemble de notre exemple de structure de pipeline CI avec GitLab:
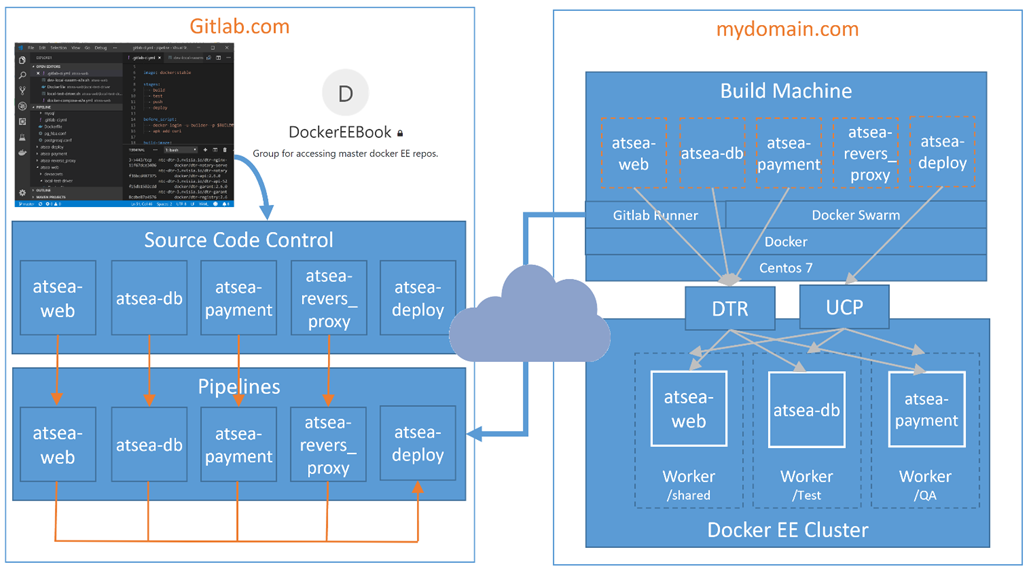
Figure 7: pipeline GitLab avec Docker Enterprise
La machine de construction exécute non seulement Docker, mais elle s’exécute également en tant que cluster Swam à nœud unique, nous pouvons donc tester notre pile d’applications avant de pousser des images fraîchement construites vers notre Docker Trusted Registry. Ce nœud de génération Swarm est distinct du Swarm exécuté dans notre cluster Docker Enterprise.
Le diagramme précédent montre le déroulement général d’un cycle de vie de développement logiciel à travers notre exemple de pipeline CI. À partir d’un niveau élevé, le développeur construit et teste leur code localement, l’archive et le pousse vers le système de contrôle de code source GitLab. GitLab recherche un fichier de définition de pipeline à la racine du dépôt ( .gitlab-ci.yml ). Une fois trouvé, GitLab exécute le pipeline. Le diagramme précédent montre comment nous avons divisé la base de code en référentiels distincts qui s’alignent avec chaque image, et chaque référentiel a un pipeline correspondant et un fichier de définition de pipeline .gitlab-ci.yml .
Le pipeline est responsable de la création et du transfert de l’image vers le Docker Trusted Registry. Les pipelines eux-mêmes planifient et surveillent l’activité de génération sur la machine de génération distante, où GitLab Runner crée des images à l’aide d’un moteur Docker local. De plus, notre configuration GitLab-Runner sur la machine de génération permet à nos conteneurs Docker de communiquer directement avec le démon Docker de l’hôte du serveur de génération. Il s’agit d’une fonctionnalité très importante pour la mise en cache et le déploiement de piles de test. Nous en reparlerons plus tard lorsque nous passerons en revue les détails de nos pipelines.
Remarquez la ligne bleue allant de la machine de construction aux pipelines, où il semble que ça va dans le mauvais sens. Cela représente la façon dont les coureurs communiquent avec les serveurs GitLab, éliminant ainsi le besoin de proxy de demandes entrantes des serveurs GitLab. Au lieu de cela, le Runner vérifie avec GitLab toutes les quelques secondes pour les mises à jour, vérifiant vraisemblablement l’état actuel et obtenant toutes les nouvelles versions. Cela fonctionne très bien car la plupart des réseaux autorisent la sortie de l’intérieur, il n’y a donc pas de configuration réseau requise pour prendre en charge la mise en œuvre de Runner. C’est vraiment sympa !
Une fois l’image créée sur le serveur de génération, elle est testée et, si elle réussit, l’image est envoyée au Docker Trusted Registry à l’aide des informations d’identification du générateur. En outre, comme illustré par les flèches orange en bas des pipelines GitLab, lorsque la génération se termine avec succès, il déclenche le pipeline pour déployer la pile de test. Dans ce cas, le pipeline de déploiement utilise le bundle client Universal Control Plane pour déployer la pile dans l’environnement de test dans le cluster Docker Enterprise à l’aide des informations d’identification du déployeur.
1.1.7.2 Connexion de GitLab à Docker Enterprise
Il existe une variété de points de contact que nous devons aligner pour que notre pipeline CI fonctionne correctement avec Docker Enterprise. Tout d’abord, le système CI doit avoir accès via un compte utilisateur au DTR, ainsi qu’aux comptes avec leurs bundles clients associés, pour accéder au plan de contrôle universel. De plus, nous devons structurer les actifs dans les référentiels DTR et les collections UCP, pour nous aligner sur notre processus CI et notre contrôle d’accès.
Tout cela semble assez facile, mais il y a beaucoup de pièces mobiles que nous allons parcourir pour transmettre les concepts, ainsi que des détails clés. Commençons par la configuration de GitLab et l’installation de GitLab Runner.
Dans la capture d’écran suivante, nous pouvons voir comment nous avons créé un groupe dans GitLab pour héberger tous nos référentiels associés (appelés projets dans GitLab) pour l’application AtSea. Bien que le mécanisme de regroupement aide à organiser les référentiels associés, il constitue un excellent endroit pour gérer les ressources partagées et stocker des informations communes à tous les projets du groupe.
Dans notre cas, c’est là que nous stockons notre configuration GitLab Runner afin qu’elle puisse être partagée entre tous les référentiels. C’est assez simple, car nous utilisons Docker pour construire tous nos référentiels en images. De plus, nous stockons des variables d’environnement communes à utiliser dans tous les référentiels. Plus précisément, nous partageons le nom d’utilisateur et le mot de passe du compte de générateur utilisés pour accéder à DTR en utilisant une variable d’environnement protégée.
Une variable d’environnement protégé gitlab ce ne peut être accessible à partir de l’intérieur d’une branche protégée (par exemple, le maître branche).
Par conséquent, il est difficile d’exposer par inadvertance une variable protégée à une personne autre qu’un propriétaire de référentiel :
Figure 8 : Projets GitLab
Les informations d’identification du générateur précédentes sont le premier point de contact vers Docker Enterprise, plus précisément le DTR. Nous utiliserons les informations d’identification du constructeur pour vous connecter à DTR, extraire nos images de base et pousser nos images d’application fraîchement construites. Bien sûr, cela nécessite un peu de planification.
1.1.7.3 Ajout d’un GitLab Runner à la machine de génération
Une fois que nous avons créé nos groupes GitLab avec notre structure de projet, nos informations d’identification de générateur DTR sont stockées au niveau du groupe GitLab (afin qu’elles puissent être partagées entre chaque pipeline de projets) en tant que variables d’environnement protégées. Nous sommes maintenant prêts à configurer notre Runner.
Le Runner est un petit morceau de code que nous allons installer sur notre machine de build pour amorcer la connexion entre notre machine de build et gitlab.com . Comme nous l’avons mentionné précédemment, notre machine de construction est un hôte Docker qui n’est pas affilié au cluster Docker Enterprise et exécute son propre cluster Swarm autonome à nœud unique.
Dans le groupe GitLab, vous pouvez accéder au paramètre pour CI/CD et développer la section Runner. Dans la section Runner, vous trouverez quelques éléments importants. Le premier est le lien vers les instructions pour installer un Runner sur votre plate-forme de machine de génération. N’oubliez pas, dans notre cas, nous voulons utiliser le service Docker Runner: https://docs.gitlab.com/Runner/install/docker.html . Les autres éléments importants sont le lien vers https://github.com/ et le jeton requis pour accéder à votre compte GitLab depuis le Runner.
Pour notre Runner, j’ai choisi d’utiliser juste un simple conteneur Docker qui est exécuté avec la commande Docker Run suivante :
docker run -d –name gitlab-Runner –restart always \
-v /srv/gitlab-Runner/config:/etc/gitlab-Runner \
-v /var/run/docker.sock:/var/run/docker.sock \
gitlab/gitlab-Runner:latest
Ce conteneur démarre simplement la petite application qui utilisera le sondage https://about.gitlab.com/ pour les travaux de génération. Jusqu’à présent, nous venons de démarrer le conteneur Runner’s Docker et il attend de faire quelque chose. Cependant, il existe certains points d’intérêt concernant la façon dont le conteneur est lancé.
Le premier paramètre notable est le montage du volume dans le répertoire hôte local srv/gitlab-Runner/config. C’est là que GitLab Runner stocke son fichier de configuration appelé config.toml . Ainsi, même si le conteneur est remplacé, la configuration de GitLab Runner sera préservée sur le système de fichiers hôte. Nous parlerons davantage du fichier de configuration de GitLab Runner peu de temps après avoir atteint la prochaine commande Docker pour enregistrer le Runner avec notre service GitLab.
Le paramètre suivant est le deuxième montage de volume de la prise Docker. Essentiellement, ce montage de volume dirige toute commande Docker qui est exécutée à l’intérieur du conteneur pour être transmise au moteur Docker de l’hôte pour exécution. Cela permet au GitLab Runner d’exécuter des commandes Docker directement contre le moteur de l’hôte de l’intérieur pour obtenir le conteneur de Runner lors de l’exécution du pipeline. Comme mentionné précédemment, cela est important à deux fins sur notre serveur de génération :
- Tout d’abord, il donne à tous les travaux de construction la possibilité de tirer parti d’un cache commun de couches d’image pour réduire les temps de construction
- Le deuxième objectif est de permettre à plusieurs conteneurs sur le même hôte de communiquer sur le réseau local du pont Docker, ou dans notre cas, d’utiliser le réseau de superposition Docker Swarm pour connecter les services Swarm
Vous verrez comment nous utilisons cela lors de nos tests de création d’image post.
Une fois le conteneur Runner chargé sur le serveur de génération, il est temps de le configurer à l’aide de la commande Docker suivante :
docker run –rm -t -i -v /srv/gitlab-Runner/config:/etc/gitlab-Runner gitlab/gitlab-Runner register \
–non-interactive \
–executor “docker” \
–docker-image docker:stable \
–url “https://gitlab.com/” \
–registration-token “XXXXXXXXXXXXXXXXXX” \
–description “docker-iscsi-Runner” \
–tag-list “docker,ntc” \
–run-untagged \
–locked=”false”
Cette commande Docker monte le répertoire de configuration de l’hôte afin qu’il puisse mettre à jour le fichier de configuration du Runner avec les paramètres qui sont passés à la commande register. Notez que nous avons l’URL et le jeton d’enregistrement de la section Runners de la page de configuration CI/CD. De plus, nous donnons au Runner un nom qui vous sera utile pour vous assurer que nos builds s’exécutent réellement sur votre Runner spécifique, au lieu d’un Runner partagé, au moment de la construction.
Après avoir enregistré le Runner, le Runner apparaîtra dans l’interface utilisateur de GitLab, comme indiqué dans la capture d’écran suivante :

Figure 9 : état de GitLab Runner
Notre Runner est presque là ! Cependant, nous utilisons Docker Enterprise et nous souhaitons peut-être une sorte d’accès par défaut à notre Docker Trusted Registry en utilisant le Runner de notre serveur de build pour pousser nos images fraîchement construites. Nous pouvons explicitement nous connecter à partir de notre CI (nous le montrerons en action plus loin dans cette section) et / ou nous pouvons ajouter une ligne spéciale dans notre fichier /srv/gitlab-Runner/config/config.toml pour donner n’importe quel travail Runner sur l’accès du serveur de génération à DTR en tant que générateur. Bien que cela soit pratique et puisse rendre les choses un peu plus fluides, vous devez également examiner les ramifications de sécurité.
Normalement, les tâches de génération ne seront exécutées qu’à partir de branches protégées dans le système CI, et les commandes Docker qu’elles peuvent émettre pour les opérations DTR sont généralement non destructives, donc ce n’est peut-être pas une idée horrible, mais procédez avec prudence.
Pour ajouter le compte de générateur en tant que connexion DTR par défaut, vous devez d’abord générer un jeton d’authentification DTR (il s’agit d’un jeton complètement différent de celui que nous avons utilisé pour accéder à GitLab). Ce jeton peut être généré en se connectant simplement au DTR à partir de la ligne de commande de votre serveur de build avec la connexion Docker dtr.mydomain.com. Ensuite, entrez votre nom d’utilisateur et votre mot de passe de générateur afin que Docker génère un jeton d’authentification dans un fichier appelé ~ / .docker / config.json . Docker utilise ensuite ce jeton d’authentification pour accéder à DTR en votre nom chaque fois que vous utilisez un actif associé à dtr.mydomain.com. Nous devons partager ce jeton d’authentification DTR avec notre fichier de configuration Runner afin qu’il puisse également accéder au DTR au nom de notre utilisateur de générateur pour envoyer des images.
Tout d’abord, nous obtiendrons le contenu de notre fichier config.json , comme indiqué dans le bloc de code suivant:
$cat .docker/config.json
{
“auths”: {
“dtr.nvisia.io”: {
“auth”: “FDfafea434r”,
“identitytoken”: “xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx”
}
},
“HttpHeaders”: {
“User-Agent”: “Docker-Client/18.09.1 (linux)”
}
Ensuite, nous devrons reformater la section auths de ce fichier à utiliser dans le fichier de configuration de GitLab Runner. Il existe plusieurs façons d’accéder au fichier de configuration Runner. Une façon consiste simplement à utiliser sudo -s pour assumer la racine sur votre serveur de build et éditer le fichier /srv/gitlab-Runner/config/config.toml . Une autre façon serait de démarrer un conteneur Docker CentOS ou Ubuntu, docker run -it -v / srv / gitlab-Runner / config: / config centos: 7 bash , puis éditez /config/config.toml à partir de ce conteneur coquille. Quelle que soit la manière dont vous choisissez de le faire, l’objectif de l’exercice est d’injecter la ligne d’ environnement = .. suivante dans le fichier de configuration Runner afin qu’elle ressemble au bloc de code suivant:
concurrent = 1
check_interval = 0
[session_server]
session_timeout = 1800
[[runners]]
name = “docker-ntc-Runner”
url = “https://gitlab.com/”
token = “xxxxxxxxxxxxxxxxx”
executor = “docker”
environment = [“DOCKER_AUTH_CONFIG={\”auths\”: {\”dtr.mydoamin.com\”:{\”auth\”:\”FDfafea434r\”,\”identitytoken\”:\”xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx\”}}}”]
[runners.docker]
tls_verify = false
image = “docker:stable”
privileged = false
disable_entrypoint_overwrite = false
oom_kill_disable = false
disable_cache = false
volumes = [“/var/run/docker.sock:/var/run/docker.sock”, “/cache”]
shm_size = 0
N’oubliez pas de remplacer vos valeurs individuelles lorsque nous fournissons “xxxx” dans le fichier de configuration précédent.
Enfin, notez le paramètre de commande tls_verify = false. Ceci n’est pas associé à la connexion DTR du Runner. Il s’agit plutôt de la connexion TLS du Runner à votre serveur GitLab. Si vous hébergez votre propre serveur avec des certificats auto-signés, assurez-vous que vous avez défini la valeur false. Sinon, le Runner peut obtenir des erreurs d’approbation de certificat X.509.
Maintenant, votre Runner devrait être prêt à partir! Maintenant que nous avons un Runner prêt à exécuter des pipelines à distance sur notre serveur de génération pour créer des images Docker, nous devons penser à structurer notre DTR cible.
1.1.7.4 Intégration DTR CI
Nous devrons configurer les espaces de noms, les utilisateurs, les équipes et les référentiels d’organisation de DTR pour prendre en charge notre processus de pipeline. Nos espaces de noms d’images doivent avoir des noms logiques qui circulent avec les étapes du pipeline (c’est-à-dire, dev, test, qa) et ces référentiels ne doivent être accessibles qu’aux utilisateurs prévus et autorisés. N’oubliez pas que les espaces de noms DTR (par exemple, dtr.mydomain.com/ namespace / myrepo: tag1 ) utilisent des noms d’utilisateur ou des noms d’organisation. Nous souhaitons, bien sûr, utiliser les noms d’organisations sur les noms d’utilisateurs et nous assurer que les noms d’organisations reflètent les équipes qui les utilisent.
Dans notre cas, il existe trois organisations au sein de notre Docker Trusted Registry. Tout d’abord, nous avons l’organisation pilote que nous avons utilisée pour déployer notre application wiki. Deuxièmement, nous avons l’organisation de développement où des images fraîchement construites arrivent de notre système CI ou de développeurs collaborant les uns avec les autres. Veuillez noter que les développeurs peuvent toujours utiliser leur espace de noms personnel pour stocker des images expérimentales pour les tests, puis déployer sur le cluster dans leur sandbox privé. Cependant, si les développeurs partagent des images, il est généralement plus facile d’utiliser l’espace de noms du référentiel de l’organisation de développement. La seule chose que nous voulons faire attention est de réserver potentiellement certaines normes pour les balises d’image. Par exemple, la réservation d’une balise commençant par RC- en tant que candidat à la version peut être automatiquement promue dans les référentiels de l’organisation de test. En règle générale, seul le compte de générateur aura accès aux référentiels de développement spéciaux. Dans notre cas, ces référentiels se terminent par _build , comme suit:
- dtr.mydomain.com/dev/atsea-db_build
- dtr.mydomain.com/dev/atsea-payment_build
- dtr.mydomain.com/dev/atsea-reverse_proxy_build
- dtr.mydomain.com/dev/atsea-web_build
L’organisation finale de cet exemple est test. Docker Trusted Registry a la possibilité de promouvoir des images d’un référentiel à un autre en fonction de critères définis par l’utilisateur. Nous voulons utiliser des stratégies DTR pour promouvoir les images de nos référentiels de développement dans nos référentiels homologues de l’organisation de test qui reflètent celles de l’organisation de développement, comme suit :
- dtr.mydomain.com/test/atsea-db_build
- dtr.mydomain.com/test/atsea-payment_build
- dtr.mydomain.com/test/atsea-reverse_proxy_build
- dtr.mydomain.com/test/atsea-web_build
Pour promouvoir ces images du développeur au test, nous utilisons une fonctionnalité du DTR appelée une politique de promotion. La politique de promotion est une tâche événementielle, où vous déterminez ce qui déclenche la promotion et les critères qui doivent être remplis. De plus, vous définissez le référentiel cible, ainsi que toutes les modifications apportées à la balise, car les images sont promues d’un référentiel au suivant.
Dans la capture d’écran suivante, nous pouvons voir l’interface Web DTR pour configurer une stratégie de promotion de référentiel :
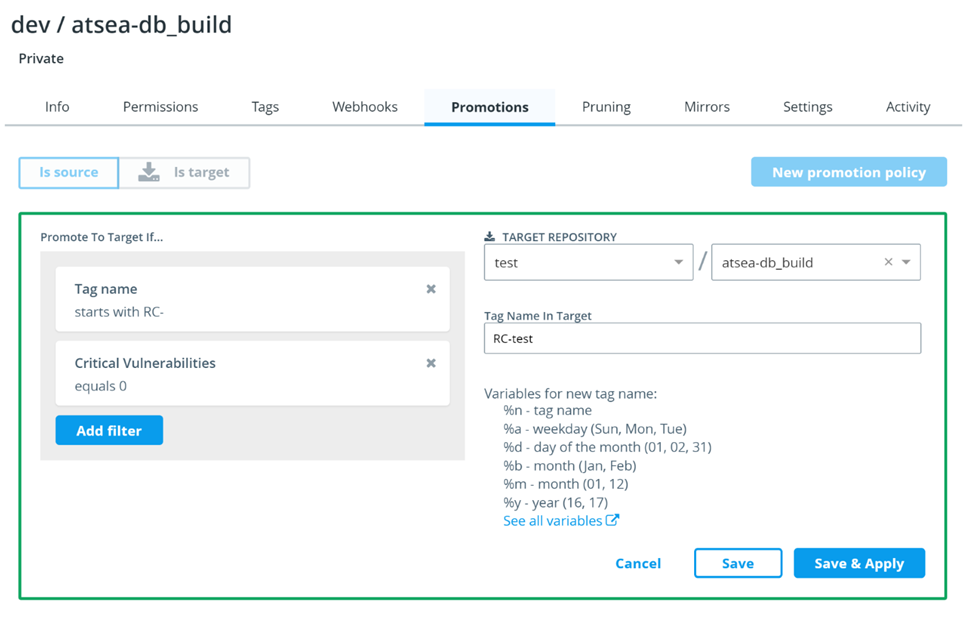
Figure 10 : Promotion d’image de registre de confiance Docker
Ici, nous regardons une image sans vulnérabilités critiques (cette politique ne se déclenchera pas tant que l’analyse d’image n’est pas terminée) et une balise commençant par RC-. Si une image correspond aux deux critères, elle sera ensuite promue dans le référentiel test / atsea-db_build avec un nom de balise RC-test. Veuillez noter les autres options d’utilisation des variables dans les noms de balises qui incluent le nom de balise d’origine, ainsi que d’autres variables connexes.
Avec nos référentiels en place, nous devons être sûrs que notre compte de générateur dispose des droits d’accès appropriés pour envoyer des images aux référentiels cibles au sein de l’organisation de développement. Une façon très simple de le faire est de donner au propriétaire de l’organisation du constructeur des privilèges au sein de l’organisation de développement, comme indiqué dans la capture d’écran suivante :

Figure 11 : Générateur en tant que propriétaire d’une organisation DTR
Avec ce travail de configuration à l’écart, nous pouvons maintenant voire comment notre application a été divisée en plusieurs référentiels de services et comment ces référentiels sont transformés en pipelines de construction.
1.1.7.5 Construire nos services
Lorsque nous nous sommes arrêtés de notre section de déploiement de cluster plus tôt dans ce chapitre, nous avons utilisé un script simple pour créer nos ressources externes et déployer la pile AtSea sur notre cluster Docker Enterprise. Nous avons accompli cela avec deux référentiels : un référentiel pour les artefacts d’application et un autre pour nos artefacts de déploiement initial.
Dans cette section, nous allons diviser les artefacts d’application en référentiels distincts pour chaque service déployable afin de pouvoir les créer indépendamment dans notre pipeline CI. Cette structure est généralement une exigence pour les grandes équipes de développement où plusieurs flux de travail doivent être pris en charge avec un minimum d’interférences entre les membres de l’équipe.
En conséquence, nous avons décomposé l’application dans les référentiels suivants :
├── atsea-db
├── atsea-deploy
├── atsea-payment
├── atsea-reverse_proxy
└── atsea-web
La pile d’applications AtSea sera composée de trois services principaux : le service Web, le service de paiement et le service db. N’oubliez pas que nous n’avons pas besoin du serveur reverse_proxy dans notre déploiement final car nous utilisons Docker Enterprise pour le routage proxy inverse de couche 7 et la terminaison du certificat TLS. Par conséquent, nous concentrerons cette section sur la création de la base de données, des paiements et des services Web . Ensuite, nous reviendrons sur le référentiel atsea-deploy, où nous reconfigurerons nos scripts pour qu’ils s’exécutent à partir d’un travail déclenché, et déploierons notre pile sur le cluster de test Docker Enterprise.
Nous allons commencer avec deux tâches de construction plus simples (atsea-db et atsea-payment), puis passer à un exemple plus complexe de construction en plusieurs étapes pour l’application atsea-web.
1.1.7.5.1 Construction simple et pipeline push pour l’image atsea-db
Tout d’abord, nous allons examiner le contenu de notre référentiel de services atsea-db . Pour la plupart, le référentiel contient le contenu du sous-répertoire de la base de données de l’ancien référentiel atsea-app. Il y a, bien sûr, un nouvel ajout essentiel : le fichier .gitlab-ci.yml :
atsea-db
├── docker-entrypoint-initdb.d
│ └── init-db.sql
├── Dockerfile
├── pg_hba.conf
├── .gitlab-ci.yml
└── postgresql.conf
Il existe une convention spéciale dans le système de contrôle de code source GitLab liée au fichier de pipeline CI. Lorsque le code est archivé dans le référentiel avec un fichier .gitlab-ci.yml à la racine du référentiel, un pipeline est créé en fonction du contenu de ce fichier.
Bien sûr, il y a beaucoup à dire sur les systèmes de pipelines CI et GitLab, mais c’est un sujet pour un autre article. Notre objectif pour cette section est de vous aider à comprendre l’interaction entre un système de pipeline CI et Docker Enterprise dans le contexte d’un cycle de développement logiciel. Nous pensons qu’un exemple est généralement le meilleur moyen de transmettre des concepts avec suffisamment de détails.
Commençons par regarder le fichier de définition de pipeline CI simple avec une brève explication de ce qui se passe avec notre pipeline db.
La première ligne du fichier est simplement un commentaire pour que les lecteurs associent le contenu du fichier qui a été montré avec la discussion sur la structure du référentiel précédemment. La section des variables est l’endroit où vous définissez les variables d’environnement dans le cadre de votre pipeline. À des fins de test, ces variables de pipeline peuvent être remplacées lorsque le pipeline est exécuté manuellement. Dans notre cas, nous utilisons une variable pour stocker le nom de domaine complet de notre serveur DTR. Cette variable est utilisée plus tard dans le fichier lorsque nous nous connectons à DTR et lorsque nous marquons et poussons nos images pendant le processus de poussée. Vous pouvez voir comment le DTR_SERVER est substitué dans la section before_script du pipeline en tant que paramètre de la commande de connexion Docker et le $ DTR_SERVER est référencé.
image: docker: stable spécifie quelle image le Runner utilisera pour exécuter les commandes de script suivantes. L’image docker: stable est une image Docker officielle (tirée de hub.docker.com/_/docker ) qui a été créée dans le but d’exécuter des commandes Docker à partir d’un conteneur. N’oubliez pas, puisque notre Runner monte le socket Docker de l’hôte (approche Docker-on-Docker), vos commandes Docker sont en fait transmises au moteur Docker de l’hôte pour une exécution sûre.
Notez que ceci est différent de l’approche Docker-in-Docker (Docker-in-Docker — DinD), où vous exécutez votre conteneur en mode privilégié pour accéder pleinement à toutes les ressources de l’hôte. Cela semble génial, mais il existe de nombreux problèmes, y compris et le plus souvent, la corruption du système de données / fichiers. Nous vous recommandons fortement de vous en tenir à Docker-on-Docker:
# atsea-db .gitlab-ci.yml
variables:
DTR_SERVER: dtr.mydomain.com
image: docker:stable
before_script:
– docker login -u builder -p $BUILDER_PW $DTR_SERVER
stages:
– build
– push
– deploy
build-image:
stage: build
script:
– docker image build -t $DTR_SERVER/dev/”$CI_PROJECT_NAME”_build:$CI_COMMIT_REF_NAME .
push-branch:
stage: push
script:
– docker push $DTR_SERVER/dev/”$CI_PROJECT_NAME”_build:$CI_COMMIT_REF_NAME
push-master:
stage: push
script:
– docker image tag $DTR_SERVER/dev/”$CI_PROJECT_NAME”_build:$CI_COMMIT_REF_NAME $DTR_SERVER/dev/”$CI_PROJECT_NAME”_build:RC-DEV
– docker image push $DTR_SERVER/dev/”$CI_PROJECT_NAME”_build:RC-DEV
– docker image rm $DTR_SERVER/dev/”$CI_PROJECT_NAME”_build:RC-DEV
only:
– master
deploy-to-test:
stage: deploy
before_script:
– apk add curl
script:
– echo “wait for image promotion…”
– sleep 10
– curl -X POST -F token=xxxxxxxxxxxxxxxxxxxx-F “ref=master” -F “variables[DEPLOY_TARGET]=test” https://gitlab.com/api/v4/projects/xxxxxxxxxxxxx/trigger/pipeline
Ensuite, nous avons la section before_script du pipeline . Ici, nous fournissons un ensemble de commandes par défaut qui seront exécutées avant le début de chacune des étapes du pipeline. Notez, cependant, que si un script before_script est défini pour une étape spécifique, il remplacera le script before_script global (le script en haut du fichier). Dans notre cas, cela fonctionne très bien, car dans notre dernière étape de déploiement, nous n’avons pas besoin de nous connecter à DTR, mais nous avons besoin d’une commande curl installée pour déclencher le déclencheur de déploiement. Nous reviendrons à l’étape de déploiement dans une minute.
Les pipelines sont appelés pipelines pour une bonne raison. Ils définissent une séquence d’étapes de pipeline dans laquelle chacune de ces étapes peut avoir plusieurs travaux exécutés en parallèle pour des temps de cycle améliorés. Dans notre cas, comme le montre la capture d’ écran ci – dessous, vous pouvez voir couler notre pipeline avec les Construire , pousser , et déployer des étapes qui sont désignés dans les précédentes étapes: . À l’intérieur de chaque étape, vous disposez des quatre tâches de notre fichier pipeline: build-image , push-branch , push-master et deploy-to-test . Veuillez noter le flux parallèle pendant l’étape Push de la génération, où nous avons les images poussées du travail push-master et push-branch vers le DTR:
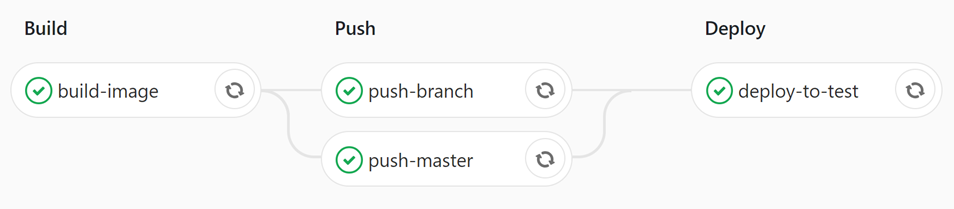
Figure 12 : Flux du pipeline GitLab
Après la section des étapes du fichier gitlab-ci.yml , nous avons défini nos travaux. Chacun de ces travaux possède des balises d’étape pour associer le travail à une étape de pipeline et une section de script où nous répertorions les commandes à exécuter dans le travail. Notez également que nous utilisons des variables d’environnement CI_ * intégrées dans lesquelles le système CI fournit un CI_PROJECT_NAME pour le nom du projet et CI_COMMIT_REF_NAME pour le nom de la branche. Étant donné que nous créons un fichier de pipeline distinct pour chaque référentiel, la variable de nom de projet n’est pas complètement nécessaire. Cependant, nous l’incluons pour illustrer l’utilisation des variables et comme étape vers la création de modèles de génération à l’échelle du groupe.
Le seul actif de projet consommé directement par ce script de génération est le Dockerfile utilisé pour créer l’ image atsea-db_build . Dans notre travail de création d’image, vous pouvez voir comment nous exécutons une génération d’ image docker pour générer un nom de balise prêt DTR et utiliser le contexte local dans le dossier atsea-db pour créer l’image. Dans le contexte local, nous trouvons le atsea-db / Dockerfile , où l’image est construite comme avant.
Une fois l’ image atsea-db_build générée , la branche push envoie une copie de l’image à l’organisation / dev du DTR. Le travail push-master ne s’exécute que si la branche en cours de construction est la branche maître, désignée par la balise only: à la fin de la définition du travail push-master.
Le push principal repère l’image de la branche avec une balise : RC-DEV , et pousse l’image vers le registre de confiance et nettoie l’image principale avant qu’elle ne se termine. Enfin, le travail de déploiement à tester installe le package curl dans le conteneur Docker, puis attend un certain temps pour que l’image de développement soit promue dans le référentiel de l’organisation de test pour le déploiement. Plutôt que d’attendre une période de temps spécifiée (sommeil 10) pour que la politique de promotion se déclenche dans DTR, vous pouvez également utiliser un hook Web piloté par les événements du DTR vers un point de terminaison de déclenchement GitLab, mais cela nécessite un peu de travail supplémentaire.
La connexion d’un hook Web à partir du référentiel test / atsea-db_build du DTR pour lancer le travail de déploiement après la promotion de l’image dans le référentiel de test est possible, mais malheureusement, vous ne pouvez pas lier DTR directement au GitLab pour le moment. Cette intégration nécessite un redirecteur / filtre de hook Web intermédiaire entre le hook Web DTR et le point de terminaison du déclencheur GitLab . Le redirecteur / filtre doit supprimer la charge utile JSON du DTR avant de publier sur le point de terminaison de déclenchement de GitLab pour éliminer l’erreur d’analyse JSON qui se produirait autrement.
Pour notre exemple de déclencheur de pipeline, nous pilotons donc la génération et le déploiement à partir de chacun des fichiers de pipeline de génération du service, comme indiqué à l’étape de déploiement précédente. Lorsque vous avez terminé, vous devriez voir de nouvelles images dans le DTR. Comme nous étions en train de construire sur le maître branche, nous avons deux images référentielles un pour le maître branche, puis l’autre pour le candidat de libération avec le RC_DEV tag. N’oubliez pas que l’image de la version candidate sera promue dans le référentiel de l’organisation test / atsea-db_build, puis déployée dans la collection de clusters / tests Docker Enterprise à partir de là:
Figure 13
Maintenant que nous avons mis en place un modèle de construction et de transmission de base, voyons si nous pouvons prendre notre fichier de pipeline et le réutiliser pour le service de paiement.
1.1.7.5.2 Construction simple et pipeline push pour l’image atsea-payment
Le fichier pipeline de l’image de paiement est identique au fichier pipeline de l’image db. Cependant, la commande docker build du pipeline récupère le fichier atsea-payment / Dockerfile de son contexte pour créer l’image de paiement :
atsea-payment
├── Dockerfile
├── .gitlab-ci.yml
└── process.sh
Par conséquent, l’utilisation d’un Dockerfile à la racine du référentiel et des variables $ CI_ pour les noms de projet et de branche donne les résultats qui sont affichés dans la capture d’écran suivante. Cela fonctionne, et vous pouvez voir comment ce pipeline de style de construction et de poussée simple peut être réutilisé :
Lorsque le pipeline est terminé et que l’image ci-dessous montre que l’image a été poussée vers le référentiel cible dans le DTR :

D’accord, ce sont de simples exemples où le pipeline CI récupère le dernier code, exécute une construction de docker et envoie l’image résultante à votre DTR. Maintenant, il est temps pour nous de passer à un pipeline plus complexe, ce que nous allons démontrer avec le référentiel de service d’application Web.
1.1.7.5.3 Génération, test de bout en bout et pipeline push pour l’image atsea-web
Maintenant, il est temps de construire à partir du dernier pipeline CI et de passer au niveau suivant. Pour notre application web, nous élevons la barre. Nous voulons : 1) créer l’image, 2) exécuter une pile d’applications de test à l’aide de la nouvelle image, et 3) connecter un pilote de test e2e à la pile d’applications Web et valider l’application. Si le test réussit, nous allons pousser l’image vers DTR. Sinon, nous échouerons la construction. Maintenant c’est cool !
Commençons par regarder le fichier de pipeline suivant, où tout a la même apparence qu’auparavant, jusqu’à ce que nous arrivions à la tâche deploy-test-on-swarm. La première ligne du script deploy-test- on-swarm contient la commande docker stack deploy que nous avons utilisée pour notre déploiement manuel plus haut dans ce chapitre, mais il y a quelques ajouts importants dans le fichier abrégé :
# atsea-web .gitlab-ci.yml
<…>
deploy-test-on-swarm:
stage: test
script:
– docker stack deploy –with-registry-auth -c docker-compose-e2e.yml atsea-web-${CI_PIPELINE_ID}
– sleep 30
– docker container run –network atsea-web-${CI_PIPELINE_ID}_front-tier –name local-test-driver-container-${CI_PIPELINE_ID} local-test-driver:${CI_PIPELINE_ID}
after_script:
– docker stack rm atsea-web-${CI_PIPELINE_ID}
– docker container rm -f local-test-driver-container-${CI_PIPELINE_ID}
– docker image rm local-test-driver:${CI_PIPELINE_ID}
<…>
Après avoir dormi pendant 30 secondes pour que la pile se déploie sur le serveur de génération, nous exécutons un conteneur de test à l’aide de l’image du pilote de test que nous avons créée à l’étape de génération. Lorsque nous exécutons le conteneur de test, nous le connectons au réseau de premier niveau de notre application. Le pilote de test exécuté dans notre conteneur de test est vraiment simple. Nous examinerons le code dans un instant, mais il utilise simplement curl pour se connecter à l’appservice sur le port 8080 et recherche une chaîne spécifique dans les résultats. Encore une fois, nous pourrions passer un chapitre ou deux sur les tests e2e, mais au moins ici, nous fournissons la plomberie pour implémenter quelque chose de plus sophistiqué comme une application de test Selenium Chrome.
Une fois le test terminé, nous nettoyons le conteneur de test et supprimons la pile d’applications de test du cluster Swarm local du serveur de génération.
Pour que notre déploiement de pile Docker utilise l’image correcte pour notre serveur d’applications en cours de test, nous avons créé une version spéciale de notre fichier YAML de composition de docker pour la pile de test. Le fichier YAML de pile de test suivant utilise la variable $ CI_COMMIT_REF_NAME pour référencer l’image de test actuelle pour le déploiement en fonction de la branche. Pour la pile de test et le conteneur de pilote de test, nous avons utilisé CI_PIPELINE_ID pour éviter tout conflit possible sur le serveur de génération.
Pour toutes les autres images, nous utilisons le dernier candidat publié par l’organisation de développement (RC-DEV), des images balisées, par exemple, dtr.mydomain.com/dev/atsea-db_build:RC-DEV . En regardant plus loin dans le dossier, nous remarquons quelque chose de spécial au sujet du réseau frontalier. Nous avons inclus le paramètre égal égal à vrai au réseau de premier niveau. Cela permet à notre conteneur de pilotes de test de se connecter au réseau interne de premier niveau de la pile. Sinon, seuls les autres services de cette pile seraient autorisés à se connecter au réseau.
Enfin, à la fin du fichier, notez que nous avons des secrets de notre pile injectés dans les secrets de portée interne de notre pile (aucun externe: vrai ) à partir de fichiers dans notre système de contrôle de code source. Nous parlerons de plus d’options concernant la pile des ressources à portée interne et l’initialisation des mots de passe lorsque nous aborderons le référentiel atsea-deploy :
# docker-compose-e2e.yml
version: “3.7”
services:
database:
image: $DTR_SERVER/dev/atsea-db_build:RC-DEV
user: postgres
environment:
POSTGRES_USER: gordonuser
POSTGRES_PASSWORD_FILE: /run/secrets/postgres_password
POSTGRES_DB: atsea
ports:
– “5432:5432”
networks:
– back-tier
secrets:
– postgres_password
appserver:
image: $DTR_SERVER/dev/atsea-web_build:$CI_COMMIT_REF_NAME
user: gordon
ports:
– “8080:8080”
networks:
– front-tier
– back-tier
secrets:
– postgres_password
payment_gateway:
image: $DTR_SERVER/dev/atsea-payment_build:RC-DEV
networks:
– payment
secrets:
– payment_token
networks:
front-tier:
driver: overlay
attachable: true
back-tier:
payment:
secrets:
postgres_password:
file: ./devsecrets/postgres_password
payment_token:
file: ./devsecrets/payment_token
Enfin, examinons comment nous avons assemblé notre conteneur de pilotes de test de bout en bout. Tout d’abord, nous avons créé un conteneur très simple qui est capable d’exécuter une commande curl. Voici le Dockerfile utilisé pour construire le pilote de test. Nous commençons avec une Alpine (très petite image), installons l’utilitaire curl et copions le fichier local-test-driver.sh dans l’image, la rendons exécutable et configurons le local-test-driver.sh pour démarrer en tant que PID 1 :
#atsea-web/local-test-driver/Dockerfile
FROM alpine:3.7
RUN apk add curl
COPY ./local-test-driver.sh .
RUN chmod +x local-test-driver.sh
CMD ./local-test-driver.sh
Maintenant, nous allons regarder le fichier de script qui a été exécuté par le Dockerfile CMD. Ensuite, nous courbons le port 8080 du service de serveur d’applications. Le nom du service, appserver, se résout car le conteneur de pilote de test est attaché à un niveau supérieur commun avec le service appserver. La réponse du serveur d’applications est analysée pour la chaîne Atsea Shop. Si la chaîne est trouvée, le conteneur se termine avec succès avec un code d’erreur 0 et la construction se poursuit. Si la chaîne n’est pas trouvée, le conteneur se ferme avec un 1 (code d’erreur différent de zéro) et échoue à la génération :
#!/bin/sh
[ $(curl –silent http://appserver:8080/index.html | grep -c “Atsea Shop”) == “1” ] || exit 1
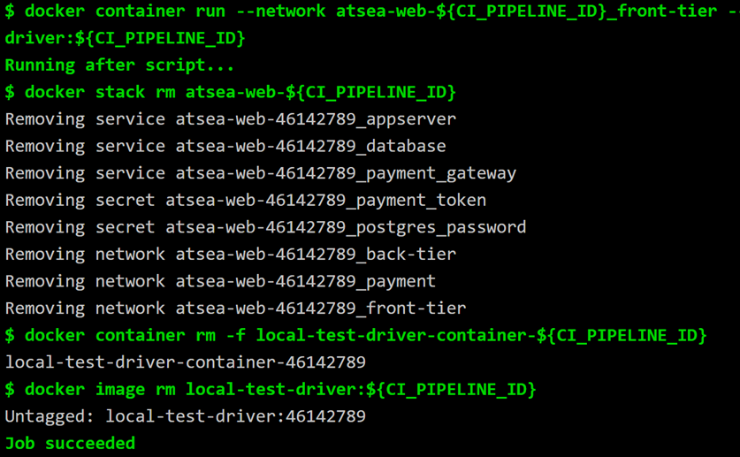
Figure 15: Gauche – Le test échoue, Droite – Le test réussit
Dans la capture d’écran précédente à gauche, nous pouvons voir où le test de conteneur échoue et, par la suite, le travail et le pipeline échouent comme prévu. Étant donné que l’étape de test a échoué, la transmission n’a jamais lieu et l’image défectueuse n’est jamais transmise au DTR.
1.1.7.6 Déploiement de pipeline vers Docker Enterprise
Enfin, nous arrivons au déploiement de CI et à la tâche finale de construction de notre pipeline pour notre application pilote personnalisée. Pour cela, nous visitons le référentiel atsea-deploy . Nous commençons par construire à partir des scripts que nous utilisons pour le déploiement manuel et ajouter un fichier de configuration de pipeline, tout comme les pipelines de service. Voici les artefacts clés de notre référentiel de déploiement :
atsea-deploy
├── .gitlab-ci.yml
├── deploy_cluster.sh
├── docker-stack-cluster.yml
├── get_bundle.sh
└── secrets
├── dev
│ ├── domain.crt
│ ├── domain.key
│ ├── payment_token
│ └── postgres_password
├── prod
│ ├── payment_token
│ └── postgres_password
└── test
├── domain.crt
├── domain.key
├── payment_token
├── postgres_password
├── wildcard.nvisia.io.key
└── wildcard.nvisia.io.server.crt
Au début du chapitre du pipeline de la figure 7, nous avons utilisé des flèches pour montrer que lorsque le code source est poussé, il déclenche une génération de pipeline pour chaque référentiel de services. La génération du référentiel de services a créé de nouvelles images à partir du code source mis à jour, les a poussés vers le DTR, puis a déclenché le travail de déploiement de l’application à l’aide d’un travail de déploiement à partir du référentiel atsea-deploy.
Nous utilisons le référentiel de déploiement comme un endroit central pour déployer notre application, que ce soit pour développer, tester, produire. Nous aurions pu dupliquer cette logique de déploiement à la fin de chacune des versions, mais cela serait devenu assez compliqué et difficile à gérer. En outre, comme indiqué dans la dernière section, nous devons pouvoir déclencher un déploiement à partir d’une variété d’événements, y compris des événements en dehors de notre système CI. Jusqu’à présent, le seul événement que nous avons vu est le déclencheur de déploiement qui est déclenché à la fin d’une génération à partir de chacun des référentiels de services. Cependant, nous voulons nous positionner de sorte que le déploiement puisse être déclenché à partir d’un script distant, ou à partir du DTR lorsqu’une image est promue ou numérisée avec succès.
Avec une approche descendante, nous décrivons notre exemple de déploiement d’application automatisé, en commençant par la façon dont le déclencheur externe pénètre dans le pipeline de déploiement, et nous nous retrouvons avec une pile d’applications exécutée dans une collection Docker Enterprise / test. Nous commençons notre parcours de déploiement avec le fichier.tsgitlab-ci.yml des référentiels atsea-deploy qui est présenté dans les sections suivantes.
1.1.7.6.1 Fichier de pipeline de déploiement
Nous utilisons notre Docker Runner avec l’image docker: stable . Cette image est basée sur une image de base d’Alpine 3.8 et fonctionne généralement très bien. Vous remarquerez peut-être que nous installons plusieurs packages supplémentaires pour le conteneur Alpine du pipeline pendant le script before_script. Celles-ci sont nécessaires pour prendre en charge les commandes de notre script de travail de déploiement de pile. Prenons une marche détaillée à travers le fichier :
# atsea-deploy .gitlab-ci.yml
image: docker:stable
stages:
– deploy
before_script:
– apk add unzip
– apk add curl
– apk add jq
– apk add bash
deploy-stack:
stage: deploy
script:
– bash
– chmod +x ./get_bundle.sh
– chmod +x ./deploy_cluster.sh
– ./get_bundle.sh
– chmod +x ./env.sh
– echo $DEPLOY_TARGET
– ./deploy_cluster.sh $DEPLOY_TARGET
only:
– trigger
Encore une fois, image: doctor: stable indique au Runner d’exécuter les commandes de script à l’intérieur de l’image Alpine 3.8 officielle de Docker avec les binaires Docker installés. N’oubliez pas que lorsque nous avons enregistré Docker Runner, nous avons spécifié un volume (-v /var/run/docker.sock:/var/run/docker.sock) pour monter la socket Docker hôte du serveur de génération. Initialement, cela signifie que les commandes Docker exécutées à partir de notre conteneur de pipeline seront transmises au démon Docker du serveur de génération pour exécution. Veuillez noter que plus tard, dans le script deploy_cluster.sh, nous allons remplacer la connexion socket en achetant notre shell Bash pour utiliser le démon Docker distant sur l’un des hôtes UCP de notre cluster Docker Enterprise. Une fois la connexion du démon distant établie, toutes nos commandes Docker s’exécutent sur le cluster! Nous en parlerons davantage lorsque nous aborderons la discussion sur le script deploy_cluster.sh.
Ce pipeline de déploiement a un travail ( deploy-stack ) et une étape ( deploy ). Par conséquent, la section de l’étape, qui aurait pu être omise car il n’y a qu’une seule étape, répertorie simplement l’étape de déploiement.
Dans la tâche deploy-stack: nous sautons directement dans la section des scripts. Tout d’abord, nous exécutons un shell Bash afin que le reste de nos commandes aient accès aux capacités de Bash, nous permettant d’accéder à la commande source avec notre bundle client. Gardez à l’esprit que nous avons installé le paquet Bash Alpine en utilisant le script before_script précédent. Ensuite, nous voulons nous assurer que ces deux scripts sont exécutables à partir de notre conteneur de pipeline. Utilisez la commande chmod + x pour ce faire. Ensuite, nous exécutons le fichier de script get_bundle.sh. Il s’agit d’une fonctionnalité importante de Docker Enterprise, où UCP fournit un ensemble client pour l’accès au cluster RBAC appliqué à distance.
Le script get_bundle.sh suivant crée un jeton d’autorisation pour se connecter aux gestionnaires Docker Enterprise UCP distants. AUTH_TOKEN est généré en frappant l’API UCP de notre Docker Enterprise avec les paramètres de nom d’utilisateur et de mot de passe du compte UCP (nous transmettons notre compte déployeur à partir d’une variable d’environnement protégée GitLab) dans l’en-tête. Cela, bien sûr, nécessite un compte d’utilisateur préexistant pour que notre déployeur soit créé dans le système d’autorisation UCP. De plus, les informations d’identification du déployeur doivent avoir été stockées en toute sécurité à l’intérieur d’une variable d’environnement protégée GitLab. Dans notre cas, nous avons stocké les informations d’identification du nom d’utilisateur et du mot de passe du déployeur dans une variable protégée au niveau du projet atsea-deploy, plutôt qu’au niveau du groupe, comme nous l’avons fait avec les informations d’identification du compte de générateur. Nous l’avons fait parce que les informations d’identification du déployeur ne sont requises que depuis le pipeline du projet atsea-deploy . Enfin, les résultats de la boucle, où nous transmettons AUTH_TOKEN dans la section des données de la publication du bundle client, est un fichier bundle.zip :
#!/bin/bash
export AUTH_TOKEN=$(curl -sk -d ‘{“username”:”‘${DEPLOYER_USER}'”,”password”:”‘${DEPLOYER_PW}'”}’ https://ucp.nvisia.io/auth/login | jq -r .auth_token 2>/dev/null)
echo “Authtoken: ${AUTH_TOKEN}”
curl -sk -H “Authorization: Bearer ${AUTH_TOKEN}” https://ucp.nvisia.io/api/clientbundle -o bundle.zip
ls -la
unzip bundle.zip
Le fichier bundle.zip contient deux types d’actifs : les certificats utilisateur et les scripts. Les certificats utilisateur sont utilisés pour créer une connexion à distance sécurisée et authentifier un utilisateur spécifique avec le contrôle d’accès basé sur le rôle ( RBAC ) d’UCP . Le bundle fournit également des scripts Linux et Windows pour connecter un shell local au cluster distant. Plus tard, dans notre script deploy_cluster.sh, nous utiliserons le script env.sh pour configurer un shell distant sécurisé depuis notre shell de pipeline (sur le serveur de génération) vers le cluster Docker Enterprise distant.
Enfin, nous listons le contenu d’un répertoire pour vérifier la taille et le contenu du fichier bundle.zip, puis nous décompressons bundle.zip. Plus tard, nous utiliserons le contenu du bundle pour se connecter dans le script deploy_cluster.
Lorsque nous revenons du script get_bundle.sh, nous voulons nous assurer que le fichier de script env.sh est disponible pour exécution en utilisant la commande chmod + x, car nous allons utiliser le script deploy-cluster. Maintenant, nous sommes prêts à déployer.
En tant que fonctionnalité de débogage et point de discussion, nous allons maintenant examiner la commande de script echo $ DEPLOY_TARGET. Cette variable est définie par l’appelant du déclencheur distant.
Notre déclencheur de pipeline a été configuré au niveau du projet atsea-deploy dans CI / CD Setting> Pipeline triggers. Lorsque vous consultez la liste .gitlab-ci.yml précédente , notez au bas de la spécification de tâche de déploiement de pile qu’il existe une contrainte only : . Nous avons spécifié que ce travail n’est exécuté que lorsqu’il est lancé par un déclencheur. Cela signifie que pour tester ce travail, nous devons utiliser une commande curl pour déclencher le pipeline et exécuter le travail.
Si vous vous souvenez, à la fin des pipelines de build de notre service, nous avons utilisé une commande curl pour déclencher nos builds. L’un des paramètres du déclencheur était la variable DEPLOY_TARGET -F “variables [DEPLOY_TARGET] = test” et, dans notre cas, nous avons défini le paramètre sur test parce que nous voulions déclencher un travail de déploiement de test. Le déploiement de test prend les images candidates de la version actuelle (test RC) de nos référentiels d’organisation de test DTR et les déploie dans une pile vers le cluster de test Docker Enterprise. Pour mieux comprendre comment cela fonctionne, nous pouvons jeter un œil au fichier de script deploy_cluster.sh suivant qui est répertorié.
À l’intérieur de notre fichier deploy_cluster.sh se trouve un commentaire important sur les secrets. Ici, vous pouvez utiliser une variété de mécanismes pour récupérer des secrets dans un magasin sécurisé distant pour remplir un fichier temporaire ou les injecter directement dans le cluster en tant que secrets externes. Dans la section suivante, nous examinerons le fichier docker-stack-cluster.yml pour voir exactement comment les secrets sont remplis au moment du déploiement.
Ensuite, nous vérifions si un paramètre a été transmis. Encore une fois, vous pourriez / devriez être plus approfondi avec la validation réelle du paramètre. Ensuite, nous nous approvisionnons en bundle client UCP pour connecter notre shell local au cluster Docker Enterprise. Si les paramètres sont trouvés, nous créons les variables d’environnement STACK et STACK_ENV. Ces variables sont référencées à l’intérieur du fichier de déploiement de la pile docker-stack-cluster.yml.
IFS = définit le spécificateur de champ interne pour le shell sur la valeur par défaut <espace><tab> <newline>. S’il n’est pas défini de cette façon, la sortie d’env.sh ne sera pas traitée correctement en tant que sous-commande $ () car la sortie de la commande env.sh n’a pas de sauts de ligne et échoue. eval $ (<env.sh exécute le script env.sh à partir du fichier bundle.zip du client UCP et pointe le client shell vers le cluster distant UCP. Par conséquent, toutes les commandes Docker suivantes sont exécutées sur le cluster UCP distant en tant qu’utilisateur UCP associé avec les bundles, dans notre cas, l’utilisateur déployeur.
Enfin, nous exécutons la commande docker stack deploy-c docker-stack-cluster.yml $ {STACK} pour lancer notre pile et utilisons la variable STACK pour la nommer :
#!/bin/bash
# Add your code to fetch and populate ./secrets/test ./secrets/prod using copy or vault etc.
# Set stack name
if [[ -z “$1” ]]; then
echo “Usage: please specify dev, test or prod”;
exit 1;
else
export STACK_ENV=$1
export STACK=atsea-deployer-${STACK_ENV}
fi
# Should fail and continue locally, but actually load the builder bundle in CI build
IFS=
eval $(<env.sh)
echo -e “Launching stack… docker stack deploy -c docker-stack-cluster.yml ${STACK} \n”
docker stack deploy -c docker-stack-cluster.yml ${STACK}
Nous y sommes presque ! Maintenant, nous devons examiner de plus près notre fichier YAML de déploiement de pile utilisé dans le fichier deploy_cluster.sh suivant, pour couvrir certains points d’intérêt subtils, mais importants.
Tout d’abord, nous faisons référence des variables d’environnement que nous avons mis dans le deployed_cluster.sh script. Encore une fois, c’est le script qui a réellement appelé le déploiement de la pile Docker et exécute ce fichier. L’utilisation de variables d’environnement est un moyen pratique d’utiliser des fichiers de pile comme modèles paramétrés. Cependant, vous devez être conscient d’une restriction clé : vous ne pouvez pas remplacer les variables d’environnement par les noms des ressources de niveau supérieur Swarm, tels que les noms des services, des réseaux, des volumes et des secrets. En d’autres termes, nous ne pouvons pas définir de services: $ {DB_NAME} -database: ou réseaux: $ {NET_NAME} -front-end: dans nos fichiers de pile . Il existe de très bonnes raisons de le faire, principalement pour éviter les collisions sur les noms de ressources communs à Swarm, mais l’isolement des ressources internes de la pile de Swarm peut aider ici. Nous en parlerons dans la section des ressources Docker Swarm .
Au bas du dossier, on remarque que nos secrets sont mis en place un peu différemment qu’auparavant. Cette fois, les secrets sont lus à partir d’un fichier directement dans les secrets de la pile. Encore une fois, ces secrets auraient pu être directement injectés à partir du coffre-fort Hashicorp ou d’un emplacement de fichier temporaire.
Sinon, ce fichier de pile ressemble faussement à la version que nous avons utilisée pour notre déploiement manuel de pile plus tôt dans ce chapitre. Cependant, il y a en fait quelques différences substantielles dans ce fichier liées aux ressources internes des versets externes !
# atsea-deploy .gitlab-ci.yml
version: “3.7”
services:
database:
image: ${DTR_SERVER}/${STACK_ENV}/atsea-db_build:RC-${STACK_ENV}
environment:
POSTGRES_USER: gordonuser
POSTGRES_DB_PASSWORD_FILE: /run/secrets/postgres_password
POSTGRES_DB: atsea
networks:
– back-tier
secrets:
– postgres_password
appserver:
image: ${DTR_SERVER}/${STACK_ENV}/atsea-web_build:RC-${STACK_ENV}
networks:
– front-tier
– back-tier
– payment
deploy:
replicas: 2
update_config:
parallelism: 2
failure_action: rollback
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
labels:
com.docker.lb.hosts: at-sea-${STACK_ENV}.mydomain.com
com.docker.lb.network: ${STACK}_front-tier
com.docker.lb.port: 8080
com.docker.lb.ssl_cert: wildcard.mydomain.com.server.crt
com.docker.lb.ssl_key: wildcard.mydomain.com.key
secrets:
– postgres_password
payment_gateway:
image: ${DTR_SERVER}/${STACK_ENV}/atsea-payment_build:RC-${STACK_ENV}
secrets:
– source: staging_token
target: payment_token
networks:
– payment
deploy:
update_config:
failure_action: rollback
networks:
front-tier:
back-tier:
payment:
driver: overlay
secrets:
postgres_password:
file: ./secrets/${STACK_ENV}/postgres_password
labels:
com.docker.ucp.access.label: /${STACK_ENV}
staging_token:
file: ./secrets/${STACK_ENV}/payment_token
labels:
com.docker.ucp.access.label: /${STACK_ENV}
wildcard.mydomain.com.key:
file: ./secrets/${STACK_ENV}/wildcard.mydomain.com.key
labels:
com.docker.ucp.access.label: /${STACK_ENV}
wildcard.mydomain.com.server.crt:
file: ./secrets/${STACK_ENV}/wildcard.mydomain.com.server.crt
L’injection de secrets à partir d’un fichier est très pratique, mais l’ajout de valeurs d’étiquettes telles que com.docker.lb.network peut être difficile.
1.1.7.6.2 Comprendre l’étendue des ressources Docker Swarm
Dans l’exemple de déploiement manuel précédent, le fichier YAML de notre pile utilisait des ressources Swarm externes. En d’autres termes, nous avons créé le réseau de premier niveau et tous nos secrets avant de lancer la pile. Ensuite, dans le fichier de pile, nous avons marqué les ressources comme externes, indiquant à Swarm que ces ressources doivent être créées à l’extérieur et avant l’étendue de cette pile. Cela fonctionne très bien lorsque vous avez l’intention de partager délibérément des ressources sur plusieurs piles dans un Docker Swarm. Cependant, ce n’est pas génial si vous ou votre système de build partagez accidentellement des ressources car ils ont par hasard les mêmes noms ! Heureusement, la communauté Docker y a réfléchi.
Lors du déploiement d’une pile à l’aide de Docker Swarm, il atteint l’étendue des ressources de la pile en ajoutant le nom de la pile en tant que préfixe à toutes les ressources internes de niveau supérieur de la pile (services, réseaux et secrets non déclarés comme externes : vrai) au moment du déploiement. Par conséquent, si nous déployons le fichier de pile indiqué précédemment avec un nom de pile atsea-deployer-test, le réseau de niveau supérieur sera créé en tant que atsea-deployer-test_back-tier. Il s’agit d’une convention utilisée par Swarm pour isoler les ressources de la pile. Les noms des ressources de pile externes ne changent pas au déploiement et devraient être présents au moment du déploiement de la pile — Swarm ne les préfixe pas.
C’est très bien, mais cela peut devenir un peu délicat pour nous lors de la définition des valeurs d’étiquette qui contiennent des ressources de portée interne. Par exemple, nous utilisons com.docker.lb.network: front-tier pour indiquer à Interlock quel réseau utiliser. Cependant, comme nous venons de l’apprendre, le nom du réseau de premier niveau sera changé en atsea-deployer-test_front-tier lorsque la pile sera déployée. Le service Interlock essaiera de trouver le réseau de premier niveau et échouera. Dans notre cas, nous avons défini l’étiquette sur com.docker.lb.network: $ {STACK} _front-tier pour que cela fonctionne.
Il convient de mentionner qu’il existe certaines variables de modèle Docker que vous pouvez utiliser dans les fichiers de pile où vous pouvez demander à Swarm les valeurs d’exécution des attributs des services comme le nom d’hôte, le montage et les propriétés env.
Plus d’informations peuvent être trouvées sur https://docs.docker.com/engine/reference/commandline/service_create/#create-services-using-templates .
Malheureusement, les propriétés de la pile sont au-dessus du service et ne sont pas disponibles pour le moment. Enfin, comme nous l’avons mentionné précédemment, vous ne pouvez pas utiliser la substitution de variables d’environnement dans le fichier de composition avec Swarm lorsque vous faites référence à des noms de ressource de niveau supérieur (par exemple, $ {STACK_NAME} de niveau supérieur) dans les sections secrètes ou réseau de notre fichier.
Il y a donc des compromis à prendre en compte lors de la création de vos fichiers de pile Swarm. Vous pouvez utiliser des ressources externes et toujours être sûr du nom, mais vous devez éviter les collisions de noms sur l’ensemble de l’essaim, peut-être en utilisant une sorte de schéma d’espacement des noms. Ou vous pouvez utiliser les noms de ressources de portée interne de Swarm et compenser en externe, en ajoutant le nom de la pile comme préfixe.
1.1.7.6.3 Déclenchement manuel du pipeline
Maintenant, il est temps de l’essayer. Pour démarrer un processus, nous devons déclencher un pipeline avec la commande curl suivante. Par conséquent, je l’exécuterai à partir d’un shell Bash sur ma machine de développement locale et nous obtiendrons un long conteneur de réponse JSON avec un lien vers le pipeline résultant :
$curl -X POST -F token=xxxxxxxxxxxxxxxx-F “ref=master” -F “variables[DEPLOY_TARGET]=test” https://gitlab.com/api/v4/projects/xxxxxxxxxxxx/trigger/pipeline
{… https://gitlab.com/dockereebook/atsea-deploy/-/jobs/156752572…}
Si nous suivons la ligne, nous pouvons voir la sortie du pipeline, comme suit. Le code source est extrait, les packages sont installés, le bundle client UCP est téléchargé, les fichiers sont décompressés, le shell est connecté et la pile est lancée :
Checking out f0d8a037 as master…
Skipping Git submodules setup
$ apk add unzip
fetch http://dl-cdn.alpinelinux.org/alpine/v3.8/main/x86_64/APKINDEX.tar.gz
fetch http://dl-cdn.alpinelinux.org/alpine/v3.8/community/x86_64/APKINDEX.tar.gz
(1/1) Installing unzip (6.0-r4)
Executing busybox-1.28.4-r3.trigger
OK: 5 MiB in 15 packages
$ apk add curl
(1/4) Installing nghttp2-libs (1.32.0-r0)
(2/4) Installing libssh2 (1.8.0-r3)
(3/4) Installing libcurl (7.61.1-r1)
(4/4) Installing curl (7.61.1-r1)
Executing busybox-1.28.4-r3.trigger
OK: 6 MiB in 19 packages
$ apk add jq
(1/2) Installing oniguruma (6.8.2-r0)
(2/2) Installing jq (1.6_rc1-r1)
Executing busybox-1.28.4-r3.trigger
OK: 7 MiB in 21 packages
$ apk add bash
(1/5) Installing ncurses-terminfo-base (6.1_p20180818-r1)
(2/5) Installing ncurses-terminfo (6.1_p20180818-r1)
(3/5) Installing ncurses-libs (6.1_p20180818-r1)
(4/5) Installing readline (7.0.003-r0)
(5/5) Installing bash (4.4.19-r1)
Executing bash-4.4.19-r1.post-install
Executing busybox-1.28.4-r3.trigger
OK: 16 MiB in 26 packages
$ bash
$ chmod +x ./get_bundle.sh
$ chmod +x ./deploy_cluster.sh
$ ./get_bundle.sh
Authtoken: xxxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxxxx
total 64
drwxrwxrwx 4 root root 4096 Feb 5 18:22 .
drwxrwxrwx 4 root root 4096 Jan 28 14:36 ..
drwxrwxrwx 5 root root 4096 Feb 5 18:22 .git
…
-rw-r–r– 1 root root 11879 Feb 5 18:22 bundle.zip
Archive: bundle.zip
extracting: ca.pem
extracting: cert.pem
extracting: key.pem
extracting: cert.pub
extracting: env.ps1
extracting: env.cmd
extracting: kube.yml
extracting: env.sh
$ chmod +x ./env.sh
$ echo $DEPLOY_TARGET
test
$ ./deploy_cluster.sh $DEPLOY_TARGET
Launching stack… docker stack deploy -c docker-stack-cluster.yml atsea-deployer-test
Creating network atsea-deployer-test_payment
Creating network atsea-deployer-test_back-tier
Creating network atsea-deployer-test_front-tier
Creating secret atsea-deployer-test_staging_token
Creating secret atsea-deployer-test_wildcard.mydomain.com.key
Creating secret atsea-deployer-test_wildcard.mydomain.com.server.crt
Creating secret atsea-deployer-test_postgres_password
Creating service atsea-deployer-test_payment_gateway
Creating service atsea-deployer-test_database
Creating service atsea-deployer-test_appserver
Job succeeded
Enfin, voici une capture d’écran UCP de notre service en cours de déploiement sur le cluster Docker Enterprise – les services sont déployés et répliqués :

Figure 16: UCP montre la pile déployée du pipeline
1.2 Résumé
Dans ce chapitre, nous avons couvert les concepts importants liés au développement et au déploiement d’applications avec Docker Enterprise. Nous avons sauvegardé les concepts avec des exemples, y compris un pipeline CI de bout en bout pour créer et déployer l’exemple d’application Docker AtSea sur un cluster Docker Enterprise. Nous avons couvert les services, la mise en réseau, le maillage de routage, le contrôle d’entrée de couche 7, les ensembles de clients UCP et l’intégration avec CI Pipelines.
Au fur et à mesure que nous poursuivons notre cheminement, nous examinerons la journalisation et la surveillance de votre nouvelle application pilote, suivis d’un sujet varié sur la préparation de votre cluster et de la production d’applications. Dans ce chapitre, nous nous sommes concentrés sur l’utilisation de Swarm comme orchestrateur, car c’est un très bon point de départ pour la plupart des entreprises. Plus loin dans cet article, nous allons revenir et redéployer notre application à l’aide de Kubernetes dans notre cluster Docker Enterprise.
2 Pilot Docker Enterprise Platform Monitoring and Logging
Alors que nous terminons notre phase pilote, nous devons réfléchir à la manière dont nous allons prendre en charge notre application pilote pendant le pilote interne. Au-delà des mesures d’accès externe telles que https://www.site24x7.com/ et d’autres le font si bien, nous devons commencer à acquérir une véritable expérience dans la journalisation et la surveillance des conteneurs.
L’exploitation forestière et la surveillance est un domaine de transformation où nous devons faire attention à ne pas ouvrir la voie de la vache. En d’autres termes, il serait facile de reprendre certaines vieilles habitudes dans le nouveau monde des conteneurs, mais cela pourrait être problématique. Traditionnellement, nous configurons nos serveurs d’applications pour gérer la journalisation. Nous l’avons généralement fait de deux manières. Nous avons soit utilisé des cadres de journalisation pour écrire des journaux dans le système de fichiers du serveur d’applications, soit nous avons installé des agents sur chacun de ces serveurs pour surveiller l’activité de journalisation. Comme nous avions un nombre relativement petit de serveurs d’applications configurés pour héberger des déploiements monolithiques et multi-applications, cela avait du sens et fonctionnait plutôt bien.
Bien que les approches de journalisation et d’agent fonctionnent toujours techniquement dans un monde de conteneurs, elles ne conviennent pas nécessairement à la nature éphémère des conteneurs où chaque application a un ou plusieurs conteneurs. Supposons que vous disposiez d’un ancien serveur d’applications exécutant cinq applications (chacune avec une application Web et une API reposante) qui se transforme en 10 conteneurs (5 x 2). Maintenant, imaginez que ces 10 conteneurs sont répartis sur un cluster à cinq nœuds. Imaginez simplement essayer de comprendre où le conteneur a fonctionné en dernier et où il a écrit les journaux. Ou, pensez à devoir instrumenter chaque conteneur de votre cluster avec un agent de journalisation et déterminer les licences pour 10 conteneurs en cours d’exécution et peut-être 30 conteneurs arrêtés !
Pas de panique ! Parallèlement à cette grande pile de technologies de conteneurs, de nombreuses solutions innovantes et rentables sont apparues.
Dans ce chapitre, nous couvrirons les sujets suivants :
- Journalisation de la communauté Docker Engine
- Journalisation et surveillance des applications de conteneurs distribués avec ELK
- Journalisation et surveillance avec Docker Enterprise
- Journalisation et surveillance open source avec Prometheus / Grafana
- Exemple de journalisation commerciale avec Sysdig
2.1 Journalisation et surveillance des applications distribuées et conteneurisées
Tout d’abord, nous commencerons par les bases de la journalisation Docker en examinant la journalisation sur un nœud Docker hôte unique, comme indiqué dans le diagramme qui suit. Comme vous vous en souvenez peut-être, Docker capture automatiquement l’erreur standard et les flux de sortie standard des conteneurs en cours d’exécution et les dirige vers les fichiers journaux Docker. Dans cette section, nous allons explorer ce que cela signifie vraiment en termes de destination des journaux et comment y accéder.
Ce diagramme représente les paramètres de configuration de journal par défaut pour un démon Docker Linux. Sur le côté gauche du diagramme, vous pouvez voir un moteur Docker représenté par une boîte. Sous la boîte Docker Engine, nous pouvons voir comment le Docker Engine utilise systemd pour écrire dans les journaux système du journal systemd-journald de l’hôte. Le système capture la sortie du démon Docker dans ce journal, où elle est accessible avec la commande journalctl, comme indiqué dans la fenêtre Terminal.
2.1.1 Journaux par défaut du moteur Docker
À l’intérieur de la boîte Docker Engine, nous pouvons voir deux conteneurs en cours d’exécution et comment leurs journaux sont écrits sur le système de fichiers hôte au format JSON. Ces journaux sont accessibles à partir de la commande Docker container logs, comme indiqué dans la fenêtre Terminal :

Figure 1: les paramètres de Docker contiennent
Les paramètres de journalisation du conteneur Docker peuvent être ajustés en modifiant un fichier situé dans le répertoire / etc / docker appelé daemon.json . En regardant la liste suivante, vous pouvez voir la liste à partir d’un exemple de fichier daemon.json que je recommande fortement comme configuration par défaut. Dans le fichier suivant, vous pouvez voir que le pilote de journal est défini sur json-file. Il s’agit de la valeur par défaut lorsque Docker est installé sur un système Linux. Les options de journalisation varient pour chaque pilote. Dans notre cas, nous utilisons l’option max-size pour définir la taille maximale d’un fichier journal à 10 Mo et l’option max-file pour spécifier le nombre de fichiers journaux à conserver. Cela signifie que Docker fera pivoter les fichiers journaux de sorte que lorsqu’un fichier atteint 10 Mo, il démarre un nouveau fichier et ne conserve que les trois derniers fichiers journaux en stockage.
C’est vraiment important car un problème grave que nous voyons sur les sites des clients est lorsque les fichiers journaux ne sont pas roulés. Ils peuvent alors devenir incontrôlables et consommer tout l’espace disque d’un nœud Docker. Le nœud peut devenir non réactif, mais cela peut facilement être évité en utilisant ces options. Ne définissez jamais le niveau de journalisation d’un moteur sur le débogage sans vérifier que vous avez une sorte de troncature de journal ou de schéma de roulement en place. À un niveau de débogage de la journalisation, vous pouvez collecter des gigaoctets de journaux en quelques heures seulement.
Notez également l’option de restauration en direct définie sur true sur ce nœud. Ce fichier de configuration provient de mon nœud d’équilibrage de charge Docker autonome (non-essaim), où HAProxy gère tout le trafic entrant vers le cluster, et je ne souhaite donc pas que ce conteneur tombe en panne, même si le démon Docker s’arrête. Veuillez noter que certains effets secondaires peuvent affecter des éléments tels que les mises à niveau, où vous souhaiterez démonter votre conteneur manuellement pour effectuer la mise à niveau, de sorte que nous sommes sûrs qu’aucune ressource n’est verrouillée pendant le processus de mise à niveau.
Sachez que si vous apportez des modifications à votre fichier JSON démon, vous devrez redémarrer votre démon Docker pour que les modifications prennent effet. De manière générale, un redémarrage du docker du service sudo devrait faire l’affaire, comme suit :
$ sudo cat /etc/docker/daemon.json
{
“log-driver”: “json-file”,
“log-opts”: {
“max-size”: “10m”,
“max-file”: “3”
},
“live-restore”: true
}
# Get the current logging driver
$ docker info –format ‘{{.LoggingDriver}}’
json-file
# Get a list of available logging plugins
$ docker info –format ‘{{.Plugins.Log}}’
[awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog]
La liste suivante répertorie les pilotes de journalisation standard inclus dans une installation prête à l’emploi du démon Linux Docker Engine-Community. N’oubliez pas que s’il n’y a pas de fichier /etc/docker/daemon.json ou s’il est vide, le pilote par défaut est le fichier.json . Vous pouvez vérifier votre fichier journal, comme indiqué dans le bloc de code précédent, avec la commande docker info –format ‘{{.LoggingDriver}}’ .
Enfin, vous pouvez voir tous les pilotes de journalisation disponibles, y compris tous les pilotes installés par des plug-ins de journalisation tiers, en utilisant la commande docker info –format ‘{{.Plugins.Log}}’ .
Vous pouvez obtenir plus d’informations sur les options de journalisation pour chaque pilote standard en visitant la page des documents Docker disponible ici: https://docs.docker.com/config/containers/logging/configure/ :
| Pilote de journal | La description |
| Aucun | Aucun journal n’est disponible pour le conteneur et les journaux Docker ne renvoient aucune sortie. |
| json ( https://docs.docker.com/config/containers/logging/json-file/ ) | Les journaux sont formatés en JSON. Le pilote de journalisation par défaut pour Docker. |
| syslog ( https://docs.docker.com/config/containers/logging/syslog/ ) | Écrit des messages de journalisation dans la fonction syslog . Le démon syslog doit être exécuté sur la machine hôte. |
| journald ( https://docs.docker.com/config/containers/logging/journald/ ) | Écrit des messages de journal dans journald . Le démon journald doit être exécuté sur la machine hôte. |
| gelf ( https://docs.docker.com/config/containers/logging/gelf/ ) | Écrit des messages de journal dans un point de terminaison Graelog Extended Log Format ( GELF ) tel que Graylog ou Logstash. |
| fluentd ( https://docs.docker.com/config/containers/logging/fluentd/ ) | Écrit les messages du journal dans fluentd (entrée directe). Le démon fluentd doit être exécuté sur la machine hôte. |
| awslogs ( https://docs.docker.com/config/containers/logging/awslogs/ ) | Écrit les messages de journal dans les journaux Amazon CloudWatch. |
| splunk ( https://docs.docker.com/config/containers/logging/splunk/ ) | Écrit des messages de journal à répartir à l’aide du collecteur d’événements HTTP. |
| etwlogs ( https://docs.docker.com/config/containers/logging/etwlogs/ ) | Écrit les messages de journal en tant qu’événements de suivi d’événements pour Windows ( ETW ). Uniquement disponible sur les plateformes Windows. |
| gcplogs ( https://docs.docker.com/config/containers/logging/gcplogs/ ) | Écrit des messages de journal dans la journalisation de Google Cloud Platform ( GCP ). |
| logentries ( https://docs.docker.com/config/containers/logging/logentries/ ) | Écrit les messages du journal dans les entrées du journal Rapid7. |
2.1.2 Journalisation centralisée
La journalisation Docker fonctionne très bien pour un seul nœud, mais que faire si j’ai un cluster de 10, 20 ou même 100 nœuds ? Comment sommes-nous censés gérer tous ces journaux sur tous ces nœuds ? La réponse est la journalisation centralisée !
Il existe différentes approches pour implémenter la journalisation centralisée. Une méthode est un modèle de publication, où tous les points de terminaison métriques publient leurs journaux sur un serveur central. Une pile ELK est un bon exemple de solution open source utilisant le modèle de publication. Une deuxième méthode de journalisation centralisée est un modèle d’interrogation, dans lequel le serveur de journalisation central interroge tous les points de terminaison métriques ciblés. Prometheus est un exemple populaire de solution open source utilisant un modèle d’interrogation.
2.1.2.1 Approche de publication avec une pile ELK
L’ELK dans la pile ELK est un acronyme représentant les composants de la pile de journalisation. E est pour Elasticsearch, L est pour Logstash et K est pour Kibana. Il s’avère que ces trois technologies open source constituent une pile de journalisation centralisée exceptionnelle. Logstash peut prendre un énorme pipeline de données, les normaliser et les livrer à Elasticsearch à grande échelle. Logstash est parfois appelé un puissant outil d’ingestion pour Elasticsearch. Elasticsearch indexe d’énormes quantités de données de journal et les rend consultables en temps réel, tandis que Kibana fournit des visualisations et des graphiques de style infographique très cool à partir de vos données de journal.
Le modèle de publication repose sur la structure du journal pour non seulement comprendre les métriques, mais tout aussi importante est la source de la métrique. Étant donné que les journaux sont envoyés au serveur central, il n’existe aucun moyen simple et fiable de déterminer la source. Le serveur ne sait rien des sources métriques en termes de configuration, donc ce n’est que par convention des balises / de la structure du journal que les informations source peuvent être déterminées. C’est pourquoi nous soulignons l’importance d’une bonne structure de journalisation pour les équipes de développement d’applications. Bien que les architectes ne puissent plus dicter le cadre de journalisation à utiliser lors de la construction de systèmes distribués (ou même de microservices), ils doivent insister sur les points suivants:
- Conventions au format de journalisation
- Les journaux sont toujours écrits dans la sortie standard et l’erreur standard
Voyons donc comment fonctionne une pile ELK dans un cluster Docker. Nous devons démarrer la configuration de chaque nœud pour le pilote de journalisation Docker Engine local. Dans notre exemple suivant, dans le diagramme suivant, nous n’utilisons plus le pilote par défaut json -file. Au lieu de cela, nous avons basculé vers le pilote de journal journald . Cela signifie que tous les journaux de conteneur sont enregistrés dans les journaux systemd-journald de l’hôte local . Alors maintenant, tous les journaux de conteneur et les services de démon Docker sont capturés dans le même fichier journal local.
Maintenant, nous devons obtenir les journaux de notre fichier journal local vers le service de stockage de journaux exécuté sur le serveur ELK. Dans notre diagramme, ce flux est représenté par les flèches rouges et est facilité par quelque chose appelé Journalbeat ( https://github.com/mheese/journalbeat ). Journalbeat s’exécute dans un conteneur, monte les journaux système locaux et envoie les nouvelles entrées au service Logstash sur l’hôte du serveur ELK distant. Ensuite, tous les nouveaux journaux de chacun des nœuds sont rapidement indexés et stockés. Enfin, Otto, notre responsable des opérations, peut utiliser l’interface utilisateur de Kibana pour rechercher tout problème ou anomalie dans les données de journal de n’importe quel conteneur sur n’importe quel nœud :
Figure 2 : Journalisation centrale ELK Stack
C’est plutôt cool, mais ce n’est que le début du voyage de journalisation central. En fait, la plomberie est la partie facile de cette configuration de plate-forme. La partie difficile est de structurer les requêtes pour découvrir les problèmes et les anomalies, et de s’assurer que les équipes d’application enregistrent les informations appropriées au bon moment.
2.1.2.2 Approche d’interrogation avec Prometheus
La deuxième approche de journalisation centralisée commune est un modèle d’interrogation, dans lequel le serveur de journalisation central interroge tous les points de terminaison métriques ciblés. Dans ce scénario, le serveur central est conscient de ses points de terminaison métriques en termes de configuration et les interroge, stockant les résultats dans une base de données centrale. Un exemple populaire du modèle de sondage est Prometheus, une plate-forme de surveillance open source très populaire.
Prometheus est une plateforme de surveillance open source simple à configurer et à utiliser. Dans le diagramme suivant , nous montrons une configuration très basique , avec un serveur Prometheus configuré via un fichier de configuration YAML, et interrogeant un conteneur d’application sur un serveur de test. Le fichier YAML décrit le comportement du serveur, tel que la fréquence à laquelle le serveur gratte / interroge les points de terminaison. Plus important encore, il décrit les points de terminaison cibles comme des travaux et le serveur utilise le chemin HTTP, l’adresse IP et le numéro de port pour collecter les mesures. Côté serveur de test, nous avons ce qu’on appelle un exportateur.
Il existe un certain nombre d’exportateurs que vous pouvez connecter à la plate-forme de déploiement de votre application, où vous déployez l’exportation avec votre application pour obtenir des métriques d’exécution d’accès sans modifier le code de votre application. Par exemple, l’exportateur Prometheus JMX ( https://github.com/prometheus/jmx_exporter ). Le fichier jar peut être téléchargé dans votre déploiement Tomcat en tant qu’application distincte et exposer les métriques JVM clés au serveur Prometheus. Cela fonctionne très bien pour les applications de levage et de décalage, mais vous pouvez faire beaucoup plus si vous souhaitez créer votre propre point de terminaison de métriques.
Prometheus possède des bibliothèques clientes officielles et non officielles pour une grande variété de langages de programmation: https://prometheus.io/docs/instrumenting/clientlibs/ . Vous pouvez utiliser ces bibliothèques clientes pour créer vos propres mesures, telles que le nombre de widgets expédiés ou de hamburgers commandés. Cela ouvre la porte à l’utilisation d’une toute nouvelle collection de métriques métier où vous pouvez créer un tableau de bord pour les utilisateurs de votre entreprise. Un mot d’avertissement, cependant ; les mainteneurs de Prometheus ne garantissent pas le type de traçabilité métrique dont vous auriez besoin pour quelque chose comme un système de facturation. Ainsi, bien que vous puissiez l’utiliser pour des mesures internes de toutes sortes, faites attention si des avocats sont impliqués ! Nous recommandons la classe Pluralsight d’Elton Stoneman ( https://www.pluralsight.com/courses/monitoring-containerized-app-health-docker ) comme un excellent endroit pour commencer avec les bibliothèques clientes Prometheus.
2.1.2.2.1 Configuration simple de Prometheus
Une fois cette configuration simple en place, Otto peut utiliser l’interface utilisateur Web de Prometheus pour configurer des graphiques et des alertes en fonction des métriques fournies par l’application d’exportation Prometheus sur le port 9323 :
Figure 3 : Moniteur d’application Web Prometheus simple
D’accord, mais qu’est-ce que cela a à voir avec Docker ? Il s’avère que Docker a exposé un point de terminaison de métriques Prometheus dans le Docker Engine. Ainsi, vous pouvez collecter une multitude d’informations, comme le nombre de conteneurs dans différents états (en pause, en cours d’exécution, arrêtés) ou le nombre de contrôles d’intégrité ayant échoué. N’oubliez pas la valeur des contrôles d’intégrité ayant échoué. N’oubliez pas que Swarm redémarrera les conteneurs qui échouent et, par conséquent, il peut masquer les problèmes où les conteneurs se bloquent après un certain temps et que l’orchestrateur les redémarre.
2.1.2.2.2 Prométhée sur Docker et vérification de Docker
Maintenant que nous savons que Docker a un point de terminaison de métriques Prometheus, nous allons configurer une démo rapide à partir d’un serveur Prometheus fonctionnant en tant que conteneur Docker, sur le même nœud où nous surveillons les métriques Docker ! Ceci est bien documenté ici.
Dans le diagramme suivant, nous examinons quelques éléments essentiels qui sont nécessaires pour faire fonctionner cette configuration. Tout d’abord, nous devons obtenir le Docker Engine pour exposer le point de terminaison Prometheus sur un port spécifique. Cela nécessite des modifications du fichier daemon.json . Le premier paramètre de configuration est le numéro de port, où le point de terminaison des métriques Prometheus du Docker peut être atteint. Le second paramètre de configuration permet d’accéder aux fonctionnalités expérimentales du Docker Engine.
Ensuite, jetez un coup d’œil à notre fichier Prometheus YAML dans le diagramme suivant. Il y a quelques éléments clés à noter :
- Le serveur Prometheus collecte en fait des métriques de lui-même
- Nous pouvons également voir comment il surveille le point de terminaison des métriques Docker
Le diagramme suivant illustre le déploiement du serveur Prometheus dans un conteneur avec une commande d’exécution de conteneur Docker et comment Otto Opsmanager peut se connecter, puis se connecter à l’interface utilisateur Web de Prometheus et voir les métriques du serveur Prometheus et d’un point de terminaison Docker :
Figure 4 : Prométhée tirant des métriques du point de terminaison du moteur Docker (expérimental)
C’est assez cool, mais je suis sûr que j’ai perdu la plupart d’entre vous en mode expérimental ! Le mode expérimental implique des fonctionnalités expérimentales dans le moteur Docker qui ne sont pas prêtes pour la production. Par conséquent, l’utilisation de ce type de surveillance directe du point de terminaison Docker Engine peut fonctionner correctement pour le développement local, mais ce n’est pas une approche aussi acceptable pour les environnements de production.
Ensuite, nous examinerons la surveillance d’un cluster Docker Enterprise avec plus de solutions de qualité production. Nous nous appuierons sur les concepts Prometheus dont nous avons discuté dans cette section, ainsi que sur un exemple de solution commerciale.
2.2 Journalisation et surveillance dans Docker Enterprise
Docker Enterprise fait un excellent travail sur la corde raide entre la fourniture de fonctionnalités d’entreprise essentielles et prêtes à l’emploi, et la flexibilité grâce à l’intégration et l’extensibilité. La surveillance est un très bon exemple de cet équilibre. Vous obtenez les informations de base dont vous avez besoin pour faire fonctionner votre cluster Docker Enterprise, mais la flexibilité d’apporter vos propres outils au jeu. Pour la surveillance, Docker utilise un emballage interne de Prometheus pour fournir certaines métriques essentielles via le tableau de bord UCP.
La capture d’écran suivante montre une vue d’ensemble des mesures du tableau de bord de l’interface utilisateur Web d’UCP, où toutes les données proviennent d’un déploiement Kubernetes de Prometheus sur les nœuds Docker Enterprise Manager :
Figure 5 : Tableau de bord UCP utilisant Prometheus
Les métriques UCP permettent aux opérateurs de cluster de voir rapidement s’il y a des problèmes avec leur cluster. Bien que ce ne soit peut-être pas une excellente solution à long terme, cela aide vraiment pendant la phase pilote, car l’équipe des opérations détermine quel type de métriques sera important dans le monde des conteneurs. Ensuite, Docker s’éloigne et vous encourage à implémenter à peu près toutes les solutions que vous souhaitez, y compris Prometheus et Grafana exécutées dans votre cluster, aux côtés de leur implémentation interne de Prometheus.
Nous disons intentionnellement que Docker encourage l’extension et l’intégration, car ils fournissent des résumés de solutions conjointement avec des solutions de partenaires certifiés. Les fiches de solution certifiées Docker sont des guides pas à pas pour vous aider à étendre et à intégrer Docker avec des fournisseurs de technologies tiers certifiés Docker que vous utilisez déjà.
2.2.1 Docker Enterprise UCP et Prometheus
L’examen de la mise en œuvre par Docker de Prometheus pour les métriques UCP fournit des informations assez intéressantes sur la façon dont Prometheus peut être utilisé dans un environnement de production. Chose intéressante, dans Docker UCP version 3.1, les métriques UCP sont collectées via un déploiement Kubernetes de Prometheus sur chaque nœud UCP Manager. Le but de leur mise en œuvre est de collecter jusqu’à 24 heures de valeur de mesure des événements UCP et des ressources pour aider les opérateurs à résoudre les problèmes de triage. En d’autres termes, s’il y a un problème, vous pouvez accéder à l’interface utilisateur de l’UCP pour consulter les métriques et cela peut vous conduire vers le diagnostic et la résolution des problèmes. Cependant, il n’est pas conçu pour déplacer votre ensemble d’outils principal pour la journalisation, la surveillance et l’alerte du système.
En plus de l’utilisation par Docker de Kubernetes pour déployer les métriques Prometheus d’UCP, ils ont également ajouté un point de terminaison API UCP ( metricsdiscovery ) pour prendre en charge leur implémentation. Ce point de terminaison révèle tous les points de terminaison métriques dont Prometheus a besoin. Si vous souhaitez voir cela en action, connectez-vous à l’interface utilisateur Web UCP, cliquez sur le lien de l’API en direct, accédez à la découverte des métriques, essayez-le, puis exécutez. Vous verrez un corps de réponse qui ressemble à ceci :
[
{
“targets”: [
“10.10.1.38:12376”,
“10.10.1.39:12376”,
“10.10.1.40:12376”,
“10.10.1.40:443”,
“10.10.1.43:12376”,
“10.10.1.43:443”,
“10.10.1.37:12376”,
“10.10.1.37:443”,
“10.10.1.44:12376”,
“10.10.1.45:12376”,
“10.10.1.41:12376”,
“10.10.1.42:12376”
]
}
]
Remarquez comment l’adresse IP est différente pour les nœuds du gestionnaire (port 443 – API UCP) et les travailleurs (port 12376 – ucp_proxy ). Docker utilise ensuite un conteneur d’inventaire (à l’intérieur du module de métriques), utilise le service de découverte des métriques de l’API UCP pour extraire les points de terminaison de l’exportateur et les enregistre sur un volume de partage, où la configuration du serveur Prometheus peut les récupérer.
Maintenant que nous avons vu comment Docker le fait, découvrons la meilleure approche pour une configuration pilote.
2.2.2 Docker Enterprise avec Prometheus et Grafana
En ce qui concerne l’utilisation de Prometheus et Grafana avec Docker Enterprise, il existe plusieurs options, car l’UCP de Docker Enterprise utilise déjà Prometheus. Une approche consiste à utiliser les exportateurs / points de terminaison de Docker Prometheus et à ajouter notre propre serveur Prometheus pour les interroger. Cela fonctionnera, bien sûr, et il est bien documenté ( https://docs.docker.com/ee/ucp/admin/configure/collect-cluster-metrics/ ), mais nous nous appuyons ensuite sur la structure de point de terminaison sous-jacente pour restent les mêmes que Docker met à jour leur implémentation des métriques UCP au fil du temps. Un moyen plus sûr serait de déployer notre propre serveur Prometheus et nos exportateurs afin que nous puissions déployer indépendamment de l’implémentation Prometheus de Docker.
Aucune de ces approches n’utilise le point de terminaison expérimental Docker Engines. Ils utilisent tous deux des exportateurs discrets, séparés du Docker Engine, pour sonder le système pour les métriques, et donc éviter l’utilisation de fonctionnalités expérimentales.
Cette approche de l’implémentation de Prometheus et Grafana est documentée dans une présentation de la solution Docker. Je vais vous guider à travers une version simplifiée rapide en utilisant Docker Swarm pour déployer nos exportateurs Prometheus, ainsi que le serveur. L’article complet est disponible ici: https://success.docker.com/article/grafana-prometheus-monitoring .
L’article commence par parler des principaux composants requis pour la solution. Fondamentalement, nous déploierons une pile de serveurs (Prometheus / Grafana / NGINX) et un ensemble de deux exportateurs sur chaque nœud du cluster.
Cette topologie est facile à réaliser avec Swarm ou Kubernetes génériques. Dans Swarm, vous pouvez utiliser la réplication globale, tandis que dans Kubernetes, vous pouvez utiliser un ensemble de démons pour les exportateurs. Cependant, UCP limite les types de charge de travail qui s’exécutent sur un certain nœud. Par exemple, les nœuds de travail sont marqués comme Swarm, Kubernetes ou Mixed. De plus, UCP peut être configuré pour interdire les charges de travail des utilisateurs sur les travailleurs DTR et les nœuds de gestionnaire UCP. Heureusement, il existe des solutions intelligentes. Heureusement, il y a un petit hack pour contourner ce problème avec Swarm, tant que vous avez un accès SSH à l’un des nœuds de gestionnaire UCP de votre cluster. Ce hack contourne UCP et utilise Swarm CE en allant directement au socket Docker du gestionnaire UCP – la désactivation des variables d’environnement pendant le déploiement de la pile avec env -i fait l’affaire. Malheureusement, si vous n’avez qu’un bundle client UCP et aucun nœud de gestionnaire SSH, vous devrez utiliser l’approche de l’ensemble de démons Kubernetes pour les exportateurs sous forme de pods.
En ce qui concerne les deux types d’exportateurs, le premier est appelé cAdvisor et sert à collecter des statistiques relatives aux conteneurs. Le deuxième type est appelé Node Exporter et collecte les métriques système de chaque hôte. La réplication globale Swarm garantira que chacun de ces conteneurs s’exécute à tout moment sur tous les nœuds, même si de nouveaux employés sont ajoutés au cluster après le déploiement.
La pile de serveurs (Prometheus / Grafana / NGINX) est composée de trois composants. Le premier composant est un serveur NGINX pour fournir un accès d’authentification de base au serveur d’interface Web Prometheus. Le deuxième composant est le serveur Prometheus lui-même, que nous avons vu auparavant. Enfin, nous avons Grafana pour afficher notre tableau de bord. Nous n’exposerons que deux ports en dehors de notre pile. Le port 33090 est utilisé pour accéder à l’interface utilisateur Web Prometheus via l’authentification de base NGINX depuis la fin, et le port 33000 est utilisé pour accéder à l’interface utilisateur Web de Grafana.
La configuration avec swarm est en fait assez simple. Nous devons effectuer les étapes suivantes:
- SSH dans un gestionnaire UCP.
- Créez un sous-répertoire prometheus, insérez-y un CD et copiez ces fichiers:
- nginx.conf ( https://success.docker.com/api/asset/.%2Fpublish%2Fgrafana-prometheus-monitoring%2F.%2Fsamples%2Fnginx.conf )
- docker-entrypoint.sh ( https://success.docker.com/api/asset/.%2Fpublish%2Fgrafana-prometheus-monitoring%2F.%2Fsamples%2Fdocker-entrypoint.sh )
- Dockerfile ( https://success.docker.com/api/asset/.%2Fpublish%2Fgrafana-prometheus-monitoring%2F.%2Fsamples%2FDockerfile )
- Créez et envoyez une image proxy d’authentification de base NGINX à votre référentiel DTR:
- génération d’image docker –rm –no-cache –tag dtr.mydomain.com/admin/monitoring-nginx:v1.
- Docker image push dtr.mydomain.com/admin/monitoring-nginx:v1
- Vous devrez peut-être ouvrir une session Docker dtr.mydomain.com avant de pousser
- Créez un secret d’essaim, comme suit:
echo ‘YourPasswordHere’| docker secret create prometheus-password –
- Mettez à jour le fichier docker-compose , comme suit:
- Mettez à jour le nom de l’image de l’image NGINX sur dtr.mydomain.com/admin/monitoring-nginx:v1
- Retirez les ports spécification du suivi-cadvisor et le suivi-node-exportateur de services car ils ne sont pas nécessaires, et peut provoquer des conflits portuaires
- Déployez la pile. Voici le hack:
env -i docker stack deploy -c docker-compose.yml grafana-prometheus
- Connectez-vous à Prometheus en utilisant l’IP et le port 33090 de n’importe quel nœud de cluster :
- Utilisez le mot de passe que vous avez enregistré dans le secret à l’étape 4.1
- Vérifier l’ état | Cibles pour voir si vos nœuds sont en place
- Connectez-vous à Grafana en utilisant l’IP et le port 33000 de n’importe quel nœud de cluster :
- L’ admin / admin
- Réinitialiser le mot de passe
- Configurer une source de données Prometheus à l’aide de vos informations d’authentification de base Prometheus
- Importez un exemple de tableau de bord à l’aide de l’URL suivante: https://grafana.com/dashboards/893
- Profitez de la magie!
Voici ma version nettoyée du fichier docker-compose , divisée en quelques morceaux:
version: ‘3.4’
services:
monitoring-nginx:
image: dtr.mydomain.com/admin/monitoring-nginx:v1
hostname: monitoring-nginx
environment:
PROMETHEUS_PASSWORD_FILE: ‘/run/secrets/prometheus-password’
secrets:
– prometheus-password
deploy:
restart_policy:
condition: any
delay: 5s
max_attempts: 5
networks:
– monitoring-frontend
– monitoring-backend
ports:
– “33090:19090”
Le service de surveillance-nginx précédent est utilisé comme frontal d’équilibrage de charge et fournit un wrapper d’authentification de base devant l’interface utilisateur Web de Prometheus.
Le bloc de code suivant montre la configuration de Grafana et Prometheus:
monitoring-grafana:
image: grafana/grafana:latest
hostname: monitoring-grafana
networks:
– monitoring-frontend
– monitoring-backend
ports:
– “33000:3000”
volumes:
– grafana-data:/var/lib/grafana
monitoring-prometheus:
image: prom/prometheus:latest
hostname: monitoring-prometheus
networks:
– monitoring-backend
command:
– ‘–config.file=/etc/prometheus/prometheus.yml’
– ‘–storage.tsdb.path=/prometheus’
volumes:
– prometheus-metrics-data:/prometheus
configs:
– source: prometheus.yml
target: /etc/prometheus/prometheus.yml
Le bloc de code suivant montre la configuration de nos deux types de sondes de surveillance qui sont déployées sur chaque nœud:
monitoring-cadvisor:
image: google/cadvisor:latest
hostname: monitoring-cadvisor
networks:
– monitoring-backend
deploy:
mode: global
volumes:
– /:/rootfs:ro
– /var/run:/var/run:rw
– /sys:/sys:ro
– /var/lib/docker/:/var/lib/docker:ro
monitoring-node-exporter:
image: prom/node-exporter:v0.15.0
hostname: monitoring-node-exporter
networks:
– monitoring-backend
deploy:
mode: global
Dans le code suivant, nous avons les volumes locaux, les réseaux, la configuration et le secret utilisés par Prométhée et Grafana:
volumes:
prometheus-metrics-data:
grafana-data:
networks:
monitoring-frontend:
driver: overlay
attachable: true
monitoring-backend:
driver: overlay
attachable: true
configs:
prometheus.yml:
file: ./prometheus.yml
secrets:
prometheus-password:
external: true
Comme vous pouvez le voir, il existe d’innombrables options pour créer des graphiques Prometheus et des tableaux de bord Grafana, mais vous avez encore du travail à faire pour arriver là où vous devez aller. En outre, depuis Grafana, consultez également le paramètre d’alerte. C’est très cool et utile ! Voici mon tableau de bord :
Figure 6: Tableau de bord Grafana
Encore une fois, c’est vraiment cool, mais faites attention aux chiffres. N’oubliez pas de comparer les numéros Prometheus / Grafana avec les métriques et les requêtes UCP de votre bundle client UCP avec un rôle d’utilisateur administrateur UCP (c’est-à-dire, le conteneur Docker ls -aq | grep -c –regex “^ [0-9, af]”). La valeur par défaut, bien qu’un exemple, montre un conteneur 1006, mais l’interface utilisateur Web UCP et les requêtes de bundle client affichent 281. En outre, les nœuds répertoriés sont les adresses IP des réseaux Swarm des exportateurs. Donc, assurez-vous de savoir ce que vous regardez et comment naviguer depuis la découverte d’un problème de tableau de bord jusqu’au dépannage d’un nœud ou d’un conteneur.
Nous venons de couvrir une option open source populaire, alors regardons maintenant une option commerciale.
2.2.3 Exemple commercial – Sysdig
Le marché des outils de surveillance traditionnels est abondant et mature. Il y a de fortes chances que vous disposiez probablement déjà d’un ou de plusieurs outils existants. Vous les avez déjà achetés, vous savez comment les utiliser et, pour la plupart, ils pourraient très bien fonctionner pour certains de vos besoins de surveillance basés sur des conteneurs. Cependant, il existe des différences fondamentales entre la surveillance des infrastructures / applications traditionnelles et la surveillance des plates-formes de conteneurs.
La première différence entre la surveillance traditionnelle et la surveillance des conteneurs est que les conteneurs sont éphémères et peuvent être de courte durée. Une fois le conteneur parti, il est difficile de comprendre ce qui aurait pu arriver. Vous devez vous assurer que votre plateforme de surveillance prend en compte la nature éphémère des conteneurs et les difficultés d’utilisation des solutions basées sur des agents, où les agents démarrent et s’arrêtent constamment, mais comprennent également comment surveiller les composants de la plateforme de conteneurs associés.
La deuxième différence entre la surveillance traditionnelle et la surveillance des conteneurs est le passage des applications monolithiques aux microservices. Dans cette ère d’application à douze facteurs, où les composants de service sont liés dynamiquement ensemble lors de l’exécution, il est très utile que votre solution de surveillance puisse naviguer dans cette typologie dynamique.
Dans cette section, nous voulions utiliser un exemple de solution commerciale, et celle que je connais le mieux est Sysdig Monitor et Sysdig Secure. Ce n’est pas une approbation officielle de Sysdig, et je ne dis pas qu’ils sont les seuls à fournir de telles fonctionnalités, mais c’est devenu mon outil de choix en raison de leur approche de conteneur premier et de leurs racines communautaires open source. Sysdig provient des créateurs de Wireshark et ses racines se trouvent dans la communauté open source Falco.
Tout d’abord, tout outil de surveillance a une valeur limitée s’il ne peut pas nous aider à déterminer la cause première d’un événement. Donc, nous cherchons quelque chose à approfondir en cas de problème. À cette fin, Sysdig dispose d’une fonctionnalité appelée capture qui vous permet de remonter dans le temps avant un événement critique et de revoir tout ce qui se passait dans l’environnement. Vous pouvez corréler les événements sur plusieurs canaux sur une chronologie commune pour suivre ce qui se passait (événements liés à l’hôte, au réseau, aux fichiers et aux conteneurs) avant un événement particulier. Nous avons inclus la capture d’ écran suivante pour vous aider à visualiser cela, et il y a une excellente vidéo de démonstration à consulter ici: https://sysdig.com/blog/sysdig-inspect/ :
Figure 7: inspection Sysdig de la capture d’événements
Notre intention ici n’est pas de détourner cette section et de la transformer en une grande brochure de vente ; il s’agit plutôt de contribuer à sensibiliser à tous les types d’outils très utiles dans un environnement de conteneur éphémère. En résumé, la plate-forme Sysdig offre la possibilité de surveiller ou d’inspecter une variété de métriques d’hôte, de réseau, de système de fichiers et de conteneur. Ensuite, en fonction des règles, le système génère des alertes et capture des mesures détaillées menant à un événement.
Maintenant, revenons à notre pilote ! À ce stade, nous avons déployé quelques applications :
- Notre confluent Wiki
- Notre application Java personnalisée que nous avons développée dans le dernier chapitre
En pratique, et parce que nous avons ouvert notre application wiki conteneurisée aux utilisateurs internes, nous souhaitons nous assurer que tout fonctionne correctement. Par conséquent, nous avons besoin d’une meilleure vue de ce qui se passe avec notre nouvelle application wiki. Nous allons donc parcourir le processus d’utilisation d’un essai gratuit de Sysdig pour surveiller le wiki pendant son fonctionnement sur notre plateforme Docker Enterprise.
2.2.3.1 Notre architecture pilote Sysdig
La solution de surveillance Sysdig que nous utilisons pour notre pilote est la version cloud de leur plate-forme de surveillance, et un essai gratuit est disponible. C’est pratique pour un pilote car vous n’avez pas besoin d’acheter quoi que ce soit (encore) et vous n’aurez qu’à installer les agents de sonde sur votre hôte Docker et vous serez prêt à partir. Veuillez noter que, pour un trafic plus élevé ou des environnements plus hautement sécurisés, Sysdig propose une variété de configurations pour leur solution basée sur le cloud, ainsi qu’une version sur site. Pendant votre pilote, nous vous recommandons la version cloud, laissant le serveur d’hébergement à Sysdig – vous pouvez toujours passer à la version sur site plus tard après avoir démarré les pneus.
2.2.3.1.1 Installation des agents Sysdig
Lors de l’installation de Sysdig sur Docker Enterprise 2.1, il existe plusieurs approches différentes. L’une des approches est décrite dans une présentation de la solution Docker ( https://success.docker.com/article/sysdig-monitoring ). La présentation de la solution Docker utilise un ensemble de démons Kubernetes pour installer les agents dans le cluster Docker Enterprise. En apparence, il s’agit d’une implémentation assez simple où vous pouvez simplement créer un secret Kubernetes puis appliquer un fichier Kubernetes YAML à partir d’un bundle client UCP pour effectuer la magie. Cependant, comme beaucoup de choses Kubernetes, il peut y avoir des complications. Dans notre cas, ces complications sont liées au module de noyau requis et à notre hébergement Docker Enterprise sur site nu. Donc, si vous utilisez simplement Swarm à ce stade de votre pilote et que vous exécutez sur site , je recommanderais fortement d’utiliser l’installation simple basée sur un conteneur comme approche plus directe et à toute épreuve pour installer les agents dans votre cluster. Tant que vous avez un accès SSH à vos hôtes de cluster Docker à l’aide d’un utilisateur du groupe Docker (vous devez exécuter une commande Docker), cela prendra environ une minute par nœud hôte.
Salut les fans de Kubernetes, ne vous inquiétez pas! Nous reviendrons sur le déploiement de Kubernetes avec la surveillance de l’état du Kube plus loin dans cet article.
Avant de pouvoir installer quoi que ce soit, veuillez visiter https://sysdig.com/ et cliquer sur le bouton de démarrage . De là, vous pouvez commencer votre essai gratuit de moniteur. Il vous suffit de vous inscrire, puis de suivre les instructions jusqu’à l’installation de l’agent. Vous devrez copier votre clé d’accès car il s’agit d’un paramètre pour notre installation Docker basée sur un conteneur.
Après avoir acquis votre clé d’accès, il vous suffit de vous connecter à chacun de vos nœuds hôtes Docker du cluster et d’utiliser la commande Docker run suivante avec votre clé d’accès (remplacez le xxxxxxxxxxxxxxx suivant par votre clé d’accès):
docker run -d –name sysdig-agent \
–restart always \
–privileged \
–net host \
–pid host \
-e ACCESS_KEY=xxxxxxxxxxxxxxxxxxxxxx \
-e SECURE=true \
-e TAGS=example_tag:example_value \
-v /var/run/docker.sock:/host/var/run/docker.sock \
-v /dev:/host/dev \
-v /proc:/host/proc:ro \
-v /boot:/host/boot:ro \
-v /lib/modules:/host/lib/modules:ro \
-v /usr:/host/usr:ro \
–shm-size=512m \
sysdig/agent
Il y a quelques points importants à souligner dans la commande Docker précédente. Encore une fois, assurez-vous d’utiliser votre propre clé d’accès d’essai gratuite à partir du site Web https://sysdig.com/ . Deuxièmement, vous avez peut-être remarqué que nous exécutons l’agent en tant que conteneur privilégié. Ce n’est pas une question banale et ce n’est pas quelque chose que vous devriez normalement considérer. Cela permet à tout ce qui s’exécute dans ce conteneur d’avoir un accès complet à votre hôte ! Jetez également un œil aux montages de volume qui incluent un accès en lecture seule pour traiter tous les répertoires du module du noyau. Cela est nécessaire car Sysdig utilise un module de noyau pour capturer les données d’événement à l’aide de syscalls. Cela permet une intégration profonde de l’hôte, mais c’est certainement une considération de sécurité que vous devez absolument discuter avec votre équipe SecOps avant l’installation.
2.2.3.1.2 Le tableau de bord pilote Wiki
En quelques minutes, après l’installation des agents, vous pourrez voir les données de votre cluster apparaître sur le tableau de bord de votre moniteur Sysdig. Il existe une variété de ressources pour vous mettre à jour: https://sysdig.com/resources/ . Si vous attendez environ 15 minutes après que les données ont commencé à circuler sur le site du moniteur Sysdig, vous pouvez regarder en bas à gauche de votre interface Web pour un petit bouton rouge appelé le projecteur. Sysdig examine le type de métriques collectées et fait des recommandations pour les tableaux de bord prédéfinis. Plus souvent qu’autrement, après nous être connectés au tableau de bord de surveillance d’un nouveau cluster Docker Enterprise qui semble fonctionner correctement, nous découvrons rapidement certains problèmes. C’est vraiment utile !
Maintenant, jetons un coup d’œil au tableau de bord pilote que j’ai mis en place pour l’application wiki que je voulais surveiller. La raison pour laquelle nous disons pilote est que, lorsque nous travaillons avec l’application, nous apporterons certainement des modifications au tableau de bord et aux alertes dans le cadre du processus d’apprentissage :
Figure 8 : Surveillance de l’application pilote Wiki
Sur la partie supérieure de mon tableau de bord se trouvent les informations de suivi liées aux services Swarm et à l’utilisation JVM de l’application wiki. Les chiffres réels dans les graphiques sur le côté droit du tableau de bord sont beaucoup moins importants que les tendances. Nous pouvons utiliser ces tendances pour corréler les mesures aux problèmes de performances ou aux plantages. Veuillez noter qu’il existe des mesures JVM de tableau de bord personnalisées, qui vous donnent une vue d’ensemble de toutes les applications Java de votre cluster.
La partie suivante de mon tableau de bord, comme le montre la capture d’écran suivante, concerne la base de données backend postgres pour le wiki. J’ai pu récupérer la plupart de ces mesures à partir d’un tableau de bord de base de données Postgres standard. Je devais juste restreindre la portée à l’application wiki :
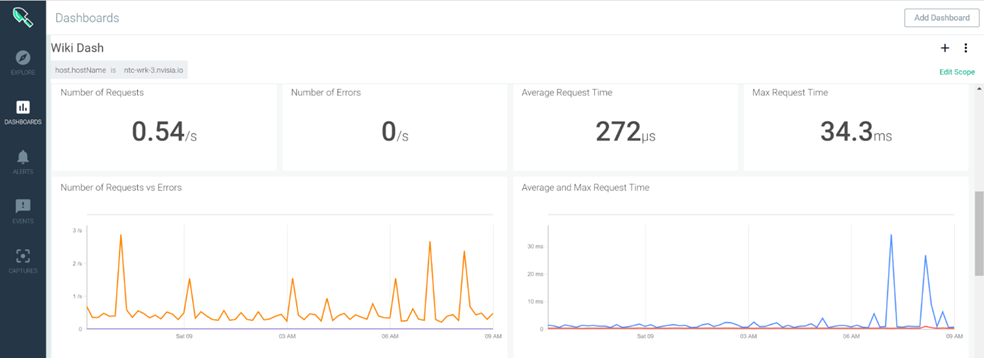
Figure 9 : Surveillance des tendances de demande pour le wiki
Donc, maintenant nous avons quelque chose à regarder s’il y a un problème, mais comment savons-nous qu’il y a un problème ? Nous pourrions attendre que les utilisateurs se plaignent, mais nous voulons être plus proactifs que cela.
2.2.3.1.3 Configuration des alarmes
Pour notre pilote, il y a encore une chose que nous devons accomplir avec le moniteur Sysdig: nous avons besoin de quelques alertes. Pour commencer avec notre alerte pilote, nous devons configurer trois alarmes différentes. Une alarme est spécifique au service wiki et les deux autres sont généralement une bonne idée dans un cluster, comme vous le verrez.
La première alarme cherche à voir si un service Swarm est hors de portée de notre pile wiki. Si vous vous souvenez, nous avons lancé notre application wiki à partir d’un déploiement de pile Docker pour deux services : une application Web et une application de base de données. Si l’un de ces services tombe en panne pendant plus d’une minute, une alarme sera déclenchée :
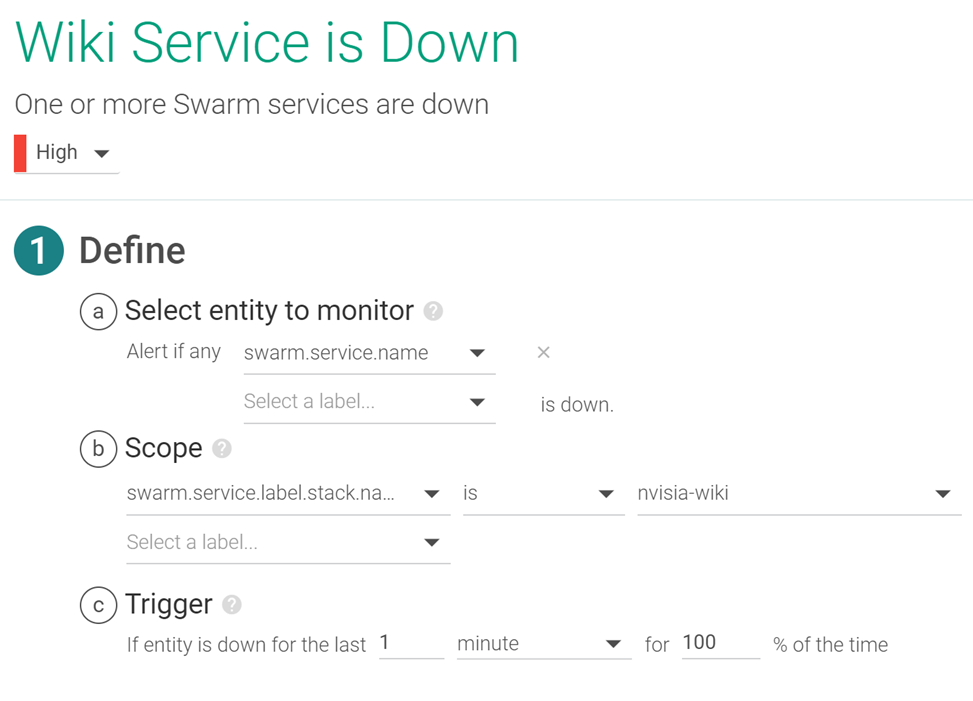
Figure 10 : Alerte d’arrêt du service Wiki
Comme le montre la capture d’écran précédente, nous pouvons voir la prochaine alarme. Cette alarme se déclenche si l’un des nœuds de notre cluster avec une étiquette de nœud de production est arrêté pendant plus de deux minutes. C’est là que vous devez considérer l’idée de fenêtres de maintenance. Vous pouvez configurer des fenêtres de maintenance de site pour les redémarrages du serveur afin que les alarmes soient ignorées pendant cette fenêtre. Si vous faites cela, vous pouvez utiliser des fenêtres beaucoup plus serrées pour l’échec que les deux minutes que j’ai ici. De plus, pour cette alarme, j’ai configuré un événement de capture, comme indiqué dans la capture d’écran suivante :
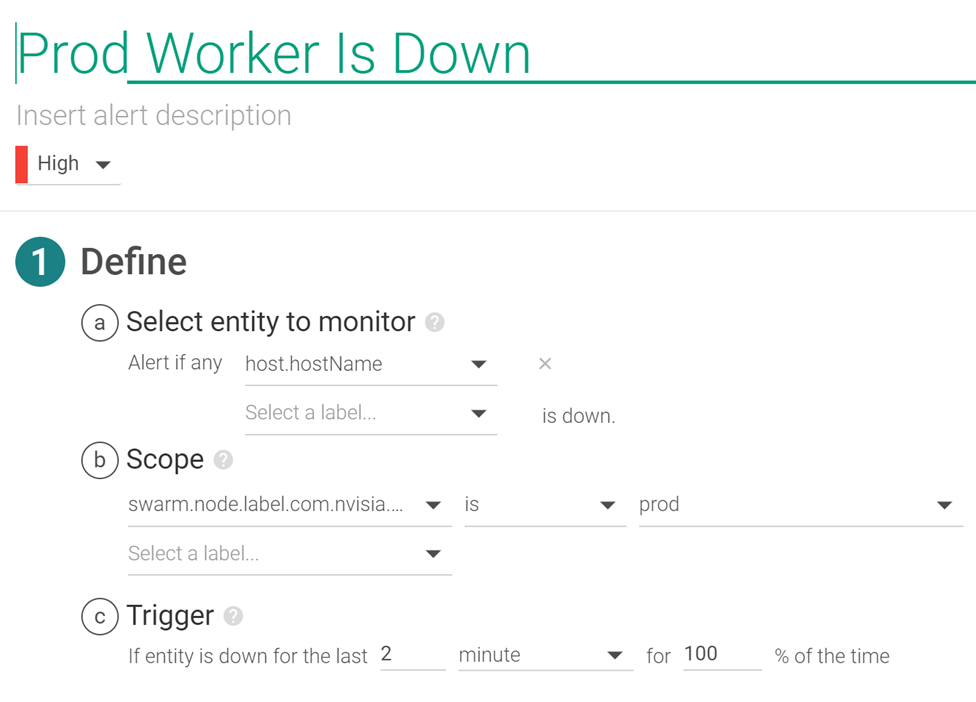
Figure 11 : le noeud Docker de production est en état d’alerte
Si le travailleur prod tombe en panne, nous capturerons tous les événements pour la période de 15 secondes avant la panne. Encore une fois, cela peut être très utile lorsque vous essayez de comprendre pourquoi les serveurs ont disparu :
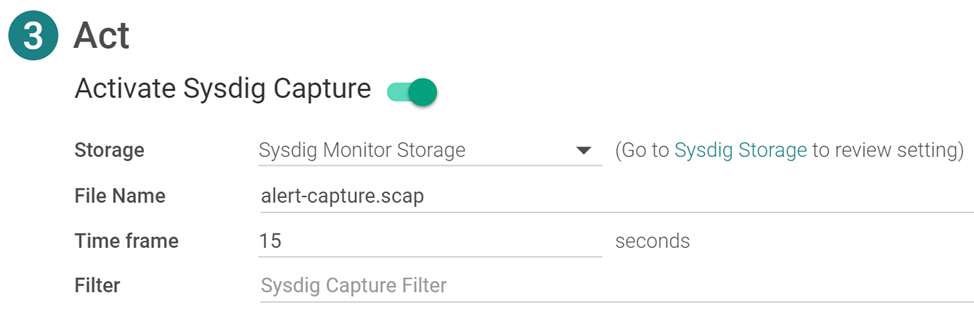
Figure 12 : Capturez tous les événements autour de l’événement Node Down
Notre dernière alarme est une alarme Swarm générale. Celui-ci semble un peu étrange, mais essentiellement, s’il y a un service sans tâche (un wrapper fin et l’unité atomique déployable de Swarm) fonctionnant pendant 3 minutes, cette alarme se déclenchera. La raison de ces 3 minutes est dans le cas où une grande image doit être extraite du registre. Tout en tirant l’image, la tâche sera à l’état de préparation :
Figure 13 : La tâche consiste à planifier une alerte d’exécution sans conteneur
2.3 Résumé
Nous avons commencé avec les journaux de base de Docker Engine où nous avons fourni une configuration par défaut recommandée pour le fichier etc / docker / daemon.json de votre Docker Engine . Sinon, vous devrez rouler / tronquer les fichiers journaux par vous-même. Si vous ne le faites pas, les journaux peuvent consommer l’intégralité du système de fichiers hôte et provoquer le verrouillage du système. Nous avons parlé de la journalisation centralisée et de son importance dans l’environnement en cluster, et en particulier avec les systèmes distribués.
Nous avons couvert deux approches open source de la journalisation et de la surveillance centrales, ainsi que le partage du rôle de l’UCP dans la surveillance et les journaux. Nous avons discuté de la pile ELK en tant que puissante solution de journalisation centrale. Ensuite, nous avons passé un certain temps à couvrir la surveillance avec Prometheus. Enfin, nous avons parlé d’une solution commerciale comme moyen de surveiller notre application pilote wiki.
Une chose qui est en quelque sorte intéressante ici est que si votre outil de surveillance fournit suffisamment d’informations pour réduire la concentration de votre problème, vous n’aurez peut-être pas besoin d’une journalisation centralisée. Par exemple, si un service se bloque et que vous êtes alerté, vous pouvez vous connecter à votre outil de surveillance, déterminer les circonstances entourant la disparition d’un conteneur spécifique et consulter les journaux de votre bundle UCP. Oui, vous pouvez utiliser une commande docker container logs sans vous connecter à un nœud spécifique sur lequel le conteneur était en cours d’exécution, car le bundle UCP vous permet de consulter les journaux ou de l’exécuter dans n’importe quel conteneur du cluster à partir de votre shell local connecté au bundle UCP . Alternativement, vous pouvez toujours revenir à l’interface utilisateur Web UCP une fois que vous avez les indices de diagnostic de votre premier outil de surveillance.
À ce stade de notre parcours, vous disposez de vos applications pilotes en cours d’exécution et d’une plate-forme pour les surveiller lorsque vos utilisateurs pilotes internes commencent à tester votre nouvelle plate-forme Docker Enterprise, ainsi que vos nouvelles compétences en matière de journalisation, de surveillance et de dépannage.
Ensuite, nous allons commencer à parler de la préparation de la production.
3 Première application en production avec Docker Enterprise
Préparer votre première application pour la production et préparer un cluster de production pour ses débuts en direct est une étape importante dans le processus d’adoption de conteneurs. C’est là que nous voyons des erreurs de recrue nuire à la réputation de technologues très intelligents. Dans un cas, sans exécuter la haute disponibilité (HA) pour la non-production, le client a construit son premier cluster HA pour la production, sans s’exercer d’abord avec le cluster non-production et l’a fait avec seulement deux nœuds de gestionnaires. S’ils avaient commencé dans la non-production, l’échec aurait été beaucoup moins visible (rappelez-vous, un nombre pair de managers signifie des problèmes)! Certaines leçons clés apprises ici ont été de garder vos architectures de cluster de non-production et de production très similaires et d’essayer toujours de nouvelles choses dans le cluster de non-production en premier.
Dans ce chapitre, nous examinerons des sujets importants liés à la sécurité et à la fiabilité du cluster de production Docker Enterprise, mais le contenu de ce chapitre est uniquement destiné à compléter vos pratiques de sécurité actuelles et non à les remplacer. Veuillez allouer suffisamment de temps aux examens de sécurité, aux analyses, aux tests de plume et aux audits avant le lancement. En fin de compte, la plupart des organisations trouvent que leurs plates-formes de conteneurs dépassent non seulement leurs normes de sécurité actuelles, mais elles sont également plus faciles à sécuriser.
Dans ce chapitre, nous couvrirons les sujets suivants :
- Considérations de conception pour une plateforme de production Docker Enterprise
- Stratégies de gestion des données de production
- Préparer la production de l’application pilote
- Maintenance et mise à jour de votre cluster de production
3.1 Cluster de production Docker Enterprise
Jusqu’à présent, dans notre parcours d’adoption de Docker Enterprise, nous avons travaillé avec notre cluster Docker Enterprise hors production. Il est maintenant temps de créer un cluster de production Docker Enterprise, en tenant compte de tout ce que nous avons appris de notre expérience pilote ainsi que des normes / politiques de sécurité d’entreprise actuelles et des sujets abordés dans ce chapitre.
Après avoir publié en interne notre application pilote, nous nous sommes familiarisés avec les nombreuses capacités et les défis du déploiement et des opérations d’applications basées sur des conteneurs. Nos pensées ont tendance à se déplacer vers des sujets tels que la gestion des données d’application basée sur des conteneurs (sauvegarde ou migration des données d’application), les mises à jour d’application, les mises à jour du logiciel Docker et les mises à jour du système d’exploitation du nœud hôte. Nous allons maintenant ajouter un cluster de production à ce mix. Comment tout cela fonctionnera-t-il?
3.1.1 Flux et concepts de cluster de haut niveau
Dans cette section, nous voulons établir une compréhension de notre chaîne d’approvisionnement de logiciels en examinant le cycle de vie de bout en bout d’une application lorsqu’elle passe en production. Cela devrait nous aider à visualiser la relation entre nos clusters de non-production et de production. Nous allons commencer avec un exemple d’organigramme de cluster de non-production à production :
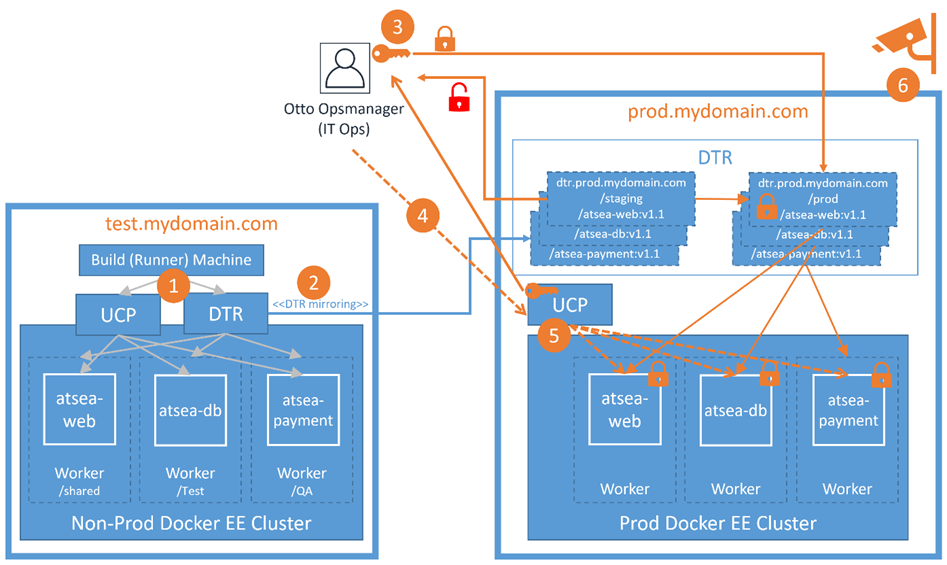
Chaîne d’approvisionnement de logiciels non-production à production
Sur le côté gauche, nous voyons notre cluster de non-production familier avec notre machine de génération, où nous hébergeons un runner GitLab. Le processus commence lorsque les développeurs poussent leurs modifications dans le contrôle du code source ; le runner GitLab crée et déploie des images dans le cluster non productif avec le Docker Trusted Registry (DTR) non productif et le plan de contrôle universel (UCP) (illustré à l’ étape 1 de la figure – Logiciels Supply Chain Non-Production to Production ). Finalement, les images sont testées et traversent le processus de promotion du référentiel pour se retrouver dans l’organisation DTR finale hors production, appelée QA.
Dans la figure — Chaîne d’approvisionnement de logiciels hors production en production, l’étape 2 illustre comment le référentiel de l’organisation QA (c’est-à-dire dtr.test.mydoamin.com/qa/atsea-web:v1.1) reflète les images vers le DTR de production.
3.1.1.1 Mise en miroir d’images
Dans l’étape 2 de la Figure-Software Chaîne d’approvisionnement non-production à la production, s’il vous plaît noter la ligne de connexion non-production DTR à la production DTR. Il s’agit d’un lien miroir DTR, une fonction DTR utilisée pour pousser (ou tirer) des images entre plusieurs DTR.
Dans notre cas, nous déplaçons notre image atsea-web du DTR hors production vers le référentiel intermédiaire dans le cluster de production DTR – dtr.prod.mydomain.com/staging/atsea- web: v1.1 . Lorsque vous utilisez des miroirs DTR, nous désignons une cible et un déclencheur, un peu comme une politique de promotion, mais au lieu d’ajouter simplement l’image à un autre référentiel local, l’image est poussée vers un registre DTR différent (dans notre cas, la production).
Dans la figure — Docker Trusted Registry Mirroring, nous voyons comment le miroir est configuré:

Mise en miroir du registre approuvé Docker
La mise en miroir peut être accomplie en poussant des images du registre source ou en tirant des images du registre cible. Dans notre exemple, nous nous éloignons du DTR hors production, mais cela nécessite de stocker les informations d’identification de production DTR dans les informations de mise en miroir de notre DTR hors production. Alternativement, nous aurions pu nous connecter à notre DTR de production et refléter un pull du repo QA DTR hors production. Cela peut être préféré par certains, car vous stockez ensuite les informations d’identification de non-production dans le DTR de production, qui est plus verrouillé.
Une dernière note sur la mise en miroir. Les métadonnées attachées à l’image, telles que les informations de signature, ne sont pas transmises au registre cible (pour le moment, cela peut changer). Par conséquent, dans notre exemple de flux précédent, nous signons l’image avec la clé de production UCP valide d’Otto après l’avoir poussée vers le DTR de production.
3.1.1.2 Signature d’ image
Revenons maintenant à la figure — Chaîne d’approvisionnement de logiciels hors production jusqu’à la production. Nous examinons l’étape 3, où Otto (le directeur des opérations) extrait l’image atsea-web non signée du référentiel d’organisation de mise en production du DTR de production, et redéfinit l’image pour la production à l’aide de la balise d’image docker dtr.prod.mydomain.com/ staging / atsea- Web: v1.1 dtr.prod.mydomain.com/ prod /atsea-web:v1.1 . Ensuite, à l’aide de cette clé de signature de cluster de production UCP, Otto signe numériquement l’image et pousse l’image signée vers le référentiel d’organisation de production du DTR, dtr.prod.mydomain.com/prod/atsea-web:v1.1 .
La configuration de la signature d’image peut être un peu fastidieuse. Le signataire doit installer le client notaire, ajouter le certificat UCP (de production), initialiser chacun des référentiels DTR cibles, faire pivoter leurs clés de cliché et s’assurer que les clés de délégation appropriées sont configurées pour les utilisateurs DTR du signataire.
Pour un joli didacticiel sur la signature d’images avec DTR à l’aide d’un pipeline GitLab à déploiement automatisé, consultez l’article d’Andy Clemenko: https://success.docker.com/article/secure-supply-chain#dockertrustedregistry .
3.1.1.3 Planification de la production UCP avec Docker Content Trust
Maintenant, nous examinons l’étape 4 de la figure — Non-production de la chaîne d’approvisionnement logicielle à la production, où Otto utilise son bundle client de production UCP pour mettre à jour les images de la pile de production existante à l’aide de la commande docker stack deploy -c docker-stack-prod.yml existing_stack_name . La dernière version du fichier production docker-stack-prod.yml utilisera les nouvelles balises d’image v1.1 signées, généralement à l’aide d’une variable d’environnement et d’un script. À ce stade, notre balise de référentiel est susceptible de correspondre à une balise de version système du code source pour la version de production, telle que la v1.1. Plus tard, lorsque vous arriverez à un déploiement de pipeline CI, vous pourrez utiliser $ {CI_COMMIT_TAG} de GitLab dans le fichier docker-stack-prod.yml .
Le code suivant est un exemple de fichier docker-stack-prod.yml dans lequel nous utilisons $ {CI_COMMIT_TAG} pour définir la version d’image correcte. Cela suppose que toutes les images des services atsea sont toutes balisées et construites avec la même balise de version que le référentiel atsea-deploy.
Dans le bloc de code suivant, nous montrons comment nous utilisons la variable $ {CI_COMMIT_TAG} pour définir la version d’image à déployer :
# atsea-deploy docker-stack-prod.yml
version: “3.7”
services:
database:
image: ${DTR_SERVER}/prod/atsea-db_build:${CI_COMMIT_TAG}
environment:
POSTGRES_USER: gordonuser
POSTGRES_DB_PASSWORD_FILE: /run/secrets/postgres_password
POSTGRES_DB: atsea
networks:
– back-tier
secrets:
– postgres_password
appserver:
image: ${DTR_SERVER}/prod/atsea-web_build:${CI_COMMIT_TAG}
networks:
– front-tier
– back-tier
– payment
<…>
Il y a quelques points importants à noter dans ce scénario de déploiement. Premièrement, la clé de signature qu’Otto utilise provient du cluster de production. Chaque cluster Docker UCP possède sa propre autorité de certification (CA) et, par conséquent, un jeu de clés différent. Par conséquent, nous ne pouvons pas utiliser les clés de signature du cluster de non-production dans le cluster de production ou vice-versa. Ceci est important car nous utilisons la fonction Docker Content Trust d’UCP pour limiter la planification des charges de travail dans le cluster de production. Nous n’autorisons que les images signées par un membre de l’équipe d’exploitation de l’UCP de production à laquelle appartient Otto. Par conséquent, sans la signature de production UCP d’Otto sur l’image, UCP n’aurait pas à la déployer sur le cluster de production.
Dans la capture d’écran suivante, nous voyons la boîte de dialogue Paramètres d’administration UCP avec l’onglet Docker Content Trust sélectionné :
Paramètre de confiance du contenu du plan de contrôle universel
Notez qu’un membre de l’équipe des opérations doit signer les images avant le déploiement. Docker Content Trust est une excellente fonctionnalité de sécurité, mais elle n’est pas toujours utilisée, du moins au départ. Heureusement, il existe une autre mesure pragmatique dans Docker Enterprise pour fournir une protection de base contre la falsification d’image.
3.1.1.4 Immuabilité pour les dépôts DTR
Alors que certaines organisations arrivent à maturité pour utiliser Content Trust, certaines organisations décident de ne pas utiliser la signature d’images dans leurs clusters de production. Dans cette situation, une fonctionnalité de sécurité pragmatique dans DTR est illustrée dans la figure — Docker Trusted Registry Immuability Setting, appelée immuabilité des balises, et elle est fortement recommandée pour les référentiels de production. Cela signifie que personne ne peut pousser un manifeste différent en utilisant le même nom de balise qu’une image existante. En fin de compte, cela rend plus difficile pour un “mauvais acteur” d’injecter des fichiers binaires néfastes en utilisant d’anciennes balises d’image de confiance. Notez que si la signature d’image avait été utilisée ici, cela aurait bloqué le déploiement de l’image falsifiée sur le cluster de production.
La fonctionnalité d’immuabilité de l’image ne fait qu’imposer une meilleure pratique générale de ne pas réutiliser les balises, comme la dernière balise. Lorsque vous réutilisez des balises, vous pouvez obtenir une version différente de l’image avec la même balise, en particulier dans un cluster avec de nombreux nœuds et chacun pouvant stocker de nombreuses anciennes versions. L’orchestrateur swarm de Docker Enterprise évite cette ambiguïté en ajoutant la balise avec le hachage sha unique de l’image. La seule façon dont il utilisera l’image en cache est s’il s’agit d’une correspondance hachée. Voici un exemple de nom d’image utilisé dans UCP: dtr.mydomain.com/test/atsea-web_build:RC-test@sha256:547e4e568593fd98b5d824f6fa76e0ee1da8b7644b953b02030505f63c1e108b .
La capture d’écran ci – dessous DTR immuabilité étant tourné sur :

Docker Trusted Registry Immuability Setting
Enfin, de retour dans notre diagramme de cluster, nous voyons l’icône de la caméra en haut à droite de la figure — Chaîne d’approvisionnement de logiciels hors production à la production. Cela représente certains outils supplémentaires utilisés dans un environnement de production. Dans notre cas, nous allons voir rapidement comment la plate-forme Sysdig Secure aide à maintenir un environnement de production sécurisé. Nous en reparlerons un peu plus tard.
3.1.1.5 Numérisation d’images en production
La numérisation d’images dans votre cluster de production est une très bonne idée. Docker Enterprise Advanced possède quelques fonctionnalités de numérisation importantes. Il met à jour sa base de données de vulnérabilités tous les soirs, puis examine tous les composants d’image dans DTR à la recherche de vulnérabilités inconnues auparavant. En d’autres termes, une image peut être nettoyée aussi propre lors de la première analyse, mais des vulnérabilités ultérieures peuvent avoir été découvertes. La version avancée de Docker Enterprise de DTR peut vous alerter des nouvelles vulnérabilités à mesure qu’elles sont découvertes dans votre registre et mettre en évidence les services / conteneurs en cours d’exécution qui exécutent des images vulnérables dans votre cluster (de production).
La capture d’écran suivante montre les résultats de l’analyse DTR de notre service de paiement atsea. Il révèle deux vulnérabilités majeures :
Analyse d’images de registre approuvée par Docker
La capture d’écran suivante montre comment les vulnérabilités sont révélées dans UCP avec notre pile d’applications atsea. Nous voyons non seulement tous les problèmes, mais le service de paiement montre les deux principales vulnérabilités de DTR:

Services UCP montrant des vulnérabilités d’image
En résumé, cela illustre un flux Docker Enterprise simple mais typique de l’air pour une première application de production. Nous promouvons en toute sécurité les images d’un cluster hors production vers un cluster de production. Nous suggérons une méthode de déploiement manuel – dans ce cas, Otto la gère – pour les déploiements initiaux des applications de production. Une fois que votre équipe est à l’aise avec cette approche, il est assez facile de créer une version de production de votre pipeline de déploiement à l’aide de l’ensemble client UCP de production.
Maintenant que nous comprenons le flux, parlons de la configuration du cluster de production.
3.1.2 Considérations relatives au cluster de production
À mesure que vous passez à la production, votre niveau de sophistication et de compréhension augmentera naturellement. Par conséquent, au fur et à mesure que vous découvrez de nouvelles options et fonctionnalités dans la phase de production de votre parcours, vous devez d’abord envisager de les appliquer dans votre cluster hors production. Encore une fois, nous devons tester autant que possible avec notre cluster hors production avant de l’appliquer à notre environnement de production.
Au fur et à mesure que vous vous éloignez du pilote, il peut être tentant de configurer plusieurs clusters supplémentaires. Après tout, nous sommes habitués à avoir des environnements distincts pour le développement, le test, l’assurance qualité, la mise en scène et la production. Prenez le temps de configurer UCP RBAC avec l’isolement des nœuds afin de n’avoir besoin que de deux nœuds, non-production et production.
3.1.2.1 Éviter l’étalement des clusters
Au chapitre 2 , Docker Enterprise – an Architectural Overview , nous avons parlé d’une conception à deux clusters (non-production et production), par opposition à la création de clusters de développement, de test, d’assurance qualité, de transfert et de production séparés. Encore une fois, cela est possible grâce aux systèmes de contrôle d’accès basés sur les rôles Docker Enterprise et Kubernetes, qui imposent l’isolation des ressources dans les clusters Docker Enterprise. L’utilisation de fonctionnalités telles que l’isolement avancé de cluster Docker Enterprise permet d’éviter l’étalement du cluster et un grand nombre de serveurs sous-utilisés.
Au début, les équipes de développement natives du cloud pensaient qu’il serait facile de faire tourner et de fermer leurs clusters. Cependant, ils ont rapidement appris que les clusters, au moins les nœuds de gestionnaire et de maître, ressemblent beaucoup plus aux animaux de compagnie qu’aux bovins.
L’histoire raconte que bon nombre de ces grappes sont restées plus longtemps que prévu. Cependant, les principaux contributeurs à l’étalement des clusters semblent être un manque de sécurité et notre compréhension de la sécurité des clusters. Par conséquent, pour la plupart des organisations, l’accès aux clusters est une proposition tout ou rien. Donc, si vous avez un certificat / clé pour accéder aux nœuds maître / gestionnaire d’un cluster, vous disposez de privilèges illimités. Ce contrôle à grain fin a rendu les équipes réticentes à partager leurs clusters avec d’autres équipes et il y avait donc des clusters partout.
3.1.2.2 Considérations de production-installation
Si nous suivons les meilleures pratiques lors de la configuration de notre environnement pilote, nous avons déjà de l’expérience dans la configuration et l’exploitation d’au moins trois nœuds de gestionnaire pour une configuration à haute disponibilité. Le but de cette section est donc de s’appuyer sur nos connaissances et notre expérience du pilote, en répétant fondamentalement ce que nous avons fait avec le cluster pilote, mais en ajoutant quelques éléments supplémentaires à notre liste de considérations importantes.
Un anti-modèle dans le passage de la phase pilote à la phase de production est de décider de ne pas maintenir une configuration à haute disponibilité pour la non-production. C’est généralement une mauvaise idée. L’une des raisons est que vous avez besoin de pouvoir pratiquer et / ou valider vos mises à jour, sauvegardes et procédures de récupération par rapport à un cluster identique, hors production. Si vos clusters manquent de symétrie suffisante entre les clusters de non-production et de production (c’est-à-dire la haute disponibilité), vous aurez deux ensembles de procédures ponctuelles. C’est pourquoi nous recommandons fortement de les garder aussi similaires que possible.
Une question que nous entendons souvent est: ai-je vraiment besoin d’une haute disponibilité pour mon cluster hors production? La réponse est généralement oui. Le cluster de non-production devient souvent plus occupé et plus grand que le cluster de production. Sans haute disponibilité, le cluster devra être mis hors ligne pour toute sorte de maintenance, y compris les mises à jour de routine. Cela est généralement inacceptable, en particulier lorsque vous entrez dans des rendez-vous d’ intégration et de test continus sur votre cluster hors production.
3.1.2.3 Nœuds du gestionnaire de production
La première question est : de combien de nœuds de gestionnaire avez-vous besoin en production ? Trois est généralement un bon point de départ, mais vous devez garder à l’esprit ce que cela signifie en termes de tolérance aux pannes. Par exemple, avec trois nœuds de gestionnaire, votre tolérance aux pannes n’est qu’un seul nœud de gestionnaire. Cela signifie que nous pouvons retirer un gestionnaire pour la maintenance et les mises à jour pendant que les deux autres continuent. Cependant, si quelque chose devait arriver à l’un des deux gestionnaires restants alors que le troisième était en cours de maintenance, les gestionnaires perdraient le quorum (ils n’ont pas le minimum de deux votes nécessaires pour qu’un groupe de consensus de radeau apporte des modifications au cluster) et vous serez impossible d’apporter des modifications au cluster. Si vous perdez le quorum, tous vos services et conteneurs continueront de fonctionner, mais vous ne pourrez pas apporter de modifications au cluster.
Le tableau suivant est un résumé de la tolérance aux pannes d’un cluster en fonction du nombre de gestionnaires d’essaims. Il s’agit du guide d’ administration de l’essaim de documents de Docker ( https://docs.docker.com/engine/swarm/admin_guide/ ):
| Nombre de managers | Majorité | Tolérance aux pannes |
|---|---|---|
| 1 | 1 | 0 |
| 3 | 2 | 1 |
| 5 | 3 | 2 |
| 7 | 4 | 3 |
| 9 | 5 | 4 |
Pour de nombreuses organisations, la configuration à trois nœuds est généralement acceptable. Cependant, certaines entreprises ont besoin que leur environnement de production soit solide comme le roc et / ou apporte des changements fréquents à leurs services. Dans cette situation, envisagez de passer à une configuration à cinq administrateurs, ce qui vous permet de tolérer la perte de deux administrateurs. En règle générale, il n’est pas nécessaire d’aller au-delà de cinq nœuds jusqu’à ce que vous fonctionniez à très grande échelle.
3.1.2.4 Dimensionnement des nœuds
Sans suivre le modèle d’adoption agile prescrit qui comprend une approche d’adoption de PoC, pilote et de production, cette étape peut être très intimidante. Imaginez si vous commenciez votre adoption de Docker Enterprise en construisant un cluster de production, sans avoir l’expérience de l’exécution de votre première application pilote interne.
Nous avons été dans cette situation avec des clients, confrontés à leur angoisse lorsque nous ne pouvons pas utiliser notre boule de cristal pour leur dire exactement la quantité de matériel dont ils auront besoin pour leur cluster. C’est une raison importante pour laquelle nous recommandons fortement la surveillance dans le cadre de la phase pilote.
Lorsque nous avons commencé à mettre en œuvre notre plate-forme pilote, nous avons juste pris une supposition sur certaines spécifications matérielles intermédiaires et avons commencé là-bas. Les enjeux étaient relativement faibles et nous nous sommes permis d’échouer car c’était un pilote. Lorsque nous sommes passés à la production , nous avons vu notre cluster fonctionner dans notre environnement lors de l’exécution de notre application pilote et nous avons collecté des métriques de base en utilisant notre plateforme de surveillance. Le processus d’adoption agile nous a bien positionnés pour notre premier déploiement d’application de production!
Dans la figure — Tendances des ressources Sysdig pour l’application pilote , nous avons nos mesures de performances de cluster:
Tendances des ressources Sysdig pour l’application pilote
Docker répertorie les exigences et recommandations suivantes pour les nœuds de gestionnaire Universal Control Plane (UCP) et les nœuds DTR (travailleur) :
| UCP | DTR |
Exigences UCP minimales :
|
Exigences minimales de DTR :
|
Exigences de production recommandées :
|
Exigences DTR de production recommandées :
|
Si vous prévoyez de numériser des images, tenez compte au minimum des exigences de production recommandées par le DTR. Plus précisément, pour éviter les problèmes d’échec ou de sauvegarde des travaux de numérisation DTR, vous aurez besoin d’au moins 16 Go de RAM.
Armé de vos mesures de cluster pilote non prod et des directives de Docker pour les nœuds de gestionnaire et DTR, vous devriez être en mesure de dimensionner en toute confiance vos nœuds de cluster.
Enfin, utilisez des SSD si possible pour les disques de production, en particulier pour le point de montage / var / lib / docker / swarm. Il s’agit du répertoire swarm et il stocke l’état swarm. Nous voulons que les mises à jour soient traitées avec une latence minimale.
3.1.2.5 Considérations de configuration et d’installation
Plutôt que de partir de zéro, nous pouvons construire à partir des processus que nous avons utilisés pour créer le cluster de non-production. Nous n’allons pas répéter cela ici. Cependant, nous allons parler de quelques considérations supplémentaires pour votre cluster de production.
3.1.2.5.1 Repères de docker du Centre for Internet Security (CIS)
Après avoir préparé vos nœuds et installé le moteur Docker Enterprise sur vos nœuds de cluster, ce serait une bonne idée d’exécuter une référence CIS sur chacun des nœuds et d’examiner les résultats avec votre équipe de sécurité. CIS est une organisation à but non lucratif dédiée à la promotion des meilleures pratiques de cyber-défense. Ils fournissent le cadre pour développer des tests pour des plates-formes spécifiques, telles que Docker. Dans notre cas, le benchmark a été produit par la communauté Docker.
Le code suivant est un exemple de rapport CIS Docker Benchmark. Commencez avec la commande Docker suivante pour exécuter le rapport :
# https://github.com/docker/docker-bench-security
$ docker run -it –net host –pid host –userns host –cap-add audit_control \
-e DOCKER_CONTENT_TRUST=$DOCKER_CONTENT_TRUST \
-v /var/lib:/var/lib \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /usr/lib/systemd:/usr/lib/systemd \
-v /etc:/etc –label docker_bench_security \
docker/docker-bench-security
La première partie de la sortie affiche les informations de version et la section de rapport de configuration d’hôte:
# — Summarized for Docker Enterprise Book Listing! —
# —————————————————————————— # Docker Bench for Security v1.3.4 /etc:/etc –label docker_bench_security d #
# Docker, Inc. (c) 2015-
#
# Checks for dozens of common best-practices around deploying Docker containers in production.
# Inspired by the CIS Docker Community Edition Benchmark v1.1.0.
# ——————————————————————————
Initializing Wed Feb 13 14:16:31 UTC 2019
[INFO] 1 – Host Configuration
…
[WARN] 1.6 – Ensure auditing is configured for Docker files and directories – /var/lib/docker
[WARN] 1.7 – Ensure auditing is configured for Docker files and directories – /etc/docker
[WARN] 1.8 – Ensure auditing is configured for Docker files and directories – docker.service
[WARN] 1.9 – Ensure auditing is configured for Docker files and directories – docker.socket
…
Jetons un coup d’œil à quelques points saillants de notre sortie de référence CIS, à commencer par 1 – Configuration de l’hôte. Il existe une variété de messages d’information omis, mais nous voulions souligner les avertissements 1.6 à 1.9, liés à l’audit ou à des répertoires spécifiques. Nous voulons nous assurer qu’aucun conteneur ne monte ces répertoires et n’altère leur contenu. C’est quelque chose que nous pouvons facilement surveiller avec des outils tels que Sysdig Secure, Aqua Security ou Twistlock. Plus loin dans le chapitre 9 , Rubriques importantes de production de Docker Enterprise , dans la section Surveillance de la production , nous verrons comment Sysdig Secure surveille toute activité d’écriture dans ces répertoires spéciaux avec une stratégie sensitive_mount :
[INFO] 2 – Docker daemon configuration
…
[INFO] 3 – Docker daemon configuration files
…
[INFO] 4 – Container Images and Build File
[WARN] 4.1 – Ensure a user for the container has been created
[WARN] * Running as root: sysdig-agent
[WARN] * Running as root: gitlab-runner
…
[INFO] 5 – Container Runtime
[WARN] 5.1 – Ensure AppArmor Profile is Enabled
[WARN] * No AppArmorProfile Found: sysdig-agent
[WARN] * No AppArmorProfile Found: gitlab-runner
[WARN] 5.2 – Ensure SELinux security options are set, if applicable
[WARN] * No SecurityOptions Found: gitlab-runner
[PASS] 5.3 – Ensure Linux Kernel Capabilities are restricted within containers
[WARN] 5.4 – Ensure privileged containers are not used
[WARN] * Container running in Privileged mode: sysdig-agent
…
La section 4, Images de conteneur et fichier de construction, fait référence à la meilleure pratique d’utilisation d’utilisateurs non root pour s’exécuter à l’intérieur des conteneurs. De nombreuses images officielles créent des utilisateurs non root (vous pouvez le voir dans leur fichier Docker) pour une exécution binaire dans leur conteneur, comme l’image officielle Postgres Dockerfile:
[INFO] 6 – Docker Security Operations
[INFO] 6.1 – Avoid image sprawl
[INFO] * There are currently: 48 images
[INFO] 6.2 – Avoid container sprawl
[INFO] * There are currently a total of 62 containers, with only 3 of them currently running
…
[INFO] 7 – Docker Swarm Configuration
[WARN] 7.1 – Ensure swarm mode is not Enabled, if not needed
[PASS] 7.2 – Ensure the minimum number of manager nodes have been created in a swarm
[WARN] 7.3 – Ensure swarm services are binded to a specific host interface
[WARN] 7.4 – Ensure data exchanged between containers are encrypted on different nodes on the overlay network
[WARN] * Unencrypted overlay network: atsea-web-46141311_front-tier (swarm)
[WARN] * Unencrypted overlay network: ingress (swarm)
Voici un exemple de configuration de l’utilisateur pour l’ image de base officielle de postgres :
# https://github.com/docker-library/postgres/11/Dockerfile
# explicitly set user/group IDs
RUN set -eux; \
groupadd -r postgres –gid=999; \
# https://salsa.debian.org/postgresql/postgresql-common/blob/997d842ee744687d99a2b2d95c1083a2615c79e8/debian/postgresql-common.postinst#L32-35
useradd -r -g postgres –uid=999 –home-dir=/var/lib/postgresql –shell=/bin/bash postgres; \
Dans le script de démarrage postgres (docker-entrypoint.sh), la commande gosu est utilisée pour s’exécuter en tant qu’utilisateur postgres (même UID) tel que configuré à l’intérieur du conteneur.
En configurant et en exécutant un utilisateur non root à l’intérieur d’un conteneur, vous atténuez les dégâts d’une attaque en petits groupes. Une attaque en petits groupes est très rare, mais une faille récente dans runc ( https://nvd.nist.gov/vuln/detail/CVE-2019-5736 ) nous rappelle qu’ils sont réels. Lorsqu’un processus est capable de sortir de l’isolement du conteneur, il peut accéder à l’hôte. Il s’agit clairement d’une mauvaise situation, mais très mauvaise si le processus de conteneur s’exécutait en tant que root. Si un processus de conteneur exécuté en tant que root sort de l’isolement, il deviendra root sur l’hôte et votre sécurité sera compromise. D’un autre côté, si le processus en petits groupes s’exécute en tant qu’utilisateur non root et que l’utilisateur non root n’est pas configuré sur l’hôte, le processus en petits groupes n’aura aucun privilège. C’est la motivation pour s’exécuter en tant qu’utilisateur non root à l’intérieur d’un conteneur.
Il y a certains sujets que vous voudrez mettre à jour votre équipe d’opérations de sécurité dès que possible. De plus, dans l’esprit de devenir un utilisateur averti, je voudrais évaluer une des plates-formes de sécurité des conteneurs leaders de l’industrie, y compris, mais sans s’y limiter, Sysdig Secure, Twistlock et Aqua Security. Le simple fait de jouer avec ces outils dans votre cluster hors production sera très instructif !
3.1.2.5.2 Verrouillage de l’accès SSH
Une mauvaise habitude des premiers utilisateurs de Docker était de donner librement accès SSH aux nœuds Docker. Cela était compréhensible, car de nombreux premiers déploiements Docker étaient des initiatives dirigées par les développeurs et, par conséquent, les développeurs avaient besoin d’un accès à distance aux nœuds Docker tout au long de la production. Cependant, vous adoptez maintenant Docker Enterprise pour opérationnaliser vos environnements Docker. Par conséquent, les seuls utilisateurs qui devraient avoir accès via SSH aux systèmes de production sont les opérateurs chargés de la maintenance, tels que les correctifs du système d’exploitation et les mises à jour de Docker Engine. En dehors de ces opérateurs, tous les autres accès doivent être gérés via les bundles clients Docker UCP pour tirer parti du contrôle d’accès et des audits basés sur les rôles de Docker Enterprise.
3.1.2.5.3 Pas d’accès public aux nœuds Docker
Pendant le PoC, nous avons configuré notre hôte avec une adresse IP publique (si vous vous souvenez, c’était une configuration cloud). C’était une question pratique, afin que nous puissions facilement SSH dans chaque nœud pour installer et configurer Docker. Dans notre configuration pilote, tous les accès externes au cluster étaient acheminés via un pare-feu, puis un équilibreur de charge interne. Cela comprenait l’accès UCP, DTR, Kubernetes API distant, ainsi que l’accès à toute application exécutée dans le cluster. Notre exemple de cluster Docker s’exécute également sur son propre sous-réseau et contrôle tous les accès via l’interface du sous-réseau avec les règles de pare-feu.
Figure – Infrastructure de plate-forme pilote, fournit un examen de notre infrastructure de plate-forme pilote :
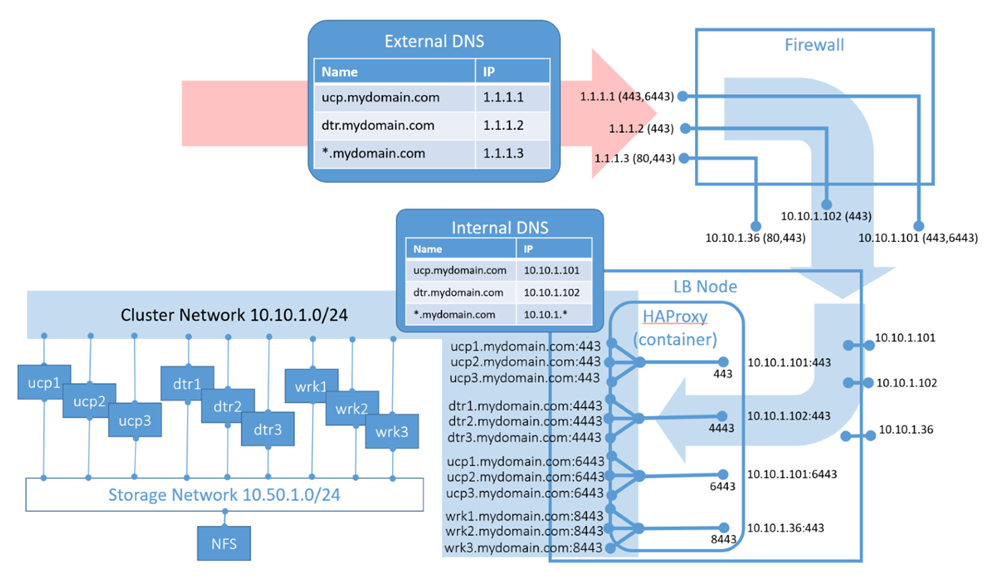
Infrastructure de la plate-forme pilote
Remarquez que tout le trafic entre le cluster à travers le LB nœud. Tout le trafic réseau externe se résout en adresses IP publiques de pare-feu et est NAT-ed aux adresses IP internes des nœuds LB. L’accès interne est géré avec DNS partagé et résolu directement aux adresses IP internes des nœuds LB.
3.1.2.5.4 Configuration UCP de production
Lorsque vous commencez avec votre UCP de production, vous pouvez commencer par un instantané de votre cluster hors production en tirant parti de la fonction de fichier de configuration d’UCP. Vous pouvez modifier le fichier et l’utiliser pour installer UCP dans le cluster de production.
Cela vous évite la frustration de cliquer sur l’interface utilisateur Web UCP. Une explication de toutes les options de configuration UCP suivantes peut être trouvée ici: https://docs.docker.com/ee/ucp/admin/configure/ucp-configuration-file/#configuration-options .
Le bloc de code suivant montre le processus de conversion d’un fichier de configuration UCP à partir d’un nœud de gestionnaire à l’aide d’un ensemble de certificats client UCP :
# cd into the folder where you unzipped a UCP Admin’s client bundle
# get the test configuration file from the test UCP using an UCP Admin’s certs and private key files
$ curl –cacert ca.pem –cert cert.pem –key key.pem https://ucp.test.mydomain.com/api/ucp/config-
toml > ucp-config.toml
Examinons maintenant la sortie de la section auth qui décrit les paramètres d’accès au système et d’autorisation:
# List the contents of the ucp-config.toml file
$ cat ucp-config.toml
[auth]
default_new_user_role = “restrictedcontrol”
backend = “managed”
samlEnabled = false
samlLoginText = “”
[auth.sessions]
lifetime_minutes = 60
renewal_threshold_minutes = 20
per_user_limit = 10
[auth.saml]
idpMetadataURL = “”
spHost = “”
rootCerts = “”
tlsSkipVerify = false
Ici, nous voyons comment UCP est intégré à DTR:
[[registries]]
host_address = “dtr.test.mydomain.com”
service_id = “8c599992-8996-43b5-b511-f26c94631fea”
ca_bundle = “—–BEGIN CERTIFICATE—–\n …<<SNIP-REMOVED>>… o=\n—–END CERTIFICATE—–\n”
batch_scanning_data_enabled = true
[scheduling_configuration]
enable_admin_ucp_scheduling = false
default_node_orchestrator = “swarm”
[tracking_configuration]
disable_usageinfo = true
disable_tracking = true
anonymize_tracking = false
cluster_label = “”
Voici la section avec les paramètres d’approbation de contenu :
[trust_configuration]
require_content_trust = false
[log_configuration]
level = “INFO”
[audit_log_configuration]
level = “”
support_dump_include_audit_logs = false
[license_configuration]
auto_refresh = false
[cluster_config]
controller_port = 443
kube_apiserver_port = 6443
swarm_port = 2376
swarm_strategy = “spread”
kv_timeout = 5000
kv_snapshot_count = 20000
profiling_enabled = false
external_service_lb = “ucp.test.mydomain”
metrics_retention_time = “24h”
metrics_scrape_interval = “1m”
rethinkdb_cache_size = “1GB”
cloud_provider = “”
cni_installer_url = “”
pod_cidr = “192.168.0.0/16”
calico_mtu = “1480”
ipip_mtu = “1480”
unmanaged_cni = false
nodeport_range = “32768-35535”
azure_ip_count = “”
local_volume_collection_mapping = false
manager_kube_reserved_resources = “cpu=250m,memory=2Gi,ephemeral-storage=4Gi”
worker_kube_reserved_resources = “cpu=50m,memory=300Mi,ephemeral-storage=500Mi”
Bien que l’une de ces valeurs puisse être modifiée, n’oubliez pas que nous voulons que nos clusters soient aussi similaires que possible. Dans cet esprit, nous vous guiderons à travers le fichier et mettrons en évidence les éléments d’intérêt particulier lors de votre passage en production :
| Élément de configuration | La description | commentaires |
| default_new_user_role = “restrictedcontrol” | Le rôle que les nouveaux utilisateurs obtiennent pour leurs ensembles de ressources privés. Les valeurs sont admin, viewonly , scheduler , restrictedcontrol ou fullcontrol . La valeur par défaut est restrictedcontrol . | Pour votre cluster de production, vous souhaiterez peut-être afficher par défaut uniquement . Nous ne devrions pas avoir d’utilisateurs exécutant des charges de travail dans leur collection privée (sandbox) sur le cluster de production. |
| backend = “géré” | Le nom du backend d’autorisation à utiliser est managé ou ldap . La valeur par défaut est gérée. | Vous souhaitez qu’un petit nombre d’utilisateurs ait accès au cluster de production. Envisagez de gérer, en utilisant une base de données utilisateur intégrée UCP. Cela peut aider à éviter les erreurs LDAP et le problème de provisionnement utilisateur juste à temps où les utilisateurs LDAP révoqués peuvent toujours accéder au cluster à l’aide de leur bundle client UCP. |
| [[registres]] tableau | Un tableau de tables qui spécifie les instances DTR que l’instance UCP actuelle gère. | Ignorez ceci à car DTR n’est pas encore installé. |
| require_content_trust = false | Défini sur true pour exiger que les images soient signées par approbation de contenu. La valeur par défaut est false. | Comme indiqué dans la section de signature d’images de ce chapitre, la définition de la valeur true ne permettra que les images signées de s’exécuter dans votre cluster. Vous définirez l’option require_signature_from pour désigner qui doit signer les images. |
| [audit_log_configuration] section | Configure les options de journalisation d’audit pour les composants UCP. | Il s’agit souvent d’une demande à la production lorsque la conformité est impliquée. S’il est utilisé, envisagez d’envoyer un pilote personnalisé pour que les journaux du contrôleur UCP soient envoyés au serveur distant et sécurisé. Si vous ne les expédiez pas, assurez-vous que les journaux standard sont tournés et tronqués car ils deviendront volumineux. Chaque action HTTP est enregistrée dans un audit ! |
| table log_configuration | Configure les options de journalisation pour les composants UCP. | Si vous n’utilisez pas de schéma de journalisation central pour votre Docker Engine, vous souhaiterez peut-être envoyer des journaux pour le composant UCP à un emplacement distant en configurant cette section. |
| enable_admin_ucp_scheduling = false | Définissez sur true pour permettre aux administrateurs de planifier des conteneurs sur les nœuds de gestionnaire. La valeur par défaut est false . | Nous ne voulons pas de charges de travail sur le directeur de production ou les maîtres. |
| [tracking_configuration] | Spécifie les données d’analyse qu’UCP collecte. | Nous les désactivons généralement pour les clusters de production. |
C’est une très bonne idée d’utiliser des certificats clients tiers d’une autorité de confiance pour UCP et DTR. Cela nous évitera d’utiliser des paramètres TLS ou non fiables. Après avoir installé votre Doctor Trusted Registry dans le cluster de production, assurez-vous d’accéder aux paramètres de planification UCP et d’interdire les charges de travail sur les serveurs DTR pour éviter les conflits de ressources. Ceci est particulièrement important si vous exécutez la numérisation d’images DTR.
3.1.2.5.5 Configuration DTR de production
Nous avons discuté d’un certain nombre de points liés à la configuration de production du DTR. Un déploiement de production typique comprendrait trois réplicas DTR pour la haute disponibilité, l’utilisation d’un certificat tiers d’une autorité de certification approuvée et les référentiels auraient l’immuabilité des balises activée. Enfin, les trois répliques DTR seraient liées au cluster de production et exécutées au sein du cluster de production. J’en parle parce que l’on nous demande souvent de partager un DTR entre les deux clusters.
Vous pouvez essayer de partager votre DTR de non-production entre les clusters de non-production et de production (ou vice versa), mais nous vous suggérons fortement de ne pas partager même un DTR HA entre les clusters. Bien que cela semble possible en théorie, il y a une bonne quantité de cohésion en ce qui concerne l’orchestrateur UCP tirant des images vers des nœuds de cluster. Vous ne voulez pas vous connecter à DTR à partir de chaque nœud de cluster en tant qu’administrateur pour extraire des images. Il est donc à la fois mal avisé et non soutenu. Sans oublier que vous souhaitez pouvoir tester les mises à jour sur votre cluster hors production avant de passer en production.
3.2 Gestion des données
L’un des sujets les plus difficiles liés au déploiement d’applications conteneurisées est la gestion des données. Il existe différentes approches pour gérer les volumes de conteneurs dans un environnement en cluster. Certains modèles sont simples et directs, mais manquent de flexibilité. D’autres conceptions sont très sophistiquées, mais comportent de nombreuses pièces mobiles à aligner. La plupart du temps, la réponse se situe quelque part au milieu.
3.2.1 Montages du volume hôte
Une approche simple et directe pour gérer la persistance des données de conteneur dans un cluster consiste à utiliser un volume monté sur l’hôte. En résumé, l’orchestrateur planifie de façon aléatoire le conteneur pour qu’il s’exécute sur le nœud A de votre cluster. Lorsqu’un conteneur s’exécute, il monte un répertoire spécifié sur le système de fichiers du nœud A et écrit ses données. Très simple, mais que se passe-t-il si l’orchestrateur redéploie le conteneur sur un nœud différent lors de sa prochaine exécution ? Lorsque le nouveau conteneur démarre sur le nœud B, il trouvera un volume vide car ses données sont toujours de retour sur le nœud A, où il a été exécuté la dernière fois. Heureusement, il existe un moyen de faire en sorte que cela fonctionne.
Swarm et Kubernetes ont tous deux des mécanismes qui limitent ou persuadent le placement des conteneurs par l’orchestrateur sur les nœuds de cluster. Ils étiquettent les nœuds du cluster, puis demandent à l’orchestrateur de faire correspondre ces étiquettes lors de la planification des conteneurs dans le cluster.
Dans le bloc de code suivant, nous ajoutons une étiquette com.mydomain.wiki.stage = prod3 au travailleur # 3 dans notre cluster de production:
$ docker node update –label-add com.mydomain.wiki.stage=prod3 prod-wrk-3.mydomain.com
Nous montrons le fichier de pile pour déployer notre application sur le travailleur # 3 en utilisant l’étiquette com.mydomain.wiki.stage = prod3 comme contrainte de déploiement. Remarquez la section deploy: placement: contraintes: et comment nous l’avons ajoutée à la fois à notre service wiki et à la base de données postgres . Cela garantit que la base de données s’exécute toujours sur le même nœud et peut trouver ses données. Nous avons placé le wiki sur le même nœud pour deux raisons. La première raison est la faible latence du réseau, car ils sont sur le même nœud et le trafic ne quitte jamais l’interface hôte. La deuxième raison est que l’application Wiki doit également monter le système de fichiers hôte pour enregistrer les magasins de documents pour les utilisateurs.
Le bloc de code suivant montre le fichier YAML de la pile Docker pour le déploiement du wiki et la pile postgres sur le noeud de production # 3:
version: ‘3.5’
services:
wiki:
image: dtr.prod.mydomain.com/pilot/wiki:v1.1.2
volumes:
– /var/local/atlassian-data:/opt/j2ee/domains/mydomain.com/wiki/webapps/atlassian-confluence/data/
ports:
– 8080:8080
networks:
– wiki_net
deploy:
placement:
constraints:
– node.labels.com.mydomain.wiki.stage==prod3
postgres:
image: dtr.nvisia.io/pilot/postgress:v1.0.1
environment:
– POSTGRES_PASSWORD=JnB8nUuT
volumes:
– /var/local/wiki-db-data:/var/lib/postgresql/data
– /var/local/wiki-init-data:/docker-entrypoint-initdb.d
networks:
– wiki_net
deploy:
placement:
constraints:
– node.labels.com.mydomain.wiki.stage==prod3
networks:
wiki_net:
Gardez à l’esprit que le point de montage de l’hôte peut être soit un dossier dans le système de fichiers hôte, soit un périphérique monté sur l’hôte. Cela signifie que nous pourrions avoir nos données de conteneur stockées dans un périphérique de stockage en bloc monté (éventuellement portable) ou tout autre type de stockage réseau qui utilise un point de montage hôte comme interface. Oui, cela signifie que vous pouvez héberger le montage d’un périphérique de fichier / bloc NFS, NAS, SAN ou iSCSI.
Veuillez noter que si vous hébergez le montage NFS de la manière standard, où vous mappez votre point de montage local dans un dossier spécifique sur l’hôte NFS au moment du montage, vous aurez besoin de montages séparés pour chaque dossier NFS isolé et c’est un peu maladroit. Ainsi, dans la section suivante, nous parlerons d’une approche plus flexible pour tirer parti de NFS à l’aide d’un plug-in de volume Docker.
3.2.2 Plugin de volume Docker NFS
L’approche suivante tire parti d’un système de fichiers basé sur un cluster, dans ce cas NFS. Il s’agit d’une option très populaire pour les implémentations sur site où vous avez un contrôle total sur le réseau. Pour les implémentations cloud où vos voisins bruyants peuvent provoquer une latence du réseau, vous devriez envisager une solution alternative conçue pour une plateforme cloud. Nous parlerons de certaines options dans la section suivante, Autres solutions de stockage en volume.
Pour utiliser le plug-in de volume NFS de Docker, vous devrez configurer le logiciel client NFS sur chaque nœud Docker.
Le bloc de code suivant montre un exemple d’installation du logiciel client NFS à l’aide du package nfs-utils sur Centos: 7.5:
## FOR EACH CLUSTER NODE ##
#*******************************************
#* NFS client Setup – just add nfs-utils *
#*******************************************
sudo yum install -y nfs-utils
Une fois le client installé sur chaque nœud, vous pouvez le tester. C’est un processus assez simple où vous créez un volume Docker, montez le volume avec un conteneur de test et créez un fichier-test.txt .
Veuillez noter les paramètres –opt que nous utilisons lorsque nous créons le volume avec le pilote local. Nous définissons le type de pilote sur nfs, fournissons l’adresse du serveur NFS distant et mappons le volume à un emplacement sur le système de fichiers NFS. Avec cette approche, nous n’avons besoin de personne pour configurer le point de montage de l’hôte NFS à l’avance. Au lieu de cela, nous utilisons l’API Docker pour créer le volume, utiliser le volume, monter le volume et supprimer le volume.
Dans le bloc de code suivant, nous utilisons le pilote de volume Docker NFS pour écrire un fichier dans NFS depuis l’intérieur d’un conteneur sur le nœud A :
##########################
## SSH to worker node A ##
#*******************************************
#* Test NFS client with Docker Volume access*
#*******************************************
$ docker volume create –driver local \
–opt type=nfs \
–opt o=addr=test-iscsi-1.mydomain.com,rw \
–opt device=:/var/nfsshare/apps \
apps
# Create test-file.txt on NFS drive
docker run -it –rm -v apps:/apps centos:7 touch /apps/test-file.txt
# List file on apps volume from inside a cento:7 container
docker run -it –rm -v apps:/apps centos:7 ls /apps
# Clean up your volume
$ docker volume rm apps
Dans ce bloc de code, nous utilisons le pilote de volume Docker NFS pour lire un fichier vers NFS depuis l’intérieur d’un conteneur sur le nœud B :
##########################
## SSH to worker node B ##
## Remember to install nfs-utils on this node
$ sudo yum install -y nfs-utils
$ docker volume create –driver local \
–opt type=nfs \
–opt o=addr=test-iscsi-1.mydomain.com,rw \
–opt device=:/var/nfsshare/apps \
apps
# List file on apps volume from inside a cento:7 container
$ docker run -it –rm -v apps:/apps centos:7 ls /apps
$ docker volume rm apps
Une fois que NFS fonctionne et est vérifié sur tous vos nœuds de cluster, il est temps de passer à l’étape suivante de préparation de votre déploiement pour tirer parti du plu gin Docker NFS.
La clé pour faire fonctionner le plug-in de volume dans votre fichier de pile YAML se trouve dans la section des volumes en bas. Voici un extrait d’un fichier utilisant des montages de volume NFS avec Docker Enterprise.
Dans le bloc de code suivant, vous pouvez voir comment les paramètres de test AR se traduisent en une configuration de pilote de volume réelle :
volumes:
wiki-init-data:
driver: local
driver_opts:
type: nfs
o: addr=ntc-iscsi-1.mydomain.com,rw,hard
device: “:/var/nfsshare/apps/wiki/db-init”
wiki-db-data:
driver: local
driver_opts:
type: nfs
o: addr=ntc-iscsi-1.mydomain.com,rw,hard
device: “:/var/nfsshare/apps/wiki/db-data”
Assurez-vous de tester toutes les applications qui utilisent la connexion NFS. Pas tant pour les problèmes liés à Docker que pour découvrir tout problème NFS. Par exemple, dans le bloc de code précédent, j’avais deux volumes NFS définis : un pour le stockage des fichiers du service Wiki et un autre pour les fichiers de données postgres . La base de données postgres fonctionnait très bien, mais l’application Wiki Confluence a rencontré un problème de partage de fichiers en raison d’une incompatibilité de verrouillage de fichiers NFS. Je l’ai suivi jusqu’à “Impossible de résoudre la référence au bean ‘luceneConnection'”.
Si vous vous souvenez, cette application Wiki était mon application de levage et de décalage depuis le début du chapitre 5 , Préparer et déployer une application pilote Docker Enterprise , l’exemple d’application Wiki pilote . À ce titre, il s’agissait de ne modifier aucun code, de le conteneuriser et de le déployer. Par conséquent, nous pouvons revenir à mettre une étiquette sur un nœud et à utiliser la contrainte de déploiement sur le service Wiki, mais peut-être autoriser la base de données à utiliser NFS si cela semble utile. Cependant, étant donné que la perte du nœud signifie que le conteneur Wiki échouera complètement de toute façon, vous pourriez tout aussi bien épingler la base de données et le Wiki au même nœud que nous l’avons fait précédemment au chapitre 5 , Préparer et déployer une application pilote Docker Enterprise . Ensuite, bien sûr, vous bénéficiez d’une latence inférieure pour être sur le même nœud.
Pour revenir à un point antérieur sur la façon de s’assurer que les clusters de non-production et de production sont aussi similaires que possible, NFS est un bon exemple de quelque chose que vous voulez dans les deux clusters afin que vous puissiez tester les applications à fond avant de les mettre en production.
3.2.3 Autres solutions de stockage en volume
Si vous hébergez un cluster Docker Enterprise dans le cloud, vous avez peut-être déjà découvert d’autres plug-ins de stockage en volume. Ces plug-ins font partie de l’écosystème docker4x (comme dans Docker Engine-Community pour Azure et Docker pour AWS) et peuvent être installés dans votre environnement cloud en suivant Docker Certified Infrastructure. Dans le chapitre 9 , Rubriques importantes sur la production de Docker Enterprise , nous explorerons les installations AWS et Azure avec Docker Enterprise.
Cloudstore est un plugin puissant qui vous permet d’accéder aux ressources natives du cloud pour l’API Docker. Par exemple, sur AWS, vous pouvez spécifier un volume soutenu par un magasin de blocs élastiques (EBS) pour le conteneur à monter. Si la charge de travail migre vers un autre nœud, AWS déplacera ce volume et le joindra à la nouvelle instance. Si vous traversez des zones de disponibilité, AWS copiera le contenu que vous avez dans votre volume EBS dans un nouveau volume dans le nouvel AZ et le montera dans l’instance où votre conteneur s’exécute. Bien que cette approche puisse sembler un peu maladroite, elle a ses avantages car vous pouvez spécifier des volumes d’EBS IOPS à très hautes performances pour répondre aux besoins de certaines applications exigeantes. Une autre façon d’implémenter le stockage cloud sur AWS est en mode partagé où le volume est soutenu par un stockage de fichiers élastique (EFS). Dans ce cas, vous pouvez avoir plusieurs conteneurs partageant le même système de fichiers principal. Certainement très flexible et pratique, mais il peut ne pas avoir les performances requises par votre application.
En plus des plugins de stockage du fournisseur de cloud, il existe environ 20 plugins certifiés Docker de différents fournisseurs de stockage. Certains d’entre eux ont des implémentations back-end gratuites, mais beaucoup d’entre eux sont conçus pour s’intégrer aux solutions de stockage fournies par les fournisseurs. Cela inclut de nombreux fournisseurs locaux tels que VMware, NetApp et Nutanix.
3.2.4 Sauvegarde des données
De toute évidence, la sauvegarde des données est essentielle pour tout environnement de production. Dans notre discussion sur Docker Enterprise, nous parlerons de trois domaines de sauvegarde : les données UCP, DTR et d’application.
Consultez la documentation la plus récente de Docker concernant les sauvegardes, mais si vous exécutez UCP 3.1.0 – 3.1.2, vous devez exécuter le script suivant avant d’exécuter l’UCF, vous sauvegardez ! Il y a un travail de nettoyage que vous devriez avoir dans le cadre d’un onglet cron pour nettoyer régulièrement les supports ucp-kubelet.
Le bloc de code suivant présente le script de nettoyage de pré-sauvegarde de Docker :
SHM_MOUNT=$(grep -m1 ‘^tmpfs./dev/shm’ /proc/mounts)
while [ $(grep -cm2 ‘^tmpfs./dev/shm’ /proc/mounts) -gt 1 ]; do
sudo umount /dev/shm
done
grep -q ‘^tmpfs./dev/shm’ /proc/mounts || sudo mount “${SHM_MOUNT}”
La sauvegarde UCP doit être exécutée à partir des nœuds du gestionnaire. Un opérateur ou un opérateur utilisant un script doit se connecter aux nœuds UCP et effectuer les opérations suivantes :
- Arrêtez le service Docker à l’aide de la commande suivante :
$ sudo service docker stop
- Sauvegardez / var / lib / docker / swarm dans un emplacement sûr
- Redémarrez le démon ($ sudo service docker start) et attendez que le nœud se stabilise
- Sauvegarder l’UCP (décrit dans la section suivante)
3.2.4.1 Sauvegarde UCP
Après le redémarrage du service Docker et le retour du nœud UCP à la santé, la sauvegarde est démarrée en exécutant la commande suivante, en notant le fichier TAR qui est créé. Ne le laissez pas sur / tmp . Spécifiez un autre répertoire sécurisé ou scpez immédiatement le fichier vers un emplacement de sauvegarde distant.
La commande de sauvegarde UCP est affichée dans le bloc de code suivant:
## SSH Into each manager node.
UCPID=$(docker run –rm -i –name ucp -v /var/run/docker.sock:/var/run/docker.sock docker/ucp id)
# Create a backup, encrypt it, and temporarily store it on /tmp/backup.tar
docker container run \
–security-opt label=disable \
–log-driver none –rm \
–interactive \
–name ucp \
-v /var/run/docker.sock:/var/run/docker.sock \
docker/ucp:3.1.2 backup \
–id $UCPID \
–passphrase “secret” > /tmp/backup.tar
# Decrypt the backup and list its contents
$ gpg –decrypt /tmp/backup.tar | tar –list
Veuillez noter que le paramètre –security-opt label = disable est pour SELinux. Pour vérifier, exécutez cat / etc / docker / daemon.json et recherchez “selinux-enabled”: “true” dans la sortie. En outre, la phrase secrète est définie sur “secret”. Vous voudrez probablement aussi ajuster cela.
Lors de l’exécution d’une sauvegarde UCP, veuillez noter que tous les conteneurs UCP sont arrêtés afin de capturer un instantané de sauvegarde fiable. Cela signifie que l’UCP en cours de sauvegarde cessera de fonctionner temporairement. Si vous êtes dans une configuration à haute disponibilité, le cluster doit continuer de fonctionner normalement. Pour cette raison, c’est généralement une bonne idée de sauvegarder pendant les périodes de faible activité et, bien sûr, de ne sauvegarder qu’un nœud à la fois. De plus, comme les conteneurs UCP doivent recommencer à s’exécuter une fois la sauvegarde terminée, accordez toujours quelques minutes aux nœuds de gestionnaire pour les récupérer. Vérifiez que le nœud est sain (le tableau de bord UCP est un bon endroit pour le vérifier) avant de procéder à la sauvegarde du nœud suivant.
3.2.4.2 Sauvegarde de DTR
Contrairement à la sauvegarde UCP, les sauvegardes DTR peuvent être effectuées à distance à l’aide du bundle client de l’administrateur UCP. Cette méthode est très simple et provoque une perturbation minimale. Veuillez noter que cette sauvegarde inclut les métadonnées de votre DTR sur l’organisation, les équipes et les référentiels, mais elle n’inclut pas les couches d’images binaires réelles. Ceux-ci sont stockés par le système de fichiers de sauvegarde que vous avez configuré lors de l’installation de DTR. Pour les implémentations locales, la sauvegarde DTR est probablement NFS et c’est là que les blobs sont stockés pour les images.
Voici la liste du bureau de Docker de ce qui est sauvegardé pendant une sauvegarde DTR:
| Les données | Sauvegardé | La description |
| Configurations | Oui | Paramètres DTR |
| Métadonnées du référentiel | Oui | Métadonnées telles que l’architecture et la taille des images |
| Contrôle d’accès aux dépôts et aux images | Oui | Données sur qui a accès à quelles images |
| Données notariales | Oui | Signatures et résumés des images signées |
| Résultats de l’analyse | Oui | Informations sur les vulnérabilités de vos images |
| Certificats et clés | Oui | Certificats TLS et clés utilisés par DTR |
| Contenu de l’image | Non | Doit être sauvegardé séparément; dépend de la configuration DTR |
| Utilisateurs, organisations, équipes | Non | Crée une sauvegarde UCP pour sauvegarder ces données |
| Base de données de vulnérabilité | Non | Peut être re-téléchargé après une restauration |
Le bloc de code suivant est un script permettant d’exécuter la sauvegarde Docker DTR à partir d’un ensemble de clients d’administration UCP et de les stocker dans le sous – répertoire dtr-backup-files. Commencez avec cet exemple simple pour démarrer, mais soyez prudent car ce script a un mot de passe administrateur intégré dans les paramètres :
#!/bin/bash
#get current ucp certificate
curl -4k https://ucp.nvisia.io/ca > ucp.ca
# list docker replicas
dtr_replicas=($(docker container ls –format “{{.Names}}” | grep dtr-registry | awk -F- ‘{print $NF}’))
for i in “${dtr_replicas[@]}”
do :
echo “backing up:$i”
docker run –log-driver none -i –rm \
docker/dtr:2.6.0 backup \
–ucp-url https://ucp.mydomain.com \
–ucp-ca “$(cat ucp.ca)” \
–ucp-username admin \
–ucp-password XXXXX \
–existing-replica-id $i > ./dtr-backup-files/backup-$i-metadata.tar
echo -e “backup complete\n\n”
done
L’exécution de ces scripts prend quelques minutes.
3.2.4.3 Sauvegarde des données d’application
Cette section est essentiellement un espace réservé pour vous rappeler de sauvegarder vos données d’application. Les conteneurs ne se sauvegardent pas automatiquement, et j’espère que vous avez appris à ne pas stocker les données qui vous intéressent à l’intérieur de vos conteneurs. Par conséquent, vous devez utiliser les volumes Docker pour stocker vos données sur le système de fichiers hôte ou avec NFS. Donc, si vous effectuez un montage d’hôte simple, vous devrez copier les données du nœud de travail vers un emplacement central, sûr et sécurisé. Lorsque les sauvegardes en direct sont une option, envisagez d’utiliser rsync pour synchroniser les fichiers vers un emplacement distant.
Les mises à jour sont disponibles sur https://docs.docker.com/ee/ucp/admin/install/upgrade/ .
3.2.5 Application des mises à jour OS et Docker
Voici quelques procédures générales pour mettre à jour votre cluster. L’exemple est orienté vers centOS, mais les idées peuvent facilement être appliquées à la plupart des configurations de cluster et des mises à jour mineures. Si vous travaillez à travers un processus de mise à niveau plus important, vous souhaitez évidemment mettre de côté une fenêtre de maintenance et commencer avec votre cluster hors production. Après avoir mis à niveau votre cluster hors production, veuillez effectuer des tests approfondis avant de procéder à toute mise à niveau sur le cluster de production.
3.2.5.1 Mises à jour du système d’exploitation et de Docker Enterprise Engine
Tout d’abord, assurez-vous que votre cluster est dans un état stable et sain. Cela signifie aucune modification majeure des nœuds de cluster ou de la configuration juste avant votre mise à jour. Ne pas ajouter, supprimer, promouvoir ou rétrograder les nœuds. De plus, ne modifiez pas les paramètres UCP ou DTR juste avant les mises à jour car l’une de ces modifications peut prendre plusieurs minutes et nous ne voulons pas démarrer une mise à jour avant qu’elle ne soit complètement propagée et que le cluster ne soit stabilisé.
La stratégie ici consiste à s’assurer que tous les moteurs Docker sont la dernière version avant d’effectuer des mises à jour des logiciels UCP et DTR, car ils attendent la dernière version du moteur Docker.
3.2.5.1.1 Nœuds de gestionnaire UCP
Effectuez ces étapes sur chaque nœud de gestionnaire UCP :
- Arrêtez Docker Engine à l’aide de $ sudo service docker stop.
- Mettez à niveau le système d’exploitation et le moteur avec $ sudo yum update -y .
- Redémarrez si nécessaire à l’aide de $ sudu reboot ou démarrez Docker Engine à l’aide de $ sudo service docker start.
- À partir d’un nœud de gestionnaire UCP, utilisez $ sudo docker node ls pour vérifier que le nœud est prêt et sain.
Une fois que le nœud est de retour et en bonne santé, passez au gestionnaire suivant. Une fois tous les gestionnaires mis à niveau, passez aux serveurs DTR.
3.2.5.1.2 Noeuds de travail
Effectuez ces étapes sur chacun des nœuds de travail du cluster :
- À partir d’un nœud de gestionnaire UCP, utilisez $ sudo docker node update –available drain {nom du nœud à mettre à jour}.
- Sur le nœud à mettre à jour, arrêtez le moteur Docker à l’aide de $ sudo service docker stop.
- Mettez à niveau le système d’exploitation et le moteur avec $ sudo yum update -y.
- Redémarrez si nécessaire à l’aide de $ sudu reboot ou démarrez Docker Engine à l’aide de $ sudo service docker start.
- À partir d’un nœud gestionnaire, utilisez $ sudo docker node update –available active {nom du nœud qui vient d’être mis à jour}.
- À partir d’un nœud de gestionnaire UCP, utilisez $ sudo docker node ls, puis attendez que le nœud soit prêt et sain.
3.2.5.2 Mise à niveau du logiciel UCP
Une fois les mises à jour du système d’exploitation et du moteur terminées sur tous les nœuds, connectez-vous aux paramètres d’administration UCP | Mettez à niveau et recherchez les mises à niveau disponibles. Si la mise à niveau est disponible, continuez.
Ici, le paramètre UCP | L’écran de mise à jour montre que l’UCP est la dernière version:
Écran de mise à niveau UCP
3.2.5.3 Mise à niveau du logiciel DTR
Avec UCP mis à jour, connectez-vous à DTR et voyez s’il y a des mises à jour en attente. La capture d’écran suivante montre que nous devons mettre à jour notre logiciel DTR :
Paramètres généraux de Docker Trusted Registry System
Accédez à https://docs.docker.com/ee/dtr/admin/upgrade/ . Ce processus nous permet d’extraire le dernier conteneur DTR et d’exécuter la commande de mise à niveau. La commande de mise à niveau mettra à jour toutes les répliques du cluster. Veuillez noter que ce processus prend environ 10 à 20 minutes.
3.3 Résumé
Dans ce chapitre, nous vous avons présenté le flux de haut niveau de la chaîne d’approvisionnement des logiciels, de la construction initiale de CI jusqu’à la production exécutant l’image. Nous avons couvert certains sujets clés importants en parcourant le pipeline. Ensuite, nous avons commencé à construire la plateforme de production.
En nous appuyant sur ce que nous avons appris dans le pilote sur l’installation et la configuration de Docker Enterprise, nous avons discuté de certains facteurs supplémentaires à prendre en compte pour votre environnement de production. Enfin, nous avons parlé de la gestion et de la maintenance des données pour vos clusters Docker Enterprise. N’oubliez pas que vous souhaitez commencer par votre cluster hors production pour tester toutes les nouvelles modifications avant de mettre à jour vos systèmes de production.
Cela devrait suffire pour démarrer votre première application en production. Cependant, nous avons encore quelques sujets importants à couvrir concernant le déploiement de l’application et l’exploitation de la plate-forme Docker Enterprise.
Dans le chapitre 9 , Rubriques importantes sur la production de Docker Enterprise , nous approfondirons les concepts de Docker Enterprise liés à l’exécution de plusieurs applications en production.
4 Sujets importants de production de Docker Enterprise
Bien que nous ayons couvert certains des éléments essentiels pour la mise en production de notre première application avec Docker Enterprise au chapitre 8 , Première application en production avec Docker Enterprise , il existe encore de nombreux concepts importants liés à l’exécution de plusieurs applications de production sur une plateforme Docker Enterprise stable et partagée. . Il n’est pas possible de couvrir tous les scénarios de déploiement de production, mais les rubriques de ce chapitre seront importantes lors du déploiement de plusieurs applications de production sur votre cluster de production.
Dans le chapitre 8 , Première application en production avec Docker Enterprise , nous avons parlé de la mise en production de la première application, mais lorsque vous déployez les applications suivantes, comment pouvez-vous vous assurer que les applications disposent de ressources suffisantes? Comment savez-vous que les conteneurs morts ne seront pas utilisés pour servir les conteneurs entrants ? Que faire en cas de problème lors de la mise à jour d’un service d’application ? Dans ce chapitre, nous répondrons à ces questions et à bien d’autres.
Dans ce chapitre, les sujets suivants seront traités :
- Explorer quelques fonctionnalités importantes des orchestrateurs utilisés en production
- Comprendre les déploiements simples d’applications bleu / vert
- Suivi de production
- Obtenir de l’aide des experts de Docker
4.1 Travailler avec des orchestrateurs en production
Au cours des dernières années, les communautés Swarm et Kubernetes ont continué d’ajouter des fonctionnalités importantes pour améliorer les performances, l’évolutivité et la fiabilité des applications. Les orchestrateurs jouent un rôle clé dans le maintien de l’intégrité des applications, la gestion des ressources et la garantie que les applications sont dans l’état souhaité.
Alors que nous commençons le déploiement en production, nous devons couvrir plusieurs sujets importants liés à la façon dont les orchestrateurs de conteneurs interagissent avec les applications en cours d’exécution. Dans cette section, nous verrons comment configurer nos orchestrateurs Docker Enterprise pour prendre en charge l’intégrité des applications et l’efficacité des clusters.
4.1.1 Contrôles de santé
L’une des principales caractéristiques d’un orchestrateur de conteneurs consiste à s’assurer que nos applications sont dans l’état souhaité, comme spécifié lors de la planification de la charge de travail. Par exemple, si mon fichier de déploiement d’application ou mon appel d’API spécifie que cinq instances d’un serveur Web NGINX doivent être exécutées à tout moment, il appartient à l’orchestrateur de s’assurer que cela se produit.
Swarm et Kubernetes surveillent l’état de leurs conteneurs ou pods planifiés pour s’assurer qu’ils sont opérationnels en comparant constamment l’état actuel avec l’état souhaité au sein du cluster. En cas de divergence, l’orchestrateur planifie une action de compensation pour atteindre l’état souhaité. Cependant, pour que cela se produise, l’intégrité du conteneur doit être observée par l’orchestrateur. Par conséquent, nous devons instrumenter notre conteneur avec des contrôles d’intégrité pour que l’orchestrateur puisse appeler.
Les contrôles d’intégrité sont un morceau de code spécial fourni par le créateur du conteneur. Le code de vérification d’intégrité est périodiquement exécuté par le moteur Docker à l’intérieur du conteneur et il signale l’état d’intégrité à l’orchestrateur. Si le contrôle d’intégrité échoue, l’orchestrateur supprime ensuite le conteneur défectueux et en crée un nouveau à sa place.
Souvent, ces vérifications sont basées sur une commande cURL, ce qui est OK dans certaines circonstances, mais présente certains inconvénients (voir le message d’Elton Stoneman dans cette rubrique: https://blog.sixeyed.com/docker-healthchecks-why-not-to -use-curl-or-iwr / ). Il est généralement préférable de créer un point de terminaison de contrôle d’intégrité personnalisé ou de tirer parti de quelque chose comme le sous-projet Actuator de Spring Boot.
L’ajout de Spring Boot’s Actuator à vos applications Java vous offre des implémentations de point de terminaison d’API prêtes à l’emploi pour tester et gérer votre application via HTTP. Les points de terminaison intégrés permettent une requête pour une grande variété d’informations sur l’état de votre application, mais le plus important pour notre conversation est le point de terminaison / health . Le point de terminaison / health renvoie le code d’état HTTP 200 lorsque l’application est saine. De plus, / health peut être personnalisé, permettant aux développeurs de définir leurs propres critères spécifiques pour la réponse / health .
Dans certains cas, nous l’avons vu utilisé de manière créative. Dans un scénario, pour compenser une fuite de mémoire dans une bibliothèque de code tiers, le contrôle d’intégrité a été configuré pour répondre avec une réponse malsaine lorsque l’utilisation de la mémoire a atteint un seuil prédéfini. Dans cette situation, lorsque la mémoire a atteint la limite prédéfinie, le point de terminaison a renvoyé un contrôle de santé échoué, provoquant l’orchestrateur pour tuer l’ancien conteneur gonflé et démarrer un nouveau conteneur propre.
4.1.1.1 Conteneurs éphémères et orchestration
Étant donné que les orchestrateurs démarrent et arrêtent régulièrement des conteneurs, le concept de conteneur éphémère devient important. Les conteneurs éphémères présentent deux aspects clés:
- Ils sont apatrides
- Ils ont des temps de démarrage et d’arrêt relativement rapides
Par apatride, nous entendons que toutes les demandes dépendent uniquement des informations incluses dans la demande (paramètres ou champs) et non des interactions précédentes avec un service. Par conséquent, une demande avec les mêmes paramètres ou champs donnera toujours le même état final du service. C’est ce qu’on appelle parfois être idempotent. L’apatridie permet une mise à l’échelle horizontale et pour les orchestrateurs, cela signifie que plusieurs conteneurs peuvent s’exécuter en toute sécurité derrière un seul service avec des demandes à charge équilibrée sur le groupe de conteneurs de sauvegarde. Si l’un de ces conteneurs cesse de fonctionner, l’orchestrateur le supprime de l’équilibreur de charge, le tue et en démarre un autre. Au cours de ce processus, les demandes de service sont dirigées vers des conteneurs alternatifs par l’équilibreur de charge du service.
L’autre aspect des conteneurs éphémères est des temps de démarrage et d’arrêt rapides pour éviter de longs écarts entre le démarrage PID 1 du conteneur et le conteneur passant son contrôle de santé et étant prêt à servir le trafic. Pendant cette période, le conteneur n’est pas disponible pour les appelants, mais occupe un emplacement de tâche, ce qui signifie qu’une de vos instances de conteneur de service est hors service au démarrage.
4.1.1.2 Démarrage de l’application et contrôles d’intégrité
Par défaut, Swarm et Kubernetes fournissent des mécanismes de contrôle d’intégrité très simples lorsqu’un contrôle d’intégrité personnalisé n’est pas défini. Dans ce cas par défaut, les deux orchestrateurs utilisent simplement l’état du PID 1 comme indicateur de l’intégrité du conteneur. Par la suite, les orchestrateurs supposent que si le PID 1 est en cours d’exécution, le conteneur est prêt pour le trafic. Cependant, il existe de nombreuses situations où ce comportement est inacceptable. En d’autres termes, nous avons besoin que l’orchestrateur retienne le trafic de notre nouveau conteneur jusqu’à ce qu’il soit complètement démarré et prêt à traiter les demandes. Pour ce faire, les deux orchestrateurs tirent parti des contrôles d’intégrité personnalisés.
Le principe du bilan de santé personnalisé est assez simple. L’orchestrateur démarre un nouveau conteneur et attend qu’il passe le contrôle d’intégrité avant de l’ajouter dans l’équilibreur de charge du service pour traiter les demandes. Dans la figure 1 , vous pouvez voir qu’un service Swarm est démarré avec trois répliques:
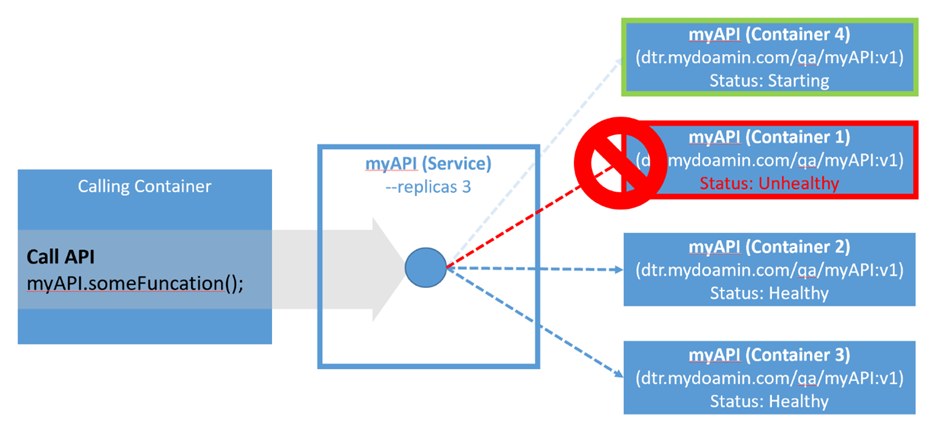
Figure 1: Docker Swarm en cours de remplacement d’un conteneur insalubre
Comme vous pouvez le voir, l’une des répliques, le conteneur 1, échoue à son contrôle d’intégrité. Ensuite, l’orchestrateur réessaie le nombre de fois prescrit et finit par tuer le conteneur 1. Veuillez noter, pendant cette fenêtre de temps d’échec (le conteneur ne répond pas, mais l’orchestrateur attend que le contrôle de santé expire – peut-être 3 essais distants de 10 secondes) ), l’appelant peut obtenir une connexion au conteneur mort. C’est pourquoi nous avons souligné les principes de programmation défensive des services distribués dans le chapitre 6 , Conception et pilotage d’un pipeline Docker Enterprise CI , dans la section Codage défensif .
Pendant le démarrage du nouveau conteneur, Swarm attend la durée spécifiée dans le paramètre –start-period (la valeur par défaut est 0) avant de commencer à exécuter des vérifications de l’état. Ainsi, pour une application de démarrage plus longue, vous voudrez remplacer la valeur par défaut par quelque chose d’approprié, peut-être 60 ou 90 secondes. Imaginez, cependant, qu’une nouvelle version de votre service ait un temps de démarrage plus long. Il est très possible que la période –start se termine et que les vérifications de l’état échouent avant le démarrage de l’application. En fait, l’orchestrateur le tuera avant qu’il ne redevienne sain, et il essaiera d’en démarrer un autre. Cela vous laisse dans une boucle de redémarrage continue et aucun conteneur en cours d’exécution pour votre service. Bien que cela soit facile à résoudre en étendant le paramètre –start-period , Kubernetes fournit une solution plus élégante au problème.
Kubernetes propose deux types de bilans de santé : une sonde de vivacité et une sonde de préparation. La sonde de vivacité est utilisée pour déterminer si l’application est en cours d’exécution, tandis que le pro readiness détermine si le service est prêt à servir le trafic. Comme vous pouvez le voir, cela peut être très utile lors d’un processus de démarrage de longue durée où nous avons un juste milieu entre sain et malsain. Ce n’est que lorsque la sonde de vivacité des pods échouera que l’orchestrateur remplacera le pod. De plus, vous bénéficiez de l’avantage que l’équilibreur de charge du service peut supprimer rapidement un conteneur de son pool principal dès que les profils de préparation. Il existe deux conditions d’échec intéressantes dans Kubernetes: lorsqu’une sonde de disponibilité a échoué, arrêtez le flux de trafic du service, et si Nà la sonde de vivacité a échoué, le pod est malsain et doit être remplacé.
Kubernetes nous permet de définir des contrôles de santé de différentes manières. Une sonde de style commande, comme nous l’avons vu avec les vérifications de santé de Docker, où la commande est exécutée à l’intérieur du conteneur et un code de sortie de 0 indique un conteneur sain. Le deuxième type est une sonde HTTP, où Kubernetes envoie une requête ping à vos applications sur le port / chemin non spécifié et recherche un code de réponse 2xx ou 3xx pour indiquer un conteneur sain. Le troisième type de sonde est une sonde TCP qui tente d’établir une connexion TCP sur un port spécifié et si la connexion est établie, Kubernetes suppose un conteneur sain.
Dans le chapitre 10 , Plus d’informations sur Kubernetes avec Docker Enterprise , nous allons travailler sur un exemple d’application Kubernetes qui inclut un contrôle de santé, mais regardons maintenant un exemple de contrôle de santé Swarm.
4.1.1.3 Service bilan de santé Swarm pour AtSea-web
Docker permet de définir un contrôle d’intégrité dans le fichier Dockerfile ou le fichier YAML de la pile Swarm. Lorsque nous ajoutons HEALTHCHECK à un Dockerfile, la vérification ajoute un indicateur d’intégrité simple aux conteneurs autonomes (la commande $ docker run) ou en tant que service Swarm (la commande $ docker service create). Bien que l’exécution d’un contrôle de santé sur un conteneur autonome n’effectue aucune action corrective automatiquement, il signale l’état du contrôle d’intégrité lorsque vous répertoriez vos conteneurs à l’aide de la commande $ docker container ls.
Le bloc de code suivant montre comment un conteneur autonome s’exécute à partir d’une image avec une directive healthcheck montrant un état d’intégrité :
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS
f90e97819351 hc-db:test “docker-entrypoint.s…” 30 seconds ago Up 29 seconds (healthy)
Vous pourriez vous donner la peine d’écrire un script qui surveille les événements Docker Engine pour redémarrer des conteneurs autonomes malsains, mais c’est ce que Swarm fait déjà pour nous ! Par conséquent, nous concentrerons notre attention sur un exemple Swarm à l’aide de l’application Web AtSea que nous avons créée au chapitre 6, Conception et pilotage d’un pipeline Docker Enterprise CI .
Pour notre exemple, nous pourrions placer la commande healthcheck dans le fichier Dockerfile ou notre fichier docker-stack-cluster.yml. Comme nous sommes susceptibles de spécifier des paramètres de contrôle d’intégrité personnalisés dans le fichier docker-stack-cluster.yml de toute façon, nous allons simplement le mettre là. Sinon, nous finissons par avoir des informations spécifiques au bilan de santé réparties à la fois dans le fichier Docker et le fichier docker-stack-cluster.yml, ce qui semble à la fois inutile et compliqué.
Ainsi, alors que nous n’ajoutons pas la directive de vérification de l’état, healthcheck, à notre Dockerfile, nous devons mettre à jour le Dockerfile avec les dépendances appropriées pour prendre en charge une commande cURL healthcheck. Dans notre cas, cela nécessite l’installation du paquet curl apk sur notre image de base Alpine JDK. Rappelez-vous, il s’agit d’un fichier de construction à plusieurs étapes et nous n’avons besoin d’installer notre package curl qu’à l’étape finale car il sera la base de notre conteneur de service.
Le bloc de code Dockerfile suivant montre comment nous utilisons le gestionnaire de packages apk pour installer le package curl afin de prendre en charge notre contrôle de santé basé sur cURL :
FROM node:latest AS jsbuild
WORKDIR /usr/src/atsea/app/react-app
COPY react-app .
RUN npm install
RUN npm run build
FROM maven:latest AS mavenbuild
WORKDIR /usr/src/atsea
COPY pom.xml .
RUN mvn -B -f pom.xml -s /usr/share/maven/ref/settings-docker.xml dependency:resolve
COPY . .
RUN mvn -B -s /usr/share/maven/ref/settings-docker.xml package -DskipTests
FROM java:8-jdk-alpine
RUN apk –update add curl
RUN adduser -Dh /home/gordon gordon
WORKDIR /static
COPY –from=jsbuild /usr/src/atsea/app/react-app/build/ .
WORKDIR /app
COPY –from=mavenbuild /usr/src/atsea/target/AtSea-0.0.1-SNAPSHOT.jar .
ENTRYPOINT [“java”, “-jar”, “/app/AtSea-0.0.1-SNAPSHOT.jar”]
CMD [“–spring.profiles.active=postgres”]
Maintenant, nous devons ajouter la section healthcheck à notre service serveur d’applications dans notre fichier de pile, comme indiqué dans le bloc de code suivant :
appserver:
image: ${DTR_SERVER}/${STACK_ENV}/atsea-web_build:RC-${STACK_ENV}
networks:
– front-tier
– back-tier
– payment
healthcheck:
test: [“CMD”, “curl”, “-f”, “http://localhost:8080/index.html”]
interval: 30s
timeout: 5s
retries: 3
start_period: 40s
deploy:
replicas: 2
update_config:
parallelism: 2
failure_action: rollback
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
labels:
com.docker.lb.hosts: at-sea-${STACK_ENV}.nvisia.io
com.docker.lb.network: ${STACK}_front-tier
com.docker.lb.port: 8080
com.docker.lb.ssl_cert: wildcard.mydomain.com.server.crt
com.docker.lb.ssl_key: wildcard.mydomain.com.key
secrets:
– postgres_password
Non seulement nous avons fourni le test: [“CMD” … en utilisant la boucle que nous avons spécifiée, nous avons également inclus quelques paramètres supplémentaires pour définir comment les contrôles sont exécutés et pour déterminer ce qui constitue une défaillance. Le premier paramètre est l’intervalle, qui spécifie le temps entre les vérifications. Le second est le paramètre de délai d’attente, qui indique combien de temps le test doit attendre une réponse. Le paramètre retries spécifie combien de fois recommencer le test avant d’échouer. Le paramètre start_period , comme nous l’avons vu dans la section Démarrage de l’application et vérifications de la santé de ce chapitre, est la durée pendant laquelle l’orchestrateur attendra avant d’exécuter la première vérification de l’état au démarrage.
4.1.1.4 Passer des signaux dans des conteneurs
Il existe certaines sémantiques importantes liées au CMD lors de la création de vos images avec un Dockerfile et de leur exécution avec un orchestrateur. Lorsque les gens commencent à utiliser Docker, ils passent généralement sous silence le concept des formes shell et exec de CMD. Souvent, ils y voient simplement un formatage JSON par rapport à un style de ligne de commande. En fait, il existe plusieurs autres différences qui sont importantes, mais pour notre conversation avec l’orchestration, nous devons parler de transfert de signal.
Les documents Docker parlent des principaux formulaires CMD, comme suit :
- CMD [“exécutable”, “param1”, “param2”] (la forme exécutée ; c’est la forme préférée)
- La commande param1 param2 CMD (forme shell)
La première forme préférée est la forme exec ; car le processus de commandes n’est pas encapsulé dans un processus shell et par la suite, tous les signaux sont transmis à tous les processus enfants. Ceci est important car si un orchestrateur émet un signal SIGTERM vers un conteneur, vous souhaiterez que vos processus reçoivent le signal et aient la possibilité de répondre par un arrêt ordonné. Si, toutefois, vous utilisez le formulaire shell, le signal ne sera pas transmis au-delà du shell aux processus enfants. Cela peut être problématique si vous exécutez un script de style entrypoint.sh qui a besoin d’un shell, tel que bash, pour s’exécuter et que vous souhaitez que les commandes, telles que Java, obtiennent des signaux de l’hôte. Heureusement, il existe une solution de contournement bien connue pour cela, en utilisant quelque chose appelé tini. En fait, Docker utilise tini.
Si vous rencontrez des problèmes liés à des signaux ne dépassant pas les processus shell ou zombie dans le shell, essayez d’utiliser tini. Je suggère de commencer par cet article: https://github.com/krallin/tini .
4.1.2 Ressources de cluster gérées et non gérées
La plupart des exemples d’exécution d’applications dans un cluster n’incluent aucune information sur les besoins en ressources ou les limites de la charge de travail de l’application. Sans informations sur les besoins en ressources et les limites de la charge de travail, l’orchestrateur n’est pas en mesure de gérer efficacement les ressources du cluster. Cette approche non gérée laisse les opérateurs de clusters s’appuyer fortement sur leur infrastructure de surveillance pour éviter la famine des ressources en faisant évoluer dynamiquement leur cluster de haut en bas selon les besoins.
Dans un environnement cloud natif de ressources élastiques illimitées, une approche non gérée peut être réalisable, mais elle est à la fois coûteuse et entraînée par des incohérences potentielles de performances d’application. Par conséquent, nous vous recommandons de limiter l’utilisation de clusters non gérés à des environnements hors production, même pour les plates-formes cloud. En outre, avec des grappes non-production non gérés, sérieusement envisager d’utiliser Docker Enterprise Advanced Edition collections pour gérer l’isolement au niveau du nœud pour réduire les situations de famine des ressources pour les environnements tests de performance et d’acceptation de l’utilisateur dans le cluster non-production.
Nous vous recommandons fortement d’adopter une approche managée de la gestion des ressources dans vos clusters de production, comme indiqué dans la section suivante.
4.1.2.1 Orchestrateurs et gestion des ressources
Dans le chapitre 8 , Première application en production avec Docker Enterprise , nous avons discuté du concept des préférences et contraintes de planification pour la planification Swarm. Lorsque nous avons besoin que nos services liés aux données s’exécutent de manière cohérente sur les mêmes nœuds où leurs volumes de données résidaient, nous avons utilisé des étiquettes de nœud en conjonction avec des contraintes de déploiement pour indiquer à Swarm où placer les services liés aux données. Maintenant, nous allons parler d’un autre sujet de planification d’orchestrateur et en savoir plus sur la façon dont Swarm et Kubernetes gèrent les ressources disponibles.
Swarm et Kubernetes gardent une trace des ressources réservées (demandées dans Kubernetes) par les conteneurs car elles sont planifiées sur chaque nœud (en outre, Kubernetes garde une trace de l’ensemble des espaces de noms / cluster pour gérer les quotas). Essentiellement, lorsqu’un conteneur est planifié sur un nœud, l’orchestrateur réduit son enregistrement pour la capacité disponible de ce nœud du montant réservé / demandé pour les conteneurs déployés.
Parlons d’un exemple simple. Dans notre exemple, nous avons trois nœuds de travail : le nœud A, le nœud B et le nœud C. Chaque nœud possède 16 Go de mémoire et quatre cœurs de processeur. Maintenant, l’orchestrateur a placé trois conteneurs sur le nœud A et chaque conteneur a réservé / demandé 3 Go de mémoire et 0,5 cœurs de processeur. Grâce à des calculs simples, l’orchestrateur sait que 7 Go (16 Go – 3 Go x 3) de mémoire et 2,5 cœurs de processeur (4 cœurs – 0,5 x 3) restent disponibles sur le nœud A. Si les prochaines demandes de planification dépassent 7 Go ou 2,5 processeurs, l’orchestrateur devra trouver un nœud différent. Si aucun autre nœud n’a la capacité, le planificateur enregistrera une erreur indiquant qu’il n’y a pas de nœuds appropriés pour satisfaire la demande de planification.
4.1.2.1.1 Réservations, demandes et limites de conteneurs
Pour accomplir la gestion des ressources, les orchestrateurs s’appuient sur deux concepts : les réservations (appelées requêtes dans Kubernetes) et les limites. Essentiellement, l’orchestrateur utilise les réservations de ressources (appelées requêtes) pour son système de comptabilité interne pour garder une trace des ressources de nœud disponibles. Les limites sont utilisées pour appliquer la quantité de ressources qu’un conteneur est autorisé à consommer lors de l’exécution. La meilleure pratique consiste à définir vos réservations à la hauteur de vos limites pour éviter de surcharger éventuellement un nœud de cluster.
Comment un nœud peut-il être dépassé dans un modèle de ressource gérée ? Voici un exemple. Nos nœuds ont chacun 16 Go de mémoire. L’orchestrateur planifie quatre conteneurs où chaque conteneur nécessite 2 Go de mémoire et définit une limite à 3 Go de mémoire. Cela a du sens pour nous car nous avons besoin d’un minimum de 2 Go pour faire fonctionner notre conteneur correctement, mais cela pourrait aller jusqu’à 3 Go de mémoire aux heures de pointe. Cependant, gardez à l’esprit que l’orchestrateur prévoit 2 Go de consommation pour chacun. Par conséquent, l’orchestrateur planifie les quatre conteneurs sur le même nœud. Dès que le conteneur utilise en moyenne plus de 2 Go d’utilisation de la mémoire, vous obtenez un nœud de cluster surchargé et affamé de ressources. Cependant, si nous avions fixé notre limite et une réservation pour qu’elles soient égales, nous aurions évité un dépassement de calendrier, mais nous pourrions alors obtenir une erreur de sous-utilisation. Cependant, dans un environnement de production, il est beaucoup mieux d’avoir des ressources sous-utilisées que d’avoir des applications privées de ressources !
Il existe une différence significative entre la façon dont les limites du processeur et de la mémoire sont gérées. Les limites de CPU limitent l’utilisation du CPU d’un conteneur, lui permettant de continuer à fonctionner à la limite de CPU spécifiée. Les limites de mémoire, d’autre part, déclencheront une exception de mémoire insuffisante ( OOME ) dans le conteneur et fermeront le conteneur. C’est important à comprendre. Pour éviter les redémarrages inattendus de conteneurs, choisissez soigneusement vos limites de mémoire, en particulier dans un environnement de production!
Maintenant que nous avons décrit les concepts des approches de cluster managées et non managées, regardons comment utiliser l’approche managée.
4.1.2.2 Définition des réservations CPU et mémoire
Pour un exemple Swarm, nous allons revenir à notre déploiement d’applications Web personnalisées AtSea et ajouter une réservation et une limite au service de serveur d’applications. Le service appserver exécute une application Spring Boot dans un environnement Java 8. Donc, nous avons deux ou trois choses à gérer dans cette situation. Le premier est lié à une version de Java antérieure à Java 10, où la JVM n’a pas pris en compte les restrictions de mémoire du groupe de contrôle du conteneur. En conséquence, la JVM s’est comportée comme si toute la mémoire de l’hôte était disponible pour la JVM, au lieu de ce qui était alloué au conteneur via cgroup. Cela entraînerait généralement la JVM d’allouer de la mémoire au-delà de la limite de conteneur et d’entraîner l’échec du conteneur avec un OOME. Donc, pour contourner ce problème, nous avons ajouté la variable d’environnement JAVA_OPTS au code suivant pour définir la mémoire maximale de la JVM à 1 Go avec l’indicateur -Xmx1G.
Maintenant, jetons un coup d’œil au déploiement de notre service de serveur d’applications avec quelques réservations de limites raisonnables :
# atsea-deploy docker-stack-cluster.yml
version: “3.7”
services:
appserver:
image: ${DTR_SERVER}/${STACK_ENV}/atsea-web_build:RC-${STACK_ENV}
environment:
JAVA_OPTS: -Xms512M -Xmx1G
networks:
– front-tier
– back-tier
– payment
healthcheck:
test: [“CMD”, “curl”, “-f”, “http://localhost:8080/index.html”]
interval: 30s
timeout: 5s
retries: 3
start_period: 40s
deploy:
resources:
limits:
cpus: ‘1’
memory: 1.5G
reservations:
cpus: ‘1’
memory: 1.5G
replicas: 2
update_config:
parallelism: 1
failure_action: rollback
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
labels:
com.docker.lb.hosts: at-sea-${STACK_ENV}.nvisia.io
com.docker.lb.network: ${STACK}_front-tier
com.docker.lb.port: 8080
com.docker.lb.ssl_cert: wildcard.nvisia.io.server.crt
com.docker.lb.ssl_key: wildcard.nvisia.io.key
secrets:
– postgres_password
…
Dans le bloc de code précédent, notez la section des ressources sous déploiement. Ici, nous pouvons trouver où les limites de ressources et les réservations sont définies. Nous fixons les réserves et les limites comme dans notre stratégie précédente. Les processeurs sont définis sur un cœur et la mémoire est définie sur 1,5 Go.
Parce que nous avons créé un pipeline CI pour déployer cette application, tout ce que nous devons faire est de modifier le fichier docker-stack-cluster.yml, de le valider et de le pousser vers GitLab. Enfin, nous déclenchons la construction avec notre commande curl GitLab:
curl -X POST -F token=xxxxxxxxxxxxxxx-F “ref=master” -F “variables[DEPLOY_TARGET]=test” https://gitlab.com/api/v4/projects/10552558/trigger/pipeline
Maintenant, nous pouvons nous diriger vers le, sous Swarm | Services, et cliquez sur atsea-deployer-test_appserver pour voir l’état de notre déploiement. Dans la figure 2, vous pouvez voir les informations de service dans l’interface utilisateur Web du plan de contrôle universel (UCP) :
Figure 2 : Informations de service dans l’interface utilisateur Web UCP
Lorsque nous regardons l’état du service précédemment dans l’UCP, nous voyons le bouton vert indiquant que le service est sain pour deux répliques sur deux. Ensuite, si nous faisons défiler vers le bas, nous verrons les limites et les réservations exactement comme elles ont été spécifiées dans le fichier de déploiement de pile.
Une autre façon d’examiner le service pour vérifier les réservations serait d’utiliser le bundle client UCP, comme indiqué dans le bloc de code suivant dans la sortie abrégée de la commande service inspect :
$ docker service inspect atsea-deployer-test_appserver
[
{
“ID”: “vqqoaglk897x0pewagj11rwyz”,
“Version”: {
“Index”: 640839
},
…
“Resources”: {
“Limits”: {
“NanoCPUs”: 1000000000,
“MemoryBytes”: 1610612736
},
“Reservations”: {
“NanoCPUs”: 1000000000,
“MemoryBytes”: 1610612736
}
},
…
Voyons maintenant comment appliquer les mêmes principes à un module Kubernetes. Dans ce cas, nous utilisons juste un exemple nginx trivial, et nous limitons la mémoire à 128 Mo et le CPU à 250 millicores (1/4 d’un cœur).
Le bloc de code suivant montre l’exemple de fichier kube-limits.yaml utilisé pour lancer nos modules de test avec des demandes et des limites:
# kube-limits.yaml
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
– name: proxy
image: nginx:1.14-alpine
resources:
requests:
memory: “128Mi”
cpu: “250m”
limits:
memory: “128Mi”
cpu: “250m”
Dans le bloc de code suivant, nous utilisons kubectl de notre bundle client UCP pour déployer les pods frontaux avec des limites et des demandes. Après le déploiement des pods, nous utilisons à nouveau kubectl pour examiner notre nouveau déploiement de pods. Nous avons mis en évidence la section des limites et des demandes dans la sortie suivante :
$ kubectl apply -f kube-limits.yaml
pod/frontend created
$ kubectl describe pod frontend
Name: frontend
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: ntc-wrk-3.mydomain.com/10.10.1.45
Start Time: Tue, 19 Feb 2019 00:12:43 -0600
…
Limits:
cpu: 250m
memory: 128Mi
Requests:
cpu: 250m
memory: 128Mi
…
Comme vous pouvez le voir, le mécanisme de déploiement des réservations, des demandes et des limites est très simple. La partie difficile consiste à déterminer les nombres à fournir comme paramètres pour les limites / réservations. Encore une fois, c’est là que vos outils de surveillance seront utiles, en particulier avec les applications Java.
La figure 3 montre un écran de métriques du moniteur Sysdig pour le serveur d’applications nouvellement déployé :
Figure 3: écran Métriques
En fin de compte, de nombreuses équipes DevOps natives du cloud sont à l’aise avec la nature dynamique et la complexité technique de la mise à l’échelle des ressources non gérées dans leur cluster. Les équipes d’opérations informatiques plus traditionnelles trouvent la nature déterministe de l’utilisation des réservations, des demandes et des limites pour gérer les ressources essentielles dans leurs environnements de production.
4.2 Entrée de production
En ce qui concerne la pénétration de la production, nous nous trouvons confrontés aux mêmes décisions dynamiques que déterministes. D’une part, nous apprécions la nature dynamique de différents outils pour la couche 7 routage, comme nous l’ avons montré previousl y dans le chapitre 6 , Conception et pilote un Docker l’ entreprise CI Pipeline , lorsque nous avons utilisé des étiquettes avec Interlock de UCP 2 et la configuration de notre marche arrière le serveur proxy (généralement NGINX de nos jours) est automatiquement configuré en déployant simplement votre service sur le cluster. Malheureusement, cette approche nécessite beaucoup de pièces mobiles, ce qui n’est pas une bonne chose dans un environnement de production où la simplicité et les garanties règnent en maître. Swarm et Kubernetes vous offrent quelques modèles de déploiement d’applications, notamment le routage dynamique (couche 7), le routage simple basé sur les ports (couche 4 IPVS) et les déploiements d’hôtes statiques.
4.2.1 Présentation du modèle d’entrée
Dans ces trois sections, nous donnerons un bref aperçu de chacun des modèles d’entrée. Ensuite, nous entrerons dans certains détails de mise en œuvre spécifiques des approches les plus courantes. À une extrémité du spectre, nous avons des modèles très dynamiques avec beaucoup de pièces mobiles, et à l’autre extrémité, nous avons des modèles déterministes qui nécessitent une configuration plus manuelle et sont potentiellement plus fragiles.
4.2.1.1 Routage dynamique de couche 7
Pour la couche 7, nous avons Interlock 2 d’UCP, le contrôleur d’entrée Kubernetes et d’autres excellents services de couche 7 similaires tels que Traefik. Ces technologies surveillent les événements de l’orchestrateur, désactivent les étiquettes et ajustent dynamiquement la configuration des serveurs proxy inverses lorsque les services sont déployés. Les wrappers de proxy inverse de couche 7 sont très cool dans le sens où ils peuvent envoyer tout mon trafic entrant via le contrôleur de couche 7 et les requêtes se retrouvent au bon endroit. C’est très cool quand cela fonctionne de manière fiable. Cependant, nous avons vu une variété de problèmes liés à la mise en réseau (réseaux fantômes) et à la sécurité (blocage de ports) où ces contrôleurs peuvent ne pas être fiables à 100%, ou les temps de convergence (le temps nécessaire pour que les modifications se propagent) sont trop longs.
Pour illustrer cette fonctionnalité, nous avons utilisé Interlock 2 dans la configuration du service de serveur d’applications de notre application Swarm AtSea tout au long de cet article. Cependant, bien qu’Interlock 2 puisse être une option pour notre application de production unique dans le chapitre 8 , Première application en production avec Docker Enterprise , nous ne sommes toujours pas vendus sur sa stabilité pour des implémentations à plus grande échelle.
Avec Swarm et Kubernetes, vous pouvez également déployer vos propres serveurs proxy inverses à l’aide de NGINX et implémenter votre propre schéma d’entrée. L’astuce avec l’approche personnalisée consiste à mettre à jour les configurations de manière dynamique et à gérer les éventuelles interruptions de service lors des mises à jour du contrôleur. La communauté Kubernetes repousse les limites de la technologie avec des modèles d’entrée fusionnables avancés ( https://github.com/nginxinc/kubernetes-ingress/tree/master/examples/mergeable-ingress-types ), mais malheureusement ces schémas d’entrée plus complexes sont hors de portée de cet article.
4.2.1.2 Routage simple basé sur les ports de la couche 4
Swarm et Kubernetes fournissent un mécanisme de routage simple, basé sur le port et à l’échelle du cluster, à la fois efficace et fiable. Avec ce modèle, vous pointez essentiellement vos équilibreurs de charge externes dans le cluster à l’aide d’un numéro de port spécifique (un port unique pour chaque service exposé) avec un nom IP ou DNS appartenant à n’importe quel nœud du cluster. Le routage de couche 4 capture la demande de la carte réseau de n’importe quel nœud sur le numéro de port spécifique et la transmet au service de cluster correct avec équilibrage de charge à l’aide d’IPVS. Il s’agit d’un bon équilibre entre l’entrée gérée et le placement dynamique de la charge de travail, car l’orchestrateur gère de manière transparente les détails spécifiques du placement du conteneur et du pod.
Nous en verrons quelques exemples plus loin dans la section Concepts clés des déploiements bleu / vert lorsque nous examinerons la section des déploiements bleu / vert.
4.2.1.3 Déploiements d’hôtes statiques
Le modèle de déploiement d’hôte statique est l’approche à l’ancienne des déploiements. C’est généralement ainsi que nous avons déployé nos premiers sites de production. Ce modèle est hautement déterministe et tire par la suite très peu d’avantages de nos fonctionnalités de plateforme de conteneurs. Pour de nombreuses organisations qui commencent tout juste avec des conteneurs de production à grande échelle, elles commencent souvent ici. Bien que cela soit parfaitement compréhensible, faites attention à appliquer les anciens modèles aux nouvelles plates-formes technologiques de conteneurs. Vous pourriez vous retrouver avec une grande partie du risque et aucun des avantages des conteneurs si vous ne faites pas attention.
Dans un modèle d’hôte statique, vos services sont déployés sur un hôte spécifique à l’aide d’une étiquette (comme nous l’avons fait pour notre application Wiki PoCP), et le port d’entrée du service est mappé directement à partir de l’adaptateur de l’hôte (généralement sur un port éphémère pour éviter les conflits de port ) au service.
Une fois le service déployé sur le serveur et le port mappé, vous configurez l’équilibreur de charge d’application avec l’adresse IP ou le nom DNS de ce nœud hôte + le numéro de port éphémère. Dans cette configuration, vous mettez à jour votre équilibreur de charge avec des informations pour chaque nœud hébergeant le service. Encore une fois, cela est très déterministe et le chemin du réseau est très efficace (pas de sauts IPVS en entrée et en sortie), mais certainement plus lourd et fragile.
4.2.2 Concepts clés des déploiements bleu / vert
Si vous êtes préoccupé par les temps d’arrêt lors de la mise à jour de vos applications de production en cours d’exécution, vous n’êtes pas seul. C’est pourquoi le modèle de déploiement bleu / vert est devenu populaire. Avec un déploiement bleu / vert, vous pouvez lever la nouvelle version de l’application et vérifier qu’elle est prête et fonctionne avant de diriger le trafic externe vers l’application.
Plus tôt dans le chapitre 3 , Mise en route – Preuve de concept Docker Enterprise , nous avons parlé du concept de déploiement d’une pile de nouveaux services en production avec Swarm, mais nous n’avons pas discuté des options de migration des mises à jour des applications. Dans cette section, je souhaite explorer un modèle très simple qui fonctionnera pour vos premières applications de production . Nous allons l’illustrer avec Swarm et Kubernetes.
4.2.2.1 Déploiements bleu / vert avec Swarm
Tout d’abord, nous parlerons du déploiement Swarm bleu / vert, où nous utiliserons un équilibreur de charge en conjonction avec deux versions d’un service Docker. Les équilibreurs de charge peuvent être externes à notre cluster ou réellement s’exécuter dans un conteneur au sein de notre cluster. Pour les besoins de notre discussion, disons que c’est un équilibreur de charge d’application externe qui se trouve devant notre cluster.
La figure 4 montre comment le processus fonctionne pour Swarm:
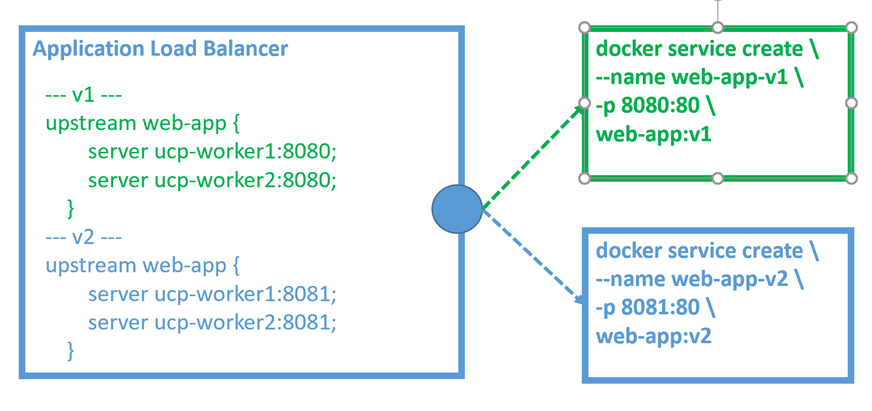
Figure 4: Le processus de migration bleu / vert de Swarm
Avant la mise à jour, seuls les éléments en vert sont présents. Le trafic arrive vers l’équilibreur de charge et est transféré via le port 8080 vers le service web-app-v1. Lorsqu’il est temps de publier une nouvelle version de notre application Web, nous déployons le service Web-app-v2 sur le cluster. Lorsque le nouveau service est opérationnel et prêt pour le trafic, nous reconfigurons l’équilibreur de charge pour diriger le trafic sur 8081. Cela coupe efficacement le trafic vers l’ancienne version et le redirige vers la nouvelle version.
En cas de problème avec la nouvelle version de notre application, nous pouvons inverser le processus et renvoyer le trafic vers l’ancienne version. Cependant, une fois que nous sommes convaincus que la nouvelle version fonctionne correctement, nous pouvons ralentir la version 1 et la supprimer du cluster.
4.2.2.2 Déploiement Kubernetes bleu / vert
Maintenant, nous pouvons jeter un œil au processus de déploiement bleu / vert de Kubernetes. Remarquez pour le processus Kubernetes que nous n’utilisons pas d’équilibreur de charge externe ; tout est géré avec les ressources Kubernetes au sein du cluster :
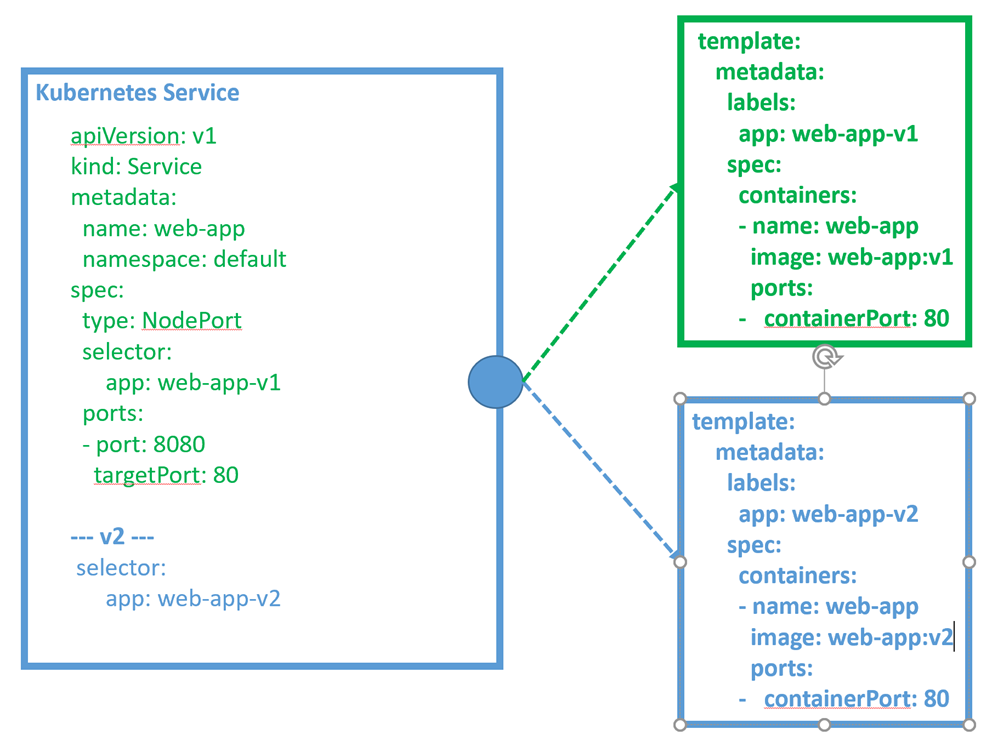
Figure 5: Processus de déploiement Kubernetes bleu / vert
Sur la gauche, nous voyons un service Kubernetes NodePort, montrant à nouveau la configuration verte pour la version 1. La version 1 du service est liée au pod vert sur la droite à l’aide de pods de correspondance de sélecteur avec l’application web-app-v1. Au moment de la mise à niveau, nous déployons web-app-v2 le ou les pods. Ensuite, nous mettons à jour le sélecteur dans le service d’application Web Kubernetes pour correspondre à la version 2 de l’application Web : Web-app-v2. Nous appliquons la modification au service d’application Web et le trafic circule désormais vers l’application Web V2.
Nous verrons comment cela pourrait être accompli dans la section de routage de la couche 4 en production.
4.2.3 Routage de couche 7 en production
Comme mentionné dans notre section Présentation du modèle Ingress, l’utilisation du routage de couche 7 dans la production, du moins en ce moment, semble risquée. Si vous explorez l’utilisation du routage de couche 7 dans votre environnement de production, nous vous recommandons fortement d’effectuer des tests approfondis à travers de nombreux déploiements, mises à jour et restaurations d’applications. Lorsque vous utilisez Interlock 2, assurez-vous de suivre les instructions pour le déploiement de production d’Interlock 2 ( https://docs.docker.com/ee/ucp/interlock/deploy/production/ ) et vérifiez que tous les réseaux sont nettoyés correctement après annuler le déploiement des piles d’applications inutilisées du cluster.
Une autre caractéristique intéressante du routage de couche 7 est la possibilité de mettre fin aux certificats SSL à l’aide du serveur proxy inverse de couche 7. C’est vraiment cool et ça pourrait rendre la vie vraiment facile. En raison de la complexité supplémentaire que cela ajoute au processus de reconfiguration automatique du proxy inverse, assurez-vous de bien tester cela dans votre environnement de production.
De plus, si vous êtes intéressé par le routage de couche 7 sans certaines des exigences de mise en réseau de superposition, vous pouvez utiliser un déploiement en mode hôte d’Interlock 2. Gardez à l’esprit que lorsque vous passez en mode hôte, vous accédez directement aux ports hôtes où Interlock les composants sont déployés. Par conséquent, si le pare-feu est activé sur vos nœuds de cluster (nous vous recommandons de le faire), vous devrez ouvrir une plage de ports pour les ports éphémères utilisés pour un fonctionnement correct. La nécessité d’ouvrir des ports de pare-feu pour une gamme de ports hôtes éphémères au sein du cluster peut être un obstacle majeur pour de nombreux professionnels de la sécurité.
J’ai créé des instructions étape par étape pour mettre à jour le service ucp-interlock pour utiliser le mode hôte. Veuillez noter que vous aurez besoin des éléments suivants :
- Ouverture de ports éphémères
- A Paramètres administrateur UCP | Planificateur cochez la case pour autoriser les administrateurs à déployer des conteneurs sur les gestionnaires UCP ou les nœuds exécutant Docker Trusted Registry (DTR)
Voici mes instructions: https://github.com/PacktPublishing/Mastering-Docker-Enterprise/tree/master/Production/Ingress/Interlock2-Swarm .
4.2.4 Routage de couche 4 en production
Le routage de couche 4 est un modèle très courant utilisé dans les environnements de production et hors production. Il offre un excellent équilibre entre contrôle et flexibilité. Vous pouvez contrôler le flux de votre trafic dans le cluster, tout en ayant la possibilité de modifier les détails d’implémentation de service, tels que l’emplacement d’exécution des conteneurs et la manière dont ils sont connectés.
L’implémentation finale de notre application de production AtSea a été mise à jour pour utiliser un modèle de couche 4. Dans la figure 6, nous voyons un diagramme de haut niveau de la configuration de l’application AtSea:

Figure 6: Configuration de l’application AtSea
Les demandes entrent sur le site avec l’URL publique de l’application, https://atsea.mydomain.com, où notre caractère générique ( * DNS DNS. Un domaine) un enregistrement) les amène au pare-feu. La demande passe par le pare-feu à l’aide du NAT de traduction d’adresses réseau ( atsea.mydomain.com:443 >> lb.mydomain.com:8443 ), où elle est récupérée par l’équilibreur de charge. L’interface de l’équilibreur de charge met fin à la connexion TLS à l’aide du certificat générique * .mydomain.com .
Le fichier .pem utilisé pour sécuriser le site se trouve dans /usr/local/etc/haproxy/certs/nvisia.io.pem et se compose des trois sections suivantes:
- Certificat de serveur
- Certificat CA intermédiaire
- Clé privée
Lorsque vous accédez au site, vous devez voir l’indicateur de site sécurisé dans votre navigateur, comme le montre la figure 7 :
Figure 7: Indicateur de site sécurisé
Cela semble bon jusqu’à présent, mais j’ai déjà été trompé par cela, où le navigateur affiche une icône sécurisée, mais j’obtiens toujours des erreurs de certificat x.509. Pour être sûr, utilisez un vérificateur SSL tel que https://ssltools.digicert.com/checker/views/checkInstallation.jsp ou https://www.sslshopper.com/ (la sortie est sur la figure 8 ) pour vérifier le certificat est tout à fait correct.
Validez vos certificats tiers, même si le verrouillage du navigateur semble bon. La validation des certificats est particulièrement importante lorsque vous installez également des certificats clients tiers pour DTR et UCP, car la CLI Docker est très pointilleuse sur la façon dont les chaînes de certificats.
Lorsque vous vérifiez votre certificat, il doit ressembler à la figure 8 :

Figure 8: https://www.sslshopper.com/ssl-checker.html
Maintenant, nous pouvons diriger notre attention vers le backend de notre pool. Puisque notre connexion TLS a été interrompue dans le frontend, le reste de notre chemin n’est pas chiffré au sein de notre réseau. Cela ne sera pas acceptable pour de nombreuses organisations. Dans les cas où il ne l’est pas, envisagez de mettre fin à TLS à l’intérieur de vos conteneurs. Alternativement, vous pouvez terminer sur le frontend avec un certificat externe et le rechiffrer avec un certificat interne de l’équilibreur de charge vers le conteneur pour trouver le service. Avec ce type de schéma, la clé du certificat interne peut être utilisée pour surveiller le trafic à l’intérieur du réseau, mais le certificat interne n’est d’aucune utilité en dehors du centre de données.
Depuis le backend, le trafic est acheminé vers le service d’application sur le port 8043. IPVS écoute sur le port 8043 et équilibre la charge de la demande sur 10.255.3.160:8080 et 10.255.3.161:8080 sur le réseau d’entrée. Voyons comment nous configurons cela avec Swarm.
Dans le bloc de code suivant, vous pouvez voir un fichier de pile partiel (seul le service appserver est affiché) pour montrer à quel point cela est simple avec Swarm:
# atsea-deploy docker-stack-cluster.yml
version: “3.7”
services:
appserver:
image: dtr.nvisia.io/prod/atsea-web_build:v1
environment:
JAVA_OPTS: -Xms512M -Xmx1G
ports:
– 8043:8080
networks:
– back-tier-app
healthcheck:
test: [“CMD”, “curl”, “-f”, “http://localhost:8080/index.html”]
interval: 30s
timeout: 5s
retries: 3
start_period: 40s
deploy:
resources:
limits:
cpus: ‘1’
memory: 1.5G
reservations:
cpus: ‘1’
memory: 1.5G
replicas: 2
update_config:
parallelism: 1
failure_action: rollback
restart_policy:
condition: on-failure
delay: 5s
max_attempts: 3
window: 120s
secrets:
– postgres_password
…
networks:
back-tier-app:
secrets:
postgres_password:
file: ./secrets/test/postgres_password
staging_token:
file: ./secrets/test/payment_token
Tout ce que nous avons à faire est de spécifier le mappage de port de 8043 comme port externe et 8080 comme port de conteneur interne. Par défaut, Docker utilise ce VIP pour équilibrer la charge entre les réplicas d’instance et publie le port 8034 sur le réseau d’entrée. Ces ports peuvent être TCP ou UDP, mais TCP est la valeur par défaut. En guise de remarque, le pilote réseau de superposition par défaut de Docker ne prend pas en charge la multidiffusion, mais le plug-in Weave Net V2 ( https://www.weave.works/docs/net/latest/install/plugin/plugin-v2/ ) ne le fait pas. et il prend en charge Swarm. Notez également que nous avons retiré les étiquettes nécessaires pour engager le contrôleur d’entrée Interlock 2.
Pour notre application pilote Atsea au chapitre 6 , Conception et pilotage d’un pipeline Docker Enterprise CI , nous avons utilisé des étiquettes pour indiquer le nom de notre réseau d’entrée Interlock 2, le port de conteneur interne et les informations de certificat SSL pour la terminaison sur le serveur proxy inverse Interlock 2. C’était une idée intéressante, mais nous n’étions pas à l’aise avec elle pour la mise en œuvre de notre solution. Maintenant, depuis que nous nous sommes arrêtés en amont sur notre équilibreur de charge d’application, nous n’avons plus besoin des informations de certificat avec le service appserver .
4.2.4.1 Mises à jour du service Docker
Lorsque vient le temps de mettre à jour votre application, il existe quelques approches courantes. Le premier est une simple mise à jour du service Docker, le second est un déploiement bleu / vert et le troisième est un déploiement canari.
La mise à jour simple de service Docker est une approche relativement simple de mettre à jour votre service avec l’API Docker mise à jour du service de commande. Vous pouvez le faire service par service à partir de la ligne de commande ou d’un script, mais la meilleure façon est d’utiliser le fichier de pile Docker pour appliquer les mises à jour.
Le fichier de pile Docker mis à jour peut inclure des modifications des versions d’image Docker ou des paramètres de déploiement de service. Vous mettez simplement à jour le fichier de pile et les appliquez avec la commande docker stack deploy en utilisant le nom de service actuel, tout comme lorsque vous avez démarré l’application. Lorsque vous exécutez la commande deploy la deuxième fois, elle compare l’état souhaité dans le nouveau fichier de pile avec l’état de la pile en cours d’exécution. À partir de là, il applique les mises à jour, en fonction de la configuration mise à jour pour chaque service.
Dans le fichier de pile précédent, regardez comment le service appserver spécifie une section update_config avec deux paramètres pour remplacer les valeurs par défaut. Le premier est le parallélisme et il définit combien de conteneurs seront mis à jour à la fois ; dans notre cas, nous voulons mettre à jour un à la fois. La valeur par défaut est de mettre à jour tous les conteneurs à la fois, ce qui peut être perturbateur et la raison pour laquelle la plupart des gens souhaitent des mises à jour continues. Le paramètre suivant est l’action d’échec, il décrit ce que l’orchestrateur doit faire si un service échoue pendant la mise à jour. Dans notre cas, nous l’avons configuré pour revenir à la version précédente.
4.2.4.2 Déploiement bleu / vert de la couche 4
Lorsque nous sommes prêts à déployer une nouvelle version de notre application sur le cluster, nous pouvons utiliser le routage de couche 4 avec votre équilibreur de charge pour effectuer un déploiement bleu / vert. Tout d’abord, placez votre nouveau service sur un nouveau numéro de port, puis déplacez l’équilibre de charge pour pointer vers le nouveau port. Pour plus de clarté, examinons un exemple.
Plus tôt dans la section Routage de la couche 4 en production, nous avons déployé la première version de notre serveur d’applications sur le port 8043 en utilisant docker stack deploy -c docker-stack-cluster.yml atseaV1. Ensuite, nous avons configuré les serveurs d’arrière-plan de notre équilibreur de charge pour pointer vers nos nœuds Swarm à l’aide du port appserver8043 et l’application fonctionnait correctement, mais un bogue a été découvert. L’équipe de développement a corrigé le bogue et a exécuté les modifications via le pipeline pour créer une nouvelle version de l’image dans le prod DTR, dtr.nvisia.io/prod/atsea-web_build:v2.
Le bloc de code suivant montre comment nous avons mis à jour notre fichier docker-stack-cluster.yml pour refléter le nouveau nom d’image et le nouveau numéro de port :
# atsea-deploy docker-stack-cluster.yml
version: “3.7”
services:
appserver:
image: dtr.nvisia.io/prod/atsea-web_build:v2
environment:
JAVA_OPTS: -Xms512M -Xmx1G
ports:
– 8044:8080
Maintenant, il est temps de placer la nouvelle pile atseaV2 à côté de l’ancienne pile atseaV1 . Nous utilisons $ docker stack deploy -c docker-stack-cluster.yml atseaV2 et attendons que le service converge.
Ensuite, pour tester le nouveau stack, nous exécutons $ curl -v http://cluster-node: 8044 / index.html pour voir le flux HTML non formaté, comme indiqué dans le bloc de code suivant:
<!doctype html><html lang=”en”><head><meta charset=”utf-8″><meta name=”viewport” content=”width=device-width,initial-scale=1″><title>Atsea Shop</title><link href=”/static/css/main.d25422c6.css” rel=”stylesheet”></head><body><style>body{max-width:100vw;overflow-x:hidden}</style><div id=”root”></div><link rel=”stylesheet” href=”//fonts.googleapis.com/css?family=Open+Sans”/><script type=”text/javascript” src=”/static/js/main.7dc2a38c.js”></script></body></html>
Il a répondu comme prévu ! Maintenant, migrons le reste du trafic vers la nouvelle version du service. Nous nous dirigeons vers le pool de serveurs d’arrière-plan de notre équilibreur de charge, remplaçons les entrées de port 8043 existantes par le nouveau numéro de port de service, 8044, et rechargeons l’équilibreur de charge pour couper le nouveau service.
Le bloc de code suivant montre les modifications requises pour rediriger le trafic vers une nouvelle pile d’applications sur le port 8044 :
backend atsea_app_upstream_servers
mode http
balance roundrobin
server atseaServer01 ntc-wrk-1:8044
server atseaServer02 ntc-wrk-2:8044
server atseaServer03 ntc-wrk-3:8044
http-request set-header X-Forwarded-Port %[dst_port]
http-request add-header X-Forwarded-Proto https if { ssl_fc }
que tout semble correct. N’oubliez pas que l’ancienne pile est toujours là si vous souhaitez revenir en arrière.
Enfin, n’oubliez pas de nettoyer l’ancienne pile ! Lorsque vous vous sentez bien dans la nouvelle pile et que vous êtes sûr que vous n’aurez pas besoin de revenir en arrière, supprimez l’ancienne pile avec $ docker stack rm atseaV1.
4.2.4.3 Déploiement des canaris de couche 4
D’accord, vous êtes peut-être un peu préoccupé par un passage complet du bleu au vert. Au lieu de cela, vous souhaitez envoyer juste un peu de trafic vers la nouvelle pile d’applications pour voir comment cela se passe. C’est ce qu’on appelle un déploiement canari et c’est un excellent moyen de voir comment la nouvelle pile va répondre au trafic. Avec la plupart des équilibreurs de charge, cela est assez facile à réaliser.
Nous reconfigurons notre équilibreur de charge pour effectuer les opérations suivantes :
- Ajoutez le nouveau serveur, atseaCanaryServer01
- Ajoutez une pondération aux serveurs du pool principal pour créer efficacement un déploiement canari
Le bloc de code suivant montre un déploiement canari avec 10% du trafic allant vers la nouvelle pile d’applications sur le port 8044 :
backend atsea_app_upstream_servers
mode http
balance roundrobin
server atseaServer01 ntc-wrk-1:8043 weight 15
server atseaServer02 ntc-wrk-2:8043 weight 15
server atseaServer03 ntc-wrk-3:8043 weight 15
server atseaCanaryServer01 ntc-wrk-3:8044 weight 5
http-request set-header X-Forwarded-Port %[dst_port]
http-request add-header X-Forwarded-Proto https if { ssl_fc }
4.3 Suivi de la production
Dans le chapitre 7 , Pilot Docker Enterprise Platform Monitoring and Logging , nous avons introduit des outils de journalisation et de surveillance pour répondre à plusieurs objectifs clés. Tout d’abord, cela devait nous aider à mieux comprendre ce qui se passait dans le cluster en ce qui concerne les ressources telles que le processeur, le disque et la mise en réseau à travers le cluster. Nous voulions identifier et diagnostiquer rapidement les problèmes autrement difficiles à trouver. Nous voulions également garder un œil attentif sur la santé de notre application pilote. Enfin, la compréhension de la consommation de ressources dans notre cluster hors production sur une durée raisonnable nous donne une certaine confiance dans le dimensionnement des nœuds lors de la construction de notre cluster de production.
Maintenant que nous entrons dans la production, nous devons garder un œil attentif sur la santé de nos applications et du cluster, mais nous devons également porter une attention particulière à la sécurité et à la conformité. À cette fin, je veux jeter un coup d’œil à certaines des choses que vous devez attendre dans la surveillance au niveau de la production avec la gestion des politiques. Encore une fois, je vais m’appuyer sur les outils de Sysdig, cette fois leur produit sécurisé.
Je ne veux pas transformer ceci en brochure d’outil Sysdig ou en infopublicité. Au lieu de cela, nous aimerions simplement montrer quelques exemples concernant les politiques basées sur les conteneurs et la conformité.
Dans l’exemple suivant, j’ai activé l’une des politiques intégrées de Sysdig, qui détecte quand quelqu’un a exécuté un processus shell Terminal à l’intérieur d’un conteneur. Ceci est souvent considéré comme une menace sérieuse. Avec cette politique en place, nous pouvons être alertés quel que soit quiconque exécute un shell de terminal dans un conteneur et, en outre, nous pouvons arrêter ou mettre en pause le conteneur où l’intrusion a lieu. Même si nous permettons au conteneur de continuer à fonctionner, nous pouvons capturer tout ce qui se passe sur ce nœud et dans ce conteneur lorsque l’événement se produit :
Figure 9 : Coque du terminal dans le conteneur
Ensuite, nous pouvons jeter un œil aux commandes qu’ils ont exécutées à l’intérieur du conteneur. Dans la figure 10, vous pouvez voir qu’ils ont exécuté le shell et une commande LS à l’intérieur du shell:
Figure 10 : Exécution de la commande ls
Nous pouvons également afficher une chronologie de la capture qui s’est produite lorsque l’événement a été déclenché. On peut voir une grande variété d’activités, comme indiqué avant et après l’événement, en baisse de mesure en millisecondes, dans la figure 11 :
Figure 11 : Aperçu de la chronologie
Vous pouvez ajuster la chronologie en bas de l’écran pour réduire les événements qui se sont produits dans cette fenêtre. Toutes les cases à l’écran vous permettent de percer les détails derrière elles.
En plus du suivi des événements et des politiques, j’ai ajouté un test de référence CIS Docker comme outil de conformité. Non seulement il vous montre si vous avez réussi ou échoué un test, mais il montre les tendances au fil du temps. Étant donné que vous n’aurez jamais un score parfait, il est utile de savoir comment vous évoluez par rapport à votre niveau de référence en termes de tests qui ont été réussis ou échoués :
Figure 12 : Conformité du nœud Docker
Encore une fois, il ne s’agit pas de montrer ou d’approuver un outil particulier. Nous ne présentons cela que pour sensibiliser aux capacités des outils de surveillance de la production basés sur des conteneurs.
4.4 Résumé
Dans ce chapitre, nous avons présenté une autre série de concepts, de techniques et d’outils pour vous rapprocher de votre environnement Docker Enterprise de production. Nous avons tenté de donner quelques conseils pratiques concernant l’architecture de production et les modèles de déploiement. Encore une fois, il ne s’agit en aucun cas d’une liste complète ou complète, car il y a tellement de variables dans chaque domaine industriel, commercial et réglementaire. Cependant, il devrait être utile pour vous déplacer vers un environnement de production réussi.
Dans le chapitre 10 , Plus d’informations sur Kubernetes avec Docker Enterprise , nous allons examiner de plus près l’exécution des applications Kubernetes sous un cluster Docker Enterprise.
5 Plus d’informations sur Kubernetes avec Docker Enterprise
Jusqu’à présent dans cet article, nous nous sommes concentrés sur Swarm pour notre orchestration. C’était intentionnel, car il est généralement beaucoup plus facile de démarrer avec Swarm, et puisque Docker Enterprise prend en charge les deux orchestrateurs, vous pouvez utiliser l’un ou les deux. Dans ce chapitre, nous nous intéressons à l’utilisation de Kubernetes sur la plateforme Docker Enterprise. Avec sa popularité et son écosystème riche, les déploiements de Kubernetes vont probablement croître et représenter une partie importante de vos applications. Après avoir mis notre première application en production avec Swarm, il est temps de revenir en arrière et de jeter un œil à l’exécution des applications Kubernetes sur votre infrastructure Docker. Dans ce chapitre, nous présenterons Kubernetes et parcourrons des exemples de déploiement d’applications avec.
Les sujets suivants seront traités dans ce chapitre :
- Docker Enterprise avec fonctionnalités et intégrations Kubernetes
- Comprendre comment tirer parti de Docker Desktop avec Docker Enterprise pour une expérience Kubernetes de bout en bout
- Principaux outils tiers Kubernetes avec Docker Enterprise
- Utilisation des volumes persistants Kubernetes et du contrôleur d’entrée de couche 7
5.1 Présentation de Docker Enterprise avec Kubernetes
Kubernetes est intégré à la plateforme Docker Enterprise. Il est installé par défaut et devient une partie de plus en plus importante des propres outils de Docker Enterprise. Par exemple, Docker Enterprise 2.1 s’appuie sur Kubernetes pour déployer les métriques Prometheus. Je soupçonne fortement que la dépendance de Docker à l’égard de Kubernetes continuera d’augmenter avec sa plate-forme d’entreprise.
D’un point de vue stratégique, cela est très important, surtout si vous envisagez Docker Enterprise, mais que vous vous interrogez sur l’engagement à long terme de Docker envers Kubernetes. La réponse est assez claire : Docker ne prend pas seulement en charge Kubernetes; il s’appuie sur elle dans le cadre de sa solution Enterprise, c’est ça l’engagement!
Puisque nous avons parlé de l’ architecture Docker Enterprise dans le chapitre 2 , Docker Enterprise – an Architectural Overview , nous allons sauter directement dans les points forts de Kubernetes. La figure 1 montre l’architecture de Docker Enterprise, avec les composants Kubernetes en vert :
Figure 1 : Architecture de Docker Enterprise 2 – Copyright © 2019 Docker, Inc. Tous droits réservés. https://docs.docker.com/ee/images/docker-ee-architecture.svg
Dans la figure 1, nous pouvons voir comment Kubernetes est réellement intégré directement dans la structure d’orchestration de Docker Enterprise. Ce n’est pas un module boulonné. En regardant les éléments en vert, nous avons déployé l’API Kubernetes sur le nœud maître qui superpose ses gestionnaires UCP / Swarm . Donc, si nous avons trois gestionnaires UCP, nous aurons trois maîtres Kubernetes. L’API Kubernetes est accessible avec le même bundle client UCP que l’API Docker / UCP. C’est transparent. Lorsque vous utilisez un bundle client distant, vous pouvez utiliser les commandes docker et kubectl pour gérer les ressources Swarm ou Kubernetes du cluster EE distant. Cependant, vous devez avoir redirigé le port 6443 vers vos nœuds de gestionnaire pour que cela fonctionne.
Ensuite, nous allons regarder la boîte verte CNI.
5.1.1 Réseau CNI
Par défaut, Docker est livré avec Kubernetes v1.11.5 et installe Calico v3.5. En outre, Docker a choisi d’implémenter la mise en œuvre de réseau BGP / IP-in-IP de Calico dans le but d’isoler la plate-forme des détails du réseau sous-jacent. Dans la plupart des cas, lorsque vous contrôlez le réseau, cela est vraiment utile. Cependant, lorsque vous êtes à la merci de la politique d’un fournisseur de cloud (les fournisseurs de cloud font ces politiques pour de bonnes raisons, bien sûr), la configuration par défaut du plugin CNI peut ne pas fonctionner du tout. Par exemple : Azure n’autorise pas le trafic IP-in-IP sur leur réseau, et par conséquent le plug-in CNI par défaut de Docker Enterprise n’est pas une option. Pour cette raison, Docker vous offre un choix de plugins CNI avec des réseaux gérés / non gérés. En fait, Docker facilite l’échange de plugins CNI.
Tous les plugins CNI doivent respecter les éléments suivants :
- Tous les conteneurs peuvent communiquer avec tous les autres conteneurs sans NAT.
- Tous les nœuds peuvent communiquer avec tous les conteneurs (et vice-versa) sans NAT.
- L’adresse IP sous laquelle un conteneur se voit est la même adresse IP que les autres le voient.
Voyons comment configurer les plug-ins CNI de Docker Enterprise.
5.1.1.1 Installation de Docker Enterprise – Kubernetes
Docker fournit plusieurs options liées à la mise en réseau Kubernetes, notamment le fournisseur CNI à utiliser. En fait, il existe plusieurs options importantes à considérer lors de l’utilisation de Kubernetes à grande échelle. Le tableau suivant contient une liste des options d’installation liées à Kubernetes:
| Option | La description |
| –kube-apiserver-port | Port pour le serveur API Kubernetes (par défaut : 6443 ). |
| –cni-installer-url | Une URL pointant vers un fichier Kubernetes YAML à utiliser comme programme d’installation pour le plugin CNI du cluster. S’il est spécifié, le plugin CNI par défaut n’est pas installé. Si l’URL utilise le schéma HTTPS, aucune vérification de certificat n’est effectuée. |
| –pod-cidr | Pool IP du cluster Kubernetes pour les pods à partir desquels allouer des adresses IP (par défaut: 192.168.0.0/16 ). |
| –unmanaged-cni | La valeur par défaut false indique que le réseau Kubernetes est géré par UCP avec son plugin CNI géré par défaut, Calico. Lorsqu’il est défini sur true , UCP ne déploie ni ne gère le cycle de vie du plug-in CNI par défaut: le plug-in CNI est déployé et géré indépendamment de UCP. Notez que lorsque unmanaged-cni = true , la mise en réseau dans le cluster ne fonctionnera pas pour Kubernetes, jusqu’à ce qu’un plug-in CNI soit déployé. |
Les ports kube-apiserver- pod et pod-cidr doivent être pris en compte lors de la conception de l’implémentation réseau initiale pour votre installation Docker Enterprise. Les paramètres liés à CNI sont des décisions plus avancées liées à votre plate-forme (c’est-à-dire Cloud ou sur site) et vous devrez acquérir de l’expérience avec vos applications à plus grande échelle avant de prendre des décisions CNI pour des environnements de production à grande échelle. Ainsi, pour un cluster pilote ou de production précoce sous des charges de travail plus légères, la plupart de ces options devraient bien fonctionner.
Les fournisseurs CNI proposent un fichier Kubernetes YAML pour la configuration, et le bloc de code suivant montre un fichier tronqué fourni par Weaveworks:
apiVersion: v1
kind: List
items:
– apiVersion: v1
kind: ServiceAccount
metadata:
name: weave-net
annotations:
cloud.weave.works/launcher-info: |-
{
“original-request”: {
“url”: “/k8s/net?k8s-<…>”,
“date”: “Sat Feb 23 2019 17:51:08 GMT+0000 (UTC)”
},
“email-address”: “support@weave.works”
}
labels:
name: weave-net
namespace: kube-system
<…>
Ce format devrait sembler très familier aux utilisateurs de Kubernetes. Un lien (enregistré sous CNI_URL) vers ce fichier est en fait inclus dans les commandes d’installation UCP suivantes.
Maintenant, pour appliquer réellement ce fichier à une installation UCP, vous pouvez utiliser ces commandes :
#Set CNI_URL to Weave’s Kubernetes YAML file.
$ CNI_URL=“https://cloud.weave.works/k8s/net?k8s-version=Q2xpZW50IFZlcnNpb246IHZlcnNpb24uSW5mb3tNYWpvcjoiMSIsIE1pbm9yOiI5IiwgR2l0VmVyc2lvbjoidjEuOS4zIiwgR2l0Q29tbWl0OiJkMjgzNTQxNjU0NGYyOThjOTE5ZTJlYWQzYmUzZDA4NjRiNTIzMjNiIiwgR2l0VHJlZVN0YXRlOiJjbGVhbiIsIEJ1aWxkRGF0ZToiMjAxOC0wMi0wN1QxMjoyMjoyMVoiLCBHb1ZlcnNpb246ImdvMS45LjIiLCBDb21waWxlcjoiZ2MiLCBQbGF0Zm9ybToibGludXgvYW1kNjQifQpTZXJ2ZXIgVmVyc2lvbjogdmVyc2lvbi5JbmZve01ham9yOiIxIiwgTWlub3I6IjgrIiwgR2l0VmVyc2lvbjoidjEuOC4yLWRvY2tlci4xNDMrYWYwODAwNzk1OWUyY2UiLCBHaXRDb21taXQ6ImFmMDgwMDc5NTllMmNlYWUxMTZiMDk4ZWNhYTYyNGI0YjI0MjBkODgiLCBHaXRUcmVlU3RhdGU6ImNsZWFuIiwgQnVpbGREYXRlOiIyMDE4LTAyLTAxVDIzOjI2OjE3WiIsIEdvVmVyc2lvbjoiZ28xLjguMyIsIENvbXBpbGVyOiJnYyIsIFBsYXRmb3JtOiJsaW51eC9hbWQ2NCJ9Cg==”
$ docker container run –rm -it –name ucp \
-v /var/run/docker.sock:/var/run/docker.sock \
docker/ucp:3.1.2 install \
–host-address <node-ip-address> \
–cni-installer-url ${CNI_URL} \
–unmanaged-cni <true|false> \
–interactive
Il convient de noter que vous pouvez reconfigurer Calico pour ne pas utiliser IP-in-IP et utiliser uniquement les politiques de Calico et compter sur le réseau sous-jacent. Assurez-vous que Kubernetes fonctionnera correctement sans lui. Par exemple : assurez-vous que vous pouvez obtenir des adresses IP routables pour les pods. Soyez simplement conscient des limitations possibles du réseau sous-jacent, telles que le nombre de pods par nœud.
5.1.1.2 Philosophie de mise en réseau avancée de Kubernetes
En ce qui concerne la mise en réseau basée sur des conteneurs, il existe deux préoccupations principales et concurrentes. Le premier est l’accessibilité, où les pods / conteneurs peuvent communiquer librement à travers le cluster et les choses fonctionnent simplement ! La deuxième préoccupation, et opposée, est l’application des politiques, où nous devons gérer et contrôler le trafic entre les pods / conteneurs.
Il n’y a pas si longtemps, ce n’était pas très difficile, car nous nous appuyions uniquement sur la sécurité du périmètre. Nous verrouillerions le périmètre de notre réseau et laisserions tout circuler librement à l’intérieur. Cependant, dans le monde d’aujourd’hui, nous devons être tout aussi vigilants face aux attaques provenant de notre propre réseau. Par conséquent, le chiffrement et la gestion des politiques deviennent très importants, en particulier dans le monde Kubernetes, où, par conception, tout fonctionne dans un espace de réseau plat.
Pour les informations clés de cette section, je tiens à remercier Christopher Liljenstolpe, évangéliste pour le projet Calico et fondateur et directeur technique de la société de produits premium de Calico, Tigera.
Il se passe beaucoup de choses dans cet espace, surtout depuis que Kubernetes est entré dans l’espace Entreprise.
5.1.2 Coexistence – Essaim et Kube
Une autre observation intéressante lorsque l’on regarde l’architecture de Docker Enterprise est la coexistence. Swarm et Kubernetes sont tous deux dans le même cluster. Beaucoup de gens pensent à cela comme une situation soit / ou, alors qu’en réalité vous pouvez les exploiter côte à côte dans le même cluster.
Swarm et Kubernete s fonctionneront très bien sur le même nœud; cependant, la gestion des ressources de leur calendrier respectif n’a aucune connaissance des engagements de ressources de l’autre programmateur. Par conséquent, vous pourriez facilement vous retrouver avec une situation dépassée, même si vous utilisiez des réservations Swarm à la demande de Kubernetes. Par conséquent, n’utilisez pas de nœuds mixtes, Swarm et Kubernetes pour les nœuds de travail dans un environnement de production.
L’une des choses les plus difficiles consiste à gérer des philosophies de réseau très différentes, car Swarm et Kubernetes sont si différents à cet égard. Essentiellement, chaque pile Swarm possède son propre réseau isolé et potentiellement des réseaux supplémentaires pour une isolation supplémentaire. Du point de vue gauche, où les développeurs peuvent utiliser des réseaux définis par logiciel pour concevoir les interactions de leur application multiservice, c’est une excellente chose. Cependant, cela nécessite une mise en réseau extrêmement éphémère, où le cycle de vie d’une adresse IP peut être mesuré en minutes au lieu d’années, et peut être recyclé souvent un jour donner.
Dans Kubernetes, toutes les ressources s’exécutent sur le même réseau. C’est l’une des principales caractéristiques des plugins CNI, en particulier les plugins premium, tels que Tigera, avec une gestion de politique multicouche sophistiquée. Ce type de politique en tant que technologie de code devient une norme pour les infrastructures modernes et doit être pris en compte lors de la conception d’un réseau Docker Enterprise Kubernetes.
5.1.3 Contrôle d’accès basé sur les rôles Docker Enterprise Kubernetes
Au chapitre 5 , Préparer et déployer une application pilote Docker Enterprise , nous avons introduit le concept de contrôle d’accès basé sur les rôles ( RBAC ) dans Docker Enterprise. Notre discussion précédente se limitait à verrouiller les ressources liées à Swarm à l’aide d’une construction appelée collections. Revoyons un scénario similaire dans la figure 2, où nous avons ajouté un espace de noms de test. La figure 2 montre comment appliquer le même modèle RBAC d’objet, de rôle et de ressource aux actifs Kubernetes, en utilisant l’espace de noms au lieu des collections comme regroupements de ressources cibles :
Figure 2: Docker Enterprise RBAC avec Kubernetes
En regardant le schéma, à gauche, nous avons un serveur LDAP intégré à nos équipes et utilisateurs. Nous sommes entrés dans les détails concernant la configuration d’UCP avec l’intégration LDAP dans le chapitre 5 , Préparer et déployer une application pilote Docker Enterprise . Je ne le revisite ici que pour renforcer le fait que Docker Enterprise relie un système de sécurité centralisé à Kubernetes RBAC.
Pour prendre en charge Kubernetes, les attributs de rôle doivent refléter la structure de l’environnement Kubernetes. En fait, Docker utilise Kubernetes RBAC natif (rôles et rôles de cluster) dans Docker Enterprise. Ainsi, lors de la définition du rôle Kubernetes pour Docker Enterprise, vous pouvez réellement utiliser un format Kubernetes YAML standard. Une fois appliqués au cluster Docker Enterprise Kubernetes, ils apparaissent comme illustré dans la figure 3 :
Figure 3: ClusterRole du plan de contrôle universel
En plus de l’accès utilisateur aux ressources de collection ou d’espace de noms, nous pouvons également lier un espace de noms à une restriction de nœud (via une collection). Cela signifie que vous pouvez restreindre un espace de noms Kubernetes à s’exécuter uniquement sur les nœuds spécifiés. Cela peut être utile pour le transfert d’espaces de noms dans lesquels des données non supprimées peuvent être utilisées pour les tests finaux. L’isolement des nœuds fait partie de l’ensemble de fonctionnalités Docker Enterprise Advanced.
Alternativement, nous pourrions introduire des clusters supplémentaires pour l’isolement, mais cela nous ramène aux ressources sous-utilisées et à un phénomène que nous appelons l’étalement des clusters. En règle générale, vous êtes mieux servi en réfléchissant à votre modèle de sécurité et en l’utilisant pour gérer un plus petit nombre de grands clusters.
5.1.4 Gestion des volumes persistants de Kubernetes
D’après notre expérience, la gestion des volumes persistants dans le monde Docker Enterprise est à peu près Kubernetes native. En règle générale, vous souhaitez disposer d’une sorte de service de provisionnement automatique de volumes persistants pour gérer la gestion des ressources de stockage communes à travers le cluster, telles que NFS.
Veuillez lire la documentation de Kubernetes pour une meilleure compréhension du cycle de vie du volume persistant de Kubernetes: https://kubernetes.io/docs/concepts/storage/persistent-volumes/ .
Il existe bien sûr des méthodes très simples, telles que l’utilisation d’un volume de type NFS directement à partir d’un pod / conteneur, où, lorsqu’un pod est déployé, le conteneur du pod effectue essentiellement un montage de volume hôte Docker avec un pilote NFS local basé sur un nœud . Bien que le résultat final soit le même (plusieurs pods partageant le même point de montage du système de fichiers quel que soit l’endroit où ils sont déployés), il peut être difficile à contrôler (en contournant les ressources contrôlées par RBAC, par exemple) et à gérer de manière centralisée l’utilisation. Plus loin dans la section Volumes persistants Kubernetes avec un serveur NFS existant, nous allons parcourir un exemple de serveur NFS existant pour provisionner automatiquement les volumes persistants Kubernetes en fonction des revendications de volumes persistants.
5.2 Docker Desktop vers Docker Enterprise Kubernetes
Dans le chapitre 6 , Conception et pilotage d’un pipeline Docker Enterprise CI , nous avons passé du temps à créer notre application Java personnalisée AtSea. Il semble désormais approprié d’utiliser les mêmes images et de les redéployer en tant qu’application Kubernetes. De plus, nous montrerons comment créer et tester une application Kubernetes sur un bureau de développeur (sans Minikube!), Et l’appliquer à notre cluster Kubernetes fonctionnant sur Docker Enterprise.
Dans cette section, nous allons convertir notre application AtSea Swarm en une application Kubernetes et la déployer sur notre cluster pilote, aux côtés de la version Swarm de l’application qui est toujours en cours d’exécution. De plus, nous effectuerons en fait un déploiement bleu / vert, où nous effectuerons une migration en direct de l’application Swarm vers l’application Kubernetes.
5.2.1 Docker Desktop – Conversion d’AtSea en Kubernetes
Plus tôt dans l’article, nous avons utilisé Docker Desktop pour créer et tester des images sur la machine de développement locale à l’aide de Swarm pour simuler la pile fonctionnant de la même manière qu’en production. Donc, nous allons faire exactement la même chose, mais cette fois avec Kubernetes. De plus, il n’est pas nécessaire de reconstruire nos images, car nous les avons déjà.
Notre approche ici, tout comme la première fois que nous avons créé l’application, est de bas en haut. La figure 4 montre comment nous mettons en place notre développement local :
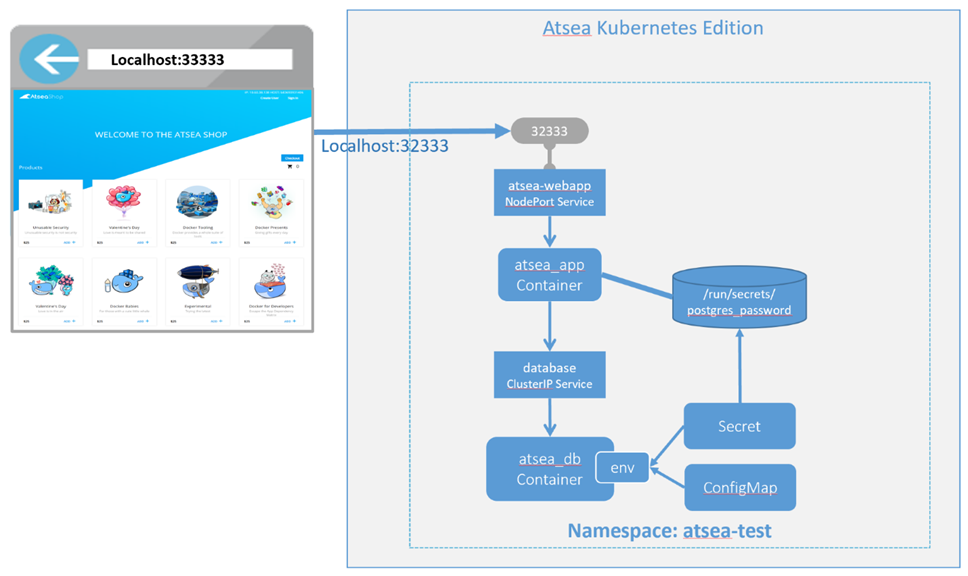
Figure 4: Application Atsea dans Kubernetes
Nous allons commencer par le conteneur de base de données, créer un déploiement de pod et injecter les propriétés ConfigMap et Secret dans les variables d’environnement du conteneur de base de données. C’est exactement là où le conteneur de base de données s’attend à les trouver, car il est identique à l’utilisation par l’application Swarm des variables d’environnement. Ensuite, nous allons créer un service ClusterIP de base de données (visible uniquement dans le cluster) en tant que point de terminaison durable pour se connecter à la base de données.
Veuillez noter que le service ClusterIP a la même base de données que le service de base de données de l’application Swarm. Cela permet à l’application Web de référencer le même nom DNS pour la base de données. Par conséquent, nous n’apporterons aucune modification de code à aucune de nos images.
Ensuite, nous créons un déploiement pour le conteneur atsea_app et injectons le mot de passe postgres de notre secret Kubernetes dans un montage de volume local, où l’application s’attend à nouveau à trouver le secret, au même endroit où l’application Swarm a injecté le secret. Ensuite, nous ajoutons le service NodePort à l’avant de nos pods web_app AtSea . Le service NodePort utilise IPVS pour publier un port sur tous les nœuds non maîtres du cluster. De cette façon, l’équilibreur de charge d’application AtSea peut diriger le trafic vers n’importe quel nœud non gestionnaire du cluster sur le port 3233, et le service NodePort de l’application Web AtSea transmettra la demande aux modules d’application Web.
Vous pouvez trouver les exemples de code pour la section dans le référentiel GitHub: https://github.com/PacktPublishing/Mastering-Docker-Enterprise/tree/master/chapter10/atsea-kube .
5.2.1.1 Configuration de Docker Desktop avec Kubernetes
Commençons par nous assurer que votre environnement Docker Desktop est correctement configuré pour exécuter Kubernetes sur votre poste de travail ou ordinateur portable. Si Docker Desktop est installé, il n’est plus nécessaire (à ma connaissance) d’utiliser Minikube. Pour ce faire, cliquez avec le bouton droit sur le puits dans votre barre d’état système et sélectionnez Paramètres, comme le montre la figure 5 :
Figure 5: menu contextuel de Docker Desktop
Cliquez ensuite sur l’onglet Kubernetes sur le côté gauche de la boîte de dialogue, comme illustré à la figure 6. Assurez-vous que la case Activer Kubernetes est cochée ; après l’avoir vérifié, attendez que Kubernetes démarre et que le point en bas à gauche de la boîte de dialogue devienne vert :

Figure 6: Activer Kubernetes
Une fois Kubernetes en cours d’exécution, fermez la boîte de dialogue, ouvrez un shell PowerShell ou Bash et exécutez la commande $ kubectl get nodes suivante. Cela ressemble à peu près à Bash ou PowerShell, comme vous pouvez le voir, mais, dans les deux cas, vous devriez voir Docker-for-desktop Ready master 40d v1.10.11 :
# Windows Powershell
PS > kubectl get nodes
NAME STATUS ROLES AGE VERSION
docker-for-desktop Ready master 40d v1.10.11
# Bash Shell
@xps-bash$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
docker-for-desktop Ready master 40d v1.10.11
En guise de remarque, Kubernetes dans la version Desktop est un peu vieux. Étonnamment, il est plus ancien que la version EE Kubernetes de 1.11.5. Je le signale parce que vous pourriez rencontrer une situation où les choses se comportent différemment sur votre bureau que sur le cluster. Cela est également vrai pour les versions de Docker.
Vous êtes prêt !
5.2.1.2 Configuration d’une application avec Kubernetes (Namespace / Secrets / ConfigMaps)
Commençons par créer un espace de noms pour notre application. Nous allons mettre toutes nos ressources Kubernetes dans l’espace de noms atsea-test. Cela rend très facile l’isolement et le nettoyage de notre machine locale lorsque nous avons terminé. Nous pouvons voir le fichier YAML que nous utiliserons pour créer l’espace de noms :
apiVersion: v1
kind: Namespace
metadata:
name: atsea-test
Ensuite, nous utilisons l’outil de ligne de commande Kubernetes, $ kubectl, pour appliquer de manière déclarative les ressources de notre fichier create-app-namespace.yaml au cluster. Le résultat est un nouvel espace de noms sur notre cluster de bureaux Kubernetes local :
$ kubectl apply -f create-app-namespace.yaml
namespace/atsea-test created
Nous pouvons maintenant parcourir le fichier ConfigMap. Les ConfigMaps sont utilisés pour stocker les informations de configuration séparément des autres artefacts de déploiement. Cela vous permet d’échanger les fichiers par vos configs cible différente entre les dev, tests et qa environnements. Dans la section de données suivante, nous stockons les paires clé-valeur de données que nous allons utiliser lors du déploiement de notre application. La section de métadonnées stocke le nom de la configuration et également l’espace de noms où ConfigMap sera stocké. Dans la version Swarm de notre application, nous avons stocké ces valeurs littérales dans notre fichier de pile :
apiVersion: v1
kind: ConfigMap
data:
db: atsea
user: gordonuser
metadata:
name: dbconfig
namespace: atsea-test
Maintenant, nous devons appliquer notre configmap au cluster et nous pouvons utiliser $ kubectl get configmap pour vérifier l’état du cluster :
$ kubectl apply -f configmap.yaml
configmap/dbconfig created
# Verify the configmap..
$ kubectl get configmap dbconfig -o yaml
apiVersion: v1
data:
db: atsea
user: gordonuser
kind: ConfigMap
metadata:
creationTimestamp: “2019-02-22T17:32:14Z”
name: dbconfig
namespace: default
ConfigMap fournit une très belle séparation des valeurs de déploiement de la configuration. Pour mémoire, Swarm propose également des configurations qui pourraient être utilisées de manière similaire, mais moins sophistiquée. Par conséquent, ce n’est pas une différence de fonctionnalité, mais plutôt une petite mise à niveau de conception effectuée lors de la conversion en Kubernetes. Il en va de même pour le YAML secret suivant :
apiVersion: v1
kind: Secret
metadata:
name: atsea-postgres-password
namespace: atsea-test
type: Opaque
stringData:
postgres_password: “gordonpass”
Ici, nous pouvons voir où postgres_password est enregistré en tant que secret .
Soyez très prudent lorsque vous utilisez les secrets de Kubernetes, car ils ne sont pas chiffrés et uniquement codés en base64 ! Pensez à utiliser un produit tiers, tel que hashicorp vault , pour sécuriser vos mots de passe, certificats et autres secrets. Dans le bloc de code suivant , vous pouvez voir avec quelle facilité il peut être récupéré puis décodé.
Enfin, nous appliquons notre secret au cluster, puis le passons en revue. Par défaut, les secrets de Kubernetes ne sont pas chiffrés, juste encodés en base64. C’est pourquoi de nombreux utilisateurs de Kubernetes utilisent un coffre-fort quelconque à la place ou en conjonction avec les secrets de Kubernetes:
$ kubectl apply -f secret.yaml
secret/atsea-postgres-password created
# Verify password
$ kubectl get secret atsea-postgres-password -o yaml
apiVersion: v1
data:
password: Z29yZG9ucGFzcw==
kind: Secret
metadata:
name: atsea-postgres-password
namespace: default
# Look at password – scary! It is just base64 encoded!
$ echo ‘Z29yZG9ucGFzcw==’ | base64 –decode
gordonpass
Passons maintenant au déploiement de la base de données pour voir comment nous utilisons ConfigMap et secret.
5.2.1.3 Conversion et test de la base de données
Commençons par regarder la première section de notre fichier de déploiement de pod de base de données :
apiVersion: apps/v1
kind: Deployment
metadata:
name: atsea-database
namespace: atsea-test
spec:
selector:
matchLabels:
run: atsea-database
replicas: 1
template:
metadata:
labels:
run: atsea-database
La première section du fichier est la section de déploiement. Il nous permet de décrire comment nous voulons que notre ensemble de pods soit déployé et combien nous voulons continuer à fonctionner (ensemble de répliques). Dans notre cas, nous avons des répliques définies sur 1, car il s’agit d’une base de données et elle est avec état.
Dans le bloc de code suivant, nous examinerons la spécification du conteneur pour voir comment le ConfigMap et le secret sont utilisés :
spec:
containers:
– name: database
image: dtr.mydomain.com/test/atsea-db_build:kV1
ports:
– containerPort: 5432
env:
– name: POSTGRES_USER
valueFrom:
configMapKeyRef:
name: dbconfig
key: user
– name: POSTGRES_DB
valueFrom:
configMapKeyRef:
name: dbconfig
key: db
– name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: atsea-postgres-password
key: postgres_password
Enfin, dans la dernière section du fichier de déploiement du pod de base de données, nous avons ajouté la gestion des ressources à notre conteneur de serveur de base de données :
resources:
limits:
cpu: “1”
memory: 1Gi
requests:
cpu: “1”
memory: 1Gi
imagePullSecrets:
– name: regcred
Nous avons limité la base de données à un processeur et 1 gig de RAM. Notez que nous définissons la demande au même niveau. Comme indiqué au chapitre 9, Rubriques importantes sur la production de Docker Enterprise , il s’agit certainement d’une meilleure pratique pour la planification de Swarm et de Kubernetes.
Enfin, au bas du fichier, notez la section imagePullSecrets ; il y a un élément appelé regcred . Vous devrez peut-être l’utiliser si vous avez une erreur imagepullbackoff lors du déploiement de vos pods. Tous les grands exemples que vous extrayez des images publiques qui ne nécessitent aucune authentification. Cependant, notre cluster Kubernetes et notre bureau local Kubernetes doivent extraire des images privées de notre DTR privé.
Donc, pour que cela fonctionne, nous devons créer un secret appelé regcred :
$ kubectl create secret -n atsea-test docker-registry regcred –docker-server=dtr.mydomain.com –docker-username=admin –docker-password=xxxxxxxxx –docker-email=sysadmin@mydomain.com
Nous pouvons maintenant déployer notre module de base de données :
$ kubectl apply -f db-pod.yaml
deployment.apps/atsea-database created
# Check Pod
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
atsea-database-6bf74cbc4b-7n5d7 1/1 Running 0 25s
Nous pouvons voir que le module de base de données est en cours d’exécution.
5.2.1.4 Création du DB ClusterIP
Maintenant , nous allons mettre le CLUSTERIP servic e devant notre base de données. Bien que l’application puisse se connecter directement au pod, cela ne nous protège pas contre le remplacement des pods par l’orchestrateur. Au lieu de cela, nous utilisons un service ClusterIP dans un point de terminaison durable pour notre application pour effectuer des demandes de base de données. De cette façon, si le pod disparaît et est remplacé, les applications Web, le point de terminaison restent les mêmes.
Notez également que le service ClusterIP n’est accessible qu’à partir du cluster. Étant donné que nous n’exposons pas la base de données en dehors du cluster, c’est un bon choix pour des raisons de sécurité.
Le bloc de code suivant montre le fichier de déploiement pour le service IP de cluster de base de données :
apiVersion: v1
kind: Service
metadata:
name: database
namespace: atsea-test
labels:
run: atsea-database
spec:
type: ClusterIP
ports:
– port: 5432
targetPort: 5432
protocol: TCP
name: http
selector:
run: atsea-database
Tout d’abord, nous voyons le nom du service, qui est important à des fins DNS. Il s’agit du nom DNS que l’application Web utilisera pour accéder à la base de données. La section des ports indique sur quel port le service est accessible et quel port correspond à l’intérieur du conteneur de base de données. Enfin, le sélecteur est ce qui est utilisé pour lier ce service au pod de base de données. Si vous regardez en arrière les métadonnées:> libellés : section du fichier de déploiement du module de base de données, vous verrez un libellé exécuté : atsea-database.
Nous devons maintenant appliquer notre service de base de données au cluster:
$ kubectl apply -f db-service.yaml
service/database created
$ kubectl describe svc/database
Name: database
Namespace: default
Labels: run=atsea-database
<…>
Type: ClusterIP
IP: 10.109.222.29
Port: http 5432/TCP
TargetPort: 5432/TCP
Endpoints: 10.1.0.28:5432
<…>
Tout d’abord, nous appliquons les modifications que nos modifications ont apportées au cluster, en ajoutant le service de base de données. Après le déploiement du service de base de données, il est judicieux de vous assurer que le service est lié à notre module de base de données. Voir les points de terminaison avec une adresse IP et un numéro de port est un très bon signe. Sinon, les points de terminaison se videraient, indiquant qu’il n’a pas pu utiliser un sélecteur pour se lier aux pods.
5.2.1.5 Conversion de l’application Web
Ensuite, nous allons commencer la conversion de l’application Web. Dans le bloc de code suivant, nous avons la première section du fichier de déploiement d’application Web :
apiVersion: apps/v1
kind: Deployment
metadata:
name: atsea-web
namespace: atsea-test
spec:
selector:
matchLabels:
run: atsea-web
replicas: 1
template:
metadata:
labels:
run: atsea-web
L’extrait précédent décrit les spécifications de déploiement et de jeu de réplicas. Mis à part quelques changements de nom, il est très similaire à la conversion et au test de la section DB. Dans le bloc de code suivant, nous voyons la spécification de conteneur pour l’application Web AtSea:
spec:
containers:
– name: atsea-web
image: dtr.mydomain.com/test/atsea-web_build:kV1
ports:
– containerPort: 8080
volumeMounts:
– name: secret
mountPath: “/run/secrets”
subPath: postgres_password
readOnly: true
resources:
limits:
cpu: “1”
memory: 1.5Gi
requests:
cpu: “1”
memory: 1.5Gi
env:
name: JAVA_OPTS
value: -Xms512M -Xmx1G
volumes:
– name: secret
secret:
defaultMode: 0666
secretName: atsea-postgres-password
imagePullSecrets:
– name: regcred L’application Web gère le secret un peu différemment. Vous pourriez reconnaître le répertoire / run / secrets de notre implémentation Swarm. Il s’agit du répertoire par défaut où Docker Swarm place des secrets. Pour émuler ce comportement avec Kubernetes, nous avons monté le chemin dans le conteneur au même emplacement. Ensuite, dans la dernière section, nous créons le volume et injectons le secret dans le volume.
Encore une fois, nous avons créé une section de ressources pour spécifier les limites et les demandes. Dans ce cas, nous limitons le conteneur à un processeur et mettons une limite de 1,5 Go de mémoire. N’oubliez pas que si le conteneur tente de dépasser la limite de mémoire, le moteur Docker pourra tuer le conteneur avec une exception de mémoire insuffisante. La demande indique à Kubernetes la quantité de ressources que le conteneur consommera sur le nœud où le conteneur est déployé, aidant l’orchestrateur Kubernetes à garder une trace des ressources restantes disponibles sur chaque nœud.
Un dernier rappel sur les applications Java exécutées dans des conteneurs : Avant la version 10 de Java, vous devez définir la quantité maximale de mémoire (Xmx) en tant que paramètre ou variable d’environnement pour la JVM. Sans cela, le conteneur Java tentera de prendre la majorité des ressources disponibles sur le nœud entier, sans respecter les limites définies pour le conteneur. Dans cette situation, vous risquez de rencontrer une exception de mémoire insuffisante si une limite est utilisée sans le paramètre JVM. Dans notre exemple, nous utilisons à la fois la limite et le paramètre JVM Xmx.
5.2.1.6 Création de la webapp NodeP ort
Nous devons maintenant exposer l’application Web avec un service en dehors du cluster, permettant à notre équilibreur de charge d’application d’atteindre l’application Web. Pour ce faire, nous utilisons un autre type de service, un service NodePort. Le bloc de code suivant montre les spécifications du service NodePort de notre application Web :
apiVersion: v1
kind: Service
metadata:
name: atsea-webapp
namespace: atsea-test
labels:
run: atsea-web
spec:
type: NodePort
ports:
– port: 8080
nodePort: 32666
selector:
run: atsea-web
Encore une fois, nous voyons un ensemble de ports spécifiés. Le port 8080 à l’intérieur du cluster et le port 32666 est le port d’accès depuis l’extérieur du cluster. Par conséquent, nous pouvons envoyer une demande de notre navigateur de bureau au port 32666, en utilisant l’hôte local et une application Web lorsque nous recevons la demande.
Plus tard, lorsque nous déploierons sur le cluster Kubernetes exécuté sur Docker Enterprise, il y aura deux différences. La première différence est le numéro de port pour nodePort, car la plage de ports éphémères par défaut pour Kubernetes sur Docker Enterprise est 32768 à 35535. Nous utiliserons le port 33333 lors du déploiement sur le cluster. La deuxième différence est plutôt que de pointer un navigateur vers le service NodePort, nous enverrons plutôt du trafic à notre équilibreur de charge d’application.
Enfin, nous devons démarrer un pod Webapp et le service NodePort, à l’aide des commandes du bloc de code suivant. Encore une fois, nous voulons nous assurer que les services sont démarrés correctement. Nous voyons à la fois les services et leur adresse de port :
$ kubectl apply -f webapp-pod.yaml
deployment.apps/atsea-web created
$ kubectl apply -f webapp-service.yaml
service/atsea-webapp created
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
atsea-webapp NodePort 10.104.35.106 <none> 8080:32666/TCP 29s
database ClusterIP 10.109.43.119 <none> 5432/TCP 1m
Notre application fonctionne maintenant sur Kubernetes!
5.2.1.7 Test local
Pour vérifier que l’application fonctionne, nous sommes maintenant prêts à utiliser notre navigateur pour se connecter à http://localhost:32666, ajouter des éléments au registre et vérifier :
Figure 7: Réussite du test local Atsea Kubernetes
5.2.2 Docker Enterprise pour une version pilote d’AtSea Kubernetes
Maintenant que nous avons préparé la version Kubernetes de notre application AtSea, nous pouvons nous préparer à la déployer sur notre cluster Docker Enterprise Kubernetes. De plus, nous voulons démontrer la capacité d’isoler notre espace de nom atsea-test avec Docker RBAC et Kubernetes.
Tout d’abord, nous allons créer notre espace de noms atsea-test. Ensuite, nous créerons un utilisateur non administratif, mpanthofer, et en utilisant une subvention Docker RBAC, nous autoriserons mpanthofer à avoir des droits administratifs uniquement dans l’espace de noms atsea-test. Maintenant, nous sommes prêts à déployer notre application à l’aide du compte utilisateur mpanthofer et du bundle client.
5.2.2.1 Configuration de Docker RBAC pour l’espace de noms atsea-test
Après vous être connecté au plan de contrôle universel en tant qu’administrateur, accédez au menu des espaces de noms. De là, cliquez sur le bouton Créer dans le coin supérieur droit, comme le montre la figure 8 :
Figure 8: espaces de noms UCP Kubernetes
Dans la figure 9, nous voyons le dialogue de création d’objet Kubernetes dans l’interface Web UCP. Ici, nous pouvons coller le code que nous avons utilisé pour créer l’espace de noms atsea-test sur notre bureau. Ensuite, nous cliquons sur Créer :

Figure 9 : Espace de noms UCP Add Kubernetes
Nous pouvons voir que l’espace de noms atsea-test a été créé dans la figure 10 :

Figure 10 : Nouvel espace de noms Kubernetes atsea-test
La figure 11 montre comment nous créons le compte d’utilisateur non administrateur pour mpanthofer à partir du contrôle d’accès | Utilisateurs | Boîte de dialogue Créer :
Figure 11 : Créer un utilisateur UCP non administrateur
Enfin, nous ajoutons attribuer cet accès administrateur utilisateur à l’espace de noms atsea-test, comme le montre la figure 12 :
Figure 12 : Liez mpanthofer en tant qu’administrateur à atsea-test
Nous créons maintenant un bundle client pour le compte mpanthofer (sans administrateur) à partir d’UCP et le téléchargeons sur une machine locale. Nous décompressons les fichiers et $ source env.sh pour nous connecter au cluster. Ensuite, nous exécutons un test rapide. Tout d’abord, nous essayons de répertorier les ressources de l’espace de noms par défaut, où nous n’avons accordé aucun droit d’accès. On nous refuse une longue liste d’avertissements interdits. Essayons maintenant la même chose contre notre espace de noms vide en mer. Comme vous pouvez le voir sur la figure 13, il se comporte comme prévu :
Figure 13: autorisations de test de mpanthofer
Déployons maintenant notre application avec le compte sans administrateur mpanthofer .
5.2.2.2 Déploiement bleu / vert d’AtSea sur le cluster Docker Enterprise Kubernetes
Tout d’abord, nous allons devoir ajouter un secret enregistré à notre nouvel espace de noms afin que l’orchestrateur Kubernetes puisse accéder à notre registre privé :
$ kubectl create secret -n atsea-test docker-registry regcred –docker-server=dtr.mydomain.com –docker-username=admin –docker-password=xxxxxxxxx –docker-email=someuser@mydomain.com
secret/regcred created
Nous allons maintenant exécuter le reste de nos commandes de déploiement, en utilisant le bundle de ligne de commande pour cibler notre cluster Docker Enterprise, en utilisant notre compte mpanthofer :
$ kubectl apply -f configmap.yaml
configmap/dbconfig created
$ kubectl apply -f secret.yaml
secret/atsea-postgres-password created
$ kubectl apply -f db-pod.yaml
deployment.apps/atsea-database created
$ kubectl apply -f db-service.yaml
service/database created
$ kubectl apply -f webapp-pod.yaml
deployment.apps/atsea-web created
$ kubectl apply -f webapp-service.yaml
service/atsea-webapp created
Maintenant, nous devons vérifier notre déploiement :
$ kubectl -n atsea-test get all
NAME READY STATUS RESTARTS AGE
pod/atsea-database-66848b4897-2jn5s 1/1 Running 0 3m
pod/atsea-web-59774bc8c9-6trcl 1/1 Running 0 3m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/atsea-webapp NodePort 10.96.203.92 <none> 8080:33333/TCP 2m
service/database ClusterIP 10.96.71.70 <none> 5432/TCP 3m
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/atsea-database 1 1 1 1 3m
deployment.apps/atsea-web 1 1 1 1 3m
NAME DESIRED CURRENT READY AGE
replicaset.apps/atsea-database-66848b4897 1 1 1 3m
replicaset.apps/atsea-web-59774bc8c9 1 1 1 3m
Il semble que tout fonctionne correctement.
5.2.2.3 Test de fumée de l’application AtSea Kubernetes
Je vais me connecter au nœud d’équilibrage de charge et exécuter un test cURL rapide sur l’un des nœuds de travail à l’aide du port 33333. S’il vérifie, je vais me diriger vers l’équilibreur de charge et commencer à diriger le trafic vers la nouvelle implémentation :
$ curl -v http://10.10.1.39:33333/index.html
* About to connect() to 10.10.1.39 port 33333 (#0)
* Trying 10.10.1.39…
* Connected to 10.10.1.39 (10.10.1.39) port 33333 (#0)
> GET /index.html HTTP/1.1
> User-Agent: curl/7.29.0
> Host: 10.10.1.39:33333
> Accept: */*
>
< HTTP/1.1 200
< X-Content-Type-Options: nosniff
< X-XSS-Protection: 1; mode=block
< Cache-Control: no-cache, no-store, max-age=0, must-revalidate
< Pragma: no-cache
< Expires: 0
< X-Frame-Options: DENY
< Last-Modified: Tue, 05 Feb 2019 00:07:40 GMT
< Accept-Ranges: bytes
< Content-Type: text/html
< Content-Length: 462
< Date: Sun, 24 Feb 2019 07:16:45 GMT
<
* Connection #0 to host 10.10.1.39 left intact
<!doctype html><html lang=”en”><head><meta charset=”utf-8″><meta name=”viewport” content=”width=device-width,initial-scale=1″><title>Atsea Shop</title><link href=”/static/css/main.d25422c6.css” rel=”stylesheet”></head><body><style>body{max-width:100vw;overflow-x:hidden}</style><div id=”root”></div><link rel=”stylesheet” href=”//fonts.googleapis.com/css?family=Open+Sans”/><script type=”text/javascript” src=”/static/js/main.04755338.js”></script></body></html>
La commande curl a réussi comme nous l’espérions. Vous pouvez le voir par le HTML en bas du bloc de code.
5.2.2.4 Configuration de l’équilibreur de charge pour le déploiement bleu / vert
Reconfigurons le backend de notre équilibreur de charge pour commencer à partager la charge entre la nouvelle implémentation et notre ancienne implémentation Swarm, qui fonctionne toujours sur notre client.
Voici à quoi ressemble le profil d’arrière-plan de l’équilibreur de charge :
backend atsea_app_upstream_servers_8043
mode http
balance roundrobin
server atseaServer01 ntc-wrk-1:33333
server atseaServer02 ntc-wrk-2:8043
server atseaServer03 ntc-wrk-3:8043
http-request set-header X-Forwarded-Port %[dst_port]
http-request add-header X-Forwarded-Proto https if { ssl_fc }
Avant de redémarrer l’équilibreur de charge, nous prenons une capture d’écran de la page de notre application AtSea Swarm, en zoomant dans le coin supérieur droit pour montrer où il répertorie l’adresse IP, à partir du pool d’adresses de Swarm:

Figure 14: Vue agrandie d’Atsea sur Swarm
Maintenant, nous redémarrons l’équilibreur de charge, actualisons la page plusieurs fois et obtenons la page de l’application AtSea Kubernetes:
Figure 15: Vue agrandie d’AtSea sur Kubernetes
Les deux applications sont en cours d’exécution et la nouvelle application semble fonctionner correctement. Nous allons maintenant diriger tout le trafic vers l’application Atsea Kubernetes et supprimer Atsea Swarm. Notre projet de conversion Kubernetes est terminé et déployé !
5.3 Intégrations Docker Enterprise Kubernetes tierces
L’écosystème Kubernetes a explosé avec toutes sortes d’extensions et d’intégrations, et il semble que nous ne faisons que commencer. Cependant, une chose que vous pourriez rencontrer est de légers problèmes avec le processus d’installation d’outils tiers basés sur Kubernetes qui s’exécutent sur Docker Enterprise. Ces problèmes sont généralement mineurs et ont à voir avec la façon dont Docker a décidé d’installer et de configurer sa version de Kubernetes.
5.3.1 Graphiques de barre sur Docker Enterprise Kubernetes
Les graphiques Helm sont un outil très populaire dans la communauté Kubernetes pour une distribution plus douce. Souvent appelé gestionnaire de packages Kubernetes , Helm simplifie l’installation et la maintenance des applications avec un cluster Kubernetes. Il existe des graphiques Helm pour à peu près tous les progiciels populaires. Vous pouvez en trouver plus ici: https://hub.helm.sh/ . Bien que je sois relativement nouveau dans les graphiques Hel m, je voulais partager quelques ajustements pour vous aider à démarrer, en utilisant l’aide de Docker Enterprise.
Passons en revue la configuration de Helm avec Docker Enterprise. Il s’avère qu’il ne manque que quelques éléments du déploiement Docker de Kubernetes qui font normalement partie de la distribution standard de Kubernetes. Tout d’abord, il nous manque une liaison de rôle et une liaison de cluster qui doivent être ajoutées avant d’installer Helm :
$ kubectl create rolebinding default-view –clusterrole=view –serviceaccount=kube-system:default –namespace=kube-system
$ kubectl create clusterrolebinding add-on-cluster-admin –clusterrole=cluster-admin –serviceaccount=kube-system:default
Ensuite, nous devons créer un ServiceAccount pour tiller (l’agent distant de Helm qui vit à l’intérieur de votre cluster). Enfin, nous devons lier le compte de service tiller au rôle d’ administrateur de cluster , comme indiqué dans le bloc de code suivant (vous pouvez trouver le code sur https://github.com/PacktPublishing/Mastering-Docker-Enterprise/tree/master / chapter10 / Helm-DockerEE ):
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
—
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
– kind: ServiceAccount
name: tiller
namespace: kube-system
Appliquez le compte de service de tiller et la liaison de cluster avec la commande $ kubectl create -f rbac-config.yaml .
Maintenant, nous devons saisir le script d’installation, définir l’autorisation sur le script et l’exécuter. Lorsque vous avez terminé, initialisez Helm et n’oubliez pas l’option de compte de service :
$ curl https://raw.githubusercontent.com/helm/helm/master/scripts/get > get_helm.sh
$ chmod 700 get_helm.sh
$ ./get_helm.sh
$ helm init –service-account tiller
La barre devrait être prête à partir ! Si vous suivez, assurez-vous de laisser Helm en cours d’exécution, car nous l’utiliserons pour installer notre provisionneur de volume persistant NFS Client et notre contrôleur d’entrée NGINX.
5.3.2 GitLab et Docker Enterprise Kubernetes
Nous aimons GitLab! Cependant, il y a quelques problèmes qui m’ont éloigné de l’utilisation de son intégration Kubernetes à notre cluster Kubernetes. L’intégration de GitLab semble être configurée principalement pour fonctionner avec GCP dès le départ, mais nous avons pu l’intégrer à l’aide de notre certificat de bundle client UCP pour accéder à notre cluster Docker Enterprise Kubernetes sur site.
Je n’ai pas pu obtenir l’intégration de l’application GitLabs Kubernetes à installer sur notre cluster (pas que je voudrais l’utiliser, car nous avons déjà installé helm / tiller dans les graphiques Helm sur la section Docker Enterprise Kubernetes). Lorsque j’ai envisagé d’installer la version Kubernetes du gitlab-runner, en utilisant Helm, par souci de sécurité et de stabilité, j’ai abandonné le plan. D’après ce que j’ai lu dans les documents GitLab, l’implémentation actuelle nécessite un mode privilégié pour exécuter Docker dans Docker. Nous ne sommes pas à l’aise avec Docker dans Docker en utilisant le mode privilégié en raison de problèmes de sécurité et d’une corruption potentielle du système de fichiers.
Actuellement, nous sommes très satisfaits de notre boîtier autonome GitLab-runner, utilisant Docker sur Docker pour monter le socket Docker et évitant les problèmes de mode privilégié.
5.3.3 Volumes persistants Kubernetes avec un serveur NFS existant
Plus tôt dans le chapitre, nous avons discuté des volumes persistants avec Kubernetes. Nous avons présenté une approche simple et alternative de l’utilisation d’un montage de volume NFS dans chaque module. Par conséquent, la solution présentée dans cette section utilise un provisionneur automatique de volume plus sophistiqué pour une approche centralisée et gérée.
Le premier défi ici était d’essayer de trouver quelque chose qui a été conçu pour fonctionner avec un serveur NFS existant. De nombreuses solutions, en particulier celles basées sur le cloud, sont conçues pour s’intégrer aux systèmes de fichiers Cloud et présenter le volume persistant de Kubernetes comme demandé. C’est cool, mais nous voulions une solution pour travailler avec un serveur NFS existant. Il s’avère que cela s’appelle un client NFS.
Vous pouvez trouver les fichiers que j’ai utilisés pour ma configuration ici: https://github.com/PacktPublishing/Mastering-Docker-Enterprise/tree/master/chapte r10 / NFS .
5.3.3.1 Attacher votre cluster UCP Kube à un serveur NFS local existant
Nous utilisons notre nouvelle installation de Helm pour nous aider à installer notre provisionneur NFS pour Kubernetes. Le provisionneur crée dynamiquement des volumes persistants lorsqu’une revendication de volume persistant est effectuée.
Notre configuration est basée sur les éléments suivants et nécessite un serveur NFS existant pour fonctionner: https://github.com/helm/charts/tree/master/stable/nfs-client-provisioner .
Si vous n’avez pas de serveur NFS et que vous souhaitez provisionner automatiquement les ressources cloud à partir de votre cluster Kubernetes, il existe un autre graphique pour cela. Nous ne le couvrons pas dans l’article, mais vous voudrez peut-être le vérifier: https://github.com/helm/charts/tree/master/stable/nfs-server-provisioner .
5.3.3.1.1 La configuration
Assurez-vous d’utiliser votre propre nfs.server et de définir nfs.path en remplaçant les {exemples de valeurs} dans la commande d’installation helm :
$ helm install –name my-release –set nfs.server = {10.50.1.46} –set nfs.path = {/ var / nfsshare / apps} stable / nfs-client-provisioner
$ kubectl appliquer -f nfs-pvc.yaml
$ kubectl obtenir pvc
NOM STATUT VOLUME CAPACITÉ MODES D’ACCÈS STORAGECLASS AGE
nfs-claim Bound pvc-eb937812-3767-11e9-88f4-0242ac110007 1Mi RWX nfs-client 20h
Jetons un coup d’œil à la liste de stockage Kubernetes d’UCP :
Figure 16: Stockage et volumes UCP Kubernetes
Ici, nous voyons les trois éléments qui ont été créés. nfs-client a été créé par le graphique Helm. Ensuite, nous avons fait une revendication de volume persistant NFS, qui a généré le volume persistant réel, où nos données résident et sont soutenues par le système de fichiers NFS.
Jetons un coup d’œil au PVC dans le bloc de code suivant :
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nfs-claim
annotations:
volume.beta.kubernetes.io/storage-class: “nfs-client”
spec:
accessModes:
– ReadWriteMany
resources:
requests:
storage: 1Mi
Examinons quelques éléments de notre classe de revendication de volume persistant. Le premier est bien sûr le nom – vous comprendrez pourquoi c’est important dans une minute. II est la classe de stockage. Cela doit pointer vers la classe de stockage que nous avons installée, nfs-client. Le dernier élément est la demande, ce qui réduit bien sûr le montant des ressources disponibles de ce montant.
Nous pouvons maintenant jeter un coup d’œil à l’utilisation réelle de notre volume persistant fraîchement fabriqué. Voici le test que nous allons utiliser pour vérifier que NFS fonctionne correctement :
kind: Pod
apiVersion: v1
metadata:
name: test-pod
spec:
containers:
– name: test-pod
image: gcr.io/google_containers/busybox:1.24
command:
– “/bin/sh”
args:
– “-c”
– “touch /mnt/SUCCESS && exit 0 || exit 1”
volumeMounts:
– name: nfs-pvc
mountPath: “/mnt”
restartPolicy: “Never”
volumes:
– name: nfs-pvc
persistentVolumeClaim:
claimName: nfs-claim
La première chose à noter est la commande réelle qui s’exécute à l’intérieur du pod. Si cela fonctionne réellement, je m’attendrais à voir un fichier appelé SUCCESS sur l’exportation du serveur NFS. La partie importante liée au volume persistant se trouve au bas du fichier de test dans le bloc de code précédent. Ici, nous voyons comment il utilise le nom de la revendication de volume persistant. Donc, nulle part, nous n’utilisons réellement le nom du volume persistant généré automatiquement. Au lieu de cela, nous nous y référons simplement par claimName.
Nous allons maintenant exécuter notre module de test et voir ce qui se passe :
$ kubectl apply -f test-nfs.yaml
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
my-release-nfs-client-provisioner-bb77bb766-rhz6x 1/1 Running 0 21h
test-pod 0/1 Completed 0 20h
Ici, nous pouvons voir que le module de test s’est exécuté et terminé. Il ne reste donc plus qu’à aller sur notre serveur NFS et voir si notre répertoire SUCCESS est apparu :
[/var/nfsshare/apps]# tree -L 2
.
├── default-nfs-claim-pvc-eb937812-3767-11e9-88f4-0242ac110007
│ └── SUCCESS
C’est intéressant de voir ce qui s’est passé ici. Sous notre répertoire d’exportation, un nouveau répertoire a été créé avec le nom de la revendication de volume persistant et l’ID. En dessous se trouve le fichier SUCCESS. Nous pouvons voir comment cela fonctionne en injectant un répertoire intermédiaire avec le nom du PVC.
5.3.4 Contrôleur d’entrée
Dans cette section, nous parlerons de l’utilisation du contrôleur d’entrée NGINX avec Docker Enterprise Kubernetes. Pour cette section, j’ai configuré l’environnement suivant :
Figure 17: Configuration de test du bureau du contrôleur d’entrée
Étant donné que notre cluster est derrière un pare-feu, nous utiliserons un tunnel SSH pour passer par notre équilibreur de charge d’application pour accéder aux nœuds du cluster. À partir de là, notre demande passe au contrôleur nginx-ingress où elle utilise des règles d’entrée pour déterminer le routage de la demande en fonction du nom d’hôte dans l’en-tête. Dans notre cas, nous avons créé une règle pour transmettre les demandes avec un en-tête de nom d’hôte ingress-app. https://www.mydomain.com/ au service de démonstration de docker, qui est ensuite transmis au module de démonstration de docker – très cool !
5.3.4.1 Installation du contrôleur d’entrée NGINX
Pour la mise en œuvre de notre contrôleur d’entrée Kubernetes, nous nous fierons à nouveau à Helm. Nous commençons par installer le graphique du contrôleur d’entrée NGINX (stable/nginx-ingress), comme indiqué dans le bloc de code suivant :
$ helm install stable/nginx-ingress –name my-nginx –set rbac.create=true
<… You will see the initial status after the install here …>
<… Vous verrez l’état initial après l’installation ici …>
Vous verrez l’état initial après l’installation, mais vous devez attendre environ cinq minutes pour obtenir de l’aide pour terminer le déploiement. Vous pouvez utiliser l’interface utilisateur Web UCP pour valider que le pod s’exécute :

Figure 18
Nous pouvons également utiliser Helm pour vérifier l’état après avoir attendu cinq minutes, comme indiqué dans le bloc de code suivant :
$ helm status my-nginx
LAST DEPLOYED: Sun Feb 24 04:34:34 2019
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1beta1/ClusterRole
NAME AGE
my-nginx-nginx-ingress 6h28m
==> v1beta1/ClusterRoleBinding
NAME AGE
my-nginx-nginx-ingress 6h28m
==> v1beta1/Role
NAME AGE
my-nginx-nginx-ingress 6h28m
==> v1beta1/RoleBinding
NAME AGE
my-nginx-nginx-ingress 6h28m
==> v1/ConfigMap
NAME DATA AGE
my-nginx-nginx-ingress-controller 1 6h28m
Dans le bloc précédent, nous voyons comment le Helm a installé les propriétés Kubernetes RBAC ainsi que ConfigMap. Ensuite, nous pouvons voir comment le déploiement et le service relient les ressources dans le bloc suivant :
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-nginx-nginx-ingress-controller LoadBalancer 10.96.154.150 <pending> 80:33394/TCP,443:34275/TCP 6h28m
my-nginx-nginx-ingress-default-backend ClusterIP 10.96.18.88 <none> 80/TCP 6h28m
==> v1beta1/Deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
my-nginx-nginx-ingress-controller 1 1 1 1 6h28m
my-nginx-nginx-ingress-default-backend 1 1 1 1 6h28m
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
my-nginx-nginx-ingress-controller-5655d75c9c-9r5h5 1/1 Running 0 6h28m
my-nginx-nginx-ingress-default-backend-898d5489b-t5m7x 1/1 Running 0 6h28m
==> v1/ServiceAccount
NAME SECRETS AGE
my-nginx-nginx-ingress 1 6h28m
Nous pouvons voir comment Helm a déployé le service my-nginx-nginx-ingress-controller en tant que type LoadBalancer (c’est ce qu’il fait, après tout), et my-nginx-nginx-ingress-default-backend du type ClusterIP. Nous utilisons les caractères gras pour indiquer les noms abrégés utilisés dans la figure 17. Cela facilitera la correspondance de cette sortie précédente avec la figure 17.
Veuillez noter l’état en attente suivant :
my-nginx-nginx-ingress-controller LoadBalancer 10.96.154.150 <pending> 80:33394/TCP,443:34275/TCP 6h28m
Pour notre configuration, cela est parfaitement correct, car nous ne nous attendons pas à ce que notre équilibreur de charge se connecte automatiquement à ce point de terminaison. Au lieu de cela, il le fera manuellement. Puisque nous utilisons un schéma DNS générique, nous avons juste besoin de le faire une fois. Le câblage automatique de LoadBalancer est généralement implémenté par les fournisseurs de cloud dans le cadre de leur intégration Kubernetes.
Nous pouvons maintenant tester la configuration.
5.3.4.2 Utilisation de l’application de démonstration Docker pour tester notre configuration d’entrée
Comme le montre la figure 17, nous allons utiliser une application spéciale pour tester notre configuration d’entrée. Nous avons trouvé l’application sur le site Web de Docker dans un article sur la configuration du routage de couche 7 avec Docker Enterprise Kubernetes. Bien qu’il y ait quelques problèmes avec les fichiers d’installation dans cet article, nous avons vraiment aimé l’application de test. Donc, à la fin, nous avons choisi d’utiliser l’installation Helm Chart pour notre contrôleur d’entrée NGINX et d’utiliser l’application échantillon Dockers cool pour le tester.
Voici un lien vers la page de documentation Docker: https://docs.docker.com/ee/ucp/kubernetes/layer-7-routing/ . Utilisez l’application de test, mais faites attention à l’installation, car elle peut ne pas fonctionner correctement (conflit de port dans le fichier de configuration).
Pour obtenir notre test prêt, nous commençons par le déploiement des dockerdemo pods un CLUSTERIP services comme frontend.
5.3.4.2.1 Installation de l’application dockerdemo et docker-demo-svc
Dans le bloc de code suivant, nous montrons le fichier de déploiement pour l’application dockerdemo :
kind: Service
apiVersion: v1
metadata:
namespace: default
name: docker-demo-svc
spec:
selector:
app: dockerdemo
ports:
– protocol: TCP
port: 8080
targetPort: 8080
—
apiVersion: apps/v1beta2
kind: Deployment
metadata:
namespace: default
name: dockerdemo-deploy
labels:
app: dockerdemo
spec:
selector:
matchLabels:
app: dockerdemo
strategy:
type: Recreate
template:
metadata:
labels:
app: dockerdemo
spec:
containers:
– image: ehazlett/docker-demo
name: docker-demo-container
env:
– name: app
value: dockerdemo
ports:
– containerPort: 8080
Dans la définition de service en haut du fichier, aucun type n’est déclaré pour le service. Par défaut, Kubernetes créera un type de service ClusterIP. Tout le reste du fichier semble être très simple – certains pods liés à un service IP de cluster pour le déploiement.
Maintenant, nous avons besoin de vous pour déployer les pods et le service définis dans le fichier en utilisant la commande suivante :
$ kubectl apply -f ingress-test-app.yaml
service/docker-demo-svc created
Nous voyons que notre application dockerdemo est créée. Vous pouvez utiliser $ kubectl get all pour vérifier l’état.
5.3.4.2.2 Configuration des règles d’entrée sur dockerdemo
Maintenant, nous allons jeter un œil au fichier de configuration utilisé pour définir les règles d’entrée, comme le montre la figure 17 :
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: dockerdemo-ingress
namespace: default
annotations:
kubernetes.io/ingress.class: “nginx”
spec:
rules:
– host: ingress-app.mydomain.com
http:
paths:
– path: /
backend:
serviceName: docker-demo-svc
servicePort: 8080
Le paramètre le plus important pour nous est sous les règles: -host: propriété, où nous définissons le nom d’hôte pour cette règle. Lorsque la règle est appliquée, le contrôleur d’entrée examine les noms d’hôte de l’en-tête de la demande entrante pour voir s’ils correspondent à l’une des règles. S’ils le font, le contrôleur le transmet au backend, en utilisant serviceName et servicePort. Dans notre cas, serviceName se résoudra en service ClusterIP que nous avons déployé avec notre application dockerdemo.
Maintenant, nous pouvons appliquer la règle au cluster et la vérifier :
$ kubectl apply -f ingress-test-conf.yaml
ingress.extensions/dockerdemo-ingress created
$ kubectl get ingress
NAME HOSTS ADDRESS PORTS AGE
dockerdemo-ingress ingress-app.mydomain.com 80 3h
Génial ! Nous avons maintenant notre contrôleur d’entrée configuré pour acheminer le trafic vers notre application dockerdemo. Maintenant, nous devons voir si cela fonctionne.
5.3.4.2.3 Test du flux du contrôleur d’entrée
À partir d’un nœud dans notre infrastructure, je le nœud où équilibreur de charge application , nous pouvons accéder à nos nœud de cluster adaptateurs afin que nous pouvons exécuter une spéciale boucle commande pour voir si notre entrée fonctionne correctement et notre demande sera faire dans le dockerdemo pod :
$ curl -H “Host: ingress-app.mydomain.com” http://10.10.1.39:33394
<!DOCTYPE html>
<html lang=”en”>
<head>
<meta charset=”utf-8″>
<title></title>
<meta http-equiv=”X-UA-Compatible” content=”IE=edge,chrome=1″ />
<meta name=”viewport” content=”width=device-width, initial-scale=1.0, maximum-scale=1.0″>
<meta name=”author” content=”Evan Hazlett”>
<meta name=”description” content=”Docker Demo”>
<script src=”https://ajax.googleapis.com/ajax/libs/jquery/2.2.4/jquery.min.js”></script>
<link rel=”stylesheet” type=”text/css” href=”static/dist/semantic.min.css”>
<link rel=”stylesheet” type=”text/css” href=”static/css/default.css”>
<script src=”static/dist/semantic.min.js”></script>
…Notez le http://10.10.1.39:33394 utilisé dans la commande curl. L’IP peut être n’importe quel nœud non maître du cluster car le contrôleur d’entrée est un service NodePort . J’ai choisi l’adresse IP de mes premiers nœuds de travail dans le cluster. Deuxièmement, notez l’adresse du port qui correspond à notre contrôleur d’entrée. Enfin, nous avons le paramètre -H “Host: ingress-app.mydomain.com” , qui est utilisé pour ajouter l’hôte à l’en-tête de la demande, permettant au contrôleur d’entrée de correspondre à l’en-tête de l’hôte et de déclencher un backend docker-demo-svc règle.
Comme vous pouvez le voir dans la réponse cURL, cela a parfaitement fonctionné !
J’ai également poussé cela un peu plus loin. Sur mon ordinateur portable de développeur, j’ai créé un enregistrement dans mon fichier Hosts pour notre domaine de test, comme suit :
# localhost name resolution is handled within DNS itself.
# 127.0.0.1 localhost
# ::1 localhost
127.0.0.1 ingress-app.mydomain.com
Ensuite, j’ai utiliséputty pour créer un tunnel SSH via mon nœud d’équilibreur de charge. Voici à quoi ressemble la configuration du mastic :
Figure 19: configuration du tunnel de mastic pour l’équilibrage de charge
Ensuite, pour mon poste de développeur, j’ai ouvert mon navigateur en utilisant ingress-app.mydomain.com:8888 pour voir l’écran suivant :
Figure 20 : Test du contrôleur d’entrée
C’est ça ! Notre contrôleur d’entrée est opérationnel.
5.4 Résumé
Dans ce chapitre, nous avons vu les fonctionnalités Kubernetes de notre Docker Enterprise en action. Nous avons assisté à la coexistence de Swarm et Kubernetes, alors que nous effectuions un déploiement canary + bleu / vert de notre pile d’applications AtSea Swarm vers notre application AtSea Kubernetes. Nous avons intégré Docker Enterprise RBAC dans notre déploiement AtSea Kubernetes.
Enfin, nous avons vu les performances des extensions Kubernetes standard avec notre cluster Docker Enterprise. Nous avons pu démontrer l’utilisation de Helm Charts avec tiller dans notre cluster Kubernetes en installant un provisionneur de volume NFS et un contrôleur d’entrée NGINX.
6 Faire entrer la plateforme Docker Enterprise dans le futur
Les conteneurs sont une technologie de base pour les microservices, sans serveur, ML / AI, le streaming, la blockchain et l’IoT, mais ils jouent également un rôle clé dans la réduction des coûts opérationnels et de support des applications traditionnelles sur les plates-formes Windows et Linux. Cela dit, il semble que les conteneurs auront un impact sur toute organisation qui héberge des API Web et des applications de service / sans tête. Donc, que vous soyez une ancienne entreprise qui se réinvente ou une entreprise de technologie de pointe, les conteneurs sont très probablement dans votre avenir. Alors, quelle est votre stratégie de conteneurs ?
J’avais l’habitude de parler de stratégies de conteneurs d’abord, mais je me souviens de la célèbre citation de Peter Drucker :
“La culture mange la stratégie pour le petit déjeuner.”
D’après mon expérience, il y a beaucoup de vérité dans ces mots. Donc, vous devriez peut-être envisager d’ajouter une culture axée sur les conteneurs au menu du déjeuner de votre entreprise, car l’adoption de conteneurs est probablement plus une question de culture qu’une stratégie. Donc, dans ce dernier chapitre, nous partagerons quelques réflexions finales sur les cultures de conteneurs d’abord et où ils peuvent vous emmener votre entreprise avec Docker Enterprise.
Les sujets suivants seront traités dans ce dernier chapitre :
- Comprendre et soutenir une culture de conteneur
- Comment le DockC Enterprise PoC, le pilote et l’adoption de la production prennent en charge une culture axée sur le conteneur
- Un aperçu de l’avenir d’une entreprise axée sur les conteneurs
6.1 Culture axée sur le conteneur
Tout d’abord, définissons ce que nous entendons par une culture axée sur le conteneur. Dans une culture axée sur les conteneurs, les conteneurs sont la plate-forme par défaut pour toutes les implémentations logicielles. Que le logiciel provienne d’un fournisseur ou soit développé par une équipe interne, le canal de livraison par défaut est les conteneurs. Donc. à moins qu’il n’y ait une très bonne raison de le faire, les conteneurs sont toujours utilisés. De plus, lorsque le conteneur d’abord est fait correctement, vous ne devez pas vous soucier de l’endroit où vos conteneurs sont déployés, que ce soit dans le cloud ou sur site.
6.1.1 La vie avant une culture en conteneur
Avant la culture du conteneur d’abord, il fallait plusieurs jours pour approvisionner un nouveau serveur de test. Notre équipe d’infrastructure devrait comprendre exactement quelles versions SQL Server de chaque logiciel étaient et comment les installer. Par exemple, un déploiement d’application .NET typique nécessiterait d’abord l’installation de SQL Server, en faisant très attention de choisir la bonne version. Ensuite, nous devons nous assurer que la version correcte du framework .NET est installée. Enfin, nous aurions besoin d’installer la version appropriée d’IIS. Une fois tout cela terminé, nous pourrions installer notre application et espérons que toutes les versions correspondent et qu’il n’y a pas de pièces manquantes. Malheureusement, beaucoup de choses tournent mal, comme ils le font souvent.
Lorsque les équipes d’infrastructure rencontraient des problèmes de déploiement, elles retournaient au développeur avec le problème et le développeur leur montrait comment cela fonctionnait parfaitement sur leur machine. Cette situation est parfois appelée le syndrome « ça marche sur ma machine ».
En raison du cycle complexe de déploiement des applications, nous n’avons pu publier des logiciels que sur un cycle de publication trimestriel, et les versions se déployaient très rarement en douceur.
6.1.2 La vie après une culture en conteneur
Après avoir adopté une culture axée sur le conteneur, l’image change considérablement. Les applications sont regroupées dans des images de conteneur et transmises à un registre d’images central appelé Docker Trusted Registry (DTR). Plutôt que de demander à l’équipe d’infrastructure de créer un serveur de test entièrement nouveau, l’équipe DevOps peut simplement extraire les dernières images d’application d’un DTR centralisé et les déployer sur n’importe quel serveur sur lequel Docker est installé. Si un serveur supplémentaire est requis, l’équipe d’infrastructure n’a qu’à installer Docker. Par la suite, un nouveau logiciel publié peut être déployé sur n’importe quelle boîte de test en quelques minutes et dans la plupart des cas, le système d’intégration continue déploie réellement l’application de test en tant que sous-produit de son processus de pipeline standard.
Par la suite, parce que le logiciel est découplé et isolé du serveur à l’aide de conteneurs, les applications peuvent s’exécuter sur le même serveur aux côtés des anciennes versions de la même application ; il n’y a plus de déploiements monolithiques. Cette flexibilité signifie que les équipes d’application sont en mesure de déployer leurs conteneurs selon leur propre calendrier, ce qui dans certains cas est un cycle de publication quotidien.
6.1.2.1 Culture du conteneur d’abord pour les développeurs
Les développeurs adorent les conteneurs. Il leur donne la possibilité d’exécuter tout ce qu’ils veulent sur ses postes de travail de développement sans rien installer. Les conteneurs nous permettent d’expérimenter avec des technologies de pointe, telles que l’apprentissage automatique, l’informatique sans serveur, les bases de données NoSQL et une variété d’applications no Node.js différentes fonctionnant sur différentes versions sans interférer avec notre environnement de développement. En plus d’expérimenter, nous pouvons essayer les dernières technologies sur nos postes de développement et effectuer des tests d’intégration sur nos postes de travail locaux. Auparavant, cela se limitait à deux machines d’essai spécialement équipées. Enfin, la technologie des conteneurs permet aux développeurs de faire un virage à gauche. Non seulement les développeurs peuvent utiliser des conteneurs pour une variété de nouveaux scénarios de test, y compris les tests d’intégration, mais ils peuvent également implémenter des incertitudes de stratégie en tant que code pour tester d’autres machines de développement local.
6.1.2.2 Conteneur d’abord pour DevOps
Dans un monde axé sur les conteneurs, DevOps est un jeu différent. Étant donné que les conteneurs regroupent le code de l’application et toutes ses dépendances dans un seul ensemble, vous travaillez avec des unités déployables complètes et ne traitez plus un tas de petites pièces mobiles. Cela réduit la complexité et augmente la fiabilité.
En outre, dans le monde dans DevOps, le conteneur en premier bénéficiera également du principe juste Docker, car vous utilisez désormais Docker pour gérer vos builds, vos tests de déploiement et la gestion de code binaire. Étant donné que vous construisez dans un environnement Docker, vous pouvez mettre en place l’intégralité de l’application multiservice dans le cadre de votre pipeline de génération pour des tests de bout en bout avant de pousser votre image vers le référentiel d’images central. Enfin, pour vous assurer que toute la chaîne logistique des logiciels est sécurisée, vous pouvez signer des images dans le cadre de votre processus de création et d’approbation.
6.1.2.3 Conteneur d’abord pour les opérations
Dans un monde à conteneurs, les équipes opérationnelles bénéficient également de Docker ; pour être tout à fait exact, juste Docker pour Windows et juste Docker pour Linux. En d’autres termes, nous pouvons prendre toutes nos charges de travail Windows, quelles que soient les versions de l’infrastructure et les versions IIS, et les exécuter côte à côte sur les mêmes machines. Il en va de même pour Linux, où nous pouvons avoir des instances Ubuntu, Alpine et CentOS exécutées sur le même nœud Docker Linux.
Donc, il y a beaucoup d’avantages, mais quelles sont les choses qui entravent le dépassement d’une culture productive axée sur les conteneurs ?
6.1.3 Défis d’adoption du conteneur d’abord
Étant donné que les conteneurs améliorent le développement de logiciels, les DevOps, les opérations et la sécurité, l’impact de l’adoption des conteneurs est important et potentiellement intimidant. Cependant, comme les conteneurs proviennent de la communauté des logiciels open source, l’obstacle à la technologie des conteneurs est très faible. Par la suite, l’expérimentation de conteneurs se produira organiquement dans des poches dans toute l’organisation, que vous le vouliez ou non. De plus, les informations issues de cette adoption organique proviendront de différentes sources, où certaines seront plus fiables et à jour que d’autres.
6.1.3.1 Le chemin nuageux vers l’adoption biologique
Il est probable que vous ayez entendu beaucoup plus de choses sur le cloud que sur le conteneur en premier. Cela nous amène au prochain défi avec l’adoption des conteneurs. L’adoption organique via le partenaire cloud d’une entreprise semble rendre l’adoption de conteneurs aussi simple que de déposer un article de votre catalogue de services cloud dans votre panier. Bien qu’il n’y ait rien de mal à la mise en œuvre de conteneurs par les fournisseurs de cloud (il y a généralement Docker quelque part), c’est un peu comme acheter toute votre eau en bouteille au livreur du Domino. Il ne faut pas longtemps pour que les gens pensent que vous devez commander une pizza pour obtenir une bouteille d’eau. Avez-vous entendu des équipes dire que mon application ne fonctionne pas dans le cloud, je ne peux donc pas utiliser de conteneurs ? Je me demande s’ils aiment la pizza ?
Malheureusement, de nombreuses organisations pensent que la seule manière raisonnable d’adopter la technologie des conteneurs est dans le cloud et de laisser votre fournisseur de cloud gérer les détails. Cependant, comme toute plate-forme technologique d’entreprise, les détails sont importants ! Une fois que vous avez dépassé l’application hello world, vous découvrez que les services liés aux conteneurs ne sont pas ce que vous pensiez qu’ils seraient. Par exemple, vous pouvez vous attendre à rencontrer des versions plus anciennes de Docker et de Kubernetes, des réseaux bruts à faire soi-même, des limitations sur le nombre de conteneurs ou de pods que vous pouvez exécuter par nœud et l’incapacité d’étendre la plate-forme Kubernetes pour répondre à vos besoins. Cependant, il est facile de démarrer et d’intégrer facilement les services du fournisseur de cloud avec votre plateforme de conteneur. C’est très bien, à moins que vous ne deviez déplacer votre charge de travail de ce fournisseur.
Enfin, le passage au cloud nécessite d’abord que toutes vos équipes investissent dans l’apprentissage des spécificités de la plateforme du fournisseur de cloud afin de construire des solutions pour celle-ci. Ces compétences sont de plus en plus difficiles à trouver et la courbe d’apprentissage est importante. D’un autre côté, si vous commencez par le conteneur en premier, les compétences les plus répandues seront les API Docker et Kubernetes que vous pourrez déployer sur n’importe quelle plateforme cloud ou dans votre propre centre de données. Vous n’avez besoin que de compétences en infrastructure cloud pour déployer votre plate-forme de conteneur (également connue sous le nom de Docker). Et si vous décidez de déplacer votre charge de travail ailleurs, seule cette petite équipe de plate-forme est affectée dans le reste de votre développement et l’équipe DevOps continue d’interagir avec les API Docker et Kubernetes.
S’il vous plaît, ne vous méprenez pas ici ; le cloud est génial et je continue d’être impressionné par la technologie que les fournisseurs de cloud fournissent à grande échelle. Ils ont une entreprise à gérer en fournissant des services à valeur ajoutée et bon nombre des services populaires de nos jours sont liés aux conteneurs. Comprenez simplement que les conteneurs ne se limitent pas au cloud et que les avantages des conteneurs commencent sur le bureau du développeur.
6.1.3.2 Essayer de déplacer tout le monde dans la même direction
De nos jours, toute personne qui lit un article sur Internet ou travaille avec du code de démonstration dans un article de blog se sent comme un expert. D’une certaine façon, c’est bien. C’est un excellent moyen d’apprendre et de gagner en confiance en tant qu’individu, mais en tant qu’organisation, vous devez développer une culture de conteneur à travers vos propres expériences et des décisions éclairées. Cela nécessite un environnement d’apprentissage collaboratif soutenu par un ensemble commun d’outils.
6.1.4 Domaines d’application cibles du conteneur d’abord
Quels sont les domaines clés dans lesquels investir lors de l’adoption d’une culture axée sur le conteneur et quels sont les objectifs typiques ?
Le premier domaine est le développement de nouvelles applications et est probablement le domaine le plus difficile en raison de l’écart potentiel de compétences entre votre personnel actuel et ce qui est nécessaire pour concevoir et créer des applications distribuées basées sur des conteneurs. Très souvent, c’est là que vous apportez de nouveaux talents en tant qu’employés à temps plein, ce qui est souvent préférable, ou consultants expérimentés. L’objectif du nouveau domaine de développement d’applications est de forger et de valider les futurs modèles d’application, tels que les microservices, et les technologies de streaming, telles que Kafka.
Le domaine suivant concerne les applications héritées qui ne sont plus développées activement. La stratégie consiste ici à conteneuriser les applications sans changer le code si possible. Une fois conteneurisées, ces applications sont facilement maintenues et migrées car toutes leurs dépendances pointilleuses ont été regroupées à l’intérieur du conteneur avec l’application elle-même. C’est le nombre d’organisations qui traitent des applications Windows 2003 et 2008 à la fermeture du support fournisseur.
Le dernier domaine d’application est la modernisation des applications Web et des API traditionnelles. Ce sont des applications qui s’exécutent sur des plates-formes .NET et Java plus anciennes mais qui sont toujours activement modifiées et maintenues. L’objectif ici est de démarrer un peu comme les applications héritées en les conteneurisant. De là, vous regardez quel code est fréquemment modifié et isolé du reste du code et factorisez certains des composants dans des conteneurs séparés. Cela réduit la quantité de tests requis lors de ces modifications typiques.
6.1.5 Considérations pour la construction d’une culture de conteneur
Tout d’abord, gardez à l’esprit la portée de la transition vers des conteneurs de pointe. Pour de nombreuses organisations, il y a beaucoup à apprendre sur ce nouveau monde et, comme nous l’avons déjà mentionné, les lacunes en matière de compétences peuvent être larges, y compris le contrôle de code source moderne basé sur Git ; pipeline comme code ; conception d’applications distribuées ; et bien sûr, Docker, la superposition de réseaux, le stockage en cluster et l’orchestration de conteneurs, tels que Swarm et Kubernetes.
6.1.5.1 Rester simple au début
Gardez à l’esprit que tout le monde n’est pas Google ou Netflix, et vous n’avez pas besoin de l’être. Surtout lorsque vous commencez sur le chemin du conteneur, restez aussi simple que possible. Par exemple, envisagez de commencer avec l’orchestrateur Swarm de Docker, puis passez à Kubernetes lorsque vous en avez besoin. Tous les enfants sympas vous diront que Kubernetes est la seule voie à suivre et que Swarm est mort, mais je vous assure que Swarm est bel et bien vivant et qu’il est cuit directement dans le moteur Docker. N’oubliez pas que ces orchestrateurs ne s’excluent pas mutuellement et, en fait, la plupart des gens exécutent Kubernetes sur des moteurs Docker où Swarm est déjà inclus. Il sera important de donner à votre équipe le choix de choisir le bon outil tout au long de son parcours d’apprentissage, et c’est une caractéristique clé de Docker Enterprise, car elle prend en charge Swarm et Kubernetes dès le départ.
6.1.5.2 Reconnaître les apprenants enthousiastes et les adoptants engagés
Toute transformation culturelle nécessite que le leadership émerge des développeurs de base, des DevOps et des équipes opérationnelles. Mener cette transformation n’est pas un travail de 9 à 5 et nécessite à la fois un engagement et un dévouement pour améliorer la plate-forme logicielle de votre organisation. Ce sont ces gens qui restent tard le soir et qui travaillent sur des problèmes pendant le week-end dans le but de faire réussir votre plate-forme basée sur des conteneurs. Ces dirigeants essaient toujours de trouver un moyen de dire oui et ils l’appuient avec des tentatives héroïques pour résoudre le problème de la meilleure façon possible. Avec le bon climat, ces acteurs émergeront et devront être reconnus si vous voulez réussir.
6.1.5.3 Établir une culture d’apprentissage
Apprendre de nouvelles technologies est très amusant, mais les mettre en œuvre dans une situation réelle impliquera quelques erreurs. Allez-vous punir les gens pour ces erreurs ? Allez-vous les récompenser pour leurs erreurs ? Ou allez-vous les récompenser pour leur apprentissage rapide en adoptant un état d’esprit infaillible au sein de votre organisation ? Il s’agit d’un environnement où vous êtes honnête et transparent sur les succès et les échecs de chaque sprint ou cycle de développement.
En plus des révisions de code habituelles et peut-être même de la programmation en binôme, au fur et à mesure que les membres de l’équipe commencent, il existe une collaboration et un partage formalisés. Rechercher des moyens de promouvoir des présentations internes et externes ou des discussions éclair sur des sujets technologiques très spécifiques liés aux efforts de développement de votre équipe peut être une excellente opportunité de croissance. Cela aide naturellement les développeurs, les DevOps et les membres de l’équipe d’exploitation à être reconnus, tout en les forçant à réfléchir aux problèmes avec un niveau de détail élevé. C’est une chose de donner à quelqu’un une démonstration de fantaisie, mais c’est tout autre chose de leur montrer votre code et de leur parler du processus de fonctionnement.
Les derniers domaines que je couvrirai dans le cadre de la culture d’apprentissage sont les outils et la formation. Assurez-vous que les équipes disposent des outils dont elles ont besoin pour réussir, à commencer par Docker Desktop pour Mac et Windows. Docker a récemment annoncé Docker Desktop Enterprise, qui suivra des modèles de distribution de logiciels d’entreprise plus traditionnels, permettant également aux administrateurs de verrouiller les paramètres réseau et proxy. Docker Desktop est vraiment tout ce dont vous avez besoin pour le développement d’une base de conteneurs locale, car il inclut le dernier moteur Docker Community Edition avec prise en charge Swarm et Kubernetes. Tout ce que vous avez à faire est de cocher la case Activer Kubernetes pour installer et démarrer un single local -node cluster Kubernetes sur votre machine de développement pour les tests. C’est beaucoup plus facile que la configuration (et la maintenance) traditionnelle de Minikube.
Un autre excellent outil d’apprentissage est les hackathons dans les projets scientifiques avec un bac à sable en quelque sorte. Il s’agit d’une autre fonctionnalité intéressante de Docker Enterprise, où vous pouvez fournir à l’équipe de développement des bundles client UCP pour accéder à un sandbox isolé sur le cluster de non-production Enterprise. Ceci est généralement accompli en utilisant une combinaison de collections et d’espaces de noms pour les ressources Kubernetes. Encore une fois, la bonne partie est qu’il n’y a vraiment rien à installer ; il s’agit simplement d’allouer de l’espace sur un cluster géré et partagé.
Sur le plan de la formation, je recommande fortement que toutes les personnes impliquées dans les initiatives de conteneurs assistent à la classe authentique Docker, Inc. Fundamentals. Cette classe couvre une quantité incroyable de terrain en 2 jours, y compris Swarm et Kubernetes. C’est beaucoup à absorber, mais même les développeurs ayant une expérience Docker tirent beaucoup de la classe. De plus, je suggère d’examiner une version sur place de la classe afin que l’instructeur puisse adapter les discussions en fonction de vos défis spécifiques. En outre, Docker propose des classes avancées pour les développeurs, les opérations et la sécurité, mais elles ont toutes les prérequis de la classe Docker Fundamentals.
6.2 Clusters gérés Docker Enterprise
Nous avons passé la majeure partie de cet article à parler des diverses fonctionnalités de Docker Enterprise, avec beaucoup de détails et d’exemples, mais où Docker Enterprise s’intègre-t-il pour prendre en charge une culture de conteneur d’abord ? Nous pouvons décrire la contribution de Docker Enterprise à une culture axée sur le conteneur selon trois axes :
- Accès cohérent
- Sécurité
- Efficacité
Un accès cohérent signifie que vous pouvez accéder aux ressources du cluster de conteneurs à des fins de test d’intégration ou de support en utilisant le même mécanisme, que votre cluster s’exécute sur site ou sur le cloud. Docker vous donne deux moyens d’accéder au cluster. La première consiste à accéder au cluster à l’aide de l’interface utilisateur Web de Universal Control Plane et à se connecter avec vos informations d’identification de contrôle d’accès basées sur les rôles. La deuxième façon consiste à utiliser le bundle client Universal Control Plane (UCP), comme nous l’avons expliqué dans l’article. Ainsi, si un développeur lance un conteneur dans la collection de développeurs du cluster, il peut utiliser l’interface utilisateur Web ou son terminal local pour afficher l’accès au conteneur dans le cluster.
L’accès sécurisé signifie RBAC transparent pour les ressources Docker Enterprise et Kubernetes et, en outre, le système BRAC intégré dans un système de sécurité d’entreprise, comme Active Directory, LDAP ou SAML 2.0, une solution d’authentification unique. Par conséquent, le contrôle centralisé des systèmes d’accès aux ressources d’entreprise est maintenu et synchronisé avec votre Docker. De plus, toutes vos images d’entreprise sont stockées dans un registre privé sécurisé à l’aide de DTR.
L’efficacité fait référence à la capacité de Docker Enterprise à isoler des ressources au sein d’un cluster. Cela vous permet d’avoir essentiellement deux clusters, comme décrit précédemment dans l’article. L’un est votre cluster hors production qui peut contenir des environnements de développement, de test, d’assurance qualité, de formation et de bac à sable isolés, et le cluster de production que nous organisons et la production finale. Le RBAC et l’isolement de Docker Enterprise pour Swarm et Kubernetes sont une excellente défense contre l’étalement des clusters que nous voyons si souvent dans les environnements cloud, ce qui peut entraîner des déficiences importantes et des factures mensuelles massives.
6.3 Adoption agile pour les conteneurs et au-delà
Tout au long de cet article, nous avons parlé de l’approche agile pour adopter Docker Enterprise. L’approche commence par une preuve de concept (PoC) comme moyen d’apprendre ce que nous ne savons pas, avant d’essayer de prendre des décisions que nous ne sommes pas prêts à prendre. Nous limitons ces efforts de PoC à de courts efforts de 2 ou 3 semaines avec des objectifs déclarés et des résultats clés mesurables. Ensuite, nous utilisons Docker Enterprise pour fournir une version interne. Ensuite, nous déplaçons la version interne en production sur une plateforme Docker Enterprise.
6.3.1 Adoption d’Agile Docker Enterprise et premier conteneur
L’approche agile d’adoption de Docker Enterprise discutée tout au long de cet article soutient intentionnellement le développement d’une culture axée sur les conteneurs de la manière suivante. Premièrement, nous structurons l’apprentissage à travers le processus de faire, en particulier dans les premières étapes. En commençant par la preuve de concept, nous nous concentrons sur l’apprentissage et l’acquisition d’une expérience réelle avec Docker Enterprise. Ensuite, nous encourageons une rétroaction honnête et en tenons compte dans la planification de la phase pilote du projet. Dans la courte fenêtre PoC, nous nous permettons d’essayer et d’échouer dans le but de trouver la meilleure façon de mettre en œuvre la plate-forme.
6.3.2 Construire votre avenir sur la plateforme
Une fois que vous avez établi la culture du conteneur d’abord avec Docker Enterprise, vous êtes en mesure de vous attaquer à presque toutes les technologies émergentes, car la plupart d’entre elles prospèrent dans un environnement de conteneur. L’apprentissage automatique, la blockchain, sans serveur et l’IoT fonctionnent tous mieux dans des conteneurs.
Le diagramme suivant illustre comment les clusters gérés de Docker Enterprise constituent une excellente base pour l’adoption de technologies émergentes :
Figure 1 : Clusters gérés prenant en charge les technologies émergentes
Enfin, la même approche que nous avons utilisée pour adopter Docker Enterprise et soutenir notre culture du conteneur d’abord peut également être appliquée aux technologies émergentes, à commencer par PoC, puis pilote, puis production. De plus, ils peuvent tous être exécutés sur votre cluster Docker Enterprise.
6.4 Sans serveur et conteneurs
L’informatique sans serveur retient beaucoup l’attention ces jours-ci. Le concept de dire voici ma fonction, de la déployer quelque part et de me donner un point final est très attrayant. De plus, vous entendrez deux types de débats, dois-je être tout à fait avec des conteneurs, ou tout à fait sans serveur ? Avec un peu de chance, nous en avons suffisamment appris pour savoir que nous avons probablement besoin des deux. Si vous avez adopté une culture de premier conteneur avec Docker Enterprise, vous êtes en bonne forme car sans serveur est généralement implémenté à l’aide de conteneurs. Par conséquent, il existe de nombreuses infrastructures sans serveur basées sur des conteneurs que vous pouvez déployer sur votre cluster Docker Enterprise.
OpenFaaS® (Fonctions en tant que service) est l’un des cadres les plus populaires dont nous entendons parler. Ce framework construit des fonctions sans serveur à l’aide de Docker et Kubernetes. Ils ont empaqueté la pile Swarm et les déploiements Kubernetes.
Vous pouvez les trouver ici :
J’ai trouvé un excellent aperçu des serveurs et conteneurs sans serveur de Winder Research and Development Ltd et vous pouvez le lire ici: https://winderresearch.com/a-comparison-of-serverless-frameworks-for-kubernetes-openfaas-openwhisk- fission-kubeless-and-more / .
Donc, avant de vous enfermer dans une infrastructure sans serveur d’un fournisseur particulier, vous voudrez peut-être d’abord vérifier ce que vous pouvez faire avec votre propre cluster Doctor Enterprise.
6.5 Résumé
Les conteneurs changent littéralement le monde du développement et du déploiement de logiciels. La création d’une culture efficace axée sur les conteneurs jouera un rôle clé dans le succès de votre organisation logicielle à l’avenir. Alors qu’une approche axée sur le cloud est la norme populaire pour la plupart des organisations informatiques, l’approche axée sur le conteneur prend de l’ampleur en raison de la nature portable du cloud et des préoccupations concernant le verrouillage des fournisseurs de cloud.
Nous pensons que Docker Enterprise deviendra la plate-forme de choix pour les acheteurs avertis dans les années à venir. Grâce à sa capacité à prendre en charge Swarm et Kubernetes, il offre aux organisations de nombreuses options pour démarrer et développer leur expertise et leur échelle en matière de conteneurs. De plus, les plates-formes de conteneurs deviennent fondamentales pour la plupart des technologies émergentes, y compris sans serveur, apprentissage automatique, blockchain, streaming et IoT.



Laisser un commentaire
Vous devez être dentifié pour poster un commentaire.