0. L’orchestration avec Kubernetes
0.1 Résumé de la publication
Kubernetes est un système open source utilisé pour automatiser le déploiement, la mise à l’échelle et la gestion des applications conteneurisées. Si vous utilisez plus de conteneurs ou souhaitez une gestion automatisée de vos conteneurs, vous avez besoin de Kubernetes à votre disposition. Pour mettre les choses en perspective, Mastering Kubernetes vous guide à travers la gestion avancée des clusters Kubernetes.
Pour commencer, vous apprendrez en détail les principes fondamentaux de l’architecture Kubernetes et de la conception Kubernetes. Vous découvrirez comment exécuter des microservices complexes avec état sur Kubernetes, y compris des fonctionnalités avancées telles que la mise à l’échelle automatique des pods horizontaux, les mises à jour continues, les quotas de ressources et le backend de stockage persistant. À l’aide de cas d’utilisation réels, vous explorerez les options de configuration du réseau et comprendrez comment configurer, utiliser et dépanner divers plug-ins de réseau Kubernetes. En plus de cela, vous vous familiariserez avec le développement et l’utilisation de ressources personnalisées dans les workflows d’automatisation et de maintenance.
Pour étendre vos connaissances sur Kubernetes, vous rencontrerez des concepts supplémentaires basés sur la version Kubernetes 1.10, tels que Promethus, le contrôle d’accès basé sur les rôles, l’agrégation d’API, etc. À la fin de cet article, vous saurez tout ce dont vous avez besoin pour passer du niveau intermédiaire à avancé de la compréhension de Kubernetes.
0.2 Objectifs de la publication
- Concevez un cluster Kubernetes robuste pour un fonctionnement de longue durée
- Découvrez les avantages de l’exécution de Kubernetes sur GCE, AWS, Azure et bare metal
- Comprendre le modèle d’identité de Kubernetes, ainsi que les options de fédération de cluster
- Surveillez et dépannez les clusters Kubernetes et exécutez un Kubernetes hautement disponible
- Créez et configurez des ressources Kubernetes personnalisées et utilisez des ressources tierces dans vos workflows d’automatisation
- Profitez de l’art d’exécuter des applications complexes avec état dans votre environnement de conteneur
- Livrer des applications sous forme de packages standard
1 CHAPITRE 1 Introduction
Kubernetes est un orchestrateur open source pour le déploiement d’applications conteneurisées. Le système a été open source par Google, inspiré par une décennie d’expérience dans le déploiement de systèmes évolutifs et fiables dans des conteneurs via des API orientées application, et développé au cours des quatre dernières années par une communauté dynamique de contributeurs open source.
Il est utilisé par un nombre important et croissant de développeurs pour déployer des systèmes distribués fiables, ainsi que pour exécuter l’apprentissage automatique, le Big Data et d’autres charges de travail par lots. Un cluster Kubernetes fournit une API d’orchestration qui permet de définir et de déployer des applications avec une syntaxe déclarative simple. De plus, le cluster Kubernetes lui-même fournit de nombreux algorithmes de contrôle en ligne, auto-réparateurs, qui réparent les applications en présence de défaillances. Enfin, l’API Kubernetes expose des concepts tels que les déploiements qui facilitent l’exécution de mises à jour sans interruption de vos logiciels et des équilibreurs de charge de service qui facilitent la répartition du trafic sur un certain nombre de répliques de votre service. De plus, Kubernetes fournit des outils pour nommer et découvrir les services afin que vous puissiez créer des architectures de microservices à couplage lâche. Kubernetes est largement utilisé dans les clouds publics et privés, ainsi que dans les infrastructures physiques.
Cet article est dédié au sujet de la gestion d’un cluster Kubernetes. Vous pouvez gérer votre propre cluster sur votre propre matériel, faire partie d’une équipe gérant un cluster pour une organisation plus grande ou un utilisateur de Kubernetes qui souhaite aller au-delà des API et en savoir plus sur les composants internes du système. Peu importe où vous en êtes dans le voyage, approfondir vos connaissances sur la gestion du système peut vous rendre plus capable d’accomplir tout ce que vous devez faire avec Kubernetes.
Lorsque nous parlons d’un cluster, nous faisons référence à une collection de machines qui fonctionnent ensemble pour fournir la puissance de calcul globale que Kubernetes met à la disposition de ses utilisateurs finaux. Un cluster Kubernetes est un ensemble de machines qui sont toutes contrôlées par une seule API et peuvent être utilisées par les consommateurs de cette API.
Il existe une variété de sujets qui composent les compétences nécessaires pour gérer un cluster Kubernetes:
- Comment le cluster fonctionne
- Comment ajuster, sécuriser et régler le cluster
- Comment comprendre votre cluster et réagir en cas de problème
- Comment étendre votre cluster avec des fonctionnalités nouvelles et personnalisées
1.1 Fonctionnement du cluster
En fin de compte, si vous allez gérer un système, vous devez comprendre comment ce système fonctionne. Quelles sont les pièces qui le composent et comment s’emboîtent-elles? Sans au moins une compréhension approximative des composants et de leur interaction, il est peu probable que vous réussissiez à gérer un système. Gérer un logiciel, en particulier un logiciel aussi complexe que Kubernetes, sans cette compréhension, c’est comme tenter de réparer une voiture sans savoir comment le tuyau d’échappement est lié au moteur. C’est une mauvaise idée.
Cependant, en plus de comprendre comment toutes les pièces s’assemblent, il est également essentiel de comprendre comment l’utilisateur consomme le cluster Kubernetes. Ce n’est qu’en sachant comment un outil comme Kubernetes doit être utilisé que vous pouvez vraiment comprendre les besoins et les exigences nécessaires à sa bonne gestion. Pour revisiter notre analogie de la voiture, sans comprendre la façon dont un conducteur s’assoit dans le véhicule et le guide sur la route, il est peu probable que vous réussissiez à gérer le véhicule. Il en va de même pour un cluster Kubernetes.
Enfin, il est essentiel que vous compreniez le rôle que joue le cluster Kubernetes dans la vie quotidienne d’un utilisateur. Qu’est-ce que le cluster accomplit pour l’utilisateur final? Quelles applications y déploient-ils? Que la complexité et les difficultés est le cluster enlève? Quelle complexité ajoute l’API Kubernetes? Pour compléter l’analogie de la voiture, afin de comprendre l’importance d’une voiture pour son utilisateur final, il est essentiel de savoir que c’est la chose qui garantit qu’une personne se présente pour travailler à l’heure. De même avec Kubernetes, si vous ne comprenez pas que le cluster est l’endroit où s’exécute l’application critique d’un utilisateur et que l’API Kubernetes est ce sur quoi un développeur s’appuie pour résoudre un problème lorsqu’un problème se produit à 3 heures du matin, vous avez gagné ‘sais pas vraiment ce qui est nécessaire pour gérer avec succès ce cluster.
1.2 Ajuster, sécuriser et régler le cluster
En plus de savoir comment les éléments du cluster s’emboîtent et comment l’API Kubernetes est utilisée par les développeurs pour créer et déployer des applications, il est également essentiel de comprendre les différentes API et options de configuration pour ajuster, sécuriser et régler votre cluster. Un cluster Kubernetes – ou vraiment n’importe quel logiciel important – n’est pas quelque chose que vous montez, commencez à exécuter et quittez simplement.
Le cluster et son utilisation ont un cycle de vie. Les développeurs rejoignent et quittent les équipes. De nouvelles équipes se forment et les anciennes meurent. Le cluster évolue avec la croissance de l’entreprise. De nouvelles versions de Kubernetes sortent pour corriger des bugs, ajouter de nouvelles fonctionnalités et améliorer la stabilité. L’augmentation de la demande sur le cluster expose des problèmes de performances qui étaient auparavant ignorés. Répondre à tous ces changements dans la durée de vie de votre cluster nécessite une compréhension des façons dont Kubernetes peut être configuré via des indicateurs de ligne de commande, des options de déploiement et des configurations d’API.
De plus, votre cluster n’est pas seulement une cible pour le déploiement d’applications. Il peut également être un vecteur d’attaque de la sécurité de vos applications. La configuration de votre cluster pour qu’il soit protégé contre de nombreuses attaques différentes, des compromis entre les applications au déni de service, est un élément essentiel de la gestion réussie d’ un cluster. La plupart du temps, ce durcissement sert simplement à éviter les erreurs. Dans de nombreux cas, le renforcement et la sécurité ont pour valeur d’empêcher une équipe ou un utilisateur d’attaquer accidentellement le service d’une autre équipe. Cependant, des attaques actives se produisent parfois et la configuration du cluster est essentielle à la fois pour détecter les attaques lorsqu’elles se produisent et pour les empêcher de se produire en premier lieu.
Enfin, selon l’utilisation du cluster, vous devrez peut-être démontrer la conformité aux différentes normes de sécurité requises pour les développeurs d’applications dans de nombreux secteurs, tels que les soins de santé, la finance ou le gouvernement. Lorsque vous comprenez comment créer un cluster conforme, vous pouvez mettre Kubernetes au travail dans ces environnements.
1.3 Répondre lorsque les choses tournent mal
Si les choses ne tournaient jamais mal, ce serait un monde formidable où vivre. Malheureusement, bien sûr, ce n’est pas comme ça que ça se passe, surtout avec aucun système informatique que je n’ai jamais aidé à gérer. Ce qui est critique lorsque les choses tournent mal, c’est que vous en soyez informé rapidement, que vous le découvrez par le biais de l’automatisation et des alertes (plutôt que par un utilisateur), et que vous êtes capable de répondre et de restaurer le système le plus rapidement possible.
La première étape pour détecter le moment où les choses se cassent et pour comprendre pourquoi elles sont cassées est d’avoir les bonnes mesures en place. Heureusement, il existe deux technologies présentes dans le cluster Kubernetes qui facilitent ce travail. Le premier est que Kubernetes lui-même est généralement déployé à l’intérieur des conteneurs. En plus de la valeur d’un emballage et d’un déploiement fiables, le conteneur lui-même forme une frontière où les mesures de base telles que le processeur, la mémoire, le réseau et l’utilisation du disque peuvent être observées. Ces mesures peuvent ensuite être enregistrées dans un système de surveillance à la fois pour l’alerte et l’introspection.
En plus de ces mesures générées par conteneur, la base de code Kubernetes elle-même a été instrumentée avec un nombre important de mesures d’application. Il s’agit notamment du nombre de demandes envoyées ou reçues par divers composants, ainsi que de la latence de ces demandes. Ces métriques sont exprimées à l’aide d’un format popularisé par le projet open source Prometheus , et elles peuvent être facilement collectées et renseignées dans Prometheus, qui peuvent être utilisées directement ou avec d’autres outils, comme Grafana, pour la visualisation et l’introspection.
Combinées ensemble, les métriques de base des conteneurs du système d’exploitation, ainsi que les métriques d’application de Kubernetes lui-même, fournissent un riche ensemble de données qui peuvent être utilisées pour générer des alertes, qui vous indiquent quand le système ne fonctionne pas correctement, ainsi que les données historiques nécessaires pour déboguer et déterminer ce qui s’est mal passé et quand.
Bien sûr, comprendre le problème n’est que la première moitié de la bataille. L’étape suivante consiste à répondre et à se remettre des problèmes du système. Heureusement, Kubernetes a été construit de manière découplée et modulaire, avec un état minimal dans le système. Cela signifie que, généralement, à tout moment, il est sûr de redémarrer tout composant du système qui peut être surchargé ou mal se comporter. Cette modularité et cette idempotence signifient que, une fois que vous avez déterminé le problème, le développement d’une solution est souvent aussi simple que le redémarrage de quelques applications.
Bien sûr, dans certains cas, quelque chose de vraiment terrible se produit et votre seul recours est de restaurer le cluster à partir d’une sauvegarde de récupération après sinistre quelque part. Cela suppose que vous avez activé ces sauvegardes en premier lieu. En plus de toute la surveillance pour vous montrer ce qui se passe, les alertes pour vous informer quand quelque chose se casse, et les playbooks pour vous dire comment le réparer, la gestion réussie d’un cluster nécessite que vous développiez et appliquiez une procédure de réponse et de récupération en cas de catastrophe . Il est important de se rappeler que l’élaboration de ce plan est insuffisante. Vous devez le pratiquer régulièrement, sinon vous ne serez pas prêt (et le plan lui-même peut être défectueux) en présence d’un vrai problème.
1.4 Extension du système avec des fonctionnalités nouvelles et personnalisées
L’une des forces les plus importantes du projet open source Kubernetes a été la croissance explosive des bibliothèques, des outils et des plates-formes qui s’appuient sur, étendent ou améliorent autrement l’utilisation d’un cluster Kubernetes.
Il existe des outils comme Spinnaker ou Jenkins pour un déploiement continu, et des outils comme Helm qui facilitent le conditionnement et le déploiement d’applications complètes. Des plates-formes comme Deis fournissent des flux de travail de développement de style push Git et de nombreuses fonctions en tant que service ( FaaS ) construites au-dessus de Kubernetes pour permettre aux utilisateurs de le consommer via des fonctions simples. Il existe même des outils pour automatiser la création et la rotation des certificats, en plus des technologies de maillage de service qui facilitent la liaison et l’introspection d’une myriade de microservices.
Tous ces outils de l’écosystème peuvent être utilisés pour améliorer, étendre et améliorer le cluster Kubernetes que vous gérez. Ils peuvent fournir de nouvelles fonctionnalités pour faciliter la vie de vos utilisateurs et rendre les logiciels qu’ils déploient plus robustes et plus faciles à gérer.
Cependant, ces outils peuvent également rendre votre cluster plus instable, moins sécurisé et plus sujet aux pannes. Ils peuvent exposer vos utilisateurs à des logiciels immatures et mal pris en charge qui ressemblent à une partie « officielle » du cluster, mais servent en fait à rendre la vie des utilisateurs plus difficile.
Une partie de la gestion d’un cluster Kubernetes consiste à savoir comment et quand ajouter ces outils, plates-formes et projets au cluster. Cela nécessite une exploration et une compréhension non seulement de ce qu’un projet particulier tente d’accomplir, mais aussi des autres solutions qui existent dans l’écosystème. Souvent, les utilisateurs viendront à vous avec une demande pour un outil particulier basé sur une vidéo ou un blog sur lequel ils se sont produits. En vérité, ils demandent souvent une capacité comme l’intégration continue et la livraison continue (CI / CD) ou la rotation des certificats.
C’est votre travail en tant que gestionnaire de cluster d’agir en tant que conservateur de ces projets. Vous êtes également un éditeur et un conseiller qui peut recommander des solutions alternatives ou déterminer si un projet particulier convient à votre cluster ou s’il existe un meilleur moyen d’atteindre le même objectif pour l’utilisateur final.
De plus, l’API Kubernetes elle-même contient des outils riches pour étendre et améliorer l’API. Un cluster Kubernetes ne se limite pas uniquement aux API qui y sont intégrées. Au lieu de cela, de nouvelles API peuvent être ajoutées et supprimées dynamiquement. Outre les extensions existantes qui viennent d’être mentionnées, le travail de gestion d’un cluster Kubernetes implique parfois de développer un nouveau code et de nouvelles extensions qui améliorent votre cluster d’une manière qui était auparavant impossible. Une partie de la gestion d’un cluster peut très bien être le développement de nouveaux outils. Bien sûr, une fois développé, partager cet outillage avec l’écosystème Kubernetes en pleine croissance est un excellent moyen de redonner à la communauté qui vous a apporté le logiciel Kubernetes en premier lieu.
1.5 Résumé
La gestion d’un cluster Kubernetes est plus que le simple fait d’installer un logiciel sur un ensemble de machines. Une gestion réussie nécessite une solide compréhension de la façon dont Kubernetes est assemblé et comment il est mis à profit par les développeurs qui sont des utilisateurs de Kubernetes. Cela nécessite que vous compreniez comment maintenir, ajuster et améliorer le cluster au fil du temps à mesure que ses modèles d’utilisation changent. De plus, vous devez savoir comment surveiller les informations rejetées par le cluster en fonctionnement et comment développer les alertes et les tableaux de bord pour vous dire quand le cluster est malade et comment le remettre en état. Enfin, vous devez comprendre quand et comment étendre le cluster Kubernetes avec d’autres outils pour le rendre encore plus utile pour vos utilisateurs. Nous espérons que dans cet article, vous trouverez des réponses et plus pour tous ces sujets et que, à la fin, vous vous retrouverez avec les compétences nécessaires pour réussir à gérer Kubernetes .
2 CHAPITRE 2 Présentation de Kubernetes
La création, le déploiement et la gestion d’applications par-dessus l’API Kubernetes est un sujet complexe à part entière. Il est hors de la portée de cet article de donner une compréhension complète de l’API Kubernetes dans tous ses détails.
En revanche, si vous êtes responsable de la gestion d’un cluster Kubernetes ou si vous avez une compréhension de haut niveau de l’API Kubernetes, ce chapitre fournit une introduction aux concepts de base de Kubernetes et à leur rôle dans le développement d’une application. Si après avoir lu ce chapitre, vous vous sentez toujours mal à l’aise d’avoir une conversation avec vos utilisateurs sur leur utilisation de Kubernetes, nous vous recommandons fortement de vous prévaloir de ces ressources supplémentaires.
Dans ce chapitre, nous introduisons d’abord la notion de conteneurs et comment ils peuvent être utilisés pour empaqueter et déployer votre application. Ensuite, nous présentons les concepts de base derrière l’API Kubernetes, et enfin, nous concluons avec quelques concepts de niveau supérieur que Kubernetes a ajoutés pour faciliter des tâches spécifiques.
2.1 Conteneurs
Docker a popularisé les conteneurs et a permis une révolution dans la manière dont les développeurs conditionnent et déploient leurs applications. Cependant, en cours de route, le mot même conteneur a pris de nombreuses significations différentes pour de nombreuses personnes différentes. Parce que Kubernetes est un orchestrateur de conteneurs pour comprendre Kubernetes, il est important de comprendre ce que nous voulons dire lorsque nous disons conteneur.
En réalité, un conteneur est composé de deux pièces différentes et d’un groupe de fonctionnalités associées. Un conteneur comprend :
- Une image de conteneur
- Un ensemble de concepts de système d’exploitation qui isole un ou plusieurs processus en cours d’exécution
L’image du conteneur contient le runtime d’application, qui se compose de fichiers binaires, de bibliothèques et d’autres données nécessaires pour exécuter le conteneur. Le développeur peut empaqueter son application en tant qu’image de conteneur sur son ordinateur portable de développement et être convaincu que lorsque cette image est déployée et exécutée dans un paramètre différent – que ce soit l’ordinateur portable d’un autre utilisateur ou un serveur dans un centre de données – le conteneur se comportera exactement comme il l’a fait sur l’ordinateur portable du développeur. Cette portabilité et cette exécution cohérente dans une variété d’environnements sont parmi les valeurs principales des images de conteneurs.
Lorsqu’une image de conteneur est exécutée, elle est également exécutée à l’aide d’espaces de noms dans le système d’exploitation. Ces espaces de noms contiennent le processus et l’isolent, ainsi que ses pairs, des autres éléments exécutés sur la machine. Cette isolation signifie, par exemple, que chaque conteneur en cours d’exécution a son propre système de fichiers séparé (comme un chroot). De plus, chaque conteneur possède son propre réseau et ses propres espaces de noms PID, ce qui signifie que le processus numéro 42 dans un conteneur est un processus différent du numéro 42 dans un autre conteneur. Il existe de nombreux autres espaces de noms dans le noyau qui séparent les différents conteneurs en cours d’exécution les uns des autres. De plus, les groupes de contrôle ( cgroups ) permettent d’isoler l’utilisation des ressources, comme la mémoire ou le processeur. Enfin, les fonctionnalités de sécurité standard du système d’exploitation, comme SELinux ou AppArmor , peuvent également être utilisées avec des conteneurs en cours d’exécution. Combiné, tout cet isolement rend plus difficile l’interférence des différents processus s’exécutant dans des conteneurs séparés.
Lorsque nous parlons d’isolement, il est extrêmement important de savoir qu’il s’agit de ressources, comme le processeur, la mémoire ou les fichiers. Les conteneurs tels qu’implémentés sous Linux et Windows ne fournissent pas actuellement une forte isolation de sécurité pour différents processus. Les conteneurs lorsqu’ils sont combinés avec d’autres isolations au niveau du noyau peuvent fournir une isolation de sécurité raisonnable pour certains cas d’utilisation. Cependant, dans le cas général, seule la sécurité au niveau de l’hyperviseur est suffisamment forte pour isoler des charges de travail vraiment hostiles.
Afin de faire tout cela, un certain nombre d’outils différents ont été créés pour aider à créer et à déployer des applications conteneurisées.
Le premier est le générateur d’image de conteneur. En règle générale, l’outil de ligne de commande docker est utilisé pour créer une image de conteneur. Cependant, le format d’image a été normalisé par la norme Open Container Initiative (OCI). Cela a permis le développement d’autres constructeurs d’images, disponibles via l’API cloud, CI / CD ou de nouveaux outils et bibliothèques alternatifs.
L’outil Docker utilise un Dockerfile , qui spécifie un ensemble d’instructions sur la façon de construire l’image conteneur. Tous les détails sur l’utilisation de l’outil Docker dépassent le cadre de cet article, mais de nombreuses ressources sont disponibles dans d’autres articles du site ou dans des ressources en ligne. Si vous n’avez jamais construit d’image de conteneur auparavant, posez cet article dès maintenant, allez lire sur les conteneurs et revenez lorsque vous aurez construit quelques images de conteneur.
Une fois qu’une image de conteneur a été créée, nous avons besoin d’un moyen de distribuer cette image depuis l’ordinateur portable d’un utilisateur vers d’autres utilisateurs, le cloud ou un centre de données privé. C’est là que le registre d’images entre en jeu. Le registre d’images est une API pour télécharger et gérer des images. Une fois qu’une image a été créée, elle est envoyée au registre d’images. Une fois que l’image est dans le registre, elle peut être extraite ou téléchargée depuis ce registre vers n’importe quelle machine ayant accès au registre. Chaque registre nécessite une certaine forme d’autorisation pour pousser une image, mais certains registres sont publics , ce qui signifie qu’une fois qu’une image est poussée, n’importe qui dans le monde peut tirer et commencer à exécuter l’image. D’autres sont privés et nécessitent également une autorisation pour extraire une image. À ce stade, il existe des registres en tant que service disponibles à partir de chaque cloud public, et il existe des serveurs de registre open source, que vous pouvez télécharger et exécuter dans votre propre environnement. Avant même de commencer à configurer votre cluster Kubernetes, c’est une bonne idée de savoir où vous allez stocker les images que vous y exécutez.
Une fois que vous avez empaqueté votre application en tant qu’image de conteneur et que vous l’avez poussée dans un registre, il est temps d’utiliser ce conteneur pour déployer l’application, et c’est là que l’orchestration de conteneurs entre en jeu.
2.2 Orchestration des conteneurs
Une fois que vous avez une image de conteneur stockée dans un registre quelque part, vous devez l’exécuter pour créer une application qui fonctionne. C’est là qu’un orchestrateur de conteneurs comme Kubernetes entre en scène. Le travail de Kuberentes consiste à prendre un groupe de machines qui fournissent des ressources, comme le processeur, la mémoire et le disque, et à les transformer en une API orientée conteneur que les développeurs peuvent utiliser pour déployer leurs conteneurs.
L’API Kubernetes vous permet de déclarer l’état souhaité du monde, par exemple : « Je veux que cette image de conteneur s’exécute, et elle a besoin de 3 cœurs et de 10 gigaoctets de mémoire pour fonctionner correctement. » Le système Kubernetes passe ensuite en revue son parc de machines, trouve un bon emplacement pour l’exécution de cette image de conteneur et planifie l’exécution de ce conteneur sur cette machine. Les développeurs voient leur image de conteneur s’exécuter et, le plus souvent, ils n’ont pas besoin de se préoccuper de l’emplacement spécifique où s’exécute leur conteneur.
Bien sûr, exécuter un seul conteneur n’est ni intéressant ni fiable, donc l’API Kubernetes fournit également des moyens simples de dire : « Je veux que trois copies de cette image de conteneur s’exécutent sur différentes machines, chacune avec 3 cœurs et 10 gigaoctets de mémoire. ”
Mais le système d’orchestration ne se limite pas à la planification de conteneurs sur des machines. En plus de cela, l’orchestrateur Kubernetes sait comment réparer ces conteneurs en cas d’échec. Si le processus à l’intérieur de votre conteneur se bloque, Kubernetes le redémarre. Si vous définissez des contrôles d’intégrité personnalisés, Kubernetes peut les utiliser pour déterminer si votre application est bloquée et doit être redémarrée (contrôles de vivacité) ou si elle doit faire partie d’un service à charge équilibrée (contrôles de préparation).
En parlant d’équilibrage de charge, Kubernetes fournit également des objets API pour définir un moyen d’équilibrer la charge du trafic entre ces différentes répliques. Il permet de dire : « Veuillez créer cet équilibreur de charge pour représenter ces conteneurs en cours d’exécution. » Ces équilibreurs de charge reçoivent également des noms faciles à découvrir afin de lier facilement différents services au sein d’un cluster.
Kubernetes possède également des objets qui effectuent des déploiements sans interruption de service et qui gèrent les configurations, les volumes persistants, les secrets et bien plus encore. Les sections suivantes détaillent les objets spécifiques de l’API Kubernetes qui rendent tout cela possible.
2.3 L’API Kubernetes
L’API Kubernetes est une API RESTful basée sur HTTP et JSON et fournie par un serveur d’API . Tous les composants de Kubernetes communiquent via l’API. Cette architecture est traitée plus en détail au chapitre 3. En tant que projet open source, l’API Kubernetes est en constante évolution, mais les objets principaux sont stables depuis des années et la communauté Kubernetes fournit une politique de dépréciation solide qui garantit que les développeurs et les opérateurs ne Je ne dois pas changer ce qu’ils font à chaque révision du système. Kubernetes fournit une spécification OpenAPI pour l’API, ainsi que de nombreuses bibliothèques clientes dans une variété de langues.
2.3.1 Objets de base: pods, jeux de réplicas et services
Bien qu’il ait un nombre important et croissant d’objets dans son API, Kubernetes a commencé avec un nombre relativement petit d’objets, et ceux-ci sont toujours au cœur de ce que fait Kubernetes.
2.3.1.1 Pods
Un pod est l’unité atomique de planification dans un cluster Kubernetes. Un pod est composé d’une collection d’un ou plusieurs conteneurs en cours d’exécution. (Un Pod est une collection de baleines, dérivée du logo de la baleine de Docker.) Lorsque nous disons qu’un Pod est atomique, ce que nous voulons dire, c’est que tous les conteneurs d’un Pod sont garantis pour atterrir sur la même machine dans le cluster. Les pods partagent également de nombreuses ressources entre les conteneurs. Par exemple, ils partagent tous le même espace de noms de réseau, ce qui signifie que chaque conteneur d’un pod peut voir les autres conteneurs du pod sur localhost. Les pods partagent également les espaces de noms de communication de processus et interprocessus afin que différents conteneurs puissent utiliser des outils, tels que la mémoire partagée et la signalisation, pour coordonner les différents processus du pod.
Ce regroupement étroit signifie que les pods sont parfaitement adaptés aux relations symbiotiques entre leurs conteneurs, comme un conteneur de service principal et un conteneur de chargement de données en arrière-plan. La séparation des images de conteneur rend généralement plus agile la possibilité pour différentes équipes de posséder ou de réutiliser les images de conteneur, mais en les regroupant dans un pod au moment de l’exécution, elles peuvent fonctionner en coopération.
Lorsque les gens rencontrent des Pods pour la première fois dans Kubernetes, ils émettent parfois de fausses hypothèses. Par exemple, un utilisateur peut voir un pod et penser : « Ah oui, un frontend et un serveur de base de données constituent un pod ». Mais ce n’est généralement pas le bon niveau de granularité. Pour voir pourquoi, considérez que le pod est également l’unité de mise à l’échelle et de réplication, ce qui signifie que, si vous regroupez votre frontend et votre base de données dans le même conteneur, vous répliquerez votre base de données au même rythme que vous répliquez vos frontends. Il est peu probable que vous souhaitiez procéder de cette manière.
Les pods permettent également de faire fonctionner votre application. Si le processus d’un conteneur se bloque, Kubernetes le redémarre automatiquement. Les pods peuvent également définir des contrôles d’intégrité au niveau de l’application qui peuvent fournir un moyen plus riche et spécifique à l’application de déterminer si le pod doit être redémarré automatiquement.
2.3.1.2 ReplicaSets
Bien sûr, si vous déployez un orchestrateur de conteneurs uniquement pour exécuter des conteneurs individuels, vous compliquez probablement trop votre vie. En général, l’une des principales raisons de l’orchestration de conteneurs est de faciliter la création de systèmes répliqués et fiables. Bien que des conteneurs individuels puissent échouer ou être incapables de répondre à la charge d’un système, la réplication d’une application sur un certain nombre de conteneurs en cours d’exécution réduit considérablement la probabilité que votre service échoue complètement à un moment donné. De plus, la mise à l’échelle horizontale vous permet de développer votre application en réponse à la charge. Dans l’API Kubernetes, ce type de réplication sans état est géré par un objet ReplicaSet . Un ReplicaSet garantit que, pour une définition de pod donnée, un certain nombre de réplicas existent dans le système. La réplication réelle est gérée par le gestionnaire de contrôleur Kubernetes, qui crée des objets Pod planifiés par le planificateur Kubernetes. Ces détails de l’architecture sont décrits dans les chapitres suivants.
ReplicaSet est un objet plus récent. Dans sa version v1, Kubernetes avait un objet API appelé ReplicationController . En raison de la politique de dépréciation, les ReplicationControllers continuent d’exister dans l’API Kubernetes, mais leur utilisation est fortement déconseillée en faveur des ReplicaSets .
2.3.1.3 Services
Une fois que vous pouvez répliquer votre application à l’aide d’un jeu de réplicas, le prochain objectif logique est de créer un équilibreur de charge pour répartir le trafic vers ces différentes répliques. Pour ce faire, Kubernetes dispose d’un objet Service. Un service représente un service à charge équilibrée TCP ou UDP . Chaque service créé, qu’il soit TCP ou UDP, obtient trois choses :
- Sa propre adresse IP
- Une entrée DNS dans le DNS du cluster Kubernetes
- Règles d’équilibrage de charge qui procurent du trafic proxy aux pods qui implémentent le service
Lorsqu’un service est créé, une adresse IP fixe lui est attribuée. Cette adresse IP est virtuelle – elle ne correspond à aucune interface présente sur le réseau. Au lieu de cela, il est programmé dans la structure réseau en tant qu’adresse IP à charge équilibrée. Lorsque les paquets sont envoyés à cette adresse IP, ils sont équilibrés en charge vers un ensemble de pods qui implémentent le service. L’équilibrage de charge effectué peut être à tour de rôle ou déterministe, en fonction des tuples d’adresse IP source et de destination.
Compte tenu de cette adresse IP fixe, un nom DNS est programmé dans le serveur DNS du cluster Kubernetes. Cette adresse DNS fournit un nom sémantique (par exemple, «frontend»), qui est le même que le nom de l’objet Service Kubernetes et qui permet à d’autres conteneurs du cluster de découvrir l’adresse IP de l’équilibreur de charge de service. Enfin, l’équilibrage de charge du service est programmé dans la structure réseau du cluster Kubernetes afin que tout conteneur qui essaie de communiquer avec l’adresse IP du service soit correctement équilibré en charge vers les pods correspondants. Cette programmation de la structure réseau est dynamique, de sorte que les pods vont et viennent en raison de défaillances ou de la mise à l’échelle d’un ReplicaSet , l’équilibreur de charge est constamment reprogrammé pour correspondre à l’état actuel du cluster. Cela signifie que les clients peuvent s’appuyer sur les connexions à l’adresse IP du service pour toujours résoudre un pod qui implémente le service.
2.3.1.4 Stockage : volumes persistants, ConfigMaps et secrets
Une question courante qui se pose après une première exploration de Kubernetes est : « Qu’en est-il de mes fichiers ? » Avec tous ces conteneurs qui vont et viennent dans le cluster et atterrissent sur différentes machines, il est difficile de comprendre comment vous devez gérer les fichiers et le stockage que vous souhaitez associer à vos conteneurs. Heureusement, Kubernetes fournit plusieurs objets API différents pour vous aider à gérer vos fichiers.
Le premier concept de stockage introduit dans Kubernetes était Volume, qui fait en fait partie de l’API Pod. Dans un pod, vous pouvez définir un ensemble de volumes. Chaque volume peut être l’un d’un grand nombre de types différents. À l’heure actuelle, il existe plus de 10 types de volumes différents que vous pouvez créer, notamment NFS, iSCSI, gitRepo , des volumes basés sur le stockage dans le cloud, etc.
Bien que l’interface Volume était initialement un point d’extensibilité via l’écriture de code dans Kubernetes, l’explosion de différents types de volume a finalement montré à quel point ce modèle n’était pas durable. Désormais, de nouveaux types de volume sont développés en dehors du code Kubernetes et utilisent la Container Storage Interface (CSI), une interface de stockage indépendante de Kubernetes.
Lorsque vous ajoutez un volume à votre pod, vous pouvez choisir de le monter à un emplacement arbitraire dans chaque conteneur en cours d’exécution. Cela permet à votre conteneur en cours d’exécution d’avoir accès au stockage dans le volume. Différents conteneurs peuvent monter ces volumes à différents endroits ou ignorer complètement le volume.
En plus des fichiers de base, il existe plusieurs types d’objets Kubernetes qui peuvent eux-mêmes être montés dans votre Pod en tant que volume. Le premier d’entre eux est l’ objet ConfigMap . Un ConfigMap représente une collection de fichiers de configuration. Dans Kubernetes, vous souhaitez avoir différentes configurations pour la même image de conteneur. Lorsque vous ajoutez un volume basé sur ConfigMap à votre pod, les fichiers dans ConfigMap s’affichent dans le répertoire spécifié dans votre conteneur en cours d’exécution.
Kubernetes utilise le type de configuration Secret pour les données sécurisées, telles que les mots de passe de base de données et les certificats. Dans le contexte de Volumes, un Secret fonctionne de manière identique à un Con figMap . Il peut être attaché à un pod via un volume et monté dans un conteneur en cours d’exécution pour utilisation.
Au fil du temps, le déploiement d’applications avec Volumes a révélé que la liaison étroite des Volumes aux Pods était en fait problématique. Par exemple, lors de la création d’un conteneur répliqué (via un ReplicaSet ), le même volume exact doit être utilisé par toutes les répliques. Dans de nombreuses situations, cela est acceptable, mais dans certains cas, vous souhaitez migrer un volume différent pour chaque réplique. De plus, la spécification d’un type de volume précis (par exemple, un volume persistant sur le disque Azure) lie votre définition de pod à un environnement spécifique (dans ce cas, le cloud Microsoft Azure), mais il est souvent souhaitable d’avoir une définition de pod qui demande un générique type de stockage (par exemple, 10 gigaoctets de stockage réseau) sans spécifier de fournisseur. Pour ce faire, Kubernetes a introduit la notion de Persis tentVolumes et PersistentVolumeClaims . Au lieu de lier un volume directement dans un pod, un volume persistant est créé en tant qu’objet séparé. Cet objet est ensuite revendiqué à un pod spécifique par un PersistentVolumeClaim et finalement monté dans le pod via cette revendication. Au début, cela semble trop compliqué, mais l’abstraction de Volume et Pod permet à la fois la portabilité et la création automatique de volume requises par les deux cas d’utilisation précédents.
2.3.2 Organisation de votre cluster avec des espaces de noms, des étiquettes et des annotations
L’API Kubernetes facilite la création d’un grand nombre d’objets dans le système, mais une telle collection d’objets peut facilement faire de l’administration d’un cluster un cauchemar. Heureusement, Kubernetes possède également de nombreux objets qui facilitent la gestion, l’interrogation et le raisonnement sur les objets de votre cluster.
2.3.2.1 Espaces de noms
Le premier objet pour organiser votre cluster est l’espace de noms. Vous pouvez considérer un espace de noms comme quelque chose comme un dossier pour vos objets API Kubernetes. Les espaces de noms fournissent des répertoires pour contenir la plupart des autres objets du cluster. Les espaces de noms peuvent également fournir une portée pour les règles de contrôle d’accès basé sur les rôles (RBAC). Comme un dossier, lorsque vous supprimez un espace de noms, tous les objets qu’il contient sont également détruits, alors faites attention ! Chaque cluster Kubernetes possède un seul espace de noms intégré nommé par défaut, et la plupart des installations de Kubernetes incluent également un espace de noms nommé kube -system, où les conteneurs d’administration de cluster sont créés.
Les objets Kubernetes sont divisés en objets avec espace de nom et sans espace de nom, selon qu’ils peuvent être placés dans un espace de nom. Les objets API Kubernetes les plus courants sont des objets à espace de noms. Mais certains objets qui s’appliquent à un cluster entier (par exemple, les objets d’espace de nom eux-mêmes ou le RBAC au niveau du cluster), ne sont pas à espace de noms.
Outre l’organisation des objets Kubernetes, les espaces de noms sont également placés dans les noms DNS créés pour les services et les chemins de recherche DNS fournis aux conteneurs. Le nom DNS complet pour un service est quelque chose comme my- service.svc.mynamespace .cluster.internal , ce qui signifie que deux différents services dans les différents espaces de noms vont se retrouver avec différents noms de domaine complets (FQDN). De plus, les chemins de recherche DNS pour chaque conteneur incluent l’espace de noms, ainsi une recherche DNS pour le frontend sera traduite en frontend.svc.foo.cluster .internal pour un conteneur dans le foo Namespace et frontend.svc.bar.cluster.internal pour un conteneur dans l’espace de noms de la barre.
2.3.2.2 Étiquettes et requêtes d’étiquettes
Chaque objet de l’API Kubernetes peut être associé à un ensemble arbitraire d’étiquettes. Les étiquettes sont des paires clé-valeur de chaîne qui aident à identifier l’objet. Par exemple, une étiquette peut être “role”: “frontend”, ce qui indique que l’objet est un frontend. Ces étiquettes peuvent être utilisées pour interroger et filtrer des objets dans l’API. Par exemple, vous pouvez demander au serveur d’API de vous fournir une liste de tous les pods où le rôle d’étiquette est backend. Ces demandes sont appelées requêtes d’étiquettes ou sélecteurs d’étiquettes. De nombreux objets de l’API Kubernetes utilisent des sélecteurs d’étiquettes pour identifier les ensembles d’objets auxquels ils s’appliquent. Par exemple, une cosse peut avoir un sélecteur de noeud qui identifie l’ensemble des noeuds sur lesquels la nacelle est éligible pour exécuter (nœuds avec GPU, par exemple). De même, un service possède un sélecteur de pod , qui identifie l’ensemble de pods sur lequel le service doit charger le trafic d’équilibrage. Les étiquettes et les sélecteurs d’étiquettes sont la manière fondamentale dont Kubernetes associe librement ses objets.
2.3.2.3 Annotations
Toutes les valeurs de métadonnées que vous souhaitez affecter à un objet API n’identifient pas des informations. Certaines informations sont simplement une annotation sur l’objet lui-même. Ainsi, chaque objet API Kubernetes peut également avoir des annotations arbitraires. Ceux-ci peuvent inclure quelque chose comme l’icône à afficher à côté de l’objet ou un modificateur qui change la façon dont l’objet est interprété par le système.
Souvent, les fonctionnalités expérimentales ou spécifiques au fournisseur dans Kubernetes sont initialement implémentées à l’aide d’annotations, car elles ne font pas partie de la spécification formelle de l’API. Dans ces cas, l’annotation elle-même doit contenir une certaine notion de la stabilité de la fonction (par exemple, beta.kubernetes.io/activate-some-beta-feature).
2.3.2.4 Concepts avancés : déploiements, entrées et ensembles d’états
Bien entendu, les services simples, répliqués et à charge équilibrée ne sont pas le seul style d’application que vous souhaiterez déployer dans des conteneurs. Et, à mesure que Kubernetes a évolué, il a ajouté de nouveaux objets API pour mieux s’adapter à des cas d’utilisation plus spécialisés, notamment des déploiements améliorés, un équilibrage et un routage basés sur HTTP et des charges de travail avec état.
2.3.2.5 Déploiements
Bien que les ReplicaSets soient la primitive pour exécuter de nombreuses copies différentes de la même image de conteneur, les applications ne sont pas des entités statiques. Ils évoluent à mesure que les développeurs ajoutent de nouvelles fonctionnalités et corrigent des bugs. Cela signifie que le fait de déployer un nouveau code dans un service est une fonctionnalité aussi importante que sa réplication pour gérer de manière fiable la charge.
L’objet Déploiement a été ajouté à l’API Kubernetes pour représenter ce type de déploiement sécurisé d’une version à une autre. Un déploiement peut contenir des pointeurs vers plusieurs licaSets de rep (par exemple, v1 et v2), et il peut contrôler la migration lente et sûre d’un ReplicaSet vers un autre.
Pour comprendre le fonctionnement d’un déploiement, imaginez que vous disposez d’une application déployée sur trois réplicas dans un ReplicaSet nommé rs-v1. Lorsque vous demandez à un déploiement ment à déployer une nouvelle image (v2), le déploiement crée une nouvelle replicaSet (rs-v2) avec une seule réplique. Le déploiement attend que cette réplique devienne saine et, lorsqu’elle l’est, le déploiement réduit à deux le nombre de répliques dans rs-v1. Il augmente ensuite le nombre de répliques dans rs-v2 à deux également, et attend que la deuxième réplique de v2 redevienne saine. Ce processus se poursuit jusqu’à ce qu’il n’y ait plus de répliques de v1 et qu’il y ait trois répliques saines de v2.
Les déploiements comportent un grand nombre de boutons différents qui peuvent être réglés pour fournir un déploiement sûr pour les détails spécifiques d’une application. En effet, dans la plupart des groupes modernes, les utilisateurs utilisent exclusivement Déployer ment des objets et ne parviennent pas ReplicaSets directement.
2.3.2.6 Équilibrage de charge HTTP avec Ingress
Bien que les objets Service fournissent un excellent moyen d’effectuer un équilibrage de charge simple au niveau TCP, ils ne fournissent pas un moyen au niveau de l’application pour effectuer l’équilibrage de charge et le routage. La vérité est que la plupart des applications que les utilisateurs déploient à l’aide de conteneurs et de Kubernetes sont des applications Web HTTP. Ceux-ci sont mieux servis par un équilibreur de charge qui comprend HTTP. Pour répondre à ces besoins, l’API Ingress a été ajoutée à Kubernetes. Ingress représente un chemin et un équilibreur de charge et un routeur HTTP basés sur l’hôte. Lorsque vous créez un objet Ingress, il reçoit une adresse IP virtuelle comme un service, mais au lieu de la relation un à un entre une adresse IP de service et un ensemble de pods, une entrée peut utiliser le contenu d’une demande HTTP pour acheminer les demandes vers différents services.
Pour mieux comprendre le fonctionnement d’Ingress, imaginez que nous avons deux services Kubernetes nommés «foo» et «bar». Chacun a sa propre adresse IP, mais nous voulons vraiment les exposer à Internet en tant que partie du même hôte. Par exemple, foo.company.com et bar.company.com. Nous pouvons le faire en créant un objet Ingress et en associant son adresse IP aux noms DNS foo.company.com et bar.company.com. Dans l’objet Ingress, nous mappons également les deux noms d’hôtes différents aux deux services Kubernetes différents. De cette façon, lorsqu’une demande pour https://foo.company.com est reçue, elle est acheminée vers le service «foo» du cluster, et de même pour https://bar.company.com . Avec Ingress, le routage peut être basé sur l’hôte ou le chemin ou les deux, donc https://company.com/bar peut également être routé vers le service « bar ».
L’API Ingress est l’une des API les plus découplées et flexibles de Kubernetes. Par défaut, bien que Kubernetes stocke les objets Ingress, rien ne se produit lors de leur création. Au lieu de cela, vous devez également exécuter un contrôleur d’entrée dans le cluster pour prendre les mesures appropriées lorsque l’objet d’entrée est créé. L’un des contrôleurs Ingress les plus populaires est nginx , mais il existe de nombreuses implémentations qui utilisent d’autres équilibreurs de charge HTTP ou qui utilisent des API d’équilibrage de charge cloud ou physique.
2.3.2.7 StatefulSets
La plupart des applications fonctionnent correctement lorsqu’elles sont répliquées horizontalement et traitées comme des clones identiques. Chaque réplique n’a pas d’identité unique indépendante des autres. Pour représenter de telles applications, un ReplicaSet Kubernetes est l’objet parfait. Cependant, certaines applications, en particulier les charges de travail de stockage avec état ou les applications fragmentées, nécessitent davantage de différenciation entre les répliques de l’application. Bien qu’il soit possible d’ajouter cette différenciation au niveau de l’application au-dessus d’un ReplicaSet , cette opération est compliquée, sujette aux erreurs et répétitive pour les utilisateurs finaux.
Pour résoudre ce problème, Kubernetes a récemment introduit les StatefulSets en complément des ReplicaSets , mais pour des charges de travail plus dynamiques. Comme ReplicaSets , StatefulSets crée plusieurs instances de la même image de conteneur s’exécutant dans un cluster Kubernetes, mais la manière dont les conteneurs sont créés et détruits est plus déterministe, tout comme les noms de chaque conteneur.
Dans un ReplicaSet , chaque pod répliqué reçoit un nom qui implique un hachage aléatoire (par exemple, frontend-14a2 ), et il n’y a aucune notion de classement dans un ReplicaSet . En revanche, avec StatefulSets , chaque réplique reçoit un index à augmentation monotone (par exemple, soutenu-0 , backend-1 , etc.).
De plus, StatefulSets garantit que le réplica zéro sera créé et redeviendra sain avant que le réplica un ne soit créé et ainsi de suite. Lorsqu’elles sont combinées, cela signifie que les applications peuvent facilement s’amorcer elles-mêmes en utilisant la réplique initiale (par exemple, backend-0 ) comme maître d’amorçage. Toutes les répliques suivantes peuvent compter sur le fait que le backend-0 doit exister. De même, lorsque les réplicas sont supprimés d’un StatefulSet , ils sont supprimés à l’index le plus élevé. Si un StatefulSet est réduit de cinq à quatre répliques, il est garanti que la cinquième réplique est celle qui sera supprimée.
De plus, les StatefulSets reçoivent des noms DNS afin que chaque réplique soit accessible directement, en plus du StatefulSet complet. Cela permet aux clients de cibler facilement des fragments spécifiques dans un service partagé.
2.3.2.8 Charges de travail par lots : travail et emploi planifié
En plus des charges de travail avec état, une autre classe spécialisée de charges de travail sont les charges de travail par lots ou ponctuelles. Contrairement aux charges de travail discutées précédemment, celles-ci ne servent pas constamment le trafic. Au lieu de cela, ils effectuent certains calculs et sont ensuite détruits lorsque le calcul est terminé.
Dans Kubernetes, un Job représente un ensemble de tâches qui doivent être exécutées. Comme ReplicaSets et StatefulSets , les Jobs fonctionnent en créant des Pods pour exécuter le travail en exécutant des images de conteneur. Cependant, contrairement aux ReplicaSets et StatefulSets , les pods créés par un Job s’exécutent uniquement jusqu’à ce qu’ils se terminent et se terminent. Un Job contient la définition des Pods qu’il crée, le nombre d’exécutions du Job et le nombre maximum de Pods à créer en parallèle. Par exemple, un Job avec 100 répétitions et un parallélisme maximum de 10 exécutera 10 Pods simultanément, créant de nouveaux Pods comme les anciens, jusqu’à ce qu’il y ait eu 100 exécutions réussies de l’image du conteneur.
ScheduledJobs s’appuie sur l’objet Job en ajoutant une planification à un Job. Un Sched uledJob contient la définition de l’objet Job que vous souhaitez créer, ainsi que la planification sur laquelle ce Job doit être créé.
2.3.3 Agents de cluster et utilitaires : DaemonSets
L’une des questions les plus courantes qui se posent lorsque les gens déménagent vers Kubernetes est : « Comment exécuter les agents de ma machine ?» Des exemples de tâches d’agents incluent la détection d’intrusion, la journalisation et la surveillance, etc. De nombreuses personnes tentent des approches non Kubernetes pour activer ces agents, telles que l’ajout de nouveaux fichiers d’unité systemd ou de scripts d’initialisation. Bien que ces approches puissent fonctionner, elles présentent plusieurs inconvénients. La première est que Kubernetes n’inclut pas l’activité des agents dans sa comptabilité des ressources utilisées sur le cluster. La seconde est que les images de conteneur et les API Kubernetes pour la vérification de l’intégrité, la surveillance, etc. ne peuvent pas être appliquées à ces agents. Heureusement, Kubernetes met l’API DaemonSet à la disposition des utilisateurs pour installer ces agents sur leurs clusters. Un DaemonSet fournit un modèle pour un pod qui doit être exécuté sur chaque machine. Lorsqu’un DaemonSet est créé, Kubernetes s’assure que ce pod s’exécute sur chaque nœud du cluster. Si, à un moment ultérieur, un nouveau nœud est ajouté, Kubernetes crée également un pod sur ce nœud. Bien que par défaut, Kubernetes place un pod sur chaque nœud du cluster, un DaemonSet peut également fournir une requête d’étiquette de sélection de nœud, et Kubernetes ne placera ce pod de DaemonSet que sur des nœuds qui correspondent à cette requête d’étiquette.
2.4 Résumé
L’objectif de cet article est de vous apprendre à gérer avec succès un cluster Kubernetes. Mais pour gérer avec succès un service, vous devez comprendre ce que ce service met à la disposition de l’utilisateur final, ainsi que la façon dont l’utilisateur utilise le service. Dans ce cas, nous fournissons une API Kubernetes fiable aux développeurs. Les développeurs, à leur tour, utilisent cette API pour créer et déployer avec succès leurs applications. Comprendre les différentes parties de l’API Kubernetes vous permettra de comprendre vos utilisateurs finaux et de mieux gérer le système dont ils dépendent pour leurs activités quotidiennes.
3 CHAPITRE 3 Architecture Kubernetes
Bien que Kubernetes soit destiné à faciliter le déploiement et la gestion des systèmes distribués, Kubernetes lui-même est un système distribué qui doit être géré. Pour être en mesure de le faire, un développeur doit avoir une solide compréhension de l’architecture du système, du rôle de chaque élément du système et de la façon dont ils s’emboîtent tous.
3.1 Concepts
Pour comprendre l’architecture de Kubernetes, il est utile, dans un premier temps, d’avoir une bonne compréhension des concepts et des principes de conception qui régissent son développement. Bien que le système puisse sembler assez complexe, il est en fait basé sur un nombre relativement restreint de concepts qui sont répétés tout au long. Cela permet à Kubernetes de se développer, tout en restant accessible aux développeurs. La connaissance d’un composant du système peut souvent être directement appliquée à d’autres.
3.1.1 Configuration déclarative
La notion de configuration déclarative – lorsqu’un utilisateur déclare un état souhaité du monde pour produire un résultat – est l’un des principaux moteurs du développement de Kubernetes. Par exemple, un utilisateur pourrait dire à Kubernetes: «Je veux qu’il y ait en tout temps cinq répliques de mon serveur Web.» Kubernetes, à son tour, prend cette déclaration déclarative et prend la responsabilité de s’assurer qu’elle est vraie. Malheureusement, Kubernetes est incapable de comprendre les instructions en langage naturel et cette déclaration est en fait sous la forme d’un document YAML ou JSON structuré.
La configuration déclarative diffère de la configuration impérative dans laquelle les utilisateurs prennent une série d’actions directes (par exemple, la création de chacune des cinq répliques qu’ils souhaitent avoir opérationnelles). Les actions impératives sont souvent plus simples à comprendre – on peut simplement dire « exécuter ceci » au lieu d’utiliser une syntaxe déclarative plus complexe. Cependant, le pouvoir de l’approche déclarative est que vous donnez au système plus qu’une séquence d’instructions – vous lui donnez une déclaration de votre état souhaité. Parce que Kubernetes comprend votre état souhaité, il peut prendre des mesures autonomes, indépendamment de l’interaction de l’utilisateur. Cela signifie qu’il peut implémenter des comportements d’auto- correction et d’auto-guérison automatiques. Pour un développeur, cela est essentiel, car cela signifie que le système peut se réparer sans vous réveiller au milieu de la nuit.
3.1.2 Rapprochement ou contrôleurs
Pour atteindre ces comportements d’auto-guérison ou d’auto-correction, Kubernetes est structuré sur la base d’un grand nombre de boucles de réconciliation ou de contrôle indépendantes. Lors de la conception d’un système comme Kubernetes, vous pouvez généralement adopter deux approches différentes : une approche basée sur un état monolithique ou une approche basée sur un contrôleur décentralisé.
Dans la conception d’un système monolithique, le système est conscient de l’état du monde entier et utilise cette vue complète pour faire avancer tout de manière coordonnée. Cela peut être très intéressant, car le fonctionnement du système est centralisé et donc plus facile à comprendre. Le problème avec l’approche monolithique est qu’elle n’est pas particulièrement stable. Si quelque chose d’inattendu se produit, le système entier peut tomber en panne.
Kubernetes adopte une approche décentralisée alternative dans sa conception. Au lieu d’un seul contrôleur monolithique, Kubernetes est composé d’un grand nombre de contrôleurs, chacun effectuant sa propre boucle de réconciliation indépendante. Chaque boucle individuelle n’est responsable que d’une petite partie du système (par exemple, la mise à jour de la liste des points de terminaison pour un équilibreur de charge particulier), et chaque petit contrôleur ignore totalement le reste du monde. Cette focalisation sur un petit problème et l’ignorance correspondante de l’état plus large du monde rend l’ensemble du système beaucoup plus stable. Chaque contrôleur est largement indépendant de tous les autres et n’est donc pas affecté par des problèmes ou des changements sans rapport avec lui-même. L’inconvénient, cependant, de cette approche distribuée est que le comportement global du système peut être plus difficile à comprendre, car il n’y a pas un seul endroit pour chercher une explication des raisons pour lesquelles le système se comporte comme il est. Au lieu de cela, il est nécessaire d’examiner l’interopérabilité d’un grand nombre de processus indépendants.
Le modèle de conception de boucle de contrôle rend Kubernetes plus flexible et stable et est répété dans tous les composants du système Kubernetes. L’idée de base derrière une boucle de contrôle est qu’elle répète continuellement les étapes suivantes, comme le montre la figure 3-1:
- Obtenez l’état souhaité du monde.
- Observez le monde.
- Trouvez des différences entre l’observation du monde et l’état souhaité du monde.
- Prenez des mesures pour que l’observation du monde corresponde à l’état souhaité.
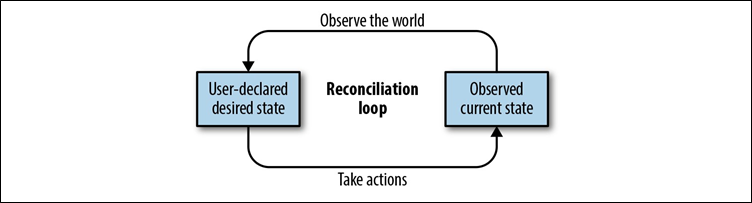
Figure 3-1. Une illustration d’une boucle de réconciliation générique
L’exemple le plus simple pour vous aider à comprendre le fonctionnement d’une boucle de contrôle de rapprochement est le thermostat de votre maison. Il a un état souhaité (la température que vous avez entrée sur le thermostat), il fait des observations du monde (la température actuelle de votre maison), il trouve la différence entre ces valeurs, et il prend ensuite des mesures (chauffage ou refroidissement) pour que le monde réel corresponde à l’état souhaité du monde.
Les contrôleurs de Kubernetes font la même chose. Ils observent l’état souhaité du monde via les déclarations déclaratives adressées au serveur API Kubernetes. Par exemple, un utilisateur peut déclarer : « Je veux quatre répliques de ce serveur Web ». Le contrôleur de réplication Kubernetes prend cet état souhaité puis observe le monde. Il se peut qu’il existe actuellement trois répliques du conteneur de service Web. Le contrôleur trouve la différence entre l’état actuel et l’état souhaité (un serveur Web manquant) puis prend des mesures pour que l’état actuel corresponde à l’état souhaité en créant un quatrième conteneur de service Web.
Bien sûr, l’un des défis de la gestion de cet état déclaratif est de déterminer l’ensemble de serveurs Web auxquels la boucle de contrôle de réconciliation doit prêter attention. C’est là que les étiquettes et les requêtes d’étiquettes entrent dans la conception de Kubernetes.
3.1.3 Regroupement implicite ou dynamique
Qu’il s’agisse de regrouper un ensemble de répliques ou d’identifier les backends d’un équilibreur de charge, il y a de nombreuses fois dans l’implémentation de Kubernetes quand il est nécessaire d’identifier un ensemble de choses. Lors du regroupement des éléments dans un ensemble, il existe deux approches possibles : le regroupement explicite / statique ou implicite / dynamique. Avec le regroupement statique, chaque groupe est défini par une liste concrète (par exemple, “Les membres de mon équipe sont Alice, Bob et Carol.”). La liste appelle explicitement le nom de chaque membre du groupe et la liste est statique, c’est-à-dire que l’appartenance ne change pas sauf si la liste elle-même change. Tout comme une approche monolithique de la conception, ce regroupement statique est facilement compréhensible. Pour savoir qui est dans un groupe, il suffit de lire la liste. Le défi du regroupement statique est qu’il est inflexible – il ne peut pas répondre à un monde en évolution dynamique. J’espère qu’à ce stade, vous savez que Kubernetes utilise une approche plus dynamique du regroupement. Dans Kubernetes, les groupes sont définis implicitement.
L’alternative aux groupes statiques explicites est les groupes dynamiques implicites. Avec les groupes implicites, au lieu de la liste des membres, le groupe est défini par une déclaration comme : « Les membres de mon équipe sont les gens qui portent de l’orange ». Ce groupe est implicitement défini. Nulle part dans la définition du groupe les membres ne sont définis ; au lieu de cela, ils sont implicites en évaluant la définition du groupe par rapport à un ensemble de personnes présentes. Parce que l’ensemble des personnes présentes peut toujours changer, la composition du groupe est également dynamique et changeante. Bien que cela puisse introduire de la complexité, en raison de la deuxième étape (dans le cas d’exemple, à la recherche de personnes portant de l’orange), il est également beaucoup plus flexible et stable, et il peut gérer un environnement changeant sans nécessiter des ajustements constants des listes statiques.
Dans Kubernetes, ce regroupement implicite est réalisé via des étiquettes et des requêtes d’étiquettes ou des sélecteurs d’étiquettes. Chaque objet API dans Kubernetes peut avoir un nombre arbitraire de paires clé / valeur appelées « étiquettes » qui sont associées à l’objet. Vous pouvez ensuite utiliser une requête d’étiquette ou un sélecteur d’étiquette pour identifier un ensemble d’objets correspondant à cette requête. Un exemple concret de cela est illustré à la figure 3-2.
Chaque objet Kubernetes possède à la fois des étiquettes et des annotations. Au début, ils peuvent sembler redondants, mais leurs utilisations sont différentes. Les étiquettes peuvent être interrogées et doivent fournir des informations permettant d’identifier l’objet d’une manière ou d’une autre. Les annotations ne peuvent pas être interrogées et doivent être utilisées pour les métadonnées générales sur l’objet – des métadonnées qui ne représentent pas son identité (par exemple, l’icône à afficher à côté de l’objet lorsqu’il est rendu graphiquement).

Figure 3-2. Exemples d’étiquettes et de sélection d’étiquettes
3.2 Structure
Maintenant que vous avez une idée des concepts de conception mis en œuvre dans le système Kubernetes, considérons les principes de conception utilisés pour créer Kubernetes. Les principes de conception fondamentaux suivants sont essentiels au développement de Kubernetes.
3.2.1 Philosophie Unix de nombreux composants
Kubernetes adhère à la philosophie générale Unix de la modularité et des petites pièces qui font bien leur travail. Kubernetes n’est pas une seule application monolithique qui implémente toutes les différentes fonctionnalités dans un seul binaire. Au lieu de cela, il s’agit d’un ensemble d’applications différentes qui fonctionnent toutes ensemble, en grande partie ignorantes les unes des autres, pour implémenter le système global connu sous le nom de Kubernetes. Même lorsqu’il existe un binaire (par exemple, le gestionnaire de contrôleur) qui regroupe un grand nombre de fonctions différentes, ces fonctions sont détenues presque entièrement indépendamment les unes des autres dans ce binaire. Ils sont compilés ensemble en grande partie pour faciliter la tâche de déploiement et de gestion de Kubernetes, pas à cause d’une liaison étroite entre les composants.
Encore une fois, l’avantage de cette approche modulaire est que Kubernetes est flexible. De grandes fonctionnalités peuvent être arrachées et remplacées sans que le reste du système ne s’en aperçoive ou ne s’en soucie. L’inconvénient, bien sûr, est la complexité, car le déploiement, la surveillance et la compréhension du système nécessitent l’intégration des informations et de la configuration à travers un certain nombre d’outils différents. Parfois, ces pièces sont compilées en un seul exécutable binaire, mais même lorsque cela se produit, elles communiquent toujours via le serveur API plutôt que directement dans le processus en cours d’exécution.
3.2.2 Interactions pilotées par l’API
La deuxième conception structurelle au sein de Kubernetes est que toutes les interactions entre les composants passent par une surface API centralisée. Un corollaire important de cette conception est que l’API que les composants utilisent est exactement la même API utilisée par tous les autres utilisateurs du cluster. Cela a deux conséquences importantes pour Kubernetes. La première est qu’aucune partie du système n’est plus privilégiée ou n’a un accès plus direct aux internes que toute autre. En effet, à l’exception du serveur API qui implémente l’API, personne n’a accès aux internes du tout. Ainsi, chaque composant peut être échangé contre une implémentation alternative, et de nouvelles fonctionnalités peuvent être ajoutées sans avoir à reconcevoir les composants principaux. Comme nous le verrons dans les chapitres suivants, même les composants de base comme le planificateur peuvent être échangés et remplacés (ou simplement augmentés) par des implémentations alternatives.
Les interactions pilotées par l’API incitent un système à être conçu de manière stable en présence d’un biais de version. Lorsque vous déployez un système distribué dans un groupe de machines, pendant un certain temps, vous aurez à la fois l’ancienne version et la nouvelle version du logiciel exécutées simultanément. Si vous n’avez pas planifié directement cette asymétrie de version, les interactions non planifiées (et souvent non testées) entre les anciennes et les nouvelles versions peuvent provoquer une instabilité et des pannes. Parce que dans Kubernetes, tout est médié via l’API et que l’API fournit des versions d’API fortement définies et une conversion entre différents numéros de version , les problèmes de biais de version peuvent être largement évités. En réalité, cependant, des problèmes occasionnels peuvent toujours survenir, et les tests de biais et de mise à niveau des versions sont une partie importante de la qualification des versions de Kubernetes.
3.3 Composants
Avec la connaissance des concepts et des structures de l’architecture Kubernetes, nous pouvons maintenant discuter des composants individuels qui composent Kubernetes. Il s’agit en quelque sorte d’un glossaire – une carte du monde à laquelle vous pouvez vous référer lorsque vous avez besoin d’un aperçu de la façon dont les différentes pièces du système Kubernetes s’emboîtent. Certains composants sont plus importants que d’autres, et sont donc traités de manière beaucoup plus détaillée dans les chapitres suivants, mais ce guide de référence aidera à fonder et à contextualiser ces explorations ultérieures.
Kubernetes est un système qui regroupe une grande flotte de machines en une seule unité pouvant être consommée via une API, mais la mise en œuvre de Kubernetes subdivise en fait l’ensemble des machines en deux groupes : les nœuds de travail et les nœuds principaux. La plupart des composants qui composent l’infrastructure Kubernetes s’exécutent sur des nœuds de tête ou de plan de contrôle. Il existe un nombre limité de ces nœuds dans un cluster, généralement un, trois ou cinq. Ces nœuds exécutent les composants qui implémentent Kubernetes, comme etcd et le serveur API. Il existe un nombre impair de ces nœuds, car ils doivent conserver le quorum dans un état partagé à l’aide d’un algorithme Raft / Paxos pour le quorum. Le travail réel du cluster est effectué sur les nœuds de travail. Ces nœuds exécutent également une sélection plus limitée de composants Kubernetes. Enfin, certains composants Kubernetes sont planifiés sur le cluster Kubernetes après sa création. Du point de vue de Kubernetes, ces composants ne se distinguent pas des autres charges de travail, mais ils implémentent une partie de l’API Kubernetes globale.
La discussion suivante sur les composants Kubernetes les répartit en trois groupes : les composants qui s’exécutent sur les nœuds principaux, les composants qui s’exécutent sur tous les nœuds et les composants qui s’exécutent sur le cluster.
3.3.1 Composants du nœud principal
Un nœud principal est le cerveau du cluster Kubernetes. Il contient une collection de composants principaux qui implémentent la fonctionnalité de l’API Kubernetes. En règle générale, seuls ces composants s’exécutent sur les nœuds principaux ; aucun conteneur utilisateur ne partage ces nœuds.
3.3.1.1 etcd
Le système etcd est au cœur de tout cluster Kubernetes. Il implémente les magasins de valeurs-clés où tous les objets d’un cluster Kubernetes sont conservés. Les serveurs etcd implémentent un algorithme de consensus distribué, à savoir Raft, qui garantit que même si l’un des serveurs de stockage tombe en panne, il y a une réplication suffisante pour maintenir les données stockées dans etcd et récupérer les données lorsqu’un serveur etcd redevient sain et se reconduit à le cluster. Les serveurs etcd fournissent également deux autres fonctionnalités importantes dont Kubernetes fait un usage intensif. Le premier est la concurrence optimiste. Chaque valeur stockée dans etcd a une version de ressource correspondante. Lorsqu’une paire clé-valeur est écrite sur un serveur etcd , elle peut être conditionnée à une version de ressource particulière. Cela signifie qu’en utilisant etcd , vous pouvez implémenter la comparaison et l’échange , qui est au cœur de tout système de concurrence. La comparaison et l’échange permettent à un utilisateur de lire une valeur et de la mettre à jour en sachant qu’aucun autre composant du système n’a également mis à jour la valeur. Ces assurances permettent au système d’avoir en toute sécurité plusieurs threads manipulant des données dans etcd sans avoir besoin de verrous pessimistes, ce qui peut réduire considérablement le débit vers le serveur.
En plus d’implémenter la comparaison et l’échange, les serveurs etcd implémentent également un protocole de surveillance. La valeur de watch est qu’elle permet aux clients de surveiller efficacement les changements dans les magasins de valeurs-clés pour un répertoire entier de valeurs. Par exemple, tous les objets d’un espace de noms sont stockés dans un répertoire dans etcd. L’utilisation d’une montre permet à un client d’attendre et de réagir efficacement aux changements sans interrogation continue du serveur etcd .
3.3.1.2 Serveur API
Bien que etcd soit au cœur d’un cluster Kubernetes, il n’y a en fait qu’un seul serveur autorisé à avoir un accès direct au cluster Kubernetes, et c’est le serveur API. Le serveur API est le hub du cluster Kubernetes; il assure la médiation de toutes les interactions entre les clients et les objets API stockés dans etcd . Par conséquent, c’est le point de rencontre central pour toutes les différentes composantes. En raison de son importance, le serveur API mérite une introspection plus approfondie et est traité dans le chapitre 4.
3.3.1.3 Planificateur
Avec etcd et le serveur API fonctionnant correctement, un cluster Kubernetes est, à certains égards, fonctionnellement complet. Vous pouvez créer tous les différents objets API, comme les déploiements et les pods. Cependant, vous constaterez qu’il ne commence jamais à fonctionner. La recherche d’un emplacement pour l’exécution d’un pod est la tâche du planificateur Kubernetes. Le planificateur analyse le serveur API pour les pods non planifiés, puis détermine les meilleurs nœuds sur lesquels les exécuter. Comme le serveur API, le planificateur est un sujet complexe et riche qui est traité plus en détail au chapitre 5.
3.3.1.4 Gestionnaire de contrôleur
Une fois que etcd , le serveur d’API et le planificateur sont opérationnels, vous pouvez créer avec succès des pods et les voir planifiés sur les nœuds, mais vous constaterez que les ReplicaSets , les déploiements et les services ne fonctionnent pas comme vous vous y attendez. Cela est dû au fait que toutes les boucles de contrôle de réconciliation nécessaires pour implémenter cette fonctionnalité ne sont pas en cours d’exécution. L’exécution de ces boucles incombe au gestionnaire de contrôleur. Le gestionnaire du contrôleur est le plus varié de tous les composants Kubernetes, puisqu’il a en elle de nombreuses différentes boucles de contrôle de la réconciliation pour mettre en œuvre de nombreuses parties du système global Kubernetes.
3.3.2 Composants sur tous les nœuds
En plus des composants qui s’exécutent exclusivement sur les nœuds principaux, il existe quelques composants qui sont présents sur tous les nœuds du cluster Kubernetes. Ces pièces implémentent les fonctionnalités essentielles requises sur tous les nœuds.
3.3.2.1 Kubelet
Le kubelet est le démon de noeud pour toutes les machines qui font partie d’un cluster Kubernetes. Le kubelet est le pont qui relie le processeur, le disque et la mémoire disponibles pour un nœud dans le grand cluster Kubernetes. Le kubelet communique avec le serveur API pour rechercher les conteneurs qui doivent être exécutés sur son nœud. De même, le kubelet communique l’état de ces conteneurs au serveur API afin que d’autres boucles de contrôle de réconciliation puissent observer l’état actuel de ces conteneurs.
En plus de planifier et de signaler l’état des conteneurs exécutés dans les pods sur leurs machines, les kubelets sont également responsables de la vérification de l’état et du redémarrage des conteneurs qui sont censés s’exécuter sur leurs machines. Il serait assez inefficace de renvoyer toutes les informations d’état d’intégrité vers le serveur API afin que les boucles de réconciliation puissent prendre des mesures pour corriger l’intégrité d’un conteneur sur une machine particulière. Au lieu de cela, le kubelet court- circuite cette interaction et exécute la boucle de réconciliation elle-même. Ainsi, si un conteneur exécuté par le kubelet meurt ou échoue à son contrôle d’intégrité, le kubelet le redémarre, tout en communiquant également cet état d’intégrité (et le redémarrage) au serveur API.
3.3.2.2 kube -proxy
L’autre composant qui s’exécute sur toutes les machines est le kube -proxy. Le kube- proxy est responsable de l’implémentation du modèle de mise en réseau d’équilibrage de charge du service Kubernetes. Le kube- proxy surveille toujours les objets de noeud final pour tous les services du cluster Kubernetes. Le kube- proxy programme ensuite le réseau sur son nœud de sorte que les requêtes du réseau à l’adresse IP virtuelle d’un service soient, en fait, acheminées vers les points de terminaison qui mettent en œuvre ce service. Chaque service de Kubernetes obtient une adresse IP virtuelle et le Kube -proxy est le démon responsable de la définition et la mise en œuvre du programme d’équilibrage de la charge locale que le trafic des routes de pods sur la machine à pods, partout dans le cluster, qui mettent en œuvre le service.
3.3.3 Composants planifiés
Lorsque tous les composants qui viennent d’être décrits fonctionnent correctement, ils fournissent un cluster Kubernetes minimalement viable. Mais il existe plusieurs composants planifiés supplémentaires qui sont essentiels au cluster Kubernetes qui dépendent en fait du cluster lui-même pour leur implémentation. Cela signifie que, bien qu’ils soient essentiels au fonctionnement du cluster, ils sont également planifiés, contrôlés, exploités et mis à jour à l’aide d’appels au serveur Kubernetes API lui-même.
3.3.3.1 KubeDNS
Le premier de ces composants planifiés est le serveur KubeDNS . Quand un Kubernetes
Le service est créé, il obtient une adresse IP virtuelle, mais cette adresse IP est également programmée dans un serveur DNS pour une découverte de service facile. Les conteneurs KubeDNS implémentent ce service de noms pour les objets du service Kubernetes. Le service KubeDNS est lui-même exprimé comme un service Kubernetes, donc le même routage fourni par le proxy kube achemine le trafic DNS vers les conteneurs KubeDNS . La seule différence importante est que le service KubeDNS reçoit une adresse IP virtuelle statique. Cela signifie que le serveur API peut programmer le serveur DNS dans tous les conteneurs qu’il crée, implémentant la dénomination et la découverte de services pour les services Kubernetes.
En plus du service KubeDNS présent dans Kubernetes depuis les premières versions, il existe également une nouvelle implémentation CoreDNS alternative qui a atteint la disponibilité générale (GA) dans la version 1.11 de Kubernetes.
La possibilité d’échanger le service DNS montre à la fois la modularité et la valeur de l’utilisation de Kubernetes pour exécuter des composants tels que le serveur DNS. Remplacer KubeDNS par CoreDNS est aussi simple que d’arrêter un pod et d’en démarrer un autre.
3.3.3.2 Heapster
L’autre composant planifié est un binaire appelé Heapster, qui est responsable de la collecte des mesures telles que l’utilisation du processeur, du réseau et du disque à partir de tous les conteneurs exécutés à l’intérieur du cluster Kubernetes. Ces mesures peuvent être transmises à un système de surveillance, comme InfluxDB, pour les alertes et la surveillance générale de l’intégrité des applications dans le cluster. Il est également important de noter que ces mesures sont utilisées pour implémenter la mise à l’échelle automatique des pods au sein du cluster Kubernetes. Kubernetes a une implémentation de mise à l’échelle automatique, qui, par exemple, peut automatiquement mettre à l’échelle la taille d’un déploiement chaque fois que l’utilisation du processeur des conteneurs dans le déploiement dépasse 80%. Heapster est le composant qui collecte et agrège ces mesures pour alimenter la boucle de réconciliation implémentée par l’autoscaler. L’autoscaler observe l’état actuel du monde via des appels d’API à Heapster .
Au moment d’écrire ces lignes, Heapster est toujours la source de métriques pour la mise à l’échelle automatique dans de nombreux clusters Kubernetes. Cependant, depuis la version 1.11, il est obsolète au profit du nouveau serveur de métriques et de l’API de métriques. Heapster sera supprimé de Kubernetes dans la version 1.13.
3.3.3.3 Modules complémentaires
En plus de ces composants de base, il existe de nombreux systèmes que vous pouvez trouver sur la plupart des installations de Kubernetes. Il s’agit notamment du tableau de bord Kubernetes, ainsi que des modules complémentaires de la communauté, comme les fonctions en tant que service ( FaaS ), les agents de certificats automatiques et bien d’autres. Il y a trop de modules complémentaires Kubernetes pour les décrire dans quelques paragraphes, donc l’extension de votre cluster Kubernetes est traitée au chapitre 13.
3.3.4 Résumé
Kubernetes est un système distribué quelque peu compliqué avec un certain nombre de composants différents qui implémentent l’API Kubernetes complète, y compris les nœuds du plan de contrôle, qui exécutent le serveur d’API, et le cluster etcd , qui constitue le magasin de sauvegarde de l’API. En outre, le planificateur interagit avec le serveur API pour planifier des conteneurs sur des nœuds de travail spécifiques, et le gestionnaire de contrôleur exploite la plupart des boucles de contrôle qui assurent le bon fonctionnement du cluster. Une fois que le cluster fonctionne correctement, de nombreux composants s’exécutent au-dessus du cluster lui-même, notamment les services DNS du cluster, l’infrastructure d’équilibrage de charge du service Kubernetes, la surveillance des conteneurs, etc. Nous explorons encore plus de composants que vous pouvez exécuter sur votre cluster dans les chapitres 12 et 13.
4 CHAPITRE 4 Le serveur API Kubernetes
Comme mentionné dans l’aperçu des composants Kubernetes, le serveur API est la passerelle vers le cluster Kubernetes. Il s’agit du point de contact central accessible à tous les utilisateurs, automatismes et composants du cluster Kubernetes. Le serveur d’API implémente une API RESTful sur HTTP, effectue toutes les opérations d’API et est responsable du stockage des objets d’API dans un backend de stockage persistant. Ce chapitre couvre les détails de cette opération.
4.1 Caractéristiques de base pour la gérabilité
Pour toute sa complexité, du point de vue de la gestion, le serveur API Kubernetes est en fait relativement simple à gérer. Étant donné que tous les états persistants du serveur API sont stockés dans une base de données externe au serveur API, le serveur lui-même est sans état et peut être répliqué pour gérer la charge des demandes et pour la tolérance aux pannes. En règle générale, dans un cluster hautement disponible, le serveur API est répliqué trois fois.
Le serveur API peut être assez bavard en termes de journaux qu’il génère. Il génère au moins une seule ligne pour chaque demande qu’il reçoit. Pour cette raison, il est essentiel qu’une certaine forme de roulement des journaux soit ajoutée au serveur API afin qu’il ne consomme pas tout l’espace disque disponible. Cependant, comme les journaux du serveur d’API sont essentiels pour comprendre le fonctionnement du serveur d’API, nous recommandons vivement que les journaux soient expédiés du serveur d’API vers un service d’agrégation de journaux pour une introspection et des requêtes ultérieures afin de déboguer les demandes des utilisateurs ou des composants vers l’API.
4.2 Pièces du serveur API
Le fonctionnement du serveur API Kubernetes implique trois fonctions principales :
1. Gestion des API
Processus par lequel les API sont exposées et gérées par le serveur
2. Traitement des demandes
Le plus grand ensemble de fonctionnalités qui traite les demandes API individuelles d’un client
3. Boucles de contrôle interne
Internes responsables des opérations d’arrière-plan nécessaires au bon fonctionnement du serveur API
Les sections suivantes couvrent chacune de ces grandes catégories.
4.2.1 Gestion des API
Bien que l’utilisation principale de l’API soit le traitement des demandes individuelles des clients, avant de pouvoir traiter les demandes d’API, le client doit savoir comment effectuer une demande d’API.
En fin de compte, le serveur d’API est un serveur HTTP – ainsi, chaque demande d’API est une demande HTTP. Mais les caractéristiques de ces requêtes HTTP doivent être décrites pour que le client et le serveur sachent communiquer. Pour les besoins de l’exploration, il est bon d’avoir un serveur API réellement opérationnel pour pouvoir le pousser. Vous pouvez soit utiliser un cluster Kubernetes existant auquel vous avez accès, soit utiliser l’ outil minikube pour un cluster Kubernetes local. Pour faciliter l’utilisation de l’outil curl pour explorer le serveur API, exécutez l’ outil kubectl en mode proxy pour exposer un serveur API non authentifié sur localhost: 8001 à l’aide de la commande suivante:
proxy kubectl
4.2.2 Chemins d’API
Chaque demande adressée au serveur d’API suit un modèle d’API RESTful où la demande est définie par le chemin HTTP de la demande. Toutes les demandes Kubernetes commencent par le préfixe / api / (les API principales) ou / apis / (API regroupées par groupe d’API). Les deux ensembles de chemins différents sont principalement historiques. Les groupes d’API n’existaient pas à l’origine dans l’API Kubernetes, de sorte que les objets d’origine ou «principaux», comme les pods et les services, sont conservés sous le préfixe «/ api /» sans groupe d’API. Les API suivantes ont généralement été ajoutées sous les groupes d’API, elles suivent donc le chemin ‘/ apis / < api -group> /’ . Par exemple, l’objet Job fait partie du groupe d’API batch et se trouve donc sous / apis / batch / v1 /… .
Une ride supplémentaire pour les chemins de ressources est de savoir si la ressource est à espace de noms . Les espaces de noms dans Kubernetes ajoutent une couche de regroupement aux objets, les ressources d’espaces de noms ne peuvent être créées que dans un espace de noms et le nom de cet espace de noms est inclus dans le chemin HTTP de la ressource d’espace de noms. Bien sûr, il existe des ressources qui ne vivent pas dans un espace de noms (l’exemple le plus évident est l’objet API de l’espace de noms lui-même) et, dans ce cas, ils n’ont pas de composant d’espaces de noms dans leur chemin HTTP. Voici les composants des deux chemins différents pour les types de ressources à espace de noms :
- / api / v1 / namespaces / / /
- / apis / / / namespaces / / /
Voici les composants des deux chemins différents pour les types de ressources sans espace de nom :
- / api / v1 / / / apis / / / /
4.2.3 Découverte d’API
Bien sûr, pour pouvoir faire des requêtes à l’API, il est nécessaire de comprendre quels objets API sont disponibles pour le client. Ce processus se produit via la découverte d’API de la part du client. Pour voir ce processus en action et explorer le serveur d’API de manière plus pratique, nous pouvons effectuer cette découverte d’API nous-mêmes.
Tout d’abord, pour simplifier les choses, nous utilisons le proxy intégré de l’outil de ligne de commande kubectl pour fournir l’authentification à notre cluster. Courir :
kubectl proxy
Cela crée un serveur simple fonctionnant sur le port 8001 sur votre machine locale.
Nous pouvons utiliser ce serveur pour démarrer le processus de découverte d’API. Nous commençons par examiner le préfixe / api :
$ curl localhost:8001/api
{
“kind”: “APIVersions”,
“versions”: [
“v1”
],
“serverAddressByClientCIDRs”: [
{
“clientCIDR”: “0.0.0.0/0”,
“serverAddress”: “10.0.0.1:6443”
}
]
}
Vous pouvez voir que le serveur a renvoyé un objet API de type APIVersions . Cet objet nous fournit un champ de versions, qui répertorie les versions disponibles.
Dans ce cas, il n’y en a qu’un seul, mais pour le préfixe / apis, il y en a plusieurs. Nous pouvons utiliser cette version pour poursuivre notre enquête :
$ curl localhost:8001/api/v1
{
“kind”: “APIResourceList”,
“groupVersion”: “v1”,
“resources”: [
{ ….
{
“name”: “namespaces”,
“singularName”: “”,
“namespaced”: false,
“kind”: “Namespace”,
“verbs”: [
“create”,
“delete”,
“get”,
“list”,
“patch”,
“update”,
“watch”
],
“shortNames”: [
“ns”
]
},
…
{
“name”: “pods”,
“singularName”: “”,
“namespaced”: true,
“kind”: “Pod”,
“verbs”: [
“create”,
“delete”,
“deletecollection”,
“get”,
“list”,
“patch”,
“proxy”,
“update”,
“watch”
],
“shortNames”: [
“po”
],
“categories”: [
“all”
]
},
{
“name”: “pods/attach”,
“singularName”: “”,
“namespaced”: true,
“kind”: “Pod”,
“verbs”: []
},
{
“name”: “pods/binding”,
“singularName”: “”,
“namespaced”: true,
“kind”: “Binding”,
“verbs”: [
“create”
]
}, ….
]
}
(Cette sortie est fortement modifiée pour plus de concision.)
Nous arrivons maintenant quelque part. Nous pouvons voir que les ressources spécifiques disponibles sur un certain chemin sont imprimées par le serveur API. Dans ce cas, l’objet renvoyé contient la liste des ressources exposées sous le chemin / api / v1 / .
La spécification OpenAPI / Swagger JSON qui décrit l’API (l’objet méta-API) contient une variété d’informations intéressantes en plus des types de ressources. Considérez la spécification OpenAPI pour l’objet Pod:
{
“name”: “pods”,
“singularName”: “”,
“namespaced”: true,
“kind”: “Pod”,
“verbs”: [
“create”,
“delete”,
“deletecollection”,
“get”,
“list”,
“patch”,
“proxy”,
“update”,
“watch”
],
“shortNames”: [
“po”
],
“categories”: [
“all”
]
},
{
“name”: “pods/attach”,
“singularName”: “”,
“namespaced”: true,
“kind”: “Pod”,
“verbs”: []
}
En regardant cet objet, le champ de nom fournit le nom de cette ressource. Il indique également le sous- chemin de ces ressources. Parce que déduire la pluralisation d’un mot anglais est difficile, la ressource API contient également un champ singularName , qui indique le nom qui doit être utilisé pour une instance singulière de cette ressource. Nous avons précédemment discuté des espaces de noms. Le champ d’espacement de noms dans la description de l’objet indique si l’objet est d’espaces de noms. Le champ kind fournit la chaîne présente dans la représentation JSON de l’objet API pour indiquer de quel type d’objet il s’agit. Le champ des verbes est l’un des plus importants de l’objet API, car il indique quels types d’actions peuvent être effectuées sur cet objet. L’objet pods contient tous les verbes possibles. La plupart des effets des verbes sont évidents d’après leurs noms. Les deux qui nécessitent un peu plus d’explications sont la montre et le proxy. watch indique que vous pouvez établir une surveillance pour la ressource. Une montre est une opération de longue durée qui fournit des notifications sur les modifications apportées à l’objet. La montre est traitée en détail dans les sections suivantes. proxy est une action spécialisée qui établit une connexion réseau proxy via le serveur API aux ports réseau. Il n’y a que deux ressources (pods et services) qui prennent actuellement en charge le proxy.
En plus des actions (décrites comme des verbes) que vous pouvez effectuer sur un objet, il existe d’autres actions qui sont modélisées comme des sous- ressources sur un type de ressource. Par exemple, la commande attach est modélisée comme une sous- ressource :
{
“name”: “pods/attach”,
“singularName”: “”,
“namespaced”: true,
“kind”: “Pod”,
“verbs”: []
}
attach vous permet de connecter un terminal à un conteneur en cours d’exécution dans un pod. La fonctionnalité exec qui vous permet d’exécuter une commande dans un pod est modélisée de manière similaire.
4.2.4 Serveur de spécifications OpenAPI
Bien sûr, connaître les ressources et les chemins que vous pouvez utiliser pour accéder au serveur API n’est qu’une partie des informations dont vous avez besoin pour accéder à l’API Kubernetes. En plus du chemin HTTP, vous devez connaître la charge utile JSON à envoyer et à recevoir.
Le serveur API fournit également des chemins pour vous fournir des informations sur les schémas des ressources Kubernetes. Ces schémas sont représentés à l’aide de la syntaxe OpenAPI (anciennement Swagger). Vous pouvez dérouler la spécification OpenAPI au chemin suivant :
/swaggerapi
Avant Kubernetes 1.10, sert Swagger 1.2
/openapi/v2
Kubernetes 1.10 et au-delà, sert OpenAPI (Swagger 2.0)
La spécification OpenAPI est un sujet complet en soi et dépasse le cadre de cet article. En tout état de cause, il est peu probable que vous ayez besoin d’y accéder dans vos opérations quotidiennes de Kubernetes. Cependant, les diverses bibliothèques de langage de programmation client sont générées à l’aide de ces spécifications OpenAPI (l’exception notable à cela est la bibliothèque cliente Go, qui est actuellement codée à la main). Ainsi, si vous ou un utilisateur rencontrez des difficultés pour accéder à certaines parties de l’API Kubernetes via une bibliothèque cliente, le premier arrêt doit être la spécification OpenAPI pour comprendre comment les objets API sont modélisés.
4.2.5 Traduction de l’API
Dans Kubernetes, une API commence comme une API alpha (par exemple, v1alpha1). La désignation alpha indique que l’API est instable et ne convient pas aux cas d’utilisation en production. Les utilisateurs qui adoptent des API alpha doivent s’attendre à la fois à ce que la surface de l’API puisse changer entre les versions de Kubernetes et que l’implémentation de l’API elle-même puisse être instable et même déstabiliser l’ensemble du cluster Kubernetes. Les API Alpha sont donc désactivées dans les clusters de production Kubernetes.
Une fois qu’une API est arrivée à maturité, elle devient une API bêta (par exemple, v1beta1). La désignation bêta indique que l’API est généralement stable mais peut avoir des bogues ou des améliorations finales de la surface de l’API. En général, les API bêta sont supposées stables entre les versions de Kubernetes, et la compatibilité descendante est un objectif. Cependant, dans des cas particuliers, les API bêta peuvent toujours être incompatibles entre les versions de Kubernetes. De même, les API bêta sont censées être stables, mais des bogues peuvent toujours exister. Les API bêta sont généralement activées dans les clusters Kubernetes de production, mais doivent être utilisées avec précaution.
Enfin, une API devient généralement disponible (par exemple, v1). La disponibilité générale (GA) indique que l’API est stable. Ces API comportent à la fois une garantie de compatibilité descendante et une garantie de dépréciation. Une fois qu’une API est marquée comme devant être supprimée, Kubernetes conserve l’API pendant au moins trois versions ou un an, selon la première éventualité. La dépréciation est également assez improbable. Les API ne sont obsolètes qu’après le développement d’une alternative supérieure. De même, les API GA sont stables et conviennent à tous les usages de production.
Une version particulière de Kubernetes peut prendre en charge plusieurs versions (alpha, bêta et GA). Pour ce faire, le serveur d’API dispose à tout moment de trois représentations différentes de l’API: la représentation externe , qui est la représentation qui arrive via une demande d’API; la représentation interne , qui est la représentation en mémoire de l’objet utilisé dans le serveur API pour le traitement; et la représentation de stockage , qui est enregistrée dans la couche de stockage pour conserver les objets API. Le serveur API contient du code qui sait comment effectuer les différentes traductions entre toutes ces représentations. Un objet API peut être soumis en tant que version v1alpha1, stocké en tant qu’objet v1, puis récupéré en tant qu’objet v1beta1 ou toute autre version prise en charge arbitrairement. Ces transformations sont obtenues avec des performances raisonnables en utilisant des bibliothèques de copie profonde générées par machine, qui effectuent les traductions appropriées.
4.3 Gestion des demandes
Le principal objectif du serveur d’API dans Kubernetes est de recevoir et de traiter les appels d’API sous forme de requêtes HTTP. Ces demandes proviennent soit d’autres composants du système Kubernetes, soit de demandes d’utilisateurs finaux. Dans les deux cas, ils sont tous traités par le serveur API Kubernetes de la même manière.
4.3.1 Types de demandes
Il existe plusieurs grandes catégories de demandes effectuées par le serveur API Kubernetes. GET
Les demandes les plus simples sont des demandes GET pour des ressources spécifiques. Ces demandes récupèrent les données associées à une ressource particulière. Par exemple, une requête HTTP GET vers le chemin / api / v1 / namespaces / default / pods / foo récupère les données d’un pod nommé foo .
LIST
Une demande un peu plus compliquée, mais encore assez simple est une collec tion GET ou LIST. Ce sont des demandes pour énumérer un certain nombre de demandes différentes. Par exemple, une requête HTTP GET vers le chemin / api / v1 / namespaces / default / pods récupère une collection de tous les pods dans l’espace de noms par défaut. Les requêtes LIST peuvent également éventuellement spécifier une requête d’étiquette, auquel cas seules les ressources correspondant à cette requête d’étiquette sont renvoyées.
POST
Pour créer une ressource, une requête POST est utilisée. Le corps de la demande est la nouvelle ressource qui doit être créée. Dans le cas d’une demande POST, le chemin est le type de ressource (par exemple, / api / v1 / namespaces / default / pods ). Pour mettre à jour une ressource existante, une demande PUT est effectuée vers le chemin de ressource spécifique (par exemple, / api / v1 / namespaces / default / pods / foo ).
DELETE
Lorsque vient le temps de supprimer une demande, une demande HTTP DELETE vers le chemin de la ressource (par exemple, / api / v1 / namespaces / default / pods / foo ) est utilisée. Il est important de noter que cette modification est permanente : une fois la demande HTTP effectuée, la ressource est supprimée.
Le type de contenu de toutes ces demandes est généralement du texte JSON (application / json), mais les versions récentes de Kubernetes prennent également en charge le codage binaire des tampons de protocole. De manière générale, JSON est meilleur pour le trafic lisible par l’homme et débogable sur le réseau entre le client et le serveur, mais il est beaucoup plus verbeux et coûteux à analyser. Les tampons de protocole sont plus difficiles à introspecter à l’aide d’outils courants, comme curl, mais permettent des performances et un débit plus élevé des demandes d’API.
En plus de ces requêtes standard, de nombreuses requêtes utilisent le protocole WebSocket pour activer les sessions de streaming entre le client et le serveur. Des exemples de tels protocoles sont les commandes exec et attach. Ces demandes sont décrites dans les sections suivantes.
4.3.2 Durée de vie d’une demande
Pour mieux comprendre ce que fait le serveur d’API pour chacune de ces différentes demandes, nous allons démonter et décrire le traitement d’une seule demande au serveur d’API.
4.3.2.1 Authentification
La première étape du traitement de la demande est l’authentification, qui établit l’identité associée à la demande. Le serveur API prend en charge plusieurs modes différents d’établissement de l’identité, notamment les certificats client, les jetons de support et l’authentification de base HTTP. En général, les certificats clients ou les jetons de support doivent être utilisés pour l’authentification ; l’utilisation de l’authentification HTTP de base est déconseillée.
Outre ces méthodes locales d’établissement de l’identité, l’authentification est enfichable et plusieurs implémentations de plug-in utilisent des fournisseurs d’identité distants. Il s’agit notamment de la prise en charge du protocole OpenID Connect (OIDC), ainsi que d’Azure
Active Directory. Ces plug-ins d’authentification sont compilés à la fois sur le serveur API et sur les bibliothèques clientes. Cela signifie que vous devrez peut-être vous assurer que les outils de ligne de commande et le serveur d’API sont à peu près la même version ou prennent en charge les mêmes méthodes d’authentification.
Le serveur API prend également en charge les configurations d’authentification à distance basées sur les webhooks, où la décision d’authentification est déléguée à un serveur externe via le transfert de jetons au porteur. Le serveur externe valide le jeton porteur de l’utilisateur final et renvoie les informations d’authentification au serveur API.
Étant donné l’importance de cela pour sécuriser un serveur, il est traité en détail dans un chapitre ultérieur.
4.3.2.2 RBAC / Autorisation
Une fois que le serveur API a déterminé l’identité d’une demande, il passe à l’autorisation pour celle-ci. Chaque demande adressée à Kubernetes suit un modèle RBAC traditionnel. Pour accéder à une demande, l’identité doit avoir le rôle approprié associé à la demande. Kubernetes RBAC est un sujet riche et compliqué, et en tant que tel, nous avons consacré un chapitre entier aux détails de son fonctionnement. Aux fins de ce résumé du serveur API, lors du traitement d’une demande, le serveur API détermine si l’identité associée à la demande peut accéder à la combinaison du verbe et du chemin HTTP dans la demande. Si l’identité de la demande a le rôle approprié, elle est autorisée à continuer. Sinon, une réponse HTTP 403 est renvoyée.
Ceci est traité de manière beaucoup plus détaillée dans un chapitre ultérieur.
4.3.2.3 Contrôle d’admission
Une fois la demande authentifiée et autorisée, elle passe au contrôle d’admission. L’authentification et RBAC déterminent si la demande est autorisée à se produire, et cela est basé sur les propriétés HTTP de la demande (en-têtes, méthode et chemin d’accès). Le contrôle d’admission détermine si la demande est bien formée et applique éventuellement des modifications à la demande avant qu’elle ne soit traitée. Le contrôle d’admission définit une interface enfichable :
apply(request): (transformedRequest, error)
Si un contrôleur d’admission trouve une erreur, la demande est rejetée. Si la demande est acceptée, la demande transformée est utilisée à la place de la demande initiale. Les contrôleurs d’admission sont appelés en série, chacun recevant la sortie du précédent.
Le contrôle d’admission étant un mécanisme général et enfichable, il est utilisé pour une grande variété de fonctionnalités différentes dans le serveur API. Par exemple, il est utilisé pour ajouter des valeurs par défaut aux objets. Il peut également être utilisé pour appliquer une stratégie (par exemple, exigeant que tous les objets aient une certaine étiquette). De plus, il peut être utilisé pour faire des choses comme injecter un conteneur supplémentaire dans chaque pod. Le maillage de service Istio utilise cette approche pour injecter son conteneur side-car de manière transparente.
Les contrôleurs d’admission sont assez génériques et peuvent être ajoutés dynamiquement au serveur API via un contrôle d’admission basé sur un webhook.
4.3.2.4 Validation
La validation des demandes a lieu après le contrôle d’admission, bien qu’elle puisse également être implémentée dans le cadre du contrôle d’admission, en particulier pour la validation basée sur un webhook externe. De plus, la validation n’est effectuée que sur un seul objet. S’il nécessite une connaissance plus large de l’état du cluster, il doit être implémenté en tant que contrôleur d’admission.
La validation de la demande garantit qu’une ressource spécifique incluse dans une demande est valide. Par exemple, il garantit que le nom d’un objet Service est conforme aux règles relatives aux noms DNS, car le nom d’un service sera finalement programmé dans le serveur DNS de découverte du service Kubernetes. En général, la validation est implémentée en tant que code personnalisé défini par type de ressource.
4.3.2.5 Demandes spécialisées
En plus des demandes RESTful standard, le serveur d’API dispose d’un certain nombre de modèles de demande spécifiques qui fournissent des fonctionnalités étendues aux clients:
/proxy, /exec, /attach, /logs
La première classe d’opérations importante est les connexions ouvertes et de longue durée au serveur API. Ces demandes fournissent des données en streaming plutôt que des réponses immédiates.
L’opération de journalisation est la première requête de streaming que nous décrivons, car elle est la plus simple à comprendre. En effet, par défaut, les journaux ne sont pas du tout une demande de streaming. Un client fait une demande pour obtenir les journaux d’un pod en ajoutant / logs à la fin du chemin pour un pod particulier (par exemple, / api / v1 / namespaces / default / pods / some-pod / logs ), puis en spécifiant le nom du conteneur en tant que paramètre de requête HTTP et demande HTTP GET. Étant donné une demande par défaut, le serveur d’API renvoie tous les journaux jusqu’à l’heure actuelle, sous forme de texte brut, puis ferme la demande HTTP. Cependant, si le client demande que les journaux soient suivis (en spécifiant le paramètre de requête de suivi), la réponse HTTP est maintenue ouverte par le serveur API et de nouveaux journaux sont écrits dans la réponse HTTP lorsqu’ils sont reçus du kubelet via le serveur API . Cette connexion est illustrée à la figure 4-1.

Figure 4-1. Le flux de base d’une demande HTTP pour les journaux de conteneur
logs est la requête de streaming la plus simple à comprendre car elle laisse simplement la requête ouverte et diffuse plus de données. Les autres opérations profitent du protocole WebSocket pour les données de streaming bidirectionnelles. Ils multiplexent également les données dans ces flux pour permettre un nombre arbitraire de flux bidirectionnels sur HTTP. Si tout cela semble un peu compliqué, c’est le cas, mais c’est aussi une partie précieuse de la surface du serveur API.
Le serveur API prend en charge deux protocoles de streaming différents. Il prend en charge le protocole SPDY, ainsi que HTTP2 / WebSocket. SPDY est remplacé par HTTP2 / WebSocket et nous concentrons donc notre attention sur le protocole WebSocket.
Le protocole WebSocket complet dépasse le cadre de cet article, mais il est documenté à plusieurs autres endroits. Pour comprendre le serveur API, vous pouvez simplement considérer WebSocket comme un protocole qui transforme HTTP en un protocole de diffusion d’octets bidirectionnel.
Cependant, en plus de ces flux, le serveur API Kubernetes introduit en fait un protocole de streaming multiplexé supplémentaire. La raison en est que, dans de nombreux cas d’utilisation, il est très utile que le serveur d’API puisse gérer plusieurs flux d’octets indépendants. Considérez, par exemple, l’exécution d’une commande dans un conteneur. Dans ce cas, il y a en fait trois flux qui doivent être conservés (stdin, stderr et stdout ).
Le protocole de base pour ce streaming est le suivant: chaque flux se voit attribuer un numéro compris entre 0 et 255. Ce numéro de flux est utilisé à la fois pour l’entrée et la sortie, et il modélise conceptuellement un flux d’octets bidirectionnel unique.
Pour chaque trame envoyée via le protocole WebSocket, le premier octet est le numéro de flux (par exemple, 0) et le reste de la trame correspond aux données qui transitent sur ce flux (figure 4-2).
Figure 4-2. Un exemple du cadrage multicanal Kubernetes WebSocket
À l’aide de ce protocole et de WebSockets , le serveur API peut multiplexer simultanément des flux de 256 octets en une seule session WebSocket.
Ce protocole de base est utilisé pour les sessions exec et attach, avec les canaux suivants:
0
Le flux stdin pour écrire dans le processus. Les données ne sont pas lues à partir de ce flux.
1
Le flux de sortie stdout pour lire la sortie standard du processus. Les données ne doivent pas être écrites dans ce flux.
2
Le flux de sortie stderr pour lire stderr à partir du processus. Les données ne doivent pas être écrites dans ce flux.
Le point de terminaison / proxy est utilisé pour transférer le trafic réseau entre le client et les conteneurs et services exécutés à l’intérieur du cluster, sans que ces points de terminaison soient exposés en externe. Pour diffuser ces sessions TCP, le protocole est légèrement plus compliqué. En plus de multiplexer les différents flux, les deux premiers octets du flux (après le numéro de flux, donc en fait les deuxième et troisième octets de la trame WebSockets ) sont le numéro de port qui est transmis, de sorte qu’une seule trame WebSockets pour / le proxy ressemble à la figure 4-3.
Figure 4-3. Un exemple de trame de données pour la redirection de port basée sur WebSockets
4.3.2.6 Opérations de veille
Outre le streaming de données, le serveur d’API prend en charge une API de surveillance. Une montre surveille un chemin pour les changements. Ainsi, au lieu d’interroger à un certain intervalle pour les mises à jour possibles, ce qui introduit soit une charge supplémentaire (en raison d’une interrogation rapide) soit une latence supplémentaire (en raison d’une interrogation lente), l’utilisation d’une montre permet à un utilisateur d’obtenir des mises à jour à faible latence avec une seule connexion. Lorsqu’un utilisateur établit une connexion de surveillance au serveur API en ajoutant le paramètre de requête ? Watch = true à une demande de serveur API, le serveur API passe en mode surveillance et laisse la connexion entre le client et le serveur ouverte. De même, les données renvoyées par le serveur API ne sont plus uniquement l’objet API, c’est un objet Watch qui contient à la fois le type de modification (créé, mis à jour, supprimé) et l’objet API lui-même. De cette façon, un client peut observer et observer toutes les modifications apportées à cet objet ou à cet ensemble d’objets.
4.3.2.7 Mises à jour simultanées optimistes
Une autre opération avancée prise en charge par le serveur d’API est la possibilité d’effectuer des mises à jour simultanées optimistes de l’API Kubernetes. L’idée derrière la concurrence optimiste est la possibilité d’effectuer la plupart des opérations sans utiliser de verrous (concurrence pessimiste) et de détecter à la place quand une écriture simultanée s’est produite, rejetant la dernière des deux écritures simultanées. Une écriture rejetée n’est pas réessayée (il appartient au client de détecter le conflit et de réessayer l’écriture lui-même).
Pour comprendre pourquoi cette concurrence optimiste et la détection des conflits sont nécessaires, il est important de connaître la structure d’une condition de concurrence critique en lecture / mise à jour / écriture. Le fonctionnement de nombreux clients de serveur API implique trois opérations :
- Lisez certaines données du serveur API.
- Mettez à jour ces données en mémoire.
- Réécrivez-le sur le serveur API.
Imaginez maintenant ce qui se passe lorsque deux de ces modèles de lecture / mise à jour / écriture se produisent simultanément.
- Le serveur A lit l’objet O.
- Le serveur B lit l’objet O.
- Le serveur A met à jour l’objet O en mémoire sur le client.
- Le serveur B met à jour l’objet O en mémoire sur le client.
- Le serveur A écrit l’objet O.
- Le serveur B écrit l’objet O.
À la fin de cela, les modifications apportées par le serveur A sont perdues car elles ont été remplacées par la mise à jour du serveur B.
Il existe deux options pour résoudre cette course. Le premier est un verrou pessimiste, qui empêcherait d’autres lectures de se produire pendant que le serveur A fonctionne sur l’objet. Le problème est qu’il sérialise toutes les opérations, ce qui entraîne des problèmes de performances et de débit.
L’autre option implémentée par le serveur API Kubernetes est la concurrence optimiste, qui suppose que tout fonctionnera correctement et ne détectera un problème que lors d’une tentative d’écriture conflictuelle. Pour ce faire, chaque instance d’un objet renvoie à la fois ses données et une version de ressource. Cette version de ressource indique l’itération actuelle de l’objet. Lorsqu’une écriture se produit, si la version de ressource de l’objet est définie, l’écriture ne réussit que si la version actuelle correspond à la version de l’objet. Si ce n’est pas le cas, une erreur HTTP 409 (conflit) est renvoyée et le client doit réessayer. Pour voir comment cela corrige la course en lecture / mise à jour / écriture qui vient d’être décrite, examinons à nouveau les opérations :
- Le serveur A lit l’objet O à la version v1.
- Le serveur B lit l’objet O à la version v1.
- Le serveur A met à jour l’objet O de la version v1 en mémoire dans le client.
- Le serveur B met à jour l’objet O à la version v1 en mémoire dans le client.
- Le serveur A écrit l’objet O dans la version v1; c’est réussi.
- Le serveur B écrit l’objet O à la version v1, mais l’objet est à la v2; un conflit 409 est renvoyé.
4.3.2.8 Codages alternatifs
En plus de prendre en charge le codage JSON des objets pour les demandes, le serveur API prend en charge deux autres formats pour les demandes. Le codage des demandes est indiqué par l’en-tête HTTP Content-Type sur la demande. Si cet en-tête est manquant, le contenu est supposé être application / json, ce qui indique le codage JSON. Le premier codage alternatif est YAML, qui est indiqué par le type de contenu application / yaml . YAML est un format texte qui est généralement considéré comme plus lisible par l’homme que JSON. Il y a peu de raisons d’utiliser YAML pour l’encodage pour communiquer avec le serveur, mais cela peut être pratique dans quelques circonstances (par exemple, envoyer manuellement des fichiers au serveur via curl).
L’autre codage alternatif pour les demandes et les réponses est le format de codage des tampons de protocole. Les tampons de protocole sont un protocole d’objet binaire assez efficace. L’utilisation de tampons de protocole peut entraîner des demandes de débit plus efficaces et plus élevées vers les serveurs API. En effet, de nombreux outils internes de Kubernetes utilisent des tampons de protocole comme moyen de transport. Le principal problème avec les tampons de protocole est qu’en raison de leur nature binaire, ils sont beaucoup plus difficiles à visualiser / déboguer dans leur format de fil. En outre, toutes les bibliothèques clientes ne prennent pas actuellement en charge les demandes ou réponses de tampons de protocole. Le format des tampons de protocole est indiqué par l’en -tête Content-Type application / vnd.kubernetes.proto buf .
4.3.2.9 Codes de réponse communs
Étant donné que le serveur API est implémenté en tant que serveur RESTful, toutes les réponses du serveur sont alignées sur les codes de réponse HTTP. Au-delà des 200 pour les réponses OK et des 500 pour les erreurs internes du serveur, voici quelques-uns des codes de réponse courants et leur signification :
202
Accepté. Une demande asynchrone de création ou de suppression d’un objet a été reçue. Le résultat répond avec un objet d’état jusqu’à ce que la demande asynchrone soit terminée, point auquel l’objet réel sera renvoyé.
400
Mauvaise Demande. Le serveur n’a pas pu analyser ou comprendre la demande.
401
Non autorisé. Une demande a été reçue sans schéma d’authentification connu.
403
Interdit. La demande a été reçue et comprise, mais l’accès est interdit.
409
Conflit. La demande a été reçue, mais il s’agissait d’une demande de mise à jour d’une ancienne version de l’objet.
422
Entité non traitable. La demande a été analysée correctement mais a échoué une sorte de validation.
4.4 Internes du serveur API
En plus des principes de base du fonctionnement du service HTTP RESTful, le serveur d’API dispose de quelques services internes qui implémentent des parties de l’API Kubernetes. Généralement, ces sortes de boucles de contrôle sont exécutées dans un binaire distinct appelé gestionnaire de contrôleur. Mais il y a quelques boucles de contrôle qui doivent être exécutées à l’intérieur du serveur API. Dans chaque cas, nous décrivons la fonctionnalité ainsi que la raison de sa présence sur le serveur API.
4.4.1 Boucle de contrôle CRD
Les définitions de ressources personnalisées (CRD) sont des objets d’API dynamiques qui peuvent être ajoutés à un serveur d’API en cours d’exécution. Étant donné que la création d’un CRD crée de manière inhérente de nouveaux chemins HTTP que le serveur API doit savoir comment servir, le contrôleur responsable de l’ajout de ces chemins est colocalisé à l’intérieur du serveur API. Avec l’ajout de serveurs d’API délégués (décrits dans un chapitre ultérieur), ce contrôleur a en fait été principalement extrait du serveur d’API. Il fonctionne actuellement toujours en cours par défaut, mais il peut également être exécuté hors processus.
La boucle de contrôle CRD fonctionne comme suit :
for crd in AllCustomResourceDefinitions:
if !RegisteredPath(crd):
registerPath
for path in AllRegisteredPaths:
if !CustomResourceExists(path):
markPathInvalid(path)
delete custom resource data
delete path
La création du chemin de ressource personnalisé est assez simple, mais la suppression d’une ressource personnalisée est un peu plus compliquée. En effet, la suppression d’une ressource personnalisée implique la suppression de toutes les données associées aux ressources de ce type. Il en est ainsi, si un CRD est supprimé puis réajouté à une date ultérieure, les anciennes données ne sont en quelque sorte pas ressuscitées.
Par conséquent, avant que le chemin de service HTTP ne puisse être supprimé, le chemin est d’abord marqué comme non valide afin que de nouvelles ressources ne puissent pas être créées. Ensuite, toutes les données associées au CRD sont supprimées et, enfin, le chemin est supprimé.
4.5 Débogage du serveur API
Bien sûr, la compréhension de la mise en œuvre du serveur API est excellente, mais le plus souvent, ce dont vous avez vraiment besoin est de pouvoir déboguer ce qui se passe réellement avec le serveur API (ainsi que les clients qui appellent à l’API serveur). Le principal moyen d’y parvenir est via les journaux que le serveur API écrit. Le serveur API exporte deux flux de journaux : les journaux standard ou de base , ainsi que les journaux d’ audit plus ciblés qui tentent de capturer pourquoi et comment les demandes ont été effectuées et l’état du serveur API modifié. De plus, une journalisation plus détaillée peut être activée pour déboguer des problèmes spécifiques.
4.5.1 Journaux de base
Par défaut, le serveur API enregistre chaque demande envoyée au serveur API. Ce journal comprend l’adresse IP du client, le chemin de la demande et le code renvoyé par le serveur. Si une erreur inattendue entraîne une panique du serveur, le serveur intercepte également cette panique, renvoie un 500 et enregistre cette erreur.
I0803 19:59:19.929302 1 trace.go:76] Trace[1449222206]:
“Create /api/v1/namespaces/default/events” (started: 2018-08-03 19:59:19.001777279 +0000 UTC m=+25.386403121) (total time: 927.484579ms):
Trace[1449222206]: [927.401927ms] [927.279642ms] Object stored in database
I0803 19:59:20.402215 1 controller.go:537] quota admission added evaluator for: { namespaces}
Dans ce journal, vous pouvez voir qu’il commence par l’horodatage I0803 19: 59:… lorsque la ligne de journal a été émise, suivi du numéro de ligne qui l’a émise, trace.go: 76, et enfin le message de journal lui-même.
4.5.2 Journaux d’audit
Le journal d’audit est destiné à permettre à un administrateur de serveur de récupérer légalement l’état du serveur et la série d’interactions client qui ont abouti à l’état actuel des données dans l’API Kubernetes. Par exemple, il permet à un utilisateur de répondre à des questions telles que « Pourquoi ce ReplicaSet a- t-il été étendu à 100 ? », « Qui a supprimé ce pod ? », Entre autres.
Les journaux d’audit ont un backend enfichable pour l’endroit où ils sont écrits. Généralement, les journaux d’audit sont écrits dans un fichier, mais il est également possible de les écrire dans un webhook. Dans les deux cas, les données consignées sont un objet JSON structuré de type événement dans le groupe d’API audit.k8s.io.
L’audit lui-même peut être configuré via un objet de stratégie dans le même groupe d’API. Cette stratégie vous permet de spécifier les règles selon lesquelles les événements d’audit sont émis dans le journal d’audit.
4.5.3 Activation de journaux supplémentaires
Kubernetes utilise le package de journalisation à niveau github.com/ golang / glog pour sa journalisation. En utilisant l’indicateur –v sur le serveur API, vous pouvez ajuster le niveau de verbosité de la journalisation. En général, le projet Kubernetes a défini le niveau de verbosité du journal 2 (–v = 2) comme valeur par défaut raisonnable pour la journalisation des messages pertinents, mais pas trop spammés. Si vous cherchez des problèmes spécifiques, vous pouvez augmenter le niveau de journalisation pour voir plus de messages (éventuellement spam).
4.5.4 Débogage du serveur API
En raison de l’impact sur les performances d’une journalisation excessive, nous vous recommandons de ne pas exécuter un niveau de journal détaillé en production. Si vous recherchez une journalisation plus ciblée, l’option -vmodule permet d’augmenter le niveau de journalisation pour les fichiers source individuels. Cela peut être utile pour une journalisation détaillée très ciblée limitée à un petit ensemble de fichiers.
4.5.5 Débogage des requêtes kubectl
Outre le débogage du serveur API via les journaux, il est également possible de déboguer les interactions avec le serveur API, via l’outil de ligne de commande kubectl . Comme le serveur API, l’ outil de ligne de commande kubectl se connecte via le package github.com/ golang / glog et prend en charge l’indicateur de verbosité –v. La définition de la verbosité au niveau 10 (–v = 10) active la journalisation au maximum. Dans ce mode, kubectl enregistre toutes les demandes qu’il fait au serveur, ainsi que les tentatives d’impression des commandes curl que vous pouvez utiliser pour répliquer ces demandes. Notez que ces commandes curl sont parfois incomplètes.
De plus, si vous souhaitez toucher directement le serveur d’API, l’approche que nous avons utilisée plus tôt pour explorer la découverte d’API fonctionne bien. L’exécution du proxy kubectl crée un serveur proxy sur localhost qui fournit automatiquement vos informations d’authentification et d’autorisation, sur la base d’un $ HOME / local . fichier kube / config . Après avoir exécuté le proxy, il est assez simple de piquer diverses demandes d’API à l’aide de la commande curl.
4.6 Résumé
En tant qu’opérateur, le service principal que vous fournissez à vos utilisateurs est l’API Kubernetes. Pour fournir efficacement ce service, il est essentiel de comprendre les composants principaux qui composent Kubernetes et la façon dont vos utilisateurs assembleront ces API pour créer des applications afin de mettre en œuvre un cluster Kubernetes utile et fiable. Après avoir lu ce chapitre, vous devriez avoir une connaissance de base de l’API Kubernetes et de son utilisation.
5 CHAPITRE 5 Planificateur
L’une des tâches principales de l’API Kubernetes consiste à planifier des conteneurs vers des nœuds de travail dans le cluster de machines. Cette tâche est accomplie par un binaire dédié dans le cluster Kubernetes appelé le planificateur Kubernetes. Ce chapitre décrit le fonctionnement du planificateur, comment il peut être étendu et comment il peut même être remplacé ou augmenté par des planificateurs supplémentaires. Kubernetes peut gérer une grande variété de charges de travail, du service Web sans état aux applications avec état, aux travaux par lots de Big Data ou à l’apprentissage automatique sur les GPU. La clé pour garantir que toutes ces applications très différentes puissent fonctionner en harmonie sur le même cluster réside dans l’application de la planification des tâches, qui garantit que chaque conteneur est placé sur le nœud de travail qui lui convient le mieux.
5.1 Un aperçu de la planification
Lorsqu’un pod est créé pour la première fois, il n’a généralement pas de champ nodeName . Le nodeName indique le nœud sur lequel le pod doit s’exécuter. Le planificateur Kubernetes analyse constamment le serveur API (via une demande de surveillance) pour les pods qui n’ont pas de nodeName ; ce sont des pods qui sont éligibles pour la planification. Le planificateur sélectionne ensuite un nœud approprié pour le pod et met à jour la définition du pod avec le nodeName que le planificateur a sélectionné. Une fois le nodeName défini, le kubelet exécuté sur ce noeud est informé de l’existence du pod (à nouveau, via une demande de surveillance) et il commence à exécuter réellement ce pod sur ce noeud.
Si vous souhaitez ignorer le planificateur, vous pouvez toujours définir le nodeName vous-même sur un pod. Ces directement planifie un pod sur un nœud spécifique. C’est en fait ainsi que le contrôleur DaemonSet planifie un seul pod sur chaque nœud du cluster. En général, cependant, la planification directe doit être évitée, car elle tend à rendre votre application plus fragile et votre cluster moins efficace. Dans le cas d’utilisation général, vous devez faire confiance au planificateur pour prendre la bonne décision, tout comme vous faites confiance au système d’exploitation pour trouver un noyau pour exécuter votre programme lorsque vous le lancez sur une seule machine.
5.2 Processus de planification
Lorsque le planificateur découvre un pod qui n’a pas été affecté à un nœud, il doit déterminer sur quel nœud planifier le pod. Le nœud correct pour un pod est déterminé par un certain nombre de facteurs différents, dont certains sont fournis par l’utilisateur et certains sont calculés par le planificateur. En général, le planificateur essaie d’optimiser une variété de critères différents pour trouver le nœud qui convient le mieux au pod particulier.
5.2.1 Prédicats
Lorsqu’il prend la décision de planifier un pod, le planificateur utilise deux concepts génériques pour prendre sa décision. Le premier est les prédicats. En termes simples, un prédicat indique si un pod s’adapte à un nœud particulier. Les prédicats sont des contraintes strictes qui, si elles sont violées, empêchent un pod de fonctionner correctement (ou pas du tout) sur ce nœud. Un exemple d’une telle contrainte est la quantité de mémoire demandée par le Pod. Si cette mémoire n’est pas disponible sur le nœud, le pod ne peut pas obtenir toute la mémoire dont il a besoin et la contrainte est violée – c’est faux. Un autre exemple de prédicat est une requête d’étiquette de sélection de nœud spécifiée par l’utilisateur. Dans ce cas, l’utilisateur a demandé qu’un pod ne s’exécute que sur certaines machines comme indiqué par les étiquettes des nœuds. Le prédicat est faux si un nœud n’a pas l’étiquette requise.
5.2.2 Priorités
Les prédicats indiquent des situations qui sont vraies ou fausses – le pod s’adapte ou non – mais il existe une interface générique supplémentaire utilisée par le planificateur pour déterminer la préférence pour un nœud par rapport à un autre. Ces préférences sont exprimées sous forme de priorités ou de fonctions prioritaires. Le rôle d’une fonction prioritaire est de noter la valeur relative de la planification d’un pod sur un nœud particulier. Contrairement aux prédicats, la fonction de priorité n’indique pas si le pod en cours de planification sur le nœud est viable – on suppose que le pod peut s’exécuter avec succès sur le nœud – mais à la place, la fonction de prédicat tente de juger de la valeur relative de planifier le pod sur ce nœud particulier.
Par exemple, une fonction prioritaire pondérera les nœuds où l’image a déjà été tirée. Par conséquent, le conteneur démarrerait plus rapidement que les nœuds où l’image n’est pas présente et devrait être retiré, retardant le démarrage du Pod .
Une fonction prioritaire importante est la fonction d’épandage. Cette fonction est chargée de hiérarchiser les nœuds dans lesquels les pods membres du même service Kubernetes ne sont pas présents. Il est utilisé pour garantir la fiabilité, car il réduit les chances qu’une panne de machine désactive tous les conteneurs d’un service particulier.
En fin de compte, toutes les différentes valeurs de prédicat sont mélangées pour obtenir un score de priorité final pour le nœud, et ce score est utilisé pour déterminer où le pod est planifié.
5.2.3 Algorithme de haut niveau
Pour chaque pod nécessitant une planification, l’algorithme de planification est exécuté. À un niveau élevé, l’algorithme ressemble à ceci :
schedule(pod): string nodes := getAllHealthyNodes()
viableNodes := [] for node in nodes: for predicate in predicates: if predicate(node, pod): viableNodes.append(node)
scoredNodes := PriorityQueue<score, Node[]> priorities := GetPriorityFunctions() for node in viableNodes: score = CalculateCombinedPriority(node, pod, priorities) scoredNodes[score].push(node)
bestScore := scoredNodes.top().score
selectedNodes := [] while scoredNodes.top().score == bestScore: selectedNodes.append(scoredNodes.pop())
node := selectAtRandom(selectedNodes) return node.Name
Vous pouvez trouver le code réel sur la page Kubernetes GitHub.
Le fonctionnement de base du planificateur est le suivant : tout d’abord, le planificateur obtient la liste de tous les nœuds actuellement connus et sains. Ensuite, pour chaque prédicat, le planificateur évalue le prédicat par rapport au nœud et au pod en cours de planification. Si le nœud est viable (le pod pourrait fonctionner dessus), le nœud est ajouté à la liste des nœuds possibles pour la planification. Ensuite, toutes les fonctions prioritaires sont exécutées contre la combinaison de Pod et de nœud. Les résultats sont poussés dans une file d’attente prioritaire classée par score, avec les nœuds les plus performants en haut de la file d’attente. Ensuite, tous les nœuds qui ont le même score sont extraits de la file d’attente prioritaire et placés dans une liste finale. Ils sont considérés comme entièrement identiques, et l’un d’eux est choisi de manière à tour de rôle et est ensuite renvoyé en tant que nœud où le pod doit être planifié. Le tournoi à la ronde est utilisé au lieu d’un choix aléatoire pour assurer une distribution uniforme des pods entre les nœuds identiques.
5.2.4 Conflits
Étant donné qu’il existe un décalage entre la planification d’un pod (heure T_1) et l’exécution effective du conteneur (heure T_N), la décision de planification peut devenir invalide, en raison d’autres actions pendant l’intervalle de temps entre la planification et l’exécution.
Dans certains cas, cela peut signifier qu’un nœud légèrement moins idéal est choisi, alors qu’un meilleur nœud aurait pu être attribué. Cela peut être dû à la fin d’un pod après l’heure T_1 mais avant l’heure T_N ou à d’autres modifications du cluster. En général, ces types de conflits de contraintes logicielles ne sont pas si importants et se normalisent globalement. Ces conflits sont ainsi ignorés par Kubernetes. Les décisions de planification ne sont optimales que pour un seul instant dans le temps – elles peuvent toujours empirer avec le temps et les changements de cluster.
Il y a du travail en cours dans la communauté Kubernetes pour améliorer quelque peu cette situation. Un projet Kubernetes- descheduler qui, s’il est exécuté dans un cluster Kubernetes, le scanne à la recherche de pods qui sont déterminés comme étant sous-optimaux significatifs. Si de tels pods sont trouvés, le désarchiveur expulse le pod de son nœud actuel. Par conséquent, le Pod est replanifié par le planificateur Kubernetes, comme s’il venait d’être créé.
Un type de conflit plus important se produit lorsqu’une modification du cluster viole une contrainte stricte du planificateur. Imaginez, par exemple, que l’ordonnanceur décide de placer le pod P sur le nœud N. Imaginez que le pod P nécessite deux cœurs pour fonctionner, et le nœud N a exactement deux cœurs de capacité disponible. Au temps T_1, l’ordonnanceur a déterminé que le nœud N a une capacité suffisante pour exécuter le pod P. Cependant, après que l’ordonnanceur a pris sa décision dans le code et avant que la décision ne soit réécrite dans le pod, un nouveau DaemonSet est créé. Ce DaemonSet crée un pod différent qui s’exécute sur chaque nœud, y compris le nœud N, qui consomme un cœur de capacité. Maintenant, Node N ne dispose que d’un seul cœur, et pourtant il a été demandé d’exécuter Pod P, qui nécessite deux cœurs. Cela n’est pas possible, compte tenu du nouvel état du nœud N, mais la décision d’ordonnancement a déjà été prise.
Lorsque le nœud remarque qu’il lui a été demandé d’exécuter un pod qui ne transmet plus les prédicats du pod et du nœud, le pod est marqué comme ayant échoué. Si le pod a été créé par un ReplicaSet , ce pod défaillant ne compte pas en tant que membre actif du caSet Repli et, par conséquent, un nouveau pod sera créé et planifié sur un nœud différent où il se trouve. Ce comportement d’échec est important à comprendre car il signifie que Kubernetes ne peut pas être compté pour exécuter de manière fiable des pods autonomes. Vous devez toujours exécuter des pods (même des singletons) via un ReplicaSet ou un déploiement.
5.3 Contrôle de la planification avec les étiquettes, l’affinité, les taches et les tolérances
Bien sûr, il y a des moments où vous voulez un contrôle plus fin des décisions de planification que Kubernetes effectue. Vous pourriez avoir cela en ajoutant vos propres prédicats et priorités, mais c’est une tâche assez lourde. Heureusement, Kubernetes vous fournit un certain nombre d’outils pour personnaliser la planification, sans avoir à implémenter quoi que ce soit dans votre propre code.
5.3.1 Sélecteurs de nœuds
N’oubliez pas que chaque objet dans Kubernetes a un ensemble d’étiquettes associé. Les étiquettes fournissent des métadonnées d’identification pour les objets Kubernetes, et les sélecteurs d’étiquette sont souvent utilisés pour identifier dynamiquement des ensembles d’objets API pour diverses opérations. Par exemple, des étiquettes et des sélecteurs d’étiquettes sont utilisés pour identifier les ensembles de pods qui servent le trafic derrière un équilibreur de charge Kubernetes .
Les sélecteurs d’étiquette peuvent également être utilisés pour identifier un sous-ensemble de nœuds dans un cluster Kubernetes qui doit être utilisé pour planifier un pod particulier. Par défaut, tous les nœuds du cluster sont des candidats potentiels pour la planification, mais en remplissant le champ spec.nodeSelec tor dans un Pod ou PodTemplate , l’ensemble initial de nœuds peut être réduit à un sous-ensemble.
À titre d’exemple, considérons la tâche de planification d’une charge de travail sur une machine dotée d’un stockage haute performance, comme un SSD soutenu par NVMe. Un tel stockage (au moins au moment de la rédaction de ce document) est très coûteux et peut donc ne pas être présent sur chaque machine. Ainsi, chaque machine disposant de ce stockage recevra une étiquette supplémentaire comme :
kind: Node
metadata:
– labels:
nvme-ssd: true
…
Pour créer un pod qui sera toujours planifié sur une machine avec un SSD NVMe , vous définissez ensuite le nodeSelector du pod pour qu’il corresponde à l’étiquette sur le noeud:
kind: Pod
spec:
nodeSelector:
nvme-ssd: true
…
5.4 Contrôle de la planification avec les étiquettes, l’affinité, les taches et les tolérances
Kubernetes a un prédicat par défaut qui requiert que chaque nœud corresponde à la requête d’étiquette nodeSelec tor, s’il est présent. Ainsi, chaque pod avec l’étiquette nvme-ssd sera toujours planifié sur un nœud avec le matériel approprié.
Comme mentionné précédemment dans la section sur les conflits, les sélecteurs de nœuds ne sont évalués qu’au moment de la planification. Si des nœuds sont activement ajoutés et supprimés, au moment où le conteneur s’exécute, son sélecteur de nœuds peut ne plus correspondre au nœud sur lequel il s’exécute.
5.4.1 Affinité des nœuds
Les sélecteurs de nœuds offrent un moyen simple de garantir qu’un pod atterrit sur un nœud particulier, mais ils manquent de flexibilité. En particulier, ils ne peuvent pas représenter des expressions logiques plus complexes (par exemple, « L’étiquette foo est soit A ou B. ») ni représenter l’antiaffinité
(“L’étiquette foo est A mais la barre d’étiquette n’est pas C.”). Enfin, les sélecteurs de nœuds sont des prédicats – ils spécifient une exigence, pas une préférence.
À partir de Kubernetes 1.2, la notion d’affinité a été ajoutée à la sélection des nœuds via la structure d’affinité dans la spécification Pod. L’affinité est une structure plus compliquée à comprendre, mais elle est nettement plus flexible si vous souhaitez exprimer des politiques de planification plus compliquées.
Prenons l’exemple que nous venons de noter, dans lequel un pod doit planifier sur un nœud qui a soit l’étiquette foo a une valeur soit A soit B. Ceci est exprimé comme la politique d’affinité suivante :
kind: Pod
…
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
– matchExpressions:
# foo == A or B
– key: foo
operator: In
values:
– A
– B
…
Pour montrer l’antiaffinité , considérez que l’étiquette de stratégie foo a la valeur A et que la barre d’étiquette n’est pas égale à C. Ceci est exprimé dans une spécification similaire, quoique légèrement plus compliquée :
kind: Pod
…
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
– matchExpressions:
# foo == A
– key: foo
operator: In
values:
– A
# bar != C
– key: bar
operator: NotIn
values:
– C
…
Ces deux exemples incluent les opérateurs In et NotIn . Kubernetes autorise également Exists, qui requiert uniquement la présence d’une clé d’étiquette quelle que soit la valeur, ainsi que NotExists , qui nécessite l’absence d’une étiquette. Il existe également des opérateurs Gt et Lt, qui implémentent respectivement supérieur et inférieur à. Si vous utilisez les opérateurs Gt ou Lt, le tableau de valeurs devrait être composé d’un seul entier et vos étiquettes de noeud devraient être intégrales.
Jusqu’à présent, nous avons vu l’affinité des nœuds fournir un moyen plus sophistiqué de sélectionner les nœuds, mais nous n’avons encore exprimé qu’un prédicat. Cela est dû à requiredDuringSchedulin gIgnoredDuringExecution , qui est une description longue mais précise du comportement d’affinité du nœud. L’expression d’étiquette doit correspondre lorsque la planification est effectuée, mais peut ne pas correspondre lorsque le pod est en cours d’exécution.
Si vous souhaitez exprimer une priorité pour un nœud au lieu d’une exigence (ou en plus d’une exigence), vous pouvez utiliser PreferredDuringSchedulingIgnoredDuringExecution . Par exemple, en utilisant notre exemple précédent, où nous avions besoin que foo soit soit A soit B, exprimons également une préférence pour la planification sur des nœuds étiquetés A. Le terme de poids dans la structure des préférences nous permet de régler l’importance d’une préférence, relative à d’autres priorités.
kind: Pod
…
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
– matchExpressions:
# foo == A or B
key: foo
operator: In
values:
– A
– B
preferredDuringSchedulingIgnoredDuringExecution:
preference:
– weight: 1
matchExpressions:
# foo == A
– key: foo
operator: In
values:
– A
…
L’affinité des nœuds est actuellement une fonctionnalité bêta. Dans Kubernetes 1.4 et au-delà, l’affinité Pod a également été introduite avec une syntaxe similaire (en substituant pod pour node). L’affinité des pods vous permet d’exprimer une exigence ou une préférence pour la planification à côté – ou loin – d’autres pods avec des étiquettes particulières.
5.4.2 Taches et tolérances
L’affinité des nœuds et des pods vous permet de spécifier les préférences d’un pod à planifier (ou non) sur un ensemble spécifique de nœuds ou à proximité d’un ensemble spécifique de pods. Cependant, cela nécessite une action de l’utilisateur lors de la création de conteneurs pour obtenir le bon comportement de planification. Parfois, en tant qu’administrateur d’un cluster, vous souhaiterez peut-être affecter la planification sans obliger vos utilisateurs à modifier leur comportement.
Par exemple, considérons un cluster hétérogène de Kubernetes. Vous pouvez avoir un mélange de types de matériel, certains avec d’anciens processeurs 1 Ghz et d’autres avec de nouveaux processeurs 3 Ghz . En général, vous ne voulez pas que vos utilisateurs planifient leur travail sur les anciens processeurs, sauf demande spécifique. Vous pouvez y parvenir avec l’ antiaffinity de noeud , car cela nécessite que chaque utilisateur ajoute explicitement l’ antiaffinity à ses pods pour les machines plus anciennes.
C’est ce cas d’utilisation qui a motivé le développement de taches de nœuds. Une tache de nœud est exactement à quoi elle ressemble. Lorsqu’une souillure est appliquée à un nœud, le nœud est considéré comme corrompu et sera exclu par défaut de la planification. Tout nœud contaminé échouera à une vérification de prédicat au moment de la planification.
Cependant, considérez un utilisateur qui souhaite accéder aux machines 1 Ghz . Leur travail n’est pas critique en temps et les machines 1 Ghz coûtent moins cher, car la demande est bien moindre. Pour ce faire, l’utilisateur opte pour les machines 1 Ghz en ajoutant une tolérance pour la souillure particulière. Cette tolérance permet au prédicat de planification de passer et permet ainsi au nœud de planifier sur la machine contaminée. Il est important de noter que, bien qu’une tolérance pour une souillure permette à un Pod de s’exécuter sur une machine contaminée, il n’est pas nécessaire que le Pod s’exécute sur la machine souillée. En effet, toutes les priorités s’exécutent comme précédemment et, par conséquent, toutes les machines du cluster sont disponibles pour s’exécuter. Forcer un pod sur une machine particulière est un cas d’utilisation pour nodeSelectors ou affinité comme décrit précédemment.
5.5 Résumé
L’une des principales fonctionnalités de Kubernetes est la possibilité de prendre la demande d’un utilisateur pour exécuter un conteneur et planifier ce conteneur sur une machine appropriée. Pour un administrateur de cluster, le fonctionnement du planificateur – et apprendre aux utilisateurs à bien l’utiliser – peut être essentiel pour créer un cluster fiable et que vous pouvez atteindre une utilisation et une efficacité élevées.
6 CHAPITRE 6 Installation de Kubernetes
Pour conceptualiser et comprendre pleinement le fonctionnement de Kubernetes, il est impératif d’expérimenter avec un cluster Kubernetes réel. Et, heureusement, il n’y a pas de pénurie d’outils pour démarrer avec Kubernetes – généralement, cela peut être réalisé en quelques minutes. Qu’il s’agisse d’une installation locale sur votre ordinateur portable avec un outil comme minikube ou d’un déploiement géré par l’un des principaux fournisseurs de cloud public, un cluster Kubernetes peut être utilisé par à peu près n’importe qui.
Bien que bon nombre de ces projets et services aient grandement contribué à banaliser le déploiement d’un cluster, de nombreuses circonstances ne permettent pas ce degré de flexibilité. Il existe peut-être des contraintes internes de conformité ou de réglementation qui empêchent l’utilisation d’un cloud public. Ou peut-être que votre organisation a déjà investi massivement dans ses propres centres de données. Quelles que soient les circonstances, vous aurez du mal à trouver un environnement qui ne convient pas à un déploiement Kubernetes.
Au-delà de la logistique où et comment vous consommez Kubernetes, afin d’apprécier pleinement le fonctionnement des composants distribués de Kubernetes, il est également important de comprendre les architectures qui font de la livraison d’applications conteneurisées prêtes pour la production une réalité. Dans ce chapitre, nous explorons les services impliqués et comment ils sont installés.
6.1 kubeadm
Parmi la large gamme de solutions d’installation de Kubernetes, on trouve l’utilitaire kubeadm pris en charge par la communauté. Cette application fournit toutes les fonctionnalités nécessaires à l’installation de Kubernetes. En fait, dans le cas le plus simple, un utilisateur peut avoir une installation Kubernetes opérationnelle en quelques minutes, avec une seule commande. Cette simplicité en fait un outil très convaincant pour les développeurs et pour ceux qui ont des besoins de production. Étant donné que le code de kubeadm vit dans l’arborescence et est publié conjointement avec une version de Kubernetes, il emprunte des primitives communes et est minutieusement testé pour un grand nombre de cas d’utilisation.
En raison de la simplicité et de la grande utilité fournies par kubeadm, de nombreux autres outils d’installation exploitent réellement kubeadm en arrière-plan. Et le nombre de projets suivant cette tendance augmente régulièrement. Donc, que vous choisissiez ou non kubeadm comme outil d’installation préféré, comprendre comment il fonctionne vous aidera probablement à mieux comprendre l’outil que vous avez choisi.
Un déploiement de niveau production de Kubernetes garantit que les données sont sécurisées, à la fois pendant le transport et au repos, que les composants Kubernetes correspondent bien à leurs dépendances, que les intégrations avec l’environnement sont bien définies et que la configuration de tous les composants du cluster fonctionne. bien ensemble. Idéalement aussi, ces clusters sont facilement mis à niveau et la configuration résultante reflète continuellement ces meilleures pratiques. kubeadm peut vous aider à réaliser tout cela.
6.1.1 Exigences
kubeadm , comme tous les binaires Kubernetes, est lié statiquement. En tant que tel, il n’y a pas de dépendances sur les bibliothèques partagées et kubeadm peut être installé sur à peu près n’importe quelle distribution x86_64, ARM ou PowerPC Linux.
Heureusement, il n’y a pas non plus grand-chose dont nous avons besoin du point de vue de l’application hôte. Plus fondamentalement, nous avons besoin d’un runtime de conteneur et du kubelet Kubernetes , mais il y a aussi quelques utilitaires Linux standard nécessaires.
Lorsqu’il s’agit d’installer un environnement d’exécution de conteneur, vous devez vous assurer qu’il adhère à l’interface d’exécution du conteneur (CRI). Cette norme ouverte définit l’interface que le kubelet utilise pour parler au runtime disponible sur l’hôte. Au moment d’écrire ces lignes, certains des environnements d’ exécution conformes à CRI les plus populaires sont Docker, rkt et CRI-O. Pour chacun d’eux, les développeurs doivent consulter les instructions d’installation fournies par les projets respectifs.
Lorsque vous choisissez un runtime de conteneur, assurez-vous de faire référence aux notes de publication de Kubernetes. Chaque version indiquera clairement les temps d’exécution des conteneurs qui ont été testés. De cette façon, vous savez quels runtimes et versions sont connus pour être à la fois compatibles et performants.
6.1.2 kubelet
Comme vous vous en souvenez peut-être du chapitre 3, le kubelet est le processus sur l’hôte responsable de l’interfaçage avec le runtime du conteneur. Dans les cas les plus courants, ce travail revient généralement à signaler l’état du nœud au serveur API et à gérer le cycle de vie complet des pods qui ont été planifiés pour l’hôte sur lequel il réside.
L’installation du kubelet est généralement aussi simple que le téléchargement et l’installation du package approprié pour la distribution cible. Dans tous les cas, vous devez vous assurer d’installer le kubelet avec une version qui correspond à la version de Kubernetes que vous avez l’intention d’exécuter. Le kubelet est le processus Kubernetes unique géré par le gestionnaire de services hôte. Dans presque tous les cas, cela sera probablement systémique.
Si vous installez le kubelet avec les packages système construits et fournis par la communauté (actuellement deb et rpm), le kubelet sera géré par systemd . Comme pour tout processus géré de cette manière, un fichier d’unité définit l’utilisateur sous lequel le service s’exécute, les options de ligne de commande, la définition de la chaîne de dépendances du service et la stratégie de redémarrage :
[Unit]
Description=kubelet: The Kubernetes Node Agent Documentation=http://kubernetes.io/docs/
[Service]
ExecStart=/usr/bin/kubelet
Restart=always
StartLimitInterval=0
RestartSec=10
[Install]
WantedBy=multi-user.target
Même si vous n’installez pas le kubelet avec les packages fournis par la communauté, l’examen des fichiers d’unité fournis est souvent utile pour comprendre les meilleures pratiques courantes pour exécuter le démon kubelet . Ces fichiers d’unité changent souvent, assurez-vous donc de référencer les versions qui correspondent à votre cible de déploiement.
Le comportement du kubelet peut être manipulé en ajoutant des fichiers d’unité supplémentaires au chemin / etc / systemd / system / kubelet.service.d / . Ces fichiers d’unité sont lus lexicalement (alors nommez-les de façon appropriée) et vous permettent de remplacer la façon dont le package configure le kubelet . Cela peut être nécessaire si votre environnement nécessite des besoins spécifiques (par exemple, des proxys de registre de conteneurs).
Par exemple, lors du déploiement de Kubernetes sur un fournisseur de cloud pris en charge, vous devez définir le paramètre –cloud-provider sur le kubelet :
$ cat /etc/systemd/system/kubelet.service.d/09-extra-args.conf
[Service]
Environment=”KUBELET_EXTRA_ARGS= –cloud-provider=aws”
Avec ce fichier supplémentaire en place, nous effectuons simplement un rechargement du démon puis redémarrons le service :
$ sudo systemctl daemon-reload
$ sudo systemctl restart kubelet
Dans l’ensemble, les configurations par défaut fournies par la communauté sont généralement plus qu’adéquates et ne nécessitent généralement pas de modification. Avec cette technique, cependant, nous pouvons utiliser les valeurs par défaut de la communauté tout en conservant simultanément notre capacité à remplacer, le cas échéant.
Le kubelet et le runtime du conteneur sont nécessaires sur tous les hôtes du cluster.
6.2 Installation du plan de contrôle
Dans Kubernetes, le composant qui dirige les actions des nœuds de travail est appelé le plan de contrôle. Comme nous l’avons vu au chapitre 3, ces composants sont constitués du serveur API, du gestionnaire de contrôleur et du planificateur. Chacun de ces démons dirige une partie du fonctionnement final du cluster.
En plus des composants Kubernetes, nous avons besoin d’un emplacement pour stocker l’état de notre cluster. Ce magasin de données est etcd .
Heureusement, kubeadm est capable d’installer tous ces démons sur un hôte (ou des hôtes) que nous, en tant qu’administrateurs, avons délégué en tant que nœud de plan de contrôle. kubeadm le fait en créant un manifeste statique pour chacun des démons dont nous avons besoin.
Avec les manifestes statiques, nous pouvons écrire les spécifications des pods directement sur le disque et le kubelet , au démarrage, tente immédiatement de lancer les conteneurs qui y sont spécifiés. En fait, le kubelet surveille également ces fichiers pour les modifications et tente de réconcilier les modifications spécifiées. Notez, cependant, que ces pods n’étant pas gérés par le plan de contrôle, ils ne peuvent pas être manipulés avec l’interface de ligne de commande kubectl .
En plus des démons, nous devons sécuriser les composants avec Transport Layer Security (TLS), créer un utilisateur qui peut interagir avec l’API et fournir la possibilité aux nœuds de travail de rejoindre le cluster. Kubeadm fait tout cela.
Dans le plus simple des scénarios, nous pouvons installer les composants du plan de contrôle sur un nœud qui a déjà été préparé avec un kubelet en cours d’exécution et un runtime de conteneur fonctionnel, comme ceci :
$ kubeadm init
Après une description détaillée des étapes que kubeadm a prises au nom de l’utilisateur, la fin de la sortie peut ressembler à ceci :
…
Your Kubernetes master has initialized successfully! To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run “kubectl apply -f [podnetwork].yaml” with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of machines by running the following on each node as root:
kubeadm join –token 878b76.ddab3219269370b2 10.1.2.15:6443 \
–discovery-token-ca-cert-hash \ sha256:312ce807a9e98d544f5a53b36ae3bb95cdcbe50cf8d1294d22ab5521ddb54d68
6.2.1 Configuration de kubeadm
Bien que kubeadm init soit le cas le plus simple pour configurer un nœud de contrôleur, kubeadm est capable de gérer toutes sortes de configurations. Cela peut être réalisé au moyen du nombre varié mais quelque peu limité d’indicateurs de ligne de commande kubeadm , ainsi que de l’ API kubeadm plus performante . L’API ressemble à ceci :
apiVersion: kubeadm.k8s.io/v1alpha1
kind: MasterConfiguration
api:
advertiseAddress: <address|string>
bindPort:
etcd: endpoints:
– <endpoint1|string>
– <endpoint2|string>
caFile: <path|string>
certFile: <path|string>
keyFile: <path|string>
networking:
dnsDomain:
serviceSubnet:
podSubnet:
kubernetesVersion:
cloudProvider:
authorizationModes:
– <authorizationMode1|string>
– <authorizationMode2|string>
token:
tokenTTL:
selfHosted:
apiServerExtraArgs:
: <value|string>
: <value|string>
controllerManagerExtraArgs:
: <value|string>
: <value|string>
schedulerExtraArgs:
: <value|string>
: <value|string>
apiServerCertSANs:
– <name1|string>
– <name2|string>
certificatesDir:
Il peut être fourni à la ligne de commande kubeadm avec l’indicateur –config. Que vous décidiez, en tant qu’administrateur, d’utiliser explicitement ce format de configuration, l’un est toujours généré en interne lors de l’exécution de kubeadm init. De plus, cette configuration est enregistrée en tant que ConfigMap dans le cluster qui vient d’être provisionné. Cette fonctionnalité a deux objectifs : premièrement, fournir une référence à ceux qui ont besoin de comprendre comment un cluster a été configuré, et deuxièmement, elle peut être utilisée lors de la mise à niveau d’un cluster. En cas de mise à niveau d’un cluster, un utilisateur modifie les valeurs de cette carte de configuration, puis exécute une mise à niveau kubeadm.
La configuration kubeadm est également accessible par l’interrogation kubectl ConfigMap standard et est, par convention, nommée ConfigMap cluster-info dans l’espace de noms kube -public.
6.2.2 Contrôles en amont
Après avoir exécuté cette commande, kubeadm exécute d’abord un certain nombre de vérifications en amont. Ces vérifications d’intégrité garantissent que notre système est approprié pour une installation. « Le kubelet fonctionne-t-il ?», « Le swap a-t-il été désactivé ?» Et « Les utilitaires système de base sont-ils installés ?» sont les types de questions qui sont posées ici. Et, naturellement, kubeadm se termine avec une erreur si ces conditions de base ne sont pas remplies.
Bien que non recommandé, il est possible de contourner les prévol contrôles avec l’–skip prévol l’option de ligne de commande -checks.
Cela ne devrait être exercé que par des administrateurs avancés.
6.2.3 Certificats
Une fois que toutes les vérifications en amont ont été satisfaites, kubeadm , par défaut, génère sa propre autorité de certification (CA) et sa propre clé. Cette autorité de certification est ensuite utilisée pour signer ultérieurement divers certificats contre elle. Certains de ces certificats sont utilisés par le serveur API lors de la sécurisation des demandes entrantes, de l’authentification des utilisateurs, des demandes sortantes (c’est-à-dire vers un serveur API agrégé) et pour un TLS mutuel entre le serveur API et tous les kubelets en aval. D’autres sont utilisés pour sécuriser les comptes de service.
Tous ces actifs de l’infrastructure à clé publique (PKI) sont placés dans le répertoire /etc/Kubernetes/pki sur le nœud du plan de contrôle :
$ ls -al /etc/kubernetes/pki/
total 56 drwxr-xr-x 2 root root 4096 Mar 15 02:42 . drwxr-xr-x 4 root root 4096 Mar 15 02:42 ..
-rw-r–r– 1 root root 1229 Mar 15 02:42 apiserver.crt
-rw——- 1 root root 1675 Mar 15 02:42 apiserver.key
-rw-r–r– 1 root root 1099 Mar 15 02:42 apiserver-kubelet-client.crt -rw——- 1 root root 1679 Mar 15 02:42 apiserver-kubelet-client.key
-rw-r–r– 1 root root 1025 Mar 15 02:42 ca.crt
-rw——- 1 root root 1675 Mar 15 02:42 ca.key
-rw-r–r– 1 root root 1025 Mar 15 02:42 front-proxy-ca.crt
-rw——- 1 root root 1675 Mar 15 02:42 front-proxy-ca.key
-rw-r–r– 1 root root 1050 Mar 15 02:42 front-proxy-client.crt
-rw——- 1 root root 1675 Mar 15 02:42 front-proxy-client.key
-rw——- 1 root root 1675 Mar 15 02:42 sa.key
-rw——- 1 root root 451 Mar 15 02:42 sa.pub
Étant donné que cette autorité de certification par défaut est auto-signée, tous les consommateurs tiers doivent également fournir la chaîne de certificats d’autorité de certification lorsqu’ils tentent d’utiliser un certificat client. Heureusement, cela n’est généralement pas problématique pour les utilisateurs de Kubernetes, car un fichier kubeconfig est capable d’incorporer ces données et est effectué automatiquement par kubeadm .
Les certificats auto-signés, bien qu’extrêmement pratiques, ne sont parfois pas l’approche privilégiée. Cela est souvent particulièrement vrai dans les environnements d’entreprise ou pour ceux qui ont des exigences de conformité plus strictes. Dans ce cas, un utilisateur peut préremplir ces actifs dans le / etc / Kubernetes / pki répertoire avant d’exécuter kubeadm initialisation. Dans ce cas, kubeadm tente d’utiliser les clés et les certificats qui peuvent déjà être en place et de générer ceux qui ne sont peut-être pas déjà présents.
6.2.4 etcd
En plus des composants Kubernetes qui sont configurés au moyen de kubeadm , par défaut, sauf indication contraire, kubeadm tente de démarrer une instance de serveur etcd locale . Ce démon est démarré de la même manière que les composants Kubernetes (manifestes statiques) et conserve ses données dans le système de fichiers du nœud du plan de contrôle via des montages de volume hôte local.
Au moment d’écrire ces lignes, kubeadm init, en soi, ne sécurise pas nativement le serveur etcd géré par kubeadm avec TLS. Cette commande de base est uniquement destinée à configurer un nœud de plan de contrôle unique et, généralement, à des fins de développement uniquement.
Les utilisateurs qui ont besoin de kubeadm pour les installations de production doivent fournir une liste des points de terminaison etcd sécurisés par TLS avec l’option –config décrite plus haut dans ce chapitre.
Bien qu’avoir une instance etcd facilement déployable soit favorable pour un processus d’installation simple de Kubernetes, il n’est pas approprié pour un déploiement de niveau production. Dans un déploiement de qualité de production, un administrateur déploie un multi – noeuds et hautement disponible ETCD cluster qui se trouve à côté du déploiement Kubernetes. Étant donné que le magasin de données etcd contiendra tous les états du cluster, il est important de le traiter avec soin. Bien que les composants Kubernetes soient facilement remplaçables, etcd ne l’est pas. Et, par conséquent, etcd a un cycle de vie des composants (installation, mise à niveau, maintenance, etc.) qui est assez différent. Pour cette raison, un cluster de production Kubernetes doit séparer ces responsabilités.
6.2.4.1 Données secrètes
Toutes les données écrites dans etcd ne sont pas chiffrées par défaut. Si quelqu’un devait obtenir un accès privilégié au support de disque etcd , les données seraient facilement disponibles. Heureusement, une grande partie des données que Kubernetes persiste sur le disque n’est pas de nature sensible.
L’exception, cependant, concerne les données secrètes. Comme son nom l’indique, les données secrètes doivent rester secrètes. Pour s’assurer que ces données sont cryptées sur leur chemin vers etcd , les administrateurs doivent utiliser le paramètre –experimental-encryption-provider-config kube-apiserver . Avec ce paramètre, les administrateurs peuvent définir des clés symétriques pour crypter toutes les données secrètes.
Au moment d’écrire ces lignes, –experimental- encryptionprovider -config est toujours un paramètre expérimental de ligne de commande kube-apiserver . Comme cela est susceptible de changer, la prise en charge native de cette fonctionnalité dans kubeadm est limitée. Vous pouvez toujours utiliser cette fonctionnalité en ajoutant encryption.conf au répertoire / etc / kubernetes / pki de tous les nœuds du plan de contrôle et en ajoutant ce paramètre de configuration au champ apiServerExtraArgs dans votre kubeadm MasterConfig avant l’initialisation de kubeadm .
Ceci est accompli avec un EncryptionConfig :
$ cat encryption.conf kind: EncryptionConfig apiVersion: v1 resources:
resources:
secrets providers: – identity: {}
aescbc: keys:
name: encryptionkey
secret: BHk4lSZnaMjPYtEHR/jRmLp+ymazbHirgxBHoJZqU/Y=
Pour le type de cryptage aescbc recommandé, le champ secret doit être une clé de 32 octets générée aléatoirement. Maintenant, en ajoutant –experimental- encryptionprovider -config = / path / to / encryption.conf aux paramètres de ligne de commande kube-apiserver , tous les secrets sont cryptés avant d’être écrits dans etcd . Cela peut aider à empêcher la fuite de données sensibles.
Vous avez peut-être remarqué que EncryptionConfig comprend également un champ de ressources. Pour notre cas d’utilisation, les secrets sont les seules ressources que nous voulons chiffrer, mais tout type de ressource peut être inclus ici. Utilisez-le en fonction des besoins de votre organisation, mais n’oubliez pas que le chiffrement de ces données a un impact marginal sur les performances des écritures du serveur d’API. En règle générale, ne cryptez que les données que vous jugez sensibles.
Cette configuration prend en charge plusieurs types de chiffrement, dont certains peuvent être plus ou moins adaptés à vos besoins spécifiques. De même, cette configuration prend également en charge la rotation des clés, une mesure qui est nécessaire pour assurer une position de sécurité solide. Assurez-vous de consulter la documentation de Kubernetes pour plus de détails sur cette fonctionnalité expérimentale.
Vos besoins en données au repos dépendront de votre architecture. Si vous avez choisi de colocaliser vos ETCD instances sur vos nœuds de plan de contrôle, en utilisant cette fonction répondre à vos besoins, car les clés de chiffrement seraient également colocalisées avec les données. Dans le cas où un accès privilégié au disque est obtenu, les clés peuvent être utilisées pour décrypter les données etcd , inversant ainsi les efforts pour sécuriser ces ressources. C’est encore une autre raison impérieuse de séparer etcd de vos nœuds de plan de contrôle Kubernetes.
6.2.5 kubeconfig
En plus de créer les actifs PKI et de configurer les manifestes statiques qui desservent les composants Kubernetes , kubeadm génère également un certain nombre de fichiers kubeconfig .
Chacun de ces fichiers sera utilisé pour certains moyens d’authentification. La plupart d’entre eux seront utilisés pour authentifier chacun des services Kubernetes par rapport à l’API, mais kubeadm crée également un fichier kubeconfig d’administrateur principal dans / etc / kubernetes / admin.conf.
Étant donné que kubeadm crée si facilement ce kubeconfig avec les informations d’identification de l’administrateur de cluster, de nombreux utilisateurs ont tendance à utiliser ces informations d’identification générées bien plus que leur utilisation prévue. Ces informations d’identification doivent être utilisées uniquement pour démarrer un cluster. Tout déploiement en production doit toujours configurer des mécanismes d’identité supplémentaires, et ceux-ci seront discutés au chapitre 7.
6.2.6 Tares
Pour les cas d’utilisation en production, nous recommandons que les charges de travail des utilisateurs soient isolées des composants du plan de contrôle. En tant que tel, kubeadm corrompre tous les nœuds du plan de contrôle avec la coloration node-role.kubernetes.io/master. Cela ordonne au planificateur d’ignorer tous les nœuds avec cette souillure, lorsqu’il détermine où un pod peut être placé.
Si votre cas d’utilisation est celui d’un maître à nœud unique, vous pouvez supprimer cette restriction en supprimant la souillure du nœud :
kubectl taint nodes node-role.kubernetes.io/master-
6.3 Installation des nœuds de travail
Les nœuds de travail suivent un mécanisme d’installation très similaire. Encore une fois, nous avons besoin de l’exécution du conteneur et du kubelet sur chaque nœud. Mais, pour les travailleurs, le seul autre composant Kubernetes dont nous avons besoin est le démon kube- proxy. Et, tout comme avec les nœuds du plan de contrôle, kubeadm démarre ce processus au moyen d’un autre manifeste statique.
Plus important encore, ce processus effectue une séquence d’amorçage TLS. Grâce à un processus d’échange de jetons partagés, kubeadm authentifie temporairement le noeud par rapport au serveur API, puis tente d’effectuer une demande de signature de certificat (CSR) contre le plan de contrôle CA. Une fois les informations d’identification du nœud signées, celles-ci servent de mécanisme d’authentification au moment de l’exécution.
Cela semble complexe, mais, encore une fois, kubeadm rend ce processus extraordinairement simple :
$ kubeadm join –token –discovery-token-ca-cert-hash \
Bien qu’il ne soit pas aussi simple que le boîtier de l’avion de contrôle, il est néanmoins assez simple. Et, dans le cas où vous utilisez kubeadm manuellement, la sortie de la commande kubeadm init fournit même la commande précise qui doit être exécutée sur un nœud de travail.
Évidemment, si nous demandons à un nœud de travail de se joindre au cluster Kubernetes, nous devons lui dire où s’enregistrer. C’est là que le paramètre < api endpoint> entre en jeu. Cela inclut l’IP (ou le nom de domaine) et le port du serveur API. Étant donné que ce mécanisme permet à un nœud d’initier la jointure, nous voulons nous assurer que cette action est sécurisée. Pour des raisons évidentes, nous ne voulons pas que n’importe quel nœud puisse rejoindre le cluster, et de même, nous voulons que le nœud de travail puisse vérifier l’authenticité du plan de contrôle. C’est là que les paramètres –token et –discovery- tokenca -cert-hash entrent en jeu.
Le paramètre –token est un jeton d’amorçage qui a été prédéfini avec le plan de contrôle. Dans notre cas d’utilisation simple, un jeton d’amorçage a été automatiquement alloué par le biais de l’invocation d’init de kubeadm . Les utilisateurs peuvent également créer ces jetons d’amorçage à la volée :
$ kubeadm token create [–ttl ]
Ce mécanisme est particulièrement pratique lors de l’ajout de nouveaux nœuds de travail au cluster. Dans ce cas, les étapes consistent simplement à utiliser le jeton kubeadm create pour définir un nouveau jeton d’amorçage, puis à utiliser ce jeton dans une commande de jointure kubeadm sur le nouveau nœud de travail.
–Discovery-token-ca-cert-hash fournit au nœud de travail un mécanisme pour valider l’autorité de certification du plan de contrôle. En pré – partageant le hachage SHA256 de l’autorité de certification, le nœud de travail peut valider que les informations d’identification qu’il a reçues provenaient en fait du plan de contrôle prévu.
La commande entière peut ressembler à ceci :
$ kubeadm join –token 878b76.ddab3219269370b2 10.1.2.15:6443 \
–discovery-token-ca-cert-hash \ sha256:312ce807a9e98d544f5a53b36ae3bb95cdcbe50cf8d1294d22ab5521ddb54d68
6.4 Modules complémentaires
Après avoir installé le plan de contrôle et fait apparaître quelques nœuds de travail, l’étape suivante évidente consiste à déployer certaines charges de travail. Avant de pouvoir le faire, nous devons déployer quelques modules complémentaires.
Au minimum, nous devons installer un plug-in CNI (Container Network Interface). Ce plug-in fournit une connectivité réseau Pod-to-Pod (également appelée est-ouest). Il existe une multitude d’options, chacune avec son propre cycle de vie spécifique, donc kubeadm ne doit pas essayer de les gérer. Dans le cas le plus simple, il s’agit d’appliquer le manifeste DaemonSet décrit par votre fournisseur CNI.
Les modules complémentaires supplémentaires que vous pourriez souhaiter dans vos clusters de production incluraient probablement l’agrégation des journaux, la surveillance et peut-être même des capacités de maillage de service. Encore une fois, car ceux-ci peuvent être complexes, kubeadm ne tente pas de les gérer.
Le module complémentaire spécial géré par kubeadm est celui du cluster DNS. kubeadm prend actuellement en charge kube-dns et CoreDNS , kube-dns étant la valeur par défaut. Comme pour toutes les parties de kubeadm, vous pouvez même choisir de renoncer à ces options standard et installer le fournisseur DNS de cluster de votre choix.
6.5 Phases
Comme nous l’avons mentionné plus tôt dans le chapitre, kubeadm sert de base à une variété d’autres outils d’installation de Kubernetes. Comme vous pouvez l’imaginer, si nous essayons d’utiliser kubeadm de cette manière, nous pouvons souhaiter que certaines parties de l’installation soient gérées par kubeadm et d’autres soient gérées par le framework d’installation de wrapping. kubeadm prend également en charge ce cas d’utilisation, avec une fonctionnalité appelée phases.
Avec les phases, un utilisateur peut utiliser kubeadm pour effectuer des actions discrètes entreprises dans le processus d’installation. Par exemple, peut-être que l’outil d’encapsulation aimerait utiliser kubeadm pour sa capacité à générer des actifs PKI. Ou peut-être que cet outil veut tirer parti des vérifications en amont de kubeadm afin de s’assurer qu’un cluster a les meilleures pratiques en place. Tout cela, et plus encore, est disponible avec les phases kubeadm.
6.6 Haute disponibilité
Si vous avez fait très attention, vous avez probablement remarqué que nous n’avions pas parlé d’un avion de contrôle hautement disponible. C’est quelque peu intentionnel.
Étant donné que la compétence de kubeadm est principalement du point de vue d’un seul nœud à la fois, faire évoluer kubeadm en un outil à usage général pour gérer les installations hautement disponibles serait relativement compliqué. Cela commencerait à brouiller les lignes de la philosophie Unix de « faire une chose et de bien la faire ».
Cela dit, kubeadm peut être (et est) utilisé pour fournir les composants nécessaires à un plan de contrôle hautement disponible. Bien qu’il existe un certain nombre d’actions précises (et parfois nuancées) qu’un utilisateur doit entreprendre pour créer un plan de contrôle hautement disponible, les étapes de base sont les suivantes :
- Créez un cluster etcd hautement disponible.
- Initialisez un nœud de plan de contrôle principal avec kubeadm init et une configuration qui utilise le cluster etcd créé à l’étape 1.
- Transférez les actifs PKI en toute sécurité vers tous les autres nœuds du plan de contrôle.
- Faites face aux serveurs API du plan de contrôle avec un équilibreur de charge.
- Joignez tous les nœuds de travail au cluster via les points de terminaison à charge équilibrée.
Si tel est votre cas d’utilisation et que vous souhaitez utiliser kubeadm pour installer un cluster de haute qualité de production, consultez la documentation de haute disponibilité de kubeadm . Cette documentation est conservée avec chaque version de Kubernetes.
6.7 Mises à niveau
Comme pour tout déploiement, il arrivera un moment où vous voudrez profiter de toutes les nouvelles fonctionnalités de Kubernetes. De même, si vous avez besoin d’une mise à jour de sécurité critique, vous souhaitez pouvoir l’activer avec le moins de perturbations possible. Heureusement, Kubernetes prévoit des mises à niveau sans interruption de service. Vos applications continuent de s’exécuter pendant que l’infrastructure sous-jacente est modifiée.
Bien qu’il existe d’innombrables façons de mettre à niveau un cluster, nous nous concentrons sur le cas d’utilisation de kubeadm, une fonctionnalité disponible depuis la version 1.8.
Il y a beaucoup de pièces mobiles dans n’importe quel cluster Kubernetes, ce qui peut compliquer l’orchestration de la mise à niveau. kubeadm simplifie considérablement cela, car il est capable de suivre des combinaisons de versions bien testées pour le kubelet , etcd , et les images de conteneur qui desservent le plan de contrôle de Kubernetes.
L’ordre des opérations lors de l’exécution d’une mise à niveau est simple. Tout d’abord, nous planifions notre mise à niveau, puis nous appliquons notre plan déterminé.
Pendant la phase de planification, kubeadm analyse le cluster en cours d’exécution et détermine les chemins de mise à niveau possibles. Dans le cas le plus simple, nous effectuons une mise à niveau vers une version mineure ou un correctif (par exemple, de 1.10.3 à 1.10.4). Un peu plus compliqué est la mise à niveau vers une toute nouvelle version mineure, c’est-à-dire deux (ou plus) versions ultérieures (par exemple, 1.8 à 1.10). Dans ce cas, nous devons parcourir les mises à niveau à travers chaque version mineure successive jusqu’à ce que nous atteignions l’état souhaité.
kubeadm effectue un certain nombre de prévol contrôles pour assurer que le groupe est en bonne santé et examine ensuite le kubeadm -config ConfigMap dans le Kube espace de noms -système. Ce ConfigMap aide kubeadm à déterminer les chemins de mise à niveau disponibles et garantit que tous les éléments de configuration personnalisés sont reportés.
Bien qu’une grande partie du levage de charges lourdes se produise automatiquement, vous vous souvenez peut-être que le kubelet (et le kubeadm lui-même) n’est pas géré par kubeadm . Lors de l’exécution du plan, kubeadm indique quels composants non gérés doivent également être mis à niveau :
root@control1:~# kubeadm upgrade plan
[preflight] Running pre-flight checks.
[upgrade] Making sure the cluster is healthy:
[upgrade/config] Making sure the configuration is correct:
[upgrade/config] Reading configuration from the cluster…
[upgrade/config] FYI: You can look at this config file with
‘kubectl -n kube-system get cm kubeadm-config -oyaml’
[upgrade/plan] computing upgrade possibilities
[upgrade] Fetching available versions to upgrade to
[upgrade/versions] Cluster version: v1.9.5
[upgrade/versions] kubeadm version: v1.10.4
[upgrade/versions] Latest stable version: v1.10.4
[upgrade/versions] Latest version in the v1.9 series: v1.9.8
Composants qui doivent être mis à niveau manuellement après avoir mis à niveau le plan de contrôle avec « mise à niveau kubeadm applicable»:
COMPONENT CURRENT AVAILABLE
Kubelet 4 x v1.9.3 v1.9.8 Upgrade to the latest version in the v1.9 series:
COMPONENT CURRENT AVAILABLE
API Server v1.9.5 v1.9.8
Controller Manager v1.9.5 v1.9.8
Scheduler v1.9.5 v1.9.8
Kube Proxy v1.9.5 v1.9.8
Kube DNS 1.14.8 1.14.8 You can now apply the upgrade by executing the following command: kubeadm upgrade apply v1.9.8 ________________________________________________________________
Components that must be upgraded manually after you have upgraded the control plane with ‘kubeadm upgrade apply’:
COMPONENT CURRENT AVAILABLE
Kubelet 4 x v1.9.3 v1.10.4 Upgrade to the latest stable version:
COMPONENT CURRENT AVAILABLE
API Server v1.9.5 v1.10.4
Controller Manager v1.9.5 v1.10.4
Scheduler v1.9.5 v1.10.4
Kube Proxy v1.9.5 v1.10.4
Kube DNS 1.14.8 1.14.8
You can now apply the upgrade by executing the following command: kubeadm upgrade apply v1.10.4
Vous devez mettre à niveau les composants du système conformément à la manière dont ils ont été installés (généralement avec le gestionnaire de packages du système d’exploitation).
Après avoir déterminé votre approche de mise à niveau planifiée, commencez à exécuter les mises à niveau dans l’ordre spécifié par kubeadm. S’il existe plusieurs versions dans le chemin de mise à niveau, effectuez-les sur chaque nœud, comme indiqué.
root@control1:~# kubeadm upgrade apply v1.10.4
Encore une fois, des vérifications en amont sont effectuées, principalement pour s’assurer que le cluster est toujours en bonne santé, des sauvegardes des différents manifestes de pod statiques sont effectuées et la mise à niveau a lieu.
En termes d’ordre des nœuds, assurez-vous d’abord de mettre à niveau les nœuds du plan de contrôle, puis effectuez les mises à niveau sur chaque nœud de travail. Les nœuds du plan de contrôle doivent être désenregistrés en amont pour tous les équilibreurs de charge orientés vers l’avant, mis à niveau, puis, une fois le plan de contrôle entier correctement mis à niveau, tous les nœuds du plan de contrôle doivent être réenregistrés en amont avec l’équilibreur de charge. Cela peut introduire une courte période de temps lorsque l’API n’est pas disponible, mais cela garantit que tous les clients ont une expérience cohérente.
Si vous effectuez des mises à niveau pour chaque travailleur en place, les travailleurs peuvent être mis à niveau en parallèle. Notez que cela peut entraîner une période de temps où il n’y a pas de kubelet disponibles pour la planification des pods. Vous pouvez également mettre à niveau les employés de manière continue. Cela garantit qu’il y a toujours un nœud qui peut être déployé.
Si votre mise à niveau implique également d’effectuer simultanément des mises à niveau perturbatrices sur les nœuds de travail (par exemple, la mise à niveau du noyau), il est conseillé d’utiliser la sémantique du cordon kubectl et / ou du drain kubectl pour vous assurer que vos charges de travail utilisateur sont replanifiées avant la maintenance.
6.8 Résumé
Dans ce chapitre, nous avons examiné comment installer facilement Kubernetes dans un certain nombre de cas d’utilisation. Bien que nous n’ayons fait qu’effleurer la surface en ce qui concerne les capacités du kubeadm, nous espérons avoir démontré à quel point il peut être un outil polyvalent.
Étant donné que de nombreux outils de déploiement disponibles aujourd’hui ont kubeadm comme support , savoir comment cela fonctionne devrait vous aider à comprendre ce que font les outils d’ordre supérieur en votre nom. Et, si vous êtes si enclin, cette compréhension peut vous aider à développer votre propre outillage de déploiement en interne.
7 CHAPITRE 7 Authentification et gestion des utilisateurs
Maintenant que nous avons installé avec succès Kubernetes, l’un des aspects les plus fondamentaux d’un déploiement réussi se concentre sur une gestion cohérente des utilisateurs. Comme pour tout système distribué à plusieurs locataires, la gestion des utilisateurs constitue la base de la manière dont Kubernetes authentifie finalement les identités, détermine les niveaux d’accès appropriés, active les capacités en libre-service et maintient l’auditabilité.
Dans ce chapitre et le suivant, nous explorons comment tirer le meilleur parti des capacités d’authentification et de contrôle d’accès de Kubernetes. Mais pour bien comprendre le fonctionnement de ces constructions, il est important de comprendre d’abord le cycle de vie d’une demande d’API.
Chaque demande d’API qui parvient au serveur d’API doit réussir à naviguer dans une série de défis, comme illustré à la figure 7-1, avant que le serveur accepte (et agisse par la suite) sur la demande. Chacun de ces tests appartient à l’un des trois groupes suivants: authentification, contrôle d’accès et contrôle d’admission.
Figure 7-1. Flux de demandes de l’API Kubernetes
Le nombre et la complexité de ces défis dépendent de la configuration du serveur API Kubernetes, mais les meilleures pratiques appellent des clusters de production à implémenter les trois sous une forme ou une mode.
Les deux premières phases du traitement d’une demande d’API (authentification et contrôle d’accès) se concentrent sur ce que nous savons d’un utilisateur. Dans ce chapitre, nous proposons une compréhension de ce qu’est un utilisateur du point de vue du serveur d’API et, en fin de compte, comment tirer parti des ressources des utilisateurs pour fournir un accès API sécurisé au cluster.
7.1 Utilisateurs
Le terme utilisateurs fait référence à la façon dont vous et moi (et peut-être même votre outil de livraison continue) vous connectez et accédez à l’API Kubernetes. Dans le cas le plus courant, les utilisateurs se connectent souvent à l’API Kubernetes à partir d’un emplacement externe, souvent via l’interface de ligne de commande kubectl . Cependant, comme l’API Kubernetes constitue la base de toutes les interactions avec le cluster, ces contrôles sont également en place pour tous les types d’accès : vos scripts et contrôleurs personnalisés, l’interface utilisateur Web et bien plus encore. Cela fournit une position cohérente et sûre à partir de laquelle commencer. Vous avez peut-être remarqué que, jusqu’à présent, nous nous sommes abstenus d’utiliser un «U» majuscule pour désigner les utilisateurs. De nombreux nouveaux arrivants à Kubernetes sont souvent surpris d’apprendre que, parmi le large éventail de ressources fournies par l’API, les utilisateurs ne sont en fait pas une ressource prise en charge de haut niveau. Ils ne sont pas manipulés directement par le biais de l’API Kubernetes, mais, le plus souvent, ils sont définis dans un système de gestion d’identité d’utilisateur externe.
Il y a une bonne raison à cela : cela soutient une bonne hygiène de gestion des utilisateurs. Si vous êtes comme la grande majorité des organisations qui ont déployé Kubernetes, vous avez presque certainement déjà une certaine forme de gestion des utilisateurs en place. Que cela se présente sous la forme d’un cluster Active Directory à l’échelle de l’entreprise ou d’un serveur LDAP (Lightweight Directory Access Protocol) unique, la façon dont vous gérez vos utilisateurs doit rester cohérente dans votre organisation, quels que soient les systèmes qui la consomment. Kubernetes prend en charge ce principe de conception en fournissant la connectivité pour tirer parti de ces systèmes existants, permettant ainsi une gestion cohérente et efficace des utilisateurs à travers votre infrastructure.
L’absence de tels systèmes ne signifie pas que vous ne pourrez pas utiliser Kubernetes. Cela peut simplement signifier que vous devrez peut-être utiliser un mécanisme différent pour authentifier les utilisateurs, comme nous le découvrirons dans la section suivante.
7.2 Authentification
Au moment d’écrire ces lignes, Kubernetes prend en charge plusieurs méthodes d’authentification par rapport à l’API. Comme pour tout mécanisme d’authentification, il sert de premier contrôleur d’accès pour tout type d’ accès programmatique . Les questions que nous évaluons ici sont : « Qui est cet utilisateur ? » et “Leurs références correspondent-elles à nos attentes ? ” À ce stade du flux d’API, nous ne nous demandons pas encore si la demande doit être accordée en fonction du rôle de l’utilisateur ou même si la demande est conforme à nos normes. La question ici est simple, et la réponse binaire : “Est-ce un véritable utilisateur ? ”
Tout comme avec de nombreuses API REST bien conçues, il existe plusieurs stratégies que Kubernetes peut utiliser pour authentifier les utilisateurs. Nous pouvons considérer chacune de ces stratégies comme appartenant à l’un des trois grands groupes :
- Authentification de base
- Certificats clients X.509
- Bearer tokens
La façon dont un utilisateur parvient finalement à obtenir les informations d’identification dépend du fournisseur d’identité activé par l’administrateur du cluster, mais le mécanisme adhère à l’un de ces grands groupes. Et bien que ces mécanismes soient très différents en termes de mise en œuvre, nous verrons comment chacun fournit finalement au serveur d’API les données dont il a besoin pour vérifier l’authenticité et les niveaux d’accès d’un utilisateur (via la ressource UserInfo ) .
7.2.1 Authentification de base
L’authentification de base est peut-être le plus primitif des plug-ins d’authentification disponibles pour un cluster Kubernetes. L’authentification de base est un mécanisme par lequel le client API (généralement kubectl ) définit l’en-tête d’autorisation HTTP sur un hachage base64 du nom d’utilisateur et du mot de passe combinés. Étant donné que base64 est simplement un hachage et ne fournit aucun niveau de cryptage pour les informations d’identification transmises, il est impératif que l’authentification de base soit utilisée conjointement avec HTTPS.
Pour configurer l’authentification de base sur le serveur API, l’administrateur doit fournir un fichier statique de noms d’utilisateur, de mots de passe, d’ID utilisateur et une liste de groupes auxquels cet utilisateur doit être associé. Le format est le suivant :
password,username,uid,”group1,group2,group3″
password,username,uid,”group1,group2,group3″
…
Notez que le format de ces lignes correspond aux champs de la ressource UserInfo . Ce fichier est fourni au serveur API Kubernetes via le paramètre de ligne de commande –basic-auth-file. Étant donné que le serveur API ne surveille pas actuellement ce fichier pour les modifications, chaque fois qu’un utilisateur est ajouté, supprimé ou mis à jour, le serveur API doit être redémarré pour que ces modifications prennent effet. En raison de cette contrainte, l’authentification de base n’est généralement pas recommandée pour les clusters de production. Ce fichier peut certainement être géré par une entité externe (par exemple, un outil de gestion de configuration) afin d’accéder à des configurations de type production, mais l’expérience montre que cela devient rapidement insoutenable.
Ces lacunes mises à part, il convient de noter que l’authentification de base peut être un excellent outil pour un test rapide et simple d’un cluster Kubernetes. En l’absence d’une configuration d’authentification plus élaborée, l’authentification de base permet à un administrateur d’expérimenter rapidement des fonctionnalités telles que le contrôle d’accès.
7.2.2 Certificats client X.509
Un mécanisme d’authentification généralement activé par la plupart des programmes d’installation de Kubernetes est le certificat client X.509. Les raisons peuvent être nombreuses, mais elles sont presque certainement dues au fait qu’elles sont sécurisées, omniprésentes et peuvent être générées relativement facilement. S’il y a accès à une autorité de certification signataire, de nouveaux utilisateurs peuvent être créés rapidement.
Lors de l’installation de Kubernetes d’une manière de qualité production, nous voulons être sûrs que non seulement les requêtes initiées par l’utilisateur sont transmises en toute sécurité, mais également que la communication de service à service est cryptée. Les certificats clients X.509 sont parfaitement adaptés à ce cas d’utilisation. Donc, si c’est déjà une exigence, pourquoi ne pas l’utiliser également pour authentifier les utilisateurs ?
C’est précisément le nombre d’outils d’installation qui fonctionnent. Par exemple, kubeadm , le programme d’installation pris en charge par la communauté, crée un certificat d’autorité de certification racine auto-signé, puis l’utilise pour signer divers certificats pour les composants de service ainsi que le certificat administratif unique qu’il crée.
Un certificat unique pour tous vos utilisateurs n’est pas le meilleur moyen de gérer les utilisateurs dans Kubernetes, mais il le fera pour que les choses soient opérationnelles. Lorsque la nécessité d’intégrer des utilisateurs supplémentaires se présente, les administrateurs peuvent signer des certificats clients supplémentaires à partir de cette autorité de signature.
Étant donné que kubeadm est destiné à être à la fois une rampe d’accès facile pour les utilisateurs pour monter un cluster et un outil pour créer des clusters de production, il est hautement configurable. Par exemple, les utilisateurs doivent utiliser leur propre autorité de certification, ils peuvent configurer kubeadm pour signer des certificats pour les exigences d’authentification du service et de l’utilisateur.
Il existe une variété d’outils qui peuvent aider un administrateur à créer et à gérer des certificats clients. Certains des choix les plus populaires sont les outils client OpenSSL et un utilitaire de Cloudflare, nommé cfssl . Si vous connaissez déjà ces outils, vous savez que les options de ligne de commande peuvent parfois être un peu lourdes. Nous nous concentrons sur cfssl ici, car il a, à notre avis, un flux de travail qui est un peu plus facile à saisir.
Nous supposons que vous disposez déjà d’une autorité de signature existante. La première étape consiste à créer un CSR, qui sera utilisé pour générer le certificat client. Encore une fois, nous devons mapper l’identité d’un utilisateur sur une ressource UserInfo . Nous pouvons le faire avec la demande de signature. Ici, notre spécification du nom commun CN correspond au nom d’utilisateur, et tous les champs Organisation O correspondent aux groupes dont l’utilisateur est membre.
cat > joesmith-csr.json <<EOF
{
“CN”: “joesmith”,
“key”: {
“algo”: “rsa”,
“size”: 2048
},
“names”: [
{
“C”: “US”,
“L”: “Boston”,
“O”: “qa”,
“O”: “infrastructure”,
“OU”: “Acme Sprockets Company”,
“ST”: “MA”
}
]
}
Dans ce cas, l’utilisateur ” joesmith ” est membre à la fois de ” qa ” et “infrastructure”.
Nous pouvons générer le certificat comme suit:
cfssl gencert \ -ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-profile=kubernetes \
joesmith-csr.json | cfssljson -bare admin
L’activation de l’authentification du certificat client X.509 sur le serveur API est aussi simple que de spécifier le –client-ca-file =, dont la valeur pointera vers le fichier de certificat sur le disque.
Même si cfssl simplifie la tâche de création de certificats clients, ce moyen d’authentification peut toujours être un peu lourd. Tout comme avec l’authentification de base, il existe certains inconvénients lorsqu’un utilisateur est intégré, supprimé ou lorsqu’un changement est nécessaire (par exemple, l’ajout d’un utilisateur à un nouveau groupe). Si les certificats sont choisis comme option d’authentification, les administrateurs doivent, au minimum, s’assurer que ce processus est automatisé d’une certaine manière et que cette automatisation comprend un processus de rotation des certificats dans le temps.
Si le nombre d’utilisateurs finaux attendus est assez faible, ou si la majorité des utilisateurs interagiront avec le cluster via un intermédiaire (par exemple, des outils de livraison continue), les certificats clients X. 509 peuvent être une solution adéquate. Si ce n’est pas le cas, cependant, certaines des options basées sur les jetons peuvent être un peu plus flexibles.
7.2.3 OpenID Connect
OIDC est une couche d’authentification basée sur OAuth 2.0. Avec ce fournisseur d’authentification, l’utilisateur s’authentifie indépendamment auprès d’un fournisseur d’identité de confiance. Si cet utilisateur s’authentifie avec succès, le fournisseur fournit ensuite à l’utilisateur, via une série de requêtes Web, un ou plusieurs jetons.
Parce que cet échange de codes et de jetons est quelque peu complexe et n’est pas vraiment pertinent pour la façon dont Kubernetes authentifie et autorise l’utilisateur, nous nous concentrons sur l’état souhaité, où l’utilisateur s’est authentifié et à la fois un id_token et un refresh_token ont été accordés.
Les jetons sont fournis à l’utilisateur au format RFC 7519 JSON Web Token (JWT). Cette norme ouverte permet la représentation des revendications des utilisateurs entre plusieurs parties. En termes plus simples, avec une quantité insignifiante de JSON analysable par l’homme, nous pouvons partager des informations, telles que le nom d’utilisateur, l’ID utilisateur et les groupes auxquels cet utilisateur peut appartenir. Ces jetons sont authentifiés avec un code d’authentification de message basé sur le hachage (HMAC) et ne sont pas chiffrés. Donc, encore une fois, assurez-vous que toutes les communications, y compris JWT, sont cryptées, de préférence avec TLS.
Une charge utile de jeton typique ressemble à ceci :
{
“iss”: “https://auth.example.com”,
“sub”: “Ch5hdXRoMHwMTYzOTgzZTdjN2EyNWQxMDViNjESBWF1N2Q2”, “aud”: “dDblg7xO7dks1uG6Op976jC7TjUZDCDz”,
“exp”: 1517266346,
“iat”: 1517179946,
“at_hash”: “OjgZQ0vauibNVcXP52CtoQ”,
“username”: “user”,
“email”: “user@example.com”,
“email_verified”: true,
“groups”: [
“qa”,
“infrastructure”
]
}
Les champs de ce document JSON sont appelés revendications et servent à identifier divers attributs de l’utilisateur. Bien que bon nombre de ces revendications soient standardisées (par exemple, iss , iat , exp), les fournisseurs d’identité peuvent également ajouter leurs propres revendications personnalisées. Heureusement, le serveur d’API nous permet d’indiquer comment ces revendications seront renvoyées à notre ressource UserInfo.
Pour activer l’authentification OIDC sur le serveur API, nous devons ajouter les paramètres – oidcissuer-url et – oidc -client-id sur la ligne de commande. Il s’agit de l’URL du fournisseur d’identité et de l’ID de la configuration client, respectivement, et ces deux valeurs sont fournies par votre fournisseur. Les deux autres options que nous souhaitons configurer, bien que ce ne soit pas obligatoire, sont – oidc -username-claim (par défaut : sub) et – oidc -group -claim (par défaut : groups). C’est génial si ces valeurs par défaut correspondent à la structure de vos jetons. Mais même s’ils ne correspondent pas, chacun vous permet de mapper les revendications sur le fournisseur d’identité à leurs attributs UserInfo respectifs.
Il existe un outil fantastique pour examiner la structure des JWT. Cet outil d’Auth0 vous permet non seulement de coller votre jeton pour l’exploration de son contenu, mais offre également une référence approfondie des bibliothèques de signature et de vérification JWT open source.
Ce type d’authentification est un peu différent des autres que nous avons examinés en ce qu’il implique un intermédiaire. Avec l’authentification de base et les certificats client X.509, le serveur API Kubernetes est en mesure d’effectuer toutes les étapes requises pour l’authentification. Comme le montre la figure 7-2, avec OIDC, l’utilisateur final s’authentifie auprès de notre fournisseur d’identité mutuellement fiable, puis utilise les jetons qu’il a reçus pour prouver par la suite son identité au serveur API. Le flux ressemble quelque chose comme l’illustration de la figure 7-2.
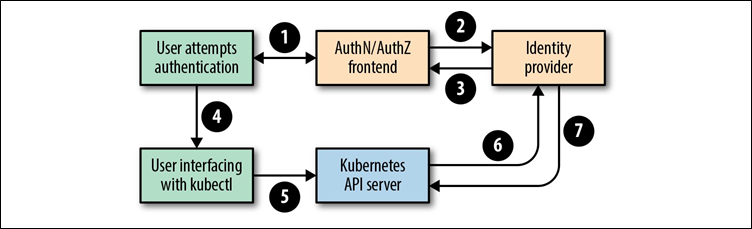
Figure 7-2. Flux OIDC de Kubernetes
- L’utilisateur authentifie et autorise l’application serveur de l’API Kubernetes.
- Le frontend d’authentification transmet les informations d’identification de l’utilisateur au fournisseur d’identité.
- Si le fournisseur d’identité est en mesure d’authentifier l’utilisateur, le fournisseur renvoie un code d’accès. Ce code d’accès est ensuite renvoyé au fournisseur d’identité et échangé contre un jeton d’identité et (généralement) un jeton d’actualisation.
- L’utilisateur ajoute ces jetons à la configuration de kubeconfig .
- Maintenant que le fichier kubeconfig contient des informations d’identité OIDC, kubectl tente d’injecter le jeton en tant que jeton porteur à chaque demande d’API Kubernetes. Si le jeton a expiré, kubectl tentera d’abord d’obtenir un nouveau jeton d’identité en échangeant le jeton d’identité expiré avec l’émetteur.
- Le serveur API Kubernetes garantit que ce jeton est légitime en demandant des informations utilisateur au fournisseur d’identité, sur la base des informations d’identification du jeton.
- Si le jeton est validé, le fournisseur d’identité renvoie les informations utilisateur et le serveur d’API Kubernetes autorise la demande d’API Kubernetes d’origine à poursuivre son flux.
7.2.4 Webhook
Dans certains scénarios, un administrateur a déjà accès à des systèmes capables de générer des jetons de support. Vous pourriez être en mesure d’imaginer un scénario dans lequel un système interne accorde à un utilisateur un jeton longue durée qu’il ou elle peut utiliser pour s’authentifier auprès de n’importe quel nombre de systèmes de l’environnement. Il n’est peut-être pas aussi élaboré ou conforme aux normes que l’OIDC, mais tant que nous pouvons contester l’authenticité de ce jeton par programme, Kubernetes est en mesure de vérifier l’identité d’un utilisateur.
Avec l’authentification de webhook en place, le serveur API extrait tout jeton de support présent sur une demande entrante et émet ensuite une demande POST client au service d’authentification. Le corps de cette demande sera une ressource de vue TokenRe sérialisée JSON incorporée avec le jeton de support d’origine.
{
“apiVersion”: “authentication.k8s.io/v1beta1”, “kind”: “TokenReview”,
“spec”: {
“token”: “some-bearer-token-string”
}
}
Une fois que le service d’authentification a évalué l’authenticité de ce jeton, il doit ensuite formuler sa propre réponse, à nouveau, avec un TokenReview comme corps. La réponse indique, avec un simple vrai ou faux, si le jeton porteur est légitime. Si la demande échoue à l’authentification, la réponse est simple :
{
“apiVersion”: “authentication.k8s.io/v1beta1”,
“kind”: “TokenReview”,
“status”: {
“authenticated”: false
}
}
S’il y a eu une erreur lors de l’authentification de l’utilisateur pour une raison quelconque, le service peut également répondre avec un champ de chaîne d’erreur en tant que frère à authentifié.
Inversement, si la réponse est que l’authentification a réussi, le fournisseur doit répondre, au minimum, avec des données sur l’utilisateur avec un objet ressource UserInfo incorporé. Cet objet a des champs pour le nom d’utilisateur, l’ uid , les groupes et même un pour les données supplémentaires que le service peut vouloir transmettre.
{
“apiVersion”: “authentication.k8s.io/v1beta1”,
“kind”: “TokenReview”,
“status”: {
“authenticated”: true,
“user”: {
“username”: “janedoe@example.com”,
“uid”: “42”,
“groups”: [
“developers”,
“qa”
],
“extra”: {
“extrafield1”: [
“extravalue1”,
“extravalue2”
]
}
}
}
}
Une fois que l’API a initié la demande et reçu une réponse, le serveur d’API accorde ou refuse la demande d’API Kubernetes, conformément aux instructions fournies par le service d’authentification.
Une chose à garder à l’esprit avec presque tous les mécanismes d’authentification basés sur les jetons est que la vérification du jeton implique souvent une demande et une réponse supplémentaires. Dans le cas de l’authentification OIDC et du webhook, par exemple, cet aller-retour supplémentaire pour authentifier le jeton peut devenir un goulot d’étranglement des performances pour la demande d’API si le fournisseur d’identité ne répond pas en temps opportun. Avec l’un de ces plug-ins en jeu, assurez-vous que vous disposez de fournisseurs à faible latence et performants.
7.2.5 Projet présenté : dex
Que se passe-t-il si aucun de ces services ne convient à votre cas d’utilisation ? Vous avez peut-être remarqué que les services d’annuaire couramment utilisés ne sont pas inclus dans la liste des plug-ins d’authentification pris en charge nativement pour Kubernetes. Par exemple, au moment d’écrire ces lignes, il n’y a pas de connecteurs pour Active Directory, LDAP ou autres.
Bien sûr, vous pouvez toujours écrire votre propre proxy d’authentification qui s’interfacerait avec ces systèmes, mais cela deviendrait rapidement un autre élément d’infrastructure à développer, gérer et maintenir.
Entrez dex , un projet de CoreOS qui peut être utilisé comme courtier OIDC. dex fournit un frontend OIDC conforme aux normes à une variété de backends courants. Il existe une prise en charge pour LDAP, Active Directory, SQL, SAML et même des fournisseurs SaaS, tels que GitHub, GitLab et LinkedIn. Imaginez votre plaisir lorsque vous recevez cette invitation de votre administrateur Kubernetes:
Je voudrais vous ajouter à mon réseau professionnel de clusters Kubernetes sur LinkedIn.
Il est important de noter que les mécanismes d’authentification configurés dans un cluster Kubernetes ne s’excluent pas mutuellement. En fait, nous vous recommandons d’activer plusieurs plug-ins simultanément.
En tant qu’administrateur, vous pouvez, par exemple, configurer à la fois le certificat client TLS et l’authentification OIDC en même temps. Bien qu’il ne soit probablement pas approprié d’utiliser plusieurs mécanismes quotidiennement, une telle configuration peut s’avérer utile lorsque vous devez déboguer un mécanisme d’authentification d’API secondaire défaillant. Dans ce scénario, vous pouvez exploiter un certificat bien connu (et, espérons-le, protégé) pour recueillir des données supplémentaires sur l’échec.
Notez que lorsque plusieurs plug-ins d’authentification sont actifs en même temps, le premier plug-in pour authentifier avec succès un utilisateur court – circuite le processus d’authentification.
7.3 kubeconfig
Avec tous les mécanismes d’authentification que nous avons décrits, nous devons créer un fichier kubeconfig qui enregistre les détails de la façon dont nous nous authentifions. kubectl utilise ce fichier de configuration pour déterminer où et comment émettre des requêtes vers le serveur API. Ce fichier se trouve généralement dans votre répertoire personnel sous ~ /. kube / config mais peut également être spécifié explicitement sur la ligne de commande avec le paramètre – kubeconfig ou via la variable d’environnement KUBECONFIG.
Que vous intégriez ou non vos informations d’identification dans votre kubeconfig dépend du mécanisme d’authentification que vous utilisez et éventuellement de votre position de sécurité. N’oubliez pas que si vous incorporez des informations d’identification dans ce fichier de configuration, elles peuvent être utilisées par toute personne ayant accès à ce fichier. Traitez ce fichier comme s’il s’agissait d’un mot de passe très sensible, car il l’est effectivement.
Pour quelqu’un qui ne connaît peut-être pas un fichier kubeconfig , il est important de comprendre ses trois structures de niveau supérieur: utilisateurs, clusters et contextes. Avec les utilisateurs, nous nommons un utilisateur et fournissons le mécanisme par lequel il ou elle s’authentifiera auprès d’un cluster. L’attribut clusters fournit toutes les données nécessaires pour se connecter à un cluster. Cela inclut, au minimum, l’IP ou le nom de domaine complet du serveur API, mais peut également inclure des éléments tels que le bundle CA pour un certificat auto-signé. Et les con textes sont l’endroit où nous associons les utilisateurs aux clusters comme une seule entité nommée. Le contexte sert de moyen par lequel kubectl se connecte et s’authentifie à un serveur API.
Toutes vos informations d’identification pour tous vos clusters peuvent être représentées avec une seule configuration kubeconfig . Mieux encore, cela est manipulé au moyen de quelques commandes kubectl :
$ export KUBECONFIG=mykubeconfig
$ kubectl config set-credentials cluster-admin –username=admin \ –password=somepassword
kubeconfig
Ensemble “cluster-admin” de l’utilisateur.
$ kubectl config set-credentials regular-user –username=user \
–password=someotherpassword User “regular-user” set.
$ kubectl config set-cluster cluster1 –server=https://10.1.1.3 Cluster “cluster1” set.
$ kubectl config set-cluster cluster2 –server=https://192.168.1.50 Cluster “cluster2” set.
$ kubectl config set-context cluster1-admin –cluster=cluster1 \
–user=cluster-admin Context “cluster1-admin” created.
$ kubectl config set-context cluster1-regular –cluster=cluster1 \
–user=regular-user Context “cluster1-regular” created.
$ kubectl config set-context cluster2-regular –cluster=cluster2 \
–user=regular-user Context “cluster2-regular” created.
$ kubectl config view
apiVersion: v1
clusters:
– cluster:
server: https://10.1.1.3
name: cluster1
cluster:
server: https://192.168.1.50
name: cluster2
contexts:
– context:
cluster: cluster1
user: cluster-admin
name: cluster1-admin
context:
cluster: cluster1
user: regular-user
name: cluster1-regular
– context:
cluster: cluster2
user: regular-user
name: cluster2-regular
current-context: “”
kind: Config
references: {}
users:
– name: cluster-admin
user:
password: somepassword
username: admin
– name: regular-user
user:
password: someotherpassword
username: user
Ici, nous avons créé deux définitions d’utilisateur, deux définitions de cluster et trois contextes. Et maintenant, avec un seul kubectl de plus, nous pouvons réinitialiser notre contexte avec une seule commande supplémentaire.
$ kubectl config use-context cluster2-regular
Switched to context “cluster2-regular”.
Il est donc extrêmement simple de passer d’un cluster au suivant, de basculer à la fois sur le cluster et sur l’utilisateur, ou même de se faire passer pour un autre utilisateur sur le même cluster (ce qui est très utile à avoir dans la boîte à outils d’un administrateur).
Bien qu’il s’agisse d’un exemple très simple utilisant l’authentification de base, les utilisateurs et les clusters peuvent être configurés avec toutes sortes d’options. Et ces configurations peuvent devenir relativement complexes. Cela dit, il s’agit d’un outil puissant simplifié avec quelques opérations en ligne de commande. Utilisez les contextes les plus pertinents pour votre cas d’utilisation.
7.4 Comptes de service
Jusqu’à présent dans ce chapitre, nous avons discuté de la façon dont les utilisateurs s’authentifient avec l’API. Et, à cette époque, nous ne nous sommes vraiment concentrés que sur l’authentification, car elle s’applique à un utilisateur externe à un cluster. Peut-être que c’est vous, exécutant une commande kubectl à partir de votre console ou même en cliquant sur l’interface Web.
Il y a cependant un autre cas d’utilisation important à considérer, et cela concerne la façon dont les processus en cours d’exécution à l’intérieur d’un pod accèdent à l’API. Au début, vous vous demandez peut-être pourquoi un processus exécuté dans le contexte d’un pod peut nécessiter un accès API.
Un cluster Kubernetes est une machine à états constituée d’une collection de contrôleurs. Chacun de ces contrôleurs est responsable de la réconciliation de l’état des ressources spécifiées par l’utilisateur. Donc, dans le cas le plus fondamental, nous devons fournir un accès API à tous les contrôleurs personnalisés que nous avons l’intention de mettre en œuvre. Mais l’accès à l’API Kubernetes à partir d’un contrôleur n’est pas le seul cas d’utilisation. Il existe d’innombrables raisons pour lesquelles un pod peut nécessiter une connaissance de soi ou même une prise de conscience du cluster dans son ensemble.
La façon dont Kubernetes gère ces cas d’utilisation utilise la ressource ServiceAccount :
$ kubectl create sa testsa
$ kubectl get sa testsa -oyaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: testsa
namespace: default
secrets:
– name: testsa-token-nr6md
Vous pouvez considérer les ServiceAccounts comme des comptes d’utilisateurs avec espace de noms pour toutes les ressources Pod.
Dans la sortie ci-dessus, notez que lorsque nous avons créé le ServiceAccount , un secret nommé testsa-token-nr6md a également été créé automatiquement. Tout comme avec l’authentification de l’utilisateur final dont nous avons discuté précédemment, c’est le jeton qui sera inclus en tant que jeton de support à chaque demande d’API. Ces informations d’identification sont montées dans le pod à un emplacement bien connu accessible par les différents clients Kubernetes.
$ kubectl run busybox –image=busybox -it — /bin/sh
If you don’t see a command prompt, try pressing enter.
/ # ls -al /var/run/secrets/kubernetes.io/serviceaccount
total 4 drwxrwxrwt 3 root root 140 Feb 11 20:17 . drwxr-xr-x 3 root root 4096 Feb 11 20:17 .. drwxr-xr-x 2 root root 100 Feb 11 20:17 \
..2982_11_02_20_17_08.558803709
lrwxrwxrwx 1 root root 31 Feb 11 20:17 ..data ->
..2982_11_02_20_17_08.558803709
lrwxrwxrwx 1 root root 13 Feb 11 20:17 ca.crt -> ..data/ca.crt lrwxrwxrwx 1 root root 16 Feb 11 20:17 namespace -> \
..data/namespace
lrwxrwxrwx 1 root root 12 Feb 11 20:17 token -> ..data/token
Même si nous tentons d’authentifier un processus, nous utilisons à nouveau des JWT, et les revendications contenues ressemblent beaucoup à ce que nous avons vu dans les scénarios de jeton d’utilisateur final. Rappelez-vous que l’un des objectifs du serveur API est de mapper des données sur cet utilisateur vers une ressource UserInfo, et ce cas n’est pas différent :
{
“iss”: “kubernetes/serviceaccount”,
“kubernetes.io/serviceaccount/namespace”: “default”,
“kubernetes.io/serviceaccount/secret.name”: “testsa-token-nr6md”,
“kubernetes.io/serviceaccount/service-account.name”: “testsa”, “kubernetes.io/serviceaccount/service-account.uid”:
“23fe204f-0f66-11e8-85d0-080027da173d”, “sub”: “system:serviceaccount:default:testsa”
}
Chaque Pod lancé est associé à un ServiceAccount .
apiVersion: v1
kind: Pod metadata:
name: testpod
spec:
serviceAccountName: testpod-sa
Si aucun n’est spécifié dans le manifeste du pod, un ServiceAccount par défaut est utilisé. Ce ServiceAccount par défaut est disponible à l’échelle de l’espace de noms et est automatiquement créé lorsqu’un espace de noms l’est.
Il existe de nombreux scénarios où il est inapproprié, du point de vue de la sécurité, de fournir à un pod un accès à l’API Kubernetes. Bien qu’il ne soit pas possible d’empêcher un pod d’avoir un ServiceAccount associé, dans le chapitre suivant, nous explorons comment ces cas d’utilisation peuvent être sécurisés.
7.5 Résumé
Dans ce chapitre, nous avons couvert les mécanismes d’authentification des utilisateurs finaux les plus couramment déployés dans Kubernetes. J’espère qu’un ou plusieurs d’entre eux se sont révélés être quelque chose que vous souhaiteriez activer dans votre environnement. Sinon, il y en a quelques autres (par exemple, des fichiers de jetons statiques, des proxys d’authentification et d’autres) qui peuvent être implémentés. Un ou plusieurs d’entre eux répondront certainement à vos besoins.
Bien que vous deviez effectuer une diligence raisonnable dès le départ pour intégrer vos utilisateurs de manière sécurisée et évolutive, n’oubliez pas que, comme pour presque tout dans Kubernetes, ces configurations peuvent évoluer avec le temps. Utilisez la solution qui a du sens pour votre organisation aujourd’hui, sachant que vous pourrez adopter des fonctionnalités supplémentaires de manière transparente à l’avenir.
8 CHAPITRE 8 Autorisation
L’authentification n’est que le premier défi pour une demande d’API Kubernetes. Comme nous l’avons présenté au chapitre 7, il existe deux tests supplémentaires pour chaque demande : le contrôle d’accès et le contrôle d’admission. Bien que l’authentification soit un composant essentiel pour garantir que seuls les utilisateurs de confiance peuvent effectuer des modifications sur un cluster, comme nous l’explorons dans ce chapitre, l’authentification devient également le catalyseur d’un contrôle précis concernant ce que ces utilisateurs peuvent faire.
Au-delà de la simple vérification de l’authenticité d’un utilisateur et de la détermination des niveaux d’accès, nous voulons également nous assurer que chaque demande est conforme à nos besoins commerciaux. Chaque organisation a un certain nombre de normes mises en œuvre. Ces politiques et procédures nous aident à comprendre les infrastructures complexes qui sont nécessaires pour apporter des applications aux environnements de production. Dans ce chapitre, nous examinons comment Kubernetes soutient cela avec les contrôleurs d’admission.
8.1 REST
Comme nous l’avons déjà vu, l’API Kubernetes est une API RESTful. Les propriétés avantageuses d’une API RESTful sont nombreuses (par exemple, l’évolutivité et la portabilité), mais sa structure simple est ce qui nous permet de déterminer les niveaux d’accès au sein de Kubernetes. Pour les lecteurs qui ne connaissent peut-être pas REST, la sémantique est simple : les ressources sont manipulées à l’aide de verbes. Comme dans les langues traditionnelles, si nous demandons à quelqu’un de « supprimer le pod », nous le faisons avec un nom et un verbe. Les API REST fonctionnent de la même manière.
Pour illustrer ce concept, regardons précisément comment kubectl demande des informations sur un Pod. En augmentant simplement le niveau de journalisation à l’aide de l’option -v, nous pouvons obtenir une vue approfondie des appels d’API que kubectl fait en notre nom.
$ kubectl -v=6 get po testpod
I0202 00:28:31.933993 17487 loader.go:357] Config loaded from file
/home/ubuntu/.kube/config
I0202 00:28:31.994930 17487 round_trippers.go:436] GET
https://10.0.0.1:6443/api/v1/namespaces/default/pods/testpod 200 OK
Dans cette simple demande d’informations Pod, nous pouvons voir que kubectl a émis une requête GET (c’est le verbe) pour la ressource pods / testpod . Vous pouvez également remarquer qu’il existe d’autres éléments du chemin URL, tels que la version de l’API, ainsi que l’espace de noms que nous interrogons (par défaut, dans ce cas). Ces éléments ajoutent un contexte supplémentaire à notre demande, mais il suffit de dire que la ressource et le verbe sont les principaux acteurs ici.
Ceux qui ont déjà rencontré REST connaîtront les quatre verbes les plus élémentaires : créer, lire, mettre à jour et supprimer (CRUD). Ces quatre actions sont mappées directement aux verbes HTTP POST, GET, PUT et DELETE, respectivement, et constituent à leur tour la grande majorité des requêtes HTTP que l’on trouve normalement sur Internet.
Vous remarquerez peut-être aussi que ces verbes ressemblent un peu aux verbes que nous utiliserions pour traiter les ressources de Kubernetes, et vous auriez raison. Nous pouvons certainement créer, supprimer, mettre à jour et même recueillir des informations sur un pod, par exemple. Tout comme avec HTTP, ces quatre verbes constituent les éléments les plus fondamentaux de la façon dont nous interagirions avec les ressources Kubernetes, mais dans notre cas, nous ne sommes pas limités à ces quatre seuls. Au sein de l’API Kubernetes, en plus d’obtenir, de mettre à jour, de supprimer et de corriger, nous avons également accès à la liste des verbes, à la surveillance, au proxy, à la redirection et à la suppression de collecte, lorsqu’il s’agit de ressources. Ce sont les verbes que kubectl (et n’importe quel client, d’ailleurs) utilise en coulisses pour nous.
Les ressources de Kubernetes sont des constructions familières – pods, services et déploiements, entre autres – que nous manipulons à l’aide de ces verbes.
8.2 Autorisation
Ce n’est pas parce que les utilisateurs sont authentifiés que nous devons tous leur accorder des droits d’accès égaux. Par exemple, nous pouvons souhaiter que les membres de l’équipe de développement Web aient la possibilité de manipuler les déploiements servant les demandes Web, mais pas les pods sous-jacents qui servent d’unités de calcul pour ces déploiements. Ou peut-être, même au sein de l’équipe Web elle-même, nous pourrions avoir un groupe qui peut créer des ressources et un autre groupe qui ne peut pas. En bref, nous aimerions déterminer quelles actions sont autorisées en fonction de qui est l’utilisateur et / ou des groupes dont il est membre.
Ce processus est connu sous le nom d’autorisation, et c’est le prochain défi que Kubernetes teste pour chaque demande d’API. Ici, nous demandons : « Cet utilisateur est-il autorisé à effectuer cette action ? »
Tout comme pour l’authentification, l’autorisation est la responsabilité du serveur API. Le serveur API peut être configuré pour implémenter divers modules d’autorisation en utilisant l’argument –authorization-mode convenablement nommé à l’exécutable kube-apiserver.
Le serveur API transmet chaque demande à ces modules dans l’ordre défini par l’argument délimité par des virgules – mode d’autorisation. Chaque module, à son tour, peut peser sur le processus de prise de décision ou choisir de s’abstenir. En cas d’abstinence, la demande d’API passe simplement au module suivant pour évaluation. Cependant, si un module prend une décision, l’autorisation est résiliée et reflète la décision du module d’autorisation. Si le module refuse la demande, l’utilisateur reçoit une réponse HTTP 403 (interdite) appropriée, et si la demande est autorisée, la demande se rend à l’étape finale du flux d’API : l’évaluation du contrôleur d’admission.
Au moment d’écrire ces lignes, six modules d’autorisation peuvent être configurés. Les modules les plus simples et les plus directs sont les modules AlwaysAllow et AlwaysDeny , et comme leur nom l’indique, ces modules autorisent ou refusent une demande, respectivement. Ces deux modules ne conviennent vraiment qu’aux environnements de test.
Le module d’autorisation des nœuds est responsable de l’application des règles d’autorisation que nous aimerions appliquer aux demandes d’API effectuées par les nœuds de travail. Tout comme les utilisateurs finaux, les processus de kubelet sur chacun des nœuds exécutent une variété de demandes d’API. Par exemple, le statut Node qui est présenté lorsque vous exécutez kubectl get nodes est possible car le kubelet a fourni son état au serveur API avec une demande PATCH.
PATCH https://k8s.example.com:6443/api/v1/nodes/node1.example.com/status 200 OK
De toute évidence, le kubelet ne devrait pas avoir accès à des ressources comme nos pods de service Web. Ce module limite les capacités du kubelet au sous-ensemble de requêtes nécessaires pour maintenir un nœud de travail fonctionnel.
8.3 Contrôle d’accès basé sur les rôles
Le moyen le plus efficace d’autorisation d’utilisateur dans Kubernetes utilise le module RBAC. Abréviation de contrôle d’accès basé sur les rôles, ce module permet la mise en œuvre de politiques de contrôle d’accès dynamique lors de l’exécution.
Ceux qui sont habitués à ce type d’autorisation d’autres cadres pourraient maintenant gémir. La façon dont certains de ces cadres ont mis en œuvre le RBAC est trop souvent un processus compliqué et compliqué. Lorsque la définition des niveaux d’accès est fastidieuse, il peut être tentant de fournir des contrôles d’accès à granularité grossière, le cas échéant. Pire encore, lorsque la configuration de ces contrôles est statique ou rigide, vous pouvez presque garantir qu’ils ne seront pas mis en œuvre efficacement.
Heureusement, Kubernetes rend la définition et la mise en œuvre des politiques RBAC extraordinairement simples. En résumé, Kubernetes mappe les attributs de l’objet User Info aux ressources et aux verbes auxquels l’utilisateur doit avoir accès.
8.3.1 Rôle et rôle de cluster
Avec le module RBAC, l’autorisation d’effectuer une action sur une ressource est définie avec les types de ressources Role ou ClusterRole . (Nous allons plonger dans la différence entre ces ressources sous peu.) Pour commencer, concentrons-nous d’abord uniquement sur la ressource Rôle. Une implémentation de l’exemple précédent (où un utilisateur a un accès en lecture-écriture aux déploiements mais uniquement un accès en lecture aux pods) pourrait ressembler à ceci:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: web-rw-deployment
namespace: some-web-app-ns
rules:
– apiGroups: [“”]
resources: [“pods”]
verbs: [“get”, “list”, “watch”]
– apiGroups: [“extensions”, “apps”]
resources: [“deployments”]
verbs: [“get”, “list”, “watch”, “create”, “update”, “patch”, “delete”]
Dans cette configuration de rôle, nous avons créé une stratégie qui permet d’appliquer des actions de type lecture aux pods et des droits d’accès en lecture-écriture complets pour les déploiements. Ce rôle imposerait que toutes les modifications apportées aux pods enfants d’un déploiement se produisent au niveau du déploiement (par exemple, les mises à jour continues ou la mise à l’échelle).
Le champ apiGroups de chaque règle indique simplement au serveur d’API l’espace de noms de l’API sur lequel il doit agir. (Cela reflète l’espace de noms API défini dans la apiVer sion domaine de la définition de votre ressource.)
Dans les deux champs suivants, ressources et verbes, nous rencontrons les constructions REST dont nous avons discuté précédemment. Et, dans le cas de RBAC, nous permettons explicitement ces types de requêtes API pour un utilisateur avec ce Web- rw rôle -Déploiement. Puisque les règles sont un tableau, nous pouvons ajouter autant de combinaisons d’autorisations que nécessaire. Toutes ces autorisations sont additives. Avec RBAC, nous ne pouvons accorder que des actions, et ce module refuse autrement par défaut.
Role et ClusterRole ont des fonctionnalités identiques et ne diffèrent que par leur portée. Dans l’exemple qui vient d’être montré, vous remarquerez peut-être que cette stratégie est liée aux ressources de l’espace de noms some-web-app-ns. Cela signifie que cette stratégie n’est appliquée qu’aux ressources de cet espace de noms.
Si nous voulons accorder une autorisation qui a des capacités d’espace de noms croisés, nous utilisons la ressource ClusterRole . Cette ressource, de la même manière, accorde un contrôle fin mais à l’échelle du cluster.
Vous vous demandez peut-être pourquoi quelqu’un ne voudrait jamais mettre en œuvre des politiques comme celle-ci. Les rôles de cluster sont généralement utilisés pour deux cas d’utilisation principaux: pour accorder facilement aux administrateurs de cluster un large degré de liberté ou pour accorder des autorisations très spécifiques à un contrôleur Kubernetes.
Le premier cas est simple. Nous souhaitons souvent que les administrateurs disposent d’un large accès afin de pouvoir facilement déboguer les problèmes. Bien sûr, nous pourrions avoir une stratégie de rôle pour chaque espace de noms que nous créerons finalement, mais il peut être plus judicieux de simplement accorder cet accès avec un ClusterRole . Étant donné que ces autorisations sont très étendues, nous utilisons cette construction avec prudence.
La plupart des contrôleurs Kubernetes souhaitent surveiller les ressources dans les espaces de noms, puis réconcilier les états de cluster de manière appropriée. Nous pouvons utiliser des stratégies ClusterRole pour nous assurer que les contrôleurs n’ont accès qu’aux ressources qui leur tiennent à cœur.
Tous les contrôleurs Kubernetes (par exemple, les déploiements ou les StatefulSets ) ont la même structure de base. Ils sont une machine à états qui surveille l’API Kubernetes pour les changements (ajouts, modifications et suppressions) et cherche à se réconcilier de l’état actuel à l’état souhaité spécifié par l’utilisateur.
Imaginez un scénario où nous voulions créer des enregistrements DNS basés sur une annotation spécifiée par l’utilisateur sur une ressource de service ou d’entrée. Notre contrôleur devrait surveiller ces ressources et prendre des mesures en cas de changement. Il ne serait pas sûr de donner à ce contrôleur l’accès à d’autres ressources et à des verbes inappropriés (par exemple, SUPPRIMER sur les pods). Nous pouvons utiliser une stratégie ClusterRole pour fournir le niveau d’accès correct comme suit :
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole metadata:
name: external-dns rules:
– apiGroups: [“”]
resources: [“services”]
verbs: [“get”, “watch”, “list”]
– apiGroups: [“extensions”]
resources: [“ingresses”]
verbs: [“get”, “watch”, “list”]
Et c’est exactement ainsi que fonctionne le projet d’incubateur externe dns Kubernetes .
Avec cette politique ClusterRole en place, un contrôleur externe du DNS peut surveiller les ajouts, les modifications ou même les suppressions de ressources de service et d’entrée et agir en conséquence. Et, plus important encore, ces contrôleurs ne pas avoir accès à tous les autres aspects de l’API.
Assurez-vous de comprendre toutes les implications lorsque vous accordez des droits d’accès aux utilisateurs avec RBAC. Cherchez toujours à ne donner que les droits nécessaires, car cela réduit considérablement votre exposition à la sécurité. Comprenez également que certains droits accordent des droits implicites – et peut-être involontaires – à d’autres ressources. En particulier, vous devez savoir que l’octroi de droits de création à un pod accorde effectivement un accès en lecture à des ressources plus sensibles et connexes, comme les secrets. Étant donné que les secrets peuvent être montés ou exposés via des variables d’environnement à un pod, les droits de création de pod permettent à un propriétaire de pod de lire ces secrets non cryptés.
8.3.2 RoleBinding et ClusterRoleBinding
Vous remarquerez que ni Role ni ClusterRole ne spécifient les utilisateurs ou groupes à cibler avec leurs règles. Les stratégies seules sont inutiles sauf si elles sont appliquées à un utilisateur ou à un groupe. Pour associer ces stratégies à des utilisateurs, des groupes ou des comptes de service, nous pouvons utiliser les ressources RoleBinding et ClusterRoleBinding . La seule différence ici est de savoir si nous essayons de lier un rôle ou un rôle de cluster. Encore une fois, les liaisons de rôles sont à espace de noms.
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: web-rw-deployment
namespace: some-web-app-ns
subjects:
– kind: User
name: “joesmith@example.com”
apiGroup: rbac.authorization.k8s.io
– kind: Group name: “webdevs”
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: web-rw-deployment
apiGroup: rbac.authorization.k8s.io
Dans cet exemple, nous avons associé le rôle web- rw- deployment dans l’espace de noms some- webapp -ns à joesmith@example.com, ainsi qu’à un groupe avec le nom web devs.
Comme vous vous en souvenez peut-être du chapitre 7, l’objectif de chaque type de mécanisme d’authentification est double : premièrement, garantir que les informations d’identification de l’utilisateur correspondent à nos attentes, et deuxièmement, obtenir des informations sur un utilisateur authentifié. Ces informations sont transmises avec la ressource UserInfo bien nommée. Les valeurs de chaîne que nous spécifions ici reflètent les informations utilisateur obtenues lors de l’authentification.
En ce qui concerne l’autorisation, il existe trois types de sujets auxquels nous pouvons appliquer la politique : les utilisateurs, les groupes et les comptes de service. Dans le cas des utilisateurs et des groupes, ceux-ci sont définis respectivement par les champs Nom d’utilisateur et Groupes UserInfo .
Les valeurs de ces champs sont des chaînes, dans le cas du nom d’utilisateur, et une liste de chaînes pour les groupes, et la comparaison utilisée pour l’inclusion est une simple correspondance de chaîne. Ces valeurs de chaîne dépendent de vous et peuvent correspondre à toutes les valeurs de chaîne uniques fournies par votre système d’autorisation pour identifier un utilisateur ou un groupe.
Les comptes de service sont spécifiés explicitement avec le type de sujet de comptage ServiceAc correctement nommé.
…
subjects:
– kind: ServiceAccount
name: testsa
namespace: some-web-app-ns
N’oubliez pas que ServiceAccounts fournit les informations d’identification de l’API Kubernetes pour tous les processus Pod en cours d’exécution. Chaque pod a un ServiceAccount associé, que nous spécifions ou non quel serviceAccountName utiliser dans le manifeste du pod. Sans surveillance, cela pourrait poser un problème de sécurité important.
Cette préoccupation peut être largement atténuée par les politiques de RBAC. Étant donné que les stratégies RBAC sont refusées par défaut, nous avons recommandé que tout pod nécessitant des capacités API ait son propre ServiceAccount (ou éventuellement partagé) avec une stratégie RBAC à granularité associée. Accordez uniquement à ce ServiceAccount les actions et les ressources dont il a besoin pour fonctionner correctement.
Rappelez l’exemple des dns externes de ClusterRole . Étant donné que la machine d’état du contrôleur émet des demandes à l’API Kubernetes à partir d’un contexte de pod, nous pouvons utiliser une liaison ClusterRole avec un objet ServiceAccount pour activer cette fonctionnalité :
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: external-dns-binding
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: external-dns subjects:
– kind: ServiceAccount
name: external-dns
namespace: default
8.3.3 Autorisation de test
À mesure que le nombre d’utilisateurs, de groupes et de charges de travail sur un cluster Kubernetes augmente, la complexité augmente également. Bien que RBAC soit un mécanisme simple permettant d’appliquer des politiques d’autorisation à une collection de sujets, la mise en œuvre et le débogage des droits d’accès peuvent parfois être difficiles. Heureusement, kubectl fournit une ressource pratique pour vérifier nos politiques sans avoir à effectuer de réel changement sur le cluster. Pour tester l’accès, utilisez simplement kubectl pour définir le contexte de l’utilisateur que vous souhaitez vérifier (ou d’un utilisateur faisant partie d’un groupe que vous devez vérifier).
$ kubectl use-context admin
$ kubectl auth can-i get pod
yes
Ici, nous pouvons voir que l’utilisateur administrateur a accès à la ressource Pod dans l’espace de noms par défaut.
Après avoir créé une politique beaucoup plus restreinte, où l’utilisateur est empêché de créer des ressources (espace de noms qui sont étendues au cluster), nous utilisons CAN- i pour confirmer cette politique :
$ kubectl use-context basic-user
$ kubectl create namespace mynamespace
Erreur du serveur (interdit): les espaces de noms sont interdits: l’utilisateur “utilisateur de base” ne peut pas créer d’espaces de noms au niveau du cluster
$ kubectl auth can-i create namespace no
Notez que l’utilisateur a reçu l’interdit approprié lors de sa première tentative de création du mynamespace namespace .
Dans ce chapitre, nous ne couvrons pas le module de contrôle d’accès basé sur les attributs (ABAC). Ce module est sémantiquement très similaire au module RBAC, à l’exception que ces politiques sont définies statiquement avec un fichier de configuration sur chacun des serveurs d’API Kubernetes. Tout comme certains des autres éléments de configuration basés sur des fichiers dont nous avons discuté, cette politique n’est pas dynamique. Un administrateur doit redémarrer le processus kube-apiserver chaque fois qu’il souhaite modifier cette stratégie. Cet aspect le rend peu pratique pour le module RBAC plus robuste et prêt pour la production.
8.4 Résumé
Dans ce chapitre, nous avons couvert la nature RESTful de l’API Kubernetes et comment sa structure se prête bien à l’application des politiques. Nous avons également exploré le lien direct entre l’autorisation et ce que nous avons déjà couvert au sujet de l’authentification. L’autorisation est l’un des composants essentiels nécessaires au déploiement d’un système distribué sécurisé à plusieurs locataires. Avec RBAC, Kubernetes nous offre la possibilité d’appliquer à la fois des politiques de balayage très grossières et extrêmement spécifiques à un utilisateur ou à un groupe. Et, parce que Kubernetes rend la définition et la maintenance de ces politiques si simples à mettre en œuvre, il n’y a vraiment aucune raison pour que même les déploiements les plus élémentaires ne puissent pas les utiliser. Il s’agit d’une première étape parfaite vers des utilisateurs, des administrateurs et des auditeurs satisfaits.
9 CHAPITRE 9 Contrôle d’admission
Comme nous l’avons mentionné dans les deux chapitres précédents, le contrôle d’admission est la troisième phase de l’intégration des demandes d’API. Au moment où nous avons atteint cette phase du cycle de vie d’une demande d’API, nous avons déjà déterminé que la demande venait d’un utilisateur réel et authentifié et que l’utilisateur est autorisé à exécuter cette demande. Ce qui nous importe maintenant, c’est de savoir si la demande répond aux critères de ce que nous considérons comme une demande valide et, sinon, quelle action prendre. Devrions-nous rejeter la demande entièrement, ou devrions-nous la modifier pour répondre à nos normes commerciales ? Pour ceux qui connaissent le concept de middleware API, les contrôleurs d’admission sont très similaires en fonction.
Bien que l’authentification et le contrôle d’admission soient tous deux essentiels à un déploiement réussi, le contrôle d’admission est l’endroit où vous, en tant qu’administrateur, pouvez vraiment commencer à gérer les charges de travail de vos utilisateurs. Ici, vous pouvez limiter les ressources, appliquer des stratégies et activer des fonctionnalités avancées. Cela permet de stimuler l’utilisation, d’ajouter un peu de raison aux diverses charges de travail et d’intégrer de manière transparente les nouvelles technologies.
Heureusement, tout comme avec les deux autres phases, Kubernetes offre un large éventail de capacités d’admission dès la sortie de la boîte. Bien que l’authentification et l’autorisation ne changent pas beaucoup entre les versions, le contrôle d’admission est tout le contraire. Il existe une liste apparemment sans fin de fonctionnalités que les utilisateurs recherchent en ce qui concerne la façon dont ils gèrent leurs clusters. Et, parce que le contrôle d’admission est l’endroit où la majeure partie de cette magie se produit, il n’est pas surprenant que ce composant évolue continuellement.
Nous pourrions écrire des articles sur les capacités natives de contrôle d’admission de Kubernetes. Cependant, comme ce n’est pas vraiment pratique, nous nous concentrons ici sur certains des contrôleurs les plus populaires, ainsi que sur la façon dont vous pouvez implémenter le vôtre.
9.1 Configuration
L’activation du contrôle d’admission est extrêmement simple. Comme il s’agit d’une fonction API, nous ajoutons l’indicateur –enable-admission-plugins aux paramètres d’exécution de kube-apiserver . Comme les autres éléments de configuration, il s’agit d’une liste délimitée par des virgules des contrôleurs d’admission que nous voulons activer.
Avant Kubernetes 1.10, l’ordre dans lequel les contrôleurs d’admission étaient spécifiés importait. Avec l’introduction du paramètre de ligne de commande – enableadmission -plugins, ce n’est plus le cas. Pour les versions 1.9 et antérieures, vous devez utiliser l’ordre – en fonction –admission contrôle paramètre.
9.2 Contrôleurs communs
La plupart des fonctionnalités que les utilisateurs tiennent pour acquises dans Kubernetes se produisent en fait au moyen de contrôleurs d’admission. Par exemple, le contrôleur d’admission ServiceAccount alloue automatiquement des pods à un ServiceAccount . De même, si vous avez essayé d’ajouter de nouvelles ressources à un espace de noms qui est actuellement dans un état de fin, votre demande a probablement été rejetée par le contrôleur NamespaceLifecycle .
Les contrôleurs d’admission prêts à l’emploi de Kubernetes ont deux objectifs principaux : garantir que les valeurs par défaut saines sont utilisées en l’absence de valeurs spécifiées par l’utilisateur, et garantir que les utilisateurs n’ont pas plus de capacités que nécessaire. Un grand nombre des actions qu’un utilisateur est autorisé à effectuer sont contrôlées avec RBAC, mais les contrôleurs d’admission permettent aux administrateurs de définir des stratégies précises supplémentaires qui vont au-delà des ressources simplistes, des actions et des stratégies de sujet proposées par l’autorisation.
9.2.1 Politiques de PodSecurity
L’un des contrôleurs d’admission les plus largement utilisés est le contrôleur PodSecurityPolicies . Avec ce contrôleur, les administrateurs peuvent spécifier les contraintes des processus sous le contrôle de Kubernetes. Avec PodSecurityPolicies , les administrateurs peuvent imposer que les pods ne peuvent pas s’exécuter dans un contexte privilégié, qu’ils ne peuvent pas se lier au hostNetwork , doivent s’exécuter en tant qu’utilisateur particulier et qu’ils sont limités par une variété d’autres attributs axés sur la sécurité.
Lorsque PodSecurityPolicies est activé, les utilisateurs ne peuvent pas intégrer de nouveaux pods à moins qu’il n’y ait des stratégies autorisées en place. Les politiques peuvent être aussi permissives ou restrictives que l’exige la posture de sécurité de votre organisation. Dans les environnements de production multi-utilisateurs, les administrateurs doivent utiliser la plupart des stratégies proposées par PodSecurityPolicies , car celles-ci améliorent considérablement la sécurité globale du cluster.
Prenons un cas simple mais typique, où nous aimerions nous assurer que les pods ne peuvent pas fonctionner dans un contexte privilégié. La définition de la politique se fait, comme d’habitude, via l’API Kubernetes:
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: non-privileged
spec:
privileged: false
Si vous deviez créer cette stratégie, l’appliquer au serveur d’API, puis tenter de créer un pod conforme, la demande serait rejetée, car votre utilisateur et / ou le compte de service ne seraient pas autorisés à utiliser la stratégie. Pour corriger cette situation, créez simplement un rôle RBAC qui permet à l’un de ces types de sujets d’utiliser cette politique PodSecurity :
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: non-privileged-user
namespace: user-namespace rules:
– apiGroups: [‘policy’]
resources: [‘podsecuritypolicies’]
verbs: [‘use’]
resources:
– non-privileged
et son RoleBinding :
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: non-privileged-user
namespace: user-namespace roleRef:
kind: Role
name: non-privileged-user
apiGroup: rbac.authorization.k8s.io
subjects:
– kind: ServiceAccount
name: some-service-account
Une fois qu’un utilisateur est autorisé à utiliser un PodSecurityPolicy , le Pod peut être déclaré tant qu’il est conforme aux politiques définies.
Étant donné que PodSecurityPolicys est implémenté en tant que contrôleur d’admission (qui applique la stratégie pendant le flux de demande d’API), les pods qui ont été planifiés avant l’activation de PodSecurityPolicy peuvent ne plus être conformes. Gardez cela à l’esprit, car les redémarrages de ces pods peuvent les rendre impossibles à planifier. Idéalement, le contrôleur d’admission PodSecurityPolicy est activé au moment de l’installation .
9.2.2 ResourceQuota
De manière générale, il est recommandé d’appliquer des quotas sur votre cluster. Les quotas garantissent qu’aucun utilisateur ne peut utiliser plus que ce qui lui a été alloué et constitue un élément essentiel pour stimuler l’utilisation globale du cluster. Si vous avez l’intention d’imposer des quotas d’utilisateurs, vous devez également activer le contrôleur ResourceQuota .
Ce contrôleur garantit que tous les pods nouvellement déclarés sont d’abord évalués par rapport à l’utilisation actuelle du quota pour l’espace de noms donné. En effectuant cette vérification lors de l’intégration de la charge de travail, nous informons immédiatement un utilisateur que son pod correspondra ou non au quota. Notez également que lorsqu’un quota est défini pour un espace de noms, toutes les définitions de pod (même si elles proviennent d’une autre ressource, telles que les déploiements ou les ReplicaSets ) sont nécessaires pour spécifier les demandes et les limites de ressources.
Les quotas peuvent être implémentés pour une liste de ressources en constante augmentation, mais certaines des plus courantes incluent le processeur, la mémoire et les volumes. Il est également possible de placer des quotas sur le nombre de ressources Kubernetes distinctes (par exemple, pods, déploiements, travaux, etc.) dans un espace de noms .
La configuration des quotas est simple:
$ cat quota.yml
apiVersion: v1
kind: ResourceQuota
metadata:
name: memoryquota
namespace: memoryexample
spec:
hard:
requests.memory: 256Mi
limits.memory: 512Mi
Maintenant, si nous essayons de dépasser la limite, même avec un seul pod, notre déclaration est immédiatement rejetée par le contrôleur d’admission ResourceQuota :
$ cat pod.yml
apiVersion: v1
kind: Pod metadata:
name: nginx
namespace: memoryexample
labels:
app: nginx
spec:
containers:
– name: nginx
image: nginx
ports:
– containerPort: 80
resources:
limits:
memory: 1Gi
requests:
memory: 512Mi
$ kubectl apply -f pod.yml
Error from server (Forbidden): error when creating “pod.yml”: pods “nginx” is forbidden: exceeded quota: memoryquota, requested: limits.memory=1Gi,requests.memory=512Mi, used: limits.memory=0,requests.memory=0,limited: limits.memory=512Mi,requests.memory=256Mi
Bien que ce soit un peu moins évident, il en va de même pour les pods créés au moyen de ressources d’ordre supérieur, comme les déploiements :
$ cat deployment.yml apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: memoryexample
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
– name: nginx
image: nginx
ports:
– containerPort: 80
resources:
limits:
memory: 256Mi
requests:
memory: 128Mi
$ kubectl apply -f deployment.yml
deployment.apps “nginx-deployment” configured
$ kubectl get po -n memoryexample
NAME READY STATUS RESTARTS AGE
nginx-deployment-55dd98c6c8-9xmjn 1/1 Running 0 25s
nginx-deployment-55dd98c6c8-hc2pf 1/1 Running 0 24s
Même si nous avons spécifié trois répliques, nous n’avons pu en satisfaire que deux sur la base du quota. Si nous décrivons le ReplicaSet résultant, nous voyons l’échec :
Warning FailedCreate 3s (x4 over 3s) replicaset-controller
(combined from similar events): Error creating: pods
“nginx-deployment-55dd98c6c8-tkrtz” is forbidden: exceeded quota: memoryquota, requested: limits.memory=256Mi,requests.memory=128Mi, used: limits.memory=512Mi,requests.memory=256Mi, limited: limits.memory=512Mi,requests.memory=256Mi
Encore une fois, cette erreur provient du contrôleur d’admission ResourceQuota , mais cette fois, l’erreur est quelque peu masquée, car elle est renvoyée au ReplicaSet du déploiement (qui est le créateur des pods).
À l’heure actuelle, il devient probablement clair que les quotas peuvent vous aider à gérer efficacement vos ressources.
9.2.3 LimitRange
Complémentaire à ResourceQuota, le contrôleur d’admission LimitRange est nécessaire si vous avez défini des stratégies LimitRange par rapport à un espace de noms. Un LimitRange , en termes simples, vous permet de placer des limites de ressources par défaut pour les pods qui sont déclarés en tant que membre d’un espace de noms particulier .
apiVersion: v1
kind: LimitRange metadata:
name: default-mem
spec:
limits:
– default:
memory: 1024Mi
defaultRequest:
memory: 512Mi
type: Container
Cette capacité est importante dans les scénarios où des quotas ont été définis. Lorsque les quotas sont activés, un utilisateur qui n’a pas défini de limites de ressources sur son pod voit sa demande rejetée. Avec le contrôleur d’admission LimitRange, un pod sans limite de ressources définie est, au lieu de cela, donné des valeurs par défaut (telles que définies par l’administrateur) et le pod est accepté.
9.3 Contrôleurs d’admission dynamiques
Jusqu’à présent, nous nous sommes concentrés sur les contrôleurs d’admission disponibles auprès de Kubernetes lui-même. Il peut cependant arriver que la fonctionnalité native ne la coupe tout simplement pas. Dans des scénarios comme celui-ci, nous devons développer des fonctionnalités supplémentaires qui nous aident à atteindre nos objectifs commerciaux. Heureusement, Kubernetes prend en charge un large éventail de points d’extensibilité, et cela est également vrai pour les contrôleurs d’admission.
Le contrôle d’admission dynamique est le mécanisme par lequel nous injectons une logique métier personnalisée dans le pipeline de contrôle d’admission. Il existe deux types de contrôle d’admission dynamique : la validation et la mutation.
Avec la validation du contrôle d’admission, notre logique métier accepte ou rejette simplement la demande d’un utilisateur, en fonction de nos besoins. En cas d’échec, un code d’état HTTP approprié et la raison de l’échec sont renvoyés à l’utilisateur. Nous incitons l’utilisateur final à déclarer des spécifications de ressources conformes et, nous l’espérons, à le faire d’une manière qui ne provoque pas de consternation.
Dans le cas du contrôleur d’admission en mutation, nous évaluons à nouveau les demandes par rapport au serveur API, mais dans ce cas, nous modifions de manière sélective la déclaration pour atteindre nos objectifs. Dans les cas simplistes, cela peut être quelque chose d’aussi simple que d’appliquer une série d’étiquettes bien connues à la ressource. Dans des cas plus élaborés, nous pouvons aller jusqu’à injecter de manière transparente un sidecar. Alors que dans ce cas, nous assumons une grande partie de la charge pour l’utilisateur final, cela peut parfois devenir un peu déroutant pour l’utilisateur lorsqu’il découvre que de la magie supplémentaire se produit dans les coulisses. Cela dit, cette capacité, si elle est bien documentée, peut être critique pour la mise en œuvre d’architectures avancées.
Dans les deux cas, cette fonctionnalité est implémentée à l’aide de webhooks définis par l’utilisateur. Ces webhooks en aval sont appelés par le serveur API lorsqu’il voit qu’une demande éligible a été effectuée. (Comme nous le verrons dans les exemples suivants, les utilisateurs peuvent qualifier les demandes d’une manière similaire à la manière dont les stratégies RBAC sont définies.) Le serveur d’API POST un objet AdmissionReview à ces webhooks. Le corps de cette demande inclut la demande d’origine, l’état de l’objet et les métadonnées sur l’utilisateur demandeur.
À son tour, le webhook fournit un simple objet AdmissionResponse . Cet objet comprend des champs pour savoir si cette demande est autorisée, une raison et un code d’échec, et même un champ pour ce à quoi ressemblerait un patch de mutation.
Pour utiliser les contrôleurs d’admission dynamiques, vous devez d’abord configurer le serveur API avec une modification du paramètre –enable-admission-plugins :
–enable-admission-plugins=…,MutatingAdmissionWebhook,\
ValidatingAdmissionWebhook
Notez que le contrôle d’admission dynamique, bien que extraordinairement puissant, est encore un peu tôt dans son cycle de maturité. Ces fonctionnalités étaient alpha à partir de 1.8 et bêta en 1.9. Comme pour toutes les nouvelles fonctionnalités, assurez-vous de consulter la documentation de Kubernetes pour des recommandations supplémentaires concernant ces points d’extension.
9.3.1 Validation des contrôleurs d’admission
Voyons comment nous pouvons implémenter notre propre contrôleur d’admission de validation et réutiliser un exemple précédent. Notre contrôleur inspectera toutes les demandes Pod CREATE pour s’assurer que chaque pod a une étiquette d’environnement et que l’étiquette a une valeur de dev ou prod.
Pour démontrer que vous pouvez écrire des contrôleurs d’admission dynamiques dans la langue de votre choix, nous utilisons une application Python Flask pour cet exemple:
import json
import os
from flask import jsonify, Flask, request
app = Flask(__name__)
@app.route(‘/’, methods=[‘POST’]) def validation():
review = request.get_json()
app.logger.info(‘Validating AdmissionReview request: %s’,
json.dumps(review, indent=4))
labels = review[‘request’][‘object’][‘metadata’][‘labels’]
response = {}
msg = None
if ‘environment’ not in list(labels):
msg = “Every Pod requires an ‘environment’ label.”
response[‘allowed’] = False
elif labels[‘environment’] not in (‘dev’, ‘prod’,):
msg = “‘environment’ label must be one of ‘dev’ or ‘prod'”
response[‘allowed’] = False
else:
response[‘allowed’] = True
status = {
‘metadata’: {},
‘message’: msg
}
response[‘status’] = status
review[‘response’] = response
return jsonify(review), 200
context = (
os.environ.get(‘WEBHOOK_CERT’, ‘/tls/webhook.crt’),
os.environ.get(‘WEBHOOK_KEY’, ‘/tls/webhook.key’),
)
app.run(host=’0.0.0.0′, port=’443′, debug=True, ssl_context=context)
Nous conteneurisons cette application et la rendons disponible en interne avec un service ClusterIP :
—
apiVersion: v1
kind: Pod
metadata:
name: label-validation
namespace: infrastructure
labels:
controller: label-validator
spec:
containers:
– name: label-validator
image: label-validator:latest
volumeMounts:
– mountPath: /tls
name: tls
volumes:
– name: tls
secret:
secretName: admission-tls
—
kind: Service
apiVersion: v1
metadata:
name: label-validation
namespace: infrastructure
spec:
selector:
controller: label-validator
ports:
– protocol: TCP
port: 443
Dans ce cas, le webhook est hébergé sur le cluster. Par souci de simplicité, nous avons utilisé un pod autonome, mais il n’y a aucune raison pour qu’il ne puisse pas être déployé avec quelque chose d’un peu plus robuste, comme un déploiement. Et, comme pour tout service Web, nous le sécurisons avec TLS.
Une fois ce service disponible, nous devons demander au serveur API d’appeler notre webhook. Nous indiquons quelles ressources et opérations nous intéressent, et le serveur API n’appelle ce webhook que lorsqu’une demande qui répond à cette qualification est observée.
apiVersion: admissionregistration.k8s.io/v1beta1
kind: ValidatingWebhookConfiguration
metadata:
name: label-validation
webhooks:
– name: admission.example.com
rules:
– apiGroups:
– “”
apiVersions:
– v1
operations:
– CREATE
resources:
– pods
clientConfig:
service:
namespace: infrastructure
name: label-validation
caBundle:
Avec une ValidatingWebhookConfiguration en place, nous pouvons maintenant vérifier que notre stratégie fonctionne comme prévu. Tenter d’appliquer un pod sans étiquette d’environnement donne:
# kubectl apply -f pod.yaml
Error from server: error when creating “pod.yaml”: admission webhook
“admission.example.com” denied the request: Every Pod requires an ‘environment’ label.
De même, avec une étiquette environment = staging :
# kubectl apply -f pod.yaml
Error from server: error when creating “pod.yaml”: admission webhook
“admission.example.com” denied the request: ‘environment’ label must be one of ‘dev’ or ‘prod’
Ce n’est que lorsque nous ajoutons une étiquette d’environnement conformément aux spécifications que nous sommes en mesure de créer avec succès un nouveau pod.
Notez que notre application est servie via TLS. Comme les demandes d’API peuvent contenir des informations sensibles, tout le trafic doit être crypté.
9.3.2 Contrôleurs d’admission mutants
Si nous modifions notre exemple, nous pouvons facilement développer un webhook mutant. Encore une fois, avec un webhook en mutation, nous essayons de modifier la définition des ressources de manière transparente pour l’utilisateur.
Dans cet exemple, nous injectons un conteneur proxy side-car. Bien que ce side-car soit simplement un processus nginx d’aide, nous pourrions modifier n’importe quel aspect de la ressource.
Soyez prudent lors de la modification des ressources lors de l’exécution, car il peut exister une logique qui dépend de valeurs bien définies et / ou précédemment définies. Une règle générale consiste à définir uniquement les champs précédemment non définis. Évitez toujours de modifier les valeurs d’espaces de noms (par exemple, les annotations de ressources).
Notre nouveau webhook ressemble à ceci :
import base64
import json
import os
from flask import jsonify, Flask, request
app = Flask(__name__)
@app.route(“/”, methods=[“POST”])
def mutation():
review = request.get_json()
app.logger.info(“Mutating AdmissionReview request: %s”,
json.dumps(review, indent=4))
response = {}
patch = [{
‘op’: ‘add’,
‘path’: ‘/spec/containers/0’,
‘value’: {
‘image’: ‘nginx’,
‘name’: ‘proxy-sidecar’,
}
}]
response[‘allowed’] = True
response[‘patch’] = base64.b64encode(json.dumps(patch))
response[‘patchType’] = ‘application/json-patch+json’
review[‘response’] = response
return jsonify(review), 200
context = (
os.environ.get(“WEBHOOK_CERT”, “/tls/webhook.crt”),
os.environ.get(“WEBHOOK_KEY”, “/tls/webhook.key”),
)
app.run(host=’0.0.0.0′, port=’443′, debug=True, ssl_context=context)
Ici, nous utilisons la syntaxe JSON Patch pour ajouter le proxy-sidecar au pod.
Tout comme avec le webhook de validation, nous conteneurisons l’application, puis configurons dynamiquement le serveur API pour transmettre les demandes au webhook. La seule différence est que nous utiliserons une MutatingWebhookConfiguration et pointerons naturellement vers le service ClusterIP interne :
apiVersion: admissionregistration.k8s.io/v1beta1
kind: MutatingWebhookConfiguration
metadata:
name: pod-mutation webhooks:
– name: admission.example.com
rules:
– apiGroups:
– “”
apiVersions:
– v1 operations:
– CREATE
resources:
– pods
clientConfig:
service:
namespace: infrastructure
name: pod-mutator
caBundle:
Maintenant, lorsque nous appliquons un Pod à conteneur unique très simple, nous obtenons quelque chose de plus :
# cat pod.yaml
—
apiVersion: v1
kind: Pod
metadata:
name: testpod
labels:
app: testpod
environment: prod
#staging
spec:
containers:
– name: busybox
image: busybox
command: [‘/bin/sleep’, ‘3600’]
Même si notre Pod n’a déclaré que le conteneur busybox , nous avons maintenant deux conteneurs à l’exécution:
# kubectl get pod testpod
NAME READY STATUS RESTARTS AGE
testpod 2/2 Running 0 1m
Et une inspection plus approfondie révèle que notre side-car a été injecté correctement:
…
spec:
containers:
– image: nginx
imagePullPolicy: Always
name: proxy-sidecar
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
– command:
– /bin/sleep
– “3600”
image: busybox
…
Avec les webhooks mutants, nous avons un outil extrêmement puissant pour standardiser les déclarations de nos utilisateurs. Utilisez ce pouvoir avec prudence.
9.4 Résumé
Le contrôle d’admission est un autre outil pour assainir l’état de votre cluster. Étant donné que cette fonctionnalité est en constante évolution, assurez-vous de rechercher de nouvelles capacités avec chaque version de Kubernetes et d’implémenter les contrôleurs qui aideront à sécuriser votre environnement et à utiliser le lecteur. Et, le cas échéant, n’ayez pas peur de retrousser vos manches, en mettant en œuvre la logique qui convient le mieux à vos cas d’utilisation particuliers.
10 CHAPITRE 10 Mise en réseau
Comme pour tout système distribué, Kubernetes s’appuie sur le réseau pour assurer la connectivité entre les services, ainsi que pour connecter les utilisateurs externes aux charges de travail exposées.
La gestion du réseau dans les architectures d’applications traditionnelles s’est toujours avérée assez difficile. Dans de nombreuses organisations, il y avait une séparation des tâches – les développeurs créeraient leurs applications et les opérateurs seraient responsables de leur exécution. Plusieurs fois, à mesure que l’application évoluait, les besoins de l’infrastructure réseau dérivaient. Dans le meilleur des cas, l’application ne fonctionnerait tout simplement pas et un opérateur prendrait des mesures correctives. Cependant, dans le pire des scénarios, des lacunes importantes dans des domaines comme la sécurité du réseau se poseraient.
Kubernetes permet aux développeurs de définir des ressources réseau et des politiques pouvant coexister avec leurs manifestes de déploiement d’applications. Ces ressources et politiques peuvent être bien définies par les administrateurs de cluster et peuvent exploiter un nombre illimité d’implémentations de technologies de pointe en utilisant des couches d’abstraction communes. En supprimant les développeurs des rouages du fonctionnement du réseau et en colocalisant les exigences de l’infrastructure avec celles de l’application, nous pouvons avoir de meilleures garanties que nos applications peuvent être livrées de manière cohérente et sécurisée.
10.1 Interface réseau de conteneurs
Avant de parler de la connexion des utilisateurs aux charges de travail conteneurisées, nous devons comprendre comment les pods communiquent avec d’autres pods. Ces pods peuvent être colocalisés sur le même nœud, sur des nœuds du même sous-réseau et même sur des nœuds de sous-réseaux différents qui sont peut-être même situés dans différents centres de données. Comme le montre la figure 10-1, quel que soit l’aspect de la plomberie du réseau, nous visons à connecter les pods de manière transparente et routable.
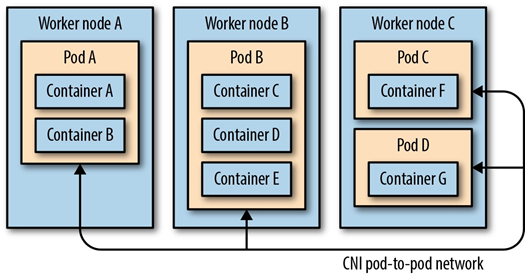
Figure 10-1. Réseautage CNI
Kubernetes s’interface avec le réseau en utilisant la spécification CNI. L’objectif de cette spécification ouverte est de normaliser la façon dont les plates-formes d’orchestration de conteneurs connectent les conteneurs au réseau sous-jacent et de le faire de manière enfichable. Il existe des dizaines de solutions, chacune avec ses propres architectures et capacités. La plupart sont des solutions open source, mais il existe également des solutions propriétaires d’un certain nombre de fournisseurs différents au sein de l’écosystème natif du cloud. Quel que soit l’environnement dans lequel vous déployez votre cluster, il y aura certainement un plug-in pour répondre à vos besoins.
Bien qu’il existe de multiples aspects de la mise en réseau au sein de Kubernetes, le rôle de CNI est simplement de faciliter la connectivité de pod à pod. La manière dont cela se produit est relativement simple. Le runtime du conteneur (par exemple, Docker) appelle l’exécutable du plug-in CNI (par exemple, Calico) pour ajouter ou supprimer une interface vers ou depuis l’espace de noms de mise en réseau du conteneur. Il s’agit des interfaces sandbox .
Comme vous vous en souvenez, chaque pod se voit attribuer une adresse IP, et le plug-in CNI est responsable de son allocation et de son affectation à un pod.
Vous vous demandez peut-être : « Si un Pod peut avoir plusieurs conteneurs, comment le CNI sait-il lequel connecter ? » Si vous avez déjà interrogé Docker pour répertorier les conteneurs s’exécutant sur un nœud Kubernetes donné, vous avez peut-être remarqué un certain nombre de conteneurs de pause associés à chacun de vos pods. Ces conteneurs de pause ne font rien de significatif sur le plan informatique. Ils servent simplement d’espaces réservés pour le réseau de conteneurs de chaque pod. En tant que tels, ils sont le premier conteneur à être lancé et le dernier à mourir dans le cycle de vie d’un pod individuel.
Une fois que le plug-in a exécuté la tâche souhaitée pour le compte de l’exécution du conteneur, il renvoie l’état de l’exécution, comme tout autre processus Linux : 0 pour réussir et tout autre code retour pour indiquer un échec. Dans le cadre d’une opération réussie, le plug-in CNI renvoie également les détails des adresses IP, des routes et des entrées DNS qui ont été manipulées par le plug-in au cours du processus.
En plus de connecter un conteneur à un réseau, CNI possède des capacités de gestion des adresses IP (IPAM). IPAM garantit que CNI a toujours une image claire des adresses utilisées, ainsi que de celles disponibles pour la configuration de nouvelles interfaces.
10.1.1 Choisir un plug-in
Lorsque vous choisissez un plug-in CNI à utiliser dans votre environnement, il y a deux considérations principales à garder à l’esprit :
Quelle est la topologie de votre réseau ?
La topologie de votre réseau dicte une grande partie de ce que vous êtes finalement en mesure de déployer dans votre environnement. Par exemple, si vous déployez sur plusieurs zones de disponibilité dans un cloud public, vous devrez probablement implémenter un plug-in qui prend en charge une certaine forme d’encapsulation (également connue sous le nom de réseau de superposition).
Quelles fonctionnalités sont impératives pour votre organisation ?
Vous devez considérer quelles fonctionnalités sont importantes pour votre déploiement. S’il existe des exigences strictes pour un TLS mutuel entre les pods, vous souhaiterez peut-être utiliser un plug-in qui offre cette fonctionnalité. De la même manière, tous les plug-ins ne prennent pas en charge NetworkPolicy. Assurez-vous d’évaluer les fonctionnalités offertes par le plug-in avant de déployer votre cluster.
Le CNI n’est pas le seul mécanisme pour appliquer le TLS mutuel entre les pods. Avec un modèle de sidecar appelé service mesh, les administrateurs de cluster peuvent exiger que les charges de travail ne communiquent que par un proxy local compatible TLS. Le maillage de service fournit non seulement un chiffrement de bout en bout, mais peut également activer des fonctionnalités de niveau supérieur, telles que la coupure de circuit, les déploiements bleu / vert et le traçage distribué. Il peut également être activé de manière transparente pour l’utilisateur final.
10.2 kube -proxy
Même avec la mise en réseau Pod-to-Pod en place, Kubernetes serait encore relativement primitif en termes de connectivité s’il ne fournissait pas quelques abstractions supplémentaires par rapport à la connectivité directe IP à IP. Comment traiterions-nous le cas où un déploiement a plusieurs répliques et, par conséquent, plusieurs adresses IP de service ? Choisissons-nous simplement l’une des adresses IP et espérons qu’elle ne sera pas supprimée à un moment donné dans le futur ? Ne serait-il pas agréable de référencer ces répliques par une IP virtuelle ? Et, en allant plus loin, ne serait-il pas agréable d’avoir un enregistrement DNS ?
Tout cela est possible avec la ressource de service Kubernetes que nous avons couverte au chapitre 2. Avec la ressource de service, nous attribuons une adresse IP virtuelle pour les services réseau exposés par une collection de pods. Les pods de support sont découverts et connectés à l’aide d’un sélecteur de pods.
De nombreux nouveaux arrivants à Kubernetes considèrent généralement la relation entre une collection de pods (c’est -à- dire un déploiement) et un service comme un à un. Étant donné que les services sont connectés aux pods au moyen de sélecteurs d’étiquettes, tout pod avec l’étiquette appropriée est considéré comme un point de terminaison de service. Cette fonctionnalité vous permet de mélanger et de faire correspondre les pods de support et peut même permettre des déploiements avancés, tels que les déploiements bleu / vert et canari.
Dans les coulisses, le composant Kubernetes qui rend tout cela possible est le processus kube- proxy. kube -proxy s’exécute généralement comme un processus de conteneur privilégié, et il est responsable de la gestion de la connectivité pour ces adresses IP de service virtuel.
Le nom du proxy est un terme impropre d’origine historique : kube -proxy a été initialement implémenté avec un proxy de l’espace utilisateur. Cela a changé depuis, et dans le scénario le plus courant, kube -proxy manipule simplement les règles iptables sur chaque nœud. Ces règles redirigent le trafic destiné à une adresse IP de service vers l’une des adresses IP de point de terminaison de support. Puisque kube -proxy est un contrôleur, il surveille les changements d’état et se réconcilie avec l’état approprié lors de toute modification.
Si nous jetons un coup d’œil à un service qui est déjà défini dans notre cluster, nous pouvons avoir une idée du fonctionnement de kube- proxy dans les coulisses :
$ kubectl get svc -n kube-system kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes-dashboard ClusterIP 10.104.154.139 443/TCP 40d
$ kubectl get ep -n kube-system kubernetes-dashboard
NAME ENDPOINTS AGE
kubernetes-dashboard 192.168.63.200:8443,192.168.63.201:8443 40d
$ sudo iptables-save | grep KUBE | grep “kubernetes-dashboard”
-A KUBE-SEP-3HWS5OGCGRHMJ23K -s 192.168.63.201/32 -m comment –comment \
“kube-system/kubernetes-dashboard:” -j KUBE-MARK-MASQ
-A KUBE-SEP-3HWS5OGCGRHMJ23K -p tcp -m comment –comment \
“kube-system/kubernetes-dashboard:” -m tcp -j DNAT \
–to-destination 192.168.63.201:8443
-A KUBE-SEP-XWHZMKM53W55IFOX -s 192.168.63.200/32 -m comment –comment \
“kube-system/kubernetes-dashboard:” -j KUBE-MARK-MASQ
-A KUBE-SEP-XWHZMKM53W55IFOX -p tcp -m comment –comment \
“kube-system/kubernetes-dashboard:” -m tcp -j DNAT \
–to-destination 192.168.63.200:8443
-A KUBE-SERVICES ! -s 192.168.0.0/16 -d 10.104.154.139/32 -p tcp -m comment \ –comment “kube-system/kubernetes-dashboard: cluster IP” -m tcp –dport 443 \
-j KUBE-MARK-MASQ
-A KUBE-SERVICES -d 10.104.154.139/32 -p tcp -m comment –comment \
“kube-system/kubernetes-dashboard: cluster IP” -m tcp –dport 443 \
-j KUBE-SVC-XGLOHA7QRQ3V22RZ
-A KUBE-SVC-XGLOHA7QRQ3V22RZ -m comment –comment \
“kube-system/kubernetes-dashboard:” -m statistic –mode random \
–probability 0.50000000000 -j KUBE-SEP-XWHZMKM53W55IFOX
-A KUBE-SVC-XGLOHA7QRQ3V22RZ -m comment –comment \
“kube-system/kubernetes-dashboard:” -j KUBE-SEP-3HWS5OGCGRHMJ23K
Cela peut être un peu difficile à suivre, alors décomposons-le. Dans ce scénario, nous examinons le service kubernetes -dashboard ClusterIP. Nous voyons qu’il a un ClusterIP de 10.104.154.139 et des points de terminaison Pod à 192.168.63.200:8443 et 192.168.63.201:8443. Ici, kube -proxy a créé un certain nombre de règles iptables pour refléter cet état sur chaque nœud. Ces règles indiquent en effet que tous les paquets provenant du pod CIDR (192.168.0.0/16) destinés au tableau de bord ClusterIP (10.104.154.139/32) sur le port TCP 443 doivent être redirigés, de manière aléatoire, vers l’un des pods en aval l’hébergement du conteneur de tableau de bord sur le port de conteneur 8443.
De cette façon, chaque pod sur chaque nœud est capable de communiquer avec des services définis par le biais de la manipulation par le démon kube- proxy des règles iptables .
iptables est l’implémentation la plus courante dans la nature. Avec Kubernetes 1.9, une nouvelle implémentation IP Virtual Server (IPVS) a été ajoutée. Ceci est non seulement plus performant mais offre également une variété d’algorithmes d’équilibrage de charge qui peuvent être utilisés.
10.3 Découverte de service
Dans tout environnement où il existe un degré élevé de planification dynamique des processus, nous voulons un moyen de découvrir de manière fiable où se trouvent les points de terminaison de service . Cela est vrai de nombreuses technologies de clustering, et Kubernetes n’est pas différent. Heureusement, avec la ressource Service, nous avons un bon endroit à partir duquel activer la découverte du service.
10.3.1 DNS
Le moyen le plus courant de découvrir les services dans Kubernetes est via DNS. Bien qu’il n’y ait pas de contrôleurs DNS natifs dans le composant Kubernetes lui-même, il existe des contrôleurs complémentaires qui peuvent être utilisés pour fournir des enregistrements DNS pour les ressources de service.
Les deux modules complémentaires les plus largement déployés dans cet espace sont les contrôleurs kube-dns et CoreDNS gérés par la communauté. Ces contrôleurs surveillent l’état du pod et du service à partir du serveur API et, à leur tour, définissent automatiquement un certain nombre d’enregistrements DNS différents. La différence entre ces deux contrôleurs est principalement l’implémentation du CoreDNS contrôleur utilise CoreDNS comme sa mise en œuvre, et Kube-dns tire parti dnsmasq .
Chaque service, lors de sa création, obtient un enregistrement DNS A associé à l’adresse IP du service virtuel, qui prend la forme de . < Espace de noms>. svc.cluster.local :
# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 35d
# kubectl run –image=alpine dns-test -it — /bin/sh If you don’t see a command prompt, try pressing enter.
/ # nslookup kubernetes
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
Pour les services sans tête, les enregistrements sont légèrement différents :
# kubectl run –image=alpine headless-test -it — /bin/sh
Si vous ne voyez pas d’invite de commande, essayez d’appuyer sur Entrée.
/ # nslookup kube-headless
Name: kube-headless
Address 1: 192.168.136.154 ip-192-168-136-154.ec2.internal
Address 2: 192.168.241.42 ip-192-168-241-42.ec2.internal
Dans ce cas, au lieu d’un enregistrement A pour le Service ClusterIP, les utilisateurs se voient présenter une liste d’enregistrements A qu’ils peuvent utiliser à leur discrétion.
Les services sans tête sont des services ClusterIP avec clusterIP = None. Ils sont utilisés lorsque vous souhaitez définir un service mais ne nécessitent pas qu’il soit géré par kube -proxy. Étant donné que vous aurez toujours accès aux points de terminaison du service, vous pouvez en tirer parti si vous souhaitez implémenter vos propres mécanismes de découverte de service.
10.3.2 Variables d’environnement
En plus du DNS, une fonctionnalité moins utilisée mais à prendre en compte est la découverte de service à l’aide de variables d’environnement injectées automatiquement. Lorsqu’un pod est lancé, une collection de variables décrivant les services ClusterIP dans l’espace de noms actuel sera ajoutée à l’environnement de processus.
# kubectl get svc test
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
test ClusterIP 10.102.163.244 8080/TCP 9m
TEST_SERVICE_PORT_8080_8080=8080
TEST_SERVICE_HOST=10.102.163.244
TEST_PORT_8080_TCP_ADDR=10.102.163.244
TEST_PORT_8080_TCP_PORT=8080
TEST_PORT_8080_TCP_PROTO=tcp
TEST_SERVICE_PORT=8080
TEST_PORT=tcp://10.102.163.244:8080
TEST_PORT_8080_TCP=tcp://10.102.163.244:8080
Ce mécanisme peut être utilisé en l’absence de capacités DNS, mais il y a une mise en garde importante à garder à l’esprit. Étant donné que l’environnement de processus est rempli au moment du démarrage du pod, toute découverte de service utilisant cette méthode nécessite que les ressources de service nécessaires soient définies avant le pod. Cette méthode ne prend pas en compte les mises à jour d’un service après le démarrage du pod.
10.4 Politique de réseau
Un aspect essentiel de la sécurisation des charges de travail des utilisateurs, que ce soit avec Kubernetes ou non, implique de s’assurer que les Services ne sont exposés qu’aux consommateurs appropriés. Si, par exemple, vous développiez une API qui nécessitait un backend de base de données, un modèle de déploiement typique serait d’exposer uniquement le point de terminaison de l’API aux consommateurs externes. L’accès à la base de données ne serait possible qu’à partir du service API lui-même. Ce type d’isolation de service au niveau des couches 3 et 4 du modèle OSI permet de garantir que la surface d’attaque est limitée. Traditionnellement, ces types de restrictions ont été implémentés avec un certain type de pare-feu et, sur les systèmes Linux, cette politique est généralement appliquée avec IPTables .
Dans des circonstances normales, les règles IPTables ne sont manipulées que par un administrateur de serveur et sont locales au nœud sur lequel elles sont implémentées. Cela pose un petit problème aux utilisateurs de Kubernetes qui souhaitent disposer de capacités en libre-service pour sécuriser leurs services.
Heureusement, Kubernetes fournit la ressource NetworkPolicy aux utilisateurs pour définir les règles de couche 3 et de couche 4 en fonction de leurs propres charges de travail. La ressource NetworkPolicy propose des règles d’entrée et de sortie qui peuvent être appliquées aux espaces de noms, aux pods et même aux blocs CIDR normaux.
Notez que NetworkPolicy ne peut être défini que dans des environnements où le plug-in CNI prend en charge cette fonctionnalité. Les Kubernetes
Le serveur API acceptera volontiers votre déclaration NetworkPolicy , mais comme il n’y a pas de contrôleur pour réconcilier l’état déclaré, aucune stratégie ne sera appliquée. Par exemple, Flannel peut fournir un réseau de superposition pour la communication Pod-to-Pod, mais il n’inclut pas d’agent de stratégie. Pour cette raison, beaucoup de ceux qui veulent la fonctionnalité de la superposition de Flannel avec les capacités NetworkPolicy se sont tournés vers Canal, qui combine la superposition de Flannel avec le moteur de stratégie de Calico.
Un manifeste NetworkPolicy typique peut ressembler à ceci :
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: backend-policy
namespace: api-backend
spec:
podSelector:
matchLabels:
role: db
policyTypes:
– Ingress
– Egress
ingress:
– from:
– namespaceSelector:
matchLabels:
project: api-midtier
– podSelector:
matchLabels:
role: api-management
ports:
– protocol: TCP
port: 3306
egress: – to:
– ipBlock:
cidr: 10.3.4.5/32
ports:
– protocol: TCP
port: 22
La lecture et l’élaboration de ces ressources NetworkPolicy peuvent prendre un peu de temps pour s’y habituer, mais une fois que vous maîtrisez le schéma, cela peut être un outil extrêmement puissant à votre disposition.
Dans cet exemple, nous déclarons une stratégie qui sera placée sur tous les pods avec les étiquettes role = db dans l’espace de noms api- backend. Les règles d’entrée en place autorisent le trafic vers le port 3306 à partir d’un espace de noms avec l’étiquette project = api-midtier ou d’un pod avec l’étiquette role = api -management. De plus, nous limitons le trafic sortant, ou sortant, des pods role = db vers un serveur SSH à 10.3.4.5. Peut-être que nous l’utiliserions pour rsynchroniser les sauvegardes vers un emplacement disponible en externe.
Bien que ces règles soient relativement spécifiques, nous pouvons également créer de larges stratégies permettant tout ou refusant tout, pour le trafic entrant et sortant, pour tout espace de noms donnés. Par exemple, la stratégie suivante (et peut-être la plus intéressante) crée une stratégie d’entrée de refus par défaut pour un espace de noms :
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny
spec:
podSelector: {}
policyTypes:
– Ingress
Il est important de noter que, par défaut, il n’y a aucune restriction de réseau pour les pods. Ce n’est que grâce à NetworkPolicy que nous pouvons commencer à verrouiller l’interconnectivité des pods.
10.5 Maillage de service
La compréhension des flux réseau entre les charges de travail peut être une entreprise compliquée. Dans le cas le plus simple, une réplique Pod unique avec un seul conteneur est dirigée par une ressource Service. Avec ce scénario, nous devons simplement analyser la provenance du trafic en consultant les journaux d’application du conteneur.
Dans un environnement de microservices, cependant, il est souvent typique que le trafic entre dans le cluster via une entrée, qui est soutenue par un service, qui est ensuite soutenu par un nombre illimité de répliques de pod. En outre, ces pods peuvent eux-mêmes se connecter à d’autres services de cluster et à leurs pods de support respectif. Comme vous pouvez probablement le voir, ces flux deviennent très rapidement complexes, et c’est là que les solutions de maillage de service peuvent aider.
Un maillage de service est simplement une collection de proxys « intelligents » qui peuvent aider les utilisateurs avec une variété de besoins de mise en réseau est-ouest ou pod-to-pod. Ces proxys peuvent fonctionner comme des conteneurs sidecar dans les pods d’application ou peuvent fonctionner comme DaemonSets, où ils sont des composants d’infrastructure locale de noeud qui peuvent être utilisés par n’importe quel pod sur un nœud donné. Configurez simplement vos pods pour proxy leur trafic vers ces proxy de maillage de service (généralement avec des variables d’environnement), et vos pods font désormais partie du maillage.
Que vous déployiez en tant que sidecar ou en tant que DaemonSet est généralement déterminé par la technologie de maillage de service que vous choisissez et / ou la disponibilité des ressources sur votre cluster. Étant donné que ces proxys s’exécutent en tant que pods, ils consomment des ressources de cluster et, en tant que tels, vous devez décider si ces ressources doivent être partagées ou associées à un pod.
Les solutions de maillage de service fournissent généralement des fonctionnalités communes.
Gestion du trafic
La plupart des solutions de maillage de services incluent certaines fonctionnalités visant à générer des demandes entrantes pour des services particuliers. Cela peut permettre des modèles avancés tels que les déploiements canaris et bleu / vert. De plus, certaines solutions sont sensibles au protocole. Au lieu d’agir comme un proxy de couche 4 « stupide », ils ont la possibilité d’introspection de protocoles de niveau supérieur et de prendre des décisions de proxy intelligentes. Par exemple, si un amont particulier devait répondre lentement aux requêtes HTTP, le proxy pourrait pondérer ce backend plus bas qu’un amont réactif.
Observabilité
Lors du déploiement de microservices sur un cluster Kubernetes, l’interconnectivité entre les pods peut rapidement devenir difficile à comprendre. Comme de plus en plus de pods communiquent entre eux, comment devez-vous déboguer un problème de connectivité signalé par l’utilisateur ? Comment trouvez-vous l’application qui tarde à répondre ? La plupart des solutions de maillage de service fournissent des mécanismes automatiques de traçage distribué (généralement basés sur la norme OpenTracing ). De manière transparente, vous pouvez suivre de manière unique le flux des demandes individuelles.
Sécurité
Dans les environnements où le réseau sous-jacent ne fournit aucun chiffrement par défaut (ce qui est courant pour la plupart des plug-ins CNI), le maillage de service peut intercéder en offrant un TLS mutuel pour tout le trafic est-ouest. Cela peut être avantageux car les stratégies peuvent être appliquées de manière à ce que toute la connectivité soit sécurisée par défaut.
Des projets comme Istio , Linkerd et Conduit sont des solutions de maillage de service couramment utilisées. Si les fonctionnalités que vous venez de mentionner correspondent à votre cas d’utilisation, prenez en compte ces projets.
10.6 Résumé
La mise en réseau dans n’importe quel système distribué est toujours complexe. Kubernetes simplifie cette capacité critique en offrant des abstractions bien conçues sur plusieurs couches de la pile réseau OSI. Souvent, ces abstractions sont mises en œuvre avec des technologies de réseau éprouvées qui ont été utilisées de manière fiable pendant des décennies. Cependant, étant donné que ces abstractions sont destinées à fournir une interface commune pour les fonctionnalités, vous, en tant qu’administrateur de cluster, êtes libre d’utiliser les implémentations qui répondent le mieux à vos besoins. Lors du couplage des exigences de mise en réseau de votre application avec ses manifestes de déploiement, il est beaucoup plus facile de déployer des architectures d’application complexes, stables et sécurisées.
11 CHAPITRE 11 Surveillance de Kubernetes
C’est bien beau de configurer ou d’utiliser un cluster Kubernetes à partir d’un fournisseur de cloud public. Mais sans la bonne stratégie pour surveiller les métriques et les journaux de ce cluster et déclencher des alertes appropriées en cas de problème, le cluster que vous avez créé est une catastrophe qui attend. Bien que Kubernetes facilite la création et le déploiement de leurs applications pour les développeurs, il crée également des applications qui dépendent de Kubernetes pour un fonctionnement réussi. Cela signifie que, lorsqu’un cluster échoue, les applications de vos utilisateurs échouent également souvent. Et, si un cluster échoue trop souvent, les utilisateurs perdent confiance dans le système et commencent à remettre en question la valeur du cluster et de ses opérateurs. Ce chapitre décrit les approches de développement et de déploiement de la surveillance et des alertes pour votre cluster Kubernetes pour éviter que cela ne se produise. De plus, nous décrivons comment vous pouvez ajouter une surveillance à votre cluster afin que les développeurs d’applications puissent en profiter automatiquement pour leurs propres applications.
11.1 Objectifs de surveillance
Avant d’entrer dans les détails de la surveillance de votre cluster, il est important de passer en revue les objectifs de cette surveillance. Tous les détails sur la façon de déployer et de gérer la surveillance sont au service de ces objectifs, et donc une idée claire du pourquoi ? aidera à comprendre le quoi.
De toute évidence, le premier et principal objectif de la surveillance est la fiabilité. Dans ce cas, la fiabilité est à la fois celle du cluster Kubernetes et celle des applications s’exécutant au-dessus du cluster. Comme exemple de cette relation, considérons un binaire, comme le gestionnaire de contrôleur. S’il cesse de fonctionner correctement, la découverte du service commencera à devenir lentement obsolète. Les services existants auront déjà été correctement propagés au serveur DNS dans le cluster, mais les nouveaux services, ou les services qui changent en raison de déploiements ou d’opérations de mise à l’échelle, ne verront pas leur DNS mis à jour.
Cet échec montre l’importance de comprendre l’architecture sous-jacente de Kubernetes. Si vous ne pouvez pas expliquer clairement le rôle du gestionnaire de contrôleur dans le cluster Kubernetes global, cela peut être un bon moment pour prendre du recul et passer en revue le chapitre 3, qui couvre les composants et l’architecture de Kubernetes.
Ce type d’échec ne se reflétera pas réellement dans le bon fonctionnement du cluster Kubernetes lui-même. Toute sa découverte de service est en grande partie statique après l’initialisation du cluster. Cependant, cela se reflète dans l’exactitude des applications s’exécutant au-dessus du cluster Kubernetes, car leur découverte de service et leur basculement commenceront eux-mêmes à échouer.
Cet exemple illustre deux points importants concernant la surveillance de Kubernetes. Le premier est que, dans de nombreux cas, le cluster lui-même semble fonctionner correctement, mais il est en train d’échouer. Cela souligne l’importance non seulement de surveiller les éléments du cluster, mais également de surveiller les fonctionnalités du cluster dont les utilisateurs ont besoin. Dans ce cas, le meilleur type de surveillance serait un moniteur de boîte noire qui déploie en continu un nouveau pod et service et qui valide que la découverte de service fonctionne comme prévu.
Tout au long de ce chapitre, nous nous référons à deux types de surveillance différents. La surveillance Whitebox examine les signaux que les applications produisent et utilise ces signaux pour détecter les problèmes. La surveillance de boîtes noires ou de sondes utilise les interfaces publiques (par exemple, Kubernetes) pour entreprendre des actions avec des résultats attendus connus (par exemple, «Créer un ReplicaSet de taille trois conduit à trois modules») et déclenche des alertes si le résultat attendu ne se produit pas.
L’autre leçon importante de cet exemple DNS est à quel point il est important d’avoir une alerte appropriée en place. Si vous remarquez uniquement un problème avec votre cluster Kubernetes lorsque des utilisateurs se plaignent des échecs de leur application, vous avez un écart de surveillance. Bien que les incidents de site en direct soient une partie inévitable de l’exécution d’un service, les incidents signalés par le client doivent être inexistants dans un système bien surveillé.
En plus de la fiabilité, une autre caractéristique importante d’un système de surveillance fournit une observabilité dans votre cluster Kubernetes. Il existe de nombreuses raisons pour lesquelles l’observation de votre cluster est importante et pertinente.
C’est une chose de pouvoir déclencher des alertes de surveillance qui indiquent qu’il y a un problème avec votre cluster. C’est un autre moyen de déterminer exactement ce qui ne va pas provoquer l’alerte, et un autre encore de pouvoir voir et corriger les problèmes avant qu’ils ne deviennent des problèmes pour l’utilisateur final. La capacité d’observer, de visualiser et d’interroger vos données de surveillance est un outil essentiel pour déterminer les problèmes qui se produisent et identifier les problèmes avant qu’ils ne deviennent des incidents.
Outre les informations sur le service de la fiabilité, un autre cas d’utilisation important pour les données de surveillance de cluster est celui de fournir aux utilisateurs des informations sur le fonctionnement du cluster. Par exemple, les utilisateurs peuvent être curieux de savoir, en moyenne, combien de temps il faut pour extraire et commencer à exécuter leurs images. Un utilisateur peut se demander à quelle vitesse, dans la pratique, un enregistrement DNS Kubernetes est créé, ou une personne des finances peut vouloir vérifier si les utilisateurs utilisent vraiment toutes les ressources de calcul qu’ils demandent. Toutes ces informations sont disponibles à partir d’un système de surveillance de cluster.
11.2 Différences entre la journalisation et la surveillance
Un sujet important à couvrir avant de nous plonger dans les détails de la surveillance de Kubernetes est la différence entre la journalisation et la surveillance. Bien qu’étroitement liés, ils sont en réalité assez différents et sont utilisés pour différents problèmes et souvent stockés dans des infrastructures différentes.
La journalisation enregistre les événements (par exemple, un pod en cours de création ou un appel d’API échoue) et la surveillance des statistiques des enregistrements (par exemple, la latence d’une demande particulière, le processeur utilisé par un processus ou le nombre de demandes à un point de terminaison particulier). Les enregistrements enregistrés, de par leur nature, sont discrets, tandis que les données de surveillance sont un échantillonnage d’une certaine valeur continue.
Les systèmes d’enregistrement sont généralement utilisés pour rechercher des informations pertinentes. (« Pourquoi la création de ce pod a-t-elle échoué ? » « Pourquoi ce service n’a-t-il pas fonctionné correctement ? ») Pour cette raison, les systèmes de stockage de journaux sont orientés vers le stockage et l’interrogation de grandes quantités de données, tandis que les systèmes de surveillance sont généralement axés sur la visualisation. (« Montrez-moi l’utilisation du processeur au cours de la dernière heure. ») Ainsi, ils sont stockés dans des systèmes qui peuvent stocker efficacement les données de séries chronologiques.
Il convient de noter que ni la journalisation ni la surveillance ne suffisent à elles seules pour comprendre votre cluster. Les données de surveillance peuvent vous donner un bon sens de la santé générale de votre cluster et peut vous aider à identifier les événements anormaux qui peuvent être survenant. La journalisation, d’autre part, est essentielle pour plonger et comprendre ce qui se passe réellement, éventuellement sur de nombreuses machines, pour provoquer un tel comportement anormal.
11.3 Création d’une pile de surveillance
Maintenant que vous comprenez pourquoi et ce dont vous pourriez avoir besoin pour surveiller votre cluster Kubernetes, examinons comment vous pouvez y parvenir.
11.3.1 Obtention de données à partir de votre cluster et de vos applications
La surveillance commence par l’exposition des données au système de surveillance. Certaines de ces données sont obtenues de manière générique à partir du noyau sur les groupes de contrôle et les espaces de noms qui composent les conteneurs de votre cluster, mais la majeure partie des informations utiles à surveiller est ajoutée aux applications elles-mêmes par le développeur. Il existe de nombreuses façons différentes d’intégrer des métriques dans votre application, mais l’une des plus populaires – et le choix de Kuberentes pour exposer les métriques – est l’interface de surveillance Prometheus .
Chaque serveur de Kubernetes expose les données de surveillance via un point de terminaison HTTP (S) qui dessert les données surveillées à l’aide du protocole Prometheus. Si vous disposez d’un serveur kubelet Kubernetes opérationnel, vous pouvez accéder à ces données via un client HTTP standard, comme curl, à l’URL suivante : http://localhost:9093.
Pour intégrer de nouvelles métriques d’application dans votre code, vous devez créer un lien dans les bibliothèques Prometheus pertinentes. Cela ajoute non seulement le bon serveur HTTP à votre application, mais expose également les mesures spécifiques à extraire de ce serveur. Prometheus possède des bibliothèques officielles pour Go, Java, Python et Ruby, en plus de bibliothèques non officielles pour de nombreuses autres langues.
Voici un exemple de comment instrumenter une application Go. Tout d’abord, vous ajoutez le serveur Prometheus à votre code :
import “github.com/prometheus/client_golang/prometheus/promhttp”
…
func main() {
…
http.Handle(“/metrics”, promhttp.Handler())
…
}
Une fois le serveur en cours d’exécution, vous devez définir une métrique et observer les valeurs:
“github.com/prometheus/client_golang/prometheus”
…
histogram := prometheus.NewHistogram(…)
…
histogram.Observe(someLatency)
…
En plus des informations de surveillance mises à disposition par Kubernetes, chacun des binaires Kubernetes enregistre une grande quantité d’informations dans le flux de fichiers stdout . Souvent, cette sortie est capturée et redirigée vers un fichier à rotation de journal, tel que / var / lib / kubernetes-apiserver.log. Si vous vous connectez au nœud maître exécutant le serveur API Kubernetes, vous pouvez trouver le fichier journal du serveur API dans /var/lib/kube-apiserver.log et vous pouvez regarder les lignes de journal en action à l’aide de la commande tail -f…. Les composants Kubernetes utilisent la bibliothèque github.com/google/ glog pour enregistrer les données dans le fichier à différents niveaux de gravité. Lorsque vous parcourez le fichier, vous pouvez détecter ces niveaux de gravité en consultant la première lettre qui a été enregistrée. Par exemple, un journal de niveau d’erreur ressemble à:
E0610 03:39:40.323732 1753 reflector.go:205] …
Vous pouvez voir le E pour le niveau du journal des erreurs, l’heure du journal et le fichier qui a été enregistré.
Les composants Kubernetes enregistrent également des données à différents niveaux de verbosité. La plupart des installations de Kubernetes définissent la verbosité à deux, ce qui est également la valeur par défaut. Cela produit un bon équilibre entre verbosité et spam. Si vous devez augmenter ou diminuer la verbosité de la journalisation, vous pouvez utiliser l’indicateur –v et le définir entre 0 et 10, où 10 indique la verbosité maximale, ce qui peut être assez spam. Vous pouvez également utiliser le – vmodule drapeau pour définir la verbosité d’un fichier ou d’un ensemble de fichiers.
Définir la verbosité de vos journaux à un niveau supérieur augmente la visibilité, mais cela a un prix, à la fois financier et en termes de performances. Le nombre absolu de journaux étant plus élevé, cela augmente les coûts de stockage et de rétention et peut ralentir vos requêtes. Lorsque vous augmentez le niveau de journalisation, ne le faites généralement que pendant une courte période et assurez-vous de ramener la journalisation à un niveau standard dès que possible.
11.3.2 Agrégation de métriques et de journaux à partir de plusieurs sources
Une fois que vos composants génèrent des données, vous avez besoin d’un emplacement pour les regrouper ou les agréger, puis, une fois agrégés, stockez-les pour interrogation et introspection. Cette section traite de l’agrégation des données de journalisation et de surveillance, et les sections suivantes traitent des choix en termes de stockage.
En matière d’agrégation, il existe deux styles différents. Dans l’agrégation par extraction, le système d’agrégation atteint de manière proactive chaque système surveillé et extrait les informations de surveillance dans le magasin d’agrégats. Une autre approche est un système de surveillance basé sur les push, dans lequel le système qui est surveillé est chargé d’envoyer ses métriques au système d’agrégation. Chacune de ces deux conceptions de surveillance différentes présente des avantages et des inconvénients et est plus facile ou plus difficile à mettre en œuvre, selon les détails du système. Lorsque vous regardez Prometheus et Fluentd , les deux systèmes que nous examinons en détail pour la journalisation et la surveillance de l’agrégation, vous pouvez voir que les deux systèmes ont des conceptions différentes. Apprendre à connaître chacun d’eux et pourquoi ils ont choisi leurs conceptions vous aide à comprendre les compromis.
Prometheus est un agrégateur basé sur l’extraction pour surveiller les métriques. Comme nous l’avons vu, lorsque vous exposez une métrique Prometheus, elle est exposée comme une page Web qui peut être grattée et agrégée dans le serveur Prometheus. Prometheus choisit cette conception car elle rend l’ajout de systèmes à surveiller assez trivial. Tant que le système implémente l’interface attendue, c’est aussi simple que d’ajouter une URL supplémentaire à la configuration de Prometheus, et les données de ce serveur commenceront à être surveillées. Étant donné que Prometheus est responsable de supprimer les données et de les agréger à son propre rythme, le système Prometheus n’a pas à se soucier des clients en rafale ou en retard qui lui envoient des données à différents intervalles. Au lieu de cela, Prometheus sait toujours exactement quelle heure il est quand il demande les données de surveillance, et il contrôle également la vitesse à laquelle il échantillonne les données, garantissant que la fréquence d’échantillonnage est cohérente et uniformément répartie sur tous les systèmes surveillés.
En revanche, le démon fluentd est un agrégateur de journaux push. Tout comme Prometheus a choisi le modèle de traction pour diverses raisons pragmatiques, Fluentd a choisi le modèle de poussée en fonction d’un certain nombre de considérations de conception réelles. La principale raison pour laquelle Fluentd a choisi un modèle push est que presque tous les systèmes qui se connectent le font dans un fichier ou un flux sur la machine locale. Par conséquent, pour s’intégrer dans la pile de journalisation, Fluentd doit lire à partir d’une grande variété de fichiers sur disque pour obtenir les derniers journaux. Il n’est généralement pas très possible d’injecter du code personnalisé dans le système surveillé (par exemple, pour imprimer sur un système de journalisation au lieu de stdout ). Par conséquent, Fluentd a choisi de prendre le contrôle des informations de journalisation, de les lire dans chacun des différents fichiers et de les pousser dans un système de journalisation agrégé, ce qui signifie que l’ajout de fluentd à un binaire existant est assez simple. Vous ne changez pas du tout le binaire. Au lieu de cela, vous configurez fluentd pour charger les données d’un fichier dans un chemin spécifique et pour transmettre ces journaux à un système de stockage de journaux. Pour illustrer cela, voici un exemple de configuration Fluentd pour surveiller et pousser les journaux d’audit du serveur API Kubernetes:
@type tail
format json
path /var/log/audit
pos_file /var/log/audit.pos
tag audit
time_key time
time_format %Y-%m-%dT%H:%M:%S.%N%z
….
Vous pouvez voir dans cet exemple que Fluentd est hautement configurable, en prenant l’emplacement du fichier, le format de fichier et les expressions pour les deux dates d’analyse des journaux et en ajoutant des balises aux données. Étant donné que les serveurs Kubernetes utilisent le package glog , les lignes de journal suivent un format cohérent, vous pouvez donc vous attendre (et extraire) des données structurées de chaque ligne que Kubernetes enregistre.
Prometheus est souvent lié à une application, mais vous pouvez toujours l’utiliser avec un logiciel standard. Il existe une grande variété d’adaptateurs Prometheus qui peuvent être exécutés en tant que side-cars à côté de votre application. Ceux-ci peuvent être des ambassadeurs entre l’application et les interfaces Prometheus attendues. Dans de nombreux cas (par exemple, Redis ou Java), l’adaptateur sait directement comment parler à l’application pour exposer ses données dans un format que Prometheus peut comprendre. De plus, il existe des adaptateurs de protocoles de surveillance courants (par exemple, StatsD ) tels que Prometheus peut également supprimer des mesures qui étaient initialement destinées à un autre système.
11.3.3 Stockage des données pour la récupération et l’interrogation
Une fois que les données de surveillance et de journalisation ont été agrégées par Prometheus ou Fluentd , les données doivent encore être stockées quelque part pour être conservées pendant une période de temps. La durée de conservation des données de surveillance dépend des besoins de votre système et des coûts que vous êtes prêt à payer, en termes d’espace de stockage pour les données. Cependant, selon notre expérience, le minimum que vous devriez avoir est de 30 à 45 jours de données. Au début, cela peut sembler beaucoup, mais la vérité est que de nombreux problèmes commencent lentement et mettent longtemps à apparaître. Avoir une perspective historique vous permet de voir les différences avant qu’elles ne deviennent des problèmes importants et d’identifier plus facilement la source du problème.
Par exemple, une version publiée il y a quatre semaines aurait pu introduire une latence supplémentaire dans le traitement des demandes. Cela n’a peut-être pas été suffisamment important pour causer des problèmes, mais lorsqu’il est combiné à une augmentation plus récente du trafic des demandes, les demandes sont traitées beaucoup trop lentement et vos alertes se déclenchent. Sans données historiques pour identifier l’augmentation initiale de la latence il y a quatre semaines, vous ne seriez pas en mesure d’identifier la version (et donc les modifications) à l’origine du problème. Vous seriez coincé à chercher dans le code à la recherche du problème, ce qui peut prendre beaucoup plus de temps.
Comme pour les agrégateurs, il existe un certain nombre de choix pour le stockage des données de surveillance et de journalisation. De nombreuses options de stockage s’exécutent en tant que services cloud. Celles-ci peuvent être de bonnes options, car elles éliminent les opérations pour la partie stockage de votre cluster, mais il existe également de bonnes raisons pour exécuter votre propre stockage, telles que la possibilité de contrôler précisément l’emplacement et la conservation des données. Même dans l’espace de stockage open source pour la journalisation et la surveillance, vous avez plusieurs choix. Dans l’intérêt du temps et de l’espace, nous en discutons ici : InfluxDB pour la maintenance des données de séries chronologiques et Elasticsearch pour le stockage des données structurées en journaux.
11.3.3.1 InfluxDB
InfluxDB est une base de données de séries chronologiques qui est capable de stocker de grandes quantités de données dans un format compact et consultable. Il s’agit d’un projet open source qui est disponible gratuitement pour une variété de systèmes d’exploitation. InfluxDB est distribué sous forme de package binaire qui peut facilement être installé.
Une série chronologique est une collection de paires de données, dans laquelle un membre est une valeur et l’autre est un instant dans le temps. Par exemple, vous pouvez avoir une série chronologique qui représente l’utilisation du processeur d’un processus au fil du temps. Chaque paire combinerait l’utilisation du processeur et l’instant auquel cette utilisation du processeur a été observée.
Une question importante lors de l’exécution d’InfluxDB est de savoir si l’exécuter en tant que conteneur sur le cluster Kubernetes lui-même. En général, ce n’est pas une configuration recommandée. Vous utilisez InfluxDB pour surveiller le cluster, vous voulez donc que les données de surveillance restent accessibles, même si le cluster lui-même rencontre des problèmes.
11.3.3.2 Elasticsearch
Elasticsearch est un système d’ingestion et de recherche de données basées sur des journaux. Contrairement à InfluxDB , qui est orienté vers le stockage de données de séries chronologiques, Elasticsearch est conçu pour ingérer de grandes quantités de fichiers journaux non structurés ou semi – structurés et pour les rendre disponibles via une interface de recherche. Elasticsearch peut être installé à partir de packages binaires.
11.3.4 Visualisation et interaction avec vos données
Bien sûr, le stockage des informations n’est pas très utile si vous ne pouvez pas y accéder de manière intéressante pour analyser et comprendre ce qui se passe dans votre système. À cette fin, la visualisation est un composant essentiel d’une pile de surveillance complète. La visualisation est différente pour la journalisation et les données métriques. Les données de surveillance des métriques sont généralement visualisées sous forme de graphiques, soit sous la forme d’une série chronologique qui montre quelques métriques au fil du temps, soit sous forme d’histogramme qui résume les statistiques d’une valeur sur une fenêtre de temps. Parfois, il est visualisé comme un agrégat sur une fenêtre de temps (par exemple, la somme de toutes les erreurs chaque heure pendant une semaine). L’une des interfaces les plus populaires pour visualiser les métriques est le tableau de bord Grafana open source, qui peut s’interfacer avec Prometheus et d’autres sources métriques et vous permettre de créer vos propres tableaux de bord ou d’importer des tableaux de bord créés par d’autres utilisateurs.
Pour les données enregistrées, l’interface de recherche est davantage orientée autour des requêtes ad hoc et de l’exploration des données enregistrées. L’une des interfaces les plus utilisées pour afficher les données de journalisation est l’interface Web de Kibana , qui vous permet de rechercher, parcourir et introspecter les données qui ont été enregistrées dans Elasticsearch.
11.3.5 Que surveiller ?
Maintenant que vous avez assemblé votre pile de surveillance, il reste encore deux questions importantes sans réponse : sur quoi surveiller et, en conséquence, sur quoi alerter ?
Lors de l’assemblage des informations de surveillance, comme avec presque tous les logiciels, il est utile d’adopter une approche en couches. Les couches à surveiller sont les machines, les bases du cluster, les modules complémentaires de cluster et, enfin, les applications utilisateur. De cette façon, en commençant par les bases, chaque couche de la pile de surveillance se construit au-dessus de la couche en dessous. Lorsqu’il est construit de cette façon, l’identification d’un problème est un exercice de plongée à travers les couches jusqu’à ce que la cause soit identifiée. Cependant, en conséquence, si une couche saine est atteinte (par exemple, toutes les machines du cluster semblent fonctionner correctement), il devient évident que le problème réside dans la couche ci-dessus (par exemple, l’infrastructure du cluster).
La surveillance décrite dans le paragraphe précédent était entièrement une surveillance en boîte blanche, ce qui signifie que la surveillance était basée sur une connaissance détaillée du système et de son assemblage. Chaque partie du système est surveillée pour détecter les écarts par rapport aux prévisions et ces écarts sont signalés.
Le contraste whitebox surveillance est blackbox ou en fonction Prober surveillance. Dans la surveillance de la boîte noire, vous ne supposez ni ne connaissez aucun détail sur la façon dont le système est construit. Au lieu de cela, vous consommez simplement l’interface externe, comme le ferait un client ou un utilisateur, et observez si vos actions ont les résultats escomptés. Par exemple, un simple testeur pour un cluster Kubernetes peut planifier un pod sur le cluster et vérifier que le pod a été créé avec succès et que l’application exécutée dans le pod (par exemple, nginx) peut être atteinte via un service Kubernetes. Si un moniteur blackbox réussit, on peut généralement supposer que le système est sain. Si la blackbox échoue, le système ne l’est pas.
La valeur de la surveillance de la blackbox est qu’elle vous donne un signal très clair sur la santé de votre système. L’inconvénient est qu’il vous donne très peu de visibilité sur les raisons de la défaillance de votre système. Il est donc essentiel de combiner les deux whitebox et Blackbox surveillance pour un système de surveillance robuste, utile.
11.3.5.1 Surveillance des machines
Les machines (physiques ou virtuelles) qui composent votre cluster sont le fondement de votre cluster Kubernetes. Si les machines de votre cluster sont surchargées ou se comportent mal, toutes les autres opérations au sein du cluster sont suspectes. La surveillance des machines est essentielle pour comprendre si votre infrastructure de base fonctionne correctement.
Heureusement, la surveillance des métriques de la machine avec Prometheus est assez simple. Le projet Prometheus dispose d’un démon d’exportateur de nœuds, qui peut s’exécuter sur chaque machine et qui expose les informations de base collectées à partir du noyau et d’autres sources système afin que Prometheus puisse gratter. Ces données comprennent :
- Utilisation du processeur
- Utilisation du réseau
- Utilisation du disque et espace disponible
- Utilisation de la mémoire
- … et bien plus
Vous pouvez télécharger l’exportateur de nœuds depuis GitHub ou le créer vous-même. Lorsque vous avez l’exportateur de nœuds binaire dans votre système, vous pouvez le configurer pour qu’il s’exécute automatiquement en tant que démon à l’aide de ce simple fichier d’unité systemd :
[Unit]
Description=Node Exporter
[Service]
User=node_exporter
EnvironmentFile=/etc/sysconfig/node_exporter ExecStart=/usr/sbin/node_exporter $OPTIONS
[Install]
WantedBy=multi-user.target
Une fois l’exportateur de nœuds opérationnel, vous pouvez configurer Prometheus pour supprimer les métriques de chaque machine de votre cluster, en utilisant la configuration de scrape suivante dans Prometheus:
– job_name: “node”
scrape_interval: “60s”
static_configs:
– targets:
– ‘server.1:9100’
– ‘server.2:9100’
– …
– ‘server.N:9100’
11.3.5.2 Surveillance de Kubernetes
Heureusement, tous les éléments de l’infrastructure Kubernetes exposent des métriques à l’aide de l’API Prometheus, et il existe également une découverte du service Kubernetes que vous pouvez utiliser pour découvrir et surveiller automatiquement les composants Kubernetes de votre cluster :
– job_name: ‘kubernetes-apiservers’
kubernetes_sd_configs:
– role: endpoints
….
Vous pouvez réutiliser cette implémentation de découverte de service pour ajouter le raclage pour plusieurs composants différents dans le cluster, comme les serveurs API et les kubelets .
11.3.5.3 Surveillance des applications
Enfin, vous pouvez également utiliser la découverte du service Kubernetes pour rechercher et extraire les métriques des pods eux-mêmes. Cela signifie que vous supprimez automatiquement les mesures des éléments du cluster Kubernetes conçus pour s’exécuter en tant que pods (par exemple, les serveurs kube-dns ) et que vous supprimez automatiquement toutes les mesures des pods exécutés par les utilisateurs, en supposant que les utilisateurs intégrer et exposer des métriques compatibles avec Prometheus. Cependant, une fois que vos utilisateurs ont constaté à quel point il est facile d’obtenir une surveillance automatisée des métriques via Prometheus, il est peu probable qu’ils utilisent une autre surveillance.
11.3.5.4 Surveillance de la Blackbox
Comme mentionné précédemment, la surveillance de la blackbox sonde l’API externe du système, s’assurant qu’elle répond correctement. Dans ce cas, l’API externe du système est l’API Kubernetes. La vérification du système peut être effectuée par un agent qui effectue des appels contre l’API Kubernetes. Il est difficile de déterminer si cet agent s’exécute à l’intérieur du cluster Kubernetes. L’exécuter à l’intérieur du cluster le rend beaucoup plus facile à gérer, mais il le rend également vulnérable aux défaillances du cluster. Si vous choisissez de surveiller le cluster à partir du cluster, il est essentiel d’avoir également une « alerte de surveillance » qui se déclenche si un testeur n’a pas été exécuté jusqu’à son terme au cours des N minutes précédentes. Il y a beaucoup de différents blackbox tests que vous pouvez concevoir pour l’API Kubernetes. Comme exemple simple, vous pouvez imaginer écrire un petit script :
#!/bin/bash
# exit on all failures set -e NAMESPACE=blackbox
# tear down the namespace no matter what
function teardown {
kubectl delete namespace ${NAMESPACE}
}
trap teardown ERR
# Create a probe namespace
kubectl create namespace ${NAMESPACE}
kubectl create -f my-deployment-spec.yaml
# Test connectivity to your app here, wget etc.
teardown
Vous pouvez exécuter ce script toutes les cinq minutes (ou tout autre intervalle) pour valider le bon fonctionnement du cluster. Un exemple plus complet pourrait être d’écrire une application qui teste en permanence l’API Kubernetes, semblable au script précédent, mais aussi d’exporter des paramètres Prometheus de sorte que vous pouvez gratter le Blackbox les données de surveillance dans Prometheus.
En fin de compte, les limites de ce que vous testez sur la blackbox sont vraiment les limites de votre imagination et de votre volonté de concevoir et de construire des tests. Au moment de la rédaction de ce document, il n’y a pas de bons sondeurs Blackbox standard pour l’API Kubernetes. C’est à vous de concevoir et de construire de tels tests.
11.3.5.5 Journaux de streaming
En plus de toutes les données de surveillance des mesures, il est également important d’obtenir les journaux de votre cluster. Cela inclut des éléments tels que les journaux de kubelet de chaque nœud, ainsi que les journaux du serveur API, du planificateur et du gestionnaire de contrôleur du maître. Ceux-ci sont généralement situés dans / var / log / kube – *. Log. Vous pouvez les configurer pour l’exportation avec une configuration Fluentd simple comme :
@type tail
path /var/log/kube-apiserver.log
pos_file /var/log/fluentd-kube-apiserver.log.pos
tag kube-apiserver
…
Il est également utile de consigner tout ce qu’un conteneur exécuté dans le cluster écrit sur stdout . Par défaut, Docker écrit tous les journaux des conteneurs dans / var / log / containers / *. Log , et vous pouvez donc utiliser cette expression dans une configuration Fluentd similaire pour exporter également les données de journal pour tous les conteneurs qui s’exécutent dans le cluster.
11.3.5.6 Alerting
Une fois que la surveillance fonctionne correctement, il est temps d’ajouter des alertes. La définition et la mise en œuvre d’alertes dans Prometheus ou d’autres systèmes dépassent le cadre de cet article. Si vous n’avez jamais fait de suivi auparavant, nous vous recommandons fortement d’obtenir un article dédié au sujet.
Cependant, en ce qui concerne les alertes à définir, il y a deux philosophies à considérer. La première, similaire à la surveillance de la boîte blanche, consiste à alerter lorsque les signaux cessent d’être nominaux. Par exemple, pour comprendre la quantité d’UC consommée par un serveur API et avertir si l’utilisation de l’UC d’un serveur API sort de cette plage.
Les avantages de cette approche de la surveillance sont que vous remarquez fréquemment des problèmes avant qu’ils n’affectent l’utilisateur. Les systèmes commencent à se comporter étrangement ou mal souvent bien avant d’avoir des pannes catastrophiques.
L’inconvénient de cette stratégie d’alerte est qu’elle peut être assez bruyante. Les signaux, comme l’utilisation du processeur, peuvent être assez variés, et alerter lorsque les choses changent – même s’il n’y a pas nécessairement un vrai problème – peut conduire des opérateurs fatigués et frustrés, qui ignorent les pages quand il y a de vraies alertes.
La stratégie de surveillance alternative, plus similaire à la surveillance de la boîte noire, consiste à alerter sur les signaux que votre utilisateur voit. Par exemple, la latence d’une demande au serveur API ou le nombre de réponses 403 (non autorisées) que votre serveur API renvoie. L’avantage de cette alerte est que, par définition, il ne peut pas y avoir d’alerte bruyante. Chaque fois qu’une telle alerte se déclenche, il y a un vrai problème. L’inconvénient d’une telle alerte est que vous ne remarquez pas de problèmes tant qu’ils ne sont pas confrontés au client.
Comme tout, le meilleur chemin pour alerter réside dans un équilibre de chacun. Pour les signaux que vous comprenez très bien, qui ont des valeurs stables, l’ alerte whitebox offre un avertissement critique avant que des problèmes importants ne se produisent. Les alertes Blackbox, en revanche, vous donnent des alertes de haute qualité causées par de vrais problèmes rencontrés par l’utilisateur. Une stratégie d’alerte réussie combine les deux styles d’alertes (et, peut-être plus critique, adapte ces alertes) à mesure que votre compréhension de vos clusters particuliers se développe.
11.4 Résumé
La journalisation et la surveillance sont des éléments essentiels pour comprendre les performances de votre cluster et de vos applications et / ou les problèmes rencontrés. La construction d’une pile d’alerte et de surveillance de haute qualité devrait être l’une des toutes premières priorités après la mise en place réussie d’un cluster. Fait correctement, une pile de journalisation et de surveillance qui est automatiquement disponible pour les utilisateurs d’un cluster Kubernetes est un différenciateur clé qui permet aux développeurs de déployer et de gérer des applications fiables à grande échelle.
12 CHAPITRE 12 Récupération après sinistre
Si vous êtes comme la plupart des utilisateurs, vous avez probablement fait appel à Kubernetes, au moins en partie, pour sa capacité à récupérer automatiquement après une défaillance. Et, bien sûr, Kubernetes fait un excellent travail pour maintenir vos charges de travail opérationnelles. Cependant, comme pour tout système complexe, il y a toujours place à l’échec. Que cet échec soit dû à quelque chose comme une panne matérielle sur un nœud, ou même une perte de données sur le cluster etcd , nous voulons avoir des systèmes en place pour garantir que nous pouvons récupérer en temps opportun et de manière fiable.
12.1 Haute disponibilité
Un premier principe dans toute stratégie de reprise après sinistre est de concevoir vos systèmes pour minimiser la possibilité de défaillance en premier lieu. Naturellement, la conception d’un système infaillible est une impossibilité, mais nous devons toujours construire avec les pires scénarios à l’esprit.
Lors de la création de clusters Kubernetes de production, les meilleures pratiques dictent toujours que les composants critiques sont hautement disponibles. Dans certains cas, comme avec le serveur API, ceux-ci peuvent avoir une configuration active-active, alors qu’avec des éléments comme le planificateur et le gestionnaire de contrôleur, ceux-ci fonctionnent de manière active-passive. Lorsque ces surfaces du plan de contrôle sont déployées correctement, un utilisateur ne doit pas remarquer qu’une défaillance s’est même produite.
De même, nous recommandons que votre magasin de sauvegarde etcd soit déployé dans une configuration de cluster à trois ou cinq modes. Vous pouvez certainement déployer des clusters plus grands (toujours avec un nombre impair de membres), mais des clusters de cette taille devraient suffire pour la grande majorité des cas d’utilisation. La tolérance de défaillance du cluster etcd augmente avec le nombre de membres présents : tolérance de défaillance à un nœud pour un cluster à trois nœuds et tolérance à deux nœuds pour un cluster à cinq nœuds. Cependant, à mesure que la taille du cluster etcd augmente, les performances du cluster peuvent se dégrader lentement. Lorsque vous choisissez la taille de votre cluster, assurez-vous toujours que vous êtes bien dans la charge etcd attendue.
Comprenez qu’une défaillance du plan de contrôle Kubernetes n’affecte généralement pas le plan de données. En d’autres termes, si votre serveur API, votre gestionnaire de contrôleur ou votre planificateur tombe en panne, vos pods continueront souvent de fonctionner tels quels. Dans la plupart des scénarios, vous n’êtes tout simplement pas en mesure d’effectuer des modifications sur le cluster tant que le plan de contrôle n’est pas remis en ligne.
12.2 État
La question au centre de chaque solution de reprise après sinistre est: «Comment restaurer un état antérieur bien défini?» Nous voulons être sûrs qu’en cas de catastrophe, nous avons des copies de toutes les données dont nous avons besoin pour revenir à un état opérationnel.
Heureusement, avec Kubernetes, la plupart de l’état opérationnel du cluster est situé au centre du cluster etcd . Par conséquent, nous passons beaucoup de temps à nous assurer que nous pouvons reconstituer son contenu en cas de défaillance.
Mais etcd n’est pas le seul état dont nous nous soucions. Nous devons également nous assurer que nous avons des sauvegardes de certains actifs statiques créés (ou, dans certains cas, fournis) pendant le déploiement. Les éléments suivants doivent être rangés en toute sécurité :
- Tous les actifs PKI utilisés par le serveur API Kubernetes
Ceux – ci sont généralement situés dans le répertoire /etc/Kubernetes/pki.
- Toutes les clés de cryptage secrètes
Ces clés sont stockées dans un fichier statique spécifié avec le paramètre – experimentalencryption -provider-config dans le paramètre de serveur API. Si ces clés sont perdues, aucune donnée secrète n’est récupérable.
Toutes les informations d’identification d’administrateur
La plupart des outils de déploiement (y compris kubeadm ) créent des informations d’identification d’administrateur statiques et les fournissent dans un fichier kubeconfig . Bien que ceux-ci puissent être recréés, leur stockage sécurisé hors cluster peut réduire le temps de récupération.
12.3 Données d’application
En plus de tout l’état nécessaire pour reconstituer Kubernetes lui-même, la récupération de pods avec état serait inutile à moins que nous ne récupérions également les données persistantes associées à ces pods.
12.3.1 Volumes persistants
Il existe différentes manières pour un utilisateur de conserver des données depuis Kubernetes. La façon dont vous sauvegardez ces données dépend de votre environnement.
Par exemple, dans un fournisseur de cloud, cela peut être aussi simple que de rattacher tous les volumes persistants à leurs pods respectifs, avec l’hypothèse de travail que votre défaillance Kubernetes n’est pas liée à la disponibilité des volumes persistants. Vous pouvez également vous fier à l’architecture sous-jacente qui soutient les volumes eux-mêmes. Par exemple, avec des volumes basés sur Ceph, avoir plusieurs répliques de vos données peut suffire.
La façon dont vous implémentez la sauvegarde des données d’application dépend fortement de l’implémentation que vous avez choisie pour la façon dont les volumes sont présentés à Kubernetes. Gardez cela à l’esprit lorsque vous développez une stratégie de reprise après sinistre plus large.
Kubernetes ne dispose pas actuellement d’un mécanisme pour définir les instantanés de volume, mais c’est une fonctionnalité qui semble être utilisée dans les conversations récentes de la communauté.
12.3.2 Données locales
Un aspect souvent négligé de la sauvegarde de données est que les utilisateurs conservent parfois sans le savoir des données critiques sur le disque local d’un nœud. Cela est particulièrement fréquent dans les environnements locaux, où le stockage connecté au réseau n’est pas toujours présent. Sans garde – fous appropriés sont en place (par exemple, PodSecurityPolicys et / ou plusieurs contrôleurs d’admission génériques), les utilisateurs peuvent utiliser emptyDir ou cheminServeur volumes, tenant éventuellement des hypothèses erronées sur la longévité de ces données.
Rappelez-vous notre discussion sur le contrôle d’admission au chapitre 7. Si vous souhaitez appliquer des restrictions sur l’accès au disque local, celles-ci peuvent être implémentées avec PodSecurityPolicys , principalement avec les volumes et les contrôles allowedHostPaths .
Ce n’est peut-être même pas un scénario d’échec où ce problème est rencontré. Étant donné que les nœuds de travail sont généralement considérés comme éphémères, même une maintenance ou une mise hors service planifiée d’un nœud peut entraîner une mauvaise expérience pour vos utilisateurs. Assurez-vous toujours d’avoir les commandes appropriées en place.
12.4 Nœuds de travail
Nous pouvons considérer les nœuds de travail comme remplaçables. Lors de la conception de notre stratégie de reprise après sinistre pour les nœuds de travail, nous avons simplement besoin d’avoir un processus en place par lequel nous pouvons recréer de manière fiable un nœud de travail. Si vous avez déployé Kubernetes sur un fournisseur de cloud, la tâche est souvent aussi simple que de lancer une nouvelle instance et de joindre ce travailleur au plan de contrôle. Dans les environnements bare-metal (ou ceux sans infrastructure dirigée par l’API), ce processus peut être un peu plus onéreux, mais il sera essentiellement identique.
Dans le cas où vous êtes en mesure d’identifier qu’un nœud approche de la panne, ou dans les cas où vous devez effectuer une maintenance, Kubernetes propose deux commandes qui peuvent être utiles.
Premièrement, et particulièrement important dans les grappes à taux de désabonnement élevé, le cordon kubectl rend un nœud imprévisible. Cela peut aider à endiguer la vague de nouveaux pods affectant notre capacité à effectuer une action de récupération sur un nœud de travail. Deuxièmement, la commande kubectl drain nous permet de supprimer et de replanifier tous les pods en cours d’exécution à partir d’un nœud cible. Ceci est utile dans les scénarios où nous avons l’intention de supprimer un nœud du cluster.
12.5 etcd
Étant donné qu’un cluster etcd conserve plusieurs répliques de son jeu de données, l’échec complet est relativement rare. Cependant, la sauvegarde de etcd est toujours considérée comme une meilleure pratique pour les clusters de production.
Tout comme avec n’importe quelle autre base de données, etcd stocke ses données sur disque, et avec cela vient une variété de façons dont nous pouvons sauvegarder ces données. Aux niveaux les plus bas, nous pouvons utiliser des instantanés de bloc et de système de fichiers, et cela pourrait bien fonctionner. Cependant, une coordination importante doit être effectuée lors de la tentative de sauvegarde. Dans les deux cas, vous devez vous assurer que etcd a été mis au repos, généralement en arrêtant le processus etcd sur le membre etcd où vous avez l’intention d’effectuer la sauvegarde. De plus, pour vous assurer que toutes les données en vol ont été enregistrées, vous devez vous assurer de geler d’abord le système de fichiers sous-jacent. Comme vous pouvez le voir, cela peut devenir assez lourd.
Cette technique peut commencer à avoir un sens avec les périphériques de bloc connectés au réseau qui supportent etcd . De nombreux clusters créés dans des environnements de cloud public choisissent d’utiliser cette technique car elle raccourcit le temps de récupération. Au lieu de remplacer les données sur le disque par une sauvegarde, ces utilisateurs se contentent de rattacher les volumes de données etcd existants aux nouveaux nœuds membres etcd et, les doigts croisés, sont de retour dans les affaires. Bien que cette solution puisse fonctionner, il existe un certain nombre de raisons pour lesquelles elle peut être loin d’être idéale. La principale d’entre elles concerne les préoccupations concernant la cohérence des données, car cette approche est relativement difficile à exécuter correctement.
L’approche la plus courante, bien qu’elle entraîne des temps de récupération légèrement plus longs, consiste à utiliser les outils de ligne de commande etcd natifs :
ETCDCTL_API=3 etcdctl –endpoints $ENDPOINT snapshot save etcd-`date +%Y%m%d`.db
Cela peut être exécuté sur un membre etcd actif et le fichier résultant doit être déchargé du cluster et stocké dans un emplacement fiable, tel qu’un magasin d’objets. Dans le cas où vous devez restaurer, vous devez simplement exécuter la commande de restauration bien nommée:
ETCDCTL_API=3 etcdctl snapshot restore etcd-$DATE.db –name $MEMBERNAME
Effectuez cette opération contre chacun des membres de remplacement d’un nouveau cluster.
Bien que toutes ces stratégies de sauvegarde soient viables, il y a des mises en garde importantes à considérer.
Tout d’abord, lorsque vous sauvegardez par l’une ou l’autre méthode, sachez que vous sauvegardez l’intégralité de l’espace de clés etcd. Il s’agit d’une copie complète de l’état de etcd au moment de la sauvegarde. Bien que notre objectif soit généralement de créer une copie conforme, il peut y avoir des scénarios dans lesquels nous ne souhaitons pas réellement la sauvegarde complète. Peut-être voulons-nous simplement mettre en place rapidement l’espace de noms de production. Avec ce type de reprise, nous restaurons sans discernement.
Deuxièmement, comme pour tout type de sauvegarde de base de données, si l’application consommatrice (dans notre cas, Kubernetes elle-même) n’est pas suspendue pendant la sauvegarde, il peut y avoir un état transitoire qui n’a pas été appliqué de manière cohérente au magasin de sauvegarde. La probabilité que cela soit hautement problématique est faible, mais elle est néanmoins présente.
Et enfin, si vous avez activé des serveurs API Kubernetes Aggregate ou avez utilisé une implémentation Calico avec etcd (qui utilisent tous deux leurs propres instances etcd ), celles-ci ne seront pas sauvegardées si vous avez uniquement ciblé les points de terminaison etcd principaux du cluster . Vous auriez besoin de développer des stratégies supplémentaires pour capturer et restaurer ces données.
Si vous utilisez une offre Kubernetes gérée, il se peut que vous n’ayez pas d’accès direct à etcd ou même aux disques qui supportent etcd. Dans ce cas, vous devez utiliser une méthodologie de sauvegarde et de restauration différente.
12.6 Ark
Ark, de Heptio, est un outil spécialement conçu pour la sauvegarde et la restauration des clusters Kubernetes. Cet outil ne concerne pas seulement la gestion des données des ressources Kubernetes, mais sert également de cadre pour la gestion des données d’application.
Ce qui rend Ark différent des méthodes que nous avons déjà décrites, c’est qu’il est conscient de Kubernetes. Au lieu de sauvegarder aveuglément les données etcd, Ark effectue des sauvegardes via l’API Kubernetes elle-même. Cela garantit que les données sont toujours cohérentes et permet des stratégies de sauvegarde plus sélectives. Prenons quelques exemples.
Sauvegarde et restauration partielles
Parce qu’Ark est compatible avec Kubernetes, il est capable de faciliter des stratégies de sauvegarde plus avancées. Par exemple, si vous souhaitez sauvegarder uniquement les charges de travail de production, vous pouvez utiliser un simple sélecteur d’étiquettes :
ark backup create prod-backup –selector env=prod
Cela sauvegarderait toutes les ressources avec le label env = prod.
Restauration dans un nouvel environnement
Ark est capable de restaurer la sauvegarde dans un cluster entièrement nouveau ou même dans un nouvel espace de noms au sein d’un cluster existant. Au-delà du sujet de la reprise après sinistre, cela peut également être utilisé pour faciliter des scénarios de test intéressants.
Restauration partielle
En période d’arrêt, il est souvent préférable de restaurer d’abord les systèmes les plus critiques. Avec une restauration partielle, Ark vous permet de hiérarchiser les ressources qui sont restaurées.
Sauvegarde de données persistante
Ark est capable de s’intégrer à une variété de fournisseurs de cloud pour prendre automatiquement des instantanés des volumes persistants. En outre, il comprend un mécanisme de hook pour effectuer des actions, telles que le gel du système de fichiers avant et après la prise de l’instantané.
Sauvegardes planifiées
Avec un état de gestion des services sur cluster, Ark est capable de planifier des sauvegardes. Cela peut être particulièrement utile pour garantir que les sauvegardes sont effectuées régulièrement.
Sauvegardes hors cluster
Ark s’intègre à diverses solutions de stockage d’objets compatibles S3. Bien que ces solutions puissent être exécutées sur un cluster, il est conseillé de décharger ces sauvegardes afin qu’elles soient disponibles en cas d’échec.
Vous n’aurez probablement pas besoin de toutes ces fonctionnalités, mais avec le large degré de liberté qu’Ark offre, vous pouvez choisir les éléments qui conviennent à votre solution de sauvegarde.
12.7 Résumé
Lors de l’élaboration d’une stratégie de reprise après sinistre pour votre cluster Kubernetes, il y a de nombreux points à considérer. La façon dont vous concevez cette stratégie dépend de vos sélections de technologies complémentaires, ainsi que des détails de votre cas d’utilisation particulier. Au fur et à mesure que vous construisez ce muscle, assurez-vous d’exercer régulièrement votre capacité à restaurer complètement vos systèmes de production avec des solutions entièrement automatisées. Cela vous prépare non seulement à l’échec, mais vous aide également à réfléchir à votre stratégie de déploiement de manière plus globale. Bien sûr, nous espérons que vous n’aurez jamais besoin d’utiliser les techniques décrites ci-dessus. Mais si le besoin s’en faisait sentir, vous feriez mieux de considérer ces cas dès le départ.
13 CHAPITRE 13 Extension de Kubernetes
Kubernetes possède une API riche qui fournit la plupart des fonctionnalités dont vous pourriez avoir besoin pour créer et exploiter un système distribué. Cependant, l’API est délibérément générique, visant les cas d’utilisation à 80%. Profiter du riche écosystème d’extensions et d’extensions qui existent pour Kubernetes peut ajouter de nouvelles fonctionnalités importantes et permettre de nouvelles expériences pour les utilisateurs de votre cluster. Vous pouvez même choisir d’implémenter vos propres modules complémentaires et extensions personnalisés qui sont adaptés aux besoins particuliers de votre entreprise ou de votre environnement.
13.1 Points d’extension Kubernetes
Il existe différentes manières d’étendre un cluster Kubernetes et chacune offre un ensemble différent de capacités et une complexité opérationnelle supplémentaire. Les sections suivantes décrivent ces différents points d’extension en détail et donnent un aperçu de la façon dont ils peuvent étendre les fonctionnalités d’un cluster et des exigences opérationnelles supplémentaires de ces extensions. Les quatre types d’extensibilité sont :
- Démons de cluster pour l’automatisation
- Assistants de cluster pour des fonctionnalités étendues
- Extension du cycle de vie du serveur API
- Ajout de plus d’API
La vérité, bien sûr, sur certaines de ces classifications, c’est qu’elles sont quelque peu arbitraires, et il existe différentes extensions qui peuvent combiner plusieurs types d’extensibilité pour fournir des fonctionnalités supplémentaires à un cluster. Les catégories décrites ici sont destinées à guider votre discussion et à planifier l’extension d’un cluster Kubernetes. Ce sont des directives, pas des règles dures et rapides.
13.2 Démons de cluster
La forme d’extensibilité de cluster la plus simple et la plus courante est le démon de cluster. Tout comme un démon ou un agent exécuté sur une seule machine ajoute une automatisation (par exemple, le roulement des journaux) à une seule machine, un démon de cluster ajoute une fonctionnalité d’automatisation à un cluster. Les démons de cluster ont deux caractéristiques définitives. L’agent doit s’exécuter sur le cluster Kubernetes lui-même et l’agent doit ajouter au cluster des fonctionnalités qui sont automatiquement fournies à tous les utilisateurs du cluster sans aucune action de leur part.
Pour pouvoir déployer un démon de cluster sur le cluster Kubernetes qu’il aide à gérer, le démon de cluster lui-même est conditionné sous forme d’image de conteneur. Il est ensuite configuré via des objets de configuration Kubernetes et exécuté sur le cluster via un DaemonSet ou un
Déploiement. En règle générale, ces démons de cluster s’exécutent dans un espace de noms dédié afin qu’ils ne soient pas accessibles aux utilisateurs du cluster, bien que, dans certains cas, les utilisateurs puissent installer des démons de cluster dans leurs propres espaces de noms. Quand vient le temps de surveiller, de mettre à niveau ou de maintenir ces démons, ils sont maintenus exactement comme toute autre application exécutée sur le cluster Kubernetes. L’exécution des agents de cette manière est plus fiable, car ils héritent de toutes les mêmes capacités qui facilitent l’exécution de toute autre application dans Kubernetes. Il est également plus cohérent, car les agents et les applications sont surveillés et maintenus à l’aide des mêmes outils.
Dans les sections suivantes, nous explorons d’autres façons dont les programmes s’exécutant sur un cluster Kubernetes peuvent étendre ou améliorer ce cluster. Cependant, ce qui distingue les agents de cluster ou les démons des autres extensions, c’est que les capacités qu’ils fournissent s’appliquent à tous les objets d’un cluster ou d’un espace de noms, sans intervention supplémentaire de l’utilisateur pour les activer. Ils sont activés automatiquement et les utilisateurs gagnent souvent la fonctionnalité sans même se rendre compte qu’ils sont présents.
13.2.1 Cas d’utilisation des démons de cluster
Il existe de nombreux types de fonctionnalités que vous pouvez fournir automatiquement à un utilisateur. Un excellent exemple est la collecte automatique de métriques à partir de serveurs qui exposent Prometheus. Lorsque vous exécutez Prometheus dans un cluster Kubernetes et que vous le configurez pour effectuer la découverte de services basée sur Kubernetes, il fonctionne comme un démon de cluster et analyse automatiquement tous les pods du cluster pour les mesures qu’il doit ingérer. Pour ce faire, il regarde le serveur API Kubernetes pour découvrir les nouveaux pods au fur et à mesure. Ainsi, toute application exécutée dans un cluster Kubernetes avec un agent de cluster Prometheus a automatiquement des métriques collectées sans configuration ni activation par le développeur.
Un autre exemple de démon de cluster est un agent qui analyse les services déployés dans le cluster à la recherche de vulnérabilités de script intersite (XSS). Ce démon de cluster surveille à nouveau le serveur API Kubernetes pour la création de nouveaux services Ingress (équilibreur de charge HTTP). Lorsque de tels services sont créés, il analyse automatiquement tous les chemins d’accès du service pour les pages Web vulnérables XSS et envoie un rapport à l’utilisateur. Encore une fois, parce qu’il est fourni par un démon de cluster, cette fonctionnalité est héritée par les développeurs qui utilisent le cluster sans aucune exigence qu’ils savent même ce XSS est ou que le balayage est INTERVENUES jusqu’à ce qu’ils déploient un service qui a une vulnérabilité. Nous voyons comment construire cet exemple à la fin de la section.
Les démons de cluster sont puissants, car ils ajoutent des fonctionnalités automatiques. Moins les développeurs doivent apprendre mais peuvent hériter automatiquement de leur environnement, plus leurs applications sont susceptibles d’être fiables et sécurisées.
13.2.2 Installation d’un démon de cluster
L’installation d’un démon de cluster se fait via des images de conteneur et des fichiers de configuration Kubernetes. Ces configurations peuvent être développées par l’administrateur du cluster, fournies par un gestionnaire de packages (comme Helm), ou fournies par le développeur du service (par exemple, un projet open source ou un éditeur de logiciel indépendant). En règle générale, l’administrateur de cluster utilise l’outil kubectl pour installer le démon de cluster sur le cluster, éventuellement avec des informations de configuration supplémentaires, telles qu’une clé de licence ou des espaces de noms à analyser. Une fois installé, le démon démarre immédiatement les opérations sur le cluster et toutes les mises à niveau, réparations ou suppressions ultérieures du démon sont effectuées via les objets de configuration de Kubernetes, comme toute autre application.
13.2.3 Considérations opérationnelles pour les démons de cluster
Bien que l’installation d’un démon de cluster soit généralement triviale – souvent un simple appel en ligne de commande – la complexité opérationnelle engendrée par l’ajout d’un tel démon peut être assez importante. La nature automatique des modules complémentaires de cluster est une épée à double tranchant. Les utilisateurs vont rapidement compter sur eux, et donc l’importance opérationnelle des modules complémentaires du démon de cluster peut être importante. C’est-à-dire que même si une partie de la valeur des démons de cluster est dérivée de leur nature transparente, les utilisateurs ne remarqueront probablement pas leur échec. Imaginez, par exemple, que votre régime de sécurité repose sur une analyse XSS automatisée via un démon de cluster, et que le démon se bloque silencieusement. Du coup, toute détection XSS pour l’ensemble de votre cluster peut être désactivée. L’installation d’un démon de cluster transfère la responsabilité de la fiabilité de ces systèmes du développeur à l’administrateur de cluster. Généralement, c’est la bonne chose à faire, car cela centralise la connaissance de ces extensions et permet à une seule équipe de créer des services partagés par un grand nombre d’autres équipes. Mais il est essentiel que les administrateurs de cluster sachent à quoi ils s’inscrivent. Vous ne pouvez pas simplement installer un démon de cluster sur un coup de tête ou à cause de la demande d’un utilisateur. Vous devez être pleinement engagé dans la gestion opérationnelle et la prise en charge de ce démon de cluster pendant toute la durée de vie du cluster.
13.2.4 Travaux pratiques : exemple de création d’un démon de cluster
La création d’un démon de cluster n’a pas besoin d’être difficile. En fait, un simple script bash que vous pourriez exécuter à partir d’une seule machine peut facilement être transformé en démon de cluster. Considérez, par exemple, le script suivant :
#!/bin/bash
for service in $(kubectl –all-namespaces get services | awk ‘{print $0}’); do
python XssPy.py -u ${service} -e
done
Ce script répertorie tous les services d’un cluster, puis utilise un script d’analyse XSS open source pour analyser chaque service et imprimer le rapport.
Pour transformer cela en un démon de cluster, nous devons simplement placer ce script dans une boucle (avec quelques retards, bien sûr) et lui donner un moyen de signaler :
#!/bin/bash
# Start a simple web server
mkdir -p www
cd www
python -m SimpleHTTPServer 8080 &
cd ..
# Scan every service and write a report.
while true; do
for service in $(kubectl –all-namespaces get services | awk ‘{print $0}’); do
python XssPy.py -u ${service} -e > www/${service}-$(date).txt
done
# Sleep ten minutes between runs
sleep 600
done
Si vous empaquetez ce script dans un pod et l’exécutez dans votre cluster, vous aurez une collection de rapports XSS disponibles à partir du pod. Bien sûr, pour vraiment produire ceci, il y a beaucoup d’autres choses dont vous pourriez avoir besoin, y compris le téléchargement de fichiers vers un référentiel central ou la surveillance / alerte. Mais cet exemple montre que la construction d’un démon de cluster ne doit pas être une tâche compliquée pour les experts de Kubernetes. Un petit script shell et un Pod sont tout ce dont vous avez besoin.
13.3 Assistants de cluster
Les assistants de cluster sont assez similaires aux démons de cluster, mais contrairement aux démons de cluster, dans lesquels la fonctionnalité est automatiquement activée pour tous les utilisateurs du cluster, un assistant de cluster exige que l’utilisateur fournisse une configuration ou un autre geste pour activer les fonctionnalités fournies par l’assistant. . Plutôt que de fournir des expériences automatiques, les assistants de cluster fournissent des fonctionnalités enrichies, mais facilement accessibles, aux utilisateurs du cluster, mais c’est une fonctionnalité que l’utilisateur doit connaître et doit fournir les informations appropriées pour l’activer.
13.3.1 Cas d’utilisation pour les assistants de cluster
Les cas d’utilisation des assistants de cluster sont généralement ceux dans lesquels un utilisateur souhaite activer certaines fonctionnalités, mais le travail pour activer les capacités est considérablement plus difficile, plus lent ou plus compliqué et sujet aux erreurs que nécessaire. Dans une telle situation, il incombe à l’assistant d’aider à automatiser ce processus pour le rendre plus facile, plus automatique et moins susceptible de souffrir de « couper-coller » ou d’autres erreurs de configuration. Les assistants simplifient les tâches fastidieuses ou par cœur dans un cluster pour faciliter la consommation des concepts.
Comme exemple concret d’un tel processus, considérez ce qui est nécessaire pour ajouter un certificat SSL à un service HTTP dans un cluster Kubernetes. Tout d’abord, un utilisateur doit obtenir un certificat. Bien que les API, comme Let’s Encrypt, aient rendu cela beaucoup plus facile, il s’agit toujours d’une tâche non triviale, nécessitant qu’un utilisateur installe l’outillage, configure un serveur et revendique un domaine. Cependant, une fois le certificat obtenu, vous n’avez toujours pas terminé. Vous devez comprendre comment le déployer sur votre serveur Web. Certains développeurs peuvent suivre les meilleures pratiques et, connaissant Kubernetes Ingress, créer un secret Kubernetes, en associant le certificat à l’équilibreur de charge HTTP. Mais d’autres développeurs peuvent emprunter la route facile (et considérablement moins sécurisée) et intégrer le certificat directement dans leur image de conteneur. D’autres encore peuvent reculer devant la complexité et décider que SSL n’est pas réellement requis pour leur cas d’utilisation.
Quel que soit le résultat, le travail supplémentaire des développeurs et les différentes implémentations de SSL sont des risques inutiles. Au lieu de cela, l’ajout d’un assistant de cluster pour automatiser le processus de provisionnement et de déploiement des certificats SSL peut réduire la complexité du développeur et garantir que tous les certificats du cluster sont obtenus, déployés et pivotés d’une manière qui suit les meilleures pratiques. Cependant, pour fonctionner correctement, l’assistant de cluster nécessite la connaissance et l’engagement de l’utilisateur final du cluster, dans ce cas, le nom de domaine du certificat et une demande explicite de connexion de SSL à l’équilibreur de charge via l’assistant de cluster. . Un tel assistant est implémenté par le projet open source cert-manager.
Pour un administrateur de cluster, les assistants de cluster centralisent les connaissances et les meilleures pratiques, réduisent les questions des utilisateurs en simplifiant les configurations de cluster complexes et s’assurent que tous les services déployés sur un cluster ont une apparence commune.
13.3.2 Installation d’un assistant de cluster
Parce que la différence entre les assistants de cluster et les démons de cluster vient du modèle d’interaction – pas de l’implémentation – l’installation d’un assistant de cluster est plus ou moins identique à l’installation d’un démon de cluster. L’assistant de cluster est présenté sous la forme d’une image de conteneur et déployé via des objets API Kubernetes standard, comme les déploiements et les pods. Comme les démons de cluster, la maintenance, les opérations et la suppression des assistants de cluster sont gérées via l’API Kubernetes.
13.3.3 Considérations opérationnelles pour les assistants de cluster
Comme les démons de cluster, les assistants de cluster ont besoin que l’administrateur de cluster assume la responsabilité opérationnelle. Étant donné que les assistants cachent la complexité à l’utilisateur final, ce qui signifie que l’utilisateur final n’est finalement pas au courant des détails de la façon dont une tâche telle que l’installation d’un certificat est réellement implémentée, il est essentiel que les assistants fonctionnent correctement. Il est peu probable que l’utilisateur final soit capable de réaliser lui-même des tâches similaires, en raison du manque d’expérience et de connaissances. Cependant, comme la fonctionnalité est optin, un utilisateur est beaucoup plus susceptible de remarquer que quelque chose ne fonctionne pas. Par exemple, l’utilisateur a demandé un certificat SSL et il n’est pas arrivé. Cependant, cela ne signifie pas que l’administrateur du cluster a moins de charge opérationnelle. Vous devez toujours surveiller et réparer de manière proactive l’infrastructure de l’assistant de cluster, mais quelqu’un est plus susceptible de remarquer les problèmes.
13.3.4 Travaux pratiques : exemple d’assistants de cluster
Pour rendre cela un peu plus concret, créons un exemple d’assistant de cluster qui ajoute automatiquement l’authentification à un service Kubernetes. L’opération de base de cet assistant est qu’il analyse en continu la liste des objets Service de votre cluster à la recherche d’objets avec une clé d’annotation spécifique : manage-k8s.io/ authentication-secret. Il est prévu que la valeur de cette clé pointe vers un secret Kubernetes qui contient a . fichier htpasswd . Par exemple :
kind: Service metadata:
name: my-service
annotations:
managing-k8s.io/authentication-secret: my-httpasswd-secret
…
Lorsque l’assistant de cluster trouve une telle annotation, il crée deux nouveaux objets Kubernetes. Tout d’abord, il crée un déploiement, qui contient un pod de serveur Web nginx répliqué. Ces pods prennent le . Fichier httpasswd référencé par le Secret dans l’annotation, et configurez nginx en tant que proxy inverse, qui transfère le trafic vers myservice mais nécessite un utilisateur et un mot de passe comme spécifié dans le . fichier htpasswd . L’assistant de cluster crée également un service Kubernetes nommé authenticated- myservice qui dirige le trafic vers cette couche d’authentification. De cette façon, un utilisateur peut exposer ce service authentifié au monde extérieur et disposer d’une authentification sans avoir à se soucier de la configuration de nginx . Bien sûr, l’authentification de base est un exemple assez simple. Vous pouvez facilement imaginer l’étendre pour couvrir OAuth ou d’autres points de terminaison d’authentification plus sophistiqués.
13.4 Extension du cycle de vie du serveur API
Les exemples précédents étaient des applications qui s’exécutent au-dessus de votre cluster, mais il y a des limites à ce qui est possible avec de telles extensions de cluster. Une sorte d’extensibilité plus profonde provient de l’extension du comportement du serveur API lui-même. Ces extensions peuvent être appliquées directement à toutes les demandes d’API, car elles sont traitées par le serveur d’API lui-même. Cela permet une extensibilité supplémentaire pour votre cluster.
13.4.1 Cas d’utilisation pour étendre le cycle de vie de l’API
Étant donné que des extensions de cycle de vie d’API existent dans le chemin du serveur d’API, vous pouvez les utiliser pour appliquer les exigences sur tous les objets API créés par le service. Par exemple, supposons que vous souhaitiez vous assurer que toutes les images de conteneur qui s’exécutent dans le cluster proviennent du registre privé de votre entreprise et qu’une convention de dénomination est maintenue. Vous pouvez, par exemple, souhaiter que toutes les images soient au format registre.my-co.com/ <nom-équipe> / : où registre.my-co.com est un fichier privé image d’ exécution de registre par votre société, et sont des équipes bien connues et des applications construites par ces équipes, et enfin, est un SourceControl engager hachage indiquant la révision à partir de laquelle l’image a été construit. Exiger un tel nom d’image garantit que les développeurs ne stockent pas leurs images de production sur des référentiels d’images publics (non authentifiés), et les conventions de dénomination garantissent que toute application (par exemple, le scanner XSS que nous avons décrit précédemment) a accès aux métadonnées nécessaires à l’envoi notifications. Exiger le git-hash garantit que les développeurs ne construisent des images qu’à partir du code source archivé (et donc révisé par le code) et qu’il est facile de passer d’une image en cours d’exécution au code source qu’il exécute.
Pour implémenter cette fonctionnalité, nous pouvons enregistrer un contrôleur d’admission personnalisé. Les contrôleurs d’admission ont été décrits dans « Durée de vie d’une demande » à la page 39. Ils sont chargés de déterminer si une demande d’API est acceptée (ou admise) dans le serveur d’API. Dans ce cas, nous pouvons enregistrer un contrôleur d’admission qui est exécuté pour tous
Objets API qui contiennent un champ d’image ( pods , déploiements, DaemonSets , Replica Sets et StatefulSets ). Le contrôleur d’admission examine le champ d’image dans ces objets et valide qu’ils correspondent au modèle de dénomination qui vient d’être décrit et que les divers composants du nom d’image sont valides (par exemple, le nom de l’ équipe est associé à une équipe connue et le git-hash est l’un dans une branche de publication du référentiel de l’équipe).
13.4.2 Installation des extensions de cycle de vie de l’API
L’installation des extensions du cycle de vie de l’API se compose de deux parties. Le premier consiste à créer un service pour gérer les appels de webhook et le second à créer un nouvel objet API Kubernetes qui ajoute l’extension. Pour créer le service qui gère les appels de webhook à partir du serveur API, vous devez créer un service Web qui peut répondre de manière appropriée.
Il existe de nombreuses façons de le faire, des fonctions en tant que service ( FaaS ) d’un fournisseur de cloud, aux implémentations FaaS sur le cluster lui-même (par exemple, OpenFaaS ), à une application Web standard implémentée dans votre langage de programmation préféré. Selon les exigences du gestionnaire de webhook et les exigences d’exploitation / de coût, vous pouvez prendre différentes décisions. Par exemple, l’utilisation d’un FaaS basé sur le cloud peut être la plus simple en termes de configuration et d’opérations, mais chaque invocation coûtera de l’argent. D’un autre côté, si vous avez déjà une implémentation FaaS open source en cours d’exécution sur votre cluster, c’est un endroit logique pour exécuter vos webhooks. Mais l’installation et la maintenance d’un système de support opérationnel (OSS) FaaS pourrait être plus de travail que cela en vaut la peine, si vous n’avez que quelques webhooks, et l’exécution d’un simple serveur Web pourrait être le bon choix. Vous devez faire de tels choix, selon votre situation.
13.4.3 Considérations opérationnelles pour les extensions de cycle de vie
D’un point de vue opérationnel, il y a deux complexités opérationnelles à considérer. La première complexité, plus évidente, vient de l’exécution d’un service pour gérer le webhook. La responsabilité opérationnelle ici varie, comme décrit précédemment, selon l’endroit où vous exécutez le webhook particulier. Quoi qu’il en soit, vous devez surveiller vos webhooks pour au moins la fiabilité au niveau de l’application (par exemple, ne pas retourner 500s) et peut-être plus. La deuxième complexité opérationnelle est plus subtile, et elle vient de l’injection de votre propre code dans le chemin critique du serveur API. Si vous implémentez un contrôleur d’admission personnalisé et qu’il commence à se bloquer et à renvoyer 500s, toutes les demandes au serveur API qui utilisent ce contrôleur d’admission échoueront. Un tel événement pourrait avoir un impact significatif sur le bon fonctionnement de votre cluster, et il pourrait provoquer une grande variété de pannes qui pourraient affecter le bon fonctionnement des applications déployées sur le dessus du contrôleur. Dans un cas moins extrême, votre code pourrait ajouter une latence supplémentaire aux appels d’API qu’il affecte. Cette latence supplémentaire pourrait provoquer des goulots d’étranglement dans d’autres parties du cluster Kubernetes (par exemple, le gestionnaire de contrôleur ou le planificateur), ou elle pourrait simplement rendre votre cluster floconneux ou lent si votre extension s’exécute parfois lentement ou échoue. Dans tous les cas, le placement du code dans le chemin d’appel du serveur API doit être fait avec soin et avec une surveillance, une réflexion et une planification pour s’assurer qu’il n’y a pas de conséquences imprévues.
13.4.4 Travaux pratiques : exemple d’extensions de cycle de vie
Pour implémenter un contrôleur d’admission, vous devez implémenter le webhook de contrôle d’admission. Le webhook de contrôle d’admission reçoit un HTTP POST avec un corps JSON qui contient un AdmissionReview . Il peut être utile d’explorer plus en détail les définitions de type.
Implémentons un service JavaScript simple qui admet les pods.
const http = require(‘http’); const isValid = (pod) => {
// validate pod here
};
const server = http.createServer((request, response) => {
var json = ”;
request.on(‘data’, (data) => {
json += data;
});
request.on(‘end’, () => {
var admissionReview = JSON.parse(json);
var pod = admissionReview.request.object;
var review = {
kind: ‘AdmissionReview’,
apiVersion: ‘admission/v1beta1’,
response: {
allowed: isValid(pod)
}
};
response.end(JSON.stringify(review));
});
});
server.listen(8080, (err) => {
if (err) {
return console.log(‘admission controller failed to start’, err); }
console.log(‘admission controller up and running.’);
});
Vous pouvez voir que nous prenons un objet AdmissionReview , extrayons le pod de la revue, le validons, puis renvoyons un objet AdmissionReview avec une réponse remplie.
Vous pouvez ensuite enregistrer ce contrôleur d’admission dynamique auprès de Kubernetes en créant l’enregistrement :
apiVersion: admissionregistration.k8s.io/v1beta1
kind: ValidatingWebhookConfiguration
metadata:
name: my-admission-controller
webhooks:
– name: my-web-hook
rules:
# register for create of v1/pod
– apiGroups:
– “”
apiVersions:
– v1
operations:
– CREATE
resources:
– pods
clientConfig:
service:
# Send requests to a Service named ‘my-admission-controller-service’
# in the kube-system namespace
namespace: kube-system
name: my-admission-controller-service
Comme avec tous les objets Kubernetes, vous pouvez instancier cet enregistrement de contrôleur d’admission dynamique avec kubectl create -f . Mais assurez-vous que le bon service est opérationnel avant de le faire, sinon les créations de pod ultérieures pourraient échouer.
13.5 Ajout d’API personnalisées à Kubernetes
Bien que nous vous ayons montré comment étendre les API existantes, ces modifications sont limitées à l’ensemble des API compilées dans le serveur d’API. Parfois, vous souhaitez ajouter des types de ressources API entièrement nouveaux à votre cluster. En particulier, bien que Kubernetes soit livré avec un riche ensemble de types d’API que vous pouvez utiliser pour implémenter votre application, vous souhaitez parfois ajouter de nouveaux types d’API à l’API Kubernetes. Cette fonctionnalité de type dynamique dans Kubernetes vous permet de prendre un cluster existant, avec une collection de types d’API intégrés, comme les pods, les services et les déploiements, et d’ajouter de nouveaux types qui ressemblent et se sentent en grande partie exactement comme s’ils avaient été intégrés. Ce type d’extensibilité est assez flexible et puissant, mais c’est aussi le plus abstrait et le plus compliqué à comprendre. Au plus haut niveau, vous pouvez considérer ce type d’extension comme l’ajout de nouveaux objets API au serveur Kubernetes API — des objets API qui semblent avoir été compilés dans Kubernetes. Tous les outils de gestion des objets Kubernetes existants s’appliquent nativement à ces extensions.
13.5.1 Cas d’utilisation pour l’ajout de nouvelles API
Étant donné que les types d’API personnalisés sont si flexibles qu’ils peuvent littéralement représenter n’importe quel objet, il existe un grand nombre de cas d’utilisation potentiels. Les exemples suivants ne font qu’effleurer la surface de ces possibilités. Dans les sections précédentes, nous avons discuté des implémentations open source de FaaS qui s’exécutent sur Kubernetes. Lorsqu’un FaaS est installé au-dessus de Kubernetes, il ajoute de nouvelles fonctionnalités au cluster. Avec cette nouvelle fonctionnalité, vous avez besoin d’une API pour créer, mettre à jour et supprimer des fonctions dans le FaaS . Bien que vous puissiez implémenter votre propre nouvelle API pour ce FaaS , vous devrez implémenter de nombreuses choses (autorisation, authentification, gestion des erreurs, etc.) que le serveur API Kubernetes a déjà implémenté pour vous. Par conséquent, il est beaucoup plus facile de modéliser les fonctions fournies par le FaaS en tant qu’extensions de l’API Kubernetes. En effet, c’est ce que font la plupart des FaaS open source populaire. Lorsque vous en installez un sur Kubernetes, il se retourne et enregistre de nouveaux types avec l’API Kubernetes. Une fois ces nouveaux types enregistrés, tous les outils Kubernetes existants (par exemple, kubectl ) s’appliquent directement à ces nouveaux objets fonction. Cette familiarité signifie que, dans de nombreux cas, les utilisateurs de clusters étendus peuvent même ne pas remarquer qu’ils utilisent des extensions API.
Un autre cas d’utilisation populaire pour les extensions API est le modèle d’opérateur défendu par CoreOS. Avec un opérateur, un nouvel objet API est introduit dans le cluster pour représenter « l’opérateur » (autrefois humain) d’un logiciel (par exemple, un administrateur de base de données). Pour ce faire, un nouvel objet API est ajouté au serveur API Kubernetes qui représente ce logiciel « exploité ». Par exemple, vous pouvez ajouter un mysqldata objet de base à Kubernetes via les extensions de l’API. Lorsqu’un utilisateur crée une nouvelle instance d’une base de données MySQL, l’opérateur utilise ensuite cet objet API pour instancier une nouvelle base de données MySQLDa, y compris une surveillance appropriée et une supervision en ligne pour maintenir automatiquement le fonctionnement correct de la base de données. Ainsi, grâce aux opérateurs et à l’extensibilité de l’API, les utilisateurs de votre cluster peuvent instancier directement des bases de données au lieu des pods qui se trouvent exécuter des bases de données.
13.5.2 Définitions de ressources personnalisées et serveurs d’API agrégés
Parce que le cycle de vie de l’API et le processus d’extension de l’API sont techniquement compliqués, Kubernetes implémente en fait deux mécanismes distincts pour ajouter de nouveaux types à l’API Kubernetes. Le premier est connu sous le nom CustomResourceDefinitions , et il consiste à utiliser l’API Kubernetes lui – même pour ajouter de nouveaux types de Kubernetes. Tous les services de stockage et d’API associés au nouveau type personnalisé sont gérés par Kubernetes lui-même. De ce fait, les définitions de ressources personnalisées sont de loin un moyen plus simple d’étendre le serveur API Kubernetes. En revanche, étant donné que Kubernetes gère l’intégralité de l’extensibilité, il existe plusieurs limitations à ces API. Par exemple, il est difficile d’effectuer la validation et la mise en défaut des API ajoutées par des définitions de ressources personnalisées ; cependant, il est possible en combinant des définitions de ressources personnalisées avec un contrôleur d’admission personnalisé.
En raison de ces limitations, Kubernetes prend également en charge la délégation d’API, dans laquelle l’appel d’API complet, y compris le stockage, des ressources est délégué à un autre serveur. Cela permet à l’extension d’implémenter une API arbitrairement complexe, mais elle s’accompagne également d’une complexité opérationnelle importante, en particulier la nécessité de gérer votre propre stockage. En raison de cette complexité, la plupart des extensions d’API utilisent des définitions de ressources personnalisées. Décrire comment implémenter des serveurs d’API délégués dépasse le cadre de cet article, et le reste de cette section décrit comment utiliser les définitions de ressources personnalisées pour étendre l’API Kubernetes.
13.5.3 Architecture pour les définitions de ressources personnalisées
Il existe plusieurs étapes différentes pour implémenter une définition de ressource personnalisée. Le premier est la création de l’objet CustomResourceDefinition lui-même. Les ressources personnalisées sont des objets Kubernetes intégrés avec la nouvelle définition de type. Après la création d’une définition de ressource personnalisée, le serveur d’API Kubernetes se programme avec un nouveau groupe d’API et un nouveau chemin de ressources dans le serveur Web d’API, ainsi que de nouveaux gestionnaires qui savent comment sérialiser et désérialiser ces nouvelles ressources personnalisées à partir du stockage Kubernetes. Si tout ce que vous voulez, c’est une simple API CRUD, cela peut être suffisant. Mais dans la plupart des cas, vous voulez réellement faire quelque chose lorsqu’un utilisateur crée une nouvelle instance de votre objet personnalisé. Pour ce faire, vous devez combiner Kubernetes CustomResourceDefinition avec une application de contrôleur qui surveille ces définitions personnalisées, puis prend des mesures en fonction des ressources que l’utilisateur crée, met à jour ou détruit. Dans de nombreux cas, ce serveur d’applications est également l’application qui enregistre la nouvelle définition de ressource personnalisée. La figure 13-1 illustre ce flux.
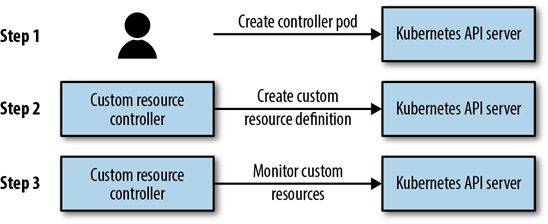
Figure 13-1. Un diagramme des trois étapes de la définition de ressource personnalisée
La combinaison d’une ressource personnalisée et d’une application de contrôleur est généralement suffisante pour la plupart des applications, mais vous souhaiterez peut-être ajouter encore plus de fonctionnalités à votre API (par exemple, pré – créer la validation ou la valeur par défaut). Pour ce faire, vous pouvez également ajouter un contrôleur d’admission pour vos ressources personnalisées nouvellement définies qui s’insère dans le cycle de vie de l’API, comme décrit dans le chapitre 4, et ajoute ces fonctionnalités à votre ressource personnalisée.
13.5.4 Installation de définitions de ressources personnalisées
Comme toutes les extensions, le code nécessaire pour gérer ces ressources personnalisées est exécuté sur le cluster Kubernetes lui-même. Le contrôleur de ressources personnalisé est empaqueté en tant qu’image de conteneur et installé sur le cluster à l’aide des objets API Kubernetes. Parce qu’une ressource personnalisée est une extension plus compliquée, d’une manière générale, la configuration de Kubernetes se compose de plusieurs objets regroupés dans un seul fichier YAML. Dans de nombreux cas, ces fichiers peuvent être obtenus auprès du projet open source ou du fournisseur de logiciels fournissant l’extension. Alternativement, ils peuvent être installés via un gestionnaire de packages, comme Helm. Comme pour toutes les autres extensions, la surveillance, la maintenance et la suppression des extensions d’API de ressources personnalisées s’effectuent à l’aide de l’API Kubernetes.
Lorsqu’une CustomResourceDefinition est supprimée, toutes les ressources correspondantes sont également supprimées du magasin de données du cluster. Ils ne peuvent pas être récupérés. Ainsi, lors de la suppression d’une ressource personnalisée, soyez prudent et assurez-vous de communiquer avec tous les utilisateurs finaux de cette ressource avant de supprimer la CustomResourceDefinition .
13.5.5 Considérations opérationnelles pour les ressources personnalisées
Les considérations opérationnelles d’une ressource personnalisée sont généralement les mêmes que pour les autres extensions. Vous ajoutez une application à votre cluster sur laquelle les utilisateurs s’appuieront et qui doit être surveillée et gérée. De plus, si votre extension utilise également un contrôleur d’admission, les mêmes préoccupations opérationnelles pour les contrôleurs d’admission s’appliquent également. Cependant, en plus des complexités décrites précédemment, il existe une complexité supplémentaire importante pour les définitions de ressources personnalisées : elles utilisent le même stockage associé à tous les objets API Kubernetes intégrés. Par conséquent, il est possible d’avoir un impact sur le fonctionnement de votre serveur API et de votre cluster en stockant des objets trop volumineux et / ou nombreux sur le serveur API à l’aide de ressources personnalisées. En général, les objets API dans Kubernetes sont destinés à être de simples objets de configuration. Ils ne sont pas destinés à représenter de gros fichiers de données. Si vous vous trouvez à stocker de grandes quantités de données dans des types d’API personnalisés, vous devriez probablement envisager d’installer une sorte de magasin de valeurs de clés dédié ou une autre API de stockage.
13.6 Résumé
Kubernetes est génial, non seulement en raison de la valeur des API principales qu’il fournit, mais également en raison de tous les points d’extension dynamiques qui permettent aux utilisateurs de personnaliser leurs clusters en fonction de leurs besoins. Que ce soit via des contrôleurs d’admission dynamiques pour valider les objets API ou de nouvelles définitions de ressources personnalisées, il existe un riche écosystème de modules complémentaires externes que vous pouvez utiliser pour créer une expérience personnalisée qui correspond parfaitement aux besoins de vos utilisateurs. Et, si une extension nécessaire n’existe pas, les détails de ce chapitre devraient vous aider à en concevoir et à en créer une.
14 CHAPITRE 14 Conclusions
Kubernetes est un outil puissant qui permet aux utilisateurs de se dissocier des machines d’exploitation et de se concentrer sur les opérations de base de leurs applications. Cela permet aux utilisateurs de créer, déployer et gérer des applications à grande échelle de manière beaucoup plus simple et efficace. Bien sûr, pour y parvenir, quelqu’un doit réellement déployer et gérer le cluster Kubernetes lui-même ; l’application Kubernetes est leur objectif.
Nous espérons que cette présentation de l’API et de l’architecture de Kubernetes et de sujets tels que RBAC, les mises à niveau, la surveillance et l’extension de Kubernetes vous donnera les connaissances nécessaires pour déployer et faire fonctionner Kubernetes avec succès afin que vos utilisateurs n’aient pas à le faire.




Laisser un commentaire
Vous devez être dentifié pour poster un commentaire.