Résumé de la publication
Le Big Data est un terme qui décrit des volumes de données volumineux et difficiles à gérer – à la fois structurés et non structurés – qui inondent les entreprises au quotidien. Mais ce n’est pas la quantité de données qui est importante. C’est ce que les organisations font avec les données qui compte. Les mégadonnées peuvent être analysées pour obtenir des informations qui conduisent à de meilleures décisions et à des mouvements commerciaux stratégiques.
Nous allons découvrir dans cet article comment mettre en place une architecture et comment exploiter les données, en analysant les différents outils avec leurs avantages et leurs inconvénients.
Objectifs de la publication
- Découvrir le concept de big data et ses origines
- En savoir plus sur les différentes caractéristiques du Big Data
- Analyse des différents types de stockages, des modèles de données, des magasins NoSQL
- Initiation à Python et R
- Définition d’un modèle de données et catégorisation des modèles de données
- Structures des modèles de données
- Modélisation de différents modèles de données
- Des exemples concret d’applications
1 Introduction au Big Data et à la gestion des données
Ce chapitre traite du concept de Big Data, de ses sources et de ses types. En outre, le chapitre se concentre sur l’établissement d’une base théorique sur la modélisation et la gestion des données. Les lecteurs vont mettre en place une plate-forme sur laquelle nous pourrons utiliser le Big Data. Les principaux sujets abordés dans ce chapitre sont résumés comme suit :
- Découvrir le concept de big data et ses origines
- En savoir plus sur les différentes caractéristiques du Big Data
- Discussion et exploration des différents défis de l’extraction de données volumineuses
- Familiarisez-vous avec la modélisation de données volumineuses et ses utilisations
- Comprendre ce qu’est la gestion de données volumineuses, son importance et ses implications
- Configurer une plateforme Big Data sur une machine locale
1.1 Le concept de Big Data
Les systèmes numériques sont progressivement liés à des activités réelles. En conséquence, une multitude de données sont enregistrées et communiquées par des systèmes d’information. Au cours des 50 dernières années, la croissance des systèmes d’information et de leurs capacités de capture, de conservation, de stockage, de partage, de transfert, d’analyse et de visualisation des données a augmenté de façon exponentielle. Outre ces avancées technologiques incroyables, les personnes et les organisations dépendent de plus en plus de dispositifs informatisés et de sources d’informations sur Internet. L’étude IDC Digital Universe réalisée en mai 2010 illustre la croissance spectaculaire des données. Cette étude a estimé que la quantité d’informations numériques (sur les ordinateurs personnels, les appareils photo numériques, les serveurs, les capteurs) stockées dépassait 1 zettaoctet et prévoyait que l’univers numérique passerait à 35 zettaoctets en 2010. L’étude IDC caractérise 35 zettabytes en pile de DVD atteignant la moitié de la distance jusqu’à Mars. C’est ce que nous appelons l’explosion de données.
Si l’on parle aujourd’hui de Big Data, il faudra parler demain de « Huge » Data. Selon une nouvelle étude IDC, le volume total de données stockées sur notre planète atteindre 175 Zo en 2025 soit 5,3 fois plus qu’aujourd’hui. La plupart des données stockées dans l’univers numérique sont très peu structurées et les organisations sont confrontées à des problèmes de capture, de conservation et d’analyse. L’une des tâches les plus difficiles pour les organisations d’aujourd’hui consiste à extraire des informations et de la valeur des données stockées dans leurs systèmes d’information. Ces données, qui sont très complexes et trop volumineuses pour être gérées par un SGBD traditionnel, sont appelées big data.
Le Big Data est un terme pour un groupe de jeux de données tellement massif et sophistiqué qu’il devient difficile de traiter à l’aide d’outils de gestion de base de données traditionnel ou d’une application de traitement moderne. Sur le marché récent, les tendances en matière de données se réfèrent à l’utilisation de l’analyse du comportement des utilisateurs, de l’analyse prédictive ou de différentes méthodes avancées d’analyse de données qui extraient de la valeur de cette nouvelle analyse de système de données.
Qu’il s’agisse de données quotidiennes, de données métiers ou de données de base, si elles représentent un volume énorme de données, qu’elles soient structurées ou non, les données sont pertinentes pour l’organisation. Cependant, ce ne sont pas uniquement les dimensions des données qui importent ; c’est la façon dont l’organisation les utilise pour extraire des informations plus profondes qui peuvent les amener à prendre de meilleures décisions commerciales et stratégiques. Ces données volumineuses peuvent être utilisées pour déterminer la qualité de la recherche, améliorer le flux de processus dans une organisation, prévenir une maladie particulière, relier des citations légales ou combattre des crimes. Les mégadonnées sont omniprésentes et peuvent être utilisées avec les outils appropriés pour les rendre plus efficaces pour l’analyse commerciale.
1.1.1 Informations intéressantes sur le Big Data
Certains faits intéressants liés au Big Data, à sa gestion et à son analyse, sont expliqués ici :
- Près de 91% des leaders mondiaux du marketing utilisent les données clients sous forme de données volumineuses pour prendre des décisions commerciales.
- Il est intéressant de noter que 90% des données mondiales totales ont été générées au cours des deux dernières années.
- 87% des personnes acceptent d’enregistrer et de distribuer les bonnes données. Il est important de mesurer efficacement le retour sur investissement (ROI) de leur propre entreprise.
- 86% des personnes sont disposées à payer davantage pour une expérience client exceptionnelle avec une marque.
- 75% des entreprises déclarent qu’elles augmenteront leurs investissements dans le Big Data au cours de la prochaine année.
- Environ 70% des mégadonnées sont créées par des individus, mais les entreprises sont soumises au stockage et au contrôle de 80% de celles-ci.
- 70% des entreprises reconnaissent que leurs efforts de marketing font l’objet d’une surveillance accrue.
1.1.2 Caractéristiques du Big Data
Nous avons exploré la popularité des données volumineuses dans la section précédente. Mais il est important de savoir quels types de données peuvent être catégorisés ou étiquetés comme des données volumineuses. Dans cette section, nous allons explorer diverses fonctionnalités du Big Data. La plupart des livres disponibles sur le marché prétendent qu’il existe six types différents, présentés comme suit :
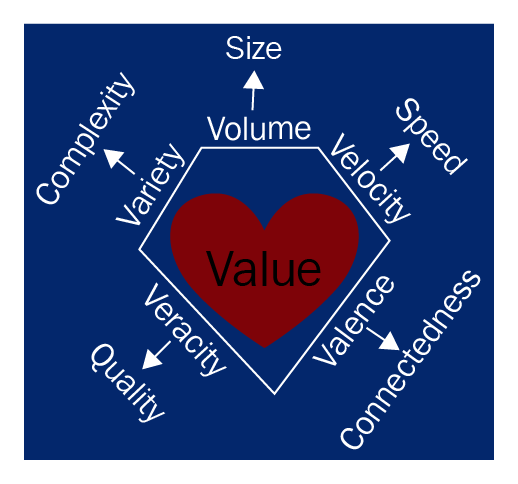
- Volume : Le Big Data implique des quantités massives de données. La taille des données joue un rôle très important dans la détermination de la valeur des données. Il s’agit également d’un facteur clé qui permet de déterminer si nous pouvons juger la taille de la masse de données. Par conséquent, le volume justifie l’un des attributs importants du Big Data.
Remarque :
Chaque minute, 204 000 000 courriels sont envoyés, 200 000 photos sont téléchargées et 1 800 000 likes sont générés sur Facebook ; Sur YouTube, 1 300 000 vidéos sont visionnées et 72 heures de vidéo téléchargées.
L’idée derrière cette agrégation de volumes de données massifs est de comprendre que les entreprises et les organisations collectent et exploitent des volumes de données géants pour renforcer leurs produits, qu’il s’agisse de sécurité, de fiabilité, de soins de santé ou de gouvernance. En résumé, l’idée est de transformer ces données volumineuses en une forme d’avantage commercial.
- Vélocité : Elle se rapporte à la vitesse croissante à laquelle le big data est créé et à la vitesse croissante à laquelle les données sont stockées et analysées. Traiter les données en temps réel pour correspondre à leur vitesse de production à mesure qu’elles sont générées est un objectif remarquable de l’analyse de données volumineuses. Le terme vitesse s’applique généralement à la rapidité avec laquelle les données sont produites et traitées pour satisfaire les demandes ; il découvre le potentiel réel des données. Le flux de données est massif et continu. Les données peuvent être stockées et traitées de différentes manières, notamment le traitement par lots, le traitement en temps quasi réel, le traitement en temps réel et la diffusion en continu :
- Le traitement en temps réel fait référence à la possibilité de capturer, stocker et traiter les données en temps réel et de déclencher une action immédiate, permettant ainsi de sauver des vies.
- Le traitement par lots consiste à introduire une grande quantité de données dans de grandes machines et à les traiter plusieurs jours à la fois. C’est encore très courant aujourd’hui.
- Variété : il fait référence à de nombreuses sources et types de données, structurées, semi-structurées ou non structurées. Nous discuterons plus en détail de ces types de données volumineuses au chapitre 5, Structures de modèles de données. Lorsque nous pensons à la variété des données, nous pensons à la complexité supplémentaire résultant du nombre accru de types de données que nous devons stocker, traiter et combiner. Les données sont aujourd’hui plus hétérogènes, telles que les données d’image BLOB, les données d’entreprise, les données de réseau, les données vidéo, les données textuelles, les cartes géographiques, les données générées ou simulées par ordinateur et les données de médias sociaux. Nous pouvons classer la variété de données en plusieurs dimensions. Certaines des dimensions sont expliquées comme suit :
- Variété structurelle : il s’agit de la représentation des données. Par exemple, une image satellite des incendies de forêt de la NASA est complètement différente des tweets envoyés par des personnes qui voient le feu se propager.
- Variété de supports : les données sont livrées sur différents supports, tels que du texte, de l’audio ou de la vidéo. Celles-ci sont appelées variété de médias.
- Variété sémantique : La variété sémantique provient de différentes hypothèses de conditions sur les données. Par exemple, nous pouvons mesurer son âge en utilisant une approche qualitative (nourrisson, juvénile ou adulte) ou quantitative (chiffres).
- Véracité : Elle fait référence à la qualité des données et est également désignée comme validité ou volatilité. Les mégadonnées peuvent être bruyantes et incertaines, pleines de biais et d’anomalies et peuvent être imprécises. L’idée que les données n’ont aucune valeur si elles ne sont pas exactes (les résultats de l’analyse de données massives n’ont que la même qualité que les données analysées) crée des difficultés pour le suivi de la qualité des données – ce qui a été capturé, l’origine des données, et comment elles ont été analysées avant son utilisation.
- Valence : Cela fait référence à la connectivité. Plus les données sont connectées, plus leurs valences sont élevées. Un jeu de données à haute valence est plus dense. Cela rend de nombreuses critiques analytiques régulièrement très inefficaces.
- Valeur : le terme, en général, fait référence aux connaissances précieuses tirées de la capacité à étudier et à identifier de nouveaux modèles et tendances issus de systèmes à volume élevé et multiplateforme. L’idée du traitement de toutes ces données volumineuses est d’apporter de la valeur à la requête en question. Le résultat final de toutes les tâches est la valeur.
Voici une représentation résumée du contenu précédent :
1.2 Sources et types de données volumineuses
Nous avons appris que le Big Data est omniprésent et qu’il peut être avantageux pour les entreprises de plusieurs manières. Avec la forte prévalence de données volumineuses provenant du matériel et des logiciels existants, les entreprises ont encore du mal à traiter, stocker, analyser et gérer les données volumineuses à l’aide d’outils et de techniques d’extraction de données traditionnels. Dans cette section, nous allons explorer les sources de ces données complexes et dynamiques et comment les utiliser.
Nous pouvons séparer les sources de données en trois grandes catégories. Le diagramme suivant présente les trois principales sources de données volumineuses :
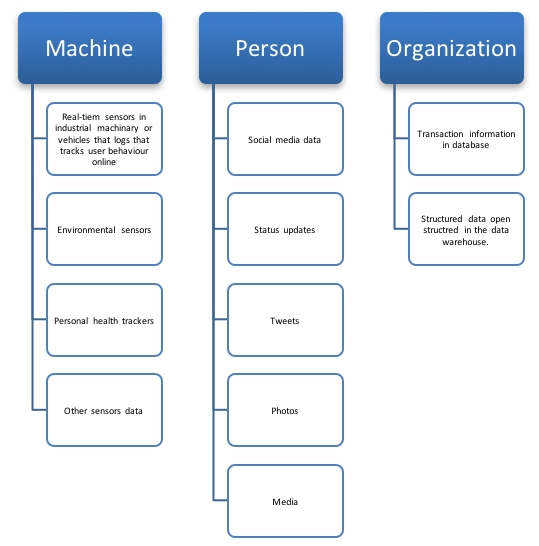
Examinons les trois sources principales une par une :
- Journaux générés par une machine : une grande partie du Big Data est générée par des capteurs en temps réel de machines industrielles ou de véhicules qui créent des journaux permettant de suivre les comportements des utilisateurs, des capteurs environnementaux ou des suivis de santé personnels et autres données de capteurs. La plupart des données créées par la machine peuvent être regroupées dans les sous-catégories suivantes :
- Journal des clicks des données de flux : Il s’agit des données qui sont capturées chaque fois qu’un utilisateur clique sur un lien d’un site Web. Une analyse détaillée de ces données peut révéler des informations relatives au comportement des clients et aux interactions profondes des utilisateurs avec le site Web actuel, ainsi que les habitudes d’achat des clients.
- Données du journal des événements du jeu : Un utilisateur effectue un ensemble de tâches lorsqu’il joue à un jeu en ligne. Chaque mouvement que l’utilisateur en ligne effectue dans un jeu peut être stocké. Ces données peuvent être analysées et les résultats peuvent être utiles pour savoir comment les utilisateurs finaux sont propulsés dans un portefeuille de jeux.
- Données du journal des capteurs : Les différents types de données du journal des capteurs impliquent des étiquettes d’identification par radiofréquence, des compteurs intelligents, des données de capteur Smartwatch, des dispositifs de capteurs médicaux tels que des capteurs de contrôle de la fréquence cardiaque et des données GPS. Ces types de données de journal de capteurs peuvent être enregistrés puis utilisés pour analyser le statut réel du sujet.
- Données d’événement de weblog : Les serveurs, les infrastructures cloud, les applications, les réseaux, etc., sont très utilisés. Ces applications fonctionnent et enregistrent toutes sortes de données sur leurs événements et leur fonctionnement. Lorsqu’elles sont stockées, ces données peuvent représenter des volumes de données énormes et peuvent être utiles pour comprendre comment traiter les contrats de niveau de service ou pour prévoir les violations de la sécurité.
- Données du journal des événements d’un point de vente : Presque tous les produits de nos jours ont un code à barres unique. Un caissier dans un magasin ou un département balaye le code-barres de tout produit lors de la vente et toutes les données associées au produit sont générées et peuvent être capturées. Ces données peuvent être analysées pour comprendre le modèle de vente d’un détaillant.
- Personne : les utilisateurs génèrent beaucoup de données volumineuses à partir de médias sociaux, de mises à jour de statut, de tweets, de photos et de téléchargements multimédias. La plupart de ces journaux sont générés par les interactions d’un utilisateur avec un réseau, tel qu’Internet. Cette révélation de données contient comment un utilisateur communique avec le réseau. Ces journaux d’interaction peuvent révéler des modèles d’interaction de contenu approfondis qui peuvent être utiles pour comprendre le comportement des utilisateurs. Cette analyse peut être utilisée pour former un modèle présentant des recommandations personnalisées d’articles Web, y compris les prochaines informations à lire, ou très probablement, les produits à envisager. Un grand nombre d’études similaires sont très en vogue dans l’industrie actuelle, notamment l’analyse des sentiments et des sujets. La plupart de ces données ne sont pas structurées, car il n’existe pas de format approprié ni de structure bien définie. La plupart de ces données se présentent sous forme de texte, de document portable, de fichier CSV ou de fichier JSON.
- Organisation : une organisation reçoit énormément de données en termes d’informations sur les transactions dans des bases de données et de données structurées ouvertes stockées dans l’entrepôt de données. Ces données sont une forme de données hautement structurée. Les organisations stockent leurs données sur un type de SGBDR, tel que SQL, Oracle et MS Access. Ces données résident dans un format fixe à l’intérieur du champ ou d’une table. Les données générées par cette organisation sont utilisées et traitées dans les technologies de l’information et des communications pour comprendre l’intelligence commerciale et l’analyse de marché.
1.2.1 Les défis du Big Data
Certains aspects essentiels rendent le Big Data très difficile. Dans cette section, nous en discuterons certains :
- Hétérogénéité : les informations consommées par l’homme sont très diverses et elles sont également tolérées. En fait, la nuance et la richesse du langage naturel fourniront une profondeur précieuse. Cependant, les algorithmes d’analyse automatique attendent des connaissances cohérentes et ne permettent pas de comprendre les nuances. Par conséquent, les connaissances doivent être soigneusement structurées avant ou avant l’analyse des connaissances. Les systèmes informatiques fonctionnent plus efficacement s’ils peuvent stocker plusieurs éléments de taille et de structure identiques. La représentation économique, l’accès et l’analyse des connaissances semi-structurées nécessitent des travaux supplémentaires.
- Protection de la vie privée : de nombreuses informations personnelles sont saisies, stockées, analysées et traitées par les fournisseurs de services Internet, les réseaux mobiles, les opérateurs, les supermarchés, les transports locaux, les établissements d’enseignement et les organismes de services médicaux et financiers, y compris les hôpitaux, banques, compagnies d’assurance et agences de cartes de crédit. Une grande quantité d’informations est stockée sur des réseaux sociaux tels que Facebook, YouTube et Google. Cela met en lumière le fait que la confidentialité est un problème dont l’importance, en particulier pour le client, augmente à mesure que la valeur du Big Data devient plus apparente. Ces données personnelles sont utilisées par les algorithmes d’exploration de données pour personnaliser le contenu des actualités et gérer les annonces, ainsi que pour d’autres avantages du commerce électronique. Ceci est clairement une violation de la vie privée.
- Échelle : comme son nom l’indique, le Big Data est énorme. Lorsque la taille augmente, des problèmes sous-jacents l’accompagnent en termes de stockage, de récupération, de traitement, de transformation et d’analyse. Comme indiqué dans l’introduction, le volume de données évolue beaucoup plus rapidement que les ressources informatiques et les vitesses de processeur, qui sont statiques.
- Actualité : il s’agit de la rapidité, car plus la taille des données à traiter est grande, plus il faudra de temps pour l’analyser. Il existe de nombreux scénarios dans lesquels les résultats de l’analyse sont requis en temps réel ou immédiatement. Cela crée un défi supplémentaire lors de la création d’un système capable de traiter les mégadonnées en temps voulu.
- Sécurisation du Big Data : la sécurité est également une préoccupation majeure des entreprises et des particuliers. Les grands magasins de données peuvent être des cibles attrayantes pour les pirates ou des menaces persistantes complexes. La sécurité est un attribut essentiel de l’architecture Big Data qui révèle des moyens de stocker et de fournir un accès aux informations en toute sécurité.
1.3 Introduction à la modélisation Big Data
Ayant une bonne idée de ce que sont les mégadonnées et leurs caractéristiques, passons maintenant à la modélisation. Supposons que nous ayons l’ensemble de données, que nous classons comme étant des données volumineuses, et avant de procéder à toute analyse sur l’ensemble de données, nous devons avoir une idée de l’apparence des données. La modélisation des données a pour objectif d’explorer de manière formelle la nature des données afin de déterminer le type de stockage dont vous avez besoin et le type de traitement que vous pouvez effectuer.
La modélisation des données est une technique qui aide à donner un aperçu significatif des données en les définissant et en les catégorisant, et en établissant des définitions et des descripteurs officiels afin que les données puissent être utilisées par tous les systèmes d’information d’une entreprise.
Nous pouvons avoir au moins deux raisons principales pour effectuer la modélisation de données :
- La modélisation de données stratégique facilite la stratégie globale de développement des systèmes d’information
- La modélisation des données peut aider au développement de nouvelles bases de données
La modélisation des données pour la définition stratégique suggère de définir le type de données dont vous aurez besoin pour les processus de votre entreprise, tandis que la modélisation dans le contexte de l’analyse est davantage axée sur la représentation des données existantes et sur la recherche de moyens de les classer. Dans le cas du Big Data, ce processus nécessite probablement de trouver des similitudes entre des données provenant de sources disparates et de confirmer qu’elles décrivent effectivement la même chose. Dans les deux cas, l’objectif final est de générer une représentation de vos données pouvant être répliquée dans votre architecture de base de données.
1.3.1 Utilisation des modèles
Dans cette section, nous allons discuter des raisons pour lesquelles nous avons besoin de modèles de données et des principaux avantages que nous pouvons obtenir en étudiant les modèles de données actuels. Un modèle de données de haut niveau illustre les concepts et principes de base de toute entreprise de manière très simpliste, en utilisant de courtes descriptions. L’un des principaux avantages de l’élaboration du modèle de haut niveau est qu’il nous aide à parvenir à une terminologie et à des définitions communes des idées et des principes.
Un modèle de données de haut niveau utilise des images graphiques simplistes pour illustrer les concepts et principes de base d’une organisation et leur signification. Un modèle de base de données montre la structure logique d’une base de données, y compris les relations et les contraintes qui déterminent la manière dont les données peuvent être stockées et accessibles.
Prenons un système simple d’enregistrement de notes par les étudiants. Un élève a un prénom, un nom de famille et un identifiant unique. Chaque étudiant est associé à une institution. Chaque élève a une date de début et d’autres données qui lui sont associées. Nous pouvons mieux représenter cela en utilisant une sorte de modèle que dans un paragraphe, ce qui est difficile à comprendre.
Convertissons-le en modèle :
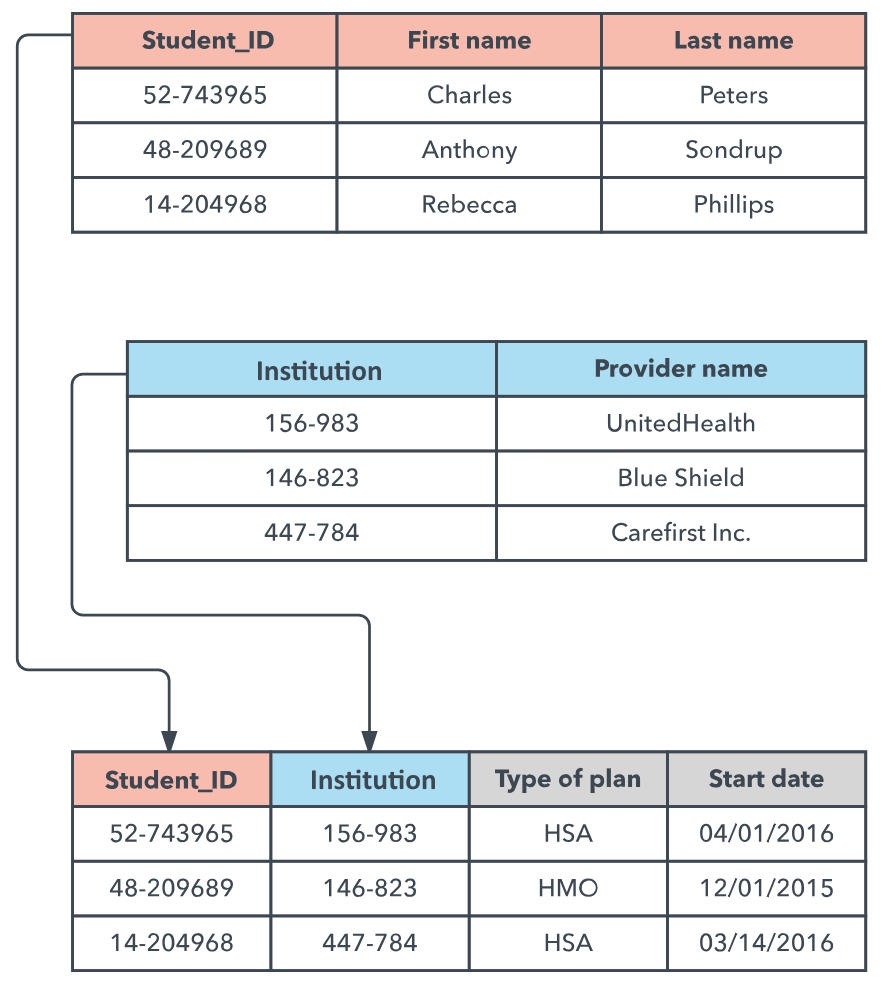
Modèle 1.1
Considérons maintenant le modèle précédent. Il montre clairement la corrélation entre les étudiants et le fournisseur de l’établissement et la façon dont ils sont enregistrés dans plusieurs tableaux. C’est plus facile à comprendre qu’un paragraphe. Analysons maintenant ce modèle et voyons quels avantages nous en retirons par rapport à d’autres représentations textuelles :
- Gagner en perspicacité : un modèle détaillé montre le processus sous différents angles. Comme dans le modèle précédent, nous pouvons voir comment les étudiants sont associés aux établissements fournisseurs, aux différents types de régimes et à quel moment débute un cours. Pour commencer avec la modélisation des données, il est important de connaître les éléments suivants :
- Comprendre le fonctionnement de l’entreprise pour comprendre le flux de données au sein de l’organisation.
- Comprendre quel type de données est collecté et stocké dans l’organisation.
- Compréhension des processus et des relations commerciales. Cette connaissance nous guide dans la création de données et de relations dans un modèle de données.
- Discussion : Le modèle de données détaillé peut être utilisé pour des discussions avec les parties prenantes.
- Transfert de connaissances : il peut être utilisé comme source de documentation pour instruire des personnes ou des développeurs. La modélisation des données est une sorte de documentation, à la fois pour les acteurs de l’entreprise et les experts techniques. En commençant par fournir un vocabulaire commun que différents rôles peuvent partager, et en continuant à fournir aux nouveaux arrivants un glossaire professionnel bien pensé, vos connaissances pour documenter et transmettre des informations sur votre entreprise sont considérablement améliorées. En plus de cela, le modèle peut être utilisé comme aide à la formation.
- Vérification : les modèles de processus sont analysés pour détecter les erreurs dans les systèmes ou les procédures. Si votre cahier des charges était complet et comprenait la fusion de données provenant de sources multiples, ainsi que des obligations en matière de requête et de reporting, vous disposiez d’opportunités de Business Intelligence inexistantes lorsque vos données existaient en silos ou dans des bases de données conçues au hasard.
- Analyse des performances : un modèle détaillé à partir des données peut être utilisé pour analyser les performances du système en utilisant plusieurs techniques disponibles, telles que les simulations, et la lecture à sec dans le modèle.
- Spécification : un modèle pertinent généré à partir des données d’une organisation peut être utilisé pour créer un document de spécification des exigences logicielles (SRS) pouvant être utilisé comme feuille de route entre un développeur et des parties prenantes de l’utilisateur final.
- Configuration : Les modèles construits à partir de données peuvent être appliqués pour configurer un système. Un modèle détaillé construit avec précision montre la relation entre les modules et comment un module peut communiquer avec un autre module. Ces informations peuvent être utilisées par n’importe quelle organisation pour renforcer l’interopérabilité entre les modules et leurs paramètres de configuration et réduire les redondances.
1.4 Introduction à la gestion du Big Data
Le but de la gestion des mégadonnées est de déterminer le type de support d’infrastructure dont vous auriez besoin pour les données. Par exemple, votre environnement doit-il conserver plusieurs répliques des données ? Avez-vous besoin de faire un calcul statistique avec les données ? Une fois que ces exigences opérationnelles ont été déterminées, vous serez en mesure de choisir le bon système qui vous permettra d’effectuer ces opérations. Le Big Data Management répond aux questions suivantes :
- Comment ingérons-nous ou consommons-nous les données ?
- Où et comment le stockons-nous ?
- Comment pouvons-nous assurer et appliquer la qualité des données ?
- Quelles opérations effectuons-nous sur les données ?
- Comment ces opérations peuvent-elles être efficaces ?
- Comment gérons-nous l’évolutivité, la variété, la vitesse et l’accès des données ?
- Comment pouvons-nous renforcer la sécurité et la confidentialité à chaque étape de la modélisation des données ?
La gestion des données volumineuses est un concept global qui englobe les politiques, procédures et techniques utilisées pour la collecte, le stockage, la gouvernance, l’organisation, l’administration et la livraison de grands référentiels de données.
Nous entrerons dans les détails de la gestion de Big Data, et nous discuterons des détails de la gestion de données ainsi que de leurs fournisseurs dans le chapitre suivant, Chapitre 2, Plateformes de modélisation et de gestion de données.
1.5 Importance et implications de la modélisation et de la gestion de données volumineuses
Nous avons constaté que les mégadonnées avaient une importance économique et scientifique. La conviction scientifique est que plus les données utilisées dans la recherche sont volumineuses, plus leur précision est grande. Les données sont générées toutes les secondes dans la vie réelle, ce qui signifie que le volume de données disponibles ne peut jamais diminuer, mais il continuera de croître. Il est également important de reconnaître qu’une grande partie de cette explosion de données est le résultat d’une explosion de périphériques situés à la périphérie du réseau, notamment de capteurs intégrés, de smartphones et de tablettes. Toutes ces données créent de nouvelles opportunités pour les analystes de données dans les domaines de la génomique humaine, des soins de santé, du pétrole et du gaz, de la recherche, de la surveillance, des finances et de nombreux autres domaines. Dans cette section, nous allons explorer les différents avantages de la gestion de données volumineuses. Dans la section suivante, nous découvrirons divers défis de la gestion de données volumineuses sur le marché actuel.
1.5.1 Avantages de la gestion de données volumineuses
Comme mentionné, le Big Data est un outil puissant. Une gestion réfléchie du Big Data constitue une avancée décisive et permet de prendre des décisions commerciales plus solides. Dans cette section, nous allons discuter de plusieurs avantages de la gestion de données volumineuses :
- Accélère les revenus : lorsque les données sont gérées correctement et efficacement, cela donne de la valeur. La valeur contribue à l’accélération des revenus des petites et moyennes entreprises.
- Amélioration du service à la clientèle : plusieurs études montrent que les entreprises qui utilisent les données précédentes pour obtenir des informations décisionnelles ont amélioré leurs services à la clientèle, les modèles exploités guidant l’activité en surmontant les goulots d’étranglement du système actuel.
- Améliore le marketing : l’analyse des données massives révèle une analyse plus approfondie des données commerciales passées et actuelles, ainsi que des informations sur la manière de gérer l’entreprise à l’avenir. Cela donne un chemin guidé pour savoir comment proposer des solutions marketing critiques et innovantes.
- Efficacité accrue : l’identification d’une nouvelle source de données a été modérément facilitée avec l’introduction d’outils à grande vitesse tels que Hadoop. Ces outils aident les entreprises à analyser les données en temps réel et à accélérer la prise de décision.
- Économies de coûts : les services en nuage attirent de plus en plus l’attention et ont été utilisés avec succès dans de nombreuses applications de gestion de données d’entreprise. Des outils tels que Hadoop sont basés sur le cloud et sont plus faciles à manipuler. Ces systèmes permettent de réduire les coûts en fournissant des interfaces plus faciles sur lesquelles stocker, analyser et visualiser des données volumineuses.
- Amélioration de la précision des analyses : La précision et la fiabilité des analyses de données volumineuses ont été améliorées par les pratiques de gestion des données. Les services de gestion de données constituent un moyen meilleur et moins coûteux de transformer des données en intelligence d’affaires, augmentant ainsi la précision et l’analyse.
1.5.2 Défis de la gestion de données volumineuses
Avec une énorme explosion de données dans plusieurs entreprises, les entreprises ont tout intérêt à explorer des solutions offrant des opportunités et des perspectives pour augmenter leurs bénéfices. Cependant, il est toujours difficile de gérer et de maintenir le Big Data. Certains des principaux défis du processus de gestion du Big Data sont décrits ci-après :
- Augmentation du nombre de magasins de données (Data Stores) : la gestion des données est une tâche très complexe et complexe, car elle nécessite un volume de données considérable et son augmentation constante. Il est également très important d’effectuer toute opération sur cet ensemble de données, car cela peut nuire à la qualité et aux performances de l’analyse. Il peut s’avérer très complexe de migrer une base de données vers une solution analytique en raison de l’expansion continue des magasins de données et des silos de données.
- Complexité des données et des structures : les entreprises ont généralement à la fois des données structurées et des données non structurées. Ces données se présentent sous un très grand nombre de formats, notamment JSON, CSV, un fichier document, un fichier texte ou des données BLOB. Une entreprise a généralement plusieurs milliers d’applications sur ses systèmes et chacune de ces applications peut numériser et écrire dans plusieurs bases de données distinctes. Par conséquent, il est souvent extrêmement difficile de cataloguer les styles de données d’une entreprise dans ses systèmes de stockage.
- Assurer la qualité des données : il est l’un des atouts essentiels des entreprises pour assurer la fiabilité et la précision des données. Comme mentionné, le manque de synchronisation entre les silos de données et les entrepôts de données peut compliquer la tâche des gestionnaires pour comprendre quelle partie des données est exacte et complète. Si un utilisateur entre les mauvaises données, la sortie générée est également incorrecte. Ceci est appelé garbage in, garbage out (GIGO). Ce type d’erreur est appelé une erreur humaine.
- Peu de personnel : Il est difficile et c’est un défi de trouver du personnel qualifié ayant une connaissance correcte du domaine problématique. Le manque de scientifiques de données, d’administrateurs de bases de données (DBA), d’analystes de données, de concepteur de modèle de données et de différents professionnels du Big Data rend le travail de gestion de données très difficile.
- Manque de soutien de la part des dirigeants : les cadres supérieurs ne comprennent généralement pas l’importance et la valeur d’une bonne gestion des données. Il est très difficile de les convaincre et de montrer les feuilles de route de la façon dont ces techniques de gestion seraient bénéfiques pour l’organisation. En d’autres termes, la plupart des cadres supérieurs sont satisfaits de leurs solutions de pointe pour le domaine problématique.
1.6 Big Data Plateformes de modélisation
Dans cette section, nous allons configurer Cloudera VM sous Windows et macOS. Nous allons utiliser cette machine virtuelle pour la plupart des exercices de ce livre.
1.6.3 Débuter sur Windows
Nous allons installer la machine virtuelle Cloudera dans notre système pour commencer à modéliser les données volumineuses. Suivez ces instructions pour télécharger et installer la machine virtuelle Cloudera Quickstart avec VirtualBox sous Windows :
- Téléchargez le logiciel à l’adresse https://www.virtualbox.org/wiki/Downloads. Une fois le téléchargement terminé, installez le logiciel VirtualBox téléchargé sur votre ordinateur.
- Téléchargez la machine virtuelle Cloudera à l’adresse https://downloads.cloudera.com/demo_vm/virtualbox/cloudera-quickstart-vm-5.4.2-0-virtualbox.zip. La machine virtuelle dépasse 4 Go. Il faudra du temps pour télécharger le logiciel.
- Cliquez avec le bouton droit de la souris sur Cloudera-quickstart-vm-5.4.2-0-virtualbox.zip et choisissez Extract All…
- Démarrez la VirtualBox.
- Importez la VM en allant dans File | Import Appliance …:

- Cliquez sur l’icône du dossier, sélectionnez cloudera-quickstart-vm-5.4.2-0-virtualbox.ovf dans le dossier où vous avez dézippé la machine virtuelle VirtualBox, puis cliquez sur Open. La capture d’écran suivante est fournie à titre d’aide :
- Cliquez sur Next pour continuer, puis sur Import, comme illustré dans la capture d’écran suivante :
- L’image de la machine virtuelle sera importée. Comme il s’agit d’un gros fichier, cela peut prendre un certain temps :
- Une fois l’importation terminée, lancez la machine virtuelle Cloudera. cloudera-quickstart-vm-5.4.2-0 VM apparaîtra à gauche dans la fenêtre de VirtualBox. Sélectionnez la machine et cliquez sur le bouton Start pour lancer la machine virtuelle :
- Le démarrage initial de la machine virtuelle Cloudera prend plusieurs minutes. Cela prend beaucoup de temps, car de nombreux outils Hadoop sont chargés et démarrés à ce processus de démarrage :
- Une fois le processus de démarrage terminé, vous verrez le bureau Cloudera VM à l’écran :
1.6.2 Démarrer sur macOS
La configuration de la machine virtuelle Cloudera sur un Mac est très similaire à celle de Windows. Si vous avez macOS, nous pouvons configurer la VM Cloudera Quickstart avec VirtualBox sur macOS. Effectuez les étapes suivantes :
- Allez sur https://www.virtualbox.org/wiki/Downloads et téléchargez la boîte virtuelle. Une fois téléchargé, installez VirtualBox dans macOS.
- Téléchargez la machine virtuelle Cloudera à l’adresse https://downloads.cloudera.com/demo_vm/virtualbox/cloudera-quickstart-vm-5.4.2-0-virtualbox.zip. La VM a plus de 4 Go, le téléchargement prendra donc un certain temps.
- Décompressez la VM Cloudera. Vous pouvez le faire en double-cliquant sur le dossier cloudera-quickstart-vm-5.4.2-0-virtualbox.zip.
- Démarrez la VirtualBox et lancez l’importation. Nous pouvons importer la VM en allant dans File | Import Applicance.
- Cliquez sur l’icône Dossier, sélectionnez cloudera-quickstart-vm-5.4.2-0-virtualbox.ovf dans le dossier où vous avez dézippé la machine virtuelle VirtualBox, puis cliquez sur Open :

- Cliquez sur Continue pour continuer:
- Cliquez sur Import :
- L’image de la machine virtuelle sera importée. Comme il s’agit d’un gros fichier, cela peut prendre un certain temps :
- Une fois l’importation terminée, lancez la machine virtuelle Cloudera. cloudera-quickstart-vm-5.4.2-0 La machine virtuelle apparaîtra à gauche dans la fenêtre de VirtualBox. Sélectionnez la machine et cliquez sur le bouton Démarrer pour lancer la machine virtuelle :
- Il faut plusieurs minutes au démarrage initial de la machine virtuelle Cloudera pour démarrer. Cela prend beaucoup de temps, car de nombreux outils Hadoop sont chargés et démarrés au cours de ce processus de démarrage :
- Une fois le processus de démarrage terminé, vous verrez le bureau Cloudera VM à l’écran :
1.7 Résumé
Les mégadonnées sont omniprésentes ; il peut être trouvé partout, des petites entreprises aux applications d’entreprise. Il est d’une importance vitale que ces données soient capturées, stockées, récupérées et analysées de la meilleure façon possible afin d’obtenir une analyse et une intelligence économique plus approfondies. Dans ce chapitre, nous avons découvert le concept des mégadonnées et leur origine. Nous avons également discuté des différentes caractéristiques des mégadonnées et des fondements théoriques de la modélisation et de la gestion des données.
En plus de cela, les lecteurs ont eu la possibilité d’installer une plate-forme Big Data sur leur machine locale pour les machines macOS et Windows. Nous utiliserons ces machines dans les prochains chapitres pour créer des modèles de base de données. Dans le prochain chapitre, nous discuterons des plates-formes de modélisation et de gestion des données.
2 Plateformes de modélisation et de gestion de données
Dans le chapitre précédent, nous avons abordé certains aspects théoriques et managériaux du big data, ainsi que l’importance du big data en général. Dans ce chapitre, nous énumérerons certaines questions incontournables concernant la gestion du Big Data. En outre, vous en apprendrez davantage sur les entreprises et les agences gouvernementales qui traitent le Big Data en termes de stockage, de gestion et de traitement. Les mégadonnées présentent de nouveaux défis, obligeant les développeurs basés sur un framework à proposer des solutions. Ils ont introduit plusieurs types d’infrastructures portables et évolutives pour le stockage, la gestion et le traitement du Big Data.
Dans ce chapitre, nous aborderons diverses approches de gestion du Big Data, notamment les étapes nécessaires à l’utilisation des différentes options, ainsi que les fournisseurs qui les fournissent. De plus, nous explorerons diverses plates-formes de programmation disponibles pour la gestion de données volumineuses.
Les sujets suivants seront abordés dans ce chapitre :
- Un aperçu de la gestion du Big Data
- Services de gestion de données volumineuses
- Fournisseurs de gestion de données volumineuses
- Stockage de données volumineuses et modèles de données
- Modèles de programmation Big Data
- Débuter avec Python
- Débuter avec R
2.1 Gestion des données volumineuses
La gestion des données volumineuses garantit un certain niveau de qualité et d’accessibilité des données pour la veille stratégique, ainsi que pour les applications d’analyse de données volumineuses. La gestion des données volumineuses intègre les politiques, les techniques et les processus utilisés pour la collecte, le stockage, l’administration et la livraison des données, ainsi que pour la livraison de grands référentiels. L’étape peut impliquer le nettoyage, l’intégration, la migration et la création de rapports.
2.1.1 Ingestion de données
L’ingestion de données fait référence au processus d’acquisition de données dans le système. Cela peut être fait via des méthodes manuelles, semi-automatiques ou automatiques.
Remarque :
L’ingestion de données désigne le processus d’introduction des données dans le système de données que nous construisons ou utilisons.
Dans un système plus petit, les utilisateurs préfèrent utiliser un formulaire Web ou une interface visuelle permettant la saisie des données afin de placer les données dans le système. Toutefois, lorsqu’il s’agit d’un système plus vaste, tel qu’un système de gestion d’hôpital, un système de gestion de compagnie aérienne, un système de gestion des archives publiques et publiques ou un site de média social, les utilisateurs préfèrent souvent automatiser autant que possible le processus d’ingestion de données. Ainsi, en ce qui concerne l’ingestion de données, nous devons explorer un ensemble de questions, telles que :
- Combien de sources de données existe-t-il ?
- Combien de données volumineuses sont disponibles ?
- Le nombre de sources de données va-t-il augmenter avec le temps ?
- Quelle est la vitesse à laquelle les données seront consommées ?
Il est très important de noter que la taille d’un enregistrement individuel est petite, mais le volume de données est assez énorme. En ce qui concerne l’ingestion de données, les développeurs aiment créer un ensemble de stratégies, appelées stratégies d’ingestion, qui guident le traitement des erreurs lors de l’ingestion de données, ainsi que le caractère incomplet des données, etc. L’ingestion de données (ainsi que ses politiques) fait partie intégrante d’un système Big Data.
2.1.2 Stockage de données
L’objectif principal d’une infrastructure de stockage est de stocker des données. Les problèmes suivants doivent être pris en compte lors du stockage des données :
- Capacité : La capacité fait référence à la quantité de mémoire à allouer (ou à la taille de la mémoire) pour stocker les données.
- Évolutivité : les périphériques de stockage connectés doivent être évolutifs, car le volume de données augmentera avec le temps. En outre, l’évolutivité concerne la possibilité de se connecter au réseau afin d’obtenir un stockage supplémentaire au fil du temps.
Dans un système de données volumineuses, nous avons le choix d’archiver une infrastructure de stockage en choisissant la quantité de chaque type de stockage dont nous avons besoin. L’utilisation de disques SSD pour stocker une grande quantité de données accélère les opérations de recherche dans les données d’au moins dix fois plus que sur des disques durs ; Cependant, cela augmente aussi le coût.
2.1.3 Qualité des données
Il est important que les données stockées soient utiles, sans erreur et destinées à l’usage auquel elles sont destinées. Des données de haute qualité donnent des informations exploitables, alors que des données de mauvaise qualité conduisent à une analyse médiocre et, conduisent, à de mauvaises décisions. Des erreurs dans les données de ces industries peuvent enfreindre les réglementations et entraîner des complications juridiques. Les facteurs suivants peuvent aider à évaluer la qualité des données :
- Complétude : manque-t-il des valeurs dans l’ensemble de données ?
- Validité : Les données correspondent à l’ensemble de règles.
- Unicité : les données ont des redondances minimes.
- Cohérence : les données sont cohérentes dans différents magasins de données.
- Actualité : les données représentent la réalité à un moment donné.
- Précision : Le degré de conformité du résultat d’une mesure, d’un calcul ou d’une spécification particulière à la valeur correcte.
2.1.4 Opérations de données
Un aspect très important de la gestion des données est la documentation, la définition, la mise en œuvre et le test de l’ensemble des opérations requises pour une application spécifique. En bref, il existe deux ensembles d’opérations distincts utilisés pour la gestion des données, à savoir :
- Une opération qui fonctionne sur un objet singulier : Par exemple, une opération qui recadre une image, en extrayant une sous-zone d’une zone de pixels, est une opération mono-objet, car nous considérons l’image comme un seul objet.
- Une opération qui fonctionne sur des collections d’objets de données : Cette opération consiste à fusionner deux collections afin de former une collection plus grande.
2.1.5 Evolutivité et sécurité des données
Aujourd’hui, la plupart des systèmes de gestion de données volumineuses sont conçus pour fonctionner sur un cluster de machines et ont la possibilité de s’ajuster lorsque de nouvelles machines sont ajoutées ou en cas de panne. La gestion de cluster (la gestion des opérations de données sur un cluster) est un composant important des systèmes de gestion de Big Data actuels.
Remarque :
La sécurité est une mesure de la capacité du système à protéger les données et les informations contre les accès non autorisés tout en fournissant un accès aux personnes et aux systèmes autorisés. Une action entreprise contre un système informatique dans l’intention de nuire est appelée une attaque et peut prendre plusieurs formes. Il peut s’agir d’une tentative non autorisée d’accéder à des données ou à des services ou de modifier des données, ou bien de refuser des services à des utilisateurs légitimes.
L’évolutivité implique l’impact de l’ajout ou de la suppression de ressources, et les mesures refléteront la disponibilité associée et le prêt attribué aux ressources existantes et nouvelles. Bien que de nombreux produits de sécurité soient disponibles, assurer la sécurité tout en assurant l’efficacité du traitement des données reste un sujet de recherche important dans le domaine de la gestion du Big Data.
2.2 Services de gestion de données volumineuses
Il existe différentes variétés de solutions de gestion de Big Data parmi lesquelles les entreprises peuvent choisir. Différents fournisseurs prennent en charge différentes piles technologiques et ont différents modèles de tarification. Certains fournisseurs proposent une variété d’outils de gestion de données volumineuses, autonomes ou multiples. Dans cette section, nous présenterons quelques services de fournisseurs de gestion de données.
2.2.1 Nettoyage des données
Le nettoyage des données est le processus d’identification et de correction des enregistrements corrompus ou erronés dans un jeu, une table ou une base de données. Il traite également de l’identification des parties incomplètes, incorrectes, inexactes ou non pertinentes des données, puis du remplacement, de la modification ou de la suppression des données infectées. La saisie et l’acquisition de données sont par nature sujettes aux erreurs, simples et complexes. Ce processus frontal nécessite beaucoup d’efforts, mais il n’en reste pas moins que les erreurs sont courantes dans les grands ensembles de données. En ce qui concerne la gestion des données volumineuses, le nettoyage des données est très important pour les raisons suivantes :
- Les données principales sont généralement réparties sur différents systèmes hérités, notamment des feuilles de calcul, des fichiers texte et des pages Web.
- En s’assurant que les données sont aussi précises que possible, une organisation peut entretenir de bonnes relations avec ses clients, améliorant ainsi son efficacité.
- Des données correctes et complètes permettent de mieux comprendre le processus concerné par les données.
Il existe des bibliothèques pour Python (Pandas) et R ( Dplyr ) qui peuvent vous aider dans ce processus. En outre, il existe d’autres services haut de gamme disponibles sur le marché, notamment Trifacta , OpenRefine , Paxata , etc.
2.2.2 Intégration de données
Dans un scénario général, les données proviennent de différentes sources. L’intégration des données est l’une des techniques permettant de combiner des données provenant de sources différentes et de fournir aux utilisateurs finaux une vue unifiée de ces données. Cela donne un sentiment d’abstraction aux utilisateurs finaux.
Mathématiquement, les systèmes d’intégration de données sont formellement définis en tant que <G, S, M>:
- G est le schéma global
- S est l’ensemble hétérogène de schémas sources
- M est le mappage qui mappe les requêtes entre les schémas source et global
Les lettres G et S sont exprimées en langues sur des alphabets composés de symboles pour chacune de leurs relations respectives. Le mappage M consiste en des assertions entre les requêtes overG et les requêtes overS.
Il existe quelques autres capacités de gestion de Big Data ; ils peuvent être expliqués comme suit :
- Migration de données : il s’agit du processus de transfert de données d’un environnement à un autre. La plupart des migrations ont lieu entre des ordinateurs et des périphériques de stockage (par exemple, le transfert de données de centres de données internes vers le cloud).
- Préparation des données : les données utilisées pour l’analyse sont souvent salissantes, incohérentes et non normalisées. Ces données doivent être collectées et nettoyées dans un fichier ou une table de données avant qu’une analyse réelle puisse avoir lieu. Cette étape est appelée préparation des données. Cela implique de manipuler des données en désordre, d’essayer de combiner des données provenant de plusieurs sources et de générer des rapports sur les sources de données saisies manuellement.
- Enrichissement des données : cette étape consiste à améliorer l’ensemble de données existant en affinant les données afin d’améliorer leur qualité. Cela peut être fait de plusieurs manières. L’ajout de nouveaux jeux de données, la correction d’erreurs miniatures ou l’extrapolation de nouvelles informations à partir de données brutes sont des méthodes courantes.
- Analyse de données : il s’agit de tirer des informations des jeux de données en les analysant à l’aide de divers algorithmes. La plupart des étapes sont automatisées à l’aide de divers outils.
- Qualité des données : Il s’agit de confirmer que les données sont exactes et fiables. La qualité des données est contrôlée de plusieurs manières.
- Master Data Management (MDM) : il s’agit d’une méthode utilisée pour définir et gérer les données importantes de toute entreprise, afin de faciliter le processus de liaison des données d’entreprise critiques à un seul ensemble principal. L’ensemble principal fonctionne comme une source unique de vérité pour l’organisation.
- Gouvernance des données : il s’agit d’un concept de gestion des données qui traite de la capacité d’une entreprise à garantir une qualité élevée des données tout au long du processus d’analyse. Ce processus consiste notamment à garantir la disponibilité, la convivialité, l’intégrité et la précision des données.
- Extraction de la charge de transformation (ETL) : comme son nom l’indique, il s’agit du processus de déplacement de données d’un référentiel existant vers une autre base de données ou un nouvel entrepôt de données.
2.3 Fournisseurs de gestion de données volumineuses
En raison de la forte prévalence du big data et de son utilisation dans la veille stratégique, il existe des milliers de fournisseurs de gestion de big data sur le marché, prêts à fournir tous les services de gestion de données. Passer par chacun d’eux irait au-delà de la portée de l’article. Dans cette section, nous allons explorer dix fournisseurs de solutions Big Data. La liste contenue dans cet article ne garantit pas la popularité ou les performances de chaque fournisseur. La liste a été créée sur la base de l’analyse de données effectuée :
- Alation : Alation est une organisation plus récente qui fournit des services de données dans le cloud, créés pour centraliser les connaissances sur les données d’une entreprise et sur la manière de les appliquer. Pour en savoir plus sur la société, cliquez sur le lien fourni dans la section Études complémentaires.
- AtScale : AtScale fournit une technologie facilitant l’utilisation d’outils de BI familiers pour interroger les données stockées dans Hadoop.
- Cloudera : Cloudera est l’une des trois principales organisations de distribution Hadoop. Il fournit sa propre pile de technologies analytiques et de gestion de Big Data Open Source aux entreprises. Intel conserve une grande participation dans la société.
- Collibra : Collibra fournit aux organisations prenant en charge l’automatisation des processus de gestion de données fonctionnant des initiatives de qualité des données, de gestion des données principales et de gestion des métadonnées.
- Confluent : Confluent est le créateur et le distributeur d’Apache Kafka, une technologie Big Data en temps réel qui fonctionne comme un système de messagerie qui permet aux environnements d’applications et de données complexes. Cette société est incubée dans LinkedIn.
- Hortonworks : Hortonworks est l’un des trois principaux fournisseurs de la distribution Hadoop et est à la base de l’initiative Open Data Platform ( ODPi ). Une partie de son financement initial provenait de la société d’incubateur Hadoop Yahoo.
- SAS : SAS est un géant de l’analyse populaire. Il fournit également une solution de gestion de données maîtresses destinée à aider les entreprises à préparer et à gérer les sources de données traditionnelles et les sources de données volumineuses.
- Verato : Verato fournit une plate-forme basée sur le cloud qui a été inventée pour maintenir des données d’identité nettes sur plusieurs systèmes de données, en s’assurant que les nouvelles données qui entrent dans le système sont précises et en reliant les enregistrements entre systèmes et au sein des entreprises.
- TIBCO : TIBCO propose des logiciels d’intégration, d’analyse et de traitement des événements destinés aux entreprises et autres organisations.
- Talend : La vision de la plate-forme unifiée de Talend fournit des capacités multi-domaines (MDM), de qualité des données et d’intégration. La société a ses racines dans le concept open source.
2.4 Stockage de données volumineuses et modèles de données
Nous avons maintenant exploré ce qu’est le big data, ainsi que son importance. La demande de stockage et de traitement d’ensembles de données à grande échelle a favorisé le développement de systèmes de stockage de données et de bases de données au cours des dernières années. Avec cette avancée, les systèmes de stockage et les modèles de données pour les mégadonnées ont été améliorés au fil du temps, du stockage local au stockage en cluster, distribué au stockage en nuage. Dans cette section, vous découvrirez certains des modèles de stockage et modèles de données les plus populaires :
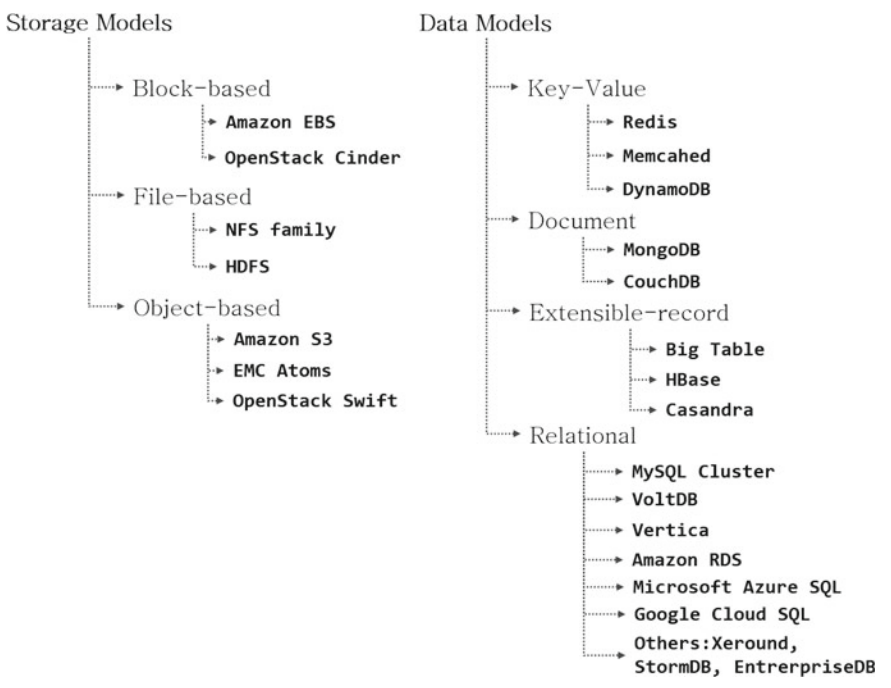
Le diagramme précédent montre la taxonomie des magasins de données et des plates-formes de données, ainsi que les systèmes correspondants actuellement disponibles sur le marché. Explorons chaque catégorie dans la section suivante.
2.4.1 Modèles de stockage
Le modèle de stockage est le composant essentiel des systèmes Big Data. Ces modèles ont un impact sur l’évolutivité, la programmation, les structures de données et les modèles informatiques du système. Dans la section suivante, nous allons explorer trois types de modèles de stockage courants : le stockage basé sur le blocage, le stockage basé sur le fichier et le stockage basé sur les objets.
2.4.1.1 Stockage par blocs (Block based)
Dans un modèle de stockage basé sur des blocs, vous rencontrez un système similaire à un modèle de stockage traditionnel, avec une capacité de stockage brute de taille fixe, tout comme le disque dur d’un serveur. Ici, le disque dur peut être installé sur un serveur distant. C’est le concept principal des systèmes de stockage basés sur des blocs.
Chaque bloc de stockage peut être traité comme un lecteur de disque indépendant et peut également être contrôlé par un système d’exploitation externe. Certains systèmes de stockage classiques basés sur des blocs sont les suivants :
- AmazonElastic BlockStore (Amazon EBS) est un service de stockage de niveau bloc
- OpenStack est fourni par le système Nova
2.4.1.2 Stockage sur fichier
Le stockage sur fichier est le modèle de stockage le plus courant et présente des avantages par rapport à d’autres modèles de stockage, en termes de facilité d’utilisation et de simplicité. Il étend l’architecture de système de fichiers traditionnelle en conservant les données dans une structure hiérarchique sous forme de fichiers. En conséquence, ce type de stockage comporte des chemins de fichiers hiérarchisés, utilisés comme entrées pour accéder aux données du stockage physique. Le Big Data utilise couramment les systèmes de fichiers distribués (DFS) comme système de stockage de base. Les utilisateurs ont besoin d’espaces de noms et de connaissances sur les chemins d’accès pour accéder aux fichiers enregistrés dans un stockage basé sur fichiers. Pour le partage de fichiers inter système, le chemin ou l’espace de nom d’un fichier se compose de trois parties principales : le protocole, le nom de domaine et le chemin du fichier. La famille NFS et HDFS sont deux modèles de stockage courants basés sur des fichiers, définis comme suit :
- Famille NFS : Il s’agit d’un protocole de système de fichiers distribué, initialement créé par Sun Microsystems. Dans ce système, un système de fichiers réseau (NFS) permet aux hôtes distants de monter des systèmes de fichiers sur un réseau et d’interagir avec ces systèmes de fichiers comme s’ils étaient montés localement. NFS a été largement utilisé dans les systèmes d’exploitation Unix et Linux, et a également encouragé le développement de systèmes de fichiers distribués modernes.
- HDFS : Le système de fichiers distribués Hadoop (HDFS) est un système de fichiers distribué créé et optimisé pour le traitement de gros volumes de données et pour une disponibilité accrue. Il se propage sur le stockage local d’un cluster composé de nombreux nœuds de serveur. HDFS est un système de fichiers distribué open source, écrit en Java. Il s’agit de l’implémentation open-source du système de fichiers Google (GFS) et constitue le stockage principal des écosystèmes Hadoop et de la majorité des plates-formes Big Data existantes. HDFS a été conçu pour la détection et la récupération d’erreur, et est capable de gérer d’énormes jeux de données.
2.4.1.3 Stockage basé sur les objets
Les modèles de stockage basés sur les objets gèrent les données en tant qu’objets. Ils peuvent être implémentés à différents niveaux, y compris les niveaux de périphérique, de système et d’interface. Le système de stockage basé sur les objets utilise un espace de noms plat, qui conserve généralement les identificateurs de données et leurs emplacements sous forme de paires clé-valeur dans le serveur d’objets. L’architecture plate simplifie la mise à l’échelle des systèmes de stockage basés sur des objets en offrant la possibilité d’ajouter des nœuds de stockage supplémentaires au système.
Il existe un certain nombre de solutions de stockage basées sur des objets, comme suit :
- Amazon S3 (Simple Storage Service) est une solution en nuage proposée par Amazon Web Services (AWS).
- EMC Atmos est une plate-forme de services de stockage sur objets développée par EMC Corporation.
- OpenStack Swift est un système de stockage évolutif, redondant et distribué basé sur des objets qui fonctionne sur la plate-forme en nuage OpenStack.
2.4.2 Modèles de données
Un modèle de données détermine la manière dont vous pouvez organiser et structurer les éléments de données. Les modèles de données constituent le cœur du stockage des données, de l’analyse et du traitement des systèmes Big Data contemporains. En général, les modèles de données peuvent être classés en deux grandes familles, qui seront décrites dans les sections suivantes.
2.4.2.1 Magasins relationnels (SQL)
MySQL, Oracle, SQL Server, PostgreSQL, etc., sont quelques systèmes de gestion de base de données relationnelle (SGBDR) qui ont dominé la communauté des bases de données pendant des décennies, jusqu’à ce qu’ils soient confrontés à la limitation de la mise à l’échelle pour des jeux de données à très grande échelle. Certaines propriétés de base de données importantes que suivent les bases de données relationnelles sont l’atomicité, la cohérence, l’isolation et la durabilité (ACID). Les magasins relationnels peuvent être classés en deux grandes familles :
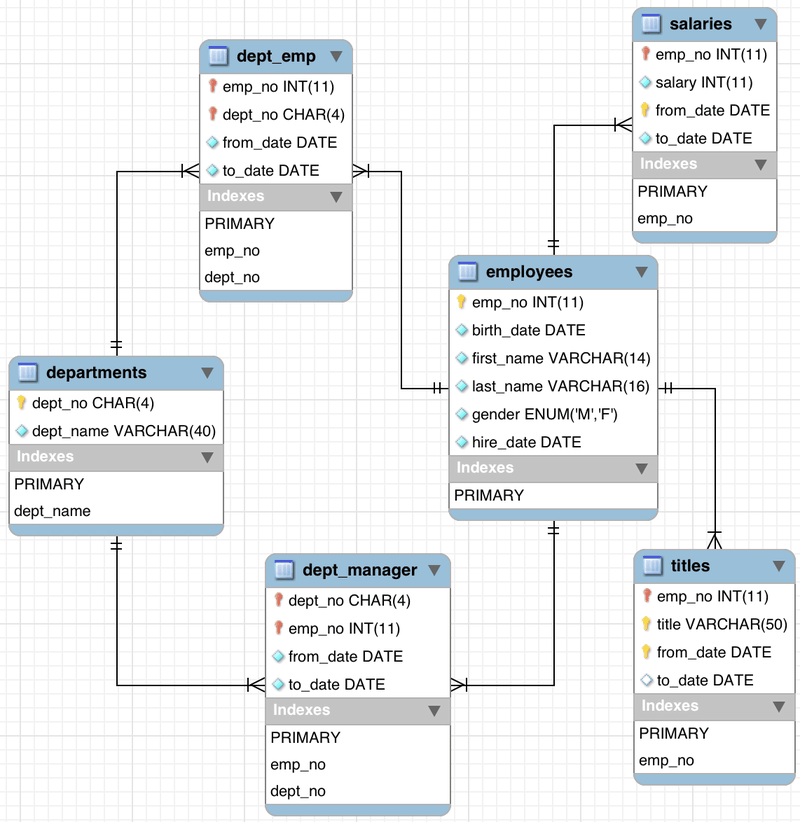
La figure illustre la manière dont les informations d’un service peuvent être stockées et leur relation. Le diagramme illustre clairement la relation qui est établie entre chacune des tables. Par exemple, la table des employés stocke le numéro d’employé comme identifiant, la date de naissance, le prénom, le nom de famille, le sexe et la date d’embauche. Les salaires des employés correspondants sont stockés dans la table des salaires.
2.4.2.2 Systèmes relationnels évolutifs
Les systèmes relationnels évolutifs présentent des améliorations par rapport aux SGBD traditionnels, afin de faire face aux performances et à l’évolutivité. Voici quelques systèmes relationnels évolutifs majeurs :
- MySQL Cluster : MySQL Cluster fait partie des principales versions de MySQL. Il s’agit d’une extension qui prend en charge les bases de données distribuées, multi-maîtres et compatibles ACID.
- VoltDB : VoltDB est une base de données en mémoire open source, basée sur SQL, conçue pour des performances élevées, ainsi que pour son évolutivité.
- Vertica Analytics Platform : Vertica Analytics Platform est un système de gestion de base de données répartie basé sur le cloud, orienté colonne.
2.4.2.3 Base de données en tant que service ( DaaS )
Base de données en tant que service ( DaaS ) est un modèle de service dans lequel un fournisseur de services tiers, qui héberge des bases de données relationnelles évolutives en tant que services, applique la technologie multi-tenants aux systèmes de base de données. Voici quelques exemples célèbres :
- Amazon RDS : Amazon RDS (service de base de données relationnelle) est un service DaaS fourni par AWS. Amazone RDS offre une capacité rentable et redimensionnable, tout en automatisant des tâches d’administration fastidieuses, telles que le provisionnement du matériel, la configuration de la base de données, les correctifs et les sauvegardes. Il permet aux utilisateurs de se concentrer sur leurs applications afin de bénéficier des performances rapides, de la haute disponibilité, de la sécurité et de la compatibilité dont ils ont besoin.
- Microsoft Azure SQL : Azure [16] est un ensemble complet de services de cloud computing que les développeurs et les professionnels de l’informatique utilisent pour créer, déployer et gérer des applications via le réseau mondial de centres de données. Le système comprend des outils intégrés, des DevOps et une assistance sur le marché qui permettent de créer efficacement des applications mobiles allant des simples applications mobiles aux solutions à l’échelle Internet.
- Google Cloud SQL : Cloud SQL est un service de base de données entièrement géré. Il est facile de configurer, gérer, gérer et administrer des bases de données relationnelles dans le cloud. Les utilisateurs peuvent utiliser Cloud SQL avec MySQL ou PostgreSQL. En plus de cela, Cloud SQL offre une évolutivité, des performances, une sécurité et une commodité élevées.
- StormDB : StormDB fournit une base de données en tant que plate-forme de nuage de services pouvant gérer de manière unique des charges de travail transactionnelles intensives en temps réel.
- Autres ( EnterpriseDB , Xeround ).
2.4.3 Magasins NoSQL
La plupart des systèmes NoSQL présentent les fonctionnalités suivantes :
- Grande évolutivité
- Haute disponibilité
- Haute tolérance aux pannes
- Flexibilité dans les modèles de données
- Modèles de cohérence plus faibles ayant abandonné les transactions ACID
- Interfaces simples
Explorons certains systèmes NoSQL dans les sections suivantes.
2.4.3.1 Magasins de documents
Dans les magasins de documents, les données sont enregistrées dans des documents. Semblables aux magasins de clés-valeurs, les documents (valeurs) sont référencés par des noms uniques (clés). Chaque document est totalement libre en ce qui concerne son schéma ; En d’autres termes, vous pouvez utiliser le schéma requis par l’application. Si la demande évolue, les adaptations sont plutôt simples. De nouveaux champs peuvent être attachés et les champs utilisés peuvent être éliminés.
MongoDB : Comme le prétend la communauté, MongoDB est une base de données polyvalente solide, flexible et évolutive. Il associe la possibilité d’évoluer avec des fonctionnalités telles que les index secondaires, les requêtes d’intervalle, le tri, les agrégations et les index géospatiaux. MongoDB est une base de données orientée document, et non relationnelle, qui présente des avantages faciles à utiliser.
MongoDB a été conçu pour être évolutif. Il garantit de hautes performances, une haute disponibilité et une mise à l’échelle automatique. S’agissant d’un modèle de données orienté document, il est plus facile de fractionner les données sur plusieurs serveurs géographiquement situés à des emplacements distincts. Le composant d’équilibrage de charge de MongoDB équilibre automatiquement les données et la charge entre les clusters et redistribue automatiquement les documents correspondants, le routage des lectures et des écritures sur les machines appropriées.
Un enregistrement dans MongoDB est appelé un document, qui est une structure de données composée de paires de champs et de valeurs. Les documents MongoDB sont très similaires aux objets JSON. Les valeurs des champs peuvent inclure d’autres documents, tableaux et tableaux de documents. Un exemple de document MongoDB est donné dans la capture d’écran suivante, qui montre un seul objet comportant un champ et une valeur. Par exemple, name est le champ et sue est la valeur correspondante. L’objet appartient à une seule personne dont le nom est sue, qui a 26 ans, qui a la valeur de status A et qui est abonnée aux groups de news et de sports :

Voici quelques caractéristiques notables de MongoDB :
- Il offre une persistance des données hautes performances et prend en charge un modèle de données intégré qui réduit l’activité d’E / S sur le système de base de données.
- Il prend en charge un langage RQL (Rich Query Language), notamment l’agrégation de données, la recherche de texte et les requêtes géospatiales.
- La fonction de réplication de MongoDB, appelée ensemble de réplicas, fournit un basculement automatique et une redondance des données. Un jeu de réplicas est un groupe de serveurs MongoDB qui conserve le même jeu de données, offrant une redondance et une disponibilité accrue des données.
- MongoDB offre une évolutivité horizontale dans le cadre de ses fonctionnalités principales.
- Il prend en charge plusieurs moteurs de stockage, dont WiredTiger Storage Engine, In-Memory Storage Engine et MMAPv1 Storage Engine.
CouchDB: CouchDB est une base de données qui englobe complètement le Web. Il stocke des données avec des documents JSON et permet d’accéder à des documents avec un navigateur Web, via HTTP. CouchDB fonctionne bien avec les applications Web et mobiles modernes. Nous pouvons distribuer nos données efficacement en utilisant la réplication incrémentielle de CouchDB. CouchDB prend en charge les configurations maître-maître, avec détection automatique des conflits :
- Les requêtes sur les documents CouchDB sont appelées vues. Il s’agit de fonctions JavaScript basées sur MapReduce spécifiant des contraintes de correspondance et une logique d’agrégation.
- CouchDB prend également en charge les verrouillages optimistes basés sur le contrôle MVCC (Multi-Versioned Concurrency Control), ce qui lui permet de ne pas être verrouillés lors des opérations de lecture.
2.4.3.2 Magasins de clés-valeur
Les magasins de clés-valeurs utilisent un modèle de données simple dans lequel les données sont considérées comme une paire définie de clés-valeurs ; les clés sont des identifiants uniques pour chaque donnée et servent également d’index lors de l’accès aux données :
- Serveur de dictionnaire distant (Redis) : La popularité croissante de Redis, une technologie NoSQL Open Source clé-valeur, résulte de la stabilité, de la puissance et de la flexibilité de Redis dans l’exécution d’un large éventail d’opérations et de tâches dans l’entreprise. Redis est utilisé par un ensemble varié de sociétés, des startups aux plus grandes sociétés de technologie. Il est écrit en C. Redis vous permet de conceptualiser et d’aborder de manière très différente les problèmes difficiles d’analyse et de manipulation des données, par rapport à un modèle de données relationnel typique. Dans une base de données relationnelle basée sur SQL, le développeur ou l’administration de la base de données crée un schéma de base de données qui organise le domaine de la solution en normalisant les données en colonnes, en lignes et en tables avec des jointures de connexion, via des relations de clé étrangère.
- DynamoDB : DynamoDB est un service de magasin NoSQL fourni par Amazon. Dynamo prend en charge un modèle de données beaucoup plus flexible, en particulier pour les magasins de valeurs clés. Les données dans Dynamo sont stockées dans des tables, chacune ayant un identifiant principal unique d’accès. Chaque table peut avoir un ensemble d’attributs sans schéma, et les types et ensembles scalaires sont pris en charge. Les données de Dynamo peuvent être manipulées en recherchant, en insérant et en supprimant des clés primaires. En outre, les opérations conditionnelles, la modification atomique et la recherche par attributs non clés sont également prises en charge (mais sont inefficaces), ce qui le rapproche également du magasin de documents. Dynamo fournit une architecture rapide et évolutive, dans laquelle le découpage et la réplication sont automatiquement effectués. En outre, Dynamo prend en charge à la fois la cohérence éventuelle et la cohérence élevée des lectures, tandis que la cohérence constante dégrade les performances.
2.4.3.3 Magasins de colonnes (extensible-record)
Les magasins de disques extensibles (également appelés magasins de colonnes) étaient initialement motivés par le projet Big Table de Google. Dans le système, les données sont prises en compte dans les tables avec les familles de lignes et de colonnes, dans lesquelles les lignes et les colonnes peuvent être réparties sur plusieurs nœuds :
- BigTable : Big Table a été introduit par Google en 2004 en tant que magasin de colonnes pour prendre en charge divers services Google. Big Table est construit sur le système de fichiers Google (GFS) et peut facilement être étendu à des centaines et des milliers de nœuds, en maintenant l’échelle de données en téraoctets et en pétaoctets.
- HBase : HBase est un projet open source Apache et a été développé en Java, basé sur les principes de BigTable de Google. HBase est construit sur le cadre Hadoop et Apache Zookeeper, dans orderto fournir une base de données colonne magasin. Comme HBase a été hérité de BigTable , ils partagent de nombreuses fonctionnalités, à la fois dans leurs modèles de données et leurs architectures.
- Cassandra : Cassandra est une base de données NoSQL open source initialement développée par Facebook, en Java. Il combine les idées de BigTable et de Dynamo. Il est maintenant open source sous licence Apache. Casandra partage la majorité de ses fonctionnalités avec d’autres magasins de disques extensibles (magasins de colonnes), à la fois en termes de modélisation de données et de fonctionnalités.
2.5 Modèles de programmation Big Data
Les modèles de programmation Big Data décrivent le style et le paradigme de l’interface permettant aux développeurs d’écrire des applications et des programmes Big Data. Les modèles de programmation sont généralement la caractéristique principale des frameworks Big Data, dans la mesure où ils affectent implicitement le modèle d’exécution des moteurs de traitement Big Data, ainsi que la visualisation et la construction d’applications et de programmes Big Data.
Dans cette section, nous discuterons et comparerons les principaux modèles de programmation pour l’écriture d’applications Big Data, en fonction de leur taxonomie.
2.5.1 MapReduce
MapReduce fait référence à un modèle de programmation adapté au traitement de grandes quantités de données. Par exemple, Hadoop est capable d’exécuter un programme MapReduce écrit dans plusieurs langages de programmation, notamment Java, C ++, Python, Ruby et autres. MapReduce est conçu pour traiter efficacement un grand volume de données, en connectant plusieurs ordinateurs standard, afin de fonctionner en parallèle. En plus de cela, MapReduce réunit des machines plus petites et plus abordables dans un seul groupe de produits rentables. MapReduce atteint cette efficacité en divisant une tâche en plusieurs parties et en les affectant à plusieurs ordinateurs. Plus tard, les résultats sont collectés dans un seul endroit et intégrés, afin de former le jeu de données résultant.
2.5.1.1 Fonctionnalité MapReduce
Tous les programmes / modules MapReduce fonctionnent en deux phases, comme suit:
- Phase de la carte : C’est la première phase. En phase de mappage, un ensemble de données est converti en un autre ensemble de données, dans lequel des éléments individuels sont divisés en tuples (paires clé-valeur).
- Phase de réduction : Il s’agit de la deuxième phase, dans laquelle la sortie de la phase de carte est prise en entrée et fusionne les nuplets de données en un plus petit ensemble de nuplets.
Il existe un JobTracker qui divise un problème donné en plusieurs tâches de mappage. Ces tâches sont réparties sur le réseau vers un certain nombre de nœuds esclaves, pour un traitement en parallèle. Ces nœuds esclaves sont appelés TaskTrackers. En règle générale, les tâches de mappage fonctionnent sur les mêmes nœuds de cluster, où les données traitées restent. Si ce nœud de serveur est déjà lourdement chargé, un autre nœud proche des données sera choisi. Examinons le processus de travail de MapReduce, comme indiqué dans le diagramme suivant :
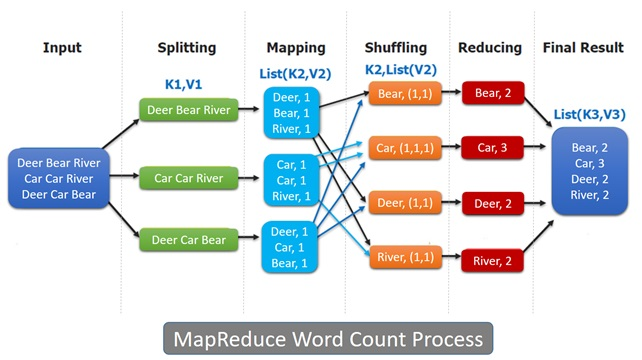
Le diagramme précédent montre un bref aperçu du fonctionnement de l’algorithme MapReduce. Il y a différentes phases impliquées. En supposant que le programme MapReduce ait à résoudre un problème, celui-ci doit s’exécuter dans l’ordre indiqué sur la figure. Inspectons chaque phase en détail, comme suit :
- Phase d’entrée : lors de la phase d’entrée, un lecteur d’enregistrement interprète chaque enregistrement dans un fichier d’entrée et envoie les données analysées au mappeur, sous la forme de paires clé-valeur. C’est la première étape du module MapReduce.
- Mappeur : un mappeur est un module de programme défini par l’utilisateur qui utilise une série de paires clé-valeur et traite chacune d’elles afin de générer des paires clé-valeur traitées en sortie.
- Clés intermédiaires : le mappeur utilise les paires clé-valeur et génère les paires clé-valeur traitées. Les paires clé-valeur générées par les mappeurs sont appelées clés intermédiaires.
- Combinateur : il existe un réducteur local qui regroupe des données similaires du mappeur en ensembles identifiables. Ils sont souvent appelés un combinateur. Il s’agit d’une phase facultative pouvant être présente ou non dans un sous-programme MapReduce particulier.
- Mélanger et trier : dans la phase de mélange et de tri, la sortie de la phase de mappeur est consommée en tant qu’entrée. Il y a généralement une grande quantité de données intermédiaires à déplacer de tous les nœuds de la carte vers tous les nœuds de réduction de la phase de lecture aléatoire. La phase de lecture aléatoire transfère les données des disques du mappeur, plutôt que de leurs mémoires principales, et la sortie intermédiaire sera triée par clés, de sorte que toutes les paires contenant les mêmes clés seront regroupées. Les données des nœuds de carte locaux sont transférées aux nœuds de réduction via le réseau.
- Réducteur : le réducteur utilise en entrée les données de pair clé-valeur groupées et exécute une fonction de réduction sur chaque paire. Il y a zéro ou plusieurs paires clé-valeur en sortie de la fonction de réduction. Cette sortie est redirigée vers la dernière étape du module MapReduce.
- Phase de sortie : Il existe un formateur de sortie qui traduit les dernières paires clé-valeur à partir de la fonction de réduction et les écrit dans un fichier à l’aide d’un graveur d’enregistrement. Le fichier de sortie contient la sortie finale du sous-programme.
2.5.1.2 Hadoop
Hadoop est très populaire dans l’écosystème du Big Data. Il est basé sur un modèle de structure de logiciel open source. Hadoop est connu pour stocker des données et exécuter des applications sur des grappes de matériel de base. Il a évolué au début des années 2000. Il garantit un stockage massif pour tout type de données, une puissance de traitement énorme et la capacité de gérer des tâches simultanées pratiquement illimitées. De plus, les technologies et les langages utilisés dans l’écosystème Hadoop sont bien connus dans la communauté.
2.5.1.3 Caractéristiques des frameworks Hadoop
Certaines fonctionnalités importantes des plates-formes Hadoop sont résumées comme suit:
- Puissance de stockage : Hadoop dispose d’une puissance de stockage et de traitement élevée en ce qui concerne les volumes de données élevés et les variétés en constante augmentation, notamment celles issues des médias sociaux et de l’Internet des objets (IoT).
- Puissance de calcul : le modèle de calcul distribué de Hadoop traite le big data très rapidement, par rapport aux autres frameworks. Plus on utilise de nœuds informatiques, plus on dispose de puissance de traitement.
- Tolérance aux pannes : le traitement des données et des applications est protégé contre les pannes matérielles. Si un nœud tombe en panne, les tâches sont automatiquement redirigées vers d’autres nœuds, afin de s’assurer que l’informatique distribuée n’échoue pas. De plus, plusieurs copies de toutes les données sont automatiquement stockées pour la sauvegarde.
- Flexibilité : contrairement aux bases de données relationnelles traditionnelles, il n’est pas nécessaire de prétraiter les données avant de les stocker. Vous pouvez stocker autant de données que vous le souhaitez et décider de leur utilisation ultérieure. Cela inclut les données non structurées, telles que le texte, les images, les vidéos, etc.
- Faible coût : le framework open source est gratuit et utilise du matériel standard pour stocker de grandes quantités de données.
- Évolutivité : vous pouvez facilement faire évoluer votre système pour gérer davantage de données, simplement en ajoutant des nœuds. Cela demande un peu d’administration, mais cela en vaut la peine.
2.5.1.4 Encore un autre négociateur de ressources (YARN : Yet Another Resource Negotiator)
Un autre négociateur de ressources (YARN) est un exemple d’extension du Framework MapReduce. YARN est le centre architectural de Hadoop et permet à plusieurs moteurs de traitement de données, tels que le SQL interactif, le traitement par lots et la diffusion en temps réel, de gérer les données stockées sur une seule plate-forme. Il est connu comme la nouvelle génération de Hadoop.
YARN améliore un cluster Hadoop de plusieurs manières. Certaines fonctionnalités importantes améliorées dans YARN sont répertoriées comme suit :
- Évolutivité : YARN a un gestionnaire de ressources qui comprend deux composants : un planificateur et un gestionnaire d’application. Comme son nom l’indique, le planificateur est responsable de l’allocation des ressources à l’application en cours d’exécution. Le gestionnaire d’application est responsable du démarrage des maîtres d’application, de leur surveillance et de leur redémarrage sur différents nœuds, en cas de défaillance.
- Compatibilité : YARN peut exécuter des applications développées pour Hadoop 1.x sans passer par le processus de modification.
- Utilisation des clusters : YARN alloue les clusters de manière dynamique, en respectant la plupart des règles MapReduce statiques.
- Multi-location : YARN permet d’accéder aux moteurs, d’utiliser Hadoop comme norme commune pour chaque lot.
2.5.2 Programmation fonctionnelle
La programmation fonctionnelle est le paradigme émergent de la prochaine génération de systèmes de traitement de données volumineuses ; Par exemple, les frameworks récents, tels que Spark et Flink, utilisent des interfaces fonctionnelles, ce qui permet aux programmeurs d’écrire des applications de données de manière simple et déclarative.
2.5.2.1 SPARK
Apache Spark est une plate-forme informatique en grappe conçue pour être rapide et polyvalente. Il est conçu pour le traitement de données volumineuses et étend le modèle populaire MapReduce afin de prendre en charge efficacement plus de types de calcul, avec de meilleures performances. Spark comprend des implémentations efficaces d’un certain nombre de transformations et d’actions pouvant être composées ensemble, afin de permettre le traitement et l’analyse des données. Spark répartit ces opérations sur un cluster tout en extrayant de nombreux détails d’implémentation sous-jacents. Spark a été conçu avec un accent mis sur l’évolutivité et l’efficacité.
2.5.2.2 Raisons pour choisir Apache Spark
Apache Spark est très populaire dans la communauté Big Data ces jours-ci. Voici certaines des principales raisons d’utiliser Apache Spark dans la modélisation et le calcul de données volumineuses :
- Vitesse : la vitesse est importante pour le traitement de grands ensembles de données. Spark offre la possibilité d’exécuter des calculs cent fois plus rapidement que Hadoop2 MapReduce en mémoire ou dix fois plus rapidement sur disque.
- Accessibilité : Spark a été développé pour être hautement accessible, offrant des API simples en Python, Java, Scala et SQL, ainsi que de riches bibliothèques intégrées. En outre, il s’intègre également à d’autres outils Big Data, notamment les clusters Hadoop et des sources telles que Cassandra3.
- Prise en charge de la plate-forme : Apache spark a été conçu pour fonctionner sur Hadoop et Mesos, en mode autonome ou dans le cloud. Il peut accéder à diverses sources de données, notamment HDFS, Cassandra, HBase et S3.
- Généralités : Spark a été développé pour couvrir un large éventail de charges de travail, notamment les applications par lots, les algorithmes itératifs, les requêtes interactives et la diffusion en continu. En prenant en charge ces charges de travail dans le même moteur, Spark permet de combiner facilement et à moindre coût différents types de traitement, ce qui est souvent nécessaire pour les pipelines de production d’analyse de données.
2.5.2.3 Flink
Apache Flink a été développé par Apache Software Foundation et est l’une des dernières entrées sur la liste des frameworks open-source axés sur l’analyse de données volumineuses. Apache Flink a publié sa première version stable d’API publiée en mars 2016 et a été conçue pour le traitement en mémoire des données de traitement par lots, à l’instar de Spark.
Ce modèle est pratique lorsque des passes répétées doivent être effectuées sur les mêmes données. Cela en fait un candidat idéal pour l’apprentissage automatique et d’autres cas d’utilisation nécessitant un apprentissage adaptatif, des réseaux d’autoapprentissage, etc.
2.5.2.4 Avantages de Flink
Apache Flink est récemment devenu populaire en tant que framework open source avec un traitement de flux et de traitement par lots puissant. Il offre les avantages suivants :
- Il dispose d’un moteur de traitement de flux réel : ce moteur peut approximer le traitement par lots plutôt que l’inverse. Il prend en charge le traitement des événements et des commandes dans l’API DataStream, en fonction du modèle de flux de données.
- Meilleure gestion de la mémoire : Apache Flink propose une gestion de la mémoire explicite qui élimine les pics occasionnels, tels que ceux trouvés dans le framework Spark.
- Vitesse : il gère les vitesses plus rapides en permettant le traitement itératif sur le même nœud, plutôt que de laisser le cluster exécuter les nœuds de manière indépendante. Vous pouvez améliorer ses performances en le modifiant pour ne traiter que la partie des données qui a été modifiée, plutôt que l’ensemble. Il offre une vitesse jusqu’à cinq fois supérieure à celle de l’algorithme de traitement standard.
- Moins de configuration : il nécessite moins de configuration par rapport aux applications de pointe. Apache Flink dispose d’API élégantes et fluides sous Java et Scala.
- Intégrations : Il intègre mieux YARN, HDFS, HBase et d’autres composants de l’écosystème Apache Hadoop.
2.5.3 Modèles de données SQL
Le langage de requête structuré (SQL) est l’un des langages de requête de données les plus classiques, inventé à l’origine pour les bases de données rationnelles basées sur l’algèbre rationnelle. Il contient quatre primitives de base, créer, lire, mettre à jour et supprimer (CRUD), permettant de modifier des ensembles de données considérés comme des tables avec des schémas. SQL est un langage déclaratif, et il inclut également quelques éléments de procédure. Certains des modèles de données de type SQL les plus courants sont répertoriés dans les sections suivantes.
2.5.3.1 Hive Query Langauge (HQL)
Apache Hive prend en charge le langage HQL (Hive Query Language). HQL est construit sur les écosystèmes Hadoop. Il s’agit d’un moteur de requête qui fournit une interface de type SQL qui lit les données d’entrée en fonction du schéma défini, puis transforme de manière transparente les requêtes en travaux MapReduce, connectés en tant que DAG (Directed Acyclic Graph). Il est basé sur SQL, mais il ne suit pas complètement le standard SQL, SQL-92.
HQL ne prend pas en charge les transactions et les vues matérialisées et ne prend en charge que les sous-requêtes et l’indexation limitée.
2.5.3.2 Le langage de requête Cassandra (CQL)
CQL est très similaire au SQL utilisé dans une base de données traditionnelle, telle que MySQL et PostgreSQL. CQL est implémenté comme alternative à l’interface RPC traditionnelle. Il fournit un modèle proche de SQL, dans le sens où les données sont placées dans des tables contenant des lignes de colonnes. Pour cette raison, lorsqu’ils sont utilisés dans ce chapitre, ces termes (tables, lignes et colonnes) ont les mêmes définitions que dans SQL.
CQL ajoute une couche d’abstraction qui masque les détails d’implémentation de sa structure de requête et présente une syntaxe native pour les collections et les codages courants. Par exemple, une syntaxe courante pour sélectionner des données dans une table est donnée comme suit :
select_statement ::= SELECT [ JSON | DISTINCT ] ( select_clause | ‘*’ )
FROM table_name
[ WHERE where_clause ] [ GROUP BY group_by_clause ] [ ORDER BY ordering_clause ] [ PER PARTITION LIMIT (integer | bind_marker) ] [ LIMIT (integer | bind_marker) ] [ ALLOW FILTERING ]
select_clause ::= selector [ AS identifier ] ( ‘,’ selector [ AS identifier ] )
selector ::= column_name
| term
| CAST ‘(‘ selector AS cql_type ‘)’
| function_name ‘(‘ [ selector ( ‘,’ selector )* ] ‘)’
| COUNT ‘(‘ ‘*’ ‘)’
where_clause ::= relation ( AND relation )*
relation ::= column_name operator term
‘(‘ column_name ( ‘,’ column_name )* ‘)’ operator tuple_literal
TOKEN ‘(‘ column_name ( ‘,’ column_name )* ‘)’ operator term
operator ::= ‘=’ | ‘<‘ | ‘>’ | ‘<=’ | ‘>=’ | ‘!=’ | IN | CONTAINS | CONTAINS KEY
group_by_clause ::= column_name ( ‘,’ column_name )*
ordering_clause ::= column_name [ ASC | DESC ] ( ‘,’ column_name [ ASC | DESC ] )*
2.5.3.3 Spark SQL
Spark SQL permet d’interroger des données structurées et semi-structurées dans le programme Spark, à l’aide d’API SQL ou DataFrame. Les DataFrames sont similaires aux tables d’une base de données relationnelle. Spark SQL peut être intégré aux programmes généraux de Spark et MLlib natifs, afin de permettre l’interactivité entre différents modules Spark.
Spark SQL fournit des abstractions DataFrame dans différents langages de programmation, tels que Python, Java et Scala, afin de travailler avec des ensembles de données structurés. Il peut également lire et écrire des données dans divers formats structurés, notamment JSON, Hive Tables et Parquet. En outre, Spark SQL permet d’interroger les données en utilisant SQL dans le programme Spark ou en utilisant des outils externes, par exemple, en se connectant à Spark SQL à l’aide de connecteurs de base de données standard (JDBC / ODBC).
2.5.3.4 Apache Drill
Apache Drill est l’une des versions les plus populaires de la structure logicielle open source du système Dremel de Google. Il s’agit d’un moteur de requête SQL sans schéma pour MapReduce, NoSQL et le stockage en nuage. Drill suit une architecture distribuée sans partage qui facilite la montée en charge incrémentielle avec du matériel à faible coût, afin de répondre aux demandes croissantes en matière de concurrence des utilisateurs et de réponses aux requêtes.
Le framework est assez populaire, en raison de sa connectivité à une variété de bases de données et de systèmes de fichiers NoSQL, notamment HBase, MongoDB, MapR- DB, HDFS, Swift, Amazon S3, Tableau, NAS, Azure Blob Storage, Google Cloud Storage et fichiers locaux.
2.6 Débuter avec Python et R
Dans cette section, nous allons commencer avec les langages de programmation open source les plus courants dans le monde du Big Data. Nous allons vous montrer comment démarrer avec Python et R sur une machine Windows et une machine macOS.
2.6.1 Python sur macOS
macOS X, High Sierra propose une version préchargée de Python 2.7. Si vous avez macOS X, vous n’aurez rien à installer ni à configurer pour utiliser Python 2. Si vous souhaitez utiliser Python3, suivez ces instructions.
Avant d’installer Python, vous devez installer GCC:
Vous pouvez obtenir GCC en téléchargeant XCode ( https://developer.apple.com/xcode/ ).
Les plus petits outils de ligne de commande, ou le paquet encore plus petit OSX-GCC-Installer, peuvent être téléchargés.
Si vous avez déjà installé XCode, n’installez pas OSX-GCC-Installer . En combinaison, le logiciel peut causer des problèmes difficiles à diagnostiquer. Si vous effectuez une nouvelle installation de XCode, vous devrez également ajouter les outils de ligne de commande en exécutant xcode -select –install sur le terminal.
Bien que macOS X soit livré avec un grand nombre d’utilitaires UNIX, ceux qui connaissent bien les systèmes Linux remarqueront la disparition d’un composant clé : un gestionnaire de paquets. Homebrew comble ce vide. Pour installer Homebrew, ouvrez un terminal et exécutez la commande suivante :
$ ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)”
Une fois Homebrew installé, insérez le répertoire Homebrew en haut de la variable d’environnement PATH. Vous pouvez le faire en ajoutant la ligne suivante au bas de votre fichier ~ /.profile . Il est important de noter que différents shells ont leurs propres fichiers de profil bash. Assurez-vous que vous choisissez le bon :
export PATH = / usr / local / bin: / usr / local / sbin : $ PATH
Maintenant, nous pouvons installer Python 3, comme suit :
$ brasser installer python
$ python3
Nous allons également lancer l’interpréteur Python 3 installé par Homebrew. Pour vérifier la version Python, nous pouvons exécuter les commandes suivantes :
$ python –version
Python 3.6.4 # Succès!
2.6.2 Python sous Windows
Python n’est pas livré pré-emballé avec Windows, mais cela ne signifie pas que les utilisateurs de Windows ne trouveront pas ce langage de programmation flexible utile. C’est assez simple d’installer Python sous Windows.
Nous pouvons installer Python à l’aide du programme d’installation. Téléchargez le programme d’installation et suivez les instructions à l’écran.
Sur le premier écran, activez l’option Add Python 3.6 to PATH, puis cliquez sur Install Now:
Une fois le message réussi, passez à l’étape suivante et configurez les variables système.
Appuyez sur Start, accédez aux paramètres système Advanced, puis sélectionnez l’option View advanced system settings. Dans la fenêtre System Properties qui s’ouvre, sous l’onglet Advanced, cliquez sur le bouton Environment Variables :
Après avoir cliqué sur Environment Variables, entrez le chemin, comme indiqué dans la capture d’écran suivante :
Ouvrez une nouvelle invite de commande (les variables d’environnement s’actualisent à chaque nouvelle invite que vous ouvrez) et tapez python3 –version :
C: \ Users \ Sureshhardiya \ python3 –version
Python 3.6.1
2.6.3 R sur macOS
Pour installer R sur macOS X, suivez ces instructions :
- Allez sur www.r-project.org et cliquez sur le lien de download R sur la page, Getting Started.
- Sélectionnez un emplacement CRAN et cliquez sur le lien correspondant.
- Cliquez sur le lien Download R for (Mac) OS X.
- Cliquez sur le fichier contenant la dernière version de R, sous Files.
- Enregistrez le fichier .pkg , double-cliquez dessus pour l’ouvrir et suivez les instructions d’installation.
- Maintenant que R est installé, vérifiez l’installation en vérifiant la version, comme suit :
2.6.4 R sous Windows
L’installation de R sur Windows est un processus très simple. Suivez ces étapes pour installer R :
- Allez sur www.r-project.org et cliquez sur le lien de téléchargement sous Getting Started.
- Vous pouvez sélectionner un emplacement CRAN et cliquer sur le lien correspondant.
- Ensuite, cliquez sur le lien Download R for Windows en haut de la page.
- Vous êtes maintenant prêt à installer R sur le système. Cliquez sur le lien Install R for the first time en haut de la page.
- Cliquez sur Download R for Windows et enregistrez le fichier exécutable à l’emplacement de votre choix. Exécutez le fichier .exe et suivez les instructions d’installation.
- Maintenant, R devrait être installé sur votre ordinateur.
2.7 Résumé
Dans ce chapitre, nous avons discuté de divers aspects théoriques de la gestion des mégadonnées. De plus, nous vous avons expliqué différents services de gestion des données, y compris le nettoyage et l’intégration des données. Il existe également différents modèles de stockage et modèles de données, que nous avons abordés brièvement dans ce chapitre. Enfin, dans ce chapitre, nous avons expliqué les différents modèles de programmation, et comment démarrer avec les langages de programmation Python et R. Dans le chapitre suivant, vous en apprendrez plus sur les différents types de modèles de données et sur les opérations structurées, non structurées et exécutées sur eux.
3 Définir des modèles de données
Ce chapitre guide le lecteur à travers diverses structures de données. Les principaux types de structures sont des données structurées, semi-structurées et non structurées. Nous appliquerons également des techniques de modélisation à ces types de jeux de données. En outre, les lecteurs découvriront diverses opérations sur le modèle de données et diverses contraintes liées au modèle de données. De plus, le chapitre donne une brève introduction à une approche unifiée de la modélisation et de la gestion de données. Nous allons discuter les suivants sujets :
- Identifier différentes structures de modèle de données, y compris des données structurées et non structurées
- Reconnaissance de différentes opérations de modèle de données, y compris la sélection, la projection, l’union et la jointure
- Comprendre les différentes contraintes du modèle de données et expliquer pourquoi elles sont utilisées pour spécifier la sémantique des données
- Une approche unifiée de la modélisation et de la gestion des données
3.1 Structures de modèle de données
Modèles de données traitent des caractéristiques données variété « data variety » des données importantes. Les modèles de données décrivent les caractéristiques des données. Il existe deux sources principales de données :
- Données structurées
- Données non structurées
3.1.1 Données structurées
Les données structurées se rapportent à des données ayant une longueur et un format définis. Certains exemples courants de données structurées incluent les nombres, les dates et les groupes de mots et les nombres, appelés chaînes. En général, les données structurées suivent un schéma semblable à celui de la figure suivante. Généralement, les données ont des colonnes et des lignes prédéfinies. Certaines des colonnes de données peuvent être manquantes, mais elles restent classées en tant que données structurées :
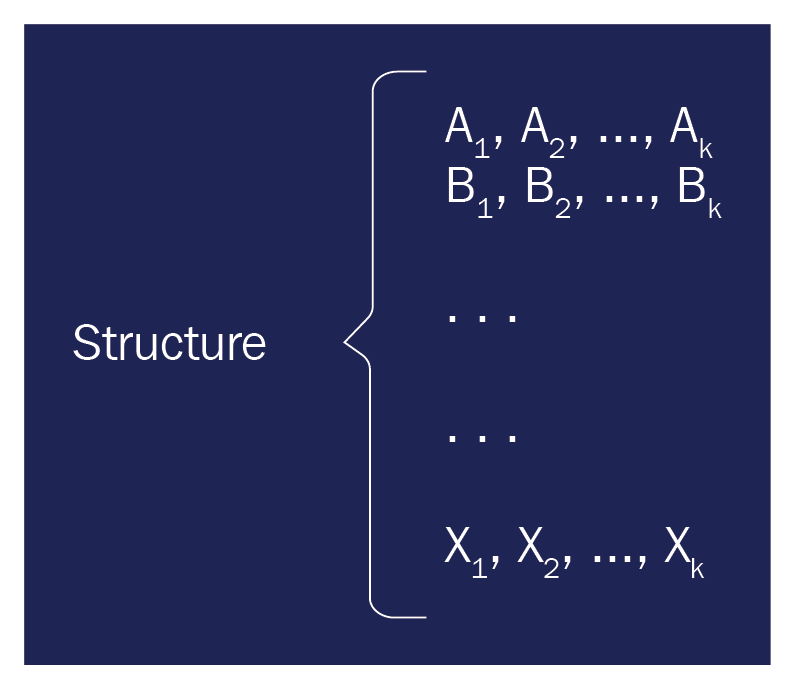
Comme le montre la figure suivante, la plupart des données structurées peuvent être classées en données générées par ordinateur ou générées par l’homme. Les données structurées générées par ordinateur comprennent les données des capteurs, les données du journal Web, les données financières et les données des points de vente. Les données générées par l’homme incluent les activités et événements liés aux médias sociaux :
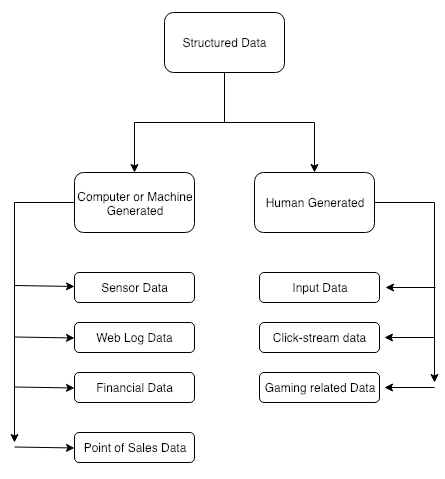
Les jeux de données de capteurs sont générés par des capteurs. Certains d’entre eux comprennent les étiquettes d’identification par radiofréquence, les compteurs intelligents, les dispositifs médicaux, les capteurs de surveillance intelligente et les données du système de positionnement global (GPS). L’extrait suivant montre un exemple de valeur de capteur comprenant des identifiants de position, un identifiant de voyage, une latitude, une longitude et un horodatage : valeurs séparées par des virgules (CSV) :
“pos_id”,”trip_id”,”latitude”,”longitude”,”altitude”,”timestamp”
“1”,”3″,”4703.7815″,”1527.4713″,”359.9″,”2017-01-19 16:19:04.742113″
“2”,”3″,”4703.7815″,”1527.4714″,”359.9″,”2017-01-19 16:19:05.741890″
“3”,”3″,”4703.7816″,”1527.4716″,”360.3″,”2017-01-19 16:19:06.738842″
“4”,”3″,”4703.7814″,”1527.4718″,”360.5″,”2017-01-19 16:19:07.744001″
“5”,”3″,”4703.7814″,”1527.4720″,”360.8″,”2017-01-19 16:19:08.746266″
“6”,”3″,”4703.7813″,”1527.4723″,”361.3″,”2017-01-19 16:19:09.742153″
“7”,”3″,”4703.7812″,”1527.4724″,”361.8″,”2017-01-19 16:19:10.751257″
“8”,”3″,”4703.7812″,”1527.4726″,”362.2″,”2017-01-19 16:19:11.753595″
“9”,”3″,”4703.7816″,”1527.4732″,”362.9″,”2017-01-19 16:19:12.751208″
“10”,”3″,”4703.7818″,”1527.4736″,”363.9″,”2017-01-19 16:19:13.741670″
“11”,”3″,”4703.7817″,”1527.4737″,”364.6″,”2017-01-19 16:19:14.740717″
“12”,”3″,”4703.7817″,”1527.4738″,”365.2″,”2017-01-19 16:19:15.739440″
“13”,”3″,”4703.7817″,”1527.4739″,”365.4″,”2017-01-19 16:19:16.743568″
“14”,”3″,”4703.7818″,”1527.4741″,”365.7″,”2017-01-19 16:19:17.743619″
“15”,”3″,”4703.7819″,”1527.4741″,”365.9″,”2017-01-19 16:19:18.744670″
“16”,”3″,”4703.7819″,”1527.4741″,”366.2″,”2017-01-19 16:19:19.745262″
“17”,”3″,”4703.7819″,”1527.4740″,”366.3″,”2017-01-19 16:19:20.747088″
“18”,”3″,”4703.7819″,”1527.4739″,”366.3″,”2017-01-19 16:19:21.745070″
“19”,”3″,”4703.7819″,”1527.4740″,”366.3″,”2017-01-19 16:19:22.752267″
“20”,”3″,”4703.7820″,”1527.4740″,”366.3″,”2017-01-19 16:19:23.752970″
“21”,”3″,”4703.7820″,”1527.4741″,”366.3″,”2017-01-19 16:19:24.753518″
“22”,”3″,”4703.7820″,”1527.4739″,”366.2″,”2017-01-19 16:19:25.745795″
“23”,”3″,”4703.7819″,”1527.4737″,”366.1″,”2017-01-19 16:19:26.746165″
“24”,”3″,”4703.7818″,”1527.4735″,”366.0″,”2017-01-19 16:19:27.744291″
“25”,”3″,”4703.7818″,”1527.4734″,”365.8″,”2017-01-19 16:19:28.745326″
“26”,”3″,”4703.7818″,”1527.4733″,”365.7″,”2017-01-19 16:19:29.744088″
“27”,”3″,”4703.7817″,”1527.4732″,”365.6″,”2017-01-19 16:19:30.743613″
“28”,”3″,”4703.7819″,”1527.4735″,”365.6″,”2017-01-19 16:19:31.750983″
“29”,”3″,”4703.7822″,”1527.4739″,”365.6″,”2017-01-19 16:19:32.750368″
“30”,”3″,”4703.7824″,”1527.4741″,”365.6″,”2017-01-19 16:19:33.762958″
“31”,”3″,”4703.7825″,”1527.4743″,”365.7″,”2017-01-19 16:19:34.756349″
“32”,”3″,”4703.7826″,”1527.4746″,”365.8″,”2017-01-19 16:19:35.754711″
…………………………………………………………..
Bloc de code : 3.1 Exemple de données de capteurs GPS où les colonnes représentent l’identificateur de position, l’identificateur de trajet, la latitude, la longitude, l’altitude et l’horodatage, respectivement.
Les données générées par l’homme structurées peuvent être des données d’entrée, des données de flux de clics ou des données relatives aux jeux. Les données d’entrée peuvent être n’importe quel élément de données qu’un humain pourrait alimenter dans un ordinateur, tel qu’un nom, un téléphone, son âge, une adresse e-mail, un revenu, des adresses physiques ou des réponses à une enquête non libre. Ces données peuvent être utiles pour comprendre le comportement de base des clients.
Les données en flux de clic peuvent générer beaucoup de données lorsque les utilisateurs naviguent sur des sites Web. Ces données peuvent être enregistrées puis utilisées pour analyser et déterminer le comportement du client et les habitudes d’achat. Ces données peuvent être utilisées pour apprendre comment un utilisateur se comporte sur le site Web, découvrir le processus suivi par l’utilisateur sur le site Web et découvrir une faille dans le processus.
Les données relatives au jeu incluent les activités des utilisateurs pendant qu’ils jouent à des jeux. Chaque année, de plus en plus de personnes utilisent Internet pour jouer à des jeux sur diverses plates-formes, notamment des ordinateurs et des consoles. Les utilisateurs naviguent sur le Web, envoient des courriels, discutent et diffusent des vidéos haute définition.
Ces données peuvent être utiles pour savoir comment les utilisateurs finaux utilisent un portefeuille de jeux. La figure suivante montre un exemple de l’apparence des données liées au jeu :

Exemple de données structurées liées au jeu
Structuré est un format réglementé permettant de présenter des informations sur une page et de classer le contenu de la page. Ces jeux de données sont de longueur finie et dans un format régulier. L’une des utilisations réelles d’un jeu de données structuré est la manière dont Google utilise les données structurées trouvées sur le Web pour comprendre le contenu de la page, ainsi que pour recueillir des informations sur le Web et le monde en général. Par exemple, voici un extrait structuré JSON-LD pouvant apparaître sur la page de contact de la société Unlimited Ball Bearings, décrivant leurs informations de contact :
<script type=”application/ld+json”>
{
“@context”: “http://schema.org”,
“@type”: “Organization”,
“url”: “http://www.example.com”,
“name”: “Unlimited Ball Bearings Corp.”,
“contactPoint”: {
“@type”: “ContactPoint”,
“telephone”: “+1-401-555-1212”,
“contactType”: “Customer service”
}
}
</script>
3.1.2 Données non structurées
Tous les documents, y compris la documentation clinique, les e-mails personnels, les notes de progression et les rapports de gestion, composés principalement de texte non structuré avec une structure ou des métadonnées prédéfinies décrivant le contenu du document peuvent être classés en tant que données non structurées. Les données non structurées sont différentes des données structurées en ce sens que leur structure est imprévisible.
Les exemples de données non structurées comprennent les documents, les courriels, les blogs, les rapports, les procès-verbaux, les notes, les images numériques, les vidéos et les images satellites. Il intègre également certaines données produites par des machines ou des capteurs. En fait, les données non structurées représentent la majorité des données qui se trouvent dans les locaux d’une entreprise, ainsi qu’à l’extérieur de toute entreprise, qu’il s’agisse de sources privées ou publiques en ligne, telles que LinkedIn, Twitter, Snapchat, Instagram, Dribble, YouTube et Facebook.
Parfois, des balises de métadonnées sont attachées pour donner des informations et un contexte sur le contenu des données. Les données avec méta-informations sont appelées semi-structurées. La ligne de démarcation entre données non structurées et données semi-structurées n’est pas absolue, bien que certains consultants en gestion de données contestent le fait que toutes les données, même celles non structurées, présentent un certain degré de structure :
Différents types de sources de données non structurées
3.1.3 Sources de données non structurées
Les données non structurées peuvent être localisées partout. En fait, la plupart des individus et des organisations exploitent et stockent des données non structurées tout au long de leur vie. Non structuré peut être généré par une machine ou par un humain. La plupart des données non structurées générées par machine sont des images satellite, des données scientifiques, des photographies ou des données radar :
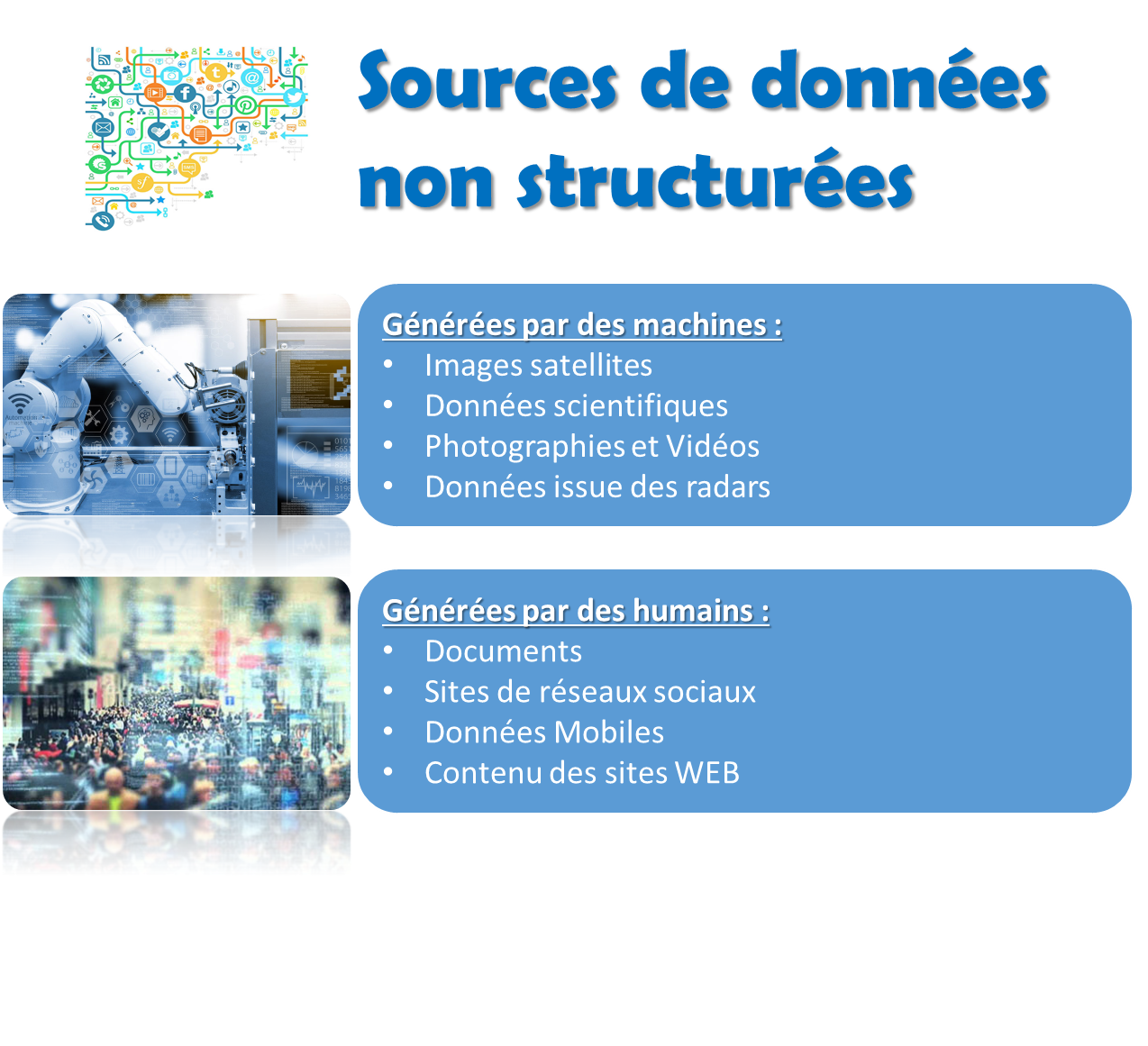
Différentes sources de jeux de données non structurés
Comme indiqué dans le diagramme précédent, les données non structurées peuvent également être classées comme générées par machine ou par humain. La plupart des jeux de données générés par machine sont des images satellite, des données scientifiques, des photographies et des vidéos, ou des données radar ou sonar. La plupart des jeux de données non structurés générés par l’homme sont des documents, des données de médias sociaux, des données mobiles et le contenu de sites Web.
3.1.4 Comparer des données structurées et non structurées
Comparons les données structurées et non structurées en ce qui concerne leurs caractéristiques, leur stockage, leur génération et les types d’applications où elles peuvent être trouvées :
| Données structurées | Données non structurées | |
| Caractéristiques |
|
|
| Réside dans |
|
|
| Généré par | Humains ou machines | Humains ou machines |
| Applications typiques |
|
|
| Exemples |
|
|
Différence entre données structurées et non structurées
3.2 Opérations de données
Le deuxième composant d’un modèle de données est un ensemble d’opérations pouvant être effectuées sur les données. Dans ce module, nous discuterons des opérations sans prendre en compte l’aspect sans taille. Désormais, les opérations spécifient les méthodes pour manipuler les données. Étant donné que différents modèles de données sont généralement associés à différentes structures, les opérations correspondantes seront différentes. Cependant, certains types d’opérations sont généralement effectués sur tous les modèles de données. Nous allons en décrire quelques-uns ici. Une opération commune extrait une partie d’une collection en fonction de la condition.
3.2.1 Sous ensemble
Souvent, lorsque nous travaillons avec un énorme ensemble de données, nous n’intervenons que dans une petite partie de votre analyse. Alors, comment pouvons-nous trier toutes les variables et observations superflues et extraire uniquement celles dont nous avons besoin ? Ce processus est présenté en tant que sous- ensemble :
Tableau montrant différents types de cancers [1]
Dans l’exemple présenté à la figure précédente, nous avons un ensemble d’enregistrements dans lesquels nous recherchons un sous-ensemble satisfaisant la condition et le cancer pour les deux sexes. En fonction du contexte, cela s’appelle également sélection ou filtrage. Si nous devons rendre la liste des enregistrements de cancer chez les hommes et les femmes, nous pouvons procéder comme suit :
Tableau de sous – répartition illustré à la figure 3.7 où le cancer a été détecté chez les deux sexes
3.2.2 Union
L’hypothèse sous-jacente au fonctionnement de l’union est que les deux collections impliquées ont la même structure. En d’autres termes, si une collection a quatre champs et une autre 14, ou si l’une a quatre champs sur les personnes et leur date de naissance et que l’autre a quatre champs sur les pays et leurs capitales, ils ne peuvent pas être combinés par une union.
Par exemple, supposons que les informations d’achat du client suivantes soient stockées dans trois tables, séparées par mois. Les noms des tableaux sont mai 2016, juin 2016 et juillet 2016. Une union de ces tables crée la table unique suivante qui contient toutes les lignes de toutes les tables :

Trois tables avec des enregistrements similaires
Si nous effectuons l’opération d’union sur ces trois tables, nous obtenons une table combinée :
Union de trois tables à combiner avec des opérations syndicales
3.2.3 Projection
Une autre opération courante consiste à récupérer une partie spécifiée d’une structure. Dans ce cas, nous spécifions que nous nous intéressons uniquement aux trois premiers champs d’une collection d’enregistrements. Mais cela produit une nouvelle collection d’enregistrements qui ne contient que ces champs.
Cette opération, comme avant, a beaucoup de noms. Le nom le plus courant est projection :
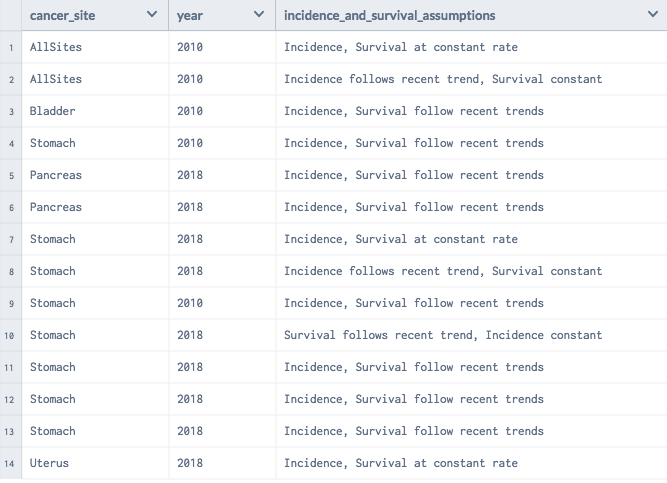
Projection de la figure
3.2.4 Jointure
Le second type de combinaison, appelé jointure, peut être utilisé lorsque les deux collections ont un contenu de données différent mais comportent des éléments communs. Imaginons que nous ayons deux tables différentes contenant des informations sur les mêmes employés. Il s’agit de la première table contenant des informations d’identification, telles que le nom, le prénom et la date :
| 101 | John | Forgeron | 10-12-2018 |
| 102 | Suresh Kumar | Mukhiya | 10-13-2018 |
| 103 | Anju | Mukhiya | 10-14-2018 |
| 104 | Dibya | Davison | 10-15-2018 |
Ceci est la deuxième table, qui contient des informations supplémentaires sur le même employé. La table contient trois champs : identifiant, département et salaire :
| 101 | Système d’Information | 70000 $ |
| 102 | Compte | 50000 $ |
| 103 | Ingénierie | 100000 $ |
| 104 | Ressources humaines | 788090 $ |
La jonction de ces deux tables devrait produire une troisième table avec des données combinées. Cela aide également à éliminer les doublons :
| 101 | John | Forgeron | 10-12-2018 | Système d’Information | 70000 $ |
| 102 | Suresh Kumar | Mukhiya | 10-13-2018 | Compte | 50000 $ |
| 103 | Anju | Mukhiya | 10-14-2018 | Ingénierie | 100000 $ |
| 104 | Dibya | Davison | 10-15-2018 | Ressources humaines | 788090 $ |
3.3 Contraintes de données
Outre la structure de modèle de données, les opérations de modèle de données et la contrainte de modèle de données constituent le troisième composant d’un modèle de données. Les contraintes sont les instructions logiques que doivent contenir les données. Il existe différents types de contraintes. Différents modèles de données ont différentes manières d’exprimer des contraintes.
3.3.1 Types de contraintes
Il existe différents types de contraintes :
- Contraintes de valeur
- Contraintes d’unicité
- Contraintes de cardinalité
- Contraintes de type
- Contraintes de domaine
- Contraintes structurelles
3.3.1.1 Contraintes de valeur
Une contrainte de valeur est une déclaration logique concernant les valeurs de données. Par exemple, supposons que la valeur de l’entité (par exemple, l’âge) ne puisse être négative.
3.3.1.2 Contraintes d’unicité
C’est l’une des contraintes les plus importantes. Cette contrainte nous permet d’identifier de manière unique chaque ligne du tableau. Par exemple, la plupart des sites Web n’autorisent pas plusieurs comptes pour la même personne. Ceci peut être imposé par des contraintes d’unicité. Par exemple, en rendant le courrier électronique unique. Il est possible d’avoir plus d’une colonne unique dans une table.
3.3.1.3 Contraintes de cardinalité
Il est facile de voir que l’application de ces contraintes nous oblige à compter le nombre de titres et à vérifier qu’il en est un. On peut maintenant généraliser ceci pour compter le nombre de valeurs associées à chaque objet et vérifier s’il se situe entre une limite supérieure et une limite inférieure. C’est ce qu’on appelle la contrainte de cardinalité.
3.3.1.4 Contraintes de type
Un type de contrainte de valeur différent peut être appliqué en limitant le type de données autorisé dans un champ. Si nous n’avons pas une telle contrainte, nous pouvons mettre n’importe quel type de données sur le terrain. Par exemple, vous pouvez avoir -99 comme valeur du nom de famille d’une personne – bien entendu, ce serait une erreur. Pour éviter que cela ne se produise, nous pouvons imposer que le type du nom de famille soit une chaîne alphabétique non numérique. L’exemple précédent montre une expression logique pour cette contrainte.
Une contrainte de type est un type spécial de contrainte de domaine. Le domaine d’une propriété de données ou d’un attribut est l’ensemble possible de valeurs autorisées pour cet attribut. Par exemple, les valeurs possibles pour la partie jour du champ de date peuvent être comprises entre 1 et 31, tandis qu’un mois peut avoir la valeur entre 1 et 12 ou une valeur comprise entre janvier, février et décembre.
3.3.1.5 Contraintes de domaine
Les contraintes de domaine sont des types de données définis par l’utilisateur, et nous pouvons les définir comme suit:
Domain Constraint = data type + Constraints (NOT NULL / UNIQUE / PRIMARY KEY / FOREIGN KEY / CHECK / DEFAULT).
Par exemple :
- La valeur de jour possible peut être comprise entre 1 et 31
- La valeur du mois possible peut être comprise entre janvier, février et décembre
- La note peut être comprise entre A-F dans n’importe quel système de notation universitaire
3.3.1.6 Contraintes structurelles
Une contrainte structurelle impose des restrictions sur la structure des données plutôt que sur les valeurs de données elles-mêmes. Nous n’avons imposé aucune restriction quant au nombre de lignes ou de colonnes, mais seulement qu’elles doivent être identiques.
Par exemple, nous pouvons limiter la matrice à la quadrature ; c’est-à-dire que le nombre de lignes doit être égal au nombre de colonnes.
3.4 Une approche unifiée de la modélisation et de la gestion des données Big Data
Comme mentionné, les mégadonnées peuvent être non structurées ou semi-structurées, avec un niveau d’hétérogénéité élevé. Les informations exprimées dans ces ensembles de données constituent un facteur essentiel du processus d’appui à la prise de décision. C’est l’une des raisons pour lesquelles des données hétérogènes doivent être intégrées et analysées afin de présenter une vue unique de l’information pour de nombreux types d’applications. Cette section aborde le problème de la modélisation et de l’intégration de données hétérogènes provenant de multiples sources hétérogènes dans le contexte des systèmes de cyber-infrastructure et des plates-formes de données volumineuses.
Le développement des mégadonnées transforme les stratégies de planification d’une réflexion à long terme en une réflexion à court terme, car la gestion de la ville peut être rendue plus efficace. Les systèmes de soins de santé sont également reconstruits selon le paradigme du Big Data, car les données sont générées à partir de sources telles que les systèmes de dossiers médicaux électroniques, les dossiers de santé mobilisés, les dossiers de santé personnels, les moniteurs de soins de santé mobiles, le séquençage génétique et l’analyse prédictive, ainsi qu’un vaste réseau de capteurs biomédicaux et appareils intelligents pouvant atteindre 1 000 pétaoctets. La motivation de cette section découle de la nécessité d’une approche unifiée du traitement des données dans les systèmes de cyber-infrastructure à grande échelle, car les caractéristiques des systèmes cyber-physiques à échelle non triviale présentent une hétérogénéité significative. Voici quelques caractéristiques importantes d’une approche unifiée de la modélisation et de la gestion des données Big Data :
- La création de modèles de données, l’analyse de modèles de données et le développement de nouvelles applications et services basés sur les nouveaux modèles. Comme indiqué au chapitre 1 , Introduction aux mégadonnées et à la gestion des données , les principales caractéristiques des mégadonnées sont le volume, la variété, la vitesse, la valeur, la volatilité et la véracité.
- L’analyse de données volumineuses consiste à examiner des ensembles volumineux de données et variés afin de découvrir des modèles cachés, les tendances du marché et les préférences des clients pouvant être utiles aux entreprises pour la veille stratégique.
- Les modèles Big Data représentent les éléments constitutifs des applications Big Data. Le chapitre 4, Catégorisation des modèles de données, classe différents types de modèles de données.
- S’agissant de la représentation et de l’agrégation de données volumineuses, l’aspect le plus important est de savoir comment représenter des données relationnelles agrégées et non relationnelles dans les moteurs de stockage. En ce qui concerne la gestion uniforme des données, une approche contextuelle nécessite un modèle approprié pour agréger, organiser sémantiquement et accéder à de grandes quantités de données dans différents formats, collectées à partir de capteurs ou d’utilisateurs.
- Apache Kafka ( https://kafka.apache.org/ ) est une solution proposant une approche unifiée du traitement hors ligne et en ligne en fournissant un mécanisme de chargement parallèle dans les systèmes Hadoop, ainsi que la possibilité de répartir la consommation en temps réel sur un groupe de machines. En plus de cela, Apache Kafka fournit une solution de publication / abonnement en temps réel.
- Afin de surmonter l’hétérogénéité des données sur les plates-formes Big Data et de fournir une vue unifiée et unique des données hétérogènes, une couche au-dessus des différents systèmes de gestion de données, avec des fonctions d’agrégation et d’intégration, doit être créée.
3.5 Résumé
À l’heure actuelle, nous connaissons très bien les différentes structures de données, y compris les données structurées, semi-structurées et non structurées. Nous avons examiné différentes structures de modèle de données et opérations de données effectuées sur le modèle. Diverses opérations peuvent être effectuées sur le modèle de données, mais avec chaque modèle vient un ensemble de contraintes. Enfin, nous avons découvert une approche unifiée de la modélisation et de la gestion des mégadonnées.
Dans le chapitre suivant, nous allons explorer différentes catégories du modèle de données et en apprendre davantage sur les niveaux de modélisation des données. De plus, nous explorerons des modèles de données de relation et d’autres modèles de données.
4 Catégories de modèles de données
Il est très important de comprendre le flux de données dans toute application logicielle. Le flux de données est un processus complexe dans un système logiciel. La modélisation est une partie importante de la compréhension du diagramme d’un système logiciel complexe et de la manière dont le flux de données dans le système logiciel est représenté à l’aide de texte et de symboles. Ce processus est généralement appelé modélisation de données . Les diagrammes générés par la modélisation des données peuvent devenir un modèle pour le développement de nouveaux logiciels ou la reconfiguration de logiciels existants. Les modèles de données et de stockage sont des composants de base de tout écosystème de mégadonnées.
Les modèles de stockage incluent l’aspect physique du stockage de données, tandis que les modèles de données stockent les représentations logiques et les structures de traitement et de gestion des données. Ainsi, comprendre le stockage des données et les modèles de stockage joue un rôle essentiel pour se familiariser avec les écosystèmes de Big Data. Dans ce chapitre, nous allons explorer divers aspects de la modélisation de données volumineuses, ainsi que des modèles de stockage.
- Les principaux sujets que nous aborderons dans ce chapitre sont les suivants :
- Explorer les différents niveaux de modélisation des données
- Découverte des différents types de modèle de données
- Présentation du modèle de données relationnel des fichiers CSV (valeurs séparées par des virgules)
- Comprendre le modèle de données de matrice d’une image
4.1 Niveaux de modélisation des données
Une entreprise est étroitement liée aux personnes, aux lieux, aux animations ou aux choses et à leurs intérêts. Un modèle de données fournit une représentation visuelle de ces aspects. En plus de fournir des repères visuels, un modèle de données sert de guide de communication entre les parties prenantes techniques et non techniques, telles que les personnes. Dans la mesure où un modèle de données est composé de symboles illustrant les concepts à communiquer et à convenir, il est souvent appelé schéma directeur des données. Ces plans sont construits à plusieurs niveaux et détails distincts, allant des exigences de haut niveau aux exigences de base en matière de configuration architecturale, en passant par les spécifications de conception détaillées. Ces plans (ou modèles) peuvent être construits à différents niveaux de conception, appelés niveaux de modélisation des données. Il existe trois niveaux de modélisation de données : la modélisation conceptuelle, la modélisation logique et la modélisation physique.
Le modèle de données conceptuel (MCD) se situe au sommet, fournissant une vue satellite de la solution métier. En outre, le CDM donne un contexte et une portée au modèle de données logique (LDM), qui produit une solution métier détaillée. Le LDM est le point de départ pour appliquer l’influence de la technologie dans le modèle de données physique. Le diagramme suivant illustre les différents niveaux de modélisation des données, ainsi que leurs objectifs :
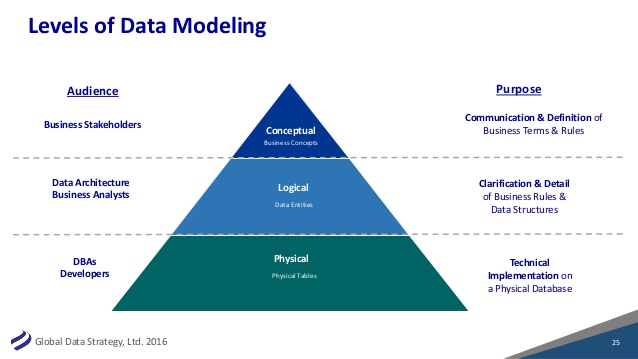
Différents niveaux de modélisation des données
4.1.1 Modélisation conceptuelle des données
La modélisation conceptuelle de données est la première étape de l’approche descendante, dont l’objectif est de capturer une vue satellite des besoins opérationnels d’une organisation. Comme l’ont prétendu de nombreux auteurs, la modélisation conceptuelle de données a pour objectif principal de donner une vue d’ensemble et de comprendre la portée des exigences de haut niveau du projet d’une organisation. Il convient de noter que les MCD sont créés en tant que précurseur d’un MLD ou en tant qu’alternative.
- La modélisation conceptuelle de données tente de répondre aux questions suivantes :
- Quels problèmes sont liés à l’entreprise et nécessitent des solutions immédiates ?
- Quels sont les concepts de base de ces problèmes ?
- Comment ces problèmes sont-ils liés les uns aux autres ?
- Y a-t-il une portée de l’effort ? Quelle est la portée par rapport aux efforts déployés ?
Le processus de modélisation des données conceptuelles donne lieu à un MDP. Le modèle créé illustre les concepts clés requis pour le développement d’une application particulière. En outre, le modèle fournit un bref aperçu des efforts requis par l’entreprise pour construire le logiciel :
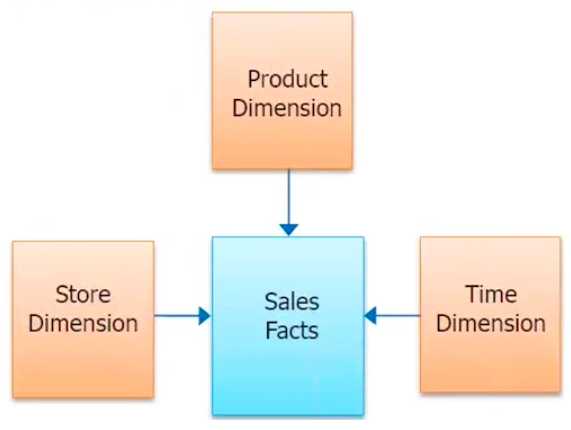
MDP pour un supermarché, avec mesures des chiffres de vente
Le diagramme précédent montre un modèle conceptuel pour un supermarché qui souhaite mesurer ses ventes. Comme indiqué dans le modèle, le supermarché a l’intention de conserver la dimension magasin, la dimension produit et la dimension temporelle afin de générer des données commerciales. Le diagramme précédent montre clairement que l’entreprise souhaite mesurer les ventes par produit, par dimension et par date. La modélisation conceptuelle des données permet de déterminer la portée et l’orientation de l’application considérée. En outre, il est utile de créer une analyse préliminaire et des définitions des termes clés. Le modèle conceptuel comprend les concepts les plus importants du projet et les exigences selon lesquelles chacun de ces concepts peut être défini et documenté. En résumé, le CDM explore les relations les plus importantes entre plusieurs entités. Par conséquent, ce type de modèle peut être appelé modèle de domaine .
4.1.2 Modélisation logique des données
Un LDM est utilisé comme étape initiale du modèle de données physique. Le LDM est constitué des structures détaillées d’un système. En outre, le LDM décrit les relations détaillées entre les structures. Un MLD peut être décrit comme détaillé s’il contient toutes les entités, attributs et groupes de clés essentiels, ainsi que les relations qu’ils entretiennent les uns avec les autres. Le LDM ne dépend pas des types de SGBD utilisés. Ainsi, les modèles doivent avoir la même apparence quel que soit le type de système de SGBD, tel que MongoDB, Oracle, etc.
4.1.2.1 Avantages de la construction de MLD
La liste suivante décrit les principaux avantages de la construction de MLD:
- Il facilite la compréhension des éléments de données d’entreprise et de leurs exigences.
- Il fournit une base pour la conception de la base de données
- Cela permet d’éviter la redondance des données et évite les incohérences entre les données et l’entreprise.
- Il favorise la réutilisation et le partage des données
- Il diminue les coûts de développement, de maintenance et de temps
- Il confirme un modèle de processus logique et aide à l’analyse d’impact
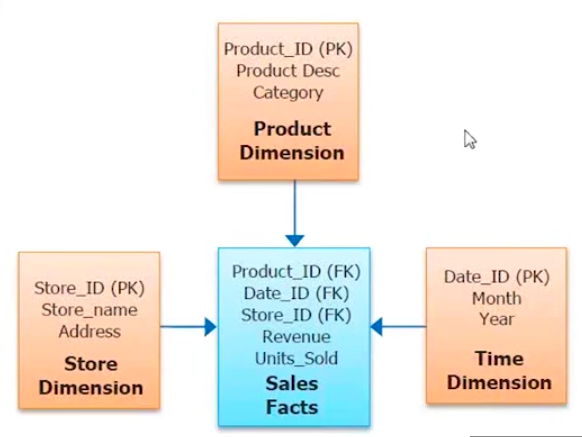
MLD du supermarché illustré précédemment
Le diagramme précédent montre le MLD du supermarché illustré à la figure précédente. À ce niveau de modélisation, nous essayons de répondre aux questions suivantes :
- À quoi devrait ressembler la collection ?
- Comment pouvons-nous sécuriser les informations ?
- Comment devrions-nous stocker les informations d’historique ?
- Comment pouvons-nous répondre aux questions des entreprises dans un délai plus court ?
- Quelle est la manière optimale de réaliser la fragmentation ?
Le LDM fournit une excellente cartographie, dans le cas de plusieurs technologies. Le LDM expliquera une perspective indépendante de la technologie, puis nous pourrons mapper cette perspective métier à chacune des différentes perspectives technologiques. La modélisation logique des données implique quatre étapes : remplir le MCD, normaliser et résumer le modèle, déterminer la forme la plus utile et enfin examiner et confirmer le modèle logique. Les fonctionnalités les plus courantes d’un modèle logique sont les suivantes :
- Toutes les entités et les relations entre les modèles sont données
- Tous les attributs sont spécifiés pour chaque entité
- La clé primaire est spécifiée pour chaque entité
- Les clés étrangères sont spécifiées
- La normalisation se produit à ce niveau
4.1.3 Modélisation physique des données
Un modèle de données physique illustre la manière dont les différents éléments seront construits, conformément aux exigences métiers fournies dans le LDM. Il donne une illustration visuelle de la structure physique d’une base de données réelle. Il peut également inclure des composants du LDM qui ont été refactorisés, afin d’optimiser la base de données et d’améliorer les performances de l’application. Dans le modèle de données physique, les objets sont définis au niveau du schéma. Ici, un schéma peut être défini comme un groupe d’objets liés dans une base de données. Pour résumer, un modèle peut être appelé modèle de données physique s’il contient toutes les structures de table, y compris les noms de colonne, les types de données de colonne, les clés primaires, les contraintes de colonne et la relation entre les tables. Une instance du modèle physique est visible dans le diagramme précédent.
4.1.4 Caractéristiques du modèle de données physique
Comme mentionné précédemment, un modèle de données physique montre la manière dont la base de données est construite, à l’aide du modèle. Dans cette section, vous découvrirez les différentes fonctionnalités d’un LDM. Certaines caractéristiques remarquables d’un modèle de données physique sont les suivantes :
- Le modèle représente toutes les tables et colonnes
- Le modèle physique contient toutes les clés étrangères utilisées pour reconnaître les relations entre les tables.
- Le modèle de données physique varie selon les SGBDR.
- Selon les besoins de l’utilisateur, une dénormalisation peut se produire dans ce modèle.
Une fois la modélisation des données logiques terminée, un diagramme de modèle de serveur contenant des tables, des colonnes, des clés et des relations au sein de la base de données devrait être généré. En outre, une documentation sur les commentaires des utilisateurs et sur la conception de la base de données devrait être produite. Le diagramme suivant montre le modèle de données physique du supermarché mentionné dans le diagramme précédent :

Modèle physique de données du supermarché de la figure 4.3
La conception d’un modèle de données physique respecte la technologie avec laquelle il sera implémenté et est optimisée en fonction des exigences de cette technologie. Certaines technologies d’implémentation courantes sont les suivantes :
- Bases de données relationnelles
- Le schéma XMS
- Données héritées
Le tableau suivant compare les différents types de modélisation et les ensembles de fonctionnalités inclus dans différents types de modélisation :
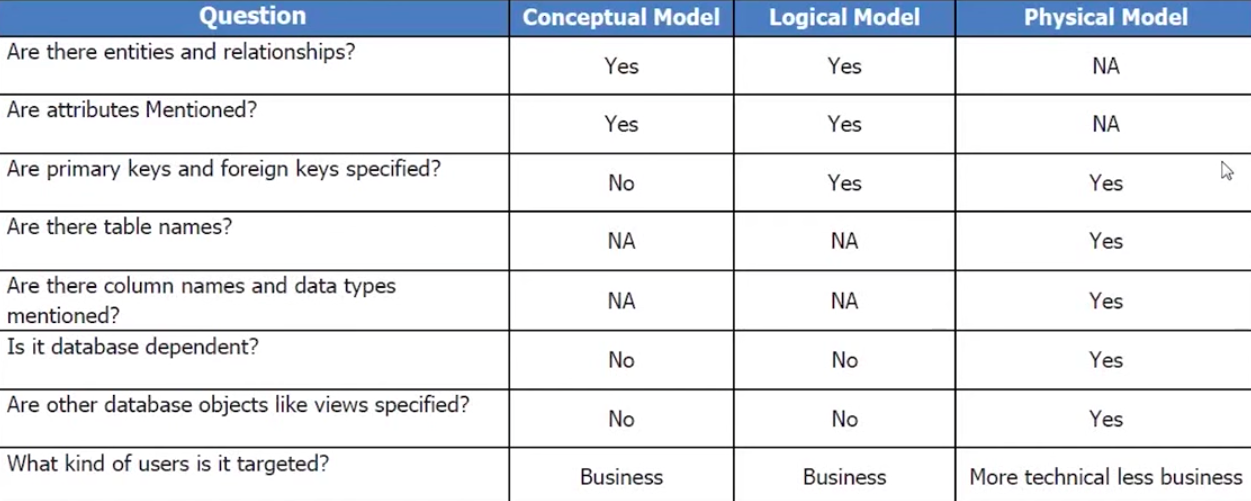
Tableau comparant différents types de modélisation
4.2 Types de modèle de données
Vous devez maintenant comprendre que les modèles de données sont très importants dans la construction d’une base de données réelle. La plupart des SGBD sont construits de manière structurelle. Ces modèles peuvent être classés en différents types, en fonction de leurs structures. Différents modèles s’appliquent aux différentes étapes du processus de conception de la base de données. Dans cette section, nous allons explorer certains des types de modèles de données les plus courants utilisés dans des scénarios métier réels.
4.2.1 Modèles de bases de données hiérarchiques
Un modèle hiérarchique utilise une structure arborescente pour représenter les données, avec un seul parent ou une racine dans chaque enregistrement. L’enregistrement correspond à une seule table, contenant des informations sur un sujet particulier, et est connecté à d’autres enregistrements via des liens. Un ordre spécifique est utilisé pour trier les enregistrements frères.
Le diagramme suivant illustre un modèle de base de données hiérarchique typique. Comme indiqué dans le diagramme suivant, chaque branche de la hiérarchie illustre un certain nombre d’enregistrements liés. Une relation dans une base de données hiérarchique est montrée par parent / enfant. Un utilisateur peut accéder aux données de ce modèle en commençant par la table racine et en descendant dans l’arborescence jusqu’aux données cibles. Bien que ce modèle stocke la structure sous forme d’arborescence, il est très important pour une personne de connaître la structure du modèle afin d’accéder aux données. Par exemple, pour accéder aux données de Labs, comme indiqué dans le diagramme suivant, un utilisateur doit comprendre l’intégralité du modèle :
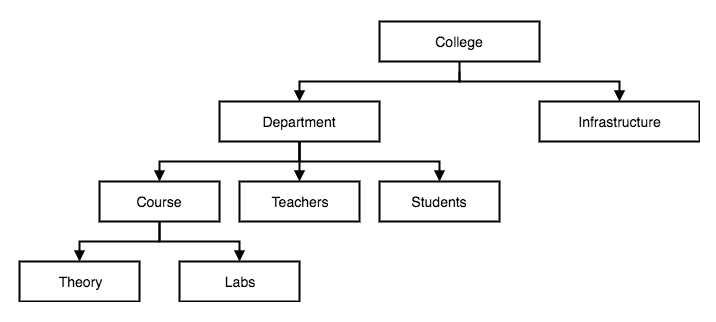
Modèle de base de données hiérarchique
4.2.2 Modèles relationnels
Les modèles relationnels trient les données dans des tables appelées relations. Les colonnes et les lignes constituent les relations. Chaque ligne contient une valeur unique, appelée un tuple. Chaque colonne contient une valeur, appelée attribut, de la même zone :
- Un domaine est constitué des attributs d’une relation
- Une clé primaire est un attribut spécifique ou une combinaison d’attributs
- Une clé primaire dans une autre table s’appelle une clé étrangère
- Un tuple inclut les données spécifiques d’une entité, telle qu’un employé particulier
- Le degré de la relation indique le nombre d’attributs ou de champs dans la relation
- La cardinalité est le nombre de tuples dans une relation
Un modèle relationnel est une méthode déclarative pouvant spécifier des données et des requêtes. Cela signifie que les utilisateurs indiquent directement quelles informations se trouvent dans la base de données et les informations dont ils ont besoin, et permettent au logiciel du système de gestion de base de données de définir les structures de données pour enregistrer les données et les méthodes de récupération pour répondre aux requêtes :

Exemple de modèle de base de données relationnelle
4.2.2.1 Avantages du modèle de données relationnel
Le modèle de données relationnel est très populaire et constitue un type commun de modèle de données utilisé dans l’écosystème de gestion de base de données. L’utilisation d’un modèle de données relationnel présente certains avantages importants :
- Le principal avantage de ce modèle est sa capacité à décrire des données dans un format simple.
- Le processus de gestion des enregistrements est simplifié par l’utilisation de certains attributs de clé appliqués pour extraire les données.
- La représentation de différents types de relation est possible avec ce modèle
4.2.3 Modèles de réseau
Le modèle de données réseau répond à certains des problèmes rencontrés avec les modèles de données hiérarchiques. Dans un modèle de données réseau, les données sont représentées en termes de nœuds et d’un ensemble de liens. Les deux termes de base à comprendre sont les suivants :
- Un nœud représente une collection d’enregistrements. Un enregistrement est analogue à une entité dans le modèle ER. Chaque nœud représentant un enregistrement est en fait un ensemble de champs ou d’attributs contenant une seule valeur de données.
- La relation entre un enregistrement et un autre est indiquée par des liens.
Un modèle de réseau utilise un diagramme de structure de données en tant que schéma. Les types de diagramme sont constitués de deux composants de base : des zones représentant des types d’enregistrement et des lignes représentant des liens. Le diagramme suivant montre la structure logique globale de la base de données.
Par exemple, un client doit être affecté à un agent, mais un agent sans client peut toujours être répertorié dans la base de données. Le diagramme suivant montre un exemple typique d’un modèle de réseau. Il existe un flux de données du vendor vers employee, customer et le product. En outre, la sales transaction extrait l’ensemble de données des trois enregistrements :
Exemple de modèle de réseau de données
4.2.4 Modèle de base de données orienté objet
Le modèle de données orienté objet est un modèle de données développé. Ce modèle peut stocker des fichiers audio, vidéo et graphiques. Celles-ci consistent en un élément de données et les méthodes qui constituent les instructions du SGBD. Il existe deux types de base de données orientée objet, comme suit :
- Une base de données multimédia stocke des supports, tels que des images qu’une base de données relationnelle ne peut pas stocker.
- Une base de données hypertexte permet de relier n’importe quel objet à n’importe quel autre objet. Cela aide à organiser des données disparates :

Exemple de modèle de base de données orienté objet
4.2.5 Modèles d’entité-relation
Les entités dans la relation entité-relationnelle se composent de points de données stockés sur des personnes, des lieux et des objets, chacun ayant certains attributs qui constituent son domaine. La cardinalité, ou les relations entre les entités, est également mappée. Le modèle de relation d’entité est basé sur la notion d’entités du monde réel et de leurs relations. Un ensemble d’entités est créé lors de la formulation du scénario du monde réel dans le modèle de base de données qui dépend de deux fonctionnalités essentielles, à savoir :
- Entités et leurs attributs : Par exemple, une entité d’étudiant peut avoir un nom, une classe et un âge en tant qu’attributs.
- Relations entre entités : par exemple, un employé travaille dans un département et un étudiant s’inscrit à un cours. Ici, Works_at et Enrolls sont appelées relations :
Diagramme entité-relation pour la gestion interne des ventes
4.2.6 Modèles relationnels-objets
Le modèle relationnel-objet est un modèle de base de données hybride qui associe la primitivité du modèle relationnel à certaines fonctionnalités supérieures du modèle de base de données orientée objet. En substance, il permet aux concepteurs de combiner des objets dans une structure de tableau familière . Il existe plusieurs langages et interfaces d’appel pour le modèle objet-relationnel. Parmi les exemples les plus courants, citons SQL3, les langages du fournisseur, ODBC et JDBC.
La liste suivante présente certains avantages fournis par le modèle objet-relationnel:
- Il prend en charge de nombreux types de géométrie (notamment les arcs, les cercles, les polygones composés, les chaînes de lignes composées et les rectangles optimisés), ce qui lui confère davantage de flexibilité.
- Il facilite la création et la gestion des index, ainsi que l’exécution de requêtes spatiales.
- Il a la maintenance d’index de la base de données Oracle
- Sa géométrie est modélisée dans une seule colonne
- Il fournit une performance optimale
Comparons les différences entre une requête relationnelle et le modèle de base de données relationnelle objet. Afin de créer une table qui stocke les informations du patient dans le SGBDR, notre requête SQL ressemblerait à ceci :
CREATE TABLE patients (
id CHAR(12) NOT NULL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
email VARCHAR(40) NOT NULL,
DOB DATE NOT NULL,
phone VARCHAR(13)
)
Pour sélectionner les informations du patient dans la table, notre requête SQL se présenterait comme suit :
SELECT name FROM patients WHERE Month(DOB) = Month(getUserDate()) AND Day(DOB) = Day(getUserDay())
Dans une base de données relationnelle-objet, quelque chose de similaire peut être obtenu via les instructions SQL suivantes :
CREATE TABLE patients (
id Patient_ID NOT NULL PRIMARY KEY,
name PatientName NOT NULL,
email PatientEmail NOT NULL,
DOB DATE NOT NULL,
phone VARCHAR(13)
)
La requête correspondante serait la suivante :
SELECT Formal (P.id) FROM patients P where Birthday(P.DOB) = TODAY;
Le modèle objet-relationnel est complexe, mais ses fonctionnalités sont très puissantes. Sur la base de l’efficacité des résultats de ce modèle, sa complexité peut être atténuée. Le modèle relationnel-objet peut facilement fonctionner avec d’autres modèles, notamment le modèle relationnel ou le modèle réseau.
4.3 Résumé
Dans ce chapitre, nous avons discuté des différents niveaux de modélisation, avec un exemple de chacun. De plus, nous avons exploré divers types de modèle de données, y compris le modèle de données relationnel, le modèle de données objet, le modèle de données hiérarchique, le modèle de données réseau et le modèle de données relationnelles d’entité, et comment ils sont utilisés dans des scénarios réels.
Nous avons exploré divers modèles de données relationnelles à l’aide de fichiers CSV et nous avons examiné le modèle de données de tableau.
Dans le chapitre suivant, nous examinerons en détail les structures des modèles de données.
5 Structures de modèles de données
Dans ce chapitre, nous continuerons à faire la lumière sur la modélisation des mégadonnées avec des approches spécifiques, notamment les modèles à espace vectoriel (VSM) et les modèles à données graphiques. Le lecteur découvrira le concept de différentes structures de modèles de données à l’aide d’exercices pratiques, tels que l’exploration de modèles de données graphiques avec Gephi et d’un modèle de données semi-structuré de fichiers JSON. Dans ce chapitre, nous aborderons les sujets suivants :
- En savoir plus sur les différentes structures du modèle de données
- En savoir plus sur le modèle de données vectorielles avec Lucene
- Explorer le modèle graphique de données en utilisant Gephi
- Exploration du modèle de données semi-structuré de fichiers JSON et de fichiers XML
5.1 Modèles de données semi-structurées
Au chapitre 3, Définition des modèles de données, nous avons découvert différents types de données, notamment structurées, semi-structurées et non structurées. Dans cette section, nous allons discuter de données plus semi-structurées. Le World Wide Web (WWW) est la source d’informations la plus importante aujourd’hui. Si nous devons classer le modèle de données derrière le Web, nous pouvons dire qu’il appartient au modèle de données semi-structuré. La plupart des données semi-structurées font référence à des données d’arborescence.
Prenons l’exemple d’une page Web :
<!DOCTYPE html>
<html>
<head>
<meta charset=”UTF-8″>
<title>Page Title</title>
</head>
<body>
<h1>This is a Heading</h1>
<p>This is a paragraph.</p>
<ul>
<li>List Item 1</li>
<li>List Item 2</li>
<li>List Item 3</li>
</ul>
<footer><center>Copyright: Hands-on exercise</center></footer>
</body>
</html>
Ici, un document HTML doit être placé dans la balise <html> et tout le contenu est inséré dans la balise <body>. Le code de l’extrait précédent peut rendre la page HTML. Toutes les données proviennent des blocs HTML et HTML slash. De même, nous avons un corps et une fin, un en-tête commence et se termine, une liste commence et se termine. La deuxième chose à noter est que, contrairement à une structure relationnelle, il existe plusieurs éléments de liste et plusieurs paragraphes. Chaque document en aurait un nombre différent. Cela signifie que si l’objet de données a une structure, il est plus flexible. C’est la marque d’un modèle de données semi-structuré de bureau.
eXtensible Markup Language (XML) est un autre standard bien connu pour la représentation des données. XML peut être perçu comme la généralisation de HTML, où les éléments, ou les marqueurs de début et de fin entre crochets angulaires, peuvent être n’importe quelle chaîne. Prenons un exemple de document XML :
<?xml version=”1.0″ encoding=”UTF-8″?>
<depression_patients>
<patient>
<name>John Doe</name>
<bill>$1115.95</bill>
<session>2</session>
<level>6</level>
<telecom>
<system value=”phone”/>
<value value=”(03) 5555 6473″/>
<use value=”work”/>
<rank value=”1″/>
</telecom>
</patient>
<patient>
<name>Ola Nordmann</name>
<bill>$7000.95</bill>
<session>3</session>
<level>9</level>
<telecom>
<system value=”phone”/>
<value value=”(03) 5555 6473″/>
<use value=”work”/>
<rank value=”1″/>
</telecom>
</patient>
<patient>
<name>Gummy Bear</name>
<bill>$43.95</bill>
<session>4</session>
<level>90</level>
<telecom>
<system value=”phone”/>
<value value=”(03) 5555 6473″/>
<use value=”work”/>
<rank value=”1″/>
</telecom>
</patient>
<patient>
<name>Reshika Adhikari</name>
<bill>$4343.50</bill>
<session>6</session>
<level>3</level>
<telecom>
<system value=”phone”/>
<value value=”(03) 5555 6473″/>
<use value=”work”/>
<rank value=”1″/>
</telecom>
</patient>
<patient>
<name>Yoshmi Mukhiya</name>
<bill>$634.95</bill>
<session>7</session>
<level>0</level>
<telecom>
<system value=”phone”/>
<value value=”(03) 5555 6473″/>
<use value=”work”/>
<rank value=”1″/>
</telecom>
</patient>
</depression_patients>
Vous pouvez en savoir plus sur les fichiers XML et leurs finalités à l’adresse https://www.w3schools.com/XML/xml_whatis.asp.
Le format JSON (JavaScript Object Notation) est un autre format très répandu utilisé pour différentes données, telles que Facebook et Twitter. Considérons l’exemple suivant, qui est exactement le même extrait représenté précédemment par XML :
{
“depression_patients”: {
“patient”: [
{
“name”: “John Doe”,
“bill”: “$1115.95”,
“session”: “2”,
“level”: “6”,
“telecom”: {
“system”: {
“_value”: “phone”
},
“value”: {
“_value”: “(03) 5555 6473”
},
“use”: {
“_value”: “work”
},
“rank”: {
“_value”: “1”
}
}
},
{
“name”: “Ola Nordmann”,
“bill”: “$7000.95”,
“session”: “3”,
“level”: “9”,
“telecom”: {
“system”: {
“_value”: “phone”
},
“value”: {
“_value”: “(03) 5555 6473”
},
“use”: {
“_value”: “work”
},
“rank”: {
“_value”: “1”
}
}
},
{
“name”: “Gummy Bear”,
“bill”: “$43.95”,
“session”: “4”,
“level”: “90”,
“telecom”: {
“system”: {
“_value”: “phone”
},
“value”: {
“_value”: “(03) 5555 6473”
},
“use”: {
“_value”: “work”
},
“rank”: {
“_value”: “1”
}
}
},
{
“name”: “Reshika Adhikari”,
“bill”: “$4343.50”,
“session”: “6”,
“level”: “3”,
“telecom”: {
“system”: {
“_value”: “phone”
},
“value”: {
“_value”: “(03) 5555 6473”
},
“use”: {
“_value”: “work”
},
“rank”: {
“_value”: “1”
}
}
},
{
“name”: “Yoshmi Mukhiya”,
“bill”: “$634.95”,
“session”: “7”,
“level”: “0”,
“telecom”: {
“system”: {
“_value”: “phone”
},
“value”: {
“_value”: “(03) 5555 6473”
},
“use”: {
“_value”: “work”
},
“rank”: {
“_value”: “1”
}
}
}
]
}
}
JSON utilise uniquement du texte, ce qui facilite l’envoi et la réception sur n’importe quel serveur. Par conséquent, il est utilisé comme format de données par de nombreux langages de programmation. Dans l’extrait précédent, nous avons une structure imbriquée similaire ; c’est-à-dire des listes contenant d’autres listes qui contiendront des nuplets constitués de paires clé-valeur. Donc, les paires clé-valeur aux noms de propriété atomique et leurs valeurs. Une façon de généraliser ces différentes formes de données semi-structurées consiste à les modéliser sous forme d’arbres :
Structure de données arborescente d’une simple page Web affichant des données semi-structurées
5.1.1 Exploration du modèle de données semi-structuré des données JSON
Consommons l’API Twitter ( https://apps.twitter.com/ ) pour télécharger des tweets et construire un modèle de données semi-structuré. Nous allons utiliser la bibliothèque Tweepy ( https://www.tweepy.org/ ) pour télécharger les tweets.
5.1.1.1 Installation de Python et de la bibliothèque Tweepy
Démarrez votre machine virtuelle et exécutez le terminal. Suivez les instructions du chapitre 1, Introduction à la gestion des données volumineuses et des données, et du chapitre 2, Modélisation et gestion des données, pour commencer à utiliser une machine virtuelle. En outre, vous devriez déjà avoir installé pip. Si vous n’avez pas installé pip, suivez les didacticiels à l’adresse https://pip.pypa.io/en/latest/installing/.
Il suffit d’exécuter pip pour installer tweepy en exécutant la commande suivante :
$ pip installer tweepy
Une fois que vous l’avez installé, l’étape suivante consiste à configurer l’API Twitter.
5.1.1.2 Obtention des informations d’identification pour accéder à l’API Twitter
Les identifiants d’autorisation peuvent être obtenus en créant une nouvelle application sur la plateforme de développement Twitter ( https://apps.twitter.com/). Twitter permet de télécharger 3 200 tweets ( https://developer.twitter.com/en/docs/api-reference-index) au format JSON. Le script pour télécharger les tweets se trouve dans CH05 à partir de la base de codes de l’article. Exécutez le script Python simplement par python tweet.py. Vous trouverez plus d’informations sur l’accès aux identifiants Twitter sur le site Web du développeur Twitter : https://developer.twitter.com/en/apply-for-access.
Après avoir créé une application sur le site, vous devriez pouvoir accéder aux clés et aux jetons similaires aux captures d’écran suivantes :
Page d’informations d’identification de l’application Twitter
Les scripts Python utilisent l’API REST fournie par Twitter pour télécharger les données et les enregistrer dans notre destination. Il vous suffit de renseigner le script avec vos propres clés et d’exécuter le script :
#!/usr/bin/env python
# encoding: utf-8
import tweepy
import json
#Twitter API credentials
consumer_key = “CONSUMER_KEY_GOES_HERE”
consumer_secret = “CONSUMER_SECRET_GOES_HERE”
access_key = “ACCESS_KEY_GOES_HERE”
access_secret = “ACCESS_SECRET_GOES_HERE”
def get_all_tweets_by_handle(screen_name):
#Twitter only allows access to a users most recent 3240 tweets with this method
#authorize twitter, initialize tweepy
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_key, access_secret)
api = tweepy.API(auth)
#initialize a list to hold all the tweepy Tweets
alltweets = []
#make initial request for most recent tweets (200 is the maximum allowed count)
new_tweets = api.user_timeline(screen_name = screen_name,count=200)
#save most recent tweets
alltweets.extend(new_tweets)
#save the id of the oldest tweet less one
oldest = alltweets[-1].id – 1
#keep grabbing tweets until there are no tweets left to grab
while len(new_tweets) > 0:
#all subsequent requests use the max_id param to prevent duplicates
new_tweets = api.user_timeline(screen_name = screen_name,count=200,max_id=oldest)
#save most recent tweets
alltweets.extend(new_tweets)
#update the id of the oldest tweet less one
oldest = alltweets[-1].id – 1
print “…%s tweets downloaded so far” % (len(alltweets))
#write tweet objects to JSON
file = open(‘tweet.json’, ‘wb’)
print “Writing tweet objects to JSON please wait…”
for status in alltweets:
json.dump(status._json,file,sort_keys = True,indent = 4)
#close the file
print “Done”
file.close()
if __name__ == ‘__main__’:
#pass in the username of the account you want to download
get_all_tweets_by_handle(“@IBM”)
Assurez-vous de remplacer la valeur de la clé par la valeur de votre clé d’application. En outre, écrivez le nom d’utilisateur à partir duquel vous souhaitez télécharger les tweets. Dans ce cas, je vais télécharger 3 200 tweets d’IBM :
if __name__ == ‘__main__’:
#pass in the username of the account you want to download
get_all_tweets(“@IBM”)
Vous pouvez exécuter le script à l’aide de la commande suivante :
tweets.py python
Une fois la commande exécutée, vous pourrez voir la sortie suivante :
Exécution du script python pour télécharger les tweets
Voici un exemple de réponse obtenu par le script :
{
“contributors”:null,
“coordinates”:null,
“created_at”:”Fri May 11 03:47:28 +0000 2018″,
“entities”:{
“hashtags”:[
{
“indices”:[
41,
46
],
“text”:”IBMQ”
},
{
“indices”:[
93,
101
],
“text”:”quantum”
}
],
“symbols”:[
],
“urls”:[
{
“display_url”:”bitly.com/2G5pSDD”,
“expanded_url”:”http://bitly.com/2G5pSDD”,
“indices”:[
69,
92
],
“url”:”https://t.co/JBSmlMqj5C”
}
],
“user_mentions”:[
{
“id”:487624974,
“id_str”:”487624974″,
“indices”:[
1,
9
],
“name”:”NC State University”,
“screen_name”:”NCState”
}
]
},
“favorite_count”:86,
“favorited”:false,
“geo”:null,
“id”:994786038236286976,
“id_str”:”994786038236286976″,
“in_reply_to_screen_name”:null,
“in_reply_to_status_id”:null,
“in_reply_to_status_id_str”:null,
“in_reply_to_user_id”:null,
“in_reply_to_user_id_str”:null,
“is_quote_status”:false,
“lang”:”en”,
“place”:null,
“possibly_sensitive”:false,
“retweet_count”:37,
“retweeted”:false,
“source”:”<a href=\”https://www.sprinklr.com\” rel=\”nofollow\”>Sprinklr</a>”,
“text”:”.@NCState to become 1st university-based #IBMQ hub in North America: https://t.co/JBSmlMqj5C #quantum”,
“truncated”:false,
“user”:{
“contributors_enabled”:false,
“created_at”:”Wed Jan 14 20:41:57 +0000 2009″,
“default_profile”:false,
“default_profile_image”:false,
“description”:”Official IBM Twitter account. Follows the IBM Social Computing Guidelines.”,
“entities”:{
“description”:{
“urls”:[
]
},
“url”:{
“urls”:[
{
“display_url”:”ibm.com”,
“expanded_url”:”https://www.ibm.com”,
“indices”:[
0,
23
],
“url”:”https://t.co/4ZyG9FgkYe”
}
]
}
},
“favourites_count”:3496,
“follow_request_sent”:false,
“followers_count”:443681,
“following”:false,
“friends_count”:6364,
“geo_enabled”:false,
“has_extended_profile”:false,
“id”:18994444,
“id_str”:”18994444″,
“is_translation_enabled”:false,
“is_translator”:false,
“lang”:”en”,
“listed_count”:5432,
“location”:”Armonk, New York”,
“name”:”IBM”,
“notifications”:false,
“profile_background_color”:”FFFFFF”,
“profile_background_image_url”:”http://pbs.twimg.com/profile_background_images/378800000152426467/Viwc1IvP.jpeg”,
“profile_background_image_url_https”:”https://pbs.twimg.com/profile_background_images/378800000152426467/Viwc1IvP.jpeg”,
“profile_background_tile”:false,
“profile_banner_url”:”https://pbs.twimg.com/profile_banners/18994444/1516234232″,
“profile_image_url”:”http://pbs.twimg.com/profile_images/925460050994270208/2IXQLOut_normal.jpg”,
“profile_image_url_https”:”https://pbs.twimg.com/profile_images/925460050994270208/2IXQLOut_normal.jpg”,
“profile_link_color”:”2FC2EF”,
“profile_sidebar_border_color”:”000000″,
“profile_sidebar_fill_color”:”252429″,
“profile_text_color”:”666666″,
“profile_use_background_image”:false,
“protected”:false,
“screen_name”:”IBM”,
“statuses_count”:10821,
“time_zone”:”Eastern Time (US & Canada)”,
“translator_type”:”none”,
“url”:”https://t.co/4ZyG9FgkYe”,
“utc_offset”:-14400,
“verified”:true
}
}
Examinons les données semi-structurées de la base de code. À partir du lien GitHub, ouvrez Ch05 / JSON / twitter.json . Suivez ces étapes:
- Ouvrez un shell terminal en cliquant sur la case noire en haut à gauche de l’écran.
- Accédez au répertoire dans lequel les données Twitter ont été téléchargées (en supposant que vous ayez exécuté les scripts précédents et que le fichier twitter.json se trouve dans Downloads dans le dossier de data :
cd Téléchargements / données
- Pour examiner le fichier JSON, vous pouvez utiliser la commande more :
plus twitter.json
- Le fichier JSON est assez long et seule une partie du fichier est affichée. Pour lire plus. section du fichier, appuyez sur la barre d’espace pour faire défiler l’écran. Appuyez sur Q pour quitter la lecture du fichier.
Le contenu du fichier est difficile à comprendre car il est emballé ensemble. Dans cette section, nous allons écrire des scripts Python pour voir le schéma du fichier JSON :
#!/usr/bin/python
#prints the schema of a json file
# usage: json_schema.py jsonfilename
import sys
import json
filename = sys.argv[1]
data = []
i = 0
try:
with open(filename) as fname:
for line in fname:
i=i+1
if i%2 == 1: #skip every other line since it is empty
data.append(json.loads(line))
except Exception:
print “Error while reading file: “, filename
print “Check if the file complies with JSON format”
print “\nUsage: json_schema.py jsonfilename”
sys.exit()
#inner dfs
def dfs_inner(x, indent):
try:
for key, value in x.iteritems():
print indent + key
try:
dfs_inner(value, indent+”….”)
except Exception:
pass
except Exception:
pass
#outer dfs
indent = ” ”
for key, value in data[0].iteritems():
print key
dfs_inner(value, indent+”….”)
Enregistrez l’extrait de code dans un fichier schema.py. Nous pouvons obtenir le schéma à partir du fichier JSON en utilisant la commande suivante :
./ json_schema.py tweet.json | plus
Vous devriez obtenir le résultat suivant :

Schéma du fichier JSON
5.2 VSM avec Lucene
Le VSM, ou le terme modèle de vecteur, est un modèle algébrique permettant de représenter des documents texte en tant que vecteurs d’identificateurs, tels que des termes d’index. Il est utilisé dans le filtrage, la récupération, l’indexation et le classement des informations.
Dans VSM, les pondérations associées aux termes sont calculées en fonction des deux nombres suivants :
- Terme fréquence (TF): combien de fois un terme particulier apparaît dans le document
- Fréquence de document inverse (IDF): l’importance d’un mot pour un document dans une collection
VSM est implémenté dans de nombreux logiciels open source, notamment Apache Lucene, Elasticsearch, Genism, Numpy , Weka, word2vec et Konstanz Information Miner ( KNIME ).
5.2.1 Lucene
Dans cette section, nous allons explorer le VSM en utilisant un outil open source appelé Lucene. Lorsque vous exécutez ce programme, si vous obtenez l’erreur Exception in thread “main” java.lang.NoClassDefFoundError lors de l’exécution des commandes de cette activité, vous devrez télécharger Lucene en lançant ces commandes:
cd $ HOME / Téléchargements
wget http://archive.apache.org/dist/lucene/java/5.5.0/lucene-5.5.0.tgz
tar – xvzf lucene-5.5.0.tgz
Regardons les étapes suivantes :
- Ouvrez un shell terminal en cliquant sur la case noire en haut à gauche de l’écran. Téléchargez les données vectorielles à partir du lien GitHub. Changer dans le répertoire vectoriel :
cd Téléchargements / CH05 / vector
Exécutez ls pour voir les scripts et le répertoire de data. Le répertoire de data contient trois fichiers CSV, contenant des données textuelles issues des actualités.
- Importer et interroger les documents texte. Exécutez les données runLuceneQuery.sh pour importer les documents dans le répertoire de data :
./runLuceneQuery.sh data
La sortie de la commande est la suivante :
Entrez les voters pour interroger ce terme :

La sortie affiche les classements et les scores de chacun des trois fichiers CSV pour les termes voters. Cela montre que news1.csv est classé premier, news2.csv est deuxième et news3.csv troisième.
Ensuite, entrez des voters pour interroger ce terme :

La sortie montre que news2.csv est classé premier, news1.csv est classé deuxième et news3.csv n’est pas affiché, car le terme delegates n’apparaît pas dans ce document.
Nous pouvons interroger plusieurs termes en les entrant ensemble ; Entrez les voters delegates pour demander les deux termes :
La sortie montre que news2.csv est classé premier, news1.csv est classé deuxième et news3.csv est classé troisième.
- Nous pouvons effectuer une requête pondérée (ou relance ) pour attribuer un terme plus important que les autres. Entrez les voters^5 delegates pour donner aux voters nommés pour un mandat multiplicateur de 5 :
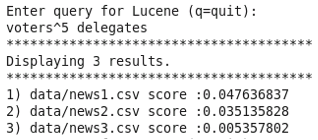
La sortie montre que news1.csv est classé premier et news2.csv est classé deuxième. Notez que ces deux classements sont inversés à partir du moment où nous avons effectué la même requête sans boost.
Entrez q pour quitter ce script.
- Voir la TF-IDF. Exécutez les données runLuceneTF-IDF.sh pour voir le TF-IDF des termes dans les documents :
./runLuceneTFIDF.sh data
La sortie devrait ressembler à la capture d’écran suivante :
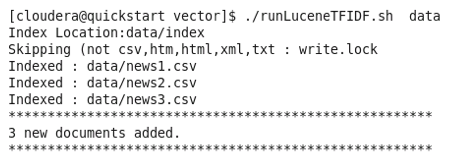
Entrez les voters pour voir le TF-IDF pour ce terme:
Entrez delegates pour voir le TF-IDF pour ce terme :
Entrez q pour quitter ce script.
5.3 Modèles de données graphiques
Un graphique est simplement une collection de sommets et d’arêtes. L’exemple le plus convaincant d’un modèle graphique-données est un réseau social. Chaque information dans ce monde est connectée. Pour stocker et traiter correctement les informations, une base de données doit englober et stocker l’entité et sa connectivité avec une autre entité. C’est là que le modèle graphique-données entre en jeu. Le stockage et l’accès aux nœuds et aux relations dans une base de données graphique est une opération simple, efficace et évolutive qui permet à l’utilisateur de parcourir rapidement les informations et d’en obtenir les informations correctes.
Mathématiquement, un graphe est une paire G = (V, E) d’ensembles qui satisfont E
(V X V). Les éléments de V sont les sommets ou les nœuds du graphe, G , et les éléments de E sont ses arêtes ou relations.
Voyons un modèle graphique de films et d’acteurs.
Modèle graphique étiqueté de films et d’acteurs
À partir du modèle de données de film donné dans le diagramme précédent, il est clair que nous avons la table de sommets suivante :
| ID | Propriété (V) |
| 1 | (Personne, Jackie Chan ) |
| 2 | (Personne, Dwayne Johnson ) |
| 3 | ( Film , Kung Fu Panda ) |
| 4 | ( Film , Moana ) |
| 5 | ( Film , gratte – ciel ) |
| 6 | (Personne, John Stevenson ) |
| 7 | (Personne, Ron Clements ) |
| 8 | (Personne, Rawson Marshall Thurber ) |
Le tableau de bord correspondant du graphique serait:
| La source | Destination | Propriété (E) |
| 1 | 3 | ACTED_IN |
| 2 | 4 | ACTED_IN |
| 2 | 5 | ACTED_IN |
| 6 | 3 | DIRECTED |
| 7 | 4 | DIRECTED |
| 8 | 5 | DIRECTED |
À partir du diagramme précédent, les observations suivantes peuvent être faites :
- Le modèle de données est un modèle graphique qui montre les nœuds (personne, vidéos) et les relations (ACTED_IN et DIRECTED).
- Les nœuds peuvent être étiquetés avec une ou plusieurs étiquettes, ce qui est bon pour l’identification
- Les nœuds peuvent contenir des propriétés où les propriétés sont stockées sous la forme d’une paire clé-valeur
- Les relations peuvent être nommées et dirigées
- Les relations ont un noeud de début et de fin
5.3.1 Modèles de données graphiques avec Gephi
Gephi doit être exécuté sur votre matériel natif, pas sur la VM Cloudera. Les instructions pour télécharger, installer et exécuter Gephi sont disponibles à l’adresse https://gephi.org/users/install . Regardons les étapes suivantes :
- Téléchargez et importez le fichier CSV. Les données utilisées dans cet exemple sont dans CH05 / graph / diseaseGraph.csv .
- Cliquez sur File et choisissez Save as pour télécharger le fichier.
Dans Gephi , cliquez sur File et choisissez Import spreadsheet…:
Allez dans Fichier puis choisissez Importer une feuille de calcul
Dans la boîte de dialogue Import spreadsheet…, cliquez sur … pour choisir le fichier CSV :

Dans la boîte de dialogue File, choisissez le fichier diseaseGraph.csv que vous avez téléchargé :
Dans la boîte de dialogue, assurez-vous As the table est définie sur Edges table :

Cliquez sur Next, puis sur Finish pour importer les données CSV dans Gephi.
- Examinez les propriétés du graphique. Dans le volet du milieu, Gephi affiche le graphique. Les cercles noirs sont les nœuds, et les lignes entre eux sont les bords:

Si vous placez la souris sur un nœud, Gephi mettra en surbrillance les nœuds qui y sont connectés, comme suit :

Dans le coin supérieur droit se trouve la sous- fenêtre Context, qui indique que le graphique comporte 777 nœuds et 998 arêtes :
- Effectuer des opérations statistiques.
Sous le volet Context se trouve le volet Statistiques, dans lequel vous pouvez effectuer divers calculs statistiques. Nous pouvons calculer le degré moyen en cliquant sur Run côté du Average Degree :
La boîte de dialogue qui s’affiche indique que le degré moyen est de 2,569. Cliquez sur Close pour fermer la boîte de dialogue.
Nous pouvons calculer les composants connectés en cliquant sur Run en Connected Components : Ceci affichera une boîte de dialogue avec le titre des Connected Components settings et demandera des calculs dirigés ou non dirigés.
La boîte de dialogue qui en résulte indique qu’il y a cinq composants faiblement connectés et 761 composants fortement connectés. Cliquez sur Close pour fermer la boîte de dialogue.
- Exécuter des algorithmes de mise en page.
Gephi peut effectuer différents algorithmes de mise en page sur le graphique. Dans le volet Layout en bas à gauche, cliquez sur la zone de liste déroulante —Choose a layout, sélectionnez Force Atlas, puis cliquez sur le bouton Run :
Gephi va changer la disposition du graphique, puis après un certain temps, cliquer sur le bouton Stop :

Dans cette présentation, les nœuds fortement connectés sont regroupés et nous pouvons également voir plusieurs clusters déconnectés du reste du graphique.
Dans la liste déroulante Layout, sélectionnez Fruchterman Reingold et cliquez sur le bouton Run :
La disposition du graphique changera pour que les nœuds soient espacés de manière égale. Une fois le graphique arrêté, cliquez sur le bouton stop, puis sur l’icône de la loupe en bas à gauche pour centrer le graphique :
Dans cette présentation, nous pouvons mieux voir quels nœuds ont beaucoup d’arêtes:
5.4 Résumé
Il existe trois types de mégadonnées : structurées, semi-structurées et non structurées. Le World Wide Web (WWW) est aujourd’hui la plus grande source d’informations, et la plupart est semi-structurée. Nous avons découvert différents types de modélisation de données non structurées et comment plusieurs outils open source peuvent être utilisés pour générer des modèles de haute qualité.
Nous avons discuté de VSM et de ses limites et avantages et exploré sa mise en œuvre avec Lucene. Ensuite, nous avons examiné le modèle de données de graphique utilisant Gephi et le modèle de données semi-structuré de fichiers JSON et de fichiers XML. Dans le chapitre suivant, nous allons explorer différents modèles de données structurées.
6 Modélisation des données structurées
Les données structurées font référence à toutes les données organisées qui se conforment à un certain format. Les données structurées peuvent être des fichiers texte, des fichiers Web ou toute autre donnée affichée dans les colonnes et les lignes intitulées; il peut ensuite être commandé et traité par des outils d’exploration de données. Ce chapitre examine des exemples concrets de données structurées rencontrées dans les activités quotidiennes au niveau de l’entreprise et comment une modélisation peut être appliquée à ces données. Les utilisateurs se saliront les mains en utilisant le langage Python. Dans ce chapitre, nous allons aborder les sujets suivants:
- Approfondissement des données structurées
- Utilisation de Python pour modéliser des données structurées
- Travailler avec IPython
6.1 Débuter avec les données structurées
Au chapitre 3, Définition des modèles de données et au chapitre 4, Catégorisation des modèles de données, nous en avons appris davantage sur les structures de données, leurs sources et des exemples. Dans ce chapitre, nous allons nous en tenir aux données structurées et utiliser des techniques de modélisation utilisant Python ; nous allons utiliser les données CSV et créer un modèle pouvant être utilisé pour prévoir les prix de l’immobilier à l’aide de Python.
Dans ce mini-projet, nous allons utiliser quatre modules ou bibliothèques Python, qui sont expliqués dans les sections suivantes.
6.1.1 NumPy
NumPy est l’abréviation de Numerical Python. Les instructions d’installation de NumPy sont disponibles dans les instructions. NumPy possède des fonctions intégrées pour prendre en charge des objets de type tableau et un ensemble de routines pouvant être utilisées pour des opérations logiques et des calculs scientifiques. Par exemple, il fournit un package pour la transformation de Fourier. Une fois la bibliothèque installée, le calcul technique devient facile. Par exemple, nous pouvons calculer les transformations de Fourier en utilisant une ligne de code:
signal_fft = fftpack.fft (signal)
Examinons maintenant certaines des opérations que nous pouvons effectuer avec NumPy.
6.1.2 Opérations utilisant NumPy
En utilisant NumPy, un développeur peut effectuer les opérations suivantes:
- Opérations mathématiques et logiques sur les tableaux
- Transformations de Fourier et routines pour la manipulation de forme
- Opérations liées à l’algèbre linéaire
- Fonctions intégrées pour la génération d’algèbre linéaire et de nombres aléatoires
Vous pouvez toujours apprendre à utiliser NumPy en lisant l’analyse pratique de l’analyse de données avec Numpy et les pandas de Curtis Miller. C’est très utile pour en savoir plus sur votre jeu de données et sur les opérations que vous pouvez y effectuer. Il peut donc être très utile de jouer avec les données d’un tableau avec cette bibliothèque pour comprendre le reste des tutoriels.
6.1.3 Pandas
Pandas (http://pandas.pydata.org/pandas-docs/stable/) est distribué sous forme de package de bibliothèque Python open source, sous licence BSD, qui fournit des structures de données rapides, flexibles et expressives conçues pour commencer à travailler avec des relations ou données étiquetées. Pandas a été utilisé avec succès dans les domaines de la finance, des statistiques, de l’économie, de l’analyse et des mégadonnées. Les instructions d’installation des pandas sont disponibles à l’adresse http://pandas.pydata.org/pandas-docs/stable/install.html.
Une fois les pandas installés sur votre système, il est facile d’importer dans votre base de code. Il peut être référencé comme suit :
#Method 1
import pandas
#Method 2
import pandas as pd
#Method 3
from pandas import DataFrame, Series
Il ne nous serait pas possible de couvrir tous les aspects des pandas dans ce livre. Nous ne sommes pas ici pour explorer les possibilités des pandas, mais pour explorer en quoi ces bibliothèques peuvent être utiles pour faciliter la modélisation de données volumineuses. Pour en savoir plus sur cette bibliothèque, consultez Learning pandas de Michael Heydt.
6.1.4 Matplotlib
C’est l’une des bibliothèques les plus utiles pour la visualisation de données en Python. Cela aide à faire des tracés 2D de tableaux en Python. La bibliothèque est polyvalente et robuste pour le traçage. Elle fournit des moyens très propres et faciles de produire des graphiques de différentes qualités avec des fonctionnalités de personnalisation avancées. Suivez ces tutoriels pour installer la dernière copie de Matplotlib sur votre système. Pour obtenir des informations détaillées sur les possibilités de Matplotlib avec vos données et sur l’amélioration de la visualisation, consultez Matplotlib for Python Developers by Packt .
6.1.5 Seaborn
Seaborn est une bibliothèque de visualisation Python basée sur Matplotlib. La bibliothèque fournit une interface de haut niveau pour dessiner des graphiques statistiques attrayants. Seaborn peut être installé avec pip ou conda. Ce qui suit montre comment l’installer avec pip :
pipinstallseaborn
Pour installer seaborn avec conda, procédez comme suit :
condainstallseaborn
6.1.6 IPython
IPython est un projet en pleine croissance, avec des composants de plus en plus indépendants de la langue. Vous pouvez suivre les instructions du site de documentation pour installer iPython sur votre système :
python3 -m pip install –upgrade pip
python3 -m pip installer jupyter
Si vous avez installé Python 2, utilisez ce qui suit :
python -m pip install –upgrade pip
python -m pip installer jupyter
Le portable doit être installé sur votre système. Pour exécuter le bloc-notes, exécutez la commande suivante sur le terminal (macOS / Linux) ou sur une invite de commande (Windows):
Jupyter notebook
6.2 Modélisation de données structurées à l’aide de Python
Voyons quel type de données nous allons analyser aujourd’hui avec IPython. Téléchargez le fichier CSV à partir de la base de code Chapitre 6 depuis GitHub. Vous devriez avoir accès au fichier de données dans le dossier CH06. Les fichiers CSV contiennent les entrées suivantes :
id,
date,
price,
bedrooms,
bathrooms,
sqft_living,
sqft_lot,
floors,waterfront,
view,
condition,
grade,
sqft_above,
sqft_basement,
yr_built,
yr_renovated,
zipcode,
lat,
long,
sqft_living15,
sqft_lot1
Tout d’abord, nous importons nos bibliothèques et notre ensemble de données. Ensuite, en utilisant la fonction head , nous examinons les quelques premières données pour voir leur apparence. Ensuite, nous utilisons la fonction describe pour afficher les centiles et d’autres statistiques clés. Commençons notre bloc- notes IPython en utilisant la commande suivante :
Jupyter notebook
Importons maintenant les bibliothèques requises :
importnumpyasnpimportpandasaspdimportmatplotlib.pyplotaspltimportseabornassnsimportmpl_toolkits
Assurez-vous que toutes ces bibliothèques sont installées avant d’exécuter le code précédent. Lisons le fichier CSV. En supposant que le nom du fichier soit house_data.csv, l’importation des données est assez simple, procédez comme suit :
data = pd.read _csv (“house_data.csv”)
Pour en savoir plus sur les données, nous pouvons utiliser la fonction describe :
data.describe ()
La sortie de la commande describe devrait ressembler à la capture d’écran suivante :
Description du jeu de données pour mieux comprendre les données
La prochaine étape consiste à visualiser les données de la figure précédente. Nous pouvons utiliser la même matplotlib bibliothèque pour visualiser les données sous la forme d’une barre graphique. Utilisons le script Python pour trouver la maison la plus commune à partir des données en fonction du nombre de chambres :
data[‘bedrooms’].value_counts().plot(kind=’bar’)plt.title(‘number of Bedroom’)plt.xlabel(‘Bedrooms’)plt.ylabel(‘Count’)sns.despine
Visualisation du jeu de données pour trouver la chambre la plus commune
Le diagramme montre que les maisons de trois chambres à coucher sont les plus vendues, suivies des maisons de quatre chambres à coucher. Ceci illustre comment un nouveau constructeur peut construire un nouvel appartement dans un lieu. Cette analyse est utile à la fois aux propriétaires d’entreprise et aux parties prenantes.
6.2.1 Visualiser l’emplacement des maisons en fonction de la latitude et de la longitude
Nous avons la latitude et la longitude de chaque maison dans le jeu de données. Regardons les endroits les plus communs et la façon dont les maisons sont placées :
plt.figure(figsize=(20,14))
sns.jointplot(x=data.lat.values,y=data.long.values,size=10)
plt.ylabel(‘Longitude’,fontsize=12)
plt.xlabel(‘Latitude’,fontsize=12)
plt.show()
sns.despine
La sortie de l’extrait précédent devrait ressembler à la capture d’écran suivante :
Visualisation du jeu de données en fonction de l’emplacement
Seaborn est une incroyable bibliothèque Python permettant de créer une multitude de graphiques et de visualiser nos données. Dans ce cas, nous utilisons la même bibliothèque pour tracer un graphique en fonction de l’emplacement. Nous avons utilisé la fonction Jointplot de la bibliothèque pour voir la concentration des données. Vous pouvez en apprendre plus sur cette fonction depuis le site de documentation. La figure 6.3 montre qu’il y a plus de maisons entre les latitudes 47,7 et 47,8 et que leur concentration est plus élevée entre les longitudes -122.2 à -122.4. La concentration des maisons pourrait indiquer plusieurs conclusions, telles que les gens aiment acheter des maisons dans ces régions.
6.2.2 Facteurs influant sur le prix des maisons
Nous avons analysé des lieux communs. En plus de l’analyse précédente, nous pouvons également voir quelques facteurs communs qui affectent le prix des maisons.
Le prix par rapport à la surface habitable de la maison :
plt.scatter(data.price,data.sqft_living)plt.title(“Price vs Square Feet”)
La sortie de l’extrait précédent devrait ressembler à la capture d’écran suivante :
Le prix par rapport à l’emplacement de la zone :
plt.scatter(data.price,data.long)plt.title(“Price vs Location of the area”)
La sortie de l’extrait précédent devrait ressembler à la capture d’écran suivante:
Le prix par rapport au nombre de chambres :
plt.scatter(data.bedrooms,data.price)plt.title(“Bedroom and Price “)plt.xlabel(“Bedrooms”)plt.ylabel(“Price”)plt.show()sns.despine
La sortie de l’extrait précédent devrait ressembler à la capture d’écran suivante:
Le prix par rapport à la latitude :
plt.scatter(data.price,data.lat)plt.xlabel(“Price”)plt.ylabel(‘Latitude’)plt.title(“Latitude vs Price”)
La sortie de l’extrait précédent devrait ressembler à la capture d’écran suivante :
Le prix par rapport au secteur riverain:
plt.scatter(data.waterfront,data.price)plt.title(“Waterfront vs Price ( 0= no waterfront)”)
La sortie de l’extrait précédent devrait ressembler à la capture d’écran suivante :
De nombreux facteurs influent sur les prix des logements dans tous les domaines, notamment la superficie en pieds carrés, l’emplacement de la maison ainsi que le nombre et la taille des chambres. La capture d’écran précédente représente la même idée. Dans la section suivante, nous allons utiliser une méthode similaire pour prédire les prix de l’immobilier en fonction d’autres paramètres.
6.3 Visualiser plus d’un paramètre
Nous avons déjà vu que nous pouvons utiliser Matplotlib pour créer un beau diagramme. Ici, nous voudrions vous montrer comment utiliser mplot3d pour visualiser plus de trois paramètres. Disons que nous voulons voir comment le nombre d’étages et le nombre de chambres à coucher sont liés à la salle de bain. La première étape consiste à importer la bibliothèque :
from mpl_toolkits.mplot3d import Axes3D
Ajoutons ensuite les paramètres requis :
fig=plt.figure(figsize=(19,12.5))
ax=fig.add_subplot(2,2,1, projection=”3d”)
ax.scatter(data[‘floors’],data[‘bedrooms’],data[‘bathrooms’],c=”darkgreen”,alpha=.5)
ax.set(xlabel=’\nFloors’,ylabel=’\nBedrooms’,zlabel=’\nBathrooms / Bedrooms’)
ax.set(ylim=[0,12])
L’extrait de code doit donner un graphique 3D, comme suit:
6.4 Gradient-boosting regression
Ces modèles peuvent être interprétés de plusieurs manières. C’est l’un des sujets avancés, cela peut être utilisé est une prédiction. Plusieurs algorithmes peuvent être appliqués afin de prévoir les prix des logements. Dans ce chapitre, nous pouvons essayer d’utiliser la régression à amplification de gradient (GBR).
Gradient boosting est l’une des techniques les plus puissantes pour la construction de modèles prédictifs. Vous pouvez en savoir plus sur l’algorithme à partir des liens fournis. Voyons comment nous pouvons utiliser cet algorithme pour prévoir les prix de l’immobilier à l’aide de notre jeu de données :
- Importez la bibliothèque de sklearn.
- Créez une variable pour le dégradé et définissez les paramètres suivants :
- n_estimators : nombre d’étapes de boosting à effectuer.
- max_depth : La profondeur du modèle d’arbre.
- learning_rate : Le taux d’apprentissage des données.
- loss: la fonction de perte à optimiser; ls fait référence à la régression des moindres carrés.
- Intégrez les données d’entraînement dans le modèle de renforcement de gradient ( GBM ).
- Vérifier la précision :
fromsklearnimportensembleclf=ensemble.GradientBoostingRegressor(n_estimators=400,max_depth=5,min_samples_split=2,learning_rate=0.1,loss=’ls’)
Nous venons d’importer le GradientBoostingRegressor de la bibliothèque et de définir les paramètres. Il est important de noter que la manière dont vous définissez ces paramètres dépend réellement d’une approche, d’une pratique et d’une expérience empiriques.
Créons maintenant une liste d’échantillons d’apprentissage et testons-la à partir du jeu de données. Pour ce faire, nous pouvons choisir un sous-ensemble de données en tant que données d’apprentissage et le reste en tant que données de test, pour voir dans quelle mesure notre modèle a appris à classer. Nous pouvons le faire en suivant l’extrait :
x_df = data.drop([‘id’,’date’,], axis = 1)
Nous avons supprimé id et date du bloc de données précédent. Maintenant, supprimons le prix du jeu de données de formation :
x_df2 = x_df.drop([‘price’], axis = 1)
Nous pouvons utiliser la fonction train_test_split disponible dans la bibliothèque sklearn pour créer des ensembles de données de formation et de test :
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x_df2,data[‘price’],test_size=0.4,random_state=4)
Dans l’extrait précédent, il est important de comprendre que nous avons créé un jeu de données d’apprentissage et un jeu de données de test à partir du même jeu de données. Essayons maintenant d’intégrer nos données d’entraînement dans le GBM :
clf.fit ( x_ train, y _train )
L’ajustement des données d’entraînement donne le résultat suivant :
GradientBoostingRegressor(alpha=0.9, criterion=’friedman_mse’, init=None,
learning_rate=0.1, loss=’ls’, max_depth=5, max_features=None,
max_leaf_nodes=None, min_impurity_split=1e-07,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=400,
presort=’auto’, random_state=None, subsample=1.0, verbose=0,
warm_start=False)
Vérifions l’exactitude de la prédiction :
clf.score ( x_test, y_test )
Le code précédent nous donne la sortie suivante :
0.91948383097569342
C’est 91,95%, ce qui est très bon. Vous pouvez essayer d’appliquer ces techniques à divers autres jeux de données. En plus de cet algorithme de renforcement du gradient, vous pouvez utiliser la régression linéaire. Cependant, dans notre cas, l’algorithme de renforcement du gradient donne une meilleure précision.
6.5 Résumé
Il y a beaucoup de données structurées dans le monde moderne et elles sont enregistrées sous forme d’informations, généralement des fichiers texte, et affichées dans des colonnes et des lignes intitulées. Dans ce chapitre, nous avons découvert les données structurées et les différents types de modélisation qui peuvent y être effectués. En plus de cela, nous nous sommes familiarisés avec certaines des bibliothèques Python importantes, y compris Numpy, Pandas, Matplotlib, Seaborn et IPython. Nous avons utilisé ces bibliothèques pour générer des modèles pour les attributs de la maison et utilisé ces modèles pour prédire le prix d’une nouvelle maison en fonction de certains paramètres.
Dans le chapitre suivant, nous examinerons les données non structurées et leurs sources, et utiliserons certains des outils open source les plus populaires pour générer des modèles à partir d’eux.
7 Modélisation avec des données non structurées
Dans les chapitres précédents, nous avons discuté des données non structurées et de leurs sources, et examiné quelques exemples. Dans ce chapitre, nous allons examiner quel type de modélisation peut être effectué à l’aide de jeux de données non structurés. Les données non structurées font référence à des données qui ne s’intègrent pas parfaitement à la structure traditionnelle en lignes et en colonnes des bases de données relationnelles. Il y a des jeux de données non structurés tout autour de nous. En fait, la plupart des données que nous trouvons sur le Web ne sont pas structurées. Et effectuer une analyse et une modélisation des données sur ces ensembles de données non structurés est en train de devenir un sujet de recherche difficile mais très favorable.
Dans ce chapitre, nous aborderons les sujets suivants :
- Nous verrons des exemples concrets de données non structurées trouvées dans les activités quotidiennes au niveau de l’entreprise, et comment la modélisation peut être appliquée à ces données.
- Les utilisateurs pourront se salir les mains en utilisant le langage de programmation R et l’outil Open Source KNIME
7.1 Débuter avec des données non structurées
L’analyse de données non structurée est récemment devenue une expression à la mode. Un grand nombre de chercheurs, d’analystes de données, de modélisateurs de données et de scientifiques de données s’efforcent de trouver de nouvelles méthodes pour améliorer la précision de l’analyse de données non structurée. Il existe différentes sources de données non structurées. Les sources les plus courantes sont les suivantes :
- Correspondance par e-mail, et la réponse, la réponse, les threads de transfert
- Messages et activités sur les médias sociaux
- Fichiers vidéo, audio ou image
- Web- navigation comportement
Selon IBM, 90% des données mondiales ont été produites au cours des deux dernières années, qu’elles soient non structurées ou semi-structurées. En raison de leur nature même, les données non structurées sont extrêmement difficiles à analyser. Dans le passé, les analystes n’ont pas pu faire grand-chose à cause du manque de technologie. Mais avec l’essor des technologies TIC, de l’analyse de données volumineuses, de l’exploration de données et des approches d’apprentissage automatique, il est possible de créer des modèles capables de classifier et d’analyser ces jeux de données.
7.1.1 Outils d’analyse intelligente
La meilleure méthode d’analyse des données non structurées consiste à rechercher des modèles. Les modèles indiquent s’il existe des similitudes dans les données ou si des processus sont impliqués. Divers outils d’exploration utilisent des techniques d’exploration de données, d’analyse statistique, des techniques de génie logiciel piloté par les modèles ( MDSE ) et des techniques d’intelligence artificielle pour analyser des données non structurées. Voici quelques-unes des techniques les plus populaires :
- Apprentissage machine
- Traitement du langage naturel (PNL)
- Informatique cognitive
Ces avancées automatiseront le processus de conservation et de maintenance des données. Les analystes sont prêts à se concentrer davantage sur l’analyse, la prévision plutôt que sur le prétraitement et la transformation des données.
7.1.2 Nouvelles méthodes de traitement de données
Le traitement de données volumineuses requiert une puissance de calcul considérable. Dans de nombreux cas, il attend plus de puissance qu’une seule machine peut en gérer. Ce problème a amené les ingénieurs à rechercher de nouvelles stratégies pour gérer des quantités énormes de données. L’avènement du cloud computing permet de gérer de grands ensembles de données en appliquant plusieurs périphériques en réseau pour créer de vastes grilles informatiques.
Contrairement au traitement parallèle classique, ce maillage de périphérique peut partager et examiner des informations sur plusieurs points de terminaison. Des algorithmes de consensus sont ensuite utilisés pour optimiser les résultats. Le modèle apprend en utilisant les données passées avec l’espoir que le maillage de l’appareil fonctionnera mieux avec les données futures. Cette méthode pourrait être utilisée pour développer un filtre anti-spam intelligent, un système de chatbot automatisé ou un système d’alerte de fraude bancaire, par exemple.
7.2 Outils d’analyse de données non structurées
Comme mentionné, la plupart de nos données actuelles sont non structurées. Nous pouvons trouver plusieurs outils pouvant faciliter les tâches d’exploration de données et l’intelligence artificielle. L’un des aspects récents de l’apprentissage automatique, appelé apprentissage en profondeur, est en train de devenir populaire dans l’analyse de jeux de données non structurés. Dans cette section, nous allons analyser certains des outils open source pouvant être utilisés dans l’analyse de données volumineuses.
7.2.1 Weka
Weka est l’un des outils de modélisation les plus populaires dans la communauté des chercheurs ; il peut être utilisé dans des tâches d’exploration de données ainsi que dans la modélisation de données volumineuses. L’application peut faciliter diverses tâches d’extraction, notamment le prétraitement, la classification, la régression, la mise en cluster, les règles d’association et la visualisation.
7.2.2 KNIME
KNIME ( https://www.knime.com/ ) est une plate-forme d’ analyse de données open source et une plate-forme de modules permettant de créer et d’exécuter des flux de travail à l’aide de composants prédéfinis appelés nœuds . Il intègre des nœuds pour le traitement des E / S de données, la modélisation, l’analyse et l’exploration de données. KNIME fournit un accès aux routines et plugins statistiques. KNIME a son siège à Zurich et des bureaux supplémentaires à Constance, Berlin et Austin.
7.2.2.1 Caractéristiques de KNIME
KNIME a une large communauté d’utilisateurs et dispose d’excellentes ressources disponibles sur son site officiel. Il existe des exemples qui nous aident à comprendre comment utiliser les données et à en tirer un modèle utile. Dans cette section, nous allons discuter de certaines des caractéristiques de KNIME :
- L’outil peut être utilisé pour extraire, transformer et analyser les données
- Il prend en charge une transformation mathématique des données pour l’analyse
- Il a une plate-forme d’intégration ouverte
- Il a un support intégré pour la visualisation de données
7.2.3 Le langage R
Nous avons abordé le langage de programmation R dans les chapitres précédents et nous l’avons installé dans notre plate-forme au chapitre 2, Plateformes de modélisation et de gestion de données. R possède des bibliothèques qui peuvent être utilisées pour l’analyse de données non structurée, notamment la mise en cluster, la classification et l’utilisation d’algorithmes d’apprentissage automatique.
Dans cette section, nous allons analyser des données non structurées à l’aide du langage de programmation R. Nous allons utiliser tm: Text Mining Package (https://cran.r-project.org/web/packages/tm/index.html) de R. Voici les étapes à suivre pour analyser des données non structurées:
- Ingestion de données
- Nettoyage des données
- Transformation de données
- Visualisation de données
7.2.4 Analyse de texte non structuré à l’aide de R
Dans cette section, nous allons utiliser des données non structurées sous forme de texte et appliquer certaines techniques de modélisation. Nous utiliserons le langage de programmation R pour modéliser ce texte. Le texte intégral utilisé dans cet exercice est disponible en ligne à l’ adresse cran.r-project.org. Nous allons créer un nuage de mots à partir du texte et effectuer d’autres opérations statistiques.
7.2.4.1 Ingestion de données
En supposant que la console R soit prête, commençons. Pour faciliter le didacticiel, nous utiliserons une petite quantité de données pour montrer comment construire des modèles :
> res <- XML::readHTMLTable(paste0(‘http://cran.r-project.org/’,+ ‘web/packages/available_packages_by_name.html’), which = 1)
R est livré avec un tas de fonctions qui peuvent être utilisées pour lire différents types de fichiers. Dans ce tutoriel, nous allons utiliser tm et XML. Si le package XML n’est pas installé, vous pouvez l’installer à l’aide de la commande suivante:
install.packages (“XML”)
Afin de voir les formats de fichier texte supportés, nous pouvons utiliser la fonction getReaders :
> getReaders()
[1] “readDataframe” “readDOC”
[3] “readPDF” “readPlain”
[5] “readRCV1” “readRCV1asPlain”
[7] “readReut21578XML” “readReut21578XMLasPlain”
[9] “readTagged” “readXML”
Au moment de la rédaction de ce livre, l’extrait de code téléchargeait 12 658 noms de bibliothèques R et leurs brèves descriptions. Le corpus est un nouveau terme auquel il faut se familiariser. Il s’agit essentiellement d’une collection de documents texte que nous pouvons inclure dans l’analyse. Nous pouvons utiliser la fonction getSources pour voir les options disponibles pour importer un corpus avec le paquet tm :
> library(tm)
Loading required package: NLP
> getSources()
[1] “DataframeSource” “DirSource” “URISource” “VectorSource”
[5] “XMLSource” “ZipSource”
Construire un corpus à partir de la source vectorielle de descriptions de paquets téléchargés à partir des listes de paquets R peut être effectué à l’aide de l’une des options précédentes. Dans ce cas, nous pouvons utiliser VectorSource :
> v <- Corpus(VectorSource(res$V2))
> v
<<SimpleCorpus>>
Metadata: corpus specific: 1, document level (indexed): 0
Content: documents: 12658
Cette étape a créé un objet VCorpus (en mémoire) contenant actuellement 12 658 descriptions de packages. Nous pouvons utiliser les fonctions inspect et head pour afficher le résultat des instructions traitées. Ainsi, afin de voir les cinq premiers documents du corpus, nous pouvons exécuter la commande suivante :
> inspect(head(v, 5))
<<SimpleCorpus>>
Metadata: corpus specific: 1, document level (indexed): 0
Content: documents: 3
[1] Accurate, Adaptable, and Accessible Error Metrics for Predictive\nModels
[2] Access to Abbyy Optical Character Recognition (OCR) API
[3] Tools for Approximate Bayesian Computation (ABC)
[4] Data Only: Tools for Approximate Bayesian Computation (ABC)
[5] Array Based CpG Region Analysis Pipeline
7.2.4.2 Nettoyage et transformation de données
Nous pouvons utiliser la fonction tm_map, qui fournit un moyen pratique d’exécuter les transformations sur le corpus pour filtrer toutes les données non pertinentes dans la recherche. Pour voir la liste des méthodes de transformation disponibles, nous pouvons utiliser la fonction getTransformations :
> getTransformations ( )
[1] ” removeNumbers ” ” removePunctuation ” ” removeWords ”
[4] ” stemDocument ” ” stripWhitespace ”
La première étape du processus de nettoyage consiste à supprimer les stopwords. Le paquet tm contient déjà la liste des stopwords dans différentes langues. Pour afficher la liste en english, utilisez la fonction suivante :
> stopwords(“english”)
[1] “i” “me” “my” “myself” “we”
[6] “our” “ours” “ourselves” “you” “your”
[11] “yours” “yourself” “yourselves” “he” “him”
[16] “his” “himself” “she” “her” “hers”
[21] “herself” “it” “its” “itself” “they”
[26] “them” “their” “theirs” “themselves” “what”
[31] “which” “who” “whom” “this” “that”
[36] “these” “those” “am” “is” “are”
[41] “was” “were” “be” “been” “being”
[46] “have” “has” “had” “having” “do”
[51] “does” “did” “doing” “would” “should”
[56] “could” “ought” “i’m” “you’re” “he’s”
[61] “she’s” “it’s” “we’re” “they’re” “i’ve”
[66] “you’ve” “we’ve” “they’ve” “i’d” “you’d”
[71] “he’d” “she’d” “we’d” “they’d” “i’ll”
[76] “you’ll” “he’ll” “she’ll” “we’ll” “they’ll”
[81] “isn’t” “aren’t” “wasn’t” “weren’t” “hasn’t”
[86] “haven’t” “hadn’t” “doesn’t” “don’t” “didn’t”
[91] “won’t” “wouldn’t” “shan’t” “shouldn’t” “can’t”
[96] “cannot” “couldn’t” “mustn’t” “let’s” “that’s”
[101] “who’s” “what’s” “here’s” “there’s” “when’s”
[106] “where’s” “why’s” “how’s” “a” “an”
[111] “the” “and” “but” “if” “or”
[116] “because” “as” “until” “while” “of”
[121] “at” “by” “for” “with” “about”
[126] “against” “between” “into” “through” “during”
[131] “before” “after” “above” “below” “to”
[136] “from” “up” “down” “in” “out”
[141] “on” “off” “over” “under” “again”
[146] “further” “then” “once” “here” “there”
[151] “when” “where” “why” “how” “all”
[156] “any” “both” “each” “few” “more”
[161] “most” “other” “some” “such” “no”
[166] “nor” “not” “only” “own” “same”
[171] “so” “than” “too” “very”
Pour supprimer les mots vides de notre corpus , nous pouvons utiliser la fonction tm_map , comme suit:
> removeWords(‘to be or not to be’, stopwords(“english”))
> v <- tm_map(v, removeWords, stopwords(“english”))
Examinons maintenant les cinq premières entrées de notre corpus :
> inspect(head(v, 5))
<<SimpleCorpus>>
Metadata: corpus specific: 1, document level (indexed): 0
Content: documents: 5
[1] Accurate, Adaptable, Accessible Error Metrics Predictive\nModels
[2] Access Abbyy Optical Character Recognition (OCR) API
[3] Tools Approximate Bayesian Computation (ABC)
[4] Data Only: Tools Approximate Bayesian Computation (ABC)
[5] Array Based CpG Region Analysis Pipeline
Nous pouvons observer que la plupart des mots de fonction courants et quelques caractères sont supprimés du nom de la description. Mais afin de traiter le scénario de casse et la ponctuation avec des espaces, nous pouvons transformer notre corpus utilisant les fonctions content_transformer, removePunctuation et stripWhitespace. Par exemple, considérons l’extrait suivant :
> removeWords(‘To be or not to be.’, stopwords(“english”))[1] “To .”
Si nous observons attentivement la sortie, la version majuscule de To n’a pas été supprimée de la phrase et le point final n’a pas non plus été supprimé. Pour résoudre ce problème, exécutons les instructions suivantes :
> v <- tm_map(v, content_transformer(tolower))> v <- tm_map(v, removePunctuation)> v <- tm_map(v, stripWhitespace)> inspect(head(v, 5))
<<SimpleCorpus>>
Metadata: corpus specific: 1, document level (indexed): 0
Content: documents: 5
[1] accurate adaptable accessible error metrics predictive models
[2] access abbyy optical character recognition ocr api
[3] tools approximate bayesian computation abc
[4] data only tools approximate bayesian computation abc
[5] array based cpg region analysis pipeline
7.2.4.3 Visualisation de données
Nous avons un peu nettoyé notre corpus. Pourtant, il y a beaucoup de mots dans notre corpus. Nous pouvons visualiser ce que nous avons dans notre corpus en utilisant le nuage mondial ou d’autres graphiques. Utilisons wordcloud pour visualiser notre corpus. Pour installer la bibliothèque, utilisez la commande suivante :
> install.packages (” wordcloud “)
Une fois la bibliothèque installée, nous pouvons obtenir le mot cloud en utilisant la fonction suivante :
> wordcloud :: wordcloud (v)
La sortie de la commande précédente doit générer le mot cloud, comme suit :
Nuage de mots du corpus
7.2.4.4 Améliorer le modèle
Dans le nuage mondial, il est clair qu’il existe encore des nombres et des mots qui ne nous concernent pas. Par exemple, il existe un package termes techniques que nous pouvons supprimer. De plus, il est redondant de montrer plusieurs versions de noms. Utilisons la fonction removeNumbers pour supprimer des nombres :
> v <- tm_map(v, removeNumbers)
Afin de supprimer certains mots fréquents spécifiques à un domaine et moins pertinents pour notre objectif, nous devons voir les mots les plus courants dans notre corpus. Pour ce faire, nous pouvons calculer TermDocumentMatrix, comme indiqué dans l’extrait de code suivant :
> tdm <- TermDocumentMatrix(v)
L’objet tdm est une matrice contenant les mots dans les lignes et les documents dans les colonnes, où les cellules indiquent le nombre d’occurrences. Par exemple, regardons les occurrences des 10 premiers mots dans les 25 premiers documents :
> inspect(tdm[1:10, 1:25])
<<TermDocumentMatrix (terms: 10, documents: 25)>>
Non-/sparse entries: 10/240
Sparsity : 96%
Maximal term length: 10
Weighting : term frequency (tf)
Sample :
Docs
Terms 1 10 2 3 4 5 6 7 8 9
abbyy 0 0 1 0 0 0 0 0 0 0
access 0 0 1 0 0 0 0 0 0 0
accessible 1 0 0 0 0 0 0 0 0 0
accurate 1 0 0 0 0 0 0 0 0 0
adaptable 1 0 0 0 0 0 0 0 0 0
api 0 0 1 0 0 0 0 0 0 0
error 1 0 0 0 0 0 0 0 0 0
metrics 1 0 0 0 0 0 0 0 0 0
models 1 0 0 0 0 0 0 0 0 0
predictive 1 0 0 0 0 0 0 0 0 0
Maintenant, nous pouvons extraire le nombre total d’occurrences pour chaque mot en utilisant la fonction findFrequentTerms. Montrons tous les termes qui apparaissent dans les descriptions au moins 100 fois :
> findFreqTerms ( tdm , lowfreq = 100)
[1] “modèles” ” api ” ” bayésien ” “outils”
[5] “données” “analyse” “basées” “paquet”
[9] “implémentation” “optimisation” “modèle” “aléatoire”
[13] “via” “les” “fichiers” “visualisation”
[17] “modélisation” “multivariée” “réseaux” “détection”
[21] “temps” “régression” “gène” “série”
[25] “fonctions” “échantillonnage” “prédiction” “clairsemées”
[29] “algorithme” “utilisant” “plusieurs” “dynamique”
[33] “distributions” “méthode” “estimation” “linéaire”
[37] “matrice” “robuste” “tests” “statistiques”
[41] “classification” “méthodes” “essais” “mélange”
[45] “généralisé” “simulation” “apprentissage” “survie”
[49] “test” “graphique” “interface” “sélection”
[53] “spatiale” “inférence” “clustering” “rapide”
[57] “fonction” “statistique” “” définit “” modélisation ”
[61] “distribution” “parcelles” “” client “” mixte ”
[65] “réseau” “” non paramétrique “” probabilité “” variable ”
Dans la liste précédente, nous pouvons voir que certains termes ne nous concernent pas. Si nous voulons nous en débarrasser, nous pouvons construire nos propres mots vides. Supposons que nous ne trouvions pas le paquet, the, via, using, ou des mots based, car ils ne sont pas pertinents pour notre propos :
> myStopwords <- c(‘the’, ‘via’, ‘package’, ‘based’, ‘using’)
Maintenant, enlevons ces mots de notre corpus :
> v <- tm_map(v, removeWords, myStopwords)
Supprimons maintenant les formes plurielles des noms. Pour ce faire, nous pouvons utiliser des algorithmes de stemming.
Les documents texte utilisent toujours différentes formes d’un mot afin de construire un sens cohérent du texte. Ce faisant, un mot peut prendre plusieurs formes, par exemple, envoyer, envoyer, envoyer, envoyer. Outre ce type de forme, il existe des ensembles de termes liés à des dérivations qui ont des significations analogues, tels que démocratie, démocratie et démocratisation. Il serait plus utile que les moteurs de recherche reconnaissent ces formes de mots et renvoient les documents contenant une autre forme du même mot. Pour ce faire, nous allons utiliser l’une des bibliothèques, appelée paquet Snowballc. Si la bibliothèque n’existe pas, nous savons comment l’installer, n’est-ce pas ?
wordStem prend en charge différentes langues et peut identifier la tige d’un vecteur de caractère. Voyons quelques exemples :
> wordStem(c(‘dogs’, ‘walk’, ‘print’, ‘printed’, ‘printer’, ‘printing’))
[1] “dog” “walk” “print” “print” “printer” “print”
Copiez les mots du corpus déjà existant dans un autre objet :
> d <- v
Ensuite, écrivez tous les mots dans les documents :
> v <- tm_map(v, stemDocument, language = “english”)
Ici, nous avons appelé la fonction stemDocument, qui encapsule la fonction wordStem du paquet Snowballc. Maintenant, nous allons appeler la stemCompletion fonction de notre répertoire copié. Ici, nous devons écrire notre propre fonction. L’idée est de scinder chaque document en mots par un espace, d’appliquer la fonction stemCompletion puis de concaténer les mots en phrases :
> stemCompletion2 <- function(x, dictionary) {
x <- unlist(strsplit(as.character(x), ” “))
x <- x[x != “”]
x <- stemCompletion(x, dictionary=dictionary)
x <- paste(x, sep=””, collapse=” “)
PlainTextDocument(stripWhitespace(x))
}
Maintenant, exécutons la fonction comme suit :
> v <- lapply(v, stemCompletion2, dictionary=d)
Cette étape utilise le processeur pendant environ 30 à 60 minutes. Vous pouvez donc suivre cette procédure ou attendre que l’opération soit terminée. Exécutez la commande suivante pour convertir en VCorpus :
> v <- Corpus(VectorSource(v))
> tdm <- TermDocumentMatrix(v)
> findFreqTerms(tdm, lowfreq = 100)
[1] “118” “164” “access” “author”
[5] “character” “content” “datetimestamp” “description”
[9] “heading” “hour” “isdst” “language”
[13] “list” “mday” “meta” “min”
[17] “model” “mon” “origin” “predict”
[21] “sec” “wday” “yday” “year”
[25] “api” “bayesian” “computation” “tool”
[29] “data” “analysing” “implement” “optim”
[33] “estimability” “random” “analyse” “file”
[37] “visual” “associate” “use” “multivariable”
[41] “network” “measure” “popular” “detect”
[45] “simulate” “time” “fit” “regression”
[49] “gene” “infer” “serial” “function”
[53] “process” “valuation” “sample” “plot”
[57] “sparse” “response” “algorithm” “design”
[61] “multiplate” “select” “dynamic” “distributed”
[65] “method” “effect” “linear” “matrix”
[69] “robust” “test” “map” “statistic”
[73] “classifcation” “read” “applicable” “mixture”
[77] “general” “learn” “survival” “graphic”
[81] “interface” “densities” “genetic” “spatial”
[85] “calculate” “cluster” “fast” “informatic”
[89] “studies” “object” “equating” “curvature”
[93] “variable” “set” “dataset” “utilities”
[97] “generate” “create” “database” “interact”
[101] “client” “mixed” “weight” “analyze”
[105] “system” “nonparametric” “structural” “tablature”
[109] “likelihood” “tree” “libraries” “correlated”
[113] “interva” “covariable”
Vérifions la densité de la matrice de termes du document :
> tdm<<TermDocumentMatrix (terms: 20202, documents: 12658)>>
Non-/sparse entries: 339239/255377677
Sparsity : 100%
Maximal term length: 33
Weighting : term frequency (tf)
Comme on peut le constater, la densité a augmenté. Cependant, nous pouvons voir qu’il existe encore des termes que nous ne voulons pas dans notre corpus. Nous pouvons affiner davantage jusqu’à atteindre les résultats souhaités.
En plus de ces résultats, nous pouvons construire TermDocumentMatrix :
> dtm<-TermDocumentMatrix(v)
> m<-as.matrix(dtm)
> v<-sort(rowSums(m),decreasing=TRUE)
> d<-data.frame(word=names(v),freq=v)
> head(d, 10)
word freq
character character 75961
list list 38009
language language 12697
description description 12686
meta meta 12668
content content 12667
origin origin 12663
year year 12662
min min 12660
sec sec 12659
Nous pouvons utiliser la bibliothèque RColorBrewer pour colorer notre graphique :
### Load the package or install if not present
if (!require(“RColorBrewer”)) {
install.packages(“RColorBrewer”)
library(RColorBrewer)
}
Et enfin :
> set.seed(1234)
> wordcloud::wordcloud(words = d$word, freq = d$freq, min.freq = 1,
+ max.words=200, random.order=FALSE, rot.per=0.35,
+ colors=brewer.pal(8, “Dark2″))
La sortie de l’extrait précédent devrait générer le modèle de nuage codé par couleur, semblable à ceci :
Nuage de mots du corpus raffiné
Si vous souhaitez tracer un graphique à barres des 10 premiers mots les plus fréquents, vous pouvez le tracer à l’aide du code suivant :
> barplot(d[1:10,]$freq, las = 2, names.arg = d[1:10,]$word,
+ col =”lightblue”, main =”Most frequent words”,
+ ylab = “Word frequencies”)
L’exécution de la commande précédente devrait générer le graphique suivant :
Diagramme à barres des 10 mots les plus fréquents
Le graphique montre que les mots les plus fréquents sont character, list, language, description, meta, content, origin, et year.
7.2.5 Résumé
Les données non structurées peuvent être trouvées partout. Malgré son omniprésence, il est très difficile d’extraire et de modéliser ces données à l’aide d’un système de gestion de base de données traditionnel. Cette complexité a été la force motrice pour développer un autre SGBD capable de gérer des ensembles de données non structurés. Dans ce chapitre, nous avons découvert Weka, KNIME et le langage de programmation R et discuté de la façon dont ils peuvent être utilisés dans la modélisation d’ensembles de données non structurés.
Dans le chapitre suivant, nous apprendrons comment diffuser des jeux de données et essayer de modéliser des données en streaming à l’aide de Python et d’autres outils.
8 Modélisation avec des données en streaming
Les modèles de données traitent de nombreux types de formats de données. Les étudiants partent souvent du principe que le format des données est identique à celui de leur modèle logique. Dans ce chapitre, l’utilisateur aura l’occasion d’explorer la différence entre le modèle de données et le format de données. Le concept de transmission de données en continu, la raison pour laquelle la transmission de données en continu est différente, ainsi que l’importance et les implications de la transmission de données en continu feront également partie intégrante de la discussion de ce chapitre. Dans ce chapitre, nous aborderons les sujets suivants :
- Explorez différents types de modèles de données et de formats de données avec leurs différences
- Résumer les caractéristiques clés d’un flux de données
- Identifier les exigences des systèmes de streaming de données
- Comprendre le flux de données, son importance et ses implications
- Explorez des exemples concrets de transmission de données en continu
8.1 Flux de données et modèle de données avec format de données
Considérez le fichier CSV indiquée dans l’extrait de code suivant. Le jeu de données est généré à des fins de maquette. Le fichier CSV suivant contient les champs : id, first_name, last_name, email, gender, ip_address, City, et Credit Card Type :
id,first_name,last_name,email,gender,ip_address,City,Credit Card Type
1,Hasty,Speechley,hspeechley0@nhs.uk,Male,163.168.85.148,Namasuba,jcb
2,Wendell,Gisby,wgisby1@wikia.com,Male,216.197.63.195,Pitalito,jcb
3,Kalle,Delooze,kdelooze2@bloglines.com,Male,79.24.89.239,Rongcheng,diners-club-international
4,Renata,Colbertson,rcolbertson3@shinystat.com,Female,90.61.186.89,Pisaras,mastercard
5,Alexandro,Penketh,apenketh4@pcworld.com,Male,68.106.188.165,Denver,jcb
6,Stacee,Klas,sklas5@sina.com.cn,Male,134.195.11.3,Mehron,jcb
7,Ron,Mateja,rmateja6@java.com,Male,190.32.1.172,As Sawdā,jcb
8,Delcina,Meeking,dmeeking7@mac.com,Female,197.137.160.159,Kunčice pod Ondřejníkem,bankcard
9,Wain,Lakenden,wlakenden8@nba.com,Male,221.12.205.207,Tangnan,jcb
10,Meagan,Glendzer,mglendzer9@unblog.fr,Female,154.211.74.91,Ash Shaykh Zuwayd,jcb
11,Opalina,Averill,oaverilla@shareasale.com,Female,56.94.239.67,Mambago,jcb
12,Jesse,Simco,jsimcob@list-manage.com,Female,195.134.25.57,Salcedo,maestro
13,Olly,Raeside,oraesidec@joomla.org,Male,18.61.169.146,Wangmo,maestro
14,Arie,Hogbourne,ahogbourned@amazon.co.jp,Male,166.248.14.22,Yanghu,jcb
15,Lin,Mableson,lmablesone@amazon.co.jp,Female,211.178.21.41,Walton,jcb
16,Leslie,Jeanesson,ljeanessonf@sfgate.com,Female,230.33.86.14,Muqi,diners-club-enroute
17,Mathias,Davenell,mdavenellg@cargocollective.com,Male,12.144.241.73,Ungca,jcb
18,Daphna,Abramamovh,dabramamovhh@wisc.edu,Female,82.147.185.165,Kailahun,jcb
19,Bucky,Blomfield,bblomfieldi@hhs.gov,Male,107.140.105.147,Ambato Boeny,diners-club-us-ca
20,Vail,Wackly,vwacklyj@princeton.edu,Male,156.230.62.14,Hankasalmi,jcb
21,Gael,Mandel,gmandelk@shareasale.com,Female,247.219.47.13,Skiáthos,china-unionpay
22,Rossy,Laing,rlaingl@google.it,Male,150.8.27.209,Pizhma,china-unionpay
23,Berrie,Scholte,bscholtem@hud.gov,Female,20.71.184.97,Gujun,bankcard
24,Freida,Sollitt,fsollittn@home.pl,Female,25.180.120.148,Yege,maestro
25,Gleda,O’ Byrne,gobyrneo@is.gd,Female,195.180.230.21,Shimen,switch
26,Garland,Veevers,gveeversp@umich.edu,Female,114.152.249.90,Photharam,jcb
27,Giff,Waskett,gwaskettq@4shared.com,Male,63.203.179.23,Jimsar,jcb
28,Isidoro,Bryenton,ibryentonr@t.co,Male,30.101.118.54,Dugongan,jcb
29,Millie,Trunkfield,mtrunkfields@topsy.com,Female,220.113.179.238,Samho-rodongjagu,diners-club-carte-blanche
30,Shayne,Mantrip,smantript@wikimedia.org,Female,101.220.213.129,Akron,jcb
31,Min,Roggero,mroggerou@nationalgeographic.com,Female,99.122.173.119,Calvinia,jcb
32,Chas,Maddyson,cmaddysonv@cnet.com,Male,128.0.94.29,Huancheng,diners-club-international
33,Allyn,Whenman,awhenmanw@indiatimes.com,Female,49.60.125.164,Ramalhal,mastercard
34,Rafaelia,O’Leagham,roleaghamx@webmd.com,Female,111.58.12.10,Tijão,jcb
35,Sylvia,Sand,ssandy@senate.gov,Female,32.122.103.182,Fálanna,visa-electron
36,Kerk,Roberds,kroberdsz@topsy.com,Male,238.151.217.216,Pruzhany,diners-club-us-ca
37,Derek,Corbett,dcorbett10@spiegel.de,Male,126.156.75.68,Václavovice,mastercard
38,Maurizia,Chasteau,mchasteau11@samsung.com,Female,165.212.42.138,Francisco Sarabia,diners-club-carte-blanche
39,Gabriele,Overal,goveral12@liveinternet.ru,Male,141.112.9.226,Kendung Timur,jcb
40,Tanitansy,Hukins,thukins13@ed.gov,Female,181.192.169.43,Aitape,jcb
41,Flo,Allkins,fallkins14@reuters.com,Female,146.82.152.88,Hafnarfjörður,mastercard
42,Aldis,Schulze,aschulze15@netvibes.com,Male,88.77.243.237,Pawitan,bankcard
43,Kenton,Taig,ktaig16@parallels.com,Male,138.180.247.81,Mustvee,diners-club-enroute
44,Ware,Islep,wislep17@ihg.com,Male,208.116.121.128,Ban Talat Nua,diners-club-enroute
45,Albrecht,Archley,aarchley18@eventbrite.com,Male,129.239.2.81,Eskilstuna,jcb
46,Nina,Brierton,nbrierton19@soup.io,Female,149.8.146.113,Baardheere,jcb
47,Rebecka,Pavlasek,rpavlasek1a@blogtalkradio.com,Female,15.60.233.61,Baolong,jcb
48,Carie,Kimmel,ckimmel1b@cbsnews.com,Female,223.159.67.155,Torzhok,visa
49,Carolina,Duplan,cduplan1c@si.edu,Female,46.8.15.131,Beihe,jcb
50,Margarette,Anear,manear1d@forbes.com,Female,41.133.57.17,Daba,solo
Nous savons que CSV signifie que le terme entre deux virgules est la valeur d’un attribut. Mais quelle est cette valeur ? Une notion commune est qu’il s’agit du contenu d’une relation unique où chaque ligne est un enregistrement qui est un tuple et la i- ème valeur du fichier CSV correspond au i- ème attribut, comme suit :
Figure 7.1: Données CSV présentées sous forme de tableau
Dans l’exemple précédent, le format de données est CSV. Maintenant, si nous regardons l’exemple différent :
Jack, profession, plumber, age, 35, wife, Jill
Jill, profession, baker, age, 32, husband, Jack
Peter, profession, auto mechanic, age, 36, friend, Jack
Il n’y a pas de différence entre le fichier CSV dans le premier extrait et le second extrait. Mais si nous générons le modèle à partir des secondes données CSV, nous voyons le diagramme suivant qui montre que CSV ne signifie pas toujours relationnel :
Un modèle généré à partir de l’extrait de code CSV
8.2 Pourquoi le streaming de données est-il différent ?
Les mégadonnées sont composées de bases de données volumineuses et de millions, voire de milliards de fichiers de documents. Le traitement par lots est l’un des moyens possibles de générer des informations à partir de ces jeux de données. L’une des approches classiques du traitement par lots s’appelle le paradigme MapReduce de Hadoop. Le temps de traitement peut durer de quelques minutes à plusieurs heures, voire davantage. Tout dépend de la taille du travail. Mais si nous pensons aux informations en temps réel, nous nous intéressons davantage à la transmission en continu des données.
Les données en continu (streaming de données) peuvent être définies comme une séquence de signaux cohérents codés numériquement utilisés pour envoyer ou recevoir des informations en cours de transmission.
Formellement, il peut être défini comme toute paire ordonnée ( S , Δ ) ( S , Δ ), où S est une séquence de tuples et Δ est une séquence d’intervalles temps réel positifs.
Pour humaniser la définition, considérons le diagramme suivant :
Convoyor Belt
Pour comprendre cette définition, nous pouvons considérer la transmission de données en continu comme un tapis roulant, comme illustré dans le diagramme précédent. Nous pouvons supposer que les éléments sur la ceinture sont des paquets de données en cours de transmission. Si nous avons une machine de tri au bout de la ceinture qui accepte ou rejette les articles en fonction de certaines conditions, nous pouvons considérer cela comme un scénario d’analyse en continu et en temps réel. Si nous remplaçons la caméra couleur par des algorithmes d’apprentissage automatique, cela montrerait à quoi ressemblerait un scénario d’analyse en continu en temps réel dans un grand ensemble de données.
8.2.1 Cas d’utilisation du traitement de flux
Le streaming est utilisé dans de nombreux scénarios différents. La plupart de ces cas d’utilisation traitent de la détection de problèmes et nous avons une réponse raisonnable pour améliorer le résultat. Voici quelques cas d’utilisation où le traitement de flux a été utilisé avec succès:
- Mouvement et prévision des cours financiers
- Gestion du service d’alimentation solaire en temps réel
- Surveillance de ligne de production
- Visioconférence et discussion
- Diffusion du signal audio
- Musique en streaming
- Streaming de données de réalité virtuelle
- Optimisations de la chaîne d’approvisionnement
- Détection, surveillance et prévention des fraudes et des intrusions
- La plupart des applications pour appareils intelligents
- Surveillance du trafic
- Promotions et publicité sensibles au contexte
- Surveillance du système informatique et du réseau
- Traitement des données géospatiales
Par exemple, FlightStats est une application qui traite environ 60 000 000 événements de vol hebdomadaires entrés dans leur système d’acquisition de données, puis les transforme en informations en temps réel pour les compagnies aériennes et des millions de voyageurs du monde entier.
8.2.2 Qu’est-ce qu’un flux de données ?
Un flux est défini comme une séquence d’éléments de données ou d’enregistrements éventuellement non liés, qui peuvent ou non être liés ou corrélés les uns aux autres. Chaque flux de données est généralement horodaté et, dans certains cas, géolocalisé. Les données en continu sont parfois appelées données d’événements, car chaque élément de données est traité comme un événement individuel dans une séquence synchronisée.
8.2.3 Systèmes de transmission de données
Les systèmes de transmission de données en continu sont un système informatisé conçu pour gérer et traiter les données en mouvement. La taille, la variété et la rapidité des mégadonnées ajoutent de nouveaux défis à ces systèmes. Ces systèmes sont conçus pour gérer des calculs relativement simples, tels qu’un enregistrement à la fois ou un ensemble d’objets dans une courte fenêtre temporelle contenant les données les plus récentes :
Illustration du système de transmission de données en continu
Dans un système de traitement de données, les calculs sont effectués en temps quasi réel, parfois en mémoire, et en tant que calculs indépendants. Les composants de traitement sont souvent abonnés à un système ou à une source de flux de manière non interactive. Cela signifie qu’ils ne renvoient rien à la source et n’établissent pas non plus d’interactions avec la source. Le concept de pilotage dynamique implique de modifier de manière dynamique les prochaines étapes ou la direction d’une application via un processus de calcul continu utilisant la diffusion en continu. Dynamic steering (pilotage dynamique) fait souvent partie de la gestion et du traitement du flux de données. Une voiture autonome est un exemple parfait d’application de pilotage dynamique, mais toutes les applications de transmission de données en continu entrent dans cette catégorie, telles que les jeux en ligne. Amazon Kinesis et d’autres projets Apache open source, tels que Storm, Flink, Spark Streaming et Samza , sont des exemples de systèmes de diffusion de données volumineuses. De nombreuses autres entreprises proposent également des systèmes de diffusion en continu de données volumineuses, qui sont fréquemment mis à jour en réponse à l’évolution rapide de la nature de ces technologies.
8.2.3 Comment fonctionne le streaming
Il existe plusieurs façons de réaliser ce processus et chacune comporte ses propres avantages et inconvénients. La première approche s’appelle le traitement de flux natif . Dans le processus de streaming natif, les événements sont traités au fur et à mesure qu’ils entrent dans l’existence, les uns après les autres. Cela se traduit par une très faible latence. Si un événement est successivement grand, il empêche le traitement d’autres événements. En plus de cela, cette technique est très coûteuse en calcul.
Une autre approche s’appelle le traitement par micro-lots . Cette technique fait le compromis opposé. Il divise les événements entrants en plusieurs lots, par heure d’arrivée ou jusqu’à ce qu’un lot ait atteint une taille limite. Le fractionnement réduit le coût de traitement du calcul. Cependant, le processus introduit une latence plus élevée. Qu’il s’agisse d’un traitement de flux natif ou d’un traitement par micro-batch, ils impliquent des étapes distinctes d’ingestion, de traitement et d’analyse de données, répertoriées comme suit:
- Ingestion de données ou collecte de données
- Traitement de l’information
- Analyse de données ou valeur dérivée
8.2.4 Collecte de données
La collecte de données, ou ingestion de données, est le processus de consommation de données provenant d’une source. Différentes méthodes sont utilisées pour utiliser les données. Par exemple, de nombreux dispositifs de détection sont utilisés dans le domaine de la santé, tels que la smartwatch, la montre Empathica E4 et les casques de réalité virtuelle tels qu’Oculus Go. Ces captations sont produites à intervalles fréquents. Les données d’intervalle sont échantillonnées, puis envoyées au serveur requis pour un prétraitement ou une analyse plus poussée.
8.2.5 Traitement de l’information
Les données stockées ou traitées doivent être traitées. Diverses plateformes de streaming open source et propriétaires pouvant être utilisées à cette fin. Apache Storm et Apache Spark Streaming sont deux des options open source les plus populaires.
8.2.6 Analyse des données
C’est l’étape où les plates-formes informatiques sont sélectionnées pour l’analyse des données. L’un des critères pouvant aider à la sélection concerne les exigences du modèle de traitement ou du type d’algorithme d’apprentissage machine à appliquer.
8.3 Importance et implications de la transmission en continu de données
Les données sont précieuses dans toutes les organisations. La transmission de données en continu, contrairement à d’autres données, contient toute la vérité et ce traitement de données est rentable dans la plupart des scénarios. Dans cette section, nous allons explorer l’importance et les implications de la transmission en continu des données.
8.3.1 Besoins en traitement de flux
Il a été prouvé que les mégadonnées tiraient les enseignements des données utilisées avec succès dans le domaine de la veille stratégique et de l’amélioration du système existant. Certaines de ces idées ont des valeurs beaucoup plus élevées peu de temps après que cela se soit produit. Le traitement de flux cible de tels scénarios. Certaines des raisons d’utiliser le traitement de flux sont les suivantes :
- Un flot continu d’événements se produit dans la vie réelle. La diffusion en continu est nécessaire pour traiter ces ensembles de données.
- Dans le cas où le volume de données est énorme, il est plus flexible de le diffuser immédiatement que de le stocker.
- Le traitement en continu permet le chargement du hangar.
- Nous avons besoin de la diffusion en direct des données dans de nombreux scénarios, tels que la vidéoconférence ou la conférence, la diffusion de musique et la diffusion de données volumineuses. Avec ces énormes quantités de données en streaming disponibles, nous avons besoin d’un processus tolérant aux pannes pour la diffusion sur Internet.
8.3.2 Défis avec le streaming de données
Le traitement de flux de données fonctionne sur deux couches : la couche de stockage et la couche de traitement. La couche de stockage doit être cohérente, efficace, rapide et économique. La couche de traitement utilise beaucoup de données de la couche de stockage et exécute divers calculs sur ces données. En plus de cela, la couche de traitement est responsable des notifications et des alertes. Il est très difficile de maintenir ces caractéristiques d’évolutivité, la durabilité des données et la tolérance aux pannes dans ces deux couches.
8.3.2 Solutions de transmission de données en continu
Il existe plusieurs solutions disponibles sur le marché pour travailler sur des données en continu. Amazon Kinesis Streams, Amazon Kinesis Firehose et Apache Spark Streaming sont parmi les solutions les plus couramment utilisées. Spark Streaming ( http://spark.apache.org/streaming/ ) est l’une des technologies de streaming les plus récentes. La structure est facile à utiliser et conçue pour l’évolutivité et les applications de diffusion en continu à tolérance de pannes. Les caractéristiques les plus frappantes d’Apache Spark Steaming sont sa facilité d’utilisation, sa tolérance aux pannes, son intégration à Spark et sa grande communauté.
8.2 Explorer les données de capteur en continu à partir de l’API Twitter
Dans cette section, nous allons utiliser l’API de streaming de Twitter pour obtenir des tweets. Tout d’abord, nous devons créer une application Twitter. Cela peut être fait en suivant les étapes suivantes :
- Allez sur https://apps.twitter.com/ .
- Connectez-vous en utilisant votre compte Twitter.
- Inscrivez-vous sur https://twitter.com/signup si vous n’avez pas de compte Twitter.
- Cliquez sur Create New App.
- Remplissez les détails de votre application et créez l’application.
- Notez que consumer_key et consumer_secret sont déjà générés pour vous. Copiez-les et exécutez les commandes suivantes en remplaçant les variables soulignées par vos valeurs uniques :
$ echo consumer_key >> auth
$ echo consumer_secret >> auth
- Cliquez sur Create my access token.
- Notez que access_token et access_token_secret apparaissent maintenant sur votre écran.
- Copiez-les et exécutez les commandes suivantes en remplaçant les variables soulignées par vos valeurs uniques :
$ echo access_token >> auth
$ echo access_token_secret >> auth
- Votre fichier d’authentification, nommé auth , est prêt avec vos informations d’identification pour une utilisation avec LiveTweets.py .
8.2.1 Analyser les données en streaming
Regardons les étapes suivantes:
- Ouvrez l’interface de ligne de commande de votre choix.
- Arrivé au répertoire requis où vous avez téléchargé le fichier de code.
cd Downloads/HandsOnBigData/CH08/json
- Utilisons le script d’ici pour afficher le contenu des tweets en temps réel en exécutant le script LiveTweets.py . Pour exécuter le script LiveTweets.py, exécutez le script suivant :
./LiveTweets.py president
La sortie affiche deux colonnes – la première est l’horodatage du tweet et la seconde le texte du tweet:
L’extrait de code donné pour LiveTweets.py est donné comme suit :
#!/usr/bin/python
import json
import sys
from tweepy import OAuthHandler, Stream
from tweepy.streaming import StreamListener
class TweetStreamListener(StreamListener):
def on_data(self, data):
tweet = json.loads(data)
if “created_at” in tweet:
print tweet[“created_at”][4:-10] + ” ” + tweet[“text”][:70] + “\n”
return True
def on_error(self, status):
print status
auth = []
f = open(“auth”, “r”)
for line in f:
auth.append(line.strip())
f.close()
try:
listener = TweetStreamListener()
auth_key = OAuthHandler(auth[0], auth[1])
auth_key.set_access_token(auth[2], auth[3])
live_twitter_stream = Stream(auth_key, listener)
live_twitter_stream.filter(track=[sys.argv[1]])
except KeyboardInterrupt, e:
sys.exit()
Lorsque vous avez suffisamment de tweets et pensez que vous avez terminé, appuyez sur Ctrl + C pour arrêter le script. Nous pouvons également utiliser le script pour voir des tweets contenant certains mots. Exécutons le LiveTweets.py script pour voir les tweets qui incluent le mot time :
./LiveTweets.py time
- Nous pouvons produire un graphique affichant la fréquence des tweets incluant un mot particulier. Exécutez PlotTweets.py president pour créer l’intrigue du mot president :
./PlotTweets.py president
La sortie est montrée comme suit :
Le graphique précédent montre la variation de temps et le nombre de tweets par seconde incluant le mot president. Nous pouvons voir que nous avons eu 11 tweets par seconde. Pour fermer, cliquez dans la fenêtre Terminal et appuyez sur Enter. L’extrait de code donné pour PlotTweet.py est donné comme suit :
#!/usr/bin/python
import json
import matplotlib.pyplot as plt
import sys
from tweepy import OAuthHandler, Stream
from tweepy.streaming import StreamListener
class TweetStreamListener(StreamListener):
def __init__(self):
self.max_sec = 30
fig = plt.figure()
self.ax = fig.add_subplot(111)
self.ax.set_autoscalex_on(False)
self.ax.set_xlim(0, self.max_sec)
self.ax.set_autoscaley_on(True)
#self.ax.set_ylim(minVal,maxVal)
plt.xlabel(‘Seconds’)
plt.ylabel(‘Count’)
fig.show()
self.x = []
self.y = []
self.count = 0
self.last_ts = “0”
def on_data(self, data):
tweet = json.loads(data)
if “created_at” in tweet:
ts = tweet[“created_at”][11:-11]
if ts == self.last_ts:
self.count = self.count + 1
else:
#print(self.count)
self.x.append(len(self.x))
self.y.append(self.count)
lines = plt.plot(self.x,self.y)
plt.setp(lines,color=’b’)
plt.draw()
self.count = 1
self.last_ts = ts
if len(self.x) > self.max_sec:
return False
return True
def on_error(self, status):
print status
auth = []
f = open(“auth”, “r”)
for line in f:
auth.append(line.strip())
f.close()
try:
listener = TweetStreamListener()
auth_key = OAuthHandler(auth[0], auth[1])
auth_key.set_access_token(auth[2], auth[3])
live_twitter_stream = Stream(auth_key, listener)
live_twitter_stream.filter(track=[sys.argv[1]])
raw_input(“Press <enter> to quit.”)
except KeyboardInterrupt, e:
sys.exit()
L’extrait de code précédent trace le graphique des tweets en direct. Nous utilisons matplotlib pour tracer le graphique. Pour obtenir le flux Twitter, nous utilisons la bibliothèque tweepy. La bibliothèque fournit des fonctions permettant d’authentifier et d’obtenir les données du flux. Nous avons créé une classe python et l’avons appelée à l’aide de la ligne de commande.
8.3 Résumé
Dans ce chapitre, nous avons eu l’occasion d’explorer différents formats de données, notamment JSON, CSV et XML. Ces formats de données sont très importants à prendre en compte lors du partage de données. Nous avons également eu l’occasion d’explorer divers modèles de données, formats de données et le concept de streaming de données, ainsi que son importance et ses implications. Enfin, nous avons exploré un exemple réel de streaming de données.
Dans le chapitre suivant, nous allons explorer les capteurs de streaming de données et comprendre comment ils peuvent être utilisés dans la vie réelle.
9 Flux de données de capteurs en continu
Le streaming de données devient omniprésent. Les données de capteur sont présentes partout, y compris dans les battements de cœur, les ondes cérébrales, l’activité électrodermale de la peau, les signaux audios de l’homme, les données de température, etc. Étant donné que les données sont en continu, ces données de capteur nécessitent une approche complexe. Dans cette leçon, vous allez acquérir de l’expérience dans l’utilisation de diverses formes de transmission en continu de données de capteur, ainsi que dans l’analyse de données de capteur.
Dans ce chapitre, nous aborderons les sujets suivants :
- Exploration des données de capteur en continu
- Lacs de données et comment les utiliser dans le traitement par lots
- La différence entre schéma sur écriture et schéma sur lecture
- Capteur de température, et visualisation avec Python
9.1 Données des capteurs
Les données de capteur sont omniprésentes et peuvent être utilisées dans divers domaines, notamment l’industrie de la santé, la prévision météorologique, l’analyse sonore et la diffusion vidéo en continu. Explorons certaines des utilisations des données de capteur, comme suit :
- Capteurs de santé : de nombreuses institutions médicales enregistrent les signes vitaux du patient en temps réel. Ces signes vitaux comprennent la fréquence cardiaque, les activités électro dermiques, les ondes cérébrales, la température et plus encore. Lorsqu’elles sont collectées, ces données de capteur en temps réel sont énormes et peuvent être considérées comme des données volumineuses. Les technologies de l’information et des communications peuvent utiliser ces données pour diagnostiquer les patients.
- Données météorologiques : La diffusion en temps réel des données météorologiques est effectuée par de nombreux satellites, afin de recueillir les signes vitaux de la météo. Ces données sont utilisées dans les prévisions météorologiques.
- Données du capteur from IoT : Beaucoup de données du capteur peuvent être collectées à partir personnalisées Internet des objets (IoT), comme le Raspberry Pi, montres Apple, les smartphones, les montres de santé, et ainsi de suite. Ces données peuvent être diffusées en temps réel, ce qui les rend disponibles pour certains serveurs.
9.2 Lacs de données
Avec la diffusion en continu de données massives d’origines diverses, dans des formats et des modèles variés, et à des vitesses différentes, il n’est pas surprenant que nous devions être en mesure d’intégrer ces données dans un système de stockage rapide et évolutif, suffisamment flexible pour en servir de nombreux futurs) processus analytiques. En ce qui concerne un système de stockage aussi dynamique, les systèmes de stockage traditionnels ne répondent pas aux exigences du Big Data pour les applications de traitement en continu et de traitement par lots. C’est là que le concept de data lake entre en jeu.
Nous pouvons stocker toutes les données structurées et non structurées à différentes échelles, dans un référentiel centralisé. Un tel référentiel est appelé un lac de données. Nous pouvons stocker nos données telles quelles, sans avoir à les structurer ou à les prétraiter. En plus de cela, nous pouvons exécuter divers types d’analyses et de visualisations, et même des analyses en temps réel.
9.2.1Différences entre les lacs de données et les entrepôts de données
Le principal objectif des entrepôts de données et des Data Lakes est le stockage. Cependant, la différence entre les deux réside dans la manière dont les données sont stockées. Cela concerne la manière dont ils permettent l’accès aux utilisateurs finaux et la manière dont un schéma est créé, mis à jour et détruit.
Remarque :
Pour analyser certaines différences communes entre les entrepôts de données et les lacs de données, reportez-vous à https://aws.amazon.com/big-data/what-is-a-data-lake/.
L’analyse d’une source de données et la compréhension du profil de processus métiers lors du développement d’un entrepôt de données prennent beaucoup de temps. Ce processus aboutit à un modèle de données structuré. Dans un lac de données, toutes les données sont conservées, peu importe la quantité utilisée. Ces données sont mises à la disposition des utilisateurs, qui peuvent les utiliser à tout moment et peuvent y effectuer des analyses commerciales. Les lacs de données prennent en charge tous les types de données.
9.2.2 Comment fonctionne un lac de données
Le diagramme suivant montre comment fonctionne un lac de données typique. Les données sont chargées à partir de leur source. Ensuite, il stocke les données dans son format natif, jusqu’à ce qu’il soit requis. Une fois les données requises, l’application peut les lire librement et leur ajouter une structure. C’est ce que nous appelons schéma sur lecture :
Fonctionnement des lacs de données
Dans un entrepôt de données traditionnel, les données sont chargées dans l’entrepôt après avoir été transformées en un format bien défini. C’est ce que nous appelons schéma sur écriture. Toute application utilisant les données doit connaître ce format. Dans cette approche, les données ne sont pas chargées dans l’entrepôt, sauf si elles sont utilisées. Cependant, l’approche basée sur le schéma en lecture des data lacs garantit que toutes les données sont stockées pour une utilisation ultérieure.
9.4 Exploration de capteur de données continue en station
Mettons nos mains dans le bain de données fumantes. En supposant que votre machine virtuelle soit sur et prête à être utilisée, commençons par ces étapes :
- Ouvrez un shell terminal. Accédez au répertoire du capteur . Dans ce cas, supposons que vous les ayez téléchargés dans le dossier Téléchargements , comme suit:
cd Téléchargements / HandsOnBigData / CH09 / capteur
- Voir les données de la station météo en streaming. Exécutez stream-data.py pour voir les données en streaming de la station météo :
./stream-data.py
L’exécution du script précédent générera une sortie similaire à celle-ci :
Les mesures apparaissent car elles sont produites par la station météorologique. En regardant l’horodatage, nous pouvons voir que les données arrivent environ toutes les secondes. De plus, différents types de mesure sont produits à différentes fréquences. Par exemple, R1 est mesuré toutes les secondes, mais R2 est moins fréquent. L’extrait de code suivant se connecte à la station météo et récupère les données en streaming :
#!/usr/bin/python
import socket
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((‘rtd.hpwren.ucsd.edu’, 12020))
for i in range(0, 60):
d = s.recv(1024)
p = d.split(‘\t’, 2)
print “{0}: {1}”.format(i, p[2])
s.close()
- Créez un tracé des données en streaming. Nous pouvons tracer les données en streaming en exécutant stream-plot-data.py, comme suit :
./stream-plot-data.py Sm
Le code pour tracer les données en continu est le suivant :
#!/usr/bin/python
import sys
import re
import time
import matplotlib.pyplot as plt
import matplotlib.dates as mdate
from pytz import timezone
x = []
y = []
file = open(sys.argv[1], ‘r’)
for line in file:
parts = re.split(“\s+”, line)
data = parts[1].split(“,”)
for field in data:
match = re.match(sys.argv[2] + ‘=(\d+\.\d+).*’, field)
if match:
timestamp = float(parts[0])
x.append(timestamp)
#time_parts = time.localtime(timestamp)
y.append(float(match.group(1)))
file.close()
#fig, ax = plt.subplots()
fig = plt.figure()
ax = fig.add_subplot(111)
secs = mdate.epoch2num(x)
ax.plot_date(secs, y)
plt.xlabel(‘time’)
plt.ylabel(sys.argv[2])
date_formatter = mdate.DateFormatter(‘%H:%M.%S’, tz=timezone(‘US/Pacific’))
ax.xaxis.set_major_formatter(date_formatter)
fig.autofmt_xdate()
plt.show()
À partir de ce diagramme, nous pouvons voir que le graphique est mis à jour moins fréquemment que le premier graphique, car les mesures de la température de l’air sont produites moins fréquemment. Pour tracer le graphique, nous avons utilisé la bibliothèque matplotlib. Pour formater l’heure et la date, nous avons utilisé la bibliothèque de timezone :
Le graphique précédent montre la vitesse moyenne du vent (Sm) et est mis à jour chaque fois qu’une nouvelle mesure est générée. Le tracé est mis à jour toutes les secondes, au fur et à mesure que de nouvelles données sont placées dans la pile.
9.3 Résumé
Les données des capteurs sont très importantes, car elles contiennent des informations très sensibles, telles que la fréquence cardiaque du patient ou la température d’une personne malade. La perte de ces données peut entraîner une erreur de prédiction ou d’analyse des données. Dans ce chapitre, vous avez appris à utiliser les données de capteur en streaming. Nous avons discuté de ce que sont les lacs de données et de la façon dont ils peuvent permettre le traitement par lots de données en streaming.
Dans le chapitre suivant, nous explorerons les différents concepts et approches de la gestion des mégadonnées.
10 Concept et approches de la gestion des données volumineuses
Ce chapitre traite de l’exploration de divers systèmes de gestion de base de données (SGBD) et d’approches du Big Data non basées sur un SGBD. Il met également l’accent sur les avantages de l’utilisation d’un SGBD par rapport au système de fichiers traditionnel, des différences entre les systèmes de fichiers parallèles et distribués et du SGBD de style MapReduce. Dans ce chapitre, nous aborderons les sujets suivants :
- Divers avantages de l’utilisation d’un SGBD par rapport au système de fichiers traditionnel
- Différences entre un système de fichiers parallèle et distribué
- SGBD de style MapReduce
10.1 Approche du Big Data non basée sur le SGBD
Dans ce chapitre, nous nous concentrerons sur les problèmes centraux du traitement et de la gestion des données à grande échelle, ainsi que sur les cas où nous devrions utiliser un SGBD pouvant effectuer des opérations parallèles et non sur les systèmes de style Hadoop ou Yarn. Dans cette section, nous allons aborder deux approches opposées de la gestion d’un grand volume de données, de systèmes de fichiers et de SGBD.
10.1.1 Systèmes de fichiers
L’approche orientée système de fichiers est la méthode traditionnelle utilisée au tout début du traitement des données. Cependant, plusieurs applications traitant de jeux de données simples et petits utilisent cette approche même aujourd’hui. Les données sont stockées et traitées à l’aide de fichiers distincts dans cette approche. Par exemple, chaque utilisateur définit et implémente ses propres fichiers requis pour une application particulière. L’un des cas d’utilisation consiste à savoir comment les bureaux de notation enregistrent le dossier de chaque élève et ses notes. Chaque fichier contient des informations sur un élève unique. De la même manière, un service de comptabilité peut conserver des fichiers distincts pour chaque étudiant en fonction de leurs frais. Ceci donne un aperçu de la façon dont la redondance des données peut être l’un des problèmes majeurs ici. En raison de cette redondance, de nombreux espaces de stockage sont gaspillés. Dans la section suivante, nous allons explorer certains des problèmes que nous pouvons rencontrer dans les systèmes de traitement de fichiers.
10.1.2 Problèmes de traitement de fichiers
Le traitement de fichiers convient à de nombreux systèmes d’information et constitue depuis de nombreuses années l’un des piliers de l’industrie informatique. Cependant, il a quelques problèmes et limitations. Celles-ci sont résumées comme suit :
- Redondance des données : dans une approche orientée système de fichiers, le même élément de données est souvent incorporé dans de nombreux fichiers. Cette répétition des mêmes éléments de données dans plusieurs fichiers est considérée comme une redondance des données. La redondance des données gaspille de l’espace de stockage et augmente le coût de la mise à jour des données communes.
- Problèmes d’intégrité des données : dans une approche orientée fichier, la validité des données ne peut pas être vérifiée. Toutes les données peuvent être ajoutées à un fichier. Il n’y a pas de restriction pour les données au moment de la saisie. Par conséquent, l’intégrité ne peut pas être imposée (rendue obligatoire). Par exemple, le champ de nom, qui accepte uniquement les alphabets, accepte également les données numériques si l’approche fichier est utilisée, bien qu’il ne s’agisse pas des données valides pour ce champ.
- Incohérence : la mise à jour ou les modifications apportées à un fichier ne sont pas répercutées dans les autres fichiers associés. Ainsi, les informations ne restent pas automatiquement cohérentes lors de l’édition de données dans un fichier.
- Problème de partage : dans le système de traitement de fichiers, les données ne peuvent pas être partagées. Si quelqu’un utilise un fichier, les autres ne peuvent pas partager ce fichier.
- Manque d’indépendance du programme / des données : dans une approche orientée fichier, le programme d’application contient généralement des formats de données qui définissent avec précision chaque champ de données à traiter. Cela a souvent pour résultat que différents fichiers ont le même élément de données stocké en utilisant des formats de données différents. La dépendance des données survient lorsque les données dépendent de l’application. En raison d’un problème de dépendance des données, lorsqu’il est nécessaire d’ajouter, de supprimer ou de modifier des formats de données, le programme d’application doit également être modifié. En d’autres termes, toute modification de la structure d’un fichier peut nécessiter la modification de tous les programmes ayant accès à un fichier.
- Flexibilité limitée de la sécurité des données : une approche axée sur les fichiers offre une sécurité des données au niveau des fichiers. Autrement dit, les restrictions d’accès aux données ne peuvent être appliquées que pour le fichier entier, pas pour un enregistrement individuel ou le champ d’un élément de données.
10.2 Approche basée sur les SGBD pour le Big Data
Dans l’approche de la base de données, un seul référentiel de données est géré, défini une fois puis consulté par différents utilisateurs. Une base de données est une collection autodescriptive d’enregistrements intégrés. Il est autodescriptif, car le système de base de données contient non seulement la base de données elle-même, mais également une définition complète de la structure et des contraintes de la base de données. Cette définition est stockée dans le catalogue de SGBD. Les enregistrements sont intégrés car une base de données contient plusieurs fichiers (généralement appelée table dans le traitement de la base de données) et les enregistrements de ces tables sont traités en fonction de leurs relations.
Dans le traitement de la base de données, le SGBD sert d’intermédiaire entre l’utilisateur ou le programme d’application et la base de données. Un SGBD est un système logiciel à usage général qui facilite les processus de définition, de construction, de manipulation et de partage de la base de données entre les différents utilisateurs et applications.
10.2.1 Avantages du SGBD
Après avoir pris connaissance des problèmes liés au traitement de fichiers, nous allons dans cette section explorer certaines des fonctionnalités de l’approche par base de données et leurs avantages par rapport aux systèmes traditionnels.
10.2.2 Langage de requête déclaratif (DQL)
SQL est un exemple de langage de requête déclaratif, dans lequel les utilisateurs peuvent exprimer les données à récupérer sans avoir besoin de savoir comment fonctionne le moteur. Les utilisateurs sont tenus de donner des instructions générales sur la tâche à exécuter plutôt que de spécifier la manière de la réaliser.
10.2.3 Indépendance des données
Les applications créées sur un SGBD n’ont pas besoin de s’inquiéter des formats et des emplacements de stockage. Le terme « indépendance des données» renvoie au fait que les programmes sont isolés des modifications apportées à la structure et au stockage des données. Un SGBD présent l’interface entre les programmes d’application et les données.
Dans une indépendance physique des données, les applications n’ont pas besoin de se soucier de la manière dont les données sont structurées ou stockées, alors que l’indépendance logique des données est la capacité de transformer le schéma conceptuel sans avoir à modifier le schéma externe ou les programmes d’application. Pour en savoir plus sur l’indépendance des données physiques et logiques, consultez les ressources mentionnées dans la section Autres lectures.
10.3.3 Contrôle de la redondance des données
Contrairement au traitement de fichier, un SGBD utilise une approche de redondance des données de contrôle. Moins de redondance signifie moins de gaspillage d’espace de stockage, et donc une facilité d’aspect économique. Pour les entreprises, cela signifie qu’il n’est pas nécessaire de répéter les mêmes données encore et encore.
10.3.4 Gestion centralisée des données et accès simultanés
Tous les fichiers sont intégrés dans un seul système, réduisant ainsi les redondances et rendant la gestion des données plus efficace. De plus, plusieurs utilisateurs peuvent accéder à la même information sans aucun conflit.
10.3.5 Intégrité des données
Cela fait référence au fait qu’un SGBD doit conserver et assurer la précision et la cohérence des données tout au long de son cycle de vie. Toutes les informations d’une base de données sont accessibles à plusieurs utilisateurs, mais un seul utilisateur peut modifier une donnée à la fois.
Dans les bases de données, une seule opération logique sur les données est appelée une transaction. Par exemple, un transfert de fonds d’une banque à une autre. Atomicity est l’une des quatre propriétés qu’une transaction devrait avoir. Les quatre propriétés, collectivement, sont appelées ACID (Atomicité, Consistance, Isolation et Durabilité).
10.3.6 Disponibilité des données
L’un des principaux avantages de l’utilisation d’un SGBD est que les mêmes données d’entreprise peuvent être mises à la disposition de différents employés à tout moment, n’importe où. Il permet un accès à l’information à distance, 24 heures sur 24, 7 jours sur 7 et sur plusieurs utilisateurs. Non seulement cette norme peut être appliquée dans le SGBD, car toutes les données de la base de données sont accessibles par une base de données centralisée.
10.3.7 Accès efficace par optimisation
Le système SGBD trouve automatiquement un moyen efficace d’accéder aux données. Ces systèmes ont construit de puissantes structures de données, des algorithmes et des principes solides pour déterminer comment un tableau spécifique doit être sauvegardé et récupéré efficacement, malgré la taille des données et la complexité des tables.
10.3 SGBD parallèle et distribué
La manière classique dont les SGBD ont traité le problème des volumes importants consiste à créer des bases de données parallèles et distribuées. Le développement de l’informatique parallèle et distribuée a eu un impact positif sur l’évolution des bases de données parallèles et distribuées.
10.3.1 SGBD parallèle
Un système de base de données parallèle cherche à améliorer les performances grâce à la parallélisation d’opérations variées, telles que le chargement de données, la construction d’index et l’évaluation de requêtes bien que les données puissent également être conservées de manière distribuée, et que la distribution dépend exclusivement de performances. Les bases de données parallèles améliorent les vitesses de traitement et d’entrée / sortie en victimisant plusieurs processeurs et disques en parallèle. Les systèmes de base de données centralisés et client-serveur ne semblent pas assez puissants pour gérer de telles applications. En traitement de données, plusieurs opérations correspondent à des mesures effectuées en même temps, en tant que traitement en série critique, dans lesquelles les étapes de calcul sont effectuées de manière consécutive.
Motivations pour les SGBD parallèles
Les progrès dans l’utilisation de machines parallèles deviennent assez courants et abordables. De plus, les bases de données grossissent en raison du volume de données transactionnelles collectées et stockées. Le but de ce stockage est de les utiliser des affaires.
Il a été démontré que l’utilisation du SGBD parallèle améliore le temps de réponse. Il est possible de traiter plusieurs transactions en parallèle. Cela améliore le débit global.
10.3.1.2 Architectures pour bases de données parallèles
Plusieurs architectures sont proposées pour la construction de SGBD parallèles. Trois architectures principales incluent la mémoire partagée, le disque partagé et rien partagé. Comme son nom l’indique, dans l’architecture à mémoire partagée, une mémoire globale est partagée. On dit que l’architecture à mémoire partagée est plus proche d’une machine conventionnelle et facile à programmer, et que le temps système est faible. D’autre part, cela pose un problème de goulot d’étranglement et peut être un peu coûteux à construire.
L’architecture de disque partagé partage un disque global. Il présente des avantages similaires à l’architecture à mémoire partagée. Dans l’architecture sans partage, chaque nœud a sa propre mémoire ainsi que son propre stockage, et rien n’est partagé entre les nœuds.
10.3.2 SGBD distribué
Dans une base de données distribuée, les données sont stockées sur plusieurs sites gérés par un SGBD capable de s’exécuter indépendamment. Une base de données distribuée ( DDB ) est un ensemble de plusieurs bases de données liées entre elles sur le plan logique et distribuées sur un réseau informatique. Un SGBD distribué est alors décrit comme le système logiciel qui permet la gestion des bases de données géographiquement situées à différents endroits et crée la transparence de la distribution pour les utilisateurs.
La figure suivante explique le concept de base d’un SGBD centralisé et d’un SGBD distribué. Comme illustré sur la figure, dans le SGBD centralisé, un stockage de données central se trouve au centre et tout le terminal utilise un réseau pour communiquer avec le stockage central. Dans un SGBD distribué, l’installation de stockage est distribuée sur plusieurs sites :
SGBD centralisé
SGBD distribué
10.3.3 Caractéristiques d’un SGBD distribué
Un SGBD distribué présente les caractéristiques suivantes :
- C’est un ensemble de données partagées liées de manière logique
- Les données du SGBD distribué sont divisées en un certain nombre de fragments.
- Les fragments peuvent être répliqués dans un système distribué
- Les fragments / répliques sont alloués à différents sites
- Les sites sont reliés par un réseau de communication
- Les données sur des sites individuels sont sous le contrôle d’un SGBD.
10.3.4 Mérites d’un SGBD distribué
Un SGBD distribué (DDBMS) présente de nombreux avantages par rapport aux SGBD traditionnels . En voici quelques-uns :
- DDBMS fournit un accès plus rapide aux données pour les utilisateurs finaux.
- DDBMS est la disposition pour le partage d’informations. Les utilisateurs finaux d’un site d’un système distribué peuvent être en mesure d’accéder aux données résidant sur les autres sites.
- Le système DDBMS permet de traiter des données sur plusieurs sites simultanément. Ces méthodes simultanées de traitement des données facilitent l’optimisation des requêtes.
- Les DDBMS sont stockés à proximité du site où la demande est la plus grande. Comme les données sont situées près du site le plus sollicité et compte tenu du parallélisme inhérent aux SGBD distribués, la vitesse d’accès à la base de données peut être supérieure à celle d’une base de données centralisée distante.
- L’extension modulaire dans le système DDBMS semble être beaucoup plus facile.
10.4 SGBD et systèmes de style MapReduce
Dans les sections précédentes, nous avons abordé le SGBD distribué et parallèle. Mais il est important de savoir que tous les problèmes de données évoqués précédemment peuvent ne pas être requis pour le traitement de données volumineuses. Cela dépend du type d’applications que vous essayez de créer. Dans cette section, nous allons discuter de la nécessité de systèmes de style MapReduce.
Le SGBD a utilisé efficacement le parallélisme avec un stockage efficace et de meilleures performances d’interrogation. Ils ont un algorithme efficace pour optimiser les performances et augmenter l’efficacité. Cependant, ces SGBD classiques ne prennent pas en compte les pannes de machines, contrairement à MapReduce, qui a été initialement développé pour le traitement distributif de grandes quantités de données. MapReduce a été créé sur des systèmes de fichiers Hadoop. Les problèmes tels que les pannes de nœuds ont donc été automatiquement pris en compte. Il a été utilisé dans des applications complexes, telles que le clustering de données ou l’exploration de données, avec des algorithmes très compliqués. La combinaison d’exigences de gestion des données et d’analyse du traitement des données a créé plusieurs défis dans le monde de la gestion des données. Parmi les défis, citons la capacité de gérer un volume élevé de données, la capacité de gérer des données en temps réel et la capacité de gérer des données en continu.
Cette combinaison d’exigences traditionnelles et de nouvelles exigences génère de nouvelles fonctionnalités et de nouveaux produits dans la technologie de gestion de données volumineuses. Une de ces technologies est le traitement de données de style MapReduce. Dans les chapitres à venir, nous aborderons certains des systèmes de gestion de données modernes dotés de certaines de ces fonctionnalités.
10.5 Résumé
Ce chapitre est resté ancré dans les aspects théoriques des approches non-SGBD et SGBD, y compris les systèmes de gestion de fichiers traditionnels et les SGBD récents. Nous avons exploré divers avantages et inconvénients de l’utilisation de systèmes basés sur des fichiers et d’approches SGBD. En plus de cela, nous avons exploré diverses fonctionnalités des systèmes de fichiers parallèles et distribués.
Dans le chapitre suivant, nous allons voir comment passer des concepts de système SGBD à un concept de système de gestion de Big Data. En plus de cela, nous explorerons certains des systèmes de paires clé-valeur de gestion des mégadonnées tels que Redis.
11 Du SGBD au BDMS
Comme vous le savez, la gestion de données volumineuses nécessite une approche différente des systèmes de gestion de bases de données en raison de la grande diversité de structure et de sources de données, qui ne se prête pas bien au SGBD traditionnel. Il existe de nombreuses applications disponibles pour vous aider dans la gestion de Big Data. Cette leçon vous présente certaines de ces applications et vous explique comment et à quel moment elles peuvent être appropriées aux défis de la gestion du Big Data.
Les principales sections abordées dans ce chapitre sont les suivantes:
- Expliquer les caractéristiques du système de gestion de données volumineuses (BDMS)
- Exploration de la gestion des données avec Remote Dictionary Server (Redis)
- Utiliser Aerospike comme un magasin clé-valeur de nouvelle génération
- Utiliser AstérixDB pour étudier des données semi-structurées
11.1 Caractéristiques du BDMS
Dans l’hypothèse d’une sortie idéale du système BDMS, il présenterait les caractéristiques suivantes :
- Un modèle de données flexible et semi-structuré : un système BDMS idéal devrait permettre de créer un modèle de données semi-structuré prenant en charge divers formats et types de données, notamment les valeurs de données textuelles, temporelles et spatiales.
- Un langage de requête complet : un BDMS idéal fournirait un langage de requête, par exemple SQL, qui est le langage de requête standard d’un système relationnel moderne.
- Exécution de requêtes parallèles : BDMS aurait une exécution de requêtes parallèle efficace et prend en charge une large gamme de tailles de requêtes.
- Capacité totale de gestion des données : les BDMS devraient être plus faciles à installer, à redémarrer et à configurer, à fournir une haute disponibilité et à rendre la gestion opérationnelle.
11.1.1 BASE propriétés
Le SGBD suit les propriétés ACID des transactions et BDMS les garantit également. Par ailleurs, étant donné que le big data contient trop de données et de mises à jour simultanées, la maintenance des propriétés ACID entraîne un ralentissement important du système. Dans un BDMS idéal, il aurait les propriétés BASE (disponibilité de base, état souple et cohérence éventuelle).
La disponibilité de base fait référence au fait que le système garantit la disponibilité des données à la demande et que les données restent cohérentes en cas de défaillance. L’état souple d’un système indique que le système est cohérent dans tous les états, comme l’état sans entrée ou l’état avec des ensembles d’entrées incorrects. La cohérence éventuelle indique que le système est finalement cohérent, de sorte qu’un utilisateur obtiendra probablement des flux Twitter une fois connecté à son compte mais ne les verra peut-être pas immédiatement.
11.2 Explorer la gestion des données avec Redis
Redis est une technologie NoSQL Open Source à valeur clé qui offre une stabilité, une puissance et une flexibilité élevées pour l’exécution d’un large éventail d’opérations de données et de tâches dans une entreprise. Redis est utilisé par de nombreuses entreprises bien connues, notamment Twitter, Weibo, Snapchat, Digg, StackOverflow , Flicker, Pinterest et GitHub.
11.2.1 Démarrer avec Redis sur macOS
En supposant que vous avez installé homebrew ( https://brew.sh/ ) sur votre système, Redis peut être configuré comme suit:
$ brew install redis
Après l’exécution réussie de la commande précédente, certaines notifications s’afficheront. Nous pouvons continuer avec le reste des commandes. Pour vérifier si Redis est installé correctement ou pour obtenir des informations sur les packages, nous pouvons exécuter les commandes suivantes:
$ brew info redis
Vous devriez pouvoir voir la sortie suivante :
Sortie de la commande
Pour exécuter le serveur Redis, nous pouvons utiliser la commande suivante :
$ redis -server
La commande redis -server devrait vous donner une sortie Terminale, telle que la capture d’écran qui suit :
Sortie du terminal après avoir exécuté le serveur Redis
Pour vérifier si le serveur Redis fonctionne, vous pouvez l’exécuter à l’aide de la commande précédente et, dans un autre terminal, exécutez la commande ping :
$ redis -cli ping
PONG
La configuration réussie reviendra immédiatement avec la réponse PONG. Nous pouvons commencer à exécuter redis -cli et créer des paires clé-valeur :
$ redis-cli
127.0.0.1:6379>
127.0.0.1:6379> set myapp:name “My Awesome E-com Store”
OK
127.0.0.1:6379> get myapp:name
“My Awesome E-com Store”
De la même manière, Redis peut être installé sur un ordinateur Windows. Suivez les instructions officielles documentées sur son site Web ( https://redis.io/ ) pour l’installer sur une machine Windows.
11.2.2 Magasins de valeurs-clés avancées
Un aspect important de Redis est la paire clé-valeur. Redis s’appelle un magasin de structure de données en mémoire. En termes simples, Redis n’est pas un SGBD à part entière. Il peut conserver des données sur des disques et enregistre ainsi son état. Toutefois, son utilisation prévue consiste à utiliser de manière optimale la mémoire et les méthodes basées sur la mémoire afin de rendre très rapides un certain nombre de structures de données communes pour de nombreux utilisateurs. Redis prend en charge les structures de données suivantes : chaînes, hachages, listes, ensembles et ensembles triés.
La flexibilité de Redis permet une grande diversité de structure et de sauvegarde des clés. Les performances et la maintenabilité de Redis peuvent être affectées de manière positive ou négative par les choix effectués dans la conception et la construction des clés Redis appliquées dans sa base de données. Une bonne pratique générale lors de la conception des clés Redis consiste à définir au moins un aperçu des informations que vous essayez de stocker dans Redis et une idée initiale de la manière dont les données seront stockées dans l’une des nombreuses structures de données Redis.
11.2.3 Redis et Hadoop
Redis est classée comme une base de données hautes performances clé-valeur devenue un élément essentiel des applications Big Data. Il aide les entreprises à donner du sens aux données en rendant la mise à l’échelle des bases de données plus pratique et plus économique.
Cela dit, nous savons que Hadoop est une plate-forme informatique distribuée. Il offre une haute disponibilité, une évolutivité, une tolérance aux pannes et de faibles coûts d’exploitation. Le système de stockage HDFS de Hadoop rend difficile le traitement des applications des utilisateurs finaux. Ainsi, les résultats informatiques sont envoyés hors ligne à un stockage tel que Redis.
L’évolutivité horizontale fait référence à la capacité d’un système à atteindre cette évolutivité lorsque le nombre de machines sur lesquelles il opère est augmenté. Redis autorise le partitionnement des données via le partitionnement par plage et le partitionnement par hachage. Supposons que nous ayons 10 machines et que nous choisissions la clé et que nous utilisions la fonction de hachage pour récupérer un numéro. Nous représentons le nombre, module 10, et le résultat, dans ce cas 2, est la machine à laquelle l’enregistrement sera attribué. La réplication est effectuée dans Redis via le mode maître-esclave. Les clients lisent à partir des esclaves pour améliorer les performances de lecture. Le processus de réplication est synchrone.
11.3 Aérospike
Aerospike est l’une des architectures de base de données NoSQL développées pour la performance, l’évolutivité et la fiabilité à haute vitesse. Comme Redis, il s’agit d’une architecture de paires clé-valeur optimisée pour le stockage flash. La base de données Aerospike est écrite en C et comporte trois couches : la couche de données, une couche de distribution autogérée et une couche client prenant en charge les clusters. La couche de distribution est répliquée dans les centres de données pour renforcer la cohérence.
Certaines des caractéristiques importantes d’Aérospike sont résumées comme suit :
- Utilisation de la mémoire hybride : Aerospike utilise le stockage flash en parallèle sur une machine pour effectuer des lectures à des latences inférieures à une milliseconde à un débit très élevé en présence d’une charge d’écriture importante. L’utilisation d’un lecteur SSD ou d’un lecteur flash impose une mise à l’échelle verticale élevée.
- Aerospike a une grande capacité de planification et d’extension pour la gestion de grappes, car il possède une distribution uniforme des données et des indexeurs de métadonnées intégrés.
- Moteur en temps réel : Aerospike intègre un moteur en temps réel offrant des performances maximales et pouvant atteindre plusieurs millions de transactions par seconde.
- Client intelligent : la couche client intelligent dans Aerospike est utilisée pour suivre la configuration du cluster dans la base de données et gérer les communications dans le nœud du serveur.
- Aerospike a été entièrement optimisé pour être utilisé par des entreprises mondiales.
- Modèle de données flexible : Il a une structure encore schema- moins modèle de données flexible qui supports tapés données pour la compatibilité interlangage.
Les détails techniques de l’Aérospike commencent avec l’architecture attendue sans partage et sont structurés en journaux. Il comporte plus de partitions de données logiques que de partitions physiques. En plus de cela, il dispose d’une réplication synchrone dans un centre de données.
11.3.1 Technologie aérospike
Aerospike contient quatre composants principaux : CLIENT , CLUSTER , SERVER et STORAGE . Ceci est illustré par le schéma suivant :
Architecture de la technologie de base de données Aerospike
La figure précédente est extraite du site officiel d’Aerospike (https://www.aerospike.com/technology/), qui présente quatre éléments distincts :
- Client : ce niveau est responsable de la création d’une interface en langue maternelle avec chaque langue pour une programmation plus facile et plus performante. Il inclut les bibliothèques de clients open source qui implémentent les API Aerospike et les nœuds de piste, et il sait quelles données sont présentes dans le cluster.
- Cluster : il existe une couche de clustering qui permet une gestion de la cohérence immédiate et éventuelle des transactions. Cette couche garantit la distribution uniforme et aléatoire des données sur tous les nœuds. Cette couche contrôle la communication des clusters et automatise le basculement, la réplication, la synchronisation entre centres de données et les migrations de données.
- Serveur : le serveur interagit avec la couche de stockage pour la persistance.
- Stockage : la couche de stockage utilise trois types de systèmes de stockage en mémoire avec une RAM ou un DRAM dynamique, un disque en rotation normal et un disque flash / SSD qui charge les données en cas de besoin.
11.4 AstérixDB
AsterixDB a été conçu à l’origine à l’Université de Californie à Irvine. C’est un SGBD NoSQL à part entière qui fournit des garanties ACID. C’est un BDMS évolutif et open source.
Avec diverses options de support de stockage et d’indexation, notamment des jeux de données gérés, des jeux de données externes et des index secondaires, AsterixDB est très flexible et offre un taux de consommation de données rapide.
Il étend les données orientées objet et JSON pour faciliter le traitement des données de la forme semi-structurée. Pour faciliter le traitement, il peut construire des grappes pour le traitement distribué et peut être étendu à plus de 1 000 cœurs et 500 disques.
11.4.1 Modèles de données
AsterixDB a des modèles de données semi-structurés de style NoSQL résultant de l’extension de JSON avec des idées de base de données d’objets. Il existe principalement trois types de données :
- Les types primitifs : Boolean, string, tinyint, smallint, Integer, bigint, float, double, binary, point, line, rectangle, circle, polygon, date, time, DateTime, duration, and UUID
- Types d’informations incomplètes : null et missing
- Types dérivés : object, array, et multiset
11.4.2 Le langage de requête Astérix
AQL (Asterix Query Language) est un langage standard pour communiquer avec AsterixDB . Dans cette section, nous allons découvrir deux types de requêtes dans AQL :
- Langage de manipulation de données (DML) : la capacité fonctionnelle du DML est organisée en commandes de manipulation telles que SELECT, UPDATE, INSERT INTO et DELETE FROM.
- Langage de définition de données (DDL) : les DDL couramment utilisés dans les requêtes SQL incluent CREATE, ALTER et DROP.
11.4.3 Débuter avec AsterixDB
Pour exécuter AsterixDB, vous devriez avoir Unix- sh environnements, tels que Linux ou Mac OS X. Pour construire à partir de la source, exécutez les ordres donnés comme suit :
$ git clone https://github.com/apache/asterixdb.git
Pour construire la base de données à partir de la branche principale, vous devez exécuter la commande suivante :
$ cd asterixdb
$ mvn clean package – DskipTests
Pour exécuter le build sur votre machine, voici les étapes :
- Démarrez une instance AsterixDB sur un seul ordinateur :
$ cd asterixdb / asterix-server / cible / asterix-server – * – binary-assembly /
$ ./opt/local/bin/start-sample-cluster.sh
C’est bien d’aller lancer des requêtes dans votre navigateur à :
http://localhost:19001
Vous devriez pouvoir voir l’interface Web, comme suit :
Interface Web pour AsterixDB
Pour arrêter le cluster exemple, utilisez la commande suivante :
$ ./opt/local/bin/stop-sample-cluster.sh
11.4.4 Données non structurées dans AsterixDB
Considérez l’extrait JSON suivant :
{
“id”:101,
“name”:”John Doe”,
“nickname”:”John”,
“username”:”johndoe”,
“email” : “johndoe@gmail.com”,
“createdAt”:”2018-08020T10:10:00″,
“friendIds”:[
2,
3,
4,
10
],
“employement”:[
{
“organizationName”:”SAS Web Tech”,
“startDate”:”2017-08-06″
},
{
“organizationName”:”Kirlosker Service Center”,
“startDate”:”2016-08-06″
}
],
“gender”:”Male”
}
Les données JSON contiennent les informations d’un employé qui a un name, un nickname et un username, ainsi que la date à laquelle l’enregistrement a été inséré. Un employé peut être associé à une ou plusieurs organisations. Pour créer un schéma dans AsterixDB, notre schéma pourrait apparaître comme suit :
create type EmploymentType as closed {
organizationName: string,
startDate: date,
endDate: date?
};
Notez que le schéma est défini comme closed. Nous pouvons maintenant définir UserType comme suit :
create type UserType as open {
id: int,
username: string,
name: string,
email: string,
nickname: string,
createdAt: datetime,
friendIds: {{ int }},
employment: [EmploymentType],
gender: string
};
Le monde des données dans AsterixDB est organisé en espaces de noms de données appelés dataverses . Pour définir les bases de données par défaut pour une série d’instructions, l’instruction use dataverse est fournie. Par exemple, pour use dataverse comme étant TinySocial, nous devons exécuter l’instruction suivante :
$ use dataverse TinySocial ;
Maintenant, create dataset est utilisé pour créer un nouveau jeu de données. Pour créer un ensemble de données pour cet exemple, nous devons exécuter les instructions suivantes:
$ create dataset Employee(UserType) primary key id;
Après cela, nous pouvons créer les exemples UserType et EmploymentType. Lorsque vous exécutez ces instructions, l’écran de sortie doit ressembler à ceci :
Écran de sortie de l’exécution de la requête
11.4.5 Insertion dans des jeux de données
Supposons que nous voulions insérer le jeu de données comme indiqué dans l’extrait précédent. Notre requête d’insertion pourrait ressembler à ceci :
insert into dataset Employee
(
{
“id”: 101,
“username”:”John”,
“name”:”John Doe”,
“nickname”:”John”,
“email”:”jonhdoe@gmail.com”,
“createdAt”:datetime(“2017-08-15T08:10:00”),
“friendIds”:{{ 2,3, 4, 10 }},
“employment”:
[
{
“organizationName”:”SAS WEB Tech”,
“startDate”: date(“2017-08-15”)
},
{
“organizationName”:”Kirlokser Service Center”,
“startDate”: date(“2016-08-15”)
}
],
“gender”: “Male”
}
);
11.4.6 Interrogation dans AstérixDB
Par défaut, AsterixDB prend en charge deux langues:
- AQL
- SQL ++: SQL pour JSON
Par exemple, pour renvoyer le sous-arbre sous le nœud racine d’un arbre de jeu de données, votre requête devrait ressembler à ceci :
SELECT VALUE user
FROM UserType user;
Pour renvoyer une sous-arborescence sous un nœud ayant satisfait un prédicat différent :
SELECT VALEUR utilisateur
FROM UserType utilisateur
WHERE array_count ( user.friendIds ) = 1
Il y a beaucoup à traiter et beaucoup de fonctions intégrées disponibles avec AsterixDB qui vont au-delà de la portée de ce livre. Nous vous suggérons de suivre la documentation et de créer votre propre schéma. Ci- dessous, après plus de lecture dans ce PDF.
11.5 Résumé
La gestion du Big Data nécessite des méthodes distinctes par rapport au SGBD traditionnel. Il existe de nombreux systèmes de gestion du Big Data qui peuvent faciliter ce processus. Le plus populaire comprend Redix, AsterixDB, Aerospike et autres. Dans ce chapitre, nous avons discuté de certaines des caractéristiques de BDMS et exploré l’utilisation de Redix, AsterixDB pour stocker des données semi-non structurées.
Dans ce chapitre suivant, nous allons utiliser Python pour importer un ensemble de données Bitcoin et les modéliser à l’aide de certaines approches de Machine Learning.
12 Modélisation de points de données Bitcoin avec Python
Dans ce chapitre, nous allons apprendre différents types de modèles pouvant être construits à partir de données Bitcoin. Nous allons essayer d’utiliser le modèle ainsi extrait pour prédire le prix de Bitcoin. En plus de cela, nous allons apprendre à utiliser iPython et à jouer avec les bibliothèques Python telles que pandas et NumPy. Nous allons être explorons les suivants sujets:
- Bitcoin data et ses paramètres
- Compréhension de différents types de modèles de régression et d’autres algorithmes
- Explorer l’utilisation d’un modèle de régression pour prédire le prix futur de Bitcoin
12.1 Introduction aux données Bitcoin
Bitcoin est une crypto-monnaie qui est actuellement très populaire. Selon Wikipedia:
Le bitcoin est une monnaie numérique décentralisée sans banque centrale ni administrateur unique et peut être envoyé d’utilisateur à utilisateur sur le réseau Bitcoin poste à poste directement, sans intermédiaire.
Il y a beaucoup de données liées à Bitcoin. Dans cet exercice, nous allons utiliser le jeu de données fourni par Kaggle. Nous allons utiliser cet ensemble de données public pour prédire le prix futur de Bitcoin.
12.2 Théorie
Les estimations de régression sont mises en pratique pour démontrer la relation entre une variable dépendante et une ou plusieurs variables indépendantes. La régression linéaire est un type d’analyse prédictive couramment utilisé et est souvent utilisée pour modéliser des relations non linéaires. La prédiction effectuée par régression linéaire est limitée à la sortie numérique. Le principal point de régression est d’inspecter deux choses :
- Un ensemble de variables prédictives permet-il de prédire une variable de résultat ?
- Quelles variables sont des prédicteurs significatifs de la variable de résultat et de quelle manière ont-elles une influence sur la variable de résultat ?
Une droite de régression linéaire a une équation de la forme Y = a + bX, où X est la variable explicative et Y est la variable dépendante. La pente de la ligne est b et a est l’ordonnée à l’origine (la valeur de y lorsque x = 0).
12.3 Importer des données Bitcoin dans iPython
Afin de traiter les données Bitcoin, la première étape consiste à utiliser iPython . Comme mentionné dans les chapitres précédents, iPython peut être installé de différentes manières. L’une de ces méthodes est décrite au Chapitre 6, Modélisation de données structurées, et au Chapitre 15, Modélisation de points de données IMDb avec Python, à l’aide d’Anaconda. En supposant que vous exécutiez iPython, ouvrons un ordinateur portable et commençons.
12.3.1 Importation des bibliothèques requises
La première étape consiste à importer toutes les bibliothèques requises. Cela peut être fait comme suit :
#import the packages
import math
import pandas as pd
import numpy as np
import os
from pandas import DataFrame
from sklearn.cluster import KMeans
from sklearn import preprocessing
import matplotlib.pyplot as plt
from matplotlib import style
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import neighbors, datasets
style.use(‘ggplot’)
import matplotlib.pylab as plt
from scipy.stats import linregress
from matplotlib.pylab import rcParams
rcParams[‘figure.figsize’] = 15, 6
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
import sklearn
from sklearn.metrics import mean_squared_error
from sklearn import datasets, linear_model
Importons maintenant les données Bitcoin dans notre cahier. Téléchargez et placez les données Bitcoin dans le même lecteur que le bloc-notes. Vous pouvez trouver le répertoire de travail actuel à l’aide de la commande suivante :
> os.getcwd()
Il devrait vous donner le répertoire courant dans lequel se trouvent les fichiers. Le résultat devrait ressembler à ceci :
Sortie de la commande getcwd
Une fois que vous avez le chemin actuel, vous pouvez placer le fichier CSV dans le répertoire. Les données Bitcoin peuvent être trouvées en ligne dans Kaggle, ou peuvent être utilisées à partir du référentiel GitHub dans CH12/Bitcoin/bitcoin.csv :
df=pd.read_csv(“bitcoin.csv”, index_col=None)
Une fois le fichier CSV importé correctement, examinons les 10 premières entrées pour voir à quoi ressemblent nos données :
df.head(10)
La sortie ressemble à ceci :
10 premières entrées dans les données Bitcoin
La figure précédente montre les 10 premières entrées du fichier CSV. Il y a huit colonnes, à l’exclusion de l’index. Chacun d’entre eux a une signification spécifique :
- Horodatage (heure Unix)
- Ouvert : prix Bitcoin en unités monétaires à l’ouverture de la période
- Elevé : prix Bitcoin le plus élevé en unités monétaires au cours de la période
- Bas : prix Bitcoin le plus bas en unités monétaires au cours de la période
- Fermer : Prix Bitcoin en unités monétaires à la clôture de la période
- Volume_ (BTC) : Volume de BTC traité dans la période
- Volume_ (Devise) : Volume de devise traité dans la période
- Prix moyen pondéré en fonction du volume (Volume-weighted average price (VWAP))
Sauvegardons maintenant les variables dans leurs variables respectives :
price=df[‘Weighted_Price’]
time=df[‘Timestamp’]
df2=DataFrame({‘price’:price,’time’:time})
Pour obtenir des statistiques simples sur n’importe quelle colonne, il existe une fonction, describe (), qui nous fournit des statistiques détaillées sur une colonne en particulier :
#descriptive statistics
df2.price.describe()
Le résultat devrait ressembler à ceci :
Description du prix pour obtenir des statistiques
De la même manière, nous pouvons obtenir les statistiques pour toutes les colonnes numériques.
12.4 Prétraitement et création de modèle
Une des questions fréquemment posées est la suivante : “Est-il vraiment important de mettre à l’échelle les données ?” ou “Quand devrions-nous mettre à l’échelle les données ?” Pour être honnête, il n’existe pas de réponse unique à cette question. Cela dépend vraiment du type de données sur lequel vous travaillez et des algorithmes qui y sont appliqués. Un algorithme tel que SVM (Support Vector Machine) converge très rapidement vers les données normalisées. Une autre bonne raison de normaliser les données est lorsque le modèle est très sensible à la magnitude et que les unités de deux ou différentes caractéristiques sont différentes. Nous considérons ici deux caractéristiques importantes : l’horodatage et le prix. Et nous sommes intéressés à savoir comment les prix évoluent dans le temps.
La prochaine étape de notre processus consiste à prétraiter le cadre de données que nous avons créé :
#pre-processing
scale=preprocessing.scale(price)
Et ensuite, tracé le prix mis à l’échelle :
plt.plot(scale)
scale
Le résultat devrait ressembler à ceci:
Données de prétraitement
Nous pouvons obtenir un petit échantillon des données et le tracer pour voir les variations :
scale
df=DataFrame(scale)
sample=df[0:100000]
sample
plt.plot(sample)
Le graphique de sortie devrait ressembler à ceci :
Exemple de données de prix de prétraitement
Une prévision est une bonne prévision de base pour une série chronologique à tendance à la hausse linéaire. La prévision de la persistance est l’endroit où l’observation du pas de temps précédent (t-1) est utilisée pour prédire l’observation au pas de temps actuel (t). Nous pouvons implémenter cela en utilisant la dernière observation à partir des données d’entraînement et de l’historique collectés par validation, puis en l’appliquant pour prédire le pas de temps actuel. Nous pouvons y parvenir en utilisant l’extrait de code suivant. Essayez de comprendre pourquoi faisons-nous cette étape avant de passer à la section suivante :
X=sample.values
X
train, test = X[0:-10000], X[-10000:]
train
test
Cela devrait produire les données de test comme suit :
Exemple de données de test en tant que sortie du fragment de code précédent
Dans l’échantillon des 100 000 premières observations, nous avons défini les 90 000 premières observations comme étant les données d’apprentissage et les 10 000 dernières comme étant les données de test. Après la formation et les prévisions, nous obtenons la prévision avec un pas en avant sous forme de graphique, ainsi que le jeu de données d’origine :
# walk-forward validation
history = [x for x in train]
predictions = list()
for i in range(len(test)):
# make prediction
predictions.append(history[-1])
# observation
history.append(test[i])
# report performance
rmse = math.sqrt(mean_squared_error(test, predictions))
print(‘RMSE: %.3f’ % rmse)
# line plot of observed vs predicted
pyplot.plot(test)
pyplot.plot(predictions)
pyplot.show()
rmse
La sortie de l’extrait précédent devrait ressembler à la capture d’écran suivante:
Sortie de l’extrait précédent
Il est important de noter que l’erreur racine moyenne au carré (RMSE) est égale à zéro dans ce cas. Donc, la prédiction était très précise.
Pour un échantillon de 50 000 personnes, nous avons défini les 40 000 premières observations comme étant les données d’apprentissage et les 10 000 dernières comme étant les données de test. Après la formation et les prévisions, nous obtenons la prévision avec un pas en avant sous forme de graphique, ainsi que le jeu de données d’origine :
#a smaller sample of 50000
sample2=sample[0:50000]
X2=sample2.values
X2
train2, test2 = X2[0:-10000], X2[-10000:]
train2
test2
# walk-forward validation
history2 = [x for x in train2]
predictions2 = list()
for i in range(len(test2)):
# make prediction2
predictions2.append(history2[-1])
# observation
history2.append(test2[i])
# report performance
rmse2 = math.sqrt(mean_squared_error(test2, predictions2))
print(‘RMSE: %.5f’ % rmse2)
# line plot of observed vs predicted
pyplot.plot(test2)
pyplot.plot(predictions2)
pyplot.show()
rmse2
La sortie de l’extrait précédent devrait ressembler à ceci:
Modèle généré avec un sous-ensemble d’échantillons de 50 000 jeux de données
Il a une erreur moyenne quadratique de 0,00006, ce qui est un très bon ajustement.
12.5 Imprimer le prix Bitcoin avec l’aide d’un réseau de neurones récurrents
Dans cette section, nous allons utiliser le même jeu de données et appliquer le réseau de neurones récurrents (RNN) pour prédire le prix du bitcoin. Créez un nouveau bloc-notes dans votre Jupyter iPython.
12.5.1 Importer des paquets
Nous allons importer des bibliothèques au fur et à mesure :
Import numpy as np
import pandas as pd from matplotlib
import py plot as plt
12.5.2 Importer des jeux de données
Nous pouvons importer les jeux de données en utilisant la fonction read_csv fournis par pandas :
dframe = pd.read _csv (‘bitcoin.csv’)
La figure (10 premières entrées dans les données Bitcoin) montre à quoi ressemble le jeu de données. Nous utilisons le même ensemble de données. Les horodatages étant encodés au format UNIX, nous allons les recoder :
dframe[‘date’] = pd.to_datetime(dframe[‘Timestamp’],unit=’s’).dt.date
group = dframe.groupby(‘date’)
Real_Price = group[‘Weighted_Price’].mean()
La principale raison pour laquelle nous transformons l’horodatage est que nous pouvons trier l’ensemble de données par date plutôt que par minute.
12.5.3 Prétraitements
Supposons que nous voulons prédire le prix pour un mois. Nous devons prendre un sous-ensemble de l’ensemble de données des 30 derniers jours en tant que données de test. Nous pouvons le faire en scindant le dataframe :
# Split the dataset so that we can take last 30 days data as test dataset
prediction_days = 30
dframe_train= Real_Price[:len(Real_Price)-prediction_days]
dframe_test= Real_Price[len(Real_Price)-prediction_days:]
Nous avons maintenant le jeu de données de test. Normalisons, remodelons et redimensionnons :
# Data preprocessing
training_set = dframe_train.values
training_set = np.reshape(training_set, (len(training_set), 1))
#import sklearn package and use MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
sc = MinMaxScaler()
training_set = sc.fit_transform(training_set)
X_train = training_set[0:len(training_set)-1]
y_train = training_set[1:len(training_set)]
X_train = np.reshape(X_train, (len(X_train), 1, 1))
12.5.4 Construire le modèle RNN
Après avoir pré-traité le jeu de données, utilisons le jeu de données test pour construire le modèle RNN. Nous pouvons le faire en utilisant l’extrait suivant :
# Importing the Keras libraries and relevant packages
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
# Initialise the RNN model
regressor = Sequential()
# Add the input layer and the LSTM layer
regressor.add(LSTM(units = 4, activation = ‘sigmoid’, input_shape = (None, 1)))
# Add the output layer
regressor.add(Dense(units = 1))
# Compile the RNN
regressor.compile(optimizer = ‘adam’, loss = ‘mean_squared_error’)
# Fit the RNN to the Training set
regressor.fit(X_train, y_train, batch_size = 5, epochs = 100)
Chacune de ces déclarations fait quelque chose de spécifique et est commentée. Veuillez les examiner un à un afin de mieux comprendre ce que nous essayons de faire et pourquoi cette étape est nécessaire. Une fois ce script exécuté, le modèle RNN commencera à être construit. Le script doit afficher la progression au fur et à mesure de sa construction. Les premières entrées sont illustrées à la figure suivante :
Sortie de l’extrait précédent lors de la construction du modèle RNN
12.5.5 Prédiction
Puisque notre modèle RNN est prêt, nous pouvons le consommer pour faire la prédiction. Nous allons utiliser le prix d’aujourd’hui pour prédire le prix du lendemain. Il est possible de prédire pour une période plus longue, mais comme il y a beaucoup de facteurs d’influence, les prédictions de plus longue durée finissent par avoir plus d’erreurs :
# Make the predictions
test_set = dframe_test.values
inputs = np.reshape(test_set, (len(test_set), 1))
inputs = sc.transform(inputs)
inputs = np.reshape(inputs, (len(inputs), 1, 1))
predicted_BTC_price = regressor.predict(inputs)
predicted_BTC_price = sc.inverse_transform(predicted_BTC_price)
Visualisons maintenant nos prévisions en les traçant sur un graphique et en comparant les différences :
# Visualize the results
plt.figure(figsize=(25,15), dpi=80, facecolor=’w’, edgecolor=’k’)
ax = plt.gca()
plt.plot(test_set, color = ‘red’, label = ‘Real Bitcoin Price’)
plt.plot(predicted_BTC_price, color = ‘blue’, label = ‘Predicted Bitcoin Price’)
plt.title(‘Bitcoin Price Prediction’, fontsize=30)
dframe_test = dframe_test.reset_index()
x=dframe_test.index
labels = dframe_test[‘date’]
plt.xticks(x, labels, rotation = ‘vertical’)
for tick in ax.xaxis.get_major_ticks():
tick.label1.set_fontsize(18)
for tick in ax.yaxis.get_major_ticks():
tick.label1.set_fontsize(18)
plt.xlabel(‘Time’, fontsize=20)
plt.ylabel(‘BTC Price(USD)’, fontsize=20)
plt.legend(loc=2, prop={‘size’: 25})
plt.show()
Le résultat de l’extrait précédent est donné comme suit:
Prix réel par rapport au prix prévu de Bitcoin pour un mois
La figure précédente montre clairement que la différence est plus grande lorsque le temps passe à l’entraînement. Allez-y et explorez d’autres types d’algorithmes sur le jeu de données d’apprentissage ; essayez de jouer pour avoir plus d’idées sur les raisons pour lesquelles cela est nécessaire.
12.6 Résumé
Dans ce chapitre, nous avons appris à quoi ressemblent les données Bitcoin et comment elles peuvent être utilisées pour générer différents modèles. En plus de cela, nous avons eu la chance d’utiliser divers algorithmes, tels que RNN dans iPython Notebook, sur un ensemble de données Bitcoin pour prédire le prix en fonction d’un horodatage.
Dans le chapitre suivant, nous allons examiner les ensembles de données météorologiques et prédire la météo future en fonction d’un ensemble de données historiques.
13 Modélisation des flux Twitter avec l’aide de Python
Les données Twitter sont utilisées à la fois dans les recherches universitaires et dans les entreprises pour extraire l’informatique décisionnelle à partir des tweets de particuliers ou d’organisations. Ce chapitre utilise les flux Twitter en tant que données volumineuses et les utilise en Python pour les modéliser selon les astuces et astuces de ce livre. Ce livre tente de consommer les données dans un format brut, de les transformer en un format correct, de les modéliser à l’aide de Python et d’interpréter le modèle ainsi produit. À la fin de ce chapitre, vous saurez comment procéder :
- Découvrez la nature des données de flux Twitter
- Modéliser des données Twitter avec Python
- En savoir plus sur les pandas, NumPy et d’autres bibliothèques Python
13.1 Importateur de données de flux Twitter
Dans ce chapitre, nous allons utiliser le jeu de données Twitter. L’ensemble de données peut être téléchargé à partir de Kaggle ( https://www.kaggle.com/kingburrito666/better-donald-trump-tweets ). En plus de cela, vous pouvez trouver le jeu de données à l’intérieur du référentiel GitHub de ce livre. Le jeu de données se trouve dans le dossier CH13. Le fichier s’appelle Donald-Tweets!.Csv.
Explorons l’exercice en exécutant le bloc- notes Jupyter que nous avons utilisé tout au long de ce livre. Une fois le bloc-notes opérationnel, importez-les packages essentiels requis. La plupart des paquets Python devraient être très familiers maintenant :
from textblob import TextBlob
import math
import pandas as pd
import numpy as np
import os
from pandas import DataFrame
from sklearn.cluster import KMeans
from sklearn import preprocessing
import matplotlib.pyplot as plt
from matplotlib import style
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import neighbors, datasets
style.use(‘ggplot’)
import matplotlib.pylab as plt
from matplotlib.pylab import rcParams
rcParams[‘figure.figsize’] = 20, 10
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
import sklearn
from sklearn.metrics import mean_squared_error
from wordcloud import WordCloud
La plupart des packages utilisés ici ont également été utilisés dans les chapitres précédents. A présent, vous devriez être familiarisé avec les bases pour importer un fichier et obtenir des statistiques plus simples. Importons le fichier de données :
tweet= pd.read_csv(u’Donald-Tweets!.csv’, index_col=None)
Comme d’habitude, nous pouvons vérifier l’aspect des données en utilisant la commande head :
tweet.head (10)
La sortie doit contenir les 10 premières entrées. Une section de la sortie est donnée comme suit :
Les 10 premières entrées du fichier CSV
Nous pouvons voir les entrées des fichiers contenant les colonnes suivantes :
- Date
- Time
- Tweet_Text
- Type
- Media_Type
- Hashtags
- Tweet_Id
- Tweet_Url
- twt_favourites_IS_THIS_LIKE_QUESTION_MARK
- Retweets
Commençons maintenant avec la modélisation réelle.
13.2 Modélisation des flux Twitter
Le premier exercice consiste maintenant à générer le modèle mot-nuage à partir des données en fonction de la fréquence des mots utilisés. Pour ce faire, nous devons travailler uniquement avec la colonne Tweet_Text. Nous extrayons donc dans une variable distincte et modifions la structure de données du texte en une chaîne :
df=tweet[‘Tweet_Text’]
#change the text to str
text=str(df)
Nous pouvons maintenant générer facilement le nuage de mots en utilisant la bibliothèque WordCloud Python. Nous l’avons déjà utilisé au chapitre 7, Modélisation à l’aide de données non structurées. Par conséquent, les étapes préliminaires du prétraitement ont été échappées :
wordcloud = WordCloud(background_color=”white”,width=1000, height=860, margin=2).generate(text)
import matplotlib.pyplot as plt
plt.imshow(wordcloud)
rcParams[‘figure.figsize’] = 20, 10
plt.axis(“off”)
plt.show()
L’extrait de code devrait générer un nuage de mots similaire à celui donné comme suit:
Nuage de mots généré à partir d’un flux de texte Twitter en fonction de la fréquence des mots utilisés dans le tweet
Il est possible de sauvegarder le fichier généré directement dans le fichier. Cela peut être fait comme suit :
wordcloud.to_file(‘wordcloud.png’)
L’extrait de code doit enregistrer le modèle graphique généré dans un fichier nommé wordcloud.png.
13.3 La fréquence des tweets
Supposons que nous ayons besoin de savoir à quelle fréquence l’utilisateur tweete. Ceci peut être extrait et tracé pour voir les statistiques. En supposant que le fichier soit toujours enregistré dans la variable tweet, examinons le code suivant :
data = tweet
time = data[‘Time’]
tweets = data[‘Tweet_Text’]
hashTag = data[‘Hashtags’]
Retweets = data[‘Retweets’]
Maintenant, en copiant toutes les valeurs dans les data, extrayons time, tweets, hashTag et Retweets :
#How often Trump tweets during a single day
hour_an = data.copy()
hour_an[‘Time’] = pd.to_datetime(data[‘Time’], yearfirst=True)
hour_an[‘Time’] = hour_an[‘Time’].dt.hour
hour_an = pd.DataFrame(hour_an.groupby([‘Time’]).size().sort_values(ascending=True).rename(‘Tweets’))
hour_an
L’extrait de code doit indiquer la fréquence à laquelle le président Trump tweete au cours d’une même journée :
Combien de fois le président Trump gazouille-t-il en une seule journée?
Nous pouvons tracer le résultat dans le graphique à secteurs. Nous pouvons dessiner un graphique à secteurs comme suit :
fig, ax = plt.subplots(figsize=(10, 10))
shap = hour_an
labels = hour_an.index.values
ax.pie(shap, labels=labels, shadow=False)
plt.title(‘Tweets in certain hours of the day’)
plt.show()
L’extrait précédent devrait générer un graphique à secteurs:
Diagramme à secteurs montrant la fréquence des tweets réalisés par Trump en une journée
Nous pouvons, bien sûr, générer d’autres statistiques à partir des données de tweet. N’hésitez pas à jouer pour obtenir plus de statistiques à partir du jeu de données.
13.4 Analyse de sentiment
Dans cette section, nous allons effectuer une analyse des sentiments sur les tweets créés par Trump. Ici, nous allons utiliser une bibliothèque Python appelée TextBlob. Comme le prétend le site Web TextBlob, il s’agit d’une bibliothèque de traitement de texte très simplifiée. Comprenons le paquet avec un exemple simple.
13.4.1 Installer TextBlob
La première étape consiste à installer la bibliothèque dans l’environnement de l’ordinateur portable. En supposant que vous utilisez Anaconda pour exécuter le bloc-notes, vous pouvez utiliser conda pour installer TextBlob ( https://anaconda.org/conda-forge/textblob ). En supposant que vous avez installé conda, la commande pour installer TextBlob est la suivante:
$ conda install -c conda -forge textblob
Cela devrait installer le paquet requis dans votre environnement Anaconda.
Remarque :
Le plus souvent, en exécutant l’exemple de code extrait de ce livre, vous rencontrerez des situations dans lesquelles un ou plusieurs packages sont manquants dans votre système ou dans l’installation d’Anaconda. Vous pouvez installer les bibliothèques manquantes en suivant les instructions fournies à l’ adresse https://conda.io/docs/user-guide/tasks/manage-pkgs.html#installing-packages.
Une fois que vous avez installé la bibliothèque TextBlob, importons-la dans notre cahier :
from textblob import TextBlob
Et effectuons un traitement de texte simple sur un paragraphe :
text = TextBlob ( “Twitter est l’un des médias sociaux les plus utilisés dans le monde. Il permet de partager les opinions, les faits et les informations concernant les personnes, les lieux, les animaux ou les objets. Ces tweets sont utilisés par plusieurs organisations non gouvernementales à exploiter différents types d’informations, dont l’intelligence d’affaires. “)
Nous stockons le texte dans une variable. Nous pouvons maintenant générer beaucoup de paramètres de traitement de texte simples.
13.4.2 Parties du discours
Disons que nous devons marquer le paragraphe avec des parties du discours. Nous pouvons le faire avec des balises de fonction simples :
text.tags
Il devrait générer la sortie suivante :
Textes avec des parties de discours marquées
13.4.3 Extraction de noms nominaux
Supposons que nous ayons besoin d’extraire des phrases nominales du texte précédent. Cela peut être fait facilement avec la fonction simple fournie par le paquet :
noun = text.noun_phrases
noun
La sortie du code précédent devrait ressembler à celle donnée comme suit :
WordList([‘twitter’, ‘important social media’, “‘s world”, “people ‘s opinions”, ‘non-governmental organizations’, ‘different types’, ‘business intelligence’])
Ce traitement peut être très utile lorsque nous nous intéressons à des personnes, des lieux, des animaux ou des objets.
13.4.4 Tokenization
Nous pouvons prendre le texte et le marquer conformément à nos exigences. La première étape consiste à générer différentes phrases à partir d’un texte. Cela peut être fait facilement en utilisant cette bibliothèque :
text.sentences
Il devrait répertorier l’ensemble des résultats, tels que :
[Sentence(“Twitter is one of the most important social media used in today’s world.”),
Sentence(“It provides the platform to share people’s opinions, facts and information regarding person, place, animals or things.”),
Sentence(“These tweets are used by several private, governmental and non-governmental organizations to mine different types of information including business intelligence.”)]
Non seulement cela, nous pouvons lister des mots de n’importe quel texte:
text.words
Exécutez l’extrait de code précédent et étudiez le résultat obtenu. Supposons que vous souhaitiez connaître la fréquence de chaque mot. Vous pouvez faire ce qui suit :
text.word_counts [‘twitter’]
1
Il devrait afficher la fréquence des mots dans le texte.
13.4.5 Sac de mots
Parfois, si nous voulons utiliser du texte dans des algorithmes d’apprentissage automatique, nous devons les convertir en représentation numérique. Nous savons que les ordinateurs sont très efficaces pour gérer les chiffres. Nous convertissons le texte en une représentation numérique appelée vecteur d’entités. Un vecteur peut être aussi simple qu’une liste de nombres. Le modèle de sac de mots est l’un des algorithmes d’extraction de caractéristiques pour le texte. Nous pouvons utiliser ce paquet pour générer un sac de mots.
Pour cela, nous devons utiliser Sklearn depuis Python :
from sklearn.feature_extraction.text import CountVectorizer
Nous allons utiliser CountVectorizer pour créer le sac de mots :
corpus = []
len(text.sentences)
for sentence in text.sentences:
corpus.append(str(sentence))
vectorizer = CountVectorizer()
print( vectorizer.fit_transform(corpus).todense() )
print( vectorizer.vocabulary_ )
La sortie de l’extrait précédent devrait ressembler à ceci :
Sac de mots utilisant la fonction CountVectorize
Maintenant, laissez TextBlob effectuer une analyse de sentiment:
test = TextBlob (text)
test.sentiment
Il devrait afficher le texte de sentiment comme suit :
Sentiment(polarity=0.20195668693009117, subjectivity=0.5995670995670995)
Il y a deux attributs pour le sentiment :
- Le score de polarité est un float dans la plage [-1.0, 1.0]
- La subjectivité est un flottant compris dans l’intervalle [0.0, 1.0], 0.0 étant très objectif et 1.0 très subjectif :
test.sentiment.polarity
out[8]:0.20195668693009117
Ecrivons une boucle pour obtenir un sentiment de chaque tweet :
#now we want to get the polarity plot:
storage=[]
for i in range(len(df)):
x=str(df[i])
y=TextBlob(x)
z=y.sentiment.polarity
storage.append(z)
Convertissons maintenant le stockage en DataFrame et établissons le tracé :
#create new dataframe of the change
change=DataFrame({‘trend’:storage})
rcParams[‘figure.figsize’] = 20, 10
#plot the trend of the sentiments (polarity plot)
change.plot.line()
La sortie devrait ressembler à la capture d’écran suivante :
Graphique de tendance de la polarité des tweets
Obtenons le tracé de la subjectivité :
storage2=[]
for i in range(len(df)):
x2=str(df[i])
y2=TextBlob(x2)
z2=y2.sentiment.subjectivity
storage2.append(z2)
Et maintenant l’intrigue :
#create new dataframe of the change
change2=DataFrame({‘trend2’:storage2})
rcParams[‘figure.figsize’] = 20, 10
#plot the trend of the sentiments (polarity plot)
change2.plot.line()
La sortie devrait ressembler à la capture d’écran suivante:
Diagramme de subjectivité des tweets
Pour effectuer un zoom avant, nous souhaitons voir une tendance claire parmi les 500 premiers tweets.
La première est la tendance de la polarité :
#now we want to get the polarity plot:
storage=[]
for i in range(500):
x=str(df[i])
y=TextBlob(x)
z=y.sentiment.polarity
storage.append(z)
#create new dataframe of the change
change=DataFrame({‘trend’:storage})
rcParams[‘figure.figsize’] = 20, 10
#plot the trend of the sentiments (polarity plot)
change.plot.line()
La sortie devrait ressembler à la capture d’écran suivante:
Graphique des tendances de polarité des 500 premiers tweets uniquement
Et nous pouvons également voir les tendances de la subjectivité :
##now we want to get the subjectivity plot:
storage2=[]
for i in range(500):
x2=str(df[i])
y2=TextBlob(x2)
z2=y2.sentiment.subjectivity
storage2.append(z2)
#create new dataframe of the change
change2=DataFrame({‘trend2’:storage2})
rcParams[‘figure.figsize’] = 20, 10
#plot the trend of the sentiments (polarity plot)
change2.plot.line()
La sortie de l’intrigue devrait ressembler à la capture d’écran suivante :
Tendances de subjectivité des 500 premiers tweets
Il existe plusieurs autres possibilités pour analyser les données Twitter afin d’en générer des statistiques. Il est largement utilisé sur le marché moderne. Le but principal de cet exercice est de vous aider à démarrer. N’hésitez pas à prendre à partir d’ici et extraire d’autres statistiques.
13.5 Résumé
Twitter est l’un des outils de médias sociaux les plus importants utilisés dans le monde d’aujourd’hui. Il fournit une plate-forme pour partager les opinions, les faits et les informations des gens concernant les personnes, les lieux, les animaux et les choses. Ces tweets sont utilisés par des organisations privées, gouvernementales et non gouvernementales pour exploiter différents types d’informations, y compris l’intelligence économique. Dans ce chapitre, nous avons appris à utiliser les données Twitter pour générer plusieurs modèles d’entreprise intelligents.
Dans le chapitre suivant, nous allons utiliser le jeu de données IMDB en Python pour générer plusieurs modèles liés aux films, aux classements et aux vues.
14 Modélisation des points de données météorologiques avec Python
Les données météorologiques peuvent être trouvées partout. Ces ensembles de données peuvent être utiles pour déterminer les régimes météorologiques et prévoir les conditions météorologiques en fonction des ensembles de données historiques. Ce chapitre utilise des points de données météorologiques en Python pour le modéliser en fonction des astuces et conseils appris dans ce livre. Nous essayons de consommer des données au format brut, de les transformer en un format correct, d’un modèle utilisant Python et d’interpréter le modèle ainsi produit. Dans ce chapitre, vous apprendrez ce qui suit :
- Comment découvrir la nature des données météorologiques
- Création de modèles à partir de données météorologiques avec Python
- Interprétation du modèle de données découvert
14.1 Introduction aux données atmosphériques
Dans ce chapitre, nous allons utiliser les données météorologiques de Kaggle. Pour maintenir l’analyse et la rapidité au niveau académique, nous n’avons pas pris en compte les aspects sans jeu de l’ensemble de données. Les fichiers de données sont structurés sous la forme de .CSV et contiennent les colonnes suivantes :
- dt (date and time)
- AverageTemperature
- AverageTemperatureUncertainty
- City
- Country
- Latitude
- Longitude
14.2 Importateur des données
Deux fichiers sont utilisés dans cet exercice. Les deux peuvent être téléchargés depuis Kaggle (https://www.kaggle.com/berkeleyearth/climate-change-earth-surface-temperature-data) ou depuis le référentiel GitHub.
Si vous utilisez le référentiel, le fichier de données peut être situé dans Chapitre 14, Modélisation des points de données météorologiques avec Python. Comme toujours, commençons à utiliser iPython Notebook. Les instructions se trouvent au Chapitre 6, Modélisation des données structurées.
14.3 Prévision des changements de température au Népal
La première étape consiste à importer les packages requis. Cela peut être fait avec l’extrait de code suivant :
#import the packages
import math
import pandas as pd
import numpy as np
import os
from pandas import DataFrame
from sklearn.cluster import KMeans
from sklearn import preprocessing
import matplotlib.pyplot as plt
from matplotlib import style
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import neighbors, datasets
style.use(‘ggplot’)
import matplotlib.pylab as plt
from matplotlib.pylab import rcParams
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
import sklearn
from sklearn.metrics import mean_squared_error
Une fois ces paquets importés, importons le fichier en mémoire :
bycountry= pd.read_csv(“GlobalLandTemperaturesByCountry.csv”, index_col=None)
bycountry.head(10)
L’extrait de code précédent doit afficher les 10 premières entrées du fichier, comme illustré dans la capture d’écran suivante :
Les dix premières entrées du fichier
14.4 Modélisation avec des données
Nous ne souhaitons plus que connaître la température au Népal. Nous allons donc filtrer tous les pays et extraire les entrées relatives au Népal uniquement :
temp=nepal[‘AverageTemperature’]
temp=temp.dropna(how=’any’)
Cela ne doit afficher que les entrées relatives au Népal, comme illustré dans la capture d’écran suivante :
Entrées liées au Népal
Sauvegardons maintenant la température dans une variable séparée pour la normaliser :
temp=nepal[‘AverageTemperature’]
temp=temp.dropna(how=’any’)
Ici, la fonction dropna supprime la valeur manquante et how = ‘any’ nous indique que si des valeurs NA sont présentes, nous devrions supprimer cette ligne ou cette colonne.
Maintenant, prétraitons la température pour la normaliser. Et puis tracez le graphique :
#pre-processing
scale=preprocessing.scale(temp)
plt.plot(scale)
scale
Nous devrions obtenir un modèle comme celui-ci:
Capture d’écran 14.3: Tracé pour l’ensemble de données de la température du Népal (données prétraitées)
Maintenant, prenons juste un petit échantillon des données et tracez-le :
#let’s get a small sample to see
scale
df=DataFrame(scale)
sample=df[0:500]
sample
plt.plot(sample)
L’extrait précédent doit générer la capture d’écran suivante :
Traçage d’un petit échantillon de 500 entrées
14.5 Prévisions de modèle de persistance
Une prévision persistante est une bonne prévision de base pour une série chronologique en augmentation linéaire. La prévision de la persistance est l’endroit où l’observation du pas de temps précédent (t-1) est utilisée pour prédire l’observation au pas de temps actuel (t). Nous pouvons implémenter ceci en prenant la dernière observation à partir des données d’entraînement et de l’historique accumulés par validation instantanée, et en nous servant de cela pour prévoir le pas de temps actuel :
#now we can see the patterns
X=sample.values
X
train, test = X[0:-100], X[-100:]
train
test
Dans l’échantillon des 500 premières observations, nous avons défini les 400 premières observations comme données d’apprentissage et les 100 dernières comme données de test. Après la formation et les prévisions, nous obtenons une prévision avec un pas en avant sous forme de graphique avec le jeu de données d’origine :
# walk-forward validation
history = [x for x in train]
predictions = list()
for i in range(len(test)):
# make prediction
predictions.append(history[-1])
# observation
history.append(test[i])
# report performance
rmse = math.sqrt(mean_squared_error(test, predictions))
print(‘RMSE: %.3f’ % rmse)
# line plot of observed vs predicted
pyplot.plot(test)
pyplot.plot(predictions)
pyplot.show()
rmse
Cet extrait de code devrait tracer la différence entre les données d’origine et les données prédites. La capture d’écran de sortie est donnée comme suit :
Données d’origine et données prévues
L’erreur quadratique moyenne totale (RMSE) totale dans notre cas était de 0,5302435957527816.
Pour une taille d’échantillon de 50, nous avons défini les 40 premières observations comme données d’apprentissage et les 10 dernières comme données de test. Après la formation et la prévision, nous obtenons la prévision avec un pas en avant sous forme de graphique avec le jeu de données d’origine :
#a smaller sample of 50
sample2=sample[0:50]
X2=sample2.values
X2
train2, test2 = X2[0:-10], X2[-10:]
train2
test2
Dans ce cas, nous avons considéré un petit échantillon pour voir l’effet avec une certaine précision. Maintenant, faisons une prédiction et voyons la différence :
# walk-forward validation
history2 = [x for x in train2]
predictions2 = list()
for i in range(len(test2)):
# make prediction2
predictions2.append(history2[-1])
# observation
history2.append(test2[i])
# report performance
rmse2 = math.sqrt(mean_squared_error(test2, predictions2))
print(‘RMSE: %.3f’ % rmse2)
# line plot of observed vs predicted
pyplot.plot(test2)
pyplot.plot(predictions2)
pyplot.show()
rmse2
Le graphique de sortie devrait ressembler à la capture d’écran suivante:
Données d’origine par rapport aux données prévues lorsque la taille de l’échantillon est petite
Dans ce cas, le RMSE est 0.6220490938792729, ce qui est beaucoup plus que dans notre cas original.
14.6 Statistiques météorologiques par pays
Générons maintenant un modèle montrant les 20 pays ayant la plus grande différence de température. Comme toujours, la première étape consiste à importer le fichier .CSV . A présent, vous devez être familiarisé avec le motif. Nous avons déjà créé un DataFrame dans l’exemple précédent. Pour que la modélisation reste simple, nous allons réimporter le fichier .CSV sous un autre nom DataFrame :
tempByCountry = pd.read_csv(‘GlobalLandTemperaturesByCountry.csv’)
countries = tempByCountry[‘Country’].unique()
Maintenant, pour visualiser les données, nous allons utiliser un autre paquet Python, appelé seaborn ( https://seaborn.pydata.org/ ). Nous pouvons importer le package comme suit :
importer seaborn as sns
Maintenant, obtenons les listes de températures minimum et maximum :
max_min_list = []
# getting max and min temperatures
for country in countries:
curr_temps = tempByCountry[tempByCountry[‘Country’] == country][‘AverageTemperature’]
max_min_list.append((curr_temps.max(), curr_temps.min()))
Il y a quelques valeurs de NaN. Nettoyons ces valeurs :
# NaN cleaning
res_max_min_list = []
res_countries = []
for i in range(len(max_min_list)):
if not np.isnan(max_min_list[i][0]):
res_max_min_list.append(max_min_list[i])
res_countries.append(countries[i])
Une fois les données nettoyées, calculons la différence :
# calculating the differences
differences = []
for tpl in res_max_min_list:
differences.append(tpl[0] – tpl[1])
Nous avons les différences dans le tableau des differences. Nous pouvons résoudre ce problème afin d’extraire les 20 entrées les plus importantes. Nous pouvons le faire avec ce qui suit :
# sorting the result
differences, res_countries = (list(x) for x in zip(*sorted(zip(differences, res_countries), key=lambda pair: pair[0], reverse=True)))
Enfin, tracé le graphique :
# ploting the chart
f, ax = plt.subplots(figsize=(8, 8))
sns.barplot(x=differences[:20], y=res_countries[:20], palette=sns.color_palette(“coolwarm”, 25), ax=ax)
texts = ax.set(ylabel=””, xlabel=”Temperature difference”, title=”Countries with the highest temperature differences”)
Nous devrions avoir un beau graphique maintenant :
Top 20 des pays avec la plus grande différence de température
14.7 Régression linéaire pour prédire la température d’une ville
Dans cette section, nous allons utiliser un autre fichier. Le fichier se trouve dans le répertoire du chapitre 14, Modélisation des points de données météorologiques avec Python. Le fichier s’appelle GlobalLandTemperaturesByMajorCity.csv.
Importons le fichier dans notre cahier :
#reading the file and collecting only the timestamp and the year
dframe= pd.read_csv(‘GlobalLandTemperaturesByMajorCity.csv’)
df_ny = dframe[dframe[‘City’]==’New York’]
df_ny= df_ny.iloc[:, :2]
C’est toujours une bonne idée d’examiner les premières entrées pour voir à quoi ressemble notre jeu de données. Cela peut être fait en utilisant une fonction head :
df_ny.head(10)
La sortie devrait ressembler à ceci :
10 premières entrées du fichier
Nous pouvons maintenant sélectionner uniquement l’année de l’horodatage et regrouper les données en fonction de la température moyenne de chaque année. Cela peut être fait en utilisant l’extrait suivant :
a = df_ny [‘dt’ ] .apply (lambda x: int (x [0: 4]))
grouped = df_ ny.groupby (a) .mean ()
grouped.head (10)
Et tracé la température par année :
#tracer les données
plt.plot (groupé [‘ MoyenneTempérature ‘])
plt.show ()
Le graphique devrait ressembler à ceci :
Température de New York par année
Nous pouvons voir qu’il y a plusieurs espaces vides dus aux blocs NaN dans les données. Nous pouvons corriger les anomalies en remplissant chacun des blocs NaN avec sa valeur de bloc précédente :
#Then Plotting the fixed data
df_ny[‘AverageTemperature’] = df_ny[‘AverageTemperature’].fillna(method = ‘ffill’)
grouped = df_ny.groupby(a).mean()
plt.plot(grouped[‘AverageTemperature’])
plt.xlabel(‘year’)
plt.ylabel(‘temperature in degree celsius’)
plt.title(‘New York average temperature versus year’)
plt.show()
Le graphique suivant montre que la AverageTemperature est une fonction croissante dans la plupart des cas :
Température de la ville de New York avec des données prétraitées
Maintenant que la date est fixe, utilisons la régression linéaire pour prédire la température future de la ville de New York. La première étape consiste à importer la bibliothèque :
from sklearn.linear_model import LinearRegression as LinReg
Et nous devons remodeler les données :
#Reshape the index of ‘grouped’ i.e. years
x= grouped.index.values.reshape(-1,1)
#obtaining values of temperature
y = grouped[‘AverageTemperature’].values
Maintenant, créons le modèle et trouvons la précision :
#Using linear regression and finding accuracy of our prediction
reg = LinReg()
reg.fit(x,y)
y_preds = reg.predict(x)
Accuracy = str(reg.score(x,y))
print(Accuracy)
La précision imprimée dans ce cas est 0.24223324942541424. Nous pouvons également tracer les données de température avec des années correspondant au modèle :
#plotting data along with regression
plt.scatter(x=x, y=y_preds)
plt.scatter(x=x,y=y, c=’r’)
plt.ylabel(‘Average Temperature in degree celsius’)
plt.xlabel(‘year’)
plt.show()
La sortie du code devrait apparaître comme suit:
Modèle de régression linéaire généré à partir du jeu de données
Utilisons maintenant le modèle pour prédire les valeurs de température futures :
#finding future values of temperature
reg.predict(2048)
La sortie dit array( [10.70528732]). De même, nous pouvons utiliser d’autres types d’algorithmes pour créer de beaux modèles pouvant être utilisés pour analyser les données.
14.8 Résumé
Les données météorologiques peuvent être trouvées partout et peuvent être utilisées pour générer de nombreuses informations utiles. Ces informations peuvent être utiles pour trouver des modèles au cours de l’année précédente et les utiliser pour la Business Intelligence. Dans ce chapitre, nous avons utilisé un jeu de données de température de Kaggle pour générer certains modèles.
Nous avons utilisé l’ensemble de données pour prédire la température future et générer des graphiques de visualisation pour l’analyse. Dans le chapitre suivant, nous allons nous salir les mains avec un jeu de données IMDb et générer des modèles plus complexes en utilisant des bibliothèques Python similaires. Si vous voulez prendre une longueur d’avance, assurez-vous de savoir ce que sont les ensembles de données IMDb et pourquoi ils sont importants.
15 Modélisation de points de données IMDb avec Python
Dans les chapitres précédents, nous avons étudié différents types de mégadonnées, leurs sources et leur gestion afin d’en extraire des informations cachées. Maintenant, il est temps d’appliquer cette connaissance à de vraies bases de données. Ce chapitre utilise les points de données IMDb sous forme de données volumineuses et les utilise en Python pour modéliser selon les astuces et astuces de ce livre. Ce livre tente de consommer les données au format brut, de les transformer en un format correct, de les modéliser à l’aide de Python et d’interpréter le modèle ainsi produit. Nous couvrirons les sujets suivants:
- Découvrir la nature des données IMDb
- Modélisation des données météorologiques avec Python
- Interprétation du modèle de données découvert
15.1 Introduction aux données IMDb
IMDb fournit un sous-ensemble de jeux de données à utiliser par les applications personnelles et les applications d’entreprise. Sous réserve de leurs conditions générales, IMDb peut être utilisé à des fins personnelles et non commerciales. Il est disponible au téléchargement sur https://datasets.imdbws.com/.
Dans ce mini projet, nous utilisons deux types de sous-ensembles :
- Données d’épisode : contient les informations sur l’épisode de télévision
- Données d’évaluation : Contient les évaluations IMDb et les informations de vote pour les titres.
15.2 Données sur les épisodes
Les données d’épisode contiennent des informations sur les épisodes de télévision. Il contient les champs suivants :
| tconst | Un champ de chaîne contenant un identifiant alphanumérique de l’épisode. |
| parentTconst | Un champ de chaîne contenant un identificateur alphanumérique de la série télévisée parente. |
| seasonNumber | Un champ entier. C’est le numéro de saison auquel l’épisode appartient. |
| episodeNumber | Un champ entier. Il contient le numéro d’épisode de tconst dans la série télévisée. |
Cet ensemble de données a été téléchargé à partir de https://datasets.imdbws.com/title.episode.tsv.gz.
15.3 Données d’évaluation
Il contient les notations IMDb et les informations de vote pour les titres. Il contient les champs suivants :
| tconst | Un champ de cordes. C’est un identifiant unique alphanumérique pour le titre. |
| averageRating | La moyenne pondérée de toutes les évaluations d’utilisateurs individuels. |
| numVotes | Le nombre de votes que le titre a reçu. |
Le but de cet exercice est de trouver des facteurs importants affectant les notes moyennes des entrées dans le jeu de données IMDb. Nous allons utiliser le clustering pour trouver les facteurs les plus importants. Nous supposons qu’un plus grand nombre d’épisodes et de votes peut conduire à une note moyenne plus élevée.
Cet ensemble de données a été téléchargé à partir de https://datasets.imdbws.com/title.ratings.tsv.gz.
15.4 Théorie
Le clustering est la tâche d’apprentissage automatique qui consiste à grouper un ensemble d’objets de telle sorte que les objets du même groupe se ressemblent davantage que ceux des autres groupes. Avec un ensemble de points de données, nous pouvons utiliser un algorithme de classification pour regrouper chaque point de données dans un groupe spécifique. En théorie, les points de données regroupés dans le même groupe devraient avoir des propriétés ou des caractéristiques similaires, alors que les points de données de différents groupes devraient avoir des propriétés ou des caractéristiques très distinctes. Le clustering est une technique courante d’analyse statistique de données utilisée dans de nombreux domaines.
Il existe différents types d’algorithmes de clustering. Les algorithmes de clustering les plus courants sont les suivants :
- K- signifie algorithme de clustering
- Clustering à décalage moyen
- Agglomération hiérarchique regroupement
- Regroupement spatial basé sur la densité
Nous utilisons le clustering pour IMDb car des jeux de données similaires sont très proches les uns des autres. Par exemple, le même équipage peut tourner des films ayant des cotes moyennes similaires. Donc, nous voulons utiliser le regroupement pour déterminer ce qui peut conduire à différents groupes dans les ensembles de données IMDb. En d’autres termes, nous voulons voir quel est le facteur le plus important pour le clustering dans le jeu de données IMDb.
15.5 Modélisation avec le jeu de données IMDb
La plupart des bibliothèques utilisées dans cet exercice pratique doivent déjà vous être familières. Les bibliothèques utilisées dans la modélisation du jeu de données sont les suivantes :
- pandas : pour une structure et une analyse de données plus simples
- NumPy : Pour ajouter la prise en charge de grands tableaux multidimensionnels et matrices
- scikit-learn : pour la plupart des algorithmes d’apprentissage automatique
- Matplotlib : pour générer des graphiques
15.5.1 Démarrer la plateforme
Commençons par modéliser les données en utilisant Python. La première étape de toute modélisation consiste à démarrer votre système. J’utilise IPython Jupyter ( http://jupyter.org/ ) pour exécuter le code. Le moyen le plus simple de se familiariser avec Jupyter consiste à l’installer à l’aide d’Anaconda ( https://anaconda.org/ ). Téléchargez la bonne plateforme à partir de https://www.anaconda.com/download/#macos . Des instructions sur la façon de démarrer avec Anaconda sont disponibles à l’ adresse https://docs.anaconda.com/anaconda/install/ .
Sur la plate-forme macOS X, une fois Anaconda installé, l’interface de la version 1.8.7 se présente comme suit :
Interface Anaconda
Une fois que c’est prêt, nous pouvons simplement lancer l’interface et lancer Jupyter pour commencer à coder. Une fois lancé, il devrait ressembler à la capture d’écran suivante :
Interface Jupyter pour exécuter IPython
L’interface est prête à commencer à coder. Alternativement, Jupyter peut être installé en suivant les instructions sur son site officiel : http://jupyter.org/install.
15.5.2 Importer les bibliothèques requises
La plupart des bibliothèques utilisées pour ce projet devraient déjà être familières. Les bibliothèques requises peuvent être importées à l’aide de l’extrait de code suivant :
#import the packages
import pandas as pd
import numpy as np
import os
from pandas import DataFrame
from sklearn.cluster import KMeans
from sklearn import preprocessing
import matplotlib.pyplot as plt
from matplotlib import style
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import neighbors, datasets
style.use(‘ggplot’)
Une fois que les instructions d’import sont entrées dans la cellule, leur code peut être exécuté immédiatement. Pour exécuter le code, cliquez simplement sur le bouton Run dans la barre d’outils Jupyter. Une fois le code exécuté, les bibliothèques sont importées dans le système et sont prêtes à être utilisées. Si vous avez plus d’une cellule, veillez à exécuter la bonne cellule. Pour choisir la bonne cellule, cliquez simplement sur la cellule active et exécutez le code.
15.5.3 Importer un fichier
Pour importer un fichier, nous allons utiliser from_csv ou read_csv, en fonction de la version de Python utilisée. Si vous utilisez Python version 2.x, l’extrait de code suivant peut être utilisé pour importer les données dans le système :
#importing average rating
rating = DataFrame.from_csv(“title.ratings.tsv”, index_col=None, sep=”\t”)
#importing episode and season info
episode=DataFrame.from_csv(“episode.tsv”, index_col=None, sep=”\t”)
Si vous utilisez la version 3.x de Python, le code précédent émettra des avertissements de dépréciation. Pour résoudre ce problème, utilisez l’extrait suivant :
rating = pd.read_csv(“title.ratings.tsv”, index_col=None, sep=”\t”)
episode= pd.read_csv(“episode.tsv”, index_col=None, sep=”\t”)
Maintenant, les deux fichiers sont importés dans le système. Pour vérifier si les fichiers ont été importés correctement, nous pouvons examiner les 10 premières entrées de chaque fichier à l’aide de la commande head :
episode.head(10)
La commande doit générer les 10 premières entrées, comme suit :
10 premières entrées du fichier d’épisode
De même, nous pouvons vérifier les 10 premières entrées du fichier de rating la manière suivante :
rating.head(10)
Il devrait générer une sortie similaire à la capture d’écran suivante :
Sortie des 10 premières entrées du fichier de notation
Dans les deux trames de données, tconst est l’identifiant ou le numéro du titre, qui est identique dans les deux cas. Pour effectuer l’analyse, nous devons combiner les deux fichiers. Pour combiner les fichiers, nous devons veiller à extraire les entrées correctes des deux fichiers et à les fusionner. Heureusement, panda fournit une fonction de fusion pour effectuer la tâche :
#we can use merge to get the data with the same titles for example tt0000000
re=rating.merge(episode)
Cela devrait fusionner ces deux fichiers avec le bon index. Pour vérifier, vérifions les 10 premières entrées :
Fichier fusionné, 10 premières entrées
Pour vérifier que la table a été fusionnée correctement, vérifions les premières entrées de la figure (10 premières entrées du fichier d’épisode). Il montre tconst de tt0033908 . Voyons maintenant l’entrée correspondante dans la table de classement. Nous pouvons utiliser la commande loc de pandas pour localiser l’entrée. La commande devrait ressembler à ceci :
rating.loc[rating[‘tconst’] == “tt0033908”]
La commande dit essentiellement : trouver les entrées de la rating dataframe où tconst est tt0033908. La sortie devrait ressembler à ceci :
Rechercher les entrées où tconst est tt0033908
Si nous examinons les figures (Rechercher les entrées où tconst est tt0033908) et (Fichier fusionné, 10 premières entrées), nous pouvons voir que le fichier est correctement fusionné.
15.5.4 Nettoyage des données
La figure (Fichier fusionné, 10 premières entrées) indique qu’il ya deux entrées, seasonNumber et episodeNumber, qui sont complètement inutiles pour notre analyse car ils contiennent la \N valeur. Le premier nettoyage que nous pouvons effectuer consiste à supprimer ces deux colonnes. Pour les nettoyer, nous pouvons exécuter la commande suivante :
#delete the data with \N
re=re[re.seasonNumber != r’\N’]
re=re[re.episodeNumber != r’\N’]
re=re[re.tconst != r’\N’]
Nous n’avons pas besoin de parentConst, nous pouvons donc laisser tomber ceci :
#we don’t need parentTconst, so, we drop it
re = re.drop(‘parentTconst’, 1)
Maintenant, nous devons convertir les entrées en leurs valeurs numériques. Nous pouvons le faire en utilisant deux méthodes. Si vous utilisez Python 2.x, la commande correcte est la suivante :
#convert the entries to numeric
re.convert_objects(convert_numeric=True)
Si vous utilisez Python 3.x, nous pouvons utiliser la méthode infer_objects :
#convert the entries to numeric
re = re.infer_objects()
Maintenant, la re trame de données est prêt pour le regroupement. Il contient toutes les colonnes dont nous avons besoin pour le clustering. Les colonnes qu’il contient sont :
- tconst
- averageRating
- numVotes
- seasonNumber
- episodeNumber
Nous devons maintenant identifier les facteurs les plus importants ayant une incidence sur les notations.
15.5.5 Clustering
Premièrement, nous utilisons des données bidimensionnelles pour voir s’il existe un cluster. Les attributs à deux dimensions sont averageRating et episodeNumber.
Nous devons définir une colonne d’index pour la mise en cluster. Pour ce faire, utilisons tconst pour le clustering :
#set ‘tconst’ to the index column
pre=re.set_index(‘tconst’)
Pour voir la relation entre le nombre d’épisodes et les notes, nous laissons tomber numVotes et seasonNumber car nous n’avons besoin que des autres variables :
ratingandepisode = pre.drop (‘numVotes’, 1)
ratingandepisode = ratingandepisode.drop (‘seasonNumber’, 1)
Après cela, pré-traitons les données et obtenons les tableaux dont nous avons besoin :
processed=preprocessing.scale(ratingandepisode)
Maintenant, traçons les données mises à l’échelle :
x,y=processed.T
plt.scatter(x,y)
L’extrait précédent doit tracer un graphique à dispersion, comme illustré dans la capture d’écran suivante :
Diagramme de dispersion tracé à l’aide de la moyenne des données bidimensionnelles Évaluation et numéro d’épisode
La figure précédente montre trois groupes distincts : haut, milieu et bas. Ainsi, Fixons n_clusters = 5 pour le nombre de grappes et utiliser les K-means algorithme des :
#We use K-means clustering
X=processed
kmeans = KMeans(n_clusters=5) #what if n_clusters=3 or 4?
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
Maintenant, le modèle a été formé. Traçons le diagramme de dispersion :
#scatter plot pour n = 5
Scatter (X [:, 0], X [:, 1], c = y_kmeans , s = 50, cmap = ‘ viridis ‘)
La sortie devrait ressembler à la capture d’écran suivante :
Nuage de points pour le nombre de grappes (cinq)
Comme on peut le constater, il existe trois grands groupes: le haut, le milieu et le bas. La grappe supérieure montre que ses données ont une cote moyenne élevée et de nombreux épisodes. Le groupe du milieu montre que, même si le nombre d’épisodes augmente, la note moyenne est toujours au milieu. Le groupe du bas montre que, bien que le nombre d’épisodes augmente, la note moyenne reste au bas. C’est-à-dire que plus d’épisodes n’entraînent pas une cote plus élevée.
Pour tracer le centre des clusters, nous pouvons exécuter l’extrait entier dans une cellule :
#scatter plot for n=5
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap=’viridis’)
#name the centers of the clusters
centers = kmeans.cluster_centers_
#plot centers
plt.scatter(centers[:, 0], centers[:, 1], c=’black’, s=200, alpha=0.5);
Notre graphique devrait montrer le centre des grappes :
Diagramme de dispersion montrant trois grappes avec des centres
Jusqu’ici, nous avons supposé n_clusters = 5 pour le cluster. Nous pouvons répéter le processus pour n_clusters = 3 et n_clusters = 4.
Pour n_clusters = 4, considérons le code suivant :
#We use K-means clustering
X=processed
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
#scatter plot for n=4
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap=’viridis’)
#name the centers of the clusters
centers = kmeans.cluster_centers_
#plot centers
plt.scatter(centers[:, 0], centers[:, 1], c=’black’, s=200, alpha=0.5);
Le diagramme de dispersion devrait ressembler à ceci :
Diagramme de dispersion montrant trois grappes avec centres et n = 4
Essayez de continuer l’exercice avec n_clusters = 3 et voyez la différence.
Disons que nous voulons voir la relation entre averageRating et numVotes . Tout d’abord, réaffectons le DataFrame à une autre variable et définissons l’index :
rn=re
#set index
rnpre=rn.set_index(‘tconst’)
Cette fois -ci, la chute du LET seasonNumber et episodeNumber :
#drop seasonNumber and episodeNumber
ratingandnum=rnpre.drop(‘seasonNumber’,1)
ratingandnum=ratingandnum.drop(‘episodeNumber’,1)
Et maintenant, nous pré-traitons et mettons à l’échelle les données :
#scale data
processedrn=preprocessing.scale(ratingandnum)
xnew2,ynew2=processedrn.T
Et maintenant, tracé le graphique :
#plot data
plt.scatter(xnew2,ynew2)
Il devrait générer le graphique suivant :
Diagramme de dispersion illustrant la relation entre moyennes et notations
Maintenant, appliquons l’algorithme de classification K-means et voyons si nous pouvons détecter certaines grappes :
#see the data, we set n_cluster=5 first
X2=processedrn
kmeans = KMeans(n_clusters=5)
kmeans.fit(X2)
y2_kmeans = kmeans.predict(X2)
plt.scatter(X2[:, 0], X2[:, 1], c=y2_kmeans, s=50, cmap=’viridis’)
#name the centers of the clusters
centers = kmeans.cluster_centers_
#plot centers
plt.scatter(centers[:, 0], centers[:, 1], c=’black’, s=200, alpha=0.5);
La figure montre que, si le nombre de votes est faible, ils ne peuvent pas obtenir une note plus élevée. Si le nombre de voix est élevé, il est possible que la note obtenue soit très élevée :
Diagramme de dispersion montrant les grappes avec n = 5
15.6 Résumé
Ceci est le dernier chapitre de ce livre. Dans ce chapitre, nous avons exploré divers ensembles de données IMDb qui ont été utilisés avec succès dans diverses recherches. Nous avons utilisé certaines des bibliothèques Python les plus populaires, y compris pandas, NumPy, scikit-learn et Matplotlib, pour analyser et visualiser cet ensemble de données et générer les modèles les plus pertinents.
L’ensemble de données, les exemples et les modèles générés dans ce chapitre sont principalement à des fins d’apprentissage et pour susciter votre intérêt pour le domaine. Le travail que nous avons effectué est hautement applicable à divers domaines, tels que les données bancaires, la médecine, la recherche, la finance et la nature. C’est à vous d’explorer ces ensembles de données et de commencer à jouer.




Laisser un commentaire
Vous devez être dentifié pour poster un commentaire.